
Алгоритмическая ошибка
Cтраница 1
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формализованного автоматического контроля, чем предыдущие типы ошибок. К алгоритмическим следует отнести прежде всего ошибки, обусловленные некорректной постановкой функциональных задач, когда в спецификациях не полностью оговорены все условия, необходимые для получения правильного результата. Эти условия формируются и уточняются в значительной части в процессе тестирования и выявления ошибок в результатах функционирования программ. Ошибки, обусловленные неполным учетом всех условий решения задач, являются наиболее частыми в этой группе и составляют до 70 % всех алгоритмических ошибок или около 30 % общего количества ошибок на начальных этапах проектирования.
[1]
Алгоритмические ошибки и ошибки кодирования, связанные с некорректной формулировкой и реализацией алгоритмов программным путем.
[2]
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формального автоматического контроля, чем все предыдущие типы ошибок. Это определяется прежде всего отсутствием для большинства логических управляющих алгоритмов строго формализованной постановки задач, которую можно использовать в качестве эталона для сравнения результатов функционирования разработанных алгоритмов. Разработка управляющих алгоритмов осуществляется обычно при наличии большого количества параметров и в условиях значительной неопределенности самой исходной постановки задачи. Эти условия формируются в значительной части в процессе выявления ошибок по результатам функционирования алгоритмов. Ошибки некорректной постановки задач приводят к сокращению полного перечня маршрутов обработки информации, необходимых для получения всей гаммы числовых и логических решений, или к появлению маршрутов обработки информации, дающих неправильный результат. Таким образом, область получающихся выходных результатов изменяется.
[3]
Алгоритмические ошибки представляют собой ошибки в программной трактовке алгоритма, например недоучет всех вариантов работы алгоритма.
[4]
К алгоритмическим ошибкам следует отнести также ошибки связей модулей и функциональных групп программ.
[5]
К алгоритмическим ошибкам следует отнести также ошибки сопряжения алгоритмических блоков, когда информация, необходимая для функционирования некоторого блока, оказывается неполностью подготовленной блоками, предшествующими по моменту включения. Этот тип ошибок также можно квалифицировать как ошибки некорректной постановки задачи, однако в данном случае некорректность может проявляться при определенной временной последовательности функционирования алгоритмических блоков.
[6]
С алгоритмическими ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая ошибка, завершается успешно. При пробных запусках программа ведет себя нормально, однако при анализе результата выясняется, что он неверный. Для того чтобы устранить алгоритмическую ошибку, приходится анализировать алгоритм, вручную прокручивать его выполнение.
[8]
Особую часть алгоритмических ошибок составляют просчеты в использовании доступных ресурсов ВС. Одновременная разработка множества модулей различными специалистами затрудняет оптимальное распределение ограниченных ресурсов ЭВМ по всем задачам, так как отсутствуют достоверные данные потребных ресурсов для решения каждой из них. В результате возникает либо недоиспользование, либо ( в подавляющем большинстве случаев) нехватка каких-то ресурсов ЭВМ для решения задач в первоначальном варианте. Наиболее крупные просчеты обычно происходят при оценке времени реализации различных групп программ и при распределении производительности ЭВМ.
[9]
Этот побочный эффект может привести к алгоритмическим ошибкам при работе программы. Для того чтобы избавить программиста от необходимости помнить о таком побочном эффекте, достаточно в начале макрокоманды сохранять, а после выполнения восстанавливать содержимое этих регистров. Для этих целей в СМ ЭВМ обычно используется стек. Необходимо отметить, что в отдельных случаях сохранение регистров не обязательно.
[10]
В предыдущем параграфе был рассмотрен характер формирования алгоритмической ошибки вычислений при отсутствии искажающих воздействий со стороны окружающей среды и вычислительной системы. В реальных условиях на процесс смены состояний АлСУ и ошибку выходных сигналов существенное влияние оказывают искажающие воздействия, которые по отношению к управляющему объекту могут быть как внешними, так и внутренними. Внешние воздействия, источником которых является внешняя ( по отношению к управляющему объекту) среда, связаны с ошибками определения параметров управляемого процесса, отказами и сбоями в работе датчиков информации, каналов связи и преобразующих устройств. Внутренние воздействия, источниками которых являются ЦВМ или комплексы ЦВМ, используемые для реализации алгоритмической системы, обусловлены сбоями, частичными отказами и прерываниями.
[11]
Кроме того, значительные трудности представляет разделение системных и алгоритмических ошибок и выделение доработок, которые не следует квалифицировать как ошибки.
[12]
Однако формула ( 29) позволяет судить о характере формирования алгоритмической ошибки в реальных системах и сделать важный вывод о несостоятельности попыток оценки качества АлСУ всякого рода контрольными просчетами.
[13]
Защита от перегрузки ЭВМ по пропускной способности предполагает обнаружение и снижение влияния последствий алгоритмических ошибок, обусловленных неправильным определением необходимой пропускной способности ЭВМ для работы в реальном времени. Кроме того, перегрузки могут быть следствием неправильного функционирования источников информации и превышения интенсивности потоков сообщений расчетного, нормального, уровня. Последствия обычно сводятся к прекращению решения некоторых функциональных задач, обладающих низким приоритетом.
[14]
В настоящее время структурные методы контроля ориентированы в основном на обнаружение и доказательство отсутствия технологических и некоторых алгоритмических ошибок в записи программ, которые выполняются на этапе программной отладки.
[15]
Страницы:
1
2
3
Аннотация: Лекция носит факультативный характер. Здесь мы рассматриваем виды допускаемых в программировании ошибок, способы тестирования и отладки программ, инструменты встроенного отладчика.
Цель лекции
Освоить работу с встроенным отладчиком, изучить категории ошибок, способы их обнаружения и устранения.
Тестирование и отладка программы
Чем больше опыта имеет программист, тем меньше ошибок в коде он совершает. Но, хотите верьте, хотите нет, даже самый опытный программист всё же допускает ошибки. И любая современная среда разработки программ должна иметь собственные инструменты для отладки приложений, а также для своевременного обнаружения и исправления возможных ошибок. Программные ошибки на программистском сленге называют багами (англ. bug — жук), а программы отладки кода — дебаггерами (англ. debugger — отладчик). Lazarus, как современная среда разработки приложений, имеет собственный встроенный отладчик, работу с которым мы разберем на этой лекции.
Ошибки, которые может допустить программист, условно делятся на три группы:
- Синтаксические
- Времени выполнения (run-time errors)
- Алгоритмические
Синтаксические ошибки
Синтаксические ошибки легче всего обнаружить и исправить — их обнаруживает компилятор, не давая скомпилировать и запустить программу. Причем компилятор устанавливает курсор на ошибку, или после неё, а в окне сообщений выводит соответствующее сообщение, например, такое:
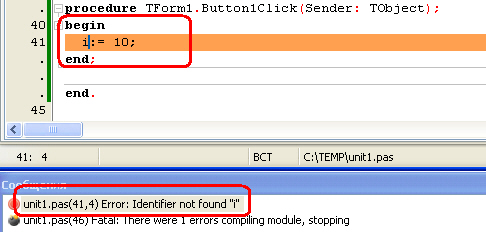
Рис.
27.1.
Найденная компилятором синтаксическая ошибка — нет объявления переменной i
Подобные ошибки могут возникнуть при неправильном написании директивы или имени функции (процедуры); при попытке обратиться к переменной или константе, которую не объявляли (
рис.
27.1); при попытке вызвать функцию (процедуру, переменную, константу) из модуля, который не был подключен в разделе uses; при других аналогичных недосмотрах программиста.
Как уже говорилось, компилятор при нахождении подобной ошибки приостанавливает процесс компиляции, выводит сообщение о найденной ошибке и устанавливает курсор на допущенную ошибку, или после неё. Программисту остается только внести исправления в код программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения (run-time errors) тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы, или во время тестирования. Если такую программу запустить из среды Lazarus, то она скомпилируется, но при попытке загрузки, или в момент совершения ошибки, приостановит свою работу, выведя на экран соответствующее сообщение. Например, такое:

Рис.
27.2.
Сообщение Lazarus об ошибке времени выполнения
В данном случае программа при загрузке должна была считать в память отсутствующий текстовый файл MyFile.txt. Поскольку программа вызвала ошибку, она не запустилась, но в среде Lazarus процесс отладки продолжается, о чем свидетельствует сообщение в скобках в заголовке главного меню, после названия проекта. Программисту в подобных случаях нужно сбросить отладчик командой меню «Запуск -> Сбросить отладчик«, после чего можно продолжить работу над проектом.
Ошибка времени выполнения может возникнуть не только при загрузке программы, но и во время её работы. Например, если бы попытка чтения несуществующего файла была сделана не при загрузке программы, а при нажатии на кнопку, то программа бы нормально запустилась и работала, пока пользователь не нажмет на эту кнопку.
Если программу запустить из самой Windows, при возникновении этой ошибки появится такое же сообщение. При этом если нажать «OK«, программа даже может запуститься, но корректно работать все равно не будет.
Ошибки времени выполнения бывают не только явными, но и неявными, при которых программа продолжает свою работу, не выводя никаких сообщений, а программист даже не догадывается о наличии ошибки. Примером неявной ошибки может служить так называемая утечка памяти. Утечка памяти возникает в случаях, когда программист забывает освободить выделенную под объект память. Например, мы объявляем переменную типа TStringList, и работаем с ней:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
end;
В данном примере программист допустил типичную для начинающих ошибку — не освободил класс TStringList. Это не приведет к сбою или аварийному завершению программы, но в итоге можно бесполезно израсходовать очень много памяти. Конечно, эта память будет освобождена после выгрузки программы (за этим следит операционная система), но утечка памяти во время выполнения программы тоже может привести к неприятным последствиям, потребляя все больше и больше ресурсов и излишне нагружая процессор. В подобных случаях после работы с объектом программисту нужно не забывать освобождать память:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
MySL.Free; //освободили объект
end;
Однако ошибки времени выполнения могут случиться и во время работы с объектом. Если есть такой риск, программист должен не забывать про возможность обработки исключительных ситуаций. В данном случае вышеприведенный код правильней будет оформить таким образом:
begin
try
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
finally
MySL.Free; //освободили объект, даже если была ошибка
end;
end;
Итак, во избежание ошибок времени выполнения программист должен не забывать делать проверку на правильность ввода пользователем допустимых значений, заключать опасный код в блоки try…finally…end или try…except…end, делать проверку на существование открываемого файла функцией FileExists и вообще соблюдать предусмотрительность во всех слабых местах программы. Не полагайтесь на пользователя, ведь недаром говорят, что если в программе можно допустить ошибку, пользователь эту возможность непременно найдет.
Алгоритмические ошибки
Если вы не допустили ни синтаксических ошибок, ни ошибок времени выполнения, программа скомпилировалась, запустилась и работает нормально, то это еще не означает, что в программе нет ошибок. Убедиться в этом можно только в процессе её тестирования.
Тестирование — процесс проверки работоспособности программы путем ввода в неё различных, даже намеренно ошибочных данных, и последующей контрольной проверке выводимого результата.
Если программа работает правильно с одними наборами исходных данных, и неправильно с другими, то это свидетельствует о наличии алгоритмической ошибки. Алгоритмические ошибки иногда называют логическими, обычно они связаны с неверной реализацией алгоритма программы: вместо «+» ошибочно поставили «-«, вместо «/» — «*», вместо деления значения на 0,01 разделили на 0,001 и т.п. Такие ошибки обычно не обнаруживаются во время компиляции, программа нормально запускается, работает, а при анализе выводимого результата выясняется, что он неверный. При этом компилятор не укажет программисту на ошибку — чтобы найти и устранить её, приходится анализировать код, пошагово «прокручивать» его выполнение, следя за результатом. Такой процесс называется отладкой.
Отладка — процесс поиска и устранения ошибок, чаще алгоритмических. Хотя отладчик позволяет справиться и с ошибками времени выполнения, которые не обнаруживаются явно.
Аннотация: Лекция носит факультативный характер. Здесь мы рассматриваем виды допускаемых в программировании ошибок, способы тестирования и отладки программ, инструменты встроенного отладчика.
Цель лекции
Освоить работу с встроенным отладчиком, изучить категории ошибок, способы их обнаружения и устранения.
Тестирование и отладка программы
Чем больше опыта имеет программист, тем меньше ошибок в коде он совершает. Но, хотите верьте, хотите нет, даже самый опытный программист всё же допускает ошибки. И любая современная среда разработки программ должна иметь собственные инструменты для отладки приложений, а также для своевременного обнаружения и исправления возможных ошибок. Программные ошибки на программистском сленге называют багами (англ. bug — жук), а программы отладки кода — дебаггерами (англ. debugger — отладчик). Lazarus, как современная среда разработки приложений, имеет собственный встроенный отладчик, работу с которым мы разберем на этой лекции.
Ошибки, которые может допустить программист, условно делятся на три группы:
- Синтаксические
- Времени выполнения (run-time errors)
- Алгоритмические
Синтаксические ошибки
Синтаксические ошибки легче всего обнаружить и исправить — их обнаруживает компилятор, не давая скомпилировать и запустить программу. Причем компилятор устанавливает курсор на ошибку, или после неё, а в окне сообщений выводит соответствующее сообщение, например, такое:
Рис.
27.1.
Найденная компилятором синтаксическая ошибка — нет объявления переменной i
Подобные ошибки могут возникнуть при неправильном написании директивы или имени функции (процедуры); при попытке обратиться к переменной или константе, которую не объявляли (
рис.
27.1); при попытке вызвать функцию (процедуру, переменную, константу) из модуля, который не был подключен в разделе uses; при других аналогичных недосмотрах программиста.
Как уже говорилось, компилятор при нахождении подобной ошибки приостанавливает процесс компиляции, выводит сообщение о найденной ошибке и устанавливает курсор на допущенную ошибку, или после неё. Программисту остается только внести исправления в код программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения (run-time errors) тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы, или во время тестирования. Если такую программу запустить из среды Lazarus, то она скомпилируется, но при попытке загрузки, или в момент совершения ошибки, приостановит свою работу, выведя на экран соответствующее сообщение. Например, такое:
Рис.
27.2.
Сообщение Lazarus об ошибке времени выполнения
В данном случае программа при загрузке должна была считать в память отсутствующий текстовый файл MyFile.txt. Поскольку программа вызвала ошибку, она не запустилась, но в среде Lazarus процесс отладки продолжается, о чем свидетельствует сообщение в скобках в заголовке главного меню, после названия проекта. Программисту в подобных случаях нужно сбросить отладчик командой меню «Запуск -> Сбросить отладчик«, после чего можно продолжить работу над проектом.
Ошибка времени выполнения может возникнуть не только при загрузке программы, но и во время её работы. Например, если бы попытка чтения несуществующего файла была сделана не при загрузке программы, а при нажатии на кнопку, то программа бы нормально запустилась и работала, пока пользователь не нажмет на эту кнопку.
Если программу запустить из самой Windows, при возникновении этой ошибки появится такое же сообщение. При этом если нажать «OK«, программа даже может запуститься, но корректно работать все равно не будет.
Ошибки времени выполнения бывают не только явными, но и неявными, при которых программа продолжает свою работу, не выводя никаких сообщений, а программист даже не догадывается о наличии ошибки. Примером неявной ошибки может служить так называемая утечка памяти. Утечка памяти возникает в случаях, когда программист забывает освободить выделенную под объект память. Например, мы объявляем переменную типа TStringList, и работаем с ней:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
end;
В данном примере программист допустил типичную для начинающих ошибку — не освободил класс TStringList. Это не приведет к сбою или аварийному завершению программы, но в итоге можно бесполезно израсходовать очень много памяти. Конечно, эта память будет освобождена после выгрузки программы (за этим следит операционная система), но утечка памяти во время выполнения программы тоже может привести к неприятным последствиям, потребляя все больше и больше ресурсов и излишне нагружая процессор. В подобных случаях после работы с объектом программисту нужно не забывать освобождать память:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
MySL.Free; //освободили объект
end;
Однако ошибки времени выполнения могут случиться и во время работы с объектом. Если есть такой риск, программист должен не забывать про возможность обработки исключительных ситуаций. В данном случае вышеприведенный код правильней будет оформить таким образом:
begin
try
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
finally
MySL.Free; //освободили объект, даже если была ошибка
end;
end;
Итак, во избежание ошибок времени выполнения программист должен не забывать делать проверку на правильность ввода пользователем допустимых значений, заключать опасный код в блоки try…finally…end или try…except…end, делать проверку на существование открываемого файла функцией FileExists и вообще соблюдать предусмотрительность во всех слабых местах программы. Не полагайтесь на пользователя, ведь недаром говорят, что если в программе можно допустить ошибку, пользователь эту возможность непременно найдет.
Алгоритмические ошибки
Если вы не допустили ни синтаксических ошибок, ни ошибок времени выполнения, программа скомпилировалась, запустилась и работает нормально, то это еще не означает, что в программе нет ошибок. Убедиться в этом можно только в процессе её тестирования.
Тестирование — процесс проверки работоспособности программы путем ввода в неё различных, даже намеренно ошибочных данных, и последующей контрольной проверке выводимого результата.
Если программа работает правильно с одними наборами исходных данных, и неправильно с другими, то это свидетельствует о наличии алгоритмической ошибки. Алгоритмические ошибки иногда называют логическими, обычно они связаны с неверной реализацией алгоритма программы: вместо «+» ошибочно поставили «-«, вместо «/» — «*», вместо деления значения на 0,01 разделили на 0,001 и т.п. Такие ошибки обычно не обнаруживаются во время компиляции, программа нормально запускается, работает, а при анализе выводимого результата выясняется, что он неверный. При этом компилятор не укажет программисту на ошибку — чтобы найти и устранить её, приходится анализировать код, пошагово «прокручивать» его выполнение, следя за результатом. Такой процесс называется отладкой.
Отладка — процесс поиска и устранения ошибок, чаще алгоритмических. Хотя отладчик позволяет справиться и с ошибками времени выполнения, которые не обнаруживаются явно.
Классификация ошибок
Ошибки, которые могут быть в программе,
принято делить на три группы:
-
синтаксические;
-
ошибки времени выполнения;
-
алгоритмические.
Синтаксические ошибки, их также называют
ошибками времени компиляции (Compile-time
error), наиболее легко устранимы. Их
обнаруживает компилятор, а программисту
остается только внести изменения в
текст программы и выполнить повторную
компиляцию.
Ошибки времени выполнения, в Delphi они
называются исключениями (exception), тоже,
как правило, легко устранимы. Они обычно
проявляются уже при первых запусках
программы и во время тестирования.
При возникновении ошибки
в программе, запущенной из Delphi, среда
разработки прерывает работу программы,
о чем свидетельствует заключенное в
скобки слово Stopped в
заголовке главного окна Delphi, и на экране
появляется диалоговое окно, которое
содержит сообщение об ошибке и информацию
о типе (классе) ошибки. На рис. 13.1 приведен
пример сообщения об ошибке, возникающей
при попытке открыть несуществующий
файл.
После возникновения ошибки
программист может либо прервать
выполнение программы, для этого надо
из менюRun выбрать
команду Program
Reset, либо продолжить
ее выполнение, например, по шагам (для
этого из менюRun надо
выбрать команду Step), наблюдая
результат выполнения каждой инструкции.
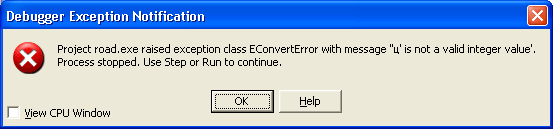
Рис. 13.1. Сообщение
об ошибке при запуске программы из
Delphi
Если программа запущена из
Windows, то при возникновении ошибки на
экране также появляется сообщение об
ошибке, но тип ошибки (исключения) в
сообщении не указывается (рис. 13.2). После
щелчка на кнопке ОКпрограмма,
в которой проявилась ошибка, продолжает
(если сможет) работу.
Рис. 13.2. Сообщение
об ошибке при запуске программы из
Windows
С алгоритмическими ошибками дело обстоит
иначе. Компиляция программы, в которой
есть алгоритмическая ошибка, завершается
успешно. При пробных запусках программа
ведет себя нормально, однако при анализе
результата выясняется, что он неверный.
Для того чтобы устранить алгоритмическую
ошибку,» приходится анализировать
алгоритм, вручную «прокручивать»
его выполнение.
Предотвращение и обработка ошибок
Как было сказано выше, в программе во
время ее работы могут возникать ошибки,
причиной которых, как правило, являются
действия пользователя. Например,
пользователь может ввести неверные
данные или, что бывает довольно часто,
удалить нужный программе файл.
Нарушение в работе программы называется
исключением. Обработку исключений
(ошибок) берет на себя автоматически
добавляемый в выполняемую программу
код, который обеспечивает, в том числе,
вывод информационного сообщения. Вместе
с тем Delphi дает возможность программе
самой выполнить обработку исключения.
Инструкция обработки исключения в общем
виде выглядит так:
try
// здесь инструкции, выполнение которых
может вызвать исключение
except //
начало секции обработки исключений
on ТипИсключения1 do Обработка1;
on ТипИсключения2 do Обработка2;
on ТипИсключенияJ do ОбработкаJ;
else
// здесь инструкции обработки остальных
исключений
end;
где:
-
try — ключевое слово, обозначающее, что
далее следуют инструкции, при выполнении
которых возможно возникновение
исключений, и что обработку этих
исключений берет на себя программа; -
except — ключевое слово, обозначающее
начало секции обработки исключений.
Инструкции этой секции будут выполнены,
если в программе возникнет ошибка; -
on — ключевое слово, за которым следует
тип исключения, обработку которого
выполняет инструкция, следующая за do; -
else — ключевое слово, за которым следуют
инструкции, обеспечивающие обработку
исключений, тип которых не указаны в
секции except.
Как было сказано выше, основной
характеристикой исключения является
его тип. В таблице 13.1 перечислены наиболее
часто возникающие исключения и указаны
причины, которые могут привести к их
возникновению.
Таблица 13.1. Типичные
исключения
|
Тип исключения |
Возникает |
||
|
EZeroDivide |
При выполнении операции деления, если |
||
|
EConvertError |
При выполнении преобразования, если |
||
|
Тип исключения |
Возникает |
||
|
EFilerError |
При обращении к файлу. Наиболее частой |
||
Ошибки выполнения:
Определения данных;
Передачи;
Преобразования;
Перезаписи;
Неправильные данные.
Логические;
Неприемлемый подход;
Неверный алгоритм;
Неверная структура данных;
Другие;
Кодирования;
Проектирования;
Некорректная работа с переменными;
Некорректные вычисления;
Ошибки интерфейсов;
Неправильная реализация алгоритма;
Другие.
Накопления погрешностей;
Игнорирование ограничений разрядной
сетки;
Игнорирование способов уменьшения
погрешностей.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Отладка программ
Введение
Успешное завершение процесса компиляции не означает, что в программе нет ошибок. Убедиться, что программа работает правильно, можно только в процессе проверки ее работоспособности, который называется тестирование. Обычно программа редко сразу начинает работать так, как надо, или работает правильно только на некотором ограниченном наборе исходных данных. Это свидетельствует о том, что в программе есть алгоритмические ошибки. Процесс поиска и устранения ошибок называется отладкой
Классификация ошибок
Введение
Ошибки, которые могут быть в программе, принято делить на три группы:
- синтаксические;
- ошибки времени выполнения;
- алгоритмические.
Синтаксические ошибки
Синтаксические ошибки, их также называют ошибками времени компиляции (Compile-time error), наиболее легко устранимы. Их обнаруживает компилятор, а программисту остается внести изменения в текст программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения, они называются исключениями (Exception), тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы и во время тестирования
При возникновении ошибки в программе, запущенной из ИСР, среда прерывает работу программы и в окне сообщений дает информацию о типе ошибки.
После возникновения ошибки программист может либо прервать выполнение программы, либо продолжить ее выполнение, например, по шагам, наблюдая результат выполнения каждой инструкции.
Если программа запущена из Windows, то при возникновении ошибки на экране также появляется сообщение об ошибке, но тип ошибки (исключения) в сообщении не указывается. После щелчка на кнопке ОК программа, в которой проявилась ошибка, продолжает (если сможет) работу.
Алгоритмические ошибки
С алгоритмическими ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая ошибка, завершается успешно. При пробных запусках программа ведет себя нормально, однако при анализе результата выясняется, что он неверный. Для того чтобы устранить алгоритмическую ошибку, приходится анализировать алгоритм, вручную “прокручивать” его выполнение.
Предотвращение и обработка ошибок
В программе во время ее работы могут возникать ошибки, причиной которых, как правило, являются действия пользователя. Например, пользователь может ввести неверные данные или, что бывает довольно часто, удалить нужный программе файл. Нарушение в работе программы называется исключением. Обработку исключений (ошибок) берет на себя автоматически добавляемый в выполняемую программу код, который обеспечивает, в том числе, вывод информационного сообщения.
FPC и ИСР предоставляют программисту мощные средства:
- Компилятор с регулируемыми опциями.
Отладчик для поиска и устранения ошибок в программе. Отладчик позволяет выполнять трассировку программы, наблюдать значения переменных, контролировать выводимые программой данные.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Ошибки, которые могут
быть в программе, принято делить на три группы:
- синтаксические;
- ошибки времени выполнения;
- алгоритмические.
Синтаксические ошибки,
их также называют ошибками времени компиляции (Compile-time error), наиболее
легко устранимы. Их обнаруживает компилятор, а программисту остается только
внести изменения в текст программы и выполнить повторную компиляцию.
Ошибки времени выполнения,
в Delphi они называются исключениями (exception), тоже, как правило, легко устранимы.
Они обычно проявляются уже при первых запусках программы и во время тестирования.
При возникновении ошибки
в программе, запущенной из Delphi, среда разработки прерывает работу программы,
о чем свидетельствует заключенное в скобки слово Stopped в заголовке
главного окна Delphi, и на экране появляется диалоговое окно, которое содержит
сообщение об ошибке и информацию о типе (классе) ошибки. На рис. 13.1 приведен
пример сообщения об ошибке, возникающей при попытке открыть несуществующий файл.
После возникновения
ошибки программист может либо прервать выполнение программы, для этого надо
из меню Run выбрать команду Program Reset, либо продолжить ее
выполнение, например, по шагам (для этого из меню
Run надо выбрать команду Step), наблюдая результат выполнения
каждой инструкции.

Рис. 13.1. Сообщение
об ошибке при запуске программы из Delphi
Если программа запущена
из Windows, то при возникновении ошибки на экране также появляется сообщение
об ошибке, но тип ошибки (исключения) в сообщении не указывается (рис. 13.2).
После щелчка на кнопке ОК программа, в которой проявилась ошибка, продолжает
(если сможет) работу.

Рис. 13.2. Сообщение
об ошибке при запуске программы из Windows
С алгоритмическими
ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая
ошибка, завершается успешно. При пробных запусках программа ведет себя нормально,
однако при анализе результата выясняется, что он неверный. Для того чтобы устранить
алгоритмическую ошибку,» приходится анализировать алгоритм, вручную «прокручивать»
его выполнение.
Improve Article
Save Article
Improve Article
Save Article
Compile-Time Errors: Errors that occur when you violate the rules of writing syntax are known as Compile-Time errors. This compiler error indicates something that must be fixed before the code can be compiled. All these errors are detected by the compiler and thus are known as compile-time errors.
Most frequent Compile-Time errors are:
- Missing Parenthesis (})
- Printing the value of variable without declaring it
- Missing semicolon (terminator)
Below is an example to demonstrate Compile-Time Error:
C++
#include <iostream>
using namespace std;
int main()
{
int x = 10;
int y = 15;
cout << " "<< (x, y)
}
C
#include<stdio.h>
void main()
{
int x = 10;
int y = 15;
printf("%d", (x, y));
}
Error:
error: expected ';' before '}' token
Run-Time Errors: Errors which occur during program execution(run-time) after successful compilation are called run-time errors. One of the most common run-time error is division by zero also known as Division error. These types of error are hard to find as the compiler doesn’t point to the line at which the error occurs.
For more understanding run the example given below.
C++
#include <iostream>
using namespace std;
int main()
{
int n = 9, div = 0;
div = n/0;
cout <<"result = " << div;
}
C
#include<stdio.h>
void main()
{
int n = 9, div = 0;
div = n/0;
printf("result = %d", div);
}
Error:
warning: division by zero [-Wdiv-by-zero]
div = n/0;
In the given example, there is Division by zero error. This is an example of run-time error i.e errors occurring while running the program.
The Differences between Compile-Time and Run-Time Error are:
| Compile-Time Errors | Runtime-Errors |
|---|---|
| These are the syntax errors which are detected by the compiler. | These are the errors which are not detected by the compiler and produce wrong results. |
| They prevent the code from running as it detects some syntax errors. | They prevent the code from complete execution. |
| It includes syntax errors such as missing of semicolon(;), misspelling of keywords and identifiers etc. | It includes errors such as dividing a number by zero, finding square root of a negative number etc. |
Improve Article
Save Article
Improve Article
Save Article
Compile-Time Errors: Errors that occur when you violate the rules of writing syntax are known as Compile-Time errors. This compiler error indicates something that must be fixed before the code can be compiled. All these errors are detected by the compiler and thus are known as compile-time errors.
Most frequent Compile-Time errors are:
- Missing Parenthesis (})
- Printing the value of variable without declaring it
- Missing semicolon (terminator)
Below is an example to demonstrate Compile-Time Error:
C++
#include <iostream>
using namespace std;
int main()
{
int x = 10;
int y = 15;
cout << " "<< (x, y)
}
C
#include<stdio.h>
void main()
{
int x = 10;
int y = 15;
printf("%d", (x, y));
}
Error:
error: expected ';' before '}' token
Run-Time Errors: Errors which occur during program execution(run-time) after successful compilation are called run-time errors. One of the most common run-time error is division by zero also known as Division error. These types of error are hard to find as the compiler doesn’t point to the line at which the error occurs.
For more understanding run the example given below.
C++
#include <iostream>
using namespace std;
int main()
{
int n = 9, div = 0;
div = n/0;
cout <<"result = " << div;
}
C
#include<stdio.h>
void main()
{
int n = 9, div = 0;
div = n/0;
printf("result = %d", div);
}
Error:
warning: division by zero [-Wdiv-by-zero]
div = n/0;
In the given example, there is Division by zero error. This is an example of run-time error i.e errors occurring while running the program.
The Differences between Compile-Time and Run-Time Error are:
| Compile-Time Errors | Runtime-Errors |
|---|---|
| These are the syntax errors which are detected by the compiler. | These are the errors which are not detected by the compiler and produce wrong results. |
| They prevent the code from running as it detects some syntax errors. | They prevent the code from complete execution. |
| It includes syntax errors such as missing of semicolon(;), misspelling of keywords and identifiers etc. | It includes errors such as dividing a number by zero, finding square root of a negative number etc. |
Чтобы разобраться, в чем разница между ошибками времени компиляции и ошибками времени выполнения в Java, разберемся в сути каждого вида.
Ошибки времени компиляции
Это синтаксические ошибки в коде, которые препятствуют его компиляции.
Пример
public class Test{
public static void main(String args[]){
System.out.println("Hello")
}
}
Итог
C:Sample>Javac Test.java
Test.java:3: error: ';' expected
System.out.println("Hello")
Ошибки времени выполнения
Исключение (или исключительное событие) – это проблема, возникающая во время выполнения программы. Когда возникает исключение, нормальный поток программы прерывается, и программа / приложение прерывается ненормально, что не рекомендуется, поэтому эти исключения должны быть обработаны.
Пример
import java.io.File;
import java.io.FileReader;
public class FilenotFound_Demo {
public static void main(String args[]) {
File file = new File("E://file.txt");
FileReader fr = new FileReader(file);
}
}
Итог
C:>javac FilenotFound_Demo.java
FilenotFound_Demo.java:8: error: unreported exception
FileNotFoundException; must be caught or declared to be thrown
FileReader fr = new FileReader(file);
^
1 error
Алгоритмическая ошибка
Cтраница 1
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формализованного автоматического контроля, чем предыдущие типы ошибок. К алгоритмическим следует отнести прежде всего ошибки, обусловленные некорректной постановкой функциональных задач, когда в спецификациях не полностью оговорены все условия, необходимые для получения правильного результата. Эти условия формируются и уточняются в значительной части в процессе тестирования и выявления ошибок в результатах функционирования программ. Ошибки, обусловленные неполным учетом всех условий решения задач, являются наиболее частыми в этой группе и составляют до 70 % всех алгоритмических ошибок или около 30 % общего количества ошибок на начальных этапах проектирования.
[1]
Алгоритмические ошибки и ошибки кодирования, связанные с некорректной формулировкой и реализацией алгоритмов программным путем.
[2]
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формального автоматического контроля, чем все предыдущие типы ошибок. Это определяется прежде всего отсутствием для большинства логических управляющих алгоритмов строго формализованной постановки задач, которую можно использовать в качестве эталона для сравнения результатов функционирования разработанных алгоритмов. Разработка управляющих алгоритмов осуществляется обычно при наличии большого количества параметров и в условиях значительной неопределенности самой исходной постановки задачи. Эти условия формируются в значительной части в процессе выявления ошибок по результатам функционирования алгоритмов. Ошибки некорректной постановки задач приводят к сокращению полного перечня маршрутов обработки информации, необходимых для получения всей гаммы числовых и логических решений, или к появлению маршрутов обработки информации, дающих неправильный результат. Таким образом, область получающихся выходных результатов изменяется.
[3]
Алгоритмические ошибки представляют собой ошибки в программной трактовке алгоритма, например недоучет всех вариантов работы алгоритма.
[4]
К алгоритмическим ошибкам следует отнести также ошибки связей модулей и функциональных групп программ.
[5]
К алгоритмическим ошибкам следует отнести также ошибки сопряжения алгоритмических блоков, когда информация, необходимая для функционирования некоторого блока, оказывается неполностью подготовленной блоками, предшествующими по моменту включения. Этот тип ошибок также можно квалифицировать как ошибки некорректной постановки задачи, однако в данном случае некорректность может проявляться при определенной временной последовательности функционирования алгоритмических блоков.
[6]
С алгоритмическими ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая ошибка, завершается успешно. При пробных запусках программа ведет себя нормально, однако при анализе результата выясняется, что он неверный. Для того чтобы устранить алгоритмическую ошибку, приходится анализировать алгоритм, вручную прокручивать его выполнение.
[8]
Особую часть алгоритмических ошибок составляют просчеты в использовании доступных ресурсов ВС. Одновременная разработка множества модулей различными специалистами затрудняет оптимальное распределение ограниченных ресурсов ЭВМ по всем задачам, так как отсутствуют достоверные данные потребных ресурсов для решения каждой из них. В результате возникает либо недоиспользование, либо ( в подавляющем большинстве случаев) нехватка каких-то ресурсов ЭВМ для решения задач в первоначальном варианте. Наиболее крупные просчеты обычно происходят при оценке времени реализации различных групп программ и при распределении производительности ЭВМ.
[9]
Этот побочный эффект может привести к алгоритмическим ошибкам при работе программы. Для того чтобы избавить программиста от необходимости помнить о таком побочном эффекте, достаточно в начале макрокоманды сохранять, а после выполнения восстанавливать содержимое этих регистров. Для этих целей в СМ ЭВМ обычно используется стек. Необходимо отметить, что в отдельных случаях сохранение регистров не обязательно.
[10]
В предыдущем параграфе был рассмотрен характер формирования алгоритмической ошибки вычислений при отсутствии искажающих воздействий со стороны окружающей среды и вычислительной системы. В реальных условиях на процесс смены состояний АлСУ и ошибку выходных сигналов существенное влияние оказывают искажающие воздействия, которые по отношению к управляющему объекту могут быть как внешними, так и внутренними. Внешние воздействия, источником которых является внешняя ( по отношению к управляющему объекту) среда, связаны с ошибками определения параметров управляемого процесса, отказами и сбоями в работе датчиков информации, каналов связи и преобразующих устройств. Внутренние воздействия, источниками которых являются ЦВМ или комплексы ЦВМ, используемые для реализации алгоритмической системы, обусловлены сбоями, частичными отказами и прерываниями.
[11]
Кроме того, значительные трудности представляет разделение системных и алгоритмических ошибок и выделение доработок, которые не следует квалифицировать как ошибки.
[12]
Однако формула ( 29) позволяет судить о характере формирования алгоритмической ошибки в реальных системах и сделать важный вывод о несостоятельности попыток оценки качества АлСУ всякого рода контрольными просчетами.
[13]
Защита от перегрузки ЭВМ по пропускной способности предполагает обнаружение и снижение влияния последствий алгоритмических ошибок, обусловленных неправильным определением необходимой пропускной способности ЭВМ для работы в реальном времени. Кроме того, перегрузки могут быть следствием неправильного функционирования источников информации и превышения интенсивности потоков сообщений расчетного, нормального, уровня. Последствия обычно сводятся к прекращению решения некоторых функциональных задач, обладающих низким приоритетом.
[14]
В настоящее время структурные методы контроля ориентированы в основном на обнаружение и доказательство отсутствия технологических и некоторых алгоритмических ошибок в записи программ, которые выполняются на этапе программной отладки.
[15]
Страницы:
1
2
3
Типичные ошибки
в программных комплексах.
Статистические характеристики ошибок
могут служить ориентиром для разработчиков
при распределении усилий на создание
программ. Кроме того, характеристики
ошибок в процессе проектирования
программ помогают:
-
оценивать реальное
состояние проекта и планировать
трудоемкость и длительность до его
завершения; -
рассчитывать
необходимую эффективность средств
оперативной защиты от невыявленных
первичных ошибок; -
оценивать
требующиеся ресурсы ЭВМ по памяти и
производительности с учетом затрат на
устранение ошибок; -
проводить
исследования и осуществлять адекватный
выбор показателей сложности компонент
и КП, а также некоторых других показателей
качества.
Анализ первичных
ошибок в программах производится на
двух уровнях детализации:
-
дифференциально
— с учетом
типов ошибок, сложности и степени
автоматизации их обнаружения, затрат
на корректировку и этапов наиболее
вероятного устранения; -
обобщенно —
по суммарным характеристикам их
обнаружения в зависимости от
продолжительности разработки,
эксплуатации и сопровождения комплекса
программ.
Технологические
ошибки
документации и фиксирования программ
в памяти ЭВМ составляют 5…10 % от общего
числа ошибок, обнаруживаемых при отладке
[12]. Большинство технологических ошибок
выявляется автоматически формализованными
методами.
Программные
ошибки по
количеству и типам в первую очередь
определяются степенью автоматизации
программирования и глубиной формализованного
контроля текстов программ. Количество
программных ошибок зависит от квалификации
разработчиков, от общего объема комплекса
программ, от глубины логического и
информационного взаимодействия модулей
и от ряда других факторов. При разработке
программ на автокодах программные
ошибки можно классифицировать по видам
используемых операций на следующие
группы: ошибки типов операций; ошибки
переменных; ошибки управления и циклов.
В комплексе программ
информационно-справочных систем эти
виды ошибок близки по удельному весу,
однако для автоматизации их обнаружений
применяются различные методы. На
начальных этапах разработки и автономной
отладки модулей программные ошибки
составляют около 1/3 всех ошибок. Ошибки
применения операций на начальных этапах
разработки достигают 14 %, а затем быстро
убь-1вают при повышении квалификации
программистов. Ошибки в переменных
составляют около 13 %, а ошибки управления
и организации циклов—около 10 %. Каждая
программная ошибка влечет за собой
необходимость изменения около шести
команд, что существенно меньше, чем при
алгоритмических и системных ошибках.
На этапах комплексной отладки и
эксплуатации удельный вес программных
ошибок падает и составляет около 15 и 3
% соответственно от общего количества
ошибок, выявляемых в единицу времени.
Алгоритмические
ошибки
значительно труднее поддаются обнаружению
методами формализованного автоматического
контроля, чем предыдущие типы ошибок.
К алгоритмическим следует отнести
прежде всего ошибки, обусловленные
некорректной постановкой функциональных
задач, когда в спецификациях не полностью
оговорены все условия, необходимые для
получения правильного результата. Эти
условия формируются и уточняются в
значительной части в процессе тестирования
и выявления ошибок в результатах
функционирования программ. Ошибки,
обусловленные неполным учетом всех
условий решения задач, являются наиболее
частыми в этой группе и составляют до
70 % всех алгоритмических ошибок или
около 30 % общего количества ошибок на
начальных этапах проектирования.
К алгоритмическим
ошибкам следует отнести также ошибки
связей модулей и функциональных групп
программ. Этот вид ошибок составляет
6…8 % от общего количества, их можно
квалифицировать как ошибки некорректной
постановки задач. Алгоритмические
ошибки проявляются в неполном учете
диапазонов изменения переменных, в
неправильной оценке точности используемых
и получаемых величин, в неправильном
учете связи между различными переменными,
в неадекватном представлении
формализованных условий решения задачи
в спецификациях или схемах, подлежащих
программированию, и т. д. Эти обстоятельства
являются причиной того, что для исправления
каждой алгоритмической ошибки приходится
изменять в среднем около 14 команд, т. е.
существенно больше, чем при программных
ошибках.
Особую часть
алгоритмических ошибок составляют
просчеты в использовании доступных
ресурсов ВС. Одновременная разработка
множества модулей различными специалистами
затрудняет оптимальное распределение
ограниченных ресурсов ЭВМ по всем
задачам, так как отсутствуют достоверные
данные потребных ресурсов для решения
каждой из них. В результате возникает
либо недоиспользование, либо (в подавляющем
большинстве случаев) нехватка каких-то
ресурсов ЭВМ для решения задач в
первоначальном варианте. Наиболее
крупные просчеты обычно происходят при
оценке времени реализации различных
групп программ и при распределении
производительности ЭВМ.
Системные ошибки
в сложных комплексах программ определяются
прежде всего неполной информацией о
реальных процессах, происходящих в
источниках и потребителях информации.
Кроме того, эти процессы зачастую зависят
от самих алгоритмов и поэтому не могут
быть достаточно определены и описаны
заранее без исследования функционирования
комплекса программ во взаимодействии
с внешней средой. На начальных стадиях
проектирования не всегда удается точно
сформулировать целевую задачу всей
системы, а также целевые задачи основных
групп программ, и эти задачи уточняются
в процессе проектирования. В соответствии
с этим уточняются и конкретизируются
технические задания или спецификации
на отдельные программы и выявляются
отклонения от уточненного задания,
которые могут квалифицироваться как
системные ошибки.
При автономной и
в начале комплексной отладки доля
системных ошибок невелика (около 10 %),
но она существенно возрастает (до 35…40
%) на завершающих этапах комплексной
отладки. В процессе эксплуатации
системные ошибки являются преобладающими
(около 80 % от всех ошибок). Следует также
отметить большое количество команд,
корректируемых при исправлении каждой
ошибки (около 25 команд на одну ошибку).
Убывание ошибок
в комплексе программ и интенсивности
их обнаружения не беспредельно. После
отладки в течение некоторого времени
интенсивность обнаружения ошибок при
самом активном тестировании снижается
настолько, что коллектив, ведущий
разработку, попадает в зону
нечувствительности к
ошибкам и отказам. При такой интенсивности
отказов трудно прогнозировать затраты
времени, необходимые для обнаружения
очередной ошибки. Создается представление
о полном отсутствии ошибок, о невозможности
и бесцельности их поиска, поэтому усилия
на отладку сокращаются и интенсивность
обнаружения ошибок еще больше снижается.
Этой предельной интенсивности обнаружения
отказов соответствует наработка на
обнаруженную ошибку, при которой
прекращается улучшение характеристик
комплекса программ на этапах отладки
и испытаний у заказчика.
Отладка программ
Введение
Успешное завершение процесса компиляции не означает, что в программе нет ошибок. Убедиться, что программа работает правильно, можно только в процессе проверки ее работоспособности, который называется тестирование. Обычно программа редко сразу начинает работать так, как надо, или работает правильно только на некотором ограниченном наборе исходных данных. Это свидетельствует о том, что в программе есть алгоритмические ошибки. Процесс поиска и устранения ошибок называется отладкой
Классификация ошибок
Введение
Ошибки, которые могут быть в программе, принято делить на три группы:
- синтаксические;
- ошибки времени выполнения;
- алгоритмические.
Синтаксические ошибки
Синтаксические ошибки, их также называют ошибками времени компиляции (Compile-time error), наиболее легко устранимы. Их обнаруживает компилятор, а программисту остается внести изменения в текст программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения, они называются исключениями (Exception), тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы и во время тестирования
При возникновении ошибки в программе, запущенной из ИСР, среда прерывает работу программы и в окне сообщений дает информацию о типе ошибки.
После возникновения ошибки программист может либо прервать выполнение программы, либо продолжить ее выполнение, например, по шагам, наблюдая результат выполнения каждой инструкции.
Если программа запущена из Windows, то при возникновении ошибки на экране также появляется сообщение об ошибке, но тип ошибки (исключения) в сообщении не указывается. После щелчка на кнопке ОК программа, в которой проявилась ошибка, продолжает (если сможет) работу.
Алгоритмические ошибки
С алгоритмическими ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая ошибка, завершается успешно. При пробных запусках программа ведет себя нормально, однако при анализе результата выясняется, что он неверный. Для того чтобы устранить алгоритмическую ошибку, приходится анализировать алгоритм, вручную “прокручивать” его выполнение.
Предотвращение и обработка ошибок
В программе во время ее работы могут возникать ошибки, причиной которых, как правило, являются действия пользователя. Например, пользователь может ввести неверные данные или, что бывает довольно часто, удалить нужный программе файл. Нарушение в работе программы называется исключением. Обработку исключений (ошибок) берет на себя автоматически добавляемый в выполняемую программу код, который обеспечивает, в том числе, вывод информационного сообщения.
FPC и ИСР предоставляют программисту мощные средства:
- Компилятор с регулируемыми опциями.
Отладчик для поиска и устранения ошибок в программе. Отладчик позволяет выполнять трассировку программы, наблюдать значения переменных, контролировать выводимые программой данные.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Справочник /
Термины /
Информатика /
Алгоритмические ошибки
Термин и определение
Алгоритмические ошибки
Опубликовано:
yuliya-aleksandrova-1973
Предмет:
Информатика
👍 Проверено Автор24
ошибки в методе, постановке, сценарии и реализации.
Научные статьи на тему «Алгоритмические ошибки»
1.
Уравнения и передаточные функции одноконтурной САУ
Рассмотрим алгоритмическую схему, которая соответствует схеме типовой одноконтурной системы автоматического…
На входе управляющего устройства с передаточной функцией Wp(p) действует сигнал рассогласования/ошибки…
Алгоритмическая схема системы автоматического управления….
Алгоритмическая схема системы автоматического управления….
Алгоритмы управления в автоматических системах управления
Алгоритмом управления устанавливается связь ошибки
Статья от экспертов
![]()
2.
Алгоритмическая и программная реализация построения оптимальных моделей прогноза
Рассматривается методика отыскания моделей прогноза с минимальными ошибками прогноза. Основу методики составляют полиномиальные модели параметрического прогноза и алгоритмическая схема поиска оптимальных моделей прогноза.
3.
Исполнитель Чертежник в среде КуМир
Исполнитель «Чертежник» в среде КуМир — это программа для формирования рисунков и чертежей, написанная на алгоритмическом…
Исполнитель Чертёжник написан на алгоритмическом языке, то есть в системе, которая имеет обозначения…
У алгоритмического языка есть свой словарный комплект, основанный на словах, употребляемых для отображения…
написано заместится на вектор, то такая запись будет непонятна Чертёжнику, и он выдаст сообщение об ошибке…
Такого типа ошибки в формулировании команды считаются синтаксическими.
Статья от экспертов
![]()
4.
Алгоритмическое исключение многолучевой погрешности из радионавигационных измерений
Предложена и проанализирована алгоритмическая процедура компенсации многолучевой ошибки в дальномерных измерениях приемника радионавигационной системы космического базирования. С помощью компьютерного моделирования выявлены условия сходимости алгоритма и область шумовых погрешностей, в пределах которой его применение имеет смысл.
Повышай знания с онлайн-тренажером от Автор24!
- 📝 Напиши термин
- ✍️ Выбери определение из предложенных или загрузи свое
- 🤝 Тренажер от Автор24 поможет тебе выучить термины, с помощью удобных и приятных
карточек
Алгоритмическая ошибка
Cтраница 1
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формализованного автоматического контроля, чем предыдущие типы ошибок. К алгоритмическим следует отнести прежде всего ошибки, обусловленные некорректной постановкой функциональных задач, когда в спецификациях не полностью оговорены все условия, необходимые для получения правильного результата. Эти условия формируются и уточняются в значительной части в процессе тестирования и выявления ошибок в результатах функционирования программ. Ошибки, обусловленные неполным учетом всех условий решения задач, являются наиболее частыми в этой группе и составляют до 70 % всех алгоритмических ошибок или около 30 % общего количества ошибок на начальных этапах проектирования.
[1]
Алгоритмические ошибки и ошибки кодирования, связанные с некорректной формулировкой и реализацией алгоритмов программным путем.
[2]
Алгоритмические ошибки значительно труднее поддаются обнаружению методами формального автоматического контроля, чем все предыдущие типы ошибок. Это определяется прежде всего отсутствием для большинства логических управляющих алгоритмов строго формализованной постановки задач, которую можно использовать в качестве эталона для сравнения результатов функционирования разработанных алгоритмов. Разработка управляющих алгоритмов осуществляется обычно при наличии большого количества параметров и в условиях значительной неопределенности самой исходной постановки задачи. Эти условия формируются в значительной части в процессе выявления ошибок по результатам функционирования алгоритмов. Ошибки некорректной постановки задач приводят к сокращению полного перечня маршрутов обработки информации, необходимых для получения всей гаммы числовых и логических решений, или к появлению маршрутов обработки информации, дающих неправильный результат. Таким образом, область получающихся выходных результатов изменяется.
[3]
Алгоритмические ошибки представляют собой ошибки в программной трактовке алгоритма, например недоучет всех вариантов работы алгоритма.
[4]
К алгоритмическим ошибкам следует отнести также ошибки связей модулей и функциональных групп программ.
[5]
К алгоритмическим ошибкам следует отнести также ошибки сопряжения алгоритмических блоков, когда информация, необходимая для функционирования некоторого блока, оказывается неполностью подготовленной блоками, предшествующими по моменту включения. Этот тип ошибок также можно квалифицировать как ошибки некорректной постановки задачи, однако в данном случае некорректность может проявляться при определенной временной последовательности функционирования алгоритмических блоков.
[6]
С алгоритмическими ошибками дело обстоит иначе. Компиляция программы, в которой есть алгоритмическая ошибка, завершается успешно. При пробных запусках программа ведет себя нормально, однако при анализе результата выясняется, что он неверный. Для того чтобы устранить алгоритмическую ошибку, приходится анализировать алгоритм, вручную прокручивать его выполнение.
[8]
Особую часть алгоритмических ошибок составляют просчеты в использовании доступных ресурсов ВС. Одновременная разработка множества модулей различными специалистами затрудняет оптимальное распределение ограниченных ресурсов ЭВМ по всем задачам, так как отсутствуют достоверные данные потребных ресурсов для решения каждой из них. В результате возникает либо недоиспользование, либо ( в подавляющем большинстве случаев) нехватка каких-то ресурсов ЭВМ для решения задач в первоначальном варианте. Наиболее крупные просчеты обычно происходят при оценке времени реализации различных групп программ и при распределении производительности ЭВМ.
[9]
Этот побочный эффект может привести к алгоритмическим ошибкам при работе программы. Для того чтобы избавить программиста от необходимости помнить о таком побочном эффекте, достаточно в начале макрокоманды сохранять, а после выполнения восстанавливать содержимое этих регистров. Для этих целей в СМ ЭВМ обычно используется стек. Необходимо отметить, что в отдельных случаях сохранение регистров не обязательно.
[10]
В предыдущем параграфе был рассмотрен характер формирования алгоритмической ошибки вычислений при отсутствии искажающих воздействий со стороны окружающей среды и вычислительной системы. В реальных условиях на процесс смены состояний АлСУ и ошибку выходных сигналов существенное влияние оказывают искажающие воздействия, которые по отношению к управляющему объекту могут быть как внешними, так и внутренними. Внешние воздействия, источником которых является внешняя ( по отношению к управляющему объекту) среда, связаны с ошибками определения параметров управляемого процесса, отказами и сбоями в работе датчиков информации, каналов связи и преобразующих устройств. Внутренние воздействия, источниками которых являются ЦВМ или комплексы ЦВМ, используемые для реализации алгоритмической системы, обусловлены сбоями, частичными отказами и прерываниями.
[11]
Кроме того, значительные трудности представляет разделение системных и алгоритмических ошибок и выделение доработок, которые не следует квалифицировать как ошибки.
[12]
Однако формула ( 29) позволяет судить о характере формирования алгоритмической ошибки в реальных системах и сделать важный вывод о несостоятельности попыток оценки качества АлСУ всякого рода контрольными просчетами.
[13]
Защита от перегрузки ЭВМ по пропускной способности предполагает обнаружение и снижение влияния последствий алгоритмических ошибок, обусловленных неправильным определением необходимой пропускной способности ЭВМ для работы в реальном времени. Кроме того, перегрузки могут быть следствием неправильного функционирования источников информации и превышения интенсивности потоков сообщений расчетного, нормального, уровня. Последствия обычно сводятся к прекращению решения некоторых функциональных задач, обладающих низким приоритетом.
[14]
В настоящее время структурные методы контроля ориентированы в основном на обнаружение и доказательство отсутствия технологических и некоторых алгоритмических ошибок в записи программ, которые выполняются на этапе программной отладки.
[15]
Страницы:
1
2
3
Аннотация: Лекция носит факультативный характер. Здесь мы рассматриваем виды допускаемых в программировании ошибок, способы тестирования и отладки программ, инструменты встроенного отладчика.
Цель лекции
Освоить работу с встроенным отладчиком, изучить категории ошибок, способы их обнаружения и устранения.
Тестирование и отладка программы
Чем больше опыта имеет программист, тем меньше ошибок в коде он совершает. Но, хотите верьте, хотите нет, даже самый опытный программист всё же допускает ошибки. И любая современная среда разработки программ должна иметь собственные инструменты для отладки приложений, а также для своевременного обнаружения и исправления возможных ошибок. Программные ошибки на программистском сленге называют багами (англ. bug — жук), а программы отладки кода — дебаггерами (англ. debugger — отладчик). Lazarus, как современная среда разработки приложений, имеет собственный встроенный отладчик, работу с которым мы разберем на этой лекции.
Ошибки, которые может допустить программист, условно делятся на три группы:
- Синтаксические
- Времени выполнения (run-time errors)
- Алгоритмические
Синтаксические ошибки
Синтаксические ошибки легче всего обнаружить и исправить — их обнаруживает компилятор, не давая скомпилировать и запустить программу. Причем компилятор устанавливает курсор на ошибку, или после неё, а в окне сообщений выводит соответствующее сообщение, например, такое:
Рис.
27.1.
Найденная компилятором синтаксическая ошибка — нет объявления переменной i
Подобные ошибки могут возникнуть при неправильном написании директивы или имени функции (процедуры); при попытке обратиться к переменной или константе, которую не объявляли (
рис.
27.1); при попытке вызвать функцию (процедуру, переменную, константу) из модуля, который не был подключен в разделе uses; при других аналогичных недосмотрах программиста.
Как уже говорилось, компилятор при нахождении подобной ошибки приостанавливает процесс компиляции, выводит сообщение о найденной ошибке и устанавливает курсор на допущенную ошибку, или после неё. Программисту остается только внести исправления в код программы и выполнить повторную компиляцию.
Ошибки времени выполнения
Ошибки времени выполнения (run-time errors) тоже, как правило, легко устранимы. Они обычно проявляются уже при первых запусках программы, или во время тестирования. Если такую программу запустить из среды Lazarus, то она скомпилируется, но при попытке загрузки, или в момент совершения ошибки, приостановит свою работу, выведя на экран соответствующее сообщение. Например, такое:
Рис.
27.2.
Сообщение Lazarus об ошибке времени выполнения
В данном случае программа при загрузке должна была считать в память отсутствующий текстовый файл MyFile.txt. Поскольку программа вызвала ошибку, она не запустилась, но в среде Lazarus процесс отладки продолжается, о чем свидетельствует сообщение в скобках в заголовке главного меню, после названия проекта. Программисту в подобных случаях нужно сбросить отладчик командой меню «Запуск -> Сбросить отладчик«, после чего можно продолжить работу над проектом.
Ошибка времени выполнения может возникнуть не только при загрузке программы, но и во время её работы. Например, если бы попытка чтения несуществующего файла была сделана не при загрузке программы, а при нажатии на кнопку, то программа бы нормально запустилась и работала, пока пользователь не нажмет на эту кнопку.
Если программу запустить из самой Windows, при возникновении этой ошибки появится такое же сообщение. При этом если нажать «OK«, программа даже может запуститься, но корректно работать все равно не будет.
Ошибки времени выполнения бывают не только явными, но и неявными, при которых программа продолжает свою работу, не выводя никаких сообщений, а программист даже не догадывается о наличии ошибки. Примером неявной ошибки может служить так называемая утечка памяти. Утечка памяти возникает в случаях, когда программист забывает освободить выделенную под объект память. Например, мы объявляем переменную типа TStringList, и работаем с ней:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
end;
В данном примере программист допустил типичную для начинающих ошибку — не освободил класс TStringList. Это не приведет к сбою или аварийному завершению программы, но в итоге можно бесполезно израсходовать очень много памяти. Конечно, эта память будет освобождена после выгрузки программы (за этим следит операционная система), но утечка памяти во время выполнения программы тоже может привести к неприятным последствиям, потребляя все больше и больше ресурсов и излишне нагружая процессор. В подобных случаях после работы с объектом программисту нужно не забывать освобождать память:
begin
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
MySL.Free; //освободили объект
end;
Однако ошибки времени выполнения могут случиться и во время работы с объектом. Если есть такой риск, программист должен не забывать про возможность обработки исключительных ситуаций. В данном случае вышеприведенный код правильней будет оформить таким образом:
begin
try
MySL:= TStringList.Create;
MySL.Add('Новая строка');
...; //работа с объектом
finally
MySL.Free; //освободили объект, даже если была ошибка
end;
end;
Итак, во избежание ошибок времени выполнения программист должен не забывать делать проверку на правильность ввода пользователем допустимых значений, заключать опасный код в блоки try…finally…end или try…except…end, делать проверку на существование открываемого файла функцией FileExists и вообще соблюдать предусмотрительность во всех слабых местах программы. Не полагайтесь на пользователя, ведь недаром говорят, что если в программе можно допустить ошибку, пользователь эту возможность непременно найдет.
Алгоритмические ошибки
Если вы не допустили ни синтаксических ошибок, ни ошибок времени выполнения, программа скомпилировалась, запустилась и работает нормально, то это еще не означает, что в программе нет ошибок. Убедиться в этом можно только в процессе её тестирования.
Тестирование — процесс проверки работоспособности программы путем ввода в неё различных, даже намеренно ошибочных данных, и последующей контрольной проверке выводимого результата.
Если программа работает правильно с одними наборами исходных данных, и неправильно с другими, то это свидетельствует о наличии алгоритмической ошибки. Алгоритмические ошибки иногда называют логическими, обычно они связаны с неверной реализацией алгоритма программы: вместо «+» ошибочно поставили «-«, вместо «/» — «*», вместо деления значения на 0,01 разделили на 0,001 и т.п. Такие ошибки обычно не обнаруживаются во время компиляции, программа нормально запускается, работает, а при анализе выводимого результата выясняется, что он неверный. При этом компилятор не укажет программисту на ошибку — чтобы найти и устранить её, приходится анализировать код, пошагово «прокручивать» его выполнение, следя за результатом. Такой процесс называется отладкой.
Отладка — процесс поиска и устранения ошибок, чаще алгоритмических. Хотя отладчик позволяет справиться и с ошибками времени выполнения, которые не обнаруживаются явно.
Алгоритмические ошибки
Предмет
Информатика
Разместил
🤓 yuliya-aleksandrova-1973
👍 Проверено Автор24
ошибки в методе, постановке, сценарии и реализации.
Научные статьи на тему «Алгоритмические ошибки»
Уравнения и передаточные функции одноконтурной САУ
Рассмотрим алгоритмическую схему, которая соответствует схеме типовой одноконтурной системы автоматического…
На входе управляющего устройства с передаточной функцией Wp(p) действует сигнал рассогласования/ошибки…
Алгоритмическая схема системы автоматического управления….
Алгоритмическая схема системы автоматического управления….
Алгоритмы управления в автоматических системах управления
Алгоритмом управления устанавливается связь ошибки

Статья от экспертов
Алгоритмическая и программная реализация построения оптимальных моделей прогноза
Рассматривается методика отыскания моделей прогноза с минимальными ошибками прогноза. Основу методики составляют полиномиальные модели параметрического прогноза и алгоритмическая схема поиска оптимальных моделей прогноза.
Исполнитель Чертежник в среде КуМир
Исполнитель «Чертежник» в среде КуМир — это программа для формирования рисунков и чертежей, написанная на алгоритмическом…
Исполнитель Чертёжник написан на алгоритмическом языке, то есть в системе, которая имеет обозначения…
У алгоритмического языка есть свой словарный комплект, основанный на словах, употребляемых для отображения…
написано заместится на вектор, то такая запись будет непонятна Чертёжнику, и он выдаст сообщение об ошибке…
Такого типа ошибки в формулировании команды считаются синтаксическими.
Статья от экспертов
Алгоритмическое исключение многолучевой погрешности из радионавигационных измерений
Предложена и проанализирована алгоритмическая процедура компенсации многолучевой ошибки в дальномерных измерениях приемника радионавигационной системы космического базирования. С помощью компьютерного моделирования выявлены условия сходимости алгоритма и область шумовых погрешностей, в пределах которой его применение имеет смысл.
Повышай знания с онлайн-тренажером от Автор24!
- Напиши термин
- Выбери определение из предложенных или загрузи свое
-
Тренажер от Автор24 поможет тебе выучить термины с помощью удобных и приятных
карточек

Алгоритмический сбой
Если копнуть глубже в некоторых из самых больших противоречий в области технологий сегодня, вы, вероятно, обнаружите, что алгоритм дает сбой: [1]
- Разногласия по поводу рекламы на YouTube: алгоритм размещал рекламу некоторых крупнейших мировых брендов на видеороликах с языком вражды.
- Противоречие видео в Facebook: алгоритм размещал видео с насилием в лентах своих пользователей.
- Google auto-complete controversy: алгоритм направлял людей, ищущих информацию о Холокосте, на неонацистские веб-сайты.
Эти ошибки в первую очередь вызваны не проблемами в данных, которые могут сделать алгоритмы дискриминационными, или их неспособностью творчески импровизировать. Нет, они проистекают из чего-то более фундаментального: того факта, что алгоритмы, даже когда они генерируют обычные прогнозы на основе непредвзятых данных, будут делать ошибки. Ошибаться — это алгоритм.
Затраты и преимущества алгоритмического принятия решений
Мы не должны отказываться от использования алгоритмов просто потому, что они делают ошибки. [2] Без них многие популярные и полезные сервисы были бы нежизнеспособны. [3] Однако мы должны признать, что алгоритмы подвержены ошибкам, и что их ошибки имеют расходы. Это указывает на важный компромисс между большим количеством полезных решений (с использованием алгоритмов) и большим количеством дорогостоящих ошибок (вызванных алгоритмом). Где баланс?
Экономика — это наука о компромиссах, так почему бы не подумать об этой теме, как экономисты? Это то, что я сделал перед написанием этого блога, создав три простых эпизода по экономике, в которых рассматриваются ключевые аспекты алгоритмического принятия решений. [4] Это ключевые вопросы:
- Риск: когда мы должны оставить решения на усмотрение алгоритмов и насколько точными должны быть эти алгоритмы?
- Надзор. Как совместить человеческий и машинный интеллект для достижения желаемых результатов?
- Масштаб. Какие факторы позволяют и ограничивают нашу способность наращивать алгоритмические процессы принятия решений?
В двух следующих разделах дается суть анализа и его значение. В приложении в конце виньетки описаны более подробно (с уравнениями!).
Моделирование моделирование
Риск: не бойтесь
Как однажды заметил американский психолог и экономист Герберт Саймон, в мире, насыщенном информацией, внимание становится дефицитным ресурсом. Это относится как к организациям, так и к отдельным лицам.
Продолжающаяся революция данных рискует подавить нашу способность обрабатывать информацию и принимать решения, и алгоритмы могут помочь в решении этой проблемы. Это машины, которые автоматизируют процесс принятия решений, потенциально увеличивая количество правильных решений, которые может принять организация. [5] Это объясняет, почему они первыми взлетели в отраслях, где объем и частота потенциальных решений превышают допустимые. человеческая рабочая сила может обрабатывать. [6]
Что движет этим процессом? Для экономиста главный вопрос заключается в том, какую ценность алгоритм принесет своими решениями. Рациональные организации будут применять алгоритмы с высокими ожидаемыми значениями.
Ожидаемая ценность алгоритма зависит от двух факторов: его точности (вероятности того, что он примет правильное решение) и баланса между вознаграждением за правильное решение и штрафом за ошибочное. [7] Более рискованные решения (где штрафы большие по сравнению с вознаграждениями) должны выполняться по высокоточным алгоритмам. Вы бы не хотели, чтобы на атомной электростанции работал шаткий робот, но было бы нормально, если бы он просто подсказывал вам, какое телешоу смотреть сегодня вечером.
Надзор: осторожно
Мы могли бы привлечь людей-контролеров, чтобы они проверяли решения, принимаемые алгоритмом, и исправляли любые обнаруженные ими ошибки. Это имеет больше смысла, если алгоритм не очень точен (руководители не тратят много времени на проверку правильных решений), а чистая выгода от исправления неправильных решений (т. Е. Дополнительных вознаграждений плюс предотвращенных штрафов) высока. Стоимость тоже имеет значение. У рациональной организации больше стимулов нанимать руководителей-людей, если им мало платят и если они высокопроизводительны (т. Е. Для выполнения работы требуется лишь несколько из них).
Следуя предыдущему примеру, если человек-супервайзер исправляет глупую рекомендацию на телевизионном веб-сайте, это вряд ли принесет большую пользу владельцу. Совершенно иная ситуация на АЭС.
Масштаб: гонка между машинами и реальностью
Что происходит, когда мы увеличиваем количество алгоритмических решений? Есть ли пределы его росту?
Это зависит от нескольких факторов, в том числе от того, приобретают или теряют точность алгоритмы по мере того, как они принимают больше решений, и от затрат на усиление алгоритмического принятия решений. В этой ситуации проходят две интересные гонки.
1. Существует гонка между способностью алгоритма извлекать уроки из принимаемых им решений и объемом информации, которую он получает из новых решений. Новые методы машинного обучения помогают алгоритмам учиться на опыте, делая их более точными, поскольку они принимают больше решений. [8] Однако большее количество решений также может ухудшить точность алгоритма. Возможно, ему приходится иметь дело с более странными случаями или новыми ситуациями, с которыми он не обучен. [9] Что еще хуже, когда алгоритм становится очень популярным (принимает больше решений), у людей появляется больше причин играть с ним. .
Я прихожу к выводу, что «энтропийные силы», ухудшающие точность алгоритмов, в конце концов победят: сколько бы больше данных вы ни собрали, сделать точные прогнозы относительно сложной динамической реальности просто невозможно.
2. Вторая гонка — между специалистами по обработке данных, создающими алгоритмы, и руководителями, проверяющими решения этих алгоритмов. Специалисты по обработке данных, вероятно, «превзойдут» человеческих руководителей, потому что их продуктивность выше: один алгоритм или улучшение алгоритма можно масштабировать на миллионы решений. Напротив, надзорным органам необходимо проверять каждое решение индивидуально. Это означает, что по мере увеличения количества решений большая часть затрат организации на оплату труда будет потрачена на надзор, с потенциально растущими расходами по мере того, как процесс надзора становится больше и усложняется.
Что происходит в конце?
При совместном рассмотрении снижение алгоритмической точности и рост затрат на рабочую силу, которые я только что описал, вероятно, ограничат количество алгоритмических решений, которые организация может принять с экономической точки зрения. Но если и когда это произойдет, зависит от специфики ситуации.
Последствия для организаций и политики
Процессы, которые я обсуждал выше, имеют много интересных организационных и политических последствий. Вот некоторые из них:
1. Поиск подходящего алгоритма и предметной области
Как я уже сказал, алгоритмы, принимающие решения в ситуациях, когда ставки высоки, должны быть очень точными, чтобы компенсировать высокие штрафы, когда что-то идет не так. [10] С другой стороны, если штраф за совершение ошибки низкий, даже неточные алгоритмы могут справиться с этой задачей.
Например, механизмы рекомендаций на таких платформах, как Amazon или Netflix, часто дают нерелевантные рекомендации, но это не большая проблема, потому что штраф за эти ошибки относительно невелик — мы просто игнорируем их. Специалист по анализу данных Хиллари Паркер обратила внимание на необходимость учитывать соответствие между точностью модели и контекстом принятия решения в недавнем выпуске подкаста Не такие стандартные отклонения:
«Большинство статистических методов были адаптированы для реализации клинических испытаний, в которых вы говорите о жизнях людей и людях, умирающих из-за неправильного лечения, тогда как в бизнес-среде компромиссы совершенно разные»
Одно из следствий этого состоит в том, что организации, работающие в условиях «низких ставок», могут экспериментировать с новыми и непроверенными алгоритмами, в том числе с алгоритмами с низкой точностью на раннем этапе. По мере их усовершенствования они могут быть переведены в «домены с высокой долей участия». Технологические компании, которые разрабатывают эти алгоритмы, часто выпускают их как программное обеспечение с открытым исходным кодом, чтобы другие могли загрузить и улучшить, что делает возможным распространение этих алгоритмов.
2. Есть ограничения на алгоритмическое принятие решений в областях с высокими ставками.
Алгоритмы необходимо применять гораздо более осторожно в областях, где штрафы за ошибки высоки, таких как здравоохранение или система уголовного правосудия, а также при работе с группами, которые более уязвимы для алгоритмических ошибок. [11] Только высокоточные алгоритмы подходят для этих рискованных решений, если они не сопровождаются дорогостоящими руководителями, которые могут находить и исправлять ошибки. Это создаст естественные ограничения для алгоритмического принятия решений: сколько людей вы можете нанять для проверки расширенного числа решений? Человеческое внимание остается препятствием для принятия большего количества решений.
Если разработчики политики хотят более широкого и лучшего использования алгоритмов в этих областях, им следует инвестировать в НИОКР для повышения алгоритмической точности, поощрять внедрение высокопроизводительных алгоритмов из других секторов и экспериментировать с новыми способами организации, которые помогают алгоритмам и их руководителям работать лучше как команда.
Коммерческие организации не застрахованы от некоторых из этих проблем: YouTube, например, начал блокировать рекламу в видеороликах с менее чем десятью тысячами просмотров. В этих видео награда от правильного алгоритмического сопоставления объявлений, вероятно, низкая (у них низкая посещаемость), а штрафы могут быть высокими (многие из этих видео имеют сомнительное качество). Другими словами, эти решения имеют низкую ожидаемую ценность, поэтому YouTube решил прекратить их принимать. Между тем, Facebook только что объявил, что нанимает 3000 человек-контролеров (почти пятая часть нынешнего штата сотрудников) для модерации контента в своей сети. Вы можете себе представить, как необходимость контролировать большее количество решений может несколько притормозить его способность бесконечно масштабировать процесс принятия алгоритмических решений.
3. Плюсы и минусы краудсорсингового надзора.
Один из способов сохранить низкие затраты на супервизию и высокий охват решений — это краудсорсинг надзора для пользователей, например, путем предоставления им инструментов для сообщения об ошибках и проблемах. YouTube, Facebook и Google сделали это в ответ на свои алгоритмические разногласия. Увы, привлечение пользователей к полицейским онлайн-сервисам может показаться несправедливым и неприятным. Как отметила Сара Т. Робертс, профессор права в недавнем интервью о скандале с видео с насилием в Facebook:
«Этот материал часто прерывают, потому что кто-то вроде вас или меня сталкивается с этим. Это означает, что целая группа людей увидела это и отметила это, внося свой труд и внося свой вклад в нечто ужасное. Как мы будем поступать с членами сообщества, которые, возможно, увидели это и получили травму сегодня? »
4. Почему вы всегда должны держать человека в курсе
Даже когда штрафы за ошибку низкие, все же имеет смысл держать людей в курсе алгоритмических систем принятия решений. [12] Их наблюдение обеспечивает буфер против внезапного снижения производительности, если (как) снижается точность алгоритмов. Когда это происходит, количество обнаруженных людьми ошибочных решений и чистая выгода от их исправления возрастают. Они также могут бить тревогу, сообщая всем, что есть проблема с алгоритмами, которую необходимо исправить. [13]
Это может быть особенно важно в ситуациях, когда ошибки приводят к штрафам с задержкой или штрафам, которые трудно измерить или скрыть (например, если ошибочные рекомендации приводят к самоисполняющимся пророчествам или к расходам, которые понесены за пределами организации).
Примеров тому множество. В споре о рекламе на YouTube большой накопленный штраф за предыдущие ошибки стал очевиден только с задержкой, когда бренды заметили, что их реклама размещается против видеороликов, разжигающих ненависть. Споры с фальшивыми новостями после выборов в США являются примером трудноизмеримых затрат: неспособность алгоритмов различать настоящие новости и подделки создает издержки для общества, потенциально оправдывая более строгие правила и усиление человеческого контроля. Политики подчеркивали это, призывая Facebook усилить борьбу с фейковыми новостями в преддверии выборов в Великобритании:
«Глядя на часть проделанной к настоящему времени работы, они не реагируют достаточно быстро или вообще не реагируют на некоторых рефералов пользователей, которых они могут получить. Они могут довольно быстро определить, когда что-то становится вирусным. Затем они должны иметь возможность проверить, является ли эта история правдой, и, если она фальшивка, заблокировать ее или предупредить людей о том, что она оспаривается. Это не могут быть просто пользователи, ссылающиеся на достоверность истории. Они [Facebook] должны решить, является ли история фальшивкой ».
5. От абстрактных моделей к реальным системам
Прежде чем использовать экономические модели для информирования о действиях, нам необходимо определить и измерить точность модели, штрафы и вознаграждения, изменения в алгоритмической производительности из-за нестабильности окружающей среды, уровни надзора и связанные с ними затраты, и это только начало. [14]
Это сложная, но важная работа, которая может опираться на существующие технологии оценки и инструменты оценки, включая методы для количественной оценки неэкономических результатов (например, в области здравоохранения). [15] Можно даже использовать обширные данные из информационных систем организации для моделирования влияние алгоритмического принятия решения и его организация до его реализации. Мы видим все больше примеров таких приложений, таких как пилотные проекты финансового« regtech », которые проводит Европейская комиссия, или инкубаторы сговора, упомянутые в недавней статье журнала Economist о ценовой дискриминации.
Coda: поэтапная социальная инженерия в эпоху алгоритмов
В прошлогодней статье в журнале Nature американские исследователи Райан Кало и Кейт Кроуфорд призвали к практическому и широко применимому анализу социальных систем, [который] учитывает все возможные воздействия систем ИИ на все стороны [опираясь на] философию, право, социологию, антропологию, исследования науки и технологий и другие дисциплины . Кало и Кроуфорд не включили в свой список экономистов. Тем не менее, как предполагает этот блог, экономическое мышление может внести большой вклад в эти важные анализы и дискуссии. Рассмотрение алгоритмических решений с точки зрения их выгод и затрат, организационных структур, которые мы можем использовать для управления их недостатками, и влияния большего количества решений на ценность, создаваемую агорифмами, может помочь нам принимать более обоснованные решения о том, когда и как их использовать.
Это напоминает мне о том, что Джарон Ланье сделал в своей книге 2010 года Кому принадлежит будущее: «с каждым годом экономика должна все больше и больше относиться к конструкции машин. которые опосредуют социальное поведение человека. Сетевая информационная система направляет людей более прямым, подробным и буквальным образом, чем политика. Другими словами, экономика должна превратиться в крупномасштабную системную версию дизайна пользовательского интерфейса ’.
Создание организаций, в которых алгоритмы и люди работают вместе для принятия лучших решений, будет важной частью этой повестки дня.
Благодарности
Этот блог был основан на комментариях Джеффа Малгана и был вдохновлен беседами с Джоном Дэвисом. На изображении выше представлена кривая точного отзыва в задаче классификации с несколькими этикетками. Он показывает склонность алгоритма классификации случайных лесов к ошибкам при установке разных правил (порогов вероятности) для помещения наблюдений в категорию.
Приложение: Три виньетки из экономики об алгоритмическом принятии решений
Три приведенные ниже виньетки представляют собой очень упрощенную формализацию ситуаций принятия алгоритмических решений. Основным источником вдохновения для меня послужила статья Джо Стиглица и Раджа Саха Человеческая ошибочность и экономическая организация 1985 года, в которой авторы моделируют, как две организационные конструкции — иерархии и полиархии (плоские организации) — справляются с человеческими ошибка. Их анализ показывает, что иерархические организации, в которых лица, принимающие решения ниже в иерархии, контролируются людьми, находящимися на более высоком уровне, как правило, отклоняют больше хороших проектов, в то время как полиархии, в которых агенты принимают решения независимо друг от друга, склонны принимать больше плохих проектов. Ключевой урок их модели заключается в том, что ошибки неизбежны, а оптимальный организационный дизайн зависит от контекста.
Виньетка 1: алгоритм говорит, что возможно
Представим себе онлайн-видео компанию, которая сопоставляет рекламу с видео в своем каталоге. Эта компания размещает миллионы видеороликов, поэтому для нее было бы экономически нецелесообразно полагаться на человеческий труд при выполнении этой работы. Вместо этого специалисты по данным разрабатывают алгоритмы, которые делают это автоматически. [16] Компания ищет алгоритм, который максимизирует ожидаемую ценность согласованных решений. Это значение зависит от трех факторов: [17]
-Точность алгоритма (a ): вероятность (от 0 до 1) того, что алгоритм примет правильное решение. [18]
Награда за решение (r ): это награда, когда алгоритм принимает правильное решение.
— Штраф за ошибку (p ): это цена за принятие неправильного решения.
Мы можем объединить точность, выгоду и штраф, чтобы рассчитать ожидаемую ценность решения:
E = ar – (1-a)p [1]
Это значение является положительным, когда ожидаемые выгоды от решения алгоритма перевешивают ожидаемые затраты (или риски):
ar > (1-a)p [2]
Это то же самое, что сказать:
a/(1-a) > p/r [3]
Вероятность принятия правильного решения должна быть выше, чем соотношение между штрафом и выплатой.
Введите человека
Мы можем снизить риск ошибок, если привлечем к работе надзорного сотрудника. Этот человек-руководитель может распознавать и исправлять ошибки в алгоритмических решениях. Влияние этой стратегии на ожидаемую ценность решения зависит от двух параметров:
-Коэффициент покрытия (k): k — это вероятность того, что человек-супервайзер проверит решение алгоритмом. Если k равно 1, это означает, что все алгоритмические решения проверяются человеком.
-Стоимость наблюдения (cs(k)): это стоимость наблюдения за решениями алгоритма. Стоимость зависит от коэффициента охвата k, потому что проверка большего количества решений требует времени.
Ожидаемое значение алгоритмического решения под контролем человека следующее: [19]
Es = ar + (1-a)kr – (1-a)kp – cs(k) [4]
Это уравнение учитывает тот факт, что одни ошибки обнаруживаются и исправляются, а другие нет. Мы вычитаем [3] из [4], чтобы получить дополнительное ожидаемое значение от наблюдения. После некоторой алгебры мы получаем это.
(r+p)(1-a)k > cs(k) [5]
Надзор имеет экономический смысл только тогда, когда его ожидаемая выгода (которая зависит от вероятности того, что алгоритм допустил ошибку, что эта ошибка обнаружена, и чистая выгода от преобразования ошибки в правильное решение) превышает стоимость надзора.
Увеличение масштаба
Здесь я рассматриваю, что происходит, когда мы начинаем увеличивать n количество решений, принимаемых алгоритмом.
Ожидаемое значение:
E(n) = nar + n(1-a)kr – n(1-a)(1-k)p [6]
И затраты C(n)
Как эти вещи меняются по мере роста n?
Я делаю некоторые предположения, чтобы упростить ситуацию: организация хочет поддерживать k постоянным, а вознаграждения r и штрафы p остаются постоянными по мере увеличения n. [20]
Это оставляет нам две переменные, которые изменяются по мере увеличения n: a и C.
- Я предполагаю, что алгоритмическая точность
aснижается с увеличением количества решений, потому что процессы, ухудшающие точность, сильнее тех, которые ее улучшают. - Я предполагаю, что
C, издержки производства, зависят только от труда специалистов по обработке данных и руководителей. Каждая из этих двух профессий получает зарплатуwdsиws.
Основываясь на этом и некоторых расчетах, мы получаем изменения в ожидаемых выгодах по мере того, как мы принимаем больше решений, таких как:
∂E(n)/∂(n) = r + (a+n(∂a/∂n))*(1-k)(r+p) - p(1-k) [7]
Это означает, что по мере того, как принимается больше решений, совокупные ожидаемые выгоды растут в зависимости от изменений предельной точности алгоритма. С одной стороны, чем больше решений, тем больше выгоды от более правильных решений. С другой стороны, снижение точности приводит к увеличению количества ошибок и штрафов. Некоторые из них компенсируются человеческими наблюдателями.
Вот что происходит с затратами:
∂C/∂n = (∂C/∂Lds)(∂Lds/∂n) + (∂C/dLs)(∂Ls/dn) [8]
По мере увеличения количества решений расходы растут, потому что организации приходится нанимать больше специалистов по обработке данных и руководителей.
[8] то же самое, что сказать:
∂C/dn = wds/(∂Lds/dn) + ws/zs/(∂Ls/∂n) [9]
Затраты на рабочую силу в каждой профессии напрямую связаны с ее заработной платой и обратно пропорциональны ее предельной производительности. Если мы предположим, что специалисты по обработке данных более продуктивны, чем супервизоры, это означает, что большая часть увеличения затрат с n будет вызвана увеличением штата супервизоров.
Ожидаемая ценность (выгоды минус затраты) от принятия решений для организации максимизируется с помощью равновесного количества решений ne, где предельная ценность дополнительного решения равна его предельным затратам:
r + (a+nda/dn)(1-k)(r+p) - p(1-k) = wds/(∂Lds/∂n) + ws/zs/(∂Ls/∂n) [10]
Расширения
Выше я упростил задачу, сделав несколько сильных предположений относительно каждой моделируемой ситуации. Что произойдет, если мы ослабим эти предположения?
Вот несколько идей:
Разновидности ошибок. Во-первых, анализ не учитывает, что разные типы ошибок (например, ложные срабатывания и отрицательные результаты, ошибки с разной степенью достоверности и т. д.) могут иметь разные вознаграждения и наказания. Я также предположил определенность в отношении вознаграждений и штрафов, когда было бы более реалистично моделировать их как случайные выборки из распределений вероятностей. Это расширение поможет включить в анализ объективность и предвзятость. Например, если ошибки с большей вероятностью повлияют на уязвимых людей (которые несут более высокие штрафы), и эти ошибки с меньшей вероятностью будут обнаружены, это может увеличить ожидаемый штраф от ошибок.
Люди тоже несовершенны. Все вышесказанное предполагает, что алгоритмы ошибаются, а люди — нет. Это явно не так. Во многих областях алгоритмы могут быть желательной альтернативой людям с глубоко укоренившимися предубеждениями и предрассудками. В таких ситуациях снижается способность людей обнаруживать и устранять ошибки, и это снижает стимулы к их вербовке (это равносильно снижению их производительности). Организации справляются со всем этим путем инвестирования в технологии (например, платформы краудсорсинга) и системы обеспечения качества (включая дополнительные уровни человеческого и алгоритмического надзора), которые управляют рисками человеческих и алгоритмических ошибок.
Нелинейные вознаграждения и штрафы. Ранее я предполагал, что предельные штрафы и вознаграждения остаются постоянными по мере увеличения количества алгоритмических решений. Так быть не должно. В таблице ниже приведены примеры ситуаций, когда эти параметры меняются в зависимости от количества принимаемых решений:

Получение эмпирического подхода к этим процессам очень важно, поскольку они могут определить, существует ли естественный предел для числа алгоритмических решений, которые организация может принять экономически в предметной области или на рынке, с потенциальными последствиями для ее регулирования.
Сноски
[1] Я использую термин алгоритм в ограниченном смысле для обозначения технологий, которые превращают информацию в прогнозы (и в зависимости от системы, получающей прогнозы, решения). Для этого существует множество процессов, включая системы на основе правил, статистические системы, системы машинного обучения и искусственный интеллект (AI). Эти системы различаются по точности, масштабируемости, интерпретируемости и способности учиться на собственном опыте, поэтому их специфические особенности следует учитывать при анализе алгоритмических компромиссов.
[2] Можно даже сказать, что машинное обучение — это наука, которая управляет компромиссами, вызванными невозможностью устранения алгоритмической ошибки. Знаменитый компромисс смещение-дисперсия между подгонкой модели к известным наблюдениям и прогнозированием неизвестных является хорошим примером этого.
[3] Некоторые люди скажут, что персонализация нежелательна, потому что она может привести к дискриминации и пузырям фильтрации, но это вопрос для другого сообщения в блоге.
[4] Экономические правила Дэни Родрика убедительно доказывают, что модели представляют собой упрощенные, но полезные формализации сложной реальности.
[5] В статье Harvard Business Review 2016 года Аджай Агравал и его коллеги обрисовали в общих чертах экономический анализ машинного обучения как технологии, снижающей затраты на прогнозирование. Мой взгляд на алгоритмы похож, потому что прогнозы являются исходными данными для принятия решений.
[6] Это включает в себя персонализированный опыт и рекомендации на сайтах электронной коммерции и социальных сетей, а также обнаружение мошенничества и алгоритмическую торговлю в сфере финансов.
[7] Например, если YouTube показывает мне рекламу, которая очень соответствует моим интересам, я могу купить продукт, и это принесет доход рекламодателю, продюсеру видео и YouTube. Если он покажет мне совершенно нерелевантную или даже оскорбительную рекламу, я могу прекратить пользоваться YouTube или подниму шум в выбранной мной социальной сети.
[8] Обучение с подкреплением создает агентов, которые используют награды и штрафы от предыдущих действий для принятия новых решений.
[9] Именно это произошло с системой Google FluTrends, используемой для прогнозирования вспышек гриппа на основе поисковых запросов в Google: люди изменили свое поведение при поиске, и алгоритм вышел из строя.
[10] Во многих случаях штрафы могут быть настолько высокими, что мы решаем, что алгоритм никогда не должен использоваться, если он не контролируется людьми.
[11] К сожалению, не всегда проявляют осторожность при реализации алгоритмических систем в ситуациях с высокими ставками. В книге Кэти О’Нил Оружие уничтожения математики приводится множество примеров этого, начиная с системы уголовного правосудия и заканчивая приемом в университеты.
[12] Механизмы подотчетности и надлежащей правовой процедуры — еще один пример человеческого надзора.
[13] Используя модель выхода, голоса и лояльности Альберта Хиршмана, мы могли бы сказать, что надзор играет роль« голоса , помогая организациям обнаруживать снижение качества до того, как пользователи начнут уходить.
[14] Приложение отмечает некоторые из моих ключевых предположений и предлагает расширения.
[15] Сюда входит тщательная оценка алгоритмического принятия решений и его организации с использованием методов рандомизированного контролируемого исследования, подобных тем, которые предлагает Лаборатория инновационного роста Nesta.
[16] Это решение может быть основано на том, насколько хорошо похожая реклама работает при сопоставлении с разными типами видео, на демографической информации о людях, которые смотрят видео, или на других вещах.
[17] Анализ в этом блоге предполагает, что результаты алгоритмических решений независимы друг от друга. Это предположение может быть нарушено в ситуациях, когда алгоритмы генерируют самоисполняющиеся пророчества (например, логически пользователь с большей вероятностью нажмет на рекламу, которую ему показывают, а это не так). Это сложная проблема, но исследователи разрабатывают методы, основанные на рандомизации алгоритмических решений для ее решения.
[18] Не различает разные типы ошибок (например, ложные срабатывания и ложноотрицания). Я вернусь к этому в конце.
[19] Здесь я предполагаю, что люди-супервизоры совершенно точны. Как мы знаем из поведенческой экономики, это очень сильное предположение. Рассматриваю этот вопрос в конце.
[20] Я рассматриваю последствия различных предположений о предельных вознаграждениях и штрафах в конце.