

Об этом SEO параметре
Ошибки в CSS могут быть неважны для поисковиков, но они могут привести к искажённому отображению страницы пользователям, что в итоге может снизить конверсию и увеличить процент посетителей, покинувших страницу. Поэтому убедитесь, что Ваша страница отображается корректно на всех устройствах (включая мобильные), которые для Вас важны.
Как правило, валидация осуществляется посредством Сервиса Валидации Разметки W3C (где W3C расшифровывается как World Wide Web Consortium).
Стили CSS используются, чтобы контролировать внешний вид и форматирование страницы, а также чтобы отделить часть кода, касающуюся структуры, от части кода, касающейся стилей, что призвано уменьшить время загрузки.
Обновлено: 23 июня, 2018
20 июня, 2018 1410 webmaster Технические Seo параметры
Общее количество 6 Голосов
0
6
Скажите нам, как мы можем улучшить это сообщение?
Читайте в этой категории вопросов —
- Использование мета-тега Refresh
- Битые ссылки
- Использование rel canonical
Добавить свой вопрос!
Утверждения и рекомендации автора, могут не совпадать с мнением читателей. Все мнения и рекомендации можно выразить в комментариях к данному материалу.
Комментарии закрыты.
Welcome to a quick tutorial on how to create custom error messages with pure CSS. By now, you should have experienced the intrusive default Javascript alert box. Every time it shows up, users get scared away.
We can create a custom non-intrusive error message with HTML <div>.
<div style="border: 1px solid darkred; background: salmon">
<i>⚠</i> ERROR!
</div>Yep, it is that simple. Let us “improve and package” this simple error notification bar so you can reuse it easily in your project – Read on!
ⓘ I have included a zip file with all the source code at the start of this tutorial, so you don’t have to copy-paste everything… Or if you just want to dive straight in.
TABLE OF CONTENTS
DOWNLOAD & NOTES

Firstly, here is the download link to the example code as promised.
QUICK NOTES
If you spot a bug, feel free to comment below. I try to answer short questions too, but it is one person versus the entire world… If you need answers urgently, please check out my list of websites to get help with programming.
EXAMPLE CODE DOWNLOAD
Click here to download the source code, I have released it under the MIT license, so feel free to build on top of it or use it in your own project.
CSS-ONLY ERROR NOTIFICATIONS

Let us start with the raw basics by creating notification bars with just pure CSS and HTML.
1) BASIC NOTIFICATION BAR
1A) THE HTML
1-basic.html
<div class="bar">Plain message</div>
<div class="bar info">Information message</div>
<div class="bar success">Successful message</div>
<div class="bar warn">Warning message</div>
<div class="bar error">Error message</div>That is actually all we need to create a custom error message, an HTML <div> with the notification message inside. Take note of the bar and info | success | warn | error CSS classes – We will use these to build the notification bar.
1B) THE CSS
error-bar.css
/* (A) THE BASE */
.bar {
padding: 10px;
margin: 10px;
color: #333;
background: #fafafa;
border: 1px solid #ccc;
}
/* (B) THE VARIATIONS */
.info {
color: #204a8e;
background: #c9ddff;
border: 1px solid #4c699b;
}
.success {
color: #2b7515;
background: #ecffd6;
border: 1px solid #617c42;
}
.warn {
color: #756e15;
background: #fffbd1;
border: 1px solid #87803e;
}
.error {
color: #ba3939;
background: #ffe0e0;
border: 1px solid #a33a3a;
}The CSS is straightforward as well –
.baris literally the “basic notification bar” with padding, margin, and border..info | .success | .warn | .errorsets various different colors to fit the “level of notification”.
Feel free to changes these to fit your own website’s theme.
1C) THE DEMO
Plain message
Information message
Successful message
Warning message
Error message
2) ADDING ICONS
2A) THE HTML
2-icon.html
<div class="bar">
<i class="ico">☀</i> Plain message
</div>
<div class="bar info">
<i class="ico">ℹ</i> Information message
</div>
<div class="bar success">
<i class="ico">✔</i> Successful message
</div>
<div class="bar warn">
<i class="ico">⚠</i> Warning message
</div>
<div class="bar error">
<i class="ico">☓</i> Error message
</div>To add icons to the notification bar, we simply prepend the messages with <i class="ico">&#XXXX</i>. For those who do not know – That &#XXXX is a “native HTML symbol”, no need to load extra libraries. Do a search for “HTML symbols list” on the Internet for a whole list of it.
P.S. Check out Font Awesome if you want more icon sets.
2B) THE CSS
error-bar.css
/* (C) ICONS */
i.ico {
display: inline-block;
width: 20px;
text-align: center;
font-style: normal;
font-weight: bold;
}Just a small addition to position the icon nicely.
2C) THE DEMO
☀ Plain message
ℹ Information message
✔ Successful message
⚠ Warning message
☓ Error message
JAVASCRIPT ERROR NOTIFICATIONS

The above notification bars should work sufficiently well, but here are a few small improvements if you are willing to throw in some Javascript.
3) ADDING CLOSE BUTTONS
3A) THE HTML
3-close.html
<div class="bar">
<div class="close" onclick="this.parentElement.remove()">X</div>
<i class="ico">☀</i> Plain message
</div>
<div class="bar info">
<div class="close" onclick="this.parentElement.remove()">X</div>
<i class="ico">ℹ</i> Information message
</div>
<div class="bar success">
<div class="close" onclick="this.parentElement.remove()">X</div>
<i class="ico">✔</i> Successful message
</div>
<div class="bar warn">
<div class="close" onclick="this.parentElement.remove()">X</div>
<i class="ico">⚠</i> Warning message
</div>
<div class="bar error">
<div class="close" onclick="this.parentElement.remove()">X</div>
<i class="ico">☓</i> Error message
</div>Not much of a difference here, except that we now add a <div class="close"> that will act as the close button.
3B) THE CSS
error-bar.css
/* (D) CLOSE BUTTON */
.bar { position: relative; }
div.close {
position: absolute;
top: 30%;
right: 10px;
color: #888;
cursor: pointer;
}There is not much added to the CSS as well. We simply position the close button to the right of the notification bar, and that’s about it.
3C) THE DEMO
4) PACKAGED ERROR NOTIFICATIONS
4A) THE HTML
4-js.html
<!-- (A) LOAD CSS + JS -->
<link href="error-bar.css" rel="stylesheet">
<script src="error-bar.js"></script>
<!-- (B) HTML CONTAINER -->
<div id="demo"></div>
<!-- (C) FOR TESTING -->
<script>
let demo = document.getElementById("demo");
ebar({ target: demo, msg: "Plain" });
ebar({ lvl: 1, target: demo, msg: "Information" });
ebar({ lvl: 2, target: demo, msg: "Success" });
ebar({ lvl: 3, target: demo, msg: "Warning" });
ebar({ lvl: 4, target: demo, msg: "Error" });
</script>The notification bar is has gotten rather messy, and it is a pain to manually copy-paste them. So why not package everything into an easy-to-use Javascript ebar() function?
targetTarget HTML container to generate the error message.msgThe error or notification message.lvlOptional, error level.
4B) THE JAVASCRIPT
error-bar.js
function ebar (instance) {
// target : target html container
// msg : notification message
// lvl : (optional) 1-info, 2-success, 3-warn, 4-error
// (A) CREATE NEW NOTIFICATION BAR
let bar = document.createElement("div");
bar.classList.add("bar");
// (B) ADD CLOSE BUTTON
let close = document.createElement("div");
close.innerHTML = "X";
close.classList.add("close");
close.onclick = () => bar.remove();
bar.appendChild(close);
// (C) SET "ERROR LEVEL"
if (instance.lvl) {
let icon = document.createElement("i");
icon.classList.add("ico");
switch (instance.lvl) {
// (C1) INFO
case 1:
bar.classList.add("info");
icon.innerHTML = "ℹ";
break;
// (C2) SUCCESS
case 2:
bar.classList.add("success");
icon.innerHTML = "☑";
break;
// (C3) WARNING
case 3:
bar.classList.add("warn");
icon.innerHTML = "⚠";
break;
// (C4) ERROR
case 4:
bar.classList.add("error");
icon.innerHTML = "☓";
break;
}
bar.appendChild(icon);
}
// (D) NOTIFICATION MESSAGE
let msg = document.createElement("span");
msg.innerHTML = instance.msg;
bar.appendChild(msg);
// (E) ADD BAR TO CONTAINER
instance.target.appendChild(bar);
}This may look complicated, but this function essentially just creates all necessary notification bar HTML.
4C) THE DEMO
LINKS & REFERENCES
- 6 Ways To Display Messages In HTML JS – Code Boxx
- 2 Ways To Display A Message After Submitting HTML Form – Code Boxx
- 10 Free CSS & JS Notification Alert Code Snippets -SpeckyBoy
- CSS Tips and Tricks for Customizing Error Messages! – Cognito Forms
THE END

Thank you for reading, and we have come to the end. I hope that it has helped you to better understand, and if you want to share anything with this guide, please feel free to comment below. Good luck and happy coding!
Как проверить CSS и HTML-код на валидность и зачем это нужно.
В статье:
-
Что такое валидность кода
-
Чем ошибки в HTML грозят сайту
-
Как проверить код на валидность
-
HTML и CSS валидаторы — онлайн-сервисы для проверки кода
Разберем, насколько критическими для работы сайта и его продвижения могут быть ошибки в HTML-коде, и зачем нужны общие стандарты верстки.
Что такое валидность кода
После разработки дизайна программисты верстают страницы сайта — приводят их к единой структуре в формате HTML. Задача верстальщика — сделать так, чтобы страницы отображались корректно у всех пользователей на любых устройствах и браузерах. Такая верстка называется кроссплатформенной и кроссбраузерной — это обязательное требование при разработке любых сайтов.
Для этого есть специальные стандарты: если им следовать, страницу будут корректно распознавать все браузеры и гаджеты. Такой стандарт разработал Консорциумом всемирной паутины — W3C (The World Wide Web Consortium). HTML-код, который ему соответствует, называют валидным.
Валидность также касается файлов стилей — CSS. Если в CSS есть ошибки, визуальное отображение элементов может нарушиться.
Разработчикам рекомендуется следовать критериям этих стандартов при верстке — это поможет избежать ошибок в коде, которые могут навредить сайту.
Чем ошибки в HTML грозят сайту
Типичные ошибки кода — незакрытые или дублированные элементы, неправильные атрибуты или их отсутствие, отсутствие кодировки UTF-8 или указания типа документа.
Какие проблемы могут возникнуть из-за ошибок в HTML-коде
- страницы загружаются медленно;
- сайт некорректно отображается на разных устройствах или в браузерах;
- посетители видят не весь контент;
- программист не замечает скрытую рекламу и вредоносный код.
Как валидность кода влияет на SEO
Валидность не является фактором ранжирования в Яндекс или Google, так что напрямую она не влияет на позиции сайта в выдаче поисковых систем. Но она влияет на мобилопригодность сайта и на то, как поисковые боты воспринимают разметку, а от этого косвенно могут пострадать позиции или трафик.
Почитать по теме:
Главное о микроразметке: подборка знаний для веб-мастеров
Представитель Google Джон Мюллер говорил о валидности кода:
«Мы упомянули использование правильного HTML. Является ли фактором ранжирования валидность HTML стандарту W3C?
Это не прямой фактор ранжирования. Если ваш сайт использует HTML с ошибками, это не значит, что мы удалим его из индекса — я думаю, что тогда у нас будут пустые результаты поиска.
Но есть несколько важных аспектов:— Если у сайта действительно битый HTML, тогда нам будет очень сложно его отсканировать и проиндексировать.
— Иногда действительно трудно подобрать структурированную разметку, если HTML полностью нарушен, поэтому используйте валидатор разметки.
— Другой аспект касается мобильных устройств и поддержки кроссбраузерности: если вы сломали HTML, то сайт иногда очень трудно рендерить на новых устройствах».
Итак, критические ошибки в HTML мешают
- сканированию сайта поисковыми ботами;
- определению структурированной разметки на странице;
- рендерингу на мобильных устройствах и кроссбраузерности.
Даже если вы уверены в своем коде, лучше его проверить — ошибки могут возникать из-за установки тем, сторонних плагинов и других элементов, и быть незаметными. Не все программисты ориентируются на стандарт W3C, так что среди готовых решений могут быть продукты с ошибками, особенно среди бесплатных.
Как проверить код на валидность
Не нужно вычитывать код и считать символы — для этого есть сервисы и инструменты проверки валидности HTML онлайн.
Что они проверяют:
- Синтаксис
Синтаксические ошибки: пропущенные символы, ошибки в написании тегов. - Вложенность тэгов
Незакрытые и неправильно закрытые теги. По правилам теги закрываются также, как их открыли, но в обратном порядке. Частая ошибка — нарушенная вложенность.
- DTD (Document Type Definition)
Соответствие кода указанному DTD, правильность названий тегов, вложенности, атрибутов. Наличие пользовательских тегов и атрибутов — то, чего нет в DTD, но есть в коде.
Обычно сервисы делят результаты на ошибки и предупреждения. Ошибки — опечатки в коде, пропущенные или лишние символы, которые скорее всего создадут проблемы. Предупреждения — бессмысленная разметка, лишние символы, какие-то другие ошибки, которые скорее всего не навредят сайту, но идут вразрез с принятым стандартом.
Валидаторы не всегда правы — некоторые ошибки не мешают браузерам воспринимать код корректно, зато, к примеру, минификация сокращает длину кода, удаляя лишние пробелы, которые не влияют на его отображение.
Почитать по теме:
Уменьшить вес сайта с помощью gzip, brotli, минификации и других способов
Поэтому анализируйте предложения сервисов по исправлениям и ориентируйтесь на здравый смысл.
Перед исправлением ошибок не забудьте сделать резервное копирование. Если вы исправите код, но что-то пойдет не так и он перестанет отображаться, как должен, вы сможете откатить все назад.
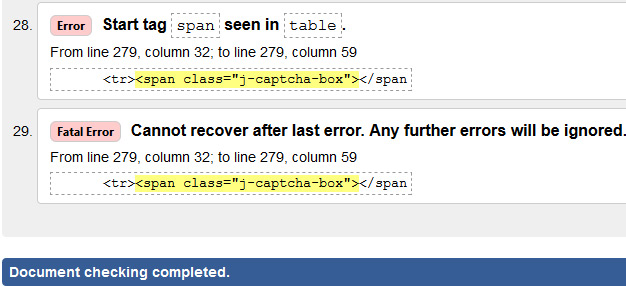
HTML и CSS валидаторы — онлайн-сервисы для проверки кода
Есть довольно много валидаторов, выберите тот, в котором вам удобнее работать. Мы рекомендуем использовать известные сервисы от создателей стандартов. Если пояснения на английском воспринимать сложно, можно использовать автоматический перевод страницы.
Валидатор от W3C
Англоязычный сервис, онлайн проверяет соответствие HTML стандартам: можно проверить код по URL, залить файл или вставить код в окошко.
Инструмент покажет список ошибок и предупреждений с пояснениями — описанием ошибки и ее типом, а также укажет номер строки, в которой нужно что-то исправить. Цветом отмечены типы предупреждений и строчки с кодом.

Валидатор CSS от W3C
Инструмент от W3C для проверки CSS, есть русский язык. Работает по такому же принципу, анализирует стили на предмет ошибок и предупреждений. Первым идет блок ошибок, предупреждения собраны ниже отдельно.

Исправления ошибок и валидации HTML и CSS может быть недостаточно: всегда есть другие возможности испортить отображение сайта. Если что-то не работает, как надо, проведите полноценный аудит, чтобы найти ошибки.
С другой стороны, не зацикливайтесь на поиске недочетов в HTML — если код работает, а контент отображается корректно, лучше направить ресурсы на что-то другое — оптимизацию и ускорение загрузки, например.
Error and Warning Codes
In order to properly use --ignore for the command-line interface, you need to know the code for warnings. You can get them with a little trial and error on the live demo and looking at the Errors / Warnings tab, but this might help you get started.
General Format
The error or warning will either just be the code (eg. block-expected) or a code with some value (eg. browser-only:ie6).
Browsers
Warnings may refer to browsers for the «value» portion of the code. Here’s a list of the browser abbreviations.
c— Google Chromeff— Mozilla Firefoxie— Microsoft’s Internet Explorero— Operas— Safari
Browsers may additionally have a version number after them, so the value of ie6 refers to Microsoft’s Internet Explorer version 6.
Errors
When these are encountered, the output will likely have chunks of CSS removed due to the invalid structure. The CSS format is invalid and needs to get fixed.
block-expected— After a selector, a ruleset should be followed by an open brace.colon-expected— After a property name in a declaration, there should be a colon.ident-after-colon— For selectors, you can use pseudo-elements and pseudo-selectors like «:hover». After the colon, there should be an IDENT token.ident-after-double-colon— Like ident-after-colon, you must have an IDENT token after a double colon in the selector.invalid-token— This is a more generic error where a token was encountered and it wasn’t expected.illegal-token-after-combinator— In a selector, using things like+and>are combinators. After a combinator, it is expected to have another selector.selector-expected— A selector followed by a comma must be followed by another selector.
Warnings
When a warning is generated, it is likely the output CSS will remain the same. Unlike errors, these are not parsing problems that must be fixed. Warnings are helpful hints to help avoid breakage, unexpected behavior, fixing typos and providing tips.
When a code could have a value, you’ll see :## at the end of its name.
add-quotes— To avoid confusion, this value should have quotes.angle— Angles should start at 0 and be less than 360.autocorrect:##— A value has been autocorrected. You will likely want to see what was changed and validate that it looks good.autocorrect-swap— A value has been autocorrected. This currently affects background attachments where the value could be misinterpreted in a CSS3 parser.browser-only:##— This feature only works in one browser.browser-quirk:##— Behaves poorly in the listed browser.browser-unsupported:##— Unsupported in the listed browser.css-deprecated:##— Marked as deprecated in the CSS version specified.css-draft— This property is only in a working draft and is subject to change.css-maximum:##— This works only up to a specific version of CSS. It may still be supported by browsers, but you can start to expect it to not work.css-minimum:##— This was introduced in a specific CSS version and isn’t supported officially before then.css-unsupported:##— This is not supported in a version of CSS.deprecated:##— Deprecated and should not be used, but you can use the value portion instead.extra-tokens-after-value— Extra tokens were found after a valid value. Browsers may discard this entire property.filter-case-sensitive— You used the wrong capitalization for a case sensitive property.filter-use-equals-instead— You must use an equals here instead of colon.font-family-one-generic— Only one generic font family should be used and it should be at the endinherit-not-allowed— The value «inherit» is not allowed here.illegal— This value is illegal.invalid-value— The value specified at this point is invalid for the property.minmax-p-q— For minmax(p,q), the p should not be bigger than q.mixing-percentages— You are not allowed to mix percentages with non-percentage values.not-forward-compatible:##— This is not compatible with the listed CSS version and forward.range-max:##— The CSS uses a value that is too large. The value listed is the maximum.range-min:##— The CSS uses a value that is too small. The value listed is the minimum.remove-quotes— This value should not be quoted.require-integer— This value must be an integer.require-positive-value— This value must be positive.require-value— Properties require a value.reserved— Reserved for future use.suggest-relative-unit:##— You should use a relative unit instead of the one specified. This is a W3C recommendation.suggest-remove-unit:##— You should remove the listed unit from this property’s value.suggest-using:##— Instead of using what’s listed in your CSS, it is suggested you use something else. The value of this is the alternate value or property name.text-align-invalid-string— If a string is specified, it must contain just one character.unknown-property:##— The value part of the warning code is not a known property.wrong-property:##— This is the wrong property name or is poorly supported and you should use the supplied property instead.
Как правило, многие вебмастера загружают свои сайты на хост сразу-же после их создания. При этом они большей частью ориентируются на правильность составления смысла текстового содержания, чем на правильность внутреннего кода страниц.
![]()
Валидация сайта
Но есть и другие факторы, которые могут и влияют на позиции сайта. И к ним относятся, в том числе, и технические факторы. Ну а к техническим относятся и валидация сайта. Так что же это такое?
Если простыми словами, то валидация сайта — это проверка кода сайта на техническое соответствие и ошибки. Ну например, вы забыли использовать закрывающий тег — /html. В последнем HTML5, визуально ничего не поменяется. Однако, это ошибка кода.
При написании кода, возможны и другие ошибки. И опять-таки, современный язык гипер разметки «стерпит» многое. Например, «забытие» закрывающего тега /head. И снова вы не увидите разницу. Но она есть))
На самом деле, при написании сайта, ошибок может быть довольно много. И что хуже, некоторые из этих ошибок, могут проявиться и визуально. Ну может блоки поплывут, может выравнивание, а может и еще что-то. Потенциальных ошибок, тысячи. И далеко не все из них, бросаются в глаза.
В чем опасность?
Ну казалось-бы, ну и что тут такого? Да, нужно сказать, что зачастую такие ошибки не видимы. Точнее, невидимы человеком. А ведь страницы нашего сайта могут посетить не только люди, но и поисковые пауки, которые полностью просматривают сайт. И каждую ошибку, которую они находят на сайте, они передают на сервера поисковиков, таких как Яндекс или Гугл.
А поисковики, в свою очередь, видя что на сайте много ошибок кода, вполне могут сделать вывод о том, что сайт плохой. И значит, не будут поднимать его в поиске. Ну а это уже будет означать, что прощай посетители с поиска.
Да, надо признать, определенная пессимизация сайта из-за ошибок валидации, это довольно редкое явление. Но это вполне возможно, а значит, над валидацией обязательно нужно работать. А что для этого нужно сделать? Понятное дело, вначале ошибки нужно найти.
Но поскольку вручную это очень трудоёмкое и ненадежное дело, то для поиска ошибок, используются специальные сервисы, так называемые «Валидаторы».
Валидатор Markup Validation Service.

Этот сервис проверяет правильность кодов HTML и XHTML, которые являются основой большей части страниц при создании практически любого сайта и определяют его внутреннюю структуру. На этот сервис валидатора можно попасть, если пройти по ссылке http://validator.w3.org
Но здесь есть обязательное условие, которое также относится и к другим валидаторам: проверяемый сайт или его проверяемые страницы должны быть закачаны на хостинг. В противном случае, валидатор не будет «знать» адрес сайта и не сможет ничего проверить. Вот сейчас можно уже рассмотреть, как работать на этом валидаторе.
После захода на страницу этого сервиса, отобразиться вся его функциональная картинка. Но большая часть изображённого и написанного к основной проверке не относится и всё своё внимание надо обратить только на окно ввода адреса проверяемой страницы:
![]()
Вот именно с него и надо начинать.
Вообще-то, проверка валидации сайта чрезвычайно проста, как и весь наш бренный мир: в адресном окне сервиса надо написать адрес сайта, т.е. его URL и затем нажать «Check». После такого простого действия, валидатор «попыхтит» несколько секунд и выдаст следующее:
![]()
Это означает, что никаких ошибок в коде страницы нет и Вы можете быть абсолютно спокойны.
Но также может быть и такой нежелательный вариант:
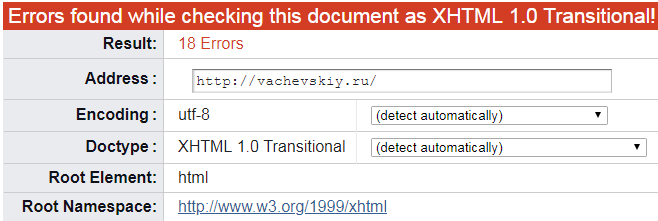
Это уже похуже и означает, что во внутреннем коде проверяемой страницы есть какие-то ошибки. Однако, это совсем не смертельно: просто надо прокрутить страницу ниже и там подробно будут написаны все найденные ошибки в процессе проверки.

Кроме того, валидатор не только перечислит найденные ошибки, но и точно покажет, на какой строке внутреннего кода эти ошибки расположены. Так что долго их искать не придётся. Здесь, ничего не преувеличивая, можно твёрдо сказать, что этот валидор работает прекрасно.
Но это ещё не всё: валидатор не только указывает местоположение обнаруженной ошибки кода, но и даёт достаточно полные рекомендации, каким образом можно устранить эти ошибки. Конечно, для этого не надо лениться и внимательно прочитать всё написанное.
В качестве краткого и обобщенного вывода, можно сказать следующее:
- данный сервис валидатора работает прекрасно и может очень быстро провести проверку сайта.
- Ну и небольшое, но очень приятное дополнение: валидация сайта производиться бесплатно.
- Сейчас можно перейти к следующему этапу: это проверка кода CSS.
Валидатор CSS Validation Service

В общем это вторая функция вышеописанного сервиса, но она «заточена» не для проверки кода HTML и XHTML, а конкретно для проверки правильности кода стиля CSS, расположенного на внешней таблице. А чтобы попасть на страницу сервиса, надо пройти по ссылке http://jigsaw.w3.org/css-validator.
Кстати, здесь стоит отметить нечто приятное: проверка на этом сервисе абсолютно бесплатна. Так что не надо вытаскивать деньги из своего кошелька — пусть они лежат до нужного момента. Однако перейдём к методике работы на этом втором сервисе.
В общем-то вся работа на валидаторе CSS абсолютно идентична проверке на чистоту кода. Поэтому, приводить отдельную картинку адресной строки валидатора нет необходимости. Просто чуть ниже кратко рассмотрим непосредственно порядок самой проверки и всё.
Для этого надо в адресной строке записать URL таблицы CSS, типа «http://мой сайт/style.css» и после этого нажать кнопку с русской надписью «Проверить». Соответственно, этот валидатор тоже несколько секунд «попыхтит» и выдаст искомый результат:
![]()
Это значит, что таблица CSS написана правильно и никаких ошибок в ней не обнаружено.
И здесь также есть приятная неожиданность: если прокрутить страницу несколько ниже, то там будет написан оптимизированный код для Вашей таблицы CSS, из которого убраны все лишние надписи и все теги кода будут расставлены в той последовательности, которая соответствует оптимальным рабочим требованиям всех поисковых систем. Остаётся только скопировать этот идеальный образец кода и вставить его в таблицу CSS.
Вполне может быть, что случиться и такой вариант:

Это значит, что обнаружены какие-то ошибки в коде CSS, но пугаться этого совсем не стоит. Сразу внизу под этой красной строкой, валидатор точно укажет, какой тег написан неправильно. Остаётся только в таблице стиля найти эти теги и сделать нужные исправления.

И конечно, после этого закачать исправленную таблицу стиля на хост и при наличии зелёной строки можно с удовольствием скопировать оптимизированный код стиля таблицы CSS. Вполне понятно, что затем лучше всего поменять старый код на новый и оптимизированный.
Краткое резюме.
Выше были рассмотрены две самых основных и обязательных проверки валидации сайта. Без этих проверок даже не стоит открывать индексацию для поисковых систем в robots.txt В противном случае, сайт может быть проигнорирован для индексации поисковыми машинами и будет считаться неисправным с соответствующими санкциями.
Чтобы этого не произошло, надо затратить всего несколько минут, чтобы быть абсолютно спокойным и полностью уверенным в техническом состоянии своего сайта и всех его страниц. Конечно, необходимо ещё произвести дополнительные проверки ссылок и анкоров, видимости сайта на мобильных устройствах и параметры других кодов. Только тогда сайт можно считать готовым для его полного функционирования и для удачного и быстрого продвижению в ТОП.
Заранее хочется сказать, что все остальные проверки проходят также быстро и просто, как и рассмотренные выше — надо только внимательно прочитать порядок работы с валидатором.
Добавлено 19.04.2018г.
Распространенные ошибки валидности при проверке html кода
Решил дополнить статью ошибками HTML кода, которые часто встречаются на сайтах. Во всяком случае у меня их было много)). Сами ошибки валидатор подсвечивает желтым цветом.
1) Error: Character reference was not terminated by a semicolon.

Ошибка: символ не был прерван точкой с запятой — соответственно надо добавить.
2) Warning: Section lacks heading. Consider using h2-h6 elements to add identifying headings to all sections.
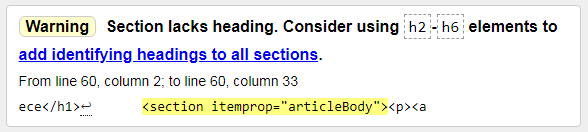
Предупреждение: Раздел не имеет заголовка. Рассмотрите возможность использования элементов h2-h6 для добавления идентифицирующих заголовков ко всем разделам. Тут все понятно, надо добавить хотя бы один подзаголовок. Это даже не ошибка, а рекомендация.
3) Error: Element noindex not allowed as child of element p in this context.
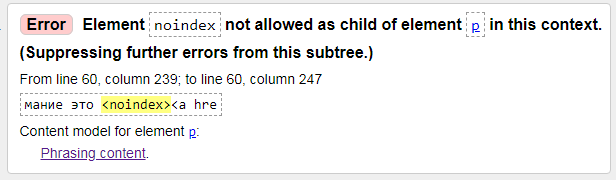
Ошибка: элемент noindex не разрешен как дочерний элемент элемента p в этом контексте. (Подавление дальнейших ошибок из этого поддерева.)
Решение простое, надо закомментировать тег ноиндекс, вид будет таким:

4) Error: The center element is obsolete.

Ошибка: тег «center» устарел — надо заменить, если речь про img то можно использовать атрибут align. Если что-то другое центрировали, то заменить на div.
5) An img element must have an alt attribute, except under certain

Ошибка: Элемент img должен иметь атрибут alt -тут все понятно, надо добавить атрибут альт, даже если он будет незаполненный, то ошибка уйдет.
6) The width attribute on the td element is obsolete. Use CSS instead.
Ошибка: Атрибут «width» на элементе «td» устарел

7) The type attribute is unnecessary for javascript resources
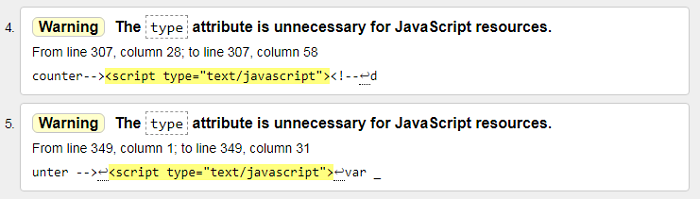
Ошибка: атрибут type не нужен для ресурсов javascript. Решение просто удаляем все лишнее и оставляем только тег «script».
![8)]() The align attribute on the img element is obsolete.
The align attribute on the img element is obsolete.

Ошибка: Атрибут align для элемента img устарел. Сделайте выравнивание изображений дивами.
Ошибка: Неправильное использование тега «li»: отсутствует тег «ul», «ol» . Нужно проверить вложенность элементов списка.
10) End tag for «div» omitted, but OMITTAG NO was specified
Ошибка: Не хватает закрывающего тега div. Решение — добавляем элемент
11) End tag for element «div» which is not open
Ошибка: закрывающий тег div лишний. Соответственно удаляем.
Жду ваших комментариев, а у вас на сайтах валидный код?
Как проверить CSS и HTML-код на валидность и зачем это нужно.
В статье:
-
Что такое валидность кода
-
Чем ошибки в HTML грозят сайту
-
Как проверить код на валидность
-
HTML и CSS валидаторы — онлайн-сервисы для проверки кода
Разберем, насколько критическими для работы сайта и его продвижения могут быть ошибки в HTML-коде, и зачем нужны общие стандарты верстки.
Что такое валидность кода
После разработки дизайна программисты верстают страницы сайта — приводят их к единой структуре в формате HTML. Задача верстальщика — сделать так, чтобы страницы отображались корректно у всех пользователей на любых устройствах и браузерах. Такая верстка называется кроссплатформенной и кроссбраузерной — это обязательное требование при разработке любых сайтов.
Для этого есть специальные стандарты: если им следовать, страницу будут корректно распознавать все браузеры и гаджеты. Такой стандарт разработал Консорциумом всемирной паутины — W3C (The World Wide Web Consortium). HTML-код, который ему соответствует, называют валидным.
Валидность также касается файлов стилей — CSS. Если в CSS есть ошибки, визуальное отображение элементов может нарушиться.
Разработчикам рекомендуется следовать критериям этих стандартов при верстке — это поможет избежать ошибок в коде, которые могут навредить сайту.
Чем ошибки в HTML грозят сайту
Типичные ошибки кода — незакрытые или дублированные элементы, неправильные атрибуты или их отсутствие, отсутствие кодировки UTF-8 или указания типа документа.
Какие проблемы могут возникнуть из-за ошибок в HTML-коде
- страницы загружаются медленно;
- сайт некорректно отображается на разных устройствах или в браузерах;
- посетители видят не весь контент;
- программист не замечает скрытую рекламу и вредоносный код.
Как валидность кода влияет на SEO
Валидность не является фактором ранжирования в Яндекс или Google, так что напрямую она не влияет на позиции сайта в выдаче поисковых систем. Но она влияет на мобилопригодность сайта и на то, как поисковые боты воспринимают разметку, а от этого косвенно могут пострадать позиции или трафик.
Почитать по теме:
Главное о микроразметке: подборка знаний для веб-мастеров
Представитель Google Джон Мюллер говорил о валидности кода:
«Мы упомянули использование правильного HTML. Является ли фактором ранжирования валидность HTML стандарту W3C?
Это не прямой фактор ранжирования. Если ваш сайт использует HTML с ошибками, это не значит, что мы удалим его из индекса — я думаю, что тогда у нас будут пустые результаты поиска.
Но есть несколько важных аспектов:— Если у сайта действительно битый HTML, тогда нам будет очень сложно его отсканировать и проиндексировать.
— Иногда действительно трудно подобрать структурированную разметку, если HTML полностью нарушен, поэтому используйте валидатор разметки.
— Другой аспект касается мобильных устройств и поддержки кроссбраузерности: если вы сломали HTML, то сайт иногда очень трудно рендерить на новых устройствах».
Итак, критические ошибки в HTML мешают
- сканированию сайта поисковыми ботами;
- определению структурированной разметки на странице;
- рендерингу на мобильных устройствах и кроссбраузерности.
Даже если вы уверены в своем коде, лучше его проверить — ошибки могут возникать из-за установки тем, сторонних плагинов и других элементов, и быть незаметными. Не все программисты ориентируются на стандарт W3C, так что среди готовых решений могут быть продукты с ошибками, особенно среди бесплатных.
Как проверить код на валидность
Не нужно вычитывать код и считать символы — для этого есть сервисы и инструменты проверки валидности HTML онлайн.
Что они проверяют:
- Синтаксис
Синтаксические ошибки: пропущенные символы, ошибки в написании тегов. - Вложенность тэгов
Незакрытые и неправильно закрытые теги. По правилам теги закрываются также, как их открыли, но в обратном порядке. Частая ошибка — нарушенная вложенность.
- DTD (Document Type Definition)
Соответствие кода указанному DTD, правильность названий тегов, вложенности, атрибутов. Наличие пользовательских тегов и атрибутов — то, чего нет в DTD, но есть в коде.
Обычно сервисы делят результаты на ошибки и предупреждения. Ошибки — опечатки в коде, пропущенные или лишние символы, которые скорее всего создадут проблемы. Предупреждения — бессмысленная разметка, лишние символы, какие-то другие ошибки, которые скорее всего не навредят сайту, но идут вразрез с принятым стандартом.
Валидаторы не всегда правы — некоторые ошибки не мешают браузерам воспринимать код корректно, зато, к примеру, минификация сокращает длину кода, удаляя лишние пробелы, которые не влияют на его отображение.
Почитать по теме:
Уменьшить вес сайта с помощью gzip, brotli, минификации и других способов
Поэтому анализируйте предложения сервисов по исправлениям и ориентируйтесь на здравый смысл.
Перед исправлением ошибок не забудьте сделать резервное копирование. Если вы исправите код, но что-то пойдет не так и он перестанет отображаться, как должен, вы сможете откатить все назад.
HTML и CSS валидаторы — онлайн-сервисы для проверки кода
Есть довольно много валидаторов, выберите тот, в котором вам удобнее работать. Мы рекомендуем использовать известные сервисы от создателей стандартов. Если пояснения на английском воспринимать сложно, можно использовать автоматический перевод страницы.
Валидатор от W3C
Англоязычный сервис, онлайн проверяет соответствие HTML стандартам: можно проверить код по URL, залить файл или вставить код в окошко.
Инструмент покажет список ошибок и предупреждений с пояснениями — описанием ошибки и ее типом, а также укажет номер строки, в которой нужно что-то исправить. Цветом отмечены типы предупреждений и строчки с кодом.
Валидатор CSS от W3C
Инструмент от W3C для проверки CSS, есть русский язык. Работает по такому же принципу, анализирует стили на предмет ошибок и предупреждений. Первым идет блок ошибок, предупреждения собраны ниже отдельно.
Исправления ошибок и валидации HTML и CSS может быть недостаточно: всегда есть другие возможности испортить отображение сайта. Если что-то не работает, как надо, проведите полноценный аудит, чтобы найти ошибки.
С другой стороны, не зацикливайтесь на поиске недочетов в HTML — если код работает, а контент отображается корректно, лучше направить ресурсы на что-то другое — оптимизацию и ускорение загрузки, например.
Ошибки в HTML-коде способны повлечь за собой некорректное отображение ресурса в выдаче, стать причиной сбоев в поисковом продвижении и работе сайта. Избежать таких неприятностей можно, соблюдая валидность кода. HTML-код, выполненный в соответствии со стандартом W3C (TheWorldWideWebConsortium), называют валидным. Главная задача верстальщика –обеспечить кроссплатформенную (кроссбраузерную) верстку согласно этому стандарту. Валидность касается и файлов стилей – CSS. Ошибка в CSS приводит к визуальному искажению элементов.
Чем страшны для сайта ошибки в HTML
Наиболее частыми ошибками в HTML-коде являются дублированные или незакрытые элементы, некорректные атрибуты или их отсутствие, а также отсутствие указания типа документа или кодировки UTF-8. Следствием таких ошибок может стать:
- медленная загрузка страниц,
- некорректное отображение сайта на разных устройствах и в браузерах,
- частичное отображение контента,
- незаметный для программиста вредоносный код или скрытая реклама.
Влияние валидности кода на SEO
Несмотря на то, что валидность не является фактором ранжирования в поисковых системах, она важна для адаптивности сайта к мобильным устройствам, влияет на то, как поисковые боты будут воспринимать разметку.
Эти варианты имеют косвенное влияние на трафик и позиции ресурса в выдаче.
По мнению представителя Google, Джона Мюллера, сайты с битым HTML-кодом сложнее сканировать и индексировать. Если код нарушен и сложно подобрать структурированную разметку, рекомендуется использовать валидатор разметки. Что касается поддержки кроссбраузерности и мобильных гаджетов, при сломанном коде сайт сложно рендерить на новых устройствах.
Итак, проблемы, вызванные критическими ошибками в HTML, касаются:
- сканирования сайта ботами,
- структуры разметки веб-страниц;
- рендеринга на мобильных гаджетах;
- кроссбраузерности.
Зачастую ошибки в HTML-коде незаметны – они могут возникать в результате установки сторонних плагинов и других дополнений. Не все программисты придерживаются W3C, поэтому пользуясь готовыми решениями, проверяйте их на наличие ошибок.
Как проверить HTML-код на валидность?
Вам не нужно самостоятельно вычитывать код и подсчитывать символы – для этого существуют инструменты и сервисы проверки HTML-кода онлайн.
В их задачи входят:
- Проверка синтаксиса. Поиск синтаксических ошибок – пропущенных символов, ошибок в тегах;
- Анализ вложенности тегов. Поиск неправильно закрытых или незакрытых тегов. Теги должны закрываться в обратном порядке тому, как открывались. Нарушенная вложенность – одна из самых частых ошибок;
- Проверка DTD (DocumentTypeDefinition). Анализируется соответствие кода указанному DTD, вложенности, атрибутов тегов. Присутствие пользовательских атрибутов и тегов – то, что отсутствует в DTD, но имеется в коде.
Результаты проверки сервисов выводятся в виде:
- Ошибок. Лишние, пропущенные символы, опечатки в коде, способные стать причиной проблем в работе ресурса;
- Предупреждений. Ненужные символы, лишняя разметка и другие ошибки, не имеющие потенциальной опасности для сайта, но не отвечающие принятому стандарту.
Валидаторы не всегда дают верную информацию – некоторые из выявленных ими ошибок могут не влиять на корректность работы кода в браузере, но зато, к примеру, минификация убирает лишние пробелы, сокращает код, что неважно для его отображения.
Вывод: стоит проанализировать рекомендации сервиса относительно ошибок и руководствоваться здравым смыслом. Перед тем, как вносить правки обязательно выполните резервное копирование, чтобы в случае форс-мажора откатить все назад.
ТОП-5 валидаторов кода HTML и CSS

Существует множество онлайн-сервисов для проверки кода. Представляем вашему вниманию подборку валидаторов от создателей стандартов.
- Валидатор от W3C. Англоязычный онлайн-сервис, проверяющий соответствие HTML-кода стандартам W3C. Можно проверить код по URL, загрузить файл или вставить HTML-код в поле. Все ошибки и предупреждения будут подробно описаны и выделены цветом.
- Валидатор CSS от WSC. Онлайн-инструмент для проверки CSS от разработчиков стандартов W3C. Сервис анализирует стили и выдает ошибки и предупреждения. Имеется русский язык.
- WDG HTML Validator. Англоязычный сервис для проверки валидации кода. Анализирует по URL, позволяет загружать файл с кодом или вставлять код в поле проверки. Сервис может проверить сразу весь сайт или пакет ссылок. Ошибки выдаются списком, символы и строки выделяются, что упрощает поиск мест для исправлений.
- FIND-XSS.NET. Онлайн-сервис для тех, кому сложно разобраться в W3C валидаторах. Имеет базовый набор инструментов для анализа веб-страниц. Простой и понятный в использовании ресурс.
- Dr.Watson Validator. Еще один неплохой валидатор, который кроме проверки синтаксиса HTML, обеспечивает анализ ссылок, проверку количества слов в тексте, код ответа страниц, анализирует совместимость с поисковыми системами и так далее.
Можно проверять HTML-код с помощью браузерных плагинов таких, как, к примеру, HTML ValidationBookmarklet, HTML TidyBrowserExtension или WebDeveloper для Chrome, HTML Validator для Chrome и Firefox, W3C MarkupValidationService или Validator для Opera, для Safari-Zappatic.
Если после проверки валидации HTML и CSS ресурс отображается некорректно, стоит провести полноценный аудит сайта и устранить найденные ошибки. Однако уделять слишком много времени поиску недочетов в коде тоже не стоит, лучше потратить силы, к примеру, на ускорение загрузки или оптимизацию и развитие сайта.
Наличие ошибок в коде страницы сайта всегда влечет за собой негативные последствия – от ухудшения позиций в ранжировании до жалоб со стороны пользователей. Ошибки валидации могут наблюдаться как на главной, так и на иных веб-страницах, их наличие свидетельствует о том, что ресурс является невалидным. Некоторые проблемы замечают даже неподготовленные пользователи, другие невозможно обнаружить без предварительного аудита, анализа. О том, что такое ошибки валидации и как их обнаружить, мы сейчас расскажем.

Ошибка валидации, что это такое?
Для написания страниц используется HTML – стандартизированный язык разметки, применяемый в веб-разработке. HTML, как любой другой язык, имеет специфические особенности синтаксиса, грамматики и т. д. Если во время написания кода правила не учитываются, то после запуска сайта будут появляться различные виды проблем. Если HTML-код ресурса не соответствует стандарту W3C, то он является невалидным, о чем мы писали выше.
Почему ошибки валидации сайта оказывают влияние на ранжирование, восприятие?
Наличие погрешностей в коде – проблема, с которой необходимо бороться сразу после обнаружения. Поисковые системы «читают» HTML-код, если он некорректный, то процесс индексации и ранжирования может быть затруднен. Поисковые роботы должны понимать, каким является ресурс, что он предлагает, какие запросы использует. Особо критичны такие ситуации для ресурсов, имеющих большое количество веб-страниц.
Как проверить ошибки валидации?

Для этой работы используется либо технический аудит сайта, либо валидаторы, которые ищут проблемы автоматически. Одним из самых популярных является сервис The W3C Markup Validation Service, выполняющий сканирование с оглядкой на World Wide Web Consortium (W3C). Рассматриваемый валидатор предлагает три способа, с помощью которых можно осуществить проверку сайта:
- ввод URL-адреса страниц, которые необходимо просканировать;
- загрузка файла страницы;
- ввод части HTML-кода, нуждающегося в проверке.
После завершения проверки вы получите развернутый список выявленных проблем, дополненных описанием, ссылками на стандарты W3C. По ходу анализа вы увидите слабые места со ссылками на правила, что позволит самостоятельно исправить проблему.
Существуют другие сервисы, позволяющие выполнить проверку валидности кода:
- Dr. Watson. Проверяет скорость загрузки страниц, орфографию, ссылки, а также исходный код;
- InternetSupervision.com. Отслеживает производительность сайта, проверяет доступность HTML.
Плагины для браузеров, которые помогут найти ошибки в коде
Решить рассматриваемую задачу можно с помощью плагинов, адаптированных под конкретный браузер. Можно использовать следующие инструменты (бесплатные):
- HTML Validator для браузера Firefox;
- HTML Validator for Chrome;
- Validate HTML для Firefox.
После проверки нужно решить, будете ли вы устранять выявленные ошибки. Многие эксперты акцентируют внимание на том, что поисковые системы сегодня уделяют больше внимания качеству внешней/внутренней оптимизации, контенту, другим характеристикам. Однако валидность нельзя оставлять без внимания, ведь если даже обнаруженные проблемы не будут мешать поисковым ботам, то они точно начнут раздражать посетителей сайта.
Как исправить ошибку валидации?

В первую очередь нужно сосредоточить внимание на слабых местах, связанных с контентом – это то, что важно для поисковых систем. Если во время сканирования было выявлено более 25 проблем, то их нельзя игнорировать из-за ряда причин:
- частичная индексация;
- медленная загрузка;
- баги, возникающие во время непосредственной коммуникации пользователя с ресурсом.
Например, игнорирование ошибок может привести к тому, что некоторые страницы не будут проиндексированы. Для решения рассматриваемой проблемы можно привлечь опытного фрилансера, однако лучшее решение – заказ услуги в веб-агентстве, что позволит исправить, а не усугубить ситуацию.
Технический и SEO-аудит
Выявление ошибок – первый шаг, ведь их еще нужно будет устранить. При наличии большого пула проблем целесообразно заказать профессиональный аудит сайта. Он поможет найти разные виды ошибок, повысит привлекательность ресурса для поисковых ботов, обычных пользователей: скорость загрузки страниц, верстка, переспам, другое.
В заключение
На всех сайтах наблюдаются ошибки валидации – их невозможно искоренить полностью, но и оставлять без внимания не стоит. Например, если провести проверку сайтов Google или «Яндекс», то можно увидеть ошибки, однако это не означает, что стоит вздохнуть спокойно и закрыть глаза на происходящее. Владелец сайта должен ставить во главу угла комплексное развитие, при таком подходе ресурс будет наполняться, обновляться и «лечиться» своевременно. Если проблем мало, то можно попробовать устранить их своими силами или с помощью привлечения стороннего частного специалиста. В остальных случаях лучше заказать услугу у проверенного подрядчика.

Разбор ошибок валидации сайта
Наконец-то появилось свободное время между бесконечной чередой заказов, и я решил заняться своим блогом. Попробуем его улучшить в плане валидации. Ниже в статье я расскажу, что такое валидация сайта, кода html и css, зачем она нужна и как привести сайт к стандартам на конкретном примере.
Что такое валидация сайта?
Простыми словами – это проверка на соответствие стандартам. Чтобы любой браузер мог отображать ваш сайт корректно. Большое влияние валидность сайта на продвижение не оказывает, но хуже точно не будет.
Конкретный пример прохождения валидации для страницы сайта
Возьмем первую попавшуюся страницу на моем сайте — Кодирование и декодирование base64 на Java 8. Забьем адрес страницы в валидатор и смотрим результат:
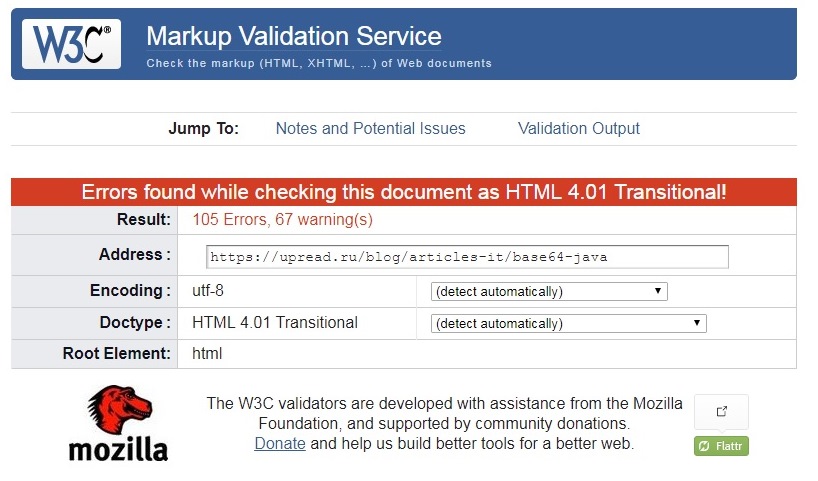
Errors found while checking this document as HTML 4.01 Transitional! Result: 105 Errors, 67 warning(s)
Да уж, картина вырисовывается неприятная: больше сотни ошибок и 67 предупреждений – как вообще поисковики индексируют мой блог, и заходят люди? Но не будем огорчаться, а научимся проходить валидацию, справлять ошибки. Итак, первое предупреждение:
Unable to Determine Parse Mode! The validator can process documents either as XML (for document types such as XHTML, SVG, etc.) or SGML (for HTML 4.01 and prior versions). For this document, the information available was not sufficient to determine the parsing mode unambiguously, because: the MIME Media Type (text/html) can be used for XML or SGML document types No known Document Type could be detected No XML declaration (e.g <?xml version="1.0"?>) could be found at the beginning of the document. No XML namespace (e.g <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">) could be found at the root of the document. As a default, the validator is falling back to SGML mode. Warning No DOCTYPE found! Checking with default HTML 4.01 Transitional Document Type. No DOCTYPE Declaration could be found or recognized in this document. This generally means that the document is not declaring its Document Type at the top. It can also mean that the DOCTYPE declaration contains a spelling error, or that it is not using the correct syntax. The document was checked using a default "fallback" Document Type Definition that closely resembles “HTML 4.01 Transitional”.
Это одно и тоже. А исправляется просто: в самом начале страницы добавить тег:
<!DOCTYPE html>
Проверяем ,что у нас получилось и видим, что одним этим тегом мы убрали 105 ошибок и 3 предупреждения! Теперь у нас осталось только 64 предупреждения. Начинаем разбирать их по одному.
Warning: The type attribute for the style element is not needed and should be omitted. From line 5, column 1; to line 5, column 23 /x-icon">↩<style type="text/css">↩↩↩↩A
Это значит, что для элемента style не нужен атрибут type – это лишнее. На странице у нас два таких замечания. Аналогичное предупреждение и по JavaScript:
Warning: The type attribute is unnecessary for JavaScript resources. From line 418, column 1; to line 418, column 31 </script>↩<script type="text/javascript">↩$(doc
Таких у нас 8 ошибок. Убираем данные атрибуты и ура – еще на 10 предупреждений меньше!
Error: CSS: background: The first argument to the linear-gradient function should be to top, not top. At line 39, column 61 0%,#E8E8E8 100%);↩ border-r
Следующая ошибка — первый аргумент у linear-gradient должен быть to top, а не top. Исправлем. Далее ошибка:
Error: CSS: Parse Error. From line 65, column 13; to line 65, column 16 margin: 0 auto;↩padd
Здесь у меня неверно закомментировано css. Надо просто убрать эту строку. Или закомментировать по-другому /* и */. Я так сделал, как привык так комментировать на Java.
Error: CSS: @import are not allowed after any valid statement other than @charset and @import.. At line 88, column 74 0,600,700,300);↩@import url(//
Теперь у нас идет ошибка импорта. Перенесем эти строчки в самое начало файла и она исчезнет.
Error: Bad value _blanck for attribute target on element a: Reserved keyword blanck used. From line 241, column 218; to line 241, column 295 cookies. <a href="//upread.ru/art.php?id=98" target="_blanck" style="display: inline;">Здесь
Далее не нравится значение атрибута target, нам сообщают, что надо использовать «blank» без нижнего подчеркивания спереди. Убираем.
Error: End tag li seen, but there were open elements. From line 379, column 2; to line 379, column 6 <ul>↩ </li>↩↩</ul
Теперь у нас идет div не на месте.
Error: Table columns in range 2…3 established by element td have no cells beginning in them. From line 262, column 5; to line 263, column 94 px;">↩<tr>↩<td colspan="3" style="width:100%; padding-bottom: 25px;padding-top: 0px; text-align:center;">↩<img
Следующая ошибка – лишний colspan у ячейки. В моем случае таблица состоит всего из одной ячейки, видимо, забыл убрать, когда менял дизайн. Теперь это и делаем.
Error: Element style not allowed as child of element div in this context. (Suppressing further errors from this subtree.) From line 486, column 1; to line 486, column 7 ↩</table>↩<tyle>↩.hleb Contexts in which element style may be used: Where metadata content is expected. In a noscript element that is a child of a head element. In the body, where flow content is expected. Content model for element div: If the element is a child of a dl element: one or more dt elements followed by one or more dd elements, optionally intermixed with script-supporting elements. If the element is not a child of a dl element: Flow content.
А эта ошибка говорит о том, что нельзя вставлять style внутри div. Переносим в начало файла.
Error: The width attribute on the table element is obsolete. Use CSS instead. From line 505, column 1; to line 505, column 21 >↩↩↩↩↩↩↩↩↩<table width ="100%">↩<tr>↩
Тут нам подсказывают, что не стоит устанавливать ширину атрибутом, а лучше сделать это отдельным тегом. Меняем на style=»width:100%;».
Error: Duplicate attribute style. At line 507, column 41 ign="top" style="padding-right
Переводим: дублируется атрибут style. Второй стиль при этом работать не будет. Объединяем
Error: Attribute name not allowed on element td at this point. From line 506, column 5; to line 507, column 82 0%;">↩<tr>↩<td style="width:1%;padding-right:10px;" valign="top" name="navigid" id="navigid">↩↩↩↩</ Attributes for element td: Global attributes colspan - Number of columns that the cell is to span rowspan - Number of rows that the cell is to span headers - The header cells for this cell
У ячейки не должно быть имени – атрибута name. Тут в принципе можно убрать, id вполне хватит.
Error: The valign attribute on the td element is obsolete. Use CSS instead. From line 506, column 5; to line 507, column 67 0%;">↩<tr>↩<td style="width:1%;padding-right:10px;" valign="top" id="navigid">↩↩↩↩</
Убираем valign. Вместо него ставим style=»vertical-align:top».
Error: & did not start a character reference. (& probably should have been escaped as &.) At line 543, column 232 при lineLength &t;= 0) и lineS
А эта ошибка вообще непонятно как оказалась ) Это я коде к статье ошибся. Меняем на <
Error: An img element must have an alt attribute, except under certain conditions. For details, consult guidance on providing text alternatives for images. From line 654, column 1; to line 654, column 30 /><br />↩<img src="img/art374-1.jpg" />↩<br /
У изображений должен быть alt. Добавляем альты с описанием картинок.
Error: CSS: padding: only 0 can be a unit. You must put a unit after your number. From line 260, column 18; to line 260, column 19 dding: 10 20;↩}↩↩#
Только ноль может быть без обозначений. Надо поставить что – это пиксели, или к примеру, проценты. Добавляем px после чисел.
Warning: The document is not mappable to XML 1.0 due to two consecutive hyphens in a comment. At line 974, column 8 ipt> ↩↩↩ <!--детектим адблок
Не нравятся комментарии. Да, в общем, их можно и убрать, не разбираясь, не особенно они и нужны.
Error: Stray end tag td. From line 982, column 1; to line 982, column 5 ↩</table>↩</td>↩↩<sty
Заблудившийся тег td. Убираем его.
Error: Bad value for attribute action on element form: Must be non-empty. From line 1102, column 6; to line 1102, column 98 /h6>↩ <form action="" id="jaloba-to-me" class="submit" method="POST" accept-charset="windows-1251"> <tabl
Здесь валидатор не устраивает пустое значение атрибута action – должен быть адрес страницы какой-то. У нас обрабатывается данная форма js, так что без разницы, поставим action=”self”
Все! Смотрим результат:
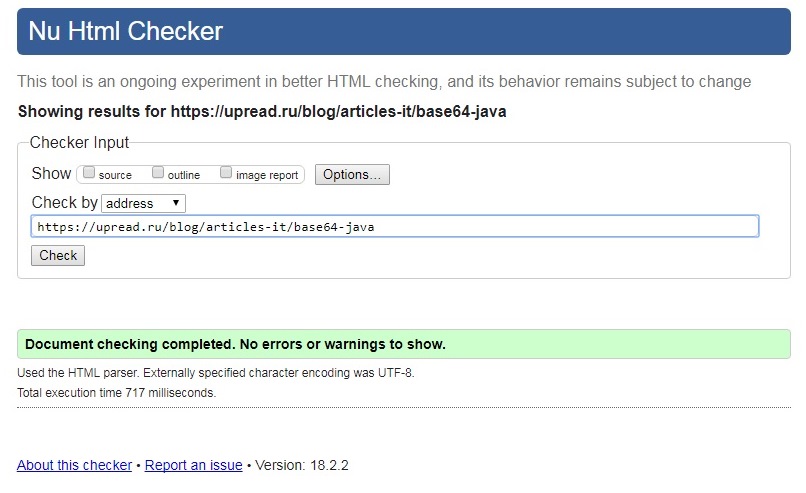
Нет ошибок или предупреждений, страница полностью валидна.
Если вам что-то непонятно в статье или вы хотите, чтобы ваш сайт полностью соответствовал спецификации и стандартам HTML ,вы можете обратиться ко мне. Я проверю и устраню любые шибки валидации.

Автор этого материала — я — Пахолков Юрий. Я оказываю услуги по написанию программ на языках Java, C++, C# (а также консультирую по ним) и созданию сайтов. Работаю с сайтами на CMS OpenCart, WordPress, ModX и самописными. Кроме этого, работаю напрямую с JavaScript, PHP, CSS, HTML — то есть могу доработать ваш сайт или помочь с веб-программированием. Пишите сюда.
![]() заметки, сайтостроение, html, валидация
заметки, сайтостроение, html, валидация
Ошибки валидации – это ошибки в коде страниц сайта, при этом ошибки на главной странице и на внутренних страницах сайта могут отличаться друг от друга. Сайт считается валидным, если у него отсутствуют ошибки в коде страниц сайта. Ошибки могут появляться в ходе разработки сайта, например, когда неверно закрыты html-теги или не закрыты вовсе, когда используются устаревшие теги, не задан тип документа (<!DOCTYPE html>), некорректно организована вложенность элементов и другие. Часть ошибок могут быть видимыми, и пользователь сможет заметить их при посещении страниц сайта, часть ошибок может быть скрытой от глаз.
Наиболее популярный и зарекомендовавший себя валидатор, на наш взгляд, – validator.w3.org, он сканирует сайт на наличие ошибок в соответствии с принятыми Консорциумом Всемирной паутины стандартами. Данный валидатор имеет 3 способа проверки на ошибки: ввести URL конкретной страницы вашего сайта, загрузить файл страницы сайта и ввести часть кода сайта, которую необходимо проверить.
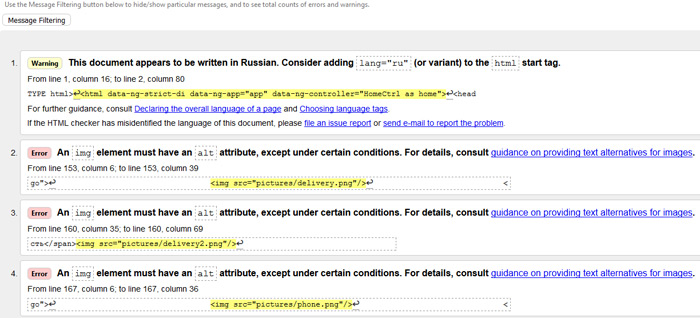
После выполнения проверки вам будет предоставлен список ошибок на странице с указанием описания ошибки, номер строки с ошибкой и в какой части строки содержится ошибка.
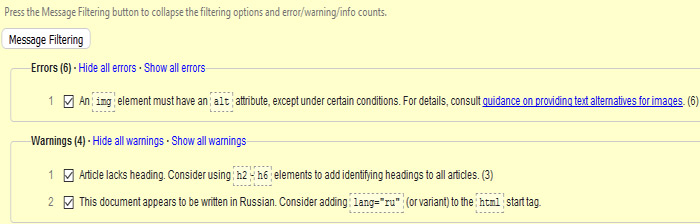
Присутствует функция фильтрации ошибок, с помощью которой вы можете исправлять по очереди конкретные группы ошибок, кроме этого для каждой ошибки предоставляется ссылка на w3c стандарты, где можно ознакомиться с причиной появления данной ошибки.
Также существуют плагины для браузеров для поиска ошибок на страницах сайта.
http://users.skynet.be/mgueury/mozilla/ – плагин для Mozilla
https://chrome.google.com/webstore/detail/html-tidy-browser-extensi/gljdonhfjnfdklljmfaabfpjlonflfnm – плагин для Chrome
https://addons.opera.com/en/extensions/details/validator/ – плагин для Opera
После того как сайт проверили на ошибки, встает вполне резонный вопрос: нужно ли их немедленно удалять и чем это чревато при SEO-продвижении?
Поисковые системы при ранжировании сайтов в поисковой выдаче все же уделяют больше внимания другим аспектам, таким как внутренняя оптимизация сайта, ссылочный профиль, контент. Но и валидацию полностью игнорировать все же не стоит.
В первую очередь рекомендую обратить внимание на ошибки, связанные с контентом, т.к. для поисковиков данный фактор является важным при ранжировании сайтов. Если ошибок на страницах сайта достаточно много (более 25), то настоятельно рекомендуется устранять ошибки в коде, т.к. сайты с большим количеством ошибок дольше загружаются, а также их сложнее проиндексировать, что может привести к отсутствию части страниц сайта в индексе поисковой системы.
Давайте проанализируем, сколько ошибок присутствует в коде страниц у крупных ресурсов.
Яндекс:
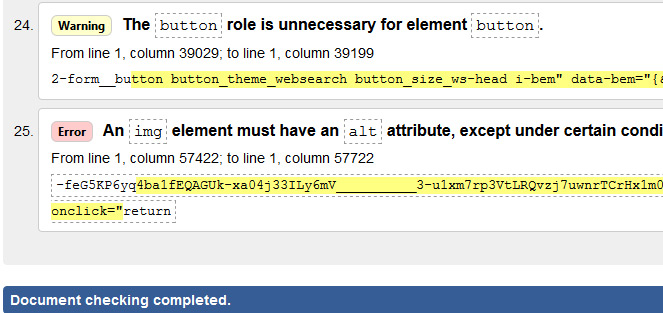
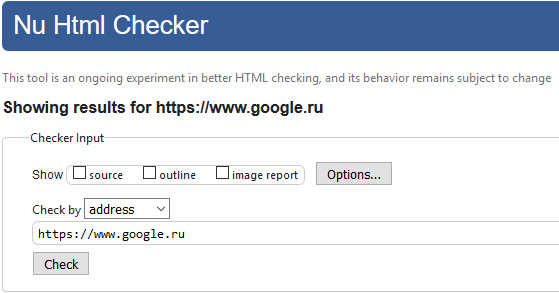
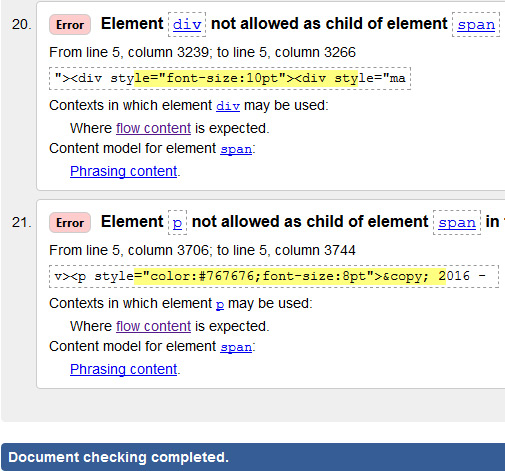
Google:
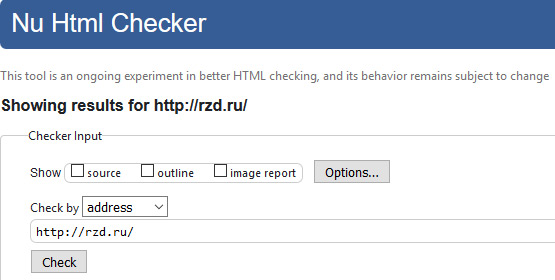
ОАО «РЖД»:
Как вы уже заметили, даже у сайтов поисковых систем присутствуют ошибки в коде страниц, что лишний раз подтверждает, что устранение ошибок носит скорее рекомендательный характер, при этом стоит упомянуть, что не нужно пренебрегать этим фактором и «запускать» ваш сайт. Развивайте сайт комплексно, всесторонне, тогда и результат будет соответствовать вашим ожиданиям.
Кстати, проверка сайта на ошибки, которые действительно влияют на продвижение, проходит в рамках SEO-аудита. Если сомневаетесь, что можете адекватно оценить свой сайт на наличие ошибок, обращайтесь.
Валидация сайта и ее влияние на работоспособность ресурса
Если вы не знали, то между обычным строительством и «возведением» сайтов есть много общего. В процессе создания дома и интернет ресурса нужно соблюдать правильные пропорции между основными частями.
При этом важно придерживаться установленных правил и стандартов, а также соблюдать размерность, указанную в проектной документации. Иначе здание или интернет ресурс могут не пройти процедуру валидации. И тогда придется все начинать сначала:

- Валидация в сайтостроении
- Валидный HTML
- Проблема валидности CSS
- Валидность XML
- Часто встречающиеся ошибки валидации
Теперь все вышесказанное «натянем» на принципы построения современного интернета. Но в виртуальном пространстве, как и в королевстве кривых зеркал все не так однозначно. И значения обоих терминов (валидации и верификации) просто слились воедино:

Под валидацией сайта понимается соответствие программного кода ресурса всем установленным и общепринятым нормам разработки, верстки и веб-дизайна. А также тем условиям, которые были выдвинуты заказчиком исполнителю и прописаны в ТЗ разрабатываемого ресурса.
Но чаще всего под валидностью подразумевается именно соответствие кода (программного, html и css) общепринятым и прописанным нормам. Существует несколько организаций, занимающихся стандартизацией современного веб-пространства. Но наиболее авторитетной из них является Консорциум Всемирной паутины (W3C):

Именно опираясь на его стандарты, чаще всего, определяется валидность ресурса или отдельного кода независимо от языка или технологии, которые использовались для написания.
Установленные консорциумом W3C стандарты являются авторитетными для всех языков программирования и технологий, применяемых для создания сайтов. А также для HTML, XML и CSS.
Для проверки валидности существуют специальные онлайн-сервисы, так называемые «валидаторы». Они позволяют проверить на соответствие стандартам W3C любой сайт или часть кода, и обнаружить ошибки валидации, которые были допущены при их написании.
Наиболее авторитетным онлайн-вадидатором является ресурс validator.w3.org:

Казалось бы, все просто! Для валидации любого сайта нужно лишь пропустить его код через валидатор, исправить ошибки и все. Но не все так просто в виртуальном пространстве. Бывает, что даже самый валидный сайт не будет корректно отображаться в одном из браузеров.
Основной причиной не валидности «работающего» html является проблема кроссбраузерности. Порой профессиональному верстальщику приходится специально писать заведомо не валидный гипертекстовый код, чтобы все части верстаемого им ресурса одинаково отображались во всех современных и устаревших версиях браузеров.
Проблема кроссбраузерности в настоящее время почти решена. И все благодаря тому, что при создании браузеров разработчики придерживаются общепринятых стандартов W3C.
Но это не является основной причиной того, от чего страдает валидация html:
- Не закрытый тег – большая часть тегов в html являются парными, то есть состоящими из открывающего и закрывающего элемента. Часто при верстке или написании скрипта веб-мастера забывают дописывать закрывающий тег. А это может привести к неправильному отображению всего сайта;
- Нарушение вложенности элементов – эта проблема возникает при блочной верстке, когда не соблюдается иерархическая вложенность всех блоков <div>. Или других парных элементов, если часть тега открыта в одном слое, а закрывается в другом. При этом возможно нарушение структуры дизайна сайта;
- Использование атрибута style – в современном сайтостроении общепринятой нормой является использование для оформления элементов дизайна каскадных таблиц стилей (CSS). Устаревший атрибут style употребляется крайне редко: при его использовании объемы html кода могут увеличиваться в разы. Это не только замедляет скорость загрузки всего сайта, но и затрудняет его понимание и последующее редактирование;
- Использование вложенного CSS – внедрение каскадных таблиц стилей внутрь html. Это также увеличивает объем кода и затрудняет его отладку. Лучше всего стилевые описания хранить в отдельных файлах:

Большая часть проблем с кроссбраузерностью возникает именно из-за ошибок отображения оформления элементов, заданного с помощью CSS.
Точнее, чтобы решить проблему корректного вывода дизайна сайта во всех браузерах, верстальщику приходиться применять не совсем «валидные» (по мнению W3C) средства:
- Комментарии – когда в комментариях (чаще всего для IE) прописывается альтернативное значение свойства, не видимое для других браузеров;
- Хаки – под ними подразумеваются специальные свойства CSS, позволяющие решить проблему некорректного отображения в одном из браузеров:

- С помощью JavaScript – изменение стилевого свойства элемента через объектную модель документа.
Применение этих способов (особенно хаков) может негативно влиять на валидность всего сайта, но в тоже время позволяет полностью решать проблему кроссбраузерности.
Валидность CSS не является гарантом работоспособности ресурса.
Намного проще все обстоит с валидностью XML. Чтобы создавать чистый код, нужно придерживаться свода основных синтаксических правил этого языка:
- Не забывать о необходимости обязательного наличия корневого элемента;
- Не забывать закрывать тег;
- Помнить о том, что XML является зависимым от регистра языком;
- Помнить о необходимости соблюдать иерархию вложенности элементов;
- Значение каждого атрибута указывается в закрывающихся кавычках.
- Unknown entity…
Чаще всего такое сообщение валидатор выдает при использовании знака амперсанда (&) в той части адресной строки, через которую передаются переменные и их значения. Для недопущения и исправления данной ошибки вместо & следует использовать &. Пример:
<a href="index1.php?pid=1&id=5">...</a> - неправильно. <a href="index1.php?pid=1& =5">...</a> - правильно.
- Missing tag
Такое сообщение выдается, если нарушена иерархическая вложенность тегов. Пример:
<p><b>Lorem</p></b> - неправильно. <p><b>Lorem</b></p> - правильно.
- Missing DOCTYPE
Чаще всего валидатор выдает это сообщение, если содержимое элемента <!DOCTYPE> и сам элемент записаны в нижнем регистре. Необходимо помнить, что данный элемент является зависимым от регистра тегом. Пример:
<!doctype html public "-//w3c//dtd xhtml 1.0 strict//en" "http://www.w3.org/tr/xhtml1/dtd/xhtml1-strict.dtd" > - неправильно. <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd" > - правильно.
- There is no such element…
Данная ошибка возникает, если один или несколько тегов записаны в верхнем регистре. Пример:
<P><B>Lorem</B></P> - неправильно. <p><b>Lorem</b></p> - правильно.
- Missing closing tag
Эта ошибка валидации возникает, если один из «пустых» тегов в своей закрывающей части не содержит слеш (в XHTML). К пустым относится тег <img>. Пример:
<img src="images/girl.png" width="189" height="255" alt="lorem"> - неправильно. <img src="images/girl.png" width="189" height="255" alt="lorem"/> - правильно.
- required attribute «alt» not specified
Подобное сообщение выдается валидатором, если тег <img src="images/girl.png" > - неправильно.
<img src="images/girl.png" alt="lorem"> - правильно.
- Missing » «
Данная ошибка возникает, если значения одного или нескольких атрибутов записаны не в кавычках. Пример:
<img src=images/girl.png width=189 height=255 alt=lorem> - неправильно. <img src="images/girl.png" width="189" height="255" alt="lorem"/> - правильно.
И в конце хотелось бы вас предостеречь от гонки за чрезмерной валидностью. Как всегда, истина находится посредине: хороший код должен быть валидным, но это никак не может сказываться на его работоспособности. И это главное!
This is usually a cascading error caused by a an undefined entity
reference or use of an unencoded ampersand (&) in an URL or body
text. See the previous message for further details.
✉
Check that you are using a proper syntax for your comments, e.g: <!— comment here —>.
This error may appear if you forget the last «—» to close one comment, therefore including the rest
of the content in your comment.
✉
Did you forget to close a (double) quote mark?
✉
This error may appear if you are using a bad syntax for your comments, such as «<!invalid comment>»
The proper syntax for comments is <!— your comment here —>.
✉
This error may appear when the validator receives an empty document. Please make sure that the document you are uploading is not empty, and report any discrepancy.
✉
You have used character data somewhere it is not permitted to appear.
Mistakes that can cause this error include:
- putting text directly in the body of the document without wrapping
it in a container element (such as a <p>aragraph</p>), or - forgetting to quote an attribute value
(where characters such as «%» and «/» are common, but cannot appear
without surrounding quotes), or - using XHTML-style self-closing tags (such as <meta … />)
in HTML 4.01 or earlier. To fix, remove the extra slash (‘/’)
character. For more information about the reasons for this, see
Empty
elements in SGML, HTML, XML, and XHTML.
✉
The element named above was found in a context where it is not allowed.
This could mean that you have incorrectly nested elements — such as a
«style» element in the «body» section instead of inside «head» — or
two elements that overlap (which is not allowed).
One common cause for this error is the use of XHTML syntax in HTML
documents. Due to HTML’s rules of implicitly closed elements, this error
can create cascading effects. For instance, using XHTML’s «self-closing»
tags for «meta» and «link» in the «head» section of a HTML document may
cause the parser to infer the end of the «head» section and the
beginning of the «body» section (where «link» and «meta» are not
allowed; hence the reported error).
✉
The mentioned element is not allowed to appear in the context in which
you’ve placed it; the other mentioned elements are the only ones that
are both allowed there and can contain the element mentioned.
This might mean that you need a containing element, or possibly that
you’ve forgotten to close a previous element.
One possible cause for this message is that you have attempted to put a
block-level element (such as «<p>» or «<table>») inside an
inline element (such as «<a>», «<span>», or «<font>»).
✉
- You forgot to close a tag, or
- you used something inside this tag that was not allowed, and the validator
is complaining that the tag should be closed before such content can be allowed.
The next message, «start tag was here»
points to the particular instance of the tag in question); the
positional indicator points to where the validator expected you to close the
tag.
✉
This is not an error, but rather a pointer to the start tag of the element
the previous error referred to.
✉
You may have neglected to close an element, or perhaps you meant to
«self-close» an element, that is, ending it with «/>» instead of «>».
✉
This is not an error, but rather a pointer to the start tag of the element
the previous error referred to.
✉
Most likely, you nested tags and closed them in the wrong order. For
example <p><em>…</p> is not acceptable, as <em>
must be closed before <p>. Acceptable nesting is:
<p><em>…</em></p>
Another possibility is that you used an element which requires
a child element that you did not include. Hence the parent element
is «not finished», not complete. For instance, in HTML the <head>
element must contain a <title> child element, lists require
appropriate list items (<ul> and <ol> require <li>;
<dl> requires <dt> and <dd>), and so on.
✉
You have used the element named above in your document, but the
document type you are using does not define an element of that name.
This error is often caused by:
- incorrect use of the «Strict» document type with a document that
uses frames (e.g. you must use the «Frameset» document type to get
the «<frameset>» element), - by using vendor proprietary extensions such as «<spacer>»
or «<marquee>» (this is usually fixed by using CSS to achieve
the desired effect instead). - by using upper-case tags in XHTML (in XHTML attributes and elements
must be all lower-case).
✉
The Validator found an end tag for the above element, but that element is
not currently open. This is often caused by a leftover end tag from an
element that was removed during editing, or by an implicitly closed
element (if you have an error related to an element being used where it
is not allowed, this is almost certainly the case). In the latter case
this error will disappear as soon as you fix the original problem.
If this error occurred in a script section of your document, you should probably
read this FAQ entry.
✉
You have used a character that is not considered a «name character» in an
attribute value. Which characters are considered «name characters» varies
between the different document types, but a good rule of thumb is that
unless the value contains only lower or upper case letters in the
range a-z you must put quotation marks around the value. In fact, unless
you have extreme file size requirements it is a very very good
idea to always put quote marks around your attribute values. It
is never wrong to do so, and very often it is absolutely necessary.
✉
An attribute name (and some attribute values) must start with one of
a restricted set of characters. This error usually indicates that
you have failed to add a closing quotation mark on a previous
attribute value (so the attribute value looks like the start of a
new attribute) or have used an attribute that is not defined
(usually a typo in a common attribute name).
✉
«VI delimiter» is a technical term for the equal sign. This error message
means that the name of an attribute and the equal sign cannot be omitted
when specifying an attribute. A common cause for this error message is
the use of «Attribute Minimization» in document types where it is not allowed,
in XHTML for instance.
How to fix: For attributes such as compact, checked or selected, do not write
e.g <option selected … but rather <option selected=»selected» …
✉
You have used the attribute named above in your document, but the
document type you are using does not support that attribute for this
element. This error is often caused by incorrect use of the «Strict»
document type with a document that uses frames (e.g. you must use
the «Transitional» document type to get the «target» attribute), or
by using vendor proprietary extensions such as «marginheight» (this
is usually fixed by using CSS to achieve the desired effect instead).
This error may also result if the element itself is not supported in
the document type you are using, as an undefined element will have no
supported attributes; in this case, see the element-undefined error
message for further information.
How to fix: check the spelling and case of the element and attribute,
(Remember XHTML is all lower-case) and/or
check that they are both allowed in the chosen document type, and/or
use CSS instead of this attribute. If you received this error when using the
<embed> element to incorporate flash media in a Web page, see the
FAQ item on valid flash.
✉
Have you forgotten the «equal» sign marking the separation
between the attribute and its declared value?
Typical syntax is attribute="value".
✉
You have specified an attribute more than once. Example: Using
the «height» attribute twice on the same
«img» tag.
✉
This error almost always means that you’ve forgotten a closing quote on an attribute value. For instance,
in:
<img src="fred.gif>
<!-- 50 lines of stuff -->
<img src="joe.gif">
The «src» value for the first
<img> is the entire
fifty lines of stuff up to the next double quote, which probably
exceeds the SGML-defined
length limit for HTML
string literals. Note that the position indicator in the error
message points to where the attribute value ended — in
this case, the "joe.gif" line.
✉
The value of an attribute contained something that is not allowed by
the specified syntax for that type of attribute. For instance, the
“selected” attribute must be
either minimized as “selected”
or spelled out in full as “selected="selected"”; the variant
“selected=""” is not allowed.
✉
It is possible that you violated the naming convention for this attribute.
For example, id and name attributes must begin with
a letter, not a digit.
✉
This attribute cannot take a space-separated list of words as a value, but only one word («token»).
This may also be caused by the use of a space for the value of an attribute which does not permit it.
✉
The value of this attribute should be a number, and you probably used a wrong syntax.
✉
It is possible that you violated the naming convention for this attribute.
For example, id and name attributes must begin with
a letter, not a digit.
✉
The attribute given above is required for an element that you’ve used,
but you have omitted it. For instance, in most HTML and XHTML document
types the «type» attribute is required on the «script» element and the
«alt» attribute is required for the «img» element.
Typical values for type are
type="text/css" for <style>
and type="text/javascript" for <script>.
✉
The value of the attribute is defined to be one of a list of possible
values but in the document it contained something that is not allowed
for that type of attribute. For instance, the “selected” attribute must be either
minimized as “selected”
or spelled out in full as “selected="selected"”; a value like
“selected="true"” is not
allowed.
✉
Check that you are using a proper syntax for your comments, e.g: <!— comment here —>.
This error may appear if you forget the last «—» to close one comment, and later open another.
✉
You have used an illegal character in your text.
HTML uses the standard
UNICODE Consortium character repertoire,
and it leaves undefined (among others) 65 character codes (0 to 31 inclusive and 127 to 159
inclusive) that are sometimes used for typographical quote marks and similar in
proprietary character sets. The validator has found one of these undefined
characters in your document. The character may appear on your browser as a
curly quote, or a trademark symbol, or some other fancy glyph; on a different
computer, however, it will likely appear as a completely different
character, or nothing at all.
Your best bet is to replace the character with the nearest equivalent
ASCII character, or to use an appropriate character
entity.
For more information on Character Encoding on the web, see Alan
Flavell’s excellent HTML Character
Set Issues reference.
This error can also be triggered by formatting characters embedded in
documents by some word processors. If you use a word processor to edit
your HTML documents, be sure to use the «Save as ASCII» or similar
command to save the document without formatting information.
✉
An «id» is a unique identifier. Each time this attribute is used in a document
it must have a different value. If you are using this attribute as a hook for
style sheets it may be more appropriate to use classes (which group elements)
than id (which are used to identify exactly one element).
✉
This error can be triggered by:
- A non-existent input, select or textarea element
- A missing id attribute
- A typographical error in the id attribute
Try to check the spelling and case of the id you are referring to.
✉
The document type could not be determined, because the document had no correct DOCTYPE declaration. The document does not look like HTML, therefore automatic fallback could not be performed, and the document was only checked against basic markup syntax.
Learn how to add a doctype to your document
from our FAQ, or use the validator’s
Document Type option to validate your document against a specific Document Type.
✉
The construct <foo<bar> is valid in HTML (it is an example of the rather obscure “Shorttags” feature)
but its use is not recommended.
In most cases, this is a typo that you will want to fix. If you really want to use shorttags,
be aware that they are not well implemented by browsers.
✉
For the current document, the validator interprets strings like
<FOO /> according to legacy rules that
break the expectations of most authors and thus cause confusing warnings
and error messages from the validator. This interpretation is triggered
by HTML 4 documents or other SGML-based HTML documents. To avoid the
messages, simply remove the «/» character in such contexts. NB: If you
expect <FOO /> to be interpreted as an
XML-compatible «self-closing» tag, then you need to use XHTML or HTML5.
This warning and related errors may also be caused by an unquoted
attribute value containing one or more «/». Example:
<a href=http://w3c.org>W3C</a>.
In such cases, the solution is to put quotation marks around the value.
✉
The construct </foo<bar> is valid in HTML (it is an example of the rather obscure “Shorttags” feature)
but its use is not recommended.
In most cases, this is a typo that you will want to fix. If you really want to use shorttags,
be aware that they are not well implemented by browsers.
✉
A DOCTYPE declares the version of the language used, as well as what the root
(top) element of your document will be. For example, if the top element
of your document is <html>, the DOCTYPE declaration
will look like: «<!DOCTYPE html».
In most cases, it is safer not to type or edit the DOCTYPE declaration at all,
and preferable to let a tool include it, or copy and paste it from a
trusted list of DTDs.
✉
This is usually a cascading error caused by a an undefined entity
reference or use of an unencoded ampersand (&) in an URL or body
text. See the previous message for further details.
✉
The construct <> is sometimes valid in HTML (it is an example of the rather obscure “Shorttags” feature)
but its use is not recommended.
In most cases, this is a typo that you will want to fix. If you really want to use shorttags,
be aware that they are not well implemented by browsers.
✉
The construct </> is valid in HTML (it is an example of the rather obscure “Shorttags” feature)
but its use is not recommended.
In most cases, this is a typo that you will want to fix. If you really want to use shorttags,
be aware that they are not well implemented by browsers.
✉
An entity reference was found in the document, but there is no reference
by that name defined. Often this is caused by misspelling the reference
name, unencoded ampersands, or by leaving off the trailing semicolon (;).
The most common cause of this error is unencoded ampersands in
URLs as described by the WDG in «Ampersands
in URLs».
Entity references start with an ampersand (&) and end with a
semicolon (;). If you want to use a literal ampersand in your document
you must encode it as «&» (even inside URLs!). Be
careful to end entity references with a semicolon or your entity
reference may get interpreted in connection with the following text.
Also keep in mind that named entity references are case-sensitive;
&Aelig; and æ are different characters.
If this error appears in some markup generated by PHP’s session handling
code, this article has
explanations and solutions to your problem.
Note that in most documents, errors related to entity references will
trigger up to 5 separate messages from the Validator. Usually these
will all disappear when the original problem is fixed.
✉
The checked page did not contain a document type («DOCTYPE») declaration.
The Validator has tried to validate with a fallback DTD,
but this is quite likely to be incorrect and will generate a large number
of incorrect error messages. It is highly recommended that you insert the
proper DOCTYPE declaration in your document — instructions for doing this
are given above — and it is necessary to have this declaration before the
page can be declared to be valid.
✉
Your document includes a DOCTYPE declaration with a public identifier
(e.g. «-//W3C//DTD XHTML 1.0 Strict//EN») but no system identifier
(e.g. «http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd»). This is
authorized in HTML (based on SGML), but not in XML-based languages.
If you are using a standard XHTML document type, it is recommended to use exactly
one of the DOCTYPE declarations from the
recommended list on the W3C QA Website.
✉
This may happen if you have consecutive comments but did not close one of them properly.
The proper syntax for comments is <!— my comment —>.
✉
If you meant to include an entity that starts with «&», then you should
terminate it with «;». Another reason for this error message is that
you inadvertently created an entity by failing to escape an «&»
character just before this text.
✉
This is generally the sign of an ampersand that was not properly escaped for inclusion
in an attribute, in a href for example. You will need to escape all instances of ‘&’
into ‘&’.
✉
This message may appear in several cases:
- You tried to include the «<» character in your page: you should escape it as «<»
- You used an unescaped ampersand «&»: this may be valid in some contexts,
but it is recommended to use «&», which is always safe. - Another possibility is that you forgot to close quotes in a previous tag.
✉
This error may occur when there is a mistake in how a self-closing tag is closed, e.g ‘…/ >’.
The proper syntax is ‘… />’ (note the position of the space).
✉
You’ve included a character reference to a character that is not defined
in the document type you’ve chosen. This is most commonly caused by
numerical references to characters from vendor proprietary
character repertoires. Often the culprit will be fancy or typographical
quote marks from either the Windows or Macintosh character repertoires.
The solution is to reference UNICODE characters instead. A list of
common characters from the Windows character repertoire and their
UNICODE equivalents can be found in the document «On the use of some MS Windows characters in HTML» maintained by
Jukka Korpela
<jkorpela@cs.tut.fi>.
✉
The following validation errors do not have an explanation yet. We invite you to use the
feedback channels to send your suggestions.
0: length of name must not exceed NAMELEN (X)
✉
1: length of parameter entity name must not exceed NAMELEN less the length of the PERO delimiter (X)
✉
2: length of number must not exceed NAMELEN (X)
✉
3: length of attribute value must not exceed LITLEN less NORMSEP (X)
✉
4: a name group is not allowed in a parameter entity reference in the prolog
✉
5: an entity end in a token separator must terminate an entity referenced in the same group
✉
6: character X invalid: only Y and token separators allowed
✉
7: a parameter separator is required after a number that is followed by a name start character
✉
8: character X invalid: only Y and parameter separators allowed
✉
9: an entity end in a parameter separator must terminate an entity referenced in the same declaration
✉
10: an entity end is not allowed in a token separator that does not follow a token
✉
11: X is not a valid token here
✉
12: a parameter entity reference can only occur in a group where a token could occur
✉
13: token X has already occurred in this group
✉
14: the number of tokens in a group must not exceed GRPCNT (X)
✉
15: an entity end in a literal must terminate an entity referenced in the same literal
✉
16: character X invalid: only minimum data characters allowed
✉
18: a parameter literal in a data tag pattern must not contain a numeric character reference to a non-SGML character
✉
19: a parameter literal in a data tag pattern must not contain a numeric character reference to a function character
✉
20: a name group is not allowed in a general entity reference in a start tag
✉
21: a name group is not allowed in a general entity reference in the prolog
✉
22: X is not a function name
✉
23: X is not a character number in the document character set
✉
24: parameter entity X not defined
✉
26: RNI delimiter must be followed by name start character
✉
29: comment started here
✉
30: only one type of connector should be used in a single group
✉
31: X is not a reserved name
✉
32: X is not allowed as a reserved name here
✉
33: length of interpreted minimum literal must not exceed reference LITLEN (X)
✉
34: length of tokenized attribute value must not exceed LITLEN less NORMSEP (X)
✉
35: length of system identifier must not exceed LITLEN (X)
✉
36: length of interpreted parameter literal must not exceed LITLEN (X)
✉
37: length of interpreted parameter literal in data tag pattern must not exceed DTEMPLEN (X)
✉
39: X invalid: only Y and parameter separators are allowed
✉
40: X invalid: only Y and token separators are allowed
✉
41: X invalid: only Y and token separators are allowed
✉
43: X declaration not allowed in DTD subset
✉
44: character X not allowed in declaration subset
✉
45: end of document in DTD subset
✉
46: character X not allowed in prolog
✉
48: X declaration not allowed in prolog
✉
49: X used both a rank stem and generic identifier
✉
50: omitted tag minimization parameter can be omitted only if OMITTAG NO is specified
✉
51: element type X already defined
✉
52: entity reference with no applicable DTD
✉
53: invalid comment declaration: found X outside comment but inside comment declaration
✉
54: comment declaration started here
✉
55: X declaration not allowed in instance
✉
56: non-SGML character not allowed in content
✉
57: no current rank for rank stem X
✉
58: duplicate attribute definition list for notation X
✉
59: duplicate attribute definition list for element X
✉
60: entity end not allowed in end tag
✉
61: character X not allowed in end tag
✉
62: X invalid: only S separators and TAGC allowed here
✉
66: document type does not allow element X here; assuming missing Y start-tag
✉
67: no start tag specified for implied empty element X
✉
72: start tag omitted for element X with declared content
✉
74: start tag for X omitted, but its declaration does not permit this
✉
75: number of open elements exceeds TAGLVL (X)
✉
77: empty end tag but no open elements
✉
78: X not finished but containing element ended
✉
80: internal parameter entity X cannot be CDATA or SDATA
✉
81: character X not allowed in attribute specification list
✉
83: entity end not allowed in attribute specification list except in attribute value literal
✉
84: external parameter entity X cannot be CDATA, SDATA, NDATA or SUBDOC
✉
85: duplicate declaration of entity X
✉
86: duplicate declaration of parameter entity X
✉
87: a reference to a PI entity is allowed only in a context where a processing instruction could occur
✉
88: a reference to a CDATA or SDATA entity is allowed only in a context where a data character could occur
✉
89: a reference to a subdocument entity or external data entity is allowed only in a context where a data character could occur
✉
90: a reference to a subdocument entity or external data entity is not allowed in replaceable character data
✉
91: the number of open entities cannot exceed ENTLVL (X)
✉
92: a reference to a PI entity is not allowed in replaceable character data
✉
93: entity X is already open
✉
94: short reference map X not defined
✉
95: short reference map in DTD must specify associated element type
✉
96: short reference map in document instance cannot specify associated element type
✉
97: short reference map X for element Y not defined in DTD
✉
98: X is not a short reference delimiter
✉
99: short reference delimiter X already mapped in this declaration
✉
100: no document element
✉
102: entity end not allowed in processing instruction
✉
103: length of processing instruction must not exceed PILEN (X)
✉
104: missing PIC delimiter
✉
106: X is not a member of a group specified for any attribute
✉
109: an attribute value specification must start with a literal or a name character
✉
110: length of name token must not exceed NAMELEN (X)
✉
113: duplicate definition of attribute X
✉
114: data attribute specification must be omitted if attribute specification list is empty
✉
115: marked section end not in marked section declaration
✉
116: number of open marked sections must not exceed TAGLVL (X)
✉
117: missing marked section end
✉
118: marked section started here
✉
119: entity end in character data, replaceable character data or ignored marked section
✉
126: non-impliable attribute X not specified but OMITTAG NO and SHORTTAG NO
✉
128: first occurrence of CURRENT attribute X not specified
✉
129: X is not a notation name
✉
130: X is not a general entity name
✉
132: X is not a data or subdocument entity
✉
133: content model is ambiguous: when no tokens have been matched, both the Y and Z occurrences of X are possible
✉
134: content model is ambiguous: when the current token is the Y occurrence of X, both the a and b occurrences of Z are possible
✉
135: content model is ambiguous: when the current token is the Y occurrence of X and the innermost containing AND group has been matched, both the a and b occurrences of Z are possible
✉
136: content model is ambiguous: when the current token is the Y occurrence of X and the innermost Z containing AND groups have been matched, both the b and c occurrences of a are possible
✉
138: comment declaration started here
✉
140: data or replaceable character data in declaration subset
✉
142: ID X first defined here
✉
143: value of fixed attribute X not equal to default
✉
144: character X is not significant in the reference concrete syntax and so cannot occur in a comment in the SGML declaration
✉
145: minimum data of first minimum literal in SGML declaration must be «»ISO 8879:1986″» or «»ISO 8879:1986 (ENR)»» or «»ISO 8879:1986 (WWW)»» not X
✉
146: parameter before LCNMSTRT must be NAMING not X
✉
147: unexpected entity end in SGML declaration: only X, S separators and comments allowed
✉
148: X invalid: only Y and parameter separators allowed
✉
149: magnitude of X too big
✉
150: character X is not significant in the reference concrete syntax and so cannot occur in a literal in the SGML declaration except as the replacement of a character reference
✉
151: X is not a valid syntax reference character number
✉
152: a parameter entity reference cannot occur in an SGML declaration
✉
153: X invalid: only Y and parameter separators are allowed
✉
154: cannot continue because of previous errors
✉
155: SGML declaration cannot be parsed because the character set does not contain characters having the following numbers in ISO 646: X
✉
156: the specified character set is invalid because it does not contain the minimum data characters having the following numbers in ISO 646: X
✉
157: character numbers declared more than once: X
✉
158: character numbers should have been declared UNUSED: X
✉
159: character numbers missing in base set: X
✉
160: characters in the document character set with numbers exceeding X not supported
✉
161: invalid formal public identifier X: missing //
✉
162: invalid formal public identifier X: no SPACE after public text class
✉
163: invalid formal public identifier X: invalid public text class
✉
164: invalid formal public identifier X: public text language must be a name containing only upper case letters
✉
165: invalid formal public identifer X: public text display version not permitted with this text class
✉
166: invalid formal public identifier X: extra field
✉
167: public text class of public identifier in notation identifier must be NOTATION
✉
168: base character set X is unknown
✉
169: delimiter set is ambiguous: X and Y can be recognized in the same mode
✉
170: characters with the following numbers in the syntax reference character set are significant in the concrete syntax but are not in the document character set: X
✉
171: there is no unique character in the document character set corresponding to character number X in the syntax reference character set
✉
172: there is no unique character in the internal character set corresponding to character number X in the syntax reference character set
✉
173: the character with number X in ISO 646 is significant but has no representation in the syntax reference character set
✉
174: capacity set X is unknown
✉
175: capacity X already specified
✉
176: value of capacity X exceeds value of TOTALCAP
✉
177: syntax X is unknown
✉
178: UCNMSTRT must have the same number of characters as LCNMSTRT
✉
179: UCNMCHAR must have the same number of characters as LCNMCHAR
✉
180: number of open subdocuments exceeds quantity specified for SUBDOC parameter in SGML declaration (X)
✉
181: entity X declared SUBDOC, but SUBDOC NO specified in SGML declaration
✉
182: a parameter entity referenced in a parameter separator must end in the same declaration
✉
184: generic identifier X used in DTD but not defined
✉
185: X not finished but document ended
✉
186: cannot continue with subdocument because of previous errors
✉
188: no internal or external document type declaration subset; will parse without validation
✉
189: this is not an SGML document
✉
190: length of start-tag before interpretation of literals must not exceed TAGLEN (X)
✉
191: a parameter entity referenced in a token separator must end in the same group
✉
192: the following character numbers are shunned characters that are not significant and so should have been declared UNUSED: X
✉
193: there is no unique character in the specified document character set corresponding to character number X in ISO 646
✉
194: length of attribute value must not exceed LITLEN less NORMSEP (-X)
✉
195: length of tokenized attribute value must not exceed LITLEN less NORMSEP (-X)
✉
196: concrete syntax scope is INSTANCE but value of X quantity is less than value in reference quantity set
✉
197: public text class of formal public identifier of base character set must be CHARSET
✉
198: public text class of formal public identifier of capacity set must be CAPACITY
✉
199: public text class of formal public identifier of concrete syntax must be SYNTAX
✉
200: when there is an MSOCHAR there must also be an MSICHAR
✉
201: character number X in the syntax reference character set was specified as a character to be switched but is not a markup character
✉
202: character number X was specified as a character to be switched but is not in the syntax reference character set
✉
203: character numbers X in the document character set have been assigned the same meaning, but this is the meaning of a significant character
✉
204: character number X assigned to more than one function
✉
205: X is already a function name
✉
206: characters with the following numbers in ISO 646 are significant in the concrete syntax but are not in the document character set: X
✉
207: general delimiter X consists solely of function characters
✉
208: letters assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT: X
✉
209: digits assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT: X
✉
210: character number X cannot be assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT because it is RE
✉
211: character number X cannot be assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT because it is RS
✉
212: character number X cannot be assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT because it is SPACE
✉
213: separator characters assigned to LCNMCHAR, UCNMCHAR, LCNMSTRT or UCNMSTRT: X
✉
214: character number X cannot be switched because it is a Digit, LC Letter or UC Letter
✉
215: pointless for number of characters to be 0
✉
216: X cannot be the replacement for a reference reserved name because it is another reference reserved name
✉
217: X cannot be the replacement for a reference reserved name because it is the replacement of another reference reserved name
✉
218: replacement for reserved name X already specified
✉
219: X is not a valid name in the declared concrete syntax
✉
220: X is not a valid short reference delimiter because it has more than one B sequence
✉
221: X is not a valid short reference delimiter because it is adjacent to a character that can occur in a blank sequence
✉
222: length of delimiter X exceeds NAMELEN (Y)
✉
223: length of reserved name X exceeds NAMELEN (Y)
✉
224: character numbers assigned to both LCNMCHAR or UCNMCHAR and LCNMSTRT or UCNMSTRT: X
✉
225: when the concrete syntax scope is INSTANCE the syntax reference character set of the declared syntax must be the same as that of the reference concrete syntax
✉
226: end-tag minimization should be O for element with declared content of EMPTY
✉
227: end-tag minimization should be O for element X because it has CONREF attribute
✉
228: element X has a declared content of EMPTY and a CONREF attribute
✉
229: element X has a declared content of EMPTY and a NOTATION attribute
✉
230: declared value of data attribute cannot be ENTITY, ENTITIES, ID, IDREF, IDREFS or NOTATION
✉
231: default value of data attribute cannot be CONREF or CURRENT
✉
232: number of attribute names and name tokens (X) exceeds ATTCNT (Y)
✉
233: if the declared value is ID the default value must be IMPLIED or REQUIRED
✉
234: the attribute definition list already declared attribute X as the ID attribute
✉
235: the attribute definition list already declared attribute X as the NOTATION attribute
✉
236: token X occurs more than once in attribute definition list
✉
237: no attributes defined for notation X
✉
238: notation X for entity Y undefined
✉
239: entity X undefined in short reference map Y
✉
240: notation X is undefined but had attribute definition
✉
241: length of interpreted parameter literal in bracketed text plus the length of the bracketing delimiters must not exceed LITLEN (X)
✉
242: length of rank stem plus length of rank suffix must not exceed NAMELEN (X)
✉
243: document instance must start with document element
✉
244: content model nesting level exceeds GRPLVL (X)
✉
245: grand total of content tokens exceeds GRPGTCNT (X)
✉
249: DTDs other than base allowed only if CONCUR YES or EXPLICIT YES
✉
250: end of entity other than document entity after document element
✉
251: X declaration illegal after document element
✉
252: character reference illegal after document element
✉
253: entity reference illegal after document element
✉
254: marked section illegal after document element
✉
255: the X occurrence of Y in the content model for Z cannot be excluded at this point because it is contextually required
✉
256: the X occurrence of Y in the content model for Z cannot be excluded because it is neither inherently optional nor a member of an OR group
✉
257: an attribute value specification must be an attribute value literal unless SHORTTAG YES is specified
✉
258: value cannot be specified both for notation attribute and content reference attribute
✉
259: notation X already defined
✉
260: short reference map X already defined
✉
261: first defined here
✉
262: general delimiter role X already defined
✉
263: number of ID references in start-tag must not exceed GRPCNT (X)
✉
264: number of entity names in attribute specification list must not exceed GRPCNT (X)
✉
265: normalized length of attribute specification list must not exceed ATTSPLEN (X); length was Y
✉
266: short reference delimiter X already specified
✉
267: single character short references were already specified for character numbers: X
✉
268: default entity used in entity attribute X
✉
269: reference to entity X uses default entity
✉
270: entity X in short reference map Y uses default entity
✉
271: no DTD X declared
✉
272: LPD X has neither internal nor external subset
✉
273: element types have different link attribute definitions
✉
274: link set X already defined
✉
275: empty result attribute specification
✉
276: no source element type X
✉
277: no result element type X
✉
278: end of document in LPD subset
✉
279: X declaration not allowed in LPD subset
✉
280: ID link set declaration not allowed in simple link declaration subset
✉
281: link set declaration not allowed in simple link declaration subset
✉
282: attributes can only be defined for base document element (not X) in simple link declaration subset
✉
283: a short reference mapping declaration is allowed only in the base DTD
✉
284: a short reference use declaration is allowed only in the base DTD
✉
285: default value of link attribute cannot be CURRENT or CONREF
✉
286: declared value of link attribute cannot be ID, IDREF, IDREFS or NOTATION
✉
287: only fixed attributes can be defined in simple LPD
✉
288: only one ID link set declaration allowed in an LPD subset
✉
289: no initial link set defined for LPD X
✉
290: notation X not defined in source DTD
✉
291: result document type in simple link specification must be implied
✉
292: simple link requires SIMPLE YES
✉
293: implicit link requires IMPLICIT YES
✉
294: explicit link requires EXPLICIT YES
✉
295: LPD not allowed before first DTD
✉
296: DTD not allowed after an LPD
✉
297: definition of general entity X is unstable
✉
298: definition of parameter entity X is unstable
✉
299: multiple link rules for ID X but not all have link attribute specifications
✉
300: multiple link rules for element type X but not all have link attribute specifications
✉
301: link type X does not have a link set Y
✉
302: link set use declaration for simple link process
✉
303: no link type X
✉
304: both document type and link type X
✉
305: link type X already defined
✉
306: document type X already defined
✉
307: link set X used in LPD but not defined
✉
308: #IMPLIED already linked to result element type X
✉
309: number of active simple link processes exceeds quantity specified for SIMPLE parameter in SGML declaration (X)
✉
310: only one chain of explicit link processes can be active
✉
311: source document type name for link type X must be base document type since EXPLICIT YES 1
✉
312: only one implicit link process can be active
✉
313: sorry, link type X not activated: only one implicit or explicit link process can be active (with base document type as source document type)
✉
314: name missing after name group in entity reference
✉
315: source document type name for link type X must be base document type since EXPLICIT NO
✉
316: link process must be activated before base DTD
✉
317: unexpected entity end while starting second pass
✉
318: type X of element with ID Y not associated element type for applicable link rule in ID link set
✉
319: DATATAG feature not implemented
✉
320: generic identifier specification missing after document type specification in start-tag
✉
321: generic identifier specification missing after document type specification in end-tag
✉
322: a NET-enabling start-tag cannot include a document type specification
✉
324: invalid default SGML declaration
✉
326: entity was defined here
✉
327: content model is mixed but does not allow #PCDATA everywhere
✉
328: start or end of range must specify a single character
✉
329: number of first character in range must not exceed number of second character in range
✉
330: delimiter cannot be an empty string
✉
331: too many characters assigned same meaning with minimum literal
✉
332: earlier reference to entity X used default entity
✉
335: unused short reference map X
✉
336: unused parameter entity X
✉
337: cannot generate system identifier for public text X
✉
339: cannot generate system identifier for parameter entity X
✉
340: cannot generate system identifier for document type X
✉
341: cannot generate system identifier for link type X
✉
342: cannot generate system identifier for notation X
✉
343: element type X both included and excluded
✉
345: minimum data of AFDR declaration must be «»ISO/IEC 10744:1997″» not X
✉
346: AFDR declaration required before use of AFDR extensions
✉
347: ENR extensions were used but minimum literal was not «»ISO 8879:1986 (ENR)»» or «»ISO 8879:1986 (WWW)»»
✉
348: illegal numeric character reference to non-SGML character X in literal
✉
349: cannot convert character reference to number X because description Y unrecognized
✉
350: cannot convert character reference to number X because character Y from baseset Z unknown
✉
351: character reference to number X cannot be converted because of problem with internal character set
✉
352: cannot convert character reference to number X because character not in internal character set
✉
353: Web SGML adaptations were used but minimum literal was not «»ISO 8879:1986 (WWW)»»
✉
354: token X can be value for multiple attributes so attribute name required
✉
355: length of hex number must not exceed NAMELEN (X)
✉
356: X is not a valid name in the declared concrete syntax
✉
357: CDATA declared content
✉
358: RCDATA declared content
✉
359: inclusion
✉
360: exclusion
✉
361: NUMBER or NUMBERS declared value
✉
362: NAME or NAMES declared value
✉
363: NUTOKEN or NUTOKENS declared value
✉
364: CONREF attribute
✉
365: CURRENT attribute
✉
366: TEMP marked section
✉
367: included marked section in the instance
✉
368: ignored marked section in the instance
✉
369: RCDATA marked section
✉
370: processing instruction entity
✉
371: bracketed text entity
✉
372: internal CDATA entity
✉
373: internal SDATA entity
✉
374: external CDATA entity
✉
375: external SDATA entity
✉
376: attribute definition list declaration for notation
✉
377: rank stem
✉
379: comment in parameter separator
✉
380: named character reference
✉
381: AND group
✉
382: attribute value not a literal
✉
383: attribute name missing
✉
384: element declaration for group of element types
✉
385: attribute definition list declaration for group of element types
✉
386: empty comment declaration
✉
388: multiple comments in comment declaration
✉
389: no status keyword
✉
390: multiple status keywords
✉
391: parameter entity reference in document instance
✉
392: CURRENT attribute
✉
393: element type minimization parameter
✉
395: #PCDATA not first in model group
✉
396: #PCDATA in SEQ group
✉
397: #PCDATA in nested model group
✉
398: #PCDATA in model group that does not have REP occurrence indicator
✉
399: name group or name token group used connector other than OR
✉
400: processing instruction does not start with name
✉
401: S separator in status keyword specification in document instance
✉
402: reference to external data entity
✉
405: SGML declaration was not implied
✉
406: marked section in internal DTD subset
✉
408: entity end in different element from entity reference
✉
409: NETENABL IMMEDNET requires EMPTYNRM YES
✉
411: declaration of default entity
✉
412: reference to parameter entity in parameter separator in internal subset
✉
413: reference to parameter entity in token separator in internal subset
✉
414: reference to parameter entity in parameter literal in internal subset
✉
415: cannot generate system identifier for SGML declaration reference
✉
416: public text class of formal public identifier of SGML declaration must be SD
✉
417: SGML declaration reference was used but minimum literal was not «»ISO 8879:1986 (WWW)»»
✉
418: member of model group containing #PCDATA has occurrence indicator
✉
419: member of model group containing #PCDATA is a model group
✉
420: reference to non-predefined entity
✉
421: reference to external entity
✉
422: declaration of default entity conflicts with IMPLYDEF ENTITY YES
✉
423: parsing with respect to more than one active doctype not supported
✉
424: cannot have active doctypes and link types at the same time
✉
425: number of concurrent document instances exceeds quantity specified for CONCUR parameter in SGML declaration (X)
✉
426: datatag group can only be specified in base document type
✉
427: element not in the base document type can’t have an empty start-tag
✉
428: element not in base document type can’t have an empty end-tag
✉
429: immediately recursive element
✉
430: invalid URN X: missing «»:»»
✉
431: invalid URN X: missing «»urn:»» prefix
✉
432: invalid URN X: invalid namespace identifier
✉
433: invalid URN X: invalid namespace specific string
✉
434: invalid URN X: extra field
✉
435: prolog can’t be omitted unless CONCUR NO and LINK EXPLICIT NO and either IMPLYDEF ELEMENT YES or IMPLYDEF DOCTYPE YES
✉
436: can’t determine name of #IMPLIED document element
✉
437: can’t use #IMPLICIT doctype unless CONCUR NO and LINK EXPLICIT NO
✉
438: Sorry, #IMPLIED doctypes not implemented
✉
439: reference to DTD data entity ignored
✉
440: notation X for parameter entity Y undefined
✉
441: notation X for external subset undefined
✉
442: attribute X can’t be redeclared
✉
443: #IMPLICIT attributes have already been specified for notation X
✉
444: a name group is not allowed in a parameter entity reference in a start tag
✉
445: name group in a parameter entity reference in an end tag (SGML forbids them in start tags)
✉
446: if the declared value is NOTATION a default value of CONREF is useless
✉
447: Sorry, #ALL and #IMPLICIT content tokens not implemented
✉
Сайт при проверке валидности кода (https://validator.w3.org) выдаёт:
Этот документ не прошёл тест: W3C CSS Validator (Level 3)
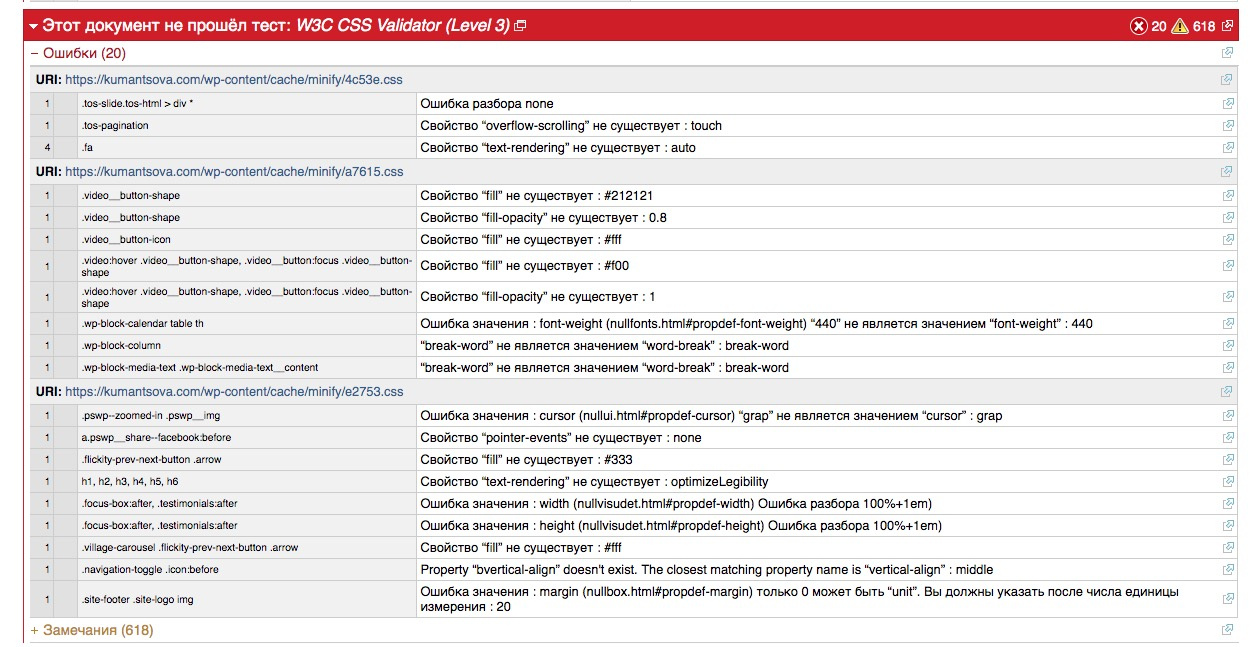
Итого: 20 ошибок и 618 замечаний.
При этом всё отображается ровно во всех браузерах и тот же гугл бот видит сайт так же как и живые гости сайта.
Как вы думаете, существенно ли это влияет на SEO? Ранжирование снижает, применяются скрытые санкции к сайту?
-
Вопрос заданболее трёх лет назад
-
354 просмотра
Пригласить эксперта
Если в браузерах отображается правильно, то не влияет. Проводил эксперимент — исправлял подобные ошибки на 10 сайтах, эффекта не было.
Конечно! Судя по тому что пишут в ошибке, в половине браузеров ваша верстка вообще работать не будет. Там часть функций, которые только в черновиках. Влияет на продвижение и очень серьезно!
-
Показать ещё
Загружается…
30 янв. 2023, в 20:37
10000 руб./за проект
30 янв. 2023, в 20:30
3000 руб./за проект
30 янв. 2023, в 20:26
1500 руб./за проект
Минуточку внимания
Валидацией называется проверка CSS-кода на соответствие спецификации CSS2.1 или CSS3. Соответственно, корректный код, не содержащий ошибок, называется валидный, а не удовлетворяющий спецификации — невалидный. Наиболее удобно делать проверку кода через сайт http://jigsaw.w3.org/css-validator/, с помощью этого сервиса можно указать адрес документа, загрузить файл или проверить набранный текст. Большим плюсом сервиса является поддержка русского и украинского языка.
Проверить URI
Эта вкладка позволяет указывать адрес страницы размещенной в Интернете. Протокол http:// можно не писать, он будет добавлен автоматически (рис. 20.1).

Рис. 20.1. Проверка документа по адресу
После ввода адреса нажмите на кнопку «Проверить» и появится одна из двух надписей: «Поздравляем! Ошибок не обнаружено» в случае успеха или «К сожалению, мы обнаружили следующие ошибки» при невалидном коде. Сообщения об ошибках или предупреждениях содержат номер строки, селектор и описание ошибки.
Проверить загруженный файл
Эта вкладка позволяет загрузить HTML или CSS-файл и проверить его на наличие ошибок (рис. 20.2).

Рис. 20.2. Проверка файла при его загрузке
Сервис автоматически распознает тип файла и если указан HTML-документ, вычленяет из него стиль для валидации.
Проверить набранный текст
Последняя вкладка предназначена для непосредственного ввода HTML или CSS-кода, при этом проверке будет подвергнут только стиль (рис. 20.3).

Рис. 20.3. Проверка введённого кода
Этот вариант представляется наиболее удобным для проведения различных экспериментов над кодом или быстрой проверки небольших фрагментов.
В CSS3 добавлено много новых стилевых свойств по сравнению с предыдущей версией, поэтому проводить проверку кода следует с учётом версии. По умолчанию в сервисе указан CSS3, так что если вы хотите проверить код на соответствие CSS2.1, это следует указать явно. Для этого щелкните по тексту «Дополнительные возможности» и в открывшемся блоке из списка «Профиль» выберите CSS2.1 (рис. 20.4).
Рис. 20.4. Указание версии CSS для проверки
htmlbook.ru
Как появился Консорциум Всемирной Паутины?
Валидность в общем смысле этого слова — соответствие нормам. В случае с Интернетом нормы и стандарты для верстки страниц и создания кода задает Всемирный консорциум W3C. Создатели этой организации стояли у истоков разработки первых версий HTML (Hyper Text Markup Language, или язык гипертекстовой разметки) и стали первооткрывателями всемирной паутины, которая постепенно обрела огромную популярность. Это открытие принадлежит сэру Тимоти Джону Бернерс-Ли совместно с Робертом Кайо. Бернес-Ли до сегодняшнего дня является главой W3C (World Wide Web Consortium, Консорциум Всемирной Паутины) и законодателем в этой сфере.
С помощью html-разметки стало возможным создавать web-страницы, а для их распознавания в привычный для пользователей вид, были созданы браузеры. W3C ввели ряд стандартов, которым должны соответствовать документы в сети, чтобы все браузеры их могли корректно распознавать. В течение всего времени развития интернета между создателями самых популярных браузеров велись войны за первенство. Некоторые из них даже пытались вводить свои новые стандарты, однако W3C благодаря своим разработкам смогли удержать роль законодателя в правилах создания кода.
версии Html 3 уже была включена поддержка CSS (Cascading Style Sheets, или каскадные таблицы стилей). Изначально стили, цвета и формы задавались непосредственно в коде html, но создание CSS значительно упростило эту задачу, разгрузило исходный код, а соответственно и время загрузки страниц. Последняя версия – это Html 5, которая все больше становится актуальна. Долгое время ее место занимал Html 4.01 (с 1999 года).
Эта историческая справка приведена для того, чтоб у вас было более целостное понимание темы сегодняшнего обзора – валидации сайтов. Если вы зайдете на официальный сайт W3C в раздел «Standards», вы увидите целый перечень подразделов со стандартами. Вот, к примеру, можно увидеть актуальный статус по Html:
По каждому из подпунктов приведены длинные списки норм, определяющих тот или иной атрибут, элемент текущей версии кода. Вот, например, неполное содержание по Html 5:
Правил, как вы понимаете, огромное множество. Чтобы проверить соответствие вашего сайта им, можно воспользоваться специальными валидаторами сайтов.
Но перед тем как рассмотреть их работу, давайте разберемся насколько важно проводить данную операцию.
Должен ли сайт быть валидным?
Единого мнения в данном вопросе нет, но есть объективные причины, которые указывают на то, что проверять валидацию сайта необходимо.
Первое, на что следует обратить внимание, это, так называемая, кроссбраузерность сайта. Т.е. в идеале сайт должен одинаково отображаться во всех браузерах. В данном случае соответствие нормам W3C гарантирует данную опцию.
Во-вторых, роботы поисковиков распознают html-код по тем же параметрам, что и браузеры. Т.е. если в вашем коде содержатся ошибки, например, незакрытые теги, битые ссылки, или поломана структура, все это может повлиять на индексацию сайта поисковыми роботами. А значит, грубые ошибки в коде могут понизить позиции ресурса в выдаче.
Однако, как мы уже видели, правил у W3C очень много, и, порою, соответствие им всем не представляется возможным. Поэтому в данном вопросе лучше придерживаться середины: исправлять в первую очередь грубые ошибки. Важно соблюдать правильный синтаксис, проверять вложенность тегов, сохранять корректную их последовательность и структуру.
pro-wordpress.ru
Зачем исправлять код Валидатором W3C
На самом деле плюсов от этого не много и все они условные, но к сожалению каждый сайт должен иметь минимальное количество ошибок в идеале ни одной. Что бы вы решили нужно ли вам это, вот его плюсы:
- Повысится скорость загрузки страницы, но чуть-чуть, это даже не будет заметно.
- В каждом браузере сайт будет отображаться одинаково.
- Когда добавляют сайт в каталог, обращают внимание на грамотность написания html и css.
Плюсов не много, но исправить ошибки html и css с помощью валидатора W3C стоит!
Как исправлять ошибки Валидатором
Принцип исправления ошибок валидатором не сложный и каждый сможет справиться с этим! Переходим по ссылки на официальный сайт валидатора, если трудно понять английский, советую пользоваться переводчиком, либо пользуетесь этим, что покажет на русском вид ошибок. Рассмотрим пример исправления валидатором:
1.Набираем в поле имя вашего сайта полностью.
2.В списке начинаем смотреть где и какая ошибка и что нужно для её устранения.
Как видно на картинки, моя ошибка в ссылке, эту проблему я нашёл в плагине share buttons. Часто приходится копаться во всех файлах, что бы найти ошибку.
3.Добавляем элемент в строку, где была найдена ошибка и проверяете валидатором опять.
Если ошибка исправлена, то это хорошо. Если нет, то придётся искать дальше.
seosko.ru
Валидатор HTML
W3C HTML Validator — HTML-валидатор W3C, который проверяет синтаксис HTML и XHTML-кода. Проверку можно осуществлять тремя способами: указать адрес страницы в интернете (Validate by URI), загрузить проверяемый файл с компьютера (Validate by File Upload) или вставит HTML-код непосредственно в проверочное окно (Validate by Direct Input).
Нажав кнопку «More Options» можно установить дополнительные настройки проверки, такие как кодировка документа, тип документа (используемый <!DOCTYPE>) и т.д.
Проверка осуществляется на правильность написания тегов, атрибутов и их некоторых значений, правильную вложенность и закрытие тегов, а также на модель содержимого HTML-элементов, так как каждый элемент может содержать только определенный список тегов.
Обращаю ваше внимание на то, что данный валидатор, как и любой другой, не производит проверку HTML на семантику кода, то есть на логичность его структурирования, так как данная задача не относится к синтаксису HTML. Поэтому, например, если вы будете использовать тег выделения длинных цитат (<BLOCKQUOTE>) для создания меню сайта, что ж, Бог вам судья и поисковики, так как они уже довольно неплохо в этом разбираются.
W3C CSS Validator — CSS-валидатор W3C на русском языке, предназначен для проверки CSS (Каскадные таблицы стилей). Как и в предыдущем случае, существует три способа проверки: указать адрес проверяемой страницы, загрузить файл с компьютера или вставить код CSS в окно валидатора.
Нажав на «Дополнительные возможности» вы сможете выбрать версию языка, тип устройства и настроить отчет о проверке.
Данный валидатор проверяет правильности написания селекторов CSS, свойств CSS и их значений, наличие фигурных скобок { } и точек с запятой (;), но он не отслеживает наличие дубликатов свойств для одного и того же элемента, так как синтаксис CSS это позволяет. Поэтому, если ошибок в вашей таблице стилей не обнаружено, но при этом какие-то из параметров не работают, то скорее всего тут дело в приоритетах стилей.
Совмещенный валидатор HTML и CSS
W3C Unicorn Validator — совмещенный валидатор W3C на русском языке, который может проводить не только проверку синтаксиса HTML и CSS, но и RSS, Atom и некоторых других кодов. Здесь вы также можете указать URL проверяемого файла, загрузить его с локальной машины или ввести код непосредственно в окно валидатора.
В меню «Задача» вы можете выбрать тип проверки или сделать ее общей (установлено по умолчанию).
seodon.ru
Преимущества использования W3C validatora?
W3C проверка является процессом исследования кода веб-проектов, чтобы определить насколько он соответствует стандартам форматирования.
Если не проводить проверку страниц ресурса на основе стандартов W3C, то может оказаться, что продвижение сайта, скорее всего, страдает от ошибок или плохого трафика вследствие ужасного форматирования и читаемости на экранах различных устройств.
Поэтому использование W3C validatora даст следующие преимущества.
Поможет улучшить рейтинг в поисковых системах
W3C проверка поможет получить ресурсу более высокий рейтинг в поисковых системах.
Ведь ошибки в коде могут повлиять на производительность сайта, а также оказать большое влияние на SEO проекта.
Боты поисковика проверяют на соответствие стандартам HTML или XHTML код сайта при индексации.
Если они находят неверное форматирование страницы, которое не соответствует официальным правилам, то это может привести к удалению её из индекса.
Если присутствуют ошибки в коде хотя бы одной веб-страницы, поисковые боты перестанут сканировать остальное содержание виртуального проекта.
Позволит лучше использовать практические навыки
Придерживаясь соответствующего шаблонам форматирования, можно разработать оптимальный внешний вид виртуального проекта.
Использование стандартов W3C улучшает практические навыки веб-дизайна.
В то время как многие, давно практикующие вебмастера научились создавать идеальный код и делать относительно небольшое число ошибок, выявляемых при проверке, большинство новичков допускают множество неточностей в HTML или XHTML коде.
Проверка разметки документов позволит начинающим корректировать дизайн виртуальной площадки и одновременно учиться на своих ошибках.
Ведь технологии, которые называют веб-стандартами, тщательно разработаны, чтобы обеспечить максимальную пользу для наибольшего числа пользователей, способствуя долгосрочной жизнеспособности любого документа.
Положительно отобразится на эффективности
Проверенные с использованием W3C validatora сайты будут легко доступны людям с современными браузерами.
Такой анализ повышает удобство и функциональность ресурсов, так как пользователи имеют меньше шансов нарваться на ошибки при их отображении на браузерах по сравнению с не апробированы сайтами.
Проверка полностью совместима с широким диапазоном динамических страниц, сценариев, активного контента и мультимедийных презентаций.
Процесс контроля разметки ресурса позволяет разработчикам веб-сайтов, исправить возникающие ошибки форматирования.
Это сказывается на производительности проекта, позволяет правильно прописав код уменьшить вес страниц, что одновременно повышает эффективность.
Из-за этого, веб-страницы отображаются намного быстрее, получаемый трафик намного больше по сравнению с ресурсами, которые не были проверены.
ДРУЖЕСКИ СКАЖЕТСЯ НА ВОСПРИЯТИИ БРАУЗЕРОВ
Правильное отображение содержимого виртуальных проектов браузерами одна из главных причин, почему была введена W3C-проверка кода.
Сайты, которые не проходили проверку, могут отображаться некорректно не только в окне одного какого-то конкретного browsera, но и прочими браузерами.
В этом состоит проблема идентичности отображения данных, с которыми сталкиваются многие ресурсы.
Сайты, которые не прошли анализ могут воспроизводиться с проблемами форматирования при их использовании в некоторых браузерах.
С другой стороны, W3C проверенные площадки отображаются без ошибок независимо от того, какой браузер используется.
Хотя и при этом существуют свои нюансы, иногда разработчики браузеров не всегда правильно понимают рекомендации и спецификации, по разработке ПО, что зачастую приводит к неправильному показу пользователям документа.
К радости, все современные программы для интернет-серфинга лишены таких проблем.
Есть пять основных веб-браузеров: Chrome, Firefox, Internet Explorer и Safari и корректное отображение ресурса в каждом из них приводит к его просмотру миллионами интернет-пользователей.
ДОСТУП БОЛЬШИНСТВУ УСТРОЙСТВ
Начавшийся рост трафика с планшетов и смартфонов, свидетельствует о том, что все больше людей получают доступ в интернет с мобильных устройств, предпочитая их настольным компьютерам.
В 2016 году объем мобильной коммерции превысил $ 119 млрд по всему миру исходя из этого некоторые компании рассчитывают на прирост мобильного трафика.
Поэтому владельцам виртуальных проектов следует максимально озаботиться удобством отображения страниц ресурса на экранах мобильных гаджетов.
Чего без использования W3C-технологий будет невозможно добиться.
Чтобы сайт был доступен для посещения как можно большему количеству пользователей следует разработать его мобильную версию и протестировать ее с помощью W3C validatora.
Это позволит страницам ресурса быстрее загружаться на мобильных устройствах.
ОБЛЕГЧИТ ТЕХНИЧЕСКОЕ ОБСЛУЖИВАНИЕ И РЕДАКТИРОВАНИЕ
Проверенное с помощью W3C validatora форматирование страницы или полностью виртуального проекта имеет свои преимущества.
Эффективно проведенная валидация кода позволяет владельцу ресурса в будущем создать новую страницу или другой веб-сайт с аналогичным форматированием.
ПОЗВОЛИТ ИСПРАВИТЬ ВЫЯВЛЕННЫЕ ОШИБКИ
Инструменты W3C validatora выделять соответствующим цветом грубые и незначительные ошибки в коде.
Если страница не отображается, как ожидалось валидатор вполне может указать вам на причину возникших проблем.
Не всегда стоит проводить исправление всех выделенных ошибок, кроме грубых, способных повлиять на работоспособность ресурса и его кроссбраузерность.
Универсальных рецептов по правке кода нет, все зависит от того какие используются элементы, в каких фрагментах выявлены неточности и прочее.
СЕРВИСЫ W3C ДЛЯ ПРОВЕРКИ КОДА
Валидацию на соответствия кода стандартам W3C лучше всего проводить с помощью бесплатных площадок для проверки, предлагаемых разработчиками: HTML валидатор, CSS валидатор.
HTML VALIDATOR
Этот валидатор проверяет правильность разметки веб-документов в формате HTML, XHTML, SMIL, MathML, и т.д.
В это понятие входит: поиск посторонних элементов, соответствие вложенности тегов, проверка синтаксиса и прочее.
CSS VALIDATOR
Данный сервис поможет разработчикам и дизайнерам при анализе и правке CSS (каскадных таблиц стилей).
Инструменты этой площадки позволяют не только провести сопоставление таблиц стилей с имеющимися спецификациями, но и дают возможность выявить неправильное применение CSS, имеющие место опечатки и прочие ошибки.
Еще одним положительным моментом является возможность получать сообщения об опасности появления трудностей с доступностью контента.
Оба сервиса позволяют осуществлять проверку по URL всего ресурса или отдельной страницы, с помощью загруженного файла или прямого ввода готового фрагмента кода.
Также существуют специальные расширения браузеров, которые позволяют тестировать просматриваемую страницу без использования W3C validatora.
- – Одним из них является плагин Tidy, который можно применять как еще один вариант для проверки страниц, хотя он не может предложить те же результаты, что и W3C валидатор. Выявленные данным расширением ошибки можно рассортировать на три основных группы:
- – Сообщения, которые были опционально сформированы. В них находятся данные о соответствии стандартам W3C кода по трем важнейшим направлениям.
- – Предупреждения. Их содержания содержат сведения об ошибках, исправление которых можно произвести в автоматическом режиме.
- – Ошибки. Здесь собраны те неточности кода, которые не поддаются исправлению этим плагином.
Одним из преимуществ HTML Tidy используют расширение вы можете проверить свои страницы непосредственно в браузере, без необходимости посетить один из сайтов валидаторов.
Но стоит учитывать, что такая онлайн-проверка имеет меньше возможностей выявить неточности кода по сравнению с тем, что позволяет определить W3C validator.
ЗАКЛЮЧЕНИЕ
Соответствие виртуального проекта принятым в W3C стандартам гарантирует:
- – На применяемых для интернет-серфинга совместимых устройствах лучшую функциональность новых стандартов.
- – Снижение возможности появления багов из-за совместимости со значительным количеством платформ и браузеров.
- – Применение и более простую поддержку полной функциональности.
При сопровождении уже разработанных виртуальных площадок или создании новых веб-проектов нелишним будет применения инструментов сервиса W3C validator для регулярного анализа кода.
Это позволит быть полностью уверенным в том, что ресурс предельно оптимизирован для корректного отображения на всех браузерах и устройствах и соответствует всем актуальным стандартам.
seoquick.com.ua
Добро пожаловать на Блог Свободного Вебмастера. Сегодня я хочу обратить Ваше внимание на еще один способ проверки сайта на соответствие общепринятым интернет-стандартам. Буквально на днях я рассказывал как проверить валидность HTML кода, на очереди CSS.
CSS (от англ. Cascading Style Sheets) — это формальный стандарт, предназначенный для описания внешнего вида документа языком разметки.
Для проверки существует очень полезный сервис, который представляет Консорциум W3C. Перейдем на страницу сервиса CSS Validation Service и проверим валидность CSS. По сложившейся традиции для примера я проверю главную страницу Яндекса. Пройдя по ссылке откроется новое окно, которое будет выглядеть следующим образом:
И здесь нас ждет приятное удивление! Все на русском языке! Кроме того, есть возможность выбора любого языка из 18 доступных. В окне присутствуют вкладки, предлагающие выбрать вариант проверки:
- URI — по ссылке на страницу
- Загруженный файл
- Набранный текст
Думаю, здесь пояснения не требуются. Продолжаем экспериментировать с Яндексом и проверим его на соответствие стандартам CSS. Для этого в текстовую строку ввожу адрес главной страницы и нажимаю на кнопку «Проверить». В ответ получаю следующее:
И снова Яндексу необходимо поработать над ошибками ? Кстати, из первых строк таблицы видно, что ошибки в основном связаны с параметром border-radius, отвечающим за скругление углов, что не поддерживает стандарт CSS2.1. На самом деле это не критично, просто браузеры, не поддерживающие такие свойства, не будут их учитывать и покажут углы без скруглений.
Настроек проверки как таковых нет, НО сервис предлагает нам сгенерированный валидный код таблицы стилей, который будет отображен после списка всех ошибок и предупреждений:
Его можно изучить, сравнить с исходным вариантом, выявить методы исправления ошибок и предупреждений, а после принять меры по их устранению.
Чтобы подтвердить, что ничего невозможного нет, привожу результат проверки валидности CSS Блога Свободного Вебмастера на момент написания поста:
Здесь меня поздравляют, что блог не содержит ошибок и предлагают в знак подтверждения соответствия правилам разместить баннер. Баннер не является обязательным, на усмотрение вебмастера. Предлагаю и Вам воспользоваться валидатором CSS и поделиться результатами в комментариях!
webliberty.ru
Что такое валидация html кода?
Html, как известно, язык разметки, который является основой для подавляющего большинства страниц в интернете. Как у любого другого языка, у html есть правила написания — синтаксис. Валидный html-код это код, который соответствует всем рекомендациям написания кода — спецификации.
Спецификации. Что это?
Как у любого другого языка, у HTML существуют свои правила написания — синтаксис. Эти правила пишет команда профессионалов, заинтересованных в развитии html и занимающихся разработкой новых элементов, отвечающих параметрам современных устройств, актуальных современным технологиям и, самое главное, отвечающих современным требованиям безопасности. Именно правила написания элементов html, установленные разработчиками языка, называются спецификацией.
После разработки основной части нового релиза html, разработчики языка выкладывают спецификацию к нему в публичный доступ на обсуждение всех желающих вебмастеров мира, внимательно читают комментарии и, если потребуется, вносят правки. После завершения всеобщего обсуждения, новый релиз языка выходит в мир и им можно пользоваться.
Каждый документ, использующий html код, должен следовать правилам языка. Последняя опубликованная версия HTML — пятая и стала относительно сложная, так что вебмастера, не прочитавшие последнюю версию спецификации, легко могут сделать ошибки в коде.
Cколько спецификаций существует.
Начиная с HTML5, разработчики и производители браузеров могут выбирать между двумя разновидностями одного и того же языка разметки: спецификациями, разработанными консорциумом W3C, и тех, что разработаны WHATWG.
В принципе эти спецификации очень похожи, однако, с годами, между ними все больше и больше отличий. Большинству вебмастеров не стоит сильно беспокоиться по этому поводу: или эти отличия спецификаций не скажутся на их проектах, или разработчики браузеров будут поддерживать оба стандарта языка.
Однако при использовании в своих проектах только что появившихся нововведениях в одной из спецификаций, у вебмастеров могут возникнуть проблемы. Например Дэвид Бэрон из Mozilla заявил:
Если HTML-спецификации W3C и WHATWG различаются, то мы стараемся следовать спецификации WHATWG.
Зачем нужна валидация?
Поисковые роботы сканируют страницы вашего сайта для поиска релевантного контента. Поисковые роботы подчиняются стандартам HTML. Если в вашем HTML коде есть грубые ошибки, то роботы могут запутаться и не найти контенте на вашей странице. Не закрытый тег или кривая верстка сильно ударят по изучению вашего сайте роботами. Наличие битых ссылок существенно замедлит индексацию вашего ресурса. Валидный код в разы упрощает индексацию страниц вашего сайта и позволяет им быстрее оказаться в выдаче.
klondike-studio.ru