
|
Максим Коллегин |
|
|
Статус: Сотрудник Группы: Администраторы Сказал «Спасибо»: 21 раз |
Автор: A__l__e__x x86 (то есть 32-разрядная версия) в windows 11 64-разрядной версии работать будет? Будет. |
|
Знания в базе знаний, поддержка в техподдержке |
|
|
|
WWW |
|
|
A__l__e__x
оставлено 18.05.2022(UTC) |


 1 пользователь поблагодарил Максим Коллегин за этот пост.
1 пользователь поблагодарил Максим Коллегин за этот пост.|
A__l__e__x |
|
|
Статус: Активный участник Группы: Участники Сказал(а) «Спасибо»: 7 раз |
Автор: Максим Коллегин Автор: A__l__e__x x86 (то есть 32-разрядная версия) в windows 11 64-разрядной версии работать будет? Будет. отлично, спасибо |
|
|
|

|
kdesys |
|
|
Статус: Новичок Группы: Участники
|
Я использую 1С в облаке, в частности 1cbiz.ru. |
|
|
|
|
Максим Коллегин |
|
|
Статус: Сотрудник Группы: Администраторы Сказал «Спасибо»: 21 раз |
Перехваты пока поддерживаются только для x86, попробуйте установить такой дистрибутив приложения для отчетности. |
|
Знания в базе знаний, поддержка в техподдержке |
|
|
|
WWW |
|
kdesys |
|
|
Статус: Новичок Группы: Участники
|
Автор: Максим Коллегин Перехваты пока поддерживаются только для x86, попробуйте установить такой дистрибутив приложения для отчетности. Я бы и рад, но у меня нет выбора какую версию ставить. Так как всё, что происходит, происходит онлайн. Есть ли какое-то решение проблемы или нужно ждать версию с «перехватами для x64»? |
|
|
|
|
Максим Коллегин |
|
|
Статус: Сотрудник Группы: Администраторы Сказал «Спасибо»: 21 раз |
Поддержка перехватов в x64 требует исследований. А службу xtacache точно выключили? |
|
Знания в базе знаний, поддержка в техподдержке |
|
|
|
WWW |
|
kdesys |
|
|
Статус: Новичок Группы: Участники
|
Автор: Максим Коллегин Поддержка перехватов в x64 требует исследований. А службу xtacache точно выключили? Нет, не выключал. |
|
|
|
|
kdesys |
|
|
Статус: Новичок Группы: Участники
|
Автор: kdesys Автор: Максим Коллегин Поддержка перехватов в x64 требует исследований. А службу xtacache точно выключили? Нет, не выключал. С отключенной службой заработало, спасибо. |
|
|
|
|
Максим Коллегин |
|
|
Статус: Сотрудник Группы: Администраторы Сказал «Спасибо»: 21 раз |
Спасибо, сделал. Отредактировано пользователем 21 мая 2022 г. 9:22:20(UTC) |
|
Знания в базе знаний, поддержка в техподдержке |
|
|
|
WWW |
|
Jumuro |
|
|
Статус: Новичок Группы: Участники Сказал(а) «Спасибо»: 1 раз |
Здравствуйте, коллеги! Уже в который раз пытаюсь заставить работать следующую связку: В самой оснастке криптопро всо ок — шифруется и расшифровывается без проблем. Цитата: Язык описания абстрактного синтаксиса данных. Базовый код ошибки кодирования сертификата. 1С:Предприятие 8.3 (8.3.20.1838) (пробовал и x86 и x64) Отредактировано пользователем 6 июня 2022 г. 19:47:33(UTC) |
|
|
|
| Пользователи, просматривающие эту тему |
|
Guest (2) |
Быстрый переход
Вы не можете создавать новые темы в этом форуме.
Вы не можете отвечать в этом форуме.
Вы не можете удалять Ваши сообщения в этом форуме.
Вы не можете редактировать Ваши сообщения в этом форуме.
Вы не можете создавать опросы в этом форуме.
Вы не можете голосовать в этом форуме.
6.2.2 Компоненты инфраструктуры открытых ключей (PKI)
Перед тем как мы подробно коснемся отдельных, предлагаемых PKI служб, в этом разделе мы дадим описание компонентов PKI.
Первоначально «PKI» было общим термином, который просто обозначал набор служб, использующих криптографию на основе открытых ключей. В наши дни «PKI» больше ассоциируется с предоставляемыми инфраструктурой открытых ключей службами либо в виде приложений, либо в виде протоколов. Некоторыми примерами таких служб являются:
- протокол безопасных соединений SSL (Secure Socket Layer);
- безопасный протокол передачи электронной почты S/MIME (Secure Multimedia Internet Mail Extension);
- протокол IPSec (IP Security);
- протокол защищенных электронных транзакций SET (Secure Electronic Transactions);
- программа шифрования PGP (Pretty Good Privacy).
Давайте рассмотрим, что необходимо для обеспечения этих служб, а также те компоненты, которые требуются современной инфраструктуре открытых ключей.
Основные компоненты инфраструктуры открытых ключей (PKI), как показано на рис. 6.17, включают:
- конечные объекты [ End Entity (EE) ];
- центр сертификации [ Certificate Authority (CA) ];
- репозиторий сертификатов [ Certificate Repository (CR) ];
- центр регистрации [ Registration Authority (RA) ];
- цифровые сертификаты [ Digital Certificates (X.509 V3) ];
Далее следуют подробные определения этих компонентов.
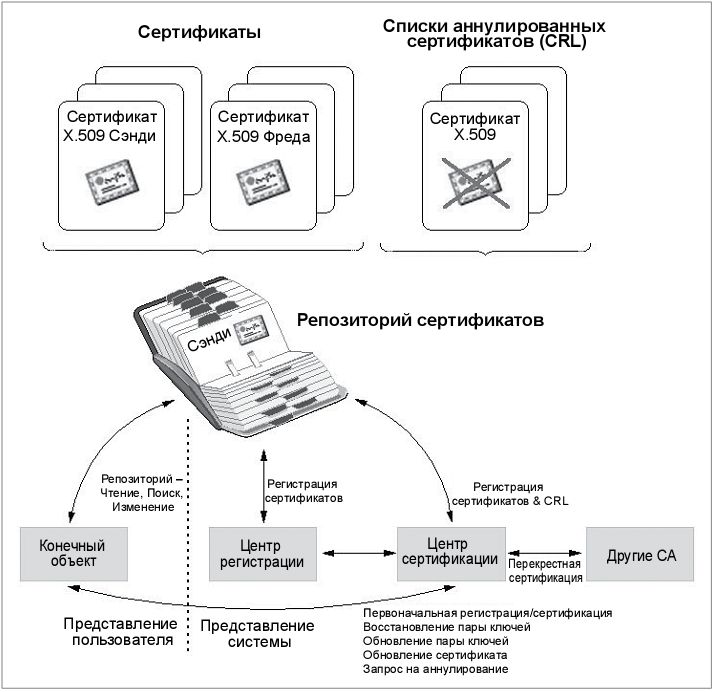
Рис.
6.17.
Компоненты PKI
Конечный объект [End-Entity (EE)]
Конечный объект лучше всего определить как пользователя сертификатов PKI либо как систему конечного пользователя, которые являются субъектами сертификатов. Другими словами, в системе PKI конечный объект является общим термином для определения субъекта, который использует некоторые службы или функции системы PKI. Это может быть владелец сертификата (к примеру, человек, организация или какой-либо другой объект) или сторона, запрашивающая сертификат или список аннулированных сертификатов (к примеру, приложение).
Центр сертификации [Certificate Authority (CA)]
Центр сертификации [ Certificate Authority (CA) ] по существу, является подписчиком сертификатов. Центр сертификации, зачастую совместно с центром регистрации (описанным далее), имеет своей обязанностью обеспечивать надлежащую идентификацию сертификата конечного объекта ( ЕЕ ). Логический домен, в котором СА выпускает сертификаты и управляет ими, называется доменом безопасности (security domain), который может быть реализован для защиты множества различных групп разных размеров, начиная от одного контрольного пользователя вплоть до департамента и далее до уровня всей организации. Основные проводимые СА операции включают: выпуск сертификатов, обновление сертификатов и аннулирование сертификатов.
Выпуск сертификатов
СА создает цифровой сертификат путем подписывания его цифровой подписью. По существу пара открытого и секретного ключей генерируется запрашивающим клиентом ( ЕЕ ). После этого клиент передает СА на рассмотрение запрос на выпуск сертификата.
Запрос на выпуск сертификата содержит по меньшей мере открытый ключ клиента и некоторую другую информацию, такую, как имя клиента, адрес электронной почты, почтовый адрес или другую относящуюся к делу информацию. Когда установлен центр регистрации ( RA ), СА делегирует ему процесс верификации клиента и другие функции управления. После подтверждения запроса клиента СА создает цифровой сертификат и подписывает его.
В качестве альтернативы СА может генерировать пару ключей клиента, а впоследствии и подписанный сертификат для этого клиента. Однако этот процесс выполняется достаточно редко, так как секретный ключ необходимо пересылать от СА к клиенту, что может стать слабым местом. Как правило, более безопасным представляется случай, когда клиенты генерируют свои собственные пары ключей, при этом секретные ключи никогда не покидают своей зоны полномочий.
В целях обеспечения правильной работы инфраструктуры открытых ключей основным предположением является то, что любая сторона, которая желает проверить сертификат, должна доверять СА, который произвел его цифровую подпись. В инфраструктуре открытых ключей «А доверяет Б» означает, что «А доверяет центру сертификации, который подписал сертификат Б». Соответственно, в общих чертах, «А доверяет центру сертификации» означает, что «А» имеет локальную копию сертификата этого центра сертификации.
К примеру, при установке безопасного HTTP-соединения посредством SSL основные Web-браузеры имеют список сертификатов нескольких, заслуживающих доверия СА (обычно упоминаемых как Trusted Roots или Trusted CAs), уже зарегистрированных при добавлении и таких, как (но необязательно только их) VeriSign, Entrust, Thawte, Baltimore, IBM World Registry и т. д. Если Web-сервер использует сертификат, который подписан подобным доверенным CA, браузеры будут полностью доверять серверу, за исключением тех случаев, когда пользователь умышленно удаляет сертификат CA-подписчика из списка доверенных СА.
СА способен выпускать определенное количество различных типов сертификатов, таких, как:
- Сертификаты пользователей. Они могут выпускаться для обыкновенного пользователя или для объекта другого типа, такого, как сервер или приложение. После получения сертификата пользователя эти конечные объекты станут доверенными для СА. Если частью инфраструктуры является центр регистрации RA, то он также должен иметь этот сертификат. Сертификат пользователя может быть ограничен до специфических случаев применения и целей (таких, как безопасная электронная почта, безопасный доступ к серверам и т. д.).
- Сертификаты центров сертификации ( СА ). Когда СА выпускает сертификат для самого себя, такой сертификат называется самоподписанным сертификатом или корневым сертификатом для этого СА. Если СА выпускает сертификат для подчиненного СА, то этот сертификат также называется сертификатом СА.
- Перекрестные сертификаты. Они используются для перекрестной сертификации, которая представляет собой процесс аутентификации между доменами безопасности.
Обновление сертификатов
Каждый сертификат имеет период достоверности и связанной с ним датой истечения срока действия. Когда срок действия сертификата истекает, то может быть инициирован процесс его обновления, после одобрения которого для конечного объекта будет выпущен новый сертификат.
Аннулирование сертификатов
Максимальный срок службы сертификата ограничен датой истечения его срока действия. Однако в некоторых случаях возникает необходимость аннулировать сертификаты до наступления этой даты. Когда это случается, CA включает сертификат в список аннулированных сертификатов [Certificate Revocation List ( CRL )]. На самом деле, если быть более точным, CA включает в этот список серийный номер сертификата вместе с некоторой другой информацией. Клиенты, которым необходимо знать о достоверности сертификата, могут осуществлять в CRL поиск по любому уведомлению об аннулировании.
Репозиторий сертификатов (CR)
Репозиторий сертификатов [Certificate Repository ( CR )] является хранилищем выпущенных сертификатов и аннулированных сертификатов в CRL. Несмотря на то что CR необязательный компонент инфраструктуры открытых ключей, он значительно способствует доступности и управляемости PKI.
Так как формат сертификатов X.509 нормально приспособлен к каталогу X.500, то соответственно наилучшим образом будет реализовать CR как каталог (Directory), который затем может быть доступен посредством наиболее общего протокола доступа – облегченного протокола доступа к каталогам LDAP (Lightweight Directory Access Protocol), последней версией которого является LDAP v3.
LDAP является наиболее эффективным и наиболее распространенным методом, с помощью которого конечные объекты или СА извлекают или модифицируют хранящиеся в CR сертификаты и информацию CRL. LDAP предлагает команды или процедуры, которые делают это эффективно и равномерно, такие, как bind, search или modify и unbind. Также для поддержки со стороны сервера LDAP, действующего как сервер CR, определены классы объектов и атрибутов [называемые схемами (Schemas)].
Для получения сертификатов или информации CRL, если в каталоге не реализован CR, существуют альтернативные методы. Однако их применять не рекомендуется, и после рассмотрения требований, которым должен соответствовать CR, все сводится к тому, что каталог на самом деле является лучшим местом для хранения информации CR. Эти требования включают: простую доступность, доступ на основе стандартов, сохранение новейшей информации, встроенную безопасность (если требуется), вопросы управления данными и возможность объединения подобных данных. В случае инфраструктуры открытых ключей в Интернете на основе Domino репозиторием сертификатов является каталог Domino (Domino Directory).
Центр регистрации (RA)
Центр регистрации [Registration Authority ( RA )] является необязательным компонентом инфраструктуры открытых ключей. В некоторых случаях роль RA выполняет CA. Там, где используется отдельный RA, он является доверенным конечным объектом, который сертифицирован CA и действует как подчиненный сервер CA. CA может делегировать некоторые из своих функций управления RA. К примеру, RA может выполнять персональные задачи аутентификации, сообщать об аннулированных сертификатах, генерировать ключи или архивировать пары ключей. Однако RA не производит выпуск сертификатов или CRL.
6.2.3 Сертификаты X.509
Ключевой частью инфраструктуры открытых ключей (и достойной собственного раздела для описания) является сертификат X.509.
Несмотря на то что для сертификатов открытых ключей было предложено несколько форматов, большинство доступных сегодня коммерческих сертификатов основаны на интернациональном стандарте, рекомендации ITU-T X.509 (ранее X.509 организации CCITT).
Сертификаты X.509 обычно используются в защищенных интернет-протоколах, таких, как те, которые мы рассматриваем в настоящей лекции, а именно:
- SSL (Secure Sockets Layer);
- S/MIME (Secure Multipurpose Internet Message Extension).
Что такое стандарт X.509?
Первоначально основной целью стандарта X.509 было определить средства для проведения аутентификации на основе сертификатов по отношению к каталогу X.500. Аутентификация каталогов в X.509 может проводиться с использованием либо техники секретных ключей, либо техники открытых ключей. Последняя основана на сертификатах открытых ключей.
В настоящее время определенный в стандарте X.509 формат сертификата открытого ключа широко используется и поддерживается в мире Интернета определенным количеством протоколов. Стандарт X.509 не устанавливает особого криптографического алгоритма, хотя и производит впечатление, что RSA является единственным наиболее широко используемым алгоритмом.
Краткая история сертификатов X.509
RFC, касающиеся электронной почты повышенной защиты [Privacy Enhanced Mail (PEM)] в Интернете, которые были опубликованы в 1993 г., включают спецификации для инфраструктуры открытых ключей на основе сертификатов X.509 v1 (за подробностями обратитесь к RFC 1422). Опыт, приобретенный при осуществлении попыток использовать RFC 1422, ясно выявил, что форматы сертификатов v1 и v2 были не совсем полными в некоторых отношениях. Наиболее существенной была необходимость в большем количестве полей для размещения требуемой и нужной информации. Для удовлетворения этих новых требований организации ISO/IEC/ITU и ANSI X9 разработали формат сертификата X.509 версии 3 (v3). Формат v3 расширил формат v2 за счет обеспечения дополнительными полями расширения.
Эти поля предоставляют большую гибкость по причине того, что они могут сообщать дополнительную информацию вдобавок к наличию только ключа и связанного с ним имени. Стандартизация основного формата v3 была завершена в июне 1996 г.
Содержимое сертификата X.509
Сертификат X.509 состоит из следующих полей:
- Версия сертификата;
- Серийный номер сертификата;
- Идентификатор алгоритма цифровой подписи (для цифровой подписи выпускающего сертификат);
- Имя выпускающего сертификат (это имя СА);
- Период достоверности;
- Имя субъекта (пользователя или сервера);
- Информация об открытом ключе субъекта: идентификатор алгоритма и значение открытого ключа;
- Уникальный идентификатор выпускающего сертификат – только для версий 2 и 3 (добавлено в версии 2);
- Уникальный идентификатор субъекта – только для версий 2 и 3 (добавлено в версии 2);
- Расширения – только для версии 3 (добавлено в версии 3);
- Цифровая подпись выпускающего сертификат для полей выше.
Стандартные расширения включают среди прочих атрибуты субъекта и выпускающего сертификат, информацию о политике сертификации, ограничения в использовании ключей. Структура сертификата X.509 V3 проиллюстрирована на рис. 6.18.
Данные сертификата записываются согласно правилу синтаксиса системы обозначений для описания абстрактного синтаксиса 1 (ASN. 1), как это можно увидеть на рис. 6.19.
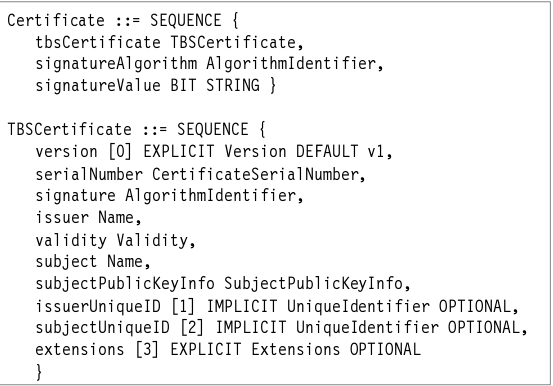
Рис.
6.19.
Представление сертификата X.509 согласно системе обозначений для описания абстрактного синтаксиса 1 (ASN. 1)
После этого они конвертируются в двоичные данные в соответствии с характерными правилами кодирования ASN.1, который является языком описания данных и определен организацией ITU-T как стандарты X.208 и X.209. Эта операция позволяет сделать данные сертификата независимыми от правил кодирования каждой конкретной платформы.
В некоторых полях сертификата для представления специальной последовательности значений параметров используется идентификатор объекта [object identifier ( OID )]. К примеру, на рис. 6.19 можно увидеть AlgorithmIdentifier для signatureAlgorithm, который фактически состоит из идентификатора объекта ( OID ) и необязательных параметров. Этот OID представляет конкретный алгоритм, используемый для цифровых подписей выпускающего сертификат ( СА ). Приложение, которое проверяет подпись сертификата, должно понимать OID, который представляет алгоритм шифрования и алгоритм сборника сообщений наряду с другой информацией.
ASN.1
| Abstract Syntax Notation One | |
| Status | In force; supersedes X.208 and X.209 (1988) |
|---|---|
| Year started | 1984 |
| Latest version | (02/21) February 2021 |
| Organization | ITU-T |
| Committee | Study Group 17 |
| Base standards | ASN.1 |
| Related standards | X.208, X.209, X.409, X.509, X.680, X.681, X.682, X.683 |
| Domain | cryptography, telecommunications |
| Website | https://www.itu.int/rec/T-REC-X.680/ |
Abstract Syntax Notation One (ASN.1) is a standard interface description language for defining data structures that can be serialized and deserialized in a cross-platform way. It is broadly used in telecommunications and computer networking, and especially in cryptography.[1]
Protocol developers define data structures in ASN.1 modules, which are generally a section of a broader standards document written in the ASN.1 language. The advantage is that the ASN.1 description of the data encoding is independent of a particular computer or programming language. Because ASN.1 is both human-readable and machine-readable, an ASN.1 compiler can compile modules into libraries of code, codecs, that decode or encode the data structures. Some ASN.1 compilers can produce code to encode or decode several encodings, e.g. packed, BER or XML.
ASN.1 is a joint standard of the International Telecommunication Union Telecommunication Standardization Sector (ITU-T) in ITU-T Study Group 17 and ISO/IEC, originally defined in 1984 as part of CCITT X.409:1984.[2] In 1988, ASN.1 moved to its own standard, X.208, due to wide applicability. The substantially revised 1995 version is covered by the X.680 series.[3] The latest revision of the X.680 series of recommendations is the 6.0 Edition, published in 2021.
Language support[edit]
ASN.1 is a data type declaration notation. It does not define how to manipulate a variable of such a type. Manipulation of variables is defined in other languages such as SDL (Specification and Description Language) for executable modeling or TTCN-3 (Testing and Test Control Notation) for conformance testing. Both these languages natively support ASN.1 declarations. It is possible to import an ASN.1 module and declare a variable of any of the ASN.1 types declared in the module.
Applications[edit]
ASN.1 is used to define a large number of protocols. Its most extensive uses continue to be telecommunications, cryptography, and biometrics.
Protocols that use ASN.1
| Protocol | Specification | Specified or customary encoding rules | Uses |
|---|---|---|---|
| Interledger Protocol | https://interledger.org/rfcs/asn1/index.html | Octet Encoding Rules | |
| NTCIP 1103 — Transport Management Protocols | NTCIP 1103 | Octet Encoding Rules | Traffic, Transportation, and Infrastructure Management |
| X.500 Directory Services | The ITU X.500 Recommendation Series | Basic Encoding Rules, Distinguished Encoding Rules | LDAP, TLS (X.509) Certificates, Authentication |
| Lightweight Directory Access Protocol (LDAP) | RFC 4511 | Basic Encoding Rules | |
| PKCS Cryptography Standards | PKCS Cryptography Standards | Basic Encoding Rules and Distinguished Encoding Rules | Asymmetric Keys, certificate bundles |
| X.400 Message Handling | The ITU X.400 Recommendation Series | An early competitor to email | |
| EMV | EMVCo Publications | Payment cards | |
| T.120 Multimedia conferencing | The ITU T.120 Recommendation Series | Basic Encoding Rules, Packed Encoding Rules | Microsoft’s Remote Desktop Protocol (RDP) |
| Simple Network Management Protocol (SNMP) | RFC 1157 | Basic Encoding Rules | Managing and monitoring networks and computers, particularly characteristics pertaining to performance and reliability |
| Common Management Information Protocol (CMIP) | ITU Recommendation X.711 | A competitor to SNMP but more capable and not nearly as popular | |
| Signalling System No. 7 (SS7) | The ITU Q.700 Recommendation Series | Managing telephone connections over the Public Switched Telephone Network (PSTN) | |
| ITU H-Series Multimedia Protocols | The ITU H.200, H.300, and H.400 Recommendation Series | Voice Over Internet Protocol (VOIP) | |
| BioAPI Interworking Protocol (BIP) | ISO/IEC 24708:2008 | ||
| Common Biometric Exchange Formats Framework (CBEFF) | NIST IR 6529-A | Basic Encoding Rules | |
| Authentication Contexts for Biometrics (ACBio) | ISO/IEC 24761:2019 | ||
| Computer-supported telecommunications applications (CSTA) | https://www.ecma-international.org/activities/Communications/TG11/cstaIII.htm | Basic Encoding Rules | |
| Dedicated short-range communications (DSRC) | SAE J2735 | Packed Encoding Rules | Vehicle communication |
| IEEE 802.11p (IEEE WAVE) | IEEE 1609.2 | Vehicle communication | |
| Intelligent Transport Systems (ETSI ITS) | ETSI EN 302 637 2 (CAM) ETSI EN 302 637 3 (DENM) | Vehicle communication | |
| Global System for Mobile Communications (GSM) | http://www.ttfn.net/techno/smartcards/gsm11-11.pdf | 2G Mobile Phone Communications | |
| General Packet Radio Service (GPRS) / Enhanced Data rates for GSM Evolution (EDGE) | http://www.3gpp.org/technologies/keywords-acronyms/102-gprs-edge | 2.5G Mobile Phone Communications | |
| Universal Mobile Telecommunications System (UMTS) | http://www.3gpp.org/DynaReport/25-series.htm | 3G Mobile Phone Communications | |
| Long-Term Evolution (LTE) | http://www.3gpp.org/technologies/keywords-acronyms/98-lte | 4G Mobile Phone Communications | |
| 5G | https://www.3gpp.org/news-events/3gpp-news/1987-imt2020_workshop | 5G Mobile Phone Communications | |
| Common Alerting Protocol (CAP) | http://docs.oasis-open.org/emergency/cap/v1.2/CAP-v1.2-os.html | XML Encoding Rules | Exchanging Alert Information, such as Amber Alerts |
| Controller–pilot data link communications (CPDLC) | Aeronautics communications | ||
| Space Link Extension Services (SLE) | Space systems communications | ||
| Manufacturing Message Specification (MMS) | ISO 9506-1:2003 | Manufacturing | |
| File Transfer, Access and Management (FTAM) | An early and more capable competitor to File Transfer Protocol, but its rarely used anymore. | ||
| Remote Operations Service Element protocol (ROSE) | ITU Recommendations X.880, X.881, and X.882 | An early form of Remote procedure call | |
| Association Control Service Element (ACSE) | ITU Recommendation X.227 | ||
| Building Automation and Control Networks Protocol (BACnet) | ASHRAE 135-2020 | BACnet Encoding Rules | Building automation and control, such as with fire alarms, elevators, HVAC systems, etc. |
| Kerberos | RFC 4120 | Basic Encoding Rules | Secure authentication |
| WiMAX 2 | Wide Area Networks | ||
| Intelligent Network | The ITU Q.1200 Recommendation Series | Telecommunications and computer networking | |
| X2AP | Basic Aligned Packed Encoding Rules |
Encodings[edit]
ASN.1 is closely associated with a set of encoding rules that specify how to represent a data structure as a series of bytes. The standard ASN.1 encoding rules include:
ASN.1 Encoding Rules
| Encoding rules | Object identifier | Object descriptor value |
Specification |
Unit of serialization |
Encoded elements |
Octet aligned |
Encoding control |
Description | |
|---|---|---|---|---|---|---|---|---|---|
| Dotted | IRI | ||||||||
| Basic Encoding Rules (BER)[4] | 2.1.1 | /ASN.1/Basic-Encoding | Basic Encoding of a single ASN.1 type | ITU X.690 | Octet | Yes | Yes | No | The first specified encoding rules. Encodes elements as tag-length-value (TLV) sequences. Typically provides several options as to how data values are to be encoded. This is one of the more flexible encoding rules. |
| Distinguished Encoding Rules (DER)[5] | 2.1.2.1 | /ASN.1/BER‑Derived/Distinguished‑Encoding | Distinguished encoding of a single ASN.1 type | ITU X.690 | Octet | Yes | Yes | No | A restricted subset of the Basic Encoding Rules (BER). Typically used for things that are digitally-signed because, since the DER allow for fewer options for encoding, and because DER-encoded values are more likely to be re-encoded on the exact same bytes, digital signatures produced by a given abstract value will be the same across implementations and digital signatures produced over DER-encoded data will be less susceptible to collision-based attacks. |
| Canonical Encoding Rules (CER)[6] | 2.1.2.0 | /ASN.1/BER‑Derived/Canonical‑Encoding | Canonical encoding of a single ASN.1 type | ITU X.690 | Octet | Yes | Yes | No | A restricted subset of the Basic Encoding Rules (BER). Employs almost all of the same restrictions as the Distinguished Encoding Rules (DER), but the noteworthy difference is that the CER specify that many large values (especially strings) are to be «chopped up» into individual substring elements at the 1000-byte or 1000-character mark (depending on the data type). |
| Basic Packed Encoding Rules (PER) Aligned[7] | 2.1.3.0.0 | /ASN.1/Packed‑Encoding/Basic/Aligned | Packed encoding of a single ASN.1 type (basic aligned) | ITU X.691 | Bit | No | Yes | No | Encodes values on bits, but if the bits encoded are not evenly divisible by eight, padding bits are added until an integral number of octets encode the value. Capable of producing very compact encodings, but at the expense of complexity, and the PER are highly dependent upon constraints placed on data types. |
| Basic Packed Encoding Rules (PER) Unaligned[7] | 2.1.3.0.1 | /ASN.1/Packed‑Encoding/Basic/Unaligned | Packed encoding of a single ASN.1 type (basic unaligned) | ITU X.691 | Bit | No | No | No | A variant of the Aligned Basic Packed Encoding Rules (PER), but it does not pad data values with bits to produce an integral number of octets. |
| Canonical Packed Encoding Rules (CPER) Aligned[7] | 2.1.3.1.0 | /ASN.1/Packed‑Encoding/Canonical/Aligned | Packed encoding of a single ASN.1 type (canonical aligned) | ITU X.691 | Bit | No | Yes | No | A variant of the Packed Encoding Rules (PER) that specifies a single way of encoding values. The Canonical Packed Encoding Rules have a similar relationship to the Packed Encoding Rules that the Distinguished Encoding Rules (DER) and the Canonical Encoding Rules (CER) have to the Basic Encoding Rules (BER). |
| Canonical Packed Encoding Rules (CPER) Unaligned[7] | 2.1.3.1.1 | /ASN.1/Packed‑Encoding/Canonical/Unaligned | Packed encoding of a single ASN.1 type (canonical unaligned) | ITU X.691 | Bit | No | No | No | A variant of the Aligned Canonical Packed Encoding Rules (CPER), but it does not pad data values with bits to produce an integral number of octets. |
| Basic XML Encoding Rules (XER)[8] | 2.1.5.0 | /ASN.1/XML‑Encoding/Basic | Basic XML encoding of a single ASN.1 type | ITU X.693 | Character | Yes | Yes | Yes | Encodes ASN.1 data as XML. |
| Canonical XML Encoding Rules (CXER)[8] | 2.1.5.1 | /ASN.1/XML‑Encoding/Canonical | Canonical XML encoding of a single ASN.1 type | ITU X.693 | Character | Yes | Yes | Yes | |
| Extended XML Encoding Rules (EXER)[8] | 2.1.5.2 | /ASN.1/XML‑Encoding/Extended | Extended XML encoding of a single ASN.1 type | ITU X.693 | Character | Yes | Yes | Yes | |
| Octet Encoding Rules (OER)[9] | 2.1.6.0 | Basic OER encoding of a single ASN.1 type | ITU X.696 | Octet | No | Yes | A set of encoding rules that encodes values on octets, but does not encode tags or length determinants like the Basic Encoding Rules (BER). Data values encoded using the Octet Encoding Rules often look like those found in «record-based» protocols. The Octet Encoding Rules (OER) were designed to be easy to implement and to produce encodings more compact than those produced by the Basic Encoding Rules (BER). In addition to reducing the effort of developing encoder/decoders, the use of OER can decrease bandwidth utilization (though not as much as the Packed Encoding Rules), save CPU cycles, and lower encoding/decoding latency. | ||
| Canonical Encoding Rules (OER)[9] | 2.1.6.1 | Canonical OER encoding of a single ASN.1 type | ITU X.696 | Octet | No | Yes | |||
| JSON Encoding Rules (JER)[10] | ITU X.697 | Character | Yes | Yes | Yes | Encodes ASN.1 data as JSON. | |||
| Generic String Encoding Rules (GSER)[11] | 1.2.36.79672281.0.0 | Generic String Encoding Rules (GSER) | RFC 3641 | Character | Yes | No | An incomplete specification for encoding rules that produce human-readable values. The purpose of GSER is to represent encoded data to the user or input data from the user, in a very straightforward format. GSER was originally designed for the Lightweight Directory Access Protocol (LDAP) and is rarely used outside of it. The use of GSER in actual protocols is discouraged since not all character string encodings supported by ASN.1 can be reproduced in it. | ||
| BACnet Encoding Rules | ASHRAE 135 | Octet | Yes | Yes | Yes | Encodes elements as tag-length-value (TLV) sequences like the Basic Encoding Rules (BER). | |||
| Signalling Specific Encoding Rules (SER) | France Telecom R&D Internal Document | Octet | Yes | Yes | Used primarily in telecommunications related protocols, such as GSM and SS7. Designed to produce an identical encoding from ASN.1 that previously-existing protocols not specified in ASN.1 would produce. | ||||
| Lightweight Encoding Rules (LWER) | Internal document by INRIA. | Memory Word | Yes | Originates from an internal document produced by INRIA detailing the «Flat Tree Light Weight Syntax» (FTLWS). Abandoned in 1997 due to the superior performance of the Packed Encoding Rules (PER). Optionally Big-Endian or Little-Endian transmission as well as 8-bit, 16-bit, and 32-bit memory words. (Therefore, there are six variants, since there are six combinations of those options.) | |||||
| Minimum Bit Encoding Rules (MBER) | Bit | Proposed in the 1980s. Meant to be as compact as possible, like the Packed Encoding Rules (PER). | |||||||
| NEMA Packed Encoding Rules | Bit | An incomplete encoding rule specification produced by NEMA. It is incomplete because it cannot encode and decode all ASN.1 data types. Compact like the Packed Encoding Rules (PER). | |||||||
| High Speed Coding Rules | «Coding Rules for High Speed Networks» | Definition of these encoding rules were a byproduct of INRIA’s work on the Flat Tree Light Weight Syntax (FTLWS). |
Encoding Control Notation[edit]
ASN.1 recommendations provide a number of predefined encoding rules. If none of the existing encoding rules are suitable, the Encoding Control Notation (ECN) provides a way for a user to define his or her own customized encoding rules.
Relation to Privacy-Enhanced Mail (PEM) Encoding[edit]
Privacy-Enhanced Mail (PEM) encoding is entirely unrelated to ASN.1 and its codecs, but encoded ASN.1 data, which is often binary, is often PEM-encoded so that it can be transmitted as textual data, e.g. over SMTP relays, or through copy/paste buffers.
Example[edit]
This is an example ASN.1 module defining the messages (data structures) of a fictitious Foo Protocol:
FooProtocol DEFINITIONS ::= BEGIN
FooQuestion ::= SEQUENCE {
trackingNumber INTEGER,
question IA5String
}
FooAnswer ::= SEQUENCE {
questionNumber INTEGER,
answer BOOLEAN
}
END
This could be a specification published by creators of Foo Protocol. Conversation flows, transaction interchanges, and states are not defined in ASN.1, but are left to other notations and textual description of the protocol.
Assuming a message that complies with the Foo Protocol and that will be sent to the receiving party, this particular message (protocol data unit (PDU)) is:
myQuestion FooQuestion ::= {
trackingNumber 5,
question "Anybody there?"
}
ASN.1 supports constraints on values and sizes, and extensibility. The above specification can be changed to
FooProtocol DEFINITIONS ::= BEGIN
FooQuestion ::= SEQUENCE {
trackingNumber INTEGER(0..199),
question IA5String
}
FooAnswer ::= SEQUENCE {
questionNumber INTEGER(10..20),
answer BOOLEAN
}
FooHistory ::= SEQUENCE {
questions SEQUENCE(SIZE(0..10)) OF FooQuestion,
answers SEQUENCE(SIZE(1..10)) OF FooAnswer,
anArray SEQUENCE(SIZE(100)) OF INTEGER(0..1000),
...
}
END
This change constrains trackingNumbers to have a value between 0 and 199 inclusive, and questionNumbers to have a value between 10 and 20 inclusive. The size of the questions array can be between 0 and 10 elements, with the answers array between 1 and 10 elements. The anArray field is a fixed length 100 element array of integers that must be in the range 0 to 1000. The ‘…’ extensibility marker means that the FooHistory message specification may have additional fields in future versions of the specification; systems compliant with one version should be able to receive and transmit transactions from a later version, though able to process only the fields specified in the earlier version. Good ASN.1 compilers will generate (in C, C++, Java, etc.) source code that will automatically check that transactions fall within these constraints. Transactions that violate the constraints should not be accepted from, or presented to, the application. Constraint management in this layer significantly simplifies protocol specification because the applications will be protected from constraint violations, reducing risk and cost.
To send the myQuestion message through the network, the message is serialized (encoded) as a series of bytes using one of the encoding rules. The Foo protocol specification should explicitly name one set of encoding rules to use, so that users of the Foo protocol know which one they should use and expect.
Example encoded in DER[edit]
Below is the data structure shown above as myQuestion encoded in DER format (all numbers are in hexadecimal):
30 13 02 01 05 16 0e 41 6e 79 62 6f 64 79 20 74 68 65 72 65 3f
DER is a type–length–value encoding, so the sequence above can be interpreted, with reference to the standard SEQUENCE, INTEGER, and IA5String types, as follows:
30 — type tag indicating SEQUENCE
13 — length in octets of value that follows
02 — type tag indicating INTEGER
01 — length in octets of value that follows
05 — value (5)
16 — type tag indicating IA5String
(IA5 means the full 7-bit ISO 646 set, including variants,
but is generally US-ASCII)
0e — length in octets of value that follows
41 6e 79 62 6f 64 79 20 74 68 65 72 65 3f — value ("Anybody there?")
Example encoded in XER[edit]
Alternatively, it is possible to encode the same ASN.1 data structure with XML Encoding Rules (XER) to achieve greater human readability «over the wire». It would then appear as the following 108 octets, (space count includes the spaces used for indentation):
<FooQuestion> <trackingNumber>5</trackingNumber> <question>Anybody there?</question> </FooQuestion>
Example encoded in PER (unaligned)[edit]
Alternatively, if Packed Encoding Rules are employed, the following 122 bits (16 octets amount to 128 bits, but here only 122 bits carry information and the last 6 bits are merely padding) will be produced:
01 05 0e 83 bb ce 2d f9 3c a0 e9 a3 2f 2c af c0
In this format, type tags for the required elements are not encoded, so it cannot be parsed without knowing the expected schemas used to encode. Additionally, the bytes for the value of the IA5String are packed using 7-bit units instead of 8-bit units, because the encoder knows that encoding an IA5String byte value requires only 7 bits. However the length bytes are still encoded here, even for the first integer tag 01 (but a PER packer could also omit it if it knows that the allowed value range fits on 8 bits, and it could even compact the single value byte 05 with less than 8 bits, if it knows that allowed values can only fit in a smaller range).
The last 6 bits in the encoded PER are padded with null bits in the 6 least significant bits of the last byte c0 : these extra bits may not be transmitted or used for encoding something else if this sequence is inserted as a part of a longer unaligned PER sequence.
This means that unaligned PER data is essentially an ordered stream of bits, and not an ordered stream of bytes like with aligned PER, and that it will be a bit more complex to decode by software on usual processors because it will require additional contextual bit-shifting and masking and not direct byte addressing (but the same remark would be true with modern processors and memory/storage units whose minimum addressable unit is larger than 1 octet). However modern processors and signal processors include hardware support for fast internal decoding of bit streams with automatic handling of computing units that are crossing the boundaries of addressable storage units (this is needed for efficient processing in data codecs for compression/decompression or with some encryption/decryption algorithms).
If alignment on octet boundaries was required, an aligned PER encoder would produce:
01 05 0e 41 6e 79 62 6f 64 79 20 74 68 65 72 65 3f
(in this case, each octet is padded individually with null bits on their unused most significant bits).
Tools[edit]
Most of the tools supporting ASN.1 do the following:
- parse the ASN.1 files,
- generates the equivalent declaration in a programming language (like C or C++),
- generates the encoding and decoding functions based on the previous declarations.
A list of tools supporting ASN.1 can be found on the ITU-T Tool web page.
Online tools[edit]
- ASN1 Web Tool (very limited)
- ASN1 Playground (sandbox)
Comparison to similar schemes[edit]
ASN.1 is similar in purpose and use to protocol buffers and Apache Thrift, which are also interface description languages for cross-platform data serialization. Like those languages, it has a schema (in ASN.1, called a «module»), and a set of encodings, typically type–length–value encodings. Unlike them, ASN.1 does not provide a single and readily usable open-source implementation, and is published as a specification to be implemented by third-party vendors. However, ASN.1, defined in 1984, predates them by many years. It also includes a wider variety of basic data types, some of which are obsolete, and has more options for extensibility. A single ASN.1 message can include data from multiple modules defined in multiple standards, even standards defined years apart.
ASN.1 also includes built-in support for constraints on values and sizes. For instance, a module can specify an integer field that must be in the range 0 to 100. The length of a sequence of values (an array) can also be specified, either as a fixed length or a range of permitted lengths. Constraints can also be specified as logical combinations of sets of basic constraints.
Values used as constraints can either be literals used in the PDU specification, or ASN.1 values specified elsewhere in the schema file. Some ASN.1 tools will make these ASN.1 values available to programmers in the generated source code. Used as constants for the protocol being defined, developers can use these in the protocol’s logic implementation. Thus all the PDUs and protocol constants can be defined in the schema, and all implementations of the protocol in any supported language draw upon those values. This avoids the need for developers to hand code protocol constants in their implementation’s source code. This significantly aids protocol development; the protocol’s constants can be altered in the ASN.1 schema and all implementations are updated simply by recompiling, promoting a rapid and low risk development cycle.
If the ASN.1 tools properly implement constraints checking in the generated source code, this acts to automatically validate protocol data during program operation. Generally ASN.1 tools will include constraints checking into the generated serialization / deserialization routines, raising errors or exceptions if out-of-bounds data is encountered. It is complex to implement all aspects of ASN.1 constraints in an ASN.1 compiler. Not all tools support the full range of possible constraints expressions. XML schema and JSON schema both support similar constraints concepts. Tool support for constraints varies. Microsoft’s xsd.exe compiler ignores them.
ASN.1 is visually similar to Augmented Backus-Naur form (ABNF), which is used to define many Internet protocols like HTTP and SMTP. However, in practice they are quite different: ASN.1 defines a data structure, which can be encoded in various ways (e.g. JSON, XML, binary). ABNF, on the other hand, defines the encoding («syntax») at the same time it defines the data structure («semantics»). ABNF tends to be used more frequently for defining textual, human-readable protocols, and generally is not used to define type–length–value encodings.
Many programming languages define language-specific serialization formats. For instance, Python’s «pickle» module and Ruby’s «Marshal» module. These formats are generally language specific. They also don’t require a schema, which makes them easier to use in ad hoc storage scenarios, but inappropriate for communications protocols.
JSON and XML similarly do not require a schema, making them easy to use. They are also both cross-platform standards that are broadly popular for communications protocols, particularly when combined with a JSON schema or XML schema.
Some ASN.1 tools are able to translate between ASN.1 and XML schema (XSD). The translation is standardised by the ITU. This makes it possible for a protocol to be defined in ASN.1, and also automatically in XSD. Thus it is possible (though perhaps ill-advised) to have in a project an XSD schema being compiled by ASN.1 tools producing source code that serializes objects to/from JSON wireformat. A more practical use is to permit other sub-projects to consume an XSD schema instead of an ASN.1 schema, perhaps suiting tools availability for the sub-projects language of choice, with XER used as the protocol wireformat.
For more detail, see Comparison of data serialization formats.
See also[edit]
- X.690
- Information Object Class (ASN.1)
- Presentation layer
References[edit]
- ^ «Introduction to ASN.1». ITU. Archived from the original on 2021-04-09. Retrieved 2021-04-09.
- ^ «ITU-T Recommendation database». ITU. Retrieved 2017-03-06.
- ^ ITU-T X.680 — Specification of basic notation
- ^ ITU-T X.690 — Basic Encoding Rules (BER)
- ^ ITU-T X.690 — Distinguished Encoding Rules (DER)
- ^ ITU-T X.690 — Canonical Encoding Rules (CER)
- ^ a b c d ITU-T X.691 — Packed Encoding Rules (PER)
- ^ a b c ITU-T X.693 — XML Encoding Rules (XER)
- ^ a b ITU-T X.696 — Octet Encoding Rules (OER)
- ^ ITU-T X.697 — JavaScript Object Notation Encoding Rules (JER)
- ^ RFC 3641 — Generic String Encoding Rules (GSER)
External links[edit]
- A Layman’s Guide to a Subset of ASN.1, BER, and DER A good introduction for beginners
- ITU-T website — Introduction to ASN.1
- A video introduction to ASN.1
- ASN.1 Tutorial Tutorial on basic ASN.1 concepts
- ASN.1 Tutorial Tutorial on ASN.1
- An open-source ASN.1->C++ compiler; Includes some ASN.1 specs., An on-line ASN.1->C++ Compiler
- ASN.1 decoder Allows decoding ASN.1 encoded messages into XML output.
- ASN.1 syntax checker and encoder/decoder Checks the syntax of an ASN.1 schema and encodes/decodes messages.
- ASN.1 encoder/decoder of 3GPP messages Encodes/decodes ASN.1 3GPP messages and allows easy editing of these messages.
- Free books about ASN.1
- List of ASN.1 tools at IvmaiAsn project
- Overview of the Octet Encoding Rules (OER)
- Overview of the JSON Encoding Rules (JER)
- A Typescript node utility to parse and validate ASN.1 messages
ASN.1
| Abstract Syntax Notation One | |
| Status | In force; supersedes X.208 and X.209 (1988) |
|---|---|
| Year started | 1984 |
| Latest version | (02/21) February 2021 |
| Organization | ITU-T |
| Committee | Study Group 17 |
| Base standards | ASN.1 |
| Related standards | X.208, X.209, X.409, X.509, X.680, X.681, X.682, X.683 |
| Domain | cryptography, telecommunications |
| Website | https://www.itu.int/rec/T-REC-X.680/ |
Abstract Syntax Notation One (ASN.1) is a standard interface description language for defining data structures that can be serialized and deserialized in a cross-platform way. It is broadly used in telecommunications and computer networking, and especially in cryptography.[1]
Protocol developers define data structures in ASN.1 modules, which are generally a section of a broader standards document written in the ASN.1 language. The advantage is that the ASN.1 description of the data encoding is independent of a particular computer or programming language. Because ASN.1 is both human-readable and machine-readable, an ASN.1 compiler can compile modules into libraries of code, codecs, that decode or encode the data structures. Some ASN.1 compilers can produce code to encode or decode several encodings, e.g. packed, BER or XML.
ASN.1 is a joint standard of the International Telecommunication Union Telecommunication Standardization Sector (ITU-T) in ITU-T Study Group 17 and ISO/IEC, originally defined in 1984 as part of CCITT X.409:1984.[2] In 1988, ASN.1 moved to its own standard, X.208, due to wide applicability. The substantially revised 1995 version is covered by the X.680 series.[3] The latest revision of the X.680 series of recommendations is the 6.0 Edition, published in 2021.
Language support[edit]
ASN.1 is a data type declaration notation. It does not define how to manipulate a variable of such a type. Manipulation of variables is defined in other languages such as SDL (Specification and Description Language) for executable modeling or TTCN-3 (Testing and Test Control Notation) for conformance testing. Both these languages natively support ASN.1 declarations. It is possible to import an ASN.1 module and declare a variable of any of the ASN.1 types declared in the module.
Applications[edit]
ASN.1 is used to define a large number of protocols. Its most extensive uses continue to be telecommunications, cryptography, and biometrics.
Protocols that use ASN.1
| Protocol | Specification | Specified or customary encoding rules | Uses |
|---|---|---|---|
| Interledger Protocol | https://interledger.org/rfcs/asn1/index.html | Octet Encoding Rules | |
| NTCIP 1103 — Transport Management Protocols | NTCIP 1103 | Octet Encoding Rules | Traffic, Transportation, and Infrastructure Management |
| X.500 Directory Services | The ITU X.500 Recommendation Series | Basic Encoding Rules, Distinguished Encoding Rules | LDAP, TLS (X.509) Certificates, Authentication |
| Lightweight Directory Access Protocol (LDAP) | RFC 4511 | Basic Encoding Rules | |
| PKCS Cryptography Standards | PKCS Cryptography Standards | Basic Encoding Rules and Distinguished Encoding Rules | Asymmetric Keys, certificate bundles |
| X.400 Message Handling | The ITU X.400 Recommendation Series | An early competitor to email | |
| EMV | EMVCo Publications | Payment cards | |
| T.120 Multimedia conferencing | The ITU T.120 Recommendation Series | Basic Encoding Rules, Packed Encoding Rules | Microsoft’s Remote Desktop Protocol (RDP) |
| Simple Network Management Protocol (SNMP) | RFC 1157 | Basic Encoding Rules | Managing and monitoring networks and computers, particularly characteristics pertaining to performance and reliability |
| Common Management Information Protocol (CMIP) | ITU Recommendation X.711 | A competitor to SNMP but more capable and not nearly as popular | |
| Signalling System No. 7 (SS7) | The ITU Q.700 Recommendation Series | Managing telephone connections over the Public Switched Telephone Network (PSTN) | |
| ITU H-Series Multimedia Protocols | The ITU H.200, H.300, and H.400 Recommendation Series | Voice Over Internet Protocol (VOIP) | |
| BioAPI Interworking Protocol (BIP) | ISO/IEC 24708:2008 | ||
| Common Biometric Exchange Formats Framework (CBEFF) | NIST IR 6529-A | Basic Encoding Rules | |
| Authentication Contexts for Biometrics (ACBio) | ISO/IEC 24761:2019 | ||
| Computer-supported telecommunications applications (CSTA) | https://www.ecma-international.org/activities/Communications/TG11/cstaIII.htm | Basic Encoding Rules | |
| Dedicated short-range communications (DSRC) | SAE J2735 | Packed Encoding Rules | Vehicle communication |
| IEEE 802.11p (IEEE WAVE) | IEEE 1609.2 | Vehicle communication | |
| Intelligent Transport Systems (ETSI ITS) | ETSI EN 302 637 2 (CAM) ETSI EN 302 637 3 (DENM) | Vehicle communication | |
| Global System for Mobile Communications (GSM) | http://www.ttfn.net/techno/smartcards/gsm11-11.pdf | 2G Mobile Phone Communications | |
| General Packet Radio Service (GPRS) / Enhanced Data rates for GSM Evolution (EDGE) | http://www.3gpp.org/technologies/keywords-acronyms/102-gprs-edge | 2.5G Mobile Phone Communications | |
| Universal Mobile Telecommunications System (UMTS) | http://www.3gpp.org/DynaReport/25-series.htm | 3G Mobile Phone Communications | |
| Long-Term Evolution (LTE) | http://www.3gpp.org/technologies/keywords-acronyms/98-lte | 4G Mobile Phone Communications | |
| 5G | https://www.3gpp.org/news-events/3gpp-news/1987-imt2020_workshop | 5G Mobile Phone Communications | |
| Common Alerting Protocol (CAP) | http://docs.oasis-open.org/emergency/cap/v1.2/CAP-v1.2-os.html | XML Encoding Rules | Exchanging Alert Information, such as Amber Alerts |
| Controller–pilot data link communications (CPDLC) | Aeronautics communications | ||
| Space Link Extension Services (SLE) | Space systems communications | ||
| Manufacturing Message Specification (MMS) | ISO 9506-1:2003 | Manufacturing | |
| File Transfer, Access and Management (FTAM) | An early and more capable competitor to File Transfer Protocol, but its rarely used anymore. | ||
| Remote Operations Service Element protocol (ROSE) | ITU Recommendations X.880, X.881, and X.882 | An early form of Remote procedure call | |
| Association Control Service Element (ACSE) | ITU Recommendation X.227 | ||
| Building Automation and Control Networks Protocol (BACnet) | ASHRAE 135-2020 | BACnet Encoding Rules | Building automation and control, such as with fire alarms, elevators, HVAC systems, etc. |
| Kerberos | RFC 4120 | Basic Encoding Rules | Secure authentication |
| WiMAX 2 | Wide Area Networks | ||
| Intelligent Network | The ITU Q.1200 Recommendation Series | Telecommunications and computer networking | |
| X2AP | Basic Aligned Packed Encoding Rules |
Encodings[edit]
ASN.1 is closely associated with a set of encoding rules that specify how to represent a data structure as a series of bytes. The standard ASN.1 encoding rules include:
ASN.1 Encoding Rules
| Encoding rules | Object identifier | Object descriptor value |
Specification |
Unit of serialization |
Encoded elements |
Octet aligned |
Encoding control |
Description | |
|---|---|---|---|---|---|---|---|---|---|
| Dotted | IRI | ||||||||
| Basic Encoding Rules (BER)[4] | 2.1.1 | /ASN.1/Basic-Encoding | Basic Encoding of a single ASN.1 type | ITU X.690 | Octet | Yes | Yes | No | The first specified encoding rules. Encodes elements as tag-length-value (TLV) sequences. Typically provides several options as to how data values are to be encoded. This is one of the more flexible encoding rules. |
| Distinguished Encoding Rules (DER)[5] | 2.1.2.1 | /ASN.1/BER‑Derived/Distinguished‑Encoding | Distinguished encoding of a single ASN.1 type | ITU X.690 | Octet | Yes | Yes | No | A restricted subset of the Basic Encoding Rules (BER). Typically used for things that are digitally-signed because, since the DER allow for fewer options for encoding, and because DER-encoded values are more likely to be re-encoded on the exact same bytes, digital signatures produced by a given abstract value will be the same across implementations and digital signatures produced over DER-encoded data will be less susceptible to collision-based attacks. |
| Canonical Encoding Rules (CER)[6] | 2.1.2.0 | /ASN.1/BER‑Derived/Canonical‑Encoding | Canonical encoding of a single ASN.1 type | ITU X.690 | Octet | Yes | Yes | No | A restricted subset of the Basic Encoding Rules (BER). Employs almost all of the same restrictions as the Distinguished Encoding Rules (DER), but the noteworthy difference is that the CER specify that many large values (especially strings) are to be «chopped up» into individual substring elements at the 1000-byte or 1000-character mark (depending on the data type). |
| Basic Packed Encoding Rules (PER) Aligned[7] | 2.1.3.0.0 | /ASN.1/Packed‑Encoding/Basic/Aligned | Packed encoding of a single ASN.1 type (basic aligned) | ITU X.691 | Bit | No | Yes | No | Encodes values on bits, but if the bits encoded are not evenly divisible by eight, padding bits are added until an integral number of octets encode the value. Capable of producing very compact encodings, but at the expense of complexity, and the PER are highly dependent upon constraints placed on data types. |
| Basic Packed Encoding Rules (PER) Unaligned[7] | 2.1.3.0.1 | /ASN.1/Packed‑Encoding/Basic/Unaligned | Packed encoding of a single ASN.1 type (basic unaligned) | ITU X.691 | Bit | No | No | No | A variant of the Aligned Basic Packed Encoding Rules (PER), but it does not pad data values with bits to produce an integral number of octets. |
| Canonical Packed Encoding Rules (CPER) Aligned[7] | 2.1.3.1.0 | /ASN.1/Packed‑Encoding/Canonical/Aligned | Packed encoding of a single ASN.1 type (canonical aligned) | ITU X.691 | Bit | No | Yes | No | A variant of the Packed Encoding Rules (PER) that specifies a single way of encoding values. The Canonical Packed Encoding Rules have a similar relationship to the Packed Encoding Rules that the Distinguished Encoding Rules (DER) and the Canonical Encoding Rules (CER) have to the Basic Encoding Rules (BER). |
| Canonical Packed Encoding Rules (CPER) Unaligned[7] | 2.1.3.1.1 | /ASN.1/Packed‑Encoding/Canonical/Unaligned | Packed encoding of a single ASN.1 type (canonical unaligned) | ITU X.691 | Bit | No | No | No | A variant of the Aligned Canonical Packed Encoding Rules (CPER), but it does not pad data values with bits to produce an integral number of octets. |
| Basic XML Encoding Rules (XER)[8] | 2.1.5.0 | /ASN.1/XML‑Encoding/Basic | Basic XML encoding of a single ASN.1 type | ITU X.693 | Character | Yes | Yes | Yes | Encodes ASN.1 data as XML. |
| Canonical XML Encoding Rules (CXER)[8] | 2.1.5.1 | /ASN.1/XML‑Encoding/Canonical | Canonical XML encoding of a single ASN.1 type | ITU X.693 | Character | Yes | Yes | Yes | |
| Extended XML Encoding Rules (EXER)[8] | 2.1.5.2 | /ASN.1/XML‑Encoding/Extended | Extended XML encoding of a single ASN.1 type | ITU X.693 | Character | Yes | Yes | Yes | |
| Octet Encoding Rules (OER)[9] | 2.1.6.0 | Basic OER encoding of a single ASN.1 type | ITU X.696 | Octet | No | Yes | A set of encoding rules that encodes values on octets, but does not encode tags or length determinants like the Basic Encoding Rules (BER). Data values encoded using the Octet Encoding Rules often look like those found in «record-based» protocols. The Octet Encoding Rules (OER) were designed to be easy to implement and to produce encodings more compact than those produced by the Basic Encoding Rules (BER). In addition to reducing the effort of developing encoder/decoders, the use of OER can decrease bandwidth utilization (though not as much as the Packed Encoding Rules), save CPU cycles, and lower encoding/decoding latency. | ||
| Canonical Encoding Rules (OER)[9] | 2.1.6.1 | Canonical OER encoding of a single ASN.1 type | ITU X.696 | Octet | No | Yes | |||
| JSON Encoding Rules (JER)[10] | ITU X.697 | Character | Yes | Yes | Yes | Encodes ASN.1 data as JSON. | |||
| Generic String Encoding Rules (GSER)[11] | 1.2.36.79672281.0.0 | Generic String Encoding Rules (GSER) | RFC 3641 | Character | Yes | No | An incomplete specification for encoding rules that produce human-readable values. The purpose of GSER is to represent encoded data to the user or input data from the user, in a very straightforward format. GSER was originally designed for the Lightweight Directory Access Protocol (LDAP) and is rarely used outside of it. The use of GSER in actual protocols is discouraged since not all character string encodings supported by ASN.1 can be reproduced in it. | ||
| BACnet Encoding Rules | ASHRAE 135 | Octet | Yes | Yes | Yes | Encodes elements as tag-length-value (TLV) sequences like the Basic Encoding Rules (BER). | |||
| Signalling Specific Encoding Rules (SER) | France Telecom R&D Internal Document | Octet | Yes | Yes | Used primarily in telecommunications related protocols, such as GSM and SS7. Designed to produce an identical encoding from ASN.1 that previously-existing protocols not specified in ASN.1 would produce. | ||||
| Lightweight Encoding Rules (LWER) | Internal document by INRIA. | Memory Word | Yes | Originates from an internal document produced by INRIA detailing the «Flat Tree Light Weight Syntax» (FTLWS). Abandoned in 1997 due to the superior performance of the Packed Encoding Rules (PER). Optionally Big-Endian or Little-Endian transmission as well as 8-bit, 16-bit, and 32-bit memory words. (Therefore, there are six variants, since there are six combinations of those options.) | |||||
| Minimum Bit Encoding Rules (MBER) | Bit | Proposed in the 1980s. Meant to be as compact as possible, like the Packed Encoding Rules (PER). | |||||||
| NEMA Packed Encoding Rules | Bit | An incomplete encoding rule specification produced by NEMA. It is incomplete because it cannot encode and decode all ASN.1 data types. Compact like the Packed Encoding Rules (PER). | |||||||
| High Speed Coding Rules | «Coding Rules for High Speed Networks» | Definition of these encoding rules were a byproduct of INRIA’s work on the Flat Tree Light Weight Syntax (FTLWS). |
Encoding Control Notation[edit]
ASN.1 recommendations provide a number of predefined encoding rules. If none of the existing encoding rules are suitable, the Encoding Control Notation (ECN) provides a way for a user to define his or her own customized encoding rules.
Relation to Privacy-Enhanced Mail (PEM) Encoding[edit]
Privacy-Enhanced Mail (PEM) encoding is entirely unrelated to ASN.1 and its codecs, but encoded ASN.1 data, which is often binary, is often PEM-encoded so that it can be transmitted as textual data, e.g. over SMTP relays, or through copy/paste buffers.
Example[edit]
This is an example ASN.1 module defining the messages (data structures) of a fictitious Foo Protocol:
FooProtocol DEFINITIONS ::= BEGIN
FooQuestion ::= SEQUENCE {
trackingNumber INTEGER,
question IA5String
}
FooAnswer ::= SEQUENCE {
questionNumber INTEGER,
answer BOOLEAN
}
END
This could be a specification published by creators of Foo Protocol. Conversation flows, transaction interchanges, and states are not defined in ASN.1, but are left to other notations and textual description of the protocol.
Assuming a message that complies with the Foo Protocol and that will be sent to the receiving party, this particular message (protocol data unit (PDU)) is:
myQuestion FooQuestion ::= {
trackingNumber 5,
question "Anybody there?"
}
ASN.1 supports constraints on values and sizes, and extensibility. The above specification can be changed to
FooProtocol DEFINITIONS ::= BEGIN
FooQuestion ::= SEQUENCE {
trackingNumber INTEGER(0..199),
question IA5String
}
FooAnswer ::= SEQUENCE {
questionNumber INTEGER(10..20),
answer BOOLEAN
}
FooHistory ::= SEQUENCE {
questions SEQUENCE(SIZE(0..10)) OF FooQuestion,
answers SEQUENCE(SIZE(1..10)) OF FooAnswer,
anArray SEQUENCE(SIZE(100)) OF INTEGER(0..1000),
...
}
END
This change constrains trackingNumbers to have a value between 0 and 199 inclusive, and questionNumbers to have a value between 10 and 20 inclusive. The size of the questions array can be between 0 and 10 elements, with the answers array between 1 and 10 elements. The anArray field is a fixed length 100 element array of integers that must be in the range 0 to 1000. The ‘…’ extensibility marker means that the FooHistory message specification may have additional fields in future versions of the specification; systems compliant with one version should be able to receive and transmit transactions from a later version, though able to process only the fields specified in the earlier version. Good ASN.1 compilers will generate (in C, C++, Java, etc.) source code that will automatically check that transactions fall within these constraints. Transactions that violate the constraints should not be accepted from, or presented to, the application. Constraint management in this layer significantly simplifies protocol specification because the applications will be protected from constraint violations, reducing risk and cost.
To send the myQuestion message through the network, the message is serialized (encoded) as a series of bytes using one of the encoding rules. The Foo protocol specification should explicitly name one set of encoding rules to use, so that users of the Foo protocol know which one they should use and expect.
Example encoded in DER[edit]
Below is the data structure shown above as myQuestion encoded in DER format (all numbers are in hexadecimal):
30 13 02 01 05 16 0e 41 6e 79 62 6f 64 79 20 74 68 65 72 65 3f
DER is a type–length–value encoding, so the sequence above can be interpreted, with reference to the standard SEQUENCE, INTEGER, and IA5String types, as follows:
30 — type tag indicating SEQUENCE
13 — length in octets of value that follows
02 — type tag indicating INTEGER
01 — length in octets of value that follows
05 — value (5)
16 — type tag indicating IA5String
(IA5 means the full 7-bit ISO 646 set, including variants,
but is generally US-ASCII)
0e — length in octets of value that follows
41 6e 79 62 6f 64 79 20 74 68 65 72 65 3f — value ("Anybody there?")
Example encoded in XER[edit]
Alternatively, it is possible to encode the same ASN.1 data structure with XML Encoding Rules (XER) to achieve greater human readability «over the wire». It would then appear as the following 108 octets, (space count includes the spaces used for indentation):
<FooQuestion> <trackingNumber>5</trackingNumber> <question>Anybody there?</question> </FooQuestion>
Example encoded in PER (unaligned)[edit]
Alternatively, if Packed Encoding Rules are employed, the following 122 bits (16 octets amount to 128 bits, but here only 122 bits carry information and the last 6 bits are merely padding) will be produced:
01 05 0e 83 bb ce 2d f9 3c a0 e9 a3 2f 2c af c0
In this format, type tags for the required elements are not encoded, so it cannot be parsed without knowing the expected schemas used to encode. Additionally, the bytes for the value of the IA5String are packed using 7-bit units instead of 8-bit units, because the encoder knows that encoding an IA5String byte value requires only 7 bits. However the length bytes are still encoded here, even for the first integer tag 01 (but a PER packer could also omit it if it knows that the allowed value range fits on 8 bits, and it could even compact the single value byte 05 with less than 8 bits, if it knows that allowed values can only fit in a smaller range).
The last 6 bits in the encoded PER are padded with null bits in the 6 least significant bits of the last byte c0 : these extra bits may not be transmitted or used for encoding something else if this sequence is inserted as a part of a longer unaligned PER sequence.
This means that unaligned PER data is essentially an ordered stream of bits, and not an ordered stream of bytes like with aligned PER, and that it will be a bit more complex to decode by software on usual processors because it will require additional contextual bit-shifting and masking and not direct byte addressing (but the same remark would be true with modern processors and memory/storage units whose minimum addressable unit is larger than 1 octet). However modern processors and signal processors include hardware support for fast internal decoding of bit streams with automatic handling of computing units that are crossing the boundaries of addressable storage units (this is needed for efficient processing in data codecs for compression/decompression or with some encryption/decryption algorithms).
If alignment on octet boundaries was required, an aligned PER encoder would produce:
01 05 0e 41 6e 79 62 6f 64 79 20 74 68 65 72 65 3f
(in this case, each octet is padded individually with null bits on their unused most significant bits).
Tools[edit]
Most of the tools supporting ASN.1 do the following:
- parse the ASN.1 files,
- generates the equivalent declaration in a programming language (like C or C++),
- generates the encoding and decoding functions based on the previous declarations.
A list of tools supporting ASN.1 can be found on the ITU-T Tool web page.
Online tools[edit]
- ASN1 Web Tool (very limited)
- ASN1 Playground (sandbox)
Comparison to similar schemes[edit]
ASN.1 is similar in purpose and use to protocol buffers and Apache Thrift, which are also interface description languages for cross-platform data serialization. Like those languages, it has a schema (in ASN.1, called a «module»), and a set of encodings, typically type–length–value encodings. Unlike them, ASN.1 does not provide a single and readily usable open-source implementation, and is published as a specification to be implemented by third-party vendors. However, ASN.1, defined in 1984, predates them by many years. It also includes a wider variety of basic data types, some of which are obsolete, and has more options for extensibility. A single ASN.1 message can include data from multiple modules defined in multiple standards, even standards defined years apart.
ASN.1 also includes built-in support for constraints on values and sizes. For instance, a module can specify an integer field that must be in the range 0 to 100. The length of a sequence of values (an array) can also be specified, either as a fixed length or a range of permitted lengths. Constraints can also be specified as logical combinations of sets of basic constraints.
Values used as constraints can either be literals used in the PDU specification, or ASN.1 values specified elsewhere in the schema file. Some ASN.1 tools will make these ASN.1 values available to programmers in the generated source code. Used as constants for the protocol being defined, developers can use these in the protocol’s logic implementation. Thus all the PDUs and protocol constants can be defined in the schema, and all implementations of the protocol in any supported language draw upon those values. This avoids the need for developers to hand code protocol constants in their implementation’s source code. This significantly aids protocol development; the protocol’s constants can be altered in the ASN.1 schema and all implementations are updated simply by recompiling, promoting a rapid and low risk development cycle.
If the ASN.1 tools properly implement constraints checking in the generated source code, this acts to automatically validate protocol data during program operation. Generally ASN.1 tools will include constraints checking into the generated serialization / deserialization routines, raising errors or exceptions if out-of-bounds data is encountered. It is complex to implement all aspects of ASN.1 constraints in an ASN.1 compiler. Not all tools support the full range of possible constraints expressions. XML schema and JSON schema both support similar constraints concepts. Tool support for constraints varies. Microsoft’s xsd.exe compiler ignores them.
ASN.1 is visually similar to Augmented Backus-Naur form (ABNF), which is used to define many Internet protocols like HTTP and SMTP. However, in practice they are quite different: ASN.1 defines a data structure, which can be encoded in various ways (e.g. JSON, XML, binary). ABNF, on the other hand, defines the encoding («syntax») at the same time it defines the data structure («semantics»). ABNF tends to be used more frequently for defining textual, human-readable protocols, and generally is not used to define type–length–value encodings.
Many programming languages define language-specific serialization formats. For instance, Python’s «pickle» module and Ruby’s «Marshal» module. These formats are generally language specific. They also don’t require a schema, which makes them easier to use in ad hoc storage scenarios, but inappropriate for communications protocols.
JSON and XML similarly do not require a schema, making them easy to use. They are also both cross-platform standards that are broadly popular for communications protocols, particularly when combined with a JSON schema or XML schema.
Some ASN.1 tools are able to translate between ASN.1 and XML schema (XSD). The translation is standardised by the ITU. This makes it possible for a protocol to be defined in ASN.1, and also automatically in XSD. Thus it is possible (though perhaps ill-advised) to have in a project an XSD schema being compiled by ASN.1 tools producing source code that serializes objects to/from JSON wireformat. A more practical use is to permit other sub-projects to consume an XSD schema instead of an ASN.1 schema, perhaps suiting tools availability for the sub-projects language of choice, with XER used as the protocol wireformat.
For more detail, see Comparison of data serialization formats.
See also[edit]
- X.690
- Information Object Class (ASN.1)
- Presentation layer
References[edit]
- ^ «Introduction to ASN.1». ITU. Archived from the original on 2021-04-09. Retrieved 2021-04-09.
- ^ «ITU-T Recommendation database». ITU. Retrieved 2017-03-06.
- ^ ITU-T X.680 — Specification of basic notation
- ^ ITU-T X.690 — Basic Encoding Rules (BER)
- ^ ITU-T X.690 — Distinguished Encoding Rules (DER)
- ^ ITU-T X.690 — Canonical Encoding Rules (CER)
- ^ a b c d ITU-T X.691 — Packed Encoding Rules (PER)
- ^ a b c ITU-T X.693 — XML Encoding Rules (XER)
- ^ a b ITU-T X.696 — Octet Encoding Rules (OER)
- ^ ITU-T X.697 — JavaScript Object Notation Encoding Rules (JER)
- ^ RFC 3641 — Generic String Encoding Rules (GSER)
External links[edit]
- A Layman’s Guide to a Subset of ASN.1, BER, and DER A good introduction for beginners
- ITU-T website — Introduction to ASN.1
- A video introduction to ASN.1
- ASN.1 Tutorial Tutorial on basic ASN.1 concepts
- ASN.1 Tutorial Tutorial on ASN.1
- An open-source ASN.1->C++ compiler; Includes some ASN.1 specs., An on-line ASN.1->C++ Compiler
- ASN.1 decoder Allows decoding ASN.1 encoded messages into XML output.
- ASN.1 syntax checker and encoder/decoder Checks the syntax of an ASN.1 schema and encodes/decodes messages.
- ASN.1 encoder/decoder of 3GPP messages Encodes/decodes ASN.1 3GPP messages and allows easy editing of these messages.
- Free books about ASN.1
- List of ASN.1 tools at IvmaiAsn project
- Overview of the Octet Encoding Rules (OER)
- Overview of the JSON Encoding Rules (JER)
- A Typescript node utility to parse and validate ASN.1 messages
Ошибка ЭДО
Добрый день всем. При создании электронного документа выдает такую ошибку.
1С:Предприятие 8.3 (8.3.12.1685)
Бухгалтерия предприятия, редакция 3.0 (3.0.67.43)
Режим : Серверный, PostgreSQL
Не удается создать электронный документ, выдает ошибку: «Выполнение операции: Заполнение XDTO.
Ошибка установки значения свойства «НалСт».
Подробности см. в журнале регистрации.»
Сообщения из журнала регистрации:
Выполнение операции: Заполнение XDTO.
Ошибка установки значения свойства «НалСт».
: Ошибка при вызове метода контекста (Установить)
ОбъектXDTO.Установить(ИмяСвойства, Значение);
по причине:
Несоответствие типов XDTO
по причине:
Ошибка проверки данных XDTO:
Значение: ‘20%’ не соответствует простому типу:
Значение не соответствует значениям фасета перечисления
Выполнение операции: Формирование ЭД.
: Выполнение операции: Заполнение XDTO.
Ошибка установки значения свойства «НалСт».
Создаем свой ЯЗЫК ПРОГРАММИРОВАНИЯ. Лексер, Парсер, Абстрактное синтаксическое дерево (AST)
ВызватьИсключение ЭлектронноеВзаимодействиеСлужебный.СоединитьОшибки(Ошибки);
Помогите пожалуйста, может кто сталкивался с данной проблемой
Источник: buh.ru
Windows 10, PowerShell: файл сертификата открытого ключа (X.509) изнутри
Раньше я не уделял внимания формату файла сертификата открытого ключа. Теперь я немного покопался в этом формате и нашел там для себя много нового и интересного. В этой статье я не ставлю себе цель описать формат файла сертификата во всей полноте (это слишком большая работа; кроме того, эта работа уже сделана в тексте соответствующего стандарта), но хочу отметить некоторые интересные моменты.
Стандарты
Формат сертификата открытого ключа описан в стандарте «X.509», который создан «Международным союзом электросвязи» (сокращенно «МСЭ», по-английски «ITU»). Точнее, над стандартом работали и работают в отделе (секторе) стандартизации электросвязи этой организации (по-английски «ITU-T», в прошлом веке он назывался «CCITT»).
Первая версия (редакция) этого стандарта появилась в 1988 году, а сейчас актуальна версия 9 от 2019 года. Над стандартом продолжают работать. Однако, насколько я понимаю, сейчас в интернете больше ориентируются на документ «RFC 5280» (над документами «RFC» работает «Инженерный совет Интернета», по-английски «IETF»), адаптирующий стандарт «X.509» к реалиям интернета. Вроде бы, именно из документа «RFC 5280» появился термин «PKIX» (инфраструктура открытых ключей [PKI] на базе стандарта «X.509»). Документ «RFC 5280» вышел в 2008 году, в нем идет речь о реализации версии 3 стандарта «X.509» (эта версия разрабатывалась в период 1997-2004 годов).
Файл для анализа и инструменты анализа
Я создал из диспетчера веб-сервера IIS самозаверенный сертификат открытого ключа для тестирования работы с локальным сайтом по протоколу HTTPS. Этот файл я и буду тут анализировать.
Ошибка построения пути сертификации
В качестве инструмента для анализа я в основном использую программу-оболочку «PowerShell» версии 7. Напомню, я работаю в операционной системе «Windows 10».
Иногда заглядываю в сохраненные консоли «certlm.msc» (хранилище сертификатов компьютера, для работы требуются права администратора компьютера) и «certmgr.msc» (хранилище сертификатов текущего пользователя, для работы достаточно прав текущего пользователя). Их легко можно вызвать прямо из командной строки из любого местоположения с помощью команд certlm и certmgr , так как эти файлы хранятся в системной папке %windir%System32 . Файлы сохраненных консолей с расширением «.msc» по умолчанию привязаны (их имена при запуске передаются в качестве входного параметра) к исполняемому файлу «mmc.exe» (компонента «Консоль управления Microsoft» операционной системы), который тоже хранится в системной папке %windir%System32 .
Просмотр хранилищ сертификатов и сертификатов в них из «PowerShell»
В файловых системах операционных систем «Windows» обычно бывает несколько «корней» (в отличие от Unix-подобных операционных систем; там в файловой системе один «корень»), которые обозначают латинскими буквами с двоеточием (например, «A:», «C:», «D:» и так далее) и называют «логическими дисками» (или «томами»), по-английски «logical drive» (или «volume»).
В принципе, слово «том» кажется теперь более правильным, потому что слова «диск» и «привод» тянутся со времен, когда запоминающие устройства (накопители) были в основном с магнитными дисками и с подвижными частями, которые приводились в движение «приводами». У нас сейчас многие переводят с английского языка слово «drive» как «диск», хотя «drive» — это «привод». Во многих случаях буквенные обозначения томов соответствуют реальным физическим устройствам-накопителям, поэтому их часто называют словом «drive».
В документации программы-оболочки «PowerShell» буквенные обозначения томов называют «file system drive» (том файловой системы).
По принципу томов файловой системы в языке «PowerShell» существуют так называемые «провайдеры» или «поставщики» (по-английски «provider»). У этих провайдеров тоже есть «приводы»: это короткие слова или даже части слов (или аббревиатуры), которые используются для предоставления (обеспечения, поставки) быстрого и простого доступа к данным или компонентам, доступ к которым другими способами затруднен. Например, для доступа к переменным среды можно использовать привод «Env:» провайдера переменных среды, для доступа к реестру Windows можно использовать приводы «HKLM:» и «HKCU:» провайдера реестра и так далее. См. статью «about_Providers» документации программы-оболочки «PowerShell».
Для доступа к хранилищам сертификатов и сертификатам в этих хранилищах можно использовать привод Cert: провайдера сертификатов. При этом с хранилищами сертификатов можно работать так же, как с обычными папками файловой системы (напомню, хранилища сертификатов не соответствуют какой-либо папке файловой системы, это просто что-то вроде фильтра, инструмента, который собирает сведения о цифровых сертификатах, физически хранящихся в разных местах на компьютере), а с сертификатами можно работать так же, как с обычными файлами в файловой системе. Удобно продолжать использовать псевдонимы cd (сменить папку) и dir (показать список файлов и папок в текущей папке) командлетов Set-Location и Get-ChildItem соответственно. См. статью «about_Certificate_Provider» документации «PowerShell».
Итак, в командной строке программы-оболочки «PowerShell» перейдем в том Cert: и выведем список хранилищ сертификатов. Вот как это выглядит у меня:
PS C:> cd Cert: PS Cert:> dir Location : CurrentUser StoreNames : Location : LocalMachine StoreNames :
Это те самые два главных хранилища сертификатов, которые описаны, к примеру, в статье «Working with Certificates» на сайте компании «Microsoft»: хранилище сертификатов текущего пользователя и хранилище сертификатов компьютера. Под названием каждого из этих хранилищ виден массив названий подхранилищ (каждый массив завершается многоточием, которое обозначает то, что все названия из массива не влезли в отведенную строку).
Теперь можно последовательно перейти к нужному хранилищу (подхранилищу) сертификатов, либо можно сразу перейти к нужному подхранилищу, набрав полный путь (если вы уже сразу знаете нужный путь целиком):
PS C:> cd Cert:LocalMachineMy PS Cert:LocalMachineMy> dir PSParentPath: Microsoft.PowerShell.SecurityCertificate::LocalMachineMy Thumbprint Subject EnhancedKeyUsageList ———- ——- ——————— D4A1741E3ACC4C8A89E5F7AA7901D8FE1C95C013 CN=IlyaComp Проверка подлинности сервера
Как видно из кода выше, в подхранилище Cert:LocalMachineMy есть только один сертификат открытого ключа. Команда dir уже вывела таблицу с тремя свойствами этого сертификата в окно терминала.
Но следует понимать, что у сертификата гораздо больше свойств, чем три. Просто остальные свойства не поместились по ширине в окно терминала. Для вывода всех свойств сертификата есть более удобные способы, чем способ по умолчанию.
Просмотр всех свойств сертификата из «PowerShell»
К конкретному сертификату можно обратиться по его так называемому «отпечатку» (thumbprint). Как видно из кода выше, отпечаток представляет собой довольно длинное шестнадцатеричное число. Очевидно, что при использовании его лучше скопировать, а не набирать вручную.
Итак, для удобства сохраним нужный объект сертификата в переменную $c , чтобы не обращаться каждый раз к длиннющему отпечатку сертификата. Затем через оператор конвейера (pipeline) | передадим объект сертификата командлету Format-List , который выведет все свойства сертификата в окно терминала в виде списка (символ звездочки * обозначает вывод всех свойств сертификата, но этому командлету можно передать ограниченный список свойств, чтобы вывести только те, которые нужны в данный момент):
PS Cert:LocalMachineMy> $c = Get-Item D4A1741E3ACC4C8A89E5F7AA7901D8FE1C95C013 PS Cert:LocalMachineMy> $c | Format-List *
PSPath : Microsoft.PowerShell.Security Certificate::LocalMachineMy D4A1741E3ACC4C8A89E5F7AA7901D8FE1C95C013 PSParentPath : Microsoft.PowerShell.SecurityCertificate::LocalMachineMy PSChildName : D4A1741E3ACC4C8A89E5F7AA7901D8FE1C95C013 PSDrive : Cert PSProvider : Microsoft.PowerShell.SecurityCertificate PSIsContainer : False EnhancedKeyUsageList : DnsNameList : SendAsTrustedIssuer : False EnrollmentPolicyEndPoint : Microsoft.CertificateServices.Commands.EnrollmentEndPointProperty EnrollmentServerEndPoint : Microsoft.CertificateServices.Commands.EnrollmentEndPointProperty PolicyId : Archived : False Extensions : FriendlyName : localhost HasPrivateKey : True PrivateKey : IssuerName : System.Security.Cryptography.X509Certificates.X500DistinguishedName NotAfter : 20.10.2023 3:00:00 NotBefore : 20.10.2022 17:56:04 PublicKey : System.Security.Cryptography.X509Certificates.PublicKey RawData : SerialNumber : 4931C370DB54C8B8426A88B0D254E17E SignatureAlgorithm : System.Security.Cryptography.Oid SubjectName : System.Security.Cryptography.X509Certificates.X500DistinguishedName Thumbprint : D4A1741E3ACC4C8A89E5F7AA7901D8FE1C95C013 Version : 3 Handle : 2125934225808 Issuer : CN=IlyaComp Subject : CN=IlyaComp
Как видно из кода выше, для некоторых свойств, которые попроще, в списке сразу выводятся значения этих свойств. Для свойств, в которых записана ссылка на объект, выводится только тип объекта. Чтобы просмотреть записанный в таком свойстве объект, нужно забираться поглубже. Значением некоторых свойств является массив байтов, в этом случае значения байтов в массиве выводятся через запятую. В некоторые свойства не записано никакого значения, поэтому их значение равно значению $null (в списке выше напротив названий таких свойств после двоеточия ничего не выведено).
В свойстве Version записано значение 3 . Насколько я понимаю, тут подразумевается версия 3 стандарта «X.509», о которой упоминалось в начале данной статьи.
В этот раз меня в первую очередь интересовали свойства, в которых может содержаться информация об именах и названиях: DnsNameList , Extensions , FriendlyName , IssuerName , SubjectName , Issuer и Subject .
При анализе значений свойств сертификата может понадобиться умение читать содержимое массивов байтов. Это не очень сложно, если знать, по каким стандартам эти байтовые массивы в значениях свойств сертификата организованы и где можно удобно просмотреть стандарты, почитать соответствующие справочники. Ниже я покажу, как можно это делать, на примере свойства IssuerName («имя издателя», то есть имя сущности, создавшей и заверившей данный сертификат открытого ключа).
Читаем байтовый массив
Как видно из списка свойств сертификата выше, свойство IssuerName содержит ссылку на объект класса System.Security. Cryptography. X509Certificates. X500DistinguishedName . Просмотрим список свойств со значениями для этого объекта:
PS Cert:LocalMachineMy> $c.IssuerName | Format-List * Name : CN=IlyaComp Oid : System.Security.Cryptography.Oid RawData :
Очевидно, что значение свойства Issuer сертификата в данном случае совпадает со значением поля Name свойства IssuerName сертификата. Но мне стало интересно, что содержится в поле RawData свойства IssuerName сертификата. Видно, что там содержится массив байтов. Но что они означают?
Сначала я предположил, что там записано то же самое, что в поле Name . И действительно, часть байтового массива содержит строку IlyaComp в кодировке UTF-8. Но там есть и что-то еще. С налета разобраться в этом не получилось, поэтому я приступил к подробному анализу. Получим в окно терминала полное содержимое разбираемого массива байтов:
PS Cert:LocalMachineMy> «» + $c.IssuerName.RawData 48 19 49 17 48 15 6 3 85 4 3 19 8 73 108 121 97 67 111 109 112
По умолчанию программа-оболочка «PowerShell» выводит массив «вертикально», то есть выделяя для каждого элемента массива отдельную строку. Это неудобно. Для вывода элементов массива «горизонтально» (в одной строке) я применяю в коде выше конкатенацию пустой строки и анализируемого массива.
Следует иметь в виду, что по умолчанию значения байтов выводятся в десятичной системе счисления. Это неудобно. Для анализа байтовых массивов принято пользоваться значениями в шестнадцатеричной системе счисления. Выведем значения байтов из байтового массива в виде чисел в шестнадцатеричной системе счисления. В языке PowerShell это сделать несложно:
PS Cert:LocalMachineMy> «» + ($c.IssuerName.RawData | ForEach-Object ToString x2) 30 13 31 11 30 0f 06 03 55 04 03 13 08 49 6c 79 61 43 6f 6d 70
В вышеприведенном коде передаем элементы массива байтов через конвейер (pipeline) | командлету ForEach-Object , который применяет к каждому входящему элементу массива (байту) метод System.Byte.ToString . Этот метод преобразует значение байта (целое число) в строку в указанном формате. В данном случае в качестве указания формата в метод System.Byte.ToString передаем строку x2 .
В этой строке формата латинская буква х указывает на вывод числа в шестнадцатеричной системе счисления (регистр буквы х в данном случае имеет значение, от него зависит регистр букв, которыми будут обозначены шестнадцатеричные цифры a, b, c, d, e, f). Число 2 указывает на число цифр в выводимых шестнадцатеричных числах. Очевидно (если вы понимаете, как сочетаются двоичная и шестнадцатеричная системы счисления), что для обозначения значения каждого байта нужно шестнадцатеричное число из двух цифр. (Тут подробнее про настройку форматирования чисел в строке.)
Язык ASN.1, способ сериализации DER и дерево идентификаторов объектов OID
Как оказалось, заполнение байтовых массивов в значениях сертификата открытого ключа по стандарту «X.509» выполняется на языке описания абстрактного синтаксиса данных «ASN.1» (расшифровывается как «Abstract Syntax Notation One»). Я немного о нем почитал и он мне понравился. Тут речь об «абстрактном синтаксисе» потому, что этот язык описывает любые структуры данных, независимо от конкретного языка программирования. Этот язык был создан в 1984 году и до сих пор разрабатывается уже упоминавшейся выше организацией «ITU-T».
Кроме описания структур данных в этом языке описаны разные способы сериализации полученного описания данных. Под словом «сериализация» подразумевают перевод данных в последовательность байтов (или в «серию» байтов, откуда и произошел термин «сериализация»). Там описано более десятка разных способов. Для сертификатов открытого ключа по стандарту «X.509» применяется способ сериализации DER (Distinguished Encoding Rules). Тут подробнее: раздел «Encodings» англоязычной статьи википедии «ASN.1», про способ сериализации DER в англоязычной статье википедии про стандарт «X.690», статья «A Warm Welcome to ASN.1 and DER» на сайте «Let’s Encrypt».
Давайте посмотрим, как это работает на практике на примере байтового массива, который я получил выше.
При сериализации по методу «DER» согласно языка «ASN.1» применяется известный метод записи данных «TLV» (расшифровывается как «type-length-value» или «tag-length-value»). По-русски название этого метода можно озвучить как «тип-длина-значение». Согласно этого метода данные (в том числе вложенные) записываются в указанном порядке: сначала тип данных, потом — длина данных в байтах, и, наконец, значение (собственно, сами данные).
Будем последовательно применять это правило для расшифровки вышеуказанного массива байтов. Возьмем первые два байта:
30 13 31 11 30 0f 06 03 55 04 03 13 08 49 6c 79 61 43 6f 6d 70 30 — SEQUENCE (тип данных) 13 — размер данных: 19₁₀ байтов данные: 31 11 30 0f 06 03 55 04 03 13 08 49 6c 79 61 43 6f 6d 70
Первый байт нашего массива со значением 30 в языке «ASN.1» означает тип данных «SEQUENCE» (набор данных разных типов; например, в языке Си эквивалентом этого типа данных является тип struct ). Кстати, для быстрого ознакомления с языком «ASN.1» рекомендую ознакомиться с большой обзорной статьей «A Warm Welcome to ASN.1 and DER» на сайте известного бесплатного центра сертификации «Let’s Encrypt». Эта статья очень удобна для начинающих, там есть разные таблицы соответствия, например, значений байтов и типов данных.
Как видно из кода выше, в нашем случае в байтовом массиве записана структура данных типа «SEQUENCE», имеющая размер в 13 (шестнадцатеричная система) байтов или 19 (десятичная система) байтов. Данными являются 19 байтов, идущие после байта, указывающего размер данных. Если посчитать, получается, что весь остаток массива, кроме первых двух байт, имеет размер в 19 байт, следовательно, кроме структуры данных «SEQUENCE» в наш массив больше ничего не записано.
Продолжим расшифровку. Возьмем следующие два байта.
SEQUENCE
Тип данных «SET» в языке «ASN.1», в принципе, похож на «SEQUENCE», только в данных типа «SEQUENCE» (последовательность) порядок вложенных элементов сохраняется (важен), а в данных типа «SET» (множество) порядок вложенных элементов не сохраняется (не имеет значения). Перейдем к следующим двум байтам (думаю, принцип действия метода «type-length-value» к этому моменту уже должен был проясниться).
SEQUENCE < SET < 30 0f 06 03 55 04 03 13 08 49 6c 79 61 43 6f 6d 70 30 — SEQUENCE (тип данных) 0f — размер данных: 15₁₀ байтов данные: 06 03 55 04 03 13 08 49 6c 79 61 43 6f 6d 70 >>
SEQUENCE < SET < SEQUENCE < 06 03 55 04 03 13 08 49 6c 79 61 43 6f 6d 70 06 — OBJECT IDENTIFIER (тип данных) 03 — размер данных: 3₁₀ байта данные: 55 04 03 13 — PrintableString (тип данных) 08 — размер данных: 8₁₀ байтов данные: 49 6c 79 61 43 6f 6d 70 >> >
На этом шаге расшифровки получилось, что в структуру данных типа «SEQUENCE» входит сразу два вложенных элемента данных: типа «OBJECT IDENTIFIER» и типа «PrintableString». Второй из них — это тип данных, эквивалентный обычной строке. В данном случае в 8 байтах 49 6c 79 61 43 6f 6d 70 закодировано имя IlyaComp в кодировке UTF-8.
Под типом данных «OBJECT IDENTIFIER» (сокращенно «OID») подразумевают стандартизированное уже несколько раз упоминавшейся организацией «ITU» и международной организацией по стандартизации «ISO/IEC» дерево идентификаторов объектов. В интернете есть ряд сайтов, предоставляющих возможность просмотреть это дерево объектов и найти нужный объект. Например: http://oidref.com.
Каждый идентификатор объекта представляет собой набор номеров пунктов (веток дерева, целых чисел) через точку. В нашем случае в трех байтах 55 04 03 закодирован идентификатор объекта из четырех чисел. Первые два числа X и Y идентификатора объекта кодируются по формуле 40₁₀ * X + Y в первый байт данных, представляющих идентификатор объекта. Раскодируем идентификатор объекта:
В идентификаторе объекта все пункты имеют определенное значение:
- 2 — ветка дерева, общая для организаций «ISO» и «ITU-T»;
- 2.5 — ветка дерева, представляющая службы каталогов;
- 2.5.4 — ветка дерева, представляющая типы атрибутов (свойств) объектов в службах каталогов;
- 2.5.4.3 — ветка дерева, представляющая тип «Common name» атрибута (сокращенно «CN»).
Результат расшифровки байтового массива:
SEQUENCE < SET < SEQUENCE < OBJECT IDENTIFIER: 2.5.4.3 (Common name) PrintableString: «IlyaComp» >> >
Это же коротко записано как CN=IlyaComp и в виде строки содержится в поле Name свойства IssuerName сертификата открытого ключа, а также в свойствах Issuer и Subject сертификата.
Источник: habr.com
Абстрактное описание синтаксиса
ASN.1 обеспечивает стандартный способ представления данных и кодирования их для передачи по сети. Основу модели SNMP составляет множество объектов, которые станции управления могут считывать и записывать при помощи агентов.
ASN.1 обеспечивает стандартный способ представления данных и кодирования их для передачи по сети.
Основу модели SNMP составляет множество объектов, которые станции управления могут считывать и записывать при помощи агентов. Чтобы устройства различных производителей могли сообщать и понимать управляющую информацию, объекты должны быть определены стандартным, не зависящим от производителя образом. Кроме того, они должны единообразно кодироваться при передаче по сети.
Иными словами, SNMP необходим стандартный язык описания объектов вместе с правилами кодирования. Этот язык — абстрактное описание синтаксиса (Abstract Syntax Notation One, ASN.1) — разработчики SNMP заимствовали из стандартов OSI. ASN.1 представляет собой высокоуровневый язык описания типов данных и определяет формат сообщений SNMP при передаче их между агентами и станциями управления. Как и большая часть OSI, он обширен, сложен и не очень эффективен.
Сам язык описания данных определен в стандарте Международной организации по стандартизации (International Standard Organization, ISO) за номером 8824 под названием «Спецификация абстрактного описания синтаксиса, один», а правила кодирования закреплены в стандарте 8825 под названием «Спецификация базовых правил кодирования для ASN.1». Абстрактный синтаксис ASN.1 позволяет определять базовые объекты и затем объединять их в более сложные. Декларации в ASN.1 с функциональной точки зрения схожи с декларациями из файлов-заголовков для программ на С.
АБСТРАКТНЫЙ СИНТАКСИС
SNMP вводит свои условные обозначения, несколько отличные от ASN.1. Базовые типы данных записывают строчными буквами (например, целочисленный тип данных — как INTEGER). Определяемые пользователем типы данных начинаются со строчной буквы, но при этом они должны содержать по крайней мере один символ, отличный от строчной буквы.
Идентификаторы переменных начинаются с прописной буквы, при этом они могут содержать прописные и строчные буквы, цифры и дефисы. Пробелы (знаки табуляции, переноса строки и т. п.) не учитываются. Комментарии начинаются с «- -» (двойного дефиса) и заканчиваются либо вместе с концом строки, либо той же последовательностью символов «- -«.
Допустимые в SNMP базовые типы данных ASN.1 приведены в Таблице 1. Переменная типа INTEGER может в теории принимать любое целочисленное значение, но область ее значений ограничивают другие правила SNMP. В качестве примера использования типов мы рассмотрим, как переменная counter типа INTEGER декларируется и (если необходимо) инициализируется значением, равным 0.
counter INTEGER ::= 0
Очень часто переменную требуется ограничить конкретными значениями или конкретным диапазоном. Это можно сделать посредством определения необходимого подтипа следующим образом:
Status ::= INTEGER < on(1), off(2), unknown(3) >
PacketSize ::= INTEGER (0..1023)
Переменные типа BIT STRING и OCTET STRING представляют собой строку из 0 и более бит или байт, соответственно. Для обоих типов пользователь может задать длину строки и начальное значение. Тип OBJECT IDENTIFIER позволяет идентифицировать объекты. Любой объект в любом официальном стандарте может быть идентифицирован уникальным образом.
Данная цель достигается за счет введения дерева стандартов, при этом каждый объект соответствующего стандарта получает свое место в дереве. Верхний уровень дерева составляют наиболее важные в мире (с точки зрения ISO) организации, а именно ISO и CCITT (теперь ITU), а также их объединение.
Нас интересует прежде всего четвертая ветвь ISO с идентификатором identified-organization(3) (признанные организации по стандартизации), далее dod(6) (Министерство обороны США), а затем internet(1). Ветвь internet содержит четыре ветви. Объекты базы управляющей информации находятся под ветвью mgmt (см. Рисунок 1).
Помимо текстового идентификатора (label) каждая ветвь имеет свой числовой идентификатор (number). Объект может записываться с использованием текстовых или числовых идентификаторов в любой их комбинации. Как видно из описанной структуры, все объекты базы управляющей информации имеют общий префикс
iso.identified-organization.
dod.internet.mgmt.mib-2
или
или
и т. п. Таким образом, любой объект может быть представлен с помощью идентификатора объекта.
Рисунок 1. Каждый объект может быть идентифицирован уникальным образом.
ASN.1 описывает несколько способов создания новых типов данных. Прежде всего, это использование простых составных типов данных (SNMP задействует только три из них). SEQUENCE — это упорядоченный список типов, подобный структуре в С, SEQUENCE OF — одномерный массив переменных одного типа, а CHOICE — объединение из заданного списка типов.
Другой способ состоит в назначении тэгов имеющимся типам данных. Тэги подразделяются на четыре класса или категории: универсальный (universal), общеприкладной (application-wide), контекстно-зависимый (context-specific) и частный (private). Каждый тэг состоит из метки и целочисленного идентификатора, например:
IpAddress ::= [APPLICATION 0] OCTET STRING (SIZE (4))
определяет общеприкладной тип данных в виде строки байт длиной в 4 октета.
ASN.1 описывает сложный механизм макросов, активно используемый в SNMP. Макрос может служить в качестве своего рода прототипа для создания множества новых типов и значений, каждого со своим собственным синтаксисом. Каждый макрос определяет несколько (возможно, необязательных) ключевых слов, используемых при вызове для идентификации параметров (иными словами, параметры макроса идентифицируются не по местоположению, а по ключевому слову).
БАЗОВЫЕ ПРАВИЛА КОДИРОВАНИЯ
Транспортный синтаксис ASN.1 определяет однозначный способ преобразования значений переменных допустимых типов в последовательность байт для передачи по сети. В ASN.1 он называется базовыми правилами кодирования (Basic Encoding Rules, BER). Правила являются рекурсивными, так что кодирование составных объектов представляет собой составление в цепочку закодированных последовательностей составляющих объектов.
Каждое передаваемое значение — как базового, так и производного типа — состоит из трех полей:
- идентификатор;
- длина поля данных (в байтах);
- поле данных.
В отличие от ASN.1, протокол SNMP требует всегда указывать длину поля данных, поэтому флаг конца поля данных не используется.
Первое поле состоит в действительности из трех полей (см. Рисунок 2). Два старших бита идентифицируют тип тэга (или, в иной терминологии, класса). Значения поля 00, 01, 10 и 11 соответствуют тэгам Universal, Application, Context-specific и Private. Следующий бит определяет принадлежность переменной к базовому или производному типу данных — 0 для базового, 1 — для производного.
Оставшиеся 5 бит могут использоваться для кодирования значения тэга (кода), не превышающего 30. Если значение тэга равно 31 или больше, то пять младших бит содержат одни единицы (11111), а реальное значение дается в следующем байте или байтах.
Рисунок 2. Первый байт всякого передаваемого элемента данных в соответствии с синтаксисом ASN.1.
Используемые правила для кодирования значений, больших 30, позволяют справляться с произвольно большими числами. Каждый последующий байт содержит 7 бит данных, а старший бит задается равным 0 во всех байтах, за исключением последнего. Таким образом, значения тэга до 27-1 могут быть переданы с помощью двух байт.
| Тип переменной | Описание | Код |
| INTEGER | Целое число произвольной длины | 2 |
| BIT STRING | Строка из 0 или более бит | 3 |
| OCTET STRING | Строка из 0 или более байт | 4 |
| NULL | Держатель места | 5 |
| OBJECT IDENTIFIER | Официально определенный тип данных | 6 |
Таблица 1 — Базовые типы переменных, допустимые в SNMP
Значение третьего поля зависит от значения первого поля. Например, базовые и простые составные типы данных принадлежат к классу Universal. Каждый базовый тип имеет свой код, как указано в третьей колонке в Таблице 1, SEQUENCE и SEQUENCE OF имеют один и тот же код 16, а CHOICE не имеет своего кода, так как реальное значение всегда принадлежит к определенному типу. Именно присвоенный код указывается в третьем поле.
Поле длины данных указывает, сколько байт занимают данные. Если данные короче 128 байт, то их длина может быть выражена при помощи одного байта, при этом значение крайнего левого бита будет равно 0. Если данные оказываются длиннее, то первый байт содержит 1 в старшем бите и длину поля длины данных (до 127 байт) в младших 7 битах. Например, если длина данных равна 1000 байт, то первый байт поля длины данных будет содержать 130, т. е. он сообщает принимающей стороне о том, что за ним следует еще два байта поля длины данных. Последующие два байта содержат действительное значение длины данных — 1000, при этом старший байт идет первым.
Кодирование поля данных зависит от конкретного типа данных. Целые числа кодируются при помощи дополнительного кода. Положительное целое число менее 128 кодируется при помощи одного байта и т. д. Старший значащий байт передается первым.
Строки бит передаются, как есть. Единственная проблема в том, что поле длины данных указывает длину в байтах, а не в битах. Принятое решение состоит во вставке одного байта перед строкой битов с указанием, сколько бит последнего байта не используются. Например, строка «010011111» длиной 9 бит будет иметь вид 07, 4F, 80 (в шестнадцатеричном представлении).
Строка байт передается справа налево — сначала старшие, а потом младшие байты. Нулевое значение указывается посредством задания поля длины данных равным 0. Никакое числовое значение реально не передается.
OBJECT IDENTIFIER кодируется в виде последовательности целых чисел, из которых он состоит. Например, ветвь mib-2 имеет префикс . Однако, поскольку первое число всегда равно 0, 1 или 2, а второе — меньше 40 (как определено ISO), первые два числа, х и y, кодируются с помощью одного байта в виде 40x+y. Таким образом, для mib-2 первый байт равен 43. Числа более 127 кодируются с помощью нескольких байт, первый бит числа задается равным 1, а количество следующих байт — в оставшихся 7 битах.
Оба типа SEQUENCE передаются следующим образом: сначала тип или тэг, затем общая длина всех последующих полей и, наконец, сами поля по порядку. Кодирование значения переменной типа CHOICE производится в соответствии с реальным передаваемым типом данных.
СТРУКТУРА УПРАВЛЯЮЩЕЙ ИНФОРМАЦИИ
Выше мы кратко рассмотрели только те части ASN.1, что используются в SNMP. В действительности документы по SNMP организованы иным образом. Так, в RFC 1442 вначале говорится, что структуры данных в SNMP будут описываться с помощью ASN.1, а затем на более чем 50 страницах перечисляются неиспользуемые части ASN.1 и вводятся новые определения.
В частности, RFC 1442 определяет четыре основных макроса и восемь новых типов данных, активно используемых в SNMP. Это своего рода надподмножество ASN.1 известно под именем структуры управляющей информации (Structure of Management Information, SMI). Оно и применяется на практике для определения структур данных SNMP.
На самом нижнем уровне переменные SNMP определяются как отдельные объекты. Взаимосвязанные объекты объединяются в группы, а группы собираются в модули. Например, объекты IP и объекты TCP имеют каждый свою группу.
Маршрутизатор может поддерживать группу IP, так как он должен предоставлять информацию, например, о потерянных пакетах, но не группу TCP, так как он функционирует на более низком уровне. Если какое-то устройство поддерживает определенную группу, то оно должно поддерживать и все объекты из этой группы. Однако поддержка производителем определенного модуля не налагает на него ответственности по поддержке всех групп этого модуля, так как не все они могут иметь отношение к конкретному устройству.
Модули MIB запускаются посредством вызова макроса MODULE-IDENTITY. Его параметры сообщают имя и адрес разработчика, данные о версии и другую информацию. За ним обычно следует вызов макроса OBJECT-TYPE, сообщающего реальные используемые переменные и их свойства.
Источник: www.osp.ru
Русские Блоги
Структура сертификата X.509 состоит в том, чтобы описать структуру данных с ASN1 (абстрактным синтаксическим обозначением) и кодирует использование синтаксиса ASN1.
Опишите грамматику ASN.1 следующим образом:
Certificate::=SEQUENCE
Где алгоритм подписи является CA tbsCertificate Алгоритм, используемый для подписей; Algorithm Identifier Грамматическое описание ASN.1 выглядит следующим образом:
AlgorithmIdentifier::=SEQUENCE
Содержание сертификата — это информация, которая должна быть подписана CA, а синтаксис ASN.1 выглядит следующим образом:
TBSCertificate::=SEQUENCE
среди них, issuerUniqueID с участием subjectUniqueID Может появиться только в версии 2 или 3; extensions Может появиться только в версии 3.
ASN1 использует блок данных для описания всей структуры данных, каждый из которых состоит из четырех частей:
1. Тип данных ID (один байт)
Простой тип больше не разложимый тип, такой как целочисленная, битовая строка, ветку октета, идентификатор объекта, дата (NUTCTIME) и т. Д.;
Структурный тип объединяется простым типом и структурным типом, таким как последовательность, последовательность, выберите тип (выбор), сбор и так далее.
- Значение блока передачи данных последовательности типа состоит из последовательных последовательных значений блока данных элементов;
- Выбор значения блока данных выбранного типа Выбирает значение блока данных в нескольких типах блоков данных элементов;
- Установленный тип блока данных построен одним или несколькими значениями типа блока данных элементов.


2. Длина блока данных (1-128 байт)
- Если длина меньше или равно 127, используйте байт;
- Если длина превышает 127, используются множество байтов. Первый байт до 1, а оставшиеся семь битов дают фактическую длину байта, начать хранение от второго байта;
- Если длина равна 128, определите патч длины блока данных, требующий идентификации конца блока данных, чтобы завершить блоку данных.
3. Значение блоков данных
Конкретные кодировки отличаются от типа блока данных.
4. Идентификация конца блока данных (необязательно)
Завершить поле маркера, два байта (0x0000), только тогда, когда значение длины неопределенно.
Структура данных кода
// Информация содержит продолжительность информации и указатель информации о информации, ISMALLC используется для отпускания контента до конца программы. struct info bool ismallc; int length; unsigned char* data; >; / / / Хранить аналитическую информацию vectorinfo>certInfo;
Объясните функцию обработки длины блока данных:
// Эта функция обрабатывает длину блока данных (1-128 байт) (Len — это длина, прочитанная из сертификата) int getLength(ifstream 128if (len 0x7F) return len; > // > 128 int lengthOflen = len ^ 0x80; unsigned char* bytes = new unsigned char[lengthOflen]; file.read((char*)bytes, lengthOflen); int length = 0; for(int i=0; ilengthOflen; i++) length = (length <8) + int(bytes[i]); > delete []bytes; return length; >
Результаты теста
Используйте команду Makecert для создания сертификата под Windows:
> makecert.exe -r -pe -$ individual -n «CN=liuyh73» -sky exchange -sr currentuser -ss my liuyh73.crt

[Примечание] При открытии исходного кода обратите внимание на использование формата кодирования GB2312, в противном случае он приведет к искажению.
Источник: russianblogs.com
ASN.1 обеспечивает стандартный способ представления данных и кодирования их для передачи по сети.
Основу модели SNMP составляет множество объектов, которые станции управления могут считывать и записывать при помощи агентов.
ASN.1 обеспечивает стандартный способ представления данных и кодирования их для передачи по сети.
Основу модели SNMP составляет множество объектов, которые станции управления могут считывать и записывать при помощи агентов. Чтобы устройства различных производителей могли сообщать и понимать управляющую информацию, объекты должны быть определены стандартным, не зависящим от производителя образом. Кроме того, они должны единообразно кодироваться при передаче по сети. Иными словами, SNMP необходим стандартный язык описания объектов вместе с правилами кодирования. Этот язык — абстрактное описание синтаксиса (Abstract Syntax Notation One, ASN.1) — разработчики SNMP заимствовали из стандартов OSI. ASN.1 представляет собой высокоуровневый язык описания типов данных и определяет формат сообщений SNMP при передаче их между агентами и станциями управления. Как и большая часть OSI, он обширен, сложен и не очень эффективен.
Сам язык описания данных определен в стандарте Международной организации по стандартизации (International Standard Organization, ISO) за номером 8824 под названием «Спецификация абстрактного описания синтаксиса, один», а правила кодирования закреплены в стандарте 8825 под названием «Спецификация базовых правил кодирования для ASN.1». Абстрактный синтаксис ASN.1 позволяет определять базовые объекты и затем объединять их в более сложные. Декларации в ASN.1 с функциональной точки зрения схожи с декларациями из файлов-заголовков для программ на С.
АБСТРАКТНЫЙ СИНТАКСИС
SNMP вводит свои условные обозначения, несколько отличные от ASN.1. Базовые типы данных записывают строчными буквами (например, целочисленный тип данных — как INTEGER). Определяемые пользователем типы данных начинаются со строчной буквы, но при этом они должны содержать по крайней мере один символ, отличный от строчной буквы. Идентификаторы переменных начинаются с прописной буквы, при этом они могут содержать прописные и строчные буквы, цифры и дефисы. Пробелы (знаки табуляции, переноса строки и т. п.) не учитываются. Комментарии начинаются с «- -» (двойного дефиса) и заканчиваются либо вместе с концом строки, либо той же последовательностью символов «- -«.
Допустимые в SNMP базовые типы данных ASN.1 приведены в Таблице 1. Переменная типа INTEGER может в теории принимать любое целочисленное значение, но область ее значений ограничивают другие правила SNMP. В качестве примера использования типов мы рассмотрим, как переменная counter типа
INTEGER
декларируется и (если необходимо) инициализируется значением, равным 0.
counter INTEGER ::= 0
Очень часто переменную требуется ограничить конкретными значениями или конкретным диапазоном. Это можно сделать посредством определения необходимого подтипа следующим образом:
Status ::= INTEGER { on(1), off(2), unknown(3) }
PacketSize ::= INTEGER (0..1023)
Переменные типа
BIT STRING
и
OCTET STRING
представляют собой строку из 0 и более бит или байт, соответственно. Для обоих типов пользователь может задать длину строки и начальное значение. Тип
OBJECT IDENTIFIER
позволяет идентифицировать объекты. Любой объект в любом официальном стандарте может быть идентифицирован уникальным образом. Данная цель достигается за счет введения дерева стандартов, при этом каждый объект соответствующего стандарта получает свое место в дереве. Верхний уровень дерева составляют наиболее важные в мире (с точки зрения ISO) организации, а именно ISO и CCITT (теперь ITU), а также их объединение. Нас интересует прежде всего четвертая ветвь ISO с идентификатором
identified-organization(3)
(признанные организации по стандартизации), далее
dod(6)
(Министерство обороны США), а затем
internet(1)
. Ветвь
internet
содержит четыре ветви. Объекты базы управляющей информации находятся под ветвью
mgmt
(см. Рисунок 1). Помимо текстового идентификатора (
label
) каждая ветвь имеет свой числовой идентификатор (
number
). Объект может записываться с использованием текстовых или числовых идентификаторов в любой их комбинации. Как видно из описанной структуры, все объекты базы управляющей информации имеют общий префикс
iso.identified-organization.
dod.internet.mgmt.mib-2
или
{1 3 6 1 2 1}
или
{internet(1) 2 1}
и т. п. Таким образом, любой объект может быть представлен с помощью идентификатора объекта.

Рисунок 1. Каждый объект может быть идентифицирован уникальным образом.
ASN.1 описывает несколько способов создания новых типов данных. Прежде всего, это использование простых составных типов данных (SNMP задействует только три из них). SEQUENCE — это упорядоченный список типов, подобный структуре в С, SEQUENCE OF — одномерный массив переменных одного типа, а CHOICE — объединение из заданного списка типов.
Другой способ состоит в назначении тэгов имеющимся типам данных. Тэги подразделяются на четыре класса или категории: универсальный (
universal
), общеприкладной (
application-wide
), контекстно-зависимый (
context-specific
) и частный (
private
). Каждый тэг состоит из метки и целочисленного идентификатора, например:
IpAddress ::= [APPLICATION 0] OCTET STRING (SIZE (4))
определяет общеприкладной тип данных в виде строки байт длиной в 4 октета.
ASN.1 описывает сложный механизм макросов, активно используемый в SNMP. Макрос может служить в качестве своего рода прототипа для создания множества новых типов и значений, каждого со своим собственным синтаксисом. Каждый макрос определяет несколько (возможно, необязательных) ключевых слов, используемых при вызове для идентификации параметров (иными словами, параметры макроса идентифицируются не по местоположению, а по ключевому слову).
БАЗОВЫЕ ПРАВИЛА КОДИРОВАНИЯ
Транспортный синтаксис ASN.1 определяет однозначный способ преобразования значений переменных допустимых типов в последовательность байт для передачи по сети. В ASN.1 он называется базовыми правилами кодирования (Basic Encoding Rules, BER). Правила являются рекурсивными, так что кодирование составных объектов представляет собой составление в цепочку закодированных последовательностей составляющих объектов.
Каждое передаваемое значение — как базового, так и производного типа — состоит из трех полей:
- идентификатор;
- длина поля данных (в байтах);
- поле данных.
В отличие от ASN.1, протокол SNMP требует всегда указывать длину поля данных, поэтому флаг конца поля данных не используется.
Первое поле состоит в действительности из трех полей (см. Рисунок 2). Два старших бита идентифицируют тип тэга (или, в иной терминологии, класса). Значения поля 00, 01, 10 и 11 соответствуют тэгам Universal, Application, Context-specific и Private. Следующий бит определяет принадлежность переменной к базовому или производному типу данных — 0 для базового, 1 — для производного. Оставшиеся 5 бит могут использоваться для кодирования значения тэга (кода), не превышающего 30. Если значение тэга равно 31 или больше, то пять младших бит содержат одни единицы (11111), а реальное значение дается в следующем байте или байтах.
Рисунок 2. Первый байт всякого передаваемого элемента данных в соответствии с синтаксисом ASN.1.
Используемые правила для кодирования значений, больших 30, позволяют справляться с произвольно большими числами. Каждый последующий байт содержит 7 бит данных, а старший бит задается равным 0 во всех байтах, за исключением последнего. Таким образом, значения тэга до 27-1 могут быть переданы с помощью двух байт.
Таблица 1
| Тип переменной | Описание | Код |
| INTEGER | Целое число произвольной длины | 2 |
| BIT STRING | Строка из 0 или более бит | 3 |
| OCTET STRING | Строка из 0 или более байт | 4 |
| NULL | Держатель места | 5 |
| OBJECT IDENTIFIER | Официально определенный тип данных | 6 |
— Базовые типы переменных, допустимые в SNMP
Значение третьего поля зависит от значения первого поля. Например, базовые и простые составные типы данных принадлежат к классу Universal. Каждый базовый тип имеет свой код, как указано в третьей колонке в Таблице 1, SEQUENCE и SEQUENCE OF имеют один и тот же код 16, а CHOICE не имеет своего кода, так как реальное значение всегда принадлежит к определенному типу. Именно присвоенный код указывается в третьем поле.
Поле длины данных указывает, сколько байт занимают данные. Если данные короче 128 байт, то их длина может быть выражена при помощи одного байта, при этом значение крайнего левого бита будет равно 0. Если данные оказываются длиннее, то первый байт содержит 1 в старшем бите и длину поля длины данных (до 127 байт) в младших 7 битах. Например, если длина данных равна 1000 байт, то первый байт поля длины данных будет содержать 130, т. е. он сообщает принимающей стороне о том, что за ним следует еще два байта поля длины данных. Последующие два байта содержат действительное значение длины данных — 1000, при этом старший байт идет первым.
Кодирование поля данных зависит от конкретного типа данных. Целые числа кодируются при помощи дополнительного кода. Положительное целое число менее 128 кодируется при помощи одного байта и т. д. Старший значащий байт передается первым.
Строки бит передаются, как есть. Единственная проблема в том, что поле длины данных указывает длину в байтах, а не в битах. Принятое решение состоит во вставке одного байта перед строкой битов с указанием, сколько бит последнего байта не используются. Например, строка «010011111» длиной 9 бит будет иметь вид 07, 4F, 80 (в шестнадцатеричном представлении).
Строка байт передается справа налево — сначала старшие, а потом младшие байты. Нулевое значение указывается посредством задания поля длины данных равным 0. Никакое числовое значение реально не передается.
OBJECT IDENTIFIER кодируется в виде последовательности целых чисел, из которых он состоит. Например, ветвь mib-2 имеет префикс {1 3 6 1 2 1}. Однако, поскольку первое число всегда равно 0, 1 или 2, а второе — меньше 40 (как определено ISO), первые два числа, х и y, кодируются с помощью одного байта в виде 40x+y. Таким образом, для mib-2 первый байт равен 43. Числа более 127 кодируются с помощью нескольких байт, первый бит числа задается равным 1, а количество следующих байт — в оставшихся 7 битах.
Оба типа SEQUENCE передаются следующим образом: сначала тип или тэг, затем общая длина всех последующих полей и, наконец, сами поля по порядку. Кодирование значения переменной типа CHOICE производится в соответствии с реальным передаваемым типом данных.
СТРУКТУРА УПРАВЛЯЮЩЕЙ ИНФОРМАЦИИ
Выше мы кратко рассмотрели только те части ASN.1, что используются в SNMP. В действительности документы по SNMP организованы иным образом. Так, в RFC 1442 вначале говорится, что структуры данных в SNMP будут описываться с помощью ASN.1, а затем на более чем 50 страницах перечисляются неиспользуемые части ASN.1 и вводятся новые определения. В частности, RFC 1442 определяет четыре основных макроса и восемь новых типов данных, активно используемых в SNMP. Это своего рода надподмножество ASN.1 известно под именем структуры управляющей информации (Structure of Management Information, SMI). Оно и применяется на практике для определения структур данных SNMP.
На самом нижнем уровне переменные SNMP определяются как отдельные объекты. Взаимосвязанные объекты объединяются в группы, а группы собираются в модули. Например, объекты IP и объекты TCP имеют каждый свою группу. Маршрутизатор может поддерживать группу IP, так как он должен предоставлять информацию, например, о потерянных пакетах, но не группу TCP, так как он функционирует на более низком уровне. Если какое-то устройство поддерживает определенную группу, то оно должно поддерживать и все объекты из этой группы. Однако поддержка производителем определенного модуля не налагает на него ответственности по поддержке всех групп этого модуля, так как не все они могут иметь отношение к конкретному устройству.
Модули MIB запускаются посредством вызова макроса MODULE-IDENTITY. Его параметры сообщают имя и адрес разработчика, данные о версии и другую информацию. За ним обычно следует вызов макроса OBJECT-TYPE, сообщающего реальные используемые переменные и их свойства.
Таблица 2
| Название | Тип | Длина в байтах | Описание |
| INTEGER | Числовой | 4 | Целое число (32 бит в текущей реализации) |
| Counter32 | Числовой | 4 | Беззнаковый 32-разрядный счетчик с обнулением |
| Gauge32 | Числовой | 4 | Беззнаковый 32-разрядный счетчик без обнуления |
| Integer32 | Числовой | 4 | 32 бит даже на 64-разрядном ЦПУ |
| Uinteger32 | Числовой | 4 | То же, что Integer32, но беззнаковый |
| Counter64 | Числовой | 8 | 64-разрядный счетчик |
| TimeTicks | Числовой | 4 | Секундомер в сотых долях секунды |
| BIT STRING | Строковый | 4 | Строка бит длиной от 1 до 32 бит |
| OCTET STRING | Строковый | >0 | Строка байт переменной длины |
| Opaque | Строковый | >0 | Устаревший, только для обратной совместимости |
| OBJECT IDENTIFIER | Строковый | >0 | Последовательность целых чисел |
| IpAddress | Строковый | 4 | Internet-адрес |
| NsapAddress | Строковый | <22 | Адрес OSI NSAP |
— Используемые SNMP типы данных
Макрос OBJECT-TYPE имеет четыре обязательных и четыре необязательных параметра. Первый обязательный параметр — SYNTAX — определяет тип переменной в соответствии с приведенным в Таблице 2 списком. По большей части эти типы говорят сами за себя. Суффикс 32 используется, если переменная должна представлять собой 32-разрядное число, даже если компьютеры имеют 64-разрядные ЦПУ. Счетчики Gauge отличаются от Counter тем, что они не обнуляются при достижении максимального значения. MAX-ACCESS содержит информацию о доступе к переменной. Наиболее типичные значения — «чтение/запись» и «только чтение». Станция может менять значение переменной с признаком «чтение/запись» и читать переменную с признаком «только чтение». STATUS имеет три возможных значения. Переменная со статусом CURRENT соответствует текущей спецификации SNMP, переменная со статусом OBSOLETE не соответствует текущей спецификации, а переменная со статусом DEPRECATED находится в некоем промежуточном состоянии. На самом деле она не нужна в стандарте, но не запрещена, дабы избежать претензий со стороны тех поставщиков, кто продолжает использовать их в своих продуктах. Последний обязательный параметр — DESCRIPTIONDESCRIPTION — содержит описание переменной. Он предназначен для людей, а не для компьютеров.
СЕТЕВОЙ ЭСПЕРАНТО
Несмотря на некоторую громоздкость, абстрактное описание синтаксиса, а точнее, его конкретная форма, используемая в SNMP, позволяет сетевым устройствам различных производителей представлять и сообщать управляющую информацию в стандартном виде. Это открывает перед разработчиками возможность создавать всеобъемлющие платформы управления сетью, так как многие современные сетевые устройства поддерживают относящиеся к ним базы управляющей информации, объекты которых описываются и передаются в соответствии с ASN.1.
Дмитрий Ганьжа — ответственный редактор LAN. С ним можно связаться по адресу: diga@lanmag.ru.![]() Официальный сертифицированный
Официальный сертифицированный
хостинг для продуктов 1С Битрикс
Ошибка кодировки таблиц без возможности автоматического исправления
19.04.2023
В случае появления ошибки при проверке системы (тестирование конфигурации): «Ошибка! Кодировки таблиц имеют ошибки, общее число ошибок N, из них автоматически могут быть исправлены: 0» требуется:
- Выполнить резервное копирование базы данных сайта перед началом проведения процедуры во избежание получения неисправимых ошибок в случае неверных действий.
- Кликнуть на иконку вопросительного знака в правой части строки с вышеуказанной ошибкой.
- В открывшемся окне кликнуть по ссылке «Подробности в журнале проверки системы».
- На экране будет отображен список ошибок по каждой таблице и полям с неверной кодировкой. Скопируйте все строки с ошибками кодировки.
- Вставьте текст с ошибками в расширенный текстовый редактор, например Notepad++ (Windows) или Sublime Text (Mac).
- Удалите все строки, где указаны ошибки кодировки в полях. Оставьте только строки с ошибками таблиц.
Например, из текста ошибок:
Кодировка таблицы «b_b24connector_button_site» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «SITE_ID» таблицы «b_b24connector_button_site» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «VENDOR_EVENT_ID» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «SYNC_STATUS» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «ENTITY_TAG» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «VERSION» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «VENDOR_VERSION_ID» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «RECURRENCE_ID» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «DATA» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «VENDOR_SECTION_ID» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «SYNC_TOKEN» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «PAGE_TOKEN» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «ACTIVE» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «LAST_SYNC_STATUS» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «VERSION_ID» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «IS_PRIMARY» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы «b_catalog_exported_product» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «SERVICE_ID» таблицы «b_catalog_exported_product» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «ERROR» таблицы «b_catalog_exported_product» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы «b_catalog_exported_product_queue» (utf8mb4) отличается от кодировки базы (utf8)
Должен получиться следующий текст:
Кодировка таблицы b_b24connector_button_site (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы b_calendar_event_connection (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы b_calendar_section_connection (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы b_catalog_exported_product (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы b_catalog_exported_product_queue (utf8mb4) отличается от кодировки базы (utf8)
Затем требуется оставить только названия таблиц. Должно получиться:
b_b24connector_button_site
b_calendar_event_connection
b_calendar_section_connection
b_catalog_exported_product
b_catalog_exported_product_queue
После необходимо добавить следующие запросы в начало строк и после названия таблиц: ALTER TABLE — CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
Должен получиться следующий текст:
ALTER TABLE b_b24connector_button_site CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
ALTER TABLE b_calendar_event_connection CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
ALTER TABLE b_calendar_section_connection CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
ALTER TABLE b_catalog_exported_product CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
ALTER TABLE b_catalog_exported_product_queue CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
Копируем получившийся результат. Затем переходим в раздел администраторской части сайта «SQL запрос» и в текстовое поле вставляем ранее скопированный текст результата. Нажать кнопку «Выполнить запрос».
Таким образом одновременно выполняется множество запросов по изменению кодировки таблиц базы данных для исправления ошибки.
Концепция и все материалы с сайта btrxboost.com включающие в себя текстовую, графическую, видео, аудио и маркетинговую информацию, защищены российским и международным законодательством. В соответствии с соглашением об охране авторских прав и интеллектуальной собственности (ст. №1259, №1260, гл. 70 “Авторское право” ГК РФ от 18.12.2006 № 230-ФЗ) и согласно сертификату собственности авторских прав на информационные материалы RID 07N-4M-48 от 12.08.2012, а также сертификата DMCA id: f25cb914-aba8-4988-a116-13afb399bba2 от 21.06.2019.
В случае нарушений данных правил, применяются следующие меры: подача официального заявления в судебные органы в т.ч. с эскалацией запроса хостинг-провайдеру на котором расположен сайт-нарушитель, а также подача запроса на исключение сайта-нарушителя из поисковых систем согласно “Online Copyright Infringement Liability Limitation Act” по ч. II, раздел 512 к закону об авторском праве по DMCA.
Для возможности использования квалифицированной электронно-цифровой подписи (далее — КЭЦП) необходимо, чтобы криптопровайдер счёл сертификат пользователя достоверным, то есть надёжным. Этого можно добиться только в том случае, если корректно выстроена линия доверия сертификата, которая состоит из трёх элементов:
-
Сертификат ключа проверки ЭП (далее — СКПЭП).
-
Промежуточный сертификат (далее — ПС).
-
Корневой сертификат (далее — KC).
Изменения хотя бы одного из этих документов повлечёт за собой недействительность сертификата, из-за чего он не сможет быть применён для заверки электронной документации. Также причинами ошибки может оказаться некорректная работа криптопровайдера, невозможность интегрирования с браузером и т.п.
Ниже мы рассмотрим, по каким причинам возникает ошибка «Этот сертификат содержит недействительную подпись», и что делать, чтобы ее исправить.

В сертификате содержится недействительная цифровая подпись: разбор ситуации, на примере «Тензор»
О том, что в сертификате присутствует недействительная ЦП, пользователь может понять в момент заверения цифрового документа КЭЦП, когда на дисплее отобразится соответствующие системное сообщение.
Для того, чтобы узнать о состоянии ключа, следует:
-
Войти в меню «Пуск».
-
Открыть раздел «Все программы» и перейти в «КриптоПро».
-
После этого нужно нажать л.к.м. на «Сертификаты».
-
В строке хранилище, отметить нужное.
-
Кликнуть на выбранный сертификат.
-
Открыть раздел «Путь сертификации».
В строке «Состояние» будет отражён статус неактивного сертификата.
Во вкладке «Общие» отображается причина, к примеру, «Этот сертификат не удалось проверить, проследив его до доверенного центра».
Сообщение об ошибке может отображаться по следующим причинам:
-
Линия доверия была нарушена (неправильно прописан путь сертификации), произошло повреждение одного или всех сертификатов (кодирование соединения не будет доверенным, либо просто не будет работать).
-
Некорректно инсталлирован криптопровайдер КриптоПро.
-
Алгоритмы шифрования СКЗИ не работают, или работают некорректно.
-
Нет доступа к реестровым документам.
-
Версия браузера устарела.
-
На компьютере выставлены неправильные хронометрические данные.
Из всего этого следует, что ошибка может быть вызвана: напрямую сертификатом, криптопровайдером, либо некорректными настройками компьютера. При этом, все эти варианты предполагают разные способы решения проблемы.

Цепочка доверия, от министерства цифрового развития и связи до пользователя
До того, как приступить к выяснению причины ошибки, в первую очередь, необходимо разобраться в алгоритме строения цепочки доверия сертификатов (далее, — ЦДС) – она является обязательной для правильной работы КЭЦП на всех существующих информационных ресурсах.
Принцип построения ЦДС
Первая ступень в построении ЦДС – это корневой сертификат ключа проверки министерства цифрового развития и связи. Именно Минкомсвязь производит аккредитацию удостоверяющих центров и предоставляет им разрешение на выпуск КЭЦП. Список аккредитованных УЦ представлен на официальном сайте Министерства цифрового развития и связи.
КС выдаётся пользователю при получении КЭЦП, также его можно загрузить с сайта roskazna.ru, либо с официального портала УЦ. В цепи доверия он занимает не последнее значение — и служит подтверждением подлинности КЭЦП.
Вторая ступень – это ПС, он предоставляется в комплекте с КС и включает в себя:
-
Данные об УЦ и срок действия ключа.
-
Электронный адрес для связи с реестром организации.
Данные сведения поступают в закодированном формате и применяются криптопровайдером для подтверждения подлинности открытого ключа КЭЦП.
В теории КЭЦП может быть украдена у владельца, но использовать её без инсталлированного сертификата УЦ не представляется возможным. Все эти меры направлены на то, чтобы минимизировать риски незаконного применения КЭЦП посторонними лицами.
СКПЭП последнее звено цепи доверия. УЦ предоставляет его вместе с открытым и закрытым ключом. Сертификат может быть предоставлен в бумажном, либо электронном виде, на него записаны основные сведения о владельце КЭЦП.
СКПЭП объединяет открытый ключ с определенным человеком, иными словами, подтверждает факт принадлежности ЭП конкретному лицу.
КС министерства цифрового развития и связи действителен, вплоть до 2036 года, а ПС предоставляется только на год, затем необходимо оплатить новый и инсталлировать его на свой компьютер.
Причиной возникновения ошибки «Этот сертификат содержит недействительную цифровую подпись» может служить повреждение любого отрезка ЦДС, начиная с Минкомсвязи РФ и заканчивая пользователем.
Пути решения ошибки
Для начала необходимо убедиться в том, что КС активен и верно инсталлирован. Для этого применяется стандартный путь: «Пуск» → «Все программы» → «КриптоПро» → «Сертификаты» → «Доверенные центры сертификации» → «Реестр». В появившемся перечне должен находиться файл от ПАК «Минкомсвязь России». Если сертификата нет, или он не активен, требуется его инсталлировать:
-
Запустите скачанный файл на компьютере и, в разделе «Общие», нажмите «Установить».
-
Поставьте отметку рядом со строчкой «Поместить в следующее хранилище».
-
Укажите хранилище «Доверенные корневые центры сертификации».
-
Для продолжения инсталляции, кликните на кнопку «ОК» и дайте согласие в окне, предупреждающем о безопасности.
После инсталляции сертификата, перезагрузите ПК.
Файл предоставляется УЦ одновременно с остальными средствами для генерации КЭЦП, если он потерян или удалён, необходимо обратиться в УЦ, предоставивший СКПЭП.
Когда с КС Минкомсвязи всё в порядке, но статус по-прежнему неактивен, необходимо его переустановить (удалить и инсталлировать повторно).
Существует ещё один вариант исправления ошибки, но он срабатывает не каждый раз. В случае, если предыдущий способ не помог, войдите в «Пуск», в строке поиска наберите regedit, после чего войдите в редактор и самостоятельно удалите следующие файлы.
На форуме CryptoPro CSP предлагается еще один вариант решения проблемы. Но работает он не всегда. Если установка документа не помогла, откройте меню «Пуск» и выполните поиск редактора реестра по его названию regedit. В редакторе найдите и вручную удалите следующие ветки:
Они могут быть как полностью, так и частично, поэтому следует удалить все, что имеется. Проверьте статус, он должен стать активным.
Следует помнить, что самовольное редактирование реестровых ключей может отразиться на работе системы, поэтому лучше поручить данную работу специалистам.

Исправление ошибки, на примере казначейства
Наиболее популярная причина недействительности сертификата – это нарушение путей сертификации. Причём неполадки могут быть не только в файлах министерства цифрового развития и связи, но и в промежуточных, а также личных СКЭП.
Ниже мы разберём причину ошибки, на примере Управления Федерального казначейства (УФК).
Изменение или повреждение файла УФК
Обязанности УЦ исполняются в территориальных органах Росказны по всей России. Для проведения аукционов и размещения на платформах сведений о госзакупках, участники должны подписывать отчёты цифровой подписью, полученной в УФК.
В случаях, когда не получается подписать документ, предоставленной казначейством ЭП, и высвечивается ошибка « Этот сертификат содержит недействительную цифровую подпись», необходимо:
-
Зайти в раздел «Личное».
-
Указать неработающий СКПЭП, после чего открыть раздел «Путь сертификации». В таком случае, основным УЦ будет выступать Мнкомсвязи РФ, а подчинённым УФК. Самым последним элементом в доверительной линии будет СКПЭП пользователя.
-
Если после этого, статус до сих пор недействительный, то следует проследить всю доверительную линию и определить слабый элемент.
-
Вернуться обратно во вкладку «Общие» и проверить, правильно ли указаны данные организации, выпустившей СКПЭП.
-
После чего перейти в «Промежуточные центры сертификации». Если выявится, что причина в данном звене, в разделе «Общие» появятся следующие данные: «Этот сертификат не удалось проверить, проследив его до …».
-
На сайте УФК войти во вкладку «Корневые сертификаты».
-
Загрузить «Сертификат УЦ Федерального казначейства».
-
Переместить файл на компьютер. Процедура перемещения такая же, как и для основного центра, но как хранилище необходимо указать «Промежуточные центры сертификации».
-
Выключите и включите ПК.
На последнем этапе нужно открыть вкладку «Личное» и указать необходимый СЭП, после чего сделать проверку пути сертификации.
Если всё прошло удачно, и проблема решена, в строке со статусом отобразится «Этот сертификат действителен». Значит, система произвела проверку ЦДС и не обнаружила отклонений.
Истечение срока
Каждый календарный год пользователю необходимо инсталлировать новый промежуточный ключ на ПК, с которого применяется КЭЦП. ОС должна в автоматическом режиме извещать пользователя, когда подойдёт срок. Если своевременно этого не сделать, то при подписании электронных документов, может отобразиться сообщение о том, что ключ не действителен. Процесс инсталляции, будет таким же, как и описанные выше. При этом удалять устаревший ПС не нужно, система просто пометит его как неактивный.
Для установки новых ключей не требуется подключения к интернету, файл будет проверен в автоматическом режиме, как только устройство выйдет в сеть.
Ошибка с отображением в КриптоПро
Когда возникает подобная ошибка, некоторые сайты могут отклонять СЭП, зато остальные с лёгкостью интегрируются с ней, потому что не все сайты производят проверку пути до основного УЦ. Исправление появившихся вследствие этого ошибок может усложняться, потому что в таких ситуациях вся цепь доверия не имеет нарушений и обозначается как активная.
В таких ситуациях может оказаться что неполадка связана с работой криптопровайдера, либо браузера.
Неправильная работа КриптоПро
Для того, чтобы убедиться в корректности работы, нужно зайти в КриптоПро CSP и открыть раздел «Алгоритмы». Если их характеристики пустые, это означает, что программа работает неправильно и её следует переустановить:
Для того, чтобы произвести переустановку, необходимо наличие специального программного обеспечения (КриптоПро), которую можно загрузить с портала разработчика. Она создана для экстренного удаления криптопровайдера. Этот способ даёт возможность полностью удалить КриптоПро с компьютера, что необходимо для качественной переустановки.
Сервисы инициализации
СЭП может высвечиваться как недействительный, в случаях, когда не активирована служба распознавания КриптоПро CSP.
Для того, чтобы проверить активность службы:
-
Активируйте системное окошко «Выполнить», зажав на клавиатуре Win+R.
-
После чего вбейте в командной строке services.msc.
-
В перечне служб, укажите «Службы инициализации».
-
Зайдите в подраздел «Свойства» и если служба неактивна, запустите её.
Выключите и включите компьютер, если всё сделано правильно КЭЦП будет работать корректно.
Что делать, если ошибка вызвана сбоем браузера
Если после коррекции цепочки доверия, устранения неисправностей криптопровайдер, ошибка всё равно высвечивается, существует вероятность того, что она вызвана сбоем браузера. В основном, так происходит при заверении документов на государственных порталах, либо сайтах контролирующих органов.
Создатели CryptoPro советуют пользоваться для работы с КЭП, только Internet Explorer, так как он уже вшит в Windows, но даже с ним может произойти сбой.
Вход под администраторскими правами
Чаще всего, после того как пользователь входит под паролем администратора, всё налаживается, и ключи начинают функционировать в стандартном режиме.
Что нужно сделать:
-
Правой кнопкой мыши нажмите на значок браузера.
-
Выберите строку «Запуск от имени администратора».
После того, как ошибка исчезнет:
-
Правой кнопкой мыши нажмите на значок браузера.
-
Кликните на «Дополнительно»
-
И выберите «Запуск от имени администратора».
Теперь каждый раз при загрузке ПК, права администратора будут вступать в силу автоматически и больше не потребуется постоянно изменять настройки.
Выключение антивирусника
Некоторые антивирусные программы, к примеру, Symantec или AVG, распознают КриптоПро, как угрозу, и начинают блокировать программные процессы. В результате возникают всевозможные ошибки с СКПЭП, поэтому для того, чтобы подписать цифровой документ, желательно на некоторое время выключить антивирусную программу, для этого:
-
Нажав правой кнопкой мыши на значок антивирусной программы, выберите «Сетевые экраны» или «Управление экранами».
-
После чего, отметьте временной отрезок, на который предусмотрено отключение ПО.
Когда электронный документ будет подписан, активируйте антивирусную программу обратно.
Настройка хронометрических данных
Также необходимо проверить, актуально ли на компьютере выставлено число и время, для этого:
-
Правой кнопкой мыши кликните на значок часов в правом нижнем углу монитора.
-
Выберите «Настройка даты и времени».
-
Выставьте нужный часовой пояс и правильные значения.
-
Сохраните изменения.
По окончанию настроек выключите, а потом включите ваш ПК.
Наш каталог продукции
У нас Вы найдете широкий ассортимент товаров в сегментах кассового, торгового, весового, банковского и офисного оборудования