
-
04.05.2023
Заменяет множество формул в каждой ячейке на одну единственную
ARRAYFORMULA — функция для массовых выражений в google таблицах
ARRAYFORMULA функция массивов, аналогичная функции ARRAY из Excel таблиц. Функция идет как дополнительный параметр, заменяющий множество функций в каждой ячейке на одну единственную в одной ячейке, распространяющую заданные выражения на соседние строки и столбцы. ARRAYFORMULA никогда не выступает в качестве самостоятельного элемента.
На примере функция массивов используется в популярной связке с функцией VLOOKUP (ВПР) и дополнительным условием, обрабатываемым функцией обработки ошибок — IFERROR (ЕСЛИОШИБКА).
Вместо тысяч формул с ВПР, в ячейку F1 вставлена функция работы с массивами — ARRAYFORMULA, которая автоматически расширяется при добавлении новых вводных данных:
={"В раб.часах";ARRAYFORMULA(IFERROR(E2:E/VLOOKUP(L2:L;'Справочник'!H:O;8;0)/24))}
Обратите внимание:
- Вместо конкретной ячейки, которая обычно указывается в качестве первого искомого аргумента в таблице функции VLOOKUP (ВПР), указан диапазон с ячейками — столбец L2:L (весь столбец, начиная со 2й ячейки).
- Вместо конкретной ячейки для обработки ошибки, в случае, если функция VLOOKUP (ВПР) не найдет искомый результат — указан столбец L2:L.
- Вместо конкретной ячейки для математического действия деления — указан столбец E2:E.
- Чтобы скрыть функцию в район неизменяемой строки с заголовками и защитить формулу от случайного удаления пользователем — используется «хук» с фигурными скобками:
={"В раб.часах"; формула }

Т.е., мы указываем функции с какими массивами (столбцами) надо работать. Размер массивов с данными должен быть одинаковым. И помещаем ее в шапку таблицы с заданным заголовком, защищая от случайного удаления пользователем.
ВАЖНО!: на пути у формулы не должно быть заполненных ячеек, иначе она сломается, выдав ошибку #REF! (#ССЫЛ!)
Массовая сцепка строк одной формулой
ARRAYFORMULA, массовая конкатенация строк в google таблицах
Функция для работы с массивами применяется не только для отображения математических выражений, но и при работе с текстовыми функциями. На примере вариант массовой конкатенации строк через функцию ARRAYFORMULA:
={"Результат";ARRAYFORMULA(C5:C&" "&D5:D)}
В данном случае, вместо привычного вида функции CONCATENATE (СЦЕПИТЬ) — используется амперсант «&».

Массовое произведение массива на число
Использование функции ARRAYFORMULA при умножении на константу
ARRAYFORMULA часто используется для выполнения математических действий c заданной константой. Константой может быть другая функция (в числовом формате) или просто произвольное число.
На примере ниже произведение данных из ограниченного диапазона D5:D21 на число 2:
={"Результат";ARRAYFORMULA(D5:D21*2)}

Разбиваем дату на составляющие
Функция ARRAYFORMULA и извлечение данных из даты
ARRAYFORMULA может помочь массово извлечь нужные данные из даты. Для этого нужно обернуть ею функцию SPLIT:
=ARRAYFORMULA(IFERROR(SPLIT(D5:D;".")))
В формуле задействована функция IFERROR, она убирает ошибку — #VALUE!, которая возникает когда SPLIT не находит данные в столбце D5:D (натыкается на пустые ячейки в столбце).

Как подружить ARRAYFORMULA и СУМЕСЛИ
Функция SUMIF и ARRAYFORMULA в гугл таблицах
Чтобы обернуть SUMIF в ARRAYFORMULA и комбинация сработала, нужно применить специальный прием объединения одинаковых массивов (столбцов) и использовать их в качестве единых аргументов:
=ARRAYFORMULA(IF(G4:G="";"";SUMIF(A4:A&B4:B&C4:C;G4:G&H4:H&I4:I;D4:D)))
В формуле задействованы функции:
- IF (ЕСЛИ) — отрабатывает проверку на заполнение данными в ячейках из столбца G4:G.
- SUMIF (СУМЕСЛИ) — проводит суммирование по объединенным столбцам с данными, месяцем и годом: A4:A&B4:B&C4:C, с условием по объединенному массиву: G4:G&H4:H&I4:I и сумме по столбцу D4:D.
Т.е., мы просто объединяем амперсантом (&) данные из одинаковых столбцов с месяцем и годом, составляя сцепленные уникальные аргументы с единой структурой и «меткой» для функции — вот такой вот прием 😉

ARRAYFORMULA с условием отмены по пустой ячейке
Функция ARRAYFORMULA и массовая сумма значений из ячеек
В том случае, если нужно массово сложить 2 числа из двух ячеек по всему диапазону (по двум столбцам) можно применить конструкцию:
={"Сумма";ARRAYFORMULA(IF(D5:D="";"";D5:D+E5:E))}
- {«Сумма»;комбинация формул} — массив с заголовком, в который помещена комбинация формул массива и определенного условия.
- ARRAYFORMULA — отрабатывающая массовую сумму чисел по ячейкам из двух столбцов.
- IF (ЕСЛИ) — функция условия, ссылающаяся на частный случай — если какая-нибудь ячейка из столбца D5:D будет пустой, то ничего не выводить, если будет число — проводить сумму чисел из ячеек Dn и En.
- D5:D — столбец D, начиная с 5-ой ячейки.
- E5:E — столбец E, начиная с 5-ой ячейки.
Обратите внимание: обязательно нужно применить условие, по которому функция массива перестанет автоматическую сумму двух ячеек из столбцов (поэтому и применена функция IF (ЕСЛИ)). В противном случае, массив будет продлен просуммирован до 25 000 + строк вниз таблицы: функция ARRAYFORMULA будет суммировать 0+0 из двух столбцов…

ARRAYFORMULA гугл таблицы
Функция ARRAYFORMULA синтаксис и основные положения
ARRAYFORMULA выступает в качестве дополнительной функции, превращая разовое выполнение других функций в массовое (получаем массив однотипных запрограммированных действий: умножение, деление, сложение, вычитание и т.д.). Функция, так же, отрабатывает массивы с текстом или датой.
=ARRAYFORMULA(array_formula) - латинская версия =ARRAYFORMULA(формула_массива) - русская версия
- array_formula (формула_массива) — диапазон, математическое действие с одним или несколькими диапазонами одного размера либо функция, результат действия которой размещается в одной, либо более чем одной ячейке.
Обратите внимание: при ограниченном диапазоне ARRAYFORMULA захватывает на 1 строку, либо 1 столбец больше. Если в таблице будет на 1 строку или столбец меньше, чем нужно для отработки функции — массив зациклится и будет добавлять строки и столбцы до максимально возможного значения.

Функция массива часто в приоритете среди других функций при работе с огромными объемами данных (тысячи строк), так как легче внести нужные корректировки в одну формулу в одной ячейке, чем изменять структуру каждой формулы в отдельных ячейках и снова протягивать их до конца столбца на постоянной основе — что здорово экономит время.
Так же, функция ARRAYFORMULA защищает результат вычисления данных от случайного удаления в ячейке, либо строке / столбце.

SEO — это рутина. Иногда приходится делать совсем тоскливые операции вроде удаления «плюсиков» в ключевых словах. Иногда — что-то более продвинутое вроде парсинга мета-тегов или консолидации данных из разных таблиц. В любом случае все это съедает тонны времени.
Но мы не любим рутину. Предлагаем 16 полезных функций Google Sheets, которые упростят работу с данными и помогут вам высвободить несколько рабочих часов или даже дней. (Уверены, о существовании некоторых функций вы не догадывались).
1. IF — базовая логическая функция
Это одна из базовых функций, знакомых вам по Excel. Она помогает при решении разных SEO-задач. Формула IF выводит одно значение, если логическое выражение истинное, и другое — если оно ложное.
Синтаксис:
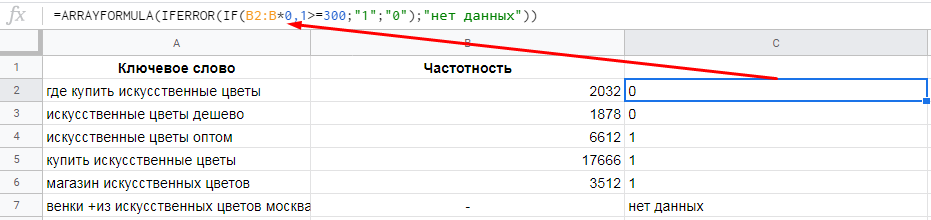
=IF(логическое_выражение;"значение_истина";"значение_ложь")Пример. Есть список ключей с частотностями. Наша цель — занять ТОП-3. При этом мы хотим выбрать только такие ключи, каждый из которых приведет нам минимум 300 посетителей в месяц.
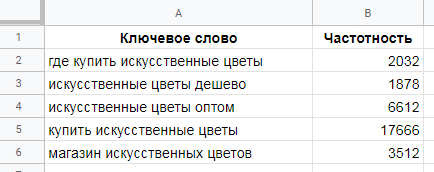
Определяем, какая доля трафика приходится на третью позицию в органике. Для этого идем в этот сервис и видим, что третья позиция приводит около 10% трафика из органики (конечно, эта цифра неточная, но это лучше, чем ничего).
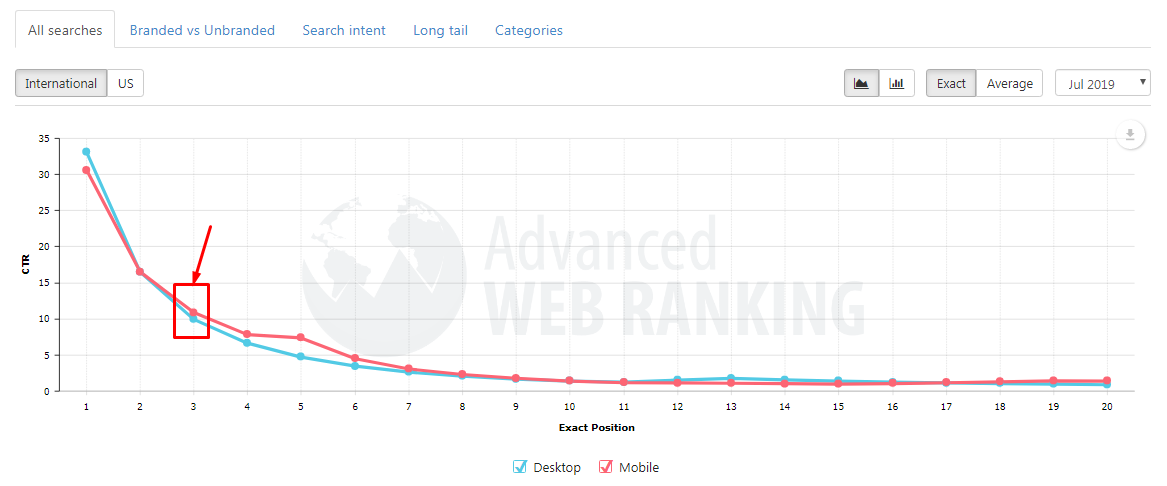
Составляем выражение IF, которое будет возвращать значение 1 для ключей, который приведут минимум 300 посетителей, и 0 — для остальных ключей:
=IF(B2*0.1>=300;"1";"0")
Обратите внимание, в строке 7 формула выдала ошибку, поскольку значение частотности задано в неверном формате. Для подобных ситуаций есть продвинутая версия функции IF — IFERROR.
Обратите внимание: использование в формуле запятой или точки для десятичных дробей определено в настройках ваших таблиц.
2. IFERROR — присваиваем свое значение в случае ошибки
Функция позволяет вывести заданное значение в ячейку, если выдается ошибка.
Синтаксис:
=IFERROR(ваша формула;"значение в случае ошибки")Используем эту функцию в примере, описанном выше. Зададим значение в случае ошибки «нет данных».
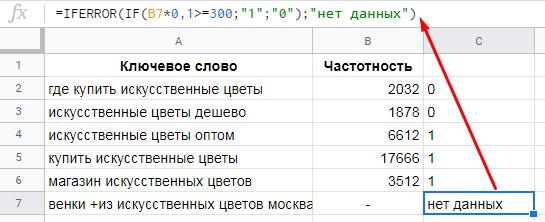
Как видите, значение #VALUE! изменило вид на понятное нам «нет данных».
3. ARRAYFORMULA — протягиваем формулу вниз в один клик
В работе с данными практически каждый раз приходится прописывать формулу для всех ячеек в столбце. «Тянуть» ее, зажав левую кнопку мыши, или копипастить — это прошлый век.
Достаточно заключить исходную функцию в функцию ARRAYFORMULA, и формула применится ко всем ячейкам ниже. Причем при удалении добавлении строк формула все равно будет работать — без пробелов в расчетах.
Синтаксис:
=ARRAYFORMULA(исходная формула)Пример. Сделаем автоматическое применение формулы, описанной выше, для всех ячеек диапазона. Для этого заключаем исходную формулу в ARRAYFORMULA:
=ARRAYFORMULA(IFERROR(IF(B2:B*0,1>=300;"1";"0");"нет данных"))Обратите внимание, что мы вместо ячейки B2 указали диапазон, для которого применяем формулу (B2:B — это весь столбец B, начиная со второй строки). Если указать одну ячейку, формула не сработает.
Лайфхак. Нажмите сочетание клавиш CTRL+SHIFT+ENTER после ввода основной формулы, и функция ARRAYFORMULA применится автоматически.
ARRAYFORMULA работает не со всеми функциями. Например, она не совместима с GOOGLETRANSLATE и IMPORTXML, о которых мы расскажем ниже.
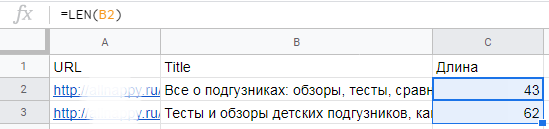
4. LEN — считаем количество символов в ячейке
Эта функция особенно полезна при составлении объявлений контекстной рекламы — когда важно не заступать за отведенное количество символов для заголовков, описаний, отображаемых URL, быстрых ссылок и уточнений.

В SEO функция LEN применяется, например, при составлении мета-тегов title и description. Символы функция считает с пробелами.
Синтаксис:
=LEN(ячейка с текстом)Пример. Нам нужно составить тайтлы для всех страниц сайта. Мы знаем, что в результатах поиска отображается около 55 символов. Наша задача — составить тайтлы так, чтобы самая важная информация была в первых 55 символах. Прописываем формулу LEN для заполняемых ячеек. Теперь мы точно знаем, когда приближаемся к отображаемым 55 символам.
5. TRIM — удаляем пробелы в начале и конце фразы
Когда парсишь семантику из разных источников, часто она содержит «мусорные» элементы — пробелы, плюсики, спецсимволы. Рассмотрим функции, которые помогают быстро почистить ядро. Одна из них — TRIM.
Эта функция удаляет пробелы в начале и конце фразы, указанной в ячейке.
Синтаксис:
=TRIM(ячейка, в которой нужно удалить пробелы до и после фразы)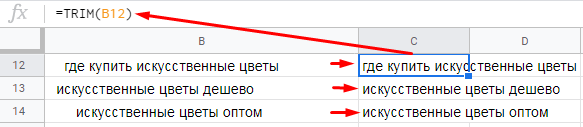
Функция удаляет все пробелы до и после фразы — сколько бы их там ни было.
6. SUBSTITUTE — меняем/удаляем пробелы и спецсимволы
Универсальная функция замены/удаления символов в ячейках.
Синтаксис:
=SUBSTITUTE(где искать;"что искать";"на что менять";номер соответствия)Номер соответствия — порядковый номер встреченного значения на замену, например, первое встреченное заменить, остальные оставить. Опциональный параметр.
Пример. У нас есть выгрузка ключевых фраз из Яндекс.Вордстат. Многие ключи содержат плюсики. Нам нужно их удалить.
Формула будет иметь вид:
=SUBSTITUTE(B12;"+";"";)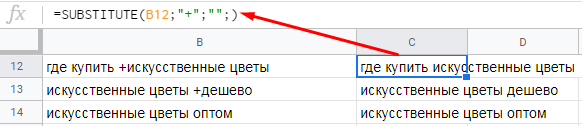
Что мы сделали:
- где искать — указали ячейку с данными;
- «что искать» — указали плюсик, который нужно удалить;
- «на что менять» — поскольку символ нужно удалить, мы указали кавычки без символов внутри; если бы нам нужна была замена, здесь бы мы прописали текст, на который нужно заменить плюсик;
- номер соответствия — здесь мы ничего не указали, и функция удалит все плюсы в фразе; если бы мы указали 1, то функция удаляла бы только первый плюсик, если 2 — второй и т. д.
7. LOWER — переводим буквы из верхнего регистра в нижний
При составлении ключей и парсинге из разных источников (например, из мета-тегов конкурентов) может так получиться, что они будут иметь буквы в верхнем регистре. Для приведения ключей в унифицированный вид нужно перевести все буквы в нижний регистр. Для этого используется функция LOWER.
Синтаксис:
=LOWER(ячейка, текст в которой нужно перевести в нижний регистр)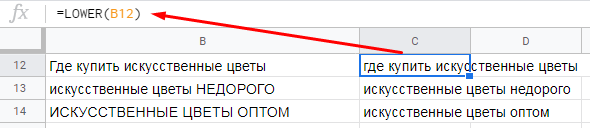
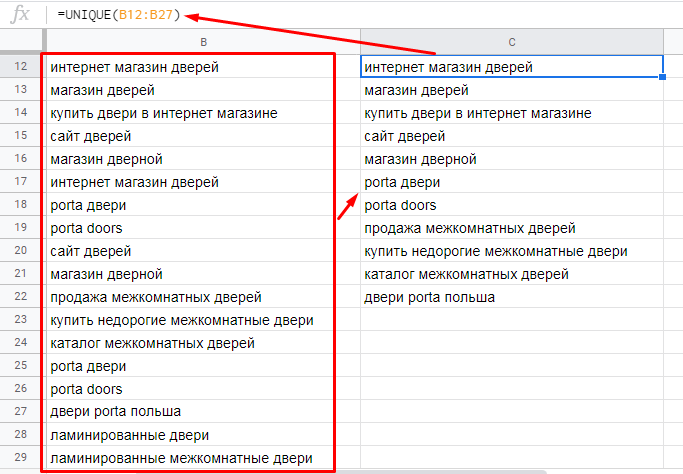
8. UNIQUE — выводим данные без дублирующихся ячеек
Функция анализирует выделенный диапазон на предмет полных дублей и выводит только уникальные строки — в том же порядке, что и в исходном диапазоне.
Синтаксис:
=UNIQUE(диапазон данных)Пример. Мы собрали ключи из Яндекс.Вордстат, поисковых подсказок, парсили слова конкурентов. Естественно, в этом массиве ключей у нас будут дубли. Нам они не нужны. Убираем их с помощью UNIQUE.
Если вы хотите «одним махом» очистить ядро от мусора, используйте бесплатный нормализатор слов. Он убирает дублирующиеся фразы (с учетом перестановок), меняет регистры, удаляет пробелы и спецсимволы. По сути, он делает то же самое, что и функции TRIM, SUBSTITUTE, LOWER и UNIQUE вместе взятые — только в один клик.
9. SEARCH — находим данные в строке
С помощью этой функции вы быстро найдете необходимые вам строки с большом массиве данных.
Синтаксис:
=SEARCH(«что искать»;где искать)Функция используется в разных ситуациях:
- выделить ключевые фразы с необходимым интентом (например, брендированные или связанные с определенной тематикой, товаром или услугой);
- найти определенные символы в URL (например, UTM-параметры или знак вопроса);
- найти URL для целей линкбилдинга — например, содержащие слова «guest-post»).
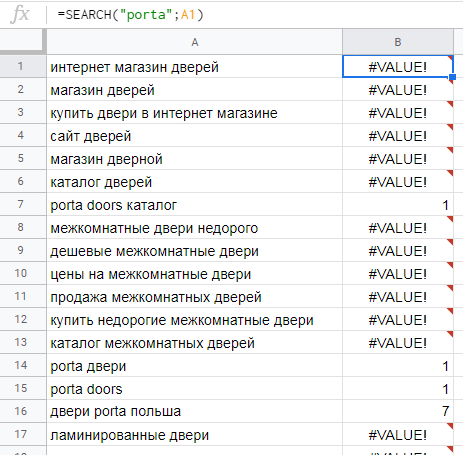
Пример. У нас есть список ключей для интернет-магазина дверей. Мы хотим найти все брендированные запросы и отметить их в таблице. Для этого используем формулу:
=SEARCH("porta";A1)Но в таком виде формула при отсутствии слова «porta» в ключе выведет нам #VALUE!.. Кроме того, при наличии этого слова в искомой ячейке функция будет проставлять номер символа, с которого начинается это слово. Выглядит результат так:
Для получения результата поиска в удобной для нас форме используем дополнительно функции IF и IFERROR:
=IFERROR(IF(SEARCH("porta";A1)>0;"бренд";"0"))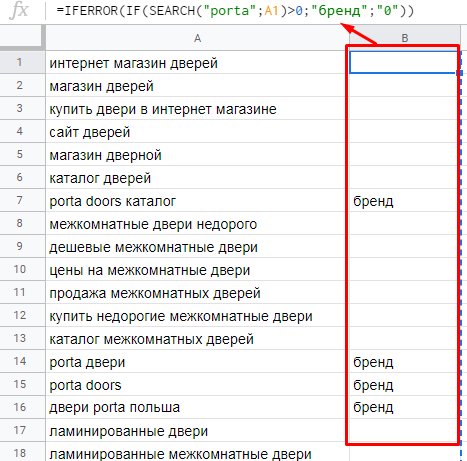
10. SPLIT — разбиваем фразы на отдельные слова
Функция делит строки на фрагменты, используя заданный разделитель.
Синтаксис:
=SPLIT(ячейка;"разделитель")Стоит иметь в виду, что вторая половина разделенного текста займет следующую колонку. Так что если у вас плотная таблица, перед применением формулы нужно добавить пустую колонку.
Пример. У нас есть список доменов. Нам нужно разделить их на названия доменов и расширения. В функции SPLIT в качестве разделителя указываем точку и получаем результат:
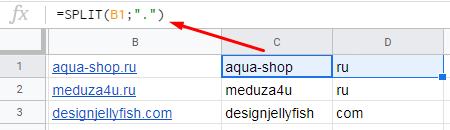
11. CONCATENATE — объединяем данные в ячейках
Эта функция, в отличие от предыдущей, объединяет данные из нескольких ячеек.
Синтаксис:
=CONCATENATE(ячейка 1;ячейка 2;...)Важно: в формулу можно вставлять не только значения ячеек, но и символы (в прямых кавычках).
Пример. В примере с функцией SPLIT мы разделили домены. Сделаем обратную операцию с помощью CONCATENATE (указываем объединяемые ячейки и между ними указываем разделитель — точку):

12. VLOOKUP — ищем значения в другом диапазоне данных
Функция выполняет поиск ключа в первом столбце диапазона и возвращает значение указанной ячейки в найденной строке.
Синтаксис:
=VLOOKUP(запрос;диапазон;номер_столбца;[сортировка])Пример 1. Есть два массива ключевых фраз, полученных из разных источников. Нужно найти ключи в первом массиве, которые не встречаются во втором массиве. Для этого используем формулу:
=VLOOKUP(A2:A;B2:B;1;false)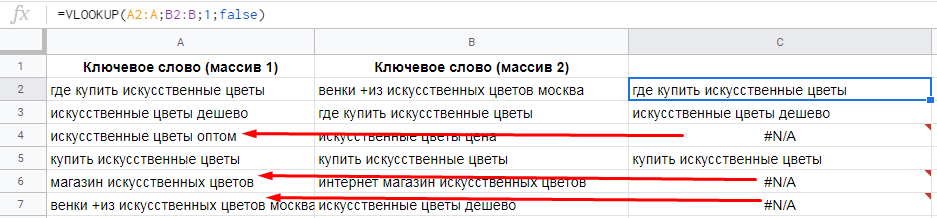
Что мы сделали:
- задали диапазон A2:A, из которого берем ключи для сравнения;
- задали диапазон B2:B, с которым сравниваем ключи из столбца А;
- задали номер столбца (1), из которого подтягиваем ключи при совпадениях;
- false — указали, что сортировка нам не нужна.
Функция VLOOKUP часто используется при поиске данных на разных листах или в разных документах.
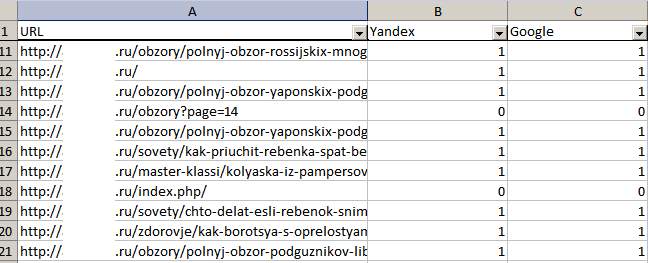
Пример 2. Мы выгрузили данные из Яндекс.Вебмастера и Google Search Console об индексации страниц сайта. Наша задача — сопоставить данные и определить, какие страницы индексируются в одном поисковике, но не индексируются в другом.
Заносим результаты выгрузок в файл Google Sheets. На одном листе — URL из Google, на втором — из Яндекса.
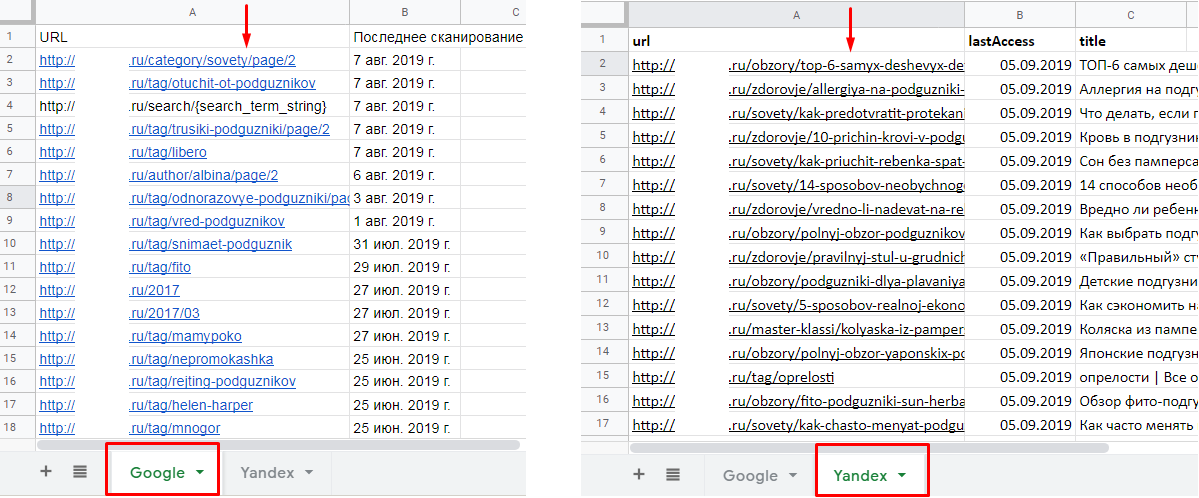
В ячейке C2 прописываем функцию VLOOKUP. Сразу заключаем в функцию в ARRAYFORMULA для автоматического протягивания вниз:
=ARRAYFORMULA(VLOOKUP(A2:A;Yandex!A2:A;1;false))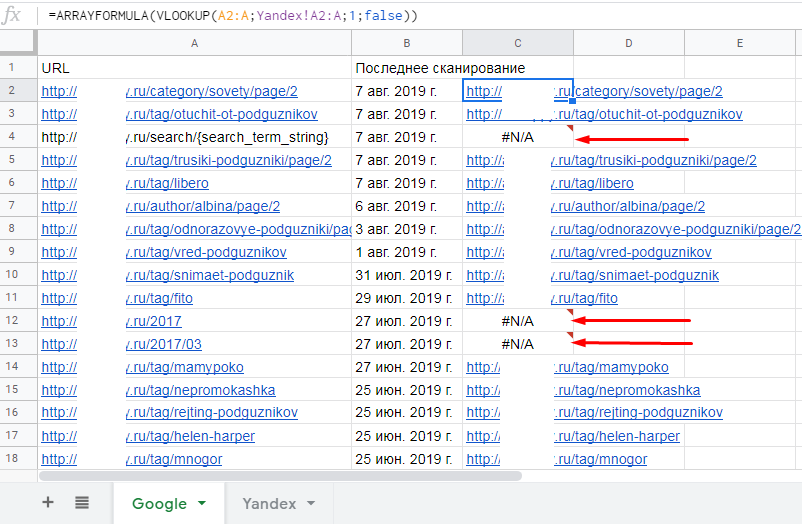
Теперь мы сразу видим, какие страницы проиндексированы в Google, но не проиндексированы в Яндексе.
Что мы сделали:
- задали диапазон A2:A текущего листа, из которого берем значение для сравнения;
- задали диапазон Yandex!A2:A листа с выгрузкой из Яндекса, с которым будем сравнивать значения URL из Google;
- указали номер столбца листа с выгрузкой из Яндекса, значения из которого подтягиваем при совпадении значений из сравниваемых диапазонов;
- false — указали, что сортировка нам не нужна.
Если же вам нужно проверить одновременно индексацию конкретных страниц в Яндексе и Google, воспользуйтесь инструментом от PromoPult. Загрузите список URL и запустите проверку. Если страница проиндексирована в поисковике, в столбце будет цифра 1, если нет — 0.
Каким пользоваться этим инструментом и в каких ситуациях он полезен, читайте в этом гайде.
13. IMPORTRANGE — импортируем данные из других таблиц
Функция позволяет вставить в текущий файл данные из других таблиц.
Синтаксис:
=IMPORTRANGE("ссылка на документ";"ссылка на диапазон данных")Пример:
=IMPORTRANGE("https://docs.google.com/spreadsheets/d/ХХХХХХХХ/","имя листа!A2:A25")Пример. Вы продвигаете сайт клиента. Над проектом работает три специалиста: линкбилдер, SEO-специалист и копирайтер. Каждый ведет свой отчет. Клиент заинтересован отслеживать процесс в режиме онлайн. Вы формируете для него один отчет с вкладками: «Ссылки», «Позиции», «Тексты». На эти вкладки с помощью функции IMPORTRANGE подтягиваются данные по каждому направлению.

Преимущество функции в том, что вы открываете доступ только к конкретным листам. При этом внутренние части отчетов специалистов остаются недоступны для клиентов.
14. IMPORTXML — парсим данные с веб-страниц
«Развесистая» функция для парсинга данных с веб-страниц с помощью XPath.
Синтаксис:
=IMPORTXML("url";"xpath-запрос")Вот лишь несколько вариантов использования этой функции:
- извлечение метаданных из списка URL (title, description), а также заголовков h1-h6;
- сбор e-mail со страниц;
- парсинг адресов страниц в соцсетях.
Пример. Нам нужно собрать содержимое тегов title для списка URL. Запрос XPath, который мы используем для получения этого заголовка, выглядит так: «//title».
Формула будет такой:
=IMPORTXML(A2;"//title")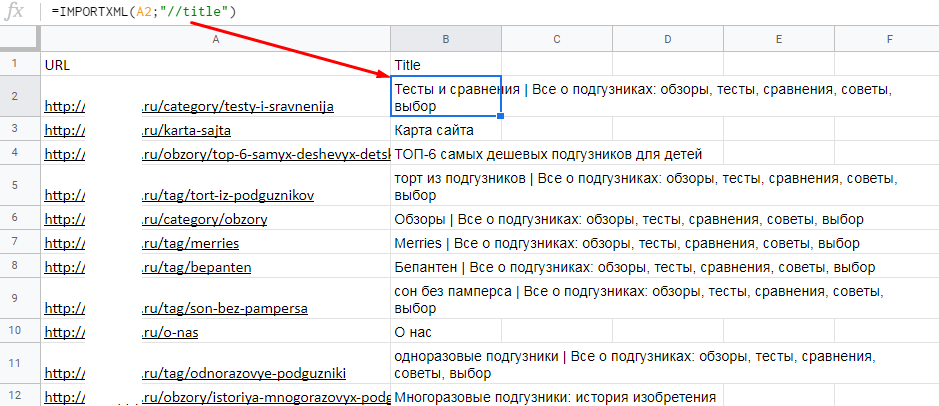
IMPORTXML не работает с ARRAYFORMULA, так что вручную копируем формулу во все ячейки.
Вот другие запросы XPath, которые вам будут полезны:
- выгрузить заголовки H1 (и по аналогии — h2-h6): //h1
- спарсить мета-теги description: //meta[@name=’description’]/@content
- спарсить мета-теги keywords: //meta[@name=’keywords’]/@content
- извлечь e-mail адреса: //a[contains(href, ‘mailTo:’) or contains(href, ‘mailto:’)]/@href
- извлечь ссылки на профили в соцсетях: //a[contains(href, ‘vk.com/’) or contains(href, ‘twitter.com/’) or contains(href, ‘facebook.com/’) or contains(href, ‘instagram.com/’) or contains(href, ‘youtube.com/’)]/@href
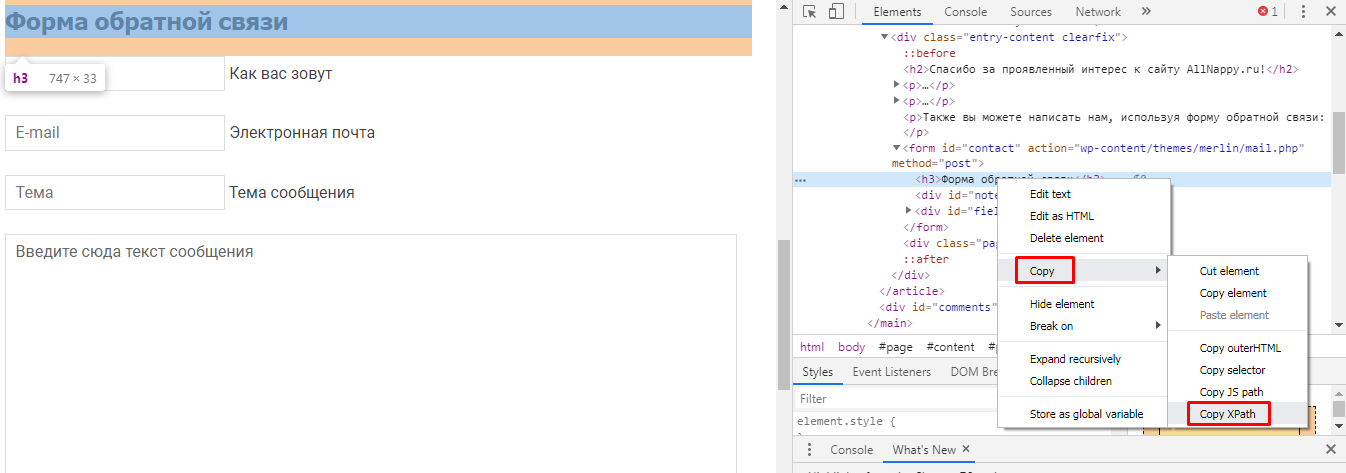
Если вам нужно узнать XPath-запрос для других элементов страницы, откройте ее в Google Chrome, перейдите в режим просмотра кода, найдите элемент, кликните по нему правой кнопкой и нажмите Copy / Copy XPath.
15. GOOGLETRANSLATE — переводим ключевики и другие данные
В мультиязычных проектах часто приходится переводить ключевые фразы. Удобнее всего это сделать с помощью функции GOOGLETRANSLATE прямо в таблице.
Синтаксис:
=GOOGLETRANSLATE(«текст»; [язык_оригинала]; [язык_перевода])Например, если нам нужно перевести ключи с русского на английский, формула будет такой:
=GOOGLETRANSLATE(A1;"ru";"en")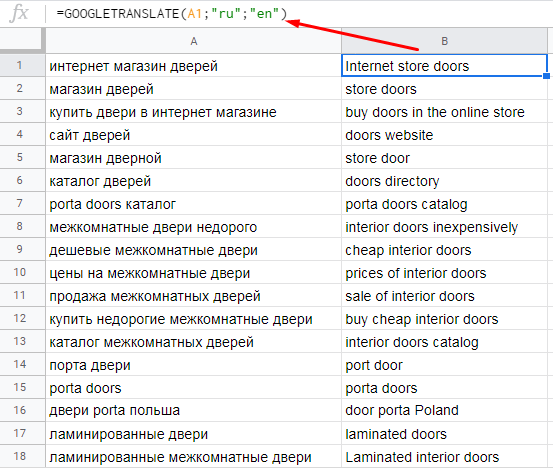
Если бы мы переводили с английского на русский, то нужно было бы изменить порядок языков:
=GOOGLETRANSLATE(A1;"en";"ru")GOOGLETRANSLATE не работает с ARRAYFORMULA, так что, как и в случае с IMPORTXML, протягиваем формулу вручную.
16. REGEXEXTRACT — извлекаем нужный текст из ячеек
Эта функция позволяет извлечь из строки с данными текст, описанный с помощью регулярных выражений RE2, поддерживаемых Google. Синтаксис регулярных выражений достаточно сложный, больше примеров вы найдете в справке Google.
Синтаксис:
=REGEXEXTRACT(где искать;”регулярное выражение”)Пример 1. У нас есть список URL. Нужно извлечь домены. Здесь нам поможет регулярное выражение:
^(?:https?://)?(?:[^@n]+@)?(?:www.)?([^:/n]+)
Пример 2. В списке ключевых фраз нужно найти брендированные ключи со словами «porta» и «порта». Для поиска фраз с вхождением любого из этих слов используем регулярное выражение:
(?i)(W|^)(porta|порта)(W|$)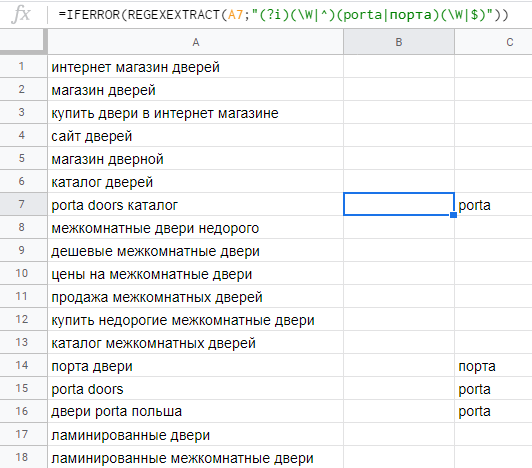
Как видите, в таблицах можно кроить и резать данные так, как вам будет нужно, достаточно разобраться в формулах.
Не только СУММ и СЦЕПИТЬ: Google Таблицы (или Google Spreadsheets) намного функциональнее и мощнее, чем это может показаться при поверхностном знакомстве.
На конкретных примерах разбираем полезные и интересные фичи, которые могут пригодиться в работе самым разным людям: владельцам бизнеса, руководителям, специалистам.
Этот обзор — только часть полезного образовательного контента от центра CyberMarketing. Вас ждут статьи, вебинары и курсы по интернет-маркетингу: SEO, PPC, SMM, веб-аналитике и другим важным тематикам.
IMPORTRANGE
IMPORTRANGE (русскоязычного названия нет) — функция, которая загружает данные из одной Google Таблицы в другую. Принимает два параметра: URL таблицы и диапазон, откуда нужно импортировать данные. Например: =IMPORTRANGE(«1iufABCDBDfT5BtDq1RJJw968xEDUWH80uM3u9ByATdoE»;»Декабрь 2017!A:B»)
Ссылку на таблицу можно вставить целиком или же взять лишь ее уникальный ID. Еще обратите внимание на второй аргумент: кириллическое название листа — без одинарных кавычек, хотя мы используем их, когда ссылаемся на такой лист в таблице.
Главное преимущество по сравнению с элементарным «Копировать → Вставить» — автоматическая загрузка новых данных. И эти новые данные легко сразу же использовать в других функциях или сводных таблицах благодаря возможности Google Spreadsheets задавать открытые диапазоны (к примеру, A2:B вместо A2:B20).
А еще IMPORTRANGE можно вложить в ВПР или QUERY, о которых речь пойдет дальше, или в другие функции, которые работают с диапазонами. Тогда можно будет не содержать дополнительный лист специально под импорт.
IMPORTHTML и IMPORTXML
Google Таблицы могут извлекать данные не только из таблиц, но и прямо с сайтов, то есть парсить их. Всего таких функций четыре, но больше пригождаются IMPORTHTML и IMPORTXML (у них тоже нет русскоязычных названий).
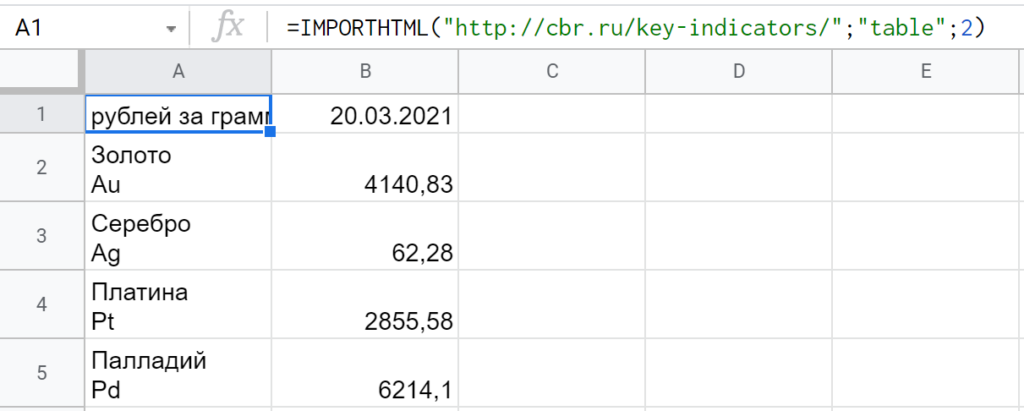
IMPORTHTML — функция, которая может импортировать данные с веб-страницы, если они представлены в виде таблицы или списка. Например, она может выглядеть так: =IMPORTHTML(«http://cbr.ru/key-indicators/»;»table»;2), где:
- URL или ссылка на ячейку с адресом сайта.
- Запрос, у которого только два варианта: «table» и «list» для таблиц и списков соответственно.
- Индекс, порядковый номер элемента. (Не всегда цифра очевидна, придется методом перебора выяснять, под каким именно номером на странице будут нужные данные.)
В данном случае функция выводит таблицу с ценами на драгоценные металлы — это информация с сайта Банка России:
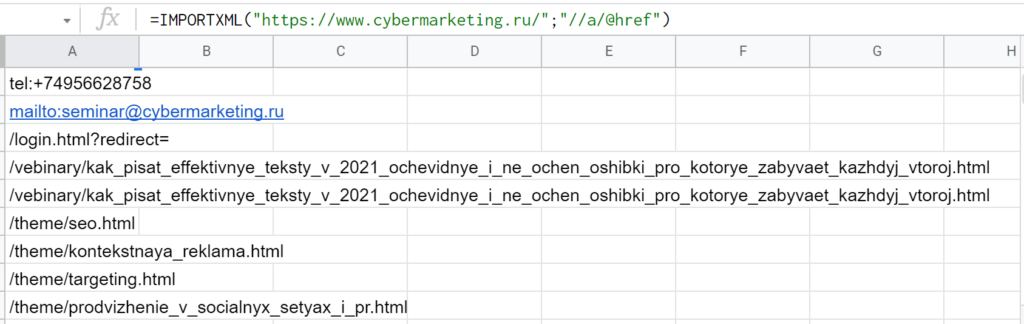
IMPORTXML тоже принимает первым параметром адрес страницы, а вторым — запрос XPath (это специальный язык для работы с XML-документами). Среди прочего эту функцию можно использовать для парсинга метатегов. Так, чтобы получить заголовок страницы, нужно вставить в ячейку текст вида: =IMPORTXML(«https://www.ozon.ru/category/tehnika-dlya-krasoty-i-zdorovya-10737/»;»//title»)
Если взять запрос «//meta[@name=’description’]/@content», Google Таблицы извлекут описание (дескрипшн), а если «//h1» — заголовок первого уровня соответственно. Чтобы выгрузить список ссылок со страницы, подойдет «//a/@href»:
Еще есть IMPORTDATA, которая работает с данными в формате CSV (значения, разделенные запятыми) или TSV (значения, разделенные табуляцией), и IMPORTFEED, которая загружает фид RSS или Atom. Но на практике они используются гораздо реже.
Конечно, есть и более удобные инструменты для парсинга метатегов и заголовков, например, Click.ru. Тем более этим функциональность не ограничивается: специалисты активно используют кластеризацию запросов, генерацию объявлений из YML, медиапланирование, создание отчетов и др. Бонус: вознаграждение до 18 % с рекламного оборота.
ВПР (VLOOKUP) и ГПР (GLOOKUP)
ВПР (VLOOKUP) — незаменимая функция для объединения данных из разных источников: листов и даже таблиц (если использовать вложенный IMPORTRANGE). Синтаксис: =ВПР(A2; ‘Отчет’!$A$2:$C; 4; 0), где:
- запрос, по которому нужно искать (здесь он будет взят из указанной ячейки);
- диапазон, в первом столбце которого нужно искать;
- номер столбца (от начала диапазона, а не листа), откуда нужно взять значение;
- дополнительный параметр, который настраивает точность поиска (по умолчанию 1, но лучше ставить 0, тогда будет возвращаться только точное совпадение).
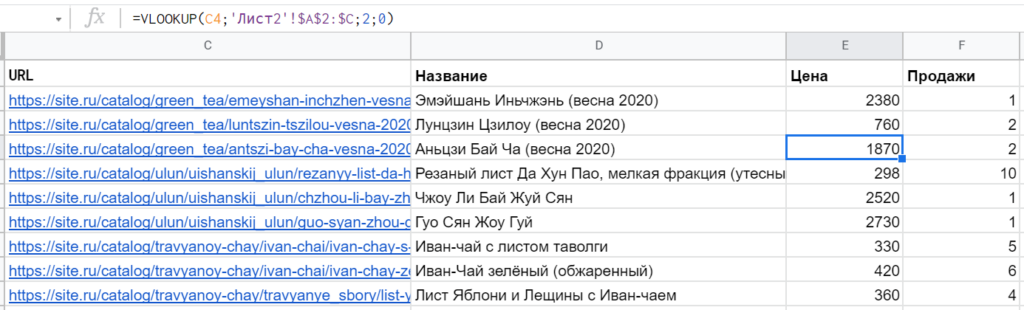
Допустим, есть два листа: на одном список URL с названиями страниц, на другом — тоже список URL, но с показателями по продажам или трафику. С помощью ВПР легко объединить эти данные в один отчёт.
Важные моменты:
- Использовать абсолютные ссылки на диапазон (со знаками доллара), иначе при протягивании ВПР они тоже будут меняться, в результате поиск может работать некорректно.
- Третьим параметром передавать номер столбца от начала диапазона, а не от начала листа. (Необязательно ссылаться на весь лист — нужные ячейки могут лежать не в A:B, а в E:F, например).
- ВПР ищет совпадения только в первом столбце диапазона и берет значения только справа от него. В остальных случаях по умолчанию эта функция не справится, но хорошо, что есть другие варианты.
Чтобы функция ВПР возвращала значения не только правее, но и левее первого столбца диапазона, есть лайфхак с использованием массива. Суть: создать виртуальную таблицу, где столбцы будут расположены в порядке, необходимом для корректной работы VLOOKUP.
Например =VLOOKUP(C2;{‘Лист2’!D:D ‘Лист2’!B:B ‘Лист2’!C:C};2;0) успешно произведет поиск по четвертому столбцу и передаст данные из второго. Потому что в массиве значения диапазона D:D идут первым столбцом — нет никаких противоречий.
Функция-побратим — ГПР (HLOOKUP) — работает похожим образом, только ищет по строкам, а не столбцам. На практике это может понадобиться гораздо реже.
ПОИСКПОЗ (MATCH) и ИНДЕКС (INDEX)
Совместное использование ПОИСКПОЗ (MATCH) и ИНДЕКС (INDEX) — еще один способ обойти ограничение функций ВПР (VLOOKUP) и ГПР (HLOOKUP), которые ищут только по первому столбцу или первой строке диапазона.
Алгоритм такой: MATCH находит значение в диапазоне (строка или столбец) и возвращает его порядковый номер, а INDEX — передает содержимое ячейки, у которой такой же порядковый номер, просто она находится в соседней строке или столбце.
Пример: =INDEX(‘Лист2′!$B$2:$B;MATCH(C3;’Лист2’!$D$2:$D;0)). Сначала запускается MATCH: находит значение из C3 на другом листе в столбце D, затем возвращает порядковый номер. INDEX берет этот номер и ищет по нему уже в столбце B, затем возвращает результат:
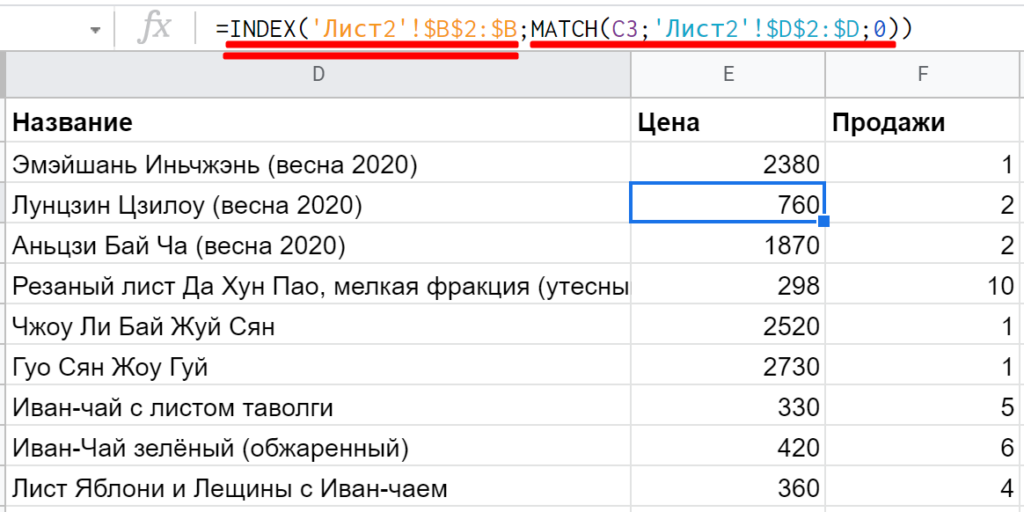
Важные моменты:
- ПОИСКПОЗ (MATCH) может работать только с одной строкой или с одним столбцом. Если попытаться отправить многомерный массив вроде A:D, функция выдаст #Н/Д! Третий параметр функции — метод поиска. Ноль требует точный поиск, показывает, что диапазон никак не отсортирован.
- ИНДЕКС (INDEX) может работать с любыми диапазонами, но в сочетании с ПОИСКПОЗ понадобится только поиск по столбцу. Поэтому третий параметр не используется — в ИНДЕКС передаются только диапазон (столбец, откуда нужно взять значение) и номер строки (его возвращает ПОИСКПОЗ).
- ИНДЕКС и ПОИСКПОЗ оперируют номерами строк/столбцов именно заданных диапазонов, а не листов — важно помнить об этом при работе.
Читайте также: 20+ ресурсов для обучения веб-аналитике: блоги, курсы, каналы, сообщества, рассылки
SPARKLINE
Спарклайн — интересный инструмент визуализации, который не требует много места: диаграмма умещается в одну ячейку. Аргументов два: диапазон или массив данных и набор опций (необязательный). В последнем можно задать, например:
- Тип диаграммы (charttype) — по умолчанию line (график), но можно поменять на bar (гистограмму) или column (столбчатую диаграмму).
- Цвет линии или столбцов диаграммы (color) — зеленый (green), желтый (yellow) и любой другой по шестнадцатеричному коду.
- Максимальное (max, ymax) и минимальное (min, ymin) значения по горизонтальной или вертикальной оси.
Такие дополнительные параметры можно передать массивом, — вставив его прямо в функцию — или сослаться на ячейки, где в первом столбце будет название параметра, а во втором — его значение.
Допустим, есть задача: изучить динамику трафика на страницы по месяцам. Если таких страниц сотни, бессмысленно для каждой из них строить большой график или диаграмму. А если оставить просто цифры, придется долго их считывать, чтобы разобраться. Тут на помощь и приходит функция SPARKLINE (русскоязычного названия нет).
Синтаксис: =SPARKLINE(B2:E2;{«charttype»»column»;»color»»green»}) где первым параметром идет диапазон с данными для визуализации, а вторым — массив с набором опций, который в данном случае указывает рисовать столбчатую диаграмму, а не график по умолчанию, и покрасить ее в зеленый цвет:
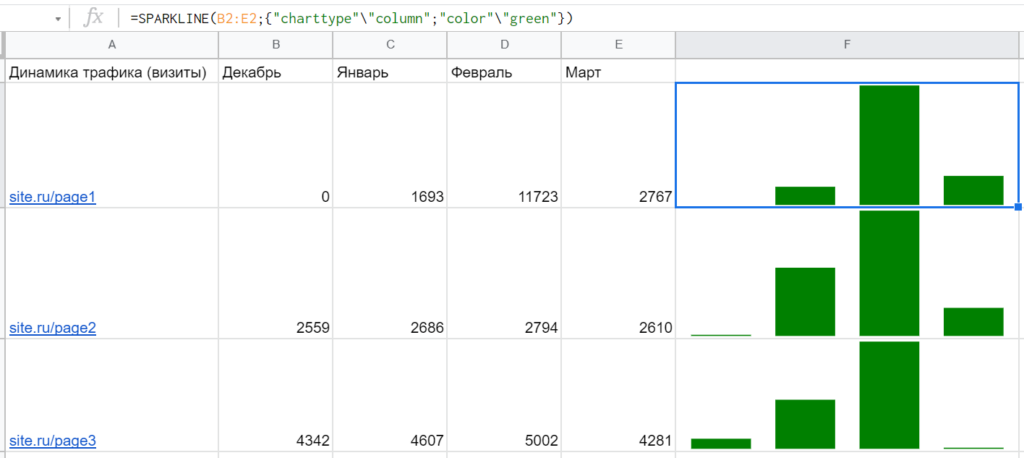
Но посмотрите внимательно на данные и сами диаграммы на этом примере. Сейчас кажется, что страница №3 сильнее всех просела по трафику в марте, хотя потеря составила всего 721 визит. Тогда как страница №1 потеряла целых 8956 визитов. Чтобы решить такую проблему, нужно как-то связать данные — например, с помощью опций ymin и ymax, которые передают максимальное и минимальное значение по всем страницам: =SPARKLINE(B2:E2;{«charttype»»column»;»color»»green»;»ymax»MAX($B$2:$E$4);»ymin»MIN($B$2:$E$4)}) Тогда получается гораздо нагляднее и реалистичнее:
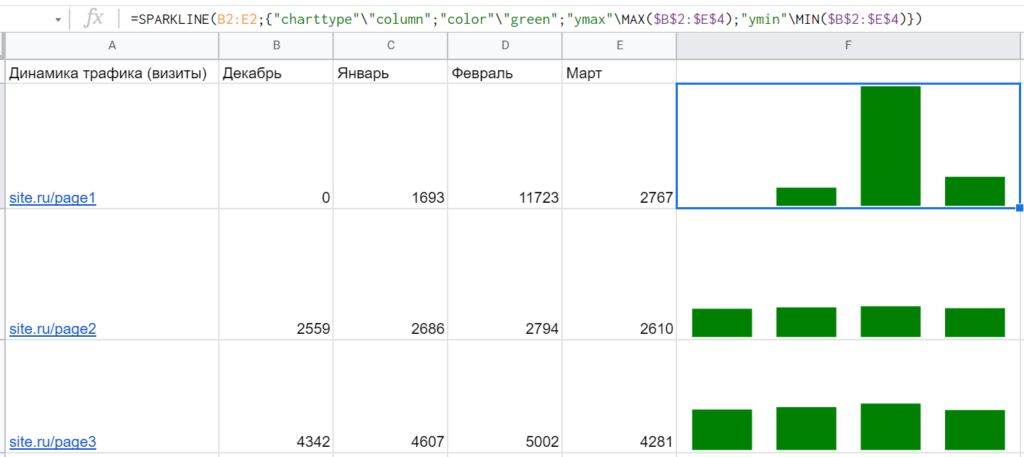
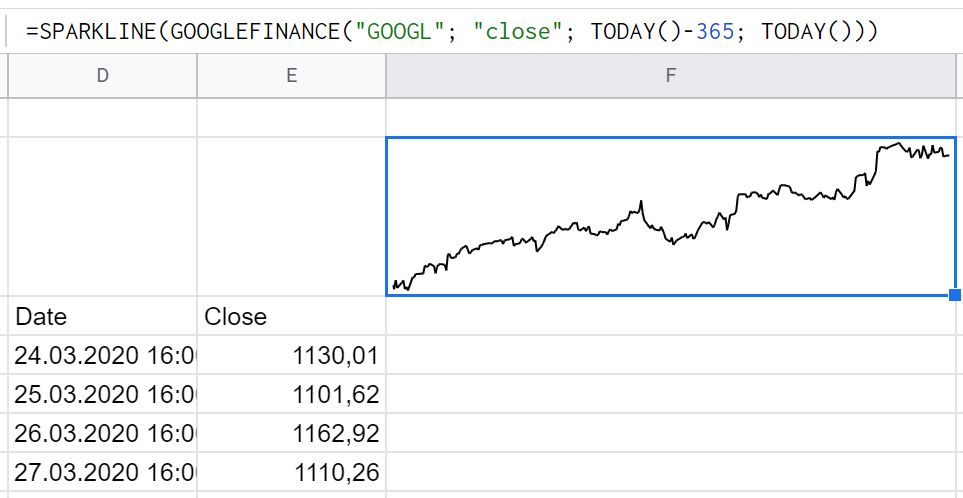
Кстати, если вы увлекаетесь инвестициями, комбинация SPARKLINE и GOOGLEFINANCE поможет изучать динамику котировок акций и курсов валют. На скриншоте — визуализация изменения стоимости акций Google за прошедший год:
ТРАНСП (TRANSPOSE)
ТРАНСП (TRANSPOSE) пригодится, когда нужно транспонировать таблицу (матрицу), то есть поменять строки и столбцы местами. В качестве аргумента можно передать диапазон или массив, например, так: =ТРАНСП(A35:G40)
Допустим, вы выгружаете из Яндекс.Метрики отчет с данными графика — чтобы посмотреть динамику трафика по определенным разделам:
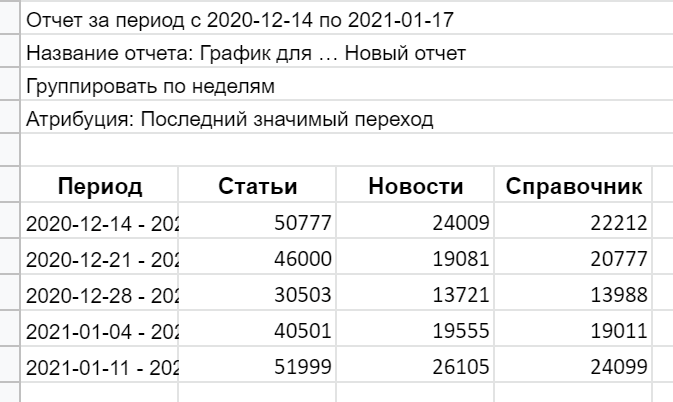
Голые цифры считываются плохо, гораздо нагляднее будет сделать визуализацию с помощью спарклайнов — диаграмм, которые умещаются в ячейку. Но для этих целей нужно расположить визиты по конкретному разделу в одну строку. Тогда сразу будет понятно, в какой временной период трафик просел или взлетел:
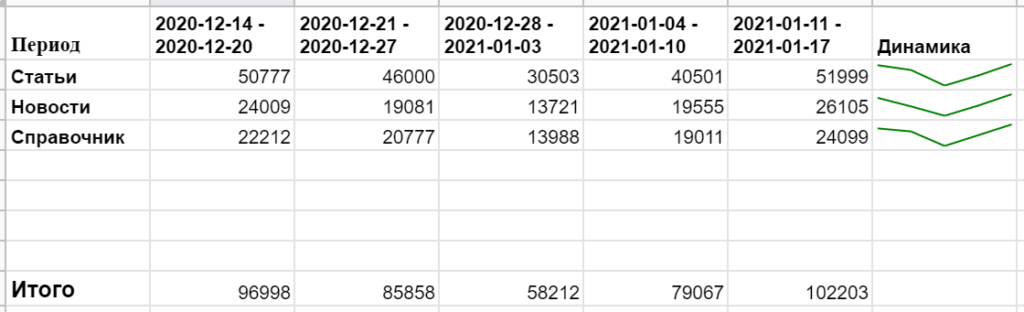
Чтобы функция создала транспонированную таблицу, необходимые для этого ячейки должны быть свободны от значений — иначе будет ошибка.
Конечно, есть и альтернативное решение без использования этой функции: скопировать нужный диапазон, кликнуть правой кнопкой мыши и выбрать «Специальная вставка → Вставить с изменением положения строк и столбцов».
IFS (множественное IF)
IFS (русскоязычного аналога нет) — расширенная версия функции ЕСЛИ (IF), которая позволяет оценивать сразу несколько условий. Возвращает то значение, которое соответствует первому истинному условию (TRUE). То есть сначала проверяет первое условие (слева), если оно истинно — отправляет первое значение, если ложно — идет дальше вправо. Синтаксис: =IFS(условие1; значение1; условие2; значение2; …) Если все условия ложные, вернёт #Н/Д!
Допустим, вы выгрузили (из системы аналитики или CMS) список URL с какими-то дополнительными данными: названиями, датами публикаций, количеством визитов, продажами и т. д. Например, такой:
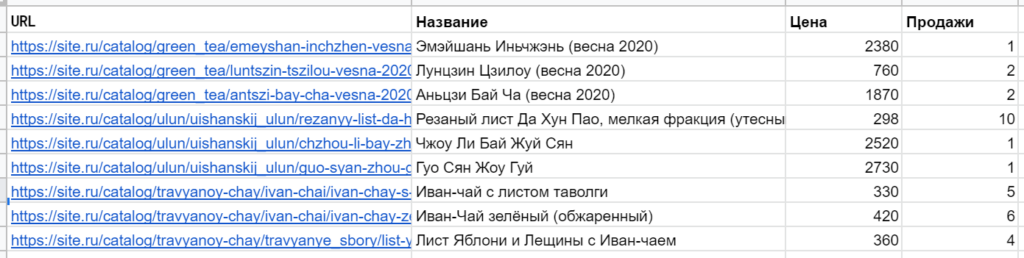
И для удобства работы и отчетности хотите создать дополнительный столбец, где будут просто и понятно указаны категории (типы), извлеченные из адресов страниц. Чтобы легко можно было отсортировать или отфильтровать таблицу, посчитать сумму показателей по конкретной категории и т. п.
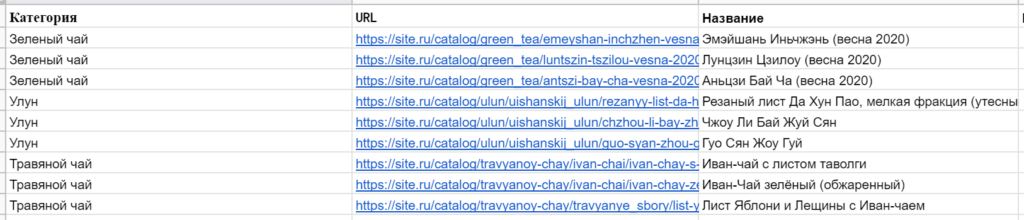
Есть разные варианты решений. Например, правее можно прописать и протянуть функцию =SPLIT(B2;»/») — она разложит URL на составляющие. Далее достаточно посмотреть, в какой ячейке лежит нужная часть адреса, и составить формулу вида: =IFS(I5=»green_tea»;»Зеленый чай»;I5=»ulun»;»Улун»;I2=»travyanoy-chay»;»Травяной чай») Недостаток такого подхода — множество лишних «технических» ячеек, они могут мешать, их придется скрывать.
Другой способ — вложить в IFS несколько других функций: НЕ (NOT), ЕОШИБКА (ISERROR), НАЙТИ (FIND). Тогда формула примет более сложный вид, но зато не нужны будут никакие дополнительные ячейки: =IFS(NOT(ISERROR(FIND(«/green_tea/»;B2)));»Зеленый чай»;NOT(ISERROR(FIND(«/ulun/»;B2)));»Улун»;NOT(ISERROR(FIND(«/travyanoy-chay/»;B2)));»Травяной чай»)
Почему такая сложная конструкция? Дело в том, что FIND возвращает #Н/Д, если не находит запрос в тексте, а это прерывает проверку всех условий в IFS. Поэтому приходится использовать ISERROR, что возвращает TRUE, если функция FIND выдает ошибку. Но TRUE опять прервет выполнение IFS — ведь условие должно наоборот быть ложным, чтобы начать проверять следующее условие. Поэтому приходится усложнять и добавлять NOT, которая поменяет TRUE на FALSE.
Есть и другой вариант реализации — через регулярные выражения и соответствующие функции Google Таблиц.
REGEXMATCH, REGEXEXTRACT, REGEXREPLACE
Эти три функции Google Таблиц предназначены для работы с регулярными выражениями (специальный язык для работы со строками и символами). REGEXMATCH ищет соответствия, REGEXEXTRACT извлекает нужный фрагмент, а REGEXREPLACE заменяет одну часть текста на другую. Синтаксис похожий: первый аргумент — текст, а второй — само регулярное выражение; в REGEXREPLACE есть еще третий — текст, который нужно вставить.
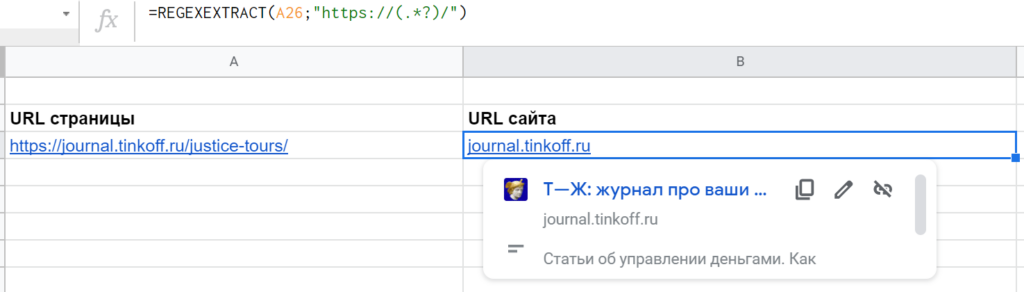
Допустим, нужно из URL конкретной страницы извлечь название сайта. Для этой цели можно использовать такой вариант: =REGEXEXTRACT(C23;»https://(.*?)/») Функция возьмет все символы, что находятся между «https://» и следующим слешем, включая дефисы и точки. Поэтому нормально будут экстрагироваться и домены второго уровня:
С помощью REGEX можно также решить задачу с категориями из предыдущего раздела про IFS. Тогда получится так: =IFS(REGEXEXTRACT(C2;»/catalog/([^/]+)»)=»travyanoy-chay»;»Травяной чай»;REGEXEXTRACT(C2;»/catalog/([^/]+)»)=»ulun»;»Улун»;REGEXEXTRACT(C2;»/catalog/([^/]+)»)=»green_tea»;»Зеленый чай»)
Почему такой вариант, и как он работает? «/catalog/» — общая часть у всех URL, поэтому можно смело начинать поиск совпадений с нее. Далее нужно взять все символы, что находятся между «/catalog/» и следующим слешем. Конструкция ([^/]+) как раз за это отвечает. Получается, функция ищет любое число любых символов, кроме слеша, на котором она и остановится. ‘^’ здесь используется как оператор отрицания, ‘+’ задаёт 1 или более повторений символов, а круглые скобки — что нужно брать только эту группу, не включая остальные части текста.
Читайте также: 15 сервисов для проверки текста
ARRAYFORMULA
ARRAYFORMULA (русскоязычного названия нет) — функция для работы с массивами. В качестве параметра принимает формулу массива или другую функцию.
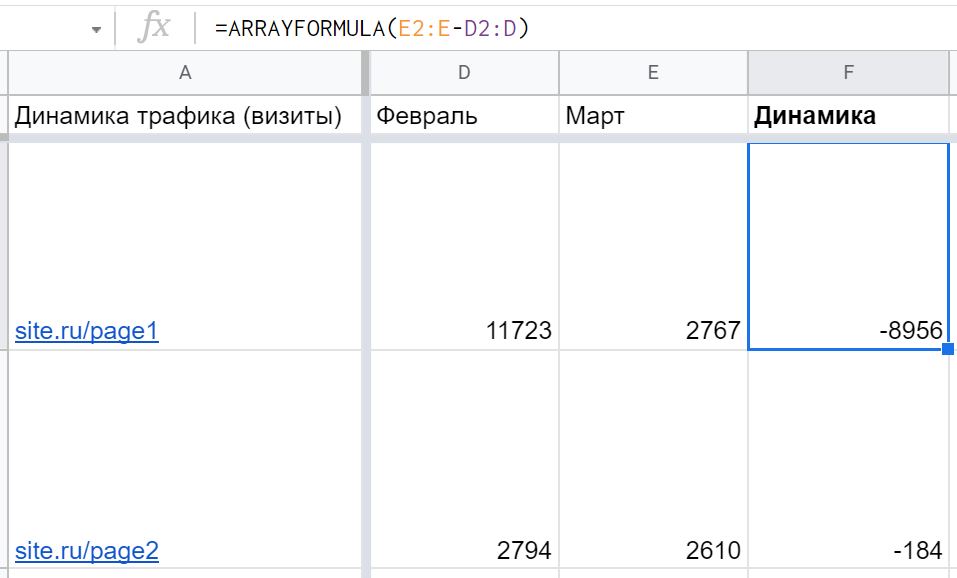
Допустим, справа от основной таблицы нужно создать столбец с каким-то вычисляемым показателем, например, чтобы тот считал разницу между другими. Конечно, это можно сделать через обычное протягивание формулы, но если таблица постоянно пополняется новыми строками — придется постоянно протягивать ее вручную все ниже и ниже. ARRAYFORMULA же позволяет автоматизировать процесс: за счет вычитания одного массива с открытым диапазоном из другого:
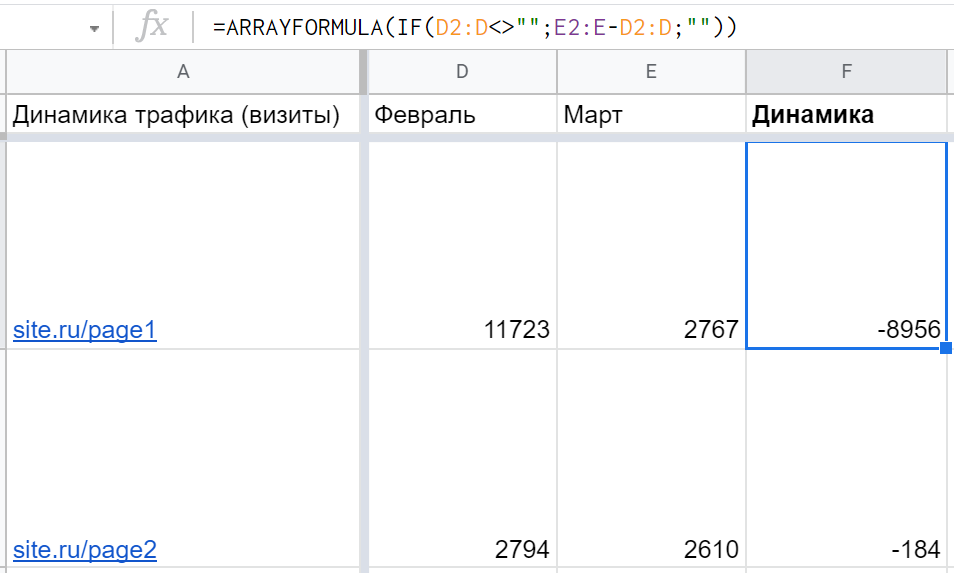
Единственное, что в данном случае формула будет заполнять ячейки до самого конца таблицы — а лишние нули это не очень красиво. Решение — дополнительно использовать IF: =ARRAYFORMULA(IF(D2:D<>»»;E2:E-D2:D;»»)) которое сообщает следующее: если в ячейке D пусто, то и вычитание не нужно, оставить ячейку пустой.
Аналогичным способом ARRAYFORMULA можно использовать вместе с ВПР(VLOOKUP), к примеру: =ARRAYFORMULA(IFERROR(VLOOKUP(A2:A;feb!$A:$D;2;0);»»)) Только здесь от лишних #N/A до конца таблицы спасает функция ЕСЛИОШИБКА (IFERROR).
Увлечение ARRAYFORMULA (особенно если еще в большом количестве используются такие функции, как VLOOKUP, MATCH, INDEX, QUERY) может существенно замедлять работу Google Таблицы. Ускориться помогает удаление лишних строк (по умолчанию их 1 000, сотни могут совсем не использоваться и только зря обрабатываться функцией ARRAYFORMULA).
SORTN
SORTN — расширенная версия функции SORT, которая может не только сортировать данные по нескольким столбцам, но и ограничивать количество возвращаемых результатов. Параметры:
- Диапазон для сортировки и вывода. (Впрочем, столбцы, по которому данные сортируются, можно не включать в этот диапазон, указать их отдельно в четвертом параметре.)
- Количество возвращаемых элементов. (Можно сделать топ-3, топ-5 и т. д.)
- Режим показа совпадений. (По умолчанию ноль. Единица, например, будет выводить дополнительные строки, — больше, чем указано во втором параметре — если в столбце для сортировки найдутся повторяющиеся значения.)
- Столбец для сортировки. (Может быть вне диапазона, указанного в первом параметре.)
- Способ сортировки столбца. ИСТИНА (TRUE) сортирует данные по возрастанию (от меньшего к большему), а ЛОЖЬ (FALSE) – по убыванию (от большего к меньшему).
(Если нужно, дальше можно также задать дополнительные столбцы и варианты сортировки.)
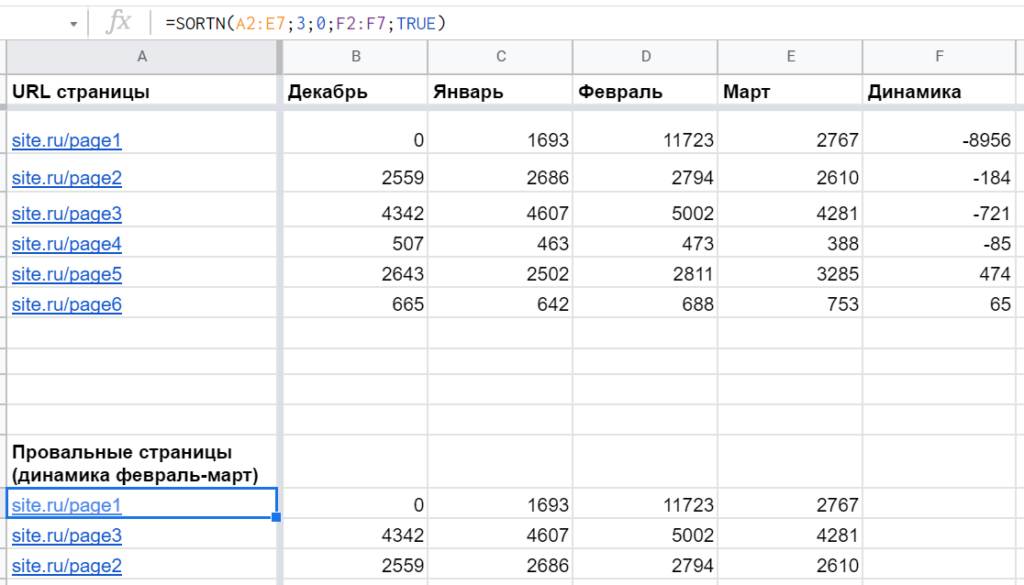
Допустим, есть таблица с показателями трафика за несколько месяцев. И нужно подготовить топ лучших или худших страниц по динамике за последние два. Для этого как раз хорошо подходит функция SORTN.
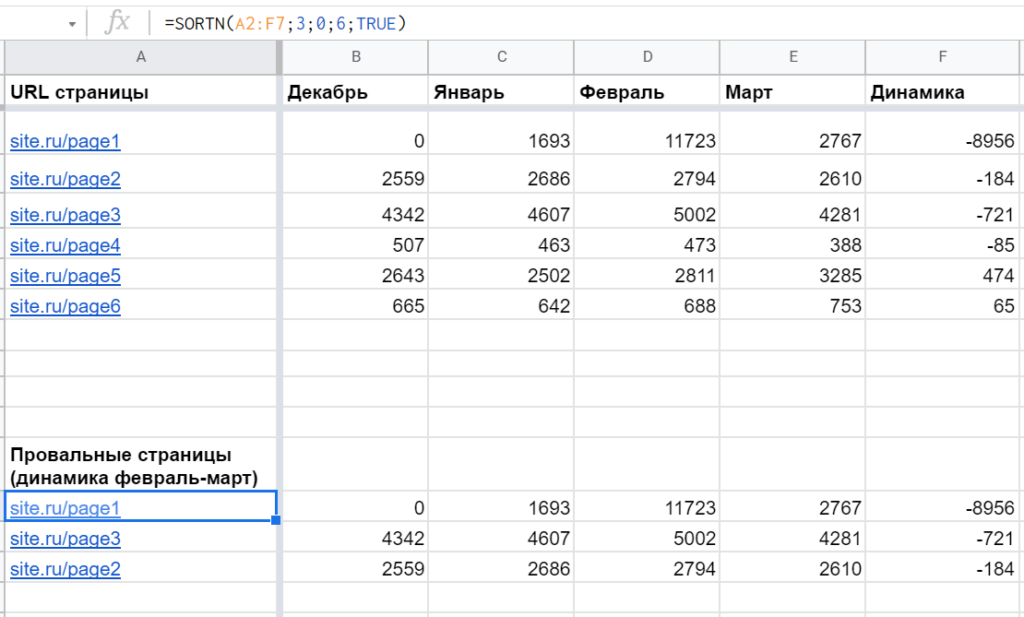
Пример: =SORTN(A2:F7;3;0;6;TRUE), которая выводит данные из A2:F7, но только первые три строки, отсортированные по шестому столбцу (F) по возрастанию:
Если столбец для сортировки не входит в первый диапазон, нужно передать его четвертым параметром (главное условие — такое же количество элементов, как у первого). Пример: =SORTN(A2:E7;3;0;F2:F7;TRUE)
Читайте также: Где в интернет-маркетинге можно автоматизировать, а где — только ручками (пока)
FILTER
FILTER (опять без русского аналога) — мощная функция Google Таблиц, которая выводит только те строки и столбцы, которые соответствуют заданным условиям. Первым аргументом принимает диапазон, вторым и последующими — условия для фильтрации.
Допустим, есть стандартный отчет по поисковым фразам и поведению пользователей, которые пришли по ним на сайт. (Первый столбец — сами запросы, второй — визиты, дальше отказы, глубина просмотра и время на сайте, в конце — достижения любой цели.) И нужно узнать наиболее приоритетные ключи для продвижения. Например, выбрать те, что дали больше 50 визитов и больше 50 конверсий за отчетный период.
Здесь подойдет такой вариант: =FILTER(‘Запросы’!A2:G;’Запросы’!B2:B>50;’Запросы’!G2:G>50), где мы сначала указываем диапазон данных для фильтрации и вывода, затем условия — во-первых, значения в столбце B должны быть больше 50, во-вторых, значения в столбце G тоже должны быть больше 50.
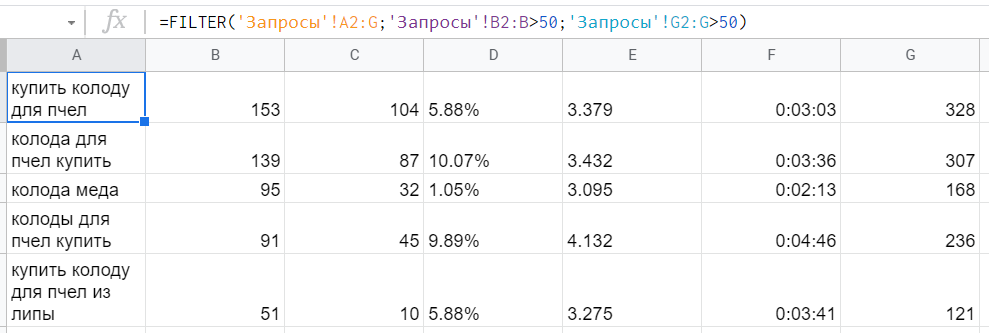
Столбцы или строки, по которым фильтруются данные, не обязаны входить в первый диапазон. Например, нет смысла в столбце, где все значения будут повторяться — а так и будет, если FILTER отбирает данные по какой-то одной единственной категории. Если в этом примере формулы поменять Запросы!A2:G на Запросы!A2:A, ничего не сломается — просто будет выводиться только первый столбец.
Теперь другой, более сложный пример использования FILTER. Допустим, вы сделали копию прайс-листа поставщика, потому что так с данными удобнее работать, но нужно периодически проверять оригинальную таблицу — что нового там появилось и стоит ли обновить свою. И нужно проверять не все позиции, а самые приоритетные и прибыльные. Это можно осуществить, сочетая FILTER с IMPORTRANGE, MATCH и ISERROR. Например, так:
=FILTER(IMPORTRANGE(«1znX3hxN9cKEvZyh_0XOj7gHpjYze8p-40cZchiDvTxY»;»Каталог!A2:E»);IMPORTRANGE(«1znX3hxN9cKEvZyh_0XOj7gHpjYze8p-40cZchiDvTxY»;»Каталог!A2:A»)=1;(ISERROR(MATCH(IMPORTRANGE(«1znX3hxN9cKEvZyh_0XOj7gHpjYze8p-40cZchiDvTxY»;»Каталог!B2:B»);B3:B7;0))))
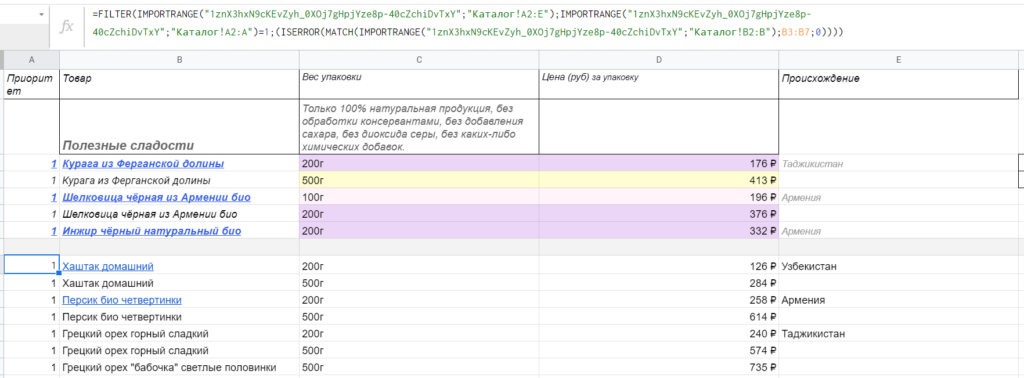
Что здесь происходит? Первый параметр — диапазон внешней таблицы A2:E, взятый с листа «Каталог». Второй — условие: значение в столбце A должно быть равно 1 (самые приоритетные позиции). Третий — подробнее:
- IMPORTRANGE подгружает столбец B из листа «Каталог».
- MATCH ищет совпадения между импортируемыми и имеющимися данными (между названиями товаров в скопированном и оригинальном прайс-листах).
- ISERROR вернет FALSE, когда MATCH найдет совпадения, и, соответственно, вернет TRUE, если таких совпадений не будет.
Получается, FILTER выдаст только те позиции с приоритетом №1, которые есть во внешнем документе, но которых нет в этой таблице.
Еще несколько моментов:
- FILTER фильтрует или строки, или столбцы. Чтобы фильтровать их одновременно, можно вложить одну функцию в другую — то есть одна FILTER будет обрабатывать выходные данные из другой FILTER.
- Не очень удобно постоянно копировать и вставлять заголовки из одной таблицы в другую. Но благодаря массиву можно подгружать их автоматически и в правильном порядке. Немного усовершенствованный предыдущий пример: ={‘Запросы’!A1:G1;FILTER(‘Запросы’!A2:G;’Запросы’!B2:B>50;’Запросы’!G2:G>50)}
БДСУММ(DSUM), БСЧЁТА(DCOUNTA), БИЗВЛЕЧЬ(DGET), ДСРЗНАЧ (DAVERAGE)…
Функции БД — серьезные инструменты, когда нужно работать с большим количеством данных и условий, — и стандартные FILTER, СУММЕСЛИ, СРЗНАЧЕСЛИ, ВПР и другие не справляются или не очень удобны в использовании.
К примеру, есть подробная база публикаций в соцсетях с указанием тематик и типов контента, названиями и датами, количеством лайков, комментариев и шеров. И интересно узнать, какая в среднем вовлеченность у постов с видео по сравнению с более текстовыми форматами.
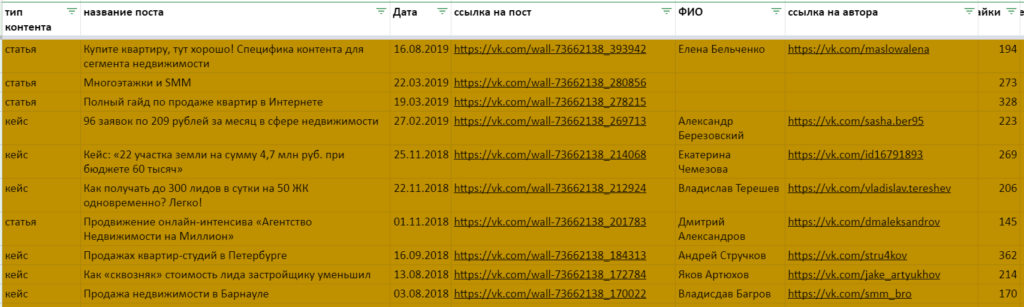
Здесь лучше всего подойдет ДСРЗНАЧ (DAVERAGE). Синтаксис у этой и остальных Д-функций похожий:
- Массив или диапазон данных — в общем, таблица, с которой нужно работать. (Первая строка обязательно должна содержать заголовки столбцов!)
- Столбец, в котором находятся нужные данные. (Можно передать номер столбца, адрес ячейки или даже просто название столбца текстом в кавычках.)
- Критерии, условия для фильтрации — можно передать их как массивом, так и диапазоном. (Важно: первый элемент должен соответствовать заголовку столбца с искомыми данными, что указан во втором параметре.)
Для начала на отдельном листе нужно подготовить критерии — список типов контента, по которым нужно рассчитать показатели. Затем уже использовать, немного модифицируя, такую формулу: =DAVERAGE(Book!A4:J;8;B1:B13). Она считает среднее арифметическое по всем значениям из столбца №8 диапазона Book!A4:J, которые соответствуют данным из диапазона B1:B13. (Напоминаем: в обоих диапазонах первыми строками идут заголовки. А вместо номера столбца — 8 — можно сослаться на ячейку его заголовка — Book!H4 — или просто передать название текстом — «лайки»).
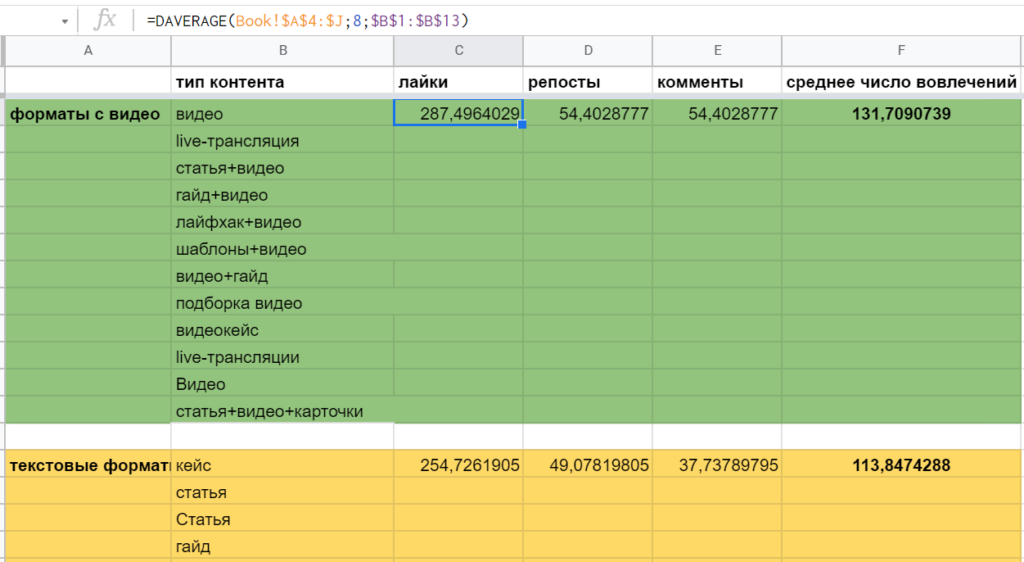
Репосты и комментарии считаются аналогично, меняется только номер столбца (8→9→10). Ну а среднее число вовлечений легко получить через обычный =AVERAGE (C2:E2).
Показатели для текстовых типов контента можно получить точно так же, единственное — нужно будет снова передавать название заголовка. Писать его ниже необязательно, можно просто добавить через массив: =DAVERAGE(Book!$A$4:$J;8;{«тип контента»;$B$15:$B$38})
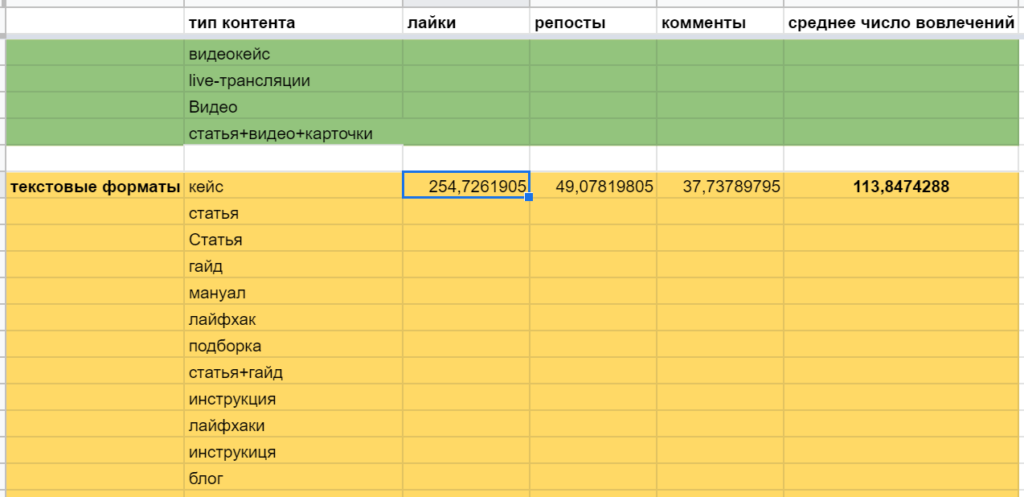
Другие функции баз данных работают аналогично, разница в функциональности: так, БСЧЁТА — считает количество числовых и текстовых значений, БДСУММ — соответственно, сумму, БДПРОИЗВЕД — произведение, БИЗВЛЕЧЬ(DGET) — извлекает нужные данные из таблицы.
Важные моменты:
- Не забывать про заголовки в столбцах/массивах — именно они являются «мостиком» между данными и позволяют находить и считать нужное.
- Нет ограничений по количеству столбцов — можно задать несколько условий для фильтрации (например, не только типы контента, но и тематики). Главное — правильно написать заголовки.
- Не использовать открытый диапазон в критериях — Д-функции не будут игнорировать пустые ячейки, будут искать по ним тоже, что драматично исказит результаты.
- В БСЧЁТ и БСЧЁТА можно указать любой столбец — ведь эти функции считают общее количество, а не производят математические операции с конкретными цифрами.
Читайте также: 10 функциональных сервисов для анализа социальных сетей
QUERY
Если FILTER — просто мощная функция, то QUERY — мощнейшая. Она выполняет запросы на языке аналогичном SQL, позволяет строить самые разные отчеты и сводные таблицы, в том числе интерактивные дашборды. Вообще по QUERY стоит писать отдельный большой гайд, поэтому тут рассмотрим лишь часть возможностей.
Синтаксис:
- Диапазон ячеек, собственно, база данных. (Можно импортировать из другой таблицы через IMPORTRANGE.)
- Запрос, записанный на языке API визуализации Google (аналог SQL). Передается в текстовом формате — можно написать в кавычках внутри функции или взять из ячейки.
- Заголовки — количество строк в верхней части раздела данных, необязательный параметр. (Заголовки можно присоединять и через массив).
QUERY очень чувствительна к синтаксису и порядку написания кляуз — так называют отдельные части запроса, которые отделяются между собой пробелами:
1. SELECT — указывает нужные столбцы и их порядок. Например, » SELECT A, B, D « Здесь сразу же можно создать пользовательский столбец, допустим: » SELECT A, B, C, H+I+J « Если же нужно просто вывести все столбцы, какие есть в исходном диапазоне, достаточно прописать » SELECT * « (Нюанс: если QUERY обрабатывает массив или импортируемый диапазон, нужно в SELECT указывать номер столбца (Col1), а не название (A).)

2. WHERE — задает условия для фильтрации данных. Можно написать » WHERE B > 50 AND D < 0 «, чтобы отсечь строки, где B < 50 и D > 0. Другой пример: » WHERE F IS NOT NULL OR G IS NULL «, который говорит: «Взять данные, где в столбце F есть какое-то значение или, наоборот, G — пустой». Для сравнения текстовых строк есть свои операторы: например, matches ищет соответствия регулярному выражению, contains — содержание в любом месте строки, starts with — в начале… Пример: » WHERE A=’Маркетинг’ AND B starts with ‘Статья’ « (Строки внутри запроса QUERY передаются в одинарных кавычках.)

3. GROUP BY — условия для группировки данных по строкам. Работает, только когда в SELECT есть агрегирующие функции: sum (считает сумму), avg (рассчитывает среднее), min (находит минимальное значение), max (выдает максимальное значение), count (подсчитывает количество). Допустим: » SELECT A, B, C, avg(H) GROUP BY B, C, A « (Каждый столбец, указанный в SELECT без агрегирующей функции, должен быть указан и в GROUP BY.)
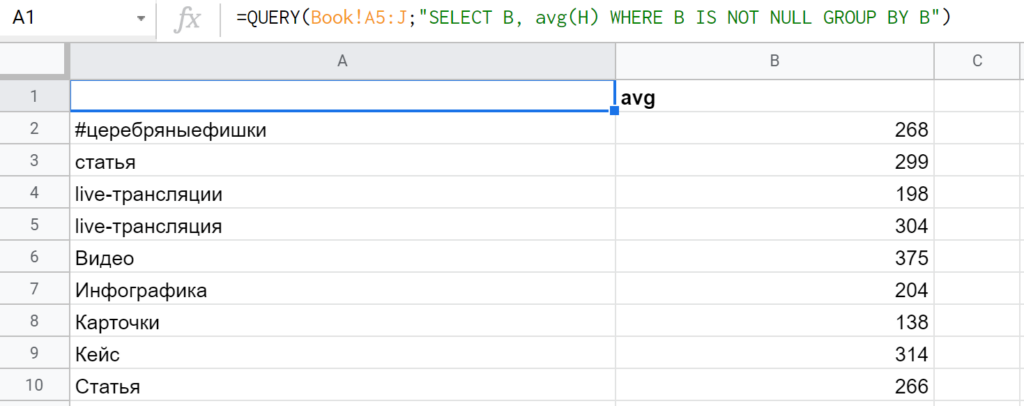
4. PIVOT — работает аналогично GROUP BY, только группирует данные по столбцам, например: » SELECT B, AVG(H) GROUP BY B PIVOT A « (Кстати, помимо агрегирующих, QUERY поддерживает и скалярные функции. Например, day возвращает номер дня из даты, now выдает текущую дату и время, а lower — приводит строку к нижнему регистру.)
5. ORDER BY — отвечает за сортировку результатов. В запросе достаточно перечислить поля и способ сортировки (по умолчанию ASC, то есть по возрастанию, если указать DESC — функция будет сортировать по убыванию.) Пример: » SELECT C, H ORDER BY H DESC «
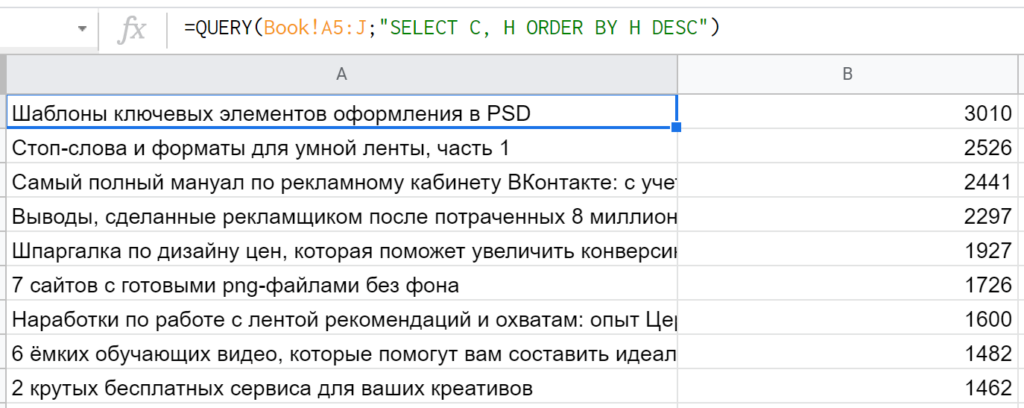
6. LIMIT — ограничивает количество возвращаемых строк. Так » SELECT * LIMIT 10 « вернет только первые 10 строк, других условий здесь нет. Это удобная кляуза для формирования всяческих топов, аутсайдеров, замены вышеупомянутой SORTN.
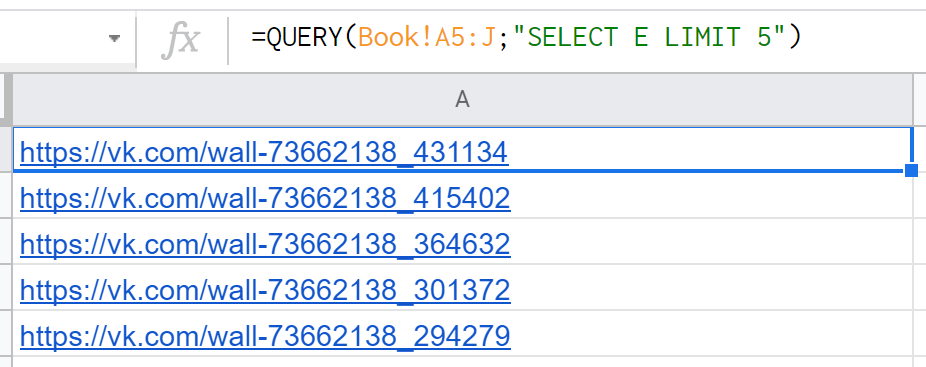
7. OFFSET — действует аналогично, только, наоборот, пропускает N-ое количество первых строк. Соответственно » SELECT * OFFSET 10 « будет возвращать все строки, начиная с 11 от начала диапазона.
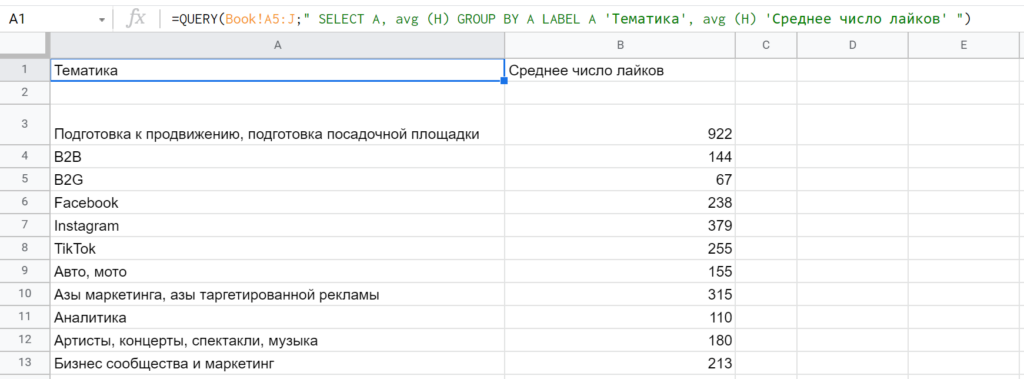
8. LABEL устанавливает подписи для столбцов. В запросе нужно сначала указать столбец или функцию, затем в одинарных кавычках — новое название. Если меток несколько, они перечисляются через запятую, как и другие параметры кляуз. Например: » SELECT A, avg (H) GROUP BY A LABEL A ‘Тематика’, avg (H) ‘Среднее число лайков’ «
9. FORMAT задает правила форматирования для ячеек в одном или нескольких столбцах. Синтаксис как у LABEL, но в кавычках нужно передавать специальные коды. Так » SELECT A, H FORMAT H ‘ #,## ‘ » будет выводить числа с разделителями разрядов. (Нужные коды можно узнать в разделе «Формат → Числа → Другие форматы«.)

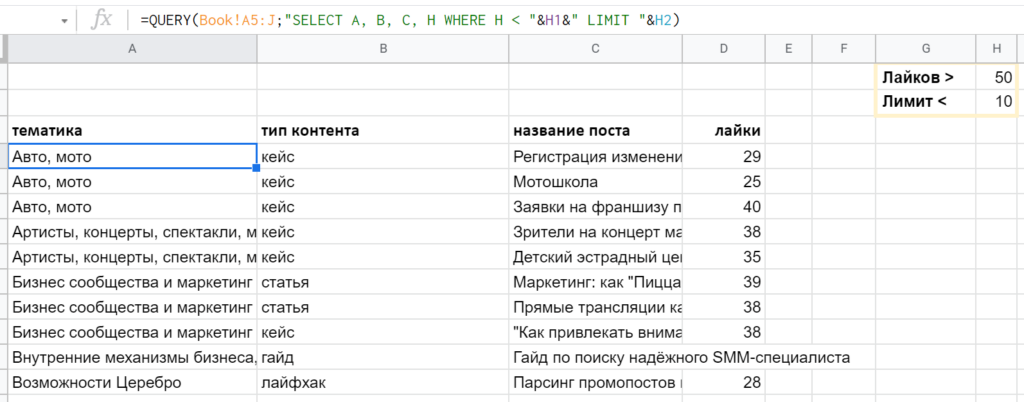
Особая прелесть QUERY в том, что запрос целиком — и его отдельные параметры — можно не указывать прямо в функции, а брать из ячеек. Для соединения строк между собой достаточно обычной конкатенации через ‘&’. Пример: » SELECT A, B, C, H WHERE H < «&H1&» LIMIT «&H2 — параметры для WHERE и LIMIT будут взяты из ячеек H1 и H2 соответственно.
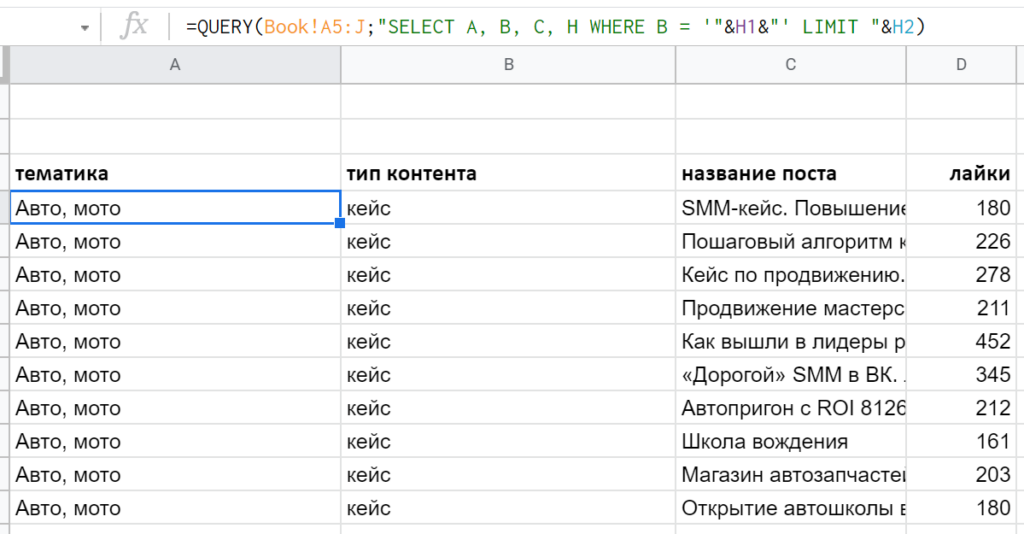
Если будете брать из ячеек текстовые значения, надо помнить про одинарные кавычки. Пример такого варианта: » SELECT A, B, C, H WHERE B = ‘ «&H1&» ‘ LIMIT «&H2
Подытожим
Google Таблицы — интересный и многофункциональный инструмент, который может решать самые разные задачи по многим направлениям: финансовому планированию, SEO, HR, SMM, веб-аналитике и т. д. и т. п. Но чтобы эффективно использовать любой, даже самый мощный сервис, нужно хорошо понимать — зачем и что именно нужно делать, какие данные брать и обрабатывать, как использовать результаты.
Обучающий центр CyberMarketing поможет освоить с нуля и дальше развиваться по всем основным тематикам интернет-маркетинга: созданию сайтов, контекстной рекламе, продвижению в соцсетях и др. У нас только полезный и качественный контент — статьи, вебинары, курсы для владельцев бизнеса, руководителей и специалистов.
If any of the queries in an array formula do not have actual data to query in the range they are hitting they return #VALUE! and mousing over the array formula reveals an error. If I take those queries and wrap them in an IFERROR I get the same results.
If I take what I wrapped in an IFERROR and split it out into its own cell to validate the query it results in displaying the error clause which in this case is a 0.
Here is a link to an example sheet.
Sheet1 has sample data.
Sheet2 is intentionally blank to simulate the issue described above.
Sheet3 has three queries on it in various states. The top two are the array formulas I am attempting to work with. The bottom Query is the IFERROR split out into its own cell to show that the query does in fact work when separated from the rest of the sort(arrayformula(etc)).
![]()
asked Feb 17, 2015 at 21:06
![]()
Try combining both ranges (from both sheets) inside 1 query instead of using 2 queries, and wrap an IFERROR() around that single query:
=ARRAYFORMULA(IFERROR(QUERY({Sheet1!A1:I500; sheet2!A1:I500}, "Select * where Col7='no'", 0), 0))
See if that works for you ?
answered Apr 23, 2015 at 7:44
![]()
JPVJPV
26.3k4 gold badges32 silver badges48 bronze badges
9
Google Docs Editors Help
Sign in
Google Help
- Help Center
- Community
- Google Docs Editors
- Privacy Policy
- Terms of Service
- Submit feedback
Send feedback on…
This help content & information
General Help Center experience
- Help Center
- Community
Google Docs Editors