

Всем привет, сегодня хочу затронуть такую тему как осуществлять исправление ошибок в тексте посетителями вашего сайта. Данная инструкция подойдет для вебмастеров у кого сайты как и у меня на WordPress
Представим себе ситуацию, что вы написали новую хорошую статью. Вы торопились при ее написании, так как вас посетило вдохновение, в момент написания вы совершили ошибку в тексте, допустим написали Ашибка. К вам зашел на сайт читатель, и заметил орфографическую ошибку. Он хотел бы чтобы вы ее исправили, в большинстве случаев люди пишут комментарии, что правильно конечно, но может затеряться если их много у статьи, вот тут у WordPress есть возможность вам помочь, дать посетителям механизм исправление ошибок в тексте. Нам поможет плагин Mistape. Как установить плагин в WordPress я уже рассматривал, так, что перейдем непосредственно к настройке плагина Mistape. Скачать Mistape можно с официального сайта wordpress, в разделе плагины.
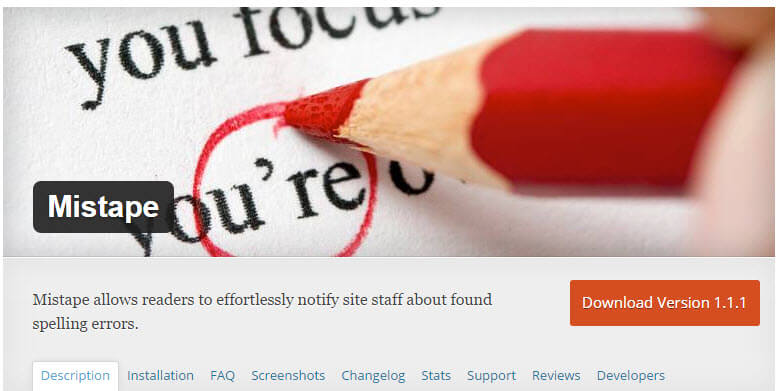
Переходим в настройки Mistape. Первым делом нужно настроить почту, на которую будут приходить уведомления от ваших посетителей сайта.
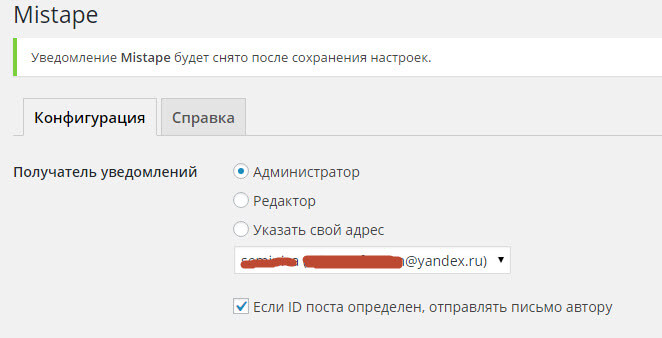
Указываем тип записей, где могут исправлять текст ваши посетители. Вы можете задать формат надписи, картинка либо текст, текст можно отредактировать.
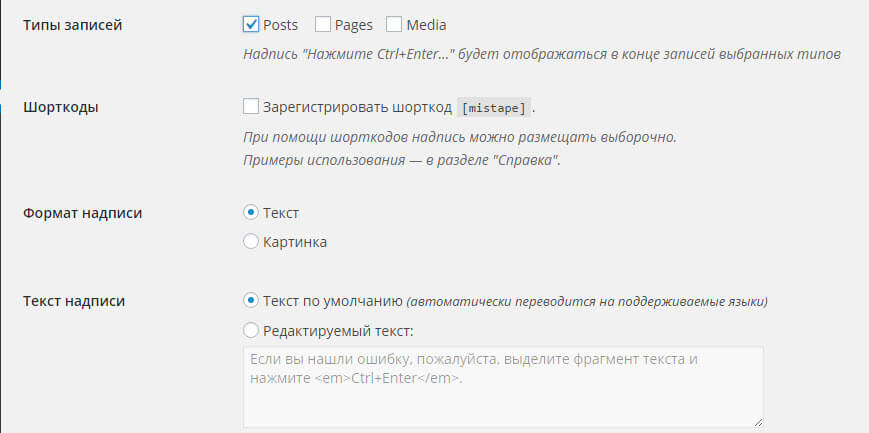
Убираем логотип Mistape и сохраняем наши изменения.
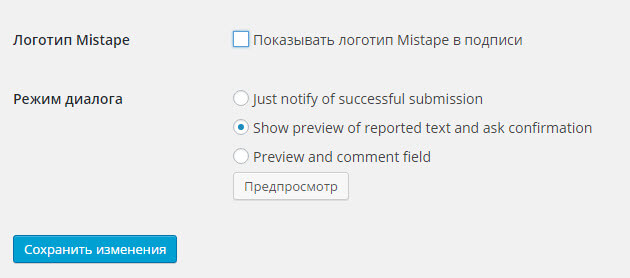
Теперь, ваш посетитель найдя ошибку выделяет ее, в моем случае это слово Ашибка
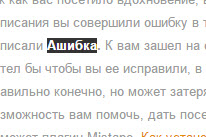
Нажимаем CTRL+Enter. У вас сразу появится окно с уведомлением, что можно оповестить автора статьи. Жмем отправить.
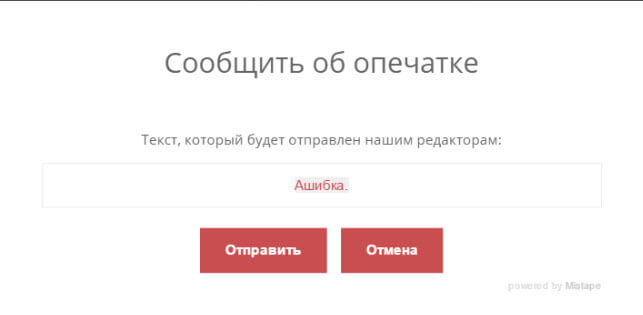
Все теперь автор увидит письмо об ошибке и исправит ее.
Все просто и бесплатно, как и весь конструктор WordPress. Главное правильно собрать части.
Материал сайта pyatilistnik.info
Сообщить об опечатке
*Подключить плагин можно в разделе консоли вашего сайта Плагины.
С помощью данного плагина посетители смогут сообщить об опечатках или ошибках, замеченных на ваших сайтах.
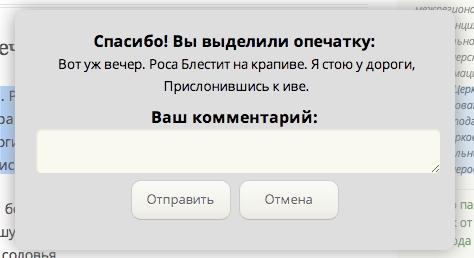
Для того, чтобы отправить сообщение об ошибке, необходимо выделить текст на странице сайта, где замечена ошибка, и нажать сочетание клавиш Ctrl+Enter или специальную ссылку. Появится диалоговое окно, в котором пользователь сможет написать комментарий и отправить сообщение об ошибке.
Уведомления об ошибках приходят на е-мэйлы, указанные в настройках плагина. Информация об опечатках в консоли сайта не хранится.
Для работы плагина нужно настроить 2 важные вещи:
- Куда будут приходить сообщения об ошибке.
- Рассказать вашим пользователям, что на вашем сайте есть возможность сообщить об опечатке и как этим пользоваться.
1. Добавление e-mail адреса, на который будет отправляться уведомление об опечатке
Для того, чтобы добавить е-мэйл получателя зайдите в раздел консоли «Настройки» — «Сообщение об опечатке».

Введите в поле е-мэйл, на который будут отправляться уведомления об опечатках:
Также вы можете указать несколько адресов, е-мэйлы пишите через запятую:
2. Информирование посетителей о том, каким образом они могут сообщить об опечатке
Вы можете разместить в любом доступном месте вашего сайта информацию о том, как можно сообщить об опечатке на вашем сайте. Можно просто разместить текст в заметном месте
Заметили опечатку?
Выделите текст и нажмите CTRL+ENTER.
Или вы можете воспользоваться виджетом, с помощью которого можно добавить ссылку, простую кнопку или любое изображение, при нажатии на которое будет срабатывать сочетание клавиш Ctrl+Enter (удобно в частности для мобильных устройств).
Зайдите в раздел консоли «Внешний вид» — «Виджеты», перетащите в нужную область виджет «Сообщение об опечатке».
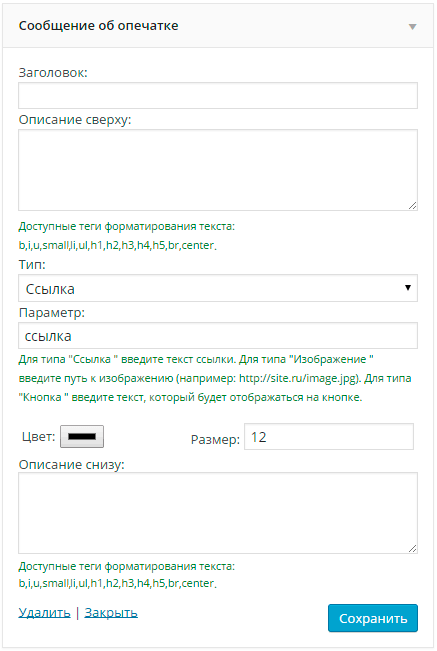
Заголовок — введите заголовок виджета (поле можно оставить пустым).
Описание сверху — добавьте описание, которое будет выводиться перед ссылкой или кнопкой. В описании можно использовать следующие html-теги форматирования текста: b,i,u,li,ul,h1,h2,h3,h4,h5,br,center,small.
Например, в этом поле можно вставить информационный текст « Заметили ошибку?
Выделите текст и нажмите CTRL+ENTER или ссылку (картинку, кнопку) ниже.»
Тип — выберите тип ссылки, при нажатии на которую будет срабатывать Ctrl+Enter.
- Ссылка — простая текстовая ссылка.
- Изображение — можно будет вывести любую картинку.
- Кнопка — будет отображаться кнопка с заданным цветом и текстом.
Параметр — Для типа «Ссылка» введите текст (например, «сообщите об ошибке»). Для типа «Изображение» введите путь к изображению (например: http://site.ru/image.jpg). Для типа «Кнопка» введите текст, который будет отображаться на кнопке.
Здесь можно посмотреть где брать ссылку на изображение, загруженное на ваш сайт.
Цвет — в данном поле можно задать цвет ссылки или цвет кнопки (в зависимости от выбранного типа).
Размер — в данном поле можно задать размер текста ссылки на кнопке, а также ширину изображения, если выбрана картинка.
Описание снизу — добавьте описание, которое будет выводиться после ссылки или кнопки. В описании можно использовать следующие теги форматирования текста: b,i,u,li,ul,h1,h2,h3,h4,h5,br,center,small.
Важно! Чтобы верхний текст, кнопка (ссылка, изображение) и нижний текст не сливались в одну массу, используйте тег <br> или просто перенос на новую строку клавишей Enter. В поле «Описание сверху» тег или перенос добавляйте после текста, а в поле «Описание снизу» — перед текстом.
Ошибки и описки на сайте
Перепробовали несколько внешних систем, позволяющих в удобной форме сообщать на почту об описках и ошибках на сайте. Все они какие-то очень кривые. В результате теперь у нас своя, встроенная. Работает как полагается.
Чтобы сообщить об описке или ошибке на сайте, выделите слово или словосочетание и нажмите Ctrl+Enter — появится вот такая форма.
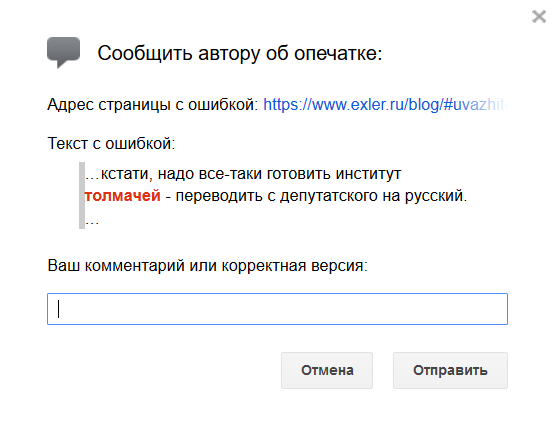
Там цитируется весь абзац (чтобы мне проще было понять, где это), можно дать свой комментарий, но это необязательно.
Возможность эта доступна только зарегистрированным и залогиненным пользователям. Если пользователь вместо сообщений об ошибках будет слать всякую ерунду, он будет баниться, а все его накопленные баллы сгорят.
Спасибо всем, кто указывает на описки и ошибки на сайте — вместе мы делаем этот мир лучше.
Правила написания сообщений об ошибках
Народная мудрость гласит, что хорошие сообщения об ошибках должны быть вежливыми, точными и конструктивными. С приходом Web к этим требованиям добавились еще несколько: делайте так, чтобы сообщение об ошибке было четко видно; в случае ошибки пользователь не должен тратить много времени на ее исправление; обучайте пользователей по ходу дела.
Правила создания эффективных сообщений об ошибках не меняются вот уже 20 лет. Хорошее сообщение об ошибке должно:
- Явно указывать, что что-то не так. Самое плохое сообщение об ошибке это то, которое не было создано. Если пользователи делают ошибку и не получают никакого отклика от системы, это самое худшее для них. Например, приложение работы с электронной почтой имеет несколько ситуаций, где указание о произошедшей ошибке было бы явно полезным. Скажем, вы отправили почтовое сообщение, которое было благополучно проглочено системой, но так и не достигло адресата. Еще пример? Вы сообщаете в письме, что прилагаете к нему файл, но просто забыли сделать это. Вот тут-то и нашлась бы работа для этой глупой скрепки из MS Office: «Похоже, вы хотели прикрепить файл к вашему сообщению, но не сделали этого. Хотите сделать это?».
- Быть написано на человеческом языке, а не с использованием таинственных кодов и сокращений типа » произошла ошибка типа 2″.
- Быть вежливым и не обвинять пользователей в том, что они такие глупые или сделали что-то не так, как например в сообщении «запрещенная команда».
- Точно описывать источник проблемы, а не просто выдавать общие фразы типа » синтаксическая ошибка».
- Давать конструктивный совет о том, как исправить проблему. Например, вместо того, чтобы сообщать о том, что товара » нет в наличии», ваше сообщение об ошибке должно либо сообщать, когда товар будет в наличии, или предлагать пользователям настроить отсылку им сообщения-уведомления, когда товар появится в наличии.
Самая распространенная ошибка в Web — 404 — нарушает большинство из этих правил. Я рекомендую вам написать свое собственное сообщение об ошибке 404 вместо того, чтобы полагаться на скупую серверную фразу «page not found».
Новые правила
Сложность работы с веб-страницами привела к появлению еще одного правила, которое не требовалось в старые времена. В интерфейсе DOS пользователи набирали команду и сообщение об ошибке появлялось в следующей строке на экране. В современных графических оболочках когда пользователь выбирает ошибочную команду, сообщение об ошибке выводится в большом диалоговом окне в центре экрана, и оно не исчезает до тех пор, пока пользователь не примет его. Однако, в Web сообщения об ошибках часто спрятаны в тексте страницы, из-за чего мы выводим следующее правило: сообщение об ошибке должно быть:
- Видимым и очень заметным, как относительно самого сообщения, так и того места, где пользователь должен исправить ошибку.
Я часто замечал, как пользователи совершают ошибку в веб-форме, подают форму и получают на экране опять ту же самую форму без какого-либо указания на то, что с ней не так. Часто в верху страницы появляется небольшое сообщение об ошибке, но так как пользователи смотрят на странице в первую очередь на то, с чем они работают (то есть, на поля формы), они как правило не замечают этого сообщения.
Точно так же неверно будет обозначать сообщение об ошибке только красным цветом. Это нарушение одного из старейших и простейших правил создания технологий, доступных пользователям, у которых проблемы со здоровьем: никогда не используйте в интерфейсе только цвет для обозначения состояния системы; всегда дополняйте его еще какими-нибудь сигналами, которые могут увидеть люди с проблемами в восприятии цвета.
Вот еще несколько правил, которые позволят смягчить неприятную ситуацию, в которую попадает пользователь при ошибке:
- Сохраняйте как можно больше от работы, сделанной пользователем. Позволяете пользователям исправить ошибку в своем действии вместо того, чтобы предлагать ему все начать сначала. Например, выводя ему результаты поиска, показывайте там же поле поиска и в нем выводите те ключевые слова, которые пользователь искал, чтобы он их мог исправить и улучшить результат. Если поиск не дал никаких результатов, дайте пользователю возможность одним щелчком мыши расширить область поиска.
- Сократите работу по исправлению ошибки. Если возможно, постарайтесь, чтобы система догадалась о правильном действии и предложила пользователю выбрать это правильное действие из небольшого списка вариантов. Например вместо того, чтобы просто написать «название города не соответствует его почтовому индексу», дайте пользователю возможность щелкнуть на кнопке и выбрать в списке город, соответствующий его почтовому индексу.
Обучение пользователей
И наконец, вы наверное уже знаетеПервый Закон Нильсена о компьютерной документации: люди ее не читают. Этот закон действует еще сильнее для веб-сайтов, где пользователи действительно избегают читать то, что не существенно для их задачи. Щелкнуть по ссылке «Помощь»? Да ни за что.
Пользователи читают документацию к системе только тогда, когда у них возникает проблема (это Второй закон). Они особенно внимательно ее читают, когда хотят исправить ошибочное действие. В этом случае вы можете использовать сообщения об ошибках в качестве обучающего материала, и подавать в них эти знания малыми порциями. Естественно, сообщения об ошибках должны быть краткими и по делу, как впрочем весь контент веб-сайта. Однако, сообщения об ошибках все-таки могут дать людям крупицы информации о том, как работает система, и подсказать, как с нею лучше работать. И в завершении этой темы, Web вводит еще одно правило:
Обзор открытых решений для исправления опечаток
Время на прочтение
11 мин
Количество просмотров 14K
У каждого пользователя когда-либо были опечатки при написании поисковых запросов. Отсутствие механизмов, которые исправляют опечатки, приводит к выдаче нерелевантных результатов, а то и вовсе к их отсутствию. Поэтому, чтобы поисковая система была более ориентированной на пользователей, в неё встраивают механизмы исправления ошибок.

Задача исправления опечаток, на первый взгляд, кажется довольно несложной. Но если отталкиваться от разнообразия ошибок, реализация решения может оказаться трудной. В целом, исправление опечаток разделяется на контекстно-независимое и контекстно-зависимое (где учитывается словарное окружение). В первом случае ошибки исправляются для каждого слова в отдельности, во втором – с учетом контекста (например, для фразы «она пошле домой» в контекстно-независимом случае исправление происходит для каждого слова в отдельности, где мы можем получить «она пошел домой», а во втором случае правильное исправление выдаст «она пошла домой»).
В поисковых запросах русскоязычного пользователя можно выделить четыре основные группы ошибок только для контекстно-независимого исправления [1]:
1) ошибки в самих словах (пмрвет → привет), к этой категории относятся всевозможные пропуски, вставки и перестановки букв – 63,7%,
2) слитно-раздельное написание слов – 16,9%,
3) искаженная раскладка (ghbdtn → привет) – 9,7 %,
4) транслитерация (privet → привет) – 1,3%,
5) смешанные ошибки – 8,3%.
Пользователи совершают опечатки приблизительно в 10-15% случаях. При этом 83,6% запросов имеют одну ошибку, 11,7% –две, 4,8% – более трёх. Контекст важен в 26% случаев.
Эта статистика была составлена на основе случайной выборки из дневного лога Яндекса в далеком 2013 году на основе 10000 запросов. В открытом доступе есть гораздо более ранняя презентация от Яндекса за 2008 год, где показано похожее распределение статистики [2]. Отсюда можно сделать вывод, что распределение разновидностей ошибок для поисковых запросов, в среднем, с течением времени не изменяется.
В общем виде механизм исправления опечаток основывается на двух моделях: модель ошибок и языковая модель. Причем для контекстно-независимого исправления используется только модель ошибок, а в контекстно-зависимом – сразу две. В качестве модели ошибок обычно выступает либо редакционное расстояние (расстояние Левенштейна, Дамерау-Левенштейна, также сюда могут добавляться различные весовые коэффициенты, методы на подобие Soundex и т. д. – в таком случае расстояние называется взвешенным), либо модель Бриля-Мура, которая работает на вероятностях переходов одной строки в другую. Бриль и Мур позиционируют свою модель как более совершенную, однако на одном из последних соревнований SpellRuEval подход Дамерау-Левенштейна показал результат лучше [3], несмотря на тот факт, что расстояние Дамерау-Левенштейна (уточнение – невзвешенное) не использует априори информацию об опечаточной статистике. Это наблюдение особо показательно в том случае, если для разных реализаций автокорректоров в библиотеке DeepPavlov использовались одинаковые обучающие тексты.
Очевидно, что возможность контекстно-зависимого исправления усложняет построение автокорректора, т. к. дополнительно к модели ошибок добавляется необходимость в языковой модели. Но если обратить внимание на статистику опечаток, то ¾ всех неверно написанных поисковых запросов можно исправлять без контекста. Это говорит о том, что польза как минимум от контекстно-независимого автокорректора может быть весьма существенной.
Также контекстно-зависимое исправление для корректировки опечаток в запросах очень требовательно по ресурсам. Например, в одном из выступлений Яндекса список пар для исправления опечаток (биграмм) слов отличался в 10 раз по сравнению с количеством слов (униграмм), что тогда говорить про триграммы? Очевидно, что это существенно зависит от вариативности запросов. Немного странно выглядит, когда автокорректор занимает половину памяти от предлагаемого продукта компании, целевое назначение которого не ориентировано на решение проблемы правописания. Так что вопрос внедрения контекстно-зависимого исправления в поисковых системах программных продуктов может быть весьма спорным.
На первый взгляд, складывается впечатление, что существует много готовых решений под любой язык программирования, которые можно использовать без особого погружения в подробности работы алгоритмов, в том числе – в коммерческих системах. Но на практике продолжается разработка своих решений. Например, сравнительно недавно в Joom было сделано собственное решение по исправлению опечаток с использованием языковых моделей для поисковых запросов [4]. Действительно ли ситуация непроста с доступностью готовых решений? С этой целью был сделан, по возможности, широкий обзор существующих решений. Перед тем как приступить к обзору, определимся с тем, как проверяется качество работы автокорректора.
Проверка качества работы
Вопрос проверки качества работы автокорректора весьма неоднозначен. Один из простых подходов проверки — через точность (Precision) и полноту (Recall). В соответствии со стандартом ISO, точность и полнота дополняются правильностью (на англ. «corectness»).

Полнота (Recall) рассчитывается следующим образом: список из правильных слов подается автокорректору (Total_list_true), и, количество слов, которое автокорректор считает правильными (Spellchecker_true), разделенное на общее количество правильных слов (Total_list_true), будет считаться полнотой.

Для определения точности (Precision) на вход автокорректора подается список из неправильных слов (Total_list_false), и, количество слов, которое автокорректор считает неправильным (Spell_checker_false), разделенное на общее количество неправильных слов (Total_list_false), определяют как точность.

Насколько вообще эти метрики информативны и как могут быть полезны, каждый определяет самостоятельно. Ведь, фактически, суть данной проверки сводится к тому, что проверяется вхождение слова в обучающий словарь. Более наглядной метрикой можно считать correctness, согласно которой автокорректор для каждого слова из тестового множества неправильных слов формирует список кандидатов-замен, на которые можно исправить это неправильное слово (следует иметь в виду, что здесь могут оказаться слова, которые не содержатся в обучающем словаре). Допустим, размер такого списка кандидатов-замен равен 5. Исходя из того, что размер списка равен 5, будет сформировано 6 групп, в одну из которых мы будем помещать наше каждое исходное неправильное слово по следующему принципу: в 1-ую группу — если в списке кандидатов-замен предполагаемое нами правильное слово стоит 1-ым, во 2-ую если стоит 2-ым и т. д., а в последнюю группу — если предполагаемого правильного слова в списке кандидатов-замен не оказалось. Разумеется, чем больше слов попало в 1-ую группу и чем меньше в 6-ую, тем лучше работает автокорректор.
Рассмотренного выше подхода придерживались авторы в статье [5], в которой сравнивались контекстно-независимые автокорректоры с уклоном на стандарт ISO. Там же приведены ссылки на другие способы оценки качества.
С одной стороны, такой подход не базируется на опечаточной статистике, в основу которого может быть положена модель ошибок Бриля-Мура [6], либо модель ошибок взвешенного расстояния Дамерау-Левенштейна.
Для проверки качества работы контекстно-независимого автокорректора был создан собственный генератор опечаток, который генерировал опечатки неверной раскладки и орфографические опечатки исходя из статистики по опечаткам, представленной Яндексом. Для орфографических опечаток генерировались произвольные вставки, замены, удаления, перестановки, а количество ошибок так же варьировалось в соответствии с этой статистикой. Для ошибок искаженной раскладки, правильное слово посимвольно изменялось целиком в соответствии с таблицей перевода символов.
Далее была проведена серия экспериментов для всего списка слов обучающего словаря (слова обучающего словаря исправлялись на неправильные в соответствии с вероятностью возникновения той или иной опечатки). В среднем, автокорректор исправляет слова верно в 75% случаев. Вне всякого сомнения, это количество будет сокращаться при пополнении обучающего словаря близкими по редакционному расстоянию словами, большом многообразии словоформ. Эта проблема может решаться за счет дополнения языковыми моделями, но здесь следует учитывать, что количество требуемых ресурсов ощутимо возрастет.
Готовые решения

Рассмотрение готовых решений проводилось с уклоном на собственное использование, и приоритет отдавался автокорректорам, которые удовлетворяют трем критериям:
1) язык реализации,
2) тип лицензии,
3) обновляемость.
В продуктовой разработке язык Java считается одним из самых популярных, поэтому приоритет при поиске библиотек отдавался ему. Из лицензий актуальны: MIT, Public, Apache, BSD. Обновляемость — не более 2-х лет с последнего обновления. В ходе поиска фиксировалась дополнительная информация, например, о поддерживаемой платформе, требуемые дополнительные программы, особенности применения, возможные затруднения при первом использовании и т. д. Ссылки с основными и полезными ресурсами на источники приведены в конце статьи. В целом, если не ограничиваться вышеупомянутыми критериями, количество существующих решений велико. Давайте кратко рассмотрим основные, а более подробно уделим внимание лишь некоторым.
Исторически одним из самых старых автокорректоров является Ispell (International Spell), написан в 1971 на ассемблере, позднее перенесен на C и в качестве модели ошибок использует редакционное расстояние Дамерау-Левенштейна. Для него даже есть словарь на русском языке. В последующем ему на замену пришли два автокорректора HunSpell (ранее MySpell) и Aspell. Оба реализованы на на C++ и распространяются под GPL лицензиями. На HunSpell также распространяется GPL/MPL и его используют для исправления опечаток в OpenOffice, LibreOffice, Google Chrome и других инструментах.
Для Интернета и браузеров есть целое множество решений на JS (сюда можно отнести: nodehun-sentences, nspell, node-markdown-spellcheck, Proofreader, Spellcheck-API — группа решений, базирующаяся на автокорректоре Hunspell; grunt-spell — под NodeJS; yaspeller-ci — обертка для автокорректора Яндекс.Спеллер, распространяется под MIT; rousseau — Lightweight proofreader in JS — используется для проверки правописания).
В категорию платных решений входят: Spellex; Source Code Spell Checker — как десктопное приложение; для JS: nanospell; для Java: Keyoti RapidSpell Spellchecker, JSpell SDK, WinterTree (у WinterTree можно даже купить исходный код за $5000).
Широкой популярностью пользуется автокорректор Питера Норвига, программный код на Python которого находится в публичном доступе в статье «How to Write a Spelling Corrector» [7]. На основе этого простого решения были построены автокорректоры на других языках, например: Norvig-spell-check, scala-norvig-spell-check (на Scala), toy-spelling-corrector — Golang Spellcheck (на GO), pyspellchecker (на Python). Разумеется, здесь никакой речи не идет о языковых моделях и контекстно-зависимом исправлении.
Для текстовых редакторов, в частности для VIM сделаны vim-dialect, vim-ditto — распространяются под публичной лицензией; для Notepad++ разработан DspellCheck на C++, лицензия GPL; для Emacs сделан инструмент автоматического определения языка при печати, называется guess-language, распространяется под публичной лицензией.
Есть отдельные сервисы от поисковых гигантов: Яндекс.Спеллер — от Яндекса, про обертку к нему было сказано выше, google-api-spelling-java (соответственно, от Google).
Бесплатные библиотеки для Java: languagetool (лицензируется под LGPL), интегрируется с библиотекой текстового поиска Lucene и допускает использование языковых моделей, для работы необходима 8 версия Java; Jazzy (аналог Aspell) распространяется под лицензией LGPLv2 и не обновлялась с 2005 года, а в 2013 была перенесена на GitHub. По подобию этого автокорректора сделано отдельное решение [8]; Jortho (Java Orthography) распространяется под GPL и разрешает бесплатное использование исключительно в некоммерческих целях, в коммерческих — за дополнительную плату; Jaspell (лицензируется под BSD и не обновлялся с 2005 года); Open Source Java Suggester — не обновлялся с 2013 года, распространяется SoftCorporation LLC и разрешает коммерческое применение; LuceneSpellChecker — автокорректор библиотеки Lucene, написана на Java и распространяется под лицензией Apache.
На протяжении длительного времени вопросом исправления опечаток занимался Wolf Garbe, им были предложены алгоритмы SymSpell (под MIT лицензией) и LinSpell (под LGPL) с реализациями на C# [9], которые используют расстояние Дамерау-Левенштейна для модели ошибок. Особенность их реализации в том, что на этапе формирования возможных ошибок для входного слова, используются только удаления, вместо всевозможных удалений, вставок, замен и перестановок. По сравнению с реализацией автокорректора Питера Норвига оба алгоритма за счет этого работают быстрее, при этом прирост в скорости существенно увеличивается, если расстояние по Дамерау-Левенштейну становится больше двух. Также за счет того, что используются только удаления, сокращается время формирования словаря. Отличие между двумя алгоритмами в том, что LinSpell более экономичен по памяти и медленнее по скорости поиска, SymSpell — наоборот. В более поздней версии SymSpell исправляет ошибки слитно-раздельного написания. Языковые модели не используются.
К числу наиболее свежих и перспективных для пользования автокорректоров, работающих с языковыми моделями и исправляющих контекстно-зависимые опечатки относятся Яндекс.Спеллер, JamSpell [10], DeepPavlov [11]. Последние 2 распространяются свободно: JamSpell (MIT), DeepPavlov (под Apache).
Яндекс.Спеллер использует алгоритм CatBoost, работает с несколькими языками и исправляет всевозможные разновидности ошибок даже с учетом контекста. Единственное из найденных решение, которое исправляет ошибки неверной раскладки и транслитерацию. Решение обладает универсальностью, что делает его популярным. Его недостатком является то, что это удаленный сервис, а про ограничения и условия пользования можно прочитать здесь [12]. Сервис работает с ограниченным количеством языков, нельзя самостоятельно добавлять слова и управлять процессом исправления. В соответствии с ресурсом [3] по результатам соревнований RuSpellEval этот автокорректор показал самое высокое качество исправлений. JamSpell — самый быстрый из известных автокорректор (C++ реализация), здесь есть готовые биндинги под другие языки. Исправляет ошибки только в самих словах и работает с конкретным языком. Использовать решение на уровне униграмм и биграмм нельзя. Для получения приемлемого качества требуется большой обучающий текст.
Есть неплохие наработки у DeepPavlov, однако интеграция этих решений и последующая поддержка в собственном продукте может вызвать затруднения, т. к. при работе с ними требуется подключение виртуального окружения и использование более ранней версии Python 3.6. DeepPavlov предоставляет на выбор три готовых реализации автокорректоров, в двух из которых применены модели ошибок Бриля-Мура и в двух языковые модели. Исправляет только ошибки орфографии, а вариант с моделью ошибок на основе расстояния Дамерау-Левенштейна может исправлять ошибки слитного написания.
Упомяну ещё про один из современных подходов к исправлению опечаток, который основан на применении векторных представлений слов (Word Embeddings). Достоинством его является то, что на нем можно построить автокорректор для исправления слов с учетом контекста. Более подробно про этот подход можно прочитать здесь [13]. Но чтобы его использовать для исправления опечаток поисковых запросов вам потребуется накопить большой лог запросов. Кроме того, сама модель может оказаться довольно емкой по потребляемой памяти, что отразится на сложности интеграцию в продукт.
Выбор Naumen

Из готовых решений для Java был выбран автокорректор от Lucene (распространяется под лицензией от Apache). Позволяет исправлять опечатки в словах. Процесс обучения быстрый: например, формирование специальной структуры данных словаря – индекса для 3 млн. строк составило 30 секунд на процессоре Intel Core i5-8500 3.00GHz, 32 Gb RAM, Lucene 8.0.0. В более ранних версиях время может быть больше в 2 раза. Размер обучающего словаря – 3 млн. строк (~73 Mb txt-файл), структура индекса ~235 Mb. Для модели ошибок можно выбирать расстояние Джаро-Винклера, Левенштейна, Дамерау-Левенштейна, N-Gram, если нужно, то можно добавить свое. При необходимости есть возможность подключения языковой модели [14]. Модели известны с 2001 года, но их сравнение с известными современными решениями в открытом доступе не было обнаружено. Следующим этапом будет проверка их работы.
Полученное решение на основе Lucene исправляет только ошибки в самих словах. К любому подобному решению несложно добавить исправление искаженной раскладки клавиатуры путем соответствующей таблицы перевода, тем самым сократить возможность нерелевантной выдачи до 10% (в соответствии с опечаточной статистикой). Кроме того, несложно добавить раздельное написание слитых 2-х слов и транслитерацию.
В качестве основных недостатков решения можно выделить необходимость знания Java, отсутствие подробных кейсов использования и подробной документации, что отражается на снижении скорости разработки решения для Data-Science специалистов. Кроме того, не исправляются опечатки с расстоянием по Дамерау-Левенштейну более 2-х. Опять же, если отталкиваться от опечаточной статистики, более 2-х ошибок в слове возникает реже, чем в 5% случаев. Обоснована ли необходимость усложнения алгоритма, в частности, увеличение потребляемой памяти? Тут уже зависит от кейса заказчика. Если есть дополнительные ресурсы, то почему бы их не использовать?
Основные ресурсы по доступным автокорректорам:
- 30 best open source spellcheck project
- Evaluation of legal words in three Java open source spell checkers: Hunspell, Basic Suggester, and Jazzy
- spell checker: Java Glossary
- nlp — Looking for Java spell checker library
- Open source spell checking library for Java
Ссылки
- Панина М. Ф. Автоматическое исправление
опечаток в поисковых запросах
без учета контекста - Байтин А. Исправление поисковых запросов в Яндексе
- DeepPavlov. Таблица сравнения автокорректоров
- Joom. Исправляем опечатки в поисковых запросах
- Dall’Oglio P. Evaluation of legal words in three Java open source spell checkers: Hunspell, Basic Suggester, and Jazzy
- Eric B. and Robert M. An Improved Error Model for Noisy Channel Spelling Correction
- Norvig P. How to Write a Spelling Corrector
- Автокорректор на основе Jazzy
- Garbe W. SymSpell vs. BK-tree: 100x faster fuzzy string search & spell checking
- Jamspell. Исправляем опечатки с учётом контекста
- DeepPavlov. Automatic spelling correction pipelines
- Условия использования сервиса «API Яндекс.Спеллер»
- Singularis. Исправление опечаток, взгляд сбоку
- Apache Lucene. Языковые модели
В этой статье мы рассмотрим, как с помощью сервиса Labrika обнаружить и исправить на сайте HTML-ошибки. Информация о таких ошибках будет полезна как для владельца веб-ресурса, который контролирует работу своего SEO-специалиста и хочет знать, какие нерешенные проблемы есть на сайте, так и для оптимизаторов, поскольку им нужно оперативно обнаружить и исправить все изъяны, мешающие продвижению ресурса.
HTML (от англ. HyperText Markup Language) — это язык гипертекстовой разметки, который применяется на каждой веб-странице в интернете и состоит из множества элементов (тегов). Как правило, ошибками в коде HTML являются незакрытые или дублированные элементы, неправильный порядок их расположения, неверные атрибуты или их отсутствие.
На примере ниже в коде страницы присутствует закрывающий тег ссылки </a> без открывающего тега <a>:

Для проверки валидности кода (то есть соответствия стандартам HTML) используются специальные инструменты. Они проверяют:
- Синтаксические ошибки: пропущенные символы, ошибки в написании тегов.
- Нарушения вложенности тэгов: незакрытые и неправильно закрытые теги. По правилам теги закрываются так же, как их открыли, только в обратном порядке.
- Соответствие кода указанному DTD (Document Type Definition): правильность названий тегов, вложенности, атрибутов. Наличие пользовательских тегов и атрибутов.
Как HTML-ошибки влияют на продвижение сайта?
Как отмечал представитель Google Джон Мюллер, валидность кода HTML не является прямым фактором ранжирования, однако критические ошибки в HTML мешают:
- сканированию сайта поисковыми ботами;
- определению структурированной разметки на странице;
- отображению на мобильных устройствах и кроссбраузерности.
В первую очередь наличие ошибок в коде HTML может привести к тому, что часть контента страницы не будет проиндексирована.
О том, что следует использовать действительный HTML, сказано в Рекомендациях Google для веб-мастеров. Среди авторитетных SEO-источников бытует мнение, что фильтр Google Panda может быть наложен на сайт за большое количество таких ошибок (отдельную статью об алгоритме Google Panda вы можете прочитать на нашем сайте).
Официальные источники Яндекса также сообщают, что подобного рода ошибки на сайте нежелательны, а верстка страниц должна соответствовать принятым стандартам.
Почему важно проверять наличие HTML-ошибок?
Ошибки в коде HTML могут быть критическими и несущественными, которые не ведут к серьезным потерям. Что касается критических, то одни из них отрицательно сказываются на функционировании сайта, а другие — на работе поисковых систем.
Современные браузеры автоматически исправляют 99% критических ошибок при загрузке сайта. Однако некоторые из них браузер исправить не может. Например, если тег <а> для создания ссылки не содержит адреса, то браузер не сможет определить, куда её направить. Или в теге <img> для размещения картинки не указан путь к ней, тогда браузер не сможет её подгрузить. Наличие таких ошибок в коде может привести к серьезным последствиям — например, не загрузятся фото товара или не будет работать корзина.
Поисковые системы также автоматически исправляют часть HTML-ошибок, но у них возникает следующая проблема: если браузеры в состоянии потратить несколько секунд на исправление ошибок, то у поисковых роботов нет такой возможности. Им приходится сканировать сотни миллиардов страниц ежемесячно, поэтому боты не могут тратить время на устранение всех ошибок. Некоторые из них поисковые системы игнорируют, а также могут не включать в индекс содержащие их страницы или проиндексировать только часть контента таких страниц.
Веб-мастера и пользователи просматривают сайты в браузере, где большая часть HTML-ошибок исправляется автоматически, и поэтому не придают им большого значения. Зачастую даже разработчики не исправляют элементарных грубых ошибок в разметке. Это приводит к тому, что критические для поисковых систем ошибки остаются на сайтах и могут стать причиной неправильной индексации страниц. В результате бюджеты на продвижение будут потрачены неэффективно, а источник проблемы так и остается неустановленным.
Как обнаружить HTML-ошибки с помощью сервиса Labrika
Labrika проверяет данные ошибки двумя способами:
- С помощью валидатора W3C, который проверяет наличие всех HTML-ошибок.
- С использованием валидатора Labrika «Критические ошибки HTML». Он устанавливает только те ошибки, которые могут повлиять на сбор данных поисковыми системами или привести к некорректному отображению сайта и нарушениям в его работе. определяет порядка 15 видов таких ошибок.
Отчет » Критические ошибки HTML» вы сможете найти в левом боковом меню в разделе «Технический аудит».
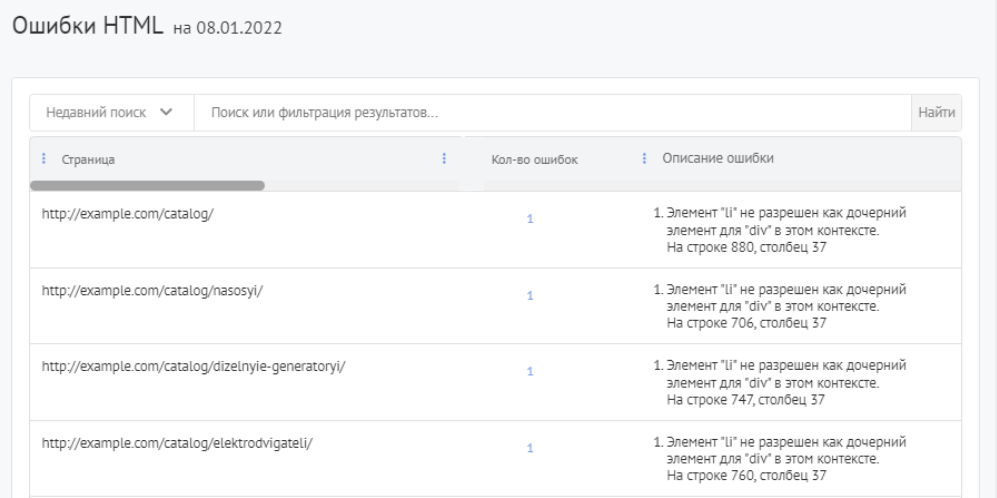
Актуальные данные в отчете вы сможете увидеть после запуска проверки сайта.
Отчет показывает:
- Страницы, которые содержат критические ошибки HTML.
- Количество и описание критических HTML-ошибок на данной странице.
При клике по их числу осуществляется переадресация на валидатор W3C, в котором вы сможете найти подробную информацию обо всех имеющихся в коде страницы ошибках.
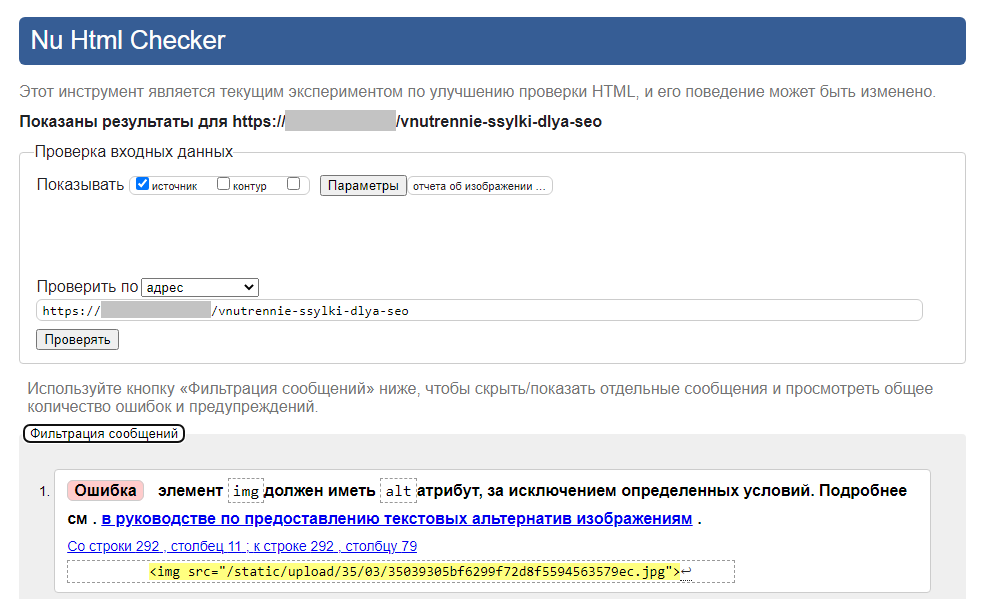
Как исправлять HTML-ошибки?
Критические HTML-ошибки необходимо исправлять в первую очередь, так как поисковые системы могут отреагировать на них отрицательно. Влияние прочих ошибок на продвижение в поиске не доказано.
Если для исправления ошибок требуется передать их список специалисту по верстке, с помощью кнопок в правой части страницы отчета вы можете скачать его данные в формате таблицы Excel или поделиться ссылкой на отчет по HTML-ошибкам с другими пользователями.

После нажатия на значок ссылки появится следующее всплывающее окно:
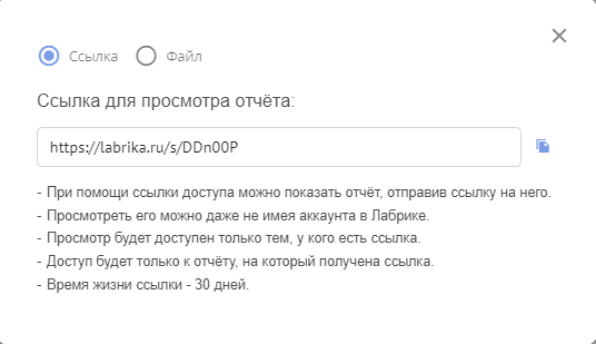
Кнопка, которая расположена справа от ссылки, позволяет скопировать её в буфер обмена. Отчет по ссылке будет доступен даже тем, кто не имеет аккаунта в Labrika.
Для ускорения работы по исправлению HTML-ошибок можно воспользоваться редакторами, которые автоматически создают закрывающие теги для документов HTML (например, Bluefish, Notepad++).
Как исправить ошибку на сайте
Содержание:
- Ошибки глазами владельцев сайта. Как быть и как исправить?
- 1.1 Вариант №1 «Устранить ошибку на сайте самостоятельно»
- 1.2 Вариант №2 «Обратиться в поддержку хостинга, CMS и т.п.»
- 1.3 Вариант №3 «Обратиться за помощью в веб-студию»
- Основные SEO ошибки сайта
- 2.1 Ошибка №1 «Дублирование контента»
- 2.2 Ошибка №2 «Отсутствие title и description»
- 2.3 Ошибка №3 «Низкая скорость загрузки сайта»
- 2.4 Ошибка №4 «Отсутствие SSL-сертификата»
- 2.5 Ошибка №5 «Нет ЧПУ»
- 2.6 Ошибка №6 «Отсутствие “хлебных крошек”»
- 2.7 Ошибка №7 «Нет фавикона»
- 2.8 Ошибка №8 «Проблемы с файлом robots.txt»
- 2.9 Ошибка №9 «На сайте есть битые ссылки»
- 2.10 Ошибка №10 «Неверная разметка H1-Н6»
- Ошибки на сайте: 404, 503, 500, 403 и т.д.
- 3.1 Ошибка 400: Bad Request
- 3.2 Ошибка 401: Unauthorized
- 3.3 Ошибка 403: Forbidden
- 3.4 Ошибка 404: Not Found
- 3.5 Ошибка 500: Internal Server Error
- 3.6 Ошибка 502: Bad Gateway
- 3.7 Ошибка 503: Service Unavailable
- 3.8 Ошибка 504: Gateway Timeout
- Ошибки в юзабилити сайта (Топ-5 ошибок UX/UI дизайна)
- 4.1 Ошибка №1 «Первый экран перегружен не имеет чёткой визуальной иерархии»
- 4.2 Ошибка №2 «Нет общего стиля для всех страниц сайта»
- 4.3 Ошибка №3 «Неверно выбраны цвета»
- 4.4 Ошибка №4 «Перегружена форма заявки, корзина или страница регистрации»
- 4.5 Ошибка №5 «Непонятно что нужно сделать на странице»
Есть масса причин, по которым могут возникать ошибки в работе web-сайтов. Среди самых распространенных следующие: неточности в коде, плохая оптимизация загрузки веб-страницы, ненастроенная адаптивность, не внимательность контент-менеджера, ошибки в изначальном наполнении сайта и другие.
Любые ошибки отражаются на посещаемости ресурса и мешают его продвижению, снижают его конверсионные параметры. А это напрямую связано с сокращением количества заявок, продаж или иных конверсий вашего сайта.

Ошибки глазами владельцев сайта. Как быть и как исправить?
Ошибки на сайте — это плохо. Но как исправить эти ошибки без супер-знаний программирования и иных сложных IT-шнык заковырок?
Давайте разберём возможные пути решения глазами владельцев сайта.
Вариант №1 «Устранить ошибку на сайте самостоятельно»

Успех самостоятельного исправления ошибке на сайте будет зависеть от многих факторов:
- Ваш уровень знаний и умений
- Возможности CMS
- Тип ошибки
Конечно, если вам нужно исправить ошибку по тексту, то шансы на успех велики. Если же ошибка связанна с каким-то скриптом или плагином, то знаний вам потребуется больше и есть риск усугубить ситуацию.
Как бы там ни было, большинство CMS могут позволить вам работать с сайтом на базовом уровне без особых проблем. Обучиться этому можно за несколько часов (азам) и далее уже углубляться в тонкости CMS по мере необходимости.
Например, если у вас сайт на WordPress, 1С-Битрикс, Joomla!, MODX (или прочей CMS такого типа), то в интернете полно подробных инструкций по администрированию данных CMS и есть много инструкций по разбору типовых ошибок
Но помните: если не уверены – не делайте! Лучше используйте варианты, которые мы опишем ниже!
Вариант №2 «Обратиться в поддержку хостинга, CMS и т.п.»

Если у вас на сайте появилась какая-то ошибка – попробуйте написать в поддержку уже активных услуг сайта. Например, в поддержку хостинг-провайдера или платной CMS (такой как 1С-Битрикс).
Возможно, вам смогут помочь и тогда не придётся решать проблему самостоятельно или платить разработчикам.
Но помните: техническая поддержка не обязана решать все ваши проблемы и «хотелки» по сайту. Они будут работать в рамках регламента и в рамках оплаченных услуг хостинга или CMS. Но попробовать точно стоит, хуже не будет.
Вариант №3 «Обратиться за помощью в веб-студию»

Конечно же самым результативным вариантом будет обращение к профильным специалистам. Вы можете связаться с разработчиками именно вашего сайта или обратиться в любую другую веб-студию.
Но и в этом варианте есть риск: вы можете выбрать недобросовестную студию. Ах, да, ещё можно попробовать нанять фрилансера, но там все те же риски и в большем объёме т.к. порог входа для «криворуких мастеров» существенно ниже.
Но не переживайте, отсеять горе-спецов достаточно легко:
- Заключайте договор
- Проверяйте сколько существует ИП или ООО
- Проверяйте сколько проектов у студии в портфолио
- Проверяйте отрицательные отзывы
Поверьте, хороших студий значительно больше, чем «криворуких».
Например, в нашей студии соблюдены все стандарты качества при работе с поддержкой сайтов:
- Заключаем договор с фиксированным объёмом часов. Дополнительно описываем список задач и прогнозируем сроки их реализации
- При необходимости проводим аудит сайта
- На рынке не первый год, имеем большое портфолио
- Несём репутационные риски т.к. наш бренд Web-Crazy официально зарегистрирован в Роспатенте
Для наших клиентов мы предлагаем 2 варианта работы:
- Тарифы с ежемесячной абонентской платой
- Персональный расчёт лимита часов под конкретные ошибки и доработки
Подробнее можете ознакомиться в разделе техническая поддержка сайтов.
Основные SEO ошибки сайта
Если сайт работает без ошибок и обеспечивает быструю скорость загрузки, то выйти в ТОП можно даже без ссылок. Но при этом стоит учитывать, что поисковые системы отдают предпочтение сайтам с хорошей оптимизацией, которые имеют четкую и понятную структуру для поисковых машин.
Ниже мы приведем перечень самых частых ошибок SEO, из-за которых сильно уменьшается эффективность раскрутки.

Ошибка №1 «Дублирование контента»
Бывает, что один и тот же контент отображается на странице с публикацией, на страницах категорий и меток. Если такая проблема имеется, ее можно решить канонизацией URL и запретом индексации служебных разделов веб-сайта.
С помощью канонических URL можно защитить web-сайт от дублей. В последних версиях у большинства CMS инструменты для работы с каноническими URL активизированы по умолчанию. Но если именно в вашей CMS они отсутствуют, сделайте установку любого плагина с подходящими функциями (например, All in One SEO, зависит от вашей CMS).
Ошибка №2 «Отсутствие title и description»
Title – это краткий тег, содержащий описание контента страницы.
Description – это более развернутое описание содержимого на странице.
За счёт данных тегов на странице, поисковый робот Яндекс и Гугл будет определять первоначальное содержание страницы. А уже после этого – изучать сам текст на странице. Поэтому важно, чтобы данные теги были уникальными, были подходящими по смыслу и были в оптимальном лимите символов.
Так же Title и Description могут формировать сниппет на странице поисковой выдачи, а это тоже очень важный параметр для сайта.
Ошибка №3 «Низкая скорость загрузки сайта»
Любой пользователь хочет, чтобы страница загружалась быстро. В противном случае потенциальный клиент может закрыть сайт, не дождавшись полной загрузки. Для проверки скорости можно использовать различные сервисы, например, PageSpeed Insights.
Исправление ошибок по скорости загрузки сайта – дело для профессиональных разработчиков. Обычными знаниями CMS тут не обойтись.
Ошибка №4 «Отсутствие SSL-сертификата»
Для безопасного соединения между браузером клиента и сервером используют сертификат ssl или Secure Sockets Layer, что переводится как уровень защищенных сокетов. Благодаря этому протоколу данные, которые передаются между устройством пользователя и web-сайтом шифруются и никак не могут попасть в третьи руки.
SSL-сертификат важен как фактор ранжирования в SEO. Поисковики проверяют его наличие.
Ошибка №5 «Нет ЧПУ»
Человеко-Понятный URL или ЧПУ – это адрес веб-страницы, который одинаково прост и понятен как для посетителей, так и для поисковых машин, понятие «Search Engine Friendly URL».
- Поисковые машины понимают ключевые слова в ЧПУ, выделяют их в поиске. В совокупности это дает повышение релевантности страницы.
- ЧПУ повышает CTR сниппета веб-страницы в поисковой выдаче, в свою очередь это улучшает поведенческие факторы.
Ошибка №6 «Отсутствие “хлебных крошек”»
Наличие «хлебных крошек» считается обязательным элементом логичной и понятной структуры web-сайта. Также это существенный фактор для юзабилити.
Этот элемент располагается в начале страницы в виде структуры вложенности: «главная — раздел — подраздел — текущая страница» и т.п.
Ошибка №7 «Нет фавикона»
Фавикон, по англ. Favicon представляет собой маленькую картинку или пиктограмму, являющуюся частью дизайна сайта.
Он отображается в следующих местах:
· вкладка перед названием web-страницы;
· поисковая выдача (рядом с названием ресурса);
· в закладках браузера.
Если есть фавикон, то отображение сайта в поисковой выдаче будет гораздо лучше, повысится узнаваемость, можно будет лучше ориентироваться во вкладках и закладках браузера.
Ошибка №8 «Проблемы с файлом robots.txt»
Robots.txt представляет собой текстовый файл, который предназначается для управления доступом поисковых машин к разделам и веб-страницам сайта. С его помощью можно запретить индексацию определённых страниц (или разрешить). Указать доступ к карте сайта, прописать хост и т.п.
Ошибка №9 «На сайте есть битые ссылки»
Время от времени сайт нужно проверять на наличие этой проблемы. Вы можете воспользоваться возможностями web-мастеров Яндекс и Гугл (Google Search Console). Для этого в GSC нужно открыть раздел «Индекс», затем выбрать «Покрытие», и в разделе «Ошибка 404» будут представлены все битые ссылки. В Яндекс.Вебмастер переходим в раздел «Индексирование», проверяем «Статистику обхода», открываем раздел «Ссылки» и после этого «Внутренние ссылки».
Ошибка №10 «Неверная разметка H1-Н6»
Теги <h1> – <h6> — это одни из элементов HTML, они помогают обозначить в тексте заголовки. Соответственно <h1> — самый важный заголовок, а далее чем больше цифра, тем заголовок менее важен.
Если рассматривать эти элементы с технической точки зрения, то они показывают поисковым системам, что фраза между тегами и есть заголовок. Главная цель, с которой используются заголовки – это разделение текста на разделы, построение их иерархии и выделение логической последовательности изложения.
Ошибки на сайте: 404, 503, 500, 403 и т.д.
Многие сталкиваются с такой ситуацией, когда при попытке зайти на сайт, выскакивает ошибка 404, 503, 500, 403. Не все знают значение этих цифр. В материале ниже раскроем смысл этих ошибок на сайте.

Ошибка 400: Bad Request
При появлении кода «Неверный запрос» в HTTP-запросе присутствует синтаксическая ошибка. Разберемся с основными причинами возникновения таких ошибок и действиями, которые необходимо предпринять:
· У юзера есть повреждения в файлах cookie – в этом случае достаточно почистить кэш и файлы cookie.
· Возникает внутренняя ошибка браузера – поможет обновление или переустановка браузера.
· Случайная опечатка при введении запроса вручную (например, в консольных командах wget или curl).
Ошибка 401: Unauthorized
Наличие кода «Не авторизованный» может появиться в случае, если есть проблемы с аутентификацией или авторизацией на ресурсе.
Частый пример, посетитель хочет посмотреть свой профиль, но забыл авторизоваться, или допустил ошибку при вводе логина или пароля. Если такое произошло, то код ответа 401 будет повторяться снова и снова, пока пользователь не введет верные учетные данные.
При частом повторении такой ошибки, администратору сайта нужно проверить файл .htpasswd с данными для входа пользователей на наличие повреждений.
Ошибка 403: Forbidden
При появлении ошибки подключения к сайту «Запрещено», пользователю стоит понимать, что у него нет доступа к запрашиваемому файлу или странице.
Подобная ситуация может возникнуть из-за:
- Отсутствия прав на открытие файла. Можно проверить, есть ли у пользователя права на чтение при помощи команды chmod.
- Запрещенный доступ в .htaccess – доступ может быть ограничен для определенных IP-адресов в файле .htaccess.
- Отсутствует индексный файл в запрашиваемой директории – можно попробовать создать индексный файл или включить листинг директорий в конфигурации web-сервера.
Ошибка 404: Not Found
Эта ошибка считается самой частой, пожалуй, в интернете нет таких юзеров, которые бы с ней никогда не сталкивались. Ее появление означает, что сервер не может найти запрашиваемый ресурс или такой страницы нет.
При 100% уверенности, что такая ошибка не должна появляться, нужно проверить ссылку на наличие опечаток и убедиться, что файл страницы не был удален или перемещен. Также проблема может возникать из-за отсутствия доступа к папке, в которой находится файл. Для его включения добавьте разрешение на чтение и выполнение для каталога.
Ошибка 500: Internal Server Error
Если возникла ошибка «Внутренняя ошибка сервера», значит данный сбой не относится ни к одной другой известной ошибке класса 5. Ошибка 500 обычно означает, что есть проблема в настройках сервера.
К самым частым причинам появления неполадок можно отнести:
· Наличие ошибки в файле .htaccess – можно попытаться переименовать его и проверить, работоспособность сайта.
· Нет нужных пакетов, неверно выбрана версия PHP. Попробуйте изменить версию PHP или выполнить установку необходимых модулей.
· Появление ошибки в коде. Если ранее всё хорошо работало, попробуйте восстановить сайт из резервной копии.
Ошибка 502: Bad Gateway
При регулярном появлении ошибки 502, обратитесь в техподдержку хостинг-провайдера. Нужно детально описать действия, из-за которых возникает проблема, и указать время обнаружения.
Ошибка 503: Service Unavailable
Если появляется код «Сервис недоступен», это означает, что есть превышение лимита по количеству HTTP-запросов. Если вы хотите ознакомиться со всеми лимитами, это можно сделать в технических характеристиках хостинга.
Такая ошибка может появиться, если при формировании страницы ваш код создает очень много обращений к файлам, типа изображений, стилей и другим. Проблема решается оптимизацией кода и уменьшенным числом HTTP-запросов. Также вы можете просто перейти на более производительный тариф хостинга.
Ошибка 504: Gateway Timeout
Ошибка «время ожидания ответа сервера истекло» возникает, если веб-сервер не получает от сайта ответ за установленный промежуток времени. По умолчанию он устанавливается на 300 секунд.
Как правило, это происходит, когда скрипты сайта выполняются слишком долго, например, при выгрузке базы данных. В таком случае можно попробовать обратиться к web-сайту, минуя веб-сервер, через порт 8081 (для сайтов, работающих на панели управления ISPmanager) или 8080 (для cPanel и Plesk). При желании настроить интервалы для ожидания ответа сайта вручную, используйте VPS, где есть более гибкие настройки сервера.
Ошибки в юзабилити сайта (Топ-5 ошибок UX/UI дизайна)
UX (полный термин User Experience или в переводе «опыт пользователя») — это то, какой опыт/впечатление получает юзер от взаимодействия с вашим интерфейсом. Получается ли у него достичь цели и как просто или быстро.
А UI (полный термин User Interface или в переводе «пользовательский интерфейс») — это как выглядит интерфейс и какие физические характеристики приобретает. Определяет цвет вашего «изделия», удобство попадания пальцем в кнопки, читабельность текстов и прочее.

Ошибка №1 «Первый экран перегружен не имеет чёткой визуальной иерархии»
Различные пользователи посещают сайт в поиске нужной информации и покидают его при плохо организованной работе. В связи с этим вся структура страницы должна быть хорошо продумана, с учетом того, что пользователю нужно быстро найти нужную ему информацию. Особенно это важно для первого экрана страницы.
Ошибка №2 «Нет общего стиля для всех страниц сайта»
Если страницы сайта имеют разный дизайн, это может сбить с толку юзера. Некоторым пользователям даже может показаться, что они перешли на другой сайт. Для того, чтобы дизайн был консистентным, нужно:
- использовать одну и ту же цветовую гамму на всех страницах;
- следить за равным расстоянием между элементами макета по вертикали и горизонтали;
- сделать заголовки на всех страницах одинаковыми по размеру;
- соблюдать единое оформление ссылок;
- обеспечить единство оформления форм.
Ошибка №3 «Неверно выбраны цвета»
Для того, чтобы не допустить такую ошибку, нужно учесть:
- Наличие у компании корпоративных цветов — если они имеются, их нужно использовать при создании дизайна.
- Наличие изображений и фотографий, которые нужно использовать – если такие имеются, отберите цвета, которые будут хорошо с ними сочетаться.
- Используйте 3 разных цвета в соотношении 60%, 30% и 10%. Если использовать много цветов, страница будет не гармоничной и не сбалансированной.
Ошибка №4 «Перегружена форма заявки, корзина или страница регистрации»
Уже прошли те времена, когда пользователям приходилось заполнять множество полей и по много раз вводить данные в поля с валидацией.
При разработке формы, учтите, что она должна быть максимально простой – при необходимости дополнительные данные можно запросить позже, не вызывая раздражения у пользователей.
Ошибка №5 «Непонятно что нужно сделать на странице»
CTA (Call to action, в переводе «Призыв к действию») – это элемент сайта, задача которого подтолкнуть пользователя к действию и показать ему, что можно сделать прямо сейчас: заказать звонок, скачать прайс или сделать расчет стоимости.
Если грамотно расположить призыв к действию, можно существенно поднять продажи. Не стоит стесняться размещать такие кнопки, ведь на коммерческий сайт люди заходят, чтобы совершить покупку. Помогите клиенту сделать первый шаг.
Важно быть честными: если на сайте встроен калькулятор с расчетом стоимости, то это должен быть действительно калькулятор, а не форма с запросом номера.