
Если ваша компания только внедряет DevOps или инструменты CI/CD, вам может быть полезно познакомиться с самыми распространенными ошибками, чтобы не повторить их и не наступать на чужие грабли.
1. Неготовность к изменению культуры и процессов
Если посмотреть на циклическую диаграмму DevOps, то видно, что в DevOps-практиках тестирование является непрерывной работой, фундаментальной частью каждого отдельного развертывания.
Тестирование и обеспечение качества в процессе разработки и доставки являются обязательной частью всего, что делают разработчики. Это требует изменения мышления, чтобы включить тестирование в каждую задачу.
Тестирование становится частью повседневной работы каждого члена команды. Переход на постоянное тестирование не проходит легко, нужно быть готовыми к этому.
2. Отсутствие обратной связи
Эффективность DevOps зависит от постоянной обратной связи. Непрерывное улучшение невозможно, если нет места для сотрудничества и общения.
Компаниям, которые не организуют ретроспективные встречи, трудно внедрить культуру непрерывной обратной связи в CI/CD. Ретроспективные встречи проводят в конце каждой итерации, на них участники группы обсуждают, что прошло хорошо, а что плохо. Ретроспективные встречи — фундамент Scrum/Agile, но они также необходимы и для DevOps.
Это связано с тем, что ретроспективные встречи прививают привычку проводить обмениваться отзывами и мнениями. Один из самых важных моментов на старте — организация повторяющихся ретро-встреч, чтобы они стали понятными и привычными для всего коллектива.
Когда дело доходит до качества программного обеспечения, все члены команды несут ответственность за его поддержание. Например, разработчики могут писать модульные тесты, а также писать код с учетом тестируемости, помогая снизить риски с самого начала.
Один из простых способов отразить изменение представлений о тестировании — называть тестировщиков не QA, а тестировщик программного обеспечения или инженер по качеству. Это изменение может показаться слишком простым или даже глупым. Но если кого-то называют «специалистом по обеспечению качества программного обеспечения», это дает неверное представление о том, кто несет ответственность за качество продукта. В практиках Agile, CI/CD и DevOps все несут ответственность за качество ПО.
Другим важным моментом является понимание, что означает качество для всей команды и каждого ее члена, организации, заинтересованных сторон.
3. Неверное понимание завершенности этапа
Если качество — непрерывный и общий процесс, нужно общее понимание завершенности этапа. Как понять, что этап закончен? Что происходит, когда этап помечен как выполненный на доске Trello или другой канбан-доске?
Определение выполненного этапа (DoD) является мощным инструментом в контексте CD DevOps/CI. Оно помогает лучше понять стандарты качества того, что и как строит команда.
Команда разработчиков должна решить, что означает «Готово». Им нужно сесть и составить список характеристик, которые должны выполняться на каждом этапе, чтобы его можно было считать завершенным.
DoD делает процесс прозрачнее и облегчает внедрение CI/CD, если он понятен всем участникам команды и взаимно согласован.
Упростить внедрение CI/CD помогут уже готовые и настроенные инструменты GitLab CE. Их можно получить в маркетплейсе MCS.
4. Отсутствие реалистичных, четко определенных целей
Это один из наиболее часто цитируемых советов, но его стоит повторить. Для успеха любого серьезного начинания, в том числе внедрения CI/CD или DevOps, нужно установить реальные цели и измерять производительность относительно них. Чего вы пытаетесь достичь с помощью CI/CD? Это позволяет быстрее выпускать релизы с лучшим качеством?
Любые поставленные цели должны быть не только прозрачными и реалистичными, но и соответствовать текущей деятельности компании. Например, как часто ваши клиенты нуждаются в новых исправлениях или версиях? Нет необходимости перегружать процессы и выпускать релизы быстрее, если в этом нет дополнительных преимуществ для пользователей.
Кроме того, вам не всегда нужно реализовывать как CD, так и CI. Например, компании с высокой степенью регулирования, такие как банки и медицинские клиники, могут работать только с CI.
CI служит хорошей отправной точкой для любой компании, внедряющей DevOps. При его внедрении в компании значительно меняются подходы к поставке программного обеспечения. После того как освоен CI, можно подумать об улучшении всего процесса, увеличении скорости выкатки и других изменениях.
Для многих организаций достаточно одного CI, и CD должен быть реализован только, если он приносит дополнительную пользу.
5. Отсутствие соответствующих панелей мониторинга и метрик
Как только вы установили цели, команда разработчиков может создать панель мониторинга для измерения KPI. До ее разработки стоит провести оценку параметров, которые будут отслеживаться.
Различные отчеты и приложения полезны для разных членов команды. Scrum-мастера больше интересует статус и охват. В то время как высшему руководству может быть интересна скорость выгорания специалистов.
Некоторые команды также используют для оценки статуса CI/CD дашборды с красными, желтыми и зелеными индикаторами, чтобы понимать, правильно ли они все делают или возникла ошибка. Красный означает, что нужно обратить внимание на происходящее.
Однако, если информационные панели не стандартизированы, они могут вводить в заблуждение. Проанализируйте, какие данные всем нужны, а затем создайте стандартизированное описание того, что они означают. Узнайте, что имеет больше смысла для заинтересованных сторон: графики, текст или числа.
6. Отсутствие ручных тестов
Автоматизация тестирования закладывает основу для хорошего конвейера CI/CD. Но автоматизированное тестирование на всех этапах не означает, что вы не должны проводить ручное тестирование.
Чтобы построить эффективный конвейер CI/CD, нужны и ручные тесты. Всегда будут некоторые аспекты тестирования, которые требуют анализа человеком.
Стоит подумать об интеграции усилий по ручному тестированию в конвейер. После того как ручное тестирование некоторых тестовых примеров завершено, вы можете перейти к этапу развертывания.
7. Нет попыток улучшить тесты
Эффективный конвейер CI/CD требует доступа к нужным инструментам, будь то управление тестированием или интеграция и постоянный мониторинг.
Создание сильной, ориентированной на качество культуры направлено на внедрение тестов, мониторинг взаимодействия с клиентами после развертывания и отслеживание улучшений.
Вот несколько практических советов, которые вы можете легко реализовать:
- Убедитесь, что тесты просты в написании и достаточно гибки, чтобы не ломаться при рефакторинге кода.
- Команды разработчиков должны быть включены в процесс тестирования — видеть список пользовательских проблем и запросов, которые важны для проверки во время конвейеров CI.
- У вас может и не быть полного покрытия тестами, но всегда следите, чтобы потоки, важные для UX и взаимодействия с клиентами, были протестированы.
Рассказываем об IT-бизнесе, технологиях и цифровой трансформации
Подпишитесь в соцсетях или по email
Последний, но не менее важный пункт
Переход к CI/CD обычно инициируется снизу вверх, но, в конце концов, это трансформация, которая требует участия руководства, затрат времени и ресурсов со стороны компании. Ведь CI/CD — это набор навыков, процессы, инструменты и культурная перестройка, внедрить такие изменения можно только системно.
Оригинал статьи на Habr.com
CI/CD (Continuous Integration, Continuous Delivery — непрерывная интеграция и доставка) — это технология автоматизации тестирования и доставки новых модулей разрабатываемого проекта заинтересованным сторонам (разработчикам, аналитикам, инженерам качества, конечным пользователям и др.).
Принципы CI/CD
Концепция непрерывной интеграции и развертывания относится к agile-методологиям разработки программного обеспечения. Ее основная цель — уделение достаточного внимания бизнес-требованиям, безопасности и качеству кода конечного продукта. В рамках подхода решаются следующие задачи:
- автоматизация последовательной сборки, упаковки и тестирования программных продуктов;
- автоматизация развертывания приложения в различных окружениях;
- минимизация ошибок и уязвимостей программного продукта.
Разработка по методике CI/CD соответствует таким основным принципам:
- Распределение ответственности. Задачи и этапы разработки разделяются между членами команды или ее подгруппами (при работе над большим проектом). Рабочий процесс организуется с учетом бизнес-логистики, внедрения сквозных функций, проведения тестов, безопасности хранения данных и т.д.
- Сокращение рисков. Каждый разработчик или подгруппа разработчиков должны стремиться минимизировать уязвимости и ошибки на всех этапах разработки. Для этого постоянно контролируется бизнес-логистика, проводится пользовательское тестирование продукта, оптимизируется хранение, обработка данных и т.д.
- Оптимизация обратной связи. Успех проекта зависит от того, как работают друг с другом разработчики, клиенты и пользователи. Это влияет на скорость внесения в приложение корректировок и обновлений. Если сборку и тестирование можно автоматизировать, то во многих других операциях требуется участие человека. Чтобы взаимодействие происходило конструктивнее, уменьшается количество посредников между заказчиком, исполнителями и пользователями.
- Создание рабочей среды. Для удобства совместной работы у разработчиков должно быть общее рабочее пространство. Помимо основной ветки процесса в нем должна быть побочная – в ней удобнее проводить тестирование, вносить корректировки, отслеживать отказоустойчивость и т.д.
СI/CD представляет собой современную аналогию конвейерного производства. Их объединяют четкое распределение труда, непрерывный, потоковый характер рабочего процесса, параллельное выполнение сразу нескольких задач (например, кодинга и тестирования). Сегодня эта концепция является доминирующей в DevOps.
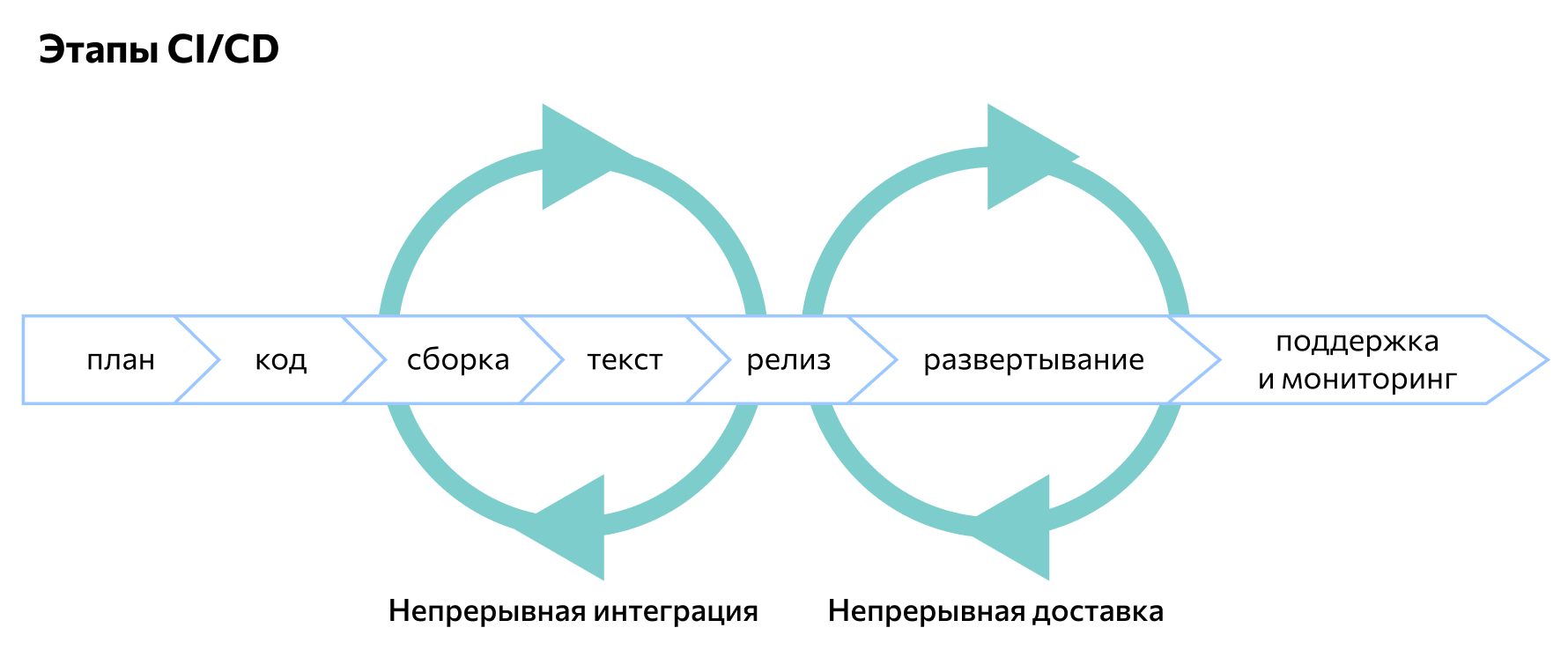
Этапы CI/CD
Написание кода. Каждый разработчик создает код отведенного ему модуля и тестирует его в ручном режиме. Затем разработанный и проверенный программный блок интегрируется в основной ветке с текущей версией продукта. Как только все модули будут опубликованы в главной ветке, команда переходит к следующему этапу.
Сборка. Заранее подобранная система контроля версий запускает автоматизированную сборку и тестирование всего продукта. Триггеры могут быть настроены автоматически или вручную. Автоматическая сборка выполняется с помощью Jenkins или другого сервера непрерывной интеграции.
Ручное тестирование. Как только CI-сервер закончит автоматизированную сборку продукта, он передается тестировщикам на проверку. Они используют различные методики тестирования для выявления и устранения ошибок и уязвимостей программы.
Релиз. После исправления ошибок вычищенный и отлаженный код переходит на этап релиза для клиентов. Его проверяет заказчик, возможно, с привлечением своих специалистов или ограниченной группы пользователей. По результатам проверки код отправляется на доработку или согласуется.
Развертывание. Текущая версия программы размещается на продакшн-серверах разработчика. Заказчик может работать с программой, исследовать ее функции, искать уязвимости.
Поддержка и отслеживание. После развертывания приложение становится доступным конечным пользователям. Параллельно этому разработчики выполняют его поддержку и одновременно мониторят реакцию пользователей, анализируют их опыт взаимодействия с программой.
Планирование. На основании данных, полученных при изучении пользовательского опыта, разработчик подготавливает план доработок, включающий новые функции, исправление ошибок и т.д. После этого он вносит все корректировки в продукт — и цикл разработки начинается снова.
Таким образом, рабочий процесс по методологии CI/CD включает как последовательные, так и параллельные этапы. Именно для распараллеливания в рабочем пространстве создается побочная ветка — в ней проще вести работу, не вмешиваясь в основной код до тех пор, пока программируемый модуль не будет готов к интеграции. Условно рабочий процесс по методологии CI/CD можно представить в виде следующей схемы:
Преимущества CI/CD
- Сокращение сроков разработки. Методология уменьшает время доработок до нескольких дней, в сложных проектах — недель. Это позволяет разработчикам быстрее тестировать и опробовать нововведения, а затем внедрять их в продукт раньше конкурентов.
- Отбор перспективных вариантов. Быстрое тестирование и большое количество итераций позволяют разработчику вовремя отсеивать бесперспективные варианты кода на начальных этапах. Это также способствует экономичному расходованию времени и ресурсов без их распыления на тупиковые направления.
- Качество тестирования. Сочетание ручной и автоматизированной проверки позволяет выявлять ошибки на ранних этапах разработки. Это снижает вероятность их накопления на этапе релиза, что еще больше сокращает время работы над проектом.
Недостатки CI/CD
- Высокие требования к опыту. Рабочий процесс в любой компании можно перевести на методологию CI/CD. Однако это требует от разработчиков как знания самой концепции на практическом уровне, так и умения быстро реорганизовать процессы в самой организации. Иными словами, CI/CD имеет достаточно большой порог вхождения в сравнении со многими традиционными методологиями.
- Сложность постоянного взаимодействия. Непрерывная интеграция и доставка программного продукта требуют от разработчиков высокой скоординированности действий. На практике это означает, что должно быть отдельное лицо, которое занимается организацией рабочего процесса и налаживанием взаимодействия между членами команды.
Инструменты для CI/CD
Так как непрерывная интеграция и развертывание подразумевает автоматизацию многих процессов в ходе разработки, для этого созданы различные программные инструменты и сервисы:
- GitLab. Эта платформа позволяет управлять хранилищами проекта, документировать результаты тестирования и доработок, анализировать и дополнять функциональность проекта, выявлять и устранять ошибки.
- Docker. СD-система, позволяющая контейнеризировать проект, то есть упаковать его со всем окружением и зависимостями.
- Travis-CI. Сервер, который можно подключать к виртуальным репозиториям GitHub с минимальными настройками. Благодаря использованию облачных технологий его не нужно отдельно устанавливать.
- Jenkins. Один из самый популярных DevOps-инструментов, совместимый со всевозможными плагинами для адаптации под различные проекты и задачи.
- PHP Censor. CI-сервер, автоматизирующий сборку PHP-проектов. Может работать с репозиториями GitLab, Mercurial и другими, с библиотеками для тестирования Atoum, PHP Spec, Behat.
Возможность оперативно вносить изменения, постоянно тестировать и дорабатывать продукт, взаимодействовать не только друг с другом, но и с клиентом — вот что делает концепцию CI/CD популярной среди разработчиков. Сегодня ее понимание и практическое освоение являются важной рекомендацией при разработке как крупных, так и небольших проектов.

Сергей Зинкевич
директор по развитию бизнеса КРОК Облачные сервисы
Для организации процесса современной ИТ-разработки в России принято использовать концепции и практики непрерывной интеграции и доставки (CI/CD). О ней говорят много, но, как часто бывает на практике, редко кто применяет правильно. Причина кроется в нехватке специалистов, которые могли бы методологически выстроить конвейер и автоматизировать её. Расскажем о том, какие распространенные ошибки в CI/CD мы видим в проектах.
Но сначала немного ликбеза
CI/CD — это целая культура, которая включает в себя набор принципов и реализует последовательность этапов доставки программного обеспечения с момента его написания разработчиком до развёртывания в продуктивном контуре. Собственно, в основе данной аббревиатуры отдельные шаги, которые принято рассматривать в комплексе:
- Continuous integration — непрерывная интеграция;
- Continuous delivery — непрерывная доставка;
- Continuous deployment — непрерывное развёртывание.
Continuous integration (CI) – это упаковка приложения разработчиком и тестирование. На шаге планирования у бизнеса или владельца продукта появляется идея, как улучшить клиентский сервис и какие фичи для этого нужны. На этом же этапе аналитик собирает бизнес-требования и передаёт их разработчику.
Тот (или скорее те, так как в крупной компании в разработке занято несколько человек) пишет код и загружает так называемый билд — изменённое приложение — в отдельную ветку. Билд тестируется — вручную и/или с помощью автотестов — и переходит на следующий этап конвейера.
Continuous delivery – это доставка приложения, то есть обеспечение его работы в промышленной эксплуатации. Здесь важно как минимум одно ручное действие – подтверждение ответственного за вывод в продакшн. Как правило, за это отвечает тимлид команды разработчиков. Непосредственно развёртывание приложения в инфраструктуре клиента должно происходить автоматизированно.
Continuous deployment – это процесс непрерывной доставки кода до продуктива без каких-либо дополнительных согласований и ручных операций. Мониторинг таких выкаток должен также осуществляться постоянно и автоматизированно. Его цель – молниеносно определить проблему с билдом и дать возможность разработчику откатить назад версию приложения и параллельно «пофиксить» ошибки.
В одной компании для решения этой задачи поступили довольно креативно — установили светофор, который интегрирован с системой мониторинга. Если в ней появляются ошибки, этот светофор мигает красным светом, требуя от сотрудников фактически мгновенной реакции.
Слабо применяется автоматизация
Неработающий конвейер – картина частая. В большинстве случаев это связано с некорректно построенными процессами внутри организации.
Например, даже в крупных компаниях зачастую при разработке очень слабо применяется автоматизация или применяется не оптимально. Это приводит к тому, что каждая операция разработчика, тестировщика, администраторов сопровождается рутинными ручными действиями: написать о статусе, передать информацию, перепоручить «раскатать» инфраструктуру и так далее.
В результате в 2-3 раза увеличивается срок выпуска в эксплуатацию приложения, а вместе с этим растет количество конфликтов внутри команды, так как сложно понять, на каком этапе процесс стопорится.
Нет формально прописанных зон ответственности
Нередко видим другую ситуацию — в целом процесс CI/СD работает неплохо, но иногда даёт сбой. ИТ-директор одного российского банка как-то жаловался, что при выкатке новой версии релиза часть пакетов и скриптов «не доезжает», а обратная связь о неработающих сервисах при этом приходит не от DevOps-инженеров, а непосредственно от пользователей.
Проблема в данном случае может быть связана с отсутствием формально прописанных зон ответственности и наличием большого количества ручных операций в конвейнере, что увеличивает шанс возникновения ошибки. Также из-за наличия такой проблемы можно сделать вывод, что функции внутри команды дублируются и теряется координация между несколькими участниками процесса.
Чтобы это исправить, рекомендуется использовать RACI-матрицу. Её, к слову, часто применяют провайдеры. Они «на берегу» определяют, кто и за что будет отвечать в проекте. Например, мы прописываем в документе свою обязанность разворачивать и поддерживать виртуальные машины и инфраструктурные компоненты там, где являемся поставщиками инфраструктуры и кластеров Kubernetes. А сам софт и доступность CI остаются на совести клиента.
Бывает, что клиент поручает нам цикл сборки и доставки целиком – в этом случае мы раскатываем приложение в продуктивную среду, а заказчик фокусируется исключительно на разработке своего продукта.
Отказ следовать IaC
На эффективность всей ИТ-разработки также влияет готовность инфраструктуры. Оправданно в данном случае следовать концепции IaC (инфраструктура как код), когда для развёртывания и управления средой пишутся скрипты и шаблоны. Они помогают быстрее развернуть типовую инфраструктуру, произвести изменения без захода в консоль управления или на конкретную виртуальную машину.
Администраторы, которые не скриптуют каждое действие с инфраструктурой, вынуждены прикладывать одни и те же усилия каждый раз, когда данная инфраструктура требуется разработчикам для нового релиза. Отказ следовать IaC-подходу увеличивает затраты на сопровождение ИТ.
Так, первичное развёртывание инфраструктуры может стоить условно 100 000 руб, но повторное, основанное на готовом шаблоне, потребует всего 35 000 руб, так как трудозатраты не пойдут ни в какое сравнение с тем, что было до автоматизации.
Постоянно растущая потребность в более быстрой и структурированной разработке привела к тому, что инструменты CI/CD стали неотъемлемой частью процессов разработки в организации.
Инструменты CI/CD помогают автоматизировать большинство основных, повторяющихся задач процесса разработки приложений от конца до конца – от выполнения базовых проверок отступов в представленном коде до развертывания скомпилированного кода на производственных серверах.
И с ростом числа функций и возможностей, которыми обладают инструменты CI/CD, они также требуют определенного уровня доступа для выполнения этих различных функций.
Рассмотрим, например, инструмент CD, который развертывает скомпилированный код на производственных серверах: этот инструмент потребует такого же уровня доступа и/или количества разрешений, которые потребовались бы человеку для автоматизации процесса развертывания.
Однако теперь, когда сборка программного обеспечения полностью автоматизирована процессами CI/CD, злоумышленники вполне могут бесшумно внедрить вредоносный код в сам процесс сборки.
В последнее время это происходит довольно часто: злоумышленники внедряют код криптовалютных майнеров в различные сборки программного обеспечения, оставаясь при этом незамеченными.
Вот почему использование неправильно настроенных или уязвимых инструментов CI/CD может привести к значительному увеличению поверхности атаки вашей организации.
Содержание
- Инциденты, связанные с безопасностью CI/CD
- Наиболее распространенные ошибки CI/CD, которые приводят к утечке данных и сетевым вторжениям
- Захаркоженные учетные данные
- Неправильно сконфигурированные контейнеры
- Неправильная конфигурация или неправильное использование переменных окружения
- Неправильно настроенные инструменты CI/CD
- Устаревшие инструменты CI/CD
- Заключение
Инциденты, связанные с безопасностью CI/CD
Нарушения в инструментах CI/CD часто происходят из-за неправильной конфигурации или устаревшего программного обеспечения.
Поскольку современные взломы часто автоматизированы, “автоматическому боту” (подобному тем, что пытаются войти в систему по SSH по всему интернету) не требуется много времени, чтобы начать сканирование узлов, на которых установлены устаревшие версии, либо с помощью захвата баннеров, либо просто перебором уязвимостей PoC на общедоступном CI/CD-инструменте.
Недавняя уязвимость в GitLab позволяла использовать серверы с устаревшими установками GitLab для проведения DoS-атак, что, помноженное на количество серверов с устаревшей версией GitLab, привело к DDoS-атакам в Интернете со скоростью более 1 ТБ/с.
Помимо рассылки интернет-атак (незаконное действие в большинстве стран), в GitLab были уязвимости, связанные с авторизацией, которые также позволяли неавторизованным пользователям войти в ваш инстанс.
Аналогично, были уязвимости, связанные с ACL, которые позволяли взломанным, но авторизованным учетным записям выталкивать и извлекать данные из зон несанкционированного доступа в вашем экземпляре GitLab.
Хотя эти уязвимости были устранены в будущих сборках GitLab, по-прежнему важно следить за обновлениями и, в свою очередь, обновлять свои экземпляры (чаще всего самостоятельно), чтобы уменьшить площадь атаки.
Аналогичным образом, популярный CI/CD-инструмент Jenkins с открытым исходным кодом в последнее время был обременен большим количеством CVE, начиная от XSS/CSRF-уязвимостей и заканчивая уязвимостями обхода разрешений, которые угрожают раскрыть конфиденциальную информацию злоумышленникам.
Глядя на приведенные выше примеры, можно подумать, что использование размещенных или SaaS CI/CD инструментов и отказ от самостоятельных инструментов кажется очевидным решением, но размещенные CI/CD инструменты могут создавать свои собственные проблемы безопасности.
Недавняя уязвимость в Travis CI привела к тому, что переменные окружения внедрялись через pull request в виде файлов .travis.yml, а учитывая принцип работы Git, простого удаления файла из Git было недостаточно для защиты различных секретов проекта.
Аналогичным образом, даже если ваш Git-репозиторий был приватным и секреты не были утечены через сам репозиторий, если ваш процесс развертывания использует Git и клонирует репозиторий на производственный экземпляр, любой пользователь, имеющий доступ к вашему производственному веб-приложению, сможет загрузить или просмотреть файл .travis.yml, содержащий секреты вашего приложения/сборки.
Наиболее распространенные ошибки CI/CD, которые приводят к утечке данных и сетевым вторжениям
Захаркоженные учетные данные
Подобно тому, как человеку требуются определенные учетные данные для доступа к машине (например, серверу), чтобы развернуть на ней собранный код, инструменты CI и CD требуют аналогичного, если не такого же, уровня доступа для сборки и развертывания кода на производственных серверах.
Эти учетные данные, хранящиеся в системах CI/CD, могут быть любыми – от SMTP-серверов, используемых для отправки почтовых уведомлений о завершении сборки или ошибках сборки, до чего-то потенциально более опасного, например, доступа на уровне SSH/root к серверным системам, которые будут использоваться для развертывания собранного кода.
Рассмотрим пример CircleCI:
version: 2.1
executors:
my-executor:
docker:
- image: cimg/ruby:3.0.3-browsers
auth:
username: mydockerhub-user
password: $DOCKERHUB_PASSWORD # context / project UI env-var reference
jobs:
my-job:
executor: my-executor
steps:
- run: echo outside the executorВ разделе auth для контейнера docker мы видим переменную $DOCKERHUB_PASSWORD, которая вводится/заменяется CircleCI в процессе сборки, так что пароль скрыт в самом конфигурационном файле.
Однако, если не использовать эти переменные и не определять пароль, учетные данные могут быть украдены, если конфигурационный файл по ошибке станет общедоступным.
Захардкоженные учетные данные являются распространенным источником компрометации, исходящей от систем CI/CD.
- 🦊 Добавление Gitleaks в пайплайн Gitlab CI
- 🌐 GitLab Watchman – Аудит Gitlab на предмет конфиденциальных и учетных данных
Неправильно сконфигурированные контейнеры
Контейнеры позволяют организациям обеспечить полную согласованность программного обеспечения между различными средами.
Контейнеры Docker стали обычным явлением в средах прода, разработки и тестирования.
Аналогичным образом, инструменты CI/CD используют контейнеры для обеспечения того, что создаваемое программное обеспечение использует ту же самую конфигурацию, что и производственная среда.
Использование неправильно настроенных контейнеров может привести к тому, что злоумышленники проникнут в контейнеры, созданные CI/CD, и внедрят вредоносный код в программное обеспечение.
см. как проверить Docker:
- 🐳 Сканирование образов Docker на наличие уязвимостей с помощью Trivy
- 🐳 Как проверить изменения в файловой системе контейнера Docker
- 🐳 dockle: линтер + проверка образов на безопасность
- 🐳 Обзор сканеров безопасности контейнеров для поиска уязвимостей
- 🐳 Как использовать Harbor для сканирования образов Docker на наличие уязвимостей
Неправильная конфигурация или неправильное использование переменных окружения
Переменные окружения стали альтернативой использованию захардкоженный переменных, но, как это часто бывает с переменными окружения, они являются глобальными для процесса сборки и могут быть использованы или утечь, поскольку они не ограничены областью доступа.
Еще один источник неправильного использования переменных окружения связан с использованием Git, где в публичные репозитории часто попадают ошибочные коммиты, содержащие файлы .env, часто используемые для хранения переменных окружения.
Удаление этих файлов из Git’а считается решением проблемы, но учитывая, что Git содержит историю каждого файла и изменения, злоумышленникам не составит труда просмотреть историю репозитория и получить эти учетные данные из удаленных в прошлом файлов.
Поскольку члены команды работают по всему миру, команды часто полагаются на инструменты обмена сообщениями, такие как Slack, для публикации информации о состоянии сборки.
Jenkins использует пайплайны для улучшения процессов CI/CD с помощью функций, которые включают объявление статуса сборки через Slack во время или после процесса сборки; например:
import groovy.json.JsonOutput
// Add whichever params you think you'd most want to have
// replace the slackURL below with the hook url provided by
// slack when you configure the webhook
def notifySlack(text, channel) {
def slackURL = 'https://hooks.slack.com/services/xxxxxxx/yyyyyyyy/zzzzzzzzzz'
def payload = JsonOutput.toJson()
sh "curl -X POST --data-urlencode 'payload=${payload}' ${slackURL}"
}Как показано выше, если хук Slack открыт для публики, а не используется как секрет/переменная среды, команды Slack могут стать жертвами спама или еще более опасной мишенью для злоумышленников, дающих им подсказки (например, о том, что ваша команда сама использует Slack).
Чтобы предотвратить подобные ситуации, URL-адрес хука должен быть настроен как секретный и не открываться открытым текстом в конфигурационных файлах.
Неправильно настроенные инструменты CI/CD
Инструменты CI/CD обладают целым рядом функций, позволяющих автоматизировать различные трудоемкие задачи или шаги, выполняемые вручную, в рамках процесса сборки программного обеспечения.
Инструменты CI/CD часто включают также этапы тестирования, которые можно использовать для автоматизации проверки того, является ли автоматизированная сборка “хорошей” или нет.
Неправильная настройка этих функций может привести к тому, что злоумышленники получат доступ к самому инструменту CI/CD, что позволит им изменять или внедрять код во время самого процесса сборки.
GitLab – это популярный инструмент с открытым исходным кодом, используемый для собственного хостинга Git и CI/CD.
Также доступны такие инструменты, как CircleCI, популярный среди различных пользователей GitHub благодаря своей тесной интеграции с GitHub.
Использование CircleCI требует создания конфигурационного файла в формате YAML под названием config.yml, который содержит различные “инструкции”, которым CircleCI следует для запуска процесса сборки.
Однако конфигурационный файл не ограничивается базовыми инструкциями по сборке – он также может содержать различные параметры, например, пароли.
Сейчас давайте рассмотрим конфигурацию CI:
version: 2.1
# Define the jobs we want to run for this project
jobs:
build:
docker:
- image: cimg/<language>:<version TAG>
auth:
username: mydockerhub-user
password: $DOCKERHUB_PASSWORD # context / project UI env-var reference
steps:
- checkout
- run: echo "this is the build job"
test:
docker:
- image: cimg/<language>:<version TAG>
auth:
username: mydockerhub-user
password: $DOCKERHUB_PASSWORD # context / project UI env-var reference
steps:
- checkout
- run: echo "this is the test job"
# Orchestrate our job run sequence
workflows:
build_and_test:
jobs:
- build
- test:
requires:
- buildКак показано выше, можно ссылаться и на частные шаблоны контейнеров docker hub через параметр имя пользователя/пароль.
Но если этот конфигурационный файл утечет из-за его публичной видимости в вашем репозитории GitHub, злоумышленники могут получить доступ к вашим приватным шаблонам контейнеров docker hub.
Аналогичным образом, популярное самораспространяемое CI/CD программное обеспечение GitLab недавно поставлялось с учетными данными по умолчанию для входа пользователя root – “5iveL!”.
Поскольку этот пароль часто оставляли без изменений, многие GitLab неизбежно подвергались взлому.
Инструменты CI/CD, не являющиеся самостоятельными хостингами, также подвержены неправильной конфигурации.
CircleCI тоже можно очень легко неправильно сконфигурировать, выложив в открытый доступ config.yml проекта.
Этот config.yml содержит каждый шаг, который должен быть выполнен CircleCI, и может содержать имена хостов и другую конфиденциальную информацию, такую как SSH-ключи для производственных или тестовых развертываний, куда будет отправлен собранный код.
Устаревшие инструменты CI/CD
Как и любой другой инструмент или программное обеспечение, инструменты CI/CD тоже могут стать жертвой взлома из-за имеющихся в них уязвимостей.
Использование устаревших инструментов CI/CD с уязвимостями может привести к тому, что злоумышленники скомпрометируют само программное обеспечение CI/CD и, в свою очередь, смогут внедрить вредоносный код в процесс сборки.
Заключение
Поскольку сквозная автоматизация играет ключевую роль в зависимости от инструментов CI CD, автоматизация сканирования и оповещения об уязвимостях безопасности, присутствующих в самих инструментах, необходима из-за неправильной конфигурации безопасности или присущих им уязвимостей.
Использование On Prem/SaaS-решений часто рассматривается как решение для снижения требований к безопасности организации, но, как показывает недавний опыт, размещенные/SaaS-инструменты также могут внести уязвимости безопасности в ваши проекты.
Включение непрерывного сканирования, обнаружения и оповещения о возможных уязвимостях в процессы сборки вашей организации играет ключевую роль в обеспечении их безопасности, независимо от того, что они собой представляют.
см. также:
🦊 GitLab настройка 2FA для всех пользователей
CI/CD (Continuous Integration, Continuous Delivery — непрерывная интеграция и доставка) — это технология автоматизации тестирования и доставки новых модулей разрабатываемого проекта заинтересованным сторонам (разработчикам, аналитикам, инженерам качества, конечным пользователям и др.).
Концепция непрерывной интеграции и развертывания относится к agile-методологиям разработки программного обеспечения. Ее основная цель — уделение достаточного внимания бизнес-требованиям, безопасности и качеству кода конечного продукта. В рамках подхода решаются следующие задачи:
- автоматизация последовательной сборки, упаковки и тестирования программных продуктов;
- автоматизация развертывания приложения в различных окружениях;
- минимизация ошибок и уязвимостей программного продукта.
Разработка по методике CI/CD соответствует таким основным принципам:
- Распределение ответственности. Задачи и этапы разработки разделяются между членами команды или ее подгруппами (при работе над большим проектом). Рабочий процесс организуется с учетом бизнес-логистики, внедрения сквозных функций, проведения тестов, безопасности хранения данных и т.д.
- Сокращение рисков. Каждый разработчик или подгруппа разработчиков должны стремиться минимизировать уязвимости и ошибки на всех этапах разработки. Для этого постоянно контролируется бизнес-логистика, проводится пользовательское тестирование продукта, оптимизируется хранение, обработка данных и т.д.
- Оптимизация обратной связи. Успех проекта зависит от того, как работают друг с другом разработчики, клиенты и пользователи. Это влияет на скорость внесения в приложение корректировок и обновлений. Если сборку и тестирование можно автоматизировать, то во многих других операциях требуется участие человека. Чтобы взаимодействие происходило конструктивнее, уменьшается количество посредников между заказчиком, исполнителями и пользователями.
- Создание рабочей среды. Для удобства совместной работы у разработчиков должно быть общее рабочее пространство. Помимо основной ветки процесса в нем должна быть побочная – в ней удобнее проводить тестирование, вносить корректировки, отслеживать отказоустойчивость и т.д.
СI/CD представляет собой современную аналогию конвейерного производства. Их объединяют четкое распределение труда, непрерывный, потоковый характер рабочего процесса, параллельное выполнение сразу нескольких задач (например, кодинга и тестирования). Сегодня эта концепция является доминирующей в DevOps.
Написание кода. Каждый разработчик создает код отведенного ему модуля и тестирует его в ручном режиме. Затем разработанный и проверенный программный блок интегрируется в основной ветке с текущей версией продукта. Как только все модули будут опубликованы в главной ветке, команда переходит к следующему этапу.
Сборка. Заранее подобранная система контроля версий запускает автоматизированную сборку и тестирование всего продукта. Триггеры могут быть настроены автоматически или вручную. Автоматическая сборка выполняется с помощью Jenkins или другого сервера непрерывной интеграции.
Ручное тестирование. Как только CI-сервер закончит автоматизированную сборку продукта, он передается тестировщикам на проверку. Они используют различные методики тестирования для выявления и устранения ошибок и уязвимостей программы.
Релиз. После исправления ошибок вычищенный и отлаженный код переходит на этап релиза для клиентов. Его проверяет заказчик, возможно, с привлечением своих специалистов или ограниченной группы пользователей. По результатам проверки код отправляется на доработку или согласуется.
Развертывание. Текущая версия программы размещается на продакшн-серверах разработчика. Заказчик может работать с программой, исследовать ее функции, искать уязвимости.
Поддержка и отслеживание. После развертывания приложение становится доступным конечным пользователям. Параллельно этому разработчики выполняют его поддержку и одновременно мониторят реакцию пользователей, анализируют их опыт взаимодействия с программой.
Планирование. На основании данных, полученных при изучении пользовательского опыта, разработчик подготавливает план доработок, включающий новые функции, исправление ошибок и т.д. После этого он вносит все корректировки в продукт — и цикл разработки начинается снова.
Таким образом, рабочий процесс по методологии CI/CD включает как последовательные, так и параллельные этапы. Именно для распараллеливания в рабочем пространстве создается побочная ветка — в ней проще вести работу, не вмешиваясь в основной код до тех пор, пока программируемый модуль не будет готов к интеграции. Условно рабочий процесс по методологии CI/CD можно представить в виде следующей схемы:

- Сокращение сроков разработки. Методология уменьшает время доработок до нескольких дней, в сложных проектах — недель. Это позволяет разработчикам быстрее тестировать и опробовать нововведения, а затем внедрять их в продукт раньше конкурентов.
- Отбор перспективных вариантов. Быстрое тестирование и большое количество итераций позволяют разработчику вовремя отсеивать бесперспективные варианты кода на начальных этапах. Это также способствует экономичному расходованию времени и ресурсов без их распыления на тупиковые направления.
- Качество тестирования. Сочетание ручной и автоматизированной проверки позволяет выявлять ошибки на ранних этапах разработки. Это снижает вероятность их накопления на этапе релиза, что еще больше сокращает время работы над проектом.
- Высокие требования к опыту. Рабочий процесс в любой компании можно перевести на методологию CI/CD. Однако это требует от разработчиков как знания самой концепции на практическом уровне, так и умения быстро реорганизовать процессы в самой организации. Иными словами, CI/CD имеет достаточно большой порог вхождения в сравнении со многими традиционными методологиями.
- Сложность постоянного взаимодействия. Непрерывная интеграция и доставка программного продукта требуют от разработчиков высокой скоординированности действий. На практике это означает, что должно быть отдельное лицо, которое занимается организацией рабочего процесса и налаживанием взаимодействия между членами команды.
Так как непрерывная интеграция и развертывание подразумевает автоматизацию многих процессов в ходе разработки, для этого созданы различные программные инструменты и сервисы:
- GitLab. Эта платформа позволяет управлять хранилищами проекта, документировать результаты тестирования и доработок, анализировать и дополнять функциональность проекта, выявлять и устранять ошибки.
- Docker. СD-система, позволяющая контейнеризировать проект, то есть упаковать его со всем окружением и зависимостями.
- Travis-CI. Сервер, который можно подключать к виртуальным репозиториям GitHub с минимальными настройками. Благодаря использованию облачных технологий его не нужно отдельно устанавливать.
- Jenkins. Один из самый популярных DevOps-инструментов, совместимый со всевозможными плагинами для адаптации под различные проекты и задачи.
- PHP Censor. CI-сервер, автоматизирующий сборку PHP-проектов. Может работать с репозиториями GitLab, Mercurial и другими, с библиотеками для тестирования Atoum, PHP Spec, Behat.
Возможность оперативно вносить изменения, постоянно тестировать и дорабатывать продукт, взаимодействовать не только друг с другом, но и с клиентом — вот что делает концепцию CI/CD популярной среди разработчиков. Сегодня ее понимание и практическое освоение являются важной рекомендацией при разработке как крупных, так и небольших проектов.
Непрерывная интеграция, доставка и развертывание — технологии разработки, возникшие из движения DevOps. Они повышают эффективность процессов создания, тестирования и выпуска ПО и позволяют доставлять продукт в руки пользователей оперативнее, чем традиционные методы. Грамотно исполненный CI/CD-пайплайн дает команде возможность быстро доставлять работающее ПО пользователю и своевременно получать обратную связь по внесенным изменениям.
Создание CI/CD-пайплайна — это не упражнение, которое делается один раз, после чего о нем можно забыть. Как и то ПО, которое вы разрабатываете, практики CI/CD требуют итеративного подхода: анализируя данные и следя за происходящим, вы сможете улучшить выстроенный вами CI/CD-процесс. В этой статье мы рассмотрим лучшие практики CI/CD, которые мы рекомендуем применить к вашему пайплайну.


Делайте коммиты рано и часто
Первое, чего требует реализация непрерывной интеграции, — это размещение всего исходного кода, конфигурационных файлов, скриптов, библиотек и исполняемых файлов в системе контроля версий/ Это позволит вам отслеживать изменения.
Однако недостаточно просто завести инструмент — важно то, как вы будете им пользоваться. Чтобы упростить процесс интеграции изменений от нескольких контрибьюторов, непрерывна интеграция предлагает публиковать небольшие изменения, но зато делать это чаще.
Каждый коммит запускает набор автоматизированных тестов, которые быстро дают вам обратную связь. При регулярных коммитах вся команда будет работать с одними и теми же исходим данными, а значит вам будет легче сотрудничать и реже придется разрешать конфликты при слиянии крупных и комплексных изменений.
Чтобы получить максимум пользы от непрерывной интеграции, важно, чтобы все разработчики публиковали свои изменения в основную ветку (master) и обновляли свою рабочую версию, подгружая изменения остальных. Общее правило: старайтесь делать коммит в master минимум раз в день.
Такие частые публикации в основную ветку могут показаться неудобными, если ваша команда привыкла работать с долгосрочными ветками. Люди могут бояться преждевременной оценки коллег, а объем некоторых задач может не укладываться в один день.
Важно создать в команде культуру сотрудничества, а не осуждения. Полезно обсудить, как именно будет происходить работа команды. Вместе разбивая задачи на более мелкие и дискретные, ваша команда сможет быстрее усвоить эту практику.
Долгосрочные ветки используются для хранения новой функциональности, которая пока не готова к релизу. Для этой цели можно также использовать флаги функций. Они позволяют контролировать видимость той или иной функциональности в разных окружениях. Вы сможете включать изменения в основную ветку и в сборки с тестами, при этом скрывая соответствующую функциональность от пользователя.

Поддерживайте сборки зелеными
Собирая решение и запуская набор автоматизированных тестов для каждого коммита, CI/CD-пайплайн дает разработчикам быструю обратную связь по их изменениям.
Цель — постоянно держать код в состоянии, пригодном для релиза. Решать проблемы сразу по возникновении — это не только более эффективный подход, но он также позволит вам быстро выпускать изменения в случае, если возникнет проблема в продакшне.
Если сборка по какой-либо причине падает, команда должна сразу заняться решением проблемы. Возникает желание обвинить того, кто внес последнее изменение в код, и оставить этого человека разбираться с проблемой. Однако обвиняя таким образом коллег, вы вряд ли создадите в команде культуру созидания, при этом причины проблем могут так и оставаться невыясненными. Возлагая ответственность за исправление сборки и выяснение причин падения на всю команду, вы сможете улучшить CI/CD-процесс в целом. Конечно, на деле, когда испытывается высокое давление и напряжение, это может оказаться не так просто. Развитие DevOps-культуры — это упражнение, которое тоже требует постоянного совершенствования.
Представьте, что вы отвлекаетесь от своей работы, принимаетесь искать причину падения и в конце концов выясняете, что оно было вызвано чем-нибудь совсем тривиальным — синтаксической ошибкой или пропущенной зависимостью. Такое может раздражать. Чтобы таких ситуаций не возникало, можно поручить членам команды выполнять сборку и базовый набор тестов локально и только после этого публиковать свои изменения. В идеале, у всех должна быть возможность использовать в качестве CI/CD одни и те же скрипты — так никому не придется делать лишнюю работу.

Собирайте один раз
Типичной ошибкой является создание новой сборки для каждого шага CI/CD.
Пересобирая приложение для разных окружений, вы рискуете нарушить консистентность и не будете знать наверняка, было ли тестирование на предыдущих шагах успешным. Поэтому на протяжении всех шагов CI/CD-пайплайна (включая конечный релиз в продакшн) необходимо использовать один и тот же артефакт.
Чтобы реализовать это, нужно сделать сборки независимыми от окружения. Любые переменные, параметры аутентификации, конфигурационные файлы и скрипты должны вызываться скриптом развертывания и не быть частью самой сборки. Это позволит делать развертывание одного и того же артефакта в каждом тестовом окружении. Тогда прохождение каждой стадии будет повышать уверенность команды в этом артефакте.
В отличие от скриптов сборки, конфигурационных файлов и скриптов развертывания, хранить которые лучше в единой системе контроля версий, артефакты сборки должны храниться отдельно. Все эти данные являются входными по отношению к процессу сборки, и конечный продукт не должен принадлежать системе контроля версий. Вместо этого сборке должна быть присвоена версия, после чего она сохраняется в центральный репозиторий артефактов, например Nexus, откуда ее всегда можно достать, чтобы выполнить развертывание.

Оптимизируйте тесты
CI/CD в значительной мере опирается на автоматизированное тестирование — оно дает уверенность в качестве разрабатываемого ПО. Однако это не значит, что вам нужно стремиться протестировать каждый возможный сценарий.
Цель CI/CD — обеспечить вам быструю обратную связь и доставлять программное обеспечение пользователям быстрее, чем это возможно с традиционными методами. А это значит, что нужно соблюдать баланс между тестовым покрытием и производительностью. Если тестирование выполняется слишком долго, люди будут искать возможность обойти эту процедуру.
Вначале запускайте те тесты, которые выполняются быстрее всего, чтобы как можно скорее получить первую порцию обратной связи. Более длительные тесты можно будет выполнить тогда, когда вы уже будете достаточно уверены в своей сборке. Что касается ручных тестов, учитывая то, что они выполняются долго и требуют привлечения коллег, лучше выполнять эту фазу тестирования после того, как у вас будут зеленые авто-тесты.
Первой прослойкой обычно выступают юнит-тесты. Ими можно обеспечить широкое покрытие, и они смогут указать вам на очевидные проблемы во вносимых изменениях. Вслед за юнит-тестами у вас может быть прослойка автоматизированных интеграционных или компонентных тестов, проверяющих взаимодействие между различными частями вашего кода.
Также вы можете вложиться в создание более сложных автоматизированных тестов (например, тестов GUI, производительности или нагрузки). После этого можно заниматься ручным исследовательским и/или приемочным тестированием. Все эти виды тестов (будь они автоматизированными или ручными) более длительны. Чтобы достичь эффективности, вам нужно сосредоточиться на вещах, которые представляют наибольший риск для вашего продукта и пользователей.

Чистите ваши окружения
Чтобы получить максимум пользы от тестирования, стоит уделять время чистке пре-продакшн окружений перед каждым развертыванием.
Когда среды работают слишком долго, отслеживать изменения конфигураций становится сложнее.
Со временем окружения отклоняются от первоначальных настроек и начинают отличаться друг от друга. А это значит, что тесты, запущенные в разных окружениях, могут выдавать разные результаты. Статические окружения требуют поддержки — это может замедлять тестирование и задерживать процедуру релиза.
Для создания окружений и запуска в них тестов можно использовать контейнеры. Они позволяют с легкостью настраивать и сбрасывать окружения каждый раз, когда вам необходимо выполнить развертывание: для этого используется скрипт, фиксирующий все необходимые шаги (подход Infrastructure as Code). Создавая новый контейнер под каждое развертывание, вы будете соблюдать консистентность. Также с контейнерами легче масштабировать окружения, поэтому при необходимости вы сможете тестировать несколько сборок параллельно.

Не позволяйте делать развертывание обходными путями
Допустим, вы построили надежный, быстрый и безопасный CI/CD-пайплайн, который действительно позволяет вам быть уверенными в качестве сборок. Но ваша работа легко обесценится, если вы будете разрешать людям идти в обход процессу по каким бы то ни было причинам.
Как правило, просьбы обойти процесс релиза поступают тогда, когда изменения небольшие либо срочные (иногда и то, и другое), но соглашаясь на них, вы оказываете медвежью услугу.
Пропуская авто-тесты, вы рискуете остаться с проблемами, которые вполне можно было бы отследить. А воспроизводить ошибки и делать отладку намного сложнее, поскольку нет возможности взять готовую сборку и развернуть ее в тестовом окружении.
Вероятно, в какой-то момент вас попросят обойти эту процедуру («ну только в этот раз!»). Вы же в этот момент, скорей всего, будете, как пожарный, всех спасать. Однако в будущем полезно поднять этот вопрос на ретроспективе или на post-mortem и разобраться, почему так произошло. Слишком ли долгий процесс? Возможно, нужно поработать над улучшением производительности. Есть ли непонимание относительно того, когда использовать CI/CD? Убедив ваших коллег в преимуществах CI/CD-пайплайнов, вы уже не столкнетесь с такого рода просьбами, если снова случится форс-мажор.

Отслеживайте и анализируйте ваш пайплайн
Создавая CI/CD-пайплайн, вы скорей всего будете реализовывать способ мониторинга продакшн-окружения, чтобы иметь возможность как можно раньше отслеживать проблемы.
Вашему CI/CD-пайплайну, как и вашему ПО, необходим цикл обратной связи.
Анализируя метрики, собранные вашим CI/CD-инструментом, вы сможете выявлять потенциальные проблемы и области, требующие улучшения.
- Сравнивая количество сборок, запускаемых в неделю, день или час, вы поймете, каким образом используется инфраструктура пайплайна, нужно ли ее масштабировать и когда случается пик нагрузки.
- Следя за скоростью развертывания (проверяя, не падает ли она), вы будете знать, пора ли заняться оптимизацией производительности или еще нет.
- Статистика по автоматизированным тестам поможет определить, имеет ли смысл что-то выполнять параллельно.
- Пересматривая результаты тестов и находя те, которые систематически пропускаются, вы будете знать, как оптимизировать тестовое покрытие.

Работайте всей командой
Создание эффективного CI/CD-пайплайна требует не только подходящих процессов и инструментов, но и командной и организационной культуры.
Непрерывная интеграция, доставка и развертывание — это DevOps-практики. Они устраняют традиционную разобщенность между разработкой, тестированием и операционной деятельностью и способствуют их коллаборации между специалистами.
Устранение разобщенности помогает командам лучше обозревать процесс, дает им возможность сотрудничать и объединять разные области знаний. Поддержкой пайплайна не должен заниматься один человек.
Ощущая общую ответственность за доставку продукта, свой вклад смогут внести все члены команды: кто-то починит сборку, кто-то переведет окружения в контейнеры, кто-то автоматизирует ручную задачу, чтобы ее можно было выполнять чаще, и т.д.
Культура доверия, при которой члены команды могут экспериментировать и делиться идеями, поможет не только сотрудникам, но и всей организации, и окажет положительный эффект на ваш продукт. Если что-то идет не так, не нужно обвинять в этом членов вашей команды; вместо этого стремитесь извлекать уроки из произошедшего, разбираться в причинах проблем и в том, как их избежать в будущем.
Не упускайте возможность улучшить свои CI/CD-процессы, сделать их устойчивее и эффективнее. Позволяя членам команды экспериментировать и создавать новое, не опасаясь ничьих упреков, вы поощрите культуру созидания и непрерывного совершенствования.
| stage | group | info | type |
|---|---|---|---|
|
Verify |
Pipeline Execution |
To determine the technical writer assigned to the Stage/Group associated with this page, see https://about.gitlab.com/handbook/product/ux/technical-writing/#assignments |
reference |
Troubleshooting CI/CD (FREE)
GitLab provides several tools to help make troubleshooting your pipelines easier.
This guide also lists common issues and possible solutions.
Verify syntax
An early source of problems can be incorrect syntax. The pipeline shows a yaml invalid
badge and does not start running if any syntax or formatting problems are found.
Edit .gitlab-ci.yml with the pipeline editor
The pipeline editor is the recommended editing
experience (rather than the single file editor or the Web IDE). It includes:
- Code completion suggestions that ensure you are only using accepted keywords.
- Automatic syntax highlighting and validation.
- The CI/CD configuration visualization,
a graphical representation of your.gitlab-ci.ymlfile.
Edit .gitlab-ci.yml locally
If you prefer to edit your pipeline configuration locally, you can use the
GitLab CI/CD schema in your editor to verify basic syntax issues. Any
editor with Schemastore support uses
the GitLab CI/CD schema by default.
If you need to link to the schema directly, it
is at:
https://gitlab.com/gitlab-org/gitlab/-/blob/master/app/assets/javascripts/editor/schema/ci.json.
To see the full list of custom tags covered by the CI/CD schema, check the
latest version of the schema.
Verify syntax with CI Lint tool
The CI Lint tool is a simple way to ensure the syntax of a CI/CD configuration
file is correct. Paste in full .gitlab-ci.yml files or individual jobs configuration,
to verify the basic syntax.
When a .gitlab-ci.yml file is present in a project, you can also use the CI Lint
tool to simulate the creation of a full pipeline.
It does deeper verification of the configuration syntax.
Verify variables
A key part of troubleshooting CI/CD is to verify which variables are present in a
pipeline, and what their values are. A lot of pipeline configuration is dependent
on variables, and verifying them is one of the fastest ways to find the source of
a problem.
Export the full list of variables
available in each problematic job. Check if the variables you expect are present,
and check if their values are what you expect.
GitLab CI/CD documentation
The complete .gitlab-ci.yml reference contains a full list of
every keyword you can use to configure your pipelines.
You can also look at a large number of pipeline configuration examples
and templates.
Documentation for pipeline types
Some pipeline types have their own detailed usage guides that you should read
if you are using that type:
- Multi-project pipelines: Have your pipeline trigger
a pipeline in a different project. - Parent/child pipelines: Have your main pipeline trigger
and run separate pipelines in the same project. You can also
dynamically generate the child pipeline’s configuration
at runtime. - Merge request pipelines: Run a pipeline
in the context of a merge request.- Merged results pipelines:
Merge request pipelines that run on the combined source and target branch - Merge trains:
Multiple merged results pipelines that queue and run automatically before
changes are merged.
- Merged results pipelines:
Troubleshooting Guides for CI/CD features
Troubleshooting guides are available for some CI/CD features and related topics:
- Container Registry
- GitLab Runner
- Merge Trains
- Docker Build
- Environments
Common CI/CD issues
A lot of common pipeline issues can be fixed by analyzing the behavior of the rules
or only/except configuration. You shouldn’t use these two configurations in the same
pipeline, as they behave differently. It’s hard to predict how a pipeline runs with
this mixed behavior.
If your rules or only/except configuration makes use of predefined variables
like CI_PIPELINE_SOURCE, CI_MERGE_REQUEST_ID, you should verify them
as the first troubleshooting step.
Jobs or pipelines don’t run when expected
The rules or only/except keywords are what determine whether or not a job is
added to a pipeline. If a pipeline runs, but a job is not added to the pipeline,
it’s usually due to rules or only/except configuration issues.
If a pipeline does not seem to run at all, with no error message, it may also be
due to rules or only/except configuration, or the workflow: rules keyword.
If you are converting from only/except to the rules keyword, you should check
the rules configuration details carefully. The behavior
of only/except and rules is different and can cause unexpected behavior when migrating
between the two.
The common if clauses for rules
can be very helpful for examples of how to write rules that behave the way you expect.
Two pipelines run at the same time
Two pipelines can run when pushing a commit to a branch that has an open merge request
associated with it. Usually one pipeline is a merge request pipeline, and the other
is a branch pipeline.
This situation is usually caused by the rules configuration, and there are several ways to
prevent duplicate pipelines.
A job is not in the pipeline
GitLab determines if a job is added to a pipeline based on the only/except
or rules defined for the job. If it didn’t run, it’s probably
not evaluating as you expect.
No pipeline or the wrong type of pipeline runs
Before a pipeline can run, GitLab evaluates all the jobs in the configuration and tries
to add them to all available pipeline types. A pipeline does not run if no jobs are added
to it at the end of the evaluation.
If a pipeline did not run, it’s likely that all the jobs had rules or only/except that
blocked them from being added to the pipeline.
If the wrong pipeline type ran, then the rules or only/except configuration should
be checked to make sure the jobs are added to the correct pipeline type. For
example, if a merge request pipeline did not run, the jobs may have been added to
a branch pipeline instead.
It’s also possible that your workflow: rules configuration
blocked the pipeline, or allowed the wrong pipeline type.
Pipeline with many jobs fails to start
A Pipeline that has more jobs than the instance’s defined CI/CD limits
fails to start.
To reduce the number of jobs in your pipeline, you can split your .gitlab-ci.yml
configuration using parent-child pipelines.
A job runs unexpectedly
A common reason a job is added to a pipeline unexpectedly is because the changes
keyword always evaluates to true in certain cases. For example, changes is always
true in certain pipeline types, including scheduled pipelines and pipelines for tags.
The changes keyword is used in combination with only/except
or rules). It’s recommended to use changes with
rules or only/except configuration that ensures the job is only added to branch
pipelines or merge request pipelines.
«fatal: reference is not a tree» error
Introduced in GitLab 12.4.
Previously, you’d have encountered unexpected pipeline failures when you force-pushed
a branch to its remote repository. To illustrate the problem, suppose you’ve had the current workflow:
- A user creates a feature branch named
exampleand pushes it to a remote repository. - A new pipeline starts running on the
examplebranch. - A user rebases the
examplebranch on the latest default branch and force-pushes it to its remote repository. - A new pipeline starts running on the
examplebranch again, however,
the previous pipeline (2) fails because offatal: reference is not a tree:error.
This occurs because the previous pipeline cannot find a checkout-SHA (which is associated with the pipeline record)
from the example branch that the commit history has already been overwritten by the force-push.
Similarly, Merged results pipelines
might have failed intermittently due to the same reason.
As of GitLab 12.4, we’ve improved this behavior by persisting pipeline refs exclusively.
To illustrate its life cycle:
- A pipeline is created on a feature branch named
example. - A persistent pipeline ref is created at
refs/pipelines/<pipeline-id>,
which retains the checkout-SHA of the associated pipeline record.
This persistent ref stays intact during the pipeline execution,
even if the commit history of theexamplebranch has been overwritten by force-push. - The runner fetches the persistent pipeline ref and gets source code from the checkout-SHA.
- When the pipeline finishes, its persistent ref is cleaned up in a background process.
Merge request pipeline messages
The merge request pipeline widget shows information about the pipeline status in
a merge request. It’s displayed above the ability to merge status widget.
«Checking ability to merge automatically» message
There is a known issue
where a merge request can be stuck with the Checking ability to merge automatically
message.
If your merge request has this message and it does not disappear after a few minutes,
you can try one of these workarounds:
- Refresh the merge request page.
- Close & Re-open the merge request.
- Rebase the merge request with the
/rebasequick action. - If you have already confirmed the merge request is ready to be merged, you can merge
it with the/mergequick action.
«Checking pipeline status» message
This message is shown when the merge request has no pipeline associated with the
latest commit yet. This might be because:
- GitLab hasn’t finished creating the pipeline yet.
- You are using an external CI service and GitLab hasn’t heard back from the service yet.
- You are not using CI/CD pipelines in your project.
- You are using CI/CD pipelines in your project, but your configuration prevented a pipeline from running on the source branch for your merge request.
- The latest pipeline was deleted (this is a known issue).
- The source branch of the merge request is on a private fork.
After the pipeline is created, the message updates with the pipeline status.
Merge request status messages
The merge request status widget shows the Merge button and whether or not a merge
request is ready to merge. If the merge request can’t be merged, the reason for this
is displayed.
If the pipeline is still running, Merge is replaced with the
Merge when pipeline succeeds button.
If Merge Trains
are enabled, the button is either Add to merge train or Add to merge train when pipeline succeeds. (PREMIUM)
«A CI/CD pipeline must run and be successful before merge» message
This message is shown if the Pipelines must succeed
setting is enabled in the project and a pipeline has not yet run successfully.
This also applies if the pipeline has not been created yet, or if you are waiting
for an external CI service. If you don’t use pipelines for your project, then you
should disable Pipelines must succeed so you can accept merge requests.
«Merge blocked: pipeline must succeed. Push a new commit that fixes the failure» message
This message is shown if the merge request pipeline,
merged results pipeline,
or merge train pipeline
has failed or been canceled.
If a merge request pipeline or merged result pipeline was canceled or failed, you can:
- Re-run the entire pipeline by selecting Run pipeline in the pipeline tab in the merge request.
- Retry only the jobs that failed. If you re-run the entire pipeline, this is not necessary.
- Push a new commit to fix the failure.
If the merge train pipeline has failed, you can:
- Check the failure and determine if you can use the
/mergequick action to immediately add the merge request to the train again. - Re-run the entire pipeline by selecting Run pipeline in the pipeline tab in the merge request, then add the merge request to the train again.
- Push a commit to fix the failure, then add the merge request to the train again.
If the merge train pipeline was canceled before the merge request was merged, without a failure, you can:
- Add it to the train again.
Project group/project not found or access denied
This message is shown if configuration is added with include and one of the following:
- The configuration refers to a project that can’t be found.
- The user that is running the pipeline is unable to access any included projects.
To resolve this, check that:
- The path of the project is in the format
my-group/my-projectand does not include
any folders in the repository. - The user running the pipeline is a member of the projects
that contain the included files. Users must also have the permission
to run CI/CD jobs in the same projects.
«The parsed YAML is too big» message
This message displays when the YAML configuration is too large or nested too deeply.
YAML files with a large number of includes, and thousands of lines overall, are
more likely to hit this memory limit. For example, a YAML file that is 200kb is
likely to hit the default memory limit.
To reduce the configuration size, you can:
- Check the length of the expanded CI/CD configuration in the pipeline editor’s
merged YAML tab. Look for
duplicated configuration that can be removed or simplified. - Move long or repeated
scriptsections into standalone scripts in the project. - Use parent and child pipelines to move some
work to jobs in an independent child pipeline.
On a self-managed instance, you can increase the size limits.
Error 500 when editing the .gitlab-ci.yml file
A loop of included configuration files
can cause a 500 error when editing the .gitlab-ci.yml file with the web editor.
A CI/CD job does not use newer configuration when run again
The configuration for a pipeline is only fetched when the pipeline is created.
When you rerun a job, uses the same configuration each time. If you update configuration files,
including separate files added with include, you must
start a new pipeline to use the new configuration.
Pipeline warnings
Pipeline configuration warnings are shown when you:
- Validate configuration with the CI Lint tool.
- Manually run a pipeline.
«Job may allow multiple pipelines to run for a single action» warning
When you use rules with a when clause without an if
clause, multiple pipelines may run. Usually this occurs when you push a commit to
a branch that has an open merge request associated with it.
To prevent duplicate pipelines, use
workflow: rules or rewrite your rules to control
which pipelines can run.
Console workaround if job using resource_group gets stuck (FREE SELF)
# find resource group by name resource_group = Project.find_by_full_path('...').resource_groups.find_by(key: 'the-group-name') busy_resources = resource_group.resources.where('build_id IS NOT NULL') # identify which builds are occupying the resource # (I think it should be 1 as of today) busy_resources.pluck(:build_id) # it's good to check why this build is holding the resource. # Is it stuck? Has it been forcefully dropped by the system? # free up busy resources busy_resources.update_all(build_id: nil)
Job log slow to update
When you visit the job log page for a running job, there could be a delay of up to
60 seconds before the log updates. The default refresh time is 60 seconds, but after
the log is viewed in the UI, the following log updates should occur every 3 seconds.
Disaster recovery
You can disable some important but computationally expensive parts of the application
to relieve stress on the database during ongoing downtime.
Disable fair scheduling on shared runners
When clearing a large backlog of jobs, you can temporarily enable the ci_queueing_disaster_recovery_disable_fair_scheduling
feature flag. This flag disables fair scheduling
on shared runners, which reduces system resource usage on the jobs/request endpoint.
When enabled, jobs are processed in the order they were put in the system, instead of
balanced across many projects.
Disable CI/CD minutes quota enforcement
To disable the enforcement of CI/CD minutes quotas on shared runners, you can temporarily
enable the ci_queueing_disaster_recovery_disable_quota feature flag.
This flag reduces system resource usage on the jobs/request endpoint.
When enabled, jobs created in the last hour can run in projects which are out of quota.
Earlier jobs are already canceled by a periodic background worker (StuckCiJobsWorker).
CI/CD troubleshooting rails console commands
The following commands are run in the rails console.
WARNING:
Any command that changes data directly could be damaging if not run correctly, or under the right conditions.
We highly recommend running them in a test environment with a backup of the instance ready to be restored, just in case.
Cancel stuck pending pipelines
project = Project.find_by_full_path('<project_path>') Ci::Pipeline.where(project_id: project.id).where(status: 'pending').count Ci::Pipeline.where(project_id: project.id).where(status: 'pending').each {|p| p.cancel if p.stuck?} Ci::Pipeline.where(project_id: project.id).where(status: 'pending').count
Try merge request integration
project = Project.find_by_full_path('<project_path>') mr = project.merge_requests.find_by(iid: <merge_request_iid>) mr.project.try(:ci_integration)
Validate the .gitlab-ci.yml file
project = Project.find_by_full_path('<project_path>') content = p.repository.gitlab_ci_yml_for(project.repository.root_ref_sha) Gitlab::Ci::Lint.new(project: project, current_user: User.first).validate(content)
Disable AutoDevOps on Existing Projects
Project.all.each do |p| p.auto_devops_attributes={"enabled"=>"0"} p.save end
Obtain runners registration token
Gitlab::CurrentSettings.current_application_settings.runners_registration_token
Seed runners registration token
appSetting = Gitlab::CurrentSettings.current_application_settings appSetting.set_runners_registration_token('<new-runners-registration-token>') appSetting.save!
Run pipeline schedules manually
You can run pipeline schedules manually through the Rails console to reveal any errors that are usually not visible.
# schedule_id can be obtained from Edit Pipeline Schedule page schedule = Ci::PipelineSchedule.find_by(id: <schedule_id>) # Select the user that you want to run the schedule for user = User.find_by_username('<username>') # Run the schedule ps = Ci::CreatePipelineService.new(schedule.project, user, ref: schedule.ref).execute!(:schedule, ignore_skip_ci: true, save_on_errors: false, schedule: schedule)
How to get help
If you are unable to resolve pipeline issues, you can get help from:
- The GitLab community forum
- GitLab Support

Сергей Зинкевич
директор по развитию бизнеса КРОК Облачные сервисы
Для организации процесса современной ИТ-разработки в России принято использовать концепции и практики непрерывной интеграции и доставки (CI/CD). О ней говорят много, но, как часто бывает на практике, редко кто применяет правильно. Причина кроется в нехватке специалистов, которые могли бы методологически выстроить конвейер и автоматизировать её. Расскажем о том, какие распространенные ошибки в CI/CD мы видим в проектах.
Но сначала немного ликбеза
CI/CD — это целая культура, которая включает в себя набор принципов и реализует последовательность этапов доставки программного обеспечения с момента его написания разработчиком до развёртывания в продуктивном контуре. Собственно, в основе данной аббревиатуры отдельные шаги, которые принято рассматривать в комплексе:
- Continuous integration — непрерывная интеграция;
- Continuous delivery — непрерывная доставка;
- Continuous deployment — непрерывное развёртывание.
Continuous integration (CI) – это упаковка приложения разработчиком и тестирование. На шаге планирования у бизнеса или владельца продукта появляется идея, как улучшить клиентский сервис и какие фичи для этого нужны. На этом же этапе аналитик собирает бизнес-требования и передаёт их разработчику.
Тот (или скорее те, так как в крупной компании в разработке занято несколько человек) пишет код и загружает так называемый билд — изменённое приложение — в отдельную ветку. Билд тестируется — вручную и/или с помощью автотестов — и переходит на следующий этап конвейера.
Continuous delivery – это доставка приложения, то есть обеспечение его работы в промышленной эксплуатации. Здесь важно как минимум одно ручное действие – подтверждение ответственного за вывод в продакшн. Как правило, за это отвечает тимлид команды разработчиков. Непосредственно развёртывание приложения в инфраструктуре клиента должно происходить автоматизированно.
Continuous deployment – это процесс непрерывной доставки кода до продуктива без каких-либо дополнительных согласований и ручных операций. Мониторинг таких выкаток должен также осуществляться постоянно и автоматизированно. Его цель – молниеносно определить проблему с билдом и дать возможность разработчику откатить назад версию приложения и параллельно «пофиксить» ошибки.
В одной компании для решения этой задачи поступили довольно креативно — установили светофор, который интегрирован с системой мониторинга. Если в ней появляются ошибки, этот светофор мигает красным светом, требуя от сотрудников фактически мгновенной реакции.
Распространённые ошибки при реализации CI/CD
Слабо применяется автоматизация
Неработающий конвейер – картина частая. В большинстве случаев это связано с некорректно построенными процессами внутри организации.
Например, даже в крупных компаниях зачастую при разработке очень слабо применяется автоматизация или применяется не оптимально. Это приводит к тому, что каждая операция разработчика, тестировщика, администраторов сопровождается рутинными ручными действиями: написать о статусе, передать информацию, перепоручить «раскатать» инфраструктуру и так далее.
В результате в 2-3 раза увеличивается срок выпуска в эксплуатацию приложения, а вместе с этим растет количество конфликтов внутри команды, так как сложно понять, на каком этапе процесс стопорится.
Нет формально прописанных зон ответственности
Нередко видим другую ситуацию — в целом процесс CI/СD работает неплохо, но иногда даёт сбой. ИТ-директор одного российского банка как-то жаловался, что при выкатке новой версии релиза часть пакетов и скриптов «не доезжает», а обратная связь о неработающих сервисах при этом приходит не от DevOps-инженеров, а непосредственно от пользователей.
Проблема в данном случае может быть связана с отсутствием формально прописанных зон ответственности и наличием большого количества ручных операций в конвейнере, что увеличивает шанс возникновения ошибки. Также из-за наличия такой проблемы можно сделать вывод, что функции внутри команды дублируются и теряется координация между несколькими участниками процесса.
Чтобы это исправить, рекомендуется использовать RACI-матрицу. Её, к слову, часто применяют провайдеры. Они «на берегу» определяют, кто и за что будет отвечать в проекте. Например, мы прописываем в документе свою обязанность разворачивать и поддерживать виртуальные машины и инфраструктурные компоненты там, где являемся поставщиками инфраструктуры и кластеров Kubernetes. А сам софт и доступность CI остаются на совести клиента.
Бывает, что клиент поручает нам цикл сборки и доставки целиком – в этом случае мы раскатываем приложение в продуктивную среду, а заказчик фокусируется исключительно на разработке своего продукта.
Отказ следовать IaC
На эффективность всей ИТ-разработки также влияет готовность инфраструктуры. Оправданно в данном случае следовать концепции IaC (инфраструктура как код), когда для развёртывания и управления средой пишутся скрипты и шаблоны. Они помогают быстрее развернуть типовую инфраструктуру, произвести изменения без захода в консоль управления или на конкретную виртуальную машину.
Администраторы, которые не скриптуют каждое действие с инфраструктурой, вынуждены прикладывать одни и те же усилия каждый раз, когда данная инфраструктура требуется разработчикам для нового релиза. Отказ следовать IaC-подходу увеличивает затраты на сопровождение ИТ.
Так, первичное развёртывание инфраструктуры может стоить условно 100 000 руб, но повторное, основанное на готовом шаблоне, потребует всего 35 000 руб, так как трудозатраты не пойдут ни в какое сравнение с тем, что было до автоматизации.
Постоянно растущая потребность в более быстрой и структурированной разработке привела к тому, что инструменты CI/CD стали неотъемлемой частью процессов разработки в организации.
Инструменты CI/CD помогают автоматизировать большинство основных, повторяющихся задач процесса разработки приложений от конца до конца – от выполнения базовых проверок отступов в представленном коде до развертывания скомпилированного кода на производственных серверах.
И с ростом числа функций и возможностей, которыми обладают инструменты CI/CD, они также требуют определенного уровня доступа для выполнения этих различных функций.
Рассмотрим, например, инструмент CD, который развертывает скомпилированный код на производственных серверах: этот инструмент потребует такого же уровня доступа и/или количества разрешений, которые потребовались бы человеку для автоматизации процесса развертывания.
Однако теперь, когда сборка программного обеспечения полностью автоматизирована процессами CI/CD, злоумышленники вполне могут бесшумно внедрить вредоносный код в сам процесс сборки.
В последнее время это происходит довольно часто: злоумышленники внедряют код криптовалютных майнеров в различные сборки программного обеспечения, оставаясь при этом незамеченными.
Вот почему использование неправильно настроенных или уязвимых инструментов CI/CD может привести к значительному увеличению поверхности атаки вашей организации.
Содержание
- Инциденты, связанные с безопасностью CI/CD
- Наиболее распространенные ошибки CI/CD, которые приводят к утечке данных и сетевым вторжениям
- Захаркоженные учетные данные
- Неправильно сконфигурированные контейнеры
- Неправильная конфигурация или неправильное использование переменных окружения
- Неправильно настроенные инструменты CI/CD
- Устаревшие инструменты CI/CD
- Заключение
Инциденты, связанные с безопасностью CI/CD
Нарушения в инструментах CI/CD часто происходят из-за неправильной конфигурации или устаревшего программного обеспечения.
Поскольку современные взломы часто автоматизированы, “автоматическому боту” (подобному тем, что пытаются войти в систему по SSH по всему интернету) не требуется много времени, чтобы начать сканирование узлов, на которых установлены устаревшие версии, либо с помощью захвата баннеров, либо просто перебором уязвимостей PoC на общедоступном CI/CD-инструменте.
Недавняя уязвимость в GitLab позволяла использовать серверы с устаревшими установками GitLab для проведения DoS-атак, что, помноженное на количество серверов с устаревшей версией GitLab, привело к DDoS-атакам в Интернете со скоростью более 1 ТБ/с.
Помимо рассылки интернет-атак (незаконное действие в большинстве стран), в GitLab были уязвимости, связанные с авторизацией, которые также позволяли неавторизованным пользователям войти в ваш инстанс.
Аналогично, были уязвимости, связанные с ACL, которые позволяли взломанным, но авторизованным учетным записям выталкивать и извлекать данные из зон несанкционированного доступа в вашем экземпляре GitLab.
Хотя эти уязвимости были устранены в будущих сборках GitLab, по-прежнему важно следить за обновлениями и, в свою очередь, обновлять свои экземпляры (чаще всего самостоятельно), чтобы уменьшить площадь атаки.
Аналогичным образом, популярный CI/CD-инструмент Jenkins с открытым исходным кодом в последнее время был обременен большим количеством CVE, начиная от XSS/CSRF-уязвимостей и заканчивая уязвимостями обхода разрешений, которые угрожают раскрыть конфиденциальную информацию злоумышленникам.
Глядя на приведенные выше примеры, можно подумать, что использование размещенных или SaaS CI/CD инструментов и отказ от самостоятельных инструментов кажется очевидным решением, но размещенные CI/CD инструменты могут создавать свои собственные проблемы безопасности.
Недавняя уязвимость в Travis CI привела к тому, что переменные окружения внедрялись через pull request в виде файлов .travis.yml, а учитывая принцип работы Git, простого удаления файла из Git было недостаточно для защиты различных секретов проекта.
Аналогичным образом, даже если ваш Git-репозиторий был приватным и секреты не были утечены через сам репозиторий, если ваш процесс развертывания использует Git и клонирует репозиторий на производственный экземпляр, любой пользователь, имеющий доступ к вашему производственному веб-приложению, сможет загрузить или просмотреть файл .travis.yml, содержащий секреты вашего приложения/сборки.
Наиболее распространенные ошибки CI/CD, которые приводят к утечке данных и сетевым вторжениям
Захаркоженные учетные данные
Подобно тому, как человеку требуются определенные учетные данные для доступа к машине (например, серверу), чтобы развернуть на ней собранный код, инструменты CI и CD требуют аналогичного, если не такого же, уровня доступа для сборки и развертывания кода на производственных серверах.
Эти учетные данные, хранящиеся в системах CI/CD, могут быть любыми – от SMTP-серверов, используемых для отправки почтовых уведомлений о завершении сборки или ошибках сборки, до чего-то потенциально более опасного, например, доступа на уровне SSH/root к серверным системам, которые будут использоваться для развертывания собранного кода.
Рассмотрим пример CircleCI:
version: 2.1
executors:
my-executor:
docker:
- image: cimg/ruby:3.0.3-browsers
auth:
username: mydockerhub-user
password: $DOCKERHUB_PASSWORD # context / project UI env-var reference
jobs:
my-job:
executor: my-executor
steps:
- run: echo outside the executorВ разделе auth для контейнера docker мы видим переменную $DOCKERHUB_PASSWORD, которая вводится/заменяется CircleCI в процессе сборки, так что пароль скрыт в самом конфигурационном файле.
Однако, если не использовать эти переменные и не определять пароль, учетные данные могут быть украдены, если конфигурационный файл по ошибке станет общедоступным.
Захардкоженные учетные данные являются распространенным источником компрометации, исходящей от систем CI/CD.
- 🦊 Добавление Gitleaks в пайплайн Gitlab CI
- 🌐 GitLab Watchman – Аудит Gitlab на предмет конфиденциальных и учетных данных
Неправильно сконфигурированные контейнеры
Контейнеры позволяют организациям обеспечить полную согласованность программного обеспечения между различными средами.
Контейнеры Docker стали обычным явлением в средах прода, разработки и тестирования.
Аналогичным образом, инструменты CI/CD используют контейнеры для обеспечения того, что создаваемое программное обеспечение использует ту же самую конфигурацию, что и производственная среда.
Использование неправильно настроенных контейнеров может привести к тому, что злоумышленники проникнут в контейнеры, созданные CI/CD, и внедрят вредоносный код в программное обеспечение.
см. как проверить Docker:
- 🐳 Сканирование образов Docker на наличие уязвимостей с помощью Trivy
- 🐳 Как проверить изменения в файловой системе контейнера Docker
- 🐳 dockle: линтер + проверка образов на безопасность
- 🐳 Обзор сканеров безопасности контейнеров для поиска уязвимостей
- 🐳 Как использовать Harbor для сканирования образов Docker на наличие уязвимостей
Неправильная конфигурация или неправильное использование переменных окружения
Переменные окружения стали альтернативой использованию захардкоженный переменных, но, как это часто бывает с переменными окружения, они являются глобальными для процесса сборки и могут быть использованы или утечь, поскольку они не ограничены областью доступа.
Еще один источник неправильного использования переменных окружения связан с использованием Git, где в публичные репозитории часто попадают ошибочные коммиты, содержащие файлы .env, часто используемые для хранения переменных окружения.
Удаление этих файлов из Git’а считается решением проблемы, но учитывая, что Git содержит историю каждого файла и изменения, злоумышленникам не составит труда просмотреть историю репозитория и получить эти учетные данные из удаленных в прошлом файлов.
Поскольку члены команды работают по всему миру, команды часто полагаются на инструменты обмена сообщениями, такие как Slack, для публикации информации о состоянии сборки.
Jenkins использует пайплайны для улучшения процессов CI/CD с помощью функций, которые включают объявление статуса сборки через Slack во время или после процесса сборки; например:
import groovy.json.JsonOutput
// Add whichever params you think you'd most want to have
// replace the slackURL below with the hook url provided by
// slack when you configure the webhook
def notifySlack(text, channel) {
def slackURL = 'https://hooks.slack.com/services/xxxxxxx/yyyyyyyy/zzzzzzzzzz'
def payload = JsonOutput.toJson()
sh "curl -X POST --data-urlencode 'payload=${payload}' ${slackURL}"
}Как показано выше, если хук Slack открыт для публики, а не используется как секрет/переменная среды, команды Slack могут стать жертвами спама или еще более опасной мишенью для злоумышленников, дающих им подсказки (например, о том, что ваша команда сама использует Slack).
Чтобы предотвратить подобные ситуации, URL-адрес хука должен быть настроен как секретный и не открываться открытым текстом в конфигурационных файлах.
Неправильно настроенные инструменты CI/CD
Инструменты CI/CD обладают целым рядом функций, позволяющих автоматизировать различные трудоемкие задачи или шаги, выполняемые вручную, в рамках процесса сборки программного обеспечения.
Инструменты CI/CD часто включают также этапы тестирования, которые можно использовать для автоматизации проверки того, является ли автоматизированная сборка “хорошей” или нет.
Неправильная настройка этих функций может привести к тому, что злоумышленники получат доступ к самому инструменту CI/CD, что позволит им изменять или внедрять код во время самого процесса сборки.
GitLab – это популярный инструмент с открытым исходным кодом, используемый для собственного хостинга Git и CI/CD.
Также доступны такие инструменты, как CircleCI, популярный среди различных пользователей GitHub благодаря своей тесной интеграции с GitHub.
Использование CircleCI требует создания конфигурационного файла в формате YAML под названием config.yml, который содержит различные “инструкции”, которым CircleCI следует для запуска процесса сборки.
Однако конфигурационный файл не ограничивается базовыми инструкциями по сборке – он также может содержать различные параметры, например, пароли.
Сейчас давайте рассмотрим конфигурацию CI:
version: 2.1
# Define the jobs we want to run for this project
jobs:
build:
docker:
- image: cimg/<language>:<version TAG>
auth:
username: mydockerhub-user
password: $DOCKERHUB_PASSWORD # context / project UI env-var reference
steps:
- checkout
- run: echo "this is the build job"
test:
docker:
- image: cimg/<language>:<version TAG>
auth:
username: mydockerhub-user
password: $DOCKERHUB_PASSWORD # context / project UI env-var reference
steps:
- checkout
- run: echo "this is the test job"
# Orchestrate our job run sequence
workflows:
build_and_test:
jobs:
- build
- test:
requires:
- buildКак показано выше, можно ссылаться и на частные шаблоны контейнеров docker hub через параметр имя пользователя/пароль.
Но если этот конфигурационный файл утечет из-за его публичной видимости в вашем репозитории GitHub, злоумышленники могут получить доступ к вашим приватным шаблонам контейнеров docker hub.
Аналогичным образом, популярное самораспространяемое CI/CD программное обеспечение GitLab недавно поставлялось с учетными данными по умолчанию для входа пользователя root – “5iveL!”.
Поскольку этот пароль часто оставляли без изменений, многие GitLab неизбежно подвергались взлому.
Инструменты CI/CD, не являющиеся самостоятельными хостингами, также подвержены неправильной конфигурации.
CircleCI тоже можно очень легко неправильно сконфигурировать, выложив в открытый доступ config.yml проекта.
Этот config.yml содержит каждый шаг, который должен быть выполнен CircleCI, и может содержать имена хостов и другую конфиденциальную информацию, такую как SSH-ключи для производственных или тестовых развертываний, куда будет отправлен собранный код.
Устаревшие инструменты CI/CD
Как и любой другой инструмент или программное обеспечение, инструменты CI/CD тоже могут стать жертвой взлома из-за имеющихся в них уязвимостей.
Использование устаревших инструментов CI/CD с уязвимостями может привести к тому, что злоумышленники скомпрометируют само программное обеспечение CI/CD и, в свою очередь, смогут внедрить вредоносный код в процесс сборки.
Заключение
Поскольку сквозная автоматизация играет ключевую роль в зависимости от инструментов CI CD, автоматизация сканирования и оповещения об уязвимостях безопасности, присутствующих в самих инструментах, необходима из-за неправильной конфигурации безопасности или присущих им уязвимостей.
Использование On Prem/SaaS-решений часто рассматривается как решение для снижения требований к безопасности организации, но, как показывает недавний опыт, размещенные/SaaS-инструменты также могут внести уязвимости безопасности в ваши проекты.
Включение непрерывного сканирования, обнаружения и оповещения о возможных уязвимостях в процессы сборки вашей организации играет ключевую роль в обеспечении их безопасности, независимо от того, что они собой представляют.
см. также:
🦊 GitLab настройка 2FA для всех пользователей