
Матрица ошибок – это метрика производительности классифицирующей модели Машинного обучения (ML).
Когда мы получаем данные, то после очистки и предварительной обработки, первым делом передаем их в модель и, конечно же, получаем результат в виде вероятностей. Но как мы можем измерить эффективность нашей модели? Именно здесь матрица ошибок и оказывается в центре внимания.
Матрица ошибок – это показатель успешности классификации, где классов два или более. Это таблица с 4 различными комбинациями сочетаний прогнозируемых и фактических значений.

Давайте рассмотрим значения ячеек (истинно позитивные, ошибочно позитивные, ошибочно негативные, истинно негативные) с помощью «беременной» аналогии.

Истинно позитивное предсказание (True Positive, сокр. TP)
Вы предсказали положительный результат, и женщина действительно беременна.
Истинно отрицательное предсказание (True Negative, TN)
Вы предсказали отрицательный результат, и мужчина действительно не беременен.
Ошибочно положительное предсказание (ошибка типа I, False Positive, FN)
Вы предсказали положительный результат (мужчина беременен), но на самом деле это не так.
Ошибочно отрицательное предсказание (ошибка типа II, False Negative, FN)
Вы предсказали, что женщина не беременна, но на самом деле она беременна.
Давайте разберемся в матрице ошибок с помощью арифметики.
Пример. Мы располагаем датасетом пациентов, у которых диагностируют рак. Зная верный диагноз (столбец целевой переменной «Y на самом деле»), хотим усовершенствовать диагностику с помощью модели Машинного обучения. Модель получила тренировочные данные, и на тестовой части, состоящей из 7 записей (в реальных задачах, конечно, больше) и изображенной ниже, мы оцениваем, насколько хорошо прошло обучение.

Модель сделала свои предсказания для каждого пациента и записала вероятности от 0 до 1 в столбец «Предсказанный Y». Мы округляем эти числа, приводя их к нулю или единице, с помощью порога, равного 0,6 (ниже этого значения – ноль, пациент здоров). Результаты округления попадают в столбец «Предсказанная вероятность»: например, для первой записи модель указала 0,5, что соответствует нулю. В последнем столбце мы анализируем, угадала ли модель.
Теперь, используя простейшие формулы, мы рассчитаем Отзыв (Recall), точность результата измерений (Precision), точность измерений (Accuracy), и наконец поймем разницу между этими метриками.
Отзыв
Из всех положительных значений, которые мы предсказали правильно, сколько на самом деле положительных? Подсчитаем, сколько единиц в столбце «Y на самом деле» (4), это и есть сумма TP + FN. Теперь определим с помощью «Предсказанной вероятности», сколько из них диагностировано верно (2), это и будет TP.
$$Отзыв = frac{TP}{TP + FN} = frac{2}{2 + 2} = frac{1}{2}$$
Точность результата измерений (Precision)
В этом уравнении из неизвестных только FP. Ошибочно диагностированных как больных здесь только одна запись.
$$Точностьspaceрезультатаspaceизмерений = frac{TP}{TP + FP} = frac{2}{2 + 1} = frac{2}{3}$$
Точность измерений (Accuracy)
Последнее значение, которое предстоит экстраполировать из таблицы – TN. Правильно диагностированных моделью здоровых людей здесь 2.
$$Точностьspaceизмерений = frac{TP + TN}{Всегоspaceзначений} = frac{2 + 2}{7} = frac{4}{7}$$
F-мера точности теста
Эти метрики полезны, когда помогают вычислить F-меру – конечный показатель эффективности модели.
$$F-мера = frac{2 * Отзыв * Точностьspaceизмерений}{Отзыв + Точностьspaceизмерений} = frac{2 * frac{1}{2} * frac{2}{3}}{frac{1}{2} + frac{2}{3}} = 0,56$$
Наша скромная модель угадывает лишь 56% процентов диагнозов, и такой результат, как правило, считают промежуточным и работают над улучшением точности модели.
SkLearn
С помощью замечательной библиотеки Scikit-learn мы можем мгновенно определить множество метрик, и матрица ошибок – не исключение.
from sklearn.metrics import confusion_matrix
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
confusion_matrix(y_true, y_pred)Выводом будет ряд, состоящий из трех списков:
array([[2, 0, 0],
[0, 0, 1],
[1, 0, 2]])Значения диагонали сверху вниз слева направо [2, 0, 2] – это число верно предсказанных значений.
Фото: @opeleye
В компьютерном зрении обнаружение объекта — это проблема определения местоположения одного или нескольких объектов на изображении. Помимо традиционных методов обнаружения, продвинутые модели глубокого обучения, такие как R-CNN и YOLO, могут обеспечить впечатляющие результаты при различных типах объектов. Эти модели принимают изображение в качестве входных данных и возвращают координаты прямоугольника, ограничивающего пространство вокруг каждого найденного объекта.
В этом руководстве обсуждается матрица ошибок и то, как рассчитываются precision, recall и accuracy метрики.
Здесь мы рассмотрим:
- Матрицу ошибок для двоичной классификации.
- Матрицу ошибок для мультиклассовой классификации.
- Расчет матрицы ошибок с помощью Scikit-learn.
- Accuracy, Precision и Recall.
- Precision или Recall?
Матрица ошибок для бинарной классификации
В бинарной классификации каждая выборка относится к одному из двух классов. Обычно им присваиваются такие метки, как 1 и 0, или положительный и отрицательный (Positive и Negative). Также могут использоваться более конкретные обозначения для классов: злокачественный или доброкачественный (например, если проблема связана с классификацией рака), успех или неудача (если речь идет о классификации результатов тестов учащихся).
Предположим, что существует проблема бинарной классификации с классами positive и negative. Вот пример достоверных или эталонных меток для семи выборок, используемых для обучения модели.
positive, negative, negative, positive, positive, positive, negativeТакие наименования нужны в первую очередь для того, чтобы нам, людям, было проще различать классы. Для модели более важна числовая оценка. Обычно при передаче очередного набора данных на выходе вы получите не метку класса, а числовой результат. Например, когда эти семь семплов вводятся в модель, каждому классу будут назначены следующие значения:
0.6, 0.2, 0.55, 0.9, 0.4, 0.8, 0.5На основании полученных оценок каждой выборке присваивается соответствующий класс. Такое преобразование числовых результатов в метки происходит с помощью порогового значения. Данное граничное условие является гиперпараметром модели и может быть определено пользователем. Например, если порог равен 0.5, тогда любая оценка, которая больше или равна 0.5, получает положительную метку. В противном случае — отрицательную. Вот предсказанные алгоритмом классы:
positive (0.6), negative (0.2), positive (0.55), positive (0.9), negative (0.4), positive (0.8), positive (0.5)Сравните достоверные и полученные метки — мы имеем 4 верных и 3 неверных предсказания. Стоит добавить, что изменение граничного условия отражается на результатах. Например, установка порога, равного 0.6, оставляет только два неверных прогноза.
Реальность: positive, negative, negative, positive, positive, positive, negative
Предсказания: positive, negative, positive, positive, negative, positive, positiveДля получения дополнительной информации о характеристиках модели используется матрица ошибок (confusion matrix). Матрица ошибок помогает нам визуализировать, «ошиблась» ли модель при различении двух классов. Как видно на следующем рисунке, это матрица 2х2. Названия строк представляют собой эталонные метки, а названия столбцов — предсказанные.
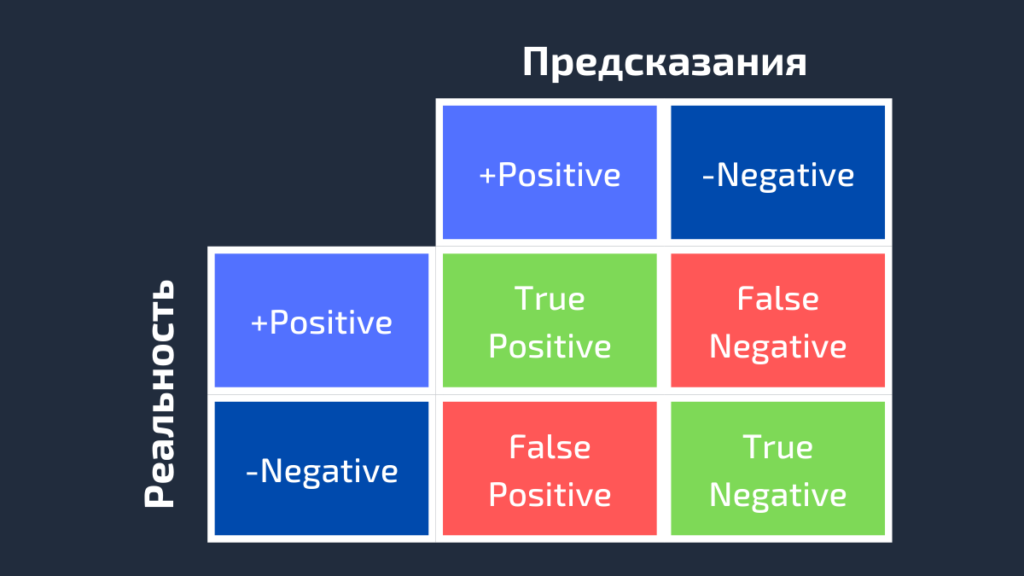
Четыре элемента матрицы (клетки красного и зеленого цвета) представляют собой четыре метрики, которые подсчитывают количество правильных и неправильных прогнозов, сделанных моделью. Каждому элементу дается метка, состоящая из двух слов:
- True или False.
- Positive или Negative.
True, если получено верное предсказание, то есть эталонные и предсказанные метки классов совпадают, и False, когда они не совпадают. Positive или Negative — названия предсказанных меток.
Таким образом, всякий раз, когда прогноз неверен, первое слово в ячейке False, когда верен — True. Наша цель состоит в том, чтобы максимизировать показатели со словом «True» (True Positive и True Negative) и минимизировать два других (False Positive и False Negative). Четыре метрики в матрице ошибок представляют собой следующее:
- Верхний левый элемент (True Positive): сколько раз модель правильно классифицировала Positive как Positive?
- Верхний правый (False Negative): сколько раз модель неправильно классифицировала Positive как Negative?
- Нижний левый (False Positive): сколько раз модель неправильно классифицировала Negative как Positive?
- Нижний правый (True Negative): сколько раз модель правильно классифицировала Negative как Negative?
Мы можем рассчитать эти четыре показателя для семи предсказаний, использованных нами ранее. Полученная матрица ошибок представлена на следующем рисунке.
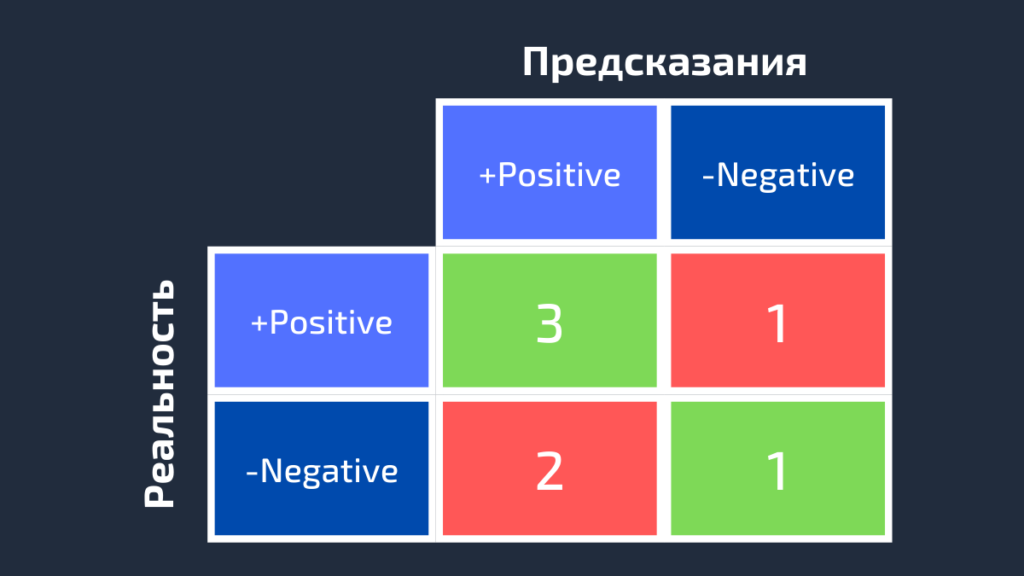
Вот так вычисляется матрица ошибок для задачи двоичной классификации. Теперь посмотрим, как решить данную проблему для большего числа классов.
Матрица ошибок для мультиклассовой классификации
Что, если у нас более двух классов? Как вычислить эти четыре метрики в матрице ошибок для задачи мультиклассовой классификации? Очень просто!
Предположим, имеется 9 семплов, каждый из которых относится к одному из трех классов: White, Black или Red. Вот достоверные метки для 9 выборок:
Red, Black, Red, White, White, Red, Black, Red, WhiteПосле загрузки данных модель делает следующее предсказание:
Red, White, Black, White, Red, Red, Black, White, RedДля удобства сравнения здесь они расположены рядом.
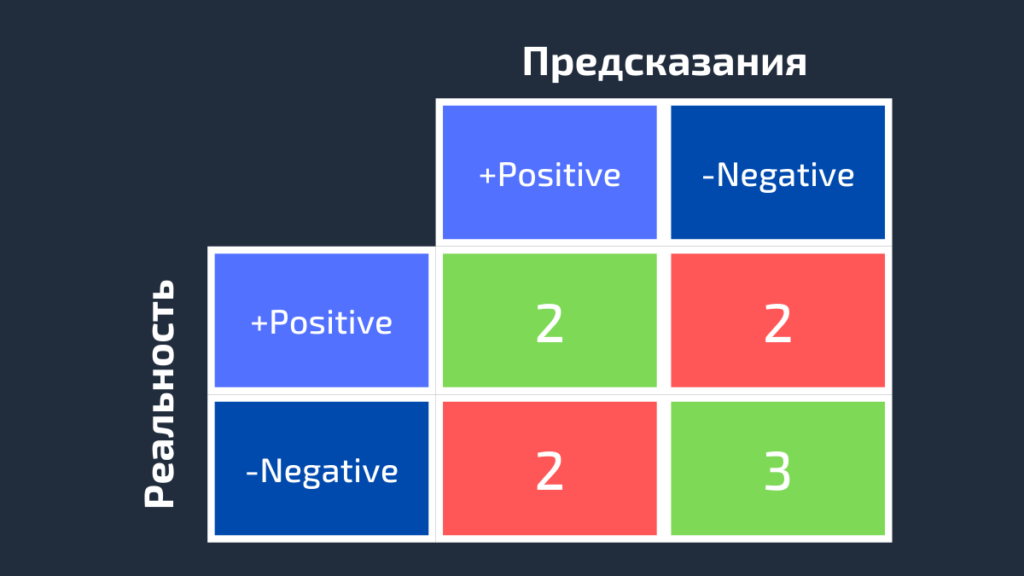
Реальность: Red, Black, Red, White, White, Red, Black, Red, White Предсказания: Red, White, Black, White, Red, Red, Black, White, RedПеред вычислением матрицы ошибок необходимо выбрать целевой класс. Давайте назначим на эту роль класс Red. Он будет отмечен как Positive, а все остальные отмечены как Negative.
Positive, Negative, Positive, Negative, Negative, Positive, Negative, Positive, Negative Positive, Negative, Negative, Negative, Positive, Positive, Negative, Negative, Positive11111111111111111111111После замены остались только два класса (Positive и Negative), что позволяет нам рассчитать матрицу ошибок, как было показано в предыдущем разделе. Стоит заметить, что полученная матрица предназначена только для класса Red.
Далее для класса White заменим каждое его вхождение на Positive, а метки всех остальных классов на Negative. Мы получим такие достоверные и предсказанные метки:
Negative, Negative, Negative, Positive, Positive, Negative, Negative, Negative, Positive Negative, Positive, Negative, Positive, Negative, Negative, Negative, Positive, NegativeНа следующей схеме показана матрица ошибок для класса White.
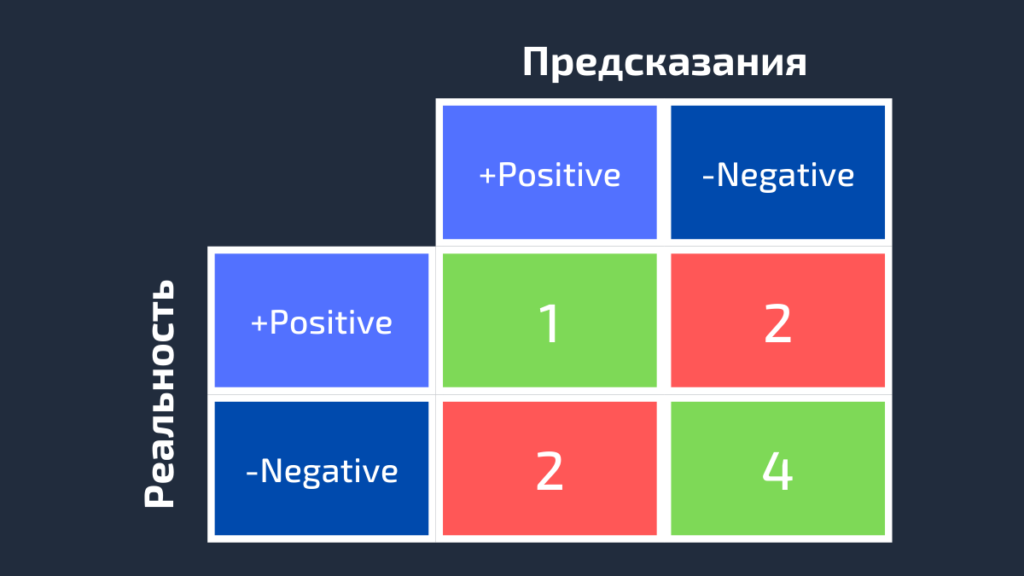
Точно так же может быть получена матрица ошибок для Black.
Расчет матрицы ошибок с помощью Scikit-Learn
В популярной Python-библиотеке Scikit-learn есть модуль metrics, который можно использовать для вычисления метрик в матрице ошибок.
Для задач с двумя классами используется функция confusion_matrix(). Мы передадим в функцию следующие параметры:
y_true: эталонные метки.y_pred: предсказанные метки.
Следующий код вычисляет матрицу ошибок для примера двоичной классификации, который мы обсуждали ранее.
import sklearn.metrics
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative"]
y_pred = ["positive", "negative", "positive", "positive", "negative", "positive", "positive"]
r = sklearn.metrics.confusion_matrix(y_true, y_pred)
print(r)
array([[1, 2],
[1, 3]], dtype=int64)Обратите внимание, что порядок метрик отличается от описанного выше. Например, показатель True Positive находится в правом нижнем углу, а True Negative — в верхнем левом углу. Чтобы исправить это, мы можем перевернуть матрицу.
import numpy
r = numpy.flip(r)
print(r)
array([[3, 1],
[2, 1]], dtype=int64)Чтобы вычислить матрицу ошибок для задачи с большим числом классов, используется функция multilabel_confusion_matrix(), как показано ниже. В дополнение к параметрам y_true и y_pred третий параметр labels принимает список классовых меток.
import sklearn.metrics
import numpy
y_true = ["Red", "Black", "Red", "White", "White", "Red", "Black", "Red", "White"]
y_pred = ["Red", "White", "Black", "White", "Red", "Red", "Black", "White", "Red"]
r = sklearn.metrics.multilabel_confusion_matrix(y_true, y_pred, labels=["White", "Black", "Red"])
print(r)
array([
[[4 2]
[2 1]]
[[6 1]
[1 1]]
[[3 2]
[2 2]]], dtype=int64)Функция вычисляет матрицу ошибок для каждого класса и возвращает все матрицы. Их порядок соответствует порядку меток в параметре labels. Чтобы изменить последовательность метрик в матрицах, мы будем снова использовать функцию numpy.flip().
print(numpy.flip(r[0])) # матрица ошибок для класса White
print(numpy.flip(r[1])) # матрица ошибок для класса Black
print(numpy.flip(r[2])) # матрица ошибок для класса Red
# матрица ошибок для класса White
[[1 2]
[2 4]]
# матрица ошибок для класса Black
[[1 1]
[1 6]]
# матрица ошибок для класса Red
[[2 2]
[2 3]]В оставшейся части этого текста мы сосредоточимся только на двух классах. В следующем разделе обсуждаются три ключевых показателя, которые рассчитываются на основе матрицы ошибок.
Как мы уже видели, матрица ошибок предлагает четыре индивидуальных показателя. На их основе можно рассчитать другие метрики, которые предоставляют дополнительную информацию о поведении модели:
- Accuracy
- Precision
- Recall
В следующих подразделах обсуждается каждый из этих трех показателей.
Метрика Accuracy
Accuracy — это показатель, который описывает общую точность предсказания модели по всем классам. Это особенно полезно, когда каждый класс одинаково важен. Он рассчитывается как отношение количества правильных прогнозов к их общему количеству.
Рассчитаем accuracy с помощью Scikit-learn на основе ранее полученной матрицы ошибок. Переменная acc содержит результат деления суммы True Positive и True Negative метрик на сумму всех значений матрицы. Таким образом, accuracy, равная 0.5714, означает, что модель с точностью 57,14% делает верный прогноз.
import numpy
import sklearn.metrics
y_true = ["positive", "negative", "negative", "positive", "positive", "positive", "negative"]
y_pred = ["positive", "negative", "positive", "positive", "negative", "positive", "positive"]
r = sklearn.metrics.confusion_matrix(y_true, y_pred)
r = numpy.flip(r)
acc = (r[0][0] + r[-1][-1]) / numpy.sum(r)
print(acc)
# вывод будет 0.571
В модуле sklearn.metrics есть функция precision_score(), которая также может вычислять accuracy. Она принимает в качестве аргументов достоверные и предсказанные метки.
acc = sklearn.metrics.accuracy_score(y_true, y_pred)
Стоит учесть, что метрика accuracy может быть обманчивой. Один из таких случаев — это несбалансированные данные. Предположим, у нас есть всего 600 единиц данных, из которых 550 относятся к классу Positive и только 50 — к Negative. Поскольку большинство семплов принадлежит к одному классу, accuracy для этого класса будет выше, чем для другого.
Если модель сделала 530 правильных прогнозов из 550 для класса Positive, по сравнению с 5 из 50 для Negative, то общая accuracy равна (530 + 5) / 600 = 0.8917. Это означает, что точность модели составляет 89.17%. Полагаясь на это значение, вы можете подумать, что для любой выборки (независимо от ее класса) модель сделает правильный прогноз в 89.17% случаев. Это неверно, так как для класса Negative модель работает очень плохо.
Precision
Precision представляет собой отношение числа семплов, верно классифицированных как Positive, к общему числу выборок с меткой Positive (распознанных правильно и неправильно). Precision измеряет точность модели при определении класса Positive.
Когда модель делает много неверных Positive классификаций, это увеличивает знаменатель и снижает precision. С другой стороны, precision высока, когда:
- Модель делает много корректных предсказаний класса Positive (максимизирует True Positive метрику).
- Модель делает меньше неверных Positive классификаций (минимизирует False Positive).
Представьте себе человека, который пользуется всеобщим доверием; когда он что-то предсказывает, окружающие ему верят. Метрика precision похожа на такого персонажа. Если она высока, вы можете доверять решению модели по определению очередной выборки как Positive. Таким образом, precision помогает узнать, насколько точна модель, когда она говорит, что семпл имеет класс Positive.
Основываясь на предыдущем обсуждении, вот определение precision:
Precision отражает, насколько надежна модель при классификации Positive-меток.
На следующем изображении зеленая метка означает, что зеленый семпл классифицирован как Positive, а красный крест – как Negative. Модель корректно распознала две Positive выборки, но неверно классифицировала один Negative семпл как Positive. Из этого следует, что метрика True Positive равна 2, когда False Positive имеет значение 1, а precision составляет 2 / (2 + 1) = 0.667. Другими словами, процент доверия к решению модели, что выборка относится к классу Positive, составляет 66.7%.
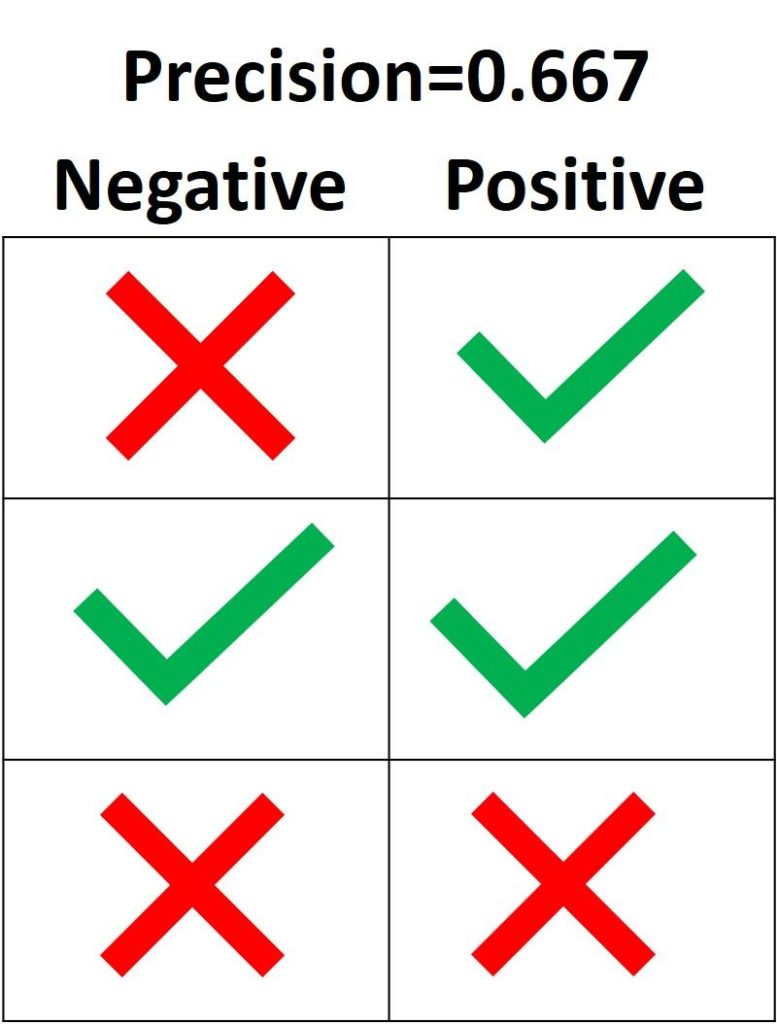
Цель precision – классифицировать все Positive семплы как Positive, не допуская ложных определений Negative как Positive. Согласно следующему рисунку, если все три Positive выборки предсказаны правильно, но один Negative семпл классифицирован неверно, precision составляет 3 / (3 + 1) = 0.75. Таким образом, утверждения модели о том, что выборка относится к классу Positive, корректны с точностью 75%.
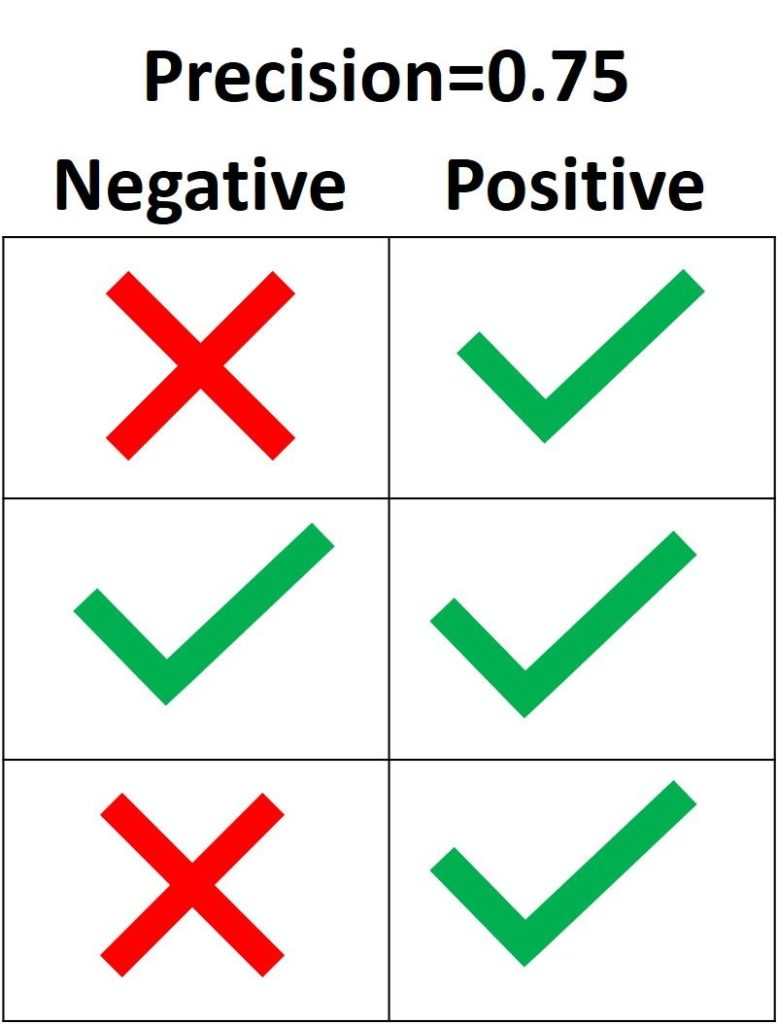
Единственный способ получить 100% precision — это классифицировать все Positive выборки как Positive без классификации Negative как Positive.
В Scikit-learn модуль sklearn.metrics имеет функцию precision_score(), которая получает в качестве аргументов эталонные и предсказанные метки и возвращает precision. Параметр pos_label принимает метку класса Positive (по умолчанию 1).
import sklearn.metrics
y_true = ["positive", "positive", "positive", "negative", "negative", "negative"]
y_pred = ["positive", "positive", "negative", "positive", "negative", "negative"]
precision = sklearn.metrics.precision_score(y_true, y_pred, pos_label="positive")
print(precision)
Вывод: 0.6666666666666666.
Recall
Recall рассчитывается как отношение числа Positive выборок, корректно классифицированных как Positive, к общему количеству Positive семплов. Recall измеряет способность модели обнаруживать выборки, относящиеся к классу Positive. Чем выше recall, тем больше Positive семплов было найдено.
Recall заботится только о том, как классифицируются Positive выборки. Эта метрика не зависит от того, как предсказываются Negative семплы, в отличие от precision. Когда модель верно классифицирует все Positive выборки, recall будет 100%, даже если все представители класса Negative были ошибочно определены как Positive. Давайте посмотрим на несколько примеров.
На следующем изображении представлены 4 разных случая (от A до D), и все они имеют одинаковый recall, равный 0.667. Представленные примеры отличаются только тем, как классифицируются Negative семплы. Например, в случае A все Negative выборки корректно определены, а в случае D – наоборот. Независимо от того, как модель предсказывает класс Negative, recall касается только семплов относящихся к Positive.

Из 4 случаев, показанных выше, только 2 Positive выборки определены верно. Таким образом, метрика True Positive равна 2. False Negative имеет значение 1, потому что только один Positive семпл классифицируется как Negative. В результате recall будет равен 2 / (2 + 1) = 2/3 = 0.667.
Поскольку не имеет значения, как предсказываются объекты класса Negative, лучше их просто игнорировать, как показано на следующей схеме. При расчете recall необходимо учитывать только Positive выборки.

Что означает, когда recall высокий или низкий? Если recall имеет большое значение, все Positive семплы классифицируются верно. Следовательно, модели можно доверять в ее способности обнаруживать представителей класса Positive.
На следующем изображении recall равен 1.0, потому что все Positive семплы были правильно классифицированы. Показатель True Positive равен 3, а False Negative – 0. Таким образом, recall вычисляется как 3 / (3 + 0) = 1. Это означает, что модель обнаружила все Positive выборки. Поскольку recall не учитывает, как предсказываются представители класса Negative, могут присутствовать множество неверно определенных Negative семплов (высокая False Positive метрика).

С другой стороны, recall равен 0.0, если не удается обнаружить ни одной Positive выборки. Это означает, что модель обнаружила 0% представителей класса Positive. Показатель True Positive равен 0, а False Negative имеет значение 3. Recall будет равен 0 / (0 + 3) = 0.
Когда recall имеет значение от 0.0 до 1.0, это число отражает процент Positive семплов, которые модель верно классифицировала. Например, если имеется 10 экземпляров Positive и recall равен 0.6, получается, что модель корректно определила 60% объектов класса Positive (т.е. 0.6 * 10 = 6).
Подобно precision_score(), функция repl_score() из модуля sklearn.metrics вычисляет recall. В следующем блоке кода показан пример ее использования.
import sklearn.metrics
y_true = ["positive", "positive", "positive", "negative", "negative", "negative"]
y_pred = ["positive", "positive", "negative", "positive", "negative", "negative"]
recall = sklearn.metrics.recall_score(y_true, y_pred, pos_label="positive")
print(recall)
Вывод: 0.6666666666666666.
После определения precision и recall давайте кратко подведем итоги:
- Precision измеряет надежность модели при классификации Positive семплов, а recall определяет, сколько Positive выборок было корректно предсказано моделью.
- Precision учитывает классификацию как Positive, так и Negative семплов. Recall же использует при расчете только представителей класса Positive. Другими словами, precision зависит как от Negative, так и от Positive-выборок, но recall — только от Positive.
- Precision принимает во внимание, когда семпл определяется как Positive, но не заботится о верной классификации всех объектов класса Positive. Recall в свою очередь учитывает корректность предсказания всех Positive выборок, но не заботится об ошибочной классификации представителей Negative как Positive.
- Когда модель имеет высокий уровень recall метрики, но низкую precision, такая модель правильно определяет большинство Positive семплов, но имеет много ложных срабатываний (классификаций Negative выборок как Positive). Если модель имеет большую precision, но низкий recall, то она делает высокоточные предсказания, определяя класс Positive, но производит всего несколько таких прогнозов.
Некоторые вопросы для проверки понимания:
- Если recall равен 1.0, а в датасете имеются 5 объектов класса Positive, сколько Positive семплов было правильно классифицировано моделью?
- Учитывая, что recall составляет 0.3, когда в наборе данных 30 Positive семплов, сколько представителей класса Positive будет предсказано верно?
- Если recall равен 0.0 и в датасете14 Positive-семплов, сколько корректных предсказаний класса Positive было сделано моделью?
Precision или Recall?
Решение о том, следует ли использовать precision или recall, зависит от типа вашей проблемы. Если цель состоит в том, чтобы обнаружить все positive выборки (не заботясь о том, будут ли negative семплы классифицированы как positive), используйте recall. Используйте precision, если ваша задача связана с комплексным предсказанием класса Positive, то есть учитывая Negative семплы, которые были ошибочно классифицированы как Positive.
Представьте, что вам дали изображение и попросили определить все автомобили внутри него. Какой показатель вы используете? Поскольку цель состоит в том, чтобы обнаружить все автомобили, используйте recall. Такой подход может ошибочно классифицировать некоторые объекты как целевые, но в конечном итоге сработает для предсказания всех автомобилей.
Теперь предположим, что вам дали снимок с результатами маммографии, и вас попросили определить наличие рака. Какой показатель вы используете? Поскольку он обязан быть чувствителен к неверной идентификации изображения как злокачественного, мы должны быть уверены, когда классифицируем снимок как Positive (то есть с раком). Таким образом, предпочтительным показателем в данном случае является precision.
Вывод
В этом руководстве обсуждалась матрица ошибок, вычисление ее 4 метрик (true/false positive/negative) для задач бинарной и мультиклассовой классификации. Используя модуль metrics библиотеки Scikit-learn, мы увидели, как получить матрицу ошибок в Python.
Основываясь на этих 4 показателях, мы перешли к обсуждению accuracy, precision и recall метрик. Каждая из них была определена и использована в нескольких примерах. Модуль sklearn.metrics применяется для расчета каждого вышеперечисленного показателя.
Мы уже рассказывали, как машинное обучение применяется для прогнозирования будущих событий в финансовом секторе, нефтегазовой промышленности, логистике, HR-менеджменте, девелопменте, страховании, муниципальном управлении, маркетинге, ритейле и других отраслях экономики. Сегодня рассмотрим еще несколько практических примеров такого приложения Machine Learning и в этом контексте разберем одно из ключевых понятий Data Science по оценке моделей. Читайте в нашей статье, что такое матрица ошибок (confusion matrix) и как она помогает измерить эффективность используемых ML-алгоритмов и других инструментов бизнес-аналитики, оценив потенциальные убытки и выгоды от возможных сценариев будущего в задаче прогнозирования спроса.
От ритейла до банка: 5 примеров применения Big Data и Machine Learning в задачах прогнозирования спроса и предложения
Вообще сегодня задача прогнозирования спроса стала довольно обыденным приложением методов Machine Learning (ML) в реальном бизнесе. В частности, в декабре 2019 года сервис объявлений «Юла» ускорил публикацию объявлений по продаже товаров с помощью функции их распознавания по фотографии. Помимо собственно распознавания того, что сфотографировано, нейросетевые модели предлагают пользователю уточнить характеристики продукта и оценивают его стоимость в среднем по рынку. При этом пользователю выдается прогноз, насколько быстро он продаст товар при различных ценах [1].
Другой пример, московский сервис приготовления и доставки еды навынос «Кухня на районе» с помощью нейросетей и ежедневной статистики продаж рассчитывает, сколько продуктов нужно привезти на каждую точку, чтобы минимизировать количество остатков. Анализируя данные по проданным позициям в разных локациях, нейросеть из 3 500 вариантов отбирает сотню блюд, которые будут максимально востребованы, чтобы готовить именно их на районных кухнях в течение следующей недели [2].
Подобным образом, на основе постоянного анализа продаж, машинное обучение позволяет эффективно решить задачу ценообразования, установив наиболее оптимальную стоимость на отдельные продукты и целые товарные категории. Например, именно это было сделано в отечественном интернет-магазине детских игрушек Babadu.ru, когда методы Machine Learning помогли разработать несколько маркетинговых стратегий, наиболее выгодных для ритейлера [3]. Аналогично строятся ML-модели эластичного спроса в другом российском гиганте интернет-торговли, Ozon.ru. Разработанный алгоритм анализирует значения более 150 признаков в истории продаж, чтобы на выходе предоставить точный прогноз по будущим заказам. При этом в модели заложена функция минимизации денежных потерь на покупку и хранение лишних товаров на складе или отток клиента (Churn Rate) из-за отсутствия нужного продукта [4].
Похожая задача прогнозирования спроса актуальна и для банков, которые стремятся оптимизировать процессы работы с наличными деньгами в своих банкоматах. Финансовые корпорации хотят, с одной стороны, чтобы средства не лежали в банкоматах «без дела»: гораздо выгоднее, например, разместить их на краткосрочном депозите. Но, клиенты будут недовольны, когда столкнутся с отказом из-за недостаточного количества денег в банкомате. Это грозит репутационными потерями, поэтому банк стремится решить данную проблему с помощью точного предсказания спроса на наличность в каждой точке расположения банкоматов. При этом нужно учитывать, что спрос на наличные зависит от множества параметров: макроэкономические факторы, политические новости, социальные события, расположение банкомата, прогноз погоды, время года, день недели и т.д. Чтобы предсказать завтрашнюю потребность в наличных для конкретного банкомата, Сбербанк, например, с 2016 года использует адаптивные алгоритмы машинного обучения вместе с классическими методами анализа временных рядов. Такие модели обеспечивают динамическое перестроение всех анализируемых параметров, предоставляя на выходе эффективный план оптимального распределения и перемещения наличных между банкоматами [5].
Машинное обучение на Python
Код курса
PYML
Ближайшая дата курса
19 июня, 2023
Длительность обучения
24 ак.часов
Стоимость обучения
49 500 руб.
Что такое матрица ошибок и зачем она нужна: пример расчета стоимости ошибки прогнозирования
Поскольку в бизнесе поиск баланса между спросом и предложением напрямую конвертируется в деньги, возникает вопрос, насколько выгодно применение методов Machine Learning для решения этой задачи. С целью сопоставления предсказаний и реальности в Data Science используется матрица ошибок (confusion matrix) – таблица с 4 различными комбинациями прогнозируемых и фактических значений. Прогнозируемые значения описываются как положительные и отрицательные, а фактические – как истинные и ложные [6]. Вообще матрица ошибок используется для оценки точности моделей в задачах классификации. Но прогнозирование и распознавание образов можно рассматривать как частный случай этой проблемы, поэтому confusion matrix актуальна и для измерения точности предсказаний. Важно, что матрица ошибок позволяет оценить эффективность прогноза не только в качественном, но и в количественном выражении, т.е. измерить стоимость ошибки в деньгах. Например, каковы будут расходы на удержание пользователя, если машинное обучение предсказало, что он перестанет приносить компании пользу [7]? Аналогичный вопрос по предсказанию оттока (Churn Rate) актуален и в HR-сфере для удержания ключевых сотрудников, мотивация которых снижается. Впрочем, матрица ошибок может использоваться не только в рамках применения Machine Learning. По сути, этот метод оценки стоимости прогноза является универсальным аналитическим инструментом.
|
Прогноз |
Реальность |
|
|
+ |
— |
|
|
+ |
True Positive (истинно-положительное решение): прогноз совпал с реальностью, результат положительный произошел, как и было предсказано ML-моделью |
False Positive (ложноположительное решение): ошибка 1-го рода, ML-модель предсказала положительный результат, а на самом деле он отрицательный |
|
— |
False Negative (ложноотрицательное решение): ошибка 2-го рода – ML-модель предсказала отрицательный результат, но на самом деле он положительный |
True Negative (истинно-отрицательное решение): результат отрицательный, ML-прогноз совпал с реальностью |

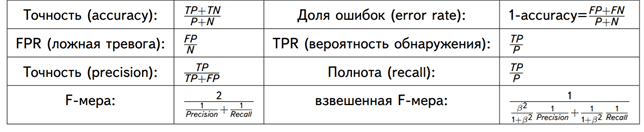
С математической точки зрения оценить точность ML-модели можно с помощью следующих метрик [8]:
- Точность – сколько всего результатов было предсказано верно;
- Доля ошибок;
- Полнота – сколько истинных результатов было предсказано верно;
- F-мера, которая позволяет сравнить 2 модели, одновременно оценив полноту и точность. Здесь используется среднее гармоническое вместо среднего арифметического, сглаживая расчеты за счет исключения экстремальных значений.
В количественном выражении это будет выглядеть так:
- P – число истинных результатов, P = TP + FN;
- N – число ложных результатов, N = TN + FP.
Рассмотрим матрицу ошибок на практическом примере для задачи прогнозирования спроса на скоропортящуюся продукцию, которая должна быть продана конечному пользователю в течение суток. Например, букеты цветов, продающиеся по цене k рублей при закупочной стоимости в p рублей. Предположим, с помощью Machine Learning было предложена 2 варианта:
- Положительный прогноз (+), что по цене k будут полностью раскуплены все цветы в количестве n букетов.
- Отрицательный прогноз (+), что по цене k будут полностью раскуплены не все цветы, останется m не проданных букетов.
Соответственно, матрица ошибок для этого случая будет выглядеть следующим образом:
|
Прогноз |
Реальность |
|
|
Проданы все букеты цветов |
Остались не проданные m букетов |
|
|
+: Проданы все n букетов по k рублей c ценой закупки p |
True Positive: прогноз совпал с реальностью, все закупленные n букетов проданы Выручка = n*k Затраты = n*p Прибыль = n*(k-p) Стоимость ошибки = 0 |
False Positive: ошибка 1-го рода, ML-модель предсказала, что будет n продаж, а на самом деле их было (n-m), осталось m не проданных букетов, которые пропали и не вернули затраты на их покупку Выручка = (n-m)*k Затраты = n*p Прибыль = n*(k-p) – m*k Стоимость ошибки = m*p |
|
—: Остались не проданные m букетов c ценой закупки p |
False Negative: ошибка 2-го рода – ML-модель предсказала, что n букетов не будет продано, поэтому закупили (n-m) букетов, но спрос был на n букетов. Эффект недополученной прибыли Выручка = (n-m)*k Затраты = (n-m)*p Прибыль = (n-m)*(k-p) Стоимость ошибки = m*k |
True Negative: ML-прогноз совпал с реальностью, было раскуплено (n-m) букетов по цене k, сколько и было изначально закуплено по цене p Выручка = (n-m)*k Затраты = (n-m)*p Прибыль = (n-m)*(k-p) Стоимость ошибки = 0 |
Аналитика больших данных для руководителей
Код курса
BDAM
Ближайшая дата курса
28 июня, 2023
Длительность обучения
24 ак.часов
Стоимость обучения
66 000 руб.
Таким образом, с помощью confusion matrix можно измерить эффективность прогноза в денежном выражении, что весьма актуально для практического бизнес-приложения Machine Learning. Впрочем, отметим еще раз, что данный метод предварительной оценки будущих сценариев можно использовать и вне сферы Data Science, оценивая риски и перспективы в рамках классического бизнес-анализа.

Другие практические вопросы системного и бизнес-анализа рассматриваются в рамках нашей Школы прикладного бизнес-анализа. А особенности практического применения больших данных и машинного обучения разбираются на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Аналитика больших данных для руководителей
- Машинное обучение на Python
Источники
- https://www.the-village.ru/village/city/news-city/371179-tseny
- https://www.the-village.ru/village/business/businessmen/371631-kuhnya-na-rayone
- https://chernobrovov.ru/articles/kak-mashinnoe-obuchenie-pomogaet-pravilno-ustanavlivat-pravilnye-ceny.html
- https://habr.com/ru/company/ozontech/blog/431950/
- http://futurebanking.ru/post/3213
- https://hranalytic.ru/kak-ponyat-matrica-nesootvetstvij-confusion-matrix/
- https://chernobrovov.ru/articles/kak-izmerit-effektivnost-machine-learning-schitaem-metriki-i-dengi-na-primere-prognozirovaniya-ottoka-polzovatelej.html
- http://www.machinelearning.ru/wiki/images/archive/5/54/20151001162720!Kitov-ML-05-Model_evaluation.pdf
Классификация — одна из наиболее популярных технологий интеллектуального анализа данных. С необходимостью построения классификаторов рано или поздно сталкивается любой аналитик. Но даже построив модель, необходимо прежде всего убедиться в ее работоспособности. Для этого разработано большое количество мер качества. Наиболее популярные из них рассматриваются в данной статье.
Для классификационных моделей, как и для моделей регрессии, актуальна задача оценки их качества для определения работоспособности моделей и их сравнения. Однако решение этой задачи для моделей классификации вообще, и бинарной классификации в частности, сложнее, чем для регрессии. Связано это с тем, что целевая переменная (метка класса) является категориальным (дискретным) значением, и, следовательно, ошибка классификации не может быть выражена числовым значением.
Поэтому в основе оценки качества классификационных моделей лежит статистика результатов классификации обучающих примеров. С ее помощью вычисляются метрики качества — показатели, которые зависят от результатов классификации и не зависят от внутреннего состояния модели.
Среди наиболее популярных методов оценки качества классификаторов можно выделить следующие:
- Матрица ошибок (Сonfusion matrix).
- Меткость (Accuracy).
- Точность (Precision).
- Полнота (Recall).
- Специфичность (Specificity).
- F1-мера (F1-score).
- Метрика P4 .
- Площадь под ROC-кривой (Area under ROC-curve, AUC-ROC).
- Площадь под кривой полнота-точность (Area under precision-recall curve, AUC-PR).
- Коэффициент корреляции Мэтьюса (Matthews correlation coefficient, MCC).
- Функция потерь логистической регрессии (Logistic loss function, Log Loss).
Матрица ошибок
Прежде чем переходить к описанию собственно метрик качества бинарных классификаторов, рассмотрим методику описания этих метрик в терминах ошибок классификации. Пусть заданы два класса y=left { 0,1 right } и алгоритм, предсказывающий принадлежность каждого объекта одному из классов. Эта задача анализа известна как бинарная классификация.
Приведем пример. Пусть в страховой компании используется аналитическая платформа для поддержки принятия решений о целесообразности страхования того или иного объекта. Если риск наступления страхового события выше определенного порога, то такие объекты страховать нецелесообразно. Именно выявление таких объектов и является целью анализа. Тогда для объектов, страхование которых целесообразно, система должна установить класс 0, а объектам, в страховании которых отказано, — класс 1.
Любой реальный классификатор совершает ошибки. В нашем случае таких ошибок может быть две:
- класс 0 распознается классификатором как класс 1, что можно интерпретировать как «ложную тревогу»;
- класс 1 распознается как класс 0, что можно трактовать как «пропуск цели».
Очевидно, что приведенные ошибки неравноценны по связанным с ними издержкам классификации. В случае «ложной тревоги» компания потеряет только потенциальную страховую премию, т.е. будет иметь место всего лишь упущенная выгода. В случае «пропуска цели» возможна потеря значительной суммы из-за наступления страхового случая. Поэтому важнее не допустить «пропуск цели», чем «ложную тревогу».
Иными словами, важнее правильно определить объект, нежелательный для страхования из-за высокого риска, чем ошибиться в распознавании желательного. Будем называть соответствующий исход классификации положительным (объект не подлежит страхованию y=1), а противоположный — отрицательным (объект подлежит страхованию y=0). Тогда возможны следующие исходы классификации:
- Объект, нежелательный для страхования, классифицирован как нежелательный, т.е. «положительный» класс распознан как положительный. Такой исход классификации (а также пример, для которого он получен) называют истинноположительным.
- Объект, желательный для страхования, распознан как желательный, т.е. «отрицательный» класс распознан как отрицательный. Такой исход классификации называют истинноотрицательными.
- Объект, желаемый для страхования, классифицирован как не желаемый, т.е. имела место ошибка, в результате которой отрицательный класс был распознан как положительный. Данный исход классификации называют ложноположительным, а ошибка классификации называется ошибкой I рода.
- Нежелательный объект распознан как желательный, т.е. имела место ошибка, в результате которой положительный класс был распознан как отрицательный. Такой исход классификации называется ложноотрицательным, а ошибка классификации — ошибкой II рода.
Таким образом, ошибка I рода, или ложноположительный исход классификации, имеет место, когда пример, с которым связано отрицательное событие распознан моделью как положительный. Ошибкой II рода, или ложноотрицательным исходом классификации, называют случай, когда пример, с которым связано положительное событие, распознан как отрицательный. Поясним это с помощью матрицы ошибок классификации, называемой также таблицей сопряженности:
| y=0 | y=1 | |
|---|---|---|
| widehat{y}=0 | Истинноположительный (True Positive — TP) | Ложноположительный (False Positive — FP) |
| widehat{y}=1 | Ложноотрицательный (False Negative — FN) | Истинноотрицательный (True Negative — TN) |
Здесь widehat{y} — отклик модели, а y — фактическое значение. Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP). В данном случае P означает, что классификатор определяет класс объекта как положительный, а N как — отрицательный. T значит, что класс предсказан правильно, соответственно, F — неправильно. Каждая строка в матрице ошибок представляет предсказанный класс, а каждый столбец — фактически наблюдаемый класс.
Идеальный классификатор, если бы он существовал, выдавал бы только истинноположительные и истинноотрицательные классификации, и его матрица ошибок содержала бы значения, отличные от нуля, только на главной диагонали.
Меткость
Представляет собой долю правильных классификаций модели:
ACC=frac{TP+TN}{TP+TN+FP+FN}.
Несложно увидеть, что сумма в знаменателе формулы представляет собой общее число классифицируемых примеров. Графически это можно интерпретировать следующим образом:
Рисунок 1. Меткость
В английском языке этот термин обозначается как «accuracy», поэтому в интернете он часто упоминается как «аккуратность», хотя это слово и не передает смыслового значения данной величины.
Несмотря на то, что эта мера хорошо интерпретируется, на практике она используется достаточно редко, поскольку плохо работает в случае дисбаланса классов в обучающей выборке.
Поясним это на примере кредитного скоринга. Пусть требуется классифицировать заемщиков на добросовестных (не допустивших просрочку) и недобросовестных (допустивших просрочку). Целью является выявление недобросовестных заемщиков, поскольку связанные с ними издержки выше. Следовательно, классификация заемщика как недобросовестного является положительным событием, а как добросовестного — отрицательным.
Выборка содержит 1000 добросовестных заемщиков, 900 из которых классификатор предсказал правильно (TN=900, FP=100), и 100 недобросовестных, 50 из которых классификатор также определил верно (TP=50, FN=50).
Несложно вычислить, что:
ACC=frac{50+900}{50+900+100+50}=0.866.
Однако, если построить «наивную» модель, которая просто будет классифицировать всех клиентов, как добросовестных (на основании того, что таковых большинство), то меткость такой модели окажется:
ACC=frac{0+1000}{0+1000+0+100}=0.909.
Таким образом, оказалось, что меткость «бесполезной» модели, не имеющей предсказательной силы, выше, чем «рабочей» модели. Это противоречит здравому смыслу. Поэтому на практике стараются использовать альтернативные меры качества.
Точность
Точность равна доле истинноположительных классификаций к общему числу положительных классификаций. Данная величина часто упоминается как positive predictive value (PPV) или положительное прогностическое значение:
Pr=PPV=frac{TP}{TP+FP}.
Поясним данное выражение с помощью рисунка:
Рисунок 2. Точность
Несложно увидеть, что попытка отнести все объекты к одному классу неизбежно приведет к росту FP и уменьшению значения точности.
Полнота
Полнота, известная еще как чувствительность или доля истинноположительных примеров (TPR — true positive rate), определяется как число истинноположительных классификаций относительно общего числа положительных наблюдений:
Re=TPR=frac{TP}{TP+FN}.
Таким образом, полноту можно рассматривать как способность классификатора обнаруживать определенный класс. Графически полноту можно проиллюстрировать с помощью рисунка:
Рисунок 3. Полнота
Точность и полноту для каждого класса легко определять с помощью матрицы ошибок. Точность равна отношению соответствующего диагонального элемента матрицы и суммы элементов всей строки класса, а полнота — отношению диагонального элемента матрицы и суммы элементов всего столбца класса.
PPV_{c}=frac{A_{cc}}{sumlimits_{i=1}^{n}A_{ci}},
TPR_{c}=frac{A_{cc}}{sumlimits_{i=1}^{n}A_{ic}},
где c — класс, n — число элементов столбца (равно числу классов), i — номер элемента в столбце, A — элемент матрицы ошибок.
Специфичность
Специфичность классификатора — это доля истинноотрицательных (True Negative Rate — TNR) классификаций в общем числе отрицательных классификаций:
Sp=TNR=frac{TN}{TN+FP}.
TNR показывает, насколько хорошо модель классифицирует отрицательные примеры. Поясним это с помощью рисунка.
Рисунок 4. Специфичность
Очевидно, что если все отрицательные примеры классифицированы правильно (т.е. число ложноположительных случаев равно 0), то TPR=1.
F1-мера
Точность и полнота, в отличие от меткости, не зависят от соотношения классов и, следовательно, могут применяться в условиях несбалансированных выборок. На практике часто встречается задача поиска оптимального баланса между точностью и полнотой. Действительно, улучшая настройку модели на один класс, например, путем изменения дискриминационного порога, мы тем самым ухудшаем настройку на другой.
Чем выше точность и полнота, тем лучше модель. Но на практике их максимальные значения одновременно недостижимы, поэтому приходится искать баланс между ними. Для этого используется метрика, объединяющая в себе информацию о точности и полноте. Она называется F1-мера и вычисляется следующим образом:
F1=frac{2cdot PPVcdot TPR}{PPV+TPR}=frac{2cdot TP}{2cdot TP+FP+FN}.
В данном выражении точность PPV и полнота TPR имеют одинаковый вес, поэтому при их уменьшении F1-мера сокращается пропорционально.
Однако на практике чаще используется сбалансированная F1-мера, в которой точности и полноте присваиваются разные веса с целью найти оптимальный баланс между данными метриками. Для этого в формулу для F1-меры вводится дополнительный балансировочный параметр, обозначаемый β. Сбалансированная F1-мера вычисляется следующим образом:
F1=frac{(1-beta ^{2})cdot PPVcdot TPR}{beta ^{2}cdot PPV+TPR}.
Если параметр принимает значения из диапазона 0< beta < 1, то приоритет имеет точность, а если beta> 1, то полнота.
Еще одним источником критики F1-меры является отсутствие симметрии. Это означает, что она может изменить свое значение при инверсии положительного и отрицательного классов.
Метрика P4
Метрика P_{4} была разработана как расширение F1-меры, обладающее симметрией относительно инверсии классов. Вычисляется по формуле:
P_{4}=frac{4cdot TPcdot TN}{4cdot TPcdot TN+(TP+TN)cdot (FP+FN)}.
Метрика P_{4} изменяется в диапазоне от 0 до 1. Чем ближе значение метрики к 1, тем лучше работает модель. Очевидно, что значение меры стремится к 0, если хотя бы один из множителей в числителе становится равным нулю, т.е. когда модель теряет способность правильно распознавать положительные или отрицательные примеры.
AUC-ROC
ROC-кривая, или кривая рабочих характеристик приемника (Receiver Operating Characteristics curve), позволяет не только оценить качество работы классификатора, но и исследовать его поведение при различных значениях дискриминационного порога. Технология оценки качества моделей бинарной классификации с помощью ROC-кривых известна как ROC-анализ.
Рассмотрим совместно TPR и TNR классификатора. TPR показывает, насколько хорошо модель классифицирует положительные примеры. Очевидно, что если все положительные примеры классифицированы правильно (т.е. число ложноотрицательных случаев равно 0), то TPR=1. TNR показывает, насколько хорошо модель классифицирует отрицательные примеры. Очевидно, что если все отрицательные примеры классифицированы правильно (т.е. число ложноположительных случаев равно 0), то TPR=1.
Таким образом, по отдельности TPR и TNR характеризуют способность модели распознавать только один из классов. Но их совместное использование помогает создать метрику, которая позволяет выбирать значение дискриминационного порога, который оптимально балансирует модель между способностью распознавать положительные и отрицательные примеры. Именно эта задача и решается с помощью ROC-кривой.
Действительно, если изменять дискриминационный порог от 0 до 1 и наносить по оси абсцисс точки 1−TNR, а по оси ординат TPR, то полученный график и будет ROC-кривой. Величину 1−TNR называют долей ложноположительных классификаций (false positive rate) или показателем ложной тревоги. Она вычисляется следующим образом:
1-TNR=FPR=frac{FP}{FP+TN}.
При пороге, равном 1, все примеры будут классифицированы как отрицательные (FPR=1, TPR=1), а при пороге, равном 0, — как положительные (FPR=0, TPR=0). Поэтому ROC-кривая всегда идет от точки (0,0) до точки (1,1).
Рисунок 5. ROC-кривая
Несложно увидеть, что для идеальной модели ROC-кривая превращается в ломаную, проходящую через точки (0,0), (0,1) и (1,1). При этом площадь под ROC-кривой (AUC — Area Under Curve) окажется равной 1. Площадь под кривой выделена на рисунке светло-серым цветом.
Точка (0,1) соответствует идеальному состоянию модели, в котором и TPR, и TNR одновременно равны 1. Т.е. модель одинаково хорошо «научилась» работать как с положительными, так и с отрицательными примерами при существующем в обучающей выборке балансе классов.
Идеальная модель является скорее гипотетической и на практике, как правило, недостижима. Поэтому обычно приходится иметь дело с ROC-кривыми, которые не проходят через точку (0,1), а приближаются к ней на определенное расстояние. Соответственно и AUC−ROC оказывается меньше 1.
Таким образом показатель AUC−ROC является удобной мерой качества классификатора относительно идеального. Принята следующая шкала оценки качества.
| AUC | Оценка |
|---|---|
| 0.9 — 1 | Отличное |
| 0.8 — 0.9 | Очень хорошее |
| 0.7 — 0.8 | Хорошее |
| 0.6 — 0.7 | Удовлетворительное |
| 0.5 — 0.7 | Плохое |
Если AUC-ROC=0.5, то ROC-кривая превращается в линию, проходящую через точки (0,0) и (1,1), которая соответствует бесполезному классификатору, работающему как случайный предсказатель. Если AUC-ROC< 0.5, то получается модель, которая работает хуже случайного предсказателя и от ее использования следует отказаться.
AUC-PR
PR-кривые определяются аналогично ROC-кривым, но только по оси абсцисс у них откладываются значения полноты, а по оси ординат — точности.
Точность и полнота — две наиболее важные метрики, на которые следует обращать внимание при оценке качества модели бинарной классификации в условиях несбалансированности классов. Они помогают увидеть, какая часть фактически положительных наблюдений была классифицирована правильно, и какие среди классифицированных как положительные, были истинноположительными.
Если точность равна 1, то ложноположительные классификации отсутствуют. Но это ничего не говорит о том, были ли распознаны все положительные примеры. Если полнота равна 1, то все положительные объекты были распознаны правильно, а ложноотрицательные классификации отсутствуют. При этом ничего не говорится о том, сколько было допущено ложноположительных классификаций.
Таким образом, точность и полнота не особенно полезны для оценки качества классификатора, если их использовать по отдельности. В задаче классификации оценка точности, равная 1 для класса C, означает, что каждый элемент, помеченный как принадлежащий классу C, действительно принадлежит к классу C, но ничего не говорит о количестве элементов из класса
C, которые не были правильно классифицированы. Тогда как полнота, равная 1, означает, что каждый элемент из класса C был помечен как принадлежащий к классу C, но ничего не говорит о том, сколько элементов из других классов были также неправильно классифицированы как принадлежащие к классу C.
Обычно показатели точности и полноты не используются по отдельности. Вместо этого либо значения одной меры сравниваются с фиксированным уровнем другой (например, точность на уровне полноты 0.75), либо обе меры объединяются в один показатель. Примерами такой комбинации и является F1-мера — взвешенное гармоническое среднее точности и полноты.
Еще одним способом комбинирования точности и полноты в задаче оценки качества классификации являются так называемые кривые полнота-точность, которые строятся в системе координат, где по оси абсцисс откладывается полнота, а по оси ординат — точность. Кривая точность-полнота показывает, как выбор порога влияет на точность классификатора, а также помогает выбрать лучшее значение дискриминационного порога для определенного баланса классов.
Рисунок 6. Кривая точность-полнота
Каждая точка PR-кривой представляет определенное значение дискриминационного порога, а ее расположение соответствует результирующей точности и полноте, когда этот порог выбран. Точка 1 на рисунке соответствует значению дискриминационного порога, равному 1, а точка 3 — значению порога 0. Точка 2 соответствует идеальному классификатору и совпадает с координатами (1,1), а точка 4 — оптимальному значению порога (точка кривой, наиболее близкая к идеальной точке (1,1)).
Преимущества PR-кривой по сравнению с ROC:
- ROC-кривая, как правило, дает чрезмерно оптимистичную картину в условиях несбалансированности классов.
- При изменении распределения классов ROC-кривая не меняется, а PR-кривая отражает изменение.
Аналогично ROC-кривой, площадь под PR-кривой (для отличия от ROC ее часто называют PR−AUC) отражает качество классификатора и позволяет сравнивать кривые, соответствующие различным балансам классов и значениям порога. Чем выше площадь, тем лучше работает модель.
Пунктирная линия внизу графика соответствует бесполезному классификатору (no-skill model — модель без навыков, или базовая модель), уровень которой изменяется при изменении баланса классов. Такая модель будет присваивать рейтинг 0.5 для любого примера.
На рисунке ниже представлена линия, соответствующая балансу классов, когда положительные примеры составляют 10% от обучающей выборки.
Рисунок 7. Кривая точность-полнота при фиксированном балансе классов
На рисунке точка 1 соответствует порогу 0.5, точка 2 соответствует порогу [0, 0.5). Для порогов (0.5, 1] точность не определена из-за деления на ноль. Можно увидеть, что точность здесь является константой, то есть PPV=0.1 (соответствует доле положительного класса), PR−AUC=0.1.
Таким образом, полнота базовой модели лежит в диапазоне (0.5, 1] независимо от дисбаланса классов, а точность равна доле положительного класса в обучающей выборке.
На следующем рисунке представлена PR-кривая для идеальной модели. На ней точка 1 соответствует порогу (0, 1], точка 2 соответствует порогу 0. Очевидно, что PR−AUC=1.
Рисунок 8. Кривая точность-полнота для идеальной модели
И, наконец, на рисунке ниже отображена PR-кривая (красная линия) для модели, которая работает хуже, чем базовая модель «без навыков» (синяя пунктирная линия). Она расположена ниже линии базовой модели.
Рисунок 9. Кривая точность-полнота для модели хуже бесполезной
Очевидный способ повысить качество «плохой» модели без каких-либо настроек — просто инвертировать классы (класс 0 изменить на класс 1). Это автоматически приведет к повышению точности по сравнению с базовой моделью.
Обычно «плохая» PR-кривая классификатора указывает на то, что в обучающих данных присутствуют проблемы: они содержат шум или классы в них плохо выражены (модель не может выявить закономерность, в соответствии с которой один класс отличается от другого). В этом случае PR−AUC не превышает доли положительных примеров обучающей выборке.
Возможен гибридный случай, когда «плохая» модель работает лучше, чем модель «без навыков», но для определенных пороговых значений.
Коэффициент корреляции Мэтьюса
Коэффициент используется в качестве показателя качества бинарных классификаторов. Он учитывает истинные и ложные классификации и обычно рассматривается как сбалансированная мера, которую можно использовать даже в условиях сильного дисбаланса классов.
MCC, по сути, коэффициент корреляции между фактическими и предсказанными моделью бинарными классификациями. Он изменяется в диапазоне от -1 до 1. MCC=1 указывает на идеальную классификацию, когда фактические и предсказанные классы совпадают для всех обучающих примеров (т.е. ложноположительные и ложноотрицательные классификации отсутствуют). Модель, для которой MCC=0, соответствует случайному предсказателю. MCC=−1 указывает на полное расхождение между фактом и предсказанием (т.е. вместо положительного класса модель всегда предсказывает отрицательный, и наоборот), следовательно, истинноположительные и истинноотрицательные классификации отсутствуют.
Формула для расчета MCC имеет вид:
MCC=frac{TPcdot TN-FPcdot FN}{sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}}.
Несложно увидеть, что если в этой формуле обнулить все ложные классификации, то MCC=1, что соответствует ранее сделанным заключениям. Если число истинных и ложных классификаций равны, то числитель формулы становится равным 0 и MCC=0. И, наконец, если число истинных классификаций равно нулю, то числитель становится отрицательным, и делает таковым результат формулы.
Если какая-либо из четырех сумм в знаменателе равна нулю, знаменатель можно произвольно установить равным единице, это приводит к нулевому коэффициенту корреляции Мэтьюса.
Функция потерь логистической регрессии (Logistic loss function, Log Loss).
Функция потерь в задачах классификации показывает, какую «цену» придется заплатить за неточность предсказаний классификационной модели. Для логистической регрессии, решающей задачу бинарной классификации, она может быть вычислена следующим образом:
Log Loss=-frac{1}{l}sumlimits_{i=1}^{l}(y_{i}cdot log(widehat{y_{i}})+(1-y_{i})cdot log(1-widehat{y_{i}})),
где l — размер выборки, y_{i}=left { 0,1 right } — бинарная метка класса, заданная в примере, widehat{y_{i}} — предсказание модели.
Несложно увидеть, что функция потерь получается путем суммирования логарифма потерь на каждом примере. Потери на каждом примере определяются следующим образом: если предсказанный класс совпадает с фактическим, то потери равны 0, в противном случае потери равны 1. Очевидно, чем больше будет неправильных классификаций, тем больше будет значение LogLoss и тем хуже будет модель. Таким образом, чтобы получить лучшую модель, нужно минимизировать функцию потерь.
Преимуществом метрики LogLoss является устойчивость к выбросам и аномальным значениям в данных и простота вычисления. Недостатком — сложность интерпретации из-за нелинейного характера.
Сравнение метрик
Подведем итоги, кратко резюмируя преимущества и недостатки рассмотренных мер качества классификационных моделей.
| Мера | Преимущества | Недостатки |
|---|---|---|
| Меткость | Хорошо интерпретируется. | Чувствительна к дисбалансу классов. Неадекватно отражает точность классификации. |
| Точность | Не чувствительна к дисбалансу классов. | Отражает качество классификации только для положительного класса. |
| Полнота | Не чувствительна к дисбалансу классов. | Не учитывает отрицательные классификации. |
| Специфичность | Просто вычисляется и интерпретируется. | Характеризует способность модели распознавать только один класс. |
| F1-мера | Позволяет найти баланс между точностью и полнотой. | Чувствительность к дисбалансу, отсутствие симметрии. |
| P4 | Симметрична относительно инверсии классов. | Чувствительность к дисбалансу классов. |
| AUC-ROC | Наглядна, хорошо интерпретируется. | В условиях дисбаланса классов завышает качество модели. Не отражает изменения баланса классов. |
| AUC-PR | Наглядна, хорошо интерпретируется. | Не учитывает отрицательные классификации. |
| Коэффициент Мэтьюса | Более информативен, поскольку использует все типы результатов классификации. | Не может применяться, если один из множителей в знаменателе обращается в 0. |
| LogLoss | Устойчивость к выбросам в данных, простота вычисления. | Сложность интерпретации из-за нелинейного характера. |
В статье рассмотрены наиболее общие меры оценки качества моделей бинарной классификации, отмечены их преимущества и недостатки. Однако в литературе авторы предлагают и другие подходы, которые показали хорошие результаты при решении конкретных задач и не претендующие на универсальность.
Другие материалы по теме:
Метрики качества линейных регрессионных моделей
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
В машинном обучении различают оценки качества для задачи классификации и регрессии. Причем оценка задачи классификации часто значительно сложнее, чем оценка регрессии.
Содержание
- 1 Оценки качества классификации
- 1.1 Матрица ошибок (англ. Сonfusion matrix)
- 1.2 Аккуратность (англ. Accuracy)
- 1.3 Точность (англ. Precision)
- 1.4 Полнота (англ. Recall)
- 1.5 F-мера (англ. F-score)
- 1.6 ROC-кривая
- 1.7 Precison-recall кривая
- 2 Оценки качества регрессии
- 2.1 Средняя квадратичная ошибка (англ. Mean Squared Error, MSE)
- 2.2 Cредняя абсолютная ошибка (англ. Mean Absolute Error, MAE)
- 2.3 Коэффициент детерминации
- 2.4 Средняя абсолютная процентная ошибка (англ. Mean Absolute Percentage Error, MAPE)
- 2.5 Корень из средней квадратичной ошибки (англ. Root Mean Squared Error, RMSE)
- 2.6 Cимметричная MAPE (англ. Symmetric MAPE, SMAPE)
- 2.7 Средняя абсолютная масштабированная ошибка (англ. Mean absolute scaled error, MASE)
- 3 Кросс-валидация
- 4 Примечания
- 5 См. также
- 6 Источники информации
Оценки качества классификации
Матрица ошибок (англ. Сonfusion matrix)
Перед переходом к самим метрикам необходимо ввести важную концепцию для описания этих метрик в терминах ошибок классификации — confusion matrix (матрица ошибок).
Допустим, что у нас есть два класса и алгоритм, предсказывающий принадлежность каждого объекта одному из классов.
Рассмотрим пример. Пусть банк использует систему классификации заёмщиков на кредитоспособных и некредитоспособных. При этом первым кредит выдаётся, а вторые получат отказ. Таким образом, обнаружение некредитоспособного заёмщика () можно рассматривать как «сигнал тревоги», сообщающий о возможных рисках.
Любой реальный классификатор совершает ошибки. В нашем случае таких ошибок может быть две:
- Кредитоспособный заёмщик распознается моделью как некредитоспособный и ему отказывается в кредите. Данный случай можно трактовать как «ложную тревогу».
- Некредитоспособный заёмщик распознаётся как кредитоспособный и ему ошибочно выдаётся кредит. Данный случай можно рассматривать как «пропуск цели».
Несложно увидеть, что эти ошибки неравноценны по связанным с ними проблемам. В случае «ложной тревоги» потери банка составят только проценты по невыданному кредиту (только упущенная выгода). В случае «пропуска цели» можно потерять всю сумму выданного кредита. Поэтому системе важнее не допустить «пропуск цели», чем «ложную тревогу».
Поскольку с точки зрения логики задачи нам важнее правильно распознать некредитоспособного заёмщика с меткой , чем ошибиться в распознавании кредитоспособного, будем называть соответствующий исход классификации положительным (заёмщик некредитоспособен), а противоположный — отрицательным (заемщик кредитоспособен ). Тогда возможны следующие исходы классификации:
- Некредитоспособный заёмщик классифицирован как некредитоспособный, т.е. положительный класс распознан как положительный. Наблюдения, для которых это имеет место называются истинно-положительными (True Positive — TP).
- Кредитоспособный заёмщик классифицирован как кредитоспособный, т.е. отрицательный класс распознан как отрицательный. Наблюдения, которых это имеет место, называются истинно отрицательными (True Negative — TN).
- Кредитоспособный заёмщик классифицирован как некредитоспособный, т.е. имела место ошибка, в результате которой отрицательный класс был распознан как положительный. Наблюдения, для которых был получен такой исход классификации, называются ложно-положительными (False Positive — FP), а ошибка классификации называется ошибкой I рода.
- Некредитоспособный заёмщик распознан как кредитоспособный, т.е. имела место ошибка, в результате которой положительный класс был распознан как отрицательный. Наблюдения, для которых был получен такой исход классификации, называются ложно-отрицательными (False Negative — FN), а ошибка классификации называется ошибкой II рода.
Таким образом, ошибка I рода, или ложно-положительный исход классификации, имеет место, когда отрицательное наблюдение распознано моделью как положительное. Ошибкой II рода, или ложно-отрицательным исходом классификации, называют случай, когда положительное наблюдение распознано как отрицательное. Поясним это с помощью матрицы ошибок классификации:
-
Истинно-положительный (True Positive — TP) Ложно-положительный (False Positive — FP) Ложно-отрицательный (False Negative — FN) Истинно-отрицательный (True Negative — TN)
Здесь — это ответ алгоритма на объекте, а — истинная метка класса на этом объекте.
Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP).
P означает что классификатор определяет класс объекта как положительный (N — отрицательный). T значит что класс предсказан правильно (соответственно F — неправильно). Каждая строка в матрице ошибок представляет спрогнозированный класс, а каждый столбец — фактический класс.
# код для матрицы ошибок # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import confusion_matrix from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (англ. Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе # Для расчета матрицы ошибок сначала понадобится иметь набор прогнозов, чтобы их можно было сравнивать с фактическими целями y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687], # [ 1891, 3530]])
Безупречный классификатор имел бы только истинно-положительные и истинно отрицательные классификации, так что его матрица ошибок содержала бы ненулевые значения только на своей главной диагонали (от левого верхнего до правого нижнего угла):
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.metrics import confusion_matrix
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist["data"], mnist["target"]
y = y.astype(np.uint8)
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки
y_test_5 = (y_test == 5)
y_train_perfect_predictions = y_train_5 # притворись, что мы достигли совершенства
print(confusion_matrix(y_train_5, y_train_perfect_predictions))
# array([[54579, 0],
# [ 0, 5421]])
Аккуратность (англ. Accuracy)
Интуитивно понятной, очевидной и почти неиспользуемой метрикой является accuracy — доля правильных ответов алгоритма:
Эта метрика бесполезна в задачах с неравными классами, что как вариант можно исправить с помощью алгоритмов сэмплирования и это легко показать на примере.
Допустим, мы хотим оценить работу спам-фильтра почты. У нас есть 100 не-спам писем, 90 из которых наш классификатор определил верно (True Negative = 90, False Positive = 10), и 10 спам-писем, 5 из которых классификатор также определил верно (True Positive = 5, False Negative = 5).
Тогда accuracy:
Однако если мы просто будем предсказывать все письма как не-спам, то получим более высокую аккуратность:
При этом, наша модель совершенно не обладает никакой предсказательной силой, так как изначально мы хотели определять письма со спамом. Преодолеть это нам поможет переход с общей для всех классов метрики к отдельным показателям качества классов.
# код для для подсчета аккуратности: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import accuracy_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(accuracy_score(y_train_5, y_train_pred)) # == (53892 + 3530) / (53892 + 3530 + 1891 +687) # 0.9570333333333333
Точность (англ. Precision)
Точностью (precision) называется доля правильных ответов модели в пределах класса — это доля объектов действительно принадлежащих данному классу относительно всех объектов которые система отнесла к этому классу.
Именно введение precision не позволяет нам записывать все объекты в один класс, так как в этом случае мы получаем рост уровня False Positive.
Полнота (англ. Recall)
Полнота — это доля истинно положительных классификаций. Полнота показывает, какую долю объектов, реально относящихся к положительному классу, мы предсказали верно.
Полнота (recall) демонстрирует способность алгоритма обнаруживать данный класс вообще.
Имея матрицу ошибок, очень просто можно вычислить точность и полноту для каждого класса. Точность (precision) равняется отношению соответствующего диагонального элемента матрицы и суммы всей строки класса. Полнота (recall) — отношению диагонального элемента матрицы и суммы всего столбца класса. Формально:
Результирующая точность классификатора рассчитывается как арифметическое среднее его точности по всем классам. То же самое с полнотой. Технически этот подход называется macro-averaging.
# код для для подсчета точности и полноты: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import precision_score, recall_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(precision_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 687) print(recall_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 1891) # 0.8370879772350012 # 0.6511713705958311
F-мера (англ. F-score)
Precision и recall не зависят, в отличие от accuracy, от соотношения классов и потому применимы в условиях несбалансированных выборок.
Часто в реальной практике стоит задача найти оптимальный (для заказчика) баланс между этими двумя метриками. Понятно что чем выше точность и полнота, тем лучше. Но в реальной жизни максимальная точность и полнота не достижимы одновременно и приходится искать некий баланс. Поэтому, хотелось бы иметь некую метрику которая объединяла бы в себе информацию о точности и полноте нашего алгоритма. В этом случае нам будет проще принимать решение о том какую реализацию запускать в производство (у кого больше тот и круче). Именно такой метрикой является F-мера.
F-мера представляет собой гармоническое среднее между точностью и полнотой. Она стремится к нулю, если точность или полнота стремится к нулю.
Данная формула придает одинаковый вес точности и полноте, поэтому F-мера будет падать одинаково при уменьшении и точности и полноты. Возможно рассчитать F-меру придав различный вес точности и полноте, если вы осознанно отдаете приоритет одной из этих метрик при разработке алгоритма:
где принимает значения в диапазоне если вы хотите отдать приоритет точности, а при приоритет отдается полноте. При формула сводится к предыдущей и вы получаете сбалансированную F-меру (также ее называют ).
-

Рис.1 Сбалансированная F-мера,
-

Рис.2 F-мера c приоритетом точности,
-

Рис.3 F-мера c приоритетом полноты,
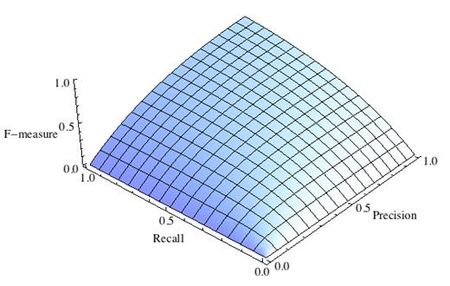
F-мера достигает максимума при максимальной полноте и точности, и близка к нулю, если один из аргументов близок к нулю.
F-мера является хорошим кандидатом на формальную метрику оценки качества классификатора. Она сводит к одному числу две других основополагающих метрики: точность и полноту. Имея «F-меру» гораздо проще ответить на вопрос: «поменялся алгоритм в лучшую сторону или нет?»
# код для подсчета метрики F-mera: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier from sklearn.metrics import f1_score mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распознавать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(f1_score(y_train_5, y_train_pred)) # 0.7325171197343846
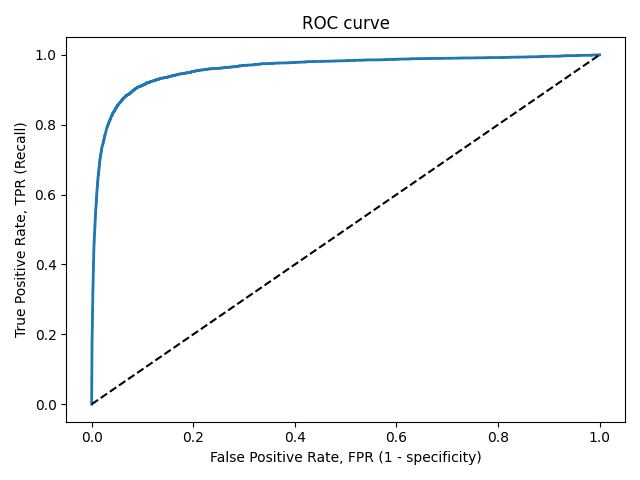
ROC-кривая
Кривая рабочих характеристик (англ. Receiver Operating Characteristics curve).
Используется для анализа поведения классификаторов при различных пороговых значениях.
Позволяет рассмотреть все пороговые значения для данного классификатора.
Показывает долю ложно положительных примеров (англ. false positive rate, FPR) в сравнении с долей истинно положительных примеров (англ. true positive rate, TPR).
Доля FPR — это пропорция отрицательных образцов, которые были некорректно классифицированы как положительные.
- ,
где TNR — доля истинно отрицательных классификаций (англ. Тrие Negative Rate), представляющая собой пропорцию отрицательных образцов, которые были корректно классифицированы как отрицательные.
Доля TNR также называется специфичностью (англ. specificity). Следовательно, ROC-кривая изображает чувствительность (англ. seпsitivity), т.е. полноту, в сравнении с разностью 1 — specificity.
Прямая линия по диагонали представляет ROC-кривую чисто случайного классификатора. Хороший классификатор держится от указанной линии настолько далеко, насколько это
возможно (стремясь к левому верхнему углу).
Один из способов сравнения классификаторов предусматривает измерение площади под кривой (англ. Area Under the Curve — AUC). Безупречный классификатор будет иметь площадь под ROC-кривой (ROC-AUC), равную 1, тогда как чисто случайный классификатор — площадь 0.5.
# Код отрисовки ROC-кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import roc_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") fpr, tpr, thresholds = roc_curve(y_train_5, y_scores) def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0, 1], [0, 1], 'k--') # dashed diagonal plt.xlabel('False Positive Rate, FPR (1 - specificity)') plt.ylabel('True Positive Rate, TPR (Recall)') plt.title('ROC curve') plt.savefig("ROC.png") plot_roc_curve(fpr, tpr) plt.show()
Precison-recall кривая
Чувствительность к соотношению классов.
Рассмотрим задачу выделения математических статей из множества научных статей. Допустим, что всего имеется 1.000.100 статей, из которых лишь 100 относятся к математике. Если нам удастся построить алгоритм , идеально решающий задачу, то его TPR будет равен единице, а FPR — нулю. Рассмотрим теперь плохой алгоритм, дающий положительный ответ на 95 математических и 50.000 нематематических статьях. Такой алгоритм совершенно бесполезен, но при этом имеет TPR = 0.95 и FPR = 0.05, что крайне близко к показателям идеального алгоритма.
Таким образом, если положительный класс существенно меньше по размеру, то AUC-ROC может давать неадекватную оценку качества работы алгоритма, поскольку измеряет долю неверно принятых объектов относительно общего числа отрицательных. Так, алгоритм , помещающий 100 релевантных документов на позиции с 50.001-й по 50.101-ю, будет иметь AUC-ROC 0.95.
Precison-recall (PR) кривая. Избавиться от указанной проблемы с несбалансированными классами можно, перейдя от ROC-кривой к PR-кривой. Она определяется аналогично ROC-кривой, только по осям откладываются не FPR и TPR, а полнота (по оси абсцисс) и точность (по оси ординат). Критерием качества семейства алгоритмов выступает площадь под PR-кривой (англ. Area Under the Curve — AUC-PR)
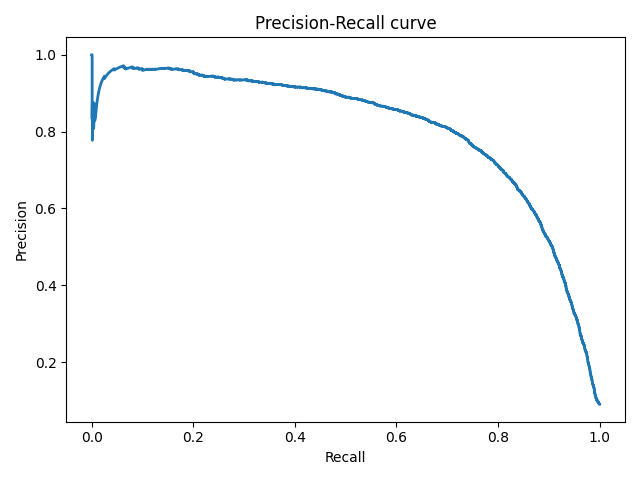
# Код отрисовки Precison-recall кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import precision_recall_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores) def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(recalls, precisions, linewidth=2) plt.xlabel('Recall') plt.ylabel('Precision') plt.title('Precision-Recall curve') plt.savefig("Precision_Recall_curve.png") plot_precision_recall_vs_threshold(precisions, recalls, thresholds) plt.show()
Оценки качества регрессии
Наиболее типичными мерами качества в задачах регрессии являются
Средняя квадратичная ошибка (англ. Mean Squared Error, MSE)
MSE применяется в ситуациях, когда нам надо подчеркнуть большие ошибки и выбрать модель, которая дает меньше больших ошибок прогноза. Грубые ошибки становятся заметнее за счет того, что ошибку прогноза мы возводим в квадрат. И модель, которая дает нам меньшее значение среднеквадратической ошибки, можно сказать, что что у этой модели меньше грубых ошибок.
- и
Cредняя абсолютная ошибка (англ. Mean Absolute Error, MAE)
Среднеквадратичный функционал сильнее штрафует за большие отклонения по сравнению со среднеабсолютным, и поэтому более чувствителен к выбросам. При использовании любого из этих двух функционалов может быть полезно проанализировать, какие объекты вносят наибольший вклад в общую ошибку — не исключено, что на этих объектах была допущена ошибка при вычислении признаков или целевой величины.
Среднеквадратичная ошибка подходит для сравнения двух моделей или для контроля качества во время обучения, но не позволяет сделать выводов о том, на сколько хорошо данная модель решает задачу. Например, MSE = 10 является очень плохим показателем, если целевая переменная принимает значения от 0 до 1, и очень хорошим, если целевая переменная лежит в интервале (10000, 100000). В таких ситуациях вместо среднеквадратичной ошибки полезно использовать коэффициент детерминации —
Коэффициент детерминации
Коэффициент детерминации измеряет долю дисперсии, объясненную моделью, в общей дисперсии целевой переменной. Фактически, данная мера качества — это нормированная среднеквадратичная ошибка. Если она близка к единице, то модель хорошо объясняет данные, если же она близка к нулю, то прогнозы сопоставимы по качеству с константным предсказанием.
Средняя абсолютная процентная ошибка (англ. Mean Absolute Percentage Error, MAPE)
Это коэффициент, не имеющий размерности, с очень простой интерпретацией. Его можно измерять в долях или процентах. Если у вас получилось, например, что MAPE=11.4%, то это говорит о том, что ошибка составила 11,4% от фактических значений.
Основная проблема данной ошибки — нестабильность.
Корень из средней квадратичной ошибки (англ. Root Mean Squared Error, RMSE)
Примерно такая же проблема, как и в MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня.
Cимметричная MAPE (англ. Symmetric MAPE, SMAPE)
Средняя абсолютная масштабированная ошибка (англ. Mean absolute scaled error, MASE)
MASE является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Обратите внимание, что в MASE мы имеем дело с двумя суммами: та, что в числителе, соответствует тестовой выборке, та, что в знаменателе — обучающей. Вторая фактически представляет собой среднюю абсолютную ошибку прогноза. Она же соответствует среднему абсолютному отклонению ряда в первых разностях. Эта величина, по сути, показывает, насколько обучающая выборка предсказуема. Она может быть равна нулю только в том случае, когда все значения в обучающей выборке равны друг другу, что соответствует отсутствию каких-либо изменений в ряде данных, ситуации на практике почти невозможной. Кроме того, если ряд имеет тенденцию к росту либо снижению, его первые разности будут колебаться около некоторого фиксированного уровня. В результате этого по разным рядам с разной структурой, знаменатели будут более-менее сопоставимыми. Всё это, конечно же, является очевидными плюсами MASE, так как позволяет складывать разные значения по разным рядам и получать несмещённые оценки.
Недостаток MASE в том, что её тяжело интерпретировать. Например, MASE=1.21 ни о чём, по сути, не говорит. Это просто означает, что ошибка прогноза оказалась в 1.21 раза выше среднего абсолютного отклонения ряда в первых разностях, и ничего более.
Кросс-валидация
Хороший способ оценки модели предусматривает применение кросс-валидации (cкользящего контроля или перекрестной проверки).
В этом случае фиксируется некоторое множество разбиений исходной выборки на две подвыборки: обучающую и контрольную. Для каждого разбиения выполняется настройка алгоритма по обучающей подвыборке, затем оценивается его средняя ошибка на объектах контрольной подвыборки. Оценкой скользящего контроля называется средняя по всем разбиениям величина ошибки на контрольных подвыборках.
Примечания
- [1] Лекция «Оценивание качества» на www.coursera.org
- [2] Лекция на www.stepik.org о кросвалидации
- [3] Лекция на www.stepik.org о метриках качества, Precison и Recall
- [4] Лекция на www.stepik.org о метриках качества, F-мера
- [5] Лекция на www.stepik.org о метриках качества, примеры
См. также
- Оценка качества в задаче кластеризации
- Кросс-валидация
Источники информации
- [6] Соколов Е.А. Лекция линейная регрессия
- [7] — Дьяконов А. Функции ошибки / функционалы качества
- [8] — Оценка качества прогнозных моделей
- [9] — HeinzBr Ошибка прогнозирования: виды, формулы, примеры
- [10] — egor_labintcev Метрики в задачах машинного обучения
- [11] — grossu Методы оценки качества прогноза
- [12] — К.В.Воронцов, Классификация
- [13] — К.В.Воронцов, Скользящий контроль