
Вектор
ош. – двоичн.
кодовое слово такой же длины как исходное,
содержащее ед-цы в тех разрядах, где
произошло искажение содержимого код.
слова. (код. слово и вектор ош. — абстракция).
Воздействие помехи на слово заменяется
слож-ем по mod2
исходн. слова с вектором ош.
Ошибки
различают на некорректируемые и
корректируемые.
Некорректир
– при которых изменение содержимого в
каком-то разряде слова не влияет на
искажение содержимого в других словах.
При
корректир – изменение содержимого под
влиянием помех влечёт искажение
содержимого некоторых других разрядах.
Различают
ош. разной кратности:
1)однократные,
2)двукратные,
3)r-кратные
(одновременное искажение содержимого
в r-
разрядах).
Однократная
ошибка вызывает искажение содержимого
только 1 разряда слова и т.д.
Вероятность
r-кратной
ошибки в n-разрядном
слове:
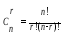 -кол-во
-кол-во
таких ошибок
Вероятность
такого события – вероятность сложного
события и определяется произведение
следующих множителей: вероятности, что
искажение произойдет в этом разряде p,
т.к. таких разрядов r
и события независимые, то — pr
, вероятности,
что в остальных (n-r)
разрядах искажения не будет определяется
как (1-p)(n—r)
, умноженных на количество возможных
r-кратных
ошибок. Т.о.
P=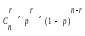
17. Формулы для определения числа избыточных разрядов и границы Хэмминга для оптимальных корректирующих кодов; их суть и связь, примеры использования.
Пусть
имеем n-разр.
слова, требуется исправлять ошибкки
вплоть до кратности S.
Определим, какое мн-во разреш-х код. слов
можно выделить на мн-ве всех n-разр-х
слов. Для каждой исправляемой ош-ки.
соотв-щее ей запрещ. код. слово. Поэтому
«вокруг» каждого разреш. слова должны
сгруппироваться те запрещ. слова, ош-ки
кот-х подлежат исправлению. Поэтому
кол-во запрещ. слов. не <, чем число
исправл-ых ошибок.
2k-1>=Q
– определяется число информационных
разрядов; 2n—k-1>=n
– определяется число разрядов
помехоустойчивого слова; n-k=m
— определяется число избыточных разрядов;
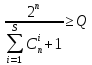 – определяется граница Хемминга.
– определяется граница Хемминга.
Дополнительных разрядов в кодовом слове
должно быть столько, чтобы породить
нужное число запрещенных слов или
классов смежности, а именно 2n—k-1.
Число классов смежности должно быть не
меньше, чем число исправляемых ошибок,
поэтому – 2n—k-1>=n
Пример:
Пусть для
построения кода, корректирующего все
однократные ошибки, используются
однобайтовые слова. Требуется определить
максимальное число разрешенных слов,
выбираемых из всего множества однобайтовых
слов.
Число
однократных ошибок
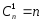 ,
,
т.е.
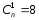 .
.
Максимальное
число разрешенных слов
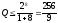 ,т.е.
,т.е.
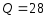
18. Построение группового корректирующего кода (на примере).
Пример:
тип
исправляемых ошибок — некоррелированные;
кратность
— S
= 1,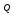 =15.
=15.
Процедура
состоит из четырех этапов.
1.
Расчет числа информационных и избыточных
разрядов:
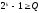 ;
;
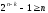
k
= 4;
n
= 7;
n
— k
=3;
где
k
— число информационных разрядов;
n
— число
избыточных разрядов;
2.
Построение таблицы опознавателей
ошибок.
Каждой
ошибке соответствует собственный
опознаватель.
|
Векторы
а7 |
опознаватели
(данный |
|
1 |
111 |
|
0 |
110 |
|
0 |
101 |
|
0 |
100 |
|
0 |
011 |
|
0 |
010 |
|
0 |
001 |
n
= 7 n
— k
=3
3.
Определение проверочных равенств.
1
— й (младший) — а1
а3
а6
а7 ;
2
— й — а2
а5
а6
а7 ;
3
— й — а1
а2
а4
а7 ;
При
отсутствии однократных ошибок в слове
дешифратор вычислит нулевой
— опознаватель
(состоящий из одних нулей — 000). Поэтому
можно записать проверочные
равенства
дешифратора в виде следующей системы
уравнений.
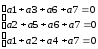 —
—
уравнения, формирующие 1-ый, 2-ой и 3-ий
разряды опознавателя.
4.
Построение алгоритма кодирования.
Имея
данную систему уравнений на роль
избыточных разрядов следует выбирать
те, которые встречаются в проверочных
равенствах по одному разу, т.е.
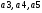 .
.
Выделение избыточных разрядов
сопровождается определением информационных
разрядов помехоустойчивого кодового
слова. При этом для данного кода будут
помечены правила кодирования в виде:
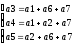
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
The error vector magnitude or EVM (sometimes also called relative constellation error or RCE) is a measure used to quantify the performance of a digital radio transmitter or receiver. A signal sent by an ideal transmitter or received by a receiver would have all constellation points precisely at the ideal locations, however various imperfections in the implementation (such as carrier leakage, low image rejection ratio, phase noise etc.) cause the actual constellation points to deviate from the ideal locations. Informally, EVM is a measure of how far the points are from the ideal locations.
Noise, distortion, spurious signals, and phase noise all degrade EVM, and therefore EVM provides a comprehensive measure of the quality of the radio receiver or transmitter for use in digital communications. Transmitter EVM can be measured by specialized equipment, which demodulates the received signal in a similar way to how a real radio demodulator does it. One of the stages in a typical phase-shift keying demodulation process produces a stream of I-Q points which can be used as a reasonably reliable estimate for the ideal transmitted signal in EVM calculation.
Definition[edit]

Constellation diagram and EVM
An error vector is a vector in the I-Q plane between the ideal constellation point and the point received by the receiver. In other words, it is the difference between actual received symbols and ideal symbols. The root mean square (RMS) average amplitude of the error vector, normalized to ideal signal amplitude reference, is the EVM. EVM is generally expressed in percent by multiplying the ratio by 100. [1]
The ideal signal amplitude reference can either be the maximum ideal signal amplitude of the constellation, or it can be the root mean square (RMS) average amplitude of all possible ideal signal amplitude values in the constellation. For many common constellations including BPSK, QPSK, and 8PSK, these two methods for finding the reference give the same result, but for higher-order QAM constellations including 16QAM, Star 32QAM, 32APSK, and 64QAM the RMS average and the maximum produce different reference values. [2]
The error vector magnitude is sometimes expressed in dB. This is related to the value of EVM in percent as follows:

The definition of EVM depends heavily on the standard that is being used, for example in 3GPP LTE the relevant documents will define exactly how EVM is to be measured. There are discussions ongoing by academics as to some of the problems around EVM measurement.[3]
Dynamic EVM[edit]
Battery life and power consumption are important considerations for a system-level RF transmitter design. Because the transmit power amplifier (PA) consumes a significant portion of the total system DC power, a number of techniques are employed to reduce PA power usage. Many PAs offer an adjustable DC supply voltage to optimize the maximum RF output power level versus its DC power consumption. Also, most PAs can be powered-down or disabled when not in use to conserve power, such as while receiving or between packets during transmission. In order to maximize power efficiency, the PA must have fast turn-on and turn-off switching times. The highest DC power efficiency occurs when the time delta between PA Enable and the RF signal is minimized, but a short delay can exacerbate transient effects on the RF signal.
Because the power-up/power-down operation of the PA can cause transient and thermal effects that degrade transmitter performance, another metric called Dynamic EVM is often tested. Dynamic EVM is measured with a square wave pulse applied to PA Enable to emulate the actual dynamic operation conditions of the transmitter. The degradation in dynamic EVM is due to the PA transient response affecting the preamble at the start of the packet and causing an imperfect channel estimate. Studies have shown that dynamic EVM with a 50% duty cycle square wave applied to PA Enable to be worse than the static EVM (PA Enable with 100% duty cycle).[4]
See also[edit]
- Modulation error ratio
- Carrier to Noise Ratio
- Signal-to-noise ratio
References[edit]
- ^ «Error Vector Magnitude (Digital Demodulation)».
- ^ «EVM Normalization Reference (Digital Demod)».
- ^ Vigilante, McCune, Reynaert. «To EVM or Two EVMs?». doi:10.1109/MSSC.2017.2714398. S2CID 6849707. CS1 maint: multiple names: authors list (link)
- ^ Power Amplifier Testing For 802.11ac
Корректирующие коды «на пальцах»
Время на прочтение
11 мин
Количество просмотров 63K
 Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Как нетрудно догадаться, ко всему этому причастны корректирующие коды. Собственно, ECC так и расшифровывается — «error-correcting code», то есть «код, исправляющий ошибки». А CRC — это один из алгоритмов, обнаруживающих ошибки в данных. Исправить он их не может, но часто это и не требуется.
Давайте же разберёмся, что это такое.
Для понимания статьи не нужны никакие специальные знания. Достаточно лишь понимать, что такое вектор и матрица, как они перемножаются и как с их помощью записать систему линейных уравнений.
Внимание! Много текста и мало картинок. Я постарался всё объяснить, но без карандаша и бумаги текст может показаться немного запутанным.
Каналы с ошибкой
Разберёмся сперва, откуда вообще берутся ошибки, которые мы собираемся исправлять. Перед нами стоит следующая задача. Нужно передать несколько блоков данных, каждый из которых кодируется цепочкой двоичных цифр. Получившаяся последовательность нулей и единиц передаётся через канал связи. Но так сложилось, что реальные каналы связи часто подвержены ошибкам. Вообще говоря, ошибки могут быть разных видов — может появиться лишняя цифра или какая-то пропасть. Но мы будем рассматривать только ситуации, когда в канале возможны лишь замены нуля на единицу и наоборот. Причём опять же для простоты будем считать такие замены равновероятными.
Ошибка — это маловероятное событие (а иначе зачем нам такой канал вообще, где одни ошибки?), а значит, вероятность двух ошибок меньше, а трёх уже совсем мала. Мы можем выбрать для себя некоторую приемлемую величину вероятности, очертив границу «это уж точно невозможно». Это позволит нам сказать, что в канале возможно не более, чем  ошибок. Это будет характеристикой канала связи.
ошибок. Это будет характеристикой канала связи.
Для простоты введём следующие обозначения. Пусть данные, которые мы хотим передавать, — это двоичные последовательности фиксированной длины. Чтобы не запутаться в нулях и единицах, будем иногда обозначать их заглавными латинскими буквами ( ,
,  ,
,  , …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
, …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
Кодирование и декодирование будем обозначать прямой стрелкой ( ), а передачу по каналу связи — волнистой стрелкой (
), а передачу по каналу связи — волнистой стрелкой ( ). Ошибки при передаче будем подчёркивать.
). Ошибки при передаче будем подчёркивать.
Например, пусть мы хотим передавать только сообщения  и
и  . В простейшем случае их можно закодировать нулём и единицей (сюрприз!):
. В простейшем случае их можно закодировать нулём и единицей (сюрприз!):

Передача по каналу, в котором возникла ошибка будет записана так:

Цепочки нулей и единиц, которыми мы кодируем буквы, будем называть кодовыми словами. В данном простом случае кодовые слова — это  и
и  .
.
Код с утроением
Давайте попробуем построить какой-то корректирующий код. Что мы обычно делаем, когда кто-то нас не расслышал? Повторяем дважды:

Правда, это нам не очень поможет. В самом деле, рассмотрим канал с одной возможной ошибкой:

Какие выводы мы можем сделать, когда получили  ? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
То есть, получившийся код обнаруживает, но не исправляет ошибки. Ну, тоже неплохо, в общем-то. Но мы пойдём дальше и будем теперь утраивать цифры.

Проверим в деле:

Получили  . Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
. Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
Если в канале связи возможна максимум одна ошибка, то первое предположение о двух ошибках становится невозможным и остаётся только один вариант — передавалась буква .
Про такой код говорят, что он исправляет одну ошибку. Две он тоже обнаружит, но исправит уже неверно.
Это, конечно, самый простой код. Кодировать легко, да и декодировать тоже. Ноликов больше — значит передавался ноль, единичек — значит единица.
Если немного подумать, то можно предложить код исправляющий две ошибки. Это будет код, в котором мы повторяем одиночный бит 5 раз.
Расстояния между кодами
Рассмотрим поподробнее код с утроением. Итак, мы получили работающий код, который исправляет одиночную ошибку. Но за всё хорошее надо платить: он кодирует один бит тремя. Не очень-то и эффективно.
И вообще, почему этот код работает? Почему нужно именно утраивать для устранения одной ошибки? Наверняка это всё неспроста.
Давайте подумаем, как этот код работает. Интуитивно всё понятно. Нолики и единички — это две непохожие последовательности. Так как они достаточно длинные, то одиночная ошибка не сильно портит их вид.
Пусть мы передавали  , а получили
, а получили  . Видно, что эта цепочка больше похожа на исходные , чем на
. Видно, что эта цепочка больше похожа на исходные , чем на  . А так как других кодовых слов у нас нет, то и выбор очевиден.
. А так как других кодовых слов у нас нет, то и выбор очевиден.
Но что значит «больше похоже»? А всё просто! Чем больше символов у двух цепочек совпадает, тем больше их схожесть. Если почти все символы отличаются, то цепочки «далеки» друг от друга.
Можно ввести некоторую величину  , равную количеству различающихся цифр в соответствующих разрядах цепочек
, равную количеству различающихся цифр в соответствующих разрядах цепочек  и
и  . Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
. Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
Например,  , так как все цифры в соответствующих позициях равны, а вот
, так как все цифры в соответствующих позициях равны, а вот  .
.
Расстояние Хэмминга называют расстоянием неспроста. Ведь в самом деле, что такое расстояние? Это какая-то характеристика, указывающая на близость двух точек, и для которой верны утверждения:
- Расстояние между точками неотрицательно и равно нулю только, если точки совпадают.
- Расстояние в обе стороны одинаково.
- Путь через третью точку не короче, чем прямой путь.
Достаточно разумные требования.
Математически это можно записать так (нам это не пригодится, просто ради интереса посмотрим):

- .


 .
.Предлагаю читателю самому убедиться, что для расстояния Хэмминга эти свойства выполняются.
Окрестности
Таким образом, разные цепочки мы считаем точками в каком-то воображаемом пространстве, и теперь мы умеем находить расстояния между ними. Правда, если попытаться сколько нибудь длинные цепочки расставить на листе бумаги так, чтобы расстояния Хэмминга совпадали с расстояниями на плоскости, мы можем потерпеть неудачу. Но не нужно переживать. Всё же это особое пространство со своими законами. А слова вроде «расстояния» лишь помогают нам рассуждать.
Пойдём дальше. Раз мы заговорили о расстоянии, то можно ввести такое понятие как окрестность. Как известно, окрестность какой-то точки — это шар определённого радиуса с центром в ней. Шар? Какие ещё шары! Мы же о кодах говорим.
Но всё просто. Ведь что такое шар? Это множество всех точек, которые находятся от данной не дальше, чем некоторое расстояние, называемое радиусом. Точки у нас есть, расстояние у нас есть, теперь есть и шары.
Так, скажем, окрестность кодового слова радиуса 1 — это все коды, находящиеся на расстоянии не больше, чем 1 от него, то есть отличающиеся не больше, чем в одном разряде. То есть это коды:

Да, вот так странно выглядят шары в пространстве кодов.
А теперь посмотрите. Это же все возможные коды, которые мы получим в канале в одной ошибкой, если отправим ! Это следует прямо из определения окрестности. Ведь каждая ошибка заставляет цепочку измениться только в одном разряде, а значит удаляет её на расстояние 1 от исходного сообщения.
Аналогично, если в канале возможны две ошибки, то отправив некоторое сообщение  , мы получим один из кодов, который принадлежит окрестности радиусом 2.
, мы получим один из кодов, который принадлежит окрестности радиусом 2.
Тогда всю нашу систему декодирования можно построить так. Мы получаем какую-то цепочку нулей и единиц (точку в нашей новой терминологии) и смотрим, в окрестность какого кодового слова она попадает.
Сколько ошибок может исправить код?
Чтобы код мог исправлять больше ошибок, окрестности должны быть как можно шире. С другой стороны, они не должны пересекаться. Иначе если точка попадёт в область пересечения, непонятно будет, к какой окрестности её отнести.
В коде с удвоением между кодовыми словами  и
и  расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
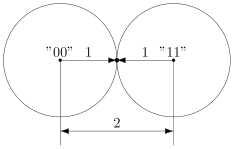
Именно это мы и получали. Мы видели, что есть ошибка, но не могли её исправить.
Что интересно, точек касания в нашем странном пространстве у шаров две — это коды и  . Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
. Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
В случае кода с утроением, между шарами будет зазор.
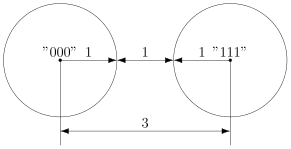
Минимальный зазор между шарами равен 1, так как у нас расстояния всегда целые (ну не могут же две цепочки отличаться в полутора разрядах).
В общем случае получаем следующее.

Этот очевидный результат на самом деле очень важен. Он означает, что код с минимальным кодовым расстоянием  будет успешно работать в канале с ошибками, если выполняется соотношение
будет успешно работать в канале с ошибками, если выполняется соотношение

Полученное равенство позволяет легко определить, сколько ошибок будет исправлять тот или иной код. А сколько код ошибок может обнаружить? Рассуждения такие же. Код обнаруживает ошибок, если в результате не получится другое кодовое слово. То есть, кодовые слова не должны находиться в окрестностях радиуса других кодовых слов. Математически это записывается так:

Рассмотрим пример. Пусть мы кодируем 4 буквы следующим образом.

Чтобы найти минимальное расстояние между различными кодовыми словами, построим таблицу попарных расстояний.
| A | B | C | D | |
|---|---|---|---|---|
| A | — | 3 | 3 | 4 |
| B | 3 | — | 4 | 3 |
| C | 3 | 4 | — | 3 |
| D | 4 | 3 | 3 | — |
Минимальное расстояние  , а значит
, а значит  , откуда получаем, что такой код может исправить до
, откуда получаем, что такой код может исправить до  ошибок. Обнаруживает же он две ошибки.
ошибок. Обнаруживает же он две ошибки.
Рассмотрим пример:

Чтобы декодировать полученное сообщение, посмотрим, к какому символу оно ближе всего.

Минимальное расстояние получилось для символа , значит вероятнее всего передавался именно он:

Итак, этот код исправляет одну ошибку, как и код с утроением. Но он более эффективен, так как в отличие от кода с утроением здесь кодируется уже 4 символа.
Таким образом, основная проблема при построении такого рода кодов — так расположить кодовые слова, чтобы они были как можно дальше друг от друга, и их было побольше.
Для декодирования можно было бы использовать таблицу, в которой указывались бы все возможные принимаемые сообщения, и кодовые слова, которым они соответствуют. Но такая таблица получилась бы очень большой. Даже для нашего маленького кода, который выдаёт 5 двоичных цифр, получилось бы  варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
Попробуем придумать способ коррекции сообщения без таблиц. Мы всегда сможем найти полезное применение освободившейся памяти.
Интерлюдия: поле GF(2)
Для изложения дальнейшего материала нам потребуются матрицы. А при умножении матриц, как известно мы складываем и перемножаем числа. И тут есть проблема. Если с умножением всё более-менее хорошо, то как быть со сложением? Из-за того, что мы работаем только с одиночными двоичными цифрами, непонятно, как сложить 1 и 1, чтобы снова получилась одна двоичная цифра. Значит вместо классического сложения нужно использовать какое-то другое.
Введём операцию сложения как сложение по модулю 2 (хорошо известный программистам XOR):

Умножение будем выполнять как обычно. Эти операции на самом деле введены не абы как, а чтобы получилась система, которая в математике называется полем. Поле — это просто множество (в нашем случае из 0 и 1), на котором так определены сложение и умножение, чтобы основные алгебраические законы сохранялись. Например, чтобы основные идеи, касающиеся матриц и систем уравнений по-прежнему были верны. А вычитание и деление мы можем ввести как обратные операции.
Множество из двух элементов  с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
У сложения есть несколько очень полезных свойств, которыми мы будем пользоваться в дальнейшем.

Это свойство прямо следует из определения.

А в этом можно убедиться, прибавив  к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
Проверяем корректность
Вернёмся к коду с утроением.
Для начала просто решим задачу проверки, были ли вообще ошибки при передаче. Как видно, из самого кода, принятое сообщение будет кодовым словом только тогда, когда все три цифры равны между собой.
Пусть мы приняли вектор-строку из трёх цифр. (Стрелочки над векторами рисовать не будем, так как у нас почти всё — это вектора или матрицы.)

Математически равенство всех трёх цифр можно записать как систему:

Или, если воспользоваться свойствами сложения в GF(2), получаем

Или

В матричном виде эта система будет иметь вид

где

Транспонирование здесь нужно потому, что — это вектор-строка, а не вектор-столбец. Иначе мы не могли бы умножать его справа на матрицу.
Будем называть матрицу  проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
Умножение на матрицу — это гораздо более эффективно, чем поиск в таблице, но у нас на самом деле есть ещё одна таблица — это таблица кодирования. Попробуем от неё избавиться.
Кодирование
Итак, у нас есть система для проверки
Её решения — это кодовые слова. Собственно, мы систему и строили на основе кодовых слов. Попробуем теперь решить обратную задачу. По системе (или, что то же самое, по матрице ) найдём кодовые слова.
Правда, для нашей системы мы уже знаем ответ, поэтому, чтобы было интересно, возьмём другую матрицу:

Соответствующая система имеет вид:

Чтобы найти кодовые слова соответствующего кода нужно её решить.
В силу линейности сумма двух решений системы тоже будет решением системы. Это легко доказать. Если  и
и  — решения системы, то для их суммы верно
— решения системы, то для их суммы верно

что означает, что она тоже — решение.
Поэтому если мы найдём все линейно независимые решения, то с их помощью можно получить вообще все решения системы. Для этого просто нужно найти их всевозможные суммы.
Выразим сперва все зависимые слагаемые. Их столько же, сколько и уравнений. Выражать надо так, чтобы справа были только независимые. Проще всего выразить  .
.
Если бы нам не так повезло с системой, то нужно было бы складывая уравнения между собой получить такую систему, чтобы какие-то три переменные встречались по одному разу. Ну, или воспользоваться методом Гаусса. Для GF(2) он тоже работает.
Итак, получаем:

Чтобы получить все линейно независимые решения, приравниваем каждую из зависимых переменных к единице по очереди.

Всевозможные суммы этих независимых решений (а именно они и будут кодовыми векторами) можно получить так:

где  равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно
равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно  сочетания.
сочетания.
Но посмотрите! Формула, которую мы только что получили — это же снова умножение матрицы на вектор.

Строчки здесь — линейно независимые решения, которые мы получили. Матрица  называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:
называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:

Найдём кодовые слова для этого кода. (Не забываем, что длина исходных сообщений должна быть равна 2 — это количество найденных решений.)

Итак, у нас есть готовый код, обнаруживающий ошибки. Проверим его в деле. Пусть мы хотим отправить 01 и у нас произошла ошибка при передаче. Обнаружит ли её код?

А раз в результате не нулевой вектор, значит код заподозрил неладное. Провести его не удалось. Ура, код работает!
Для кода с утроением, кстати, порождающая матрица выглядит очень просто:

Подобные коды, которые можно порождать и проверять матрицей называются линейными (бывают и нелинейные), и они очень широко применяются на практике. Реализовать их довольно легко, так как тут требуется только умножение на константную матрицу.
Ошибка по синдрому
Ну хорошо, мы построили код обнаруживающий ошибки. Но мы же хотим их исправлять!
Для начала введём такое понятие, как вектор ошибки. Это вектор, на который отличается принятое сообщение от кодового слова. Пусть мы получили сообщение , а было отправлено кодовое слово  . Тогда вектор ошибки по определению
. Тогда вектор ошибки по определению

Но в странном мире GF(2), где сложение и вычитание одинаковы, будут верны и соотношения:

В силу особенностей сложения, как читатель сам может легко убедиться, в векторе ошибки на позициях, где произошла ошибка будет единица, а на остальных ноль.
Как мы уже говорили раньше, если мы получили сообщение с ошибкой, то  . Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
. Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
Назовём результат умножения на проверочную матрицу синдромом:

И заметим следующее

Это означает, что для ошибки синдром будет таким же, как и для полученного сообщения.
Разложим все возможные сообщения, которые мы можем получить из канала связи, по кучкам в зависимости от синдрома. Тогда из последнего соотношения следует, что в каждой кучке будут вектора с одной и той же ошибкой. Причём вектор этой ошибки тоже будет в кучке. Вот только как его узнать?
А очень просто! Помните, мы говорили, что у нескольких ошибок вероятность ниже, чем у одной ошибки? Руководствуясь этим соображением, наиболее правдоподобным будет считать вектором ошибки тот вектор, у которого меньше всего единиц. Будем называть его лидером.
Давайте посмотрим, какие синдромы дают всевозможные 5-элементные векторы. Сразу сгруппируем их и подчеркнём лидеров — векторы с наименьшим числом единиц.
 |
|
|---|---|
|
 |
|
 |
|
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
 |
В принципе, для корректирования ошибки достаточно было бы хранить таблицу соответствия синдрома лидеру.
Обратите внимание, что в некоторых строчках два лидера. Это значит для для данного синдрома два паттерна ошибки равновероятны. Иными словами, код обнаружил две ошибки, но исправить их не может.
Лидеры для всех возможных одиночных ошибок находятся в отдельных строках, а значит код может исправить любую одиночную ошибку. Ну, что же… Попробуем в этом убедиться.

Вектор ошибки равен  , а значит ошибка в третьем разряде. Как мы и загадали.
, а значит ошибка в третьем разряде. Как мы и загадали.
Ура, всё работает!
Что же дальше?
Чтобы попрактиковаться, попробуйте повторить рассуждения для разных проверочных матриц. Например, для кода с утроением.
Логическим продолжением изложенного был бы рассказ о циклических кодах — чрезвычайно интересном подклассе линейных кодов, обладающим замечательными свойствами. Но тогда, боюсь, статья уж очень бы разрослась.
Если вас заинтересовали подробности, то можете почитать замечательную книжку Аршинова и Садовского «Коды и математика». Там изложено гораздо больше, чем представлено в этой статье. Если интересует математика кодирования — то поищите «Теория и практика кодов, контролирующих ошибки» Блейхута. А вообще, материалов по этой теме довольно много.
Надеюсь, когда снова будет свободное время, напишу продолжение, в котором расскажу про циклические коды и покажу пример программы для кодирования и декодирования. Если, конечно, почтенной публике это интересно.
Э. Акар, Analog Devices, специалист по измерениям радиочастотных систем
Как измерение модуля вектора ошибки помогает оптимизировать общие характеристики системы
Статья опубликована в журнале Электроника НТБ № 8 2021
![]()
Модуль вектора ошибки (Error Vector Magnitude, EVM) — широко применяемый показатель системного уровня, который регламентируется различными стандартами в области связи для испытаний на соответствие в таких приложениях, как беспроводные локальные сети (WLAN 802.11), мобильная связь (4G LTE, 5G) и многие другие. Кроме того, это чрезвычайно важная системная характеристика, позволяющая количественно оценить совокупное влияние всех возможных проблем в системе с помощью одного, простого для понимания параметра. В статье проанализировано, как характеристики более низкого уровня влияют на EVM, рассмотрен ряд практических примеров использования EVM для оптимизации характеристик устройства на уровне системы, показано, как добиться снижения EVM на 15 дБ по сравнению с требованиями большинства стандартов связи.
Большинство инженеров, работающих в области радиочастотных систем, оперируют такими характеристиками, как коэффициент шума, точка пересечения третьего порядка и отношение сигнал — шум. Понимание совокупного влияния этих параметров на общие рабочие характеристики системы может быть сложной задачей. Модуль вектора ошибки позволяет быстро получить представление о работе системы в целом, вместо того, чтобы оценивать несколько разных показателей.
Что такое модуль вектора ошибки?
EVM — это простой показатель для количественной оценки комбинации всех искажений сигнала в системе. Он часто определяется для устройств, использующих цифровую модуляцию, которая может быть представлена в виде графика синфазных (I) и квадратурных (Q) векторов, известного также как «диаграмма созвездия» (constellation diagram) (рис. 1a). Как правило, EVM вычисляется путем нахождения идеального местоположения созвездия для каждого принятого символа, как показано на рис. 1б. Среднеквадратичное значение всех модулей вектора ошибки между местоположениями принятых символов и их ближайшими идеальными местоположениями в созвездии определяет величину EVM устройства [1].

Рис. 1. а — диаграмма созвездия и граница принятия решения; б — вектор ошибки между принятым символом и идеальным местоположением символа
В стандарте IEEE 802.11 приведена формула для вычисления EVM [2]:

где: Lp — количество кадров, Nc — количество несущих, Ri, j — принятый символ, а Si, j — идеальное местоположение символа.
EVM тесно связан с частотой битовых ошибок (BER) данной системы. Когда принятые символы располагаются далеко от целевой точки созвездия, вероятность их попадания в границу принятия решения другой точки созвездия увеличивается. Это приводит к увеличению BER. Важное различие между BER и EVM состоит в том, что BER для переданного сигнала вычисляется на основе переданной битовой комбинации, в то время как EVM вычисляется на основе расстояния от ближайшей точки созвездия символов до местоположения символа. В некоторых случаях символы могут пересекать границу принятия решения, и им присваивается неправильная битовая комбинация. Если символ попадает ближе к другому идеальному местоположению символа, это может улучшить EVM для этого символа. Таким образом, хотя EVM и BER тесно связаны, эта связь может быть нарушена при очень высоких уровнях искажения сигнала.
Современные стандарты в области связи устанавливают минимально допустимый уровень EVM на основе характеристик передаваемого или принятого сигнала, таких как скорость передачи данных и полоса пропускания. Устройства, которые достигают целевого уровня EVM, соответствуют стандарту, в то время как устройства, которые не достигают целевого уровня EVM, не соответствуют его требованиям. Испытательное и измерительное оборудование, предназначенное для проверки на соответствие стандартам, обычно ориентировано на более строгие целевые значения EVM, которые могут быть на порядок ниже требуемых в стандарте. Это позволяет оборудованию определять EVM тестируемого устройства без значительных искажений сигнала.
Что влияет на EVM?
Как показатель ошибки, EVM тесно связан со всеми источниками искажений в системе. Мы можем количественно оценить влияние всех отклонений в системе на EVM, вычислив, как они искажают принимаемые и передаваемые сигналы. Проанализируем влияние нескольких ключевых видов помех, таких как тепловой шум, фазовый шум и нелинейности, на EVM.
Белый шум
Белый шум присутствует во всех радиочастотных системах. Когда шум является единственным искажением в системе, результирующий EVM можно рассчитать по следующей формуле:

где SNR — отношение сигнал — шум системы в дБ, а PAPR — отношение пиковой мощности к средней мощности данного сигнала в дБ.
Обратите внимание, что SNR обычно определяется для однотонального сигнала. Для модулированного сигнала необходимо учитывать PAPR сигнала. Поскольку PAPR однотонального сигнала составляет 3 дБ, это число необходимо вычесть из значения SNR для сигнала с произвольным значением PAPR.
Для высокоскоростных АЦП и ЦАП, уравнение 2 может быть выражено через спектральную плотность шума (NSD):

где NSD — спектральная плотность шума в дБ ПШ / Гц, BW — ширина полосы сигнала в Гц, PAPR — отношение пиковой мощности к средней, а Pbackoff — разница между пиковой мощностью сигнала и полным диапазоном измерений преобразователя.
Эта формула может быть очень удобна для прямого расчета ожидаемого значения EVM устройства с использованием значения NSD, которое обычно указывается для современных высокоскоростных преобразователей. Обратите внимание, что для высокоскоростных преобразователей необходимо учитывать также шум квантования. Величина NSD большинства высокоскоростных преобразователей также включает шум квантования. Следовательно, для этих устройств уравнение 3 отражает не только тепловой шум, но также шум квантования.
Как показывают эти два уравнения, EVM сигнала напрямую зависит от общей полосы пропускания сигнала, отношения пиковой мощности к средней и теплового шума системы.
Как фазовый шум влияет на EVM
Другим видом шума, который влияет на EVM системы, является фазовый шум, который представляет собой случайные флуктуации фазы и частоты сигнала [3]. Все нелинейные элементы схемы вносят фазовый шум. Основные источники фазового шума в данной системе могут быть прослежены вплоть до генераторов. Генератор частоты дискретизации преобразователя данных, используемый для преобразования частоты гетеродин и генератор опорной частоты — все эти устройства могут вносить вклад в общий фазовый шум системы.
Ухудшение характеристик из-за фазового шума зависит от частоты. Для типичного генератора большая часть энергии несущей приходится на его основную частоту генерации, которая называется центральной частотой. Часть энергии сигнала будет распределяться около этой центральной частоты. Отношение амплитуды сигнала в полосе частот 1 Гц при определенном сдвиге частоты к его амплитуде на центральной частоте определяется как фазовый шум при этом конкретном частотном сдвиге, как показано на рис. 2.

Фазовый шум системы напрямую влияет на ее EVM. EVM из-за фазового шума системы можно рассчитать путем интегрирования фазового шума в полосе пропускания. Для большинства современных стандартов связи, в которых используется ортогональная частотная модуляция (OFDM), фазовый шум должен быть интегрирован в диапазоне от примерно 10% разнесения поднесущих до полной ширины полосы сигнала:

где L — плотность фазового шума в одиночной боковой полосе, fsc — разнесение поднесущих, BW — ширина полосы сигнала.
Большинство устройств, генерирующих частоту, имеют низкий фазовый шум на частотах <2 ГГц с типичными уровнями интегрированного джиттера на несколько порядков ниже предельных значений EVM, устанавливаемых в стандартах. Однако для более высокочастотных и более широкополосных сигналов интегрированные уровни фазового шума могут быть значительно выше, что может привести к гораздо более высоким значениям EVM. Обычно это относится к устройствам миллиметрового диапазона, которые работают на частотах выше 20 ГГц. Как мы подробнее обсудим в разделе, посвящен ном описанию примеров проектов, фазовый шум следует рассчитывать для всей системы, чтобы достичь наименьшего общего EVM.
Расчет влияния нелинейностей на EVM
Нелинейности системного уровня приводят к появлению интермодуляционных составляющих, которые могут попадать в полосу пропускания сигнала. Эти помехи могут перекрываться с поднесущими, воздействуя на их амплитуду и фазу. Можно вычислить вектор ошибки, возникающий из-за интермодуляционных помех. Выведем простую формулу для расчета EVM системы из-за интермодуляционных составляющих третьего порядка.

Рис. 3. Интермодуляционные составляющие OFDM-сигнала
Как показано на рис. 3a, двухтональный сигнал создает две интермодуляционные составляющие. Мощность интермодуляционных составляющих можно рассчитать следующим образом:

где Ptone — мощность тестового сигнала, OIP3 — точка пересечения третьего порядка на выходе, Pe — сигнал ошибки, представляющий собой разность мощностей основной частоты и интермодуляционной составляющей.
Для OFDM-сигнала с N тонами, как показано на рис. 3б, уравнение 6 принимает следующий вид:

где Pe, i — ошибка для каждой пары тонов.
Поскольку в каждом местоположении поднесущей имеется N / 2 интермодуляционных составляющих, которые перекрываются, уравнение можно переписать как:

Общая ошибка, включая все местоположения поднесущих, становится равной:

Подставляя уравнение 6 в уравнение 8, EVM можно выразить следующим образом:

где PRMS — среднеквадратичное значение сигнала, C — константа, которая находится в диапазоне от 0 до 3 дБ в зависимости от схемы модуляции.
Как показывает уравнение 11, EVM уменьшается по мере увеличения OIP3 системы. Это ожидаемо, поскольку более высокое значение OIP3 обычно указывает на более линейную систему. Кроме того, когда среднеквадратичная мощность сигнала уменьшается, EVM уменьшается по мере уменьшения мощности нелинейных составляющих.
Оптимизация системных характеристик с помощью EVM
Обычно проектирование на уровне системы начинается с каскадного анализа, при котором низкоуровневые параметры функциональных блоков используются для определения общих характеристик системы, построенной на базе этих блоков. Существуют хорошо зарекомендовавшие себя аналитические формулы и инструменты, которые можно использовать для расчета этих параметров. Однако многие инженеры не знают, как правильно использовать инструменты каскадного анализа для проектирования полностью оптимизированных систем.
В качестве системной характеристики EVM предоставляет инженерам-разработчикам ценную информацию для оптимизации системы. Вместо того, чтобы рассматривать несколько параметров, разработчики получают возможность выбрать оптимальное среднеквадратичное
значение EVM и, тем самым, найти наилучшее проектное решение.
U-образная кривая EVM
Мы можем объединить все параметры системы в один график, учитывая вклад EVM каждого искажения в системе и уровень выходной мощности. На рис. 4 показана типичная U-образная кривая EVM для системы в зависимости от уровня рабочей мощности. При низких уровнях рабочей мощности EVM определяется шумовыми характеристиками системы. На высоких уровнях мощности на EVM влияют нелинейности в системе. Самый низкий уровень EVM для системы обычно определяется комбинацией всех источников ошибок, включая фазовый шум.
Мы можем найти суммарный EVM с помощью уравнения 12:

где EVMWN — вклад EVM, возникающий из-за белого шума, EVMPhN — вклад фазового шума, EVMlinearity — EVM, возникающий из-за нелинейных искажений. Для заданного уровня мощности сумма мощностей всех этих ошибок определяет общий уровень EVM в системе.

Рис. 4. U-образная кривая зависимости EVM от рабочей мощности
Наряду с уравнением 12, U-образная кривая может быть очень полезной для системной оптимизации, когда можно визуализировать комбинацию всех ошибок данной системы.
Пример проекта
Рассмотрим пример проектирования сигнальной цепочки, используя EVM в качестве системного показателя. В этом примере мы спроектируем передатчик миллиметрового диапазона с использованием РЧ ЦАП с дискретизацией, модулятора и генераторов частоты миллиметрового диапазона, а также других устройств формирования сигнала (рис. 5).

Рис. 5. Сигнальная цепь передатчика миллиметрового диапазона
В этой сигнальной цепи используется микросхема AD9082, которая содержит четыре ЦАП и два АЦП с частотой выборки 12 и 6 ГГц соответственно. Эти преобразователи с прямым РЧ-преобразованием обеспечивают гибкость проектного решения для сигнальной цепи миллиметрового диапазона и непревзойденную производительность. На рис. 6 показаны результаты измерения значения EVM для типовой микросхемы AD9082 с помощью 12‑разрядного АЦП AD9213, который обеспечивает скорость выборки 10 Гвыб / с. Кольцевой тест для этой схемы показал уровень EVM всего -62 дБ, что на 27 дБ ниже предельной допустимой величины, определяемой стандартом.

Рис. 6. Результаты измерения EVM для микросхемы AD9082 на промежуточной частоте 400 МГц для сигнала IEEE 802.11ax с полосой пропускания 80 МГц с модуляцией QAM‑1024
В этой схеме также используется интегрированный миллиметровый модулятор ADMV1013, который содержит ряд традиционных блоков сигнальной цепи, таких как умножители частоты, квадратурные смесители и усилители. Чтобы упростить фильтрацию, в этом проекте используется довольно сложная топология цепи промежуточной частоты, в которой на квадратурные смесители модуляторов подаются сигналы с фазой 90°. Это устраняет одну из боковых полос сигнала, преобразованного с повышением частоты, тем самым уменьшается сложность фильтрации по сравнению с преобразованием сигнала с двумя боковыми полосами.
Чтобы оптимизировать эту сигнальную цепь для получения наименьшего значения EVM, сначала проанализируем фазовый шум на уровне системы, затем найдем оптимальное соотношение шума и линейности и, наконец, соберем все функциональные блоки в одну систему.
Улучшение EVM путем оптимизации фазового шума
Как мы обсуждали ранее, фазовый шум всей системы может ограничивать возможность минимизации EVM на частотах миллиметрового диапазона. Проанализируем вклад фазового шума каждого каскада, чтобы убедиться, что выбраны наилучшие компоненты для данной сигнальной цепи. Компоненты, формирующие частоты в этой сигнальной цепи, — это ЦАП, который синхронизируется с помощью синтезатора, и гетеродин. Общий фазовый шум можно выразить следующим образом:

где LTx – общий фазовый шум передатчика, lIF – фазовый шум на выходе ЦАП, lLO – фазовый шум сигнала гетеродина.
Используемый в этом примере ЦАП AD9082 имеет исключительно низкий аддитивный фазовый шум. Общий фазовый шум на выходе, который представляет собой сигнал ПЧ, можно рассчитать по простой формуле:

где LCLK – интегрированный фазовый шум тактового сигнала, fIF – ПЧ-частота на выходе ЦАП, fCLK – частота выборки для ЦАП.
Чтобы выбрать компоненты минимальной сложности и с наименьшим фазовым шумом, проанализируем характеристики двух микросхем, рассматриваемых в качестве кандидатов на роль генератора тактовой частоты и источника сигнала гетеродина.

Рис. 7. Фазовый шум тактового сигнала и сигнала гетеродина для ADF4372 и ADF4401A
На рис. 7 показана характеристика фазового шума сигнала с одной боковой полосой для двух микросхем, наилучшим образом подходящих для использования в качестве синтезаторов частоты для этой сигнальной цепи. Интегрированный фазовый шум для сигнала 5G NR может быть рассчитан путем интегрирования фазового шума источников сигнала в полосе от 6 кГц до 100 МГц (табл. 1).

На типичных для этой сигнальной цепи промежуточных частотах как ADF4372, так и ADF4401A демонстрируют чрезвычайно низкие уровни интегрированного шума. Поскольку для ADF4372 требуется гораздо меньшая площадь печатной платы, это хороший выбор для формирования
частоты выборки для РЧ-преобразователя, который создает ПЧ-сигнал. Микросхема ADF4401A становится выбором для генератора сигнала гетеродина из-за присущего ей низкого начального фазового шума. На частоте 30 ГГц он примерно на 20 дБ ниже интегрированного шума для ADF4372. Такой низкий уровень шума гарантирует, что фазовый шум сигнала гетеродина не станет ограничивать общие показатели EVM для всей системы.
Используя уравнение 13, можно рассчитать общий EVMPhN из-за фазового шума:

Такой уровень модуля вектора ошибка из-за фазового шума более чем достаточен для измерения сигналов с EVM порядка -30 дБ, как определено стандартом для 5G NR.
Оптимизация соотношения шума и линейности
Одна из основных проблем при проектировании РЧ-систем — поиск оптимального соотношения шума и линейности. Улучшение одного из этих двух параметров обычно приводит к неоптимальной величине другого. Анализ EVM на уровне системы может быть очень полезным инструментом для улучшения характеристик системы в целом.

Рис. 8. Оптимизация соотношения шума и линейности системы
Рис. 8 иллюстрирует поиск оптимального соотношения шума и линейности для созданной нами сигнальной цепи. Каждая из кривых получена путем регулировки управляющего напряжения интегрированного усилителя. Для каждой кривой изменялся уровень выходной мощности ЦАП. Заметим, что по мере увеличения уровня мощности EVM уменьшается из-за увеличения общего отношения сигнал – шум системы. После определенного уровня мощности нелинейности всего тракта прохождения сигнала начинают ухудшать показатель EVM. Результирующая U-образная кривая EVM для данной конфигурации усилителя очень узкая.
Регулируя управляющее напряжение усилителя, мы можем перейти к другой кривой, на которой система имеет более низкий EVM. Пунктирная линия на рис. 8 отражает оптимизацию на уровне системы, которая может быть достигнута с помощью интегрированных усилителей микросхемы ADMV1013. Результирующая U-образная кривая после этой оптимизации становится намного шире, что обеспечивает сверхнизкий EVM в широком диапазоне уровней выходной мощности.
Заключение
В статье мы рассмотрели EVM в качестве системного показателя и обсудили, как с помощью EVM можно оптимизировать характеристики системы. Как мы показали, EVM – хороший индикатор многих проблем системного уровня. Все источники ошибок приводят к возникновению поддающегося измерению EVM, который можно использовать для оптимизации общих показателей системы. Мы продемонстрировали также, что с помощью новейших высокоскоростных преобразователей и интегрированных модуляторов миллиметрового диапазона можно достичь характеристик системы приборного уровня и значений EVM на порядки величин более низких по сравнению с требованиями стандартов в области связи.
ЛИТЕРАТУРА
1. Voelker K. M. Apply Error Vector Measurements in Communication Design. – Microwaves & RF, December 1995.
2. IEEE 802.11a‑1999. IEEE Standard for Telecommunications and Information Exchange Between Systems. LAN / MAN Specific Requirements. Part 11: Wireless Medium Access Control (MAC) and Physical Layer (PHY) Specifications: High Speed Physical Layer in the 5 GHz Band. – IEEE Standard
Association, September 1999.
3. Kester W. MT‑008 Tutorial: Converting Oscillator Phase Noise to Time Jitter. – Analog Devices, Inc., 2009.
Что такое вектор ошибки
Модуль вектора ошибки (Error Vector Magnitude, EVM) — широко применяемый показатель системного уровня, который регламентируется различными стандартами в области связи для испытаний на соответствие в таких приложениях, как беспроводные локальные сети (WLAN 802.11), мобильная связь (4G LTE, 5G) и многие другие. Кроме того, это чрезвычайно важная системная характеристика, позволяющая количественно оценить совокупное влияние всех возможных проблем в системе с помощью одного, простого для понимания параметра. В статье проанализировано, как характеристики более низкого уровня влияют на EVM, рассмотрен ряд практических примеров использования EVM для оптимизации характеристик устройства на уровне системы, показано, как добиться снижения EVM на 15 дБ по сравнению с требованиями большинства стандартов связи.
Большинство инженеров, работающих в области радиочастотных систем, оперируют такими характеристиками, как коэффициент шума, точка пересечения третьего порядка и отношение сигнал — шум. Понимание совокупного влияния этих параметров на общие рабочие характеристики системы может быть сложной задачей. Модуль вектора ошибки позволяет быстро получить представление о работе системы в целом, вместо того, чтобы оценивать несколько разных показателей.
Что такое модуль вектора ошибки?
EVM — это простой показатель для количественной оценки комбинации всех искажений сигнала в системе. Он часто определяется для устройств, использующих цифровую модуляцию, которая может быть представлена в виде графика синфазных (I) и квадратурных (Q) векторов, известного также как «диаграмма созвездия» (constellation diagram) (рис. 1a). Как правило, EVM вычисляется путем нахождения идеального местоположения созвездия для каждого принятого символа, как показано на рис. 1б. Среднеквадратичное значение всех модулей вектора ошибки между местоположениями принятых символов и их ближайшими идеальными местоположениями в созвездии определяет величину EVM устройства [1].
где: Lp — количество кадров, Nc — количество несущих, Ri, j — принятый символ, а Si, j — идеальное местоположение символа.
EVM тесно связан с частотой битовых ошибок (BER) данной системы. Когда принятые символы располагаются далеко от целевой точки созвездия, вероятность их попадания в границу принятия решения другой точки созвездия увеличивается. Это приводит к увеличению BER. Важное различие между BER и EVM состоит в том, что BER для переданного сигнала вычисляется на основе переданной битовой комбинации, в то время как EVM вычисляется на основе расстояния от ближайшей точки созвездия символов до местоположения символа. В некоторых случаях символы могут пересекать границу принятия решения, и им присваивается неправильная битовая комбинация. Если символ попадает ближе к другому идеальному местоположению символа, это может улучшить EVM для этого символа. Таким образом, хотя EVM и BER тесно связаны, эта связь может быть нарушена при очень высоких уровнях искажения сигнала.
Современные стандарты в области связи устанавливают минимально допустимый уровень EVM на основе характеристик передаваемого или принятого сигнала, таких как скорость передачи данных и полоса пропускания. Устройства, которые достигают целевого уровня EVM, соответствуют стандарту, в то время как устройства, которые не достигают целевого уровня EVM, не соответствуют его требованиям. Испытательное и измерительное оборудование, предназначенное для проверки на соответствие стандартам, обычно ориентировано на более строгие целевые значения EVM, которые могут быть на порядок ниже требуемых в стандарте. Это позволяет оборудованию определять EVM тестируемого устройства без значительных искажений сигнала.
Что влияет на EVM?
Как показатель ошибки, EVM тесно связан со всеми источниками искажений в системе. Мы можем количественно оценить влияние всех отклонений в системе на EVM, вычислив, как они искажают принимаемые и передаваемые сигналы. Проанализируем влияние нескольких ключевых видов помех, таких как тепловой шум, фазовый шум и нелинейности, на EVM.
Белый шум
Белый шум присутствует во всех радиочастотных системах. Когда шум является единственным искажением в системе, результирующий EVM можно рассчитать по следующей формуле:
где NSD — спектральная плотность шума в дБ ПШ / Гц, BW — ширина полосы сигнала в Гц, PAPR — отношение пиковой мощности к средней, а Pbackoff — разница между пиковой мощностью сигнала и полным диапазоном измерений преобразователя.
Эта формула может быть очень удобна для прямого расчета ожидаемого значения EVM устройства с использованием значения NSD, которое обычно указывается для современных высокоскоростных преобразователей. Обратите внимание, что для высокоскоростных преобразователей необходимо учитывать также шум квантования. Величина NSD большинства высокоскоростных преобразователей также включает шум квантования. Следовательно, для этих устройств уравнение 3 отражает не только тепловой шум, но также шум квантования.
Как показывают эти два уравнения, EVM сигнала напрямую зависит от общей полосы пропускания сигнала, отношения пиковой мощности к средней и теплового шума системы.
Как фазовый шум влияет на EVM
Другим видом шума, который влияет на EVM системы, является фазовый шум, который представляет собой случайные флуктуации фазы и частоты сигнала [3]. Все нелинейные элементы схемы вносят фазовый шум. Основные источники фазового шума в данной системе могут быть прослежены вплоть до генераторов. Генератор частоты дискретизации преобразователя данных, используемый для преобразования частоты гетеродин и генератор опорной частоты — все эти устройства могут вносить вклад в общий фазовый шум системы.
Ухудшение характеристик из-за фазового шума зависит от частоты. Для типичного генератора большая часть энергии несущей приходится на его основную частоту генерации, которая называется центральной частотой. Часть энергии сигнала будет распределяться около этой центральной частоты. Отношение амплитуды сигнала в полосе частот 1 Гц при определенном сдвиге частоты к его амплитуде на центральной частоте определяется как фазовый шум при этом конкретном частотном сдвиге, как показано на рис. 2.
Оптимизация приемника при помощи анализа модуля вектора ошибки
Теоретические основы анализа модуля вектора ошибки
На рис. 1 изображена векторная диаграмма, на которой показаны два вектора — опорный вектор, R (k), и реальный измеренный вектор, Z (k), который соответствует траектории принятого символа. Опорный вектор определяет координаты идеальной траектории символа при отсутствии ошибок. Разность между опорным вектором и вектором реально измеренного символа называется вектором ошибки.

Модуль вектора ошибки (EVM, error vector magnitude) представляет собой евклидово расстояние между координатами идеального и реально измеренного символов. В общем случае, EVM усредняется по ансамблю траекторий символов и описывается следующим выражением:

Таким образом, параметр EVM является мерой отношения вектора ошибки к опорному вектору. В совершенной системе, в которой отсутствуют шумы и нелинейности, способные внести искажения в сигнал, измеренный и опорный векторы совпадали бы, и EVM был бы равен нулю. Рассмотрим влияние отношения «сигнал — шум» (ОСШ) для принимаемого символа. При очень большом ОСШ разница между измеренным и опорным векторами, обусловленная шумом и искажениями, очень мала, а EVM стремится к нулю. И, наоборот, большое значение EVM подразумевает, что вектор измеренного символа значительно отличается от идеального опорного вектора, что может быть вызвано только шумом и искажениями (при условии, что при задании опорного вектора не была допущена ошибка). Таким образом, ОСШ и EVM модулированного сигнала связаны друг с другом обратной зависимостью, которая описывается уравнением:

где L — это выигрыш за счет кодирования.
Параметр L учитывает выигрыш, который достигается за счет схемы кодирования сигнала. Информативное сообщение может кодироваться различными способами. Например, в системах с расширением спектра прямой последовательностью информационное сообщение подвергается расширению спектра путем умножения каждого передаваемого бита на прямую (псевдослучайную) последовательность, представляющую собой случайную последовательность нулей и единиц. Последовательность подбирается таким образом, чтобы она была уникальной и слабо коррелированной с последовательностями, которые применяются для кодирования других потоков, передаваемых на той же частоте несущей. Для систем с расширением спектра усиление за счет кодирования равно количеству элементов, или «чипов», в последовательности, используемой для кодирования каждого бита. В децибелах эта величина выражается как 10log10 (частота следования элементов последовательности / скорость данных). Например, для передачи потока данных со скоростью 12,2 кбит/с в трансивере стандарта UMTS используется последовательность со скоростью 3,84 Мчип/с; при этом выигрыш за счет кодирования равен 3,84×10 6 /12,2×10 3 = 314,75, или 25 дБ.
Для нахождения зависимости между EVM и BER необходимо определить, как связаны друг с другом ОСШ и вероятность ошибки на символ для конкретной схемы модуляции. Вероятность ошибки на символ для сигналов с квадратурной амплитудной модуляцией (QAM) описывается выражением (3):

где M — порядок модуляции (например, 64 для 64-QAM), γb — среднее значение ОСШ на бит, k — число битов на символ (например, 6 битов на комплексный символ для 64-QAM).
Используя выражения (2) и (3), можно построить зависимости частоты ошибки на символ (SER, symbol error rate) и EVM от ОСШ. Зависимость SER от ОСШ показана на рис. 2а. Для форматов QAM с различным порядком она имеет классический вид типа «водопад». Для тех же схем модуляции на рис. 2б изображены зависимости EVM от ОСШ. С помощью этих зависимостей разработчики могут оценить значение частоты ошибок на бит для конкретного приемника. Например, если измеренное значение EVM для некодированного сигнала с модуляцией 256-QAM равно 3%, то ожидаемая частота ошибок на символ составит 600 млн –1 . Другими словами, в последовательности из 10 000 символов в среднем 6 символов будут ошибочными, что соответствует 75 ошибочным битам в последовательности из 1 миллиона битов (BER = 7,5×10 -5 ).

Используя зависимости, показанные на рис. 2, а также подходящий векторный анализатор сигналов, разработчик может достаточно быстро оптимизировать производительность системы. Это достигается путем контроля значения EVM при изменении таких характеристик сигнального тракта, как тип фильтра, межкаскадное согласование и усиление преобразования. Рис. 3 иллюстрирует некоторые распространенные искажения сигнальных созвездий, которые могут возникать в реальной системе. На основании формы сигнального созвездия можно сделать определенные выводы о природе шумов или искажений, являющихся потенциальной причиной ухудшения EVM.

Пример оптимизации: подсистема трактов ПЧ и модулирующих частот AD8348/AD8362
На рис. 4 показана приемная подсистема для переноса сигнала из области ПЧ в область модулирующих частот с замкнутым контуром автоматической регулировки уровня (automatic level control — ALC), основанная на квадратурном демодуляторе и детекторе среднеквадратической мощности. Микросхема AD8348 обеспечивает точную квадратурную демодуляцию сигналов с частотой от 50 МГц до 1 ГГц. Внутренний делитель частоты гетеродина позволяет работать с частотой гетеродина, равной удвоенной частоте несущей, что облегчает решение проблемы, связанной с паразитным захватом частоты гетеродина (LO-pulling) в полнодуплексных трансиверах. В рассматриваемом примере входной сигнал имеет частоту (ПЧ), равную 190 МГц, а сигнал гетеродина имеет уровень, равный 10 дБм, и частоту, равную 380 МГц. Интегрированный входной усилитель с переменным коэффициентом усиления (variable gain amplifier — VGA), состоящий из резистивного переменного аттенюатора и пост-усилителя с высоким значением IP, обеспечивает переменный коэффициент усиления при сохранении постоянного динамического диапазона, свободного от побочных составляющих. Микросхема AD8362 — это прецизионный измеритель мощности, способный измерять среднеквадратическое значение мощности сигналов в диапазоне от произвольных низких частот до 2,7 ГГц. Данная микросхема не чувствительна к изменению пик-фактора сигнала, что делает ее подходящим решением для измерения истинной среднеквадратической мощности сигналов с цифровой модуляцией.

В схеме на рис. 4 обеспечивается измерение среднеквадратической мощности сигнала в полосе модулирующих частот, поступающего с синфазного канала. Выбор синфазного или квадратурного канала для детектирования произволен, если вектора I и Q имеют псевдослучайный характер, что соответствует истине для большинства схем цифровой модуляции. На основании результата измерения среднеквадратической мощности интегрированный усилитель ошибки формирует управляющий сигнал, подаваемый на вход управления усилением квадратурного демодулятора. Замкнутый контур регулировки адаптивно подстраивает усиление преобразования демодулятора для поддержания постоянного среднеквадратического уровня мощности модулирующего сигнала независимо от его формы. Выходной уровень задается подачей соответствующего напряжения контрольной точки на вывод VSET. Для нахождения оптимальной контрольной точки в схеме ALC и определения подходящего фильтра для цифровой модуляции 256-QAM со скоростью 1 Мсимвол/с использовался метод анализа вектора ошибки.
Несимметричные сигналы с выхода демодулятора подаются на фильтр нижних частот. Для минимизации широкополосного шума и подавления мешающих смежных каналов приема в обоих каналах, I и Q, использовались фильтры Бесселя четвертого порядка. Выбор в пользу фильтра Бесселя обусловлен его малой групповой задержкой, что является необходимым требованием для минимизации межсимвольных помех. На этапе тестирования сначала использовались фильтры Баттерворта и Чебышева, но из-за большей групповой задержки в полосе пропускания значения EVM в системе были хуже. С помощью анализатора сигналов можно очень быстро измерить показатели системы, что позволяет подобрать оптимальную схему фильтра за короткий промежуток времени.

Для измерения EVM в полосе модулирующих частот использовался векторный анализатор сигналов FSQ8 производства Rohde&Schwarz. Оптимальное значение напряжения контрольной точки было найдено путем изменения этого напряжения и наблюдения соответствующего значения EVM. Как показано на рис. 5, при правильном выборе контрольной точки EVM составляет не более 2% в диапазоне входных уровней, превышающем 40 дБ. На рис. 6 показано экспериментально полученное сигнальное созвездие для модуляции 256-QAM. Переменное усиление преобразования демодулятора позволяет создавать схемы, обладающие оптимальными характеристиками BER в более широком динамическом диапазоне, чем при использовании модуляторов с фиксированным коэффициентом усиления.

Рис. 7 иллюстрирует показатели EVM для модуляции QAM меньших порядков при той же ширине полосы сигнала. Для достижения адекватных значений BER при использовании схем модуляции более низкого порядка требуется меньшее ОСШ. Поэтому неудивительно, что для таких схем модуляции показатели EVM еще лучше, а динамический диапазон — немного больше.

Значение EVM можно оценить по напряжению RSSI (Received Signal Strength Indication, индикация уровня принимаемого сигнала) микросхемы AD8362. На рис. 8 показаны результаты измерений напряжения RSSI для нескольких схем модуляции. Зная напряжение RSSI, можно определить уровень мощности сигнала на входе демодулятора с приемлемой погрешностью, который затем может быть использован для предсказания значения EVM при этом уровне входной мощности.

Заключение
Измерение EVM и связанных с ним величин позволяет оценить качество цифрового радиоприемника. Кроме того, при правильном применении методы анализа EVM позволяют идентифицировать вид искажений сигнала и, следовательно, конкретное место возникновения ошибок. Таким образом, анализ EVM представляет собой удобный инструмент для оптимизации сигнального тракта и предсказания динамических характеристик системы.
Корректирующие коды «на пальцах»
 Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Как нетрудно догадаться, ко всему этому причастны корректирующие коды. Собственно, ECC так и расшифровывается — «error-correcting code», то есть «код, исправляющий ошибки». А CRC — это один из алгоритмов, обнаруживающих ошибки в данных. Исправить он их не может, но часто это и не требуется.
Давайте же разберёмся, что это такое.
Для понимания статьи не нужны никакие специальные знания. Достаточно лишь понимать, что такое вектор и матрица, как они перемножаются и как с их помощью записать систему линейных уравнений.
Внимание! Много текста и мало картинок. Я постарался всё объяснить, но без карандаша и бумаги текст может показаться немного запутанным.
Каналы с ошибкой
Разберёмся сперва, откуда вообще берутся ошибки, которые мы собираемся исправлять. Перед нами стоит следующая задача. Нужно передать несколько блоков данных, каждый из которых кодируется цепочкой двоичных цифр. Получившаяся последовательность нулей и единиц передаётся через канал связи. Но так сложилось, что реальные каналы связи часто подвержены ошибкам. Вообще говоря, ошибки могут быть разных видов — может появиться лишняя цифра или какая-то пропасть. Но мы будем рассматривать только ситуации, когда в канале возможны лишь замены нуля на единицу и наоборот. Причём опять же для простоты будем считать такие замены равновероятными.
Ошибка — это маловероятное событие (а иначе зачем нам такой канал вообще, где одни ошибки?), а значит, вероятность двух ошибок меньше, а трёх уже совсем мала. Мы можем выбрать для себя некоторую приемлемую величину вероятности, очертив границу «это уж точно невозможно». Это позволит нам сказать, что в канале возможно не более, чем ошибок. Это будет характеристикой канала связи.
Для простоты введём следующие обозначения. Пусть данные, которые мы хотим передавать, — это двоичные последовательности фиксированной длины. Чтобы не запутаться в нулях и единицах, будем иногда обозначать их заглавными латинскими буквами (, , , …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
Кодирование и декодирование будем обозначать прямой стрелкой (), а передачу по каналу связи — волнистой стрелкой (). Ошибки при передаче будем подчёркивать.
Например, пусть мы хотим передавать только сообщения и . В простейшем случае их можно закодировать нулём и единицей (сюрприз!):
Передача по каналу, в котором возникла ошибка будет записана так:
Цепочки нулей и единиц, которыми мы кодируем буквы, будем называть кодовыми словами. В данном простом случае кодовые слова — это и .
Код с утроением
Давайте попробуем построить какой-то корректирующий код. Что мы обычно делаем, когда кто-то нас не расслышал? Повторяем дважды:
Правда, это нам не очень поможет. В самом деле, рассмотрим канал с одной возможной ошибкой:
Какие выводы мы можем сделать, когда получили ? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
То есть, получившийся код обнаруживает, но не исправляет ошибки. Ну, тоже неплохо, в общем-то. Но мы пойдём дальше и будем теперь утраивать цифры.
Проверим в деле:
Получили . Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
Если в канале связи возможна максимум одна ошибка, то первое предположение о двух ошибках становится невозможным и остаётся только один вариант — передавалась буква .
Про такой код говорят, что он исправляет одну ошибку. Две он тоже обнаружит, но исправит уже неверно.
Это, конечно, самый простой код. Кодировать легко, да и декодировать тоже. Ноликов больше — значит передавался ноль, единичек — значит единица.
Если немного подумать, то можно предложить код исправляющий две ошибки. Это будет код, в котором мы повторяем одиночный бит 5 раз.
Расстояния между кодами
Рассмотрим поподробнее код с утроением. Итак, мы получили работающий код, который исправляет одиночную ошибку. Но за всё хорошее надо платить: он кодирует один бит тремя. Не очень-то и эффективно.
И вообще, почему этот код работает? Почему нужно именно утраивать для устранения одной ошибки? Наверняка это всё неспроста.
Давайте подумаем, как этот код работает. Интуитивно всё понятно. Нолики и единички — это две непохожие последовательности. Так как они достаточно длинные, то одиночная ошибка не сильно портит их вид.
Пусть мы передавали , а получили . Видно, что эта цепочка больше похожа на исходные , чем на . А так как других кодовых слов у нас нет, то и выбор очевиден.
Но что значит «больше похоже»? А всё просто! Чем больше символов у двух цепочек совпадает, тем больше их схожесть. Если почти все символы отличаются, то цепочки «далеки» друг от друга.
Можно ввести некоторую величину , равную количеству различающихся цифр в соответствующих разрядах цепочек и . Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
Например, , так как все цифры в соответствующих позициях равны, а вот .
Расстояние Хэмминга называют расстоянием неспроста. Ведь в самом деле, что такое расстояние? Это какая-то характеристика, указывающая на близость двух точек, и для которой верны утверждения:
- Расстояние между точками неотрицательно и равно нулю только, если точки совпадают.
- Расстояние в обе стороны одинаково.
- Путь через третью точку не короче, чем прямой путь.
Достаточно разумные требования.
Математически это можно записать так (нам это не пригодится, просто ради интереса посмотрим):
- .
Предлагаю читателю самому убедиться, что для расстояния Хэмминга эти свойства выполняются.
Окрестности
Таким образом, разные цепочки мы считаем точками в каком-то воображаемом пространстве, и теперь мы умеем находить расстояния между ними. Правда, если попытаться сколько нибудь длинные цепочки расставить на листе бумаги так, чтобы расстояния Хэмминга совпадали с расстояниями на плоскости, мы можем потерпеть неудачу. Но не нужно переживать. Всё же это особое пространство со своими законами. А слова вроде «расстояния» лишь помогают нам рассуждать.
Пойдём дальше. Раз мы заговорили о расстоянии, то можно ввести такое понятие как окрестность. Как известно, окрестность какой-то точки — это шар определённого радиуса с центром в ней. Шар? Какие ещё шары! Мы же о кодах говорим.
Но всё просто. Ведь что такое шар? Это множество всех точек, которые находятся от данной не дальше, чем некоторое расстояние, называемое радиусом. Точки у нас есть, расстояние у нас есть, теперь есть и шары.
Так, скажем, окрестность кодового слова радиуса 1 — это все коды, находящиеся на расстоянии не больше, чем 1 от него, то есть отличающиеся не больше, чем в одном разряде. То есть это коды:
Да, вот так странно выглядят шары в пространстве кодов.
А теперь посмотрите. Это же все возможные коды, которые мы получим в канале в одной ошибкой, если отправим ! Это следует прямо из определения окрестности. Ведь каждая ошибка заставляет цепочку измениться только в одном разряде, а значит удаляет её на расстояние 1 от исходного сообщения.
Аналогично, если в канале возможны две ошибки, то отправив некоторое сообщение , мы получим один из кодов, который принадлежит окрестности радиусом 2.
Тогда всю нашу систему декодирования можно построить так. Мы получаем какую-то цепочку нулей и единиц (точку в нашей новой терминологии) и смотрим, в окрестность какого кодового слова она попадает.
Сколько ошибок может исправить код?
Чтобы код мог исправлять больше ошибок, окрестности должны быть как можно шире. С другой стороны, они не должны пересекаться. Иначе если точка попадёт в область пересечения, непонятно будет, к какой окрестности её отнести.
В коде с удвоением между кодовыми словами и расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
Именно это мы и получали. Мы видели, что есть ошибка, но не могли её исправить.
Что интересно, точек касания в нашем странном пространстве у шаров две — это коды и . Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
В случае кода с утроением, между шарами будет зазор.
Минимальный зазор между шарами равен 1, так как у нас расстояния всегда целые (ну не могут же две цепочки отличаться в полутора разрядах).
В общем случае получаем следующее.
Этот очевидный результат на самом деле очень важен. Он означает, что код с минимальным кодовым расстоянием будет успешно работать в канале с ошибками, если выполняется соотношение
Полученное равенство позволяет легко определить, сколько ошибок будет исправлять тот или иной код. А сколько код ошибок может обнаружить? Рассуждения такие же. Код обнаруживает ошибок, если в результате не получится другое кодовое слово. То есть, кодовые слова не должны находиться в окрестностях радиуса других кодовых слов. Математически это записывается так:
Рассмотрим пример. Пусть мы кодируем 4 буквы следующим образом.
Чтобы найти минимальное расстояние между различными кодовыми словами, построим таблицу попарных расстояний.
| A | B | C | D | |
|---|---|---|---|---|
| A | — | 3 | 3 | 4 |
| B | 3 | — | 4 | 3 |
| C | 3 | 4 | — | 3 |
| D | 4 | 3 | 3 | — |
Минимальное расстояние , а значит , откуда получаем, что такой код может исправить до ошибок. Обнаруживает же он две ошибки.
Чтобы декодировать полученное сообщение, посмотрим, к какому символу оно ближе всего.
Минимальное расстояние получилось для символа , значит вероятнее всего передавался именно он:
Итак, этот код исправляет одну ошибку, как и код с утроением. Но он более эффективен, так как в отличие от кода с утроением здесь кодируется уже 4 символа.
Таким образом, основная проблема при построении такого рода кодов — так расположить кодовые слова, чтобы они были как можно дальше друг от друга, и их было побольше.
Для декодирования можно было бы использовать таблицу, в которой указывались бы все возможные принимаемые сообщения, и кодовые слова, которым они соответствуют. Но такая таблица получилась бы очень большой. Даже для нашего маленького кода, который выдаёт 5 двоичных цифр, получилось бы варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
Попробуем придумать способ коррекции сообщения без таблиц. Мы всегда сможем найти полезное применение освободившейся памяти.
Интерлюдия: поле GF(2)
Для изложения дальнейшего материала нам потребуются матрицы. А при умножении матриц, как известно мы складываем и перемножаем числа. И тут есть проблема. Если с умножением всё более-менее хорошо, то как быть со сложением? Из-за того, что мы работаем только с одиночными двоичными цифрами, непонятно, как сложить 1 и 1, чтобы снова получилась одна двоичная цифра. Значит вместо классического сложения нужно использовать какое-то другое.
Введём операцию сложения как сложение по модулю 2 (хорошо известный программистам XOR):
Умножение будем выполнять как обычно. Эти операции на самом деле введены не абы как, а чтобы получилась система, которая в математике называется полем. Поле — это просто множество (в нашем случае из 0 и 1), на котором так определены сложение и умножение, чтобы основные алгебраические законы сохранялись. Например, чтобы основные идеи, касающиеся матриц и систем уравнений по-прежнему были верны. А вычитание и деление мы можем ввести как обратные операции.
Множество из двух элементов с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
У сложения есть несколько очень полезных свойств, которыми мы будем пользоваться в дальнейшем.
Это свойство прямо следует из определения.
А в этом можно убедиться, прибавив к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
Проверяем корректность
Вернёмся к коду с утроением.
Для начала просто решим задачу проверки, были ли вообще ошибки при передаче. Как видно, из самого кода, принятое сообщение будет кодовым словом только тогда, когда все три цифры равны между собой.
Пусть мы приняли вектор-строку из трёх цифр. (Стрелочки над векторами рисовать не будем, так как у нас почти всё — это вектора или матрицы.)
Математически равенство всех трёх цифр можно записать как систему:
Или, если воспользоваться свойствами сложения в GF(2), получаем
В матричном виде эта система будет иметь вид
Транспонирование здесь нужно потому, что — это вектор-строка, а не вектор-столбец. Иначе мы не могли бы умножать его справа на матрицу.
Будем называть матрицу проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
Умножение на матрицу — это гораздо более эффективно, чем поиск в таблице, но у нас на самом деле есть ещё одна таблица — это таблица кодирования. Попробуем от неё избавиться.
Кодирование
Итак, у нас есть система для проверки
Её решения — это кодовые слова. Собственно, мы систему и строили на основе кодовых слов. Попробуем теперь решить обратную задачу. По системе (или, что то же самое, по матрице ) найдём кодовые слова.
Правда, для нашей системы мы уже знаем ответ, поэтому, чтобы было интересно, возьмём другую матрицу:
Соответствующая система имеет вид:
Чтобы найти кодовые слова соответствующего кода нужно её решить.
В силу линейности сумма двух решений системы тоже будет решением системы. Это легко доказать. Если и — решения системы, то для их суммы верно
что означает, что она тоже — решение.
Поэтому если мы найдём все линейно независимые решения, то с их помощью можно получить вообще все решения системы. Для этого просто нужно найти их всевозможные суммы.
Выразим сперва все зависимые слагаемые. Их столько же, сколько и уравнений. Выражать надо так, чтобы справа были только независимые. Проще всего выразить .
Если бы нам не так повезло с системой, то нужно было бы складывая уравнения между собой получить такую систему, чтобы какие-то три переменные встречались по одному разу. Ну, или воспользоваться методом Гаусса. Для GF(2) он тоже работает.
Чтобы получить все линейно независимые решения, приравниваем каждую из зависимых переменных к единице по очереди.
Всевозможные суммы этих независимых решений (а именно они и будут кодовыми векторами) можно получить так:
где равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно сочетания.
Но посмотрите! Формула, которую мы только что получили — это же снова умножение матрицы на вектор.
Строчки здесь — линейно независимые решения, которые мы получили. Матрица называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:
Найдём кодовые слова для этого кода. (Не забываем, что длина исходных сообщений должна быть равна 2 — это количество найденных решений.)
Итак, у нас есть готовый код, обнаруживающий ошибки. Проверим его в деле. Пусть мы хотим отправить 01 и у нас произошла ошибка при передаче. Обнаружит ли её код?
А раз в результате не нулевой вектор, значит код заподозрил неладное. Провести его не удалось. Ура, код работает!
Для кода с утроением, кстати, порождающая матрица выглядит очень просто:
Подобные коды, которые можно порождать и проверять матрицей называются линейными (бывают и нелинейные), и они очень широко применяются на практике. Реализовать их довольно легко, так как тут требуется только умножение на константную матрицу.
Ошибка по синдрому
Ну хорошо, мы построили код обнаруживающий ошибки. Но мы же хотим их исправлять!
Для начала введём такое понятие, как вектор ошибки. Это вектор, на который отличается принятое сообщение от кодового слова. Пусть мы получили сообщение , а было отправлено кодовое слово . Тогда вектор ошибки по определению
Но в странном мире GF(2), где сложение и вычитание одинаковы, будут верны и соотношения:
В силу особенностей сложения, как читатель сам может легко убедиться, в векторе ошибки на позициях, где произошла ошибка будет единица, а на остальных ноль.
Как мы уже говорили раньше, если мы получили сообщение с ошибкой, то . Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
Назовём результат умножения на проверочную матрицу синдромом:
И заметим следующее
Это означает, что для ошибки синдром будет таким же, как и для полученного сообщения.
Разложим все возможные сообщения, которые мы можем получить из канала связи, по кучкам в зависимости от синдрома. Тогда из последнего соотношения следует, что в каждой кучке будут вектора с одной и той же ошибкой. Причём вектор этой ошибки тоже будет в кучке. Вот только как его узнать?
А очень просто! Помните, мы говорили, что у нескольких ошибок вероятность ниже, чем у одной ошибки? Руководствуясь этим соображением, наиболее правдоподобным будет считать вектором ошибки тот вектор, у которого меньше всего единиц. Будем называть его лидером.
Давайте посмотрим, какие синдромы дают всевозможные 5-элементные векторы. Сразу сгруппируем их и подчеркнём лидеров — векторы с наименьшим числом единиц.
В принципе, для корректирования ошибки достаточно было бы хранить таблицу соответствия синдрома лидеру.
Обратите внимание, что в некоторых строчках два лидера. Это значит для для данного синдрома два паттерна ошибки равновероятны. Иными словами, код обнаружил две ошибки, но исправить их не может.
Лидеры для всех возможных одиночных ошибок находятся в отдельных строках, а значит код может исправить любую одиночную ошибку. Ну, что же… Попробуем в этом убедиться.
Вектор ошибки равен , а значит ошибка в третьем разряде. Как мы и загадали.
Ура, всё работает!
Что же дальше?
Чтобы попрактиковаться, попробуйте повторить рассуждения для разных проверочных матриц. Например, для кода с утроением.
Логическим продолжением изложенного был бы рассказ о циклических кодах — чрезвычайно интересном подклассе линейных кодов, обладающим замечательными свойствами. Но тогда, боюсь, статья уж очень бы разрослась.
Если вас заинтересовали подробности, то можете почитать замечательную книжку Аршинова и Садовского «Коды и математика». Там изложено гораздо больше, чем представлено в этой статье. Если интересует математика кодирования — то поищите «Теория и практика кодов, контролирующих ошибки» Блейхута. А вообще, материалов по этой теме довольно много.
Надеюсь, когда снова будет свободное время, напишу продолжение, в котором расскажу про циклические коды и покажу пример программы для кодирования и декодирования. Если, конечно, почтенной публике это интересно.
Оптимизация приемника при помощи анализа модуля вектора ошибки
http://habr.com/ru/post/328202/
Вектор
ош. – двоичн.
кодовое слово такой же длины как исходное,
содержащее ед-цы в тех разрядах, где
произошло искажение содержимого код.
слова. (код. слово и вектор ош. — абстракция).
Воздействие помехи на слово заменяется
слож-ем по mod2
исходн. слова с вектором ош.
Ошибки
различают на некорректируемые и
корректируемые.
Некорректир
– при которых изменение содержимого в
каком-то разряде слова не влияет на
искажение содержимого в других словах.
При
корректир – изменение содержимого под
влиянием помех влечёт искажение
содержимого некоторых других разрядах.
Различают
ош. разной кратности:
1)однократные,
2)двукратные,
3)r-кратные
(одновременное искажение содержимого
в r-
разрядах).
Однократная
ошибка вызывает искажение содержимого
только 1 разряда слова и т.д.
Вероятность
r-кратной
ошибки в n-разрядном
слове:
-кол-во
таких ошибок
Вероятность
такого события – вероятность сложного
события и определяется произведение
следующих множителей: вероятности, что
искажение произойдет в этом разряде p,
т.к. таких разрядов r
и события независимые, то — pr
, вероятности,
что в остальных (n-r)
разрядах искажения не будет определяется
как (1-p)(n—r)
, умноженных на количество возможных
r-кратных
ошибок. Т.о.
P=
17. Формулы для определения числа избыточных разрядов и границы Хэмминга для оптимальных корректирующих кодов; их суть и связь, примеры использования.
Пусть
имеем n-разр.
слова, требуется исправлять ошибкки
вплоть до кратности S.
Определим, какое мн-во разреш-х код. слов
можно выделить на мн-ве всех n-разр-х
слов. Для каждой исправляемой ош-ки.
соотв-щее ей запрещ. код. слово. Поэтому
«вокруг» каждого разреш. слова должны
сгруппироваться те запрещ. слова, ош-ки
кот-х подлежат исправлению. Поэтому
кол-во запрещ. слов. не <, чем число
исправл-ых ошибок.
2k-1>=Q
– определяется число информационных
разрядов; 2n—k-1>=n
– определяется число разрядов
помехоустойчивого слова; n-k=m
— определяется число избыточных разрядов;
– определяется граница Хемминга.
Дополнительных разрядов в кодовом слове
должно быть столько, чтобы породить
нужное число запрещенных слов или
классов смежности, а именно 2n—k-1.
Число классов смежности должно быть не
меньше, чем число исправляемых ошибок,
поэтому – 2n—k-1>=n
Пример:
Пусть для
построения кода, корректирующего все
однократные ошибки, используются
однобайтовые слова. Требуется определить
максимальное число разрешенных слов,
выбираемых из всего множества однобайтовых
слов.
Число
однократных ошибок
,
т.е.
.
Максимальное
число разрешенных слов
,т.е.
18. Построение группового корректирующего кода (на примере).
Пример:
тип
исправляемых ошибок — некоррелированные;
кратность
— S
= 1,=15.
Процедура
состоит из четырех этапов.
1.
Расчет числа информационных и избыточных
разрядов:
;
k
= 4;
n
= 7;
n
— k
=3;
где
k
— число информационных разрядов;
n
— число
избыточных разрядов;
2.
Построение таблицы опознавателей
ошибок.
Каждой
ошибке соответствует собственный
опознаватель.
|
Векторы
а7 |
опознаватели
(данный |
|
1 |
111 |
|
0 |
110 |
|
0 |
101 |
|
0 |
100 |
|
0 |
011 |
|
0 |
010 |
|
0 |
001 |
n
= 7 n
— k
=3
3.
Определение проверочных равенств.
1
— й (младший) — а1
а3
а6
а7 ;
2
— й — а2
а5
а6
а7 ;
3
— й — а1
а2
а4
а7 ;
При
отсутствии однократных ошибок в слове
дешифратор вычислит нулевой
— опознаватель
(состоящий из одних нулей — 000). Поэтому
можно записать проверочные
равенства
дешифратора в виде следующей системы
уравнений.
—
уравнения, формирующие 1-ый, 2-ой и 3-ий
разряды опознавателя.
4.
Построение алгоритма кодирования.
Имея
данную систему уравнений на роль
избыточных разрядов следует выбирать
те, которые встречаются в проверочных
равенствах по одному разу, т.е.
.
Выделение избыточных разрядов
сопровождается определением информационных
разрядов помехоустойчивого кодового
слова. При этом для данного кода будут
помечены правила кодирования в виде:
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
The error vector magnitude or EVM (sometimes also called relative constellation error or RCE) is a measure used to quantify the performance of a digital radio transmitter or receiver. A signal sent by an ideal transmitter or received by a receiver would have all constellation points precisely at the ideal locations, however various imperfections in the implementation (such as carrier leakage, low image rejection ratio, phase noise etc.) cause the actual constellation points to deviate from the ideal locations. Informally, EVM is a measure of how far the points are from the ideal locations.
Noise, distortion, spurious signals, and phase noise all degrade EVM, and therefore EVM provides a comprehensive measure of the quality of the radio receiver or transmitter for use in digital communications. Transmitter EVM can be measured by specialized equipment, which demodulates the received signal in a similar way to how a real radio demodulator does it. One of the stages in a typical phase-shift keying demodulation process produces a stream of I-Q points which can be used as a reasonably reliable estimate for the ideal transmitted signal in EVM calculation.
Definition[edit]
Constellation diagram and EVM
An error vector is a vector in the I-Q plane between the ideal constellation point and the point received by the receiver. In other words, it is the difference between actual received symbols and ideal symbols. The root mean square (RMS) average amplitude of the error vector, normalized to ideal signal amplitude reference, is the EVM. EVM is generally expressed in percent by multiplying the ratio by 100. [1]
The ideal signal amplitude reference can either be the maximum ideal signal amplitude of the constellation, or it can be the root mean square (RMS) average amplitude of all possible ideal signal amplitude values in the constellation. For many common constellations including BPSK, QPSK, and 8PSK, these two methods for finding the reference give the same result, but for higher-order QAM constellations including 16QAM, Star 32QAM, 32APSK, and 64QAM the RMS average and the maximum produce different reference values. [2]
The error vector magnitude is sometimes expressed in dB. This is related to the value of EVM in percent as follows:
The definition of EVM depends heavily on the standard that is being used, for example in 3GPP LTE the relevant documents will define exactly how EVM is to be measured. There are discussions ongoing by academics as to some of the problems around EVM measurement.[3]
Dynamic EVM[edit]
Battery life and power consumption are important considerations for a system-level RF transmitter design. Because the transmit power amplifier (PA) consumes a significant portion of the total system DC power, a number of techniques are employed to reduce PA power usage. Many PAs offer an adjustable DC supply voltage to optimize the maximum RF output power level versus its DC power consumption. Also, most PAs can be powered-down or disabled when not in use to conserve power, such as while receiving or between packets during transmission. In order to maximize power efficiency, the PA must have fast turn-on and turn-off switching times. The highest DC power efficiency occurs when the time delta between PA Enable and the RF signal is minimized, but a short delay can exacerbate transient effects on the RF signal.
Because the power-up/power-down operation of the PA can cause transient and thermal effects that degrade transmitter performance, another metric called Dynamic EVM is often tested. Dynamic EVM is measured with a square wave pulse applied to PA Enable to emulate the actual dynamic operation conditions of the transmitter. The degradation in dynamic EVM is due to the PA transient response affecting the preamble at the start of the packet and causing an imperfect channel estimate. Studies have shown that dynamic EVM with a 50% duty cycle square wave applied to PA Enable to be worse than the static EVM (PA Enable with 100% duty cycle).[4]
See also[edit]
- Modulation error ratio
- Carrier to Noise Ratio
- Signal-to-noise ratio
References[edit]
- ^ «Error Vector Magnitude (Digital Demodulation)».
- ^ «EVM Normalization Reference (Digital Demod)».
- ^ Vigilante, McCune, Reynaert. «To EVM or Two EVMs?». doi:10.1109/MSSC.2017.2714398. S2CID 6849707. CS1 maint: multiple names: authors list (link)
- ^ Power Amplifier Testing For 802.11ac
From Wikipedia, the free encyclopedia
The error vector magnitude or EVM (sometimes also called relative constellation error or RCE) is a measure used to quantify the performance of a digital radio transmitter or receiver. A signal sent by an ideal transmitter or received by a receiver would have all constellation points precisely at the ideal locations, however various imperfections in the implementation (such as carrier leakage, low image rejection ratio, phase noise etc.) cause the actual constellation points to deviate from the ideal locations. Informally, EVM is a measure of how far the points are from the ideal locations.
Noise, distortion, spurious signals, and phase noise all degrade EVM, and therefore EVM provides a comprehensive measure of the quality of the radio receiver or transmitter for use in digital communications. Transmitter EVM can be measured by specialized equipment, which demodulates the received signal in a similar way to how a real radio demodulator does it. One of the stages in a typical phase-shift keying demodulation process produces a stream of I-Q points which can be used as a reasonably reliable estimate for the ideal transmitted signal in EVM calculation.
Definition[edit]
Constellation diagram and EVM
An error vector is a vector in the I-Q plane between the ideal constellation point and the point received by the receiver. In other words, it is the difference between actual received symbols and ideal symbols. The root mean square (RMS) average amplitude of the error vector, normalized to ideal signal amplitude reference, is the EVM. EVM is generally expressed in percent by multiplying the ratio by 100. [1]
The ideal signal amplitude reference can either be the maximum ideal signal amplitude of the constellation, or it can be the root mean square (RMS) average amplitude of all possible ideal signal amplitude values in the constellation. For many common constellations including BPSK, QPSK, and 8PSK, these two methods for finding the reference give the same result, but for higher-order QAM constellations including 16QAM, Star 32QAM, 32APSK, and 64QAM the RMS average and the maximum produce different reference values. [2]
The error vector magnitude is sometimes expressed in dB. This is related to the value of EVM in percent as follows:
The definition of EVM depends heavily on the standard that is being used, for example in 3GPP LTE the relevant documents will define exactly how EVM is to be measured. There are discussions ongoing by academics as to some of the problems around EVM measurement.[3]
Dynamic EVM[edit]
Battery life and power consumption are important considerations for a system-level RF transmitter design. Because the transmit power amplifier (PA) consumes a significant portion of the total system DC power, a number of techniques are employed to reduce PA power usage. Many PAs offer an adjustable DC supply voltage to optimize the maximum RF output power level versus its DC power consumption. Also, most PAs can be powered-down or disabled when not in use to conserve power, such as while receiving or between packets during transmission. In order to maximize power efficiency, the PA must have fast turn-on and turn-off switching times. The highest DC power efficiency occurs when the time delta between PA Enable and the RF signal is minimized, but a short delay can exacerbate transient effects on the RF signal.
Because the power-up/power-down operation of the PA can cause transient and thermal effects that degrade transmitter performance, another metric called Dynamic EVM is often tested. Dynamic EVM is measured with a square wave pulse applied to PA Enable to emulate the actual dynamic operation conditions of the transmitter. The degradation in dynamic EVM is due to the PA transient response affecting the preamble at the start of the packet and causing an imperfect channel estimate. Studies have shown that dynamic EVM with a 50% duty cycle square wave applied to PA Enable to be worse than the static EVM (PA Enable with 100% duty cycle).[4]
See also[edit]
- Modulation error ratio
- Carrier to Noise Ratio
- Signal-to-noise ratio
References[edit]
- ^ «Error Vector Magnitude (Digital Demodulation)».
- ^ «EVM Normalization Reference (Digital Demod)».
- ^ Vigilante, McCune, Reynaert. «To EVM or Two EVMs?». doi:10.1109/MSSC.2017.2714398. S2CID 6849707. CS1 maint: multiple names: authors list (link)
- ^ Power Amplifier Testing For 802.11ac
Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Как нетрудно догадаться, ко всему этому причастны корректирующие коды. Собственно, ECC так и расшифровывается — «error-correcting code», то есть «код, исправляющий ошибки». А CRC — это один из алгоритмов, обнаруживающих ошибки в данных. Исправить он их не может, но часто это и не требуется.
Давайте же разберёмся, что это такое.
Для понимания статьи не нужны никакие специальные знания. Достаточно лишь понимать, что такое вектор и матрица, как они перемножаются и как с их помощью записать систему линейных уравнений.
Внимание! Много текста и мало картинок. Я постарался всё объяснить, но без карандаша и бумаги текст может показаться немного запутанным.
Каналы с ошибкой
Разберёмся сперва, откуда вообще берутся ошибки, которые мы собираемся исправлять. Перед нами стоит следующая задача. Нужно передать несколько блоков данных, каждый из которых кодируется цепочкой двоичных цифр. Получившаяся последовательность нулей и единиц передаётся через канал связи. Но так сложилось, что реальные каналы связи часто подвержены ошибкам. Вообще говоря, ошибки могут быть разных видов — может появиться лишняя цифра или какая-то пропасть. Но мы будем рассматривать только ситуации, когда в канале возможны лишь замены нуля на единицу и наоборот. Причём опять же для простоты будем считать такие замены равновероятными.
Ошибка — это маловероятное событие (а иначе зачем нам такой канал вообще, где одни ошибки?), а значит, вероятность двух ошибок меньше, а трёх уже совсем мала. Мы можем выбрать для себя некоторую приемлемую величину вероятности, очертив границу «это уж точно невозможно». Это позволит нам сказать, что в канале возможно не более, чем ошибок. Это будет характеристикой канала связи.
Для простоты введём следующие обозначения. Пусть данные, которые мы хотим передавать, — это двоичные последовательности фиксированной длины. Чтобы не запутаться в нулях и единицах, будем иногда обозначать их заглавными латинскими буквами (, , , …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
Кодирование и декодирование будем обозначать прямой стрелкой (), а передачу по каналу связи — волнистой стрелкой (). Ошибки при передаче будем подчёркивать.
Например, пусть мы хотим передавать только сообщения и . В простейшем случае их можно закодировать нулём и единицей (сюрприз!):
Передача по каналу, в котором возникла ошибка будет записана так:
Цепочки нулей и единиц, которыми мы кодируем буквы, будем называть кодовыми словами. В данном простом случае кодовые слова — это и .
Код с утроением
Давайте попробуем построить какой-то корректирующий код. Что мы обычно делаем, когда кто-то нас не расслышал? Повторяем дважды:
Правда, это нам не очень поможет. В самом деле, рассмотрим канал с одной возможной ошибкой:
Какие выводы мы можем сделать, когда получили ? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
То есть, получившийся код обнаруживает, но не исправляет ошибки. Ну, тоже неплохо, в общем-то. Но мы пойдём дальше и будем теперь утраивать цифры.
Проверим в деле:
Получили . Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
Если в канале связи возможна максимум одна ошибка, то первое предположение о двух ошибках становится невозможным и остаётся только один вариант — передавалась буква .
Про такой код говорят, что он исправляет одну ошибку. Две он тоже обнаружит, но исправит уже неверно.
Это, конечно, самый простой код. Кодировать легко, да и декодировать тоже. Ноликов больше — значит передавался ноль, единичек — значит единица.
Если немного подумать, то можно предложить код исправляющий две ошибки. Это будет код, в котором мы повторяем одиночный бит 5 раз.
Расстояния между кодами
Рассмотрим поподробнее код с утроением. Итак, мы получили работающий код, который исправляет одиночную ошибку. Но за всё хорошее надо платить: он кодирует один бит тремя. Не очень-то и эффективно.
И вообще, почему этот код работает? Почему нужно именно утраивать для устранения одной ошибки? Наверняка это всё неспроста.
Давайте подумаем, как этот код работает. Интуитивно всё понятно. Нолики и единички — это две непохожие последовательности. Так как они достаточно длинные, то одиночная ошибка не сильно портит их вид.
Пусть мы передавали , а получили . Видно, что эта цепочка больше похожа на исходные , чем на . А так как других кодовых слов у нас нет, то и выбор очевиден.
Но что значит «больше похоже»? А всё просто! Чем больше символов у двух цепочек совпадает, тем больше их схожесть. Если почти все символы отличаются, то цепочки «далеки» друг от друга.
Можно ввести некоторую величину , равную количеству различающихся цифр в соответствующих разрядах цепочек и . Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
Например, , так как все цифры в соответствующих позициях равны, а вот .
Расстояние Хэмминга называют расстоянием неспроста. Ведь в самом деле, что такое расстояние? Это какая-то характеристика, указывающая на близость двух точек, и для которой верны утверждения:
- Расстояние между точками неотрицательно и равно нулю только, если точки совпадают.
- Расстояние в обе стороны одинаково.
- Путь через третью точку не короче, чем прямой путь.
Достаточно разумные требования.
Математически это можно записать так (нам это не пригодится, просто ради интереса посмотрим):
- .
Предлагаю читателю самому убедиться, что для расстояния Хэмминга эти свойства выполняются.
Окрестности
Таким образом, разные цепочки мы считаем точками в каком-то воображаемом пространстве, и теперь мы умеем находить расстояния между ними. Правда, если попытаться сколько нибудь длинные цепочки расставить на листе бумаги так, чтобы расстояния Хэмминга совпадали с расстояниями на плоскости, мы можем потерпеть неудачу. Но не нужно переживать. Всё же это особое пространство со своими законами. А слова вроде «расстояния» лишь помогают нам рассуждать.
Пойдём дальше. Раз мы заговорили о расстоянии, то можно ввести такое понятие как окрестность. Как известно, окрестность какой-то точки — это шар определённого радиуса с центром в ней. Шар? Какие ещё шары! Мы же о кодах говорим.
Но всё просто. Ведь что такое шар? Это множество всех точек, которые находятся от данной не дальше, чем некоторое расстояние, называемое радиусом. Точки у нас есть, расстояние у нас есть, теперь есть и шары.
Так, скажем, окрестность кодового слова радиуса 1 — это все коды, находящиеся на расстоянии не больше, чем 1 от него, то есть отличающиеся не больше, чем в одном разряде. То есть это коды:
Да, вот так странно выглядят шары в пространстве кодов.
А теперь посмотрите. Это же все возможные коды, которые мы получим в канале в одной ошибкой, если отправим ! Это следует прямо из определения окрестности. Ведь каждая ошибка заставляет цепочку измениться только в одном разряде, а значит удаляет её на расстояние 1 от исходного сообщения.
Аналогично, если в канале возможны две ошибки, то отправив некоторое сообщение , мы получим один из кодов, который принадлежит окрестности радиусом 2.
Тогда всю нашу систему декодирования можно построить так. Мы получаем какую-то цепочку нулей и единиц (точку в нашей новой терминологии) и смотрим, в окрестность какого кодового слова она попадает.
Сколько ошибок может исправить код?
Чтобы код мог исправлять больше ошибок, окрестности должны быть как можно шире. С другой стороны, они не должны пересекаться. Иначе если точка попадёт в область пересечения, непонятно будет, к какой окрестности её отнести.
В коде с удвоением между кодовыми словами и расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
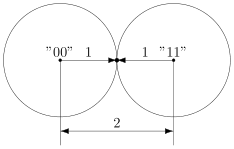
Именно это мы и получали. Мы видели, что есть ошибка, но не могли её исправить.
Что интересно, точек касания в нашем странном пространстве у шаров две — это коды и . Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
В случае кода с утроением, между шарами будет зазор.

Минимальный зазор между шарами равен 1, так как у нас расстояния всегда целые (ну не могут же две цепочки отличаться в полутора разрядах).
В общем случае получаем следующее.
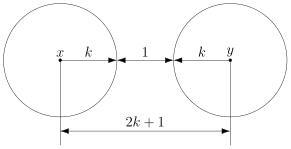
Этот очевидный результат на самом деле очень важен. Он означает, что код с минимальным кодовым расстоянием будет успешно работать в канале с ошибками, если выполняется соотношение
Полученное равенство позволяет легко определить, сколько ошибок будет исправлять тот или иной код. А сколько код ошибок может обнаружить? Рассуждения такие же. Код обнаруживает ошибок, если в результате не получится другое кодовое слово. То есть, кодовые слова не должны находиться в окрестностях радиуса других кодовых слов. Математически это записывается так:
Рассмотрим пример. Пусть мы кодируем 4 буквы следующим образом.
Чтобы найти минимальное расстояние между различными кодовыми словами, построим таблицу попарных расстояний.
| A | B | C | D | |
|---|---|---|---|---|
| A | — | 3 | 3 | 4 |
| B | 3 | — | 4 | 3 |
| C | 3 | 4 | — | 3 |
| D | 4 | 3 | 3 | — |
Минимальное расстояние , а значит , откуда получаем, что такой код может исправить до ошибок. Обнаруживает же он две ошибки.
Рассмотрим пример:
Чтобы декодировать полученное сообщение, посмотрим, к какому символу оно ближе всего.
Минимальное расстояние получилось для символа , значит вероятнее всего передавался именно он:
Итак, этот код исправляет одну ошибку, как и код с утроением. Но он более эффективен, так как в отличие от кода с утроением здесь кодируется уже 4 символа.
Таким образом, основная проблема при построении такого рода кодов — так расположить кодовые слова, чтобы они были как можно дальше друг от друга, и их было побольше.
Для декодирования можно было бы использовать таблицу, в которой указывались бы все возможные принимаемые сообщения, и кодовые слова, которым они соответствуют. Но такая таблица получилась бы очень большой. Даже для нашего маленького кода, который выдаёт 5 двоичных цифр, получилось бы варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
Попробуем придумать способ коррекции сообщения без таблиц. Мы всегда сможем найти полезное применение освободившейся памяти.
Интерлюдия: поле GF(2)
Для изложения дальнейшего материала нам потребуются матрицы. А при умножении матриц, как известно мы складываем и перемножаем числа. И тут есть проблема. Если с умножением всё более-менее хорошо, то как быть со сложением? Из-за того, что мы работаем только с одиночными двоичными цифрами, непонятно, как сложить 1 и 1, чтобы снова получилась одна двоичная цифра. Значит вместо классического сложения нужно использовать какое-то другое.
Введём операцию сложения как сложение по модулю 2 (хорошо известный программистам XOR):
Умножение будем выполнять как обычно. Эти операции на самом деле введены не абы как, а чтобы получилась система, которая в математике называется полем. Поле — это просто множество (в нашем случае из 0 и 1), на котором так определены сложение и умножение, чтобы основные алгебраические законы сохранялись. Например, чтобы основные идеи, касающиеся матриц и систем уравнений по-прежнему были верны. А вычитание и деление мы можем ввести как обратные операции.
Множество из двух элементов с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
У сложения есть несколько очень полезных свойств, которыми мы будем пользоваться в дальнейшем.
Это свойство прямо следует из определения.
А в этом можно убедиться, прибавив к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
Проверяем корректность
Вернёмся к коду с утроением.
Для начала просто решим задачу проверки, были ли вообще ошибки при передаче. Как видно, из самого кода, принятое сообщение будет кодовым словом только тогда, когда все три цифры равны между собой.
Пусть мы приняли вектор-строку из трёх цифр. (Стрелочки над векторами рисовать не будем, так как у нас почти всё — это вектора или матрицы.)
Математически равенство всех трёх цифр можно записать как систему:
Или, если воспользоваться свойствами сложения в GF(2), получаем
Или
В матричном виде эта система будет иметь вид
где
Транспонирование здесь нужно потому, что — это вектор-строка, а не вектор-столбец. Иначе мы не могли бы умножать его справа на матрицу.
Будем называть матрицу проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
Умножение на матрицу — это гораздо более эффективно, чем поиск в таблице, но у нас на самом деле есть ещё одна таблица — это таблица кодирования. Попробуем от неё избавиться.
Кодирование
Итак, у нас есть система для проверки
Её решения — это кодовые слова. Собственно, мы систему и строили на основе кодовых слов. Попробуем теперь решить обратную задачу. По системе (или, что то же самое, по матрице ) найдём кодовые слова.
Правда, для нашей системы мы уже знаем ответ, поэтому, чтобы было интересно, возьмём другую матрицу:
Соответствующая система имеет вид:
Чтобы найти кодовые слова соответствующего кода нужно её решить.
В силу линейности сумма двух решений системы тоже будет решением системы. Это легко доказать. Если и — решения системы, то для их суммы верно
что означает, что она тоже — решение.
Поэтому если мы найдём все линейно независимые решения, то с их помощью можно получить вообще все решения системы. Для этого просто нужно найти их всевозможные суммы.
Выразим сперва все зависимые слагаемые. Их столько же, сколько и уравнений. Выражать надо так, чтобы справа были только независимые. Проще всего выразить .
Если бы нам не так повезло с системой, то нужно было бы складывая уравнения между собой получить такую систему, чтобы какие-то три переменные встречались по одному разу. Ну, или воспользоваться методом Гаусса. Для GF(2) он тоже работает.
Итак, получаем:
Чтобы получить все линейно независимые решения, приравниваем каждую из зависимых переменных к единице по очереди.
Всевозможные суммы этих независимых решений (а именно они и будут кодовыми векторами) можно получить так:
где равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно сочетания.
Но посмотрите! Формула, которую мы только что получили — это же снова умножение матрицы на вектор.
Строчки здесь — линейно независимые решения, которые мы получили. Матрица называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:
Найдём кодовые слова для этого кода. (Не забываем, что длина исходных сообщений должна быть равна 2 — это количество найденных решений.)
Итак, у нас есть готовый код, обнаруживающий ошибки. Проверим его в деле. Пусть мы хотим отправить 01 и у нас произошла ошибка при передаче. Обнаружит ли её код?
А раз в результате не нулевой вектор, значит код заподозрил неладное. Провести его не удалось. Ура, код работает!
Для кода с утроением, кстати, порождающая матрица выглядит очень просто:
Подобные коды, которые можно порождать и проверять матрицей называются линейными (бывают и нелинейные), и они очень широко применяются на практике. Реализовать их довольно легко, так как тут требуется только умножение на константную матрицу.
Ошибка по синдрому
Ну хорошо, мы построили код обнаруживающий ошибки. Но мы же хотим их исправлять!
Для начала введём такое понятие, как вектор ошибки. Это вектор, на который отличается принятое сообщение от кодового слова. Пусть мы получили сообщение , а было отправлено кодовое слово . Тогда вектор ошибки по определению
Но в странном мире GF(2), где сложение и вычитание одинаковы, будут верны и соотношения:
В силу особенностей сложения, как читатель сам может легко убедиться, в векторе ошибки на позициях, где произошла ошибка будет единица, а на остальных ноль.
Как мы уже говорили раньше, если мы получили сообщение с ошибкой, то . Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
Назовём результат умножения на проверочную матрицу синдромом:
И заметим следующее
Это означает, что для ошибки синдром будет таким же, как и для полученного сообщения.
Разложим все возможные сообщения, которые мы можем получить из канала связи, по кучкам в зависимости от синдрома. Тогда из последнего соотношения следует, что в каждой кучке будут вектора с одной и той же ошибкой. Причём вектор этой ошибки тоже будет в кучке. Вот только как его узнать?
А очень просто! Помните, мы говорили, что у нескольких ошибок вероятность ниже, чем у одной ошибки? Руководствуясь этим соображением, наиболее правдоподобным будет считать вектором ошибки тот вектор, у которого меньше всего единиц. Будем называть его лидером.
Давайте посмотрим, какие синдромы дают всевозможные 5-элементные векторы. Сразу сгруппируем их и подчеркнём лидеров — векторы с наименьшим числом единиц.
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В принципе, для корректирования ошибки достаточно было бы хранить таблицу соответствия синдрома лидеру.
Обратите внимание, что в некоторых строчках два лидера. Это значит для для данного синдрома два паттерна ошибки равновероятны. Иными словами, код обнаружил две ошибки, но исправить их не может.
Лидеры для всех возможных одиночных ошибок находятся в отдельных строках, а значит код может исправить любую одиночную ошибку. Ну, что же… Попробуем в этом убедиться.
Вектор ошибки равен , а значит ошибка в третьем разряде. Как мы и загадали.
Ура, всё работает!
Что же дальше?
Чтобы попрактиковаться, попробуйте повторить рассуждения для разных проверочных матриц. Например, для кода с утроением.
Логическим продолжением изложенного был бы рассказ о циклических кодах — чрезвычайно интересном подклассе линейных кодов, обладающим замечательными свойствами. Но тогда, боюсь, статья уж очень бы разрослась.
Если вас заинтересовали подробности, то можете почитать замечательную книжку Аршинова и Садовского «Коды и математика». Там изложено гораздо больше, чем представлено в этой статье. Если интересует математика кодирования — то поищите «Теория и практика кодов, контролирующих ошибки» Блейхута. А вообще, материалов по этой теме довольно много.
Надеюсь, когда снова будет свободное время, напишу продолжение, в котором расскажу про циклические коды и покажу пример программы для кодирования и декодирования. Если, конечно, почтенной публике это интересно.
Э. Акар, Analog Devices, специалист по измерениям радиочастотных систем
Как измерение модуля вектора ошибки помогает оптимизировать общие характеристики системы
Статья опубликована в журнале Электроника НТБ № 8 2021
![]()
Модуль вектора ошибки (Error Vector Magnitude, EVM) — широко применяемый показатель системного уровня, который регламентируется различными стандартами в области связи для испытаний на соответствие в таких приложениях, как беспроводные локальные сети (WLAN 802.11), мобильная связь (4G LTE, 5G) и многие другие. Кроме того, это чрезвычайно важная системная характеристика, позволяющая количественно оценить совокупное влияние всех возможных проблем в системе с помощью одного, простого для понимания параметра. В статье проанализировано, как характеристики более низкого уровня влияют на EVM, рассмотрен ряд практических примеров использования EVM для оптимизации характеристик устройства на уровне системы, показано, как добиться снижения EVM на 15 дБ по сравнению с требованиями большинства стандартов связи.
Большинство инженеров, работающих в области радиочастотных систем, оперируют такими характеристиками, как коэффициент шума, точка пересечения третьего порядка и отношение сигнал — шум. Понимание совокупного влияния этих параметров на общие рабочие характеристики системы может быть сложной задачей. Модуль вектора ошибки позволяет быстро получить представление о работе системы в целом, вместо того, чтобы оценивать несколько разных показателей.
Что такое модуль вектора ошибки?
EVM — это простой показатель для количественной оценки комбинации всех искажений сигнала в системе. Он часто определяется для устройств, использующих цифровую модуляцию, которая может быть представлена в виде графика синфазных (I) и квадратурных (Q) векторов, известного также как «диаграмма созвездия» (constellation diagram) (рис. 1a). Как правило, EVM вычисляется путем нахождения идеального местоположения созвездия для каждого принятого символа, как показано на рис. 1б. Среднеквадратичное значение всех модулей вектора ошибки между местоположениями принятых символов и их ближайшими идеальными местоположениями в созвездии определяет величину EVM устройства [1].
Рис. 1. а — диаграмма созвездия и граница принятия решения; б — вектор ошибки между принятым символом и идеальным местоположением символа
В стандарте IEEE 802.11 приведена формула для вычисления EVM [2]:
где: Lp — количество кадров, Nc — количество несущих, Ri, j — принятый символ, а Si, j — идеальное местоположение символа.
EVM тесно связан с частотой битовых ошибок (BER) данной системы. Когда принятые символы располагаются далеко от целевой точки созвездия, вероятность их попадания в границу принятия решения другой точки созвездия увеличивается. Это приводит к увеличению BER. Важное различие между BER и EVM состоит в том, что BER для переданного сигнала вычисляется на основе переданной битовой комбинации, в то время как EVM вычисляется на основе расстояния от ближайшей точки созвездия символов до местоположения символа. В некоторых случаях символы могут пересекать границу принятия решения, и им присваивается неправильная битовая комбинация. Если символ попадает ближе к другому идеальному местоположению символа, это может улучшить EVM для этого символа. Таким образом, хотя EVM и BER тесно связаны, эта связь может быть нарушена при очень высоких уровнях искажения сигнала.
Современные стандарты в области связи устанавливают минимально допустимый уровень EVM на основе характеристик передаваемого или принятого сигнала, таких как скорость передачи данных и полоса пропускания. Устройства, которые достигают целевого уровня EVM, соответствуют стандарту, в то время как устройства, которые не достигают целевого уровня EVM, не соответствуют его требованиям. Испытательное и измерительное оборудование, предназначенное для проверки на соответствие стандартам, обычно ориентировано на более строгие целевые значения EVM, которые могут быть на порядок ниже требуемых в стандарте. Это позволяет оборудованию определять EVM тестируемого устройства без значительных искажений сигнала.
Что влияет на EVM?
Как показатель ошибки, EVM тесно связан со всеми источниками искажений в системе. Мы можем количественно оценить влияние всех отклонений в системе на EVM, вычислив, как они искажают принимаемые и передаваемые сигналы. Проанализируем влияние нескольких ключевых видов помех, таких как тепловой шум, фазовый шум и нелинейности, на EVM.
Белый шум
Белый шум присутствует во всех радиочастотных системах. Когда шум является единственным искажением в системе, результирующий EVM можно рассчитать по следующей формуле:
где SNR — отношение сигнал — шум системы в дБ, а PAPR — отношение пиковой мощности к средней мощности данного сигнала в дБ.
Обратите внимание, что SNR обычно определяется для однотонального сигнала. Для модулированного сигнала необходимо учитывать PAPR сигнала. Поскольку PAPR однотонального сигнала составляет 3 дБ, это число необходимо вычесть из значения SNR для сигнала с произвольным значением PAPR.
Для высокоскоростных АЦП и ЦАП, уравнение 2 может быть выражено через спектральную плотность шума (NSD):
где NSD — спектральная плотность шума в дБ ПШ / Гц, BW — ширина полосы сигнала в Гц, PAPR — отношение пиковой мощности к средней, а Pbackoff — разница между пиковой мощностью сигнала и полным диапазоном измерений преобразователя.
Эта формула может быть очень удобна для прямого расчета ожидаемого значения EVM устройства с использованием значения NSD, которое обычно указывается для современных высокоскоростных преобразователей. Обратите внимание, что для высокоскоростных преобразователей необходимо учитывать также шум квантования. Величина NSD большинства высокоскоростных преобразователей также включает шум квантования. Следовательно, для этих устройств уравнение 3 отражает не только тепловой шум, но также шум квантования.
Как показывают эти два уравнения, EVM сигнала напрямую зависит от общей полосы пропускания сигнала, отношения пиковой мощности к средней и теплового шума системы.
Как фазовый шум влияет на EVM
Другим видом шума, который влияет на EVM системы, является фазовый шум, который представляет собой случайные флуктуации фазы и частоты сигнала [3]. Все нелинейные элементы схемы вносят фазовый шум. Основные источники фазового шума в данной системе могут быть прослежены вплоть до генераторов. Генератор частоты дискретизации преобразователя данных, используемый для преобразования частоты гетеродин и генератор опорной частоты — все эти устройства могут вносить вклад в общий фазовый шум системы.
Ухудшение характеристик из-за фазового шума зависит от частоты. Для типичного генератора большая часть энергии несущей приходится на его основную частоту генерации, которая называется центральной частотой. Часть энергии сигнала будет распределяться около этой центральной частоты. Отношение амплитуды сигнала в полосе частот 1 Гц при определенном сдвиге частоты к его амплитуде на центральной частоте определяется как фазовый шум при этом конкретном частотном сдвиге, как показано на рис. 2.
Фазовый шум системы напрямую влияет на ее EVM. EVM из-за фазового шума системы можно рассчитать путем интегрирования фазового шума в полосе пропускания. Для большинства современных стандартов связи, в которых используется ортогональная частотная модуляция (OFDM), фазовый шум должен быть интегрирован в диапазоне от примерно 10% разнесения поднесущих до полной ширины полосы сигнала:
где L — плотность фазового шума в одиночной боковой полосе, fsc — разнесение поднесущих, BW — ширина полосы сигнала.
Большинство устройств, генерирующих частоту, имеют низкий фазовый шум на частотах <2 ГГц с типичными уровнями интегрированного джиттера на несколько порядков ниже предельных значений EVM, устанавливаемых в стандартах. Однако для более высокочастотных и более широкополосных сигналов интегрированные уровни фазового шума могут быть значительно выше, что может привести к гораздо более высоким значениям EVM. Обычно это относится к устройствам миллиметрового диапазона, которые работают на частотах выше 20 ГГц. Как мы подробнее обсудим в разделе, посвящен ном описанию примеров проектов, фазовый шум следует рассчитывать для всей системы, чтобы достичь наименьшего общего EVM.
Расчет влияния нелинейностей на EVM
Нелинейности системного уровня приводят к появлению интермодуляционных составляющих, которые могут попадать в полосу пропускания сигнала. Эти помехи могут перекрываться с поднесущими, воздействуя на их амплитуду и фазу. Можно вычислить вектор ошибки, возникающий из-за интермодуляционных помех. Выведем простую формулу для расчета EVM системы из-за интермодуляционных составляющих третьего порядка.
Рис. 3. Интермодуляционные составляющие OFDM-сигнала
Как показано на рис. 3a, двухтональный сигнал создает две интермодуляционные составляющие. Мощность интермодуляционных составляющих можно рассчитать следующим образом:
где Ptone — мощность тестового сигнала, OIP3 — точка пересечения третьего порядка на выходе, Pe — сигнал ошибки, представляющий собой разность мощностей основной частоты и интермодуляционной составляющей.
Для OFDM-сигнала с N тонами, как показано на рис. 3б, уравнение 6 принимает следующий вид:
где Pe, i — ошибка для каждой пары тонов.
Поскольку в каждом местоположении поднесущей имеется N / 2 интермодуляционных составляющих, которые перекрываются, уравнение можно переписать как:
Общая ошибка, включая все местоположения поднесущих, становится равной:
Подставляя уравнение 6 в уравнение 8, EVM можно выразить следующим образом:
где PRMS — среднеквадратичное значение сигнала, C — константа, которая находится в диапазоне от 0 до 3 дБ в зависимости от схемы модуляции.
Как показывает уравнение 11, EVM уменьшается по мере увеличения OIP3 системы. Это ожидаемо, поскольку более высокое значение OIP3 обычно указывает на более линейную систему. Кроме того, когда среднеквадратичная мощность сигнала уменьшается, EVM уменьшается по мере уменьшения мощности нелинейных составляющих.
Оптимизация системных характеристик с помощью EVM
Обычно проектирование на уровне системы начинается с каскадного анализа, при котором низкоуровневые параметры функциональных блоков используются для определения общих характеристик системы, построенной на базе этих блоков. Существуют хорошо зарекомендовавшие себя аналитические формулы и инструменты, которые можно использовать для расчета этих параметров. Однако многие инженеры не знают, как правильно использовать инструменты каскадного анализа для проектирования полностью оптимизированных систем.
В качестве системной характеристики EVM предоставляет инженерам-разработчикам ценную информацию для оптимизации системы. Вместо того, чтобы рассматривать несколько параметров, разработчики получают возможность выбрать оптимальное среднеквадратичное
значение EVM и, тем самым, найти наилучшее проектное решение.
U-образная кривая EVM
Мы можем объединить все параметры системы в один график, учитывая вклад EVM каждого искажения в системе и уровень выходной мощности. На рис. 4 показана типичная U-образная кривая EVM для системы в зависимости от уровня рабочей мощности. При низких уровнях рабочей мощности EVM определяется шумовыми характеристиками системы. На высоких уровнях мощности на EVM влияют нелинейности в системе. Самый низкий уровень EVM для системы обычно определяется комбинацией всех источников ошибок, включая фазовый шум.
Мы можем найти суммарный EVM с помощью уравнения 12:
где EVMWN — вклад EVM, возникающий из-за белого шума, EVMPhN — вклад фазового шума, EVMlinearity — EVM, возникающий из-за нелинейных искажений. Для заданного уровня мощности сумма мощностей всех этих ошибок определяет общий уровень EVM в системе.
Рис. 4. U-образная кривая зависимости EVM от рабочей мощности
Наряду с уравнением 12, U-образная кривая может быть очень полезной для системной оптимизации, когда можно визуализировать комбинацию всех ошибок данной системы.
Пример проекта
Рассмотрим пример проектирования сигнальной цепочки, используя EVM в качестве системного показателя. В этом примере мы спроектируем передатчик миллиметрового диапазона с использованием РЧ ЦАП с дискретизацией, модулятора и генераторов частоты миллиметрового диапазона, а также других устройств формирования сигнала (рис. 5).
Рис. 5. Сигнальная цепь передатчика миллиметрового диапазона
В этой сигнальной цепи используется микросхема AD9082, которая содержит четыре ЦАП и два АЦП с частотой выборки 12 и 6 ГГц соответственно. Эти преобразователи с прямым РЧ-преобразованием обеспечивают гибкость проектного решения для сигнальной цепи миллиметрового диапазона и непревзойденную производительность. На рис. 6 показаны результаты измерения значения EVM для типовой микросхемы AD9082 с помощью 12‑разрядного АЦП AD9213, который обеспечивает скорость выборки 10 Гвыб / с. Кольцевой тест для этой схемы показал уровень EVM всего -62 дБ, что на 27 дБ ниже предельной допустимой величины, определяемой стандартом.
Рис. 6. Результаты измерения EVM для микросхемы AD9082 на промежуточной частоте 400 МГц для сигнала IEEE 802.11ax с полосой пропускания 80 МГц с модуляцией QAM‑1024
В этой схеме также используется интегрированный миллиметровый модулятор ADMV1013, который содержит ряд традиционных блоков сигнальной цепи, таких как умножители частоты, квадратурные смесители и усилители. Чтобы упростить фильтрацию, в этом проекте используется довольно сложная топология цепи промежуточной частоты, в которой на квадратурные смесители модуляторов подаются сигналы с фазой 90°. Это устраняет одну из боковых полос сигнала, преобразованного с повышением частоты, тем самым уменьшается сложность фильтрации по сравнению с преобразованием сигнала с двумя боковыми полосами.
Чтобы оптимизировать эту сигнальную цепь для получения наименьшего значения EVM, сначала проанализируем фазовый шум на уровне системы, затем найдем оптимальное соотношение шума и линейности и, наконец, соберем все функциональные блоки в одну систему.
Улучшение EVM путем оптимизации фазового шума
Как мы обсуждали ранее, фазовый шум всей системы может ограничивать возможность минимизации EVM на частотах миллиметрового диапазона. Проанализируем вклад фазового шума каждого каскада, чтобы убедиться, что выбраны наилучшие компоненты для данной сигнальной цепи. Компоненты, формирующие частоты в этой сигнальной цепи, — это ЦАП, который синхронизируется с помощью синтезатора, и гетеродин. Общий фазовый шум можно выразить следующим образом:
где LTx – общий фазовый шум передатчика, lIF – фазовый шум на выходе ЦАП, lLO – фазовый шум сигнала гетеродина.
Используемый в этом примере ЦАП AD9082 имеет исключительно низкий аддитивный фазовый шум. Общий фазовый шум на выходе, который представляет собой сигнал ПЧ, можно рассчитать по простой формуле:
где LCLK – интегрированный фазовый шум тактового сигнала, fIF – ПЧ-частота на выходе ЦАП, fCLK – частота выборки для ЦАП.
Чтобы выбрать компоненты минимальной сложности и с наименьшим фазовым шумом, проанализируем характеристики двух микросхем, рассматриваемых в качестве кандидатов на роль генератора тактовой частоты и источника сигнала гетеродина.
Рис. 7. Фазовый шум тактового сигнала и сигнала гетеродина для ADF4372 и ADF4401A
На рис. 7 показана характеристика фазового шума сигнала с одной боковой полосой для двух микросхем, наилучшим образом подходящих для использования в качестве синтезаторов частоты для этой сигнальной цепи. Интегрированный фазовый шум для сигнала 5G NR может быть рассчитан путем интегрирования фазового шума источников сигнала в полосе от 6 кГц до 100 МГц (табл. 1).
На типичных для этой сигнальной цепи промежуточных частотах как ADF4372, так и ADF4401A демонстрируют чрезвычайно низкие уровни интегрированного шума. Поскольку для ADF4372 требуется гораздо меньшая площадь печатной платы, это хороший выбор для формирования
частоты выборки для РЧ-преобразователя, который создает ПЧ-сигнал. Микросхема ADF4401A становится выбором для генератора сигнала гетеродина из-за присущего ей низкого начального фазового шума. На частоте 30 ГГц он примерно на 20 дБ ниже интегрированного шума для ADF4372. Такой низкий уровень шума гарантирует, что фазовый шум сигнала гетеродина не станет ограничивать общие показатели EVM для всей системы.
Используя уравнение 13, можно рассчитать общий EVMPhN из-за фазового шума:
Такой уровень модуля вектора ошибка из-за фазового шума более чем достаточен для измерения сигналов с EVM порядка -30 дБ, как определено стандартом для 5G NR.
Оптимизация соотношения шума и линейности
Одна из основных проблем при проектировании РЧ-систем — поиск оптимального соотношения шума и линейности. Улучшение одного из этих двух параметров обычно приводит к неоптимальной величине другого. Анализ EVM на уровне системы может быть очень полезным инструментом для улучшения характеристик системы в целом.
Рис. 8. Оптимизация соотношения шума и линейности системы
Рис. 8 иллюстрирует поиск оптимального соотношения шума и линейности для созданной нами сигнальной цепи. Каждая из кривых получена путем регулировки управляющего напряжения интегрированного усилителя. Для каждой кривой изменялся уровень выходной мощности ЦАП. Заметим, что по мере увеличения уровня мощности EVM уменьшается из-за увеличения общего отношения сигнал – шум системы. После определенного уровня мощности нелинейности всего тракта прохождения сигнала начинают ухудшать показатель EVM. Результирующая U-образная кривая EVM для данной конфигурации усилителя очень узкая.
Регулируя управляющее напряжение усилителя, мы можем перейти к другой кривой, на которой система имеет более низкий EVM. Пунктирная линия на рис. 8 отражает оптимизацию на уровне системы, которая может быть достигнута с помощью интегрированных усилителей микросхемы ADMV1013. Результирующая U-образная кривая после этой оптимизации становится намного шире, что обеспечивает сверхнизкий EVM в широком диапазоне уровней выходной мощности.
Заключение
В статье мы рассмотрели EVM в качестве системного показателя и обсудили, как с помощью EVM можно оптимизировать характеристики системы. Как мы показали, EVM – хороший индикатор многих проблем системного уровня. Все источники ошибок приводят к возникновению поддающегося измерению EVM, который можно использовать для оптимизации общих показателей системы. Мы продемонстрировали также, что с помощью новейших высокоскоростных преобразователей и интегрированных модуляторов миллиметрового диапазона можно достичь характеристик системы приборного уровня и значений EVM на порядки величин более низких по сравнению с требованиями стандартов в области связи.
ЛИТЕРАТУРА
1. Voelker K. M. Apply Error Vector Measurements in Communication Design. – Microwaves & RF, December 1995.
2. IEEE 802.11a‑1999. IEEE Standard for Telecommunications and Information Exchange Between Systems. LAN / MAN Specific Requirements. Part 11: Wireless Medium Access Control (MAC) and Physical Layer (PHY) Specifications: High Speed Physical Layer in the 5 GHz Band. – IEEE Standard
Association, September 1999.
3. Kester W. MT‑008 Tutorial: Converting Oscillator Phase Noise to Time Jitter. – Analog Devices, Inc., 2009.
Если комбинации кода известны и
он используется для исправления ошибок, то способ разбиения множества U на подмножества Ai
определяется статистикой ошибок, возникающих в его комбинациях. Обычно это
разбиение выполняется так, чтобы минимизировать среднюю вероятность появления
ложной комбинации на входе декодера.
В дальнейшем будем рассматривать
только двоичные коды, как получившие наибольшее распространение.
20. Понятие «вектор ошибок»
Для удобства представления
ошибок, возникающих в комбинациях двоичного корректирующего кода, используется
понятие вектор ошибок. Под вектором ошибок понимается комбинация длины N символов с 2-мя возможными значениями 0 и 1, в которой
единицы занимают позиции в комбинациях кода, на которых стоят ошибочные символы.
Все остальные позиции заняты нулями. Вес вектора ошибок ei W(ei)
= ν, где ν – кратность ошибок.
Искаженная комбинация кода V* при использовании понятия вектор ошибок
может быть представлена как результат суммы по модулю два одноименных символов
неискаженной комбинации V и вектора ошибок ei , то есть
![]() (7)
(7)
Поскольку в комбинации кода может
быть искажено любое число символов в пределах n и эти
символы могут занимать любые позиции в комбинации, то число ненулевых векторов
ошибок:
![]() (8)
(8)
где единица соответствует
нулевому вектору ошибок.
Если известен вектор ошибок, то
процедура исправления ошибок в принятой комбинации состоит в сложении по модулю
два принятой комбинации с вектором ошибок.
Действительно, ![]()
21. Методы определения разрядности блокового корректирующего
кода и нахождение его комбинаций.
Говоря ранее о разбиении
множества запрещенных комбинаций U на подмножества Ai, мы предполагали, что комбинации кода известны,
однако практике это не так.
Известно число комбинаций,
которые должны входить в код, и подлежащие исправлению ошибки в этих
комбинациях исходя из статистики появления ошибок. При этом задача заключается
в том, чтобы найти код, который бы содержал n комбинаций и позволял исправлять известные ошибки.
Корректирующие коды «на пальцах» +54
Алгоритмы, Математика
Рекомендация: подборка платных и бесплатных курсов Java — https://katalog-kursov.ru/
Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Как нетрудно догадаться, ко всему этому причастны корректирующие коды. Собственно, ECC так и расшифровывается — «error-correcting code», то есть «код, исправляющий ошибки». А CRC — это один из алгоритмов, обнаруживающих ошибки в данных. Исправить он их не может, но часто это и не требуется.
Давайте же разберёмся, что это такое.
Для понимания статьи не нужны никакие специальные знания. Достаточно лишь понимать, что такое вектор и матрица, как они перемножаются и как с их помощью записать систему линейных уравнений.
Внимание! Много текста и мало картинок. Я постарался всё объяснить, но без карандаша и бумаги текст может показаться немного запутанным.
Каналы с ошибкой
Разберёмся сперва, откуда вообще берутся ошибки, которые мы собираемся исправлять. Перед нами стоит следующая задача. Нужно передать несколько блоков данных, каждый из которых кодируется цепочкой двоичных цифр. Получившаяся последовательность нулей и единиц передаётся через канал связи. Но так сложилось, что реальные каналы связи часто подвержены ошибкам. Вообще говоря, ошибки могут быть разных видов — может появиться лишняя цифра или какая-то пропасть. Но мы будем рассматривать только ситуации, когда в канале возможны лишь замены нуля на единицу и наоборот. Причём опять же для простоты будем считать такие замены равновероятными.
Ошибка — это маловероятное событие (а иначе зачем нам такой канал вообще, где одни ошибки?), а значит, вероятность двух ошибок меньше, а трёх уже совсем мала. Мы можем выбрать для себя некоторую приемлемую величину вероятности, очертив границу «это уж точно невозможно». Это позволит нам сказать, что в канале возможно не более, чем ошибок. Это будет характеристикой канала связи.
Для простоты введём следующие обозначения. Пусть данные, которые мы хотим передавать, — это двоичные последовательности фиксированной длины. Чтобы не запутаться в нулях и единицах, будем иногда обозначать их заглавными латинскими буквами (, , , …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
Кодирование и декодирование будем обозначать прямой стрелкой (), а передачу по каналу связи — волнистой стрелкой (). Ошибки при передаче будем подчёркивать.
Например, пусть мы хотим передавать только сообщения и . В простейшем случае их можно закодировать нулём и единицей (сюрприз!):
Передача по каналу, в котором возникла ошибка будет записана так:
Цепочки нулей и единиц, которыми мы кодируем буквы, будем называть кодовыми словами. В данном простом случае кодовые слова — это и .
Код с утроением
Давайте попробуем построить какой-то корректирующий код. Что мы обычно делаем, когда кто-то нас не расслышал? Повторяем дважды:
Правда, это нам не очень поможет. В самом деле, рассмотрим канал с одной возможной ошибкой:
Какие выводы мы можем сделать, когда получили ? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
То есть, получившийся код обнаруживает, но не исправляет ошибки. Ну, тоже неплохо, в общем-то. Но мы пойдём дальше и будем теперь утраивать цифры.
Проверим в деле:
Получили . Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
Если в канале связи возможна максимум одна ошибка, то первое предположение о двух ошибках становится невозможным и остаётся только один вариант — передавалась буква .
Про такой код говорят, что он исправляет одну ошибку. Две он тоже обнаружит, но исправит уже неверно.
Это, конечно, самый простой код. Кодировать легко, да и декодировать тоже. Ноликов больше — значит передавался ноль, единичек — значит единица.
Если немного подумать, то можно предложить код исправляющий две ошибки. Это будет код, в котором мы повторяем одиночный бит 5 раз.
Расстояния между кодами
Рассмотрим поподробнее код с утроением. Итак, мы получили работающий код, который исправляет одиночную ошибку. Но за всё хорошее надо платить: он кодирует один бит тремя. Не очень-то и эффективно.
И вообще, почему этот код работает? Почему нужно именно утраивать для устранения одной ошибки? Наверняка это всё неспроста.
Давайте подумаем, как этот код работает. Интуитивно всё понятно. Нолики и единички — это две непохожие последовательности. Так как они достаточно длинные, то одиночная ошибка не сильно портит их вид.
Пусть мы передавали , а получили . Видно, что эта цепочка больше похожа на исходные , чем на . А так как других кодовых слов у нас нет, то и выбор очевиден.
Но что значит «больше похоже»? А всё просто! Чем больше символов у двух цепочек совпадает, тем больше их схожесть. Если почти все символы отличаются, то цепочки «далеки» друг от друга.
Можно ввести некоторую величину , равную количеству различающихся цифр в соответствующих разрядах цепочек и . Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
Например, , так как все цифры в соответствующих позициях равны, а вот .
Расстояние Хэмминга называют расстоянием неспроста. Ведь в самом деле, что такое расстояние? Это какая-то характеристика, указывающая на близость двух точек, и для которой верны утверждения:
- Расстояние между точками неотрицательно и равно нулю только, если точки совпадают.
- Расстояние в обе стороны одинаково.
- Путь через третью точку не короче, чем прямой путь.
Достаточно разумные требования.
Математически это можно записать так (нам это не пригодится, просто ради интереса посмотрим):
- .
Предлагаю читателю самому убедиться, что для расстояния Хэмминга эти свойства выполняются.
Окрестности
Таким образом, разные цепочки мы считаем точками в каком-то воображаемом пространстве, и теперь мы умеем находить расстояния между ними. Правда, если попытаться сколько нибудь длинные цепочки расставить на листе бумаги так, чтобы расстояния Хэмминга совпадали с расстояниями на плоскости, мы можем потерпеть неудачу. Но не нужно переживать. Всё же это особое пространство со своими законами. А слова вроде «расстояния» лишь помогают нам рассуждать.
Пойдём дальше. Раз мы заговорили о расстоянии, то можно ввести такое понятие как окрестность. Как известно, окрестность какой-то точки — это шар определённого радиуса с центром в ней. Шар? Какие ещё шары! Мы же о кодах говорим.
Но всё просто. Ведь что такое шар? Это множество всех точек, которые находятся от данной не дальше, чем некоторое расстояние, называемое радиусом. Точки у нас есть, расстояние у нас есть, теперь есть и шары.
Так, скажем, окрестность кодового слова радиуса 1 — это все коды, находящиеся на расстоянии не больше, чем 1 от него, то есть отличающиеся не больше, чем в одном разряде. То есть это коды:
Да, вот так странно выглядят шары в пространстве кодов.
А теперь посмотрите. Это же все возможные коды, которые мы получим в канале в одной ошибкой, если отправим ! Это следует прямо из определения окрестности. Ведь каждая ошибка заставляет цепочку измениться только в одном разряде, а значит удаляет её на расстояние 1 от исходного сообщения.
Аналогично, если в канале возможны две ошибки, то отправив некоторое сообщение , мы получим один из кодов, который принадлежит окрестности радиусом 2.
Тогда всю нашу систему декодирования можно построить так. Мы получаем какую-то цепочку нулей и единиц (точку в нашей новой терминологии) и смотрим, в окрестность какого кодового слова она попадает.
Сколько ошибок может исправить код?
Чтобы код мог исправлять больше ошибок, окрестности должны быть как можно шире. С другой стороны, они не должны пересекаться. Иначе если точка попадёт в область пересечения, непонятно будет, к какой окрестности её отнести.
В коде с удвоением между кодовыми словами и расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
Именно это мы и получали. Мы видели, что есть ошибка, но не могли её исправить.
Что интересно, точек касания в нашем странном пространстве у шаров две — это коды и . Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
В случае кода с утроением, между шарами будет зазор.
Минимальный зазор между шарами равен 1, так как у нас расстояния всегда целые (ну не могут же две цепочки отличаться в полутора разрядах).
В общем случае получаем следующее.
Этот очевидный результат на самом деле очень важен. Он означает, что код с минимальным кодовым расстоянием будет успешно работать в канале с ошибками, если выполняется соотношение
Полученное равенство позволяет легко определить, сколько ошибок будет исправлять тот или иной код. А сколько код ошибок может обнаружить? Рассуждения такие же. Код обнаруживает ошибок, если в результате не получится другое кодовое слово. То есть, кодовые слова не должны находиться в окрестностях радиуса других кодовых слов. Математически это записывается так:
Рассмотрим пример. Пусть мы кодируем 4 буквы следующим образом.
Чтобы найти минимальное расстояние между различными кодовыми словами, построим таблицу попарных расстояний.
| A | B | C | D | |
|---|---|---|---|---|
| A | — | 3 | 3 | 4 |
| B | 3 | — | 4 | 3 |
| C | 3 | 4 | — | 3 |
| D | 4 | 3 | 3 | — |
Минимальное расстояние , а значит , откуда получаем, что такой код может исправить до ошибок. Обнаруживает же он две ошибки.
Рассмотрим пример:
Чтобы декодировать полученное сообщение, посмотрим, к какому символу оно ближе всего.
Минимальное расстояние получилось для символа , значит вероятнее всего передавался именно он:
Итак, этот код исправляет одну ошибку, как и код с утроением. Но он более эффективен, так как в отличие от кода с утроением здесь кодируется уже 4 символа.
Таким образом, основная проблема при построении такого рода кодов — так расположить кодовые слова, чтобы они были как можно дальше друг от друга, и их было побольше.
Для декодирования можно было бы использовать таблицу, в которой указывались бы все возможные принимаемые сообщения, и кодовые слова, которым они соответствуют. Но такая таблица получилась бы очень большой. Даже для нашего маленького кода, который выдаёт 5 двоичных цифр, получилось бы варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
Попробуем придумать способ коррекции сообщения без таблиц. Мы всегда сможем найти полезное применение освободившейся памяти.
Интерлюдия: поле GF(2)
Для изложения дальнейшего материала нам потребуются матрицы. А при умножении матриц, как известно мы складываем и перемножаем числа. И тут есть проблема. Если с умножением всё более-менее хорошо, то как быть со сложением? Из-за того, что мы работаем только с одиночными двоичными цифрами, непонятно, как сложить 1 и 1, чтобы снова получилась одна двоичная цифра. Значит вместо классического сложения нужно использовать какое-то другое.
Введём операцию сложения как сложение по модулю 2 (хорошо известный программистам XOR):
Умножение будем выполнять как обычно. Эти операции на самом деле введены не абы как, а чтобы получилась система, которая в математике называется полем. Поле — это просто множество (в нашем случае из 0 и 1), на котором так определены сложение и умножение, чтобы основные алгебраические законы сохранялись. Например, чтобы основные идеи, касающиеся матриц и систем уравнений по-прежнему были верны. А вычитание и деление мы можем ввести как обратные операции.
Множество из двух элементов с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
У сложения есть несколько очень полезных свойств, которыми мы будем пользоваться в дальнейшем.
Это свойство прямо следует из определения.
А в этом можно убедиться, прибавив к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
Проверяем корректность
Вернёмся к коду с утроением.
Для начала просто решим задачу проверки, были ли вообще ошибки при передаче. Как видно, из самого кода, принятое сообщение будет кодовым словом только тогда, когда все три цифры равны между собой.
Пусть мы приняли вектор-строку из трёх цифр. (Стрелочки над векторами рисовать не будем, так как у нас почти всё — это вектора или матрицы.)
Математически равенство всех трёх цифр можно записать как систему:
Или, если воспользоваться свойствами сложения в GF(2), получаем
Или
В матричном виде эта система будет иметь вид
где
Транспонирование здесь нужно потому, что — это вектор-строка, а не вектор-столбец. Иначе мы не могли бы умножать его справа на матрицу.
Будем называть матрицу проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
Умножение на матрицу — это гораздо более эффективно, чем поиск в таблице, но у нас на самом деле есть ещё одна таблица — это таблица кодирования. Попробуем от неё избавиться.
Кодирование
Итак, у нас есть система для проверки
Её решения — это кодовые слова. Собственно, мы систему и строили на основе кодовых слов. Попробуем теперь решить обратную задачу. По системе (или, что то же самое, по матрице ) найдём кодовые слова.
Правда, для нашей системы мы уже знаем ответ, поэтому, чтобы было интересно, возьмём другую матрицу:
Соответствующая система имеет вид:
Чтобы найти кодовые слова соответствующего кода нужно её решить.
В силу линейности сумма двух решений системы тоже будет решением системы. Это легко доказать. Если и — решения системы, то для их суммы верно
что означает, что она тоже — решение.
Поэтому если мы найдём все линейно независимые решения, то с их помощью можно получить вообще все решения системы. Для этого просто нужно найти их всевозможные суммы.
Выразим сперва все зависимые слагаемые. Их столько же, сколько и уравнений. Выражать надо так, чтобы справа были только независимые. Проще всего выразить .
Если бы нам не так повезло с системой, то нужно было бы складывая уравнения между собой получить такую систему, чтобы какие-то три переменные встречались по одному разу. Ну, или воспользоваться методом Гаусса. Для GF(2) он тоже работает.
Итак, получаем:
Чтобы получить все линейно независимые решения, приравниваем каждую из зависимых переменных к единице по очереди.
Всевозможные суммы этих независимых решений (а именно они и будут кодовыми векторами) можно получить так:
где равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно сочетания.
Но посмотрите! Формула, которую мы только что получили — это же снова умножение матрицы на вектор.
Строчки здесь — линейно независимые решения, которые мы получили. Матрица называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:
Найдём кодовые слова для этого кода. (Не забываем, что длина исходных сообщений должна быть равна 2 — это количество найденных решений.)
Итак, у нас есть готовый код, обнаруживающий ошибки. Проверим его в деле. Пусть мы хотим отправить 01 и у нас произошла ошибка при передаче. Обнаружит ли её код?
А раз в результате не нулевой вектор, значит код заподозрил неладное. Провести его не удалось. Ура, код работает!
Для кода с утроением, кстати, порождающая матрица выглядит очень просто:
Подобные коды, которые можно порождать и проверять матрицей называются линейными (бывают и нелинейные), и они очень широко применяются на практике. Реализовать их довольно легко, так как тут требуется только умножение на константную матрицу.
Ошибка по синдрому
Ну хорошо, мы построили код обнаруживающий ошибки. Но мы же хотим их исправлять!
Для начала введём такое понятие, как вектор ошибки. Это вектор, на который отличается принятое сообщение от кодового слова. Пусть мы получили сообщение , а было отправлено кодовое слово . Тогда вектор ошибки по определению
Но в странном мире GF(2), где сложение и вычитание одинаковы, будут верны и соотношения:
В силу особенностей сложения, как читатель сам может легко убедиться, в векторе ошибки на позициях, где произошла ошибка будет единица, а на остальных ноль.
Как мы уже говорили раньше, если мы получили сообщение с ошибкой, то . Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
Назовём результат умножения на проверочную матрицу синдромом:
И заметим следующее
Это означает, что для ошибки синдром будет таким же, как и для полученного сообщения.
Разложим все возможные сообщения, которые мы можем получить из канала связи, по кучкам в зависимости от синдрома. Тогда из последнего соотношения следует, что в каждой кучке будут вектора с одной и той же ошибкой. Причём вектор этой ошибки тоже будет в кучке. Вот только как его узнать?
А очень просто! Помните, мы говорили, что у нескольких ошибок вероятность ниже, чем у одной ошибки? Руководствуясь этим соображением, наиболее правдоподобным будет считать вектором ошибки тот вектор, у которого меньше всего единиц. Будем называть его лидером.
Давайте посмотрим, какие синдромы дают всевозможные 5-элементные векторы. Сразу сгруппируем их и подчеркнём лидеров — векторы с наименьшим числом единиц.
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
В принципе, для корректирования ошибки достаточно было бы хранить таблицу соответствия синдрома лидеру.
Обратите внимание, что в некоторых строчках два лидера. Это значит для для данного синдрома два паттерна ошибки равновероятны. Иными словами, код обнаружил две ошибки, но исправить их не может.
Лидеры для всех возможных одиночных ошибок находятся в отдельных строках, а значит код может исправить любую одиночную ошибку. Ну, что же… Попробуем в этом убедиться.
Вектор ошибки равен , а значит ошибка в третьем разряде. Как мы и загадали.
Ура, всё работает!
Что же дальше?
Чтобы попрактиковаться, попробуйте повторить рассуждения для разных проверочных матриц. Например, для кода с утроением.
Логическим продолжением изложенного был бы рассказ о циклических кодах — чрезвычайно интересном подклассе линейных кодов, обладающим замечательными свойствами. Но тогда, боюсь, статья уж очень бы разрослась.
Если вас заинтересовали подробности, то можете почитать замечательную книжку Аршинова и Садовского «Коды и математика». Там изложено гораздо больше, чем представлено в этой статье. Если интересует математика кодирования — то поищите «Теория и практика кодов, контролирующих ошибки» Блейхута. А вообще, материалов по этой теме довольно много.
Надеюсь, когда снова будет свободное время, напишу продолжение, в котором расскажу про циклические коды и покажу пример программы для кодирования и декодирования. Если, конечно, почтенной публике это интересно.
Если комбинации кода известны и
он используется для исправления ошибок, то способ разбиения множества U на подмножества Ai
определяется статистикой ошибок, возникающих в его комбинациях. Обычно это
разбиение выполняется так, чтобы минимизировать среднюю вероятность появления
ложной комбинации на входе декодера.
В дальнейшем будем рассматривать
только двоичные коды, как получившие наибольшее распространение.
20. Понятие «вектор ошибок»
Для удобства представления
ошибок, возникающих в комбинациях двоичного корректирующего кода, используется
понятие вектор ошибок. Под вектором ошибок понимается комбинация длины N символов с 2-мя возможными значениями 0 и 1, в которой
единицы занимают позиции в комбинациях кода, на которых стоят ошибочные символы.
Все остальные позиции заняты нулями. Вес вектора ошибок ei W(ei)
= ν, где ν – кратность ошибок.
Искаженная комбинация кода V* при использовании понятия вектор ошибок
может быть представлена как результат суммы по модулю два одноименных символов
неискаженной комбинации V и вектора ошибок ei , то есть
![]() (7)
(7)
Поскольку в комбинации кода может
быть искажено любое число символов в пределах n и эти
символы могут занимать любые позиции в комбинации, то число ненулевых векторов
ошибок:
![]() (8)
(8)
где единица соответствует
нулевому вектору ошибок.
Если известен вектор ошибок, то
процедура исправления ошибок в принятой комбинации состоит в сложении по модулю
два принятой комбинации с вектором ошибок.
Действительно, ![]()
21. Методы определения разрядности блокового корректирующего
кода и нахождение его комбинаций.
Говоря ранее о разбиении
множества запрещенных комбинаций U на подмножества Ai, мы предполагали, что комбинации кода известны,
однако практике это не так.
Известно число комбинаций,
которые должны входить в код, и подлежащие исправлению ошибки в этих
комбинациях исходя из статистики появления ошибок. При этом задача заключается
в том, чтобы найти код, который бы содержал n комбинаций и позволял исправлять известные ошибки.