
Cправка — Search Console
Войти
Справка Google
- Справочный центр
- Сообщество
- Search Console
- Политика конфиденциальности
- Условия предоставления услуг
- Отправить отзыв
Тема отзыва
Информация в текущем разделе Справочного центра
Общие впечатления о Справочном центре Google
- Справочный центр
- Сообщество
Search Console
На сайте постоянно увеличивается количество страниц с ошибками Слишком мелкий шрифт и Интерактивные элементы расположены слишком близко
При открытии страницы висит соотв надпись: Страница не оптимизирована для мобильных устройств
Нажимаю «проверить на сайте» и далее 2 варианта: либо страница оптимизирована, что никак не влияет на то, что она остается в ошибках, либо страница не оптимизирована, и в результатах проверки следующее:
Ресурсы страницы
17 ресурсов из 19 не удалось загрузить, среди которой и CSS со значением: Другая ошибка
Другими словами он тупо не жрет CSS, но делает четкий вывод что у меня ошибки…
Как такое можно починить?
На ум приходит только ловить его по агенту, и вставлять CSS в HTML (а может и JS тоже)
 В «Google Search Console» есть штука называемая «Mobile-Friendly Test tool«, на результаты которой опирается гугл решая индексировать ли страницу или нет.
В «Google Search Console» есть штука называемая «Mobile-Friendly Test tool«, на результаты которой опирается гугл решая индексировать ли страницу или нет.
Относительно с недавних (с конца 2016-го года) пор гугл ударился в «Mobile-first Indexing», а потому теперь рейтинг страницы и позиция в поисковой выдаче напрямую зависит от степени её оптимизированости под мобильные устройства:
Подготовка к индексированию с приоритетом мобильного контента
При индексировании, ориентированном на мобильные устройства, рейтинг страниц зависит главным образом от их мобильной версии. Раньше релевантность контента оценивалась в первую очередь на основе версии для компьютеров. Поскольку большинство пользователей сейчас открывают Google Поиск на мобильных устройствах, сканирование и индексирование страниц теперь выполняет в первую очередь робот Googlebot для смартфонов.
Проблемы Mobile-Friendly Test tool
Главная проблема с «Mobile-Friendly Test tool» в том, что работает оно криво и косо, что проявляется в ничем не обоснованных ошибках типа:
Исправьте 2 указанные ниже проблемы
- Слишком мелкий шрифт
- Интерактивные элементы расположены слишком близко
При этом, а ни изменение размера шрифта, ни расстояние между элементами не решают проблему.
В правой части окна результатов проверки «Mobile-Friendly Test tool» можно видеть «Проблемы при загрузке страницы. Подробнее», кликнув на «Подробнее» нашему взору откроются «Данные о ходе загрузки страницы»:
Страница частично загружена
Не удалось загрузить все элементы страницы. Это может повлиять на то, как Google видит и обрабатывает вашу страницу. Устраните проблемы.
Далее по тексту там будем видеть «Не удалось загрузить 30 ресурсов страницы», среди которых в основном будут изображения с типом «Изображение» и статусом «Другая ошибка».
Изображение — Другая ошибка
Данный глюк, а это именно глюк, в «Mobile-Friendly Test tool» существует довольно давно, выполоскал мозги многим СЕО-пропихаторам и вызвал множественные холивары на просторах Интернетов:
Гугл не видит большинство картинок на сайте — Cправка — Search Console
…
Это проблема инструмента проверки мобильности, он просто ограничен в ресурсах и на ошибке сбивается, что приводит к вываливанию в «другую ошибку». Причин может быть море, начиная от размера картинок и заканчивая размером js-скриптов и css.
Уже более года обещают пофиксить данный инструмент.
Аналогичные глюки имеют место быть и при проверке нашего сайта, который на данный момент расположен на VPS, а значит мы имеем полный доступ к лог-файлам сервера в режиме реального времени. Для чистоты эксперимента был полностью отключен брандмауэр, также логи были изучены на предмет наличия записей о превышении лимита подключений.
Так вот, проверка страницы в «Mobile-Friendly Test tool» и одновременный анализ лог-файлов сервера показал, что выдавая «Другая ошибка» по изображениям, — в отрезок времени с начала проверки и до момента завершения эти самые изображения никем, включая робота гугла, не запрашивались, записей о превышении лимитов на подключения не наблюдалось.
По неизвестным причинам аналогичные глюки могут быть с другими типами, например «Скрипт Другая ошибка».
Сообщения из консоли JavaScript
Ещё один глюкодром «Mobile-Friendly Test tool«.
Uncaught TypeError: $(...).tooltip is not a function at HTMLDocument.<anonymous> ...
Примечательно, что в консоли браузера никаких подобных ошибок не наблюдается, и при проверке другой страницы с теми же скриптами и порядком их загрузки «Mobile-Friendly Test tool» подобными ошибками не глюкает.
Другие глюки
«Mobile-Friendly Test tool» может засыпать также и другим бредом в стиле «preloaded using link preload but not used«:
The resource /…/*.min.js was preloaded using link preload but not used within a few seconds from the window’s load event. Please make sure it has an appropriate `as` value and it is preloaded intentionally.
Глюкам «Mobile-Friendly Test tool» нет счёта, потому перечислить их все не представляется возможным.
Выводы
Выводы думаю здесь очевидны:
- «Mobile-Friendly Test tool» — совсем не «Friendly» и как «Test tool» рассматриваться не может;
- От этой байды у многих не по праву страдает посещаемость;
- Гуглу очевидно многие лета плевать на «кривожопость» ихней системы оценки сайтов на оптимизированость под мобильные устройства.
Кроме всего прочего у многих переходы с гугла упали в результате вынимания мозгов «рэкаптчей» при каждом поисковом запросе в поиск даже не смотря на то, что ты «залогинен» в гугляцком аккаунте.
Сам давно почти не пользуюсь гугл поиском из-за его постоянных подозрений что я робот даже при всём том, что ты «залогинен» в гугляцком аккаунте и несколько секунд назад уже пробивал ту конченную «рэкаптчу» отмечая там пачками мосты/холмы/машины/пешеходные переходы.
Особую ненависть испытываю ко всем сайтам, а вернее их разработчикам/админам, которые используют «рэкаптчу» и обхожу такие сайты стороной. ИМХО иногда нет иной возможности выйти в сеть кроме как через ТОР, а пришибленная «рэкаптча» кроме своей жуткой «кумарности» ещё довольно часто тупо и наглухо блокирует ТОР сети.
В последние 2-3 года поиск от гугла превратился в глюкодромное, рэкаптчей мозгвыносящее … лала-ла-лала-ла. А теперь все вместе: Гугло х.йло! Лала-ла-лала-ла.
Я получаю сообщение об ошибке «Не удалось загрузить ресурсы на 23 страницах»
https://search.google.com/test/mobile-friendly
Тем не менее, сообщение об ошибке (довольно недружелюбно) «Другая ошибка».
Когда я захожу на сайт в Chrome с помощью Инструментов разработчика и устанавливаю на панели инструментов устройства значение «Отзывчивый», он работает нормально, без ошибок, а когда я захожу в консоль поиска Google и выполняю Crawl-> Fetch As Google, я не получаю ошибок.
Ответы:
У меня было 6 случаев «других ошибок» (4 изображения и 2 таблицы стилей), и постоянное нажатие кнопки обновления не помогло. вот что я думаю окончательно исправил это для меня:
-
Я переключил 2 изображения с относительных на абсолютные пути. это исправило оба из них.
-
Я удалил type = «text / css» из моих тегов css head, которые называются 2 таблицами стилей. так что теперь у них есть только rel и href — вот так
<link rel="stylesheet" href="https://www.example.com/styles.css">. это исправило оставшиеся 4 ошибки. (очевидно, оставшиеся 2 изображения были названы в таблицах стилей.)
«загрузить 23 страницы ресурсов», которая звучит так, как будто ваша страница имеет много ресурсов для загрузки.
Мобильный тестер не любит «тяжелые» страницы.
Существует множество способов, которые имитируют загрузку реального мобильного устройства с нестабильным соединением для передачи данных.
Сделайте страницу «светлее» — загрузка будет меньше «грубой», и страница загрузится быстрее, а значит, и «дружелюбнее».
Согласно этой ветке поддержки , «Другая ошибка» может заключаться в том, что робот Googlebot достиг предела числа запросов, которые он готов сделать к серверу, чтобы он не перегружал веб-сайт запросами.
Не было никакого определенного ответа, но это, кажется, ответ. Если это правда, я бы хотел, чтобы сообщение об ошибке было изменено на что-то вроде «Достигнут предел скорости» …
Проверьте файл robots.txt, чтобы узнать, не блокирует ли он GoogleBot для загрузки страницы.
Например, вы можете использовать CSS-скрипт, <head>который вызывает URL-адрес, запрещенный в вашем файле robots.txt.
За последние годы Google Webmaster Tools существенно изменился. Изменилось даже название сервиса — Google Search Console. И теперь, когда Google Analytics не предоставляет данные о ключевых словах, приходится больше полагаться на Search Console.
В старом Webmaster Tools отсутствовали, в частности, разделы «Search Analytics» и «Links to Your Site». И хотя мы никогда не будем полностью довольны инструментами Google, все же эти сервисы предоставляют полезную информацию (время от времени) для эффективного SEO продвижения сайта.
Ошибки сканирования сайтов (Crawl Errors)
Одно из изменений, произошедших в последние годы в Search Console — интерфейс ошибок (Crawl Errors). Поисковая консоль включает в себя два главных раздела: Site Errors и URL Errors. Категоризация ошибок таким образом выглядит достаточно наглядно — ведь важно различать ошибки на уровне сайта и ошибки на уровне страницы.
") Первые представляются более критичными т.к. влияют на юзабилити сайта в целом. Ошибки URL, с другой стороны, относятся к отдельным страницам, т.е. не требуют столь срочного устранения.
Первые представляются более критичными т.к. влияют на юзабилити сайта в целом. Ошибки URL, с другой стороны, относятся к отдельным страницам, т.е. не требуют столь срочного устранения.
1) Ошибки сайта
В разделе Site Errors показаны общие ошибки веб-сайта за последние 90 дней.
Если вы производили определенную активность за последние 90 дней, это будет выглядеть так:
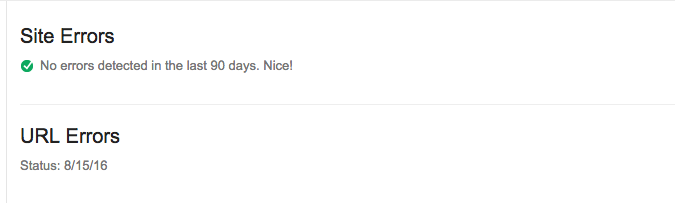
 Если за последние 90 дней у вас не было ошибок, вы увидите следующее:
Если за последние 90 дней у вас не было ошибок, вы увидите следующее:
 Ошибки должны проверяться как минимум каждые 90 дней. Регулярные проверки — это лучший вариант.
Ошибки должны проверяться как минимум каждые 90 дней. Регулярные проверки — это лучший вариант.
A) Ошибки DNS
Если у Googlebot возникают сложности с DNS, это значит, что нет возможности установить связь с вашим доменом из-за проблем с маршрутизацией DNS или нерабочего DNS-сервера.
Если возникает серьезная проблема с DNS, ее необходимо сразу же устранить. Бывают и незаметные сложности, которые мешают Google сканировать сайт.
DNS является важным аспектом, т.к. это первое, что открывает доступ к сайту.
Google рекомендует использовать инструмент Fetch as Google. Также можно проконсультироваться насчет возможного наличия проблем у DNS-провайдера. И убедиться в том, что сервер высвечивает код ошибок 404 или 500.

Другие полезные инструменты:
- ISUP.me
- Web-Sniffer.net
Б) Ошибки сервера
Ошибки сервера чаще всего связаны с тем, что серверу требуется слишком много времени на ответ. Ошибки DNS означают, что Googlebot не может даже обнаружить ваш URL из-за сложностей, связанных с DNS, тогда как серверные ошибки не позволяют загрузить страницу, даже несмотря на то, что Googlebot может подключиться к вашему сайту.
Серверные ошибки, как правило, случаются из-за перегруженности сайта большим объемом трафика. Во избежание этого следует лишний раз проверить, что хостинг-провайдер справляется со внезапным притоком веб-трафика.
Официальная информация Google по устранению ошибок: «Используйте Fetch as Google, чтобы выяснить, может ли Googlebot получить доступ к сайту. Если Fetch as Google возвращает контент домашней страницы без каких-либо проблем, можно предположить, что у Google есть доступ к вашему сайту».
Прежде, чем переходить к устранению серверных ошибок, необходимо установить характер ошибки:
- Истечение времени ожидания (Timeout)
- Усеченные заголовки (Truncated headers)
- Обрыв соединения (Connection reset)
- Усеченный отклик (Truncated response)
- Отказано в соединении (Connection refused)
- Не удалось установить соединение (Connect failed)
- Истечение времени ожидания соединения (Connect timeout)
- Нет отклика (No response)
В) Ошибки доступа к файлу robots.txt
Это значит, что Googlebot не может извлечь ваш файл robots.txt, расположенный по адресу [вашдомен.com]/robots.txt.
Search Console help:
«Файл robots.txt нужен лишь в том случае, если на сайте присутствует определенный контент, который вы бы хотели добавить в индекс поисковых систем. Если хотите, чтобы поисковые системы индексировали весь контент сайта, файл robots.txt не нужен».
Это важный аспект. Для небольших веб-сайтов, которые нечасто обновляются, устранение данной ошибки не требует такой уж безотлагательности. Файл robots.txt более важен для сайтов, которые ежедневно публикуют новый контент.
Если Googlebot не может загрузить ваш robots.txt, Google не будет сканировать сайт, а равно и индексировать новые страницы и изменения. Это может привести к существенным проблемам в продвижении сайта под Google.
Важно проверить конфигурации файла robots.txt и страницы, доступные для сканирования Googlebot. Убедиться, что линия «Disallow: /» отсутствует, за исключением ситуаций, когда по определенным причинам вы не хотите, чтобы сайт появлялся в поисковых результатах.
Лучше вообще обойтись без robots.txt. Если файла robots.txt нет, тогда Google будет сканировать сайт как обычно. Если файл содержит ошибки, Google приостановит сканирование, до тех пор пока ошибки не будут исправлены.
2) Ошибки URL
Ошибки URL влияют только на отдельные страницы сайта, а не на сайт в целом.

Google Search Console выделяет следующие категории ошибок: десктоп, смартфон, простой телефон. Для крупных сайтов этого может быть недостаточно, но для большинства такой подход охватывает все известные проблемы.
Совет: если ошибок слишком много, и вам надоело их исправлять, просто отметьте все как исправленные.
Если вы произвели значительные изменения на сайте в целях устранения ошибок, или же считаете, что многие URL-ошибки уже не повторяются, тогда можно отметить все ошибки как исправленные, и провести повторную проверку через несколько дней.

Через несколько дней информация об ошибках появится вновь, но если вы их действительно устранили, этого не произойдет.
A) Программные ошибки 404 (Soft 404)
Программная ошибка 404 (или т.н. «мягкая ошибка» Soft 404) — это когда страница высвечивает 200 (найдена), вместо 404 (не найдена).
И тот факт, что страница 404 выглядит как 404, еще не значит, что все и на самом деле так.
«Если на странице появляется сообщение «404 Файл не найден», это не означает, что это страница 404. Если на клетке с жирафом висит табличка «собака», это не значит, что в клетке действительно собака», — support.google.com.
Видимый пользователю аспект страницы 404 — это контент. Визуальное сообщение дает возможность понять, что запрашиваемая страница исчезла. Часто владельцы сайтов предлагают пользователям персонализированные страницы или страницы со списками похожих ссылок.
«Обратная сторона» страницы 404 — это видимый для веб-паука код ответа HTTP.

Google рекомендует: «Настроить веб-сайт так, чтобы при запросе несуществующих страниц возвращался код ответа 404 (страница не найдена) или 410 (страница удалена)».
") Еще одна ситуация, когда может появиться программная ошибка 404 — страницы 301, перенаправляющие на другие страницы, например, на главную. В справочном пособии Google о последствиях этого сообщается достаточно неопределенно:
Еще одна ситуация, когда может появиться программная ошибка 404 — страницы 301, перенаправляющие на другие страницы, например, на главную. В справочном пособии Google о последствиях этого сообщается достаточно неопределенно:
«При возвращении кода для несуществующей страницы, отличного от 404 и 410, (или при перенаправлении на другую страницу, например на главную, вместо возвращения кода 404), могут возникнуть дополнительные проблемы».
Когда множество страниц перенаправляется на главную, Google рассматривает эти страницы как soft 404, а не как 301.
Для страниц, которых больше не существует:
- Удостоверьтесь, что при запросе несуществующих страниц возвращается код ответа 404 (страница не найдена) или 410 (страница удалена), а не 200 (успешный запрос).
- Сделайте перенаправление (301) для каждой старой страницы на соответствующую страницу сайта.
- Не перенаправляйте большое количество «мертвых» страниц на главную. Они должны быть 404, или перенаправляться на похожие страницы.
Для рабочих страниц:
- Удостоверьтесь, что существует достаточный объем контента на странице, т.к. небольшой объем может спровоцировать ошибку soft 404.
- Soft 404 — это некий гибрид 404 и обычных страниц, — отсюда и сложности. Проведите проверку на предмет наличия у большей части страниц ошибки soft 404.
Б) 404
Ошибка 404 означает, что Googlebot пытался сканировать страницу, которой нет на сайте. Googlebot находит страницы 404, когда другие сайты или страницы ведут к этим не существующим страницам.
Google сообщает, что «В общем, ошибки 404 не влияют на рейтинг сайта в Google, поэтому их можно смело игнорировать».
Но если это важная страница, игнорировать ошибку 404 нельзя.
Совет Рэнда Фишкина:
«Если страница:
а) Не получает важные ссылки от внешних источников,
а) Посещаемость страницы невысока,
в) И/или у нее нет заметного URL-адреса, на который посетители могут заходить,
Тогда можно оставить страницу как 404».
Если важные страницы высвечиваются как 404:
- Удостоверьтесь, что опубликованная страница из вашей CMS не находится в режиме черновика и не удалена.
- Проверьте, появляется ли эта ошибка на версиях сайта с www или без www, http или https.
Проще говоря, если ваша страница «мертвая», оживите ее. Если вы не хотите делать ее рабочей, сделайте перенаправление 301 на корректную страницу.
Как сделать, чтобы старые 404 не показывались в отчете о сканировании
Если 404 URL не важен, просто игнорируйте его, как советует Google. Но чтобы ошибок не было видно в отчете, придется проделать дополнительную работу. Google показывает только ошибки 404, если ваш сайт или внешний сайт ведут на страницу 404.
Найти ссылки, ведущие на страницу 404, можно так: Crawl Errors > URL Errors.

Затем кликните URL, который хотите исправить

Искомая ссылка быстрее найдется в исходом коде страницы:

Довольно трудоемкий процесс, но если действительно нужно, чтобы старые 404 не присутствовали в отчете, понадобится удалить ссылки с каждой страницы.
В) Отказ в доступе (Access denied)
Отказ в доступе означает, что Googlebot не может сканировать страницу.
Причины:
- Вы требуете от пользователей ввести логин и пароль, чтобы зайти на сайт, и таким образом Googlebot блокируется
- Ваш файл robots.txt блокирует доступ Googlebot к отдельным URL, папкам, или сайту в целом
- Хостинг-провайдер препятствует доступу Googlebot к сайту, или же сервер требует от пользователей аутентификацию через прокси-сервер
Ошибка, сходная с soft и 404. Если блокируемая страница важна и должна индексироваться, тогда требуется незамедлительное вмешательство. Если нет — можно игнорировать подобные ошибки.
Для исправления понадобится устранить элементы, блокирующие доступ Googlebot:
- Уберите вход по логину (логин на странице или всплывающее окно) для страниц, которые нужны для индексации
- Убедитесь, что в файле robots.txt содержатся страницы, которые Googlebot не должен сканировать
- Используйте Fetch as Google, чтобы узнать, как Googlebot сканирует ваш сайт
- Просканируйте сайт с помощью инструмента Screaming Frog
И хотя эти ошибки не так распространены, как 404, сложности по части доступа могут негативно влиять на рейтинг сайта, если важные страницы заблокированы.
Решение некоторых технических вопросов, о которых шла речь в статье, представляется задачей довольно трудоемкой. Никто не хочет искать кажущиеся незначительными ошибки URL, или наоборот впадать в панику при появлении экрана с тысячами ошибок на сайте. Но с опытом и неоднократным повторением действий формируется мышечная память, и пользователь практически автоматически сортирует важные ошибки и те, которые можно игнорировать.
This error in GSC is terribly vague and it is really hard to know what they are referring to when you see this in the reports. So, don’t feel alone in finding this report confusing! When you see this report, you have to step through and see if you can find what error Google is flagging. Keep in mind, it can be a false positive too where Googlebot caught something odd during their crawl.
Along with WhereGoes and checking the Location as Stephen noted, here are a few other thoughts that might help you with debugging:
When you inspect the URL, what do you see when you view the crawled page? Does the HTML code shown match the redirect destination’s HTML? If so, that confirms Google is able to follow the redirect successfully. You can also try testing the live URL to see if that returns something different (with the live test you can see the code and a screenshot which can make confirming this easier).
As another way to see what Google is seeing, you can test with Web Sniffer. Unlike WhereGoes, you can change your user agent to Googlebot and then test the redirect. (You can change your user agent in other tools too, including Chrome but I think Web Sniffer is easiest to work with.) That way you can confirm that the redirect works for Googlebot. It should but sometimes there is an odd configuration that prevents certain user agents from processing the redirect.
This error also sometimes seems to happen because the redirect times out. A good tool to measure this is Byte Check. Byte Check shows you the time it takes to process all redirects within the page load. So long as the redirect happens quickly, you should be okay. However, if the redirect takes, say, more than 150ms then that is a pretty slow redirect. Note that Google has never said that redirect speed is a problem but this is based on my anecdotal evidence working through these problems with various clients.
Finally, you blurred out the URL, but what was the URL’s protocol? I’ve seen instances where you end up with redirect errors due to a «chain» that happens when a link redirects first to HTTPS and then redirects again to the final destination. It isn’t a chain in the problematic sense but Google can sometimes report it that way. If that is the case, that is likely a false positive that you can ignore. You could also try to collapse that redirect chain to see if that resolves the problem.
If you can’t find anything in debugging, then it is likely a false positive. In that case, it should clear out on its own eventually. You could try to get Google to recrawl the redirected page (for example, link to the redirected URL on a page you know Google crawls often, like the home page) as that might prompt Google to reconsider it more quickly too.
This error in GSC is terribly vague and it is really hard to know what they are referring to when you see this in the reports. So, don’t feel alone in finding this report confusing! When you see this report, you have to step through and see if you can find what error Google is flagging. Keep in mind, it can be a false positive too where Googlebot caught something odd during their crawl.
Along with WhereGoes and checking the Location as Stephen noted, here are a few other thoughts that might help you with debugging:
When you inspect the URL, what do you see when you view the crawled page? Does the HTML code shown match the redirect destination’s HTML? If so, that confirms Google is able to follow the redirect successfully. You can also try testing the live URL to see if that returns something different (with the live test you can see the code and a screenshot which can make confirming this easier).
As another way to see what Google is seeing, you can test with Web Sniffer. Unlike WhereGoes, you can change your user agent to Googlebot and then test the redirect. (You can change your user agent in other tools too, including Chrome but I think Web Sniffer is easiest to work with.) That way you can confirm that the redirect works for Googlebot. It should but sometimes there is an odd configuration that prevents certain user agents from processing the redirect.
This error also sometimes seems to happen because the redirect times out. A good tool to measure this is Byte Check. Byte Check shows you the time it takes to process all redirects within the page load. So long as the redirect happens quickly, you should be okay. However, if the redirect takes, say, more than 150ms then that is a pretty slow redirect. Note that Google has never said that redirect speed is a problem but this is based on my anecdotal evidence working through these problems with various clients.
Finally, you blurred out the URL, but what was the URL’s protocol? I’ve seen instances where you end up with redirect errors due to a «chain» that happens when a link redirects first to HTTPS and then redirects again to the final destination. It isn’t a chain in the problematic sense but Google can sometimes report it that way. If that is the case, that is likely a false positive that you can ignore. You could also try to collapse that redirect chain to see if that resolves the problem.
If you can’t find anything in debugging, then it is likely a false positive. In that case, it should clear out on its own eventually. You could try to get Google to recrawl the redirected page (for example, link to the redirected URL on a page you know Google crawls often, like the home page) as that might prompt Google to reconsider it more quickly too.
Регулярная проверка и оперативное устранение ошибок – залог эффективной работы сайта.
Автор: Джо Робисон (Joe Robison) – основатель и главный консультант SEO-агентства Green Flag Digital, эксперт Moz.
В последние годы вебмастера всё больше полагаются на Google Search Console как источник ценных данных. Google также создал множество справочных документов, призванных облегчить пользователям сервиса поиск и устранение ошибок.
Возможно, исправлять ошибки не так интересно, как заниматься другими SEO-задачами. Тем не менее, данный пласт работ чрезвычайно важен.
Регулярно проверяя сайт на наличие ошибок сканирования и оперативно устраняя недочёты, вы сможете взять ситуацию под контроль. В противном случае, ресурсу могут грозить серьёзные проблемы.
Категоризация ошибок сканирования
В Search Console ошибки сканирования разделяются на две основные группы: ошибки сайта и ошибки URL. Такой подход очень удобен, поскольку проблемы на уровне сайта и на уровне страницы – это разные вещи. Ошибки из первой группы обычно более масштабные и влияют на юзабилити ресурса в целом. В свою очередь ошибки URL относятся к конкретным страницам и, соответственно, менее срочные.
Самый быстрый путь к ошибкам сканирования – через панель управления в Search Console. Главная панель даёт общий обзор ситуации по сайту и включает три самых важных инструмента для управления им: «Ошибки сканирования», «Анализ поисковых запросов» и «Файлы Sitemap».
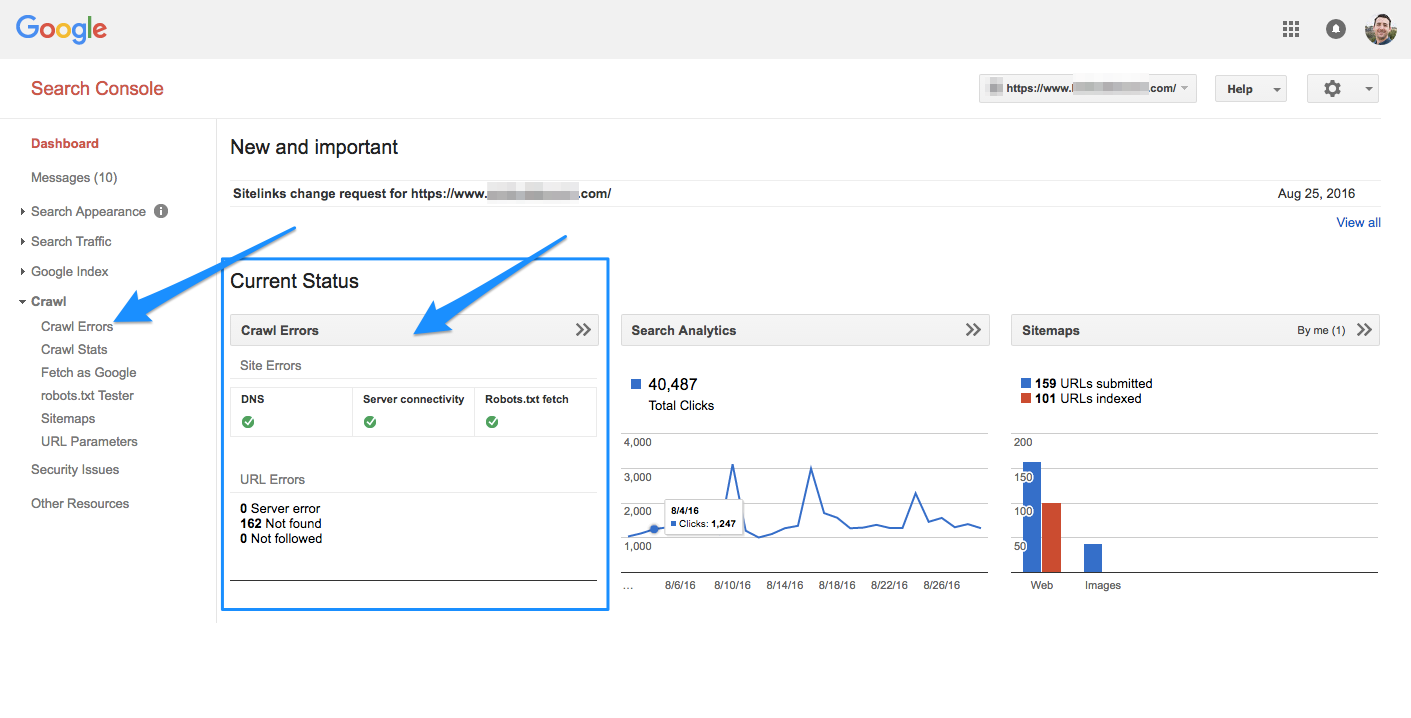
1. Ошибки сайта
Ошибки, которые содержатся в этом разделе, влияют на работу сайта в целом. Google предоставляет данные за последние 90 дней.
При наличии проблем, этот раздел будет выглядеть примерно так:
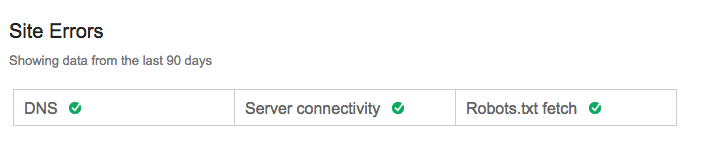
При отсутствии ошибок – так:
Как часто проверять наличие ошибок сайта?
В идеале ежедневно. Эта задача может показаться монотонной, поскольку в большинстве случаев всё будет в порядке. Однако этим нужно заниматься, чтобы затем не корить себя за критические ошибки в работе сайта.
Как минимум, проверять наличие ошибок сайта следует каждые 90 дней. Но лучше, всё же, делать это чаще.
A) Ошибки DNS
Что это такое?
Ошибки DNS (Domain Name System) могут повлечь за собой огромные проблемы для сайта. Поэтому они очень важны и всегда идут первыми.
Наличие ошибок этого типа означает, что робот Googlebot не может связаться с сервером DNS – либо потому что он не работает, либо из-за проблем с маршрутизацией DNS для вашего домена.
Важны ли они?
Google утверждает, что большая часть ошибок, связанных с DNS, не влияет на возможность сканирования страниц роботом Googlebot. Тем не менее, при выявлении серьёзной ошибки DNS следует действовать незамедлительно.
Появление таких ошибок может означать медленную загрузку, а это ухудшает опыт пользователей.
Ошибки DNS, которые затрудняют Google доступ к сайту, нужно решать сразу.
Как устранить
- Google рекомендует в первую очередь использовать инструмент «Просмотреть как Googlebot» в Search Console. Если нужно проверить статус соединения с DNS-сервером, можно использовать только функцию «Сканировать». Функция «Получить и отобразить» нужна, чтобы сравнить, как видят сайт Googlebot и пользователь.
- Свяжитесь с DNS-провайдером. Если Google не может правильно просканировать и отобразить страницу, эту проблему нужно решить. Проверьте, не связана ли она с поставщиком услуг DNS.
- Убедитесь, что сервер выдаёт код ошибки HTTP 404 («не найдено») или 500 («внутренняя ошибка сервера»). Эти коды ответа сервера более точны, чем ошибка DNS.
Другие инструменты
ISUP.me – позволяет сразу узнать, доступен ли сайт другим пользователям или же проблема только с вашей стороны.
Web-Sniffer.net – показывает текущий HTTP-запрос и заголовок ответа. Полезно использовать для пункта № 3, приведённого выше.
B) Ошибки сервера
Что это значит
Ошибки сервера обычно означают, что Google не может получить доступ к сайту, потому что сервер слишком долго не отвечает. Googlebot, который пытается просканировать сайт, может подождать ответа от сервера в течение определённого промежутка времени, после чего он прекращает свои попытки.
Ошибки сервера могут иметь место при большом наплыве трафика, с которым сервер не может справиться. Чтобы избежать таких проблем, убедитесь, что хостинг-провайдер может обеспечить бесперебойную работу сервера даже при резком увеличении аудитории сайта. Все хотят, чтобы их сайт стал мегапопулярным, но не все к этому готовы!
Важны ли они?
Как и ошибки DNS, ошибки сервера решать нужно устранять же, как только информация о них появилась в Search Console. Это фундаментальные ошибки, которые вредят сайту в целом.
Первый шаг – проверка возможности связи с сервером DNS. При наличии проблем с подключением к серверу, Googlebot не сможет просканировать страницы и покинет сайт спустя какое-то время.
Как устранить
Если сайт работает нормально, а в Search Console отображается ошибка, это означает, что ошибки сервера наблюдались ранее. Хотя на данный момент проблема может быть решена, следует внести некоторые изменения, чтобы предотвратить повторное появление таких ошибок.
При наличии ошибок сервера Google рекомендует следующее:
«Чтобы выяснить, может ли Googlebot в настоящее время обрабатывать ваш сайт, воспользуйтесь Сканером Google. Если при отображении содержания главной страницы вашего сайта с помощью этого инструмента не возникают ошибки, значит сайт доступен для робота Googlebot».
Перед тем, как приступить к устранению ошибок сервера, следует определить их тип. В Google выделяют такие типы:
- Таймаут
- Усечённые заголовки
- Сброс подключения
- Усечённое тело ответа
- В подключении отказано
- Истекло время ожидания подключения
- Нет отклика
Как устранить все эти ошибки, можно узнать в Справке Search Console.
C) Ошибка доступа к файлу robots.txt
Эта ошибка означает, что Googlebot не удаётся получить файл robots.txt сайта.
Что это значит
Файл robots.txt нужен не всегда, а лишь в том случае, если нужно запретить Googlebot доступ к определённым страницам сайта.
В Справке Search Console говорится следующее:
«Файл robots.txt нужен только в том случае, если на вашем сайте есть содержание, которое не следует включать в индекс поисковых систем. Если вы хотите, чтобы поисковые системы индексировали все страницы вашего сайта, то вам не нужен файл robots.txt, даже пустой. Если файл robots.txt отсутствует, сервер возвратит код статуса 404 в ответ на запрос робота Googlebot, и процесс сканирования сайта будет продолжен. Это не вызовет никаких проблем».
Важна ли она?
Да, это важная проблема. Для некрупных и относительно статичных сайтов с небольшим количеством новых страниц и изменений она не является очень срочной. Но её нужно решить.
При ежедневном обновлении сайта данная проблема перейдёт в разряд срочных. Если Googlebot не может загрузить файл robots.txt, сканирование будет отложено.Такой подход позволяет Google избежать индексирования URL, которые вы запретили сканировать.
Как устранить
Убедитесь, что файл robots.txt правильно настроен. Проверьте, какие страницы вы запретили сканировать.
Если файл настроен правильно, но ошибки по-прежнему отображаются, используйте инструмент для проверки заголовков ответа сервера. Возможно, файл возвращает ошибку 202 или 404.
В целом, лучше вообще не иметь файла robots.txt, чем иметь неправильно настроенный. Если у вас нет этого файла, Google будет сканировать сайт в обычном режиме. Если файл возвращает ошибку, Google отложит сканирование, пока она не будет устранена.
Несмотря на то, что файл robots.txt содержит лишь несколько строк текста, он может иметь огромное влияние на сайт. Поэтому важно регулярно проверять его.
2. Ошибки URL
В отличие от ошибок из предыдущей группы, ошибки URL затрагивают лишь отдельные страницы сайта.

В Search Console проблемы этого рода разделены на несколько категорий – для десктопов, смартфонов и обычных телефонов. Для большинства сайтов этот раздел охватывает все известные проблемы.
Сходите с ума от количества ошибок? Пометьте все, как исправленные
Многие владельцы сайтов видят большое количество ошибок URL, и это их пугает. Важно помнить: а) в списке сначала идут самые важные ошибки; б) некоторые из этих ошибок уже могут быть устранены.
Если вы внесли какие-то радикальные изменения на сайт, чтобы исправить эти ошибки, или же считаете, что они уже устранены, можно пометить все ошибки как исправленные и повторно проверить раздел через несколько дней.
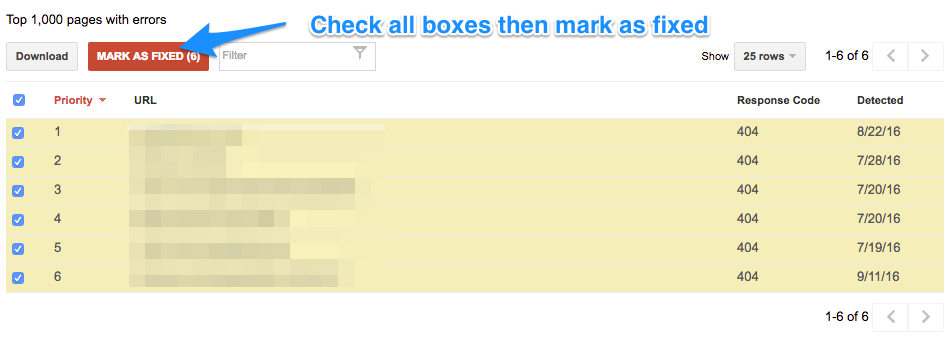
Если причины ошибок не были устранены, эти URL снова появятся в списке после следующего сканирования сайта. В таком случае, нужно будет с ними разбираться.
A) Soft 404
«Мягкие» или ложные ошибки 404 появляются, если несуществующие страницы отдают код 200 («найдено») вместо 404 («не найдено»).
Что это означает
Появление на странице сообщения «404 Файл не найден» ещё не значит, что это страница 404.
Для пользователя видимым признаком страницы 404 является наличие на ней контента. Из сообщения на странице должно быть понятно, что запрашиваемый URL отсутствует.
Владельцы сайтов часто добавляют на такие страницы список ссылок на популярные разделы сайта или другую информацию, которая может заинтересовать пользователей.
Сервер в ответ на запрос несуществующей страницы должен возвращать код ответа 404 («не найдено») или 410 («удалено»).
На схеме ниже показано, как выглядят HTTP-запросы и ответы:
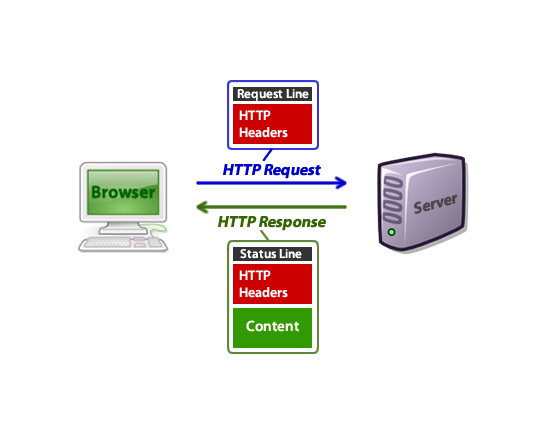
Если вы возвращаете страницу 404, и она регистрируется как «мягкая» ошибка 404, это значит, что код ответа сервера был отличен от 404. Согласно рекомендациям Google, сервер всегда должен возвращать код ответа HTTP 404 или 410 при запросе несуществующей страницы.

Ложные ошибки 404 также появляются, если на страницах настроен 301 редирект на нерелевантные URL, такие как главная страница.
Google говорит об ошибках soft 404 следующее:
«При возвращении для несуществующей страницы кода, отличного от 404 и 410, (или при перенаправлении на другую страницу, например на главную, вместо возвращения кода 404), возникают дополнительные проблемы».
Хотя здесь поисковик даёт некие ориентиры, до конца непонятно, в каких случаях переадресация с устаревшей страницы на главную допустима, а в каких – нет.
На практике, если вы переадресовываете большое количество страниц на главную, Google может интерпретировать эти редиректы как ложные ошибки 404, а не перенаправление 301.
При этом при переадресации устаревшей страницы на похожую регистрация «мягкой» ошибки 404 маловероятна.
Важны ли они?
Если URL, помеченные как soft 404, не являются критически важными для сайта и не «съедают» краулинговый бюджет сайта, тогда работу над ними можно отложить.
Если важные страницы сайта регистрируются как soft 404, необходимо исправить эти ошибки. Страницы товаров, категорий или генерации лидов не должны регистрироваться как soft 404,если это актуальные страницы. Уделите особое внимание тем страницам, которые приносят сайту доход.
Если у вас большое количество «мягких» ошибок 404 по отношению к общему объёму страниц на сайте, действовать нужно быстро. Наличие таких ошибок может съедать бюджет сканирования вашего сайта.
Как устранить
Несуществующие страницы:
- Убедитесь, что сервер возвращает код ответа HTTP 404 или 410, а не 200;
- Проверьте, чтобы с помощью 301 редиректа устаревшие страницы переадресовывались на релевантные, похожие страницы сайта;
- Не перенаправляйте большое количество устаревших страниц на главную страницу. Они должны возвращать ошибку 404 или переадресовываться на похожие страницы.
Актуальные страницы:
- Убедитесь, что страница содержит достаточное количество контента. Страницы с неинформативным содержимым могут расцениваться как ложные ошибки 404.
- Убедитесь, что контент на странице не обозначает её как страницу 404, если при этом возвращается код ответа сервера 200.
Soft 404 – это странные ошибки. Они вносят много путаницы, поскольку являются гибридом страниц 404 и нормальных страниц. При этом причины, вызывающие их появление, не всегда понятны. Убедитесь, что самые важные страницы на вашем сайте не возвращают «мягкие» ошибки 404.
B) 404
Ошибка 404 означает, что Googlebot пытался просканировать несуществующую страницу. Поисковый робот находит страницы 404, когда другие сайты ссылаются на отсутствующие страницы.
Что это означает?
Этот вид ошибок сканирования чаще всего воспринимается неверно. Самой частой реакцией на них является страх.
При этом Google утверждает, что бояться таких ошибок не стоит:
«Ошибки 404 не наносят никакого вреда (а во многих случаях даже полезны). Однако предотвратить их появление, контролируя каждую ссылку на свой сайт, практически невозможно. Вместо этого мы рекомендуем вам сосредоточиться на критических ошибках и по мере возможности устранять их».
Тем не менее, это не совсем так. Нельзя игнорировать ошибки 404, если их возвращают важные страницы на сайте.
В каких случаях ошибки 404 нужно исправлять, а в каких – можно игнорировать, не всегда понятно. Глава Moz Рэнд Фишкин в 2009 году предложил следующий полезный совет (и он до сих пор актуален):
«Сталкиваясь с ошибками 404, не стоит предпринимать никаких действий до тех пор, пока эти страницы:
- не получают важных ссылок с внешних источников;
- не получают значимого количества трафика;
- не имеют очевидного URL, который посетители/ссылки намерены достичь».
Здесь уже важно разобраться, что считать важными внешними ссылками и значимым количеством трафика для конкретного URL.
Энни Кушинг из агентства SEER Interactive также предпочитает метод Фишкина и рекомендует следующее:
«Двумя самыми важными метриками, которые помогают понять, не теряете ли вы ценные ссылки, являются входящие ссылки и общее количество посещений целевой страницы».
Кроме того, важно быть в курсе офлайн-кампаний, подкастов и других активностей, в которых используются запоминающиеся URL-адреса. Например, это может быть объявление в журнале со ссылкой на специальную страницу сайта и т.п. Такие URL необходимо отслеживать, чтобы убедиться, что они не возвращают ошибку 404.
Важны ли они?
Ошибки 404 нужно срочно исправлять, если их возвращают важные страницы сайта. В противном случае, их можно игнорировать.
Видеть сотни таких ошибок в Search Console неприятно. Однако пока вы не докопаетесь до причин, которыми они вызваны, они никуда не денутся.
Как устранить
Если важные страницы возвращают ошибку 404, для её устранения выполните следующие шаги:
- Убедитесь, что в CMS страница опубликована, а не сохранена как черновик или удалена.
- Убедитесь, что URL с ошибкой 404 – нужная страница, а не один из её вариантов.
- Проверьте, отображается ли эта ошибка в www и не-www версиях сайта. Также проверьте http и https версии ресурса.
- Если вы хотите настроить переадресацию, убедитесь, что она будет вести на релевантную страницу.
Другими словами, если страница устарела, оживите её. Если вам это не нужно, настройте 301 редирект на подходящую страницу.
Как сделать так, чтобы устаревшие URL с ошибкой 404 не отображались в отчёте
В отчёте об ошибках первыми показываются те страницы 404, на которые есть внутренние или внешние ссылки.
Чтобы найти ссылки на страницы 404, нужно перейти в раздел «Ошибки сканирования» и выбрать «Ошибки URL»:
Затем кликните на URL, который вы хотите исправить.
В коде страницы найдите ссылку:
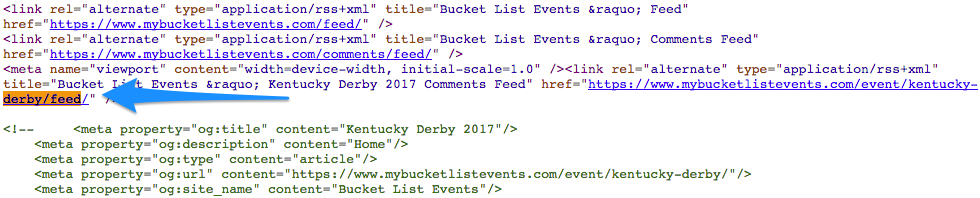
Чтобы устаревшие страницы с ошибкой 404 не показывались в отчёте, нужно удалить все ссылки на них с каждой страницы, которая на них ссылается – включая другие сайты.
Кроме того, ссылки на устаревшие страницы могут содержаться в старых файлах Sitemap. В таком случае нужно настроить код ответа сервера 404 для этих файлов. Переадресовывать их на актуальную карту сайта не нужно.
C) Доступ запрещён
Наличие этих ошибок говорит о том, что Googlebot не удалось получить доступ к URL.
Что это означает
Ошибки «Доступ запрещен» могут возникнуть по следующим причинам:
- Googlebot не удалось получить доступ к URL, поскольку для просмотра содержимого на сайте нужно выполнить вход.
- Файл robots.txt заблокировал Googlebot доступ ко всему сайту либо к отдельным его страницам или каталогам.
- Для работы с сайтом требуется аутентификация с помощью прокси-сервера, или же хостинг-провайдер заблокировал доступ к сайту для робота Googlebot.
Важны ли они?
Если заблокированные страницы важны, то наличие таких ошибок требует срочных действий.
Если необходимости в сканировании и индексации страницы нет, эти ошибки можно игнорировать.
Как исправить?
Чтобы устранить такие ошибки, нужно убрать причину, по которой Googlebot не может получить доступ к странице:
- уберите со страницы форму авторизации;
- проверьте настройки файла robots.txt и убедитесь, что он не блокирует Googlebot;
- используйте инструмент для проверки файла robots.txt. С его помощью вы сможете увидеть, как робот Googlebot будет интерпретировать содержание файла robots.txt;
- чтобы понять, как Googlebot видит ваш сайт, используйте инструмент «Просмотреть как Googlebot».
Просканируйте свой сайт с помощью Screaming Frog. Он покажет, требуется ли авторизация на страницах.
Хотя ошибки «Доступ запрещён» не так часты, как 404, они могут повредить ранжированию сайта. Это возможно в том случае, если заблокированы важные страницы.
D) Ошибки невыполнения перехода
Что это означает
В этой категории перечислены URL, на которые робот Googlebot не смог перейти. Чаще всего такие ошибки связаны с использованием Flash, Javascript и редиректов на сайте.
Важны ли они?
Если такие ошибки связаны с важными страницами, они требуют срочных действий. Если же проблемы обнаружены на устаревших URL, или же речь идёт о параметрах, которые необязательно индексировать, спешить не стоит. Тем не менее, разобраться с этими проблемами нужно.
Как устранить
Некоторые средства, используемые на сайте, могут затруднять процесс его сканирования роботами поисковых систем. В их числе – JavaScript, файлы cookie, идентификаторы сеансов, фреймы, DHTML или Flash.
Для проверки сайта на наличие подобных проблем Google рекомендует использовать текстовый браузер Lynx или инструмент «Просмотреть как Googlebot». Ещё один полезный инструмент – расширение User-Agent Switcher для Chrome.
При возникновении проблем со сканированием параметров проверьте, как Google их обрабатывает. Если вы хотите, чтобы Google по-другому обрабатывал ваши параметры, сообщите Google об изменениях с помощью инструмента «Параметры URL».
Если ошибки невыполнения перехода связаны с редиректами, сделайте следующее:
- Проверьте цепочки редиректов. Если перенаправлений слишком много (больше 5), Googlebot не будет переходить по всей цепочке.
- При возможности обновите архитектуру сайта, чтобы на каждую его страницу вела хотя бы одна статическая текстовая ссылка. Минимизируйте количество редиректов.
- Не включайте URL с переадресацией в файл Sitemap. Включайте целевой URL.
Больше данных об ошибках можно получить с помощью Search Console API.
Другие инструменты
- Screaming Frog SEO Spider – отличный инструмент для сканирования сайта и выявления ошибок переадресации;
- Moz Pro Site Crawl;
- Raven Tools Site Auditor.
E) Ошибки сервера и ошибки DNS
В разделе «Ошибки URL» также могут отображаться ошибки сервера и ошибки DNS. Устранять их нужно теми же способами, которые описаны для раздела «Ошибки сайта».
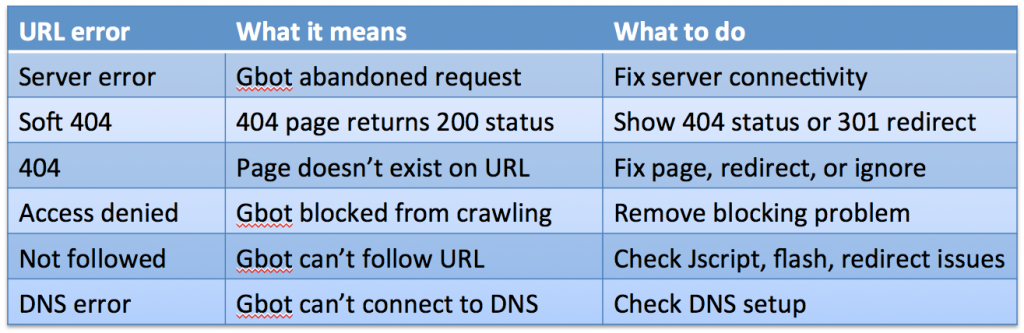
Ниже – общая таблица по ошибкам URL, которую можно использовать в качестве памятки:
Заключение
Работа над устранением ошибок важна и нужна. Видя сотни недочётов, поначалу трудно разобраться, какие из них требуют срочных действий. Однако со временем вы сможете довольно легко отличать важные проблемы от тех, которые можно спокойно игнорировать.
Автор рекомендует всем вебмастерам ознакомиться со справочной документацией по Google Search Console. При появлении вопросов можно обратиться к следующим ресурсам:
- Webmaster Central Help Forum
- Webmaster Central FAQs: Crawling, indexing, & ranking
- Webmaster Central Blog
- Справочная статья об ошибках сканирования в Search Console
Search Console – это один из самых мощных (и бесплатных) инструментов для диагностики ошибок сайта. Устранение описанных выше проблем поможет не только повысить позиции ресурса в поиске Google, но и улучшить опыт пользователей и быстрее достичь намеченных бизнес-целей.

Загрузка…
Search Console — основной опорный инструмент для продвижения сайтов в Google (и не только). По функциональности консоль может уступать некоторым более продвинутым SEO-инструментам, но у нее есть три ключевых преимущества: она бесплатная, интуитивно понятная и самое важное – предоставляет данные прямо от Google. Через GSC, не опираясь на гипотезы, можно узнать, как алгоритмы оценивают ваш сайт, при этом все рекомендации по улучшению технической части вебмастер получает напрямую от первого лица, т. е. Google. И в этом плане Search Console вряд ли когда-нибудь превзойдет какой-либо коммерческий SEO-инструмент.
Используя функциональность одной лишь консоли, можно выполнить базовую поисковую оптимизацию сайта, что особенно удобно для проектов с небольшим бюджетом и тех, кто продвигает свои проекты самостоятельно. В одной из предыдущих статей мы говорили о возможностях GSC при работе с поисковыми запросами, подробно разобрав:
- как проанализировать запросы, по которым сайт получает трафик, и узнать их позиции;
- как точечно исследовать ключи, по которым ранжируются конкретные страницы, и отслеживать показатели их эффективности;
- как использовать данные из GSC на практике, для расширения присутствия в выдаче (поиск упущенной семантики, доработка потенциально сильных ключей и т. д.).
Работа с запросами, безусловно, важна для эффективного продвижения сайта в поиске, но семантика – далеко не все, на чем держится успех в SEO. Прежде чем страницы начнут ранжироваться по релевантным запросам, они должны быть правильно просканированы и проиндексированы поисковыми роботами. Это очень важный процесс, и здесь Google Search Console является самым надежным информатором и техническим помощником. В вебмастерке всегда можно узнать, какие из документов были проиндексированы, а какие нет, когда совершался последний обход сайта, на каких страницах есть проблемы и как их лучше всего устранить по мнению Google. Об этих и других функциях индексирования в GSC – рассказываем в представленном материале.
Отслеживаем индексацию страниц и исправляем ошибки
Индексирование – это процесс, во время которого поисковые боты Google (краулеры) последовательно посещают все страницы сайта и сканируют их содержимое. Если просканированные документы соответствуют требованиям Google о качестве сайтов, они попадают в индекс поисковой системы и начинают отображаться в результатах поиска. В некоторых случаях краулеры могут совершать обходы и добавлять страницы в индекс, даже если сайт закрыт от индексации (подробнее об этом – ниже).
Первое, что смотрят при проведении любого SEO-аудита, — получает ли Google доступ ко всем страницам, которые следует отображать в поиске. Вся нужная информация на этот счет доступна в разделе «Покрытие». Здесь можно посмотреть URL всех страниц, которые попали в поисковый индекс, а также другие документы, например, PDF-файлы, ранжирующиеся в поиске.
Есть много причин, по которым обход Google может быть заблокирован на определенных страницах. Иногда это происходит случайно, иногда проблемы возникают после проведения технических работ или передаются в наследство от предыдущих SEO-подрядчиков. Такие ошибки являются критичными: недоступные для индексирования страницы будут простаивать, не принося поискового трафика и делая ваши усилия по SEO бесполезными. Данные из раздела «Покрытие» позволяют своевременно обнаруживать и исправлять подобного рода недоработки.
Чтобы проверить, имеются ли на сайте проблемы с индексацией, откройте Google Search Console и перейдите на вкладку Индекс → Покрытие – здесь будет доступен статус всех страниц сайта.
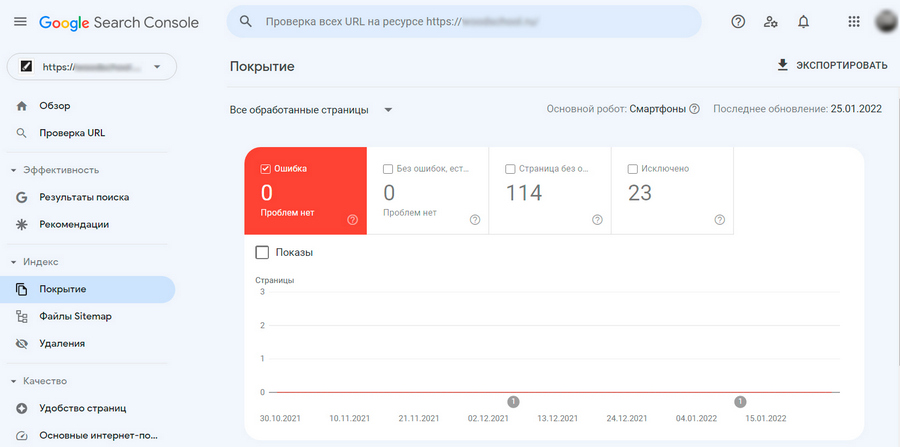
В первую очередь обратите внимание на разделы «Ошибка» и «Без ошибок, есть предупреждения», чтобы выяснить, что не так с указанными страницами и как устранить имеющиеся проблемы.
Ошибки. Типичные проблемы и как их исправить
В отчет об ошибках в GSC попадают все страницы, которые НЕ удалось проиндексировать поисковым роботам Google. Как правило, это происходит, поскольку конкретные URL-адреса имеют ограничения доступа или же потому, что их больше не существует. Такие проблемы являются критичными, и их следует решать в первую очередь.
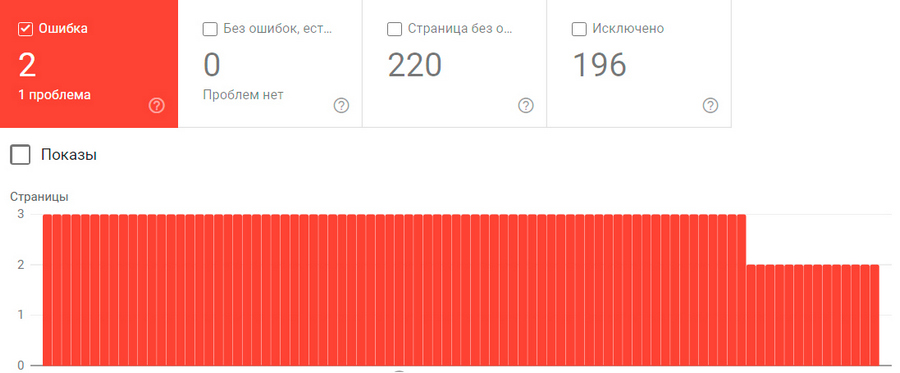
Под графиком в разделе «Сведения» система уведомляет, какая именно проблема с индексированием присутствует на сайте, например:
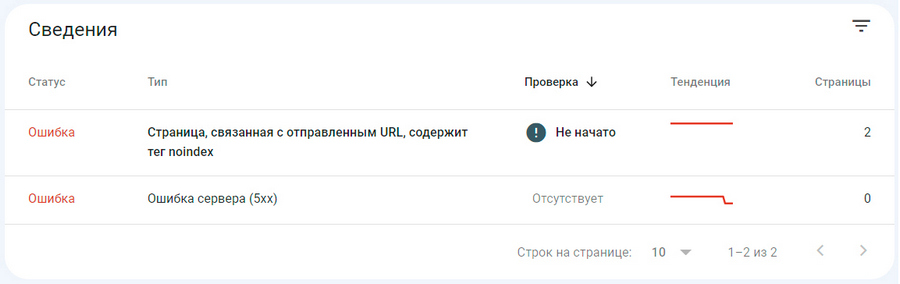
Вы можете кликнуть на каждую ошибку, чтобы перейти на вкладку с расширенным списком всех затронутых URL-адресов. Здесь можно посмотреть детали по каждому URL в отдельности и проверить конкретный адрес на предмет текущего статуса индексации и других проблем.
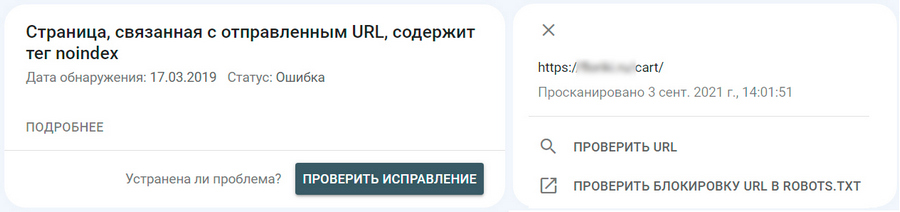
Теперь поговорим о наиболее распространенных ошибках индексации и том, как их лучше всего исправить.
URL-адреса недоступны для индексирования
Эта группа ошибок возникает, когда Google дают указание проиндексировать конкретный URL-адрес, но сама страница по каким-то причинам недоступна для обхода поисковыми роботами. Вот наиболее типичный пример такой ситуации:

Первое, что нужно проверить в этом случае: действительно ли вы хотите, чтобы страница отображалась в поиске. Если речь идет о URL, который не должен индексироваться – такие страницы есть на любом сайте и о них можно почитать здесь – тогда нужно отозвать свой запрос на обход, чтобы Google прекратил безуспешные попытки отправить страницу в индекс. Наиболее вероятная причина подобных ошибок заключается в том, что нежелательный URL-адрес по недосмотру был добавлен в карту сайта. В этом случае необходимо просто отредактировать файл Sitemap.xml, удалив из него проблемный URL-адрес (подробнее об этом – ниже).
Если же вы хотите, чтобы страница с красным уведомлением, отображалась в поиске, необходимо разобраться, почему ей отказано в индексировании и устранить ошибку. Как правило, это происходит по следующим причинам:
Неиндексируемая страница закрыта директивой noindex. Решение: удалить тег noindex из HTML-кода или из заголовка ответа HTTP X-Robots-Tag.
Страница запрещена к индексированию в robots.txt. Решение: проверить файл robots.txt специальным инструментом Google, после чего удалить или изменить все ненужные запрещающие директивы и исправить найденные ошибки.
При обращении к URL возникает ошибка 404. Подобное происходит, когда страница удалена или изменен ее изначальный URL-адрес. Решение: восстановить исходный URL или настроить 301-редирект на новую версию страницы.
URL возвращает ложную ошибку (soft 404). Такое происходит, когда страница физически существует (сервер помечает ее статусом OK), но Google решил, что URL имеет статус 404 (страница не найдена). Как правило, это происходит при отсутствии контента на странице (или его незначительности), а также из-за манипуляций с редиректами, когда внутренняя переадресация ведется на тематически НЕблизкую страницу. Решение: проверить страницу на предмет «тонкого» контента или нерелевантных редиректов.
URL возвращает ошибку 401 (неавторизованный запрос). Это значит, что робот Google не может получить доступ к нужной странице из-за запрашиваемой авторизации. Решение: отменить требование авторизации либо разрешить Googlebot доступ к странице.
URL возвращает ошибку 403. Googlebot выполняет вход на сервер, но ему не предоставлен доступ к контенту. Решение: если вы хотите, чтобы страница попала в индекс, откройте к ней доступ анонимным посетителям.
После того как найдены и исправлены причины, препятствующие индексации, страницу отправляют на переобход с помощью инструмента проверки URL-адресов (подробнее об этом — немного ниже).
Наличие ошибок переадресации
Иногда нужная страница не может быть проиндексирована по причине некорректно работающего редиректа. Выше мы уже описали, как это происходит в случае с перенаправлением на нерелевантную страницу (ошибка soft 404), но на практике существуют и другие ошибки переадресации. Страница может не попадать в индекс по причине слишком длинной связки перенаправлений, из-за циклических редиректов или битых URL в цепочке переадресаций.
Решение: проверьте URL на предмет некорректно работающих 301- или 302-редиректов и примите меры по их отладке.
Подробнее по теме:
FAQ по 301-редиректу. Как перенаправления соотносятся с SEO: настройка, отслеживание проблем, сценарии использования редиректов
Проблемы на стороне хостера

Ошибка 5xx возникает, когда поисковым роботам Google не удается получить доступ к серверу. Возможно, сервер вышел из строя, истекло время ожидания или он был недоступен, когда Googlebot проводил обход сайта (скорее всего, причина именно в этом).
Решение: проверьте URL с помощью инструмента «Проверка URL-адреса», отображается ли ошибка в настоящее время. Если сервер в порядке, отправьте страницу на переобход, в противном случае внимательно ознакомьтесь с тем, что предлагает Google для решения этой проблемы или свяжитесь со своим хостинг-провайдером.
Без ошибок, есть предупреждения
Если Google проиндексировал содержимое сайта, но до конца не уверен, что это было необходимо, то консоль пометит эти страницы как действительные с предупреждением, и они будут выглядеть вот так:
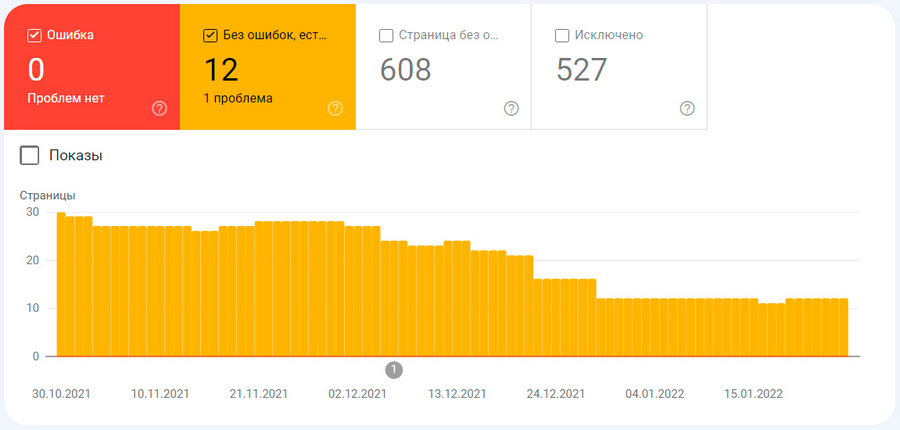
С точки зрения SEO страницы с такими предупреждениями могут принести даже больше проблем, чем ошибки, поскольку в поиск в этом случае часто попадают документы, которые владелец сайта не хотел делать общедоступными. Поэтому все URL, попавшие в желтую категорию, требуют особенно пристального внимания со стороны вебмастера.
Проиндексировано, несмотря на блокировку в файле robots.txt

Это, пожалуй, самая распространенная причина, по которой страницы сайта попадают в желтую категорию проблем индексирования. Многие, как правило, еще неопытные вебмастера и SEO-специалисты ошибочно полагают, что robots.txt — это правильный механизм для сокрытия страниц от попадания в индекс Google. Это не так. Добавление директив в служебный файл robots.txt полностью не запрещает индексирование указанных URL. Вебмастера используют этот способ в основном, чтобы избежать лишних запросов со стороны краулеров и не перегружать сайт.
Чтобы гарантированно исключить попадание нежелательных страниц в индекс, используют другие механизмы: добавление noindex в HTML-код страницы или настройку HTTP-заголовка X-Robots-Tag. Запреты в robots.txt поисковик же расценивает исключительно как рекомендации: он не будет сканировать страницу, отклоненную в роботс, во время обхода сайта, но эта же страница может быть проиндексирована, если на нее ведут другие ссылки. Отсюда следует один очень важный момент: из-за запрета в robots.txt, страницы могут попадать в индекс в неполной версии, поскольку поисковые роботы смогли просканировать лишь отдельные фрагменты «закрытого» документа.
Как решить такую проблему? В первую очередь следует внимательно изучить все «желтые» URL и определиться, нужно ли блокировать конкретную страницу или нет. Если вы уверены, что странице не место в индексе – ограничиваем к ней доступ поисковых ботов с помощью noindex или X-Robots-Tag. От страниц, не представляющих ценности ни для пользователей, ни для поисковых лучше избавиться вовсе. Как правильно удалять страницы из индекса Google и Яндекса без вреда для SEO – читайте в отдельной статье.
Страница проиндексирована без контента
Такое предупреждение означает, что страница проиндексирована, но по какой-то причине Google не смог распознать ее контент. Это определенно плохо для SEO и нередко служит предвестником ручных санкций. Проблема может возникнуть из-за преднамеренных манипуляций, когда вебмастера используют разные методы клоакинга (маскировки и подмены содержимого), или когда формат страницы не распознается Google. Отдельно отметим, что такие ошибки не связаны с блокировкой доступа в robots.txt, о чем говорилось выше на примере частичного индексирования страниц.
Чтобы устранить эту проблему, необходимо внимательно ознакомиться со всеми рекомендациями в разделе «Покрытие» и внедрить предложенные правки. В некоторых случаях может потребоваться дополнительная проверка кода страницы, поскольку отчеты Search Console далеко не всегда способны обнаруживать недочеты, связанные с указанной проблемой. Более глубокий технический SEO-аудит, проведенный с использованием специальных программ, поможет обнаружить битые изображения или видео, повторяющиеся заголовки и метаописания, проблемы с локализацией и другие недочеты, из-за которых страницы могут индексироваться без контента.
Исключено
Google Search Console также уведомляет о страницах, которые не попали в индекс, но присутствуют на сайте. Эта информация отображается в красном блоке «Исключено».
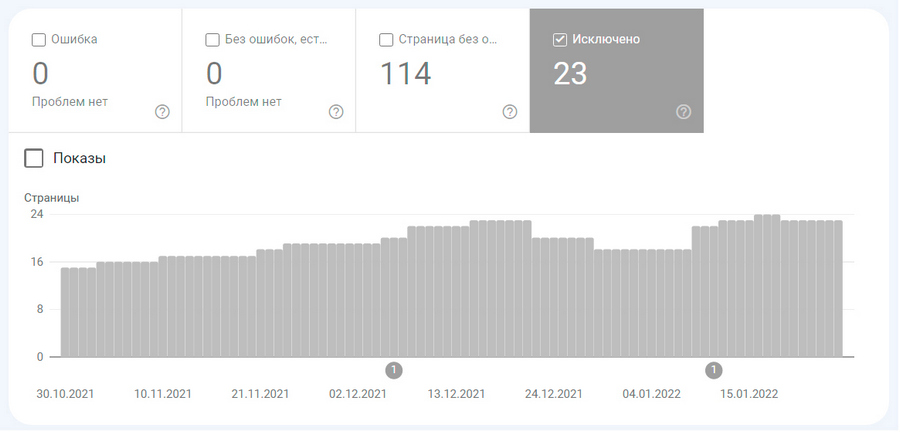
Большинство страниц попадает сюда, по указанию вебмастера и это не связано с техническими проблемами. Например, такое происходит когда:
- обход страниц запрещен через noindex или X-Robots-Tag;
- прописаны запрещающие директивы в файле robots.txt;
- страница является неканонической, т. е. дублем, правильно размеченным атрибутом rel=«canonical».
Но иногда попадание страниц в блок «Исключено» может свидетельствовать о наличии технических проблем или недоработок, например:
- страница не проиндексирована из-за неавторизованного запроса (ошибка 401), переноса в другое место или удаления (404), запрета доступа (403), ложной ошибки (soft 404);
- присутствие на странице некорректно настроенного редиректа;
- страница является дублем, без указания канонического URL.
- Google выбрал канонический вариант страницы не таким, как его указал вебмастер (соответственно, из индекса вылетели важные URL).
Таким образом, отслеживая все, что попадает в блок «Исключено», можно получать сигналы о недоработках в техническом SEO и своевременно устранять недочеты. Отдельно отметим, что сюда иногда залетают и полностью «здоровые» страницы, например, те, что были просканированы, но пока не попали в индекс. Отправлять на принудительную переиндексацию такие URL не нужно.
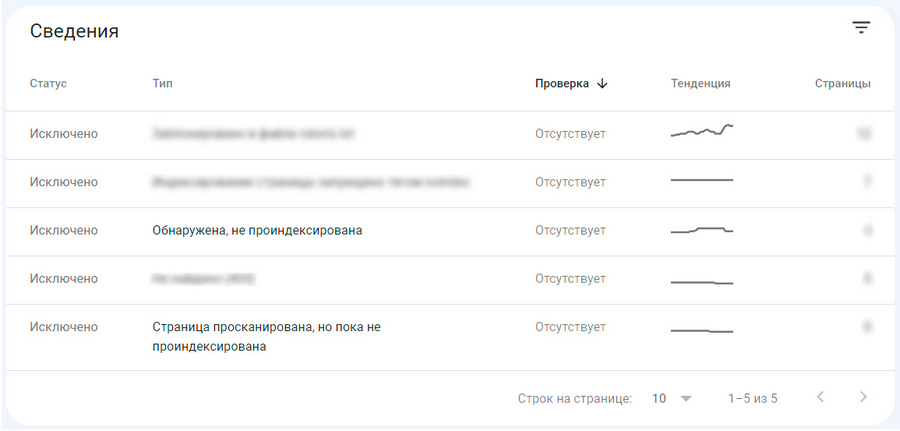
Ускоряем индексирование приоритетных страниц
Принудительный переобход позволяет страницам попадать в индекс значительно быстрее. В этом случае не нужно ждать, пока краулеры найдут и просканируют документ в плановом порядке. Таким образом, страница сможет быстрее появляться в результатах поиска и вся SEO-стратегия будет реализовываться без лишних простоев. В дополнение к этому, привычка отправлять только что опубликованные материалы на переобход, поможет уменьшить риски при воровстве или копипасте вашего контента. Подробнее на эту тему – читайте здесь.
Делайте запрос на переиндексацию каждый раз после публикации новой страницы или существенного обновления старого контента. Для этого нужно ввести исходный адрес в верхнее поле поиска Google Search Console и нажать Enter. Через несколько секунд система предоставит информацию о текущем статусе URL, после нужно нажать «Запросить индексирование».
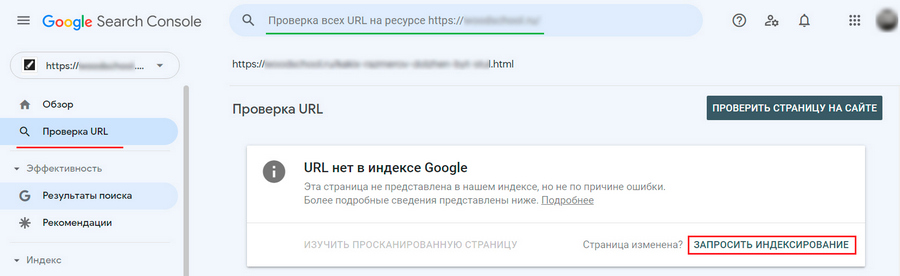
Инструмент быстро просканирует страницу на предмет проблем, и при отсутствии таковых добавит URL в очередь на приоритетный обход. Запрос на ускоренную индексацию или переобход большого количества страниц делают через отправку файла Sitemap (об этом – в следующем пункте).
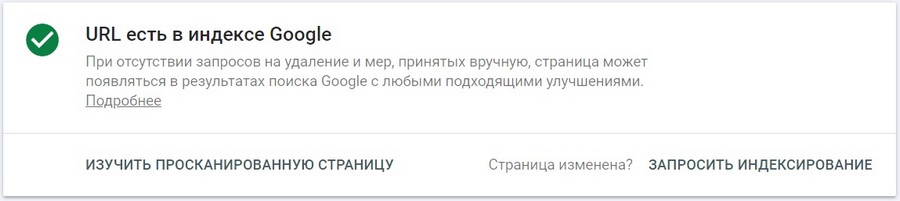
Об успешном попадании страницы в индекс сообщит такое уведомление. Оно будет доступно не сразу. На практике переобход документа может занять от нескольких минут до нескольких дней, но в любом случае это будет быстрее, чем если бы происходила органическая индексация. Не стоит пытаться подгонять поисковых ботов Google: множественные запросы на сканирование одного и того же URL никак не повлияют на скорость переобхода.
Оптимизируем индексацию с помощью Sitemap
Карта сайта — это специальный файл (sitemap.xml), который размещают в корневой папке, чтобы помочь поисковым роботам Google лучше ориентироваться в структуре ресурса. В хml-файле содержится перечень всех URL сайта с информацией об их последнем обновлении и указанием, какие из страниц нужно сканировать в первую очередь. Таким образом хml-карта упрощает краулерам поиск URL для индексирования, выступая в роли вспомогательной навигации по сайту.
Файл sitemap.xml можно создать одним из нескольких способов:
- Написать вручную, в соответствии с правилами синтаксиса (сегодня почти никто так уже не делает).
- Сгенерировать автоматически при помощи специальных программ или онлайн-сервисов.
- Воспользоваться встроенным функционалом некоторых CMS (например, такая опция предусмотрена в Битрикс).
- Сгенерировать и настроить XML-карту при помощи WP-плагинов (эта опция доступна в двух популярных SEO-плагинах: All in One SEO и Yoast).
Два последних способа являются самыми популярными, главным образом потому, что позволяют полностью автоматизировать процесс обновления sitemap; другими словами, вам не придется вносить изменения в карту сайта, каждый раз, когда будет добавляться новая страница.
Чтобы передать созданную карту сайта в Search Console и/или проверить ее на наличие ошибок, достаточно перейти в раздел «Файлы Sitemap», ввести путь доступа к xml-файлу и нажать «Отправить».
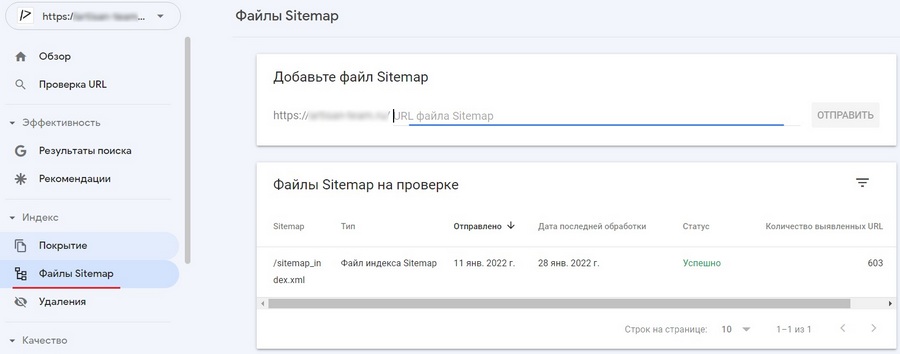
В плане технических требований файл Sitemap должен:
- соответствовать правилам синтаксиса (ошибки в файле можно проверить специальными валидаторами);
- иметь размер, не превышающий 50 МБ;
- содержать не более 50 000 URL-адресов, а если количество URL на сайте превышает указанный лимит, необходимо добавить несколько файлов sitemap.xml.
Без Sitemap содержимое сайта все равно будет попадать в индекс. В этом случае Google станет самостоятельно сканировать URL и проверять их на наличие обновлений, но он будет делать это так часто и в такой приоритетности URL, как посчитает нужным. Очевидно, что это не лучшим образом отразится на скорости индексирования важных страниц. В то же время возлагать на sitemap большие ожидания тоже не стоит. Карта сайта – это в первую очередь рекомендация, которую поисковик может брать во внимание, а может и не учитывать.
Так ли важна карта сайта?
С учетом всего вышесказанного может возникнуть вопрос: нужна ли вообще карта сайта? Ответ однозначный: да нужна. Хотя Google утверждает, что относительно небольшим сайтам (до 500 страниц) можно пренебречь Sitemap, этого лучше не делать. В первую очередь потому что любой молодой проект по умолчанию имеет слабый ссылочный профиль, а этот фактор важен в том числе и для краулеров. Поэтому, если на сайт ведет мало ссылок, его сложнее найти – отсюда проблемы с органической индексацией.
Во время сканирования роботы Google переходят во все важные разделы ресурса, следуя по ссылкам с главной страницы, поэтому логичная и оптимизированная структура сайта – залог успешной органической индексации. Но идеальной структурой способны похвастаться далеко не все сайты. Разделы могут иметь нелогичную иерархию или же вовсе оказаться не связанными друг с другом. Если не перечислить такие URL в файле Sitemap, успешность их самостоятельного сканирования — под большим вопросом.
Отдельно отметим, что на многих сайтах есть проблемы с перелинковкой. Внутренняя система ссылок может быть не проработанной по естественным причинам, когда просто не хватает страниц для линкования, или же являться не оптимизированной из-за банального непонимания ее важности. Это также вносит свою лепту в плохое качество органической индексации, и является еще одним аргументом в пользу Sitemap.
Для каких сайтов Sitemap является обязательным
Для некоторых проектов значимость карты сайтов не вызывает сомнений, в первую очередь это:
- Ресурсы, у которых много страниц (500+ URL).
- Сайты с большим архивом документов, иерархически не связанных друг с другом.
- Крупные сайты с логичной, но сложноорганизованной структурой.
- Площадки с большой долей мультимедийного контента (видео/изображения).
- Часто обновляемые ресурсы (магазины, новостники и т. д.).
Для указанной категории сайтов Sitemap является не только инструментом оптимизации индексирования, но и дополнительным источником информации о потенциальных проблемах. Чтобы обнаруживать возможные недочеты, связанные с индексированием, сканированием или дублированием контента, сравнивайте количество страниц, отправленных через файл Sitemap, с фактическим числом URL, проиндексированных в поиске Google.
Отслеживаем индексирование AMP-страниц
Если на сайте внедрена технология быстрых AMP-страниц, в Search Console будет доступен специальный отчет для мониторинга их эффективности. В этом разделе можно посмотреть, какие AMP-страницы попали в индекс, а также узнать текущие ошибки, из-за которых ускоренные версии отображаются в поиске Google как обычные.
Структура отчета здесь в целом такая же, как и для стандартных страниц на вкладке «Покрытие». Вверху на графике показано общее количество URL с ошибками, предупреждениями и без ошибок.
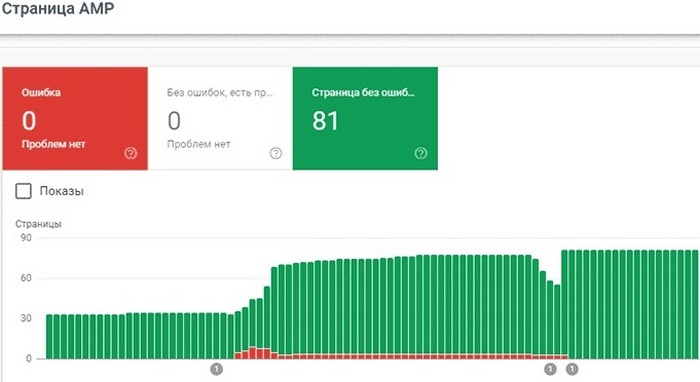
Уведомления об ошибках являются наиболее важными, и на них нужно обращать внимание в первую очередь. Все «красные» оповещения сгруппированы по типу проблем. Кликнув по той или иной строке внизу отчета, будут доступны расширенные сведения о конкретной ошибке, а также рекомендуемые способы ее устранения. В этом отчете консоль уведомляет не только о стандартных ошибках индексации, но и специфических проблемах, присущих исключительно AMP-страницам (с их полным перечнем можно ознакомиться здесь).
Ошибки на AMP-страницах часто носят массовый характер. Поэтому в первую очередь имеет смысл устранять проблемы, которые встречаются на множестве страниц, а затем фиксить единичные неполадки. В целом GSC выстраивает уведомления об ошибках в порядке приоритетности, и именно в такой последовательности их лучше исправлять. Внеся технические правки, рекомендуемые системой, нужно сообщить о принятых мерах и отправить AMP-страницу на переобход.
Предупреждения – это не ошибки. Они носят характер рекомендации и не препятствуют индексированию ускоренной версии URL. Однако следует знать, что АMP-страницам из желтого блока могут быть недоступны определенные опции на выдаче, например, они не попадают в некоторые колдунщики, а отображаются простым сниппетом.
Для своевременного обнаружения проблем с индексацией, следите за тем, чтобы фактическое число созданных AMP-страниц на сайте сильно не отличалось от суммарного количества URL из всех трех блоков в отчете.
Я получаю сообщение об ошибке «Не удалось загрузить ресурсы на 23 страницах»
https://search.google.com/test/mobile-friendly
Тем не менее, сообщение об ошибке (довольно недружелюбно) «Другая ошибка».
Когда я захожу на сайт в Chrome с помощью Инструментов разработчика и устанавливаю на панели инструментов устройства значение «Отзывчивый», он работает нормально, без ошибок, а когда я захожу в консоль поиска Google и выполняю Crawl-> Fetch As Google, я не получаю ошибок.
Ответы:
У меня было 6 случаев «других ошибок» (4 изображения и 2 таблицы стилей), и постоянное нажатие кнопки обновления не помогло. вот что я думаю окончательно исправил это для меня:
-
Я переключил 2 изображения с относительных на абсолютные пути. это исправило оба из них.
-
Я удалил type = «text / css» из моих тегов css head, которые называются 2 таблицами стилей. так что теперь у них есть только rel и href — вот так
<link rel="stylesheet" href="https://www.example.com/styles.css">. это исправило оставшиеся 4 ошибки. (очевидно, оставшиеся 2 изображения были названы в таблицах стилей.)
«загрузить 23 страницы ресурсов», которая звучит так, как будто ваша страница имеет много ресурсов для загрузки.
Мобильный тестер не любит «тяжелые» страницы.
Существует множество способов, которые имитируют загрузку реального мобильного устройства с нестабильным соединением для передачи данных.
Сделайте страницу «светлее» — загрузка будет меньше «грубой», и страница загрузится быстрее, а значит, и «дружелюбнее».
Согласно этой ветке поддержки , «Другая ошибка» может заключаться в том, что робот Googlebot достиг предела числа запросов, которые он готов сделать к серверу, чтобы он не перегружал веб-сайт запросами.
Не было никакого определенного ответа, но это, кажется, ответ. Если это правда, я бы хотел, чтобы сообщение об ошибке было изменено на что-то вроде «Достигнут предел скорости» …
Проверьте файл robots.txt, чтобы узнать, не блокирует ли он GoogleBot для загрузки страницы.
Например, вы можете использовать CSS-скрипт, <head>который вызывает URL-адрес, запрещенный в вашем файле robots.txt.
Адаптивность под мобильные устройства важна вне зависимости от тематики и функциональности веб-ресурса. Большинство из нас сталкивалось с неудобствами пользования различными интернет-ресурсами через планшет или смартфон по причине отсутствия в них адаптивности. Мелкий шрифт, частично скрывающийся за границами экрана контент или вся страница, перекрывающие друг друга элементы – это классика для множества сайтов.
Но даже при соблюдении правил адаптивного дизайна нужно понимать, что сайт посещают не только люди, но и роботы поисковых систем. И как ни странно, для этих неэмоциональных машин тоже важен данный показатель. Способность оценить, удобен ли сайт для просмотра на различных устройствах, дает возможность поисковой системе делать определенные выводы, что вполне может повлиять на ранжирование в поисковой выдаче – как позитивно, так и негативно.
Так как поисковые роботы смотрят и оценивают страницы ресурса не привычными для нас глазами, а по средствам загрузки и анализа кода страниц, они вполне могут увидеть и понять намного больше, чем представлено в визуальной части. Но, чтобы обеспечить корректное восприятие, необходимо правильно настроить файл robots.txt. Если вы не знаете, что это за файл такой и для чего предназначен, рекомендую прежде ознакомиться с этой статьей в нашем блоге. Очень важна именно индивидуальная настройка robots.txt под конкретный сайт. Таким образом, можно добиться корректного восприятия контента поисковыми системами.
Для максимально правильной настройки robots.txt для поискового робота Googlebot более опытными веб-мастерами и SEO-специалистами используется сервис Google Mobile-friendly.
Google Mobile-friendly: что это?
Представленный компанией Google инструмент для веб-разработчиков помогает определить, пригодна ли адаптивность сайта для отображения на мобильных устройствах и корректно ли ее воспринимает поисковый робот Googlebot.
Страница сервиса находится по адресу: https://search.google.com/test/mobile-friendly.
Максимально простой в использовании – достаточно лишь вставить ссылку на страницу тестируемого ресурса и нажать кнопку «Проверить страницу».
После недолгого ожидания получаем результат. Тут стоит заметить, что результат проверки для каждого сайта будет индивидуален, даже для отдельных страниц в рамках одного сайта. Поэтому желательно, кроме главной, проверить страницу категорий, товара, статьи и т. п.
Как пользоваться Mobile-friendly
Рассмотрим основные моменты в использовании сервиса на примере не адаптированного сайта.
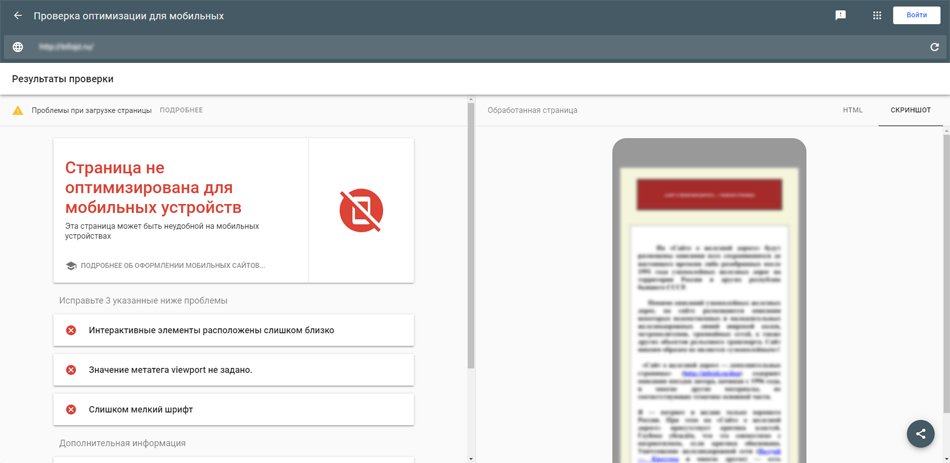
Интерфейс поделен на две части. Слева итог проверки, в данном случае – неутешительный вердикт о том, что страница не оптимизирована для мобильных устройств, а ниже список проблем, которые требуется исправить.
В данном случае необходимо увеличить шрифт до рекомендуемых 14pt, увеличить отступы между плотно расположенными элементами страницы (пункты меню, кнопки и т.п.) и обязательно добавить мета-тег viewport между <head> и </head>, пример: <meta name=»viewport» content=»width=device-width, initial-scale=1.0″>. Но нужно понимать, в этом случае приведенные рекомендации – не универсальный рецепт для любого сайта, настройка адаптивности должна быть индивидуальной.
Продолжим. Справа представление о том, как видит анализируемую страницу Googlebot. Здесь два режима: «Скриншот» – визуальное представление и «HTML» – полученный код страницы позволяет понять, актуальную ли версию страницы получает поисковый робот.
Вернемся к левой части, помимо вышесказанного, в самом верху есть кнопка «Подробнее» – открывает отчет о проверке.
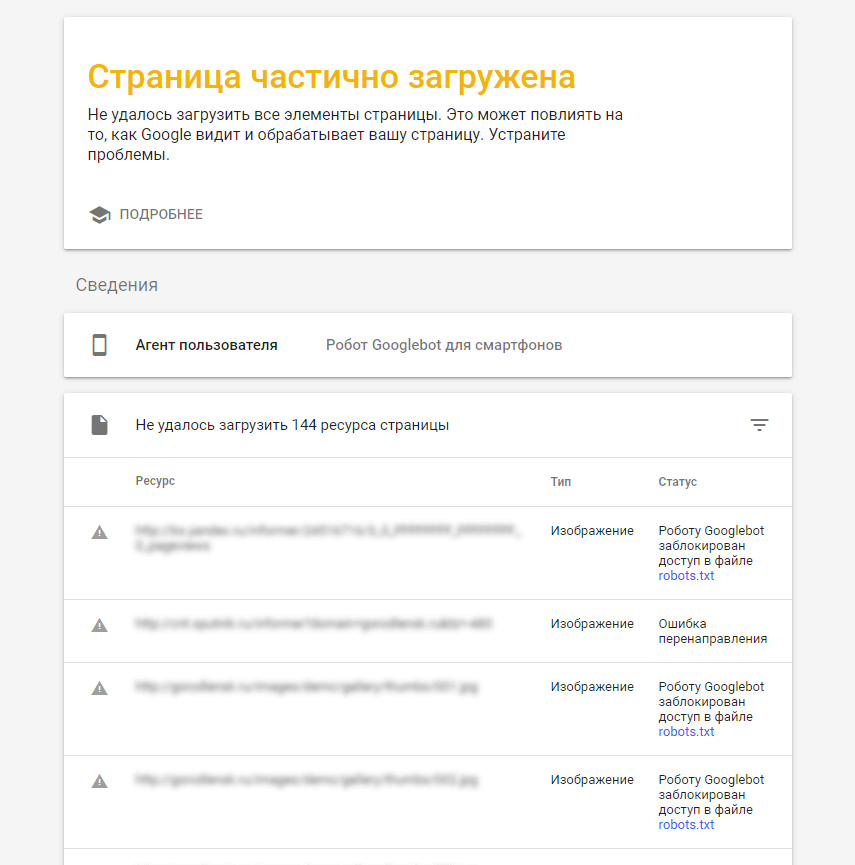
По различным причинам робот Googlebot может получить страницу не полностью. Сперва необходимо обратить внимание на колонку «Ресурс», так как проблема может находиться не только на проверяемом сайте, но и на стороннем. Чаще всего это различные скрипты (счетчики метрики, кнопки соц. сетей и т. п.), CDN-сервисы и прочие ресурсы.
К сожалению, повлиять самостоятельно на такой род ошибок не удастся, разве что попытаться связаться с администратором ресурса и попросить принять необходимые меры по исправлению. Мы же рассмотрим исправление ошибок на стороне своего сайта.
Исправление ошибки «Роботу Googlebot заблокирован доступ к файлу»
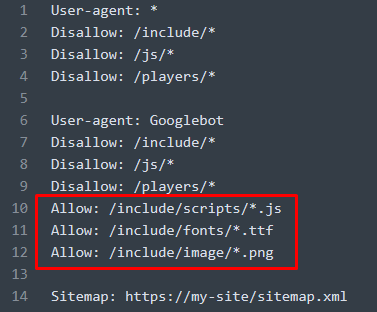
Решение проблемы рассмотрим на примере заведомо корректно настроенного User-agent: *
Тут все просто: необходимо открыть файл robots.txt в текстовом редакторе, добавить юзер-агента для поискового робота Google: User-agent: Googlebot. Скопировать все директивы Disallow у User-agent: * и вставить для User-agent: Googlebot.
Для поискового робота Googlebot добавить директивы Allow, открывающие доступ к ресурсам с данной ошибкой.
Пример:
Исправление «Ошибка перенаправления»
Происходит, как правило, когда ресурс, на который направляет ссылка (изображение, скрипт, файл), пытается произвести редирект, но Googlebot может неправильно это интерпретировать или просто отказаться его исполнять. Например, веб-сайт работает по защищенному протоколу безопасности https, но в ссылке указан – http.
Чтобы убедиться в предположении, стоит воспользоваться любым сервисом по проверке ответа сервера и проанализировать проблемную ссылку, после чего найти ее у себя на сайте и исправить согласно конечному редиректу. Или связаться с администратором ссылаемого ресурса и попробовать решить проблему совместно.
Исправление «Другая ошибка» в Mobile-friendly
Эта ошибка часто встречается даже на хорошо оптимизированных сайтах. Причины появления таких ошибок бывают различными. Это может быть ограничением отдачи контента поисковику на стороне сайта или сервера, либо внутренним лимитом на загрузку контента на стороне Googlebot. Как вариант, можно вставить ссылку на проверяемую страницу в поле поисковика Google и открыть сохраненную копию.
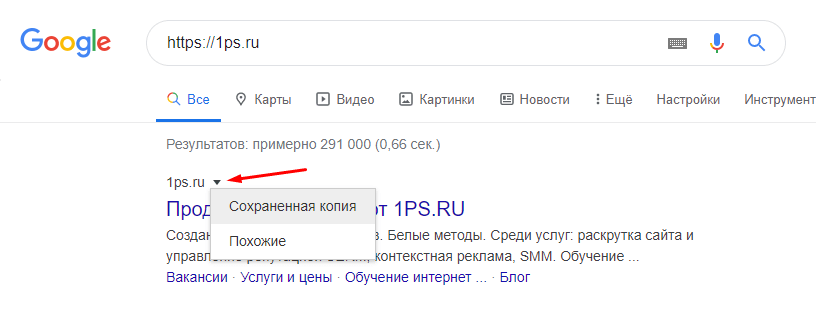
Если проблемный контент отображается в сохраненной странице, то беспокоиться тут не о чем, так как поисковик его видит. В ином случае стоит связаться со своим хостинг-провайдером, описать суть проблемы и попытаться совместно ее решить.
Заключение
Инструмент Mobile-friendly от компании Google – отличный помощник веб-мастера или SEO-специалиста. Ранее он был частью интерфейса Google Webmaster, но обрел самостоятельность и успешно помогает в настройке оптимизации сайта.
Знайте, что если вам необходима профессиональная помощь в проведении адаптации и оптимизации своего интернет-ресурса, вы можете обратиться к нам за помощью.
В «Google Search Console» есть штука называемая «Mobile-Friendly Test tool«, на результаты которой опирается гугл решая индексировать ли страницу или нет.
Относительно с недавних (с конца 2016-го года) пор гугл ударился в «Mobile-first Indexing», а потому теперь рейтинг страницы и позиция в поисковой выдаче напрямую зависит от степени её оптимизированости под мобильные устройства:
Подготовка к индексированию с приоритетом мобильного контента
При индексировании, ориентированном на мобильные устройства, рейтинг страниц зависит главным образом от их мобильной версии. Раньше релевантность контента оценивалась в первую очередь на основе версии для компьютеров. Поскольку большинство пользователей сейчас открывают Google Поиск на мобильных устройствах, сканирование и индексирование страниц теперь выполняет в первую очередь робот Googlebot для смартфонов.
Проблемы Mobile-Friendly Test tool
Главная проблема с «Mobile-Friendly Test tool» в том, что работает оно криво и косо, что проявляется в ничем не обоснованных ошибках типа:
Исправьте 2 указанные ниже проблемы
- Слишком мелкий шрифт
- Интерактивные элементы расположены слишком близко
При этом, а ни изменение размера шрифта, ни расстояние между элементами не решают проблему.
В правой части окна результатов проверки «Mobile-Friendly Test tool» можно видеть «Проблемы при загрузке страницы. Подробнее», кликнув на «Подробнее» нашему взору откроются «Данные о ходе загрузки страницы»:
Страница частично загружена
Не удалось загрузить все элементы страницы. Это может повлиять на то, как Google видит и обрабатывает вашу страницу. Устраните проблемы.
Далее по тексту там будем видеть «Не удалось загрузить 30 ресурсов страницы», среди которых в основном будут изображения с типом «Изображение» и статусом «Другая ошибка».
Изображение — Другая ошибка
Данный глюк, а это именно глюк, в «Mobile-Friendly Test tool» существует довольно давно, выполоскал мозги многим СЕО-пропихаторам и вызвал множественные холивары на просторах Интернетов:
Гугл не видит большинство картинок на сайте — Cправка — Search Console
…
Это проблема инструмента проверки мобильности, он просто ограничен в ресурсах и на ошибке сбивается, что приводит к вываливанию в «другую ошибку». Причин может быть море, начиная от размера картинок и заканчивая размером js-скриптов и css.
Уже более года обещают пофиксить данный инструмент.
Аналогичные глюки имеют место быть и при проверке нашего сайта, который на данный момент расположен на VPS, а значит мы имеем полный доступ к лог-файлам сервера в режиме реального времени. Для чистоты эксперимента был полностью отключен брандмауэр, также логи были изучены на предмет наличия записей о превышении лимита подключений.
Так вот, проверка страницы в «Mobile-Friendly Test tool» и одновременный анализ лог-файлов сервера показал, что выдавая «Другая ошибка» по изображениям, — в отрезок времени с начала проверки и до момента завершения эти самые изображения никем, включая робота гугла, не запрашивались, записей о превышении лимитов на подключения не наблюдалось.
По неизвестным причинам аналогичные глюки могут быть с другими типами, например «Скрипт Другая ошибка».
Сообщения из консоли JavaScript
Ещё один глюкодром «Mobile-Friendly Test tool«.
Uncaught TypeError: $(...).tooltip is not a function at HTMLDocument.<anonymous> ...
Примечательно, что в консоли браузера никаких подобных ошибок не наблюдается, и при проверке другой страницы с теми же скриптами и порядком их загрузки «Mobile-Friendly Test tool» подобными ошибками не глюкает.
Другие глюки
«Mobile-Friendly Test tool» может засыпать также и другим бредом в стиле «preloaded using link preload but not used«:
The resource /…/*.min.js was preloaded using link preload but not used within a few seconds from the window’s load event. Please make sure it has an appropriate `as` value and it is preloaded intentionally.
Глюкам «Mobile-Friendly Test tool» нет счёта, потому перечислить их все не представляется возможным.
Выводы
Выводы думаю здесь очевидны:
- «Mobile-Friendly Test tool» — совсем не «Friendly» и как «Test tool» рассматриваться не может;
- От этой байды у многих не по праву страдает посещаемость;
- Гуглу очевидно многие лета плевать на «кривожопость» ихней системы оценки сайтов на оптимизированость под мобильные устройства.
Кроме всего прочего у многих переходы с гугла упали в результате вынимания мозгов «рэкаптчей» при каждом поисковом запросе в поиск даже не смотря на то, что ты «залогинен» в гугляцком аккаунте.
Сам давно почти не пользуюсь гугл поиском из-за его постоянных подозрений что я робот даже при всём том, что ты «залогинен» в гугляцком аккаунте и несколько секунд назад уже пробивал ту конченную «рэкаптчу» отмечая там пачками мосты/холмы/машины/пешеходные переходы.
Особую ненависть испытываю ко всем сайтам, а вернее их разработчикам/админам, которые используют «рэкаптчу» и обхожу такие сайты стороной. ИМХО иногда нет иной возможности выйти в сеть кроме как через ТОР, а пришибленная «рэкаптча» кроме своей жуткой «кумарности» ещё довольно часто тупо и наглухо блокирует ТОР сети.
В последние 2-3 года поиск от гугла превратился в глюкодромное, рэкаптчей мозгвыносящее … лала-ла-лала-ла. А теперь все вместе: Гугло х.йло! Лала-ла-лала-ла.
Хочу Вам помочь. Писать бесполезно. Приведу кусочек своей программы с подключением CSS и один из файлов CSS. Моя программа работала безотказно. Посмотрите, как у Вас организовано и как у меня.
Вот начало программы
<!DOCTYPE HTML PUBLIC «-//W3C//DTD HTML 4.01//EN»
«http://www.w3.org/TR/html4/strict.dtd» >
<HTML>
<HEAD>
<TITLE> Новости.</TITLE>
<META http-equiv= «Content-Type» content=»text/html; charset= windows-1251;» >
<META http-equiv= «Content-Language» content= «ru» >
……………
<LINK REL= «stylesheet» TYPE= «text/css» HREF= «diz0.css» >
<LINK REL= «stylesheet» TYPE= «text/css» HREF= «diz2.css» >
</HEAD>
<BODY>
<DIV ID= «j0»>
<FONT FACE=»Times» SIZE=»1″ >
<P ID= «p0»>
<IMG SRC= «s24.jpg» WIDTH= «1210px» HEIGHT= «260px» ALT= «Разрез Мутный»
TITLE= «Разрез Мутный» ><BR><BR>
</P>
А в файле diz0.css находится следующий текст CSS:
body { padding: 0; margin: 0;
text: #006633; topmargin: 20; leftmargin: 10; bgcolor: #ffccff;
marginheight: 20; marginwidth: 10; link: #cc99ff; alink: #cc00ff; vlink: #cc99ff; }
img { border: 0; padding: 0; margin: 0; }
div { padding: 0; margin: 0; }
form { padding: 0; margin: 0; }
ul { padding: 0; margin: 0; vertical-align: top; list-style-position: inside; }
li { padding: 0; margin: 0; }
table.design { padding: 10px; margin: 10px; border-spacing: 0; empty-cells: show;
border-collapse: collapse; width: 100%; table-layout: fixed; }
.dbg { display: block; border: solid 1px #888; }
.invis { display: none; }
Это всегда эти простые проблемы, которые мешают мне.
У меня есть очень простая страница, которую я создаю, и я хочу, чтобы гиперссылки не были специально окрашены (не синий, а не фиолетовый для посещения) или подчеркнуты.
Я делал это на других сайтах раньше без проблем, просто используя
a, a:visited, a:hover, a:active {
text-decoration: none;
color: none;
}
Однако на этом конкретном сайте это не делает трюк для цвета, в то время как подчеркивание успешно удаляется. Я даже попытался добавить ужасный тег !important без эффекта.
Эта проблема наблюдается в Chrome, IE 11 и Android (WebView).
Когда я проверяю ссылки с помощью консоли Chrome Developer, он вытаскивает свой атрибут color из user agent stylesheet, а именно:
a:-webkit-any-link {
color: -webkit-link;
}
Итак, я попытался переопределить это явно в моей таблице стилей, добавив a:-webkit-any-link в мой список тегов, чтобы применить атрибут color: none, чтобы снова не повлиять. Я также добавил a:any-link и a:link в различных комбинациях, но безрезультатно.
Мысли о очевидном решении, о котором я не замечаю?