
Отладка, или debugging, — это поиск (локализация), анализ и устранение ошибок в программном обеспечении, которые были найдены во время тестирования.
Виды ошибок
Ошибки компиляции
Это простые ошибки, которые в компилируемых языках программирования выявляет компилятор (программа, которая преобразует текст на языке программирования в набор машинных кодов). Если компилятор показывает несколько ошибок, отладку кода начинают с исправления самой первой, так как она может быть причиной других.
В интерпретируемых языках (например Python) текст программы команда за командой переводится в машинный код и сразу исполняется. К моменту обнаружения ошибки часть программы уже может исполниться.
Ошибки компоновки
Ошибки связаны с разрешением внешних ссылок. Выявляет компоновщик (редактор связей) при объединении модулей программы. Простой пример — ситуация, когда требуется обращение к подпрограмме другого модуля, но при компоновке она не найдена. Ошибки также просто найти и устранить.
Ошибки выполнения (RUNTIME Error)
Ошибки, которые обнаруживают операционная система, аппаратные средства или пользователи при выполнении программы. Они считаются непредсказуемыми и проявляются после успешной компиляции и компоновки. Можно выделить четыре вида проявления таких ошибок:
- сообщение об ошибке, которую зафиксировали схемы контроля машинных команд. Это может быть переполнение разрядной сетки (когда старшие разряды результата операции не помещаются в выделенной области памяти), «деление на ноль», нарушение адресации и другие;
- сообщение об ошибке, которую зафиксировала операционная система. Она же, как правило, и документирует ошибку. Это нарушение защиты памяти, отсутствие файла с заданным именем, попытка записи на устройство, защищенное от записи;
- прекращение работы компьютера или зависание. Это и простые ошибки, которые не требуют перезагрузки компьютера, и более сложные, когда нужно выключать ПК;
- получение результатов, которые отличаются от ожидаемых. Программа работает стабильно, но выдает некорректный результат, который пользователь воспринимает за истину.
Ошибки выполнения можно разделить на три большие группы.
Ошибки определения данных или неверное определение исходных данных. Они могут появиться во время выполнения операций ввода-вывода.
К ним относятся:
- ошибки преобразования;
- ошибки данных;
- ошибки перезаписи.
Как правило, использование специальных технических средств для отладки (API-логгеров, логов операционной системы, профилировщиков и пр.) и программирование с защитой от ошибок помогает обнаружить и решить лишь часть из них.
Логические ошибки. Они могут возникать из ошибок, которые были допущены при выборе методов, разработке алгоритмов, определении структуры данных, кодировании модуля.
В эту группу входят:
- ошибки некорректного использования переменных. Сюда относятся неправильный выбор типов данных, использование индексов, выходящих за пределы определения массивов, использование переменных до присвоения переменной начального значения, нарушения соответствия типов данных;
- ошибки вычислений. Это некорректная работа с переменными, неправильное преобразование типов данных в процессе вычислений;
- ошибки взаимодействия модулей или межмодульного интерфейса. Это нарушение типов и последовательности при передаче параметров, области действия локальных и глобальных переменных, несоблюдение единства единиц измерения формальных и фактических параметров;
- неправильная реализация логики при программировании.
Ошибки накопления погрешностей. Могут возникать при неправильном округлении, игнорировании ограничений разрядной сетки, использовании приближенных методов вычислений и т.д.
Методы отладки программного обеспечения
Метод ручного тестирования
Отладка программы заключается в тестировании вручную с помощью тестового набора, при работе с которым была допущена ошибка. Несмотря на эффективность, метод не получится использовать для больших программ или программ со сложными вычислениями. Ручное тестирование применяется как составная часть других методов отладки.
Метод индукции
В основе отладки системы — тщательный анализ проявлений ошибки. Это могут быть сообщения об ошибке или неверные результаты вычислений. Например, если во время выполнения программы завис компьютер, то, чтобы найти фрагмент проявления ошибки, нужно проанализировать последние действия пользователя. На этапе отладки программы строятся гипотезы, каждая из них проверяется. Если гипотеза подтвердилась, информация об ошибке детализируется, если нет — выдвигаются новые.
Вот как выглядит процесс:
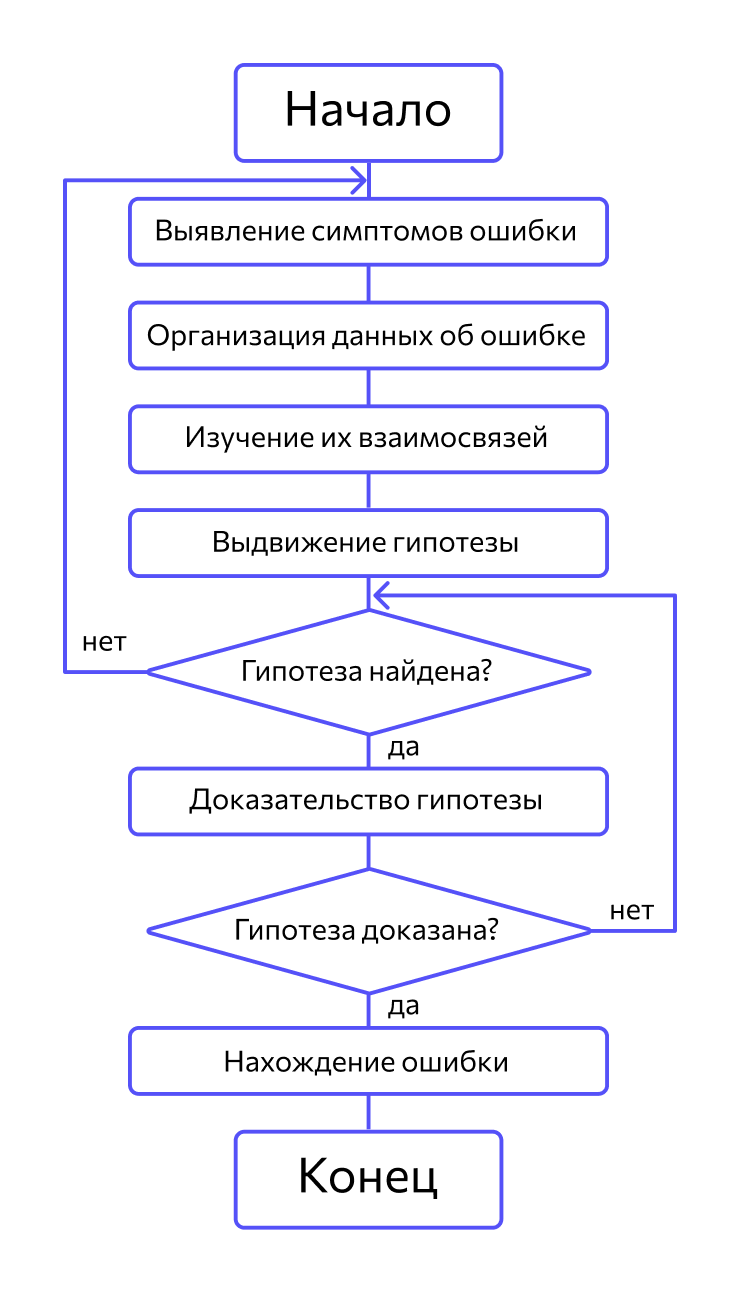
Важно, чтобы выдвинутая гипотеза объясняла все проявления ошибки. Если объясняется только их часть, то либо гипотеза неверна, либо ошибок несколько.
Метод дедукции
Сначала специалисты предлагают множество причин, по которым могла возникнуть ошибка. Затем анализируют их, исключают противоречащие имеющимся данным. Если все причины были исключены, проводят дополнительное тестирование. В обратном случае наиболее вероятную причину пытаются доказать.
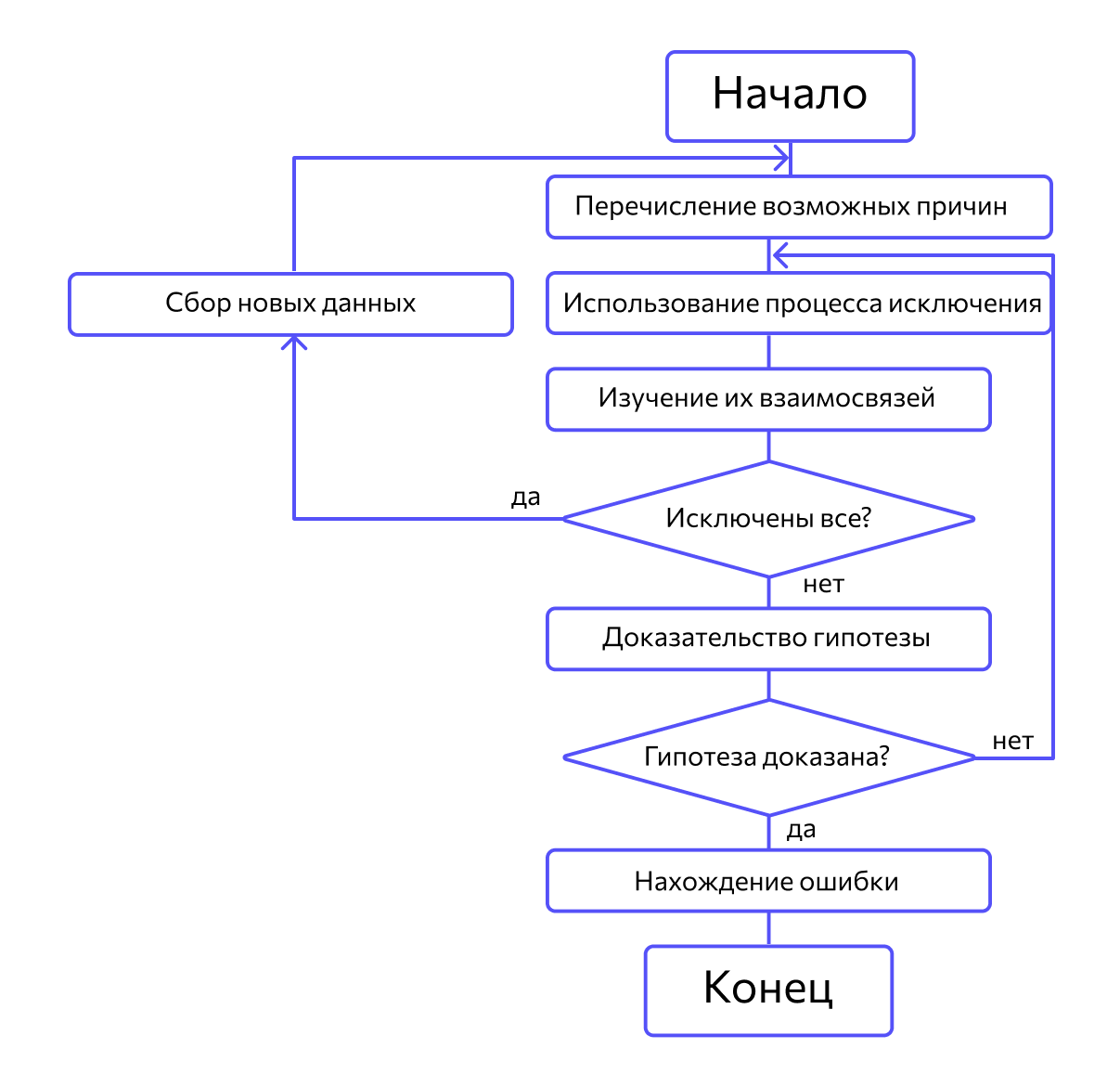
Метод обратного прослеживания
Эффективен для небольших программ. Начинается с точки вывода неправильного результата. Для точки выдвигается гипотеза о значениях основных переменных, которые могли привести к ошибке. Далее на основании этой гипотезы строятся предположения о значениях переменных в предыдущей точке. Процесс продолжается до момента, пока не найдут ошибку.
Как выполняется отладка в современных IDE
Ранние отладчики, например gdb, представляли собой отдельные программы с интерфейсами командной строки. Более поздние, например первые версии Turbo Debugger, были автономными, но имели собственный графический интерфейс для облегчения работы. Сейчас большинство IDE имеют встроенный отладчик. Он использует такой же интерфейс, как и редактор кода, поэтому можно выполнять отладку в той же среде, которая используется для написания кода.
Отладчик позволяет разработчику контролировать выполнение и проверять (или изменять) состояние программ. Например, можно использовать отладчик для построчного выполнения программы, проверяя по ходу значения переменных. Сравнение фактических и ожидаемых значений переменных или наблюдение за ходом выполнения кода может помочь в отслеживании логических (семантических) ошибок.
Пошаговое выполнение — это набор связанных функций отладчика, позволяющих поэтапно выполнять код.
Шаг с заходом (step into)
Команда выполняет очередную инструкцию, а потом приостанавливает процесс, чтобы с помощью отладчика было можно проверить состояние программы. Если в выполняемом операторе есть вызов функции, step into заставляет программу переходить в начало вызываемой функции, где она приостанавливается.
Шаг с обходом (step over)
Команда также выполняет очередную инструкцию. Однако когда step into будет входить в вызовы функций и выполнять их строка за строкой, step over выполнит всю функцию, не останавливаясь, и вернет управление после ее выполнения. Команда step over позволяет пропустить функции, если разработчик уверен, что они уже исправлены, или не заинтересован в их отладке в данный момент.
Шаг с выходом (step out)
В отличие от step into и step over, step out выполняет не следующую строку кода, а весь оставшийся код функции, исполняемой в настоящее время. После возврата из функции он возвращает управление разработчику. Эта команда полезна, когда специалист случайно вошел в функцию, которую не нужно отлаживать.
Как правило, при пошаговом выполнении можно идти только вперед. Поэтому легко перешагнуть место, которое нужно проверить. Если это произошло, необходимо перезапустить отладку.
У некоторых отладчиков (таких как GDB 7.0, Visual Studio Enterprise Edition 15.5 и более поздних версий) есть возможность вернуться на шаг назад. Это полезно, если пропущена цель либо нужно повторно проверить выполненную инструкцию.
-
Отладка по – классификация ошибок: ошибки компиляции, компоновки, выполнения; причины ошибок выполнения.
Отладка-это
процесс локализации и исправления
ошибок, обнаруженных при тестировании
программного обеспечения. Локализацией
называют
процесс определения оператора программы,
выполнение которого вызвало нарушение
нормального вычислительного процесса.
До исправления ошибки необходимо
определить ее причину,
т. е. определить оператор или фрагмент,
содержащие ошибку. Причины ошибок могут
быть как очевидны, так и очень глубоко
скрыты.
В целом сложность
отладки обусловлена следующими причинами:
• требует от
программиста глубоких знаний специфики
управления используемыми техническими
средствами, операционной системы, среды
и языка программирования, реализуемых
процессов, природы и специфики различных
ошибок, методик отладки и соответствующих
программных средств;
• психологически
дискомфортна, так как необходимо искать
собственные ошибки и, как правило, в
условиях ограниченного времени;
• возможно
взаимовлияние ошибок в разных частях
программы, например, за счет затирания
области памяти одного модуля другим
из-за ошибок адресации;
• отсутствуют
четко сформулированные методики отладки.
В соответствии с
этапом обработки, на котором проявляются
ошибки, различаю:
• синтаксические
ошибки —
ошибки, фиксируемые компилятором
(транслятором, интерпретатором) при
выполнении синтаксического и частично
семантического анализа программы;
•ошибки компоновки
— ошибки,
обнаруженные компоновщиком (редактором
связей) при объединении модулей программы;
•ошибки выполнения
— ошибки,
обнаруженные операционной системой,
аппаратными средствами или пользователем
при выполнении программы.
Синтаксические
ошибки. Синтаксические
ошибки относят к группе самых простых,
так как синтаксис языка, как правило,
строго формализован, и ошибки сопровождаются
развернутым комментарием с указанием
ее местоположения. Определение причин
таких ошибок, как правило, труда не
составляет, и даже при нечетком знании
правил языка за несколько прогонов
удается удалить все ошибки данного
типа.
Следует иметь в
виду, что чем лучше формализованы правила
синтаксиса языка, тем больше ошибок из
общего количества может обнаружить
компилятор и, соответственно, меньше
ошибок будет обнаруживаться на следующих
этапах. В связи с этим говорят о языках
программирования с защищенным синтаксисом
и с незащищенным синтаксисом. К первым,
безусловно, можно отнести Pascal, имеющий
очень простой и четко определенный
синтаксис, хорошо проверяемый при
компиляции программы, ко вторым — Си со
всеми его модификациями. Чего стоит
хотя бы возможность выполнения
присваивания в условном операторе в
Си, например: if (c = n) x = 0; /* в данном случае
не проверятся равенство с и n, а выполняется
присваивание с значения n, после чего
результат операции сравнивается с
нулем, если программист хотел выполнить
не присваивание, а сравнение, то эта
ошибка будет обнаружена только на этапе
выполнения при получении результатов,
отличающихся от ожидаемых */
Ошибки компоновки.
Ошибки
компоновки, как следует из названия,
связаны с проблемами,
обнаруженными при
разрешении внешних ссылок. Например,
предусмотрено обращение к подпрограмме
другого модуля, а при объединении модулей
данная подпрограмма не найдена или не
стыкуются списки параметров. В большинстве
случаев ошибки такого рода также удается
быстро локализовать и устранить.
Ошибки выполнения.
К самой
непредсказуемой группе относятся ошибки
выполнения. Прежде всего они могут иметь
разную природу, и соответственно
по-разному проявляться. Часть ошибок
обнаруживается и документируется
операционной системой. Выделяют четыре
способа проявления таких ошибок:
• появление
сообщения об ошибке, зафиксированной
схемами контроля выполнения машинных
команд, например, переполнении разрядной
сетки, ситуации «деление на ноль»,
нарушении адресации и т. п.;
• появление
сообщения об ошибке, обнаруженной
операционной системой, например,
нарушении защиты памяти, попытке записи
на устройства, защищенные от записи,
отсутствии файла с заданным именем и
т. п.;
• «зависание»
компьютера, как простое, когда удается
завершить программу без перезагрузки
операционной системы, так и «тяжелое»,
когда для продолжения работы необходима
перезагрузка;
• несовпадение
полученных результатов с ожидаемыми.
Причины ошибок
выполнения очень разнообразны, а потому
и локализация может оказаться крайне
сложной. Все возможные причины ошибок
можно разделить на следующие группы:
• неверное
определение исходных данных,
• логические
ошибки,
• накопление
погрешностей результатов вычислений.
Неверное
определение исходных данных
происходит, если возникают любые ошибки
при выполнении операций ввода-вывода:
ошибки передачи, ошибки преобразования,
ошибки перезаписи и ошибки данных.
Причем использование специальных
технических средств и программирование
с защитой от ошибок позволяет обнаружить
и предотвратить только часть этих
ошибок, о чем безусловно не следует
забывать.
Логические ошибки
имеют разную природу. Так они могут
следовать из ошибок, допущенных при
проектировании, например, при выборе
методов, разработке алгоритмов или
определении структуры классов, а могут
быть непосредственно внесены при
кодировании модуля.
К последней группе
относят:
• ошибки
некорректного использования переменных,
например, неудачный выбор типов данных,
использование переменных до их
инициализации, использование индексов,
выходящих за границы определения
массивов, нарушения соответствия типов
данных при использовании явного или
неявного переопределения типа данных,
расположенных в памяти при использовании
нетипизированных переменных, открытых
массивов, объединений, динамической
памяти, адресной арифметики и т. п.;
• ошибки
вычислений,
например, некорректные вычисления над
неарифметическими переменными,
некорректное использование целочисленной
арифметики, некорректное преобразование
типов данных в процессе вычислений,
ошибки, связанные с незнанием приоритетов
выполнения операций для арифметических
и логических выражений, и т. п.;
•ошибки
межмодульного интерфейса,
например, игнорирование системных
соглашений, нарушение типов и
последовательности при передачи
параметров, несоблюдение единства
единиц измерения формальных и фактических
параметров, нарушение области действия
локальных и глобальных переменных;
• другие ошибки
кодирования,
например, неправильная реализация
логики программы при кодировании,
игнорирование особенностей или
ограничений конкретного языка
программирования.
Накопление
погрешностей
результатов числовых вычислений
возникает, например, при некорректном
отбрасывании дробных цифр чисел,
некорректном использовании приближенных
методов вычислений, игнорировании
ограничения разрядной сетки представления
вещественных чисел в ЭВМ и т. п.
Все указанные выше
причины возникновения ошибок следует
иметь в виду в процессе отладки. Кроме
того, сложность отладки увеличивается
также вследствие влияния следующих
факторов:
• опосредованного
проявления ошибок;
• возможности
взаимовлияния ошибок;
• возможности
получения внешне одинаковых проявлений
разных ошибок;
• отсутствия
повторяемости проявлений некоторых
ошибок от запуска к запуску – так
называемые стохастические ошибки;
• возможности
устранения внешних проявлений ошибок
в исследуемой ситуации при внесении
некоторых изменений в программу,
например, при включении в программу
диагностических фрагментов может
аннулироваться или измениться внешнее
проявление ошибок;
• написания
отдельных частей программы разными
программистами.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•операционной системы,
•среды и языка программирования,
•реализуемых процессов,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 10.1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•логические ошибки,
•накопление погрешностей результатов вычислений (рис. 10.2).
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см.§ 2.7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т. п.;
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т. п.;
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
ручного тестирования;
индукции;
дедукции;
обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
David Drysdale, Beginner’s guide to linkers (http://www.lurklurk.org/linkers/linkers.html).
Цель данной статьи — помочь C и C++ программистам понять сущность того, чем занимается компоновщик. За последние несколько лет я объяснил это большому количеству коллег и наконец решил, что настало время перенести этот материал на бумагу, чтоб он стал более доступным (и чтоб мне не пришлось объяснять его снова). [Обновление в марте 2009: добавлена дополнительная информация об особенностях компоновки в Windows, а также более подробно расписано правило одного определения (one-definition rule).
Типичным примером того, почему ко мне обращались за помощью, служит следующая ошибка компоновки:
g++ -o test1 test1a.o test1b.o
test1a.o(.text+0x18): In function `main':
: undefined reference to `findmax(int, int)'
collect2: ld returned 1 exit status
Если Ваша реакция — ‘наверняка забыл extern «C»’, то Вы скорее всего знаете всё, что приведено в этой статье.
Содержание
- Определения: что находится в C файле?
- Что делает C компилятор
- Что делает компоновщик: часть 1
- Что делает операционная система
- Что делает компоновщик: часть 2
- C++ для дополнения картины
- Динамически загружаемые библиотеки
- Дополнительно
Определения: что находится в C файле?
Эта глава — краткое напоминание о различных составляющих C файла. Если всё в листинге, приведённом ниже, имеет для Вас смысл, то скорее всего Вы можете пропустить эту главу и сразу перейти к следующей.
Сперва надо понять разницу между объявлением и определением. Определение связывает имя с реализацией, что может быть либо кодом либо данными:
- Определение переменной побуждает компилятор зарезервировать некоторую область памяти, возможно задав ей некоторое определённое значение.
- Определение функции заставляет компилятор сгенерировать код для этой функции
Объявление говорит компилятору, что определение функции или переменной (с определённым именем) существует в другом месте программы, вероятно в другом C файле. (Заметьте, что определение также является объявлением — фактически это объявление, в котором «другое место» программы совпадает с текущим).
Для переменных существует определения двух видов:
- глобальные переменные, которые существуют на протяжении всего жизненного цикла программы («статическое размещение») и которые доступны в различных функциях;
- локальные переменные, которые существуют только в пределах некоторой исполняемой функции («локальное размещение») и которые доступны только внутри этой самой функции.
При этом под термином «доступны» следует понимать «можно обратиться по имени, ассоциированным с переменной в момент определения».
Существует пара частных случаев, которые с первого раза не кажутся очевидными:
- статичные (
static) локальные переменные на самом деле являются глобальными, потому что существуют на протяжении всей жизни программы, даже если они видимы только в пределах одной функции. - статичные глобальные переменные также являются глобальными с той лишь разницей, что они доступны только в пределах одного файла, где они определены.
Стоит отметить, что, определяя функцию статичной, просто сокращается количество мест, из которых можно обратиться к данной функции по имени.
Для глобальных и локальных переменных, мы можем различать инициализирована переменная или нет, т.е. будет ли пространство, отведённое для переменной в памяти, заполнено определённым значением.
И наконец, мы можем сохранять информацию в памяти, которая динамически выделена посредством malloc или new. В данном случае нет возможности обратиться к выделенной памяти по имени, поэтому необходимо использовать указатели — именованные переменные, содержащие адрес неименованной области памяти. Эта область памяти может быть также освобождена с помощью free или delete. В этом случае мы имеем дело с «динамическим размещением».
Подытожим:
| Код | Данные | |||||
| Глобальные | Локальные | Динамические | ||||
| Инициа- лизиро- ванные |
Неинициа- лизиро- ванные |
Инициа- лизиро- ванные |
Неинициа- лизиро- ванные |
|||
| Объяв- ление |
int fn(int x); |
extern int x; |
extern int x; |
N/A | N/A | N/A |
| Опреде- ление |
int fn(int x) { ... } |
int x = 1;(область действия — файл) |
int x;(область действия — файл) |
int x = 1;(область действия — функция) |
int x;(область действия — функция) |
int* p = malloc(sizeof(int)); |
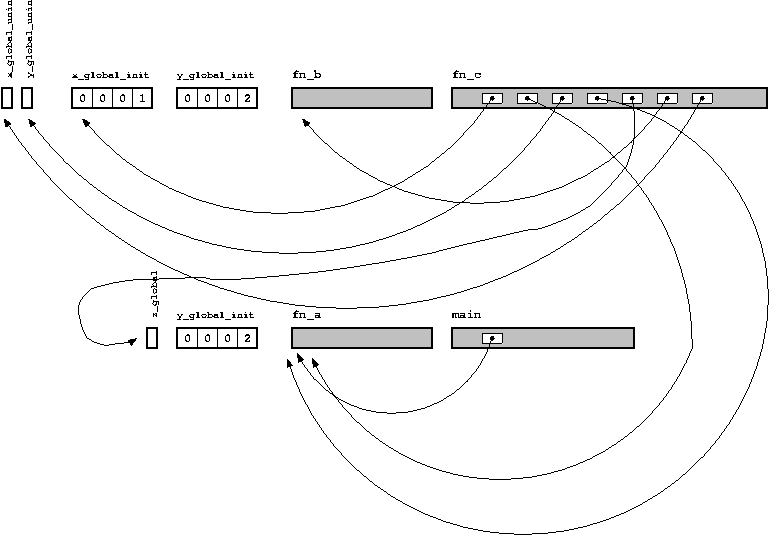
Вероятно более лёгкий путь усвоить — это просто посмотреть на пример программы.
/* Определение неинициализированной глобальной переменной */
int x_global_uninit;
/* Определение инициализированной глобальной переменной */
int x_global_init = 1;
/* Определение неинициализированной глобальной переменной, к которой
* можно обратиться по имени только в пределах этого C файла */
static int y_global_uninit;
/* Определение инициализированной глобальной переменной, к которой
* можно обратиться по имени только в пределах этого C файла */
static int y_global_init = 2;
/* Объявление глобальной переменной, которая определена где-нибудь
* в другом месте программы */
extern int z_global;
/* Объявлени функции, которая определена где-нибудь другом месте
* программы (Вы можете добавить впереди "extern", однако это
* необязательно) */
int fn_a(int x, int y);
/* Определение функции. Однако будучи помеченной как static, её можно
* вызвать по имени только в пределах этого C файла. */
static int fn_b(int x)
{
return x+1;
}
/* Определение функции. */
/* Параметр функции считается локальной переменной. */
int fn_c(int x_local)
{
/* Определение неинициализированной локальной переменной */
int y_local_uninit;
/* Определение инициализированной локальной переменной */
int y_local_init = 3;
/* Код, который обращается к локальным и глобальным переменным,
* а также функциям по имени */
x_global_uninit = fn_a(x_local, x_global_init);
y_local_uninit = fn_a(x_local, y_local_init);
y_local_uninit += fn_b(z_global);
return (x_global_uninit + y_local_uninit);
}
Что делает C компилятор
Работа компилятора C заключается в конвертировании текста, (обычно) понятного человеку, в нечто, что понимает компьютер. На выходе компилятор выдаёт объектный файл. На платформах UNIX эти файлы имеют обычно суффикс .o; в Windows — суффикс .obj. Содержание объектного файла — в сущности две вещи:
- код, соответствующий определению функции в C файле
- данные, соответствующие определению глобальных переменных в C файле (для инициализированных глобальных переменных начальное значение переменной тоже должно быть сохранено в объектном файле).
Код и данные, в данном случае, будут иметь ассоциированные с ними имена — имена функций или переменных, с которыми они связаны определением.
Объектный код — это последовательность (подходящим образом составленных) машинных инструкций, которые соответствуют C инструкциям, написанных программистом: все эти if‘ы и while‘ы и даже goto. Эти заклинания должны манипулировать информацией определённого рода, а информация должна быть где-нибудь находится — для этого нам и нужны переменные. Код может также ссылаться на другой код (в частности на другие C функции в программе).
Где бы код ни ссылался на переменную или функцию, компилятор допускает это, только если он видел раньше объявление этой переменной или функции. Объявление — это обещание, что определение существует где-то в другом месте программы.
Работа компоновщика проверить эти обещания. Однако, что компилятор делает со всеми этими обещаниями, когда он генерирует объектный файл?
По существу компилятор оставляет пустые места. Пустое место (ссылка) имеет имя, но значение соответствующее этому имени пока не известно.
Учитывая это, мы можем изобразить объектный файл, соответствующей программе, приведённой выше, следующим образом:
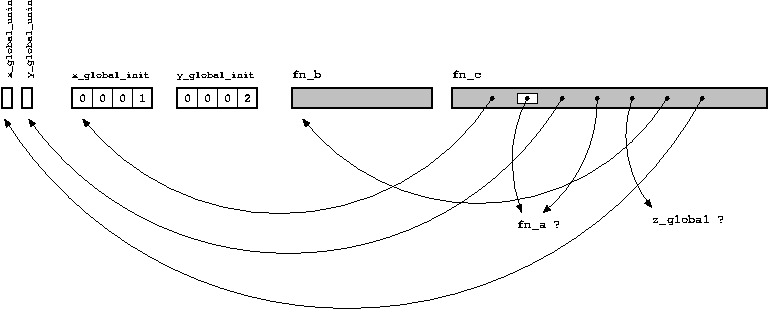
Анализирование объектного файла
До сих пор мы рассматривали всё на высоком уровне. Однако полезно посмотреть, как это работает на практике. Основным инструментом для нас будет команда nm, которая выдаёт информацию о символах объектного файла на платформе UNIX. Для Windows команда dumpbin с опцией /symbols является приблизительным эквивалентом. Также есть портированные под Windows инструменты GNU binutils, которые включают nm.exe.
Давайте посмотрим, что выдаёт nm для объектного файла, полученного из нашего примера выше:
Symbols from c_parts.o:
Name Value Class Type Size Line Section
fn_a | | U | NOTYPE| | |*UND*
z_global | | U | NOTYPE| | |*UND*
fn_b |00000000| t | FUNC|00000009| |.text
x_global_init |00000000| D | OBJECT|00000004| |.data
y_global_uninit |00000000| b | OBJECT|00000004| |.bss
x_global_uninit |00000004| C | OBJECT|00000004| |*COM*
y_global_init |00000004| d | OBJECT|00000004| |.data
fn_c |00000009| T | FUNC|00000055| |.text
Результат может выглядеть немного по разному на разных платформах (обратитесь к man‘ам, чтобы получить соответствующую информацию), но ключевыми сведениями являются класс каждого символа и его размер (если присутствует). Класс может иметь различны значения:
- Класс U обозначает неопределённые ссылки, те самые «пустые места», упомянутые выше. Для этого класса существует два объекта:
fn_aиz_global. (Некоторые версииnmмогут выводить секцию, которая была бы*UND*илиUNDEFв этом случае.) - Классы t и T указывают на код, который определён; различие между t и T заключается в том, является ли функция локальной (t) в файле или нет (T), т.е. была ли функция объявлена как
static. Опять же в некоторых системах может быть показана секция, например.text. - Классы d и D содержат инициализированные глобальные переменные. При этом статичные переменные принадлежат классу d. Если присутствует информация о секции, то это будет .data.
- Для неинициализированных глобальных переменных, мы получаем b, если они статичные и B или C иначе. Секцией в этом случае будет скорее всего .bss или *COM*.
Также можно увидеть символы, которые не являются частью исходного C кода. Мы не будем заострять наше внимание на этом, так как это обычно часть внутреннего механизма компилятора, для того чтобы Ваша программа всё-таки смогла быть потом скомпонована.
Что делает компоновщик: часть 1
Ранее мы обмолвились, что объявление функции или переменной — это обещание компилятору, что где-то в другом месте программы есть определение этой функции или переменной, и что работа компоновщика заключается в осуществлении этого обещания. Глядя на диаграмму объектного файла, мы можем описать этот процесс, как «заполнение пустых мест».
Проиллюстрируем это на примере, рассматривая ещё один C файл в дополнение к тому, что был приведён выше.
/* Инициализированная глобальная переменная */
int z_global = 11;
/* Вторая глобальная переменная с именем y_global_init, но они обе static */
static int y_global_init = 2;
/* Объявление другой глобальной переменной */
extern int x_global_init;
int fn_a(int x, int y)
{
return(x+y);
}
int main(int argc, char *argv)
{
const char *message = "Hello, world";
return fn_a(11,12);
}
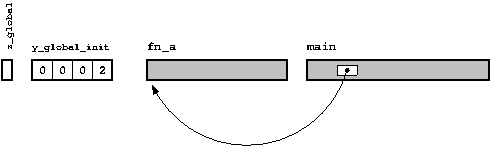
Исходя из обоих диаграмм, мы можем видеть, что все точки могут быть соединены (если нет, то компоновщик выдал бы сообщение об ошибке). Каждая вещь имеет своё место, и каждое место имеет свою вещь. Также компоновщик может заполнить все пустые места как показано здесь (на системах UNIX процесс компоновки обычно вызывается командой ld).
Также как и для объектных файлов, мы можем использовать nm для исследования конечного исполняемого файла.
Symbols from sample1.exe:
Name Value Class Type Size Line Section
_Jv_RegisterClasses | | w | NOTYPE| | |*UND*
__gmon_start__ | | w | NOTYPE| | |*UND*
__libc_start_main@@GLIBC_2.0 | U | FUNC|000001ad| |*UND*
_init |08048254| T | FUNC| | |.init
_start |080482c0| T | FUNC| | |.text
__do_global_dtors_aux|080482f0| t | FUNC| | |.text
frame_dummy |08048320| t | FUNC| | |.text
fn_b |08048348| t | FUNC|00000009| |.text
fn_c |08048351| T | FUNC|00000055| |.text
fn_a |080483a8| T | FUNC|0000000b| |.text
main |080483b3| T | FUNC|0000002c| |.text
__libc_csu_fini |080483e0| T | FUNC|00000005| |.text
__libc_csu_init |080483f0| T | FUNC|00000055| |.text
__do_global_ctors_aux|08048450| t | FUNC| | |.text
_fini |08048478| T | FUNC| | |.fini
_fp_hw |08048494| R | OBJECT|00000004| |.rodata
_IO_stdin_used |08048498| R | OBJECT|00000004| |.rodata
__FRAME_END__ |080484ac| r | OBJECT| | |.eh_frame
__CTOR_LIST__ |080494b0| d | OBJECT| | |.ctors
__init_array_end |080494b0| d | NOTYPE| | |.ctors
__init_array_start |080494b0| d | NOTYPE| | |.ctors
__CTOR_END__ |080494b4| d | OBJECT| | |.ctors
__DTOR_LIST__ |080494b8| d | OBJECT| | |.dtors
__DTOR_END__ |080494bc| d | OBJECT| | |.dtors
__JCR_END__ |080494c0| d | OBJECT| | |.jcr
__JCR_LIST__ |080494c0| d | OBJECT| | |.jcr
_DYNAMIC |080494c4| d | OBJECT| | |.dynamic
_GLOBAL_OFFSET_TABLE_|08049598| d | OBJECT| | |.got.plt
__data_start |080495ac| D | NOTYPE| | |.data
data_start |080495ac| W | NOTYPE| | |.data
__dso_handle |080495b0| D | OBJECT| | |.data
p.5826 |080495b4| d | OBJECT| | |.data
x_global_init |080495b8| D | OBJECT|00000004| |.data
y_global_init |080495bc| d | OBJECT|00000004| |.data
z_global |080495c0| D | OBJECT|00000004| |.data
y_global_init |080495c4| d | OBJECT|00000004| |.data
__bss_start |080495c8| A | NOTYPE| | |*ABS*
_edata |080495c8| A | NOTYPE| | |*ABS*
completed.5828 |080495c8| b | OBJECT|00000001| |.bss
y_global_uninit |080495cc| b | OBJECT|00000004| |.bss
x_global_uninit |080495d0| B | OBJECT|00000004| |.bss
_end |080495d4| A | NOTYPE| | |*ABS*
Он содержит символы обоих объектных файлов и все неопределённые ссылки исчезли. Символы переупорядочены так, что похожие типы находятся вместе. А также существует немного дополнений, чтобы помочь ОС иметь дело с такой штукой, как исполняемый файл.
Существует достаточное количество сложных деталей, загромождающих вывод, но если вы выкинете всё, что начинается с подчёркивания, то станет намного проще.
Повторяющиеся символы
В предыдущей главе было упомянуто, что компоновщик выдаёт сообщение об ошибке, если не может найти определение для символа, на который найдена ссылка. А что случится, если найдено два определения для символа во время компоновки?
В C++ решение прямолинейное. Язык имеет ограничение, известное как правило одного определения, которое гласит, что должно быть только одно определение для каждого символа, встречающегося во время компоновки, ни больше, ни меньше. (Соответствующей главой стандарта C++ является 3.2, которая также упоминает некоторые исключения, которые мы рассмотрим несколько позже.)
Для C положение вещей менее очевидно. Должно быть точно одно определение для любой функции и инициализированной глобальной переменной, но определение неинициализированной переменной может быть трактовано как предварительное определение. Язык C таким образом разрешает (или по крайней мере не запрещает) различным исходным файлам содержать предварительное определение одного и того же объекта.
Однако, компоновщики должны уметь обходится также и с другими языками кроме C и C++, для которых правило одного определения не обязательно соблюдается. Например, для Fortran’а является нормальным иметь копию каждой глобальной переменной в каждом файле, который на неё ссылается. Компоновщику необходимо тогда убрать дубликаты, выбрав одну копию (самого большого представителя, если они отличаются в размере) и выбросить все остальные. Эта модель иногда называется «общей моделью» компоновки из-за ключевого слова COMMON (общий) языка Fortran.
Как результат, вполне распространённо для UNIX компоновщиков не ругаться на наличие повторяющихся символов, по крайней мере, если это повторяющиеся символы неинициализированных глобальных переменных (эта модель компоновки иногда называется «моделью с ослабленной связью» [прим. перев. это мой вольный перевод relaxed ref/def model. Более удачные предложения приветствуются]). Если это Вас волнует (вероятно и должно волновать), обратитесь к документации Вашего компоновщика, чтобы найти опцию --работай-правильно, которая усмиряет его поведение. Например, в GNU тулчейне опция компилятора -fno-common заставляет поместить неинициализированную переменную в сегмент BBS вместо генерирования общих (COMMON) блоков.
Что делает операционная система
Теперь, когда компоновщик произвёл исполняемый файл, присвоив каждой ссылке на символ подходящее определение, можно сделать короткую паузу, чтобы понять, что делает операционная система, когда Вы запускаете программу на выполнение.
Запуск программы разумеется влечёт за собой выполнение машинного кода, т.е. ОС очевидно должна перенести машинный код исполняемого файла с жёстокого диска в операционную память, откуда CPU сможет его забрать. Эти порции называются сегментом кода (code segment или text segment).
Код без данных сам по себе бесполезен. Следовательно всем глобальным переменным тоже необходимо место в памяти компьютера. Однако, существует разница между инициализированными и неинициализированными глобальными переменными. Инициализированные переменные имеют определённые стартовые значения, которые тоже должны храниться в объектных и исполняемом файлах. Когда программа запускается на старт, ОС копирует эти значения в виртуальное пространство программы, в сегмент данных.
Для неинициализированных переменных ОС может предположить, что они все имеют 0 в качестве начального значения, т.е. нет надобности копировать какие-либо значения. Кусок памяти, который инициализируется нулями, известен как bss сегмент.
Это означает, что место под глобальные переменные может быть отведено в выполняемом файле, хранящемся на диске; для инициализированных переменных должны быть сохранены их начальные значения, но для неинициализированных нужно только сохранить их размер.
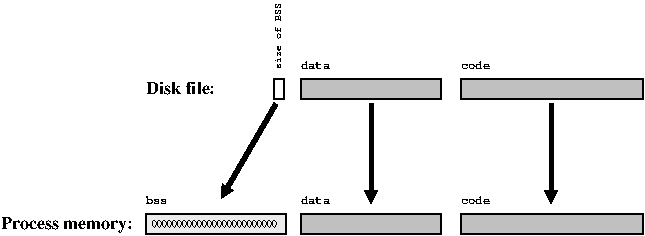
Как Вы могли заметить, до сих пор во всех рассуждениях об объектных файлах и компоновщике речь заходила только о глобальных переменных; при этом мы не упоминались локальные переменные и динамически занимаемая память, упомянутые раньше.
Эти данные не нуждаются во вмешательстве компоновщика, потому что время их жизни начинается и заканчивается во время исполнения программы — гораздо позже того, как компоновщик уже сделал своё дело. Однако, для полноты описания, мы коротко укажем, что:
- локальные переменные располагаются в области памяти, называемым стеком, который растёт и сужается по мере вызова и выполнения различных функций.
- динамически выделяемая память берётся из области памяти, известной как куча, и функция malloc контролирует доступ к свободному пространству в этой области.
Для полноты картины стоит добавить, как выглядит пространство памяти выполняемого процесса. Так как куча и стек могут изменять свои размеры динамически, вполне распространенным является факт, что стек растёт в одном направлении, а куча обратном. Таким образом, программа выдаст ошибку отсутствия свободной памяти, только если стек и куча встретятся где-нибудь в середине (в этом случае пространство памяти программы будет действительно заполнено).
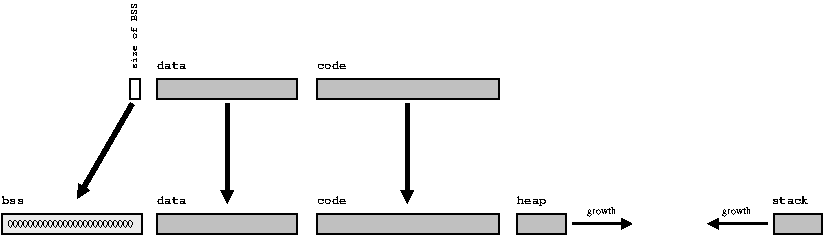
Что делает компоновщик; часть 2
Теперь, после того как мы рассмотрели основы основ того, что делает компоновщик, мы можем погрузиться в описание более сложных деталей — примерно в том хронологическом порядке, как они были добавлены к компоновщику.
Главное наблюдение, которое затрагивает функции компоновщика следующее: если ряд различных программ делают примерно одни и те же вещи (вывод на экран, чтение файлов с жёсткого диска и т.д.), тогда очевидно имеет смысл обособить этот код в определённом месте и дать другим программам его использовать.
Одним из возможных решений было бы использование одних и тех же объектных файлов, однако было бы гораздо удобнее держать всю коллекцию… объектных файлов в одном легко доступном месте: библиотеке.
Техническое отступление: Эта глава полностью опускает важное свойство компоновщика: переадресация (relocation). Разные программы имеют различные размеры, т.е. если разделяемая библиотека отображается в адресное пространство различных программ, она будет иметь различные адреса. Это в свою очередь означает, что все функции и переменные в библиотеке будут на различных местах. Теперь, если все обращения к адресам относительные («значение +1020 байта отсюда») нежели абсолютные («значение в 0x102218BF»), то это не проблема, однако так бывает не всегда. В таких случаях всем абсолютным адресам необходимо прибавить подходящий офсет — это и есть relocation. Я не собираюсь возвращается к этой теме снова, однако добавлю, что так как это практически всегда скрыто от C/C++ программиста — очень редко проблемы компоновки вызваны трудностями переадресации.
Статические библиотеки
Самое простое воплощение библиотеки — это статическая библиотека. В предыдущей главе было упомянуто, что можно разделять (share), код просто повторно используя объектные файлы; это и есть суть статичных библиотек.
В системах UNIX командой для сборки статичной библиотеки обычно является ar, и библиотечный файл, который при этом получается, имеет расширение *.a. Также эти файлы обычно имеют префикс «lib» в своём названии и они передаются компоновщику с опцией «-l» с последующим именем библиотеки без префикса и расширения (т.е. «-lfred» подхватит файл «libfred.a»).
(Раньше программа, называемая ranlib, также была нужна для статических библиотек, чтобы сгенерировать список символов вначале библиотеки. В наши дни инструменты ar делают это сами.)
В системе Windows статические библиотеки имеют расширение .LIB и собираются инструментами LIB, однако этот факт может ввести в заблуждение, так как такое же расширение используется и для «import library», которая содержит в себе только список того, что имеется в DLL — смотрите главу о Windows DLL
По мере того как компоновщик перебирает коллекцию объектных файлов, чтобы объединить их вместе, он ведёт список символов, которые не могут быть пока реализованы. Как только все явно указанные объектные файлы обработаны, у компоновщика теперь есть новое место для поиска символов, которые остались в списке — в библиотеке. Если нереализованный символ определён в одном из объектов библиотеки, тогда объект добавляется, точно также как если бы он был бы добавлен в список объектных файлов пользователем, и компоновка продолжается.
Обратите внимание на гранулярность того, что добавляется из библиотеки: если необходимо определение некоторого символа, тогда весь объект, содержащий определение символа, будет включён. Это означает, что этот процесс может быть как шагом вперёд, так и шагом назад — свеже добавленный объект может как и разрешить неопределённую ссылку, так и привнести целую коллекцию новых неразрешённых ссылок.
Другая важная деталь — это порядок событий; библиотеки привлекаются только, когда нормальная компоновка завершена, и они обрабатываются в порядке слева на право. Это значит, что если объект, извлекаемый из библиотеки в последнюю очередь, требует наличие символа из библиотеки, стоящей раньше в строке команды компоновки, то компоновщик не найдёт его автоматически.
Приведём пример, чтоб прояснить ситуацию; предположим у нас есть следующие объектные файлы и строка команды компоновки, которая содержит a.o, b.o, -lx и -ly.
| Файл | a.o |
b.o |
libx.a |
liby.a |
||||
| Объект | a.o |
b.o |
x1.o |
x2.o |
x3.o |
y1.o |
y2.o |
y3.o |
| Опредe- ления |
a1, a2, a3 |
b1, b2 |
x11, x12, x13 |
x21, x22, x23 |
x31, x32 |
y11, y12 |
y21, y22 |
y31, y32 |
| Неразре- шённые ссылки |
b2, x12 |
a3, y22 |
x23, y12 |
y11 |
y21 |
x31 |
Как только компоновщик обработал a.o и b.o, ссылки на b2 и a3 будут разрешены, в то время как x12 и y22 будут всё ещё неразрешёнными. В этот момент компоновщик проверяет первую библиотеку libx.a на наличие недостающих символов и находит, что он может включить x1.o, чтобы компенсировать ссылку на x12; однако делая это, x23 и y12 добавляются в список неопределённых ссылок (теперь список выглядит как y22, x23, y12).
Компоновщик всё ещё имеет дело с libx.a, поэтому ссылка на x23 легко компенсируется, включая x2.o из libx.a. Однако это добавляет y11 к списку неопределённых (который стал y22, y12, y11). Ни одна из этих ссылок не может быть разрешена использованием libx.a, таким образом компоновщик принимается за liby.a.
Здесь происходит примерно тоже самое и компоновщик включает y1.o и y2.o. Первым объектом добавляется ссылка на y21, но так как y2.o всё равно будет включено, эта ссылка разрешается просто. Результатом этого процесса является то, что все неопределённые ссылки разрешены, и некоторые (но не все) объекты библиотек включены в конечный исполняемый файл.
Заметьте, что ситуация несколько изменяется, если скажем b.o тоже имел бы ссылку на y32. Если это было бы так, то компоновка libx.a происходила бы также, но обработка liby.a повлекла бы включение y3.o. Включением этого объекта мы добавим x31 к списку неразрешённых символов и эта ссылка останется неразрешённой — на этой стадии компоновщик уже завершил обработку libx.a и поэтому уже не найдёт определение этого символа (в x3.o).
(Между прочим этот пример имеет циклическую зависимость между библиотеками libx.a и liby.a; обычно это плохо особенно под Windows)
Динамические разделяемые библиотеки
Для популярных библиотек таких как стандартная библиотека C (обычно libc) быть статичной библиотекой имеет явный недостаток — каждая исполняемая программа будет иметь копию одного и того же кода. Действительно, если каждый исполняемый файл будет иметь копию printf, fopen и тому подобных, то будет занято неоправданно много дискового пространства.
Менее очевидный недостаток это то, что в статически скомпонованной программе код фиксируется навсегда. Если кто-нибудь найдёт и исправит баг в printf, то каждая программа должна будет скомпонована заново, чтобы заполучить исправленный код.
Чтоб избавиться от этих и других проблем, были представлены динамически разделяемые библиотеки (обычно они имеют расширение .so или .dll в Windows и .dylib в Mac OS X). Для этого типа библиотек компоновщик не обязательно соединяет все точки. Вместо этого компоновщик выдаёт купон типа «IOU» (I owe you = я тебе должен) и откладывает обналичивание этого купона до момента запуска программы.
Всё это сводится к тому, что если компоновщик обнаруживает, что определение конкретного символа находится в разделяемой библиотеке, то он не включает это определение в конечный исполняемый файл. Вместо этого компоновщик записывает имя символа и библиотеки, откуда этот символ должен предположительно появится.
Когда программа вызывается на исполнение, ОС заботится о том, чтобы оставшиеся части процесса компоновки были выполнены вовремя до начала работы программы. Прежде чем будет вызвана функция main, малая версия компоновщика (часто называемая ld.so) проходится по списку обещания и выполняет последний акт компоновки прямо на месте — помещает код библиотеки и соединяет все точки.
Это значит, что ни один выполняемый файл не содержит копии кода printf. Если новая версия printf будет доступна, то её можно использовать просто изменив libc.so — при следующем запуске программы вызовется новая printf.
Существует другое большое отличие между тем, как динамические библиотеки работают по сравнению со статическими и это проявляется в гранулярности компоновки. Если конкретный символ берётся из конкретной динамической библиотеки (скажем printf из libc.so), то всё содержимое библиотеки помещается в адресное пространство программы. Это основное отличие от статических библиотек, где добавляются только конкретные объекты, относящиеся к неопределённому символу.
Сформулируем иначе, разделяемые библиотеки сами получаются как результат работы компоновщика (а не как формирование большой кучи объектов, как это делает ar), содержащий ссылки между объектами в самой библиотеке. Повторю ещё, nm — полезный инструмент для иллюстрации происходящего: для приведённого выше примера он выдаст множество исходов для каждого объектного файла в отдельности, если этот инструмент запустить на статической версии библиотеки, но для разделяемой версии библиотеки liby.so имеет только один неопределённый символ x31. Также в примере с порядком включения библиотек в конце предыдущей главы тоже никаких проблем не будет: добавление ссылки на y32 в b.c не повлечёт никаких изменений, так как всё содержимое y3.o и x3.o уже было задействовано.
Так между прочим, другой полезный инструмент — это ldd; на платформе Unix он показывает все разделяемые библиотеки, от которых зависит исполняемый бинарник (или же другая разделяемая библиотека), вместе с указанием, где эти библиотеки можно найти. Для того чтобы программа удачно запустилась, загрузчику необходимо найти все эти библиотеки вместе со всеми их зависимостями. (Обычно загрузчик ищет библиотеки в списке директорий, указанных в переменной окружения LD_LIBRARY_PATH.)
/usr/bin:ldd xeyes
linux-gate.so.1 => (0xb7efa000)
libXext.so.6 => /usr/lib/libXext.so.6 (0xb7edb000)
libXmu.so.6 => /usr/lib/libXmu.so.6 (0xb7ec6000)
libXt.so.6 => /usr/lib/libXt.so.6 (0xb7e77000)
libX11.so.6 => /usr/lib/libX11.so.6 (0xb7d93000)
libSM.so.6 => /usr/lib/libSM.so.6 (0xb7d8b000)
libICE.so.6 => /usr/lib/libICE.so.6 (0xb7d74000)
libm.so.6 => /lib/libm.so.6 (0xb7d4e000)
libc.so.6 => /lib/libc.so.6 (0xb7c05000)
libXau.so.6 => /usr/lib/libXau.so.6 (0xb7c01000)
libxcb-xlib.so.0 => /usr/lib/libxcb-xlib.so.0 (0xb7bff000)
libxcb.so.1 => /usr/lib/libxcb.so.1 (0xb7be8000)
libdl.so.2 => /lib/libdl.so.2 (0xb7be4000)
/lib/ld-linux.so.2 (0xb7efb000)
libXdmcp.so.6 => /usr/lib/libXdmcp.so.6 (0xb7bdf000)
Причина большей гранулярности заключается в том, что современные операционные системы достаточно интеллигентны, чтобы позволить делать больше, чем просто сэкономить сохранение повторяющихся элементов на диске, чем страдают статические библиотеки. Различные исполняемые процессы, которые используют одну и туже разделяемую библиотеку, также могут совместно использовать сегмент кода (но не сегмент данных или сегмент bss — например, два различных процесса могут находится в различных местах при использовании, скажем, strtok). Чтобы этого достичь, вся библиотека должна быть адресована одним махом, чтобы все внутренние ссылки были выстроены однозначным образом. Действительно, если один процесс подхватывает a.o и c.o, а другой b.o и c.o, то ОС не сможет использовать никаких совпадений.
Windows DLL
Несмотря на то, что общие принципы разделяемых библиотек примерно одинаковы как на платформах Unix, так и на Windows, всё же есть несколько деталей, на которые могут подловиться новички.
Экспортируемые символы
Самое большое отличие заключается в том, что в библиотеках Windows символы не экспортируются автоматически. В Unix все символы всех объектных файлов, которые были подлинкованы к разделяемой библиотеке, видны пользователю этой библиотеки. В Windows, программист должен явно делать некоторые символы видимыми, т.е. экспортировать их.
Есть три способа как экспортировать символ и Windows DLL (и все эти три способа можно перемешивать в одной и той же библиотеке).
- В исходном коде объявить символ как
__declspec(dllexport), примерно так:__declspec(dllexport) int my_exported_function(int x, double y) - При выполнении команды компоновщика использовать опцию
LINK.EXEexport:symbol_to_exportLINK.EXE /dll /export:my_exported_function - Скормить компоновщику файл определения модуля (DEF) (используя опцию
/DEF:def_file), включив в этот файл секциюEXPORT, которая содержит символы, подлежащие экспортированию.EXPORTS my_exported_function my_other_exported_function
Как только к этой мешанине подключается C++, первая из этих опций становится самой простой, так как в этом случае компилятор берёт на себя обязательства позаботиться о декорировании имён
.LIB и другие относящиеся к библиотеке файлы
Мы подошли ко второй трудности, связанной с библиотеками Windows: информация об экспортируемых символах, которые компоновщик должен связать с остальными символам, не содержится в самом DLL. Вместо этого данная информация содержится в соответствующем .LIB файле.
.LIB файл, ассоциированный с DLL описывает какие (экспортируемые) символы находятся в DLL вместе с их расположением. Любой бинарник, который использует DLL, должен обращаться к .LIB файлу, чтобы связать символы корректно.
Чтобы сделать всё ещё более запутанным, расширение .LIB также используется для статических библиотек.
На самом деле существует целый ряд различных файлов, которые могут относиться каким-либо образом к библиотекам Windows. Наряду с .LIB файлом, а также (опциональным) .DEF файлом Вы можете увидеть все нижеперечисленные файлы, ассоциированные с Вашей Windows библиотекой.
- Файлы на выходе компоновки
- library
.DLL: собственно код библиотеки; этот файл нужен (во время исполнения) любому бинарнику, использующему библиотеку. - library
.LIB: файл «импортирования библиотеки», который описывает где и какой символ находится в результирующейDLL. Этот файл генерируется, если толькоDLLэкспортирует некоторые её символы. Если символы не экспортируются, то смысла в.LIBфайле нет. Этот файл нужен во время компоновки. - library
.EXP: «Экспорт файл» компилируемой библиотеки, который нужен если имеет место компоновка бинарников с циклической зависимостью. - library
.ILK: Если опция/INCREMENTALбыла применена во время компоновки, которая активирует инкрементную компоновку, то этот файл содержит в себе статус инкрементной компоновки. Он нужен для будущих инкрементных компоновок с этой библиотекой. - library
.PDB: Если опция/DEBUGбыла применена во время компоновки, то этот файл является программной базой данных, содержащей отладочную информацию для библиотеки. - library
.MAP: Если опция/MAPбыла применена во время компоновки, то этот файл содержит описание внутреннего формата библиотеки.
- library
- Файлы на входе компоновки:
- library
.LIB: Файл «импорта библиотеки», которые описывает где и какие символы находятся в другихDLL, которые нужны для компоновки. - library
.LIB: Статическая библиотека, которая содержит коллекцию объектов, необходимых при компоновке. Обратите внимание на неоднозначное использование расширения.LIB - library
.DEF: Файл «определений», который позволяет управлять различными деталями скомпонованной библиотеки, включая экспорт символов. - library
.EXP: Файл экспорта компонуемой библиотеки, который может сигнализировать, что предыдущее выполнениеLIB.EXEуже создало файл.LIBдля библиотеки. Имеет значение при компоновке бинарников с циклическими зависимостями. - library
.ILK: Файл состояния инкрементной компоновки; см. выше. - library
.RES: Файл ресурсов, который содержит информацию о различных GUI виджетах, используемых исполняемым файлом. Эти ресурсы включаются в конечный бинарник.
- library
Это является большим отличием к Unix, где почти вся информация, содержащаяся в этих всех дополнительных файлах, просто добавляется в саму библиотеку.
Импортируемые символы
Вместе с требованием к DLL явно объявлять экспортируемые символы, Windows также разрешает бинарникам, которые используют код библиотеки, явно объявлять символы, подлежащие импортированию. Это не является обязательным, но даёт некоторую оптимизацию по скорости, вызванную историческими свойствами 16-ти битных окон.
Для этого объявляем символ как __declspec(dllimport) в исходном коде примерно так:
__declspec(dllimport) int function_from_some_dll(int x, double y);
__declspec(dllimport) extern int global_var_from_some_dll;
При этом индивидуальное объявление функций или глобальных переменных в одном заголовочном файле является хорошим тоном программирования на C. Это приводит к некоторому ребусу: код в DLL, содержащий определение функции/переменной должен экспортировать символ, но любой другой код, использующий DLL, должен импортировать символ.
Стандартный выход из этой ситуации — это использование макросов препроцессора.
#ifdef EXPORTING_XYZ_DLL_SYMS
#define XYZ_LINKAGE __declspec(dllexport)
#else
#define XYZ_LINKAGE __declspec(dllimport)
#endif
XYZ_LINKAGE int xyz_exported_function(int x);
XYZ_LINKAGE extern int xyz_exported_variable;
Файл с исходниками в DLL, который определяет функцию и переменную гарантирует, что переменная препроцессора EXPORTING_XYZ_DLL_SYMS определена (по средством #define) до включения соответствующего заголовочного файла и таким образом экспортирует символ. Любой другой код, который включает этот заголовочный файл не определяет этот символ и таким образом импортирует его.
Циклические зависимости
Ещё одной трудностью, связанной с использованием DLL, является тот факт, что Windows относится строже к требованию, что каждый символ должен быть разрешён во время компоновки. В Unix вполне возможно скомпоновать разделяемую библиотеку, которая содержит неразрешённые символы, т.е. символы, определение которых неведомо компоновщику В этой ситуации любой другой код, использующий эту разделяемую библиотеку, должен будет предоставить определение незразрешённых символов, иначе программа не будет запущена. Windows не допускает такой распущенности.
Для большинства систем — это не проблема. Выполняемые файлы зависят от высокоуровевых библиотек, высокоуровневые библиотеки зависят от библиотек низкого уровня, и всё компонуется в обратном порядке — сначала библиотеки низкого уровня, потом высокого, а затем и выполняемый файл, который зависит от всех остальных
Однако, если имеет место циклическая зависимость между бинарниками, тогда всё немного усложняется. Если X.DLL нуждается в символе из Y.DLL, а Y.DLL нуждается в символе из X.DLL, тогда необходимо решить задачу про курицу и яйцо: какая бы библиотека ни компоновалась бы первой, она не сможет найти разрешение ко всем символам.
Windows предоставил обходной приём примерно следующего содержания.
- Сначала имитируем компоновку библиотеки X. Запускаем
LIB.EXE(неLINK.EXE), чтобы получить файлX.LIBточно такой же, какой был бы получен сLINK.EXE. При этомX.DLLне будет сгенерирован, но вместо него будет получен файлX.EXP. - Компонуем библиотеку
Yкак обычно, используяX.LIB, полученную на предыдущем шаге, и получаем на выходе какY.DLLтак иY.LIB. - В конце концов компонуем библиотеку
Xтеперь уже полноценно. Это происходит почти как обычно, используя дополнительно файлX.EXP, полученный на первом шаге. Обычное в этом шаге то, что компоновщик используетY.LIBи производитX.DLL. Необычное — компоновщик пропускает шаг созданияX.LIB, так как этот файл был уже создан на первом шаге, чему свидетельствует наличие.EXPфайла.
Но несомненно лучше всё же реорганизовать библиотеки таким образом, чтоб избежать любых циклических зависимостей…
C++ для дополнения картины
C++ предлагает ряд дополнительных возможностей сверх того, что доступно в C, и часть этих возможностей влияет на работу компоновщика. Так было не всегда — первые реализации C++ появились в качестве внешнего интерфейса к компилятору C, поэтому о совместимости работы компоновщика не было нужды. Однако со временем были добавлены более продвинутые особенности языка, так что компоновщик уже должен был быть изменён, чтобы их поддерживать.
Перегрузка функций и декорирование имён
Первое отличие C++ заключается в том, что функции могут быть перегружены, то есть одновременно могут существовать функции с одним и тем же именем, но с различными принимаемыми типами (различной сигнатурой функции):
int max(int x, int y)
{
if (x>y) return x;
else return y;
}
float max(float x, float y)
{
if (x>y) return x;
else return y;
}
double max(double x, double y)
{
if (x>y) return x;
else return y;
}
Такое положение вещей определённо затрудняет работу компоновщика: если какой-нибудь код обращается к функции max, какая именно имелась в виду?
Решение к этой проблеме названо декорированием имён (name mangling), потому что вся информация о сигнатуре функции переводится (to mangle = искажать, деформировать, прим.пер.) в текстовую форму, которая становится собственно именем символа с точки зрения компоновщика. Различные сигнатуры переводятся в различные имена. Таким образом проблема уникальности имён решена.
Я не собираюсь вдаваться в детали используемых схем декорирования (которые к тому же отличаются от платформы к платформе), но беглый взгляд на объектный файл, соответствующий коду выше, даст идею, как всё это понимать (запомните, nm — Ваш друг!):
Symbols from fn_overload.o:
Name Value Class Type Size Line Section
__gxx_personality_v0| | U | NOTYPE| | |*UND*
_Z3maxii |00000000| T | FUNC|00000021| |.text
_Z3maxff |00000022| T | FUNC|00000029| |.text
_Z3maxdd |0000004c| T | FUNC|00000041| |.text
Здесь мы видим три функции max, каждая из которых получила отличное имя в объектном файле, и мы можем проявить смекалку и предположить, что две следующие буквы после «max» обозначают типы входящих параметров — «i» как int, «f» как float и «d» как double (однако всё значительно усложняется, если классы, пространства имён, шаблоны и перегруженные операторы вступают в игру!).
Также стоит отметить, что обычно есть способ конвертирования между именами, видимых программисту и именами, видимых компоновщику. Это может быть и отдельная программа (например, c++filt) или опция в командной строке (например --demangle для GNU nm), которая выдаёт что-то похожее на это:
Symbols from fn_overload.o:
Name Value Class Type Size Line Section
__gxx_personality_v0| | U | NOTYPE| | |*UND*
max(int, int) |00000000| T | FUNC|00000021| |.text
max(float, float) |00000022| T | FUNC|00000029| |.text
max(double, double) |0000004c| T | FUNC|00000041| |.text
Область, где схемы декорирования чаще всего заставляют ошибиться, находится в месте переплетения C и C++. Все символы, произведённые C++ компилятором, декорированы; все символы, произведённые C компилятором, выглядят так же, как и в исходном коде. Чтобы обойти это, язык C++ разрешает поместить extern "C" вокруг объявления и определения функций. По сути этим мы сообщаем C++ компилятору, что определённое имя не должно быть декорировано — либо потому что это определение C++ функции, которая будет вызываться кодом C, либо потом что это определение C функции, которая будет вызываться кодом C++.
Возвращаясь к примеру в самом начале статьи, можно легко заметить, что существует достаточно большая вероятность, что кто-то забыл использовать extern "C" при компоновке C и C++ объектов.
g++ -o test1 test1a.o test1b.o
test1a.o(.text+0x18): In function `main':
: undefined reference to `findmax(int, int)'
collect2: ld returned 1 exit status
Большой подсказкой является то, что сообщение об ошибке содержит сигнатуру функции — это не просто сообщение о том, что findmax не найдено. Другими словами C++ код ищет что-то вроде "_Z7findmaxii", а находит только "findmax". Поэтому возникает ошибка компоновки.
Кстати заметьте, что объявление extern "C" игнорируется для функций-членов классов (§7.5.4 стандарта С++)
Инициализация статических объектов
Следующее выходящее за рамки С свойство C++, которое затрагивает работу компоновщика, — это существование конструкторов объектов. Конструктор — это кусок кода, который задаёт начальное состояние объекта. По сути его работа концептуально эквивалентна инициализации значения переменной, однако с той важной разницей, что речь идёт о произвольных фрагментах кода.
Вспомним из первой главы, что глобальные переменные могут начать своё существование уже с определённым значением. В C конструкция начального значения такой глобальной переменной — дело простое: определённое значение просто копируется из сегмента данных выполняемого файла в соответствующее место в памяти программы, которая вот-вот-начнёт-выполняться.
В C++ процесс инициализации может быть гораздо сложнее, чем просто копирование фиксированных значений; весь код в различных конструкторах по всей иерархии классов должен быть выполнен, прежде чем сама программа фактически начнёт выполняться.
Чтобы с этим справиться, компилятор помещает немного дополнительной информации в объектный файл для каждого C++ файла; а именно это список конструкторов, которые должны быть вызваны для конкретного файла. Во время компоновки компоновщик объединяет все эти списки в один большой список, а также помещает код, которые проходит через весь этот список, вызывая конструкторы всех глобальных объектов.
Обратим внимание, что порядок, в котором конструкторы глобальных объектов вызываются не определён — он полностью находится во власти того, что именно компоновщик намерен делать. (См. «Эффективный C++» Скотта Майерса для дальнейших деталей — заметка 47 во второй редакции, заметка 4 в третьей редакции)
Мы можем проследить за этими списками, опять же прибегнув к помощи nm. Рассмотрим следующий C++ файл:
class Fred {
private:
int x;
int y;
public:
Fred() : x(1), y(2) {}
Fred(int z): x(z), y(3) {}
};
Fred theFred;
Fred theOtherFred(55);
Для этого кода (недекорированный) вывод nm выглядит так:
Symbols from global_obj.o:
Name Value Class Type Size Line Section
__gxx_personality_v0| | U | NOTYPE| | |*UND*
__static_initialization_and_destruction_0(int, int)
|00000000| t | FUNC|00000039| |.text
Fred::Fred(int) |00000000| W | FUNC|00000017| |.text._ZN4FredC1Ei
Fred::Fred() |00000000| W | FUNC|00000018| |.text._ZN4FredC1Ev
theFred |00000000| B | OBJECT|00000008| |.bss
theOtherFred |00000008| B | OBJECT|00000008| |.bss
global constructors keyed to theFred
|0000003a| t | FUNC|0000001a| |.text
Как обычно, мы можем увидеть здесь кучу разных вещей, но одна из них наиболее интересна для нас это записи с классом W (что означает «слабый» символ («weak» symbol)) а также записи именем секции типа «.gnu.linkonce.t.stuff«. Это маркеры для конструкторов глобальных объектов и мы видим, что соответствующее поле «Name» показывает то, что мы собственно и могли там ожидать — каждый из двух конструкторов задействованы.
Шаблоны
Ранее мы приводили пример с тремя различными реализациями функции max, каждая из которых принимала аргументы различных типов. Однако, мы видим, что код тела функции во всех трёх случаях идентичен. А мы знаем, что дублировать один и тот же код — это дурной тон программирования.
C++ вводит понятия шаблона (templates), который позволяет использовать код, приведённый ниже, сразу для всех случаев. Мы можем создать заголовочный файл max_template.h с только одной копией кода функции max:
template <class T>
T max(T x, T y)
{
if (x>y) return x;
else return y;
}
и включим этот файл в исходный файл, чтобы испробовать шаблонную функцию:
#include "max_template.h"
int main()
{
int a=1;
int b=2;
int c;
c = max(a,b); // Компилятор автоматически определяет, что нужно именно max<int>(int,int)
double x = 1.1;
float y = 2.2;
double z;
z = max<double>(x,y); // Компилятор не может определить, поэтому требуем max<double>(double,double)
return 0;
}
Этот написанный на C++ код использует max<int>(int,int) и max<double>(double,double). Однако, какой-нибудь другой код мог бы использовать и другие инстанции этого шаблона. Ну, скажем, max<float>(float,float) или даже max<MyFloatingPointClass>(MyFloatingPointClass,MyFloatingPointClass).
Каждая из этих различных инстанций порождает различный машинный код. Таким образом на то время, когда программа будет окончательна скомпонована, компилятор и компоновщик должны гарантировать, что код каждого используемого экземпляра шаблона включён в программу (и ни один неиспользуемый экземпляр шаблона не включён, чтобы не раздуть размер программы).
Как же это делается? Обычно есть два пути действия: либо прореживание повторяющихся инстанций либо откладывание инстанциирования до стадии компоновки (я обычно называю эти подходы как разумный путь и путь компании Sun).
Способ прореживания повторяющихся инстанций подразумевает, что каждый объектный файл содержит код всех повстречавшихся шаблонов. Например, для приведённого выше файла, содержимое объектного файла выглядит так:
Symbols from max_template.o:
Name Value Class Type Size Line Section
__gxx_personality_v0 | | U | NOTYPE| | |*UND*
double max<double>(double, double) |00000000| W | FUNC|00000041| |.text _Z3maxIdET_S0_S0_
int max<int>(int, int) |00000000| W | FUNC|00000021| |.text._Z3maxIiET_S0_S0_
main |00000000| T | FUNC|00000073| |.text
И мы видим присутствие обоих инстанций max<int>(int,int) и max<double>(double,double).
Оба определения помечены как слабые символы, и это значит, что компоновщик при создании конечного выполняемого файла может выкинуть все повторяющиеся инстанции одного и того же шаблона и оставить только одну (и если он посчитает нужным, то он может проверить действительно ли все повторяющиеся инстанции шаблона отображаются в один и тот же код). Самый большой минус в этом подходе — это увеличение размеров каждого отдельного объектного файла.
Другой подход (который используется в Solaris C++) — это не включать шаблонные определения в объектные файлы вообще, а пометить их как неопределённые символы. Когда дело доходит до стадии компоновки, то компоновщик может собрать все неопределённые символы, которые собственно относятся к шаблонным инстанциям, и потом сгенерировать машинный код для каждой из них.
Это определённо редуцирует размер каждого объектного файла, однако минус этого подхода проявляется в том, что компоновщик должен отслеживать где исходной код находится и должен уметь запускать C++ компилятор во время компоновки (что может замедлить весь процесс)
Динамически загружаемые библиотеки
Последняя особенность, которую мы здесь обсудим, — это динамическая загрузка разделяемых библиотек. В предыдущей главе мы видели, как использование разделяемых библиотек откладывает конечную компоновку до момента, когда программа собственно запускается. В современных ОС это даже возможно на более поздних стадиях.
Это осуществляется парой системных вызовов dlopen и dlsym (примерные эквиваленты в Windows соответственно называются LoadLibrary и GetProcAddress). Первый берёт имя разделяемой библиотеки и догружает её в адресное пространство запущенного процесса. Конечно, эта библиотека может также иметь неразрешённые символы, поэтому вызов dlopen может повлечь за собой подгрузку других разделяемых библиотек.
dlopen предлагает на выбор либо ликвидировать все неразрешённости сразу, как только библиотека загружена, (RTLD_NOW) либо разрешать символы по мере необходимости (RTLD_LAZY). Первый способ означает, что вызов dlopen может занять достаточно времени, однако второй способ закладывает определённый риск, что во время выполнения программы будет обнаружена неопределённая ссылка, которая не может быть разрешена — в этот момент программа будет завершена.
Конечно же, символы из динамически загружаемой библиотеки не могут иметь имени. Однако, это просто решается, также как решаются и другие программистские задачки, добавлением дополнительного уровня обходных путей. В этом случае используется указатель на пространство символа. Вызов dlsym принимает литеральный параметр, который сообщает имя символа, который нужно найти, и возвращает указатель на его местоположение (или NULL, если символ не найден).
Взаимодействие с C++
Процесс динамической загрузки достаточно прямолинеен, но как он взаимодействует с различными особенностями C++, которые воздействуют на всё поведение компоновщика?
Первое наблюдение касается декорирования имён. При вызове dlsym, передаётся имя символа, который нужно найти. Значит это должно быть версия имени, видимая компоновщику, т.е. декорированное имя.
Так как процесс декорирования может меняться от платформы к платформе и от компилятора к компилятору, это означает, что практически невозможно динамически найти C++ символ универсальным методом. Даже если Вы работаете только с одним компилятором и углубляетесь в его внутренний мир, существуют и другие проблемы — кроме простых C-подобных функций, есть куча других вещей (таблицы виртуальных методов и тому подобное), о которых тоже надо заботиться.
Подводя итог изложенному выше, отметим следующее: обычно лучше иметь одну заключённую в extern "C" точку вхождения, которая может быть найдена dlsym‘ом. Эта точка вхождения может быть фабричным методом, который возвращает указатели на все инстанции C++ класса, разрешая доступ ко всем прелестям C++.
Компилятор вполне может разобраться с конструкторами глобальных объектов в библиотеке, подгружаемой dlopen, так как есть парочка специальных символов, которые могут быть добавлены в библиотеку, и которые будут вызваны компоновщиком (неважно во время загрузки или исполнения), если библиотека динамически догружается или выгружается — то есть необходимые вызовы конструкторов или деструкторов могут произойти здесь. В Unix это функции _init и _fini, или для более новых систем, использующих GNU инструментарий существуют функции, маркированные как __attribute__((constructor)) или __attribute__((destructor)). В Windows соответствующая функция — DllMain с параметром DWORD fdwReason равным DLL_PROCESS_ATTACH или DLL_PROCESS_DETACH.
И в заключении добавим, что динамическая загрузка справляется отлично с «прореживанием повторяющихся инстанций», если речь идёт об инстанциировании шаблонов; и всё выглядит неоднозначно с «откладыванием инстанциирования», так как «стадия компоновки» наступает после того, как программа уже запущена (и вполне вероятно на другой машине, которая не хранит исходники). Обращайтесь к документации компилятора и компоновщика, чтобы найти выход из такой ситуации.
Дополнительно
В этой статье были намеренно пропущены многие детали о том, как компоновщик работает, потому что я считаю, что содержимое написанного покрывает 95% повседневных проблем, с которыми программист имеет дело при компоновке своей программы.
Если Вы хотите узнать больше, то можно почерпнуть информацию из ниже приведённых ссылок:
- John Levine, Linkers and Loaders: содержит огромнейшее количество информации о тонкостях работы компоновщика и загрузчика, включая все вещи, пропущенные в этой статье. Также существует онлайн-версия этой книги (или её черновик) здесь.
- Отличная ссылка на описание формата Mach-O для бинарников на Mac OS X.
- Peter Van Der Linden, Expert C Programming: отличная книга, включающая больше информации о том, как код, написанный на C, трансформируется в запускаемую программу, чем любой другой труд о C, прочитанный мной.
- Scott Meyers, More Effective C++: заметка 34 описывает ловушки, встречающиеся на пути комбинирования C и C++ в одной программе (касается не только работы компоновщика)
- Bjarne Stroustrup, The Design and Evolution of C++: в главе 11.3 обсуждается компоновка в C++ и как это происходит.
- Margaret A. Ellis & Bjarne Stroustrup, The Annotated C++ Reference Manual: глава 7.2c описывает конкретную схему декорирования имён
- ELF format reference [PDF]
- Две интересные статьи о создании легковесных выполняемых файлов в Linux и о минимальном Hello World в частности.
- «How To Write Shared Libraries» [PDF] небезызвестного Ulrich Drepper содержит больше деталей о ELF и переадресации.
Many thanks to Mike Capp and Ed Wilson for useful suggestions about this page.
Copyright © 2004-2005,2009-2010 David Drysdale
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.1 or any later version published by the Free Software Foundation; with no Invariant Sections, with no Front-Cover Texts, and with no Back-Cover Texts. A copy of the license is available here.
Причины возникновения ошибок:
-
некорректность текста (синтаксические ошибки);
-
некорректность компоновки (ошибки редактирования);
-
некорректность данных (семантические ошибки);
-
некорректность алгоритма (семантические ошибки).
Синтаксические ошибки проявляются на этапе компиляции (система программирования выводит сообщение об ошибке и указывает место в программе, содержащее ошибку).
После компиляции следует компоновка программы, при которой могут быть ошибки редактирования (неправильное использование подключаемых модулей).
Семантические ошибки могут проявляться как на этапе выполнения программы (до её завершения), так и после выполнения программы. К первым относятся такие ошибки, как, например, деление на ноль, выход за границы диапазона, нехватка памяти и т.п. О них выводится сообщение компилятором, что облегчает исправление. Семантические ошибки второго типа находить и исправлять гораздо сложнее, так как компилятор их не может найти (они связаны с погрешностями самого алгоритма).
Для поиска этих ошибок используются различные специальные приёмы. Они основаны на получении дополнительной информации о ходе вычислительного процесса.
Некоторые из этих приёмов:
-
Слежение:
-
трассировка – построчное выполнение программы (клавиши F7, F8 в Turbo Delphi);
-
математическое слежение – контроль за изменением значений определенных переменных в процессе расчёта (подсказки при наведении курсора на идентификатор при трассировке).
-
Печать в узлах – вывод значений заданных переменных в узловых точках программы (разветвление или схождение алгоритма, точки входа и выхода из подпрограммы и др.).
-
Прокрутка – вывод значений всех переменных используемых в программе после выполнения каждого оператора в программе.
Лекция 6.
Вычислительные комплексы и сети
Обработка информации при помощи ЭВМ развивается по двум направлениям:
-
с использованием вычислительных комплексов;
-
с использованием вычислительных сетей.
Вычислительные комплексы служат для повышения производительности и надежности обработки информации. Они объединяют несколько ЭВМ, территориально расположенных в одном месте, и делятся на два типа:
-
многомашинные комплексы (несколько самостоятельных ЭВМ, в том числе и резервных, объединенных общим управлением);
-
многопроцессорные комплексы (несколько процессоров, работающих с одной общей памятью с различными возможными типами доступа к ней).
Использование вычислительных комплексов позволяет разделить поставленную задачу на несколько подзадач (если это позволяет сама задача) и решать их параллельно.
Вычислительная или компьютерная сеть (КС) – это совокупность ПО и компьютеров, соединенных с помощью каналов связи и специального сетевого оборудования (см. далее) в единую систему для распределённой обработки данных.
Компьютерные сети могут классифицироваться по разным критериям. Например, по территориальному признаку, т.е. по масштабу охвата территории, сети делят на локальные (LAN – Local Area NetWork), региональные (MAN – Metropolia Area NetWork) и глобальные (WAN – Wide Area NetWork):
— локальные сети, как правило, размещаются в одном здании или на территории одного предприятия (примером локальной сети является локальная сеть в учебном классе);
— региональные сети объединяют несколько предприятий или город (примером сетей такого типа является сеть кабельного телевидения);
— глобальные сети охватывают значительную территорию, часто целую страну или континент, и представляют собой объединение сетей меньшего размера (примером глобальной сети является сеть Интернет).
Информация в сети передаётся по каналам связи, которые могут быть:
-
кабельными каналами (телефонный кабель, витая пара, коаксиальный кабель, оптоволоконный кабель);
-
радиоканалами.
Для подключения к сети используется специальное оборудование — устройства сопряжения, предназначенные для согласования сигналов внутреннего интерфейса ЭВМ с сигналами сети:
-
модемы (при подключении через телефонную сеть);
-
сетевые адаптеры (при подключении к одному каналу);
-
мультиплексоры (при подключении к нескольким каналам),
Компьютерные сети используются в следующих целях:
-
совместного использования ресурсов (данных, оборудования, программ);
-
обеспечения надёжного хранения данных (в разных местах);
-
для передачи данных между удалёнными друг от друга пользователями.
Взаимодействие в КС происходит по определенным правилам – протоколам, которые обеспечивают подключение к сети разнотипных ЭВМ с различными ОС.
Основные характеристики компьютерных сетей:
-
скорость передачи (Мбит/с);
-
достоверность передачи информации (ошибок/знак);
-
надёжность (среднее время безотказной работы в сетях).
Компьютеры сети могут быть серверами и клиентами (рабочими станциями).
Сервер – компьютер, обеспечивающий пользователей сети ресурсами (оборудованием, данными и программами, выполняющими задания пользователей). Серверы могут быть файловыми (предназначены для хранения и обработки большого объема данных для всех пользователей), выделенными (на них устанавливается общая сетевая ОС и общие внешние устройства – принтеры, модемы, винчестеры т.п.), а также – одновременно файловыми и выделенными.
Клиент – компьютер, через который пользователь получает доступ к сети.
Компьютеры, объединенные в локальную сеть, физически могут располагаться различным образом. Однако порядок их подсоединения к сети определяется топологией – усредненной геометрической схемой соединений узлов сети.
Наиболее распространенными топологиями локальных сетей, в которых передающей средой является кабель, являются кольцо, шина, звезда (рисунки 14, 15 и 16).
Топология кольцо предусматривает соединение узлов сети замкнутым контуром и используется для построения сетей, занимающих чаще всего сравнительно небольшое пространство. Выход одного узла сети соединяется с входом другого. Информация по кольцу передаются от узла к узлу в одном направлении. Каждый промежуточный узел ретранслирует посланное сообщение. Принимающий узел распознает и получает только адресованное ему послание.
Последовательная организация обслуживания узлов сети снижает ее быстродействие, а выход из строя одного из узлов может привести к нарушению функционирования кольца (при отсутствии дополнительного контура).

Рисунок 14 — Топология кольцо
При топологии шина узлы подключены к одной передающей линии — шине. Они передают свои сообщения по очереди в режиме распределенного по времени интерфейса. Сообщение от каждого узла распространяется по шине в обе стороны. Оно поступает на все узлы, но принимает его только тот узел, которому оно адресовано. Узлы не ретранслируют сообщение, поэтому выход из строя одного узла не приводит к нарушению функционирования сети. Производительность сети зависит от количества узлов в сети (при увеличении количества узлов она уменьшается), так как в каждый момент времени передачу может вести только один узел.

Рисунок 15 — Топология шина
При топологии звезда все устройства сети связаны с центральным узлом, который ретранслирует, коммутирует и маршрутизирует (находит путь от источника к приёмнику) все передаваемые данные. В качестве центрального узла может выступать либо концентратор (hub), который передаёт сообщение широковещательно (на все узлы), а воспринимает его только узел — приёмник, либо — коммутатор (switch), который передаёт сообщение только приёмнику (за счет чего повышается пропускная способность).
Данная топология значительно упрощает взаимодействие узлов сети друг с другом, но в то же время работоспособность локальной вычислительной сети зависит от надежности работы центрального узла.

Рисунок 16 — Топология звезда
При построении реальных вычислительных сетей используются эти топологии, а так же их сочетания.
Сеть Интернет
Сеть Интернет – глобальная компьютерная сеть, точнее — сообщество сетей. В состав его на добровольной основе входят различные региональные и локальные сети. У этого сообщества нет единого центра управления.
Протоколы Интернета можно разделить на два типа:
-
базовые (обеспечивают физическую передачу сообщений между узлами в сети – протоколы нижнего уровня):
-
протокол TCP — используется для управления передачей данных (регулировка, синхронизация, организация их в виде пакетов);
-
протокол IP — используется для определения адресов получателей сообщений;
-
прикладные (обеспечивают функционирование служб сети Интернет – протоколы высокого уровня):
-
протокол HTTP – служит для передачи гипертекстовых документов;
-
протокол FTP – используется для передачи файлов;
-
протокол SMTP – используется для передачи электронной почты.
Каждому компьютеру, подключенному к сети Интернет (даже временно), присваивается числовой адрес, называемый IP-адресом. IP-адрес содержит информацию, необходимую для идентификации узла в сети. Он состоит из четырех чисел, разделенных точками.
IP-адрес трудно запоминаем пользователем, поэтому некоторые узлы в сети Интернет имеют символьные DNS-адреса (Domain Name System – система доменных имен), например, www.site.net. В сети Интернет существуют специальные DNS-серверы, которые по DNS-адресу выдают его IP-адрес. DNS-адрес может иметь произвольную длину, образуется как символьный адрес в локальной сети и включает в себя несколько уровней доменов. Уровни доменов разделяются точками. Самый правый домен – домен верхнего уровня. Чем левее домен, тем ниже его уровень.
Для доступа к ресурсам расположенных в сети компьютеров используется унифицированный указатель ресурса – URL (Uniform Resource Locator). Адрес URL является сетевым расширением понятия полного имени ресурса, например, файла или приложения и пути к нему в ОС. В адресе URL, кроме имени файла и директории, где он находится, указывается сетевое имя компьютера, на котором этот ресурс расположен, и протокол доступа к ресурсу, который можно использовать для обращения к нему. Ресурсы предоставляются только для чтения и копирования.
Информация в сети передается небольшими порциями – пакетами (группами байт фиксированной длины). Любой Клиент и любой Сервер умеют преобразовывать поток передаваемой информации в набор отдельных пакетов и «склеивать» полученные пакеты обратно в поток информации. Обычно размер пакетов в сети небольшой — от нескольких байт до нескольких килобайт.
Каждый пакет состоит из заголовка и информационной части. Заголовок — это аналог почтового конверта. В заголовке указывается, кому и от кого этот пакет передан — адрес отправителя пакета и адрес получателя, а также иная служебная информация, необходимая для успешной «склейки» пакетов получателем. В информационной части — собственно сама передаваемая информация. Адреса отправителя/получателя в заголовке пакета используется сетевым оборудованием для определения — куда какой пакет отправлять.
Применение пакетной передачи данных позволяет повысить надежность передачи информации и строить сеть таким образом, что маршруты доставки от одной точки сети до другой пакетов информации могут проходить по разным физическим каналам связи и, меняться в зависимости от их работоспособности или загрузки. Это значительно увеличивает «живучесть» сети в целом — даже если часть каналов связи будут неработоспособными, информация все равно может быть доставлена по другим работающим каналам.
Классификация ошибок
Отладка – это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
В целом сложность отладки обусловлена следующими причинами:
- требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
- психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
- возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
- отсутствуют четко сформулированные методики отладки.
В соответствии с этапом обработки, на котором проявляются ошибки, различают:
- синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы;
- логические ошибки — …;
- ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
- ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых.
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами, обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
- появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
- появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
- «зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
- несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
- неверное определение исходных данных,
- логические ошибки,
- накопление погрешностей результатов вычислений.

Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
- ручного тестирования;
- индукции;
- дедукции;
- обратного прослеживания.
Метод ручного тестирования
Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которыми была обнаружена ошибка. Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций. Данный метод часто используют как составную часть других методов отладки.
Метод индукции
Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рисунке в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о её проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов. В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции
По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину.
Метод обратного прослеживания
Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Методы и средства получения дополнительной информации
Для получения дополнительной информации об ошибке можно выполнить добавочные тесты или использовать специальные методы и средства:
- отладочный вывод;
- интегрированные средства отладки;
- независимые отладчики.
Отладочный вывод. Метод требует включения в программу дополнительного отладочного вывода в узловых точках. Узловыми считают точки алгоритма, в которых основные переменные программы меняют свои значения. Например, отладочный вывод следует предусмотреть до и после завершения цикла изменения некоторого массива значений. (Если отладочный вывод предусмотреть в цикле, то будет выведено слишком много значений, в которых, как правило, сложно разбираться.) При этом предполагается, что, выполнив анализ выведенных значений, программист уточнит момент, когда были получены неправильные значения, и сможет сделать вывод о причине ошибки.
Данный метод не очень эффективен и в настоящее время практически не используется, так как в сложных случаях в процессе отладки может потребоваться вывод большого количества — «трассы» значений многих переменных, которые выводятся при каждом изменении. Кроме того, внесение в программы дополнительных операторов может привести к изменению проявления ошибки, что нежелательно, хотя и позволяет сделать определенный вывод о ее природе.
Примечание. Ошибки, исчезающие при включении в программу или удалению из нее каких-либо «безобидных» операторов, как правило, связаны с «затиранием» памяти. В результате добавления или удаления операторов область затирания может сместиться в другое место и ошибка либо перестанет проявляться, либо будет проявляться по-другому.
Интегрированные средства отладки. Большинство современных сред программирования (Delphi, Builder C++, Visual Studio и т. д.) включают средства отладки, которые обеспечивают максимально эффективную отладку. Они позволяют:
- выполнять программу по шагам, причем как с заходом в подпрограммы, так и выполняя их целиком;
- предусматривать точки останова;
- выполнять программу до оператора, указанного курсором;
- отображать содержимое любых переменных при пошаговом выполнении;
- отслеживать поток сообщений и т. п.
Отладка с использованием независимых отладчиков.
При отладке программ иногда используют специальные программы — отладчики, которые позволяют выполнить любой фрагмент программы в пошаговом режиме и проверить содержимое интересующих программиста переменных. Как правило такие отладчики позволяют отлаживать программу только в машинных командах, представленных в 16-ричном коде.
Общая методика отладки программного обеспечения
Суммируя все сказанное выше, можно предложить следующую методику отладки программного обеспечения:
1 этап — изучение проявления ошибки — если выдано какое-либо сообщение или выданы неправильные или неполные результаты, то необходимо их изучить и попытаться понять, какая ошибка могла так проявиться. При этом используют индуктивные и дедуктивные методы отладки. В результате выдвигают версии о характере ошибки, которые необходимо проверить. Для этого можно применить методы и средства получения дополнительной информации об ошибке. Если ошибка не найдена или система просто «зависла», переходят ко второму этапу.
2 этап — локализация ошибки — определение конкретного фрагмента, при выполнении которого произошло отклонение от предполагаемого вычислительного процесса. Локализация может выполняться:
- путем отсечения частей программы, причем, если при отсечении некоторой части программы ошибка пропадает, то это может означать как то, что ошибка связана с этой частью, так и то, что внесенное изменение изменило проявление ошибки;
- с использованием отладочных средств, позволяющих выполнить интересующих нас фрагмент программы в пошаговом режиме и получить дополнительную информацию о месте проявления и характере ошибки, например, уточнить содержимое указанных переменных.
При этом если были получены неправильные результаты, то в пошаговом режиме проверяют ключевые точки процесса формирования данного результата. Как подчеркивалось выше, ошибка не обязательно допущена в том месте, где она проявилась. Если в конкретном случае это так, то переходят к следующему этапу.
3 этап — определение причины ошибки — изучение результатов второго этапа и формирование версий возможных причин ошибки. Эти версии необходимо проверить, возможно, используя отладочные средства для просмотра последовательности операторов или значений переменных.
4 этап — исправление ошибки — внесение соответствующих изменений во все операторы, совместное выполнение которых привело к ошибке.
5 этап — повторное тестирование — повторение всех тестов с начала, так как при исправлении обнаруженных ошибок часто вносят в программу новые.
Следует иметь в виду, что процесс отладки можно существенно упростить, если следовать основным рекомендациям структурного подхода к программированию:
- программу наращивать «сверху-вниз», от интерфейса к обрабатывающим подпрограммам, тестируя ее по ходу добавления подпрограмм;
- выводить пользователю вводимые им данные для контроля и проверять их на допустимость сразу после ввода;
- предусматривать вывод основных данных во всех узловых точках алгоритма (ветвлениях, вызовах подпрограмм).
Кроме того, следует более тщательно проверять фрагменты программного обеспечения, где уже были обнаружены ошибки, так как вероятность ошибок в этих местах по статистике выше. Это вызвано следующими причинами. Во-первых, ошибки чаще допускают в сложных местах или в тех случаях, если спецификации на реализуемые операции недостаточно проработаны. Во-вторых, ошибки могут быть результатом того, что программист устал, отвлекся или плохо себя чувствует. В-третьих, как уже упоминалось выше, ошибки часто появляются в результате исправления уже найденных ошибок.
Источник:
1. Причины и типы ошибок
ПРИЧИНЫ И ТИПЫ ОШИБОК
2. Классификация ошибок по причине возникновения
• синтаксические ошибки;
• семантические ошибки;
• логические ошибки.
3. Синтаксические ошибки
это ошибки, возникающие в связи с
нарушением синтаксических правил
написания предложений используемого
языка программирования (к таким ошибкам
относятся пропущенные точки с запятой,
ссылки на неописанные переменные,
присваивание переменной значений
неверного типа и т. д.).
4. Семантические ошибки
• Причина возникновения ошибок данного
типа связана с нарушением семантических
правил написания программ (примером
являются ситуации попытки открыть
несуществующий файл или выполнить
деление на нуль).
5. Логические ошибки
• связаны с неправильным применением тех
или иных алгоритмических конструкций.
• Эти ошибки при выполнении программы могут
проявиться явно (выдано сообщение об
ошибке, нет результата или выдан неверный
результат, программа «зацикливается»), но
чаще они проявляют себя только при
определенных сочетаниях параметров или
вообще не вызывают нарушения работы
программы, которая в этом случае выдает
правдоподобные, но неверные результаты.
6. Классификация ошибок по этапу обработки программы
Ошибки, которые могут быть в программе,
принято делить на три группы:
• ошибки компиляции;
• ошибки компоновки;
• ошибки выполнения.
7.
Ошибки компиляции
Ошибки компиляции (Compile-time error) – ошибки,
фиксируемые компилятором (транслятором, интерпретатором)
при выполнении синтаксического и частично семантического
анализа программы;
Наиболее легко устранимы.
Их обнаруживает компилятор, а программисту остается только
внести изменения в текст программы и выполнить повторную
компиляцию.
Компилятор просматривает программу от начала. Если
обнаруживается
ошибка,
то
процесс
компиляции
приостанавливается и в окне редактора кода выделяется строка,
которая, по мнению компилятора, содержит ошибочную
конструкцию.
8.
Ошибки компиляции
В нижнюю часть окна редактора кода компилятор выводит сообщения об
ошибках. Первая ошибка – это первая от начала текста программы
синтаксическая ошибка, обнаруженная компилятором. Наличие в тексте даже
одной синтаксической ошибки приводит к возникновению второй, фатальной
ошибки (Fatal Error) – невозможности генерации исполняемой программы.
9. Наиболее типичные ошибки компиляции
Сообщения компилятора
Undeclared identifier
(Необъявленный
идентификатор)
Вероятная причина
Используется переменная, не объявленная в
разделе var программы;
Ошибка при написании имени переменной;
Ошибка при написании имени инструкции
(оператора).
Unterminated string
При записи строковой константы не
(Незавершенная строка)
поставлена завершающая кавычка.
Incompaible types … and В операторе присваивания тип выражения
…
не соответствует или не может быть
(Несовместимые типы)
приведен к типу переменной, получающей
значение выражения.
Missing operator or
Не поставлена точка с запятой после
semicolon
инструкции программы.
(Отсутствует оператор или точка
с запятой)
10. Ошибки компоновки
Ошибки компоновки – ошибки, обнаруженные
компоновщиком (редактором связей) при объединении
модулей программы.
Эти ошибки связаны с проблемами, обнаруженными при
разрешении внешних ссылок. Например, предусмотрено
обращение к подпрограмме другого модуля, а при
объединении модулей данная подпрограмма не найдена
или не стыкуются списки параметров.
В большинстве случаев ошибки такого рода также
удается быстро локализовать и устранить.
11. Ошибки выполнения
Ошибки выполнения – ошибки, обнаруженные
операционной системой, аппаратными средствами или
пользователем при выполнении программы.
Могут иметь разную природу, и соответственно поразному проявляться.
Часть ошибок обнаруживается и документируется
операционной системой.
12. Ошибки выполнения
Выделяют четыре способа проявления таких ошибок:
появление сообщения об ошибке, зафиксированной схемами
контроля выполнения машинных команд, например,
переполнении разрядной сетки, нарушении адресации и
т.п.;
появление
сообщения
об
ошибке,
обнаруженной
операционной системой, например, нарушении защиты
памяти, попытке записи на устройства, защищенные от
записи, отсутствии файла с заданным именем и т.п.;
«зависание» компьютера, как простое, когда удается
завершить программу без перезагрузки операционной
системы, так и «тяжелое», когда для продолжения работы
необходима перезагрузка;
несовпадение полученных результатов с ожидаемыми.
13. Причины ошибок выполнения
Все возможные причины ошибок можно разделить на
следующие группы:
• неверное определение исходных данных,
• логические ошибки,
• накопление погрешностей результатов вычислений.
14. Причины ошибок выполнения
15. Предотвращение и обработка исключений
• При
разработке
проекта
программист
должен
предусмотреть все возможные варианты некорректных
действий пользователя, которые могут привести к
возникновению ошибок времени выполнения, и
обеспечить способы защиты от них.
16. Предотвращение и обработка исключений
Инструкция обработки исключения в общем виде:
try // инструкции, выполнение которых может вызвать
исключение
except // начало секции обработки исключений
on ТипИсключения1 do Обработка1;
on ТипИсключения2 do Обработка2;
…;
else // инструкции обработки остальных исключений
end;
17. Предотвращение и обработка исключений
где:
• try — ключевое слово, обозначающее, что далее следуют
инструкции, при выполнении которых возможно
возникновение исключений, и что обработку этих
исключений берет на себя программа;
• except — ключевое слово, обозначающее начало секции
обработки исключений. Инструкции этой секции будут
выполнены, если в программе возникнет ошибка;
• on — ключевое слово, за которым следует тип
исключения, обработку которого выполняет инструкция,
следующая за do;
• else — ключевое слово, за которым следуют инструкции,
обеспечивающие обработку исключений, тип которых не
указаны в секции except.
18. Типичные исключения
Тип
исключения
Возникает
EZeroDivide
При выполнении операции деления, если
делитель равен нулю
EConvertError
При выполнении преобразования, если
преобразуемая величина не может быть
приведена к требуемому виду. Наиболее часто
возникает при преобразовании строки символов в
число
EFilerError
При обращении к файлу. Наиболее частой
причиной является отсутствие требуемого файла
или, в случае использования сменного диска,
отсутствие диска в накопителе
19. Пример: Обработка исключения типа EZeroDivide
procedure TForm1.Button1Click(Sender: TObject);
Var u, r, i: real; // напряжение , сопротивление, ток
begin
Labels.Caption := ‘ ‘;
try // инструкции, которые могут вызвать исключение (ошибку)
u := StrToFloat(Edit1.Text);
r := StrToFloat(Edit2.Text);
i := u/r;
except // секция обработки исключений
onEZeroDivide do // деление на ноль
begin
ShowMessage(‘Сопротивление не может быть равно нулю!’);
exit;
end;
on EConvertError do // ошибка преобразования строки в число
begin
ShowMessage(‘Напряжение и сопротивление должны быть заданы числом. ‘ );
exit;
end; end;
20. Отладка и тестирование
ОТЛАДКА И ТЕСТИРОВАНИЕ
21.
Немного истории
Долгое время было принято считать, что целью тестирования
является доказательство отсутствия ошибок в программе.
Но полный
перебор
всех
возможных
вариантов
выполнения
программы
находится
за
пределами
вычислительных возможностей даже для очень небольших
программ.
«Тестирование – это процесс выполнения программ с
целью обнаружения ошибок».
Гленфорд Майерс
Майерс, Г. Искусство тестирования программ, 1982
22.
Немного истории
До начала 80-х годов процесс тестирования программного
обеспечения (ПО) был разделен с процессом разработки: вначале
программисты реализовывали заданную функциональность, а
затем тестировщики приступали к проверке качества созданных
программ.
Проблемы:
• разработка программ может оказаться достаточно длительной –
чем в это время должны заниматься тестировщики?
• Плохая предсказуемости результатов такого процесса разработки.
Ключевой вопрос: сколько времени потребуется на завершение
продукта, в котором существует 500 известных ошибок?
23.
Немного истории
Статистика:
Даже
однострочное
изменение
в
программе
с
вероятностью 55 % либо не исправляет старую ошибку,
либо вносит новую. Если же учитывать изменения любого
объема, то в среднем менее 20 % изменений корректны с
первого раза.
24.
Немного истории
В 90-х годах появилась другая методика разработки
(zero-defect mindset), основная идея которой заключается в
том, что качество программ проверяется постоянно в
процессе разработки.
Тестирование становится центральной частью любого
процесса разработки программ
Данная методика предъявляет существенно более высокие требования к
квалификации инженера тестирования: в сферу его ответственности
попадает не только функциональное тестирование, но и организация
процесса разработки (процесс ежедневной сборки, участие в инспекциях,
сквозных просмотрах и обычное чтение исходных текстов тестируемых
программ). Поэтому идеальной кандидатурой на позицию тестировщика
становится наиболее опытный программист в команде.
25. Зависимость вероятности правильного исправления ошибок и стоимости исправления ошибок от этапа разработки
Многократно проводимые исследования показали, что чем
раньше обнаруживаются те или иные несоответствия или
ошибки, тем больше вероятность их правильного
исправления (рис. а) и ниже его стоимость (рис. б).
26.
Основные понятия, связанные с
тестированием и отладкой
Отладка программного средства – это деятельность,
направленная на обнаружение и исправление ошибок в ПС с
использованием процессов выполнения его программ.
Тестирование программного средства — процесс выполнения
программ на некотором наборе данных, для которого заранее
известен результат применения или известны правила поведения
этих программ.
Отладка = Тестирование + Поиск ошибок + Редактирование
27.
Основные понятия, связанные с
тестированием и отладкой
Процесс отладки включает:
• действия, направленные на выявление ошибок
(тестирование);
• диагностику и локализацию ошибок (определение
характера ошибок и их местонахождение);
• внесение исправлений в программу с целью устранения
ошибок (редактирование).
Отладка = Тестирование + Поиск ошибок + Редактирование
Самым трудоемким и дорогим является тестирование,
затраты на которое приближаются к 45% общих затрат на
разработку ПС и от 30 до 60% общей трудоемкости создания
программного продукта.
28.
Две задачи тестирования
Первая задача тестирования – подготовить набор тестов и
применить к ним ПС, чтобы обнаружить в нём по возможности
большее число несоответсвий.
Вторая задача тестирования — определить момент окончания
отладки ПС (или отдельной его компоненты).
29.
Для повышения качества тестирования рекомендуется
соблюдать следующие основные принципы:
• предполагаемые результаты должны быть известны до
тестирования;
• следует избегать тестирования программы автором;
• необходимо досконально изучать результаты каждого
теста;
• необходимо проверять действия программы на неверных
данных;
• необходимо проверять программу на неожиданные
побочные эффекты на неверных данных.
30. Требования к программному продукту и тестирование
Разработка любого программного продукта начинается с
выявления требований к этому продукту.
Спецификация (англ. Software Requirements Specification, SRS) документ, в котором отражены все требования к продукту описываются, как функциональные (что должна делать
программа, варианты взаимодействия между пользователями
и программным обеспечением), так и нефункциональные
(например, на каком оборудовании должна работать
программа,
производительность, стандарты качества)
требования.
31. Рекомендуемая стандартом IEEE 830 структура SRS
Введение
– Цели
– Соглашения о терминах
– Предполагаемая аудитория и последовательность восприятия
– Масштаб проекта
– Ссылки на источники
Общее описание
– Видение продукта
– Функциональность продукта
– Классы и характеристики пользователей
– Среда функционирования продукта (операционная среда)
– Рамки, ограничения, правила и стандарты
– Документация для пользователей
– Допущения и зависимости
Функциональность системы
– Функциональный блок X (таких блоков может быть несколько)
• Описание и приоритет
• Причинно-следственные связи, алгоритмы
• Функциональные требования
32. Рекомендуемая стандартом IEEE 830 структура SRS (продолжение)
Требования к внешним интерфейсам
– Интерфейсы пользователя (UX)
– Программные интерфейсы
– Интерфейсы оборудования
– Интерфейсы связи и коммуникации
Нефункциональные требования
– Требования к производительности
– Требования к сохранности (данных)
– Критерии качества программного обеспечения
– Требования к безопасности системы
Прочие требования
– Приложение А: Глоссарий
– Приложение Б: Модели процессов и предметной области и другие
диаграммы
– Приложение В: Список ключевых задач
33.
Подходы к выработке стратегии
проектирования тестов
1. Тестирование по отношению к спецификациям функциональный подход
2. Тестирование по отношению к текстам программ структурный подход
34. Стратегия проектирования тестов
В тестирование ПС входят
• постановка задачи для теста,
• проектирование,
• написание тестов,
• выполнение тестов,
• изучение результатов тестирования.
35.
По объекту тестирования
Функциональное тестирование
Тестирование производительности
Нагрузочное тестирование
Стресс-тестирование
Тестирование стабильности
Конфигурационное тестирование
Юзабилити-тестирование
Тестирование интерфейса пользователя
Тестирование безопасности
Тестирование локализации
Тестирование совместимости
По знанию системы
Тестирование чёрного ящика
Тестирование белого ящика
Тестирование серого ящика
По степени автоматизации –
Ручное тестирование
Автоматизированное тестирование
Полуавтоматизированное тестирование
По степени изолированности компонентов
Модульное тестирование
Интеграционное тестирование
Системное тестирование
По времени проведения тестирования
Альфа-тестирование
Дымовое тестирование
Тестирование новой функции
Подтверждающее тестирование
Регрессионное тестирование
Приёмочное тестирование
Бета-тестирование
По признаку позитивности сценариев
Позитивное тестирование
Негативное тестирование
По степени подготовленности к
тестированию
Тестирование по документации
(формальное тестирование)
Интуитивное тестирование (англ. ad hoc
testing)
36.
Подходы к выработке стратегии
проектирования тестов
Функциональный подход основывается на том, что
структура программного обеспечения не известна (программа
рассматривается как «черный ящик»). В этом случае тесты
проектируют, исследуя внешние спецификации или
спецификации сопряжения программы или модуля, которые
он тестирует.
Логика проектировщика тестов такова: «Меня не
интересует, как выглядит эта программа, и выполнил ли я все
команды. Я удовлетворен, если программа будет вести себя
так, как указано в спецификациях».
В идеале — проверить все возможные комбинации
и значения на входе.
37.
Подходы к выработке стратегии
проектирования тестов
Структурный подход базируется на том, что известна
структура тестируемого программного обеспечения, в том
числе его алгоритмы («стеклянный ящик»). В этом случае
тесты строят так, чтобы проверить правильность реализации
заданной логики в коде программы.
Проектировщики
тестов
стремятся
подготовить
достаточное число тестов, чтобы каждая команда была
выполнена, хотя бы, один раз. Чтобы каждая команда
условного перехода выполнялась в каждом направлении
хотя бы раз.
В идеале — проверить каждый путь, каждую ветвь
алгоритма.
38.
Подходы к выработке стратегии
проектирования тестов
Тестирование
по отношению
к спецификациям
Тестирование
по отношению
к текстам программ
Оптимальная
стратегия
Оптимальная
стратегия
проектирования
тестов
расположена внутри интервала между этими крайними
подходами, но ближе к левому краю
Наборы тестов, полученные в соответствии с методами
этих
подходов,
обычно
объединяют,
обеспечивая
всестороннее тестирование программного обеспечения.
39.
Критерии полноты тестирования
40.
Критерии полноты тестирования
Только на основании выбранного критерия можно определить
тот момент времени, когда конечное множество тестов
окажется достаточным для проверки программы с некоторой
полнотой (степень полноты, определяется экспериментально).
Используется два вида критериев: критерии черного и белого
ящика.
Соответственно тесты делятся на функциональные и
структурные.
• функциональные тесты составляются исходя
из спецификации программы;
• структурные тесты составляются исходя из
текста программы.
41. Критерии полноты тестирования
• Функциональные критерии:
• Структурные критерии:
1)
2)
3)
4)
5)
Покрытие операторов
Покрытие условий
Покрытие путей
Покрытие функций
Покрытие вход/выход
42. Критерии полноты тестирования
Критерий тестирования функций
43. Критерии полноты тестирования
Критерии тестирования входных и
выходных данных
44. Критерий тестирования функций
Критерии тестирования входных и
выходных данных
• Пример. Программа для учета кадров предприятия
45. Критерии тестирования входных и выходных данных
Тестирование области допустимых значений
Процесс тестирования области допустимых значений
можно разделить на три этапа:
1. Проверка в нормальных условиях.
2. Проверка в экстремальных условиях.
3. Проверка в исключительных ситуациях.
Проверка в нормальных условиях
Проверка в нормальных условиях предполагает тестирование на основе
данных, которые характерны для реальных условий функционирования
программы. Проверка в нормальных условиях должна показать, что
программа выдает правильные результаты для характерных
совокупностей данных.
46. Критерии тестирования входных и выходных данных
• Проверка в экстремальных условиях
Тестовые данные этого этапа включают граничные значения области
изменения входных переменных, которые должны восприниматься
программой как правильные данные.
Для нецифровых данных необходимо использовать подобные
типичные символы, охватывающие все возможные ситуации.
Для цифровых данных в качестве экстремальных условий следует
брать начальное и конечное значения допустимой области
изменения переменной при одновременном изменении длины
соответствующего поля от минимальной до максимальной.
Типичными примерами таких экстремальных значений являются
очень большие числа, очень малые числа и отсутствие
информации.
Каждая
программа
характеризуется
своими
собственными экстремальными данными, которые должны
подбираться программистом.
47. Критерии тестирования входных и выходных данных
Проверка в экстремальных условиях (продолжение)
Особый интерес представляют так называемые нулевые примеры.
Для цифрового ввода — это обычно нулевые значения вводимых
данных; для последовательностей символов — это цепочка пробелов
или нулей.
Нулевые примеры представляют собой один из лучших тестов,
поскольку они имитируют состояние данных, которое время от
времени имеет место в реальных условиях эксплуатации программы.
Если подобное тестирование не выполняется, то впоследствии часто
приходится сталкиваться с непонятным поведением программы.
48. Критерии тестирования входных и выходных данных
• Проверка в исключительных ситуациях.
проводится с использованием данных, значения которых
лежат за пределами допустимой области изменения.
Например:
• Что произойдет, если программе, не рассчитанной на обработку
отрицательных или нулевых значений переменных, в результате
какой-либо ошибки придется иметь дело как раз с такими данными?
• Как будет вести себя программа, работающая с массивами, если
количество их элементов превысит величину, указанную в описании?
• Что случится, если цепочки символов окажутся длиннее или короче,
чем это предусмотрено?
49. Критерии тестирования входных и выходных данных
Структурные критерии
Структурные критерии — критерии покрытия кода.
Покрытие кода — мера, используемая при тестировании
программного обеспечения. Она показывает процент, насколько
исходный код программы был протестирован.
• Покрытие операторов — каждая ли строка исходного кода была
выполнена и протестирована?
• Покрытие условий — каждая ли точка решения (вычисления
истинно ли или ложно выражение) была выполнена и
протестирована?
• Покрытие путей — все ли возможные пути через заданную
часть кода были выполнены и протестированы?
• Покрытие функций — каждая ли функция программы была
выполнена
• Покрытие вход/выход — все ли вызовы функций и возвраты из
них были выполнены
50. Критерии тестирования входных и выходных данных
Пример. Показывает отличие количества тестов при различных выбранных
структурных критериях.
В случае выбора критерия «Покрытие операторов» достаточен 1 тест
(рис.а)
В случае выбора критерия «Покрытие условий» достаточно двух тестов,
покрывающих пути 1, 4 или 2, 3 (рис.б)
В случае выбора критерия «Покрытие путей необходимо четыре теста
для всех четырех путей (рис.б)
51. Структурные критерии
Покрытие операторов
Пример 1
If ((A>1) and (B =0))
then X := X/A;
If ((A=2) or (X>1))
then X:=X+1;
Можно выполнить каждый оператор,
записав один-единственный тест,
который реализовал бы путь асе.
Иными словами, если бы в точке а были
установлены значения А = 2, В = 0 и Х =
3, каждый оператор выполнялся бы
один раз (в действительности Х может
принимать любое значение)
52.
Покрытие операторов
Пример 2
53. Покрытие операторов
Покрытие условий
Пример 1
If ((A>1) and (B =0))
then X = X/A;
If ((A=2) or (X>1))
then X:=X+1;
Покрытие условий может быть выполнено двумя тестами,
покрывающими либо пути асе и abd, либо пути acd и abe.
Если мы выбираем последнее альтернативное покрытие, то входами двух тестов являются A = 3, В = 0, Х = 1 и A = 2, В = 1, Х = 1.
54. Покрытие операторов
Покрытие условий
Пример 2
a:=7;
while a>x do a:=a-1;
b:=1/a;
a:=7
a>x
—
b:=1/a
+
a:=a-1
Для того чтобы удовлетворить критерию покрытия ветвей в данном
случае достаточно одного теста. Например такого, чтобы х был равен
6 или 5. Все ветви будут пройдены. Но ошибка в программе
обнаружена так и не будет. Она проявится в единственном случае,
когда х=0. Но такого теста от нас критерий покрытия ветвей не
требует.
55. Покрытие условий
Покрытие путей
Пример 1
If ((A>1) and (B =0))
then X = X/A;
If ((A=2) or (X>1))
then X:=X+1;
Покрытие путей (все возможные пути
через заданную часть кода должны быть
выполнены и протестированы) может быть
выполнено четырьмя тестами:
a,c,e – A=2, B=0, X=3
a,b,e – A=2, B=1, X=1
a,b,d – A=3, B=1, X=1
a,c,d – A=3, B=0, X=1
56. Покрытие условий
Покрытие путей
a
Пример 1
If ((A>1) and (B =0))
then X = X/A;
If ((A=2) or (X>1))
then X:=X+1;
c
b
е
d
57. Покрытие путей
Критерий комбинаторного покрытия условий
Пример 2
If (a=0) or (b=0) or (c=0)
Then d:=1/(a+b)
Else d:=1;
Ошибка будет выявлена только при a=0 и b=0.
Критерий покрытия путей не гарантирует
проверки такой ситуации.
Для решения этой проблемы был предложен критерий комбинаторного
покрытия условий, который требует подобрать такой набор тестов, чтобы
хотя бы один раз выполнялась любая комбинация простых условий.
Критерий значительно более надежен, чем покрытие путей, но обладает
двумя существенными недостатками.
• Во-первых, он может потребовать очень большого числа тестов.
Количество тестов, необходимых для проверки комбинаций n простых
условий, равно 2n.
• Во-вторых, даже комбинаторное покрытие условий не гарантирует
надежную проверку циклов.
58. Покрытие путей
Уровни тестирования
• Модульное тестирование (автономное тестирование,
юнит-тестирование) — тестируется минимально
возможный для тестирования компонент, например,
отдельный класс или функция. Часто модульное
тестирование осуществляется разработчиками ПО.
• Интеграционное тестирование — тестируются
интерфейсы между компонентами, подсистемами. При
наличии резерва времени на данной стадии тестирование
ведётся итерационно, с постепенным подключением
последующих подсистем.
• Системное тестирование — тестируется интегрированная
система на её соответствие требованиям.
59.
Основные этапы разработки
сценария автономного тестирования
1. На основании спецификации отлаживаемого модуля
подготовить тесты для
– каждой логической возможности ситуации;
– каждой границы областей возможных значений всех
входных данных;
– каждой области недопустимых значений;
– каждого недопустимого условия.
2. Проверить текст модуля, чтобы убедиться, что каждое
направление любого разветвления будет пройдено хотя
бы один раз. Добавить недостающие тесты.
60. Два основных вида тестирования
Основные этапы разработки
сценария автономного тестирования
3. Проверить текст модуля, чтобы убедиться, что для
каждого цикла существуют тесты, обеспечивающие, по
крайней мере, три следующие ситуации
– тело цикла не выполняется ни разу;
– тело цикла выполняется один раз;
– тело цикла выполняется максимальное число раз;
4. Проверить текст модуля, чтобы убедиться, что существуют
тесты, проверяющие чувствительность к отдельным
особым значениям входных данных. Добавить
недостающие тесты.
61. Уровни тестирования
Основная особенность практики
тестирования ПС
По мере роста числа обнаруженных и исправленных
ошибок в ПС растёт также относительная вероятность
существования в нём необнаруженных ошибок.
Это подтверждает важность предупреждения ошибок на
всех стадиях разработки ПС.
62. Основные этапы разработки сценария автономного тестирования
Творческая работа
1. Разделиться на группы
2. Получить тему (практические работы по Delphi №№ 3, 5, 7,
9, 10)
3. Составить спецификацию
4. Разработать программу тестирования:
4.1. Определить виды тестирования
4.2. Определить объекты тестирования
4.3. Определить субъекты тестирования
4.4. Определить классы входных данных
4.5. Написать тест-кейсы для тестирования функций и ожидаемые
результаты
4.6. Написать тест-кейсы для структурного тестирования и
ожидаемые результаты
Составить чек-листы для проведения всех видов тестирования
5. Провести тестирование
6. Сделать выводы
63. Основные этапы разработки сценария автономного тестирования
Содержание ПЗ к проекту
Титульный лист
Бриф
Спецификация
ТЗ
Пользователи
Интерфейсы
Информационно-логическая схема
Схема БД
Алгоритм одной процедуры
Программа тестирования
Результаты тестирования
Пример неправильной компоновки c явным относительным размером:

В этом примере для надписи задана высота 100%. При этом у контейнера VBox по умолчанию используется высота AUTO, то есть по содержимому.
Пример неправильной компоновки c expand:

Expand неявно задаёт относительную высоту 100% для label, что, как и в примере выше, неверно. В таких случаях экран может выглядеть некорректно, часть компонентов может пропадать или иметь нулевые размеры. При возникновении проблем с компоновкой в первую очередь проверьте правильность указания относительных размеров.
Какие существуют методы анализа и локализации ошибки
Под тестированием следует понимать процесс исполнения программы с целью обнаружения ошибок, в качестве которых принимается любое отклонение от эталонов. Хорошим считается тест, который имеет высокую вероятность обнаружения еще не выявленных ошибок.
Под отладкой понимается процесс, позволяющий получить программу, функционирующую с требуемыми характеристиками в заданной области входных данных. Таким образом, в результате отладки программа должна соответствовать некоторой фиксированной совокупности правил и показателей качества, принимаемой за эталонную для данной программы.
Существует три основных способа тестирования:
Алгоритмическое тестирование применяется для контроля этапов алгоритмизации и программирования. Проектируются тесты и начинаются готовиться эталонные результаты на этапе алгоритмизации, а используются они на этапе отладки.
Функциональное или аналитическое тестирование
Аналитическое тестирование служит для контроля выбранного метода решения задачи, правильности его работы в выбранных режимах и с установленными диапазонами данных. Тесты проектируют и начинают готовить сразу после выбора метода, а используют их на последнем этапе отладки, в ходе тестирования, наряду со сверкой на совпадение, применяются и качественные оценки результатов.
Содержательное тестирование служит для проверки правильности постановки задачи. Для контроля при этом используются, как правило, качественные оценки и статистические характеристики программы, физический смысл полученных результатов и т.п. в проведении содержательного тестирования, принципы которого формулируются в техническом задании, самое активное участие должны принимать заказчики или идущие пользователи программы.
Содержательные и аналитические тесты проверяют правильность работы программы в целом или крупных ее частей, в то время как алгоритмические тесты в первую очередь должны проверять работу отдельных блоков или операторов программы.
Тот вид контроля, который рассматривался выше, можно назвать тестированием основных функциональных возможностей программы — основной тест.
Этот тест затрагивает работу программы в самой минимальной степени. Обычно тест служит для проверки правильности выполнения самых внешних функций программы, например, обращения к ней и выхода из нее.
Тест граничных значений
Тест проверяет работу программы для граничных значений параметров, определяющих вычислительный процесс. Часто для граничных значений параметра работа программы носит особый характер, который, тем самым, требует и особого контроля.
Тест проверяет реакцию программы на возникновение разного рода аварийных ситуаций в программе, в частности, вызванных неправильными исходными данными. Другими словами, проверяется диагностика, выдаваемая программой, а также окончание ее работы или, может быть, попытка исправления неверных исходных данных.
Локализация ошибок
После того, как с помощью тестов (или каким либо другим путем) установлено, что в программе или в конкретном ее блоке имеется ошибка, возникает задача ее локализации, то есть установления точного места в программе, где находится ошибка.
Процесс локализации ошибок состоит из следующих трех компонент:
Получение на машине тестовых результатов.
Анализ тестовых результатов и сверка их с эталонными.
Выявление ошибки или формулировка предположения о характере и месте ошибки в программе.
Технология отладки автоматизированного рабочего места
При отладке программы использовались следующие методы контроля и локализации ошибок: просмотр текста программы с целью обнаружения явных синтаксических и логических ошибок и трансляция программы (транслятор выдает сообщения об обнаруженных им ошибках в тексте программы).
Тестирование проводилось посредством ввода исходных данных, с дальнейшей их обработкой, выводом результатов на экран. Результаты работы программы сравнивались с требованиями в техническом задании.
1) Отладка программы производилась следующим образом:
2) Запуск программы с набором тестовых входных данных и выявление наличия ошибок.
3) Выделение области программы, в которой может находиться ошибка.
4) Просмотр листинга программы с целью возможного визуального обнаружения ошибок. В противном случае — установка контрольной точки примерно в середине выделенной области.
Новая прогонка программы. Если работа программы прервалась до обработки контрольной точки, значит, ошибка произошла раньше. Контрольная точка переносится, и процесс отладки возвращается к шагу 2.
Если контрольная точка программы была обработана, то далее следует изучение значений стека, переменных и параметров программы с тем, чтобы убедиться в их правильности. При появлении ошибки — новый перенос контрольной точки и возврат к шагу 2.
В случае если ошибка не была обнаружена, далее выполнение программы производится покомандно, с контролем правильности выполнения переходов и содержимого регистров и памяти в контрольных точках. При локализации ошибки, она исправляется, и процесс возвращается к шагу 1.
В данном разделе были рассмотрены вопросы разработки, отладки и тестирования программных продуктов. Было приведено обоснование необходимости и важности этапа отладки в процессе разработки программного обеспечения, даны краткие описания основных способов отладки и тестирования.
В отношении разработанной в специальной части программы было дано описание алгоритма, использовавшегося при ее отладки и тестировании. Представлено обоснование выбора языка программирования.
7. Локализация ошибок
После того, как с помощью контрольных тестов (или каким либо другим путем) установлено, что в программе или в конкретном ее блоке имеется ошибка, возникает задача ее локализации, то есть установления точного места в программе, где находится ошибка.
Процесс локализации ошибок состоит из следующих трех компонент:
1. Получение на машине тестовых результатов.
2. Анализ тестовых результатов и сверка их с эталонными.
3. Выявление ошибки или формулировка предположения о характере и месте ошибки в программе.
По принципам работы средства локализации разделяются на 4 типа :
1. Аварийная печать.
2. Печать в узлах.
АВАРИЙНАЯ ПЕЧАТЬ осуществляется один раз при работе отлаживаемой программы, в момент возникновения аварийной ситуации в программе, препятствующей ее нормальному выполнению. Тем самым, конкретное место включения в работу аварийной печати определяется автоматически без использования информации от программиста, который должен только определить список выдаваемых на печать переменных.
ПЕЧАТЬ В УЗЛАХ включается в работу в выбранных программистом местах программы; после осуществления печати значений данных переменных продолжается выполнение отлаживаемой программы.
СЛЕЖЕНИЕ производится или по всей программе, или на заданном программистом участке. Причем слежение может осуществляться как за переменными (арифметическое слежение), так и за операторами (логическое слежение). Если обнаруживается, что происходит присваивание заданной переменной или выполнение оператора с заданной меткой, то производится печать имени переменной или метки и выполнение программы продолжается. Отличием от печати в узлах является то, что место печати может точно и не определяться программистом (для арифметического слежения); отличается также и содержание печати.
ПРОКРУТКА производится на заданных участках программы, и после выполнения каждого оператора заданного типа (например, присваивания или помеченного) происходит отладочная печать.
По типам печатаемых значений (числовые и текстовые или меточные) средства разделяются на арифметические и логические.
7.2. Классификация средств локализации ошибок
Ниже дана классификация средств локализации.
ТИПЫ СРЕДСТВ ЛОКАЛИЗАЦИИ ОШИБОК :
СРЕДСТВА ЛОКАЛИЗАЦИИ:
1. Аварийная печать (арифметическая).
1.1. Специальные средства языка.
1.2. Системные средства.
2. Печать в узлах (арифметическая).
2.1. Обычные средства языка.
2.2. Специальные средства языка.
3. Слежение (специальные средства).
4. Прокрутка (специальные средства).
8. Технология отладки программы автоматизации учета движения товаров на складе малого предприятия
При отладке программы использовались следующие методы контроля и локализации ошибок (обзор методов см. в теоретической части раздела) :
1. Просмотр текста программы и прокрутка с целью обнаружения явных синтаксических и логических ошибок.
2. Трансляция программы (транслятор выдает сообщения об обнаруженных им ошибках в тексте программы).
3. Тестирование. Тестирование проводилось посредством ввода исходных данных, с дальнейшей их обработкой, выводом результатов на печать и экран. Результаты работы программы сравнивались заданными в техническом задании.
4. При локализации ошибок преимущественно использовалась печать в узлах, которыми являлись в основном глобальные переменные, переменные, используемые при обмене данными основной программы с подпрограммами.
Отладка программы производилась по следующему алгоритму :
1. Прогонка программы с набором тестовых входных данных и выявление наличия ошибок.
2. Выделение области программы, в которой может находиться ошибка. Просмотр листинга программы с целью возможного визуального обнаружения ошибок. В противном случае — установка контрольной точки примерно в середине выделенной области.
3. Новая прогонка программы. Если работа программы прервалась до обработки контрольной точки, значит, ошибка произошла раньше. Контрольная точка переносится, и процесс отладки возвращается к шагу 2.
4. Если контрольная точка программы была обработана, то далее следует изучение значений регистров, переменных и параметров программы с тем, чтобы убедиться в их правильности. При появлении ошибки — новый перенос контрольной точки и возврат к шагу 2.
5. В случае не обнаружения ошибки продолжение выполнения программы покомандно, с контролем правильности выполнения переходов и содержимого регистров и памяти в контрольных точках. При локализации ошибки она исправляется и процесс возвращается к шагу 1.
В качестве тестовых входных данных использовалась последовательность частотных выборок, генерируемых имитатором в режиме 1. (Каждому интервалу соответствует фиксированное значение выборок.)
Итоговый тест по дисциплине «Поддержка и тестирование программных модулей»

Является ли программа аналогом математической формулы?
Варианты ответов
- Да
- Нет
- Математические формулы и программы не сводятся друг к другу
Вопрос 2
Какие подходы используются для обоснования истинности программ?
Варианты ответов
- использование аналогий
- эксперимент над программой
- доказательство программы
- формальный и интерпретационный
Вопрос 3
Отметьте верные утверждения
Варианты ответов
- тестирование – процесс поиска ошибок
- в фазу тестирования входят поиски и исправление ошибок
- отладка – процесс локализации и исправления ошибок
Вопрос 4
Зачем нужна спецификация тестирования?
Варианты ответов
- для формирования команды тестировщиков
- для разработки тестового набора
- для понимания смысла программы
Вопрос 5
Варианты ответов
- выполнение программы в уме
- пошаговое выполнение
- метод контрольных точек и анализа трасс
Вопрос 6
Зачем нужен Log-файл?
Варианты ответов
- для изучения результатов тестирования в режиме on-line
- для фиксации результатов прогона test-suite
- для записи комментариев после прогона тестов
Вопрос 7
Варианты ответов
- разработка тестового набора
- прогон программы на тестовом наборе
- доказательство правильности программы
- анализ результатов тестирования
Вопрос 8
Варианты ответов
- определение областей эквивалентности входных параметров
- анализ покрытия тестами всех возможных случаев поведения
- проверка граничных значений
Вопрос 9
Что такое управляющий граф программы (УГП)?
Варианты ответов
- множество операторов программы.
- граф, вершины которого кодируют операторы программы, а дуги — управления (порядок исполнения) операторов
- множество операторов управления
Вопрос 10
Варианты ответов
- множество связанных дуг УГП
- последовательность вершин и дуг УГП с фиксированными начальной и конечной вершиной
- последовательность ветвей УГП с фиксированными начальной вершиной первой ветви и конечной вершиной последней ветви пути
Вопрос 11
Варианты ответов
- нереализуемый путь недоступен при корректном исполнении программы
- нереализуемый путь недоступен всегда
- нереализуемый путь доступен при сбое
- нереализуемый путь доступен при реализации недопустимых состояний переменных программы
Вопрос 12
Возможно ли тестирование программы на всех допустимых значениях параметров?
Варианты ответов
- да, всегда
- никогда
- возможно в отдельных случаях
Вопрос 13
Какие предъявляются требования к идеальному критерию тестирования?
Варианты ответов
- достаточность
- достижимость
- полнота
- проверяемость
Вопрос 14
Какие классы критериев тестируемости известны
Варианты ответов
- структурные критерии
- мутационные критерии
- функциональные критерии
- сценарные критерии
- стохастические критерии
Вопрос 15
Варианты ответов
- сценарный критерий
- такого критерия не существует
- критерий «черного ящика»
Вопрос 16
Варианты ответов
- критерий тестирования команд
- критерий тестирования ветвей
- критерий тестирования циклов
- критерий тестирования путей
Вопрос 17
Варианты ответов
- не проверяется соответствие со спецификацией
- не проверяется соответствие со спецификацией, не зафиксированное в структуре программы
- не проверяются ошибки в структурах данных
Вопрос 18
Варианты ответов
- тестирование пунктов спецификации
- тестирование классов входных данных
- тестирование классов выходных данных
- тестирование функций
- тестирование правил
Вопрос 19
Варианты ответов
- не проверяется соответствие со спецификацией
- не проверяются ошибки, требования к которым не зафиксированы в спецификации
- не проверяются ошибки в структурах данных, требования к которым не зафиксированы в спецификации
Вопрос 20
Варианты ответов
- создание программ-мутантов на основе изменения модульной структуры основной программы
- создание программ-мутантов с функциональными дефектами
- оценка числа ошибок в программе на основе искусственно внесенных мелких ошибок
Вопрос 21
Варианты ответов
- оценка проекта интегрирует оценки оттестированности модулей
- оценка проекта может вычисляться инкрементально
- в результате получаем наихудшую оценку оттестированности
- в результате получаем наилучшую оценку оттестированности
Вопрос 22
Какие существуют разновидности уровней тестирования?
Варианты ответов
- модульное
- интеграционное
- структурное
- системное
- регрессионное
Вопрос 23
Какие задачи у модульного тестирования?
Варианты ответов
- выявление ошибок при вызове модулей
- выявление ошибок взаимодействия модуля с окружением
- выявление локальных ошибок реализации алгоритмов модулей
Вопрос 24
На основе каких принципов строятся тесты для модульного тестирования?
Варианты ответов
- анализ потоков управления модуля
- анализ потоков данных модуля
- анализ покрытия в соответствии с заданными структурными критериями
Вопрос 25
Варианты ответов
- построение УГП (управляющего графа программы)
- выбор тестовых путей
- генерация тестов, соответствующих выбранным тестовым путям
Вопрос 26
Варианты ответов
- статические
- динамические
- методы реализуемых путей
Вопрос 27
Варианты ответов
- Регрессионное тестирование
- монолитное тестирование
- нисходящее тестирование
- восходящее тестирование
Вопрос 28
Варианты ответов
- необходимость разработки заглушек
- параллельная разработка эффективных модулей
- необходимость разработки среды управления очередностью вызовов модулей
- необходимость разработки драйверов
Вопрос 29
Варианты ответов
- тесты оперируют пользовательским или другими внешними интерфейсами
- структура проекта тестируется на уровне подсистем
- тестированию подлежит система в целом
- тестирование осуществляется по методу «черного ящика»
Вопрос 30
Варианты ответов
- выявление дефектов в функционировании приложения или в работе с ним
- выявление дефектов использования ресурсов
- выявление несовместимости с окружением
- выявление непредусмотренных сценариев применения или использования непредусмотренных комбинаций данных
Вопрос 31
Варианты ответов
- перетестирование предусматривает только контроль частей приложения, связанных с изменениями
- выбор между полным и частичным перетестированием и пополнением тестовых наборов
- регрессионное тестирование является подмножеством системного тестирования
Вопрос 32
Какие типы дефектов выявляются при системном и регрессионном тестировании
Программные ошибки. Методы отладки
Прежде всего определимся с некоторыми понятиями, связанными с отладкой программного обеспечения.
Программная ошибка — это расхождение между программой и ее спецификацией, причем тогда и только тогда, когда спецификация существует и она правильна. Также можно определить, что программная ошибка — это ситуация, когда программа не делает того, что пользователь от нее вполне обоснованно ожидает.
Отладкой называют процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения.
Локализация — это определение оператора/операторов программы, выполнение которого вызвало нарушение вычислительного процесса.
Для исправления ошибки необходимо определить ее причину, т.е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть и очевидными, и очень глубоко скрытыми.
В соответствии с этапом обработки, на котором появляются ошибки, различают ошибки компиляции, ошибки компоновки, ошибки выполнения (рис. 5.1) [7].

Рис. 5.1. Группы программных ошибок
Ошибки компиляции — это синтаксические ошибки, фиксируемые компилятором (транслятором, интерпретатором). Ошибки компиляции являются самыми простыми, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются подробным комментарием с указанием местоположения ошибки. Чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок возникнет на следующих этапах.
Ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы. Ошибки компоновки связаны с проблемами, обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров.
Ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы. Ошибки выполнения являются самыми непредсказуемыми. Некоторые из них обнаруживаются и документируются операционной системой. Они могут иметь разную природу и поэтому по-разному проявляться:
- • появление сообщения об ошибке, например, деление на ноль, нарушение адресации, переполнение разрядов и т.п.;
- • появление сообщения об ошибке, обнаруженной операционной системой, например при попытке записи на защищенные устройства памяти, при ссылке на отсутствующий файл и т.п.;
- • «зависание» компьютера (иногда для продолжения работы необходима его перезагрузка);
- • несовпадение полученных результатов с ожидаемыми.
Причины ошибок выполнения очень разнообразны, а потому их
сложно локализовать. Все возможные причины ошибок выполнения можно разделить на следующие группы:
- • ошибки определения данных;
- • логические ошибки;
- • ошибки накопления погрешностей.
Ошибки определения данных (неверное определение исходных данных) возникают при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи, ошибки данных. Использование специальных технических средств и программирование с защитой от ошибок позволяют обнаружить и предотвратить только часть этих ошибок.
Логические ошибки имеют разную природу и могут следовать из ошибок, допущенных при проектировании, например при выборе методов, разработке алгоритмов или определении структуры данных (классов), а могут быть непосредственно внесены при кодировании модуля. К ошибкам кодирования относятся:
- • ошибки некорректного использования переменных, например неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных и т.п.;
- • ошибки вычислений, например некорректная работа с переменными, некорректное преобразование типов данных в процессе вычислений и т.п.;
• ошибки взаимодействия модулей, т.е. межмодульного интерфейса, например нарушение типов и последовательности при передаче параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных.
Возможны и другие ошибки кодирования, например неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
Ошибки накопления погрешностей возникают в результате накопления погрешностей результатов числовых вычислений, например при некорректном отбрасывании дробных цифр чисел, при некорректном использовании приближенных методов вычислений и т.п.
Процесс отладки требует от разработчика глубоких знаний специфики среды и языка программирования, используемых технических средств, операционной системы. На сложность отладки оказывают влияние следующие факторы:
- • опосредованное проявление ошибок;
- • возможность взаимного влияния ошибок;
- • возможность получения внешне одинаковых проявлений разных ошибок;
- • стохастические ошибки, которые могут не проявиться от запуска к запуску;
- • может аннулироваться или измениться внешнее проявление ошибок при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов. Отладка программы всегда предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить, тщательно анализируя текст программы и результаты тестирования.
Методы отладки программного обеспечения можно классифицировать следующим образом [7]:
- • метод ручного тестирования;
- • метод индукции;
- • метод дедукции;
- • метод обратного прослеживания.
Метод ручного тестирования — самый простой и естественный способ отладки программы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которыми была обнаружена ошибка. Метод эффективен, но не применим для больших программных систем и программ со сложными вычислениями. Этот метод часто используют как составную часть других методов отладки.
Метод индукции предусматривает подробный анализ проявления ошибки. Это могут быть неверные результаты вычислений или сообщение об ошибке. Если компьютер просто «зависает», то место проявления ошибки в программном обеспечении определяют исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию можно изучить, просматривая соответствующий фрагмент программы. В результате выдвигаются гипотезы об ошибках, которые затем проверяются. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке.
Метод дедукции работает по следующему алгоритму. Сначала формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем, анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то необходима дополнительная информация об ошибке и следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину.
Метод обратного прослеживания используется для небольших программ и заключается в следующем. Определяется точка вывода неправильного результата. Затем строится гипотеза о значениях основных переменных, которые могли бы привести к получению этого результата. Исходя из этой гипотезы, делают предположения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Рассмотрим категории программных ошибок, которые встречаются наиболее часто.
Функциональные недостатки. Данные недостатки присущи программе, если она не делает того, что должна, выполняет одну из своих функций плохо или не полностью. Функции программы должны быть подробно описаны в ее спецификации, и именно на основе утвержденной спецификации тестировщик строит свою работу.
Недостатки пользовательского интерфейса. Лучше всего оценить удобство и правильность работы пользовательского интерфейса может только пользователь в процессе работы с ним. Проверить это возможно с помощью прототипа программного обеспечения, на котором проводятся обкатка и согласование всех требований к пользовательскому интерфейсу с дальнейшей фиксацией их в спецификации требований. После утверждения спецификации требований любые отклонения от нее или невыполнение последних являются ошибкой. Это в полной мере касается и пользовательского интерфейса.
Недостаточная производительность. При разработке некоторого программного продукта очень важной его характеристикой может оказаться скорость работы, иногда этот критерий задается в требованиях заказчика к программному обеспечению. Недопустимо, если программа не удовлетворяет заданным в спецификации требований характеристикам. Это уже ошибка, которая должна быть обязательно устранена.
Некорректная обработка ошибок. Правильно определив ошибку, программа должна выдать о ней сообщение. Отсутствие такого сообщения является ошибкой в работе программы.
Некорректная обработка граничных условий. Существует много различных граничных ситуаций. Любой аспект работы программы, к которому применимы понятия «больше» или «меньше», «раньше» или «позже», «первый» или «последний», «короче» или «длиннее», обязательно должен быть проверен на границах диапазона. Внутри диапазонов программа может работать правильно, а на их границах могут происходить неожиданные ситуации, которые, в свою очередь, приводят к ошибкам в работе программного обеспечения.
Ошибки вычислений. К ошибкам вычислений относятся ошибки, вызванные неправильным выбором алгоритма вычислений, неправильными формулами либо формулами, неприменимыми к обрабатываемым данным. Самыми распространенными среди ошибок вычислений являются ошибки округления.
Ошибки управления потоком. По логике работы программы вслед за первым действием должно быть выполнено второе. Если вместо этого выполняется третье или четвертое действие, значит, в управлении потоком допущена ошибка.
Ситуация гонок. Предположим, в системе ожидаются два события: А и Б. Если первым наступит событие А, то выполнение программы продолжится, а если событие Б, то в работе программы произойдет сбой. Разработчики предполагают, что первым всегда должно быть событие А, и не ожидают, что Б может выиграть гонки и наступить раньше. Такова классическая ситуация гонок. Тестировать ситуации гонок довольно сложно. Наиболее типичны они для систем, где параллельно выполняются взаимодействующие процессы и потоки, а также для многопользовательских систем реального времени. Ошибки в таких системах трудно воспроизвести, и на их выявление обычно требуется очень много времени.
Перегрузки. Сбои в работе программы могут происходить из-за нехватки памяти или отсутствия других необходимых системных ресурсов. У каждой программы свои пределы, программа может не справляться с повышенными нагрузками, например со слишком большими объемами данных. Вопрос в том, соответствуют ли реальные возможности программы, ее требования к ресурсам спецификации программы, и как она себя поведет при перегрузках.
Некорректная работа с аппаратурой компьютера. Программы могут отправлять аппаратным устройствам неверные данные, игнорировать их сообщения об ошибках, пытаться использовать устройства, которые заняты или вообще отсутствуют. Даже если нужное устройство просто неисправно, программа должна понять это, а не «зависать» при попытке к нему обратиться.
Слайд 1Глава 9 Отладка программного обеспечения
Введение
Отладка – это процесс локализации и
исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс
определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Для исправления ошибки необходимо определить ее причину, т.е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Отладка программы – один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
специфики управления используемыми техническими средствами;
операционной системы;
среды и языка программирования;
реализуемых процессов;
природы и специфики различных ошибок;
методик отладки и соответствующих программных средств.

Слайд 29.1 Классификация ошибок
В соответствии с этапом обработки, на котором проявляются
ошибки, различают:
синтаксические ошибки;
ошибки компоновки;
ошибки выполнения.

Слайд 39.1 Классификация ошибок (2)
Синтаксические ошибки
Синтаксические ошибки относятся к группе
самых простых, так как синтаксис языка, как правило, строго формализован,
и ошибки сопровождаются развернутым комментарием с указанием ее местоположения.
Чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор.
В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом.
К первым, безусловно, можно отнести Паскаль, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы.
Ко вторым – С со всеми его модификациями.
Синтаксические ошибки Синтаксические ошибки относятся к группе самых")
Слайд 49.1 Классификация ошибок (3)
Ошибки компоновки
Ошибки компоновки связаны с
проблемами, обнаруженными при разрешении внешних ссылок.
Например, предусмотрено обращение к
подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения
К самой непредсказуемой группе относятся ошибки выполнения.
Они могут иметь разную природу, и соответственно по-разному проявляться.
Часть ошибок обнаруживается и документируется операционной системой.
Выделяют четыре способа проявления таких ошибок:
Ошибки компоновки Ошибки компоновки связаны с проблемами, обнаруженными")
Слайд 59.1 Классификация ошибок (4)
появление сообщения об ошибке, зафиксированной схемами контроля
выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на
ноль», нарушении адресации и т.п.;
появление сообщения об ошибке, обнаруженные операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т.п.;
«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
несовпадение полученных результатов с ожидаемыми.
появление сообщения об ошибке, зафиксированной схемами контроля выполнения")
Слайд 69.1 Классификация ошибок (5)
Все возможные причины ошибок выполнения можно разделить
на следующие группы:
Все возможные причины ошибок выполнения можно разделить на следующие группы:")
Слайд 79.2 Методы отладки
Отладка программы в любом случае предполагает обдумывание и
логическое осмысление всей имеющейся информации об ошибке. При этом можно
использовать различные методы:
метод тестирования;
метод индукции;
метод дедукции;
метод обратного прослеживания.
Метод тестирования
Самый простой и естественный способ данной группы предлагает при обнаружении ошибки выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, если ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используется как составная часть других методов отладки

Слайд 89.2 Методы отладки(2)
Метод индукции
Метод основан на тщательном анализе симптомов
ошибки, которыми могут проявляться как неверные результаты вычислений или как
сообщение об ошибке.
Процесс отладки с использованием метода индукции можно представить в виде алгоритма.
Самый ответственный этап – получение необходимой информации об ошибке. Дополнительную информацию можно получить в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод индукции Метод основан на тщательном анализе симптомов ошибки,")
Слайд 99.2 Методы отладки(2)
Метод дедукции
По методу дедукции вначале формируют множество
причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя
причины, исключают те, которые противоречат имеющимся данным.
Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента.
В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе – проверяют следующую причину.
Метод дедукции По методу дедукции вначале формируют множество причин,")
Слайд 109.3 Общая методика отладки ПО
Можно предложить следующую методику отладки программного
обеспечения, написанного на универсальных языках программирования для выполнения в операционных
системах MS DOS и Win32:
1 этап. Изучение проявления ошибки.
2 этап. Локализации ошибки .
3 этап. Определение причины ошибки.
4 этап. Исправление ошибки .
5 этап. Повторное тестирование.
Следует иметь в виду, что процесс отладки можно существенно упростить, если следовать основным рекомендациям структурного подхода к программированию.
