
Состояние перевода: На этой странице представлен перевод статьи dd. Дата последней синхронизации: 2 февраля 2022. Вы можете помочь синхронизировать перевод, если в английской версии произошли изменения.
dd — это основная утилита, основной задачей которой является конвертация и копирование файлов.
Как и cp, по умолчанию dd делает точную копию файла, но позволяет контролировать параметры ввода-вывода на низком уровне.
Подробности можно почитать в dd(1) или полной документации.
Совет: По умолчанию dd ничего не пишет в консоль в процессе работы. Чтобы следить за процессом, можно использовать опцию status=progress.
Важно: Будьте крайне осторожны при использовании dd, так как её использование может необратимо уничтожить данные.
Установка
dd входит в состав GNU coreutils. Другие утилиты из этого пакета описаны в статье Основные утилиты.
Клонирование диска и восстановление
Команда dd — это простой, но универсальный и мощный инструмент. Она может использоваться для копирования, блок за блоком, независимо от типа файловой системы или операционной системы. Нередко dd используется в LiveCD.
Важно: Как и с любыми командами подобного рода, при использовании dd нужно быть очень осторожным; она может уничтожить данные. Запомните опции, задающие входной файл (if=) и выходной файл (of=), и не меняйте их местами! Всегда проверяйте, что целевой диск или раздел (of=) имеет равный или больший размер, чем исходный (if=).
Клонирование раздела
Копирование раздела 1 на диске /dev/sda в раздел 1 на диске /dev/sdb:
# dd if=/dev/sda1 of=/dev/sdb1 bs=64K conv=noerror,sync status=progress
Примечание: Проверяйте существование файла целевого устройства (в данном примере sdb1). Если он не существует, то dd создаст новый файл, который будет занимать место в вашей файловой системе.
Клонирование всего диска
Копирование физического диска /dev/sda в диск /dev/sdb:
# dd if=/dev/sda of=/dev/sdb bs=64K conv=noerror,sync status=progress
Эта команда скопирует диск целиком, в том числе таблицу разделов, загрузчик, разделы, UUID и данные.
bs=устанавливает размер блока. По умолчанию 512 байт, что является «классическим» размером блока для жёстких дисков с начала 1980-х годов, но не самым удобным. Используйте большее значение, 64K или 128K. Также прочитайте предупреждение ниже, потому что это не просто «размер блока» — это также влияет на обработку ошибок чтения. Смотрите [1] и [2] для получения подробной информации и определения наилучшего значения bs для вашего случая.noerrorуказывает dd продолжить работу, игнорируя все ошибки чтения. По умолчанию dd прекращает работу при любой ошибке.syncзаполняет входные блоки нулями, если были ошибки чтения, чтобы смещения данных оставались правильными.status=progressпоказывает статистику передачи данных, которая позволяет оценить время завершения.
Примечание: Размер блока, который вы указываете, влияет на то, как обрабатываются ошибки чтения (смотрите ниже). Для восстановления данных используйте ddrescue.
Утилита dd технически имеет «размер входного блока» (IBS) и «размер выходного блока» (OBS). Когда вы устанавливаете bs, вы фактически устанавливаете и IBS, и OBS. Обычно, если размер блока, скажем, 1 МиБ, dd считывает 1024×1024 байт и записывает столько же байт. Но если произойдет ошибка чтения, всё пойдет не так. Многие думают, что dd «заполнит ошибки чтения нулями», если вы используете опции noerror,sync, но это не так. dd, согласно документации, дополнит размер OBS до размера IBS после завершения чтения, что означает добавление нулей в конце блока. То есть, весь 1 МиБ будет испорчен из-за одной ошибки чтения в 512 байт в начале чтения: 12ERROR89 станет 128900000 вместо 120000089.
Если вы уверены, что ваш диск не содержит ошибок, вы можете использовать больший размер блока, что увеличит скорость копирования в несколько раз. Например, изменение bs с 512 до 64K изменило скорость копирования с 35 МБ/с до 120 МБ/с на простой системе Celeron 2,7 ГГц. Но имейте в виду, что ошибки чтения на исходном диске будут в конечном итоге выглядеть как ошибки блоков на целевом диске, то есть одна ошибка чтения 512 байт испортит весь выходной блок размером 64 КиБ.
Примечание:
- Чтобы сделать UUID файловых систем ext2/3/4 снова уникальными после копирования, используйте
tune2fs /dev/sdXY -U randomдля каждого раздела. Для разделов подкачки используйтеmkswap /dev/sdXY. - Если вы копируете GPT-диск, вы можете использовать sgdisk для рандомизации GUID диска и разделов и восстановления их уникальности.
- Изменения таблицы разделов, которые внёс dd на целевом диске, не регистрируются ядром. Чтобы попросить ядро перечитать таблицы разделов без перезагрузки, можно использовать утилиту partprobe (часть GNU Parted).
Резервное копирование таблицы разделов
Смотрите fdisk (Русский)#Резервное копирование и восстановление таблицы разделов или GPT fdisk (Русский)#Резервное копирование и восстановление таблицы разделов.
Создание образа диска
Загрузитесь в LiveCD и убедитесь, что разделы исходного диска не примонтированы.
Затем смонтируйте целевой диск и запишите на него резервную копию:
# dd if=/dev/sda conv=sync,noerror bs=64K | gzip -c > /путь/к/копии.img.gz
При необходимости (например, если результирующие файлы будут храниться в файловой системе FAT32) можно разделить образ диска на несколько частей (смотрите также split(1)):
# dd if=/dev/sda conv=sync,noerror bs=64K | gzip -c | split -a3 -b2G - /путь/к/копии.img.gz
Если не хватает свободного места на локальном диске, можно отправить образ через ssh:
# dd if=/dev/sda conv=sync,noerror bs=64K | gzip -c | ssh user@local dd of=копия.img.gz
Наконец, сохраните дополнительную информацию о геометрии диска, необходимую для интерпретации таблицы разделов, хранящейся в образе. Наиболее важной из них является размер цилиндра.
# fdisk -l /dev/sda > /путь/к/list_fdisk.info
Примечание: Вы можете использовать размер блока (bs=), равный объёму кэша на диске, с которого выполняется копирование. Например, bs=8192K подходит для кэша 8 МиБ. Упомянутые в этой статье 64 КиБ лучше, чем стандартные bs=512 байт, но при большем bs= копирование будет ещё быстрее.
Совет: gzip использует всего одно ядро процессора для сжатия, из-за чего скорость копирования может оказаться сильно меньше, чем скорость записи на современных накопителях. Чтобы использовать многоядерное сжатие и быстрее создать образ диска, можно, например, установить пакет pigz и просто заменить команду gzip -c на pigz -c. Для больших дисков это может сэкономить часы. Также можно попробовать другие алгоритмы сжатия, например zstd.
Восстановление системы
Чтобы восстановиться из такой резервной копии:
# gunzip -c /путь/к/копии.img.gz | dd of=/dev/sda
Если образ был разделён на несколько частей командой split, используйте другую команду (обратите внимание на звёздочку):
# cat /путь/к/копии.img.gz* | gunzip -c | dd of=/dev/sda
Патчинг бинарных файлов
Если нужно заменить заменить три байта FF C0 14 по смещению 0x123AB, это можно сделать с помощью такой команды:
# printf 'xffxc0x14' | dd seek=$((0x123AB)) conv=notrunc bs=1 of=/путь/к/файлу
Резервное копирование и восстановление MBR
Перед внесением изменений на диск можно создать резервную копию таблицы разделов и схемы разделов диска. Также можно использовать резервную копию для копирования одной и той же схемы разделов на несколько дисков.
MBR хранится в первых 512 байтах диска. Она состоит из 4 частей:
- Первые 440 байт содержат загрузочный код (загрузчик).
- Следующие 6 байт содержат сигнатуру диска.
- Следующие 64 байта содержат таблицу разделов (4 записи по 16 байт каждая, по одной записи на каждый основной раздел).
- Последние 2 байта содержат сигнатуру загрузки.
Сохранение MBR в mbr_file.img:
# dd if=/dev/sdX of=/путь/к/mbr_file.img bs=512 count=1
Также можно извлечь MBR из полного образа диска dd:
# dd if=/путь/к/образу.img of=/путь/к/mbr_file.img bs=512 count=1
Для восстановления (будьте осторожны, это уничтожит существующую таблицу разделов, а вместе с ней и доступ ко всем данным на диске):
# dd if=/путь/к/mbr_file.img of=/dev/sdX bs=512 count=1
Важно: Восстановление MBR с несоответствующей таблицей разделов сделает ваши данные нечитаемыми и практически невозможными для восстановления. Если вам просто нужно переустановить загрузчик, смотрите соответствующие страницы, поскольку они также используют DOS compatibility region: GRUB (Русский) или Syslinux (Русский).
Если вы хотите восстановить только загрузчик, но не информацию о разделах, просто восстановите первые 440 байт MBR:
# dd if=/путь/к/mbr_file.img of=/dev/sdX bs=440 count=1
Восстановление только таблицы разделов без затрагивания загрузчика и сигнатуры:
# dd if=/путь/к/mbr_file.img of=/dev/sdX bs=1 skip=446 count=64
Удаление загрузчика
Чтобы стереть загрузочный код MBR (может быть полезно, если вам нужно сделать полную переустановку другой операционной системы), можно обнулить первые 440 байт:
# dd if=/dev/zero of=/dev/sdX bs=440 count=1
Решение проблем
Partial read
Файлы, созданные с помощью dd, могут иметь меньший размер, чем запрошено, если полный входной блок недоступен и системный вызов read(2) завершается раньше времени. Это может произойти при чтении из pipe(7) или при чтении с /dev/random и недостаточной энтропии[3], или с /dev/urandom при чтении более 32 МиБ[4].
Возможно, но не гарантировано, что dd предупредит вас об этой проблеме:
dd: warning: partial read (X bytes); suggest iflag=fullblock
Решается это так, как и предлагает предупреждение: добавлением iflag=fullblock к команде dd:
$ dd if=/dev/random of=bigsecret.img bs=1K count=1 iflag=fullblock $ dd if=/dev/urandom of=bigsecret.img bs=40M count=1 iflag=fullblock
Примечание: Крайне желательно всегда использовать iflag=fullblock при чтении из /dev/random или /dev/urandom.
Для /dev/urandom также можно задать большее число копируемых блоков:
$ dd if=/dev/urandom of=bigsecret.img bs=1M count=40
При чтении из pipe альтернативой для для iflag=fullblock может быть прописывние для bs значения PIPE_BUF, которое определено в /usr/include/linux/limits.h [5]. Например:
$ cat input.img | dd of=output.img bs=4k count=100
Время на прочтение
4 мин
Количество просмотров 557K

В UNIX системах есть одна очень древняя команда, которая называется dd. Она предназначена для того, чтобы что-то куда-то копировать побайтово. На первый взгляд — ничего выдающегося, но если рассмотреть все возможности этого универсального инструмента, то можно выполнять довольно сложные операции без привлечения дополнительного ПО, например: выполнять резервную копию MBR, создавать дампы данных с различных накопителей, зеркалировать носители информации, восстанавливать из резервной копии данные на носители и многое другое, а, при совмещении возможностей dd и поддержке криптографических алгоритмов ядра Linux, можно даже создавать зашифрованные файлы, содержащие в себе целую файловую систему.
Опять же, в заметке я опишу самые часто используемые примеры использования команды, которые очень облегчают работу в UNIX системах.
Начну с небольшого примера, наглядно иллюстрирующего основные параметры команды:
# dd if=/dev/urandom of=/dev/null bs=100M count=5
Параметры:
- if: указывает на источник, т.е. на то, откуда копируем. Указывается файл, который может быть как обычным файлом, так и файлом устройства.
- of: указывает на файл назначения. То же самое, писать можем как в обычный файл, так и напрямую в устройство.
- bs: количество байт, которые будут записаны за раз. Можно представлять этот аргумент как размер куска данные, которые будут записаны или прочитаны, а количество кусков регулируется уже следующим параметром.
- count: как раз то число, которое указывает: сколько кусочков будет скопировано.
Таким образом, описанная команда читает 5*100 мегабайт из устройства /dev/urandom в устройство /dev/null. Придавая этой команде смысловую нагрузку получается, что система сгенерирует 500 мегабайт случайных значений и запишет их в null устройство. Конечно, единственное, что сделает эта команда: нагрузит процессор на несколько секунд. Рассмотрим примеры из практики:
Создание образа диска:
# dd if=/dev/cdrom of=image.iso
Команда будет считывать из устройства данные и записывать в файл до тех пор, пока не достигнет окончания устройства. Если диск битый, можно попробовать его прочитать, игнорируя ошибки чтения:
# dd if=/dev/cdrom of=image.iso conv=noerror
Параметр «conv» позволяет подключать несколько фильтров, применимых к потоку данных. Фильтр «noerror» как раз отключает остановку работы программы, когда наткнется на ошибку чтения. Таким образом, некоторые данные с диска все же можно будет прочитать. Точно таким образом я спас данные со своей флешки Corsair, которую погнули: подобрал подходящее положение, когда контакт есть, и сделал дамп файловой системы.
Подключить, кстати, такие образы можно при помощи команды mount с ключем «-o loop»:
# mount -o loop image.iso /mnt/image
Если что-то не получается, процесс разбивается на 2 уровня:
# losetup -e /dev/loop0 image.iso
# mount /dev/loop0 /mnt/image
Если и так не работает, значит файловая система образа полетела.
Работа с носителями информации
Очень простое, хоть и не оптимальное решение клонирования жесткого диска:
# dd if=/dev/sda of=/dev/sdb bs=4096
Все то же побайтовой копирование с размером буфера 4 Кб. Минус способа в том, что при любой заполненности разделов копироваться будут все биты, что не выгодно при копировании разделов с маленькой заполненностью. Чтобы уменьшить время копирования при манипуляции с большими объемами данных, можно просто перенести MBR на новый носитель (я ниже опишу как), перечитать таблицу разделов ядра (при помощи того же fdisk), создать файловые системы и просто скопировать файлы (не забыв сохранить права доступа к файлам).
Как вариант, можно даже по расписанию делать бекап раздела по сети. Разрулив ключи ssh будет работать такая схема:
# dd if=/dev/DEVICE | ssh user@host «dd of=/home/user/DEVICE.img».
Когда-то читал исследование, согласно которому очень большая доля жестких дисков на барахолке подвергается восстановлению данных без привлечения чего-то специализированного, и содержит конфиденциальную информацию. Чтобы на носителе ничего нельзя было восстановить — можно забить его нулями:
# dd if=/dev/zero of=/dev/DEVICE
Думаю, понятно на что нужно заменить DEVICE. После проведения лекций по Linux, я очень тщательно стал следить за тем, что пишу.
Проверить можно тем же dd, но преобразовав данные в hex:
# dd if=/dev/sda | hexdump -C
Должны посыпаться нули.
Операции с MBR
MBR расположена в первых 512 байтах жесткого диска, и состоит из таблицы разделов, загрузчика и пары доп. байт. Иногда, ее приходится бекапить, восстанавливать и т.д. Бекап выполняется так:
# dd if=/dev/sda of=mbr.img bs=512 count=1
Восстановить можно проще:
# dd if=mbr.img of=/dev/sda
Причины этих махинаций с MBR могут быть разные, однако хочу рассказать одну особенность, взятую из опыта: после восстановления давней копии MBR, где один из разделов был ext3, а позже стал FAT и использовался Windows, раздел перестал видиться виндой. Причина — ID раздела, который хранится в MBR. Если UNIX монтирует файловые системы согласно суперблоку, то винды ориентируются на ID разделов из MBR. Поэтому всегда нужно проверять ID разделов при помощи fdisk, особенно если на компьютере есть винды.
Генерация файлов
При помощи dd можно генерировать файлы, а затем использовать их как контейнеры других файловых систем даже в зашифрованном виде. Технология следующая:
При помощи dd создается файл, забитый нулями (случайными числами забивать не рационально: долго и бессмысленно):
# dd if=/dev/zero of=image.crypted bs=1M count=1000
Создался файл размером почти в гигабайт. Теперь нужно сделать этот файл блочным устройством и, при этом, пропустить его через механизм шифрования ядра linux. Я выберу алгоритм blowfish. Подгрузка модулей:
# modprobe cryptoloop
# modprobe blowfish
Ассоциация образа с блочным устройством со включенным шифрованием:
# losetup -e blowfish /dev/loop0 image.crypted
Команда запросит ввести пароль, который и будет ключем к образу. Если ключ введен не правильно, система не смонтируется. Можно будет заново создать данные в образе, используя новый ключ, но к старым данным доступа не будет.
Создаем файловую систему и монтируем:
# mkfs.ext2 /dev/loop0
# mount /dev/loop0 /mnt/image
Образ готов к записи данных. После завершения работы с ним, нужно не забыть его отмонтировать и отключить от блочного loop устройства:
# umount /dev/loop0
# losetup -d /dev/loop0
Теперь шифрованный образ готов.
Основные идеи я расписал, однако множество задач, которые можно решить при помощи маленькой программки, имя которой состоит из двух букв, намного шире. Программа «dd» — яркий пример того, что IT’шники называют «UNIX way»: одна программа — часть механизма, выполняет исключительно свою задачу, и выполняет ее хорошо. В руках человека, который знает свое дело, которому свойственен не стандартный подход к решению задачи, такие маленькие программки помогут быстро и эффективно решать комплексные задачи, которые, на первый взгляд, должны решать крупные специализированные пакеты.
0
1
Пишу 7.5 Гб img в /dev/sdb
На 1.3 Гб I/O error
Можно ли пропустить?
fsck проверяет ФС (sdb1), а пишется в sdb. Если что,
fsck.ext4 -p -f /dev/sdb1 0.0% non-contiguous- Ссылка

Ответ на:
комментарий
от OldFatMan 17.11.11 21:20:37 MSK

> ключ conv=noerror не то?
man dd
conv=noerror
continue after read errors
———————————————
с conv=noerror тоже до 1.3 Гб пишет, значит тут write error
puding ☆
(17.11.11 21:24:41 MSK)
- Показать ответы
- Ссылка
Ответ на:
комментарий
от puding 17.11.11 21:24:41 MSK
![]()
а зачем писать в умирающий девайс?
anonymous
(17.11.11 21:30:06 MSK)
- Ссылка
Нет смысла пропускать ошибку записи. Пропуск ошибок чтения предусмотрен для случаев, когда необходимо вытащить хоть что-то, даже в испорченном виде. Записывать же что-то в заведомо испорченном виде смысла нет.
GotF ★★★★★
(17.11.11 21:33:52 MSK)
- Ссылка
Ответ на:
комментарий
от puding 17.11.11 21:24:41 MSK
Ответ на:
комментарий
от puding 17.11.11 21:24:41 MSK
И кстати: анонимус и GotF правы — если у тебя ошибка записи, то какой толк будет с такой записи?
- Ссылка
Ответ на:
комментарий
от OldFatMan 17.11.11 21:34:19 MSK
rescued: 8011 MB, errsize: 0 B, current rate: 13041 kB/s
ipos: 8011 MB, errors: 0, average rate: 13061 kB/s
opos: 8011 MB, time from last successful read: 0 s
Finished
Всем спасибо, ddrescue знает свое дело!
puding ☆
(17.11.11 21:43:56 MSK)
- Ссылка
Вы не можете добавлять комментарии в эту тему. Тема перемещена в архив.
Похожие темы
-
Форум
ext4 дефрагментация (2010) -
Форум
fsck о чем говорит результат? (2020) -
Форум
Ошибка при загрузке, кратко: fsck что-то находит, но при загрузке всё-равно exit status 4 (2009) -
Форум
16GB Flash / ошибка ввода/вывода (2019) -
Форум
Ошибка монтирования диска ext4 (2017)
-
Форум
(Fedora 20) Не форматируется флешка?! (2014) -
Форум
помогите устранить ошибки при компиле glibc (2011) -
Форум
[hdd]Он мертв или жить будет (2011) -
Форум
Умирает hdd? (2023) -
Форум
проблема автомонтирования фотика (2008)

В Linux все является файлом, и блочные устройства не исключение. Часто нам приходится работать с блочными устройствами. Как пользователи Linux, мы выполняем различные операции с блочными устройствами, например, – создание резервной копии диска или раздела, резервное копирование главной загрузочной записи (MBR), создание загрузочного USB-накопителя и т.д. Конечно, мы можем использовать графические инструменты для выполнения всех этих операций. Однако большинство администраторов Linux предпочитают использовать команду dd из-за ее богатой функциональности и надежности.
Синтаксис команды dd
Наиболее распространенный синтаксис команды dd следующий:
dd [if=][of=]
В приведенном выше синтаксисе:
- if – представляет входной или исходный файл.
- of – представляет выходной или конечный файл.
Предупреждение – Важно отметить, что команда dd должна использоваться очень осторожно при работе с блочными устройствами. Небольшая ошибка может привести к необратимой потере данных. Поэтому настоятельно рекомендуется сначала опробовать эти операции на тестовой машине.
1. Как скопировать файл в Linux
Одним из основных способов использования команды dd является копирование файла в текущий каталог. Для начала создадим простой текстовый файл:
echo "this is a sample text file" > file-1.txt
Теперь создадим его копию с помощью команды dd:
dd if=file-1.txt of=file-2.txt
В этом примере параметр if представляет исходный файл, а параметр of – конечный файл.

Разве она не похожа на команду cp? Тогда что особенного в команде dd?
Команда dd намного мощнее обычной команды cp.
2. Как преобразовать текст из нижнего регистра в верхний
Команда dd позволяет нам выполнять преобразование регистра. Для этого мы можем использовать с ней параметр conv.
Чтобы понять это, сначала выведите содержимое файла file-1.txt:
cat file-1.txt this is a sample text file
Теперь преобразуем содержимое файла в верхний регистр с помощью следующей команды:
dd if=file-1.txt of=upper-case.txt conv=ucase
В этом примере опция conv=ucase используется для преобразования строчных букв в прописные.
Наконец, проверьте содержимое вновь созданного файла:
cat upper-case.txt THIS IS A SAMPLE TEXT FILE

3. Как перевести текст из верхнего регистра в нижний
Аналогичным образом мы можем использовать команду dd для преобразования букв верхнего регистра в буквы нижнего регистра:
Давайте воспользуемся опцией conv=lcase для преобразования букв верхнего регистра в строчные:
dd if=upper-case.txt of=lower-case.txt conv=lcase
Теперь отобразим содержимое созданного файла и убедимся, что преобразование было выполнено правильно:
cat lower-case.txt this is a sample text file

4. Избегайте перезаписи файла назначения в Linux
По умолчанию команда dd заменяет файл назначения, что означает, что она перезапишет файл, если он существует в месте назначения с тем же именем.
Однако, мы можем отключить это поведение по умолчанию, используя опцию conv=excl, как показано на рисунке.
dd if=file-1.txt of=file-2.txt conv=excl dd: failed to open 'file-2.txt' File exists
Здесь мы видим, что команда dd прервала операцию, потому что файл с тем же именем присутствует в месте назначения.
5. Добавление данных в файл с помощью команды dd
Иногда мы хотим обновить файл в режиме добавления, что означает, что новое содержимое должно быть добавлено в конец конечного файла.
Мы можем достичь этого, комбинируя два флага – oflag=append и conv=notrunc. Здесь oflag представляет собой флаг вывода, а опция notrunc используется для отключения усечения в месте назначения.
Чтобы понять это, сначала создадим новый текстовый файл:
echo "append example demo" > dest.txt
Далее, добавим содержимое в файл dest.txt с помощью следующей команды:
dd if=file-1.txt of=dest.txt oflag=append conv=notrunc
Теперь, проверим содержимое файла dest.txt:
cat dest.txt append example demo this is a sample text file

6. Пропуск байтов или символов при чтении входного файла
Мы можем указать команде dd пропустить первые несколько символов при чтении входного файла, используя опции ibs и skip.
Сначала выведем содержимое файла file-1.txt:
cat file-1.txt this is a sample text file
Следующая команда:
dd if=file-1.txt of=file-2.txt ibs=8 skip=1
Теперь проверим содержимое файла file-2.txt:
cat file-2.txt a sample text file

В приведенном выше выводе видно, что команда пропустила первые 8 символов.
7. Резервное копирование раздела диска Linux с помощью команды dd
До сих пор мы обсуждали основные примеры команды dd, не требующие root-доступа. Теперь давайте рассмотрим некоторые продвинутые случаи использования.
Как и в случае с файлами, мы можем сделать резервную копию раздела диска с помощью команды dd. Например, приведенная ниже команда создает резервную копию раздела /dev/sda1 в файл partition-bak.img:
sudo dd if=/dev/sda1 of=partition-bak.img

8. Восстановление раздела диска Linux с помощью команды dd
В предыдущем примере мы создали резервную копию раздела /dev/sda1 в файл partition-bak.img.
Теперь давайте восстановим его в раздел /dev/sdb1 с помощью следующей команды:
sudo dd if=partition-bak.img of=/dev/sdb1

Важно отметить, что размер целевого раздела должен быть равен или больше размера резервной копии.
9. Резервное копирование всего жесткого диска Linux с помощью команды dd
Диск может иметь несколько разделов. Поэтому создание и восстановление резервной копии каждого раздела может занять много времени при увеличении количества разделов. Чтобы преодолеть это ограничение, мы можем создать резервную копию всего диска, как и разделов.
Так, давайте создадим резервную копию диска /dev/sda с помощью следующей команды:
sudo dd if=/dev/sda of=disk-bak.img

Приведенная выше команда создает резервную копию всего диска, включая его разделы.
10. Восстановление жесткого диска Linux с помощью команды dd
Как и разделы, мы можем восстановить резервную копию всего диска. В предыдущем примере мы сделали резервную копию всего диска в файл disk-bak.img. Теперь воспользуемся тем же для восстановления резервной копии на диске /dev/sdb.
Сначала удалим все разделы с диска /dev/sdb и проверим, что все разделы удалены:
lsblk /dev/sdb
Следующим образом восстановим резервную копию на диске /dev/sdb с помощью следующей команды:
sudo dd if=disk-bak.img of=/dev/sdb
Наконец, убедимся, что раздел был создан на диске /dev/sdb:
lsblk /dev/sdb

11. Резервное копирование главной загрузочной записи с помощью команды dd
Главная загрузочная запись (MBR) находится в первом секторе загрузочного диска. Она хранит информацию о разделах диска. Мы можем использовать команду dd, как показано ниже, чтобы сделать ее резервную копию:
sudo dd if=/dev/sda of=mbr.img bs=512 count=1
Приведенная выше команда делает резервную копию первых 512 байт, то есть одного сектора.

Важно отметить, что приведенная выше команда должна быть выполнена на загрузочном диске.
12. Восстановление главной загрузочной записи с помощью команды dd
В предыдущем примере мы создали резервную копию главной загрузочной записи (MBR). Теперь восстановим ее на диске /dev/sdb с помощью следующей команды:
sudo dd if=mbr.img of=/dev/sdb

13. Копирование содержимого CD/DVD-привода с помощью команды dd
По аналогии с разделами и дисками, мы можем использовать команду dd для копирования содержимого CD или DVD-привода. Поэтому давайте воспользуемся следующей командой:
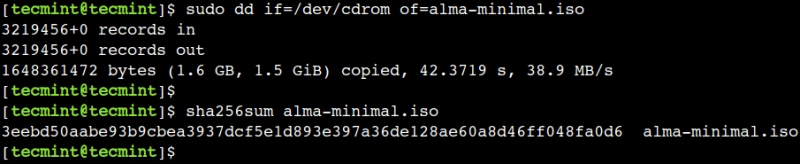
sudo dd if=/dev/cdrom of=alma-minimal.iso
В Linux привод CD/DVD представлен устройством /dev/cdrom. Поэтому мы используем его в качестве исходного файла.
Теперь давайте проверим, что содержимое диска было успешно скопировано, проверив его контрольную сумму командой:
sha256sum alma-minimal.iso
14. Создание загрузочного USB-накопителя с помощью команды dd
В предыдущем примере мы создали iso-образ Alma Linux. Теперь давайте используем его для создания загрузочного USB-накопителя:
sudo dd if=alma-minimal.iso of=/dev/sdb

Важно отметить, что приведенная выше команда должна быть выполнена с правильным USB-накопителем.
15. Как показать индикатор прогресса
По умолчанию команда dd не показывает прогресс при выполнении операции копирования. Однако мы можем отменить это поведение по умолчанию с помощью опции status.
Так что давайте используем опцию status=progress с командой dd, чтобы показать индикатор выполнения:
sudo dd if=alma-minimal.iso of=/dev/sdb status=progress

Вывод
В этой статье мы рассмотрели некоторые практические примеры использования команды dd. Опытные пользователи могут обращаться к этим примерам в повседневной жизни при работе с системами Linux. Однако при выполнении этих команд нужно быть очень осторожным. Ведь небольшая ошибка может привести к перезаписи содержимого всего диска.

Зарубин Иван
Эксперт по Linux и Windows
Опытный системный администратор с большим стажем работы на крупном российском заводе. Иван является энтузиастом OpenSource и любителем Windows, проявляя высокую компетентность в обоих операционных системах.
Благодаря его технической грамотности и умению решать сложные задачи, Иван стал неотъемлемой частью команды нашего проекта, обеспечивая непрерывную авторскую работу.
Похожие статьи
- 20 примеров команды ls в Linux
- Как управлять файлами журнала с помощью Logrotate в Linux
- Как создать пользователя sudo в Ubuntu
- Лучшие эмуляторы терминала для Linux
- Используйте sysfs для перезапуска любого PCI-устройства в Linux
I’m trying to copy data off a rather damaged CD using the following command:
dd if=/dev/sr1 of=IDT.img conv=sync,noerror status=progress
However, the ‘of’ device got disconnected and the dd stopped (output below).
...
dd: error reading '/dev/sr1': Input/output error
1074889+17746 records in
1092635+0 records out
559429120 bytes (559 MB, 534 MiB) copied, 502933 s, 1.1 kB/s
dd: writing to 'IDT.img': Input/output error
1074889+17747 records in
1092635+0 records out
559429120 bytes (559 MB, 534 MiB) copied, 502933 s, 1.1 kB/s
Can I resume with:
dd if=/dev/sr1 of=IDT.img conv=sync,noerror status=progress seek=1092635 skip=1092635
Or should the seek/skip numbers be both 1092636, or should skip/seek be different from each other, or something entirely different?
PS I know I’m probably using the wrong command for this, e.g. ddrescue is probably better. But I’m probably stuck with dd now(?). I don’t expect any more errors on the output file side of things.