
Погрешности
средств измерений —
отклонения метрологических свойств
или параметров средств измерений от
номинальных, влияющие на погрешности
результатов измерений (создающие так
называемые инструментальные ошибки
измерений).
Погрешность результата
измерения — отклонение результата
измерения от действительного (истинного)
значения измеряемой величины , определяемая
по формуле — погрешность измерения.
Аддитивная
погрешность–
погрешность измерения которая при всех
значениях входной измеряемой величины
Х значения выходной величины Y
изменяются на одну и ту же величину
большую или меньшую от номинального
значения.

Если
абсолютная погрешность не зависит от
значения измеряемой величины, то полоса
определяется аддитивной погрешностью .
Ярким
примером аддитивной погрешности является
погрешность квантования (оцифровки).
Класс
точности измерений :
—
для аддитивной погрешности:
![]() где
где
Х — верхний предел шкалы, ∆0 —
абсолютная аддитивная погрешность.
Мультипликативной
погрешностью называется
погрешность, линейно возрастающая или
убывающая с ростом измеряемой величины.

Если
постоянной величиной является
относительная погрешность, то полоса
погрешностей меняется в пределах
диапазона измерений и погрешность
называется мультипликативной
Класс
точности измерений :
—
для мультипликативной погрешности:
![]()
![]() —
—
это условие определяет порог
чувствительности прибора (измерений).
17.Погрешность квантования.
Погрешности
средств измерений —
отклонения метрологических свойств
или параметров средств измерений от
номинальных, влияющие на погрешности
результатов измерений (создающие так
называемые инструментальные ошибки
измерений).
Погрешность результата
измерения — отклонение результата
измерения от действительного (истинного)
значения измеряемой величины , определяемая
по формуле — погрешность измерения.

Разным
значениям непрерывной измеряемой
величины
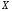 соответствуют дискретные значения
соответствуют дискретные значения
выходной величины .
.
Показания прибора дискретны с шагом
квантования ,
,
где — чувствительность линейной функции
— чувствительность линейной функции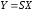 ,
,
которая имела бы место при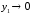 .
.
Значение
 ,
,
соответствующее зависимости заменяется дискретным значением
заменяется дискретным значением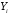 ,
,
равнымближайшему
уровню квантования. Несовпадение
 и
и будет определять погрешность квантования.
будет определять погрешность квантования.
Значения погрешности квантования лежат в пределе от
лежат в пределе от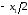 до
до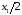 .
.
При этом все значения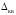 равновероятны и математическое ожидание
равновероятны и математическое ожидание
такой погрешности равно 0. Из этого
следует, что в этом случае погрешность
квантования есть чисто случайная
погрешность с равномерным распределением.
18.Понятие класса точности. Нормирование точности средств измерения.
Класс
точности
(КТ)—
это обобщенная характеристика средства
измерений, выражаемая пределами его
допускаемых основной и дополнительных
погрешностей, а также другими
характеристиками, влияющими на точность.
Класс
точности средств измерений
характеризует их свойства в отношении
точности, но не является непосредственным
показателем точности измерений,
выполняемых при помощи этих средств.
Для
того чтобы заранее оценить погрешность,
которую внесет данное средство измерений
в результат, пользуются нормированными
значениями погрешности.
Под ними понимают предельные
для данного типа средства измерений
погрешности.
Погрешность
данного измерительного прибора не
должна превосходить нормированного
значения.
Если
обозначаемое на шкале значение класса
точности обведено кружком, например
1,5, это означает, что погрешность
чувствительности γs=1,5%.
Так нормируют погрешности масштабных
преобразователей (делителей напряжения,
шунтов, измерительных трансформаторов
тока и напряжения и т. п.).
Если
на шкале измерительного прибора цифра
класса точности не подчеркнута, например
0,5, это означает, что прибор нормируется
приведенной погрешностью нуля γ
о=0,5
%.
Однако
будет грубейшей ошибкой полагать, что
амперметр класса точности 0,5 обеспечивает
во всем диапазоне измерений погрешность
результатов измерений
±0,5 %.
На
измерительных приборах с резко
неравномерной шкалой (например на
омметрах) класс точности указывают в
долях от длины шкалы и обозначают как
1,5 с обозначением ниже цифр знака «угол».
Если
обозначение класса точности на шкале
измерительного прибора дано в виде
дроби (например 0,02/0,01), это указывает на
то, что приведенная погрешность в конце
диапазона измерений γк
= ±0,02 %, а в нуле диапазона γн
= ±0,01 %. К таким измерительным приборам
относятся высокоточные цифровые
вольтметры, потенциометры постоянного
тока и другие высокоточные приборы. В
этом случае
δ(х)
= γк
+ γн
(Хк/Х — 1),
где
Хк — верхний предел измерений (конечное
значение шкалы прибора), Х — измеряемое
значение.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
For the additive errors model, the class of instrumental precision δ0 is equal to the limiting reduced relative error δ0 R defined by
From: Statistical Data Analysis, 2011
Spectrophotometry
Simon G. Kaplan, Manuel A. Quijada, in Experimental Methods in the Physical Sciences, 2014
4.3.5 Interreflections
Interreflections between the sample and the detector, spectrometer, or other optical elements in a spectrophotometric measurement system introduce additive error terms to the measurand. In particular, light that is reflected back to an FTS by the sample or other optical element can pass through the beamsplitter back to the interferometer mirrors, be modulated a second time by the scanning mirror, recombine, and then pass through the sample again to the detector. For a given wavenumber σ, any part of the optical power that is modulated twice by the FTS will experience twice the path length change and thus be recorded at 2σ. Successive interreflections can generate higher harmonics in the spectrum [22]. Other interreflections not involving the FTS directly will still add an error to the measurement that can include spectral features of other components in the system. This situation is illustrated for a transmittance measurement in Fig. 4.13.

Figure 4.13. Schematic layout of a sample transmittance measurement with an FTS showing possible interreflections and their elimination through the use of semicircular beam blocks.
In a focused sample geometry, one way to eliminate interreflections is to insert semicircular beam blocks before and after the sample, as shown in Fig. 4.13. The reflection of the half-cone beam incident on the sample will thus be blocked from reentering the FTS, and similarly any light reflected from the detector will not return to the sample or to the spectrometer. An example of the effects of interreflections on a transmittance measurement (normal incidence, f/3 focusing geometry) of a 0.25-mm thick Si wafer is shown in Fig. 4.14.

Figure 4.14. Effects of interreflections on a normal incidence transmittance measurement of a 0.25 mm Si wafer. The lettered curves show the results of inserting half-blocks illustrated in Fig. 4.13 compared to the expected transmittance (solid curve).
Without any half-blocks in the beam, curve A shows large deviations from the expected transmittance curve. These include both wavenumber-doubled spectral features originating from the spectral irradiance of the incident FTS beam and high-frequency fringes due to doubling of the etalon spectrum of the Si wafer sample. Inserting a half-block between the sample and detector (curve B) lowers the error at low wavenumbers, but does not get rid of the interreflections with the FTS. Curve C with the half-block before the sample eliminates the sample-FTS interreflection, while curve D with both half-blocks gives a result close to the expected transmittance spectrum.
The use of half-beam blocks, or half-field stops, can effectively eliminate interreflection errors at the cost of 50% reduction in signal, and some increase in sensitivity to beam geometry errors as discussed below. Other options include filters between the sample and FTS, or simply tilting the sample, which may be the simplest approach if knowledge of the precise incident beam geometry is not critical to the measurement. Si represents close to the worst case, being approximately 50% transmitting; lower index materials will have less uncertainty. Finally, one may also consider interreflections on the source side of the FTS. These in principle can lead to errors in the reference spectrum that can propagate to the measured transmittance.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123860224000042
Errors in instrumental measurements
Milan Meloun, Jiří Militký, in Statistical Data Analysis, 2011
1.2.1 Absolute and Relative Errors
The calibration of an instrument requires that for known values of the input quantity x, (e.g., the concentration of hydrogen ions [H+], in solution), the corresponding values of the measured output analytical signal yi, (e.g., the EMF of a glass electrode cell) be at disposal measured. Repeated measurements are made for each of several values of xt so that the dependence y = f(x) can be found. An approximate graphical interpretation shows the uncertainty band in the plot (Figure 1.2).

Figure 1.2. The uncertainty band and three types of instrumental errors: (a) additive, (b) multiplicative, and (c) combined error
The middle curve in the uncertainty band is called the nominal characteristic ynom (or xnom) and it is usually declared by the instrument manufacturer. The nominal characteristic ynom (or xnom ) differs from the real characteristic yreal (or xreal) by the error of the instrument, Δ* = yreal – ynom. For any selected y the error due to the instrument is Δ = xreal − xnom. [We will use errors Δ, which are in units of measurement quantities (e.g. pH)].
The absolute error of the signal measurement Δ is not convenient for expressing an instrument’s precision because it is given in the specific units of the instrument used; more convenient is the relative error defined by
(1.3)δ=100Δ/x%
or the reduced relative error defined by
(1.4)δR=100Δ/xmax−xmin=100Δ/R%
where R is the range of measurements.
The limiting error of an instrument Δ0 (absolute) or δ0 (relative) is, under given experimental conditions, the highest possible error which is not obscured by any other random errors.
The reduced limiting error of an instrument δ0,R (relative), for the actual value of the measured variable x. and the given experimental conditions, is defined by the ratio of the limiting error Δ0 to the highest value of the instrumental range R, δ0,R = Δ0/R. Often, the reduced limiting error is given as a percentage of the instrument range, [see Eq. (1.5)].
From the shape of the uncertainty band, various types of measurement errors can be identified, hence some corrections for their elimination may be suggested.
- (a)
-
Absolute measurement errors of an instrument are limited for the whole signal range by the constant limiting error Δ0 that corresponds to the additive errors model. The systematic additive error is a result of the incorrect setting of an instrument’s zero point. Today, however, instruments contain an automatic correction for zero, and systematic additive errors thus appear rarely.
- (b)
-
The magnitude of absolute measurement errors grows with the value of the input quantity x and for x = 0, it is Δ = 0. This is a case of the multiplicative errors model. Such errors are called errors of instrument sensitivity. Systematic multiplicative errors are caused by defects of the instrument.
Real instruments have errors that include both types of effects, and are expressed by the nonlinear function y = f(x).
Problem 1.1 The absolute and relative errors of a pH-meter
A glass electrode for pH measurement has a resistance of 500 MΩ at 25 °C, and the input impedance of the pH meter is 2 × 1011 Ω. Estimate the absolute (Δ0) and relative (δ0) error of EMF measurement when the voltage measured is U = 0.624 V.
Solution: Ucorr = 0.624 (2⋅1011+ 5 108)/(2⋅1011) = 0.6254 V; Δ0 = 0.6254 – 0.624 = 0.0016 V; δ0 = 100⋅0.0016/0.624 = 0.25%.
Conclusion: The absolute error is 1.6 mV and the relative error 0.25%.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780857091093500017
Covariance Structure Models for Maximal Reliability of Unit-Weighted Composites
Peter M. Bentler, in Handbook of Latent Variable and Related Models, 2007
9 Conclusions
Like the 1-factor based internal consistency reliability coefficients, the proposed approach to maximal unit-weighted reliability requires modeling the sample covariance matrix. This must be a successful enterprise, as estimation of reliability only makes sense when the model does an acceptable job of explaining the sample data. Of course, since a k-factor model rather than a 1-factor model would typically be used in the proposed approach, the odds of adequately modeling the sample covariance matrix are greatly improved. The selected model can be a member of a much wider class of models, including exploratory or confirmatory factor models or any arbitrary structural model with additive errors. Whatever the resulting dimensionality k, and whether the typical “small-k” or theoretical alternative ”large-k” approach is used, or whether a general structural model with additive errors is used, the proposed identification conditions assure that the resulting internal consistency coefficient ρˆkk represents the proportion of variance in the unit-weighted composite score that is attributable to the common factor generating maximal internal consistency. The proposed coefficient can be interpreted as representing unidimensional reliability even when the instrument under study is multifactorial, since, as was seen in (3), the composite score can be modeled by a single factor as X = μX + λXξ1 + ɛX. Nonetheless, it equally well has an interpretation as summarizing the internal consistency of the k-dimensional composite. Although generally there is a conflict between unidimensionality and reliability, as noted by ten Berge and Sočan (2004), our approach reconciles this conflict.
When the large-k approach is used to model the covariance matrix, the theory of dimension-free and greatest lower bound coefficients can be applied. This is based on a tautological model that defines factors that precisely reproduce the covariance matrix. As these theories have been developed in the past, reliability is defined on scores that are explicitly multidimensional. However, we have shown here that the dimension-free and greatest lower-bound coefficients can equivalently be defined for the single most reliable dimension among the many that are extracted. Based on this observation, new approaches to these coefficients may be possible.
The optimal unit-weighted coefficient developed here also applies to composites obtained from any latent variable covariance structure model with p-dimensional additive errors. Although we used a specific type of model as given in (7) to develop this approach, we are in no way limited to that specific linear model structure. Our approach holds equally for any completely arbitrary structural model with additive errors that we can write in the form Σ = Σ(θ) + Ψ, where Σ(θ) and Ψ are non-negative definite matrices. Then we can decompose Σ(θ) = ΛΛ′ and proceed as described previously, e.g., we can compute the factor loadings for the maximally reliable factor via λ = {1′(Σ − Ψ)1}−1/2(Σ − Ψ)1. The maximal reliability coefficient for a unit weighted composite based on any model that can be specified as a Bentler and Weeks (1980) model has been available in EQS 6 for several years.
With regard to reliability of differentially weighted composites, we extended our maximal reliability for a unit-weighted composite (4) to maximal reliability for a weighted composite (18). While both coefficients have a similar sounding name, they represent quite different types of “maximal” reliability, and, in spite of the recent enthusiasm for (18), in our opinion this coefficient ought to be used only rarely. Weighted maximal reliability does not describe the reliability of a typical total score or scale. Such a scale score, in common practice, is a unit-weighted composite of a set of items or components. Our unit-weighted maximal reliability (4) or (5) describes this reliability. In contrast, maximal reliability (18) gives the reliability of a differentially weighted composite, and if one is not using such a composite, to report it would be misleading. Of course, if a researcher actually might consider differentially weighting of items or parts in computing a total score, then a comparison of (4) to (18) can be very instructive. If (18) is only a marginal improvement over (4), there would be no point to differential weighting. On the other hand, if (4) is not too large while (18) is substantially larger, differential weighting might make sense.
Finally, all of the theoretical coefficients described in this chapter were specified in terms of population parameters, and their estimation was assumed to be associated with the usual and simple case of independent and identically distributed observations. When data have special features, such as containing missing data, estimators of the population parameters will be somewhat different in obvious ways. For example, maximum likelihood estimators based on an EM algorithm may be used to obtain structured or unstructured estimates of Σ (e.g., Jamshidian and Bentler, 1999) for use in the defining formulae. In more complicated situations, such as multilevel modeling (e.g., Liang and Bentler, 2004), it may be desirable to define and evaluate internal consistency reliability separately for within-cluster and for between-cluster variation. The defining formulae described here can be generalized to such situations in the obvious ways and are already available in EQS 6.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780444520449500045
Computational Analysis and Understanding of Natural Languages: Principles, Methods and Applications
Qiang Wu, Paul Vos, in Handbook of Statistics, 2018
9 Prediction and Model Selection
Consider using a scalar- or vector-valued input (predictor) variable X to predict a scalar-valued target (response) variable Y. The target Y can be a continuous random variable such as in linear regressions or a categorical random variable such as in logistic regressions and classifications. When X is vector-valued, its elements are sometimes called features so model selection is also referred to as feature selection. A prediction model fˆ(x) can be estimated from a training sample (y1,x1),. . .,(yn,xn). For a continuous response variable, fˆ(x) is a predicted value of the response at X = x. When the target is a K-group categorical variable, fˆ(x) is either a classifier with a single one and K − 1 zeros or a vector of predicted probabilities that x belongs to the K groups.
The error between a response y and its prediction fˆ(x) can be measured by a loss function L(y,fˆ(x)). For continuous response variables, frequently used loss functions include the squared error loss (y−fˆ(x))2 and the absolute error loss |y−fˆ(x)|. For categorical target variables, the 0-1 loss
L(y,fˆ(x))=I(y≠fˆ(x))=1y≠fˆ(x)0y=fˆ(x)
is often used for classification purpose. When the prediction fθˆ(y|x) is a pdf or pmf indexed by a parameter estimate θˆ, the log-likelihood loss
L(y,fθˆ(y|x))=−2logfθˆ(y|x)
is often used.
Definition 20
The expected prediction error (i.e., test error) of a prediction fˆ(x) over an independent test sample is defined as Err=E[L(Y,fˆ(X))], where the expectation is taken over Y, X, as well as the randomness in the training sample.
When a test sample {(Y1, X1), …, (Ym, Xm)} exists, the test error of a prediction fˆ(x) can be estimated by the average loss 1m∑i=1mL(Yi,fˆ(Xi)) over the test sample.
Definition 21
The training error of a prediction fˆ(x) is the average loss over the training sample err=1n∑i=1nL(yi,fˆ(xi)).
In general, model selection assesses different models and selects the one with the (approximate) smallest test error. However, the training error usually is not a good estimate of the testing error. The training error tends to decrease as model complexity increases and leads to overfitting (i.e., choosing an overly complex model). To appropriately estimate the test error, the data are usually separated into a training set and a validation set. The training set is used to fit the model, while the validation set is used to assess test error for model selection. When a final model is selected, however, a separate test set should be obtained to assess the test error of the final model. See Hastie et al. (2001) for more details and reference. This chapter serves as a brief review of the involved topics.
Example 56
Consider an additive error model Y = f(X) + ϵ with a linear fit on p inputs or basis functions, where the error ϵ has mean zero and variance σϵ2>0. For example, linear or polynomial regressions and B-splines are additive error models with a linear fit. When a squared error loss is used, the test error at X = x becomes
Err(x)=EY−fˆ(x)2=σϵ2+Efˆ(x)−f(x)2+Efˆ(x)−Efˆ(x)2=σϵ2+Bias2(x)+Variance(x),
where σϵ2 is an irreducible error. When p is large (i.e., model complexity is high), the model fit fˆ(x) is able to approach the true value f(x) more closely so model bias is low. However, since the fit fˆ(x) depends greatly on the training data a small change in the training data will result in a big change in the fit, leading to a large model variance. On the other hand, when p is small (i.e., model complexity is low), the model bias is high but the fit is more stable so that the model variance is low. For example, if the true model is a polynomial regression but the fit used a linear regression, then the model bias is high but the variance is low. Model selection seeks a balance between the bias and the variance. As model complexity (e.g., p) increases, it is normal that the test error first decreases and then increases. Where it turns is the optimal model complexity.
9.1 Model Selection
The training error will usually be less than the test error because the same data used to fit the model is employed to assess its training error. In other words, a fitted model usually adapts to the training data and hence its training error will be overly optimistic (too small). In fact, it is often the case that the training error steadily decreases as the size of the model increases. If training error was used for model selection, it will most likely lead to overfitting the model. The ultimate goal of model selection is to minimize the test error without overfitting. Part of the discrepancy between the training error and the test error is because the training set and the test set have different input values. To evaluate the prediction model fˆ(x) on the same realized input values, consider the in-sample error.
Definition 22
The in-sample error of a fitted model fˆ(x) is defined by
Errin=1n∑i=1nEEL(Yi,fˆ(xi))|y,x|x,
where y = (y1, . . . , yn) and x = (x1, . . . , xn) are the response and predictor values of the training set.
For the same reason that the test error is bigger than the training error, the in-sample error is usually bigger than the training error too. For squared error, 0-1 and a lot of other loss functions, it can be shown that the in-sample error is equal to
(26)Errin=E[err|x]+2n∑i=1nCov(fˆ(xi),yi|x),
where Cov(fˆ(xi),yi|x) stands for the conditional covariance between fˆ(xi) and yi given the predictor values x. The higher the model complexity is, the larger Cov(fˆ(xi),yi|x) will be, thereby increases the difference between the in-sample error and the training error (i.e., the optimism).
Example 57
For the additive error model Y = f(X) + ϵ in Example 56, the in-sample error simplifies to
Errin=E[err|x]+2pnσϵ2=1nE∑i=1nL(yi,fˆ(xi))|x+2pσϵ2.
So the optimism increases linearly with the number of inputs or basis functions, penalizing complex models with large number of inputs or basis functions. An estimate of Errin is
Errˆin=err+2pnσˆϵ2=1n∑i=1nL(yi,fˆ(xi))+2pσˆϵ2,
where σˆϵ2=1n−p∑i(yi−fˆ(xi))2 is an estimate of the error variance using the mean squared error.
Definition 23
When a squared error loss is used to evaluate a linear fit of an additive error model, the Cp statistic
Cp=1n∑i=1n(yi−fˆ(xi))2+2pσˆϵ2
is an estimate of Errin.
When the prediction fθˆ(y|x) is a pdf or pmf fitted by maximum likelihood and a log-likelihood loss is used, the Akaike information criterion (AIC, Akaike, 1973) is used to estimate Errin.
Definition 24
When a log-likelihood loss is used to evaluate a maximum likelihood fit of a pdf or pmf, the Akaike information criterion
AIC=−2∑i=1nlogfθˆ(yi|xi)+2p
is an estimate of Errin.
Example 58
For a logistic regression model with a binomial log-likelihood, the AIC becomes
AIC=−2∑i=1n(yilog(pi)+(1−yi)log(1−pi))+2p,
where log(pi/(1−pi))=xiTβˆ.
For a linear regression model with normal errors, the AIC is equivalent to the Cp statistic. Like AIC, the Bayesian information criterion (BIC, Schwarz, 1978) is applicable when maximum likelihood is used for fitting the model.
Definition 25
When a log-likelihood loss is used to evaluate a maximum likelihood fit of a pdf or pmf, the Bayesian information criterion is defined by
BIC=−2∑i=1nlogfθˆ(yi|xi)+log(n)p.
By replacing 2 with log(n), the BIC penalizes complex models (with large p) more heavily than the AIC, giving preference to simpler models. The training error measures the goodness-of-fit and p measures the model complexity. The number 2 in AIC and log(n) in BIC can be treated as a tunning parameter controlling the balance between goodness-of-fit and model complexity. There are other similar model selection criteria developed to improve AIC and BIC. For example, Foster and George (1994) proposed the risk inflation criterion (RIC) by replacing log(n) in BIC (or 2 in AIC) with 2log(p).
In general, model selection seeks the optimal complexity p with the smallest value of Cp, AIC, BIC, or other similar criteria. However, an exhaustive search would require fitting all models with all subsets of the inputs and hence is practically infeasible. In regression settings, forward and stepwise procedures have been used for variable selection referring to their test statistics or p-values. Such adaptive procedures can be applied with Cp, AIC, BIC, or other similar criteria too. First, select a model with a single input variable which achieves the smallest value of the chosen criterion. Then, variables that lead to the greatest decreases (or least increases) in the criterion are added into the model sequentially. Once the value of the criterion starts to increase (or stops to decrease) when more variables are added, the procedure is stopped and the final model is found.
Another group of methods in variable selection is by shrinking the regression parameters. For a multiple linear regression model Y = XTβ + ϵ, the LSE of β is found by
βˆ=arg minβ∑i=1n(yi−xiTβ)2=(xTx)−1xTy.
If X involves many input variables not contributing to the regression, not only the fitting is unnecessarily complex but the model is ill posed and the fitting might be unstable. For example, when the number of inputs p ≥ n, the LSE βˆ may not exist.
Example 59
Ridge regression is one of the methods to shrink the estimates and potentially set some of them to zero by minimizing an L2 (squared) penalized term
∑i=1n(yi−xiTβ)2+βTΓTΓβ.
The ridge regression estimates of β is βˆridge=(xTx+ΓTΓ)−1xTy. A typical choice for Γ is a multiple of the identity matrix αI. In the L2 regularization, preference is given to solutions with smaller norms and α is a tunning parameter controlling the degree of shrinkage.
Least absolute shrinkage and selection operator (LASSO, Tibshirani, 1996) is a more popular shrinkage regression method. Instead of regularizing the minimization with an L2 norm, LASSO employs an L1 (absolute) norm in order to enhance accuracy and stability in prediction.
Example 60
LASSO estimates of regression parameters β are found by minimizing an L1 penalized term
∑i=1n(yi−xiTβ)2+λ∑j=1p|βj|,
where λ is a tunning parameter controlling the degree of shrinkage.
Recently, some generalizations including elastic net, group lasso, fused lasso, and adaptive lasso are developed to address the shortcomings of LASSO. Each of them uses different penalty terms. For example, the elastic net adds an additional L2 term so the penalty becomes λ1∑j=1p|βj|+λ2∑j=1pβj2, and fused lasso uses a penalty term λ1∑j=1p|βj|+λ2∑j=2p|βj−βj−1|. Special algorithms such as subgradient methods, least-angle regression, and proximal gradient methods are required to find the minimum.
9.2 Cross-Validation
Unlike AIC and BIC criteria which estimate the in-sample error, cross-validation can be used to directly estimate the test error of prediction especially when the sample size is large. Particularly, the whole sample is split into K equal pieces for a K-fold cross-validation. When K = n the sample size, the method is called a leave-one-out cross-validation. Each time, one of the K subsamples is left out for validation purpose and the rest K − 1 subsamples are used for model fitting. Denote fˆ−k(x) the fitted model computed from all subsamples except the k-th for k = 1, …, K.
Definition 26
The cross-validation (CV) estimate of the test error is
CV=1n∑i=1nL(yi,fˆ−k(i)(xi)),
where k(i) = k if the i-th observation is in the k-th subsample.
Typical values of K are 5 or 10, but leave-one-out cross-validation has many applications too. Generally speaking, the larger the number K is, the lower the model bias is but the model variance is higher. For leave-one-out cross-validation, CV is an unbiased estimator for the test error but can have high variance. When K is small such as 5, CV has lower variance but bias can be an issue. If the original sample is large like 200 or more, a small K such as 5 may suffice. If the original sample is small, a larger K may be better. We can also try different K values for the same problem, if computational burden is not an issue.
Example 61
For a linear model fitting using a squared error loss, the prediction can be written as yˆ=Hy where H = X(XTX)−1XT is the hat matrix. The leave-one-out cross-validation error is
CV=1n∑i=1nyi−fˆ−i(xi)2=1n∑i=1nyi−fˆ(xi)1−Hii2,
where Hii is the i-th diagonal element of H. A generalized cross-validation that provides a convenient approximation in computation is
GCV=1n∑i=1nyi−fˆ(xi)1−trace(H)/n2.
When model complexity is controlled by a tuning parameter α, the fitted model is denoted as fˆ−k(x|α) and the estimated test error becomes
CV(α)=1n∑i=1nL(yi,fˆ−k(i)(xi|α)).
It defines an estimated test error curve on α. The final model is chosen to be fˆ(x|αˆ) with a tuning parameter αˆ that minimizes CV (α).
9.3 From Bagging to Random Forests
Bootstrap aggregating (bagging) and random forests are resampling methods proposed to boost both accuracy and stability of regression- and classification-type predictions. Let (y1(b),x1(b)),. . .,(yn(b),xn(b)) be a bootstrap sample from the original training set for b=1,. . .,B. A typical size of B is 500. Denote fˆ(b)(x) the fitted model computed from the b-th bootstrap sample.
Definition 27
The bagging estimate is defined by
fˆbag(x)=1B∑b=1Bfˆ(b)(x).
For a regression problem, each bootstrap prediction fˆ(b)(x) is the predicted value of the response at x so that fˆ(x) is the average over B bootstrap estimates. The variance of the prediction at each x value can be estimated by
σˆ2(x)=∑b=1Bfˆ(b)(x)−fˆbag(x)2B−1.
For a K-group classification problem, each bootstrap prediction fˆ(b)(x) is either a classifier with a single one and K − 1 zeroes or a vector of predicted probabilities that x belongs to the K groups so that the bagging estimate is a vector of estimated probabilities fˆbag(x)=(pˆ1(x),…,pˆK(x)) with pˆk(x) equal to the average probability that x belongs to the k-th group.
Definition 28
A bagging classifier is defined by
Ĝbag(x)=arg maxkfˆbag(x),
which is the class receiving the greatest number of votes from the B bootstrap predictions.
For an input x and its corresponding target y, let
p(x)=1B∑b=1BI(y=arg maxkfˆ(b)(x))
be the percent of times over B bagging classifiers that x is correctly classified. The quantities p(x) − (1 − p(x)) = 2p(x) − 1 are called margins. Large margins are always desirable because that means the overall classification is more stable. Let Cb be a set of indices of all (out-of-bag) observations that do not belong to the b-th bootstrap sample and |Cb| be its cardinality. To accurately estimate the test error, only out-of-bag observations should be used to evaluate the model. Bagging is considered more efficient than cross-validation because the training set can be used for both model fitting and evaluation.
Definition 29
The out-of-bag prediction error is defined by
1B∑b=1B1|Cb|∑i∈CbL(yi,fˆ(b)(xi)).
When sampling with replacement, if a bootstrap sample is the same size as the original sample, it is expected to have about 63.2% of unique observations from the original sample and the other 36.8% are repetitions. In other words, each |Cb| is expected to be about 36.8% of the sample size n.
The random forests algorithm takes one step further when classification or regression trees are built from the bootstrap samples. At each split of a tree, a random subset of the input features are selected and used to construct the split. After each tree is built, the out-of-bag data are dropped down the tree and predicted classifications or means are recorded. Lastly, for each observation in the dataset, one either counts the number of trees that have classified it in one of the categories and assigns each observation to a final category by a majority vote over the set of trees or averages the predicted means from the set of trees. The random forests algorithm helps reduce model variance by averaging over trees that are more independent. It also helps reduce model bias by considering a large number of predictors. Trees are usually grown so that there are only a few observations in each terminal node. Sampling 2–5 input features at each split is often adequate. Sometimes, one vote for classification in a rare category might count the same as two votes for classification in the common category. Stratified bootstrap samples can be used to include some underrepresented subgroups of individuals.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S0169716118300099
Nonlinear Regression Analysis
H.-H. Huang, … S.-Y. Huang, in International Encyclopedia of Education (Third Edition), 2010
Good Initials
For a linear model, the Gauss–Newton method will find the minimum in one single iteration from any initial parameter estimates. For a model which is close to being linear, the convergence for Gauss–Newton method will be rapid and not depend heavily on the initial parameter estimates. However, as the magnitude of model nonlinearity becomes more and more prominent, convergence will be slow or even may not occur, and the resulting parameter estimates may not be reliable. In that case, good initials are important.
One approach to find initial values is through transformation, so that the linear regression analysis under the assumption of additive error terms can be utilized (Bates and Watts, 1988; Ryan, 1997). For instance, the reciprocal of the Michaelis-Menten regression function
[9]f(x;θ)=θ1xθ2+x
leads to the model
y−1=1θ1+θ2θ1(1x)+ɛ
Indeed, this is a linear regression model denoted as
y˜=β0+β1x˜+ɛ
with y˜=y−1,β0=θ1−1,β1=θ2θ1−1, and x˜=x−1. The least-squares estimates of β1 and β2 can therefore be transformed to provide initial values for the parameters in the Michaelis–Menten model. Alternatively, we can adopt a grid search, which evaluates the residual sum of squares at these parameter grid points and then finds the minimizing point among these grid points to provide initial values. In many occasions, the grid search helps to avoid improper initial values that lead to local, but not global, minimum of the residual sum of squares. Another alternative is to use uniform design points to replace the lattice grid points. Uniform design points are so designed to be as uniform and as space filling as possible and provide a more efficient search scheme (Fang et al., 2000).
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978008044894701352X
Matrix-Based Methods
Esam M.A. Hussein, in Computed Radiation Imaging, 2011
10.4.10 Modeling-Error Compensation
The minimization of the residual-error functional of Eq. (10.8) presumes that the difference between the actual measurements, e^, and the corresponding computed ones, Ac, is within the range of the uncertainties in e^. In practice, as indicated in Part I of this book, the forward model is an approximation. As such, the error expressed in Eq. (10.8) by ∥Ac−e^∥ is not only a residual error, in the numerical sense, but also includes a modeling error. However, the modeling error is not random, and is in general an additive error, since it is the result of ignoring effects that are complicated to model (such as scattering in transmission and emission imaging and multiple scattering in scatter imaging). The modeling error can be estimated using a reference object as:
(10.33)B∗=e∗−Ac∗
where it is assumed that the reference measurements, e∗, are acquired with low statistical variability, for an object with known physical attributes, c∗. Then, as Eq. (10.33) indicates, the difference between the actual measurements and those modeled by the forward model gives the modeling error, B∗ for the reference object. For an object with unknown features, but not expected to be very different from the reference object, the modeling error can be estimated as βB∗, with β≥0 being an adjustment parameter that can be estimated a priori, perhaps by comparing ∥e∥ for the imaged object to ∥e∥∗ of the reference object (Arendtsz and Hussein, 1995a). Then, the functional of Eq. (10.8) can be replaced by:
(10.34)χ(c)=∥Ac+βB∗−e^∥2
This becomes the data fidelity norm (actual residual) error, which can be vulnerable to the random variability in e^, as well as to uncertainties in determining β. One can then devise a regularization function to moderate the effect of modeling errors as:
(10.35)η(c)=B=e^−Ac
where B is the unknown modeling error for the problem at hand. Note that the regularization functional now is the residual error of Eq. (10.35), if the modeling error is not taken into account, while the residual error, Eq. (10.34), incorporates some estimate of the modeling error. One now needs to minimize the objective function:
(10.36)min[W(Ac+βB∗−e^)]T[W(Ac+βB∗−e^)]+α2(e^−Ac)2
which leads to the solution:
(10.37)c^=ATW2A−α2ATA−1ATW2(e^−βB∗)−α2ATe^
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123877772000100
Nonlinear Regression Models
Milan Meloun, Jiří Militký, in Statistical Data Analysis, 2011
Problem 8.1 Formulation of the parameters and variables of a regression model
The dependence of a rate constant for a chemical reaction, k, on temperature T is described by the Arrhenius equation
(8.1)k=k0exp−E/RT
where k0 is the activation entropy of the chemical reaction, E is the activation energy, and R is the universal gas constant. Formulate the model parameters and examine their correlation.
Solution: The rate constant k (response variable, y) was measured at various temperatures, T (explanatory variable, x). The unknown parameters in the regression model [Eq. (8.1)] are β1 = k0 and β2 = −E/R. If the additive errors model is used
(8.2)yi=fxiβ+εi=β1+expβ2/xi+εi
Here, b1 and b2 are estimates of β1, and β2 and are determined from experimental data {ki,Ti}, i = 1, …, n, based on a regression criterion. When errors εi. in Eq. (8.2) are independent (values of yi are mutually independent) random variables of the same distribution, and have constant variance σ2(y).
The regression criterion corresponding to the least-squares method may be used. That is
(8.3)Uβ=∑i=1nyi−fxiβ
The estimates b then minimize the criterion U(β).
It can be shown here that a strong correlation exists between estimates In b1 and b2. This correlation may be expressed by the paired correlation coefficient
(8.4)r=C2+cln1+1/c
where c = T1/(Tn − T1) is related to minimum (T1) and maximum (Tn) temperatures. When T1 = 300 K and T2 = 360 K, then r = 0.9986 and ln b1 and b2 are nearly linearly dependent. This means that the ratio (ln b1) / b2 is constant and hence, individual parameters cannot be estimated independently. When parameters are correlated, unfortunately a change in the first parameter is often compensated for by a change in the second one. There may be several different pairs of parameter estimates (ln b1, b2) which give nearly same values of the least squares criterion U(b). The parameter estimates achieved by various regression programs may differ by some orders of magnitude, but nevertheless apparently a “best” fit to the experimental data, and low values of U(b) are reached.
Conclusion: Even a simple nonlinear model may lead to difficulties in the accuracy of the parameter estimates and also in their interpretation.
Often, attempts are made to apply nonlinear regression models in situations which are totally inappropriate. Models are often applied outside the range of their validity, and generally, it is supposed that they can substitute for missing data. In chemical kinetics, for example, attempts may be made to estimate parameters, from data far from equilibrium. The calculated parameters then differ significantly from the true equilibrium parameters, and should be interpreted as model parameters only.
The result of nonlinear regression depends on the quality of the regression triplet, i.e. (1) the data, (2) the model, and (3) the regression criterion. Correct formulation leads to parameter estimates which have meaning not only formally but also physically.
In this chapter, we solve problems for which a regression model is known. For solving calibration problems or searching for empirical models, the regression model is appropriate. Some procedures are mentioned in Chapter 9.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978085709109350008X
Data Science: Theory and Applications
Victor B. Talisa, Chung-Chou H. Chang, in Handbook of Statistics, 2021
2.2 Bias-variance decomposition
We generally cannot estimate (1) directly; instead we usually estimate the unconditional MSEY:
(2)MSEY=EStr,X,YY−f(X;Str)2.
A brief analysis of (2) will reveal several concepts essential to prediction modeling. Consider MSEY conditional on X:
MSEY(x)=EStr,YY−f(x;Str)2X=x.
In words, this is the expected prediction error at a fixed point X = x, where the expectation is taken over the distribution of all training sets and the conditional distribution of Y|X = x. First of all, the function f(x;Str) minimizing MSEY(x) is the conditional expectation μ(x) = E[Y|X = x]. Thus, if μ(x) were known for all x, MSEY would be minimized and we would have our optimal prediction function for Y. However, we only ever observe noisy variates from μ(x) in our data, so at best we can hope to generate an imperfect (but hopefully useful) estimate from our training data, μˆ(x;Str). Therefore, moving forward we refer to the prediction function f(⋅) as μˆ(⋅). The bias-variance decomposition is an important tool for analyzing the sources of error when doing prediction with μˆ(x). To start, let us assume an additive errors model with constant variance: Y = μ(X) + ϵ, where ϵ has mean 0 and variance σϵ2:
(3)MSEY(x)=EStr,YY−μˆ(x;Str)2X=x=σϵ2+EStrμˆ(x;Str)−μ(x)2+EStrμˆ(x;Str)−EStr[μˆ(x;Str)]2
This decomposition explicitly shows how bias and variance contribute to MSEY(x), and therefore MSEY (since MSEY = EX[MSEY(X)]). The second term in (3) is the square of the bias of μˆ(x;Str); if we fit a new model to all possible training samples, the bias would be the difference between the averaged predictions from each fit evaluated at X = x and the true conditional mean at X = x. This bias is the result of misspecifying our model μˆ(⋅). The third term is the estimation variance of μˆ(x;Str), the result of using a random sample to estimate μ(x). The first term is the irreducible error associated with the stochastic target Y. Even if we had the true μ(x) as our prediction function, and thus no bias or estimation variance, the minimum MSEY could not be reduced below the value of σϵ2.
The second and third terms in (3) combine to form the MSE of μˆ(x;Str) for estimating μ(x):
(4)MSEμ(x)=EStr(μˆ(x;Str)−μ(x))2X=x,
where MSEμ = EX[MSEμ(X)]. Thus, the standard prediction problem (at least when using squared error loss) can be expressed as an estimation problem, where the parameter of interest is the function μ(x). The advantage of using MSEY for model selection is that we do not need access to μ(x), unlike MSEμ, making estimation more straightforward. As we will see in concrete examples below, in many cases the bias-variance decomposition reveals that the prediction modeler seeking to minimize MSEY may not find it among the class of unbiased, “correct” estimators of μ(x), unless it also achieves lower variance than other unbiased models. Often the “wrong” model (a biased one) is preferable for having a lower MSEY, and therefore better prediction performance as a whole. Although it may be very unlikely that a modeling procedure captures every nuance of nature necessary to produce truly unbiased estimates of μ(x), the hope is that some will provide a good enough approximation as to be useful in predicting Y.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S0169716120300432
For the additive errors model, the class of instrumental precision δ0 is equal to the limiting reduced relative error δ0 R defined by
From: Statistical Data Analysis, 2011
Spectrophotometry
Simon G. Kaplan, Manuel A. Quijada, in Experimental Methods in the Physical Sciences, 2014
4.3.5 Interreflections
Interreflections between the sample and the detector, spectrometer, or other optical elements in a spectrophotometric measurement system introduce additive error terms to the measurand. In particular, light that is reflected back to an FTS by the sample or other optical element can pass through the beamsplitter back to the interferometer mirrors, be modulated a second time by the scanning mirror, recombine, and then pass through the sample again to the detector. For a given wavenumber σ, any part of the optical power that is modulated twice by the FTS will experience twice the path length change and thus be recorded at 2σ. Successive interreflections can generate higher harmonics in the spectrum [22]. Other interreflections not involving the FTS directly will still add an error to the measurement that can include spectral features of other components in the system. This situation is illustrated for a transmittance measurement in Fig. 4.13.
Figure 4.13. Schematic layout of a sample transmittance measurement with an FTS showing possible interreflections and their elimination through the use of semicircular beam blocks.
In a focused sample geometry, one way to eliminate interreflections is to insert semicircular beam blocks before and after the sample, as shown in Fig. 4.13. The reflection of the half-cone beam incident on the sample will thus be blocked from reentering the FTS, and similarly any light reflected from the detector will not return to the sample or to the spectrometer. An example of the effects of interreflections on a transmittance measurement (normal incidence, f/3 focusing geometry) of a 0.25-mm thick Si wafer is shown in Fig. 4.14.
Figure 4.14. Effects of interreflections on a normal incidence transmittance measurement of a 0.25 mm Si wafer. The lettered curves show the results of inserting half-blocks illustrated in Fig. 4.13 compared to the expected transmittance (solid curve).
Without any half-blocks in the beam, curve A shows large deviations from the expected transmittance curve. These include both wavenumber-doubled spectral features originating from the spectral irradiance of the incident FTS beam and high-frequency fringes due to doubling of the etalon spectrum of the Si wafer sample. Inserting a half-block between the sample and detector (curve B) lowers the error at low wavenumbers, but does not get rid of the interreflections with the FTS. Curve C with the half-block before the sample eliminates the sample-FTS interreflection, while curve D with both half-blocks gives a result close to the expected transmittance spectrum.
The use of half-beam blocks, or half-field stops, can effectively eliminate interreflection errors at the cost of 50% reduction in signal, and some increase in sensitivity to beam geometry errors as discussed below. Other options include filters between the sample and FTS, or simply tilting the sample, which may be the simplest approach if knowledge of the precise incident beam geometry is not critical to the measurement. Si represents close to the worst case, being approximately 50% transmitting; lower index materials will have less uncertainty. Finally, one may also consider interreflections on the source side of the FTS. These in principle can lead to errors in the reference spectrum that can propagate to the measured transmittance.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123860224000042
Errors in instrumental measurements
Milan Meloun, Jiří Militký, in Statistical Data Analysis, 2011
1.2.1 Absolute and Relative Errors
The calibration of an instrument requires that for known values of the input quantity x, (e.g., the concentration of hydrogen ions [H+], in solution), the corresponding values of the measured output analytical signal yi, (e.g., the EMF of a glass electrode cell) be at disposal measured. Repeated measurements are made for each of several values of xt so that the dependence y = f(x) can be found. An approximate graphical interpretation shows the uncertainty band in the plot (Figure 1.2).
Figure 1.2. The uncertainty band and three types of instrumental errors: (a) additive, (b) multiplicative, and (c) combined error
The middle curve in the uncertainty band is called the nominal characteristic ynom (or xnom) and it is usually declared by the instrument manufacturer. The nominal characteristic ynom (or xnom ) differs from the real characteristic yreal (or xreal) by the error of the instrument, Δ* = yreal – ynom. For any selected y the error due to the instrument is Δ = xreal − xnom. [We will use errors Δ, which are in units of measurement quantities (e.g. pH)].
The absolute error of the signal measurement Δ is not convenient for expressing an instrument’s precision because it is given in the specific units of the instrument used; more convenient is the relative error defined by
(1.3)δ=100Δ/x%
or the reduced relative error defined by
(1.4)δR=100Δ/xmax−xmin=100Δ/R%
where R is the range of measurements.
The limiting error of an instrument Δ0 (absolute) or δ0 (relative) is, under given experimental conditions, the highest possible error which is not obscured by any other random errors.
The reduced limiting error of an instrument δ0,R (relative), for the actual value of the measured variable x. and the given experimental conditions, is defined by the ratio of the limiting error Δ0 to the highest value of the instrumental range R, δ0,R = Δ0/R. Often, the reduced limiting error is given as a percentage of the instrument range, [see Eq. (1.5)].
From the shape of the uncertainty band, various types of measurement errors can be identified, hence some corrections for their elimination may be suggested.
- (a)
-
Absolute measurement errors of an instrument are limited for the whole signal range by the constant limiting error Δ0 that corresponds to the additive errors model. The systematic additive error is a result of the incorrect setting of an instrument’s zero point. Today, however, instruments contain an automatic correction for zero, and systematic additive errors thus appear rarely.
- (b)
-
The magnitude of absolute measurement errors grows with the value of the input quantity x and for x = 0, it is Δ = 0. This is a case of the multiplicative errors model. Such errors are called errors of instrument sensitivity. Systematic multiplicative errors are caused by defects of the instrument.
Real instruments have errors that include both types of effects, and are expressed by the nonlinear function y = f(x).
Problem 1.1 The absolute and relative errors of a pH-meter
A glass electrode for pH measurement has a resistance of 500 MΩ at 25 °C, and the input impedance of the pH meter is 2 × 1011 Ω. Estimate the absolute (Δ0) and relative (δ0) error of EMF measurement when the voltage measured is U = 0.624 V.
Solution: Ucorr = 0.624 (2⋅1011+ 5 108)/(2⋅1011) = 0.6254 V; Δ0 = 0.6254 – 0.624 = 0.0016 V; δ0 = 100⋅0.0016/0.624 = 0.25%.
Conclusion: The absolute error is 1.6 mV and the relative error 0.25%.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780857091093500017
Covariance Structure Models for Maximal Reliability of Unit-Weighted Composites
Peter M. Bentler, in Handbook of Latent Variable and Related Models, 2007
9 Conclusions
Like the 1-factor based internal consistency reliability coefficients, the proposed approach to maximal unit-weighted reliability requires modeling the sample covariance matrix. This must be a successful enterprise, as estimation of reliability only makes sense when the model does an acceptable job of explaining the sample data. Of course, since a k-factor model rather than a 1-factor model would typically be used in the proposed approach, the odds of adequately modeling the sample covariance matrix are greatly improved. The selected model can be a member of a much wider class of models, including exploratory or confirmatory factor models or any arbitrary structural model with additive errors. Whatever the resulting dimensionality k, and whether the typical “small-k” or theoretical alternative ”large-k” approach is used, or whether a general structural model with additive errors is used, the proposed identification conditions assure that the resulting internal consistency coefficient ρˆkk represents the proportion of variance in the unit-weighted composite score that is attributable to the common factor generating maximal internal consistency. The proposed coefficient can be interpreted as representing unidimensional reliability even when the instrument under study is multifactorial, since, as was seen in (3), the composite score can be modeled by a single factor as X = μX + λXξ1 + ɛX. Nonetheless, it equally well has an interpretation as summarizing the internal consistency of the k-dimensional composite. Although generally there is a conflict between unidimensionality and reliability, as noted by ten Berge and Sočan (2004), our approach reconciles this conflict.
When the large-k approach is used to model the covariance matrix, the theory of dimension-free and greatest lower bound coefficients can be applied. This is based on a tautological model that defines factors that precisely reproduce the covariance matrix. As these theories have been developed in the past, reliability is defined on scores that are explicitly multidimensional. However, we have shown here that the dimension-free and greatest lower-bound coefficients can equivalently be defined for the single most reliable dimension among the many that are extracted. Based on this observation, new approaches to these coefficients may be possible.
The optimal unit-weighted coefficient developed here also applies to composites obtained from any latent variable covariance structure model with p-dimensional additive errors. Although we used a specific type of model as given in (7) to develop this approach, we are in no way limited to that specific linear model structure. Our approach holds equally for any completely arbitrary structural model with additive errors that we can write in the form Σ = Σ(θ) + Ψ, where Σ(θ) and Ψ are non-negative definite matrices. Then we can decompose Σ(θ) = ΛΛ′ and proceed as described previously, e.g., we can compute the factor loadings for the maximally reliable factor via λ = {1′(Σ − Ψ)1}−1/2(Σ − Ψ)1. The maximal reliability coefficient for a unit weighted composite based on any model that can be specified as a Bentler and Weeks (1980) model has been available in EQS 6 for several years.
With regard to reliability of differentially weighted composites, we extended our maximal reliability for a unit-weighted composite (4) to maximal reliability for a weighted composite (18). While both coefficients have a similar sounding name, they represent quite different types of “maximal” reliability, and, in spite of the recent enthusiasm for (18), in our opinion this coefficient ought to be used only rarely. Weighted maximal reliability does not describe the reliability of a typical total score or scale. Such a scale score, in common practice, is a unit-weighted composite of a set of items or components. Our unit-weighted maximal reliability (4) or (5) describes this reliability. In contrast, maximal reliability (18) gives the reliability of a differentially weighted composite, and if one is not using such a composite, to report it would be misleading. Of course, if a researcher actually might consider differentially weighting of items or parts in computing a total score, then a comparison of (4) to (18) can be very instructive. If (18) is only a marginal improvement over (4), there would be no point to differential weighting. On the other hand, if (4) is not too large while (18) is substantially larger, differential weighting might make sense.
Finally, all of the theoretical coefficients described in this chapter were specified in terms of population parameters, and their estimation was assumed to be associated with the usual and simple case of independent and identically distributed observations. When data have special features, such as containing missing data, estimators of the population parameters will be somewhat different in obvious ways. For example, maximum likelihood estimators based on an EM algorithm may be used to obtain structured or unstructured estimates of Σ (e.g., Jamshidian and Bentler, 1999) for use in the defining formulae. In more complicated situations, such as multilevel modeling (e.g., Liang and Bentler, 2004), it may be desirable to define and evaluate internal consistency reliability separately for within-cluster and for between-cluster variation. The defining formulae described here can be generalized to such situations in the obvious ways and are already available in EQS 6.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780444520449500045
Computational Analysis and Understanding of Natural Languages: Principles, Methods and Applications
Qiang Wu, Paul Vos, in Handbook of Statistics, 2018
9 Prediction and Model Selection
Consider using a scalar- or vector-valued input (predictor) variable X to predict a scalar-valued target (response) variable Y. The target Y can be a continuous random variable such as in linear regressions or a categorical random variable such as in logistic regressions and classifications. When X is vector-valued, its elements are sometimes called features so model selection is also referred to as feature selection. A prediction model fˆ(x) can be estimated from a training sample (y1,x1),. . .,(yn,xn). For a continuous response variable, fˆ(x) is a predicted value of the response at X = x. When the target is a K-group categorical variable, fˆ(x) is either a classifier with a single one and K − 1 zeros or a vector of predicted probabilities that x belongs to the K groups.
The error between a response y and its prediction fˆ(x) can be measured by a loss function L(y,fˆ(x)). For continuous response variables, frequently used loss functions include the squared error loss (y−fˆ(x))2 and the absolute error loss |y−fˆ(x)|. For categorical target variables, the 0-1 loss
L(y,fˆ(x))=I(y≠fˆ(x))=1y≠fˆ(x)0y=fˆ(x)
is often used for classification purpose. When the prediction fθˆ(y|x) is a pdf or pmf indexed by a parameter estimate θˆ, the log-likelihood loss
L(y,fθˆ(y|x))=−2logfθˆ(y|x)
is often used.
Definition 20
The expected prediction error (i.e., test error) of a prediction fˆ(x) over an independent test sample is defined as Err=E[L(Y,fˆ(X))], where the expectation is taken over Y, X, as well as the randomness in the training sample.
When a test sample {(Y1, X1), …, (Ym, Xm)} exists, the test error of a prediction fˆ(x) can be estimated by the average loss 1m∑i=1mL(Yi,fˆ(Xi)) over the test sample.
Definition 21
The training error of a prediction fˆ(x) is the average loss over the training sample err=1n∑i=1nL(yi,fˆ(xi)).
In general, model selection assesses different models and selects the one with the (approximate) smallest test error. However, the training error usually is not a good estimate of the testing error. The training error tends to decrease as model complexity increases and leads to overfitting (i.e., choosing an overly complex model). To appropriately estimate the test error, the data are usually separated into a training set and a validation set. The training set is used to fit the model, while the validation set is used to assess test error for model selection. When a final model is selected, however, a separate test set should be obtained to assess the test error of the final model. See Hastie et al. (2001) for more details and reference. This chapter serves as a brief review of the involved topics.
Example 56
Consider an additive error model Y = f(X) + ϵ with a linear fit on p inputs or basis functions, where the error ϵ has mean zero and variance σϵ2>0. For example, linear or polynomial regressions and B-splines are additive error models with a linear fit. When a squared error loss is used, the test error at X = x becomes
Err(x)=EY−fˆ(x)2=σϵ2+Efˆ(x)−f(x)2+Efˆ(x)−Efˆ(x)2=σϵ2+Bias2(x)+Variance(x),
where σϵ2 is an irreducible error. When p is large (i.e., model complexity is high), the model fit fˆ(x) is able to approach the true value f(x) more closely so model bias is low. However, since the fit fˆ(x) depends greatly on the training data a small change in the training data will result in a big change in the fit, leading to a large model variance. On the other hand, when p is small (i.e., model complexity is low), the model bias is high but the fit is more stable so that the model variance is low. For example, if the true model is a polynomial regression but the fit used a linear regression, then the model bias is high but the variance is low. Model selection seeks a balance between the bias and the variance. As model complexity (e.g., p) increases, it is normal that the test error first decreases and then increases. Where it turns is the optimal model complexity.
9.1 Model Selection
The training error will usually be less than the test error because the same data used to fit the model is employed to assess its training error. In other words, a fitted model usually adapts to the training data and hence its training error will be overly optimistic (too small). In fact, it is often the case that the training error steadily decreases as the size of the model increases. If training error was used for model selection, it will most likely lead to overfitting the model. The ultimate goal of model selection is to minimize the test error without overfitting. Part of the discrepancy between the training error and the test error is because the training set and the test set have different input values. To evaluate the prediction model fˆ(x) on the same realized input values, consider the in-sample error.
Definition 22
The in-sample error of a fitted model fˆ(x) is defined by
Errin=1n∑i=1nEEL(Yi,fˆ(xi))|y,x|x,
where y = (y1, . . . , yn) and x = (x1, . . . , xn) are the response and predictor values of the training set.
For the same reason that the test error is bigger than the training error, the in-sample error is usually bigger than the training error too. For squared error, 0-1 and a lot of other loss functions, it can be shown that the in-sample error is equal to
(26)Errin=E[err|x]+2n∑i=1nCov(fˆ(xi),yi|x),
where Cov(fˆ(xi),yi|x) stands for the conditional covariance between fˆ(xi) and yi given the predictor values x. The higher the model complexity is, the larger Cov(fˆ(xi),yi|x) will be, thereby increases the difference between the in-sample error and the training error (i.e., the optimism).
Example 57
For the additive error model Y = f(X) + ϵ in Example 56, the in-sample error simplifies to
Errin=E[err|x]+2pnσϵ2=1nE∑i=1nL(yi,fˆ(xi))|x+2pσϵ2.
So the optimism increases linearly with the number of inputs or basis functions, penalizing complex models with large number of inputs or basis functions. An estimate of Errin is
Errˆin=err+2pnσˆϵ2=1n∑i=1nL(yi,fˆ(xi))+2pσˆϵ2,
where σˆϵ2=1n−p∑i(yi−fˆ(xi))2 is an estimate of the error variance using the mean squared error.
Definition 23
When a squared error loss is used to evaluate a linear fit of an additive error model, the Cp statistic
Cp=1n∑i=1n(yi−fˆ(xi))2+2pσˆϵ2
is an estimate of Errin.
When the prediction fθˆ(y|x) is a pdf or pmf fitted by maximum likelihood and a log-likelihood loss is used, the Akaike information criterion (AIC, Akaike, 1973) is used to estimate Errin.
Definition 24
When a log-likelihood loss is used to evaluate a maximum likelihood fit of a pdf or pmf, the Akaike information criterion
AIC=−2∑i=1nlogfθˆ(yi|xi)+2p
is an estimate of Errin.
Example 58
For a logistic regression model with a binomial log-likelihood, the AIC becomes
AIC=−2∑i=1n(yilog(pi)+(1−yi)log(1−pi))+2p,
where log(pi/(1−pi))=xiTβˆ.
For a linear regression model with normal errors, the AIC is equivalent to the Cp statistic. Like AIC, the Bayesian information criterion (BIC, Schwarz, 1978) is applicable when maximum likelihood is used for fitting the model.
Definition 25
When a log-likelihood loss is used to evaluate a maximum likelihood fit of a pdf or pmf, the Bayesian information criterion is defined by
BIC=−2∑i=1nlogfθˆ(yi|xi)+log(n)p.
By replacing 2 with log(n), the BIC penalizes complex models (with large p) more heavily than the AIC, giving preference to simpler models. The training error measures the goodness-of-fit and p measures the model complexity. The number 2 in AIC and log(n) in BIC can be treated as a tunning parameter controlling the balance between goodness-of-fit and model complexity. There are other similar model selection criteria developed to improve AIC and BIC. For example, Foster and George (1994) proposed the risk inflation criterion (RIC) by replacing log(n) in BIC (or 2 in AIC) with 2log(p).
In general, model selection seeks the optimal complexity p with the smallest value of Cp, AIC, BIC, or other similar criteria. However, an exhaustive search would require fitting all models with all subsets of the inputs and hence is practically infeasible. In regression settings, forward and stepwise procedures have been used for variable selection referring to their test statistics or p-values. Such adaptive procedures can be applied with Cp, AIC, BIC, or other similar criteria too. First, select a model with a single input variable which achieves the smallest value of the chosen criterion. Then, variables that lead to the greatest decreases (or least increases) in the criterion are added into the model sequentially. Once the value of the criterion starts to increase (or stops to decrease) when more variables are added, the procedure is stopped and the final model is found.
Another group of methods in variable selection is by shrinking the regression parameters. For a multiple linear regression model Y = XTβ + ϵ, the LSE of β is found by
βˆ=arg minβ∑i=1n(yi−xiTβ)2=(xTx)−1xTy.
If X involves many input variables not contributing to the regression, not only the fitting is unnecessarily complex but the model is ill posed and the fitting might be unstable. For example, when the number of inputs p ≥ n, the LSE βˆ may not exist.
Example 59
Ridge regression is one of the methods to shrink the estimates and potentially set some of them to zero by minimizing an L2 (squared) penalized term
∑i=1n(yi−xiTβ)2+βTΓTΓβ.
The ridge regression estimates of β is βˆridge=(xTx+ΓTΓ)−1xTy. A typical choice for Γ is a multiple of the identity matrix αI. In the L2 regularization, preference is given to solutions with smaller norms and α is a tunning parameter controlling the degree of shrinkage.
Least absolute shrinkage and selection operator (LASSO, Tibshirani, 1996) is a more popular shrinkage regression method. Instead of regularizing the minimization with an L2 norm, LASSO employs an L1 (absolute) norm in order to enhance accuracy and stability in prediction.
Example 60
LASSO estimates of regression parameters β are found by minimizing an L1 penalized term
∑i=1n(yi−xiTβ)2+λ∑j=1p|βj|,
where λ is a tunning parameter controlling the degree of shrinkage.
Recently, some generalizations including elastic net, group lasso, fused lasso, and adaptive lasso are developed to address the shortcomings of LASSO. Each of them uses different penalty terms. For example, the elastic net adds an additional L2 term so the penalty becomes λ1∑j=1p|βj|+λ2∑j=1pβj2, and fused lasso uses a penalty term λ1∑j=1p|βj|+λ2∑j=2p|βj−βj−1|. Special algorithms such as subgradient methods, least-angle regression, and proximal gradient methods are required to find the minimum.
9.2 Cross-Validation
Unlike AIC and BIC criteria which estimate the in-sample error, cross-validation can be used to directly estimate the test error of prediction especially when the sample size is large. Particularly, the whole sample is split into K equal pieces for a K-fold cross-validation. When K = n the sample size, the method is called a leave-one-out cross-validation. Each time, one of the K subsamples is left out for validation purpose and the rest K − 1 subsamples are used for model fitting. Denote fˆ−k(x) the fitted model computed from all subsamples except the k-th for k = 1, …, K.
Definition 26
The cross-validation (CV) estimate of the test error is
CV=1n∑i=1nL(yi,fˆ−k(i)(xi)),
where k(i) = k if the i-th observation is in the k-th subsample.
Typical values of K are 5 or 10, but leave-one-out cross-validation has many applications too. Generally speaking, the larger the number K is, the lower the model bias is but the model variance is higher. For leave-one-out cross-validation, CV is an unbiased estimator for the test error but can have high variance. When K is small such as 5, CV has lower variance but bias can be an issue. If the original sample is large like 200 or more, a small K such as 5 may suffice. If the original sample is small, a larger K may be better. We can also try different K values for the same problem, if computational burden is not an issue.
Example 61
For a linear model fitting using a squared error loss, the prediction can be written as yˆ=Hy where H = X(XTX)−1XT is the hat matrix. The leave-one-out cross-validation error is
CV=1n∑i=1nyi−fˆ−i(xi)2=1n∑i=1nyi−fˆ(xi)1−Hii2,
where Hii is the i-th diagonal element of H. A generalized cross-validation that provides a convenient approximation in computation is
GCV=1n∑i=1nyi−fˆ(xi)1−trace(H)/n2.
When model complexity is controlled by a tuning parameter α, the fitted model is denoted as fˆ−k(x|α) and the estimated test error becomes
CV(α)=1n∑i=1nL(yi,fˆ−k(i)(xi|α)).
It defines an estimated test error curve on α. The final model is chosen to be fˆ(x|αˆ) with a tuning parameter αˆ that minimizes CV (α).
9.3 From Bagging to Random Forests
Bootstrap aggregating (bagging) and random forests are resampling methods proposed to boost both accuracy and stability of regression- and classification-type predictions. Let (y1(b),x1(b)),. . .,(yn(b),xn(b)) be a bootstrap sample from the original training set for b=1,. . .,B. A typical size of B is 500. Denote fˆ(b)(x) the fitted model computed from the b-th bootstrap sample.
Definition 27
The bagging estimate is defined by
fˆbag(x)=1B∑b=1Bfˆ(b)(x).
For a regression problem, each bootstrap prediction fˆ(b)(x) is the predicted value of the response at x so that fˆ(x) is the average over B bootstrap estimates. The variance of the prediction at each x value can be estimated by
σˆ2(x)=∑b=1Bfˆ(b)(x)−fˆbag(x)2B−1.
For a K-group classification problem, each bootstrap prediction fˆ(b)(x) is either a classifier with a single one and K − 1 zeroes or a vector of predicted probabilities that x belongs to the K groups so that the bagging estimate is a vector of estimated probabilities fˆbag(x)=(pˆ1(x),…,pˆK(x)) with pˆk(x) equal to the average probability that x belongs to the k-th group.
Definition 28
A bagging classifier is defined by
Ĝbag(x)=arg maxkfˆbag(x),
which is the class receiving the greatest number of votes from the B bootstrap predictions.
For an input x and its corresponding target y, let
p(x)=1B∑b=1BI(y=arg maxkfˆ(b)(x))
be the percent of times over B bagging classifiers that x is correctly classified. The quantities p(x) − (1 − p(x)) = 2p(x) − 1 are called margins. Large margins are always desirable because that means the overall classification is more stable. Let Cb be a set of indices of all (out-of-bag) observations that do not belong to the b-th bootstrap sample and |Cb| be its cardinality. To accurately estimate the test error, only out-of-bag observations should be used to evaluate the model. Bagging is considered more efficient than cross-validation because the training set can be used for both model fitting and evaluation.
Definition 29
The out-of-bag prediction error is defined by
1B∑b=1B1|Cb|∑i∈CbL(yi,fˆ(b)(xi)).
When sampling with replacement, if a bootstrap sample is the same size as the original sample, it is expected to have about 63.2% of unique observations from the original sample and the other 36.8% are repetitions. In other words, each |Cb| is expected to be about 36.8% of the sample size n.
The random forests algorithm takes one step further when classification or regression trees are built from the bootstrap samples. At each split of a tree, a random subset of the input features are selected and used to construct the split. After each tree is built, the out-of-bag data are dropped down the tree and predicted classifications or means are recorded. Lastly, for each observation in the dataset, one either counts the number of trees that have classified it in one of the categories and assigns each observation to a final category by a majority vote over the set of trees or averages the predicted means from the set of trees. The random forests algorithm helps reduce model variance by averaging over trees that are more independent. It also helps reduce model bias by considering a large number of predictors. Trees are usually grown so that there are only a few observations in each terminal node. Sampling 2–5 input features at each split is often adequate. Sometimes, one vote for classification in a rare category might count the same as two votes for classification in the common category. Stratified bootstrap samples can be used to include some underrepresented subgroups of individuals.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S0169716118300099
Nonlinear Regression Analysis
H.-H. Huang, … S.-Y. Huang, in International Encyclopedia of Education (Third Edition), 2010
Good Initials
For a linear model, the Gauss–Newton method will find the minimum in one single iteration from any initial parameter estimates. For a model which is close to being linear, the convergence for Gauss–Newton method will be rapid and not depend heavily on the initial parameter estimates. However, as the magnitude of model nonlinearity becomes more and more prominent, convergence will be slow or even may not occur, and the resulting parameter estimates may not be reliable. In that case, good initials are important.
One approach to find initial values is through transformation, so that the linear regression analysis under the assumption of additive error terms can be utilized (Bates and Watts, 1988; Ryan, 1997). For instance, the reciprocal of the Michaelis-Menten regression function
[9]f(x;θ)=θ1xθ2+x
leads to the model
y−1=1θ1+θ2θ1(1x)+ɛ
Indeed, this is a linear regression model denoted as
y˜=β0+β1x˜+ɛ
with y˜=y−1,β0=θ1−1,β1=θ2θ1−1, and x˜=x−1. The least-squares estimates of β1 and β2 can therefore be transformed to provide initial values for the parameters in the Michaelis–Menten model. Alternatively, we can adopt a grid search, which evaluates the residual sum of squares at these parameter grid points and then finds the minimizing point among these grid points to provide initial values. In many occasions, the grid search helps to avoid improper initial values that lead to local, but not global, minimum of the residual sum of squares. Another alternative is to use uniform design points to replace the lattice grid points. Uniform design points are so designed to be as uniform and as space filling as possible and provide a more efficient search scheme (Fang et al., 2000).
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978008044894701352X
Matrix-Based Methods
Esam M.A. Hussein, in Computed Radiation Imaging, 2011
10.4.10 Modeling-Error Compensation
The minimization of the residual-error functional of Eq. (10.8) presumes that the difference between the actual measurements, e^, and the corresponding computed ones, Ac, is within the range of the uncertainties in e^. In practice, as indicated in Part I of this book, the forward model is an approximation. As such, the error expressed in Eq. (10.8) by ∥Ac−e^∥ is not only a residual error, in the numerical sense, but also includes a modeling error. However, the modeling error is not random, and is in general an additive error, since it is the result of ignoring effects that are complicated to model (such as scattering in transmission and emission imaging and multiple scattering in scatter imaging). The modeling error can be estimated using a reference object as:
(10.33)B∗=e∗−Ac∗
where it is assumed that the reference measurements, e∗, are acquired with low statistical variability, for an object with known physical attributes, c∗. Then, as Eq. (10.33) indicates, the difference between the actual measurements and those modeled by the forward model gives the modeling error, B∗ for the reference object. For an object with unknown features, but not expected to be very different from the reference object, the modeling error can be estimated as βB∗, with β≥0 being an adjustment parameter that can be estimated a priori, perhaps by comparing ∥e∥ for the imaged object to ∥e∥∗ of the reference object (Arendtsz and Hussein, 1995a). Then, the functional of Eq. (10.8) can be replaced by:
(10.34)χ(c)=∥Ac+βB∗−e^∥2
This becomes the data fidelity norm (actual residual) error, which can be vulnerable to the random variability in e^, as well as to uncertainties in determining β. One can then devise a regularization function to moderate the effect of modeling errors as:
(10.35)η(c)=B=e^−Ac
where B is the unknown modeling error for the problem at hand. Note that the regularization functional now is the residual error of Eq. (10.35), if the modeling error is not taken into account, while the residual error, Eq. (10.34), incorporates some estimate of the modeling error. One now needs to minimize the objective function:
(10.36)min[W(Ac+βB∗−e^)]T[W(Ac+βB∗−e^)]+α2(e^−Ac)2
which leads to the solution:
(10.37)c^=ATW2A−α2ATA−1ATW2(e^−βB∗)−α2ATe^
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123877772000100
Nonlinear Regression Models
Milan Meloun, Jiří Militký, in Statistical Data Analysis, 2011
Problem 8.1 Formulation of the parameters and variables of a regression model
The dependence of a rate constant for a chemical reaction, k, on temperature T is described by the Arrhenius equation
(8.1)k=k0exp−E/RT
where k0 is the activation entropy of the chemical reaction, E is the activation energy, and R is the universal gas constant. Formulate the model parameters and examine their correlation.
Solution: The rate constant k (response variable, y) was measured at various temperatures, T (explanatory variable, x). The unknown parameters in the regression model [Eq. (8.1)] are β1 = k0 and β2 = −E/R. If the additive errors model is used
(8.2)yi=fxiβ+εi=β1+expβ2/xi+εi
Here, b1 and b2 are estimates of β1, and β2 and are determined from experimental data {ki,Ti}, i = 1, …, n, based on a regression criterion. When errors εi. in Eq. (8.2) are independent (values of yi are mutually independent) random variables of the same distribution, and have constant variance σ2(y).
The regression criterion corresponding to the least-squares method may be used. That is
(8.3)Uβ=∑i=1nyi−fxiβ
The estimates b then minimize the criterion U(β).
It can be shown here that a strong correlation exists between estimates In b1 and b2. This correlation may be expressed by the paired correlation coefficient
(8.4)r=C2+cln1+1/c
where c = T1/(Tn − T1) is related to minimum (T1) and maximum (Tn) temperatures. When T1 = 300 K and T2 = 360 K, then r = 0.9986 and ln b1 and b2 are nearly linearly dependent. This means that the ratio (ln b1) / b2 is constant and hence, individual parameters cannot be estimated independently. When parameters are correlated, unfortunately a change in the first parameter is often compensated for by a change in the second one. There may be several different pairs of parameter estimates (ln b1, b2) which give nearly same values of the least squares criterion U(b). The parameter estimates achieved by various regression programs may differ by some orders of magnitude, but nevertheless apparently a “best” fit to the experimental data, and low values of U(b) are reached.
Conclusion: Even a simple nonlinear model may lead to difficulties in the accuracy of the parameter estimates and also in their interpretation.
Often, attempts are made to apply nonlinear regression models in situations which are totally inappropriate. Models are often applied outside the range of their validity, and generally, it is supposed that they can substitute for missing data. In chemical kinetics, for example, attempts may be made to estimate parameters, from data far from equilibrium. The calculated parameters then differ significantly from the true equilibrium parameters, and should be interpreted as model parameters only.
The result of nonlinear regression depends on the quality of the regression triplet, i.e. (1) the data, (2) the model, and (3) the regression criterion. Correct formulation leads to parameter estimates which have meaning not only formally but also physically.
In this chapter, we solve problems for which a regression model is known. For solving calibration problems or searching for empirical models, the regression model is appropriate. Some procedures are mentioned in Chapter 9.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978085709109350008X
Data Science: Theory and Applications
Victor B. Talisa, Chung-Chou H. Chang, in Handbook of Statistics, 2021
2.2 Bias-variance decomposition
We generally cannot estimate (1) directly; instead we usually estimate the unconditional MSEY:
(2)MSEY=EStr,X,YY−f(X;Str)2.
A brief analysis of (2) will reveal several concepts essential to prediction modeling. Consider MSEY conditional on X:
MSEY(x)=EStr,YY−f(x;Str)2X=x.
In words, this is the expected prediction error at a fixed point X = x, where the expectation is taken over the distribution of all training sets and the conditional distribution of Y|X = x. First of all, the function f(x;Str) minimizing MSEY(x) is the conditional expectation μ(x) = E[Y|X = x]. Thus, if μ(x) were known for all x, MSEY would be minimized and we would have our optimal prediction function for Y. However, we only ever observe noisy variates from μ(x) in our data, so at best we can hope to generate an imperfect (but hopefully useful) estimate from our training data, μˆ(x;Str). Therefore, moving forward we refer to the prediction function f(⋅) as μˆ(⋅). The bias-variance decomposition is an important tool for analyzing the sources of error when doing prediction with μˆ(x). To start, let us assume an additive errors model with constant variance: Y = μ(X) + ϵ, where ϵ has mean 0 and variance σϵ2:
(3)MSEY(x)=EStr,YY−μˆ(x;Str)2X=x=σϵ2+EStrμˆ(x;Str)−μ(x)2+EStrμˆ(x;Str)−EStr[μˆ(x;Str)]2
This decomposition explicitly shows how bias and variance contribute to MSEY(x), and therefore MSEY (since MSEY = EX[MSEY(X)]). The second term in (3) is the square of the bias of μˆ(x;Str); if we fit a new model to all possible training samples, the bias would be the difference between the averaged predictions from each fit evaluated at X = x and the true conditional mean at X = x. This bias is the result of misspecifying our model μˆ(⋅). The third term is the estimation variance of μˆ(x;Str), the result of using a random sample to estimate μ(x). The first term is the irreducible error associated with the stochastic target Y. Even if we had the true μ(x) as our prediction function, and thus no bias or estimation variance, the minimum MSEY could not be reduced below the value of σϵ2.
The second and third terms in (3) combine to form the MSE of μˆ(x;Str) for estimating μ(x):
(4)MSEμ(x)=EStr(μˆ(x;Str)−μ(x))2X=x,
where MSEμ = EX[MSEμ(X)]. Thus, the standard prediction problem (at least when using squared error loss) can be expressed as an estimation problem, where the parameter of interest is the function μ(x). The advantage of using MSEY for model selection is that we do not need access to μ(x), unlike MSEμ, making estimation more straightforward. As we will see in concrete examples below, in many cases the bias-variance decomposition reveals that the prediction modeler seeking to minimize MSEY may not find it among the class of unbiased, “correct” estimators of μ(x), unless it also achieves lower variance than other unbiased models. Often the “wrong” model (a biased one) is preferable for having a lower MSEY, and therefore better prediction performance as a whole. Although it may be very unlikely that a modeling procedure captures every nuance of nature necessary to produce truly unbiased estimates of μ(x), the hope is that some will provide a good enough approximation as to be useful in predicting Y.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S0169716120300432
Аддитивная и мультипликативная погрешности.
По характеру
зависимости погрешности от значения
измеряемой величины (входного сигнала)
среди погрешностей выделяются аддитивные
и мультипликативные погрешности. Оба
эти типа погрешностей
могут иметь как инструментальный, так
и методический характер. Для их частичного
устранения в результаты измерений
вводят соответствующие
поправки, которые определяются при
градуировке измерительного средства
или в дополнительных экспериментах.
Наиболее четко
аддитивная и мультипликативная
составляющие погрешности могут быть
идентифицированы графически (Рис.2).
А
ддитивная
погрешность
остается постоянной при изменении
измеряемой входной величины. Графически
она выражается в постоянном смещении
нулевого отсчета средства измерений.
(Рис. 2а).. В
измерительных приборах ее причиной
может быть смещение, дрейф напряжения
источника питания, неточная
установкой нуля прибора, наличие
паразитных сигналов, в т.ч. паразитной
термоЭДС, помехи в измерительных цепях
и другие факторы.
Мультипликативная
погрешность
есть погрешность средства измерений,
которая изменяется пропорционально
измеряемой величине и определяется
нестабильностью коэффициента передачи
элементов измерительной цепи. Эта
нестабильность может быть связана с,
изменениями характеристик этих элементов
во времени (старение), под воздействием
внешней среды, условий внешней среды,
отличием условий эксплуатации средства
измерений от нормальных. Например,
изменение входного сопротивления
прибора при изменении температуры.
Статическая и динамическая погрешность.
Статическая
погрешность это
погрешность средств измерения, которая
возникает при измерении физической
величины, остающейся неизменной в
процессе измерений.
Динамическая
погрешность возникает
при измерении физических величин,
изменяющихся во времени. Величина
динамической погрешности определяются
двумя факторами:
-
собственными
динамическими (инерционными) свойствами
средства измерения -
характером
(скоростью) изменения измеряемой
величины
При неизменных
условиях измерений динамические
погрешности обычно рассматриваются
как систематические. Однако если условия
измерений могут изменяться случайным
образом, или сама измеряемая величина
имеет случайный характер, то динамические
погрешности приходится рассматривать
как случайные
Характер проявления погрешностей.
Полная (абсолютная)
погрешность измерений
определяется суммой трех составляющих
— систематической ,
случайной
и грубой
погрешностей, независимо от природы и
источника этих погрешностей
![]()
…(4)
-
Систематическая
погрешность
— составляющая абсолютной погрешности,
остающаяся постоянной или закономерно
изменяющаяся в течение всего цикла
измерений или (и) при повторных измерениях
одной и той же физической величины.
Источником
систематических погрешностей служат
несовершенство технических средств и
методик измерения, процессы, происходящие
в окружающей среде, при взаимодействии
средства и объекта измерений и многое
другое
Систематическая
погрешность может быть постоянной и
переменной.
Постоянная
систематическая погрешность
остается неизменной в процессе
измерений. Простыми примерами такой
погрешности могут служить погрешности,
связанные с неправильной градуировка
шкалы прибора, с ошибками в определении
начала точки отсчета, АЦП
Переменная
систематическая погрешность
может быть прогрессирующей, т.е. монотонно
возрастать или убывать со временем, и
периодической. Переменная систематическая
погрешность может вызываться, например,
колебаниями параметров окружающей
среды, дрейфом напряжения питания,
старением элементов измерительного
средства, влиянием на средства и метод
измерений режимов работы оборудования
и пр.
-
Случайная
погрешность
– составляющая абсолютной погрешности,
которая изменяется случайным образом
при повторных измерениях одной и той
же физической величины. С физической
точки зрения случайные погрешности
порождаются различного рода флуктуациями
(флуктуация — случайные отклонения тех
или иных физических величин от их
средних значений).
Основным источником
случайных погрешностей являются шумы
и помехи различной природы, которые
возникают в самом объекте измерения, в
используемых средствах измерений,
окружающей среде, устройствах передачи
измерительной информации.
-
Грубая погрешность
– погрешность, которая вызывается, как
правило, однократными причинами, и
существенно превышает величину
погрешности, ожидаемой в данных условиях.
Такими причинами
могут быть, например, сбои аппаратуры,
ошибки персонала, резкие изменения
условий окружающей среды.
Разделение
погрешностей на систематические и
случайные является весьма условным.
Погрешности, имеющие
одинаковую физическую природу, в одной
ситуации могут рассматриваться как
систематические, в другой — как случайные,
а в третьей их вообще будет затруднительно
отнести к тому или другому виду. Например,
погрешность измерений, связанная с
воздействием на измерительную цепь
электромагнитных коммутационных помех,
можно рассматривать и как случайную,
и как систематическую, и как грубую. Все
будет зависеть характеристик помехи,
от того, какие используются средства
измерений, какие способы применяются
для снижения и учета возникающей
погрешности.
Поэтому в 1981 году
Международным комитетом мер и весов
была принята официальная рекомендация,
согласно которой предлагается:
-
классифицировать
погрешности не по характеру их проявления
(случайные и систематические), а по
возможности или невозможности
использовать для их определения методы
математической статистики.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Погрешности
средств измерений —
отклонения метрологических свойств
или параметров средств измерений от
номинальных, влияющие на погрешности
результатов измерений (создающие так
называемые инструментальные ошибки
измерений).
Погрешность результата
измерения — отклонение результата
измерения от действительного (истинного)
значения измеряемой величины , определяемая
по формуле — погрешность измерения.
Аддитивная
погрешность–
погрешность измерения которая при всех
значениях входной измеряемой величины
Х значения выходной величины Y
изменяются на одну и ту же величину
большую или меньшую от номинального
значения.
Если
абсолютная погрешность не зависит от
значения измеряемой величины, то полоса
определяется аддитивной погрешностью .
Ярким
примером аддитивной погрешности является
погрешность квантования (оцифровки).
Класс
точности измерений :
—
для аддитивной погрешности:
![]() где
где
Х — верхний предел шкалы, ∆0 —
абсолютная аддитивная погрешность.
Мультипликативной
погрешностью называется
погрешность, линейно возрастающая или
убывающая с ростом измеряемой величины.
Если
постоянной величиной является
относительная погрешность, то полоса
погрешностей меняется в пределах
диапазона измерений и погрешность
называется мультипликативной
Класс
точности измерений :
—
для мультипликативной погрешности:
![]()
![]() —
—
это условие определяет порог
чувствительности прибора (измерений).
17.Погрешность квантования.
Погрешности
средств измерений —
отклонения метрологических свойств
или параметров средств измерений от
номинальных, влияющие на погрешности
результатов измерений (создающие так
называемые инструментальные ошибки
измерений).
Погрешность результата
измерения — отклонение результата
измерения от действительного (истинного)
значения измеряемой величины , определяемая
по формуле — погрешность измерения.
Разным
значениям непрерывной измеряемой
величины
соответствуют дискретные значения
выходной величины.
Показания прибора дискретны с шагом
квантования,
где— чувствительность линейной функции,
которая имела бы место при.
Значение
,
соответствующее зависимостизаменяется дискретным значением,
равнымближайшему
уровню квантования. Несовпадение
ибудет определять погрешность квантования.
Значения погрешности квантованиялежат в пределе отдо.
При этом все значенияравновероятны и математическое ожидание
такой погрешности равно 0. Из этого
следует, что в этом случае погрешность
квантования есть чисто случайная
погрешность с равномерным распределением.
18.Понятие класса точности. Нормирование точности средств измерения.
Класс
точности
(КТ)—
это обобщенная характеристика средства
измерений, выражаемая пределами его
допускаемых основной и дополнительных
погрешностей, а также другими
характеристиками, влияющими на точность.
Класс
точности средств измерений
характеризует их свойства в отношении
точности, но не является непосредственным
показателем точности измерений,
выполняемых при помощи этих средств.
Для
того чтобы заранее оценить погрешность,
которую внесет данное средство измерений
в результат, пользуются нормированными
значениями погрешности.
Под ними понимают предельные
для данного типа средства измерений
погрешности.
Погрешность
данного измерительного прибора не
должна превосходить нормированного
значения.
Если
обозначаемое на шкале значение класса
точности обведено кружком, например
1,5, это означает, что погрешность
чувствительности γs=1,5%.
Так нормируют погрешности масштабных
преобразователей (делителей напряжения,
шунтов, измерительных трансформаторов
тока и напряжения и т. п.).
Если
на шкале измерительного прибора цифра
класса точности не подчеркнута, например
0,5, это означает, что прибор нормируется
приведенной погрешностью нуля γ
о=0,5
%.
Однако
будет грубейшей ошибкой полагать, что
амперметр класса точности 0,5 обеспечивает
во всем диапазоне измерений погрешность
результатов измерений
±0,5 %.
На
измерительных приборах с резко
неравномерной шкалой (например на
омметрах) класс точности указывают в
долях от длины шкалы и обозначают как
1,5 с обозначением ниже цифр знака «угол».
Если
обозначение класса точности на шкале
измерительного прибора дано в виде
дроби (например 0,02/0,01), это указывает на
то, что приведенная погрешность в конце
диапазона измерений γк
= ±0,02 %, а в нуле диапазона γн
= ±0,01 %. К таким измерительным приборам
относятся высокоточные цифровые
вольтметры, потенциометры постоянного
тока и другие высокоточные приборы. В
этом случае
δ(х)
= γк
+ γн
(Хк/Х — 1),
где
Хк — верхний предел измерений (конечное
значение шкалы прибора), Х — измеряемое
значение.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Аддитивные и мультипликативные погрешности

Аддитивной погрешностью называется погрешность, постоянная в каждой точке шкалы.
Мультипликативной называется погрешность, линейно возрастающая или убывающая с ростом измеряемой величины.
Различать аддитивные и мультипликативные п. легче всего по полосе погрешностей.
 Полоса погрешностей
Полоса погрешностей
Если абсолютная погрешность не зависит от значения измеряемой величины, то полоса определяется аддитивной п. (рис. а). Иногда такую п. называют погрешностью нуля. Если постоянной величиной является относительная погрешность, то полоса погрешностей меняется в пределах диапазона измерений и п. называется мультипликативной (рис. б). Ярким примером аддитивной п. является погрешность квантования (оцифровки).
Класс точности измерений зависит от вида погрешностей. Рассмотрим класс точности измерений для аддитивной и мультипликативной п.
Для аддитивной п.:
 Формула для класса точности аддитивной погрешности
Формула для класса точности аддитивной погрешности
где X — верхний предел шкалы, ∆0 — абсолютная аддитивная п.
Для мультипликативной п.:
 Формула для класса точности мультипликативной погрешности
Формула для класса точности мультипликативной погрешности
∆x/x=1 — это условие определяет порог чувствительности прибора (измерений).
Абсолютная величина погрешности для обоих типов может быть выражена одной формулой:
 Выражение для абсолютной величины
Выражение для абсолютной величины
где ∆0 — аддитивная п., y0x — мультипликативная п.
Относительная погрешность с учетом вышесказанного выражается:
 Формула для относительной величины погрешности
Формула для относительной величины погрешности
и, при уменьшении измеряемой величины, возрастает до бесконечности. Приведенное значение погрешности возрастает с увеличением измеряемой величины:
 Формула погрешности при возрастании величины измерения
Формула погрешности при возрастании величины измерения
Добавить комментарий
For the additive errors model, the class of instrumental precision δ0 is equal to the limiting reduced relative error δ0 R defined by
From: Statistical Data Analysis, 2011
Spectrophotometry
Simon G. Kaplan, Manuel A. Quijada, in Experimental Methods in the Physical Sciences, 2014
4.3.5 Interreflections
Interreflections between the sample and the detector, spectrometer, or other optical elements in a spectrophotometric measurement system introduce additive error terms to the measurand. In particular, light that is reflected back to an FTS by the sample or other optical element can pass through the beamsplitter back to the interferometer mirrors, be modulated a second time by the scanning mirror, recombine, and then pass through the sample again to the detector. For a given wavenumber σ, any part of the optical power that is modulated twice by the FTS will experience twice the path length change and thus be recorded at 2σ. Successive interreflections can generate higher harmonics in the spectrum [22]. Other interreflections not involving the FTS directly will still add an error to the measurement that can include spectral features of other components in the system. This situation is illustrated for a transmittance measurement in Fig. 4.13.
Figure 4.13. Schematic layout of a sample transmittance measurement with an FTS showing possible interreflections and their elimination through the use of semicircular beam blocks.
In a focused sample geometry, one way to eliminate interreflections is to insert semicircular beam blocks before and after the sample, as shown in Fig. 4.13. The reflection of the half-cone beam incident on the sample will thus be blocked from reentering the FTS, and similarly any light reflected from the detector will not return to the sample or to the spectrometer. An example of the effects of interreflections on a transmittance measurement (normal incidence, f/3 focusing geometry) of a 0.25-mm thick Si wafer is shown in Fig. 4.14.
Figure 4.14. Effects of interreflections on a normal incidence transmittance measurement of a 0.25 mm Si wafer. The lettered curves show the results of inserting half-blocks illustrated in Fig. 4.13 compared to the expected transmittance (solid curve).
Without any half-blocks in the beam, curve A shows large deviations from the expected transmittance curve. These include both wavenumber-doubled spectral features originating from the spectral irradiance of the incident FTS beam and high-frequency fringes due to doubling of the etalon spectrum of the Si wafer sample. Inserting a half-block between the sample and detector (curve B) lowers the error at low wavenumbers, but does not get rid of the interreflections with the FTS. Curve C with the half-block before the sample eliminates the sample-FTS interreflection, while curve D with both half-blocks gives a result close to the expected transmittance spectrum.
The use of half-beam blocks, or half-field stops, can effectively eliminate interreflection errors at the cost of 50% reduction in signal, and some increase in sensitivity to beam geometry errors as discussed below. Other options include filters between the sample and FTS, or simply tilting the sample, which may be the simplest approach if knowledge of the precise incident beam geometry is not critical to the measurement. Si represents close to the worst case, being approximately 50% transmitting; lower index materials will have less uncertainty. Finally, one may also consider interreflections on the source side of the FTS. These in principle can lead to errors in the reference spectrum that can propagate to the measured transmittance.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123860224000042
Errors in instrumental measurements
Milan Meloun, Jiří Militký, in Statistical Data Analysis, 2011
1.2.1 Absolute and Relative Errors
The calibration of an instrument requires that for known values of the input quantity x, (e.g., the concentration of hydrogen ions [H+], in solution), the corresponding values of the measured output analytical signal yi, (e.g., the EMF of a glass electrode cell) be at disposal measured. Repeated measurements are made for each of several values of xt so that the dependence y = f(x) can be found. An approximate graphical interpretation shows the uncertainty band in the plot (Figure 1.2).
Figure 1.2. The uncertainty band and three types of instrumental errors: (a) additive, (b) multiplicative, and (c) combined error
The middle curve in the uncertainty band is called the nominal characteristic ynom (or xnom) and it is usually declared by the instrument manufacturer. The nominal characteristic ynom (or xnom ) differs from the real characteristic yreal (or xreal) by the error of the instrument, Δ* = yreal – ynom. For any selected y the error due to the instrument is Δ = xreal − xnom. [We will use errors Δ, which are in units of measurement quantities (e.g. pH)].
The absolute error of the signal measurement Δ is not convenient for expressing an instrument’s precision because it is given in the specific units of the instrument used; more convenient is the relative error defined by
(1.3)δ=100Δ/x%
or the reduced relative error defined by
(1.4)δR=100Δ/xmax−xmin=100Δ/R%
where R is the range of measurements.
The limiting error of an instrument Δ0 (absolute) or δ0 (relative) is, under given experimental conditions, the highest possible error which is not obscured by any other random errors.
The reduced limiting error of an instrument δ0,R (relative), for the actual value of the measured variable x. and the given experimental conditions, is defined by the ratio of the limiting error Δ0 to the highest value of the instrumental range R, δ0,R = Δ0/R. Often, the reduced limiting error is given as a percentage of the instrument range, [see Eq. (1.5)].
From the shape of the uncertainty band, various types of measurement errors can be identified, hence some corrections for their elimination may be suggested.
- (a)
-
Absolute measurement errors of an instrument are limited for the whole signal range by the constant limiting error Δ0 that corresponds to the additive errors model. The systematic additive error is a result of the incorrect setting of an instrument’s zero point. Today, however, instruments contain an automatic correction for zero, and systematic additive errors thus appear rarely.
- (b)
-
The magnitude of absolute measurement errors grows with the value of the input quantity x and for x = 0, it is Δ = 0. This is a case of the multiplicative errors model. Such errors are called errors of instrument sensitivity. Systematic multiplicative errors are caused by defects of the instrument.
Real instruments have errors that include both types of effects, and are expressed by the nonlinear function y = f(x).
Problem 1.1 The absolute and relative errors of a pH-meter
A glass electrode for pH measurement has a resistance of 500 MΩ at 25 °C, and the input impedance of the pH meter is 2 × 1011 Ω. Estimate the absolute (Δ0) and relative (δ0) error of EMF measurement when the voltage measured is U = 0.624 V.
Solution: Ucorr = 0.624 (2⋅1011+ 5 108)/(2⋅1011) = 0.6254 V; Δ0 = 0.6254 – 0.624 = 0.0016 V; δ0 = 100⋅0.0016/0.624 = 0.25%.
Conclusion: The absolute error is 1.6 mV and the relative error 0.25%.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780857091093500017
Covariance Structure Models for Maximal Reliability of Unit-Weighted Composites
Peter M. Bentler, in Handbook of Latent Variable and Related Models, 2007
9 Conclusions
Like the 1-factor based internal consistency reliability coefficients, the proposed approach to maximal unit-weighted reliability requires modeling the sample covariance matrix. This must be a successful enterprise, as estimation of reliability only makes sense when the model does an acceptable job of explaining the sample data. Of course, since a k-factor model rather than a 1-factor model would typically be used in the proposed approach, the odds of adequately modeling the sample covariance matrix are greatly improved. The selected model can be a member of a much wider class of models, including exploratory or confirmatory factor models or any arbitrary structural model with additive errors. Whatever the resulting dimensionality k, and whether the typical “small-k” or theoretical alternative ”large-k” approach is used, or whether a general structural model with additive errors is used, the proposed identification conditions assure that the resulting internal consistency coefficient ρˆkk represents the proportion of variance in the unit-weighted composite score that is attributable to the common factor generating maximal internal consistency. The proposed coefficient can be interpreted as representing unidimensional reliability even when the instrument under study is multifactorial, since, as was seen in (3), the composite score can be modeled by a single factor as X = μX + λXξ1 + ɛX. Nonetheless, it equally well has an interpretation as summarizing the internal consistency of the k-dimensional composite. Although generally there is a conflict between unidimensionality and reliability, as noted by ten Berge and Sočan (2004), our approach reconciles this conflict.
When the large-k approach is used to model the covariance matrix, the theory of dimension-free and greatest lower bound coefficients can be applied. This is based on a tautological model that defines factors that precisely reproduce the covariance matrix. As these theories have been developed in the past, reliability is defined on scores that are explicitly multidimensional. However, we have shown here that the dimension-free and greatest lower-bound coefficients can equivalently be defined for the single most reliable dimension among the many that are extracted. Based on this observation, new approaches to these coefficients may be possible.
The optimal unit-weighted coefficient developed here also applies to composites obtained from any latent variable covariance structure model with p-dimensional additive errors. Although we used a specific type of model as given in (7) to develop this approach, we are in no way limited to that specific linear model structure. Our approach holds equally for any completely arbitrary structural model with additive errors that we can write in the form Σ = Σ(θ) + Ψ, where Σ(θ) and Ψ are non-negative definite matrices. Then we can decompose Σ(θ) = ΛΛ′ and proceed as described previously, e.g., we can compute the factor loadings for the maximally reliable factor via λ = {1′(Σ − Ψ)1}−1/2(Σ − Ψ)1. The maximal reliability coefficient for a unit weighted composite based on any model that can be specified as a Bentler and Weeks (1980) model has been available in EQS 6 for several years.
With regard to reliability of differentially weighted composites, we extended our maximal reliability for a unit-weighted composite (4) to maximal reliability for a weighted composite (18). While both coefficients have a similar sounding name, they represent quite different types of “maximal” reliability, and, in spite of the recent enthusiasm for (18), in our opinion this coefficient ought to be used only rarely. Weighted maximal reliability does not describe the reliability of a typical total score or scale. Such a scale score, in common practice, is a unit-weighted composite of a set of items or components. Our unit-weighted maximal reliability (4) or (5) describes this reliability. In contrast, maximal reliability (18) gives the reliability of a differentially weighted composite, and if one is not using such a composite, to report it would be misleading. Of course, if a researcher actually might consider differentially weighting of items or parts in computing a total score, then a comparison of (4) to (18) can be very instructive. If (18) is only a marginal improvement over (4), there would be no point to differential weighting. On the other hand, if (4) is not too large while (18) is substantially larger, differential weighting might make sense.
Finally, all of the theoretical coefficients described in this chapter were specified in terms of population parameters, and their estimation was assumed to be associated with the usual and simple case of independent and identically distributed observations. When data have special features, such as containing missing data, estimators of the population parameters will be somewhat different in obvious ways. For example, maximum likelihood estimators based on an EM algorithm may be used to obtain structured or unstructured estimates of Σ (e.g., Jamshidian and Bentler, 1999) for use in the defining formulae. In more complicated situations, such as multilevel modeling (e.g., Liang and Bentler, 2004), it may be desirable to define and evaluate internal consistency reliability separately for within-cluster and for between-cluster variation. The defining formulae described here can be generalized to such situations in the obvious ways and are already available in EQS 6.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780444520449500045
Computational Analysis and Understanding of Natural Languages: Principles, Methods and Applications
Qiang Wu, Paul Vos, in Handbook of Statistics, 2018
9 Prediction and Model Selection
Consider using a scalar- or vector-valued input (predictor) variable X to predict a scalar-valued target (response) variable Y. The target Y can be a continuous random variable such as in linear regressions or a categorical random variable such as in logistic regressions and classifications. When X is vector-valued, its elements are sometimes called features so model selection is also referred to as feature selection. A prediction model fˆ(x) can be estimated from a training sample (y1,x1),. . .,(yn,xn). For a continuous response variable, fˆ(x) is a predicted value of the response at X = x. When the target is a K-group categorical variable, fˆ(x) is either a classifier with a single one and K − 1 zeros or a vector of predicted probabilities that x belongs to the K groups.
The error between a response y and its prediction fˆ(x) can be measured by a loss function L(y,fˆ(x)). For continuous response variables, frequently used loss functions include the squared error loss (y−fˆ(x))2 and the absolute error loss |y−fˆ(x)|. For categorical target variables, the 0-1 loss
L(y,fˆ(x))=I(y≠fˆ(x))=1y≠fˆ(x)0y=fˆ(x)
is often used for classification purpose. When the prediction fθˆ(y|x) is a pdf or pmf indexed by a parameter estimate θˆ, the log-likelihood loss
L(y,fθˆ(y|x))=−2logfθˆ(y|x)
is often used.
Definition 20
The expected prediction error (i.e., test error) of a prediction fˆ(x) over an independent test sample is defined as Err=E[L(Y,fˆ(X))], where the expectation is taken over Y, X, as well as the randomness in the training sample.
When a test sample {(Y1, X1), …, (Ym, Xm)} exists, the test error of a prediction fˆ(x) can be estimated by the average loss 1m∑i=1mL(Yi,fˆ(Xi)) over the test sample.
Definition 21
The training error of a prediction fˆ(x) is the average loss over the training sample err=1n∑i=1nL(yi,fˆ(xi)).
In general, model selection assesses different models and selects the one with the (approximate) smallest test error. However, the training error usually is not a good estimate of the testing error. The training error tends to decrease as model complexity increases and leads to overfitting (i.e., choosing an overly complex model). To appropriately estimate the test error, the data are usually separated into a training set and a validation set. The training set is used to fit the model, while the validation set is used to assess test error for model selection. When a final model is selected, however, a separate test set should be obtained to assess the test error of the final model. See Hastie et al. (2001) for more details and reference. This chapter serves as a brief review of the involved topics.
Example 56
Consider an additive error model Y = f(X) + ϵ with a linear fit on p inputs or basis functions, where the error ϵ has mean zero and variance σϵ2>0. For example, linear or polynomial regressions and B-splines are additive error models with a linear fit. When a squared error loss is used, the test error at X = x becomes
Err(x)=EY−fˆ(x)2=σϵ2+Efˆ(x)−f(x)2+Efˆ(x)−Efˆ(x)2=σϵ2+Bias2(x)+Variance(x),
where σϵ2 is an irreducible error. When p is large (i.e., model complexity is high), the model fit fˆ(x) is able to approach the true value f(x) more closely so model bias is low. However, since the fit fˆ(x) depends greatly on the training data a small change in the training data will result in a big change in the fit, leading to a large model variance. On the other hand, when p is small (i.e., model complexity is low), the model bias is high but the fit is more stable so that the model variance is low. For example, if the true model is a polynomial regression but the fit used a linear regression, then the model bias is high but the variance is low. Model selection seeks a balance between the bias and the variance. As model complexity (e.g., p) increases, it is normal that the test error first decreases and then increases. Where it turns is the optimal model complexity.
9.1 Model Selection
The training error will usually be less than the test error because the same data used to fit the model is employed to assess its training error. In other words, a fitted model usually adapts to the training data and hence its training error will be overly optimistic (too small). In fact, it is often the case that the training error steadily decreases as the size of the model increases. If training error was used for model selection, it will most likely lead to overfitting the model. The ultimate goal of model selection is to minimize the test error without overfitting. Part of the discrepancy between the training error and the test error is because the training set and the test set have different input values. To evaluate the prediction model fˆ(x) on the same realized input values, consider the in-sample error.
Definition 22
The in-sample error of a fitted model fˆ(x) is defined by
Errin=1n∑i=1nEEL(Yi,fˆ(xi))|y,x|x,
where y = (y1, . . . , yn) and x = (x1, . . . , xn) are the response and predictor values of the training set.
For the same reason that the test error is bigger than the training error, the in-sample error is usually bigger than the training error too. For squared error, 0-1 and a lot of other loss functions, it can be shown that the in-sample error is equal to
(26)Errin=E[err|x]+2n∑i=1nCov(fˆ(xi),yi|x),
where Cov(fˆ(xi),yi|x) stands for the conditional covariance between fˆ(xi) and yi given the predictor values x. The higher the model complexity is, the larger Cov(fˆ(xi),yi|x) will be, thereby increases the difference between the in-sample error and the training error (i.e., the optimism).
Example 57
For the additive error model Y = f(X) + ϵ in Example 56, the in-sample error simplifies to
Errin=E[err|x]+2pnσϵ2=1nE∑i=1nL(yi,fˆ(xi))|x+2pσϵ2.
So the optimism increases linearly with the number of inputs or basis functions, penalizing complex models with large number of inputs or basis functions. An estimate of Errin is
Errˆin=err+2pnσˆϵ2=1n∑i=1nL(yi,fˆ(xi))+2pσˆϵ2,
where σˆϵ2=1n−p∑i(yi−fˆ(xi))2 is an estimate of the error variance using the mean squared error.
Definition 23
When a squared error loss is used to evaluate a linear fit of an additive error model, the Cp statistic
Cp=1n∑i=1n(yi−fˆ(xi))2+2pσˆϵ2
is an estimate of Errin.
When the prediction fθˆ(y|x) is a pdf or pmf fitted by maximum likelihood and a log-likelihood loss is used, the Akaike information criterion (AIC, Akaike, 1973) is used to estimate Errin.
Definition 24
When a log-likelihood loss is used to evaluate a maximum likelihood fit of a pdf or pmf, the Akaike information criterion
AIC=−2∑i=1nlogfθˆ(yi|xi)+2p
is an estimate of Errin.
Example 58
For a logistic regression model with a binomial log-likelihood, the AIC becomes
AIC=−2∑i=1n(yilog(pi)+(1−yi)log(1−pi))+2p,
where log(pi/(1−pi))=xiTβˆ.
For a linear regression model with normal errors, the AIC is equivalent to the Cp statistic. Like AIC, the Bayesian information criterion (BIC, Schwarz, 1978) is applicable when maximum likelihood is used for fitting the model.
Definition 25
When a log-likelihood loss is used to evaluate a maximum likelihood fit of a pdf or pmf, the Bayesian information criterion is defined by
BIC=−2∑i=1nlogfθˆ(yi|xi)+log(n)p.
By replacing 2 with log(n), the BIC penalizes complex models (with large p) more heavily than the AIC, giving preference to simpler models. The training error measures the goodness-of-fit and p measures the model complexity. The number 2 in AIC and log(n) in BIC can be treated as a tunning parameter controlling the balance between goodness-of-fit and model complexity. There are other similar model selection criteria developed to improve AIC and BIC. For example, Foster and George (1994) proposed the risk inflation criterion (RIC) by replacing log(n) in BIC (or 2 in AIC) with 2log(p).
In general, model selection seeks the optimal complexity p with the smallest value of Cp, AIC, BIC, or other similar criteria. However, an exhaustive search would require fitting all models with all subsets of the inputs and hence is practically infeasible. In regression settings, forward and stepwise procedures have been used for variable selection referring to their test statistics or p-values. Such adaptive procedures can be applied with Cp, AIC, BIC, or other similar criteria too. First, select a model with a single input variable which achieves the smallest value of the chosen criterion. Then, variables that lead to the greatest decreases (or least increases) in the criterion are added into the model sequentially. Once the value of the criterion starts to increase (or stops to decrease) when more variables are added, the procedure is stopped and the final model is found.
Another group of methods in variable selection is by shrinking the regression parameters. For a multiple linear regression model Y = XTβ + ϵ, the LSE of β is found by
βˆ=arg minβ∑i=1n(yi−xiTβ)2=(xTx)−1xTy.
If X involves many input variables not contributing to the regression, not only the fitting is unnecessarily complex but the model is ill posed and the fitting might be unstable. For example, when the number of inputs p ≥ n, the LSE βˆ may not exist.
Example 59
Ridge regression is one of the methods to shrink the estimates and potentially set some of them to zero by minimizing an L2 (squared) penalized term
∑i=1n(yi−xiTβ)2+βTΓTΓβ.
The ridge regression estimates of β is βˆridge=(xTx+ΓTΓ)−1xTy. A typical choice for Γ is a multiple of the identity matrix αI. In the L2 regularization, preference is given to solutions with smaller norms and α is a tunning parameter controlling the degree of shrinkage.
Least absolute shrinkage and selection operator (LASSO, Tibshirani, 1996) is a more popular shrinkage regression method. Instead of regularizing the minimization with an L2 norm, LASSO employs an L1 (absolute) norm in order to enhance accuracy and stability in prediction.
Example 60
LASSO estimates of regression parameters β are found by minimizing an L1 penalized term
∑i=1n(yi−xiTβ)2+λ∑j=1p|βj|,
where λ is a tunning parameter controlling the degree of shrinkage.
Recently, some generalizations including elastic net, group lasso, fused lasso, and adaptive lasso are developed to address the shortcomings of LASSO. Each of them uses different penalty terms. For example, the elastic net adds an additional L2 term so the penalty becomes λ1∑j=1p|βj|+λ2∑j=1pβj2, and fused lasso uses a penalty term λ1∑j=1p|βj|+λ2∑j=2p|βj−βj−1|. Special algorithms such as subgradient methods, least-angle regression, and proximal gradient methods are required to find the minimum.
9.2 Cross-Validation
Unlike AIC and BIC criteria which estimate the in-sample error, cross-validation can be used to directly estimate the test error of prediction especially when the sample size is large. Particularly, the whole sample is split into K equal pieces for a K-fold cross-validation. When K = n the sample size, the method is called a leave-one-out cross-validation. Each time, one of the K subsamples is left out for validation purpose and the rest K − 1 subsamples are used for model fitting. Denote fˆ−k(x) the fitted model computed from all subsamples except the k-th for k = 1, …, K.
Definition 26
The cross-validation (CV) estimate of the test error is
CV=1n∑i=1nL(yi,fˆ−k(i)(xi)),
where k(i) = k if the i-th observation is in the k-th subsample.
Typical values of K are 5 or 10, but leave-one-out cross-validation has many applications too. Generally speaking, the larger the number K is, the lower the model bias is but the model variance is higher. For leave-one-out cross-validation, CV is an unbiased estimator for the test error but can have high variance. When K is small such as 5, CV has lower variance but bias can be an issue. If the original sample is large like 200 or more, a small K such as 5 may suffice. If the original sample is small, a larger K may be better. We can also try different K values for the same problem, if computational burden is not an issue.
Example 61
For a linear model fitting using a squared error loss, the prediction can be written as yˆ=Hy where H = X(XTX)−1XT is the hat matrix. The leave-one-out cross-validation error is
CV=1n∑i=1nyi−fˆ−i(xi)2=1n∑i=1nyi−fˆ(xi)1−Hii2,
where Hii is the i-th diagonal element of H. A generalized cross-validation that provides a convenient approximation in computation is
GCV=1n∑i=1nyi−fˆ(xi)1−trace(H)/n2.
When model complexity is controlled by a tuning parameter α, the fitted model is denoted as fˆ−k(x|α) and the estimated test error becomes
CV(α)=1n∑i=1nL(yi,fˆ−k(i)(xi|α)).
It defines an estimated test error curve on α. The final model is chosen to be fˆ(x|αˆ) with a tuning parameter αˆ that minimizes CV (α).
9.3 From Bagging to Random Forests
Bootstrap aggregating (bagging) and random forests are resampling methods proposed to boost both accuracy and stability of regression- and classification-type predictions. Let (y1(b),x1(b)),. . .,(yn(b),xn(b)) be a bootstrap sample from the original training set for b=1,. . .,B. A typical size of B is 500. Denote fˆ(b)(x) the fitted model computed from the b-th bootstrap sample.
Definition 27
The bagging estimate is defined by
fˆbag(x)=1B∑b=1Bfˆ(b)(x).
For a regression problem, each bootstrap prediction fˆ(b)(x) is the predicted value of the response at x so that fˆ(x) is the average over B bootstrap estimates. The variance of the prediction at each x value can be estimated by
σˆ2(x)=∑b=1Bfˆ(b)(x)−fˆbag(x)2B−1.
For a K-group classification problem, each bootstrap prediction fˆ(b)(x) is either a classifier with a single one and K − 1 zeroes or a vector of predicted probabilities that x belongs to the K groups so that the bagging estimate is a vector of estimated probabilities fˆbag(x)=(pˆ1(x),…,pˆK(x)) with pˆk(x) equal to the average probability that x belongs to the k-th group.
Definition 28
A bagging classifier is defined by
Ĝbag(x)=arg maxkfˆbag(x),
which is the class receiving the greatest number of votes from the B bootstrap predictions.
For an input x and its corresponding target y, let
p(x)=1B∑b=1BI(y=arg maxkfˆ(b)(x))
be the percent of times over B bagging classifiers that x is correctly classified. The quantities p(x) − (1 − p(x)) = 2p(x) − 1 are called margins. Large margins are always desirable because that means the overall classification is more stable. Let Cb be a set of indices of all (out-of-bag) observations that do not belong to the b-th bootstrap sample and |Cb| be its cardinality. To accurately estimate the test error, only out-of-bag observations should be used to evaluate the model. Bagging is considered more efficient than cross-validation because the training set can be used for both model fitting and evaluation.
Definition 29
The out-of-bag prediction error is defined by
1B∑b=1B1|Cb|∑i∈CbL(yi,fˆ(b)(xi)).
When sampling with replacement, if a bootstrap sample is the same size as the original sample, it is expected to have about 63.2% of unique observations from the original sample and the other 36.8% are repetitions. In other words, each |Cb| is expected to be about 36.8% of the sample size n.
The random forests algorithm takes one step further when classification or regression trees are built from the bootstrap samples. At each split of a tree, a random subset of the input features are selected and used to construct the split. After each tree is built, the out-of-bag data are dropped down the tree and predicted classifications or means are recorded. Lastly, for each observation in the dataset, one either counts the number of trees that have classified it in one of the categories and assigns each observation to a final category by a majority vote over the set of trees or averages the predicted means from the set of trees. The random forests algorithm helps reduce model variance by averaging over trees that are more independent. It also helps reduce model bias by considering a large number of predictors. Trees are usually grown so that there are only a few observations in each terminal node. Sampling 2–5 input features at each split is often adequate. Sometimes, one vote for classification in a rare category might count the same as two votes for classification in the common category. Stratified bootstrap samples can be used to include some underrepresented subgroups of individuals.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S0169716118300099
Nonlinear Regression Analysis
H.-H. Huang, … S.-Y. Huang, in International Encyclopedia of Education (Third Edition), 2010
Good Initials
For a linear model, the Gauss–Newton method will find the minimum in one single iteration from any initial parameter estimates. For a model which is close to being linear, the convergence for Gauss–Newton method will be rapid and not depend heavily on the initial parameter estimates. However, as the magnitude of model nonlinearity becomes more and more prominent, convergence will be slow or even may not occur, and the resulting parameter estimates may not be reliable. In that case, good initials are important.
One approach to find initial values is through transformation, so that the linear regression analysis under the assumption of additive error terms can be utilized (Bates and Watts, 1988; Ryan, 1997). For instance, the reciprocal of the Michaelis-Menten regression function
[9]f(x;θ)=θ1xθ2+x
leads to the model
y−1=1θ1+θ2θ1(1x)+ɛ
Indeed, this is a linear regression model denoted as
y˜=β0+β1x˜+ɛ
with y˜=y−1,β0=θ1−1,β1=θ2θ1−1, and x˜=x−1. The least-squares estimates of β1 and β2 can therefore be transformed to provide initial values for the parameters in the Michaelis–Menten model. Alternatively, we can adopt a grid search, which evaluates the residual sum of squares at these parameter grid points and then finds the minimizing point among these grid points to provide initial values. In many occasions, the grid search helps to avoid improper initial values that lead to local, but not global, minimum of the residual sum of squares. Another alternative is to use uniform design points to replace the lattice grid points. Uniform design points are so designed to be as uniform and as space filling as possible and provide a more efficient search scheme (Fang et al., 2000).
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978008044894701352X
Matrix-Based Methods
Esam M.A. Hussein, in Computed Radiation Imaging, 2011
10.4.10 Modeling-Error Compensation
The minimization of the residual-error functional of Eq. (10.8) presumes that the difference between the actual measurements, e^, and the corresponding computed ones, Ac, is within the range of the uncertainties in e^. In practice, as indicated in Part I of this book, the forward model is an approximation. As such, the error expressed in Eq. (10.8) by ∥Ac−e^∥ is not only a residual error, in the numerical sense, but also includes a modeling error. However, the modeling error is not random, and is in general an additive error, since it is the result of ignoring effects that are complicated to model (such as scattering in transmission and emission imaging and multiple scattering in scatter imaging). The modeling error can be estimated using a reference object as:
(10.33)B∗=e∗−Ac∗
where it is assumed that the reference measurements, e∗, are acquired with low statistical variability, for an object with known physical attributes, c∗. Then, as Eq. (10.33) indicates, the difference between the actual measurements and those modeled by the forward model gives the modeling error, B∗ for the reference object. For an object with unknown features, but not expected to be very different from the reference object, the modeling error can be estimated as βB∗, with β≥0 being an adjustment parameter that can be estimated a priori, perhaps by comparing ∥e∥ for the imaged object to ∥e∥∗ of the reference object (Arendtsz and Hussein, 1995a). Then, the functional of Eq. (10.8) can be replaced by:
(10.34)χ(c)=∥Ac+βB∗−e^∥2
This becomes the data fidelity norm (actual residual) error, which can be vulnerable to the random variability in e^, as well as to uncertainties in determining β. One can then devise a regularization function to moderate the effect of modeling errors as:
(10.35)η(c)=B=e^−Ac
where B is the unknown modeling error for the problem at hand. Note that the regularization functional now is the residual error of Eq. (10.35), if the modeling error is not taken into account, while the residual error, Eq. (10.34), incorporates some estimate of the modeling error. One now needs to minimize the objective function:
(10.36)min[W(Ac+βB∗−e^)]T[W(Ac+βB∗−e^)]+α2(e^−Ac)2
which leads to the solution:
(10.37)c^=ATW2A−α2ATA−1ATW2(e^−βB∗)−α2ATe^
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123877772000100
Nonlinear Regression Models
Milan Meloun, Jiří Militký, in Statistical Data Analysis, 2011
Problem 8.1 Formulation of the parameters and variables of a regression model
The dependence of a rate constant for a chemical reaction, k, on temperature T is described by the Arrhenius equation
(8.1)k=k0exp−E/RT
where k0 is the activation entropy of the chemical reaction, E is the activation energy, and R is the universal gas constant. Formulate the model parameters and examine their correlation.
Solution: The rate constant k (response variable, y) was measured at various temperatures, T (explanatory variable, x). The unknown parameters in the regression model [Eq. (8.1)] are β1 = k0 and β2 = −E/R. If the additive errors model is used
(8.2)yi=fxiβ+εi=β1+expβ2/xi+εi
Here, b1 and b2 are estimates of β1, and β2 and are determined from experimental data {ki,Ti}, i = 1, …, n, based on a regression criterion. When errors εi. in Eq. (8.2) are independent (values of yi are mutually independent) random variables of the same distribution, and have constant variance σ2(y).
The regression criterion corresponding to the least-squares method may be used. That is
(8.3)Uβ=∑i=1nyi−fxiβ
The estimates b then minimize the criterion U(β).
It can be shown here that a strong correlation exists between estimates In b1 and b2. This correlation may be expressed by the paired correlation coefficient
(8.4)r=C2+cln1+1/c
where c = T1/(Tn − T1) is related to minimum (T1) and maximum (Tn) temperatures. When T1 = 300 K and T2 = 360 K, then r = 0.9986 and ln b1 and b2 are nearly linearly dependent. This means that the ratio (ln b1) / b2 is constant and hence, individual parameters cannot be estimated independently. When parameters are correlated, unfortunately a change in the first parameter is often compensated for by a change in the second one. There may be several different pairs of parameter estimates (ln b1, b2) which give nearly same values of the least squares criterion U(b). The parameter estimates achieved by various regression programs may differ by some orders of magnitude, but nevertheless apparently a “best” fit to the experimental data, and low values of U(b) are reached.
Conclusion: Even a simple nonlinear model may lead to difficulties in the accuracy of the parameter estimates and also in their interpretation.
Often, attempts are made to apply nonlinear regression models in situations which are totally inappropriate. Models are often applied outside the range of their validity, and generally, it is supposed that they can substitute for missing data. In chemical kinetics, for example, attempts may be made to estimate parameters, from data far from equilibrium. The calculated parameters then differ significantly from the true equilibrium parameters, and should be interpreted as model parameters only.
The result of nonlinear regression depends on the quality of the regression triplet, i.e. (1) the data, (2) the model, and (3) the regression criterion. Correct formulation leads to parameter estimates which have meaning not only formally but also physically.
In this chapter, we solve problems for which a regression model is known. For solving calibration problems or searching for empirical models, the regression model is appropriate. Some procedures are mentioned in Chapter 9.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978085709109350008X
Data Science: Theory and Applications
Victor B. Talisa, Chung-Chou H. Chang, in Handbook of Statistics, 2021
2.2 Bias-variance decomposition
We generally cannot estimate (1) directly; instead we usually estimate the unconditional MSEY:
(2)MSEY=EStr,X,YY−f(X;Str)2.
A brief analysis of (2) will reveal several concepts essential to prediction modeling. Consider MSEY conditional on X:
MSEY(x)=EStr,YY−f(x;Str)2X=x.
In words, this is the expected prediction error at a fixed point X = x, where the expectation is taken over the distribution of all training sets and the conditional distribution of Y|X = x. First of all, the function f(x;Str) minimizing MSEY(x) is the conditional expectation μ(x) = E[Y|X = x]. Thus, if μ(x) were known for all x, MSEY would be minimized and we would have our optimal prediction function for Y. However, we only ever observe noisy variates from μ(x) in our data, so at best we can hope to generate an imperfect (but hopefully useful) estimate from our training data, μˆ(x;Str). Therefore, moving forward we refer to the prediction function f(⋅) as μˆ(⋅). The bias-variance decomposition is an important tool for analyzing the sources of error when doing prediction with μˆ(x). To start, let us assume an additive errors model with constant variance: Y = μ(X) + ϵ, where ϵ has mean 0 and variance σϵ2:
(3)MSEY(x)=EStr,YY−μˆ(x;Str)2X=x=σϵ2+EStrμˆ(x;Str)−μ(x)2+EStrμˆ(x;Str)−EStr[μˆ(x;Str)]2
This decomposition explicitly shows how bias and variance contribute to MSEY(x), and therefore MSEY (since MSEY = EX[MSEY(X)]). The second term in (3) is the square of the bias of μˆ(x;Str); if we fit a new model to all possible training samples, the bias would be the difference between the averaged predictions from each fit evaluated at X = x and the true conditional mean at X = x. This bias is the result of misspecifying our model μˆ(⋅). The third term is the estimation variance of μˆ(x;Str), the result of using a random sample to estimate μ(x). The first term is the irreducible error associated with the stochastic target Y. Even if we had the true μ(x) as our prediction function, and thus no bias or estimation variance, the minimum MSEY could not be reduced below the value of σϵ2.
The second and third terms in (3) combine to form the MSE of μˆ(x;Str) for estimating μ(x):
(4)MSEμ(x)=EStr(μˆ(x;Str)−μ(x))2X=x,
where MSEμ = EX[MSEμ(X)]. Thus, the standard prediction problem (at least when using squared error loss) can be expressed as an estimation problem, where the parameter of interest is the function μ(x). The advantage of using MSEY for model selection is that we do not need access to μ(x), unlike MSEμ, making estimation more straightforward. As we will see in concrete examples below, in many cases the bias-variance decomposition reveals that the prediction modeler seeking to minimize MSEY may not find it among the class of unbiased, “correct” estimators of μ(x), unless it also achieves lower variance than other unbiased models. Often the “wrong” model (a biased one) is preferable for having a lower MSEY, and therefore better prediction performance as a whole. Although it may be very unlikely that a modeling procedure captures every nuance of nature necessary to produce truly unbiased estimates of μ(x), the hope is that some will provide a good enough approximation as to be useful in predicting Y.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S0169716120300432
For the additive errors model, the class of instrumental precision δ0 is equal to the limiting reduced relative error δ0 R defined by
From: Statistical Data Analysis, 2011
Spectrophotometry
Simon G. Kaplan, Manuel A. Quijada, in Experimental Methods in the Physical Sciences, 2014
4.3.5 Interreflections
Interreflections between the sample and the detector, spectrometer, or other optical elements in a spectrophotometric measurement system introduce additive error terms to the measurand. In particular, light that is reflected back to an FTS by the sample or other optical element can pass through the beamsplitter back to the interferometer mirrors, be modulated a second time by the scanning mirror, recombine, and then pass through the sample again to the detector. For a given wavenumber σ, any part of the optical power that is modulated twice by the FTS will experience twice the path length change and thus be recorded at 2σ. Successive interreflections can generate higher harmonics in the spectrum [22]. Other interreflections not involving the FTS directly will still add an error to the measurement that can include spectral features of other components in the system. This situation is illustrated for a transmittance measurement in Fig. 4.13.
Figure 4.13. Schematic layout of a sample transmittance measurement with an FTS showing possible interreflections and their elimination through the use of semicircular beam blocks.
In a focused sample geometry, one way to eliminate interreflections is to insert semicircular beam blocks before and after the sample, as shown in Fig. 4.13. The reflection of the half-cone beam incident on the sample will thus be blocked from reentering the FTS, and similarly any light reflected from the detector will not return to the sample or to the spectrometer. An example of the effects of interreflections on a transmittance measurement (normal incidence, f/3 focusing geometry) of a 0.25-mm thick Si wafer is shown in Fig. 4.14.
Figure 4.14. Effects of interreflections on a normal incidence transmittance measurement of a 0.25 mm Si wafer. The lettered curves show the results of inserting half-blocks illustrated in Fig. 4.13 compared to the expected transmittance (solid curve).
Without any half-blocks in the beam, curve A shows large deviations from the expected transmittance curve. These include both wavenumber-doubled spectral features originating from the spectral irradiance of the incident FTS beam and high-frequency fringes due to doubling of the etalon spectrum of the Si wafer sample. Inserting a half-block between the sample and detector (curve B) lowers the error at low wavenumbers, but does not get rid of the interreflections with the FTS. Curve C with the half-block before the sample eliminates the sample-FTS interreflection, while curve D with both half-blocks gives a result close to the expected transmittance spectrum.
The use of half-beam blocks, or half-field stops, can effectively eliminate interreflection errors at the cost of 50% reduction in signal, and some increase in sensitivity to beam geometry errors as discussed below. Other options include filters between the sample and FTS, or simply tilting the sample, which may be the simplest approach if knowledge of the precise incident beam geometry is not critical to the measurement. Si represents close to the worst case, being approximately 50% transmitting; lower index materials will have less uncertainty. Finally, one may also consider interreflections on the source side of the FTS. These in principle can lead to errors in the reference spectrum that can propagate to the measured transmittance.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123860224000042
Errors in instrumental measurements
Milan Meloun, Jiří Militký, in Statistical Data Analysis, 2011
1.2.1 Absolute and Relative Errors
The calibration of an instrument requires that for known values of the input quantity x, (e.g., the concentration of hydrogen ions [H+], in solution), the corresponding values of the measured output analytical signal yi, (e.g., the EMF of a glass electrode cell) be at disposal measured. Repeated measurements are made for each of several values of xt so that the dependence y = f(x) can be found. An approximate graphical interpretation shows the uncertainty band in the plot (Figure 1.2).
Figure 1.2. The uncertainty band and three types of instrumental errors: (a) additive, (b) multiplicative, and (c) combined error
The middle curve in the uncertainty band is called the nominal characteristic ynom (or xnom) and it is usually declared by the instrument manufacturer. The nominal characteristic ynom (or xnom ) differs from the real characteristic yreal (or xreal) by the error of the instrument, Δ* = yreal – ynom. For any selected y the error due to the instrument is Δ = xreal − xnom. [We will use errors Δ, which are in units of measurement quantities (e.g. pH)].
The absolute error of the signal measurement Δ is not convenient for expressing an instrument’s precision because it is given in the specific units of the instrument used; more convenient is the relative error defined by
(1.3)δ=100Δ/x%
or the reduced relative error defined by
(1.4)δR=100Δ/xmax−xmin=100Δ/R%
where R is the range of measurements.
The limiting error of an instrument Δ0 (absolute) or δ0 (relative) is, under given experimental conditions, the highest possible error which is not obscured by any other random errors.
The reduced limiting error of an instrument δ0,R (relative), for the actual value of the measured variable x. and the given experimental conditions, is defined by the ratio of the limiting error Δ0 to the highest value of the instrumental range R, δ0,R = Δ0/R. Often, the reduced limiting error is given as a percentage of the instrument range, [see Eq. (1.5)].
From the shape of the uncertainty band, various types of measurement errors can be identified, hence some corrections for their elimination may be suggested.
- (a)
-
Absolute measurement errors of an instrument are limited for the whole signal range by the constant limiting error Δ0 that corresponds to the additive errors model. The systematic additive error is a result of the incorrect setting of an instrument’s zero point. Today, however, instruments contain an automatic correction for zero, and systematic additive errors thus appear rarely.
- (b)
-
The magnitude of absolute measurement errors grows with the value of the input quantity x and for x = 0, it is Δ = 0. This is a case of the multiplicative errors model. Such errors are called errors of instrument sensitivity. Systematic multiplicative errors are caused by defects of the instrument.
Real instruments have errors that include both types of effects, and are expressed by the nonlinear function y = f(x).
Problem 1.1 The absolute and relative errors of a pH-meter
A glass electrode for pH measurement has a resistance of 500 MΩ at 25 °C, and the input impedance of the pH meter is 2 × 1011 Ω. Estimate the absolute (Δ0) and relative (δ0) error of EMF measurement when the voltage measured is U = 0.624 V.
Solution: Ucorr = 0.624 (2⋅1011+ 5 108)/(2⋅1011) = 0.6254 V; Δ0 = 0.6254 – 0.624 = 0.0016 V; δ0 = 100⋅0.0016/0.624 = 0.25%.
Conclusion: The absolute error is 1.6 mV and the relative error 0.25%.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780857091093500017
Covariance Structure Models for Maximal Reliability of Unit-Weighted Composites
Peter M. Bentler, in Handbook of Latent Variable and Related Models, 2007
9 Conclusions
Like the 1-factor based internal consistency reliability coefficients, the proposed approach to maximal unit-weighted reliability requires modeling the sample covariance matrix. This must be a successful enterprise, as estimation of reliability only makes sense when the model does an acceptable job of explaining the sample data. Of course, since a k-factor model rather than a 1-factor model would typically be used in the proposed approach, the odds of adequately modeling the sample covariance matrix are greatly improved. The selected model can be a member of a much wider class of models, including exploratory or confirmatory factor models or any arbitrary structural model with additive errors. Whatever the resulting dimensionality k, and whether the typical “small-k” or theoretical alternative ”large-k” approach is used, or whether a general structural model with additive errors is used, the proposed identification conditions assure that the resulting internal consistency coefficient ρˆkk represents the proportion of variance in the unit-weighted composite score that is attributable to the common factor generating maximal internal consistency. The proposed coefficient can be interpreted as representing unidimensional reliability even when the instrument under study is multifactorial, since, as was seen in (3), the composite score can be modeled by a single factor as X = μX + λXξ1 + ɛX. Nonetheless, it equally well has an interpretation as summarizing the internal consistency of the k-dimensional composite. Although generally there is a conflict between unidimensionality and reliability, as noted by ten Berge and Sočan (2004), our approach reconciles this conflict.
When the large-k approach is used to model the covariance matrix, the theory of dimension-free and greatest lower bound coefficients can be applied. This is based on a tautological model that defines factors that precisely reproduce the covariance matrix. As these theories have been developed in the past, reliability is defined on scores that are explicitly multidimensional. However, we have shown here that the dimension-free and greatest lower-bound coefficients can equivalently be defined for the single most reliable dimension among the many that are extracted. Based on this observation, new approaches to these coefficients may be possible.
The optimal unit-weighted coefficient developed here also applies to composites obtained from any latent variable covariance structure model with p-dimensional additive errors. Although we used a specific type of model as given in (7) to develop this approach, we are in no way limited to that specific linear model structure. Our approach holds equally for any completely arbitrary structural model with additive errors that we can write in the form Σ = Σ(θ) + Ψ, where Σ(θ) and Ψ are non-negative definite matrices. Then we can decompose Σ(θ) = ΛΛ′ and proceed as described previously, e.g., we can compute the factor loadings for the maximally reliable factor via λ = {1′(Σ − Ψ)1}−1/2(Σ − Ψ)1. The maximal reliability coefficient for a unit weighted composite based on any model that can be specified as a Bentler and Weeks (1980) model has been available in EQS 6 for several years.
With regard to reliability of differentially weighted composites, we extended our maximal reliability for a unit-weighted composite (4) to maximal reliability for a weighted composite (18). While both coefficients have a similar sounding name, they represent quite different types of “maximal” reliability, and, in spite of the recent enthusiasm for (18), in our opinion this coefficient ought to be used only rarely. Weighted maximal reliability does not describe the reliability of a typical total score or scale. Such a scale score, in common practice, is a unit-weighted composite of a set of items or components. Our unit-weighted maximal reliability (4) or (5) describes this reliability. In contrast, maximal reliability (18) gives the reliability of a differentially weighted composite, and if one is not using such a composite, to report it would be misleading. Of course, if a researcher actually might consider differentially weighting of items or parts in computing a total score, then a comparison of (4) to (18) can be very instructive. If (18) is only a marginal improvement over (4), there would be no point to differential weighting. On the other hand, if (4) is not too large while (18) is substantially larger, differential weighting might make sense.
Finally, all of the theoretical coefficients described in this chapter were specified in terms of population parameters, and their estimation was assumed to be associated with the usual and simple case of independent and identically distributed observations. When data have special features, such as containing missing data, estimators of the population parameters will be somewhat different in obvious ways. For example, maximum likelihood estimators based on an EM algorithm may be used to obtain structured or unstructured estimates of Σ (e.g., Jamshidian and Bentler, 1999) for use in the defining formulae. In more complicated situations, such as multilevel modeling (e.g., Liang and Bentler, 2004), it may be desirable to define and evaluate internal consistency reliability separately for within-cluster and for between-cluster variation. The defining formulae described here can be generalized to such situations in the obvious ways and are already available in EQS 6.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780444520449500045
Computational Analysis and Understanding of Natural Languages: Principles, Methods and Applications
Qiang Wu, Paul Vos, in Handbook of Statistics, 2018
9 Prediction and Model Selection
Consider using a scalar- or vector-valued input (predictor) variable X to predict a scalar-valued target (response) variable Y. The target Y can be a continuous random variable such as in linear regressions or a categorical random variable such as in logistic regressions and classifications. When X is vector-valued, its elements are sometimes called features so model selection is also referred to as feature selection. A prediction model fˆ(x) can be estimated from a training sample (y1,x1),. . .,(yn,xn). For a continuous response variable, fˆ(x) is a predicted value of the response at X = x. When the target is a K-group categorical variable, fˆ(x) is either a classifier with a single one and K − 1 zeros or a vector of predicted probabilities that x belongs to the K groups.
The error between a response y and its prediction fˆ(x) can be measured by a loss function L(y,fˆ(x)). For continuous response variables, frequently used loss functions include the squared error loss (y−fˆ(x))2 and the absolute error loss |y−fˆ(x)|. For categorical target variables, the 0-1 loss
L(y,fˆ(x))=I(y≠fˆ(x))=1y≠fˆ(x)0y=fˆ(x)
is often used for classification purpose. When the prediction fθˆ(y|x) is a pdf or pmf indexed by a parameter estimate θˆ, the log-likelihood loss
L(y,fθˆ(y|x))=−2logfθˆ(y|x)
is often used.
Definition 20
The expected prediction error (i.e., test error) of a prediction fˆ(x) over an independent test sample is defined as Err=E[L(Y,fˆ(X))], where the expectation is taken over Y, X, as well as the randomness in the training sample.
When a test sample {(Y1, X1), …, (Ym, Xm)} exists, the test error of a prediction fˆ(x) can be estimated by the average loss 1m∑i=1mL(Yi,fˆ(Xi)) over the test sample.
Definition 21
The training error of a prediction fˆ(x) is the average loss over the training sample err=1n∑i=1nL(yi,fˆ(xi)).
In general, model selection assesses different models and selects the one with the (approximate) smallest test error. However, the training error usually is not a good estimate of the testing error. The training error tends to decrease as model complexity increases and leads to overfitting (i.e., choosing an overly complex model). To appropriately estimate the test error, the data are usually separated into a training set and a validation set. The training set is used to fit the model, while the validation set is used to assess test error for model selection. When a final model is selected, however, a separate test set should be obtained to assess the test error of the final model. See Hastie et al. (2001) for more details and reference. This chapter serves as a brief review of the involved topics.
Example 56
Consider an additive error model Y = f(X) + ϵ with a linear fit on p inputs or basis functions, where the error ϵ has mean zero and variance σϵ2>0. For example, linear or polynomial regressions and B-splines are additive error models with a linear fit. When a squared error loss is used, the test error at X = x becomes
Err(x)=EY−fˆ(x)2=σϵ2+Efˆ(x)−f(x)2+Efˆ(x)−Efˆ(x)2=σϵ2+Bias2(x)+Variance(x),
where σϵ2 is an irreducible error. When p is large (i.e., model complexity is high), the model fit fˆ(x) is able to approach the true value f(x) more closely so model bias is low. However, since the fit fˆ(x) depends greatly on the training data a small change in the training data will result in a big change in the fit, leading to a large model variance. On the other hand, when p is small (i.e., model complexity is low), the model bias is high but the fit is more stable so that the model variance is low. For example, if the true model is a polynomial regression but the fit used a linear regression, then the model bias is high but the variance is low. Model selection seeks a balance between the bias and the variance. As model complexity (e.g., p) increases, it is normal that the test error first decreases and then increases. Where it turns is the optimal model complexity.
9.1 Model Selection
The training error will usually be less than the test error because the same data used to fit the model is employed to assess its training error. In other words, a fitted model usually adapts to the training data and hence its training error will be overly optimistic (too small). In fact, it is often the case that the training error steadily decreases as the size of the model increases. If training error was used for model selection, it will most likely lead to overfitting the model. The ultimate goal of model selection is to minimize the test error without overfitting. Part of the discrepancy between the training error and the test error is because the training set and the test set have different input values. To evaluate the prediction model fˆ(x) on the same realized input values, consider the in-sample error.
Definition 22
The in-sample error of a fitted model fˆ(x) is defined by
Errin=1n∑i=1nEEL(Yi,fˆ(xi))|y,x|x,
where y = (y1, . . . , yn) and x = (x1, . . . , xn) are the response and predictor values of the training set.
For the same reason that the test error is bigger than the training error, the in-sample error is usually bigger than the training error too. For squared error, 0-1 and a lot of other loss functions, it can be shown that the in-sample error is equal to
(26)Errin=E[err|x]+2n∑i=1nCov(fˆ(xi),yi|x),
where Cov(fˆ(xi),yi|x) stands for the conditional covariance between fˆ(xi) and yi given the predictor values x. The higher the model complexity is, the larger Cov(fˆ(xi),yi|x) will be, thereby increases the difference between the in-sample error and the training error (i.e., the optimism).
Example 57
For the additive error model Y = f(X) + ϵ in Example 56, the in-sample error simplifies to
Errin=E[err|x]+2pnσϵ2=1nE∑i=1nL(yi,fˆ(xi))|x+2pσϵ2.
So the optimism increases linearly with the number of inputs or basis functions, penalizing complex models with large number of inputs or basis functions. An estimate of Errin is
Errˆin=err+2pnσˆϵ2=1n∑i=1nL(yi,fˆ(xi))+2pσˆϵ2,
where σˆϵ2=1n−p∑i(yi−fˆ(xi))2 is an estimate of the error variance using the mean squared error.
Definition 23
When a squared error loss is used to evaluate a linear fit of an additive error model, the Cp statistic
Cp=1n∑i=1n(yi−fˆ(xi))2+2pσˆϵ2
is an estimate of Errin.
When the prediction fθˆ(y|x) is a pdf or pmf fitted by maximum likelihood and a log-likelihood loss is used, the Akaike information criterion (AIC, Akaike, 1973) is used to estimate Errin.
Definition 24
When a log-likelihood loss is used to evaluate a maximum likelihood fit of a pdf or pmf, the Akaike information criterion
AIC=−2∑i=1nlogfθˆ(yi|xi)+2p
is an estimate of Errin.
Example 58
For a logistic regression model with a binomial log-likelihood, the AIC becomes
AIC=−2∑i=1n(yilog(pi)+(1−yi)log(1−pi))+2p,
where log(pi/(1−pi))=xiTβˆ.
For a linear regression model with normal errors, the AIC is equivalent to the Cp statistic. Like AIC, the Bayesian information criterion (BIC, Schwarz, 1978) is applicable when maximum likelihood is used for fitting the model.
Definition 25
When a log-likelihood loss is used to evaluate a maximum likelihood fit of a pdf or pmf, the Bayesian information criterion is defined by
BIC=−2∑i=1nlogfθˆ(yi|xi)+log(n)p.
By replacing 2 with log(n), the BIC penalizes complex models (with large p) more heavily than the AIC, giving preference to simpler models. The training error measures the goodness-of-fit and p measures the model complexity. The number 2 in AIC and log(n) in BIC can be treated as a tunning parameter controlling the balance between goodness-of-fit and model complexity. There are other similar model selection criteria developed to improve AIC and BIC. For example, Foster and George (1994) proposed the risk inflation criterion (RIC) by replacing log(n) in BIC (or 2 in AIC) with 2log(p).
In general, model selection seeks the optimal complexity p with the smallest value of Cp, AIC, BIC, or other similar criteria. However, an exhaustive search would require fitting all models with all subsets of the inputs and hence is practically infeasible. In regression settings, forward and stepwise procedures have been used for variable selection referring to their test statistics or p-values. Such adaptive procedures can be applied with Cp, AIC, BIC, or other similar criteria too. First, select a model with a single input variable which achieves the smallest value of the chosen criterion. Then, variables that lead to the greatest decreases (or least increases) in the criterion are added into the model sequentially. Once the value of the criterion starts to increase (or stops to decrease) when more variables are added, the procedure is stopped and the final model is found.
Another group of methods in variable selection is by shrinking the regression parameters. For a multiple linear regression model Y = XTβ + ϵ, the LSE of β is found by
βˆ=arg minβ∑i=1n(yi−xiTβ)2=(xTx)−1xTy.
If X involves many input variables not contributing to the regression, not only the fitting is unnecessarily complex but the model is ill posed and the fitting might be unstable. For example, when the number of inputs p ≥ n, the LSE βˆ may not exist.
Example 59
Ridge regression is one of the methods to shrink the estimates and potentially set some of them to zero by minimizing an L2 (squared) penalized term
∑i=1n(yi−xiTβ)2+βTΓTΓβ.
The ridge regression estimates of β is βˆridge=(xTx+ΓTΓ)−1xTy. A typical choice for Γ is a multiple of the identity matrix αI. In the L2 regularization, preference is given to solutions with smaller norms and α is a tunning parameter controlling the degree of shrinkage.
Least absolute shrinkage and selection operator (LASSO, Tibshirani, 1996) is a more popular shrinkage regression method. Instead of regularizing the minimization with an L2 norm, LASSO employs an L1 (absolute) norm in order to enhance accuracy and stability in prediction.
Example 60
LASSO estimates of regression parameters β are found by minimizing an L1 penalized term
∑i=1n(yi−xiTβ)2+λ∑j=1p|βj|,
where λ is a tunning parameter controlling the degree of shrinkage.
Recently, some generalizations including elastic net, group lasso, fused lasso, and adaptive lasso are developed to address the shortcomings of LASSO. Each of them uses different penalty terms. For example, the elastic net adds an additional L2 term so the penalty becomes λ1∑j=1p|βj|+λ2∑j=1pβj2, and fused lasso uses a penalty term λ1∑j=1p|βj|+λ2∑j=2p|βj−βj−1|. Special algorithms such as subgradient methods, least-angle regression, and proximal gradient methods are required to find the minimum.
9.2 Cross-Validation
Unlike AIC and BIC criteria which estimate the in-sample error, cross-validation can be used to directly estimate the test error of prediction especially when the sample size is large. Particularly, the whole sample is split into K equal pieces for a K-fold cross-validation. When K = n the sample size, the method is called a leave-one-out cross-validation. Each time, one of the K subsamples is left out for validation purpose and the rest K − 1 subsamples are used for model fitting. Denote fˆ−k(x) the fitted model computed from all subsamples except the k-th for k = 1, …, K.
Definition 26
The cross-validation (CV) estimate of the test error is
CV=1n∑i=1nL(yi,fˆ−k(i)(xi)),
where k(i) = k if the i-th observation is in the k-th subsample.
Typical values of K are 5 or 10, but leave-one-out cross-validation has many applications too. Generally speaking, the larger the number K is, the lower the model bias is but the model variance is higher. For leave-one-out cross-validation, CV is an unbiased estimator for the test error but can have high variance. When K is small such as 5, CV has lower variance but bias can be an issue. If the original sample is large like 200 or more, a small K such as 5 may suffice. If the original sample is small, a larger K may be better. We can also try different K values for the same problem, if computational burden is not an issue.
Example 61
For a linear model fitting using a squared error loss, the prediction can be written as yˆ=Hy where H = X(XTX)−1XT is the hat matrix. The leave-one-out cross-validation error is
CV=1n∑i=1nyi−fˆ−i(xi)2=1n∑i=1nyi−fˆ(xi)1−Hii2,
where Hii is the i-th diagonal element of H. A generalized cross-validation that provides a convenient approximation in computation is
GCV=1n∑i=1nyi−fˆ(xi)1−trace(H)/n2.
When model complexity is controlled by a tuning parameter α, the fitted model is denoted as fˆ−k(x|α) and the estimated test error becomes
CV(α)=1n∑i=1nL(yi,fˆ−k(i)(xi|α)).
It defines an estimated test error curve on α. The final model is chosen to be fˆ(x|αˆ) with a tuning parameter αˆ that minimizes CV (α).
9.3 From Bagging to Random Forests
Bootstrap aggregating (bagging) and random forests are resampling methods proposed to boost both accuracy and stability of regression- and classification-type predictions. Let (y1(b),x1(b)),. . .,(yn(b),xn(b)) be a bootstrap sample from the original training set for b=1,. . .,B. A typical size of B is 500. Denote fˆ(b)(x) the fitted model computed from the b-th bootstrap sample.
Definition 27
The bagging estimate is defined by
fˆbag(x)=1B∑b=1Bfˆ(b)(x).
For a regression problem, each bootstrap prediction fˆ(b)(x) is the predicted value of the response at x so that fˆ(x) is the average over B bootstrap estimates. The variance of the prediction at each x value can be estimated by
σˆ2(x)=∑b=1Bfˆ(b)(x)−fˆbag(x)2B−1.
For a K-group classification problem, each bootstrap prediction fˆ(b)(x) is either a classifier with a single one and K − 1 zeroes or a vector of predicted probabilities that x belongs to the K groups so that the bagging estimate is a vector of estimated probabilities fˆbag(x)=(pˆ1(x),…,pˆK(x)) with pˆk(x) equal to the average probability that x belongs to the k-th group.
Definition 28
A bagging classifier is defined by
Ĝbag(x)=arg maxkfˆbag(x),
which is the class receiving the greatest number of votes from the B bootstrap predictions.
For an input x and its corresponding target y, let
p(x)=1B∑b=1BI(y=arg maxkfˆ(b)(x))
be the percent of times over B bagging classifiers that x is correctly classified. The quantities p(x) − (1 − p(x)) = 2p(x) − 1 are called margins. Large margins are always desirable because that means the overall classification is more stable. Let Cb be a set of indices of all (out-of-bag) observations that do not belong to the b-th bootstrap sample and |Cb| be its cardinality. To accurately estimate the test error, only out-of-bag observations should be used to evaluate the model. Bagging is considered more efficient than cross-validation because the training set can be used for both model fitting and evaluation.
Definition 29
The out-of-bag prediction error is defined by
1B∑b=1B1|Cb|∑i∈CbL(yi,fˆ(b)(xi)).
When sampling with replacement, if a bootstrap sample is the same size as the original sample, it is expected to have about 63.2% of unique observations from the original sample and the other 36.8% are repetitions. In other words, each |Cb| is expected to be about 36.8% of the sample size n.
The random forests algorithm takes one step further when classification or regression trees are built from the bootstrap samples. At each split of a tree, a random subset of the input features are selected and used to construct the split. After each tree is built, the out-of-bag data are dropped down the tree and predicted classifications or means are recorded. Lastly, for each observation in the dataset, one either counts the number of trees that have classified it in one of the categories and assigns each observation to a final category by a majority vote over the set of trees or averages the predicted means from the set of trees. The random forests algorithm helps reduce model variance by averaging over trees that are more independent. It also helps reduce model bias by considering a large number of predictors. Trees are usually grown so that there are only a few observations in each terminal node. Sampling 2–5 input features at each split is often adequate. Sometimes, one vote for classification in a rare category might count the same as two votes for classification in the common category. Stratified bootstrap samples can be used to include some underrepresented subgroups of individuals.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S0169716118300099
Nonlinear Regression Analysis
H.-H. Huang, … S.-Y. Huang, in International Encyclopedia of Education (Third Edition), 2010
Good Initials
For a linear model, the Gauss–Newton method will find the minimum in one single iteration from any initial parameter estimates. For a model which is close to being linear, the convergence for Gauss–Newton method will be rapid and not depend heavily on the initial parameter estimates. However, as the magnitude of model nonlinearity becomes more and more prominent, convergence will be slow or even may not occur, and the resulting parameter estimates may not be reliable. In that case, good initials are important.
One approach to find initial values is through transformation, so that the linear regression analysis under the assumption of additive error terms can be utilized (Bates and Watts, 1988; Ryan, 1997). For instance, the reciprocal of the Michaelis-Menten regression function
[9]f(x;θ)=θ1xθ2+x
leads to the model
y−1=1θ1+θ2θ1(1x)+ɛ
Indeed, this is a linear regression model denoted as
y˜=β0+β1x˜+ɛ
with y˜=y−1,β0=θ1−1,β1=θ2θ1−1, and x˜=x−1. The least-squares estimates of β1 and β2 can therefore be transformed to provide initial values for the parameters in the Michaelis–Menten model. Alternatively, we can adopt a grid search, which evaluates the residual sum of squares at these parameter grid points and then finds the minimizing point among these grid points to provide initial values. In many occasions, the grid search helps to avoid improper initial values that lead to local, but not global, minimum of the residual sum of squares. Another alternative is to use uniform design points to replace the lattice grid points. Uniform design points are so designed to be as uniform and as space filling as possible and provide a more efficient search scheme (Fang et al., 2000).
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978008044894701352X
Matrix-Based Methods
Esam M.A. Hussein, in Computed Radiation Imaging, 2011
10.4.10 Modeling-Error Compensation
The minimization of the residual-error functional of Eq. (10.8) presumes that the difference between the actual measurements, e^, and the corresponding computed ones, Ac, is within the range of the uncertainties in e^. In practice, as indicated in Part I of this book, the forward model is an approximation. As such, the error expressed in Eq. (10.8) by ∥Ac−e^∥ is not only a residual error, in the numerical sense, but also includes a modeling error. However, the modeling error is not random, and is in general an additive error, since it is the result of ignoring effects that are complicated to model (such as scattering in transmission and emission imaging and multiple scattering in scatter imaging). The modeling error can be estimated using a reference object as:
(10.33)B∗=e∗−Ac∗
where it is assumed that the reference measurements, e∗, are acquired with low statistical variability, for an object with known physical attributes, c∗. Then, as Eq. (10.33) indicates, the difference between the actual measurements and those modeled by the forward model gives the modeling error, B∗ for the reference object. For an object with unknown features, but not expected to be very different from the reference object, the modeling error can be estimated as βB∗, with β≥0 being an adjustment parameter that can be estimated a priori, perhaps by comparing ∥e∥ for the imaged object to ∥e∥∗ of the reference object (Arendtsz and Hussein, 1995a). Then, the functional of Eq. (10.8) can be replaced by:
(10.34)χ(c)=∥Ac+βB∗−e^∥2
This becomes the data fidelity norm (actual residual) error, which can be vulnerable to the random variability in e^, as well as to uncertainties in determining β. One can then devise a regularization function to moderate the effect of modeling errors as:
(10.35)η(c)=B=e^−Ac
where B is the unknown modeling error for the problem at hand. Note that the regularization functional now is the residual error of Eq. (10.35), if the modeling error is not taken into account, while the residual error, Eq. (10.34), incorporates some estimate of the modeling error. One now needs to minimize the objective function:
(10.36)min[W(Ac+βB∗−e^)]T[W(Ac+βB∗−e^)]+α2(e^−Ac)2
which leads to the solution:
(10.37)c^=ATW2A−α2ATA−1ATW2(e^−βB∗)−α2ATe^
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123877772000100
Nonlinear Regression Models
Milan Meloun, Jiří Militký, in Statistical Data Analysis, 2011
Problem 8.1 Formulation of the parameters and variables of a regression model
The dependence of a rate constant for a chemical reaction, k, on temperature T is described by the Arrhenius equation
(8.1)k=k0exp−E/RT
where k0 is the activation entropy of the chemical reaction, E is the activation energy, and R is the universal gas constant. Formulate the model parameters and examine their correlation.
Solution: The rate constant k (response variable, y) was measured at various temperatures, T (explanatory variable, x). The unknown parameters in the regression model [Eq. (8.1)] are β1 = k0 and β2 = −E/R. If the additive errors model is used
(8.2)yi=fxiβ+εi=β1+expβ2/xi+εi
Here, b1 and b2 are estimates of β1, and β2 and are determined from experimental data {ki,Ti}, i = 1, …, n, based on a regression criterion. When errors εi. in Eq. (8.2) are independent (values of yi are mutually independent) random variables of the same distribution, and have constant variance σ2(y).
The regression criterion corresponding to the least-squares method may be used. That is
(8.3)Uβ=∑i=1nyi−fxiβ
The estimates b then minimize the criterion U(β).
It can be shown here that a strong correlation exists between estimates In b1 and b2. This correlation may be expressed by the paired correlation coefficient
(8.4)r=C2+cln1+1/c
where c = T1/(Tn − T1) is related to minimum (T1) and maximum (Tn) temperatures. When T1 = 300 K and T2 = 360 K, then r = 0.9986 and ln b1 and b2 are nearly linearly dependent. This means that the ratio (ln b1) / b2 is constant and hence, individual parameters cannot be estimated independently. When parameters are correlated, unfortunately a change in the first parameter is often compensated for by a change in the second one. There may be several different pairs of parameter estimates (ln b1, b2) which give nearly same values of the least squares criterion U(b). The parameter estimates achieved by various regression programs may differ by some orders of magnitude, but nevertheless apparently a “best” fit to the experimental data, and low values of U(b) are reached.
Conclusion: Even a simple nonlinear model may lead to difficulties in the accuracy of the parameter estimates and also in their interpretation.
Often, attempts are made to apply nonlinear regression models in situations which are totally inappropriate. Models are often applied outside the range of their validity, and generally, it is supposed that they can substitute for missing data. In chemical kinetics, for example, attempts may be made to estimate parameters, from data far from equilibrium. The calculated parameters then differ significantly from the true equilibrium parameters, and should be interpreted as model parameters only.
The result of nonlinear regression depends on the quality of the regression triplet, i.e. (1) the data, (2) the model, and (3) the regression criterion. Correct formulation leads to parameter estimates which have meaning not only formally but also physically.
In this chapter, we solve problems for which a regression model is known. For solving calibration problems or searching for empirical models, the regression model is appropriate. Some procedures are mentioned in Chapter 9.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978085709109350008X
Data Science: Theory and Applications
Victor B. Talisa, Chung-Chou H. Chang, in Handbook of Statistics, 2021
2.2 Bias-variance decomposition
We generally cannot estimate (1) directly; instead we usually estimate the unconditional MSEY:
(2)MSEY=EStr,X,YY−f(X;Str)2.
A brief analysis of (2) will reveal several concepts essential to prediction modeling. Consider MSEY conditional on X:
MSEY(x)=EStr,YY−f(x;Str)2X=x.
In words, this is the expected prediction error at a fixed point X = x, where the expectation is taken over the distribution of all training sets and the conditional distribution of Y|X = x. First of all, the function f(x;Str) minimizing MSEY(x) is the conditional expectation μ(x) = E[Y|X = x]. Thus, if μ(x) were known for all x, MSEY would be minimized and we would have our optimal prediction function for Y. However, we only ever observe noisy variates from μ(x) in our data, so at best we can hope to generate an imperfect (but hopefully useful) estimate from our training data, μˆ(x;Str). Therefore, moving forward we refer to the prediction function f(⋅) as μˆ(⋅). The bias-variance decomposition is an important tool for analyzing the sources of error when doing prediction with μˆ(x). To start, let us assume an additive errors model with constant variance: Y = μ(X) + ϵ, where ϵ has mean 0 and variance σϵ2:
(3)MSEY(x)=EStr,YY−μˆ(x;Str)2X=x=σϵ2+EStrμˆ(x;Str)−μ(x)2+EStrμˆ(x;Str)−EStr[μˆ(x;Str)]2
This decomposition explicitly shows how bias and variance contribute to MSEY(x), and therefore MSEY (since MSEY = EX[MSEY(X)]). The second term in (3) is the square of the bias of μˆ(x;Str); if we fit a new model to all possible training samples, the bias would be the difference between the averaged predictions from each fit evaluated at X = x and the true conditional mean at X = x. This bias is the result of misspecifying our model μˆ(⋅). The third term is the estimation variance of μˆ(x;Str), the result of using a random sample to estimate μ(x). The first term is the irreducible error associated with the stochastic target Y. Even if we had the true μ(x) as our prediction function, and thus no bias or estimation variance, the minimum MSEY could not be reduced below the value of σϵ2.
The second and third terms in (3) combine to form the MSE of μˆ(x;Str) for estimating μ(x):
(4)MSEμ(x)=EStr(μˆ(x;Str)−μ(x))2X=x,
where MSEμ = EX[MSEμ(X)]. Thus, the standard prediction problem (at least when using squared error loss) can be expressed as an estimation problem, where the parameter of interest is the function μ(x). The advantage of using MSEY for model selection is that we do not need access to μ(x), unlike MSEμ, making estimation more straightforward. As we will see in concrete examples below, in many cases the bias-variance decomposition reveals that the prediction modeler seeking to minimize MSEY may not find it among the class of unbiased, “correct” estimators of μ(x), unless it also achieves lower variance than other unbiased models. Often the “wrong” model (a biased one) is preferable for having a lower MSEY, and therefore better prediction performance as a whole. Although it may be very unlikely that a modeling procedure captures every nuance of nature necessary to produce truly unbiased estimates of μ(x), the hope is that some will provide a good enough approximation as to be useful in predicting Y.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S0169716120300432
Погрешность средств измерения и результатов измерения.
Погрешности средств измерений – отклонения метрологических свойств или параметров средств измерений от номинальных, влияющие на погрешности результатов измерений (создающие так называемые инструментальные ошибки измерений).
Погрешность результата измерения – отклонение результата измерения от действительного (истинного) значения измеряемой величины.
Инструментальные и методические погрешности.
Методическая погрешность обусловлена несовершенством метода измерений или упрощениями, допущенными при измерениях. Так, она возникает из-за использования приближенных формул при расчете результата или неправильной методики измерений. Выбор ошибочной методики возможен из-за несоответствия (неадекватности) измеряемой физической величины и ее модели.
Причиной методической погрешности может быть не учитываемое взаимное влияние объекта измерений и измерительных приборов или недостаточная точность такого учета. Например, методическая погрешность возникает при измерениях падения напряжения на участке цепи с помощью вольтметра, так как из-за шунтирующего действия вольтметра измеряемое напряжение уменьшается. Механизм взаимного влияния может быть изучен, а погрешности рассчитаны и учтены.
Инструментальная погрешность обусловлена несовершенством применяемых средств измерений. Причинами ее возникновения являются неточности, допущенные при изготовлении и регулировке приборов, изменение параметров элементов конструкции и схемы вследствие старения. В высокочувствительных приборах могут сильно проявляться их внутренние шумы.
Статическая и динамическая погрешности.
- Статическая погрешность измерений – погрешность результата измерений, свойственная условиям статического измерения, то есть при измерении постоянных величин после завершения переходных процессов в элементах приборов и преобразователей.
Статическая погрешность средства измерений возникает при измерении с его помощью постоянной величины. Если в паспорте на средства измерений указывают предельные погрешности измерений, определенные в статических условиях, то они не могут характеризовать точность его работы в динамических условиях. - Динамическая погрешность измерений – погрешность результата измерений, свойственная условиям динамического измерения. Динамическая погрешность появляется при измерении переменных величин и обусловлена инерционными свойствами средств измерений. Динамической погрешностью средства измерений является разность между погрешностью средсва измерений в динамических условиях и его статической погрешностью, соответствующей значению величины в данный момент времени. При разработке или проектировании средства измерений следует учитывать, что увеличение погрешности измерений и запаздывание появления выходного сигнала связаны с изменением условий.
Статические и динамические погрешности относятся к погрешностям результата измерений. В большей части приборов статическая и динамическая погрешности оказываются связаны между собой, поскольку соотношение между этими видами погрешностей зависит от характеристик прибора и характерного времени изменения величины.
Систематическая и случайная погрешности.
Систематическая погрешность измерения – составляющая погрешности измерения, остающаяся постоянной или закономерно изменяющаяся при повторных измерениях одной и той же физической величины. Систематические погрешности являются в общем случае функцией измеряемой величины, влияющих величин (температуры, влажности, напряжения питания и пр.) и времени. В функции измеряемой величины систематические погрешности входят при поверке и аттестации образцовых приборов.
Причинами возникновения систематических составляющих погрешности измерения являются:
- отклонение параметров реального средства измерений от расчетных значений, предусмотренных схемой;
- неуравновешенность некоторых деталей средства измерений относительно их оси вращения, приводящая к дополнительному повороту за счет зазоров, имеющихся в механизме;
- упругая деформация деталей средства измерений, имеющих малую жесткость, приводящая к дополнительным перемещениям;
- погрешность градуировки или небольшой сдвиг шкалы;
- неточность подгонки шунта или добавочного сопротивления, неточность образцовой измерительной катушки сопротивления;
- неравномерный износ направляющих устройств для базирования измеряемых деталей;
- износ рабочих поверхностей, деталей средства измерений, с помощью которых осуществляется контакт звеньев механизма;
- усталостные измерения упругих свойств деталей, а также их естественное старение;
- неисправности средства измерений.
Случайной погрешностью называют составляющие погрешности измерений, изменяющиеся случайным образом при повторных измерениях одной и той же величины. Случайные погрешности определяются совместным действием ряда причин: внутренними шумами элементов электронных схем, наводками на входные цепи средств измерений, пульсацией постоянного питающего напряжения, дискретностью счета.
Погрешности адекватности и градуировки.
Погрешность градуировки средства измерений – погрешность действительного значения величины, приписанного той или иной отметке шкалы средства измерений в результате градуировки.
Погрешностью адекватности модели называют погрешность при выборе функциональной зависимости. Характерным примером может служить построение линейной зависимости по данным, которые лучше описываются степенным рядом с малыми нелинейными членами.
Погрешность адекватности относится к измерениям для проверки модели. Если зависимость параметра состояния от уровней входного фактора задана при моделировании объекта достаточно точно, то погрешность адекватности оказывается минимальной. Эта погрешность может зависеть от динамического диапазона измерений, например, если однофакторная зависимость задана при моделировании параболой, то в небольшом диапазоне она будет мало отличаться от экспоненциальной зависимости. Если диапазон измерений увеличить, то погрешность адекватности сильно возрастет.
Абсолютная, относительная и приведенная погрешности.
Абсолютная погрешность – алгебраическая разность между номинальным и действительным значениями измеряемой величины. Абсолютная погрешность измеряется в тех же единицах измерения, что и сама величина, в расчетах её принято обозначать греческой буквой – ∆. На рисунке ниже ∆X и ∆Y – абсолютные погрешности.
Относительная погрешность – отношение абсолютной погрешности к тому значению, которое принимается за истинное. Относительная погрешность является безразмерной величиной, либо измеряется в процентах, в расчетах обозначается буквой – δ.
Приведённая погрешность – погрешность, выраженная отношением абсолютной погрешности средства измерений к условно принятому значению величины, постоянному во всем диапазоне измерений или в части диапазона. Вычисляется по формуле
где Xn – нормирующее значение, которое зависит от типа шкалы измерительного прибора и определяется по его градуировке:
– если шкала прибора односторонняя и нижний предел измерений равен нулю (например диапазон измерений 0…100), то Xn определяется равным верхнему пределу измерений (Xn=100);
– если шкала прибора односторонняя, нижний предел измерений больше нуля, то Xn определяется как разность между максимальным и минимальным значениями диапазона (для прибора с диапазоном измерений 30…100, Xn=Xmax-Xmin=100-30=70);
– если шкала прибора двухсторонняя, то нормирующее значение равно ширине диапазона измерений прибора (диапазон измерений -50…+50, Xn=100).
Приведённая погрешность является безразмерной величиной, либо измеряется в процентах.
Аддитивные и мультипликативные погрешности.
- Аддитивной погрешностью называется погрешность, постоянную в каждой точке шкалы.
- Мультипликативной погрешностью называется погрешность, линейно возрастающую или убывающую с ростом измеряемой величины.
Различать аддитивные и мультипликативные погрешности легче всего по полосе погрешностей (см.рис.).
Если абсолютная погрешность не зависит от значения измеряемой величины, то полоса определяется аддитивной погрешностью (а). Иногда аддитивную погрешность называют погрешностью нуля.
Если постоянной величиной является относительная погрешность, то полоса погрешностей меняется в пределах диапазона измерений и погрешность называется мультипликативной (б). Ярким примером аддитивной погрешности является погрешность квантования (оцифровки).
Класс точности измерений зависит от вида погрешностей. Рассмотрим класс точности измерений для аддитивной и мультипликативной погрешностей:
– для аддитивной погрешности:
аддитивная погрешность
где Х – верхний предел шкалы, ∆0 – абсолютная аддитивная погрешность.
– для мультипликативной погрешности:
мультипликативная погрешность
порог чувствительности прибора – это условие определяет порог чувствительности прибора (измерений).
Справочник /
Термины /
Стандартизация /
Аддитивная погрешность
Термин и определение
Аддитивная погрешность
Опубликовано:
fyodorov.vitalij.1998
Предмет:
Стандартизация
👍 Проверено Автор24
погрешность, значение которой не изменяется во всем диапазоне измерения.
Еще термины по предмету «Стандартизация»
Базисные показатели
предназначены для обеспечения сохранности качества продукции и информирования потребителей о её свойствах. Среди показателей этой группы наиболее важными являются требования к маркировке.
Межгосударственный стандарт содержит меньше
Если при подготовке из межгосударственного стандарта исключают отдельные положения, отдельные структурные элементы (разделы, подразделы, пункты, подпункты, приложения) международного стандарта (международного документа), которые нецелесообразно применять, то официальный перевод исключенных отдельных положений, отдельных структурных элементов приводят в приложении.
Этапы по принципам
измерительные методы подразделяются на: — Физические – определение физической величины товаров — температура, плотность; — Химические – определение химического состава или других показателей с помощью каких-либо химических веществ; — Физико–химический – исследование показателей качества с использованием комплексно физических и химических приемов и параметров; — Биологический – подопытное кормление животных, воздействие на клетки (простейшие организмы); — Микробиологический – определение количественного и качественного состава микрофлоры; — Биохимический – исследование, как воздействуют в организме или продуктах те или иные химические элементы.
Похожие
-
Аддитивность
-
Аддитивный
-
Аддитивные гены
-
Аддитивная полимеризация
-
Закон аддитивности
-
Модель аддитивная
-
Аддитивная группа
-
Аддитивный оператор
-
Аддитивная радиопомеха
-
Аддитивный цвет
-
Погрешность
-
Погрешность измерений (абсолютная погрешность)
-
Арифметическая погрешность (округления погрешность)
-
Аддитивная физическая величина
-
Аддитивная теория чисел
-
Относительная погрешность
-
Приведённая погрешность
-
Систематическая погрешность
-
Случайная погрешность
-
Абсолютная погрешность
Смотреть больше терминов
Научные статьи на тему «Аддитивная погрешность»
1.
Классы точности
Главные свойства представлены пределами допускаемых основных и дополнительных погрешностей….
Возможно нормирование погрешности….
Относительная погрешность нормируется в части результата измерения….
Приведенная погрешность нормируется в части длины (верхнего предела) шкалы измерительного прибора….
Основная абсолютная погрешность может иметь как аддитивный, так и мультипликативный характер.
Статья от экспертов
![]()
2.
Коррекция аддитивных погрешностей средств измерений
3.
Разработка датчика тока
Расчет погрешностей….
При расчете погрешности датчика тока рассчитываются следующие ее виды (в зависимости от результатов предыдущих…
этапов разработки): аддитивные составляющие погрешности интегратора, аналого-цифрового преобразователя…
, усилителя; нелинейная составляющая погрешности интегратора и аналого-цифрового преобразователя; погрешности…
квантования аналого-цифрового преобразователя; мультипликативной погрешности усилителя, интегратора
Статья от экспертов
![]()
4.
Эффективность коррекции аддитивной погрешности в двухтактных ваттметрах
В статье рассмотрены зависимости для коэффициентов подавления аддитивной помехи двух-, трех-, и четырехтактных интегрирующих ваттметров с учетом эффективности интегрирования и учетом влияния низких и высоких частот, установлено влияние фазы входных величин по отношению к помехам. Показано, что при переменном характере спектра помехи дисперсия показаний прибора от влияния аддитивной погрешности будет больше, чем для приборов, функционирующих за меньшее количество тактов.
Повышай знания с онлайн-тренажером от Автор24!
- 📝 Напиши термин
- ✍️ Выбери определение из предложенных или загрузи свое
- 🤝 Тренажер от Автор24 поможет тебе выучить термины, с помощью удобных и приятных
карточек
Аддитивная погрешность
Предмет
Стандартизация
Разместил
🤓 fyodorov.vitalij.1998
👍 Проверено Автор24
погрешность, значение которой не изменяется во всем диапазоне измерения.
Научные статьи на тему «Аддитивная погрешность»
Классы точности
Главные свойства представлены пределами допускаемых основных и дополнительных погрешностей….
Возможно нормирование погрешности….
Относительная погрешность нормируется в части результата измерения….
Приведенная погрешность нормируется в части длины (верхнего предела) шкалы измерительного прибора….
Основная абсолютная погрешность может иметь как аддитивный, так и мультипликативный характер.

Статья от экспертов
Коррекция аддитивных погрешностей средств измерений
Разработка датчика тока
Расчет погрешностей….
При расчете погрешности датчика тока рассчитываются следующие ее виды (в зависимости от результатов предыдущих…
этапов разработки): аддитивные составляющие погрешности интегратора, аналого-цифрового преобразователя…
, усилителя; нелинейная составляющая погрешности интегратора и аналого-цифрового преобразователя; погрешности…
квантования аналого-цифрового преобразователя; мультипликативной погрешности усилителя, интегратора
Статья от экспертов
Эффективность коррекции аддитивной погрешности в двухтактных ваттметрах
В статье рассмотрены зависимости для коэффициентов подавления аддитивной помехи двух-, трех-, и четырехтактных интегрирующих ваттметров с учетом эффективности интегрирования и учетом влияния низких и высоких частот, установлено влияние фазы входных величин по отношению к помехам. Показано, что при переменном характере спектра помехи дисперсия показаний прибора от влияния аддитивной погрешности будет больше, чем для приборов, функционирующих за меньшее количество тактов.
Повышай знания с онлайн-тренажером от Автор24!
- Напиши термин
- Выбери определение из предложенных или загрузи свое
-
Тренажер от Автор24 поможет тебе выучить термины с помощью удобных и приятных
карточек
Аддитивные и мультипликативные погрешности
Аддитивной погрешностью называется погрешность, постоянная в каждой точке шкалы.
Мультипликативной называется погрешность, линейно возрастающая или убывающая с ростом измеряемой величины.
Различать аддитивные и мультипликативные п. легче всего по полосе погрешностей.
Полоса погрешностей
Если абсолютная погрешность не зависит от значения измеряемой величины, то полоса определяется аддитивной п. (рис. а). Иногда такую п. называют погрешностью нуля. Если постоянной величиной является относительная погрешность, то полоса погрешностей меняется в пределах диапазона измерений и п. называется мультипликативной (рис. б). Ярким примером аддитивной п. является погрешность квантования (оцифровки).
Класс точности измерений зависит от вида погрешностей. Рассмотрим класс точности измерений для аддитивной и мультипликативной п.
Для аддитивной п.:
Формула для класса точности аддитивной погрешности
где X — верхний предел шкалы, ∆0 — абсолютная аддитивная п.
Для мультипликативной п.:
Формула для класса точности мультипликативной погрешности
∆x/x=1 — это условие определяет порог чувствительности прибора (измерений).
Абсолютная величина погрешности для обоих типов может быть выражена одной формулой:
Выражение для абсолютной величины
где ∆0 — аддитивная п., y0x — мультипликативная п.
Относительная погрешность с учетом вышесказанного выражается:
Формула для относительной величины погрешности
и, при уменьшении измеряемой величины, возрастает до бесконечности. Приведенное значение погрешности возрастает с увеличением измеряемой величины:
Формула погрешности при возрастании величины измерения