
—
прямой метод
—
косвенный метод
+
обратный метод
В
каких пределах может колебаться значение
коэффициента корреляции?
—
от 0 до 1
—
от 0 до 2
—
от 0,5 до 1
+
от -1 до +1
—
от -10% до +10%
От
чего зависит объем выборочной совокупности?
—
от принятой вероятности безошибочного
прогноза и степени однородности
изучаемого явления
—
от достаточного количества единиц в
генеральной совокупности
—
от принятой вероятности безошибочного
прогноза и величины предельной ошибки
+
от величины предельной ошибки и степени
однородности изучаемого явления
Укажите
критерии, характеризующие степень
разнообразия варьирующего признака:
—
коэффициент вариации, мода, медиана
—
коэффициент вариации, среднее
квадратическое отклонение, центили
+
лимит, амплитуда, среднее квадратическое
отклонение, коэффициент вариации
—
лимиты, центили, амплитуда, коэффициент
вариации, среднее квадратическое
отклонение
При
сравнении интенсивных показателей,
полученных на однородных по своему
составу совокупностях, необходимо
применять:
—
оценку показателей соотношения
—
определение относительной величины
—
стандартизацию
+
оценку достоверности различия показателей
При
увеличении числа наблюдений величина
средней ошибки:
—
увеличивается
—
не изменяется
+
уменьшается
Величина
средней ошибки прямо пропорциональна:
—
числу наблюдений
+
разнообразию признака
Разность
между двумя относительными показателями
считается достоверной с вероятностью
95,5% при значении критерия Стьюдента:
+
2 и более
—
менее 2
В
каких границах возможны случайные
колебания средней величины с вероятностью
95,5%?
—
M +/- m
+
M +/- 2m
—
M +/- 3m
Какой
степени вероятности соответствует
доверительный интервал P+/-m?
+
вероятности 68,3%
—
вероятности 95,5%
—
вероятности 99,7%
Какой
степени вероятности соответствует
доверительный интервал М+/-3m?
—
вероятности 68,3%
—
вероятности 95,5%
+
вероятности 99,7%
Чем
меньше разнообразие признака, тем
величина средней ошибки:
+
меньше
—
больше
Чтобы
уменьшить ошибку выборки, число наблюдений
нужно:
+
увеличить
—
уменьшить
Чем
меньше число наблюдений, тем величина
средней ошибки:
—
меньше
+
больше
Не
считается достоверной для научных
исследований:
+
вероятность 68,3%
—
вероятность 95,5%
—
вероятность 99,7%
Укажите
первый этап при вычислении стандартизованных
показателей прямым методом:
—
выбор стандарта
—
расчет <ожидаемых чисел>
+
расчет погрупповых интенсивных
показателей
—
распределение в стандарте
—
получение общего интенсивного
стандартизованного показателя
Укажите
второй этап при вычислении стандартизованных
показателей прямым методом:
+
выбор стандарта
—
расчет <ожидаемых чисел>
—
расчет погрупповых интенсивных
показателей
—
распределение в стандарте
—
получение общего интенсивного
стандартизованного показателя
Укажите
третий этап при вычислении стандартизованных
показателей прямым методом:
—
выбор стандарта
—
расчет <ожидаемых чисел>
—
расчет погрупповых интенсивных
показателей
+
распределение в стандарте
—
получение общего интенсивного
стандартизованного показателя
Укажите
четвертого этап при вычислении
стандартизованных показателей прямым
методом:
—
выбор стандарта
+
расчет <ожидаемых чисел>
—
расчет погрупповых интенсивных
показателей
—
распределение в стандарте
—
получение общего интенсивного
стандартизованного показателя
Укажите
пятого этап при вычислении стандартизованных
показателей прямым методом:
—
выбор стандарта
—
расчет <ожидаемых чисел>
—
расчет погрупповых интенсивных
показателей
—
распределение в стандарте
+
получение стандартизованного показателя
Коэффициент
корреляции между показателем заболеваемости
населения и показателем госпитализации
равняется +0,88:
—
зависимость между рассматриваемыми
явлениями отсутствует, так как коэффициент
корреляции имеет положительный знак
—
зависимость между рассматриваемыми
явлениями сильная и обратная
+
зависимость между рассматриваемыми
явлениями прямая и сильная
—
зависимость между рассматриваемыми
явлениями средняя и прямая
Случайным
событием называют
—
событие, которое может произойти при
любых заданных условиях
+
событие, которое при заданных условиях
может произойти или не произойти
—
событие, которое при заданных условиях
может произойти
—
событие, которое может произойти при
не заданных условиях
Вероятность
— это:
—
явление, исход которого можно предсказать
+
величина, определяющая перспективу
того или иного исхода в предстоящем
испытании
—
величина среднего квадратичного
отклонения параметров вариационного
ряда
Непараметрические
критерии различия могут быть использованы
при сравнении совокупностей:
+
по количественным признакам
+
по качественным признакам
Для
использования непараметрических
критериев нужно ли знать характер
распределения?
—
да
+
нет
Непараметрические
показатели связи:
—
зависят от закона распределения
+
не зависят от закона распределения
Применение
непараметрических методов по сравнению
с параметрическими имеет:
+
меньше ограничений в отношении исходных
данных
—
больше ограничений в отношении исходных
данных
Определение
социальной гигиены как науки:
+
социальная гигиена — наука о закономерностях
общественного здоровья населения и
здравоохранения
—
социальная гигиена — наука о социальных
проблемах практической медицины
—
социальная гигиена — система мероприятий
по охране здоровья населения
—
социальная гигиена — наука о социологии
здоровья
Последипломное
обучение медицинских кадров осуществляется
в следующих учебных заведениях:
+
институтах усовершенствования врачей
+
академиях последипломного образование
+
факультетах усовершенствования врачей
при медицинских вузах
—
на базе областных медицинских учреждений
Основные
методы социально-гигиенических
исследований:
+
исторический
+
статистический
+
экспериментальный
+
экономический
—
дифференцированный
Оптимальным
путем развития здравоохранения на
современном этапе является:
—
государственная система
+
бюджетно-страховая медицина
—
частная практика
Медицинская
этика — это:
+
специфические проявление общей этики
в деятельности врача
+
наука о гуманизме, долге, чести, совести
медицинских работников
+
способность врача к нравственной
ориентации в ситуациях
—
проявление гражданского долга в
профессиональной деятельности медицинских
работников
Биомедицинская
этика и деонтология — это:
—
проявление гражданского долга в
профессиональной деятельности медицинских
работников
—
наука о гуманизме, долге и чести
медицинских работников
—
наука о совести, достоинстве и
нравственности медицинских работников
+
свод моральных правил и норм поведения
медицинских работников
Назовите
три главные организации из которых
состоит ВОЗ
+
Всемирная ассамблея здравоохранения
+
Исполнительный комитет
+
Секретариат
—
Совет по международному сотрудничеству
Назовите
основной документ, которым регламентируется
деятельность ВОЗ
+
Устав ВОЗ
—
Положение о деятельности ВОЗ
—
Международный договор о сотрудничестве
стран, входящих в состав ВОЗ
В
каком документе ВОЗ дано определение
понятия <здоровье>?
+
в Уставе ВОЗ
—
в Положении о деятельности ВОЗ
—
в Международном договоре о сотрудничестве
стран, входящих в состав ВОЗ
Имеет
ли право ВОЗ формировать и по мере
надобности пересматривать Международную
статистическую классификацию болезней,
травм и причин смерти?
+
имеет право самостоятельно решать
вопрос
—
не имеет права
—
имеет право с согласия других международных
организаций
Когда
впервые на международном уровне был
рассмотрен вопрос о первичной
медико-санитарной помощи?
+
в 1978 г. в г.Алма-Ата на международной
конференции ВОЗ (ЮНИСЕФ)
—
на заседании Панамериканского санитарного
бюро (ПАСБ, 1902 г.)
—
на заседании Международного бюро
общественной гигиены (МБОГ, 1907 г.)
Укажите,
является ли сферой компетенции ВОЗ
рассмотрение следующих вопросов:
+
улучшение питания, жилищных и санитарных
условий, условий труда и отдыха, поощрение
работы в области психогигиены
+
пересмотр МКБ
+
установление международных стандартов
для пищевых, биологических, фармацевтических
препаратов
—
контроль за деятельностью национальных
органов управления здравоохранением
Как
часто созываются очередные сессии
Ассамблеи ВОЗ?
—
ежегодно
—
1 раз в 3 года
+
1 раз в 5 лет
Общественное
здоровье и здравоохранение изучает:
+
общественное здоровье
—
индивидуальное здоровье
Структура
предмета общественного здоровья и
здравоохранения:
+
социальная гигиена
+
организация здравоохранения
+
медицинская информатика
+
управление здравоохранением
+
история медицины
—
медицинская психология
Имеется
ли различие между понятиями <система
охраны здоровья населения> и <система
здравоохранения>?
+
да
—
нет
Система
охраны здоровья населения — это комплекс
мероприятий:
+
социально-экономических
+
медико-биологических
+
экологических
—
по организации медицинских организаций
МЗ РФ
Система
здравоохранения — это:
—
система мероприятий по поддержанию
общественного здоровья
+
система медицинских организаций МЗ РФ
Является
ли производственная среда частью
окружающей среды?
+
да
—
нет
Является
ли социальная среда частью окружающей
среды?
+
да
—
нет
Основные
принципы здравоохранения:
+
ответственность государства за соблюдение
прав граждан в области охраны здоровья
+
обеспечение прав человека в области
охраны здоровья
+
доступность медицинской помощи
+
социальная защищенность в случае утраты
трудоспособности
+
приоритет профилактических мероприятий
над лечебными
+
приоритет пациента в оказании медицинской
помощи
+
приоритет оказания медицинской помощи
детям
+
сохранение врачебной тайны
+
запрет отказа в оказании медицинской
помощи
—
бесплатность
Социально-гигиенический
мониторинг проводится на базе:
—
медицинские организации
—
научно-исследовательских институтов
+
Центра гигиены и эпидемиологии
—
министерства здравоохранения
—
медицинских вузов
Окружающая
среда включает в себя:
+
природную среду
+
производственную среду
+
социальную среду
—
образ жизни
Когда
была открыта в России первая кафедра
социальной гигиены?
—
в 1917 году
—
в 1941 году
+
в 1922 году
—
в 1960 году
Основными
показателями индивидуального здоровья
являются:
+
показатели заболеваемости
+
показатели инвалидности
+
показатели физического развития
+
демографические показатели
+
группы здоровья
—
показатели обеспеченности койками
Основными
показателями общественного здоровья
являются:
+
затраты на здравоохранение от ВВП
+
степень иммунизации и вакцинации
населения
+
степень обследования беременных женщин
+
питание детей и подростков
—
группы здоровья
Основным
методом изучения образа жизни является:
—
наблюдение
—
тестирование
—
анкетирование
—
эксперимент
+
опрос-интервью
Теоретическими
основами социальной гигиены являются:
+
диалектический материализм
+
политэкономия
—
законодательные акты по здравоохранению
—
конституция РФ
По
определению здоровье человека
характеризуется состоянием:
—
физического благополучия
—
физического и социального благополучия
—
физического и социального благополучия
при полной адаптации к условиям внешней
среды
+
физического, психического и социального
благополучия при полной адаптации к
условиям внешней среды
Среди
факторов, определяющих здоровье
населения, наибольшее влияние оказывает:
—
организация медицинской помощи
—
природно-климатическая среда
—
биологические факторы
+
образ жизни
Медицинскими
характеристиками здоровья населения
являются:
+
заболеваемость
+
инвалидность
+
физическое развитие
+
медико-демографические данные
—
образ жизни
Факторы
окружающей среды:
+
социально-экономические
+
природно-климатические
+
биологические
—
политические
Статистическими
измерителями индивидуального здоровья
населения являются:
+
демографические показатели
+
заболеваемость
+
инвалидность
+
физическое развитие
—
посещаемость ЛПУ
Основными
источниками информации о здоровье
населения являются:
+
официальной информации о смерти населения
—
данных страховых компаний
+
эпидемиологической информации
+
данных мониторинга окружающей среды и
здоровья
+
регистров заболеваний, несчастных
случаев и травм
На
сохранение и укрепление здоровья
населения влияют следующие факторы:
+
уровень культуры населения
+
экологические факторы среды
+
качество и доступность медицинской
помощи
+
безопасные условия труда
+
сбалансированность питания
—
наследственность
Под
физическим развитием понимают:
+
совокупность всех антропологических
признаков и результаты функциональных
измерений
+
соматические признаки и показатели
+
данные о телосложении
—
заболевания
Основные
пути получения информации о заболеваемости:
+
по причинам смерти
+
по обращаемости
—
по данным переписи населения
+
по данным медицинских осмотров
+
по данным опроса
Первичная
заболеваемость — это:
+
заболевания, впервые выявленные в этом
году и нигде ранее не учтенные
—
заболеваемость, регистрируемая врачом
и записанная им в медицинской документации
—
совокупность всех имеющихся среди
населения заболеваний, впервые выявленных
в данном году или известных ранее, по
поводу которых больные вновь обратились
в данном году
Сущность
термина <болезненность>?
—
показатель заболеваемости по данным
обращаемости
—
заболеваемость, регистрируемая врачом
и записанная им в медицинской документации
+
совокупность всех имеющихся среди
населения заболеваний, впервые выявленных
в данном году или известных ранее, по
поводу которых больные вновь обратились
в данном году
Под
статистическим термином <обращаемость>
понимается:
+
число больных, впервые обратившихся за
медицинской помощью по поводу заболевания
—
соотношение числа всех первичных
посещений по поводу болезни к общему
числу обслуживаемого населения
—
абсолютное число всех первичных и
повторных посещений больными медицинского
учреждения
Заболевание,
которым больной страдает в течение ряда
лет и ежегодно обращается к врачу
поликлиники войдет в статистику
—
первичной заболеваемости
+
общей заболеваемости
—
патологической пораженности
При
анализе первичной заболеваемости
населения учитываются
+
статистические талоны со знаком (+)
—
все статистические талоны
—
статистические талоны со знаком (-)
При
анализе общей заболеваемости населения
учитываются
—
статистические талоны только со знаком
(+)
+
все статистические талоны
—
статистические талоны без знака (+)
Укажите,
как регистрируется первичная заболеваемость
населения
+
статистический талон со знаком (+)
—
статистический талон со знаком (-)
Укажите
основные виды заболеваний:
+
эпидемическая заболеваемость
+
важнейшая неэпидемическая заболеваемость
+
госпитализированная заболеваемость
+
заболеваемость с ВУТ
+
по данным обращаемости
—
диспансерная заболеваемость
В
течение какого времени и в какое лечебное
учреждение направляется извещение о
важнейшем неэпидемическом заболевании:
—
в диспансер соответствующего профиля
в течение 1 месяца
—
в Роспотребнадзор в течение 5 часов
+
в диспансер соответствующего профиля
в течение 1 недели
—
в диспансер соответствующего профиля
в течение 2 недель
Какие
объективные факторы влияют на уровень
заболеваемости по данным обращаемости?
+
объем и доступность медицинской помощи
+
санитарно-культурный уровень населения
—
материальное состояние пациента
Укажите
основные методы изучения заболеваемости:
+
обращаемость
+
профилактические осмотры
+
регистрация причин смерти
+
опрос
—
перепись
У
больного язвенная болезнь желудка.
Болеет 10 лет, каждый год обращается к
врачу. Сколько статистических талонов
на него будет заполнено и сколько из
них со знаком (+)?
+
10 статистических талонов, первый их них
со знаком (+)
—
10 статистических талонов, каждый их них
со знаком (+)
—
1 статистический талон со знаком (+)
У
женщины родился живой ребенок, который
умер через 35 минут. Какие документы на
него требуется заполнить?
+
медицинское свидетельство о рождении
+
медицинское свидетельство о перинатальной
смерти
—
медицинское свидетельство о смерти
Укажите
единый нормативный документ для
статистических разработок госпитализированной
заболеваемости:
—
международная классификация болезней,
травм и причин смерти
+
статистическая карта выбывшего из
стационара, ф. N066/у
—
листок учета движения больных и коечного
фонда стационара, ф. N007/у
—
сводная ведомость учета движения больных
и коечного фонда по стационару, отделению
или профилю коек, ф. N016/у
При
изучении эпидемической заболеваемости
применяется
—
журнал регистрации инфекционных
заболеваний в ЛПУ
+
экстренное извещение об инфекционном
заболевании, пищевом отравлении,
профессиональном заболевании
—
отчет ежемесячный и годовой о числе
инфекционных заболеваний
Впервые
в жизни установленный диагноз относится
к понятию:
—
первичное посещение
+
первичная заболеваемость
—
болезненность
—
обращаемость
—
острые заболевания
При
выявлении у больного инфекционного
заболевания врач заполняет:
—
медицинскую карту больного
+
экстренное извещение об инфекционном
заболевании, пищевом, остром профессиональном
отравлении
—
извещение о важнейшем заболевании
—
листок нетрудоспособности
Документ
учета и регистрации выявленного
туберкулеза:
—
экстренное извещение об инфекционном
заболевании, пищевом, остром профессиональном
отравлении
—
медицинскую карту больного
+
извещение о больном с впервые в жизни
установленным диагнозом туберкулеза
—
статистический талон для регистрации
уточненного (заключительного) диагноза
При
выявлении онкологического заболевания
или подозрении на него врач заполняет:
—
экстренное извещение об инфекционном
заболевании, пищевом, остром профессиональном
отравлении
—
извещение о больном с впервые в жизни
установленным диагнозом психического
заболевания
+
извещение о больном с впервые в жизни
установленным диагнозом рака или другого
злокачественного новообразования
—
статистический талон для регистрации
уточненного (заключительного) диагноза
Уровень
заболеваемости по обращаемости среди
женщин в сравнении с мужчинами:
—
ниже
—
одинаковый
+
выше
Уровень
заболеваемости по данным медицинских
осмотров среди женщин в сравнении с
мужчинами:
—
ниже
—
одинаковый
+
выше
Уровень
заболеваемости детей в сравнении с
взрослыми:
—
ниже
—
одинаковый
+
выше
Наиболее
высокий уровень заболеваемости детей
отмечается в возрасте:
—
от 0 до 3 лет
+
от 1 до 3 лет
—
от 3 до 7 лет
—
от 7 до 10 лет
—
от 10 до 14 лет
Первое
место в структуре заболеваемости детей
в возрасте до 1 года занимают болезни:
—
инфекционные и паразитарные
—
нервной системы и органов чувств
+
органов дыхания
—
кожи и подкожной клетчатки
—
органов пищеварения
Уровень
хронической заболеваемости среди женщин
в сравнении с мужчинами:
—
ниже
—
одинаковый
+
выше
Первое
место в структуре заболеваемости женщин
занимают болезни:
—
системы кровообращения
—
женской половой сферы
+
органов дыхания
—
нервной системы
—
костно-мышечной системы
Для
оценки заболеваемости населения
используются такие критерии, как:
+
уровень заболеваемости
+
структура заболеваемости
+
кратность заболеваний
—
длительность инкубационного периода
Количественным
показателем заболеваемости является:
—
средняя продолжительность лечения
—
средняя длительность пребывания больного
в стационаре
+
уровень заболеваемости
—
структура заболеваемости
—
все перечисленное
Качественным
показателем заболеваемости является:
—
средняя продолжительность лечения
—
кратность заболеваний в год
—
уровень заболеваемости
+
структура заболеваемости
—
все перечисленное
Уровень
общей заболеваемости населения
характеризуется коэффициентом:
—
экстенсивным
—
соотношения
+
интенсивным
—
наглядности
В
структуре заболеваемости населения по
данным обращаемости на первом месте
стоят болезни:
—
системы кровообращения
—
системы пищеварения
+
органов дыхания
—
нервной системы
—
костно-мышечной системы
Основной
учетный документ при изучении
заболеваемости с временной утратой
трудоспособности:
—
медицинская карта пациента, получающего
медицинскую помощь в амбулаторных
условиях
+
листок нетрудоспособности
—
экстренное извещение
—
статистическая карта выбывшего из
стационара
—
статистический талон для регистрации
уточненного диагноза
Основной
учетный документ при изучении общей
заболеваемости по обращаемости:
—
медицинская карта пациента, получающего
медицинскую помощь в амбулаторных
условиях
—
листок нетрудоспособности
—
экстренное извещение
—
статистическая карта выбывшего из
стационара
+
статистический талон для регистрации
уточненного диагноза
Основной
учетный документ при изучении эпидемической
заболеваемости:
—
медицинская карта пациента, получающего
медицинскую помощь в амбулаторных
условиях
—
листок нетрудоспособности
+
экстренное извещение об инфекционном
заболевании, пищевом, остром профессиональном
отравлении
—
статистическая карта выбывшего из
стационара
—
статистический талон для регистрации
уточненного диагноза
При
расчете показателя собственно
заболеваемости учитываются:
—
талоны на прием к врачу
+
статистические талоны со знаком (+)
—
статистические талоны со знаком (-)
—
листки нетрудоспособности
При
расчете показателя болезненности
учитываются:
—
талоны на прием к врачу
+
статистические талоны со знаком (+)
+
статистические талоны со знаком (-)
—
листки нетрудоспособности
Отчетным
документом по заболеваемости с временной
утратой трудоспособности является:
—
годовой отчет ЛПУ
—
сводная ведомость зарегистрированных
заболеваний в поликлинике
+
форма 16-ВН
—
дневник врача
—
отчет-вкладыш по туберкулезу
Показатели
общей заболеваемости по обращаемости
рассчитываются на стандарт:
+
1000
—
100
—
10 000
—
100 000
Показатели
важнейшей неэпидемической заболеваемости
рассчитываются на стандарт:
—
100
—
1000
—
10 000
+
100 000
Показатели
госпитализированной заболеваемости
рассчитываются на стандарт:
—
100
+
1000
—
10 000
—
100 000
Показатели
заболеваемости с временной утратой
трудоспособности рассчитываются на
стандарт:
+
100
—
1000
—
10 000
—
100 000
Международная
классификация болезней — это:
—
перечень диагнозов в определенном
порядке
—
перечень симптомов, синдромов и отдельных
состояний, расположенных по определенному
принципу
+
система рубрик, в которые отдельные
патологические состояния включены в
соответствии с определенными установленными
критериями
—
перечень наименований болезней, диагнозов
и синдромов, расположенных в определенном
порядке
Карта
выбывшего из стационара является учетным
документом заболеваемости:
—
с временной утратой трудоспособности
—
эпидемической
—
по данным медицинского осмотра
+
госпитализированной
Уровень
первичной заболеваемости населения
края находится в пределах:
+
941,5-1068,9
—
456,4-674,3
—
782,0-843,9
Уровень
общей заболеваемости населения края
находится в пределах:
—
2028,0-2207,9
—
1987,4-2006,7
+
2386,3-2653,9
Уровень
первичной заболеваемости туберкулезом
населения края:
+
111,9
—
78,5
—
86,8
—
107,3
Уровень
распространенности туберкулеза среди
населения края:
+
329,3
—
423,5
—
218,3
—
299
Уровень
смертности от туберкулеза населения
края:
+
29,5
—
21,3
—
44,5
—
70
Уровень
первичной заболеваемости сифилисом
населения края:
+
51,0
—
77,6
—
79,2
—
88,4
Уровень
первичной заболеваемости злокачественными
новобразованиями населения (на 1000)
края:
+
15,3
—
130,5
—
45,9
—
72,1
Уровень
больных с психическими расстройствами
состоящих под наблюдением (на 100 тыс.
населения) в крае:
+
184,5
—
128,0
—
98,5
—
1053,2
Уровень
случаев нетрудоспособности населения
края находится в пределах (на 100
работающих):
—
44,1-45,1
+
36,3-40,1
—
58,7-66,2
—
77,5-78,9
Уровень
дней нетрудоспособности населения края
находится в пределах (на 100 работающих):
+
590.4-660,3
—
557,8-579,4
—
348,7-389,1
—
834,2-843,6
Средняя
длительность случая нетрудоспособности
населения края находится в пределах (в
днях):
—
14-15
—
18-20
—
10-13
+
16-17
Уровень
первичного выхода на инвалидность
населения края находится в пределах
(на 10 тыс.):
+
50,7-59,8
—
98,7-100,2
—
67,7-72,3
—
24,5-36,1
Основными
причинами выхода на инвалидность
населения края являются:
+
болезни системы кровообращения
+
злокачественные новообразования
+
болезни костно-мышечной системы
+
травмы
—
болезни нервной системы
Общий
показатель смертности населения
вычисляется по формуле:
+
(число умерших за 1 год х 1000) / среднегодовая
численность населения
—
(число умерших за 1 год х 1000) / численность
населения
—
(число умерших старше 1 года х 1000) / средняя
численность населения
—
(число умерших старше 1 года х 1000) /
численность населения старше 1 года
—
(число умерших х 1000) / численность
населения на конец года
Показатель
материнской смертности вычисляется по
формуле:
+
число умерших беременных, рожениц и
родильниц (в том числе и случаи смерти
спустя 42 дня после родов) х 100 000
живорожденных / число живорожденных
—
(число умерших беременных х 1000
живорожденных) / суммарное число
беременностей
—
(число умерших после 28 недель беременности
х 100 000 живорожденных) / суммарное
число беременностей
—
(число умерших беременных х 100 000
живорожденных и мертворожденных) /
суммарное число беременных после 28
недель
—
(число умерших беременных после 28 недель
х 100 000 живорожденных) / суммарное
число беременностей после 28 недель
Расхождения
между величиной какого-либо показателя,
найденного посредством статистического
наблюдения, и действительными его
размерами называются ошибками
наблюдения.В зависимости от
причин возникновения различают ошибки
регистрации и ошибки репрезентативности.
Ошибки
регистрациивозникают в результате
неправильного установления фактов или
ошибочной записи в процессе наблюдения
или опроса. Они бывают случайными или
систематическими. Случайные ошибки
регистрации могут быть допущены как
опрашиваемыми в их ответах, так и
регистраторами. Систематические ошибки
могут быть и преднамеренными, и
непреднамеренными. Преднамеренные –
сознательные, тенденциозные искажения
действительного положения дела.
Непреднамеренные вызываются различными
случайными причинами (небрежность,
невнимательность).
Ошибки
репрезентативности(представительности)
возникают в результате неполного
обследования и в случае, если обследуемая
совокупность недостаточно полно
воспроизводит генеральную совокупность.
Они могут быть случайными и систематическими.
Случайные ошибки репрезентативности
– это отклонения, возникающие при
несплошном наблюдении из-за того, что
совокупность отобранных единиц наблюдения
(выборка) неполно воспроизводит всю
совокупность в целом. Систематические
ошибки репрезентативности – это
отклонения, возникающие вследствие
нарушения принципов случайного отбора
единиц. Ошибки репрезентативности
органически присущи выборочному
наблюдению и возникают в силу того, что
выборочная совокупность не полностью
воспроизводит генеральную. Избежать
ошибок репрезентативности нельзя,
однако, пользуясь методами теории
вероятностей, основанными на использовании
предельных теорем закона больших чисел,
эти ошибки можно свести к минимальным
значениям, границы которых устанавливаются
с достаточно большой точностью.
Ошибки
выборки –разность между
характеристиками выборочной и генеральной
совокупности. Для среднего значения
ошибка будет определяться по формуле
![]()
(7.1)
где
![]()
Величина
![]() называетсяпредельной ошибкойвыборки.
называетсяпредельной ошибкойвыборки.
Предельная
ошибка выборки – величина случайная.
Исследованию закономерностей случайных
ошибок выборки посвящены предельные
теоремы закона больших чисел. Наиболее
полно эти закономерности раскрыты в
теоремах П. Л. Чебышева и А. М. Ляпунова.
Теорему П.
Л. Чебышева применительно к
рассматриваемому методу можно
сформулировать следующим образом: при
достаточно большом числе независимых
наблюдений можно с вероятностью, близкой
к единице (т. е. почти с достоверностью),
утверждать, что отклонение выборочной
средней от генеральной будет сколько
угодно малым. В теореме П. Л. Чебышева
доказано, что величина ошибки не должна
превышать![]() .
.
В свою очередь величина![]() ,
,
выражающая среднее квадратическое
отклонение выборочной средней от
генеральной средней, зависит от
колеблемости признака в генеральной
совокупности![]() и числа отобранных единицn. Эта
и числа отобранных единицn. Эта
зависимость выражается формулой
![]() ,
,
(7.2)
где
![]() зависит также от способа производства
зависит также от способа производства
выборки.
Величину
![]() =
=![]() называютсредней ошибкой выборки. В
называютсредней ошибкой выборки. В
этом выражении![]() – генеральная дисперсия,n– объем
– генеральная дисперсия,n– объем
выборочной совокупности.
Рассмотрим, как
влияет на величину средней ошибки число
отбираемых единиц n. Логически
нетрудно убедиться, что при отборе
большого числа единиц расхождения между
средними будут меньше, т. е. существует
обратная связь между средней ошибкой
выборки и числом отобранных единиц. При
этом здесь образуется не просто обратная
математическая зависимость, а такая
зависимость, которая показывает, что
квадрат расхождения между средними
обратно пропорционален числу отобранных
единиц.
Увеличение
колеблемости признака влечет за собой
увеличение среднего квадратического
отклонения, а следовательно, и ошибки.
Если предположить, что все единицы будут
иметь одинаковую величину признака, то
среднее квадратическое отклонение
станет равно нулю и ошибка выборки
также исчезнет. Тогда нет необходимости
применять выборку. Однако следует иметь
в виду, что величина колеблемости
признака в генеральной совокупности
неизвестна, поскольку неизвестны размеры
единиц в ней. Можно рассчитать лишь
колеблемость признака в выборочной
совокупности. Соотношение между
дисперсиями генеральной и выборочной
совокупности выражается формулой
![]()
Поскольку
величина
![]() при достаточно большихnблизка к
при достаточно большихnблизка к
единице, можно приближенно считать, что
выборочная дисперсия равна генеральной
дисперсии, т. е.![]()
Следовательно,
средняя ошибка выборки показывает,
какие возможны отклонения характеристик
выборочной совокупности от соответствующих
характеристик генеральной совокупности.
Однако о величине этой ошибки можно
судить с определенной вероятностью. На
величину вероятности указывает множитель
![]()
Теорема А.
М. Ляпунова. А. М. Ляпунов доказал,
что распределение выборочных средних
(следовательно, и их отклонений от
генеральной средней) при достаточно
большом числе независимых наблюдений
приближенно нормально при условии, что
генеральная совокупность обладает
конечной средней и ограниченной
дисперсией.
Математически
теорему Ляпуноваможно записать
так:
 (7.3)
(7.3)
где
![]() ,
,
(7.4)
где ![]() – математическая постоянная;
– математическая постоянная;
![]() –предельная ошибка выборки,которая дает возможность выяснить, в
–предельная ошибка выборки,которая дает возможность выяснить, в
каких пределах находится величина
генеральной средней.
Значения этого
интеграла для различных значений
коэффициента доверия tвычислены и
приводятся в специальных математических
таблицах. В частности, при:

Поскольку tуказывает на вероятность расхождения![]() ,
,
т. е. на вероятность того, на какую
величину генеральная средняя будет
отличаться от выборочной средней, то
это может быть прочитано так: с вероятностью
0,683 можно утверждать, что разность между
выборочной и генеральной средними не
превышает одной величины средней ошибки
выборки. Другими словами, в 68,3 % случаев
ошибка репрезентативности не выйдет
за пределы![]() С вероятностью 0,954 можно утверждать,
С вероятностью 0,954 можно утверждать,
что ошибка репрезентативности не
превышает![]() (т. е. в 95 % случаев). С вероятностью
(т. е. в 95 % случаев). С вероятностью
0,997, т. е. довольно близкой к единице,
можно ожидать, что разность между
выборочной и генеральной средней не
превзойдет трехкратной средней ошибки
выборки и т. д.
Логически связь
здесь выглядит довольно ясно: чем больше
пределы, в которых допускается
возможная ошибка, тем с большей
вероятностью судят о ее величине.
Зная выборочную
среднюю величину признака
![]() и предельную ошибку выборки
и предельную ошибку выборки![]() ,
,
можно определить границы (пределы),
в которых заключена генеральная
средняя
![]() (7.5)
(7.5)
1.
Собственно-случайная выборка–
этот способ ориентирован на выборку
единиц из генеральной совокупности без
всякого расчленения на части или группы.
При этом для соблюдения основного
принципа выборки – равной возможности
всем единицам генеральной совокупности
быть отобранным – используются схема
случайного извлечения единиц путем
жеребьевки (лотереи) или таблицы случайных
чисел. Возможен повторный и бесповторный
отбор единиц
Средняя ошибка
собственно-случайной выборки
представляет собой среднеквадратическое
отклонение возможных значений выборочной
средней от генеральной средней. Средние
ошибки выборки при собственно-случайном
методе отбора представлены в табл. 7.2.
Таблица 7.2
|
Средняя ошибка |
При отборе |
|
|
повторном |
бесповторном |
|
|
Для средней |
|
|
|
Для доли |
|
|

В таблице
использованы следующие обозначения:
![]() – дисперсия выборочной совокупности;
– дисперсия выборочной совокупности;
![]() – численность выборки;
– численность выборки;
![]() – численность генеральной совокупности;
– численность генеральной совокупности;
![]() – выборочная доля единиц, обладающих
– выборочная доля единиц, обладающих
изучаемым признаком;
![]() – число единиц, обладающих изучаемым
– число единиц, обладающих изучаемым
признаком;
![]() – численность выборки.
– численность выборки.
Для увеличения
точности вместо множителя
![]() следует
следует
брать множитель
![]() ,
,
но при большой численностиNразличие
между этими выражениями практического
значения не имеет.
Предельная
ошибка собственно-случайной выборки
![]() рассчитывается по формуле
рассчитывается по формуле
![]() ,
,
(7.6)
где t
– коэффициент доверия зависит от
значения вероятности.
Пример.При
обследовании ста образцов изделий,
отобранных из партии в случайном порядке,
20 оказалось нестандартными. С вероятностью
0,954 определите пределы, в которых
находится доля нестандартной продукции
в партии.
Решение.
Вычислим генеральную долю (Р):
![]() .
.
Доля нестандартной
продукции:
 .
.
Предельная
ошибка выборочной доли с вероятностью
0,954 рассчитывается по формуле (7.6) с
применением формулы табл. 7.2 для доли:

![]()
С вероятностью
0,954 можно утверждать, что доля нестандартной
продукции в партии товара находится в
пределах 12 % ≤ P≤ 28 %.
В практике
проектирования выборочного наблюдения
возникает потребность определения
численности выборки, которая необходима
для обеспечения определенной точности
расчета генеральных средних. Предельная
ошибка выборки и ее вероятность при
этом являются заданными. Из формулы
![]() и формул средних ошибок выборки
и формул средних ошибок выборки
устанавливается необходимая численность
выборки. Формулы для определения
численности выборки (n) зависят от
способа отбора. Расчет численности
выборки для собственно-случайной выборки
приведен в табл. 7.3.
Таблица 7.3
|
Предполагаемый |
Формулы |
|
|
для средней |
для доли |
|
|
Повторный |
|
|
|
Бесповторный |
|
|



2.
Механическая выборка– при этом
методе исходят из учета некоторых
особенностей расположения объектов в
генеральной совокупности, их упорядоченности
(по списку, номеру, алфавиту). Механическая
выборка осуществляется путем отбора
отдельных объектов генеральной
совокупности через определенный интервал
(каждый 10-й или 20-й). Интервал рассчитывается
по отношению![]() ,
,
гдеn– численность выборки,N–
численность генеральной совокупности.
Так, если из совокупности в 500 000 единиц
предполагается получить 2 %-ную выборку,
т. е. отобрать 10 000
единиц, то пропорция отбора составит![]() Отбор
Отбор
единиц осуществляется в соответствии
с установленной пропорцией через равные
интервалы. Если расположение объектов
в генеральной совокупности носит
случайный характер, то механическая
выборка по содержанию аналогична
случайному отбору. При механическом
отборе применяется только бесповторная
выборка [1, 5–10].
Средняя ошибка
и численность выборки при механическом
отборе подсчитывается по формулам
собственно-случайной выборки (см.
табл. 7.2 и 7.3).
3.
Типическая выборка, при котрой
генеральная совокупность делится по
некоторым существенным признакам на
типические группы; отбор единиц
производится из типических групп. При
этом способе отбора генеральная
совокупность расчленяется на однородные
в некотором отношении группы, которые
имеют свои характеристики, и вопрос
сводится к определению объема выборок
из каждой группы. Может бытьравномерная
выборка– при этом способе из каждой
типической группы отбирается одинаковое
число единиц![]() Такой подход оправдан лишь при равенстве
Такой подход оправдан лишь при равенстве
численностей исходных типических групп.
При типическом отборе, непропорциональном
объему групп, общее число отбираемых
единиц делится на число типических
групп, полученная величина дает
численность отбора из каждой типической
группы.
Более совершенной
формой отбора является пропорциональная
выборка. Пропорциональной называется
такая схема формирования выборочной
совокупности, когда численность выборок,
взятых из каждой типической группы в
генеральной совокупности, пропорциональна
численностям, дисперсиям (или комбинированно
и численностям, и дисперсиям). Условно
определяем численность выборки в 100
единиц и отбираем единицы из групп:
– пропорционально
численности их генеральной совокупности
(табл. 7.4). В таблице
обозначено:
Ni– численность типической группы;
dj
– доля (Ni/N);
N– численность
генеральной совокупности;
ni– численность выборки из типической
группы вычисляется:
![]() , (7.7)
, (7.7)
n – численность выборки из генеральной
совокупности.
Таблица
7.4
-
Группы
Ni
dj
ni
1
300
0,3
30
2
500
0,5
50
3
200
0,2
20
1000
1,0
100
–
пропорционально среднему квадратическому
отклонению(табл. 7.5).
здесь
i– среднее
квадратическое отклонение типических
групп;
ni
– численность выборки из типической
группы вычисляется по формуле

(7.8)
Таблица
7.5
-
Ni
i

ni
300
5
0,25
25
500
7
0,35
35
200
8
0,40
40
1000
20
1,0
100
–
комбинированно (табл. 7.6).
Численность
выборки вычисляется по формуле
![]() . (7.9)
. (7.9)
Таблица 7.6
-

i
iNi


300
5
1500
0,23
23
500
7
2100
0,53
53
200
8
1600
0.24
24
1000
20
6600
1,0
100
При проведении
типической выборки непосредственный
отбор из каждой группы проводится
методом случайного отбора.
Средние ошибки
выборки рассчитываются по формулам
табл. 7.7 в зависимости от способа отбора
из типических групп.
Таблица 7.7
|
Способ |
Повторный |
Бесповторный |
||
|
для |
для |
для |
для |
|
|
Непропорциональный |
|
|
|
|
|
Пропорциональный объему групп |
|
|
|
|
|
Пропорциональный |
|
|
|
|





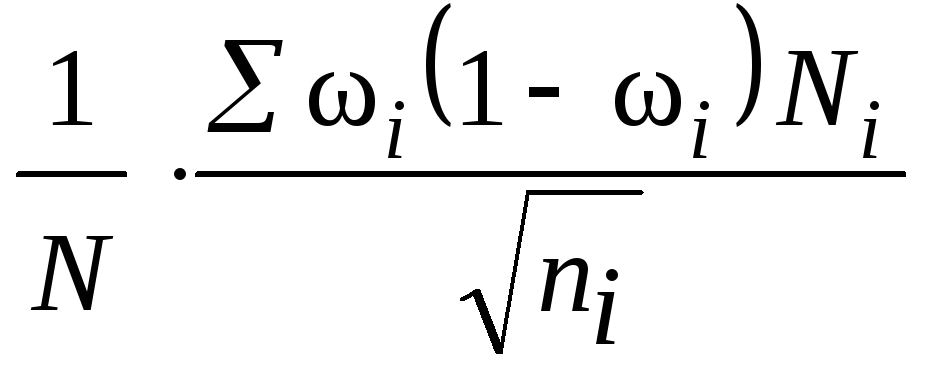


здесь
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
типических групп;
![]() – доля единиц, обладающих изучаемым
– доля единиц, обладающих изучаемым
признаком;
![]() – средняя из внутригрупповых дисперсий
– средняя из внутригрупповых дисперсий
для доли;
![]() – среднее квадратическое отклонение
– среднее квадратическое отклонение
в выборке изi-й типической группы;
![]() – объем выборки из типической группы;
– объем выборки из типической группы;
![]() – общий объем выборки;
– общий объем выборки;
![]() –
–
объем типической группы;
![]() – объем генеральной совокупности.
– объем генеральной совокупности.
Численность
выборки из каждой типической группы
должна быть пропорциональна среднему
квадратическому отклонению в этой
группе
![]() .Расчет численности
.Расчет численности
![]() производится по формулам, приведенным
производится по формулам, приведенным
в табл. 7.8.
Таблица 7.8
|
Повторный |
Бесповторный |
|
|
Для определения |
|
|
|
Для определения |
|
|
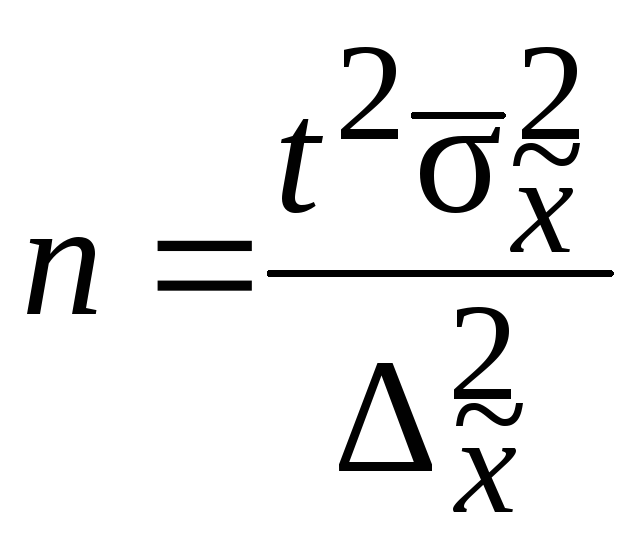

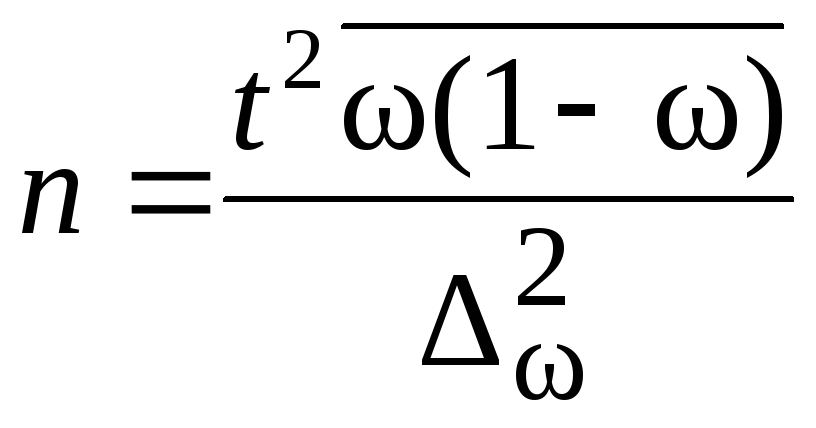

4. Серийная
выборка– удобена в тех случаях,
когда единицы совокупности объединены
в небольшие группы или серии. При серийной
выборке генеральную совокупность делят
на одинаковые по объему группы – серии.
В выборочную совокупность отбираются
серии. Сущность серийной выборки
заключается в случайном или механическом
отборе серий, внутри которых производится
сплошное обследование единиц. Средняя
ошибка серийной выборки с равновеликими
сериями зависит от величины только
межгрупповой дисперсии. Средние ошибки
сведены в табл. 7.9.
Таблица 7.9
|
Способ |
Формулы |
|
|
для |
для |
|
|
Повторный |
|
|
|
Бесповторный |
|
|


Здесь
R– число серий в генеральной
совокупности;
r – число
отобранных серий;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
средних;
![]() – межсерийная (межгрупповая) дисперсия
– межсерийная (межгрупповая) дисперсия
доли.
При серийном
отборе необходимую численность отбираемых
серий определяют так же, как и при
собственно-случайном методе отбора.
Расчет численности
серийной выборки производится по
формулам, приведенным в табл. 7.10.
Таблица 7.10
|
Повторный |
Бесповторный |
|
|
Для |
|
|
|
Для |
|
|
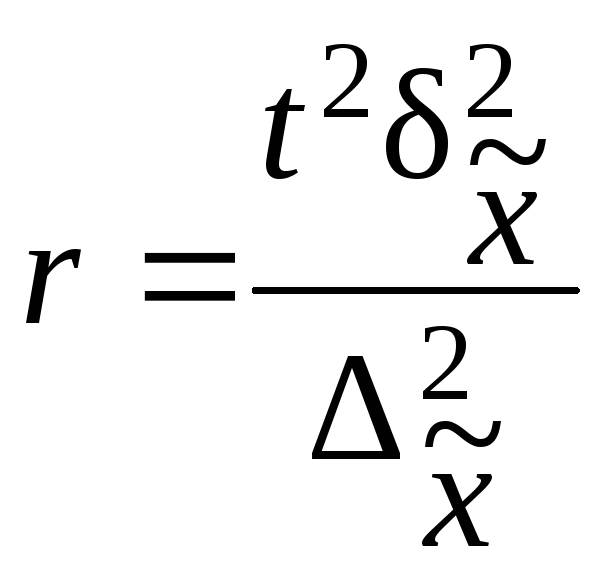

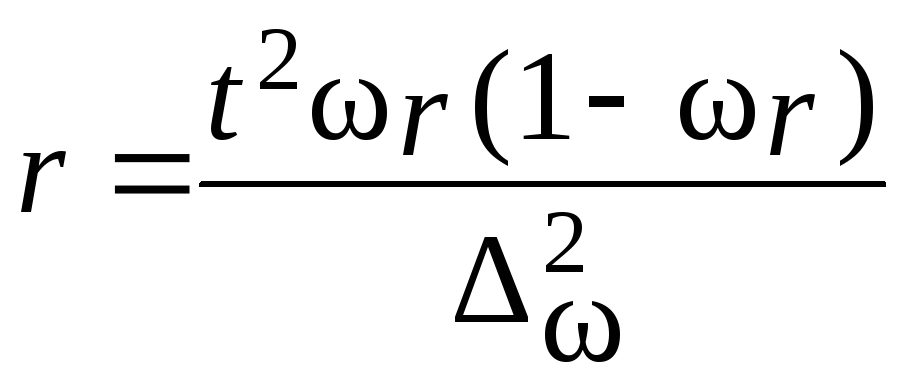

Пример.В
механическом цехе завода в десяти
бригадах работает 100 рабочих. В целях
изучения квалификации рабочих была
произведена 20 %-ная серийная бесповторная
выборка, в которую вошли две бригады.
Получено следующее распределение
обследованных рабочих по разрядам:
|
Рабочие |
Разряды рабочих |
Разряды рабочих |
Рабочие |
Разряды |
Разряды |
|
1 2 3 4 5 |
2 4 5 2 5 |
3 6 1 5 3 |
6 7 8 9 10 |
6 5 8 4 5 |
4 2 1 3 2 |
Необходимо
определить с вероятностью 0,997 пределы,
в которых находится средний разряд
рабочих механического цеха.
Решение.
Определим выборочные средние по
бригадам и общую среднюю как среднюю
взвешенную из групповых средних:

Определим
межсерийную дисперсию по формулам
(5.25):
![]()
Рассчитаем
среднюю ошибку выборки по формуле табл.
7.9:
![]()
Вычислим
предельную ошибку выборки с вероятностью
0,997:
![]()
С вероятностью
0,997 можно утверждать, что средний разряд
рабочих механического цеха находится
в пределах
![]()
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Как мы уже знаем, репрезентативность — свойство выборочной совокупности представлять характеристику генеральной. Если совпадения нет, говорят об ошибке репрезентативности — мере отклонения статистической структуры выборки от структуры соответствующей генеральной совокупности. Предположим, что средний ежемесячный семейный доход пенсионеров в генеральной совокупности составляет 2 тыс. руб., а в выборочной — 6 тыс. руб. Это означает, что социолог опрашивал только зажиточную часть пенсионеров, а в его исследование вкралась ошибка репрезентативности. Иными словами, ошибкой репрезентативности называется расхождение между двумя совокупностями — генеральной, на которую направлен теоретический интерес социолога и представление о свойствах которой он хочет получить в конечном итоге, и выборочной, на которую направлен практический интерес социолога, которая выступает одновременно как объект обследования и средство получения информации о генеральной совокупности.
Наряду с термином «ошибка репрезентативности» в отечественной литературе можно встретить другой — «ошибка выборки». Иногда они употребляются как синонимы, а иногда «ошибка выборки» используется вместо «ошибки репрезентативности» как количественно более точное понятие.
Ошибка выборки — отклонение средних характеристик выборочной совокупности от средних характеристик генеральной совокупности.
На практике ошибка выборки определяется путем сравнения известных характеристик генеральной совокупности с выборочными средними. В социологии при обследованиях взрослого населения чаще всего используют данные переписей населения, текущего статистического учета, результаты предшествующих опросов. В качестве контрольных параметров обычно применяются социально-демографические признаки. Сравнение средних генеральной и выборочной совокупностей, на основе этого определение ошибки выборки и ее уменьшение называется контролированием репрезентативности. Поскольку сравнение своих и чужих данных можно сделать по завершении исследования, такой способ контроля называется апостериорным, т.е. осуществляемым после опыта.
В опросах Института Дж. Гэллапа репрезентативность контролируется по имеющимся в национальных переписях данным о распределении населения по полу, возрасту, образованию, доходу, профессии, расовой принадлежности, месту проживания, величине населенного пункта. Всероссийский центр изучения общественного мнения (ВЦИОМ) использует для подобных целей такие показатели, как пол, возраст, образование, тип поселения, семейное положение, сфера занятости, должностной статус респондента, которые заимствуются в Государственном комитете по статистике РФ. В том и другом случае генеральная совокупность известна. Ошибку выборки невозможно установить, если неизвестны значения переменной в выборочной и генеральной совокупностях.
Специалисты ВЦИОМ обеспечивают при анализе данных тщательный ремонт выборки, чтобы минимизировать отклонения, возникшие на этапе полевых работ. Особенно сильные смещения наблюдаются по параметрам пола и возраста. Объясняется это тем, что женщины и люди с высшим образованием больше времени проводят дома и легче идут на контакт с интервьюером, т.е. являются легко достижимой группой по сравнению с мужчинами и людьми «необразованными»35.
Ошибка выборки обусловливается двумя факторами: методом формирования выборки и размером выборки.
Ошибки выборки подразделяются на два типа — случайные и систематические. Случайная ошибка — это вероятность того, что выборочная средняя выйдет (или не выйдет) за пределы заданного интервала. К случайным ошибкам относят статистические погрешности, присущие самому выборочному методу. Они уменьшаются при возрастании объема выборочной совокупности.
Второй тип ошибок выборки — систематические ошибки. Если социолог решил узнать мнение всех жителей города о проводимой местными органами власти социальной политике, а опросил только тех, у кого есть телефон, то возникает предумышленное смещение выборки в пользу зажиточных слоев, т.е. систематическая ошибка.
Таким образом, систематические ошибки — результат деятельности самого исследователя. Они наиболее опасны, поскольку приводят к довольно значительным смещениям результатов исследования. Систематические ошибки считаются страшнее случайных еще и потому, что они не поддаются контролю и измерению.
Они возникают, когда, например:
- выборка не соответствует задачам исследования (социолог решил изучить только работающих пенсионеров, а опросил всех подряд);
- налицо незнание характера генеральной совокупности (социолог думал, что 70% всех пенсионеров не работает, а оказалось, что не работает только 10%);
- отбираются только «выигрышные» элементы генеральной совокупности (например, только обеспеченные пенсионеры).
Внимание! В отличие от случайных ошибок систематические ошибки при возрастании объема выборки не уменьшаются.
Обобщив все случаи, когда происходят систематические ошибки, методисты составили их реестр. Они полагают, что источником неконтролируемых перекосов в распределении выборочных наблюдений могут быть следующие факторы:
- нарушены методические и методологические правила проведения социологического исследования;
- выбраны неадекватные способы формирования выборочной совокупности, методы сбора и расчета данных;
- произошла замена требуемых единиц наблюдения другими, более доступными;
- отмечен неполный охват выборочной совокупности (недополучение анкет, неполное их заполнение, труднодоступность единиц наблюдения).
Намеренные ошибки социолог допускает редко. Чаще ошибки возникают из-за того, что социологу плохо известна структура генеральной совокупности: распределение людей по возрасту, профессии, доходам и т.д.
Систематические ошибки легче предупредить (по сравнению со случайными), но их очень трудно устранить. Предупреждать систематические ошибки, точно предвидя их источники, лучше всего заранее — в самом начале исследования.
Вот некоторые способы избежать ошибок выборки:
- каждая единица генеральной совокупности должна иметь равную вероятность попасть в выборку;
- отбор желательно производить из однородных совокупностей;
- надо знать характеристики генеральной совокупности;
- при составлении выборочной совокупности надо учитывать случайные и систематические ошибки.
Если выборочная совокупность (или просто выборка) составлена правильно, то социолог получает надежные результаты, харастеризующие всю генеральную совокупность. Если она составлена неправильно, то ошибка, возникшая на этапе составления выборки, на каждом следующем этапе проведения социологического исследования приумножается и достигает в конечном счете такой величины, которая перевешивает ценность проведенного исследования. Говорят, что от такого исследования больше вреда, нежели пользы.
Подобные ошибки могут произойти только с выборочной совокупностыо. Чтобы избежать или уменьшить вероятность ошибки, самый простой способ — увеличивать размеры выборки (в идеале до объема генеральной: когда обе совокупности совпадут, ошибка выборки вообще исчезнет). Экономически такой метод невозможен. Остается другой путь — совершенствовать математические методы составления выборки. Они то и применяются на практике. Таков первый канал проникновения в социологию математики. Второй канал — математическая обработка данных.
Особенно важной проблема ошибок становится в маркетинговых исследованиях, где используются не очень большие выборки. Обычно они составляют несколько сотен, реже — тысячу респондентов. Здесь исходным пунктом расчета выборки выступает вопрос об определении размеров выборочной совокупности. Численность выборочной совокупности зависит от двух факторов:
- стоимости сбора информации,
- стремления к определенной степени статистической достоверности результатов, которую надеется получить исследователь.
Конечно, даже не искушенные в статистике и социологии люди интуитивно понимают, что чем больше размеры выборки, т.е. чем ближе они к размерам генеральной совокупности в целом, тем более надежны и достоверны полученные данные. Однако выше мы уже говорили о практической невозможности сплошных опросов в тех случаях, когда они проводятся на объектах, численность которых превышает десятки, сотни тысяч и даже миллионы. Понятно, что стоимость сбора информации (включающая оплату тиражирования инструментария, труда анкетеров, полевых менеджеров и операторов по компьютерному вводу) зависит от той суммы, которую готов выделить заказчик, и слабо зависит от исследователей. Что же касается второго фактора, то мы остановимся на нем чуть подробнее.
Итак, чем больше величина выборки, тем меньше возможная ошибка. Хотя необходимо отметить, что при желании увеличить точность вдвое вам придется увеличить выборку не в два, а в четыре раза. Например, чтобы сделать в два раза более точной оценку данных, полученных путем опроса 400 человек, вам потребуется опросить не 800, а 1600 человек. Впрочем, вряд ли маркетинговое исследование испытывает нужду в стопроцентной точности. Если пивовару необходимо узнать, какая часть потребителей пива предпочитает именно его марку, а не сорт его конкурента, — 60% или 40%, то на его планы никак не повлияет разница между 57%, 60 или 63%.
Ошибка выборки может зависеть не только от ее величины, но и от степени различий между отдельными единицами внутри генеральной совокупности, которую мы исследуем. Например, если нам нужно узнать, какое количество пива потребляется, то мы обнаружим, что внутри нашей генеральной совокупности нормы потребления у различных людей существенно различаются (гетерогенная генеральная совокупность). В другом случае мы будем изучать потребление хлеба и установим, что у разных людей оно различается гораздо менее существенно {гомогенная генеральная совокупность). Чем больше различия (или гетерогенность) внутри генеральной совокупности, тем больше величина возможной ошибки выборки. Указанная закономерность лишь подтверждает то, что нам подсказывает простой здравый смысл. Таким образом, как справедливо утверждает В. Ядов, «численность (объем) выборки зависит от уровня однородности или разнородности изучаемых объектов. Чем более они однородны, тем меньшая численность может обеспечить статистически достоверные выводы».
Определение объема выборки зависит также от уровня доверительного интервала допустимой статистической ошибки. Здесь имеются в виду так называемые случайные ошибки, которые связаны с природой любых статистических погрешностей. В.И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5%-ной ошибки:
Это означает,что если вы, опросив, предположим, 400 человек в районном городе, где численность взрослого платежеспособного населения составляет 100 тыс. человек, выявили, что 33% опрошенных покупателей предпочитают продукцию местного мясокомбината, то с 95%-ной вероятностью можете утверждать, что постоянными покупателями этой продукции являются 33+5% (т.е. от 28 до 38%) жителей этого города.
Можно также воспользоваться расчетами института Гэллапа для оценки соотношения размеров выборки и ошибки выборки.

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
ШПАРГАЛКА (скопируйте ссылку или текст)
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
Подборка по базе: СТ 02-16-12 Требования к содержанию и оформлению ВКР редакция 1., Статья (1 редакция).docx, PDF_СП 52.13330.2016 Естественное и искусственное освещение. Ак, 1.Об утверждении положения о лоцманах на внутренних водных путях, 11Д.и. операционной медицинской сестры (новая редакция).doc, 10. СП 36.13330.2012 Магистральные трубопроводы. Актуализированн, новая редакция Спартакиада.docx, Инвентаризация по ДЭС новая редакция ноябрь 2022.docx, Приказ Минэнерго РФ от 12.08.2022 N 811 — Редакция от 12.08.2022, БАЗНАТ КУРСОВАЯ 3 КУРС РЕДАКЦИЯ.docx
Редакция 3 от 04.04.2012г

УДК 614.2.001.12 (075)
ББК 51.1(2)
УМО – 75.07.02.05
Составители:
профессор В. И. Сабанов,
ст. преподаватель, канд. мед. наук Н. П. Багметов,
доцент, канд. мед. наук В. В. Ивашева,
ассистент, канд. мед. наук А. Н. Голубев,
ассистент А. С. Рогова
Рецензенты:
д-р мед. наук, профессор, гл. специалист по общественному
здоровью и здравоохранению ЮФО, зав. кафедрой общественного здоровья и здравоохранения с курсами информатики, истории медицины и культурологи АГМА Сердюков А. Г.,
канд. мед. наук, доцент, зав. кафедрой общественного здоровья
и здравоохранения № 2 факультета повышения
квалификации РГМУ Салатич А. И.
Квалификационные тесты по специальности «Организация здравоохранения и общественное здоровье»: Метод. указания / Сост.: В. И. Сабанов, Н. П. Багметов, В. В. Ивашева,
А. Н. Голубев, А. С. Рогова. — Изд. 3-е, испр. и доп. — Волгоград: Изд-во ВолГМУ, 2009. — 284 с.
Методические указания рекомендуются слушателям факультетов усовершенствования врачей, организаторам здравоохранения всех типов лечебно-профилактических учреждений, специалистам фондов обязательного медицинского страхования и страховых медицинских организаций, преподавателям кафедр общественного здоровья и здравоохранения для подготовки и сдачи экзамена по специальности «Организация здравоохранения и общественное здоровье».
ОГЛАВЛЕНИЕ
РАЗДЕЛ 01.
«МЕДИКО-САНИТАРНАЯ СТАТИСТИКА» 4
РАЗДЕЛ 02.
«МЕДИКО-ДЕМОГРАФИЧЕСКИЕ АСПЕКТЫ
ОРГАНИЗАЦИИ ЗДРАВООХРАНЕНИЯ» 27
РАЗДЕЛ 03.
«ЗАБОЛЕВАЕМОСТЬ.
МЕТОДИКА ЕЕ ИЗУЧЕНИЯ» 48
РАЗДЕЛ 04.
«ОРГАНИЗАЦИЯ ЗДРАВООХРАНЕНИЯ» 69
РАЗДЕЛ 05.
«КАЧЕСТВО МЕДИЦИНСКОЙ ПОМОЩИ» 124
РАЗДЕЛ 06.
«ЭКСПЕРТИЗА ВРЕМЕННОЙ
И СТОЙКОЙ УТРАТЫ ТРУДОСПОСОБНОСТИ» РЕД.04.04.2012г 135
РАЗДЕЛ 07.
«МЕДИЦИНА КАТАСТРОФ» 180
РАЗДЕЛ 08.
«МЕДИЦИНСКОЕ СТРАХОВАНИЕ» 188
РАЗДЕЛ 09.
«ЭКОНОМИКА, ПЛАНИРОВАНИЕ
И УПРАВЛЕНИЕ В ЗДРАВООХРАНЕНИИ» 203
РАЗДЕЛ 10.
«ГРАЖДАНСКОЕ И ТРУДОВОЕ ПРАВО» 240
РАЗДЕЛ 11.
«МЕЖДУНАРОДНЫЕ АСПЕКТЫ ЗДРАВООХРАНЕНИЯ» 264
РАЗДЕЛ 12.
«АСУ В ЗДРАВООХРАНЕНИИ» 271
РАЗДЕЛ 01. «МЕДИКО-САНИТАРНАЯ СТАТИСТИКА
001. Интенсивные показатели принято изображать в виде диаграмм:
а) Столбиковых
б) Секторных
в) Комбинированных
г) Радиальных
002. Динамические показатели характеризуют:
а) Структуру явления
б) Частоту явления в другой среде
в) Изменение величины явления во времени
003. Экстенсивные показатели характеризуют:
а) Структуру явления
б) Частоту явления в другой среде
в) Изменение величины явления во времени
004. Интенсивные показатели характеризуют:
а) Структуру явления
б) Частоту явления в изучаемой среде
в) Частоту явления в другой среде
г) Изменение величины явления во времени
005. Величина, наиболее часто встречающаяся
в вариационном ряду, называется:
а) Медианой (Ме)
б) Средней арифметической (Мср)
в) Модой (Мо)
г) Средним квадратическим отклонением
006. Если в вариационном ряду каждая варианта повторяется несколько раз, то этот ряд:
а) Простой
б) Сложный
в) Сгруппированный
г) Комбинированный
007. Коэффициент вариации, равный 25 %, свидетельствует о разнообразии признака:
а) Сильном
б) Среднем
в) Слабом
008. В городе N в структуре младенческой смертности в 1980 г. на долю инфекций дыхательных путей приходилось 42 %, а кишечных инфекций — 35 %, в 1995 г. — 38 % и 30 % соответственно. Верен ли вывод о снижении младенческой смертности от этих видов патологии:
а) Верен, показатели действительно снизились
б) Не верен, по структуре нельзя судить о частоте явления
в) Не верен, не указана достоверность различия показателей
г) Верен, определяется явная достоверность различия по амплитуде
009. Достоверность различия двух средних величин определяется с помощью:
а) Ошибки репрезентативности
б) Коэффициента вариации
в) Средней арифметической
г) Критерия Стьюдента
010. Доверительный интервал — это:
а) Степень разнообразия единиц по изучаемому признаку
б) Пределы варьирования средней величины при разной степени вероятности
в) Мера колеблемости ряда
г) Мерило изменчивости средней арифметической или относительной величины
011. О наличии сильной положительной корреляционной зависимости можно говорить при значении коэффициента корреляции:
а) Больше или равно 0,6
б) Меньше или равно 0,10
в) Больше или равно 0,9
г) Меньше или равно 0,4
012. Репрезентативность выборки обеспечивается:
а) Соответствующим объемом и случайностью отбора единиц наблюдения
б) Соответствующим объемом и стандартизацией
г) Стандартизацией и нормированием когорт наблюдения
013. Какие из перечисленных ниже пар показателей являются интенсивными:
а) Показатели рождаемости и заболеваемости населения гепатитом
б) Показатель рождаемости и структура причин инвалидности
в) Структура причин инвалидности и заболеваемость населения гепатитом
014. Для графического изображения экстенсивных показателей используются диаграммы:
а) Секторная
б) Столбиковая
в) Динамическая
г) Линейная
015. Для определения структуры заболеваемости, смертности применяется показатель:
а) Экстенсивный
б) Интенсивный
в) Соотношения
г) Наглядности
016. Какой из перечисленных ниже показателей является показателем соотношения:
а) Обеспеченность населения врачами
б) Общая смертность
в) Летальность
017. Если t-критерий (Стьюдента) больше или равен 2, то различия двух средних величин:
а) Достоверны
б) Недостоверны
в) Сравнимы
г) Несравнимы
д) Выборочны
018. Если в вариационном ряду каждая варианта ни разу не повторяется, то этот ряд:
а) Простой
б) Сложный
в) Сгруппированный
г) Комбинированный
019. Мера достоверности средней величины:
а) Амплитуда
б) Ошибка репрезентативности
в) Критерий Стьюдента
г) Варианта
д) Медиана
020. Коэффициент вариации, равный 7 %, свидетельствует о разнообразии признака:
а) Сильного
б) Среднего
в) Слабого
021. Степень представительности выборки оценивается с помощью:
а) Коэффициента корреляции
б) Среднего квадратического отклонения
в) Ошибки репрезентативности
022. Для сравнения показателей, полученных на неоднородных по своему составу совокупностях, используется метод:
а) Корреляции
б) Выравнивания динамических рядов
в) Стандартизации
г) Экстраполяции
023. Статистическое наблюдение может быть:
а) Текущим и единовременным
б) Фактическим и результативным
в) Единовременным и стандартизованным
г) Фактическим и единовременным
024. Какие ошибки, учитываемые статистическими методами, не могут быть полностью устранены:
а) Арифметические
б) Степени точности вычисления
в) Методические
г) Репрезентативности
025. Какой из перечисленных ниже показателей является экстенсивным:
а) Структура причин смерти
б) Младенческая смертность
в) Уровень заболеваемости населения дифтерией
026. Укажите последовательность этапов статистического исследования, обозначенных буквами, выбрав соответствующую комбинацию букв: A) сбор материала и статистическое наблюдение; B) разработка плана и программы исследования; C) анализ результатов исследования; D) разработка материала
а) АВСD
б) DBAC
в) BADC
027. Для большинства медико-биологических и социальных исследований достоверными считаются доверительные границы, установленные при вероятности безошибочного прогноза, равном и более:
а) 68 %
б) 90 %
в) 92 %
г) 95 %
028. Частоту или распространенность явления характеризует показатель:
а) Экстенсивный
б) Интенсивный
в) Соотношения
г) Корреляции
029. В городе А сердечно-сосудистые заболевания составляют 20 %, а в городе Б — 30 % от всех заболеваний. Можно ли утверждать, что в городе Б эти заболевания встречаются чаще:
1) можно, процент заболеваний в городе Б явно выше; 2) можно, данные показатели характеризуют уровень сердечно-сосудистых заболеваний; 3) можно, данные показатели характеризуют частоту сердечно-сосудистых заболеваний, а в городе Б она выше;
4) нельзя, мы не знаем ошибки данных показателей; 5) нельзя, процент сердечно-сосудистых заболеваний в городе Б может быть выше за счет меньшего удельного веса других заболеваний; по структуре нельзя судить о частоте
а) 1
б) 2
в) 3
г) 4
д) 5
030. Если t-критерий (Стьюдента) меньше 2, то различия двух средних величин:
а) Достоверны
б) Недостоверны
в) Сравнимы
г) Несравнимы
д) Выборочны
031. Коэффициент вариации, равный 35 %, свидетельствует о разнообразии признака:
а) Сильного
б) Среднего
в) Слабого
032. Отражает ли структурное распределение заболеваемости населения такие показатели, как средняя продолжительность лечения и кратность заболеваний в год:
а) Да
б) Нет
033. Уровень общей заболеваемости населения характеризуется коэффициентом:
а) Экстенсивным
б) Соотношения
в) Интенсивным
г) Наглядности
034. Укажите показатели, в которых должны быть представлены результаты исследования при изучении распространенности гипертонической болезни у лиц разного возраста:
а) Интенсивные
б) Экстенсивные
в) Соотношения
г) Наглядности
035. Дайте определение вариационного ряда:
1) однородная в качественном отношении статистическая совокупность, отдельные единицы которой характеризуют количественные различия изучаемого признака или явления; 2) ряд чисел, характеризующих качественно неоднородную совокупность; 3) количественное выражение различных признаков
а) 1
б) 2
в) 3
036. Варианта — это:
а) Числовое выражение признака
б) Средняя величина
в) Относительный показатель
г) Качественная характеристика признака
037. Выберите правильное определение понятия «Единица статистического наблюдения»: 1) составная часть объекта наблюдения, подлежащая изучению и регистрации в соответствии с программой исследования; 2) явление, которое подлежит детальному изучению и все учетные признаки которого могут быть измерены только количественно; 3) явление, которое подлежит детальному изучению и его учетные признаки должны носить только качественный, описательный характер
а) 1
б) 2
в) 3
038. Объект статистического наблюдения — это:
1) статистическая совокупность явлений (предметов), о которых должны быть собраны статистические сведения; 2) каждое отдельное явление, которое подвергается углубленному изучению и регистрации на специальной учетной форме (бланке); 3) место или территория, где осуществляется статистическое наблюдение
а) 1
б) 2
в) 3
039. Для оценки обеспеченности населения врачами используется показатель:
а) Интенсивности
б) Экстенсивности
в) Соотношения
г) Наглядности
040. Показатель наглядности используется для:
а) Определения удельного веса изучаемого признака
б) Характеристики структуры
в) Сравнения явлений в динамике
г) Оценки распространенности явления
041. Репрезентативность — это: 1) соответствие средней арифметической величины выборочной совокупности аналогичному параметру генеральной совокупности; 2) достоверность полученного результата при сплошном исследовании; 3) понятие, характеризующее связь между признаками; 4) характеристика методики исследования
а) 1
б) 2
в) 3
г) 4
042. С увеличением объема наблюдений ошибка репрезентативности:
а) Увеличивается
б) Остается без изменений
в) Уменьшается
043. Предметом изучения медицинской статистики является: 1) здоровье населения; 2) выявление и установление зависимостей между уровнем здоровья и факторами окружающей среды; 3) данные о сети, деятельности, кадрах учреждений здравоохранения;
4) достоверность результатов клинических и экспериментальных исследований; 5) все вышеперечисленное
а) 1
б) 2
в) 3
г) 4
д) 5
044. Коэффициент корреляции между двумя выборками равен 0. Вывод о взаимной независимости выборок можно сделать:
а) В любом случае
б) Если обе выборки имеют одинаковое распределение
в) Если обе выборки имеют нормальное распределение
г) Если хотя бы одна выборка имеет нормальное распределение
045. Коэффициент корреляции между двумя выборками равен 1. Такой результат позволяет предложить наличие взаимосвязи между ними:
а) В любом случае
б) Если обе выборки имеют одинаковое распределение
в) Если обе выборки имеют нормальное распределение
г) Если хотя бы одна выборка имеет нормальное распределение
046. Под статистикой понимают: 1) самостоятельную общественную науку, изучающую количественную сторону массовых общественных явлений в неразрывной связи с их качественной стороной; 2) сбор, обработку и хранение информации, характеризующей количественные закономерности общественных явлений; 3) анализ массовых количественных данных с использованием статистических методов; 4) анализ массовых количественных данных с использованием статистическо-математических методов; 5) статистическо-математические методы при сборе, обработке и хранении информации
а) 1
б) 2
в) 3
г) 4
д) 5
047. Под медицинской статистикой понимают:
1) отрасль статистики, изучающую здоровье населения; 2) совокупность статистических методов, необходимых для анализа деятельности ЛПУ; 3) отрасль статистики, изучающую вопросы, связанные с медициной, гигиеной, санитарией и здравоохранением; 4) отрасль статистики, изучающую вопросы, связанные с медициной и социальной гигиеной; 5) отрасль статистики, изучающую вопросы, связанные с социальной гигиеной, планированием и прогнозированием деятельности ЛПУ
а) 1
б) 2
в) 3
г) 4
д) 5
048. Предметом изучения медицинской статистики является информация о:
а) Здоровье населения
б) Влиянии факторов окружающей среды на здоровье человека
в) Кадрах, сети и деятельности учреждений и служб здравоохранения
г) Результатах клинических и экспериментальных исследований в медицине
д) Всем вышеперечисленном
049. Здоровье населения рассматривается (изучается) как: 1) многофакторная проблема, включающая в себя цели и задачи по изучению здоровья населения и влияющих факторов окружающей среды; 2) совокупность показателей, характеризующих здоровье общества как целостного функционирующего организма; 3) все вышеперечисленное
а) 1
б) 2
в) 3
050. Виды относительных величин все, кроме:
а) Интенсивных показателей
б) Экстенсивных показателей
в) Показателей наглядности
г) Показателей соотношения
д) Средних величин
051. Показатель соотношения характеризует:
а) Структуру, состав явления
б) Частоту явления в своей среде
в) Соотношение двух разнородных совокупностей
г) Распределение целого на части
052. В каких показателях должны быть представлены результаты исследования при изучении структуры госпитализированных больных по отделениям стационара:
а) Экстенсивных
б) Интенсивных
053. К интенсивным статистическим показателям относятся:
а) Распределение больных по полу и возрасту
б) Показатели заболеваемости, смертности
в) Структура заболеваний по нозологическим формам
054. Диаграммой, наиболее наглядно характеризующей сезонность заболеваемости, служит:
а) Секторная
б) Радиальная
в) Столбиковая
055. Какой статистический показатель характеризует развитие явления в среде, непосредственно с ним не связанной:
а) Экстенсивный
б) Интенсивный
в) Соотношения
г) Наглядности
д) Средняя арифметическая
056. Какие показатели позволяют демонстрировать сдвиги явления во времени или по территории, не раскрывая истинного уровня этого явления:
а) Экстенсивные
б) Интенсивные
в) Соотношения
г) Наглядности
д) Регрессии
057. Статистическая совокупность как объект статистического исследования включает группу или множество относительно однородных элементов, обладающих признаками:
а) Сходства
б) Различия
в) Сходства и различия
058. Программа статистического исследования — это:
а) Перечень вопросов
б) Совокупность изучаемых признаков
в) Определение масштаба исследования
г) Определение времени исследования
059. Из приведенных ниже примеров характерным для единовременного наблюдения является:
а) Рождаемость
б) Заболеваемость
в) Профилактический осмотр
г) Смертность
060. Выборочное наблюдение — это: 1) наблюдение, охватывающее часть единиц совокупности для характеристики целого; 2) наблюдение, приуроченное к одному какому-либо моменту; 3) наблюдение в порядке текущей регистрации; 4) обследование всех без исключения единиц изучаемой совокупности
а) 1
б) 2
в) 3
г) 4
061. Сплошное наблюдение — это: 1) наблюдение, охватывающее часть единиц совокупности для характеристики целого; 2) наблюдение, приуроченное к одному какому-либо моменту; 3) наблюдение в порядке текущей регистрации; 4) обследование всех без исключения единиц изучаемой совокупности
а) 1
б) 2
в) 3
г) 4
062. Единовременное наблюдение — это: 1) наблюдение, охватывающее часть единиц совокупности для характеристики целого; 2) наблюдение, приуроченное к одному какому-либо моменту; 3) наблюдение в порядке текущей регистрации; 4) обследование всех без исключения единиц изучаемой совокупности
а) 1
б) 2
в) 3
г) 4
063. Текущее наблюдение — это: 1) наблюдение, охватывающее часть единиц совокупности для характеристики целого; 2) наблюдение, приуроченное к одному какому-либо моменту; 3) наблюдение в порядке текущей регистрации; 4) обследование всех без исключения единиц изучаемой совокупности
а) 1
б) 2
в) 3
г) 4
064. Из перечисленных видов статистических таблиц наилучшее представление об исследуемой совокупности дает:
а) Простая таблица
б) Групповая таблица
в) Комбинационная таблица
065. Единица наблюдения — это: 1) первичный элемент объекта статистического наблюдения, являющийся носителем признаков, подлежащих регистрации;
2) массив единиц, являющихся носителем изучаемого признака; 3) наблюдение, приуроченное к какому-либо моменту; 4) определение объема наблюдений
а) 1
б) 2
в) 3
г) 4
066. Вариационный ряд — это:
а) Ряд чисел
б) Совокупность вариантов
в) Ряд чисел, характеризующих определенный признак
г) Варианты, расположенные в определенной последовательности
067. Средняя величина — это:
а) Частота явления
б) Структура явления
в) Обобщающая характеристика варьирующего признака
068. При корреляционном анализе используются коэффициенты:
а) Вариации
б) Регрессии
в) Корреляции
г) Соотношения
д) Все вышеперечисленные
069. При соблюдении каких условий средняя арифметическая наиболее точно характеризует средний уровень варьирующего признака: 1) при условии симметричности совокупности, полном представлении выборочной совокупности специфических особенностей генеральной совокупности; 2) при условии симметричности совокупности, числа наблюдений в ней не менее 100; 3) только в генеральной совокупности;
4) в нормальном распределении при достаточно большом числе наблюдений и однородности изучаемого явления; 5) при достаточно большом числе наблюдений и однородности изучаемого явления
а) 1
б) 2
в) 3
г) 4
д) 5
070. Показатель наглядности — это показатель, который: 1) характеризует отношение между двумя, не связанными друг с другом, совокупностями; 2) указывает, во сколько раз или на сколько процентов произошло увеличение или уменьшение сравниваемых величин; 3) указывает на отношение части к целому;
4) указывает на частоту изучаемого явления в среде
а) 1
б) 2
в) 3
г) 4
071. В каких пределах может колебаться значение коэффициента корреляции:
а) от 0 до 1
б) от 0 до 2
в) от 0,5 до 1
г) от –1 до +1
072. В больнице № 1 показатель больничной летальности составил 2,1 ± 0,4 %, а в больнице № 2 —
1,2 ± 0,3 %. В какой больнице качество лечения лучше, на основании чего сделан вывод: 1) сравнению данные показатели не подлежат; 2) в данном случае для сравнения качества лечения нужно применить метод стандартизации, но данных для этого недостаточно;
3) утверждать, что в больнице № 2 качество лечения лучше, нельзя, т. к. по критерию Стьюдента t < 2, т. е. для окончательного вывода надо увеличить число наблюдений; 4) в больнице № 2 качество лечения выше, чем в больнице № 1, т. к. по критерию Стьюдента t > 2
а) 1
б) 2
в) 3
г) 4
073. Медиана ряда (Ме) — это:
а) Наибольшая по значению варианта
б) Варианта, встречающаяся чаще других
в) Центральная варианта, делящая ряд пополам
074. Назовите крайние варианты вариационного ряда, если известно, что Мср. = 40,0 кг, s = 3,0 кг:
а) 37 – 43 кг
б) 31 – 49 кг
в) 39 – 42 кг
075. Укажите формулу, по которой рассчитывается отклонение (d):
а) d = V — Mср.
б) d = Mср. — V
в) d = Mср. — s
г) d = s — Mср.
076. Какая варианта вариационного ряда чаще всего принимается за условную среднюю:
а) Мода
б) Медиана
в) V max
г) V min
077. При сравнении интенсивных показателей, полученных на однородных по своему составу совокупностях, необходимо применять:
а) Оценку показателей соотношения
б) Определение относительной величины
в) Стандартизацию
г) Оценку достоверности разности показателей
д) Все вышеперечисленное
078. Разность между двумя относительными показателями считается достоверной, если превышает свою ошибку:
а) В 2 и более раза
б) Меньше, чем в 2 раза
079. В каких границах возможны случайные колебания средней величины с вероятностью 95,5 %:
а) M ± m
б) M ± 2m
в) M ± 3m
080. Какой степени вероятности соответствует доверительный интервал Р ± 2m:
а) 68,3 %
б) 95,5 %
в) 99,7 %
081. Какой степени вероятности соответствует доверительный интервал М ± 3m:
а) 68,3 %
б) 95,5 %
в) 99,7 %
082. Чем меньше колеблемость признака, тем величина средней ошибки:
а) Меньше
б) Больше
в) Остается неизменной
083. Чтобы уменьшить ошибку выборки, число наблюдений нужно:
а) Увеличить
б) Уменьшить
в) Оставить без изменения
084. Чем меньше число наблюдений, тем величина средней ошибки:
а) Меньше
б) Больше
в) Эти показатели не связаны друг с другом
085. Разница между средними величинами считается достоверной, если:
а) t=1
б) t=2 и больше
в) t<1,5
г) t=1,5
086. Не считается достоверной для научных медико-социальных исследований вероятность:
а) 68,3 %
б) 95,5 %
в) 99,7 %
087. Случайным называют событие, которое:
а) Может произойти при любых заданных условиях
б) При заданных условиях может произойти или не прои-зойти
в) При заданных условиях может произойти
г) Может произойти при не заданных условиях
д) Может не произойти при заданных условиях
088. Средним квадратическим отклонением называется: 1) средняя величина абсолютных отклонений величин признака у членов совокупности от средней арифметической величины данного признака в совокупности; 2) квадратный корень из среднего квадрата отклонения величин признака у членов совокупности от средней арифметической величины данного признака в совокупности; 3) квадратный корень из абсолютных отклонений величины признака у членов совокупности
а) 1
б) 2
в) 3
089. При изучении состояния здоровья населения используются следующие виды относительных показателей:
а) Интенсивные и экстенсивные показатели
б) Показатели соотношения
в) Все вышеперечисленные
090. Интенсивный показатель — это показатель, который: 1) характеризует отношение между двумя, не связанными друг с другом, совокупностями; 2) указывает на отношение части к целому; 3) указывает, во сколько раз или на сколько процентов произошло увеличение или уменьшение сравниваемых величин;
4) указывает на частоту изучаемого явления в среде
а) 1
б) 2
в) 3
г) 4
091. Экстенсивный показатель — это показатель, который: 1) характеризует отношение между двумя, не связанными друг с другом, совокупностями; 2) указывает на отношение части к целому; 3) указывает, во сколько раз или на сколько процентов произошло увеличение или уменьшение сравниваемых величин;
4) указывает на частоту изучаемого явления в среде
а) 1
б) 2
в) 3
г) 4
092. Показатель соотношения — это показатель, который: 1) характеризует отношение между двумя, не связанными друг с другом, совокупностями; 2) указывает на отношение части к целому; 3) указывает, во сколько раз или на сколько процентов произошло увеличение или уменьшение сравниваемых величин;
4) указывает на частоту изучаемого явления в среде
а) 1
б) 2
в) 3
г) 4
093. Общественное здоровье — это:
а) Наука о социологии здоровья
б) Система лечебно-профилактических мероприятий по охране здоровья
в) Наука о социальных проблемах медицины
г) Наука о закономерностях здоровья населения
д) Система социально-экономических мероприятий по охране здоровья
094. Здравоохранение — это:
а) Наука о социологии здоровья
б) Система лечебно-профилактических мероприятий по охране здоровья
в) Наука о социальных проблемах медицины
г) Наука о закономерностях здоровья населения
д) Система социально-экономических мероприятий по охране здоровья
095. Основателем кафедры общественного здоровья и здравоохранения в нашей стране является:
а) Ю. П. Лисицын
б) Н. А. Семашко
в) З. З. Френкель
г) А. В. Петров
д) З. П. Соловьев
096. Общественное здоровье характеризует здоровье:
а) Населения в целом
б) Отдельных возрастно-половых групп населения
в) Каждого жителя страны
г) Каждого жителя региона
д) Больных, страдающих каким-либо хроническим заболеванием
е) Правильные ответы а, б, д
ж) Все ответы правильные
з) Все ответы неправильные
097. Основными группами показателей общественного здоровья являются:
а) Показатели заболеваемости
б) Обращения за медицинской помощью
в) Показатели инвалидности
г) Показатели физического развития
д) Демографические показатели
е) Летальность
ж) Все ответы правильные
з) Верно а, в, г, д
098. К группам факторов, определяющих общественное здоровье, относятся:
а) Биологические
б) Природно-климатические
в) Социально-экономические
г) Образ жизни
д) Уровень организации медицинской помощи
е) Все ответы правильные
ж) Все ответы неправильные
099. Среди факторов, определяющих здоровье населения, лидируют:
а) Экологические
б) Биологические
в) Образ жизни
г) Уровень организации медицинской помощи
д) Качество медицинской помощи
100. Свойство репрезентативности характерно для статистической совокупности:
а) Генеральной
б) Выборочной
101. К средним величинам относятся все величины, кроме:
а) Средней арифметической простой
б) Моды
в) Средней арифметической взвешенной
г) Ошибки средней величины
д) Медианы
102. Для определения достоверности разности двух средних величин необходимо знать:
а) Значения сравниваемых средних величин и их ошибки
б) Величину доверительного коэффициента «t» и объем наблюдения
в) Среднее квадратичное отклонение и ошибки сравниваемых величин
103. Разность показателей является существенной, если величина «t» равна:
а) 0,5
б) 1,0
в) 1,5
г) 2,0
д) 2,5
е) Верно а, г
ж) Верно г, д
з) Верно б, в
104. Оценка коэффициента корреляции производится по следующим параметрам:
а) Характеру (направлению)
б) Стандарту
в) Силе
г) Достоверности
д) Нормативу
е) Верно а, в, г
ж) Верно б, г, д
з) Все ответы неправильные
105. Из применяемых методов стандартизации наиболее точным является:
а) Обратный
б) Косвенный
в) Прямой
106. В медицинских исследованиях малой выборкой называется статистическая совокупность, насчитывающая объем исследования в количестве:
а) До 20 единиц наблюдения
б) До 30 единиц наблюдения
в) До 50 единиц наблюдения
г) До 100 единиц наблюдения
107. К текущим наблюдениям относятся:
а) Перепись населения
б) Регистрация случаев рождения живого ребенка
в) Определение возрастного состава студентов
г) Учет коечного фонда
д) Регистрация случаев смерти
е) Верно б, д
ж) Верно а, в, г
з) Все ответы неправильные
108. Статистические таблицы могут быть:
а) Простыми
б) Комбинационными
в) Контрольными
г) Аналитическими
д) Групповыми
е) Верно а, б, д
ж) Верно в, г, д
з) Верно б, в, г
109. Оптимальным числом взаимосвязанных признаков в комбинационной таблице следует считать:
а) Один–два
б) Три–четыре
в) Пять–шесть
г) Более шести
110. При проведении статистического исследования контрольная группа применяется:
а) Для сравнения с результатами основной группы
б) Для выявления факторов риска
в) Для выявления благоприятных факторов здоровья
г) Все ответы правильные
д) Все ответы неправильные
111. Основными задачами общественного здоровья и здравоохранения в нашей стране являются все, кроме:
а) Разработки мероприятий по сохранению и улучшению здоровья населения
б) Изучения факторов социальной среды, оказывающих влияние на здоровье населения
в) Изучения факторов, способствующих повышению качества медицинской помощи
г) Разработки мероприятий по улучшению жилищных условий населения
ОТВЕТЫ К РАЗДЕЛУ 01
«МЕДИКО-САНИТАРНАЯ СТАТИСТИКА»
001-а 002-в 003-а 004-б 005-в
006-в 007-а 008-б 009-г 010-б
011-в 012-а 013-а 014-а 015-а
016-а 017-а 018-а 019-б 020-в
021-в 022-в 023-а 024-г 025-а
026-в 027-г 028-б 029-д 030-б
031-а 032-б 033-в 034-а 035-а
036-а 037-а 038-а 039-в 040-в
041-а 042-в 043-д 044-в 045-а
046-а 047-в 048-д 049-в 050-д
051-в 052-а 053-б 054-б 055-в
056-г 057-а 058-б 059-в 060-а
061-г 062-б 063-в 064-в 065-а
066-в 067-в 068-в 069-г 070-б
071-г 072-б 073-в 074-б 075-а
076-а 077-г 078-а 079-б 080-б
081-в 082-а 083-а 084-б 085-б
086-а 087-б 088-б 089-а 090-г
091-б 092-а 093-г 094-б 095-б
096-е 097-з 098-е 099-в 100-б
101-г 102-а 103-ж 104-е 105-в
106-б 107-е 108-е 109-б 110-г
111-г