
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•операционной системы,
•среды и языка программирования,
•реализуемых процессов,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 10.1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•логические ошибки,
•накопление погрешностей результатов вычислений (рис. 10.2).
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см.§ 2.7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т. п.;
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т. п.;
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
ручного тестирования;
индукции;
дедукции;
обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Отладка — это локализация и устранение
ошибок. Отладка является следствием
успешного тестирования. Это значит, что
если тестовый вариант обнаруживает
ошибку, то процесс отладки уничтожает
ее.
Итак, процессу отладки предшествует
выполнение тестового варианта. Его
результаты оцениваются, регистрируется
несоответствие между ожидаемым и
реальным результатами. Несоответствие
является симптомом скрытой причины.
Процесс отладки пытается сопоставить
симптом с причиной, вследствие чего
приводит к исправлению ошибки. Возможны
два исхода процесса отладки:
1) причина найдена, исправлена, уничтожена;
2) причина не найдена.
Во втором случае отладчик может
предполагать причину. Для проверки этой
причины он просит разработать
дополнительный тестовый вариант, который
поможет проверить предположение. Таким
образом, запускается итерационный
процесс коррекции ошибки.
Возможные разные способы проявления
ошибок:
1) программа завершается нормально, но
выдает неверные результаты;
2) программа зависает;
3) программа завершается по прерыванию;
4) программа завершается, выдает ожидаемые
результаты, но хранимые данные испорчены
(это самый неприятный вариант).
Характер проявления ошибок также может
меняться. Симптом ошибки может быть:
-
постоянным;
-
мерцающим;
-
пороговым (проявляется при превышении
некоторого порога в обработке — 200
самолетов на экране отслеживаются, а
201-й — нет);
-
отложенным (проявляется только после
исправления маскирующих ошибок).
В ходе отладки мы встречаем ошибки в
широком диапазоне: от мелких неприятностей
до катастроф. Следствием увеличения
ошибок является усиление давления на
отладчика — «найди ошибки быстрее!!!».
Часто из-за этого давления разработчик
устраняет одну ошибку и вносит две новые
ошибки.
Английский термин debugging
(отладка) дословно
переводится как «ловля блох», который
отражает специфику процесса — погоню
за объектами отладки, «блохами».
Рассмотрим, как может быть организован
этот процесс «ловли блох» [3], [64].
Различают две группы методов отладки:
-
аналитические;
-
экспериментальные.
Аналитические методы базируются на
анализе выходных данных для тестовых
прогонов. Экспериментальные методы
базируются на использовании вспомогательных
средств отладки (отладочные печати,
трассировки), позволяющих уточнить
характер поведения программы при тех
или иных исходных данных.
Общая стратегия отладки — обратное
прохождение от замеченного симптома
ошибки к исходной аномалии (месту в
программе, где ошибка совершена).
В простейшем случае место проявления
симптома и ошибочный фрагмент совпадают.
Но чаще всего они далеко отстоят друг
от друга.
Цель отладки
— найти оператор программы, при исполнении
которого правильные аргументы приводят
к неправильным результатам. Если место
проявления симптома
ошибки не является искомой аномалией,
то один из аргументов оператора должен
быть неверным. Поэтому надо перейти к
исследованию предыдущего оператора,
выработавшего этот неверный аргумент.
В итоге пошаговое обратное прослеживание
приводит к искомому ошибочному месту.
В разных методах прослеживание
организуется по-разному. В аналитических
методах — на основе логических заключений
о поведении программы. Цель — шаг за
шагом уменьшать область программы,
подозреваемую в наличии ошибки. Здесь
определяется корреляция между значениями
выходных данных и особенностями
поведения.
Основное преимущество
аналитических методов отладки состоит
в том, что исходная программа остается
без изменений.
В экспериментальных методах для
прослеживания выполняется:
-
Выдача значений переменных в указанных
точках. -
Трассировка переменных (выдача их
значений при каждом изменении). -
Трассировка потоков управления (имен
вызываемых процедур, меток, на которые
передается управление, номеров операторов
перехода).
Преимущество экспериментальных
методов отладки состоит
в том, что основная рутинная работа по
анализу процесса вычислений перекладывается
на компьютер. Многие трансляторы имеют
встроенные средства отладки для получения
информации о ходе выполнения программы.
Недостаток экспериментальных
методов отладки — в
программу вносятся изменения, при
исключении которых могут появиться
ошибки. Впрочем, некоторые системы
программирования создают специальный
отладочный экземпляр программы, а в
основной экземпляр не вмешиваются.
Темы
3.4.-3.6. Тестирование. Типы и методы
тестирования. Ручное и автоматизированное
тестирование. Инструментальные средства.
В целом
разработчики различают дефекты
программного обеспечения и сбои. В
случае сбоя программа ведет себя не
так, как ожидает пользователь. Дефект
— это ошибка/неточность, которая может
быть (а может и не быть) следствием сбоя.
Общепринятая
практика состоит в том, что после
завершения продукта и до передачи его
заказчику независимой группой
тестировщиков проводится тестирование
ПО. Эта практика часто выражается в виде
отдельной фазы тестирования (в общем
цикле разработки ПО), которая часто
используется для компенсирования
задержек, возникающих на предыдущих
стадиях разработки. Другая практика
состоит в том, что тестирование начинается
вместе с началом проекта и продолжается
параллельно созданию продукта до
завершения проекта. Второй путь обычно
требует больших трудозатрат, но качество
тестирования при этом будет выше.
Уровни
тестирования:
• модульное
тестирование. Тестируется минимально
возможный для тестирования компонент,
например отдельный класс или функция;
• интеграционное
тестирование. Проверяется, есть ли
какие-либо проблемы в интерфейсах и
взаимодействии между интегрируемыми
компонентами, например, не передается
информация, передается некорректная
информация;
• системное
тестирование. Тестируется интегрированная
система на ее соответствие исходным
требованиям:
— альфа-тестирование
— имитация реальной работы с системой
штатными разработчиками либо реальная
работа с системой потенциальными
пользователями/заказчиком на стороне
разработчика. Часто альфа-тестирование
применяется для законченного продукта
в качестве внутреннего приемочного
тестирования. Иногда альфа-тестирование
выполняется под отладчиком или с
использованием окружения, которое
помогает быстро выявлять найденные
ошибки. Обнаруженные ошибки могут быть
переданы тестировщикам для дополнительного
исследования в окружении, подобном
тому, в котором будет использоваться
ПО;
— бета-тестирование
— в некоторых случаях выполняется
распространение версии с ограничениями
(по функциональности или времени работы)
для некоторой группы лиц с тем, чтобы
убедиться, что продукт содержит достаточно
мало ошибок. Иногда бета-тестирование
выполняется для того, чтобы получить
обратную связь о продукте от его будущих
пользователей.
Термины
и определения
Выполнение
программы с целью обнаружения ошибок
называется тестированием.
Виды
ошибок и способы их обнаружения приведены
в табл. 5.1.
Таблица
5.1. Виды программных ошибок и способы
их обнаружения
|
Виды |
Способы |
|
Синтаксические |
Статический |
|
Ошибки
а)
б) в) |
Динамический
аппаратурой
run-time операционной |
|
Программа |
Целенаправленное |
|
Спецификация |
Испытания, |
Эффективность
контроля 1-го вида зависит и от языка, и
от компилятора. Контроль 2-го вида
осуществляется с помощью исключений —
Exceptions и весьма полезен для проверки
правдоподобности промежуточных
результатов.
Тест —
это набор контрольных входных данных
совместно с ожидаемыми результатами.
В число входных данных время зависимых
программ входят события и временные
параметры.
Ключевой
вопрос — полнота тестирования: какое
количество каких тестов гарантирует,
возможно, более полную проверку программы?
Исчерпывающая
проверка на всем множестве входных
данных недостижима. Пример: программа,
вычисляющая функцию двух переменных:
Y=f(X, Z). Если X, Y, Z — real, то полное число
тестов (232)2 = 264« 1031
Если на
каждый тест тратить 1 мс, то 264 мс = 800 млн
лет. Следовательно:
• в любой
нетривиальной программе на любой стадии
ее готовности содержатся необнаруженные
ошибки;
• тестирование
— технико-экономическая проблема,
основанная на компромиссе время —
полнота. Поэтому нужно стремиться к
возможно меньшему количеству хороших
тестов с желательными свойствами.
Детективность:
тест должен с большой вероятностью
обнаруживать возможные ошибки
Покрывающая
способность:
один тест должен выявлять как можно
больше ошибок.
Воспроизводимость:
ошибка должна выявляться независимо
от изменяющихся условий (например, от
временных соотношений) — это труднодостижимо
для времязависимых программ, результаты
которых часто невоспроизводимы.
Только
на основании выбранного критерия можно
определить тот момент времени, когда
конечное множество тестов окажется
достаточным для проверки программы с
некоторой полнотой (степень полноты,
впрочем, определяется экспериментально).
Используется два вида критериев (табл.
5.2):
• функциональные
тесты составляются исходя из спецификации
программы;
• структурные
тесты составляются исходя из текста
программы.
На рис.
5.1, а видно отличие тестирования команд
(достаточен один тест) от С1 (необходимы
два теста как минимум). Рисунок 5.1, б
иллюстрирует различие С1 (достаточно
двух тестов, покрывающих пути 1, 4 или 2,
3) от С2 (необходимо четыре теста для всех
четырех путей). С2 недостижим в реальных
програм мах из-за их цикличности, поэтому
ограничиваются тремя путями для каждого
цикла: 0, 1 и N повторений цикла.
Таблица
5.2. Виды критериев и их функциональность
|
Вид |
Функциональность |
|
Функциональные |
|
|
Тестирование |
Содержать |
|
Тестирование |
|
|
Тестирование |
Каждая |
|
Структурные |
|
|
Тестирование |
Каждая |
|
Критерий |
Каждая |
|
Критерий |
Каждый |
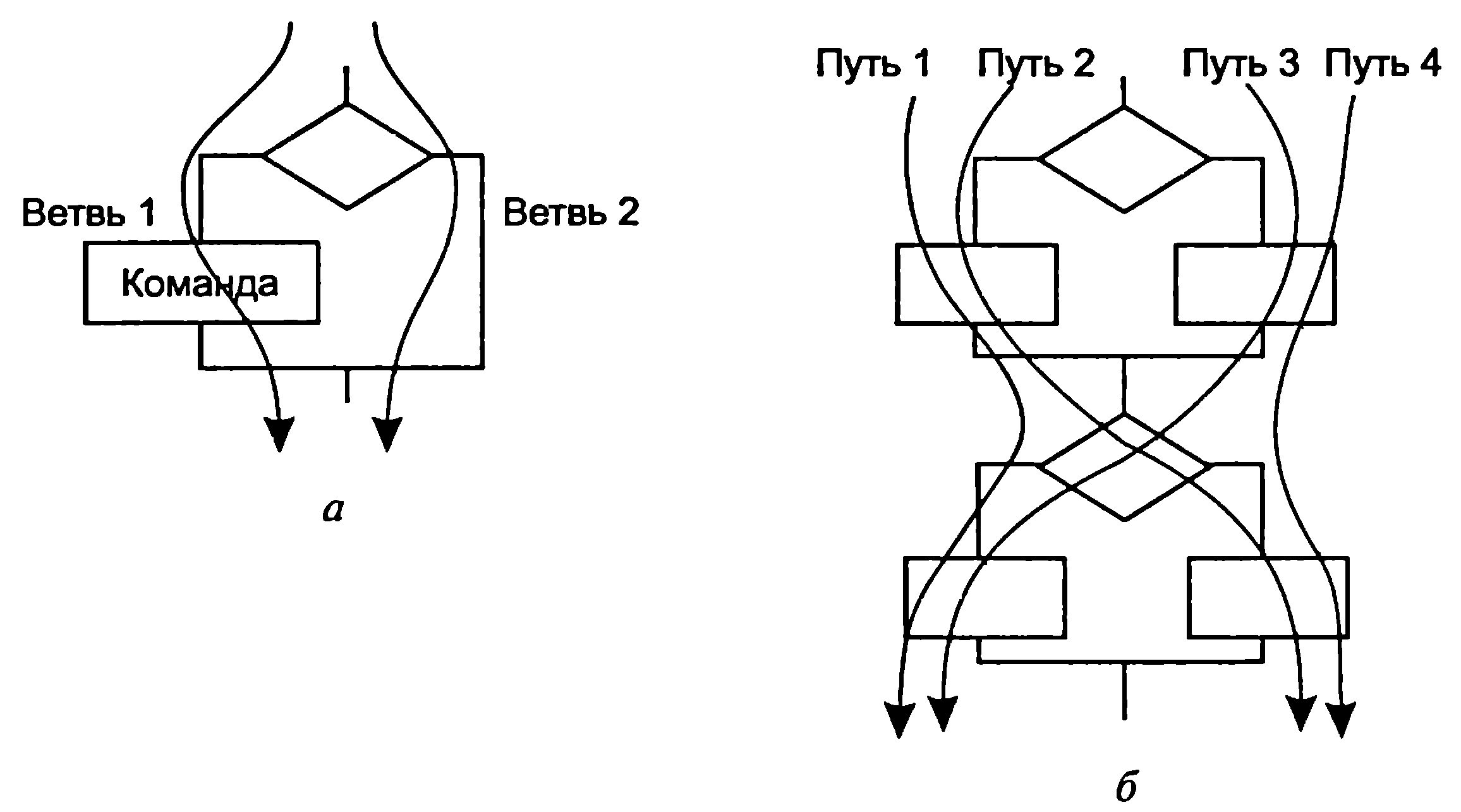
Рис. 5.1.
Траектории вычислений при структурном
тестировании
Остаются
проблемы назначения классов входных/выходных
данных для функционального тестирования
и проектирования тестов для структурного
тестирования. Классы, как правило,
назначаются исходя из семантики решаемой
задачи [6].
Рассмотрим
пример. Найти минимальный набор тестов
для программы нахождения вещественных
корней квадратного уравнения ах2 + Ъх +
с — 0.
Решение
представлено в табл. 5.3.
Таблица
5.3. Поиск численного решения минимального
набора тестов
|
Номер |
а |
b |
с |
Ожидаемый |
Что |
|
1 |
2 |
-5 |
2 |
X1 |
Случай |
|
2 |
3 |
2 |
5 |
Сообщение |
Случай |
|
3 |
3 |
-12 |
0 |
x1 |
Нулевой |
|
4 |
0 |
0 |
10 |
Сообщение |
Неразрешимое |
|
5 |
0 |
0 |
0 |
Сообщение |
Неразрешимое |
|
6 |
0 |
5 |
17 |
Сообщение |
Неквадратное |
|
7 |
9 |
0 |
0 |
X1 |
(деление Корень |
Таким
образом, для этой программы предлагается
минимальный набор функциональных
тестов, исходя из 7 классов выходных
данных.
Тестирование
«белого ящика» и «черного ящика»
В
терминологии профессионалов тестирования
(программного и некоторого аппаратного
обеспечения) фразы тестирование «белого
ящика» и тестирование «черного ящика»
относятся к тому, имеет ли разработчик
тестов доступ к исходному коду тестируемого
ПО, или же тестирование выполняется
через пользовательский интерфейс либо
прикладной программный интерфейс,
предоставленный тестируемым модулем.
При
тестировании «белого ящика» (англ.
white-box testing, также говорят — прозрачного
ящика) разработчик теста имеет доступ
к исходному коду и может писать код,
который связан с библиотеками тестируемого
ПО. Это типично для юнит-тестирования
(англ. unit testing), при котором тестируются
только отдельные части системы. Оно
обеспечивает то, что компоненты
конструкции работоспособны и устойчивы
до определенной степени.
При
тестировании «черного ящика» (англ.
black-box testing) тестировщик имеет доступ к
ПО только через те же интерфейсы, что и
заказчик или пользователь, либо через
внешние интерфейсы, позволяющие другому
компьютеру либо другому процессу
подключиться к системе для тестирования.
Например, тестирующий модуль может
виртуально нажимать клавиши или кнопки
мыши в тестируемой программе с помощью
механизма взаимодействия процессов с
уверенностью в том, что эти события
вызывают тот же отклик, что и реальные
нажатия клавиш и кнопок мыши.
Если
альфа- и бета-тестирование относятся к
стадиям до выпуска продукта (а также,
неявно, к объему тестирующего сообщества
и ограничениям на методы тестирования),
тестирование «белого ящика» и «черного
ящика» имеет отношение к способам,
которыми тестировщик достигает цели.
Бета-тестирование
в целом ограничено техникой «черного
ящика» (хотя постоянная часть тестировщиков
обычно продолжает тестирование «белого
ящика» параллельно бета-тестированию).
Таким образом, термин бета-тестирование
может указывать на состояние программы
(ближе к выпуску, чем альфа) или может
указывать на некоторую группу тестировщиков
и процесс, выполняемый этой группой.
Итак, тестировщик может продолжать
работу по тестированию «белого ящика»,
хотя ПО уже «в бете» (стадия), но в этом
случае он не является частью
бета-тестирования (группы/процесса).
Порядок
разработки тестов
По внешней
спецификации разрабатываются тесты
[3]:
• для
каждого класса входных данных;
• для
граничных и особых значений входных
данных.
Контролируется,
все ли классы выходных данных при этом
проверяются, и добавляются при
необходимости нужные тесты.
Разрабатываются
тесты для тех функций, которые не
проверяются в п. 1.
По тексту
программы проверяется, все ли условные
переходы выполнены в каждом направлении
(С1). При необходимости добавляются новые
тесты.
Аналогично
проверяется, проходятся ли пути для
каждого цикла: без выполнения тела, с
однократным и максимальным числом
повторений.
Готовятся
тесты, проверяющие исключительные
ситуации, недопустимые входные данные,
аварийные ситуации. Функциональное
тестирование дополняется здесь
структурным. Классы входных/выходных
данных должны быть определены в плане
тестирования уже во внешней спецификации.
Согласно
статистике 1-й и 2-й пункты обеспечивают
степень охвата С1 в среднем 40—50 %. Проверка
по С1 (пункт 3) обычно выявляет 90 % всех
ошибок, найденных при тестировании.
(Все программное обеспечение ВВС США
принимается с проверкой по С1.)
Систематическое
тестирование предполагает также ведение
журнала отладки (Bug Book), в котором
фиксируется ошибка (описание, дата
обнаружения, автор модуля) и в дальнейшем
— исправление (дата, автор).
Приведем
так называемые аксиомы тестирования.
1. Тест
должен быть направлен на обнаружение
ошибки, а не на подтверждение правильности
программы.
2. Автор
теста — не автор программы.
3. Тесты
разрабатываются одновременно или до
разработки программы.
4. Необходимо
предсказывать ожидаемые результаты
теста до его выполнения и анализировать
причины расхождения результатов.
5. Предыдущее
тестирование необходимо повторять
после каждого внесения исправлений в
программу.
6. Следует
повторять полное тестирование после
внесения изменений в программу или
после переноса ее в другую среду.
7. В те
программы, в которых обнаружено много
ошибок, необходимо дополнить первоначальный
набор тестов [6].
Автоматизация
тестирования
А.
Автоматизация прогона тестов актуальна
для 5-й и 6-й аксиом Майерса. Пишутся
командные файлы для запуска программы
с каждым тестом из набора и сравнением
реального результата с ожидаемым.
Существуют специальные средства
(например система MIL-S для PL/1 фирмы IBM).
Разрабатывается стандарт ШЕЕ скриптового
языка для описания тестовых наборов
[3].
Б. Средства
автоматизации подготовки тестов и
анализа их результатов.
1. Генераторы
случайных тестов в заданных областях
входных данных.
2. Отладчики
(для локализации ошибок).
3. Анализаторы
динамики (profilers). Обычно входят в состав
отладчиков; применяются для проверки
соответствия тестовых наборов структурным
критериям тестирования.
4. Средства
автоматической генерации структурных
тестов методом «символического
выполнения» Кинга.
Модульное
тестирование
Модульное
тестирование — это тестирование
программы на уровне отдельно взятых
модулей, функций или классов. Цель
модульного тестирования заключается
в выявлении локализованных в модуле
ошибок в реализации алгоритмов, а также
в определении степени готовности системы
к переходу на следующий уровень разработки
и тестирования. Модульное тестирование
проводится по принципу «белого ящика»,
т. е. основывается на знании внутренней
структуры программы и часто включает
те или иные методы анализа покрытия
кода.
Модульное
тестирование обычно подразумевает
создание вокруг каждого модуля
определенной среды, включающей заглушки
для всех интерфейсов тестируемого
модуля. Некоторые из них могут
использоваться для подачи входных
значений, другие — для анализа результатов,
присутствие третьих может быть
продиктовано требованиями, накладываемыми
компилятором и сборщиком.
На уровне
модульного тестирования проще всего
обнаружить дефекты, связанные с
алгоритмическими ошибками и ошибками
кодирования алгоритмов, типа работы с
условиями и счетчиками циклов, а также
с использованием локальных переменных
и ресурсов. Ошибки, связанные с неверной
трактовкой данных, некорректной
реализацией интерфейсов, совместимостью,
производительностью и т. п., обычно
пропускаются на уровне модульного
тестирования и выявляются на более
поздних стадиях тестирования.
Именно
эффективность обнаружения тех или иных
типов дефектов должна определять
стратегию модульного тестирования, т.
е. расстановку акцентов при определении
набора входных значений. У организации,
занимающейся разработкой программного
обеспечения, как правило, имеется
историческая база данных (Repository)
разработок, хранящая конкретные сведения
о разработке предыдущих проектов: о
версиях и сборках кода (build), зафиксированных
в процессе разработки продукта, о
принятых решениях, допущенных просчетах,
ошибках, успехах и т. п. Проведя анализ
характеристик прежних проектов, подобных
заказанному разработчику, можно
предохранить новую разработку от старых
ошибок, например, определив типы дефектов,
поиск которых наиболее эффективен на
различных этапах тестирования.
В данном
случае анализируется этап модульного
тестирования. Если анализ не дал нужной
информации, например, в случае проектов,
в которых соответствующие данные не
собирались, то основным правилом
становится поиск локальных дефектов,
у которых код, ресурсы и информация,
вовлеченные в дефект, характерны именно
для данного модуля. В этом случае на
модульном уровне ошибки, связанные,
например, с неверным порядком или
форматом параметров модуля, могут быть
пропущены, поскольку они вовлекают
информацию, затрагивающую другие модули
(а именно, спецификацию интерфейса), в
то время как ошибки в алгоритме обработки
параметров довольно легко обнаруживаются.
Являясь
по способу исполнения структурным
тестированием или тестированием «белого
ящика», модульное тестирование
характеризуется степенью, в которой
тесты выполняют или покрывают логику
программы (исходный текст). Тесты,
связанные со структурным тестированием,
строятся по следующим принципам:
• на
основе анализа потока управления. В
этом случае элементы, которые должны
быть покрыты при прохождении тестов,
определяются на основе структурных
критериев тестирования СО, CI, C2. К ним
относятся вершины, дуги, пути управляющего
графа программы (УГП), условия, комбинации
условий и т. п.
• на
основе анализа потока данных, когда
элементы, которые должны быть покрыты,
определяются на основе потока данных,
т. е. информационного графа программы.
Тестирование
на основе потока управления.
Особенности использования структурных
критериев тестирования СО, CI, С2 были
рассмотрены в разд. 5.2. К ним следует
добавить критерий покрытия условий,
заключающийся в покрытии всех логических
(булевых) условий в программе. Критерии
покрытия решений (ветвей — С1) и условий
не заменяют друг друга, поэтому на
практике используется комбинированный
критерий покрытия условий/решений,
совмещающий требования по покрытию и
решений, и условий.
К популярным
критериям относится критерий покрытия
функций программы, согласно которому
каждая функция программы должна быть
вызвана хотя бы 1 раз, и критерий покрытия
вызовов, согласно которому каждый вызов
каждой функции в программе должен быть
осуществлен хотя бы 1 раз. Критерий
покрытия вызовов известен также как
критерий покрытия пар вызовов (call pair
coverage).
Тестирование
на основе потока данных.
Этот вид тестирования направлен на
выявление ссылок на неинициализированные
переменные и избыточные присваивания
(аномалий потока данных). Как основа для
стратегии тестирования поток данных
впервые был описан в [14]. Предложенная
там стратегия требовала тестирования
всех взаимосвязей, включающих в себя
ссылку (использование) и определение
переменной, на которую
указывает
ссылка (т. е. требуется покрытие дут
информационного графа программы).
Недостаток стратегии в том, что она не
включает критерий С1 и не гарантирует
покрытия решений.
Стратегия
требуемых пар
[15] также тестирует упомянутые взаимосвязи.
Использование переменной в предикате
дублируется в соответствии с числом
выходов решения, и каждая из таких
требуемых взаимосвязей должна быть
протестирована. К популярным критериям
принадлежит критерий СР, заключающийся
в покрытии всех таких пар дуг v и w, что
из дуги v достижима дуга w, поскольку
именно на дуге может произойти потеря
значения переменной, которая в дальнейшем
уже не должна использоваться. Для
покрытия еще одного популярного критерия
Cdu достаточно тестировать пары (вершина,
дуга), поскольку определение переменной
происходит в вершине УГП, а ее использование
— на дугах, исходящих из решений, или в
вычислительных вершинах.
Методы
проектирования тестовых путей для
достижения заданной степени тестированности
в структурном тестировании.
Процесс
построения набора тестов при структурном
тестировании принято делить на три
фазы:
• конструирование
УГП;
• выбор
тестовых путей;
• генерация
тестов, соответствующих тестовым путям.
Первая
фаза соответствует статическому анализу
программы, задача которого состоит в
получении графа программы и зависящего
от него и от критерия тестирования
множества элементов, которые необходимо
покрыть тестами.
На третьей
фазе по известным путям тестирования
осуществляется поиск подходящих тестов,
реализующих прохождение этих путей.
Вторая
фаза обеспечивает выбор тестовых путей.
Выделяют три подхода к построению
тестовых путей:
• статические
методы;
• динамические
методы;
• методы
реализуемых путей.
Статические
методы.
Самое простое и легко реализуемое
решение — построение каждого пути
посредством постепенного его удлинения
за счет добавления дуг, пока не будет
достигнута выходная вершина управляющего
графа программы. Эта идея может быть
усилена в так называемых адаптивных
методах, которые каждый раз добавляют
только один тестовый путь (входной
тест), используя предыдущие пути (тесты)
как руководство для выбора последующих
путей в соответствии с некоторой
стратегией. Чаще всего адаптивные
стратегии применяются по отношению к
критерию С1. Основной недостаток
статических методов заключается в том,
что не учитывается возможная
нереализуемость
построенных путей тестирования.
Динамические
методы.
Такие методы предполагают построение
полной системы тестов, удовлетворяющих
заданному
критерию,
путем одновременного решения задачи
построения покрывающего множества
путей и тестовых данных. При этом можно
автоматически учитывать реализуемость
или нереализуемость ранее рассмотренных
путей или их частей. Основной идеей
динамических методов является
подсоединение к начальным реализуемым
отрезкам путей дальнейших их частей
так, чтобы:
1) не терять
при этом реализуемости вновь полученных
путей;
2) покрыть
требуемые элементы структуры программы.
Методы
реализуемых путей.
Данная методика [16] заключается в
выделении из множества путей подмножества
всех реализуемых путей. После этого
покрывающее множество путей строится
из полученного подмножества реализуемых
путей.
Достоинство
статических методов состоит в сравнительно
небольшом количестве необходимых
ресурсов как при использовании, так и
при разработке. Однако их реализация
может содержать непредсказуемый процент
брака (нереализуемых путей).
Кроме
того, в этих системах переход от
покрывающего множества путей к полной
системе тестов пользователь должен
осуществить вручную, а эта работа
достаточно трудоемкая. Динамические
методы требуют значительно больших
ресурсов как при разработке, так и при
эксплуатации, однако увеличение затрат
происходит в основном за счет разработки
и эксплуатации аппарата определения
реализуемости пути (символический
интерпретатор, решатель неравенств).
Достоинство этих методов заключается
в том, что их продукция имеет некоторый
качественный уровень — реализуемость
путей. Методы реализуемых путей дают
самый лучший результат [33].
Интеграционное
тестирование
Интеграционное
тестирование — это тестирование части
системы, состоящей из двух и более
модулей. Основная задача интеграционного
тестирования — поиск дефектов, связанных
с ошибками в реализации и интерпретации
интерфейсного взаимодействия между
модулями.
С
технологической точки зрения интеграционное
тестирование является количественным
развитием модульного, поскольку так
же, как и модульное тестирование,
оперирует интерфейсами модулей и
подсистем и требует создания тестового
окружения, включая заглушки (Stub) на месте
отсутствующих модулей.
Основная
разница между модульным и интеграционным
тестированием состоит в целях, т. е. в
типах обнаруживаемых дефектов, которые,
в свою очередь, определяют стратегию
выбора входных данных и методов анализа.
В частности, на уровне интеграционного
тестирования часто применяются методы,
связанные с покрытием интерфейсов,
например, вызовов функций или методов,
или анализ использования интерфейсных
объектов, таких как глобальные ресурсы,
средства коммуникаций, предоставляемых
операционной системой.
На рис.
5.2 приведена структура комплекса программ
К, состоящего из оттестированных на
этапе модульного тестирования модулей
М1, М2, М11, М12, М21, М22. Задача, решаемая
методом интеграционного тестирования,
— тестирование межмодульных связей,
реализующихся при исполнении программного
обеспечения комплекса К. Интеграционное
тестирование использует модель «белого
ящика» на модульном уровне. Поскольку
тестировщику текст программы известен
с детальностью до вызова всех модулей,
входящих в тестируемый комплекс,
применение структурных критериев на
данном этапе возможно и оправданно.
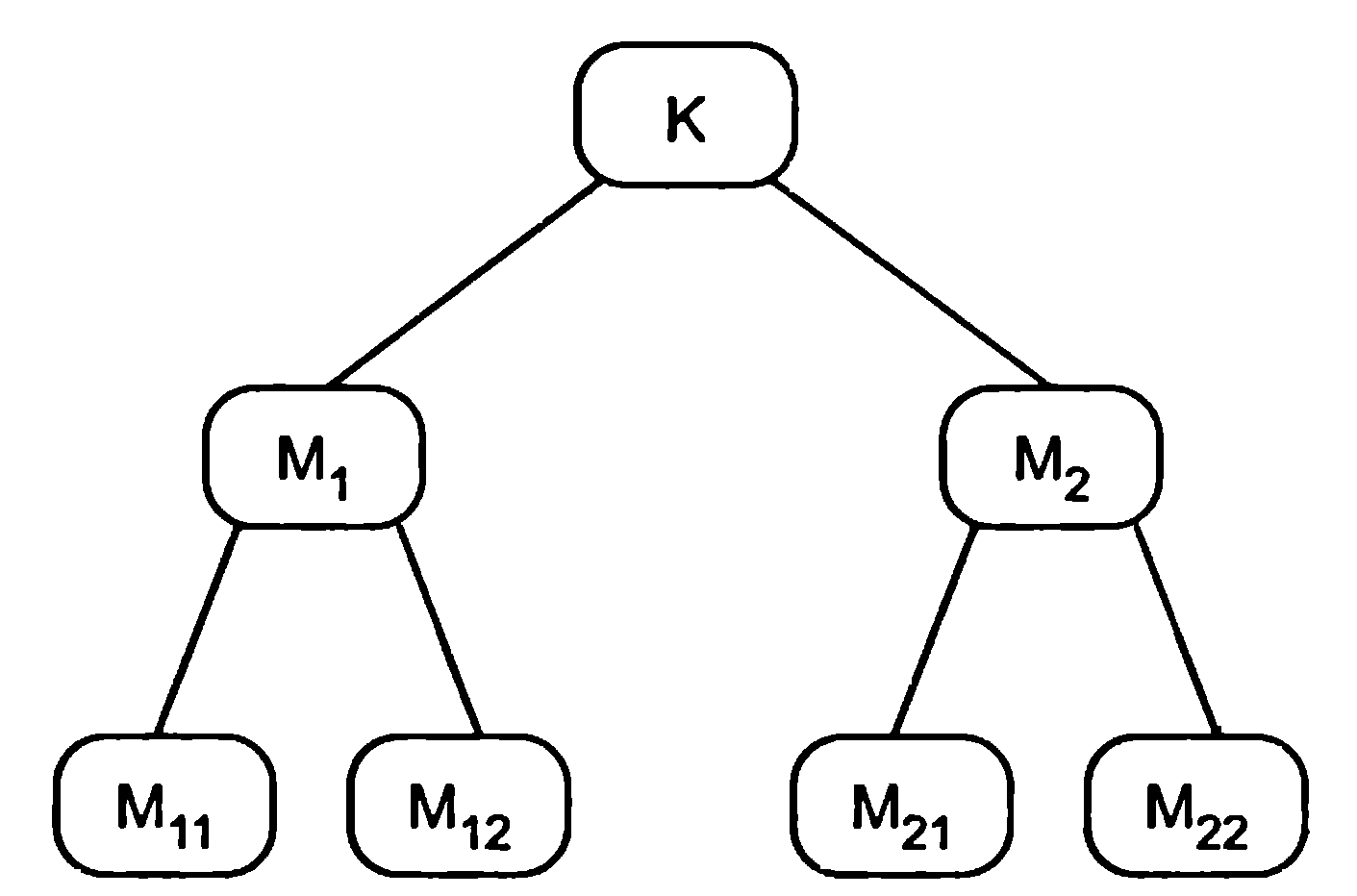
Рис. 5.2.
Пример структуры комплекса программ
Интеграционное
тестирование применяется на этапе
сборки модульно оттестированных модулей
в единый комплекс.
Известны
два метода сборки модулей:
• монолитный,
характеризующийся одновременным
объединением всех модулей в тестируемый
комплекс;
• инкрементальный,
характеризующийся пошаговым (помодульным)
наращиванием комплекса программ с
пошаговым тестированием собираемого
комплекса. В инкрементальном методе
выделяют две стратегии добавления
модулей:
— «сверху
вниз» и соответствующее ему восходящее
тестирование;
— «снизу
вверх» и соответственно нисходящее
тестирование.
Особенности
монолитного тестирования заключаются
в следующем: для замены не разработанных
к моменту тестирования модулей, кроме
самого верхнего (К на рис. 5.2), необходимо
дополнительно разрабатывать драйверы
(test driver) и/или заглушки (stub) [9], замещающие
отсутствующие на момент сеанса
тестирования модули нижних уровней.
Сравнение
монолитного и интегрального подходов
дает следующие результаты.
Монолитное
тестирование требует больших трудозатрат,
связанных с дополнительной разработкой
драйверов и заглушек и со сложностью
идентификации ошибок, проявляющихся в
пространстве собранного кода.
Пошаговое
тестирование связано с меньшей
трудоемкостью идентификации ошибок за
счет постепенного наращивания объема
тестируемого кода и соответственно
локализации добавленной области
тестируемого кода.
Монолитное
тестирование предоставляет большие
возможности распараллеливания работ,
особенно на начальной фазе тестирования.
Особенности
нисходящего тестирования заключаются
в следующем: организация среды для
исполняемой очередности вызовов
оттестированными модулями тестируемых
модулей, постоянная разработка и
использование заглушек, организация
приоритетного тестирования модулей,
содержащих операции обмена с окружением,
или модулей, критичных для тестируемого
алгоритма.
Например,
порядок тестирования комплекса К (см.
рис. 5.2) при нисходящем тестировании
может быть таким, как показано в примере
5.3, где тестовый набор, разработанный
для модуля Mi, обозначен как XYi = (X, Y)i.
1) К ->
XYK
2) М1 ->
XY1
3)MM->XYM
4)
М2
-> XY2
5)
М22
-> XY22
6)
M21
-> XY21
7) M12 ->
XY12
Пример
5.1. Возможный порядок тестов при нисходящем
тестировании (html, txt).
Недостатки
нисходящего тестирования:
• проблема
разработки достаточно «интеллектуальных»
заглушек, т. е. заглушек, способных к
использованию при моделировании
различных режимов работы комплекса,
необходимых для тестирования;
• сложность
организации и разработки среды для
реализации исполнения модулей в нужной
последовательности;
• параллельная
разработка модулей верхних и нижних
уровней приводит к не всегда эффективной
реализации модулей из-за подстройки
(специализации) еще не тестированных
модулей нижних уровней к уже оттестированным
модулям верхних уровней.
Особенности
восходящего тестирования в организации
порядка сборки и перехода к тестированию
модулей, соответствующему порядку их
реализации.
Например,
порядок тестирования комплекса К (см.
рис. 5.2) при восходящем тестировании
может быть следующим (см. пример 5.4).
1)М11->ХУ11
2) M12 ->
XY12
3) М1 ->
XY1
4)
М21
-> XY21
5)
M2(M21, Stub(M22)) -> XY2
6)
К(М1,
M2(M2I, Stub(M22)) -> XYK
7) М22 ->
XY22
 М2 ->
М2 ->
XY2
9) К ->
XYK
Пример
5.2. Возможный порядок тестов при восходящем
тестировании.
Недостатки
восходящего тестирования:
• запаздывание
проверки концептуальных особенностей
тестируемого комплекса;
• необходимость
в разработке и использовании драйверов
[33].
Системное
тестирование
Системное
тестирование качественно отличается
от интеграционного и модульного уровней.
Системное тестирование рассматривает
тестируемую систему в целом и оперирует
на уровне пользовательских интерфейсов,
в отличие от последних фаз интеграционного
тестирования, которое оперирует на
уровне интерфейсов модулей. Различны
и цели этих уровней тестирования. На
уровне системы часто сложно и малоэффективно
анализировать прохождение тестовых
траекторий внутри программы или
отслеживать правильность работы
конкретных функций.
Основная
задача системного тестирования —
выявления дефектов, связанных с работой
системы в целом, таких как неверное
использование ресурсов системы,
непредусмотренные комбинации данных
пользовательского уровня, несовместимость
с окружением, непредусмотренные сценарии
использования, отсутствующая или
неверная функциональность, неудобство
в применении и т. п.
Системное
тестирование производится над проектом
в целом с помощью метода «черного ящика».
Структура программы не имеет никакого
значения, для проверки доступны только
входы и выходы, видимые пользователю.
Тестированию подлежат коды и
пользовательская документация.
Категории
тестов системного тестирования:
1. Полнота
решения функциональных задач.
2. Стрессовое
тестирование — на предельных объемах
нагрузки входного потока.
3.
Корректность использования ресурсов
(утечка памяти, возврат ресурсов).
4. Оценка
производительности.
5.
Эффективность защиты от искажения
данных и некорректных действий.
6. Проверка
инсталляции и конфигурации на разных
платформах.
7.
Корректность документации.
Поскольку
системное тестирование проводится на
пользовательских интерфейсах, создается
иллюзия того, что построение специальной
системы автоматизации тестирования не
всегда необходимо. Однако объемы данных
на этом уровне таковы, что обычно более
эффективным подходом является полная
или частичная автоматизация тестирования,
что приводит к созданию тестовой системы,
гораздо более сложной, чем система
тестирования, применяемая на уровне
тестирования модулей или их комбинаций.
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•операционной системы,
•среды и языка программирования,
•реализуемых процессов,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 10.1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•логические ошибки,
•накопление погрешностей результатов вычислений (рис. 10.2).
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см.§ 2.7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т. п.;
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т. п.;
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
ручного тестирования;
индукции;
дедукции;
обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
 Рис Пример отладки приложения
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
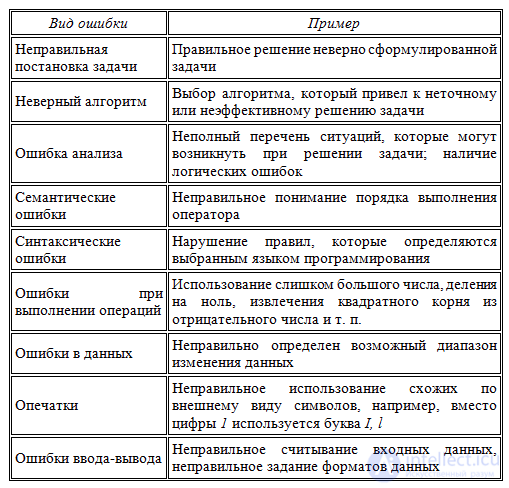
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
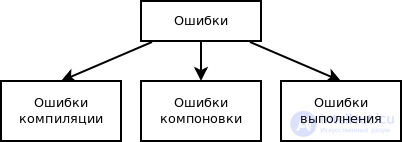
Классификация ошибок по этапу обработки программы
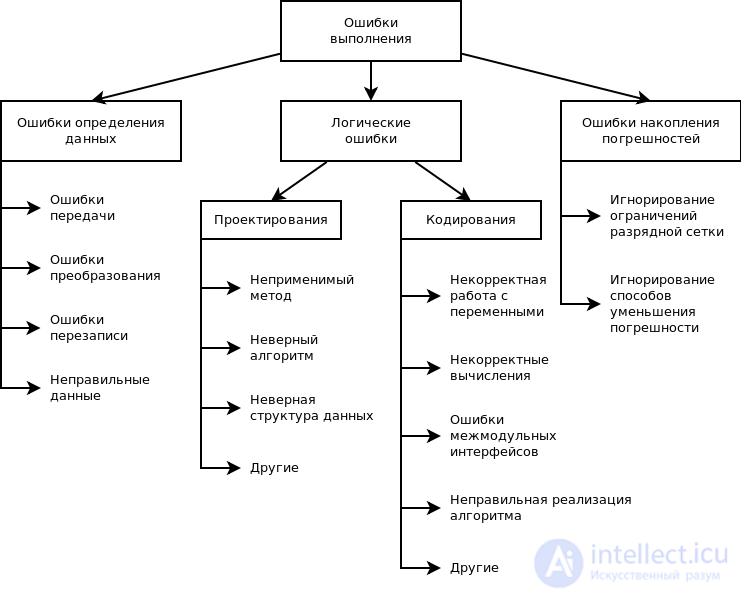
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
См. также
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
Отладка, или debugging, — это поиск (локализация), анализ и устранение ошибок в программном обеспечении, которые были найдены во время тестирования.
Это простые ошибки, которые в компилируемых языках программирования выявляет компилятор (программа, которая преобразует текст на языке программирования в набор машинных кодов). Если компилятор показывает несколько ошибок, отладку кода начинают с исправления самой первой, так как она может быть причиной других.
В интерпретируемых языках (например Python) текст программы команда за командой переводится в машинный код и сразу исполняется. К моменту обнаружения ошибки часть программы уже может исполниться.
Ошибки связаны с разрешением внешних ссылок. Выявляет компоновщик (редактор связей) при объединении модулей программы. Простой пример — ситуация, когда требуется обращение к подпрограмме другого модуля, но при компоновке она не найдена. Ошибки также просто найти и устранить.
Ошибки, которые обнаруживают операционная система, аппаратные средства или пользователи при выполнении программы. Они считаются непредсказуемыми и проявляются после успешной компиляции и компоновки. Можно выделить четыре вида проявления таких ошибок:
- сообщение об ошибке, которую зафиксировали схемы контроля машинных команд. Это может быть переполнение разрядной сетки (когда старшие разряды результата операции не помещаются в выделенной области памяти), «деление на ноль», нарушение адресации и другие;
- сообщение об ошибке, которую зафиксировала операционная система. Она же, как правило, и документирует ошибку. Это нарушение защиты памяти, отсутствие файла с заданным именем, попытка записи на устройство, защищенное от записи;
- прекращение работы компьютера или зависание. Это и простые ошибки, которые не требуют перезагрузки компьютера, и более сложные, когда нужно выключать ПК;
- получение результатов, которые отличаются от ожидаемых. Программа работает стабильно, но выдает некорректный результат, который пользователь воспринимает за истину.
Ошибки выполнения можно разделить на три большие группы.
Ошибки определения данных или неверное определение исходных данных. Они могут появиться во время выполнения операций ввода-вывода.
К ним относятся:
- ошибки преобразования;
- ошибки данных;
- ошибки перезаписи.
Как правило, использование специальных технических средств для отладки (API-логгеров, логов операционной системы, профилировщиков и пр.) и программирование с защитой от ошибок помогает обнаружить и решить лишь часть из них.
Логические ошибки. Они могут возникать из ошибок, которые были допущены при выборе методов, разработке алгоритмов, определении структуры данных, кодировании модуля.
В эту группу входят:
- ошибки некорректного использования переменных. Сюда относятся неправильный выбор типов данных, использование индексов, выходящих за пределы определения массивов, использование переменных до присвоения переменной начального значения, нарушения соответствия типов данных;
- ошибки вычислений. Это некорректная работа с переменными, неправильное преобразование типов данных в процессе вычислений;
- ошибки взаимодействия модулей или межмодульного интерфейса. Это нарушение типов и последовательности при передаче параметров, области действия локальных и глобальных переменных, несоблюдение единства единиц измерения формальных и фактических параметров;
- неправильная реализация логики при программировании.
Ошибки накопления погрешностей. Могут возникать при неправильном округлении, игнорировании ограничений разрядной сетки, использовании приближенных методов вычислений и т.д.
Отладка программы заключается в тестировании вручную с помощью тестового набора, при работе с которым была допущена ошибка. Несмотря на эффективность, метод не получится использовать для больших программ или программ со сложными вычислениями. Ручное тестирование применяется как составная часть других методов отладки.
В основе отладки системы — тщательный анализ проявлений ошибки. Это могут быть сообщения об ошибке или неверные результаты вычислений. Например, если во время выполнения программы завис компьютер, то, чтобы найти фрагмент проявления ошибки, нужно проанализировать последние действия пользователя. На этапе отладки программы строятся гипотезы, каждая из них проверяется. Если гипотеза подтвердилась, информация об ошибке детализируется, если нет — выдвигаются новые.
Вот как выглядит процесс:

Важно, чтобы выдвинутая гипотеза объясняла все проявления ошибки. Если объясняется только их часть, то либо гипотеза неверна, либо ошибок несколько.
Сначала специалисты предлагают множество причин, по которым могла возникнуть ошибка. Затем анализируют их, исключают противоречащие имеющимся данным. Если все причины были исключены, проводят дополнительное тестирование. В обратном случае наиболее вероятную причину пытаются доказать.

Эффективен для небольших программ. Начинается с точки вывода неправильного результата. Для точки выдвигается гипотеза о значениях основных переменных, которые могли привести к ошибке. Далее на основании этой гипотезы строятся предположения о значениях переменных в предыдущей точке. Процесс продолжается до момента, пока не найдут ошибку.
Ранние отладчики, например gdb, представляли собой отдельные программы с интерфейсами командной строки. Более поздние, например первые версии Turbo Debugger, были автономными, но имели собственный графический интерфейс для облегчения работы. Сейчас большинство IDE имеют встроенный отладчик. Он использует такой же интерфейс, как и редактор кода, поэтому можно выполнять отладку в той же среде, которая используется для написания кода.
Отладчик позволяет разработчику контролировать выполнение и проверять (или изменять) состояние программ. Например, можно использовать отладчик для построчного выполнения программы, проверяя по ходу значения переменных. Сравнение фактических и ожидаемых значений переменных или наблюдение за ходом выполнения кода может помочь в отслеживании логических (семантических) ошибок.
Пошаговое выполнение — это набор связанных функций отладчика, позволяющих поэтапно выполнять код.
Команда выполняет очередную инструкцию, а потом приостанавливает процесс, чтобы с помощью отладчика было можно проверить состояние программы. Если в выполняемом операторе есть вызов функции, step into заставляет программу переходить в начало вызываемой функции, где она приостанавливается.
Команда также выполняет очередную инструкцию. Однако когда step into будет входить в вызовы функций и выполнять их строка за строкой, step over выполнит всю функцию, не останавливаясь, и вернет управление после ее выполнения. Команда step over позволяет пропустить функции, если разработчик уверен, что они уже исправлены, или не заинтересован в их отладке в данный момент.
В отличие от step into и step over, step out выполняет не следующую строку кода, а весь оставшийся код функции, исполняемой в настоящее время. После возврата из функции он возвращает управление разработчику. Эта команда полезна, когда специалист случайно вошел в функцию, которую не нужно отлаживать.
Как правило, при пошаговом выполнении можно идти только вперед. Поэтому легко перешагнуть место, которое нужно проверить. Если это произошло, необходимо перезапустить отладку.
У некоторых отладчиков (таких как GDB 7.0, Visual Studio Enterprise Edition 15.5 и более поздних версий) есть возможность вернуться на шаг назад. Это полезно, если пропущена цель либо нужно повторно проверить выполненную инструкцию.
Автомобили
Астрономия
Биология
География
Дом и сад
Другие языки
Другое
Информатика
История
Культура
Литература
Логика
Математика
Медицина
Металлургия
Механика
Образование
Охрана труда
Педагогика
Политика
Право
Психология
Религия
Риторика
Социология
Спорт
Строительство
Технология
Туризм
Физика
Философия
Финансы
Химия
Черчение
Экология
Экономика
Электроника
Работа по программированию начинается с того, что программист, используя тот или иной текстовой редактор, записывает текст программы, который как и любой другой электронный документ сохраняется в виде файла.
Однако, как уже отмечалось, написание программы еще не означает, что она работает правильно. Программы проверяются с использованием методов доказательства правильности программ. При этом различают понятия отладка и тестирование программы.
Отладка программы – это процесс поиска и устранения неисправностей (ошибок) в программе, производимый по результатам её прогона на компьютере.
Тестирование (англ. test – испытание) – это испытание, проверка правильности работы программы в целом либо её составных частей.
Отладка и тестирование – это два четко различимых и непохожих друг на друга этапа:
· при отладке происходит локализация и устранение синтаксических ошибок и явных ошибок;
· в процессе же тестирования проверяется работоспособность программы, не содержащей явных ошибок.
Отладка начинается с нахождения и устранения синтаксических ошибок. После этого выявляются явные ошибки программы функционирования, связанные с неправильной ее организацией – переходы на неверные метки, неправильное использование подпрограмм и модулей.
И отладка и тестирование проводятся на основе подготовленных тестовых примеров. Сформулируем рекомендации к организации отладки, которые применимы и при структурном и при функциональном подходах к его проведению.
Вычислять эталонные результаты нужно обязательно до, а не послеполучения машинных результатов. В противном случае имеется опасность невольной подгонки вычисляемых значений под желаемые, полученные ранее на машине.
Первый тест должен быть максимально прост, чтобы проверить, работает ли программа вообще. Очередной тестовый прогон должен контролировать нечто такое, что еще не было проверено на предыдущих прогонах. Возникающие затруднения следует четко разделять и устранять строго поочередно. Усложнение тестовых данных должно происходить постепенно;
Арифметические операции в тестах должны предельно упрощаться для уменьшения объема вычислений. Количества элементов последовательностей, точность для итерационных вычислений, количество проходов цикла в тестовых примерах должны задаваться из соображений сокращения объема вычислений. Минимизация вычислений не должна снижать надежности контроля;
Тестирование должно быть целенаправленным и систематизированным, так как случайный выбор исходных данных привел бы к трудностям в определении ручным способом ожидаемых результатов; кроме того, при случайном выборе тестовых данных могут оказаться непроверенными многие ситуации;
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
· ручной отладки;
· индукции;
· дедукции;
· обратного прослеживания.
Метод ручной отладки – самый простой и естественный способ отладки. Человеку свойственно ошибаться – при наборе текста программы он может допустить опечатки, что–то упустить и т. д. Поэтому, прежде всего, необходимо обнаружить ошибки в программе именно такие – очевидные и грубые. Сначала надо попробовать это сделать путем обычного внимательного просмотра текста. Текст программы просматривается на предмет обнаружения описок и расхождений с алгоритмом. Нужно просмотреть организацию всех циклов, чтобы убедиться в правильности операторов, задающих кратности циклов. Полезно посмотреть еще раз условия в условных операторах, аргументы в обращениях к подпрограммам и т. п.
Отладка программ сегодня производится в основном с использованием специализированных программных пакетов на ЭВМ, но прежде чем «нагружать» ее этой работой можно проверку программы осуществить и в «ручном режиме», что всегда полезно как первый этап отладки программы перед дальнейшей ее отладкой на ЭВМ. В этом случае нужно представить, что Вы – машина, и, начав с первого оператора программы, выполнять оператор за оператором до обнаружения ошибки. Эту работу нужно вести методично и терпеливо, стремясь не делать правдоподобных догадок и не перескакивая через несколько операторов.
Чтобы имитировать работу программы, необходимо хорошо понимать, как работает микропроцессорная система и как выполняются отдельные команды. Для имитации работы микропроцессора по выполнению программы нужно иметь: программу; переменные с их текущими значениями. При этом роль памяти микропроцессора будет играть лист бумаги, на котором в отведенных местах записывается вся модифицируемая информация.
При выполнении программы на листе бумаги указывают имя той переменной, которая впервые встретилась при реализации очередной команды, и ее значение. Если оно изменяется, то старое значение зачеркивают, рядом пишут новое. Выполняя программу вручную, нужно забыть ее «цель» и формально реализовывать команду за командой. При поиске ошибки в программе, выполняя ее на листе, необходимо переключаться из состояния «робота» в состояние человека, обладающего интеллектом. Сначала Вы – «робот» и выполняете команду точно так, как это делает микропроцессор, потом опять становитесь человеком и спрашиваете: «Тот ли получен результат, которого я ожидал?» Если да, то продолжаете выполнение программы. Если нет, решаете, почему программа работает неправильно.
Отладка программ на ЭВМ позволяет уйти от рутинной работы и исключить «человеческие» ошибки, связанные, например, с тем, что Вы неправильно интерпретируете действие той или иной команды.
После этого можно перейти к процедуре трансляции программы. Если в программе остались синтаксические ошибки, то на этом этапе они выявляются полностью. Однако имейте в виду очевидное: отсутствие сообщений машины о синтаксических ошибках является необходимым, но не достаточным условием, чтобы считать программу правильной. Многие ошибки транслятору выявить невозможно, так как транслятору неизвестны замыслы программиста. Существует множество ошибок, которые транслятор выявить не в состоянии, если используемые в программе операторы сформированы (записаны) верно. Такие ошибки Вы обнаружите уже позже в процессе тестирования.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции.Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе – выдвигают другую гипотезу.
Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап – выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.

Рис. Схема процесса отладки методом индукции
Метод дедукции.По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе – проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания.Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.

Рис. Схема процесса отладки методом дедукции
Помощь в ✍️ написании работы
Поиск по сайту:
©2015-2020 mykonspekts.ru Все права принадлежат авторам размещенных материалов.
Отладка и тестирование программ.
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
прогоняем программу и получаем результаты;
сверяем результаты с эталонными и анализируем несоответствие;
выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3. Принципы отладки
Принципы локализации ошибок:
Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
Там, где найдена одна ошибка, возможно, есть и другие.
Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
— Использование дампа (распечатки) памяти.
Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
— Использование отладочной печати в тексте программы — произвольно и в большом количестве.
Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
— Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.
Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
write(‘Введите второе число ‘); readln(b);
write(‘Введите третье число ‘); readln(c);
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else if (b>a)and(<strong>a</strong>>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,<strong>b</strong>:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=list>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная печать
Добавляем промежуточную печать:
— вывод a, b, c после ввода (проверяем, правильно ли получили данные)
— вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке. Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
— вводе данных;
— расчетном блоке;
— собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
— арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
— логическое (когда и как выполняется выбранная последовательность операторов),
— контроль выхода индексов за допустимые пределы,
— отслеживание обращений к переменным,
— отслеживание обращений к подпрограммам,
— проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
— просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
— прервать выполнение программы;
— внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
6. Классификация ошибок
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
— ошибки обращения к данным,
— ошибки описания данных,
— ошибки вычислений,
— ошибки при сравнении,
— ошибки в передаче управления,
— ошибки ввода-вывода,
— ошибки интерфейса,
и так до бесконечности
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
в компиляторе,
операционной системе,
аппаратной части,
электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
![]()
Программы не всегда правильно работают сразу после набора их кода и компиляции. Если программа правильно сработала при первом ее запуске, то все равно нет полной уверенности в том, что она не содержит ошибок. Поэтому важная и трудоемкая часть процесса разработки программ – их отладка и тестирование.
Тестированием называются пробные запуски программы с различными вариантами входных значений и проверка правильности работы. Для того чтобы убедиться в правильности работы программы, нужно проверить, что варианты входных значений охватывают все типичные случаи использования программы.
Особое внимание нужно уделить так называемым «граничным случаям» входных значений. Например, если входными данными некоторой программы является число из некоторого диапазона, то для проверки правильности программы нужно запустить ее со значением входной переменной, равной значению в начале разрешенного диапазона, потом – равной значению в конце диапазона и третий раз запустить программу со значением входной переменной, взятым из середины диапазона.
Если при тестировании программы были обнаружены ошибки, то нужно проводить ее отладку. Отладка – это комплекс действий, предназначенный для нахождения и исправления ошибок в программе. При отладке анализируются результаты тестирования, причины, по которым могла произойти ошибка, фрагменты программы, которые могли вызвать эту ошибку. Производятся также дополнительные тесты, которые позволят локализовать ошибку, т. е. уточнить, в какой части программы ее следует искать.
Простейший способ тестирования и отладки программ состоит в их запуске «по шагам» и в просмотре значений переменных после выполнения каждого оператора в программе. Такой способ легко применить при наличии интегрированной среды разработки, и он в некоторых случаях позволяет быстро найти ошибку.
При увеличении размера программ такой способ тестирования приводит к значительному объему работы, часто бесполезной. Основной способ снизить этот объем – проанализировать ситуацию перед тем, как начинать отладку и тестирование программы.
В рамках изучения дисциплины «Технология программирования» используется платформа для разработки приложений, в которой отсутствуют средства для выполнения программы «по шагам» и просмотра значений переменных. Это сделано с целью выработки у студентов навыков правильного тестирования и отлаживания программы.
Грамотный подход к тестированию состоит в том, что нужно заранее (чаще всего до написания самой программы) составить набор тестов. Отладка любой нетривиальной программы требует неоднократного тестирования после каждой исправленной ошибки, поэтому нужно написать вспомогательную программу или функцию, которая автоматически выполняла бы весь набор тестов. Пример такой программы приведен в приложении. В примере тестируется функция, которая находит количество элементов в наиболее длинной последовательности одинаковых элементов в массиве. В программе заданы три возможных варианта входных значений этой функции и приведен правильный результат, который должна выдать тестируемая функция. Тестируемая функция запускается три раза, и на экран выводятся результаты тестирования: входные данные, полученный результат.
Если не использовать подобные тесты, а пытаться вручную запускать функцию в трех вариантах после каждого исправления ее кода, потребуется выполнить много работы. Чаще всего это приводит к тому, что после исправления ошибки функция тестируется не на все возможные варианты входных значений, что, в свою очередь, приводит к тому, что не все ошибки будут обна-ружены.
После того, как при тестировании будут обнаружены ошибки, нужно их найти. Часто о месте нахождения ошибки в программе можно судить по результатам теста. В других случаях нужно внимательно анализировать код программы и ход ее выполнения.
Просмотр значений переменных, как и тестирование, можно также «автоматизировать». Для этого нужно определить критические участки программы. Далее требуется решить, какие значения переменных нужны для анализа критического участка. После этого следует временно вставить в критический участок оператор, распечатывающий значения нужных переменных. Например, при построении циклов значения переменных лучше смотреть после окончания цикла, интересующими значениями в данном случае обычно являются счетчик циклов и переменные, входящие в условие его окончания.

После этого можно запустить программу и увидеть значения сразу всех переменных на всех критических участках. Такой способ выгодно отличается от просмотра значений отдельных переменных в режиме отладки тем, что, во-первых, видны значения всех переменных в разные моменты времени сразу и, во-вторых, не затрачиваются усилия на то, чтобы остановить выполнение программы и вывести значения переменных.
Для того чтобы быстрее включать и выключать оператор печати отладочных сообщений, можно воспользоваться директивами препроцессора компилятора языка С. Директивы препроцессора – это специальные команды, которые компилятор выполняет во время компиляции.
Для включения или отключения части кода в программу можно воспользоваться директивой «#ifdef символ код #endif». Если определен символ «символ», то «код» будет скомпилирован и включен в программу, иначе «код» будет просто пропущен.
Для того чтобы определить символ препроцессора, можно либо воспользоваться директивой «#define символ», либо указать этот символ непосредственно компилятору с помощью ключа «-D». Примеры использования директив для условной компиляции можно посмотреть в приложении.
При структурной разработке программ тестировать нужно как программу целиком, так и каждую функцию в отдельности. Причем каждая функция должна тестироваться по полной программе так, как если бы это была отдельная программа. В этом состоит еще одно серьезное преимущество структурного подхода. Обнаружив ошибку, можно быстро ее локализовать, запустив тесты функций, лежащих по структуре ниже, чем функция, в которой была обнаружена ошибка.
При таком нисходящем тестировании может быть обнаружен случай входных данных, который не входит в первоначальный набор тестов, но возникает при тестировании вышестоящих функций и приводит к ошибке. Этот случай входных данных должен быть добавлен в набор тестов.
Задание к работе
Разработать набор функций для работы с числами в n-ичной системе (n = = (номер варианта %15) + 10):
1) напишите функцию печати цифры, включите проверку корректности входных данных (цифра входит в нужный диапазон); напишите функцию печати числа, сделайте ее так, чтобы ей передавался указатель на массив;
2) напишите функции копирования, сложения и вычитания чисел. Учтите, что при сложении может возникнуть перенос в следующий разряд, при вычитании – заем;
3) напишите функции инициализации числа из целой переменной и сохранения числа в целую переменную;
4) напишите программу, печатающую в файл таблицу, строки которой соответствуют десятичным числам от 1 до 25, а в столбцах эти числа выводятся в десятичной, двоичной, шестнадцатеричной и n-ичной системах. Столбцы выровнять по правому краю.
Особое внимание следует уделить не просто написанию программы, а следованию принципам структурного программирования, изложенным в теоретической части. Структура программы данной лабораторной работы дается в задании. Для каждой функции из этой структуры должны быть разработаны тесты, проверяющие ее работу, при необходимости должны быть включены отладочные сообщения. При выполнении работы должны строго выполняться требования по оформлению и комментариям к программе. Число представляется в виде массива int[10] (число может содержать не более 10 n-ичных цифр). Цифры больше девяти записываются буквами латинского алфавита (A – 10, B – 11 и т. д.).
Содержание отчета
Отчет должен содержать листинг программы, в которой реализованы задание и функции тестирования, представлены результаты работы программы.
Контрольные вопросы
1) Как в общем виде записывается функция на языке С?
2) Перечислите базовые конструкции структурного программирования.
3) Какая конструкция выбора используется в языке С?
4) Что такое отладка программы?
5) Что такое тестирование программы?
6) Какая директива определяет символ для компилятора?
Лабораторная работа 2
ЦИКЛЫ
Цель работы: овладение навыками построения простых и вложенных циклов, повторение основных форм записи циклов на языке С.
Работа по программированию начинается с того, что программист, применяя тот либо другой текстовой процессор, записывает текст программы, что как и каждый электронный документ сохраняется в виде файла.
Но, как уже отмечалось, написание программы еще не свидетельствует, что она трудится верно. Программы проверяются с применением способов доказательства правильности программ. Наряду с этим различают понятия тестирование и отладка программы.
Отладка программы – это устранения неисправностей и процесс поиска (неточностей) в программе, создаваемый по итогам её прогона на компьютере.
Тестирование (англ. test – опробование) – это опробование, проверка правильности работы программы в целом или её составных частей.
тестирование и Отладка – это два четко различимых и непохожих друг на друга этапа:
- при отладке происходит устранение и локализация синтаксических явных ошибок и ошибок;
- в ходе же тестирования проверяется работоспособность программы, не содержащей явных неточностей.
Отладка начинается с устранения и нахождения синтаксических неточностей. Затем выявляются явные неточности программы функционирования, которые связаны с неправильной ее организацией – переходы на неверные метки, неправильное применение модулей и подпрограмм.
И тестирование и отладка проводятся на базе подготовленных тестовых примеров. Сформулируем советы к организации отладки, каковые применимы и при структурном и при функциональном подходах к его проведению.
Вычислять эталонные результаты необходимо в обязательном порядке до, а не послеполучения машинных результатов. В другом случае имеется опасность невольной подгонки вычисляемых значений под желаемые, полученные ранее на машине.
Первый тест должен быть максимально несложен, дабы проверить, трудится ли программа по большому счету. Очередной тестовый прогон обязан осуществлять контроль что-то такое, что еще не было установлено на прошлых прогонах. Появляющиеся затруднения направляться четко разделять и ликвидировать строго поочередно. Усложнение тестовых разрешённых должно происходить неспешно;
Арифметические операции в тестах должны предельно упрощаться для уменьшения количества вычислений. Количества элементов последовательностей, точность для итерационных вычислений, количество проходов цикла в тестовых примерах должны задаваться из-за сокращения количества вычислений. Минимизация вычислений не должна снижать надежности контроля;
Тестирование должно быть целенаправленным и систематизированным, поскольку случайный выбор данных привел бы к трудностям в определении ручным методом ожидаемых результатов; помимо этого, при случайном выборе тестовых разрешённых могут оказаться непроверенными многие ситуации;
Отладка программы в любом случае предполагает логическое осмысление и обдумывание всей имеющейся информации об неточности. Большая часть неточностей возможно найти по косвенным показателям при помощи результатов тестирования текстов и тщательного анализа программ без получения дополнительной информации. Наряду с этим применяют разные способы:
- ручной отладки;
- индукции;
- дедукции;
- обратного прослеживания.
Способ ручной отладки – самый несложный и естественный метод отладки. Человеку характерно ошибаться – при комплекте текста программы он может допустить опечатки, что–то потерять и т. д. Исходя из этого, в первую очередь, нужно найти неточности в программе как раз такие – очевидные и неотёсанные. Сперва нужно попытаться это сделать методом простого внимательного просмотра текста. Текст программы просматривается на предмет расхождений и обнаружения описок с методом. Необходимо просмотреть организацию всех циклов, дабы убедиться в правильности операторов, задающих кратности циклов. Полезно взглянуть еще раз условия в условных операторах, доводы в обращениях к подпрограммам и т. п.
Отладка программ сейчас производится по большей части с применением специальных программных пакетов на ЭВМ, но перед тем как «нагружать» ее данной работой возможно диагностику программы осуществить и в «ручном режиме», что неизменно полезно как первый этап отладки программы перед предстоящей ее отладкой на ЭВМ. В этом случае необходимо представить, что Вы – машина, и, начав с первого оператора программы, делать оператор за оператором до обнаружения неточности. Эту работу необходимо вести методично и терпеливо, стремясь не делать правдоподобных предположений и не перескакивая через пара операторов.
Дабы имитировать работу программы, нужно прекрасно осознавать, как трудится микропроцессорная совокупность и как выполняются отдельные команды. Для имитации работы процессора по исполнению программы необходимо иметь: программу; переменные с их текущими значениями. Наряду с этим роль памяти процессора будет играться лист бумаги, на котором в отведенных местах записывается вся модифицируемая информация.
При исполнении программы на листе бумаги показывают имя той переменной, которая в первый раз встретилась при реализации очередной команды, и ее значение. Если оно изменяется, то старое значение зачеркивают, рядом пишут новое. Делая программу вручную, необходимо забыть ее «цель» и формально реализовывать команду за командой. При поиске неточности в программе, делая ее на странице, нужно переключаться из состояния «робота» в состояние человека, владеющего интеллектом. Сперва Вы – «робот» и делаете команду совершенно верно так, как это делает процессор, позже снова становитесь человеком и задаёте вопросы: «Тот ли взят итог, которого я ожидал?» В случае если да, то продолжаете исполнение программы. В случае если нет, решаете, из-за чего программа трудится неправильно.
Отладка программ на ЭВМ разрешает уйти от рутинной работы и исключить «человеческие» неточности, связанные, к примеру, с тем, что Вы неправильно интерпретируете воздействие той либо другой команды.
Затем возможно перейти к процедуре трансляции программы. В случае если в программе остались синтаксические неточности, то на этом этапе они выявляются всецело. Но имейте в виду очевидное: отсутствие сообщений автомобили о синтаксических неточностях есть нужным, но не достаточным условием, дабы вычислять программу верной. Многие неточности транслятору распознать нереально, поскольку транслятору малоизвестны планы программиста. Существует множество неточностей, каковые транслятор распознать не в состоянии, в случае если применяемые в программе операторы организованы (записаны) правильно. Такие неточности Вы найдёте уже позднее в ходе тестирования.
Способ весьма действен, но не применим для громадных программ, программ со сложными вычислениями и в тех случаях, в то время, когда неточность связана с неверным понятием программиста о исполнении некоторых операций.
Этот способ довольно часто применяют как составную часть вторых способов отладки.
Способ индукции.Способ основан на тщательном анализе признаков неточности, каковые смогут проявляться как неверные результаты вычислений либо как сообщение об неточности. В случае если компьютер «», то фрагмент проявления неточности вычисляют, исходя из последних взятых действий и результатов пользователя. Взятую так данные организуют и шепетильно изучают, просматривая соответствующий фрагмент программы. В следствии этих действий выдвигают догадки об неточностях, каждую из которых контролируют. В случае если догадка верна, то детализируют данные об неточности, в противном случае – выдвигают другую догадку.
Последовательность исполнения отладки способом индукции продемонстрирована на рис. 10.3 в виде схемы метода.
Самый важный этап – обнаружение признаков неточности. Организуя информацию об неточности, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с неточностью выполняется нормально, так и ситуации, в которых неточность проявляется. В случае если в следствии изучения данных никаких догадок не появляется, то нужна дополнительная информация об неточности. Дополнительную данные возможно взять, к примеру, в следствии исполнения схожих тестов.
В ходе доказательства пробуют узнать, все ли проявления неточности растолковывает эта догадка, если не все, то или догадка не верна, или неточностей пара.
Рис. Схема процесса отладки способом индукции
Способ дедукции.По способу дедукции сначала формируют множество обстоятельств, каковые имели возможность бы позвать данное проявление неточности. После этого разбирая обстоятельства, исключают те, каковые противоречат имеющимся данным. В случае если все обстоятельства исключены, то направляться выполнить дополнительное тестирование исследуемого фрагмента. В другом случае самая вероятную догадку пробуют доказать. В случае если догадка растолковывает полученные показатели неточности, то неточность отыскана, в противном случае – контролируют следующую обстоятельство (рис. 10.4).
Способ обратного прослеживания.Для маленьких программ действенно использование способа обратного прослеживания. Начинают с точки вывода неправильного результата. Для данной точки строится догадка о значениях главных переменных, каковые имели возможность бы привести к получению имеющегося результата. Потом, исходя из данной догадки, делают предложения о значениях переменных в прошлой точке. Процесс продолжают, пока не найдут обстоятельство неточности.
Рис. Схема процесса отладки способом дедукции
Typ
Похожие статьи:
- Методы тестирования. требования и рекомендации по тестированию программ
- Как внести порядок в повседневную трудовую жизнь
- Способы и методы норм-я труда
Содержание:

ВВЕДЕНИЕ
Сегодня многие программисты и организации занимаются прикладным и системным программированием и созданием программного обеспечения для постоянно растущих потребностей пользователей. При этом значительная часть временных и финансовых ресурсов тратится на отладку и тестирование создаваемых ими приложений. Но тем не менее, несмотря на колоссальные затраты, конечный продукт очень часто вызывает много претензий у пользователя, и проблема качества продукта говорит нам о несомненной важности процессов отладки и тестирования программ на сегодняшний день. Этим обусловлена актуальность затрагиваемых в работе проблем. Причем многие «производители» до сих пор внятно даже не смогут дать точное определение тому, что же все-таки называется тестированием и отладкой. Некомпетентность в этом вопросе является одной из причин наводнения рынка некорректным и некачественным программным обеспечением (далее ПО).
Тестированием называется процесс, гарантирующий правильность функционирования программы и показывающий отсутствие ошибок в программном продукте. Можно заметить, что данное определение не совсем корректно и даже неправильно. Человек с некоторым опытом прикладного программирования знает, что полное отсутствие ошибок в программе выявить и показать невозможно. Более правильным будет определить процесс тестирования и отладки как завершающий этап создания программного продукта, который заключается в выполнении программы с целью выявления сбоев и ошибок программного кода. Вместо того, чтобы гарантировать отсутствие ошибок в новой программе, разумней будет хотя бы продемонстрировать их наличие. Если приложение корректно работает при выполнении множества различных тестов, это придает некоторую уверенность, но еще не гарантирует отсутствие в ней ошибок. Это лишь показывает, что нам пока неизвестно, в каких случаях программа может дать сбой.
Нереально внести в программу надежность в результате тестирования, она определяется правильностью этапов проектирования. Наилучшим решением здесь будет — с самого начала не делать ошибок в создаваемой программе. Но стопроцентный безошибочный результат практически невозможен. Вот и роль тестирования и отладки состоит как раз в том, чтобы определить местонахождение немногих ошибок, присутствующих в хорошо спроектированном программном продукте.
Тема работы: «Тестирование и отладка программного обеспечения». Отладка и тестирование тема очень хорошая и важная, какой бы язык программирования или платформа ни использовались. Именно на этой стадии разработчики сталкиваются со многими трудностями, что многих даже приводит в ярость. Отладка заставляет проводить над ней ночи напролет.
Ошибки в программах — это отличная практика. Они помогают нам узнать, как все это работает. Поиск багов и выявление ошибок дает нам ни с чем несравнимый опыт. Этим подтверждается практическая значимость выбранной темы. Разработчику следует найти их до того, как заказчик увидит результат вашей работы. А вот если ошибки в ваших программах находят заказчики, это совсем плохо.
Данная курсовая работа состоит из двух глав и приложений. В первой главе необходимо будет определить, что такое тестирование и отладка программ, что представляет собой сам процесс, какие приемы и способы существуют. Во второй главе будут раскрыты стратегии тестирования и отладки программного обеспечения.
1. ПОНЯТИЕ ТЕСТИРОВАНИЯ И ОТЛАДКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
1.1 Принципы тестирование и отладка программного обеспечения
История тестирования программного обеспечения показывает развитие разработки самого программного обеспечения. В течение долгого времени разработка программного обеспечения уделяла главное внимание масштабным научным программам, а также программам Министерства обороны Российской Федерации, связанным с системами корпоративных баз данных, которые разрабатывались на базе универсальной электронно-вычислительной машины. Первые тесты фиксировали на бумаге. По этим данным проверялись целевые потоки управления, подсчеты не простых алгоритмов и манипулирование данными. Заключительные шаги тестовых процессов могли эффектно протестировать целиком всю систему. Тестирование чаще всего начиналось после выполнения планаграфика проекта и осуществлялось тем же составом.
«Тестирование — процесс, подтверждающий правильность программы и демонстрирующий, что ошибок в программе нет.» Главная недоработка подобной формулировки состоит в том, что она совсем неверна; на самом деле это можно сказать определение антонима слова «тестирование». Люди с определенным опытом программирования, вероятно, осознают, что невозможно выразить отсутствие ошибок в программе. В связи с этим определение обрисовывает невозможную задачу, а т.к. тестирование весьма часто все же завершается с успехом, по крайней мере, с частичным успехом, то такое определение закономерно не верно. Правильное и верное определение тестирования будет звучать так: Тестирование — процесс выполнения программы с намерением найти ошибки.
Практически невозможно поручиться за отсутствие ошибок в нетривиальной программе; При самом благоприятном условии можно попытаться выразить наличие ошибок. Если программа на ваш взгляд правильно ведет себя для приличного набора тестов, нет оснований отстаивать, что в ней отсутствуют ошибки; Несомненно, можно лишь утверждать, что ещё не известно, когда эта ошибка проявится и программа даст сбой и не будет работать как должна. Разумеется, если есть веские доводы считать этот набор тестов способным с крупной вероятностью обнаружить некоторые возможные ошибки, то можно начинать разговор о некотором уровне убеждении в правильности программы, устанавливаемом данными тестами.
Подавляющее большинство программистов, поставив цель (например, показать, что ошибок нет и не будет), ориентируется в своей работе на достижение данной цели. Тестировщик подсознательно не позволяет себе функционировать против цели, т. е. разработать тест, который выявил бы одну из оставшихся или известных в программе ошибок. Так как мы все знаем, что совершенство в проектировании и кодировании любой программы неисполнимо и в связи с этим все программы включают в себя небольшое, а у немногих и большое, количество ошибок, самым продуктивным использованием тестирования будет найти все возможные из них. Если мы хотим сделать это и уйти от психологического барьера, который мешает нам действовать против нашей поставленной цели, наша цель обязана состоять в том, чтобы обнаружить как можно больше ошибок.
Появление ПК у людей, дало старт эталонирования данной отрасли, так как приложения стали поначалу создаваться для работы с доступной, общей операционной системой. Внедрение ПК открыло новую эпоху и привело к стремительному и бурному всплеску коммерческих разработок. Коммерческие приложения жестоко боролись за превосходство, выживание и главенство. Пользователи персональных компьютеров принимали выжившие программы как стандарты «де-факто». Пакетная обработка сменивалась системами, работающими в реальном времени.
Тестирование систем реального времени требовало других подходов к планированию тестирования из-за того, что у рабочих потоков была возможность вызываться в любом порядке. Эта специфика привела к пришествию огромного кол-ва процедур тестирования, которые могут поддержать бесконечное число перемещений и сочетаний.
Сформулируем основной вывод:
- Если ваша цель — доказать отсутствие ошибок, то вы их найдете не слишком много.
- Если же ваша цель — доказать наличие ошибок, вы обязательно найдете значительную их часть.
Источник значительных бед разработчиков являются программные сбои и ошибки, из-за которых на их несчастные головы сваливаются и издавна просроченные и забытые проекты, и разработчики лишаются сна. Ошибки могут изменить жизнь разработчиков и на самом деле действительно несчастной, так как, достаточно малозначительным ошибкам вторгнуться в их программы, как заказчики прерывают использование данными программами, а сами они могут лишиться работы.
Надежность нельзя занести в программу в результате тестирования, она формируется с помощью правильных этапов проектирования. Практически идеальное решение проблем надежности — изначально не допускать никаких ошибок в программе.
Впрочем, шанс того, что удастся идеально спроектировать серьёзную, значительную по объёму программу, крайне мала. Роль тестирования заключается как раз в том, чтобы определить расположение немногочисленных ошибок, которые остались в качественно спроектированной программе. В случае если программа плохо спроектирована, тестировать и надеяться на её надежность будет крайне неудачным решением.
Значительное время на ошибки смотрели как на незначительные неприятности. Разумеется, это далеко от истины. В связи с общей компьютеризацией, все шире захватываются такие важнейшие области, как управление системами жизнеобеспечения, медицинские приборы и сверхдорогую компьютерную аппаратуру, над ошибками тут уж точно нельзя так просто посмеиваться или смотреть на них как что то имеющее значение только на этапах начала разработки.
Тестирование оказывается достаточно необычным и интересным процессом (Но не смотря на его интересность, оно считается поистине трудным и тяжелым делом), так как этот процесс разрушительный. Ведь цель тестировщика — заставить программу выдать ошибку и сбиться. Он радуется, если это получилось; если же программа на его тесте не сбивается, не ошибается и не крашится, то он не удовлетворен и вероятно очень расстроен.
Есть ещё причина, из-за которой тяжело говорить о тестировании — это тот факт, что о нем известно очень мало. Допустим, сегодня мы имеем 20% тех знании о конструировании и фактически, о программировании (кодировании), то о тестировании нам известно менее 5%.
1.2 Основные понятия
Однако в тестировании нужно обратить внимание на несколько различных процессов, такие термины, как тестирование, отладка, доказательство, контроль и испытание, часто используются как синонимы и, к сожалению, для разных разработчиков имеют разный смысл. Однако стандартизованных, общепринятых определений данных терминов нет, попытка создать их была инициирована на симпозиуме по тестированию программ. Классификацию разных форм тестирования я начну с того, что покажу эти определения, чуть-чуть дополнив и расширив их список.
Тестирование (testing), как мы уже выяснили,—процесс выполнения программы с намерением найти ошибки.
Доказательство (proof) — попытка найти ошибки в программе безотносительно к внешней для программы среде. Большинство методов доказательства предполагает формулировку утверждений о поведении программы и затем вывод и доказательство математических теорем о правильности программы.
Контроль (verification) — попытка найти ошибки, выполняя программу в тестовой, или моделируемой, среде.
Испытание (validation) — попытка найти ошибки, выполняя программу в заданной реальной среде.
Аттестация (certification) — авторитетное подтверждение правильности программы, аналогичные аттестации электротехнического оборудования. При тестировании целью является, сравнение с заранее определенным стандартом.
Отладка (debugging) не является разновидностью тестирования.
Тестирование модуля, или автономное тестирование — контроль отдельного программного модуля, обычно в изолированной среде.
Тестирование сопряжении — контроль сопряжении между частями системы.
Тестирование внешних функций — контроль внешнего поведения системы, определенного внешними спецификациями.
Комплексное тестирование — контроль и/или испытание системы по отношению к исходным целям.
Тестирование приемлемости — проверка соответствия программы требованиям пользователя.
Тестирование настройки — проверка соответствия каждого конкретного варианта установки системы с целью выявить любые ошибки, возникшие в процессе настройки системы.
1.3 Классификация видов тестирования
Тестирование ПО – это процесс его исследования с целью получения информации о качестве. Целью тестирования служит выявление дефектов в программном обеспечении. Благодаря тестам нельзя доказать отсутствие дефектов и корректность функционирования анализируемой программы.
Тестирование программного обеспечения содержит целый ряд видов деятельности, аналогичной последовательности процессов разработки ПО. В них входят постановка задач для теста, проектирование, написание тестов, тестирование тестов и выполнение тестов, и изучение результатов тестирования. Решающую роль играет проектирование теста.
Состав и содержание документации, сопутствующей процессу тестирования, определяется зарубежным стандартом IEEE 829-2008 Standard for Software Test Documentation.
Существует несколько оснований, по которым принято производить классификацию видов тестирования.
- По объекту тестирования
- Функциональное тестирование
- Нагрузочное тестирование
- Тестирование удобства использования
- Тестирование интерфейса пользователя
- Тестирование безопасности
- Тестирование локализации
- Тестирование совместимости
- По знаниям о тестируемой системе
- Тестирование методом «черного ящика»
- Тестирование методом «белого ящика»
- Тестирование методом «серого ящика»
- По уровню автоматизации
- Ручное тестирование
- Автоматизированное тестирование
- По степени изолированности
- Модульное тестирование
- Интеграционное тестирование
- Системное тестирование
- По уровню готовности
- Альфа-тестирование
- Бета-тестирование
- Приемосдаточные испытания
1.4 Функциональное тестирование и тестирование качества
Функциональное тестирование проводится для проверки выполнения системой функциональных требований.
Нагрузочные тестирования проводятся для анализа работы систем при различных уровнях нагрузок. Благодаря нагрузочным тестированиям можно экспериментально установить требования к ресурсам ПК, масштабируемость и надежность сформированной системы. Нагрузочное тестирование является одним из способов проверки работы системы в условиях, приближенных к реальным.
Одним из главных показателем производительности информационной системы, в ходе тестирования, являются:
- Время отклика
- Число операций, выполняемых в единицу времени
Основным результатом нагрузочного тестирования являются измерения производительности информационной системы. В процессе нагрузочного тестирования можно построить «кривую деградацию» — график, показывающий зависимость производительности системы.
Стрессовое тестирование проводится в условиях недостаточных системных ресурсов и позволяет оценить надежность работы системы под нагрузкой.
Тестирование удобства использования имеет целью оценить оптимальность пользовательского интерфейса приложения.
Тестирование интерфейса пользователя предполагает проверку соответствия ПО требованиям к графическому интерфейсу пользователя. Различают следующие виды тестирования графического интерфейса пользователя:
- Тестирование на соответствие стандартам графических интерфейсов;
- Тестирование с различными разрешениями экрана;
- Тестирование локализованных версий: проверка длины названий элементов интерфейса и т.п.;
- Тестирование графического интерфейса пользователя на различных целевых устройствах.
В ходе тестирования безопасности производится проверка на уязвимость к атакам. Тестирование безопасности проверяет систему на попытки взлома и обхода. Во время тестирования безопасности проверяются следующие аспекты безопасности системы:
- Тестирование механизмов контроля;
- Тестирование авторизации пользователей;
- Тестирование процедур проверки корректности ввода;
- Тестирование криптографических механизмов защиты;
- Тестирование правильности обработки ошибок;
- Тестирование на переполнение буфера;
- Тестирование конфигурации сервера.
Задача создателя системы заключается в том, чтобы сделать затраты на организацию атаки выше, чем цена получаемой в результате информации.
В процессе тестирования локализации проверяются различные аспекты, связанные с региональными особенностями (Языковые данные, системное время, дата и т.д.).
Тестирование совместимости — проверка совместимости системы с различными вариантами программно-аппаратного окружения.
1.5 Виды тестирования
Отмечают три уровня тестирования: модульное, интеграционное и системное.
Модульное тестирование — тестирование, имеющее целью проверить работоспособность отдельных модулей. Модульное тестирование распространено для систем малого и среднего размера. Тестирование выполняется независимо для каждого программного модуля. Стандарт IEEE 1008-1987 определяет содержание фаз процесса модульного тестирования.
Модульные тесты проверяют, что определенные воздействия на модуль приводят к желаемому результату. Модульные тесты делаются с использованием метода «белого ящика». При наличии зависимостей тестируемого модуля от других модулей вместо них используются так называемые mock-объекты, предоставляющие фиктивную реализацию их интерфейсов. С использованием mock-объектов могут быть протестированы такие аспекты функционирования, которые невозможно проверить с использованием реальных зависимых модулей.
Модульное тестирование позволяет программистам безопасно проводить рефакторинг, будучи уверенными, что измененный модуль по-прежнему работает корректно.
В большей части известных ЯП высокого уровня существуют инструменты и библиотеки модульного тестирования (например, NUnit, JUnit, CppUnit).
Интеграционное тестирование — одна из стадий тестирования программного обеспечения, при котором некоторые программные модули объединяются и тестируются в комплексе. Чаще всего, интеграционное тестирование используют после модульного и перед системным тестированием. Целью данного вида тестирования является нахождение проблем взаимодействия модулей. Тестирование выполняется через интерфейс модулей с использованием метода «черного ящика».
Монолитное тестирование предполагает, что отдельные компоненты системы серьезного тестирования не проходили. Система проверяется вся в целом после разработки всех модулей. Несмотря на то что при монолитном тестировании проверяется работа всей системы в целом, основная задача этого тестирования — определить проблемы взаимодействия отдельных модулей системы. Основные недостатки монолитного тестирования заключаются в сложности выявления источников ошибок, а также в сложности автоматизации данного вида тестирования. Каждый модуль тестируют по мере готовности отдельно, а потом включают в уже готовую композицию. Для одних частей тестирование получается нисходящим, для других — восходящим.
Системное тестирование — это тестирование полной, интегрированной системы с целью проверки ее соответствия системным требованиям и показателям качества. Системные тесты учитывают такие аспекты системы, как устойчивость в работе, производительность, соответствие системы ожиданиям пользователя и т.п. Для определения полноты системного тестирования оцениваются выполнение всех возможных сценариев работы различные методы взаимодействия системы с внешней средой и т.д. Системное тестирование, как правило, использует метод «черного ящика».
1.6 Этапы тестирования программного обеспечения
На первом месте действия в планировании испытаний предполагают разработку стратегий тестирования на высоком уровне. Чаще всего стратегия тестирования должна предопределять объемы тестовых работ, типы методик тестирования, которые должны применяться для обнаружения дефектов, процедуры, уведомляющие об обнаружении и устраняющие дефекты, критерии входа и выхода из испытаний, которые управляют различными видами тестирования. При построении общей стратегии должно быть рассчитано как статическое, так и динамическое тестирование.
Автоматизация требует выполнения независимых параллельных работ, которые должны тщательно планироваться и выполняться только в тех случаях, когда это не приводит к снижению эффективности. Автоматизация должна быть в общем плане тестирования.
Существуют разные подходы к построению стратегии тестирования:
- понять объемы тестовых работ путем анализа документов, содержащих требования к программному продукту, чтобы понимать, что конкретно необходимо тестировать. Проанализировать тестирования, которые не входят непосредственно в документы с требованиями, такие как тестирование возможности установки и увеличения возможностей программного обеспечения, способности к взаимодействию с другим видом аппаратных средств из среды заказчика и другие;
- выбрать подход к тестированию за счет выбора между статическим и динамическим тестированием, связанным с каждым этапом разработки. Тут потребуется добавить описания всех рабочих продуктов, которые обязана подготовить тестовая группа;
- узнать правила входа и выхода для всех стадий тестирования, так же как и все точки контроля качества;
- определить план автоматизации в случае, если планируется использование автоматизации какого-либо вида тестовой деятельности. Автоматизация должна тщательно планироваться и делаться только тогда, когда это не приведёт к уменьшению эффективности.
Определение масштаб тестовых работ
Протестировать всё просто невозможно, очень важно правильно выбрать то, что необходимо протестировать. В случае, если будет перебор в тестировании, то для отладки программного продукта потребуется намного больше времени, что ставит под угрозу срок сдачи проекта. В случае, если тестирование окажется недостаточным, то сильно увеличится риск пропуска какого либо дефекта, и в будущем исправление может стоить очень дорого, особенно, после релиза ПО. Найти нужный баланс между двумя крайностями поможет опыт и способ измерения успеха теста.
Вот несколько вариантов по стратегии тестирования, которые помогут найти оптимальную золотую середину:
Тестировать в первую очередь запросы с наивысшим приоритетом.
Тестировать новые функциональные возможности и программный код, который изменили с целью исправления или совершенствования предыдущих функциональных средств
Использовать разбиение на эквивалентные классы и анализ граничных значений для понижения затрат на тестирование
Тестировать те участки, в которых вероятнее всего присутствие проблем
Сконцентрировать свое внимание на конфигурациях и функциях, с которыми чаще всего будет иметь дело конечный пользователь.
Определение подхода к тестированию
Второй раздел определения стратегии тестирования относится определения подхода к тестированию. Строение подхода к тестированию начинается с анализа каждой стадии цикла разработки с целью подбора тестов динамического и статического тестирований, которые могут быть поэксплуатированы на соответствующей стадии тестирования. Не имеет значения, какая модель жизненного цикла разработки используется: спиралевидная, каскадная или модель с итеративными версиями — для подбора результативных тестов можно исследовать этапы любой перечисленной модели. Для примера, возьмем каскадную модель и определим, какие виды тестирования могут использоваться:
Стадия системного проектирования
Стадия формулирования требований
Системные испытания
Стадии тестирования проектов программ, программных кодов, модульного тестирования и комплексных испытаний
Регрессионное тестирование
Приемочные испытания
Определение критериев тестирования и точек контроля качества
Подход к тестированию должен отражаться в документах, содержащих планы проведения испытаний.
Существует пять типов критериев, которые могут определяться перед началом системного тестирования:
Критерий выхода. Описывает то, что вы считается необходимым для завершения испытаний.
Критерий входа. Описывает, что нужно сделать перед началом тестирования.
Критерий успешного/неудачного прохождения теста. Прогон каждого теста должен давать заранее известные результаты.
Критерий приостановки/возобновления. Описывает, что произойдет, если из-за дефектов продолжение тестирования окажется невозможным.
Другие критерии, определяемые стандартами или процессом. Если программный продукт обязан соответствовать стандарту или заказчик предъявляет конкретные требования к исполняемому процессу, то, нужно иметь в виду ряд дополнительных критериев.
Установление стратегии автоматизации.
При существовании реальных планов и рациональных предположений применение автоматизированных инструментальных средств и автоматизированных тестовых случаях проявляет собой великолепный способ понижения временных затрат на тестирование ПО. Все задачи, которые повторяются неоднократно, становятся кандидатами на автоматизацию. Хотя обычно на автоматизацию, какой либо задачи тратиться немного больше времени, чем на ее исполнение. Делая анализ возможной пользы, необходимо не забывать, что для данной автоматизации характерен собственный автономный жизненный цикл.
Результативная автоматизация нуждается в специальной подготовки персонала, разработки, отладки и верификации. Беспорядочная и плохо сделанная автоматизация обозначает не только безуспешную трату ресурсов, она даже может нарушить график выполняемых работ, если время будет расходоваться на отладку автоматизации, а не на тестирование.
1.7 Цели и задачи тестирования программного обеспечения
Цели тестирования:
Увеличить вероятность того, что приложение, предназначенное для тестирования, работать будет правильно при всех обстоятельствах.
Увеличить вероятность того, что приложение, предназначенное для тестирования, будет подходить по всем требованиям заказчика.
Задачи тестирования:
Проверить, что данная система работает в соответствии с определенными временами отклика сервера и клиента.
Протестировать, что самые критические шаги действий с системой пользователя выполняются верно.
Проконтролировать работу пользовательских интерфейсов
Проконтролировать, что преобразование баз данных не причиняют неблагоприятного влияния на присутствующие программные модули.
При конструировании тестов свести к минимуму переработку тестов при вероятных изменениях приложения.
Пускать в дело инструменты автоматизированного тестирования там, где это рационально.
Осуществлять тестирование таким образом, чтобы обнаруживать и предсказывать дефекты.
При конструировании автоматизированных тестов использовать стандарты разработки так, чтобы сделать многократно используемые и сопровождаемые скрипты.
1.8 Комплексное тестирование программного обеспечения
Задачей комплексного тестирования является проверка того, что каждый модуль программного продукта точно согласуется с другими модулями продукта. При комплексном тестировании может использоваться технология обработки сверху вниз и снизу вверх, при которой все модули, являются листом в дереве системы, интегрируется со соседним модулем более низкого или более высокого уровня, пока не будет создано дерево программного продукта. Данная технология тестирования направлена на проверку тех параметров, которые передаются меж двух компонентов и на проверку глобальных параметров и, в случае объектно-ориентированного приложения, всех классов верхнего уровня.
Все процедуры комплексного тестирования состоят из тестовых скриптов верхнего уровня, которые моделируют выполнение пользователем конкретного задания, используя модульные тесты нижнего уровня с необходимыми настройками для проверки интерфейса. После проверки всех отчетов о проблемах модульного тестирования, модули объединяются инкрементно и тестируются уже вместе на основе управляющей логики. Так как модули могут содержать в себе другие модули, часть работы по комплексному тестированию может быть проведена во время модульного тестирования. Если скрипты для модульного тестирования были созданы с помощью инструментов автоматизированного тестирования, их можно соединить и добавить новые скрипты для тестирования межмодульных связей.
Операции комплексного тестирования делаются и должным образом уточняются, отчеты о багах документируются и отслеживаются. Отчеты о проблемах, как принято, классифицируют в зависимости от степени их серьезности в диапазоне от 1 до 4 (1 более критично, 4 – менее критично). После обработки этих отчетов тестировщик исполняет регрессионное тестирование, что бы убедиться, что ошибки устранены.
1.9 Восходящее и нисходящее тестирование
Восходящее тестирование — это идеальный способ найти местоположение ошибок. Представим, что ошибка найдена при тестировании одного модуля, то разумеется, что она живёт именно в нем и для поиска ее источника не нужно анализировать весь код системы досконально. А если ошибка находится при общей работе двух модулей, которые уже прошли проверку поодиночке, значит, дело в интерфейсе. Еще одним преимуществом восходящего тестирования то, что выполняющий его программист концентрируется на очень узкой области. В связи с этим тестирование делается более тщательно и с большей вероятностью выявляет ошибки.
Главным недостатком восходящего тестирования является написания специального кода-оболочки, вызывающего тестируемый модуль. Если он, вызывает другой модуль, для него нужно сделать «заглушку». Заглушка — это имитация функции, которую вызывают, которая возвращает те же данные, и больше ничего не делает.
Разумеется, что написание оболочек и заглушек немного замедляет работу, а для продукта они абсолютно бесполезны.
В противоположность восходящему тестированию, стратегия целостного тестирования предполагает, что до полной интеграции системы ее отдельные модули не проходят особо тщательного тестирования.
Достоинством такой стратегии является то, что не надо писать дополнительный код. В связи с этим многие руководители выбирают этот способ из-за экономии времени — они считают, что лучше создать один обширный набор тестов и с его помощью за один раз проверить всю систему. Но такое представление ошибочно, и вот почему.
Очень трудно найти источник ошибки. Это самая главная проблема. Поскольку ни один из модулей не проверен как должно, и по статистике в большинстве из них есть ошибки. Получается, что вопрос не столько в том, в каком модуле произошла обнаруженная ошибка, сколько в том, какая из ошибок во всех вовлеченных в процесс модулях привела к полученному результату. И когда накладываются ошибки нескольких модулей, ситуацию может быть гораздо труднее локализовать и повторить.
Бывает, что ошибка в одном модуле может блокировать тестирование другого. Как проверить функцию, если вызывающий ее модуль не работает? Если не создать для этой функции программу-оболочку, придется ждать отладки модуля, а это может затянуться надолго и может быть безрезультатно.
Трудно организовать исправление ошибок. Если программу пишут несколько программистов (в крупных проектах именно так и работают), и при этом никто не знает, в каком модуле ошибка, кто её найдёт и исправит? Первый разработчик переведёт стрелки на второго, тот проверит свой код и в случае, если всё хорошо, переведёт стрелки обратно на первого, а в результате будет сильно страдать скорость разработки.
Процесс теста плохо автоматизирован. То, что на первый взгляд кажется достоинством целостного тестирования — нет необходимости писать оболочки и заглушки, — потом оборачивается его недостатком. В процессе разработки программа ежечасно меняется, и ее приходится тестировать опять и опять. А оболочки и заглушки помогут автоматизировать этот однообразный труд.
Существует и еще один схема организации тестирования, при котором программа так же, как и при восходящем способе, тестируется не вся, а по кускам. Только направление движения меняется — сначала тестируется самый верхний уровень модулей, а от него тестер постепенно спускается вниз. Такая технология называется нисходящей. Обе технологии — и нисходящую и восходящую — называют инкрементальными.
При нисходящем тестировании исключается необходимость в написании оболочек, но заглушки остаются. По мере тестирования заглушки по очереди заменяются на реальные модули.
Взгляды специалистов о том, какая из инкрементальных стратегий тестирования более результативна, сильно расходятся. На практике обычно всё решается намного проще: каждый модуль тестируется сразу после его написания, в результате последовательность тестирования одних частей программы может быть восходящей, а других — нисходящей.
2. СТРАТЕГИЯ ТЕСТИРОВАНИЯ И ОТЛАДКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
2.1 Метод Сандвича
Компромисс между нисходящим и восходящим подходами называют тестирование методом Сандвича. Достоинство этого метода заключается в том, что используется попытка объединить преимущества обоих подходов, исключая их недостатки. Используя данный метод, начинают свою работу одновременно нисходящее и восходящее тестирования, которые собирают программу как сверху, так и снизу, в итоге встречаются примерно в середине. При изучении структуры программы, такая точка встречи должна заранее определяться. К примеру, если программист имеет возможность представить свою систему в качестве различных уровней: прикладных модулей, модулей обработки запросов, уровня примитивных функций, то он также может принять решение применить нисходящий подход на уровне прикладных модулей (программируя вместо модулей обработки запросов заглушки), но на всех остальных уровнях использовать восходящий подход. Применение метода сандвича является разумным подходом к интеграции больших программ, таких как пакет прикладных программ или операционная система.
Метод сандвича на самом раннем этапе сохраняет достоинство восходящего и нисходящего подходов, как начало интеграции системы. Так как вершина программы вступает в строй рано, как и в нисходящем методе, уже на раннем этапе получаем работающую основу программы. Поскольку нижние уровни программы создаются восходящим методом, снимаются те проблемы нисходящего метода, которые были связаны с отсутствием возможности тестировать некоторые условия в глубине программы.
При тестировании методом сандвича возникает та же проблема, что и при нисходящем подходе, хоть и стоит она здесь не так остро. Проблема заключается в том, что невозможно детально тестировать отдельные модули. Восходящий этап тестирования по методу сандвича решает эту проблему для модулей нижних уровней, но она может по-прежнему оставаться открытой для нижней половины верхней части программы. В модифицированном методе сандвича нижние уровни также тестируются строго снизу вверх. А модули верхних уровней сначала тестируются изолированно, а затем собираются нисходящим методом. Таким образом, модифицированный метод сандвича также представляет собой компромисс между восходящим и нисходящим подходами.
2.2 Метод «белого ящика»
Термин «белый ящик» понимают так, что при разработке тестовых случаев тестировщики используют любые доступную информацию о коде или внутренней структуре. Технологии, которые применяют при тестировании «белого ящика», чаще всего называют как технологии статического тестирования.
Данный метод не ставит цель выявить синтаксические ошибки, потому что дефекты подобного рода часто обнаруживает компилятор. Методы белого ящика направлены на локализацию ошибок, которые сложнее выявить, найти и зафиксировать. С их помощью можно обнаружить логические ошибки и проверить степень покрытия тестами.
Тестовые процедуры, которые связанны с использованием стратегии белого ящика, используют управляющую логику процедур. Они предоставляют ряд услуг, в том числе:
- дают гарантию того, что все независимые пути в модуле проверены хотя бы один раз;
- проверяют все логические решения на предмет истины;
- выполняют все циклы внутри операционных границ и с использованием граничных значений;
- исследуют структуры внутренних данных для проверки их достоверности.
Тестирование посредством белого ящика обычно включает в себя стратегию модульного тестирования, при котором тестирование ведется на функциональном или модульном уровне и работы по тестированию направлены на исследование внутреннего устройства модуля. Такой тип тестирования также называют модульным тестированием, тестированием прозрачного ящика (clear box) или прозрачным (translucent) тестированием, так как работники, которые проводят тестирование, имеют доступ к программному коду и имеют возможность видеть работу программного обеспечения изнутри. Данный подход к тестированию также известен как структурный подход.
На этом уровне тестирования проверяется управляющая логика, которая проявляется на модульном уровне. Тестовые драйверы используются для того, чтобы все пути в данном модуле были проверены хотя бы один раз, все логические решения рассмотрены во всевозможных условиях, циклы были выполнены с использованием верхних и нижних границ и роконтролированы структуры внутренних данных.
При вводе неверных значений тестировщик заставляет коды возврата показывать ошибки и смотрит на реакцию кода. Это хороший способ моделирования определенных событий, например переполнения диска, нехватки памяти и т.д. Популярным методом является замена alloc() функцией, которая возвращает значение NULL в 10% случаев с целью выяснения, сколько сбоев будет в результате. Данный подход еще называют тестированием ошибочных входных данных. При этом тестировании проверяется обработка как верных, так и неверных входных данных. Тестировщики выбирают значения, которые проверяют диапазон входных/выходных параметров, и кроме того значения, выходящие за границу диапазона.
При создании кода каждого модуля программного продукта проводится модульное тестирование для проверки того, что код работает верно и корректно реализует архитектуру. При модульном тестировании новый код проверяется на соответствие подробному описанию архитектуры; обследуются пути в коде, устанавливается, что экраны, ниспадающие меню и сообщения должным образом отформатированы; проверяются диапазон и тип вводимых данных, а также то, что каждый блок кода, при необходимости, генерирует исключения и возвращает ошибки (еггог returns). Тестирование каждого модуля программы проводится для того, чтобы проверить корректность алгоритмов и логики, а также то, что программный модуль удовлетворяет предъявляемым требованиям и обеспечивает необходимую функциональность. По итогам модульного тестирования фиксируются ошибки, которые относятся к логике программного продукта, перегрузке и выходу из диапазона, времени работы и утечке памяти.
Во время использования данного метода признается, что нереально на практике проверить каждое возможное условие возникновения ошибки. Поэтому программа обработки ошибок может сгладить последствия при возникновении неожиданных ошибок. Тестер должен убедиться, что приложение правильным образом выдает сообщение об ошибке. Так, приложение, которое сообщает о системной ошибке, которая возникла из-за промежуточного программного обеспечения, представляет небольшую ценность, как для тестера, так и для конечного пользователя.
При тестировании утечки памяти приложение исследуется для обнаружения ситуаций, при которых приложение не освобождает выделенную память, в результате чего снижается производительность или возникает тупиковая ситуация. Такая технология применяется как для тестирования версии приложения, так и для тестирования готового программного продукта. Возможно применение инструментов тестирования. Они могут следить за использованием памяти приложения в течение нескольких часов или даже дней, для того чтобы проверить, будет ли расти объем используемой памяти или же нет. С их помощью также можно выявить такие операторы программы, которые не освобождают выделенную память.
Целью комплексного тестирования является проверка того, что каждый модуль программного продукта корректно согласуется с остальными модулями продукта. При комплексном тестировании может использоваться технология обработки сверху вниз и снизу вверх, при которой каждый модуль, который является листом в дереве системы, интегрируется со следующим модулем более низкого или более высокого уровня, до тех пор, пока не будет создано дерево программы. Такая технология тестирования направлена на проверку не только тех параметров, которые передаются между двумя компонентами, но и на проверку глобальных параметров и, в случае объектно-ориентированного приложения, всех классов верхнего уровня.
Тестирование цепочек направлено на проверку группы модулей, которые составляют функцию программы. Такие действия известны также как модульное тестирование, с его помощью обеспечивается адекватное тестирование компонентов системы. Такое тестирование выявляет, достаточно ли надежно работают модули, чтобы образовать единый модуль, и выдает ли модуль программного продукта точные и согласующиеся результаты.
При выборе инструмента для исследования покрытия важно, чтобы группа тестирования проанализировала тип покрытия, который необходим для приложения. Исследование покрытия можно провести с помощью разных технологий. Метод покрытия операторов часто называют С1, что также означает покрытие узлов. Эти измерения показывают, был ли проверен каждый исполняемый оператор. Такой метод тестирования часто использует программу протоколирования производительности.
Метод покрытия решений нацелен на определение (в процентном соотношении) всех возможных исходов решений, которые были проверены с помощью комплекта тестовых процедур. Метод покрытия решений можно отнести к покрытию ветвей и называют С2. Для него необходимо, чтобы каждая точка входа и выхода в программе была достигнута хотя бы единожды, чтобы все возможные условия для решений в программе были проверены как минимум один раз, и чтобы каждое решение в программе хотя бы единожды было протестировано при использовании всех возможных исходов.
Покрытие условий похоже на покрытие решений. Оно нацелено на проверку точности истинных или ложных результатов всех логических выражений. Данный метод включает в себя тесты, проверяющие выражения независимо друг от друга. Результаты таких проверок аналогичны тем, что получают при применении метода покрытия решений, за исключением того, что метод покрытия решений более чувствителен к управляющей логике программы.
2.3 Метод «черного ящика»
Тестирование, которое основывается на стратегии черного ящика возможно только при наличии установленных открытых интерфейсов, таких как интерфейс пользователя или программный интерфейс приложения (API). Если тестирование на основе стратегии белого ящика исследует внутреннюю работу программы, то методы тестирования черного ящика сравнивают поведение приложения с соответствующими требованиями. Также такие методы обычно направлены на выявление трех основных видов ошибок: функциональности, поддерживаемой программным продуктом; производимых вычислений; допустимого диапазона или области действия значений данных, которые могут быть обработаны программным продуктом. На таком уровне тестеры не исследуют внутреннюю работу компонентов программного продукта, но все же они проверяются неявно. Группа тестирования изучает входные и выходные данные программного продукта. В таком ракурсе тестирование с применением методов черного ящика рассматривается как синоним тестирования на уровне системы, хоть и методы черного ящика также применяются во время модульного или компонентного тестирования.
При тестировании методами черного ящика важно участие пользователей, так как именно они лучше всего знают, каких результатов следует ожидать от бизнес-функций. Ключом к успешному завершению системного тестирования является корректность данных. Соответственно на фазе создания данных для тестирования крайне важно, чтобы конечные пользователи предоставили как можно больше входных данных.
Тестирование с помощью методов черного ящика нацелено на получение множеств входных данных, которые наиболее полно проверяют все функциональные требования системы. Это не альтернатива тестированию по методу белого ящика. Этот тип тестирования нацелен на поиск ошибок, которые относятся к целому ряду категорий, которые включают в себя:
- неверную или пропущенную функциональность;
- ошибки интерфейса;
- проблемы удобства использования;
- методы тестирования на основе автоматизированных инструментов;
- ошибки в структурах данных или ошибки доступа к внешним базам данных;
- проблемы снижения производительности и другие ошибки производительности;
- ошибки загрузки;
- ошибки многопользовательского доступа;
- ошибки инициализации и завершения;
- проблемы сохранения резервных копий и способности к восстановлению работы;
- проблемы безопасности;
Исчерпывающее тестирование входных данных обычно неосуществимо. Именно поэтому следует проводить тестирование с использованием подмножества входных данных.
При тестировании ошибок, которые связанны с выходом за пределы области допустимых значений, применяют три основных типа эквивалентных классов: значения внутри границы диапазона, за границей диапазона и на границе. Оправдывает себя практика создания тестовых процедур, которые проверяют граничные случаи плюс/минус один, чтобы избежать пропуска ошибок «на единицу больше» или «на единицу меньше». Помимо разработки тестовых процедур, которые используют сильно структурированные классы эквивалентности, группа тестирования должна провести исследовательское тестирование. Тестовые процедуры, при выполнении которых выдаются ожидаемые результаты, называются правильными тестами. Тестовые процедуры, проведение которых должно привести к ошибке, имеют название неправильных тестов.
Составление диаграмм причинно-следственных связей является методом, который дает четкое представление о логических условиях и соответствующих действиях. Данный метод предполагает четыре этапа. Первый этап заключается в составлении перечня причин (условий ввода) и следствий (действий) для модуля и в присвоении идентификатора каждому модулю. На втором этапе разрабатывается диаграмма причинно-следственных связей. На третьем этапе диаграмма преобразуется в таблицу решений. Четвертый этап включает в себя установление причин и следствий в процессе чтения спецификации функций. Каждой причине и следствию присваивается собственный идентификатор. Причины перечисляются в столбике с левой стороны листа бумаги, а следствия — с правой. После чего причины и следствия соединяются линиями таким образом, чтобы отражены имеющиеся между ними соответствия. На диаграмме проставляются булевы выражения, которые объединяют две или более причин, связанных со следствием. Далее правила таблицы решений преобразуются в тестовые процедуры.
Термин «системное тестирование» обычно употребляется в качестве синоним «тестирования с помощью методов черного ящика», так как во время системного тестирования группа тестирования рассматривает в основном «внешнее поведение» приложения. Системное тестирование включает в себя несколько подтипов тестирования, в том числе функциональное, регрессионное, безопасности, перегрузок, производительности, удобства использования, случайное, целостности данных, преобразования данных, сохранения резервных копий и способности к восстановлению, готовности к работе, приемо-сдаточные испытания и альфа/бета тестирование.
Функциональное тестирование проверяет системное приложение в отношении функциональных требований для обнаружения несоответствия требованиям конечного пользователя. Для большинства программ тестирования программного продукта такой метод тестирования является главным. Его основной задачей является оценка того, работает ли приложение в соответствии с предъявляемыми требованиями.
Смысл проведения тестирования заключается в обнаружении дефектов, их документировании и отслеживании вплоть до устранения. Тестировщик должен быть уверен, что меры, которые принимаются для устранения найденных ошибок, не породят в свою очередь новые ошибки в других областях системы. Регрессионное тестирование дает возможность выяснить, не появились ли какие-либо ошибки при ликвидации уже обнаруженных ошибок. Именно для регрессионного тестирования применение инструментов автоматизированного тестирования дает наибольшую отдачу. Все созданные ранее скрипты можно использовать еще раз для подтверждения того, что в результате изменений, которые были внесены при устранении ошибки, не появились новые дефекты. Такая цель легко достижима, так как скрипты можно выполнять без ручного вмешательства и использовать необходимое количество раз для обнаружения ошибок.
Тестирование безопасности включает в себя проверку работы механизмов доступа к системе и к данным. Для этого придумывают тестовые процедуры, которые пытаются преодолеть защиту системы. тестер проверяет степень безопасности и ограничения доступа, выявляя подобным образом соответствие установленным требованиям к безопасности и всем применяемым
При тестировании перегрузок выполняется проверка системы без учета ограничений архитектуры для выявления технических ограничений системы. Такие тесты проводятся на пике обработки транзакций и при непрерывной загрузке большого объема данных. Тестирование перегрузок измеряет пропускную способность системы и ее эластичность на всех аппаратных платформах. Данный метод подразумевает единовременное обращение со стороны многих пользователей к определенным функциям системы, причем некоторые вводят значения, которые выходят за пределы нормы. От системы требуется обработка огромного количества данных или выполнение большого числа функциональных запросов в течение короткого периода времени.
Тесты производительности проверяют, удовлетворяет ли системное приложение требованиям по производительности. При применении тестирования производительности, можно замерить и составить отчеты по таким показателям, как скорость передачи входных и выходных данных, общее число действий по вводу и выводу данных, среднее время, затрачиваемое базой данных на отклик на запрос, и интенсивность использования центрального процессора. Обычно для автоматической проверки степени производительности, которая проводится в рамках тестирования производительности, используются те же инструменты, что и при тестировании перегрузок.
Тесты удобства использования нацелены на подтверждение простоты применения системы и того, что пользовательский интерфейс выглядит привлекательно. Подобные тесты учитывают человеческий фактор в работе системы. Тестеру необходимо оценить приложение с точки зрения конечного пользователя.
2.4 Методы отладки программного обеспечения
Отладка программы обычно принимает рассмотрение и логическое решение доступной информации об ошибках. Большая часть ошибок может быть отнесена к косвенным знакам посредством тщательного анализа текстов программ и результатов тестирования, не получая дополнительной информации. Как правило, используются различные методы:
- ручное тестирование;
- прологи;
- снижения;
- обратная трассировка.
Метод ручного тестирования является самым простым и естественным методом данной группы. Данный метод является очень эффективным, но не имеет применения по отношению к большим программам, к программам с трудными расчетами. Такой метод обычно используется как компонент других методов при ликвидации неисправностей
Метод пролога основан на тщательном анализе симптомов ошибки, которая может появиться из-за неправильных результатов.
При методе снижения используется анализ причин, которые могут противоречить имеющимся данным и могли вызвать данную ошибку. Если же все причины отпадают, то появляется необходимость провести дополнительное тестирование изучаемого фрагмента.
Метод обратной трассировки используется для небольших программ. Обычно начинают с точки вывода неправильного результата. Кроме того, формулируется гипотеза о значении основных переменных, с помощью которых появляется возможность получить необходимый результат.
ЗАКЛЮЧЕНИЕ
Невозможно гарантировать отсутствие ошибок в нетривиальной программе; в лучшем случае можно попытаться показать наличие ошибок. Если программа правильно ведет себя для солидного набора тестов, нет оснований утверждать, что в ней нет ошибок; со всей определённостью можно лишь утверждать, что не известно, когда эта программа не работает. Конечно, если есть причины считать данный набор тестов способным с большой вероятностью обнаружить все возможные ошибки, то можно говорить o некотором уровне уверенности в правильности программы, устанавливаемом этими тестами. Надёжность невозможно внести в программу в результате тестирования, она определяется правильностью этапов проектирования. Наилучшее решение проблемы надёжности — с самого начала не допускать ошибок в программе. Однако вероятность того, что удастся безупречно спроектировать большую программа, бесконечно мала.
Испытания таких программ, как системы реального времени, операционные системы и программы управления данными, которые сохраняют «память» o предыдущих входных данных, особенно трудны. Нам потребовалось бы тестировать программу не только для каждого входного значения, но и для каждой последовательности, каждой комбинации входных данных. Поэтому исчерпывающее тестирование для всех входных данных любой разумной программы неосуществимо.
Тестирование является завершающим этапом разработки. Ему предшествует этап статической и динамической отладки программ. Основным методом динамической отладки является тестирование. В узком смысле цель тестирования состоит в обнаружении ошибок, цель же отладки — не только в обнаружении, но и в устранении ошибок. Однако ограничиться только отладкой программы, если есть уверенность в том, что все ошибки в ней устранены, нельзя. Цели у отладки и тестирования разные. Полностью отлаженная программа может не обладать определёнными потребительскими свойствами и тем самым быть непригодной к использованию по своему назначению.
БИБЛИОГРАФИЯ:
1.Бейзер Б. Тестирование черного ящика. Технологии функционального тестирования программного обеспечения и систем [текст] / Б. Бейзер; — Питер, 2004, 320 с. ISBN 5-94723-698-2.
2.Брауде Э.Д. Технология разработки программного обеспечения [текст] / Э.Д. Брауде; — Питер, 2004, 656 с. ISBN 5-94723-663-X.
3.Винниченко И.В. Автоматизация процессов тестирования [текст] / И. В. Винниченко; — Питер, 2005, 208 с. ISBN 5-469-00798-7.
4.Канер С. Тестирование программного обеспечения. Фундаментальные концепции менеджмента бизнес-приложений [текст] / С. Канер; — ДиаСофт, 2001, 544 с, ISBN 966-7393-87-9.
5.Калбертсон Р. Быстрое тестирование [текст] / Р. Калбертсон, К. Браун, Г. Кобб; — Вильямс, 2002, 384 с. ISBN 5-8459-0336-X.
6.Коликова Т.В. Основы тестирования программного обеспечения. Учебное пособие [текст] / Т.В. Коликова, В.П. Котляров; — Интуит, 2006, — 285 с. ISBN 5-85582-186-2.
7.Касперски К. Техника отладки программ без исходных текстов [текст] / К. Касперски; — БХВ-Петербург, 2005, 832 с. ISBN 5-94157-229-8.
8.Макгрегор Д. Тестирование объектно-ориентированного программного обеспечения. Практическое пособие [текст] / Д. Макгрегор, Д. Сайкс; — ТИД «ДС», 2004, 432 с. ISBN 966-7992-12-8.
9.Плаксин М. Тестирование и отладка программ — для профессионалов будущих и настоящих [текст] / М. Пласкин; — Бином. Лаборатория знаний, 2007, — 168 с. ISBN 978-5-94774-458-3.
10.Роберт М. Быстрая разработка программ: принципы, примеры, практика [текст] / М. Роберт, Д. Ньюкирк; — Вильямс, 2004, 752 с. ISBN 5-8459-0558-3.
11.Фолк Д. Тестирование программного обеспечения [текст] / Д. Фолк, Е. К. Нгуен, С. Канер; — Диасофт, 2003 , 400 с. ISBN 966-7393-87-9.
12.Элфрид Д. Автоматизированное тестирование программного обеспечения. Внедрение, управление и эксплуатация [текст] / Элфрид Д., Джефф Р., Джон П.;- Лори, 2003, ISBN 5-85582-186-2.
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
Классификация ошибок по этапу обработки программы
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
Вау!! 😲 Ты еще не читал? Это зря!
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.