
Подборка по базе: Презентация красная книга России.pptx, Проект Книга или компьютер.docx, 07-Ежемесячная книга за Июль 2022г. г.Шымкент .doc, ГО и МобП Тема №3 зан.1 Организационная структура гражданской об, 4 Книга ВШК факультативы.doc, Электронная кНИГА.pptx, Учебник сержанта артиллерии. Книга 1 — 1944. Part 2.djvu, ГО и МобП Тема №3 зан.1 Организационная структура гражданской об, 3.5 Книга ВШК календ. и поур. планы.docx, Красная книга Республики Казахстан 9 (1).pdf
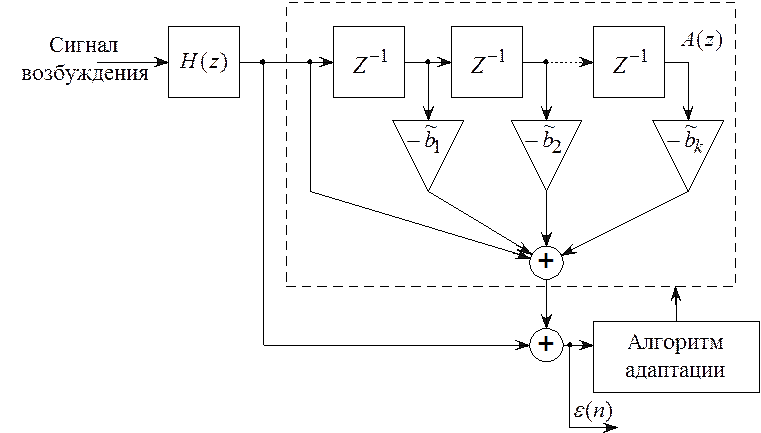
7.6.1. Решетчатый фильтр сигнала ошибки предсказания
В процедуре вычисления коэффициентов предсказания Левинсона –
Дарбина в качестве промежуточных величин используются коэффициенты
k m , которые называются коэффициентами отражения. Их физический смысл заключается в следующем. Голосовой тракт человека представляет собой трубу, состоящую из секций, соединенных последовательно и имею- щих разный диаметр. При прохождении звуковой волны через такую сис- тему возникают отражения на стыках секций, так как каждый стык являет- ся неоднородностью. Коэффициент отражения характеризует величину проходимости стыка двух секций (сред) и равен
136 1
;
1 1;
0 1
s
s
m
m
r
r
s
m
m
i
s
s
m
m
−
+
=
− ≤
≤
⇐
≥
+
+
Поясним его смысл на рис. 7.5: жирной линией показана m-я – секция голосового тракта.
Рис. 7.5. Коэффициент отражения
Если
1
rm = −
, то произойдет обрыв в цепи передачи сигнала (обрыв прямой ветви). Такого быть не должно.
Модель акустических труб может быть представлена в виде фильтра, имеющего решетчатую (или лестничную) структуру. Основные параметры такого фильтра – коэффициенты отражения [40, 42].
Система акустических труб – резонансная система, поэтому если фильтр без потерь, то на его амплитудно-частотной характеристике (АЧХ) будут наблюдаться разрывы (всплески в бесконечность). В действительно- сти на месте этих всплесков будут резонансные пики. Частоты таких пиков называются формантными. Обычно в голосовых трактах человека фор- мантных частот (или формант) не более трех.
Так как коэффициенты отражения и коэффициенты предсказания вы- числяются в рамках одной и той же процедуры алгоритма Левинсона –
Дарбина, то они могут быть выражены друг через друга. Рассмотрим эти алгоритмы.
Прямая рекурсия. Коэффициенты предсказания находят по коэффици- ентам отражения
( )
устанавливается,
1,
( )
(
1)
(
1),
1,
1,
( ),
1,
m
a
r
m
m
m
M
m
m
m
a
a
r a
j
m
j
j
m m
j
M
a
a
j
M
j
j
⎫
= −
−
⎪
=
⎬
−
−
⎪
=
+
=
−
−
⎭
=
=
Обратная рекурсия. Коэффициенты отражения находят по коэффици- ентам предсказания
1
rm = −
1
rm =
S m
0 1
S m
=
+
S m
1
S m
→∞
+
m m
137
( )
,
1, ,
( ) устанавливается,
( )
( )
( )
,
, 1.
(
1)
,
1,
1.
2 1
M
a
a
j
M
j
j
m
r
a
m
m
m
m
m
m M
a
a
a
j
m
m
j
m
a
j
m
j
rm
=
=
⎫
= −
−
⎪
⎪
=
⎬
+
−
−
⎪
=
=
−
⎪
−
⎭
Как уже было сказано, фильтры сигнала ошибки представляют собой
КИХ-фильтры, или нерекурсивные фильтры, что означает отсутствие вет- вей обратной связи. Системы с КИХ также могут обладать строго линей- ной фазо-частотной характеристикой (ФЧХ). Линейность ФЧХ – очень важное свойство применительно к речевому сигналу в тех случаях, когда требуется сохранить взаимное расположение элементов сигнала. Это су- щественно облегчает задачу проектирования фильтров и позволяет уделять внимание лишь аппроксимации их АЧХ. За это достоинство приходится расплачиваться необходимостью аппроксимации протяженной импульсной реакции в случае фильтров с крутыми АЧХ [39, 40].
Изобразим граф фильтра, имеющего решетчатую структуру 3-го по- рядка (рис. 7.6).
Рис. 7.6. Граф решетчатого фильтра
В отличие от формирующего фильтра этот фильтр имеет один вход и два выхода:
ei – последовательность отсчетов сигнала ошибки прямого линейного предсказания;
bi – последовательность отсчетов сигнала ошибки обратного линей- ного предсказания, где
1 1
1
b
x
x
n
n
n
=
−
−
−
− .
Важность bi определяется тем, что по ним совместно с сигналом ошибки ei могут быть оценены коэффициенты отражения:
(0)
n
e
1 1
(1)
n
e
1 1
(2)
n
e
1 1
(3)
n
e
n
e
n
x
1
r
2
r
3
r
1
r
2
r
3
r
1
z
−
1 1
z
−
1 1
z
−
1
(0)
n
b
(0)
1
n
b
−
(1)
n
b
(1)
1
n
b
−
(2)
n
b
(2)
1
n
b
−
(3)
n
b
n
b
138
(
)
(
)
(
1) (
1)
1 2
2
(
1)
(
1)
1 1
N
m
m
e
b
n
n
n
rm
N
N
m
m
e
b
n
n
n
n
−
−
∑
=
= −
−
−
∑
∑
=
=
, (7.9) где N – количество отсчетов в сегменте.
Полученная формула для расчета коэффициентов отражения имеет также другой физический смысл – расчет коэффициентов корреляции ме- жду последовательностью отсчетов сигнала ошибки прямого и обратного линейных предсказаний.
Приведем также рекуррентные разностные уравнения решетчатого фильтра сигнала ошибки:
(
1),
( )
(
1)
1 1,
,
(
1)
( )
(
1),
1
m
m
m
e
e
r b
n
n
m n
m
M
m
m
m
b
b
r e
n
m n
n
−
−
⎧
⎫
=
+
⎪
⎪
−
=
⎨
⎬
−
−
⎪
⎪
=
+
−
⎩
⎭
где
( )
( )
;
M
M
e
e
b
b
n
n
n
n
=
=
– выход фильтра, а начальные условия для ре- куррентной процедуры – (0)
(0)
;
e
x
b
x
n
n
n
n
=
=
7.6.2. Реализация ДИКМ
Зная метод определения коэффициентов предсказания, рассмотрим блок-схему практической системы ДИКМ, показанную на рис. 7.7 [39, 40].
В этой схеме предсказатель стоит в цепи обратной связи, охватываю- щей квантователь (К). Вход предсказателя обозначен xn. Он представляет собой сигнальный отсчет
xn
, искаженный в результате квантования сигна- ла ошибки. Выход предсказателя (П)
ˆ
1
M
x
a x
n
k n k
k
= ∑
−
=
(7.10)
Рис. 7.7. Блок-схема практической системы ДИКМ
( )
x t
{ }
n
x
{ }
n
e
{ }
n
e
к модему
+ _
{ }
ˆ
n
x
{ }
n
x
АЦП
К
П
139
Разность
ˆ
e
x
x
n
n
n
=
−
– вход квантователя, а en – его выход. Величи- на квантованной ошибки предсказания
en
кодируется последовательно- стью двоичных символов и передается через канал в пункт приема.
Квантованную ошибку en также суммируют с предсказанной величи- ной ˆxn, чтобы получить xn.
В месте приема используют такой же предсказатель, как и на передаче.
Выход речевого сигнала ˆxn суммируют с en, чтобы получить xn (рис. 7.8).
Рис. 7.8. Схема предсказателя на приеме и передаче
Сигналы
xn
являются входными для предсказателя. По ним с помо- щью ЦАП восстанавливается сигнал
( )
x t . Ошибка в xn становится ошиб- кой квантования
q
e
e
n
n
n
=
−
. Использование обратной связи вокруг кван- тователя позволяет избежать накопления предыдущих ошибок квантова- ния при декодировании
ˆ
(
)
q
e
e
e
x
x
x
x
n
n
n
n
n
n
n
n
=
−
=
−
−
=
−
Следовательно,
x
x
q
n
n
n
=
+
, что означает, что квантованный отсчет
xn отличается от входа xn ошибкой квантования qn независимо от исполь- зования предсказателя. Значит, ошибки квантования не накапливаются.
В рассмотренной выше системе ДИКМ оценка, или предсказанная ве- личина ˆxn отсчета сигнала, получается посредством линейной комбинации предыдущих значений
xn k
−
, k = 1, 2, …, M. Улучшенное качество оценки можно получить включением в неё линейно отфильтрованных последних значений квантованной ошибки.
Оценку ˆxn можно выразить так:
?
1 1
m
l
x
a x
b e
n
k n k
k n k
k
k
=
+
∑
∑
−
−
=
=
,
{ }
n
e
{ }
n
x
к ЦАП
{ }
ˆ
n
x
{ }
k
a
П
140
где
{ }
bk – коэффициенты фильтра для квантованной последовательности ошибок en. Блок-схемы кодера на передаче и декодера на приеме приведе- ны ниже (рис. 7.9, 7.10).
Рис. 7.9. Блок-схема кодера на передаче
Рис. 7.10. Блок-схема декодера на приеме
Здесь два ряда коэффициентов
{ }
ak и
{ }
bk выбираются так, чтобы минимизировать некоторую функцию ошибки
ˆ
e
x
x
n
n
n
=
−
, например среднеквадратическую ошибку.
7.7. Способы кодирования речи на основе анализа
временных параметров
При цифровом кодировании стремятся по возможности к наиболее точному представлению речевого сигнала для того, чтобы по этому циф- ровому представлению восстановить исходный акустический сигнал. Дру- гая задача – представление речевого сигнала совокупностью свойств или
( )
x t
{ }
n
x
{ }
n
e
{ }
n
e
к модему
+ _
{ }
ˆ
n
x
{ }
n
e
{ }
n
x
АЦП
К
Лин. фильтр
{ }
k
b
Лин. фильтр
{ }
k
a
{ }
n
e
{ }
n
x
к ЦАП
{ }
ˆ
n
x
{ }
k
b
{ }
k
a
Лин. фильтр
Лин. фильтр
141
параметров модели. Ряд сравнительно простых и полезных характеристик можно определить путем непосредственных измерений параметров самого сигнала, а именно по его ИКМ-представлению.
Ключ ко всем параметрическим представлениям – процедура кратко- временного анализа [46].
7.7.1. Измерение энергии
Одна из характеристик сигнала – его энергия. Энергия вещественно- го дискретного во времени сигнала
( )
x n
( )
2
E
x n
n
∞
= ∑
= −∞
. (7.11)
Для нестационарных сигналов, например, речевого, более удобно вычислять изменяющуюся во времени энергию в виде:
( )
( ) (
)
N 1
m 0
2
E n
w m x n m
−
=
⎡
⎤
=
−
∑ ⎣
⎦ , (7.12) где ( )
w m – весовая последовательность, или окно, которое выделяет уча- сток ( )
x n , a N – количество отсчетов в окне. Таким образом, один из спо- собов измерения энергии (7.12) основывается на сглаживании последова- тельности ( )
x n фильтром с импульсной реакцией ( )
W n .
Как и следовало ожидать, функция ( )
E n отображает изменяющиеся во времени амплитудные свойства речевого сигнала. Однако формула
(7.12) нуждается в тщательной интерпретации. Во-первых, это касается выбора окна, задача которого состоит в приписывании меньших весов бо- лее старым отсчетам речи, поэтому с увеличением m ( )
w m , как правило, монотонно стремится к нулю. Если на всем интервале отсчеты должны иметь одинаковый вес, используют прямоугольное окно.
Во-вторых, трудность заключается в выборе интервала измерения
N . При слишком малом N , когда его величина меньше периода основного тона, величина энергии Е(n), определяемой выражением (7.12), подверже- на быстрым флуктуациям, зависящим от тонкой структуры сигнала. Если
N слишком велико и равно нескольким периодам основного тона, величи- на ( )
E n изменяется незначительно и поэтому не может отразить изменяю- щиеся свойства речевого сигнала. Практически наиболее подходящее зна- чение N при частоте дискретизации 10 кГц составляет величину порядка
100 – 200 отсчетов (10 – 20 мс речи).
142
Основное значение характеристики ( )
E n состоит в том, что она мо- жет служить хорошим критерием разделения вокализованных и невокали- зованных участков речи. На невокализованных участках величина ( )
E n намного меньше, чем на вокализованных. Кроме того, чем меньше N , тем меньше ошибка определения точного положения границ, где невокализи- рованная речь переходит в вокализированную и обратно. Более того, при- менительно к высококачественной речи энергию можно использовать для отделения невокализированных участков речи от паузы.
Процедура измерения энергии осложняется тем обстоятельством, что величина уровня возводится в квадрат, тем самым в ( )
E n появляются большие перепады. Один из сравнительно простых способов преодоления этой трудности – использование для оценки энергии функции, в которой вместо суммы квадратов вычисляется сумма абсолютных величин
( ) (
)
1 0
ˆ
N
m
E
w n x n m
−
=
=
−
∑
(7.13)
7.7.2. Измерение числа переходов через нуль
Еще один весьма простой способ анализа временных параметров сигнала основан на измерении числа переходов через нуль. Имея в виду цифровое представление сигнала, можно утверждать, что между момента- ми взятия n -го и (
1
n
− )-го отсчетов произошло пересечение нулевого уровня, если
[
]
[
]
sign ( )
sign (
1)
x n
x n
≠
− . (7.14)
Это измерение несложно в реализации и часто используется для гру- бой оценки частотного содержания речевого сигнала. Возможность его применения объясняется тем, что для синусоидального сигнала с частотой
0
f среднее число пересечений нулевого уровня за 1 с
2 0
m
f
=
. (7.15)
Однако соотношение (7.15) нельзя без оговорок распространить на речевой сигнал, поскольку большая часть звуков речи имеет широкий спектр частот. Тем не менее иногда достаточно даже такой грубой оценки.
Например, хорошо известно, что энергия вокализованной речи обычно концентрируется в диапазоне ниже 3 кГц, тогда как энергия фри- кативных звуков в основном сосредоточена выше 3 кГц. На этом основа- нии результаты измерений числа переходов через нуль (наряду с информа- цией об энергии) часто используются для принятия решения о том, вокали- зованный или не вокализованный характер имеет данный участок речи.
Если частота пересечений высока, то это свидетельствует о не вокализо-
143
ванном характере речи, если же она мала, то весьма вероятно, что анализи- руется вокализованный участок. Число переходов через нуль в сочетании с измерением основного тона речи используется при оценке параметров воз- буждения, а также при распознавании речи [43].
При цифровой реализации измерений числа переходов через нуль следует учитывать ряд важных обстоятельств. Хотя в соответствии с ос- новным алгоритмом требуется произвести лишь сравнение знаков двух следующих друг за другом отсчетов, необходимо также весьма тщательно выполнять и саму процедуру дискретизации. Большие искажения в резуль- таты измерений числа переходов через нуль вносят наличие шума, смеще- ние уровня постоянного тока и напряжение фона с частотой питающей се- ти 50 Гц, поэтому для ослабления мешающего влияния указанных факто- ров перед устройством дискретизации вместо фильтра нижних частот ста- вится полосовой фильтр. Кроме того, поскольку временное разрешение при измерении числа переходов через нуль определяется периодом дис- кретизации Т, его повышение сопряжено с увеличением частоты дискрети- зации. Для измерения числа переходов через нуль можно применять двух- уровневое квантование.
7.7.3. Кратковременный автокорреляционный анализ
Функция автокорреляции дискретного во времени сигнала ( )
x n оп- ределяется как
( )
( ) (
)
N
N
n
N
1
m
lim
x n x n m
2N 1
ϕ
→∞
=−
=
+
∑
+
. (7.16)
Автокорреляционная функция весьма полезна для выявления струк- туры любого сигнала, и в этом смысле речь не составляет исключения [46].
Если, например, некоторый сигнал имеет структуру с периодом T :
(
)
( )
x n T
x n
+
=
для всех n , то
( )
(
)
m
m T
ϕ
ϕ
=
+
. (7.17)
Таким образом, периодичность автокорреляционной функции указы- вает на периодичность исходного сигнала. Если автокорреляционная функция в окрестности точки
0
m
= имеет острый пик и с возрастанием m быстро падает к нулю, то это указывает на отсутствие в сигнале предска- зуемой структуры.
Как уже отмечалось, речь является нестационарным сигналом. Одна- ко на коротких интервалах времени свойства речевого сигнала сохраняют- ся неизменными. Как мы уже видели, это свойство служит основой крат- ковременного анализа.
144
Рассмотрим для примера отрезок сигнала из N отсчетов:
( )
(
),
0 1
x n
x n l
n N
l
=
+
≤ ≤ − , (7.18) где l – начало этого отрезка. В этом случае кратковременная автокорреля- ционная функция может быть определена как
( )
( ) (
)
1 1
, 0 1
0 0
p
m
x n x n m
m M
l
l
l
N n
ϕ
−
=
+
≤ ≤
−
∑
=
, (7.19) где 0
M – максимально требуемая задержка. Так, например, для выявления периодичности сигнала необходимо выполнить условие M T
> . Значение целого числа p оговорено ниже.
Выражение (7.19) можно трактовать как автокорреляцию отрезка ре- чевого сигнала протяженностью N отсчетов, начиная с отсчета l . Если
p N
= , то для вычисления используются отсчеты, находящиеся вне отрезка
1
l n N l
< < + − ; если p N m
= − , то – отсчеты только внутри интервала. В последнем случае исследуемый отрезок часто взвешивается с помощью функции окна, которая плавно сводит к нулю величины отсчетов на концах отрезка.
Обычно предполагается, что для хранения существенных признаков речевого сигнала при его кодировании с помощью ИКМ может потребо- ваться частота дискретизации от 6 до 20 кГц, однако кодирование медлен- но изменяющихся параметров модели возможно со значительно меньшей частотой (от 50 до 100 Гц). Предположим для примера, что частота дис- кретизации речевого сигнала равна 10 кГц, а кратковременная автокорре- ляция должна вычисляться 100 раз в секунду. Оценка величины автокор- реляции обычно производится на отрезках речевого сигнала длительно- стью 20 – 40 мс (для оценки периодичности сигнала длительность окна должна быть достаточной для перекрытия как минимум двух периодов ре- чевого сигнала). Таким образом, при частоте дискретизации 10 кГц коли- чество отсчетов находится в интервале 200 400
N
< <
, а требуемые оценки величины автокорреляции должны вычисляться для приращения, равного
100 отсчетам [46].
При использовании кратковременной автокорреляционной функции для оценки периода основного тона желательно, чтобы эта функция имела острые пики с интервалом, кратным периоду T . Корреляционная функция речи не имеет острых пиков, поскольку структуру каждого периода рече- вого сигнала в значительной степени можно предсказать заранее.
145
7.8. Кодирование речи на основе адаптивного
mel-кепстрального анализа
Mel-кепстральные коэффициенты – популярные характеристики при исследовании речи и распознавании спикера.
Достаточно часто системы кодирования речи используют авторег- рессионное (AR – autoregressive) спектральное представление для кратко- временного предсказания. Однако в некоторых случаях кепстральные ко- эффициенты позволяют достичь лучших результатов [4].
Кепстр – спектр, полученный преобразованием Фурье логарифма сигнала. Спектр, представленный mel-кепстральными коэффициентами, должен иметь разрешающую способность, по частоте подобную человече- скому слуху, который имеет более высокую разрешающую способность на низких частотах. Поэтому ожидается, что использование mel-кепстра мо- жет быть эффективным для спектрального моделирования в кодерах речи вместо AR-моделирования.
Чтобы продемонстрировать эффективность mel-кепстрального пред- ставления в кодировании речи, рассмотрим кодер АДИКМ, который ис- пользует кратковременный адаптивный предсказатель, основанный на mel- кепстральном представлении спектра речи. При этом mel-кепстральные коэффициенты будут обработаны алгоритмом для адаптивного mel- кепстрального анализа. Так как передаточная функция шумового форми- рования и постфильтрования также определена через mel-кепстральные коэффициенты, эффекты шумового формирования и постфильтрования должны соответствовать особенностям человеческого слухового ощуще- ния.
Качество речи кодера оценивается объективными и субъективными исследованиями. Показано, что высококачественная речь, соответствую- щая CCITT G.721 ADPCM-кодеру на скорости 32 кбит/с, может быть вос- произведена кодером на основе mel-кепстра на скорости 16 кбит/с без ал- горитмической задержки.
7.8.1. Адаптивный mel-кепстральный анализ
Модель спектра речи
(
)
j
D e
ω
, использующая М-й порядок mel-кепстральных коэффициентов ( )
C m , имеет вид
( )
( )
M
m
D z
exp
C m z
m 0
−
=
∑
=
, (7.20) где
1 1
1
,
1 1
z
z
z
α α
α
−
−
−
−
=
<
−
. (7.21)
146
Например, когда частота дискретизации равна 8 кГц, фазовая харак- теристика
ω
и передаточная функция при
0,31
α
=
будут приближенными к масштабу me1-частоты, основанному на субъективных оценках основно- го тона [4].
В mel-кепстральном анализе коэффициент усиления ( )
D z предпола- гается равным единице. При этом условии коэффициенты( )
C m однознач- но минимизированы:
2
( )
E e n
ε
⎡
⎤
= ⎣
⎦ ,
где ( )
e n – выход обратного фильтра
( )
1 D z , как показано на рис. 7.11.
Адаптивный mel- кепстральный анализ решает проблему минимизации ошиб- ки с использованием оценки для градиента
ε
. Исследования показывают, что адаптивный алгоритм имеет достаточно быструю сходимость при ана- лизе речи.
Сигнал ( )
e n может рассматриваться как ошибка линейного предска- зания, поэтому адаптивный mel-кепстральный анализ может использо- ваться для кратковременного адаптивного предсказания вместо метода ли- нейного предсказания.
7.8.2. Структура кодера
Базовая структура кодера, основанного на адаптивном mel-кепстральном анализе, приведена на рис. 7.12.
Рис. 7.12. Базовая структура кодера
Z-преобразование декодированной речи ˆ( )
x n будет иметь вид:
ˆ ( )
( )
( )
X z
X z
Q z
=
+
, (7.22)
( )
x n
Кодировщик
Q
( )
1
D z
−
( )
ˆe n
Цифровой канал
Декодер
( )
D z
( )
ˆx n
( )
x n
( )
1 D z
( )
e n
Рис. 7.11. Схема адаптивного mel-кепстрального анализа
147
где ( )
X z и
( )
Q z – это Z-преобразования от
( )
x n и ( )
q n соответственно,
( )
q n – квантованный шум, создаваемый квантователем Q . Передаточная функция ( )
D z реализуется при использовании MLSA-фильтров.
MLSA (Mel Logarithmic Spectral Approximation) – mel-лога- рифмический спектральный фильтр приближения, коэффициенты которого определяются mel-кепстральными коэффициентами согласно информации о высоте тона [10].
Ограничение шума и постфильтрация
Передаточные функции ( )
D z и
( )
D z
реализуются при использова- нии MLSA-фильтров. Мы можем также реализовать
( )
D
z
γ
и
( z )
D
β
тем же способом, что и ( )
D z и ( )
D z : умножением ( )
C m на
γ
и
β
соответст- венно. Чтобы избежать изменения усиления на выходе постфильтра, до- бавляем регулятор выходного усиления, который поддерживает выходной сигнал постфильтра таким образом, чтобы он имел приблизительно ту же самую мощность (энергию), что и нефильтрованная речь [4].
Передаточная функция ( )
D z
аналогична ( )
D z за исключением того, что (1)
C
γ
должно быть равно нулю, чтобы уравновешивать глобальный спектральный наклон. Настраиваемые параметры
γ
и
β
регулируют вели- чину ограничения шума и постфильтрования соответственно.
Рис. 7.13 показывает структуру кодера, основанного на mel-кепстральном анализе с ограничением шума и постфильтрованием.
Рис. 7.13. Структура кодера, основанного на адаптивном mel-кепстральном анализе
Z-преобразование от декодированной речи ˆ( )
x n будет иметь вид:
{
}
ˆ ( )
( )
( )
( )
( )
X z
X z
D
z
Q z D
z
β
γ
=
+
+
. (7.23)
Передаточная функция
( )
D
z
γ
ограничивает спектр шумов и
( )
D
z
β
– постфильтрование.
( )
x n
Кодировщик
Q
( )
1
D
z
γ
−
( )
1
D z
−
( )
ˆe n
Цифровой канал
( )
D z
( )
D
z
β
( )
ˆx n
Декодер
148
Структура с предсказателем основного тона
Рис. 7.14 показывает структуру кодера с предсказателем основного тона.
Рис. 7.14. Структура кодера с предсказателем основного тона
Z-преобразование от декодированной речи
ˆ ( )
x n
будет иметь вид:
( )
ˆ ( )
( )
( )
( )
( )
( )
D z
X z
X z
Q z A z D
z
p
A z
n
γ
β
⎧
⎫
⎪
⎪
=
+
+
⎨
⎬
⎪
⎪
⎩
⎭
. (7.24)
Передаточную функцию фильтра предсказания основного тона нахо- дят по формуле
1
( ) 1
( )
1
p
k
A z
a k z
k
p
+
−
= +
∑
= −
. (7.25)
Период основного тона p и коэффициенты предсказателя основного тона ( )
a k вычисляют на основе корреляции
ˆ( )
e n
,
получающейся при ис- пользовании экспоненциального окна [4].
Передаточные функции
( z )
An
и
( z )
A p
определяют по формулам:
1
( ) 1
( )
1
p
k
z
a k
A
z
n
n
k
p
ε
+
−
= +
∑
= −
, (7.26)
( )
x n
Кодер
Q
( )
p
ˆ
e
z
Цифровой канал
e( n )
Декодер
( )
1 A z
( )
D z
( )
p
A z
( )
D
z
β
( )
ˆx n
( )
1
n
A z
−
( )
1
D
z
γ
−
( )
1
A z
−
D(z)–1
e( n )
149 1
1 1
( )
1
( )
1
( )
1 1
p
p
z
a k
a k
A
z
p
p
p
k
p
k
p
ε
ε
⎛
⎞
⎛
⎞
+
+
−
⎜
⎟
⎜
⎟
= −
−
∑
∑
⎜
⎟
⎜
⎟
= −
= −
⎝
⎠
⎝
⎠
. (7.27)
Настраиваемые параметры n
ε
и
p
ε
регулируют величину ограниче- ния шума и постфильтрования соответственно. В декодере p и ( )
a k всегда вычисляют по квантованным значениям ˆ( )
e n .
7.9. Кодирование речи в стандарте GSM
GSM – это цифровая система, следовательно, аналоговая речь долж- на быть оцифрована на входе и восстановлена на выходе.
Кодер речи – первый элемент собственно цифрового участка пере- дающего тракта АЦП. Основная задача кодера – предельно возможное сжатие сигнала речи, т.е. предельно возможное устранение избыточности речевого сигнала но при сохранении приемлемого качества. Компромисс между степенью сжатия и сохранением качества отыскивается экспери- ментально, а проблема получения высокой степени сжатия без чрезмерно- го снижения качества составляет основную трудность при разработке ко- дера. В приемном тракте перед ЦАП размещен декодер речи; задача деко- дера – восстановление цифрового сигнала речи по принятому кодирован- ному сигналу (с присущей ему естественной избыточностью). Сочетание кодера и декодера называют кодеком.
Кодирование сигнала источника первоначально основывалось на данных о механизмах речеобразования. Этот метод использовал модель голосового тракта и приводил к системам типа анализ-синтез, получившим название вокодеров (кодер голоса, или кодер речи). Ранние вокодеры по- зволяли получать весьма низкую скорость передачи информации при ха- рактерном «синтетическом» качестве речи на выходе, поэтому вокодерные методы долгое время оставались в основном областью приложения усилий исследователей и энтузиастов и не находили широкого практического применения.
Ситуация существенно изменилась с появлением метода линейного предсказания, предложенного в 1960-х гг. и получившего мощное развитие в 1980-х гг. на основе достижений микроэлектроники.
В настоящее время в системах подвижной связи получили распро- странение вокодерные методы на базе метода линейного предсказания.
Суть кодирования речи методом линейного предсказания (Linear
Predictive Coding – LРС) заключается в том, что по линии связи переда-
150
ются не параметры речевого сигнала, а параметры фильтра, в определен- ном смысле эквивалентного голосовому тракту, и параметры сигнала воз- буждения этого фильтра, в качестве которого используется фильтр ли- нейного предсказания. Задача кодирования на передающем конце линии связи состоит в оценке параметров фильтра и параметров сигнала возбу- ждения, а задача декодирования на приемном конце – в пропускании сиг- нала возбуждения через фильтр, на выходе которого получается восста- новленный сигнал речи.
Значения коэффициентов предсказания, постоянные на интервале кодируемого сегмента речи (на практике длительность сегмента составляет
20 мс), находят из условия минимизации среднеквадратического значения остатка предсказания на интервале сегмента.
Таким образом, процедура кодирования речи в методе линейного предсказания сводится к следующему:
−
оцифрованный сигнал речи нарезается на сегменты длительностью по 20 мс;
−
для каждого сегмента оцениваются параметры фильтра линейного предсказания и параметры сигнала возбуждения; в качестве сигнала воз- буждения в простейшем случае может выступать остаток предсказания, получаемый при пропускании сегмента речи через фильтр с параметрами, найденными из оценки для данного сегмента;
−
параметры фильтра и параметры сигнала возбуждения кодируются по определенному закону и передаются в канал связи.
Процедура декодирования речи заключается в пропускании принято- го сигнала возбуждения через синтезирующий фильтр известной структу- ры, параметры которого переданы одновременно с сигналом возбуждения.
Линейное предсказание является кратковременным (STP – Short-
Term Prediction) и не обеспечивает достаточной степени устранения из- быточности речи, поэтому в дополнение к кратковременному предсказа- нию используется еще долговременное (LTP – Long-Term Prediction), в значительной мере устраняющее остаточную избыточность и прибли- жающее остаток предсказания по своим статистическим характеристи- кам к белому шуму.
В стандарте GSM применяется метод полноскоростного (13,6 кбит/с) кодирования речи RPE-LTP (Regular Pulse Excited Long-Term Predictor – линейное предсказание с возбуждением регулярной последовательностью импульсов и долговременным предсказателем) – стандарт GSM 06.10. Уп- рощенная блок-схема кодека приведена на рис. 7.15, 7.16 [15].
151
Рис. 7.15. Блок-схема кодера кодека в стандарте GSM 06.10
Кодирование
1. Непрерывный речевой сигнал дискретизуется с частотой 8 кГц, и оцифровывается с равномерным законом квантования и разрядно- стью 13 бит/отсчет: число уровней квантования
13 4096 2
M
= ±
=
, уровень шумов квантования
2 10 lg1 12 2 90дБ
,дБ
R
Dq
−
= ⋅
⋅
≈ −
2.
Для повышения разборчивости речи осуществляют предыска- жение входного сигнала при помощи цифрового фильтра, подчеркивающе- го верхние частоты.
Рис. 7.16. Блок-схема декодера кодека в стандарте GSM 06.10 3.
Непрерывная последовательность отсчетов разбивается на сег- менты по 160 отсчетов (длительностью 160·1/8 кГц = 20 мс).
ДЕКОДЕР
От кодера
fn′
en′
Sn′
Формирование сигнала возбужде- ния
Фильтр-анализатор долговрем. пред- сказания
( )
R Z
Фильтр-синтезатор кратковрем. пред- сказания
( )
H z
Постфильтрация
КОДЕР
Sn
fn
en
На декодер
Предварит. обработка
Оценка параметров фильтра кратковрем. предсказания
Фильтр-анализатор кратковрем. пред- сказания
( )
A Z
Оценка параметров фильтра долговрем. предсказания
Фильтр-анализатор кратковрем. пред- сказания
( )
P z
Оценка параметров сигнала возбужде- ния
152 4.
Проводят «взвешивание» каждого сегмента окном Хэмминга –
«косинус на пьедестале», при этом амплитуда сигнала внутри сегмента плавно падает от центра окна к краям. Это делается для того, чтобы не бы- ло резких разрывов сигнала на краях сегментов.
5.
Для каждого 20-миллисекундного сегмента (160 «взвешенных» отсчетов сигнала) оценивают параметры фильтра кратковременного ли- нейного предсказания. Оптимальные коэффициенты фильтра кратковре- менного линейного предсказания ak находят путем решения системы ли- нейных уравнений Юла – Волкера:
(
)
( ),
1, 2, 3, ,
,
8
M
a R k l
R l
l
M
M
k
k l
…
− =
=
=
∑
=
, которая в матричной форме записывается следующим образом:
(0)
(1)
(2)
(
1)
(1)
1
(1)
(0)
(1)
(
2)
(2)
2
(2)
(1)
(0)
(
3)
(3)
3
(
1)
(
2)
(
3)
(
0)
( )
a
R
R
R
R M
R
a
R
R
R
R M
R
a
R
R
R
R M
R
R M
R M
R M
R M
R M
aM
−
−
⋅
=
−
−
−
−
−
…
…
…
…
…
…
…
…
…
…
Здесь (0)
( )
R
R M
…
– значения кратковременной автокорреляцион- ной функции речевого сигнала, вычисленные по его отсчетам на текущем сегменте
1
( )
( ) (
), 0 1, 0
,
160,
8 0
N
R k
x i x i k
i N
k M N
M
i
−
=
−
≤ ≤ −
≤ ≤
=
=
∑
=
6.
На основе полученных коэффициентов фильтра кратковременно- го предсказания проводят фильтрацию текущего речевого сегмента
(160 отсчетов) фильтром-анализатором кратковременного предсказания
(инверсным фильтром) с передаточной характеристикой
( ) 1 1
M
k
A z
a z
k
k
−
= − ∑
=
На выходе получается остаток (ошибка) кратковременного предска- зания en (160 отсчетов ошибки кратковременного предсказания). При этом из-за наличия в речевом сигнале долговременной повторяемости (перио- дичности), обусловленной гласными звуками, в ошибке кратковременного предсказания остаются периодические всплески достаточно большой ам- плитуды. Для их устранения (уменьшения) используется долговременное линейное предсказание.
153 7.
Вычисляют параметры фильтра долговременного линейного предсказания с передаточной характеристикой
( ) 1
D i
P z
G z
i
i
− −
= − ∑
Сегмент остатка кратковременного линейного предсказания
(160 отсчетов) разбивается на четыре подсегмента размером по 40 отсче- тов. Параметры долговременного предсказания – коэффициент предска- зания G и задержка D – оценивают для каждого подсегмента в отдель- ности. Укорочение интервала анализа долговременного предсказания обусловлено тем, что параметры сигнала возбуждения (с которыми связа- на его периодичность) изменяются гораздо быстрее, чем параметры голо- сового тракта (которые вошли в коэффициенты кратковременного линей- ного предсказания ak ).
В каждом подсегменте находят параметр задержки D (период ос- новного тона, определяемый как среднее расстояние между периодиче- скими всплесками автокорреляционной функции остатка кратковременно- го предсказания) и коэффициент предсказания G (определяемый как на- клон огибающей автокорреляционной функции остатка кратковременного предсказания). При этом параметр задержки D для текущего подсегмента вычисляют путем сглаживания (усреднения) текущего значения D и трех предшествующих ему значений (определенных на трех предыдущих под- сегментах).
8.
Сигнал остатка кратковременного линейного предсказания (под- сегмент длительностью в 40 отсчетов) en обрабатывается фильтром- анализатором долговременного линейного предсказания с параметрами G и D , найденными для этого подсегмента, и на его выходе получается оста- ток долговременного и кратковременного предсказания fn . Далее по это- му сигналу будут находиться параметры сигнала возбуждения (в отдельно- сти для каждого из подсегментов).
9.
Сигнал возбуждения одного подсегмента состоит из 13 импуль- сов, следующих через равные промежутки времени (втрое реже, чем ин- тервал дискретизации исходного сигнала) и имеющих различные амплиту- ды. Для формирования сигнала возбуждения 40 отсчетов подсегмент ос- татка
fn обрабатывают следующим образом.
Последний (40-й) отсчет отбрасывают, а первые 39 отсчетов проре- живают и разбивают на три подпоследовательности: в первую включаются
1, 4, … 37-й отсчеты, во вторую – отсчеты с номерами 2, 5, … 38, в тре- тью – отсчеты с номерами 3, 6, … 39. В качестве сигнала возбуждения вы- бирают ту подпоследовательность, энергия которой больше. Амплитуды
154
импульсов нормируют по отношению к импульсу с наибольшей амплиту- дой. Нормированные амплитуды кодируют тремя битами каждую (с ли- нейным законом квантования). Абсолютное значение наибольшей ампли- туды кодируют шестью битами в логарифмическом масштабе. Положение первого импульса 13-элементной последовательности кодируют двумя би- тами, т.е. фактически кодируют номер последовательности, выбранной в качестве сигнала возбуждения для данного подсегмента.
Таким образом, выходная информация кодера для одного
20-миллисекундного сегмента речи включает:
−
параметры фильтра кратковременного линейного предсказания – во- семь коэффициентов на сегмент, кодируют 36 битами;
−
параметры фильтра долговременного линейного предсказания – ко- эффициент предсказания G и задержка D – для каждого из четырех под- сегментов, также кодируют 36 битами;
−
параметры сигнала возбуждения – номер подпоследовательности n , максимальная амплитуда v , нормированные амплитуды импульсов после- довательности
,
1 13
b i
i
=
…
– для каждого из четырех подсегментов. Все вместе кодируют 188 битами.
Итого на 20 -миллисекундный сегмент речи (160 отсчетов) получает- ся 260 бит. При этом коэффициент сжатия сегмента (по сравнению с ИКМ, использующей логарифмическую шкалу квантования 160 отсчетов по
8 бит/отсчет) составляет 1280/260 = 4,92
≈ 5.
Декодирование
Последовательность выполняемых при декодировании функций представлена на рис. 7.16. Блок формирования сигнала возбуждения, ис- пользуя полученные параметры сигнала возбуждения, восстанавливает 13- импульсную последовательность сигнала возбуждения для каждого из подсегментов, включая амплитуды импульсов и их расположение во вре- мени. Сформированный таким образом сигнал возбуждения обрабатывает- ся фильтром-синтезатором долговременного предсказания, на выходе ко- торого получается восстановленный остаток кратковременного предсказа- ния. Последний обрабатывается фильтром-синтезатором кратковременного предсказания. Выходной сигнал фильтра-синтезатора кратковременного предсказания (а это уже почти синтезированный речевой сигнал) фильтру- ется цифровым фильтром низких частот, компенсирующим предыскаже- ние, внесенное входным фильтром блока предварительной обработки ко- дера. Сигнал с выхода низкочастотного постфильтра является восстанов- ленным цифровым сигналом речи.
Все перечисленные процедуры несмотря на их сложность выполня- ются в реальном масштабе времени процессором обработки речи, реализо- ванным аппаратно-программно в мобильном телефоне стандарта GSM.
155
Контрольные вопросы
1.
Что дает кодирование речи?
2.
Изложите методы кодирования речевой информации.
3.
Каковы особенности ИКМ?
4.
Каковы особенности законов
μ
и
A
, применяемых в кодирова- нии речи?
5.
Каковы особенности ДИКМ на основе ЛП?
6.
Чем характеризуется алгоритм Левинсона – Дарбина?
7.
Что такое решетчатый фильтр. Какова его граф-структура?
8.
Каковы особенности практической системы ДИКМ?
9.
Что такое кратковременный анализ речевого сигнала?
10.
Как определяется энергия речевого сигнала?
11.
Как определяется число переходов через нуль при анализе рече- вого сигнала?
12.
Каковы особенности автокорреляционного анализа?
13.
Каковы особенности кодирования на основе линейного предсказания?
14.
Что такое постфильтрация и для чего она применяется?
15.
Какова структура предсказателя основного тона?
16.
Как происходят процессы кодирования и декодирования в стан- дарте GSM?
спектров, и глубокие провалы, характерные для СС—спектров. АРСС—спектр, показанный на рис.2.1в, представляет собой результат объединения АР— и СС—спектров, показанных на рис.2.1а и 2.1б. АРСС—спектр пригоден для моделирования как острых пиков, так и глубоких провалов.
2.2. Авторегрессионный процесс и свойства его спектра
Из всех описанных выше моделей временных рядов наибольшее внимание в технической литературе уделяется АР—процессам по двум причинам. Во—первых, АР— модель применяется для спектрального оценивания, если необходимы спектры с острыми пиками, что часто связывается с высоким частотным разрешением. Кроме того, оценки АР—параметров получаются из решения системы линейных уравнений, в отличие от других моделей. Итак, АР—процесс описывается следующим линейным разностным уравнением с комплексными коэффициентами, которое получается, если в уравнении (2.1) все СС—параметры, за исключением b[0]=1, положить равными нулю:
|
p |
|
|
x[n] = − åa[k]x[n − k] + u[n], |
(2.13) |
|
k=1 |
|
|
где x[n] — АР — последовательность на выходе каузального фильтра, который формирует |
наблюдаемые данные, u[n] — входная возбуждающая последовательность,
|
соответствующая белому шуму с нулевым среднем и дисперсией ρw . |
||||||
|
Если в уравнении (2.8) положить |
q = 0, то получим спектральную |
плотность |
||||
|
мощности АР—процесса: |
||||||
|
PAP ( f ) = |
Tρw |
= |
Tρw |
|||
|
| A( f ) |2 |
eHp ( f )aaH e p ( f ) , |
(2.14) |
||||
|
p |
||||||
|
где полином A( f ) = 1 + å a(k) exp( − j2πfkT ) , вектор комплексных |
синусоид |
k =1
ep(f) и вектор параметров a имеют следующий вид:
41
|
é |
1 |
ù |
é 1 |
ù |
|
|
ê exp( j2πfT ) |
ú |
ê a[1] |
ú |
||
|
ê |
. |
ú |
ê |
ú |
|
|
ê |
ú |
ê . |
ú |
||
|
e p ( f ) = ê |
. |
ú,a = ê |
ú |
||
|
ê |
ú |
ê . |
ú |
, |
|
|
ê |
. |
ú |
ê . |
ú |
|
|
ê |
ú |
ê |
ú |
||
|
ëexp( j2πfpT )û |
ëa[ p]û |
а надстрочный символ «H» означает эрмитово сопряжение (или эрмитово транспонирование) вектора, получаемое в результате комплексного сопряжения его элементов с последующей их транспозицией, т.е. образованием вектор—строки.
Полагая в (2.12) q = 0, получаем уравнение, связывающее автокорреляционную последовательность с параметрами автокорреляционной модели:
|
ì |
p |
|
ï |
— å a[k]rxx [m — k], m > 0, |
|
ï |
k=1 |
|
ï |
p |
|
rxx [m] = í- å a[k]rxx [—k] + ρw , m = 0, |
|
|
ï |
k=1 |
|
ï |
rxx* [—m], m < 0. |
|
ï |
|
|
î |
(2.15)
Это выражение можно записать для p +1 значений индекса временного сдвига
0 ≤ m ≤ p , затем представить в матричной форме
42
|
érxx[0] |
rxx[—1] |
. . . |
|
ê r [1] |
r [0] |
. . . |
|
ê xx |
xx |
|
|
ê |
. |
. |
|
ê . |
||
|
ê . |
. |
. |
|
ê . |
. |
. |
ê
ërxx[ p] rxx[ p —1] . . .
|
r [— p] |
ù |
é 1 |
ù |
éρ |
ù |
||
|
xx |
ú |
ê |
ú |
ê |
w |
ú |
|
|
rxx[— p +1]ú |
ê a[1] |
ú |
ê |
0 |
ú |
||
|
. |
ú |
ê . |
ú |
ê . |
ú |
||
|
. |
ú |
× ê |
ú |
= ê |
ú. |
||
|
ú |
ê . |
ú |
ê . |
ú (2.16) |
|||
|
. |
ú |
ê . |
ú |
ê . |
ú |
||
|
rxx[0] |
ú |
ê |
ú |
ê |
0 |
ú |
|
|
û |
ëa[ p]û |
ë |
û |
Таким образом, если задана автокорреляционная последовательность для 0 ≤ m ≤ p , то
АР—параметры можно найти в результате решения уравнений (2.16), которые называются
нормальными уравнениями Юла—Уолкера для АР—процесса. Автокорреляционная матрица в
|
(2.16) является теплицевой и эрмитовой, поскольку |
r* |
[k] = r [−k] . Очевидно, что |
||||
|
xx |
xx |
|||||
|
для СПМ АР—процесса справедливы следующие эквивалентные выражения: |
||||||
|
Tρw |
∞ |
|||||
|
PAP ( f ) = |
= T årxx[k]exp(− j2πfkT) . |
(2.17) |
||||
|
| A( f ) |2 |
||||||
|
k =−∞ |
Заметим, что значения автокорреляции, соответствующие индексам временного сдвига от 0 до p, позволяют определить из уравнения Юла—Уолкера дисперсию белого шума ρw
|
и АР — параметры a[1],a[2],…,a[ p] , а затем по (2.17) |
вычислить АР СПМ. Можно |
|
также рассчитать значения автокорреляции для m > p по |
соотношению |
|
p |
|
|
rxx[m] = − åa[k]rxx [m − k], |
(2.18) |
k=1
идалее воспользоваться второй частью (2.17) для вычисления АР СПМ, хотя это и не всегда эффективно на практике. Здесь уместно сравнить АР СПМ с оценкой СПМ, полученной классическим коррелограммным методом. Напомним, что этот метод
позволяет по p + 1 значениям автокорреляции получить оценку СПМ в виде
p
Pкор ( f ) = T å rxx [k]exp( − j2πfkT ) .
k = − p
43

Можно заметить, что в коррелограммном методе значения АКП вне интервала суммирования, то есть для | k |> p , полагаются нулевыми, в то время как для АР —
оценки они экстраполируются в соответствие с (2.18). Этот факт отображен на рис.2.2.
Именно применением этой ненулевой экстраполяции АКП при вычислении АР СПМ с помощью (2.17) и объясняется то высокое разрешение, которое характерно для оценок АР СПМ. Поскольку при получении оценок АР СПМ не используется обработка АКП с помощью функции окна, им не свойственны эффекты, вызванные наличием боковых лепестков, всегда присутствующих в классических спектральных оценках.
Рис.2.2. Экстраполяция автокорреляционной последовательности (АКП): а — исходная бесконечная АКП и истинный спектр процесса, состоящего из одной действительной синусоиды в
белом шуме; б — нулевая экстраполяция АКЩ подразумеваемая при использовании коррелограммного метода оценивания СПМ, и соответствующая спектральная оценка; в —
экстраполяция при использовании авторегрессионного метода оценивания СПМ и соответствующая спектральная оценка.
44
2.2.1.Связь с анализом, основанным на линейном предсказании
Уравнения, соответствующие линейному предсказанию, по своей структуре идентичны уравнениям Юла—Уолкера для авторегрессионного процесса, а потому существует тесная связь между фильтром линейного предсказания и АР—процессом.
Рассмотрим оценки линейного предсказания вперед:
|
m |
|
|
x€f [n] = − åa f [k]x[n − k] |
(2.19) |
k =1
где крышка « ^ » обозначает оценку, надстрочный индекс f (от forward — вперед) используется для обозначения оценки вперед. Предсказание вперед понимается в том смысле, что оценка, соответствующая временному индексу n, вычисляется по m предыдущим временным отсчетам. Комплексная ошибка линейного предсказания вперед:
|
e f [n] = x[n] − x€f [n], |
(2.20) |
|
имеет действительную дисперсию: |
|
|
ρ f =<| e f [n] |2 >, |
(2.21) |
Показано [1], что коэффициенты линейного предсказания вперед, минимизирующие дисперсию ошибки (2.21), определятся из следующей системы нормальных уравнений, представленной в матричном виде:
|
é |
. . |
. |
ù |
é |
1 |
ù |
é |
f ù |
||||||
|
êrxx[0] |
rxx[1] |
rxx[m] |
ú |
ê |
f |
[1] |
ú |
êρ |
ú |
|||||
|
ê rxx[1] |
rxx[0] |
. . |
. |
rxx[m—1]ú |
ê a |
ú |
ê |
0 |
ú |
|||||
|
ê |
. |
. |
. |
ú |
ê |
. |
ú |
ê |
. |
ú |
||||
|
ê . |
ú |
× ê |
ú |
= ê |
ú |
|||||||||
|
ê . |
. |
. |
. |
ú |
ê |
. |
ú |
ê |
. |
ú.(2.22) |
||||
|
ê |
. |
. |
. |
ú |
ê |
. |
ú |
ê |
. |
ú |
||||
|
ê . |
ú |
ê |
ú |
ê |
ú |
|||||||||
|
êr [m] |
r |
[m—1] . . |
. |
r |
[0] |
ú |
a f [m] |
ê |
0 |
ú |
||||
|
ë |
û |
|||||||||||||
|
ë xx |
xx |
xx |
û |
ë |
û |
|||||||||
|
Можно заметить, |
что |
эти матричные |
уравнения |
по |
своей |
структуре |
идентичны |
уравнениям Юла—Уолкера (2.16) для авторегрессионного процесса. Если выражение (2.20)
переписать в виде
45

u[n]
|
m |
|
|
x[n] = − å a[k]x[n − k] + e f [n], |
(2.23) |
k =1
то можно заметить его подобие уравнению (2.13) для авторегрессионного процесса. В
уравнении (2.13) последовательность соответствует белому шумовому процессу,
который используется в качестве входного воздействия авторегрессионного фильтра, а x[n]— представляет собой выходной сигнал фильтра. В отличие от (2.13) в уравнении
(2.23) последовательность значений ошибки e f [n] представляет собой выход фильтра
ошибки линейного предсказания вперед, а x[n]— входное воздействие фильтра ошибки
предсказания. Если последовательность x[n] генерируется как АР(p) — процесс с m=p, то последовательность значений ошибки будет белым шумовым процессом, коэффициенты линейного предсказания вперед будут идентичны АР—параметрам (a f [k] = a[k]) , а
фильтр ошибки предсказания можно рассматривать как фильтр, отбеливающий процесс x[n]. На рис.2.3 показаны БИХ—фильтр с передаточной функцией 1/A(z), формирующий
АР—процесс из белого шума, и КИХ—фильтр с передаточной функцией A(z),
отбеливающий АР—процесс.
|
u[n] |
1 |
x[n] |
A(z) |
u[n] |
||
|
A(z) |
||||||
|
Рис. 2.3. |
||||||
Аналогичные рассуждения можно провести относительно оценки линейного предсказания назад [надстрочный индекс b (от back — назад)]:
|
xb [n]= − åm ab [k]x[n + k], |
(2.24) |
|
k=1 |
|
|
которая определяется по m последующим временным отсчетам, |
ввести ошибку |
|
линейного предсказания назад |
eb [n]= x[n − m]− x€b [n − m]= x[n − m]+ åm ab [k]x[n − m + k](2.25)
k=1
46
ипоказать [1], что коэффициенты линейного предсказания назад ab [k],
|
минимизирующие |
дисперсию |
ошибки ρ b =<| eb [n] |2 >, |
будут комплексно — |
|
сопряженными |
величинами |
коэффициентам линейного |
предсказания вперед |
ab[k] = (a f [k])*, где 1≤ k ≤ m, а дисперсии ошибок одинаковы ρb = ρ f .
2.2.2.Алгоритм Левинсона
Решение системы эрмитовых теплицевых уравнений Юла—Уолкера (2.16) и системы (2.22) возможно с помощью эффективной рекуррентной процедуры, получившей название алгоритма Левинсона. Согласно этому алгоритму систему уравнений решают для последовательно увеличивающихся порядков АР—модели m=1,2,…,p. Так рекурсивное решение уравнений Юла—Уолкера методом Левинсона связывает АР—параметры порядка m с параметрами порядка (m-1) соотношением:
|
am [n] = am −1[n] + K m am* −1[m − n] , |
(2.26) |
||||
|
где n изменяется от 1 до (m-1). |
|||||
|
Коэффициент |
K m = am [m], |
получивший название коэффициента отражения, |
|||
|
определяется по значениям автокорреляции, соответствующим сдвигам от 0 до (m-1): |
|||||
|
1 |
m−1 |
||||
|
Km = am [m] = − |
åam−1[n]rxx [m − n], для m=2,3,… |
(2.27) |
|||
|
ρm−1 n=0 |
|||||
|
где полагается am−1[0] = 1, а K1 = a1[1] = −rxx [1] / rxx [0]. |
|||||
|
Рекурсивное уравнение для дисперсии белого шума имеет вид: |
|||||
|
ρm = ρm−1 (1− | Km |2 ), |
(2.28) |
с начальным условием ρ0 = rxx[0].
В рекурсии Левинсона без дополнительных вычислительных затрат находятся АР—
коэффициенты всех моделей, порядок которых m=1, 2, …, p. Можно также заметить,
что коэффициенты АР(p)-модели могут быть определены по известным (вычисленным)
величинам rxx(0) и коэффициентам отражения K1, K2, …, Kp. Поэтому эти коэффициенты также полностью определяют АР(p)-процесс, который, следовательно, имеет три эквивалентных представления, как это отображено на рис.2.4.
47

rxx [0],…, rxx [ p]
Автокорреляционная последовательность
r[0], r[1],…, r[ p]
|
ρ, a[1], a[2],…, a[ p] |
r[0],K1,…, K p |
|
|
Авторегрессионные |
Коэффициенты |
|
|
параметры |
отражения |
Рис.2.4. Три эквивалентных представления авторегрессионного процесса
АР(p)-процесс может быть представлен: в виде бесконечно протяженной автокорреляционной последовательности, в виде конечной последовательности
авторегрессионных коэффициентов и в виде конечной последовательности коэффициентов отражения. Хотя АКП АР(p)-процесса бесконечна, полная АКП
однозначно определяется конечной последовательностью с помощью
рекуррентного соотношения (2.18). Алгоритм Левинсона, описанный соотношениями (2.26) – (2.28), позволяет определить и АР—параметры, и коэффициенты отражения по заданной АКП, соответствующей временным сдвигам от 0 до p. Используя только
|
уравнение (2.26) с начальным условием a1[1] = K1 , можно получить |
рекурсивное |
|
соотношение, которое будет определять АР—параметры для всех порядков от |
m=1 до m=p |
|
на основе заданной последовательности коэффициентов отражения от K1 |
до Kp, и в |
результате определить однозначное соответствие между коэффициентами отражения и авторегрессионными параметрами. Можно также обратить направление рекурсий Левинсона, что позволит вычислять АКП, используя либо набор АР—параметров, либо набор коэффициентов отражения.
2.3. Методы авторегрессионного спектрального оценивания
Рассмотренные свойства АР—модели, позволяют рассчитать ее параметры и, следовательно, функцию СПМ по известным значениям АКП, исследуемого случайного процесса. При практических измерениях эта функция (АКП) обычно неизвестна, поэтому разработано большое количество методов нахождения АР СПМ, по имеющимся отсчетам
48
данных. Все эти методы можно разбить на два класса: алгоритмы для обработки блоков данных и алгоритмы для обработки последовательных данных. Мы рассмотрим методы,
предназначенные для обработки целых блоков накопленных отсчетов данных некоторого фиксированного объема. Блочные методы можно описать как алгоритмы с фиксированным временем, рекурсивные относительно порядка в том смысле, что они
применяются к фиксированным блокам временных отсчетов данных и позволяют рекурсивным образом получать оцени параметров АР—модели более высокого порядка по оценкам параметров АР— модели более низкого порядка. С другой стороны,
последовательные методы можно рассматривать как алгоритмы с фиксированным порядком, рекурсивные относительно времени в том смысле, что они применяются для последовательной обработки данных с целью обновления оценок параметров АР—модели фиксированного порядка. Применение таких алгоритмов целесообразно для слежения за спектрами, медленно изменяющимися во времени.
Блочные алгоритмы, в свою очередь, также можно разделить на три категории в соответствии с эквивалентными представлениями АР—процессов и их связью с процедурой линейного предсказания по критерию наименьших квадратов. Так называемый метод Юла—Уолкера использует оценивание АР—параметров по последовательности оценок АКП. В методе Берга АР—параметры определяются по оценкам коэффициентов отражения.
Ковариационный и модифицированный ковариационный методы предполагают вычисление коэффициентов линейного предсказания по критерию наименьших квадратов.
2.3.1.Метод Юла-Уолкера
Наиболее очевидный подход к АР — оцениванию СПМ состоит в решении уравнений Юла—Уолкера (2.16), в которые вместо значений неизвестной автокорреляционной функции подставляются их оценки. Так для отсчетов данных x[0], x[1]…,x[N −1] можно получить оценки автокорреляции в форме:
|
ì |
1 |
N −m−1 |
|||||||
|
ï |
å |
x[n + m]x*[n],0 £ m |
£ N —1; |
||||||
|
ï |
(N — m) n=0 |
(2.29) |
|||||||
|
r€xx [m] = í |
1 |
N −|m|−1 |
|||||||
|
ï |
|||||||||
|
å |
x*[n+ | m |]x[n],—(N —1) £ m < 0. |
||||||||
|
ï |
(N — | m |) |
n=0 |
|||||||
|
î |
|||||||||
|
Эти оценки |
являются |
несмещенными, поскольку < r€xx[m] >= rxx[m] и |
|||||||
|
состоятельными, |
поскольку |
при |
неограниченном возрастании N, |
дисперсия оценки |
49
стремится к нулю. Другой вариант получения смещенных оценок автокорреляции, имеет вид:
|
ì |
1 |
N −m−1 |
|||||||||||
|
ï |
å |
x[n — m]x*[n],0 £ m £ N —1; |
|||||||||||
|
N |
|||||||||||||
|
ï |
n=0 |
(2.30) |
|||||||||||
|
r xx[m] = í |
1 |
N −|m|−1 |
|||||||||||
|
ï |
å |
x*[n— | m |]x[n],—(N —1) £ m < 0. |
|||||||||||
|
ï |
n=0 |
||||||||||||
|
î N |
|||||||||||||
|
При |
конечном |
N |
эта |
оценка |
будет |
смещенной, |
поскольку |
||||||
|
| m | |
|||||||||||||
|
< r xx[m] >= (1− |
)rxx[m]. |
При |
использовании смещенных |
оценок |
|||||||||
|
N |
автокорреляции получаемая оценка АР—параметров, всегда соответствуют устойчивому АР — фильтру, что для несмещенных оценок не всегда имеет место.
Поскольку автокорреляционная матрица в системе уравнений (2.16) по своей структуре является теплицевой, так как элементы любой ее диагонали одинаковы, и эрмитовой, так
как rxx [−k ] = rxx* [k ] , то для получения решения ρw , a[1],a[2],…,a[p] при подстановке оценок автокорреляции в (2.16) можно использовать рекурсивный алгоритм Левинсона.
Таким образом, метод Юла—Уолкера отвечает совокупности соотношений (2.26) — (2.30) для определения АР—параметров, по которым в соответствие с (2.17), определяется оценка СПМ. В случае длинных записей данных, метод Юла—Уолкера, может давать вполне приемлемые спектральные оценки, однако для коротких записей данных, получаемые с его помощью, спектральные оценки имеют худшее разрешение, по сравнению с оценками, получаемыми другими АР—методами. В [1] приведена программа YULEWALKER , реализующая метод Юла—Уолкера.
2.3.2.Метод Берга
Один из первых алгоритмов, послужившим толчком к активному исследованию методов авторегрессионного спектрального оценивания, был предложен Бергом [1]. Идея алгоритма использует тот факт, что в рассмотренных выше формулах (2.26) — (2.28) только коэффициент отражения Kp непосредственно зависит от автокорреляционной функции АКП, а это означает, что одна из процедур получения АР — оценки СПМ в том случае, когда имеется некоторый блок отсчетов данных, может быть основана на
50
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
—
компрессия (сжатие) речевых сигналов в системах с линейным предсказанием (вокодерах),
которые рассматриваются ниже.
11.2 Линейное предсказание
Линейное предсказание (ЛП) – это
вычислительная процедура, позволяющая по некоторой линейной комбинации L
предшествующих взвешенных отсчетов сигнала предсказать (с некоторой точностью)
будущее значение отсчета. Практическая важность линейного предсказания для
спектрального анализа состоит в получении оценки спектра исследуемого сигнала
на его отрезке (кадре) длиной в L отсчетов, а с точки зрения фильтрации
– в получении рекурсивного адаптивного фильтра порядка M – 1
на участке квазистационарности, т.е. на том временном отрезке длительностью LТ
(Т – период дискретизации), где коэффициенты фильтра остаются
постоянными. Итогом решения задач ЛП является получение коэффициентов
адаптивного фильтра, АЧХ которого с хорошей степенью приближения соответствует
спектру сигнала на кадре.
Задача линейного предсказания может быть сформулирована следующим образом: на выходе некоторой
системы наблюдается сигнал ![]() ; известно,
; известно,
что это система полюсного типа с передаточной функцией вида
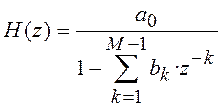
(11.1)
имеет порядок ![]() и возбуждается белым шумом.
и возбуждается белым шумом.
Требуется найти коэффициенты ![]() .
.
Суть процедуры решения состоит в
следующем (рисунок 11.2). Согласно (11.1) отсчеты сигнала ![]() на выходе системы определяются
на выходе системы определяются
выражением
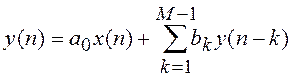 (11.2)
(11.2)
Включим последовательно с искомой
системой КИХ-фильтр с передаточной функцией
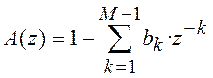
(11.3)
коэффициенты
которой ![]() . Общая передаточная функция
. Общая передаточная функция
получит вид:
Рисунок
11.2-Решение задачи линейного предсказания
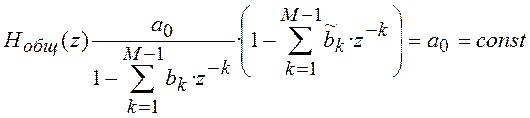 (11.4)
(11.4)
Фильтр с передаточной функцией ![]() называется фильтром линейного
называется фильтром линейного
предсказания или фильтром-предсказателем.
В действительности коэффициенты ![]() будут отличаться от точных
будут отличаться от точных ![]() , поэтому предсказываемое
, поэтому предсказываемое
значение сигнала ![]() будет отличаться от
будет отличаться от
точного ![]() на величину ошибки
на величину ошибки
предсказания (при ![]() )
)
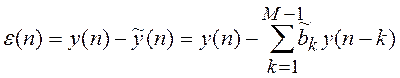 , (10.5)
, (10.5)
которую
называют остатком. Отсюда нетрудно получить передаточную функцию
КИХ-фильтра линейного предсказания (фильтр-предсказатель):
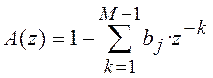
(10.6)
сигнал на
выходе которого представляет собой остаток ![]() .
.
Выражения (11.1-11.6) показывают, что передаточная функция искомой системы
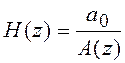 , (10.7)
, (10.7)
с точностью до
коэффициента ![]() представляет собой обратную
представляет собой обратную
передаточную функцию (а потому и частотную характеристику)
фильтра-предсказателя.
Коэффициенты линейного предсказания ![]() вычисляются согласно критерию
вычисляются согласно критерию
минимума среднеквадратической ошибки (СКО) предсказания:
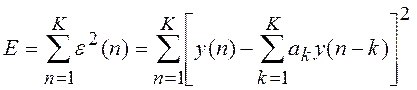 . (10.8)
. (10.8)
Коэффициенты ![]() можно найти, положив
можно найти, положив
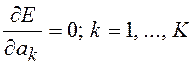 , (10.9)
, (10.9)
что приводит к
системе из L уравнений для определения K коэффициентов:
Линейное предсказание является
чрезвычайно эффективным при построении вокодеров – систем сжатия речи. Оно
позволяет получать на приеме синтезированный речевой сигнал по качеству, очень
близкому к естественному звучанию. Линейное предсказание нашло также широкое
применение в обработке изображений для сжатия видеоданных.
Вокодеры с линейным предсказанием
Важнейшей областью применения
линейного предсказания является сжатие речевого сигнала с целью снижения
скорости передачи речи по каналам телекоммуникации. Необходимость постановки
такой задачи объясняется следующим. Передача стандартного телефонного сигнала,
ограниченного полосой (0,3–3,4) кГц, по цифровым каналам связи при стандартной
частоте дискретизации 8 кГц и несложном АЦП с разрядностью 12 битов потребует
скорости передачи
![]() бит/с и,
бит/с и,
следовательно, в идеальном случае полосы пропускания канала 48 кГц.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание — внизу страницы.