
Мы закончили рассмотрение паттернов 64-битных ошибок. Последнее на чем мы остановимся в связи с этими ошибками, является то, как они могут проявляться в программах.
Дело в том, что не так просто показать в примере, что приведенный 64-битный код приведет к ошибке при большом значении N:
size_t N = ...
for (int i = 0; i != N; ++i)
{
...
}Вы можете попробовать подобный простой пример и увидеть, что код работает. Дело в том, каким образом построит код оптимизирующий компилятор. Будет работать код или нет зависит от размера тела цикла. В примерах он всегда маленький, и для счетчиков могут использоваться 64-битные регистры. В реальных программах, с большими телами циклов, ошибка легко возникает, когда компилятор будет сохранять значение переменной «i» в памяти. А теперь давайте попробуем разобраться с непонятным текстом, который вы только что прочитали.
При описании ошибок, очень часто использовался термин «потенциальная ошибка» или словосочетание «возможно возникновение ошибки». В основном это объясняется тем, что один и тот же код можно считать как корректным, так и некорректным в зависимости от его назначения. Простой пример — использование для индексации элементов массива переменной типа int. Если с помощью этой переменной мы обращаемся к массиву графических окон, то все корректно. Не бывает нужно, да и не получится работать с миллиардами окон. А вот индексация с использованием переменной типа int к элементам массива в 64-битных математических программах или базах данных, вполне может представлять собой проблему, когда количество элементов выйдет из диапазона 0..INT_MAX.
Но есть и еще одна, куда более тонкая причина называть ошибки «потенциальными». Дело в том, проявит себя ошибка или нет, зависит не только от входных данных, но и от настроения оптимизатора компилятора. Большинство из рассмотренных в уроках ошибок хорошо проявляют себя в debug-версии, и «потенциальны» в release-версиях. Однако не всякую программу, собранную как debug, можно отлаживать на больших объемах данных. Возникает ситуация, когда debug-версия тестируется только на самых простых наборах данных. А нагрузочное тестирование и тестирование конечными пользователями на реальных данных, выполняется на release-версиях, где ошибки могут быть временно скрыты.
Впервые мы столкнулись с особенностями оптимизации компилятора Visual C++ 2005 при подготовке программы OmniSample. Это проект, который входит в состав дистрибутива PVS-Studio и предназначен для демонстрации всех ошибок, которые диагностирует анализатор Viva64. Примеры, которые содержатся в этом проекте, должны корректно работать в 32-битном режиме и приводить к ошибкам в 64-битном варианте. В отладочной версии все работало замечательно, а вот с release версией возникли затруднения. Тот код, который в 64-битном режиме должен был зависать или приводить к аварийному завершению программы — успешно работал! Причина оказалась в оптимизации. Решением стало дополнительное избыточное усложнение кода примеров и расстановка ключевых слов «volatile», которые вы сможете наблюдать в коде проекта OmniSample.
То же самое относится и к Visual C++ 2008/2010. Код будет конечно несколько разным, но все что будет написано здесь можно отнести как к Visual C++ 2005, так и к Visual C++ 2008.
Если вам покажется, что это только хорошо, если некоторые ошибки не проявляют себя, то гоните скорее эту мысль прочь. Код с подобными ошибками становится крайне нестабильным. И малейшее изменение кода, напрямую не связанное с ошибкой, может приводить к изменению поведения. На всякий случай подчеркну, что виноват в этом не компилятор, а скрытые дефекты кода. Далее будут показаны примерные фантомные ошибки, которые исчезают и появляются в release-версиях при малейших изменениях кода, и на которых можно долго и утомительно охотиться.
Рассмотрим первый пример кода, который работает в release-режиме, хотя делать этого не должен:
int index = 0;
size_t arraySize = ...;
for (size_t i = 0; i != arraySize; i++)
array[index++] = BYTE(i);Данный код корректно заполняет весь массив значениями, даже если размер массива гораздо больше INT_MAX. Теоретически это невозможно, поскольку переменная index имеет тип int. Через некоторое время из-за переполнения должен произойти доступ к элементам по отрицательному индексу. Однако оптимизация приводит к генерации следующего кода:
0000000140001040 mov byte ptr [rcx+rax],cl
0000000140001043 add rcx,1
0000000140001047 cmp rcx,rbx
000000014000104A jne wmain+40h (140001040h)Как видите, используются 64-битные регистры и переполнение не происходит. Но сделаем совсем маленькое исправление кода:
int index = 0;
size_t arraySize = ...;
for (size_t i = 0; i != arraySize; i++)
{
array[index] = BYTE(index);
++index;
}Будем считать, что так код выглядит более красиво. Согласитесь, что функционально он остался прежним. А вот результат будет существенным — произойдет аварийное завершение программы. Рассмотрим сгенерированный компилятором код:
0000000140001040 movsxd rcx,r8d
0000000140001043 mov byte ptr [rcx+rbx],r8b
0000000140001047 add r8d,1
000000014000104B sub rax,1
000000014000104F jne wmain+40h (140001040h)Происходит то самое переполнение, которое должно было быть и в предыдущем примере. Значение регистра r8d = 0x80000000 расширяется в rcx как 0xffffffff80000000. И как следствие — запись за пределами массива.
Рассмотрим другой пример оптимизации и как легко все испортить. Пример:
unsigned index = 0;
for (size_t i = 0; i != arraySize; ++i) {
array[index++] = 1;
if (array[i] != 1) {
printf("Errorn");
break;
}
}Ассемблерный код:
0000000140001040 mov byte ptr [rdx],1
0000000140001043 add rdx,1
0000000140001047 cmp byte ptr [rcx+rax],1
000000014000104B jne wmain+58h (140001058h)
000000014000104D add rcx,1
0000000140001051 cmp rcx,rdi
0000000140001054 jne wmain+40h (140001040h)Компилятор решил использовать 64-битный регистр rdx для хранения переменной index. В результате код может корректно обрабатывать массивы размером более UINT_MAX.
Но мир хрупок. Достаточно немного усложнить код и он станет неверен:
volatile unsigned volatileVar = 1;
...
unsigned index = 0;
for (size_t i = 0; i != arraySize; ++i) {
array[index] = 1;
index += volatileVar;
if (array[i] != 1) {
printf("Errorn");
break;
}
}Использование вместо index++ выражения «index += volatileVar;» приводит к тому, что в коде начинают участвовать 32-битные регистры, из-за чего происходят переполнения:
0000000140001040 mov ecx,r8d
0000000140001043 add r8d,dword ptr [volatileVar (140003020h)]
000000014000104A mov byte ptr [rcx+rax],1
000000014000104E cmp byte ptr [rdx+rax],1
0000000140001052 jne wmain+5Fh (14000105Fh)
0000000140001054 add rdx,1
0000000140001058 cmp rdx,rdi
000000014000105B jne wmain+40h (140001040h)Напоследок приведем интересный, но большой пример. К сожалению, мы не смогли его сократить, чтобы сохранить необходимее поведение. Именно этим и опасны такие ошибки, так как невозможно предугадать к чему приводит простейшее изменение кода.
ptrdiff_t UnsafeCalcIndex(int x, int y, int width) {
int result = x + y * width;
return result;
}
...
int domainWidth = 50000;
int domainHeght = 50000;
for (int x = 0; x != domainWidth; ++x)
for (int y = 0; y != domainHeght; ++y)
array[UnsafeCalcIndex(x, y, domainWidth)] = 1;Данный код не может корректно заполнить массив, состоящий из 50000*50000 элементов. Невозможно это по той причине, что при вычислении «int result = x + y * width;» должно происходить переполнение.
Благодаря чуду массив все же корректно заполняется в release-варианте. Функция UnsafeCalcIndex встраивается внутрь цикла, используются 64-битные регистры:
0000000140001052 test rsi,rsi
0000000140001055 je wmain+6Ch (14000106Ch)
0000000140001057 lea rcx,[r9+rax]
000000014000105B mov rdx,rsi
000000014000105E xchg ax,ax
0000000140001060 mov byte ptr [rcx],1
0000000140001063 add rcx,rbx
0000000140001066 sub rdx,1
000000014000106A jne wmain+60h (140001060h)
000000014000106C add r9,1
0000000140001070 cmp r9,rbx
0000000140001073 jne wmain+52h (140001052h)Все это произошло из-за того, что функция UnsafeCalcIndex проста и может быть легко встроена. Стоит ее немного усложнить, или компилятору посчитать, что встраивать ее не стоит, и возникнет ошибка, которая проявит себя на больших объемах данных.
Немного модифицируем (усложним) функцию UnsafeCalcIndex. Обратите внимание, что логика функции ничуть не изменилась:
ptrdiff_t UnsafeCalcIndex(int x, int y, int width) {
int result = 0;
if (width != 0)
result = y * width;
return result + x;
}Результат — аварийное завершение программы, при выходе за границы массива:
0000000140001050 test esi,esi
0000000140001052 je wmain+7Ah (14000107Ah)
0000000140001054 mov r8d,ecx
0000000140001057 mov r9d,esi
000000014000105A xchg ax,ax
000000014000105D xchg ax,ax
0000000140001060 mov eax,ecx
0000000140001062 test ebx,ebx
0000000140001064 cmovne eax,r8d
0000000140001068 add r8d,ebx
000000014000106B cdqe
000000014000106D add rax,rdx
0000000140001070 sub r9,1
0000000140001074 mov byte ptr [rax+rdi],1
0000000140001078 jne wmain+60h (140001060h)
000000014000107A add rdx,1
000000014000107E cmp rdx,r12
0000000140001081 jne wmain+50h (140001050h)Надеемся, нам удалось продемонстрировать, как работающая 64-битная программа может легко стать неработающей, после того как вы внесете в нее самые безобидные правки или соберете другой версией компилятора.
Также вам теперь будут понятны некоторые странности и причудливости кода в проекте OmniSample, которые сделаны для того, чтобы продемонстрировать ошибку в простых примерах даже в режиме оптимизации кода.
Авторы курса: Андрей Карпов (karpov@viva64.com), Евгений Рыжков (evg@viva64.com).
Правообладателем курса «Уроки разработки 64-битных приложений на языке Си/Си++» является ООО «Системы программной верификации». Компания занимается разработкой программного обеспечения в области анализа исходного кода программ. Сайт компании: http://www.viva64.com.
В информатике , то проблема фантом ( непоследовательно чтения ) является ошибкой , которая может произойти с несколькими параллельными базами данных доступов . Если новые записи данных с этим свойством вставляются в транзакцию, которая выполняется одновременно во время транзакции, которая относится к нескольким записям данных с указанным свойством, это может привести к несогласованным данным в первой транзакции.
Примеры фантомной проблемы
- Ссылка должна рассчитываться по всему столбцу
В частности, это может быть, например, формирование среднего значения столбца. Транзакция 1 сначала определяет общую сумму, используя столбец в таблице; затем транзакция 2 добавляет новую запись. На третьем этапе транзакция 1 вычисляет количество записей в столбцах. В конце заранее определенная сумма всех данных из нашего столбца делится на количество записей данных. Единственная проблема с вычислением заключается в том, что сумма подсчитанных записей данных выше, потому что новая запись данных была вставлена в середину. Это искажает среднее значение.
| время | Транзакция 1 | Транзакция 2 |
|---|---|---|
| 1 |
ВЫБЕРИТЕ СУММУ (число) ИЗ инвентаря;
Результат: Общее количество товаров на складе, например B. для двух разных статей с одной копией для каждой значение 2. |
|
| 2 | ВСТАВИТЬ В инвентарь (артикул, номер) ЗНАЧЕНИЯ (‘Wikipedia: Das Buch’, 3); | |
| 3 |
ВЫБЕРИТЕ КОЛИЧЕСТВО (*) ИЗ инвентаря;
Результат: количество различных товаров на складе. После параллельного выполнения INSERT возвращается значение 3. Если результат, полученный ранее, делится на это значение для определения среднего числа копий, правильный результат (5/3) не вычисляется, а значение слишком низкое (2 / 3). |
Избегание
Самый простой способ избежать этой проблемы — заблокировать всю таблицу в транзакции, подверженной фантомной проблеме. Однако этого достаточно, чтобы предотвратить изменения затронутого столбца в затронутых записях данных, если в то же время можно гарантировать, что нельзя будет добавить новые записи или можно будет удалить существующие записи, которые также будут введены позже в транзакции.
Базы данных знают возможность сериализации параллельных операций , соответствующие на уровне изоляции Serializable из в SQL стандарта. Если используется этот уровень изоляции, приложения, которые обращаются к базе данных, должны иметь возможность справляться с результирующими неудачными обращениями (ошибками сериализации).
Ловушки
Многие базы данных имеют способность повторяемого чтения в соответствии с уровнем изоляции Многократное чтение в SQL стандарты. Это означает, что при изменении записи данных время изменения также сохраняется. Транзакция, которая началась до этого изменения, не «увидит» это изменение. Однако это часто не относится к вновь созданным записям данных, а только гарантирует, что новый процесс чтения данных, которые уже были прочитаны в рамках транзакции, будет иметь тот же результат.
Смотри тоже
- Согласованность (хранение данных)
- Потерянные обновления
- Конфликт записи-чтения
- Неповторимое чтение
веб ссылки
- «Transaction Isolation» из документации PostgreSQL
- «Изоляция транзакций» в MySQL с InnoDB
- «Изоляция транзакций» в Oracle DB
Фантомные ошибки при создании документа |
Я |
18.12.12 — 15:49
При создании документа возникает фантомная ошибка в процедуре обработки заполнения модуля документа. Ошибка возникает не сразу, а после около часа работы пользователя с данным видом документа. Очистка кеша не помогает. Откат конфы и обновление еще раз(НЕ ДИНАМИЧЕСКИ) не помогло. Вариант работы — клиент-серверный. Такая штука происходит только у пользователей, которые лезут в базу со своих ПК локально. Платформа последняя на сегодняшний день — только вчера установлена
1 — 18.12.12 — 15:50
Фантомные ошибки — что-то новое. давно появились?
2 — 18.12.12 — 15:51
текст ошибки или описание будут?
3 — 18.12.12 — 15:52
или только страх нагонять?
4 — 18.12.12 — 15:52
+(2) буква А
5 — 18.12.12 — 15:55
(2) ну что ты как маленький — они же фантомные…
6 — 18.12.12 — 15:57
Ошибка при выполнении обработчика — «ОбработкаЗаполнения»
по причине: МодульОбъекта(2115) — Значение не является значением объектного типа (Ссылка)
По этой строке все пусто и ругается почему-то при создании НОВОГО документа
7 — 18.12.12 — 15:58
(6) где фантомность? что это такое вообще?
8 — 18.12.12 — 15:58
(7) Ругается на текст, которого нет. Прочитай заголовок полностью
9 — 18.12.12 — 15:58
«Платформа последняя на сегодняшний день» —
будте конкретне эту ветку могут читать и через год.
как потенциальным читателям понять о каких версиях ПО Вы сообщили.
10 — 18.12.12 — 15:59
(9) 8.2.17.143
11 — 18.12.12 — 15:59
(6) Обработка заполнения вызывается и для новых документов
то, что у тебя криво она написана — решай проблему
12 — 18.12.12 — 15:59
тонкий клиент? раньше вроде была такая ошибка — вместо ссылка приходила на клиент какая-то хрень
13 — 18.12.12 — 16:00
(6) потому что у НОВОГО нет ссылки
14 — 18.12.12 — 16:00
(11) Ошибки нет — система выдает старый код
15 — 18.12.12 — 16:01
(12) Толстый
16 — 18.12.12 — 16:01
Еще раз повторюсь — код на который ругается — отсутствует?
17 — 18.12.12 — 16:02
(11) Это когда это обработка заполнения вызывается для независимо создаваемого нового документа??
18 — 18.12.12 — 16:02
может вызывается оработка ТЧ. если кофигурация типовая.
19 — 18.12.12 — 16:03
остановку по ошибке предлагать?
20 — 18.12.12 — 16:03
(17) может документ через копирование создают?
21 — 18.12.12 — 16:04
(19) не останавливается. ТАКОГО КОДА НЕТ
22 — 18.12.12 — 16:04
(20) не копируют
23 — 18.12.12 — 16:04
(21) суслика не видишь, а он есть, есть еще кеш сервера, есть кеш клиента
24 — 18.12.12 — 16:05
(18) в каком смысле?
25 — 18.12.12 — 16:05
(17) ДокументОбъект.<Имя документа> (DocumentObject.<Имя документа>)
ОбработкаЗаполнения (Filling)
Синтаксис:
ОбработкаЗаполнения(<ДанныеЗаполнения>, <СтандартнаяОбработка>)
Параметры:
<ДанныеЗаполнения>
Тип: Произвольный.
Значение, которое используется как основание для заполнения.
Если обработчик вызван при выполнении метода Заполнить, параметр равен параметру <ДанныеЗаполнения> метода Заполнить.
При обработке заполнения во время ввода на основании параметр имеет значение основания.
При интерактивном вводе нового из формы списка параметр является структурой, элементы которой соответствуют тем параметрам отбора формы списка, у которых способ сравнения Равно или ВСписке с единственным элементом списка. Если таких элементов отбор списка не содержит, данный параметр равен Неопределено. Если параметр <СтандартнаяОбработка> по окончании работы обработчика равен Истина (установлен по умолчанию), система автоматически произведет заполнение одноименными элементами структуры.
<СтандартнаяОбработка>
Тип: Булево.
В данный параметр передается признак выполнения стандартной (системной) обработки события. Если в теле процедуры-обработчика установить данному параметру значение Ложь, стандартная обработка события производиться не будет. Отказ от стандартной обработки не отменяет действие.
Значение по умолчанию: Истина.
Описание:
Возникает при вводе документа на основании, а также при выполнении метода Заполнить, при вводе на основании, а также при интерактивном вводе нового. В процедуре-обработчике этого события должен быть описан сам алгоритм заполнения реквизитов документа на основании переданного значения.
Примечание:
При копировании (как интерактивном, так и средствами встроенного языка), данный обработчик не вызывается.
См. также:
ДокументОбъект, метод Заполнить
продпм СП, недорого
26 — 18.12.12 — 16:05
(24) если бы проблема была в кеше сервака, то такая трабла была бы у всех, не так ли
27 — 18.12.12 — 16:06
+25 читать с «При интерактивном вводе нового из формы списка параметр является структурой»
28 — 18.12.12 — 16:07
(27) спс, ща гляну
29 — 18.12.12 — 16:07
перешли с 8.1 на 8.2?
ОбработкаЗаполнения ведет теперь иначе
30 — 18.12.12 — 16:08
освятить сервер. однозначно
31 — 18.12.12 — 16:09
(24)
Внешние обработки по заполнению табличных частей
32 — 18.12.12 — 16:09
Епрст сток хохмачей… А по сути только единицы ответили. Им спасибо
33 — 18.12.12 — 16:11
(32) ты не правильно пишешь ник Ёпрст-а )
34 — 18.12.12 — 16:13
(33) ))
35 — 18.12.12 — 16:16
эт фигня, вот как я искал ошибку «Операция не может быть выполнена из-за несоответствия версии или отсутствия записи азы данных (возможно, запись была изменена или удалена)» для нового документа…
36 — 18.12.12 — 16:18
(26) чем лечил?)
37 — 18.12.12 — 16:18
*(35)
38 — 18.12.12 — 16:19
(37) поиском и устранением кольцевых ссылок на ДокументОбъект
39 — 18.12.12 — 16:20
(35) не надо было ее допускать )
40 — 18.12.12 — 16:20
Как насчет подписок?
41 — 18.12.12 — 16:21
(39) я только лечу
ТС прав, фантомные ошибки в 82 существуют и их природа кроется в передаче управления с сервера на клинет, т.е. когда серверный метод отработал, то каким-то чудным образом переменные в нем не терминируються при выходе иногда и тогда вылазеет этот фантом «Не объектого типа» «Тип не обнаружен » и прочие ля-ля
Выход, топорно теминировать «тяжелые» переменные серверного метода в конце его кода или при возврате для функции
ТаблицаЗначенийЛяля = 0;
ДеревоЗначенийЛяля = 0;
Фантомная ошибка приложения
Мой опыт главным образом с Windows XP на этом. Я сильно предпочитаю использовать встроенный Windows Zero Configuration utility потому что:
-
Я могу управлять им с Групповой политикой и настроить ПК с различным SSIDs и настройками безопасности автоматически.
-
Это правильно пройдет проверку подлинности с WPA/RADIUS или средами WPA2/RADIUS во время начальной загрузки, чтобы позволить групповой политике, сценариям запуска, и т.д., работать до входа в систему.
-
Я могу дать последовательную технологию. поддерживайте опыт пользователям, сообщающим о проблемах, потому что я очень знаком со встроенной функциональностью.
-
Это не облуплено как некоторые сторонние программы, которые я использовал — встроенная функциональность не особенно сексуальна, но это работает.
-
Встроенная функциональность исправляется whtn, ОС исправляется и не создает другой объект для меня для поддержки патчей w/.
Единственный «довод»против»», с которым я знаком, — то, что «функциональность» Ловца WiFi на некоторых единицах Dell связывается с их грязным сторонним программным обеспечением. Приводя это к сбою, у меня не было проблем.
Править:
Если Вы уверены в функции сторонней беспроводной программы менеджера для установки определенных настроек при соединении с конкретным SSID Вы могли бы хотеть посмотреть «на Сетевые Профили» (см. http://code.google.com/p/netprofiles/). Это — открытый исходный код utilitiy, который может установить настройки прокси, выполнить сценарии и внести много других изменений на основе ассоциации беспроводного NIC с данным SSID. (Мне действительно жаль, что это не было связано в Windows «Сетевой сервис» Осведомленности Местоположения, но это — незначительное схватывание…),
задан
15 December 2009 в 15:56
Ссылка
2 ответа
Можно сохранить Фантомные изображения в той же папке, пока их называют по-другому, точно так же, как любой другой тип файла не нужно влиять на другой.
Эта ошибка могла быть вызвана парой разных вещей, таких как ошибки сетевого подключения или просто плохое изображение. Вы обработки изображений через сеть?
При ударе Аварийного прекращения работы, когда ошибка подходит, необходимо ли получить другой код ошибки, что то, что один?
ответ дан
5 December 2019 в 20:57
Ссылка
Symnantec предлагает несколько мыслей здесь. У меня были изображения, кажутся поврежденными из-за проблемы диска, которую, таким образом, определенно стоит проверить. Howwever, образ может просто быть поврежден из-за другой проблемы, и необходимо повторно отобразить.
Когда файл изображения повреждается, он не может быть восстановлен. Фантом не включает функций восстановления поврежденных файлов изображений. Необходимо создать новый файл изображения вместо этого.
В некоторых случаях, что, кажется, поврежденный файл изображения, на самом деле повреждение на исходном диске (диск, что Вы создали изображение). Прежде, чем создать новый файл изображения, определите, является ли повреждение на самом деле в файле изображения или является ли повреждение на исходном диске. Если повреждение находится на исходном диске, восстановите исходный диск прежде, чем создать новый файл изображения.
Выполнять проверку целостности из Windows (Фантом Symantec 8.x и позже)
Выполните Ghost32.exe. По умолчанию это расположено в:
C:Program FilesSymantecGhostGhost32.exe.
Выберите Local> Check> Image File. Обзор к файлу изображения и нажимает Open. Выберите Yes для продолжения проверку целостности.
ответ дан Dave M
5 December 2019 в 20:57
Ссылка
Теги
Похожие вопросы
- Remove From My Forums
-
Question
-
Hello,
I have a package that when I open it up, gives me this error:
Error 1 Error loading myPackage.dtsx: The connection «{AEDA784A-4076-4661-BC99-B4D819E0C21B}» is not found. This error is thrown by Connections collection when the specific connection element is not found.
However, I don’t know what this error is possibly referrring to. All of my tasks, where needed, have the appropriate ole db connection and are NOT pointing to this non-existent connection. I deleted all connections except the one I use.
I addition, none of my tasks are showing ANY errors whatsover and package executes perfectly.
So what’s the problem here?
Thanks
Answers
-
Actually, I see exactly what I deleted. It was a «Direct Input» for a Execute SQL Task which I had disabled, but not updated. It’s very possible that it was still pointing to the bad connection. duh.
After deleting from the code, the Execute SQL Task is still there, but the direct input and connection are now empty.
Уровень сложности
Средний
Время на прочтение
8 мин
Количество просмотров 11K

В последнее время появилось много микроконтроллеров на ядрах ARM Cortex-M*, которые поддерживают аппаратную реализацию математики плавающей запятой (FPU). В основном FPU работают с одиночной точностью (float) и её вполне достаточно для работы с сигналами, полученными с АЦП. FPU позволяет забыть о проблемах дискретизации и проблемах переполнения целочисленных вычислений. FPU быстр — все математические операции с одиночными float, кроме деления и взятия корня, занимают на Cortex-M4F один такт. Поэтому после перехода на Cortex-M4F мы вздохнули свободно и стали писать математику на float. Как же мы удивились, найдя в скомпилированном коде математические операции над double с программной, очень медленной эмуляцией.
В статье рассказывается, как обнаружить и исправить присутствие double в прошивках, где ядро аппаратно поддерживает тип float, но не поддерживает double.
Работа ведётся в среде IAR Embedded Workbench на примере реального кода на языке Си.
Проблема double чисел в ARM Cortex-M*
А велика ли проблема, что часть математики выполнилась с программной эмуляцией double, вместо аппаратно поддерживаемых float? Вот здесь показывается, что double медленнее в 27 раз, а здесь числа поменьше (я насчитал разницу в 7-15 раз). Согласитесь, что терять в скорости математических алгоритмов на порядок из-за ошибочного использования double, где достаточно float, достаточно грустно. При этом в качестве решения проблем фантомных double иногда предлагается просто не использовать FPU:
My mantra is not to use any floating point data types in embedded applications,
or at least to avoid them whenever possible: for most applications they are not
necessary and can be replaced by fixed point operations. Not only floating point
operations have numerical problems, but they can also lead to performance problems…
Ну а мы бояться performance problems не будем и научимся фантомных double избегать.
Нам интересны ядра Cortex-M, в которых FPU для single precision есть, а для double precision — нет. Ниже приведена таблица ядер Cortex-M. Наличие FPU у помеченных ✅ ядер опционально. Ядра, имеющие этот блок, часто помечаются суффиксом F: например, Cortex-M4F.
|
Версия ядра |
FPU (half precision) |
FPU (single precision) |
FPU (double precision) |
|---|---|---|---|
|
Cortex-M0 |
❌ |
❌ |
❌ |
|
Cortex-M0+ |
❌ |
❌ |
❌ |
|
Cortex-M1 |
❌ |
❌ |
❌ |
|
Cortex-M3 |
❌ |
❌ |
❌ |
|
Cortex-M4 |
❌ |
✅ (Optional) |
❌ |
|
Cortex-M7 |
❌ |
✅ (Optional) |
|
|
Cortex-M23 |
❌ |
❌ |
❌ |
|
Cortex-M33 |
❌ |
✅ (Optional) |
❌ |
|
Cortex-M35P |
❌ |
✅ (Optional) |
❌ |
|
Cortex-M55 |
✅ (Optional) |
||
|
Cortex-M85 |
✅ (Optional) |
Программная эмуляция
Стандарт Си требует поддержки чисел с плавающей точкой, как float, так и double. Как же компилируется код для ядер без аппаратной поддержки дробных типов? Каждая математическая операция заменяется на вызов функции программной эмуляции. У каждого компилятора своя реализация подобных эмуляторов. Всякая работа с дробными типами на ядрах без соответствующего FPU приведёт к вызову эмулирующих функций! Более того, если отдельно не включить опцию поддержки FPU в настройках компилятора, то будет использоваться программная эмуляция для чисел с плавающей запятой, даже если они могли бы выполняться аппаратно.
Рассмотрим случай эмуляции чисел с плавающей запятой.
// Example for no-FPU device
const int N = 1000;
int half_of_N;
// 1) Inefficient way
half_of_N = 0.5 * N; // C standard treats 0.5 as double literal
// 2) Optimized way
half_of_N = N / 2;Умножение целого числа на 0.5 пройдет в четыре этапа:
-
конвертация N в
doubleтип, вызов соответствующей функции..._i2d() -
умножение
doubleконстанты0.5на сконвертированный вdoubleN, т.е. вызов эмулирующей функции —..._dmul() -
конвертация результата обратно в
int— функция..._d2i() -
присваивание результата в half_of_N.
Простое умножение на дробное число на ядре без FPU привело к вызову минимум трёх сторонних функций. Более того, в прошивку были прилинкованы реализации этих функций, что увеличивает её размер грубо на 1 кБ. Чтобы прошивка не увеличивалась нужно найти все места использования программной эмуляции и убрать их.
Проверка наличия double эмуляции
Итак, мы решили проверить, нет ли в нашей прошивке случайного использования double. Иногда диагностику может провести сам компилятор (cсылка, смотреть комментарии). Так, например, gcc имеет специальный флаг -Wdouble-promotion, который может оповестить программиста о неявной конвертации float в double. Также дробные константы могут быть интерпретированы как float, если gcc передать флаг -fsingle-precision-constant. В IAR Embedded Workbench нет встроенного инструмента для решения этой проблемы. Придётся заниматься реверсом процесса сборки прошивки с конца.
-
Откройте проект и перейдите в его настройки.
-
Выберите подпункт
Linker->Listи поставьте галочку в чекбоксGenerate linker map file.
Окно включения генерации вывода map файла линковщика IAR EWARM -
Соберите проект. В папке output в дереве проектов должен появится *.map файл.

Демонстрация появления в папке Output файла *.map -
Откройте его и отлистайте до секции «ENTRY LIST». В ней вы найдёте имена всех функций, которые используются в коде. В том числе и всевозможные
..._f2d(),..._dmul()и прочие. -
Достаточно провести поиск по функциям конвертации
f2d,ui2dиl2d. В моём случае я нашёл следующие функции.
Содержимое *.map файла в случае присутствия программной эмуляции операций над double



Это значит, что фантомный double в прошивке есть. На скиншоте видно, что в списке присутствует еще много функций конвертации типов и программной эмуляции математических операций с плавающей запятой. В момент избавления от последнего использования типа double они разом исчезнут.
Поиск double в коде.
Напоминаю, что мы оптимизируем код для ядра с FPU, который поддерживает только float. Cortex-M4F, например.
Первая ступень — поиск по тексту кода
Пропустим неинтересный поиск по всем файлам проекта (Ctrl+Shift+F) слова double. Оказалось, что где-то рука программиста дрогнула и он его всё-таки написал.

А вот тут можно поискать частую ошибку:
// ST5918L3008 parameters are used as default values.
const static StepperParameters_t StepperParametersDefault =
{
.L = 0.0076 * 0.1f, // H -> 0.1H
.R = 2.2 * 0.1f, // Ohm -> 0.1Ohm
.Fm = 0.009 * 100.0f, // Wb -> cWb
};
static void StepperFOCSensorless_PIDReconfigureCallback(void)
{
/*
* Update PID if SPID was changed
* 1. Kp, Ki, Kd units in firmware: mA/rad, mA/(rad*T) and mA*T/rad, where T is period.
* 2. Kp, Ki, Kd units in GUI: A/rad, A/(rad*s), A*s/rad but XiLab multiplies them on 0.001 before sending.
* 4. Parameters can be changed during movement.
*/
// assign new values
PositionRegulator_param.Kp = 1e6 * BCDFlashParams.SPID.Kpf; // rad -> mA
PositionRegulator_param.Kd = 1e6 * BCDFlashParams.SPID.Kdf * STEPPER_FOC_PWM_FREQ ; // rad/T -> mA
PositionRegulator_param.Ki = 1e6 * BCDFlashParams.SPID.Kif * STEPPER_FOC_PWM_PERIOD_FLOAT; // rad T -> mA
}Язык C коварен тем, что по умолчанию все дробные числа трактует как double. Например, 0.0076 — это double. Если мы умножаем его на 0.1f, то результирующий тип выбирается, как более расширенный из двух, то есть double. Ещё большее коварство проявляется при работе с экспоненциальной формой: число 1e6 не является целочисленным, его тип тоже double. Используйте суффикс f/F на конце числовых констант, чтобы явно указать тип float. Например 1e6f.
Как найти в прошивке неправильные константы? Для этого используем поиск по регулярным выражениям, который встроен в IAR Embedded Workbench. Выражение для поиска [^.dw#][0-9]+[.eE][0-9]*[^.w0-9].

Регулярное выражение ищет не начинающиеся с букв, точек и # цифры, где есть точка или буква экспоненты в середине или в конце, после чего не идёт точка, буква или цифра. Такое регулярное выражение даёт много срабатываний в комментариях к коду, что довольно быстро фильтруется визуально. Оно также может не обрабатывать константы 3e-4 или 1e3L, не имеющим тип float , но мне хватило и такого регулярного выражения.
Теперь ошибки посложнее:
/*
* right half of voltage cicle is inside current circle
* NOTE: if voltage circle is inside current circle (Imax > Iu + I0) then intersection point does not exists,
* but Iu^2 - Imax^2 - I0^ < -2*I0^2 -2*I0*Iu and Id < -I0 - Iu <= I0
*/
if (Id_limit < -I0)
{
// FW_VOLTAGE_ONLY: limit only voltage
if (fabs(Irq) < Iu)
{
pIr->d = -I0 + sqrtf(Iu * Iu - Irq * Irq);
if (pIr->d > 0)
{
pIr->d = 0.0f;
}
pIr->q = Irq;
return; // nolimit
}
else
{
pIr->d = -I0;
if (Irq > 0.0f)
{
pIr->q = Iu;
}
else
{
pIr->q = -Iu;
}
return; // limit
}
}
/*
* Main case: Id_limit is between located between -I0 and 0.
*/
/*
* Check if line Iq = Irq intersects the voltage circle
* then calculate intersection Id coordinate and check if it is is not greater then Id_limit
*/
if (fabs(Irq) >= Iu || (Id_fw = -I0 + sqrtf(Iu * Iu - Irq * Irq)) < Id_limit)
{
/*
* LIMIT_MAIN_CASE: apply maximal current in Irq direction
*/
pIr->d = Id_limit;
pIr->q = sqrtf(Imax * Imax - Id_limit * Id_limit);
if (Irq < 0)
{
pIr->q = -pIr->q;
}
return; // limit
}В этом коде все дробные переменные имеют тип float, но double всё-таки возникает. И дело в вызове функций. Попробуйте догадаться о какой функции идёт речь.
А пока немного теории именования функций математической библиотеки. Для функций взятия корня, синуса, косинуса, и даже для модуля числа есть функции, принимающие и возвращающие тип double, а есть их более быстрые альтернативы, работающие с типом float. Они имеют суффикс f в конце.
// Double functions
sin(x); // double
cos(x); // double
sqrt(x); // double
fabs(x) // double
// Float functions
sinf(x); // float alternative
cosf(x); // float alternative
sqrtf(x); // float alternative
fabsf(x); // float alternative
В нашем случае дело было в fabs(). На первый взгляд может показаться, и мне казалось, что fabs() уже возвращает float. Это не так. fabs означает floating point abs, возвращающий double. А fabsf — floating point abs for float, это уже float функция.
Как найти функции, принимающие double тип? Могу только посоветовать пройтись поиском по математическим функциям: sqrt, cos, sin, fabs… Замените их на float аналоги: sqrtf, cosf, sinf, fabsf…
Первая стадия завершена. Скомпилируйте проект и проведите повторную диагностику. В нашем случае диагностика показала наличие double. Поэтому мы копнули глубже.
Вторая ступень — поиск по объектным файлам
Если первая ступень не избавила вас от double, то нужно хотя бы сузить пространство поиска. Для этого составьте список найденных в диагностике эмулирующих функций, а затем сделайте поиск имён этих функций в объектных файлах, *.o. Идея здесь такова: линкер присоединил их в проект, так как в одном или более объектном файле на них стоит ссылка. Ссылка записывается именем функции, а мы его знаем. Для поиска мы использовали Double Commander. Это open source, cross platform клон Total Commander.

В одном из объектных файлов найдётся использование функций из *.map файла (если нет, то вы линкуете еще какой-то бинарный код, например библиотеки; в нашем случае это было не так). Соответствующий *.c файл явно или неявно требует использования double. К сожалению дальше остаётся только просматривать код строчка за строчкой и искать проблемы глазами. И тем не менее, это лучше, чем ничего 
Так например, поиск по объектным файлам подсказал мне, что double используется в файле bldc.c. Внимательно изучая код, я наткнулся на незнакомую библиотечную функцию arm_inv_clarke_f32. Перейдя в её определение, я нашёл проблему:

Оказалось, что это ошибка реализации библиотечной функции в arm_math.h из CMSIS, revision: v1.4.4. Тут мы видим знакомое по примеру выше умножение на 0.5. Это double тип! Пришлось патчить системную библиотеку.
Выводы
То, что делается в GCC одним-двумя флагами, делается в IAR поиском с регулярными выражениями, а также поиском в бинарных файлах, а затем пристальным просматриванием кода. И самая сложная ошибка нашлась в библиотеке CMSIS. То есть даже, если вы пишете код без ошибок, то это не гарантирует отсутствия фантомных double. Они могут наследоваться из библиотек и на порядок замедлять работу математических алгоритмов.
Результат был достигнут: с помощью изложенных в данной статье действий удалось избавиться от double в реальной прошивке для Cortex-M4F. Все примеры кода настоящие. Работа заняла около 6 часов. Количество объектных файлов в прошивке около 80.
Напоследок пример дизассемблера фрагмента кода до и после изменений.
 и после (справа) избавления от фантомных double типов")
Авторы: Запуниди Сергей, Шамплетов Никита
#android
#Android
Вопрос:
В любом из проектов, которые я открыл, внезапно появляются ошибки. Я пробовал переустановить java, eclipse и Android, но ничего не работает. Однако, когда я импортирую проекты на свой другой компьютер, у них нет ошибок. Мне нужно будет форматировать свой компьютер? Я только что прошел через все процессы, кроме этого, и я действительно не хочу тратить день только на переформатирование и переустановку всего программного обеспечения, которое мне нужно ….. Но я это сделаю.
Ошибки находятся в корневом файле проектов в верхней части дерева, но нигде во всем дереве ошибок нет project…..so чертовски странно
Комментарии:
1. Вы должны открыть представление проблем и сообщить нам, какие ошибки вы видите.
2. Возможно, вы сможете увидеть, в чем проблема, посмотрев на
Problemsview (Window > Show View > Problems). Редактировать: Сниколас опередил меня в этом 🙂3. Я не был уверен, что это за ошибки, пока, наконец, что-то не нашел. Тип java.lang. Перечисление не может быть разрешено. На него косвенно ссылаются файлы required .class — типа java.lang. Объект не может быть разрешен. На него косвенно ссылаются файлы required .class — Перечисление типов не является универсальным; его нельзя параметризовать с помощью аргументов Эти ошибки были перечислены в верхней части одного из моих файлов .java, но в этом файле не было реальных случаев какой-либо такой ошибки
Ответ №1:
Комментарии:
1. Это было, чувак, спасибо тебе 🙂 все мои проекты вернулись к нормальной жизни. Однако теперь у меня возникла проблема с моим последним проектом. Там осталась ошибка, о которой я упоминал выше
2. Я это тоже исправил. Я просто стер проект из eclipse и переделал его как новый проект …. ура мне: p
Ответ №2:
Переформатирование.. может быть .. экстремальным. Если эти фантомные ошибки происходят только в eclipse, то удалите его, посмотрите на следующем, где eclipse хранит свои настройки (раньше я помнил это, но забыл), удалите эти папки. Теперь установите eclipse снова, желательно в другой структуре папок. Надеюсь, это сработает для вас.
Комментарии:
1. Ааааа….. Я не потрудился поискать папку настроек : p спасибо …. если я не смогу заставить ее работать первой, я просто уничтожу все следы eclipse, которые смогу, и начну полностью сначала 🙂
Ответ №3:
Я обновил Android ADT с помощью справки> Установил новое программное обеспечение в eclipse. Он избавился от ошибок и обновил мой AVD Manager

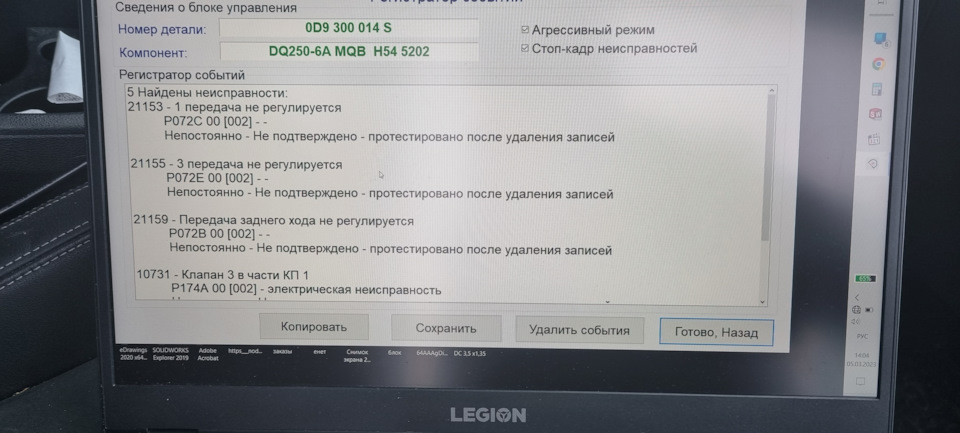
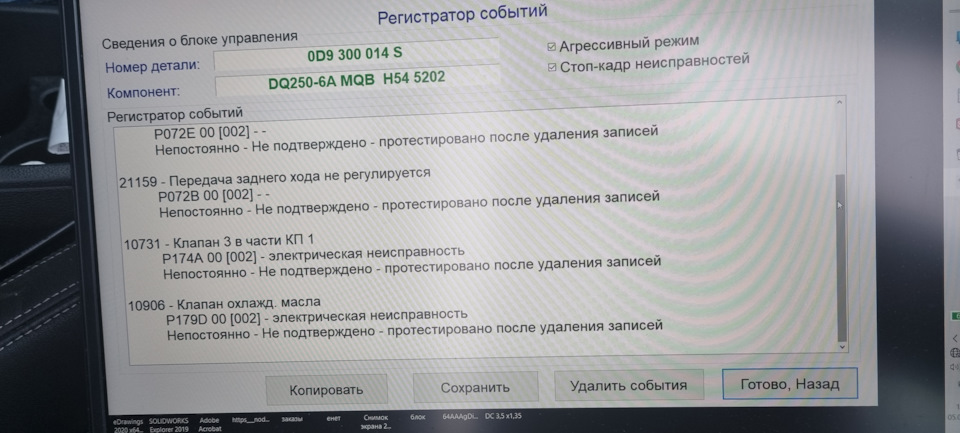
Всем привет, заехал ко мне свежий карок 2020 года на замену масла. А у него по коробке вываливают странные ошибки при передвижении селектора по всем скоростям. Ошибки без даты и пробега, как будто они есть, а по факту общий сброс помогает и показывает, что нет ошибок.
Начинаешь двигать селектор и все по новой.
Да и работает все более или менее адекватно.
Кто-то сталкивался с проблемой?
Полный размер
Полный размер
Войдите или зарегистрируйтесь, чтобы писать комментарии, задавать вопросы и участвовать в обсуждении.
Ошибка «анализ разбора XML: несвязанный префикс» появляется на моем основном макете: main.xml при первом открытии Eclipse. Чтобы ошибка исчезла, все, что мне нужно сделать, это внести изменения в файл, затем отменить, а затем нажать «Сохранить» (необходимо внести изменения, чтобы сохранить файл и тем самым запустить новую проверку синтаксиса).
Моя среда:
Fedora Eclipse Platform
Version: 3.4.2
Based on build id: 20090211-1700
Моя цель — уровень API Android 5.
В первый раз, когда я увидел ошибку, которую я потратил много времени, пытаясь отследить «проблему», но позже понял, что на самом деле это не проблема, это просто ошибка phantom.
Снимок экрана: http://i50.tinypic.com/2i89iee.jpg
Кому я должен сообщить об этом?