
Программное обеспечение Forkplayer продолжает набирать популярность среди пользователей со всего мира. Это отличное решение для просмотра FXML, которое удобно в использовании при изучении страниц в интернете. Данное ПО используется исключительно для запроса и обработки материалов fxml-сайтов, а также для непосредственного просмотра их содержимого. Можно открывать отдельные файлы, а можно заранее подготовленные плей-листы. Программное обеспечение идеально подходит и для просмотра потокового видео, а именно так его и используют в подавляющем большинстве случаев.

Например, наличие Forkplayer дает возможность просматривать на телевизоре практически все имеющиеся в интернете телевизионные передачи, сериалы и фильмы. По сути, в данном случае речь идет про некий аналог классического браузера в формате приложения, имеющим возможность автоматического обновления плейлистов. Это дает возможность пользователям прослушивать любимые треки, слушать радио, смотреть фильмы, программы и другой контент в формате видео и аудио. Учитывая то, что данное ПО крайне удобно в использовании, до настоящего времени наблюдается рост его популярности.
Даже столь качественный продукт порой может работать некорректно. Например, сегодня мы поговорим о достаточно распространенной проблеме – это ошибка парсинга страницы. Практика показывает, что время от времени с ней сталкиваются многие пользователи, однако существует несколько способов решения этой проблемы. Для этого не нужно вызывать компьютерного мастера или обладать какими-то специальными знаниями. Рассмотрим эту тему максимально подробно и простым языком, чтобы каждый читатель мог вникнуть в суть.
Важно понимать, что все последующие рекомендации будут ориентированы на людей, которых можно позиционировать в качестве уверенных пользователей ПК. Например, они должны уметь устанавливать официальное приложение Forkplayer, а также изменять ДНС и уметь его настраивать. Впрочем, в этом таже нет ничего сложного, поэтому разобраться сможет каждый.
Чаще всего люди сталкиваются с данной проблемой, когда пытаются зайти на какой-то кино-портал в интернете или же запустить плейлист. В результате они видят распространенную ошибку, связанную с парсингом внутри приложения Forkplayer.
Способы решения ошибки
Чтобы избавиться от этой проблемы, потребуется зайти в меню, а после этого нажать на «Выйти из Forkplayer». Эту манипуляцию обязательно стоит сделать первым делом.
Следующий шаг – повторный запуск программного обеспечения на вашем устройстве. Велика вероятность того, что банальный перезапуск приложения исправит появившуюся ошибку, а после этого вы сможете им пользоваться в штатном режиме. Важно предварительно выйти из программы, используя для этого соответствующий пункт меню. Бывает так, что решить проблему не получается с первого раза. В таком случае стоит произвести манипуляцию повторно.
Существует и еще один способ решения проблемы с парсингом страницы в Forkplayer. Например, в таком случае нужно перейти в адресную строку и прописать там ссылку http://fork-portal.ru. После этого появится возможность изучить всю информацию относительно использования данного приложения.
Обратите внимание что адрес должен начинаться именно с «http», а не «https». Скорее всего ошибка парсинга случается при работе по защищенному протоколу, разработчики уже занимаются решением этой проблемы.
Заключение
Как видите, избавиться от ошибки парсинга страницы в Forkplayer – это дело нескольких минут. Каждый из описанных вариантов будет одинаково действенным. Практика показывает, что банальной перезагрузки приложения на устройстве будет вполне достаточно. Также важно проверить правильность настроек, наличие доступа к сети Интернет. В остальном нет никаких проблем с тем, чтобы восстановить работоспособность этого программного обеспечения и продолжить просмотр контента FXML на просторах интернета. Надеемся, материал этой публикации был для вас действительно полезен и помог решить ошибку в Forkplayer за пару минут!
DOMParser — Интерфейсы веб API
Experimental
Это экспериментальная технология
Так как спецификация этой технологии ещё не стабилизировалась, смотрите таблицу совместимости по поводу использования в различных браузерах. Также заметьте, что синтаксис и поведение экспериментальной технологии может измениться в будущих версиях браузеров, вслед за изменениями спецификации.
DOMParser может парсить XML или HTML источник содержащийся в строке в DOM Document. Спецификация DOMParser находится в DOM Parsing and Serialization.
Заметьте, что XMLHttpRequest поддерживает парсинг XML и HTML из интернет ресурсов (по ссылке)
Для того чтобы создать DOMParser просто используйте new DOMParser().
Для большей информации о создании DOMParser в расширениях Firefox, пожалуйста прочитайте документацию : nsIDOMParser.
Как только вы создали объект парсера, вы можете парсить XML из строки, используя метод
parseFromString:
var parser = new DOMParser();
var doc = parser.parseFromString(stringContainingXMLSource, "application/xml");
Обработка ошибок
Заметьте, если процесс парсинга не удастся , DOMParser теперь не выдаёт исключение, но вместо этого выдаёт документ ошибки (see баг 45566):
<parsererror xmlns="http://www.mozilla.org/newlayout/xml/parsererror.xml">
(Описание ошибки)
<sourcetext>(отрывок XML документа)</sourcetext>
</parsererror>
Ошибки синтаксического анализа также сообщаются в консоль ошибок, с идентификатором URI документа (см. Ниже) в качестве источника ошибки.
DOMParser так же может быть использован для разбора SVG документа (Firefox 10.0 / Thunderbird 10.0 / SeaMonkey 2.7) или HTML документа (Firefox 12.0 / Thunderbird 12.0 / SeaMonkey 2.9). На выходе возможны 3 варианта, в зависимости от переданного MIME типа.
s*text/htmls*(?:;|$)/i.test(type)) {
var
doc = document.implementation.createHTMLDocument(«»)
;
if (markup.toLowerCase().indexOf(‘<!doctype’) > -1) {
doc.documentElement.innerHTML = markup;
}
else {
doc.body.innerHTML = markup;
}
return doc;
} else {
return nativeParse.apply(this, arguments);
}
};
}(DOMParser));
DOMParser from Chrome/JSM/XPCOM/Privileged Scope
Смотрите статью по ссылке: nsIDOMParser
| Feature | Chrome | Edge | Firefox (Gecko) | Internet Explorer | Opera | Safari (WebKit) |
|---|---|---|---|---|---|---|
| XML support | 1 | (Да) | 1.0 (1.7 или ранее) | 9 | 8 | 3.2 |
| SVG support | 4 | (Да) | 10.0 (10.0) | 10 | 15 | 3.2 |
| HTML support | 30 | (Да) | 12.0 (12.0) | 10 | 17 | 7.1 |
| Feature | Android | Edge | Firefox Mobile (Gecko) | IE Mobile | Opera Mobile | Safari Mobile |
|---|---|---|---|---|---|---|
| XML support | (Да) | (Да) | (Да) | ? | (Да) | ? |
| SVG support | ? | (Да) | 10.0 (10.0) | ? | ? | ? |
| HTML support | ? | (Да) | 12.0 (12.0) | ? | ? | ? |
xml.parsers.expat — Быстрый парсинг XML с использованием Expat — Документация Python 3.8.8
Предупреждение
Модуль pyexpat не защищен от злонамеренно созданных данных. Если
необходимо проанализировать ненадежные или неподтвержденные данные, см.
раздел
Уязвимости XML.
Модуль xml.parsers.expat является интерфейсом Python к Expat не
проверяющему XML парсеру. Модуль обеспечивает единственный дополнительный
тип, xmlparser, который представляет текущее состояние XML парсера. После
создания объекта xmlparser различные атрибуты объекта могут быть
установлены в функции обработчика. Когда документ XML подается в
парсер, функции обработчик вызываются для символ данных и разметки в
документе XML.
Модуль использует модуль pyexpat для обеспечения доступа к Expat
парсеру. Прямое использование модуля
pyexpat запрещено.
Модуль предоставляет одно исключение и один объект типа:
-
exception
xml.parsers.expat.ExpatError -
Исключение, возникшее при сообщении Expat об ошибке. Посмотрите раздел
Исключения ExpatError для получения дополнительной информации об интерпретации ошибок
Expat.
-
exception
xml.parsers.expat.error -
Псевдоним для
ExpatError.
-
xml.parsers.expat.XMLParserType -
Тип возвращаемого значения из функции
ParserCreate().
Модуль
xml.parsers.expat содержит две функции:
-
xml.parsers.expat.ErrorString(errno) -
Возвращает пояснительную строку для данного номера ошибки errno.
-
xml.parsers.expat.ParserCreate(encoding=None, namespace_separator=None) -
Создание и возвращаемого нового объекта
xmlparser. encoding, если определено,
должен быть строкой, обозначающей используемую кодировку XML-данных.
Expat не поддерживает столько кодировок, сколько Python, и его
репертуар кодировок не может быть расширен; поддерживает UTF-8, UTF-16,
ISO-8859-1 (Latin1) и ASCII.
Если задано значение encoding , это
переопределит неявную или явную кодировку документа.Expat можете дополнительно выполнить обработку пространства имен XML для
вас, включив, предоставив значение для namespace_separator. Значение должено быть
односимвольной строкой; будет поднятоValueError, если строка имеет
недопустимую длину (Noneсчитается таким же, как упущение). То, когда
обработка пространства имен включена, элемент вводят имена и имена атрибут,
которые принадлежат пространству имен, будет расширено. Имя элемента, переданное
элементу обработчики
StartElementHandlerиEndElementHandler, будет конкатенацией URI
пространства имен, разделителя пространства имен символ и локальная части
имени. Если разделитель пространства имен является нулевым байтом (chr(0)),
URI пространства имен и локальная часть будут конкатенированы без какого-либо
разделителя.Например, если namespace_separator установлен в символ пробела (
' ') и
распарсен следующий документ:<?xml version="1.0"?> <root xmlns = "http://default-namespace.org/" xmlns:py = "http://www.python.org/ns/"> <py:elem1 /> <elem2 xmlns="" /> </root>StartElementHandlerполучит следующие строки для каждого элемента:
http://default-namespace.org/ root http://www.python.org/ns/ elem1 elem2
Из-за ограничений в библиотеке
Expat, используемойpyexpat,
возвращенный экземплярxmlparserможет использоваться только для разбора одного
XML документа. ВызовитеParserCreateдля каждого документа, чтобы предоставить уникальные
экземпляры парсера.

Объекты XMLParser
Объекты xmlparser содержат следующие методы:
-
xmlparser.Parse(data[, isfinal]) -
Анализирует содержимое строки data, вызывая соответствующие функции
обработчика для обработки проанализированных данных.isfinal должен иметь
значение true при окончательном вызове этого метода; это позволяет парсинг
единственного файла во фрагментах, не подачу нескольких файлов. data
может быть пустым строка в любое время.

-
xmlparser.ParseFile(file) -
Анализ данных XML, считываемых из объекта file. file только должен
предоставить методread(nbytes), возвращая пустой строка, когда больше нет
данных.
-
xmlparser.SetBase(base) -
Устанавливает основу быть используемый для решения относительного URIs в
системных идентификаторах в декларациях. Решение относительных идентификаторов
оставляют применению: через это значение пройдут как аргументbase
ExternalEntityRefHandler(),NotationDeclHandler()и функциямUnparsedEntityDeclHandler().
-
xmlparser.GetBase() -
Возвращает строку, содержащая базовый набор при предыдущем вызове
SetBase(), илиNone, еслиSetBase()не был вызван.
-
xmlparser.GetInputContext() -
Возвращает входные данные, которые сгенерировали текущее событие как строка.
Данные находятся в кодировка объекта, содержащего текст. При вызове, когда
событие обработчик неактивно, возвращает значение является
None.
-
xmlparser.ExternalEntityParserCreate(context[, encoding]) -
Создайте «ребенка» парсера, который может быть используемый, чтобы разобрать
внешнюю разобранную сущность, упомянутую содержанием, разобранным родительским
парсер. Параметр context должен быть строка, переданным функции
ExternalEntityRefHandler()обработчик, описанной ниже. Ребенок парсер создан с набором
ordered_attributesиspecified_attributesк значения этого парсер.
-
xmlparser.SetParamEntityParsing(flag) -
Управление парсингом объекта параметров (включая внешнее подмножество DTD).
Возможны flag значенияXML_PARAM_ENTITY_PARSING_NEVER,
XML_PARAM_ENTITY_PARSING_UNLESS_STANDALONEиXML_PARAM_ENTITY_PARSING_ALWAYS.
Возвращает true, если установка флага прошла успешно.
-
xmlparser.UseForeignDTD([flag]) -
Запрос этого с истинным значение для flag (по умолчанию) заставит
Expat называтьExternalEntityRefHandlerсNoneдля всех аргументов, чтобы
позволить альтернативной дАТЕ быть загруженной. Если документ не содержит
объявление типа документа, то вызовExternalEntityRefHandlerвсе равно будет выполнен, но
вызовStartDoctypeDeclHandlerиEndDoctypeDeclHandlerвыполняться не будет.Передача значения false для flag отменит предыдущее требование,
которое передало истинный значение, но иначе не имеет никакого эффекта.Метод можно вызвать только до вызова методов
Parse()илиParseFile();
запрос его после любого из тех назвали причинамиExpatError, который будет
поднят с наборомcodeатрибут доerrors.codes[errors.XML_ERROR_CANT_CHANGE_FEATURE_ONCE_PARSING].
Объекты xmlparser содержат следующие атрибуты:
-
xmlparser.buffer_size -
Размер используемого буфера, когда
buffer_texttrue. Новый размер буфера может
быть установлен, назначив новый целочисленный значение на этот атрибут.
При изменении размера буфер будет очищен.
-
xmlparser.buffer_text -
Установка этого значения в true приводит к тому, что объект
xmlparserбуферизует текст
содержимое, возвращаемое Expat, чтобы избежать нескольких обращений к
обратному вызовуCharacterDataHandler(), когда это возможно. Это может улучшить
производительность существенно, так как Expat обычно разбивает данные
символ в чанки при каждом окончании линии. Этот атрибут false по
умолчанию и может быть изменен в любое время.
 Это может улучшить
Это может улучшить-
xmlparser.buffer_used -
Если параметр
buffer_textвключен, количество байтов, хранящихся в буфере. Эти
байты представляют текст UTF-8 кодированный. Этот атрибут не имеет значимой
интерпретации, когдаbuffer_textявляется false.
-
xmlparser.ordered_attributes -
Настройка этого атрибута к отличному от нуля целому числу заставляет
атрибуты сообщаться как список, а не словарь. атрибуты представлены в
порядке, указанном в тексте документа. Для каждого атрибут представлены две
записи списка: имя атрибут и атрибут значение. (Более старые версии
этого модуля также используемый этот формат.) По умолчанию этот атрибут
false; он может быть изменен в любое время.
-
xmlparser.specified_attributes -
Если задано ненулевое целое число, то парсер будет сообщать только те
атрибуты, которые были указаны в документе сущность, а не те, которые были
получены из объявлений атрибут. Приложения, которые это задают, должны быть
особенно осторожны, чтобы использовать, какая дополнительная информация доступна
из объявлений по мере необходимости, чтобы соответствовать стандартам поведения
процессоров XML. По умолчанию этот атрибут false; он может быть изменен в
любое время.
Следующие атрибуты содержат значения, относящиеся к последней ошибке,
обнаруженной объектом xmlparser, и будут иметь правильную значения только
после вызова Parse() или ParseFile(), вызвавшего исключение xml.parsers.expat.ExpatError.
-
xmlparser.ErrorByteIndex -
Байтовый индекс, в котором произошла ошибка.
-
xmlparser. ErrorCode -
Числовая код, указывающая проблему. Этот значение может быть передан
к функцииErrorString(), или по сравнению с одной из констант, определенных в
объектеerrors.

-
xmlparser.ErrorColumnNumber -
Номер столбца, в котором произошла ошибка.
-
xmlparser.ErrorLineNumber -
Номер строки, в которой произошла ошибка.
Следующие атрибуты содержат значения, относящиеся к текущему расположению
синтаксического анализа в объекте xmlparser. Во время сообщения колбэк о
событии синтаксического анализа они указывают местоположение первого из
последовательности символов, которые создали событие. При вызове вне колбэк
обозначенная позиция будет только после последнего события синтаксического
анализа (независимо от наличия связанного колбэк).
-
xmlparser.CurrentByteIndex -
Текущий индекс байта на входе парсера.
-
xmlparser.CurrentColumnNumber -
Номер текущего столбца на входе парсера.
-
xmlparser.CurrentLineNumber -
Текущий номер строки на входе парсера.
Вот список обработчики, которые могут быть установлены. Чтобы установить
обработчик на xmlparser возражают o, используют o.handlername = func.
handlername должен быть взят из следующего списка, а func должен быть
вызываемым объектом, принимающим правильное количество аргументов. Все аргументы
являются строки, если не указано иное.
-
xmlparser.XmlDeclHandler(version, encoding, standalone) -
Вызывается при анализе XML-объявления. XML-объявление является (необязательным)
объявлением применимой версии рекомендации XML, кодировка текста документа и
необязательного «автономного» объявления. version и encoding будут
строки, и standalone будет1, если документ объявлен автономным,
0если он объявлен не автономным, или-1если автономный
клаузула был опущен. Это доступно только в версии Expat 1.95.0 или
более поздней.
 version и encoding будут
version и encoding будут-
xmlparser.StartDoctypeDeclHandler(doctypeName, systemId, publicId, has_internal_subset) -
Названный, когда Expat начинает парсинг декларация (
<!DOCTYPE ...) типа
документа. doctypeName обеспечен точно, как представлено. Параметры systemId
и publicId дают системные и public идентификаторы, если они указаны, или
None, если опущены. has_internal_subset будет верным, если документ содержит и
подмножество объявления внутреннего документа. Для этого требуется Expat
версии 1.2 или более поздней.
-
xmlparser.EndDoctypeDeclHandler() -
Названный, когда Expat сделан парсинг декларация типа документа. Для
этого требуется Expat версии 1.2 или более поздней.
-
xmlparser.ElementDeclHandler(name, model) -
Вызывается один раз для каждого объявления типа элемента. name — имя типа
элемента, а model — представление модели содержимого.
-
xmlparser.AttlistDeclHandler(elname, attname, type, default, required) -
Требовавшийся каждый объявил атрибут для типа элемента. Если объявление
списка атрибут объявляет три атрибуты, это обработчик вызывается три
раза, один раз для каждого атрибут. elname — название элемента, к
которому применяется декларация, и attname — название объявленного
атрибут. Тип атрибут является строка, переданным как type;
возможные значения'CDATA','ID','IDREF',… default дает
по умолчаниюу значение для атрибут используемый, когда атрибут не определен
документом сущность илиNone, если нет никакого по умолчаниюа значение
(#IMPLIEDзначения). Если атрибут требуется, чтобы, даны в документе
сущность, required, будет верно. Для этого требуется Expat версии
1.95.0 или более поздней.
 Если атрибут требуется, чтобы, даны в документе
Если атрибут требуется, чтобы, даны в документе-
xmlparser.StartElementHandler(name, attributes) -
Вызывается для начала каждого элемента. name является строка,
содержащим имя элемента, а attributes — элемент атрибуты. Еслиordered_attributes
true, это — список (см.ordered_attributesдля полного описания). В противном случае
это словарь, отображающий имена на значения.
-
xmlparser.EndElementHandler(name) -
Вызывается для окончания каждого элемента.
-
xmlparser.ProcessingInstructionHandler(target, data) -
Вызывается для каждой инструкции по обработке.
-
xmlparser.CharacterDataHandler(data) -
Вызван для получения символ данных. Это будет вызываться для обычных
символ данных, содержимого, помеченного CDATA, и игнорируемого пробела.
Заявления, которые должны отличить эти случаи, могут использоватьStartCdataSectionHandler,
EndCdataSectionHandlerиElementDeclHandlerколбэки, чтобы собрать запрошенную информацию.
-
xmlparser.UnparsedEntityDeclHandler(entityName, base, systemId, publicId, notationName) -
Вызван вызов объявлений объектов без анализа (NDATA). Это присутствует только
для версии 1.2 библиотеки Expat; для более поздних версий вместо этого
используйте командуEntityDeclHandler. (Базовая функция в библиотеке Expat
объявлена устаревшей.)
-
xmlparser.EntityDeclHandler(entityName, is_parameter_entity, value, base, systemId, publicId, notationName) -
Вызывается для всех объявлений сущности.
Для параметров и внутренних объектов
value будет представлять собой строка, дающую объявленное содержимое
объекта; это будетNoneдля внешних сущностей. Параметр notationName будет
Noneдля проанализированных сущностей, а имя нотации — для неназначенных
сущностей. is_parameter_entity будет верным, если сущность является параметрической или
false для общих сущностей (большинство приложений должны быть связаны только с
общими сущностями). Это доступно только начиная с версии 1.95.0 библиотеки
Expat.
 Для параметров и внутренних объектов
Для параметров и внутренних объектов-
xmlparser.NotationDeclHandler(notationName, base, systemId, publicId) -
Вызвал объявление нотации. notationName, base, и systemId и publicId
— строки, если дали. Если идентификатор public опущен, publicId
будетNone.
-
xmlparser.StartNamespaceDeclHandler(prefix, uri) -
Вызывается, когда элемент содержит объявление пространства имен. Объявления
пространства имен обрабатываются перед вызовомStartElementHandlerдля элемента, на
который помещаются объявления.
-
xmlparser.EndNamespaceDeclHandler(prefix) -
Вызывается при достижении закрывающего тега для элемента, содержащего объявление
пространства имен. Это вызывается один раз для каждого объявления пространства
имен на элементе в обратном порядке, для которогоStartNamespaceDeclHandlerбыл вызван, чтобы
указать начало область видимости каждого объявления пространства имен. Звонки к этому
обработчик сделаны после соответствующегоEndElementHandlerдля конца элемента.
-
xmlparser.CommentHandler(data) -
Звонили за комментариями. data — текст комментария, исключая ведущий
'<!--'и конечный'-->'.
-
xmlparser.StartCdataSectionHandler() -
Вызывается в начале раздела CDATA. Это и
EndCdataSectionHandlerнеобходимы для определения
синтаксического начала и конца для разделов CDATA.
-
xmlparser.EndCdataSectionHandler() -
Вызывается в конце раздела CDATA.
-
xmlparser.DefaultHandler(data) -
Требовавшийся любые знаки в документе XML, для которого не был определен никакой
применимый обработчик. Это означает знаки, которые являются частью конструкции,
о которой можно было сообщить, но для которого поставлялся № обработчик.
-
xmlparser.DefaultHandlerExpand(data) -
Это то же самое, что и
DefaultHandler(), но не препятствует расширению внутренних
сущностей. Ссылка на объект не будет передана обработчик по умолчанию.
-
xmlparser.NotStandaloneHandler() -
Вызывается, если XML-документ не объявлен как автономный документ. Это
происходит, когда существует внешнее подмножество или ссылка на сущность
параметра, но XML-объявление не устанавливает автономнуюyesв XML-
объявлении. Если это обработчик возвращает0, то парсер вызовет
ошибкуXML_ERROR_NOT_STANDALONE. Если этот обработчик не установлен, никакое исключение не
поднято парсер для этого условия.
-
xmlparser.ExternalEntityRefHandler(context, base, systemId, publicId) -
Вызывается для ссылок на внешние объекты. base — текущая база,
установленная предыдущим вызовом наSetBase(). Идентификаторы public и
системы systemId и publicId строки, если они указаны; если
идентификатор public не задан, publicId будетNone. context
значение является непрозрачным и должен быть используемый только как описано
ниже. Для анализа внешних сущностей этот обработчик должен быть реализован. Это
ответственно за создание sub-парсер, использующегоExternalEntityParserCreate(context),
инициализируя его с соответствующим колбэки и парсинг сущность. Этот
обработчик должен возвращает целое число; если это, возвращает0,
парсер поднимет ошибкуXML_ERROR_EXTERNAL_ENTITY_HANDLING, иначе парсинг, продолжится.Если эта обработчик не предоставляется, внешние объекты сообщаются
DefaultHandler
колбэк, если они предоставляются.

Исключения ExpatError
ExpatError исключения имеют ряд интересных атрибуты:
-
ExpatError.code -
Внутренний номер ошибки Expat для конкретной ошибки. Словарь
errors.messages
сопоставляет эти номера ошибок с сообщениями об ошибках Expat. Например:from xml.parsers.expat import ParserCreate, ExpatError, errors p = ParserCreate() try: p.Parse(some_xml_document) except ExpatError as err: print("Error:", errors.messages[err.code])Модуль
errorsтакже предоставляет константы сообщений об ошибках и словарь
codes, отображающий эти сообщения обратно на коды об ошибках, см.
ниже.
-
ExpatError.lineno -
Номер строки, на которой была обнаружена ошибка. Первая строка нумеруется как
1.
-
ExpatError.offset -
Смещение символа в строке, в которой произошла ошибка. Первый столбец нумеруется
как0.
Пример
Следующая программа определяет три обработчика, которые просто распечатывают свои
аргументы:
import xml.parsers.expat
# 3 handler functions
def start_element(name, attrs):
print('Start element:', name, attrs)
def end_element(name):
print('End element:', name)
def char_data(data):
print('Character data:', repr(data))
p = xml. parsers.expat.ParserCreate()
p.StartElementHandler = start_element
p.EndElementHandler = end_element
p.CharacterDataHandler = char_data
p.Parse("""<?xml version="1.0"?>
<parent><child1 name="paul">Text goes here</child1>
<child2 name="fred">More text</child2>
</parent>""", 1)
 parsers.expat.ParserCreate()
p.StartElementHandler = start_element
p.EndElementHandler = end_element
p.CharacterDataHandler = char_data
p.Parse("""<?xml version="1.0"?>
<parent><child1 name="paul">Text goes here</child1>
<child2 name="fred">More text</child2>
</parent>""", 1)
parsers.expat.ParserCreate()
p.StartElementHandler = start_element
p.EndElementHandler = end_element
p.CharacterDataHandler = char_data
p.Parse("""<?xml version="1.0"?>
<parent><child1 name="paul">Text goes here</child1>
<child2 name="fred">More text</child2>
</parent>""", 1)
Выходные данные этой программы::
Start element: parent {'id': 'top'}
Start element: child1 {'name': 'paul'}
Character data: 'Text goes here'
End element: child1
Character data: 'n'
Start element: child2 {'name': 'fred'}
Character data: 'More text'
End element: child2
Character data: 'n'
End element: parent
Описание модели контента
Модели содержимого описываются с помощью вложенных кортежей. Каждый кортеж
содержит четыре значения: тип, квантификатор, имя и кортеж детей. Дочерние
элементы — это просто дополнительные описания моделей содержимого.
значения первых двух полей — константы, определенные в модуле xml.parsers.expat.model. Эти
константы можно собрать в две группы: группу типа модели и группу
квантификатора.
Константы в группе типов модели:
-
xml.parsers.expat.model.XML_CTYPE_ANY -
Элемент, названный именем модели, был объявлен имеющим модель содержимого
ANY.
-
xml.parsers.expat.model.XML_CTYPE_CHOICE -
Именованный элемент допускает выбор из ряда опций; это используемый для моделей
содержимого, таких как(A | B | C).
-
xml.parsers.expat.model.XML_CTYPE_EMPTY -
Элементы, объявленные
EMPTY, имеют этот тип модели.
-
xml.parsers.expat.model.XML_CTYPE_MIXED
-
xml.parsers.expat.model.XML_CTYPE_NAME
-
xml.parsers.expat.model.XML_CTYPE_SEQ -
Модели, представляющие ряд моделей, следующих одна за другой, обозначаются этим
типом модели. Это используемый для таких моделей, как (A, B, C).
 Это используемый для таких моделей, как
Это используемый для таких моделей, как Константы в группе квантификаторов:
-
xml.parsers.expat.model.XML_CQUANT_NONE -
Модификатор не задан, поэтому он может появиться ровно один раз, как для
A.
-
xml.parsers.expat.model.XML_CQUANT_OPT -
Модель необязательна: может появиться один раз или вообще нет, как для
A?.
-
xml.parsers.expat.model.XML_CQUANT_PLUS -
Модель должна выполняться один или несколько раз (например,
A+).
-
xml.parsers.expat.model.XML_CQUANT_REP -
Модель должна иметь нулевое или большее количество раз, как для
A*.
Expat константы ошибок
В модуле xml.parsers.expat.errors предусмотрены следующие константы. Эти константы полезны
при интерпретации некоторых атрибуты объектов исключения ExpatError,
возникших при возникновении ошибки. С тех пор по назад причинам совместимости,
значение констант — ошибка message а не числовая ошибка code, вы
делаете это, сравнивая его code атрибут с errors.codes[errors.XML_ERROR_CONSTANT_NAME].
Модуль errors содержит следующие атрибуты:
-
xml.parsers.expat.errors.codes -
Словарь, отображающий описания строк на их коды ошибок.
Добавлено в версии 3.2.
-
xml.parsers.expat.errors.messages -
Словарь, отображающий числовые коды ошибок в их строковые описания.
Добавлено в версии 3.2.
-
xml.parsers.expat.errors.XML_ERROR_ASYNC_ENTITY
-
xml.parsers.expat.errors.XML_ERROR_ATTRIBUTE_EXTERNAL_ENTITY_REF -
Ссылка на объект в атрибут значение ссылается на внешний объект, а не на
внутренний объект.
-
xml.parsers.expat.errors.XML_ERROR_BAD_CHAR_REF -
Ссылка символ, ссылающаяся на символ, которая является недопустимой в XML
(например, символ0или „“).
-
xml.parsers.expat.errors.XML_ERROR_BINARY_ENTITY_REF -
Ссылка на объект ссылается на объект, который был объявлен с нотацией, поэтому
не может быть проанализирован.
-
xml.parsers.expat.errors.XML_ERROR_DUPLICATE_ATTRIBUTE -
атрибут был используемый несколько раз в тэге начала.
-
xml.parsers.expat.errors.XML_ERROR_INCORRECT_ENCODING
-
xml.parsers.expat.errors.XML_ERROR_INVALID_TOKEN -
Возникает, когда входной байт не может быть правильно назначен символ;
например, байт NUL (значение0) во входном потоке UTF-8.
-
xml.parsers.expat.errors.XML_ERROR_JUNK_AFTER_DOC_ELEMENT -
После элемента документа произошло нечто иное, чем пробел.
-
xml.parsers.expat.errors.XML_ERROR_MISPLACED_XML_PI -
XML-объявление найдено в месте, отличном от начала входных данных.
-
xml.parsers.expat.errors.XML_ERROR_NO_ELEMENTS -
Документ не содержит элементов (XML требует, чтобы все документы содержали
только один элемент верхнего уровня)..
-
xml.parsers.expat.errors.XML_ERROR_NO_MEMORY -
Expat не удалось выделить внутреннюю память.
-
xml.parsers.expat.errors.XML_ERROR_PARAM_ENTITY_REF -
Найдена ссылка на объект параметра, где она не разрешена.
-
xml.parsers.expat.errors.XML_ERROR_PARTIAL_CHAR -
Во входных данных обнаружена неполная символ.

-
xml.parsers.expat.errors.XML_ERROR_RECURSIVE_ENTITY_REF -
Ссылка на объект содержит другую ссылку на тот же объект; возможно, через другое
имя, и, возможно, косвенно.
-
xml.parsers.expat.errors.XML_ERROR_SYNTAX -
Обнаружена неустановленная синтаксическая ошибка.
-
xml.parsers.expat.errors.XML_ERROR_TAG_MISMATCH -
Конечный тег не соответствует самому внутреннему открытому начальному тегу.
-
xml.parsers.expat.errors.XML_ERROR_UNCLOSED_TOKEN -
Какой-либо маркер (например, начальный тег) не был закрыт до конца потока или
был обнаружен следующий маркер.
-
xml.parsers.expat.errors.XML_ERROR_UNDEFINED_ENTITY -
Была сделана ссылка на объект, который не был определен.
-
xml.parsers.expat.errors.XML_ERROR_UNKNOWN_ENCODING -
Кодировка документа не поддерживается Expat.
-
xml.parsers.expat.errors.XML_ERROR_UNCLOSED_CDATA_SECTION -
Помеченный раздел CDATA не закрыт.
-
xml.parsers.expat.errors.XML_ERROR_EXTERNAL_ENTITY_HANDLING
-
xml.parsers.expat.errors.XML_ERROR_NOT_STANDALONE -
парсер определил, что документ не является «автономным», хотя он объявляется в
XML-объявлении, аNotStandaloneHandlerбыл установлен и возвращенный0.
-
xml.parsers.expat.errors.XML_ERROR_UNEXPECTED_STATE
-
xml.parsers.expat.errors.XML_ERROR_ENTITY_DECLARED_IN_PE
-
xml.parsers.expat.errors.XML_ERROR_FEATURE_REQUIRES_XML_DTD -
Запрошена операция, требующая компиляции поддержки DTD в, но настройка
Expat была выполнена без поддержки DTD. Об этом никогда не должна сообщать
стандартная сборка модуляxml.parsers.expat.
 Об этом никогда не должна сообщать
Об этом никогда не должна сообщать-
xml.parsers.expat.errors.XML_ERROR_CANT_CHANGE_FEATURE_ONCE_PARSING -
Изменение в поведении запрошенный после того, как парсинг начался, который
может только быть изменен, прежде чем парсинг начался. Это (в настоящее
время) только поднимаетсяUseForeignDTD().
-
xml.parsers.expat.errors.XML_ERROR_UNBOUND_PREFIX -
При включенной обработке пространства имен обнаружен необъявленный префикс.
-
xml.parsers.expat.errors.XML_ERROR_UNDECLARING_PREFIX -
Документ попытался удалить объявление пространства имен, связанное с префиксом.
-
xml.parsers.expat.errors.XML_ERROR_INCOMPLETE_PE -
Объект параметра содержал неполную разметку.
-
xml.parsers.expat.errors.XML_ERROR_XML_DECL -
Документ вообще не содержал элемента документа.
-
xml.parsers.expat.errors.XML_ERROR_TEXT_DECL -
Была ошибка парсинг текстовая декларация во внешней сущности.
-
xml.parsers.expat.errors.XML_ERROR_PUBLICID -
В идентификаторе public найдены недопустимые символы.
-
xml.parsers.expat.errors.XML_ERROR_SUSPENDED -
Запрошенная операция была выполнена на приостановленном парсер, но не
разрешена. Это включает в себя попытки предоставить дополнительный ввод или
остановить парсер.
-
xml.parsers.expat.errors.XML_ERROR_NOT_SUSPENDED -
Попытка возобновления парсер была предпринята, когда действие парсер
не было приостановлено.
-
xml.parsers.expat.errors.XML_ERROR_ABORTED -
Об этом не следует сообщать приложениям Python.
-
xml.parsers.expat.errors.XML_ERROR_FINISHED -
Запрошенная операция выполнена на парсер, которая была завершена
парсинг вводе, но не разрешена. Это включает в себя попытки предоставить
дополнительный ввод или остановить парсер.
-
xml.parsers.expat.errors.XML_ERROR_SUSPEND_PE
Сноски
Часть: /Word/document.xml, Строка: x, Столбец: xxxx
I have been trying for days to recover a word document that has become corrupted. the document.xml file is the culprit it is throwing up an error upon opening the document i am met with:
XML Parsing Error
Location: Part: /Word/document.xml, Line: 2, Column: 17062826
(Premature end of data in tag document line 2)
I have reformatted the document using the XML Tools plugin in Notepad++ and i cannot see any issue with the line referred to.
When opening this document in XML Marker it looks like the issue is at the end of the document on the closing tag.
Although to me it looks fine it looks like it is written correctly.
Im not great with xml so i really cant see what im supposed to change to fix this i have tried for days and also looked on the net and on here although people have the same issue and it is posted about i haven’t been able to find anything that helps me understand what im looking at in the XML (again i am no good with xml code).
I would really appreciate any help with this so i can understand what i need to change and why. That way if it happens in future ill understand it.
When opening the xml it lags my computer for a few seconds so cant paste here but i have uploaded the whole xml here: http://www54.zippyshare.com/v/a0zZzBW7/file.html
Can anybody assist me with this because im loosing my mind here.
I have also take a screenshot of the file open in xml marker:
Below is the bottom part of the xml code:
Xml Marker says Expecting <, </ or text
i dont understand why or even where to put that as i thought </x:xxxx>. is the correct syntax to end the xml but some of you guys who know xml will be able to show me where i am going wrong here.
is the correct syntax to end the xml but some of you guys who know xml will be able to show me where i am going wrong here.
<w:headerReference w:type="default" r:id="rId79"/>
<w:headerReference w:type="first" r:id="rId80"/>
<w:pgSz w:w="19200" w:h="10800" w:orient="landscape"/>
<w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440" w:header="720" w:footer="720" w:gutter="0"/>
<w:cols w:space="720"/>
</w:sectPr>
</w:body>
</w:document>
Я пытаюсь в течение нескольких дней восстанавливать документ, который был поврежден. файл document.xml является виновником его вырвет ошибку при открытии документа я встретился с:
ошибки синтаксического анализа
Расположение: Часть: /Word/document.xml, Line: 2, Колонка: 17062826
(Преждевременный конец данных в строке документа тега 2)
Я переформатировал документ, используя плагин XML Tools в Notepad ++, и я не вижу никакой проблемы с указанной строкой.
При открытии этого документа в XML-маркере похоже, что проблема находится в конце документа в закрывающем теге.
Хотя для меня это выглядит нормально, похоже, что оно написано правильно.
Im не очень хорошо с xml, поэтому я действительно не могу видеть, что им должен был изменить, чтобы исправить это, я пробовал в течение нескольких дней, а также посмотрел на сеть и здесь, хотя у людей такая же проблема, и она опубликована о том, что я не смог найти что-нибудь, что поможет мне понять, на что я смотрю в XML (опять-таки, мне нехорошо с xml-кодом).
Я бы очень признателен за любую помощь в этом, чтобы я мог понять, что мне нужно изменить и почему. Таким образом, если это случится в будущем, плохо это поймете.
При открытии XML-он запаздывает мой компьютер в течение нескольких секунд, так что косяк паста здесь, но я загрузил весь XML здесь: http://www54. zippyshare.com/v/a0zZzBW7/file.html
zippyshare.com/v/a0zZzBW7/file.html
Может кто-нибудь помочь мне с этим, потому что им потерять свой ум здесь.
Я также сделать скриншот файла, открытого в XML-маркера:
Ниже нижняя часть кода XML:
Xml Marker говорит Expecting <, </ or text
я не понимаю, почему или даже где положить, что, как я думал </x:xxxx>. это правильный синтаксис для завершения xml, но некоторые из вас, ребята, знающие xml, смогут показать мне, где я здесь не так.
<w:headerReference w:type="default" r:id="rId79"/>
<w:headerReference w:type="first" r:id="rId80"/>
<w:pgSz w:w="19200" w:h="10800" w:orient="landscape"/>
<w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440" w:header="720" w:footer="720" w:gutter="0"/>
<w:cols w:space="720"/>
</w:sectPr>
</w:body>
</w:document>
xml ms-word document corrupt495
Глава 12. XML
Добавлено 5 июля 2020 в 11:59
Сохранить или поделиться
Содержание главы
Погружение
Большинство глав в этой книге строятся на фрагментах примеров кода. Но xml – это больше данные, нежели код. Один из способов применения xml – это «объединяющие каналы», такие как список последних статей в блоге, на форуме или на другом часто обновляемом сайте. Большинство популярного программного обеспечения для ведения блогов может создавать каналы (ленты, фиды) и обновлять их, когда публикуются новые статьи, темы форума или посты блога. Вы можете следить за блогом, подписавшись на его RSS канал, а также вы можете следить за несколькими блогами при помощи «агрегаторов каналов», таких как Google Reader (сейчас уже закрытый, примечание переводчика).
Итак, ниже представлены XML данные, с которыми мы будем работать в этой главе. Это фид в формате Atom syndication feed.
Скачать файл feed. xml.
xml.
<?xml version='1.0' encoding='utf-8'?>
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title>dive into mark</title>
<subtitle>currently between addictions</subtitle>
<id>tag:diveintomark.org,2001-07-29:/</id>
<updated>2009-03-27T21:56:07Z</updated>
<link rel='alternate' type='text/html' href='http://diveintomark.org/'/>
<link rel='self' type='application/atom+xml' href='http://diveintomark.org/feed/'/>
<entry>
<author>
<name>Mark</name>
<uri>http://diveintomark.org/</uri>
</author>
<title>Dive into history, 2009 edition</title>
<link rel='alternate' type='text/html'
href='http://diveintomark.org/archives/2009/03/27/dive-into-history-2009-edition'/>
<id>tag:diveintomark.org,2009-03-27:/archives/20090327172042</id>
<updated>2009-03-27T21:56:07Z</updated>
<published>2009-03-27T17:20:42Z</published>
<category scheme='http://diveintomark.org' term='diveintopython'/>
<category scheme='http://diveintomark.org' term='docbook'/>
<category scheme='http://diveintomark.org' term='html'/>
<summary type='html'>Putting an entire chapter on one page sounds
bloated, but consider this &mdash; my longest chapter so far
would be 75 printed pages, and it loads in under 5 seconds&hellip;
On dialup.</summary>
</entry>
<entry>
<author>
<name>Mark</name>
<uri>http://diveintomark.org/</uri>
</author>
<title>Accessibility is a harsh mistress</title>
<link rel='alternate' type='text/html'
href='http://diveintomark. org/archives/2009/03/21/accessibility-is-a-harsh-mistress'/>
<id>tag:diveintomark.org,2009-03-21:/archives/20090321200928</id>
<updated>2009-03-22T01:05:37Z</updated>
<published>2009-03-21T20:09:28Z</published>
<category scheme='http://diveintomark.org' term='accessibility'/>
<summary type='html'>The accessibility orthodoxy does not permit people to
question the value of features that are rarely useful and rarely used.</summary>
</entry>
<entry>
<author>
<name>Mark</name>
</author>
<title>A gentle introduction to video encoding, part 1: container formats</title>
<link rel='alternate' type='text/html'
href='http://diveintomark.org/archives/2008/12/18/give-part-1-container-formats'/>
<id>tag:diveintomark.org,2008-12-18:/archives/20081218155422</id>
<updated>2009-01-11T19:39:22Z</updated>
<published>2008-12-18T15:54:22Z</published>
<category scheme='http://diveintomark.org' term='asf'/>
<category scheme='http://diveintomark.org' term='avi'/>
<category scheme='http://diveintomark.org' term='encoding'/>
<category scheme='http://diveintomark.org' term='flv'/>
<category scheme='http://diveintomark.org' term='GIVE'/>
<category scheme='http://diveintomark.org' term='mp4'/>
<category scheme='http://diveintomark.org' term='ogg'/>
<category scheme='http://diveintomark.org' term='video'/>
<summary type='html'>These notes will eventually become part of a
tech talk on video encoding.</summary>
</entry>
</feed>12.2 5-минутный ускоренный курс в XML
Если Вы уже знакомы с XML, то можете пропустить этот раздел.
XML – это язык разметки для описания иерархически структурированных данных. XML документ содержит один или более элементов, разделённых открывающими и закрывающими тегами. Вот правильный, хотя и неинтересный, XML документ:
<foo> ①
</foo> ②- Строка 1. Это открывающий (начальный) тег элемента
foo. - Строка 2. Это соответствующий закрывающий (конечный) тег элемента
foo. Как и в математике и языках программирования у каждой открывающей скобки должна быть соответствующая закрывающая скобка, в XML каждый открывающий тег должен быть закрыт соответствующим закрывающим тегом.
Элементы могут быть вложены друг в друга, при этом глубина вложения не ограничена. Так как элемент bar вложен в элемент foo, то его называют подэлементом или дочерним элементом элемента foo.
<foo>
<bar></bar>
</foo>Первый элемент любого XML документа называется корневым. XML документ может содержать только один корневой элемент. Пример, представленный ниже, не является XML документом, так как он содержит два корневых элемента:
<foo></foo>
<bar></bar>Элементы могут иметь атрибуты, состоящие из пары имя-значение. Атрибуты перечисляются внутри открывающего тега элемента и разделяются пробелами. Имена атрибутов не могут повторяться внутри одного элемента. Значения атрибутов должны быть заключены в одинарные или двойные кавычки.
<foo lang='en'> ①
<bar lang="fr"></bar> ②
</foo>- Строка 1. Элемент
fooимеет один атрибут с именемlang. Значение атрибута lang– это строка en. - Строка 2. Элемент
barимеет два атрибута, их именаidиlang. Значение атрибутаlang– это fr. Это не приводит к конфликту с атрибутомlangэлементаfoo, так как каждый элемент имеет свой набор атрибутов.
 Значение атрибута
Значение атрибута Если элемент имеет более одного атрибута, то порядок атрибутов не имеет значения. Атрибуты элемента формируют неупорядоченный набор ключей и значений подобно словарям в Python. Для каждого элемента можно указать неограниченное число атрибутов.
Элементы могут иметь текстовый контент.
<foo lang='en'>
<bar lang='fr'>PapayaWhip</bar>
</foo>Элементы, которые не содержат текста и дочерних элементов называются пустыми.
<foo></foo>Для записи пустых элементов существует сокращенный вариант. Поместив слеш (/) в конце открывающего тега, вы можете опустить закрывающий тег. XML документ из предыдущего примера может быть записан следующим образом:
<foo/>Как функции в Python могут быть объявлены в разных модулях, XML элементы могут быть объявлены в разных пространствах имён (namespace). Пространства имён обычно выглядят как URL. Для объявления пространства имён по умолчанию используется директива xmlns. Объявление пространства имён очень похоже на атрибут, но у него другое назначение.
<feed xmlns='http://www.w3.org/2005/Atom'> ①
<title>dive into mark</title> ②
</feed>- Строка 1. Элемент
feedнаходится в пространстве имён http://www.w3.org/2005/Atom. - Строка 2. Элемент
titleтакже находится в пространстве имён http://www. w3.org/2005/Atom. Пространство имён применяется и к элементу, в котором оно было определено, и ко всем его дочерним элементам.
 w3.org/2005/Atom. Пространство имён применяется и к элементу, в котором оно было определено, и ко всем его дочерним элементам.
w3.org/2005/Atom. Пространство имён применяется и к элементу, в котором оно было определено, и ко всем его дочерним элементам.Вы также можете использовать объявление xmlns:prefix, чтобы определить пространство имен и назначить ему префикс. Тогда каждый элемент в данном пространстве имён должен быть явно объявлен с указанием этого префикса.
<atom:feed xmlns:atom='http://www.w3.org/2005/Atom'> ①
<atom:title>dive into mark</atom:title> ②
</atom:feed>- Строка 1. Элемент
feedнаходится в пространстве имён http://www.w3.org/2005/Atom. - Строка 2. Элемент
titleтакже находится в пространстве имён http://www.w3.org/2005/Atom.
С точки зрения синтаксического анализатора XML, предыдущие два XML документа идентичны. Пара «пространство имён» + «имя элемента» задают идентичность XML. Префиксы используются только для ссылки на пространство имён, но не изменяют имени атрибута, поэтому данное имя префикса (atom:) не имеет значения. Если пространства имён совпадают, имена элементов совпадают, атрибуты (или их отсутствие) совпадают, и текстовый контент элементов совпадает, то XML документы одинаковы.
И, наконец, XML документы могут содержать информацию о кодировке символов в первой строке до корневого элемента (если вам интересно как документ может содержать информацию, которая должна быть известна до анализа документа, то для разрешения уловки 22 смотрите раздел F спецификации XML).
<?xml version='1.0' encoding='utf-8'?>Теперь вы знаете об XML достаточно, чтобы «вынести» следующие разделы главы!
12.3 Структура фида Atom
Рассмотрим блог или любой сайт с часто обновляемым контентом, например CNN.com. Сайт содержит заголовок («CNN.com»), подзаголовок («Breaking News, U.S. , World, Weather, Entertainment & Video News»), дату последнего изменения («updated 12:43 p.m. EDT, Sat May 16, 2009») и список статей, опубликованных в разное время. Каждая статья, в свою очередь, также имеет заголовок, дату первой публикации (и, возможно, дату последнего обновления, в случае если статья была изменена, или исправлены опечатки) и уникальный URL.
, World, Weather, Entertainment & Video News»), дату последнего изменения («updated 12:43 p.m. EDT, Sat May 16, 2009») и список статей, опубликованных в разное время. Каждая статья, в свою очередь, также имеет заголовок, дату первой публикации (и, возможно, дату последнего обновления, в случае если статья была изменена, или исправлены опечатки) и уникальный URL.
Формат объединения Atom был разработан, чтобы хранить информацию подобного рода стандартным образом. Мой блог и CNN.com абсолютно разные по дизайну, содержанию и аудитории, но они оба имеют сходную структуру. У CNN.com есть заголовок, и у моего блога тоже есть заголовок. CNN.com публикует статьи, и я публикую статьи.
На верхнем уровне находится корневой элемент, который должен быть у каждого фида Atom: элемент feed из пространства имен http://www.w3.org/2005/Atom.
<feed xmlns='http://www.w3.org/2005/Atom' ①
xml:lang='en'> ②- Строка 1. http://www.w3.org/2005/Atom – это пространство имён Atom
- Строка 2. Каждый элемент может содержать атрибут
xml:lang, который определяет язык элемента и его дочерних элементов. В данном случае атрибутxml:lang, объявленный в корневом элементе, задаёт английский язык для всего фида.
Фид Atom содержит дополнительную информацию о себе в дочерних элементах корневого элемента feed:
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title>dive into mark</title> ①
<subtitle>currently between addictions</subtitle> ②
<id>tag:diveintomark.org,2001-07-29:/</id> ③
<updated>2009-03-27T21:56:07Z</updated> ④
<link rel='alternate' type='text/html' href='http://diveintomark. org/'/> ⑤ org/'/> ⑤
org/'/> ⑤- Строка 2. Заголовок
titleсодержит текст ‘dive into mark‘. - Строка 3. Подзаголовок
subtitleфида – это строка ‘currently between addictions‘. - Строка 4. Каждый фид должен иметь глобальный уникальный идентификатор. RFC 4151 содержит информацию, как создавать такие идентификаторы.
- Строка 5. Данный фид был обновлён последний раз 27 марта 2009 в 21:56 GMT. Обычно элемент
updatedэквивалентен дате последнего изменения последней статьи на сайте. - Строка 6. А вот здесь начинается самое интересное. Элемент ссылки
linkне имеет текстового контента, но имеет три атрибута:rel,typeиhref. Значение атрибутаrelговорит о типе ссылки;rel='alternate'значит, что это ссылка для альтернативного представления данного фида. Атрибутtype='text/html'означает, что это ссылка на HTML страницу. И, собственно, путь ссылки содержится в атрибутеhref.
Теперь мы знаем, что представленный выше фид получен с сайта «dive into mark». Сайт доступен по адресу http://diveintomark.org/ и последний раз был обновлён 27 марта 2009.
Хотя в некоторых XML документах порядок элементов может иметь значение, в фидах Atom порядок элементов не важен.
После метаданных о фиде идёт список последних статей. Статья выглядит следующим образом:
<entry>
<author> ①
<name>Mark</name>
<uri>http://diveintomark.org/</uri>
</author>
<title>Dive into history, 2009 edition</title> ②
<link rel='alternate' type='text/html' ③
href='http://diveintomark. org/archives/2009/03/27/dive-into-history-2009-edition'/>
<id>tag:diveintomark.org,2009-03-27:/archives/20090327172042</id> ④
<updated>2009-03-27T21:56:07Z</updated> ⑤
<published>2009-03-27T17:20:42Z</published>
<category scheme='http://diveintomark.org' term='diveintopython'/> ⑥
<category scheme='http://diveintomark.org' term='docbook'/>
<category scheme='http://diveintomark.org' term='html'/>
<summary type='html'>Putting an entire chapter on one page sounds ⑦
bloated, but consider this &mdash; my longest chapter so far
would be 75 printed pages, and it loads in under 5 seconds&hellip;
On dialup.</summary>
</entry> ⑧ org/archives/2009/03/27/dive-into-history-2009-edition'/>
<id>tag:diveintomark.org,2009-03-27:/archives/20090327172042</id> ④
<updated>2009-03-27T21:56:07Z</updated> ⑤
<published>2009-03-27T17:20:42Z</published>
<category scheme='http://diveintomark.org' term='diveintopython'/> ⑥
<category scheme='http://diveintomark.org' term='docbook'/>
<category scheme='http://diveintomark.org' term='html'/>
<summary type='html'>Putting an entire chapter on one page sounds ⑦
bloated, but consider this &mdash; my longest chapter so far
would be 75 printed pages, and it loads in under 5 seconds&hellip;
On dialup.</summary>
</entry> ⑧
org/archives/2009/03/27/dive-into-history-2009-edition'/>
<id>tag:diveintomark.org,2009-03-27:/archives/20090327172042</id> ④
<updated>2009-03-27T21:56:07Z</updated> ⑤
<published>2009-03-27T17:20:42Z</published>
<category scheme='http://diveintomark.org' term='diveintopython'/> ⑥
<category scheme='http://diveintomark.org' term='docbook'/>
<category scheme='http://diveintomark.org' term='html'/>
<summary type='html'>Putting an entire chapter on one page sounds ⑦
bloated, but consider this &mdash; my longest chapter so far
would be 75 printed pages, and it loads in under 5 seconds&hellip;
On dialup.</summary>
</entry> ⑧- Строка 2. Элемент
authorсообщает о том, кто написал статью: некий парень по имени Mark, которого вы можете найти бездельничающего на http://diveintomark.org/. (В данном случае ссылка на сайт автора совпадает с альтернативной ссылкой в метаданных фида, но это не всегда так, поскольку многие блоги имеют несколько авторов, у каждого из которых есть свой сайт.) - Строка 6. Элемент
titleсодержит заголовок статьи «Dive into history, 2009 edition». - Строка 7. Как и с альтернативной ссылкой на фид, в элементе
linkнаходится адрес HTML версии данной статьи. - Строка 9. Элемент
entry, как и фид, имеет уникальный идентификатор. - Строка 10. Элемент
entryсодержит две даты: дату первой публикации (published) и дату последнего изменения (updated). - Строка 12. Элементы
entryмогут иметь произвольное количество категорий (элементовcategory). Рассматриваемая статья попадёт в категории diveintopython, docbook и html. - Строка 15. Элемент
summaryдаёт краткий обзор статьи. (Бывает также не представленный здесь элемент содержанияcontent, предназначенный для включения в фид полного текста статьи.) Данный элементsummaryсодержит специфичный для фидов Atom атрибутtype='html', указывающий, что содержимое элемента представлено в формате HTML, а не в виде простого текста. Это важно, так как HTML-объекты (—и…), присутствующие в элементе должны отображаться как «—» и «…», а не печататься «как есть». - Строка 19. И, наконец, закрывающий тег элемента
entryговорит о конце метаданных для данной статьи.
 Рассматриваемая статья попадёт в категории diveintopython, docbook и html.
Рассматриваемая статья попадёт в категории diveintopython, docbook и html.12.4 Синтаксический разбор XML
В Python документы XML могут быть обработаны несколькими способами. Язык имеет традиционные парсеры DOM и SAX, но я сфокусируюсь на другой библиотеке под названием ElementTree.
Скачать файл feed.xml.
>>> import xml.etree.ElementTree as etree ①
>>> tree = etree.parse('examples/feed.xml') ②
>>> root = tree.getroot() ③
>>> root ④
<Element {http://www.w3.org/2005/Atom}feed at cd1eb0>- Строка 1. Модуль
ElementTreeвходит в стандартную библиотеку Python и находится вxml.etree.ElementTree. - Строка 2. Основная точка входа в библиотеку
ElementTree– это функцияparse(), которая принимает имя файла или файлоподобный объект. Данная функция выполняет синтаксический анализ документа за раз. Если памяти недостаточно, то есть способы для поэтапного анализа XML-документа. - Строка 3. Функция
parse() возвращает объект, представляющий весь документ. Однако объектtreeне является корневым элементом. Чтобы получить ссылку на корневой элемент, необходимо вызвать методgetroot(). - Строка 4. Как и следовало ожидать, корневой элемент – это элемент
feedв пространстве имён http://www.w3.org/2005/Atom. Строковое представление объектаrootещё раз подчёркивает важный момент: XML элемент – это комбинация пространства имён и его имени тега (так же называемого локальным именем). Каждый элемент в данном документе находится в пространстве Atom, поэтому корневой элемент представлен как {http://www.w3.org/2005/Atom}feed.

Модуль ElementTree всегда представляет элементы XML как ‘{пространство имён}локальное имя‘. Вам неоднократно предстоит увидеть и использовать этот формат при использовании API ElementTree.
12.4.1 Элементы – это списки
В API ElementTree элемент действует как встроенный тип Python, список. А элементы списка – это дочерние XML элементы.
# продолжение предыдущего примера
>>> root.tag ①
'{http://www.w3.org/2005/Atom}feed'
>>> len(root) ②
8
>>> for child in root: ③
... print(child) ④
...
<Element {http://www.w3.org/2005/Atom}title at e2b5d0>
<Element {http://www.w3.org/2005/Atom}subtitle at e2b4e0>
<Element {http://www.w3.org/2005/Atom}id at e2b6c0>
<Element {http://www.w3.org/2005/Atom}updated at e2b6f0>
<Element {http://www.w3.org/2005/Atom}link at e2b4b0>
<Element {http://www.w3.org/2005/Atom}entry at e2b720>
<Element {http://www.w3.org/2005/Atom}entry at e2b510>
<Element {http://www. w3.org/2005/Atom}entry at e2b750> w3.org/2005/Atom}entry at e2b750>
w3.org/2005/Atom}entry at e2b750>- Строка 2. Продолжим предыдущий пример, корневой элемент – это {http://www.w3.org/2005/Atom}feed.
- Строка 4. «Длина» корневого элемента
rootравна количеству дочерних элементов. - Строка 6. Вы можете использовать элемент как итератор, чтобы пройтись по всем дочерним элементам.
- Строка 7. Из вывода видно, что в элементе
root8 дочерних элементов: 5 элементов с метаданными о фиде (title,subtitle,id,updatedиlink) и 3 элементаentryсо статьями.
Вы, должно быть, уже догадались, но я хочу явно указать на следующее: список дочерних элементов содержит только непосредственные дочерние элементы. Каждый дочерний элемент entry, в свою очередь, содержит свои дочерние элементы, но они не будут включены в этот список. Они будут включены в список дочерних элементов самого элемента entry, но не будут включены в список дочерних элементов элемента feed. Найти определённые элементы любого уровня вложенности можно несколькими способами; позже, в данной главе, мы рассмотрим два из них.
12.4.2 Атрибуты – это словари
XML – это не просто набор элементов; каждый элемент также имеет собственный набор атрибутов. Имея ссылку на конкретный XML элемент, вы можете легко получить его атрибуты в виде словаря Python.
# продолжение предыдущего примера
>>> root.attrib ①
{'{http://www.w3.org/XML/1998/namespace}lang': 'en'}
>>> root[4] ②
<Element {http://www.w3.org/2005/Atom}link at e181b0>
>>> root[4].attrib ③
{'href': 'http://diveintomark.org/',
'type': 'text/html',
'rel': 'alternate'}
>>> root[3] ④
<Element {http://www. w3.org/2005/Atom}updated at e2b4e0>
>>> root[3].attrib ⑤
{} w3.org/2005/Atom}updated at e2b4e0>
>>> root[3].attrib ⑤
{}
w3.org/2005/Atom}updated at e2b4e0>
>>> root[3].attrib ⑤
{}- Строка 2. Свойство
attribпредставляет собой словарь атрибутов элемента. Исходная разметка XML была следующей<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>. Префиксxml:ссылается на стандартное пространство имён, которое любой XML документ может использовать без объявления. - Строка 4. Пятый дочерний элемент (с индексом
[4], так как списки Python начинаются с 0) – это элементlink. - Строка 6. Элемент
linkимеет три атрибутаhref,typeиrel. - Строка 10. Четвёртый дочерний элемент (с индексом
[3]в списке, начинающемся с 0) – это элементupdated. - Строка 12. Элемент
updatedне имеет атрибутов, следовательно, свойство.attrib– это просто пустой словарь.
12.5 Поиск узлов в XML документе
До настоящего момента мы работали с XML документом «сверху вниз», начиная с корневого элемента, затем получая его дочерние элементы, и так далее через весь документ. Однако во многих случаях при работе с XML вам необходимо искать конкретные элементы. etree справится и с этой задачей.
>>> import xml.etree.ElementTree as etree
>>> tree = etree.parse('examples/feed.xml')
>>> root = tree.getroot()
>>> root.findall('{http://www.w3.org/2005/Atom}entry') ①
[<Element {http://www.w3.org/2005/Atom}entry at e2b4e0>,
<Element {http://www.w3.org/2005/Atom}entry at e2b510>,
<Element {http://www.w3.org/2005/Atom}entry at e2b540>]
>>> root.tag
'{http://www.w3.org/2005/Atom}feed'
>>> root.findall('{http://www. w3.org/2005/Atom}feed') ②
[]
>>> root.findall('{http://www.w3.org/2005/Atom}author') ③
[] w3.org/2005/Atom}feed') ②
[]
>>> root.findall('{http://www.w3.org/2005/Atom}author') ③
[]
w3.org/2005/Atom}feed') ②
[]
>>> root.findall('{http://www.w3.org/2005/Atom}author') ③
[]- Строка 4. Метод
findall()выполняет поиск дочерних элементов удовлетворяющих конкретному запросу (формат этого запроса рассматривается ниже). - Строка 10. Метод
findall()есть у всех элементов (включая корневой и дочерние). Он ищет среди дочерних все элементы, соответствующие запросу. Почему он ничего не нашел? Хотя это может показаться неочевидным, данный запрос ищет только среди дочерних элементов. Так как корневой элементfeedне имеет дочерних элементов с именемfeed, то запрос возвращает пустой список. - Строка 12. Этот результат также может вас удивить. В данном XML документе есть элемент
author; на самом деле, их даже три (по одному в каждом элементеentry). Но эти элементыauthorне являются непосредственными дочерними элементами корневого элемента; они – как бы «внуки» (дочерние элементы дочернего элемента). Если вам нужно найти элементыauthorна любом уровне вложенности, то вы можете это сделать, но формат запроса будет немного отличаться.
>>> tree.findall('{http://www.w3.org/2005/Atom}entry') ①
[<Element {http://www.w3.org/2005/Atom}entry at e2b4e0>,
<Element {http://www.w3.org/2005/Atom}entry at e2b510>,
<Element {http://www.w3.org/2005/Atom}entry at e2b540>]
>>> tree.findall('{http://www.w3.org/2005/Atom}author') ②
[]- Строка 1. Для удобства объект
tree(который возвращается функциейetree.parse()) имеет несколько методов, идентичных методам корневого элемента. Результаты будут такими же, как и при вызове методаtree.getroot().findall(). - Строка 5. Возможно, для вас это может оказаться сюрпризом, но данный запрос не находит элементов
authorв данном документе. Почему же? Потому что, этот вызов идентичен вызову tree.getroot().findall('{http://www.w3.org/2005/Atom}author'), что значит, «найти все элементыauthor, которые являются дочерними элементами корневого элемента». Элементыauthorне являются дочерними для корневого элемента; они дочерние элементы элементовentry. Таким образом, при выполнении запроса совпадений не найдено.
 Почему же? Потому что, этот вызов идентичен вызову
Почему же? Потому что, этот вызов идентичен вызову Помимо метода findall() есть метод find(), который возвращает первый найденный элемент. Это может быть полезно, когда вы ожидаете только одно совпадение, или, если есть несколько совпадений, но вам важен только первый найденных элементов.
>>> entries = tree.findall('{http://www.w3.org/2005/Atom}entry') ①
>>> len(entries)
3
>>> title_element = entries[0].find('{http://www.w3.org/2005/Atom}title') ②
>>> title_element.text
'Dive into history, 2009 edition'
>>> foo_element = entries[0].find('{http://www.w3.org/2005/Atom}foo') ③
>>> foo_element
>>> type(foo_element)
<class 'NoneType'>- Строка 1. Как вы видели в предыдущем примере,
findall()возвращает список всех элементовatom:entry. - Строка 4. Метод
find()принимает запросElementTreeи возвращает первый элемент, удовлетворяющий этому запросу. - Строка 7. В элементе
fooотсутствуют дочерние элементы, поэтомуfind()возвращает объектNone.
Здесь необходимо отметить «подводный камень» при использовании метода find(). В логическом контексте объекты элементов ElementTree, не содержащие дочерних элементов, равны значению False (т.е. if len(element) вычисляется как 0). Это значит, что код if element. проверяет не то, что нашёл ли метод  find('...')
find('...')find() удовлетворяющий запросу элемент; этот код проверяет, содержит ли найденный элемент дочерние элементы! Чтобы проверить, нашёл ли метод find() элемент, необходимо использовать if element.find('...') is not None.
Рассмотрим поиск внутри элементов-потомков, т.е. дочерних элементов, дочерних элементов уже дочерних элементов («внуков») и так далее, элементов любого уровня вложенности.
>>> all_links = tree.findall('//{http://www.w3.org/2005/Atom}link') ①
>>> all_links
[<Element {http://www.w3.org/2005/Atom}link at e181b0>,
<Element {http://www.w3.org/2005/Atom}link at e2b570>,
<Element {http://www.w3.org/2005/Atom}link at e2b480>,
<Element {http://www.w3.org/2005/Atom}link at e2b5a0>]
>>> all_links[0].attrib ②
{'href': 'http://diveintomark.org/',
'type': 'text/html',
'rel': 'alternate'}
>>> all_links[1].attrib ③
{'href': 'http://diveintomark.org/archives/2009/03/27/dive-into-history-2009-edition',
'type': 'text/html',
'rel': 'alternate'}
>>> all_links[2].attrib
{'href': 'http://diveintomark.org/archives/2009/03/21/accessibility-is-a-harsh-mistress',
'type': 'text/html',
'rel': 'alternate'}
>>> all_links[3].attrib
{'href': 'http://diveintomark.org/archives/2008/12/18/give-part-1-container-formats',
'type': 'text/html',
'rel': 'alternate'}- Строка 1. Этот запрос –
//{http://www.w3.org/2005/Atom}link– очень похож на запросы из предыдущих примеров, он отличается только двумя слешами//в начале запроса. Эти два слеша означают: «искать не только непосредственных дочерних элементов; я хочу найти все элементы независимо от уровня вложенности». Поэтому метод возвращает список из четырёх элементов link, а не из одного. - Строка 7. Первый элемент в результате – это непосредственный дочерний элемент корневого элемента. Как мы видим из его атрибутов, это альтернативная ссылка уровня элемента
feed, которая указывает на HTML версию веб-сайта, который описывается фидом. - Строка 11. Остальные три элемента в результате – это альтернативные ссылки уровня элементов
entry. Каждый из элементовentryимеет по одному дочернему элементуlink. А так как в начале запросаfindall()находился двойной слеш, то этот запрос нашел их всех.
 Поэтому метод возвращает список из четырёх элементов
Поэтому метод возвращает список из четырёх элементов В целом, метод findall() библиотеки ElementTree – это довольно мощный инструмент поиска, однако формат запроса может быть немного непредсказуем. Официально формат запросов ElementTree описан как «ограниченная поддержка выражений XPath». XPath – это стандарт W3C для построения запросов к элементам XML документа. Язык запросов ElementTree при выполнении простого поиска достаточно похож на XPath, но он и отличается от него настолько, что может начать раздражать, если вы уже знаете XPath. Теперь давайте рассмотрим сторонние библиотеки XML, позволяющие расширить API ElementTree до полной поддержки стандарта XPath.
12.6 Продолжаем работать с
lxml
lxml – это сторонняя библиотека с открытым исходным кодом, построенная на базе популярного синтаксического анализатора libxml2. Она обеспечивает стопроцентную совместимость с API ElementTree, полностью поддерживает XPath 1.0 и имеет несколько других приятных фишек. Для Windows доступен установщик; пользователям Linux следует проверить наличие скомпилированных пакетов в репозиториях дистрибутива с помощью, например, yum или apt-get. В противном случае вам придётся установить lxml вручную.
>>> from lxml import etree ①
>>> tree = etree. parse('examples/feed.xml') ②
>>> root = tree.getroot() ③
>>> root.findall('{http://www.w3.org/2005/Atom}entry') ④
[<Element {http://www.w3.org/2005/Atom}entry at e2b4e0>,
<Element {http://www.w3.org/2005/Atom}entry at e2b510>,
<Element {http://www.w3.org/2005/Atom}entry at e2b540>]- Строка 1. При импорте
lxmlпредоставляет абсолютно такой же API, как встроенная библиотекаElementTree. - Строка 2. Функция
parse()такая же, как в ElementTree. - Строка 3. Метод
getroot()тоже такой же. - Строка 4. Метод
findall()точно такой же.
При обработке больших XML документов lxml значительно быстрее, чем встроенная библиотека ElementTree. Если вы используете только API ElementTree и хотите, чтобы обработка выполнялась как можно быстрее, то можно попробовать импортировать библиотеку lxml и, в случае её отсутствия, использовать встроенную ElementTree.
try:
from lxml import etree
except ImportError:
import xml.etree.ElementTree as etreeОднако библиотека lxml не только быстрее, чем ElementTree. Ее метод findall() поддерживает более сложные выражения.
>>> import lxml.etree ①
>>> tree = lxml.etree.parse('examples/feed.xml')
>>> tree.findall('//{http://www.w3.org/2005/Atom}*[@href]') ②
[<Element {http://www.w3.org/2005/Atom}link at eeb8a0>,
<Element {http://www.w3.org/2005/Atom}link at eeb990>,
<Element {http://www.w3.org/2005/Atom}link at eeb960>,
<Element {http://www. w3.org/2005/Atom}link at eeb9c0>]
>>> tree.findall("//{http://www.w3.org/2005/Atom}*[@href='http://diveintomark.org/']") ③
[<Element {http://www.w3.org/2005/Atom}link at eeb930>]
>>> NS = '{http://www.w3.org/2005/Atom}'
>>> tree.findall('//{NS}author[{NS}uri]'.format(NS=NS)) ④
[<Element {http://www.w3.org/2005/Atom}author at eeba80>,
<Element {http://www.w3.org/2005/Atom}author at eebba0>] w3.org/2005/Atom}link at eeb9c0>]
>>> tree.findall("//{http://www.w3.org/2005/Atom}*[@href='http://diveintomark.org/']") ③
[<Element {http://www.w3.org/2005/Atom}link at eeb930>]
>>> NS = '{http://www.w3.org/2005/Atom}'
>>> tree.findall('//{NS}author[{NS}uri]'.format(NS=NS)) ④
[<Element {http://www.w3.org/2005/Atom}author at eeba80>,
<Element {http://www.w3.org/2005/Atom}author at eebba0>]
w3.org/2005/Atom}link at eeb9c0>]
>>> tree.findall("//{http://www.w3.org/2005/Atom}*[@href='http://diveintomark.org/']") ③
[<Element {http://www.w3.org/2005/Atom}link at eeb930>]
>>> NS = '{http://www.w3.org/2005/Atom}'
>>> tree.findall('//{NS}author[{NS}uri]'.format(NS=NS)) ④
[<Element {http://www.w3.org/2005/Atom}author at eeba80>,
<Element {http://www.w3.org/2005/Atom}author at eebba0>]- Строка 1. В данном примере я импортирую
lxml.etree(вместо предыдущего способа:from lxml import etree), чтобы подчеркнуть, что описываемые возможности характерны именно дляlxml. - Строка 3. Этот запрос найдёт все элементы в пространстве имён Atom (любой вложенности), которые имеют атрибут
href. Двойной слеш//в начале запроса означает «элементы любой вложенности (а не только дочерние элементы корневого элемента)».{http://www.w3.org/2005/Atom}означает «только элементы пространства имён Atom». Символ*значит «элементы с любым локальным именем». И[@href]означает «элемент имеет атрибутhref». - Строка 8. Запрос находит все элементы Atom с атрибутом
href, значение которого равно http://diveintomark.org/. - Строка 11. После небольшого форматирования строки (иначе составные запросы становятся неимоверно длинными) данный запрос ищет элементы Atom
author, имеющие дочерние элементы Atomuri. Запрос возвращает только 2 элементаauthor: в первом и во втором элементахentry. В последнем элементеentryэлементauthorсодержит толькоname,uriу него нет.
Вам недостаточно? lxml также имеет встроенную поддержку для выражений XPath 1. 0. Мы не будем детально рассматривать синтаксис XPath, так как это тема для отдельной книги. Но мы рассмотрим пример использования XPath в
0. Мы не будем детально рассматривать синтаксис XPath, так как это тема для отдельной книги. Но мы рассмотрим пример использования XPath в lxml.
>>> import lxml.etree
>>> tree = lxml.etree.parse('examples/feed.xml')
>>> NSMAP = {'atom': 'http://www.w3.org/2005/Atom'} ①
>>> entries = tree.xpath("//atom:category[@term='accessibility']/..", ②
... namespaces=NSMAP)
>>> entries ③
[<Element {http://www.w3.org/2005/Atom}entry at e2b630>]
>>> entry = entries[0]
>>> entry.xpath('./atom:title/text()', namespaces=NSMAP) ④
['Accessibility is a harsh mistress']- Строка 3. Чтобы выполнить XPath запрос элементов из пространства имён, необходимо определить отображение префикса этого пространства имен. На самом деле это обычный словарь Python.
- Строка 4. А вот и XPath запрос. Данное выражение выполняет поиск элементов
category(пространства имён Atom), содержащие атрибутtermсо значением accessibility. Но это не совсем то, что возвращает запрос. Посмотрите в самый конец строки запроса. Вы заметили символы/..? Это означает, «а затем верни родительский элемент элементаcategory, которого ты только что нашел». Таким образом, одним XPath запросом мы найдём все элементыentryс дочерними элементами<category term='accessibility'>. - Строка 6. Функция
xpath()возвращает список объектовElementTree. В данном документе всего один элементentryс дочерним элементомcategory, у которого атрибутtermравен значению accessibility. - Строка 9. Выражение XPath не всегда возвращает список элементов. Формально, DOM разобранного документа XML не содержит элементов, она содержит узлы (node). В зависимости от типа узлы могут быть элементами, атрибутами или даже текстовым контентом. Результатом запроса XPath всегда является список узлов. Данный запрос возвращает список текстовых узлов: текстовый контент (
text()) элементаtitle(atom:title), который является дочерним элементом текущего элемента (./).
 Формально, DOM разобранного документа XML не содержит элементов, она содержит узлы (node). В зависимости от типа узлы могут быть элементами, атрибутами или даже текстовым контентом. Результатом запроса XPath всегда является список узлов. Данный запрос возвращает список текстовых узлов: текстовый контент (
Формально, DOM разобранного документа XML не содержит элементов, она содержит узлы (node). В зависимости от типа узлы могут быть элементами, атрибутами или даже текстовым контентом. Результатом запроса XPath всегда является список узлов. Данный запрос возвращает список текстовых узлов: текстовый контент (12.7 Создание XML
Поддержка XML в Python не ограничивается только парсингом существующих документов. Вы также можете создавать XML документы «с нуля».
>>> import xml.etree.ElementTree as etree
>>> new_feed = etree.Element('{http://www.w3.org/2005/Atom}feed', ①
... attrib={'{http://www.w3.org/XML/1998/namespace}lang': 'en'}) ②
>>> print(etree.tostring(new_feed)) ③
<ns0:feed xmlns:ns0='http://www.w3.org/2005/Atom' xml:lang='en'/>- Строка 2. Для создания нового элемента необходимо создать объект класса
Element. В качестве первого аргумента мы передаём имя элемента (пространство имён + локальное имя). Данное выражение создаёт элементfeedв пространстве Atom. Это будет корневой элемент нашего нового XML документа. - Строка 3. Чтобы добавить атрибуты к только что созданному элементу, мы передаём словарь имён атрибутов и их значений во втором аргументе
attrib. Обратите внимание, что имена атрибутов должны задаваться в форматеElementTree, {пространство_имён}локальное_имя. - Строка 4. В любой момент вы можете сериализовать элемент и его дочерние элементы с помощью функции
tostring()библиотекиElementTree.
Результат сериализации стал для вас неожиданностью? Формально ElementTree сериализует XML элементы правильно, но не оптимально. Пример XML документа в начале главы определял пространство имен по умолчанию (
Пример XML документа в начале главы определял пространство имен по умолчанию (xmlns='http://www.w3.org/2005/Atom'). Определение пространства по умолчанию полезно для документов (таких как фидов Atom), в которых все элементы принадлежат одному пространству имен, поскольку вы можете объявить пространство один раз, а элементы объявлять, используя только их локальные имена (<feed>, <link>, <entry>). Если вы не собираетесь объявлять элементы из другого пространства имён, то нет необходимости использовать префиксы.
Синтаксический анализатор XML не «заметит» разницы между XML документом с пространством имен по умолчанию и документом, использующим префикс пространства имён перед каждым элементом. Итоговая модель DOM этой сериализации
<ns0:feed xmlns:ns0='http://www.w3.org/2005/Atom' xml:lang='en'/>что идентична модели DOM этой сериализации
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'/>Единственная разница заключается в том, что второй вариант на несколько символов короче. Если мы переделаем весь наш пример, используя префикс ns0: в каждом открывающем и закрывающем тегах, это добавило бы 4 символа на открывающий тег × 79 тегов + 4 символа на объявление собственно пространства имён, всего 320 символов. В кодировке UTF-8 это составило бы 320 байт. (После архивации gzip разница уменьшается до 21 байта; однако, 21 байт – это всё еще 21 байт). Возможно, для вас это не имеет значения, но для чего-то, подобного фидам Atom, которые могут скачиваться несколько тысяч раз при каждом изменении, выигрыш нескольких байт на одном запросе может быстро разрастись.
Встроенная библиотека ElementTree не предоставляет тонкого управления над сериализацией элементов в пространствах имен. И тут снова в игру вступает lxml.
>>> import lxml.etree
>>> NSMAP = {None: 'http://www. w3.org/2005/Atom'} ①
>>> new_feed = lxml.etree.Element('feed', nsmap=NSMAP) ②
>>> print(lxml.etree.tounicode(new_feed)) ③
<feed xmlns='http://www.w3.org/2005/Atom'/>
>>> new_feed.set('{http://www.w3.org/XML/1998/namespace}lang', 'en') ④
>>> print(lxml.etree.tounicode(new_feed))
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'/>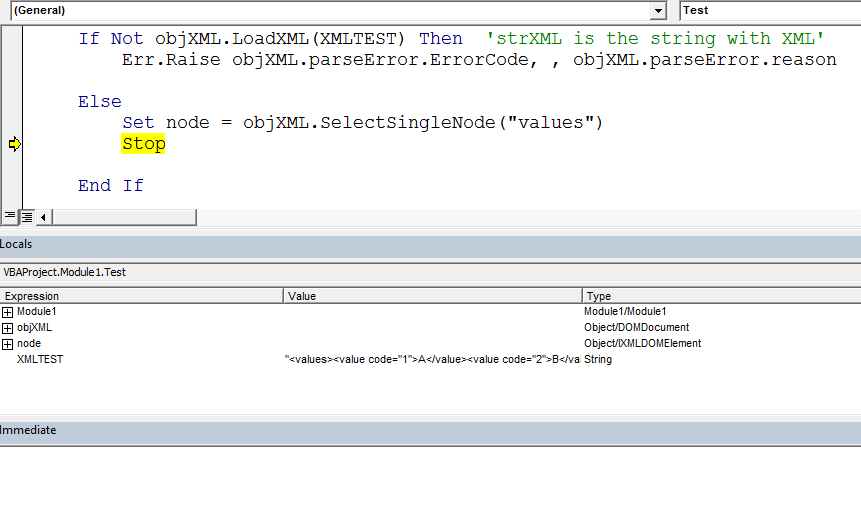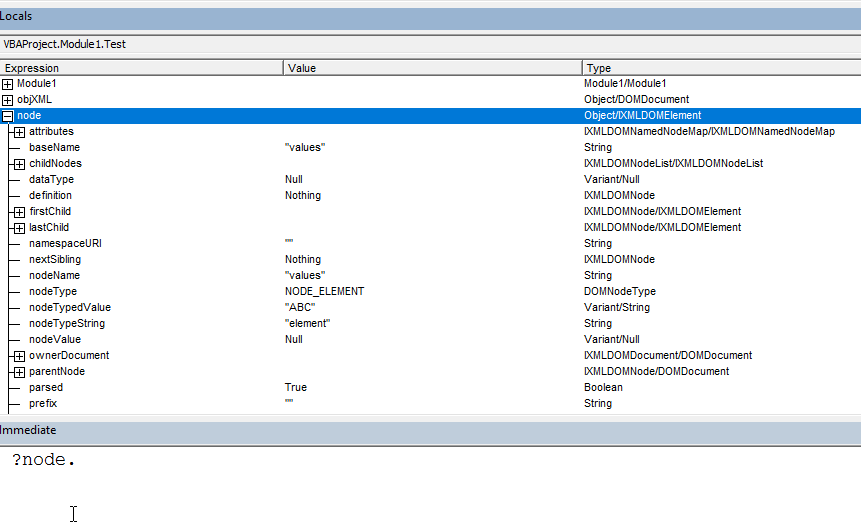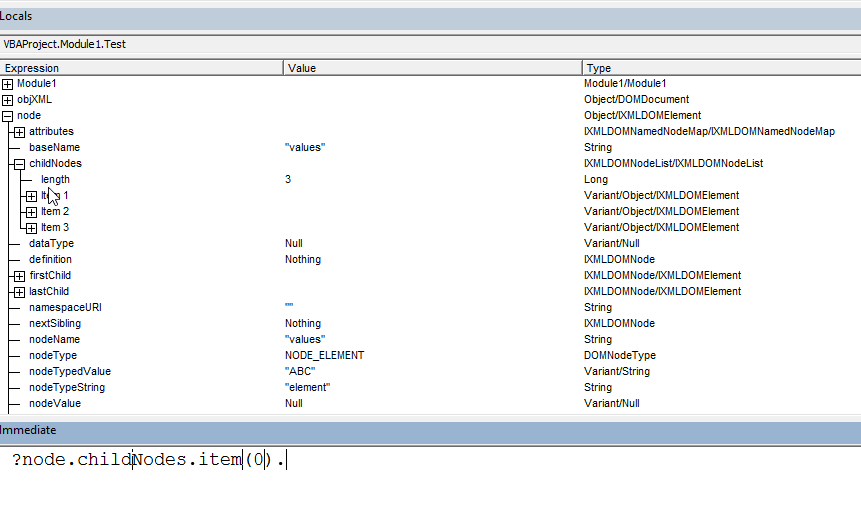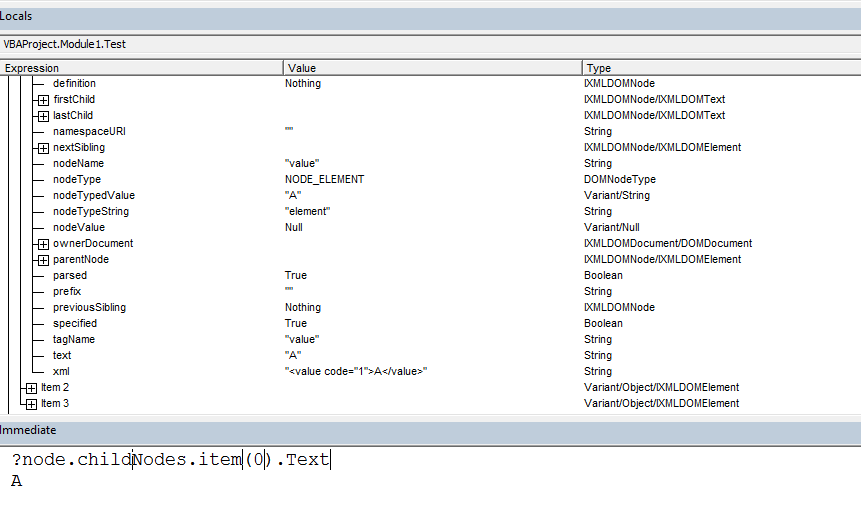 w3.org/2005/Atom'} ①
>>> new_feed = lxml.etree.Element('feed', nsmap=NSMAP) ②
>>> print(lxml.etree.tounicode(new_feed)) ③
<feed xmlns='http://www.w3.org/2005/Atom'/>
>>> new_feed.set('{http://www.w3.org/XML/1998/namespace}lang', 'en') ④
>>> print(lxml.etree.tounicode(new_feed))
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'/>
w3.org/2005/Atom'} ①
>>> new_feed = lxml.etree.Element('feed', nsmap=NSMAP) ②
>>> print(lxml.etree.tounicode(new_feed)) ③
<feed xmlns='http://www.w3.org/2005/Atom'/>
>>> new_feed.set('{http://www.w3.org/XML/1998/namespace}lang', 'en') ④
>>> print(lxml.etree.tounicode(new_feed))
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'/>- Строка 2. Для начала определим пространство имён, используя словарь. Значения словаря – это пространства имен; ключи словаря – это задаваемый префикс. Используя объект
Noneв качестве префикса, мы задаем пространство имен по умолчанию. - Строка 3. Теперь, при создании элемента, мы можем передать специфичный для
lxmlаргументnsmap, используемый для передачи префиксов пространств имён. - Строка 4. Как и ожидалось, данная сериализация определяет пространство имён по умолчанию Atom и объявляет элемент
feedбез префикса пространства имён. - Строка 6. Упс, мы забыли добавить атрибут
xml:lang. Добавить атрибут к любому элементу всегда можно с помощью методаset(). Он принимает два аргумента: имя атрибута в стандартном форматеElementTreeи значение атрибута. (Данный метод не специфичен для библиотекиlxml. Единственная особенность, специфичная дляlxml, в данном примере – это аргументnsmapдля управления префиксами пространств имён в сериализованном выводе.)
Разве XML документы ограничиваются только одним элементом в документе? Конечно, нет. Мы так же легко можем создавать дочерние элементы.
>>> title = lxml.etree.SubElement(new_feed, 'title', ①
... attrib={'type':'html'}) ②
>>> print(lxml. etree.tounicode(new_feed)) ③
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'><title type='html'/></feed>
>>> title.text = 'dive into …' ④
>>> print(lxml.etree.tounicode(new_feed)) ⑤
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'><title type='html'>dive into &hellip;</title></feed>
>>> print(lxml.etree.tounicode(new_feed, pretty_print=True)) ⑥
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title type='html'>dive into&hellip;</title>
</feed> etree.tounicode(new_feed)) ③
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'><title type='html'/></feed>
>>> title.text = 'dive into …' ④
>>> print(lxml.etree.tounicode(new_feed)) ⑤
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'><title type='html'>dive into &hellip;</title></feed>
>>> print(lxml.etree.tounicode(new_feed, pretty_print=True)) ⑥
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title type='html'>dive into&hellip;</title>
</feed>
etree.tounicode(new_feed)) ③
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'><title type='html'/></feed>
>>> title.text = 'dive into …' ④
>>> print(lxml.etree.tounicode(new_feed)) ⑤
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'><title type='html'>dive into &hellip;</title></feed>
>>> print(lxml.etree.tounicode(new_feed, pretty_print=True)) ⑥
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title type='html'>dive into&hellip;</title>
</feed>- Строка 1. Для создания дочернего элемента существующего элемента необходимо создать объект класса
SubElement. Обязательные аргументы – это родительский элемент (в данном случаеnew_feed) и имя нового элемента. Поскольку дочерний элемент наследует пространство имён от родителя, то здесь нет необходимости заново объявлять пространство имён или префикс. - Строка 2. Также вы можете передать словарь с атрибутами. Ключи – это имена атрибутов; значения словаря – это значения атрибутов.
- Строка 3. Как и ожидалось, новый элемент
titleбыл создан в пространстве Atom, и он является дочерним элементом элементаfeed. Так как элементtitleне имеет текстового контента и дочерних элементов, тоlxmlсериализует его как пустой элемент (с помощью сокращенной записи/>). - Строка 5. Чтобы добавить текстовый контент в элемент, просто задаём его свойство
.text. - Строка 6. Теперь элемент
titleсериализуется со своим текстовым контентом. Если в тексте содержатся символы «меньше чем» или амперсанды, то при сериализации они должны быть экранированы.lxmlобрабатывает это экранирование автоматически. - Строка 8. При сериализации вы можете применить «красивую печать» (
pretty_print), при которой вставляются разрывы строки после закрывающих тегов и после открывающих тегов элементов, содержащих дочерние элементы, но не имеющих текстового контента. С технической точки зрения,lxmlдобавляет «незначащие пробельные символы», чтобы сделать вывод более читаемым.

Вам, возможно, будет интересно попробовать xmlwitch, ещё одну стороннюю библиотеку для создания XML. Она повсеместно использует оператор with, чтобы сделать код создания XML более читаемым.
12.8 Синтаксический анализ «сломанного» XML
Спецификация XML предписывает, что все синтаксические анализаторы XML должны выполнять «драконовскую (строгую) обработку ошибок». То есть, они должны остановиться и выкинуть исключение при обнаружении в XML документе «некорректности» любого типа. Ошибки корректности включают в себя несовпадающие открывающий и закрывающий теги, неопределённые объекты, неправильные символы Юникод и другие эзотерические ситуации. Такая обработка ошибок сильно контрастирует на фоне других известных форматов, например, HTML, – ваш браузер не останавливает отрисовку web-страницы, если вы забыли закрыть HTML тег или экранировать амперсанд в значении атрибута. (Существует распространённое заблуждение, что в HTML не оговорена обработка ошибок. На самом деле, обработка HTML ошибок отлично документирована, но она гораздо сложнее, чем просто «остановиться и выдать аварийное сообщение».)
Некоторые (и я в том числе) считают, что со стороны разработчиков формата XML было ошибкой заставлять так строго обрабатывать ошибки. Не поймите меня неправильно, я, конечно же, за упрощение правил обработки ошибок. Однако на практике понятие «корректности» оказывается коварнее, чем кажется, особенно для XML документов (таких как фиды Atom), которые публикуются в интернете и передаются по протоколу HTTP. Несмотря на зрелость XML, который стандартизовал драконовскую обработку ошибок в 1997, исследования постоянно показывают, что значительная часть фидов Atom в интернете содержат ошибки корректности.
У меня есть и теоретические, и практические причины обрабатывать XML документы «любой ценой», то есть не останавливаться и взрываться при первой ошибке. Если вы окажетесь в похожей ситуации, то lxml может вам помочь.
Ниже приведён фрагмент «битого» XML документа.
<?xml version='1.0' encoding='utf-8'?>
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title>dive into …</title>
...
</feed>Здесь есть ошибка, так как последовательность … не определена в формате XML (она определена в HTML). Если попробовать разобрать этот битый фид с настройками по умолчанию, lxml споткнётся на неопределённой последовательности.
>>> import lxml.etree
>>> tree = lxml.etree.parse('examples/feed-broken.xml')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "lxml.etree.pyx", line 2693, in lxml.etree.parse (src/lxml/lxml.etree.c:52591)
File "parser.pxi", line 1478, in lxml.etree._parseDocument (src/lxml/lxml.etree.c:75665)
File "parser.pxi", line 1507, in lxml.etree._parseDocumentFromURL (src/lxml/lxml.etree.c:75993)
File "parser.pxi", line 1407, in lxml.etree._parseDocFromFile (src/lxml/lxml.etree.c:75002)
File "parser.pxi", line 965, in lxml.etree._BaseParser._parseDocFromFile (src/lxml/lxml.etree.c:72023)
File "parser.pxi", line 539, in lxml.etree._ParserContext._handleParseResultDoc (src/lxml/lxml.etree.c:67830)
File "parser.pxi", line 625, in lxml.etree._handleParseResult (src/lxml/lxml.etree.c:68877)
File "parser.pxi", line 565, in lxml.etree._raiseParseError (src/lxml/lxml.etree.c:68125)
lxml.etree.XMLSyntaxError: Entity 'hellip' not defined, line 3, column 28Чтобы обработать этот битый XML документ, необходимо создать новый синтаксический анализатор XML.
>>> parser = lxml. etree.XMLParser(recover=True) ①
>>> tree = lxml.etree.parse('examples/feed-broken.xml', parser) ②
>>> parser.error_log ③
examples/feed-broken.xml:3:28:FATAL:PARSER:ERR_UNDECLARED_ENTITY: Entity 'hellip' not defined
>>> tree.findall('{http://www.w3.org/2005/Atom}title')
[<Element {http://www.w3.org/2005/Atom}title at ead510>]
>>> title = tree.findall('{http://www.w3.org/2005/Atom}title')[0]
>>> title.text ④
'dive into '
>>> print(lxml.etree.tounicode(tree.getroot())) ⑤
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title>dive into </title>
.
. [rest of serialization snipped for brevity]
. etree.XMLParser(recover=True) ①
>>> tree = lxml.etree.parse('examples/feed-broken.xml', parser) ②
>>> parser.error_log ③
examples/feed-broken.xml:3:28:FATAL:PARSER:ERR_UNDECLARED_ENTITY: Entity 'hellip' not defined
>>> tree.findall('{http://www.w3.org/2005/Atom}title')
[<Element {http://www.w3.org/2005/Atom}title at ead510>]
>>> title = tree.findall('{http://www.w3.org/2005/Atom}title')[0]
>>> title.text ④
'dive into '
>>> print(lxml.etree.tounicode(tree.getroot())) ⑤
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title>dive into </title>
.
. [rest of serialization snipped for brevity]
.
etree.XMLParser(recover=True) ①
>>> tree = lxml.etree.parse('examples/feed-broken.xml', parser) ②
>>> parser.error_log ③
examples/feed-broken.xml:3:28:FATAL:PARSER:ERR_UNDECLARED_ENTITY: Entity 'hellip' not defined
>>> tree.findall('{http://www.w3.org/2005/Atom}title')
[<Element {http://www.w3.org/2005/Atom}title at ead510>]
>>> title = tree.findall('{http://www.w3.org/2005/Atom}title')[0]
>>> title.text ④
'dive into '
>>> print(lxml.etree.tounicode(tree.getroot())) ⑤
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title>dive into </title>
.
. [rest of serialization snipped for brevity]
.- Строка 1. Чтобы создать новый парсер, инициализируем класс
lxml.etree.XMLParser. Он может принимать ряд различных именованных аргументов. В данном случае нас интересует аргументrecover. При присвоении этому аргументу значенияTrueпарсер XML будет делать всё, чтобы «восстановить» документ и избавиться от ошибки построения. - Строка 2. Чтобы разобрать XML документ новым анализатором, передаём в функцию
parse()объектparserв качестве второго аргумента. Обратите внимание, чтоlxmlне выбрасывает исключение при неопределённой последовательности …. - Строка 3. Анализатор хранит журнал о найденных ошибках корректности (на самом деле это не зависит от включения восстановления).
- Строка 8. Так как анализатор не знает, что делать с неопределённым …, то он просто тихо отбрасывает его. Текстовый контент элемента
titleпревращается в ‘dive into ‘. - Строка 10. Как видно из сериализации, последовательность … была просто выброшена.
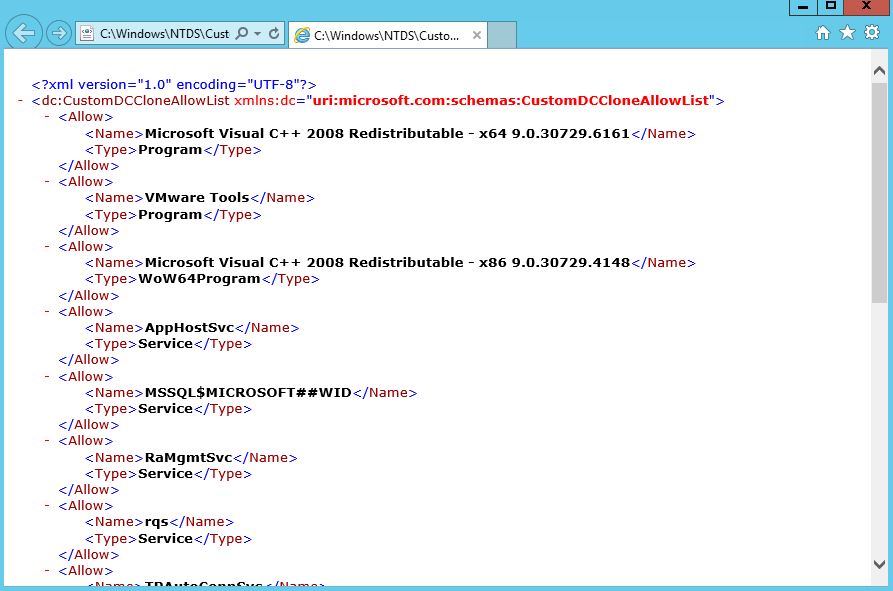 Как видно из сериализации, последовательность … была просто выброшена.
Как видно из сериализации, последовательность … была просто выброшена.Важно отметить, что нет никакой гарантии совместимости «восстановления» у XML анализаторов. Другой анализатор может быть умнее и распознать, что … является корректной последовательностью HTML, и заменить её на &hellip;. «Лучше» ли это? Возможно. Является ли это «более правильным»? Нет, так как оба решения с точки зрения формата XML неверны. Правильное поведение (согласно спецификации XML) – прекратить обработку и выдать исключение. Если же вы решили не следовать спецификации, то вы делаете это на свой страх и риск.
12.9 Материалы для дальнейшего чтения
Источник:
- Mark Pilgrim. Dive Into Python 3
Теги
lxmlPythonXMLВысокоуровневые языки программированияПарсерПрограммированиеЯзыки программирования
Сохранить или поделиться
Импорт данных XML — Excel
Если вы ранее создали карту XML,вы можете использовать ее для импорта данных XML в ячейки, которые были совмещены, но есть несколько способов и команд импорта данных XML без карты XML.
При наличии карты XML сделайте следующее для импорта данных XML в сопоставленные ячейки:
-
В карте XML выберите одну из сопоставленных ячеек.
-
На вкладке Разработчик нажмите кнопку Импорт.
Если вкладка Разработчик не отображается, см.
раздел Отображение вкладки «Разработчик». -
В диалоговом окне Импорт XML найдите и выберите файл данных XML (XML-файл), который вы хотите импортировать, и нажмите кнопку Импорт.
 раздел Отображение вкладки «Разработчик».
раздел Отображение вкладки «Разработчик».Другие способы импорта данных XML
Дополнительные сведения о проблемах см. в разделе Типичные проблемы при импорте данных XML в конце этой статьи.
Импорт файла данных XML в качестве XML-таблицы
-
На вкладке Разработчик нажмите кнопку Импорт.
Если вкладка Разработчик не отображается, см. раздел Отображение вкладки «Разработчик».
-
В диалоговом окне Импорт XML найдите и выберите файл данных XML (XML-файл), который вы хотите импортировать, и нажмите кнопку Импорт.
Если файл данных XML не ссылается ни на какую схему, Excel создает ее на основе этого файла.
-
В диалоговом окне Импорт данных выполните одно из следующих действий:
-
Выберите XML-таблицу на существующем компьютере, чтобы импортировать содержимое файла данных XML в XML-таблицу на вашем компьютере в указанной ячейке.
-
Выберите XML-таблицу на новом файле, чтобы импортировать содержимое файла в XML-таблицу на новом файле, начиная с ячейки A1. Карта файла данных XML отобразится в области задач Источник XML.
-
-
Если файл данных XML не ссылается ни на какую схему, Excel создает ее на основе этого файла.
-
Чтобы управлять поведением данных XML (например, привязки данных, формата и макета), нажмите кнопку «Свойства», чтобы отобразить диалоговое окно свойств карты XML. Например, существующие данные в таком диапазоне будут перезаписаны при импорте данных по умолчанию, но это можно изменить.
Импорт нескольких файлов данных XML
-
Выберите сопоставленную ячейку, чтобы импортировать несколько XML-файлов в один набор сопоставленных ячеек.
Если вы хотите импортировать несколько XML-файлов в несколько наборов сопоставленных ячеек, щелкните любую несопоставленную ячейку листа.
-
На вкладке Разработчик нажмите кнопку Импорт.
Если вкладка Разработчик не отображается, см. раздел Отображение вкладки «Разработчик».
-
В диалоговом окне Импорт XML найдите и выберите файл данных XML (XML-файл), который вы хотите импортировать.
-
Если файлы являются смежными, нажмите клавишу SHIFT, а затем щелкните первый и последний файл в списке. Все данные из XML-файлов будут импортированы и добавлены в сопоставленные ячейки.
-
Если файлы не являются смежными, нажмите клавишу CTRL, а затем щелкните все файлы списка, которые вы хотите импортировать.
-
-
Нажмите кнопку Импорт.
Если вы выбрали файлы, которые не являются contiguous, появится диалоговое окно <>.xml импортируемых файлов. Выберите карту XML, соответствующую импортируемому файлу данных XML.
Чтобы использовать одну карту для всех выделенных файлов, которые еще не были импортированы, установите флажок Использовать эту карту XML для всех выбранных файлов этой схемы.

Импорт нескольких файлов данных XML в качестве внешних данных
Если нужно импортировать несколько XML-файлов с одним пространством имен, но с разными схемами XML, вы можете воспользоваться командой Из импорта данных XML. Excel создаст уникальную карты XML для каждого импортируемого файла данных XML.
Примечание: При импорте нескольких XML-файлов, в которых не определено пространство имен, считается, что они используют одно пространство имен.
-
Если вы используете Excel с подпискойMicrosoft 365, нажмите кнопку Data > Get Data > From File > From XML.
Если вы используете Excel 2016 или более раннюю версию, на вкладке Данные нажмите кнопку Из других источников, а затем щелкните Из импорта данных XML.
-
Выберите диск, папку или расположение в Интернете, где находится файл данных XML (XML-файл), который вы хотите импортировать.
-
Выберите файл и нажмите кнопку Открыть.
-
В диалоговом окне Импорт данных выберите один из следующих параметров:
-
В XML-таблицу в существующей книге. Содержимое файла импортируется в новую таблицу XML на новом листе. Если файл данных XML не ссылается ни на какую схему, Excel создает ее на основе этого файла.
-
Существующий таблица Данные XML импортируется в двумерную таблицу со строками и столбцами, в качестве заголовков столбцов в качестве XML-тегов показаны XML-теги, а данные — в строках под заголовками столбцов. Первый элемент (корневой узел) используется в качестве названия и отображается в указанной ячейке. Остальные теги отсортировали по алфавиту во второй строке. В этом случае схема не создается и вы не можете использовать карту XML.
-
На новый лист. Excel добавляет в книгу новый лист и автоматически помещает данные XML в его левый верхний угол. Если файл данных XML не ссылается ни на какую схему, Excel создает ее на основе этого файла.
-
-
Чтобы контролировать поведение данных XML, таких как привязка данных, форматирование и макет, нажмите кнопку «Свойства», чтобы отобразить диалоговое окно свойств карты XML. Например, при импорте данных по умолчанию существующие данные в таком диапазоне перезаписываются, но это можно изменить.

Открытие файла данных XML для импорта данных
-
Выберите команду Файл > Открыть.
Если вы используете Excel 2007, нажмите Microsoft Office кнопку
>«Открыть».
-
В диалоговом окне Открытие файла выберите диск, папку или веб-адрес, где расположен нужный файл.
-
Выберите файл и нажмите кнопку Открыть.
-
Если открывается диалоговое окно импорта XML, файл ссылается на одну или несколько таблиц стилей XSLT, поэтому можно использовать один из следующих параметров:
-
Открытие файла без применения таблицы стилей Данные XML импортируется в двумерную таблицу со строками и столбцами, в качестве заголовков столбцов в качестве XML-тегов показаны XML-теги, а данные — в строках под заголовками столбцов. Первый элемент (корневой узел) используется в качестве названия и отображается в указанной ячейке. Остальные теги отсортировали по алфавиту во второй строке. В этом случае схема не создается и вы не можете использовать карту XML.
-
Открыть файл, применив следующую таблицу стилей (выберите одну). Выберите таблицу стилей, которую вы хотите применить, и нажмите кнопку ОК. Данные XML будут отформатированы в соответствии с выбранным листом стилей.
Примечание: Данные XML будут открыты в Excel в режиме «только для чтения», что позволяет предотвратить случайное сохранение первоначального исходного файла в формате книги Excel с поддержкой макросов (XLSM). В этом случае схема не создается и вы не можете использовать карту XML.
-
-
Если появится диалоговое окно «Открытие XML», в XML-файле нет ссылок на таблицу стилей XSLT. Чтобы открыть файл, выберите один из следующих параметров:
-
Щелкните XML-таблица для создания XML-таблицы в новой книге.
Содержимое файла импортируется в XML-таблицу. Если файл данных XML не ссылается ни на какую схему, Excel создает ее на основе этого файла.
-
Щелкните «Как книгу, которая будет только для чтения».
Данные XML импортируется в двумерную таблицу со строками и столбцами, в качестве заголовков столбцов в качестве XML-тегов показаны XML-теги, а данные — в строках под заголовками столбцов. Первый элемент (корневой узел) используется в качестве названия и отображается в указанной ячейке. Остальные теги отсортировали по алфавиту во второй строке. В этом случае схема не создается и вы не можете использовать карту XML.
Данные XML будут открыты в Excel в режиме «только для чтения», что позволяет предотвратить случайное сохранение первоначального исходного файла в формате книги Excel с поддержкой макросов (XLSM). В этом случае схема не создается и вы не можете использовать карту XML.
-
Щелкните Использовать область задач XML-источника.
Карта файла данных XML отобразится в области задач Источник XML. Для сопоставления элементов схемы с листом их можно перетащить на лист.
Если файл данных XML не ссылается ни на какую схему, Excel создает ее на основе этого файла.
-
Распространенные проблемы при импорте данных XML
Excel выводит диалоговое окно ошибки импорта XML, если не может проверить данные в соответствии с картой XML. Чтобы получить дополнительные сведения об ошибке, нажмите кнопку Сведения в этом диалоговом окне. В следующей ниже таблице описаны ошибки, которые часто возникают при импорте данных.
|
Ошибка |
Объяснение |
|
Ошибка при проверке схемы |
Когда вы выбрали в диалоговом окне Свойства карты XML параметр Проверять данные на соответствие схеме при импорте и экспорте, данные были импортированы, но не проверены на соответствие указанной карте XML. |
|
Некоторые данные были импортированы как текст |
Часть импортированных данных или все данные были преобразованы из объявленного типа в текст. Чтобы использовать эти данные в вычислениях, необходимо преобразовать их в числа или даты. Например, значение даты, преобразованное в текст, не будет работать должным образом в функции ГОД, пока не будет преобразовано в тип данных «Дата». Excel преобразует данные в текст в следующих случаях:
|
|
Ошибка разбора XML |
Средству синтаксического анализа XML не удается открыть указанный XML-файл. Убедитесь, что в XML-файле отсутствуют синтаксические ошибки и XML построен правильно. |
|
Не удается найти карту XML, соответствующую этим данным |
Эта проблема может возникнуть в том случае, если для импорта выбрано несколько файлов данных XML и Excel не удается найти соответствующую карту XML для одного из них. Импортируйте схему для файла, указанного в строке заголовка этого диалогового окна, сначала следует, а затем повторно выполните импорт файла. |
|
Не удается изменить размер XML-таблицы для включения данных |
Вы пытаетесь добавить строки путем импорта или добавления данных в XML-таблицу, однако таблицу невозможно расширить. XML-таблицу можно дополнять только снизу. Например, сразу под XML-таблицей может находиться объект, такой как рисунок или даже другая таблица, который не позволяет расширить ее. Кроме того, возможно, что при расширении XML-таблицы будет превышен установленный в Excel предел по количеству строк (1 048 576). Чтобы исправить эту проблему, измените расположение таблиц и объектов на листе, чтобы XML-таблица могла дополняться снизу. |
Указанный XML-файл не ссылается на схему
XML-файл, который вы пытаетесь открыть, не ссылается на схему XML. Для работы с данными XML, содержащимися в файле, Excel требуется схема, основанная на его содержимом. Если такая схема неверна или не отвечает вашим требованиям, удалите ее из книги. Затем создайте файл схемы XML и измените файл данных XML так, чтобы он ссылался на схему. Дополнительные сведения см. в статье Сопоставление XML-элементов с ячейками карты XML.
Примечание: Схему, созданную Excel, невозможно экспортировать в качестве отдельного файла данных схемы XML (XSD-файла). Хотя существуют редакторы схем XML и другие способы создания файлов схемы XML, возможно, вы не имеете к ним доступа или не знаете, как ими пользоваться.
Выполните следующие действия, чтобы удалить из книги схему, созданную Excel:
-
На вкладке Разработчик выберите команду Источник.
Если вкладка Разработчик не отображается, см. раздел Отображение вкладки «Разработчик».
-
В области задач Источник XML выберите пункт Карты XML.
-
В диалоговом окне Карты XML щелкните карту XML, созданную Excel ,и нажмите кнопку Удалить.
Возникают проблемы при импорте нескольких XML-файлов, которые используют одно пространство имен, но разные схемы
При работе с несколькими файлами данных XML и несколькими схемами XML стандартным подходом является создание карты XML для каждой схемы, сопоставление нужных элементов, а затем импорт каждого из файлов данных XML в соответствующую карту XML. При использовании команды Импорт для открытия нескольких XML-файлов с одним пространством имен можно использовать только одну схему XML. Если эта команда используется для импорта нескольких XML-файлов, использующих одно пространство имен при разных схемах, можно получить непредсказуемые результаты. Например, это может привести к тому, что данные будут перезаписаны или файлы перестанут открываться.
Если нужно импортировать несколько XML-файлов с одним пространством имен, но с разными схемами XML, вы можете воспользоваться командой Из импорта данных XML (выберите Данные > Из других источников). Эта команда позволяет импортировать несколько XML-файлов с одним пространством имен и разными схемами XML. Excel создаст уникальную карты XML для каждого импортируемого файла данных XML.
Примечание: При импорте нескольких XML-файлов, в которых не определено пространство имен, считается, что они используют одно пространство имен.
Отображение вкладки «Разработчик»
Если вкладка Разработчик недоступна, выполните следующие действия, чтобы открыть ее.
См. также
Просмотр XML в Excel
Сопоставление XML-элементов с ячейками карты XML
Экспорт данных XML
Записать, прочитать XML файл из DomDocument
В 1С можно распарсить XML файл с помощью COM объекта «Msxml2.DOMDocument». В зависимости от установленного программного обеспечения, доступны различные версии «Дом документа». Подробно, свойства и методы различных версий DOMDocument описаны в MSDN.
Версии DomDocument
Msxml2.DOMDocument.3.0
Msxml2.DOMDocument.4.0
Msxml2.DOMDocument.5.0
Msxml2.DOMDocument.6.0
Для того чтобы создать или парсить xml, существуют примеры написанные с использованием встроенных объектов (ЗаписьXML, ЧтениеXML) языка программирования 1С. При сложной структуре xml, объём программного кода в таких примерах может быть очень большим. При использовании «Msxml2.DOMDocument» программный код можно сделать более компактным и получить более гибкий механизм обращения к узлам XML документа.
Технология DOMDocument предоставляет удобные методы для работы с данными в виде XML. В данном объекте, структура данных представлена в виде дерева узлов. Все узлы, являются подчиненными к корневому. Благодаря DOMDocument можно перебирать, создавать, удалять, копировать узлы и выполнять многие другие действия.
Создать, записать XML файл
Функция СоздатьXML()Попытка
DomDocument = Новый COMОбъект("MSXML2.DOMDocument.6.0");
Исключение
Сообщить("Ошибка: объект MSXML2.DOMDocument не создан");
Возврат Ложь;
КонецПопытки;//Записать объявление XML
XML = DomDocument.createProcessingInstruction("xml", "version=""1.0"" encoding=""UTF-8""");
DomDocument.insertBefore(XML,);//Создать корневой узел
ElementRootTag = DomDocument.createElement("RootTag");//Создать подчиненный узел
ElementTag = DomDocument.createElement("Tag");
ElementTag.setAttribute("ИмяАтрибута","ЗначениеАтрибута");
ElementText = DomDocument.createTextNode("Текст");
ElementTag.appendChild(ElementText);
CDATA = DomDocument.createCDATASection("Значение");
ElementTag.appendChild(CDATA);//Записать узлы
ElementRootTag.appendChild(ElementTag);
DomDocument.appendChild(ElementRootTag);//Записать файл
DomDocument.Save("C:Test.xml");//Сформированный XML текст
XMLТекст = DomDocument.xml;КонецФункции
Прочитать XML файл
Функция СчитатьXML()Попытка
DomDocument = Новый COMОбъект("MSXML2.DOMDocument.6.0");
Исключение
Сообщить("Ошибка: объект MSXML2.DOMDocument не создан");
Возврат Ложь;
КонецПопытки;//Загрузить XML из строки
DomDocument.loadXML("<?xml version=""1.0"" encoding=""UTF-8""?>
|<RootTag>
|<Tag Имя=""Значение"">Текст[CDATA[Значение]]</Tag>
|</RootTag>");//Загрузить файл XML
DomDocument.load("C:Test.xml");Если DomDocument.parseError.errorCode <> 0 Тогда
Сообщить("Ошибка: XML файл не валидный");
Возврат Ложь;
КонецЕсли;//Выбрать узлы
Nodes = DomDocument.SelectNodes("Tag");Для Индекс = 0 По Nodes.Length - 1 Цикл
ЗначениеАтрибута = Nodes.Item(Индекс).getAttribute("ИмяАтрибута");
Tag = Nodes.Item(Индекс);
КонецЦикла;КонецФункции
Похожие статьи:
ЗаписьXML, ЧтениеXML в 1С:Предприятии
Запись, чтение XML из ДокументDOM
XML — Погружение в Python 3
Погружение
Большинство глав в этой книге строятся на отрывках, примерах кода. Но xml это больше данные, нежели код. Один из способов применения xml это «синдикация контента» такого, как последние статьи с блога, форума или других часто обновляемых сайтов. Большинство популярного ПО для ведения блогов может создавать ленты (фиды) и обновлять их, когда новые статьи, темы публикуются. Вы можете следить за блогом подписавшись на его канал, также вы можете следить за несколькими блогами при помощи «программ-агрегаторов» таких, как Google Reader [1]
Итак, ниже представлены XML данные с которыми мы будем работать в этой главе. Это фид формата Atom syndication feed
<?xml version='1.0' encoding='utf-8'?>
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title>dive into mark</title>
<subtitle>currently between addictions</subtitle>
<id>tag:diveintomark.org,2001-07-29:/</id>
<updated>2009-03-27T21:56:07Z</updated>
<link rel='alternate' type='text/html' href='http://diveintomark.org/'/>
<link rel='self' type='application/atom+xml' href='http://diveintomark.org/feed/'/>
<entry>
<author>
<name>Mark</name>
<uri>http://diveintomark.org/</uri>
</author>
<title>Dive into history, 2009 edition</title>
<link rel='alternate' type='text/html'
href='http://diveintomark.org/archives/2009/03/27/dive-into-history-2009-edition'/>
<id>tag:diveintomark.org,2009-03-27:/archives/20090327172042</id>
<updated>2009-03-27T21:56:07Z</updated>
<published>2009-03-27T17:20:42Z</published>
<category scheme='http://diveintomark.org' term='diveintopython'/>
<category scheme='http://diveintomark.org' term='docbook'/>
<category scheme='http://diveintomark.org' term='html'/>
<summary type='html'>Putting an entire chapter on one page sounds
bloated, but consider this &mdash; my longest chapter so far
would be 75 printed pages, and it loads in under 5 seconds&hellip;
On dialup.</summary>
</entry>
<entry>
<author>
<name>Mark</name>
<uri>http://diveintomark.org/</uri>
</author>
<title>Accessibility is a harsh mistress</title>
<link rel='alternate' type='text/html'
href='http://diveintomark.org/archives/2009/03/21/accessibility-is-a-harsh-mistress'/>
<id>tag:diveintomark.org,2009-03-21:/archives/20090321200928</id>
<updated>2009-03-22T01:05:37Z</updated>
<published>2009-03-21T20:09:28Z</published>
<category scheme='http://diveintomark.org' term='accessibility'/>
<summary type='html'>The accessibility orthodoxy does not permit people to
question the value of features that are rarely useful and rarely used.</summary>
</entry>
<entry>
<author>
<name>Mark</name>
</author>
<title>A gentle introduction to video encoding, part 1: container formats</title>
<link rel='alternate' type='text/html'
href='http://diveintomark.org/archives/2008/12/18/give-part-1-container-formats'/>
<id>tag:diveintomark.org,2008-12-18:/archives/20081218155422</id>
<updated>2009-01-11T19:39:22Z</updated>
<published>2008-12-18T15:54:22Z</published>
<category scheme='http://diveintomark.org' term='asf'/>
<category scheme='http://diveintomark.org' term='avi'/>
<category scheme='http://diveintomark.org' term='encoding'/>
<category scheme='http://diveintomark.org' term='flv'/>
<category scheme='http://diveintomark.org' term='GIVE'/>
<category scheme='http://diveintomark.org' term='mp4'/>
<category scheme='http://diveintomark.org' term='ogg'/>
<category scheme='http://diveintomark.org' term='video'/>
<summary type='html'>These notes will eventually become part of a
tech talk on video encoding.</summary>
</entry>
</feed>
5-минутное введение в XML
Если Вы уже знакомы с XML, то можете пропустить эту главу.
XML — это язык разметки для описания иерархии структурированных данных. XML документ содержит один или более элементов разделённых открывающими и закрывающими тегами. Это правильный, хотя и неинтересный, XML документ:
① Это открывающий (начальный) тег элемента foo.
② Это соответствующий закрывающий (конечный) тег элемента foo. Как в математике и языках программирования каждая открывающая скобка должна иметь соответствующую закрывающую, в XML каждый открывающий тег должен быть закрыт соответствующим закрывающим.
Элементы могут быть неограниченно вложены друг в друга. Так как элемент bar вложен в элемент foo, то его называют подэлементом или дочерним элементом элемента foo.
Первый элемент каждого XML документа называется корневым. XML документ может содержать только один корневой элемент. Пример представленный ниже не является XML документом, так как он имеет два корневых элемента:
Элементы могут иметь атрибуты состоящие из пары имя-значение. Атрибуты перечисляются внутри открывающего тега элемента и разделяются пробелами. Имена атрибутов не могут повторяться внутри одно элемента. Значения атрибутов должны быть обрамлены одинарными или двойными кавычками.
<foo lang='en'> ① <bar lang="fr"></bar> ② </foo>
① Элемент foo имеет один атрибут именованный как lang. Значению атрибута lang присваивается строка en.
② Элемент bar имеет два атрибута: id и lang. Значение lang есть fr. Это не приводит к конфликту с атрибутом lang элемента foo, так как каждый элемент имеет свой набор атрибутов.
Если элемент имеет больше чем один атрибут, то порядок атрибутов не играет роли. Атрибуты элементов есть неупорядоченный набор ключей и значений подобно словарям в Python. Для каждого элемента можно указать неограниченное число атрибутов.
Элементы могут иметь текст (текстовое содержание).
<foo lang='en'> <bar lang='fr'>PapayaWhip</bar> </foo>
Элементы которые не содержат текста и дочерних элементов называются пустыми.
Существует сокращённая запись пустого элемента. Поместив знак дроби / в конце открывающего тега, вы можете пропустить закрывающий тег. XML документ предыдущего примера с пустым элементов может быть записан следующим образом:
Подобно тому как функции Python могут быть объявлены в разных модулях, XML элементы могут быть объявлены в разных пространствах имён (namespaces). Пространства имён обычно выглядят как URL-пути. Для объявления пространства имён по умолчанию используется директива xmlns. Объявление пространства имён очень похоже на атрибут, но имеет специальное значение.
<feed xmlns='http://www.w3.org/2005/Atom'> ① <title>dive into mark</title> ② </feed>
① Элемент feed находится в пространстве имён http://www.w3.org/2005/Atom.
② Элемент title также находится в пространстве имён http://www.w3.org/2005/Atom. Пространство имён применяется как к элементу в котором оно было определено так и ко всем дочерним элементам.
Вы можете объявлять пространство имён xmlns:prefix и ставить ему в соответствие префикс prefix. Тогда каждый элемент в данном пространстве имён должен быть явно объявлен с указанием префикса prefix.
<atom:feed xmlns:atom='http://www.w3.org/2005/Atom'> ① <atom:title>dive into mark</atom:title> ② </atom:feed>
① Элемент feed находится в пространстве имён http://www.w3.org/2005/Atom.
② Элемент title также находится в пространстве имён http://www.w3.org/2005/Atom.
С точки зрения синтаксического анализатора XML, предыдущие два XML документа идентичны. Пара «пространство имён» + «имя элемента» задают XML идентичность. Префиксы используются только для ссылки на пространство имён, но не изменяют имени атрибута. Если пространства имён совпадают, имена элементов совпадают, атрибуты (или их отсутствие) совпадают и тексты элементов совпадают, то XML документы одинаковы.
И, наконец, XML документы могут содержать информацию о кодировке символов в первой строке до корневого элемента. (Если Вам интересно как документ может содержать информацию которая должна быть известна XML-анализатору до анализа XML документа, то смотрите Catch-22 раздел F XML спецификации)
<?xml version='1.0' encoding='utf-8'?>
Теперь Вы знаете об XML достаточно чтобы «вынести» следующие разделы главы!
Структура формата синдикации фида Atom
Рассмотрим блог (weblog) или любой сайт с часто обновляемым контентом, например CNN.com. Сайт содержит заголовок («CNN.com»), подзаголовок («Breaking News, U.S., World, Weather, Entertainment & Video News»), дату последнего изменения («обновлено 12:43 p.m. EDT, Sat May 16, 2009») и список статей опубликованных в разное время. Каждая статья в свою очередь также имеет заголовок, дату первой публикации (и, возможно, дату последнего обновления, в случае если статья была корректирована) и уникальный URL.
Формат синдикации Atom разработан с целью хранить информацию подобного рода стандартным образом. Мой блог и CNN.com абсолютно разные по дизайну, содержанию и посетителям сайты, но оба имеют сходную структуру. Оба сайта имеют заголовки и публикуют статьи.
На верхнем уровне фид Atom должен иметь корневой элемент по имени feed находящийся в пространстве имен http://www.w3.org/2005/Atom.
<feed xmlns='http://www.w3.org/2005/Atom' ①
xml:lang='en'> ②
① http://www.w3.org/2005/Atom — пространство имён Atom
② Каждый элемент может содержать атрибут xml:lang который определяет язык элемента и его дочерних элементов. В данном случае атрибут xml:lang объявленный в корневом элементе задаёт английский язык для всего фида.
Фид Atom содержит дополнительную информацию о себе в дочерних элементах корневого элемента:
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'> <title>dive into mark</title> ① <subtitle>currently between addictions</subtitle> ② <id>tag:diveintomark.org,2001-07-29:/</id> ③ <updated>2009-03-27T21:56:07Z</updated> ④ <link rel='alternate' type='text/html' href='http://diveintomark.org/'/> ⑤
① Заголовок title содержит текст ‘dive into mark’.
② Подзаголовок subtitle фида есть строка ‘currently between addictions’.
③ Каждый фид должен иметь глобальный уникальный идентификатор. RFC 4151 содержит информацию как создавать такие идентификаторы.
④ Данный фид был обновлён последний раз 27 марта 2009 в 21:56 GMT. Обычно элемент updated эквивалентен дате последнего изменения какой-либо из статей на сайте.
⑤ А вот здесь начинается самое интересное. Элемент ссылки link не имеет текстового содержания, но имеет три атрибута: rel, type и href. Значение атрибута rel говорит о том какого типа ссылка. rel=’alternate’ значит, что это альтернативная ссылка этого фида. Атрибут type=’text/html’ говорит, что это ссылка на HTML страницу. И, собственно, путь ссылки содержится в атрибуте href.
Теперь мы знаем, что представленный выше фид получен с сайта «dive into mark». Сайт доступен по адресу http://diveintomark.org/ и последний раз был обновлён 27 марта 2009.
|
Хотя в некоторых XML документах порядок элементов может иметь значение, в фидах Atom порядок элементов — произвольный. |
Продолжим дальше рассматривать строение фида: после метаинформации о фиде идёт список последних статей. Статья выглядит следующим образом:
<entry>
<author> ①
<name>Mark</name>
<uri>http://diveintomark.org/</uri>
</author>
<title>Dive into history, 2009 edition</title> ②
<link rel='alternate' type='text/html' ③
href='http://diveintomark.org/archives/2009/03/27/dive-into-history-2009-edition'/>
<id>tag:diveintomark.org,2009-03-27:/archives/20090327172042</id> ④
<updated>2009-03-27T21:56:07Z</updated> ⑤
<published>2009-03-27T17:20:42Z</published>
<category scheme='http://diveintomark.org' term='diveintopython'/> ⑥
<category scheme='http://diveintomark.org' term='docbook'/>
<category scheme='http://diveintomark.org' term='html'/>
<summary type='html'>Putting an entire chapter on one page sounds ⑦
bloated, but consider this &mdash; my longest chapter so far
would be 75 printed pages, and it loads in under 5 seconds&hellip;
On dialup.</summary>
</entry> ⑧
① Элемент author сообщает о том, кто написал статью: некоторый парень по имени Марк (Mark), который валяет дурака на сайте http://diveintomark.org/ (В данном случае ссылка на сайт автора совпадает с альтернативной ссылкой в метаинформации о фиде, но это не всегда правда, так как многие блоги имеют несколько авторов, у каждого из которых — свой сайт.)
② Элемент title содержит заголовок статьи «Dive into history, 2009 edition».
③ Как и с альтернативной ссылкой на фид, в элементе link находится адрес HTML версии данной статьи.
④ Элемент entry, подобно фидам, имеет уникальный идентификатор.
⑤ Элемент entry имеет две даты: дату первой публикации и дату последнего изменения.
⑥ Элементы entry могут иметь произвольное количество категорий category. Рассматриваемая статья попадёт в категории diveintopython, docbook и html.
⑦ Элемент summary даёт краткий обзор статьи. (Бывает также не представленный здесь элемент содержания content предназначенный для включения в фид полного текста статьи.) Данный элемент summary содержит специфичный для фидов Atom атрибут type=’html’ указывающий что содержимое элемента есть текст в формате HTML. Это важно, так как HTML-объекты — и … присутствующие в элементе должны отображаться как «—» и «…», а не печататься «как есть».
⑧ И, наконец, закрывающий тег элемента entry говорит о конце метаданных для этой статьи.
Синтаксический разбор XML
В Python документы XML могут быть обработаны c использованием разных библиотек. Язык имеет обычные синтаксические анализаторы DOM и SAX, но я буду использовать другую библиотеку ElementTree.
>>> import xml.etree.ElementTree as etree ①
>>> tree = etree.parse('examples/feed.xml') ②
>>> root = tree.getroot() ③
>>> root ④
<Element {http://www.w3.org/2005/Atom}feed at cd1eb0>
① Модуль ElementTree входит в стандартную библиотеку Python, путь для импорта xml.etree.ElementTree.
② Функция parse() — это базовая функция модуля ElementTree. Функция принимает имя файла или файлоподобный объект. Эта функция выполняет синтаксическй анализ документа за раз. Если разрабатываемая программа должна экономить память, то можно анализировать XML документ частями.
③ Функция parse() возращает объект, который является представлением всего документа. Однако объект tree не является корневым элементом. Чтобы получить ссылку на корневой элемент, необходимо вызвать метод getroot().
④ Как и следовало ожидать, корневой элемент есть элемент фида в пространстве имён http://www.w3.org/2005/Atom. Строковое представление объекта root ещё раз подчёркивает важный момент: XML элемент — это комбинация пространства имён и его имени-тега (так же называемого локальным именем). Каждый элемент в данном документе находится в пространстве Atom, поэтому корневой элемент представлен как {http://www.w3.org/2005/Atom}feed.
|
Модуль ElementTree всегда представляет элементы XML как ‘{пространство имён}локальное имя’. Вам неоднократно предстоит использовать этот формат при использовании API ElementTree. |
Элементы XML есть списки Python
В API ElementTree элементы представляются встроенным типом Python — списком. Каждый из элементов списка представляет собой дочерние XML элементы.
# продолжение предыдущего примера
>>> root.tag ①
'{http://www.w3.org/2005/Atom}feed'
>>> len(root) ②
8
>>> for child in root: ③
... print(child) ④
...
<Element {http://www.w3.org/2005/Atom}title at e2b5d0>
<Element {http://www.w3.org/2005/Atom}subtitle at e2b4e0>
<Element {http://www.w3.org/2005/Atom}id at e2b6c0>
<Element {http://www.w3.org/2005/Atom}updated at e2b6f0>
<Element {http://www.w3.org/2005/Atom}link at e2b4b0>
<Element {http://www.w3.org/2005/Atom}entry at e2b720>
<Element {http://www.w3.org/2005/Atom}entry at e2b510>
<Element {http://www.w3.org/2005/Atom}entry at e2b750>
① Продолжим предыдущий пример: корневой элемент root — {http://www.w3.org/2005/Atom}feed
② «Длина» корневого элемента есть количество дочерних элементов root.
③ Вы можете использовать элемент как итератор по всем дочерним элементам.
④ Из сообщений видно, что в элементе root 8 дочерних элементов: 5 элементов с метаинформацией о фиде (title, subtitle, id, updated и link) и 3 элемента со статьями entry.
Вы, должно быть, уже догадались, но я хочу явно указать на следующее: список дочерних элементов содержит только прямые дочерние элементы. В свою очередь каждый дочерний элемент entry может содержать свои дочерние элементы, но они не будут включены в список. Они будут включены в список элемента entry, а не в список подэлементов элемента feed. Найти определённые элементы любого уровня вложенности можно несколькими способами; ниже мы рассмотрим 2 из них.
Атрибуты XML есть словари Python
Напомним, что документ XML это не только набор элементов; каждый элемент так же имеет набор атрибутов. Имея конкретный XML элемент, Вы можете легко получить его атрибуты как словарь Python.
# продолжение предыдущего примера
>>> root.attrib ①
{'{http://www.w3.org/XML/1998/namespace}lang': 'en'}
>>> root[4] ②
<Element {http://www.w3.org/2005/Atom}link at e181b0>
>>> root[4].attrib ③
{'href': 'http://diveintomark.org/',
'type': 'text/html',
'rel': 'alternate'}
>>> root[3] ④
<Element {http://www.w3.org/2005/Atom}updated at e2b4e0>
>>> root[3].attrib ⑤
{}
① Свойство attrib возращает словарь атрибутов элемента. Исходная разметка XML была следующая <feed xmlns=’http://www.w3.org/2005/Atom’ xml:lang=’en’>. Префикс xml: ссылается на стандартное пространство имён, которое любой XML документ может использовать без объявления.
② Пятый подэлемент есть элемент link (используется индекс [4], так как списки Python индексируются начиная с 0).
③ Подэлемент link имеет три атрибута href, type и rel.
④ Четвёртый подэлемент (с индексом [3] в списке начинающемся с 0) — это элемент updated.
⑤ Подэлемент updated не имеет атрибутов, следовательно свойство .attrib возращает пустой словарь.
Поиск узлов в XML документе
До настоящего момента мы рассматривали XML документ «сверху вниз», начиная с корневого элемента, далее к его дочерним элементы и так вглубь всего документа. Однако во многих случаях при работе с XML Вам необходимо искать конкретные элементы. Etree справится и с этой задачей.
>>> import xml.etree.ElementTree as etree
>>> tree = etree.parse('examples/feed.xml')
>>> root = tree.getroot()
>>> root.findall('{http://www.w3.org/2005/Atom}entry') ①
[<Element {http://www.w3.org/2005/Atom}entry at e2b4e0>,
<Element {http://www.w3.org/2005/Atom}entry at e2b510>,
<Element {http://www.w3.org/2005/Atom}entry at e2b540>]
>>> root.tag
'{http://www.w3.org/2005/Atom}feed'
>>> root.findall('{http://www.w3.org/2005/Atom}feed') ②
[]
>>> root.findall('{http://www.w3.org/2005/Atom}author') ③
[]
① Метод findall() выполняет поиск дочерних элементов удовлетворяющих запросу. (Формат запроса рассматривается ниже.)
② Все элементы (включая корневой и дочерние) имеют метод findall(). Метод находит все элементы среди дочерних соответствующие запросу. Почему же метод вернул пустой список? Хотя это может показаться неочевидным, данный запрос ищет только в дочерних элементах. Так как корневой элемент feed не имеет дочерних элементов по имени feed, то запрос возвращает пустой список.
③ Этот результат также может Вас удивить. В документе XML действительно есть элемент author; на самом деле, их даже три (по одному в каждом элементе entry). Но эти элементы author не являются прямыми подэлементами (direct children) корневого элемента; они — «подподэлементы» (подэлементы подэлемента). Если Вам нужно найти элементы author любого уровня вложенности, то придётся изменить строку запроса.
>>> tree.findall('{http://www.w3.org/2005/Atom}entry') ①
[<Element {http://www.w3.org/2005/Atom}entry at e2b4e0>,
<Element {http://www.w3.org/2005/Atom}entry at e2b510>,
<Element {http://www.w3.org/2005/Atom}entry at e2b540>]
>>> tree.findall('{http://www.w3.org/2005/Atom}author') ②
[]
① Для удобства объект tree (который возвращает функция etree.parse()) имеет несколько методов идентичных методам корневого элемента. Результаты функции такие же как при вызове метода tree.getroot().findall().
② Наверное, удивлены, однако этот запрос не находит элемента author в данном документе. Почему же? Потому что, этот вызов идентичен вызову tree.getroot().findall(‘{http://www.w3.org/2005/Atom}author’), что значит «найти все элементы author, которые являются подэлементами корневого элемента». Элементы author не являются дочерними для корневого элемента; они подэлементы элементов entry. Таким образом, при выполнении запроса совпадений не найдено.
Помимо метода findall() есть метод find() который возвращает только первый найденный элемент. Метод может быть полезен в случаях когда в результате поиска Вы ожидаете только один элемент или Вам важен только первый элемент из списка найденных.
>>> entries = tree.findall('{http://www.w3.org/2005/Atom}entry') ①
>>> len(entries)
3
>>> title_element = entries[0].find('{http://www.w3.org/2005/Atom}title') ②
>>> title_element.text
'Dive into history, 2009 edition'
>>> foo_element = entries[0].find('{http://www.w3.org/2005/Atom}foo') ③
>>> foo_element
>>> type(foo_element)
<class 'NoneType'>
① Как Вы видели в предыдущем примере findall() возвращает список элементов atom:entry.
② Метод find() принимает запрос ElementTree и возвращает первый удовлетворяющий запросу элемент.
③ Во элементе foo отсутствуют дочерние элементы, поэтому find() возвращает объект None.
|
Здесь необходимо отметить закавыку при использовании метода find(). В логическом контексте объекты элементов ElementTree не содержащие дочерних элементов равны значению False (т.е if len(element) вычисляется как 0). Код if element.find(‘…’) проверяет не то, что нашёл ли метод find() удовлетворяющий запросу элемент; код проверяет содержит ли найденный элемент дочерние элементы! Для того чтобы проверить нашёл ли метод find() элемент необходимо использовать if element.find(‘…’) is not None. |
Рассмотрим поиск внутри дочерних элементов, т.е подэлементов, подподэлементов и так далее любого уровня вложенности.
>>> all_links = tree.findall('//{http://www.w3.org/2005/Atom}link') ①
>>> all_links
[<Element {http://www.w3.org/2005/Atom}link at e181b0>,
<Element {http://www.w3.org/2005/Atom}link at e2b570>,
<Element {http://www.w3.org/2005/Atom}link at e2b480>,
<Element {http://www.w3.org/2005/Atom}link at e2b5a0>]
>>> all_links[0].attrib ②
{'href': 'http://diveintomark.org/',
'type': 'text/html',
'rel': 'alternate'}
>>> all_links[1].attrib ③
{'href': 'http://diveintomark.org/archives/2009/03/27/dive-into-history-2009-edition',
'type': 'text/html',
'rel': 'alternate'}
>>> all_links[2].attrib
{'href': 'http://diveintomark.org/archives/2009/03/21/accessibility-is-a-harsh-mistress',
'type': 'text/html',
'rel': 'alternate'}
>>> all_links[3].attrib
{'href': 'http://diveintomark.org/archives/2008/12/18/give-part-1-container-formats',
'type': 'text/html',
'rel': 'alternate'}
① Этот запрос — //{http://www.w3.org/2005/Atom}link — очень похож на запросы из предыдущих примеров. Отличие заключается в двух символах косой черты // в начале строки запроса. Символы // обозначают «Я хочу найти все элементы независимо от уровня вложенности, а не только непосредственные дочерние элементы». Поэтому метод возвращает список из четырёх элементов, а не из одного.
② Первый элемент результата — прямой подэлемент корневого элемента. Как мы видим из его атрибутов, это альтернативная ссылка уровня фида, которая указывает на html версию вебсайта на котором располагается фид.
③ Остальные три элемента результата есть альтернативные ссылки уровня элементов entry. Каждый из элементов entry имеет по одному подэлементу link. Так как запрос findall() содержал символы двойной черты в начале запроса, то результат поиска содержит все подэлементы link.
В целом, метод findall() библиотеки ElementTree довольно мощный инструмент поиска, однако формат запроса может быть немного непредсказуем. Официально формат запросов ElementTree описан как «ограниченная поддержка выражений XPath». XPath это стандарт организации W3C для построения запросов поиска внутри XML документа. С одной стороны формат запросов ElementTree достаточно похож на формат XPath для выполнения простейших поисков. С другой стороны он отличается настолько, что может начать раздражать если Вы уже знаете XPath. Далее мы рассмотрим сторонние библиотеки XML позволяющие расширить API ElementTree до полной поддержки стандарта XPath.
Работаем с LXML
lxml это сторонняя библиотека с открытым кодом основанная на известном синтаксическом анализаторе libxml2. Библиотека обеспечивает стопроцентную совместимость с API ElementTree, полностью поддерживает XPath 1.0 и имеет несколько других приятных фишек. Для Windows можно скачать инсталлятор; пользователям Linux следует проверить наличие скомпилированных пакетов в репозиториях дистрибутива (например, используя инструменты yum или apt-get). В противном случае придётся устанавливать lxml вручную.
>>> from lxml import etree ①
>>> tree = etree.parse('examples/feed.xml') ②
>>> root = tree.getroot() ③
>>> root.findall('{http://www.w3.org/2005/Atom}entry') ④
[<Element {http://www.w3.org/2005/Atom}entry at e2b4e0>,
<Element {http://www.w3.org/2005/Atom}entry at e2b510>,
<Element {http://www.w3.org/2005/Atom}entry at e2b540>]
① При импорте lxml предоставляет абсолютно такой же API как встроенная библиотека ElementTree.
② Функция parse(): такая же как в ElementTree.
③ Метод getroot(): такой же.
④ Метод findall(): точно такой же.
При обработке больших XML документов lxml значительно быстрее чем встроенная библиотека ElementTree. Если Вы используете функции только из API ElementTree и хотите чтобы обработка выполнялась как можно быстрее, то можно попробовать импортировать библиотеку lxml и, в случае её отсутствия, использовать ElementTree.
try:
from lxml import etree
except ImportError:
import xml.etree.ElementTree as etree
Однако, lxml не только быстрее чем ElementTree: метод findall() поддерживает более сложные запросы.
>>> import lxml.etree ①
>>> tree = lxml.etree.parse('examples/feed.xml')
>>> tree.findall('//{http://www.w3.org/2005/Atom}*[@href]') ②
[<Element {http://www.w3.org/2005/Atom}link at eeb8a0>,
<Element {http://www.w3.org/2005/Atom}link at eeb990>,
<Element {http://www.w3.org/2005/Atom}link at eeb960>,
<Element {http://www.w3.org/2005/Atom}link at eeb9c0>]
>>> tree.findall("//{http://www.w3.org/2005/Atom}*[@href='http://diveintomark.org/']") ③
[<Element {http://www.w3.org/2005/Atom}link at eeb930>]
>>> NS = '{http://www.w3.org/2005/Atom}'
>>> tree.findall('//{NS}author[{NS}uri]'.format(NS=NS)) ④
[<Element {http://www.w3.org/2005/Atom}author at eeba80>,
<Element {http://www.w3.org/2005/Atom}author at eebba0>]
① В этом примере я импортирую объект lxml.etree (вместо объекта etree: from lxml import etree) чтобы подчеркнуть, что описываемые возможности реализуемы только с lxml.
② Этот запрос найдёт все элементы в пространстве имён Atom (любой вложенности), которые имеют атрибут href. Символы // в начале запроса обозначают «элементы любой вложенности, а не только потомки корневого элемента». {http://www.w3.org/2005/Atom} обозначает «только элементы пространства имён Atom». Символ * значит «элементы с любым локальным именем». И [@href] обозначает «элемент имеет атрибут href».
③ В результате запроса найдены все элементы Atom с атрибутом href равным http://diveintomark.org/.
④ После преобразования строки (иначе эти запросы становятся неимоверно длинны) данный запрос ищет элементы Atom author имеющие подэлементы Atom uri. Запрос возвращает только 2 элемента author: в первом и во втором элементах entry. В последнем элементе entry элемент author содержит только имя name, но не uri.
Вам мало? lxml имеет встроенную поддержку для выражений XPath 1.0. Мы не будем детально рассматривать синтаксис XPath, так как это тема для отдельной книги. Однако мы рассмотрим пример использования XPath в lxml.
>>> import lxml.etree
>>> tree = lxml.etree.parse('examples/feed.xml')
>>> NSMAP = {'atom': 'http://www.w3.org/2005/Atom'} ①
>>> entries = tree.xpath("//atom:category[@term='accessibility']/..", ②
... namespaces=NSMAP)
>>> entries ③
[<Element {http://www.w3.org/2005/Atom}entry at e2b630>]
>>> entry = entries[0]
>>> entry.xpath('./atom:title/text()', namespaces=NSMAP) ④
['Accessibility is a harsh mistress']
① Чтобы выполнить XPath запрос элементов из пространства имён, необходимо определить отображение префикса этого пространства. На самом деле это обычный словарь Python.
② А вот и XPath запрос. Данное выражение выполняет поиск элементов category (пространства имён Atom) содержащие атрибут с парой имя-значение term=’accessibility’. Но это не совсем то, что возвращает запрос. Вы заметили символы /.. в конце строки запроса? Это обозначает «верни не найденный элемент, а его родителя». И так, одним запросом мы найдём все элементы entry с дочерними элементами <category term=’accessibility’>.
③ Функция xpath() возвращает список объектов ElementTree. В анализируемом документе всего один элемент entry с атрибутом term=’accessibility’.
④ Выражение XPath не всегда возвращает список элементов. Формально, DOM разобранного документа XML не содержит элементов, она содержит узлы (nodes). В зависимости от их типа узлы могут быть элементами, атрибутами или даже текстом. Результатом запроса XPath всегда является список узлов. Этот запрос возвращает список текстовых узлов: текст text() элемента title (atom:title) есть подэлемент текущего элемента (./).
Создание XML
ElementTree умеет не только разбирать существующие XML документы, но и создавать их «с нуля».
>>> import xml.etree.ElementTree as etree
>>> new_feed = etree.Element('{http://www.w3.org/2005/Atom}feed', ①
... attrib={'{http://www.w3.org/XML/1998/namespace}lang': 'en'}) ②
>>> print(etree.tostring(new_feed)) ③
<ns0:feed xmlns:ns0='http://www.w3.org/2005/Atom' xml:lang='en'/>
① Для создания нового элемента необходимо создать объект класса Element. В качестве первого параметра в конструктор мы передаём имя элемента (пространство имён и локальное имя). Данное выражение создаёт элемент feed в пространстве Atom. Этот будет корневой элемент нашего нового документа XML.
② Для того чтобы добавить атрибуты к создаваемому элементу мы передаём словарь имён атрибутов и их значений в втором аргументе attrib. Заметьте, что имена атрибутов должны задаваться в формате ElementTree {пространство_имён}локальное_имя.
③ В любой момент Вы можете сериализовать элемент и его подэлементы используя функцию tostring() библиотеки ElementTree.
Вы удивлены результату сериализации new_feed? Формально ElementTree сериализует XML элементы правильно, но не оптимально. Пример XML документа в начале главы определён в пространстве по умолчанию xmlns=’http://www.w3.org/2005/Atom’. Определение пространства по умолчанию полезно для документов (например, фидов Atom), где все элементы принадлежат одному пространству, то есть Вы можете объявить пространство один раз, а на элементы ссылаться используя локальное имя (<feed>, <link>, <entry>). Если Вы не собираетесь объявлять элементы из другого пространства имён, то нет необходимости использовать префикс пространства по умолчанию.
Синтаксический анализатор XML не «заметит» разницы между документом XML с пространством по умолчанию и документом с использованием префикса пространства имён перед каждым элементом. Результирующая модель DOM данной сериализации выглядит как
<ns0:feed xmlns:ns0='http://www.w3.org/2005/Atom' xml:lang='en'/>
что равнозначно
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'/>
Единственная разница в том, что второй вариант на несколько символов короче. Если мы переделаем наш пример с использованием префикса ns0: в каждом открывающем и закрывающем тэгах, это добавило бы 4 символа на открывающий тэг × 79 тэгов + 4 символа на объявление собственно пространства имён, всего 320 символов. В кодировке UTF-8 это составило бы 320 байт. (После архивации gzip разница уменьшается до 21 байта; однако 21 байт это 21 байт). Возможно, Вы бы не обратили внимания на эти десятки байтов, но для фидов Atom, которые загружаются тысячу раз при изменении, выигрыш нескольких байт на одном запросе быстро превращается в килобайты.
Ещё одно преимущество lxml: в отличие от стандартной библиотеки ElementTree lxml предоставляет более тонкое управление сериализацией элементов.
>>> import lxml.etree
>>> NSMAP = {None: 'http://www.w3.org/2005/Atom'} ①
>>> new_feed = lxml.etree.Element('feed', nsmap=NSMAP) ②
>>> print(lxml.etree.tounicode(new_feed)) ③
<feed xmlns='http://www.w3.org/2005/Atom'/>
>>> new_feed.set('{http://www.w3.org/XML/1998/namespace}lang', 'en') ④
>>> print(lxml.etree.tounicode(new_feed))
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'/>
① Для начала определим пространство имён используя словарь. Значения словаря и есть пространство имён; ключи словаря — задаваемый префикс. Используя объект None в качестве префикса мы задаём пространство имён по умолчанию.
② При создании элемента мы передаём специфичный для lxml аргумент nsmap, используемый для передачи префиксов пространств имён.
③ Как и ожидали, при сериализации определено пространство имён по умолчанию Atom и объявлен один элемент feed без префикса пространства имён.
④ Опа, мы забыли добавить атрибут xml:lang. Используя метод set(), можно всегда добавить атрибут к любому элементу. Метод принимает два аргумента: имя атрибута в стандартном формате ElementTree и значение атрибута. (Данный метод есть и в библиотеке ElementTree. Единственное отличие lxml и ElementTree в данном примере это передача аргумента nsmap для указания префиксов пространств имён.)
Разве наши документы ограничены только одним элементом? Конечно, нет. Мы можем запросто создать дочерние элементы.
>>> title = lxml.etree.SubElement(new_feed, 'title', ①
... attrib={'type':'html'}) ②
>>> print(lxml.etree.tounicode(new_feed)) ③
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'><title type='html'/></feed>
>>> title.text = 'dive into …' ④
>>> print(lxml.etree.tounicode(new_feed)) ⑤
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'><title type='html'>dive into &hellip;</title></feed>
>>> print(lxml.etree.tounicode(new_feed, pretty_print=True)) ⑥
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title type='html'>dive into&hellip;</title>
</feed>
① Для создания подэлемента существующего элемента необходимо создать объект класса SubElement. В конструктор класса передаются элемент родителя (в данном случае new_feed) и имя нового элемента. Мы не объявляем заново пространство имён для создаваемого потомка, так как он наследует пространство имён от родителя.
② Также мы передаём словарь с атрибутами для элемента. В качестве имён атрибутов выступают ключи словаря, в качестве значений атрибутов — значения словаря.
③ Неудивительно, что новый элемент title был создан в пространстве Atom и является подэлементом элемента feed. Так как элемент title не имеет текстового содержания и подэлементов, то lxml сериализует его как пустой элемент и закрывает символами />.
④ Для того чтобы добавить текстовое содержание, мы задаём свойство .text.
⑤ Теперь элемент title сериализуется с только что заданным текстовым содержанием. Если в тексте содержатся знаки «меньше чем» < или «амперсанд» ‘, то при сериализации они должны быть экранированы escape-последовательностью. Такие ситуации lxml обрабатывает автоматически.
⑥ При сериализации Вы можете применить «приятную печать» («pretty printing»), при которой вставляется разрыв строки после закрывающего тэга или открывающего тэга элементов с подэлементами но без текстового содержания. С технической точки зрения lxml добавляет незначащие пробелы и переносы строк («insignificant whitespace») чтобы вывести XML более читаемым.
|
Вам, возможно, будет интересно попробовать ещё одну стороннюю библиотеку xmlwitch, которая повсеместно использует оператор Python with для того чтобы сделать код создания XML более читаемым. |
Синтаксический разбор нецелых XML
XML спецификация предписывает, что все XML синтаксические анализаторы должны выполнять «драконову (строгую) обработку ошибок». То есть, при обнаружении в XML документе формальной ошибки или не«правильнопостроенности» (wellformedness) анализаторы должны сразу же прервать анализ и «вспыхнуть». Ошибки правильнопостроенности включают несогласованность открывающих и закрывающих тэгов, неопределённые элементы, неправильные символы Юникод и другие эзотерические ситуации. Такая обработка ошибок сильно контрастирует на фоне других известных форматов, например, HTML — браузер не останавливается отрисовывать web-страницу если в странице забыт закрывающий HTML тэг или значение атрибута тэга содержит неэкранированный амперсанд. (Существует распространённое заблуждение, что в формате HTML не оговорена обработка ошибок. На самом деле, обработка HTML ошибок отлично документирована, но она гораздо сложнее чем просто «остановиться и загореться на первой ошибке».)
Некоторые считают (и я в том числе), что это было ошибкой со стороны разработчиков формата XML заставлять так строго обрабатывать ошибки. Не поймите меня неправильно, я конечно же за упрощение правил обработки ошибок. Однако, на практике понятие «правильнопостроенности» оказывается коварнее чем кажется, особенно для XML документов которые публикуются в интернете и передаются по протоколу HTTP (например, фиды Atom). Несмотря на зрелость XML, который стандартизовал драконову обработку ошибок в 1997, исследования постоянно показывают, что значительная часть фидов Atom в интернете содержат ошибки правильнопостроенности.
Итак, у меня есть и теоретические и практические причины обрабатывать XML документы «любой ценой», то есть не останавливаться и взрываться при первой ошибке. Если Вы окажетесь в похожей ситуации, то lxml может помочь.
Ниже приведён фрагмент «битого» XML документа.
<?xml version='1.0' encoding='utf-8'?> <feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'> <title>dive into …</title> ... </feed>
В фиде ошибка, так как последовательность … не определена в формате XML (она определена в HTML). Если попробовать разобрать битый фид с настройками по умолчанию, то lxml споткнётся на неопределённом вхождении hellip.
>>> import lxml.etree
>>> tree = lxml.etree.parse('examples/feed-broken.xml')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "lxml.etree.pyx", line 2693, in lxml.etree.parse (src/lxml/lxml.etree.c:52591)
File "parser.pxi", line 1478, in lxml.etree._parseDocument (src/lxml/lxml.etree.c:75665)
File "parser.pxi", line 1507, in lxml.etree._parseDocumentFromURL (src/lxml/lxml.etree.c:75993)
File "parser.pxi", line 1407, in lxml.etree._parseDocFromFile (src/lxml/lxml.etree.c:75002)
File "parser.pxi", line 965, in lxml.etree._BaseParser._parseDocFromFile (src/lxml/lxml.etree.c:72023)
File "parser.pxi", line 539, in lxml.etree._ParserContext._handleParseResultDoc (src/lxml/lxml.etree.c:67830)
File "parser.pxi", line 625, in lxml.etree._handleParseResult (src/lxml/lxml.etree.c:68877)
File "parser.pxi", line 565, in lxml.etree._raiseParseError (src/lxml/lxml.etree.c:68125)
lxml.etree.XMLSyntaxError: Entity 'hellip' not defined, line 3, column 28
Для того чтобы обрабатывать XML документ с ошибками, необходимо создать новый синтаксический анализатор XML.
>> parser = lxml.etree.XMLParser(recover=True) ①
>>> tree = lxml.etree.parse('examples/feed-broken.xml', parser) ②
>>> parser.error_log ③
examples/feed-broken.xml:3:28:FATAL:PARSER:ERR_UNDECLARED_ENTITY: Entity 'hellip' not defined
>>> tree.findall('{http://www.w3.org/2005/Atom}title')
[<Element {http://www.w3.org/2005/Atom}title at ead510>]
>>> title = tree.findall('{http://www.w3.org/2005/Atom}title')[0]
>>> title.text ④
'dive into '
>>> print(lxml.etree.tounicode(tree.getroot())) ⑤
<feed xmlns='http://www.w3.org/2005/Atom' xml:lang='en'>
<title>dive into </title>
.
. [остальной вывод сериализации пропущен для краткости]
.
① Для того чтобы создать новый анализатор мы создаём новый класс lxml.etree.XMLParser. Хотя он может принимать много разных параметров, для нас представляет интерес только один — аргумент восстановления recover. При присвоении аргументу значения True lxml будет из кожи вон лезть чтобы восстановить ошибки правильнопостроенности.
② Для того чтобы разобрать XML документ новым анализатором мы передаём объект parser в качестве второго аргумента в функцию parse(). На этот раз lxml не выбрасывает исключительную ситуацию при неопределённой последовательности ….
③ Анализатор содержит сообщения обо всех найденных ошибках. (На самом деле эти сообщения сохраняются независимо от параметра recover.)
④ Так как анализатор не знает что делать с неопределённым …, то он просто выбрасывает слово. Текстовое содержание элемента title превращается в ‘dive into ‘.
⑤ И ещё раз: после сериализации последовательность … исчезла, lxml её выбросил.
Важно отметить, что нет никакой гарантии переносимости восстановления ошибок у XML анализаторов. Другой анализатор может быть умнее и распознать что … является валидной последовательностью HTML и восстановить её как амперсанд. «Лучше» ли это? Возможно. Является ли это «более правильным»? Нет, так как оба решения с точки зрения формата XML неверны. Правильное поведение (согласно XML спецификации) прекратить обработку и загореться. Если же необходимо не следовать спецификации, то Вы делаете это на свой страх и риск.
Материалы для дальнейшего чтения
XML на Википедии
The ElementTree XML API(англ.)
Elements and Element Trees — Элементы и деревья элементов(англ.)
XPath Support in ElementTree — Поддержка XPath в ElementTree(англ.)
The ElementTree iterparse Function — Функция iterparse в ElementTree(англ.)
lxml(англ.)
Parsing XML and HTML with lxml — обработка XML и HTML в lxml(англ.)
XPath and XSLT with lxml — XPath и XSLT в lxml(англ.)
xmlwitch(англ.)
java — Ошибка синтаксического анализа XML-документа
java — Ошибка синтаксического анализа XML-документа — qaru
Присоединяйтесь к Stack Overflow , чтобы учиться, делиться знаниями и строить свою карьеру.
Спросил
8 лет, 11 мес. Назад
Просмотрено
542 раза
Я использую Xerces 2.11.0 для моего проекта. Но во время рома я получаю сообщение об ошибке. Трассировка стека ошибки выглядит следующим образом:
java.lang.Exception: org.openid4java.discovery.DiscoveryException: 0x70d: ошибка синтаксического анализа XML-документа
в org.iitk.brihaspati.modules.actions.GoogleRequest.performDiscoveryOnUserSuppliedIdentifier (GoogleRequest.java:83)
на org.iitk.brihaspati.modules.actions.GoogleLogin.doPerform (GoogleLogin.java:86)
в org.apache.turbine.modules.actions.VelocityAction.doPerform (VelocityAction.java:84)
в org.apache.turbine.util.velocity.VelocityActionEvent.perform (VelocityActionEvent.java:120)
в org.apache.turbine.modules.actions.VelocityAction.perform (VelocityAction.java:110)
в org.apache.turbine.modules.ActionLoader.exec (ActionLoader.java:134)
в org.apache.turbine.modules.pages.DefaultPage.doBuild (DefaultPage.java:154)
в org.apache.turbine.modules.Page.build (Page.java:91)
в org.apache.turbine.modules.PageLoader.exec (PageLoader.java:136)
на org.apache.turbine.Turbine.doGet (Turbine.java:796)
на org.apache.turbine.Turbine.doPost (Turbine.java:891)
в javax.servlet.http.HttpServlet.service (HttpServlet.java:760)
в javax.servlet.http.HttpServlet.service (HttpServlet.java:853)
в org.apache.catalina.servlets.InvokerServlet.serveRequest (InvokerServlet.java:466)
в org.apache.catalina.servlets.InvokerServlet.doPost (InvokerServlet.java:216)
на javax.servlet.http.HttpServlet.service (HttpServlet.java:760)
в javax.servlet.http.HttpServlet.service (HttpServlet.java:853)
в org.apache.catalina.core.ApplicationFilterChain.internalDoFilter (ApplicationFilterChain.java:247)
в org.apache.catalina.core.ApplicationFilterChain.doFilter (ApplicationFilterChain.java:193)
в org.apache.catalina.core.StandardWrapperValve.invoke (StandardWrapperValve.java:256)
в org.apache.catalina.core.StandardPipeline $ StandardPipelineValveContext.invokeNext (StandardPipeline.java:643)
в org.apache.catalina.core.StandardPipeline.invoke (StandardPipeline.java:480)
в org.apache.catalina.core.ContainerBase.invoke (ContainerBase.java:995)
в org.apache.catalina.core.StandardContextValve.invoke (StandardContextValve.java:191)
в org.apache.catalina.core.StandardPipeline $ StandardPipelineValveContext.invokeNext (StandardPipeline.java:643)
в org.apache.catalina.authenticator.AuthenticatorBase.invoke (AuthenticatorBase.java: 494)
в org.apache.catalina.core.StandardPipeline $ StandardPipelineValveContext.invokeNext (StandardPipeline.java:641)
в org.apache.catalina.core.StandardPipeline.invoke (StandardPipeline.java:480)
в org.apache.catalina.core.ContainerBase.invoke (ContainerBase.java:995)
в org.apache.catalina.core.StandardContext.invoke (StandardContext.java:2417)
в org.apache.catalina.core.StandardHostValve.invoke (StandardHostValve.java:180)
на org.apache.catalina.core.StandardPipeline $ StandardPipelineValveContext.invokeNext (StandardPipeline.java:643)
в org.apache.catalina.valves.ErrorDispatcherValve.invoke (ErrorDispatcherValve.java:171)
в org.apache.catalina.core.StandardPipeline $ StandardPipelineValveContext.invokeNext (StandardPipeline.java:641)
в org.apache.catalina.valves.ErrorReportValve.invoke (ErrorReportValve.java:172)
в org.apache.catalina.core.StandardPipeline $ StandardPipelineValveContext.invokeNext (StandardPipeline.java: 641)
в org.apache.catalina.valves.AccessLogValve.invoke (AccessLogValve.java:577)
в org.apache.catalina.core.StandardPipeline $ StandardPipelineValveContext.invokeNext (StandardPipeline.java:641)
в org.apache.catalina.core.StandardPipeline.invoke (StandardPipeline.java:480)
в org.apache.catalina.core.ContainerBase.invoke (ContainerBase.java:995)
в org.apache.catalina.core.StandardEngineValve.invoke (StandardEngineValve.java:174)
на org.apache.catalina.core.StandardPipeline $ StandardPipelineValveContext.invokeNext (StandardPipeline.java:643)
в org.apache.catalina.core.StandardPipeline.invoke (StandardPipeline.java:480)
в org.apache.catalina.core.ContainerBase.invoke (ContainerBase.java:995)
в org.apache.catalina.connector.http.HttpProcessor.process (HttpProcessor.java:1040)
в org.apache.catalina.connector.http.HttpProcessor.run (HttpProcessor.java:1151)
в java.lang.Thread.run (Thread.java:636)
Вызвано: org.openid4java.discovery.DiscoveryException: 0x70d: ошибка синтаксического анализа XML-документа
в org.openid4java.discovery.xrds.XrdsParserImpl.parseXmlInput (XrdsParserImpl.java:197)
в org.openid4java.discovery.xrds.XrdsParserImpl.parseXrds (XrdsParserImpl.java:50)
в org.openid4java.discovery.yadis.YadisResolver.retrieveXrdsLocation (YadisResolver.java:448)
в org.openid4java.discovery.yadis.YadisResolver.discover (YadisResolver.java:252)
в org.openid4java.discovery.yadis.YadisResolver.обнаружить (YadisResolver.java:232)
в org.openid4java.discovery.yadis.YadisResolver.discover (YadisResolver.java:166)
в org.openid4java.discovery.Discovery.discover (Discovery.java:147)
в org.openid4java.discovery.Discovery.discover (Discovery.java:129)
в org.openid4java.consumer.ConsumerManager.discover (ConsumerManager.java:542)
в org.iitk.brihaspati.modules.actions.GoogleRequest.performDiscoveryOnUserSuppliedIdentifier (GoogleRequest.java:74)
... еще 46
Вызвано: org.xml.sax.SAXParseException: s4s-att-invalid-value: недопустимое значение атрибута для 'targetNamespace' в элементе 'schema'. Записанная причина: cvc-datatype-valid.1.2.1: 'xri: // $ xrd * ($ v * 2.0)' не является допустимым значением для 'anyURI'.
в org.apache.xerces.parsers.DOMParser.parse (неизвестный источник)
в org.apache.xerces.jaxp.DocumentBuilderImpl.parse (неизвестный источник)
в javax.xml.parsers.DocumentBuilder.parse (неизвестный источник)
в org.openid4java.discovery.xrds.XrdsParserImpl.parseXmlInput (XrdsParserImpl.java: 188)
... еще 55
Я пробовал и другие версии, такие как Xerces 2.8.1 и Xerces 2.8.0. Но каждый раз я получаю одну и ту же ошибку.
UVM
9,51655 золотых знаков3939 серебряных знаков6363 бронзовых знака
задан 16 мая ’12 в 9: 222012-05-16 09:22
Проблема и возможное решение приведены здесь:
Создан 16 мая ’12 в 9: 302012-05-16 09:30
paulsm4paulsm4
98.4k1515 золотых знаков124124 серебряных знака157157 бронзовых знаков
2
Не тот ответ, который вы ищете? Просмотрите другие вопросы с метками java linux или задайте свой вопрос.
язык-Java
Stack Overflow лучше всего работает с включенным JavaScript
Ваша конфиденциальность
Нажимая «Принять все файлы cookie», вы соглашаетесь с тем, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Принимать все файлы cookie
Настроить параметры
android — ошибка синтаксического анализа XML неправильно сформирована
Это, вероятно, простой вопрос, но я огляделся и попытался исправить свой код, но безрезультатно.Я получаю неверно сформированную ошибку синтаксического анализа XML в строке:
android: text = "@ string / button_string"
Мой файл strings.xml:
<ресурсы>
Практическое приложение
Настройки
Привет, мир!
я
aldo
GRA
AME
cush
conn
меню
И мой файл activity_main:
<Кнопка
android: id = "@ + id / button1"
android: layout_width = "50sp"
android: layout_height = "50sp"
android: layout_above = "@ + id / button2"
android: layout_alignLeft = "@ + id / button2"
android: layout_marginBottom = "12dp"
android: background = "@ drawable / round_button"
android: gravity = "center_vertical | center_horizontal"
android: text = "@ строка / button_string"
android: textColor = "# fff" />
...
Заранее благодарим за любые предложения / помощь в решении этой проблемы.
blogger — Ошибка синтаксического анализа XML, строка 2152, столбец 10: структуры XML-документа должны начинаться и заканчиваться в одном объекте
blogger — Ошибка синтаксического анализа XML, строка 2152, столбец 10: структуры XML-документа должны начинаться и заканчиваться в одном объекте — Стек Переполнение
Присоединяйтесь к Stack Overflow , чтобы учиться, делиться знаниями и строить свою карьеру.
Спросил
6 лет, 7 мес. Назад
Просмотрено
3к раз
Закрыто. Этот вопрос требует подробностей отладки. В настоящее время он не принимает ответы.
Хотите улучшить этот вопрос? Обновите вопрос, чтобы он соответствовал теме Stack Overflow.
Закрыт 6 лет назад.
Помогите пожалуйста.Я не уверен, к какому «объекту» относится ошибка. Я попытался скопировать ответы на предыдущие вопросы, подобные этому, но я думаю, что это зависит от HTML. Я знаю, что это не так сложно, но я новичок в этом, поэтому я не знаком с настройкой html существующего шаблона blogger.
Я ценю быстрые ответы.
Создан 25 авг.
Люкс Ганзон
111 серебряный знак11 бронзовый знак
5
Сущность XML для целей этого сообщения — это внешняя анализируемая сущность.То есть кусок XML, находящийся в каком-то другом месте, который включается в ваш XML через определение DTD. Ошибка сообщает вам, что начало ( ) и его соответствующий конец ( ) должны находиться внутри одного и того же объекта — исходного основного ввода XML или одного внешнего встроенного элемента. Нельзя начинать одним и заканчивать другим.
Создан 25 авг.
bmarguliesbmargulies
90.8k3838 золотых знаков165165 серебряных знаков288288 бронзовых знаков
Не тот ответ, который вы ищете? Посмотрите другие вопросы с метками xml blogger head или задайте свой вопрос.
lang-xml
Stack Overflow лучше всего работает с включенным JavaScript
Ваша конфиденциальность
Нажимая «Принять все файлы cookie», вы соглашаетесь с тем, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Принимать все файлы cookie
Настроить параметры
XML-mas — Исправление «Ошибка синтаксического анализа XML в строке …»
23 декабря, 2015
| Рави Мистри
XML-mas — Исправление «Ошибка синтаксического анализа XML в строке…»
Недавно я столкнулся с проблемой, которую никогда раньше не видел, и подумал, что поделюсь своим опытом и исправлением, которое я нашел с помощью Tableau.xml, который находится под книгой. Сама по себе эта проблема встречается довольно редко, но если она возникает, то это один из подходов к решению этой конкретной проблемы.
Иногда Tableau становится поврежденным; одна из таких проблем — «Ошибка синтаксического анализа XML в строке <вставьте сюда любое число> файла…» при открытии книги. Это когда вы думаете, что действительно облажались. В статье базы знаний Tableau рекомендуется отправить их им, если размер книги превышает 0 КБ, что может занять время, чтобы отправить и вернуть.Хотя, как говорится в этой статье, если в вашей рабочей тетради указано, что это 0 КБ… Вам придется начинать заново.
Но если это файл больше 0 КБ, еще не все потеряно! Вы можете попробовать это решение, если оно вам подходит, но для того, чтобы выполнить это решение, вам потребуется;
- Рабочая книга Tableau в формате .twb
- Примечание: если вы сохранили его как файл .twbx, все, что вам нужно сделать, это перейти туда, где вы его сохранили на своем компьютере, щелкните правой кнопкой мыши и выберите «Распаковать», и он разделит рабочую книгу Tableau ( .twb) от остальных данных.
- Программа текстового редактора, например Notepad ++ .
- В примере, который я собираюсь показать, в качестве инструмента редактирования XML используется Notepad ++
Получили? Хорошо! Пойдем и спасем эту тетрадь.
Я собираюсь использовать здесь в качестве примера свое собственное тематическое исследование.
Когда мне представили эту проблему, я попробовал множество разных вещей, прежде чем решил открыть.twb в Блокноте ++.
Но зачем вам в первую очередь открывать его в Блокноте ++? И что же такое XML рабочей книги Tableau?
Как говорится в этом ответе Джонатана Драмми в сообществе Tableau (которое является отличным местом для устранения неполадок, изучения и оттачивания навыков работы с Tableau), файл .twb — это файл XML, который содержит метаданные для книги Tableau.
Когда вы его открываете, это выглядит примерно так:
Этот XML-файл .twb включает подключения к источникам данных, информационные панели, рабочие листы, используемые цвета, параметры и практически все, что позволяет рабочей книге функционировать.Когда я открыл книгу и перешел к строке, в которой возникла ошибка (в моем сообщении об ошибке говорилось: «Ошибка синтаксического анализа XML в строке 411386…»), меня поприветствовал именно этот вид.
Ха — Это «NULL» значения в конце XML, выделенные выше —
Возможно, он пытался написать еще немного XML до того, как компьютер сломался или что-то подобное. Первым делом я попытался просто удалить все файлы NULL в этой строке и снова открыть ее. Никаких кубиков.
Затем, немного поразмыслив, я подумал, что могу сравнить конец этого.twb в другой «здоровый» файл .twb, который у меня был. Как выглядел XML * этого * файла, показано ниже.
Бинго! Это решение, которое я ищу.
Похоже, что произошло следующее: когда компьютер вышел из строя и файл стал поврежденным, окончательная упаковка метаданных не была завершена, то есть XML-файл остался открытым и неполным. Я выделил и расширил то, что я имею в виду, говоря об упаковке с тегами xml в конце книги.
Чтобы проверить эту теорию, я скопировал здесь три части; торцевые детали (показаны выше) и вклеил в свои поврежденные.twb, чтобы заменить символы NULL.
И, как по волшебству, тетрадь ожила!
Я, вероятно, должен добавить, что я уверен, что есть больше деталей для работы с XML рабочей книги Tableau, чем я описал здесь, и я должен сказать, что этот XML очень важен, поэтому не следует чрезмерно путаться с ним, если вы ‘ Вы не уверены, к каким последствиям приведет то, что вы делаете. Единственный раз, когда я столкнулся с использованием этого метода, чтобы заглянуть «под капот» a.twb, должен был изменить все экземпляры «9.1» на «9.0» во время клиентских проектов в Data School. Этот трюк означал, что если мы случайно создали что-то в бета-версии Tableau 9.1 и захотели поделиться этим с заказчиком после завершения проекта, они могли бы открыть файл в Tableau 9.0.
Но, надеюсь, это решит хотя бы одну проблему другого человека, когда в Таблице появится сообщение «Ошибка синтаксического анализа XML в строке X файла: элемент не найден».
Ошибка
Word: ошибка синтаксического анализа XML
При экспорте отчета иногда проблемы не возникают, пока вы не откроете документ Word.Если вас приветствуют следующие сведения об ошибке, используйте это руководство для отладки и устранения ошибки:
Ошибка синтаксического анализа XML
Расположение: Часть: /word/document.xml. Строка: 19159, Колонка: 8
Это, вероятно, наиболее распространенное сообщение об ошибке, которое выдает документ Word. Поскольку это настолько общий характер, нет быстрого универсального решения проблемы. Но Location действительно дает нам возможность быстро определить источник ошибки, чтобы мы могли ее устранить.
Чтобы устранить эту ошибку:
-
Переименуйте файл с
.docxили.docmв.zip. Например, переименуйте dradis-word_report-151.docm в dradis-word_report-151.zip . -
Распакуйте файл и откройте новую папку (например, dradis-word_report-151/). Откройте файл, указанный в
Locationвыше, в вашем любимом текстовом редакторе (например, / word / document.xml ). -
Прокрутите вниз до конкретной строки, указанной в сообщении об ошибке (например, , строка 19159 , и проверьте содержимое до / после этой строки.
Источник ошибки может быть до или после конкретной строки, указанной в сообщении об ошибке. По сути, мы ищем текстовую строку как можно ближе к конкретной строке, чтобы мы могли найти источник ошибки в нашем проекте Dradis.
-
Найдите в своем проекте строку, указанную выше, и исследуйте ее содержимое.
-
Если вы не можете найти ничего интересного вокруг первой строки поиска, попробуйте вернуться к XML и использовать строку поиска из содержимого непосредственно после строки, указанной в сообщении об ошибке.
И, если вы не можете найти ничего подозрительного в проекте Dradis, попробуйте проверить свой шаблон отчета Dradis на предмет «Сумасшедших треугольников».
-
После устранения ошибки в проекте Dradis попробуйте снова экспортировать отчет. Если вы получите еще одну ошибку анализа
XML, обязательно проверьте новое расположение, указанное в сообщении об ошибке.
Например, если строка в сообщении об ошибке идет после строки, которая ссылается на:
HTTP-сервер Apache 1.3 Ожидает межсайтового скриптинга заголовка
Найдите в своем проекте Apache 1.3 HTTP и исследуйте его содержимое.
Обратите внимание на ссылки, которые имеют странный формат, код / специальные символы, не заключенные в блок кода, или ошибочные восклицательные знаки.
Ошибка синтаксического анализа XML: как интерпретировать то, что вам сообщает машина
| 1 | Анализатор обнаружил недопустимый символ при сканировании пробелов вне содержимого элемента. |
| 2 | Анализатор обнаружил недопустимое начало инструкции обработки, элемента, комментария или объявления типа документа вне содержимого элемента. |
| 3 | Анализатор обнаружил повторяющееся имя атрибута. |
| 4 | Анализатор обнаружил символ разметки «<» в значении атрибута. |
| 5 | Имена начального и конечного тегов элемента были разными. |
| 6 | Анализатор обнаружил недопустимый символ в содержимом элемента. |
| 7 | Анализатор обнаружил недопустимое начало элемента, комментария, инструкции обработки или раздела CDATA (символьные данные) в содержимом элемента. |
| 8 | Анализатор обнаружил в содержимом элемента последовательность закрывающих символов CDATA ‘]]>’ без соответствующей последовательности открывающих символов ‘ |
| 9 | Анализатор обнаружил недопустимый символ в комментарии. |
| 10 | Синтаксический анализатор обнаружил в комментарии последовательность символов «-» (два дефиса) без символа «>». |
| 11 | Анализатор обнаружил недопустимый символ в сегменте данных инструкции обработки. |
| 12 | Целевым именем инструкции обработки было «xml» в любом из нижних, верхних или переключаемых регистров. |
| 13 | Синтаксический анализатор обнаружил недопустимую цифру в шестнадцатеричной символьной ссылке (в форме & # xdddd; например, & # x0eb1). |
| 14 | Анализатор обнаружил недопустимую цифру в ссылке на десятичный символ (в форме & # dddd;). |
| 15 | Ссылка на символ не относится к авторизованному символу XML. |
| 16 | Анализатор обнаружил недопустимый символ в имени ссылки на объект. |
| 17 | Анализатор обнаружил недопустимый символ в значении атрибута. |
| 18 | Анализатор обнаружил возможное недопустимое начало объявления типа документа. |
| 19 | Анализатор обнаружил объявление второго типа документа. |
| 20 | Имя элемента указано неверно. Начальный символ не был буквой «_» или «:», либо синтаксический анализатор обнаружил недопустимый символ в имени элемента или после него. |
| 21 | Атрибут указан неправильно. Начальный символ имени атрибута не был буквой, ‘_’ или ‘:’, или после имени атрибута был обнаружен символ, отличный от ‘=’, или один из разделителей значения был неправильным, или Обнаружен недопустимый символ в имени или после него. |
| 22 | Пустой тег элемента не заканчивался символом языка разметки ‘>’, следующим за ‘/’. |
| 23 | Конечный тег элемента указан неправильно. Начальный символ не был буквой «_» или «:», или тег не заканчивался знаком «>». |
| 24 | Анализатор обнаружил недопустимое начало комментария или раздела CDATA в содержимом элемента. |
| 25 | Целевое имя инструкции обработки указано неправильно.Начальным символом целевого имени инструкции обработки не была буква, «_» или «:», либо синтаксический анализатор обнаружил недопустимый символ в имени целевого объекта инструкции обработки или после него. |
| 26 | Инструкция обработки не была завершена последовательностью закрывающих символов ‘?>’. |
| 27 | Синтаксический анализатор обнаружил недопустимый символ, следующий за «&» в ссылке на символ или ссылку на объект. |
| 28 | Информация о версии отсутствовала в декларации XML. |
| 29 | «Версия» в декларации XML указана неверно. ‘версия’ не сопровождалась ‘=’, или значение отсутствовало или было неправильно разделено, или значение указывало неверный символ, или начальный и конечный разделители не совпадали, или синтаксический анализатор обнаружил недопустимый символ, следующий за версией закрывающий ограничитель информационного значения в XML-объявлении. |
| 30 | Анализатор обнаружил недопустимый атрибут вместо необязательного объявления кодировки в объявлении XML. |
| 31 | Значение объявления кодировки в объявлении XML отсутствует или неверно. Значение не начинается со строчных или прописных букв от A до Z, или за ‘кодировкой’ не следовало ‘=’, или значение отсутствовало или неправильно разделено, или оно указывало неверный символ, или начальный и конечный разделители не использовались. совпадение, или анализатор обнаружил недопустимый символ после закрывающего разделителя. |
| 32 | Анализатор обнаружил недопустимый атрибут вместо необязательного автономного объявления в объявлении XML. |
| 33 | Атрибут «standalone» в объявлении XML указан неправильно. ‘standalone’ не сопровождался знаком ‘=’, или значение отсутствовало или было неправильно разделено, или значение не было ни ‘да’, ни ‘нет’, или значение указывало неверный символ, или начальный и конечный разделители не совпало, или анализатор обнаружил недопустимый символ после закрывающего разделителя. |
| 34 | Объявление XML не было завершено правильной последовательностью символов «?>» Или содержало недопустимый атрибут. |
| 35 | Анализатор обнаружил начало объявления типа документа после конца корневого элемента. |
| 36 | Анализатор обнаружил начало элемента после конца корневого элемента. |
| 300 | Синтаксический анализатор дошел до конца соответствующего документа до того, как документ был завершен. |
| 301 | Процедура% HANDLER для XML-INTO или XML-SAX вернула ненулевое значение, в результате чего синтаксический анализ XML завершился. |
| 302 | Синтаксический анализатор не поддерживает запрошенное значение CCSID или первый символ XML-документа не был «<«. |
| 303 | Соответствующий документ слишком велик для обработки парсером. Синтаксический анализатор попытался проанализировать неполный документ, но данные в конце документа были необходимы для завершения синтаксического анализа. |
| 500-999 | Внутренняя ошибка внешнего анализатора. Сообщите об ошибке представителю сервисной службы. |
| 10001-19999 | Внутренняя ошибка анализатора. Сообщите об ошибке представителю сервисной службы. |
XML-документ должен содержать сообщение об ошибке «элемент верхнего уровня» при попытке назначить запись с 20–50 дочерними записями или при попытке предоставить общий доступ к записи более чем 20–50 пользователям одновременно в Microsoft CRM
Ошибка «Ошибка синтаксического анализатора XML: XML-документ должен иметь элемент верхнего уровня» возникает в Microsoft Business Solutions — CRM (861319).
Симптомы
Когда вы пытаетесь поделиться записью с более чем 20-50 пользователями или пытаетесь назначить запись с 20-50 дочерними записями одновременно в Microsoft CRM, вы получаете следующие сообщения об ошибке:
Ошибка синтаксического анализатора XML: документ XML должен иметь элемент верхнего уровня.
Произошла ошибка в сценарии на этой странице. Вы хотите продолжить выполнение сценариев на этой странице?
Причина
Когда вы делитесь записью примерно с 20-50 пользователями одновременно, Microsoft CRM истекает время ожидания и не может выполнить запрос. Когда вы копируете роль безопасности с большими или сложными иерархиями бизнес-единиц, приложение Microsoft CRM выходит из строя и не может выполнить запрос.
Разрешения
Разрешение 1
Если вы планируете делиться записями более чем с 20 людьми одновременно, мы рекомендуем вам создать группы для совместного использования. Для этого выполните следующие действия:
-
Щелкните Параметры , щелкните Бизнес-единицы и параметры , щелкните Команды , а затем щелкните Создайте команду, чтобы включить всех пользователей, которым вы хотите предоставить общий доступ к записи .
-
Зайдите в запись и поделитесь ею со своей вновь созданной командой.
Разрешение 2
Вы также можете увеличить время ожидания на сервере Microsoft CRM, выполнив следующие действия:
-
На сервере Microsoft CRM найдите System Drive / WINNT% Microsoft.Нетто Framework v1.0.3705 Config.
Примечание. В Microsoft Windows Server 2003 папка WINNT% будет называться WINDOWS.
Примечание. Для .NET Framework 1.1 папка v1.0.3705 будет называться v1.1.4322.
-
Щелкните правой кнопкой мыши файл Machine.config и выберите Открыть с помощью . Щелкните Блокнот , а затем щелкните ОК .
-
Выполните поиск с использованием executionTimeout = «90», а затем измените значение по умолчанию с 90 на 1200.
-
Выполните поиск с помощью responseDeadlockInterval = «00:03:00», а затем измените значение по умолчанию с 00:03:00 на 00:20:00
-
Сохраните изменения и закройте файл Machine.config.
Дополнительная информация
Для получения дополнительных сведений о копировании ролей безопасности щелкните следующий номер статьи в базе знаний Microsoft:
835292 Копирование роли не работает в Microsoft Business Solutions CRM версии 1.
python — Ошибка парсинге сайта
Короче есть код для парсинга сайта, первый раз он почти спарсил всё что нужно, но потом при повторных перезапусках в строке 42 он может выдавать ошибку «occupations» или в 74 «workers», а может выдать одну из них отпарсив уже несколько страниц, хотя первые разы такого не было, в чем проблема? Строки с ошибками пометил комментариями
import json
import time
import requests
from bs4 import BeautifulSoup
import os
from colorama import init, Fore, Back, Style
def fetch(url,params):
headers = params['headers']
body = params['body']
if params['method']=='GET':
return requests.get(url,headers=headers)
if params['method']=='POST':
return requests.post(url,headers=headers,data=body)
return requests
main_page = fetch("https://uslugi.yandex.ru/api/213-moscow/get_home_rubrics?lr=213&workersCount=true", {
"headers": {
"accept": "application/json, text/plain, */*",
"accept-language": "ru-RU,ru;q=0.9",
"content-type": "application/json;charset=UTF-8",
"sec-ch-ua": ""Chromium";v="102", "Opera GX";v="88", ";Not A Brand";v="99"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": ""Windows"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"x-app-version": "2.![]() 2447.0-15f89d2af056750a15086038994cba0e5bfeea51.0",
"x-csrf-token": "da2f836cc33b86d110f223c0f134d10fd47f75e1:1656503032",
"x-expected-puid": "",
"x-requested-with": "XMLHttpRequest",
"x-retpath-y": "https://uslugi.yandex.ru/213-moscow/catalog?rubric=%2Fkrasota",
"cookie": "yandexuid=2585937781656503024; i=gWrntQ7lN3x3Uw5qP0Qz15+IdJQ5aqQRg67OJMWpzHPOsjah4cLe4bx1+Vp/twBpHbZv9BdJW9noXS+kKVTl8HPt7l0=; _yasc=2w/cmb9EmlLja6ze+YvsuHHaSC1fsXOTMKq4gKynm/cOzsMs; yuidss=2585937781656503024; ymex=1971863025.yrts.1656503025; gdpr=0; _ym_uid=1656503024996753070; _ym_d=1656503025; _ym_visorc=b; spravka=dD0xNjU2NTAzMDMyO2k9OTUuMzEuMTY0LjE0NztEPTkzRTg4RUU2M0VBMTg2NjNFNTQzNTNCREIyNEUzMTVFNjU1QTVGMjI1NzU2NDNGRjMxRTk3NTE2NEYyN0Y4Q0VBNzBCQ0M2NDt1PTE2NTY1MDMwMzI4NjY4NzEzNjk7aD0zYThmYTliZWYzNTU1NDMzZjk0MmM0NDMyNjAwYTk5Mg==; _ym_isad=2",
"Referer": "https://uslugi.yandex.ru/213-moscow/catalog?rubric=%2Fkrasota",
"Referrer-Policy": "strict-origin-when-cross-origin",
'User-Agent': 'Mozilla/5. 0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.115 Safari/537.36 OPR/88.0.4412.65'
},
"body": "{"data":{"params":{}}}",
"method": "POST"
})
for i in range(58):
name_for_dir = main_page.json()['occupations'][8]['specializations'][i]['name'] # Ошибка occupations
os.mkdir(f'{name_for_dir}')
print('t'+Fore.RED + main_page.json()['occupations'][8]['specializations'][i]['name']+Fore.RESET)
krasota_specializations_id = main_page.json()['occupations'][8]['specializations'][i]['numberId']
krasota_specializations_seoID = 'https://uslugi.yandex.ru/api/213-moscow/category' + main_page.json()['occupations'][8]['specializations'][i]['seoId']
for page in range(10):
print('t'+Fore.RED+f'Page: {page} from 10'+Fore.RESET)
workers = fetch(f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}", {
"headers": {
"accept": "application/json, text/plain, */*",
"accept-language": "ru-RU,ru;q=0.9",
"sec-ch-ua": ""Chromium";v="102", "Opera GX";v="88", ";Not A Brand";v="99"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": ""Windows"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"x-app-version": "2.
2447.0-15f89d2af056750a15086038994cba0e5bfeea51.0",
"x-csrf-token": "5d9ba3e6858087eb66d56266930eee265a79cf3d:1656503276",
"x-expected-puid": "",
"x-requested-with": "XMLHttpRequest",
"x-retpath-y": f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}",
"x-uslugi-apitargeturl": f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}",
"cookie": "yandexuid=2585937781656503024; i=gWrntQ7lN3x3Uw5qP0Qz15+IdJQ5aqQRg67OJMWpzHPOsjah4cLe4bx1+Vp/twBpHbZv9BdJW9noXS+kKVTl8HPt7l0=; yuidss=2585937781656503024; ymex=1971863025.yrts.1656503025; gdpr=0; _ym_uid=1656503024996753070; _ym_d=1656503025; _ym_visorc=b; spravka=dD0xNjU2NTAzMDMyO2k9OTUuMzEuMTY0LjE0NztEPTkzRTg4RUU2M0VBMTg2NjNFNTQzNTNCREIyNEUzMTVFNjU1QTVGMjI1NzU2NDNGRjMxRTk3NTE2NEYyN0Y4Q0VBNzBCQ0M2NDt1PTE2NTY1MDMwMzI4NjY4NzEzNjk7aD0zYThmYTliZWYzNTU1NDMzZjk0MmM0NDMyNjAwYTk5Mg==; _ym_isad=2; is_gdpr=0; is_gdpr_b=CNzDcxC+ew==; _yasc=/BObO2mO50Khb3LNMjsrTAvUhIW7wjC4qHpExN/rupJa65vp",
"Referer": f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}",
"Referrer-Policy": "strict-origin-when-cross-origin",
'User-Agent': 'Mozilla/5.
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.115 Safari/537.36 OPR/88.0.4412.65'
},
"body": None,
"method": "GET"
})
print(f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}")
persons = workers.json()['workers']['items'] # Ошибка workers
for person in persons:
person_name = persons[person]['personalInfo']['displayName']
try:
person_description = persons[person]['personalInfo']['description'].strip()
except:
person_description = ''
continue
person_socialLinks_appointments = persons[person]['personalInfo']['socialLinks']['appointments']
person_socialLinks_messengers = persons[person]['personalInfo']['socialLinks']['messengers']
person_socialLinks_other = persons[person]['personalInfo']['socialLinks']['other']
person_socialLinks_appointments_list = {}
person_socialLinks_messengers_list = {}
person_socialLinks_other_list = {}
for ln in person_socialLinks_appointments:
first = ln
second = person_socialLinks_appointments[ln]
person_socialLinks_appointments_list[first] = second
for ln in person_socialLinks_messengers:
first = ln
second = person_socialLinks_messengers[ln]
person_socialLinks_messengers_list[first]= second
for ln in person_socialLinks_other:
first = ln
second = person_socialLinks_other[ln]
person_socialLinks_messengers_list[first]= second
if person_socialLinks_appointments == {}:
person_socialLinks_appointments = ''
if person_socialLinks_messengers == {}:
person_socialLinks_messengers = ''
if person_socialLinks_other == {}:
person_socialLinks_other = ''
person_data = []
person_data.
append(
{
'Name: ':person_name,
'Appointments: ':person_socialLinks_appointments_list,
'Messangers: ': person_socialLinks_messengers_list,
'Other Links: ': person_socialLinks_other_list,
'Description: ': person_description
}
)
print(Fore.YELLOW+'Name: '+Fore.RESET+f'{person_name}nn'+Fore.YELLOW+'Links:n'+Fore.GREEN+'Appointments: '+Fore.RESET+f'{person_socialLinks_appointments}n'+
Fore.GREEN+'Messengers: '+Fore.RESET+f'{person_socialLinks_messengers}n'+Fore.GREEN+'Other: '+Fore.RESET+f'{person_socialLinks_other}nn'+Fore.YELLOW+'Description: '+
Fore.RESET+f'{person_description}n')
print(Fore.RED+'----------------------'+Fore.RESET)
with open(f'{name_for_dir}/page_{page+1}.json','a',encoding='utf-8') as file:
json.dump(person_data,file,indent=4,ensure_ascii=False)
2447.0-15f89d2af056750a15086038994cba0e5bfeea51.0",
"x-csrf-token": "da2f836cc33b86d110f223c0f134d10fd47f75e1:1656503032",
"x-expected-puid": "",
"x-requested-with": "XMLHttpRequest",
"x-retpath-y": "https://uslugi.yandex.ru/213-moscow/catalog?rubric=%2Fkrasota",
"cookie": "yandexuid=2585937781656503024; i=gWrntQ7lN3x3Uw5qP0Qz15+IdJQ5aqQRg67OJMWpzHPOsjah4cLe4bx1+Vp/twBpHbZv9BdJW9noXS+kKVTl8HPt7l0=; _yasc=2w/cmb9EmlLja6ze+YvsuHHaSC1fsXOTMKq4gKynm/cOzsMs; yuidss=2585937781656503024; ymex=1971863025.yrts.1656503025; gdpr=0; _ym_uid=1656503024996753070; _ym_d=1656503025; _ym_visorc=b; spravka=dD0xNjU2NTAzMDMyO2k9OTUuMzEuMTY0LjE0NztEPTkzRTg4RUU2M0VBMTg2NjNFNTQzNTNCREIyNEUzMTVFNjU1QTVGMjI1NzU2NDNGRjMxRTk3NTE2NEYyN0Y4Q0VBNzBCQ0M2NDt1PTE2NTY1MDMwMzI4NjY4NzEzNjk7aD0zYThmYTliZWYzNTU1NDMzZjk0MmM0NDMyNjAwYTk5Mg==; _ym_isad=2",
"Referer": "https://uslugi.yandex.ru/213-moscow/catalog?rubric=%2Fkrasota",
"Referrer-Policy": "strict-origin-when-cross-origin",
'User-Agent': 'Mozilla/5. 0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.115 Safari/537.36 OPR/88.0.4412.65'
},
"body": "{"data":{"params":{}}}",
"method": "POST"
})
for i in range(58):
name_for_dir = main_page.json()['occupations'][8]['specializations'][i]['name'] # Ошибка occupations
os.mkdir(f'{name_for_dir}')
print('t'+Fore.RED + main_page.json()['occupations'][8]['specializations'][i]['name']+Fore.RESET)
krasota_specializations_id = main_page.json()['occupations'][8]['specializations'][i]['numberId']
krasota_specializations_seoID = 'https://uslugi.yandex.ru/api/213-moscow/category' + main_page.json()['occupations'][8]['specializations'][i]['seoId']
for page in range(10):
print('t'+Fore.RED+f'Page: {page} from 10'+Fore.RESET)
workers = fetch(f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}", {
"headers": {
"accept": "application/json, text/plain, */*",
"accept-language": "ru-RU,ru;q=0.9",
"sec-ch-ua": ""Chromium";v="102", "Opera GX";v="88", ";Not A Brand";v="99"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": ""Windows"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"x-app-version": "2.
2447.0-15f89d2af056750a15086038994cba0e5bfeea51.0",
"x-csrf-token": "5d9ba3e6858087eb66d56266930eee265a79cf3d:1656503276",
"x-expected-puid": "",
"x-requested-with": "XMLHttpRequest",
"x-retpath-y": f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}",
"x-uslugi-apitargeturl": f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}",
"cookie": "yandexuid=2585937781656503024; i=gWrntQ7lN3x3Uw5qP0Qz15+IdJQ5aqQRg67OJMWpzHPOsjah4cLe4bx1+Vp/twBpHbZv9BdJW9noXS+kKVTl8HPt7l0=; yuidss=2585937781656503024; ymex=1971863025.yrts.1656503025; gdpr=0; _ym_uid=1656503024996753070; _ym_d=1656503025; _ym_visorc=b; spravka=dD0xNjU2NTAzMDMyO2k9OTUuMzEuMTY0LjE0NztEPTkzRTg4RUU2M0VBMTg2NjNFNTQzNTNCREIyNEUzMTVFNjU1QTVGMjI1NzU2NDNGRjMxRTk3NTE2NEYyN0Y4Q0VBNzBCQ0M2NDt1PTE2NTY1MDMwMzI4NjY4NzEzNjk7aD0zYThmYTliZWYzNTU1NDMzZjk0MmM0NDMyNjAwYTk5Mg==; _ym_isad=2; is_gdpr=0; is_gdpr_b=CNzDcxC+ew==; _yasc=/BObO2mO50Khb3LNMjsrTAvUhIW7wjC4qHpExN/rupJa65vp",
"Referer": f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}",
"Referrer-Policy": "strict-origin-when-cross-origin",
'User-Agent': 'Mozilla/5.
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.115 Safari/537.36 OPR/88.0.4412.65'
},
"body": None,
"method": "GET"
})
print(f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}")
persons = workers.json()['workers']['items'] # Ошибка workers
for person in persons:
person_name = persons[person]['personalInfo']['displayName']
try:
person_description = persons[person]['personalInfo']['description'].strip()
except:
person_description = ''
continue
person_socialLinks_appointments = persons[person]['personalInfo']['socialLinks']['appointments']
person_socialLinks_messengers = persons[person]['personalInfo']['socialLinks']['messengers']
person_socialLinks_other = persons[person]['personalInfo']['socialLinks']['other']
person_socialLinks_appointments_list = {}
person_socialLinks_messengers_list = {}
person_socialLinks_other_list = {}
for ln in person_socialLinks_appointments:
first = ln
second = person_socialLinks_appointments[ln]
person_socialLinks_appointments_list[first] = second
for ln in person_socialLinks_messengers:
first = ln
second = person_socialLinks_messengers[ln]
person_socialLinks_messengers_list[first]= second
for ln in person_socialLinks_other:
first = ln
second = person_socialLinks_other[ln]
person_socialLinks_messengers_list[first]= second
if person_socialLinks_appointments == {}:
person_socialLinks_appointments = ''
if person_socialLinks_messengers == {}:
person_socialLinks_messengers = ''
if person_socialLinks_other == {}:
person_socialLinks_other = ''
person_data = []
person_data.
append(
{
'Name: ':person_name,
'Appointments: ':person_socialLinks_appointments_list,
'Messangers: ': person_socialLinks_messengers_list,
'Other Links: ': person_socialLinks_other_list,
'Description: ': person_description
}
)
print(Fore.YELLOW+'Name: '+Fore.RESET+f'{person_name}nn'+Fore.YELLOW+'Links:n'+Fore.GREEN+'Appointments: '+Fore.RESET+f'{person_socialLinks_appointments}n'+
Fore.GREEN+'Messengers: '+Fore.RESET+f'{person_socialLinks_messengers}n'+Fore.GREEN+'Other: '+Fore.RESET+f'{person_socialLinks_other}nn'+Fore.YELLOW+'Description: '+
Fore.RESET+f'{person_description}n')
print(Fore.RED+'----------------------'+Fore.RESET)
with open(f'{name_for_dir}/page_{page+1}.json','a',encoding='utf-8') as file:
json.dump(person_data,file,indent=4,ensure_ascii=False)
 0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.115 Safari/537.36 OPR/88.0.4412.65'
},
"body": "{"data":{"params":{}}}",
"method": "POST"
})
for i in range(58):
name_for_dir = main_page.json()['occupations'][8]['specializations'][i]['name'] # Ошибка occupations
os.mkdir(f'{name_for_dir}')
print('t'+Fore.RED + main_page.json()['occupations'][8]['specializations'][i]['name']+Fore.RESET)
krasota_specializations_id = main_page.json()['occupations'][8]['specializations'][i]['numberId']
krasota_specializations_seoID = 'https://uslugi.yandex.ru/api/213-moscow/category' + main_page.json()['occupations'][8]['specializations'][i]['seoId']
for page in range(10):
print('t'+Fore.RED+f'Page: {page} from 10'+Fore.RESET)
workers = fetch(f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}", {
"headers": {
"accept": "application/json, text/plain, */*",
"accept-language": "ru-RU,ru;q=0.9",
"sec-ch-ua": ""Chromium";v="102", "Opera GX";v="88", ";Not A Brand";v="99"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": ""Windows"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"x-app-version": "2.
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.115 Safari/537.36 OPR/88.0.4412.65'
},
"body": "{"data":{"params":{}}}",
"method": "POST"
})
for i in range(58):
name_for_dir = main_page.json()['occupations'][8]['specializations'][i]['name'] # Ошибка occupations
os.mkdir(f'{name_for_dir}')
print('t'+Fore.RED + main_page.json()['occupations'][8]['specializations'][i]['name']+Fore.RESET)
krasota_specializations_id = main_page.json()['occupations'][8]['specializations'][i]['numberId']
krasota_specializations_seoID = 'https://uslugi.yandex.ru/api/213-moscow/category' + main_page.json()['occupations'][8]['specializations'][i]['seoId']
for page in range(10):
print('t'+Fore.RED+f'Page: {page} from 10'+Fore.RESET)
workers = fetch(f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}", {
"headers": {
"accept": "application/json, text/plain, */*",
"accept-language": "ru-RU,ru;q=0.9",
"sec-ch-ua": ""Chromium";v="102", "Opera GX";v="88", ";Not A Brand";v="99"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": ""Windows"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"x-app-version": "2. 2447.0-15f89d2af056750a15086038994cba0e5bfeea51.0",
"x-csrf-token": "5d9ba3e6858087eb66d56266930eee265a79cf3d:1656503276",
"x-expected-puid": "",
"x-requested-with": "XMLHttpRequest",
"x-retpath-y": f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}",
"x-uslugi-apitargeturl": f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}",
"cookie": "yandexuid=2585937781656503024; i=gWrntQ7lN3x3Uw5qP0Qz15+IdJQ5aqQRg67OJMWpzHPOsjah4cLe4bx1+Vp/twBpHbZv9BdJW9noXS+kKVTl8HPt7l0=; yuidss=2585937781656503024; ymex=1971863025.yrts.1656503025; gdpr=0; _ym_uid=1656503024996753070; _ym_d=1656503025; _ym_visorc=b; spravka=dD0xNjU2NTAzMDMyO2k9OTUuMzEuMTY0LjE0NztEPTkzRTg4RUU2M0VBMTg2NjNFNTQzNTNCREIyNEUzMTVFNjU1QTVGMjI1NzU2NDNGRjMxRTk3NTE2NEYyN0Y4Q0VBNzBCQ0M2NDt1PTE2NTY1MDMwMzI4NjY4NzEzNjk7aD0zYThmYTliZWYzNTU1NDMzZjk0MmM0NDMyNjAwYTk5Mg==; _ym_isad=2; is_gdpr=0; is_gdpr_b=CNzDcxC+ew==; _yasc=/BObO2mO50Khb3LNMjsrTAvUhIW7wjC4qHpExN/rupJa65vp",
"Referer": f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}",
"Referrer-Policy": "strict-origin-when-cross-origin",
'User-Agent': 'Mozilla/5.
2447.0-15f89d2af056750a15086038994cba0e5bfeea51.0",
"x-csrf-token": "5d9ba3e6858087eb66d56266930eee265a79cf3d:1656503276",
"x-expected-puid": "",
"x-requested-with": "XMLHttpRequest",
"x-retpath-y": f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}",
"x-uslugi-apitargeturl": f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}",
"cookie": "yandexuid=2585937781656503024; i=gWrntQ7lN3x3Uw5qP0Qz15+IdJQ5aqQRg67OJMWpzHPOsjah4cLe4bx1+Vp/twBpHbZv9BdJW9noXS+kKVTl8HPt7l0=; yuidss=2585937781656503024; ymex=1971863025.yrts.1656503025; gdpr=0; _ym_uid=1656503024996753070; _ym_d=1656503025; _ym_visorc=b; spravka=dD0xNjU2NTAzMDMyO2k9OTUuMzEuMTY0LjE0NztEPTkzRTg4RUU2M0VBMTg2NjNFNTQzNTNCREIyNEUzMTVFNjU1QTVGMjI1NzU2NDNGRjMxRTk3NTE2NEYyN0Y4Q0VBNzBCQ0M2NDt1PTE2NTY1MDMwMzI4NjY4NzEzNjk7aD0zYThmYTliZWYzNTU1NDMzZjk0MmM0NDMyNjAwYTk5Mg==; _ym_isad=2; is_gdpr=0; is_gdpr_b=CNzDcxC+ew==; _yasc=/BObO2mO50Khb3LNMjsrTAvUhIW7wjC4qHpExN/rupJa65vp",
"Referer": f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}",
"Referrer-Policy": "strict-origin-when-cross-origin",
'User-Agent': 'Mozilla/5. 0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.115 Safari/537.36 OPR/88.0.4412.65'
},
"body": None,
"method": "GET"
})
print(f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}")
persons = workers.json()['workers']['items'] # Ошибка workers
for person in persons:
person_name = persons[person]['personalInfo']['displayName']
try:
person_description = persons[person]['personalInfo']['description'].strip()
except:
person_description = ''
continue
person_socialLinks_appointments = persons[person]['personalInfo']['socialLinks']['appointments']
person_socialLinks_messengers = persons[person]['personalInfo']['socialLinks']['messengers']
person_socialLinks_other = persons[person]['personalInfo']['socialLinks']['other']
person_socialLinks_appointments_list = {}
person_socialLinks_messengers_list = {}
person_socialLinks_other_list = {}
for ln in person_socialLinks_appointments:
first = ln
second = person_socialLinks_appointments[ln]
person_socialLinks_appointments_list[first] = second
for ln in person_socialLinks_messengers:
first = ln
second = person_socialLinks_messengers[ln]
person_socialLinks_messengers_list[first]= second
for ln in person_socialLinks_other:
first = ln
second = person_socialLinks_other[ln]
person_socialLinks_messengers_list[first]= second
if person_socialLinks_appointments == {}:
person_socialLinks_appointments = ''
if person_socialLinks_messengers == {}:
person_socialLinks_messengers = ''
if person_socialLinks_other == {}:
person_socialLinks_other = ''
person_data = []
person_data.
0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.115 Safari/537.36 OPR/88.0.4412.65'
},
"body": None,
"method": "GET"
})
print(f"{krasota_specializations_seoID}--{krasota_specializations_id}?p={page}")
persons = workers.json()['workers']['items'] # Ошибка workers
for person in persons:
person_name = persons[person]['personalInfo']['displayName']
try:
person_description = persons[person]['personalInfo']['description'].strip()
except:
person_description = ''
continue
person_socialLinks_appointments = persons[person]['personalInfo']['socialLinks']['appointments']
person_socialLinks_messengers = persons[person]['personalInfo']['socialLinks']['messengers']
person_socialLinks_other = persons[person]['personalInfo']['socialLinks']['other']
person_socialLinks_appointments_list = {}
person_socialLinks_messengers_list = {}
person_socialLinks_other_list = {}
for ln in person_socialLinks_appointments:
first = ln
second = person_socialLinks_appointments[ln]
person_socialLinks_appointments_list[first] = second
for ln in person_socialLinks_messengers:
first = ln
second = person_socialLinks_messengers[ln]
person_socialLinks_messengers_list[first]= second
for ln in person_socialLinks_other:
first = ln
second = person_socialLinks_other[ln]
person_socialLinks_messengers_list[first]= second
if person_socialLinks_appointments == {}:
person_socialLinks_appointments = ''
if person_socialLinks_messengers == {}:
person_socialLinks_messengers = ''
if person_socialLinks_other == {}:
person_socialLinks_other = ''
person_data = []
person_data. append(
{
'Name: ':person_name,
'Appointments: ':person_socialLinks_appointments_list,
'Messangers: ': person_socialLinks_messengers_list,
'Other Links: ': person_socialLinks_other_list,
'Description: ': person_description
}
)
print(Fore.YELLOW+'Name: '+Fore.RESET+f'{person_name}nn'+Fore.YELLOW+'Links:n'+Fore.GREEN+'Appointments: '+Fore.RESET+f'{person_socialLinks_appointments}n'+
Fore.GREEN+'Messengers: '+Fore.RESET+f'{person_socialLinks_messengers}n'+Fore.GREEN+'Other: '+Fore.RESET+f'{person_socialLinks_other}nn'+Fore.YELLOW+'Description: '+
Fore.RESET+f'{person_description}n')
print(Fore.RED+'----------------------'+Fore.RESET)
with open(f'{name_for_dir}/page_{page+1}.json','a',encoding='utf-8') as file:
json.dump(person_data,file,indent=4,ensure_ascii=False)
append(
{
'Name: ':person_name,
'Appointments: ':person_socialLinks_appointments_list,
'Messangers: ': person_socialLinks_messengers_list,
'Other Links: ': person_socialLinks_other_list,
'Description: ': person_description
}
)
print(Fore.YELLOW+'Name: '+Fore.RESET+f'{person_name}nn'+Fore.YELLOW+'Links:n'+Fore.GREEN+'Appointments: '+Fore.RESET+f'{person_socialLinks_appointments}n'+
Fore.GREEN+'Messengers: '+Fore.RESET+f'{person_socialLinks_messengers}n'+Fore.GREEN+'Other: '+Fore.RESET+f'{person_socialLinks_other}nn'+Fore.YELLOW+'Description: '+
Fore.RESET+f'{person_description}n')
print(Fore.RED+'----------------------'+Fore.RESET)
with open(f'{name_for_dir}/page_{page+1}.json','a',encoding='utf-8') as file:
json.dump(person_data,file,indent=4,ensure_ascii=False)
Ошибка парсинга параметра метода rest типа дата — Вопросы и проблемы
osipenko. aleksey
aleksey
(Osipenko Aleksey)
27.08.2020 01:28:27
#1
Вызываем любой метод rest сервиса с параметром типа Date. При преобразовании строки в дату теряются секунды
belyaev
(Andrey Belyaev)
27.08.2020 07:09:29
#2
А можете сделать небольшую программу, в которой воспроизводится эта проблема? Потому что непонятно, какие библиотеки вы используете, откуда берутся данные и как описана модель сущностей.
Есть пример по использованию retrofit для получения данных из внешних REST API, посмотрите, возможно, поможет.
osipenko.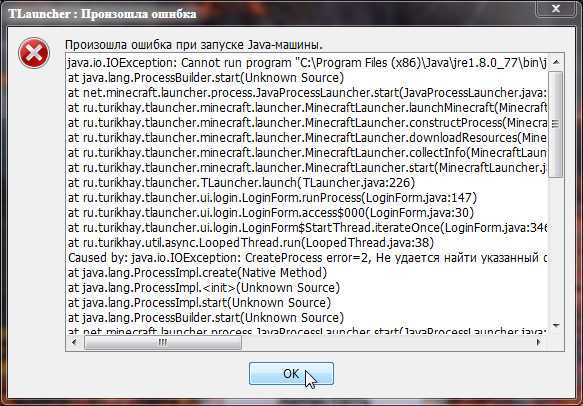 aleksey
aleksey
(Osipenko Aleksey)
27.08.2020 07:20:19
#3
Вы можете создать сами тестовый проект. Создать сервис с одним и параметром типа Date. Далее вызвать этот метод с помощью post запроса и передать значение параметра строку ‘2020-01-01T23:59:59’ после преобразования кубы этого параметра у него пропадают секунды. То есть вы получите дату 2020-01-01 00:00:00
subbotin
(Andrey Subbotin)
27.08.2020 07:33:52
#4
Там точно java.util.Date в качестве аргумента?
Из документации —
Parameter value must be passed in a format defined for the corresponding datatype. For example:
For example:
- if the parameter type is
java.util.Date, then the value pattern is taken from theDateTimeDatatype. By default it isyyyy-MM-dd HH:mm:ss.SSS - for
java.sql.Dateparameter type, the value pattern is taken from theDateDatatypeand it isyyyy-MM-ddby default - for
java.sql.Timethe datatype isTimeDatatypeand the default format isHH:mm:ss
osipenko.aleksey
(Osipenko Aleksey)
27.08.2020 07:46:54
#5
Непонятно то есть формат даты ISO не поддерживается?
subbotin
(Andrey Subbotin)
27. 08.2020 07:52:32
08.2020 07:52:32
#6
В REST сейчас нет ISO формата. Все преобразования данных из строки в объект и обратно зависят от datatype.
osipenko.aleksey
(Osipenko Aleksey)
27.08.2020 07:53:51
#7
Почему так?
osipenko.aleksey
(Osipenko Aleksey)
27.08.2020 07:54:19
#8
Добавьте пожалуйста iso формат для даты
subbotin
(Andrey Subbotin)
27. 08.2020 07:54:26
08.2020 07:54:26
#9
Попробуйте передать дату в формате 2015-01-02 01:02:03.004 и в сервисе аргумент должен быть типа java.util.Date. По автотестам — это сейчас работает. Если не сработает у вас — будем отдельно разбираться.
subbotin
(Andrey Subbotin)
27.08.2020 08:00:31
#10
С добавлением ISO не все так просто: нужно обеспечить совместимость со старыми клиентами, чтобы могло работать и старое и новое поведение, так же необходимо исправление не только для формата данных типа Date (а и для всех остальных примитивных типов) — на это есть тикет: https://github.com/cuba-platform/restapi/issues/89
Почему так: делали единообразие форматирования данных в разных клиентах REST/GUI.
osipenko.aleksey
(Osipenko Aleksey)
27.08.2020 14:09:44
#11
Хорошо, тогда подскажите как нам решить проблему? Может быть мы сможем переопределеить метод который парсит даты передаваемые по rest?
subbotin
(Andrey Subbotin)
28.08.2020 08:35:17
#12
Для сервисов парсинг параметров запроса происходит в spring бине: RestParseUtils. Возможно переопределить этот бин, чтобы парсить дату по своему.
Что это такое и как их исправить
- Блог Hubspot
-
HubSpot. com
 com
com
Загрузка
- Проверьте введенные вами формулы и убедитесь, что они верны.
- Использовать функцию ЕСЛИОШИБКА и отображать другой результат в случае возникновения ошибки. Например. «Не найден.»
- Проверьте правильность написания и убедитесь, что все скобки стоят на своих местах.
- Убедитесь, что вы используете правильные операторы.
- Используйте ссылки на ячейки вместо жестко закодированных значений в формулах.
- Если вы используете текстовые значения, убедитесь, что они заключены в кавычки.
-
Как выделить дубликаты в Google Таблицах [шаг за шагом]
12 июля 2022 г.
-
Как сделать гистограмму в Google Таблицах [5 шагов]
10 июня 2022 г.
-
30 ярлыков Google Sheets, которые нужно знать маркетологам
22 апр. 2022 г.
-
Ошибки синтаксического анализа формул: что это такое и как их исправить
15 апр. 2022 г.
-
Как сортировать в Google Sheets
15 апр. 2022 г.
-
Как использовать функцию «если» в Google Sheets
08 апр. 2022 г.
-
Практическое руководство: условное форматирование на основе другой ячейки в Google Sheets
10 марта 2022 г.
-
Как создать выпадающее меню Google Sheets
03 марта 2022 г.
-
Полное руководство по Google Таблицам
02 февраля 2022 г.
-
21 из лучших бесплатных шаблонов Google Sheets на 2022 год
14 января 2022 г.
- Приложение, которое вы пытаетесь загрузить, может быть несовместимо с вашим устройством.
- Файл приложения, которое вы пытаетесь загрузить, неполный или поврежден.
- Устройство, на которое вы пытаетесь загрузить его, не имеет необходимого разрешения для его загрузки.
- Проблема с самим Android-устройством.
- В приложении, которое вы пытаетесь установить, могут быть некоторые изменения.
- Антивирусное программное обеспечение вашего телефона препятствует установке приложения.
О нет! Мы не смогли найти ничего подобного.
Попробуйте еще раз поискать, и мы постараемся.
Вы работаете с электронной таблицей и хотите использовать функцию.
Вы пишете формулу, взволнованная получением результатов, а затем видите сообщение «Ошибка синтаксического анализа формулы», которое оставляет вас в замешательстве и чувствуете себя немного побежденным.
Давайте рассмотрим, что это на самом деле означает и что может привести к этому сообщению об ошибке.
Что такое ошибка синтаксического анализа формулы?
Ошибка синтаксического анализа формулы возникает, когда вы вводите формулу в ячейку, а программа для работы с электронными таблицами не может понять, что вы от нее хотите.
Это все равно, что пытаться говорить на другом языке, не тратя время на его изучение.
Программное обеспечение может понять, что вы говорите, но недостаточно хорошо, чтобы дать вам точный результат.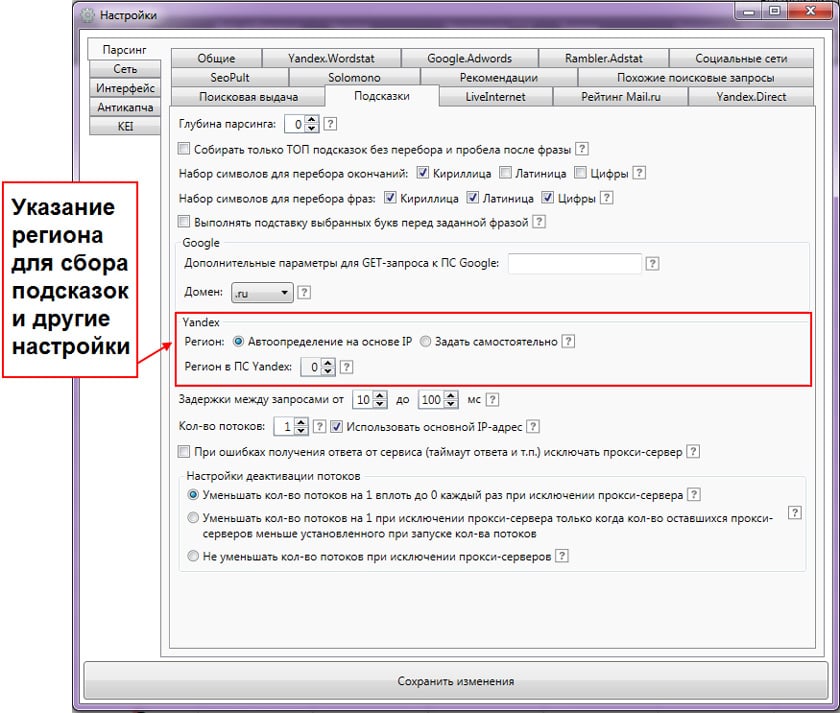
Возможны две причины этой ошибки: опечатка в формуле или неясный порядок операций.
Мы рассмотрим несколько примеров каждого из них, чтобы вы могли определить и исправить их в своих собственных формулах.
Распространенные ошибки синтаксического анализа формулы
Обычно ошибка синтаксического анализа формулы возникает из-за:
Неправильного синтаксиса – Например: ввод =+ вместо =, забывание заключать текстовые значения в кавычки, размещение двух операторов рядом друг с другом без чего-либо между ними
Неполный синтаксис – напр. Опуская скобки.
Другая причина, по которой вы можете получить эти ошибки, заключается в том, что вы пытаетесь использовать текстовые значения вместо чисел.
Давайте рассмотрим конкретные типы ошибок, с которыми вы можете столкнуться:
#N/A Error
Одной из наиболее распространенных ошибок является #N/A. Это происходит, когда формула не может найти то, что ищет.
Например, если вы используете функцию ВПР для поиска значения в таблице, а искомого значения нет в таблице, вы получите ошибку #Н/Д.
#DIV/0 Ошибка
Это происходит при попытке разделить число на ноль.
Например, если у вас есть формула =A17/B17 и значение в B17 равно 0, вы получите #DIV/0! ошибка.
#ССЫЛКА! Ошибка
Если формула содержит недопустимую ссылку на ячейку, вы получите это сообщение об ошибке.
Например, если у вас есть формула, которая ссылается на ячейки A17:A22, и вы удаляете строку 21, формула вернет ошибку #ССЫЛКА! ошибка, потому что у него больше нет действительной ссылки.
Ошибка #ЗНАЧ
Ошибка #ЗНАЧ! ошибка возникает, когда формула содержит недопустимое значение.
Например, если у вас есть формула, которая умножает две ячейки, и одна из ячеек содержит текст вместо числа, вы получите эту ошибку.
#NAME Error
Эта ошибка возникает, когда формула содержит недопустимое имя.
Например, если у вас есть именованный диапазон под названием «Цены», и вы случайно введете «цена» в свою формулу, вы получите ошибку #ИМЯ? ошибка.
#ЧИСЛО Ошибка
#ЧИСЛО! ошибка возникает, когда формула содержит недопустимое число.
Допустим, у вас есть формула, которая делит две ячейки, и результат слишком велик для отображения, вы получите эту ошибку.
Теперь, когда мы знаем, что может вызвать ошибку синтаксического анализа формулы, давайте посмотрим, как мы можем ее исправить.
Как исправить ошибки синтаксического анализа формул
Лучший способ избежать ошибок синтаксического анализа формул — тщательно проверять синтаксис при вводе. Если вы не уверены, в каком порядке должны выполняться операции, вернитесь к порядку операций, предложенному используемым вами программным обеспечением.
Если вы получаете ошибки анализа формулы, вот несколько шагов, которые вы можете предпринять, чтобы исправить их:
Следуя этим шагам, вы сможете избежать ошибок при синтаксическом анализе формул и получить точные результаты из ваших формул.
Темы:
Google Таблицы
Не забудьте поделиться этим постом!
Похожие статьи

Ошибка пакета синтаксического анализа Android — что это такое и как это исправить
— Реклама —
Android-устройства очень популярны по разным причинам. Они поставляются с удобными функциями, а также подходят для любого размера кармана. В отличие от Apple, им не нужна его экосистема для работы, и по этой причине у Android огромное количество поклонников.
Несмотря на то, что они довольно просты в эксплуатации и использовании, существует множество различных ошибок, которые устройство может выдать перед вами. Сегодня мы обсудим одну конкретную ошибку, которая называется анализом ошибки пакета. Мы обсудим шаги по устранению проблемы с Android при анализе ошибки пакета.
Здесь для вас много информации, так что следите за обновлениями!!
Начнем!
Прежде чем двигаться дальше, давайте сначала разберемся, что такое ошибка синтаксического анализа.
Ошибка синтаксического анализа возникает на устройстве Android, когда не удается установить приложение. Это сообщение об ошибке является не чем иным, как указанием на основную проблему. Существует множество проблем, из-за которых приложение может не установиться. Главное, что следует отметить при разборе ошибки пакета, это то, что приложение не удалось установить.
Если вы хотите установить приложение, вам придется решить проблему Android с анализом ошибки пакета.
Ошибка синтаксического анализа может быть вызвана сторонним приложением. Таким образом, когда вы устанавливаете приложение, но оно не устанавливается, вы увидите сообщение типа «ошибка синтаксического анализа» или «возникла проблема при синтаксическом анализе пакета». Эта ошибка может появиться не только в сторонних приложениях, но и при загрузке приложения из Google Play Store. Однако это менее распространенное явление.
Подробнее: — 6 простых шагов для установки новейшей бета-версии Android 12L на Google Pixel
По каким причинам может возникнуть эта ошибка? Наиболее распространенные причины:

Как исправить ошибку Android при анализе ошибки пакета?
Есть несколько способов исправить ошибку синтаксического анализа Android. Вы можете попробовать любой из них, а затем посмотреть, исправлена ли ошибка. Если в случае, если один метод не дал никакого результата, вы можете перейти к следующему.
1. Самое простое и очевидное, что нужно сделать, это обновить Android. Возможно, приложение, которое вы пытаетесь установить, совместимо с последней версией Android. Если текущая версия Android несовместима с приложением, оно будет постоянно показывать ошибку синтаксического анализа.
В худшем случае вам, возможно, придется купить новый телефон, потому что ваш старый телефон может вообще не поддерживать новую версию Android.
2. Следующая возможная причина может заключаться в том, что вы отключили разрешение на установку приложений из сторонних источников. Если вы доверяете источнику приложения, включите разрешение на установку приложений из сторонних источников. Эта опция отключена по умолчанию.
3. Попробуйте включить отладку по USB. Вы можете попробовать установить приложение, включив режим разработчика на своем Android, а затем включив опцию отладки по USB.
4. Попробуйте временно отключить параметры безопасности на вашем телефоне. Если вы доверяете источнику приложения, которое пытаетесь установить, вы можете попробовать установить его один раз после отключения всех функций безопасности. . Функции безопасности вашего телефона могут ошибочно рассматривать приложение как угрозу, из-за чего у приложения могут возникнуть проблемы при установке.
5. Попробуйте снова загрузить и переустановить файл .apk. Как упоминалось выше, файл приложения может быть неполным или поврежденным. Чтобы исправить это, вы можете вернуться на веб-сайт и снова попытаться загрузить исходный файл .apk.
6. Для более продвинутых пользователей одним из возможных решений может быть восстановление измененного файла манифеста. Ошибка синтаксического анализа может возникнуть из-за изменений, внесенных в файл Androidmanifest.xml, который содержится в файле .apk. Вы можете попробовать восстановить файл в исходном виде. Затем повторите попытку установки файла .apk.
7. Если больше ничего не работает, попробуйте восстановить заводские настройки телефона Android. Этот метод немного сложен, потому что он удалит все ваши данные. Это вариант приветствия, который означает, что его следует использовать только тогда, когда вы безуспешно пробовали все другие варианты. Как только вы его перезагрузите, обновите устройство Android до последней версии, а затем попробуйте переустановить приложение.

Forklayer программное обеспечение, которое становиться популярнее с каждым днём, во всём мире. С его помощью легко просматривать FXML, а также с ним удобно изучать интернет аккаунты. ПО нацелено на запросы и обработку FXML-сайтов, и изучение их наполнения. Есть возможность открытия индивидуальных файлов либо подготовленные плей — листы. ПО будет прекрасным решением, для просмотра потокового видео, чаще всего именно для этих целей устанавливают данное программное обеспечение.
Forklayer позволяет смотреть на экране ТВ любые видео, находящиеся на интернет ресурсах. Это своего рода, замена традиционного браузера, в виде программы, позволяющей автоматически обновлять плейлисты. Просмотр фильмов, прослушивание аудио и радио являются преимуществом программы. За счёт удобства приложения спрос на него увеличен.
Редко, но бывают замечены сбои программы. Одна из самых частых проблем – ошибка парсинга страницы. Есть несколько вариантов для разрешения ситуации. Они просты и понятны простым пользователям. Ниже подробно рассказано всё, что связано с этой проблемой.

forkplayer
Как поступить если показывает ошибку парсинга в программе
Наши рекомендации довольно просты, поэтому понять и использовать их сможет даже новичок. Указанная ошибка, возникает при посещении киносайтов либо при прослушивании треков. Итогом таких интернет сеансов становиться ошибка парсинга в программе.
Варианты решения проблемы
Для того чтобы решить проблему и устранить ошибку, необходимо выполнить следующие действия:
- Зайти в меню программы и клацнуть по кнопке «Выйти из Forklayer».

выход
- Перезапустить приложение.
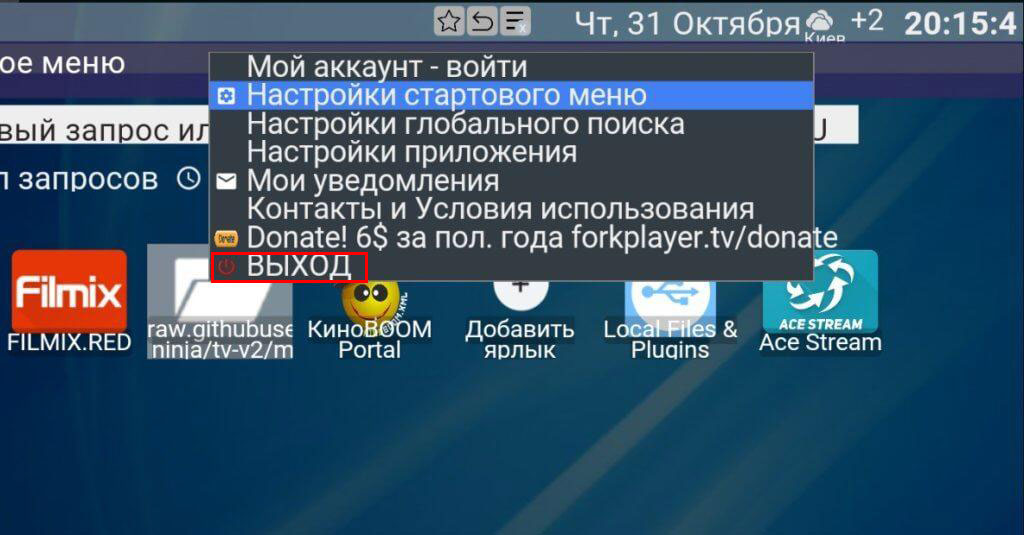
Эти несложные действия могут решить проблему, после чего можно пользоваться им как обычно. Обязательно нужно выйти из программы. В случае если этот метод не помог можно попробовать перезапустить ещё раз.
Если решить проблему так и не получилось, то можно набрать в адресной строке http://fork-portal.ru. На сайте можно получить всю информацию, касающеюся программы.
Стоит учесть, что адрес должен начинаться с «http», без символа «S». Это может стать одной из причин неполадок в работе.
Может быть интересно: Как отключить голосовое сопровождение на телевизоре Самсунг
Заключение
Решить проблему парсинга можно, буквально, за пару минут. Помимо перезагрузки рекомендуется проверить настройки и уровень сигнала интернета. Эти методы помогут продолжить просмотр и прослушивание любимого контента.
Оценка статьи:
![]() Загрузка…
Загрузка…

Импорт файла CSV может быть неприятным. Мы все боролись с импортом и повторным импортом файла, который все еще содержит надоедливые, трудно идентифицируемые проблемы. Хотя ошибки импорта CSV могут сильно различаться, мы заметили, что люди, вероятно, будут сталкиваться с одной и той же горсткой ошибок синтаксического анализа CSV снова и снова. Если вы научитесь выявлять и устранять эти ошибки, импорт данных может занять значительно меньше времени и энергии… чего мы все хотели бы иметь больше.
Мы здесь, чтобы помочь, используя как пять советов ниже, так и наш удаленный браузер для файлов CSV в облаке. CSV Studio предлагает надежный синтаксический анализатор и автоматическое исправление ошибок для несовместимых и плохо отформатированных файлов CSV. Он позволяет удаленно просматривать файлы на сервере данных, автоматически выявлять и исправлять ошибки и экспортировать файл в базу данных без ошибок синтаксического анализа. Смотрите демонстрации, чтобы узнать больше.
# 1 — Нераспознанный Юникод / недопустимая кодовая точка
Даже если это не самая распространенная проблема, это определенно первая проблема, с которой вы можете столкнуться при работе с CSV. Если вы используете python для обработки данных, эта проблема проявится очень быстро, поскольку ввод-вывод python вызовет исключение при первых признаках проблемы. Многие парсеры не могут отображать или обрабатывать текстовое поле с недопустимым кодом, и вы вынуждены немедленно найти правильную кодировку, прежде чем пытаться выполнить любую дальнейшую диагностику.

Утилита, такая как команда «file -e», может работать, если для работы достаточно кодовых точек. Имейте в виду, что даже несмотря на то, что большая часть Интернета и персональных компьютеров принимает кодировку UTF-8 по умолчанию как должное, ISO-8859 Latin-1 так же хорош, как и любой другой, для данных, происходящих из базы данных.
# 2 — Текстовое поле с неэкранированным разделителем
Если разделитель столбцов отображается в текстовом поле без экранирования, это приведет к тому, что в строке появится дополнительный столбец. Обычно проблема возникает, когда в CSV-файле не используются двойные кавычки для заключения текстовых и числовых полей. Имена и адреса часто являются результатом ввода с клавиатуры, что означает, что они могут содержать все виды управляющих символов: /, , |, ^, стрелки влево и вправо, возврат каретки, перевод строки и т. Д.

Рациональное решение — повторно экспортировать файл, заключив столбцы в двойные кавычки. Если это невозможно и возникает необходимость удалить лишние разделители, использование CSV Studio для исключения лишних разделителей может помочь вам сохранить рассудок.
# 3 — Строка в кавычках с неэкранированными двойными кавычками
Многие файлы CSV принимают разумные меры предосторожности, заключающие весь текст в кавычки. Неэкранированные двойные кавычки становятся потенциальной проблемой.

Случайное использование DJ ”S вместо DJ’S создает единственную проблему в файле с 600 000 строками. Эта проблема является фатальной: остальная часть файла отображается как одна строка. Наилучший подход — повторно экспортировать файл CSV и правильно избегать двойных кавычек. Если это необходимо сделать после того, как это произошло, в CSV Studio есть алгоритм для поиска лишних двойных кавычек, которые нужно экранировать.
# 4 — Нестандартные escape-символы
Файлы в стиле Unix часто используют обратную косую черту () внутри строк в кавычках, чтобы избежать разделителя строк.
›« В этой строке есть »
Однако вместо использования обратной косой черты CSV-файлы RFC-4180 удваивают разделитель строк в качестве механизма выхода.
›« В этой строке есть «» »
При кодировании файлов CSV следует последовательно применять один из этих механизмов выхода. Однако иногда встречаются файлы, в которых одновременно используются оба метода выхода. Это создает двусмысленность всякий раз, когда встречается escape-последовательность (см. Таблицу).

# 5 — Окончания строк CRLF / Dos
Концы строк не являются проблемой для CSV. Окончания строк в Windows и Unix различаются, и это, конечно, повлияет на файлы данных так же, как и на любой другой файл. Официальный разделитель строк RFC 4180 для CSV — это последовательность CRLF (символ возврата каретки, за которым следует символ новой строки). При обработке файла CSV с окончанием строки CRLF нередко обнаруживается нежелательный символ ^ M (или CR) в конце каждой строки. Это может даже вызвать проблемы с некоторыми парсерами CSV. Обработка файла с помощью утилиты dos2unix — стандартный способ решения этой проблемы.

У вас есть действительно плохой файл CSV, которым вы хотите поделиться? Заинтересованы в простом способе отображения и исправления этих проблем без использования самодельных сценариев регулярных выражений? Прочтите этот пост, посетите сайт или электронную почту.