
Обновлено: 29.01.2023
XML ( англ. eXtensible Markup Language) — расширяемый язык разметки, предназначенный для хранения и передачи данных.
Простейший XML-документ выглядит следующим образом:
Первая строка — это XML декларация. Здесь определяется версия XML (1.0) и кодировка файла. На следующей строке описывается корневой элемент документа <book> (открывающий тег). Следующие 4 строки описывают дочерние элементы корневого элемента ( title , author , year , price ). Последняя строка определяет конец корневого элемента </book> (закрывающий тег).
Документ XML состоит из элементов (elements). Элемент начинается открывающим тегом (start-tag) в угловых скобках, затем идет содержимое (content) элемента, после него записывается закрывающий тег (end-teg) в угловых скобках.
Информация, заключенная между тегами, называется содержимым или значением элемента: <author>Erik T. Ray</author> . Т.е. элемент author принимает значение Erik T. Ray . Элементы могут вообще не принимать значения.
Элементы могут содержать атрибуты, так, например, открывающий тег <title lang=»en»> имеет атрибут lang , который принимает значение en . Значения атрибутов заключаются в кавычки (двойные или ординарные).
Некоторые элементы, не содержащие значений, допустимо записывать без закрывающего тега. В таком случае символ / ставится в конце открывающего тега:
XML документ должен содержать корневой элемент. Этот элемент является «родительским» для всех других элементов.
Все элементы в XML документе формируют иерархическое дерево. Это дерево начинается с корневого элемента и разветвляется на более низкие уровни элементов.
Все элементы могут иметь подэлементы (дочерние элементы):
Правила синтаксиса (Валидность)¶
Структура XML документа должна соответствовать определенным правилам. XML документ отвечающий этим правилам называется валидным (англ. Valid — правильный) или синтаксически верным. Соответственно, если документ не отвечает правилам, он является невалидным .
Основные правила синтаксиса XML:
- Теги XML регистрозависимы — теги XML являются регистрозависимыми. Так, тег <Letter> не то же самое, что тег <letter> .
Открывающий и закрывающий теги должны определяться в одном регистре:
- XML элементы должны соблюдать корректную вложенность:
- У XML документа должен быть корневой элемент — XML документ должен содержать один элемент, который будет родительским для всех других элементов. Он называется корневым элементом.
- Значения XML атрибутов должны заключаться в кавычки:
Сущности¶
Некоторые символы в XML имеют особые значения и являются служебными. Если вы поместите, например, символ < внутри XML элемента, то будет сгенерирована ошибка, так как парсер интерпретирует его, как начало нового элемента.
В примере ниже будет сгенерирована ошибка, так как в значении «ООО<Мосавтогруз>» атрибута НаимОрг содержатся символы < и > .
Также ошибка будет сгенерирована и в слудющем примере, если название организации взять в обычные кавычки (английские двойные):
Чтобы ошибки не возникали, нужно заменить символ < на его сущность. В XML существует 5 предопределенных сущностей:
| Сущность | Символ | Значение |
|---|---|---|
| < | < | меньше, чем |
| > | > | больше, чем |
| & | & | амперсанд |
| ' | ‘ | апостроф |
| " | « | кавычки |
Таблица I.1 — Сущности ¶
Только символы < и & строго запрещены в XML. Символ > допустим, но лучше его всегда заменять на сущность.
Таким образом, корректными будут следующие формы записей:
В последнем примере английские двойные кавычки заменены на французские кавычки («ёлочки»), которые не являются служебными символами.
Поиск информации в XML файлах (XPath)¶
XPath ( англ. XML Path Language) — язык запросов к элементам XML-документа. XPath расширяет возможности работы с XML.
XML имеет древовидную структуру. В документе всегда имеется корневой элемент (инструкция <?xml version=”1.0”?> к дереву отношения не имеет). У элемента дерева всегда существуют потомки и предки, кроме корневого элемента, у которого предков нет, а также тупиковых элементов (листьев дерева), у которых нет потомков. Каждый элемент дерева находится на определенном уровне вложенности (далее — «уровень»). У элементов на одном уровне бывают предыдущие и следующие элементы.
Это очень похоже на организацию каталогов в файловой системе, и строки XPath, фактически, — пути к «файлам» — элементам. Рассмотрим пример списка книг:
XPath запрос /bookstore/book/price вернет следующий результат:
Сокращенная форма этого запроса выглядит так: //price .
В приведенной ниже таблице представлены некоторые выражения XPath и результат их работы:
Кодировки¶
И еще один важный момент, который стоит рассмотреть — кодировки. Существует множество кодировок, о них подробнее можно прочитать в статье Набор символов.
Самыми распространенными кириллическими кодировками являются Windows-1251 и UTF-8 . Последняя является одним из стандартов, но большая часть ФНС отчетности имеет кодировку Windows-1251 .
В XML файле кодировка объявляется в декларации:
Часто можно столкнуться с ситуацией, когда текстовый редаткор некорректно распознает кодировку и отображает кракозябры. В такой случае, необходимо выбрать кодировку вручную, для этого выполните:
| Программа | Кодировка |
|---|---|
| Notepad++ | «Документ → Кодировка» |
| Geany | «Документ → Установить кодировку» |
| Firefox | «Вид → Кодировка» |
| Chrome | «Настройка → Дополнительные инструменты → Кодировка» |
Таблица I.3 — Смена кодировки в разных программах ¶
В большинстве случаев при работе с русскоязычными файлами помогает переключение кодировки на Windows-1251 или UTF-8 . Если все равно не удается прочитать содержимое XML документа, стоит открыть его в Mozilla Firefox, он отлично распознает кодировки.
Если ничего не помогает, вполне возможно, что файл был поврежден.
XSD схема¶
XML Schema — язык описания структуры XML-документа, его также называют XSD. Как большинство языков описания XML, XML Schema была задумана для определения правил, которым должен подчиняться документ. Но, в отличие от других языков, XML Schema была разработана так, чтобы её можно было использовать в создании программного обеспечения для обработки документов XML.
После проверки документа на соответствие XML Schema читающая программа может создать модель данных документа, которая включает:
- словарь (названия элементов и атрибутов);
- модель содержания (отношения между элементами и атрибутами и их структура);
- типы данных.
Каждый элемент в этой модели ассоциируется с определённым типом данных, позволяя строить в памяти объект, соответствующий структуре XML-документа. Языкам объектно-ориентированного программирования гораздо легче иметь дело с таким объектом, чем с текстовым файлом.
Файл abbyy pdf transformer.exe из ABBYY является частью ABBYY PDF Transformer v9 0 102 46. abbyy pdf transformer.exe, расположенный в d. dreamdisk 2014 christmas editionsoftwareofficepdf abbyy pdf transformer .exe с размером файла 189737804 байт, версия файла Unknown version, подпись a5040812c0bc670eb16bd0d493ef1fc4.
- Запустите приложение Asmwsoft Pc Optimizer.
- Потом из главного окна выберите пункт «Clean Junk Files».
- Когда появится новое окно, нажмите на кнопку «start» и дождитесь окончания поиска.
- потом нажмите на кнопку «Select All».
- нажмите на кнопку «start cleaning».

- Запустите приложение Asmwsoft Pc Optimizer.
- Потом из главного окна выберите пункт «Fix Registry problems».
- Нажмите на кнопку «select all» для проверки всех разделов реестра на наличие ошибок.
- 4. Нажмите на кнопку «Start» и подождите несколько минут в зависимости от размера файла реестра.
- После завершения поиска нажмите на кнопку «select all».
- Нажмите на кнопку «Fix selected».
P.S. Вам может потребоваться повторно выполнить эти шаги.
3- Настройка Windows для исправления критических ошибок abbyy pdf transformer.exe:

- Нажмите правой кнопкой мыши на «Мой компьютер» на рабочем столе и выберите пункт «Свойства».
- В меню слева выберите » Advanced system settings».
- В разделе «Быстродействие» нажмите на кнопку «Параметры».
- Нажмите на вкладку «data Execution prevention».
- Выберите опцию » Turn on DEP for all programs and services . » .
- Нажмите на кнопку «add» и выберите файл abbyy pdf transformer.exe, а затем нажмите на кнопку «open».
- Нажмите на кнопку «ok» и перезагрузите свой компьютер.
Как другие пользователи поступают с этим файлом?
Всего голосов ( 181 ), 115 говорят, что не будут удалять, а 66 говорят, что удалят его с компьютера.
В данной статье речь пойдёт о причинах возникновения фатальной ошибки «Ошибка разбора XML» и способах устранения данной неполадки. Также будет дана инструкция не по устранению, но «обходу» ошибки, то есть действиям на опережение.
XML (с английского – extensible markup language – расширяемый язык разметки) – это язык разметки, который рекомендует Консорциум Всемирной паутины. Обычно язык разметки XML служит для описания документации, соответствующего типа, а также описывает действия соответствующих процессоров. Расширяемый язык разметки имеет довольно простой синтаксис, поэтому используется по всему миру, чтобы создавать и обрабатывать документацию программным способом. Он создавался именно для использования в Интернете. XML назвали именно расширяемым языком разметки, так как в нём нет фиксации разметки, которая содержится внутри документа, а именно: программист может создавать любую разметку, а ограничения будут встречаться лишь в синтаксисе.
2. Устранение Ошибки разбора XML в 1С
«Ошибка разбора XML» возникает исключительно в тонком клиенте 1С. Также стоит отметить, что «Ошибка разбора XML» также довольна схожа с ошибкой по формату потока, которая возникает в толстом клиенте. Обычно в 1С «Ошибка разбора XML» возникает по причине наличия кэша метаданных. И если очистить кэш, то ошибка будет устранена. Выглядит окно с ошибкой, а также окно с комментариями от технической поддержки следующим образом:

Рис. 1 Окно Ошибки разбора XML в 1С
XML данные читаются по потокам, так что в каждый из моментов времени объект «сосредоточен» в некотором узле XML. Из-за этого также может возникать фатальная ошибка «Ошибка разбора XML». Для того чтобы её устранить, можно вызвать функцию «ИсключениеЧтенияXml», как показано на скриншоте примера ниже:

Рис. 2 Вызов функции ИсключениеЧтенияXML для устранения Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
Данные два способа (очистка кэша метаданных и функция «ИсключениеЧтенияXml») – не все возможные варианты устранения ошибки разбора XML. Далее рассмотрим нестандартный подход, который позволит избежать ошибки еще до её возникновения.
Для наглядности будем работать в конфигурации 1С:Бухгалтерия предприятия, одной из наиболее распространенных программ фирмы 1С. У многих людей, которые пользуются программой 1С:Отчётность появляются неполадки при попытках открыть данные/файлы от налоговой. Чтобы открыть такой файл повторяем следующие действия:
· Переходим по пути: «Настройки 1С:Отчётности → Журнал обмена с контролирующими органами», как показано на скриншоте ниже:

Рис. 3 Настройка 1С Отчетности
· Далее кликаем на «Запросы» и выделяем ту выписку, которую не было возможности открыть из-за ошибки, как продемонстрировано на скриншоте ниже:

Рис. 4 Выбор выписки с Ошибкой разбора XML в 1С

Рис. 5 Стадия отправки документа с Ошибкой разбора XML в 1С
Несколько пользователей сообщают о Ошибка синтаксического анализа XML всякий раз, когда они пытаются открыть документ Microsoft Word, который они ранее экспортировали. Эта проблема обычно возникает после того, как пользователь обновился до более новой версии Office или после того, как документ Word был ранее экспортирован из другой программы. Эта проблема обычно возникает на компьютерах с Windows 7 и Windows 9.

Ошибка разбора Word XML
Что вызывает ошибку синтаксического анализа XML в Microsoft Word?
Мы исследовали проблему, просматривая различные пользовательские отчеты и пытаясь воспроизвести проблему. Как выясняется, есть несколько преступников, которые могут в конечном итоге вызвать эту конкретную проблему:
Если вы в настоящее время пытаются решить Ошибка синтаксического анализа XML, эта статья предоставит вам список проверенных шагов по устранению неполадок. Ниже приведен список методов, которые другие пользователи в аналогичной ситуации использовали для решения проблемы.
Чтобы обеспечить наилучшие результаты, следуйте приведенным ниже методам, чтобы найти исправление, эффективное для решения проблемы. Давай начнем!
Способ 1: установка графического обновления Windows SVG
Этот метод обычно считается успешным в Windows 7 и Windows 8, но мы успешно воссоздали шаги для Windows 10. Эта проблема возникает из-за ошибки, которую WU (Центр обновления Windows) делает при установке определенных обновлений.
Как выясняется, это конкретное обновление (которое создает проблему) должно автоматически устанавливаться компонентом обновления, поскольку оно включено в число WSUS (службы обновления Windows Server) утвержденные обновления.
К счастью, вы также можете установить недостающее обновление (KB2563227) через онлайн-страницу Microsoft. Вот краткое руководство о том, как это сделать:
Если вы все еще сталкиваетесь с Ошибка синтаксического анализа XML ошибка, продолжайте следующим способом ниже.
Способ 2: устранение ошибки с помощью Notepad ++ и Winrar или Winzip
Если первый метод не помог решить проблему, вполне вероятно, что код XML, сопровождающий документ Word, не соответствует спецификации XML. Скорее всего, код XML, сопровождающий текст, содержит ошибки кодирования.
Вы можете заметить, что атрибут Location указывает на файл .xml, когда вы пытаетесь открыть файл word. Хотите знать, почему это? Это потому, что файл .doc на самом деле является файлом .zip, который содержит коллекцию файлов .xml.
Следуйте приведенным ниже инструкциям, чтобы использовать Notepad ++ и WinRar для решения проблемы и открыть документ Word без Ошибка синтаксического анализа XML:
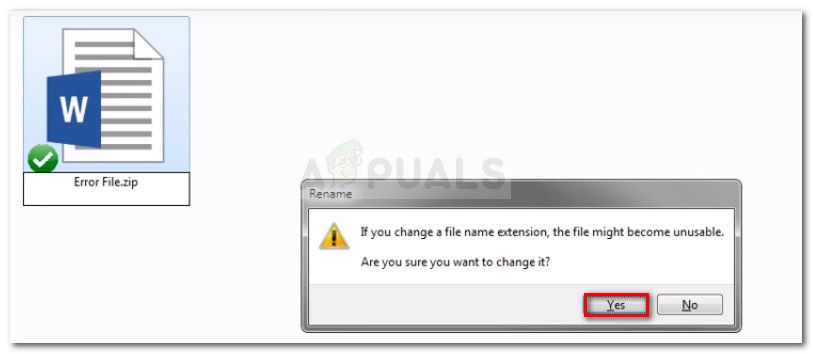
-
Щелкните правой кнопкой мыши документ, который вызывает ошибку, и измените форму расширения. .доктор кзастежка-молния. Когда вас попросят подтвердить изменение имени добавочного номера, нажмите да подтвердить.
Изменение расширения с .doc на .zip
Замечания: Если вы не можете просмотреть расширение файла, перейдите к Посмотреть вкладка в Проводник и убедитесь, что поле связано с Расширения имени файла проверено.
Замечания: Если вы не можете открыть документ .zip, загрузите Winzip по этой ссылке (Вот).
Читайте также:
- Vipnet coordinator hw1000 firewall настройка
- Как обновить яндекс дзен на компьютере
- Cassida zeus ошибка ps2
- Hyperx alloy origins core black usb обзор
- Как в bluestacks загрузить фото с компьютера
Содержание
- Как исправить ошибку доступа к файлу в FineReader
- Ошибка при установке
- Ошибка при запуске
- Вопросы и ответы
![]()
FineReader — чрезвычайно полезная программа для конвертации текстов из растрового в цифровой формат. Ее часто применяют для редактирования конспектов, сфотографированных объявлений или статей, а также отсканированных текстовых документов. При установке или запуске FineReader может возникнуть ошибка, которая отображается как «Нет доступа к файлу».
Попробуем разобраться, как устранить эту проблему и пользоваться распознавателем текстов в своих целях.
Скачать последнюю версию FineReader
Ошибка при установке
Первое, что нужно проверить при возникновении ошибки доступа — проверить, не включен ли антивирус на вашем компьютере. Выключите его, если он активен.
В том случае, если проблема осталась, проделайте следующие шаги:
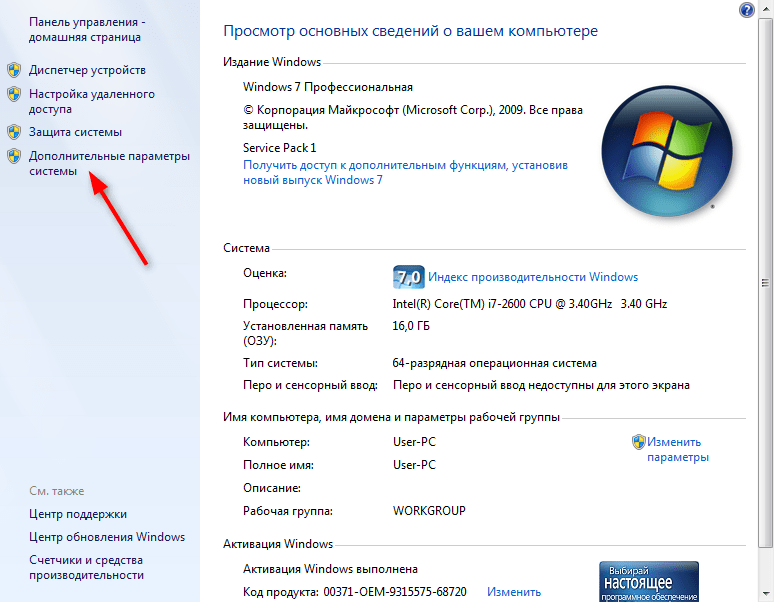
Нажмите «Пуск» и щелкните правой кнопкой мыши на «Компьютер». Выберите «Свойства».
Если у вас установлена Windows 7, щелкните на «Дополнительные параметры системы».
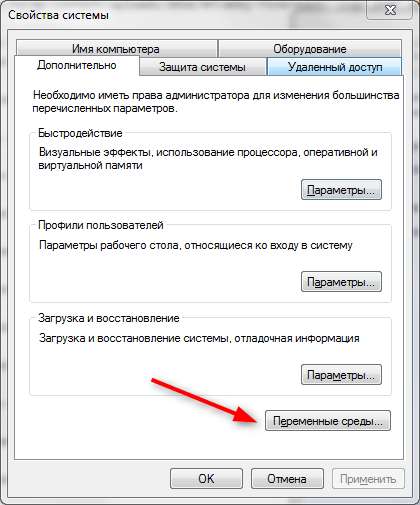
На вкладке «Дополнительно» найдите внизу окна свойств кнопку «Переменные среды» и нажмите ее.
В окне «Переменные среды выделите строку TMP и нажмите кнопку «Изменить».
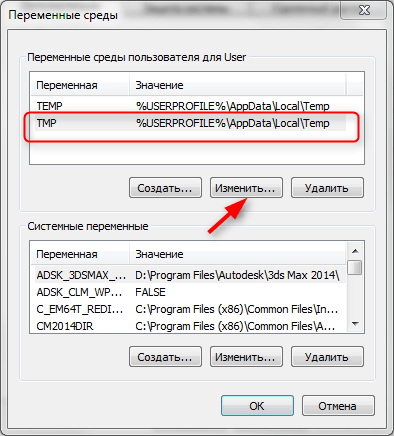
В строке «Значение переменной» пропишите C:Temp и нажмите «ОК».
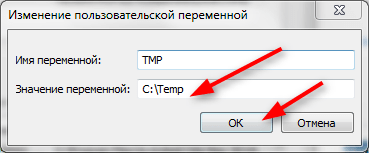

Проделайте тоже самое для строки TEMP. Щелкните «ОК» и «Применить».
После этого попробуйте начать установку заново.
Установочный файл всегда запускайте от имени администратора.
Ошибка при запуске
Ошибка доступа при запуске возникает в том случае, если пользователь не имеет полного доступа к папке «Licenses» на своем компьютере. Исправить это достаточно просто.
Нажмите сочетание клавиш Win+R. Откроется окно «Выполнить».
В строке этого окна введите C:ProgramDataABBYYFineReader12.0 (или другое место, куда установлена программа) и нажмите «ОК».
Обратите внимание на версию программы. Прописывайте ту, которая установлена у вас.

Найдите в каталоге папку «Licenses» и, щелкнув по ней правой кнопкой мыши, выберите «Свойства».
На вкладке «Безопасность» в окне «Группы или пользователи» выделите строку «Пользователи» и нажмите кнопку «Изменить».
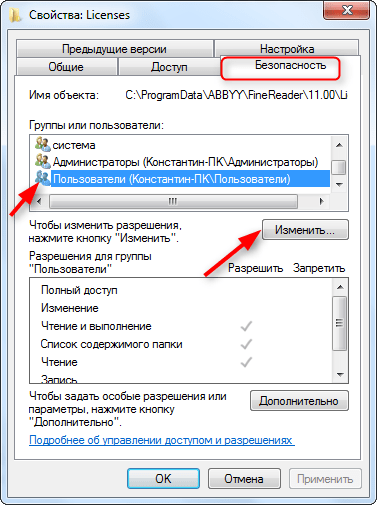
Снова выделите строку «Пользователи» и установите галочку напротив «Полный доступ». Нажмите «Применить». Закройте все окна, нажимая «ОК».
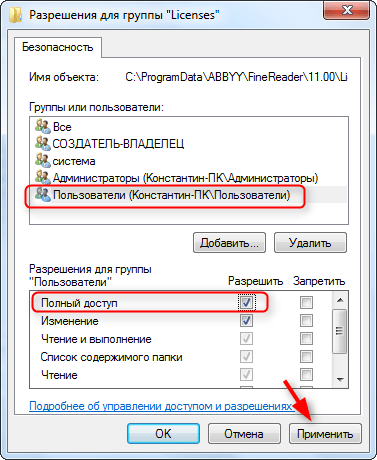
Читайте на нашем сайте: Как пользоваться FineReader
Таким образом исправляется ошибка доступа при установке и запуске FineReader. Надеемся, эта информация будет вам полезна.
Еще статьи по данной теме:
Помогла ли Вам статья?
|
Пользователь 47773 Заглянувший Сообщений: 4 |
#1 26.08.2010 09:24:07 Добрый день, настроил инфоблок Новости и экспорт новостей в RSS. Однако при клике на иконку RSS подписки на странице Новости появляется следующая ошибка «Ошибка разбора XML: синтаксическая ошибка (Строка: 1, Символ: 0)»
Подскажите пожалуйста как решить эту проблему? |
||
|
удалить первую строчку из вашего xml файла животное = зверь |
|
|
Пользователь 47773 Заглянувший Сообщений: 4 |
#3 26.08.2010 10:25:49
при удалении этой строчки, возникает ошибка уже во второй строчке <?xml version=»1.0″ encoding=»Windows-1251″?> |
||
|
Пользователь 57352 Посетитель Сообщений: 31 |
#4 26.08.2010 11:12:50 Ваш файл должен иметь вид подобный этому:
животное = зверь |
||
#1
Serg83
- Городсанкт-петербург
Отправлено 23 Апрель 2014 — 11:14
добрый день.
Яндекс-Маркет стал выдавать ошибки:
«Ошибки при разборе файла:
Предупреждение: Кодировка XML не определена (строка 0, столбец 0)
Фатальная ошибка: Ошибка парсинга XML: Error parsing XML feed: Unknown element ‘html’ (строка 1, столбец 6)»
Подскажите что случилось, если выгрузка идет с помощью встроенного сервиса Стореленд?
- Наверх
#2
Сake
Сake
-

- Модератоpы
-
- 5 979 сообщений
Активный участник

Отправлено 24 Апрель 2014 — 00:07
Пожалуйста, сообщите какой именно YML файл (приложите ссылку на файл) вы загружаете в яндекс.маркет?
- Наверх
#3
Serg83
Serg83
- Городсанкт-петербург
Отправлено 24 Апрель 2014 — 08:41
 Сake (24 Апрель 2014 — 00:07) писал:
Сake (24 Апрель 2014 — 00:07) писал:
Пожалуйста, сообщите какой именно YML файл (приложите ссылку на файл) вы загружаете в яндекс.маркет?
http://knife-for-lif…t/5803/1f538a64
- Наверх
#4
Serg83
Serg83
- Городсанкт-петербург
Отправлено 24 Апрель 2014 — 17:23
вопрос то как бы СРОЧНЫЙ!!! уже несколько дней не работает прайс на Маркете…
- Наверх
#5
Сake
Сake
-
- Модератоpы
-
- 5 979 сообщений
Активный участник
Отправлено 25 Апрель 2014 — 06:30
Вы верно адрес файла указываете маркету? Возможно проблема из-за определения типа документа. Сервер возвращает text/html, а должен по идее text/xml. Передам информацию о данной проблеме разработчикам.
- Наверх
#6
Serg83
Serg83
- Городсанкт-петербург
Отправлено 25 Апрель 2014 — 08:48
Сake (25 Апрель 2014 — 06:30) писал:
Вы верно адрес файла указываете маркету? Возможно проблема из-за определения типа документа. Сервер возвращает text/html, а должен по идее text/xml. Передам информацию о данной проблеме разработчикам.
Маркету адрес был сообщен года 1,5 назад и с тех пор ничего не менялось и работало отлично.
Прайс для Маркета генерирует Ваш сервис.
и до этой недели проблем не возникало.
еще раз повторюсь — уже неделю Маркет не работает из-за этих ошибок и мы теряем массу клиентов!
- Наверх
#7
support 2.0
support 2.0
-
- Модераторы
-
- 4 950 сообщений
Активный участник

Отправлено 25 Апрель 2014 — 20:03
Serg83 (25 Апрель 2014 — 08:48) писал:
Маркету адрес был сообщен года 1,5 назад и с тех пор ничего не менялось и работало отлично.
Прайс для Маркета генерирует Ваш сервис.
и до этой недели проблем не возникало.
еще раз повторюсь — уже неделю Маркет не работает из-за этих ошибок и мы теряем массу клиентов!
Возможно, фильтр, который у нас стоит от ddos периодически блокировал ip адрес от яндекс маркета. Бывало такое, что первый раз ошибка писалась в первой строчке и через 5 минут больше никаких ошибок не было обнаружено и файл корректно продолжал работать.
Мы написали в ДЦ. В течении сегодняшнего-завтрашнего дня ситуация должна пропасть.
- Наверх
#8
Serg83
Serg83
- Городсанкт-петербург
Отправлено 28 Апрель 2014 — 10:36
support 2.0 (25 Апрель 2014 — 20:03) писал:
Возможно, фильтр, который у нас стоит от ddos периодически блокировал ip адрес от яндекс маркета. Бывало такое, что первый раз ошибка писалась в первой строчке и через 5 минут больше никаких ошибок не было обнаружено и файл корректно продолжал работать.
Мы написали в ДЦ. В течении сегодняшнего-завтрашнего дня ситуация должна пропасть.
ок, пробуем снова включить Маркет
- Наверх
#9
Serg83
Serg83
- Городсанкт-петербург
Отправлено 28 Апрель 2014 — 15:52
благодарю, сейчас все работает корректно
- Наверх
#10
77mds77
77mds77
-
- Пользователи
-
- 3 сообщений
Новичок


Отправлено 07 Июль 2014 — 11:54
У меня такаже проблема:
Определена кодировка: utf-8 (строка 0, столбец 0)
Дата из файла: 2014-07-07 12:53 (строка 3, столбец 38)
Фатальная ошибка: Ошибка парсинга XML: Error parsing XML feed: Invalid character (Unicode: 0x15) (строка 1124, столбец 62)
SL-296570ПОМОГИТЕ!!!!СРОЧНО!!!!
- Наверх
#11
Сake
Сake
-
- Модератоpы
-
- 5 979 сообщений
Активный участник
Отправлено 08 Июль 2014 — 01:14
У вас по всей видимости некорректный символ расположен на строке 1124, столбец 62. Вам необходимо удалить этот символ. Например — если символ располагается в описании товара, то вам необходимо изменить описание товара. Если у вас не получится самостоятельно разобраться с данной проблемой, то приложите ссылку на ваш импортируемый файл с ошибкой.
- Наверх
#12
77mds77
77mds77
-
- Пользователи
-
- 3 сообщений
Новичок
Отправлено 09 Июль 2014 — 10:48
как это сделать, когда открывается этот yml файл в браузере???????
Цитата
- Наверх
#13
Сake
Сake
-
- Модератоpы
-
- 5 979 сообщений
Активный участник
Отправлено 10 Июль 2014 — 02:16
В браузере вам лучше не открывать содержимое файла, так как это будет не удобно для нахождения ошибки. Лучше всего скачать файл и открыть его для редактирования в блокноте, например notepad++. В данном случае будет отображаться номер строки и столбец. Главное не используйте стандартный windows блокнот для редактирования файла.
- Наверх
#14
77mds77
77mds77
-
- Пользователи
-
- 3 сообщений
Новичок
Отправлено 10 Июль 2014 — 14:13
Сake (10 Июль 2014 — 02:16) писал:
В браузере вам лучше не открывать содержимое файла, так как это будет не удобно для нахождения ошибки. Лучше всего скачать файл и открыть его для редактирования в блокноте, например notepad++. В данном случае будет отображаться номер строки и столбец. Главное не используйте стандартный windows блокнот для редактирования файла.
http://mds77.ru/expo…/12828/4c4e08e3
- Наверх
#15
Сake
Сake
-
- Модератоpы
-
- 5 979 сообщений
Активный участник
Отправлено 10 Июль 2014 — 23:55
По всей видимости анализатор яндекса не правильно информирует об возникшей ошибке, так как на строке 1124 проблем с символами нет. Проблема находится немного дальше, строка 1543 в товаре /goods/Setka-svarnaya-25-25-1-6-oc-1
Для исправления проблемы вам необходимо переписать название товара вручную. Ошибка могла возникнуть при копировании текста из другого документа.
- Наверх
#16
Serg83
Serg83
- Городсанкт-петербург
Отправлено 18 Август 2014 — 10:35
Господа админитраторы, снова началась такая же ошибка в Маркете!!!
исправьте уже свои ddos фильтры!
ошибка повторяется уже несколько дней
«Ошибки при разборе файла:
Предупреждение: Кодировка XML не определена (строка 0, столбец 0)
Фатальная ошибка: Ошибка парсинга XML: Error parsing XML feed: Unknown element ‘html’ (строка 1, столбец 6)»
- Наверх
#17
support 2.0
support 2.0
-
- Модераторы
-
- 4 950 сообщений
Активный участник
Отправлено 18 Август 2014 — 23:02
Serg83 (18 Август 2014 — 10:35) писал:
Господа админитраторы, снова началась такая же ошибка в Маркете!!!
исправьте уже свои ddos фильтры!
ошибка повторяется уже несколько дней
«Ошибки при разборе файла:
Предупреждение: Кодировка XML не определена (строка 0, столбец 0)
Фатальная ошибка: Ошибка парсинга XML: Error parsing XML feed: Unknown element ‘html’ (строка 1, столбец 6)»
DDOS не исправляют. Ddos это атака на сервера. Что касается фильтра от ddos, то работает он исправно. 17.08 около 12.00 по Московскому времени дос-атака прекратилась, соответственно все должно с этого момента работать исправно.
- Наверх
#18
Serg83
Serg83
- Городсанкт-петербург
Отправлено 21 Август 2014 — 09:29
прайс отправляется в яндекс на проверку ежедневно!!!
ответы идентичны, вот копия от 20-го августа:
Ошибки при разборе файла:
Предупреждение: Кодировка XML не определена (строка 0, столбец 0)
Фатальная ошибка: Ошибка парсинга XML: Error parsing XML feed: Unknown element ‘html’ (строка 1, столбец 6)
———————————-
С поисковиками тоже проблемы с 16-го числа.
все переходы считаются внутренними переходами с сайта… отдельно завел тему на этот счет.
——————————-
с Робокассой тоже проблемы!
уведомления не приходят (по крайней мере вчера-сегодня) и в админке сайта статус заказа также автоматически не меняетяс после оплаты заказа клиентом
- Наверх
#19
Serg83
Serg83
- Городсанкт-петербург
Отправлено 24 Август 2014 — 20:46
ау!!!!
и где обещанные решения проблемы?!
я вам уже каждый день в течение недели звоню и каждый день одно и тоже — «да, да, сегодня ответим»…
- Наверх
#20
Serg83
Serg83
- Городсанкт-петербург
Отправлено 25 Август 2014 — 11:17
Убрав скрипт аб теста по совету в соседней ветке, прайс прошел проверку.
Только вопросы остались.
1) почему именно с 16 августа аб тест стал мешать Яндекс-маркету
2) возможно ли проведение аб тестирования без подобных ошибок?
- Наверх
Содержание:
1. XML – расширяемый язык разметки
2. Устранение Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
1. XML – расширяемый язык разметки
В данной статье речь пойдёт о причинах возникновения фатальной ошибки «Ошибка разбора XML» и способах устранения данной неполадки. Также будет дана инструкция не по устранению, но «обходу» ошибки, то есть действиям на опережение.
XML (с английского – extensible markup language – расширяемый язык разметки) – это язык разметки, который рекомендует Консорциум Всемирной паутины. Обычно язык разметки XML служит для описания документации, соответствующего типа, а также описывает действия соответствующих процессоров. Расширяемый язык разметки имеет довольно простой синтаксис, поэтому используется по всему миру, чтобы создавать и обрабатывать документацию программным способом. Он создавался именно для использования в Интернете. XML назвали именно расширяемым языком разметки, так как в нём нет фиксации разметки, которая содержится внутри документа, а именно: программист может создавать любую разметку, а ограничения будут встречаться лишь в синтаксисе.
2. Устранение Ошибки разбора XML в 1С
«Ошибка разбора XML» возникает исключительно в тонком клиенте 1С. Также стоит отметить, что «Ошибка разбора XML» также довольна схожа с ошибкой по формату потока, которая возникает в толстом клиенте. Обычно в 1С «Ошибка разбора XML» возникает по причине наличия кэша метаданных. И если очистить кэш, то ошибка будет устранена. Выглядит окно с ошибкой, а также окно с комментариями от технической поддержки следующим образом:
Рис. 1 Окно Ошибки разбора XML в 1С
XML данные читаются по потокам, так что в каждый из моментов времени объект «сосредоточен» в некотором узле XML. Из-за этого также может возникать фатальная ошибка «Ошибка разбора XML». Для того чтобы её устранить, можно вызвать функцию «ИсключениеЧтенияXml», как показано на скриншоте примера ниже:

Рис. 2 Вызов функции ИсключениеЧтенияXML для устранения Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
Данные два способа (очистка кэша метаданных и функция «ИсключениеЧтенияXml») – не все возможные варианты устранения ошибки разбора XML. Далее рассмотрим нестандартный подход, который позволит избежать ошибки еще до её возникновения.
Для наглядности будем работать в конфигурации 1С:Бухгалтерия предприятия, одной из наиболее распространенных программ фирмы 1С. У многих людей, которые пользуются программой 1С:Отчётность появляются неполадки при попытках открыть данные/файлы от налоговой. Чтобы открыть такой файл повторяем следующие действия:
· Переходим по пути: «Настройки 1С:Отчётности → Журнал обмена с контролирующими органами», как показано на скриншоте ниже:

Рис. 3 Настройка 1С Отчетности
· Далее кликаем на «Запросы» и выделяем ту выписку, которую не было возможности открыть из-за ошибки, как продемонстрировано на скриншоте ниже:

Рис. 4 Выбор выписки с Ошибкой разбора XML в 1С
· Обращаем внимание на стадию отправки, которая располагается внизу этого сообщения, и кликаем два раза на зелёный круг:

Рис. 5 Стадия отправки документа с Ошибкой разбора XML в 1С
· Появляется транспортное сообщение, в нём кликаем на «Выгрузить» и выбираем папку, куда необходимо провести выгрузку, после чего сохраняем данный файл. Пробуем открыть его, при помощи любого из графических редакторов, который может поддерживать формат PDF, как показано на скриншоте ниже:

Рис. 6 Результат обхода Ошибки разбора XML в 1С
· Всё успешно открылось, а ошибка даже не успела возникнуть.
Специалист компании «Кодерлайн»
Айдар Фархутдинов
Исправление ошибок сканирования в ABBYY Finereader
Abbyy Finereader – программа для распознавания текста с изображениями. Источником картинок, как правило, является сканер или МФУ.
Прямо из окна приложения можно произвести сканирование, после чего автоматически перевести изображение в текст.
Кроме того, Файн Ридер умеет сконвертировать полученные со сканера изображения в формат PDF и 2, что полезно при создании электронных книг и документации для последующей печати.
Как устранить проблему: ABBYY Finereader не видит сканер.
Для корректной работы Abbyy Finereader 14 (последняя версия) на компьютере должны выполняться следующие требования:
- процессор с частотой от 1 ГГц и поддержкой набора инструкций SSE2;
- ОС Windows 10, 8.1, 8, 7;
- оперативная память от 1 Гб, рекомендованная – 4Гб;
- TWAIN- или WIA-совместимое устройство ввода изображений;
- доступ в интернет для активации.
Если ваше оборудование не отвечает данным требованиям, программа может работать некорректно. Но и при соблюдении всех условий, Abbyy FineReader часто выдаёт разные ошибки сканирования, такие как:
- невозможно открыть источник TWAIN;
- параметр задан неверно;
- внутренняя программная ошибка;
- ошибка инициализации источника.
В подавляющем большинстве случаев проблема связана с самим приложением и его настройками. Но иногда ошибки возникают после обновления системы либо после подключения нового оборудования. Рассмотрим наиболее распространённые рекомендации, что делать, если ABBYY FineReader не видит сканер и выдаёт сообщения об ошибках.
Исправление ошибок
Есть ряд общих советов по исправлению некорректной работы:
- Обновите драйверы оборудования до последних версий с официального сайта производителя.
- Проверьте права текущего пользователя в системе, при необходимости повысьте уровень доступа.
- Иногда помогает установка более старой версии приложения, особенно если вы работаете на не новом оборудовании.
- Проверьте, видит ли сканер сама система. Если он не отображается в диспетчере устройств или показан с жёлтым восклицательным знаком, то проблема в оборудовании, а не программе. Обратитесь к инструкции или в техподдержку производителя.
- На официальном сайте ABBYY работает неплохая техническая поддержка https://www.abbyy.com/ru-ru/support. Вы можете задать вопрос, подробно описав конкретно свою проблему, и получить профессиональное решение из первых рук абсолютно бесплатно.
Устранение ошибки «Параметр задан неверно»
В последней версии ABBYY FineReader также может носить название «Ошибка инициализации источника». Инициализация – это процесс подключения и распознавания системой оборудования.
Если Файн Ридер не видит сканер при запуске диалогового окна сканирования и выдаёт такие ошибки, то должны помочь следующие действия:
- Перезапустите программу FineReader.
- Зайдите в меню «Инструменты», выберите «OCR-редактор».
- Нажмите «Инструменты», потом «Настройки».
- Включите раздел «Основные».
- Перейдите к «Выбор устройства для получения изображений», затем «Выберите устройство».
- Нажмите на выпадающий список доступных драйверов. Проверьте работоспособность сканирования поочерёдно с каждым из списка. В случае успеха с каким-то из них, используйте его в дальнейшем.
ВНИМАНИЕ. Возможна и такая ситуация, что ни с каким из доступных драйверов выполнить сканирование не получилось. Тогда нажмите «Использовать интерфейс сканера».
Если и это не помогло, вам понадобится утилита TWAIN_32 Twacker. Её можно скачать с официального сайта ABBYY по ссылке ftp://ftp.abbyy.com/TechSupport/twack_32.zip.
После этого следуйте инструкции:
- Выйдите из Файн Ридер.
- Распакуйте архив twack_32.zip в любую папку.
- Дважды щёлкните по Twack_32.exe.
- После запуска программы зайдите в меню «File», затем «Acquire».
- Нажмите «Scan» в открывшемся диалоге.
- Если документ успешно отсканировался, откройте меню «File» и щёлкните «Select Source».
- Синим цветом окажется отображён драйвер, через который утилита успешно выполнила сканирование.
- Выберите этот же файл драйвера в файнридере.
Если при запуске в Abbyy Finereader этого сделать опять не удалось, значит, проблема в работе программы. Отправьте запрос в техническую поддержку ABBYY. Если же и 32 Twacker не смог выполнить команду «Scan», то, вероятно, некорректно работает само устройство или его драйвер. Обратитесь в техподдержку производителя сканера.
Внутренняя программная ошибка
Бывает, что при запуске сканирования приложение сообщает «Внутренняя программная ошибка, код 142». Она обычно связана с удалением или повреждением системных файлов программы. Для исправления и предотвращения повторных появлений выполните следующее:
- Добавьте Fine Reader в исключения антивирусного ПО.
- Перейдите в «Панель управления», «Установка и удаление программ».
- Найдите Fine Reader и нажмите «Изменить».
- Теперь выберите «Восстановить».
- Запустите программу и попробуйте отсканировать документ.
Иногда Файнридер может не видеть сканер из-за ограничений в доступе. Запустите программу от имени администратора либо повысьте права текущего пользователя.
Как распознать текст со сканера
Покажу как это сделать быстро и качественно на примере программы Abbyy FineReader версии 8.0. Принципы, изложенные здесь, можно с успехом применить и в любой другой программе распознавания текста, и в любой другой версии программы FineReader. FineReader на пост-советском пространстве – самая распространённая и успешная программа для этой задачи.
Итак, для того чтобы получить отличный результат нам нужно качественно сосканировать оригинал. Легче всего этого достичь с листов формата А4, распечатанных на принтере, труднее с книг, журналов, газет. Качество сканирования – основа, от которой будет зависеть дальнейший успех работы.
Несколько слов об автоматизации процессов распознавания.
Хотя от версии к версии авторы программы FineReader улучшают алгоритмы автоматического распознавания сложных макетов (Scan&Read – когда достаточно запустить программу и нажать одну кнопку, а остальное программа сделает за Вас сама, и Вам остаётся лишь насладиться результатами процесса), эти алгоритмы срабатывают не всегда корректно. Искусственный интеллект ещё не скоро заменит человеческую смекалку и здравый смысл. Причиной чего и послужило написание этой статьи.
Сканирование текста
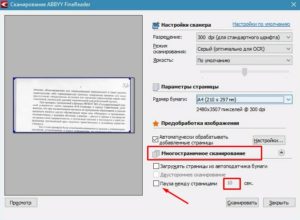
Запускаем программу Abbyy FineReader, нажимаем кнопочку «Сканировать», ложим наш оригинал в сканер и делаем пробное сканирование. Для оптимальной скорости и качества сканирования в драйвере сканера достаточно выставить режим сканирования «Чёрно-белое» и разрешение 300 точек на дюйм.
Если мы используем для сканирования twain-драйвер Mustek точно так же выбираем режим сканирования «Чёрно-белое» (Black-white) и выставляем разрешение 300 dpi. При необходимости понижаем уровень шума регулирование яркости-контрастности либо уровнями
Если мы используем для сканирования «Мастер работы со сканером или цифровой камерой» — выбираем «Чёрно-белое изображение», а в Настройках — «разрешение» , в свойствах «Мастера работы со сканером или цифровой камерой» выставляем разрешение и регулируем яркость
Если у нас сканер Epson, либо какой-то другой, в twain-драйвере точно так же ищем пункты «Тип изображения» («Image Type») — чёрно-белое (black-white, b/w), Разрешение («Resolution») — выставляем 300dpi и при необходимости регулируем «Яркость-контрастность», либо «Уровни», либо «Светлые и тёмные тона»
Режимы «Оттенки серого» и «Цветное изображение» тоже подходят, но от этого увеличивается время сканирования и возможно, пострадает качество распознавания текста (Серый или цветной фон, особенно если он неоднородный может существенно ухудшить качество распознавания текста).
В идеале нам нужно добиться чтобы на белом фоне были чёрные буквы и больше никаких посторонних объектов.
Смотрим на результат, если он нас устраивает: буквы видно отчётливо, шума, грязи практически нет, то продолжаем сканирование далее, если шума много (такое бывает, например, если оригинал отпечатан на жёлтой бумаге) – ползунками яркости и контрастности двигаем так, чтобы шум максимально пропал, а буквы стало видно более отчётливо, делаем ещё несколько пробных сканирований пока не добьёмся нужного результата. Как только приемлемый результат получен – приступаем к основному сканированию. Если нам нужно сканировать одновременно участки текста из разных источников (несколько книг, журналов, газетных вырезок), то такую калибровку для достижения приемлемого результата часто приходится делать для каждого источника отдельно.
Поворот страниц
В программу FineReader встроен механизм автоматического определения ориентации страниц и автоматического же их поворота.
В простых случаях этот механизм отлично работает и не требует от нас никакого участия, но если текст видно не очень отчётливо, либо если разные страницы отсканирываны под разными углами, здесь мы получаем сбой и в результате получаем вместо текста абракадабры. Потому имеет смысл осуществлять поворот вручную.
Выделяем несколько страниц, повёрнутых в одинаковую сторону с зажатой клавишей «Ctrl» и поворачиваем при помощи меню правой кнопки мыши
Распознавание текста
Сосканировав все листы документа можно приступать к его распознаванию. Выбираем язык распознаваемого документа.
Это важно потому что буквы в разных языках разные и если, например мы будем распознавать украинский текст как русский, то в конечном результате в распознанном тексте будет распознано практически всё более-менее правильно, но украинские буквы «і», «ї» «є» не будут распознаны и FineReader заменит их на что-то более-менее похожее и в конце прийдётся все эти огрехи выправлять вручную. То же самое бывает когда в русском тексте встречаются адреса электронной почты, сайтов, какие-то слова, набранные на иностранном языке, а мы текст распознаём как «русский», то эти символы FineReader заменит на что-то более-менее похожее из русского алфавита. В таком случае перед распознаванием нужно FineReader-у указать, что текст состоит из нескольких языков, отметив нужные галочками. Не стоит также злоупотреблять выбором языков, отметив все возможные какие есть. В этом случае мы тоже можем в результате получить «катавасию» из всех возможных символов вместо искомого результата.
Следующий пункт после выбора языка распознавания – анализ макета, то есть нам нужно разобрать страницы нашего документа на составляющие: текстовые блоки, таблицы и изображения. В случае если мы имеем дело с простым текстом, набранным на листах формата А4, то этот пункт можно смело пропускать.
Программа FineReader отлично справится с этим и сама. В противном случае нужно ещё немного поработать ручками. В данном случае я запускаю процесс автоматического анализа макета всех страниц и по его окончании просматриваю результаты, и в случае неправильного анализа вручную его поправляю.
Программа не всегда правильно различает области текста, иногда таблицы путает с текстом, картинки с текстом, текст с картинками, иногда области с тенями, пятнами воспринимает как текст, не всегда нам в конечном результате нужно чтобы присутствовали номера страниц, колонтитулы исходного материала и т.д.
Наша задача – выправить эти огрехи ещё на стадии подготовительных работ. Сейчас это сделать намного легче, чем править уже на последнем этапе работ.
Когда макеты разобраны можно приступать непосредственно к самому процессу распознавания. То есть нам нужно просто нажать на кнопочку «Распознать» и, откинувшись в кресле, дождаться окончания процесса распознавания.
А по его окончании, бегло глянув на распознанные страницы, убедиться что тексты, таблицы и прочие объекты распознаны корректно, т.е.
процентов на 90-95 (в идеале конечно на все 100) и можно приступать к завершающему этапу работ: постбоработке и сохранению результатов.
Несмотря на все наши предыдущие старания огрехи распознавания будут, и их количество зависит от того, на сколько старательно мы выполняли предыдущие этапы. FineReader помогает нам в этом, подсвечивая участки, в качестве распознавания которых он не уверен, синим цветом. На них мы обращаем внимание в первую очередь и если эти участки распознаны неверно – поправляем их.
Сохранение результатов распознавания можно сделать двумя способами: непосредственно в текстовый редактор (например Microsoft Word) или через буфер обмена. Первый способ нам может пригодиться когда нам нужно максимально сохранить исходное форматирование документа: заголовки, шрифты, взаимное расположение текстовых колонок и графических элементов. Но иногда исходное форматирование нам не нужно и более того, вредно, потому что в текстовом редакторе потом бывает очень сложно потом разобраться что за чем идёт и почему, и как, как сделать по другому, так как нам это будет нужно. При передаче текста через буфер обмена мы избегаем этих моментов и на выходе имеем чистый текстовый массив, который можем уже обрабатывать форматировать на наше усмотрение. И уже в Ворде мы выполняем последний этап работ: убираем лишние детали: множественные пробелы, пробелы перед запятыми, точками, знаки табуляции, исправляем кавычки, знаки тире, исправляем неправильно распознанные участки текста и т.д.Ну и завершающий этап работ – собственно для чего это всё и затевалось: толи нам нужен был просто распознанный текст, толи нам нужно в него внести изменения для дальнейшей работы.
Как работать в ABBYY FineReader 12
26.01.2016
| Функциональное решение для сканирования документов ABBYY FineReader предоставляет возможность пользователю выбрать, в каком из популярных текстовых форматов сохранить файл. Помимо сканирования документации программа может перевести текстовую информацию из формата Word, например, в файл PDF обратно.ABBYY FineReader 12, имеющаяся в наличии в SoftMagazin, обладает множеством полезных функций и значительно упрощает процесс распознавания текста и перевода его в формат PDF.Как пользоваться программой ABBYY FineReader 12, описано в инструкции к программе, однако у пользователей могут остаться некоторые вопросы по ее настройке и запуску. В данном обзоре будут даны ответы о работе в ABBYY FineReader, как пользоваться этой программой, в частности последними ее версиями. |
ABBYY FineReader: как работатьДля эффективной работы со сканируемыми документами нужно знать, для чего нужна ABBYY FineReader, как пользоваться основными функциями программы и правильно запускать ее. Инструмент для сканирования предельно точно распознает текст в выбранном печатном документе, не перенося постранично информацию. Кроме того, программа старается сохранить шрифты, колонтитулы и разметку текста на странице максимально близко к оригиналу.Особых различий в версии ABBYY FineReader 11, и как пользоваться 12 выпуском программы не наблюдается. Обе версии отличаются наличием хорошего функционала, поддержкой более 150 языков, в том числе и языков программирования и математических формул. Чтобы начать пользоваться программой, достаточно установить лицензионную версию на домашний или рабочий ПК и запустить ярлык ABBYY FineReader с рабочего стола или из меню Пуск. |
Как установить ABBYY FineReader 11Для установки программы на ПК нужно после приобретения лицензии, запустить из папки с программой или диска файл setup.exe и выбрать один из видов инсталляции. Обычный режим установит FineReader в стандартной конфигурации на компьютер. В процессе установки необходимо будет выбрать язык интерфейса, место размещения программы и другие стандартные пункты по установке. |
Как запустить ABBYY FineReaderЗапустить ярлык с рабочего стола компьютераВыбрать в меню Пуск раздел Программы и запустить ABBYY FineReaderЕсли вы пользуетесь приложениями Microsoft Office, то достаточно нажать на инструментальной панели значок программыВыберите в проводнике нужный документ и нажав правой кнопкой мыши, выберите в появившемся меню «Открыть с помощью ABBYY FineReader». |
Как настроить ABBYY FineReader 12 ProfessionalПрофессиональная версия ABBYY FineReader приобретается организациями для эффективной работы с программой в корпоративной сети и совместного редактирования файлов. Настройка и запуск ABBYY FineReader 12 Professional функционально не отличается от установки других версий. Инструмент автоматически распознает языки, сложные таблицы и списки, так что практически не требуется дополнительного редактирования.Все автоматические функции могут использоваться в ручном режиме. Для комфортной работы перейдите на панели инструментов в «Сервис» и выберите пункт «Настройки», чтобы отрегулировать параметры. Можно самостоятельно задать настройки вида документа, режима сканирования, распознавания и сохранения файла. |
ABBYY FineReader — как переводитьДля качественной конвертации документов в программе предусмотрены встроенные стандартные задачи, используя которые можно перевести документ в нужный формат, затратив минимум усилий. Стандартные настройки предлагают перевести текстовый файл в документ Word, создать таблицу Exel, конвертировать в PDF-файл и другие нужные форматы. После выбора действия нужно будет указать язык распознавания, режим распознавания (цветной или черно-белый) и задать дополнительные пункты распознавания. |
<
ABBYY FineReader: как распознать текстДля качественной конвертации полученной информации в PDF-формат, программа должна ее распознать. В ABBYY FineReader можно установить режим автоматического распознавания текста или ручного. Качество отсканированного документа можно отрегулировать настройками распознавания, такими как: режим сканирования, язык распознавания, тип печати и многое другое. Перед распознаванием текста, на этапе сканирования программа будет работать по одному из стандартных сценариев, который можно выбрать.В меню выберите «Сервис», перейдите в «Опции» и укажите режим распознавания: тщательное или быстрое распознавание. Тщательный режим будет удобен для работы с некачественными текстовыми файлами, текстами на цветном фоне или сложными таблицами. Быстрое распознавание рекомендовано для больших объемов файлов или когда ограничены временные рамки. |
Как в ABBYY FineReader изменить текстЧтобы не возникало сложностей при редактировании в ABBYY FineReader 12, как изменить текст в этой программе, разработчики создали интуитивно понятный интерфейс и удобную навигацию по пунктам. Отредактировать текст можно двумя способами: непосредственно в окне «Текст», либо выбрав на панели инструментов «Сервис» и далее «Проверка». Доступные средства для изменения текста находятся над окном «Текст» и включают в себя стандартный набор для редактирования шрифта, его размера, отступов и замены символов. Для редактирования непосредственно PDF-изображения, нужно зайти в меню в «Редактор изображений» и выбрать из списка нужную функцию. |
ABBYY FineReader 12 Professional — бессрочная лицензия
Обзор ABBYY FineReader 12
← Назад к списку
, Понедельник-четверг с 09.00 до 19.00
Пятница с 09.00 до 18.00
Как распознать отсканированный текст при помощи Abbyy FineReader!
Здравствуйте. Сегодня я расскажу о том, как с помощью программы Abbyy FineReader распознать текст c изображения, которое вы могли получить в результате сканирования.
Ваш сканированный текст будет полностью в документе Microsoft Word и этот распознанный текст можно будет редактировать! Распознать текст при помощи Abbyy Finereader может пригодиться тем, кто учится, работает с текстами и переводами. Программа, к сожалению, является платной.
Как-то доводилось попробовать одну из бесплатных вариантов аналогичных программ, но весьма хорошо отсканированный текст распознается просто ужасно… А распознать текст в Abbyy FineReader получается весьма качественно! Сейчас я покажу как пользоваться программой Abbyy FineReader для быстрого распознавания текста с изображения.
ABBYY FineReader имеет пробную версию на 30 дней с возможностью распознавания до 100 страниц и сохранением не более 3-х страниц из документа. Т.е. в течение этого времени вы можете увидеть возможности программы и принять взвешенное решение — нужна ли она вам, стоит ли её покупать или нет.
Как установить Abbyy FineReader!
Перед тем как пользоваться Abbyy Finereader её необходимо установить. Рассмотрим процесс установки этой программы…
Для начала выбираем язык программы. Нажимаем «ОК».
Принимаем условия лицензионного соглашения (при желании можно прочесть лицензионный договор, если вам интересно о чём там речь). Нажимаем «Далее».
Далее вы должны выбрать режим установки.
При обычном режиме программа не спросит вас и установит то, что в программе задано по умолчанию, а именно — все компоненты: саму программу Abbyy Finereader для распознавания текста, компонент для программ Microsoft Office и компонент для проводника Windows (позволяющий быстро распознавать изображения, не открывая отдельно программу). Советую отметить выборочную установку чтобы настроить так, как вам нужно. Тем более это не займет и 15 минут 🙂 Внизу указана папка куда установится программа. Желательно оставить выбор по умолчанию, чтобы потом не было никаких проблем при использовании программы. Нажимаем «Далее».
Компоненты программы. Это окно как раз появится в случае, если вы выберите тип установки «Выборочная». Компоненты — это что-то вроде вспомогательных приложений к программе. Первый компонент «Интеграция с программами Microsoft Office и Проводником Windows».
Этот компонент будет отображен в меню Microsoft Office и если вы щелкните по изображению у себя на компьютере правой кнопкой мыши, то там будет пункт с этой программой. Вот так будет выглядеть ваше меню в Microsoft Office после добавления этого компонента.
А вот что будет если вы щелкните правой кнопкой мыши по изображению:
Т.е. появится меню, в котором вы можете сделать быстрое распознавание текста с отправкой результатов в Word, Excel или PDF.
Второй компонент позволит вам распознать текст с экрана компьютера. Это значит, что вы сможете сделать скриншот и также распознать текст. Если вы не хотите устанавливать один из этих компонентов, или вовсе не хотите устанавливать оба, то нужно нажать на стрелочку вниз и выбрать «Данный компонент будет недоступен». Тогда компонент установлен не будет. Я оставила оба.
Далее 4 пункта. 1-ый означает то, что сведения о том, как вы пользуетесь программой Abbyy Finereader будут переданы разработчику. Данный пункт советую не отмечать, чтобы программа лишний раз не выходила в интернет ради отправки сведений о работе с ней.
Тем более, мало ли какие ещё сведения будут отправляться 🙂 2-ой пункт создает ярлык программы на рабочем столе. 3-ий означает, что программа будет запускаться при включении компьютера, а 4-ый будет проверять обновления программы. Я оставляю только второй и напротив него оставляю галочку.
Закрываем все приложения Microsoft Office, потому что так требует установщик и нажимаем «Установить».
Нужно подождать пару минут чтобы программа загрузилась и нажать «Далее».
Все, установка завершена! Нажимаем «Готово».
Как при помощи Abbyy Finereader распознать текст c отсканированного или любого другого изображения?
Рассмотрим, как пользоваться программой. К примеру, у вас есть отсканированный текст. Теперь, чтобы распознать текст в Abbyy FineReader, открываем программу. Нажимаем «Открыть».
Выбираем нужное нам изображение и нажимаем открыть.
Когда вы откроете нужный документ, Abbyy Finereader начнёт распознавать текст. Чем больше документ, тем дольше будет длиться распознавание. Распознавание одной страницы может занять несколько секунд.
После того как текст распознается вам останется только сохранить результат в документ Microsoft Word, чтобы затем вы могли отредактировать в нём что угодно. Для этого нажмите кнопку «Сохранить» на верхней панели инструментов, после чего выберите в какую папку будет сохранён документ Word и под каким названием.
Если у вас подключён к компьютеру сканер, то вы можете запустить сканирование прямо из программы, и после чего отсканированный документ сразу будет распознаваться. Для этого на верхней панели инструментов нажмите кнопку «Сканировать». Далее действия будут зависеть от программы-драйвера для вашего принтера. Вам нужно только следовать указаниям мастера сканирования.
Как видите, все очень просто и быстро. Теперь вы знаете, как пользоваться Abbyy FineReader для распознавания текста с изображений! Надеюсь, что эта информация очень поможет многим:) Удачи!
Содержание:
1. XML – расширяемый язык разметки
2. Устранение Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
1. XML – расширяемый язык разметки
В данной статье речь пойдёт о причинах возникновения фатальной ошибки «Ошибка разбора XML» и способах устранения данной неполадки. Также будет дана инструкция не по устранению, но «обходу» ошибки, то есть действиям на опережение.
XML (с английского – extensible markup language – расширяемый язык разметки) – это язык разметки, который рекомендует Консорциум Всемирной паутины. Обычно язык разметки XML служит для описания документации, соответствующего типа, а также описывает действия соответствующих процессоров. Расширяемый язык разметки имеет довольно простой синтаксис, поэтому используется по всему миру, чтобы создавать и обрабатывать документацию программным способом. Он создавался именно для использования в Интернете. XML назвали именно расширяемым языком разметки, так как в нём нет фиксации разметки, которая содержится внутри документа, а именно: программист может создавать любую разметку, а ограничения будут встречаться лишь в синтаксисе.
2. Устранение Ошибки разбора XML в 1С
«Ошибка разбора XML» возникает исключительно в тонком клиенте 1С. Также стоит отметить, что «Ошибка разбора XML» также довольна схожа с ошибкой по формату потока, которая возникает в толстом клиенте. Обычно в 1С «Ошибка разбора XML» возникает по причине наличия кэша метаданных. И если очистить кэш, то ошибка будет устранена. Выглядит окно с ошибкой, а также окно с комментариями от технической поддержки следующим образом:
Рис. 1 Окно Ошибки разбора XML в 1С
XML данные читаются по потокам, так что в каждый из моментов времени объект «сосредоточен» в некотором узле XML. Из-за этого также может возникать фатальная ошибка «Ошибка разбора XML». Для того чтобы её устранить, можно вызвать функцию «ИсключениеЧтенияXml», как показано на скриншоте примера ниже:
Рис. 2 Вызов функции ИсключениеЧтенияXML для устранения Ошибки разбора XML в 1С
3. «Обход» Ошибки разбора XML в 1С
Данные два способа (очистка кэша метаданных и функция «ИсключениеЧтенияXml») – не все возможные варианты устранения ошибки разбора XML. Далее рассмотрим нестандартный подход, который позволит избежать ошибки еще до её возникновения.
Для наглядности будем работать в конфигурации 1С:Бухгалтерия предприятия, одной из наиболее распространенных программ фирмы 1С. У многих людей, которые пользуются программой 1С:Отчётность появляются неполадки при попытках открыть данные/файлы от налоговой. Чтобы открыть такой файл повторяем следующие действия:
· Переходим по пути: «Настройки 1С:Отчётности → Журнал обмена с контролирующими органами», как показано на скриншоте ниже:
Рис. 3 Настройка 1С Отчетности
· Далее кликаем на «Запросы» и выделяем ту выписку, которую не было возможности открыть из-за ошибки, как продемонстрировано на скриншоте ниже:
Рис. 4 Выбор выписки с Ошибкой разбора XML в 1С
· Обращаем внимание на стадию отправки, которая располагается внизу этого сообщения, и кликаем два раза на зелёный круг:
Рис. 5 Стадия отправки документа с Ошибкой разбора XML в 1С
· Появляется транспортное сообщение, в нём кликаем на «Выгрузить» и выбираем папку, куда необходимо провести выгрузку, после чего сохраняем данный файл. Пробуем открыть его, при помощи любого из графических редакторов, который может поддерживать формат PDF, как показано на скриншоте ниже:
Рис. 6 Результат обхода Ошибки разбора XML в 1С
· Всё успешно открылось, а ошибка даже не успела возникнуть.
Специалист компании «Кодерлайн»
Айдар Фархутдинов

FineReader — чрезвычайно полезная программа для конвертации текстов из растрового в цифровой формат. Ее часто применяют для редактирования конспектов, сфотографированных объявлений или статей, а также отсканированных текстовых документов. При установке или запуске FineReader может возникнуть ошибка, которая отображается как «Нет доступа к файлу».
Попробуем разобраться, как устранить эту проблему и пользоваться распознавателем текстов в своих целях.
Скачать последнюю версию FineReader
Как исправить ошибку доступа к файлу в FineReader
Ошибка при установке
Первое, что нужно проверить при возникновении ошибки доступа — проверить, не включен ли антивирус на вашем компьютере. Выключите его, если он активен.
В том случае, если проблема осталась, проделайте следующие шаги:
Нажмите «Пуск» и щелкните правой кнопкой мыши на «Компьютер». Выберите «Свойства».
Если у вас установлена Windows 7, щелкните на «Дополнительные параметры системы».
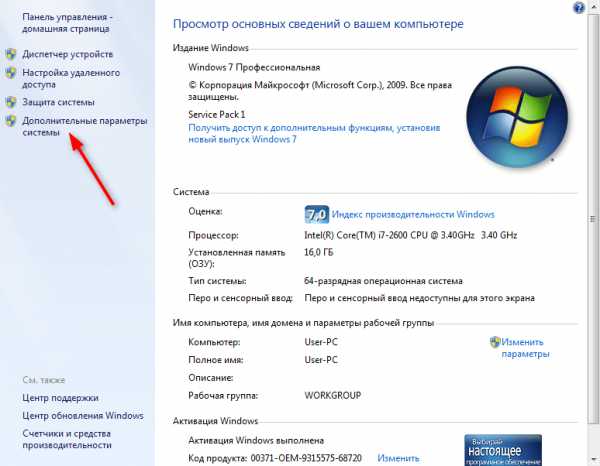
На вкладке «Дополнительно» найдите внизу окна свойств кнопку «Переменные среды» и нажмите ее.
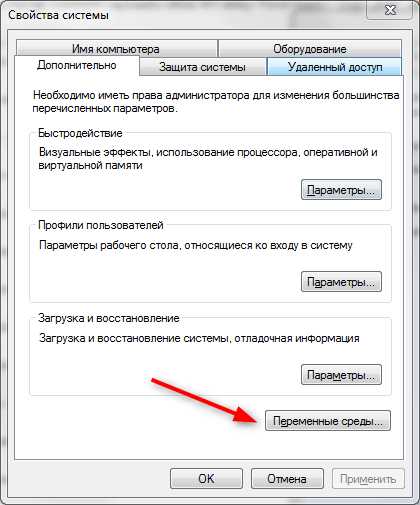
В окне «Переменные среды выделите строку TMP и нажмите кнопку «Изменить».

В строке «Значение переменной» пропишите C:Temp и нажмите «ОК».
Проделайте тоже самое для строки TEMP. Щелкните «ОК» и «Применить».
После этого попробуйте начать установку заново.
Установочный файл всегда запускайте от имени администратора.
Ошибка при запуске
Ошибка доступа при запуске возникает в том случае, если пользователь не имеет полного доступа к папке «Licenses» на своем компьютере. Исправить это достаточно просто.
Нажмите сочетание клавиш Win+R. Откроется окно «Выполнить».
В строке этого окна введите C:ProgramDataABBYYFineReader12.0 (или другое место, куда установлена программа) и нажмите «ОК».
Обратите внимание на версию программы. Прописывайте ту, которая установлена у вас.
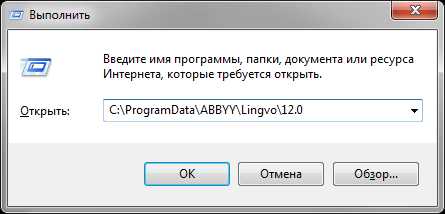
Найдите в каталоге папку «Licenses» и, щелкнув по ней правой кнопкой мыши, выберите «Свойства».
На вкладке «Безопасность» в окне «Группы или пользователи» выделите строку «Пользователи» и нажмите кнопку «Изменить».
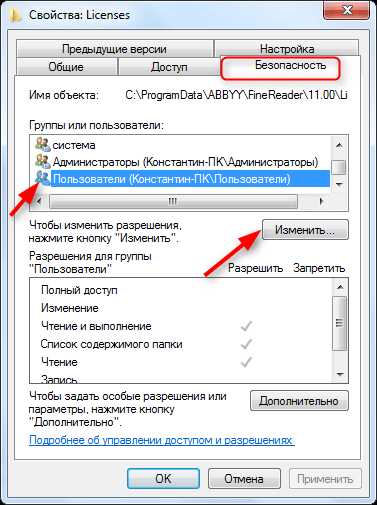
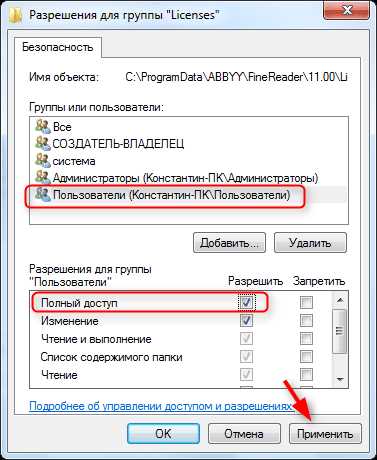
Снова выделите строку «Пользователи» и установите галочку напротив «Полный доступ». Нажмите «Применить». Закройте все окна, нажимая «ОК».
Читайте на нашем сайте: Как пользоваться FineReader
Таким образом исправляется ошибка доступа при установке и запуске FineReader. Надеемся, эта информация будет вам полезна.
Мы рады, что смогли помочь Вам в решении проблемы.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Помогла ли вам эта статья?
ДА НЕТ
lumpics.ru
Ошибка при запуске программы «Нет доступа к файлу C:ProgramDataABBYYLingvo12.0LicensesLicensing.bin»
Номер статьи: 1060 |
Категория: Общие вопросы |
Тип: Патч |
Последнее обновление: 21.08.2012
Ошибка при запуске программы «Нет доступа к файлу C:ProgramDataABBYYLingvo12.0LicensesLicensing.bin»
Описание
Программа установилась, но при запуске возникает сообщение
«Нет доступа к файлу C:ProgramDataABBYYLingvo12.0LicensesLicensing.bin».
Причина
Такая ситуация может возникать в случае, если у пользователя не установлены права
Полный доступ (Full control) на папку Licenses и файлы в ней, в том числе и на файл Licensing.bin.
Решение
1. Откройте командную строку через Пуск (Start)>Выполнить (Run). Если в выпадающем меню Пуск (Start) отсутствует пункт Выполнить (Run), то нажмите на клавиатуре кнопку с эмблемой Windows и одновременно с ней кнопку с буквой R.
2. В командную строку введите:
C:ProgramDataABBYYLingvo12.0
и нажмите OK.
3. В открывшейся папке найдите папку Licenses. Наведите курсор мыши на название папки Licenses и нажмите правую кнопку мыши. В выпадающем меню выберите Свойства (Properties). В диалоге Свойства (Properties) перейдите на закладку Безопасность (Security).
4. В списке пользователей и групп диалога безопасность найдите группу «Пользователи». Этой группе необходимо дать права
Полный доступ (Full control). Для этого нажмите кнопку Изменить (Edit), в новом окне выберите группу «Пользователи» и поставьте галочку в графе разрешение напротив пункта Полный доступ (Full control). Нажмите Применить (Apply) и после этого OK во всех окнах.
773 считают это полезным.
Была ли эта информация вам полезна?
kb.abbyy.ru
Что делать, если ABBYY FineReader не видит сканер
Abbyy Finereader – программа для распознавания текста с изображениями. Источником картинок, как правило, является сканер или МФУ. Прямо из окна приложения можно произвести сканирование, после чего автоматически перевести изображение в текст. Кроме того, Файн Ридер умеет сконвертировать полученные со сканера изображения в формат PDF и FB2, что полезно при создании электронных книг и документации для последующей печати.

Как устранить проблему: ABBYY Finereader не видит сканер.
Для корректной работы Abbyy Finereader 14 (последняя версия) на компьютере должны выполняться следующие требования:
- процессор с частотой от 1 ГГц и поддержкой набора инструкций SSE2;
- ОС Windows 10, 8.1, 8, 7;
- оперативная память от 1 Гб, рекомендованная – 4Гб;
- TWAIN- или WIA-совместимое устройство ввода изображений;
- доступ в интернет для активации.
Если ваше оборудование не отвечает данным требованиям, программа может работать некорректно. Но и при соблюдении всех условий, Abbyy FineReader часто выдаёт разные ошибки сканирования, такие как:
- невозможно открыть источник TWAIN;
- параметр задан неверно;
- внутренняя программная ошибка;
- ошибка инициализации источника.
В подавляющем большинстве случаев проблема связана с самим приложением и его настройками. Но иногда ошибки возникают после обновления системы либо после подключения нового оборудования. Рассмотрим наиболее распространённые рекомендации, что делать, если ABBYY FineReader не видит сканер и выдаёт сообщения об ошибках.
Исправление ошибок
Есть ряд общих советов по исправлению некорректной работы:
- Обновите драйверы оборудования до последних версий с официального сайта производителя.
- Проверьте права текущего пользователя в системе, при необходимости повысьте уровень доступа.
- Иногда помогает установка более старой версии приложения, особенно если вы работаете на не новом оборудовании.
- Проверьте, видит ли сканер сама система. Если он не отображается в диспетчере устройств или показан с жёлтым восклицательным знаком, то проблема в оборудовании, а не программе. Обратитесь к инструкции или в техподдержку производителя.
- На официальном сайте ABBYY работает неплохая техническая поддержка https://www.abbyy.com/ru-ru/support. Вы можете задать вопрос, подробно описав конкретно свою проблему, и получить профессиональное решение из первых рук абсолютно бесплатно.

Устранение ошибки «Параметр задан неверно»
В последней версии ABBYY FineReader также может носить название «Ошибка инициализации источника». Инициализация – это процесс подключения и распознавания системой оборудования. 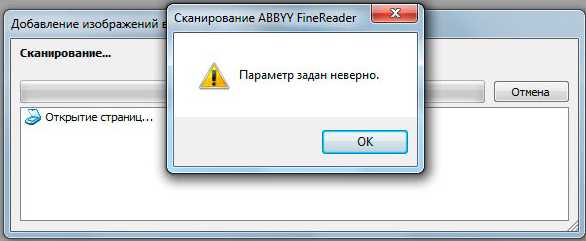
Если Файн Ридер не видит сканер при запуске диалогового окна сканирования и выдаёт такие ошибки, то должны помочь следующие действия:
- Перезапустите программу FineReader.
- Зайдите в меню «Инструменты», выберите «OCR-редактор».
- Нажмите «Инструменты», потом «Настройки».
- Включите раздел «Основные».
- Перейдите к «Выбор устройства для получения изображений», затем «Выберите устройство».
- Нажмите на выпадающий список доступных драйверов. Проверьте работоспособность сканирования поочерёдно с каждым из списка. В случае успеха с каким-то из них, используйте его в дальнейшем.
ВНИМАНИЕ. Возможна и такая ситуация, что ни с каким из доступных драйверов выполнить сканирование не получилось. Тогда нажмите «Использовать интерфейс сканера».
Если и это не помогло, вам понадобится утилита TWAIN_32 Twacker. Её можно скачать с официального сайта ABBYY по ссылке ftp://ftp.abbyy.com/TechSupport/twack_32.zip.
После этого следуйте инструкции:
- Выйдите из Файн Ридер.
- Распакуйте архив twack_32.zip в любую папку.
- Дважды щёлкните по Twack_32.exe.
- После запуска программы зайдите в меню «File», затем «Acquire».
- Нажмите «Scan» в открывшемся диалоге.
- Если документ успешно отсканировался, откройте меню «File» и щёлкните «Select Source».
- Синим цветом окажется отображён драйвер, через который утилита успешно выполнила сканирование.
- Выберите этот же файл драйвера в файнридере.
Если при запуске в Abbyy Finereader этого сделать опять не удалось, значит, проблема в работе программы. Отправьте запрос в техническую поддержку ABBYY. Если же и 32 Twacker не смог выполнить команду «Scan», то, вероятно, некорректно работает само устройство или его драйвер. Обратитесь в техподдержку производителя сканера.
Внутренняя программная ошибка
Бывает, что при запуске сканирования приложение сообщает «Внутренняя программная ошибка, код 142». Она обычно связана с удалением или повреждением системных файлов программы. Для исправления и предотвращения повторных появлений выполните следующее:
- Добавьте Fine Reader в исключения антивирусного ПО.
- Перейдите в «Панель управления», «Установка и удаление программ».
- Найдите Fine Reader и нажмите «Изменить».
- Теперь выберите «Восстановить».
- Запустите программу и попробуйте отсканировать документ.
Иногда Файнридер может не видеть сканер из-за ограничений в доступе. Запустите программу от имени администратора либо повысьте права текущего пользователя.
Таким образом решается проблема подключения программы Fine Reader к сканеру. Иногда причина в конфликте драйверов или несовместимости оборудования. А бывает, сбой сканирования возникает из-за внутренних программных ошибок. Если вы сталкивались с подобными проблемами в файнридере, оставляйте советы и способы решения в комментариях.
nastroyvse.ru
Не удалось открыть изображение finereader. Ошибка «Параметр задан неверно» при сканирование в FineReader. Как убрать ошибку «Параметр задан неверно»
Если вам по работе или учебе часто приходится работать с текстом, то наверняка у вас есть специализированное ПО для этого. К примеру, многие решают — программу, которая позволяет сканировать текст и переводить его в цифровой формат, осуществлять оцифровку документов, редактирование и многое другое.
Это ПО невероятно полезное. И поэтому очень остро ощущаются всевозможные проблемы, связанные с его работой. Например, программа не видит сканер. Или сканируется только часть текста. К счастью, все это решаемо.
Возможные проблемы в Abbyy Finereader и их устранение
При работе с программой могут возникнуть следующие проблемы и ошибки:
- ПО не может подключиться к сканеру или другому оборудованию;
- программа не видит документы;
- Abbyy Finereader сканирует только часть страницы;
- невозможно открыть источник TWAIN;
- выявляется ошибка инициализации источника.
С чем они связаны? В первую очередь, следует проверить доступное оборудование. В частности, состояние кабелей и других компонентов. Если же тут все в порядке, то ошибки могут быть программного характера. Помните, что рекомендуется использовать только лицензионное ПО. Взломанные версии ввиду наличия изменений в коде могут работать некорректно. Также стоит попробовать обновить программу до последней актуальной версии. Сюда же следует отнести и обновление драйверов самого оборудования. Если Abbyy Finereader не сканирует, то в большинстве случаев такой подход решает проблему. Свежие версии загружаются с официального сайта производителя. Еще очень часто проблемы возникают при отсутствии необходимого уровня доступа для пользователя (необходимо повысить).
Некоторые проблемы можно решить в настройках программы. Например, ошибку, свидетельствующую о том, что параметр задан неверно. При появлении подобного нужно выполнить следующие действия:
- открыть меню «Инструменты», перейти к пункту «OCR-редактор»;
- перейти к настройкам — основные;
- перейти к разделу «Выбор устройства для получения изображений»;
- найти выпадающий список с драйверами;
- проверить работу программы и сканера с каждым из них по очереди;
- оставить драйвер, с которым не возникает сбоев.
В большинстве случаев этот список действий помогает решить 90% проблем. В том числе и ситуацию с ошибкой, свидетельствующей о том, что не удалось открыть изображение» (последнее также может быть из-за неправильного формата файла или его повреждения).
Выбирая тему для этой статьи, я целый день думал что буду писать о том, как разобрать и почистить ноутбук HP ProBook 4545s. Но думал я так до тех пор, пока ко мне не пришли и не попросили помочь разобраться в настройке сканера. Потому что, при попытке отсканировать любой документ, на экране появляется ошибка со следующим текстом: «».
Хотя, пользователь утверждал, что делал все как и раньше. Так же, пользователь сказал, что ранее отключал МФУ от компьютера, а когда он понадобился подключил обратно, после чего и появилась данная проблема.
Подойдя к компьютеру, первым делом, я убедился правильно ли подключено устройство (МФУ
) к ПК. Кстати, для тех кто не в курсе как это сделать, я специально подготовил статью о том: . В общем, само устройство было подключено правильно. Сев за компьютер, я попробовал запустить сканирование для того, что бы увидеть на каком этапе вылетает ошибка, в результате только нажав на кнопку «Сканировать», буквально в тот же момент появилось сообщение: «Параметр задан неверно».
Пройдясь по всем параметрам окна сканирования, я не заметил ничего странного. Все было выставлено правильно, хотя, я все равно попробовал изменить пару пунктов, но результата это не принесло. Так же, хочу акцентировать внимание на том, что для сканирование использовалась программа ABBYY FineReader 10
. Как я потом узнал, что чаще всего ошибка «Параметр задан неверно», появляется именно на этой версии программного обеспечения.
Как убрать ошибку «Параметр задан неверно»
Наконец, закончив все эксперименты с окном сканирования, я перешёл к настройкам самого FineReader’а. Потому что, появление такого типа ошибок, чаще все связанно с неправильно выбранным драйвером для сканера.
На самом деле, исправить такую ошибку очень легко. Для начала, открываем окошко ABBYY FineReader и наведя мышку на панель меню нажимаем на «
Сервис
» -> «Опции…
». Так же, можно воспользоваться сочетание клавиш «Cntr+Shift+O
», которое отвечает за экспресс открытие окна настроек.
Теперь, в окне настроек нажимаем по вкладке «СканироватьОткрыть
», где спустившись чуть ниже выбираем подходящий для нашего устройства драйвер. Как правило, для корректной работы сканера, нужно выбирать драйвер такого типа: [
Название модели
]
(TWAIN)
. У меня это: Canon MF4400 Series
(TWAIN)
. Закончив с настройкой, нажимаем на «ОК
» для сохранения всех изменений.
Если именно с этим драйвером работоспособность сканера не восстановится и снова появилась ошибка «Параметр задан неверно», обязательно попробуйте таким же образом выбрать другой драйвер (Canon MF4400 Series (WIA)
)
и проверить результат.
В моем случае было все чуть сложнее. Перепробовав все драйвера ничего не выходило. Поэтому, я решил полностью удалить из системы устройство и любое программное обеспечение которое с ним связанно. А потом, скачать с сайта производителя новую версию ПО и заново (Вот
вы сможет найти пример, как это сделать на Windows XP
). В общем, после установки всех драйверов и нового подключения МФУ, я проделал все выше описанные
действия. И только после это, сканер начал работать как надо.
А на каких версиях ABBYY FineReader у вас появлялась ошибка «Параметр задан неверно»? И помог ли Вам вариант решения неполадки, с помощью простого выбора драйвера? Все ответы оставляйте в комментария и с помощью их мы сможем точно определить, что является причиной появления ошибки, программа или драйвер.
Abbyy Finereader – программа для распознавания текста с изображениями. Источником картинок, как правило, является сканер или МФУ. Прямо из окна приложения можно произвести сканирование, после чего автоматически перевести изображение в текст. Кроме того, Файн Ридер умеет сконвертировать полученные со сканера изображения в формат PDF и FB2, что полезно при создании электронных книг и документации для последующей печати.
Как устранить проблему: ABBYY Finereader не видит сканер.
Для корректной работы Abbyy Finereader 14 (последняя версия) на компьютере должны выполняться следующие требования:
- процессор с частотой от 1 ГГц и поддержкой набора инструкций SSE2;
- ОС Windows 10, 8.1, 8, 7;
- оперативная память от 1 Гб, рекомендованная – 4Гб;
- TWAIN- или WIA-совместимое устройство ввода изображений;
- доступ в интернет для активации.
Если ваше оборудование не отвечает данным требованиям, программа может работать некорректно. Но и при соблюдении всех условий, Abbyy FineReader часто выдаёт разные ошибки сканирования, такие как:
- невозможно открыть источник TWAIN;
- параметр задан неверно;
- внутренняя программная ошибка;
- ошибка инициализации источника.
В подавляющем большинстве случаев проблема связана с самим приложением и его настройками. Но иногда ошибки возникают после обновления системы либо после подключения нового оборудования. Рассмотрим наиболее распространённые рекомендации, что делать, если ABBYY FineReader не видит сканер и выдаёт сообщения об ошибках.
Исправление ошибок
Есть ряд общих советов по исправлению некорректн
erfa.ru
Параметр задан неверно / Невозможно открыть источник TWAIN – ABBYY
Для устранения этой ошибки выполните следующие действия:
- Запустите программу ABBYY FineReader.
- Выберите пункт меню Сервис > Настройки (Опции).
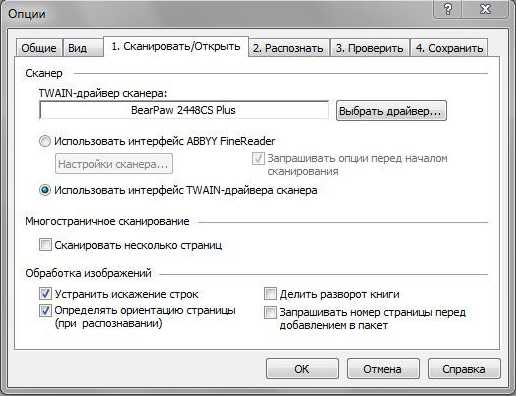
- Перейдите на вкладку Общие (Сканировать/Открыть в FineReader 12).
- В выпадающем списке Выберите устройство должно быть несколько доступных драйверов для вашего сканера. Попробуйте отсканировать изображение с каждым из них. В дальнейшем при работе с программой используйте тот драйвер, сканирование с которым происходит без ошибки.
Если ни с одним из драйверов сканирование не работает корректно, рекомендуется проверить работоспособность драйвера сканера с помощью утилиты TWAIN_32 Twacker:
- Закройте программу ABBYY FineReader.
- Сохраните на ваш компьютер приложение Twack_32.zip.
- Запустите распакованный файл Twack_32.exe.
- В окне приложения TWAIN_32 Twacker выберите меню File > Acquire.
- В появившемся диалоговом окне нажмите кнопку Scan.
- Если в приложении Twacker сканирование прошло успешно, выберите пункт меню File > Select Source. Синим будет выделен драйвер, использованный для сканирования. Выберите тот же драйвер в программе ABBYY FineReader и произведите сканирование.
Если в этом случае сканирование в программе ABBYY FineReader завершается ошибкой – обратитесь в службу технической поддержки. - Если сканировать в приложении Twacker также не удается, значит программное обеспечение Вашего сканера работает неправильно. В этом случае рекомендуется обновить или переустановить драйвер сканера. За рекомендациями по переустановке вы можете обратиться в техническую поддержку производителя сканера.
support.abbyy.com
Как удалить или заменить лицензию ABBYY FineReader?
Номер статьи: 686 |
Категория: Активация |
Тип: Задача – Решение |
Последнее обновление: 01.06.2017
Как удалить или заменить лицензию ABBYY FineReader?
Решение
Для того чтобы удалить лицензию, выполните следующие действия:
- Удалите файл лицензии вида <серийный номер>.ABBYY.License.
Файл расположен в папке:- Windows Vista и более поздних: C:ProgramDataABBYYFineReader<номер версии>Licenses
- Windows XP: C:Documents and SettingsAll UsersApplication Data ABBYYFineReader<номер версии>Licenses
- Перезапустите службу лицензирования ABBYY FineReader Licensing Service. Для этого:
- Нажмите кнопку Пуск (для OS Windows 8 и более поздних версий правой кнопкой мыши) .
- Выберите Панель управления.
- Перейдите в раздел Администрирование.
- Выберите Службы.
- В списке служб найдите и выберите ABBYY FineReader Licensing Service.
- Щелкните правой клавишей мыши и выберите пункт Перезапустить.
- Запустите программу ABBYY FineReader. При запуске Мастер Активации предложит активировать программу.
Если лицензия активирована локально, удаление можно провести непосредственно из интерфейса программы:
- Запустите программу ABBYY FineReader.
- Перейдите в меню Помощь > О программе.
- Нажмите на ссылку Информация о лицензиях.
- Выберите лицензию и нажмите на кнопку «Удалить».
1764 считают это полезным.
Была ли эта информация вам полезна?
kb.abbyy.ru
Параметр задан неверно / Невозможно открыть источник TWAIN
Параметр задан неверно / Невозможно открыть источник TWAIN
Номер статьи: 493
Категория: Сканирование
Тип: Патч
Последнее обновление: 15.10.2013
Описание
При сканировании возникает сообщение Параметр задан неверно или Невозможно открыть источник TWAIN.
Решение
Для устранения этой ошибки выполните следующие действия:
- Запустите программу ABBYY FineReader.
- Выберите пункт меню Файл > Выбрать сканер.
- В выпадающем списке Драйвер должно быть несколько доступных драйверов для вашего сканера. Попробуйте отсканировать изображение с каждым из них. В дальнейшем при работе с программой используйте тот драйвер, сканирование с которым происходит без ошибки.
Если ни с одним из драйверов сканирование не работает корректно, рекомендуется проверить работоспособность драйвера сканера с помощью утилиты TWAIN_32 Twacker:
- Закройте программу ABBYY FineReader.
- Сохраните на ваш компьютер приложение Twack_32.zip.
- Запустите распакованный файл Twack_32.exe.
- В окне приложения TWAIN_32 Twacker выберите меню File > Acquire.
- В появившемся диалоговом окне нажмите кнопку Scan.
- Если в приложении Twacker сканирование прошло успешно, выберите пункт меню File > Select Source. Синим будет выделен драйвер, использованный для сканирования. Выберите тот же драйвер в программе ABBYY FineReader и произведите сканирование.
Если в этом случае сканирование в программе ABBYY FineReader завершается ошибкой – обратитесь в службу технической поддержки. - Если сканировать в приложении Twacker также не удается, значит программное обеспечение Вашего сканера работает неправильно. В этом случае рекомендуется обновить или переустановить драйвер сканера. За рекомендациями по переустановке вы можете обратиться в техническую поддержку производителя сканера.
kb.abbyy.ru