
Сегодня будет сделанный с любовью обзор функций ошибок и функционалов качества в задачах регрессии.

Выкладываю часть главы «Метрики качества» из своей вечно недописанной книги. Она полностью сделана по материалам моего курса в МГУ. Краткое содержание:
- Качество работы алгоритма
- Функции ошибки в задачах регрессии
- Средний модуль отклонения (MAE – Mean Absolute Error или MAD – Mean Absolute Deviation)
- Средний квадрат отклонения (MSE – Mean Squared Error), корень из этой ошибки: RMSE – Root Mean Squared Error, коэффициент детерминации (R2)
- функция ошибки Хьюбера (Huber loss) и logcosh
- Обобщения MAE и RMSE
- Средний процент отклонения (MAPE – Mean Absolute Percent Error)
- Симметричный средний процент отклонения (SMAPE – Symmetric Mean Absolute Percentage Error)
- MRAE – Mean Relative Absolute Error, REL_MAE, Percent Better
- MASE (Mean Absolute Scaled Error)
- eB – процент случаев, когда ответ алгоритма верен с некоторой заранее заданной точностью
- Несимметричные функции ошибки
- Реализация функций ошибок в scikit-learn
Материал ещё сырой, поэтому все замечания, предложения, найденные неточности и ошибки пишите в комментарии.
Предыдущие посты из этой серии:
- Логистическая функция ошибки
- AUC ROC (площадь под кривой ошибок)
- Задачки про AUC (ROC)
И побуду «заядлым блогером»: если пост наберёт больше 2000 просмотров, то опубликую продолжение главы;)
Постановка задачи регрессии

Задача регрессии — это один из основных типов моделей машинного обучения. И хотя, большинство задач на практике относятся к другому типу — классификации, мы начнем знакомство с машинным обучением именно с регрессии. Регрессионные модели были известны задолго до появления машинного обучения как отрасли и активно применяются в статистике, эконометрике, математическом моделировании. Машинное обучение предлагает новый взгляд на уже известные в математике модели. И этот новый взгляд позволит строить более сложные и мощные модели, чем классические математические дисциплины.
Задача регрессии относится к категории задач обучения с учителем. Это значит, что набор данных, который используется для обучения, должен иметь определенную структуру. Обычно, датасеты для машинного обучения представляют собой таблицу, в которой по строкам перечислены разные объекты наблюдений или измерений. В столбцах — различные характеристики, или атрибуты, объектов. А на пересечении строк и столбцов — значение данной характеристики у данного объекта. Обычно один атрибут (или переменная) имеет особый характер — именно ее значение мы и хотим научиться предсказывать с помощью модели машинного обучения. Эта характеристика объекта называется целевая переменная. И если эта целевая переменная выражена числом (а точнее, некоторой непрерывной величиной) — то мы говорим о задаче регрессии.
Задача регрессии в машинном обучении — это задача предсказания какой-то численной характеристики объекта предметной области по определенному набору его параметров (атрибутов).
Задачи регрессии на практике встречаются довольно часто. Например, предсказание цены объекта недвижимости — классическая регрессионная задача. В таких проблемах атрибутами выступают разные характеристики квартир или домов — площадь, этажность, расположение, расстояние до центра города, количество комнат, год постройки. В разных наборах данных собрана разная информация И, соответственно, модели тоже должны быть разные. Другой пример — предсказание цены акций или других финансовых активов. Или предсказание температуры завтрашним днем.
Во всех таких задачах нам нужно иметь данные, которые позволят осуществить такое предсказание. Да, “предсказание” — это условный термин, не всегда мы говорим о будущих событиях. Зачастую говорят именно о “моделировании” значения целевой переменной. Регрессионные модели используют информацию об объектах в обучающем наборе данных, чтобы сделать вывод о возможном значении целевой переменной. И для этого нужно, чтобы ее значение имело какую-то зависимость от имеющихся у нас атрибутов. Если построить модель предсказания цены акции, но на вход подать информацию о футбольных матчах — ничего не получится. Мы предполагаем, что в наборе данных собраны именно те атрибуты объектов, которые имеют влияние на на значение целевой переменной. И чем больше это предположение выполняется, тем точнее будет потенциально наша модель.
Немного поговорим о терминах. Набор данных который мы используем для обучения модели называют датасетом (dataset) или обучающей выборкой (training set). Объекты, которые описываются в датасете еще называют точками данных (data points). Целевую переменную еще называют на статистический манер зависимой переменной (dependent variable) или результативной, выходной (output), а остальные атрибуты — независимыми переменными (independent variables), или признаками (features), или факторами, или входными переменными (input). Значения одного конкретного атрибута для всех объектов обучающей выборки часто представляют как вектор этого признака (feature vector). А всю таблицу всех атрибутов называют матрицей атрибутов (feature matrix). Соответственно, еще есть вектор целевой переменной, он не входит в матрицу атрибутов.
Датасет, набор данных — совокупность информации в определенной структурированной форме, которая используется для построения модели машинного обучения для решения определенной задачи. Датасет обычно представляется в табличной форме. Датасет описывает некоторое множество объектов предметной области — точек данных.
С точки зрения информатики, регрессионная модель — это функция, которая принимает на вход значения атрибутов какого-то конкретного объекта и выдает на выходе предполагаемое значение целевой переменной. В большинстве случаев мы предполагаем, что целевая переменная у нас одна. Если стоит задача предсказания нескольких характеристик, то их чаще воспринимают как несколько независимых задач регрессии на одних и тех же атрибутах.
Мы пока ничего не говорили о том, как изнутри устроена регрессионная модель. Это потому, что она может быть какой угодно. Это может быть математическое выражение, условный алгоритм, сложная программа со множеством ветвлений и циклов, нейронная сеть — все это можно представить регрессионной моделью. Единственное требование к модели машинного обучения — она должна быть параметрической. То есть иметь какие-то внутренние параметры, от которых тоже зависит результат вычисления. В простых случаях, чаще всего в качестве регрессионной модели используют аналитические функции. Таких функций бесконечное количество, но чаще всего используется самая простая функция, с которой мы и начнем изучение регрессии — линейная функция.
Регрессионные модели подразделяют на парную и множественную регрессии. Парная регрессия — это когда у нас всего один атрибут. Множественная — когда больше одного. Конечно, на практике парная регрессия не встречается, но на примере такой простой модели мы поймем основные концепции машинного обучения. Плюс, парную регрессию очень удобно и наглядно можно изобразить на графике. Когда у нас больше двух переменных, графики уже не особо построишь, и модели приходится визуализировать иначе, более косвенно.
Выводы:
- Регрессия — это задача машинного обучения с учителем, которая заключается в предсказании некоторой непрерывной величины.
- Для использования регрессионных моделей нужно, чтобы в датасете были характеристики объектов и “правильные” значения целевой переменной.
- Примеры регрессионных задач — предсказание цены акции, оценка цены объекта недвижимости.
- Задача регрессии основывается на предположении, что значение целевой переменной зависит от значения признаков.
- Регрессионная модель принимает набор значений и выдает предсказание значения целевой переменной.
- В качестве регрессионных моделей часто берут аналитические функции, например, линейную.
Парная линейная регрессия
Функция гипотезы
Напомним, что в задачах регрессии мы принимаем входные переменные и пытаемся получить более-менее достоверное значение целевой переменной. Любая функция, даже самая простая линейная может выдавать совершенно разные значения для одних и тех же входных данных, если в функции будут разные параметры. Поэтому, любая регрессионная модель — это не какая-то конкретная математическая функция, а целое семейство функций. И задача алгоритма обучения — подобрать значения параметров таким образом, чтобы для объектов обучающей выборки, для которых мы уже знаем правильные ответы, предсказанные (или теоретические, вычисленные из модели) значения были как можно ближе к тем, которые есть в датасете (эмпирические, истинные значения).
Функция гипотезы — преобразование, которое принимает на вход набор значений признаков определенного объекта и выдает оценку значения целевой переменной данного объекта. Она лежит в основе модели машинного обучения.
Парная, или одномерная (univariate) регрессия используется, когда вы хотите предсказать одно выходное значение (чаще всего обозначаемое $y$), зависящее от одного входного значения (обычно обозначается $x$). Сама функция называется функцией гипотезы или моделью. В качестве функции гипотезы для парной регрессии можно выбрать любую функцию, но мы пока потренируемся с самой простой функцией одной переменной — линейной функцией. Тогда нашу модель можно назвать парной линейной регрессией.
В случае парной линейной регрессии функция гипотезы имеет следующий общий вид:
[hat{y} = h_b (x) = b_0 + b_1 x]
Обратите внимание, что это похоже на уравнение прямой. Эта модель соответствует множеству всех возможных прямых на плоскости. Когда мы конкретизируем модель значениями параметров (в данном случае — $b_0$ и $b_1$), мы получаем конкретную прямую. И наша задача состоит в том, чтобы выбрать такую прямую, которая бы лучше всего “легла” в точки из нашей обучающей выборки.
В данном случае, мы пытаемся подобрать функцию h(x) таким образом, чтобы отобразить данные нам значения x в данные значения y. Допустим, мы имеем следующий обучающий набор данных:
| входная переменная x | выходная переменная y |
| 0 | 4 |
| 1 | 7 |
| 2 | 7 |
| 3 | 8 |
Мы можем составить случайную гипотезу с параметрами $ b_0 = 2, b_1 = 2 $. Тогда для входного значения $ x=1 $ модель выдаст предсказание, что $ y=4 $, что на 3 меньше данного. Значение $y$, которое посчитала модель будем называть теоретическим или предсказанным (predicted), а значение, которое дано в наборе данных — эмпирическим или истинным (true). Задача регрессии состоит в нахождении таких параметров функции гипотезы, чтобы она отображала входные значения в выходные как можно более точно (чтобы теоретические значения были как можно ближе к эмпирическим), или, другими словами, описывала линию, наиболее точно ложащуюся в данные точки на плоскости $(x, y)$.
Выводы:
- Модель машинного обучения — это параметрическая функция.
- Задача обучения состоит в том, чтобы подобрать параметры модели таким образом, чтобы она лучше всего описывала обучающие данные.
- Парная линейная регрессия работает, если есть всего одна входящая переменная.
- Парная линейная регрессия — одна из самых простых моделей машинного обучения.
- Парная линейная регрессия соответствует множеству всех прямых на плоскости. Из них мы выбираем одну, наиболее подходящую.
Функция ошибки
Как мы уже говорили, разные значения параметров дают разные конкретные модели. Для того, чтобы подобрать наилучшую модель, нам нужно средство измерения “точности” модели, некоторая функция, которая показывает, насколько модель хорошо или плохо соответствует имеющимся данным.

В простых случаях мы можем отличить хорошие модели от плохих, только взглянув на график. Но это затруднительно, если количество признаков очень велико, или если модели лишь немного отличаются друг от друга. Да и для автоматизации процесса нужен способ формализовать наше общее представление о том, что модель “ложится” в точки данных.
Такая функция называется функцией ошибки (cost function). Она измеряет отклонения теоретических значений (то есть тех, которые предсказывает модель) от эмпирических (то есть тех, которые есть в данных). Чем выше значение функции ошибки, тем хуже модель соответствует имеющимся данным, хуже описывает их. Если модель полностью соответствует данным, то значение функции ошибки будет нулевым.

В задачах регрессии в качестве функции ошибки чаще всего берут среднеквадратичное отклонение теоретических значений от эмпирических. То есть сумму квадратов отклонений, деленную на удвоенное количество измерений. Казалось бы, что это довольно произвольный выбор. Но он вполне обоснован и логичен. Давайте порассуждаем. Чтобы оценить, насколько хороша модель, мы должны оценить, насколько отклоняются эмпирические значения, то есть (y_i) от теоретических, предсказанных моделью, то есть (h_b(x_i)). Проще всего это отклонение выразить в виде разницы между этими двумя значениями. Но эта разница будет характеризовать отклонение только в одной точке данных, а в датасете может быть их произвольное количество. Поэтому имеет смысл взять сумму этих разностей для всех точек данных:
[J = sum_{i=1}^{m} (h_b(x_i) — y_i)]
Но с этим подходом есть одна проблема. Дело в том, что отклонения реальных значений от предсказанных могут быть как положительные, так и отрицательные. И если мы просто их все сложим, то положительные как бы скомпенсируют отрицательные. И в итоге даже очень плохие модели могут выглядеть, как имеющие маленькие ошибки. Фактически, для любого набора данных, если модель проходит через геометрический центр распределения, то такая ошибка будет равна нулю. То есть для достижения нулевой ошибки линии регрессии достаточно проходить через одну определенную точку. Таких моделей, очевидно, бесконечное количество, и все они будут иметь нулевую сумму отклонений. Конечно, так не пойдет и нужно придумать такую формулу, чтобы положительные и отрицательные отклонения не взаимоуничтожались, а складывались без учета знака.
Можно было бы взять отклонения по модулю. Но у такого подхода есть один большой недостаток: Функция абсолютного значения не везде дифференцируема. В одной точке у нее не существует производной. А чуть позже нам очень понадобится брать производную от функции ошибки. Поэтому модуль нам не подходит. Но в математике есть и другие функции, которые позволяют “избавиться” от знака числа. Например, возведение в квадрат. Его как раз и применяют в функции ошибки:
[J = sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
У этого подхода есть еще одно неочевидное достоинство. Квадратичная функция дополнительно сильно увеличивает размер больших чисел. То есть, если среди наших отклонений будет какое-то очень большое, то после возведения в квадрат оно станет еще непропорционально больше. Таким образом квадратичная функция ошибки как бы сильнее “штрафует” сильные отклонения предсказанных значений от реальных.
Но есть еще одна проблема. Дело в том, что в разных наборах данных может быть разное количество точек. Если мы просто будем считать сумму отклонений, то чем больше точек будем суммировать, тем больше итоговое отклонение будет только из-за количества слагаемых. Поэтому модели, обученные на маленьких объемах данных будут иметь преимущество. Это тоже неправильно и поэтому берут не сумму, а среднее из отклонений. Для этого достаточно лишь поделить эту сумму на количество точек данных:
[J = frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
В итоге мы как раз получаем среднеквадратичное отклонение реальных значений от предсказанных. Эта функция дает хорошее представление о том, какая конкретная модель хорошо соответствует имеющимся данным, а какая — хуже или еще лучше.
[J(b_0, b_1)
= frac{1}{2m} sum_{i=1}^{m} (hat{y_i} — y_i)^2
= frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
Эту функцию называют «функцией квадрата ошибки» или «среднеквадратичной ошибкой» (mean squared error, MSE). Среднее значение уменьшено вдвое для удобства вычисления градиентного спуска, так как производная квадратичной функции будет отменять множитель 1/2. Вообще, функцию ошибки можно свободно домножить или разделить на любое число (положительное), ведь нам не важна конкретная величина этой функции. Нам важно, что какие-то модели (то есть наборы значений параметров модели) имеют низкую ошибку, они нам подходят больше, а какие-то — высокую ошибку, они подходят нам меньше.
Обратите внимание, что в качестве аргументов у функции ошибки выступают параметры нашей функции гипотезы. Ведь функция ошибки оценивает отклонение конкретной функции гипотезы (то есть набора значений параметров этой функции) от эмпирических значений, то есть ставит в соответствие каждому набору параметров модели число, характеризующее ошибку этого набора.
Давайте проследим формирование функции ошибки на еще более простом примере. Возьмем упрощенную форму линейной модели — прямую пропорциональность. Она выражается формулой:
[hat{y} = h_b (x) = b_1 x]
Эта модель поможет нам, так как у нее всего один параметр. И функцию ошибки можно будет изобразить на плоскости. Возьмем фиксированный набор точек и попробуем несколько значений параметра для вычисления функции ошибки. Слева на графике изображены точки данных и текущая функция гипотезы, а на правом графике бы будем отмечать значение использованного параметра (по горизонтали) и получившуюся величину функции ошибки (по вертикали):

При значении $b_1 = -1$ линия существенно отклоняется от точек. Отметим уровень ошибки (примерно 10) на правом графике.

Если взять значение $b_1 = 0$ линия гораздо ближе к точкам, но ошибка все еще есть. Отметим новое значение на правом графике в точке 0.

При значении $b_1 = 1$ график точно ложится в точки, таким образом ошибка становится равной нулю. Отмечаем ее так же.

При дальнейшем увеличении $b_1$ линия становится выше точек. Но функция ошибки все равно будет положительной. Теперь она опять станет расти.

На этом примере мы видим еще одно преимущество возведения в квадрат — это то, что такая функция в простых случаях имеет один глобальный минимум. На правом графике формируется точка за точкой некоторая функция, которая похожа очертаниями на параболу. Но мы не знаем аналитического вида этой параболы, мы можем лишь строить ее точка за точкой.

В нашем примере, в определенной точке функция ошибки обращается в ноль. Это соответствует “идеальной” функции гипотезы. То есть такой, когда она проходит четко через все точки. В нашем примере это стало возможно благодаря тому, что точки данных и так располагаются на одной прямой. В общем случае это не выполняется и функция ошибки, вообще говоря, не обязана иметь нули. Но она должна иметь глобальный минимум. Рассмотрим такой неидеальный случай:





Какое бы значение параметра мы не использовали, линейная функция неспособна идеально пройти через такие три точки, которые не лежат на одной прямой. Эта ситуация называется “недообучение”, об этом мы еще будем говорить дальше. Это значит, что наша модель слишком простая, чтобы идеально описать данные. Но зачастую, идеальная модель и не требуется. Важно лишь найти наилучшую модель из данного класса (например, линейных функций).
Выше мы рассмотрели упрощенный пример с функцией гипотезы с одним параметром. Но у парной линейной регрессии же два параметра. В таком случае, функция ошибки будет описывать не параболу, а параболоид:

Теперь мы можем конкретно измерить точность нашей предсказывающей функции по сравнению с правильными результатами, которые мы имеем, чтобы мы могли предсказать новые результаты, которых у нас нет.
Если мы попытаемся представить это наглядно, наш набор данных обучения будет разбросан по плоскости x-y. Мы пытаемся подобрать прямую линию, которая проходит через этот разбросанный набор данных. Наша цель — получить наилучшую возможную линию. Лучшая линия будет такой, чтобы средние квадраты вертикальных расстояний точек от линии были наименьшими. В лучшем случае линия должна проходить через все точки нашего набора данных обучения. В таком случае значение J будет равно 0.


В более сложных моделях параметров может быть еще больше, но это не важно, ведь нам не нужно строить функцию ошибки, нам нужно лишь оптимизировать ее.
Выводы:
- Функция ошибки нужна для того, чтобы отличать хорошие модели от плохих.
- Функция ошибки показывает численно, насколько модель хорошо описывает данные.
- Аргументами функции ошибки являются параметры модели, ошибка зависит от них.
- Само значение функции ошибки не несет никакого смысла, оно используется только в сравнении.
- Цель алгоритма машинного обучения — минимизировать функцию ошибки, то есть найти такой набор параметров модели, при которых ошибка минимальна.
- Чаще всего используется так называемая L2-ошибка — средний квадрат отклонений теоретических значений от эмпирических (метрика MSE).
Метод градиентного спуска
Таким образом, у нас есть функция гипотезы, и способ оценить, насколько хорошо конкретная гипотеза вписывается в данные. Теперь нам нужно подобрать параметры функции гипотезы. Вот где приходит на помощь метод градиентного спуска. Идея этого метода достаточно проста, но потребует для детального знакомства вспомнить основы математического анализа и дифференциального исчисления.
Несмотря на то, что мы настоятельно советуем разобраться в основах функционирования метода градиентного спуска шаг за шагом для более полного понимания того, как модели машинного обучения подбирают свои параметры, если читатель совсем не владеет матанализом, данные объяснения можно пропустить, они не являются критичными для повседневного понимания сути моделей машинного обучения.
Это происходит при помощи производной функции ошибки. Напомним, что производная функции показывает направление роста этой функции с ростом аргумента. Необходимое условие минимума функции — обращение в ноль ее производной. А так как мы знаем, что квадратичная функция имеет один глобальный экстремум — минимум, то наша задача очень проста — вычислить производную функции ошибки и найти, где она равна нулю.
Давайте найдем производную среднеквадратической функции ошибки. Так как эта функция зависит от двух аргументов — (b_0) и (b_1), то нам понадобится взять частные производные этой функции по всем ее аргументам. Для начала вспомним формулу самой функции ошибки:
[J(b_0, b_1) = frac{1}{2 m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
Частная производная обозначается (frac{partial f}{partial x}) или (frac{partial}{partial x} f) и является обобщением обычной (полной) производной для функций нескольких аргументов. Частая производная показывает наклон функции в направлении изменения определенного аргумента, то есть как бы “в разрезе” этого аргумента. Градиент — это вектор частных производных функции по всем ее аргументам. Вектор градиента показывает направление максимального роста функции.
Что бы посчитать производную по какому-то из аргументов нам понадобятся обычные правила вычисления производной. Во-первых, общий множитель можно вынести из-под производной, Во-вторых, производная суммы равна сумме производных, поэтому знак суммы тоже можно вынести из-под производной. Поэтому получаем:
[frac{partial}{partial b_i} J =
frac{1}{2 m} sum_{i=1}^{m} frac{partial}{partial b_i} (h_b(x_i) — y^{(i)})^2]
Теперь самое сложное — производная сложной функции. По правилу она равна производной внешней функции, умноженной на производную внутренней. Внешняя функция — это квадратическая, ее производная равна удвоенному подквадратному выражению ((frac{d}{dt} t^2 = 2 t)). Подставляем (t = h_b(x_i) — y^{(i)}) и получаем:
[frac{partial}{partial b_i} J =
frac{1}{m} sum_{i=1}^{m} (h_b(x_i) — y^{(i)}) cdot frac{partial}{partial b_i} h_b(x_i)]
Обратите внимание, что эта самая двойка прекрасно сократилась со знаменателем в постоянном множителе функции ошибки. Именно за этим он и был нужен.
Чтобы продолжить вычисление производной дальше, нужно представить функцию гипотезы как линейную функцию:
[J(b_0, b_1) = frac{1}{2m} sum_{i=1}^{m} (b_0 + b_1 x_i — y_i)^2]
И теперь мы уже не можем говорить о какой-то частной производной в общем, нужно отдельно посчитать производные по разным значениям параметров. Но тут все как раз очень просто, так как нам осталось посчитать производные линейной функции. Они равны просто коэффициентам при соответствующих аргументах. Для свободного коэффициента аргумент равен, очевидно, 1:
[frac{partial J}{partial b_0} =
frac{1}{m} sum (b_0 + b_1 x_i — y_i) =
frac{1}{m} sum (h_b(x_i) — y_i)]
А для коэффициента при $x_i$ производная равна самому значению $x_i$:
[frac{partial J}{partial b_1} =
frac{1}{m} sum (b_0 + b_1 x_i — y_i) cdot x_i =
frac{1}{m} sum (h_b(x_i) — y_i) cdot x_i]
Теперь для нахождения минимального значения функции ошибки нам нужно только приравнять эти производные к нулю, то есть решить для $b_0, b_1$ следующую систему уравнений:
[frac{partial J}{partial b_0} =
frac{1}{m} sum (h_b(x_i) — y_i) = 0]
[frac{partial J}{partial b_1} =
frac{1}{m} sum (h_b(x_i) — y_i) cdot x_i = 0]
Проблема в том, что мы не можем просто решить эти уравнения аналитически. Ведь мы не знаем общий вид функции ошибки, не то, что ее производной. Ведь он зависит от всех точек данных. Но мы можем вычислить эту функцию (и ее производную) в любой точке. А точка на этой функции — это конкретный набор значений параметров модели. Поэтому пришлось изобрести численный алгоритм. Он работает следующим образом.
Сначала, мы выбираем произвольное значение параметров модели. То есть, произвольную точку в области определения функции. Мы не знаем, является ли эта точка оптимальной (скорее нет), не знаем, насколько она далека от оптимума. Но мы можем вычислить направление к оптимуму. Ведь мы знаем наклон касательной к графику функции ошибки.

Наклон касательной является производной в этой точке, и это даст нам направление движения в сторону самого крутого уменьшения значения функции. Если представить себе функцию одной переменной (параболу), то там все очень просто. Если производная в точке отрицательна, значит функция убывает, значит, что оптимум находится справа от данной точки. То есть, чтобы приблизиться к оптимуму надо увеличить аргумент функции. Если же производная положительна, то все наоборот — функция возрастает, оптимум находится слева и нам нужно уменьшить значение аргумента. Причем, чем дальше от оптимума, тем быстрее возрастает или убывает функция. То есть значение производной дает нам не только направление, но и величину нужного шага. Сделав шаг, пропорциональный величине производной и в направлении, противоположном ей, можно повторить процесс и еще больше приблизиться к оптимуму. С каждой итерацией мы будем приближаться к минимуму ошибки и математически доказано, что мы можем приблизиться к ней произвольно близко. То есть, данный метод сходится в пределе.
В случае с функцией нескольких переменных все немного сложнее, но принцип остается прежним. Только мы оперируем не полной производной функции, а вектором частных производных по каждому параметру. Он задает нам направление максимального увеличения функции. Чтобы получить направление максимального спада функции нужно просто домножить этот вектор на -1. После этого нужно обновить значения каждого компонента вектора параметров модели на величину, пропорциональную соответствующему компоненту вектора градиента. Таким образом мы делаем шаги вниз по функции ошибки в направлении с самым крутым спуском, а размер каждого шага пропорционален определяется параметром $alpha$, который называется скоростью обучения.
Алгоритм градиентного спуска:
повторяйте до сходимости:
[b_j := b_j — alpha frac{partial}{partial b_j} J(b_0, b_1)]
где j=0,1 — представляет собой индекс номера признака.
Это общий алгоритм градиентного спуска. Она работает для любых моделей и для любых функций ошибки. Это итеративный алгоритм, который сходится в пределе. То есть, мы никогда не придем в сам оптимум, но можем приблизиться к нему сколь угодно близко. На практике нам не так уж важно получить точное решение, достаточно решения с определенной точностью.
Алгоритм градиентного спуска имеет один параметр — скорость обучения. Он влияет на то, как быстро мы будем приближаться к оптимуму. Кажется, что чем быстрее, тем лучше, но оказывается, что если значение данного параметра слишком велико, то мы буем постоянно промахиваться и алгоритм будет расходиться.

Алгоритм градиентного спуска для парной линейной регрессии:
повторяйте до сходимости:
[b_0 := b_0 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)} )- y^{(i)})]
[b_1 := b_1 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x^{(i)}]
На практике “повторяйте до сходимости” означает, что мы повторяем алгоритм градиентного спуска до тех пор, пока значение функции ошибки не перестанет значимо изменяться. Это будет означать, что мы уже достаточно близко к минимуму и дальнейшие шаги градиентного спуска слишком малы, чтобы быть целесообразными. Конечно, это оценочное суждение, но на практике обычно, нескольких значащих цифр достаточно для практического применения моделей машинного обучения.
Алгоритм градиентного спуска имеет одну особенность, про которую нужно помнить. Он в состоянии находить только локальный минимум функции. Он в принципе, по своей природе, локален. Поэтому, если функция ошибки будет очень сложна и иметь несколько локальных оптимумов, то результат работы градиентного спуска будет зависеть от выбора начальной точки.
На практике эту проблему решают методом семплирования — запускают градиентный спуск из множества случайных точек и выбирают то минимум, который оказался меньше по значению функции ошибки. Но этот подход понадобится нам при рассмотрении более сложных и глубоких моделей машинного обучения. Для простых линейных, полиномиальных и других моделей метод градиентного спуска работает прекрасно. В настоящее время этот алгоритм — это основная рабочая лошадка классических моделей машинного обучения.
Выводы:
- Метод градиентного спуска нужен, чтобы найти минимум функции, если мы не можем ее вычислить аналитически.
- Это численный итеративный алгоритм локальной оптимизации.
- Для запуска градиентного спуска нужно знать частную производную функции ошибки.
- Для начала мы берем произвольные значения параметров, затем обновляем их по данной формуле.
- Доказано, что этот метод сходится к локальному минимуму.
- Если функция ошибки достаточно сложная, то разные начальные точки дадут разный результат.
- Метод градиентного спуска имеет свой параметр — скорость обучения. Обычно его подстаивают автоматически.
- Метод градиентного спуска повторяют много раз до тех пор, пока функция ошибки не перестанет значимо изменяться.
Регрессия с несколькими переменными
Множественная линейная регрессия

Парная регрессия, как мы увидели выше, имеет дело с объектами, которые характеризуются одним числовым признаком ($x$). На практике, конечно, объекты характеризуются несколькими признаками, а значит в модели должна быть не одна входящая переменная, а несколько (или, что то же самое, вектор). Линейная регрессия с несколькими переменными также известна как «множественная линейная регрессия». Введем обозначения для уравнений, где мы можем иметь любое количество входных переменных:
$ x^{(i)} $- вектор-столбец всех значений признаков i-го обучающего примера;
$ x_j^{(i)} $ — значение j-го признака i-го обучающего примера;
$ x_j $ — вектор j-го признака всех обучающих примеров;
m — количество примеров в обучающей выборке;
n — количество признаков;
X — матрица признаков;
b — вектор параметров регрессии.
Задачи множественной регрессии уже очень сложно представить на графике, ведь количество параметров каждого объекта обучающей выборки соответствует измерению, в котором находятся точки данных. Плюс нужно еще одно измерение для целевой переменной. И вместо того, чтобы подбирать оптимальную прямую, мы будем подбирать оптимальную гиперплоскость. Но в целом идея линейной регрессии остается неизменной.
Для удобства примем, что $ x_0^{(i)} = 1 $ для всех $i$. Другими словами, мы ведем некий суррогатный признак, для всех объектов равный единице. Это никак не сказывается на самой функции гипотезы, это лишь условность обозначения, но это сильно упростит математические выкладки, особенно в матричной форме.
Вообще, уравнения для алгоритмов машинного обучения, зависящие от нескольких параметров часто записываются в матричной форме. Это лишь способ сделать запись уравнений более компактной, а не какое-то новое знание. Если вы не владеете линейной алгеброй, то можете просто безболезненно пропустить эти формы записи уравнений. Однако, лучше, конечно, разобраться. Особенно это пригодится при изучении нейронных сетей.
Теперь определим множественную форму функции гипотезы следующим образом, используя несколько признаков. Она очень похожа на парную, но имеет больше входных переменных и, как следствие, больше параметров.
Общий вид модели множественной линейной регрессии:
[h_b(x) = b_0 + b_1 x_1 + b_2 x_2 + … + b_n x_n]
Или в матричной форме:
[h_b(x) = X cdot vec{b}]
Используя определение матричного умножения, наша многопараметрическая функция гипотезы может быть кратко представлена в виде: $h(x) = B X$.
Обратите внимание, что в любой модели линейной регрессии количество параметров на единицу больше количества входных переменных. Это верно для любой линейной модели машинного обучения. Вообще, всегда чем больше признаков, тем больше параметров. Это будет важно для нас позже, когда мы будем говорить о сложности моделей.
Теперь, когда мы знаем виды функции гипотезы, то есть нашей модели, мы можем переходить к следующему шагу: функции ошибки. Мы построим ее по аналогии с функцией ошибки для парной модели. Для множественной регрессии функция ошибки от вектора параметров b выглядит следующим образом:
Функция ошибки для множественной линейной регрессии:
[J(b) = frac{1}{2m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)})^2]
Или в матричной форме:
[J(b) = frac{1}{2m} (X b — vec{y})^T (X b — vec{y})]
Обратите внимание, что мы специально не раскрываем выражение (h_b(x^{(i)})). Это нужно, чтобы подчеркнуть, что форма функции ошибки не зависит от функции гипотезы, она выражается через нее.
Теперь нам нужно взять производную этой функции ошибки. Здесь уже нужно знать производную самой функции гипотезы, так как:
[frac{partial}{partial b_i} J =
frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot frac{partial}{partial b_i} h_b(x^{(i)})]
В такой формулировке мы представляем частные производные функции ошибки (градиент) через частную производную функции гипотезы. Это так называемое моделенезависимое представление градиента. Ведь для этой формулы совершенно неважно, какой функцией будет наша гипотеза. Пока она является дифференцируемой, мы можем использовать градиент ее функции ошибки. Именно поэтому метод градиентного спуска работает с любыми аналитическими моделями, и нам не нужно каждый раз заново “переизобретать” математику градиентного спуска, адаптировать ее к каждой конкретной модели машинного обучения. Достаточно изучить этот метод один раз, в общей форме.
Метод градиентного спуска для множественной регрессии определяется следующими уравнениями:
повторять до сходимости:
[b_0 := b_0 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_0^{(i)}]
[b_1 := b_1 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_1^{(i)}]
[b_2 := b_2 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_2^{(i)}]
[…]
Или в матричной форме:
[b := b — frac{alpha}{m} X^T (X b — vec{y})]
Выводы:
- Множественная регрессия очень похожа на парную, но с большим количеством признаков.
- Для удобства и однообразия, почти всегда обозначают $x_0 = 1$.
- Признаки образуют матрицу, поэтому уравнения множественной регрессии часто приводят в матричной форме, так короче.
- Алгоритм градиентного спуска для множественной регрессии точно такой же, как и для парной.
Нормализация признаков
Мы можем ускорить сходимость метода градиентного спуска, преобразовав входные данные таким образом, чтобы все атрибуты имели значения примерно в том же диапазоне. Это называется нормализация данных — приведение всех признаков к одной шкале. Это ускоряет сходимость градиентного спуска за счет эффекта масштаба. Дело в том, что зачастую значения разных признаков измеряются по шкалам с очень разным порядком величины. Например, $x_1$ измеряется в миллионах, а $x_2$ — в долях единицы.
В таком случае форма функции ошибки будет очень вытянутой. Это не проблема для математической формализации градиентного спуска — при достаточно малых $alpha$ метод все равно рано или поздно сходится. Проблема в практической реализации. Получается, что если выбрать скорость обучения выше определенного предела по самому компактному признаку, спуск разойдется. Значит, скорость обучения надо делать меньше. Но тогда в направлении второго признака спуск будет проходить слишком медленно. И получается, что градиентный спуск потребует гораздо больше итераций для завершения.
Эту проблему можно решить если изменить диапазоны входных данных, чтобы они выражались величинами примерно одного порядка. Это не позволит одному измерению численно доминировать над другим. На практике применяют несколько алгоритмов нормализации, самые распространенные из которых — минимаксная нормализация и стандартизация или z-оценки.
Минимаксная нормализация — это изменение входных данных по следующей формуле:
[x’ = frac{x — x_{min}}{x_{max} — x_{min}}]
После преобразования все значения будут лежать в диапазоне $x in [0; 1]$.
Z-оценки или стандартизация производится по формуле:
[x’ = frac{x — M[x]}{sigma_x}]
В таком случае данный признак приводится к стандартному распределению, то есть такому, у которого среднее 0, а дисперсия — 1.
У каждого из этих двух методов нормализации есть по два параметра. У минимаксной — минимальное и максимальное значение признака. У стандартизации — выборочные среднее и дисперсия. Параметры нормализации, конечно, вычисляются по каждому признаку (столбцу данных) отдельно. Причем, эти параметры надо запомнить, чтобы при использовании модели для предсказании использовать именно их (вычисленные по обучающей выборке). Даже если вы используете тестовую выборку, ее надо нормировать с использованием параметров, вычисленных по обучающей. Да, при этом может получиться, что при применении модели на данных, которых не было в обучающей выборке, могут получиться значения, например, меньше нуля или больше единицы (при использовании минимаксной нормализации). Это не страшно, главное, что будет соблюдена последовательность вычисления нормированных значений.
Про использование обучающей и тестовой выборок мы будем говорить значительно позже, при рассмотрении диагностики моделей машинного обучения.
Целевая переменная не нормируется. Это просто не нужно, а если ее нормировать, это сильно усложнит все математические расчеты и преобразования.
При использовании библиотечных моделей машинного обучения беспокоиться о нормализации входных данных вручную, как правило, не нужно. Большинство готовых реализаций моделей уже включают нормализацию как неотъемлемый этап подготовки данных. Более того, некоторые типы моделей обучения с учителем вовсе не нуждаются в нормализации. Но об этом пойдет речь в следующих главах.
Выводы:
- Нормализация нужна для ускорения метода градиентного спуска.
- Есть два основных метода нормализации — минимаксная и стандартизация.
- Параметры нормализации высчитываются по обучающей выборке.
- Нормализация встроена в большинство библиотечных методов.
- Некоторые методы более чувствительны к нормализации, чем другие.
- Нормализацию лучше сделать, чем не делать.
Полиномиальная регрессия

Функция гипотезы не обязательно должна быть линейной, если это не соответствует данным. На практике вы не всегда будете иметь данные, которые можно хорошо аппроксимировать линейной функцией. Наглядный пример вы видите на иллюстрации. Вполне очевидно, что в среднем увеличение целевой переменной замедляется с ростом входной переменной. Это значит, что данные демонстрируют нелинейную динамику. И это так же значит, что мы никак не сможем их хорошо приблизить линейной моделью.
Надо подчеркнуть, что это не свидетельствует о несовершенстве наших методов оптимизации. Мы действительно можем найти самую лучшую линейную функцию для данных точек, но проблема в том, что мы всегда выбираем лучшую функцию из некоторого класса функций, в данном случае — линейных. То есть проблема не в алгоритмах оптимизации, а в ограничении самого вида модели.
вполне логично предположить, что для описания таких нелинейных наборов данных следует использовать нелинейные же функции моделей. Но очень бы не хотелось, для каждого нового класса функций изобретать собственный метод оптимизации, поэтому мы постараемся максимально “переиспользовать” те подходы, которые описали выше. И механизм множественной регрессии в этом сильно поможет.
Мы можем изменить поведение или кривую нашей функции гипотезы, сделав ее квадратичной, кубической или любой другой формой.
Например, если наша функция гипотезы
$ hat{y} = h_b (x) = b_0 + b_1 x $,
то мы можем добавить еще один признак, основанный на $ x_1 $, получив квадратичную функцию
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 x^2]
или кубическую функцию
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 x^2 + b_3 x^3]
В кубической функции мы по сути ввели два новых признака:
$ x_2 = x^2, x_3 = x^3 $.
Точно таким же образом, мы можем создать, например, такую функцию:
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 sqrt{x}]
В любом случае, мы из парной линейной функции сделали какую-то другую функцию. И к этой нелинейной функции можно относиться по разному. С одной стороны, это другой класс функций, который обладает нелинейным поведением, а следовательно, может описывать более сложные зависимости в данных. С другой стороны, это линейна функция от нескольких переменных. Только сами эти переменные оказываются в функциональной зависимости друг от друга. Но никто не говорил, что признаки должны быть независимы.
И вот такое представление нелинейной функции как множественной линейной позволяет нам без изменений воспользоваться алгоритмом градиентного спуска для множественной линейной регрессии. Только вместо $ x_2, x_3, … , x_n $ нам нужно будет подставить соответствующие функции от $ x_1 $.
Очевидно, что нелинейных функций можно придумать бесконечное количество. Поэтому встает вопрос, как выбрать нужный класс функций для решения конкретной задачи. В случае парной регрессии мы можем взглянув на график точек обучающей выборки сделать предположение о том, какой вид нелинейной зависимости связывает входную и целевую переменные. Но если у нас множество признаков, просто так проанализировать график нам не удастся. Поэтому по умолчанию используют полиномиальную регрессию, когда в модель добавляют входные переменные второго, третьего, четвертого и так далее порядков.
Порядок полиномиальной регрессии подбирается в качестве компромисса между качеством получаемой регрессии, и вычислительной сложностью. Ведь чем выше порядок полинома, тем более сложные зависимости он может аппроксимировать. И вообще, чем выше степень полинома, тем меньше будет ошибка при прочих равных. Если степень полинома на единицу меньше количества точек — ошибка будет нулевая. Но одновременно с этим, чем выше степень полинома, тем больше в модели параметров, тем она сложнее и занимает больше времени на обучение. Есть еще вопросы переобучения, но про это мы поговорим позднее.
А что делать, если изначально в модели было несколько признаков? Тогда обычно для определенной степени полинома берутся все возможные комбинации признаком соответствующей степени и ниже. Например:
Для регрессии с двумя признаками.
Линейная модель (полином степени 1):
[h_b (x) = b_0 + b_1 x_1 + b_2 x_2]
Квадратичная модель (полином степени 2):
[h_b (x) = b_0 + b_1 x + b_2 x_2 + b_3 x_1^2 + b_4 x_2^2 + b_5 x_1 x_2]
Кубическая модель (полином степени 3):
[hat{y} = h_b (x) = b_0 + b_1 x_1 + b_2 x_2 + b_3 x_1^2 + b_4 x_2^2 + b_5 x_1 x_2 + b_6 x_1^3 + b_7 x_2^3 + b_7 x_1^2 x_2 + b_8 x_1 x_2^2]
При этом количество признаков и, соответственно, количество параметров растет экспоненциально с ростом степени полинома. Поэтому полиномиальные модели обычно очень затратные в обучении при больших степенях. Но полиномы высоких степеней более универсальны и могут аппроксимировать более сложные данные лучше и точнее.
Выводы:
- Данные в датасете не всегда располагаются так, что их хорошо может описывать линейная функция.
- Для описания нелинейных зависимостей нужна более сложная, нелинейная модель.
- Чтобы не изобретать алгоритм обучения заново, можно просто ввести в модель суррогатные признаки.
- Суррогатный признак — это новый признак, который считается из существующих атрибутов.
- Чаще всего используют полиномиальную регрессию — это когда в модель вводят полиномиальные признаки — степени существующих атрибутов.
- Обычно берут все комбинации факторов до какой-то определенной степени полинома.
- Полиномиальная регрессия может аппроксимировать любую функцию, нужно только подобрать степень полинома.
- Чем больше степень полиномиальной регрессии, тем она сложнее и универсальнее, но вычислительно сложнее (экспоненциально).
Практическое построение регрессии
В данной главе мы посмотрим, как можно реализовать методы линейной регрессии на практике. Сначала мы попробуем создать алгоритм регрессии с нуля, а затем воспользуемся библиотечной функцией. Это поможет нам более полно понять, как работают модели машинного обучения в целом и в библиотеке sckikit-learn (самом популярном инструменте для создания и обучения моделей на языке программирования Python) в частности.
Для понимания данной главы предполагаем, что читатель знаком с основами языка программирования Python. Нам понадобится знание его базового синтаксиса, немного — объектно-ориентированного программирования, немного — использования стандартных библиотек и модулей. Никаких продвинутых возможностей языка (типа метапрограммирования или декораторов) мы использовать не будем.
Как должны быть представлены данные для машинного обучения?
Применение любых моделей машинного обучения начинается с подготовки данных в необходимом формате. Для этого очень удобными для нас будут библиотеки numpy и pandas. Они практически всегда используются совместно с библиотекой sckikit-learn и другими инструментами машинного обучения. В первую очередь мы будем использовать numpy для создания массивов и операций с векторами и матрицами. Pandas нам понадобится для работы с табличными структурами — датасетами.
Если вы хотите самостоятельно задать в явном виде данные обучающей выборки, то нет ничего лучше использования обычных массивов ndarray. Обычно в одном массиве хранятся значения атрибутов — x, а в другом — значения целевой переменной — y.
1
2
3
4
5
6
7
8
9
10
11
import numpy as np
x = np.array([1.46, 1.13, -2.30, 1.74, 0.04,
-0.61, 0.32, -0.76, 0.58, -1.10,
0.87, 1.62, -0.53, -0.25, -1.07,
-0.38, -0.17, -0.32, -2.06, -0.88, ])
y = np.array([101.16, 78.44, -159.24, 120.72, 2.92,
-42.33, 22.07, -52.67, 40.32, -76.10,
59.88, 112.38, -36.54, -17.25, -74.24,
-26.57, -11.93, -22.31, -142.54, -60.74,])
Если мы имеем дело с задачей множественной регрессии, то в массиве атрибутов будет уже двумерный массив, состоящий из нескольких векторов атрибутов, вот так:
1
2
3
4
5
x = np.array([
[0, 1, 2, 3, 4],
[5, 4, 9, 6, 3],
[7.8, -0.1, 0.0, -2.14, 10.7],
])
Важно следить за тем, чтобы в массиве атрибутов в каждом вложенном массиве количество элементов было одинаковым и в свою очередь совпадало с количеством элементов в массиве целевой переменной. Это называется соблюдение размерности задачи. Если размерность не соблюдается, то модели машинного обучения будут работать неправильно. А библиотечные функции чаще всего будут выдавать ошибку, связанную с формой массива (shape).
Но чаще всего вы не будете задавать исходные данные явно. Практически всегда их приходится читать из каких-либо входных файлов. Удобнее всего это сделать при помощи библиотеки pandas вот так:
1
2
3
4
import pandas as pd
x = pd.read_csv('x.csv', index_col=0)
y = pd.read_csv('y.csv', index_col=0)
Или, если данные лежат в одном файле в общей таблице (что происходит чаще всего), тогда его читают в один датафрейм, а затем выделяют целевую переменную, и факторные переменные:
1
2
3
4
5
6
7
8
import pandas as pd
data = pd.read_csv('data.csv', index_col=0)
y = data.Y
y = data["Y"]
x = data.drop(["Y"])
Обратите внимание, что матрицу атрибутов проще всего сформировать, удалив из полной таблицы целевую переменную. Но, если вы хотите выбрать только конкретные столбцы, тогда можно использовать более явный вид, через перечисление выбранных колонок.
Если вы используете pandas или numpy для формирования массивов данных, то получившиеся переменные будут разных типов — DataFrame или ndarray, соответственно. Но на дальнейшую работу это не повлияет, так как интерфейс работы с этими структурами данных очень похож. Например, неважно, какие именно массивы мы используем, их можно изобразить на графике вот так:
1
2
3
4
5
import maiplotlib.pyplot as plt
plt.figure()
plt.scatter(x, y)
plt.show()
Конечно, такая визуализация будет работать только в случае задачи парной регрессии. Если x многомерно, то простой график использовать не получится.
Давайте соберем весь наш код вместе:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import numpy as np
import pandas as pd
import maiplotlib.pyplot as plt
# x = pd.read_csv('x.csv', index_col=0)
x = np.array([1.46, 1.13, -2.30, 1.74, 0.04,
-0.61, 0.32, -0.76, 0.58, -1.10,
0.87, 1.62, -0.53, -0.25, -1.07,
-0.38, -0.17, -0.32, -2.06, -0.88, ])
# y = pd.read_csv('y.csv', index_col=0)
y = np.array([101.16, 78.44, -159.24, 120.72, 2.92,
-42.33, 22.07, -52.67, 40.32, -76.10,
59.88, 112.38, -36.54, -17.25, -74.24,
-26.57, -11.93, -22.31, -142.54, -60.74,])
plt.figure()
plt.scatter(x, y)
plt.show()
Это код генерирует вот такой вот график:

Как работает метод машинного обучения “на пальцах”?
Для того, чтобы более полно понимать, как работает метод градиентного спуска для линейной регрессии, давайте реализуем его самостоятельно, не обращаясь к библиотечным методам. На этом примере мы проследим все шаги обучения модели.
Мы будем использовать объектно-ориентированный подход, так как именно он используется в современных библиотеках. Начнем строить класс, который будет реализовывать метод парной линейной регрессии:
1
2
3
4
5
class hypothesis(object):
"""Модель парной линейной регрессии"""
def __init__(self):
self.b0 = 0
self.b1 = 0
Здесь мы определили конструктор класса, который запоминает в полях экземпляра параметры регрессии. Начальные значения этих параметров не очень важны, так как градиентный спуск сойдется из любой точки. В данном случае мы выбрали нулевые, но можно задать любые другие начальные значения.
Реализуем метод, который принимает значение входной переменной и возвращает теоретическое значение выходной — это прямое действие нашей регрессии — метод предсказания результата по факторам (в случае парной регрессии — по одному фактору):
1
2
def predict(self, x):
return self.b0 + self.b1 * x
Название выбрано не случайно, именно так этот метод называется и работает в большинстве библиотечных классов.
Теперь зададим функцию ошибки:
1
2
def error(self, X, Y):
return sum((self.predict(X) - Y)**2) / (2 * len(X))
В данном случае мы используем простую функцию ошибки — среднеквадратическое отклонение (mean squared error, MSE). Можно использовать и другие функции ошибки. Именно вид функции ошибки будет определять то, какой вид регрессии мы реализуем. Существует много разных вариаций простого алгоритма регрессии. О большинстве распространенных методах регрессии можно почитать в официальной документации sklearn.
Теперь реализуем метод градиентного спуска. Он должен принимать массив X и массив Y и обновлять параметры регрессии в соответствии в формулами градиентного спуска:
1
2
3
4
5
6
def BGD(self, X, Y):
alpha = 0.5
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
О выборе конкретного значения alpha мы говорить пока не будем,на практике его довольно просто подбирают, мы же возьмем нейтральное значение.
Давайте создадим объект регрессии и проверим начальное значение ошибки. В примерах приведены значения на модельном наборе данных, но этот метод можно использовать на любых данных, которые подходят по формату — x и y должны быть одномерными массивами чисел.
1
2
3
4
5
6
7
8
hyp = hypothesis()
print(hyp.predict(0))
print(hyp.predict(100))
J = hyp.error(x, y)
print("initial error:", J)
0
0
initial error: 36271.58344889084
Как мы видим, для начала оба параметра регрессии равны нулю. Конечно, такая модель не дает надежных предсказаний, но в этом и состоит суть метода градиентного спуска: начиная с любого решения мы постепенно его улучшаем и приходим к оптимальному решению.
Теперь все готово к запуску градиентного спуска.
1
2
3
4
5
6
7
8
9
10
hyp.BGD(x, y)
J = hyp.error(x, y)
print("error after gradient descent:", J)
error after gradient descent: 6734.135540194945
X0 = np.linspace(60, 180, 100)
Y0 = hyp.predict(X0)
plt.figure()
plt.scatter(x, y)
plt.plot(X0, Y0, 'r')
plt.show()
Как мы видим, численное значение ошибки значительно уменьшилось. Да и линия на графике существенно приблизилась к точкам. Конечно, наша модель еще далека от совершенства. Мы прошли всего лишь одну итерацию градиентного спуска. Модифицируем метод так, чтобы он запускался в цикле пока ошибка не перестанет меняться существенно:
1
2
3
4
5
6
7
8
9
10
11
12
13
def BGD(self, X, Y, alpha=0.5, accuracy=0.01, max_steps=5000):
step = 0
old_err = hyp.error(X, Y)
new_err = hyp.error(X, Y)
dJ = 1
while (dJ > accuracy) and (step < max_steps):
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
old_err = new_err
new_err = hyp.error(X, Y)
dJ = abs(old_err - new_err)
Заодно мы проверяем, насколько изменилось значение функции ошибки. Если оно изменилось на величину, меньшую, чем заранее заданная точность, мы завершаем спуск. Таким образом, мы реализовали два стоп-механизма — по количеству итераций и по стабилизации ошибки. Вы можете выбрать любой или использовать оба в связке.
Запустим наш градиентный спуск:
1
2
3
4
5
hyp = hypothesis()
hyp.BGD(x, y)
J = hyp.error(x, y)
print("error after gradient descent:", J)
error after gradient descent: 298.76881676471504
Как мы видим, теперь ошибка снизилась гораздо больше. Однако, она все еще не достигла нуля. Заметим, что нулевая ошибка не всегда возможна в принципе из-за того, что точки данных не всегда будут располагаться на одной линии. Нужно стремиться не к нулевой, а к минимально возможной ошибке.
Посмотрим, как теперь наша регрессия выглядит на графике:
1
2
3
4
5
6
X0 = np.linspace(60, 180, 100)
Y0 = hyp.predict(X0)
plt.figure()
plt.scatter(x, y)
plt.plot(X0, Y0, 'r')
plt.show()

Уже значительно лучше. Линия регрессии довольно похожа на оптимальную. Так ли это на самом деле, глядя на график, сказать сложно, для этого нужно проанализировать, как ошибка регрессии менялась со временем:
Как оценить качество регрессионной модели?
В простых случаях качество модели можно оценить визуально на графике. Но если у вас многомерная задача, это уже не представляется возможным. Кроме того, если ошибка и сама модель меняется незначительно, то очень сложно определить, стало хуже или лучше. Поэтому для диагностики моделей машинного обучения используют кривые.
Самая простая кривая обучения — зависимость ошибки от времени (итерации градиентного спуска). Для того, чтобы построить эту кривую, нам нужно немного модифицировать наш метод обучения так, чтобы он возвращал нужную нам информацию:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def BGD(self, X, Y, alpha=0.1, accuracy=0.01, max_steps=1000):
steps, errors = [], []
step = 0
old_err = hyp.error(X, Y)
new_err = hyp.error(X, Y) - 1
dJ = 1
while (dJ > accuracy) and (step < max_steps):
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
old_err = new_err
new_err = hyp.error(X, Y)
dJ = abs(old_err - new_err)
step += 1
steps.append(step)
errors.append(new_err)
return steps, errors
Мы просто запоминаем в массивах на номер шаа и ошибку на каждом шаге. Получив эти данные можно легко построить их на графике:
1
2
3
4
5
6
hyp = hypothesis()
steps, errors = hyp.BGD(x, y)
plt.figure()
plt.plot(steps, errors, 'g')
plt.show()

На этом графике наглядно видно, что в начале обучения ошибка падала быстро, но в ходе градиентного спуска она вышла на плато. Учитывая, что мы используем гладкую функцию ошибки второго порядка, это свидетельствует о том, что мы достигли локального оптимума и дальнейшее повторение алгоритма не принесет улучшения модели.
Если бы мы наблюдали на графике обучения ситуацию, когда по достижении конца обучения ошибка все еще заметно снижалась, это значит, что мы рано прекратили обучение, и нужно продолжить его еще на какое-то количество итераций.
При анализе графиков с библиотечными моделями не получится таких гладких графиков, они больше напоминают случайные колебания. Это из-за того, что в готовых реализациях используется очень оптимизированный вариант метода градиентного спуска. А он может работать с произвольными флуктуациями. В любом случае, нас интересует общий вид этой кривой.
Как подбирать скорость обучения?
В нашей реализации метода градиентного спуска есть один параметр — скорость обучения — который нам приходится так же подбирать руками. Какой смысл автоматизировать подбор параметров линейной регрессии, если все равно приходится вручную подбирать какой-то другой параметр?
На самом деле подобрать скорость обучения гораздо легче. Нужно использовать тот факт, что при превышении определенного порогового значения ошибка начинает возрастать. Кроме того, мы знаем, что скорость обучения должна быть положительна, но меньше единицы. Вся проблема в этом пороговом значении, которое сильно зависит от размерности задачи. При одних данных хорошо работает $ alpha = 0.5 $, а при каких-то приходится уменьшать ее на несколько порядков, например, $ alpha = 0.00000001 $.
Мы еще не говорили о нормализации данных, которая тоже практически всегда применяется при обучении. Она “благотворно” влияет на возможный диапазон значений скорости обучения. При использовании нормализации меньше вероятность, что скорость обучения нужно будет уменьшать очень сильно.
Подбирать скорость обучения можно по следующему алгоритму. Сначала мы выбираем $ alpha $ близкое к 1, скажем, $ alpha = 0.7 $. Производим одну итерацию градиентного спуска и оцениваем, как изменилась ошибка. Если она уменьшилась, то ничего не надо менять, продолжаем спуск как обычно. Если же ошибка увеличилась, то скорость обучения нужно уменьшить. Например, раа в два. После чего мы повторяем первый шаг градиентного спуска. Таким образом мы не начинаем спуск, пока скорость обучения не снизится настолько, чтобы он начал сходиться.
Как применять регрессию с использованием scikit-learn?
Для серьезной работы, все-таки рекомендуется использовать готовые библиотечные решения. Они работаю гораздо быстрее, надежнее и гораздо проще, чем написанные самостоятельно. Мы будем использовать библиотеку scikit-learn для языка программирования Python как наш основной инструмент реализации простых моделей. Сегодня это одна их самых популярных библиотек для машинного обучения. Мы не будем повторять официальную документацию этой библиотеки, которая на редкость подробная и понятная. Наша задача — на примере этих инструментов понять, как работают и как применяются модели машинного обучения.
В библиотеке scikit-learn существует огромное количество моделей машинного обучения и других функций, которые могут понадобиться для их работы. Поэтому внутри самой библиотеки есть много разных пакетов. Все простые модели, например, модель линейной регрессии, собраны в пакете linear_models. Подключить его можно так:
1
from sklearn import linear_model
Надо помнить, что все модели машинного обучения из это библиотеки имеют одинаковый интерфейс. Это очень удобно и универсально. Но это значит, в частности, что все модели предполагают, что массив входных переменных — двумерный, а массивы целевых переменных — одномерный. Отдельного класса для парной регрессии не существует. Поэтому надо убедиться, что наш массив имеет нужную форму. Проще всего для преобразования формы массива использовать метод reshape, например, вот так:
Если вы используете DataFrame, то они обычно всегда настроены правильно, поэтому этого шага может не потребоваться. Важно запомнить, что все методы библиотечных моделей машинного обучения предполагают, что в x будет двумерный массив или DataFrame, а в y, соответственно, одномерный массив или Series.
Эта строка преобразует любой массив в вектор-столбец. Это если у вас один признак, то есть парная регрессия. Если признаков несколько, то вместо 1 следует указать число признаков. -1 на первой позиции означает, что по нулевому измерению будет столько элементов, сколько останется в массиве.
Само использование модели машинного обучения в этой библиотеке очень просто и сводится к трем действиям: создание экземпляра модели, обучение модели методом fit(), получение предсказаний методом predict(). Это общее поведение для любых моделей библиотеки. Для модели парной линейной регрессии нам понадобится класс LinearRegression.
1
2
3
4
5
6
reg = linear_model.LinearRegression()
reg.fit(x, y)
y_pred = reg.predict(x)
print(reg.score(x, y))
print("Коэффициенты: n", reg.coef_)
В этом классе кроме уже упомянутых методов fit() и predict(), которые есть в любой модели, есть большое количество методов и полей для получения дополнительной информации о моделях. Так, практически в каждой модели есть встроенный метод score(), который оценивает качество полученной модели. А поле coef_ содержит коэффициенты модели.
Обратите внимание, что в большинстве моделей коэффициентами считаются именно параметры при входящих переменных, то есть $ b_1, b_2, …, b_n $. Коэффициент $b_0$ считается особым и хранится отдельно в поле intercept_
Так как мы работаем с парной линейной регрессией, результат можно нарисовать на графике:
1
2
3
4
plt.figure(figsize=(12, 9))
plt.scatter(x, y, color="black")
plt.plot(x, y_pred, color="blue", linewidth=3)
plt.show()
Как мы видим, результат ничем не отличается от модели, которую мы обучили сами, вручную:

Соберем код вместе и получим пример довольно реалистичного фрагмента работы с моделью машинного обучение. Примерно такой код можно встретить и в промышленных проектах по интеллектуальному анализу данных:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from sklearn.linear_model import LinearRegression
x = x.reshape((-1, 1))
reg = LinearRegression()
reg.fit(x, y)
print(reg.score(x, y))
from sklearn.metrics import mean_squared_error, r2_score
y_pred = reg.predict(x)
print("Коэффициенты: n", reg.coef_)
print("Среднеквадратичная ошибка: %.2f" % mean_squared_error(y, y_pred))
print("Коэффициент детерминации: %.2f" % r2_score(y, y_pred))
plt.figure(figsize=(12, 9))
plt.scatter(x, y, color="black")
plt.plot(x, y_pred, color="blue", linewidth=3)
plt.show()
Регрессия как задача машинного обучения
38 мин на чтение
(55.116 символов)
Постановка задачи регрессии
Источник: Analytics Vidhya.
Задача регрессии — это одна из основных задач машинного обучения. И хотя, большинство задач на практике относятся к другому типу — классификации, мы начнем знакомство с машинным обучением именно с регрессии. Регрессионные модели были известны задолго до появления машинного обучения как отрасли и активно применяются в статистике, эконометрике, математическом моделировании. Машинное обучение предлагает новый взгляд на уже известные модели. И этот новый взгляд позволит строить более сложные и мощные модели, чем классические математические дисциплины.
Задача регрессии относится к категории задач обучения с учителем. Это значит, что набор данных, который используется для обучения, должен иметь определенную структуру. Обычно, наборы данных для машинного обучения представляют собой таблицу, в которой по строкам перечислены разные объекты наблюдений или измерений. В столбцах — различные характеристики, или атрибуты, объектов. А на пересечении строк и столбцов — значение данной характеристики у данного объекта. Обычно один атрибут (или переменная) имеет особый характер — именно ее значение мы и хотим научиться предсказывать с помощью модели машинного обучения. Эта характеристика объекта называется целевая переменная. И если эта целевая переменная выражена числом (а точнее, некоторой непрерывной величиной) — то мы говорим о задаче регрессии.
Задачи регрессии на практике встречаются довольно часто. Например, предсказание цены объекта недвижимости — классическая регрессионная задача. В таких проблемах атрибутами выступают разные характеристики квартир или домов — площадь, этажность, расположение, расстояние до центра города, количество комнат, год постройки. В разных наборах данных собрана разная информация И, соответственно, модели тоже должны быть разные. Другой пример — предсказание цены акций или других финансовых активов. Или предсказание температуры завтрашним днем.
Во всех таких задачах нам нужно иметь данные, которые позволят осуществить такое предсказание. Да, “предсказание” — это условный термин, не всегда мы говорим о будущих событиях. Регрессионные модели используют информацию об объектах в обучающем наборе данных, чтобы сделать вывод о возможном значении целевой переменной. И для этого нужно, чтобы ее значение имело какую-то зависимость от имеющихся у нас атрибутов. Если построить модель предсказания цены акции, но на вход подать информацию о футбольных матчах — ничего не получится. Мы предполагаем, что в наборе данных собраны именно те атрибуты объектов, которые имеют влияние на на значение целевой переменной. И чем больше это предположение выполняется, тем точнее будет потенциально наша модель.
Немного поговорим о терминах. Набор данных который мы используем для обучения модели называют датасетом (dataset) или обучающей выборкой (training set). Объекты, которые описываются в датасете еще называют точками данных (data points). Целевую переменную еще называют на статистический манер зависимой переменной (dependent variable) или результативной, выходной (output), а остальные атрибуты — независимыми переменными (dependent variables), или признаками (features), или факторами, или входными переменными (input). Значения одного конкретного атрибута для всех объектов обучающей выборки часто представляют как вектор этого признака (feature vector). А всю таблицу всех атрибутов называют матрицей атрибутов (feature matrix). Соответственно, еще есть вектор целевой переменной, он не входит в матрицу атрибутов.
С точки зрения информатики, регрессионная модель — это функция, которая принимает на вход значения атрибутов какого-то конкретного объекта и выдает на выходе предполагаемое значение целевой переменной. В большинстве случаев мы предполагаем, что целевая переменная у нас одна. Если стоит задача предсказания нескольких характеристик, то их чаще воспринимают как несколько независимых задач регрессии на одних и тех же атрибутах.
Мы пока ничего не говорили о том, как изнутри устроена регрессионная модель. Это потому, что она может быть какой угодно. Это может быть математическое выражение, условный алгоритм, сложная программа со множеством ветвлений и циклов, нейронная сеть — все это можно представить регрессионной моделью. Единственное требование к модели машинного обучения — она должна быть параметрической. То есть иметь какие-то внутренние параметры, от которых тоже зависит результат вычисления. В простых случаях, чаще всего в качестве регрессионной модели используют аналитические функции. Таких функций бесконечное количество, но чаще всего используется самая простая функция, с которой мы и начнем изучение регрессии — линейная функция.
Так же надо сказать, что иногда регрессионные модели подразделяют на парную и множественную регрессии. Парная регрессия — это когда у нас всего один атрибут. Множественная — когда больше одного. Конечно, на практике парная регрессия почти не встречается, но на примере такой простой модели мы поймем основные концепции машинного обучения. Плюс, парную регрессию очень удобно и наглядно можно изобразить на графике. Когда у нас больше двух переменных, графики уже не особо построишь, и модели приходится визуализировать иначе, более косвенно.
Выводы:
- Регрессия — это задача машинного обучения с учителем, которая заключается в предсказании некоторой непрерывной величины.
- Для использования регрессионных моделей нужно, чтобы в датасете были характеристики объектов и “правильные” значения целевой переменной.
- Примеры регрессионных задач — предсказание цены акции, оценка цены объекта недвижимости.
- Задача регрессии основывается на предположении, что значение целевой переменной зависит от значения признаков.
- Регрессионная модель принимает набор значений и выдает предсказание значения целевой переменной.
- В качестве регрессионных моделей часто берут аналитические функции, например, линейную.
Линейная регрессия с одной переменной
Функция гипотезы

Напомним, что в задачах регрессии мы принимаем входные переменные и пытаемся получить более-менее достоверное значение целевой переменной. Любая функция, даже самая простая линейная может выдавать совершенно разные значения для одних и тех же входных данных, если в функции будут разные параметры. Поэтому, любая регрессионная модель — это не какая-то конкретная математическая функция, а целое семейство функций. И задача алгоритма обучения — подобрать значения параметров таким образом, чтобы для объектов обучающей выборки, для которых мы уже знаем правильные ответы, предсказанные (или теоретические, вычисленные из модели) значения были как можно ближе к тем, которые есть в датасете (эмпирические, истинные значения).
Парная, или одномерная (univariate) регрессия используется, когда вы хотите предсказать одно выходное значение (чаще всего обозначаемое $y$), зависящее от одного входного значения (обычно обозначается $x$). Сама функция называется функцией гипотезы или моделью. В качестве функции гипотезы для парной регрессии можно выбрать любую функцию, но мы пока потренируемся с самой простой функцией одной переменной — линейной функцией. Тогда нашу модель можно назвать парной линейной регрессией.
В случае парной линейной регрессии функция гипотезы имеет следующий общий вид:
[hat{y} = h_b (x) = b_0 + b_1 x]
Обратите внимание, что это похоже на уравнение прямой. Эта модель соответствует множеству всех возможных прямых на плоскости. Когда мы конкретизируем модель значениями параметров (в данном случае — $b_0$ и $b_1$), мы получаем конкретную прямую. И наша задача состоит в том, чтобы выбрать такую прямую, которая бы лучше всего “легла” в точки из нашей обучающей выборки.
В данном случае, мы пытаемся подобрать функцию h(x) таким образом, чтобы отобразить данные нам значения x в данные значения y.
Допустим, мы имеем следующий обучающий набор данных:
| входная переменная x | выходная переменная y |
| 0 | 4 |
| 1 | 7 |
| 2 | 7 |
| 3 | 8 |
Мы можем составить случайную гипотезу с параметрами $ b_0 = 2, b_1 = 2 $. Тогда для входного значения $ x=1 $ модель выдаст предсказание, что $ y=4 $, что на 3 меньше данного. Значение $y$б которое посчитала модель будем называть теоретическим или предсказанным (predicted), а значение, которое дано в наборе данных — эмпирическим или истинным (true). Задача регрессии состоит в нахождении таких параметров функции гипотезы, чтобы она отображала входные значения в выходные как можно более точно, или, другими словами, описывала линию, наиболее точно ложащуюся в данные точки на плоскости $(x, y)$.
Выводы:
- Модель машинного обучения — это параметрическая функция.
- Задача обучения состоит в том, чтобы подобрать параметры модели таким образом, чтобы она лучше всего описывала обучающие данные.
- Парная линейная регрессия работает, если есть всего одна входящая переменная.
- Парная линейная регрессия — одна из самых простых моделей машинного обучения.
- Парная линейная регрессия соответствует множеству всех прямых на плоскости. Из них мы выбираем одну, наиболее подходящую.
Функция ошибки
Как мы уже говорили, разные значения параметров дают разные модели. Для того, чтобы подобрать наилучшую модель, нам нужно средство измерения “точности” модели, некоторая функция, которая показывает, насколько модель хорошо или плохо соответствует имеющимся данным.
В простых случаях мы можем отличить хорошие модели от плохих, только взглянув на график. Но это затруднительно, если количество признаков очень велико, если модели лишь немного отличаются друг от друга. Да и для автоматизации процесса нужен способ формализовать наше общее представление о том, что модель “ложится” в точки данных.
Такая функция называется функцией ошибки (cost function). Она измеряет отклонения теоретических значений (то есть тех, которые предсказывает модель) от эмпирических (то есть тех, которые есть в данных). Чем выше значение функции ошибки, тем хуже модель соответствует имеющимся данным, хуже описывает их. Если модель полностью соответствует данным, то значение функции ошибки будет нулевым.
В задачах регрессии в качестве функции ошибки чаще всего берут среднеквадратичное отклонение теоретических значений от эмпирических. То есть сумму квадратов отклонений, деленную на удвоенное количество измерений.
[J(b_0, b_1)
= frac{1}{2m} sum_{i=1}^{m} (hat{y_i} — y_i)^2
= frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
Эту функцию называют «функцией квадрата ошибки» или «среднеквадратичной ошибкой» (mean squared error, MSE). Среднее значение уменьшено вдвое для удобства вычисления градиентного спуска, так как производная квадратичной функции будет отменять множитель 1/2. Вообще, функцию ошибки можно свободно домножить или разделить на любое число (положительное), ведь нам не важна конкретная величина этой функции. Нам важно, что какие-то модели (то есть наборы значений параметров модели) имеют низкую ошибку, они нам подходят больше, а какие-то — высокую ошибку, они подходят нам меньше.
Возведение в квадрат в этой формуле нужно для того, чтобы положительные отклонения не компенсировали отрицательные. Можно было бы для этого брать, например, абсолютное значение, но эта функция не везде дифференцируема, а это станет нам важно позднее.
Обратите внимание, что в качестве аргументов у функции ошибки выступают параметры нашей функции гипотезы. Ведь функция ошибки оценивает отклонение конкретной функции гипотезы (то есть набора значений параметров этой функции) от эмпирических значений, то есть ставит в соответствие каждому набору параметров модели число, характеризующее ошибку этого набора.
Давайте проследим формирование функции ошибки на еще более простом примере. Возьмем упрощенную форму линейной модели — прямую пропорциональность. Она выражается формулой:
[hat{y} = h_b (x) = b_1 x]
Эта модель поможет нам, так как у нее всего один параметр. И функцию ошибки можно будет изобразить на плоскости. Возьмем фиксированный набор точек и попробуем несколько значений параметра для вычисления функции ошибки. Слева на графике изображены точки данных и текущая функция гипотезы, а на правом графике бы будем отмечать значение использованного параметра (по горизонтали) и получившуюся величину функции ошибки (по вертикали):
При значении $b_1 = -1$ линия существенно отклоняется от точек. Отметим уровень ошибки (примерно 10) на правом графике.
Если взять значение $b_1 = 0$ линия гораздо ближе к точкам, но ошибка все еще есть. Отметим новое значение на правом графике в точке 0.
При значении $b_1 = 1$ график точно ложится в точки, таким образом ошибка становится равной нулю. Отмечаем ее так же.
При дальнейшем увеличении $b_1$ линия становится выше точек. Но функция ошибки все равно будет положительной. Теперь она опять станет расти.
На этом примере мы видим еще одно преимущество возведения в квадрат — это то, что такая функция в простых случаях имеет один глобальный минимум. На правом графике формируется точка за точкой некоторая функция, которая похожа очертаниями на параболу. Но мы не знаем аналитического вида этой параболы, мы можем лишь строить ее точка за точкой.
В нашем примере, в определенной точке функция ошибки обращается в ноль. Это соответствует “идеальной” функции гипотезы. То есть такой, когда она проходит четко через все точки. В нашем примере это стало возможно благодаря тому, что точки данных и так располагаются на одной прямой. В общем случае это не выполняется и функция ошибки, вообще говоря, не обязана иметь нули. Но она должна иметь глобальный минимум. Рассмотрим такой неидеальный случай:
Какое бы значение параметра мы не использовали, линейная функция неспособна идеально пройти через такие три точки, которые не лежат на одной прямой. Эта ситуация называется “недообучение”, об этом мы еще будем говорить дальше. Это значит, что наша модель слишком простая, чтобы идеально описать данные. Но зачастую, идеальная модель и не требуется. Важно лишь найти наилучшую модель из данного класса (например, линейных функций).
Выше мы рассмотрели упрощенный пример с функцией гипотезы с одним параметром. Но у парной линейной регрессии же два параметра. В таком случае, функция ошибки будет описывать не параболу, а параболоид:
Теперь мы можем конкретно измерить точность нашей предсказывающей функции по сравнению с правильными результатами, которые мы имеем, чтобы мы могли предсказать новые результаты, которых у нас нет.
Если мы попытаемся представить это наглядно, наш набор данных обучения будет разбросан по плоскости x-y. Мы пытаемся подобрать прямую линию, которая проходит через этот разбросанный набор данных. Наша цель — получить наилучшую возможную линию. Лучшая линия будет такой, чтобы средние квадраты вертикальных расстояний точек от линии были наименьшими. В лучшем случае линия должна проходить через все точки нашего набора данных обучения. В таком случае значение J будет равно 0.
В более сложных моделях параметров может быть еще больше, но это не важно, ведь нам не нужно строить функцию ошибки, нам нужно лишь оптимизировать ее.
Выводы:
- Функция ошибки нужна для того, чтобы отличать хорошие модели от плохих.
- Функция ошибки показывает численно, насколько модель хорошо описывает данные.
- Аргументами функции ошибки являются параметры модели, ошибка зависит от них.
- Само значение функции ошибки не несет никакого смысла, оно используется только в сравнении.
- Цель алгоритма машинного обучения — минимизировать функцию ошибки, то есть найти такой набор параметров модели, при которых ошибка минимальна.
- Чаще всего используется так называемая L2-ошибка — средний квадрат отклонений теоретических значений от эмпирических (метрика MSE).
Метод градиентного спуска
Таким образом, у нас есть функция гипотезы, и способ оценить, насколько хорошо конкретная гипотеза вписывается в данные. Теперь нам нужно подобрать параметры функции гипотезы. Вот где приходит на помощь метод градиентного спуска.
Это происходит при помощи производной функции ошибки. Необходимое условие минимума функции — обращение в ноль ее производной. А так как мы знаем, что квадратичная функция имеет один глобальный экстремум — минимум, то наша задача очень проста — вычислить производную функции ошибки и найти, где она равна нулю.
Давайте найдем производную среднеквадратической функции ошибки:
[J(b_0, b_1) = frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
[J(b_0, b_1) = frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
[frac{partial}{partial b_i} J =
frac{1}{m} sum_{i=1}^{m} (h_b(x_i) — y^{(i)}) cdot frac{partial}{partial b_i} h_b(x_i)]
[J(b_0, b_1) = frac{1}{2m} sum_{i=1}^{m} (b_0 + b_1 x_i — y_i)^2]
[frac{partial J}{partial b_0} =
frac{1}{m} sum (b_0 + b_1 x_i — y_i) =
frac{1}{m} sum (h_b(x_i) — y_i)]
[frac{partial J}{partial b_1} =
frac{1}{m} sum (b_0 + b_1 x_i — y_i) cdot x_i =
frac{1}{m} sum (h_b(x_i) — y_i) cdot x_i]
Проблема в том, что мы не можем просто решить эти уравнения аналитически. Ведь мы не знаем общий вид функции ошибки, не то, что ее производной. Ведь он зависит, от всех точек данных. Но мы можем вычислить эту функцию (и ее производную) в любой точке. А точка на этой функции — это конкретный набор значений параметров модели. Поэтому пришлось изобрести численный алгоритм. Он работает следующим образом.
Сначала, мы выбираем произвольное значение параметров модели. То есть, произвольную точку в области определения функции. Мы не знаем, является ли эта точка оптимальной (скорее нет), не знаем, насколько она далека от оптимума. Но мы можем вычислить направление к оптимуму. Ведь мы знаем наклон касательной к графику функции ошибки.
Наклон касательной является производной в этой точке, и это даст нам направление движения в сторону самого крутого уменьшения значения функции. Если представить себе функцию одной переменной (параболу), то там все очень просто. Если производная в точке отрицательна, значит функция убывает, значит, что оптимум находится справа от данной точки. То есть, чтобы приблизиться к оптимуму надо увеличить аргумент функции. Если же производная положительна, то все наоборот — функция возрастает, оптимум находится слева и нам нужно уменьшить значение аргумента. Причем, чем дальше от оптимума, тем быстрее возрастает или убывает функция. То есть значение производной дает нам не только направление, но и величину нужного шага. Сделав шаг, пропорциональный величине производной и в направлении, противоположном ей, можно повторить процесс и еще больше приблизиться к оптимуму. С каждой итерацией мы будем приближаться к минимуму ошибки и математически доказано, что мы можем приблизиться к ней произвольно близко. То есть, данный метод сходится в пределе.
В случае с функцией нескольких переменных все немного сложнее, но принцип остается прежним. Только мы оперируем не полной производной функции, а вектором частных производных по каждому параметру. Он задает нам направление максимального увеличения функции. Чтобы получить направление максимального спада функции нужно просто домножить этот вектор на -1. После этого нужно обновить значения каждого компонента вектора параметров модели на величину, пропорциональную соответствующему компоненту вектора градиента. Таким образом мы делаем шаги вниз по функции ошибки в направлении с самым крутым спуском, а размер каждого шага пропорционален определяется параметром $alpha$, который называется скоростью обучения.
Алгоритм градиентного спуска:
повторяйте до сходимости:
[b_j := b_j — alpha frac{partial}{partial b_j} J(b_0, b_1)]
где j=0,1 — представляет собой индекс номера признака.
Это общий алгоритм градиентного спуска. Она работает для любых моделей и для любых функций ошибки. Это итеративный алгоритм, который сходится в пределе. То есть, мы никогда не придем в сам оптимум, но можем приблизиться к нему сколь угодно близко. На практике нам не так уж важно получить точное решение, достаточно решения с определенной точностью.
Алгоритм градиентного спуска имеет один параметр — скорость обучения. Он влияет на то, как быстро мы будем приближаться к оптимуму. Кажется, что чем быстрее, тем лучше, но оказывается, что если значение данного параметра слишком велико, то мы буем постоянно промахиваться и алгоритм будет расходиться.
Алгоритм градиентного спуска для парной линейной регрессии:
повторяйте до сходимости:
[b_0 := b_0 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)} )- y^{(i)})]
[b_1 := b_1 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x^{(i)}]
На практике “повторяйте до сходимости” означает, что мы повторяем алгоритм градиентного спуска до тех пор, пока значение функции ошибки не перестанет значимо изменяться. Это будет означать, что мы уже достаточно близко к минимуму и дальнейшие шаги градиентного спуска слишком малы, чтобы быть целесообразными. Конечно, это оценочное суждение, но на практике обычно, нескольких значащих цифр достаточно для практического применения моделей машинного обучения.
Алгоритм градиентного спуска имеет одну особенность, про которую нужно помнить. Он в состоянии находить только локальный минимум функции. Он в принципе, по своей природе, локален. Поэтому, если функция ошибки будет очень сложна и иметь несколько локальных оптимумов, то результат работы градиентного спуска будет зависеть от выбора начальной точки:


На практике эту проблему решают методом семплирования — запускают градиентный спуск из множества случайных точек и выбирают то минимум, который оказался меньше по значению функции ошибки. Но этот подход понадобится нам при рассмотрении более сложных и глубоких моделей машинного обучения. Для простых линейных, полиномиальных и других моделей метод градиентного спуска работает прекрасно. В настоящее время этот алгоритм — это основная рабочая лошадка классических моделей машинного обучения.
Выводы:
- Метод градиентного спуска нужен, чтобы найти минимум функции, если мы не можем ее вычислить аналитически.
- Это численный итеративный алгоритм локальной оптимизации.
- Для запуска градиентного спуска нужно знать частную производную функции ошибки.
- Для начала мы берем произвольные значения параметров, затем обновляем их по данной формуле.
- Доказано, что этот метод сходится к локальному минимуму.
- Если функция ошибки достаточно сложная, то разные начальные точки дадут разный результат.
- Метод градиентного спуска имеет свой параметр — скорость обучения. Обычно его подстаивают автоматически.
- Метод градиентного спуска повторяют много раз до тех пор, пока функция ошибки не перестанет значимо изменяться.
Регрессия с несколькими переменными
Множественная линейная регрессия
Парная регрессия, как мы увидели выше, имеет дело с объектами, которые характеризуются одним числовым признаком ($x$). На практике, конечно, объекты характеризуются несколькими признаками, а значит в модели должна быть не одна входящая переменная, а несколько (или, что то же самое, вектор). Линейная регрессия с несколькими переменными также известна как «множественная линейная регрессия». Введем обозначения для уравнений, где мы можем иметь любое количество входных переменных:
$ x^{(i)} $- вектор-столбец всех значений признаков i-го обучающего примера;
$ x_j^{(i)} $ — значение j-го признака i-го обучающего примера;
$ x_j $ — вектор j-го признака всех обучающих примеров;
m — количество примеров в обучающей выборке;
n — количество признаков;
X — матрица признаков;
b — вектор параметров регрессии.
Задачи множественной регрессии уже очень сложно представить на графике, ведь количество параметров каждого объекта обучающей выборки соответствует измерению, в котором находятся точки данных. Плюс нужно еще одно измерение для целевой переменной. И вместо того, чтобы подбирать оптимальную прямую, мы будем подбирать оптимальную гиперплоскость. Но в целом идея линейной регрессии остается неизменной.
Для удобства примем, что $ x_0^{(i)} = 1 $ для всех $i$. Другими словами, мы ведем некий суррогатный признак, для всех объектов равный единице. Это никак не сказывается на самой функции гипотезы, это лишь условность обозначения, но это сильно упростит математические выкладки, особенно в матричной форме.
Теперь определим множественную форму функции гипотезы следующим образом, используя несколько признаков. Она очень похожа на парную, но имеет больше входных переменных и, как следствие, больше параметров.
Общий вид модели множественной линейной регрессии:
[h_b(x) = b_0 + b_1 x_1 + b_2 x_2 + … + b_n x_n]
Или в матричной форме:
[h_b(x) = X cdot vec{b}]
Используя определение матричного умножения, наша многопараметрическая функция гипотезы может быть кратко представлена в виде: $h(x) = B X$.
Обратите внимание, что в любой модели линейной регрессии количество параметров на единицу больше количества входных переменных. Это верно для любой линейной модели машинного обучения. Вообще, всегда чем больше признаков, тем больше параметров. Это будет важно для нас позже, когда мы будем говорить о сложности моделей.
Теперь, когда мы знаем виды функции гипотезы, то есть нашей модели, мы можем переходить к следующему шагу: функции ошибки. Мы построим ее по аналогии с функцией ошибки для парной модели. Для множественной регрессии функция ошибки от вектора параметров b выглядит следующим образом:
Функция ошибки для множественной линейной регрессии:
[J(b) = frac{1}{2m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)})^2]
Или в матричной форме:
[J(b) = frac{1}{2m} (X b — vec{y})^T (X b — vec{y})]
Обратите внимание, что мы специально не раскрываем выражение (h_b(x^{(i)})). Это нужно, чтобы подчеркнуть, что форма функции ошибки не зависит от функции гипотезы, она выражается через нее.
Теперь нам нужно взять производную этой функции ошибки. Здесь уже нужно знать производную самой функции гипотезы, так как:
[frac{partial}{partial b_i} J =
frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot frac{partial}{partial b_i} h_b(x^{(i)})]
В такой формулировке мы представляем частные производные функции ошибки (градиент) через частную производную функции гипотезы. Это так называемое моделенезависимое представление градиента. Ведь для этой формулы совершенно неважно, какой функцией будет наша гипотеза. Пока она является дифференцируемой, мы можем использовать градиент ее функции ошибки. Именно поэтому метод градиентного спуска работает с любыми аналитическими моделями, и нам не нужно каждый раз заново “переизобретать” математику градиентного спуска, адаптировать ее к каждой конкретной модели машинного обучения. Достаточно изучить этот метод один раз, в общей форме.
Метод градиентного спуска для множественной регрессии определяется следующими уравнениями:
повторять до сходимости:
[b_0 := b_0 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_0^{(i)}]
[b_1 := b_1 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_1^{(i)}]
[b_2 := b_2 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_2^{(i)}]
[…]
Или в матричной форме:
[b := b — frac{alpha}{m} X^T (X b — vec{y})]
Выводы:
- Множественная регрессия очень похожа на парную, но с большим количеством признаков.
- Для удобства и однообразия, почти всегда обозначают $x_0 = 1$.
- Признаки образуют матрицу, поэтому уравнения множественной регрессии часто приводят в матричной форме, так короче.
- Алгоритм градиентного спуска для множественной регрессии точно такой же, как и для парной.
Нормализация признаков
Мы можем ускорить сходимость метода градиентного спуска, преобразовав входные данные таким образом, чтобы все атрибуты имели значения примерно в том же диапазоне. Это называется нормализация данных — приведение всех признаков к одной шкале. Это ускоряет сходимость градиентного спуска за счет эффекта масштаба. Дело в том, что зачастую значения разных признаков измеряются по шкалам с очень разным порядком величины. Например, $x_1$ измеряется в миллионах, а $x_2$ — в долях единицы.
В таком случае форма функции ошибки будет очень вытянутой. Это не проблема для математической формализации градиентного спуска — при достаточно малых $alpha$ метод все равно рано или поздно сходится. Проблема в практической реализации. Получается, что если выбрать скорость обучения выше определенного предела по самому компактному признаку, спуск разойдется. Значит, скорость обучения надо делать меньше. Но тогда в направлении второго признака спуск будет проходить слишком медленно. И получается, что градиентный спуск потребует гораздо больше итераций для завершения.
Эту проблему можно решить если изменить диапазоны входных данных, чтобы они выражались величинами примерно одного порядка. Это не позволит одному измерению численно доминировать над другим. На практике применяют несколько алгоритмов нормализации, самые распространенные из которых — минимаксная нормализация и стандартизация или z-оценки.
Минимаксная нормализация — это изменение входных данных по следующей формуле:
[x’ = frac{x — x_{min}}{x_{max} — x_{min}}]
После преобразования все значения будут лежать в диапазоне $x in [0; 1]$.
Z-оценки или стандартизация производится по формуле:
[x’ = frac{x — M[x]}{sigma_x}]
В таком случае данный признак приводится к стандартному распределению, то есть такому, у которого среднее 0, а дисперсия — 1.
У каждого из этих двух методов нормализации есть по два параметра. У минимаксной — минимальное и максимальное значение признака. У стандартизации — выборочные среднее и дисперсия. Параметры нормализации, конечно, вычисляются по каждому признаку (столбцу данных) отдельно. Причем, эти параметры надо запомнить, чтобы при использовании модели для предсказании использовать именно их (вычисленные по обучающей выборке). Даже если вы используете тестовую выборку, ее надо нормировать с использованием параметров, вычисленных по обучающей. Да, при этом может получиться, что при применении модели на данных, которых не было в обучающей выборке, могут получиться значения, например, меньше нуля или больше единицы (при использовании минимаксной нормализации). Это не страшно, главное, что будет соблюдена последовательность вычисления нормированных значений.
Целевая переменная не нормируется.
При использовании библиотечных моделей машинного обучения беспокоиться о нормализации входных данных вручную, как правило, не нужно. Большинство готовых реализаций моделей уже включают нормализацию как неотъемлемый этап подготовки данных. Более того, некоторые типы моделей обучения с учителем вовсе не нуждаются в нормализации. Но об этом пойдет речь в следующих главах.
Выводы:
- Нормализация нужна для ускорения метода градиентного спуска.
- Есть два основных метода нормализации — минимаксная и стандартизация.
- Параметры нормализации высчитываются по обучающей выборке.
- Нормализация встроена в большинство библиотечных методов.
- Некоторые методы более чувствительны к нормализации, чем другие.
- Нормализацию лучше сделать, чем не делать.
Полиномиальная регрессия
Функция гипотезы не обязательно должна быть линейной, если это не соответствует данным. На практике вы не всегда будете иметь данные, которые можно хорошо аппроксимировать линейной функцией. Наглядный пример вы видите на иллюстрации. Вполне очевидно, что в среднем увеличение целевой переменной замедляется с ростом входной переменной. Это значит, что данные демонстрируют нелинейную динамику. И это так же значит, что мы никак не сможем их хорошо приблизить линейной моделью.
Надо подчеркнуть, что это не свидетельствует о несовершенстве наших методов оптимизации. Мы действительно можем найти самую лучшую линейную функцию для данных точек, но проблема в том, что мы всегда выбираем лучшую функцию из некоторого класса функций, в данном случае — линейных. То есть проблема не в алгоритмах оптимизации, а в ограничении самого вида модели.
вполне логично предположить, что для описания таких нелинейных наборов данных следует использовать нелинейные же функции моделей. Но очень бы не хотелось, для каждого нового класса функций изобретать собственный метод оптимизации, поэтому мы постараемся максимально “переиспользовать” те подходы, которые описали выше. И механизм множественной регрессии в этом сильно поможет.
Мы можем изменить поведение или кривую нашей функции гипотезы, сделав ее квадратичной, кубической или любой другой формой.
Например, если наша функция гипотезы
$ hat{y} = h_b (x) = b_0 + b_1 x $,
то мы можем добавить еще один признак, основанный на $ x_1 $, получив квадратичную функцию
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 x^2]
или кубическую функцию
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 x^2 + b_3 x^3]
В кубической функции мы по сути ввели два новых признака:
$ x_2 = x^2, x_3 = x^3 $.
Точно таким же образом, мы можем создать, например, такую функцию:
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 sqrt{x}]
В любом случае, мы из парной линейной функции сделали какую-то другую функцию. И к этой нелинейной функции можно относиться по разному. С одной стороны, это другой класс функций, который обладает нелинейным поведением, а следовательно, может описывать более сложные зависимости в данных. С другой стороны, это линейна функция от нескольких переменных. Только сами эти переменные оказываются в функциональной зависимости друг от друга. Но никто не говорил, что признаки должны быть независимы.
И вот такое представление нелинейной функции как множественной линейной позволяет нам без изменений воспользоваться алгоритмом градиентного спуска для множественной линейной регрессии. Только вместо $ x_2, x_3, … , x_n $ нам нужно будет подставить соответствующие функции от $ x_1 $.

Источник: Wikimedia.
Очевидно, что нелинейных функций можно придумать бесконечное количество. Поэтому встает вопрос, как выбрать нужный класс функций для решения конкретной задачи. В случае парной регрессии мы можем взглянув на график точек обучающей выборки сделать предположение о том, какой вид нелинейной зависимости связывает входную и целевую переменные. Но если у нас множество признаков, просто так проанализировать график нам не удастся. Поэтому по умолчанию используют полиномиальную регрессию, когда в модель добавляют входные переменные второго, третьего, четвертого и так далее порядков.
Порядок полиномиальной регрессии подбирается в качестве компромисса между качеством получаемой регрессии, и вычислительной сложностью. Ведь чем выше порядок полинома, тем более сложные зависимости он может аппроксимировать. И вообще, чем выше степень полинома, тем меньше будет ошибка при прочих равных. Если степень полинома на единицу меньше количества точек — ошибка будет нулевая. Но одновременно с этим, чем выше степень полинома, тем больше в модели параметров, тем она сложнее и занимает больше времени на обучение. Есть еще вопросы переобучения, но про это мы поговорим позднее.
А что делать, если изначально в модели было несколько признаков? Тогда обычно для определенной степени полинома берутся все возможные комбинации признаком соответствующей степени и ниже. Например:
Для регрессии с двумя признаками.
Линейная модель (полином степени 1):
[h_b (x) = b_0 + b_1 x_1 + b_2 x_2]
Квадратичная модель (полином степени 2):
[h_b (x) = b_0 + b_1 x + b_2 x_2 + b_3 x_1^2 + b_4 x_2^2 + b_5 x_1 x_2]
Кубическая модель (полином степени 3):
[hat{y} = h_b (x) = b_0 + b_1 x_1 + b_2 x_2 + b_3 x_1^2 + b_4 x_2^2 + b_5 x_1 x_2 + b_6 x_1^3 + b_7 x_2^3 + b_7 x_1^2 x_2 + b_8 x_1 x_2^2]
При этом количество признаков и, соответственно, количество параметров растет экспоненциально с ростом степени полинома. Поэтому полиномиальные модели обычно очень затратные в обучении при больших степенях. Но полиномы высоких степеней более универсальны и могут аппроксимировать более сложные данные лучше и точнее.
Выводы:
- Данные в датасете не всегда располагаются так, что их хорошо может описывать линейная функция.
- Для описания нелинейных зависимостей нужна более сложная, нелинейная модель.
- Чтобы не изобретать алгоритм обучения заново, можно просто ввести в модель суррогатные признаки.
- Суррогатный признак — это новый признак, который считается из существующих атрибутов.
- Чаще всего используют полиномиальную регрессию — это когда в модель вводят полиномиальные признаки — степени существующих атрибутов.
- Обычно берут все комбинации факторов до какой-то определенной степени полинома.
- Полиномиальная регрессия может аппроксимировать любую функцию, нужно только подобрать степень полинома.
- Чем больше степень полиномиальной регрессии, тем она сложнее и универсальнее, но вычислительно сложнее (экспоненциально).
Практическое построение регрессии
В данном разделе мы посмотрим, как можно реализовать методы линейной регрессии на практике. Сначала мы попробуем создать алгоритм регрессии с нуля, а затем воспользуемся библиотечной функцией. Это поможет нам более полно понять, как работают модели машинного обучения в целом и в библиотеке sckikit-learn (самом популярном инструменте для создания и обучения моделей на языке программирования Python) в частности.
Для понимания данного раздела предполагаем, что читатель знаком с основами языка программирования Python. Нам понадобится знание его базового синтаксиса, немного — объектно-ориентированного программирования, немного — использования стандартных библиотек и модулей. Никаких продвинутых возможностей языка (типа метапрограммирования или декораторов) мы использовать не будем.
Как должны быть представлены данные для машинного обучения?
Применение любых моделей машинного обучения начинается с подготовки данных в необходимом формате. Для этого очень удобными для нас будут библиотеки numpy и pandas. Они практически всегда используются совместно с библиотекой sckikit-learn и другими инструментами машинного обучения. В первую очередь мы будем использовать numpy для создания массивов и операций с векторами и матрицами. Pandas нам понадобится для работы с табличными структурами — датасетами.
Если вы хотите самостоятельно задать в явном виде данные обучающей выборки, то нет ничего лучше использования обычных массивов ndarray. Обычно в одном массиве хранятся значения атрибутов — x, а в другом — значения целевой переменной — y.
1
2
3
4
5
6
7
8
9
10
11
import numpy as np
x = np.array([1.46, 1.13, -2.30, 1.74, 0.04,
-0.61, 0.32, -0.76, 0.58, -1.10,
0.87, 1.62, -0.53, -0.25, -1.07,
-0.38, -0.17, -0.32, -2.06, -0.88, ])
y = np.array([101.16, 78.44, -159.24, 120.72, 2.92,
-42.33, 22.07, -52.67, 40.32, -76.10,
59.88, 112.38, -36.54, -17.25, -74.24,
-26.57, -11.93, -22.31, -142.54, -60.74,])
Если мы имеем дело с задачей множественной регрессии, то в массиве атрибутов будет уже двумерный массив, состоящий из нескольких векторов атрибутов, вот так:
1
2
3
4
5
x = np.array([
[0, 1, 2, 3, 4],
[5, 4, 9, 6, 3],
[7.8, -0.1, 0.0, -2.14, 10.7],
])
Важно следить за тем, чтобы в массиве атрибутов в каждом вложенном массиве количество элементов было одинаковым и в свою очередь совпадало с количеством элементов в массиве целевой переменной. Это называется соблюдение размерности задачи. Если размерность не соблюдается, то модели машинного обучения будут работать неправильно. А библиотечные функции чаще всего будут выдавать ошибку, связанную с формой массива (shape).
Но чаще всего вы не будете задавать исходные данные явно. Практически всегда их приходится читать из каких-либо входных файлов. Удобнее всего это сделать при помощи библиотеки pandas вот так:
1
2
3
4
import pandas as pd
x = pd.read_csv('x.csv', index_col=0)
y = pd.read_csv('y.csv', index_col=0)
Или, если данные лежат в одном файле в общей таблице (что происходит чаще всего), тогда его читают в один датафрейм, а затем выделяют целевую переменную, и факторные переменные:
1
2
3
4
5
6
7
8
import pandas as pd
data = pd.read_csv('data.csv', index_col=0)
y = data.Y
y = data["Y"]
x = data.drop(["Y"])
Обратите внимание, что матрицу атрибутов проще всего сформировать, удалив из полной таблицы целевую переменную. Но, если вы хотите выбрать только конкретные столбцы, тогда можно использовать более явный вид, через перечисление выбранных колонок.
Если вы используете pandas или numpy для формирования массивов данных, то получившиеся переменные будут разных типов — DataFrame или ndarray, соответственно. Но на дальнейшую работу это не повлияет, так как интерфейс работы с этими структурами данных очень похож. Например, неважно, какие именно массивы мы используем, их можно изобразить на графике вот так:
1
2
3
4
5
import maiplotlib.pyplot as plt
plt.figure()
plt.scatter(x, y)
plt.show()
Конечно, такая визуализация будет работать только в случае задачи парной регрессии. Если x многомерно, то простой график использовать не получится.
Давайте соберем весь наш код вместе:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import numpy as np
import pandas as pd
import maiplotlib.pyplot as plt
# x = pd.read_csv('x.csv', index_col=0)
x = np.array([1.46, 1.13, -2.30, 1.74, 0.04,
-0.61, 0.32, -0.76, 0.58, -1.10,
0.87, 1.62, -0.53, -0.25, -1.07,
-0.38, -0.17, -0.32, -2.06, -0.88, ])
# y = pd.read_csv('y.csv', index_col=0)
y = np.array([101.16, 78.44, -159.24, 120.72, 2.92,
-42.33, 22.07, -52.67, 40.32, -76.10,
59.88, 112.38, -36.54, -17.25, -74.24,
-26.57, -11.93, -22.31, -142.54, -60.74,])
plt.figure()
plt.scatter(x, y)
plt.show()
Это код генерирует вот такой вот график:
Как работает метод машинного обучения “на пальцах”?
Для того, чтобы более полно понимать, как работает метод градиентного спуска для линейной регрессии, давайте реализуем его самостоятельно, не обращаясь к библиотечным методам. На этом примере мы проследим все шаги обучения модели.
Мы будем использовать объектно-ориентированный подход, так как именно он используется в современных библиотеках. Начнем строить класс, который будет реализовывать метод парной линейной регрессии:
1
2
3
4
5
class hypothesis(object):
"""Модель парной линейной регрессии"""
def __init__(self):
self.b0 = 0
self.b1 = 0
Здесь мы определили конструктор класса, который запоминает в полях экземпляра параметры регрессии. Начальные значения этих параметров не очень важны, так как градиентный спуск сойдется из любой точки. В данном случае мы выбрали нулевые, но можно задать любые другие начальные значения.
Реализуем метод, который принимает значение входной переменной и возвращает теоретическое значение выходной — это прямое действие нашей регрессии — метод предсказания результата по факторам (в случае парной регрессии — по одному фактору):
1
2
def predict(self, x):
return self.b0 + self.b1 * x
Название выбрано не случайно, именно так этот метод называется и работает в большинстве библиотечных классов.
Теперь зададим функцию ошибки:
1
2
def error(self, X, Y):
return sum((self.predict(X) - Y)**2) / (2 * len(X))
В данном случае мы используем простую функцию ошибки — среднеквадратическое отклонение (mean squared error, MSE). Можно использовать и другие функции ошибки. Именно вид функции ошибки будет определять то, какой вид регрессии мы реализуем. Существует много разных вариаций простого алгоритма регрессии. О большинстве распространенных методах регрессии можно почитать в официальной документации sklearn.
Теперь реализуем метод градиентного спуска. Он должен принимать массив X и массив Y и обновлять параметры регрессии в соответствии в формулами градиентного спуска:
1
2
3
4
5
6
def BGD(self, X, Y):
alpha = 0.5
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
О выборе конкретного значения alpha мы говорить пока не будем,на практике его довольно просто подбирают, мы же возьмем нейтральное значение.
Давайте создадим объект регрессии и проверим начальное значение ошибки. В примерах приведены значения на модельном наборе данных, но этот метод можно использовать на любых данных, которые подходят по формату — x и y должны быть одномерными массивами чисел.
1
2
3
4
5
6
7
8
hyp = hypothesis()
print(hyp.predict(0))
print(hyp.predict(100))
J = hyp.error(x, y)
print("initial error:", J)
0
0
initial error: 36271.58344889084
Как мы видим, для начала оба параметра регрессии равны нулю. Конечно, такая модель не дает надежных предсказаний, но в этом и состоит суть метода градиентного спуска: начиная с любого решения мы постепенно его улучшаем и приходим к оптимальному решению.
Теперь все готово к запуску градиентного спуска.
1
2
3
4
5
6
7
8
9
10
hyp.BGD(x, y)
J = hyp.error(x, y)
print("error after gradient descent:", J)
error after gradient descent: 6734.135540194945
X0 = np.linspace(60, 180, 100)
Y0 = hyp.predict(X0)
plt.figure()
plt.scatter(x, y)
plt.plot(X0, Y0, 'r')
plt.show()
Как мы видим, численное значение ошибки значительно уменьшилось. Да и линия на графике существенно приблизилась к точкам. Конечно, наша модель еще далека от совершенства. Мы прошли всего лишь одну итерацию градиентного спуска. Модифицируем метод так, чтобы он запускался в цикле пока ошибка не перестанет меняться существенно:
1
2
3
4
5
6
7
8
9
10
11
12
13
def BGD(self, X, Y, alpha=0.5, accuracy=0.01, max_steps=5000):
step = 0
old_err = hyp.error(X, Y)
new_err = hyp.error(X, Y)
dJ = 1
while (dJ > accuracy) and (step < max_steps):
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
old_err = new_err
new_err = hyp.error(X, Y)
dJ = abs(old_err - new_err)
Заодно мы проверяем, насколько изменилось значение функции ошибки. Если оно изменилось на величину, меньшую, чем заранее заданная точность, мы завершаем спуск. Таким образом, мы реализовали два стоп-механизма — по количеству итераций и по стабилизации ошибки. Вы можете выбрать любой или использовать оба в связке.
Запустим наш градиентный спуск:
1
2
3
4
5
hyp = hypothesis()
hyp.BGD(x, y)
J = hyp.error(x, y)
print("error after gradient descent:", J)
error after gradient descent: 298.76881676471504
Как мы видим, теперь ошибка снизилась гораздо больше. Однако, она все еще не достигла нуля. Заметим, что нулевая ошибка не всегда возможна в принципе из-за того, что точки данных не всегда будут располагаться на одной линии. Нужно стремиться не к нулевой, а к минимально возможной ошибке.
Посмотрим, как теперь наша регрессия выглядит на графике:
1
2
3
4
5
6
X0 = np.linspace(60, 180, 100)
Y0 = hyp.predict(X0)
plt.figure()
plt.scatter(x, y)
plt.plot(X0, Y0, 'r')
plt.show()
Уже значительно лучше. Линия регрессии довольно похожа на оптимальную. Так ли это на самом деле, глядя на график, сказать сложно, для этого нужно проанализировать, как ошибка регрессии менялась со временем:
Как оценить качество регрессионной модели?
В простых случаях качество модели можно оценить визуально на графике. Но если у вас многомерная задача, это уже не представляется возможным. Кроме того, если ошибка и сама модель меняется незначительно, то очень сложно определить, стало хуже или лучше. Поэтому для диагностики моделей машинного обучения используют кривые.
Самая простая кривая обучения — зависимость ошибки от времени (итерации градиентного спуска). Для того, чтобы построить эту кривую, нам нужно немного модифицировать наш метод обучения так, чтобы он возвращал нужную нам информацию:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def BGD(self, X, Y, alpha=0.1, accuracy=0.01, max_steps=1000):
steps, errors = [], []
step = 0
old_err = hyp.error(X, Y)
new_err = hyp.error(X, Y) - 1
dJ = 1
while (dJ > accuracy) and (step < max_steps):
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
old_err = new_err
new_err = hyp.error(X, Y)
dJ = abs(old_err - new_err)
step += 1
steps.append(step)
errors.append(new_err)
return steps, errors
Мы просто запоминаем в массивах на номер шаа и ошибку на каждом шаге. Получив эти данные можно легко построить их на графике:
1
2
3
4
5
6
hyp = hypothesis()
steps, errors = hyp.BGD(x, y)
plt.figure()
plt.plot(steps, errors, 'g')
plt.show()
На этом графике наглядно видно, что в начале обучения ошибка падала быстро, но в ходе градиентного спуска она вышла на плато. Учитывая, что мы используем гладкую функцию ошибки второго порядка, это свидетельствует о том, что мы достигли локального оптимума и дальнейшее повторение алгоритма не принесет улучшения модели.
Если бы мы наблюдали на графике обучения ситуацию, когда по достижении конца обучения ошибка все еще заметно снижалась, это значит, что мы рано прекратили обучение, и нужно продолжить его еще на какое-то количество итераций.
При анализе графиков с библиотечными моделями не получится таких гладких графиков, они больше напоминают случайные колебания. Это из-за того, что в готовых реализациях используется очень оптимизированный вариант метода градиентного спуска. А он может работать с произвольными флуктуациями. В любом случае, нас интересует общий вид этой кривой.
Как подбирать скорость обучения?
В нашей реализации метода градиентного спуска есть один параметр — скорость обучения — который нам приходится так же подбирать руками. Какой смысл автоматизировать подбор параметров линейной регрессии, если все равно приходится вручную подбирать какой-то другой параметр?
На самом деле подобрать скорость обучения гораздо легче. Нужно использовать тот факт, что при превышении определенного порогового значения ошибка начинает возрастать. Кроме того, мы знаем, что скорость обучения должна быть положительна, но меньше единицы. Вся проблема в этом пороговом значении, которое сильно зависит от размерности задачи. При одних данных хорошо работает $ alpha = 0.5 $, а при каких-то приходится уменьшать ее на несколько порядков, например, $ alpha = 0.00000001 $.
Мы еще не говорили о нормализации данных, которая тоже практически всегда применяется при обучении. Она “благотворно” влияет на возможный диапазон значений скорости обучения. При использовании нормализации меньше вероятность, что скорость обучения нужно будет уменьшать очень сильно.
Подбирать скорость обучения можно по следующему алгоритму. Сначала мы выбираем $ alpha $ близкое к 1, скажем, $ alpha = 0.7 $. Производим одну итерацию градиентного спуска и оцениваем, как изменилась ошибка. Если она уменьшилась, то ничего не надо менять, продолжаем спуск как обычно. Если же ошибка увеличилась, то скорость обучения нужно уменьшить. Например, раа в два. После чего мы повторяем первый шаг градиентного спуска. Таким образом мы не начинаем спуск, пока скорость обучения не снизится настолько, чтобы он начал сходиться.
Как применять регрессию с использованием scikit-learn?
Для серьезной работы, все-таки рекомендуется использовать готовые библиотечные решения. Они работаю гораздо быстрее, надежнее и гораздо проще, чем написанные самостоятельно. Мы будем использовать библиотеку scikit-learn для языка программирования Python как наш основной инструмент реализации простых моделей. Сегодня это одна их самых популярных библиотек для машинного обучения. Мы не будем повторять официальную документацию этой библиотеки, которая на редкость подробная и понятная. Наша задача — на примере этих инструментов понять, как работают и как применяются модели машинного обучения.
В библиотеке scikit-learn существует огромное количество моделей машинного обучения и других функций, которые могут понадобиться для их работы. Поэтому внутри самой библиотеки есть много разных пакетов. Все простые модели, например, модель линейной регрессии, собраны в пакете linear_models. Подключить его можно так:
1
from sklearn import linear_model
Надо помнить, что все модели машинного обучения из это библиотеки имеют одинаковый интерфейс. Это очень удобно и универсально. Но это значит, в частности, что все модели предполагают, что массив входных переменных — двумерный, а массивы целевых переменных — одномерный. Отдельного класса для парной регрессии не существует. Поэтому надо убедиться, что наш массив имеет нужную форму. Проще всего для преобразования формы массива использовать метод reshape, например, вот так:
Если вы используете DataFrame, то они обычно всегда настроены правильно, поэтому этого шага может не потребоваться. Важно запомнить, что все методы библиотечных моделей машинного обучения предполагают, что в x будет двумерный массив или DataFrame, а в y, соответственно, одномерный массив или Series.
Эта строка преобразует любой массив в вектор-столбец. Это если у вас один признак, то есть парная регрессия. Если признаков несколько, то вместо 1 следует указать число признаков. -1 на первой позиции означает, что по нулевому измерению будет столько элементов, сколько останется в массиве.
Само использование модели машинного обучения в этой библиотеке очень просто и сводится к трем действиям: создание экземпляра модели, обучение модели методом fit(), получение предсказаний методом predict(). Это общее поведение для любых моделей библиотеки. Для модели парной линейной регрессии нам понадобится класс LinearRegression.
1
2
3
4
5
6
reg = linear_model.LinearRegression()
reg.fit(x, y)
y_pred = reg.predict(x)
print(reg.score(x, y))
print("Коэффициенты: n", reg.coef_)
В этом классе кроме уже упомянутых методов fit() и predict(), которые есть в любой модели, есть большое количество методов и полей для получения дополнительной информации о моделях. Так, практически в каждой модели есть встроенный метод score(), который оценивает качество полученной модели. А поле coef_ содержит коэффициенты модели.
Обратите внимание, что в большинстве моделей коэффициентами считаются именно параметры при входящих переменных, то есть $ b_1, b_2, …, b_n $. Коэффициент $b_0$ считается особым и хранится отдельно в поле intercept_
Так как мы работаем с парной линейной регрессией, результат можно нарисовать на графике:
1
2
3
4
plt.figure(figsize=(12, 9))
plt.scatter(x, y, color="black")
plt.plot(x, y_pred, color="blue", linewidth=3)
plt.show()
Как мы видим, результат ничем не отличается от модели, которую мы обучили сами, вручную:
Соберем код вместе и получим пример довольно реалистичного фрагмента работы с моделью машинного обучение. Примерно такой код можно встретить и в промышленных проектах по интеллектуальному анализу данных:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from sklearn.linear_model import LinearRegression
x = x.reshape((-1, 1))
reg = LinearRegression()
reg.fit(x, y)
print(reg.score(x, y))
from sklearn.metrics import mean_squared_error, r2_score
y_pred = reg.predict(x)
print("Коэффициенты: n", reg.coef_)
print("Среднеквадратичная ошибка: %.2f" % mean_squared_error(y, y_pred))
print("Коэффициент детерминации: %.2f" % r2_score(y, y_pred))
plt.figure(figsize=(12, 9))
plt.scatter(x, y, color="black")
plt.plot(x, y_pred, color="blue", linewidth=3)
plt.show()
АКТУАЛЬНОСТЬ ТЕМЫ
Общие положения
Про регрессионный анализ вообще, и его применение в DataScience написано очень много. Есть множество учебников, монографий, справочников и статей по прикладной статистике, огромное количество информации в интернете, примеров расчетов. Можно найти множество кейсов, реализованных с использованием средств Python. Казалось бы — что тут еще можно добавить?
Однако, как всегда, есть нюансы:
1. Регрессионный анализ — это прежде всего процесс, набор действий исследователя по определенному алгоритму: «подготовка исходных данных — построение модели — анализ модели — прогнозирование с помощью модели». Это ключевая особенность. Не представляет особой сложности сформировать DataFrame исходных данных и построить модель, запустить процедуру из библиотеки statsmodels. Однако подготовка исходных данных и последующий анализ модели требуют гораздо больших затрат человеко-часов специалиста и строк программного кода, чем, собственно, построение модели. На этих этапах часто приходится возвращаться назад, корректировать модель или исходные данные. Этому, к сожалению, во многих источниках, не удаляется достойного внимания, а иногда — и совсем не уделяется внимания, что приводит к превратному представлению о регрессионном анализе.
2. Далеко не во всех источниках уделяется должное внимание интерпретации промежуточных и финальных результатов. Специалист должен уметь интерпретировать каждую цифру, полученную в ходе работы над моделью.
3. Далеко не все процедуры на этапах подготовки исходных данных или анализа модели в источниках разобраны подробно. Например, про проверку значимости коэффициента детерминации найти информацию не представляет труда, а вот про проверку адекватности модели, построение доверительных интервалов регрессии или про специфические процедуры (например, тест Уайта на гетероскедастичность) информации гораздо меньше.
4. Своеобразная сложность может возникнуть с проверкой статистических гипотез: для отечественной литературы по прикладной статистике больше характерно проверять гипотезы путем сравнения расчетного значения критерия с табличным, а в иностранных источниках чаще определяется расчетный уровень значимости и сравнивается с заданным (чаще всего 0.05 = 1-0.95). В разных источниках информации реализованы разные подходы. Инструменты python (прежде всего библиотеки scipy и statsmodels) также в основном оперируют с расчетным уровнем значимости.
5. Ну и, наконец, нельзя не отметить, что техническая документация библиотеки statsmodels составлена, на мой взгляд, далеко не идеально: информация излагается путано, изобилует повторами и пропусками, описание классов, функций и свойств выполнено фрагментарно и количество примеров расчетов — явно недостаточно.
Поэтому я решил написать ряд обзоров по регрессионному анализу средствами Python, в которых акцент будет сделан на практических примерах, алгоритме действий исследователя, интерпретации всех полученных результатов, конкретных методических рекомендациях. Буду стараться по возможности избегать теории (хотя совсем без нее получится) — все-таки предполагается, что специалист DataScience должен знать теорию вероятностей и математическую статистику, хотя бы в рамках курса высшей математики для технического или экономического вуза.
В данном статье остановимся на самои простом, классическом, стереотипном случае — простой линейной регрессии (simple linear regression), или как ее еще принято называть — парной линейной регрессионной модели (ПЛРМ) — в ситуации, когда исследователя не подстерегают никакие подводные камни и каверзы — исходные данные подчиняются нормальному закону, в выборке отсутствуют аномальные значения, отсутствует ложная корреляция. Более сложные случаи рассмотрим в дальнейшем.
Для построение регрессионной модели будем пользоваться библиотекой statsmodels.
В данной статье мы рассмотрим по возможности полный набор статистических процедур. Некоторые из них (например, дескриптивная статистика или дисперсионный анализ регрессионной модели) могут показаться избыточными. Все так, но эти процедуры улучшают наше представление о процессе и об исходных данных, поэтому в разбор я их включил, а каждый исследователь сам вправе для себя определить, потребуются ему эти процедуры или нет.
Краткий обзор источников
Источников информации по корреляционному и регрессионному анализу огромное количество, в них можно просто утонуть. Поэтому позволю себе просто порекомендовать ряд источников, на мой взгляд, наиболее полезных:
-
Кобзарь А.И. Прикладная математическая статистика. Для инженеров и научных работников. — М.: ФИЗМАТЛИТ, 2006. — 816 с.
-
Львовский Е.Н. Статистические методы построения эмпирических формул. — М.: Высшая школа, 1988. — 239 с.
-
Фёрстер Э., Рёнц Б. Методы корреляционного и регрессионного анализа / пер с нем. — М.: Финансы и статистика, 1983. — 302 с.
-
Афифи А., Эйзен С. Статистический анализ. Подход с использованием ЭВМ / пер с англ. — М.: Мир, 1982. — 488 с.
-
Дрейпер Н., Смит Г. Прикладной регрессионный анализ. Книга 1 / пер.с англ. — М.: Финансы и статистика, 1986. — 366 с.
-
Айвазян С.А. и др. Прикладная статистика: Исследование зависимостей. — М.: Финансы и статистика, 1985. — 487 с.
-
Прикладная статистика. Основы эконометрики: В 2 т. 2-е изд., испр. — Т.2: Айвазян С.А. Основы эконометрики. — М.: ЮНИТИ-ДАНА, 2001. — 432 с.
-
Магнус Я.Р. и др. Эконометрика. Начальный курс — М.: Дело, 2004. — 576 с.
-
Носко В.П. Эконометрика. Книга 1. — М.: Издательский дом «Дело» РАНХиГС, 2011. — 672 с.
-
Брюс П. Практическая статистика для специалистов Data Science / пер. с англ. — СПб.: БХВ-Петербург, 2018. — 304 с.
-
Уатт Дж. и др. Машинное обучение: основы, алгоритмы и практика применения / пер. с англ. — СПб.: БХВ-Петербург, 2022. — 640 с.
Прежде всего следует упомянуть справочник Кобзаря А.И. [1] — это безусловно выдающийся труд. Ничего подобного даже близко не издавалось. Всем рекомендую иметь под рукой.
Есть очень хорошее практическое пособие [2] — для начинающих и практиков.>
Добротная работа немецких авторов [3]. Все разобрано подробно, обстоятельно, с примерами — очень хорошая книга. Примеры приведены из области экономики.
Еще одна добротная работа — [4], с примерами медико-биологического характера.
Работа [5] считается одним из наиболее полных изложений прикладного регрессионного анализа.
Более сложные работы — [6] (классика жанра), [7], [8], [9] — выдержаны на достаточно высоком математическом уровне, примеры из экономической области.
Свежие работы [10] (с примерами на языке R) и [11] (с примерами на python).
Cтатьи
Статей про регрессионный анализ в DataScience очень много, обращаю внимание на некоторые весьма полезные из них.
Серия статей «Python, корреляция и регрессия», охватывающая весь процесс регрессионного анализа:
-
первичная обработка данных, визуализация и корреляционный анализ;
-
регрессия;
-
теория матриц в регрессионном анализе, проверка адекватности, мультиколлинеарность;
-
прогнозирование с помощью регрессионных моделей.
Очень хороший обзор «Интерпретация summary из statsmodels для линейной регрессии». В этой статье даны очень полезные ссылки:
-
Statistical Models
-
Interpreting Linear Regression Through statsmodels .summary()
Статья «Регрессионные модели в Python».
Основные предпосылки (гипотезы) регрессионного анализа
Очень кратко — об этом написано тысячи страниц в учебниках — но все же вспомним некоторые основы теории.
Проверка исходных предпосылок является очень важным моментом при статистическом анализе регрессионной модели. Если мы рассматриваем классическую линейную регрессионную модель вида:
![]()
то основными предпосылками при использовании обычного метода наименьших квадратов (МНК) для оценки ее параметров являются:
-
Среднее значение (математическое ожидание) случайной составляющей равно нулю:
![]()
-
Дисперсия случайной составляющей является постоянной:
![]()
В случае нарушения данного условия мы сталкиваемся с явлением гетероскедастичности.
-
Значения случайной составляющей статистически независимы (некоррелированы) между собой:
![]()
В случае нарушения данного условия мы сталкиваемся с явлением автокорреляции.
-
Условие существования обратной матрицы
![]()
что эквивалентно одному из двух следующих условий:

то есть число наблюдений должно превышать число параметров.
-
Значения случайной составляющей некоррелированы со значениями независимых переменных:
![]()
-
Случайная составляющая имеет нормальный закон распределения (с математическим ожиданием равным нулю — следует из условия 1):
![]()
Более подробно — см.: [3, с.90], [4, с.147], [5, с.122], [6, с.208], [7, с.49], [8, с.68], [9, с.88].
Кроме гетероскедастичности и автокорреляции возможно возникновение и других статистических аномалий — мультиколлинеарности, ложной корреляции и т.д.
Доказано, что оценки параметров, полученные с помощью МНК, обладают наилучшими свойствами (несмещенность, состоятельность, эффективность) при соблюдении ряда условий:
-
выполнение приведенных выше исходных предпосылок регрессионного анализа;
-
число наблюдений на одну независимую переменную должно быть не менее 5-6;
-
должны отсутствовать аномальные значения (выбросы).
Кроме обычного МНК существуют и другие его разновидности (взвешенный МНК, обобщенный МНК), которые применяются при наличии статистических аномалий. Кроме МНК применяются и другие методы оценки параметров моделей. В этом обзоре мы эти вопросы рассматривать не будем.
Алгоритм проведения регрессионного анализа
Алгоритм действий исследователя при построении регрессионной модели (полевые работы мы, по понятным причинам, не рассматриваем — считаем, что исходные данные уже получены):
-
Подготовительный этап — постановка целей и задач исследования.
-
Первичная обработка исходных данных — об этом много написано в учебниках и пособиях по DataScience, сюда могут относится:
-
выявление нерелевантных признаков (признаков, которые не несут полезной информации), нетипичных данных (выбросов), неинформативных признаков (имеющих большое количество одинаковых значений) и работа с ними (удаление/преобразование);
-
выделение категориальных признаков;
-
работа с пропущенными значениями;
-
преобразование признаков-дат в формат datetime и т.д.
-
Визуализация исходных данных — предварительный графический анализ.
-
Дескриптивная (описательная) статистика — расчет выборочных характеристик и предварительные выводы о свойствах исходных данных.
-
Исследование закона распределения исходных данных и, при необходимости, преобразование исходных данных к нормальному закону распределения.
-
Выявление статистически аномальных значений (выбросов), принятие решения об их исключении.
Этапы 4, 5 и 6 могут быть при необходимости объединены.
-
Корреляционный анализ — исследование корреляционных связей между исходными данными; это разведка перед проведением регрессионного анализа.
-
Построение регрессионной модели:
-
выбор моделей;
-
выбор методов;
-
оценка параметров модели.
-
Статистический анализ регрессионной модели:
-
оценка ошибок аппроксимации (error metrics);
-
анализ остатков (проверка нормальности распределения остатков и гипотезы о равенстве нулю среднего значения остатков);
-
проверка адекватности модели;
-
проверка значимости коэффициента детерминации;
-
проверка значимости коэффициентов регрессии;
-
проверка мультиколлинеарности (для множественных регрессионных моделей; вообще мультиколлинеарные переменные выявляются еще на стадии корреляционного анализа);
-
проверка автокорреляции;
-
проверка гетероскедастичности.
Этапы 8 и 9 могут быть при необходимости повторяться несколько раз.
-
Сравнительный анализ нескольких регрессионных моделей, выбор наилучшей (при необходимости).
-
Прогнозирование с помощью регрессионной модели и оценка качества прогноза.
-
Выводы и рекомендации.
Само собой, этот алгоритм не есть истина в последней инстанции — в зависимости от особенностей исходных данных и вида модели могут возникать дополнительные задачи.
Применение пользовательских функций
Далее в обзоре мной будут использованы несколько пользовательских функций для решения разнообразных задач. Все эти функции созданы для облегчения работы и уменьшения размера программного кода. Данные функции загружается из пользовательского модуля my_module__stat.py, который доступен в моем репозитории на GitHub. Лично мне так удобнее работать, хотя каждый исследователь сам формирует себе инструменты по душе — особенно в части визуализации. Желающие могут пользоваться этими функциями, либо создать свои.
Итак, вот перечень данных функций:
-
graph_scatterplot_sns — функция позволяет построить точечную диаграмму средствами seaborn и сохранить график в виде png-файла;
-
graph_hist_boxplot_probplot_XY_sns — функция позволяет визуализировать исходные данные для простой линейной регрессии путем одновременного построения гистограммы, коробчатой диаграммы и вероятностного графика (для переменных X и Y) средствами seaborn и сохранить график в виде png-файла; имеется возможность выбирать, какие графики строить (h — hist, b — boxplot, p — probplot);
-
descriptive_characteristics — функция возвращает в виде DataFrame набор статистических характеристики выборки, их ошибок и доверительных интервалов;
-
detecting_outliers_mad_test — функция выполняет проверку наличия аномальных значений (выбросов) по критерию наибольшего абсолютного отклонения (более подробно — см.[1, с.547]);
-
norm_distr_check — проверка нормальности распределения исходных данных с использованием набора из нескольких статистических тестов;
-
corr_coef_check — функция выполняет расчет коэффициента линейной корреляции Пирсона, проверку его значимости и расчет доверительных интервалов; об этой функции я писал в своей статье.
-
graph_regression_plot_sns — — функция позволяет построить график регрессионной модели.
Ряд пользовательских функций мы создаем в процессе данного обзора (они тоже включены в пользовательский модуль my_module__stat.py):
-
regression_error_metrics — расчет ошибок аппроксимации регрессионной модели;
-
ANOVA_table_regression_model — вывод таблицы дисперсионного анализа регрессионной модели;
-
regression_model_adequacy_check — проверка адекватности регрессионной модели по критерию Фишера;
-
determination_coef_check — проверка значимости коэффициента детерминации по критерию Фишера;
-
regression_coef_check — проверка значимости коэффициентов регрессии по критеирю Стьюдента;
-
Goldfeld_Quandt_test, Breush_Pagan_test, White_test — проверка гетероскедастичности с использование тестов Голдфелда-Квандта, Бриша-Пэгана и Уайта соответственно;
-
regression_pair_predict — функция для прогнозирования с помощью парной регрессионной модели: рассчитывает прогнозируемое значение переменной Y по заданной модели, а также доверительные интервалы среднего и индивидуального значения для полученного прогнозируемого значения Y;
-
graph_regression_pair_predict_plot_sns — прогнозирование: построение графика регрессионной модели (с доверительными интервалами) и вывод расчетной таблицы с данными для заданной области значений X.
ПОСТАНОВКА ЗАДАЧИ
В качестве примера рассмотрим практическую задачу из области экспертизы промышленной безопасности — калибровку ультразвукового прибора для определения прочности бетона.
Итак, суть задачи: при обследовании несущих конструкций зданий и сооружений эксперт определяет прочность бетона с использованием ультразвукового прибора «ПУЛЬСАР-2.1», для которого необходимо предварительно построить градуировочную зависимость. Заключается это в следующем — производятся замеры с фиксацией следующих показателей:
-
X — показания ультразвукового прибора «ПУЛЬСАР-2.1» (м/с)
-
Y — результаты замера прочности бетона (методом отрыва со скалыванием) склерометром ИПС-МГ4.03.
Предполагается, что между показателями X и Y имеется линейная регрессионная зависимость, которая позволит прогнозировать прочность бетона на основании измерений, проведенных прибором «ПУЛЬСАР-2.1».
Были выполнены замеры фактической прочности бетона конструкций для бетонов одного вида с одним типом крупного заполнителя, с единой технологией производства. Для построения были выбраны 14 участков (не менее 12), включая участки, в которых значение косвенного показателя максимальное, минимальное и имеет промежуточные значения.
Настройка заголовков отчета:
# Общий заголовок проекта
Task_Project = 'Калибровка ультразвукового прибора "ПУЛЬСАР-2.1" nдля определения прочности бетона'
# Заголовок, фиксирующий момент времени
AsOfTheDate = ""
# Заголовок раздела проекта
Task_Theme = ""
# Общий заголовок проекта для графиков
Title_String = f"{Task_Project}n{AsOfTheDate}"
# Наименования переменных
Variable_Name_X = "Скорость УЗК (м/с)"
Variable_Name_Y = "Прочность бетона (МПа)"
# Константы
INCH = 25.4 # мм/дюйм
DecPlace = 5 # number of decimal places - число знаков после запятой
# Доверительная вероятность и уровень значимости:
p_level = 0.95
a_level = 1 - p_level Подключение модулей и библиотек:
# Стандартные модули и библиотеки
import os # загрузка модуля для работы с операционной системой
import sys
import platform
print('{:<35}{:^0}'.format("Текущая версия Python: ", platform.python_version()), 'n')
import math
from math import * # подключаем все содержимое модуля math, используем без псевдонимов
import numpy as np
#print ("Текущая версия модуля numpy: ", np.__version__)
print('{:<35}{:^0}'.format("Текущая версия модуля numpy: ", np.__version__))
from numpy import nan
import scipy as sci
print('{:<35}{:^0}'.format("Текущая версия модуля scipy: ", sci.__version__))
import scipy.stats as sps
import pandas as pd
print('{:<35}{:^0}'.format("Текущая версия модуля pandas: ", pd.__version__))
import matplotlib as mpl
print('{:<35}{:^0}'.format("Текущая версия модуля matplotlib: ", mpl.__version__))
import matplotlib.pyplot as plt
import seaborn as sns
print('{:<35}{:^0}'.format("Текущая версия модуля seaborn: ", sns.__version__))
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.graphics.api as smg
import statsmodels.stats.api as sms
from statsmodels.compat import lzip
print('{:<35}{:^0}'.format("Текущая версия модуля statsmodels: ", sm.__version__))
import statistics as stat # module 'statistics' has no attribute '__version__'
import sympy as sym
print('{:<35}{:^0}'.format("Текущая версия модуля sympy: ", sym.__version__))
# Настройки numpy
np.set_printoptions(precision = 4, floatmode='fixed')
# Настройки Pandas
pd.set_option('display.max_colwidth', None) # текст в ячейке отражался полностью вне зависимости от длины
pd.set_option('display.float_format', lambda x: '%.4f' % x)
# Настройки seaborn
sns.set_style("darkgrid")
sns.set_context(context='paper', font_scale=1, rc=None) # 'paper', 'notebook', 'talk', 'poster', None
# Настройки Mathplotlib
f_size = 8 # пользовательская переменная для задания базового размера шрифта
plt.rcParams['figure.titlesize'] = f_size + 12 # шрифт заголовка
plt.rcParams['axes.titlesize'] = f_size + 10 # шрифт заголовка
plt.rcParams['axes.labelsize'] = f_size + 6 # шрифт подписей осей
plt.rcParams['xtick.labelsize'] = f_size + 4 # шрифт подписей меток
plt.rcParams['ytick.labelsize'] = f_size + 4
plt.rcParams['legend.fontsize'] = f_size + 6 # шрифт легенды
# Пользовательские модули и библиотеки
Text1 = os.getcwd() # вывод пути к текущему каталогу
#print(f"Текущий каталог: {Text1}")
sys.path.insert(1, "D:REPOSITORYMyModulePython")
from my_module__stat import *ФОРМИРОВАНИЕ ИСХОДНЫХ ДАННЫХ
Показания ультразвукового прибора «ПУЛЬСАР-2.1» (м/с):
X = np.array([
4416, 4211, 4113, 4110, 4122,
4427, 4535, 4311, 4511, 4475,
3980, 4490, 4007, 4426
])Результаты замера прочности бетона (методом отрыва со скалыванием) прибором ИПС-МГ4.03:
Y = np.array([
34.2, 35.1, 31.5, 30.8, 30.0,
34.0, 35.4, 35.8, 38.0, 37.7,
30.0, 37.8, 31.0, 35.2
])Запишем данные в DataFrame:
calibrarion_df = pd.DataFrame({
'X': X,
'Y': Y})
display(calibrarion_df)
calibrarion_df.info()Сохраняем данные в csv-файл:
calibrarion_df.to_csv(
path_or_buf='data/calibrarion_df.csv',
mode='w+',
sep=';')Cоздаем копию исходной таблицы для работы:
dataset_df = calibrarion_df.copy()ВИЗУАЛИЗАЦИЯ ДАННЫХ
Границы значений переменных (при построении графиков):
(Xmin_graph, Xmax_graph) = (3800, 4800)
(Ymin_graph, Ymax_graph) = (25, 45)# Пользовательская функция
graph_scatterplot_sns(
X, Y,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=Ymin_graph, Ymax=Ymax_graph,
color='orange',
title_figure=Task_Project,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
s=100,
file_name='graph/scatterplot_XY_sns.png')
Существует универсальный набор графиков — гистограмма, коробчатая диаграмма, вероятностный график — которые позволяют исследователю сделать предварительные выводы о свойствах исходных данных.
Так как объем выборки невелик (n=14), строить гистограммы распределения переменных X и Y не имеет смысла, поэтому ограничимся построением коробчатых диаграмм и вероятностных графиков:
# Пользовательская функция
graph_hist_boxplot_probplot_XY_sns(
data_X=X, data_Y=Y,
data_X_min=Xmin_graph, data_X_max=Xmax_graph,
data_Y_min=Ymin_graph, data_Y_max=Ymax_graph,
graph_inclusion='bp', # выбираем для построения виды графиков: b - boxplot, p - probplot)
data_X_label=Variable_Name_X,
data_Y_label=Variable_Name_Y,
title_figure=Task_Project,
file_name='graph/hist_boxplot_probplot_XY_sns.png') 
Для сравнения характера распределений переменных X и Y возможно также построить совмещенную коробчатую диаграмму по стандартизованным данным:
# стандартизуем исходные данные
standardize_df = lambda X: ((X - np.mean(X))/np.std(X))
dataset_df_standardize = dataset_df.copy()
dataset_df_standardize = dataset_df_standardize.apply(standardize_df)
display(dataset_df_standardize)
# построим график
fig, axes = plt.subplots(figsize=(210/INCH, 297/INCH/2))
axes.set_title("Распределение стандартизованных переменных X и Y", fontsize = 16)
sns.boxplot(
data=dataset_df_standardize,
orient='h',
width=0.5,
ax=axes)
plt.show()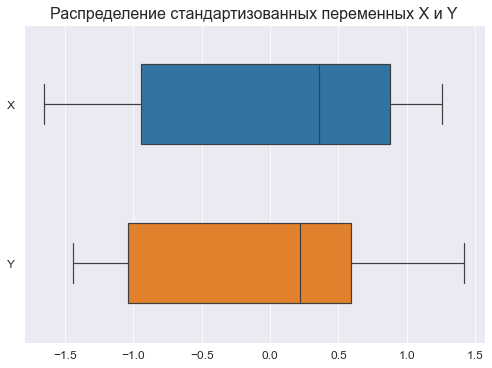
Графический анализ позволяет сделать следующие выводы:
-
Отсутствие выбросов на коробчатых диаграммах свидетельствует об однородности распределения переменных.
-
Смещение медианы вправо на коробчатых диаграммах свидетельствует о левосторонней асимметрии распределения.
ДЕСКРИПТИВНАЯ (ОПИСАТЕЛЬНАЯ СТАТИСТИКА)
Собственно говоря, данный этап требуется проводить далеко не всегда, однако с помощью статистических характеристик выборки мы тоже можем сделать полезные выводы.
Описательная статистика исходных данных средствами библиотеки Pandas — самый простой вариант:
dataset_df.describe()
Описательная статистика исходных данных средствами библиотеки statsmodels — более развернутый вариант, с большим количеством показателей:
from statsmodels.stats.descriptivestats import Description
result = Description(
dataset_df,
stats=["nobs", "missing", "mean", "std_err", "ci", "ci", "std", "iqr", "mad", "coef_var", "range", "max", "min", "skew", "kurtosis", "mode",
"median", "percentiles", "distinct", "top", "freq"],
alpha=a_level,
use_t=True)
display(result.summary())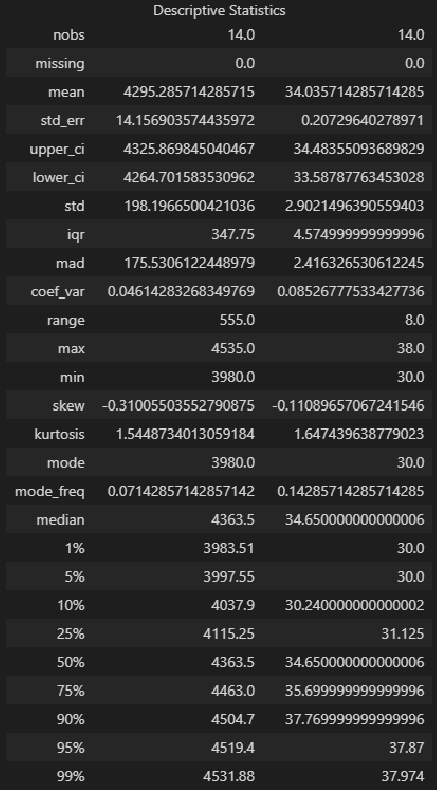
Описательная статистика исходных данных с помощью пользовательской функции descriptive_characteristics:
# Пользовательская функция
descriptive_characteristics(X)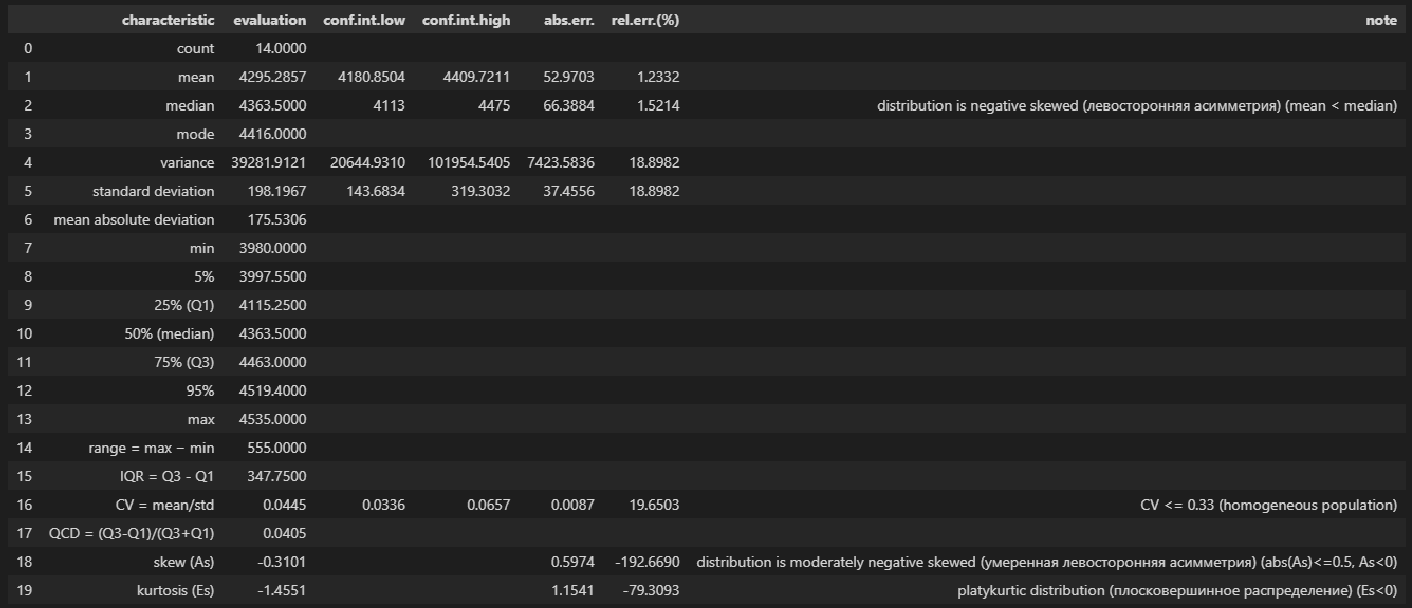
Выводы:
-
Сравнение показателей среднего арифметического (mean) и медианы (median) свидетельствует о левосторонней асимметрии (т.к.mean < median).
-
Значение коэффициента вариации CV = 0.0445 и доверительный интервал для него 0.0336 ≤ CV ≤ 0.0657 свидетельствует об однородности исходных данных (т.к. CV ≤ 0.33).
-
Значение показателя асимметрии skew (As) = -0.3101 свидетельствует об умеренной левосторонней асимметрии распределении (т.к. |As| ≤ 0.5, As < 0).
-
Значение показателя эксцесса kurtosis (Es) = -1.4551 свидетельствует о плосковершинном распределении (platykurtic distribution) (т.к. Es < 0).
# Пользовательская функция
descriptive_characteristics(Y)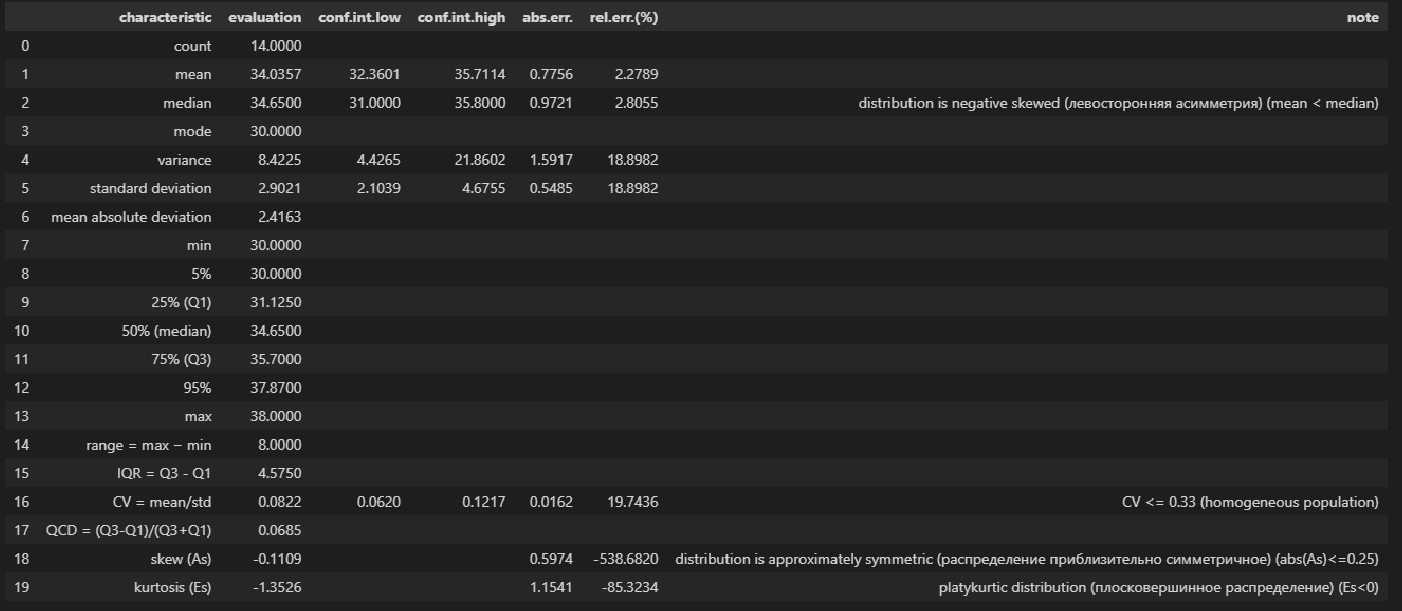
Выводы:
-
Сравнение показателей среднего арифметического (mean) и медианы (median) свидетельствует о левосторонней асимметрии (т.к.mean < median).
-
Значение коэффициента вариации CV = 0.0822 и доверительный интервал для него 0.06202 ≤ CV ≤ 0.1217 свидетельствует об однородности исходных данных (т.к. CV ≤ 0.33).
-
Значение показателя асимметрии skew (As) = -0.1109 свидетельствует о приблизительно симметричном распределении (т.к. |As| ≤ 0.25).
-
Значение показателя эксцесса kurtosis (Es) = -1.3526 свидетельствует о плосковершинном распределении (platykurtic distribution) (т.к. Es < 0).
ПРОВЕРКА НОРМАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ
Для проверки нормальности распределения использована пользовательская функция norm_distr_check, которая объединяет в себе набор стандартных статистических тестов проверки нормальности. Все тесты относятся к стандартному инструментарию Pyton (библиотека scipy, модуль stats), за исключением теста Эппса-Палли (Epps-Pulley test); о том, как реализовать этот тест средствами Pyton я писал в своей статье https://habr.com/ru/post/685582/.
Примечание: для использования функции norm_distr_check в каталог с ipynb-файлом необходимо поместить папку table c файлом Tep_table.csv, который содержит табличные значения статистики критерия Эппса-Палли.
# пользовательская функция
norm_distr_check(X)
# Пользовательская функция
norm_distr_check (Y)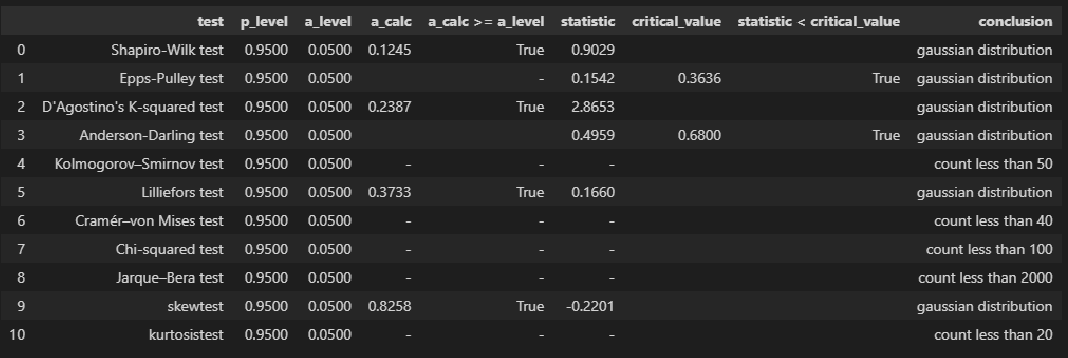
Вывод: большинство статистических тестов позволяют принять гипотезу о нормальности распределения переменных X и Y.
ПРОВЕРКА АНОМАЛЬНЫХ ЗНАЧЕНИЙ (ВЫБРОСОВ)
Статистическую проверку аномальных значений (выбросов) не стоит путать с проверкой выбросов, которая проводится на этапе первичной обработки результатов наблюдений. Последняя проводится с целью отсеять явные ошибочные данные (например, в результате неправильно поставленной запятой величина показателя может увеличиться/уменьшиться на порядок); здесь же мы говорим о статистической проверке данных, которые уже прошли этап первичной обработки.
Имеется довольно много критериев для проверки аномальных значений (подробнее см.[1]); вообще данная процедура довольно неоднозначная:
-
критерии зависят от вида распределения;
-
мало данных о сравнительной мощности этих критериев;
-
даже в случае принятии гипотезы о нормальном распределении в выборке могут быть обнаружены аномальные значения и пр.
Кроме существует дилемма: если какие-то значения в выборке признаны выбросами — стоит или не стоит исследователю исключать их? Ведь каждое значение несет в себе информацию, причем иногда весьма ценную, а сильно отклоняющиеся от основного массива данные (которые не являются выбросами в смысле первичной обработки, но являются статистическим значимыми аномальными значениями) могут кардинально изменить статистический вывод.
В общем, о задаче выявления аномальных значений (выбросов) можно написать отдельно, а пока, в данном разборе, ограничимся проверкой аномальных значений по критерию наибольшего максимального отклонения (см.[1, с.547]) с помощью пользовательской функции detecting_outliers_mad_test. Данные функция возвращает DataFrame, которые включает список аномальных значений со следующими признаками:
-
value — проверяемое значение из выборки;
-
mad_calc и mad_table — расчетное и табличное значение статистики критерия;
-
outlier_conclusion — вывод (выброс или нет).
Обращаю внимание, что критерий наибольшего максимального отклонения можно использовать только для нормально распределенных данных.
# пользовательская функция
print("Проверка наличия выбросов переменной X:n")
result = detecting_outliers_mad_test(X)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])
# пользовательская функция
print("Проверка наличия выбросов переменной Y:n")
result = detecting_outliers_mad_test(Y)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])
Вывод: в случае обеих переменных X и Y список пуст, следовательно, аномальных значений (выбросов) не выявлено.
КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
Корреляционный анализ — это разведка перед построением регрессионной модели.
Выполним расчет коэффициента линейной корреляции Пирсона, проверку его значимости и построение доверительных интервалов с помощью пользовательской функции corr_coef_check (про эту функцию более подробно написано в моей статье https://habr.com/ru/post/683442/):
# пользовательская функция
display(corr_coef_check(X, Y, scale='Evans'))
Выводы:
-
Значение коэффициента корреляции coef_value = 0.8900 свидетельствует о весьма сильной корреляционной связи (по шкале Эванса).
-
Коэффициент корреляции значим по критерию Стьюдента: t_calc ≥ t_table, a_calc ≤ a_level.
-
Доверительный интервал для коэффициента корреляции: 0.6621 ≤ coef_value ≤ 0.9625.
РЕГРЕССИОННЫЙ АНАЛИЗ
Предварительная визуализация
python позволяет выполнить предварительную визуализацию, например, с помощью функции jointplot библиотеки seaborn:
fig = plt.figure(figsize=(297/INCH, 210/INCH))
axes = sns.jointplot(
x=X, y=Y,
kind='reg',
ci=95)
plt.show()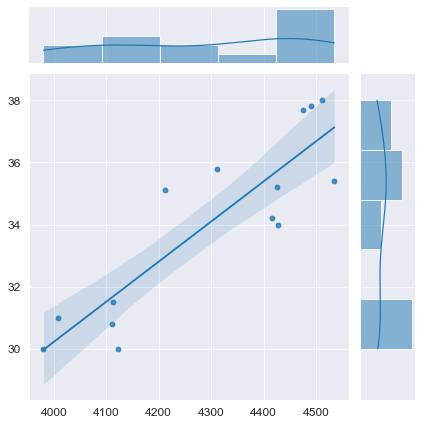
Построение модели
Выполним оценку параметров и анализ простой линейной регрессии (simple linear regression), используя библиотеку statsmodels (https://www.statsmodels.org/) и входящий в нее модуль линейной регрессии Linear Regression (https://www.statsmodels.org/stable/regression.html).
Данный модуль включает в себя классы, реализующие различные методы оценки параметров моделей линейной регрессии, в том числе:
-
класс OLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.OLS.html#statsmodels.regression.linear_model.OLS) — Ordinary Least Squares (обычный метод наименьших квадратов).
-
класс WLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.WLS.html#statsmodels.regression.linear_model.WLS) — Weighted Least Squares (метод взвешенных наименьших квадратов) (https://en.wikipedia.org/wiki/Weighted_least_squares), применяется, если имеет место гетероскедастичность данных (https://ru.wikipedia.org/wiki/Гетероскедастичность).
-
класс GLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.GLS.html#statsmodels.regression.linear_model.GLS) — Generalized Least Squares (обобщенный метод наименьших квадратов) (https://en.wikipedia.org/wiki/Generalized_least_squares), применяется, если существует определенная степень корреляции между остатками в модели регрессии.
-
класс GLSAR (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.GLSAR.html#statsmodels.regression.linear_model.GLSAR) — Generalized Least Squares with AR covariance structure (обобщенный метод наименьших квадратов, ковариационная структура с автокорреляцией — экспериментальный метод)
-
класс RecurciveLS (https://www.statsmodels.org/stable/examples/notebooks/generated/recursive_ls.html) — Recursive least squares (рекурсивный метод наименьших квадратов) (https://en.wikipedia.org/wiki/Recursive_least_squares_filter)
-
классы RollingOLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.rolling.RollingOLS.html#statsmodels.regression.rolling.RollingOLS) и RollingWLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.rolling.RollingWLS.html#statsmodels.regression.rolling.RollingWLS) — скользящая регрессия (https://www.statsmodels.org/stable/examples/notebooks/generated/rolling_ls.html, https://help.fsight.ru/ru/mergedProjects/lib/01_regression_models/rolling_regression.htm)
и т.д.
Так как исходные данные подчиняются нормальному закону распределения и аномальные значения (выбросы) отсутствуют, воспользуемся для оценки параметров обычным методом наименьших квадратов (класс OLS):
model_linear_ols = smf.ols(formula='Y ~ X', data=dataset_df)
result_linear_ols = model_linear_ols.fit()
print(result_linear_ols.summary())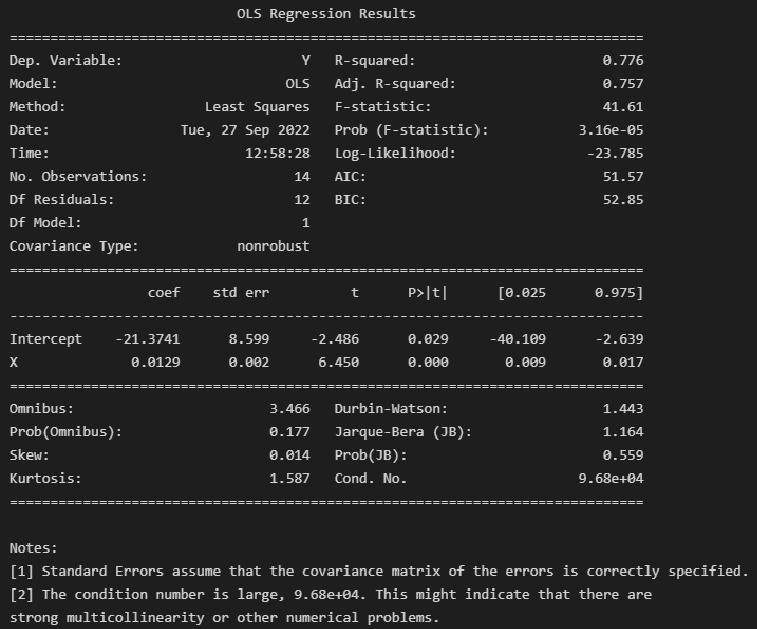
Альтернативная форма выдачи результатов:
print(result_linear_ols.summary2())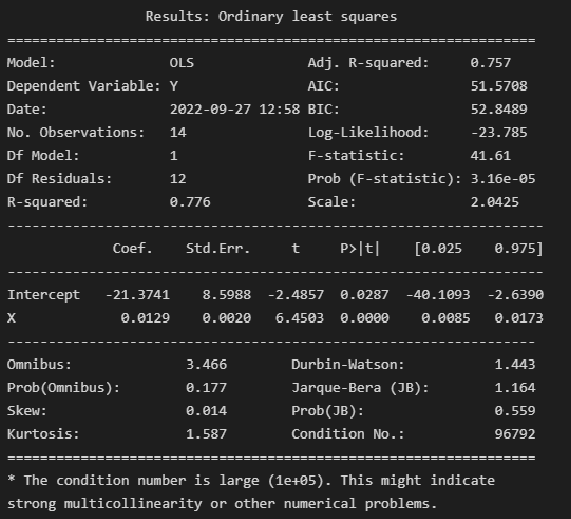
Результаты построения модели мы получаем как класс statsmodels.regression.linear_model.RegressionResults (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.html#statsmodels.regression.linear_model.RegressionResults).
Экспресс-выводы, которые мы можем сразу сделать из результатов построения модели:
-
Коэффициенты регрессии модели Y = b0 + b1∙X:
-
Intercept = b0 = -21.3741
-
b1 = 0.0129
-
-
Коэффициент детерминации R-squared = 0.776, его скорректированная оценка Adj. R-squared = 0.757 — это означает, что регрессионная модуль объясняет 75.75% вариации переменной Y.
-
Проверка значимости коэффициента детерминации:
-
расчетное значение статистики критерия Фишера: F-statistic = 41.61
-
расчетный уровень значимости Prob (F-statistic) = 3.16e-05
-
так как значение Prob (F-statistic) < 0.05, то нулевая гипотеза R-squared = 0 НЕ ПРИНИМАЕТСЯ, т.е. коэффициент детерминации ЗНАЧИМ
-
-
Проверка значимости коэффициентов регрессии:
-
расчетный уровень значимости P>|t| не превышает 0.05 — это означает, что оба коэффициента регрессии значимы
-
об этом же свидетельствует то, что доверительный интервал для обоих коэффициентов регрессии ([0.025; 0.975]) не включает в себя точку 0
Также в таблице результатов содержится прочая информация по коэффициентам регрессии: стандартная ошибка Std.Err. расчетное значение статистики критерия Стьюдента t для проверки гипотезы о значимости.
-
-
Анализ остатков модели:
-
Тест Omnibus — про этот тест подробно написано в https://en.wikipedia.org/wiki/Omnibus_test, https://medium.com/swlh/interpreting-linear-regression-through-statsmodels-summary-4796d359035a, http://work.thaslwanter.at/Stats/html/statsModels.html.
Расчетное значение статистики критерия Omnibus = 3.466 — по сути расчетное значение F-критерия (см. https://en.wikipedia.org/wiki/Omnibus_test).
Prob(Omnibus) = 0.177 — показывает вероятность нормального распределения остатков (значение 1 указывает на совершенно нормальное распределение).
Учитывая, что в дальнейшем мы проверим нормальность распределения остатков по совокупности различных тестов, в том числе с достаточно высокой мощностью, и все тесты позволят принять гипотезу о нормальном распределении — в данном случае к тесту Omnibus возникают вопросы. С этим тестом нужно разбираться отдельно.
-
Skew = 0.014 и Kurtosis = 1.587 — показатели асимметрии и эксцесса остатков свидетельствуют, что распределение остатков практически симметричное, островершинное.
-
проверка нормальности распределения остатков по критерию Харке-Бера: расчетное значение статистики критерия Jarque-Bera (JB) = 1.164 и расчетный уровень значимости Prob(JB) = 0.559. К данным результатам также возникают вопросы, особенно, если учесть, что критерий Харке-Бера является асимптотическим, расчетное значение имеет распределение хи-квадрат, поэтому данный критерий рекомендуют применять только для больших выборок (см. https://en.wikipedia.org/wiki/Jarque–Bera_test). Проверку нормальности распределения остатков модели лучше проводить с использованием набора стандартных статистических тестов python (см. далее).
-
-
Проверка автокорреляции по критерию Дарбина-Уотсона: Durbin-Watson = 1.443.
Мы не будем здесь разбирать данный критерий, так как явление автокорреляции больше характерно для данных, выражаемых в виде временных рядов. Однако, для грубой оценки считается, что при расчетном значении статистики криетрия Дарбина=Уотсона а интервале [1; 2] автокорреляция отсутствует (см.https://en.wikipedia.org/wiki/Durbin–Watson_statistic).
Более подробно про критерий Дарбина-Уотсона — см. [1, с.659].
Прочая информация, которую можно извлечь из результатов построения модели:
-
Covariance Type — тип ковариации, подробнее см. https://habr.com/ru/post/681218/, https://towardsdatascience.com/simple-explanation-of-statsmodel-linear-regression-model-summary-35961919868b#:~:text=Covariance type is typically nonrobust,with respect to each other.
-
Scale — масштабный коэффициент для ковариационной матрицы (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.scale.html#statsmodels.regression.linear_model.RegressionResults.scale), равен величине Mean squared error (MSE) (cреднеквадратической ошибке), об подробнее см. далее, в разделе про ошибки аппроксимации моделей.
-
Показатели сравнения качества различных моделей:
-
Log-Likelihood — логарифмическая функция правдоподобия, подробнее см. https://en.wikipedia.org/wiki/Likelihood_function#Log-likelihood, https://habr.com/ru/post/433804/
-
AIC — информационный критерий Акаике (Akaike information criterion), подробнее см. https://en.wikipedia.org/wiki/Akaike_information_criterion
-
BIC — информационный критерий Байеса (Bayesian information criterion), подробнее см. https://en.wikipedia.org/wiki/Bayesian_information_criterion
В данной статье мы эти показатели рассматривать не будем, так как задача выбора одной модели из нескольких перед нами не стоит.
-
-
Число обусловленности Cond. No = 96792 используется для проверки мультиколлинеарности (считается, что мультиколлинеарность есть, если значение Cond. No > 30) (см. http://work.thaslwanter.at/Stats/html/statsModels.html). В нашем случае парной регрессионной модели о мультиколлинеарности речь не идет.
Далее будем извлекать данные из стандартного набора выдачи результатов и анализировать их более подробно. Последующие этапы вовсе не обязательно проводить в полном объеме при решении задач, но здесь мы рассмотрим их подробно.
Параметры и уравнение регрессионной модели
Извлечем параметры полученной модели — как свойство params модели:
print('Параметры модели: n', result_linear_ols.params, type(result_linear_ols.params))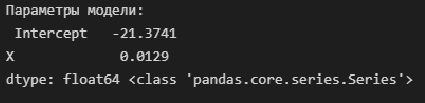
Имея параметры модели, можем формализовать уравнение модели Y = b0 + b1*X:
b0 = result_linear_ols.params['Intercept']
b1 = result_linear_ols.params['X']
Y_calc = lambda x: b0 + b1*xГрафик регрессионной модели
Для построения графиков регрессионных моделей можно воспользоваться стандартными возможностями библиотек statsmodels, seaborn, либо создать пользовательскую функцию — на усмотрение исследователя:
1. Построение графиков регрессионных моделей с использованием библиотеки statsmodels
С помощью функции statsmodels.graphics.plot_fit (https://www.statsmodels.org/stable/generated/statsmodels.graphics.regressionplots.plot_fit.html#statsmodels.graphics.regressionplots.plot_fit) — отображается график Y and Fitted vs.X (фактические и расчетные значения Y с доверительным интервалом для каждого значения Y):
fig, ax = plt.subplots(figsize=(297/INCH, 210/INCH))
fig = sm.graphics.plot_fit(
result_linear_ols, 'X',
vlines=True, # это параметр отвечает за отображение доверительных интервалов для Y
ax=ax)
ax.set_ylabel(Variable_Name_Y)
ax.set_xlabel(Variable_Name_X)
ax.set_title(Task_Project)
plt.show()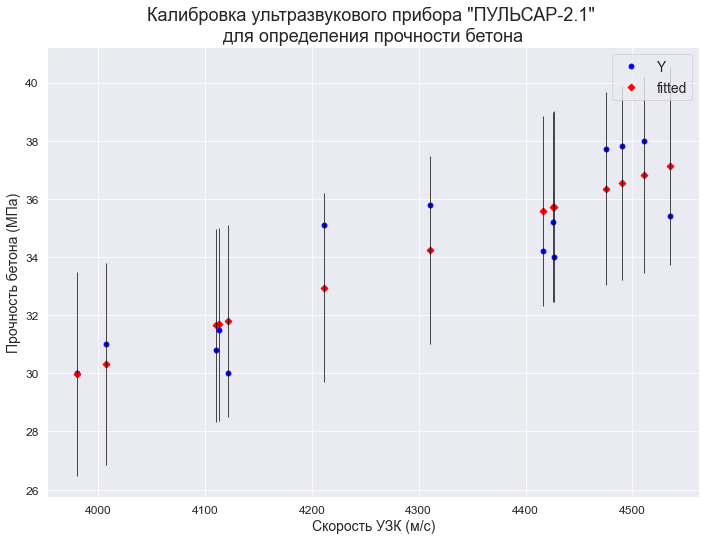
С помощью функции statsmodels.graphics.plot_regress_exog (https://www.statsmodels.org/stable/generated/statsmodels.graphics.regressionplots.plot_regress_exog.html#statsmodels.graphics.regressionplots.plot_regress_exog) — отображается область 2х2, которая содержит:
-
предыдущий график Y and Fitted vs.X;
-
график остатков Residuals versus X;
-
график Partial regression plot — график частичной регрессии, пытается показать эффект добавления другой переменной в модель, которая уже имеет одну или несколько независимых переменных (более подробно см. https://en.wikipedia.org/wiki/Partial_regression_plot);
-
график CCPR Plot (Component-Component plus Residual Plot) — еще один способ оценить влияние одной независимой переменной на переменную отклика, принимая во внимание влияние других независимых переменных (более подробно — см. https://towardsdatascience.com/calculating-price-elasticity-of-demand-statistical-modeling-with-python-6adb2fa7824d, https://www.kirenz.com/post/2021-11-14-linear-regression-diagnostics-in-python/linear-regression-diagnostics-in-python/).
fig = plt.figure(figsize=(297/INCH, 210/INCH))
sm.graphics.plot_regress_exog(result_linear_ols, 'X', fig=fig)
plt.show()
2. Построение графиков регрессионных моделей с использованием библиотеки seaborn
Воспользуемся модулем regplot библиотеки seaborn (https://seaborn.pydata.org/generated/seaborn.regplot.html). Данный модуль позволяет визуализировать различные виды регрессии:
-
линейную
-
полиномиальную
-
логистическую
-
взвешенную локальную регрессию (LOWESS — Locally Weighted Scatterplot Smoothing) (см. http://www.machinelearning.ru/wiki/index.php?title=Алгоритм_LOWESS, https://www.statsmodels.org/stable/generated/statsmodels.nonparametric.smoothers_lowess.lowess.html)
Более подробно про модуль regplot можно прочитать в статье: https://pyprog.pro/sns/sns_8_regression_models.html.
Есть более совершенный модуль lmplot (https://seaborn.pydata.org/generated/seaborn.lmplot.html), который объединяет в себе regplot и FacetGrid, но мы его здесь рассматривать не будем.
# создание рисунка (Figure) и области рисования (Axes)
fig = plt.figure(figsize=(297/INCH, 420/INCH/1.5))
ax1 = plt.subplot(2,1,1)
ax2 = plt.subplot(2,1,2)
# заголовок рисунка (Figure)
title_figure = Task_Project
fig.suptitle(title_figure, fontsize = 18)
# заголовок области рисования (Axes)
title_axes_1 = 'Линейная регрессионная модель'
ax1.set_title(title_axes_1, fontsize = 16)
# график регрессионной модели
order_mod = 1 # порядок модели
#label_legend_regr_model = 'фактические данные'
sns.regplot(
#data=dataset_df,
x=X, y=Y,
#x_estimator=np.mean,
order=order_mod,
logistic=False,
lowess=False,
robust=False,
logx=False,
ci=95,
scatter_kws={'s': 30, 'color': 'red'},
line_kws={'color': 'blue'},
#label=label_legend_regr_model,
ax=ax1)
ax1.set_ylabel(Variable_Name_Y)
ax1.legend()
# график остатков
title_axes_2 = 'График остатков'
ax2.set_title(title_axes_2, fontsize = 16)
sns.residplot(
#data=dataset_df,
x=X, y=Y,
order=order_mod,
lowess=False,
robust=False,
scatter_kws={'s': 30, 'color': 'darkorange'},
ax=ax2)
ax2.set_xlabel(Variable_Name_X)
plt.show()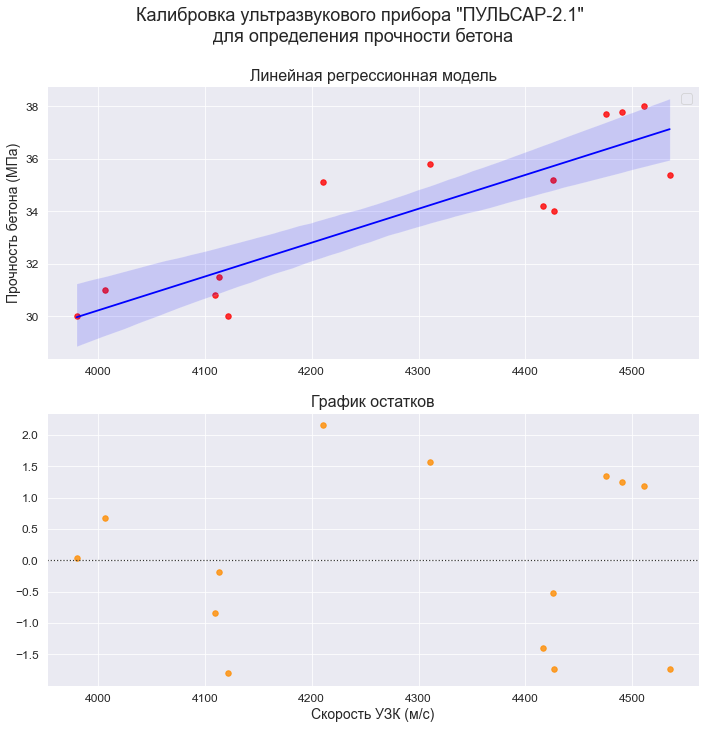
3. Построение графиков регрессионных моделей с помощью пользовательской функции
# Пользовательская функция
graph_regression_plot_sns(
X, Y,
regression_model=Y_calc,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=Ymin_graph, Ymax=Ymax_graph,
title_figure=Task_Project,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X',
s=80,
file_name='graph/regression_plot_lin.png')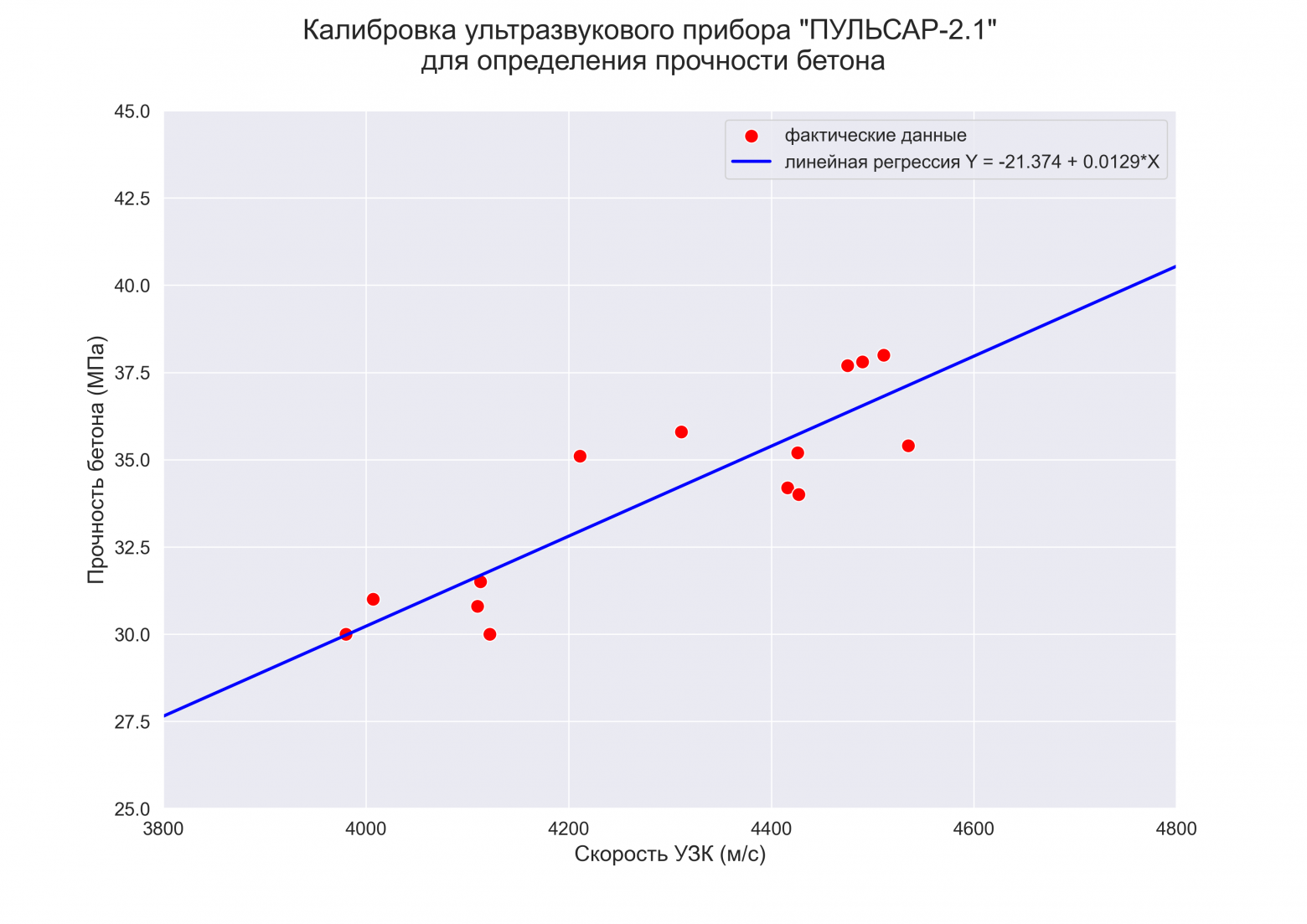
Статистический анализ регрессионной модели
1. Расчет ошибки аппроксимации (Error Metrics)
Ошибки аппроксимации (Error Metrics) позволяют получить общее представление о качестве модели, а также позволяют сравнивать между собой различные модели.
Создадим пользовательскую функцию, которая рассчитывает основные ошибки аппроксимации для заданной модели:
-
Mean squared error (MSE) или Mean squared deviation (MSD) — среднеквадратическая ошибка (https://en.wikipedia.org/wiki/Mean_squared_error):

-
Root mean square error (RMSE) или Root mean square deviation (RMSD) — квадратный корень из MSE (https://en.wikipedia.org/wiki/Root-mean-square_deviation):
![]()
-
Mean absolute error (MAE) — средняя абсолютная ошибка (https://en.wikipedia.org/wiki/Mean_absolute_error):

-
Mean squared prediction error (MSPE) — среднеквадратическая ошибка прогноза (среднеквадратическая ошибка в процентах) (https://en.wikipedia.org/wiki/Mean_squared_prediction_error):
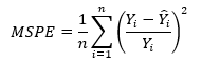
-
Mean absolute percentage error (MAPE) — средняя абсолютная ошибка в процентах (https://en.wikipedia.org/wiki/Mean_absolute_percentage_error):

Про выбор метрики см. также https://machinelearningmastery.ru/how-to-select-the-right-evaluation-metric-for-machine-learning-models-part-2-regression-metrics-d4a1a9ba3d74/.
# Пользовательская функция
def regression_error_metrics(model, model_name=''):
model_fit = model.fit()
Ycalc = model_fit.predict()
n_fit = model_fit.nobs
Y = model.endog
MSE = (1/n_fit) * np.sum((Y-Ycalc)**2)
RMSE = sqrt(MSE)
MAE = (1/n_fit) * np.sum(abs(Y-Ycalc))
MSPE = (1/n_fit) * np.sum(((Y-Ycalc)/Y)**2)
MAPE = (1/n_fit) * np.sum(abs((Y-Ycalc)/Y))
model_error_metrics = {
'MSE': MSE,
'RMSE': RMSE,
'MAE': MAE,
'MSPE': MSPE,
'MAPE': MAPE}
result = pd.DataFrame({
'MSE': MSE,
'RMSE': RMSE,
'MAE': MAE,
'MSPE': "{:.3%}".format(MSPE),
'MAPE': "{:.3%}".format(MAPE)},
index=[model_name])
return model_error_metrics, result
(model_error_metrics, result) = regression_error_metrics(model_linear_ols, model_name='linear_ols')
display(result)
В литературе по прикладной статистике нет единого мнения о допустимом размере относительных ошибок аппроксимации: в одних источниках допустимой считается ошибка 5-7%, в других она может быть увеличена до 8-10%, и даже до 15%.
Вывод: модель хорошо аппроксимирует фактические данные (относительная ошибка аппроксимации MAPE = 3.405% < 10%).
2. Дисперсионный анализ регрессионной модели (ДАРМ)
ДАРМ не входит в стандартную форму выдачи результатов Regression Results, однако я решил написать здесь о нем по двум причинам:
-
Именно анализ дисперсии регрессионной модели, разложение этой дисперсии на составляющие дает фундаментальное представление о сути регрессии, а термины, используемые при ДАРМ, применяются на последующих этапах анализа.
-
С терминами ДАРМ в литературе по прикладной статистике имеется некоторая путаница, в разных источниках они могут именоваться по-разному (см., например, [8, с.52]), поэтому, чтобы двигаться дальше, необходимо определиться с понятиями.
При ДАРМ общую вариацию результативного признака (Y) принято разделять на две составляющие — вариация, обусловленная регрессией и вариация, обусловленная отклонениями от регрессии (остаток), при этом в разных источниках эти термины могут именоваться и обозначаться по-разному, например:
-
Вариация, обусловленная регрессией — может называться Explained sum of squares (ESS), Sum of Squared Regression (SSR) (https://en.wikipedia.org/wiki/Explained_sum_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684), Sum of squared deviations (SSD).
-
Вариация, обусловленная отклонениями от регрессии (остаток) — может называться Residual sum of squares (RSS), Sum of squared residuals (SSR), Squared estimate of errors, Sum of Squared Error (SSE) (https://en.wikipedia.org/wiki/Residual_sum_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684); в отчественной практике также применяется термин остаточная дисперсия.
-
Общая (полная) вариация — может называться Total sum of squares (TSS), Sum of Squared Total (SST) (https://en.wikipedia.org/wiki/Partition_of_sums_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684).
Как видим, путаница знатная:
-
в разных источниках под SSR могут подразумеваться различные показатели;
-
легко перепутать показатели ESS и SSE;
-
в библиотеке statsmodel также есть смешение терминов: для показателя Explained sum of squares используется свойство ess, а для показателя Sum of squared (whitened) residuals — свойство ssr.
Мы будем пользоваться системой обозначений, принятой в большинстве источников — SSR (Sum of Squared Regression), SSE (Sum of Squared Error), SST (Sum of Squared Total). Стандартная таблица ДАРМ в этом случае имеет вид:

Примечания:
-
Здесь приведена таблица ДАРМ для множественной линейной регрессионной модели (МЛРМ), в нашем случае при ПЛРМ мы имеем частный случай p=1.
-
Показатели Fcalc-ad и Fcalc-det — расчетные значения статистики критерия Фишера при проверке адекватности модели и значимости коэффициента детерминации (об этом — см.далее).
Более подробно про дисперсионный анализ регрессионной модели — см.[4, глава 3].
Класс statsmodels.regression.linear_model.RegressionResults позволяет нам получить данные для ANOVA (см. https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.html#statsmodels.regression.linear_model.RegressionResults) как свойства класса:
-
Сумма квадратов, обусловленная регрессией / SSR (Sum of Squared Regression) — свойство ess.
-
Сумма квадратов, обусловленная отклонением от регрессии / SSE (Sum of Squared Error) — свойство ssr.
-
Общая (полная) сумма квадратов / SST (Sum of Squared Total) — свойство centered_tss.
-
Кол-во наблюдений / Number of observations — свойство nobs.
-
Число степеней свободы модели / Model degrees of freedom — равно числу переменных модели (за исключением константы, если она присутствует — свойство df_model.
-
Среднеквадратичная ошибка модели / Mean squared error the model — сумма квадратов, объясненная регрессией, деленная на число степеней свободы регрессии — свойство mse_model.
-
Среднеквадратичная ошибка остатков / Mean squared error of the residuals — сумма квадратов остатков, деленная на остаточные степени свободы — свойство mse_resid.
-
Общая среднеквадратичная ошибка / Total mean squared error — общая сумма квадратов, деленная на количество наблюдений — свойство mse_total.
Также имеется модуль statsmodels.stats.anova.anova_lm, который позволяет получить результаты ДАРМ (нескольких типов — 1, 2, 3):
# тип 1
print('The type of Anova test: 1')
display(sm.stats.anova_lm(result_linear_ols, typ=1))
# тип 2
print('The type of Anova test: 2')
display(sm.stats.anova_lm(result_linear_ols, typ=2))
# тип 3
print('The type of Anova test: 3')
display(sm.stats.anova_lm(result_linear_ols, typ=3))
На мой взгляд, форма таблица результатов statsmodels.stats.anova.anova_lm не вполне удобна, поэтому сформируем ее самостоятельно, для чего создадим пользовательскую функцию ANOVA_table_regression_model:
# Пользовательская функция
def ANOVA_table_regression_model(model_fit):
n = int(model_fit.nobs)
p = int(model_fit.df_model)
SSR = model_fit.ess
SSE = model_fit.ssr
SST = model_fit.centered_tss
result = pd.DataFrame({
'sources_of_variation': ('regression (SSR)', 'deviation from regression (SSE)', 'total (SST)'),
'sum_of_squares': (SSR, SSE, SST),
'degrees_of_freedom': (p, n-p-1, n-1)})
result['squared_error'] = result['sum_of_squares'] / result['degrees_of_freedom']
R2 = 1 - result.loc[1, 'sum_of_squares'] / result.loc[2, 'sum_of_squares']
F_calc_adequacy = result.loc[2, 'squared_error'] / result.loc[1, 'squared_error']
F_calc_determ_check = result.loc[0, 'squared_error'] / result.loc[1, 'squared_error']
result['F-ratio'] = (F_calc_determ_check, F_calc_adequacy, '')
return result
result = ANOVA_table_regression_model(result_linear_ols)
display(result)
print(f"R2 = 1 - SSE/SST = {1 - result.loc[1, 'sum_of_squares'] / result.loc[2, 'sum_of_squares']}")
print(f"F_calc_adequacy = MST / MSE = {result.loc[2, 'squared_error'] / result.loc[1, 'squared_error']}")
print(f"F_calc_determ_check = MSR / MSE = {result.loc[0, 'squared_error'] / result.loc[1, 'squared_error']}")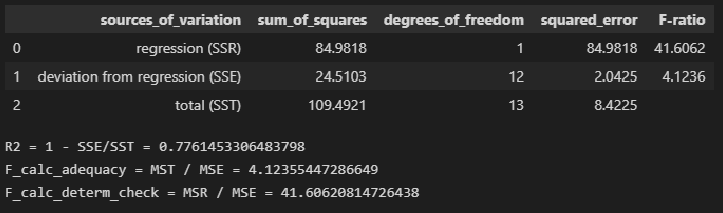
ДАРМ позволяет визуализировать вариацию:
fig, axes = plt.subplots(figsize=(210/INCH, 297/INCH/1.5))
axes.pie(
(result.loc[0, 'sum_of_squares'], result.loc[1, 'sum_of_squares']),
labels=(result.loc[0, 'sources_of_variation'], result.loc[1, 'sources_of_variation']),
autopct='%.1f%%',
startangle=60)
plt.show()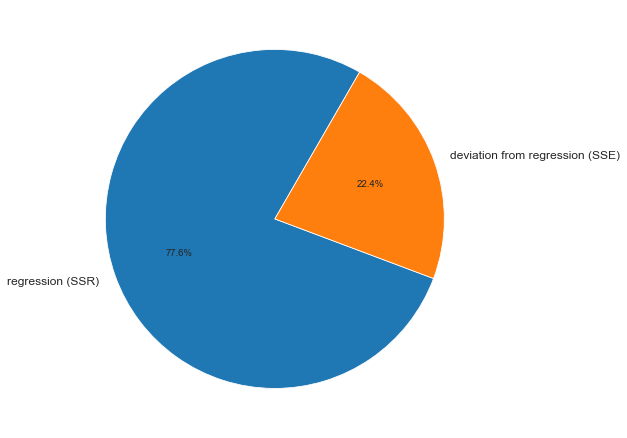
На основании данных ДАРМ мы рассчитали ряд показателей (R2, Fcalc-ad и Fcalc-det), которые будут использоваться в дальнейшем.
3. Анализ остатков (проверка нормальности распределения остатков и гипотезы о равенстве нулю среднего значения остатков)
Проверка нормальности распределения остатков — один их важнейших этапов анализа регрессионной модели. Требование нормальности распределения остатков не требуется для отыскания параметров модели, но необходимо в дальнейшем для проверки статистических гипотез с использованием критериев Фишера и Стьюдента (проверка адекватности модели, значимости коэффициента детерминации, значимости коэффициентов регрессии) и построения доверительных интервалов [5, с.122].
Остатки регрессионной модели:
print('Остатки регрессионной модели:n', result_linear_ols.resid, type(result_linear_ols.resid))
res_Y = np.array(result_linear_ols.resid)statsmodels может выдавать различные преобразованные виды остатков (см. https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.resid_pearson.html, https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.wresid.html).
График остатков:
# Пользовательская функция
graph_scatterplot_sns(
X, res_Y,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=-3.0, Ymax=3.0,
color='red',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=18,
x_label=Variable_Name_X,
y_label='ΔY = Y - Ycalc',
s=75,
file_name='graph/residuals_plot_sns.png')
Проверка нормальности распределения остатков:
# Пользовательская функция
graph_hist_boxplot_probplot_sns(
data=res_Y,
data_min=-2.5, data_max=2.5,
graph_inclusion='bp',
data_label='ΔY = Y - Ycalc',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=16,
file_name='graph/residuals_hist_boxplot_probplot_sns.png') 
norm_distr_check(res_Y)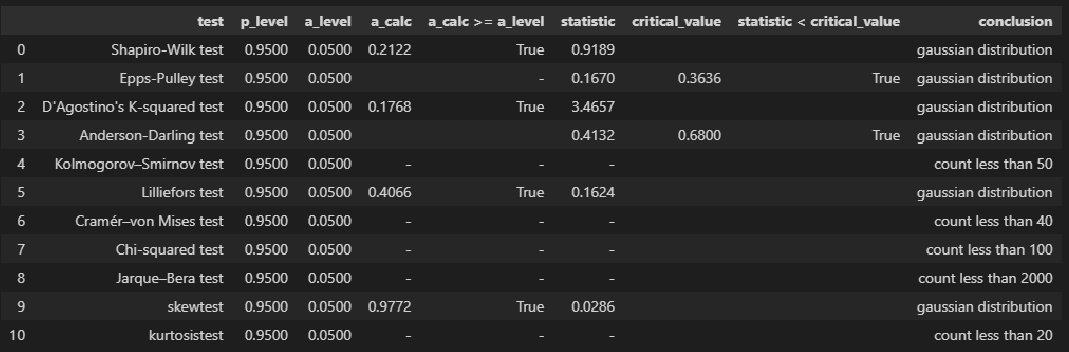
Вывод: большинство статистических тестов позволяют принять гипотезу о нормальности распределения остатков.
Проверка гипотезы о равенстве нулю среднего значения остатков — так как остатки имеют нормальное распределение, воспользуемся критерием Стьюдента (функция scipy.stats.ttest_1samp, https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_ind.html):
sps.ttest_1samp(res_Y, popmean=0)![]()
Вывод: так как расчетный уровень значимости превышает заданный (0.05), то нулевая гипотеза о равенстве нулю остатков ПРИНИМАЕТСЯ.
4. Проверка адекватности модели
Суть проверки адекватности регрессионной модели заключается в сравнении полной дисперсии MST и остаточной дисперсии MSE — проверяется гипотеза о равенстве этих дисперсий по критерию Фишера. Если дисперсии различаются значимо, то модель считается адекватной. Более подробно про проверку адекватности регрессионной — см.[1, с.658], [2, с.49], [4, с.154].
Для проверки адекватности регрессионной модели создадим пользовательскую функцию regression_model_adequacy_check:
def regression_model_adequacy_check(
model_fit,
p_level: float=0.95,
model_name=''):
n = int(model_fit.nobs)
p = int(model_fit.df_model) # Число степеней свободы регрессии, равно числу переменных модели (за исключением константы, если она присутствует)
SST = model_fit.centered_tss # SST (Sum of Squared Total)
dfT = n-1
MST = SST / dfT
SSE = model_fit.ssr # SSE (Sum of Squared Error)
dfE = n - p - 1
MSE = SSE / dfE
F_calc = MST / MSE
F_table = sci.stats.f.ppf(p_level, dfT, dfE, loc=0, scale=1)
a_calc = 1 - sci.stats.f.cdf(F_calc, dfT, dfE, loc=0, scale=1)
conclusion_model_adequacy_check = 'adequacy' if F_calc >= F_table else 'adequacy'
# формируем результат
result = pd.DataFrame({
'SST': (SST),
'SSE': (SSE),
'dfT': (dfT),
'dfE': (dfE),
'MST': (MST),
'MSE': (MSE),
'p_level': (p_level),
'a_level': (a_level),
'F_calc': (F_calc),
'F_table': (F_table),
'F_calc >= F_table': (F_calc >= F_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'adequacy_check': (conclusion_model_adequacy_check),
},
index=[model_name]
)
return result
regression_model_adequacy_check(result_linear_ols, p_level=0.95, model_name='linear_ols')
Вывод: модель является АДЕКВАТНОЙ.
5. Коэффициент детерминации и проверка его значимости
Различают несколько видов коэффициента детерминации:
-
Собственно обычный коэффициент детерминации:

Его значение может быть получено как свойство rsquared модели.
-
Скорректированный (adjusted) коэффициент детерминации — используется для того, чтобы была возможность сравнивать модели с разным числом признаков так, чтобы число регрессоров (признаков) не влияло на статистику R2, при его расчете используются несмещённые оценки дисперсий:


Его значение может быть получено как свойство rsquared_adj модели.
-
Обобщённый (extended) коэффициент детерминации — используется для сравнения моделей регрессии со свободным членом и без него, а также для сравнения между собой регрессий, построенных с помощью различных методов: МНК, обобщённого метода наименьших квадратов (ОМНК), условного метода наименьших квадратов (УМНК), обобщённо-условного метода наименьших квадратов (ОУМНК). В данном разборе ПЛРМ рассматривать этот коэффициент мы не будем.
Более подробно с теорией вопроса можно ознакомиться, например: http://www.machinelearning.ru/wiki/index.php?title=Коэффициент_детерминации), а также в [7].
Значения коэффициента детерминации и скорректированного коэффициента детерминации, извлеченные с помощью свойств rsquared и rsquared_adj модели.
print('R2 =', result_linear_ols.rsquared)
print('R2_adj =', result_linear_ols.rsquared_adj)
Значимость коэффициента детерминации можно проверить по критерию Фишера [3, с.201-203; 8, с.83].
Расчетное значение статистики критерия Фишера может быть получено с помощью свойства fvalue модели:
print(f"result_linear_ols.fvalue = {result_linear_ols.fvalue}")![]()
Расчетный уровень значимости при проверке гипотезы по критерию Фишера может быть получено с помощью свойства f_pvalue модели:
print(f"result_linear_ols.f_pvalue = {result_linear_ols.f_pvalue}")![]()
Можно рассчитать уровень значимости самостоятельно (так сказать, для лучшего понимания и общей демонстрации возможностей) — для этого воспользуемся библиотекой scipy, модулем распределения Фишера scipy.stats.f, свойством cdf (функция распределения):
df1 = int(result_linear_ols.df_model)
df2 = int(result_linear_ols.nobs - result_linear_ols.df_model - 1)
F_calc = result_linear_ols.fvalue
a_calc = 1 - sci.stats.f.cdf(F_calc, df1, df2, loc=0, scale=1)
print(a_calc)![]()
Как видим, результаты совпадают.
Табличное значение статистики критерия Фишера получить с помощью Regression Results нельзя. Рассчитаем его самостоятельно — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.f, свойством ppf (процентные точки):
F_table = sci.stats.f.ppf(p_level, df1, df2, loc=0, scale=1)
print(F_table)![]()
Для удобства создадим пользовательскую функцию determination_coef_check для проверки значимости коэффициента детерминации, которая объединяет все вышеперечисленные расчеты:
# Пользовательская функция
def determination_coef_check(
model_fit,
p_level: float=0.95):
a_level = 1 - p_level
R2 = model_fit.rsquared
R2_adj = model_fit.rsquared_adj
n = model_fit.nobs # объем выборки
p = model_fit.df_model # Model degrees of freedom. The number of regressors p. Does not include the constant if one is present.
F_calc = R2 / (1 - R2) * (n-p-1)/p
df1 = int(p)
df2 = int(n-p-1)
F_table = sci.stats.f.ppf(p_level, df1, df2, loc=0, scale=1)
a_calc = 1 - sci.stats.f.cdf(F_calc, df1, df2, loc=0, scale=1)
conclusion_determ_coef_sign = 'significance' if F_calc >= F_table else 'not significance'
# формируем результат
result = pd.DataFrame({
'notation': ('R2'),
'coef_value (R)': (sqrt(R2)),
'coef_value_squared (R2)': (R2),
'p_level': (p_level),
'a_level': (a_level),
'F_calc': (F_calc),
'df1': (df1),
'df2': (df2),
'F_table': (F_table),
'F_calc >= F_table': (F_calc >= F_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'significance_check': (conclusion_determ_coef_sign),
'conf_int_low': (''),
'conf_int_high': ('')
},
index=['Coef. of determination'])
return result
determination_coef_check(
result_linear_ols,
p_level=0.95)
Вывод: коэффициент детерминации ЗНАЧИМ.
6. Коэффициенты регрессии и проверка их значимости
Ранее мы уже извлекли коэффициенты регрессии как параметры модели b0 и b1 (как свойство params модели). Также можно получить их значения, как свойство bse модели:
print(b0, b1)
print(result_linear_ols.bse, type(result_linear_ols.bse))
Значимость коэффициентов регрессии можно проверить по критерию Стьюдента [3, с.203-212; 8, с.78].
Расчетные значения статистики критерия Стьюдента могут быть получены с помощью свойства tvalues модели:
print(f"result_linear_ols.tvalues = n{result_linear_ols.tvalues}")
Расчетные значения уровня значимости при проверке гипотезы по критерию Стьюдента могут быть получены с помощью свойства pvalues модели:
print(f"result_linear_ols.pvalues = n{result_linear_ols.pvalues}")
Доверительные интервалы для коэффициентов регрессии могут быть получены с помощью свойства conf_int модели:
print(result_linear_ols.conf_int(), 'n')
Можно рассчитать уровень значимости самостоятельно (как ранее для критерия Фишера — для лучшего понимания и общей демонстрации возможностей) — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.t, свойством cdf (функция распределения):
t_calc = result_linear_ols.tvalues
df = int(result_linear_ols.nobs - result_linear_ols.df_model - 1)
a_calc = 2*(1-sci.stats.t.cdf(abs(t_calc), df, loc=0, scale=1))
print(a_calc)![]()
Как видим, результаты совпадают.
Табличные значения статистики критерия Стьюдента получить с помощью Regression Results нельзя. Рассчитаем их самостоятельно — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.t, свойством ppf (процентные точки):
t_table = sci.stats.t.ppf((1 + p_level)/2 , df)
print(t_table)![]()
Для удобства создадим пользовательскую функцию regression_coef_check для проверки значимости коэффициентов регрессии, которая объединяет все вышеперечисленные расчеты:
def regression_coef_check(
model_fit,
notation_coef: list='',
p_level: float=0.95):
a_level = 1 - p_level
# параметры модели (коэффициенты регрессии)
model_params = model_fit.params
# стандартные ошибки коэффициентов регрессии
model_bse = model_fit.bse
# проверка гипотезы о значимости регрессии
t_calc = abs(model_params) / model_bse
n = model_fit.nobs # объем выборки
p = model_fit.df_model # Model degrees of freedom. The number of regressors p. Does not include the constant if one is present.
df = int(n - p - 1)
t_table = sci.stats.t.ppf((1 + p_level)/2 , df)
a_calc = 2*(1-sci.stats.t.cdf(t_calc, df, loc=0, scale=1))
conclusion_ = ['significance' if elem else 'not significance' for elem in (t_calc >= t_table).values]
# доверительный интервал коэффициента регрессии
conf_int_low = model_params - t_table*model_bse
conf_int_high = model_params + t_table*model_bse
# формируем результат
result = pd.DataFrame({
'notation': (notation_coef),
'coef_value': (model_params),
'std_err': (model_bse),
'p_level': (p_level),
'a_level': (a_level),
't_calc': (t_calc),
'df': (df),
't_table': (t_table),
't_calc >= t_table': (t_calc >= t_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'significance_check': (conclusion_),
'conf_int_low': (conf_int_low),
'conf_int_high': (conf_int_high),
})
return result
regression_coef_check(
result_linear_ols,
notation_coef=['b0', 'b1'],
p_level=0.95)
Вывод: коэффициенты регрессии b0 и b1 ЗНАЧИМЫ.
7. Проверка гетероскедастичности
Для проверка гетероскедастичности statsmodels предлагает нам следующие инструменты:
-
тест Голдфелда-Квандта (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_goldfeldquandt.html#statsmodels.stats.diagnostic.het_goldfeldquandt) — теорию см. [8, с.178], также https://ru.wikipedia.org/wiki/Тест_Голдфелда_—_Куандта.
-
тест Бриша-Пэгана (Breush-Pagan test) (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_breuschpagan.html#statsmodels.stats.diagnostic.het_breuschpagan) — теорию см.[8, с.179], также https://en.wikipedia.org/wiki/Breusch–Pagan_test.
-
тест Уайта (White test) (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_white.html#statsmodels.stats.diagnostic.het_white) — теорию см.[8, с.177], а также https://ru.wikipedia.org/wiki/Тест_Уайта.
Тест Голдфелда-Квандта (Goldfeld–Quandt test)
# тест Голдфелда-Квандта (Goldfeld–Quandt test)
test = sms.het_goldfeldquandt(result_linear_ols.resid, result_linear_ols.model.exog)
test_result = lzip(['F_calc', 'p_calc'], test) # распаковка результатов теста
# расчетное значение статистики F-критерия
F_calc_tuple = test_result[0]
F_calc = F_calc_tuple[1]
print(f"Расчетное значение статистики F-критерия: F_calc = {round(F_calc, DecPlace)}")
# расчетный уровень значимости
p_calc_tuple = test_result[1]
p_calc = p_calc_tuple[1]
print(f"Расчетное значение доверительной вероятности: p_calc = {round(p_calc, DecPlace)}")
#a_calc = 1 - p_value
#print(f"Расчетное значение уровня значимости: a_calc = 1 - p_value = {round(a_calc, DecPlace)}")
# вывод
if p_calc < a_level:
conclusion_GQ_test = f"Так как p_calc = {round(p_calc, DecPlace)} < a_level = {round(a_level, DecPlace)}" +
", то дисперсии в подвыборках отличаются значимо, т.е. гипотеза о наличии гетероскедастичности ПРИНИМАЕТСЯ"
else:
conclusion_GQ_test = f"Так как p_calc = {round(p_calc, DecPlace)} >= a_level = {round(a_level, DecPlace)}" +
", то дисперсии в подвыборках отличаются незначимо, т.е. гипотеза о наличии гетероскедастичности ОТВЕРГАЕТСЯ"
print(conclusion_GQ_test)
Для удобства создадим пользовательскую функцию Goldfeld_Quandt_test:
def Goldfeld_Quandt_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_goldfeldquandt(model_fit.resid, model_fit.model.exog)
test_result = lzip(['F_statistic', 'p_calc'], test) # распаковка результатов теста
# расчетное значение статистики F-критерия
F_calc_tuple = test_result[0]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости
p_calc_tuple = test_result[1]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('Goldfeld–Quandt test'),
'p_level': (p_level),
'a_level': (a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
Goldfeld_Quandt_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Тест Бриша-Пэгана (Breush-Pagan test)
# тест Бриша-Пэгана (Breush-Pagan test)
name = ["Lagrange multiplier statistic", "p-value", "f-value", "f p-value"]
test = sms.het_breuschpagan(result_linear_ols.resid, result_linear_ols.model.exog)
lzip(name, test)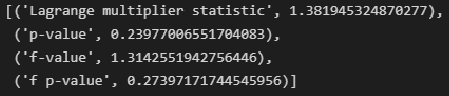
Для удобства создадим пользовательскую функцию Breush_Pagan_test:
def Breush_Pagan_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_breuschpagan(model_fit.resid, model_fit.model.exog)
name = ['Lagrange_multiplier_statistic', 'p_calc_LM', 'F_statistic', 'p_calc']
test_result = lzip(name, test) # распаковка результатов теста
# расчетное значение статистики теста множителей Лагранжа
LM_calc_tuple = test_result[0]
Lagrange_multiplier_statistic = LM_calc_tuple[1]
# расчетный уровень значимости статистики теста множителей Лагранжа
p_calc_LM_tuple = test_result[1]
p_calc_LM = p_calc_LM_tuple[1]
# расчетное значение F-статистики гипотезы о том, что дисперсия ошибки не зависит от x
F_calc_tuple = test_result[2]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости F-статистики
p_calc_tuple = test_result[3]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('Breush-Pagan test'),
'p_level': (p_level),
'a_level': (a_level),
'Lagrange_multiplier_statistic': (Lagrange_multiplier_statistic),
'p_calc_LM': (p_calc_LM),
'p_calc_LM < a_level': (p_calc_LM < a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
Breush_Pagan_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Тест Уайта (White test)
# тест Уайта (White test)
name = ["Lagrange multiplier statistic", "p-value", "f-value", "f p-value"]
test = sms.het_white(result_linear_ols.resid, result_linear_ols.model.exog)
lzip(name, test)
Для удобства создадим пользовательскую функцию White_test:
def White_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_white(model_fit.resid, model_fit.model.exog)
name = ['Lagrange_multiplier_statistic', 'p_calc_LM', 'F_statistic', 'p_calc']
test_result = lzip(name, test) # распаковка результатов теста
# расчетное значение статистики теста множителей Лагранжа
LM_calc_tuple = test_result[0]
Lagrange_multiplier_statistic = LM_calc_tuple[1]
# расчетный уровень значимости статистики теста множителей Лагранжа
p_calc_LM_tuple = test_result[1]
p_calc_LM = p_calc_LM_tuple[1]
# расчетное значение F-статистики гипотезы о том, что дисперсия ошибки не зависит от x
F_calc_tuple = test_result[2]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости F-статистики
p_calc_tuple = test_result[3]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('White test'),
'p_level': (p_level),
'a_level': (a_level),
'Lagrange_multiplier_statistic': (Lagrange_multiplier_statistic),
'p_calc_LM': (p_calc_LM),
'p_calc_LM < a_level': (p_calc_LM < a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
White_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Объединим результаты всех тестов гетероскедастичность в один DataFrame:
Goldfeld_Quandt_test_df = Goldfeld_Quandt_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Breush_Pagan_test_df = Breush_Pagan_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
White_test_df = White_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
heteroscedasticity_tests_df = pd.concat([Breush_Pagan_test_df, White_test_df, Goldfeld_Quandt_test_df])
display(heteroscedasticity_tests_df)
Выводы
Итак, мы провели статистический анализ регрессионной модели и установили:
-
исходные данные имеют нормальное распределение;
-
между переменными имеется весьма сильная корреляционная связь;
-
регрессионная модель хорошо аппроксимирует фактические данные;
-
остатки модели имеют нормальное распределение;
-
регрессионная модель адекватна по критерию Фишера;
-
коэффициент детерминации значим по критеию Фишера;
-
коэффициенты регрессии значимы по критерию Стьюдента;
-
гетероскедастичность отсутствует.
Применительно к рассматриваемой задаче выполнять проверку автокорреляции не имеет особого смысла из-за особенностей исходных данных (результаты замеров прочности бетона на разных участках здания).
Про статистический анализ регрессионных моделей с помощью statsmodels— см. еще https://www.statsmodels.org/stable/examples/notebooks/generated/regression_diagnostics.html.
Доверительные интервалы регрессионной модели
Для регрессионных моделей определяют доверительные интервалы двух видов [3, с.184-192; 4, с.172; 8, с.205-209]:
-
Доверительный интервал средних значений переменной Y.
-
Доверительный интервал индивидуальных значений переменной Y.
При этом размер доверительного интервала для индивидуальных значений больше, чем для средних значений.
Доверительные интервалы регрессионных моделей (ДИРМ) могут быть найдены разными способами:
-
непосредственно путем расчетов по формулам (см., например, https://habr.com/ru/post/558158/);
-
с использованием инструментария библиотеки statsmodels (см., например, https://www.stackfinder.ru/questions/17559408/confidence-and-prediction-intervals-with-statsmodels).
Разбререм более подробно способ с использованием библиотеки statsmodels. Прежде всего, с помощью свойства summary_table класса statsmodels.stats.outliers_influence.OLSInfluence (https://www.statsmodels.org/stable/generated/statsmodels.stats.outliers_influence.OLSInfluence.html?highlight=olsinfluence) мы можем получить таблицу данных, содержащую необходимую нам информацию:
-
Dep Var Population — фактические значения переменной Y;
-
Predicted Value — предсказанные значения переменной Y по по регрессионной модели;
-
Std Error Mean Predict — среднеквадратическая ошибка предсказанного среднего;
-
Mean ci 95% low и Mean ci 95% upp — границы доверительного интервала средних значений переменной Y;
-
Predict ci 95% low и Predict ci 95% upp — границы доверительного интервала индивидуальных значений переменной Y;
-
Residual — остатки регрессионной модели;
-
Std Error Residual — среднеквадратическая ошибка остатков;
-
Student Residual — стьюдентизированные остатки (подробнее см. http://statistica.ru/glossary/general/studentizirovannie-ostatki/);
-
Cook’s D — Расстояние Кука (Cook’s distance) — оценивает эффект от удаления одного (рассматриваемого) наблюдения; наблюдение считается выбросом, если Di > 4/n (более подробно — см.https://translated.turbopages.org/proxy_u/en-ru.ru.f584ceb5-63296427-aded8f31-74722d776562/https/en.wikipedia.org/wiki/Cook’s_distance, http://www.machinelearning.ru/wiki/index.php?title=Расстояние_Кука).
from statsmodels.stats.outliers_influence import summary_table
st, data, ss2 = summary_table(result_linear_ols, alpha=0.05)
print(st, 'n', type(st))
В нашем случае критическое значение расстояния Кука равно:
print(f'D_crit = 4/n = {4/result_linear_ols.nobs}')![]()
то есть выбросов, смещающих оценки коэффициентов регрессии, не наблюдается.
Мы получили данные как класс statsmodels.iolib.table.SimpleTable. Свойство data преобразует данные в список. Далее для удобства работы преобразуем данные в DataFrame:
st_data_df = pd.DataFrame(st.data)Будем использовать данный DataFrame в дальнейшем, несколько преобразуем его:
-
изменим наименование столбцов (с цифр на названия показателей из таблицы summary_table)
-
удалим строки с текстовыми значениями
-
изменим индекс
-
добавим новый столбец — значения переменной X
-
отсортируем по возрастанию значений переменной X (это необходимо, чтобы графики границ доверительных интервалов выглядели как линии)
st_df = st_data_df.copy()
# изменим наименования столбцов
str = st_df.iloc[0,0:] + ' ' + st_df.iloc[1,0:]
st_df = st_df.rename(str, axis='columns')
# удалим строки 0, 1
st_df = st_df.drop([0,1])
# изменим индекс
st_df = st_df.set_index(np.arange(0, result_linear_ols.nobs))
# добавим новый столбец - значения переменной X
st_df.insert(1, 'X', X)
# отсортируем по возрастанию значений переменной X
st_df = st_df.sort_values(by='X')
display(st_df)
С помощью полученных данных мы можем построить график регрессионной модели с доверительными интервалами:
# создание рисунка (Figure) и области рисования (Axes)
fig, axes = plt.subplots(figsize=(297/INCH, 210/INCH))
# заголовок рисунка (Figure)
title_figure = Task_Project
fig.suptitle(title_figure, fontsize = 16)
# заголовок области рисования (Axes)
title_axes = 'Линейная регрессионная модель'
axes.set_title(title_axes, fontsize = 14)
# фактические данные
sns.scatterplot(
x=st_df['X'], y=st_df['Dep Var Population'],
label='фактические данные',
s=50,
color='red',
ax=axes)
# график регрессионной модели
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X'
sns.lineplot(
x=st_df['X'], y=st_df['Predicted Value'],
label=label_legend_regr_model,
color='blue',
ax=axes)
# доверительный интервал средних значений переменной Y
Mean_ci_low = st_df['Mean ci 95% low']
plt.plot(
st_df['X'], Mean_ci_low,
color='magenta', linestyle='--', linewidth=1,
label='доверительный интервал средних значений Y')
Mean_ci_upp = st_df['Mean ci 95% upp']
plt.plot(
st_df['X'], Mean_ci_upp,
color='magenta', linestyle='--', linewidth=1)
# доверительный интервал индивидуальных значений переменной Y
Predict_ci_low = st_df['Predict ci 95% low']
plt.plot(
st_df['X'], Predict_ci_low,
color='orange', linestyle='-.', linewidth=2,
label='доверительный интервал индивидуальных значений Y')
Predict_ci_upp = st_df['Predict ci 95% upp']
plt.plot(
st_df['X'], Predict_ci_upp,
color='orange', linestyle='-.', linewidth=2)
axes.set_xlabel(Variable_Name_X)
axes.set_ylabel(Variable_Name_Y)
axes.legend(prop={'size': 12})
plt.show()
Однако, мы получили данные о границах доверительных интервалов регрессионной модели только в пределах области фактических значений переменной X. Как быть, если мы хотим распространить прогноз за пределы этой области?
Прогнозирование
Под прогнозированием мы в данном случае будем понимать определение значений переменной Y и доверительных интервалов для ее средних и индивидуальных значений при заданном X. По сути, нам предстоит построить аналог рассмотренной выше таблицы summary_table, только с другими значениями X, причем эти значения могут выходить за пределы тех значений, которые использовались нами для построения регрессии.
Методика расчета доверительных интервалов регрессионных моделей разобрана в статье «Python, корреляция и регрессия: часть 4» (https://habr.com/ru/post/558158/), всем рекомендую ознакомиться.
Найти прогнозные значения Y не представляет труда, так как ранее мы уже формализовали модель в виде лямбда-функции, а вот для построения доверительных интервалов придется выполнить расчеты по формулам. Для этого создадим пользовательскую функцию regression_pair_predict, которая в случае парной регрессии (pair regression) для заданного значения X возвращает:
-
прогнозируемое по регрессионной модели значение y_calc
-
доверительный интервал [y_calc_mean_ci_low, y_calc_mean_ci_upp] средних значений переменной Y
-
доверительный интервал [y_calc_predict_ci_low, y_calc_predict_ci_upp] индивидуальных значений переменной Y
Алгоритм расчета доверительных интервалов для множественной регрессии (multiple regression) отличается и в данном обзоре не рассматривается (рассмотрим в дальнейшем).
Про прогнозирование с помощью регрессионных моделей — см.также:
-
https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.predict.html?highlight=predict#statsmodels.regression.linear_model.RegressionResults.predict
-
How to Make Predictions Using Regression Model in Statsmodels
-
https://www.statsmodels.org/stable/examples/notebooks/generated/predict.html
def regression_pair_predict(
x_in,
model_fit,
regression_model,
p_level: float=0.95):
a_level = 1 - p_level
X = pd.DataFrame(model_fit.model.exog)[1].values # найти лучшее решение
Y = model_fit.model.endog
# вспомогательные величины
n = int(result_linear_ols.nobs)
SSE = model_fit.ssr # SSE (Sum of Squared Error)
dfE = n - p - 1
MSE = SSE / dfE # остаточная дисперсия
Xmean = np.mean(X)
SST_X = np.sum([(X[i] - Xmean)**2 for i in range(0, n)])
t_table = sci.stats.t.ppf((1 + p_level)/2 , dfE)
S2_y_calc_mean = MSE * (1/n + (x_in - Xmean)**2 / SST_X)
S2_y_calc_predict = MSE * (1 + 1/n + (x_in - Xmean)**2 / SST_X)
# прогнозируемое значение переменной Y
y_calc=regression_model(x_in)
# доверительный интервал средних значений переменной Y
y_calc_mean_ci_low = y_calc - t_table*sqrt(S2_y_calc_mean)
y_calc_mean_ci_upp = y_calc + t_table*sqrt(S2_y_calc_mean)
# доверительный интервал индивидуальных значений переменной Y
y_calc_predict_ci_low = y_calc - t_table*sqrt(S2_y_calc_predict)
y_calc_predict_ci_upp = y_calc + t_table*sqrt(S2_y_calc_predict)
result = y_calc, y_calc_mean_ci_low, y_calc_mean_ci_upp, y_calc_predict_ci_low, y_calc_predict_ci_upp
return resultСравним результаты расчета доверительных интервалов разными способами — с использованием функции regression_pair_predict и средствами statsmodels, для этого сформируем DaraFrame с новыми данными:
regression_pair_predict_df = pd.DataFrame(
[regression_pair_predict(elem, result_linear_ols, regression_model=Y_calc) for elem in st_df['X'].values],
columns=['y_calc', 'y_calc_mean_ci_low', 'y_calc_mean_ci_upp', 'y_calc_predict_ci_low', 'y_calc_predict_ci_upp'])
regression_pair_predict_df.insert(0, 'X', st_df['X'].values)
display(regression_pair_predict_df)
Видим, что результаты расчетов идентичны, следовательно мы можем использовать функцию regression_pair_predict для прогнозирования.
def graph_regression_pair_predict_plot_sns(
model_fit,
regression_model_in,
Xmin=None, Xmax=None, Nx=10,
Ymin_graph=None, Ymax_graph=None,
title_figure=None, title_figure_fontsize=18,
title_axes=None, title_axes_fontsize=16,
x_label=None,
y_label=None,
label_fontsize=14, tick_fontsize=12,
label_legend_regr_model='', label_legend_fontsize=12,
s=50, linewidth_regr_model=2,
graph_size=(297/INCH, 210/INCH),
result_output=True,
file_name=None):
# фактические данные
X = pd.DataFrame(model_fit.model.exog)[1].values # найти лучшее решение
Y = model_fit.model.endog
X = np.array(X)
Y = np.array(Y)
# границы
if not(Xmin) and not(Xmax):
Xmin=min(X)
Xmax=max(X)
Xmin_graph=min(X)*0.99
Xmax_graph=max(X)*1.01
else:
Xmin_graph=Xmin
Xmax_graph=Xmax
if not(Ymin_graph) and not(Ymax_graph):
Ymin_graph=min(Y)*0.99
Ymax_graph=max(Y)*1.01
# формируем DataFrame данных
Xcalc = np.linspace(Xmin, Xmax, num=Nx)
Ycalc = regression_model_in(Xcalc)
result_df = pd.DataFrame(
[regression_pair_predict(elem, model_fit, regression_model=regression_model_in) for elem in Xcalc],
columns=['y_calc', 'y_calc_mean_ci_low', 'y_calc_mean_ci_upp', 'y_calc_predict_ci_low', 'y_calc_predict_ci_upp'])
result_df.insert(0, 'x_calc', Xcalc)
# заголовки графика
fig, axes = plt.subplots(figsize=graph_size)
fig.suptitle(title_figure, fontsize = title_figure_fontsize)
axes.set_title(title_axes, fontsize = title_axes_fontsize)
# фактические данные
sns.scatterplot(
x=X, y=Y,
label='фактические данные',
s=s,
color='red',
ax=axes)
# график регрессионной модели
sns.lineplot(
x=Xcalc, y=Ycalc,
color='blue',
linewidth=linewidth_regr_model,
legend=True,
label=label_legend_regr_model,
ax=axes)
# доверительный интервал средних значений переменной Y
Mean_ci_low = result_df['y_calc_mean_ci_low']
plt.plot(
result_df['x_calc'], Mean_ci_low,
color='magenta', linestyle='--', linewidth=1,
label='доверительный интервал средних значений Y')
Mean_ci_upp = result_df['y_calc_mean_ci_upp']
plt.plot(
result_df['x_calc'], Mean_ci_upp,
color='magenta', linestyle='--', linewidth=1)
# доверительный интервал индивидуальных значений переменной Y
Predict_ci_low = result_df['y_calc_predict_ci_low']
plt.plot(
result_df['x_calc'], Predict_ci_low,
color='orange', linestyle='-.', linewidth=2,
label='доверительный интервал индивидуальных значений Y')
Predict_ci_upp = result_df['y_calc_predict_ci_upp']
plt.plot(
result_df['x_calc'], Predict_ci_upp,
color='orange', linestyle='-.', linewidth=2)
axes.set_xlim(Xmin_graph, Xmax_graph)
axes.set_ylim(Ymin_graph, Ymax_graph)
axes.set_xlabel(x_label, fontsize = label_fontsize)
axes.set_ylabel(y_label, fontsize = label_fontsize)
axes.tick_params(labelsize = tick_fontsize)
#axes.tick_params(labelsize = tick_fontsize)
axes.legend(prop={'size': label_legend_fontsize})
plt.show()
if file_name:
fig.savefig(file_name, orientation = "portrait", dpi = 300)
if result_output:
return result_df
else:
return
graph_regression_pair_predict_plot_sns(
model_fit=result_linear_ols,
regression_model_in=Y_calc,
Xmin=Xmin_graph-300, Xmax=Xmax_graph+200, Nx=25,
Ymin_graph=Ymin_graph-5, Ymax_graph=Ymax_graph+5,
title_figure=Task_Project, title_figure_fontsize=16,
title_axes='Линейная регрессионная модель', title_axes_fontsize=14,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X',
s=50,
result_output=True,
file_name='graph/regression_plot_lin.png')

Выводы и рекомендации
Исследована зависимость показаний ультразвукового прибора «ПУЛЬСАР-2.1» (X) и результатов замера прочности бетона (методом отрыва со скалыванием) склерометром ИПС-МГ4.03 (Y).
Между переменными имеется весьма сильная линейная корреляционная связь. Получена регрессионная модель:
Y = b0 + b1∙X = -21.3741 + 0.0129∙X
Модель хорошо аппроксимирует фактические данные, является адекватной, значимой и может использоваться для предсказания прочности бетона.
Также построен график прогноза с доверительными интервалами.
ИТОГИ
Итак, мы рассмотрели все этапы регрессионного анализа в случае простой линейной регрессии (simple linear regression) с использованием библиотеки statsmodels на конкретном практическом примере; подробно остановились на статистическом анализа модели с проверкой гипотез; также предложен ряд пользовательских функций, облегчающих работу исследователя и уменьшающих размер программного кода.
Конечно, мы разобрали далеко не все вопросы анализа регрессионных моделей и возможности библиотеки statsmodels применительно к simple linear regression, в частности статистики влияния (Influence Statistics), инструмент Leverage, анализ стьюдентизированных остатков и пр. — это темы для отдельных обзоров.
Исходный код находится в моем репозитории на GitHub.
Надеюсь, данный обзор поможет специалистам DataScience в работе.

«Функция потерь» является важной частью оптимизации машинного обучения. Считается, что функции потерь L1 и L2 знакомы большинству людей. Знаете ли вы потерю Губера, потерю Лог-Коша и потерю квантиля, которые обычно используются для расчета интервалов прогнозирования? Это наиболее часто используемые функции потери регрессии для машинного обучения, Даниэль!
Все алгоритмы в машинном обучении должны максимизировать или минимизировать функцию, которая называется «целевой функцией». из их,Обычно мы называем тип минимизированной функции «функцией потерь».Он может измерять способность прогнозирования модели в соответствии с результатом прогнозирования.
В практических применениях выбор функции потерь будет ограничен многими факторами, такими как наличие выбросов, выбор алгоритмов машинного обучения, сложность во времени градиентного спуска, сложность получения производной и достоверность предсказанного значения. Следовательно, не существует одной функции потерь, подходящей для обработки всех типов данных. В этой статье будут представлены различные типы функций потерь и их роль.
Функции потерь можно условно разделить на две категории:Функция потерь задачи классификации и функция потерь задачи регрессии.В этой статье я остановлюсь на потере регрессии.
Мы сохранили коды и диаграммы в этой статье здесь:https://nbviewer.jupyter.org/github/groverpr/Machine-Learning/blob/master/notebooks/05_Loss_Functions.ipynb

Сравнение функций потерь для задач классификации и регрессии
01
Среднеквадратичная ошибка

Среднеквадратичная ошибка (MSE) — наиболее часто используемая функция потерь регрессии. Метод расчета — найти квадратную сумму расстояния между прогнозируемым значением и истинным значением. Формула показана на рисунке.
На следующем рисунке показано изображение функции MSE, где целевое значение равно 100, прогнозируемое значение находится в диапазоне от -10000 до 10000, значение MSE, представленное осью Y, находится в диапазоне от 0 до положительной бесконечности и достигает минимума при прогнозируемом значении 100.

Прогнозируемое значение потерь MSE (ось Y) (ось X)
02
Среднее абсолютное значение погрешности L1 потерь

Средняя абсолютная ошибка (MAE) — это еще одна функция потерь, используемая в регрессионных моделях. MAE — это сумма абсолютного значения разницы между целевым значением и прогнозируемым значением. Он только измеряет среднюю длину модуля предсказанной ошибки значения, независимо от направления, и диапазон значений также составляет от 0 до положительной бесконечности (если вы учитываете направление,Является ли сумма остатков / среднеквадратичных отклонений (MBE))。

MAE потери (ось Y) — прогнозируемое значение (ось X)
Проще говоря, MSE легко рассчитать, но MAE более устойчив к выбросам. Давайте представим причины различий между ними.
При обучении модели машинного обучения наша цель — найти точку, где функция потерь достигает минимума. Когда прогнозируемое значение равно истинному значению, эти две функции могут достигать минимума.
Ниже приведен код Python для этих двух функций потерь. Вы можете написать свои собственные функции или использовать встроенные функции sklearn.
<pre >
true: Array of true target variable
pred: Array of predictions
def mse(true, pred):
return np.sum((true - pred)**2)
def mae(true, pred):
return np.sum(np.abs(true - pred))
also available in sklearn
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
</pre>Давайте рассмотрим результаты расчета MAE и RMSE (то есть квадратный корень из MSE с той же величиной, что и MAE) в двух примерах. В первом примере прогнозируемое значение очень близко к истинному значению, и дисперсия ошибки также мала. Во втором примере ошибка очень велика из-за ненормальной точки.

Слева: ошибка относительно близка. Справа: одна ошибка намного больше, чем другие
Что вы можете узнать по картинке? Как выбрать функцию потерь?
MSE возводит в квадрат ошибку (пусть e = значение, предсказанное истинным значением), поэтому, если e> 1, MSE еще больше увеличит ошибку. Если в данных есть аномалия, значение e будет большим, и e² будет намного больше, чем | e |.
Интуитивно это можно понять следующим образом: если мы минимизируем MSE, чтобы дать только одно прогнозируемое значение для всех точек выборки, то это значение должно быть средним из всех целевых значений. Однако, если MAE минимизирован, то это значение будет медианой целевых значений всех точек выборки. Как мы все знаем, для выбросов,Медиана является более устойчивой, чем средняя, поэтому MAE также более устойчив к выбросам, чем MSE.
Однако MAE имеет серьезную проблему (особенно для нейронных сетей): обновленный градиент всегда один и тот же, то есть даже для небольших значений потерь градиент велик. Это не способствует модели обучения. Чтобы устранить этот дефект, мы можем использовать переменную скорость обучения, чтобы уменьшить скорость обучения, когда потери близки к минимуму.
MSE очень хорошо работает в этой ситуации и может эффективно сходиться даже при фиксированной скорости обучения. Градиент потерь MSE увеличивается с увеличением потерь и уменьшается, когда потери приближаются к нулю. Это делает результаты использования модели MSE более точными в конце обучения.

Выберите функцию потерь в соответствии с различными ситуациями
Если ненормальная точка представляет ненормальную ситуацию, которая очень важна в бизнесе и должна быть обнаружена, следует использовать функцию потери MSE. Наоборот, если только поврежденные данные рассматриваются как ненормальные значения, следует использовать функцию потерь MAE.
Здесь потеря L1 и потеря L2 — просто другое название для MAE и MSE。В общем, при работе с ненормальными точками функция потерь L1 более стабильна, но ее производная является прерывистой, поэтому эффективность решения ниже. Функция потерь L2 более чувствительна к выбросам, но, сделав ее производной 0, можно получить более устойчивое замкнутое решение.
Проблема обоих заключается в том, что в некоторых случаях две вышеуказанные функции потерь не могут удовлетворить спрос. Например, если 90% выборок в данных соответствуют целевому значению 150, оставшиеся 10% находятся в диапазоне от 0 до 30. Тогда модель, использующая MAE в качестве функции потерь, может игнорировать выброс на 10%, и прогнозируемое значение для всех выборок составляет 150.
Это потому, что модель предсказывает по медиане. Модель, использующая MSE, даст много значений прогнозирования между 0 и 30, потому что модель сместится к ненормальной точке. Приведенные выше два результата нежелательны во многих бизнес-сценариях.
Что мне делать в этих ситуациях? Самый простой способ — преобразовать целевую переменную. Другой метод заключается в изменении функции потерь, что приводит к описанию ниже третьей функции потерь, а именно функции потерь Хьюбера.
Потеря Хьюбера, сглаженная средняя абсолютная ошибка
Потеря Губера не так чувствительна к выбросам в данных, как потеря квадрата ошибки. Это может также быть дифференцировано в 0. По сути, потеря Хьюбера является абсолютной ошибкой, но она становится квадратной ошибкой, когда ошибка мала. Сколько часов ошибка падает до вторичной ошибки, определяется гиперпараметром дельта (delta). Когда потеря Хьюбера находится между [0-δ, 0 + δ], она эквивалентна MSE, и это MAE, когда [-∞, δ] и [δ, + ∞]


График потерь Хьюбера (ось Y) и прогнозируемого значения (ось X). Истинное значение 0
Выбор гиперпараметра дельта здесь очень важен, потому что он определяет ваше определение аномальных точек. Когда остаток больше дельты, для минимизации следует использовать L1 (менее чувствительный к большим выбросам), а остаток меньше гиперпараметра, тогда для минимизации следует использовать L2.
04
Зачем использовать потери Хубера?
Одной из самых больших проблем использования MAE для обучения нейронных сетей является постоянный большой градиент, который может привести к тому, что минимальная точка будет пропущена, когда градиентный спуск подходит к концу. Для MSE градиент будет уменьшаться с уменьшением потерь, делая результат более точным.
В этом случае потеря Хубера очень полезна. Он упадет вблизи минимального значения из-за уменьшения градиента. Он более устойчив к выбросам, чем MSE. Поэтому потеря Хубера сочетает в себе преимущества MSE и MAE. но,Проблема с потерей Хьюбера состоит в том, что нам может потребоваться постоянно корректировать дельту гиперпараметра.
Log-cosh — это еще одна функция потерь, которая используется в задачах регрессии и является более гладкой, чем L2. Его метод вычисления — логарифм гиперболического косинуса ошибки предсказания.


Логарифмические потери (ось Y) и прогнозируемое значение (ось X). Истинное значение 0
Преимущества: для меньших x log (cosh (x)) приблизительно равна (x ^ 2) / 2, для больших x приблизительно равна abs (x) -log (2). Это означает, что «logcosh» в основном похож на среднеквадратичную ошибку, но не так легко подвержен выбросам.Он обладает всеми преимуществами потери Хьюбера, но в отличие от потери Хьюбера, второй порядок Лог-кош незначителен.
Зачем нам вторая производная? Многие модели машинного обучения, такие как XGBoost, используют метод Ньютона, чтобы найти лучшее преимущество. Метод Ньютона требует решения второй производной (гессиана). Следовательно, для систем машинного обучения, таких как XGBoost, необходима дифференцируемость второго порядка функции потерь.

Целевая функция, используемая в XgBoost. Обратите внимание на зависимость от первой и второй производных
Но потеря Лог-Коша не идеальна, и все еще есть некоторые проблемы. Например, если ошибка велика, градиент и гессиан станут фиксированными, что приведет к отсутствию точек разделения в XGBoost.
Код Python для функций потерь Хьюбера и Лог-коша:
В большинстве реальных проблем прогнозирования мы обычно хотим понять неопределенность в прогнозировании. Четкое прогнозирование масштаба прогноза, а не просто оценка баллов, очень полезно при принятии решений по многим вопросам бизнеса.
Функция потери квантиля полезна, когда мы фокусируемся больше на интервальном прогнозировании, чем на точечном прогнозировании. Интервальное прогнозирование с использованием регрессии методом наименьших квадратов основано на предположении, что остаток (y-y_hat) является независимой переменной, а дисперсия остается неизменной.
Как только это предположение нарушается, модель линейной регрессии не устанавливается. Однако поэтому мы не можем думать, что лучше использовать нелинейную функцию или древовидную модель и отказаться от модели линейной регрессии в качестве базового метода. В настоящее время полезны квантильные потери и квантильная регрессия, поскольку даже для остатков с изменяющейся дисперсией или ненормальным распределением регрессия, основанная на квантильных потерях, может дать разумные интервалы прогнозирования.
Давайте посмотрим на практический пример ниже, чтобы лучше понять, как регрессия, основанная на квантильных потерях, работает на гетероскедастических данных.
**** квантильная регрессия и регрессия наименьших квадратов ****

Слева: b / wX1 и Y линейные. Имеет постоянную остаточную дисперсию.
Справа: b / wX2 и Y линейны, но дисперсия Y увеличивается с увеличением X2. (Гетероскедастичность)
Оранжевая линия представляет оценку OLS в обоих случаях

Квантильная регрессия. Пунктирная линия представляет регрессию, основанную на функциях квантильных потерь 0,05 и 0,95
Прикрепите код квантильной регрессии, показанный на рисунке:
https://github.com/groverpr/Machine-Learning/blob/master/notebooks/09_Quantile_Regression.ipynb
**** Понимание функции квантильных потерь ****
Как выбрать соответствующее значение квантиля, зависит от того, насколько мы оцениваем положительные и отрицательные ошибки. Функция потерь дает различные штрафы за переоценку и недооценку через квантильное значение (γ). Например, когда функция квантильных потерь γ = 0,25, штраф за переоценку больше, делая прогнозируемое значение немного ниже медианы.

γ — требуемый квантиль, и его значение находится между 0 и 1.

График потерь квантиля (ось Y) и прогнозируемое значение (ось X). Истинное значение Y равно 0
Эта функция потерь также может бытьРасчет интервалов прогнозирования в нейронных сетях или древовидных моделях。Ниже приведен пример использования Sklearn для реализации регрессионной модели градиентного лифтингового дерева.

Использовать квантильную потерю (регрессия с повышением градиента) для прогнозирования интервалов
Рисунок выше показывает, что использование квантильных потерь в регрессии подъема градиента библиотеки sklearn может получить 90% интервал прогнозирования. Верхний предел равен γ = 0,95, а нижний предел равен γ = 0,05.
07
Сравнительное исследование
Чтобы доказать характеристики всех вышеперечисленных функций потерь, давайте взглянем на сравнительное исследование. Сначала мы строим набор данных, выбранный из функции sinc (x), и вводим два искусственных шума: компонент гауссовского шума ε ~ N (0, σ2) и компонент импульсного шума ξ ~ Берн (p).
Импульсный шум добавлен, чтобы проиллюстрировать эффект модели. Ниже приведены результаты подбора регрессора GBM с использованием различных функций потерь.

Функция непрерывной потери:
A: функция потери MSE;
B: функция потери MAE;
C: функция потерь Хьюбера;
D: функция квантильных потерь. Пример подгонки гладкой GBM к шумным данным sinc (x):
E: исходная функция sinc (x);
F: гладкий GBM с потерями MSE и MAE;
G: гладкий GBM с потерей Хьюбера и δ = {4,2,1};
H: гладкий GBM с квантильными потерями, и α = {0,5,0,1,0,9}.
Некоторые наблюдения сравнения симуляции:
-
На результат прогнозирования модели потерь MAE меньше влияет импульсный шум, в то время как результат прогнозирования функции потерь MSE слегка компенсируется этим эффектом.
-
Результаты предсказания модели потерь Хьюбера не чувствительны к выбранным гиперпараметрам.
-
Модель квантильных потерь может дать хорошую оценку при соответствующем уровне достоверности.
Наконец, давайте поместим все функции потерь в картинку, и мы получим красивую картинку ниже! Разница между ними ясна с первого взгляда ~

Я думаю, вам может понравиться


“Мир полон волшебных вещей, терпеливо ожидающих того момента, когда наши чувства станут острее”. — У.Б. Йейтс
Что стоит за #(хэштегом)?
Совсем недавно я начала новую серию статей, смысл которых выражен хэштегом: #TheNotSoToughML (#НисколькоНеСложноеМО).
Предыдущие части: Часть 1, Часть 2.
Мне хотелось бы дать вам упрощенные решения некоторых проблем, возникающих в связи с алгоритмами/концепциями. Вместо того, чтобы сразу вдаваться в математику, я обращаюсь к вашей интуиции. Поверьте: машинное обучение вовсе не сложно. Оно больше похоже на интуитивное постижение, проверяемое алгоритмически.
Концепция 1: Функция ошибки. Измерение результатов
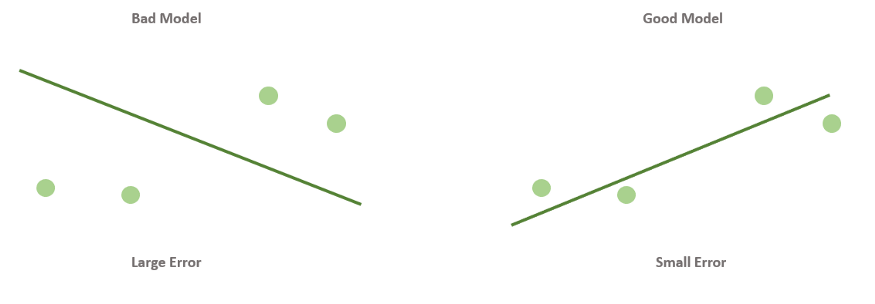
Когда вы смотрите на две модели выше и сравниваете их, приходите ли вы к тому же выводу, что и я? Как по-вашему, является ли плохая модель действительно “плохой” по сравнению с моделью справа? Если да, это значит, что вы сконцентрировали внимание на “зазоре” или расстоянии линии от каждой точки данных; таким образом, в среднем (или по совокупности признаков) вам показалось, что модель слева имеет большее расстояние между точками и линией по сравнению с моделью справа.
Функция ошибки помогает нам понять то же самое! Это метрика, показывающая то, как работает наша модель.
Функция ошибки будет присваивать большее значение модели слева и меньшее — модели справа. В специальной литературе такие функции также называют функциями потерь или функциями затрат.
Теперь перейдем к более важному вопросу.
Как определить, насколько точно работает функция ошибки для моделей линейной регрессии?
Сейчас мы поговорим об абсолютной ошибке и квадратичной ошибке.
Абсолютная ошибка — метрика, которая складывает расстояния и показывает, насколько хороша наша модель.
Это самый простой для понимания и интерпретации показатель.
Это просто суммирование расстояний между точками данных и линией. Оно называется “абсолютным”, потому что расстояние может быть положительным или отрицательным в зависимости от расположения точек данных по отношению к линии. Следовательно, чтобы не упустить ни одного нюанса в поведении модели, мы принимаем абсолютное значение ошибок.
Итак, мы знаем, что хорошая модель линейной регрессии — это та модель, в которой линия близка к точкам данных.
Но что значит “близка”?
Выбираем ли мы линию, которая близка к некоторым точкам и далека от других? Или мы выбираем линию, которая близка ко всем точкам?
Вот тут-то и пригодится функция абсолютной ошибки. Мы выбираем линию, которая минимизирует абсолютную ошибку, т.е. ту, для которой сумма вертикальных расстояний от каждой точки до линии минимальна.
На рисунке ниже показаны разные абсолютные ошибки.
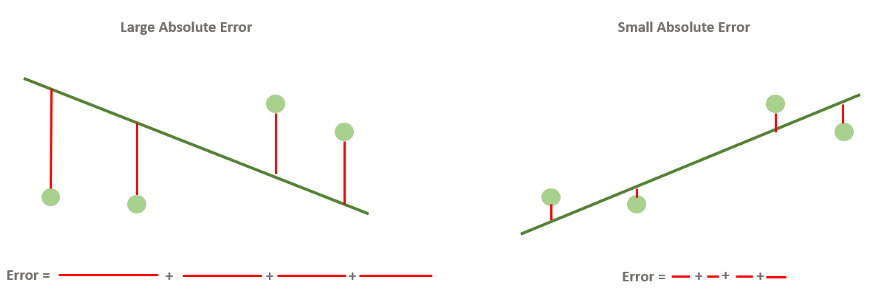
Теперь перейдем к следующему приему, связанному с ошибками.
Квадратичная ошибка — метрика, которая складывает квадраты расстояний и показывает, насколько хороша наша модель.
Квадратичная ошибка очень похожа на абсолютную ошибку. Но теперь, вместо того, чтобы брать абсолютное значение разницы между меткой и прогнозированной меткой, мы используем квадрат, что снова превращает число в положительное.
Давайте попробуем представить это так же, как мы это делали для абсолютной ошибки!
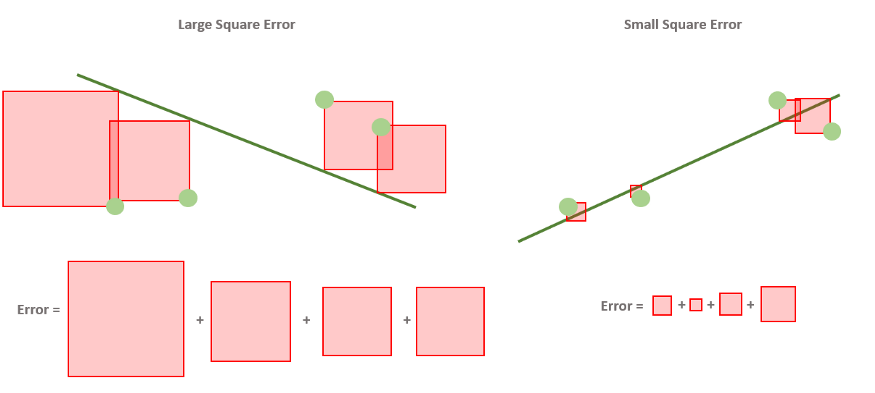
Квадратичная ошибка используется на практике чаще, чем абсолютная. Почему? Одна из причин заключается в том, что у квадрата гораздо более наглядная производная, чем у абсолютного значения, что очень удобно в процессе обучения.
Мы убедимся в этом чуть ниже.
Средняя абсолютная ошибка и (корневая) средняя квадратичная ошибка — самые распространенные и наиболее полезные ошибки для нашей модели
Абсолютная и квадратичная ошибки, показанные выше, служили простыми примерами того, что такое ошибки и как они могут выглядеть. Однако наиболее часто используемыми ошибками в проектах машинного обучения, особенно когда мы имеем дело с регрессионными моделями, являются средняя абсолютная ошибка (MAE) и средняя квадратичная ошибка (MSE).
Они определяются практически так же, только вместо вычисления сумм мы вычисляем средние значения.
Итак, MAE — это среднее значение вертикальных расстояний от точек до линии, а MSE — среднее значение квадратов этих же расстояний.
Эти ошибки более полезны, чем абсолютная и квадратичная ошибка, которые мы вычисляли в предыдущем разделе, и вот почему. Допустим, мы пытаемся подогнать одну и ту же модель к двум разным наборам данных, в одном из которых всего 10 точек данных, а в другом — миллион. Если ошибка является суммой величин (как в случае абсолютной или квадратичной ошибки), то она, вероятно, будет намного выше в наборе данных, состоящем из миллиона точек, потому что мы будем складывать гораздо больше чисел. Но эта проблема решается с помощью средних значений.
Еще один полезный показатель — среднеквадратичная ошибка (RMSE). Как следует из названия, это корень из средней квадратичной ошибки. Этот показатель используется для сопоставления единиц в задаче, а также для того, чтобы дать нам лучшее представление о том, насколько сильно модель ошибается при прогнозировании.
Концепция 2: Градиентный спуск. Уменьшение функции ошибки путем медленного “спуска с горы”
Теперь поговорим о перемещении линий на некоторое расстояние в контексте МО.
Поскольку цель этого цикла — объяснить интуитивный подход, а математические понятия использовать только там, где это абсолютно необходимо, мы воздержимся от того, чтобы углубляться в технические аспекты в этом разделе. Но если вы хотите разобраться в расчетах, которые проводятся при градиентном спуске, можете зайти на этот сайт и ознакомиться с ними.
Пока же мы попробуем понять, как градиентный спуск помогает нам уменьшить ошибку модели. При этом постараемся не погружаться в высшую математику. Скромная попытка, но все же.
Давайте решим вышеуказанную задачу в следующем порядке:
- Кратко разберем, как работает градиентный спуск.
- Расскажем, как он может решить задачу уменьшения ошибки
- Выясним, как с помощью полученных знаний мы узнаем, когда нужно останавливать работу алгоритма.
Как работает градиентный спуск
Представьте, что вы находитесь на вершине высокой горы — скажем, горы “Эррорест”.
Вы хотите спуститься с нее, но стоит очень туманная погода и вы видите только на расстоянии около 1 метра от себя. Что же делать? Вот вам дельный совет — оглянитесь вокруг себя и определите, в каком направлении можно сделать один единственный шаг так, чтобы спуститься максимально низко.
Нашли это направление? Теперь сделайте маленький шаг. Поскольку этот шаг был сделан в направлении максимального спуска, то, скорее всего, вы спуститесь на небольшое расстояние.
Теперь вам нужно повторять это действие много раз до тех пор, пока вы не достигнете подножия горы (хотелось бы надеяться на это).
Я написал “хотелось бы надеяться”, потому что в этом примере слишком много нюансов, которые мы разбирать не будем, чтобы не вдаваться в сложные математические понятия. Вы можете достичь подножия горы, а можете очутиться в долине, и вам больше некуда будет идти. Сейчас мы не станем разбирать все эти варианты.
Суть в том, что при градиентном спуске мы делаем один шаг за раз в направлении самой низкой точки (в нашем примере — подножия горы).
Как градиентный спуск помогает решить задачу уменьшения ошибки
Напомню, что мы определяем алгоритм линейной регрессии по следующей схеме:
- Начинаем с любой линии.
- Находим наилучшее направление, в котором можно немного сдвинуть нашу линию, используя прием из сферы абсолютных или квадратичных значений.
- Перемещаем линию в этом направлении.
- Повторяем эти шаги 2, 3 и более раз.
В предыдущем разделе мы говорили о градиентном спуске. Чтобы закрепить принцип его работы с помощью примера с горой, пройдем описанные этапы еще раз:
- Мы находимся на вершине горы.
- Находим оптимальное направление для первого маленького шага.
- Делаем маленький шаг в этом направлении.
- Повторяем эти шаги 2, 3 и более раз.
Знакомая схема, не так ли? Посмотрим на рисунок ниже.
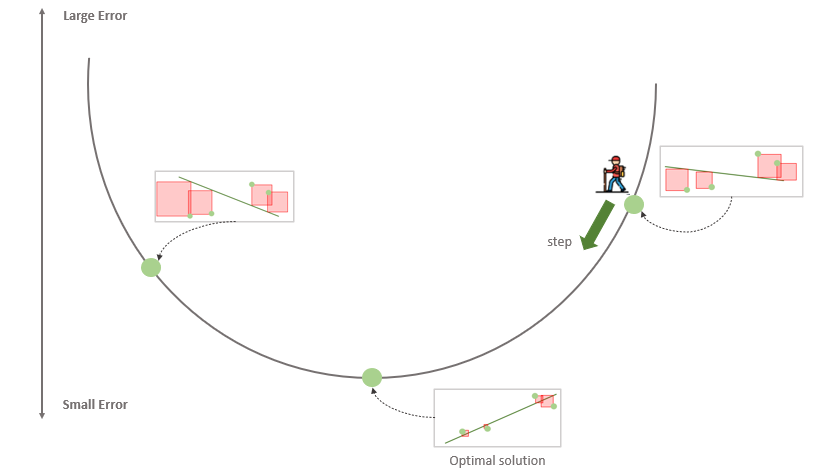
Единственное отличие от нашего прежнего понимания линейной регрессии заключается в том, что эта функция ошибки больше напоминает долину, чем гору. Наша цель — спуститься в самую низкую точку. Каждая точка в этой долине соответствует некоторой модели (линии), которая пытается подогнать наши данные. Высота точки — это ошибка, которую выдает данная модель. Таким образом, плохие модели располагаются сверху, а хорошие — снизу. Мы стараемся опуститься как можно ниже. Каждый шаг ведет нас от худшей модели к чуть лучшей. Если мы будем делать такие шаги много раз, то в конце концов дойдем до лучшей модели (или, по крайней мере, довольно хорошей!).
Подытожим: что же нам нужно делать?
Мы хотим найти линию, которая лучше всего соответствует нашим данным. У нас есть метрика “функция ошибки”, которая показывает, насколько линия далека от данных. Таким образом, если мы сможем уменьшить это число как можно больше, мы найдем наиболее подходящую линию.
Этот процесс часто используется во многих областях математики и называется минимизацией функций (т.е. нахождение наименьшего возможного значения, которое может вернуть функция). В данном случае функция, которую мы пытаемся минимизировать, — это ошибка (абсолютная или квадратичная) нашей модели. Для минимизации этой функции мы используем градиентный спуск.
Как узнать, когда нужно останавливать работу алгоритма?
Давайте рассчитаем RMSE для любого набора данных, где мы пытаемся предсказать неизвестные значения (“метки”) и получить новые метки после запуска нашей модели (“прогнозы”):
def rmse(labels, predictions):
n = len(labels)
differences = np.subtract(labels, predictions)
return np.sqrt(1.0/n * (np.dot(differences, differences)))
Теперь построим график, отобразив на нем, помимо прочего, количество эпох (итераций), в течение которых работает ваша модель. В итоге вы получите результат, похожий на тот, который вышел у меня, когда я тестировал таким образом свой образец набора данных:
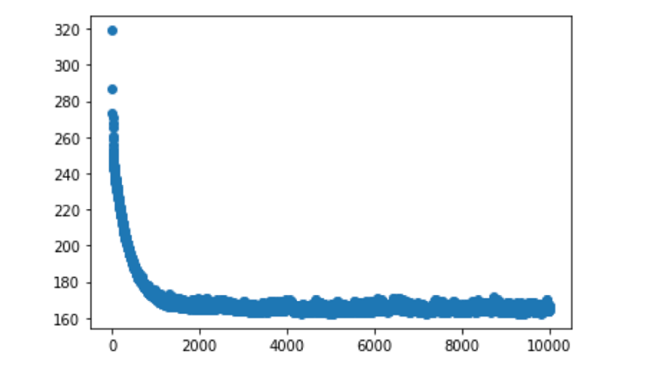
Мы видим стремительное падение примерно после 1000 итераций, и после этого изменений на графике практически не наблюдается. Это говорит нам о том, что для данной конкретной модели мы можем запустить алгоритм обучения не на 10 000, а всего на 1000 или 2000 итераций. Тем не менее, мы все равно получим схожие результаты.
В целом, функция ошибки предоставляет надежную информацию, помогающую определиться с тем, когда следует прекращать выполнение алгоритма. Очень часто такое решение основывается на доступном нам времени и вычислительной мощности. Однако есть и другие полезные факторы, на которые часто ориентируются специалисты в сфере данных. Выполнение алгоритма также прекращают в следующих случаях:
- когда функция потерь достигает определенного значения, которое мы заранее установили;
- когда функция потерь не уменьшается в течение нескольких эпох.
Что дальше?
Это был краткий обзор работы функции ошибки и того, как градиентный спуск помогает нам уменьшить ее. Но, думаю, вы уже поняли, что есть масса других моментов, которые я не стал затрагивать в этой статье, чтобы не перегружать вас. Если у вас возникли дополнительные вопросы, можете заняться самообразованием и продолжать “копать” в этом направлении дальше.
Тем не менее, представленный в этой статье материал должен дать вам базовое представление о том, как работает большинство моделей. Наверняка вы убедились в том, что вам не нужны глубинные познания в математике, чтобы понять принципы машинного обучения!
В следующей статье мы рассмотрим другую форму подгонки, а именно полиномиальную подгонку к данным (а не линейную) и будем использовать ее в дальнейшем, чтобы понять, как можно спасти наши модели от “недо/переподгонки”.
Самое главное, мы поймем, как функции ошибок и концепция градиентного спуска помогают регулировать веса, находить лучшее решение при оптимальном завершении процесса, и узнаем, как определить, что наша модель действительно работает!
Эта статья, как и многие другие, была написана под впечатлением от книги, которую я сейчас читаю — “Grokking Machine Learning” Луиса Серрано. Книга еще не вышла, но я приобрела ранний доступ к ней и думаю, что поступила правильно. Я считаю, что книги/материалы этого автора определенно заслуживают того, чтобы их прочитал каждый, кто хочет получить полное представление об алгоритмах и о том, как работают модели МО.
Читайте также:
- Создание модели машинного обучения с помощью Google Colab без дополнительных настроек
- 6 концептов книги Эндрю Ына «Жажда машинного обучения»
- Самая лучшая идея в науке о данных
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Anushree Chatterjee, #03TheNotSoToughML | Regression: Errors → Descending from a Mountain Top
Гораздо легче что-то измерить, чем понять, что именно вы измеряете
Джон Уильям Салливан
Задачи машинного обучения с учителем как правило состоят в восстановлении зависимости между парами (признаковое описание, целевая переменная) по данным, доступным нам для анализа. Алгоритмы машинного обучения (learning algorithm), со многими из которых вы уже успели познакомиться, позволяют построить модель, аппроксимирующую эту зависимость. Но как понять, насколько качественной получилась аппроксимация?
Почти наверняка наша модель будет ошибаться на некоторых объектах: будь она даже идеальной, шум или выбросы в тестовых данных всё испортят. При этом разные модели будут ошибаться на разных объектах и в разной степени. Задача специалиста по машинному обучению – подобрать подходящий критерий, который позволит сравнивать различные модели.
Перед чтением этой главы мы хотели бы ещё раз напомнить, что качество модели нельзя оценивать на обучающей выборке. Как минимум, это стоит делать на отложенной (тестовой) выборке, но, если вам это позволяют время и вычислительные ресурсы, стоит прибегнуть и к более надёжным способам проверки – например, кросс-валидации (о ней вы узнаете в отдельной главе).
Выбор метрик в реальных задачах
Возможно, вы уже участвовали в соревнованиях по анализу данных. На таких соревнованиях метрику (критерий качества модели) организатор выбирает за вас, и она, как правило, довольно понятным образом связана с результатами предсказаний. Но на практике всё бывает намного сложнее.
Например, мы хотим:
- решить, сколько коробок с бананами нужно завтра привезти в конкретный магазин, чтобы минимизировать количество товара, который не будет выкуплен и минимизировать ситуацию, когда покупатель к концу дня не находит желаемый продукт на полке;
- увеличить счастье пользователя от работы с нашим сервисом, чтобы он стал лояльным и обеспечивал тем самым стабильный прогнозируемый доход;
- решить, нужно ли направить человека на дополнительное обследование.
В каждом конкретном случае может возникать целая иерархия метрик. Представим, например, что речь идёт о стриминговом музыкальном сервисе, пользователей которого мы решили порадовать сгенерированными самодельной нейросетью треками – не защищёнными авторским правом, а потому совершенно бесплатными. Иерархия метрик могла бы иметь такой вид:
- Самый верхний уровень: будущий доход сервиса – невозможно измерить в моменте, сложным образом зависит от совокупности всех наших усилий;
- Медианная длина сессии, возможно, служащая оценкой радости пользователей, которая, как мы надеемся, повлияет на их желание продолжать платить за подписку – её нам придётся измерять в продакшене, ведь нас интересует реакция настоящих пользователей на новшество;
- Доля удовлетворённых качеством сгенерированной музыки асессоров, на которых мы потестируем её до того, как выставить на суд пользователей;
- Функция потерь, на которую мы будем обучать генеративную сеть.
На этом примере мы можем заметить сразу несколько общих закономерностей. Во-первых, метрики бывают offline и online (оффлайновыми и онлайновыми). Online метрики вычисляются по данным, собираемым с работающей системы (например, медианная длина сессии). Offline метрики могут быть измерены до введения модели в эксплуатацию, например, по историческим данным или с привлечением специальных людей, асессоров. Последнее часто применяется, когда метрикой является реакция живого человека: скажем, так поступают поисковые компании, которые предлагают людям оценить качество ранжирования экспериментальной системы еще до того, как рядовые пользователи увидят эти результаты в обычном порядке. На самом же нижнем этаже иерархии лежат оптимизируемые в ходе обучения функции потерь.
В данном разделе нас будут интересовать offline метрики, которые могут быть измерены без привлечения людей.
Функция потерь $neq$ метрика качества
Как мы узнали ранее, методы обучения реализуют разные подходы к обучению:
- обучение на основе прироста информации (как в деревьях решений)
- обучение на основе сходства (как в методах ближайших соседей)
- обучение на основе вероятностной модели данных (например, максимизацией правдоподобия)
- обучение на основе ошибок (минимизация эмпирического риска)
И в рамках обучения на основе минимизации ошибок мы уже отвечали на вопрос: как можно штрафовать модель за предсказание на обучающем объекте.
Во время сведения задачи о построении решающего правила к задаче численной оптимизации, мы вводили понятие функции потерь и, обычно, объявляли целевой функцией сумму потерь от предсказаний на всех объектах обучающей выборке.
Важно понимать разницу между функцией потерь и метрикой качества. Её можно сформулировать следующим образом:
-
Функция потерь возникает в тот момент, когда мы сводим задачу построения модели к задаче оптимизации. Обычно требуется, чтобы она обладала хорошими свойствами (например, дифференцируемостью).
-
Метрика – внешний, объективный критерий качества, обычно зависящий не от параметров модели, а только от предсказанных меток.
В некоторых случаях метрика может совпадать с функцией потерь. Например, в задаче регрессии MSE играет роль как функции потерь, так и метрики. Но, скажем, в задаче бинарной классификации они почти всегда различаются: в качестве функции потерь может выступать кросс-энтропия, а в качестве метрики – число верно угаданных меток (accuracy). Отметим, что в последнем примере у них различные аргументы: на вход кросс-энтропии нужно подавать логиты, а на вход accuracy – предсказанные метки (то есть по сути argmax логитов).
Бинарная классификация: метки классов
Перейдём к обзору метрик и начнём с самой простой разновидности классификации – бинарной, а затем постепенно будем наращивать сложность.
Напомним постановку задачи бинарной классификации: нам нужно по обучающей выборке ${(x_i, y_i)}_{i=1}^N$, где $y_iin{0, 1}$ построить модель, которая по объекту $x$ предсказывает метку класса $f(x)in{0, 1}$.
Первым критерием качества, который приходит в голову, является accuracy – доля объектов, для которых мы правильно предсказали класс:
$$ color{#348FEA}{text{Accuracy}(y, y^{pred}) = frac{1}{N} sum_{i=1}^N mathbb{I}[y_i = f(x_i)]} $$
Или же сопряженная ей метрика – доля ошибочных классификаций (error rate):
$$text{Error rate} = 1 — text{Accuracy}$$
Познакомившись чуть внимательнее с этой метрикой, можно заметить, что у неё есть несколько недостатков:
- она не учитывает дисбаланс классов. Например, в задаче диагностики редких заболеваний классификатор, предсказывающий всем пациентам отсутствие болезни будет иметь достаточно высокую accuracy просто потому, что больных людей в выборке намного меньше;
- она также не учитывает цену ошибки на объектах разных классов. Для примера снова можно привести задачу медицинской диагностики: если ошибочный положительный диагноз для здорового больного обернётся лишь ещё одним обследованием, то ошибочно отрицательный вердикт может повлечь роковые последствия.
Confusion matrix (матрица ошибок)
Исторически задача бинарной классификации – это задача об обнаружении чего-то редкого в большом потоке объектов, например, поиск человека, больного туберкулёзом, по флюорографии. Или задача признания пятна на экране приёмника радиолокационной станции бомбардировщиком, представляющем угрозу охраняемому объекту (в противовес стае гусей).
Поэтому класс, который представляет для нас интерес, называется «положительным», а оставшийся – «отрицательным».
Заметим, что для каждого объекта в выборке возможно 4 ситуации:
- мы предсказали положительную метку и угадали. Будет относить такие объекты к true positive (TP) группе (true – потому что предсказали мы правильно, а positive – потому что предсказали положительную метку);
- мы предсказали положительную метку, но ошиблись в своём предсказании – false positive (FP) (false, потому что предсказание было неправильным);
- мы предсказали отрицательную метку и угадали – true negative (TN);
- и наконец, мы предсказали отрицательную метку, но ошиблись – false negative (FN). Для удобства все эти 4 числа изображают в виде таблицы, которую называют confusion matrix (матрицей ошибок):
Не волнуйтесь, если первое время эти обозначения будут сводить вас с ума (будем откровенны, даже профи со стажем в них порой путаются), однако логика за ними достаточно простая: первая часть названия группы показывает угадали ли мы с классом, а вторая – какой класс мы предсказали.

Пример
Попробуем воспользоваться введёнными метриками в боевом примере: сравним работу нескольких моделей классификации на Breast cancer wisconsin (diagnostic) dataset.
Объектами выборки являются фотографии биопсии грудных опухолей. С их помощью было сформировано признаковое описание, которое заключается в характеристиках ядер клеток (таких как радиус ядра, его текстура, симметричность). Положительным классом в такой постановке будут злокачественные опухоли, а отрицательным – доброкачественные.
Модель 1. Константное предсказание.
Решение задачи начнём с самого простого классификатора, который выдаёт на каждом объекте константное предсказание – самый часто встречающийся класс.
Зачем вообще замерять качество на такой модели?При разработке модели машинного обучения для проекта всегда желательно иметь некоторую baseline модель. Так нам будет легче проконтролировать, что наша более сложная модель действительно дает нам прирост качества.
from sklearn.datasets
import load_breast_cancer
the_data = load_breast_cancer()
# 0 – "доброкачественный"
# 1 – "злокачественный"
relabeled_target = 1 - the_data["target"]
from sklearn.model_selection import train_test_split
X = the_data["data"]
y = relabeled_target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
from sklearn.dummy import DummyClassifier
dc_mf = DummyClassifier(strategy="most_frequent")
dc_mf.fit(X_train, y_train)
from sklearn.metrics import confusion_matrix
y_true = y_test y_pred = dc_mf.predict(X_test)
dc_mf_tn, dc_mf_fp, dc_mf_fn, dc_mf_tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 0 | FN = 53 |
| Истинный класс — | FP = 0 | TN = 90 |
Обучающие данные таковы, что наш dummy-классификатор все объекты записывает в отрицательный класс, то есть признаёт все опухоли доброкачественными. Такой наивный подход позволяет нам получить минимальный штраф за FP (действительно, нельзя ошибиться в предсказании, если положительный класс вообще не предсказывается), но и максимальный штраф за FN (в эту группу попадут все злокачественные опухоли).
Модель 2. Случайный лес.
Настало время воспользоваться всем арсеналом моделей машинного обучения, и начнём мы со случайного леса.
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
y_true = y_test
y_pred = rfc.predict(X_test)
rfc_tn, rfc_fp, rfc_fn, rfc_tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 52 | FN = 1 |
| Истинный класс — | FP = 4 | TN = 86 |
Можно сказать, что этот классификатор чему-то научился, т.к. главная диагональ матрицы стала содержать все объекты из отложенной выборки, за исключением 4 + 1 = 5 объектов (сравните с 0 + 53 объектами dummy-классификатора, все опухоли объявляющего доброкачественными).
Отметим, что вычисляя долю недиагональных элементов, мы приходим к метрике error rate, о которой мы говорили в самом начале:
$$text{Error rate} = frac{FP + FN}{ TP + TN + FP + FN}$$
тогда как доля объектов, попавших на главную диагональ – это как раз таки accuracy:
$$text{Accuracy} = frac{TP + TN}{ TP + TN + FP + FN}$$
Модель 3. Метод опорных векторов.
Давайте построим еще один классификатор на основе линейного метода опорных векторов.
Не забудьте привести признаки к единому масштабу, иначе численный алгоритм не сойдется к решению и мы получим гораздо более плохо работающее решающее правило. Попробуйте проделать это упражнение.
from sklearn.svm import LinearSVC
from sklearn.preprocessing import StandardScaler
ss = StandardScaler() ss.fit(X_train)
scaled_linsvc = LinearSVC(C=0.01,random_state=42)
scaled_linsvc.fit(ss.transform(X_train), y_train)
y_true = y_test
y_pred = scaled_linsvc.predict(ss.transform(X_test))
tn, fp, fn, tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 50 | FN = 3 |
| Истинный класс — | FP = 1 | TN = 89 |
Сравним результаты
Легко заметить, что каждая из двух моделей лучше классификатора-пустышки, однако давайте попробуем сравнить их между собой. С точки зрения error rate модели практически одинаковы: 5/143 для леса против 4/143 для SVM.
Посмотрим на структуру ошибок чуть более внимательно: лес – (FP = 4, FN = 1), SVM – (FP = 1, FN = 3). Какая из моделей предпочтительнее?
Замечание: Мы сравниваем несколько классификаторов на основании их предсказаний на отложенной выборке. Насколько ошибки данных классификаторов зависят от разбиения исходного набора данных? Иногда в процессе оценки качества мы будем получать модели, чьи показатели эффективности будут статистически неразличимыми.
Пусть мы учли предыдущее замечание и эти модели действительно статистически значимо ошибаются в разную сторону. Мы встретились с очевидной вещью: на матрицах нет отношения порядка. Когда мы сравнивали dummy-классификатор и случайный лес с помощью Accuracy, мы всю сложную структуру ошибок свели к одному числу, т.к. на вещественных числах отношение порядка есть. Сводить оценку модели к одному числу очень удобно, однако не стоит забывать, что у вашей модели есть много аспектов качества.
Что же всё-таки важнее уменьшить: FP или FN? Вернёмся к задаче: FP – доля доброкачественных опухолей, которым ошибочно присваивается метка злокачественной, а FN – доля злокачественных опухолей, которые классификатор пропускает. В такой постановке становится понятно, что при сравнении выиграет модель с меньшим FN (то есть лес в нашем примере), ведь каждая не обнаруженная опухоль может стоить человеческой жизни.
Рассмотрим теперь другую задачу: по данным о погоде предсказать, будет ли успешным запуск спутника. FN в такой постановке – это ошибочное предсказание неуспеха, то есть не более, чем упущенный шанс (если вас, конечно не уволят за срыв сроков). С FP всё серьёзней: если вы предскажете удачный запуск спутника, а на деле он потерпит крушение из-за погодных условий, то ваши потери будут в разы существеннее.
Итак, из примеров мы видим, что в текущем виде введенная нами доля ошибочных классификаций не даст нам возможности учесть неравную важность FP и FN. Поэтому введем две новые метрики: точность и полноту.
Точность и полнота
Accuracy — это метрика, которая характеризует качество модели, агрегированное по всем классам. Это полезно, когда классы для нас имеют одинаковое значение. В случае, если это не так, accuracy может быть обманчивой.
Рассмотрим ситуацию, когда положительный класс это событие редкое. Возьмем в качестве примера поисковую систему — в нашем хранилище хранятся миллиарды документов, а релевантных к конкретному поисковому запросу на несколько порядков меньше.
Пусть мы хотим решить задачу бинарной классификации «документ d релевантен по запросу q». Благодаря большому дисбалансу, Accuracy dummy-классификатора, объявляющего все документы нерелевантными, будет близка к единице. Напомним, что $text{Accuracy} = frac{TP + TN}{TP + TN + FP + FN}$, и в нашем случае высокое значение метрики будет обеспечено членом TN, в то время для пользователей более важен высокий TP.
Поэтому в случае ассиметрии классов, можно использовать метрики, которые не учитывают TN и ориентируются на TP.
Если мы рассмотрим долю правильно предсказанных положительных объектов среди всех объектов, предсказанных положительным классом, то мы получим метрику, которая называется точностью (precision)
$$color{#348FEA}{text{Precision} = frac{TP}{TP + FP}}$$
Интуитивно метрика показывает долю релевантных документов среди всех найденных классификатором. Чем меньше ложноположительных срабатываний будет допускать модель, тем больше будет её Precision.
Если же мы рассмотрим долю правильно найденных положительных объектов среди всех объектов положительного класса, то мы получим метрику, которая называется полнотой (recall)
$$color{#348FEA}{text{Recall} = frac{TP}{TP + FN}}$$
Интуитивно метрика показывает долю найденных документов из всех релевантных. Чем меньше ложно отрицательных срабатываний, тем выше recall модели.
Например, в задаче предсказания злокачественности опухоли точность показывает, сколько из определённых нами как злокачественные опухолей действительно являются злокачественными, а полнота – какую долю злокачественных опухолей нам удалось выявить.
Хорошее понимание происходящего даёт следующая картинка: 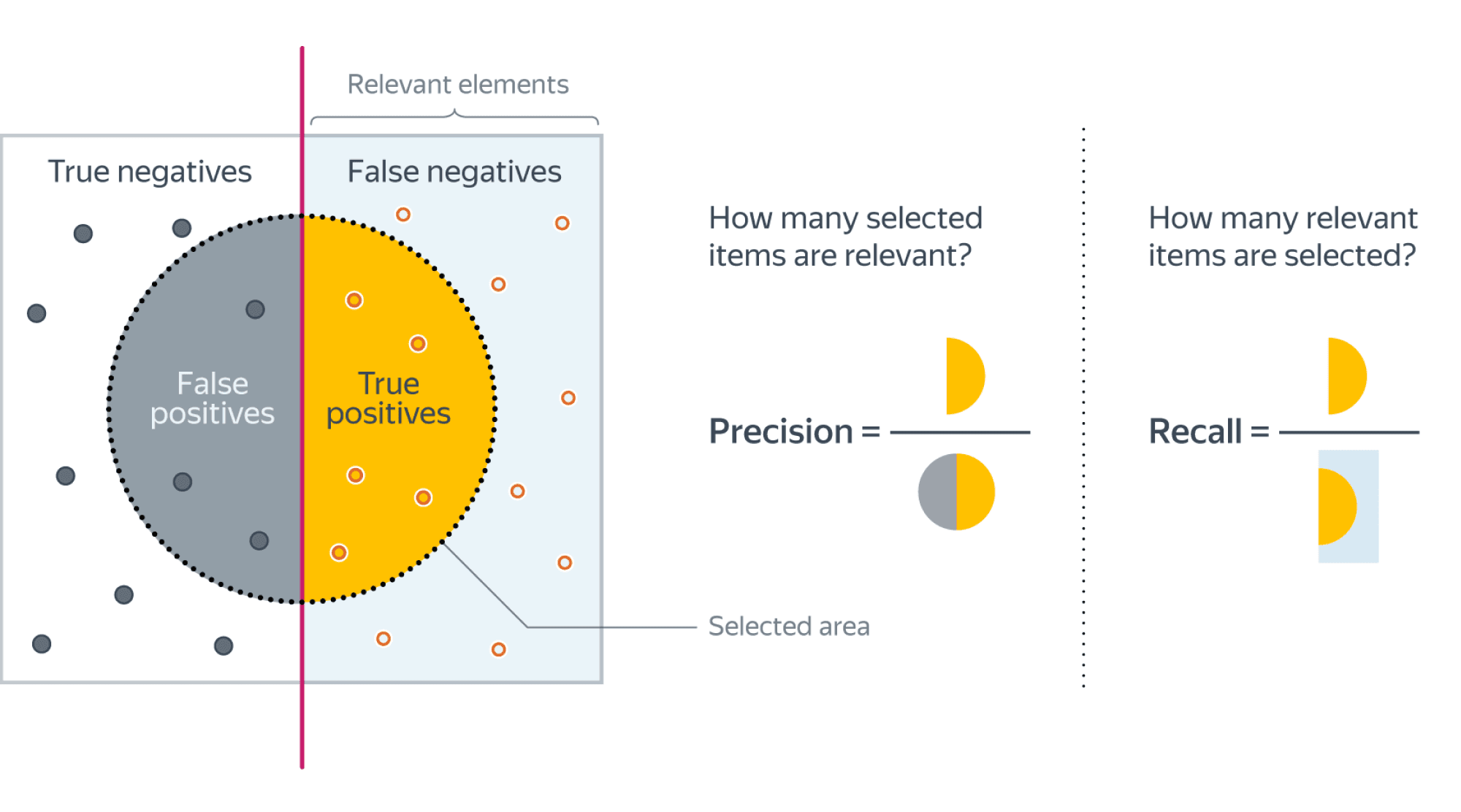 (источник картинки)
(источник картинки)
Recall@k, Precision@k
Метрики Recall и Precision хорошо подходят для задачи поиска «документ d релевантен запросу q», когда из списка рекомендованных алгоритмом документов нас интересует только первый. Но не всегда алгоритм машинного обучения вынужден работать в таких жестких условиях. Может быть такое, что вполне достаточно, что релевантный документ попал в первые k рекомендованных. Например, в интерфейсе выдачи первые три подсказки видны всегда одновременно и вообще не очень понятно, какой у них порядок. Тогда более честной оценкой качества алгоритма будет «в выдаче D размера k по запросу q нашлись релевантные документы». Для расчёта метрики по всей выборке объединим все выдачи и рассчитаем precision, recall как обычно подокументно.
F1-мера
Как мы уже отмечали ранее, модели очень удобно сравнивать, когда их качество выражено одним числом. В случае пары Precision-Recall существует популярный способ скомпоновать их в одну метрику — взять их среднее гармоническое. Данный показатель эффективности исторически носит название F1-меры (F1-measure).
$$
color{#348FEA}{F_1 = frac{2}{frac{1}{Recall} + frac{1}{Precision}}} = $$
$$ = 2 frac{Recall cdot Precision }{Recall + Precision} = frac
{TP} {TP + frac{FP + FN}{2}}
$$
Стоит иметь в виду, что F1-мера предполагает одинаковую важность Precision и Recall, если одна из этих метрик для вас приоритетнее, то можно воспользоваться $F_{beta}$ мерой:
$$
F_{beta} = (beta^2 + 1) frac{Recall cdot Precision }{Recall + beta^2Precision}
$$
Бинарная классификация: вероятности классов
Многие модели бинарной классификации устроены так, что класс объекта получается бинаризацией выхода классификатора по некоторому фиксированному порогу:
$$fleft(x ; w, w_{0}right)=mathbb{I}left[g(x, w) > w_{0}right].$$
Например, модель логистической регрессии возвращает оценку вероятности принадлежности примера к положительному классу. Другие модели бинарной классификации обычно возвращают произвольные вещественные значения, но существуют техники, называемые калибровкой классификатора, которые позволяют преобразовать предсказания в более или менее корректную оценку вероятности принадлежности к положительному классу.
Как оценить качество предсказываемых вероятностей, если именно они являются нашей конечной целью? Общепринятой мерой является логистическая функция потерь, которую мы изучали раньше, когда говорили об устройстве некоторых методов классификации (например уже упоминавшейся логистической регрессии).
Если же нашей целью является построение прогноза в терминах метки класса, то нам нужно учесть, что в зависимости от порога мы будем получать разные предсказания и разное качество на отложенной выборке. Так, чем ниже порог отсечения, тем больше объектов модель будет относить к положительному классу. Как в этом случае оценить качество модели?
AUC
Пусть мы хотим учитывать ошибки на объектах обоих классов. При уменьшении порога отсечения мы будем находить (правильно предсказывать) всё большее число положительных объектов, но также и неправильно предсказывать положительную метку на всё большем числе отрицательных объектов. Естественным кажется ввести две метрики TPR и FPR:
TPR (true positive rate) – это полнота, доля положительных объектов, правильно предсказанных положительными:
$$ TPR = frac{TP}{P} = frac{TP}{TP + FN} $$
FPR (false positive rate) – это доля отрицательных объектов, неправильно предсказанных положительными:
$$FPR = frac{FP}{N} = frac{FP}{FP + TN}$$
Обе эти величины растут при уменьшении порога. Кривая в осях TPR/FPR, которая получается при варьировании порога, исторически называется ROC-кривой (receiver operating characteristics curve, сокращённо ROC curve). Следующий график поможет вам понять поведение ROC-кривой.
Желтая и синяя кривые показывают распределение предсказаний классификатора на объектах положительного и отрицательного классов соответственно. То есть значения на оси X (на графике с двумя гауссианами) мы получаем из классификатора. Если классификатор идеальный (две кривые разделимы по оси X), то на правом графике мы получаем ROC-кривую (0,0)->(0,1)->(1,1) (убедитесь сами!), площадь под которой равна 1. Если классификатор случайный (предсказывает одинаковые метки положительным и отрицательным объектам), то мы получаем ROC-кривую (0,0)->(1,1), площадь под которой равна 0.5. Поэкспериментируйте с разными вариантами распределения предсказаний по классам и посмотрите, как меняется ROC-кривая.
Чем лучше классификатор разделяет два класса, тем больше площадь (area under curve) под ROC-кривой – и мы можем использовать её в качестве метрики. Эта метрика называется AUC и она работает благодаря следующему свойству ROC-кривой:
AUC равен доле пар объектов вида (объект класса 1, объект класса 0), которые алгоритм верно упорядочил, т.е. предсказание классификатора на первом объекте больше:
$$
color{#348FEA}{operatorname{AUC} = frac{sumlimits_{i = 1}^{N} sumlimits_{j = 1}^{N}mathbb{I}[y_i < y_j] I^{prime}[f(x_{i}) < f(x_{j})]}{sumlimits_{i = 1}^{N} sumlimits_{j = 1}^{N}mathbb{I}[y_i < y_j]}}
$$
$$
I^{prime}left[f(x_{i}) < f(x_{j})right]=
left{
begin{array}{ll}
0, & f(x_{i}) > f(x_{j}) \
0.5 & f(x_{i}) = f(x_{j}) \
1, & f(x_{i}) < f(x_{j})
end{array}
right.
$$
$$
Ileft[y_{i}< y_{j}right]=
left{
begin{array}{ll}
0, & y_{i} geq y_{j} \
1, & y_{i} < y_{j}
end{array}
right.
$$
Чтобы детальнее разобраться, почему это так, советуем вам обратиться к материалам А.Г.Дьяконова.
В каких случаях лучше отдать предпочтение этой метрике? Рассмотрим следующую задачу: некоторый сотовый оператор хочет научиться предсказывать, будет ли клиент пользоваться его услугами через месяц. На первый взгляд кажется, что задача сводится к бинарной классификации с метками 1, если клиент останется с компанией и $0$ – иначе.
Однако если копнуть глубже в процессы компании, то окажется, что такие метки практически бесполезны. Компании скорее интересно упорядочить клиентов по вероятности прекращения обслуживания и в зависимости от этого применять разные варианты удержания: кому-то прислать скидочный купон от партнёра, кому-то предложить скидку на следующий месяц, а кому-то и новый тариф на особых условиях.
Таким образом, в любой задаче, где нам важна не метка сама по себе, а правильный порядок на объектах, имеет смысл применять AUC.
Утверждение выше может вызывать у вас желание использовать AUC в качестве метрики в задачах ранжирования, но мы призываем вас быть аккуратными.
ПодробнееУтверждение выше может вызывать у вас желание использовать AUC в качестве метрики в задачах ранжирования, но мы призываем вас быть аккуратными.» details=»Продемонстрируем это на следующем примере: пусть наша выборка состоит из $9100$ объектов класса $0$ и $10$ объектов класса $1$, и модель расположила их следующим образом:
$$underbrace{0 dots 0}_{9000} ~ underbrace{1 dots 1}_{10} ~ underbrace{0 dots 0}_{100}$$
Тогда AUC будет близка к единице: количество пар правильно расположенных объектов будет порядка $90000$, в то время как общее количество пар порядка $91000$.
Однако самыми высокими по вероятности положительного класса будут совсем не те объекты, которые мы ожидаем.
Average Precision
Будем постепенно уменьшать порог бинаризации. При этом полнота будет расти от $0$ до $1$, так как будет увеличиваться количество объектов, которым мы приписываем положительный класс (а количество объектов, на самом деле относящихся к положительному классу, очевидно, меняться не будет). Про точность же нельзя сказать ничего определённого, но мы понимаем, что скорее всего она будет выше при более высоком пороге отсечения (мы оставим только объекты, в которых модель «уверена» больше всего). Варьируя порог и пересчитывая значения Precision и Recall на каждом пороге, мы получим некоторую кривую примерно следующего вида:
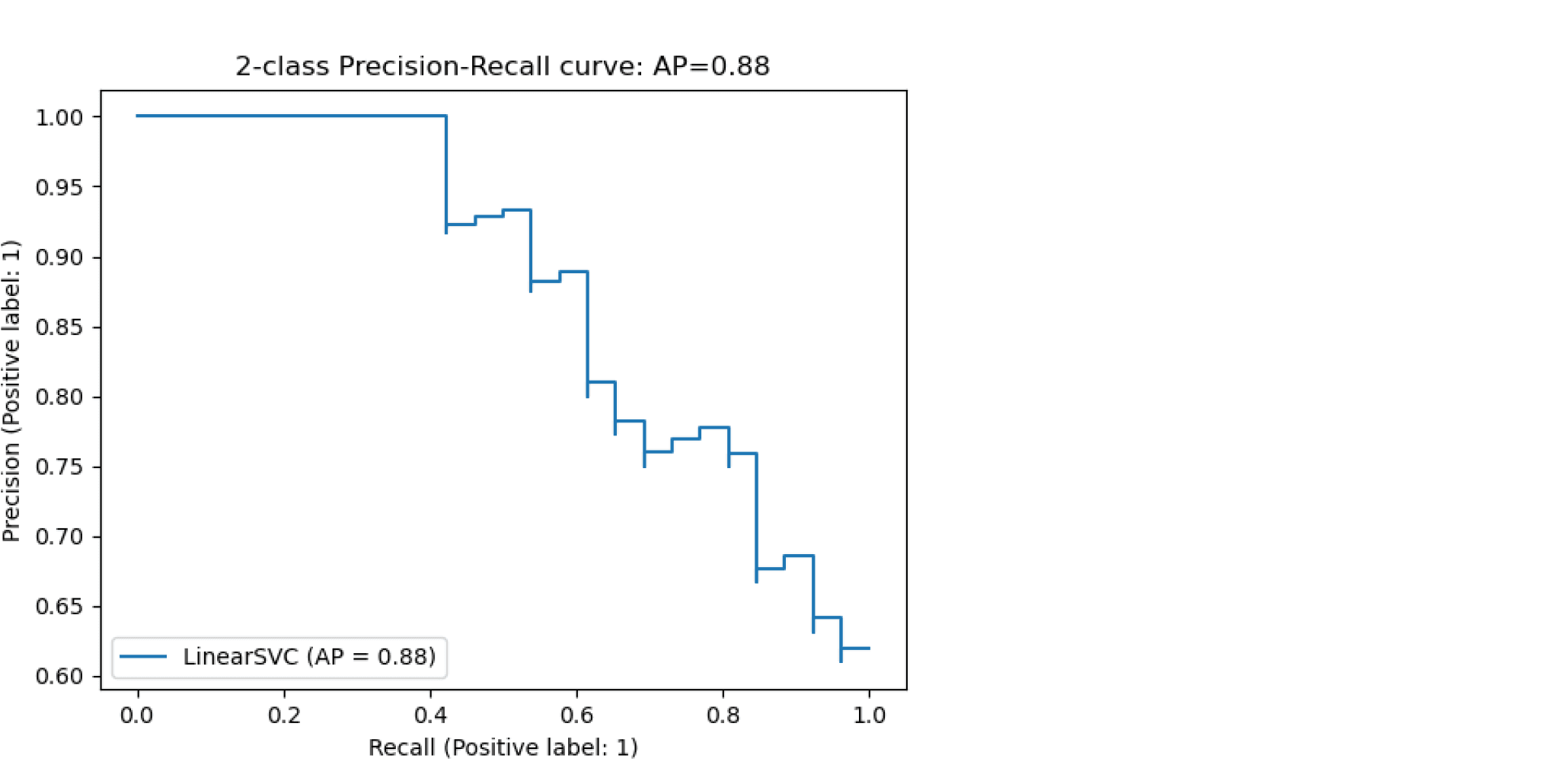 (источник картинки)
(источник картинки)
Рассмотрим среднее значение точности (оно равно площади под кривой точность-полнота):
$$ text { AP }=int_{0}^{1} p(r) d r$$
Получим показатель эффективности, который называется average precision. Как в случае матрицы ошибок мы переходили к скалярным показателям эффективности, так и в случае с кривой точность-полнота мы охарактеризовали ее в виде числа.
Многоклассовая классификация
Если классов становится больше двух, расчёт метрик усложняется. Если задача классификации на $K$ классов ставится как $K$ задач об отделении класса $i$ от остальных ($i=1,ldots,K$), то для каждой из них можно посчитать свою матрицу ошибок. Затем есть два варианта получения итогового значения метрики из $K$ матриц ошибок:
- Усредняем элементы матрицы ошибок (TP, FP, TN, FN) между бинарными классификаторами, например $TP = frac{1}{K}sum_{i=1}^{K}TP_i$. Затем по одной усреднённой матрице ошибок считаем Precision, Recall, F-меру. Это называют микроусреднением.
- Считаем Precision, Recall для каждого классификатора отдельно, а потом усредняем. Это называют макроусреднением.
Порядок усреднения влияет на результат в случае дисбаланса классов. Показатели TP, FP, FN — это счётчики объектов. Пусть некоторый класс обладает маленькой мощностью (обозначим её $M$). Тогда значения TP и FN при классификации этого класса против остальных будут не больше $M$, то есть тоже маленькие. Про FP мы ничего уверенно сказать не можем, но скорее всего при дисбалансе классов классификатор не будет предсказывать редкий класс слишком часто, потому что есть большая вероятность ошибиться. Так что FP тоже мало. Поэтому усреднение первым способом сделает вклад маленького класса в общую метрику незаметным. А при усреднении вторым способом среднее считается уже для нормированных величин, так что вклад каждого класса будет одинаковым.
Рассмотрим пример. Пусть есть датасет из объектов трёх цветов: желтого, зелёного и синего. Желтого и зелёного цветов почти поровну — 21 и 20 объектов соответственно, а синих объектов всего 4.
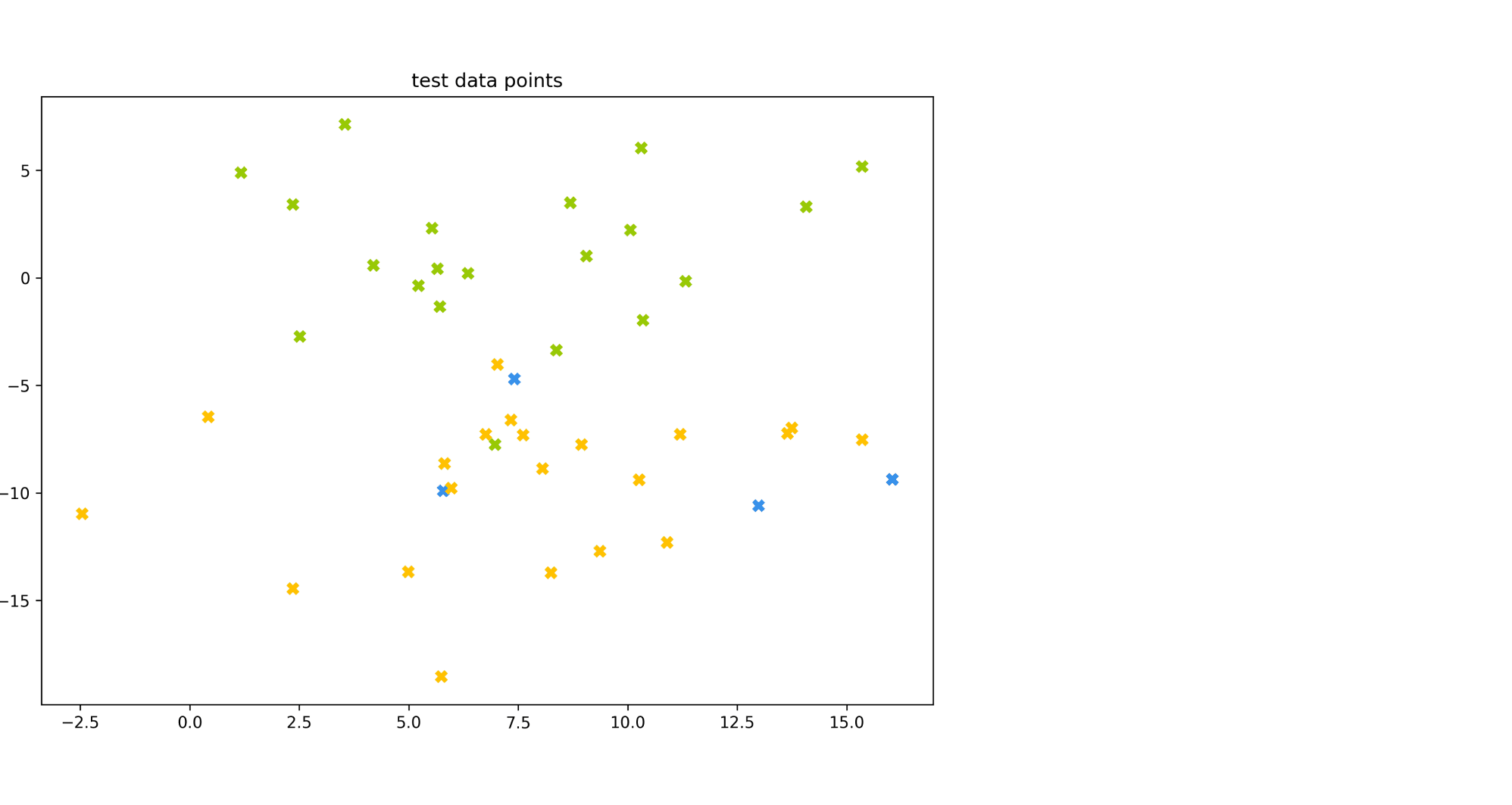
Модель по очереди для каждого цвета пытается отделить объекты этого цвета от объектов оставшихся двух цветов. Результаты классификации проиллюстрированы матрицей ошибок. Модель «покрасила» в жёлтый 25 объектов, 20 из которых были действительно жёлтыми (левый столбец матрицы). В синий был «покрашен» только один объект, который на самом деле жёлтый (средний столбец матрицы). В зелёный — 19 объектов, все на самом деле зелёные (правый столбец матрицы).
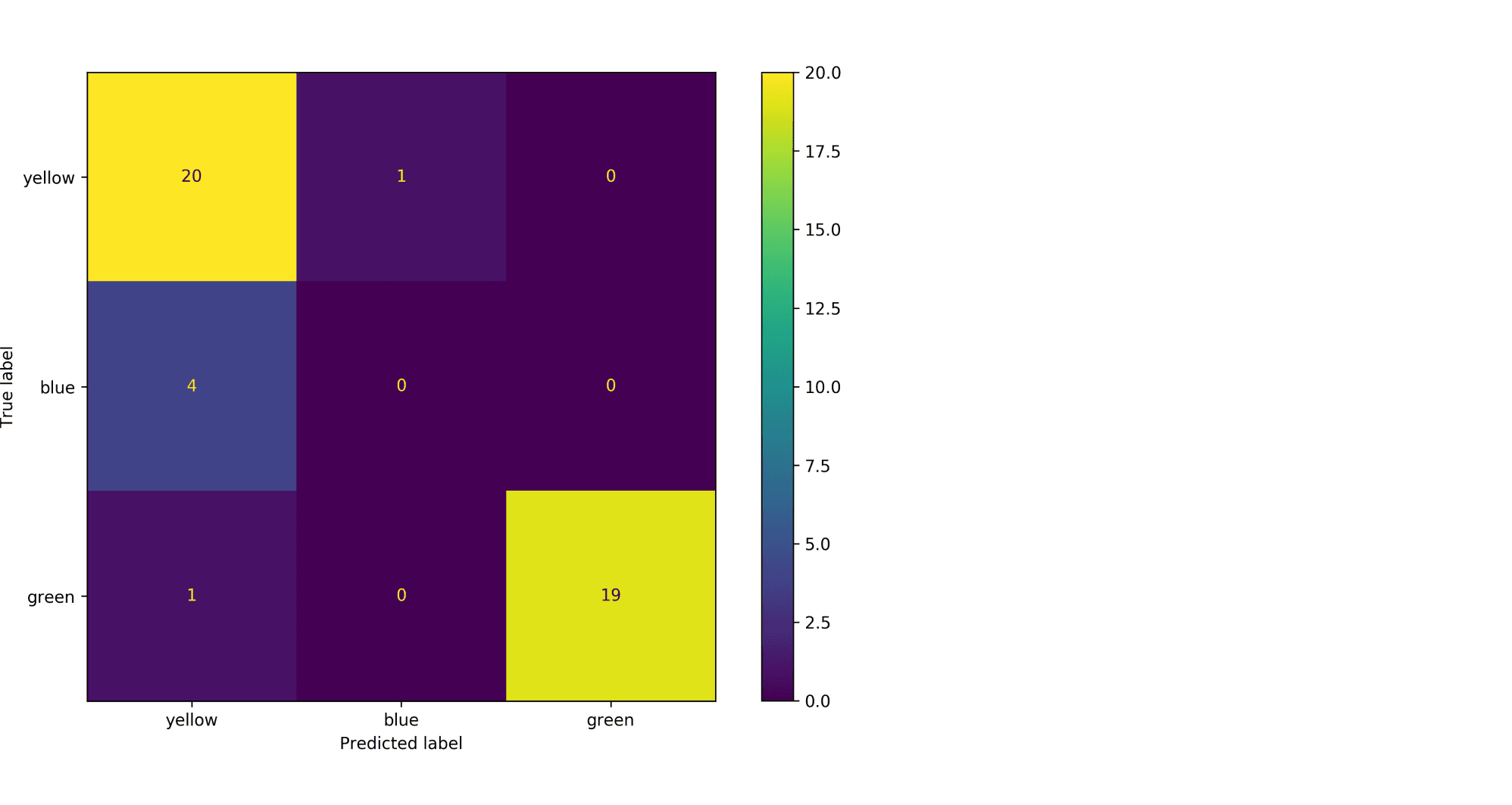
Посчитаем Precision классификации двумя способами:
- С помощью микроусреднения получаем $$
text{Precision} = frac{dfrac{1}{3}left(20 + 0 + 19right)}{dfrac{1}{3}left(20 + 0 + 19right) + dfrac{1}{3}left(5 + 1 + 0right)} = 0.87
$$ - С помощью макроусреднения получаем $$
text{Precision} = dfrac{1}{3}left( frac{20}{20 + 5} + frac{0}{0 + 1} + frac{19}{19 + 0}right) = 0.6
$$
Видим, что макроусреднение лучше отражает тот факт, что синий цвет, которого в датасете было совсем мало, модель практически игнорирует.
Как оптимизировать метрики классификации?
Пусть мы выбрали, что метрика качества алгоритма будет $F(a(X), Y)$. Тогда мы хотим обучить модель так, чтобы $F$ на валидационной выборке была минимальная/максимальная. Лучший способ добиться минимизации метрики $F$ — оптимизировать её напрямую, то есть выбрать в качестве функции потерь ту же $F(a(X), Y)$. К сожалению, это не всегда возможно. Рассмотрим, как оптимизировать метрики иначе.
Метрики precision и recall невозможно оптимизировать напрямую, потому что эти метрики нельзя рассчитать на одном объекте, а затем усреднить. Они зависят от того, какими были правильная метка класса и ответ алгоритма на всех объектах. Чтобы понять, как оптимизировать precision, recall, рассмотрим, как расчитать эти метрики на отложенной выборке. Пусть модель обучена на стандартную для классификации функцию потерь (LogLoss). Для получения меток класса специалист по машинному обучению сначала применяет на объектах модель и получает вещественные предсказания модели ($p_i in left(0, 1right)$). Затем предсказания бинаризуются по порогу, выбранному специалистом: если предсказание на объекте больше порога, то метка класса 1 (или «положительная»), если меньше — 0 (или «отрицательная»). Рассмотрим, что будет с метриками precision, recall в крайних положениях порога.
- Пусть порог равен нулю. Тогда всем объектам будет присвоена положительная метка. Следовательно, все объекты будут либо TP, либо FP, потому что отрицательных предсказаний нет, $TP + FP = N$, где $N$ — размер выборки. Также все объекты, у которых метка на самом деле 1, попадут в TP. По формуле точность $text{Precision} = frac{TP}{TP + FP} = frac1N sum_{i = 1}^N mathbb{I} left[ y_i = 1 right]$ равна среднему таргету в выборке. А полнота $text{Recall} = frac{TP}{TP + FN} = frac{TP}{TP + 0} = 1$ равна единице.
- Пусть теперь порог равен единице. Тогда ни один объект не будет назван положительным, $TP = FP = 0$. Все объекты с меткой класса 1 попадут в FN. Если есть хотя бы один такой объект, то есть $FN ne 0$, будет верна формула $text{Recall} = frac{TP}{TP + FN} = frac{0}{0+ FN} = 0$. То есть при пороге единица, полнота равна нулю. Теперь посмотрим на точность. Формула для Precision состоит только из счётчиков положительных ответов модели (TP, FP). При единичном пороге они оба равны нулю, $text{Precision} = frac{TP}{TP + FP} = frac{0}{0 + 0}$то есть при единичном пороге точность неопределена. Пусть мы отступили чуть-чуть назад по порогу, чтобы хотя бы несколько объектов были названы моделью положительными. Скорее всего это будут самые «простые» объекты, которые модель распознает хорошо, потому что её предсказание близко к единице. В этом предположении $FP approx 0$. Тогда точность $text{Precision} = frac{TP}{TP + FP} approx frac{TP}{TP + 0} approx 1$ будет близка к единице.
Изменяя порог, между крайними положениями, получим графики Precision и Recall, которые выглядят как-то так:
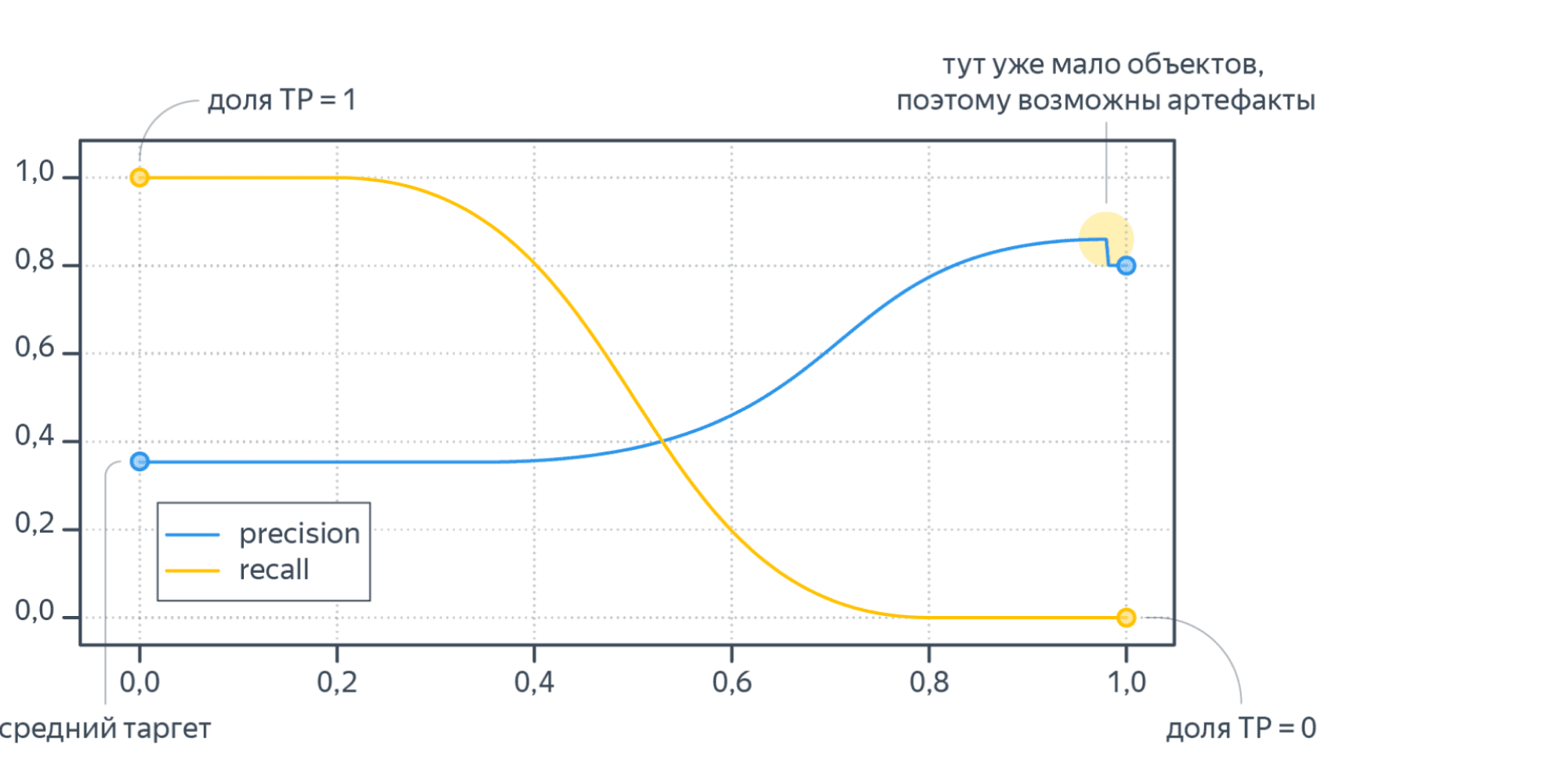
Recall меняется от единицы до нуля, а Precision от среднего тагрета до какого-то другого значения (нет гарантий, что график монотонный).
Итого оптимизация precision и recall происходит так:
- Модель обучается на стандартную функцию потерь (например, LogLoss).
- Используя вещественные предсказания на валидационной выборке, перебирая разные пороги от 0 до 1, получаем графики метрик в зависимости от порога.
- Выбираем нужное сочетание точности и полноты.
Пусть теперь мы хотим максимизировать метрику AUC. Стандартный метод оптимизации, градиентный спуск, предполагает, что функция потерь дифференцируема. AUC этим качеством не обладает, то есть мы не можем оптимизировать её напрямую. Поэтому для метрики AUC приходится изменять оптимизационную задачу. Метрика AUC считает долю верно упорядоченных пар. Значит от исходной выборки можно перейти к выборке упорядоченных пар объектов. На этой выборке ставится задача классификации: метка класса 1 соответствует правильно упорядоченной паре, 0 — неправильно. Новой метрикой становится accuracy — доля правильно классифицированных объектов, то есть доля правильно упорядоченных пар. Оптимизировать accuracy можно по той же схеме, что и precision, recall: обучаем модель на LogLoss и предсказываем вероятности положительной метки у объекта выборки, считаем accuracy для разных порогов по вероятности и выбираем понравившийся.
Регрессия
В задачах регрессии целевая метка у нас имеет потенциально бесконечное число значений. И природа этих значений, обычно, связана с каким-то процессом измерений:
- величина температуры в определенный момент времени на метеостанции
- количество прочтений статьи на сайте
- количество проданных бананов в конкретном магазине, сети магазинов или стране
- дебит добывающей скважины на нефтегазовом месторождении за месяц и т.п.
Мы видим, что иногда метка это целое число, а иногда произвольное вещественное число. Обычно случаи целочисленных меток моделируют так, словно это просто обычное вещественное число. При таком подходе может оказаться так, что модель A лучше модели B по некоторой метрике, но при этом предсказания у модели A могут быть не целыми. Если в бизнес-задаче ожидается именно целочисленный ответ, то и оценивать нужно огрубление.
Общая рекомендация такова: оценивайте весь каскад решающих правил: и те «внутренние», которые вы получаете в результате обучения, и те «итоговые», которые вы отдаёте бизнес-заказчику.
Например, вы можете быть удовлетворены, что стали ошибаться не во втором, а только в третьем знаке после запятой при предсказании погоды. Но сами погодные данные измеряются с точностью до десятых долей градуса, а пользователь и вовсе может интересоваться лишь целым числом градусов.
Итак, напомним постановку задачи регрессии: нам нужно по обучающей выборке ${(x_i, y_i)}_{i=1}^N$, где $y_i in mathbb{R}$ построить модель f(x).
Величину $ e_i = f(x_i) — y_i $ называют ошибкой на объекте i или регрессионным остатком.
Весь набор ошибок на отложенной выборке может служить аналогом матрицы ошибок из задачи классификации. А именно, когда мы рассматриваем две разные модели, то, глядя на то, как и на каких объектах они ошиблись, мы можем прийти к выводу, что для решения бизнес-задачи нам выгоднее взять ту или иную модель. И, аналогично со случаем бинарной классификации, мы можем начать строить агрегаты от вектора ошибок, получая тем самым разные метрики.
MSE, RMSE, $R^2$
MSE – одна из самых популярных метрик в задаче регрессии. Она уже знакома вам, т.к. применяется в качестве функции потерь (или входит в ее состав) во многих ранее рассмотренных методах.
$$ MSE(y^{true}, y^{pred}) = frac1Nsum_{i=1}^{N} (y_i — f(x_i))^2 $$
Иногда для того, чтобы показатель эффективности MSE имел размерность исходных данных, из него извлекают квадратный корень и получают показатель эффективности RMSE.
MSE неограничен сверху, и может быть нелегко понять, насколько «хорошим» или «плохим» является то или иное его значение. Чтобы появились какие-то ориентиры, делают следующее:
-
Берут наилучшее константное предсказание с точки зрения MSE — среднее арифметическое меток $bar{y}$. При этом чтобы не было подглядывания в test, среднее нужно вычислять по обучающей выборке
-
Рассматривают в качестве показателя ошибки:
$$ R^2 = 1 — frac{sum_{i=1}^{N} (y_i — f(x_i))^2}{sum_{i=1}^{N} (y_i — bar{y})^2}.$$
У идеального решающего правила $R^2$ равен $1$, у наилучшего константного предсказания он равен $0$ на обучающей выборке. Можно заметить, что $R^2$ показывает, какая доля дисперсии таргетов (знаменатель) объяснена моделью.
MSE квадратично штрафует за большие ошибки на объектах. Мы уже видели проявление этого при обучении моделей методом минимизации квадратичных ошибок – там это проявлялось в том, что модель старалась хорошо подстроиться под выбросы.
Пусть теперь мы хотим использовать MSE для оценки наших регрессионных моделей. Если большие ошибки для нас действительно неприемлемы, то квадратичный штраф за них — очень полезное свойство (и его даже можно усиливать, повышая степень, в которую мы возводим ошибку на объекте). Однако если в наших тестовых данных присутствуют выбросы, то нам будет сложно объективно сравнить модели между собой: ошибки на выбросах будет маскировать различия в ошибках на основном множестве объектов.
Таким образом, если мы будем сравнивать две модели при помощи MSE, у нас будет выигрывать та модель, у которой меньше ошибка на объектах-выбросах, а это, скорее всего, не то, чего требует от нас наша бизнес-задача.
История из жизни про бананы и квадратичный штраф за ошибкуИз-за неверно введенных данных метка одного из объектов оказалась в 100 раз больше реального значения. Моделировалась величина при помощи градиентного бустинга над деревьями решений. Функция потерь была MSE.
Однажды уже во время эксплуатации случилось ч.п.: у нас появились предсказания, в 100 раз превышающие допустимые из соображений физического смысла значения. Представьте себе, например, что вместо обычных 4 ящиков бананов система предлагала поставить в магазин 400. Были распечатаны все деревья из ансамбля, и мы увидели, что постепенно число ящиков действительно увеличивалось до прогнозных 400.
Было решено проверить гипотезу, что был выброс в данных для обучения. Так оно и оказалось: всего одна точка давала такую потерю на объекте, что алгоритм обучения решил, что лучше переобучиться под этот выброс, чем смириться с большим штрафом на этом объекте. А в эксплуатации у нас возникли точки, которые плюс-минус попадали в такие же листья ансамбля, что и объект-выброс.
Избежать такого рода проблем можно двумя способами: внимательнее контролируя качество данных или адаптировав функцию потерь.
Аналогично, можно поступать и в случае, когда мы разрабатываем метрику качества: менее жёстко штрафовать за большие отклонения от истинного таргета.
MAE
Использовать RMSE для сравнения моделей на выборках с большим количеством выбросов может быть неудобно. В таких случаях прибегают к также знакомой вам в качестве функции потери метрике MAE (mean absolute error):
$$ MAE(y^{true}, y^{pred}) = frac{1}{N}sum_{i=1}^{N} left|y_i — f(x_i)right| $$
Метрики, учитывающие относительные ошибки
И MSE и MAE считаются как сумма абсолютных ошибок на объектах.
Рассмотрим следующую задачу: мы хотим спрогнозировать спрос товаров на следующий месяц. Пусть у нас есть два продукта: продукт A продаётся в количестве 100 штук, а продукт В в количестве 10 штук. И пусть базовая модель предсказывает количество продаж продукта A как 98 штук, а продукта B как 8 штук. Ошибки на этих объектах добавляют 4 штрафных единицы в MAE.
И есть 2 модели-кандидата на улучшение. Первая предсказывает товар А 99 штук, а товар B 8 штук. Вторая предсказывает товар А 98 штук, а товар B 9 штук.
Обе модели улучшают MAE базовой модели на 1 единицу. Однако, с точки зрения бизнес-заказчика вторая модель может оказаться предпочтительнее, т.к. предсказание продажи редких товаров может быть приоритетнее. Один из способов учесть такое требование – рассматривать не абсолютную, а относительную ошибку на объектах.
MAPE, SMAPE
Когда речь заходит об относительных ошибках, сразу возникает вопрос: что мы будем ставить в знаменатель?
В метрике MAPE (mean absolute percentage error) в знаменатель помещают целевое значение:
$$ MAPE(y^{true}, y^{pred}) = frac{1}{N} sum_{i=1}^{N} frac{ left|y_i — f(x_i)right|}{left|y_iright|} $$
С особым случаем, когда в знаменателе оказывается $0$, обычно поступают «инженерным» способом: или выдают за непредсказание $0$ на таком объекте большой, но фиксированный штраф, или пытаются застраховаться от подобного на уровне формулы и переходят к метрике SMAPE (symmetric mean absolute percentage error):
$$ SMAPE(y^{true}, y^{pred}) = frac{1}{N} sum_{i=1}^{N} frac{ 2 left|y_i — f(x_i)right|}{y_i + f(x_i)} $$
Если же предсказывается ноль, штраф считаем нулевым.
Таким переходом от абсолютных ошибок на объекте к относительным мы сделали объекты в тестовой выборке равнозначными: даже если мы делаем абсурдно большое предсказание, на фоне которого истинная метка теряется, мы получаем штраф за этот объект порядка 1 в случае MAPE и 2 в случае SMAPE.
WAPE
Как и любая другая метрика, MAPE имеет свои границы применимости: например, она плохо справляется с прогнозом спроса на товары с прерывистыми продажами. Рассмотрим такой пример:
| Понедельник | Вторник | Среда | |
|---|---|---|---|
| Прогноз | 55 | 2 | 50 |
| Продажи | 50 | 1 | 50 |
| MAPE | 10% | 100% | 0% |
Среднее MAPE – 36.7%, что не очень отражает реальную ситуацию, ведь два дня мы предсказывали с хорошей точностью. В таких ситуациях помогает WAPE (weighted average percentage error):
$$ WAPE(y^{true}, y^{pred}) = frac{sum_{i=1}^{N} left|y_i — f(x_i)right|}{sum_{i=1}^{N} left|y_iright|} $$
Если мы предсказываем идеально, то WAPE = 0, если все предсказания отдаём нулевыми, то WAPE = 1.
В нашем примере получим WAPE = 5.9%
RMSLE
Альтернативный способ уйти от абсолютных ошибок к относительным предлагает метрика RMSLE (root mean squared logarithmic error):
$$ RMSLE(y^{true}, y^{pred}| c) = sqrt{ frac{1}{N} sum_{i=1}^N left(vphantom{frac12}log{left(y_i + c right)} — log{left(f(x_i) + c right)}right)^2 } $$
где нормировочная константа $c$ вводится искусственно, чтобы не брать логарифм от нуля. Также по построению видно, что метрика пригодна лишь для неотрицательных меток.
Веса в метриках
Все вышеописанные метрики легко допускают введение весов для объектов. Если мы из каких-то соображений можем определить стоимость ошибки на объекте, можно брать эту величину в качестве веса. Например, в задаче предсказания спроса в качестве веса можно использовать стоимость объекта.
Доля предсказаний с абсолютными ошибками больше, чем d
Еще одним способом охарактеризовать качество модели в задаче регрессии является доля предсказаний с абсолютными ошибками больше заданного порога $d$:
$$frac{1}{N} sum_{i=1}^{N} mathbb{I}left[ left| y_i — f(x_i) right| > d right] $$
Например, можно считать, что прогноз погоды сбылся, если ошибка предсказания составила меньше 1/2/3 градусов. Тогда рассматриваемая метрика покажет, в какой доле случаев прогноз не сбылся.
Как оптимизировать метрики регрессии?
Пусть мы выбрали, что метрика качества алгоритма будет $F(a(X), Y)$. Тогда мы хотим обучить модель так, чтобы F на валидационной выборке была минимальная/максимальная. Аналогично задачам классификации лучший способ добиться минимизации метрики $F$ — выбрать в качестве функции потерь ту же $F(a(X), Y)$. К счастью, основные метрики для регрессии: MSE, RMSE, MAE можно оптимизировать напрямую. С формальной точки зрения MAE не дифференцируема, так как там присутствует модуль, чья производная не определена в нуле. На практике для этого выколотого случая в коде можно возвращать ноль.
Для оптимизации MAPE придётся изменять оптимизационную задачу. Оптимизацию MAPE можно представить как оптимизацию MAE, где объектам выборки присвоен вес $frac{1}{vert y_ivert}$.