
| Сообщение | Кратко | Сообщается ли номер теста? | Значение вердикта | Возможная причина |
|---|---|---|---|---|
| OK | OK | Нет | Решение зачтено | Программа верно работает на соответствующем наборе тестов |
| Compilation error | CE | Нет | Компиляция программы завершилась с ошибкой | 1. в программе допущена синтаксическая или семантическая ошибка 2. неправильно указан язык |
| Wrong answer | WA | Да | Ответ неверен | 1. ошибка в программе 2. неверный алгоритм |
| Presentation error | PE | Да | Тестирующая система не может проверить выходные данные, так как их формат не соответствует описанному в условиях задачи | 1. неверный формат вывода 2. программа не печатает результат 3. лишний вывод |
| Time-limit exceeded | TL | Да | Программа превысила установленный лимит времени | 1. ошибка в программе 2. неэффективное решение |
| Memory limit exceeded | ML | Да | Программа превысила установленный в условиях лимит памяти | 1. ошибка в программе (например, бесконечная рекурсия) 2. неэффективное решение |
| Output limit exceeded | OL | Да | Программа превысила установленный в условиях лимит вывода | 1. программа выводит больше информации, чем установлено в ограничениях |
| Run-time error | RE | Да | Программа завершила работу с ненулевым кодом возврата | 1. ошибка выполнения 2. программа на C или C++ не завершается оператором return 0 3. ненулевой код возврата указан явно 4. Программа на Java описана в пакете |
| Precompile check failed | PCF | Нет | Программа не прошла проверку на качество кода перед компиляцией | 1. плохое качество кода 2. неправильно отформатированный код |
| Idleness limit exceeded | IL | Да | Программа слишком долго не отвечала на запросы системы и не выполняла действий | 1. программа ожидает ввода с консоли, которого не должно быть 2. не использован flush() |
Yandex Contest

Яндекс.Контест — сервис для онлайн-проверки заданий по программированию. Он предназначен для проведения состязаний любого уровня: олимпиады, соревнования международного класса, домашние задания. Его можно использовать также для подготовки к турнирам и для приёма экзаменов. Решения проверяются автоматически — с помощью набора тестов, составленных авторами заданий. Участники отправляют свои решения в тестирующую систему, а та выдает результат.
Мы предлагаем ознакомиться с краткой инструкцией по данной платформе, чтобы вы могли уделить свое время только решению задач.
Инструкция
В конце каждой прослушанной лекции на данной платформе будут даваться задачи для самостоятельного решения.
Перейдя по ссылке к домашней работе, вам в первую очередь нужно будет авторизоваться на платформе через аккаунт в Яндексе.

Если у вас нет аккаунта, то пройдите самую обычную процедуру регистрации.

Далее вы увидите кнопку регистрации, по которой нужно перейти для выполнения задач.
Обратите внимание, что на картинке изображен обратный отсчет. Но обычно мы не делаем ограничений по времени на сдачу домашнего задания.

После старта вы увидите основную информацию о соревновании: название, количество оставшегося времени, кнопка досрочного завершения. Нас будет интересовать ссылка на решение задач.

Основная информация о задаче представлена на картинке:

Есть несколько типов вердиктов после отправки вашего ответа:
- OK — ответ/код правильный;
- WA — есть ошибка.

И другие. Подробнее про них вы можете прочитать здесь, а также ниже.
При этом стоит обратить внимание, что Система засчитывает задание решенным, если хотя бы одно из отправленных решений был верным (если не оговорено другое). После него вы можете отправлять хоть 10 неверных ответов, однако в системе все равно будет зафиксировано, что вы давали верный ответ.
Если вы закончили решать задачи раньше установленного времени, то можете завершить соревнование и сохранить ваши результаты:

Если такой кнопки в контесте нет — ничего страшного. Соревнование завершится автоматически по достижению дедлайна.
Типы ошибок в Яндекс. Контест и способы их устранения.
Как уже было сказано выше, при отправке решений в Яндекс. Контест тестовая система может не принимать решения, выдавая некоторую ошибку. Возможные типы ошибок с их краткими описаниями уже приводились выше. Ниже будут более подробно разобраны некоторые ошибки и их возможные исправления.
CE (Compilation Error)
Данная ошибка возникает, если ваша программа написана не по правилам языка Python. Попробуйте сначала запустить вашу программу в Google Colab. При этом обратите внимание на следующие моменты:
- Не нужно забывать про отступы. Не нужно делать никаких лишних отступов. При этом, в каждом блоке должно быть одинаковое количество пробелов в качестве отступов (рекомендуется использовать 4 пробела). В противном случае Яндекс. Контест выдаст ошибку CE (Compilation Error).
Например, ошибочным будет такой код:
x = 123 print(x) # Ошибка будет здесь, т.к. перед print стоят лишние отступы
Также ошибка будет в таком фрагменте:
x = 1 if x==1: print("One") else: print("Else") # Ошибка будет здесь, т.к. во всех блоках программы должно быть одинаковое # количество отступов, здесь внутри else перед print используется 1 отступ, хотя # ранее после if перед print использовалось 4 отступа
- Проверьте, что в качестве отступов везде используется либо только пробелы, либо только t. Обратите внимание, что Tab не всегда равен 8 проблелам. t и несколько пробелов – это разные символы. Поэтому если в программе для отступов используется и t, и пробелы – система может выдать ошибку.
- Не забывайте закрывать все скобки и кавычки. Например, ошибку CE вызывают следующие фрагменты кода:
print('str',print('123)и т.д. - Проверьте наличие двоеточия после строчки с
if, else, for, while(if x>y:).
PE (Presentation error)
Данная ошибка может возникать, если формат вывода программы неверный.
При возникновении этой ошибки рекомендуется проверить следующее:
- В Google Colab для вывода значения переменной достаточно указать просто её имя:

Это допущение сделано для упрощения разработки. В Яндекс. Контесте такого нет. Необходимо явно использовать print(), чтобы вывести значение переменной:
- Тестовая система проверяет ответ с эталонным посимвольно. Поэтому отличие хотя бы в одном символе может привести к ошибке. Поэтому перед отправкой решений проверяйте, что в программе нет лишних (или недостающих) пробелов, переходов на новую строку и других символов.
- Лишним также могут быть вспомогательные сообщения, которые указываются в параметрах
input()илиprint(), т.к. эти сообщения попадают в стандартный поток вывода и рассматриваются тестирующей системой как часть ответа.
Как правило, в задачах требуется просто ввести или вывести какие-то значения без каких-то дополнительных подсказок.
Т.е. не нужно писатьinput(“Введите число: ”)илиprint(“Искомый результат: ”, res)(здесь res — некоторая переменная, показывающая результат работы программы). Нужно писать простоinput()илиprint(res).
RE (Runtime error)
Самая частая ошибка. Возникает, если код написан в целом по правилам языка Python, однако в ходе выполнения программы обнаруживаются какие-то ошибки.
При возникновении этой ошибки следует проверить следующее:
- Проверьте, что выполнены все рекомендации при возникновении ошибки Presentation error (эти же ситуации иногда могут приводить и к RE).
- Попробуйте запустить код в Google Colab и самостоятельно поискать ошибку.
- При использовании сторонних библиотек (
numpy,pandas,math,fractions,itertoolsи др.) не забывайте делать соответствующийimport:
- Если программа использует работу с файлами – проверьте точное совпадение имен входного и выходного файла в вашей программе с тем, что указано в условии.
- Проверьте, что имена стандартных функций и арифметические операции записаны верно (при этом не забывайте, что Python чувствителен к регистру букв, т.е.
Print()иprint()– это разные функции). Например,2^3– неверная запись операции возведения в степень (нужно2**3). Аналогично,Print('string')– неверно, т.к. написано с большой буквы (верноprint('string')). - Не забывайте, сколько и каких параметров принимает каждая функция. Например, функция
write()принимает только одну строку в отличие отprint()(который принимает сколько угодно параметров, а также именованные параметры вродеsepиend). Также функцияfloat()принимает в качестве параметра строку, представляющую вещественное число, где в качестве разделителя используется точка, а не запятая. Т.е. записьfloat("3,14")приведёт к ошибке (нужноfloat("3.14")). - Проверьте, что нигде в вашей программе не может возникнуть деление на ноль при определённых входных данных или обращение к элементу списка/словаря с несуществующим индексом/ключом (например, для
lst=[1, 2, 3]обращениеlst[500]вызовет ошибку, т.к. элемента с индексом 500 в списке нет. Аналогично, для словаряd = {‘cat’: 3, ‘lion’: 2, ‘dog’: 7}вызовет ошибку обращениеd[‘mouse’](т.к. такого ключа в словаре нет)).
WA (Wrong answer)
Эта ошибка возникает в том случае, когда код написан без ошибок, связанных с языком Python, однако где-то в логике программы присутствует ошибка.
Тестовая система проверяет ваш код на различных входных данных (так называемых тестах) и сверяет ответ работы программы с эталонным. Если хотя бы на одном тесте ответ отличается, программа выдаёт ошибку WA. При этом, в таблице с вердиктом (она находится внизу решения на сайте Яндекс. Контест) в строке, соответствующей ошибке WA в столбце «Тест» указывается номер теста, на котором ответ вашей программы не совпал с эталонным.

В случае возникновения этой ошибки, проверьте следующие моменты:
- Проверьте, что выполнены все рекомендации при возникновении ошибки Presentation error (эти же ситуации иногда могут приводить и к WA).
- Если ошибка возникает на тесте № 1 – следует проверить корректность работы программы на данных из условия (обычно в условии есть пример ввода и вывода).
- Если ошибка возникает на тесте с номером больше 1 – стоит внимательно перечитать условие и комментарии к нему и проверить, что всё учтено:
- Верно указаны имена входных и выходных файлов (если программа подразумевает работу с файлами).
- Соблюдён формат выходных данных (всегда печатается нужное количество знаков после точки в вещественных числах, в .csv-файлах используются верные разделители, а названия колонок в точности совпадают с теми, что требуются в условии).
- Попытайтесь подумать, на каких входных данных, которые не совпадают с примером из условия, но соответствуют условию, ваша программа может работать некорректно.

Решаю вот эту задачу(пробный контест):
A. Быстрый старт
Ограничение времени 1 секунда
Ограничение памяти 64Mb
Ввод стандартный ввод или input.txt
Вывод стандартный вывод или output.txt
В этом году третий раз одна известная компания проводит соревнование по программированию искусственного интеллекта для игровых стратегий. В этот раз участникам предложили написать искусственный интеллект для управления командой хоккеистов. Вася решил побороться за главный приз. Прочитав раздел “Быстрый старт”, он приступил к делу. Не прошло и нескольких часов, как хоккеисты начали ездить за шайбой по площадке. Но Вася заметил, что не всегда у игрока получается взять шайбу. Перечитав внимательно документацию, он выяснил, что для расчета вероятности подобрать шайбу нужно подсчитать коэффициент, равный максимальному значению из двух характеристик хоккеиста — ловкости D и подвижности A. Помогите Васе по известным значениям ловкости и подвижности определить этот коэффициент.
Формат ввода
Во входном файле заданы два целых числа D и A (0 ≤ D, A ≤ 109) — ловкость и подвижность хоккеиста соответственно.
Формат вывода
В выходной файл выведите коэффициент
Пример 1
Ввод Вывод
100 64 100
Пример 2
Ввод Вывод
31 14 31
Код:
| Python | ||
|
выводит ошибку Run-time error
хотя при проверке вроде все работало
__________________
Помощь в написании контрольных, курсовых и дипломных работ, диссертаций здесь
Yandex Contest
Яндекс.Контест — сервис для онлайн-проверки заданий по программированию. Он предназначен для проведения состязаний любого уровня: олимпиады, соревнования международного класса, домашние задания. Его можно использовать также для подготовки к турнирам и для приёма экзаменов. Решения проверяются автоматически — с помощью набора тестов, составленных авторами заданий. Участники отправляют свои решения в тестирующую систему, а та выдает результат.
Мы предлагаем ознакомиться с краткой инструкцией по данной платформе, чтобы вы могли уделить свое время только решению задач.
Инструкция
В конце каждой прослушанной лекции на данной платформе будут даваться задачи для самостоятельного решения.
Перейдя по ссылке к домашней работе, вам в первую очередь нужно будет авторизоваться на платформе через аккаунт в Яндексе.
Если у вас нет аккаунта, то пройдите самую обычную процедуру регистрации.
Далее вы увидите кнопку регистрации, по которой нужно перейти для выполнения задач.
Обратите внимание, что на картинке изображен обратный отсчет. Но обычно мы не делаем ограничений по времени на сдачу домашнего задания.
После старта вы увидите основную информацию о соревновании: название, количество оставшегося времени, кнопка досрочного завершения. Нас будет интересовать ссылка на решение задач.
Основная информация о задаче представлена на картинке:
Есть несколько типов вердиктов после отправки вашего ответа:
- OK — ответ/код правильный;
- WA — есть ошибка.
И другие. Подробнее про них вы можете прочитать здесь, а также ниже.
При этом стоит обратить внимание, что Система засчитывает задание решенным, если хотя бы одно из отправленных решений был верным (если не оговорено другое). После него вы можете отправлять хоть 10 неверных ответов, однако в системе все равно будет зафиксировано, что вы давали верный ответ.
Если вы закончили решать задачи раньше установленного времени, то можете завершить соревнование и сохранить ваши результаты:
Если такой кнопки в контесте нет — ничего страшного. Соревнование завершится автоматически по достижению дедлайна.
Типы ошибок в Яндекс. Контест и способы их устранения.
Как уже было сказано выше, при отправке решений в Яндекс. Контест тестовая система может не принимать решения, выдавая некоторую ошибку. Возможные типы ошибок с их краткими описаниями уже приводились выше. Ниже будут более подробно разобраны некоторые ошибки и их возможные исправления.
CE (Compilation Error)
Данная ошибка возникает, если ваша программа написана не по правилам языка Python. Попробуйте сначала запустить вашу программу в Google Colab. При этом обратите внимание на следующие моменты:
- Не нужно забывать про отступы. Не нужно делать никаких лишних отступов. При этом, в каждом блоке должно быть одинаковое количество пробелов в качестве отступов (рекомендуется использовать 4 пробела). В противном случае Яндекс. Контест выдаст ошибку CE (Compilation Error).
Например, ошибочным будет такой код:
x = 123 print(x) # Ошибка будет здесь, т.к. перед print стоят лишние отступы
Также ошибка будет в таком фрагменте:
x = 1 if x==1: print("One") else: print("Else") # Ошибка будет здесь, т.к. во всех блоках программы должно быть одинаковое # количество отступов, здесь внутри else перед print используется 1 отступ, хотя # ранее после if перед print использовалось 4 отступа
- Проверьте, что в качестве отступов везде используется либо только пробелы, либо только t. Обратите внимание, что Tab не всегда равен 8 проблелам. t и несколько пробелов – это разные символы. Поэтому если в программе для отступов используется и t, и пробелы – система может выдать ошибку.
- Не забывайте закрывать все скобки и кавычки. Например, ошибку CE вызывают следующие фрагменты кода:
print('str',print('123)и т.д. - Проверьте наличие двоеточия после строчки с
if, else, for, while(if x>y:).
PE (Presentation error)
Данная ошибка может возникать, если формат вывода программы неверный.
При возникновении этой ошибки рекомендуется проверить следующее:
- В Google Colab для вывода значения переменной достаточно указать просто её имя:
Это допущение сделано для упрощения разработки. В Яндекс. Контесте такого нет. Необходимо явно использовать print(), чтобы вывести значение переменной:
- Тестовая система проверяет ответ с эталонным посимвольно. Поэтому отличие хотя бы в одном символе может привести к ошибке. Поэтому перед отправкой решений проверяйте, что в программе нет лишних (или недостающих) пробелов, переходов на новую строку и других символов.
- Лишним также могут быть вспомогательные сообщения, которые указываются в параметрах
input()илиprint(), т.к. эти сообщения попадают в стандартный поток вывода и рассматриваются тестирующей системой как часть ответа.
Как правило, в задачах требуется просто ввести или вывести какие-то значения без каких-то дополнительных подсказок.
Т.е. не нужно писатьinput(“Введите число: ”)илиprint(“Искомый результат: ”, res)(здесь res — некоторая переменная, показывающая результат работы программы). Нужно писать простоinput()илиprint(res).
RE (Runtime error)
Самая частая ошибка. Возникает, если код написан в целом по правилам языка Python, однако в ходе выполнения программы обнаруживаются какие-то ошибки.
При возникновении этой ошибки следует проверить следующее:
- Проверьте, что выполнены все рекомендации при возникновении ошибки Presentation error (эти же ситуации иногда могут приводить и к RE).
- Попробуйте запустить код в Google Colab и самостоятельно поискать ошибку.
- При использовании сторонних библиотек (
numpy,pandas,math,fractions,itertoolsи др.) не забывайте делать соответствующийimport:
- Если программа использует работу с файлами – проверьте точное совпадение имен входного и выходного файла в вашей программе с тем, что указано в условии.
- Проверьте, что имена стандартных функций и арифметические операции записаны верно (при этом не забывайте, что Python чувствителен к регистру букв, т.е.
Print()иprint()– это разные функции). Например,2^3– неверная запись операции возведения в степень (нужно2**3). Аналогично,Print('string')– неверно, т.к. написано с большой буквы (верноprint('string')). - Не забывайте, сколько и каких параметров принимает каждая функция. Например, функция
write()принимает только одну строку в отличие отprint()(который принимает сколько угодно параметров, а также именованные параметры вродеsepиend). Также функцияfloat()принимает в качестве параметра строку, представляющую вещественное число, где в качестве разделителя используется точка, а не запятая. Т.е. записьfloat("3,14")приведёт к ошибке (нужноfloat("3.14")). - Проверьте, что нигде в вашей программе не может возникнуть деление на ноль при определённых входных данных или обращение к элементу списка/словаря с несуществующим индексом/ключом (например, для
lst=[1, 2, 3]обращениеlst[500]вызовет ошибку, т.к. элемента с индексом 500 в списке нет. Аналогично, для словаряd = {‘cat’: 3, ‘lion’: 2, ‘dog’: 7}вызовет ошибку обращениеd[‘mouse’](т.к. такого ключа в словаре нет)).
WA (Wrong answer)
Эта ошибка возникает в том случае, когда код написан без ошибок, связанных с языком Python, однако где-то в логике программы присутствует ошибка.
Тестовая система проверяет ваш код на различных входных данных (так называемых тестах) и сверяет ответ работы программы с эталонным. Если хотя бы на одном тесте ответ отличается, программа выдаёт ошибку WA. При этом, в таблице с вердиктом (она находится внизу решения на сайте Яндекс. Контест) в строке, соответствующей ошибке WA в столбце «Тест» указывается номер теста, на котором ответ вашей программы не совпал с эталонным.
В случае возникновения этой ошибки, проверьте следующие моменты:
- Проверьте, что выполнены все рекомендации при возникновении ошибки Presentation error (эти же ситуации иногда могут приводить и к WA).
- Если ошибка возникает на тесте № 1 – следует проверить корректность работы программы на данных из условия (обычно в условии есть пример ввода и вывода).
- Если ошибка возникает на тесте с номером больше 1 – стоит внимательно перечитать условие и комментарии к нему и проверить, что всё учтено:
- Верно указаны имена входных и выходных файлов (если программа подразумевает работу с файлами).
- Соблюдён формат выходных данных (всегда печатается нужное количество знаков после точки в вещественных числах, в .csv-файлах используются верные разделители, а названия колонок в точности совпадают с теми, что требуются в условии).
- Попытайтесь подумать, на каких входных данных, которые не совпадают с примером из условия, но соответствуют условию, ваша программа может работать некорректно.
Тренируюсь решать задачи Яндекса.
Вот условие:
Дан упорядоченный по неубыванию массив целых 32-разрядных чисел. Требуется удалить из него все повторения.
Желательно получить решение, которое не считывает входной файл целиком в память, т.е., использует лишь константный объем памяти в процессе работы.
Первая строка входного файла содержит единственное число n, n ≤ 1000000.
На следующих n строк расположены числа — элементы массива, по одному на строку. Числа отсортированы по неубыванию.
У меня возникает Runtime error, а из-за чего — не могу понять. Не сказано же какая. В чём может быть проблема?
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class WooHoo {
public static void main(String[] args) throws Exception {
BufferedReader r = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(r.readLine());
int prev = Integer.parseInt(r.readLine());
System.out.println(prev);
for (int i = 1; i < n; i++) {
int cur = Integer.parseInt(r.readLine());
if (prev == cur) {
continue;
} else {
prev = cur;
System.out.println(cur);
}
}
}
}
Содержание
- Работа с тестирующей системой, расшифровка сообщений. «Задача A+B» на разных языках
- Задача «A+B» на разных языках программирования
- Pascal
- Delphi
- Сообщения тестирующей системы
- Компиляторы
- Примеры ошибок в решениях:
- Presentation Error (PE)
- Wrong Answer (WA)
- Compile Error (CE)
- Runtime Error (RE)
- Time Limit (TL)
- Memory Limit (ML)
- presentation error. Не могу найти причину ошибки в своём коде.
- Проверка решения
- Задачи с автоматической проверкой
- Задачи с ручной проверкой
- Все решения
- Фильтрация
- Статусы задач
- Проверка на плагиат
- Проверка решения
- Задачи с автоматической проверкой
- Задачи с ручной проверкой
- Все решения
- Фильтрация
- Статусы задач
- Проверка на плагиат
Работа с тестирующей системой, расшифровка сообщений. «Задача A+B» на разных языках
Тестирующая система TestSys расположена по адресу: ts.lokos.net.
Для входа в систему следует использовать логин (обычно — 2 цифры) и пароль выданные преподавателем.
Задача «A+B» на разных языках программирования
Нужно ввести из входного файла два целых числа и вывести их сумму в выходной файл.
Pascal
Delphi
Сообщения тестирующей системы
- Accepted— Все в порядке! Ваша программа принята! Она откомпилировалась без ошибок и прошла все тесты.
- Presentation Error (PE) — неправильный формат вывода, проверяющая программа не смогла прочитать ваш выходной файл или ваша программа вообще не создала выходной файл.
- Wrong Answer (WA)— неправильный ответ на тест.
- Compile Error (CE) — ошибки компиляции программы. Посмотрите что вы отправляете (нажмите view в отправках).
- Runtime Error (RT) — ошибка времени выполнения (выход за границы массива, переполнение переменной, деление на ноль, корень из отрицательного числа, ошибка в имени входного файла).
- Time Limit (TL) — ваша программа выполнялась на каком-то тесте больше времени по условию задачи.
- Memory Limit (ML) — ваша программа использовала больше памяти, чем разрешено по условию задачи.
Компиляторы
- Pascal: Borland Delphi 7.0, Free Pascal 2.6.0;
- C/C++: Visual C++ 2010 Express Edition, GNU C++ 4.6.1 (MinGW), Code::Blocks 10.05;
- C#: Visual C# 2010 Express Edition;
- Java: Sun JDK 7 update 9, Eclipse 4.2.
- Python: Python 3.3.0, Wing IDE 101 4.1.9.
Примеры ошибок в решениях:
Presentation Error (PE)
Неправильное имя выходного файла:
Программа выводит на экран вместо файла:
Wrong Answer (WA)
Точности/разрядности типов данных не хватает:
Compile Error (CE)
Комментарий тестирующей системы:
Runtime Error (RE)
Программа завершилась с ненулевым кодом возврата, либо создала исключительную ситуацию (exception) и не обработала ее.
Для поиска RE в программе на Delphi используйте директивы:
Time Limit (TL)
Программа не завершилась за отведенный период времени.
Возможные причины:
- Неэффективное решение;
- Ошибка в программе (например, зацикливание).
Memory Limit (ML)
Программа попыталась использовать больше памяти, чем разрешается.
Источник
presentation error. Не могу найти причину ошибки в своём коде.
Для игры в «Поле чудес» используется круглый барабан, разделенный на сектора, и стрелка. В каждом секторе записано некоторое число. В различных секторах может быть записано одно и то же число. Однажды ведущий игры решил изменить правила. Он сам стал вращать барабан и называть игроку (который барабана не видел) все числа подряд в том порядке, в котором на них указывала стрелка в процессе вращения барабана. Получилось так, что барабан сделал целое число оборотов, то есть последний сектор совпал с первым. После этого, ведущий задал участнику вопрос: какое наименьшее число секторов может быть на барабане? Требуется написать программу, отвечающую на этот вопрос ведущего.
Входные данные
В первой строке входного файла INPUT.TXT записано число N – количество чисел, которое назвал ведущий (2 ≤ N ≤ 30000). Во второй строке записано N чисел, на которые указывала стрелка в процессе вращения барабана. Первое число всегда совпадает с последним (в конце стрелка указывает на тот же сектор, что и в начале). Числа, записанные в секторах барабана – натуральные, не превышающие 32000.
Выходные данные
В выходной файл OUTPUT.TXT необходимо вывести одно число – минимальное число секторов, которое может быть на барабане.
1 13
5 3 1 3 5 2 5 3 1 3 5 2 56
#include
using namespace std;
int main() <
int n, x;
cin >> n;
int *p = new int[n + 1];
for (int i = 0; i > *(p + i); >
p[n] = ‘’;
for (int i = 1; i Лучший ответ
int main() <
int n, len;
cin >> n;
for (int i = 0; i > numbers[i]; >
Источник
Проверка решения
Задачи с автоматической проверкой
| Вердикт | Расшифровка |
|---|---|
| OK | Решение зачтено, программа на всех тестах работает корректно. |
| runtime-error | Ошибка при выполнении программы: программа завершила работу с ненулевым кодом возврата. |
| time-limit-exceeded | Превышен лимит времени: решение неэффективное или в программе ошибка. |
| wrong-answer | Неверный ответ: в программе ошибка или алгоритм неверный. |
| presentation-error | Неверный формат вывода. |
| compilation-error | Ошибка оформления кода: допущена синтаксическая или семантическая ошибка. |
| memory-limit-exceeded | Превышен лимит памяти: решение неэффективное или в программе ошибка. |
| crash | Ошибка проверки, обратитесь в поддержку. |
| precompile-check-failed | Программа не прошла проверку на качество кода перед компиляцией. |
| output-limit-exceeded | Программа превысила лимит вывода, установленный в условиях. |
| ignored | Ошибка оформления кода: допущена синтаксическая или семантическая ошибка. |
| idleness-limit-exceeded | Программа долго не отвечала на запросы и не выполняла действий. |
| Вердикт | Расшифровка |
|---|---|
| OK | Решение зачтено, программа на всех тестах работает корректно. |
| runtime-error | Ошибка при выполнении программы: программа завершила работу с ненулевым кодом возврата. |
| time-limit-exceeded | Превышен лимит времени: решение неэффективное или в программе ошибка. |
| wrong-answer | Неверный ответ: в программе ошибка или алгоритм неверный. |
| presentation-error | Неверный формат вывода. |
| compilation-error | Ошибка оформления кода: допущена синтаксическая или семантическая ошибка. |
| memory-limit-exceeded | Превышен лимит памяти: решение неэффективное или в программе ошибка. |
| crash | Ошибка проверки, обратитесь в поддержку. |
| precompile-check-failed | Программа не прошла проверку на качество кода перед компиляцией. |
| output-limit-exceeded | Программа превысила лимит вывода, установленный в условиях. |
| ignored | Ошибка оформления кода: допущена синтаксическая или семантическая ошибка. |
| idleness-limit-exceeded | Программа долго не отвечала на запросы и не выполняла действий. |
В правой части экрана появится окно с подробными результатами автоматической проверки.
Задачи с ручной проверкой
Для некоторых задач с ручной проверкой предусмотрен набор предварительных тестов. Вам останется проверить, например, использует ли ученик нужные конструкции или не списывают ли в группе.
Часть решений, например в творческих задачах, нужно полностью проверять вручную.
Ученику будет назначено максимальное количество баллов за задачу.
По умолчанию указано максимально возможное количество баллов.
Все решения
Вы можете посмотреть все решения, которые отправили ученики, на вкладке Решения . Последние попытки решений отображаются в начале списка.
Фильтрация
Статусы задач
| Статус | Расшифровка |
|---|---|
| Автопроверка | Решение отправлено на проверку в Яндекс Контест |
| На ручной проверке | Решение ожидает ручной проверки |
| Доработать | Решение не прошло проверку и вернулось к ученику на доработку |
| Зачтено | Решение прошло проверку, ученик получил за него баллы, задача считается сданной |
| Зачтено после дедлайна | Решение прошло проверку, но ученик не получит за него баллы, потому что решение отправлено после дедлайна |
| Статус | Расшифровка |
|---|---|
| Автопроверка | Решение отправлено на проверку в Яндекс Контест |
| На ручной проверке | Решение ожидает ручной проверки |
| Доработать | Решение не прошло проверку и вернулось к ученику на доработку |
| Зачтено | Решение прошло проверку, ученик получил за него баллы, задача считается сданной |
| Зачтено после дедлайна | Решение прошло проверку, но ученик не получит за него баллы, потому что решение отправлено после дедлайна |
Проверка на плагиат
Каждая попытка решения задачи проходит проверку на плагиат. Проверка происходит автоматически, попытка ученика сравнивается с попытками решения той же задачи других учеников Лицея Академии Яндекса.
Если подозрение на плагиат есть, рядом с номером решения появляется значок .
Чтобы проверить попытку на плагиат:
Проверка решения
Задачи с автоматической проверкой
| Вердикт | Расшифровка |
|---|---|
| OK | Решение зачтено, программа на всех тестах работает корректно. |
| runtime-error | Ошибка при выполнении программы: программа завершила работу с ненулевым кодом возврата. |
| time-limit-exceeded | Превышен лимит времени: решение неэффективное или в программе ошибка. |
| wrong-answer | Неверный ответ: в программе ошибка или алгоритм неверный. |
| presentation-error | Неверный формат вывода. |
| compilation-error | Ошибка оформления кода: допущена синтаксическая или семантическая ошибка. |
| memory-limit-exceeded | Превышен лимит памяти: решение неэффективное или в программе ошибка. |
| crash | Ошибка проверки, обратитесь в поддержку. |
| precompile-check-failed | Программа не прошла проверку на качество кода перед компиляцией. |
| output-limit-exceeded | Программа превысила лимит вывода, установленный в условиях. |
| ignored | Ошибка оформления кода: допущена синтаксическая или семантическая ошибка. |
| idleness-limit-exceeded | Программа долго не отвечала на запросы и не выполняла действий. |
| Вердикт | Расшифровка |
|---|---|
| OK | Решение зачтено, программа на всех тестах работает корректно. |
| runtime-error | Ошибка при выполнении программы: программа завершила работу с ненулевым кодом возврата. |
| time-limit-exceeded | Превышен лимит времени: решение неэффективное или в программе ошибка. |
| wrong-answer | Неверный ответ: в программе ошибка или алгоритм неверный. |
| presentation-error | Неверный формат вывода. |
| compilation-error | Ошибка оформления кода: допущена синтаксическая или семантическая ошибка. |
| memory-limit-exceeded | Превышен лимит памяти: решение неэффективное или в программе ошибка. |
| crash | Ошибка проверки, обратитесь в поддержку. |
| precompile-check-failed | Программа не прошла проверку на качество кода перед компиляцией. |
| output-limit-exceeded | Программа превысила лимит вывода, установленный в условиях. |
| ignored | Ошибка оформления кода: допущена синтаксическая или семантическая ошибка. |
| idleness-limit-exceeded | Программа долго не отвечала на запросы и не выполняла действий. |
В правой части экрана появится окно с подробными результатами автоматической проверки.
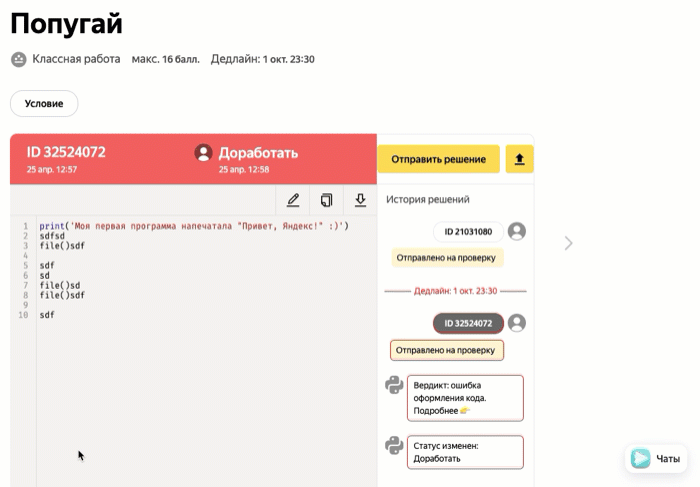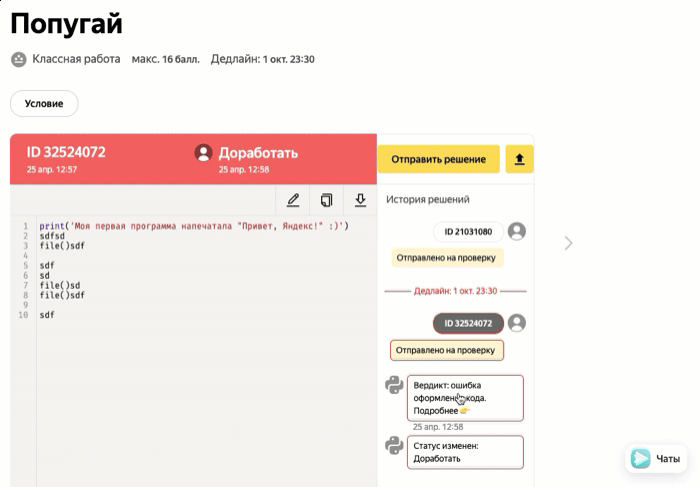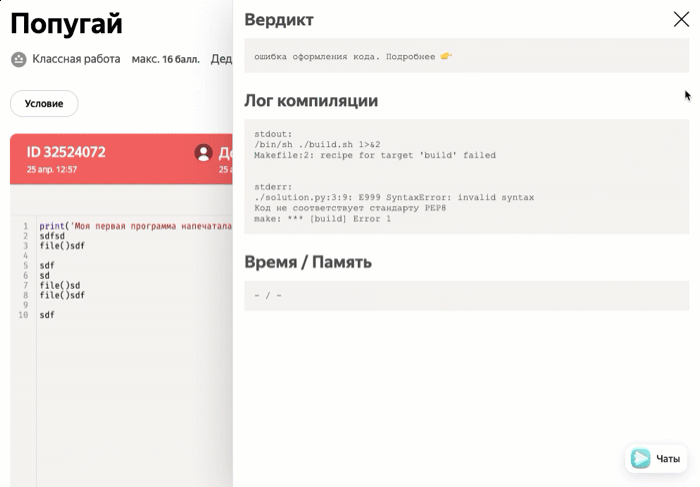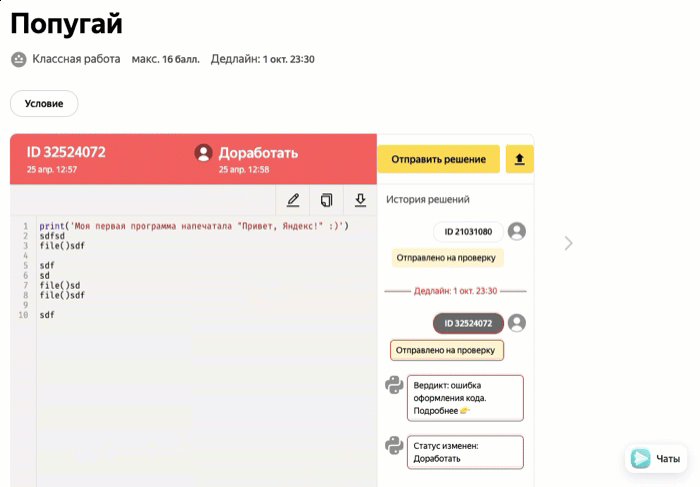
Задачи с ручной проверкой
Для некоторых задач с ручной проверкой предусмотрен набор предварительных тестов. Вам останется проверить, например, использует ли ученик нужные конструкции или не списывают ли в группе.
Часть решений, например в творческих задачах, нужно полностью проверять вручную.
Ученику будет назначено максимальное количество баллов за задачу.
По умолчанию указано максимально возможное количество баллов.
Все решения
Вы можете посмотреть все решения, которые отправили ученики, на вкладке Решения . Последние попытки решений отображаются в начале списка.
Фильтрация
Статусы задач
| Статус | Расшифровка |
|---|---|
| Автопроверка | Решение отправлено на проверку в Яндекс Контест |
| На ручной проверке | Решение ожидает ручной проверки |
| Доработать | Решение не прошло проверку и вернулось к ученику на доработку |
| Зачтено | Решение прошло проверку, ученик получил за него баллы, задача считается сданной |
| Зачтено после дедлайна | Решение прошло проверку, но ученик не получит за него баллы, потому что решение отправлено после дедлайна |
| Статус | Расшифровка |
|---|---|
| Автопроверка | Решение отправлено на проверку в Яндекс Контест |
| На ручной проверке | Решение ожидает ручной проверки |
| Доработать | Решение не прошло проверку и вернулось к ученику на доработку |
| Зачтено | Решение прошло проверку, ученик получил за него баллы, задача считается сданной |
| Зачтено после дедлайна | Решение прошло проверку, но ученик не получит за него баллы, потому что решение отправлено после дедлайна |
Проверка на плагиат
Каждая попытка решения задачи проходит проверку на плагиат. Проверка происходит автоматически, попытка ученика сравнивается с попытками решения той же задачи других учеников Лицея Академии Яндекса.
Если подозрение на плагиат есть, рядом с номером решения появляется значок  .
.
Источник
Разве вы не ненавидите, когда вы пытаетесь запустить программу и получаете сообщение об ошибке «Ошибка выполнения»? К сожалению, несмотря на то, что люди регулярно раздражают, ужасная ошибка времени выполнения не очень хорошо объясняет сама себя и то, что именно произошло.
Ошибки времени выполнения бывают разных форм и размеров, и они печально известны тем, что мешают вашему рабочему процессу. Таким образом, вот некоторые из наиболее распространенных ошибок времени выполнения, их причины и способы их устранения.
Что такое ошибки во время выполнения?
Ошибка выполнения возникает в программе, пока она выполняется. Ошибки времени выполнения определяются тем, как они возникают после компиляции программы, а не во время разработки программы. Ошибки времени выполнения разочаровывают тем, что они могут привести к неожиданному завершению работы программы, и иногда бывает трудно определить единственную причину.
Различные типы ошибок времени выполнения
Во время выполнения могут возникать несколько различных типов ошибок, поэтому рекомендуется узнать, что они из себя представляют и что их вызывает. Таким образом, вы будете точно знать, что делать, когда кто-то поднимает свою уродливую голову.
1. Ошибка деления на ноль
Ваш компьютер выполняет много математических операций при обработке данных, а это означает, что ошибки могут возникать даже при выполнении простых арифметических действий. Например, одна распространенная ошибка времени выполнения называется ошибкой «Делить на ноль». Этот симпатичный на носу; это происходит, когда ваш компьютер производит вычисления и пытается разделить число на 0.
Когда вы пытаетесь разделить число на 0, вы получите неопределенное число. Когда компьютер делает это, он не знает, что делать с неопределенным числом, и вызывает сбой программы.
К сожалению, это не та ошибка, которую вы можете решить на своей стороне. Если вы обнаружите ошибку деления на ноль, лучше всего обратиться к разработчику программного обеспечения.
2. Ошибки, вызванные неполной установкой
Иногда в процессе установки что-то идет не так. Существует множество причин, по которым программа не устанавливается должным образом, и когда это происходит, это может привести к проблемам.
Иногда некоторые файлы не устанавливаются или в установочном пакете есть ошибки. В любом случае, если программа не установлена должным образом, определенные файлы, которые ей необходимо запустить, могут не существовать, что приведет к ошибке выполнения. В этом случае лучше всего переустановить программу или попробовать найти другую версию установочного пакета.
3. Логические ошибки в программировании программного обеспечения.
Независимо от того, насколько хорош программист, всегда возникают случайные ошибки. Логическая ошибка — это тип ошибки времени выполнения, который может указывать на ошибку в кодировании.
По теме: Типы ошибок программирования и как их избежать
Горячий ответ: кодирование — это довольно сложно. Существуют тысячи и тысячи символов, которые необходимо правильно ввести для правильной работы программы. Если в коде есть опечатки, это может привести к неожиданным результатам. Из-за этого программа может глючить или даже вообще вылетать.
Лучше всего обратиться к разработчику программного обеспечения. Вы также должны проверить, используете ли вы самую последнюю версию программного обеспечения. В более поздней версии проблема может быть решена.
4. Ошибки, вызванные утечками памяти.
Еще одна довольно распространенная ошибка времени выполнения — ошибка утечки памяти. Когда программа запущена, она использует часть оперативной памяти. Затем, когда программа завершается, она сообщает системе, что она завершена, и освобождает эту оперативную память, чтобы другие программы могли ее использовать. Однако иногда программа этого не делает, и программы продолжают использовать новую оперативную память, пока она не закончится.
Связанный: Как устранить нехватку оперативной памяти или утечки памяти в Windows
Представьте себе жилой комплекс с 10 квартирами, восемь из которых заняты. Если трое жильцов уезжают, не сообщив об этом руководству квартиры, офис считает, что восемь квартир все еще заняты, когда заняты только пять. Затем, когда еще три человека хотят переехать, офис отказывает одному человеку, полагая, что для него нет места.
Утечка памяти может привести к проблемам с ОЗУ, снижению производительности и сбоям программы. В этом случае хорошим решением будет перезагрузка компьютера. Это полностью очистит всю оперативную память.
5. Ошибка ненулевого статуса выхода.
Программное обеспечение состоит из множества строк кода. Каждая линия должна функционировать должным образом, чтобы все работало бесперебойно. К сожалению, бывают случаи, когда линия работает не так, как должна, что приводит к ошибкам.
Одна такая ошибка называется ошибкой ненулевого статуса выхода. Для разных систем кодирования каждой строке кода присваивается статус выхода, который представляет собой число, указывающее, была ли она выполнена успешно или нет. Если компьютер успешно выполнил линию, он получает 0 в качестве статуса выхода. Если оно находится в диапазоне от 1 до 255, значит, это сбой. Хороший пример: если вы запустите строку, которая пытается получить доступ к файлу, которого нет на компьютере, она, скорее всего, получит код выхода 1.
Связанный: Способы проверить, существует ли файл с помощью Python
6. Ошибка переполнения
Когда дело доходит до кодирования, всегда есть ограничения. Например, когда вы пытаетесь поместить число в переменную (также известную как свойство), существует ограничение на то, насколько большим может быть это число. Если вы попытаетесь назначить большее число, чем этот предел, вы получите ошибку переполнения во время выполнения, что может привести к тому, что программа перестанет отвечать.
Когда вы получаете ошибку переполнения, вы должны начать с проверки, является ли ваша версия программного обеспечения последней. Если вы используете последнюю версию, попробуйте переустановить программное обеспечение.
7. Ошибка ошибки сегментации
Ошибки ошибки сегментации являются наиболее распространенным типом ошибок времени выполнения. Существуют определенные правила, которым программа должна следовать при доступе к памяти и записи в нее. Когда некоторые из этих правил нарушаются, вы рискуете получить ошибку ошибки сегментации.
Ошибка сегментации может произойти несколькими способами. Вот некоторые общие причины:
-
когда программа пытается записать в постоянную память
-
когда программа пытается получить доступ к памяти, к которой ей не разрешен доступ
-
когда программа пытается разыменовать освобожденную память или указатели NULL
-
когда программа пытается получить доступ к большему количеству данных, чем разрешено
-
когда программа пытается записать место, которое ей не разрешено
Если вы столкнетесь с одной из этих проблем, Переполнение стека есть отличный список решений, которые вы можете попробовать, поэтому обязательно ознакомьтесь с ним.
Множество ошибок во время выполнения в дикой природе
Когда дело доходит до ошибок времени выполнения, это только верхушка айсберга. Этот список можно продолжить, так как существует множество ошибок и еще больше способов их вызвать. Лучшее, что можно сделать, — это изучить больше ошибок времени выполнения, как их идентифицировать и как их решать; это может помочь предотвратить множество неприятностей.
При решении тренировочного задания столкнулся с ошибкой Presentation error.
Тестирующая система не может проверить выходные данные, так как их формат не соответствует описанному в условиях задачи
Хотя, на локальной машине никаких проблем с выводом не возникает.
Само задание:
Даны два числа A и B. Вам нужно вычислить их сумму A+B. В этой задаче для работы с входными и выходными данными вы можете использовать и файлы и потоки на ваше усмотрение.
Ввод: стандартный ввод или input.txt
Вывод: стандартный вывод или output.txt
package main
import (
"fmt"
"io"
"os"
"strconv"
"strings"
)
func main() {
input, err := os.Open("input.txt")
if err != nil {
fmt.Println(err)
return
}
defer input.Close()
file, err := os.Create("output.txt")
if err != nil {
fmt.Println(err)
return
}
defer file.Close()
output, err := os.OpenFile("output.txt", os.O_APPEND|os.O_WRONLY, 0777)
if err != nil {
fmt.Println(err)
return
}
defer output.Close()
data := make([]byte, 64)
for {
n, err := input.Read(data)
if err == io.EOF {
break
}
arr := strings.Split(string(data[:n]), " ")
a, err := strconv.Atoi(arr[0])
if err != nil {
fmt.Println(err)
return
}
b, err := strconv.Atoi(arr[1])
if err != nil {
fmt.Println(err)
return
}
if _, err = output.WriteString(strconv.Itoa(a + b)); err != nil {
fmt.Println(err)
return
}
_, err = os.Open("output.txt")
if err != nil {
fmt.Println(err)
return
}
}
}Содержание
- 1 Общий принцип
- 2 Ввод и вывод данных
- 3 Тестирование решений
- 3.1 CE — Ошибка компиляции (Compilation Error)
- 3.2 TLE — Нарушен предел времени (Time Limit Exceeded)
- 3.3 ILE — Нарушен предел ожидания (Idleness Limit Exceeded)
- 3.4 MLE — Нарушен предел памяти (Memory Limit Exceeded)
- 3.5 RTE — Ошибка во время выполнения (Run-time Error)
- 3.6 PE — Ошибка представления (Presentation Error)
- 3.7 WA — Неправильный ответ (Wrong Answer)
- 3.8 OK — Принято (Accepted)
- 3.9 CF — Ошибка тестирования (Check Failed)
- 3.10 SV — Нарушение безопасности (Security Violation)
- 4 Особенности языков программирования
- 4.1 Выбор языка программирования
- 5 Конфигурация тестирующего сервера
- 6 Языки программирования
Общий принцип
В систему посылаются только файлы с исходным кодом, а сама посылаемая программа должна состоять только из одного файла: *.dpr, *.cpp, *.java, *.pas и т. д. Нельзя отправить в систему скомпилированный exe-файл, файл проекта Visual Studio и т. п.
В решениях запрещается:
- осуществлять доступ к сети;
- выполнять любые операции ввода/вывода, кроме открывания, закрывания, чтения и записи стандартных потоков stdin, stdout, stderr и файлов с именами, явно прописанными в условии задачи;
- сознательно «ломать» тестирующую систему;
- выполнять другие программы и порождать новые процессы;
- изменять права доступа к файловой системе;
- работать с поддиректориями;
- создавать и манипулировать ресурсами GUI (окна, диалоговые сообщения и т. д.);
- работать со внешними устройствами (звук, принтер и т. д.);
- выполнять прочие действия, призванные нарушить ход учебного процесса.
Решения выполняются в специальном окружении, обеспечивающем безопасный запуск, и попытка выполнить какие-либо из указанных действий закончится, скорее всего, получением вердикта «Ошибка во время выполнения».
Ввод и вывод данных
Во всех задачах необходимо считывать входные данные из текстового файла и выводить результат в текстовый файл. Имена файлов указаны в условии задачи. Предполагается, что файлы располагаются в текущем каталоге программы, поэтому в решениях можно и нужно использовать только их имена без абсолютных путей в файловой системе тестирующего сервера.
Можно считать, что изначально при запуске решения выходной файл будет отсутствовать, и решение должно его создать и записать туда ответ.
Внимательно проверяйте имена файлов в решениях на соответствие условию задачи.
Если в коде решения имена файлов указаны неверно, это может приводить к непредсказуемым последствиям. Так, если имя выходного файла указано неверно и требуемый по условию файл не создаётся, система, скорее всего, выдаст вердикт «Ошибка представления».
В случае, когда в решении на Java перепутано имя входного файла и делается попытка открыть несуществующий файл, выбрасывается исключение. Если автор решения не перехватывает его, программа завершается с вердиктом «Ошибка во время выполнения». Если же исключение обрабатывается, то вполне возможны и другие вердикты в зависимости от того, отработает ли программа и что окажется в выходном файле. Если в решении на C++ неправильно указан входной файл и ошибки специально не обрабатываются, чтение из файла может приводить к чтению произвольных данных («мусора»). Если в программе вместо чтения из файла делается попытка считать данные со стандартного ввода (stdin, который обычно связан с клавиатурой консоли), программа заблокируется («повиснет») в ожидании ввода и будет завершена с вердиктом «Превышен предел времени».
Решение может выводить произвольные данные «в консоль», то есть в стандартные потоки stdout, stderr, которые обычно связаны с консольным окном (например для отладки). Это не запрещается и не влияет на результат. Проверяется только содержимое выходного файла. Следует помнить, что на вывод тратится дополнительное время, поэтому большой объём отладочной информации может критически замедлить вашу программу. Вывод в stderr медленнее, чем в stdout, поскольку не буферизируется.
Тестирование решений
Каждое отправленное решение проходит на сервере проверку на нескольких тестах. Задача считается решённой только в случае прохождения всех тестов. Решение запускается на всех тестах, которые есть по задаче, и процесс тестирования не прерывается на первом непройденном тесте, как это делается в соревнованиях типа ACM.
Тестирование осуществляется автоматически, поэтому решения должны строго следовать формату входных и выходных данных, который описан в условии. В случае неясности можно задавать вопросы преподавателям. Если не сказано явно, все входные данные можно считать корректными и удовлетворяющими ограничениям из условия. Например, если сказано, что на входе целое число от 1 до 100 включительно, то можно считать, что это так и есть, и проверять неравенства и выводить ошибку в случае, если это не так, в коде решения нет необходимости.
Тесты по каждой задаче не упорядочены по сложности, по размеру входных данных, по какому-то иному критерию, а следуют в исторически сложившемся порядке их добавления в систему.
Не гарантируется, что первый тест в системе будет совпадать с тестом из условия (зачастую это не так).
Результатом проверки является итоговое сообщение системы и, возможно, в скобках номер первого теста, вызвавшего ошибку (если таковая имела место). Например, вердикт «Неправильный ответ (43)» означает, что решение успешно скомпилировалось и прошло без ошибок первые 42 теста по задаче, но на тесте под номером 43 выдало неверный ответ.
Далее опишем все допустимые сообщения тестирующей системы и укажем возможные причины их появления.
CE — Ошибка компиляции (Compilation Error)
Не удалось скомпилировать решение и получить исполняемый файл для запуска. Решение в таком случае, очевидно, не может быть проверено ни на одном тесте.
Посмотреть вывод компилятора и понять, почему код не удаётся скомпилировать, можно путём нажатия на иконку ![]() в таблице с вашими решениями. Наиболее частые причины ошибки компиляции: выбран неверный компилятор (для другого языка программирования или же несовместимая версия, например Java v7 вместо Java v8), отправляется не тот файл (файл проекта IDE вместо файла с исходным кодом).
в таблице с вашими решениями. Наиболее частые причины ошибки компиляции: выбран неверный компилятор (для другого языка программирования или же несовместимая версия, например Java v7 вместо Java v8), отправляется не тот файл (файл проекта IDE вместо файла с исходным кодом).
Время работы компилятора ограничено 30 секундами. Если он не успел отработать по каким-либо причинам, также будет выставлен вердикт «Ошибка компиляции».
TLE — Нарушен предел времени (Time Limit Exceeded)
Для каждого теста установлено своё ограничение по времени (Time Limit) в секундах. Для разных тестов по одной задаче ограничение по времени может быть разным.
Тестирующая система учитывает так называемое процессорное время (CPU Time) выполнения процесса в операционной системе. Нет смысла делать решение задачи многопоточным, потому что распараллеливание хоть и позволяет сократить реальное время работы (Wall Time), но не уменьшает процессорное время.
Процесс-решение запускается на тесте, и если процесс не успевает завершиться в течение отведённого времени, он принудительно завершается и выставляется вердикт «Нарушен предел времени». В качестве времени работы решения на тесте указывается то время, которое процесс фактически проработал до того, как был приостановлен. Нет возможности узнать, сколько бы программа проработала, если бы не была снята по времени. Если при ограничении по времени на тест в 1 секунду вы видите, что решение получает вердикт «Нарушен предел времени» и работает 1015 мс, то нельзя это понимать как «решение чуть-чуть не успевает, надо ускорить его на 15 мс». Если решение останавливается по времени, то вывод программы никак не проверяется на предмет его правильности.
Возможные причины появления ошибки «Нарушен предел времени»:
- неэффективный алгоритм (например, в решении реализован алгоритм с временной сложностью Ω(n2), хотя задача предполагает решение за O(n log n));
- недостаточно эффективная программная реализация (идея и алгоритм правильные, но код написан не очень хорошо: например, ввод данных из файла осуществляется медленно, чрезмерно часто выделяется и освобождается память);
- попытка чтения данных с консоли (
std::cin,scanf(),getchar()в C++,System.inв Java), тогда как нужно читать входные данные из файла (в этом случае программа блокируется в ожидании ввода и зависает, не расходуя при этом CPU Time, поэтому такой случай тестирующая система обрабатывает отдельно); - ошибка в программе (например, программа входит в бесконечный цикл).
Не рекомендуется «пропихивать» медленное решение, отправляя его многократно, пока система не «согласится» его принять. Решение в любой момент может быть перетестировано и, соответственно, может перестать быть принятым из-за нарушения предела времени.
ILE — Нарушен предел ожидания (Idleness Limit Exceeded)
Программа зависла в ожидании, не потребляя при этом ресурсы процессора.
Такое может быть, например, если согласно условию чтение входных данных осуществляется из файла, а решение выполняет ввод с консоли. В этом случае процесс решения заблокируется в ожидании нажатия клавиш на клавиатуре. Через некоторое время система тестирования принудительно завершит этот процесс и выставит вердикт ILE.
MLE — Нарушен предел памяти (Memory Limit Exceeded)
Программа использует слишком много оперативной памяти, стоит проанализировать использование памяти и оптимизировать его.
Также причиной чрезмерного использования памяти может быть ошибка в программе, например, вечный цикл в теле которого на каждой или некоторых итерациях выделяется дополнительная память. К используемой памяти относится не только память с данными, но также память с кодом и программным стеком.
Ограничение по памяти есть не для всех задач. Гарантируется, что для всех тестов в рамках одной задачи ограничение по памяти одинаково.
Как и в случае нарушения ограничения по времени, программа при нарушении ограничения по памяти аварийно завершается тестирующей системой, её вывод не проверяется на правильность. Точно так же не следует воспринимать размер памяти, использованной до момента аварийного завершения, как объём, которого решению хватило бы для успешной работы. Более точно, вердикт MLE, полученный с использованием 257 МБ памяти, говорит о том, что приложение успело использовать 257 МБ памяти и было принудительно остановлено, но ничего не говорит о том, сколько памяти использовало бы приложение, не будучи принудительно остановленным.
В некоторых случаях при разовом выделении чрезмерно большого блока в памяти, этот запрос может быть не выполнен операционной системой, что в результате может привести к ошибке во время выполнения или (значительно реже) другому результату неопределённого поведения в случае с языком C++.
RTE — Ошибка во время выполнения (Run-time Error)
В операционной системе есть такое понятие, как код завершения процесса (Exit Code). Этот подход используется как в Windows, так и в ОС семейства UNIX. Это целое число, которое остаётся после прекращения выполнения программы. Общепринятое соглашение гласит, что нулевой код завершения свидетельствует о нормальном завершении процесса без ошибок, любой другой — об ошибке. Тестирующая система проверяет код завершения вашего решения, и если он не равен нулю, выставляет вердикт «Ошибка во время выполнения». При этом никак не проверяется то, что решение успело вывести в выходной файл.
Укажем типичные причины ошибок во время выполнения.
- Использована директива
packageв коде программы на Java.- В результате программа на Java находится не в пакете по умолчанию. Компилятор Java сгенерировал класс в некотором пакете (ошибки компиляции нет), а при запуске виртуальная машина Java не смогла найти этот класс, потому что искала в пакете по умолчанию (возникло исключение
ClassNotFoundExceptionс сообщением Could not find or load main class).
- В результате программа на Java находится не в пакете по умолчанию. Компилятор Java сгенерировал класс в некотором пакете (ошибки компиляции нет), а при запуске виртуальная машина Java не смогла найти этот класс, потому что искала в пакете по умолчанию (возникло исключение
- Выход за границы допустимой области памяти в программе на C++.
- Выход за границы массива, разыменование неправильного указателя, обращение к нулевому указателю.
- Переполнение системного стека.
- Эта причина является частой в случае рекурсии. Вообще, системный стек используется для размещения параметров функций, локальных переменных. Его размер, как правило, невелик и по умолчанию равен 1 МБ. При вызове функции стековая структура позволяет естественным образом сохранить текущие состояния всех локальных переменных и вернуться к ним, когда вызов завершится и управление вернётся в исходную точку. Если в алгоритме используется глубокая рекурсия, то размера стека может не хватить для хранения контекстов всех вызовов. Решений этой проблемы два:
- переписать алгоритм нерекурсивно (например с использованием своего стека, а не системного);
- увеличить размер системного стека, что делается по-разному для разных языков программирования (см. примеры для C++ (Visual Studio) и Java).
- Эта причина является частой в случае рекурсии. Вообще, системный стек используется для размещения параметров функций, локальных переменных. Его размер, как правило, невелик и по умолчанию равен 1 МБ. При вызове функции стековая структура позволяет естественным образом сохранить текущие состояния всех локальных переменных и вернуться к ним, когда вызов завершится и управление вернётся в исходную точку. Если в алгоритме используется глубокая рекурсия, то размера стека может не хватить для хранения контекстов всех вызовов. Решений этой проблемы два:
- Ошибка ввода-вывода (попытка открыть несуществующий входной файл).
- Нужно проверить правильность имени входного файла.
- Программа целенаправленно была завершена с ненулевым кодом выхода.
- В программе на C++ это может быть, если функция
main()в C++ вернула ненулевой код (return (non-zero)в функцииmain()). Рекомендуется завершать функциюmain()операторомreturn 0(в старых компиляторах C++ это обязательно, современные компиляторы же подразумевают возврат нулевого кода автоматически). Также программу на C++ с произвольным кодом завершает вызовexit(). - В программе на Java можно завершить процесс с произвольным кодом с помощью
System.exit().
- В программе на C++ это может быть, если функция
- Необработанное исключение.
- Причин возникновения исключений может быть масса. Например, если в Java функции
Integer.parseInt()/Double.parseDouble()была передана строка, содержащая пробельные символы (ASCII-коды 9, 10, 13, 32), выбрасывается исключениеNumberFormatException.
- Причин возникновения исключений может быть масса. Например, если в Java функции
- Целочисленное деление на ноль.
- При выполнении деления нужно всегда думать, а не может ли делитель оказаться равным нулю. В то же время стоит отметить, что вещественное деление на ноль (в типах с плавающей точкой
double,float) по умолчанию не приводит к завершению программы, а даёт специальные значения+Inf,-InfилиNaN.
- При выполнении деления нужно всегда думать, а не может ли делитель оказаться равным нулю. В то же время стоит отметить, что вещественное деление на ноль (в типах с плавающей точкой
PE — Ошибка представления (Presentation Error)
Наиболее частая причина возникновения этой ошибки — не найден выходной файл. Возможно, вы забыли создать выходной файл и выводите ответ в консоль (он в таком случае игнорируется). Проверьте имена входного и выходного файла в вашей программе на соответствие условию задачи. Исторически сложилось, что в разных задачах входной и выходной файл именуются по разным правилам: input.txt и output.txt, in.txt и out.txt, input.in и output.out (обратите внимание, что нет расширения txt), [задача].in и [задача].out…
Для некоторых задач программа проверки (checker) дополнительно удостоверяется, что ваш вывод соответствует определённому формату, и выдаёт ошибку представления в случае, если это не так. Например, если в задаче нужно вывести число, а вы выводите строку. Или если в задаче нужно вывести сначала число k, затем k чисел, а ваше решение выводит число k и далее (k + 1) чисел (то есть решение выводит в файл лишние данные).
Также имейте в виду, что отлавливание исключений и других ошибок не должно быть самоцелью. Если исключение не обрабатывается каким-либо образом, обычно нет смысла его ловить по следующей причине. Аварийное завершение работы программы в результате ошибки во время выполнения приводит к вердикту «Ошибка во время выполнения», только если соответствующее исключение было «проброшено» наружу, а не «заглушено» на каком-то этапе. Если исключение отлавливается, но никак не обрабатывается, то в результате возникновения соответствующей ошибки следует ожидать вердикт «Ошибка представления» или же «Неправильный ответ» (реже).
WA — Неправильный ответ (Wrong Answer)
Для многих задач ответ однозначен, и проверяется просто побайтовое совпадение вашего выходного файла и сохранённого правильного ответа. Такая проверка требует строгого соблюдения формата файла, не допускает незначащих пробелов и пустых строк. Например, если правильный ответ имеет вид (пробелы обозначены символом ␣)
5 1␣2␣3␣4␣5
и решение вывело
5 1␣2␣3␣4␣5␣
(лишний пробел в конце второй строки), то будет получен вердикт «Неправильный ответ». Для некоторых задач написаны проверяющие программы (checker), которые к таким различиям лояльны и засчитывают ответы с лишними пробелами как правильные. Всегда точно следуйте формату файла и не выводите лишних пробелов, и проблем не будет.
После последней строки файла можно выводить или не выводить перевод строки — не важно. Есть две точки зрения в зависимости от того, с какой стороны смотреть на символ перевода строки:
- каждая строка завершается переводом строки, поэтому
nв конце файла нужен; - перевод строки является разделителем между соседними строками, поэтому
nв конце файла не нужен.
Первая точка зрения является общепринятой. Так, компилятор gcc, система контроля версий git и многие другие программы выдают предупреждение no newline at the end of file, если в самом конце файла нет символов новой строки. Обсуждение вопроса можно почитать на stackoverflow.
Поэтому рекомендуется придерживаться первого подхода и завершать все строки переводами строк.
Другие очевидные причины получения неправильного ответа:
- неверный алгоритм;
- ошибка в программе.
Бывает такое, что решение от запуска к запуску даёт разные ответы, или же правильно работает на одном компьютере и неправильно на другом. Такие случаи, как правило, связаны с ошибками в решениях.
OK — Принято (Accepted)
Программа работает правильно и прошла все тесты с соблюдением всех ограничений.
Если решение принято системой, это ещё не означает, что в его основе лежит правильный алгоритм. В любой момент могут появиться новые наборы входных данных, на которых будут заново протестированы все решения по задаче. Если ваше решение на самом деле не полностью верно и прошло только из-за недостаточно сильного набора тестов, оно может в будущем потерять статус «Принято».
CF — Ошибка тестирования (Check Failed)
Если указан номер теста, то программа успешно завершается на предложенном тесте (укладывается в отведённые время и память и не совершает ошибок во время выполнения), но результат не удаётся проверить из-за ошибок в программе проверки. Вашей ошибки в этом случае, возможно, никакой нет и после исправления программы проверки будет получен вердикт OK. Не исключены ещё два варианта: WA, PE.
Имейте в виду, что если ошибка тестирования возникает на первом же тесте, то на остальных Ваше решение не запускается вовсе. Соответственно, в этом случае после устранения ошибок программы проверки вердикты TLE, MLE, RTE также могут возникнуть в любом тесте, кроме первого.
Если же номер теста, на котором возникает ошибка тестирования, не указан, значит, программа проверки не была скомпилирована, а Ваше решение не запускалось вовсе. В этом случае правильным может быть любой вердикт, отличный от CF.
Если у Вас возникла ошибка тестирования, мы, скорее всего, это заметим достаточно быстро. Тем не менее, имеет смысл задать вопрос через пункт «Сообщения» в меню курса. Не забывайте выбрать задачу, которой касается этот вопрос.
SV — Нарушение безопасности (Security Violation)
Ошибка означает, что программа попыталась выполнить запрещённые действия.
К их числу относится попытка создания новых процессов. Вашим решениям запрещено запускать на выполнение другие программы. Например, в коде
порождается новый процесс командной оболочки cmd.exe и в нём выполняется команда pause. Пожалуйста, не пишите так, для достижения аналогичного эффекта можно использовать другие приёмы.
Особенности языков программирования
У каждого конкретного языка программирования есть свои особенности, о которых полезно знать. Далее рассмотрены отдельные особенности написания решений на разных языках программирования:
- C++;
- Java;
- C#;
- Python.
Выбор языка программирования
Разные задачи можно решать на разных языках. Часто для конкретной задачи тот или иной язык оказывается предпочтительным. Например, если в задаче требуются тяжёлые вычисления, то её может быть проще сдать на C++, чем на Java, за счёт более быстрой работы программы на C++ (для кода на Java могут потребоваться более изощрённые оптимизации, чтобы он прошёл по времени). С другой стороны, если задача требует проведения вычислений с большими целыми числами, выходящими за пределы диапазона 64-битных переменных, то есть «длинной арифметики», то решение существенно проще написать на Java, воспользовавшись готовым качественно написанным классом BigInteger для операций с числами произвольной длины.
Конфигурация тестирующего сервера
Сервер, на котором осуществляется запуск решений, является виртуальной машиной, выполняющейся внутри Microsoft Hyper-V Server 2012 R2. Виртуальный компьютер работает под управлением Windows 7 Professional x64, оснащён процессором Intel® Core™ i3-4130 (Haswell, кэш 3 МБ, 3,40 ГГц, доступно только одно ядро) и 4 ГБ оперативной памяти. Для хранения входных и выходных файлов используется RAM-диск, чтобы обеспечить максимальную производительность ввода-вывода.
Языки программирования
На странице учебного курса в системе на вкладке «Компиляторы» можно ознакомиться с актуальным списком доступных языков программирования, версиями компиляторов и параметрами командной строки их вызова.
Размер системного стека явно не задаётся (используется размер по умолчанию). При компиляции кода на C++ включен режим оптимизации O2.
Содержание
- presentation error. Не могу найти причину ошибки в своём коде.
- Name already in use
- Data-Analysis-with-Python / Python / instructions / yandex_contest.md
- presentation error. Не могу найти причину ошибки в своём коде.
- Name already in use
- Data-Analysis-with-Python / Python / instructions / yandex_contest.md
presentation error. Не могу найти причину ошибки в своём коде.
Для игры в «Поле чудес» используется круглый барабан, разделенный на сектора, и стрелка. В каждом секторе записано некоторое число. В различных секторах может быть записано одно и то же число. Однажды ведущий игры решил изменить правила. Он сам стал вращать барабан и называть игроку (который барабана не видел) все числа подряд в том порядке, в котором на них указывала стрелка в процессе вращения барабана. Получилось так, что барабан сделал целое число оборотов, то есть последний сектор совпал с первым. После этого, ведущий задал участнику вопрос: какое наименьшее число секторов может быть на барабане? Требуется написать программу, отвечающую на этот вопрос ведущего.
Входные данные
В первой строке входного файла INPUT.TXT записано число N – количество чисел, которое назвал ведущий (2 ≤ N ≤ 30000). Во второй строке записано N чисел, на которые указывала стрелка в процессе вращения барабана. Первое число всегда совпадает с последним (в конце стрелка указывает на тот же сектор, что и в начале). Числа, записанные в секторах барабана – натуральные, не превышающие 32000.
Выходные данные
В выходной файл OUTPUT.TXT необходимо вывести одно число – минимальное число секторов, которое может быть на барабане.
1 13
5 3 1 3 5 2 5 3 1 3 5 2 56
#include
using namespace std;
int main() <
int n, x;
cin >> n;
int *p = new int[n + 1];
for (int i = 0; i > *(p + i); >
p[n] = ‘’;
for (int i = 1; i Лучший ответ
int main() <
int n, len;
cin >> n;
for (int i = 0; i > numbers[i]; >
Источник
Name already in use
Data-Analysis-with-Python / Python / instructions / yandex_contest.md
- Go to file T
- Go to line L
- Copy path
- Copy permalink
Copy raw contents
Copy raw contents
Яндекс.Контест — сервис для онлайн-проверки заданий по программированию. Он предназначен для проведения состязаний любого уровня: олимпиады, соревнования международного класса, домашние задания. Его можно использовать также для подготовки к турнирам и для приёма экзаменов. Решения проверяются автоматически — с помощью набора тестов, составленных авторами заданий. Участники отправляют свои решения в тестирующую систему, а та выдает результат.
Мы предлагаем ознакомиться с краткой инструкцией по данной платформе, чтобы вы могли уделить свое время только решению задач.
В конце каждой прослушанной лекции на данной платформе будут даваться задачи для самостоятельного решения.
Перейдя по ссылке к домашней работе, вам в первую очередь нужно будет авторизоваться на платформе через аккаунт в Яндексе.
Если у вас нет аккаунта, то пройдите самую обычную процедуру регистрации.
Далее вы увидите кнопку регистрации, по которой нужно перейти для выполнения задач.
Обратите внимание, что на картинке изображен обратный отсчет. Но обычно мы не делаем ограничений по времени на сдачу домашнего задания.
После старта вы увидите основную информацию о соревновании: название, количество оставшегося времени, кнопка досрочного завершения. Нас будет интересовать ссылка на решение задач.
Основная информация о задаче представлена на картинке:
Есть несколько типов вердиктов после отправки вашего ответа:
- OK — ответ/код правильный;
- WA — есть ошибка.
И другие. Подробнее про них вы можете прочитать здесь, а также ниже.
При этом стоит обратить внимание, что Система засчитывает задание решенным, если хотя бы одно из отправленных решений был верным (если не оговорено другое). После него вы можете отправлять хоть 10 неверных ответов, однако в системе все равно будет зафиксировано, что вы давали верный ответ.
Если вы закончили решать задачи раньше установленного времени, то можете завершить соревнование и сохранить ваши результаты:
Если такой кнопки в контесте нет — ничего страшного. Соревнование завершится автоматически по достижению дедлайна.
Типы ошибок в Яндекс. Контест и способы их устранения.
Как уже было сказано выше, при отправке решений в Яндекс. Контест тестовая система может не принимать решения, выдавая некоторую ошибку. Возможные типы ошибок с их краткими описаниями уже приводились выше. Ниже будут более подробно разобраны некоторые ошибки и их возможные исправления.
CE (Compilation Error)
Данная ошибка возникает, если ваша программа написана не по правилам языка Python. Попробуйте сначала запустить вашу программу в Google Colab. При этом обратите внимание на следующие моменты:
- Не нужно забывать про отступы. Не нужно делать никаких лишних отступов. При этом, в каждом блоке должно быть одинаковое количество пробелов в качестве отступов (рекомендуется использовать 4 пробела). В противном случае Яндекс. Контест выдаст ошибку CE (Compilation Error).
Например, ошибочным будет такой код:
Также ошибка будет в таком фрагменте:
- Проверьте, что в качестве отступов везде используется либо только пробелы, либо только t. Обратите внимание, что Tab не всегда равен 8 проблелам. t и несколько пробелов – это разные символы. Поэтому если в программе для отступов используется и t, и пробелы – система может выдать ошибку.
- Не забывайте закрывать все скобки и кавычки. Например, ошибку CE вызывают следующие фрагменты кода: print(‘str’ , print(‘123) и т.д.
- Проверьте наличие двоеточия после строчки с if, else, for, while ( if x>y: ).
PE (Presentation error)
Данная ошибка может возникать, если формат вывода программы неверный.
При возникновении этой ошибки рекомендуется проверить следующее:
- В Google Colab для вывода значения переменной достаточно указать просто её имя:
Это допущение сделано для упрощения разработки. В Яндекс. Контесте такого нет. Необходимо явно использовать print() , чтобы вывести значение переменной:
- Тестовая система проверяет ответ с эталонным посимвольно. Поэтому отличие хотя бы в одном символе может привести к ошибке. Поэтому перед отправкой решений проверяйте, что в программе нет лишних (или недостающих) пробелов, переходов на новую строку и других символов.
- Лишним также могут быть вспомогательные сообщения, которые указываются в параметрах input() или print() , т.к. эти сообщения попадают в стандартный поток вывода и рассматриваются тестирующей системой как часть ответа.
Как правило, в задачах требуется просто ввести или вывести какие-то значения без каких-то дополнительных подсказок. Т.е. не нужно писать input(“Введите число: ”) или print(“Искомый результат: ”, res) (здесь res — некоторая переменная, показывающая результат работы программы). Нужно писать просто input() или print(res) .
RE (Runtime error)
Самая частая ошибка. Возникает, если код написан в целом по правилам языка Python, однако в ходе выполнения программы обнаруживаются какие-то ошибки. При возникновении этой ошибки следует проверить следующее:
- Проверьте, что выполнены все рекомендации при возникновении ошибки Presentation error (эти же ситуации иногда могут приводить и к RE).
- Попробуйте запустить код в Google Colab и самостоятельно поискать ошибку.
- При использовании сторонних библиотек ( numpy , pandas , math , fractions , itertools и др.) не забывайте делать соответствующий import :
- Если программа использует работу с файлами – проверьте точное совпадение имен входного и выходного файла в вашей программе с тем, что указано в условии.
- Проверьте, что имена стандартных функций и арифметические операции записаны верно (при этом не забывайте, что Python чувствителен к регистру букв, т.е. Print() и print() – это разные функции). Например, 2^3 – неверная запись операции возведения в степень (нужно 2**3 ). Аналогично, Print(‘string’) – неверно, т.к. написано с большой буквы (верно print(‘string’) ).
- Не забывайте, сколько и каких параметров принимает каждая функция. Например, функция write() принимает только одну строку в отличие от print() (который принимает сколько угодно параметров, а также именованные параметры вроде sep и end ). Также функция float() принимает в качестве параметра строку, представляющую вещественное число, где в качестве разделителя используется точка, а не запятая. Т.е. запись float(«3,14») приведёт к ошибке (нужно float(«3.14») ).
- Проверьте, что нигде в вашей программе не может возникнуть деление на ноль при определённых входных данных или обращение к элементу списка/словаря с несуществующим индексом/ключом (например, для lst=[1, 2, 3] обращение lst[500] вызовет ошибку, т.к. элемента с индексом 500 в списке нет. Аналогично, для словаря d = <‘cat’: 3, ‘lion’: 2, ‘dog’: 7>вызовет ошибку обращение d[‘mouse’] (т.к. такого ключа в словаре нет)).
WA (Wrong answer)
Эта ошибка возникает в том случае, когда код написан без ошибок, связанных с языком Python, однако где-то в логике программы присутствует ошибка.
Тестовая система проверяет ваш код на различных входных данных (так называемых тестах) и сверяет ответ работы программы с эталонным. Если хотя бы на одном тесте ответ отличается, программа выдаёт ошибку WA. При этом, в таблице с вердиктом (она находится внизу решения на сайте Яндекс. Контест) в строке, соответствующей ошибке WA в столбце «Тест» указывается номер теста, на котором ответ вашей программы не совпал с эталонным.
В случае возникновения этой ошибки, проверьте следующие моменты:
- Проверьте, что выполнены все рекомендации при возникновении ошибки Presentation error (эти же ситуации иногда могут приводить и к WA).
- Если ошибка возникает на тесте № 1 – следует проверить корректность работы программы на данных из условия (обычно в условии есть пример ввода и вывода).
- Если ошибка возникает на тесте с номером больше 1 – стоит внимательно перечитать условие и комментарии к нему и проверить, что всё учтено:
- Верно указаны имена входных и выходных файлов (если программа подразумевает работу с файлами).
- Соблюдён формат выходных данных (всегда печатается нужное количество знаков после точки в вещественных числах, в .csv-файлах используются верные разделители, а названия колонок в точности совпадают с теми, что требуются в условии).
- Попытайтесь подумать, на каких входных данных, которые не совпадают с примером из условия, но соответствуют условию, ваша программа может работать некорректно.
Источник
presentation error. Не могу найти причину ошибки в своём коде.
Для игры в «Поле чудес» используется круглый барабан, разделенный на сектора, и стрелка. В каждом секторе записано некоторое число. В различных секторах может быть записано одно и то же число. Однажды ведущий игры решил изменить правила. Он сам стал вращать барабан и называть игроку (который барабана не видел) все числа подряд в том порядке, в котором на них указывала стрелка в процессе вращения барабана. Получилось так, что барабан сделал целое число оборотов, то есть последний сектор совпал с первым. После этого, ведущий задал участнику вопрос: какое наименьшее число секторов может быть на барабане? Требуется написать программу, отвечающую на этот вопрос ведущего.
Входные данные
В первой строке входного файла INPUT.TXT записано число N – количество чисел, которое назвал ведущий (2 ≤ N ≤ 30000). Во второй строке записано N чисел, на которые указывала стрелка в процессе вращения барабана. Первое число всегда совпадает с последним (в конце стрелка указывает на тот же сектор, что и в начале). Числа, записанные в секторах барабана – натуральные, не превышающие 32000.
Выходные данные
В выходной файл OUTPUT.TXT необходимо вывести одно число – минимальное число секторов, которое может быть на барабане.
1 13
5 3 1 3 5 2 5 3 1 3 5 2 56
#include
using namespace std;
int main() <
int n, x;
cin >> n;
int *p = new int[n + 1];
for (int i = 0; i > *(p + i); >
p[n] = ‘’;
for (int i = 1; i Лучший ответ
int main() <
int n, len;
cin >> n;
for (int i = 0; i > numbers[i]; >
Источник
Name already in use
Data-Analysis-with-Python / Python / instructions / yandex_contest.md
- Go to file T
- Go to line L
- Copy path
- Copy permalink
Copy raw contents
Copy raw contents
Яндекс.Контест — сервис для онлайн-проверки заданий по программированию. Он предназначен для проведения состязаний любого уровня: олимпиады, соревнования международного класса, домашние задания. Его можно использовать также для подготовки к турнирам и для приёма экзаменов. Решения проверяются автоматически — с помощью набора тестов, составленных авторами заданий. Участники отправляют свои решения в тестирующую систему, а та выдает результат.
Мы предлагаем ознакомиться с краткой инструкцией по данной платформе, чтобы вы могли уделить свое время только решению задач.
В конце каждой прослушанной лекции на данной платформе будут даваться задачи для самостоятельного решения.
Перейдя по ссылке к домашней работе, вам в первую очередь нужно будет авторизоваться на платформе через аккаунт в Яндексе.
Если у вас нет аккаунта, то пройдите самую обычную процедуру регистрации.
Далее вы увидите кнопку регистрации, по которой нужно перейти для выполнения задач.
Обратите внимание, что на картинке изображен обратный отсчет. Но обычно мы не делаем ограничений по времени на сдачу домашнего задания.
После старта вы увидите основную информацию о соревновании: название, количество оставшегося времени, кнопка досрочного завершения. Нас будет интересовать ссылка на решение задач.
Основная информация о задаче представлена на картинке:
Есть несколько типов вердиктов после отправки вашего ответа:
- OK — ответ/код правильный;
- WA — есть ошибка.
И другие. Подробнее про них вы можете прочитать здесь, а также ниже.
При этом стоит обратить внимание, что Система засчитывает задание решенным, если хотя бы одно из отправленных решений был верным (если не оговорено другое). После него вы можете отправлять хоть 10 неверных ответов, однако в системе все равно будет зафиксировано, что вы давали верный ответ.
Если вы закончили решать задачи раньше установленного времени, то можете завершить соревнование и сохранить ваши результаты:
Если такой кнопки в контесте нет — ничего страшного. Соревнование завершится автоматически по достижению дедлайна.
Типы ошибок в Яндекс. Контест и способы их устранения.
Как уже было сказано выше, при отправке решений в Яндекс. Контест тестовая система может не принимать решения, выдавая некоторую ошибку. Возможные типы ошибок с их краткими описаниями уже приводились выше. Ниже будут более подробно разобраны некоторые ошибки и их возможные исправления.
CE (Compilation Error)
Данная ошибка возникает, если ваша программа написана не по правилам языка Python. Попробуйте сначала запустить вашу программу в Google Colab. При этом обратите внимание на следующие моменты:
- Не нужно забывать про отступы. Не нужно делать никаких лишних отступов. При этом, в каждом блоке должно быть одинаковое количество пробелов в качестве отступов (рекомендуется использовать 4 пробела). В противном случае Яндекс. Контест выдаст ошибку CE (Compilation Error).
Например, ошибочным будет такой код:
Также ошибка будет в таком фрагменте:
- Проверьте, что в качестве отступов везде используется либо только пробелы, либо только t. Обратите внимание, что Tab не всегда равен 8 проблелам. t и несколько пробелов – это разные символы. Поэтому если в программе для отступов используется и t, и пробелы – система может выдать ошибку.
- Не забывайте закрывать все скобки и кавычки. Например, ошибку CE вызывают следующие фрагменты кода: print(‘str’ , print(‘123) и т.д.
- Проверьте наличие двоеточия после строчки с if, else, for, while ( if x>y: ).
PE (Presentation error)
Данная ошибка может возникать, если формат вывода программы неверный.
При возникновении этой ошибки рекомендуется проверить следующее:
- В Google Colab для вывода значения переменной достаточно указать просто её имя:
Это допущение сделано для упрощения разработки. В Яндекс. Контесте такого нет. Необходимо явно использовать print() , чтобы вывести значение переменной:
- Тестовая система проверяет ответ с эталонным посимвольно. Поэтому отличие хотя бы в одном символе может привести к ошибке. Поэтому перед отправкой решений проверяйте, что в программе нет лишних (или недостающих) пробелов, переходов на новую строку и других символов.
- Лишним также могут быть вспомогательные сообщения, которые указываются в параметрах input() или print() , т.к. эти сообщения попадают в стандартный поток вывода и рассматриваются тестирующей системой как часть ответа.
Как правило, в задачах требуется просто ввести или вывести какие-то значения без каких-то дополнительных подсказок. Т.е. не нужно писать input(“Введите число: ”) или print(“Искомый результат: ”, res) (здесь res — некоторая переменная, показывающая результат работы программы). Нужно писать просто input() или print(res) .
RE (Runtime error)
Самая частая ошибка. Возникает, если код написан в целом по правилам языка Python, однако в ходе выполнения программы обнаруживаются какие-то ошибки. При возникновении этой ошибки следует проверить следующее:
- Проверьте, что выполнены все рекомендации при возникновении ошибки Presentation error (эти же ситуации иногда могут приводить и к RE).
- Попробуйте запустить код в Google Colab и самостоятельно поискать ошибку.
- При использовании сторонних библиотек ( numpy , pandas , math , fractions , itertools и др.) не забывайте делать соответствующий import :
- Если программа использует работу с файлами – проверьте точное совпадение имен входного и выходного файла в вашей программе с тем, что указано в условии.
- Проверьте, что имена стандартных функций и арифметические операции записаны верно (при этом не забывайте, что Python чувствителен к регистру букв, т.е. Print() и print() – это разные функции). Например, 2^3 – неверная запись операции возведения в степень (нужно 2**3 ). Аналогично, Print(‘string’) – неверно, т.к. написано с большой буквы (верно print(‘string’) ).
- Не забывайте, сколько и каких параметров принимает каждая функция. Например, функция write() принимает только одну строку в отличие от print() (который принимает сколько угодно параметров, а также именованные параметры вроде sep и end ). Также функция float() принимает в качестве параметра строку, представляющую вещественное число, где в качестве разделителя используется точка, а не запятая. Т.е. запись float(«3,14») приведёт к ошибке (нужно float(«3.14») ).
- Проверьте, что нигде в вашей программе не может возникнуть деление на ноль при определённых входных данных или обращение к элементу списка/словаря с несуществующим индексом/ключом (например, для lst=[1, 2, 3] обращение lst[500] вызовет ошибку, т.к. элемента с индексом 500 в списке нет. Аналогично, для словаря d = <‘cat’: 3, ‘lion’: 2, ‘dog’: 7>вызовет ошибку обращение d[‘mouse’] (т.к. такого ключа в словаре нет)).
WA (Wrong answer)
Эта ошибка возникает в том случае, когда код написан без ошибок, связанных с языком Python, однако где-то в логике программы присутствует ошибка.
Тестовая система проверяет ваш код на различных входных данных (так называемых тестах) и сверяет ответ работы программы с эталонным. Если хотя бы на одном тесте ответ отличается, программа выдаёт ошибку WA. При этом, в таблице с вердиктом (она находится внизу решения на сайте Яндекс. Контест) в строке, соответствующей ошибке WA в столбце «Тест» указывается номер теста, на котором ответ вашей программы не совпал с эталонным.
В случае возникновения этой ошибки, проверьте следующие моменты:
- Проверьте, что выполнены все рекомендации при возникновении ошибки Presentation error (эти же ситуации иногда могут приводить и к WA).
- Если ошибка возникает на тесте № 1 – следует проверить корректность работы программы на данных из условия (обычно в условии есть пример ввода и вывода).
- Если ошибка возникает на тесте с номером больше 1 – стоит внимательно перечитать условие и комментарии к нему и проверить, что всё учтено:
- Верно указаны имена входных и выходных файлов (если программа подразумевает работу с файлами).
- Соблюдён формат выходных данных (всегда печатается нужное количество знаков после точки в вещественных числах, в .csv-файлах используются верные разделители, а названия колонок в точности совпадают с теми, что требуются в условии).
- Попытайтесь подумать, на каких входных данных, которые не совпадают с примером из условия, но соответствуют условию, ваша программа может работать некорректно.
Источник
Решаю вот эту задачу(пробный контест):
A. Быстрый старт
Ограничение времени 1 секунда
Ограничение памяти 64Mb
Ввод стандартный ввод или input.txt
Вывод стандартный вывод или output.txt
В этом году третий раз одна известная компания проводит соревнование по программированию искусственного интеллекта для игровых стратегий. В этот раз участникам предложили написать искусственный интеллект для управления командой хоккеистов. Вася решил побороться за главный приз. Прочитав раздел “Быстрый старт”, он приступил к делу. Не прошло и нескольких часов, как хоккеисты начали ездить за шайбой по площадке. Но Вася заметил, что не всегда у игрока получается взять шайбу. Перечитав внимательно документацию, он выяснил, что для расчета вероятности подобрать шайбу нужно подсчитать коэффициент, равный максимальному значению из двух характеристик хоккеиста — ловкости D и подвижности A. Помогите Васе по известным значениям ловкости и подвижности определить этот коэффициент.
Формат ввода
Во входном файле заданы два целых числа D и A (0 ≤ D, A ≤ 109) — ловкость и подвижность хоккеиста соответственно.
Формат вывода
В выходной файл выведите коэффициент
Пример 1
Ввод Вывод
100 64 100
Пример 2
Ввод Вывод
31 14 31
Код:
| Python | ||
|
выводит ошибку Run-time error
хотя при проверке вроде все работало
__________________
Помощь в написании контрольных, курсовых и дипломных работ, диссертаций здесь
Тренируюсь решать задачи Яндекса.
Вот условие:
Дан упорядоченный по неубыванию массив целых 32-разрядных чисел. Требуется удалить из него все повторения.
Желательно получить решение, которое не считывает входной файл целиком в память, т.е., использует лишь константный объем памяти в процессе работы.
Первая строка входного файла содержит единственное число n, n ≤ 1000000.
На следующих n строк расположены числа — элементы массива, по одному на строку. Числа отсортированы по неубыванию.
У меня возникает Runtime error, а из-за чего — не могу понять. Не сказано же какая. В чём может быть проблема?
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class WooHoo {
public static void main(String[] args) throws Exception {
BufferedReader r = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(r.readLine());
int prev = Integer.parseInt(r.readLine());
System.out.println(prev);
for (int i = 1; i < n; i++) {
int cur = Integer.parseInt(r.readLine());
if (prev == cur) {
continue;
} else {
prev = cur;
System.out.println(cur);
}
}
}
}
| Сообщение | Кратко | Сообщается ли номер теста? | Значение вердикта | Возможная причина |
|---|---|---|---|---|
| OK | OK | Нет | Решение зачтено | Программа верно работает на соответствующем наборе тестов |
| Compilation error | CE | Нет | Компиляция программы завершилась с ошибкой | 1. в программе допущена синтаксическая или семантическая ошибка 2. неправильно указан язык |
| Wrong answer | WA | Да | Ответ неверен | 1. ошибка в программе 2. неверный алгоритм |
| Presentation error | PE | Да | Тестирующая система не может проверить выходные данные, так как их формат не соответствует описанному в условиях задачи | 1. неверный формат вывода 2. программа не печатает результат 3. лишний вывод |
| Time-limit exceeded | TL | Да | Программа превысила установленный лимит времени | 1. ошибка в программе 2. неэффективное решение |
| Memory limit exceeded | ML | Да | Программа превысила установленный в условиях лимит памяти | 1. ошибка в программе (например, бесконечная рекурсия) 2. неэффективное решение |
| Output limit exceeded | OL | Да | Программа превысила установленный в условиях лимит вывода | 1. программа выводит больше информации, чем установлено в ограничениях |
| Run-time error | RE | Да | Программа завершила работу с ненулевым кодом возврата | 1. ошибка выполнения 2. программа на C или C++ не завершается оператором return 0 3. ненулевой код возврата указан явно 4. Программа на Java описана в пакете |
| Precompile check failed | PCF | Нет | Программа не прошла проверку на качество кода перед компиляцией | 1. плохое качество кода 2. неправильно отформатированный код |
| Idleness limit exceeded | IL | Да | Программа слишком долго не отвечала на запросы системы и не выполняла действий | 1. программа ожидает ввода с консоли, которого не должно быть 2. не использован flush() |
Содержание
- 1 Общий принцип
- 2 Ввод и вывод данных
- 3 Тестирование решений
- 3.1 CE — Ошибка компиляции (Compilation Error)
- 3.2 TLE — Нарушен предел времени (Time Limit Exceeded)
- 3.3 ILE — Нарушен предел ожидания (Idleness Limit Exceeded)
- 3.4 MLE — Нарушен предел памяти (Memory Limit Exceeded)
- 3.5 RTE — Ошибка во время выполнения (Run-time Error)
- 3.6 PE — Ошибка представления (Presentation Error)
- 3.7 WA — Неправильный ответ (Wrong Answer)
- 3.8 OK — Принято (Accepted)
- 3.9 CF — Ошибка тестирования (Check Failed)
- 3.10 SV — Нарушение безопасности (Security Violation)
- 4 Особенности языков программирования
- 4.1 Выбор языка программирования
- 5 Конфигурация тестирующего сервера
- 6 Языки программирования
Общий принцип
В систему посылаются только файлы с исходным кодом, а сама посылаемая программа должна состоять только из одного файла: *.dpr, *.cpp, *.java, *.pas и т. д. Нельзя отправить в систему скомпилированный exe-файл, файл проекта Visual Studio и т. п.
В решениях запрещается:
- осуществлять доступ к сети;
- выполнять любые операции ввода/вывода, кроме открывания, закрывания, чтения и записи стандартных потоков stdin, stdout, stderr и файлов с именами, явно прописанными в условии задачи;
- сознательно «ломать» тестирующую систему;
- выполнять другие программы и порождать новые процессы;
- изменять права доступа к файловой системе;
- работать с поддиректориями;
- создавать и манипулировать ресурсами GUI (окна, диалоговые сообщения и т. д.);
- работать со внешними устройствами (звук, принтер и т. д.);
- выполнять прочие действия, призванные нарушить ход учебного процесса.
Решения выполняются в специальном окружении, обеспечивающем безопасный запуск, и попытка выполнить какие-либо из указанных действий закончится, скорее всего, получением вердикта «Ошибка во время выполнения».
Ввод и вывод данных
Во всех задачах необходимо считывать входные данные из текстового файла и выводить результат в текстовый файл. Имена файлов указаны в условии задачи. Предполагается, что файлы располагаются в текущем каталоге программы, поэтому в решениях можно и нужно использовать только их имена без абсолютных путей в файловой системе тестирующего сервера.
Можно считать, что изначально при запуске решения выходной файл будет отсутствовать, и решение должно его создать и записать туда ответ.
Внимательно проверяйте имена файлов в решениях на соответствие условию задачи.
Если в коде решения имена файлов указаны неверно, это может приводить к непредсказуемым последствиям. Так, если имя выходного файла указано неверно и требуемый по условию файл не создаётся, система, скорее всего, выдаст вердикт «Ошибка представления».
В случае, когда в решении на Java перепутано имя входного файла и делается попытка открыть несуществующий файл, выбрасывается исключение. Если автор решения не перехватывает его, программа завершается с вердиктом «Ошибка во время выполнения». Если же исключение обрабатывается, то вполне возможны и другие вердикты в зависимости от того, отработает ли программа и что окажется в выходном файле. Если в решении на C++ неправильно указан входной файл и ошибки специально не обрабатываются, чтение из файла может приводить к чтению произвольных данных («мусора»). Если в программе вместо чтения из файла делается попытка считать данные со стандартного ввода (stdin, который обычно связан с клавиатурой консоли), программа заблокируется («повиснет») в ожидании ввода и будет завершена с вердиктом «Превышен предел времени».
Решение может выводить произвольные данные «в консоль», то есть в стандартные потоки stdout, stderr, которые обычно связаны с консольным окном (например для отладки). Это не запрещается и не влияет на результат. Проверяется только содержимое выходного файла. Следует помнить, что на вывод тратится дополнительное время, поэтому большой объём отладочной информации может критически замедлить вашу программу. Вывод в stderr медленнее, чем в stdout, поскольку не буферизируется.
Тестирование решений
Каждое отправленное решение проходит на сервере проверку на нескольких тестах. Задача считается решённой только в случае прохождения всех тестов. Решение запускается на всех тестах, которые есть по задаче, и процесс тестирования не прерывается на первом непройденном тесте, как это делается в соревнованиях типа ACM.
Тестирование осуществляется автоматически, поэтому решения должны строго следовать формату входных и выходных данных, который описан в условии. В случае неясности можно задавать вопросы преподавателям. Если не сказано явно, все входные данные можно считать корректными и удовлетворяющими ограничениям из условия. Например, если сказано, что на входе целое число от 1 до 100 включительно, то можно считать, что это так и есть, и проверять неравенства и выводить ошибку в случае, если это не так, в коде решения нет необходимости.
Тесты по каждой задаче не упорядочены по сложности, по размеру входных данных, по какому-то иному критерию, а следуют в исторически сложившемся порядке их добавления в систему.
Не гарантируется, что первый тест в системе будет совпадать с тестом из условия (зачастую это не так).
Результатом проверки является итоговое сообщение системы и, возможно, в скобках номер первого теста, вызвавшего ошибку (если таковая имела место). Например, вердикт «Неправильный ответ (43)» означает, что решение успешно скомпилировалось и прошло без ошибок первые 42 теста по задаче, но на тесте под номером 43 выдало неверный ответ.
Далее опишем все допустимые сообщения тестирующей системы и укажем возможные причины их появления.
CE — Ошибка компиляции (Compilation Error)
Не удалось скомпилировать решение и получить исполняемый файл для запуска. Решение в таком случае, очевидно, не может быть проверено ни на одном тесте.
Посмотреть вывод компилятора и понять, почему код не удаётся скомпилировать, можно путём нажатия на иконку ![]() в таблице с вашими решениями. Наиболее частые причины ошибки компиляции: выбран неверный компилятор (для другого языка программирования или же несовместимая версия, например Java v7 вместо Java v8), отправляется не тот файл (файл проекта IDE вместо файла с исходным кодом).
в таблице с вашими решениями. Наиболее частые причины ошибки компиляции: выбран неверный компилятор (для другого языка программирования или же несовместимая версия, например Java v7 вместо Java v8), отправляется не тот файл (файл проекта IDE вместо файла с исходным кодом).
Время работы компилятора ограничено 30 секундами. Если он не успел отработать по каким-либо причинам, также будет выставлен вердикт «Ошибка компиляции».
TLE — Нарушен предел времени (Time Limit Exceeded)
Для каждого теста установлено своё ограничение по времени (Time Limit) в секундах. Для разных тестов по одной задаче ограничение по времени может быть разным.
Тестирующая система учитывает так называемое процессорное время (CPU Time) выполнения процесса в операционной системе. Нет смысла делать решение задачи многопоточным, потому что распараллеливание хоть и позволяет сократить реальное время работы (Wall Time), но не уменьшает процессорное время.
Процесс-решение запускается на тесте, и если процесс не успевает завершиться в течение отведённого времени, он принудительно завершается и выставляется вердикт «Нарушен предел времени». В качестве времени работы решения на тесте указывается то время, которое процесс фактически проработал до того, как был приостановлен. Нет возможности узнать, сколько бы программа проработала, если бы не была снята по времени. Если при ограничении по времени на тест в 1 секунду вы видите, что решение получает вердикт «Нарушен предел времени» и работает 1015 мс, то нельзя это понимать как «решение чуть-чуть не успевает, надо ускорить его на 15 мс». Если решение останавливается по времени, то вывод программы никак не проверяется на предмет его правильности.
Возможные причины появления ошибки «Нарушен предел времени»:
- неэффективный алгоритм (например, в решении реализован алгоритм с временной сложностью Ω(n2), хотя задача предполагает решение за O(n log n));
- недостаточно эффективная программная реализация (идея и алгоритм правильные, но код написан не очень хорошо: например, ввод данных из файла осуществляется медленно, чрезмерно часто выделяется и освобождается память);
- попытка чтения данных с консоли (
std::cin,scanf(),getchar()в C++,System.inв Java), тогда как нужно читать входные данные из файла (в этом случае программа блокируется в ожидании ввода и зависает, не расходуя при этом CPU Time, поэтому такой случай тестирующая система обрабатывает отдельно); - ошибка в программе (например, программа входит в бесконечный цикл).
Не рекомендуется «пропихивать» медленное решение, отправляя его многократно, пока система не «согласится» его принять. Решение в любой момент может быть перетестировано и, соответственно, может перестать быть принятым из-за нарушения предела времени.
ILE — Нарушен предел ожидания (Idleness Limit Exceeded)
Программа зависла в ожидании, не потребляя при этом ресурсы процессора.
Такое может быть, например, если согласно условию чтение входных данных осуществляется из файла, а решение выполняет ввод с консоли. В этом случае процесс решения заблокируется в ожидании нажатия клавиш на клавиатуре. Через некоторое время система тестирования принудительно завершит этот процесс и выставит вердикт ILE.
MLE — Нарушен предел памяти (Memory Limit Exceeded)
Программа использует слишком много оперативной памяти, стоит проанализировать использование памяти и оптимизировать его.
Также причиной чрезмерного использования памяти может быть ошибка в программе, например, вечный цикл в теле которого на каждой или некоторых итерациях выделяется дополнительная память. К используемой памяти относится не только память с данными, но также память с кодом и программным стеком.
Ограничение по памяти есть не для всех задач. Гарантируется, что для всех тестов в рамках одной задачи ограничение по памяти одинаково.
Как и в случае нарушения ограничения по времени, программа при нарушении ограничения по памяти аварийно завершается тестирующей системой, её вывод не проверяется на правильность. Точно так же не следует воспринимать размер памяти, использованной до момента аварийного завершения, как объём, которого решению хватило бы для успешной работы. Более точно, вердикт MLE, полученный с использованием 257 МБ памяти, говорит о том, что приложение успело использовать 257 МБ памяти и было принудительно остановлено, но ничего не говорит о том, сколько памяти использовало бы приложение, не будучи принудительно остановленным.
В некоторых случаях при разовом выделении чрезмерно большого блока в памяти, этот запрос может быть не выполнен операционной системой, что в результате может привести к ошибке во время выполнения или (значительно реже) другому результату неопределённого поведения в случае с языком C++.
RTE — Ошибка во время выполнения (Run-time Error)
В операционной системе есть такое понятие, как код завершения процесса (Exit Code). Этот подход используется как в Windows, так и в ОС семейства UNIX. Это целое число, которое остаётся после прекращения выполнения программы. Общепринятое соглашение гласит, что нулевой код завершения свидетельствует о нормальном завершении процесса без ошибок, любой другой — об ошибке. Тестирующая система проверяет код завершения вашего решения, и если он не равен нулю, выставляет вердикт «Ошибка во время выполнения». При этом никак не проверяется то, что решение успело вывести в выходной файл.
Укажем типичные причины ошибок во время выполнения.
- Использована директива
packageв коде программы на Java.- В результате программа на Java находится не в пакете по умолчанию. Компилятор Java сгенерировал класс в некотором пакете (ошибки компиляции нет), а при запуске виртуальная машина Java не смогла найти этот класс, потому что искала в пакете по умолчанию (возникло исключение
ClassNotFoundExceptionс сообщением Could not find or load main class).
- В результате программа на Java находится не в пакете по умолчанию. Компилятор Java сгенерировал класс в некотором пакете (ошибки компиляции нет), а при запуске виртуальная машина Java не смогла найти этот класс, потому что искала в пакете по умолчанию (возникло исключение
- Выход за границы допустимой области памяти в программе на C++.
- Выход за границы массива, разыменование неправильного указателя, обращение к нулевому указателю.
- Переполнение системного стека.
- Эта причина является частой в случае рекурсии. Вообще, системный стек используется для размещения параметров функций, локальных переменных. Его размер, как правило, невелик и по умолчанию равен 1 МБ. При вызове функции стековая структура позволяет естественным образом сохранить текущие состояния всех локальных переменных и вернуться к ним, когда вызов завершится и управление вернётся в исходную точку. Если в алгоритме используется глубокая рекурсия, то размера стека может не хватить для хранения контекстов всех вызовов. Решений этой проблемы два:
- переписать алгоритм нерекурсивно (например с использованием своего стека, а не системного);
- увеличить размер системного стека, что делается по-разному для разных языков программирования (см. примеры для C++ (Visual Studio) и Java).
- Эта причина является частой в случае рекурсии. Вообще, системный стек используется для размещения параметров функций, локальных переменных. Его размер, как правило, невелик и по умолчанию равен 1 МБ. При вызове функции стековая структура позволяет естественным образом сохранить текущие состояния всех локальных переменных и вернуться к ним, когда вызов завершится и управление вернётся в исходную точку. Если в алгоритме используется глубокая рекурсия, то размера стека может не хватить для хранения контекстов всех вызовов. Решений этой проблемы два:
- Ошибка ввода-вывода (попытка открыть несуществующий входной файл).
- Нужно проверить правильность имени входного файла.
- Программа целенаправленно была завершена с ненулевым кодом выхода.
- В программе на C++ это может быть, если функция
main()в C++ вернула ненулевой код (return (non-zero)в функцииmain()). Рекомендуется завершать функциюmain()операторомreturn 0(в старых компиляторах C++ это обязательно, современные компиляторы же подразумевают возврат нулевого кода автоматически). Также программу на C++ с произвольным кодом завершает вызовexit(). - В программе на Java можно завершить процесс с произвольным кодом с помощью
System.exit().
- В программе на C++ это может быть, если функция
- Необработанное исключение.
- Причин возникновения исключений может быть масса. Например, если в Java функции
Integer.parseInt()/Double.parseDouble()была передана строка, содержащая пробельные символы (ASCII-коды 9, 10, 13, 32), выбрасывается исключениеNumberFormatException.
- Причин возникновения исключений может быть масса. Например, если в Java функции
- Целочисленное деление на ноль.
- При выполнении деления нужно всегда думать, а не может ли делитель оказаться равным нулю. В то же время стоит отметить, что вещественное деление на ноль (в типах с плавающей точкой
double,float) по умолчанию не приводит к завершению программы, а даёт специальные значения+Inf,-InfилиNaN.
- При выполнении деления нужно всегда думать, а не может ли делитель оказаться равным нулю. В то же время стоит отметить, что вещественное деление на ноль (в типах с плавающей точкой
PE — Ошибка представления (Presentation Error)
Наиболее частая причина возникновения этой ошибки — не найден выходной файл. Возможно, вы забыли создать выходной файл и выводите ответ в консоль (он в таком случае игнорируется). Проверьте имена входного и выходного файла в вашей программе на соответствие условию задачи. Исторически сложилось, что в разных задачах входной и выходной файл именуются по разным правилам: input.txt и output.txt, in.txt и out.txt, input.in и output.out (обратите внимание, что нет расширения txt), [задача].in и [задача].out…
Для некоторых задач программа проверки (checker) дополнительно удостоверяется, что ваш вывод соответствует определённому формату, и выдаёт ошибку представления в случае, если это не так. Например, если в задаче нужно вывести число, а вы выводите строку. Или если в задаче нужно вывести сначала число k, затем k чисел, а ваше решение выводит число k и далее (k + 1) чисел (то есть решение выводит в файл лишние данные).
Также имейте в виду, что отлавливание исключений и других ошибок не должно быть самоцелью. Если исключение не обрабатывается каким-либо образом, обычно нет смысла его ловить по следующей причине. Аварийное завершение работы программы в результате ошибки во время выполнения приводит к вердикту «Ошибка во время выполнения», только если соответствующее исключение было «проброшено» наружу, а не «заглушено» на каком-то этапе. Если исключение отлавливается, но никак не обрабатывается, то в результате возникновения соответствующей ошибки следует ожидать вердикт «Ошибка представления» или же «Неправильный ответ» (реже).
WA — Неправильный ответ (Wrong Answer)
Для многих задач ответ однозначен, и проверяется просто побайтовое совпадение вашего выходного файла и сохранённого правильного ответа. Такая проверка требует строгого соблюдения формата файла, не допускает незначащих пробелов и пустых строк. Например, если правильный ответ имеет вид (пробелы обозначены символом ␣)
5 1␣2␣3␣4␣5
и решение вывело
5 1␣2␣3␣4␣5␣
(лишний пробел в конце второй строки), то будет получен вердикт «Неправильный ответ». Для некоторых задач написаны проверяющие программы (checker), которые к таким различиям лояльны и засчитывают ответы с лишними пробелами как правильные. Всегда точно следуйте формату файла и не выводите лишних пробелов, и проблем не будет.
После последней строки файла можно выводить или не выводить перевод строки — не важно. Есть две точки зрения в зависимости от того, с какой стороны смотреть на символ перевода строки:
- каждая строка завершается переводом строки, поэтому
nв конце файла нужен; - перевод строки является разделителем между соседними строками, поэтому
nв конце файла не нужен.
Первая точка зрения является общепринятой. Так, компилятор gcc, система контроля версий git и многие другие программы выдают предупреждение no newline at the end of file, если в самом конце файла нет символов новой строки. Обсуждение вопроса можно почитать на stackoverflow.
Поэтому рекомендуется придерживаться первого подхода и завершать все строки переводами строк.
Другие очевидные причины получения неправильного ответа:
- неверный алгоритм;
- ошибка в программе.
Бывает такое, что решение от запуска к запуску даёт разные ответы, или же правильно работает на одном компьютере и неправильно на другом. Такие случаи, как правило, связаны с ошибками в решениях.
OK — Принято (Accepted)
Программа работает правильно и прошла все тесты с соблюдением всех ограничений.
Если решение принято системой, это ещё не означает, что в его основе лежит правильный алгоритм. В любой момент могут появиться новые наборы входных данных, на которых будут заново протестированы все решения по задаче. Если ваше решение на самом деле не полностью верно и прошло только из-за недостаточно сильного набора тестов, оно может в будущем потерять статус «Принято».
CF — Ошибка тестирования (Check Failed)
Если указан номер теста, то программа успешно завершается на предложенном тесте (укладывается в отведённые время и память и не совершает ошибок во время выполнения), но результат не удаётся проверить из-за ошибок в программе проверки. Вашей ошибки в этом случае, возможно, никакой нет и после исправления программы проверки будет получен вердикт OK. Не исключены ещё два варианта: WA, PE.
Имейте в виду, что если ошибка тестирования возникает на первом же тесте, то на остальных Ваше решение не запускается вовсе. Соответственно, в этом случае после устранения ошибок программы проверки вердикты TLE, MLE, RTE также могут возникнуть в любом тесте, кроме первого.
Если же номер теста, на котором возникает ошибка тестирования, не указан, значит, программа проверки не была скомпилирована, а Ваше решение не запускалось вовсе. В этом случае правильным может быть любой вердикт, отличный от CF.
Если у Вас возникла ошибка тестирования, мы, скорее всего, это заметим достаточно быстро. Тем не менее, имеет смысл задать вопрос через пункт «Сообщения» в меню курса. Не забывайте выбрать задачу, которой касается этот вопрос.
SV — Нарушение безопасности (Security Violation)
Ошибка означает, что программа попыталась выполнить запрещённые действия.
К их числу относится попытка создания новых процессов. Вашим решениям запрещено запускать на выполнение другие программы. Например, в коде
порождается новый процесс командной оболочки cmd.exe и в нём выполняется команда pause. Пожалуйста, не пишите так, для достижения аналогичного эффекта можно использовать другие приёмы.
Особенности языков программирования
У каждого конкретного языка программирования есть свои особенности, о которых полезно знать. Далее рассмотрены отдельные особенности написания решений на разных языках программирования:
- C++;
- Java;
- C#;
- Python.
Выбор языка программирования
Разные задачи можно решать на разных языках. Часто для конкретной задачи тот или иной язык оказывается предпочтительным. Например, если в задаче требуются тяжёлые вычисления, то её может быть проще сдать на C++, чем на Java, за счёт более быстрой работы программы на C++ (для кода на Java могут потребоваться более изощрённые оптимизации, чтобы он прошёл по времени). С другой стороны, если задача требует проведения вычислений с большими целыми числами, выходящими за пределы диапазона 64-битных переменных, то есть «длинной арифметики», то решение существенно проще написать на Java, воспользовавшись готовым качественно написанным классом BigInteger для операций с числами произвольной длины.
Конфигурация тестирующего сервера
Сервер, на котором осуществляется запуск решений, является виртуальной машиной, выполняющейся внутри Microsoft Hyper-V Server 2012 R2. Виртуальный компьютер работает под управлением Windows 7 Professional x64, оснащён процессором Intel® Core™ i3-4130 (Haswell, кэш 3 МБ, 3,40 ГГц, доступно только одно ядро) и 4 ГБ оперативной памяти. Для хранения входных и выходных файлов используется RAM-диск, чтобы обеспечить максимальную производительность ввода-вывода.
Языки программирования
На странице учебного курса в системе на вкладке «Компиляторы» можно ознакомиться с актуальным списком доступных языков программирования, версиями компиляторов и параметрами командной строки их вызова.
Размер системного стека явно не задаётся (используется размер по умолчанию). При компиляции кода на C++ включен режим оптимизации O2.

Числа с плавающей точкой — это быстрый и эффективный способ хранения и работы с числами, но они имеют ряд подводных камней, которые наверняка ставят в тупик многих начинающих программистов, а возможно, и опытных! Классический пример, демонстрирующий подводные камни плавающих чисел, выглядит следующим образом:
>>> 0.1 + 0.2 == 0.3 False
Увидев это в первый раз, вы можете быть дезориентированы. Но не выбрасывайте свой компьютер в мусорную корзину. Это правильное поведение!
В этой статье вы узнаете, почему ошибки с плавающей точкой, подобные приведенной выше, встречаются часто, почему они имеют смысл, и что можно сделать, чтобы справиться с ними в Python.
Ваш компьютер — лжец (вроде того)
Вы видели, что 0,1 + 0,2 не равно 0,3, но на этом безумие не заканчивается. Вот еще несколько сбивающих с толку примеров:
>>> 0.2 + 0.2 + 0.2 == 0.6 False >>> 1.3 + 2.0 == 3.3 False >>> 1.2 + 2.4 + 3.6 == 7.2 False
Проблема также не ограничивается сравнением равенства:
>>> 0.1 + 0.2 <= 0.3 False >>> 10.4 + 20.8 > 31.2 True >>> 0.8 - 0.1 > 0.7 True
Так что же происходит? Ваш компьютер обманывает вас? Похоже на то, но под поверхностью происходит нечто большее.
Когда вы вводите число 0.1 в интерпретатор Python, оно сохраняется в памяти как число с плавающей точкой. При этом происходит преобразование. 0,1 — это десятичная дробь по основанию 10, но числа с плавающей точкой хранятся в двоичном формате. Другими словами, 0,1 преобразуется из основания 10 в основание 2.
Полученное двоичное число может не точно представлять исходное число по основанию 10. 0,1 — один из примеров. Двоичное представление 0.000111. То есть, 0,1 является бесконечно повторяющейся десятичной дробью при записи по основанию 2. То же самое происходит, когда вы записываете дробь ⅓ в виде десятичной дроби по основанию 10. В итоге вы получаете бесконечно повторяющуюся десятичную дробь 0.33.
Память компьютера ограничена, поэтому бесконечно повторяющееся двоичное дробное представление 0,1 округляется до конечной дроби. Значение этого числа зависит от архитектуры вашего компьютера (32-битная или 64-битная). Один из способов увидеть значение с плавающей точкой, которое хранится для 0,1, — использовать метод .as_integer_ratio() для плавающих чисел, чтобы получить числитель и знаменатель представления с плавающей точкой:
>>> numerator, denominator = (0.1).as_integer_ratio()
>>> f"0.1 ≈ {numerator} / {denominator}"
'0.1 ≈ 3602879701896397 / 36028797018963968'
Теперь используйте format(), чтобы показать дробь с точностью до 55 знаков после запятой:
>>> format(numerator / denominator, ".55f") '0.1000000000000000055511151231257827021181583404541015625'
Поэтому 0,1 округляется до числа, которое немного больше его истинного значения.
Эта ошибка, известная как ошибка представления с плавающей точкой (floating-point representation error), случается гораздо чаще, чем вы можете себе представить.
Ошибка репрезентативности действительно распространена
Существует три причины, по которым число округляется при представлении в виде числа с плавающей точкой:
- Число имеет больше значащих цифр, чем позволяет плавающая точка.
- Число иррационально.
- Число рационально, но имеет нетерминированное двоичное представление.
64-битные числа с плавающей точкой имеют 16 или 17 значащих цифр. Любое число с большим количеством значащих цифр округляется. Иррациональные числа, такие как π и e, не могут быть представлены ни одной конечной дробью ни в одной целочисленной базе. Поэтому, опять же, несмотря ни на что, иррациональные числа будут округляться при хранении в виде плавающих чисел.
Эти две ситуации создают бесконечное множество чисел, которые нельзя точно представить в виде числа с плавающей запятой. Но если вы не химик, имеющий дело с крошечными числами, или физик, имеющий дело с астрономически большими числами, вы вряд ли столкнетесь с этими проблемами.
А как насчет рациональных чисел без конца, например, 0,1 в основании 2? Именно здесь вы столкнетесь с большинством проблем с плавающей запятой, а благодаря математике, определяющей, заканчивается ли дробь, вы столкнетесь с ошибкой представления чаще, чем вы думаете.
В основании 10 дробь конечна, если ее знаменатель является произведением степеней простых множителей 10.
Два простых множителя 10 это 2 и 5, поэтому дроби ½, ¼, ⅕, ⅛ и ⅒ все конечны, а ⅓, ⅐ и ⅑ — нет. Однако в основании 2 есть только один простой множитель — 2. Поэтому только дроби, знаменатель которых равен степени 2, имеют конечный результат. В результате дроби типа ⅓, ⅕, ⅙, ⅐, ⅑ и ⅒, выраженные в двоичной форме, являются непересекающимися.
Теперь вы можете понять исходный пример в этой статье. 0.1, 0.2 и 0.3 округляются при преобразовании в числа с плавающей точкой:
>>> # -----------vvvv Display with 17 significant digits >>> format(0.1, ".17g") '0.10000000000000001' >>> format(0.2, ".17g") '0.20000000000000001' >>> format(0.3, ".17g") '0.29999999999999999'
При сложении 0,1 и 0,2 получается число, немного большее, чем 0,3:
>>> 0.1 + 0.2 0.30000000000000004
Поскольку 0,1 + 0,2 немного больше, чем 0,3, а 0,3 представляется числом, которое немного меньше его самого, выражение 0,1 + 0,2 == 0,3 имеет значение False.
Как сравнивать плавающие числа в Python
Как же бороться с ошибками представления с плавающей точкой при сравнении плавающих чисел в Python? Хитрость заключается в том, чтобы избежать проверки равенства. Никогда не используйте ==, >= или <= с плавающей точкой. Вместо этого используйте функцию math.isclose():
>>> import math >>> math.isclose(0.1 + 0.2, 0.3) True
math.isclose() проверяет, близок ли первый аргумент ко второму. Но что именно это значит? Основная идея заключается в том, чтобы проверить расстояние между первым и вторым аргументом, которое эквивалентно абсолютному значению разности этих величин:
>>> a = 0.1 + 0.2 >>> b = 0.3 >>> abs(a - b) 5.551115123125783e-17
Если abs(a — b) меньше некоторого процента от большего из a или b, то a считается достаточно близким к b, чтобы быть «равным» b. Этот процент называется относительным допуском.
Вы можете указать относительный допуск с помощью аргумента rel_tol ключевого слова math.isclose(), который по умолчанию равен 1e-9. Другими словами, если abs(a — b) меньше 1e-9 * max(abs(a), abs(b)), то a и b считаются «близкими» друг к другу. Это гарантирует, что a и b равны примерно до девяти знаков после запятой.
При необходимости вы можете изменить относительный допуск:
>>> math.isclose(0.1 + 0.2, 0.3, rel_tol=1e-20) False
Конечно, относительный допуск зависит от ограничений, установленных решаемой вами задачей. Однако для большинства повседневных приложений достаточно относительного допуска по умолчанию.
Однако существует проблема, если одно из a или b равно нулю, а rel_tol меньше единицы. В этом случае, как бы близко ненулевое значение ни было к нулю, относительный допуск гарантирует, что проверка на близость всегда будет неудачной. В этом случае использование абсолютного допуска работает как запасной вариант:
>>> # Relative check fails! >>> # ---------------vvvv Relative tolerance >>> # ----------------------vvvvv max(0, 1e-10) >>> abs(0 - 1e-10) < 1e-9 * 1e-10 False >>> # Absolute check works! >>> # ---------------vvvv Absolute tolerance >>> abs(0 - 1e-10) < 1e-9 True
math.isclose() выполнит эту проверку автоматически. Аргумент ключевого слова abs_tol определяет абсолютный допуск. Однако по умолчанию abs_tol равен 0.0, поэтому вам придется задать его вручную, если вам нужно проверить, насколько близко значение к нулю.
В целом, math.isclose() возвращает результат следующего сравнения, которое объединяет относительный и абсолютный тесты в одно выражение:
abs(a - b) <= max(rel_tol * max(abs(a), abs(b)), abs_tol)
math.isclose() была введена в PEP 485 и доступна с Python 3.5.
Когда следует использовать math.isclose()?
В целом, следует использовать math.isclose() всякий раз, когда вам нужно сравнить значения с плавающей точкой. Замените == на math.isclose():
>>> # Don't do this: >>> 0.1 + 0.2 == 0.3 False >>> # Do this instead: >>> math.isclose(0.1 + 0.2, 0.3) True
Также нужно быть осторожным со сравнениями >= и <=. Обработайте равенство отдельно с помощью math.isclose(), а затем проверьте строгое сравнение:
>>> a, b, c = 0.1, 0.2, 0.3 >>> # Don't do this: >>> a + b <= c False >>> # Do this instead: >>> math.isclose(a + b, c) or (a + b < c) True
Существуют различные альтернативы math.isclose(). Если вы используете NumPy, вы можете использовать numpy.allclose() и numpy.isclose():
>>> import numpy as np >>> # Use numpy.allclose() to check if two arrays are equal >>> # to each other within a tolerance. >>> np.allclose([1e10, 1e-7], [1.00001e10, 1e-8]) False >>> np.allclose([1e10, 1e-8], [1.00001e10, 1e-9]) True >>> # Use numpy.isclose() to check if the elements of two arrays >>> # are equal to each other within a tolerance >>> np.isclose([1e10, 1e-7], [1.00001e10, 1e-8]) array([ True, False]) >>> np.isclose([1e10, 1e-8], [1.00001e10, 1e-9]) array([ True, True])
Имейте в виду, что относительные и абсолютные допуски по умолчанию не совпадают с math.isclose(). Относительный допуск по умолчанию для numpy.allclose() и numpy.isclose() равен 1e-05, а абсолютный допуск по умолчанию для обоих вариантов равен 1e-08.
Метод math.isclose() особенно полезен для модульных тестов, хотя есть и альтернативы. Встроенный в Python модуль unittest имеет метод unittest.TestCase.assertAlmostEqual(). Однако этот метод использует только тест на абсолютное различие. Кроме того, это утверждение, а значит, при сбоях возникает ошибка AssertionError, что делает его непригодным для сравнений в вашей бизнес-логике.
Отличной альтернативой math.isclose() для модульного тестирования является функция pytest.approx() из пакета pytest. В отличие от math.isclose(), pytest.approx() принимает только один аргумент — ожидаемое значение:
>>> import pytest >>> 0.1 + 0.2 == pytest.approx(0.3) True
pytest.approx() имеет ключевые аргументы rel_tol и abs_tol для установки относительных и абсолютных допусков. Однако значения по умолчанию отличаются от math.isclose(). rel_tol по умолчанию имеет значение 1e-6, а abs_tol по умолчанию имеет значение 1e-12.
Если аргумент, переданный в pytest.approx(), является массивоподобным, то есть это итерабельность Python, например, список или кортеж, или даже массив NumPy, то pytest.approx() ведет себя аналогично numpy.allclose() и возвращает, равны ли два массива в пределах допусков:
>>> import numpy as np >>> np.array([0.1, 0.2]) + np.array([0.2, 0.4]) == pytest.approx(np.array([0.3, 0.6])) True
pytest.approx() будет работать даже со словарными значениями:
>>> {'a': 0.1 + 0.2, 'b': 0.2 + 0.4} == pytest.approx({'a': 0.3, 'b': 0.6})
True
Числа с плавающей точкой отлично подходят для работы с числами, когда не требуется абсолютная точность. Они быстрые и занимают мало памяти. Но если вам нужна точность, то следует рассмотреть некоторые альтернативы плавающим числам.
Точные альтернативы с плавающей точкой
В Python есть два встроенных числовых типа, которые обеспечивают полную точность в ситуациях, когда плавающие числа не подходят: Decimal и Fraction.
Тип Decimal может хранить десятичные значения с той точностью, которая вам необходима. По умолчанию Decimal сохраняет 28 значащих цифр, но вы можете изменить это значение на любое необходимое для решения конкретной задачи:
>>> # Import the Decimal type from the decimal module
>>> from decimal import Decimal
>>> # Values are represented exactly so no rounding error occurs
>>> Decimal("0.1") + Decimal("0.2") == Decimal("0.3")
True
>>> # By default 28 significant figures are preserved
>>> Decimal(1) / Decimal(7)
Decimal('0.1428571428571428571428571429')
>>> # You can change the significant figures if needed
>>> from decimal import getcontext
>>> getcontext().prec = 6 # Use 6 significant figures
>>> Decimal(1) / Decimal(7)
Decimal('0.142857')
Подробнее о типе Decimal можно прочитать в документации Python.
Тип дроби
Другой альтернативой числам с плавающей точкой является тип Fraction. Дробь может точно хранить рациональные числа и преодолевает проблемы ошибок представления, с которыми сталкиваются числа с плавающей точкой:
>>> # import the Fraction type from the fractions module >>> from fractions import Fraction >>> # Instantiate a Fraction with a numerator and denominator >>> Fraction(1, 10) Fraction(1, 10) >>> # Values are represented exactly so no rounding error occurs >>> Fraction(1, 10) + Fraction(2, 10) == Fraction(3, 10) True
Дробные и десятичные числа обладают многочисленными преимуществами по сравнению со стандартными значениями с плавающей точкой. Однако за эти преимущества приходится платить: снижение скорости и увеличение потребления памяти. Если вам не нужна абсолютная точность, лучше остановиться на плавающей точке. Но для таких задач, как финансовые и критически важные приложения, компромисс между дробью и десятичной дробью может оказаться оправданным.
Заключение
Значения с плавающей точкой — это одновременно и преимущество, и недостаток. Они обеспечивают быстрое выполнение арифметических операций и эффективное использование памяти ценой неточного представления. В этой статье вы узнали:
- Почему числа с плавающей точкой являются неточными
- Почему часто встречаются ошибки представления чисел с плавающей точкой
- Как правильно сравнивать значения с плавающей точкой в Python
- Как точно представлять числа с помощью типов Python Fraction и Decimal
Возможно вам будет интересно:
Алгоритмы сортировки 26 видов
Алгоритмы и структуры данных на Python
100+ сложных упражнений по программированию на Python
Числа с плавающей точкой представлены в компьютерах в виде двоичных дробей. Например, десятичная дробь 0.125 имеет значение 1/10 + 2/100 + 5/1000, и таким же образом двоичная дробь 0.001 имеет значение 0/2 + 0/4 + 1/8. Эти две дроби имеют одинаковые значения, единственное реальное отличие состоит в том, что первая записана в дробной записи с основанием 10, а вторая — с основанием 2.
К сожалению, большинство десятичных дробей не могут быть представлены точно как двоичные дроби. Следствием этого является то, что, как правило, вводимые десятичные числа с плавающей запятой аппроксимируются только двоичными числами с плавающей запятой, фактически сохраненными в машине.
Сначала проблему легче понять из базы 10. Рассмотрим дробь 1/3. Вы можете приблизить это как основную 10 фракцию: 0.3 или лучше, 0.33или лучше, 0.333 и так далее. Независимо от того, сколько цифр вы хотите записать, результат никогда не будет ровно 1/3, но будет все более приближенным к 1/3.
Таким же образом, независимо от того, сколько цифр из 2-х оснований вы хотите использовать, десятичное значение 0,1 не может быть представлено в точности как дробь из 2-х оснований. В базе 2 1/10 — бесконечно повторяющаяся дробь 0.0001100110011001100110011...
Остановитесь на любом конечном количестве битов, и вы получите приближение. На большинстве современных машин числа с плавающей запятой аппроксимируются с использованием двоичной дроби, а числитель использует первые 53 бита, начиная с самого старшего бита, а знаменатель — как степень двух. В случае 1/10 двоичная дробь равна 3602879701896397/2 ** 55, что близко, но не точно равно истинному значению 1/10.
Многие пользователи не знают о приближении из-за способа отображения значений. Python печатает только десятичное приближение к истинному десятичному значению двоичного приближения, хранящегося на машине. На большинстве машин, если бы Python должен был печатать истинное десятичное значение двоичного приближения, хранящегося для 0.1, он должен был бы отображать
>>> 0.1 # 0.1000000000000000055511151231257827021181583404541015625
Это больше цифр, чем большинство людей считают полезным, поэтому Python сохраняет количество цифр управляемым, отображая округленное значение вместо
Просто помните, что хотя напечатанный результат выглядит как точное значение 1/10, фактическое сохраненное значение является ближайшей представимой двоичной дробью.
Интересно, что существует много разных десятичных чисел, которые имеют одну и ту же ближайшую приблизительную двоичную дробь. Например, числа 0.1 и 0.10000000000000001 и 0.1000000000000000055511151231... все приблизительно равны 3602879701896397/2 ** 55. Поскольку все эти десятичные значения имеют одинаковую аппроксимацию, любое из них может отображаться при сохранении инварианта eval(repr(x)) == x.
Исторически Python и встроенная функция repr() выбирали функцию с 17 значащими цифрами, 0.10000000000000001. Начиная с Python 3.1 в большинстве систем теперь может выбирать самый короткий из них и просто отображать 0.1.
Обратите внимание, что это по своей природе двоичное число с плавающей точкой: это не ошибка в Python и не ошибка в вашем коде. Вы увидите то же самое на всех языках, которые поддерживают арифметику с плавающей запятой.
Для более приятного вывода вы можете использовать форматирование строки для получения ограниченного числа значащих цифр:
>>> import math >>> format(math.pi, '.12g') # '3.14159265359' >>> format(math.pi, '.2f') # '3.14' >>> repr(math.pi) # '3.141592653589793'
Важно понимать, что в действительности это иллюзия: вы просто округляете отображение истинного значения.
Одна иллюзия может породить другую. Например, поскольку 0,1 не является точно 1/10, суммирование трех значений 0,1 может также не дать точно 0,3:
>>> 0.1 + 0.1 + 0.1 == 0.3 # False
Кроме того, поскольку 0,1 не может приблизиться к точному значению 1/10, а 0,3 не может приблизиться к точному значению 3/10, предварительное округление функцией round() может не помочь:
>>> round(0.1, 1) + round(0.1, 1) + round(0.1, 1) == round(0.3, 1) # False
Двоичная арифметика с плавающей точкой содержит много сюрпризов, подобных этому. Проблема с 0.1 подробно объясняется в разделе «Ошибка представления». Смотрите также «Опасности с плавающей точкой» для более полного описания других распространенных сюрпризов.
Как говорится, «простых ответов нет». Тем не менее, не следует чрезмерно опасаться чисел с плавающей запятой! Ошибки в операциях с плавающей запятой Python наследуются от аппаратного обеспечения чисел с плавающей запятой, и на большинстве машин они имеют порядок не более одной части в 2 ** 53 на операцию. Это более чем достаточно для большинства задач, но вам нужно помнить, что это не десятичная арифметика и что каждая операция с плавающей запятой может подвергаться новой ошибке округления.
Несмотря на то, что патологические случаи существуют, для наиболее случайного использования арифметики с плавающей запятой вы увидите ожидаемый результат в конце, если просто округлите отображение окончательных результатов до ожидаемого количества десятичных цифр. str() обычно достаточно, и для более точного управления смотрите спецификаторы формата метода str.format().
Для случаев использования, которые требуют точного десятичного представления, попробуйте использовать модуль decimal, который реализует десятичную арифметику, подходящую для приложений бухгалтерского учета и высокоточных приложений.
Другая форма точной арифметики поддерживается модулем fractions, который реализует арифметику, основанную на рациональных числах, поэтому числа, такие как 1/3 могут быть представлены точно.
Если вы большой пользователь операций с плавающей запятой, вам следует взглянуть на пакет Numeric Python и многие другие пакеты для математических и статистических операций, предоставляемых проектом SciPy.
Python предоставляет инструменты, которые могут помочь в тех редких случаях, когда вы действительно хотите узнать точное значение числа с плавающей точкой. Метод float.as_integer_ratio() выражает значение типа float в виде дроби:
>>> x = 3.14159 >>> x.as_integer_ratio() # (3537115888337719, 1125899906842624)
Поскольку отношение является точным, оно может быть использовано для воссоздания исходного значения без потерь:
>>> x == 3537115888337719 / 1125899906842624 # True
Метод float.hex() выражает число с плавающей запятой в шестнадцатеричном формате (основание 16), снова давая точное значение, сохраненное компьютером:
>>> x.hex() # '0x1.921f9f01b866ep+1'
Это точное шестнадцатеричное представление может быть использовано для точного восстановления значения с плавающей точкой:
>>> x == float.fromhex('0x1.921f9f01b866ep+1') True
Поскольку представление является точным, оно полезно для надежного переноса значений между различными версиями Python и обмена данными с другими языками, поддерживающими тот же формат, например Java.
Другим полезным инструментом является функция math.fsum(), которая помогает уменьшить потерю точности во время суммирования. Она отслеживает «потерянные цифры», когда значения добавляются в промежуточный итог. Это может повлиять на общую точность, так что ошибки не накапливаются до такой степени, что бы влиять на итоговую сумму:
>>> import math >>> sum([0.1] * 10) == 1.0 False >>> math.fsum([0.1] * 10) == 1.0 True
Ошибка представления.
В этом разделе подробно объясняется пример 0.1 и показано, как вы можете выполнить точный анализ подобных случаев самостоятельно. Предполагается базовое знакомство с двоичным представлением чисел с плавающей точкой.
Ошибка представления относится к тому факту, что фактически большинство десятичных дробей не могут быть представлены точно как двоичные дроби (основание 2) . Это главная причина, почему Python или Perl, C, C++, Java, Fortran и многие другие языки часто не будут отображать точное десятичное число, которое ожидаете.
Это почему? 1/10 не совсем представимо в виде двоичной дроби. Почти все машины сегодня используют арифметику IEEE-754 с плавающей точкой, и почти все платформы отображают плавающие значения Python в IEEE-754 с «двойной точностью». При вводе, компьютер стремится преобразовать 0,1 в ближайшую дробь по форме J / 2 ** N, где J — целое число, содержащее ровно 53 бита.
Перепишем 1 / 10 ~= J / (2**N) как J ~= 2**N / 10 и напоминая, что J имеет ровно 53 бита, это >= 2**52, но < 2**53, наилучшее значение для N равно 56:
>>> 2**52 <= 2**56 // 10 < 2**53 # True
То есть 56 — единственное значение для N, которое оставляет J точно с 53 битами. Наилучшее возможное значение для J тогда будет округлено:
>>> q, r = divmod(2**56, 10) >>> r # 6
Поскольку остаток больше половины от 10, наилучшее приближение получается округлением вверх:
>>> q+1 # 7205759403792794
Поэтому наилучшее возможное приближение к 1/10 при двойной точности 754: 7205759403792794 / 2 ** 56. Деление числителя и знаменателя на два уменьшает дробь до: 3602879701896397 / 2 ** 55
Обратите внимание, поскольку мы округлили вверх, то значение на самом деле немного больше, чем 1/10. Если бы мы не округлили, то значение был бы немного меньше 1/10. Но ни в коем случае это не может быть ровно 1/10!
Таким образом, компьютер никогда не «видит» 1/10: то, что он видит, это точная дробь, указанная выше, наилучшее двоичное приближение 754, которое он может получить:
>>> 0.1 * 2 ** 55 # 3602879701896397.0
Если мы умножим эту дробь на 10 ** 55, мы увидим значение до 55 десятичных цифр:
>>> 3602879701896397 * 10 ** 55 // 2 ** 55 # 1000000000000000055511151231257827021181583404541015625
Это означает, что точное число, хранящееся в компьютере, равно десятичному значению полученному выше. Вместо отображения полного десятичного значения многие языки, включая более старые версии Python округляют результат до 17 значащих цифр:
>>> format(0.1, '.17f') '0.10000000000000001'
Модули fractions and decimal упрощают эти вычисления:
>>> from decimal import Decimal >>> from fractions import Fraction >>> Fraction.from_float(0.1) # Fraction(3602879701896397, 36028797018963968) >>> (0.1).as_integer_ratio() # (3602879701896397, 36028797018963968) >>> Decimal.from_float(0.1) # Decimal('0.1000000000000000055511151231257827021181583404541015625') >>> format(Decimal.from_float(0.1), '.17') # '0.10000000000000001'
Я столкнулся с ошибкой, то есть ошибкой представления. Будучи новичком в c++, я застрял в следующем вопросе:
Две машины (X и Y) уходят в одном направлении. Автомобиль X оставляет с постоянной скоростью 60 км/ч, а автомобиль Y оставляет с постоянной скоростью 90 км/ч.
Через один час (60 минут) автомобиль Y может получить расстояние в 30 километров от автомобиля X, другими словами, он может уйти один километр за каждые 2 минуты.
Прочтите расстояние (в км) и подсчитайте, сколько времени потребуется (в минутах) для автомобиля Y, чтобы пройти это расстояние по отношению к другому автомобилю.
Input:
30
Output:
60 minutos (minutes in portuguese)
Теперь, после отправки кода, он говорит об ошибке представления. Может ли кто-нибудь помочь мне найти решение этой ошибки. Заранее спасибо.
Мой код:
#include <iostream>
using namespace std;
int main(){
int Y;
cin >> Y;
cout << 2*Y << " minutos " << endl;
return 2*Y;
}
20 апр. 2016, в 05:15
Поделиться
Источник
2 ответа
PE является общей ошибкой в OJ ACM. вы можете проверить пространство, символ новой строки или что-то, что вы пропустили. например:
#include <iostream>
using namespace std;
int main(){
int Y;
cin >> Y;
cout << 2*Y << " minutos (minutes in portuguese)" << endl;
return 0;
}
вы можете попробовать, удачи вам.
JellyWang
20 апр. 2016, в 05:07
Поделиться
Чтобы исправить вашу проблему, попробуйте вернуть нуль, поскольку основная функция должна его вернуть, если ваш код нечеткий из ошибок.
Попытайтесь следовать этому соглашению, чтобы всегда возвращать 0 в основном.
Ваш код должен выглядеть так:
#include <iostream>
using namespace std;
int main()
{
int Y;
cin >> Y;
cout << 2*Y << " minutos " << endl;
return 0;
}
В заключение просто используйте cout вместо возврата.
FieryCod
20 апр. 2016, в 04:16
Поделиться
Ещё вопросы
- 0MySQL: извлечение значения регулярного выражения из запроса
- 0переменная объема не изменяется — angularjs
- 1Что означает судебный процесс Oracle против Google для разработчиков Android?
- 0Как сделать систему комментариев для конкретного поста и получить его?
- 0Как запрашивать данные из ссылок в AngularFire
- 1Горячая клавиша для закрытия блока кода с помощью фигурных скобок в Eclipse
- 1не удается скрыть бар Лебель на временной шкале Google
- 1Класс Mock Abstract с использованием Moq
- 0Javascript не может разобрать строку JSON
- 0Поворот 3D камеры с помощью DirectX11
- 0_score при выполнении индексации вasticsearch
- 0условное форматирование по отрицательному значению
- 0PHP-код по умолчанию с ошибкой, когда это не должно быть
- 1Что означает выполнение микрозадачи после каждого обратного вызова?
- 1Как импортировать библиотеку задач Google в Python
- 1Использование itertools для условия с перечислением для получения только определенных индексов списка (python)
- 0Как добавить нового пользователя в Kamailio, используя PHP shell_exec?
- 1Плагин com.mysema.querydsl querydsl-apt не генерирует классы QueryDSL
- 0Ionic + ngCordova + фоновая геолокация + DeviceReady выпуск
- 1Android обнаруживает, что активность находится на вершине стека истории
- 1Как внедрить конфигурацию среды в разные угловые модули?
- 1многопоточный код с выпущенным GIL и сложными потоками медленнее в Python
- 0EF Code First Foreign Key Relationship
- 1Gensim Word2Vec выбирает второстепенный набор векторов слов из предварительно обученной модели
- 1Как найти позицию объекта в сериализованном общем списке
- 0Класс элемента не отражается после append ()
- 1Как вызвать исходную функцию JavaScript, которая сначала была переопределена расширением?
- 0Загружая контент в div с помощью jQuery.load (), как я могу заставить новые изображения исчезать при загрузке?
- 0Сессионизация на основе событий, а не временных меток с MySQL
- 1Как смоделировать RestTemplate метод getForObject, используя jmockit?
- 1Java ConcurrentSkipListSet несовместим с документацией
- 0Как привязать угловую директиву с помощью ng-repeat к Owl Carousel
- 0Возвращать переменные на фабриках Angular JS?
- 1Получить средние строки, столбца матрицы из текстового файла
- 0Почему мой процесс останавливается при запуске в фоновом режиме?
- 0Nodejs Sequelize отношения не работают
- 0CSS: всплывающее окно расширения таблицы, даже с установленной шириной / максимальной шириной
- 0Получение информации о состоянии браузера с помощью JQuery
- 1Удалить пробелы из первого и последнего символа в заголовках нескольких размеров
- 1Как исправить ошибку при обновлении targetSdkVersion с версии 25 до 27?
- 1Android обрабатывает все ограничения AlarmManager
- 1Получение определенных элементов после чтения из файла
- 1IEEE 754 с плавающей запятой — почему это работает?
- 0Почему я получаю сообщение об ошибке для последней строки кода?
- 1Получение значений из удаленных строк в сетках данных с использованием winforms
- 1Модель не доступна вне пространства имен
- 0Выходной каталог MSBuild CL Task
- 0отрицательные расстояния с cv :: HoughLines?
- 1Visual Studio Странность Панель инструментов Нажмите Перетащите
- 1Добавление тега метаданных google_analytics_adid_collection_enabled в Cordova AndroidManifest.xml

Время на прочтение
9 мин
Количество просмотров 35K

К старту курса по Fullstack-разработке на Python делимся решениями классической проблемы неточности чисел с плавающей точкой. В материале вы найдёте примеры работы с функциями и классами, предназначенными специально для решения проблем чисел с плавающей точкой.
Числа с плавающей точкой — быстрый и эффективный способ хранения чисел и работы с ними. Но он связан с рядом трудностей для начинающих и опытных программистов! Вот классический пример:
>>> 0.1 + 0.2 == 0.3
FalseВпервые увидев такое, можно растеряться. Такое поведение корректно! Поговорим о том, почему ошибки при операциях над числами с плавающей точкой так распространены, почему они возникают и как с ними справиться в Python.
Компьютер обманывает вас
Вы видели, что 0.1 + 0.2 не равно 0.3, но безумие на этом не заканчивается. Вот ещё пара примеров, сбивающих с толку:
>>> 0.2 + 0.2 + 0.2 == 0.6
False
>>> 1.3 + 2.0 == 3.3
False
>>> 1.2 + 2.4 + 3.6 == 7.2
FalseПроблема касается и сравнения:
>>> 0.1 + 0.2 <= 0.3
False
>>> 10.4 + 20.8 > 31.2
True
>>> 0.8 - 0.1 > 0.7
TrueЧто происходит? Когда вы вводите в интерпретатор Python число 0.1, оно сохраняется в памяти как число с плавающей точкой и происходит преобразование. 0.1 — это десятичное число с основанием 10, но числа с плавающей точкой хранятся в двоичной записи. То есть основание 0.1 преобразуется из 10 в 2.
Получающееся двоичное число может недостаточно точно представлять исходное число с основанием 10. 0.1 — один из примеров. Двоичным представлением будет 0.0(0011). То есть 0.1 — это бесконечно повторяющееся десятичное число, записанное с основанием 2. То же происходит, когда в виде десятичного числа с основанием 10 записывается дробь ⅓. Получается бесконечно повторяющееся десятичное число 0.3(3).
Память компьютера конечна, поэтому бесконечно повторяющееся представление двоичной дроби 0.1 округляется до конечной дроби. Её значение зависит от архитектуры компьютера (32- или 64-разрядная).
Увидеть значение с плавающей точкой, которое сохраняется для 0.1, можно с помощью метода .as_integer_ratio(). Представление с плавающей точкой состоит из числителя и знаменателя:
>>> numerator, denominator = (0.1).as_integer_ratio()
>>> f"0.1 ≈ {numerator} / {denominator}"
'0.1 ≈ 3602879701896397 / 36028797018963968'Чтобы отобразить дробь с точностью до 55 знаков после запятой, используем format():
>>> format(numerator / denominator, ".55f")
'0.1000000000000000055511151231257827021181583404541015625'Так 0.1 округляется до числа чуть больше, чем его истинное значение.
Узнайте больше о числовых методах, подобных .as_integer_ratio(), в моей статье 3 Things You Might Not Know About Numbers in Python («3 факта о числах в Python, которые вы могли не знать»).
Эта ошибка представления чисел с плавающей точкой встречается куда чаще, чем может показаться.
Ошибка представления числа очень типична
Существуют три причины, почему число округляется при его представлении в виде числа с плавающей точкой:
-
В числе больше значащих разрядов, чем позволяет плавающая точка.
-
Это иррациональное число.
-
Число рациональное, но без конечного двоичного представления.
64-разрядные числа с плавающей точкой имеют 16 или 17 значащих разрядов. Любое число, у которого значащих разрядов больше, округляется. Иррациональные числа, такие как π и e, нельзя представить конечной дробью с целочисленным основанием. И, опять же, иррациональные числа в любом случае округляются при сохранении в виде чисел с плавающей точкой.
В этих двух ситуациях создаётся бесконечный набор чисел, которые нельзя точно представить в виде числа с плавающей точкой. Но вы вряд ли столкнётесь с этими проблемами, не будучи химиком, имеющим дело с крошечными числами, или физиком — с астрономически большими числами.
А как на счёт бесконечных рациональных чисел, например 0.1 с основанием 2? Именно здесь вам встретится большинство связанных с плавающей точкой трудностей и благодаря математике — позволяющей определять, конечная дробь или нет, — вы будете сталкиваться с ошибками представления чаще, чем думаете.
С основанием 10 дробь можно представить как конечную, если её знаменатель — произведение степеней простых множителей 10. Два простых множителя 10 — это 2 и 5, поэтому дроби ½, ¼, ⅕, ⅛ и ⅒ — конечные, а ⅓, ⅐ и ⅑ — нет. У основания 2 только один простой множитель — 2.
Конечные дроби здесь только те, знаменатель которых равен степени числа 2. В результате дроби ⅓, ⅕, ⅙, ⅐, ⅑ и ⅒ — бесконечные, когда представлены в двоичной записи.
Теперь наш первый пример должен стать понятнее. 0.1, 0.2 и 0.3 при преобразовании в числа с плавающей точкой округляются:
>>> # -----------vvvv Display with 17 significant digits
>>> format(0.1, ".17g")
'0.10000000000000001'
>>> format(0.2, ".17g")
'0.20000000000000001'
>>> format(0.3, ".17g")
'0.29999999999999999'При сложении 0.1 и 0.2 получается число чуть больше 0.3:
>>> 0.1 + 0.2
0.30000000000000004А поскольку 0.1 + 0.2 чуть больше, чем 0.3, и 0.3 представлено числом, которое чуть меньше 0.3, выражение 0.1 + 0.2 == 0.3 оказывается False.
Об ошибке представления чисел с плавающей точкой должен знать каждый программист на любом языке — и уметь с ней справляться. Она характерна не только для Python. Результат вывода 0.1 + 0.2 на разных языках можно увидеть на сайте с подходящим названием 0.30000000000000004.com.
Как сравнивать числа с плавающей точкой в Python
Как же справляться с ошибками представления чисел с плавающей точкой при сравнении таких чисел в Python? Хитрость заключается в том, чтобы избегать проверки на равенство. Вместо ==, >= или <= всегда используйте с числами с плавающей точкой функцию math.isclose():
>>> import math
>>> math.isclose(0.1 + 0.2, 0.3)
TrueВ math.isclose() проверяется, достаточно ли близок первый аргумент ко второму. То есть проверяется расстояние между двумя аргументами. Оно равно абсолютной величине разницы обоих значений:
>>> a = 0.1 + 0.2
>>> b = 0.3
>>> abs(a - b)
5.551115123125783e-17Если abs(a — b) меньше некоего процента от большего значения a или b, то a считается достаточно близким к b, чтобы считаться «равным» b. Этот процент называется относительной погрешностью и указывается именованным аргументом rel_tol функции math.isclose(), который по умолчанию равен 1e-9.
То есть если abs(a — b) меньше 0.00000001 * max(abs(a), abs(b)), то a и b считаются «близкими» друг к другу. Это гарантирует, что a и b будут приблизительно с девятью знаками после запятой.
Если нужно, можно изменить относительную погрешность:
>>> math.isclose(0.1 + 0.2, 0.3, rel_tol=1e-20)
FalseКонечно, относительная погрешность зависит от ограничений задачи, но для большинства повседневных приложений стандартной относительной погрешности должно быть достаточно. Проблема возникает, если a или b равно нулю, а rel_tol меньше единицы. Тогда, как бы ни было близко ненулевое значение к нулю, относительной погрешностью гарантируется, что проверка на близость будет неудачной. В качестве запасного варианта здесь применяется абсолютная погрешность:
>>> # Relative check fails!
>>> # ---------------vvvv Relative tolerance
>>> # ----------------------vvvvv max(0, 1e-10)
>>> abs(0 - 1e-10) < 1e-9 * 1e-10
False
>>> # Absolute check works!
>>> # ---------------vvvv Absolute tolerance
>>> abs(0 - 1e-10) < 1e-9
TrueВ math.isclose() эта проверка выполняется автоматически. Абсолютная погрешность определяется с помощью именованного аргумента abs_tol. Но abs_tol по умолчанию равен 0.0, поэтому придётся задать его вручную, если нужно проверить близость значения к нулю.
В итоге в функции math.isclose() возвращается результат следующего сравнения — с относительными и абсолютными проверками в одном выражении:
abs(a - b) <= max(rel_tol * max(abs(a), abs(b)), abs_tol)math.isclose() появилась в PEP 485 и доступна с Python 3.5.
Когда стоит использовать math.isclose()?
В целом math.isclose() следует применять, сравнивая значения с плавающей точкой. Заменим == на math.isclose():
>>> # Don't do this:
>>> 0.1 + 0.2 == 0.3
False
>>> # Do this instead:
>>> math.isclose(0.1 + 0.2, 0.3)
TrueСо сравнениями >= и <= нужно быть осторожным. Обработаем равенство отдельно, используя math.isclose(), а затем проверим строгое сравнение:
>>> a, b, c = 0.1, 0.2, 0.3
>>> # Don't do this:
>>> a + b <= c
False
>>> # Do this instead:
>>> math.isclose(a + b, c) or (a + b < c)
TrueЕсть альтернативы math.isclose(). Если вы работаете с NumPy, можете использовать numpy.allclose() и numpy.isclose():
>>> import numpy as np
>>> # Use numpy.allclose() to check if two arrays are equal
>>> # to each other within a tolerance.
>>> np.allclose([1e10, 1e-7], [1.00001e10, 1e-8])
False
>>> np.allclose([1e10, 1e-8], [1.00001e10, 1e-9])
True
>>> # Use numpy.isclose() to check if the elements of two arrays
>>> # are equal to each other within a tolerance
>>> np.isclose([1e10, 1e-7], [1.00001e10, 1e-8])
array([ True, False])
>>> np.isclose([1e10, 1e-8], [1.00001e10, 1e-9])
array([ True, True])Имейте в виду: стандартные относительные и абсолютные погрешности — не то же самое, что math.isclose(). Стандартная относительная погрешность для numpy.allclose() и numpy.isclose() равна 1e-05, а стандартная абсолютная погрешность — 1e-08.
math.isclose() особенно удобна для модульных тестов, хотя и здесь имеются альтернативы. Во встроенном модуле unittest в Python есть метод unittest.TestCase.assertAlmostEqual().
Но в нём применяется только проверка абсолютной разницы. А это ещё и утверждение, то есть при сбоях возникает ошибка AssertionError, из-за которой оно непригодно для сравнений в бизнес-логике.
Отличная альтернатива math.isclose() для модульного тестирования — это функция pytest.approx() из pytest pytest. Как и в math.isclose(), здесь принимаются два аргумента и возвращается, равны они или нет в пределах некой погрешности:
>>> import pytest
>>> 0.1 + 0.2 == pytest.approx(0.3)
TrueКак и в math.isclose(), в pytest.approx() для задания относительной и абсолютной погрешностей есть именованные аргументы rel_tol и abs_tol. Но стандартные значения различаются. У rel_tol оно 1e-6, а у abs_tol — 1e-12.
Если первые переданные в pytest.approx() два аргумента подобны массиву (то есть это итерируемый объект Python, такой же, как список или кортеж или даже массив NumPy), тогда в pytest.approx() поведение подобно numpy.allclose() и возвращается то, равны эти два массива или нет в пределах погрешностей:
>>> import numpy as np
>>> np.array([0.1, 0.2]) + np.array([0.2, 0.4]) == pytest.approx(np.array([0.3, 0.6]))
TrueДля pytest.approx() сгодятся даже значения словаря:
>>> {'a': 0.1 + 0.2, 'b': 0.2 + 0.4} == pytest.approx({'a': 0.3, 'b': 0.6})
TrueЧисла с плавающей точкой отлично подходят для работы с числами, когда абсолютная точность не требуется. Они быстры и эффективны с точки зрения потребления памяти. Но, если точность нужна, стоит рассмотреть ряд альтернатив числам с плавающей точкой.
Точные альтернативы числам с плавающей точкой
В Python есть два встроенных числовых типа, которые обеспечивают полную точность в ситуациях, когда числа с плавающей точкой не подходят: Decimal и Fraction.
Тип Decimal
В типе Decimal могут храниться десятичные значения именно с той точностью, какая нужна. По умолчанию в нём сохраняются 28 значащих цифр (это число можно изменить согласно конкретной решаемой задаче):
>>> # Import the Decimal type from the decimal module
>>> from decimal import Decimal
>>> # Values are represented exactly so no rounding error occurs
>>> Decimal("0.1") + Decimal("0.2") == Decimal("0.3")
True
>>> # By default 28 significant figures are preserved
>>> Decimal(1) / Decimal(7)
Decimal('0.1428571428571428571428571429')
>>> # You can change the significant figures if needed
>>> from decimal import getcontext
>>> getcontext().prec = 6 # Use 6 significant figures
>>> Decimal(1) / Decimal(7)
Decimal('0.142857')Больше узнать о типе Decimal можно в документации Python.
Тип Fraction
Альтернатива числам с плавающей точкой — тип Fraction. В нём могут точно сохраняться рациональные числа. При этом устраняются проблемы с ошибками представления, возникающие в числах с плавающей точкой:
>>> # import the Fraction type from the fractions module
>>> from fractions import Fraction
>>> # Instantiate a Fraction with a numerator and denominator
>>> Fraction(1, 10)
Fraction(1, 10)
>>> # Values are represented exactly so no rounding error occurs
>>> Fraction(1, 10) + Fraction(2, 10) == Fraction(3, 10)
TrueУ типов Fraction и Decimal много преимуществ по сравнению со стандартными значениями с плавающей точкой. Но есть и недостатки: меньшая скорость и повышенное потребление памяти.
Если абсолютная точность не нужна, лучше оставаться с числами с плавающей точкой. А вот в случае с финансовыми и критически важными приложениями эти недостатки типов Fraction и Decimal могут оказаться неприемлемыми.
Заключение
Значения с плавающей точкой — это и благо, и проклятие одновременно. Они обеспечивают быстрые арифметические операции и эффективное потребление памяти за счёт неточного представления. Из этой статьи вы узнали:
-
Почему числа с плавающей точкой неточны.
-
Почему ошибка представления с плавающей точкой типична.
-
Как корректно сравнивать значения с плавающей точкой.
-
Как точно представлять числа, используя типы Fraction и Decimal.
Узнайте о числах в Python ещё больше. Например, знаете ли вы, что int — не единственный целочисленный тип в Python? Узнайте, какой есть ещё, а также о других малоизвестных фактах о числах в моей статье.
А мы поможем вам прокачать скиллы или с самого начала освоить профессию, востребованную в любое время:
-
Профессия Fullstack-разработчик на Python
-
Профессия Data Analyst
Выбрать другую востребованную профессию.

Не удалось применить выборку таблицы.
Выборка не может быть применена к содержимому в представлении таблицы. Подтвердите, что все правки объектов и процессы загрузки данных завершены.
Поля таблицы не найдены.
Схема данных таблицы и данных больше не совпадают. Подтвердите, что все правки схемы завершены.
Ошибка инициализации таблицы.
Произошла внутренняя ошибка при инициализации таблицы, возможно, в указанном программном компоненте. Попробуйте закрыть и открыть приложение.
Встречен недопустимый ID строки.
Представление таблицы не распознает ID строки, скорее всего потому, что в ней значительно больше или меньше строк, чем ожидалось. Подтвердите, что все правки объектов и процессы загрузки данных завершены.
Поле OID таблицы не найдено.
Для представления таблицы необходимо отсутствующее значение уникального идентификатора объекта (OID) для каждой строки. Эта ошибка может возникать с определенными типами данных, особенно из источников, не относящихся к базе данных, таких как текстовые файлы с разделителями-запятыми (.csv). Обновите данные, добавив поле OID или конвертируйте их в другой формат, например, DBF или файловую базу геоданных, которые добавляют поле OID автоматически.
Не удалось получить строку.
Строка из представления таблицы не может быть загружена. Попробуйте закрыть и открыть приложение и убедитесь, что значения данных не повреждены.
Слой или отдельная таблица не найдены.
Слой или отдельная таблица не найдены на текущей карте. Попробуйте закрыть и открыть приложение и убедитесь, что значения данных не повреждены.
Не удалось создать временную таблицу.
Невозможно создать временную таблицу на вашей машине, возможно потому, что закончилось место на диске или нет соответствующих прав. Проверьте доступное дисковое пространство и права, а затем попробуйте снова.
Таблица базы данных для поля не найдена.
Для лучшей поддержки подтипов и доменов в присоединенных таблицах, таблица базы данных ссылается на каждое поле. Не удалось найти таблицу базы данных для поля. Попробуйте закрыть и открыть приложение, или снова создайте соединение.
Таблица базы данных не найдена.
Таблицу базы данных невозможно найти в текущем проекте. Попробуйте закрыть и открыть приложение, не сохраняя проект. Возможно, потребуется заново восстановить ссылки на ресурсы в проекте.
Не удалось создать курсор таблицы.
Произошла ошибка при поиске в базе данных, и курсор не смог выполнить итерацию.
Не удалось создать курсор таблицы.
Произошла ошибка при поиске и базе данных при получении доступа к странице данных.
Поле OID курсора страницы не найдено.
Произошла ошибка после выполнения поиска в базе данных и получении поля OID от страницы курсора.
Не удалось получить страницу строк.
Произошла ошибка при получении страницы строк.
Проект таблицы не найден.
Не найден проект для таблицы. Попробуйте закрыть и открыть приложение.
Сеанс таблицы не найден.
Таблица выполнила запрос после того, как она была закрыта. Попробуйте открыть таблицу и выполнить задачу, которую вы пытались выполнить до появления ошибки.
Не удается создать курсор отсортированной таблицы.
Произошла ошибка при выполнении поиска с сортировкой в базе данных.
[Ошибка базы данных]
Когда происходят ошибки в ядре базы данных, появляются описания этих ошибок. Найдите ошибку по ее номеру в справке, чтобы узнать о возможных решениях.