
Как вычислить сбой программы по смещению

|
От: | Аноним | |
| Дата: | 29.04.11 05:59 | ||
| Оценка: |
Добрый день!
Коллеги. Прошу оказать помощь.
Дело в том, что у меня создалась критическая ситуация. Программа, над которой мы работаем падает через 2 — 3 суток непрерывной работы. Анализ сбоя осложняется двумя обстоятельствами: 1. Падает она на машине заказчика, находящегося далеко, в другом городе, и 2. На наших рабочих местах этот дефект ну никак не проявляется (работает несколько суток подряд) + очень трудно работать с людьми, не желающими хоть как то объяснить свои действия и наблюдения. Однако, есть зацепка, как мне кажется. Это сообщение в журнале приложений ОС Windows. К моему глубокому сожалению я очень плохо знаю assembler, да и PE-структуру файла образа тоже. Однако сейчас не время посыпать голову пеплом, и его так же нет для глубокого изучения этих дисциплин. Может кто-нибудь поможет или хотя бы подскажет где искать решение моей проблемы?
Так вот. Привожу текст сообщения из журнала Windows, который все таки дает информацию о том где надо копать:
Имя сбойного приложения: znz32-dics.exe, версия: 1.0.0.0, отметка времени: 0x4db6a210
Имя сбойного модуля: znz32-dics.exe, версия: 1.0.0.0, отметка времени 0x4db6a210
Код исключения: 0xc0000005
Смещение ошибки: 0x005186ac <- Предполагаю, что по этому смещению можно вычислить место ошибки. Не знаю как!!!
Идентификатор сбойного процесса: 0xff8
Время запуска сбойного приложения: 0x01cc04afbf1ea3f6
Путь сбойного приложения: E:poisk-companyZNZ32znz32-dics.exe
Путь сбойного модуля: E:poisk-companyZNZ32znz32-dics.exe
Код отчета: 16229c5b-715d-11e0-9d62-6cf049e03dfe
Замечу, что сбой проявляется с завидным постоянством, в том смысле что смещение всегда одно и тоже.
Благодарю за внимание!
С уважением
Владимир Павлов.
Re: Как вычислить сбой программы по смещению
|
|
От: | Аноним | |
| Дата: | 29.04.11 06:12 | ||
| Оценка: |
Проще всего попросить заказчика прислать креш-дамп.
Вот тут к примеру есть инструкция для чайников: http://kb.acronis.com/content/2192
Re[2]: Как вычислить сбой программы по смещению
|
|
От: | Аноним | |
| Дата: | 29.04.11 07:40 | ||
| Оценка: |
Здравствуйте, Аноним, Вы писали:
А>Проще всего попросить заказчика прислать креш-дамп.
А>Вот тут к примеру есть инструкция для чайников: http://kb.acronis.com/content/2192
Спасибо.
А нет креш-дампа. Система не падает. Падает только программа.
А если заказчик не сечет, как это делать?
Re[3]: Как вычислить сбой программы по смещению
|
|
От: | Аноним | |
| Дата: | 29.04.11 08:05 | ||
| Оценка: |
А>Спасибо.
А>А нет креш-дампа. Система не падает. Падает только программа.
А>А если заказчик не сечет, как это делать?
Там по ссылке написано как снять креш дамп для упавшей программы. С картинками. Для разных осей. Инструкция написана для идиотов, т.е заказчик должен разобраться.
Re[4]: Как вычислить сбой программы по смещению
|
|
От: |
Аноним
|
|
| Дата: | 29.04.11 09:25 | ||
| Оценка: |
Здравствуйте, Аноним, Вы писали:
А>>Спасибо.
А>>А нет креш-дампа. Система не падает. Падает только программа.
А>>А если заказчик не сечет, как это делать?
А>Там по ссылке написано как снять креш дамп для упавшей программы. С картинками. Для разных осей. Инструкция написана для идиотов, т.е заказчик должен разобраться.
Еще раз большое спасибо!!!
Да посмотрел, и уже написал инструкцию заказчику, как сделать дамп памяти. Попробую этот вариант если удастся его получить. Я почему то думал, что создание дампа происходит на автомате при крахе программы, во всяком случае видел это в XP, иногда она предлагает сохранить дамп![]() .
.
Да, еще один момент. Анализ дампа обязательно производить на ОС того же типа, которая его создала?
Но хотя бы чисто теоретически, как можно вычислить сбой по смещению, указанному в журнале?
Re: Как вычислить сбой программы по смещению

|
От: |
Геннадий Майко |
|
| Дата: | 29.04.11 09:51 | ||
| Оценка: |

Здравствуйте,
А> Так вот. Привожу текст сообщения из журнала Windows, который все таки дает информацию о том где надо копать:
А>Имя сбойного приложения: znz32-dics.exe, версия: 1.0.0.0, отметка времени: 0x4db6a210
А>Имя сбойного модуля: znz32-dics.exe, версия: 1.0.0.0, отметка времени 0x4db6a210
А>Код исключения: 0xc0000005
А>Смещение ошибки: 0x005186ac <- Предполагаю, что по этому смещению можно вычислить место ошибки. Не знаю как!!!
А>Идентификатор сбойного процесса: 0xff8
А>Время запуска сбойного приложения: 0x01cc04afbf1ea3f6
А>Путь сбойного приложения: E:poisk-companyZNZ32znz32-dics.exe
А>Путь сбойного модуля: E:poisk-companyZNZ32znz32-dics.exe
А>Код отчета: 16229c5b-715d-11e0-9d62-6cf049e03dfe
А>
А>Замечу, что сбой проявляется с завидным постоянством, в том смысле что смещение всегда одно и тоже.
—
Попробуйте построить *.map файл для этой программы и определить из него, код какой функции находится по этому адресу.
C уважением,
Геннадий Майко.
Re[2]: Как вычислить сбой программы по смещению
|
|
От: | Аноним | |
| Дата: | 29.04.11 10:52 | ||
| Оценка: |
Здравствуйте, Геннадий Майко, Вы писали:
ГМ>Здравствуйте,
А>> Так вот. Привожу текст сообщения из журнала Windows, который все таки дает информацию о том где надо копать:
А>>Имя сбойного приложения: znz32-dics.exe, версия: 1.0.0.0, отметка времени: 0x4db6a210
А>>Имя сбойного модуля: znz32-dics.exe, версия: 1.0.0.0, отметка времени 0x4db6a210
А>>Код исключения: 0xc0000005
А>>Смещение ошибки: 0x005186ac <- Предполагаю, что по этому смещению можно вычислить место ошибки. Не знаю как!!!
А>>Идентификатор сбойного процесса: 0xff8
А>>Время запуска сбойного приложения: 0x01cc04afbf1ea3f6
А>>Путь сбойного приложения: E:poisk-companyZNZ32znz32-dics.exe
А>>Путь сбойного модуля: E:poisk-companyZNZ32znz32-dics.exe
А>>Код отчета: 16229c5b-715d-11e0-9d62-6cf049e03dfe
А>>
А>>Замечу, что сбой проявляется с завидным постоянством, в том смысле что смещение всегда одно и тоже.
ГМ>—
ГМ>Попробуйте построить *.map файл для этой программы и определить из него, код какой функции находится по этому адресу.
ГМ>C уважением,
ГМ>Геннадий Майко.
Спасибо, Геннадий. Но ведь в этом то и заключается моя проблема!!! ![]()
Открыл я этот map-файл, смотрю на него как баран на новые ворота, и задаю себе вопрос. А что значит это смещение в формате этого самого map-файла? В прямую адреса такого нет, там в левой колонке они представлены с префиксом в виде сегмента памяти. Если для древних еще ДОСОВЫХмашин, то этот сегмент был равен 16 байт, то какой он сейчас? И к какому сегменту относится искомое смещение? А может это смещение от начала памяти в процессе, т.е. того самого крэш-дампа? Или надо танцевать от формата PE-файла? Надо ли вычитать из него смещение старта программы (400000) или нет?
С уважением,
Владимир.
Re[3]: Как вычислить сбой программы по смещению
|
|
От: |
Геннадий Майко |
|
| Дата: | 29.04.11 11:56 | ||
| Оценка: |
Здравствуйте,
А>Спасибо, Геннадий. Но ведь в этом то и заключается моя проблема!!! ![]()
А>Открыл я этот map-файл, смотрю на него как баран на новые ворота, и задаю себе вопрос. А что значит это смещение в формате этого самого map-файла? В прямую адреса такого нет, там в левой колонке они представлены с префиксом в виде сегмента памяти. Если для древних еще ДОСОВЫХмашин, то этот сегмент был равен 16 байт, то какой он сейчас? И к какому сегменту относится искомое смещение? А может это смещение от начала памяти в процессе, т.е. того самого крэш-дампа? Или надо танцевать от формата PE-файла? Надо ли вычитать из него смещение старта программы (400000) или нет?
—
Посмотрите вот здесь, например http://www.codeproject.com/KB/debug/mapfile.aspx или попробуйте найти формальное описание *.map файла где-то в сети. Не забудьте, что он может меняться с версией компилятора.
Но, вообше-то говоря, информация в этом *.map файле, скажем так, интуитивно понятна. Что конкретно в этом файле не понятно?
C уважением,
Геннадий Майко.
Re[4]: Как вычислить сбой программы по смещению
|
|
От: | Аноним | |
| Дата: | 29.04.11 12:09 | ||
| Оценка: |
Спасибо, Геннадий, Вы писали:
ГМ>Посмотрите вот здесь, например http://www.codeproject.com/KB/debug/mapfile.aspx или попробуйте найти формальное описание *.map файла где-то в сети. Не забудьте, что он может меняться с версией компилятора.
ГМ>Но, вообше-то говоря, информация в этом *.map файле, скажем так, интуитивно понятна. Что конкретно в этом файле не понятно?
Ну если просто так на него смотреть, то понятна. А если начать разбираться в деталях… (для меня во всяком случае ![]() ). Ну вот такого адреса я и близко не нашел.
). Ну вот такого адреса я и близко не нашел.
Что из себя представляет адрес смещения 005186ac, в контексте map? Как вычислить абсолютный адрес (я правильно выражаюсь?) если он представлен в виде 0001:00050406, например? Как можно соотнести такое представление адреса с искомым? И можно ли вообще?
За ссылку еще раз горячее спасибо. Обязательно посмотрю.
С уважением,
Владимир.
Re[5]: Как вычислить сбой программы по смещению
|
|
От: | Аноним | |
| Дата: | 29.04.11 12:09 | ||
| Оценка: |
А>Да, еще один момент. Анализ дампа обязательно производить на ОС того же типа, которая его создала?
Нет, дамп загружается в отладчик. Лучше всего в windbg. Дальше указываем путь файл с отладочными символами ( pdb ), который был создан для упавшей программы. Если ошибка тривиальная — отладчик покажет точно место сбоя.
А>Но хотя бы чисто теоретически, как можно вычислить сбой по смещению, указанному в журнале?
Можно анализировать map файл, как Геннадий прелагает.
Если падение внутри exe модуля, то можно загрузить аналогичный модуль в локальный отладчик и, учитывая что адрес загрузки модуля программы будет тот же, в дизасме посмотреть, что находится по указанному в журнале адресу.
Re[6]: Как вычислить сбой программы по смещению

|
От: |
ononim |
|
| Дата: | 29.04.11 12:30 | ||
| Оценка: |
А>>Но хотя бы чисто теоретически, как можно вычислить сбой по смещению, указанному в журнале?
А>Можно анализировать map файл, как Геннадий прелагает.
А>Если падение внутри exe модуля, то можно загрузить аналогичный модуль в локальный отладчик и, учитывая что адрес загрузки модуля программы будет тот же, в дизасме посмотреть, что находится по указанному в журнале адресу.
Смещение ошибки в репорте винды — это смещение относительно базы модуля, так что u znz32-dics + 5186ac и все дела.
Как много веселых ребят, и все делают велосипед…
Re[7]: Как вычислить сбой программы по смещению
|
|
От: |
Аноним
|
|
| Дата: | 29.04.11 12:54 | ||
| Оценка: |
Вы писали:
O>Смещение ошибки в репорте винды — это смещение относительно базы модуля, так что u znz32-dics + 5186ac и все дела.
База модуля это типа адрес 400000 старта программы?
Re[8]: Как вычислить сбой программы по смещению
|
|
От: |
ononim |
|
| Дата: | 29.04.11 12:59 | ||
| Оценка: |
O>>Смещение ошибки в репорте винды — это смещение относительно базы модуля, так что u znz32-dics + 5186ac и все дела.
А>База модуля это типа адрес 400000 старта программы?
как когда. Укажите znz32-dics + 5186ac и все будет ок (в виндбг как минимум)
Как много веселых ребят, и все делают велосипед…
Re[4]: Как вычислить сбой программы по смещению
|
|
От: | Аноним | |
| Дата: | 29.04.11 13:00 | ||
| Оценка: |
Геннадий, Вы писали:
ГМ>Посмотрите вот здесь, например http://www.codeproject.com/KB/debug/mapfile.aspx или попробуйте найти формальное описание *.map файла где-то в сети. Не забудьте, что он может меняться с версией компилятора.
Да. наверное. Судя по этой ссылке посчитанный мною адрес указывает на библиотечную функцию стороннего производителя. А это вызывает сомнение? Искать надо прежде у себя.
В примере приводится работа с 6 версией VS. там возможно формирования строк. Я работаю с VS2005, а она не формирует строки.
нашел диапазон адресов куда попадает мое смещение. Оно огромно.
Спасибо всем. С праздником!!!
Re[9]: Как вычислить сбой программы по смещению
|
|
От: |
Аноним
|
|
| Дата: | 29.04.11 13:06 | ||
| Оценка: |
Здравствуйте, ononim, Вы писали:
O>>>Смещение ошибки в репорте винды — это смещение относительно базы модуля, так что u znz32-dics + 5186ac и все дела.
А>>База модуля это типа адрес 400000 старта программы?
O>как когда. Укажите znz32-dics + 5186ac и все будет ок (в виндбг как минимум)
Сделал. Но наверное что то не так. Вот что написал windbg
Unable to retrieve information, HRESULT 0x80040205: Произошло непредвиденное исключение
Re[5]: Как вычислить сбой программы по смещению
|
|
От: | Аноним | |
| Дата: | 29.04.11 13:29 | ||
| Оценка: |
Здравствуйте, Аноним, Вы писали:
А>Геннадий, Вы писали:
ГМ>>Посмотрите вот здесь, например http://www.codeproject.com/KB/debug/mapfile.aspx или попробуйте найти формальное описание *.map файла где-то в сети. Не забудьте, что он может меняться с версией компилятора.
А>Да. наверное. Судя по этой ссылке посчитанный мною адрес указывает на библиотечную функцию стороннего производителя. А это вызывает сомнение? Искать надо прежде у себя.
А>В примере приводится работа с 6 версией VS. там возможно формирования строк. Я работаю с VS2005, а она не формирует строки.
А>нашел диапазон адресов куда попадает мое смещение. Оно огромно.
А>Спасибо всем. С праздником!!!
арбузы бы шел продавать лучше, а не программы писать, незнать вещи типа виртуальной адресации стыдно
Re[6]: Как вычислить сбой программы по смещению
|
|
От: | Аноним | |
| Дата: | 29.04.11 14:16 | ||
| Оценка: |
Здравствуйте, Аноним, Вы писали:
А>Здравствуйте, Аноним, Вы писали:
А>>Геннадий, Вы писали:
ГМ>>>Посмотрите вот здесь, например http://www.codeproject.com/KB/debug/mapfile.aspx или попробуйте найти формальное описание *.map файла где-то в сети. Не забудьте, что он может меняться с версией компилятора.
А>>Да. наверное. Судя по этой ссылке посчитанный мною адрес указывает на библиотечную функцию стороннего производителя. А это вызывает сомнение? Искать надо прежде у себя.
А>>В примере приводится работа с 6 версией VS. там возможно формирования строк. Я работаю с VS2005, а она не формирует строки.
А>>нашел диапазон адресов куда попадает мое смещение. Оно огромно.
А>>Спасибо всем. С праздником!!!
А>арбузы бы шел продавать лучше, а не программы писать, незнать вещи типа виртуальной адресации стыдно
А я не хочу продавать арбузы.
Я пишу программы. Да, к сожалению не знаю виртуальную адресацию. Стыдно? Может быть и стыдно. Но я не боюсь своего не знания. Я много чего не знаю, хоть прожил 54 года. Но я стремлюсь это знать. А посылать… Посылать я тоже умею, но это не конструктивно. И не место здесь это делать. Не хочешь делиться знаниями — не пиши. Молчи в тряпочку, и не вякай!!!!
Re: Как вычислить сбой программы по смещению

|
От: |
pva |
|
| Дата: | 29.04.11 16:47 | ||
| Оценка: |
Здравствуйте, Аноним, Вы писали:
А>Код исключения: 0xc0000005
А>Смещение ошибки: 0x005186ac <- Предполагаю, что по этому смещению можно вычислить место ошибки. Не знаю как!!!
Грузите в иду, ждете конца анализа. Подгружаете .map файл. Идете по адресу 5186ac, смотрите что это за функция дальше по контексту. Много думаете.
Адресное пространство в виндовз линейное. Забудьте про сегменты.
newbie
Re[2]: Как вычислить сбой программы по смещению
|
|
От: | Аноним | |
| Дата: | 29.04.11 18:00 | ||
| Оценка: |
Здравствуйте и спасибо, pva, Вы писали:
pva>Здравствуйте, Аноним, Вы писали:
А>>Код исключения: 0xc0000005
А>>Смещение ошибки: 0x005186ac <- Предполагаю, что по этому смещению можно вычислить место ошибки. Не знаю как!!!
pva>Грузите в иду, ждете конца анализа. Подгружаете .map файл. Идете по адресу 5186ac, смотрите что это за функция дальше по контексту. Много думаете.
pva>Адресное пространство в виндовз линейное. Забудьте про сегменты.
Так ведь думать то никогда не вредно! ![]()
Вот Windbg отказал в анализе. Не смог показать мне этот адрес. Как тут не задуматься?
Попробую иду. IDA pro насколько я понимаю? В свободно распространяемой версии этот режим не ограничен?
На работе с пиратскими версиями работать нельзя! Придется дома изощряться.
С уважением,
Владимир.
Re[5]: Как вычислить сбой программы по смещению

|
От: |
Евгений Музыченко |
https://software.muzychenko.net/ru |
| Дата: | 01.05.11 17:22 | ||
| Оценка: |
Здравствуйте, <Аноним>, Вы писали:
А>Да посмотрел, и уже написал инструкцию заказчику, как сделать дамп памяти.
Если заказчик совсем тормоз, и не сможет настроить DrWatson — попробуйте дать ему командный файл:
@if not "%EnableCmdEcho%" == "1" echo off
@echo off
rem set TestEcho=echo
set DrWtsnKey=HKLMSOFTWAREMicrosoftDrWatson
set AeDebugKey=HKLMSOFTWAREMicrosoftWindows NTCurrentVersionAeDebug
set DumpDir=%~1
if "%~1" == "" (
echo "%~n0: <Full path to Dr Watson dump directory>"
pause
exit /b 1
)
if not exist "%DumpDir%" (
mkdir "%DumpDir%"
if errorlevel 1 exit /b 1
)
%TestEcho% reg add "%DrWtsnKey%" /v "DumpSymbols" /t REG_DWORD /d 1 /f
if errorlevel 1 exit /b 1
%TestEcho% reg add "%DrWtsnKey%" /v "DumpAllThreads" /t REG_DWORD /d 1 /f
if errorlevel 1 exit /b 1
%TestEcho% reg add "%DrWtsnKey%" /v "AppendToLogFile" /t REG_DWORD /d 1 /f
if errorlevel 1 exit /b 1
%TestEcho% reg add "%DrWtsnKey%" /v "VisualNotification" /t REG_DWORD /d 1 /f
if errorlevel 1 exit /b 1
%TestEcho% reg add "%DrWtsnKey%" /v "CreateCrashDump" /t REG_DWORD /d 1 /f
if errorlevel 1 exit /b 1
rem Full crash dump
%TestEcho% reg add "%DrWtsnKey%" /v "CrashDumpType" /t REG_DWORD /d 2 /f
if errorlevel 1 exit /b 1
%TestEcho% reg add "%DrWtsnKey%" /v "Instructions" /t REG_DWORD /d 100 /f
if errorlevel 1 exit /b 1
%TestEcho% reg add "%DrWtsnKey%" /v "MaximumCrashes" /t REG_DWORD /d 10 /f
if errorlevel 1 exit /b 1
%TestEcho% reg add "%DrWtsnKey%" /v "LogDumpDir" /t REG_EXPAND_SZ /d "%DumpDir%" /f
if errorlevel 1 exit /b 1
%TestEcho% reg add "%DrWtsnKey%" /v "CrashDumpFile" /t REG_EXPAND_SZ /d "%DumpDir%user.dmp" /f
if errorlevel 1 exit /b 1
%TestEcho% reg add "%DrWtsnKey%" /v "LogFilePath" /t REG_EXPAND_SZ /d "%DumpDir%" /f
if errorlevel 1 exit /b 1
%TestEcho% reg add "%AeDebugKey%" /v "Auto" /t REG_SZ /d "0" /f
if errorlevel 1 exit /b 1
%TestEcho% reg add "%AeDebugKey%" /v "Debugger" /t REG_SZ /d "drwtsn32 -p %%ld -e %%ld -g" /f
if errorlevel 1 exit /b 1Всякие EnableCmdEcho и TestEcho — для отладки командников, не стал убирать.
А>Я почему то думал, что создание дампа происходит на автомате при крахе программы, во всяком случае видел это в XP, иногда она предлагает сохранить дамп![]() .
.
При отказе программы выполняются действия, указанные в AeDebug.
Еще заказчик может запустить программу под MSVSMON или WinDbg, когда упадет — подключитесь на своей стороне клиентом, будете в живом виде смотреть переменные.
… << RSDN@Home 1.1.4 stable SR1 rev. 568>>

- Переместить
- Удалить
- Выделить ветку
Пока на собственное сообщение не было ответов, его можно удалить.
Выпускная квалификационная работа. Часть 5.
5.1 Основные определения
5.2 Погрешности АЦП
5.3 Экспериментальные исследования
5.4 Выводы
5.1 Основные определения
Измерение – это операция, в результате которой мы узнаем, во сколько раз измеряемая величина больше или меньше соответствующей величины, принятой за эталон.
Интегральная нелинейность — представляет собой максимальное отклонение любого кода от прямой линии, проведенной через крайние точки передаточной функции АЦП. Крайними точками являются: нулевая, находящаяся на 0.5LSB ниже точки появления первого кода, и последняя — на 0.5LSB выше граничного кода шкалы.
Дифференциальная нелинейность DNL (differential non-linearity) — представляет собой разницу между измеренной и идеальной шириной 1 кванта (1 LSB) АЦП.
Ошибка смещения — представляет собой отклонение момента первичной смены кода с (000Н) на (001Н) от идеального значения, то есть +0.5LSB.
Ошибка усиления — представляет отклонение реального коэффициента усиления тот идеального.
LSB (least significant bit) или МЗБ (младший значащий бит) – это наименьшее значение напряжения, которое может быть измерено АЦП. Находиться по формуле:
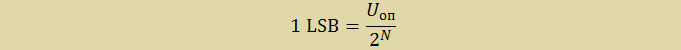
где Uоп – значения источника опорного напряжения (ИОН), N разрядность АЦП. В данном случае:
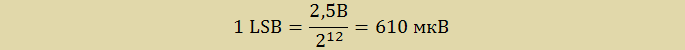
Uоп = 2,5 В — значение напряжения внутреннего ИОН.
Систематические ошибки – ошибки, величина которых одинакова во всех измерениях, приводящих одним и тем же методом с помощью одних и тех же измерительных приборов. Ошибка смещения и ошибка усиления относятся к случайным ошибкам.
Случайные ошибки – ошибки, величина которых различна даже дл измерений, выполненных одинаковым образом. Интегральная и дифференциальная нелинейности относятся к систематические ошибкам.
5.2 Погрешности АЦП
В АЦП и ЦАП различают четыре типа погрешностей по постоянному току: погрешность смещения, погрешность усиления и два типа погрешностей, связанных с линейностью: интегральная и дифференциальная нелинейность. Погрешности смещения и усиления АЦП и ЦАП аналогичны погрешностям смещения и усиления в усилителях.

Рисунок 5.1 – Погрешность смещения нуля
Погрешность смещения равна погрешности нуля во всем диапазоне входного напряжения и постоянна.

Рисунок 5.2 – Погрешность усиления
Погрешность усиления вызывает погрешность смещения. Причем погрешность смещения не постоянна и не равна погрешность смещения нуля.
Интегральная нелинейность ЦАП и АЦП аналогична нелинейности усилителя и определяется как максимальное отклонение фактической характеристики передачи преобразователя от прямой линии. В общем случае, она выражается в процентах от полной шкалы (но может представляться в значениях младших разрядов). Существует два общих метода аппроксимации характеристики передачи: метод конечных точек и метод наилучшей прямой.

Рисунок 5.3 – Определение погрешности измерения по а) методу конечных точек и по б) методу наилучшей прямой
При использовании метода конечных точек измеряется отклонение произвольной точки характеристики от прямой, проведенной из начала координат. Таким образом, измеряют значения интегральной нелинейности преобразователей, используемых в задачах измерения и управления.
Метод наилучшей прямой дает более адекватный прогноз искажений в приложениях, имеющих дело с сигналами переменного тока. Он менее чувствителен к нелинейностям технических характеристик. По методу наилучшего приближения через характеристику передачи устройства проводят прямую линию, используя стандартные методы интерполяции кривой. После этого максимальное отклонение измеряется от построенной прямой. Как правило, интегральная нелинейность, измеренная таким образом, учитывает только 50% нелинейности, оцененной методом конечных точек.
Другой тип нелинейности преобразователей – дифференциальная нелинейность. Она связана с нелинейностью кодовых переходов преобразователя. В идеальном случае изменение на единицу младшего разряда цифрового кода точно соответствует изменению аналогового сигнала на величину единицы младшего разряда. В АЦП, при переходе с одного цифрового уровня на следующий, значение сигнала на аналоговом входе должно измениться точно на величину, соответствующую младшему разряду цифровой шкалы. Наиболее распространенным проявлением DNL в АЦП являются пропущенные коды.
Переходы АЦП (идеальные) имеют место, начиная с 1/2 LSB выше нуля, и далее через каждый LSB, до 11/2 LSB ниже полной аналоговой шкалы. Так как входной аналоговый сигнал АЦП может иметь любое значение, а выходной цифровой сигнал квантуется, может существовать различие до 1/2 LSB между реальным входным аналоговым сигналом и точным значением выходного цифрового сигнала. Этот эффект известен как ошибка или неопределенность квантования. В приложениях, использующих сигналы переменного тока, эта ошибка квантования вызывает явление, называемое шумом квантования.

Рисунок 5.4 – Шум квантования АЦП
Среднеквадратичное значение шума. приблизительно равно весу наименьшего значащего разряда (LSB) Δ, деленному на √12. При этом предполагается, что амплитуда сигнала составляет, по крайней мере, несколько младших разрядов, так что выход АЦП изменяет свое состояние почти при каждом отсчете. Сигнал ошибки квантования от входного линейного пилообразного сигнала аппроксимируется сигналом пилообразной формы с максимальным размахом Δ , и его среднеквадратичное значение равно Δ/( √12). Поэтому средняя мощность шума кантования равна:

Отношение среднеквадратичного значения синусоидального сигнала, соответствующего полной шкале, к среднеквадратичному значению шума квантования (выраженное в дБ) равно:
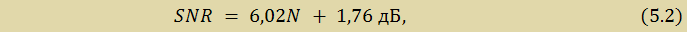
где SNR (signal to noise ratio) – отношение сигнал-шум, N — число разрядов в идеальном АЦП. Это уравнение имеет силу только в том случае, если шум измерен на полной ширине полосы Найквиста от 0 до fД/2.
Таким образом, для АЦП микроконвертора ADUC842, используемого в лабораторном стенде LESO1, справедливо:
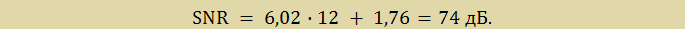
Для оценки погрешностей АЦП приведем характеристику АЦП, где указаны погрешности в значениях LSB и в напряжениях.
Таблица 5.1 – Характеристики АЦП ADuc842
| Параметры | Значение в LSB | Значение в мкВ | Примечание | |
| Точность по постоянному току | Разрядность | 12 битный | От внутреннего ИОН Uоп = 2,5 В | |
| Интегральная нелинейность | ±1 макс. ±0,3 сред. |
±610 макс. ±183 сред. |
||
| Дифференциальная нелинейность | ±1 макс. ±0,3 сред. |
±610 макс. ±183 макс. |
||
| Калибровочные ошибки конечных точек шкалы | Ошибка смещения | ±3 макс | ±1830 макс. | |
| Ошибка усиления | ±3 макс. | ±1830 макс. | ||
| Аналоговый вход | Диапазон входных напряжений | 0 ÷ Uоп В. | ||
| Входной ток | ±1 мкА макс. | |||
| Входная емкость | 32 пФ сред. |
Так как интегральная и дифференциальная нелинейности относятся к случайным ошибкам и являются независимыми друг от друга ошибками их необходимо сложить по «закону сложения независимых случайных ошибок»:
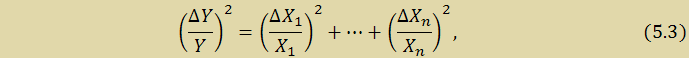
где X1,…,Xn – номинальные значения независимых случайных величин, ΔX1,…,ΔXn – ошибки случайных величин, Y — номинальное значение конечной измеряемой величины, ΔY – абсолютная ошибка конечной измеряемой величины.
Случайная ошибка АЦП будет состоять из интегральной и дифференциальной нелинейности, а также из ошибки квантования, которая составляет Δ/2 = 610мкВ/2 = 305мкВ = 0,305·10-3 В. Номинальное значения этих величин есть опорное напряжение АЦП, которое равно 2,5В.
Итак, относительная ошибка измерения АЦП:
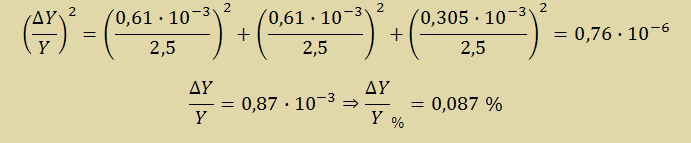
Из относительной ошибки измерения АЦП найдем абсолютное значение ошибки измерения:
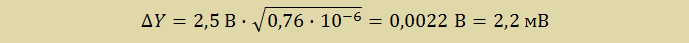
Систематическую ошибку составляют ошибка смещения нуля и ошибка усиления. Так как основную часть ошибки смещения и ошибки усиления вносит тракт передачи сигнала (инструментальный усилитель и масштабирующее звено), поправки вносятся программной калибровкой в LabVIEW.

Рисунок 5.5 – Калибровка в LabVIEW
5.3 Экспериментальные исследования
В задачу каждого измерения входит оценка точности полученного результата. Но в результате измерении мы всегда получаем нужную величину с некоторой погрешностью.Смысл экспериментальных исследований состоит в том, чтобы проверить на опыте теоретические выкладки и дать оценку характеристикам прибора.
Результат экспериментального исследования АЧХ устройства без цифрового фильтра или аналогового фильтра Бесселя записан в таблице 5.2. Экспериментальные данные были сняты с помощью низкочастотного генератора сигналов Г3-112.
Таблица 5.2 – Измеренное АЧХ устройства без цифрового фильтра
 |
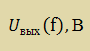 |
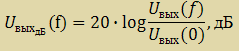 |
| 0 | 5,00 | 0,00 |
| 10 | 5,00 | 0,00 |
| 20 | 4,88 | -0,21 |
| 30 | 4,68 | -0,58 |
| 40 | 4,31 | -1,28 |
| 50 | 3,95 | -2,04 |
| 60 | 3,43 | -3,28 |
| 70 | 2,90 | -4,72 |
| 80 | 2,34 | -6,60 |
| 90 | 1,77 | -8,99 |
| 100 | 1,24 | -12,10 |
| 110 | 0,94 | -14,56 |
| 120 | 0,64 | -17,90 |
| 130 | 0,43 | -21,36 |
| 140 | 0,26 | -25,75 |
| 150 | 0,18 | -29,00 |
| 160 | 0,13 | -31,77 |
Проверим, действие цифрового фильтра на сигнал. Результаты измерения АЧХ после цифрового фильтра приведены в таблице 5.3.
Таблица 5.2 – Измеренное АЧХ устройства без цифрового фильтра
|
|
|
| 0 | 5,00 | 0,00 |
| 10 | 5,00 | 0,00 |
| 20 | 5,00 | 0,00 |
| 30 | 5,00 | 0,00 |
| 40 | 5,00 | 0,00 |
| 50 | 5,00 | 0,00 |
| 60 | 4,80 | -0,36 |
| 70 | 4,23 | -1,45 |
| 80 | 3,67 | -2,69 |
| 90 | 2,94 | -4,62 |
| 100 | 2,26 | -6,91 |
| 110 | 1,61 | -9,83 |
| 120 | 0,73 | -16,67 |
| 130 | 0,23 | -26,60 |
| 140 | 0,08 | -35,85 |
| 150 | 0,00 | -60,32 |
| 160 | 0,00 | -71,66 |
Для сравнения действия цифрового фильтра, приведем графики АЧХ устройства без и с цифровым фильтром. Как видно из рисунка 6.6, цифровой фильтр выравнивает амплитудную неравномерность. Полоса пропускания цифрового осциллографа-приставки на уровне -3 дБ, равна от 0 до 80 кГц.
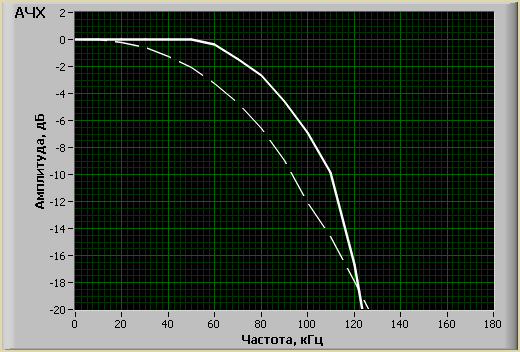
Рисунок 5.6 – АЧХ устройства без цифрового фильтр (штрих.) и с цифровым фильтром (сплош.)
Нелинейные искажения измерительного тракта можно оценить по первой гармонике. Уровень первой гармоники при номинальном входном напряжении Uвх = 5В на частоте 10 кГц равен -65дБ.
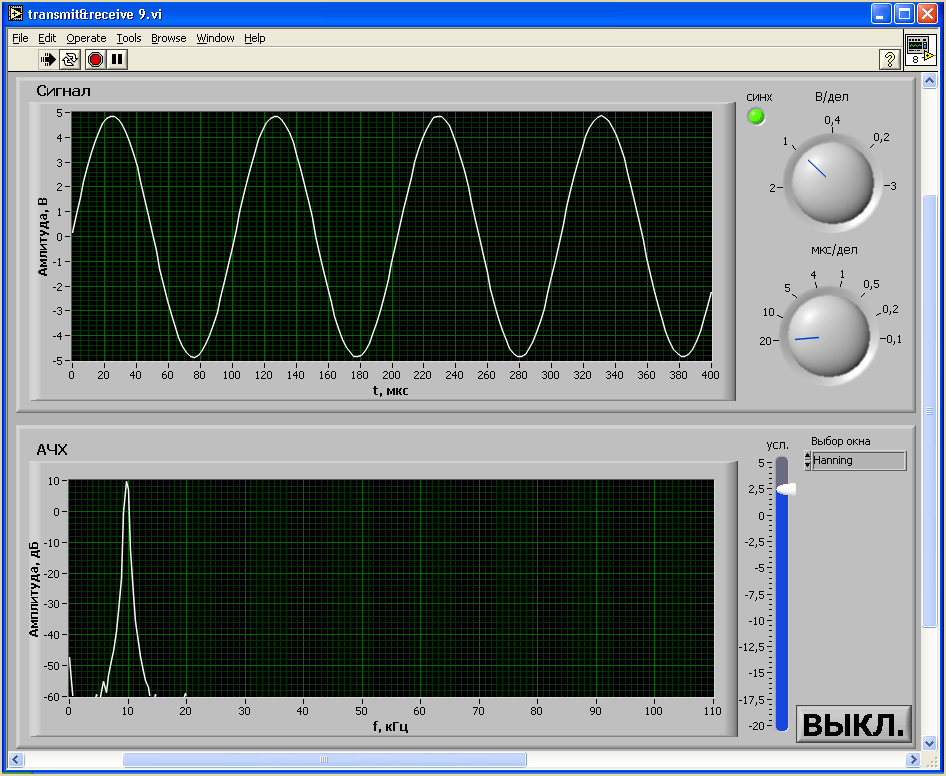
Рисунок 5.7 — Уровень первой гармоники при номинальном входном напряжении 5В
На цифровой осциллограф-приставку подавались тестовые испытательные сигналы трех видов: синусоидального, треугольного и прямоугольного частотой 10 кГц. Результаты измерений приведены на рисунках 5.8, 5.9 и 5.10 соответственно синусоидального, треугольного и прямоугольного сигналов.
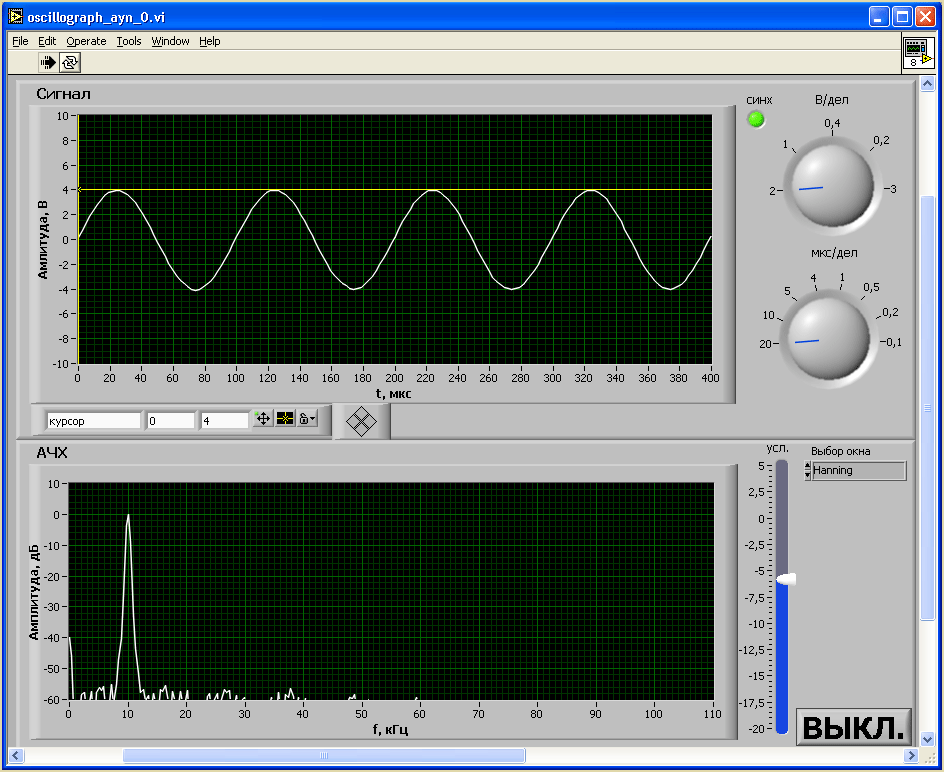
Рисунок 5.8 — Измерение синусоидального сигнала цифровым осциллографом-приставкой
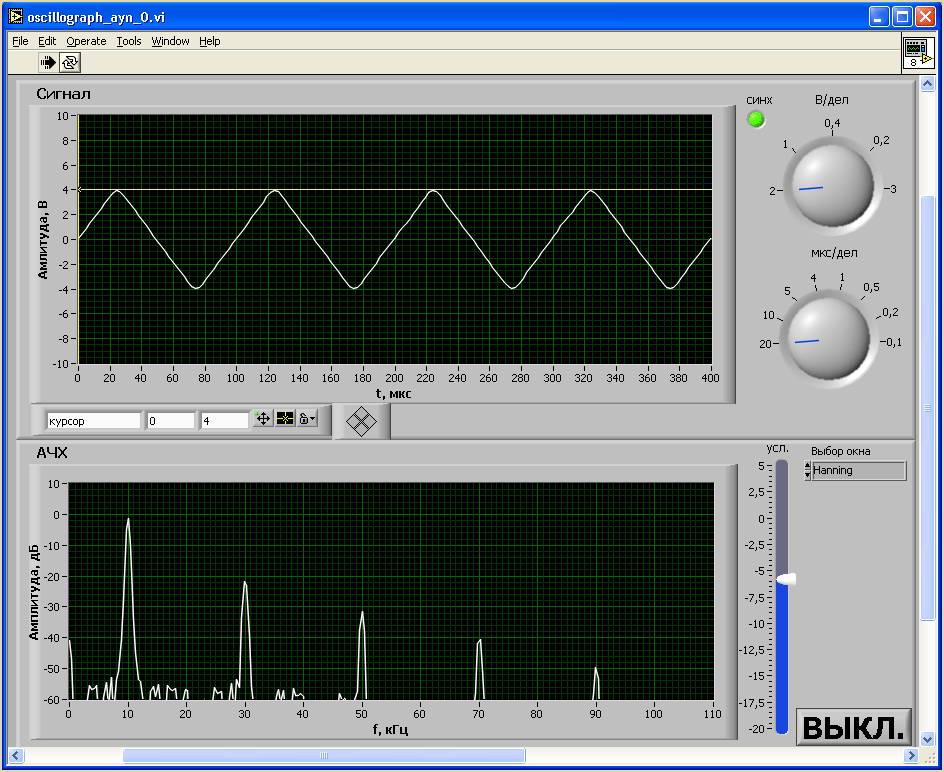
Рисунок 5.9 — Измерение треугольного сигнала цифровым осциллографом-приставкой

Рисунок 5.10 — Измерение прямоугольного сигнала цифровым осциллографом-приставкой
5.4 Выводы
Проанализированы основные источники погрешности измерений, определено из чего состоит ошибка измерения цифровым осциллографом-приставкой. Она состоит в из случайной и систематической ошибок. Случайная ошибка АЦП менее 0,1 %, а систематическая корректируется программной калибровкой в LabVIEW.
На рисунке 5.6 показано, насколько цифровой фильтр корректирует АЧХ аналогового фильтра.
Экспериментальные исследования тестовыми сигналами показывают, что уровень первой гармоники при номинальном входном напряжении Uвх = 5В на частоте 10 кГц равен -65дБ, что очень хорошо.
INL
определяется как интеграл ошибок DNL.
Ошибка INL показывает, как далеко от
идеальной функции происходит передача
результата преобразования. Так INL-ошибка,
составляющая ±2МЗР для 12-разрядного
АЦП, означает, что значение максимальной
ошибки нелинейности равно 2:4096 или 0,05%.
С INL ±0,5МЗР точность составляет 0,012%. Надо
отметить, что ошибки INL не могут быть
легко откалиброваны или скорректированы.
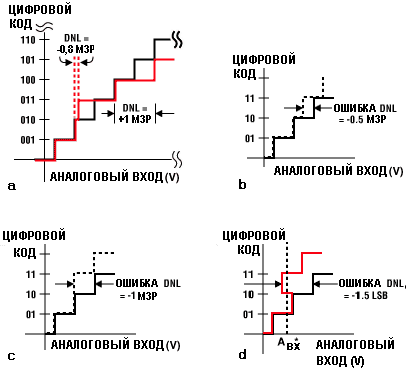
Рис.
10.4. К определению DNL: a) коды не пропадают;
b) коды не пропадают; c) код 10 потерян;
d) в точке A*ВХ цифровой код
может иметь одно из трех возможных
значений. Когда входное напряжение
колеблется, код 10 будет потерян
Ошибки смещения и коэффициента передачи
Эти
ошибки могут быть легко откалиброваны
при использовании микропроцессора. В
биполярных системах ошибка смещения
перемещает функцию передачи, но не
уменьшает число доступных кодов.
Коррекция
ошибок выполняется по следующей методике.
На вход АЦП подают нулевое напряжение.
Результат преобразования представляет
биполярную ошибку смещения нуля. Делая
преобразование во всем диапазоне входных
напряжений, передвигая ошибку смещения
в ноль по осям напряжение/код, получим
линию 2 (калибровка смещения). Используя
точку А (рис. 10.5) как шарнир, поворачиваем
всю линию до положения, параллельного
идеальной линии передачи. Здесь опять
потребуется смещение полученной линии
до совпадения с идеальной. Во всех этих
случаях ступенчатая функция заменяется
непрерывной линией, так как размер
одного шага мал.
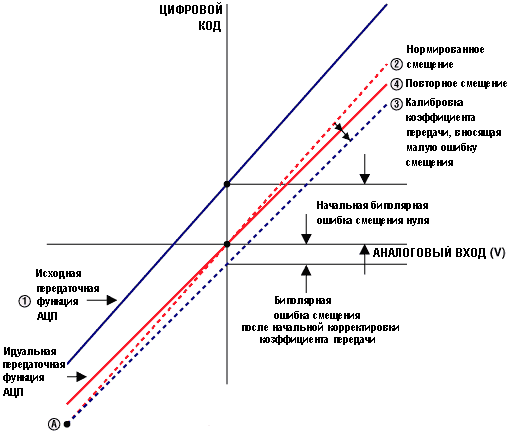
Рис.
10.5. Корректировка ошибки смещения
и коэффициента передачи
Ошибка
коэффициента передачи определяется
как разность полной шкалы (FS) и ошибки
смещения (рис. 10.6). Ошибка коэффициента
передачи легко корректируется в
программном обеспечении с помощью
линейной функции у = (m1/m2)х(Х),
где: m1 – коэффициент наклона для идеальной
передаточной функции, а m2 – для измеряемой
передаточной функции.
Другие источники ошибки
Шум
граничных кодов
Шум
граничных кодов – количество шума,
который появляется при переходе
передаточной функции от одного значения
к следующему. В технических данных
обычно не указывается. Особенно это
касается АЦП с высоким разрешением (до
16 разрядов), у которых единица МЗР имеет
меньшее
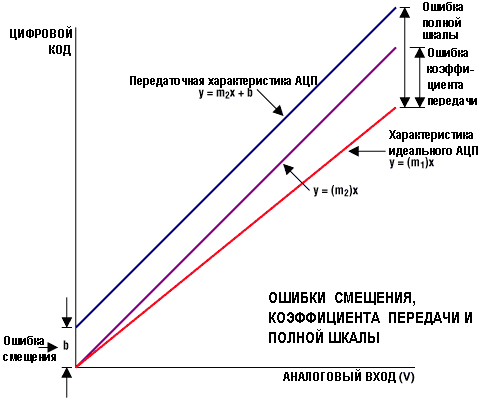
Рис.
10.6. Ошибки смещения коэффициента передачи
и полной шкалы
весовое
значение и шум граничных кодов более
распространен. Иногда величина шума
граничных кодов может
достигать нескольких единиц МЗР. В этом
случае преобразование аналогового
сигнала может закончиться кодовым
мерцанием в младших значащих разрядах.
Чтобы эффективно устранить неточность
преобразования из-за шумов граничных
кодов, надо провести необходимое число
замеров и усреднить результаты. Например,
если среднестатистическое значение
составляет 2/3 МЗР, это приравнивается
приблизительно к 4 МЗР от пика до
пика. Чтобы свести неточность преобразования
к 1 МЗР, необходимо
выбрать в квадрат раз больше замеров,
чем величина шума. В данном случае 42
составляет 16 замеров.
Опорное
напряжение
Одним
из наиболее потенциальных источников
ошибок в АЦП является источник опорного
напряжения (ИОН). ИОН может быть встроен
в чип или быть отдельным прибором, но
всегда необходимо обращать внимание
на 3 параметра: температурный дрейф, шум
напряжения и нестабильность выходного
напряжения (или тока) от нагрузки. Для
устранения ошибки преобразования от
температурного дрейфа необходимо
запитать источник сигнала от ИОН.
Шум
напряжения часто определяется как
среднеквадратическая величина или как
величина полного размаха. Если опорное
напряжение 2,5 В имеет полный размах
шума величиной 500 мкВ, то это представляет
ошибку 0,02 %, что соответствует только
12-разрядному преобразованию. Поэтому
ошибка преобразования от шума опорного
напряжения рассматривается прежде, чем
любая другая. Если, при встроенном ИОН,
Вы не получаете требуемую точность, то
попробуйте использовать внешний
прецизионный источник и сделайте
соответствующие выводы.
Часто
источник опорного напряжения используется
для других устройств и/или микросхем.
Ток, который при этом отбирается, приводит
к нестабильности опорного напряжения.
Чем больший ток потребляют внешние
схемы, тем ниже падает опорное напряжение.
Если дополнительные устройства включаются
периодически, то опорное напряжение
будет также раскачиваться вверх-вниз.
Если стабильность по току для опорного
напряжения 2,5 В составляет 0,5 мкВ/мкА
и на другие устройства отбирается 800
мкА, то изменение опорного напряжения
может достигать 400 мкВ, или 0,016%
(400 мкВ/2,5 В).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
30.04.2022386.56 Кб18.doc
- #
30.04.2022736.77 Кб380.doc
- #
30.04.2022736.77 Кб681.doc
- #
30.04.2022739.84 Кб282.doc
СМЕЩЕНИЕ, СИСТЕМАТИЧЕСКАЯ ОШИБКА
- СМЕЩЕНИЕ, СИСТЕМАТИЧЕСКАЯ ОШИБКА
-
- СМЕЩЕНИЕ, СИСТЕМАТИЧЕСКАЯ ОШИБКА
-
(bias) Тенденция к систематическому завышению или занижению оценок переменных величин. Систематическая ошибка может возникать из-за метода статистической выборки (sample selection) и формулировки вопросов или в ходе расчетов, производимых на базе накопленных данных. Исследователи стараются делать случайные статистические выборки, которые позволяют избежать заведомых ошибок в результатах, и стремятся точно формулировать вопросы, не допускающие уклончивых ответов. Если остаточная систематическая ошибка известна, требуется соответствующим образом изменить методы расчетов.
Экономика. Толковый словарь. — М.: «ИНФРА-М», Издательство «Весь Мир».
.
2000.
Экономический словарь.
2000.
Смотреть что такое «СМЕЩЕНИЕ, СИСТЕМАТИЧЕСКАЯ ОШИБКА» в других словарях:
-
Систематическая ошибка измерений, вызванная влиянием пола (sex bias in measurement) — С. о. и. имеет место в тех случаях, когда группы реагируют по разному на задания в тестах достижений, интеллекта или способностей, либо в др. измерительных инструментах, таких как опросники интересов. С. о. и., вызванная влиянием пола, имеет… … Психологическая энциклопедия
-
Систематическая ошибка тестов, обусловленная культурными факторами (cultural bias in tests) — Между разными соц. и расовыми группами наблюдаются существенные различия в средних значениях оценок по стандартизованным тестам умственных способностей, широко применяемым при приеме в школы и колледжи, наборе в вооруженные силы и найме на работу … Психологическая энциклопедия
-
смещение — 3.3 смещение (bias): Разность между математическим ожиданием результатов измерений и истинным (принятым опорным) значением. [ЕН 482] Источник: ГОСТ Р ЕН 13205 2010: Воздух рабочей зоны. Оценка характеристик приборов для определения содержания… … Словарь-справочник терминов нормативно-технической документации
-
систематическая погрешность — 3.8 систематическая погрешность (bias): Разность между математическим ожиданием результатов измерений и истинным (или в его отсутствие принятым опорным) значением. Примечание 5 Большее систематическое отклонение от принятого опорного значения… … Словарь-справочник терминов нормативно-технической документации
-
смещение (результата проверки) — 3.13. смещение (результата проверки) Разность между математическим ожиданием результатов проверки и принятым нормальным значением (по ИСО 5725.1). Примечание Смещение это общая систематическая ошибка в противоположность случайной ошибке. Может… … Словарь-справочник терминов нормативно-технической документации
-
СМЕЩЕНИЕ — (BIAS) Систематическая ошибка или смещение это разница между истинным значением переменной и ее средним значением, полученным при проведении повторных исследований. Любое расхождение между истинным и исследовательским значениями в пределах одного … Социологический словарь
-
Оценка и принятие решений (judgment and decision making) — Исслед. в области О. и п. р. можно разбить на четыре категории: поведенческие, когнитивные, организационные и системы поддержки решения. Каждая из этих категорий имеет свою собственную теорет. перспективу и методологию, применяемую при анализе… … Психологическая энциклопедия
-
ГОСТ Р 50779.10-2000: Статистические методы. Вероятность и основы статистики. Термины и определения — Терминология ГОСТ Р 50779.10 2000: Статистические методы. Вероятность и основы статистики. Термины и определения оригинал документа: 2.3. (генеральная) совокупность Множество всех рассматриваемых единиц. Примечание Для случайной величины… … Словарь-справочник терминов нормативно-технической документации
-
Культурно свободные тесты (culture fair tests) — Термин «К. с. т.» относится к тестам, «справедливым» в отношении любой конкретной культурной группы. И хотя технически невозможно разраб. тест, полностью лишенный систематических ошибок, обусловленных культурными факторами, существует множество… … Психологическая энциклопедия
-
точность — 3.1.1 точность (accuracy): Степень близости результата измерений к принятому опорному значению. Примечание Термин «точность», когда он относится к серии результатов измерений, включает сочетание случайных составляющих и общей систематической… … Словарь-справочник терминов нормативно-технической документации
Время на прочтение
15 мин
Количество просмотров 13K
предыдущие главы
20 Смещение и разброс: Два основных источника ошибок
замечание переводчика До изменения, данная глава называлась «Систематические и случайные: Два основных источника ошибок», т. е. я использовал термины «случайной ошибки» и «систематической ошибки» для перевода bias и variance. Однако, форумчанин робот@Phaker в комментарии справедливо заметил, что в области машинного обучения в русскоязычной терминологии для данных терминов закрепляются понятия «смещение» и «разброс». Я посмотрел работы К.В. Воронцова, который заслужено является одним из авторитетов в области машинного обучения в России и ресурсы профессионального сообщества, и согласился с замечанием робот@Phaker. Несмотря на то, что с моей точки зрения, между «смещением» (bias) и «разбросом» (variance) при обучении алгоритмов и «систематической ошибкой» и «случайной ошибкой» физического эксперимента существует глубокая содержательная аналогия, кроме того они одинаково выражаются математически, все же правильно использовать устоявшиеся в данной области термины. Поэтому я переработал перевод данной и последующих глав, заменив «Систематическую и Случайные ошибки» на «Смещение и Разброс» и буду придерживаться этого подхода в дальнейшем.
Предположим, ваша тренировочная, валидационная и тестовая выборки имеют одно и то же распределение. Тогда нужно брать больше данных для обучения, это только улучшит качество работы алгоритма, верно ли это?
Несмотря на то, что получение большего количества данных не может повредить работе, к сожалению, новые данные не всегда помогают настолько, насколько можно ожидать. В некоторых случаях работа по получению дополнительных данных может оказаться пустой тратой усилий. Как принять решение — в каких случаях добавлять данные, а когда не стоит об этом беспокоиться.
В машинном обучении присутствуют два главных источника ошибок: смещение и разброс (дисперсия). Понимание того, что они из себя представляют поможет вам решить — нужно ли добавлять еще данные, так же поможет выбрать тактику по улучшению качества работы классификатора.
Предположим, вы надеетесь построить кошачий распознователь, имеющий 5% ошибок. На текущий момент ошибка вашего классификатора на тренировочной выборке 15%, на валидационной выборке 16%. В таком случае добавление тренировочных данных вряд ли поможет существенно увеличить качество. Вы должны сконцентрироваться на других изменениях системы. В действительности, добавление большего количества примеров в вашу тренировочную выборку только усложнит для вашего алгоритма получение хорошего результата на этой выборке (почему так получается будет объяснено в следующих главах).
Если доля ваших ошибок на тренировочной выборке составляет 15% (что соответствует точности 85%), но вашей целью является доля ошибок в 5% (95% точность), тогда прежде всего нужно улучшить качество работы вашего алгоритма на тренировочной выборке. Качество работы алгоритма на валидационной / тестовой выборках обычно хуже, чем качество его работы на выборке для обучения (на тренировочной выборке). Нужно понимать, что те подходы, которые привели вас к точности, не превышающей 85% на примерах, с которыми ваш алгоритм знаком, не позволят получить точность в 95% на примерах, которые этот алгоритм даже не видел.
Предположим, как указано выше, доля ошибок вашего алгоритма составляет 16% (точность составляет 84%) на валидационной выборке. Мы должны разбить ошибку в 16% на два компонента:
- Первый, доля ошибок алгоритма на тренировочной выборке. В данном примере это 15%. Мы неофициально называть его смещением (bias).
- Второй, насколько хуже алгоритм работает на валидационной (или тестовой) выборке, чем на тренировочной. В нашем примере, на 1% хуже на валидационной выборке, чем на тренировочной. Будем так же неофициально считать его разбросом (variance) алгоритма.
замечание автора В статистике присутствует более точное определение для смещения и разброса (систематической и случайной ошибок), но нас это не должно тревожить. Грубо говоря, будем считать, что смещение — это ошибка вашего алгоритма на вашей тренировочной выборке, когда вы имеете очень большую тренировочную выборку. Разброс — это насколько хуже алгоритм работает на тестовой выборке по сравнению с тренировочной при тех же настройках параметров. Если использовать среднеквадратичную ошибку, то можно записать формулы, определяющие эти две величины и доказать, что общая ошибка равна сумме смещения и разброса (сумме случайных и систематических погрешностей). Но для наших целей улучшения алгоритмов в задачах машинного обучения, достаточно неформального определения смещения и разброса.
Некоторые изменения при обучении алгоритма влияют на первый компонент ошибки — на смещение ( bias ) и улучшают выполнение алгоритма на тренировочной выборке. Некоторые изменения влияют на второй компонент — на разброс ( variance ) и помогают лучше обобщить работу алгоритма на валидационную и тестовую выборки. Для выбора наиболее эффективных изменений, которые нужно внести в систему, крайне полезно понимать, как каждый из этих двух компонентов ошибки влияет на общую ошибку системы.
замечание автора: Так же есть некоторые подходы, которые одновременно уменьшают смещение и разброс, внося существенные изменения в архитектуру системы. Но их, как правило, сложнее найти и реализовать
Для выбора наиболее эффективных изменений, которые нужно внести в систему, крайне полезно понимать, как каждый из этих двух компонентов ошибки влияет на общую ошибку системы.
Развитие интуиции в понимании, какой вклад в ошибку вносит Смещение, а какой Разброс, поможет вам эффективно выбирать пути улучшения вашего алгоритма.
21 Примеры классификации ошибок
Рассмотрим нашу задачу по классификации кошек. Идеальный классификатор (например, человек) может достичь превосходного качества выполнения этой задачи.
Предположим, что качество работы нашего алгоритма следующее:
- Ошибка на тренировочной выборке = 1%
- Ошибка на валидационной выборке = 11%
Какая проблема у этого классификатора? Применив определения из предыдущей главы, мы оценим смещение в 1% и разброс в 10% (=11% — 1%). Таким образом, у нашего алгоритма большой разброс. Классификатор имеет очень низкую ошибку на тренировочной выборке, но не может обобщить результаты обучения на валидационную выборку. Другими словами, мы имеем дело с переобучением (overfitting).
Теперь рассмотрим такую ситуацию:
- Ошибка на тренировочной выборке = 15%
- Ошибка на валидационной выборке = 16%
Тогда мы оценим смещение в 15% и разброс в 1%. Этот классификатор плохо обучился на тренировочной выборке, при этом его ошибка на валидационной выборке чуть больше, чем на тренировочной. Таким образом этот классификатор имеет большое смещение, но маленький разброс. Можно сделать вывод, что этот алгоритм недообучился (underfitting).
Еще рассмотрим такое распределение ошибок:
- Ошибка на тренировочной выборке = 15%
- Ошибка на валидационной выборке = 30%
В этом случае смещение 15% и разброс тоже 15%. У данного классификатора высокие и смещение и разброс: он плохо работает на тренировочной выборке, имея высокое смещение, и его качество на валидационной выборке намного хуже, чем на тренировочной, т.е. разброс тоже велик. Данный случай трудно описать в терминах переобучения/недообучения, этот классификатор одновременно и переобучился и недообучился.
И наконец рассмотрим такую ситуацию:
- Ошибка на тренировочной выборке = 0.5%
- Ошибка на валидационной выборке = 1%
Это отлично работающий классификатор, у него низкие и смещение и разброс. Поздравим инженеров с достижением прекрасного результата!
22 Сравнение с оптимальной долей ошибок
В нашем примере по распознаванию кошек, идеальной долей ошибок является уровень, доступный «оптимальному» классификатору и этот уровень близок к 0%. Человек, рассматривающий картинку почти всегда способен распознать, присутствует ли на картинке кошка или нет и мы можем надеяться, что рано или поздно машина будет делать это так же хорошо.
Но есть и более сложные задачи. Например, представьте, что вы разрабатываете систему распознавания речи, и обнаружили, что 14% аудио записей имеют столько фонового шума или настолько неразборчивую речь, что даже человек не может разобрать, что там было сказано. В этом случае даже самая «оптимальная» система распознавания речи может иметь ошибку в районе 14%.
Допустим в приведенной задаче по распознаванию речи наш алгоритм достиг следующих результатов:
- Ошибка на тренировочной выборке = 15%
- Ошибка на валидационной выборке = 30%
Качество работы классификатора на тренировочной выборке уже близко к оптимальному, имеющему долю ошибок в 14%. Таким образом, в данном случае у нас не так много возможностей для уменьшения смещения (улучшения работы алгоритма на тренировочной выборке). Однако, не получается обобщить работу этого алгоритма на валидационную выборку, поэтому есть большое поле для деятельности по уменьшению разброса.
Этот случай похож на третий пример из предыдущей главы, в которой ошибка на тренировочной выборке так же равна 15% и ошибка на валидационной выборке 30%. Если оптимальная доля ошибки находится около 0%, тогда ошибка на тренировочной выборке в 15% дает большое пространство для работ по улучшению алгоритма. При таком предположении, усилия, направленные на уменьшение смещения в работе алгоритма могут быть весьма плодотворны. Но если оптимальная доля ошибок классификации не может быть ниже 14%, то аналогичная доля ошибок алгоритма на тренировочной выборке (т. е. в районе 14-15%) говорит о том, что возможности по уменьшению смещения практически исчерпаны.
Для задач, в которых оптимальная доля ошибок классификации существенно отличается от нуля, можно предложить более подробную структуризацию ошибок. Продолжим рассматривать приведенный выше пример с распознаванием речи, общая ошибка в 30% на валидационной выборке может быть разложена на следующие составные части (таким же образом можно анализировать ошибки на тестовой выборке):
- Оптимальное смещение (unavoidable bias): 14%. Представим, мы решили, что даже возможно наилучшая система распознавания речи в мире, будет иметь долю ошибки в 14%. Мы будем говорить об этом, как о «неустранимой» (unavoidable) части смещения обучающегося алгоритма.
- Устранимое смещение (Avoidable bias): 1%. Эта величина рассчитывается как разница между долей ошибок на тренировочной выборке и оптимальной долей ошибок.
замечание автора: Если данная величина получилась отрицательной, таким образом, ваш алгоритм на тренировочной выборке показывает меньшую ошибку, чем «оптимальная». Это означает, что вы переобучились на тренировочной выборке, ваш алгоритм запомнил примеры (и их классы) тренировочной выборки. В этом случае вы должны сосредоточиться на методах уменьшения разброса, а не на дальнейшем уменьшении смещения.
- Разброс (Variance): 15%. Разница между ошибками на тренировочной выборке и на валидационной выборке
Соотнеся это с нашими прежними определениями, смещение и устранимое смещение связаны следующим образом:
Смещение (bias) = Оптимальное смещение ( «unavoidable bias» ) + Устранимое смещение ( «avoidable bias» )
замечание автора: Эти определения выбраны для лучшего объяснения, как можно улучшить качество работы обучающегося алгоритма. Эти определения отличаются от формальных определений смещения и разброса, принятых в статистике. Технически то, что я определяю, как «Смещение» следовало бы назвать «ошибкой, которая заложена в структуре данных, (ее нельзя выявить и устранить)» и «Устранимое смещение» нужно определить, как «Смещение обучающегося алгоритма, которая превышает оптимальное смещение».
Устранимое смещение (avoidable bias) показывает, насколько хуже качество вашего алгоритма на тренировочной выборке, чем качество «оптимального классификатора».
Основная идея разброса (variance) остается прежней. В теории мы всегда можем уменьшить разброс практически до нуля, тренируясь на достаточно большой тренировочной выборке. Таким образом любой разброс является «устранимым» (avoidable) при наличие достаточно большой выборки, поэтому не может быть такого понятия, как «неустранимый разброс» (unavoidable variance).
Рассмотрим еще один пример, в котором оптимальная ошибка составляет 14% и мы имеем:
- Ошибка на тренировочной выборке = 15%
- Ошибка на валидационной выборке = 16%
В предыдущей главе классификатор с такими показателями мы оценивали, как классификатор с высоким смещением, в текущих условиях мы скажем, что «устранимое смещение» (avoidable bias) составляет 1%, и разброс составляет порядка 1%. Таким образом, алгоритм уже работает достаточно хорошо и почти нет резервов для улучшения качества его работы. Качество работы данного алгоритма всего на 2% ниже оптимального.
Из этих примеров понятно, что знание величины неустранимой ошибки полезно для принятия решения о дальнейших действиях. В статистике оптимальную долю ошибки называют так же ошибкой Байеса ( Bayes error rate ).
Как узнать размер оптимальной доли ошибки? Для задач, с которыми хорошо справляется человек, таких как распознавание изображений или расшифровка аудио клипов, можно попросить асессоров разметить данные, а потом измерить точность человеческой разметки на тренировочной выборке. Это даст оценку оптимальной доли ошибок. Если вы работаете над проблемой, с которой сложно справиться даже человеку (например, предсказать, какой фильм рекомендовать или какую рекламу показать пользователю), в этом случае довольно тяжело оценить оптимальную долю ошибок.
В разделе «Сравнение с человеческим уровнем качества» (Comparing to Human-Level Performance, главы с 33 по 35), я буду более подробно обсуждать процесс сравнения качества работы обучающегося алгоритма с уровнем качества, которого может достигнуть человек.
В последних главах, вы узнали, как оценивать устранимые / неустранимые смещение и разброс, анализируя долю ошибок классификатора на тренировочной и валидационной выборках. В следующей главе будет рассмотрено, как вы можете использовать выводы из такого анализа для принятия решения о том, сконцентрироваться на методах, уменьшающих смещение или на методах, которые уменьшают разброс. Подходы к борьбе со смещением сильно отличаются от подходов к уменьшению разброса, поэтому техники, которые вы должны применять в вашем проекте для улучшения качества, сильно зависят от того, что является проблемой на настоящий момент — большое смещение или большой разброс.
Читайте дальше!
23 Устранение смещения и разброса
Приведем простую формулу устранения смещения и разброса:
- Если у вас большое устранимое смещение (avoidable bias), увеличьте сложность вашей модели (например, увеличьте вашу нейронную сеть, добавив слоев или (и) нейронов)
- Если у вас большой разброс, добавьте примеров в вашу тренировочную выборку
Если у вас есть возможность увеличивать размер нейронной сети и безлимитно добавлять данные в тренировочную выборку, это поможет добиться хорошего результата для большого количества задач машинного обучения.
На практике увеличение размера модели в конечном счете вызовет вычислительные сложности, так как обучение очень больших моделей происходит медленно. Также вы можете исчерпать лимит доступных для обучения данных. (Даже во всем Интернете количество изображений с кошками конечно!)
Различные архитектуры моделей алгоритмов, например, различные архитектуры нейронных сетей, будут давать различные значения для смещения и разброса, применительно к вашей задаче. Вал недавних исследований в области глубинного обучения позволил создать большое количество инновационных архитектур моделей нейронных сетей. Таким образом, если вы используете нейронные сети, научная литература может быть прекрасным источником для вдохновения. Также имеется большое количество отличных реализаций алгоритмов в открытых источниках, например на GitHub. Однако, результаты попыток использовать новые архитектуры существенно менее предсказуемые, чем приведенная выше простая формула — увеличивайте размер модели и добавляйте данные.
Увеличение размера модели обычно уменьшает смещение, но оно же может вызвать увеличение разброса, также возрастает риск переобучения. Однако, проблема переобучения встает только тогда, когда вы не используете регуляризацию. Если включить хорошо спроектированный метод регуляризации в модель, обычно удается безопасно увеличить размер модели, не допустив переобучения.
Предположим, вы применяете глубокое обучение, используя L2 регуляризацию или dropout (Замечание переводчика: про Dropout можно почитать, например, здесь: https://habr.com/company/wunderfund/blog/330814/), используя параметры регуляризации, безупречно работающие на валидационной выборке. Если вы увеличите размер модели, обычно качество работы вашего алгоритма остается таким же или вырастает; его существенное снижение маловероятно. Единственная причина, из-за которой приходится отказываться от увеличения размера модели — большие вычислительные издержки.
24 Компромисс между смещением и разбросом
Вы могли слышать о «компромиссе между смещением и разбросом». Среди множества изменений, которые можно внести в обучающиеся алгоритмы, встречаются такие, которые уменьшают смещение и увеличивают разброс или наоборот. В таком случае говорят о «компромиссе» между смещением и разбросом.
Например, увеличение размерам модели — добавление нейронов и (или) слоев нейронной сети, или добавление входных признаков обычно уменьшают смещение, но могут увеличить разброс. Наоборот, добавление регуляризации часто увеличивает смещение, но уменьшает разброс.
На сегодняшний день у нас обычно есть доступ к большому количеству данных и вычислительных мощностей хватает для обучения больших нейронных сетей (для глубокого обучения). Таким образом, проблема компромисса не стоит так остро, и в нашем распоряжении есть много инструментов для уменьшения смещения, не навредив сильно значению разброса и наоборот.
Например, обычно вы можете увеличить размер нейронной сети и настроить регуляриацию таким образом, чтобы уменьшить смещение без заметного увеличения разброса. Добавление данных в тренировочную выборку, так же, как правило, уменьшает разброс, не влияя на смещение.
Если удачно подобрать архитектуру модели, хорошо соответствующую задаче, можно одновременно уменьшить и смещение и разброс. Но выбор такой архитектуры может оказаться сложной задачей.
В следующих нескольких главах, мы обсудим другие специфические техники, направленные на борьбу со смещением и разбросом.
25 Подходы к уменьшению устранимого смещения
Если ваш обучающийся алгоритм страдает большим устранимым смещением, вы можете попробовать следующие подходы:
- Увеличение размеров модели (такие, как количество нейронов и слоев): этот подход уменьшает смещение, таким образом у вас появляется возможность лучше подгонять алгоритм к тренировочной выборке. Если вы обнаружили, что при этом увеличивается разброс, используйте регуляризацию, которая обычно устраняет увеличение разброса.
- Модифицируйте входящие признаки, основываясь на идеях, пришедших при анализе ошибок. Предположим анализ ошибок побудил вас создать новые дополнительные признаки, которые помогают алгоритму избавиться от определенной категории ошибок (в следующих главах мы обсудим этот аспект). Эти новые признаки могут помочь как со смещением, так и с разбросом. В теории добавление новых признаков может увеличить разброс; но если такое случится, вы всегда можете использовать регуляризацию, которая, как правило, помогает справиться с увеличением разброса.
- Уменьшение или отказ от регуляризации (L2 регуляризация, L1 регуляризация, Dropout): этот подход уменьшает устранимое смещение, однако, приводит к росту разброса.
- Модификация архитектуры модели (например, архитектуры нейронной сети) чтобы она больше подходила для вашей задачи: Этот подход влияет как на разброс, так и на смещение
Один не очень полезный метод:
- Добавление данных в тренировочную выборку: Этот подход помогает уменьшать разброс, но обычно не оказывает существенного воздействия на смещение.
26 Анализ ошибок на тренировочной выборке
Только после хорошего качества алгоритма на тренировочной выборке, можно ожидать от него приемлемых результатов на валидационной/тестовой выборках.
В дополнение к методам, описанным ранее, применяемым к большому смещению, я иногда так же переношу анализ ошибок на данные тренировочной выборки, следуя тому же подходу, который использовался при анализе валидационной выборки глазного яблока. Это может помочь, если ваш алгоритм имеет высокое смещение, т. е. если алгоритм не смог хорошо обучиться на тренировочной выборке.
Например, предположим вы разрабатываете систему распознавания речи для какого-то приложения и собрали тренировочную выборку аудио клипов от волонтеров. Если ваша система не работает хорошо на тренировочной выборке, вы можете рассмотреть возможность прослушивания набора, состоящего из 100 примеров, на которых алгоритм отработал плохо для того, чтобы понять основные категории ошибок на тренировочной выборке. Аналогично анализу ошибок на валидационной выборке, вы можеет посчитать ошибки в разрезе категорий:
В этом примере вы могли бы понять, что ваш алгоритм испытывает особенные трудности с тренировочными примерами, имеющих много фонового шума. Таким образом вы можете сфокусироваться на методах, которые позволят ему лучше работать на тренировочных примерах с фоновым шумом.
Вы так же можете повторно проверить, насколько человек может разобрать такие аудио-клипы, дав ему послушать те же записи, что и обучающемуся алгоритму. Если в них настолько много фонового шума, что просто невозможно кому-либо понять, что там говорят, тогда может быть бессмысленно ожидать, что какой-либо алгоритм правильно распознает такое произношение. Мы обсудим в дальнейших главах пользу, которую приносит сравнение качества работы нашего алгоритма с уровнем качества, доступным человеку.
27 Подходы к уменьшению разброса
Если ваш алгоритм страдает от большого разброса, вы можете попробовать следующие подходы:
- Добавить больше данных в тренировочную выборку: Это наиболее простой и реализуемый путь к уменьшению разброса, он работает до тех пор, пока у вас есть возможность существенно увеличивать количество используемых данных и имеется достаточно вычислительных мощностей для их обработки.
- Добавить регуляризацию (L1 регуляризация, L2 регуляризация, dropout): этот подход уменьшает разброс, но увеличивает смещение.
- Добавить раннюю остановку (т. е. остановить градиентный спуск раньше, базируясь на значении ошибки на валидационной выборке): Эта техника уменьшает разброс, но увеличивает смещение. Ранняя остановка сильно напоминает метод регуляризации, поэтому некоторые авторы относят ее к регуляризации.
- Отбор признаков для уменьшения количества/типов входящих признаков: Этот подход может помочь с проблемой разброса, но также может увеличить смещение. Незначительное уменьшение количества признаков (скажем, с 1000 признаков до 900) вряд ли окажет большой эффект на смещение. Существенное уменьшение (скажем от 1000 признаков до 100 или 10 кратное уменьшение) более вероятно окажет существенный эффект, эффект будет увеличиваться до тех пор, пока вы не исключите слишком много полезных признаков. В современном глубинном обучении, когда данных много, происходит отход от тщательного отбора признаков, и сегодня мы скорее всего возьмем все признаки, которые у нас есть и будем на них обучать алгоритм, давая возможность алгоритму самому решить, какие из них использовать, базируясь на большом количестве обучающих примеров. Однако, если ваша тренировочная выборка маленькая, отбор признаков может оказаться очень полезным.
- Уменьшение размера (сложности) модели (такие как количество нейронов / слоев). Используйте с осторожностью! Этот подход может уменьшить разброс и одновременно, возможно, увеличит смещение. Однако, я бы не стал рекомендовать этот подход для уменьшения разброса. Добавление регуляризации обычно приводит к лучшему качеству классификации. Преимуществом уменьшения размера модели является уменьшение вашей потребности в вычислительных мощностях и таким образом ускоряется процесс тренировки моделей. Если увеличение скорости тренировки моделей будет полезным, тогда нужно рассмотреть вариант с уменьшением размера модели. Однако, если вашей задачей является только уменьшение разброса и вы не испытываете дефицита вычислительных мощностей, лучше рассмотреть возможности дополнительной регуляризации.
Здесь я привожу два дополнительных тактических приема, повторяя сказанное в предыдущих главах, применительно к уменьшению смещения:
- Модифицируйте входящие признаки, базируясь на понимании, полученном из анализа ошибок: Скажем, ваша анализ ошибок привел к идеи о том, что можно создать дополнительные признаки, которые помогут алгоритму избавиться от некоторых категорий ошибок. Эти новые признаки помогут уменьшить и разброс и смещение. Теоретически, добавление новых признаков может увеличить разброс; но если это случится, вы всегда можете воспользоваться регуляризацией, которая обычно нивелирует увеличение разброса.
- Модифицируйте архитектуру модели (например, архитектуру нейронной сети) делая ее более подходящей для вашей задачи: Этот подход может уменьшить и смещение и разброс.
продолжение