
Основные
принципы построения трансляторов.
Трансляторы,
компиляторы, интерпретаторы – общая
схема работы.
Определение
транслятора, компилятора, интерпретатора
Для
начала дадим несколько определений —
что же все-таки такое есть уже многократно
упоминавшиеся трансляторы и компиляторы.
Формальное
определение транслятора
Транслятор
—
это программа, которая переводит входную
программу на исходном (входном) языке
в эквивалентную ей выходную программу
на результирующем
(выходном) языке. В этом определении
слово «программа» встречается три раза,
и это не ошибка и не тавтология. В работе
транслятора, действительно, участвуют
всегда три программы.
Во-первых,
сам транслятор является программой1
— обычно он входит в состав системного
программного обеспечения вычислительной
системы. То есть транслятор
— это часть программного обеспечения
(ПО), он представляет собой набор
машинных команд и данных и выполняется
компьютером, как и все прочие программы
в рамках операционной системы (ОС). Все
составные части транслятора
представляют собой фрагменты или модули
программы со своими входными
и выходными данными.
Во-вторых,
исходными данными для работы транслятора
служит текст входной программы
— некоторая последовательность
предложений входного языка программирования.
Обычно это символьный файл, но этот файл
должен содержать текст
программы, удовлетворяющий синтаксическим
и семантическим требованиям
входного языка. Кроме того, этот файл
несет в себе некоторый смысл, определяемый
семантикой входного языка.
В-третьих,
выходными данными транслятора является
текст результирующей программы.
Результирующая программа строится по
синтаксическим правилам, заданным
в выходном языке транслятора, а ее смысл
определяется семантикой выходного
языка. Важным требованием в определении
транслятора является эквивалентность
входной и выходной программ. Эквивалентность
двух программ означает
совпадение их смысла с точки зрения
семантики входного языка (для исходной
программы) и семантики выходного языка
(для результирующей программы).
Без выполнения этого требования сам
транслятор теряет всякий практический
смысл.
Итак,
чтобы создать транслятор, необходимо
прежде всего выбрать входной и
выходной языки. С точки зрения
преобразования предложений входного
языка
в эквивалентные им предложения выходного
языка транслятор выступает как переводчик.
Например, трансляция программы с языка
С в язык ассемблера по сути
ничем не отличается от перевода, скажем,
с русского языка на английский, с
той только разницей, что сложность
языков несколько иная (почему не
существует
трансляторов с естественных языков —
см. раздел «Классификация языков
и грамматик», глава 9). Поэтому и само
слово «транслятор» (английское:
translator)
означает «переводчик».
Результатом
работы транслятора будет результирующая
программа, но только в
том случае, если текст исходной программы
является правильным — не содержит
ошибок с точки зрения синтаксиса и
семантики входного языка. Если исходная
программа неправильная (содержит хотя
бы одну ошибку), то результатом
работы транслятора будет сообщение об
ошибке (как правило, с дополнительными
пояснениями и указанием места ошибки
в исходной программе). В
этом смысле транслятор сродни переводчику,
например, с английского, которому
подсунули неверный текст.
Теоретически
возможна реализация транслятора с
помощью аппаратных средств. Автору
встречались
такого рода разработки, однако широкое
практическое применение их не известно.
В таком случае и все составные части
транслятора могут быть реализованы в
виде аппаратных
средств и их фрагментов — вот тогда
схема распознавателя может получить
вполне
практическое воплощение!
Определение
компилятора.
Отличие
компилятора от транслятора
Кроме
понятия «транслятор» широко употребляется
также близкое ему по смыслу
понятие «компилятор».
Компилятор
— это
транслятор, который осуществляет перевод
исходной программы
в эквивалентную ей объектную программу
на языке машинных команд или на
языке ассемблера.
Таким
образом, компилятор отличается от
транслятора лишь тем, что его результирующая
программа всегда должна быть написана
на языке машинных кодов.или на языке
ассемблера. Результирующая программа
транслятора, в общем случае,
может быть написана на любом языке —
возможен, например, транслятор программ
с языка Pascal
на язык С. Соответственно, всякий
компилятор является
транслятором, но не наоборот — не всякий
транслятор будет компилятором. Например,
упомянутый выше транслятор с языка
Pascal
на С компилятором являться
не будет1.
Само
слово «компилятор» происходит от
английского термина «compiler»
(«составитель»,
«компоновщик»). Видимо, термин обязан
своему происхождению способности
компиляторов составлять объектные
программы на основе исходных
программ.
Результирующая
программа компилятора называется
«объектной программой» или
«объектным кодом». Файл, в который она
записана, обычно называется «объектным
файлом». Даже в том случае, когда
результирующая программа порождается
на языке машинных команд, между объектной
программой (объектным файлом) и исполняемой
программой (исполняемым файлом) есть
существенная разница.
Порожденная компилятором программа не
может непосредственно выполняться
на компьютере, так как она не привязана
к конкретной области памяти,
где должны располагаться ее код и данные
(более подробно — см. раздел «Принципы
функционирования систем программирования»,
глава 15)2.
Компиляторы,
безусловно, самый распространенный вид
трансляторов (многие считают
их вообще единственным видом трансляторов,
хотя это не так). Они имеют
самое широкое практическое применение,
которым обязаны широкому распространению
всевозможных языков программирования.
Далее всегда будем говорить
о компиляторах, подразумевая, что
выходная программа написана на
Естественно,
трансляторы и компиляторы, как и все
прочие программы, разрабатывает
человек (люди) — обычно это группа
разработчиков. В принципе они могли бы
создавать его непосредственно на языке
машинных команд, однако объем
кода и данных современных компиляторов
таков, что их создание на языке
машинных команд практически невозможно
в разумные сроки при разумных трудозатратах.
Поэтому практически все современные
компиляторы также создаются
с помощью компиляторов (обычно в этой
роли выступают предыдущие версии
компиляторов той же фирмы-производителя).
И в этом качестве компилятор
является уже выходной программой для
другого компилятора, которая ничем не
лучше и не хуже всех прочих порождаемых
выходных программ2.
Определение
интерпретатора. Разница между
интерпретаторами
и трансляторами
Кроме
схожих между собой понятий «транслятор»
и «компилятор» существует принципиально
отличное от них понятие интерпретатора.
Интерпретатор
— это
программа, которая воспринимает входную
программу на исходном
языке и выполняет ее.
В
отличие от трансляторов интерпретаторы
не порождают результирующую программу
(и вообще какого-либо результирующего
кода) — и в этом принципиальная
разница между ними. Интерпретатор, так
же как и транслятор, анализирует текст
исходной программы. Однако он не порождает
результирующей программы, а
сразу же выполняет исходную в соответствии
с ее смыслом, заданным семантикой
входного языка. Таким образом, результатом
работы интерпретатора будет результат,
заданный смыслом исходной программы,
в том случае, если эта программа
правильная, или сообщение об ошибке,
если исходная программа неверна.
Конечно,
чтобы исполнить исходную программу,
интерпретатор так или иначе должен
преобразовать ее в язык машинных кодов,
поскольку иначе выполнение программ
на компьютере невозможно. Он и делает
это, однако полученные машинные
коды не являются доступными — их не
видит пользователь интерпретатора.
Эти машинные коды порождаются
интерпретатором, исполняются и унич-
1
Следует особо упомянуть, что сейчас в
современных системах программирования
стали появляться
компиляторы, в которых результирующая
программа создается не на языке машинных
команд и не на языке ассемблера, а на
некотором промежуточном языке. Сам по
себе этот промежуточный язык не может
непосредственно исполняться на
компьютере,
а требует специального промежуточного
интерпретатора для выполнения написанных
на нем программ. Хотя в данном случае
термин «транслятор» был бы, наверное,
более
правильным, в литературе употребляется
понятие «компилятор», поскольку
промежуточный язык является языком
очень низкого уровня, будучи родственным
машинным
командам и языкам ассемблера.
Здесь
возникает извечный вопрос «о курице и
яйце». Конечно, в первом поколении самые
первые компиляторы писались непосредственно
на машинных командах, но потом, с
появлением компиляторов, от этой практики
отошли. Даже самые ответственные части
компиляторов
создаются, как минимум, с применением
языка ассемблера — а он тоже обрабатывается
компилятором. тожаются
по мере надобности — так, как того
требует конкретная реализа) интерпретатора.
Пользователь же видит результат
выполнения этих кодов -есть результат
выполнения исходной программы (требование
об эквивалент сти
исходной программы и порожденных
машинных кодов и в этом случае, ( условно,
должно выполняться).
Более подробно
вопросы, связанные с реализацией
интерпретаторов и их от чием от
компиляторов, рассмотрены далее в
соответствующем разделе.
Назначение
трансляторов, компиляторов и
интерпретаторов. Примеры реализации
Первые
программы, которые создавались еще для
ЭВМ первого поколения, сались
непосредственно на языке машинных
кодов. Это была поистине аде работа.
Сразу стало ясно, что человек не должен
и не может говорить на яз машинных
команд, даже если он специалист по
вычислительной технике. О; ко
и все попытки научить компьютер говорить
на языках людей успехов увенчались
и вряд ли когда-либо увенчаются (на что
есть определенные o6i
тивные
причины, рассмотренные в первой главе
этого пособия).
С
тех пор все развитие программного
обеспечения компьютеров неразрывно i
зано
с возникновением и развитием компиляторов.
Первыми
компиляторами были компиляторы с языков
ассемблера или, как назывались,
мнемокодов. Мнемокоды превратили
«филькину грамоту» яз машинных
команд в более-менее доступный пониманию
специалиста язык ^ монических
(преимущественно англоязычных) обозначений
этих команд. ( давать программы уже стало
значительно проще, но исполнять сам
мнемс (язык
ассемблера) ни один компьютер неспособен,
соответственно, возникла обходимость
в создании компиляторов. Эти компиляторы
элементарно про но
они продолжают играть существенную
роль в системах программировани сей
день. Более подробно о языке ассемблера
и компиляторах с него расска: далее
в соответствующем разделе.
Следующим
этапом стало создание языков высокого
уровня. Языки высо] уровня (к ним относится
большинство языков программирования)
предста ют собой некоторое промежуточное
звено между чисто формальными язык и
языками естественного общения людей.
От первых им досталась строгая с мализация
синтаксических структуру предложений
языка, от вторых — зн тельная
часть словарного запаса, семантика
основных конструкций и выражс (с
элементами математических операций,
пришедшими из алгебры).
Появление
языков высокого уровня существенно
упростило процесс програи рования,
хотя и не свело его до «уровня домохозяйки»,
как самонадеянно п гали
некоторые авторы на заре рождения языков
программирования1.
Снатаких
языков были единицы, затем десятки,
сейчас, наверное, их насчитывается более
сотни. Процессу этому не видно конца.
Тем не менее по-прежнему преобладают
компьютеры традиционной, «неймановской»,
архитектуры, которые умеют
понимать только машинные команды,
поэтому вопрос о создании компиляторов
продолжает быть актуальным.
Как
только возникла массовая потребность
в создании компиляторов, стала развиваться
и специализированная теория. Со временем
она нашла практическое приложение
во множестве созданных компиляторов.
Компиляторы создавались и
продолжают создаваться не только для
новых, но и для давно известных языков.
Многие производители от известных,
солидных фирм (таких, как Microsoft
или
Inprise)
до мало кому знакомых коллективов
авторов выпускают на рынок все
новые и новые образцы компиляторов. Это
обусловлено рядом причин, которые
будут рассмотрены далее.
Наконец,
с тех пор как большинство теоретических
аспектов в области компиляторов
получили свою практическую реализацию
(а это, надо сказать, произошло
довольно быстро, в конце 60-х годов),
развитие компиляторов пошло по пути их
дружественности человеку — пользователю,
разработчику программ на языках высокого
уровня. Логичным завершением этого
процесса стало создание систем
программирования — программных
комплексов, объединяющих в себе кроме
непосредственно компиляторов множество
связанных с ними компонентов
программного обеспечения. Появившись,
системы программирования быстро
завоевали
рынок и ныне в массе своей преобладают
на нем (фактически, обособленные
компиляторы — это редкость среди
современных программных средств). О
том, что представляют собой и как
организованы современные системы
программирования,
см. в главе «Современные системы
программирования». Ныне компиляторы
являются неотъемлемой частью любой
вычислительной системы.
Без их существования программирование
любой прикладной задачи было бы
затруднено, а то и просто невозможно.
Да и программирование специализированных
системных задач, как правило, ведется
если не на языке высокого уровня (в этой
роли в настоящее время чаще всего
применяется язык С), то на языке
ассемблера, следовательно, применяется
соответствующий компилятор. Программирование
непосредственно на языках машинных
кодов происходит исключительно
редко и только для решения очень узких
вопросов. Несколько
слов о примерах реализации компиляторов
и интерпретаторов, а также о том, как
они соотносятся с другими существующими
программными средствами. Компиляторы,
как будет показано далее, обычно несколько
проще в реализации, чем
интерпретаторы. По эффективности они
также превосходят их — очевидно, что
откомпилированный код будет исполняться
всегда быстрее, чем происходит
интерпретация
аналогичной исходной программы. Кроме
того, не каждый язык программирования
допускает построение простого
интерпретатора. Однако интерпретаторы
имеют одно существенное преимущество
— откомпилированный код
всегда привязан к архитектуре
вычислительной системы, на которую он
ориентирован,
а исходная программа — только к семантике
языка программирования,
которая гораздо легче поддается
стандартизации. Этот аспект первоначально
не принимали во внимание. Первыми
компиляторами были компиляторы с
мнемокодов. Их потомки — современные
компиляторы с языков ассемблера —
существую практически для всех
известных вычислительных систем. Они
предельно жестко ориентированы на
архитектуру. Затем появились компиляторы
с таких языков, как FORTRAN,
ALGOL-68,
PL/1.
Они были ориентированы на большие ЭВМ
с пакетной обработкой
задач. Из вышеперечисленных только
FORTRAN,
пожалуй, продолжает использоваться
по сей день, поскольку имеет огромное
количество библиотек различного
назначения [7]. Многие языки, родившись,
так и не получили широкого
распространения — ADA,
Modula,
Simula
известны лишь узкому кругу специалистов.
В то же время на рынке программных систем
доминируют компиляторы языков,
которым не прочили светлого будущего.
В первую очередь, сейчас это С и C++. Первый
из них родился вместе с операционными
системами типа UNIX,
вместе с нею завоевал свое «место под
солнцем», а затем перешел под ОС других
типов. Второй удачно воплотил в себе
пример реализации идей объектно-ориентированного
программирования на хорошо зарекомендовавшей
себя практической
базе1.
Еще можно упомянуть довольно
распространенный Pascal,
который
неожиданно для многих вышел за рамки
чисто учебного языка для университетской
среды.
История
интерпретаторов не столь богата (пока!).
Как уже было сказано, изначально
им не предавали существенного значения,
поскольку почти по всем параметрам
они уступают компиляторам. Из известных
языков, предполагавших интерпретацию,
можно упомянуть разве что Basic,
хотя большинству сейчас известна
его компилируемая реализация Visual
Basic,
сделанная фирмой Microsoft
[3,
63]. Тем не менее сейчас ситуация несколько
изменилась, поскольку вопрос о
переносимости программ и их
аппаратно-платформенной независимости
приобретает все большую актуальность
с развитием сети Интернет. Самый известный
сейчас
пример — это язык Java
(сам по себе он сочетает компиляцию и
интерпретацию),
а также связанный с ним JavaScript.
В конце концов, язык HTML,
на котором зиждется протокол HTTP,
давший толчок столь бурному развитию
Всемирной
сети, — это тоже интерпретируемый язык.
По мнению автора, в области появления
новых интерпретаторов всех еще ждут
сюрпризы, и появились уже первые из них
— например, язык С# («си-диез», но название
везде идет как «Си шарп»),
анонсируемый фирмой Microsoft.
О б
б
истории языков программирования и
современном состоянии рынка компиляторов
можно говорить долго и много. Автор
считает возможным ограничиться уже
сказанным, поскольку это не является
целью данного пособия. Желающие могут
обратиться к литературе [7, 8, 14, 23, 30, 45,
66, 77, 81].
Этапы
трансляции. Общая схема работы
транслятора
На
рис. 13.1 представлена общая схема работы
компилятора. Из нее видно, что ъ
целом
процесс компиляции состоит из двух
основных этапов — синтеза и анализа.
На этапе анализа
выполняется распознавание текста
исходной программы, создание и
заполнение таблиц идентификаторов.
Результатом его работы служит некое
внутреннее представление программы,
понятное компилятору.
На
этапе синтеза на основании внутреннего
представления программы и информации,
содержащейся в таблице (таблицах)
идентификаторов, порождается текст
результирующей
программы. Результатом этого этапа
является объектный код.
Кроме
того, в составе компилятора присутствует
часть, ответственная за анализ и
исправление ошибок, которая при наличии
ошибки в тексте исходной программы
должна максимально полно информировать
пользователя о типе ошибки и месте
ее возникновения. В лучшем случае
компилятор может предложить пользователю
вариант исправления ошибки.
Эти
этапы, в свою Очередь, состоят из более
мелких этапов, называемых фазами
компиляции.
Состав фаз компиляции приведен в самом
общем виде, их конкретная
реализация и процесс взаимодействия
Во-первых,
он является распознавателем для языка
исходной программы. То ее он
должен получить на вход цепочку символов
входного языка, проверить принадлежность
языку и, более того, выявить правила, по
которым эта цепоч была
построена (поскольку сам ответ на вопрос
о принадлежности «да» и. «нет»
представляет мало интереса). Интересно,
что генератором цепочек входи го
языка выступает пользователь — автор
входной программы.
Во-вторых,
компилятор является генератором для
языка результирующей пр граммы.
Он должен построить на выходе цепочку
выходного языка по опре; ленным
правилам, предполагаемым языком машинных
команд или языком i
семблера.
Распознавателем этой цепочки будет
выступать уже вычислительн система,
под которую создается результирующая
программа.
Далее
дается перечень основных фаз (частей)
компиляции и краткое описан их
функций. Более подробная информация
дана в подразделах, соответству щих
этим фазам.
Лексический
анализ (сканер)
— это часть компилятора, которая читает
лите] программы
на исходном языке и строит из них слова
(лексемы) исходного яз ка.
На вход лексического анализатора
поступает текст исходной программ а
выходная информация передаётся для
дальнейшей обработки компилятор на
этапе синтаксического разбора. С
теоретической точки зрения лексическ
анализатор
не является обязательной, необходимой
частью компилятора. Од1 ко
существует причины, которые определяют
его присутствие практически всех
компиляторах. Более подробно см. раздел
«Лексические анализаторы (а неры).
Принципы построения сканеров».
Синтаксический
разбор —
это основная часть компилятора на этапе
анализа. О выполняет
выделение синтаксических конструкций
в тексте исходной прогре мы,
обработанном лексическим анализатором.
На этой же фазе компиляц проверяется
синтаксическая правильность программы.
Синтаксический раз£ играет
главную роль — роль распознавателя
текста входного языка програмл рования
(см. раздел «Синтаксические анализаторы.
Синтаксически управл; мый
перевод» этой главы).
Семантический
анализ —
это часть компилятора, проверяющая
правильно* текста исходной программы
с точки зрения семантики входного языка.
Крс непосредственно
проверки, семантический анализ должен
выполнять преоб; зования
текста, требуемые семантикой входного
языка (такие, как добавлен функций
неявного преобразования типов). В
различных реализациях компи. торов
семантический анализ может частично
входить в фазу синтаксическ* разбора,
частично — в фазу подготовки к генерации
кода.
Подготовка
к генерации кода —
это фаза, на которой компилятором
выполнят ся
предварительные действия, непосредственно
связанные с синтезом текста зультирующей
программы, но еще не ведущие к порождению
текста на вых ном языке. Обычно в эту
фазу входят действия, связанные с
идентификащ элементов
языка, распределением памяти и т. п. (см.
раздел «Семантическ анализ и подготовка
к генерации кода», глава 14).
Генерация
кода —
это фаза, непосредственно связанная с
порождением кома составляющих
предложения выходного языка и в целом
текст результируюи
могут,
конечно, различаться в зависимости
от версии компилятора. Однако в том или
ином виде все представленные фазы
практически всегда присутствуют в
каждом конкретном компиляторе [26,
40].
Компилятор
в целом с точки зрения теории формальных
языков выступает в «двух ипостасях»,
выполняет две основные функции. программы.
Это основная фаза на этапе синтеза
результирующей программы. Кроме
непосредственного порождения текста
результирующей программы, генерация
обычно включает в себя также оптимизацию
— процесс, связанный с обработкой
уже порожденного текста. Иногда
оптимизацию выделяют в отдельную фазу
компиляции, так как она оказывает
существенное влияние на качество и
эффективность
результирующей программы (см. разделы
«Генерация кода. Методы генерации
кода» и « Оптимизация кода. Основные
методы оптимизации», глава
14).
Таблицы
идентификаторов (иногда
— «таблицы символов») — это специальным
образом
организованные наборы данных, служащие
для хранения информации об элементах
исходной программы, которые затем
используются для порождения
текста результирующей программы. Таблица
идентификаторов в конкретной
реализации компилятора может быть одна,
или же таких таблиц может быть несколько.
Элементами исходной программы, информацию
о которых нужно хранить в процессе
компиляции, являются переменные,
константы, функции и т. п. — конкретный
состав набора элементов зависит от
используемого входного языка
программирования.
Понятие «таблицы» вовсе не предполагает,
что это хранилище данных
должно быть организовано именно в виде
таблиц или других массивов информации
— возможные методы их организации
подробно рассмотрены далее, в
разделе «Таблицы идентификаторов.
Организация таблиц идентификаторов».
Представленное
на рис. 13.1 деление процесса компиляции
на фазы служит скорее методическим
целям и на практике может не соблюдаться
столь строго. Далее
в подразделах этого пособия рассматриваются
различные варианты технической
организации представленных фаз
компиляции. При этом указано, как они
могут
быть связаны между собой. Здесь рассмотрим
только общие аспекты такого
рода взаимосвязи.
Во-первых,
на фазе лексического анализа лексемы
выделяются из текста входной
программы постольку, поскольку они
необходимы для следующей фазы
синтаксического
разбора. Во-вторых, как будет показано
ниже, синтаксический разбор
и генерация кода могут выполняться
одновременно. Таким образом, эти три
фазы компиляции могут работать
комбинированно, а вместе с ними может
выполняться
и подготовка к генерации кода. Далее
рассмотрены технические вопросы
реализации основных фаз компиляции,
которые тесно связаны с понятием
прохода.
Понятие
прохода. Многопроходные и
однопроходные компиляторы
Как
уже было сказано, процесс компиляции
программ состоит из нескольких фаз. В
реальных компиляторах состав этих фаз
может несколько отличаться от
рассмотренного
выше — некоторые из них могут быть
разбиты на составляющие, другие,
напротив, объединены в одну фазу. Порядок
выполнения фаз компиляции также
может меняться в разных вариантах
компиляторов. В одном случае компилятор
просматривает текст исходной программы,
сразу выполняет все фазы компиляции
и получает результат — объектный код.
В другом варианте он выполняет
над исходным текстом только некоторые
из фаз компиляции и получает не конечный
результат, а набор некоторых промежуточных
данных. Эти данные затем
снова подвергаются обработке, причем
этот процесс может повторяться несколько
раз.
Реальные компиляторы,
как правило, выполняют трансляцию текста
исходной программы за несколько проходов.
Проход
— это
процесс последовательного чтения
компилятором данных из внешней
памяти, их обработки и помещения
результата работы во внешнюю память.
Чаще всего один проход включает в себя
выполнение одной или нескольких фаз
компиляции.
Результатом промежуточных проходов
является внутреннее представление
исходной программы, результатом
последнего прохода — результирующая
объектная программа.
В
качестве внешней памяти могут выступать
любые носители информации — оперативная
память компьютера, накопители на
магнитных дисках, магнитных лентах и
т. п. Современные компиляторы, как
правило, стремятся максимально
использовать для хранения данных
оперативную память компьютера, и только
при
недостатке объема доступной памяти
используются накопители на жестких
магнитных
дисках. Другие носители информации в
современных компиляторах не
используются из-за невысокой скорости
обмена данными.
При
выполнении каждого прохода компилятору
доступна информация, полученная
в результате всех предыдущих проходов.
Как правило, он стремится использовать
в первую очередь только информацию,
полученную на проходе, непосредственно
предшествовавшем текущему, но в принципе
может обращаться и
к данным от более ранних проходов вплоть
до исходного текста программы. Информация,
получаемая компилятором при выполнении
проходов, недоступна пользователю.
Она либо хранится в оперативной памяти,
которая освобождается
компилятором после завершения процесса
трансляции, либо оформляется в
виде временных файлов на диске, которые
также уничтожаются после завершения
работы компилятора. Поэтому человек,
работающий с компилятором, может
даже не знать, сколько проходов выполняет
компилятор — он всегда видит только
текст исходной программы и результирующую
объектную программу. Но количество
выполняемых проходов — это важная
техническая характеристика компилятора,
солидные фирмы — разработчики компиляторов
обычно указывают
ее в описании своего продукта.
Понятно,
что разработчики стремятся максимально
сократить количество проходов,
выполняемых компиляторами. При этом
увеличивается скорость работы компилятора,
сокращается объем необходимой ему
памяти. Однопроходный компилятор,
получающий на вход исходную программу
и сразу же порождающий результирующую
объектную программу, — это идеальный
вариант.
Однако
сократить число проходов не всегда
удается. Количество необходимых проходов
определяется прежде всего грамматикой
и семантическими правилами исходного
языка. Чем сложнее грамматика языка и
чем больше вариантов предполагают
семантические правила — тем больше
проходов будет выполнять компилятор
(конечно, играет свою роль и квалификация
разработчиков компилятора). Например,
именно поэтому обычно компиляторы с
языка Pascal
работают быстрее,
чем компиляторы с языка С — грамматика
языка Pascal
более проста, а
семантические правила более жесткие.
Однопроходные
компиляторы — редкость, они возможны
только для очень простых
языков. Реальные компиляторы выполняют,
как правило, от двух до пяти проходов.
Таким образом, реальные компиляторы
являются многопроходными. Наиболее
распространены двух- и трехпроходные
компиляторы, например: первый
проход — лексический анализ, второй —
синтаксический разбор и семантический
анализ, третий — генерация и оптимизация
кода (варианты исполнения, конечно,
зависят от разработчика). В современных
системах программирования нередко
первый проход компилятора (лексический
анализ кода) выполняется параллельно
с редактированием кода исходной программы
(такой вариант построения
компиляторов рассмотрен далее в этой
главе).
Интерпретаторы.
Особенности построения интерпретаторов
Интерпретатор
—
это программа, которая воспринимает
входную программу на исходном
языке и выполняет ее. Как уже было сказано
выше, основное отличие интерпретаторов
от трансляторов и компиляторов заключается
в том, что интерпретатор
не порождает результирующую программу,
а просто выполняет исходную программу.
Термин
«интерпретатор» (interpreter),
как и «транслятор», означает «переводчик».
С точки зрения терминологии эти понятия
схожи, но с точки зрения теории
формальных языков и компиляции между
ними большая принципиальная разница.
Если понятия «транслятор» и «компилятор»
почти неразличимы, то с
понятием «интерпретатор» их путать
никак нельзя.
Простейшим
способом реализации интерпретатора
можно было бы считать вариант,
когда исходная программа сначала
полностью транслируется в машинные
команды,
а затем сразу же выполняется. В такой
реализации интерпретатор, по сути,
мало бы чем отличался от компилятора с
той лишь разницей, что результирующая
программа в нем была бы недоступна
пользователю. Недостатком такого
интерпретатора было бы то, что пользователь
должен был бы ждать компиляции
всей исходной программы прежде, чем
начнется ее выполнение. По сути, в
таком интерпретаторе не было бы никакого
особого смысла — он не давал бы никаких
преимуществ по сравнению с аналогичным
компилятором1.
Поэтому
подавляющее большинство интерпретаторов
действует так, что исполняет исходную
программу последовательно, по мере ее
поступления на вход интерпретатора.
Тогда пользователю не надо ждать
завершения компиляции всей исходной
программы. Более того, он может
последовательно вводить исходную
программу
и тут же наблюдать результат ее выполнения
по мере ввода команд [82].
При
таком порядке работы интерпретатора
проявляется существенная особенность,
которая отличает его от компилятора, —
если интерпретатор исполняет команды
по мере их поступления, то он не может
выполнять оптимизацию исходной
программы. Следовательно, фаза оптимизации
в общей структуре интер-
претатора будет отсутствовать. В
остальном же она будет мало отличаться
от структуры
аналогичного компилятора. Следует
только учесть, что на последнем этапе
— генерации кода — машинные команды не
записываются в объектный файл,
а выполняются по мере их порождения.
Отсутствие
шага оптимизации определяет еще одну
особенность, характерную для многих
интерпретаторов: в качестве внутреннего
представления программы в
них очень часто используется обратная
польская запись (см. раздел «Генерация
кода. Методы генерации кода», глава 14).
Эта удобная форма представления операций
обладает только одним существенным
недостатком — она плохо поддается
оптимизации. Но в интерпретаторах именно
это как раз и не требуется.
Далеко
не все языки программирования допускают
построение интерпретаторов которые
могли бы выполнять исходную программу
по мере поступления команд Для
этого язык должен допускать возможность
существования компилятора выполняющего
разбор исходной программы за один
проход. Кроме того, язык не может
интерпретироваться по мере поступления
команд, если он допускает по явление
обращений к функциям и структурам данных
раньше их непосредствен ного
описания. Поэтому данным методом не
могут интерпретироваться такш языки,
как С и Pascal.
Отсутствие
шага оптимизации ведет к тому, что
выполнение программы с помо щью
интерпретатора является менее эффективным,
чем с помощью аналогично го компилятора.
Кроме того, при интерпретации исходная
программа должна за ново разбираться
всякий раз при ее выполнении, в то время
как при компиляци] она разбирается
только один раз, а после этого всегда
используется объектны] файл. Таким
образом, интерпретаторы всегда проигрывают
компиляторам в про изводительности.
Преимуществом
интерпретатора является независимость
выполнения програм мы
от архитектуры целевой вычислительной
системы. В результате компиляци:
получается
объектный код, который всегда ориентирован
на определенную архн тектуру.
Для перехода на другую архитектуру
целевой вычислительной систем] программу
требуется откомпилировать заново. А
для интерпретации программ] необходимо
иметь только ее исходный текст и
интерпретатор с соответствующе го
языка.
Интерпретаторы
долгое время значительно уступали в
распространенности коь
пиляторам.
Как правило, интерпретаторы существовали
для ограниченного крз га
относительно простых языков программирования
(таких, например, как Basic
Высокопроизводительные
профессиональные средства разработки
программш го
обеспечения строились на основе
компиляторов.
Новый
импульс развитию интерпретаторов
придало распространение глобал] ных
вычислительных сетей. Такие сети могут
включать в свой состав ЭВМ ра: личной
архитектуры, и тогда требование
единообразного выполнения на каждс из
них текста исходной программы становится
определяющим. Поэтому с разв] тием
глобальных сетей и распространением
всемирной сети Интернет появило< много
новых систем, интерпретирующий текст
исходной программы. Мноп языки
программирования, применяемые во
Всемирной сети, предполагают име: но
интерпретацию текста исходной программы
без порождения объектного код
В
современных системах программирования
существуют реализации программного
обеспечения, сочетающие в себе и функции
компилятора, и функции интерпретатора
— в зависимости от требований пользователя
исходная программа либо
компилируется, либо исполняется
(интерпретируется). Кроме того, некоторые
современные языки программирования
предполагают две стадии разработки:
сначала исходная программа компилируется
в промежуточный код (некоторый
язык низкого уровня), а затем этот
результат компиляции выполняется с
помощью
интерпретатора данного промежуточного
языка. Более подробно варианты таких
систем рассмотрены в главе «Современные
системы программирования».
Широко
распространенным примером интерпретируемого
языка может служить HTML
(Hypertext
Markup
Language)
— язык описания гипертекста. На его
основе
в настоящее время функционирует
практически вся структура сети Интернет.
Другой пример — языки Java
и JavaScript
— сочетают в себе функции компиляции
и интерпретации. Текст исходной программы
компилируется в некоторый промежуточный
двоичный код, не зависящий от архитектуры
целевой вычислительной системы, этот
код распространяется по сети и выполняется
на принимающей
стороне — интерпретируется.
Трансляторы
с языка ассемблера («ассемблеры»)
Язык
ассемблера — это
язык низкого уровня. Структура и
взаимосвязь цепочек этого
языка близки к машинным командам целевой
вычислительной системы, где
должна выполняться результирующая
программа. Применение языка ассемблера
позволяет разработчику управлять
ресурсами (процессором, оперативной
памятью, внешними устройствами и т. п.)
целевой вычислительной системы на
уровне машинных команд. Каждая команда
исходной программы на языке ассемблера
в результате компиляции преобразуется
в одну машинную команду.
Транслятор
с языка ассемблера всегда, безусловно,
будет и компилятором, поскольку
языком результирующей программы являются
машинные коды. Транслятор с языка
ассемблера зачастую просто называют
«ассемблер» или «программа ассемблера».
Реализация
компиляторов с языка ассемблера
Язык
ассемблера, как правило, содержит
мнемонические коды машинных команд.
Чаще всего используется англоязычная
мнемоника команд, но существуют и
другие варианты языков ассемблера (в
том числе существуют и русскоязычные
варианты). Именно поэтому язык ассемблера
раньше носил названия «язык мнемокодов»
(сейчас это название уже практически
не употребляется). Все возможные
команды в каждом языке ассемблера можно
разбить на две группы: в
первую группу входят обычные команды
языка, которые в процессе трансляции
преобразуются в машинные команды; вторую
группу составляют специальные
команды языка, которые в машинные команды
не преобразуются, но используются
компилятором для выполнения задач
компиляции (таких, например, как
задача распределения памяти). Синтаксис
языка чрезвычайно прост. Команды исходной
программы записыв ются
обычно таким образом, чтобы на одной
строке программы располагала одна
команда. Каждая команда языка ассемблера,
как правило, может быть рг делена на три
составляющих, следующих последовательно
одна за другой: по метки, код операции
и поле операндов. Компилятор с языка
ассемблера обыч] предусматривает
и возможность наличия во входной
программе комментарш которые
отделяются от команд заданным разделителем
[93].
Поле
метки содержит идентификатор,
представляющий собой метку, либо явл
ется
пустым. Каждый идентификатор метки
может встречаться в программе языке
ассемблера только один раз. Метка
считается описанной там, где она у
посредственно
встретилась в программе (предварительное
описание меток требуется).
Метка может быть использована для
передачи управления на поь ченную
ею команду. Нередко метка отделяется
от остальной части команды сг циальным
разделителем (чаще всего — двоеточием
«:»).
Код
операции всегда представляет собой
строго определенную мнемонику одн из
возможных команд процессора или также
строго определенную команду ( мого
компилятора. Код операции записывается
алфавитными символами вхс ного
языка. Чаще всего его длина составляет
3-4, реже — 5 или 6 символов.
Поле
операндов либо является пустым, либо
представляет собой список из одг го,
двух, реже — трех операндов. Количество
операндов строго определено и : висит
от кода операции — каждая операция
языка ассемблера предусматривг жестко
заданное число своих операндов.
Соответственно, каждому из этих вар
антов
соответствуют безадресные, одноадресные,
двухадресные или трехадресн команды
(большее число операндов практически
не используется, в совреме ных ЭВМ даже
трехадресные команды встречаются
редко). В качестве опер; дов
могут выступать идентификаторы или
константы.
Особенностью
языка ассемблера является то, что ряд
идентификаторов в н выделяется
специально для обозначения регистров
процессора. Такие идет фикаторы,
с одной стороны, не требуют предварительного
описания, но, с Д1 гой,
они не могут быть использованы
пользователем для иных целей. Набор эт
идентификаторов
предопределен для каждого языка
ассемблера.
Иногда
язык ассемблера допускает использование
в качестве операндов оп] деленных
ограниченных сочетаний обозначений
регистров, идентификатор и
констант, которые объединены некоторыми
знаками операций. Такие соче ния
чаще всего используются для обозначения
типов адресации, допустим в
машинных командах целевой вычислительной
системы.
Например, следующая
последовательность команд
datas
db
16 dup(O)
loops:
mov
datas[bx+4].cx
dec
bx
jnz
loops
представляет
собой пример последовательности команд
языка ассемблера п; цессоров семейства
Intel
80×86. Здесь присутствуют команда описания
наб( данных
(db),
метка (loops),
коды операций (mov,
dec
и jnz).
Операндами яв. ются идентификатор набора
данных (datas),
обозначения регистров процессе
(Ьх
и сх), метка (loops)
и константа (4). Составной операнд
datas[bx+4]
отображает
косвенную адресацию набора данных datas
по базовому регистру Ьх со смещением
4.
Подобный
синтаксис языка без труда может быть
описан с помощью регулярной грамматики.
Поэтому построение распознавателя для
языка ассемблера не представляет
труда. По этой же причине в компиляторах
с языка ассемблера лексический
и синтаксический разбор, как правило,
совмещены в один распознаватель.
Семантика
языка ассемблера целиком и полностью
определяется целевой вычислительной
системой, на которую ориентирован данный
язык. Семантика языка ассемблера
определяет, какая машинная команда
соответствует каждой команде языка
ассемблера, а также то, какие операнды
и в каком количестве допустимы для
того или иного кода операции.
Поэтому
семантический анализ в компиляторе с
языка ассемблера также прост, как и
синтаксический. Основной его задачей
является проверить допустимость
операндов для каждого кода операции, а
также проверить, что все идентификаторы
и метки, встречающиеся во входной
программе, описаны и обозначающие их
идентификаторы не совпадают с
предопределенными идентификаторами,
используемыми
для обозначения кодов операции и
регистров процессора.
Схемы
синтаксического и семантического
анализа в компиляторе с языка ассемблера
могут быть, таким образом, реализованы
на основе обычного конечного автомата.
Именно эта особенность определила тот
факт, что компиляторы с языка ассемблера
исторически явились первыми компиляторами,
созданными для ЭВМ. Существует
также ряд других особенностей, которые
присущи именно языкам ассемблера и
упрощают построение компиляторов для
них.
Во-первых,
в компиляторах с языка ассемблера не
выполняется дополнительная идентификация
переменных — все переменные языка
сохраняют имена, присвоенные
им пользователем. За уникальность имен
в исходной программе отвечает ее
разработчик, семантика языка никаких
дополнительных требований на этот
процесс
не накладывает. Во-вторых, в компиляторах
с языка ассемблера предельно
упрощено распределение памяти. Компилятор
с языка ассемблера работает только
со статической памятью. Если используется
динамическая память, то для работы
с нею нужно использовать соответствующую
библиотеку или функции ОС,
а за ее распределение отвечает разработчик
исходной программы. За передачу
параметров и организацию дисплея памяти
процедур и функций также отвечает
разработчик исходной программы. Он же
должен позаботиться и об отделении
данных от кода программы — компилятор
с языка ассемблера, в отличие от
компиляторов
с языков высокого уровня, автоматически
такого разделения не выполняет. И
в-третьих, на этапе генерации кода в
компиляторе с языка ассемблера
не производится оптимизация, поскольку
разработчик исходной программы
сам отвечает за организацию вычислений,
последовательность машинных команд
и распределение регистров процессора.
За
исключением этих особенностей компилятор
с языка ассемблера является обычным
компилятором, но значительно упрощенным
по сравнению с любым компилятором
с языка высокого уровня. Компиляторы с
языка ассемблера реализуются чаще всего
по двухпроходной схеме.
На первом проходе компилятор выполняет
разбор исходной программы, ее
преобразование в машинные коды и
одновременно заполняет таблицу
идентификаторов. Но на первом проходе
в машинных командах остаются незаполненными
адреса тех операндов, которые размещаются
в оперативной памяти. На втором
проходе компилятор заполняет эти адреса
и одновременно обнаруживает неописанные
идентификаторы. Это связано с тем, что
операнд может быть описан в программе
после того, как он первый раз был
использован. Тогда его адрес еще
не известен на момент построения машинной
команды, а поэтому требуется
второй проход. Типичным примером такого
операнда является метка, предусматривающая
переход вперед по ходу последовательности
команд.
Макроопределения
и макрокоманды
Разработка
программ на языке ассемблера — достаточно
трудоемкий процесс, требующий зачастую
простого повторения одних и тех же
многократно встречающихся
операций. Примером может служить
последовательность команд, выполняемых
каждый раз для организации стекового
дисплея памяти при входе в процедуру
или функцию.
Для
облегчения труда разработчика были
созданы так называемые макрокоманды.
Макрокоманда
представляет
собой текстовую подстановку, в ходе
выполнения которой
каждый идентификатор определенного
вида заменяется на цепочку символов
из некоторого хранилища данных. Процесс
выполнения макрокоманды называется
макрогенерацией, а цепочка символов,
получаемая в результате выполнения
макрокоманды, — макрорасширением.
Процесс
выполнения макрокоманд заключается в
последовательном просмотре текста
исходной программы, обнаружении в нем
определенных идентификаторов
и их замене на соответствующие строки
символов. Причем выполняется именно
текстовая замена одной цепочки символов
(идентификатора) на другую цепочку
символов (строку). Такая замена называется
макроподстановкой [66, 83,
93].
Для
того чтобы указать, какие идентификаторы
на какие строки необходимо заменять,
служат макроопределения. Макроопределения
присутствуют непосредственно
в тексте исходной программы. Они
выделяются специальными ключевыми
словами либо разделителями, которые не
могут встречаться нигде больше в
тексте программы. В процессе обработки
все макроопределения полностью
исключаются
из текста входной программы, а содержащаяся
в них информация запоминается
для обработки при выполнении макрокоманд.
Макроопределение
может содержать параметры. Тогда каждая
соответствующая ему
макрокоманда должна при вызове содержать
строку символов вместо каждого параметра.
Эта строка подставляется при выполнении
макрокоманды в каждое место,
где в макроопределении встречается
соответствующий параметр. В качестве
параметра макрокоманды может оказаться
другая макрокоманда, тогда она будет
рекурсивно вызвана всякий раз, когда
необходимо выполнить подстановку
параметра.
В принципе макрокоманды могут образовывать
последовательность
рекурсивных
вызовов, аналогичную последовательности
рекурсивных вызовов процедур
и функций, но только вместо вычислений
и передачи параметров они выполняют
лишь текстовые подстановки1.
Макрокоманды
и макроопределения обрабатываются
специальным модулем, называемым
макропроцессором или макрогенератором.
Макрогенератор получает на вход текст
исходной программы, содержащий
макроопределения и макрокоманды,
а на выходе его появляется текст
макрорасширения исходной программы,
не содержащий макроопределений и
макрокоманд. Оба текста являются только
текстами программы, никакая другая
обработка не выполняется. Именно
макрорасширение
исходного текста поступает на вход
компилятора.
Синтаксис
макрокоманд и макроопределений не
является строго заданным. Он может
различаться в зависимости от реализации
компилятора с языка ассемблера. Но
сам принцип выполнения макроподстановок
в тексте программы неизменен
и не зависит от их синтаксиса.
Макрогенератор
чаще всего не существует в виде отдельного
программного модуля,
а входит в состав компилятора с языка
ассемблера. Макрорасширение исходной
программы обычно недоступно ее
разработчику. Более того, макроподстановки
могут выполняться последовательно при
разборе исходного текста на первом
проходе компилятора вместе с разбором
всего текста программы, и тогда
макрорасширение
исходной программы в целом может и вовсе
не существовать как таковое.
Например,
следующий текст определяет макрокоманду
push_0
в языке ассемблера
процессора типа Intel
8086:
push_O
macro
хог
ах,ах
■
push ax endm
Семантика
этой макрокоманды заключается в записи
числа «0» в стек через регистр
процессора ах. Тогда везде в тексте
программы, где встретится макрокоманда
push_O
она
будет заменена в результате макроподстановки
на последовательность команд:
хог
ах,ах ■ push
ax
Это
самый простой вариант макроопределения.
Существует возможность создавать
более сложные макроопределения с
параметрами. Одно из таких макроопределений
описано ниже:
Глубина
такой рекурсии, как правило, сильно
ограничена. На последовательность
рекурсивных вызовов макрокоманд
налагаются обычно существенно более
жесткие ограничения, чем на
последовательность рекурсивных вызовов
процедур и функций, которая при стековой
организации дисплея памяти ограничена
только размером стека передачи
параметров.
add_abx
macro xl,x2
add ax.xl
add bx.xl
add cx,x2
push ax
endm
Тогда
в тексте программы макрокоманда также
должна быть указана с соответствующим
числом параметров. В данном примере
макрокоманда
add_abx4,8
будет
в результате макроподстановки заменена
на последовательность команд:
add
ах,4
add bx.4 add
ex,8 push ax
Во
многих компиляторах с языка ассемблера
возможны еще более сложные конструкции,
которые могут содержать локальные
переменные и метки. Примером такой
конструкции может служить макроопределение:
loop_ax
macro
xl,x2,yl
local
loopax
mov
ax.xl
хог
bx.bx
loopax:
add
bx.yl
sub ax,x2
jge loopax
endm
Здесь
метка 1 oopax
является локальной, определенной только
внутри данного макроопределения.
В этом случае уже не может быть выполнена
простая текстовая подстановка макрокоманды
в текст программы, поскольку если данную
макрокоманду
выполнить дважды, то это приведет к
появлению в тексте программы двух
одинаковых меток 1 оорах. В таком варианте
макрогенератор должен использовать
более сложные методы текстовых
подстановок, аналогичные тем, что
используются
в компиляторах при идентификации
лексических элементов входной
программы, чтобы дать всем возможным
локальным переменным и меткам макрокоманд
уникальные имена в пределах всей
программы. Макроопределения
и макрокоманды нашли применение не
только в языках ассемблера,
но и во многих языках высокого уровня.
Там их обрабатывает специальный
модуль, называемый препроцессором языка
(например, широко известен препроцессор
языка С). Принцип обработки остается
тем же самым, что и для программ
на языке ассемблера — препроцессор
выполняет текстовые подстановки
непосредственно над строками самой
исходной программы. В
языках высокого уровня макроопределения
должны быть отделены от текста самой
исходной программы, чтобы препроцессор
не мог спутать их с синтаксическими
конструкциями входного языка. Для этого
используются либо специальные символы
и команды (команды препроцессора),
которые никогда не могут встречаться
в тексте исходной программы, либо
макроопределения встречаются
внутри
незначащей части исходной программы —
входят в состав комментариев (такая
реализация существует, например, в
компиляторе с языка Pascal,
созданном
фирмой Borland).
Макрокоманды, напротив, могут встречаться
в произвольном месте исходного текста
программы, и синтаксически их вызов
может не отличаться
от вызова функций во входном языке.
Следует
помнить, что, несмотря на схожесть
синтаксиса вызова, макрокоманды
принципиально
отличаются от процедур и функций,
поскольку не порождают результирующего
кода, а представляют собой текстовую
подстановку, выполняемую
прямо в тексте исходной программы.
Результат вызова функции и макрокоманды
может из-за этого серьезно отличаться.
Рассмотрим
пример на языке С. Если
описана функция
int
fKint
a)
{ return
a
+ а: } и
аналогичная ей макрокоманда
#define
f2(a)
((a)
+ (а))
то
результат их вызова не всегда будет
одинаков.
Действительно,
вызовы j=fl(i)
и j=f2(i)
(где i
и j
— некоторые целочисленные переменные)
приведут к одному и тому же результату.
Но вызовы j=fl(++i)
и j=f2(++i)
дадут разные значения переменной j.
Дело в том, что поскольку f2
— это
макроопределение, то во втором случае
будет выполнена текстовая подстановка,
которая приведет к последовательности
операторов j=((++i)
+ (++i)).
Видно, что
в этой последовательности операция ++i
будет выполнена дважды, в отличие от
вызова функции fl(++i),
где она выполняется только один раз.
5. Таблицы
идентификаторов. Организация таблиц
идентификаторов. Назначение и особенности
построения таблиц идентификаторов.
Простейшие методы построения таблиц
идентификаторов. Хэш-функция и
хэш-адресация.
Таблицы
идентификаторов. Организация
таблиц идентификаторов
Назначение
и особенности построения таблиц
идентификаторов
Проверка
правильности семантики и генерация
кода требуют знания характеристик
переменных, констант, функций и других
элементов, встречающихся в программе
на исходном языке. Все эти элементы в
исходной программе, как правило,
обозначаются идентификаторами. Выделение
идентификаторов и других элементов
исходной программы происходит на фазе
лексического анализа. Их характеристики
определяются на фазах синтаксического
разбора, семантического
анализа и подготовки к генерации кода.
Состав возможных характеристик и методы
их определения зависят от семантики
входного языка. В
любом случае компилятор должен иметь
возможность хранить все найденные
идентификаторы
и связанные с ними характеристики в
течение всего процесса компиляции,
чтобы иметь возможность использовать
их на различных фазах
компиляции.
Для этой цели, как было сказано выше, в
компиляторах используются
специальные хранилища данных, называемые
таблицами
символов или
таблицами
идентификаторов.
Любая
таблица идентификаторов состоит из
набора полей, количество которых равно
числу различных идентификаторов,
найденных в исходной программе. Каждое
поле содержит в себе полную информацию
о данном элементе таблицы. Компилятор
может работать с одной или несколькими
таблицам идентификаторов — их
количество зависит от реализации
компилятора. Например, можно организовывать
различные таблицы идентификаторов для
различных модулей исходной
программы или для различных типов
элементов входного языка.
Состав
информации, хранимой в таблице
идентификаторов для каждого элемента
исходной программы, зависит от семантики
входного языка и типа элемента. Например,
в таблицах идентификаторов может
храниться следующая информация:
□ для
переменных:
О имя переменной;
О тип данных
переменной;
О область памяти,
связанная с переменной;
□ для
констант:
О название константы
(если оно имеется);
О значение константы;
О тип данных
константы (если требуется);
□ для
функций:
О имя функции;
О количество и
типы формальных аргументов функции;
О тип возвращаемого
результата;
О адрес кода
функции.
Приведенный
выше состав хранимой информации, конечно
же, является только примерным. Другие
примеры такой информации указаны в [23,
42, 74]. Конкретное
наполнение таблиц идентификаторов
зависит от реализации компилятора.
Кроме
того, не вся информация, хранимая в
таблице идентификаторов, заполняется
компилятором
сразу — он может несколько раз выполнять
обращение к данным в таблице идентификаторов
на различных фазах компиляции. Например,
имена переменных могут быть выделены
на фазе лексического анализа, типы
данных для
переменных — на фазе синтаксического
разбора, а область памяти связывается
с переменной только на фазе подготовки
к генерации кода.
Вне
зависимости от реализации компилятора
принцип его работы с таблицей
идентификаторов
остается одним и тем же — на различных
фазах компиляции компилятор вынужден
многократно обращаться к таблице для
поиска информации и записи новых
данных. Как правило, каждый элемент в
исходной программе
однозначно идентифицируется своим
именем (вопросы идентификации более
подробно
рассмотрены в разделе «Семантический
анализ и подготовка к генерации
кода», глава 14). Поэтому компилятору
приходится часто выполнять поиск
необходимого
элемента в таблице идентификаторов по
его имени, в то время как процесс
заполнения таблицы выполняется нечасто
— новые идентификаторы описываются
в программе гораздо реже, чем используются.
Отсюда можно сделать
вывод, что таблицы идентификаторов
должны быть организованы таким образом,
чтобы компилятор имел возможность
максимально быстрого поиска нужного
ему элемента [33].
Простейшие
методы построения таблиц идентификаторов
Простейший
способ организации таблицы состоит в
том, чтобы добавлять элементы
в порядке их поступления. Тогда таблица
идентификаторов будет представлять
собой неупорядоченный массив информации,
каждая ячейка которого будет содержать
данные о соответствующем элементе
таблицы.
Поиск
нужного элемента в таблице будет в этом
случае заключаться в последовательном
сравнении искомого элемента с каждым
элементом таблицы, пока не будет найден
подходящий. Тогда, если за единицу
принять время, затрачиваемое компилятором
на сравнение двух элементов (как правило,
это сравнение двух строк),
то для таблицы, содержащей N элементов,
в среднем будет выполнено N/2
сравнений [14].
Заполнение
такой таблицы будет происходить
элементарно просто — добавлением
нового элемента в ее конец, и время,
требуемое на добавление элемента (Т3),
не
будет зависеть от числа элементов в
таблице N. Но если N велико, то поиск
потребует
значительных затрат времени. Время
поиска (Т„) в такой таблице можно оценить
как Тп
= O(N).
Поскольку поиск в таблице идентификаторов
является
чаще всего выполняемой компилятором
операцией, а количество различных
идентификаторов даже в реальной исходной
программе достаточно велико
(от нескольких сотен до нескольких тысяч
элементов), то такой способ организации
таблиц идентификаторов является
неэффективным.
Поиск
может быть выполнен более эффективно,
если элементы таблицы упорядочены
(отсортированы) согласно некоторому
естественному порядку.
В
нашем случае, когда поиск будет
осуществляться по имени идентификатора,
наиболее
естественно расположить элементы
таблицы в прямом или обратном алфавитном
порядке. Эффективным методом поиска в
упорядоченном списке из N
элементов является бинарный или
логарифмический поиск. Символ, который
следует найти, сравнивается с элементом
(N+l)/2
в середине таблицы. Если этот элемент
не является искомым, то мы должны
просмотреть только блок элементов,
пронумерованных от 1 до (N+l)/2-l,
или блок элементов от (N+l)/2+l
до
N в зависимости от того, меньше или больше
искомый элемент того, с которым
его сравнили. Затем процесс повторяется
над нужным блоком в два раза меньшего
размера. Так продолжается до тех пор,
пока либо элемент не будет найден, либо
алгоритм не дойдет до очередного блока,
содержащего один или два элемента (с
которыми уже можно выполнить прямое
сравнение искомого элемента).
Так
как на каждом шаге число элементов,
которые могут содержать искомый элемент,
сокращается наполовину, то максимальное
число сравнений равно l+log2(N).
Тогда
время поиска элемента в таблице
идентификаторов можно оценить как Тп
= O(log2
N).
Для сравнения: при N=128 бинарный поиск
требует самое большее
8 сравнений, а поиск в неупорядоченной
таблице — в среднем 64 сравнения. Метод
называют «бинарным поиском», поскольку
на каждом шаге объем рассматриваемой
информации сокращается в два раза, а
«логарифмическим» — поскольку время,
затрачиваемое на поиск нужного элемента
в массиве, имеет логарифмическую
зависимость от общего количества
элементов в нем.
Недостатком
метода является требование упорядочивания
таблицы идентификаторов.
Так как массив информации, в котором
выполняется поиск, должен быть
упорядочен, то время его заполнения уже
будет зависеть от числа элементов
в массиве. Таблица идентификаторов
зачастую просматривается еще до того,
как она заполнена полностью, поэтому
требуется, чтобы условие упорядоченности
выполнялось на всех этапах обращения
к ней. Следовательно, для построения
таблицы можно пользоваться только
алгоритмом прямого упорядоченного
включения элементов.
При
добавлении каждого нового элемента в
таблицу сначала надо определить место,
куда поместить новый элемент, а потом
выполнить перенос части информации
в таблице, если элемент добавляется не
в ее конец. Если пользоваться стандартными
алгоритмами, применяемыми для организации
упорядоченных массивов
данных [14], а поиск места включения вести
с помощью алгоритма бинарного поиска,
то среднее время, необходимое на помещение
всех элементов в таблицу,
можно оценить следующим образом:
Т3
= O(N*log2
N)
+ k*O(№).
Здесь
к — некоторый коэффициент, отражающий
соотношение между временами,
затрачиваемыми компьютером на выполнение
операции сравнения и операции
переноса данных.
В
итоге при организации логарифмического
поиска в таблице идентификаторов мы
добиваемся существенного сокращения
времени поиска нужного элемента за
счет увеличения времени на помещение
нового элемента в таблицу. Поскольку
добавление новых элементов в таблицу
идентификаторов происходит существенно
реже1,
чем обращение к ним, то этот метод следует
признать более эффективным,
чем метод организации неупорядоченной
таблицы.
Построение
таблиц идентификаторов по
методу бинарного дерева
Можно
сократить время поиска искомого элемента
в таблице идентификаторов,
не увеличивая значительно время,
необходимое на ее заполнение. Для этого
надо
отказаться от организации таблицы в
виде непрерывного массива данных.
Как
минимум при добавлении нового
идентификатора в таблицу компилятор
должен проверить,
существует или нет там такой идентификатор,
так как в большинстве языков программирования
ни один идентификатор не может быть
описан более одного раза. Следовательно,
каждая операция добавления нового
элемента влечет, как правило, не менее
одной операции поиска.
Существует метод построения таблиц,
при котором таблица имеет форму бинарного
дерева. Каждый узел дерева представляет
собой элемент таблицы, причем корневой
узел является первым элементом,
встреченным при заполнении таблицы.
Дерево называется бинарным, так как
каждая вершина в нем может иметь не
более
двух ветвей (и, следовательно, не более
двух нижележащих вершин). Для определенности
будем называть две ветви «правая» и
«левая».
Рассмотрим
алгоритм заполнения бинарного дерева.
Будем считать, что алгоритм
работает с потоком входных данных,
содержащим идентификаторы (в компиляторе
этот поток данных порождается в процессе
разбора текста исходной программы).
Первый идентификатор, как уже было
сказано, помещается в вершину
дерева. Все дальнейшие идентификаторы
попадают в дерево по следующему
алгоритму.
Шаг
1. Выбрать
очередной идентификатор из входного
потока данных. Если очередного
идентификатора нет, то построение дерева
закончено.
Шаг
2. Сделать
текущим узлом дерева корневую вершину.
Шаг
3. Сравнить
очередной идентификатор с идентификатором,
содержащемся в текущем
узле дерева.
Шаг
4. Если
очередной идентификатор меньше, то
перейти к шагу 5, если равен
— сообщить об ошибке и прекратить
выполнение алгоритма (двух одинаковых
идентификаторов быть не должно!), иначе
— перейти к шагу 7. Шаг
5.
Если у текущего узла существует левая
вершина, то сделать ее текущим узлом и
вернуться к шагу 3, иначе — перейти к
шагу 6.
Шаг
6. Создать
новую вершину, поместить в нее очередной
идентификатор, сделать
эту новую вершину левой вершиной текущего
узла и вернуться к шагу 1.
Шаг
7. Если
у текущего узла существует правая
вершина, то сделать ее текущим узлом
и вернуться к шагу 3, иначе — перейти к
шагу 8.
Шаг
8. Создать
новую вершину, поместить в нее очередной
идентификатор, сделать
эту новую вершину правой вершиной
текущего узла и вернуться к шагу 1.
Рассмотрим
в качестве примера последовательность
идентификаторов GA,
Dl,
М22, Е,
А12, ВС, F.
На рис. 13.2 проиллюстрирован весь процесс
построения бинарного дерева
для этой последовательности идентификаторов.
Поиск нужного
элемента в дереве выполняется по
алгоритму, схожему с алгоритмом
заполнения дерева.
Шаг
1. Сделать
текущим узлом дерева корневую вершину.
Шаг
2. Сравнить
искомый идентификатор с идентификатором,
содержащемся в текущем узле дерева.
Шаг
4. Если
идентификаторы совпадают, то искомый
идентификатор найден, алгоритм
завершается, иначе — надо перейти к
шагу 5.
Шаг
5. Если
очередной идентификатор меньше, то
перейти к шагу 6, иначе — перейти
к шагу 7.
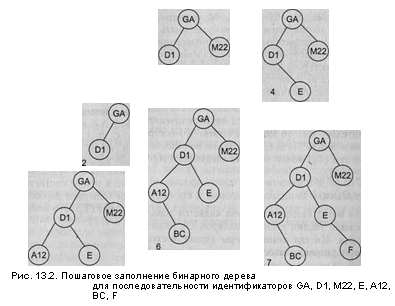
Шаг
6. Если
у текущего узла существует левая вершина,
то сделать ее текущим узлом
и вернуться к шагу 2, иначе искомый
идентификатор не найден, алгоритм
завершается.
Шаг
7. Если
у текущего узла существует правая
вершина, то сделать ее текущим узлом
и вернуться к шагу 2, иначе искомый
идентификатор не найден, алгоритм
завершается.
Например,
произведем поиск в дереве, изображенном
на рис. 13.2, идентификатора
А12. Берем корневую вершину (она становится
текущим узлом), сравниваем
идентификаторы GA
и А12. Искомый идентификатор меньше —
текущим узлом
становится левая вершина D1.
Опять сравниваем идентификаторы.
Искомый идентификатор меньше —
текущим узлом становится левая вершина
А12. При
следующем сравнении искомый идентификатор
найден.
Если искать
отсутствующий идентификатор — например,
АН, — то поиск опять пойдет от корневой
Если
искать отсутствующий идентификатор —
например, АН, — то поиск опять пойдет
от корневой вершины. Сравниваем
идентификаторы GA
и АН. Искомый идентификатор
меньше — текущим узлом становится левая
вершина D1.
Опять сравниваем
идентификаторы. Искомый идентификатор
меньше — текущим узлом становится
левая вершина А12. Искомый идентификатор
меньше, но левая вершина
у узла А12 отсутствует, поэтому в данном
случае искомый идентификатор
не найден.
Для
данного метода число требуемых сравнений
и форма получившегося дерева во
многом зависят от того порядка, в котором
поступают идентификаторы. Сравниваем
идентификаторы GA
и АН. Искомый идентификатор
меньше — текущим узлом становится левая
вершина D1.
Опять сравниваем
идентификаторы. Искомый идентификатор
меньше —
текущим
узлом становится левая вершина А12.
Искомый идентификатор меньше, но левая
вершина
у узла А12 отсутствует, поэтому в данном
случае искомый идентификатор
не найден.
Для
данного метода число требуемых сравнений
и форма получившегося дерева во
многом зависят от того порядка, в котором
поступают идентификаторы. Например,
если в рассмотренном выше примере вместо
последовательности идеи-тификаторов
GA,
Dl,
M22,
E,
A12,
ВС, F
взять последовательность А12, GA,
Dl,
M22,
E,
ВС, F,
то полученное дерево будет иметь иной
вид. А если в качестве примера
взять последовательность идентификаторов
А, В, С, D,
E,
F,
то дерево выродится
в упорядоченный однонаправленный
связный список. Эта особенность является
недостатком данного метода организации
таблиц идентификаторов. Другим
недостатком является необходимость
работы с динамическим выделением памяти
при построении дерева.
Если
предположить, что последовательность
идентификаторов в исходной программе
является статистически неупорядоченной
(что в целом соответствует действительности),
то можно считать, что построенное
бинарное дерево будет невырожденным.
Тогда среднее время на заполнение дерева
(Т3)
и на поиск элемента
в нем (Т„) можно оценить следующим
образом [6, т. 2]:
Т3
= N*O(log2
N). Tn
— O(log2
N).
В
целом метод бинарного дерева является
довольно удачным механизмом для
организации
таблиц идентификаторов. Он нашел свое
применение в ряде компиляторов.
Иногда компиляторы строят несколько
различных деревьев для идентификаторов
разных типов и разной длины [23, 74].
Хэш-функции
и хэш-адресация
Принципы
работы хэш-функций
Логарифмическая
зависимость времени поиска и времени
заполнения таблицы идентификаторов —
это самый хороший результат, которого
можно достичь за счет применения
различных методов организации таблиц.
Однако в реальных исходных
программах количество идентификаторов
столь велико, что даже логарифмическую
зависимость времени поиска от их числа
нельзя признать удовлетворительной.
Необходимы более эффективные методы
поиска информации в
таблице идентификаторов.
Лучших результатов
можно достичь, если применить методы,
связанные с использованием хэш-функций
и хэш-адресации.
Хэш-функцией
F
называется некоторое отображение
множества входных элементов
R
на множество целых неотрицательных
чисел Z:
F(r)
= n,
reR,
neZ.
Сам термин
«хэш-функция» происходит от английского
термина «hash
function»
(hash
— «мешать», «смешивать», «путать»).
Вместо термина «хэширование» иногда
используются термины «рандомизация»,
«переупорядочивание».
Множество
допустимых входных элементов R
называется областью определения
хэш-функции. Множеством значений
хэш-функции F
называется подмножество М из множества
целых неотрицательных чисел Z:
McZ,
содержащее все возможные
значения, возвращаемые функцией F:
VreR:
F(r)eM.
Процесс отображения
области определения хэш-функции на
множество значений называется
«хэшированием».
При
работе с таблицей идентификаторов
хэш-функция должна выполнять отображение
имен идентификаторов на множество целых
неотрицательных чисел.
Областью
определения хэш-функции будет множество
всех возможных имен идентификаторов.
Хэш-адресация
заключается в использовании значения,
возвращаемого хэш-функцией,
в качестве адреса ячейки из некоторого
массива данных. Тогда размер массива
данных должен соответствовать области
значений используемой хэш-функции.
Следовательно, в реальном компиляторе
область значений хэш-функции
никак не должна превышать размер
доступного адресного пространства
компьютера.
Метод
организации таблиц идентификаторов,
основанный на использовании хэш-адресации,
заключается в размещении каждого
элемента таблицы в ячейке, адрес которой
возвращает хэш-функция, вычисленная
для этого элемента. Тогда в идеальном
случае для размещения любого элемента
в таблице идентификаторов достаточно
только вычислить его хэш-функцию и
обратиться к нужной ячейке массива
данных. Для поиска элемента в таблице
необходимо вычислить хэш-функцию
для искомого элемента и проверить, не
является ли заданная ею ячейка массива
пустой (если она не пуста — элемент
найден, если пуста — не найден).

Поиск
Идентификаторы
Результат
поиска
На
рис. 13.3 проиллюстрирован метод организации
таблиц идентификаторов с использованием
хэш-адресации. Трем различным
идентификаторам Alf
A2,
А3
соответствуют
на рисунке три значения хэш-функции nlf
n2,
п3.
В ячейки, адресуемые
щ,
п2,
п3,
помещается информация об идентификаторах
А,, А2,
А3.
При поиске
идентификатора А3
вычисляется значение адреса п3
и выбираются данные из соответствующей
ячейки таблицы.
Рис.
13.3. Организация
таблицы идентификаторов с
использованием хэш-адресации
Этот
метод весьма эффективен — как время
размещения элемента в таблице, так и
время его поиска определяются только
временем, затрачиваемым на вычисление
хэш-функции, которое в общем случае
несопоставимо меньше времени, необходимого
на многократные сравнения элементов
таблицы.
Метод
имеет два очевидных недостатка. Первый
из них — неэффективное использование
объема памяти под таблицу идентификаторов:
размер массива для ее хранения должен
соответствовать области значений
хэш-функции, в то время
как реально хранимых в таблице
идентификаторов может быть существенно
меньше.
Второй недостаток — необходимость
соответствующего разумного выбора
хэш-функции. Этому существенному вопросу
посвящены следующие два подраздела.
Построение
таблиц идентификаторов на
основе хэш-функций
Существуют
различные варианты хэш-функций. Получение
результата хэш-функции
— «хэширование» — обычно достигается
за счет выполнения над цепочкой
символов некоторых простых арифметических
и логических операций. Самой простой
хэш-функцией для символа является код
внутреннего представления
в ЭВМ литеры символа. Эту хэш-функцию
можно использовать и для цепочки
символов, выбирая первый символ в
цепочке. Так, если двоичное ASCII
представление
символа А есть 00100001, то результатом
хэширования идентификатора
АТаЫе будет код 00100001.
Идентификаторы
Хэш-функция,
предложенная выше, очевидно не
удовлетворительна: при использовании
такой хэш-функции возникнет новая
проблема — двум различным идентификаторам,
начинающимся с одной и той же буквы,
будет соответствовать
одно и то же значение хэш-функции. Тогда
при хэш-адресации в одну ячейку
таблицы идентификаторов по одному и
тому же адресу должны быть помещены
два различных идентификатора, что явно
невозможно. Такая ситуация, когда двум
или более идентификаторам соответствует
одно и то же значение функции, называется
коллизией.
Возникновение
коллизии проиллюстрировано на рис. 13.4
— двум
различным идентификаторам At
и А2
соответствуют два совпадающих значения
хэш-функции, п, = п2.
Рис.
13.4. Возникновение коллизии при
использовании хэш-адресации
Естественно,
что хэш-функция, допускающая коллизии,
не может быть напрямую
использована для хэш-адресации в таблице
идентификаторов. Причем достаточно
получить хотя бы один случай коллизии
на всем множестве идентификаторов,
чтобы такой хэш-функцией нельзя было
пользоваться непосредственно. Но в
примере взята самая элементарная
хэш-функция. А возможно ли построить
нетривиальную хэш-функцию, которая бы
полностью исключала возникновение
коллизий?
Очевидно,
что для полного исключения коллизий
хэш-функция должна быть взаимно
однозначной: каждому элементу из области
определения хэш-функции должно
соответствовать одно значение из ее
множества значений, но и каждому значению
из множества значений этой функции
должен соответствовать только один
элемент из области ее определения. Тогда
любым двум произвольным элементам
из области определения хэш-функции
будут всегда соответствовать два
различных
ее значения. Теоретически для
идентификаторов такую хэш-функцию
построить можно, так как и область
определения хэш-функции (все возможные
имена идентификаторов), и область ее
значений (целые неотрицательные
числа) являются бесконечными счетными
множествами. Теоретически можно
организовать взаимно однозначное
отображение одного счетного множества
на другое, но практически это сделать
исключительно сложно1.
Практически
существует ограничение, делающее
создание взаимно однозначной хэш-функции
для идентификаторов невозможным. Дело
в том, что в реальности область значений
любой хэш-функции ограничена размером
доступного адресного пространства
в данной архитектуре компьютера. При
организации хэш-адресации значение,
используемое в качестве адреса таблицы
идентификаторов, не может
выходить за пределы, заданные адресной
сеткой компьютера2.
Множество адресов
любого компьютера с традиционной
архитектурой может быть велико, но
всегда конечно, то есть ограничено.
Организовать взаимно однозначное
отображение бесконечного множества
на конечное даже теоретически невозможно.
Можно
учесть, что длина принимаемой во внимание
строки идентификатора в
реальных компиляторах также практически
ограничена — обычно она лежит в
пределах от 32 до 128 символов (то есть и
область определения хэш-функции конечна).
Но и тогда количество элементов в
конечном множестве, составляющем
область определения функции, будет
превышать их количество в конечном
множестве
области значений функции (количество
всех возможных идентификаторов
все равно больше количества допустимых
адресов в современных компьютерах).
Таким образом, создать взаимно однозначную
хэш-функцию практи-чески
ни в каком варианте невозможно.
Следовательно, невозможно избежать
возникновения
коллизий.
Пока
для двух различных элементов результаты
хэширования различны, время поиска
совпадает со временем, затраченным на
хэширование. Однако возникает затруднение,
когда результаты хэширования двух
разных элементов совпадают.
Для
решения проблемы коллизии можно
использовать много способов. Одним из
них является метод «рехэширования»
(или «расстановки»). Согласно этому
методу,
если для элемента А адрес h(A),
вычисленный с помощью хэш-функции,
указывает
на уже занятую ячейку, то необходимо
вычислить значение функции ni=ht(A)
и проверить занятость ячейки по адресу
щ.
Если
и она занята, то вычисляется
значение Ь2(А),
и так до тех пор, пока либо не будет
найдена свободная ячейка,
либо очередное значение h;(A)
совпадет с h(A).
В последнем случае считается,
что таблица идентификаторов заполнена
и места в ней больше нет — выдается
информация об ошибке размещения
идентификатора в таблице. Особенностью
метода является то, что первоначально
таблица идентификаторов должна
быть заполнена информацией, которая
позволила бы говорить о том, что все
ее ячейки являются пустыми (не содержат
данных). Например, если используются
указатели для хранения имен идентификаторов,
то таблицу надо предварительно
заполнить пустыми указателями.
Такую таблицу
идентификаторов можно организовать по
следующему алгоритму размещения
элемента.
Шаг
1. Вычислить
значение хэш-функции n
= h(A)
для нового элемента А.
Шаг
2. Если
ячейка по адресу п пустая, то поместить
в нее элемент А и завершить
алгоритм, иначе i:=l
и перейти к шагу 3.
Шаг
3. Вычислить
n;
= hj(A).
Если ячейка по адресу П| пустая, то
поместить в нее элемент
А и завершить алгоритм, иначе перейти
к шагу 4.
Шаг
4. Если
п = щ,
то
сообщить об ошибке и завершить алгоритм,
иначе i:-i+l
и вернуться
к шагу 3.
Тогда
поиск элемента А в таблице идентификаторов,
организованной таким образом,
будет выполняться по следующему
алгоритму.
Шаг
1. Вычислить
значение хэш-функции n
= h(A)
для нового элемента А.
Шаг
2. Если
ячейка по адресу п пустая, то элемент
не найден, алгоритм завершен, иначе
сравнить имя элемента в ячейке п с именем
искомого элемента А. Если
они совпадают, то элемент найден и
алгоритм завершен, иначе i:=
1 и перейти
к шагу 3.
Шаг
3. Вычислить
П] = h;(A).
Если ячейка по адресу п, пустая или п =
щ,
то
элемент не найден и алгоритм завершен,
иначе сравнить имя элемента в ячейке
П; с именем
искомого элемента А. Если они совпадают,
то элемент найден и алгоритм
завершен, иначе i:=i+l
и повторить к шаг 3.
Алгоритмы
размещения и поиска элемента схожи по
выполняемым операциям. Поэтому
они будут совпадать и по оценкам времени,
необходимого для их выполнения.
При такой организации таблиц идентификаторов
в случае возникновения коллизии
алгоритм размещает элементы в пустых
ячейках таблицы, выбирая их определенным
образом. При этом элементы могут попадать
в ячейки с адресами, которые
потом будут совпадать со значениями
хэш-функции, что приведет к возникновению
новых, дополнительных коллизий. Таким
образом, количество операций,
необходимых для поиска или размещения
в таблице элемента, зависит от заполненности
таблицы. Естественно, функции hj(A
) должны вычисляться единообразно
на этапах размещения и поиска элемента.
Вопрос только в том, как организовать
вычисление функций h;(A).
Самым
простым методом вычисления функции
hj(A)
является ее организация в
виде hi(A)
= (h(A)
+ pj)
mod
Nm,
где pj
— некоторое вычисляемое целое число,
a
Nm
— максимальное число элементов в таблице
идентификаторов. В свою очередь,
самым простым подходом здесь будет
положить pj
= i.
Тогда получаем формулу
h;(A)
= (h(A)+i)
mod
Nm.
В этом случае при совпадении значений
хэш-функции
для каких-либо элементов поиск свободной
ячейки в таблице начинается
последовательно от текущей позиции,
заданной хэш-функцией h(A).
Этот
способ нельзя признать особенно удачным
— при совпадении хэш-адресов элементы
в таблице начинают группироваться
вокруг них, что увеличивает число
необходимых сравнений при поиске и
размещении. Среднее время поиска элемента
в такой таблице в зависимости от числа
операций сравнения можно оценить
следующим образом [23]:
Тп-O((l-Lf/2)/(l-LQ).
Здесь
Lf
— (load
factor)
степень заполненности таблицы
идентификаторов — отношение
числа занятых ячеек таблицы к максимально
допустимому числу элементов
в ней: Lf
= N/Nm.
Рассмотрим
в качестве примера ряд последовательных
ячеек таблицы п(,
п2,
п3,
п4,
п5
и ряд идентификаторов, которые надо
разместить в ней: А(,
А2,
А3,
А4,
А5
при
условии, что h(Aj)
= h(A2)
= h(A5)
= n^
h(A3)
= n2;
h(A4)
= n4.
Последовательность
размещения идентификаторов в таблице
при использовании простейшего
метода рехэширования показана на рис.
13.5. В итоге после размещения в
таблице для поиска идентификатора А)
потребуется 1 сравнение, для А2
— 2
сравнения, для А3
— 2 сравнения, для А4
— 1 сравнение и для А5
— 5 сравнений.
Даже
такой примитивный метод рехэширования
является достаточно эффективным
средством организации таблиц
идентификаторов при неполном заполнении
таблицы. Имея, например, даже заполненную
на 90 % таблицу для 1024 идентификаторов,
в среднем необходимо выполнить 5,5
сравнений для поиска одного идентификатора,
в то время как даже логарифмический
поиск дает в среднем от 9 до 10 сравнений.
Сравнительная эффективность метода
будет еще выше при росте
числа идентификаторов и снижении
заполненности таблицы.
Среднее
время на помещение одного элемента в
таблицу и на поиск элемента в
таблице можно снизить, если применить
более совершенный метод рехэширования.
Одним из таких методов является
использование в качестве р, для функции
h,(A)
— (h(A)+pi)modNm
последовательности псевдослучайных
целых чисел ри
р2,
…, Рк- При хорошем выборе генератора
псевдослучайных чисел длина по-
следовательности
к будет k=Nm.
Тогда среднее время поиска одного
элемента в таблице можно оценить
следующим образом [23]:
|
m |
Ai |
|
П2 |
A2 |
|
ПЗ |
Аз |
h(Ai>
h(A2) ►г
►П1
hi(A2)
h(A3>
П2
hi(A3)
En
= O((l/Lf)*log2(l-Lf)).
|
Ai |
||
|
A? |
||
|
П1 |
Ai |
|
П2 |
A2 |
|
ПЗ |
A3 |
|
h(A4) ► |
A4 |
|
4 |
h(A5) ►
ni
h2(As)
h3(A5)
П4(А5)
A5
П2
ПЗ
П4
П5
5
Рис.
13.5. Заполнение таблицы идентификаторов
при использовании простейшего
рехэширования
Существуют
и другие методы организации функций
рехэширования и,(А), основанные
на квадратичных вычислениях или,
например, на вычислении по формуле:
hj(A)
= (h(A)*i)
mod
Nm,
если Nm
— простое число [23]. В целом рехэширование
позволяет
добиться неплохих результатов для
эффективного поиска элемента в таблице
(лучших, чем бинарный поиск и бинарное
дерево), но эффективность метода
сильно зависит от заполненности таблицы
идентификаторов и качества используемой
хэш-функции — чем реже возникают
коллизии, тем выше эффективность
метода. Требование неполного заполнения
таблицы ведет к неэффективному
использованию объема доступной памяти.
Построение
таблиц идентификаторов по методу цепочек
Неполное
заполнение таблицы идентификаторов
при применении хэш-функций ведет к
неэффективному использованию всего
объема памяти, доступного компилятору.
Причем объем неиспользуемой памяти
будет тем выше, чем больше информации
хранится для каждого идентификатора.
Этого недостатка можно избежать,
если дополнить таблицу идентификаторов
некоторой промежуточной хэщ-таблицей.
В
ячейках хэш-таблицы может храниться
либо пустое значение, либо значение
указателя
на некоторую область памяти из основной
таблицы идентификаторов. Тогда хэш-функция
вычисляет адрес, по которому происходит
обращение сначала
к хэш-таблице, а потом уже через нее по
найденному адресу — к самой таблице
идентификаторов. Если соответствующая
ячейка таблицы идентификаторов пуста,
то ячейка хэш-таблицы будет содержать
пустое значение. Тогда вовсе не обязательно
иметь в самой таблице идентификаторов
ячейку для каждого возможного
значения хэш-функции — таблицу можно
сделать динамической так, чтобы
ее объем рос по мере заполнения
(первоначально таблица идентификаторов
не содержит ни одной ячейки, а все ячейки
хэш-таблицы имеют пустое значение).
Такой
подход позволяет добиться двух
положительных результатов: во-первых,
нет
необходимости заполнять пустыми
значениями таблицу идентификаторов —
это
можно сделать только для хэш-таблицы;
во-вторых, каждому идентификатору
будет соответствовать строго одна
ячейка в таблице идентификаторов (в ней
не будет пустых неиспользуемых ячеек).
Пустые ячейки в таком случае будут
только
в хэш-таблице, и объем неиспользуемой
памяти не будет зависеть от объема
информации, хранимой для каждого
идентификатора — для каждого значения
хэш-функции будет расходоваться только
память, необходимая для хранения
одного указателя на основную таблицу
идентификаторов.
На
основе этой схемы можно реализовать
еще один способ организации таблиц
идентификаторов с помощью хэш-функций,
называемый «метод цепочек». Для метода
цепочек в таблицу идентификаторов для
каждого элемента добавляется еще
одно поле, в котором может содержаться
ссылка на любой элемент таблицы.
Первоначально
это поле всегда пустое (никуда не
указывает). Также для этого метода
необходимо иметь одну специальную
переменную, которая всегда указывает
на первую свободную ячейку основной
таблицы идентификаторов (первоначально
— указывает на начало таблицы).
Метод цепочек
работает следующим образом по следующему
алгоритму.
,
Шаг
1. Во
все ячейки хэш-таблицы поместить пустое
значение, таблица идентификаторов
не должна содержать ни одной ячейки,
переменная FreePtr
(указатель
первой
свободной ячейки) указывает на начало
таблицы идентификаторов; i:=l.
Шаг
2. Вычислить
значение хэш-функции щ
для
нового элемента Aj.
Если ячейка хэш-таблицы по адресу П(
пустая, то поместить в нее значение
переменной FreePtr
и
перейти к шагу 5; иначе — перейти к шагу
3.
Шаг
3. Положить
j:=l,
выбрать из хэш-таблицы адрес ячейки
таблицы идентификаторов
nij
и перейти к шагу 4.
Шаг
4. Для
ячейки таблицы идентификаторов по
адресу nij
проверить значение поля
ссылки. Если оно пустое, то записать в
него адрес из переменной FreePtr
и
перейти
к шагу 5; иначе j:=j+l,
выбрать из поля ссылки адрес m.j
и повторить шаг 4. Шаг
5. Добавить
в таблицу идентификаторов новую ячейку,
записать в нее информацию для элемента
А, (поле ссылки должно быть пустым), в
переменную FreePtr
поместить
адрес за концом добавленной ячейки.
Если больше нет идентификаторов,
которые надо разместить в таблице, то
выполнение алгоритма закончено,
иначе i:=i+l
и перейти к шагу 2.
Поиск
элемента в таблице идентификаторов,
организованной таким образом, будет
выполняться по следующему алгоритму.
Шаг
1. Вычислить
значение хэш-функции п для искомого
элемента А. Если ячейка
хэш-таблицы по адресу п пустая, то элемент
не найден и алгоритм завершен,
иначе положить j:=l,
выбрать из хэш-таблицы адрес ячейки
таблицы идентификаторов nij=n.
дет
не столь велико. Тогда и время поиска
одного среди них будет незначительным
(в принципе при высоком качестве
хеш-функции подойдет даже перебор по
неупорядоченному
списку).
Такой
подход имеет преимущество по сравнению
с методом цепочек: для хранения
идентификаторов с совпадающими значениями
хэш-функции используются
области памяти, не пересекающиеся с
основной таблицей идентификаторов, а
значит, их размещение не приведет к
возникновению дополнительных коллизий.
Недостатком метода является необходимость
работы с динамически распределяемыми
областями памяти. Эффективность такого
метода, очевидно, в первую
очередь зависит от качества применяемой
хэш-функции, а во вторую — от
метода организации дополнительных
хранилищ данных. Хэш-адресация
— это метод, который применяется не
только для организации таблиц
идентификаторов в компиляторах. Данный
метод нашел свое применение
и в операционных системах (см. часть 1
данного пособия), и в системах управления
базами данных. Интересующиеся читатели
могут обратиться к соответствующей
литературе [23, 74].
Существует множество
ошибок, которые транслятор выявить не
в состоянии, если используемые в программе
операторы сформированы верно. Приведем
примеры таких ошибок.
Логические
ошибки:
-
неверное указание
ветви алгоритма после проверки некоторого
условия; -
неполный учет
возможных условий; -
пропуск в программе
одного или более блоков алгоритма.
Ошибки в циклах:
-
неправильное
указание начала цикла; -
неправильное
указание условий окончания цикла; -
неправильное
указание числа повторений цикла; -
бесконечный цикл.
Ошибки ввода-вывода;
ошибки при работе с данными:
-
неправильное
задание тип данных; -
организация
считывания меньшего или большего объёма
даных, чем требуется; -
неправильное
редактирование данных.
Ошибки в
использовании переменных:
-
использование
переменных без указания их начальных
значений; -
ошибочное указание
одной переменной вместо другой.
Ошибки при работе
с массивами:
-
массивы предварительно
не обнулены; -
массивы неправильно
описаны; -
индексы следуют
в неправильном порядке.
Ошибки в
арифметических операциях:
-
неверное указание
типа переменной (например, целочисленного
вместо вещественного); -
неверное определение
порядка действий; -
деление на нуль;
-
извлечение
квадратного корня из отрицательного
числа; -
потеря значащих
разрядов числа.
Все эти ошибки
обнаруживаются с помощью тестирования.
8.13. Сопровождение программы
Сопровождение
программ
— это работы, связанные с обслуживанием
программ в процессе их эксплуатации.
Многократное
использование разработанной программы
для решения различных задач заданного
класса требует проведения следующих
дополнительных работ:
-
исправление
обнаруженных ошибок; -
модификация
программы для удовлетворения изменяющихся
эксплуатационных требований; -
доработка программы
для решения конкретных задач; -
проведениe
дополнительных тестовых просчетов; -
внесение исправлений
в рабочую документацию; -
усовершенствование
программы и т.д.
Применительно ко
многим программам работы по сопровождению
поглощают более половины затрат,
приходящихся на весь период времени
существования программы (начиная от
выработки первоначальной концепции и
кончая моральным ее устареванием) в
стоимостном выражении.
Программа,
предназначеная для длительной
эксплуатации, должна иметь соответствующую
документацию и инструкцию по её
использованию.
9.Применение компьютерной техники
9.1. Использувание компьютеров в быту
В последнее время
компьютеры <проникли> в жилища людей
и постепенно становятся предметами
первой необходимости. Есть два основных
направления использования компьютеров
дома.
-
Обеспечение
нормальной жизнедеятельности жилища:
-
охранная автоматика,
противопожарная автоматика,
газоанализаторная автоматика; -
управление
освещенностью, расходом электроэнергии,
отопительной системой, управление
микроклиматом; -
электроплиты,
холодильники, стиральные машины со
встроенными микропроцессорами.
Обеспечение
информационных потребностей людей,
находящихся в жилище:
-
заказы на товары
и услуги; -
процессы
обучения; -
общение с базами
данных
и знаний; -
сбор данных о
состоянии
здоровья; -
обеспечение
досуга и развлечений; -
обеспечение
справочной информацией; -
электронная
почта,
телеконференции; -
Интернет.
Соседние файлы в предмете Информатика
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Екатерина Андреевна Гапонько
Эксперт по предмету «Информатика»
Задать вопрос автору статьи
Виды ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
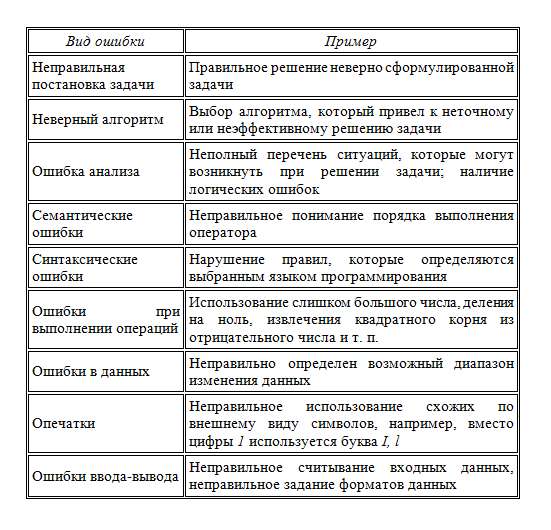
Рассмотрим более подробно некоторые из вышеприведенных видов ошибок.
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы.
Начни разбираться в искусстве
Обучающие курсы по психологии, маркетингу, нутрициологии и работе в сфере кино
Выбрать программу
Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примерами синтаксических ошибок является:
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Синтаксическая ошибка «Не задан идентификатор»:
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
«Ошибки в программах » 👇
Логические ошибки:
- после проверки заданного условия неправильно указана ветвь алгоритма;
- неполный перечень возможных условий при решении задачи;
- один или более блоков алгоритма в программе пропущен.
Ошибки в циклах:
- неправильно указано начало цикла;
- неправильно указаны условия окончания цикла;
- неправильно указано количество повторений цикла;
- использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными:
- неправильно задан тип данных;
- организовано считывание меньшего или большего объёма данных, чем нужно;
- неправильно отредактированы данные.
Ошибки в использовании переменных:
- используются переменных, для которых не указаны начальные значения;
- ошибочно указана одна переменная вместо другой.
Ошибки при работе с массивами:
- пропущено предварительное обнуление массивов;
- неправильное описание массивов;
- индексы массивов следуют в ошибочном порядке.
Ошибки в арифметических операциях:
- неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная);
- неправильно определен порядок действий;
- выполняется деление на нуль;
- при расчете выполняется попытка извлечения квадратного корня из отрицательного числа;
- не учитываются значащие разряды числа.
Ошибка в арифметических операциях «Деление на нуль»:

Все вышеописанные ошибки можно обнаружить методом тестирования.
Сопровождение программы
Сопровождением программ называются работы по обслуживанию программ в процессе их эксплуатации.
В случае многократного использования разработанной программы для решения различных задач определенного класса требуется проведение таких дополнительных работ, как:
- при обнаружении ошибок работы программы они должны исправляться;
- при изменении требований эксплуатации необходимая модификация программы;
- выполнение доработки программы с целью решения конкретных задач;
- выполнение дополнительных тестовых расчетов;
- внесение исправлений в рабочую документацию;
- улучшение программы и т.д.
Замечание 1
При проведении работ по сопровождению многих программ стоимость этого сопровождения превышает половину затрат, которые приходятся на весь период времени существования программы (от разработки начального алгоритма до морального ее устаревания).
Программа, которая предназначена для длительной эксплуатации, должна сопровождаться соответствующей документацией и инструкцией по ее использованию.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
| [ начало главы ] [ предыдущий ] |
[ содержание ] |
8.12. Какие ошибки не
обнаруживаются транслятором?
Существует множество ошибок, которые
транслятор выявить не в состоянии, если
используемые в программе операторы
сформированы верно. Приведем примеры таких
ошибок.
Логические ошибки:
Ошибки в циклах:
Ошибки ввода-вывода; ошибки
при работе с данными:
Ошибки в использовании
переменных:
Ошибки при работе с
массивами:
Ошибки в арифметических
операциях:
Все эти ошибки обнаруживаются с помощью
тестирования.
Кто не делится найденным, подобен свету в дупле секвойи (древняя индейская пословица)
Библиографическая запись:
Принципы построения транслирующих и интерпретирующих систем. — Текст : электронный // Myfilology.ru – информационный филологический ресурс : [сайт]. – URL: https://myfilology.ru//165/yazyki-programmirovaniya-i-ix-ispolzovanie-v-informaczionnyx-sistemax/princzipy-postroeniya-transliruyushhix-i-interpretiruyushhix-sistem/ (дата обращения: 7.06.2023)
В общем случае компиляторы и интерпретаторы называются языковыми процессорами.
Трансляторы
Транслятор (от англ. translate – переводить) – это программа, которая считывает текст программы, написанной на одном языке (входном), и транслирует (переводит) его в эквивалентный текст на другом языке (выходном).
В работе транслятора участвуют три программы. Во-первых, сам транслятор является программой. То есть транслятор — это часть программного обеспечения (ПО), он представляет собой набор машинных команд и данных и выполняется компьютером, как и нее прочие программы в рамках операционной системы (ОС). Все составные части транслятора представляют собой динамически загружаемые библиотеки или модули этой программы со своими входными и выходными данными.
Во-вторых, исходными данными для работы транслятора служит программа на исходном языке программирования — некоторая последовательность предложений входного языка. Эта программа называется входной, или исходной, программой. Обычно это символьный файл, но этот файл должен содержать текст программы, удовлетворяющий синтаксическим и семантическим требованиям входного языка. Кроме того, этот файл несет в себе некоторый смысл, определяемый семантикой входного языка. Часто файл, содержащий текст исходной программы, называют исходным файлом.
В-третьих, выходными данными транслятора является программа на результирующем языке. Эта программа называется результирующей программой. Результирующая программа строится по синтаксическим правилам выходного языка транслятора, а ее смысл определяется семантикой выходного языка.
Важным пунктом в определении транслятора является эквивалентность исходной и результирующей программ. Эквивалентность этих двух программ означает совпадение их смысла с точки зрения семантики входного языка и семантики выходного языка. Без выполнения этого требования сам транслятор теряет всякий практический смысл.
Чтобы создать транслятор, необходимо, прежде всего, выбрать входной и выходной языки. С точки зрения преобразования предложений входного языка в эквивалентные им предложения выходного языка транслятор выступает как переводчик. Например, трансляция программы с языка С в язык ассемблера по сути ничем не отличается от перевода с русского языка на английский, с той лишь разницей, что сложность языков несколько иная. Поэтому и само слово «транслятор» (англ.: translator) означает «переводчик».
Результатом работы транслятора будет результирующая программа, но только в том случае, если текст исходной программы является правильным — не содержит ошибок с точки зрения синтаксиса и семантики входного языка. Если исходная программа неправильная (содержит хотя бы одну ошибку), то результатом работы транслятора будет сообщение об ошибке (как правило, с дополнительными пояснениями и указанием места ошибки в исходной программе). В этом смысле транслятор сродни переводчику, например, с английского, которому подсунули неверный текст.
Одна из важных ролей транслятора состоит в сообщении об ошибках в исходной программе, обнаруженных в процессе трансляции.
Компилятор
Кроме понятия «транслятор» широко употребляется также близкое ему по смыслу понятие «компилятор».
Компилятор (от англ. compile – составлять, компоновать) – это транслятор, который осуществляет перевод исходной программы в эквивалентную ей результирующую программу на машинном языке или на языке ассемблера. Результирующая программа компилятора называется объектной программой, или объектным кодом, а исходную программу в этом случае часто называют исходным кодом. Файл, в который записана объектная программа, обычно называется объектным файлом. Даже в том случае, когда результирующая программа порождается на языке машинных команд, между объектной программой (объектным файлом) и исполняемой программой (исполняемым файлом) есть существенная разница. Порожденная компилятором программа не может непосредственно выполняться на компьютере.
Компилятор отличается от транслятора тем, что его результирующая программа всегда должна быть написана на языке машинных кодов или на языке ассемблера. Результирующая программа транслятора, в общем случае, может быть написана на любом языке — возможен, например, транслятор программ с языка Pascal на язык С.
Всякий компилятор является транслятором, но не наоборот — не всяким транслятор будет компилятором. Например, упомянутый выше транслятор с языка Pascal на С компилятором не является.
Само слово «компилятор» происходит от английского термина «compiler» («составитель», «компоновщик»). Термин обязан своему происхождению способности компиляторов составлять объектную программу из фрагментов машинных кодов, соответствующих синтаксическим конструкциям исходной программы. Поскольку первоначально компиляторы ничего другого делать не умели, то этот термин и закрепился за ними.
Результирующая программа, созданная компилятором, строится на языке машинных кодов или ассемблера, то есть на языках, которые обязательно ориентированы на определенную вычислительную систему. Следовательно, такая результирующая программа всегда предназначена для выполнения на вычислительной системе с определенной архитектурой.
Следует упомянуть, что в современных системах программирования существуют компиляторы, в которых результирующая программа создается не на языке машинных команд и не на языке ассемблера, а на некотором промежуточном языке. Сам по себе этот промежуточный язык не может непосредственно исполняться на компьютере, а требует специального промежуточного интерпретатора для выполнения написанных на нем программ. Хотя в данном случае термин «транслятор» был бы, наверное, более правильным, в литературе употребляется понятие «компилятор», поскольку промежуточный язык является языком очень низкого уровня, будучи родственным машинным командам и языкам ассемблера.
Вычислительная система, на которой выполняется результирующая (объектная) программа, созданная компилятором, называется целевой вычислительной системой.
Принцип работы
Компиляция — в общем случае многоступенчатый процесс, включающий следующие фазы:
- лексический и морфологический анализ — проверка лексического состава входного текста и перевод составных символов (операторов, скобок, идентификаторов и пр.) в некоторую промежуточную внутреннюю форму (таблицы, графы, стеки, гиперссылки), удобную для дальнейшей обработки;
- синтаксический анализ — проверка правильности конструкций, использованных программистом при подготовке текста;
- семантический анализ — выявление несоответствий типов и структур переменных, функций и процедур;
- генерация объектного кода — завершающая фаза трансляции.
Интерпретаторы
Интерпретатор, так же как и транслятор, анализирует текст исходной программы. Однако он не порождает результирующую программу, а сразу же выполняет исходную. Результатом работы интерпретатора будет результат, определенный смыслом исходной программы, в том случае, если эта программа синтаксически и семантически правильная с точки зрения входного языка программирования, или сообщение об ошибке в противном случае.
Скорость исполнения откомпилированного объектного кода обычно выше, чем при исполнении кода интерпретатором. Этот недостаток ограничивает применение интерпретаторов.
Существует вариант транслятора, сочетающий в себе и компиляцию, и интерпретацию. В этом случае результатом работы транслятора является не объектный код, а некоторый промежуточный двоичный код, который не может быть непосредственно выполнен, а должен быть обработан специальным интерпретатором.
Схема работы
В целом процесс компиляции состоит из двух основных этапов — анализа и синтеза. На этапе анализа выполняется распознавание текста исходной программы, создание и заполнение таблиц идентификаторов. Результатом его работы служит некое внутреннее представление программы, попятное компилятору.
На этапе синтеза на основании внутреннего представления программы и информации, содержащейся в таблице идентификаторов, порождается текст результирующей программы. Результатом этого этапа является объектный код. Кроме того, в составе компилятора присутствует часть, ответственная за анализ и исправление ошибок, которая при наличии ошибки в тексте исходной программы должна максимально полно информировать пользователя о типе ошибки и месте ее возникновения. В лучшем случае компилятор может предложить пользователю вариант исправления ошибки. Эти этапы, в свою очередь, состоят из более мелких этапов, называемых фазами компиляции.
Лексический анализ (сканер) — это часть компилятора, которая читает литеры программы на исходном языке и строит из них слова (лексемы) исходного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического разбора. С теоретической точки зрения лексический анализатор не является обязательной, необходимой частью компилятора. Однако существуют причины, которые определяют его присутствие практически во всех компиляторах.
Синтаксический разбор — это основная часть компилятора на этапе анализа. Она выполняет выделение синтаксических конструкций в тексте исходной программы, обработанном лексическим анализатором. На этой же фазе компиляции проверяется синтаксическая правильность программы. Синтаксический разбор играет главную роль — роль распознавателя текста входного языка программирования.
Семантический анализ — это часть компилятора, проверяющая правильность текста исходной программы с точки зрения семантики входного языка. Кроме непосредственно проверки семантический анализ должен выполнять преобразования текста, требуемые семантикой входного языка (например, такие, как добавление функций неявного преобразования типов). В различных реализациях компиляторов семантический анализ может частично входить в фазу синтаксического разбора, частично — в фазу подготовки к генерации кода.
Подготовка к генерации кода — это (раза, на которой компилятором выполняются предварительные действия, непосредственно связанные с синтезом текста результирующей программы, но еще не ведущие к порождению текста на выходном языке. Обычно в эту фазу входят действия, связанные с идентификацией элементов языка, распределением памяти и т. п.
Генерация кода — это фаза, непосредственно связанная с порождением команд, составляющих предложения выходного языка и в целом текст результирующей программы. Это основная фаза на этапе синтеза результирующей программы. Кроме непосредственного порождения текста результирующей программы генерация обычно включает в себя также оптимизацию — процесс, связанный с обработкой уже порожденного текста. Иногда оптимизацию выделяют в отдельную фазу компиляции, так как она оказывает существенное влияние на качество и эффективность результирующей программы.
Таблицы идентификаторов (иногда «таблицы символов») — это специальным образом организованные наборы данных, служащие для хранения информации об элементах исходной программы, которые затем используются для порождения текста результирующей программы. В конкретной реализации компилятора может быть как одна, так и несколько таблиц идентификаторов. Элементами исходной программы, информацию о которых необходимо хранить в процессе компиляции, являются переменные, константы, функции и т. п. — конкретный состав набора элементов зависит от используемого входного языка программирования. Понятие «таблицы» не предполагает, что это хранилище данных должно быть организовано именно в виде таблиц или других массивов информации.
Состав фаз компиляции приведен в самом общем виде, их конкретная реализация и процесс взаимодействия могут различаться в зависимости от версии компилятора. Однако в том или ином виде все представленные фазы практически всегда присутствуют в каждом конкретном компиляторе.
Принципы построения
Нельзя говорить о разработке транслятора, если нет точного и строгого описания языка, для которого этот транслятор изготавливается. Конечно при создании новых языков ситуация не всегда так определенна. Документ, определяющий язык — его спецификация, — бывает, пишется одновременно с разработкой компилятора.
В ходе реализации (создания транслятора) в язык могут вноситься изменения и уточнения. Но рано или поздно спецификация должна быть сформулирована.
Для многих распространенных языков существуют международные стандарты. И если речь идет об уже существующем языке, без его спецификации разработчику компилятора обойтись невозможно.
Важно подчеркнуть, что не любое описание языка годится на роль документа, руководствуясь которым можно программировать компилятор. О различных языках программирования написано множество книг, но ни одна из таких книг не годится в качестве описания языка при создании компилятора — разработчику компилятора требуется спецификация.
Спецификация — это максимально точное определение языка, его синтаксиса и семантики. Спецификация — строгий и сухой документ, который не может служить учебником по программированию. Она обычно содержит не слишком много примеров, не дает рекомендаций по применению тех или иных конструкций, а лишь определяет их форму и смысл.
Чтобы создать транслятор, необходимо, прежде всего, выбрать входной и выходной языки. С точки зрения преобразования предложений входного языка в эквивалентные им предложения выходного языка транслятор выступает как переводчик. Например, трансляция программы с языка С в язык ассемблера по сути ничем не отличается от перевода с русского языка на английский,
с той лишь разницей, что сложность языков несколько иная. Поэтому и само слово «транслятор» (англ.: translator) означает «переводчик».
Результатом работы транслятора будет результирующая программа, но только в том случае, если текст исходной программы является правильным — не содержит ошибок с точки зрения синтаксиса и семантики входного языка. Если исходная программа неправильная (содержит хотя бы одну ошибку), то результатом работы транслятора будет сообщение об ошибке (как правило, с дополнительными пояснениями и указанием места ошибки в исходной программе). В этом смысле транслятор сродни переводчику, например, с английского, которому подсунули неверный текст.
Процесс компиляции программ состоит из нескольких фаз. В реальных компиляторах состав этих фаз может несколько отличаться от рассмотренного выше — некоторые из них могут быть разбиты на составляющие, другие, напротив, объединены в одну фазу. Порядок выполнения (раз компиляции также может меняться в разных вариантах компиляторов. В одном случае компилятор просматривает текст исходной программы, сразу выполняет все фазы компиляции и получает результат — объектный код. В другом варианте он выполняет над исходным текстом только некоторые из фаз компиляции и получает не конечный результат, а набор некоторых промежуточных данных. Эти данные затем снова подвергаются обработке, причем этот процесс может повторяться несколько раз. Реальные компиляторы, как правило, выполняют трансляцию текста исходной программы за несколько проходов.
Проход — это процесс последовательного чтения компилятором данных из внешней памяти, их обработки и помещения результата работы во внешнюю память. Чаще всего один проход включает в себя выполнение одной или нескольких фаз компиляции. Результатом промежуточных проходов является внутреннее представление исходной программы, результатом последнего прохода — объектная программа.
Разработчики стремятся максимально сократить количество проходов, выполняемых компиляторами. При этом увеличивается скорость работы компилятора, сокращается объем необходимой ему памяти. Однопроходный компилятор, получающий на вход исходную программу и сразу же порождающий результирующую объектную программу, — это идеальный вариант. Однако сократить число проходов не всегда удается. Количество необходимых проходов определяется прежде всего грамматикой и семантическими правилами исходного языка. Чем сложнее грамматика языка и чем больше вариантов предполагают семантические правила — тем больше проходов будет выполнять компилятор (конечно, играет свою роль и квалификация разработчиков компилятора). Например, именно поэтому обычно компиляторы с языка Pascal работают быстрее, чем компиляторы с языка С — грамматика Pascal более проста, а семантические правила более жесткие.
Однопроходные компиляторы — редкость, они возможны только для очень простых языков. Реальные компиляторы выполняют, как правило, от двух до пяти проходов. Таким образом, реальные компиляторы являются многопроходными.
Наиболее распространены двух- и трехпроходные компиляторы, например: первый проход — лексический анализ, второй — синтаксический разбор и семантический анализ, третий — генерация и оптимизация кода (варианты исполнения зависят от разработчика). В современных системах программирования нередко первый проход компилятора (лексический анализ кода) выполняется параллельно с редактированием кода исходной программы.
Особенности построения и функционирования компиляторов
Для задания языка программирования необходимо решить три задачи:
- 1. определить множество допустимых символов языка;
- 2. определить множество правильных программ языка;
- 3. задать смысл для каждой правильной программы.
Главную проблему при этом представляет третья задача, поскольку она, в принципе, не относится к теории формальных языков. Чисто формальные языки лишены всякого смысла, а потому для решения этой задачи нужно использовать другие подходы.
В качестве таких подходов можно указать следующие:
- 1. изложить смысл программы, написанной на языке программирования, на другом языке, который может воспринимать пользователь программы или компьютер;
- 2. использовать для проверки смысла некоторую «идеальную машину», которая предназначена для выполнения программ, написанных на данном языке.
Все, кто писал программы, так или иначе обязательно использовали первый подход. Например, комментарии в хорошо написанной программе — это и есть изложение ее смысла. Построение блок-схемы, а равно любое другое описание алгоритма исходной программы — это тоже способ изложить смысл программы на другом языке (например, языке графических символов блок-схем алгоритмов, смысл которого, в свою очередь, изложен в соответствующем ГОСТе). Но все эти способы ориентированы на человека, которому они, конечно же, более понятны.
Однако не существует пока универсального способа проверить, насколько описание соответствует программе. Компьютер умеет воспринимать только машинные команды. С точки зрения человека можно сказать, что компьютер понимает только язык машинных команд. Поэтому изложить для компьютера смысл исходной программы, написанной на любом языке программирования, значит перевести эту программу на язык машинных команд. Для человека выполнение этой операции — слишком трудоемкая задача. Именно таким переводом занимаются компиляторы для языков программирования. Следовательно, первый подход, а именно изложение смысла исходной программы на языке машинных команд, составляет основу функционирования компиляторов.
Главная проблема перевода исходной программы с языка программирования на язык машинных команд заключается в том, что в отличие от человека ни один компилятор не способен понять смысл всей исходной программы в целом. Отсюда проистекают многие проблемы, связанные с созданием программ на любом языке программирования и работой компиляторов. Эти проблемы остаются нерешенными по сей день и, по всей видимости, никогда не будут решены, поскольку нет и не будет теоретической основы для их решения. Главная проблема заключается в том, что компилятор способен обнаруживать только самые простейшие семантические (смысловые) ошибки в исходной программе, а большую часть такого рода ошибок должен обнаруживать человек (разработчик программы или ее пользователь).
Второй подход используется при отладке программы. В качестве «идеальной машины» может выступать интерпретатор, который непосредственно воспринимает и выполняет исходную программу. Однако чаще такой «идеальной машиной» является компьютер, на котором выполняется откомпилированная программа. При этом предполагается, что компилятор переводит программу с языка программирования на язык машинных команд без изменения ее смысла (исключаются из рассмотрения ошибки компиляции), а также не рассматриваются ошибки и сбои функционирования целевой вычислительной системы. Но оценку результатов выполнения программы при отладке выполняет человек. Любые попытки поручить это дело машине лишены смысла вне контекста решаемой задачи.
Например, предложение в программе на языке Pascal вида: i :-0: while i-0 do 1 -0. может быть легко оценено любой машиной как бессмысленное. Но если в задачу входит обеспечение взаимодействия с другой параллельно выполняемой программой или просто проверка надежности и долговечности процессора или какой-то ячейки памяти, то это же предложение покажется уже не лишенным смысла.
Но многие современные компиляторы позволяют выявить сомнительные с точки зрения смысла места в исходной программе. Такими подозрительными на наличие семантической (смысловой) ошибки местами являются недостижимые операторы, неиспользуемые переменные, неопределенные результаты функций и т. п. Обычно компилятор указывает такие места в виде дополнительных предупреждений, которые разработчик может принимать или не принимать во внимание. Для достижения этой цели компилятор должен иметь представление о том, как программа будет выполняться, и во время компиляции отследить пути выполнения отдельных фрагментов исходной программы — там, где это возможно. То есть компилятор использует второй подход для поиска потенциальных мест возможных семантических ошибок. Но в обоих случаях осмысление исходной программы закладывает в компилятор его создатель (или коллектив создателей) — то есть человек, который руководствуется неформальными методами (чаше всего, описанием входного языка).
В теории формальных языков вопрос о смысле программ не решается.
Особенности построения интерпретаторов
Интерпретатор — это программа, которая воспринимает исходную программу на входном (исходном) языке и выполняет ее. Основное отличие интерпретаторов от трансляторов и компиляторов заключается в том, что интерпретатор не порождает результирующую программу, а просто выполняет исходную программу.
Простейшим способом реализации интерпретатора можно было бы считать вариант, когда исходная программа сначала полностью транслируется в машинные команды, а затем сразу же выполняется. В такой реализации интерпретатор мало чем отличается от компилятора с той лишь разницей, что результирующая программа в нем недоступна пользователю. Недостатком такого интерпретатора является то, что пользователь должен ждать компиляции всей исходной программы прежде, чем начнется ее выполнение. По сути, в таком интерпретаторе не было бы никакого особого смысла — он не давал бы никаких преимуществ
по сравнению с аналогичным компилятором. Поэтому подавляющее большинство интерпретаторов действуют так, что исполняют исходную программу последовательно, по мере ее поступления на вход интерпретатора. Тогда пользователю не надо ждать завершения компиляции всей исходной программы. Более того, он может последовательно вводить исходную программу и тут же наблюдать результат ее выполнения по мере поступления.
При таком порядке работы интерпретатора проявляется существенная особенность, которая отличает его от компилятора, — если интерпретатор исполняет команды по мере их поступления, то он не может выполнять оптимизацию исходной программы. Следовательно, фаза оптимизации в общей структуре интерпретатора будет отсутствовать. В остальном же структура интерпретатора будет мало отличаться от структуры аналогичного компилятора. Следует только учесть, что на последнем этапе — генерации кода — машинные команды не записываются в объектный файл, а выполняются по мере их порождения.
Отсутствие шага оптимизации определяет еще одну особенность, характерную для многиx интерпретаторов: в качестве внутреннего представления программы в них очень часто используется обратная польская запись (форма записи математических и логических выражений, в которой операнды расположены перед знаками операций). Эта удобная форма представления операций обладает только одним существенным недостатком — она плохо поддается оптимизации. Но в интерпретаторах это как раз и не требуется.
Далеко не все языки программирования допускают построение интерпретаторов, которые могли бы выполнять исходную программу по мере поступления команд. Для этого язык должен допускать возможность существования компилятора, выполняющего разбор исходной программы за один проход. Кроме того, язык не может интерпретироваться по мере поступления команд, если он допускает появление обращений к функциям и структурам данных раньше их непосредственного описания. Поэтому таким методом не могут интерпретироваться такие языки, как С и Pascal.
Отсутствие шага оптимизации ведет к тому, что выполнение программы с помощью интерпретатора является менее эффективным, чем с помощью аналогичного компилятора. Кроме того, при интерпретации исходная программа должна заново разбираться всякий раз при ее выполнении, в то время как при компиляции она разбирается только один раз, а после этого всегда используется объектный файл. Также очевидно, что объектный код будет исполняться всегда быстрее, чем происходит интерпретация аналогичной исходной программы. Таким образом, интерпретаторы всегда проигрывают компиляторам в производительности.
Преимуществом интерпретатора является независимость выполнения программы от архитектуры целевой вычислительной системы. В результате компиляции получается объектный код, который всегда ориентирован на определенную целевую вычислительную систему. Для перехода на другую целевую вычислительную систему исходную программу требуется откомпилировать заново. А для интерпретации программы необходимо иметь только ее исходный текст и интерпретатор с соответствующего языка.
В современных системах программирования существуют реализации программного обеспечения, сочетающие в себе и функции компилятора, и функции интерпретатора — в зависимости от требований пользователя исходная программа либо компилируется, либо исполняется (интерпретируется). Кроме того, некоторые современные языки программирования предполагают две стадии разработки: сначала исходная программа компилируется в промежуточный код (некоторый язык низкого уровня), а затем этот результат компиляции выполняется с помощью интерпретатора данного промежуточного языка.
Широко распространенным примером интерпретируемого языка может служить HTML (Hypertext Markup Language) — язык описания гипертекста. На его основе в настоящее время функционирует практически вся структура сети Интернет. Другой пример — языки Java и JavaScript сочетают в себе функции компиляции и интерпретации (текст исходной программы компилируется в некоторый промежуточный код, не зависящий от архитектуры целевой вычислительной системы, этот кол распространяется по сети и интерпретируется на принимающей стороне).
- Молдованова О. В. Языки программирования и методы трансляции: Учебное пособие. – Новосибирск: СибГУТИ, 2012. – 134с.
- Опалева Э. А. Языки программирования и методы трансляции / Опалева Э. А., Самойленко В. П. — СПб.: БХВ-Петербург, 2005. — 480 с.
- Свердлов С. 3. Языки программирования и методы трансляции: Учебное пособие. — СПб.: Питер, 2007. — 638 с.
- Молчанов А. Ю. Системное программное обеспечение: Учебник для вузов / А. Ю. Молчанов. — СПб.: Питер, 2003. — 396 с.
- Карпов Ю. Г. Теория и технология программирования. Основы построения трансляторов. — СПб.: БХВ-Петербург, 2005. — 272 с.
- Голицына О. Л. Языки программирования : учебное пособие. — 2-е изд., перераб. и доп. — М. : ФОРУМ, 2010. — 400 с. : ил
 08.02.2022, 982 просмотра.
08.02.2022, 982 просмотра.