
Простая случайная выборка
При
простой случайной выборке отбор единиц
в выборочную совокупность производится
непосредственно из всей массы единиц
генеральной совокупности в форме
случайного отбора, при котором каждой
единице генеральной совокупности
обеспечивается одинаковая вероятность
(возможность) быть выбранной. Единица
отбора совпадает с единицей наблюдения.
Случайный отбор осуществляется путем
применения жеребьевки (лотереи) или
путем использования таблиц случайных
чисел.
Случайный
отбор может быть проведен в двух формах:
в форме возвратной (повторной) выборки
и в форме безвозвратной (бесповторной)
выборки. При повторном отборе вероятность
попадания каждой единицы генеральной
совокупности остается постоянной, так
как после отбора какой-то единицы она
снова возвращается в генеральную
совокупность и может быть выбранной.
При бесповторном отборе выбранная
единица не возвращается в генеральную
совокупность и вероятность попадания
отдельных единиц в выборку все время
изменяется (для оставшихся единиц она
возрастает).
Применение
простой случайной повторной выборки
на прак-тике весьма ограниченно; обычно
используется бесповторная выборка.
Теорема
Чебышева утверждает принципиальную
возможность определения генеральной
средней по данным случайной повтор-ной
выборки. Теорема Чебышева дополняется
теоремой Ляпунова, которая позволяет
рассчитать максимальную ошибку выборочной
средней при данном достаточно большом
числе независимых наблюдений. Согласно
этой теореме при достаточно большом
числе независимых наблюдений в генеральной
совокупости с конечной средней и
ограниченной дисперсией вероятность
того, что расхождение между выборочной
и генеральной средней (
)
не превзойдет по абсолютной величине
некоторую величину
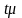
,
равна интегралу Лапласа. Это можно
записать так:
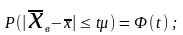

где
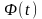
—
интеграл Лапласа (удвоенная нормированная
функция Лапласа).
Величина
,
обозначаемая

,
называется предельной ошибкой выборки.
Следовательно,

где
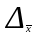
—
предельная (максимально возможная)
ошибка средней;

—предельная
(максимально возможная) ошибка доли;
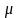
—
величина
средней квадратической стандартной
ошибки (стандартная или средняя ошибка);
t
— коэффициент кратности средней ошибки
выборки, зависящий от вероятности, с
которой гарантируется величина предельной
ошибки.
В
зависимости от принятой вероятности Р
определяется значение коэффициента
кратности (t)
по удвоенной нормированной функции
Лапласа (см. приложение 3).
Величина
средней (стандартной) ошибки в условиях
большой выборки (п
> 30) рассчитывается по известным из
теории вероятностей формулам:
а) при
случайной повторной выборке:

б) при
случайной бесповторной выборке:

При
расчете ошибок возникает существенное
затруднение: величины
и р
по генеральной совокупности неизвестны.
Эти величины в условиях большой выборки
заменяют величинами
(выборочная дисперсия) и w
(выборочная доля), рассчитанными по
выборочным данным. В табл. 6.1 приведены
формулы расчета ошибок простой случайной
выборки.
Таблица
6.1
Формулы
ошибок простой случайной выборки

Формулы
предельной ошибки позволяют решать
задачи трех видов:
1. Определение
пределов генеральных характеристик с
заданной степенью надежности (доверительной
вероятностью) на основе показателей,
полученных по данным выборки.
Доверительные
интервалы для генеральной средней:
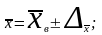

Доверительные
интервалы для генеральной доли:
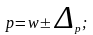
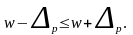
2. Определение
доверительной вероятности того, что
генеральная характеристика может
отличаться от выборочной не более чем
на определенную заданную величину.
Доверительная
вероятность является функцией от t,
определяемой по формуле:
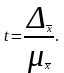
По
величине t
определяется доверительная вероятность
(приложение 3 Практикума).
3. Определение
необходимого объема выборки, который
с практической вероятностью обеспечивает
заданную точность выборки.
Для
расчета объема выборки необходимо иметь
следующие данные:
а) размер
доверительной вероятности (Р);
б) коэффициент
t,
зависящий от принятой вероятности
(определяется по приложению 3 Практикума);
в) величину
(или pq)
в генеральной совокупности; они заменяются
величинами, полученными в предшествующих
обследованиях или при пробных выборках
[
или w(1—w)];
г) величину
максимально допустимой ошибки (
или
);
д) объем
генеральной совокупности (N).
Необходимый
объем выборки определяется на основе
допустимой величины ошибки:

В
табл. 6.2 приведены формулы для расчета
численности простой случайной выборки.
Таблица
6.2
Формулы
для определения численности простой
случайной выборки

*
В случаях, когда частость w
даже приблизительно неизвестна, в расчет
вводят максимальную величину дисперсии
доли, равную 0,25 (если w
= 0,5, то w(l—
w)
= 0,25).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
29.03.20161.08 Mб9ОТК учебник-2.docx
- #
- #
- #
- #
- #
- #
- #
- #
- #
Повторный и бесповторный отбор.
Ошибка выборки
Краткая теория
На основании выборочных данных дается оценка статистических
показателей по всей (генеральной) совокупности. Подобное возможно, если выборка
основывается на принципах случайности отбора и репрезентативности
(представительности) выборочных данных. Каждая единица генеральной совокупности
должна иметь равную возможность (вероятность) попасть в выборку.
При формировании выборочной совокупности используются следующие
способы отбора: а) собственно-случайный отбор; б) механическая выборка; в)
типический (районированный) отбор; г) многоступенчатая (комбинированная)
выборка; д) моментно-выборочное наблюдение.
Выборка может осуществляться по схеме повторного и бесповторного
отбора.
В первом случае единицы совокупности, попавшие в выборку, снова
возвращаются в генеральную, а во втором случае – единицы совокупности, попавшие
в выборку, в генеральную совокупность уже не возвращаются.
Выборка может осуществляться отдельными единицами или сериями
(гнездами).
Собственно-случайная выборка
Отбор в этом случае производится либо по жребию, либо по таблицам
случайных чисел.
На основании приемов классической выборки решаются следующие
задачи:
а) определяются границы среднего значения показателя по генеральной
совокупности;
б) определяются границы доли признака по генеральной совокупности.
Предельная ошибка средней при собственно-случайном отборе
исчисляется по формулам:
а) при повторном отборе:
б) при бесповторном отборе:
где
– численность выборочной совокупности;
– численность генеральной совокупности;
– дисперсия признака;
– критерий кратности ошибки: при
;
при
;
при
.
Значения
определяются
по таблице функции Лапласа.
Границы (пределы) среднего значения признака по генеральной
совокупности определяются следующим неравенством:
где
– среднее значение признака по выборочной
совокупности.
Предельная ошибка доли при собственно-случайном отборе определяется
по формулам:
а) при повторном отборе:
при бесповторном отборе:
где
– доля единиц совокупности с заданным
значением признака в обзей численности выборки,
– дисперсия доли признака.
Границы (пределы) доли признака по всей (генеральной) совокупности
определяются неравенством:
где
– доля признака по генеральной совокупности.
Типическая (районированная) выборка
Особенность этого вида
выборки заключается в том, что предварительно генеральная совокупность по
признаку типизации разбивается на частные группы (типы, районы), а затем в
пределах этих групп производится выборка.
Предельная ошибка средней
при типическом бесповторном отборе определяется по формуле:
где
– средняя из внутригрупповых дисперсий
по каждой типичной группе.
При пропорциональном отборе из групп генеральной совокупности
средняя из внутригрупповых дисперсий определяется по формуле:
где
– численности единиц совокупности групп по выборке.
Границы (пределы) средней по генеральной совокупности на основании
данных типической выборки определяются по тому же неравенству, что при
собственно-случайной выборке. Только предварительно необходимо вычислить общую
выборочную среднюю
из частных выборочных средних
.
Для случая пропорционального отбора это определяется по формуле:
При непропорциональном отборе средняя из внутригрупповых дисперсий вычисляется по
формуле:
где
– численность единиц групп по генеральной
совокупности.
Общая выборочная средняя в этом случае определяется по формуле:
Предельная ошибка доли
признака при типическом бесповторном отборе определяется формулой:
Средняя дисперсия доли
признака из групповых дисперсий доли
при
типической пропорциональной выборке вычисляется по формуле:
Средняя доля признака по
выборке из показателей групповых долей рассчитывается формуле:
Средняя дисперсия доли при
непропорциональном типическом отборе определяется следующим образом:
а средняя доля признака:
Формулы ошибок выборки при типическом повторном отборе будут те же,
то и для случая бесповторного отбора. Отличие заключается только в том, что в
них будет отсутствовать по корнем сомножитель
.
Серийная выборка
Серийная ошибка выборки
может применяться в двух вариантах:
а) объем серий различный
б) все серии имеют
одинаковое число единиц (равновеликие серии).
Наиболее распространенной
в практике статистических исследований является серийная выборка с
равновеликими сериями. Генеральная совокупность делится на одинаковые по объему
группы-серии
и
производится отбор не единиц совокупности, а серий
. Группы (серии) для обследования отбирают в
случайном порядке или путем механической выборки как повторным, так и
бесповторными способами. Внутри каждой отобранной серии осуществляется сплошное
наблюдение. Предельные ошибки выборки
при
серийном отборе исчисляются по формулам:
а) при повторном отборе
б) при бесповторном отборе
где
– число
серий в генеральной совокупности;
– число
отобранных серий;
– межсерийная дисперсия, исчисляемая для случая равновеликих
серий по формуле:
где
–
среднее значение признака в каждой из отобранных серий;
– межсерийная
средняя, исчисляемая для случая равновеликих серий по формуле:
Определение численности выборочной совокупности
При проектировании
выборочного наблюдения важно наряду с организационными вопросами решить одну из
основных постановочных задач: какова должна быть необходимая численность
выборки с тем, чтобы с заданной степенью точности (вероятности) заранее
установленная ошибка выборки не была бы превзойдена.
Примеры решения задач
Задача 1
На основании результатов проведенного на заводе 5%
выборочного наблюдения (отбор случайный, бесповторный) получен следующий ряд
распределения рабочих по заработной плате:
| Группы рабочих по размеру заработной платы, тыс.р. | до 200 | 200-240 | 240-280 | 280-320 | 320 и выше | Итого |
| Число рабочих | 33 | 35 | 47 | 45 | 40 | 200 |
На основании приведенных данных определите:
1) с вероятностью 0,954 (t=2) возможные пределы, в которых
ожидается средняя заработная плата рабочего в целом по заводу (по генеральной
совокупности);
2) с вероятностью 0,997 (t=3) предельную ошибку и границы доли
рабочих с заработной платой от 320 тыс.руб. и выше.
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Вычислим среднюю з/п: Для этого просуммируем произведения середин
интервалов и соответствующих частот, и полученную сумму разделим на сумму
частот.
2) Выборочная дисперсия:
Найдем доверительный интервал для средней. Предельная ошибка выборочной
средней считается по формуле:
где
—
аргумент функции Лапласа.
Искомые возможные пределы, в которых ожидается средняя заработная плата
рабочего в целом по заводу:
Найдем доверительный интервал для выборочной доли. Предельная ошибка
выборочной доли считается по формуле:
Доля рабочих с з/п от 320 тыс.р.:
Искомые границы доли рабочих с заработной платой от 320 тыс.руб. и выше:
Задача 2
В
городе 23560 семей. В порядке механической выборки предполагается определить
количество семей в городе с числом детей трое и более. Какова должна быть
численность выборки, чтобы с вероятностью 0,954 ошибка выборки не превышала
0,02 человека. На основе предыдущих обследований известно, что дисперсия равна
0,3.
Решение
Численность
выборки можно найти по формуле:
В нашем случае:
Вывод к задаче
Таким образом численность
выборки должна составить 2661 чел.
Задача 3
С
целью определения средней месячной заработной платы персонала фирмы было
проведено 25%-ное выборочное обследование с отбором
единиц пропорционально численности типических групп. Для отбора сотрудников
внутри каждого филиала использовался механический отбор. Результаты
обследования представлены в следующей таблице:
| Номер филиала |
Средняя месячная заработная плата, руб. |
Среднее квадратическое отклонение, руб. |
Число сотрудников, чел. |
| 1 | 870 | 40 | 30 |
| 2 | 1040 | 160 | 80 |
| 3 | 1260 | 190 | 140 |
| 4 | 1530 | 215 | 190 |
С
вероятностью 0,954 определите пределы средней месячной заработной платы всех
сотрудников гостиниц.
Решение
Предельная
ошибка выборочной средней:
Средняя
из внутригрупповых дисперсий:
Получаем:
Средняя
месячная заработная плата по всей совокупности филиалов:
Искомые
пределы средней месячной заработной платы:
Вывод к задаче
Таким
образом с вероятностью 0,954 средняя месячная заработная плата всех сотрудников
гостиниц находится в пределах от 1294,3 руб. до 1325,7 руб.

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет