
Продолжаем цикл занятий, посвященный
темам технологий беспроводной связи.
Сегодняшнее занятие посвящено такой
актуальной теме, как линейные блочные
коды, кодирование. Мы посмотрим, какие
есть варианты, какие способы кодирования
информации используются в работе.
Начнем с простых кодов. Простые коды ⏤
линейные блочные коды — некоторые
информационные сообщения разбиваются
на блоки, и каждый блок по-отдельности
кодируется, по-отдельности принимается
и декодируется. То есть каждый блок ⏤
некая независимая единица.
Примером линейного блочного кода,
который мы уже рассматривали, является
код Хемминга. Мы рассматривали, как он
устроен на примере кода Хемминга (7,4) —
где 7 бит ⏤ это длина блока, из них 4 бита
⏤ информационные, а 3 бита ⏤ контрольные.
Рассмотрим код Хемминга (n,k), где под n ⏤
общее количество бит в блоке и k ⏤
количество информационных бит в блоке.
Линейные коды достаточно распространены,
их много разнообразных вариаций. Вы
можете сами придумать какой-либо свой
линейный блочный код и
использовать его. Коды Хемминга в свое
время были очень популярны ввиду простоты
их реализации, что очень немаловажно,
когда вы придумываете свой код, и,
соответственно, они решают свою задачу.
А именно, код Хемминга (7,4) исправляет
однократную ошибку.
Давайте разберемся,
почему он исправляет однократную ошибку?
Вернемся к коду Хемминга (n,k), где
-
k ⏤ количество информационных бит,
-
n ⏤ это общая длина блока,
-
r = n – k ⏤ это количество проверочных, или
контрольных бит.
Таким образом, у нас k=4, 4 информационных
бита.
Вообще говоря, Код Хемминга ⏤ двоичный
код, он работает на алфавите, алфавит в
нашем случае ⏤ это множество {0; 1}.
Поэтому количество возможных вариантов
так называемых входных слов 2k,
при k=4 количество возможных вариантов
входных слов будет 24 = 16.
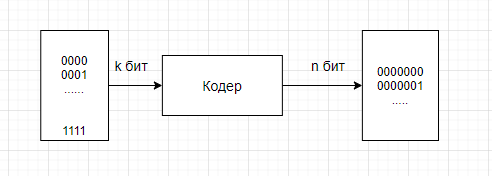
Что делает кодер?
Поступает некоторый блок из k бит,
далее есть устройство или программа,
которая называется кодер. Она кодирует
ваше входное сообщение, то есть добавляет
в него некоторые дополнительные
проверочные символы. Фактически кодер
удлиняет сообщение на количество
проверочных символов r, и возвращает
некоторое закодированное слово длиной
уже n бит. Так работает любой кодер,
какой бы мы не смотрели, блочный он или
нет.
Таким образом, в случае кодирования
кода Хемминга (7,4) на входе есть таблица
шестнадцати вариантов: 0000, 0001, …, 1111, а
на выходе те же самые 16 вариантов, но
они снабжены еще проверочными символами.
Множество выходных слов отличается
друг от друга попарно всегда на 3
контрольных бита.
Рассмотрим пример. Пусть k=1, то есть
вы хотите передать 1 бит, но так, чтобы
при возникновении ошибки его можно было
бы поправить. Сколько потребуется
дополнительных бит, чтобы можно было
восстановить сообщение?
Пусть отправляемый бит: 0.
Если вы предположите, что достаточно
одного проверочного бита, значит,
количество единичек должно быть четным,
то есть вы добавляете в данном случае
0, тогда во время движения по каналу
связи сообщение может исказиться:
00 ➞ 10 —
четность изменилась (однократная ошибка)
01 — четность изменилась
(однократная ошибка)
00 — в этом случае понимаем,
что сообщение не исказилось
В случае с комбинациями (10 и 01) непонятно
какой символ был передан: 1 или 0? В данном
случае эти варианты равноправны, поэтому
одного проверочного символа никак не
хватает. Следовательно, нужно использовать
два проверочных символа.
И если вы передаете один бит данных (D)
и у вас два контрольных бита (K1 и K2), то в
зависимости от того, какой на входе бит,
будут определяться контрольные символы.
D кодируется ➞ DK1K2
0 кодируется ➞ 000 ➞ при
возникновении ошибки на выходе получим
следующие варианты: 100, 010, 001.
Отсюда легко понять, что был передан
именно 0.
Рассмотрим первый вариант — 100. Проверяем
контрольные суммы.
D + K1 = 1 (mod 2) — значит,
ошибка либо в первом (D), либо во втором
бите (K1), далее приемник сравнивает данные
и второй контрольный бит
D + K2 = 1 ( mod 2) — значит,
ошибка либо в первом (D), либо в третьем
бите (K2),
две ошибки в переданном сигнале быть
не может, поэтому ошибка в данных.
Далее рассуждаем аналогично. Для сигнала
010:
D + K1 = 1 (mod 2) — значит,
ошибка либо в первом бите (D), либо во
втором бите (K1)
D + K2 = 0 (mod 2) — значит,
ошибка именно в первом бите (D)
И продолжая рассуждение, мы можем
определить, что ошибка в данном случае
в во втором контрольном бите.
Те же самые рассуждения можно привести
и для случая, если вы передаете три
единички.
D кодируется ➞ DK1K2
1 кодируется ➞ 111 ➞ при
возникновении ошибки на выходе получим
следующие варианты: 011, 101, 110.
При передаче трех нулей в случае, когда
в канале может быть ошибка, на выходе
может прийти три различных варианта.
При передаче трех единиц в случае, когда
в канале может быть ошибка, на выходе
тоже может прийти три различных варианта.
И нужно помнить о том, что могут быть
приняты сообщения без ошибок: 000, 111.
Всего два варианта на стороне передатчика,
которые могут быть переданы, 111 и 000. А
различных вариантов, которые могут быть
приняты, с ошибками и без ошибок, восемь.
При этом какой бы вариант вам не пришел,
вы всегда можете определить, что конкретно
было на стороне передатчика. Зная, как
устроен кодер, программа кодера, которая
таким образом закодировала сигнал, вы
может разобраться, что было на входе, 0
или 1.
Обратите внимание, что мы обнаружили и
исправили однократную ошибку благодаря
тому, что исходные варианты, которые
сформировал кодер, отличаются именно
на три бита (000 и 111), если бы они отличались
на два бита, тогда было бы непонятно, с
какой стороны сигнала находится ошибка.
В данном примере расстояние Хемминга
будет равно 3. Под
расстоянием Хемминга подразумевается
количество бит, на которые отличаются
два сравниваемых числа.
Давайте попробуем разобраться, на какое
количество бит наши кодовые комбинации
должны отличаться, если мы хотим исправить
двукратную ошибку.
Пусть,
-
квадратик — разрешенная комбинация,
то есть та комбинация, которую выдает
кодер, -
крестик — комбинация, которая содержит
в себе ошибки, то есть это те коды,
которые наш кодер никак не мог выдать
нам; это комбинации, которые появились
в процессе приема, уже на стороне
приемника.
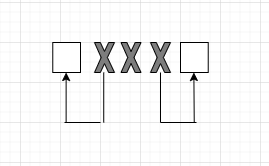
Итак, если принятый код имеет вид ◻ХХХ◻,
то комбинации,
которые содержат в себе ошибки — Х —
говорят о том, что на самом деле были
переданы ближние к ним разрешенные
комбинации — ◻, была допущена однократная
ошибка.
Если мы получили
вариант, где стоит средний Х, это означает,
что мы фиксируем ошибку, что такая
комбинация не может быть, ее нет в
перечне, и это двукратная ошибка.
Что привело к возникновению этой
двукратной ошибки, откуда она, мы не
знаем.
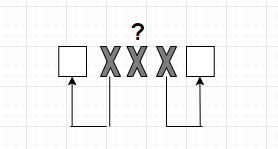
Мы можем только обнаружить ее, а исправить
не можем.
Теперь возвращаясь
к вопросу: как исправить двукратную
ошибку?
Рассмотрим ситуацию, изображенную на
рисунке.
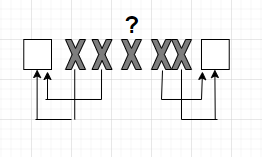
Принятый код имеет вид ◻ХХХХХ◻. Если
мы принимаем эту комбинацию, то стрелками
покажем с какими разрешенными комбинациями
будут отождествляться комбинации с
ошибками. Почему именно так? Потому что
мы ищем ближайший разрешенный код. Но
мы не знаем откуда произошла ошибка,
которая находится в середине комбинации.
Ошибка обнаружена, мы не можем её
исправить. Таким образом, чтобы исправить
двукратную ошибку, нужно, чтобы ближайшие
кодовые слова отличались на минимум
пять бит.
Такую схему рассуждения можно применить,
если вы хотите сгенерировать код, который
исправляет трехкратную или четырехкратную
ошибку в вашем коде и так далее. Эти
несложные рассуждения позволяют
разобраться, сколько нужно проверочных
символов, и как должны быть устроены
слова, которые выдает кодер. Как слова
должны отличаться друг от друга.
Мы поговорили про кодирование в случае,
когда мы хотим разработать код, который
исправляет однократную, двукратную,
трехкратную ошибку. Это так называемые
общие принципы. Возвратимся к нашему
коду Хемминга 7,4.
Код Хемминга 7,4 является совершенным
кодом. Почему? Потому что все комбинации,
которые возвращает ваш кодер, отличаются
друг от друга ровно на 3 бита, то есть
нет никакой избыточности, кодовое
пространство заполняется максимально
плотно. Количество комбинаций, которое
может принять пользователь в случае,
если вы работаете с кодом Хемминга 7,4,
равно 27 = 128.
Поэтому, когда вы работаете с кодом
Хемминга 7,4, его можно использовать как
некоторый табличный код. Вообще говоря,
табличный код — это самый простой в
реализации код, когда вы четко ставите
в соответствии с входом — выход. Когда
вы декодируете, соответственно, тот
код, который вы приняли (принятый сигнал)
вы сравниваете с одним из 16 вариантов.
Там, где он ближе всего — где расстояние
по коду будет 1 или 0, будет сигнал,
который был на входе. Удалив контрольные
символы, получаете ту посылку, которую
передали.
В случае, когда вы кодируете 1 бит данных,
то есть утраиваете ваш код, получается
очень высокая избыточность. В этом
случае можно использовать таблицы. То
есть у вас будет таблица на стороне
кодера и декодера, и кодер по номеру
входного сигнала сразу возвращает
выходной, при этом декодер действует
также. Поэтому написать код Хемминга
7,4 можно, просто перечислив в массиве
все возможные варианты.
На практике коды используются длинные.
Код должен спасать вас не только от
однократной ошибки, но и от многократной
ошибки (от двух-, трехкратной). Он должен
вас защищать, чтобы повысить надежность
канала связи. Поэтому используются коды
длиной 100, 200. А теперь представьте,
например, 2100 — это количество
вариантов, которые нужно закодировать
или найти, то есть это 1,267·1030
вариантов. Это, скажем, такой жесткий
вариант, когда вы простым перебором,
методом грубой силы декодируете сигнал?
Конечно, в современных устройствах так
не делают, то есть если в таком, простом
варианте это можно было сделать, то в
современных системах нет.
Для кодирования слов линейными блочными
кодами используется генерирующая
матрица или матрица-генератор. Это
более простой подход, который позволяет
кодировать намного быстрее.
Матрица-генератор как раз имеет размер
(n*k), и в этом случае вам не надо хранить
всю таблицу 2n, а достаточно всего
n умножить на k чисел, что намного меньше.
Теперь посмотрим, как устроен кодер,
как устроена генерирующая таблица для
кода 7,4. Посмотрим, как она работает. То,
что мы рассмотрим, можно будет использовать
на более длинные коды.
Генерирующая матрица обозначается
буквой G, и для кода 7,4 она может быть
построена на основе тех контрольных
сумм, которые вы захотите сформулировать,
то есть то, как сейчас она будет выглядеть,
не означает, что это жесткий вариант,
который мы будем использовать. Возможен
другой вариант. Он может быть сформирован
вами самостоятельно, в зависимости от
того, на какие биты вы делаете ставку.
У нас 4 бита данных, поскольку мы
рассматриваем код 7,4: d1 d2 d3 d4.
Контрольные суммы P1, P2, P3
устроим следующим образом:
P1 = d4 + d3 + d2 (mod 2)
P2 = d4 + d3 + d1 (mod 2)
P3 = d4 + d2 + d1 (mod 2)
Если формировать контрольные суммы
иначе, например, вместо d4 поставить
и от них все отписать, это нисколько не
помешает нашей работе.
Матрица-генератор составляется следующим
образом.
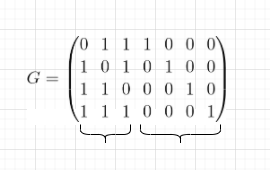
Первый столбец: смотрим на первую
контрольную сумму, сюда не входил d1,
поэтому на ее месте — 0, а входили
d2, d3, d4,
на их место ставим 1, 1, 1 соответственно.
Второй столбец: во
вторую контрольную сумму входил d1,
поэтому на его месте — 1, не входил d2
— на его месте 0, d3, d4
— входит — 1, 1. Аналогично, строим третий
столбец.
Следующая часть соответствует битам
данных.
Теперь попробуем закодировать какое-то
сообщение с помощью матрицы-генератора.
Сообщение, которое мы хотим передать
состоит из нескольких 1 и 0, это двоичные
коды.
Сообщение: 1010. Мы хотим его передать.
Сообщение-слово будем обозначать w.
Кодовое слово, которое мы закодируем
Cw = w * G
Обратите внимание w — строка, G
— матрица
Поэлементно умножаем строку на столбец.
В результате получим строку из 7 элементов.
Первый элемент будет следующий: 1 × 0 + 0
× 1 + 1 × 1 + 0 × 1 (mod 2) = 1. Второй элемент:
умножаем эту же строчку на следующий
столбик и так далее.
Таким образом, в результате кодирования
мы получили следующее:
(1010)→ G(кодер)→ (1011010).
Обратите внимание на следующий интересный
момент: в последовательности 1011010
последние 4 символа — это наши данные, а
первые 3 символа — это контрольные биты.
И именно эта посылка уже уезжает дальше.
Для размышления
Закодируйте сообщение 1100 с помощью матрицы-генератора.
Материалы
- Сагалович Ю.Л. Введение в алгебраические коды (глава 4)
- Видео об Алгоритме кодирования и обнаружения ошибки кодом Хемминга
- Королев А.И.
Коды и устройства помехоустойчивого кодирования информации. Мн.: 2002. — 286 с. (объёмный материал о кодировании за исключением глав 4 и 6)
Минимальное расстояние между допустимыми словами кода с контролем по четности равно двум (из
рис.
14.2 видно, что никакие два кодовых слова в рамочках не соединены линиями, то есть не являются соседними). Именно по этой причине одиночная ошибка в кодовом слове превращает это слово в недопустимое.
Платой за помехоустойчивость является необходимость увеличения длины слов по сравнению с обычным кодом. В данном примере только два разряда являются информационными. Это они образуют четыре разных слова. Третий разряд является контрольным и служит только для увеличения расстояния между допустимыми словами. В передаче информации контрольный разряд не участвует, так как является линейно зависимым от информационных. Код с контролем по четности, рассмотренный в качестве примера, позволяет обнаружить одиночные ошибки в блоках данных при передаче данных. Однако он не сможет обнаружить двукратные ошибки потому, что двукратная ошибка переводит кодовое слово через промежуток между допустимыми словами и превращает его в другое допустимое слово.
Таким образом, для того чтобы код приобрел способность к обнаружению и коррекции ошибок, необходимо отказаться от его безызбыточности. Для этого и разделяют всё множество возможных комбинаций двоичных символов на два подмножества: допустимых кодовых слов и недопустимых. Разбиение осуществляется таким образом, чтобы увеличить минимальное кодовое расстояние между допустимыми словами. В этом случае любая однократная ошибка превращает допустимое кодовое слово в недопустимое, что позволяет её обнаружить.
Естественно, что введение дополнительных контрольных разрядов увеличивает затраты на хранение или передачу кодированной информации. При этом фактический объем полезной информации остается неизменным. В этом случае можно говорить об избыточности помехоустойчивого кода, которую формально можно определить как отношение числа контрольных разрядов к общему числу разрядов кодового слова.
Мы уже отмечали, что контрольные разряды не передают информацию и в этом смысле бесполезны. Относительное число контрольных разрядов называется избыточностью Q помехоустойчивого кода

где n – общее число двоичных разрядов в блоке, а k – число контрольных разрядов.
Например, избыточность рассмотренного трехразрядного кода с контролем по четности составляет:
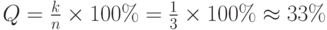
Избыточность является важной характеристикой кода, причем чрезмерное увеличение избыточности нежелательно. Важной задачей теории информации является синтез кодов с минимальной избыточностью, обеспечивающих заданную обнаруживающую и корректирующую способность.
В качестве иллюстрирующего примера рассмотрим один из простейших кодов, позволяющих обнаруживать и исправлять однократные ошибки – код Хэмминга. Кодовое слово длиной n содержит k информационных и m контрольных разрядов. Коррекция искаженного i-го разряда заключается в сложении (по модулю 2) принятого кодового слова с вектором вида 0…010…0, содержащем единицу в i-ом разряде.
Для n-разрядного кодового слова существует n таких векторов, соответствующих однократным ошибкам, и один нулевой вектор, соответствующий случаю приема слова без ошибок. Таким образом, m контрольных разрядов должны обеспечивать формирование n + 1 вектора ошибки, то есть должно выполняться неравенство  . В результате получается (2m-1, 2m-1-m) код, называемый кодом Хэмминга.
. В результате получается (2m-1, 2m-1-m) код, называемый кодом Хэмминга.
Простейший нетривиальный случай, соответствующий m=3, образует (7,4)-код, который можно синтезировать следующим образом. Сопоставим каждому вектору ошибки порядковый номер – синдром (
таблица
14.1). При этом нулевому вектору ошибки соответствует нулевой синдром.
| a6 | a5 | a4 | a3 | a2 | a1 | a0 | s2 | s1 | s0 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 |
| 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Рассматривая функции si как свертку по модулю 2 разрядов кодовых слов, получим:

Функции si должны обращаться в единицу при наличии ошибки в одном из образующих их разрядов, и в ноль – при отсутствии ошибок. Обеспечение этого требования возможно лишь при условии, что часть разрядов формируется специальным образом. В частности, разряды a0, a1, a2 можно рассматривать как свертку по модулю 2 остальных разрядов, участвующих в соответствующих уравнениях:

Найденные зависимости позволяют генерировать кодовые слова по заданным информационным, а также вычислять синдромы для принятых кодовых слов.
Допустим, исходное информационное слово равно 1101, то есть a6=1, a5=1, a4=1, a3=1. Для преобразования его в допустимое кодовое слово помехоустойчивого (7,4) —кода Хэмминга рассчитаем контрольные разряды по найденным выше зависимостям. В частности,

Таким образом, с учетом контрольных разрядов кодовое слово будет равно 1101001.
Если в процессе передачи или хранения слово осталось неискаженным, то его синдром s0…s2 будет соответственно равен: 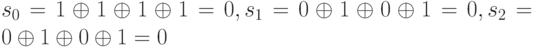 ,. Синдром, состоящий из одних нулей, указывает на отсутствие ошибки и соответствует нулевому вектору ошибки.
,. Синдром, состоящий из одних нулей, указывает на отсутствие ошибки и соответствует нулевому вектору ошибки.
Предположим, что в процессе передачи или хранения в результате воздействия внешних факторов оказался искаженным отдельный разряд кодового слова. Например, вместо слова 1101001 было принято слово 1001001. В этом случае синдром окажется отличным от нуля: s0…s2 будет соответственно равен: 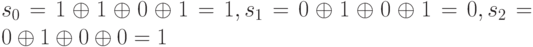 Синдром 101 соответствует вектору ошибки 0100000, при этом единица указывает на разряд, в котором эта ошибка произошла. Для ее коррекции достаточно сложить по модулю 2 принятое искаженное кодовое слово с вектором ошибки.
Синдром 101 соответствует вектору ошибки 0100000, при этом единица указывает на разряд, в котором эта ошибка произошла. Для ее коррекции достаточно сложить по модулю 2 принятое искаженное кодовое слово с вектором ошибки.
Рассчитаем избыточность (7,4) —кода Хэмминга:
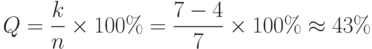
Это очень большое значение. На практике часто применяются существенно более сложные коды, обеспечивающие лучшие характеристики помехоустойчивости при меньшей избыточности.
Циклический код относится к классу
систематических кодов. Ранее было
показано, что при обнаружении одиночной
ошибки минимальное кодовое расстояние
равно
![]() .
.
Это значит, достаточно одного
дополнительного разряда в кодовой
комбинации, содержащего информационные
символы, чтобы обнаружить однократную
ошибку.
Код однократной ошибки
![]() представляет
представляет
полином вида![]() ,
,
где![]() .
.
Код ошибки суммируется по модулю два с
одним из символовn-разрядной
кодовой комбинации![]() :
:
![]() .
.
(5.17)
Среди всех неприводимых полиномов
![]() полином вида
полином вида![]() обладает наименьшей степенью. Двоичный
обладает наименьшей степенью. Двоичный
код, соответствующий этому полиному,
записывается как 11. При делении любого
полинома степени![]() на
на
полином![]() имеется единственный остаток, равный
имеется единственный остаток, равный
«0» или «1». Остаток, равный «1» — это
признак ошибки в кодовой комбинации, и
это свойство легло в основу создания и
обнаружения однократной ошибки.
Образование кода. Положим![]() — код, проверочный символ которого
— код, проверочный символ которого![]() неизвестен. Разделим кодовую комбинацию
неизвестен. Разделим кодовую комбинацию![]() на код 11 неприводимого полинома
на код 11 неприводимого полинома![]() .
.
В результате деления получится остаток.
Проверочный символ![]() заменяется остатком.
заменяется остатком.
|
|
1 |
0 |
0 |
0 |
1 |
1 |
|
1 |
1 |
1 |
1 |
|||
|
|
0 |
1 |
0 |
|||
|
1 |
1 |
|||||
|
|
0 |
1 |
0 |
|||
|
1 |
1 |
|||||
|
Оста- ток |
0 |
1 |
||||
|
Рис. 5.7 Процедура обнаружения однократной |
|
|
1 |
0 |
1 |
|
1 |
1 |
|
1 |
1 |
1 |
1 |
|||
|
|
0 |
1 |
1 |
|||
|
1 |
1 |
|||||
|
00 |
|
|||||
|
Рис. 5.6 Процедура |
Например, пусть кодовая комбинация
101 представляет информационные символы.
На рисунке 5.6 представлена процедура
определения значения символа![]() .
.
Последняя строка на этом рисунке –
остаток, равный нулю, поэтому символ![]() =0.
=0.
На рисунке 5.7 представлена процедура
обнаружения однократной ошибки. Ошибка
в коде обозначена жирным шрифтом. В
результате деления кода с ошибкой на
неприводимый полином
![]() образовался остаток, равный «1» — признак
образовался остаток, равный «1» — признак
ошибки.
5.2.2 Исправление однократной ошибки
Исправление одиночной ошибки связано
с определением разряда, в котором
произошла ошибка. Это производится на
основании анализа остатков от деления
многочленов ошибок
![]() на неприводимый полином
на неприводимый полином![]() .
.
Каждому остатку соответствует один из
разрядов кодовой комбинации, в которой
произошла ошибка. Чем больше остатков,
тем больше ошибок можно исправить.
Наибольшее число остатков дает
неприводимый полином![]() ,
,
так как он не содержит ни одного
сомножителя кроме самого себя.
Боузом и Чоудхури доказано[20],
что существует циклический код разрядности
![]() ,
,
(5.18)
где m= 1, 2, 3, …,
с кодовым расстоянием
![]() .
.
(5.19)
При этом число проверочных символов
удовлетворяет соотношению
![]() .
.
(5.20)
Питерсеном [Коды, исправляющие
ошибки] доказано, что полином вида
![]() (5.21)
(5.21)
может быть представлен в виде произведения
неприводимых многочленов, степени
которых являются делителями числа mот 1 доmвключительно
[Березюк].
Соотношение между числом исправляемых
ошибок s, числом информационных
символов и числом проверочных символов
регулируется формулой (5.6).
В таблице 5.4 приведены значения числа
символов nв кодовой
последовательности в зависимости от
величиныm,обеспечивающие кодовое расстояниеd=3
|
Таблица 5.4 |
|||||
|
m |
2 |
3 |
4 |
5 |
… |
|
n |
3 |
7 |
15 |
31 |
… |
|
r |
2 |
3 |
4 |
5 |
… |
|
k |
1 |
4 |
11 |
26 |
… |
при исправлении одиночной ошибки.
Для значенийn= 3, 7, 15 по
формуле (5.21) получены множества
неприводимых многочленов
![]() ,
,
![]() ,
,
![]() .
.
Не
каждый многочлен даёт необходимое число
остатков. Например, при исправлении
однократной ошибки в 15-разрядном коде
необходимо 15 остатков , полученных от
деления кода ошибки на неприводимый
полином. Однако, если выбран полином ![]() будет всего шесть остатков. В то же время
будет всего шесть остатков. В то же время
полином![]() даёт 15 остатков. Двоичное значение
даёт 15 остатков. Двоичное значение
полинома![]()
![]() 11001.
11001.
Образование циклического кода.n-разрядная кодовая
комбинация имеет вид![]() ,
,![]() .
.
Положим, определеныk,rиn. Тогда известны неприводимый многочлен![]() и многочлен
и многочлен![]() ,
,
соответствующийk-разрядной
комбинации информационных символов![]() .
.
Необходимо определить проверочные
символы![]() .
.
Один из методов образования кода
заключается в следующем.
Многочлен
![]() умножается на
умножается на![]() .
.
Это соответствует приписываниюrнулей справа в кодовой последовательности![]() .
.
Произведение![]() делится на неприводимый полином
делится на неприводимый полином![]() и получается
и получается![]() —
—
разрядный остаток![]() .
.
Все символы![]() в кодовой последовательности
в кодовой последовательности![]() замещаются символами остатка. В результате
замещаются символами остатка. В результате
имеем многочлен
![]() .
.
Полученный многочлен делится без остатка
на неприводимый многочлен. Действительно,
 ,
,
где
![]() частное от деления
частное от деления![]() ,
,
остаток отсутствует.
Если в одном из разрядов символ изменил
своё значение, остаток от деления
![]() не равен нулю. Каждому ошибочному символу
не равен нулю. Каждому ошибочному символу
в кодовой комбинации![]() соответствует свой остаток (синдром).
соответствует свой остаток (синдром).
Пусть n= 7,k= 4,r= 3. Выберем полином![]()
![]() 1011,
1011,
который дает 7 остатков. Положим,![]() .
.
Неизвестными являются проверочные
символы![]() .
.
Определим полиномы и соответствующие
им коды
![]()
![]() 1110000,
1110000,![]()
![]() 1011. Остаток от деления полинома
1011. Остаток от деления полинома![]() на
на
полином![]() равен
равен![]()
![]() 100.
100.
Заменим нули проверочной части кода
1110000 кодом остатка и получим закодированную
кодовую комбинацию 1110100, которому
соответствует полином вида
![]() .
.
Разделив полином![]() на
на
полином![]() ,
,
получим полином![]()
![]() 000.
000.
Исправление однократной ошибки. Для
исправления однократных ошибок определим
коды ошибок, соответствующие каждому
разряду кодовой комбинации. Заменяя
исправный символ в коде 1110100 ошибочным
и деля полученный код на код неприводимого
многочлена, получим код ошибки (синдром)
для соответствующего разряда. В результате
получится таблица 5.5. Если искажён
символ, скажем![]() ,
,
то после деления кода с искажённым
символом на код неприводимого многочлена
получим синдром 011, что позволит
инвертировать символ![]() .
.
-
Таблица 5.5
Код сообщения




Синдром S
101
111
110
011
100
010
001
Исправление однократной ошибки возможно
несколькими методами. Используя методы
исправление однократной ошибки
систематическими кодами можно так же
создать проверочную матрицу, а по ней
записать проверочные уравнения. Другим
методом является метод, основанный на
свойствах записи циклических кодов и
весе однократной ошибки, равный единице.
Считается, множество кодов, составляющие
разрешённые комбинации , образовано с
помощью выбранного неприводимого
полинома и он остается неизменным во
время исправления однократной ошибки.
В зафиксированной кодовой комбинации
содержится однократная ошибка.При делении зафиксированной кодовой
комбинации на код образующего полинома
получается остаток. Если все разряды
кода не искажены, остаток равен нулю.
Искажение одного из символов приводит
к остатку, отличного от нуля. Анализ
остатка позволяет определить искажённый
символ. Ввиду того, что ошибка однократная
и надо найти разряд, в котором произошла
ошибка, то вес остатка![]() должен быть равен единице. Чтобы проверить
должен быть равен единице. Чтобы проверить
каждый разряд кода на наличие ошибки
производится поэтапно циклический
сдвиг влево на один разряд кодовой
комбинации. На каждом этапе осуществляется
деление сдвинутого кода на неприводимый
полином и определяется вес остатка![]() .
.
Процедура циклических сдвигов
останавливается, если вес остатка![]() =1.
=1.
Этот остаток служит индикатором того,
что последний разряд в сдвинутом коде
ошибочный и его надо инвертировать.
Инвертирование достигается суммированием
по модулю 2 сдвинутого кода с кодом
остатка.
Чтобы восстановить неискажённую кодовую
комбинацию производятся циклические
сдвиги вправо столько раз, сколько
производились циклические сдвиги влево.
Пример 5.6 Пустьn= 7,k= 4,r= 3. Выберем полином![]()
![]()
1011, который дает 7 остатков. Выберем из
множества разрешённых кодовых комбинаций
код 1110100 и внесём ошибку в 4-ый разряд
1111100. На рисунке 5.8 показана процедура
определения искажённого символа.
Разделив кодовую комбинацию с ошибкой
на неприводимый полином, убедимся, что
вес остаткаw
а б
г д
Рис. 5.8 Процедура определения искажённого
|
больше 1, рисунок 5.8 а. На рисунках 5.8 б,
5.8 в, 5.8 г показаны процедуры циклического
сдвига и получения остатков, больших
единицы. На рисунке 5.8.д демонстрируется,
после очередного циклического сдвига
и деления полученного кода на неприводимый
полином остаток равен единице,
следовательно вес остатка w=1.
Это значит последний сдвинутый символ
ошибочный. Чтобы исправить ошибочный
символ, последнюю кодовую комбинацию
сложим по модулю 2 с остатком, рисунок
5.8.е. Произведя последовательно 4 раза
циклический перенос вправо кодовой
комбинации с исправленным символом,
получим безошибочную кодовую комбинацию:
1001110
0100111, 1010011, 1101001,1110100.
Оглавление
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Продолжаем цикл занятий, посвященный
темам технологий беспроводной связи.
Сегодняшнее занятие посвящено такой
актуальной теме, как линейные блочные
коды, кодирование. Мы посмотрим, какие
есть варианты, какие способы кодирования
информации используются в работе.
Начнем с простых кодов. Простые коды ⏤
линейные блочные коды — некоторые
информационные сообщения разбиваются
на блоки, и каждый блок по-отдельности
кодируется, по-отдельности принимается
и декодируется. То есть каждый блок ⏤
некая независимая единица.
Примером линейного блочного кода,
который мы уже рассматривали, является
код Хемминга. Мы рассматривали, как он
устроен на примере кода Хемминга (7,4) —
где 7 бит ⏤ это длина блока, из них 4 бита
⏤ информационные, а 3 бита ⏤ контрольные.
Рассмотрим код Хемминга (n,k), где под n ⏤
общее количество бит в блоке и k ⏤
количество информационных бит в блоке.
Линейные коды достаточно распространены,
их много разнообразных вариаций. Вы
можете сами придумать какой-либо свой
линейный блочный код и
использовать его. Коды Хемминга в свое
время были очень популярны ввиду простоты
их реализации, что очень немаловажно,
когда вы придумываете свой код, и,
соответственно, они решают свою задачу.
А именно, код Хемминга (7,4) исправляет
однократную ошибку.
Давайте разберемся,
почему он исправляет однократную ошибку?
Вернемся к коду Хемминга (n,k), где
-
k ⏤ количество информационных бит,
-
n ⏤ это общая длина блока,
-
r = n – k ⏤ это количество проверочных, или
контрольных бит.
Таким образом, у нас k=4, 4 информационных
бита.
Вообще говоря, Код Хемминга ⏤ двоичный
код, он работает на алфавите, алфавит в
нашем случае ⏤ это множество {0; 1}.
Поэтому количество возможных вариантов
так называемых входных слов 2k,
при k=4 количество возможных вариантов
входных слов будет 24 = 16.
Что делает кодер?
Поступает некоторый блок из k бит,
далее есть устройство или программа,
которая называется кодер. Она кодирует
ваше входное сообщение, то есть добавляет
в него некоторые дополнительные
проверочные символы. Фактически кодер
удлиняет сообщение на количество
проверочных символов r, и возвращает
некоторое закодированное слово длиной
уже n бит. Так работает любой кодер,
какой бы мы не смотрели, блочный он или
нет.
Таким образом, в случае кодирования
кода Хемминга (7,4) на входе есть таблица
шестнадцати вариантов: 0000, 0001, …, 1111, а
на выходе те же самые 16 вариантов, но
они снабжены еще проверочными символами.
Множество выходных слов отличается
друг от друга попарно всегда на 3
контрольных бита.
Рассмотрим пример. Пусть k=1, то есть
вы хотите передать 1 бит, но так, чтобы
при возникновении ошибки его можно было
бы поправить. Сколько потребуется
дополнительных бит, чтобы можно было
восстановить сообщение?
Пусть отправляемый бит: 0.
Если вы предположите, что достаточно
одного проверочного бита, значит,
количество единичек должно быть четным,
то есть вы добавляете в данном случае
0, тогда во время движения по каналу
связи сообщение может исказиться:
00 ➞ 10 —
четность изменилась (однократная ошибка)
01 — четность изменилась
(однократная ошибка)
00 — в этом случае понимаем,
что сообщение не исказилось
В случае с комбинациями (10 и 01) непонятно
какой символ был передан: 1 или 0? В данном
случае эти варианты равноправны, поэтому
одного проверочного символа никак не
хватает. Следовательно, нужно использовать
два проверочных символа.
И если вы передаете один бит данных (D)
и у вас два контрольных бита (K1 и K2), то в
зависимости от того, какой на входе бит,
будут определяться контрольные символы.
D кодируется ➞ DK1K2
0 кодируется ➞ 000 ➞ при
возникновении ошибки на выходе получим
следующие варианты: 100, 010, 001.
Отсюда легко понять, что был передан
именно 0.
Рассмотрим первый вариант — 100. Проверяем
контрольные суммы.
D + K1 = 1 (mod 2) — значит,
ошибка либо в первом (D), либо во втором
бите (K1), далее приемник сравнивает данные
и второй контрольный бит
D + K2 = 1 ( mod 2) — значит,
ошибка либо в первом (D), либо в третьем
бите (K2),
две ошибки в переданном сигнале быть
не может, поэтому ошибка в данных.
Далее рассуждаем аналогично. Для сигнала
010:
D + K1 = 1 (mod 2) — значит,
ошибка либо в первом бите (D), либо во
втором бите (K1)
D + K2 = 0 (mod 2) — значит,
ошибка именно в первом бите (D)
И продолжая рассуждение, мы можем
определить, что ошибка в данном случае
в во втором контрольном бите.
Те же самые рассуждения можно привести
и для случая, если вы передаете три
единички.
D кодируется ➞ DK1K2
1 кодируется ➞ 111 ➞ при
возникновении ошибки на выходе получим
следующие варианты: 011, 101, 110.
При передаче трех нулей в случае, когда
в канале может быть ошибка, на выходе
может прийти три различных варианта.
При передаче трех единиц в случае, когда
в канале может быть ошибка, на выходе
тоже может прийти три различных варианта.
И нужно помнить о том, что могут быть
приняты сообщения без ошибок: 000, 111.
Всего два варианта на стороне передатчика,
которые могут быть переданы, 111 и 000. А
различных вариантов, которые могут быть
приняты, с ошибками и без ошибок, восемь.
При этом какой бы вариант вам не пришел,
вы всегда можете определить, что конкретно
было на стороне передатчика. Зная, как
устроен кодер, программа кодера, которая
таким образом закодировала сигнал, вы
может разобраться, что было на входе, 0
или 1.
Обратите внимание, что мы обнаружили и
исправили однократную ошибку благодаря
тому, что исходные варианты, которые
сформировал кодер, отличаются именно
на три бита (000 и 111), если бы они отличались
на два бита, тогда было бы непонятно, с
какой стороны сигнала находится ошибка.
В данном примере расстояние Хемминга
будет равно 3. Под
расстоянием Хемминга подразумевается
количество бит, на которые отличаются
два сравниваемых числа.
Давайте попробуем разобраться, на какое
количество бит наши кодовые комбинации
должны отличаться, если мы хотим исправить
двукратную ошибку.
Пусть,
-
квадратик — разрешенная комбинация,
то есть та комбинация, которую выдает
кодер, -
крестик — комбинация, которая содержит
в себе ошибки, то есть это те коды,
которые наш кодер никак не мог выдать
нам; это комбинации, которые появились
в процессе приема, уже на стороне
приемника.
Итак, если принятый код имеет вид ◻ХХХ◻,
то комбинации,
которые содержат в себе ошибки — Х —
говорят о том, что на самом деле были
переданы ближние к ним разрешенные
комбинации — ◻, была допущена однократная
ошибка.
Если мы получили
вариант, где стоит средний Х, это означает,
что мы фиксируем ошибку, что такая
комбинация не может быть, ее нет в
перечне, и это двукратная ошибка.
Что привело к возникновению этой
двукратной ошибки, откуда она, мы не
знаем.
Мы можем только обнаружить ее, а исправить
не можем.
Теперь возвращаясь
к вопросу: как исправить двукратную
ошибку?
Рассмотрим ситуацию, изображенную на
рисунке.
Принятый код имеет вид ◻ХХХХХ◻. Если
мы принимаем эту комбинацию, то стрелками
покажем с какими разрешенными комбинациями
будут отождествляться комбинации с
ошибками. Почему именно так? Потому что
мы ищем ближайший разрешенный код. Но
мы не знаем откуда произошла ошибка,
которая находится в середине комбинации.
Ошибка обнаружена, мы не можем её
исправить. Таким образом, чтобы исправить
двукратную ошибку, нужно, чтобы ближайшие
кодовые слова отличались на минимум
пять бит.
Такую схему рассуждения можно применить,
если вы хотите сгенерировать код, который
исправляет трехкратную или четырехкратную
ошибку в вашем коде и так далее. Эти
несложные рассуждения позволяют
разобраться, сколько нужно проверочных
символов, и как должны быть устроены
слова, которые выдает кодер. Как слова
должны отличаться друг от друга.
Мы поговорили про кодирование в случае,
когда мы хотим разработать код, который
исправляет однократную, двукратную,
трехкратную ошибку. Это так называемые
общие принципы. Возвратимся к нашему
коду Хемминга 7,4.
Код Хемминга 7,4 является совершенным
кодом. Почему? Потому что все комбинации,
которые возвращает ваш кодер, отличаются
друг от друга ровно на 3 бита, то есть
нет никакой избыточности, кодовое
пространство заполняется максимально
плотно. Количество комбинаций, которое
может принять пользователь в случае,
если вы работаете с кодом Хемминга 7,4,
равно 27 = 128.
Поэтому, когда вы работаете с кодом
Хемминга 7,4, его можно использовать как
некоторый табличный код. Вообще говоря,
табличный код — это самый простой в
реализации код, когда вы четко ставите
в соответствии с входом — выход. Когда
вы декодируете, соответственно, тот
код, который вы приняли (принятый сигнал)
вы сравниваете с одним из 16 вариантов.
Там, где он ближе всего — где расстояние
по коду будет 1 или 0, будет сигнал,
который был на входе. Удалив контрольные
символы, получаете ту посылку, которую
передали.
В случае, когда вы кодируете 1 бит данных,
то есть утраиваете ваш код, получается
очень высокая избыточность. В этом
случае можно использовать таблицы. То
есть у вас будет таблица на стороне
кодера и декодера, и кодер по номеру
входного сигнала сразу возвращает
выходной, при этом декодер действует
также. Поэтому написать код Хемминга
7,4 можно, просто перечислив в массиве
все возможные варианты.
На практике коды используются длинные.
Код должен спасать вас не только от
однократной ошибки, но и от многократной
ошибки (от двух-, трехкратной). Он должен
вас защищать, чтобы повысить надежность
канала связи. Поэтому используются коды
длиной 100, 200. А теперь представьте,
например, 2100 — это количество
вариантов, которые нужно закодировать
или найти, то есть это 1,267·1030
вариантов. Это, скажем, такой жесткий
вариант, когда вы простым перебором,
методом грубой силы декодируете сигнал?
Конечно, в современных устройствах так
не делают, то есть если в таком, простом
варианте это можно было сделать, то в
современных системах нет.
Для кодирования слов линейными блочными
кодами используется генерирующая
матрица или матрица-генератор. Это
более простой подход, который позволяет
кодировать намного быстрее.
Матрица-генератор как раз имеет размер
(n*k), и в этом случае вам не надо хранить
всю таблицу 2n, а достаточно всего
n умножить на k чисел, что намного меньше.
Теперь посмотрим, как устроен кодер,
как устроена генерирующая таблица для
кода 7,4. Посмотрим, как она работает. То,
что мы рассмотрим, можно будет использовать
на более длинные коды.
Генерирующая матрица обозначается
буквой G, и для кода 7,4 она может быть
построена на основе тех контрольных
сумм, которые вы захотите сформулировать,
то есть то, как сейчас она будет выглядеть,
не означает, что это жесткий вариант,
который мы будем использовать. Возможен
другой вариант. Он может быть сформирован
вами самостоятельно, в зависимости от
того, на какие биты вы делаете ставку.
У нас 4 бита данных, поскольку мы
рассматриваем код 7,4: d1 d2 d3 d4.
Контрольные суммы P1, P2, P3
устроим следующим образом:
P1 = d4 + d3 + d2 (mod 2)
P2 = d4 + d3 + d1 (mod 2)
P3 = d4 + d2 + d1 (mod 2)
Если формировать контрольные суммы
иначе, например, вместо d4 поставить
и от них все отписать, это нисколько не
помешает нашей работе.
Матрица-генератор составляется следующим
образом.
Первый столбец: смотрим на первую
контрольную сумму, сюда не входил d1,
поэтому на ее месте — 0, а входили
d2, d3, d4,
на их место ставим 1, 1, 1 соответственно.
Второй столбец: во
вторую контрольную сумму входил d1,
поэтому на его месте — 1, не входил d2
— на его месте 0, d3, d4
— входит — 1, 1. Аналогично, строим третий
столбец.
Следующая часть соответствует битам
данных.
Теперь попробуем закодировать какое-то
сообщение с помощью матрицы-генератора.
Сообщение, которое мы хотим передать
состоит из нескольких 1 и 0, это двоичные
коды.
Сообщение: 1010. Мы хотим его передать.
Сообщение-слово будем обозначать w.
Кодовое слово, которое мы закодируем
Cw = w * G
Обратите внимание w — строка, G
— матрица
Поэлементно умножаем строку на столбец.
В результате получим строку из 7 элементов.
Первый элемент будет следующий: 1 × 0 + 0
× 1 + 1 × 1 + 0 × 1 (mod 2) = 1. Второй элемент:
умножаем эту же строчку на следующий
столбик и так далее.
Таким образом, в результате кодирования
мы получили следующее:
(1010)→ G(кодер)→ (1011010).
Обратите внимание на следующий интересный
момент: в последовательности 1011010
последние 4 символа — это наши данные, а
первые 3 символа — это контрольные биты.
И именно эта посылка уже уезжает дальше.
Для размышления
Закодируйте сообщение 1100 с помощью матрицы-генератора.
Материалы
- Сагалович Ю.Л. Введение в алгебраические коды (глава 4)
- Видео об Алгоритме кодирования и обнаружения ошибки кодом Хемминга
- Королев А.И.
Коды и устройства помехоустойчивого кодирования информации. Мн.: 2002. — 286 с. (объёмный материал о кодировании за исключением глав 4 и 6)
В практических схемах вместо МЭ
используют пороговый элемент ПЭ, который не фиксирует появление неисправляемой
ошибки.
Рисунок 6.
Для проверки остальных символов
кода достаточно произвести циклическую перестановку записанной кодограммы. С
этой целью переключатель 2 устанавливается в положение 1 и подается импульс
сдвига. На рис.6 приведен результат такого сдвига на один такт. Теперь
декодер реализует следующие соотношения: 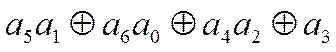 . Сравнив
. Сравнив
их с (12), можно убедиться, что декодер осуществляет проверки относительно
символа ![]() . Таким образом, для проверки и исправления
. Таким образом, для проверки и исправления
информационных символов потребуется k тактов работы.
В рассмотренном примере имеется 4
соотношения проверки. Нетрудно заметить, что любая однократная ошибка нарушает
только одну контрольную проверку. Следовательно. МЭ исправит однократную
ошибку. Двукратные ошибки (ошибки в двух символах кодограммы) не могут быть
исправлены (голоса разделяются поровну), но будут обнаружены.
В проверках (12) каждый символ ![]() , участвует один раз. Такие проверки, называют
, участвует один раз. Такие проверки, называют
разделенными. Следует иметь в виду, что разделенные проверки получаются
не всегда, т.е. один или несколько символов могут входить в проверки не один
раз. В этом случае и однократная ошибка может нарушать более чем одну проверку.
Мажоритарный декодер МД-2
использует тот факт, что элементы синдрома есть суммы по mod2
определенных символов принимаемой комбинации. Действительно, пусть для некоторого
циклического кода генератор синдрома представлен на рис.7. Формирование
синдрома при поступлении кодограммы ![]() отображается в табл.4.
отображается в табл.4.
На 7-м такте работы схема
образует синдром (S1,S2,S3).
Рисунок
7.
Таблица 4.
|
ЯП |
||||
|
Такт |
1 |
2 |
3 |
Вых |
|
3 |
|
|
|
|
|
4а 4б |
|
|
|
|
|
5а 5б |
|
|
|
|
|
6а 6б |
|
|
|
|
|
7а 7б |
|
|
|
|
|
8а 8б |
0
|
|
|
|
Причем согласно таблице 4 имеем:
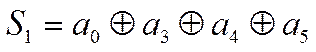 ,
,
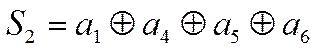 ,
,
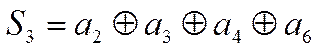 .
.
Если ошибок нет, то очевидно, что
эти суммы равны нулю (нулевой синдром – основной признак отсутствия ошибок).
Значит равны нулю суммы:
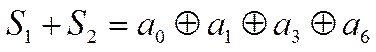 ,
,
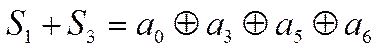 .
.
Наличие ошибки только в старшем
разряде приводит к тому, что последние 4 суммы оказываются равными единице ( S1=0 т.к. в нее ![]() не входит).
не входит).
Если же имеет место ошибка в
любом другом разряде, то равными единице оказываются только две суммы из
четырех. Это обстоятельство можно использовать для исправления ошибки с помощью
схемы, приведенной на рис.8. На вход ПЭ подаются четыре суммы: ![]() ,
, ![]() ,
,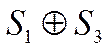 ,
,![]() Если, проверяемый
Если, проверяемый
первым 7-й разряд ошибочен, то все эти суммы равны единице и на выходе ПЭ
появится «1» (4>3).
Рисунок 8.
Таким образом, на 8-м такте
ошибка 6удет исправлена. При этом синдром должен стать, очевидно, нулевым (так
как ошибка однократная и исправлена). Анализируя 8-ю строку табл.4, можно
видеть, что содержимое только первой ячейки генератора синдрома отлично от нуля
(![]() зависит от
зависит от ![]() , а
, а ![]() и
и ![]() от
от ![]() не зависят). Суммирование
не зависят). Суммирование ![]() , с “1” на выходе ПЭ (осуществляется связью, показанной на рис. 8 пунктиром) переводит первую ячейку в состояние «0».
, с “1” на выходе ПЭ (осуществляется связью, показанной на рис. 8 пунктиром) переводит первую ячейку в состояние «0».
Вывод остальных символов из БР теперь уже не будет сопровождаться коррекцией.
Если однократная ошибка имеет
место в 6-м разряде, то на 8-м такте ПЭ даст отклик «0» и поэтому 7-й
символ кодограммы покинет БР без исправления. Синдром также не корректируется,
и, следовательно, содержимое генератора синдрома определяется 8-й строкой табл.4.
Ошибочный 6-й разряд обращает
все четыре суммы в “1”, а ошибка в любом другом разряде — только две из них.
Следовательно. ПЭ распознает ошибку в 6-м разряде. На последующих тактах работы
аналогичным образом проверяются остальные разряды комбинации.
3. ОПИСАНИЕ МАКЕТА КОДИРУЮЩЕГО
УСТРОЙСТВА
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание — внизу страницы.
![]()
21
2.Применение групповых систематических кодов
втелекоммуникационных системах
Вданной главе исследуются групповые систематические коды, принципы их построения и декодирования. Также проводится анализ способов реализации кодирующих и декодирующих устройств в трактах передачи дискретных сообщений.
2.1.Общие сведения из теории
2.1.1.Групповые систематические коды
Групповым кодом называется векторное подпространство векторного пространства всех последовательностей длины n. Групповые коды являются линейными алгебраическими кодами, для которых справедливо соотношение dmin =Wmin , т.е. минимальное кодовое расстояние равно ми-
нимальному весу кодовой комбинации. Действительно, по определению кодового расстояния dmin =W (Vi V j ), где Vi и V j V . Но согласно аксиоме замкнутости линейная комбинация Vi V j =Vµ V . Следовательно,
справедливо сформулированное выше утверждение. Поэтому если известен спектр весов кодовых векторов группового кода, то однозначно можно определить линейное кодовое расстояние и, следовательно, корректирующую способность кода. Заметим, что линейные алгебраические коды обозначаются как (n, m, d)-коды, где n, m и d – соответственно длина кодовых векторов, число информационных символов и минимальное кодовое расстояние.
Кодовые векторы группового систематического кода (ГСК) имеют формат вида
|
(a1, a2 ,…, ai ,…, am ,c1,…,c j ,…,ck ) = (a1,…, am , am+1, am+2 ,…, an ) |
(2.1) |
т.е. на первых слева подряд идущих m позициях располагаются информационные символы кода, а на последующих подряд идущих k позициях − избыточные символы кода. Информационные символы кода будем обо-
значать через {ai }, i =1, m , а избыточные символы – через {c j }, j =1, k . В общем случае, как видно из (2.1),
ai(i=m+1,n) = c j( j=1,k ) .
ГСК нашел широкое применение на практике по ряду причин:

22
1.Сохраняется в неизменном виде исходная, т.е. кодируемая в неизбыточном (первичном) коде, информационная часть.
2.С меньшими задержками, т.е. существенно проще реализуются операции кодирования и декодирования информации.
Порождающая матрица G группового систематического кода имеет приведенно-ступенчатую форму:
|
1 |
0 … |
0 |
p |
p |
… |
p |
|||||||||||
|
11 |
12 |
1k |
|||||||||||||||
|
0 |
1 … |
0 |
p21 |
p22 … |
p2k |
(2.2) |
|||||||||||
|
G =[I m P]= |
, |
||||||||||||||||
|
… … … … … |
… … |
… |
|||||||||||||||
|
0 |
0 0 |
1 |
pm1 |
p2m … |
pmk |
||||||||||||
|
где Im – единичная матрица размерности [ m ×m ]; |
P – кодирующая мат- |
||||||||||||||||
|
рица размерности [ m ×k ]. |
|||||||||||||||||
|
В этом случае операция кодирования в ГСК может быть представле- |
|||||||||||||||||
|
на как умножение информационного вектора |
u |
= (a1 , a2 ,…, am ) на G: |
|||||||||||||||
|
u |
|||||||||||||||||
|
G =V |
. |
(2.3) |
|||||||||||||||
|
В координатной форме данное уравнение имеет вид |
|||||||||||||||||
|
(a1, a2 ,…, ai ,…, am ) [Im P]= (a1, a2 ,…, ai ,…, am , c1,…, c j ,…, ck ), |
(2.3, а) |
||||||||||||||||
|
m |
|||||||||||||||||
|
c j = ∑ai pij , j =1, k. |
|||||||||||||||||
|
i=1 |
Выражения вида (2.3, а) для вычисления избыточных разрядов ГСК по известным информационным разрядам называют операторами кодиро-
вания.
Проверочная матрица ГСК
|
H =[PT Ik ], |
(2.4) |
|||||||||
|
где PT – транспонированная кодирующая матрица P; |
Ik |
– единичная мат- |
||||||||
|
рица размерности [ k ×k ]. |
||||||||||
|
Пример 2.1. Построим порождающую и проверочную матрицы ГСК |
||||||||||
|
(5, 3, 2): |
||||||||||
|
1 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
1 |
0 |
|
|
G =[I3P]= 0 1 0 1 1 ; H = [PT I2 |
||||||||||
|
]= |
1 |
1 |
0 |
. |
||||||
|
0 |
1 |
|||||||||
|
0 |
1 |
0 |
||||||||
|
0 |
1 |

23
Из (2.3) следует, что u = (a1 , a2 , a3 ) [I3 P]=V = (a1 , a2 , a3 , c1 , c2 ) .
Тогда операторы кодирования имеют следующий вид:
c1 = a1 a2 , c2 = a2 a3.
Из (2.3) и (2.3, а) V H T = 0, т.е. (a1, a2 , a3, c1, c2 ) [PT I2 ] = (0,0) . Сле-
довательно, справедливо, что
|
a a |
c = 0; |
отсюда |
c |
= a |
a |
; |
|
|
1 |
2 |
1 |
1 |
1 |
2 |
||
|
a2 a3 c2 = 0, |
c2 = a2 a3. |
Отметим, что благодаря приведенно-ступенчатой форме матриц G и H получается система из k алгебраических уравнений, в каждом из которых содержится по одной переменной, и упрощаются процедуры кодирования и декодирования в ГСК. Любые линейные алгебраические коды, исправляющие однократные ошибки, т.е. коды с dmin = 3 и dmin = 4, называются кодами Хемминга. Тогда синдром ГСК Хемминга совпадает со столбцом проверочной матрицы Н, номер которого соответствует номеру ошибочной позиции. Для кодов Хемминга иногда выбирают другую форму представления кодовых векторов, при которой избыточные разряды расположены на позициях кодового слова, номера которых равны степеням двойки. В этом случае синдром представляет собой двоичное число, указывающее номер пораженной позиции. В данном разделе ГСК Хемминга будут рассматриваться как частный случай ГСК с форматом (2.1).
2.1.2. Техника построения группового систематического кода
Блок-схема алгоритма построения ГСК представлена на рис. 2.1. Приведенный обобщенный алгоритм синтеза операторов кодирова-
ния пригоден для любого алгебраического кода с точностью до раскрытия ряда операторов. Ниже алгоритм рассматривается для ГСК и оговариваются некоторые особенности его применения для других типов кодов:
1. Исходные данные. Ими являются:
–число информационных символов кода (m) либо множество передаваемых сообщений (М);
–модель канала связи;
–допустимая вероятность правильной передачи (или вероятность трансформации).
Пусть задан канал связи с независимыми ошибками, описываемый биномиальным распределением ошибок с вероятностью ошибки на символ, равной (p).

24
2. Выбор типа кода, оптимального для заданной модели канала связи. Для каналов связи с независимыми ошибками оптимальными являются групповые коды и циклические (БЧХ) коды. Если бы канал описывался моделью канала с памятью, то необходимо было бы выбрать коды, оптимальные в каналах с пакетирующими ошибками, например циклические коды Файра, Абрамсона, перемежающиеся и др. Итак, мы выбрали ГСК.
1.Исходные
данные
2.Выбор типа кода
3.S = 0
4.S = S + 1
5.Выбор параметров кода
6. Выбор ближайшего табл. кода
7. Выбор укороченного кода
8. Построение операторов кодирования
Рис. 2.1. Обобщенная блок-схема алгоритма построения алгебраического (ГСК) кода
3. На данном шаге алгоритма реализуются операторы 3, 4 и 5, связанные с выбором методом перебора параметров кода: корректирующей
25
способности (s), числа избыточных символов (k), которые обеспечивают требуемые характеристики достоверности передачи информации. Для ГСК выбор параметров кода осуществляется с помощью верхней границы Хемминга. Для БЧХ-кодов аналогичная задача решается с помощью границы существования кода БЧХ. Итак, из границы Хемминга для фиксированных значений m и последовательно перебираемых значений s определяются длины кодовых слов n = m + k. Для каждых n и s находится вероятность правильной передачи сообщения Pпр = P(m):
|
s |
n |
− p)n−i . |
(2.5) |
|
|
P(m) = ∑ |
pi (1 |
|||
|
i=0 |
||||
|
i |
Далее значение Pпр сравнивается с [Pд], допустимой вероятностью правильной передачи кодового слова (сообщения). Если Pпр < [Pд], то кратность исправляемых ошибок увеличивается на единицу и расчет повторяется, иначе переходим к оператору 6.
4.Выбор ближайшего табличного кода. Граница Хемминга не является границей существования кода и потому не гарантирует существования ГСК с параметрами, определенными на предыдущих шагах алгоритма.
Поэтому обращаемся к табличным ГСК и находим ближайший код (nT, mT, dT), удовлетворяющий условию dT ≥ d, т.е. sT ≥ s, mT ≥ m .
5.Выбор укороченного кода. Отыскиваем число i = mТ −m , на кото-
рое укорачиваем число информационных символов кода, т.е. реализуем переход от параметров табличного кода к укороченному коду: (nТ, mТ, dТ) i →(nT −i, mT −i, d ) = (n, m, d) . Найденный укороченный код и является искомым кодом, т. к. удовлетворяет всем исходным данным. В принципе после этого шага можно уточнить значение P(m) (5), которое должно измениться за счет уменьшения длины кода на величину i .
6. Построение операторов кодирования. Операторы кодирования (2.3, а) табличных кодов приводятся в стандартных таблицах ГСК. Для построения операторов кодирования укороченного ГСК необходимо в операторах кодирования табличных кодов зачеркнуть i первых информационных символов (a1 , a2 ,…, ai ) .
Пример 2.2. Проиллюстрируем приведенный алгоритм на примере построения ГСК, исправляющего однократную ошибку, т.е. кода Хеммин-
га с dmin = 3 и dmin = 4. Выберем в качестве исходных данных m = 4, s = 1. Следует отметить, что в данном примере из методических соображений
опущена переборная часть алгоритма, связанная с анализом логического условия, так как это чисто вычислительная процедура, загромождающая пример. Напомним, что из границы Хемминга отыскиваются параметры кодов с нечетным кодовым расстоянием. Далее будет показано, как пере-
26
ходить от кодов с нечетным кодовым расстоянием dH, исправляющих ошибку кратности s, к кодам с ближайшим большим четным кодовым расстоянием (dЧ = dH + 1), исправляющим s-кратные ошибки и обнаруживающим ошибки кратности r = s +1.
С учетом изложенного в данном примере отыскиваем операторы ко-
|
дирования для ГСК Хемминга с dmin = 3 и m = 4: |
||||||
|
2m ≤ |
2n |
; 24 ≤ |
2n |
. |
||
|
1 + n |
1 + n |
|||||
Перебором устанавливаем параметры кода: n = 7, m = 4, k = 3, т.е. (7, 4, 3)-код. Такой код существует, и операторы кодирования можно выписать из стандартной кодовой таблицы ГСК. Ниже покажем, как можно самостоятельно строить операторы кодирования по проверочной матрице ГСК. Для этого рассмотрим построение проверочной матрицы Н. Несложно показать, что столбцами матрицы являются k-разрядные ненулевые
|
двоичные |
векторы, образующие линейно-независимые множества из |
|
r = d −1 |
векторов. Данное утверждение основано на следующем. Если |
ГСК обнаруживает ошибки кратности r и меньше, то синдром должен быть ненулевым при умножении вектора ошибки веса r и меньше на Н.
Для построения матрицы Н размерности [k ×n] ГСК Хемминга дос-
таточно в качестве n столбцов выписать различные k-разрядные ненулевые двоичные векторы. В рассматриваемом примере построим проверочную
|
матрицу H′ размерности [3 ×7]: |
||||||
|
0 |
0 |
0 |
1 |
1 |
1 |
1 |
|
H ′ = 0 1 1 |
0 |
0 |
1 |
1 . |
||
|
0 |
1 |
0 |
1 |
0 |
||
|
1 |
1 |
|||||
Далее с помощью эквивалентного преобразования (перестановка столбцов) приведем матрицу H′ в приведенно-ступенчатую форму Н
(2.4):
|
1 |
1 |
0 |
1 |
1 |
0 |
0 |
|
H = 1 1 1 |
0 |
0 |
1 0 . |
|||
|
0 |
1 |
1 |
0 |
0 |
||
|
1 |
1 |
|||||
Из (2.3) и (2.3, а) следует

|
27 |
|||||||||||||||
|
(a , a |
, a , a |
, c , c |
, c ) |
hT |
= 0 , (i = |
j = |
|||||||||
|
2 |
4 |
2 |
1,7; |
1,3), |
|||||||||||
|
1 |
3 |
1 |
3 |
ij |
|||||||||||
|
откуда и получаются искомые операторы кодирования: |
|||||||||||||||
|
c1 = a1 a2 a4 ; |
|||||||||||||||
|
c2 = a1 a2 a4 ; |
(2.6) |
c3 = a1 a3 a4.
Пусть u = (a1 , a2 , a3 , a4 ) = (1101) , тогда с учетом (2.6)
V = (a1 , a2 , a3 , a4 , c1 , c2 , c3 ) = (1101100) .
Пусть потребовалось укоротить построенный код (7, 4, 3) на i = 2 информационных символа, т.е. перейти к укороченному коду (5, 2, 3):
(7, 4,3) i =2→(5, 2,3). Тогда операторы кодирования (5, 2, 3)-кода можно
построить по операторам кодирования (2.6), используя правило, сформулированное в п. 6 алгоритма:
|
c1 = a4 ; |
||
|
c2 |
= a3; |
(2.6, а) |
|
c3 |
= a3 a4. |
Вектор укороченного (5, 2, 3)-кода имеет вид
V = (a3 ,a4 ,c1,c2 ,c3 ) = = (01101).
Рассмотрим переход от кода с нечетным кодовым расстоянием dH к коду с ближайшим четным кодовым расстоянием dЧ = dH + 1. Для такого перехода достаточно ввести еще один дополнительный избыточный разряд ck+1, значение которого определяется из общей проверки на четность:
|
m |
k |
|
|
ck +1 = ∑ai ∑c j . |
(2.7) |
|
|
i=1 |
j =1 |
Таким образом, если параметры исходного кода (n, m, dH), то параметры кода с dЧ = dH + 1 таковы: n+1, m, dЧ, т.е. число информационных символов сохранилось, а число избыточных символов увеличилось на один.
Пример 2.3. Для кода (7, 4, 3) из примера 2.2 код (8, 4, 4) будет кодом с ближайшим большим четным кодовым расстоянием. При этом дополнительный избыточный разряд общей проверки на четность

|
28 |
|
|
4 |
3 |
|
c4 = ∑ai ∑c j . |
|
|
i=1 |
j =1 |
Если в (2.7) подставить выражения для cj из (2.3, а), то уравнение (2.7) упростится. Можно предложить следующее правило вычисления сk+1 через информационные символы исходного (n, m, dH)-кода.
Правило. Если информационный символ входит четное число раз в операторы кодирования (n, m, dH)-кода (2.3, а), то он сохраняется в (2.7), если же информационный символ входит нечетное число раз, то он не сохраняется в выражении (2.7).
С учетом сформулированного правила и операторов кодирования кода (7, 4, 3) в выражении (2.6) уравнение для c4 имеет следующий вид: c4 = a2 a3 a4. Тогда вектор кода (8, 4, 4)
V = (a1,a2 ,a3 ,a4 ,c1,c2 ,c3 ,c4 ) = (11011000).
2.1.3.Декодирование группового систематического кода
Декодер ГСК реализует синдромное декодирование, суть которого основана на вычислении синдрома в соответствии с уравнениями синдрома. Итак, синдромное декодирование состоит из следующих этапов:
1. По принятому кодовому вектору V ′=V e находим синдром
S= (s1, s2 ,…, s j ,…, sk ).
2.По вычисленному значению синдрома однозначно отыскиваем вектор ошибок e = (e1,e2 ,…,e j ,…,en ).
3.Производим исправление ошибок и выдачу скорректированного кодового слова (сообщения) получателю: V =V ′ e, либо стирание полу-
ченного кодового слова, если кратность ошибок в кодовом слове s′ удовлетворяет соотношению s < s′ ≤ r, где r − кратность обнаруживаемых ошибок.
Пример 2.4. Проиллюстрируем синдромное декодирование на примере кода (8, 4, 4) из примера 2.3. В процессе данного примера будет сделан ряд замечаний общего характера, связанных с реализацией корректирующих возможностей кода с четным кодовым расстоянием. Итак, для кода (8, 4, 4) уравнение синдрома с учетом (1.6) имеет вид
|
s1 = a1′ a2′ |
a4′ |
‘ |
|||||||
|
c1; |
|||||||||
|
s2 = a1′ a2′ |
a3′ |
||||||||
|
c2‘ ; (7,4,3) |
|||||||||
|
′ |
′ |
′ |
‘ |
(2.8) |
|||||
|
(8,4,4) |
|||||||||
|
s3 = a1 |
a3 |
a4 |
c3 |
; |
|||||
|
s |
4 |
4 |
|||||||
|
4 |
= ∑a′ |
∑c′. |
|||||||
|
i |
j |
||||||||
|
i=1 |
j =1 |

|
29 |
|
|
Отметим, что (2.8) можно записать |
и через вектор ошибок: |
|
e = (e1,e2 ,e3,e4 ,e5,e6 ,e7 ,e8 ) . Синдром кода (8, |
4, 4) − это четырехразряд- |
ный вектор s = (s1, s2 , s3 , s4 ) , у которого первые три разряда (в общем слу-
чае k-разрядов) вычисляются согласно уравнениям кода (7, 4, 3) (в общем случае (n, m, dH)), а последний разряд s4 (в общем случае (k+1)-й разряд) − согласно общей проверке на четность,
|
S |
m |
k +1 |
(2.9) |
|
|
k +1 |
= ∑a′ ∑c′ . |
|||
|
i |
j |
|||
|
i=1 |
j =1 |
При этом минимизация выражения (2.9) недопустима. Таким образом, общая структура синдрома кода (n + 1, m, dЧ = dH + 1) такова: S = (s1,…, s j ,…, sk , sk +1). При этом первые k-разрядов вычисляются по урав-
нениям для кода (n, m, dH), а последний (k + 1)-й разряд – по (2.9) для кода (n + 1, m, dЧ). При декодировании кода Хемминга с dmin = 4, исправляющего одну и обнаруживающего две ошибки, анализ кратности ошибок в кодовом векторе V ′ на входе декодера производится в соответствии с табл. 2.1.
|
Таблица 2.1 |
|||||
|
№ |
S1, S2,…, Sj,…, Sk |
Sk+1 |
Кратность ошибок в векторе V |
′ |
|
|
п/п |
|||||
|
1 |
0 |
0 |
Ошибок нет |
||
|
2 |
≠0 |
1 |
Ошибки нечетной кратности, в частно- |
||
|
сти однократная ошибка |
|||||
|
3 |
≠0 |
0 |
Ошибки четной кратности, в частности |
||
|
двукратная ошибка |
|||||
|
4 |
0 |
1 |
Ошибки в символе c |
||
|
k+1 |
Вданной таблице символ «0» означает, что все координаты вектора нулевые; символ «≠0» показывает, что хотя бы одна координата вектора ненулевая.
Таким образом, декодер исправляет однократную ошибку в ситуациях 2 и 4 и стирает сообщение при двукратной ошибке (ситуация 3).
Врассматриваемом примере для кода (8, 4, 4) при исправлении однократной ошибки таблица соответствия значений синдрома и места ошиб-
ки − это табл. 2.2.
Значения (S1, S2, S3) совпадают с соответствующим столбцом матрицы Н кода (7, 4, 3) в примере 2.2.

30
|
Таблица 2.2 |
||||||
|
S1 S2 S3 |
S4 |
{ej} |
||||
|
0 |
0 |
0 |
0 |
0 |
||
|
0 |
0 |
1 |
1 |
e7 (c3) |
||
|
0 |
1 |
0 |
1 |
e6 (c2) |
||
|
0 |
1 |
1 |
1 |
e3 (а3) |
||
|
1 |
0 |
0 |
1 |
e5 (c1) |
||
|
1 |
0 |
1 |
1 |
e4 (а4) |
||
|
1 |
1 |
0 |
1 |
e2 (а2) |
||
|
1 |
1 |
1 |
1 |
e1 (а1) |
||
|
0 |
0 |
0 |
1 |
e8 (c4) |
||
|
≠0 |
0 |
2кр |
Комбинационная схема для обнаружения двукратной ошибки и стирания сообщения при аппаратной реализации строки 3 табл. 2.1 представлена на рис. 2.2, а. На рис. 2.2, б показана реализация схемы стирания для кода (8, 4, 4).
Рис. 2.2. Комбинационная схема, реализующая стирание кодовой комбинации с двукратной ошибкой для
(n+1, m, 4)-кода (а) и для (8, 4, 4)-кода (б)
Аппаратная реализация кодеров и декодеров ГСК и оценка сложности будут рассмотрены более подробно в последующих подразделах.
Программная реализация синдромного декодирования сводится к суммированию хранящихся в памяти столбцов проверочной матрицы Н с номерами, соответствующими единицам принятого вектора, что равносильно реализации уравнения синдрома. Вектор ошибок выбирается из таблицы ошибок, подобной табл. 2.2, содержащей 2k строк. Таким образом, затраты ячеек памяти для аппаратно-программной реализации в микропро-
Соседние файлы в папке Лабораторная работа №2
- #
10.12.2013196.85 Кб13GSK_template.mdl
- #