

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
Расхождения
между величиной какого-либо показателя,
найденного посредством статистического
наблюдения, и действительными его
размерами называются ошибками
наблюдения.В зависимости от
причин возникновения различают ошибки
регистрации и ошибки репрезентативности.
Ошибки
регистрациивозникают в результате
неправильного установления фактов или
ошибочной записи в процессе наблюдения
или опроса. Они бывают случайными или
систематическими. Случайные ошибки
регистрации могут быть допущены как
опрашиваемыми в их ответах, так и
регистраторами. Систематические ошибки
могут быть и преднамеренными, и
непреднамеренными. Преднамеренные –
сознательные, тенденциозные искажения
действительного положения дела.
Непреднамеренные вызываются различными
случайными причинами (небрежность,
невнимательность).
Ошибки
репрезентативности(представительности)
возникают в результате неполного
обследования и в случае, если обследуемая
совокупность недостаточно полно
воспроизводит генеральную совокупность.
Они могут быть случайными и систематическими.
Случайные ошибки репрезентативности
– это отклонения, возникающие при
несплошном наблюдении из-за того, что
совокупность отобранных единиц наблюдения
(выборка) неполно воспроизводит всю
совокупность в целом. Систематические
ошибки репрезентативности – это
отклонения, возникающие вследствие
нарушения принципов случайного отбора
единиц. Ошибки репрезентативности
органически присущи выборочному
наблюдению и возникают в силу того, что
выборочная совокупность не полностью
воспроизводит генеральную. Избежать
ошибок репрезентативности нельзя,
однако, пользуясь методами теории
вероятностей, основанными на использовании
предельных теорем закона больших чисел,
эти ошибки можно свести к минимальным
значениям, границы которых устанавливаются
с достаточно большой точностью.
Ошибки
выборки –разность между
характеристиками выборочной и генеральной
совокупности. Для среднего значения
ошибка будет определяться по формуле
![]()
(7.1)
где
![]()
Величина
![]() называетсяпредельной ошибкойвыборки.
называетсяпредельной ошибкойвыборки.
Предельная
ошибка выборки – величина случайная.
Исследованию закономерностей случайных
ошибок выборки посвящены предельные
теоремы закона больших чисел. Наиболее
полно эти закономерности раскрыты в
теоремах П. Л. Чебышева и А. М. Ляпунова.
Теорему П.
Л. Чебышева применительно к
рассматриваемому методу можно
сформулировать следующим образом: при
достаточно большом числе независимых
наблюдений можно с вероятностью, близкой
к единице (т. е. почти с достоверностью),
утверждать, что отклонение выборочной
средней от генеральной будет сколько
угодно малым. В теореме П. Л. Чебышева
доказано, что величина ошибки не должна
превышать![]() .
.
В свою очередь величина![]() ,
,
выражающая среднее квадратическое
отклонение выборочной средней от
генеральной средней, зависит от
колеблемости признака в генеральной
совокупности![]() и числа отобранных единицn. Эта
и числа отобранных единицn. Эта
зависимость выражается формулой
![]() ,
,
(7.2)
где
![]() зависит также от способа производства
зависит также от способа производства
выборки.
Величину
![]() =
=![]() называютсредней ошибкой выборки. В
называютсредней ошибкой выборки. В
этом выражении![]() – генеральная дисперсия,n– объем
– генеральная дисперсия,n– объем
выборочной совокупности.
Рассмотрим, как
влияет на величину средней ошибки число
отбираемых единиц n. Логически
нетрудно убедиться, что при отборе
большого числа единиц расхождения между
средними будут меньше, т. е. существует
обратная связь между средней ошибкой
выборки и числом отобранных единиц. При
этом здесь образуется не просто обратная
математическая зависимость, а такая
зависимость, которая показывает, что
квадрат расхождения между средними
обратно пропорционален числу отобранных
единиц.
Увеличение
колеблемости признака влечет за собой
увеличение среднего квадратического
отклонения, а следовательно, и ошибки.
Если предположить, что все единицы будут
иметь одинаковую величину признака, то
среднее квадратическое отклонение
станет равно нулю и ошибка выборки
также исчезнет. Тогда нет необходимости
применять выборку. Однако следует иметь
в виду, что величина колеблемости
признака в генеральной совокупности
неизвестна, поскольку неизвестны размеры
единиц в ней. Можно рассчитать лишь
колеблемость признака в выборочной
совокупности. Соотношение между
дисперсиями генеральной и выборочной
совокупности выражается формулой
![]()
Поскольку
величина
![]() при достаточно большихnблизка к
при достаточно большихnблизка к
единице, можно приближенно считать, что
выборочная дисперсия равна генеральной
дисперсии, т. е.![]()
Следовательно,
средняя ошибка выборки показывает,
какие возможны отклонения характеристик
выборочной совокупности от соответствующих
характеристик генеральной совокупности.
Однако о величине этой ошибки можно
судить с определенной вероятностью. На
величину вероятности указывает множитель
![]()
Теорема А.
М. Ляпунова. А. М. Ляпунов доказал,
что распределение выборочных средних
(следовательно, и их отклонений от
генеральной средней) при достаточно
большом числе независимых наблюдений
приближенно нормально при условии, что
генеральная совокупность обладает
конечной средней и ограниченной
дисперсией.
Математически
теорему Ляпуноваможно записать
так:
 (7.3)
(7.3)
где
![]() ,
,
(7.4)
где ![]() – математическая постоянная;
– математическая постоянная;
![]() –предельная ошибка выборки,которая дает возможность выяснить, в
–предельная ошибка выборки,которая дает возможность выяснить, в
каких пределах находится величина
генеральной средней.
Значения этого
интеграла для различных значений
коэффициента доверия tвычислены и
приводятся в специальных математических
таблицах. В частности, при:

Поскольку tуказывает на вероятность расхождения![]() ,
,
т. е. на вероятность того, на какую
величину генеральная средняя будет
отличаться от выборочной средней, то
это может быть прочитано так: с вероятностью
0,683 можно утверждать, что разность между
выборочной и генеральной средними не
превышает одной величины средней ошибки
выборки. Другими словами, в 68,3 % случаев
ошибка репрезентативности не выйдет
за пределы![]() С вероятностью 0,954 можно утверждать,
С вероятностью 0,954 можно утверждать,
что ошибка репрезентативности не
превышает![]() (т. е. в 95 % случаев). С вероятностью
(т. е. в 95 % случаев). С вероятностью
0,997, т. е. довольно близкой к единице,
можно ожидать, что разность между
выборочной и генеральной средней не
превзойдет трехкратной средней ошибки
выборки и т. д.
Логически связь
здесь выглядит довольно ясно: чем больше
пределы, в которых допускается
возможная ошибка, тем с большей
вероятностью судят о ее величине.
Зная выборочную
среднюю величину признака
![]() и предельную ошибку выборки
и предельную ошибку выборки![]() ,
,
можно определить границы (пределы),
в которых заключена генеральная
средняя
![]() (7.5)
(7.5)
1.
Собственно-случайная выборка–
этот способ ориентирован на выборку
единиц из генеральной совокупности без
всякого расчленения на части или группы.
При этом для соблюдения основного
принципа выборки – равной возможности
всем единицам генеральной совокупности
быть отобранным – используются схема
случайного извлечения единиц путем
жеребьевки (лотереи) или таблицы случайных
чисел. Возможен повторный и бесповторный
отбор единиц
Средняя ошибка
собственно-случайной выборки
представляет собой среднеквадратическое
отклонение возможных значений выборочной
средней от генеральной средней. Средние
ошибки выборки при собственно-случайном
методе отбора представлены в табл. 7.2.
Таблица 7.2
|
Средняя ошибка |
При отборе |
|
|
повторном |
бесповторном |
|
|
Для средней |
|
|
|
Для доли |
|
|

В таблице
использованы следующие обозначения:
![]() – дисперсия выборочной совокупности;
– дисперсия выборочной совокупности;
![]() – численность выборки;
– численность выборки;
![]() – численность генеральной совокупности;
– численность генеральной совокупности;
![]() – выборочная доля единиц, обладающих
– выборочная доля единиц, обладающих
изучаемым признаком;
![]() – число единиц, обладающих изучаемым
– число единиц, обладающих изучаемым
признаком;
![]() – численность выборки.
– численность выборки.
Для увеличения
точности вместо множителя
![]() следует
следует
брать множитель
![]() ,
,
но при большой численностиNразличие
между этими выражениями практического
значения не имеет.
Предельная
ошибка собственно-случайной выборки
![]() рассчитывается по формуле
рассчитывается по формуле
![]() ,
,
(7.6)
где t
– коэффициент доверия зависит от
значения вероятности.
Пример.При
обследовании ста образцов изделий,
отобранных из партии в случайном порядке,
20 оказалось нестандартными. С вероятностью
0,954 определите пределы, в которых
находится доля нестандартной продукции
в партии.
Решение.
Вычислим генеральную долю (Р):
![]() .
.
Доля нестандартной
продукции:
 .
.
Предельная
ошибка выборочной доли с вероятностью
0,954 рассчитывается по формуле (7.6) с
применением формулы табл. 7.2 для доли:

![]()
С вероятностью
0,954 можно утверждать, что доля нестандартной
продукции в партии товара находится в
пределах 12 % ≤ P≤ 28 %.
В практике
проектирования выборочного наблюдения
возникает потребность определения
численности выборки, которая необходима
для обеспечения определенной точности
расчета генеральных средних. Предельная
ошибка выборки и ее вероятность при
этом являются заданными. Из формулы
![]() и формул средних ошибок выборки
и формул средних ошибок выборки
устанавливается необходимая численность
выборки. Формулы для определения
численности выборки (n) зависят от
способа отбора. Расчет численности
выборки для собственно-случайной выборки
приведен в табл. 7.3.
Таблица 7.3
|
Предполагаемый |
Формулы |
|
|
для средней |
для доли |
|
|
Повторный |
|
|
|
Бесповторный |
|
|



2.
Механическая выборка– при этом
методе исходят из учета некоторых
особенностей расположения объектов в
генеральной совокупности, их упорядоченности
(по списку, номеру, алфавиту). Механическая
выборка осуществляется путем отбора
отдельных объектов генеральной
совокупности через определенный интервал
(каждый 10-й или 20-й). Интервал рассчитывается
по отношению![]() ,
,
гдеn– численность выборки,N–
численность генеральной совокупности.
Так, если из совокупности в 500 000 единиц
предполагается получить 2 %-ную выборку,
т. е. отобрать 10 000
единиц, то пропорция отбора составит![]() Отбор
Отбор
единиц осуществляется в соответствии
с установленной пропорцией через равные
интервалы. Если расположение объектов
в генеральной совокупности носит
случайный характер, то механическая
выборка по содержанию аналогична
случайному отбору. При механическом
отборе применяется только бесповторная
выборка [1, 5–10].
Средняя ошибка
и численность выборки при механическом
отборе подсчитывается по формулам
собственно-случайной выборки (см.
табл. 7.2 и 7.3).
3.
Типическая выборка, при котрой
генеральная совокупность делится по
некоторым существенным признакам на
типические группы; отбор единиц
производится из типических групп. При
этом способе отбора генеральная
совокупность расчленяется на однородные
в некотором отношении группы, которые
имеют свои характеристики, и вопрос
сводится к определению объема выборок
из каждой группы. Может бытьравномерная
выборка– при этом способе из каждой
типической группы отбирается одинаковое
число единиц![]() Такой подход оправдан лишь при равенстве
Такой подход оправдан лишь при равенстве
численностей исходных типических групп.
При типическом отборе, непропорциональном
объему групп, общее число отбираемых
единиц делится на число типических
групп, полученная величина дает
численность отбора из каждой типической
группы.
Более совершенной
формой отбора является пропорциональная
выборка. Пропорциональной называется
такая схема формирования выборочной
совокупности, когда численность выборок,
взятых из каждой типической группы в
генеральной совокупности, пропорциональна
численностям, дисперсиям (или комбинированно
и численностям, и дисперсиям). Условно
определяем численность выборки в 100
единиц и отбираем единицы из групп:
– пропорционально
численности их генеральной совокупности
(табл. 7.4). В таблице
обозначено:
Ni– численность типической группы;
dj
– доля (Ni/N);
N– численность
генеральной совокупности;
ni– численность выборки из типической
группы вычисляется:
![]() , (7.7)
, (7.7)
n – численность выборки из генеральной
совокупности.
Таблица
7.4
-
Группы
Ni
dj
ni
1
300
0,3
30
2
500
0,5
50
3
200
0,2
20
1000
1,0
100
–
пропорционально среднему квадратическому
отклонению(табл. 7.5).
здесь
i– среднее
квадратическое отклонение типических
групп;
ni
– численность выборки из типической
группы вычисляется по формуле

(7.8)
Таблица
7.5
-
Ni
i

ni
300
5
0,25
25
500
7
0,35
35
200
8
0,40
40
1000
20
1,0
100
–
комбинированно (табл. 7.6).
Численность
выборки вычисляется по формуле
![]() . (7.9)
. (7.9)
Таблица 7.6
-

i
iNi


300
5
1500
0,23
23
500
7
2100
0,53
53
200
8
1600
0.24
24
1000
20
6600
1,0
100
При проведении
типической выборки непосредственный
отбор из каждой группы проводится
методом случайного отбора.
Средние ошибки
выборки рассчитываются по формулам
табл. 7.7 в зависимости от способа отбора
из типических групп.
Таблица 7.7
|
Способ |
Повторный |
Бесповторный |
||
|
для |
для |
для |
для |
|
|
Непропорциональный |
|
|
|
|
|
Пропорциональный объему групп |
|
|
|
|
|
Пропорциональный |
|
|
|
|





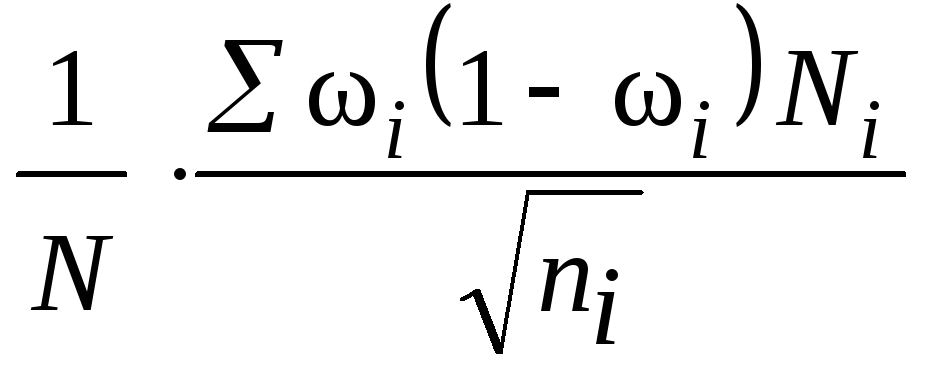


здесь
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
типических групп;
![]() – доля единиц, обладающих изучаемым
– доля единиц, обладающих изучаемым
признаком;
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
для доли;
![]() – среднее квадратическое отклонение
– среднее квадратическое отклонение
в выборке изi-й типической группы;
![]() – объем выборки из типической группы;
– объем выборки из типической группы;
![]() – общий объем выборки;
– общий объем выборки;
![]() –
–
объем типической группы;
![]() – объем генеральной совокупности.
– объем генеральной совокупности.
Численность
выборки из каждой типической группы
должна быть пропорциональна среднему
квадратическому отклонению в этой
группе
![]() .Расчет численности
.Расчет численности
![]() производится по формулам, приведенным
производится по формулам, приведенным
в табл. 7.8.
Таблица 7.8
|
Повторный |
Бесповторный |
|
|
Для определения |
|
|
|
Для определения |
|
|
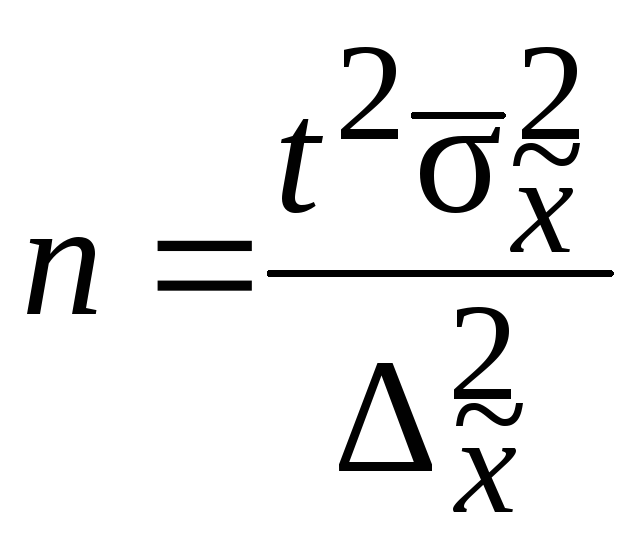

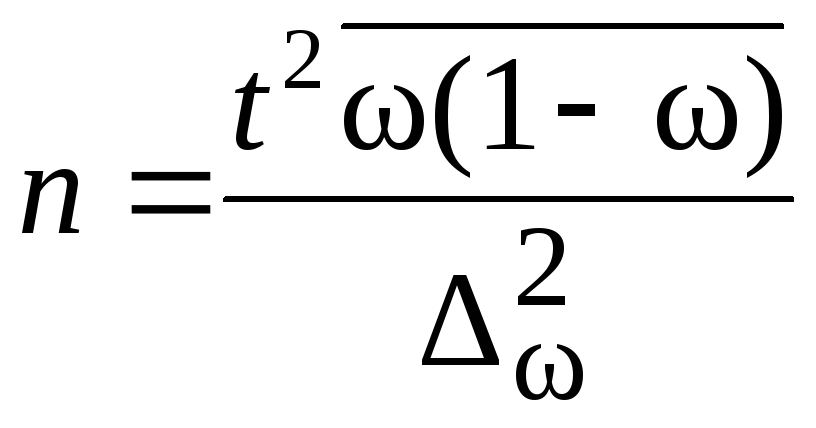

4. Серийная
выборка– удобена в тех случаях,
когда единицы совокупности объединены
в небольшие группы или серии. При серийной
выборке генеральную совокупность делят
на одинаковые по объему группы – серии.
В выборочную совокупность отбираются
серии. Сущность серийной выборки
заключается в случайном или механическом
отборе серий, внутри которых производится
сплошное обследование единиц. Средняя
ошибка серийной выборки с равновеликими
сериями зависит от величины только
межгрупповой дисперсии. Средние ошибки
сведены в табл. 7.9.
Таблица 7.9
|
Способ |
Формулы |
|
|
для |
для |
|
|
Повторный |
|
|
|
Бесповторный |
|
|


Здесь
R– число серий в генеральной
совокупности;
r – число
отобранных серий;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
средних;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
доли.
При серийном
отборе необходимую численность отбираемых
серий определяют так же, как и при
собственно-случайном методе отбора.
Расчет численности
серийной выборки производится по
формулам, приведенным в табл. 7.10.
Таблица 7.10
|
Повторный |
Бесповторный |
|
|
Для |
|
|
|
Для |
|
|
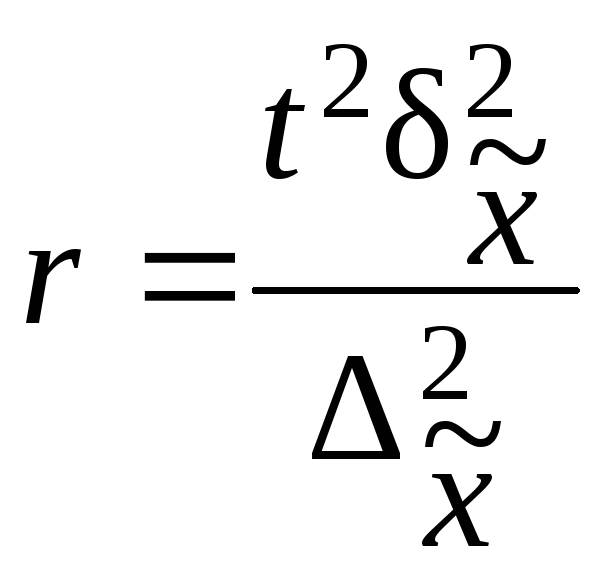

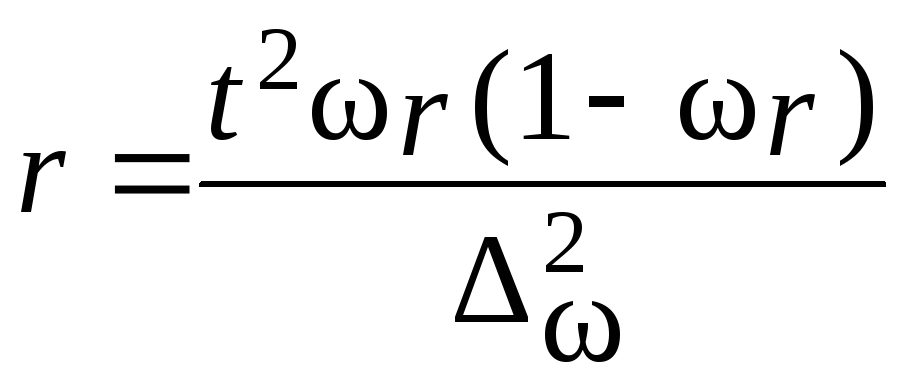

Пример.В
механическом цехе завода в десяти
бригадах работает 100 рабочих. В целях
изучения квалификации рабочих была
произведена 20 %-ная серийная бесповторная
выборка, в которую вошли две бригады.
Получено следующее распределение
обследованных рабочих по разрядам:
|
Рабочие |
Разряды рабочих |
Разряды рабочих |
Рабочие |
Разряды |
Разряды |
|
1 2 3 4 5 |
2 4 5 2 5 |
3 6 1 5 3 |
6 7 8 9 10 |
6 5 8 4 5 |
4 2 1 3 2 |
Необходимо
определить с вероятностью 0,997 пределы,
в которых находится средний разряд
рабочих механического цеха.
Решение.
Определим выборочные средние по
бригадам и общую среднюю как среднюю
взвешенную из групповых средних:

Определим
межсерийную дисперсию по формулам
(5.25):
![]()
Рассчитаем
среднюю ошибку выборки по формуле табл.
7.9:
![]()
Вычислим
предельную ошибку выборки с вероятностью
0,997:
![]()
С вероятностью
0,997 можно утверждать, что средний разряд
рабочих механического цеха находится
в пределах
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
In statistics, sampling errors are incurred when the statistical characteristics of a population are estimated from a subset, or sample, of that population. Since the sample does not include all members of the population, statistics of the sample (often known as estimators), such as means and quartiles, generally differ from the statistics of the entire population (known as parameters). The difference between the sample statistic and population parameter is considered the sampling error.[1] For example, if one measures the height of a thousand individuals from a population of one million, the average height of the thousand is typically not the same as the average height of all one million people in the country.
Since sampling is almost always done to estimate population parameters that are unknown, by definition exact measurement of the sampling errors will not be possible; however they can often be estimated, either by general methods such as bootstrapping, or by specific methods incorporating some assumptions (or guesses) regarding the true population distribution and parameters thereof.
Description[edit]
Sampling Error[edit]
The sampling error is the error caused by observing a sample instead of the whole population.[1] The sampling error is the difference between a sample statistic used to estimate a population parameter and the actual but unknown value of the parameter.[2]
Effective Sampling[edit]
In statistics, a truly random sample means selecting individuals from a population with an equivalent probability; in other words, picking individuals from a group without bias. Failing to do this correctly will result in a sampling bias, which can dramatically increase the sample error in a systematic way. For example, attempting to measure the average height of the entire human population of the Earth, but measuring a sample only from one country, could result in a large over- or under-estimation. In reality, obtaining an unbiased sample can be difficult as many parameters (in this example, country, age, gender, and so on) may strongly bias the estimator and it must be ensured that none of these factors play a part in the selection process.
Even in a perfectly non-biased sample, the sample error will still exist due to the remaining statistical component; consider that measuring only two or three individuals and taking the average would produce a wildly varying result each time. The likely size of the sampling error can generally be reduced by taking a larger sample.[3]
Sample Size Determination[edit]
The cost of increasing a sample size may be prohibitive in reality. Since the sample error can often be estimated beforehand as a function of the sample size, various methods of sample size determination are used to weigh the predicted accuracy of an estimator against the predicted cost of taking a larger sample.
Bootstrapping and Standard Error[edit]
As discussed, a sample statistic, such as an average or percentage, will generally be subject to sample-to-sample variation.[1] By comparing many samples, or splitting a larger sample up into smaller ones (potentially with overlap), the spread of the resulting sample statistics can be used to estimate the standard error on the sample.
In Genetics[edit]
The term «sampling error» has also been used in a related but fundamentally different sense in the field of genetics; for example in the bottleneck effect or founder effect, when natural disasters or migrations dramatically reduce the size of a population, resulting in a smaller population that may or may not fairly represent the original one. This is a source of genetic drift, as certain alleles become more or less common), and has been referred to as «sampling error»,[4] despite not being an «error» in the statistical sense.
See also[edit]
- Margin of error
- Propagation of uncertainty
- Ratio estimator
- Sampling (statistics)
References[edit]
- ^ a b c Sarndal, Swenson, and Wretman (1992), Model Assisted Survey Sampling, Springer-Verlag, ISBN 0-387-40620-4
- ^ Burns, N.; Grove, S. K. (2009). The Practice of Nursing Research: Appraisal, Synthesis, and Generation of Evidence (6th ed.). St. Louis, MO: Saunders Elsevier. ISBN 978-1-4557-0736-2.
- ^ Scheuren, Fritz (2005). «What is a Margin of Error?». What is a Survey? (PDF). Washington, D.C.: American Statistical Association. Archived from the original (PDF) on 2013-03-12. Retrieved 2008-01-08.
- ^ Campbell, Neil A.; Reece, Jane B. (2002). Biology. Benjamin Cummings. pp. 450–451. ISBN 0-536-68045-0.
Ошибка выборки — определение, типы, контроль и уменьшение ошибок
Опубликовано 2023-02-11 19:54 пользователем

Что такое ошибка выборки?
Ошибка выборки возникает, когда выборка, используемая в исследовании, не является репрезентативной для всей популяции. Ошибки выборки случаются часто, поэтому исследователи всегда рассчитывают предел ошибки при получении окончательных результатов в качестве статистической практики. Предел погрешности — это величина погрешности, допустимая при неправильном расчете, представляющая собой разницу между выборкой и реальной популяцией.
Выберите своих респондентов
Каковы наиболее распространенные ошибки выборки в маркетинговых исследованиях?
Вот четыре основные ошибки маркетинговых исследований при составлении выборки:
- Ошибка спецификации популяции: Ошибка спецификации популяции возникает, когда исследователи не знают, кого именно нужно опросить. Например, представьте себе исследование, посвященное детской одежде. Кого нужно опросить? Это могут быть оба родителя, только мать или ребенок. Родители принимают решение о покупке, но дети могут повлиять на их выбор.
- Ошибка выборочной совокупности: Ошибки выборочной совокупности возникают, когда исследователи неправильно ориентируются на субпопуляцию при отборе выборки. Например, выборка из телефонного справочника может иметь ошибочные включения, поскольку люди меняют свои города. Ошибочные исключения происходят, когда люди предпочитают не указывать свои номера. Богатые домохозяйства могут иметь более одного подключения, что приводит к многократным включениям.
- Ошибка отбора: Ошибка отбора происходит, когда респонденты сами выбирают себя для участия в исследовании. Отвечают только те, кто заинтересован. Ошибки отбора можно контролировать, если сделать дополнительный шаг и запросить ответы у всей выборки. Планирование перед опросом, последующие действия и аккуратный и чистый дизайн опроса повысят процент участия респондентов. Кроме того, попробуйте такие методы, как CATI-опросы и личные интервью, чтобы максимизировать количество ответов.
- Ошибки выборки: Ошибки выборки возникают из-за неравномерной репрезентативности респондентов. В основном это происходит, когда исследователь не планирует тщательно свою выборку. Эти ошибки выборки можно контролировать и устранять, создавая тщательный план выборки, имея достаточно большую выборку, отражающую все население, или используя для сбора ответов онлайн-выборку или аудиторию опроса.
Контроль ошибки выборки
Статистические теории помогают исследователям измерить вероятность ошибки выборки в зависимости от размера выборки и населения. Размер выборки, рассматриваемой из совокупности, в первую очередь определяет размер ошибки выборки. При больших размерах выборки вероятность ошибки ниже. Для понимания и оценки погрешности исследователи используют метрику, известную как предел погрешности. Обычно желаемым уровнем достоверности считается уровень достоверности в 95%.
Про совет: Если вам нужна помощь в расчете собственного предела погрешности, вы можете воспользоваться нашим калькулятором предела погрешности.
Каковы шаги по сокращению ошибок выборки?
Ошибки выборки легко выявить. Вот несколько простых шагов по уменьшению ошибки выборки:
- Увеличение размера выборки: Больший размер выборки дает более точный результат, поскольку исследование приближается к реальному размеру популяции.
- Разделение популяции на группы: Тестируйте группы в соответствии с их размером в популяции вместо случайной выборки. Например, если люди определенной демографической группы составляют 20% населения, убедитесь, что ваше исследование состоит из этой переменной, чтобы уменьшить смещение выборки.
- Знать свое население: Изучите свое население и поймите его демографический состав. Знайте, какие демографические группы используют ваш продукт и услугу, и убедитесь, что вы нацелены только на ту выборку, которая имеет значение.
Мы также создали инструмент, который поможет вам легко определить вашу выборку: Калькулятор размера выборки.
Ошибка выборки поддается измерению, и исследователи могут использовать ее в своих интересах, чтобы оценить точность своих выводов и оценить дисперсию.
Рубрика:
- Бизнес
Ключевые слова:
- аудитория
Автор:
- Dan Fleetwood
Источник:
- questionpro
Перевод:
- Дмитрий Л
11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ( ).
).
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
 — при оценивании среднего значения признака;
— при оценивании среднего значения признака;
 — если признак альтернативный, и оценивается доля.
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
 — для среднего значения признака;
— для среднего значения признака;
 — для доли.
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки ( ) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
 .
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
Таблица
11.2.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:

Итак, определение границ генеральной средней и доли состоит из следующих этапов:
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
Таблица
11.3.
Формулы для расчета средней ошибки собственно случайной и механической выборки ()
 |
|
где |
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
Таблица
11.4.
| Уровень фондоотдачи, руб. | До 1,4 | 1,4-1,6 | 1,6-1,8 | 1,8-2,0 | 2,0-2,2 | 2,2 и выше | Итого |
|---|---|---|---|---|---|---|---|
| Количество предприятий | 13 | 15 | 17 | 15 | 16 | 14 | 90 |
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
Таблица
11.5.
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xixb4 | xixb4fi | xixb42fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная средняя

Выборочная дисперсия изучаемого признака

- Определяем среднюю ошибку повторной случайной выборки

- Зададим вероятность, на уровне которой будем говорить о величине предельной ошибки выборки. Чаще всего она принимается равной 0,999; 0,997; 0,954.

Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
- Предельная ошибка выборки с вероятностью 0,954 равна
- Найдем доверительные границы для среднего значения уровня фондоотдачи в генеральной совокупности


Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле

Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:

Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:

Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
 ;
;
- средняя ошибка выборки при использовании повторной схемы отбора составит

Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит

- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):

- установим границы для генеральной доли с вероятностью 0,997:

Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N1 + N2 + … + Ni + … + Nk = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n1 + n2 + … + ni + … + nk = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = ni · Ni/N
где ni — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.
Таблица
11.6.
Формулы для расчета средней ошибки выборки ( ) при использовании типического отбора, пропорционального объему типических групп
) при использовании типического отбора, пропорционального объему типических групп

Здесь  — средняя из групповых дисперсий типических групп.
— средняя из групповых дисперсий типических групп.
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
Таблица
11.7.
| Номер курса | Всего студентов, чел., Ni | Обследовано в результате выборочного наблюдения, чел., ni | Среднее число посещений библиотеки одним студентом за семестр, xi | Внутригрупповая выборочная дисперсия,  |
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности:
n = 2550/130*5 =128 (чел.);
- количество единиц, отобранных из каждой типической группы:

аналогично для других групп:
n2 = 31 (чел.);
n3 = 29 (чел.);
n4 = 18 (чел.);
n5 = 17 (чел.).
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:
- Средняя из внутригрупповых дисперсий
- Средняя ошибка выборки:
С вероятностью 0,954 находим предельную ошибку выборки:
- Доверительные границы для среднего значения признака в генеральной совокупности:





Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
- Малая выборка. В связи с небольшим объемом выборочной совокупности те формулы для определения ошибок выборки, которые использовались нами ранее при «больших» выборках, становятся неподходящими и требуют корректировки.
Среднюю ошибку малой выборки определяют по формуле

Предельная ошибка малой выборки:

Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
- Среднее значение признака в выборке равно
- Значение среднего квадратического отклонения составляет
- Средняя ошибка выборки:
- Значение коэффициента доверия t = 2,365 для п = 8 и Р = 0,95 .
- Предельная ошибка выборки:
- Доверительный интервал для среднего значения признака в генеральной совокупности:





То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч.
11.2.2. Определение численности выборочной совокупности
Перед непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
- вид предполагаемой выборки;
- способ отбора (повторный или бесповторный);
- выбор оцениваемого параметра (среднего значения признака или доли).
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
Таблица
11.8.
Формулы для определения численности выборочной совокупности

Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить

При бесповторном случайном отборе потребуется проверить

Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.

Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.
Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!
Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:
где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).
Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
ШПАРГАЛКА (скопируйте ссылку или текст)
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:
Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)
где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.
Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).
Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.
Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.
При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет