
1) Кислотно-основного титриметрического определения уксусной кислоты в уксусной эссенции;
2) Гравиметрического определения хроматов в электролите для хромирования.
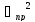
Абсолютная погрешность аналитических
весов 0,1мг
Абсолютная погрешность (ошибка)
∆x=xi—xист.
Xi-измеренное
значениеXист-истинное
значение ( если истинное значение не
известно – берется среднее)
Абсолютная погрешность не может ясно
охарактеризовать точность измерения,
так как она не связана с измеренным
значением.
Относительная погрешность (ошибка)
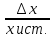 ·100%
·100%
Систематические погрешности (ошибки)– возникают при действии постоянных
причин, их можно выявить устранить или
учесть изменяются по постоянно
действующему закону .
-
Инструментальные погрешности–связанные с инструментами для измерения
аналитического сигнала (весы, посуда)
уменьшить можно периодической проверкой
аналитических приборов. Обычно составляют
небольшую долю . -
Методические ошибки–
обусловлены методом анализа (например
погрешности пробоотбора и пробоподготовки.)
вносят основной вклад в общую погрешность. -
Реактивные– связаны с чистотой
используемых реактивов. -
Оперативные ошибки –зависят
от правильности и точности выполнения
аналитических операций (например,
недостаточное или излишнее промывание
или прокаливания осадков, недостаточное
тщательное перемещение осадка из одной
посуды в другую, неправильный способ
выливания раствора из пипетки и т.д.) -
Индивидуальные ошибки(личные) – это результат некоторых
физических недостатков экспериментатора,
которые мешают ему правильно проводить
известные операции.
Способы выявления систематических
погрешностей
1)варьирование величин пробы
Увеличив размер в кратное число раз
можно обнаружить по изменению найденного
содержания постоянную систематическую
погрешность
2)способ «введено найдено»
Добавить точно известное количество
компонента в той же форме, в которой
находится аналитический объект. Введенная
добавка проводится через все стадии
анализа. Если на конечной стадии
определяется добавка с точностью, то
систематической ошибки нет.
3) сравнение результата анализа с
результатом, полученным другим независимым
методом
4)анализ стандартного образца
Проведение всех стадий анализа, на
стадии обработки сравнивается с
паспортом, если все совпадает , то
систематической ошибки нет.
Типы погрешностей
-
Погрешности известной природы, могут
быть рассчитаны и учтены введение
соответствующей поправки -
Погрешности известной природы, значение
которых может быть оценены в ходе
химического анализа
Релятивизация — способ устранения
систематической погрешности, когда в
идентичных условиях проводят отдельные
аналитические операции таким образом,
что происходит нивелирование
систематической ошибки
-
Погрешность невыясненной природы,
значение который неизвестно, их сложно
выявить и устранить , используют прием
рандомизации
Рандомизация – переведение систематической
ошибки в разряд случайной
Случайные ошибки– обрабатываются
по правилам матемтической статистики,
связаны с влиянием неконтролируемых
параметров, непредвиденны и неучтимы.
Промахи– грубые ошибки, сильно
искажающие результаты анализа (ошибки
при расчётах, неправильный отчёт по
шкале, проливание раствора или просыпание
осадка). Результат с промахом отбрасывается
при выводе среднего значения.
6. Случайные
ошибки. Метрологические характеристики,
отражающие случайные ошибки. Оценка и
критерии воспроизводимости и правильности.
Рассмотрите на примере титриметрического
комплексонометрического определения
меди (II).
Случайные ошибки–отражают
неопределенность результата , присущую
любому измерению, обрабатываются по
правилам матемтической статистики,
связаны с влиянием неконтролируемых
параметров, непредвиденны и неучтимы.
Причины таких погрешностей:
Изменение температуры во время измерения,
ослабление внимания при работе, случайные
потери, загрязнение, использование
разной посуды, весов и тд.
метрологические характеристики:
Правильность— характеризует степень
близости измеренного результата
некоторой величины к её истинному
значению
Воспроизводимость— характеризует
степень близости друг к другу единичный
определений (рассеяние единичных
результатов относительно среднего
значения
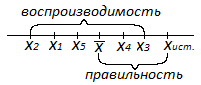
Точность— собирательная характеристика
метода или методики , включающая их
правильность и воспроизводимость .
Чувствительность— величина,
определяемая минимальным количеством
вещества, которое можно обнаружить
данным методом
Чувствительность – собирательное
понятие , включающее три характеристики:
1)Коэффициент чувствительности
коэффициент чувствительности sхарактеризует отклик аналитического
сигналаyна содержание
компонентаc,s-
это значение первой производной
градуировочной функции при определенном
содержании компонента, для прямолинейных
градуировочных графиковs– это тангенс угла наклона прямойy=Sc+b
s=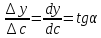
чем больше s, тем меньшие
количества компонента можно обнаружить
, используя один и тот же аналитический
сигнал, чем большеs, тем
точнее можно определить одно и то же
количество вещества
2)предел обнаружения Сminнаименьшее содержание при котором по
данной методике можно обнаружить
присутствие компонента с заданной
доверительной вероятностью, относится
к области качественного анализа и
определяет минимальное содержание
компонента
3)нижняя граница определяемого содержания
Сн
В количественном анализе обычно приводят
интервал определяемых содержаний-
область значений определяемых содержаний,
предусмотренная данной методикой и
ограниченная нижней и верхней границами.
Верхняя граница Свнаибольшее
значение количества или концентрации
компонента, определяемое по данной
методике.
нижняя граница Сн-наименьшее
содержание компонента , определяемое
по данной методике . З нижнюю границу
обычно принимают то минимальное
количество или концентрацию, которые
можно определить с относительным
стандартным отклонением Ϭr≤0,33
Оценка и критерии воспроизводимости
1)Среднее арифметическое
 =
=
2)Отклонение
di=xi—
3)Медиана— тот единичный результат
, относительно которого число результатов
с большими и меньшими значениями
одинаковое, если количество значений
нечетное, то медиана совпадает с
центральным результатом ранжированной
выборки , если количество значений
четное, то медиана есть среднее
арифметическое между двумя центральными
значениями ранжированной выборки
4)среднее отклонение-среднее
арифметическое единичных отклонений,
без учет знака
 =
=
5)Дисперсия
Ϭ2илиs2
Ϭ2=
еслиn>10
Ϭ2=
еслиn≤10
6)стандартное отклонениеϬx=
7)Относительное стандартное отклонение
Ϭr=
Титриметрическое комплексонометрическое
определения меди (II).
Выполнение определениея
1)Титрование исследуемого раствора
стандартным раствором ЭДТА
2)расчет граммового содержания меди
Ход анализа:Титрование исследуемого
раствора стандартным раствором ЭДТА.
Анализируемый раствор помещают в мерную
колбу на 100 мл, довдят водой до метки,
тщательно перемешивают. В коническую
колбу дл титрования берут аликвоту,
добавляют индикатор мурексид на кончике
шпателя и титруют раствором ЭДТА сначала
до грязно-розового цвета, натем добавляют
несколько капель 10%-ного раствора аммиака
до появления изумрудной или желтой
окраски раствора и дотитровывают
раствором ЭДТА до перехода окраски в
фиолетовую.
Формула для расчета граммового содержания
меди:
mCu,г=C( ЭДТА)·
ЭДТА)· ЭДТА·K
ЭДТА·K
ЭДТА·Mэкв(Cu)·P·10-3
Формула для расчета процентного
содержания меди:
ωCu= ·100%
·100%
Возможные причины возникновения
случайных ошибокв комплексонометрическом
титровании меди возникают в процессе
измерения объемов: неточное доведение
до метки мерной колбы, использование
разных пипеток, потеря титранта (капнуло
мимо), использование непромытой посуды.
Так же могут возникать ошибки из-за
неточного определения перехода окраски
, но эти ошибки будут относиться к
категории систематических индивидуальных
ошибок.
7. Гравиметрическое
определение бария в минерале альстонит:
этапы определения, возможные формулы
осадителей, осаждаемой и гравиметрической
формы, механизм образования осадка,
возможные варианты загрязнения осадка,
приемы повышения чистоты осадка,
погрешности определения. Условия
аналитического выделения осадков бария.
Минерал альстонит минерал, безводный
двойной карбонат бария и кальция
BaCa(CO3)2
Этапы определения:
1)взятие навески и её растворение
2)расчет количества осадителя
3)приготовление раствора осадителя
4)осаждение
5)фильтрование и промывание
6)высушивание и прокаливание осадка
7)взвешивание осадка, расчёт содержания
бария
Для количественного определения бария
его осаждают в виде сульфата BaSO4
(осаждаемая форма)
BaCO3+H2SO4=
BaSO4+H2CO3
В качестве осадителя, посташика
сульфат-ионов используют серную кислоту
H2SO4(осадитель)
После прокаливания осадка его формула
не меняется и остается так же в виде
сульфата бария BaSO4
(гравиметрическая форма)
Механизм образования осадка:
В процессе образования осадка различают
три стадии :
1)образование зародышей кристаллов
2)рост кристаллов
3)объединение (агрегация) хаотично
ориентированных кристаллов
Насыщение=>пересыщение=>ПКИ>ПР=>
образование мельчайших зародышей
кристаллов
Осаждение происходит при определенной
степени пересыщения раствора
P= =
= s-растворимость,
s-растворимость, -относительное
-относительное
пересыщение,Q-концентрация
кристаллизующегося вещества в растворе
Центром кристалла может служить твердая
частица этого вещества или любая другая
твердая частица, которую мы вносим в
раствор, твердые частицы могут изначально
присутствовать в растворе как примесь.
Если осаждение происходи из разбавленных
растворов, то появление осадка занимает
время-индукцинный период.
В процессе добавления каждой новой
порции осадителя происходит мгновенное
пересыщение раствора, зародыши растут
быстро за счет окружающих их ионов, как
только зародыш дотиг определенного
размера выпадает осадок
Рост кристаллов идет параллельно 1-ой
стадии, происходит за счет диффузии
ионов к поверхности растущего кристалла.
Число и размер частиц осадка (дисперсность
системы кол-во в единицы объёма) зависит
от соотношения скоростей 1-ой и 2-ой
стадий
V1— скорость образования
зародышейV2-скорость
роста кристаллов
V1>>V2-мелкодисперсный
осадокV1<<V2-крупнокристаллический
осадок
Лимитирующую стадию определяет скорость
осаждения и концентрации ионов
При медленном осаждении лимитирующей
стадией является кристаллизация ,
частица окружена однородным слоем
осаждаемый ионов в результате получается
кристалл правильной форм
При высокой концентрации ионов
лимитирующей стадией становится диффузия
, образуются кристаллы не правильной
формы с большой площадью поверхности
Следует отметить, что на скорость
процесса кристаллизации влияет
 ,
,
влияние различно на скорость образования
различно на скорость образования
зародышей и на скорость роста кристаллов
В случае образования зародышей
V1=k·( экспоненциальный
экспоненциальный
закон
В случае роста кристаллов V2=k·
При высокой степени
 образуются
образуются
мелкодисперсные осадки, при уменьшении ,
,
образуются крупнокристаллические
осадки
Агрегация происходит в гетерогенной
системе, в значительной степени
определяется числом центров кристаллизации.
Чем больше центров кристаллизации , тем
в меньшей степени они укрупняются на
второй стадии , тем хуже структура и тем
выше дисперсность осадков.
К аналитическим свойствам осадка
относятся: растворимость, чистота,
фильтруемость.
Лучшими свойствами обладают
крупнокристаллические осадки.
Загрязнение осадков
В гарвиметрическом определении часто
возникают ошибки , вызванные переходом
осадка в раствор или веществ из раствора
в осадок-соосождение
Соосаждение происходит в процессе
образования осадка
Отрицательная роль : загрязнение осадка
Положительная роль :используется для
концентрирования микропримесей
Существует три типа соосаждения:
1)Адсорбция- соосаждение примесей на
поверхности уже сформированного осадка,
происходит в результате нескомпенсированности
зарядов внутри и на поверхности.
Характеризуется ярко выраженной
избирательность, преимущественно
адсорбируются те ионы, которые входят
в структуру осадка, противоионы-примеси
Адсорбция противоионов подчиняется
правилам Панета-Фаянса-Гана
А)при одинаковых концентрациях
адсорбируются многозарядные ионы
Б)при одинаковых зарядах адсорбируются
те, концентрация которых выше
В)при одинаковых концентрациях и
зарядах-те, которые образуют с ионами
решетки менее растворимое соединение
Г)в кислой среде соосаждение ионов
уменьшается в следствии конкурентной
адсорбции H3O+
Количество адсорбируемой примеси
зависит от величины поверхности осадка,
концентрации адсорбируемой примеси и
температуры ( с ↑ поверхности и ↑
концентрации- адсорбция ↑; с ↑ температуры
адсорбция ↓)
2)Окклюзия- загрязнение осадка в результате
захвата примеси внутрь растущего
кристалла, происходит в процессе
формирования осадка.
Различают 2-х видов: абсорбционная и
механическая
Механическа- случайный захват частиц
маточного раствора внутрь твердой фазы
вследствие нарушения механической
структуры
Характерна при выделении аморфных
осадков.
Окклюзированные примеси равномерно
распределены внутри, но не принимают
участие в построении решетки кристалла.
Адсорбционная-возникает при быстром
росте кристалла, когда ионы на поверхности
обратают кристаллизованным веществом.
Протекает вследствии адсорбции примесей
по микротрещинам кристаллической
структуры.
Окклюзия подчиняется тем же правилам,
что и адсорбция
Общие правила понижения окклюзии–замедление процесса выделения твердой
фазы-осаждение при малом пересыщении
, работают с разбавленными растворами
, осадитель добавляют по каплям, при
постоянном перемешивании.
3)изоморфное соосаждение характерно
для изоморфно кристаллизующегося
веществ, которые могут образовывать
смешанные кристаллы, примесь участвует
в построении кристаллической решетки,
наблюдается лишь в тех случаях, когда
вещества сходны по химическим свойствам
или ионы имеют одинаковые кч и радиус.
Совместное осаждение-выделение в твердую
фазу нескольких веществ, для которых в
услових осаждения достигнуты величины
их Kst
Последовательное осаждение- веделение
примеси на поверхности уже сформированного
осадка
Приемы и методы повышения чистоты
осадка
Зависят от типа соосаждения
1)адсорбционные примеси хорошо удаляются
промыванием осадка, более эффективно
многократное промывание малыми порциями
Выбор промывочной жидкости:
Не увеличивает растворимость осадка и
не ухудшает его фильтруемость, водой
промывают осадки с k~10-11/-12,
не подвергаемых пептизации, кристаллические
осадки с конст, растворимости 10-9/-11промывают разбавленным раствором
осадителя, аморфные осадки промывают
разбавленными растворами электролитов
коагуляторов, чтобы избежать пептизации
Промывние кристаллических осадков
проводят холодной промывочной жидкостью,
чтоб не увеличивать растворимость,
аморфные наоборот горячими
2)окклюзированные примеси , для избавления
от них:
Для кристаллических осадков-старение
Для аморфных-переосаждение
Погрешность гравиметрического
метода анализа
Общая погрешность анализа
Ϭ2=
 +
+
 -погрешность
-погрешность
пробоотбораm-число пробn-число параллельных
определений
 -погрешность
-погрешность
измерений
Результат находится по формуле
P,%= ·100%
·100%
Методическая ошибка, обусловлена
неколичественным выпадением осадка,
её устранить нельзя
Qоб= s-растворимость осадка
s-растворимость осадка
г/100мл воды, -объём
-объём
фильтрата, —
—
масса гравиметрической формы
Случайные ошибки
Относительное стандартное отклонение
 =
=
 -дисперсия
-дисперсия
массы гравиметрической формы
 -масса
-масса
гравиметрической формы
Ϭa1-погрешность
взвешивания тары
Ϭa2-погрешность
взвешивания тары с навеской
 =
= =0,0003
=0,0003
г Ϭa1= Ϭa2=0,0002г
Суммарная ошибка
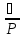 =
=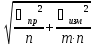
n-число проб
m-число измерений
 -погрешность
-погрешность
прибора
 -погрешность
-погрешность
измерения
8. Гравиметрическое
определение алюминия в каолине: этапы
определения, возможные формулы осадителей,
осаждаемой и гравиметрической формы,
механизм образования осадка, возможные
варианты загрязнения осадка, приемы
повышения чистоты осадка, погрешности
определения. Преимущества органических
осадителей. Условия аналитического
выделения осадков алюминия.
Механизм образования осадка:
В процессе образования осадка различают
три стадии :
1)образование зародышей кристаллов
2)рост кристаллов
3)объединение (агрегация) хаотично
ориентированных кристаллов
Насыщение=>пересыщение=>ПКИ>ПР=>
образование мельчайших зародышей
кристаллов
Осаждение происходит при определенной
степени пересыщения раствора
P= =
= s-растворимость,
s-растворимость, -относительное
-относительное
пересыщение,Q-концентрация
кристаллизующегося вещества в растворе
Центром кристалла может служить твердая
частица этого вещества или любая другая
твердая частица, которую мы вносим в
раствор, твердые частицы могут изначально
присутствовать в растворе как примесь.
Если осаждение происходи из разбавленных
растворов, то появление осадка занимает
время-индукцинный период.
В процессе добавления каждой новой
порции осадителя происходит мгновенное
пересыщение раствора, зародыши растут
быстро за счет окружающих их ионов, как
только зародыш дотиг определенного
размера выпадает осадок
Рост кристаллов идет параллельно 1-ой
стадии, происходит за счет диффузии
ионов к поверхности растущего кристалла.
Число и размер частиц осадка (дисперсность
системы кол-во в единицы объёма) зависит
от соотношения скоростей 1-ой и 2-ой
стадий
V1— скорость образования
зародышейV2-скорость
роста кристаллов
V1>>V2-мелкодисперсный
осадокV1<<V2-крупнокристаллический
осадок
Лимитирующую стадию определяет скорость
осаждения и концентрации ионов
При медленном осаждении лимитирующей
стадией является кристаллизация ,
частица окружена однородным слоем
осаждаемый ионов в результате получается
кристалл правильной форм
При высокой концентрации ионов
лимитирующей стадией становится диффузия
, образуются кристаллы не правильной
формы с большой площадью поверхности
Следует отметить, что на скорость
процесса кристаллизации влияет
 ,
,
влияние различно на скорость образования
различно на скорость образования
зародышей и на скорость роста кристаллов
В случае образования зародышей
V1=k·( экспоненциальный
экспоненциальный
закон
В случае роста кристаллов V2=k·
При высокой степени
 образуются
образуются
мелкодисперсные осадки, при уменьшении ,
,
образуются крупнокристаллические
осадки
Агрегация происходит в гетерогенной
системе, в значительной степени
определяется числом центров кристаллизации.
Чем больше центров кристаллизации , тем
в меньшей степени они укрупняются на
второй стадии , тем хуже структура и тем
выше дисперсность осадков.
К аналитическим свойствам осадка
относятся: растворимость, чистота,
фильтруемость.
Лучшими свойствами обладают
крупнокристаллические осадки.
Загрязнение осадков
В гарвиметрическом определении часто
возникают ошибки , вызванные переходом
осадка в раствор или веществ из раствора
в осадок-соосождение
Соосаждение происходит в процессе
образования осадка
Отрицательная роль : загрязнение осадка
Положительная роль :используется для
концентрирования микропримесей
Существует три типа соосаждения:
1)Адсорбция- соосаждение примесей на
поверхности уже сформированного осадка,
происходит в результате нескомпенсированности
зарядов внутри и на поверхности.
Характеризуется ярко выраженной
избирательность, преимущественно
адсорбируются те ионы, которые входят
в структуру осадка, противоионы-примеси
Адсорбция противоионов подчиняется
правилам Панета-Фаянса-Гана
А)при одинаковых концентрациях
адсорбируются многозарядные ионы
Б)при одинаковых зарядах адсорбируются
те, концентрация которых выше
В)при одинаковых концентрациях и
зарядах-те, которые образуют с ионами
решетки менее растворимое соединение
Г)в кислой среде соосаждение ионов
уменьшается в следствии конкурентной
адсорбции H3O+
Количество адсорбируемой примеси
зависит от величины поверхности осадка,
концентрации адсорбируемой примеси и
температуры ( с ↑ поверхности и ↑
концентрации- адсорбция ↑; с ↑ температуры
адсорбция ↓)
2)Окклюзия- загрязнение осадка в результате
захвата примеси внутрь растущего
кристалла, происходит в процессе
формирования осадка.
Различают 2-х видов: абсорбционная и
механическая
Механическа- случайный захват частиц
маточного раствора внутрь твердой фазы
вследствие нарушения механической
структуры
Характерна при выделении аморфных
осадков.
Окклюзированные примеси равномерно
распределены внутри, но не принимают
участие в построении решетки кристалла.
Адсорбционная-возникает при быстром
росте кристалла, когда ионы на поверхности
обратают кристаллизованным веществом.
Протекает вследствии адсорбции примесей
по микротрещинам кристаллической
структуры.
Окклюзия подчиняется тем же правилам,
что и адсорбция
Общие правила понижения окклюзии–замедление процесса выделения твердой
фазы-осаждение при малом пересыщении
, работают с разбавленными растворами
, осадитель добавляют по каплям, при
постоянном перемешивании.
3)изоморфное соосаждение характерно
для изоморфно кристаллизующегося
веществ, которые могут образовывать
смешанные кристаллы, примесь участвует
в построении кристаллической решетки,
наблюдается лишь в тех случаях, когда
вещества сходны по химическим свойствам
или ионы имеют одинаковые кч и радиус.
Совместное осаждение-выделение в твердую
фазу нескольких веществ, для которых в
услових осаждения достигнуты величины
их Kst
Последовательное осаждение- веделение
примеси на поверхности уже сформированного
осадка
Приемы и методы повышения чистоты
осадка
Зависят от типа соосаждения
1)адсорбционные примеси хорошо удаляются
промыванием осадка, более эффективно
многократное промывание малыми порциями
Выбор промывочной жидкости:
Не увеличивает растворимость осадка и
не ухудшает его фильтруемость, водой
промывают осадки с k~10-11/-12,
не подвергаемых пептизации, кристаллические
осадки с конст, растворимости 10-9/-11промывают разбавленным раствором
осадителя, аморфные осадки промывают
разбавленными растворами электролитов
коагуляторов, чтобы избежать пептизации
Промывние кристаллических осадков
проводят холодной промывочной жидкостью,
чтоб не увеличивать растворимость,
аморфные наоборот горячими
2)окклюзированные примеси , для избавления
от них:
Для кристаллических осадков-старение
Для аморфных-переосаждение
Погрешность гравиметрического
метода анализа
Общая погрешность анализа
Ϭ2=
 +
+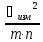
 -погрешность
-погрешность
пробоотбораm-число пробn-число параллельных
определений
 -погрешность
-погрешность
измерений
Результат находится по формуле
P,%= ·100%
·100%
Методическая ошибка, обусловлена
неколичественным выпадением осадка,
её устранить нельзя
Qоб= s-растворимость осадка
s-растворимость осадка
г/100мл воды, -объём
-объём
фильтрата, —
—
масса гравиметрической формы
Случайные ошибки
Относительное стандартное отклонение
 =
=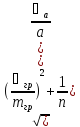
 -дисперсия
-дисперсия
массы гравиметрической формы
 -масса
-масса
гравиметрической формы
Ϭa1-погрешность
взвешивания тары
Ϭa2-погрешность
взвешивания тары с навеской
 =
= =0,0003
=0,0003
г Ϭa1= Ϭa2=0,0002г
Суммарная ошибка
 =
=
n-число проб
m-число измерений
 -погрешность
-погрешность
прибора
 -погрешность
-погрешность
измерения
9. Гравиметрическое
определение железа в руде: этапы
определения, возможные формулы осадителя,
осаждаемой и гравиметрической формулы,
механизм образования коллоидной частицы,
процессы, приводящие к образованию
осадка, возможные варианты загрязнения
осадка, приемы повышения чистоты осадка,
погрешности. Условия аналитического
выделения осадков железа.
Гравиметрическое определение железа(III)
основано на его осаждении в виде
гидроксида железа(III)Fe(OH)3.
Трехвалентное железо осаждают раствором
аммиака, осаждаемой формой являетсяFe(OH)3.
Реакция:Fe(NO3)3+3NH3·H2O=Fe(OH)3+3NH4NO3.
При прокаливании гидроксид железа(III)
превращается в оксид железа(III),
который является гравиметрической
формой:Fe(OH)3=(t°)Fe2O3+3H2O.
Этапы определения:1) взятие навески
и ее растворение; 2) приготовление
раствора осадителя; 3) осаждение; 4)
фильтрование и промывание осадка; 5)
высушивание и прокаливание; 6) взвешивание
осадка, расчет содержания железа.
Расчет ведут по формулам


ωFe2O3=
 ,
,
ωFe
=

Механизм образования коллоидной
частицы:
Fe(NO3)3+3NH4OH(изб.)=Fe(OH)3↓+3NH4NO3
{[Fe(OH)3]m
· nOH—
·(n-x)NH4+}-x
·xNH4+


агрегат плотный слой
диффузный слой Мицелла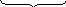
Ядро 
Коллоидная частица
Вещество в коллоидной системе имеет
большую развитую поверхность и
нескомпенсированный заряд на границе
разлела фаз. Существование
нескомпенсированного силового поля
ведет к адсорбции из раствора молекул
или ионов. Если коллоидная система
возникла в результате проведения
химической реакции осаждения, то частицы
адсорбируют в первую очередь те ионы,
которые могут достраивать кристаллическую
решетку. Адсорбированные ионы сообщают
частице «+» или «-« заряд. Слой
адсорбированных ионов на ядре – это
первичный адсорбционный слой. Заряд,
созданный таким слоем, достаточно высок
и обуславливает электростатическое
взаимодействие с иоами противоположного
знака. В результате образуется слой
противоионов, который выравнивает заряд
первичного слоя. Слой противоионов
имеет диффузный характер. Часть
противоионов, прочно связанных с
первичным слоем – это плотный слой,
остальные противоионы составляют
диффузный слой.
Образование осадкапроисходит
тогда, когда раствор становится
пересыщенным, т.е. [A+]m[B-]n>Ks(ПКИ>ПР). Образование осадков связано
с процессом укрупнения частиц, с
образованием кристаллической решетки
вещества. Этот процесс определяется
числом центров кристаллизации: чем
больше центров, тем в меньшей степени
они укрупняются и тем хуже структура и
выше дисперсность осадка.
Возможные варианты загрязнения:
1)Путем адсорбции ( для конкретного
примера хлорид-ионов на поверхности
осадка); 2)Окклюзия; 3)Изоморфное
соосаждение; 4) Совместное осаждение;
5) Последующее осаждение.
Приемы повышения чистоты осадка:
1) Адсорбированные на поверхности примеси
хорошо удаляются при промывании осадков
на фильтре при помощи промывных жидкостей,
т.к. примеси переходят в промывную
жидкость и уходят через поры фильтра.
Эффективно многократное промывание
небольшими порциями промывной жидкости.
Промывную жидкость выбирают максимально
тщательно, чтобы не увеличивать
растворимость осадка и не ухудшать его
фильтрацию. Кристаллические осадки
промывают холодными промывными
жидкостями, чтобы не увеличить
растворимость осадка, а аморфные –
наоборот горячими. Водой промывают
осадки с низкими константами растворимости
(ниже 10-11-10-12), а также те,
которые не подвергаются пептизации.
Если константа растворимости осадка
10-9-10-11и он кристаллический,
то его промывают разбавленным раствором
осадителя. Аморфные осадки промывают
разбавленными растворами
электролитов-коагулянтов (солиNH4+),
чтобы избежать пептизации(в опыте с
железом осадок промывали растворомNH4NO3).
Повышение температуры также способствует
уменьшению адсорбции (на конкретном
примере горячий раствор, содержащий
10% аммиак разбавляют горячей водой для
уменьшения адсорбции хлорид-ионов на
поверхности осадка). 2) Для очищения
окклюдированных примесей в случае
кристаллических осадков используют
старение, в случае аморфных осадков –
переосаждение.Степень окклюзии в
процессе осаждения можно уменьшить
медленным добавлением осадителя по
каплям, при перемешивании.
Погрешности:
1) Общая погрешность анализа σ2=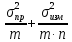 ,
,
где σпр2– погрешность
пробоотбора, σизм2–
погрешность измерения,m– число проб,n– число
параллельных определений.
2) Методическая ошибка OобOоб=
—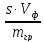 ,
,
гдеs– растворимость
осадка, г/100 мл воды;Vф
– объем фильтрата и промывных вод,
мл;mгр– масса
полученного осадка, г.
3) Относительное стандартное отклонение
 =
= , гдеσгр – дисперсия
, гдеσгр – дисперсия
массы гравиметрической формы;mгр– масса гравиметрической формы; σa– дисперсия массы исходной навески;a– масса исходной навески;p– процентное содержание вещества в
исследуемой пробе;n–число
измерений.
4) Погрешность взвешивания тары σa1и тары с навескойσa2σa1=σa2=0,0002
г, σгр= = 0,0003 г. 5) Относительное стандартное
= 0,0003 г. 5) Относительное стандартное
отклонение с учетом стадий пробоотбора
и пробоподготовки =
= , гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
, гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
Fe(OH)3– типичный пример осадка в аморфном
состоянии, легко дающий коллоидный
раствор.
Условия его осаждения следующие:
1)осаждение проводят из горячего раствора
анализируемого вещества горячим
раствором осадителя при перемешивании;
2)осаждение проводят из достаточно
концентрированного исследуемого
раствора концентрированным раствором
осадителя с последующим разбавлением(при
разбавлении устанавливается адсорбционное
равновесие, часть адсорбированных ионов
переходи в раствор, и осадок становится
более чистым); 3)осаждение проводят в
присутствии подходящего
электролита-коагулятора;
4)аморфные осадки почти не требуют
времени для созревания, их необходимо
фильтровать сразу после разбавления
раствора. Аморфные осадки нельзя
оставлять более, чем на несколько минут,
т.к. сильное уплотнение их затрудняет
последующее отмывание примесей, а также
при стоянии увеличивается количество
примесей, адсорбированных поверхностью
осадка.
10. Гравиметрическое определение никеля
в нихромовом сплаве: этапы определения,
возможные формулы осадителей, осаждаемой
и гравиметрической формулы, механизм
образования осадка, возможные варианты
загрязнения осадка, приемы повышения
чистоты осадка, погрешности. Условия
аналитического выделения осадков
никеля.
Гравиметрическое определение никеля
в нихромовом сплаве основано на его
осаждении в виде диметилглиоксимата
никеля Ni(HDMG)2.
Никель осаждают 1 %-ным спиртовым раствором
диметикглиоксимаH2DMG,
осаждаемой формой являетсяNi(HDMG)2.
Реакция:Ni2++2H2DMG=Ni(HDMG)2+2H+.
После высушивания осадка остается сухойNi(HDMG)2,
который является гравиметрической
формой.
Этапы определения:1) взятие навески
и ее растворение; 2) приготовление
раствора осадителя; 3) осаждение; 4)
фильтрование и промывание осадка; 5)
высушивание; 6) взвешивание осадка,
расчет содержания никеля.
Расчет ведут по формуле ωNi=

Механизм образования осадка:в
процессе образования осадка различают
3 параллельных процесса: 1) образование
зародышей кристалла (центров
кристаллизации); 2) рост кристаллов; 3)
объединение (агрегация) хаотично
ориентированных мелких кристаллов. В
начальный момент происходит насыщение
раствора, а затем его пересыщение. В
момент определенной пересыщенности
раствора, начинается выпадение
осадка.Центром кристалла может служить
твердая частица этого вещества или
любая другая твердая частица, которую
мы вносим в раствор, твердые частицы
могут изначально присутствовать в
растворе как примесь.
Если осаждение происходит из разбавленных
растворов, то появление осадка занимает
время-индукционный период.
В процессе добавления каждой новой
порции осадителя происходит мгновенное
пересыщение раствора, зародыши растут
быстро за счет окружающих их ионов, как
только зародыш достиг определенного
размера выпадает осадок.
Рост кристаллов идет параллельно 1-ой
стадии, происходит за счет диффузии
ионов к поверхности растущего кристалла.
Число и размер частиц осадка (дисперсность
системы кол-во в единицы объёма) зависит
от соотношения скоростей 1-ой и 2-ой
стадий (V1— скорость
образования зародышей,V2-скорость
роста кристаллов):V1>>V2-мелкодисперсный
осадок,V1<<V2-крупнокристаллический
осадок. Какая из стадий будет лимитировать
определяет скорость осаждения и
концентрации ионов. При медленном
осаждении лимитирующей стадией является
кристаллизация, частица окружена
однородным слоем осаждаемых ионов в
результате получается кристалл правильной
формы. При высокой концентрации ионов
лимитирующей стадией становится
диффузия, образуются кристаллы
неправильной формы с большой площадью
поверхности. Следует отметить, что на
скорость процесса кристаллизации влияет ,
,
влияние различно на скорость образования
различно на скорость образования
зародышей и на скорость роста кристаллов.
При высокой степени образуются
образуются
мелкодисперсные осадки, при уменьшении образуются крупнокристаллические
образуются крупнокристаллические
осадки. Агрегация происходит в гетерогенной
системе, в значительной степени
определяется числом центров
кристаллизации.Чем больше центров
кристаллизации, тем в меньшей степени
они укрупняются на второй стадии, тем
хуже структура и тем выше дисперсность
осадков.
К аналитическим свойствам осадка
относятся: растворимость, чистота,
фильтруемость.Лучшими свойствами
обладают крупнокристаллические осадки.
Возможные варианты загрязнения: 1)
Путем адсорбции ( для конкретного примера
хлорид-ионов на поверхности осадка); 2)
Окклюзия; 3) Изоморфное соосаждение; 4)
Совместное осаждение; 5) Последующее
осаждение.
Приемы повышения чистоты осадка:
1) Адсорбированные на поверхности примеси
хорошо удаляются при промывании осадков
на фильтре при помощи промывных жидкостей,
т.к. примеси переходят в промывную
жидкость и уходят через поры фильтра.
Эффективно многократное промывание
небольшими порциями промывной жидкости.
Промывную жидкость выбирают максимально
тщательно, чтобы не увеличивать
растворимость осадка и не ухудшать его
фильтрацию. Кристаллические осадки
промывают холодными промывными
жидкостями, чтобы не увеличить
растворимость осадка, а аморфные –
наоборот горячими. Водой промывают
осадки с низкими константами растворимости
(ниже 10-11-10-12), а также те,
которые не подвергаются пептизации.
Если константа растворимости осадка
10-9-10-11и он кристаллический,
то его промывают разбавленным раствором
осадителя. Аморфные осадки промывают
разбавленными растворами
электролитов-коагулянтов (солиNH4+),
чтобы избежать пептизации (в опыте с
железом осадок промывали растворомNH4NO3).
Повышение температуры также способствует
уменьшению адсорбции (на конкретном
примере горячий раствор, содержащий
10% аммиак разбавляют горячей водой для
уменьшения адсорбции хлорид-ионов на
поверхности осадка). 2) Для очищения
окклюдированных примесей в случае
кристаллических осадков используют
старение, в случае аморфных осадков –
переосаждение.Степень окклюзии в
процессе осаждения можно уменьшить
медленным добавлением осадителя по
каплям, при перемешивании.
Погрешности:1) Общая погрешность
анализа σ2=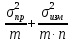 ,
,
где σпр2– погрешность
пробоотбора, σизм2–
погрешность измерения,m– число проб,n– число
параллельных определений.
2) Методическая ошибка OобOоб=
— ,
,
гдеs– растворимость
осадка, г/100 мл воды;Vф
– объем фильтрата и промывных вод,
мл;mгр– масса
полученного осадка, г.
3) Относительное стандартное отклонение
 =
= , гдеσгр – дисперсия
, гдеσгр – дисперсия
массы гравиметрической формы;mгр– масса гравиметрической формы; σa– дисперсия массы исходной навески;a– масса исходной навески;p– процентное содержание вещества в
исследуемой пробе;n–число
измерений.
4) Погрешность взвешивания тары σa1и тары с навескойσa2σa1=σa2=0,0002
г, σгр= = 0,0003 г.
= 0,0003 г.
5) Относительное стандартное отклонение
с учетом стадий пробоотбора и
пробоподготовки
 =
= , гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
, гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
Ni(HDMG)2– кристаллический осадок.
Условия его осаждения следующие:
1) осаждение ведут из достаточно
разбавленного исследуемого раствора
разбавленным раствором осадителя
(концентрации исследуемого раствора и
раствора осадителя должны быть примерно
одинаковыми);
2) раствор осадителя прибавляют медленно,
по каплям, при постоянном перемешивании
стеклянной палочкой (это предотвращает
явление окклюзии);
3) осаждение ведут из подогретого
исследуемого раствора горячим раствором
осадителя (для предотвращения пептизации);
4) к раствору прибавляют вещества,
способствующие повышению растворимости
осадка (увеличивают Iраствора), а затем понижают его
растворимость путем прибавления избытка
осадителя;
5) осадок оставляют на «созревание».
11. Гравиметрическое определение меди:
этапы определения, возможные формулы
осадителей, осаждаемой и гравиметрической
формулы, механизм образования осадка,
возможные варианты загрязнения осадка,
приемы повышения чистоты осадка,
погрешности. Преимущества органических
осадителей. Условия выделения осадков.
При гравиметрическом определении меди
медь из раствора осаждают различными
осадителями: 1) раствор аммиака осаждает
из нагретого раствора осадок Cu(OH)2;
2) Тиокарбонат калияK2CS3осаждает из нагретого раствора осадокCuS, который сушат при
100-110 ;
;
3) В виде оксалата медь осаждается в
присутствиеCH3COOH;
4) При определении меди в виде
тетророданомеркуриатамедиCu[Hg(SCN)4]
медь осаждают из нагретого до кипения
раствора содержащего серную или азотную
кислоту, действиемK2[Hg(SCN)4].
Метод рекомендован для определения
меди в медных рудах; 5) Соль Рейнеке
(тетрароданодиаминохромат аммония)
NH4[Cr(NH3)2(SCN)4]
является избирательным реагентом для
определения меди в присутствие многих
посторонних ионов. Осаждение проводят
как в кислом, так и в аммиачном растворе
в виде [Cu(NH3)4][Cr(NH3)2(SCN)4]2
после предварительного восстановления
меди до одновалентного состояния
оловом(II). Для осаждения меди используются
также различные органические реагенты:
1) 8- оксихинолин осаждает медь в
уксуснокислом, аммиачном и щелочном
растворах при pH=5.33 — 14.55. Осадок, высушенный
при 105-110°С, соответствует составу
Cu(C9H6ON)2; 2) Медь осаждается
спиртовым раствором β-бензоиноксима в
слабощелочной среде в виде хлопьевидного
зеленого осадка составаCu(C6H5CHOCNOC6H5)2.
Осадок высушивают при 105-110 ;
;
3) Салицилальдиоксим осаждает Cu (II) в
виде внутрикомплексного соединения
Cu(C7H6O2N)2в
уксуснокислой среде, среде ацетатного
буфера или ацетата аммония; 4) При действии
купферона наCu(II)
образуется купферонат меди (II)
с формулой Cu(C6H5N(NO)O)2;
5) При действии глицина на медь образуется
кристаллический осадок глицината меди
(II)Cu(NH2CH2COO)2.
Рассмотрим гравиметрическое определение
меди на примере осаждения ее
глицином.Реакция:CuO+2NH2CH2COOH=Cu(NH2CH2COO)2+H2OВданном случае глицинNH2CH2COOHявляется
осадителем, глицинат меди (II)Cu(NH2CH2COO)2– осаждаемой формой. При высушивании
получается гравиметрическая форма
сухогоCu(NH2CH2COO)2.
Этапы определения:1) взятие навески
и её растворение;2) приготовление раствора
осадителя;3) осаждение;4) фильтрование
и промывание;5) высушивание осадка;6)
взвешивание осадка, расчёт содержания
меди.
Механизм образования осадка:в
процессе образования осадка различают
3 параллельных процесса: 1) образование
зародышей кристалла (центров
кристаллизации); 2) рост кристаллов; 3)
объединение (агрегация) хаотично
ориентированных мелких кристаллов. В
начальный момент происходит насыщение
раствора, а затем его пересыщение. В
момент определенной пересыщенности
раствора, начинается выпадение осадка.
Центром кристалла может служить твердая
частица этого вещества или любая другая
твердая частица, которую мы вносим в
раствор, твердые частицы могут изначально
присутствовать в растворе как примесь.
Если осаждение происходит из разбавленных
растворов, то появление осадка занимает
время-индукционный период.
В процессе добавления каждой новой
порции осадителя происходит мгновенное
пересыщение раствора, зародыши растут
быстро за счет окружающих их ионов, как
только зародыш достиг определенного
размера выпадает осадок.
Рост кристаллов идет параллельно 1-ой
стадии, происходит за счет диффузии
ионов к поверхности растущего кристалла.
Число и размер частиц осадка (дисперсность
системы кол-во в единицы объёма) зависит
от соотношения скоростей 1-ой и 2-ой
стадий (V1— скорость
образования зародышей,V2-скорость
роста кристаллов):V1>>V2-мелкодисперсный
осадок,V1<<V2-крупнокристаллический
осадок. Какая из стадий будет лимитировать
определяет скорость осаждения и
концентрации ионов. При медленном
осаждении лимитирующей стадией является
кристаллизация, частица окружена
однородным слоем осаждаемых ионов в
результате получается кристалл правильной
формы. При высокой концентрации ионов
лимитирующей стадией становится
диффузия, образуются кристаллы
неправильной формы с большой площадью
поверхности. Следует отметить, что на
скорость процесса кристаллизации влияет ,
,
влияние различно на скорость образования
различно на скорость образования
зародышей и на скорость роста кристаллов.
При высокой степени образуются
образуются
мелкодисперсные осадки, при уменьшении образуются крупнокристаллические
образуются крупнокристаллические
осадки. Агрегация происходит в гетерогенной
системе, в значительной степени
определяется числом центров
кристаллизации.Чем больше центров
кристаллизации, тем в меньшей степени
они укрупняются на второй стадии, тем
хуже структура и тем выше дисперсность
осадков.
К аналитическим свойствам осадка
относятся: растворимость, чистота,
фильтруемость.Лучшими свойствами
обладают крупнокристаллические осадки.
Возможные варианты загрязнения: 1)
Путем адсорбции ( для конкретного примера
хлорид-ионов на поверхности осадка); 2)
Окклюзия; 3) Изоморфное соосаждение; 4)
Совместное осаждение; 5) Последующее
осаждение.
Приемы повышения чистоты осадка:
1) Адсорбированные на поверхности примеси
хорошо удаляются при промывании осадков
на фильтре при помощи промывных жидкостей,
т.к. примеси переходят в промывную
жидкость и уходят через поры фильтра.
Эффективно многократное промывание
небольшими порциями промывной жидкости.
Промывную жидкость выбирают максимально
тщательно, чтобы не увеличивать
растворимость осадка и не ухудшать его
фильтрацию. Кристаллические осадки
промывают холодными промывными
жидкостями, чтобы не увеличить
растворимость осадка, а аморфные –
наоборот горячими. Водой промывают
осадки с низкими константами растворимости
(ниже 10-11-10-12), а также те,
которые не подвергаются пептизации.
Если константа растворимости осадка
10-9-10-11и он кристаллический,
то его промывают разбавленным раствором
осадителя. Аморфные осадки промывают
разбавленными растворами
электролитов-коагулянтов (солиNH4+),
чтобы избежать пептизации (в опыте с
железом осадок промывали растворомNH4NO3).
Повышение температуры также способствует
уменьшению адсорбции (на конкретном
примере горячий раствор, содержащий
10% аммиак разбавляют горячей водой для
уменьшения адсорбции хлорид-ионов на
поверхности осадка). 2) Для очищения
окклюдированных примесей в случае
кристаллических осадков используют
старение, в случае аморфных осадков –
переосаждение.Степень окклюзии в
процессе осаждения можно уменьшить
медленным добавлением осадителя по
каплям, при перемешивании.
Погрешности:1) Общая погрешность
анализа σ2 =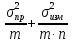 ,
,
где σпр2– погрешность
пробоотбора, σизм2–
погрешность измерения,m– число проб,n– число
параллельных определений
2) Методическая ошибка OобOоб=
—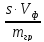 ,
,
гдеs– растворимость
осадка, г/100 мл воды;Vф
– объем фильтрата и промывных вод,
мл;mгр– масса
полученного осадка, г.
3) Относительное стандартное отклонение
 =
= , гдеσгр – дисперсия
, гдеσгр – дисперсия
массы гравиметрической формы;mгр– масса гравиметрической формы; σa– дисперсия массы исходной навески;a– масса исходной навески;p– процентное содержание вещества в
исследуемой пробе;n–число
измерений.
4) Погрешность взвешивания тары σa1и тары с навескойσa2σa1=σa2=0,0002
г, σгр= = 0,0003 г.
= 0,0003 г.
5) Относительное стандартное отклонение
с учетом стадий пробоотбора и
пробоподготовки
 =
= , гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
, гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
Преимущества органических осадителей:
1. Пользуясь органическими осадителями,
можно осаждать и разделять различные
элементы из очень сложных смесей.
Например, при помощи диметилглиоксима
возможно количественное осаждение
катионов никеля в присутствии многих
других катионов.
2. Осадки, получающиеся с органическими
осадителями, хорошо отфильтровываются
и промываются (например, осадки комплексных
соединений катионов, содержащих в
качестве лигандов пиридин или другие
органические соединения). Это дает
возможность легко отмывать от осадков
примеси, содержащиеся в анализируемом
растворе.
3. Осадки, получающиеся при действии на
катионы или анионы органических
осадителей, отличаются большим
молекулярным весом. Вследствие этого
точность анализа повышается. Например,
определение магния, алюминия и других
катионов проводится с большой точностью
осаждением их в виде оксихинолятов,
обладающих большим молекулярным весом.
4. В составе осадков, являющихся
соединениями неорганических веществ
с органическими компонентами, обычно
содержится мало соосаждающихся пиримесей.
Cu(NH2CH2COO)2– кристаллический осадок, поэтому
условия его выделения следующие:
1) осаждение ведут из достаточно
разбавленного исследуемого раствора
разбавленным раствором осадителя
(концентрации исследуемого раствора и
раствора осадителя должны быть примерно
одинаковыми);
2) раствор осадителя прибавляют медленно,
по каплям, при постоянном перемешивании
стеклянной палочкой (это предотвращает
явление окклюзии);
3) осаждение ведут из подогретого
исследуемого раствора горячим раствором
осадителя (для предотвращения пептизации);
4) к раствору прибавляют вещества,
способствующие повышению растворимости
осадка (увеличивают Iраствора), а затем понижают его
растворимость путем прибавления избытка
осадителя;
5) осадок оставляют на «созревание».
12. Гравиметрическое определение
кремния в силикатных породах: этапы
определения, возможные формулы осадителя,
осаждаемой и гравиметрической формулы,
механизм образования коллоидной частицы,
процессы, приводящие к образованию
осадка, возможные варианты загрязнения
осадка, приемы повышения чистоты осадка,
погрешности. Классификация коллоидных
систем. Условия аналитического выделения
кремнекислоты.
При гравиметрическом определении
кремния растворимый силикат натрия
Na2SiO3,
полученный в результате сплавления не
разлагаемой кремниевой кислоты с содойNa2CO3,
обрабатывается сильной кислотойHCl.
Реакция:Na2SiO3+2HCl=H2SiO3↓+2NaCl.
Осадителем в данном случае являетсяHCl, осаждаемой формой –H2SiO3.
При высушивании и прокаливании получается
гравиметрическая формаSiO2.
Этапы определения:1) взятие навески
и ее растворение; 2) приготовление
раствора осадителя; 3) осаждение; 4)
фильтрование и промывание осадка; 5)
высушивание и прокаливание осадка;; 6)
взвешивание осадка, расчет содержания
кремния.
Механизм образования коллоидной
частицы: Вещество в коллоидной системе
имеет большую развитую поверхность и
нескомпенсированный заряд на границе
разлела фаз. Существование
нескомпенсированного силового поля
ведет к адсорбции из раствора молекул
или ионов. Если коллоидная система
возникла в результате проведения
химической реакции осаждения, то частицы
адсорбируют в первую очередь те ионы,
которые могут достраивать кристаллическую
решетку. Адсорбированные ионы сообщают
частице “+» или “-“ заряд. Слой
адсорбированных ионов на ядре – это
первичный адсорбционный слой. Заряд,
созданный таким слоем, достаточно высок
и обуславливает электростатическое
взаимодействие с иоами противоположного
знака. В результате образуется слой
противоионов, который выравнивает заряд
первичного слоя. Слой противоионов
имеет диффузный характер. Часть
противоионов, прочно связанных с
первичным слоем – это плотный слой,
остальные противоионы составляют
диффузный слой.
Образование осадкапроисходит
тогда, когда раствор становится
пересыщенным, т.е. [A+]m[B-]n>Ks(ПКИ>ПР). Образование осадков связано
с процессом укрупнения частиц, с
образованием кристаллической решетки
вещества. Этот процесс определяется
числом центров кристаллизации: чем
больше центров, тем в меньшей степени
они укрупняются и тем хуже структура и
выше дисперсность осадка.
Возможные варианты загрязнения:1)
Путем адсорбции ( для конкретного примера
хлорид-ионов на поверхности осадка); 2)
Окклюзия; 3) Изоморфное соосаждение; 4)
Совместное осаждение; 5) Последующее
осаждение.
Приемы повышения чистоты осадка:
1) Адсорбированные на поверхности примеси
хорошо удаляются при промывании осадков
на фильтре при помощи промывных жидкостей,
т.к. примеси переходят в промывную
жидкость и уходят через поры фильтра.
Эффективно многократное промывание
небольшими порциями промывной жидкости.
Промывную жидкость выбирают максимально
тщательно, чтобы не увеличивать
растворимость осадка и не ухудшать его
фильтрацию. Кристаллические осадки
промывают холодными промывными
жидкостями, чтобы не увеличить
растворимость осадка, а аморфные –
наоборот горячими. Водой промывают
осадки с низкими константами растворимости
(ниже 10-11-10-12), а также те,
которые не подвергаются пептизации.
Если константа растворимости осадка
10-9-10-11и он кристаллический,
то его промывают разбавленным раствором
осадителя. Аморфные осадки промывают
разбавленными растворами
электролитов-коагулянтов (солиNH4+),
чтобы избежать пептизации (в опыте с
железом осадок промывали растворомNH4NO3).
Повышение температуры также способствует
уменьшению адсорбции (на конкретном
примере горячий раствор, содержащий
10% аммиак разбавляют горячей водой для
уменьшения адсорбции хлорид-ионов на
поверхности осадка). 2) Для очищения
окклюдированных примесей в случае
кристаллических осадков используют
старение, в случае аморфных осадков –
переосаждение.Степень окклюзии в
процессе осаждения можно уменьшить
медленным добавлением осадителя по
каплям, при перемешивании.
Погрешности:
1) Общая погрешность анализа σ2 = ,
,
где σпр2– погрешность
пробоотбора, σизм2–
погрешность измерения,m– число проб,n– число
параллельных определений.
2) Методическая ошибка OобOоб=
— ,
,
гдеs– растворимость
осадка, г/100 мл воды;Vф
– объем фильтрата и промывных вод,
мл;mгр– масса
полученного осадка, г.
3) Относительное стандартное отклонение
 =
= , гдеσгр – дисперсия
, гдеσгр – дисперсия
массы гравиметрической формы;mгр– масса гравиметрической формы; σa– дисперсия массы исходной навески;a– масса исходной навески;p– процентное содержание вещества в
исследуемой пробе;n–число
измерений.
4) Погрешность взвешивания тары σa1и тары с навескойσa2σa1=σa2=0,0002
г, σгр= = 0,0003 г.
= 0,0003 г.
5) Относительное стандартное отклонение
с учетом стадий пробоотбора и
пробоподготовки
 =
= , гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
, гдеn– число проб;m– число параллельных измерений; σпр2– погрешность пробоотбора; σизм2– погрешность измерения.
Классификация коллоидных систем. В
зависимости от характера межмолекулярных
сил, которые действуют на границе раздела
фаз коллоидные растворы делят на
лиофильные и лиофобные. Вокруг лиофильной
частицы располагается прочная сольватная
оболочка. В этих оболочках молекулы
ориентированы определенным образом и
образуют более или менее правильные
структуры. Вокруг лиофобной частицы
раствора также имеются сольватные
оболочки, но они непрочные и не предохраняют
молекулы от слипания.
H2SiO3– аморфный осадок, поэтому
условия его осаждения следующие:
1)осаждение проводят из горячего раствора
анализируемого вещества горячим
раствором осадителя при перемешивании;
2)осаждение проводят из достаточно
концентрированного исследуемого
раствора концентрированным раствором
осадителя с последующим разбавлением(при
разбавлении устанавливается адсорбционное
равновесие, часть адсорбированных ионов
переходи в раствор, и осадок становится
более чистым); 3)осаждение проводят в
присутствии подходящего
электролита-коагулятора;
4)аморфные осадки почти не требуют
времени для созревания, их необходимо
фильтровать сразу после разбавления
раствора. Аморфные осадки нельзя
оставлять более, чем на несколько минут,
т.к. сильное уплотнение их затрудняет
последующее отмывание примесей, а также
при стоянии увеличивается количество
примесей, адсорбированных поверхностью
осадка.
Если вы устраняете систематическую ошибку модели, то уже слишком поздно

Введение
Машинное обучение — это технологический прорыв, случающийся раз в поколение. Однако с ростом его популярности основной проблемой становятся систематические ошибки алгоритма. Если модели ML не обучаются на репрезентативных данных, у них могут развиться серьёзные систематические ошибки, оказывающие существенный вред недостаточно представленным группам и приводящие к созданию неэффективных продуктов. Мы изучили массив данных CoNLL-2003, являющийся стандартом для создания алгоритмов распознавания именованных сущностей в тексте, и выяснили, что в данных присутствует серьёзный перекос в сторону мужских имён. При помощи наших технологии мы смогли компенсировать эту систематическую ошибку:
- Мы обогатили данные, чтобы выявить сокрытые систематические ошибки
- Дополнили массив данных недостаточно представленными примерами, чтобы компенсировать гендерный перекос
Модель, обученная на нашем расширенном массиве данных CoNLL-2003, характеризуется снижением систематической ошибки и повышенной точностью, и это показывает, что систематическую ошибку можно устранить без каких-либо изменений в модели. Мы выложили в open source наши аннотации Named Entity Recognition для исходного массива данных CoNLL-2003, а также его улучшенную версию, скачать их можно здесь.
Систематическая ошибка алгоритма: слабое место ИИ
Сегодня тысячи инженеров и исследователей создают системы, самостоятельно обучающиеся тому, как достигать существенных прорывов — повышать безопасность на дорогах при помощи беспилотных автомобилей, лечить болезни оптимизированными ИИ процедурами, бороться с изменением климата при помощи управления энергопотреблением.
Однако сила самообучающихся систем является и их слабостью. Так как фундаментом всех процессов машинного обучения являются данные, обучение на несовершенных данных может привести к искажённым результатам.
ИИ-системы имеют большие полномочия, поэтому они могут наносить существенный ущерб. Недавние протесты против полицейской жестокости, приведшей к смертям Джорджа Флойда, Бреонны Тейлор, Филандо Кастиле, Сандры Блэнд и многих других, является важным напоминанием о систематическом неравенстве в нашем обществе, которое не должны усугублять ИИ-системы. Но нам известны многочисленные примеры (закрепляющие гендерные стереотипы результаты поиска картинок, дискриминация чёрных подсудимых в системах управления данными нарушителей и ошибочная идентификация цветных людей системами распознавания лиц), показывающие, что предстоит пройти долгий путь, прежде чем проблема систематических ошибок ИИ будет решена.
Распространённость ошибок вызвана лёгкостью их внесения. Например, они проникают в «золотые стандарты» моделей и массивов данных в open source, ставшие фундаментом огромного объёма работы в сфере ML. Массив данных для определения эмоционального настроя текста word2vec, используемый в построении моделей других языков, искажён по этнической принадлежности, а word embeddings — способ сопоставления слов и значений алгоритмом ML — содержит сильно искажённые допущения о занятиях, с которыми ассоциируются женщины.
Проблема (и, как минимум, часть её решения) лежит в данных. Чтобы проиллюстрировать это, мы провели эксперимент с одним из самых популярных массивов данных для построения систем распознавания именованных сущностей в тексте: CoNLL-2003.
Что такое «распознавание именованных сущностей»?
Распознавание именованных сущностей (Named-Entity Recognition, NER) — один из фундаментальных камней моделей естественных языков, без него были бы невозможны онлайн-поиск, извлечение информации и анализ эмоционального настроя текста.
Миссия нашей компании заключается в ускорении разработки ИИ. Естественный язык — одна из основных сфер наших интересов. Наш продукт Scale Text содержит NER, заключающееся в аннотировании текста согласно заданному списку меток. На практике, среди прочего, это может помочь крупным розничным сетям анализировать онлайн-обсуждение их продуктов.
Многие модели NER обучаются и подвергаются бенчмаркам на CoNLL-2003 — массиве данных из примерно 20 тысяч предложений новостных статей Reuters, аннотированных такими атрибутами, как «PERSON», «LOCATION» и «ORGANIZATION».
Нам захотелось изучить эти данные на наличие систематических ошибок. Для этого мы воспользовались своим конвейером разметки, чтобы категоризировать все имена в массиве данных, размечая их как мужские, женские или гендерно-нейтральные, исходя из традиционного использования имён.
При этом мы выявили существенную разницу. Мужские имена упоминались почти в пять раз чаще женских, и менее 2% имён были гендерно-нейтральными:

Это вызвано тем, что по социальным причинам новостные статьи в основном содержат мужские имена. Однако из-за этого модель NER, обученная на таких данных, лучше будет справляться с выбором мужских имён, чем женских. Например, поисковые движки используют модели NER для классификации имён в поисковых запросах, чтобы выдавать более точные результаты. Но если внедрить модель NER с перекосом, то поисковый движок хуже будет идентифицировать женские имена по сравнению с мужскими, и именно подобная малозаметная распространённая систематическая ошибка может проникнуть во многие системы реального мира.
Новый эксперимент по снижению систематической ошибки
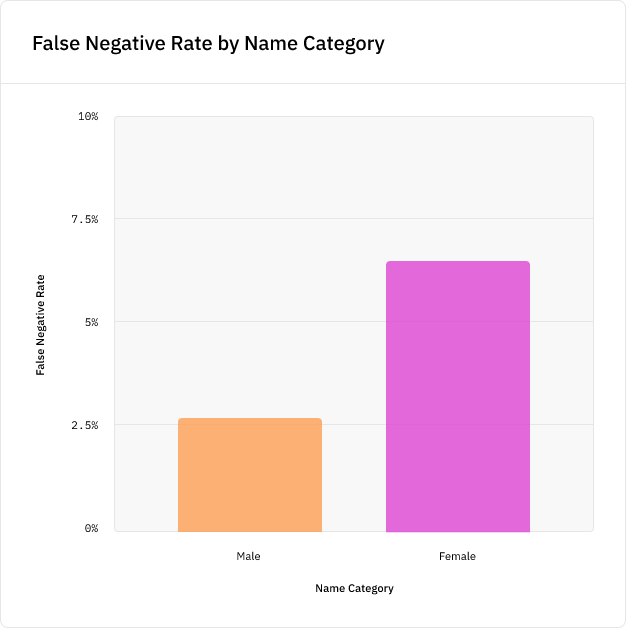
Чтобы проиллюстрировать это, мы обучили модель NER для изучения того, как этот гендерный перекос повлияет на её точность. Был создан алгоритм извлечения имён, выбирающий метки PERSON при помощи популярной NLP-библиотеки spaCy, и на подмножестве данных CoNLL была обучена модель. Затем мы протестировали модель на новых именах из тестовых данных, не присутствовавших в данных обучения, и обнаружили, что модель с вероятностью на 5% больше пропустит новое женское имя, чем новое мужское имя, а это серьёзное расхождение в точности:
Мы наблюдали схожие результаты, когда применили модель к шаблону «NAME is a person», подставив 100 самых популярных мужских и женских имён на каждый год переписи населения США. Результаты работы модели оказались значительно хуже для женских имён во все года переписи:
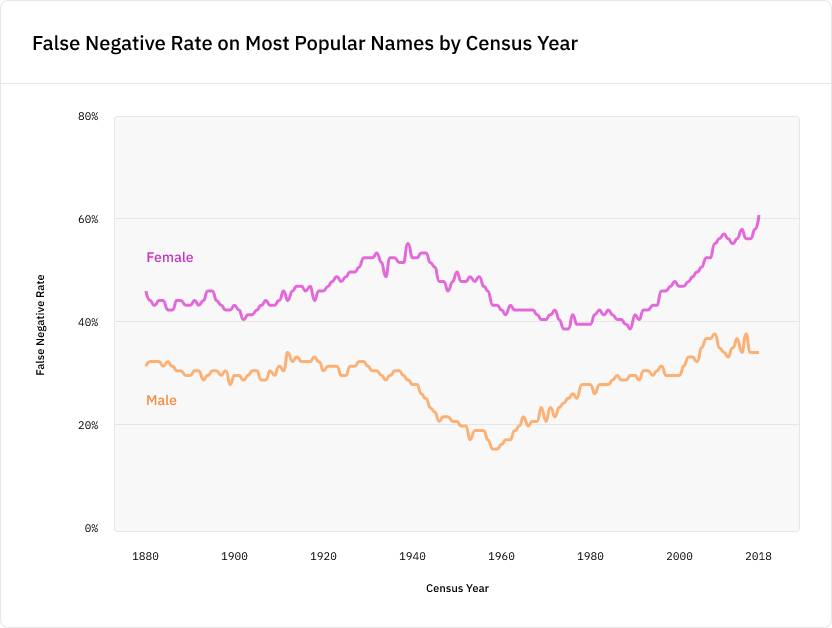
Критически важно то, что наличие перекоса в данных обучения приводит к смещению ошибок в сторону недостаточно представленных категорий. Эксперимент с переписями демонстрирует это и другим образом: точность модели существенно деградирует после 1997 года (точки отсечения статей Reuters в массиве данных CoNLL), потому что массив данных больше не является репрезентативным отображением популярности имён каждого последующего года.
Модели обучаются соответствовать трендам данных, на которых они обучены. Нельзя ожидать их хорошей точности в случаях, когда они видели лишь малое количество примеров.
Если вы исправляете систематическую ошибку модели, то уже слишком поздно
Как же это исправить?
Один из способов — попробовать устранить систематическую ошибку модели, например, выполнив постобработку модели или добавив целевую функцию для смягчения перекоса, оставив определение подробностей самой модели.
Но это не лучший подход по множеству причин:
- Справедливость — это очень сложная проблема, и мы не можем ждать, что алгоритм решит её сам. Исследование показало, что обучение алгоритма на одинаковый уровень точности для всех подмножеств населения не обеспечит справедливости и нанесёт вред обучению модели.
- Добавление новых целевых функций может навредить точности модели, приводя к негативному побочному эффекту. Вместо этого лучше обеспечить простоту алгоритма и сбалансированность данных, что повысит точность модели и позволит избежать негативных эффектов.
- Неразумно ожидать, что модель покажет хорошие результаты в случаях, примеров которых она видела очень мало. Наилучший способ обеспечения хороших результатов заключается в повышении разнообразия данных.
- Попытки устранения систематической ошибки при помощи инженерных техник — это дорогой и длительный процесс. Гораздо дешевле и проще изначально обучать модели на данных без перекосов, освободив ресурсы инженеров для работы над реализацией.
Данные — это лишь одна часть проблемы систематических ошибок. Однако эта часть фундаментальна и влияет на всё, что идёт после неё. Именно поэтому мы считаем, что данные содержат ключ к частичному решению, обеспечивая потенциальные систематические улучшения в исходных материалах. Если вы не размечаете критические классы (например, гендер или этническую принадлежность) явным образом, то невозможно сделать так, чтобы эти классы не были источником систематической ошибки.
Такая ситуация контринтуитивна. Кажется, что если нам нужно построить модель, не зависящую от чувствительных характеристик наподобие гендера, возраста или этнической принадлежности, то лучше исключить эти свойства из данных обучения, чтобы модель не могла их учитывать.
Однако принцип «справедливости, реализуемой через неведение» на самом деле усугубляет проблему. Модели ML превосходно справляются с выводом заключений из признаков, они не прекращают делать этого, если мы не разметили эти признаки явным образом. Систематические ошибки просто остаются невыявленными, из-за чего их сложнее устранить.
Единственный надёжный способ решения проблемы заключается в разметке большего количества данных, чтобы сбалансировать распределение имён. Мы использовали отдельную модель ML для идентификации предложений в корпусах Reuters и Brown, с большой вероятностью содержащих женские имена, а затем разметили эти предложения в нашем конвейере NER, чтобы дополнить CoNLL.
Получившийся массив данных, который мы назвали CoNLL-Balanced, содержит на 400 с лишним больше женских имён. После повторного обучения на нём модели NER мы обнаружили, что алгоритм больше не имеет систематической ошибки, приводящей к снижению показателей при распознавании женских имён:

Кроме того, модель улучшила показатели и при распознавании мужских имён.
Это стало впечатляющей демонстрацией важности данных. Благодаря устранению перекоса в исходном материале нам не пришлось вносить никаких изменений в нашу модель ML, что позволило сэкономить на времени разработки. И мы достигли этого без негативного влияния на точность модели; на самом деле, она даже слегка увеличилась.
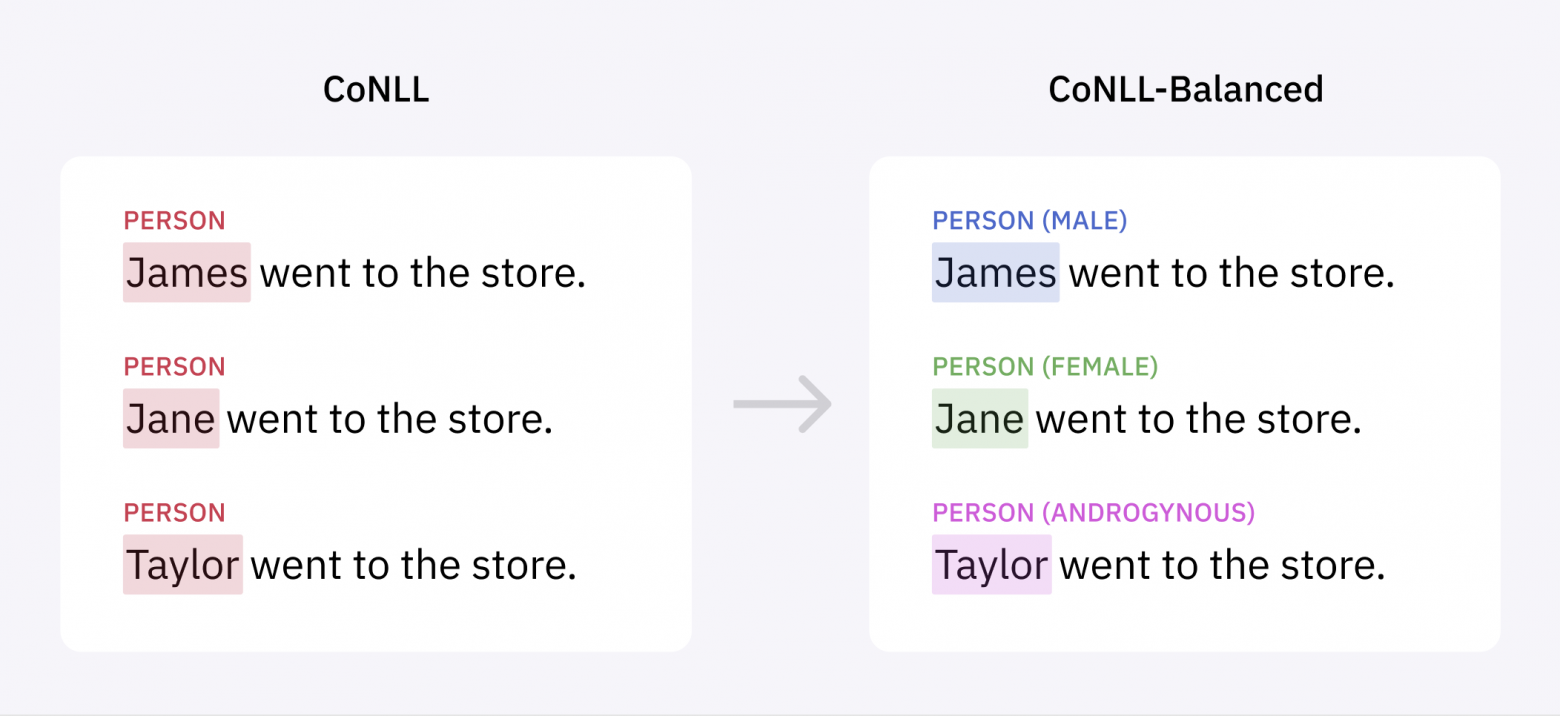
Чтобы позволить сообществу разработчиков развивать нашу работу и устранять гендерный перекос в моделях, построенных на основе CoNLL-2003, мы выложили на наш веб-сайте дополненный массив данных в open source, в том числе и добавив гендерную информацию.
Сообщество разработчиков ИИ/ML имеет проблемы с культурными различиями, но мы испытываем умеренный оптимизм от этих результатов. Они намекают на то, что мы, возможно, сможем предложить техническое решение насущной социальной проблемы, если займёмся проблемой сразу же, выявим сокрытые систематические ошибки и улучшим точность модели для всех.
Сейчас мы изучаем, как этот подход можно применить к ещё одному критичному атрибуту — этнической принадлежности — чтобы придумать, как создать надёжную систему для устранения перекоса в массивах данных, распространяющегося и на другие охраняемые от дискриминации категории населения.
Кроме того, это показывает, почему наша компания уделяет так много внимания качеству данных. Если нельзя доказать, что данные точны, сбалансированы и лишены систематических ошибок, то нет гарантии того, что создаваемые на их основе модели будут безопасными и точными. А без этого мы не сможем создавать качественно новых ИИ-технологий, идущих на пользу всем людям.
Благодарности
Упоминаемый в этом посте массив данных CoNLL 2003 — это тестовый набор Reuters-21578, Distribution 1.0, доступный для скачивания на странице проекта исходного эксперимента 2003 года: https://www.clips.uantwerpen.be/conll2003/ner/.
Результаты наблюдений,
полученные при наличии систематической
погрешности, называются неисправленными.
При проведении
измерений стараются в максимальной
степени исключить или учесть влияние
систематических погрешностей. Это может
быть достигнуто следующими путями:
• устранением источников погрешностей
до начала измерений. В большинстве
областей измерений известны главные
источники систематических погрешностей
и разработаны методы, исключающие
их возникновение или устраняющие их
влияние на результат измерения. В связи
с этим в практике измерений стараются
устранить систематические погрешности
не путем обработки экспериментальных
данных, а применением СИ, реализующих
соответствующие методы измерений;
• определением
поправок и внесением их в результат
измерения;
• оценкой границ неисключенных
систематических погрешностей.
Постоянная систематическая
погрешность не может быть найдена
методами совместной обработки результатов
измерений. Однако она не искажает ни
показатели точности измерений,
характеризующие случайную погрешность,
ни результат нахождения переменной
составляющей систематической погрешности.
Действительно, результат одного
измерения
![]()
где хи
– истинное значение измеряемой величины;
Δi
– i-я
случайная погрешность; θi
– i-я
систематическая погрешность. После
усреднения результатов многократных
измерений получаем среднее арифметическое
значение измеряемой величины
![]()
Если систематическая
погрешность постоянна во всех измерениях,
т.е. θi=θ
, то
![]()
Таким образом, постоянная систематическая
погрешность не устраняется при
многократных измерениях.
Постоянные систематические
погрешности могут быть обнаружены
лишь путем сравнения
результатов измерений с другими,
полученными с помощью более высокоточных
методов и средств. Иногда эти
погрешности могут быть устранены
специальными приемами проведения
процесса измерений. Эти методы рассмотрены
ниже.
Наличие существенной переменной
систематической погрешности искажает
оценки характеристик случайной
погрешности и аппроксимацию ее
распределения. Поэтому она должна
обязательно выявляться и исключаться
из результатов измерений.
Для устранения постоянных систематических
погрешностей применяют следующие
методы:
• Метод
замещения,
представляющий собой
разновидность метода сравнения,
когда сравнение осуществляется заменой
измеряемой величины известной
величиной, причем так, что при этом в
состоянии и действии всех используемых
средств измерений не происходит
никаких изменений. Этот метод дает
наиболее полное решение задачи. Для
его реализации необходимо иметь
регулируемую меру, величина которой
однородна измеряемой.
• Метод
противопоставления,
являющийся разновидностью
метода сравнения, при котором измерение
выполняется дважды и проводится так,
чтобы в обоих случаях причина постоянной
погрешности оказывала разные, но
известные по закономерности воздействия
на результаты наблюдений. Например,
способ взвешивания Гаусса [3].
Пример 7.1. Измерить
сопротивление с помощью одинарного
моста методом противопоставления.
Сначала измеряемое
сопротивление Rx
уравновешивают известным сопротивлением
R1
включенным в плечо сравнения моста. При
этом Rх
= R1·R3
/R4,
где R3,
R4
– сопротивления плеч моста. Затем
резисторы Rx
и R1
меняют местами и вновь уравновешивают
мост, регулируя сопротивление
резистора R1.
В этом случае Rx
= R΄1·R3/R4.
Из двух последних уравнений
исключается отношение R3/R4.
Тогда
![]()
• Метод
компенсации погрешности по знаку
(метод изменения знака
систематической погрешности),
предусматривающий измерение с двумя
наблюдениями, выполняемыми так, чтобы
постоянная систематическая погрешность
входила в результат каждого из них с
разными знаками.
Пример 7.2. Измерить ЭДС
потенциометром постоянного тока,
имеющим паразитную термо–ЭДС.
При выполнении одного
измерения получаем ЭДС Е1
Затем меняем полярность измеряемой ЭДС
и направление тока в потенциометре.
Вновь проводим его уравновешивание –
получаем значение Е2.
Если термо–ЭДС дает погрешность ΔЕ
и Е1=Еx+ΔЕ,
то Е2=Еx–ΔЕ.
Отсюда Еx
= (Е
1+
Е2)/2.
Следовательно, систематическая
погрешность, обусловленная действием
термо–ЭДС, устранена.
• Метод
рандомизации –
наиболее универсальный способ исключения
неизвестных постоянных систематических
погрешностей. Суть его состоит в том,
что одна и та же величина измеряется
различными методами (приборами).
Систематические погрешности каждого
из них для всей совокупности являются
разными случайными величинами.
Вследствие этого при увеличении
числа используемых методов (приборов)
систематические погрешности взаимно
компенсируются.
Для устранения переменных и монотонно
изменяющихся систематических
погрешностей применяют следующие приемы
и методы.
• Анализ
знаков неисправленных случайных
погрешностей.
Если знаки
неисправленных случайных погрешностей
чередуются с какой-либо закономерностью,
то наблюдается переменная систематическая
погрешность. Если последовательность
знаков «+» у случайных погрешностей
сменяется последовательностью знаков
«–» или наоборот, то присутствует
монотонно изменяющаяся систематическая
погрешность. Если группы знаков «»+ и
«–» у случайных погрешностей чередуются,
то присутствует периодическая
систематическая погрешность.
• Графический
метод. Он
является одним из наиболее простых
способов обнаружения переменной
систематической погрешности в ряду
результатов наблюдений и заключается
в построении графика последовательности
неисправленных значений результатов
наблюдений. На графике через построенные
точки проводят плавную кривую, которая
выражает тенденцию результата измерения,
если она существует. Если тенденция не
прослеживается, то переменную
систематическую погрешность считают
практически отсутствующей.
• Метод
симметричных наблюдений.
Рассмотрим сущность
этого метода на примере измерительного
преобразователя, передаточная функция
которого имеет вид у = kх
+ у0,
где х, у – входная и выходная величины
преобразователя; k
– коэффициент, погрешность которого
изменяется во времени по линейному
закону; у0
– постоянная.
Для устранения систематической
погрешности трижды измеряется
выходная величина у через равные
промежутки времени Δt.
При первом и третьем измерениях на вход
преобразователя подается сигнал х0
от образцовой меры. В результате измерений
получается система уравнений:
![]()
;
![]()
;
![]()
Ее решение позволяет получить
значение х, свободное от переменной
систематической погрешности, обусловленной
изменением коэффициента k:
![]()
Специальные статистические
методы. К
ним относятся способ последовательных
разностей, дисперсионный анализ, и др.
Рассмотрим подробнее некоторые из
них.
Способ последовательных
разностей (критерий Аббе).
Применяется для обнаружения
изменяющейся во времени систематической
погрешности и состоит в следующем.
Дисперсию результатов наблюдений
можно оценить двумя способами: обычным
![]()
и вычислением суммы квадратов
последовательных (в порядке
проведения измерений) разностей
(хi–1
– хi)2
![]()
Если в процессе измерений
происходило смещение центра группирования
результатов наблюдений, т.е. имела место
переменная систематическая погрешность,
то σ2[x]
дает преувеличенную оценку дисперсии
результатов наблюдений. Это объясняется
тем, что на σ2[x]
влияют вариации
![]()
.
В то же время изменения центра
группирования
весьма мало сказываются на значениях
последовательных разностей di
= хi+1
– хi
поэтому смещения
почти не отразятся на значении Q2[x].
Отношение
![]()
является критерием для обнаружения
систематических смещений центра
группирования результатов наблюдений.
Критическая область для этого критерия
(критерия Аббе) определяется как
Р(v<vq)=q,
где q=1–Р
– уровень значимости, Р
– доверительная вероятность. Значения
vч
для различных
уровней значимости q
и числа наблюдений n
приведены в табл. 7.1. Если полученное
значение критерия Аббе меньше v
при заданных q
и n,
то гипотеза о постоянстве центра
группирования результатов наблюдений
отвергается, т.е. обнаруживается
переменная систематическая погрешность
результатов измерений.
Таблица 7.1
Значения критерия Аббе Vq.
-
n
Vq
при q,
равномn
Vq
при q,
равном0,001
0,01
0,05
0,001
0,01
0,05
4
5
6
7
8
9
10
11
12
0,295
0,208
0,182
0,185
0,202
0,221
0,241
0,260
0,278
0,313
0,269
0,281
0,307
0,331
0,354
0,376
0,396
0,414
0,390
0,410
0,445
0,468
0,491
0,512
0,531
0,548
0,564
13
14
15
16
17
18
19
20
0,295
0,311
0,327
0,341
0,355
0,368
0,381
0,393
0,431
0,447
0,461
0,474
0,487
0,499
0,510
0,520
0,578
0,591
0,603
0,614
0,624
0,633
0,642
0,650
Пример 7.3. Используя
способ после до нательных разностей,
определить, присутствует ли систематическая
погрешность в ряду результатов
наблюдений, приведенных во втором
столбце табл. 7.2.
Таблица 7.2
Результаты наблюдений
-
n
xi
d1=xi+1–xi
di2

vi2
1
13,4
–
–
–0,6
0,36
2
13,3
–0,1
0,01
–0,7
0,49
3
14,5
+1,2
1,44
+0,5
0,25
4
13,8
–0,7
0,49
–0,2
0,04
5
14,5
+0,7
0,49
+0,5
0,25
6
14,6
+0,1
0,01
+0,6
0,36
7
14,1
–0,5
0,25
+0,1
0,01
8
14,3
+0,2
0,04
+0,3
0,09
9
14,0
+0,3
0,09
0,0
0,0
10
14,3
+0,3
0,09
+0,3
0,09
11
14,2
–1,1
1,21
–0,8
0,64
Σ154,0
–0,2
4,12
0,0
2,58
Для приведенного ряда
результатов вычисляем: среднее
арифметическое
= 154,0/11 = 14; оценку дисперсии σ2[х]
= 2,58/10 = 0,258; значение Q2[х]
= 4,12/(2·10)
= 0,206; критерий Аббе v
= 0,206/0,258 = 0,8.
Как видно из табл. 7.1, для
всех уровней значимости (q
= 0,001; 0,01 и 0,05) при n
= 11 имеем v
>vq,
т.е. подтверждается
нулевая гипотеза о постоянстве центра
группирования. Следовательно, условия
измерений для приведенного ряда
оставались неизменными и систематических
расхождений между результатами
наблюдений нет.
Дисперсионный анализ
(критерий Фишера). В
практике измерений часто бывает
необходимо выяснить наличие систематической
погрешности результатов наблюдений,
обусловленной влиянием какого-либо
постоянно действующего фактора, или
определить, вызывают ли изменения этого
фактора систематическое смещение
результатов измерений. В данном случае
проводят многократные измерения,
состоящие из достаточного числа серий,
каждая из которых соответствует
определенным (пусть неизвестным, но
различным) значениям влияющего фактора.
Влияющими факторами, по которым
производится объединение результатов
наблюдений по сериям, могут быть внешние
условия (температура, давление и т.д.),
временная последовательность проведения
измерений и т.п.
После проведения N
измерений их разбивают на s
серий (s>3)
по nj
результатов наблюдений (snj
= N)
в каждой серии и затем устанавливают,
имеется или отсутствует систематическое
расхождение между результатами наблюдений
в различных сериях. При этом должно
быть установлено, что результаты в
сериях распределены нормально.
Рассеяние результатов наблюдений в
пределах каждой серии отражает только
случайные влияния, характеризует лишь
случайные погрешности измерений в
пределах этой серии.
Характеристикой совокупности случайных
внутрисерийных погрешностей будет
средняя сумма дисперсий результатов
наблюдений, вычисленных раздельно
для каждой серии, т.е.
![]()
,
где
![]()
,
x
ji
– результат i-го
измерения в j-й
серии.
Внутрисерийная дисперсия
![]()
,
характеризует случайные погрешности
измерений, так как только случайные
влияния обусловливают те различия
(отклонения результатов наблюдений),
на которых она основана. В то же время
рассеяние
![]()
различных серий обусловливается не
только случайными погрешностями
измерений, но и систематическими
различиями (если они существуют) между
результатами наблюдений, сгруппированными
по сериям. Следовательно, усредненная
межсерийная дисперсия
![]()
где
![]()
–
выражает силу действия фактора,
вызывающего систематические различия
между сериями.
Таким образом,
![]()
характеризует долю дисперсии всех
результатов наблюдений, обусловленную
наличием случайных погрешностей
измерений, а
![]()
– долю дисперсии, обусловленную
межсерийными различиями результатов
наблюдений.
Первую из них называют
коэффициентом ошибки,
вторую – показателем
дифференциации.
Чем больше отношение
показателя дифференциации к
коэффициенту ошибки, тем сильнее действие
фактора, по которому группировались
серии, и тем больше систематическое
различие между ними.
Критерием оценки наличия
систематических погрешностей в данном
случае является дисперсионный критерий
Фишера
.
Критическая область для
критерия Фишера соответствует Р(F>
Fq)
= q.
Значения Fq
для различных уровней значимости q,
числа измерений N
и числа серий s
приведены в таблице в конце лекции, где
k2=
N – s,
k1
= s
– 1. Если полученное
значение критерия Фишера больше Fq
(при заданных q,
N и s),
то гипотеза об отсутствии систематических
смещения результатов наблюдений по
сериям отвергается, т.е. обнаруживается
систематическая погрешность, вызываемая
тем фактором, по которому группировались
результаты наблюдений,
Пример 7.4. Было сделано
38 измерений диаметра детали восемью
различными штангенциркулями. Каждым
из них проводились
по пять измерений. Внутрисерийная
дисперсия равна 0,054 мм2,
межсерийная — 0,2052 мм2.
Определить наличие систематической
погрешности измерения диаметра детали.
Расчетное значение критерия
Фишера F
= 0,2052/0,054 = 3,8. Для s
–1 = 7, N
– s
= 30 по табл. П1.3 приложения 1 имеем при q
= 0,05 F0,05
= 2,3 и при q
= 0,01 F0,01
= 3,3. Полученное значение F
больше, чем 2,2 и 2,9. Следовательно, в
результатах наблюдений обнаруживается
наличие систематических погрешностей.
Из всех рассмотренных способов обнаружения
систематических погрешностей дисперсионный
анализ является наиболее эффективным
и достоверным, так как позволяет не
только установить факт наличия
погрешности, но и дает возможность
проанализировать источники ее
возникновения.
Критерий Вилкоксона.
Если закон распределения результатов
измерений неизвестен, то для обнаружения
систематической погрешности применяют
статистический критерий Вилкоксона.
Из двух групп результатов
измерений x1,
х2,…,
хn
и у1,
у2,…,
уm,
где n![]()
m
5
составляется
вариационный ряд, в котором все n+m
значений х1,
х2,…,
хn;
у1,
у2,…,
уm
располагают в порядке их возрастания
и приписывают им ранги – порядковые
номера членов вариационного ряда.
Различие средних значений каждого из
рядов можно считать допустимым, если
выполняется неравенство
![]()
где Ri
– ранг (номер) члена xi
равный его номеру в вариационном ряду;
![]()
и
![]()
– нижнее и верхнее критические значения
для выбранного уровня значимости q.
При m
< 15 эти критические значения
определяются по табл. 7.3. При m>15
они рассчитываются по формулам:
![]()
![]()
где zр
– квантиль нормированной функции
Лапласа.
Более полная таблица
значений критических значений
и
приведена в рекомендации МИ 2091-90
«ГСИ. Измерения физических величин.
Общие требования».
Таблица №7.3
Критические
значения
и
при q
= 0,05 и 0,01
-
n
m
q
= 0,05q
= 0,018
8
10
15
49
53
65
87
99
127
43
47
56
93
105
136
9
9
15
62
79
109
146
56
69
115
156
10
10
15
78
94
132
166
71
84
139
176
12
12
15
115
127
185
209
105
115
195
221
14
14
15
160
164
246
256
147
151
259
268
15
15
184
282
171
294
Если вы устраняете систематическую ошибку модели, то уже слишком поздно
Время на прочтение
7 мин
Количество просмотров 5.5K

Введение
Машинное обучение — это технологический прорыв, случающийся раз в поколение. Однако с ростом его популярности основной проблемой становятся систематические ошибки алгоритма. Если модели ML не обучаются на репрезентативных данных, у них могут развиться серьёзные систематические ошибки, оказывающие существенный вред недостаточно представленным группам и приводящие к созданию неэффективных продуктов. Мы изучили массив данных CoNLL-2003, являющийся стандартом для создания алгоритмов распознавания именованных сущностей в тексте, и выяснили, что в данных присутствует серьёзный перекос в сторону мужских имён. При помощи наших технологии мы смогли компенсировать эту систематическую ошибку:
- Мы обогатили данные, чтобы выявить сокрытые систематические ошибки
- Дополнили массив данных недостаточно представленными примерами, чтобы компенсировать гендерный перекос
Модель, обученная на нашем расширенном массиве данных CoNLL-2003, характеризуется снижением систематической ошибки и повышенной точностью, и это показывает, что систематическую ошибку можно устранить без каких-либо изменений в модели. Мы выложили в open source наши аннотации Named Entity Recognition для исходного массива данных CoNLL-2003, а также его улучшенную версию, скачать их можно здесь.
Систематическая ошибка алгоритма: слабое место ИИ
Сегодня тысячи инженеров и исследователей создают системы, самостоятельно обучающиеся тому, как достигать существенных прорывов — повышать безопасность на дорогах при помощи беспилотных автомобилей, лечить болезни оптимизированными ИИ процедурами, бороться с изменением климата при помощи управления энергопотреблением.
Однако сила самообучающихся систем является и их слабостью. Так как фундаментом всех процессов машинного обучения являются данные, обучение на несовершенных данных может привести к искажённым результатам.
ИИ-системы имеют большие полномочия, поэтому они могут наносить существенный ущерб. Недавние протесты против полицейской жестокости, приведшей к смертям Джорджа Флойда, Бреонны Тейлор, Филандо Кастиле, Сандры Блэнд и многих других, является важным напоминанием о систематическом неравенстве в нашем обществе, которое не должны усугублять ИИ-системы. Но нам известны многочисленные примеры (закрепляющие гендерные стереотипы результаты поиска картинок, дискриминация чёрных подсудимых в системах управления данными нарушителей и ошибочная идентификация цветных людей системами распознавания лиц), показывающие, что предстоит пройти долгий путь, прежде чем проблема систематических ошибок ИИ будет решена.
Распространённость ошибок вызвана лёгкостью их внесения. Например, они проникают в «золотые стандарты» моделей и массивов данных в open source, ставшие фундаментом огромного объёма работы в сфере ML. Массив данных для определения эмоционального настроя текста word2vec, используемый в построении моделей других языков, искажён по этнической принадлежности, а word embeddings — способ сопоставления слов и значений алгоритмом ML — содержит сильно искажённые допущения о занятиях, с которыми ассоциируются женщины.
Проблема (и, как минимум, часть её решения) лежит в данных. Чтобы проиллюстрировать это, мы провели эксперимент с одним из самых популярных массивов данных для построения систем распознавания именованных сущностей в тексте: CoNLL-2003.
Что такое «распознавание именованных сущностей»?
Распознавание именованных сущностей (Named-Entity Recognition, NER) — один из фундаментальных камней моделей естественных языков, без него были бы невозможны онлайн-поиск, извлечение информации и анализ эмоционального настроя текста.
Миссия нашей компании заключается в ускорении разработки ИИ. Естественный язык — одна из основных сфер наших интересов. Наш продукт Scale Text содержит NER, заключающееся в аннотировании текста согласно заданному списку меток. На практике, среди прочего, это может помочь крупным розничным сетям анализировать онлайн-обсуждение их продуктов.
Многие модели NER обучаются и подвергаются бенчмаркам на CoNLL-2003 — массиве данных из примерно 20 тысяч предложений новостных статей Reuters, аннотированных такими атрибутами, как «PERSON», «LOCATION» и «ORGANIZATION».
Нам захотелось изучить эти данные на наличие систематических ошибок. Для этого мы воспользовались своим конвейером разметки, чтобы категоризировать все имена в массиве данных, размечая их как мужские, женские или гендерно-нейтральные, исходя из традиционного использования имён.
При этом мы выявили существенную разницу. Мужские имена упоминались почти в пять раз чаще женских, и менее 2% имён были гендерно-нейтральными:

Это вызвано тем, что по социальным причинам новостные статьи в основном содержат мужские имена. Однако из-за этого модель NER, обученная на таких данных, лучше будет справляться с выбором мужских имён, чем женских. Например, поисковые движки используют модели NER для классификации имён в поисковых запросах, чтобы выдавать более точные результаты. Но если внедрить модель NER с перекосом, то поисковый движок хуже будет идентифицировать женские имена по сравнению с мужскими, и именно подобная малозаметная распространённая систематическая ошибка может проникнуть во многие системы реального мира.
Новый эксперимент по снижению систематической ошибки
Чтобы проиллюстрировать это, мы обучили модель NER для изучения того, как этот гендерный перекос повлияет на её точность. Был создан алгоритм извлечения имён, выбирающий метки PERSON при помощи популярной NLP-библиотеки spaCy, и на подмножестве данных CoNLL была обучена модель. Затем мы протестировали модель на новых именах из тестовых данных, не присутствовавших в данных обучения, и обнаружили, что модель с вероятностью на 5% больше пропустит новое женское имя, чем новое мужское имя, а это серьёзное расхождение в точности:
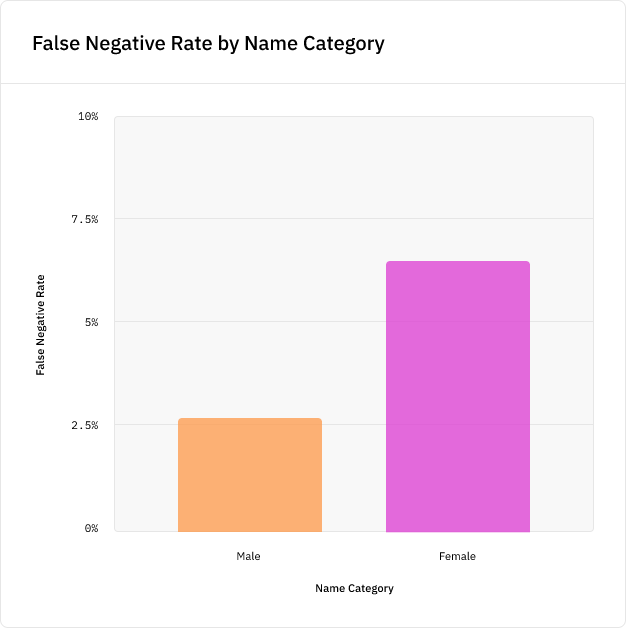
Мы наблюдали схожие результаты, когда применили модель к шаблону «NAME is a person», подставив 100 самых популярных мужских и женских имён на каждый год переписи населения США. Результаты работы модели оказались значительно хуже для женских имён во все года переписи:

Критически важно то, что наличие перекоса в данных обучения приводит к смещению ошибок в сторону недостаточно представленных категорий. Эксперимент с переписями демонстрирует это и другим образом: точность модели существенно деградирует после 1997 года (точки отсечения статей Reuters в массиве данных CoNLL), потому что массив данных больше не является репрезентативным отображением популярности имён каждого последующего года.
Модели обучаются соответствовать трендам данных, на которых они обучены. Нельзя ожидать их хорошей точности в случаях, когда они видели лишь малое количество примеров.
Если вы исправляете систематическую ошибку модели, то уже слишком поздно
Как же это исправить?
Один из способов — попробовать устранить систематическую ошибку модели, например, выполнив постобработку модели или добавив целевую функцию для смягчения перекоса, оставив определение подробностей самой модели.
Но это не лучший подход по множеству причин:
- Справедливость — это очень сложная проблема, и мы не можем ждать, что алгоритм решит её сам. Исследование показало, что обучение алгоритма на одинаковый уровень точности для всех подмножеств населения не обеспечит справедливости и нанесёт вред обучению модели.
- Добавление новых целевых функций может навредить точности модели, приводя к негативному побочному эффекту. Вместо этого лучше обеспечить простоту алгоритма и сбалансированность данных, что повысит точность модели и позволит избежать негативных эффектов.
- Неразумно ожидать, что модель покажет хорошие результаты в случаях, примеров которых она видела очень мало. Наилучший способ обеспечения хороших результатов заключается в повышении разнообразия данных.
- Попытки устранения систематической ошибки при помощи инженерных техник — это дорогой и длительный процесс. Гораздо дешевле и проще изначально обучать модели на данных без перекосов, освободив ресурсы инженеров для работы над реализацией.
Данные — это лишь одна часть проблемы систематических ошибок. Однако эта часть фундаментальна и влияет на всё, что идёт после неё. Именно поэтому мы считаем, что данные содержат ключ к частичному решению, обеспечивая потенциальные систематические улучшения в исходных материалах. Если вы не размечаете критические классы (например, гендер или этническую принадлежность) явным образом, то невозможно сделать так, чтобы эти классы не были источником систематической ошибки.
Такая ситуация контринтуитивна. Кажется, что если нам нужно построить модель, не зависящую от чувствительных характеристик наподобие гендера, возраста или этнической принадлежности, то лучше исключить эти свойства из данных обучения, чтобы модель не могла их учитывать.
Однако принцип «справедливости, реализуемой через неведение» на самом деле усугубляет проблему. Модели ML превосходно справляются с выводом заключений из признаков, они не прекращают делать этого, если мы не разметили эти признаки явным образом. Систематические ошибки просто остаются невыявленными, из-за чего их сложнее устранить.
Единственный надёжный способ решения проблемы заключается в разметке большего количества данных, чтобы сбалансировать распределение имён. Мы использовали отдельную модель ML для идентификации предложений в корпусах Reuters и Brown, с большой вероятностью содержащих женские имена, а затем разметили эти предложения в нашем конвейере NER, чтобы дополнить CoNLL.
Получившийся массив данных, который мы назвали CoNLL-Balanced, содержит на 400 с лишним больше женских имён. После повторного обучения на нём модели NER мы обнаружили, что алгоритм больше не имеет систематической ошибки, приводящей к снижению показателей при распознавании женских имён:
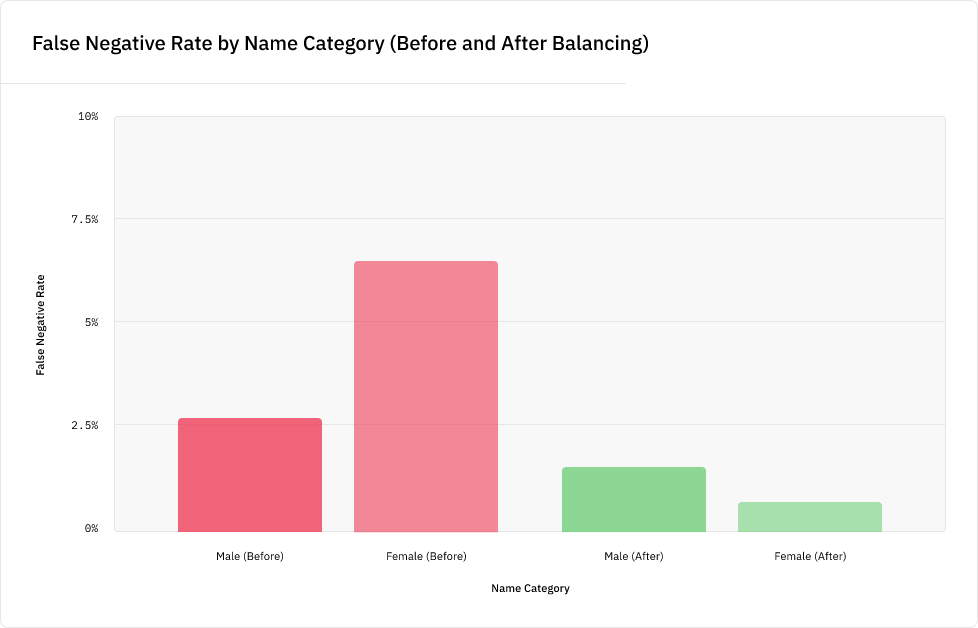
Кроме того, модель улучшила показатели и при распознавании мужских имён.
Это стало впечатляющей демонстрацией важности данных. Благодаря устранению перекоса в исходном материале нам не пришлось вносить никаких изменений в нашу модель ML, что позволило сэкономить на времени разработки. И мы достигли этого без негативного влияния на точность модели; на самом деле, она даже слегка увеличилась.
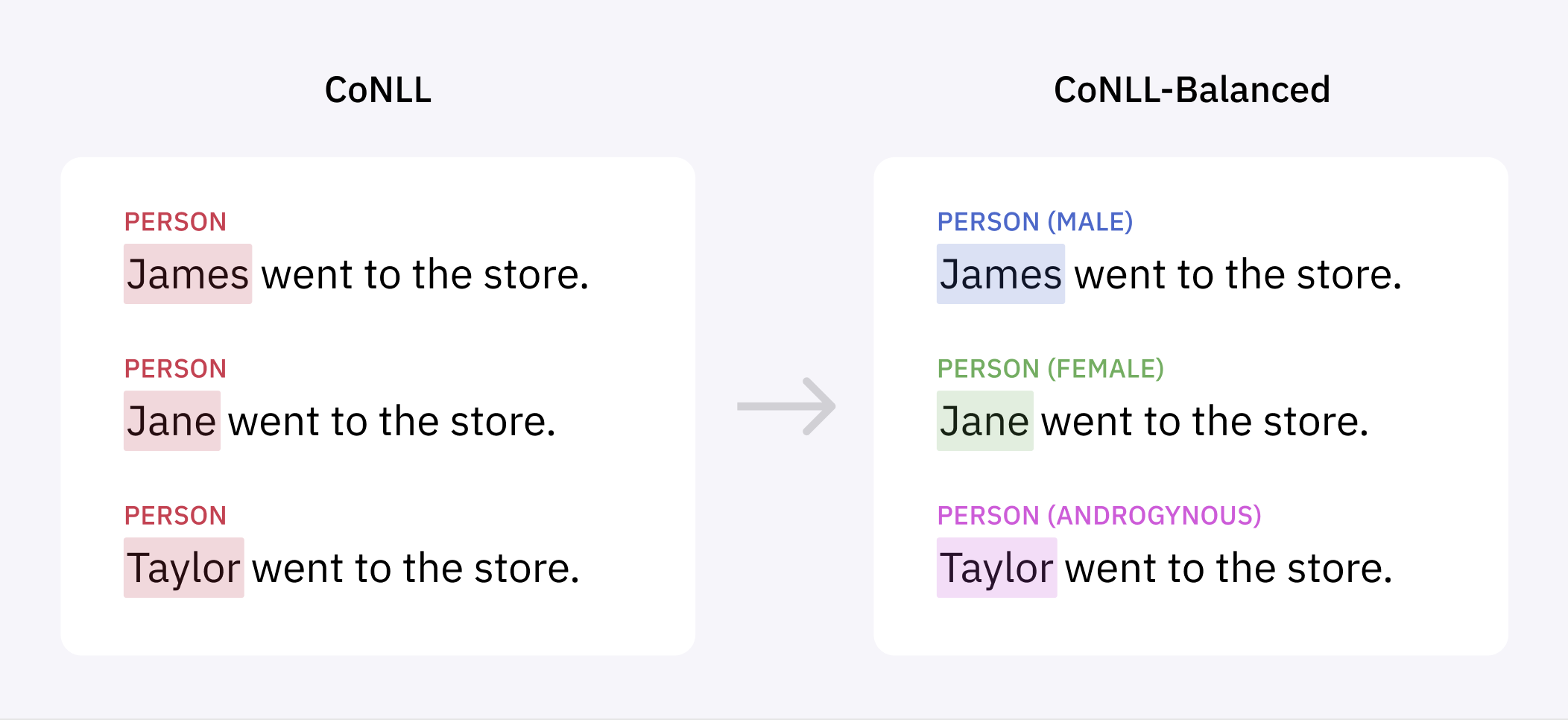
Чтобы позволить сообществу разработчиков развивать нашу работу и устранять гендерный перекос в моделях, построенных на основе CoNLL-2003, мы выложили на наш веб-сайте дополненный массив данных в open source, в том числе и добавив гендерную информацию.
Сообщество разработчиков ИИ/ML имеет проблемы с культурными различиями, но мы испытываем умеренный оптимизм от этих результатов. Они намекают на то, что мы, возможно, сможем предложить техническое решение насущной социальной проблемы, если займёмся проблемой сразу же, выявим сокрытые систематические ошибки и улучшим точность модели для всех.
Сейчас мы изучаем, как этот подход можно применить к ещё одному критичному атрибуту — этнической принадлежности — чтобы придумать, как создать надёжную систему для устранения перекоса в массивах данных, распространяющегося и на другие охраняемые от дискриминации категории населения.
Кроме того, это показывает, почему наша компания уделяет так много внимания качеству данных. Если нельзя доказать, что данные точны, сбалансированы и лишены систематических ошибок, то нет гарантии того, что создаваемые на их основе модели будут безопасными и точными. А без этого мы не сможем создавать качественно новых ИИ-технологий, идущих на пользу всем людям.
Благодарности
Упоминаемый в этом посте массив данных CoNLL 2003 — это тестовый набор Reuters-21578, Distribution 1.0, доступный для скачивания на странице проекта исходного эксперимента 2003 года: https://www.clips.uantwerpen.be/conll2003/ner/.
Введение
Машинное обучение — это технологический прорыв, случающийся раз в поколение. Однако с ростом его популярности основной проблемой становятся систематические ошибки алгоритма. Если модели ML не обучаются на репрезентативных данных, у них могут развиться серьёзные систематические ошибки, оказывающие существенный вред недостаточно представленным группам и приводящие к созданию неэффективных продуктов. Мы изучили массив данных CoNLL-2003, являющийся стандартом для создания алгоритмов распознавания именованных сущностей в тексте, и выяснили, что в данных присутствует серьёзный перекос в сторону мужских имён. При помощи наших технологии мы смогли компенсировать эту систематическую ошибку:
- Мы обогатили данные, чтобы выявить сокрытые систематические ошибки
- Дополнили массив данных недостаточно представленными примерами, чтобы компенсировать гендерный перекос
Модель, обученная на нашем расширенном массиве данных CoNLL-2003, характеризуется снижением систематической ошибки и повышенной точностью, и это показывает, что систематическую ошибку можно устранить без каких-либо изменений в модели. Мы выложили в open source наши аннотации Named Entity Recognition для исходного массива данных CoNLL-2003, а также его улучшенную версию, скачать их можно здесь.
Систематическая ошибка алгоритма: слабое место ИИ
Сегодня тысячи инженеров и исследователей создают системы, самостоятельно обучающиеся тому, как достигать существенных прорывов — повышать безопасность на дорогах при помощи беспилотных автомобилей, лечить болезни оптимизированными ИИ процедурами, бороться с изменением климата при помощи управления энергопотреблением.
Однако сила самообучающихся систем является и их слабостью. Так как фундаментом всех процессов машинного обучения являются данные, обучение на несовершенных данных может привести к искажённым результатам.
ИИ-системы имеют большие полномочия, поэтому они могут наносить существенный ущерб. Недавние протесты против полицейской жестокости, приведшей к смертям Джорджа Флойда, Бреонны Тейлор, Филандо Кастиле, Сандры Блэнд и многих других, является важным напоминанием о систематическом неравенстве в нашем обществе, которое не должны усугублять ИИ-системы. Но нам известны многочисленные примеры (закрепляющие гендерные стереотипы результаты поиска картинок, дискриминация чёрных подсудимых в системах управления данными нарушителей и ошибочная идентификация цветных людей системами распознавания лиц), показывающие, что предстоит пройти долгий путь, прежде чем проблема систематических ошибок ИИ будет решена.
Распространённость ошибок вызвана лёгкостью их внесения. Например, они проникают в «золотые стандарты» моделей и массивов данных в open source, ставшие фундаментом огромного объёма работы в сфере ML. Массив данных для определения эмоционального настроя текста word2vec, используемый в построении моделей других языков, искажён по этнической принадлежности, а word embeddings — способ сопоставления слов и значений алгоритмом ML — содержит сильно искажённые допущения о занятиях, с которыми ассоциируются женщины.
Проблема (и, как минимум, часть её решения) лежит в данных. Чтобы проиллюстрировать это, мы провели эксперимент с одним из самых популярных массивов данных для построения систем распознавания именованных сущностей в тексте: CoNLL-2003.
Что такое «распознавание именованных сущностей»?
Распознавание именованных сущностей (Named-Entity Recognition, NER) — один из фундаментальных камней моделей естественных языков, без него были бы невозможны онлайн-поиск, извлечение информации и анализ эмоционального настроя текста.
Миссия нашей компании заключается в ускорении разработки ИИ. Естественный язык — одна из основных сфер наших интересов. Наш продукт Scale Text содержит NER, заключающееся в аннотировании текста согласно заданному списку меток. На практике, среди прочего, это может помочь крупным розничным сетям анализировать онлайн-обсуждение их продуктов.
Многие модели NER обучаются и подвергаются бенчмаркам на CoNLL-2003 — массиве данных из примерно 20 тысяч предложений новостных статей Reuters, аннотированных такими атрибутами, как «PERSON», «LOCATION» и «ORGANIZATION».
Нам захотелось изучить эти данные на наличие систематических ошибок. Для этого мы воспользовались своим конвейером разметки, чтобы категоризировать все имена в массиве данных, размечая их как мужские, женские или гендерно-нейтральные, исходя из традиционного использования имён.
При этом мы выявили существенную разницу. Мужские имена упоминались почти в пять раз чаще женских, и менее 2% имён были гендерно-нейтральными:
Это вызвано тем, что по социальным причинам новостные статьи в основном содержат мужские имена. Однако из-за этого модель NER, обученная на таких данных, лучше будет справляться с выбором мужских имён, чем женских. Например, поисковые движки используют модели NER для классификации имён в поисковых запросах, чтобы выдавать более точные результаты. Но если внедрить модель NER с перекосом, то поисковый движок хуже будет идентифицировать женские имена по сравнению с мужскими, и именно подобная малозаметная распространённая систематическая ошибка может проникнуть во многие системы реального мира.
Новый эксперимент по снижению систематической ошибки
Чтобы проиллюстрировать это, мы обучили модель NER для изучения того, как этот гендерный перекос повлияет на её точность. Был создан алгоритм извлечения имён, выбирающий метки PERSON при помощи популярной NLP-библиотеки spaCy, и на подмножестве данных CoNLL была обучена модель. Затем мы протестировали модель на новых именах из тестовых данных, не присутствовавших в данных обучения, и обнаружили, что модель с вероятностью на 5% больше пропустит новое женское имя, чем новое мужское имя, а это серьёзное расхождение в точности:
Мы наблюдали схожие результаты, когда применили модель к шаблону «NAME is a person», подставив 100 самых популярных мужских и женских имён на каждый год переписи населения США. Результаты работы модели оказались значительно хуже для женских имён во все года переписи:
Критически важно то, что наличие перекоса в данных обучения приводит к смещению ошибок в сторону недостаточно представленных категорий. Эксперимент с переписями демонстрирует это и другим образом: точность модели существенно деградирует после 1997 года (точки отсечения статей Reuters в массиве данных CoNLL), потому что массив данных больше не является репрезентативным отображением популярности имён каждого последующего года.
Модели обучаются соответствовать трендам данных, на которых они обучены. Нельзя ожидать их хорошей точности в случаях, когда они видели лишь малое количество примеров.
Если вы исправляете систематическую ошибку модели, то уже слишком поздно
Как же это исправить?
Один из способов — попробовать устранить систематическую ошибку модели, например, выполнив постобработку модели или добавив целевую функцию для смягчения перекоса, оставив определение подробностей самой модели.
Но это не лучший подход по множеству причин:
- Справедливость — это очень сложная проблема, и мы не можем ждать, что алгоритм решит её сам. Исследование показало, что обучение алгоритма на одинаковый уровень точности для всех подмножеств населения не обеспечит справедливости и нанесёт вред обучению модели.
- Добавление новых целевых функций может навредить точности модели, приводя к негативному побочному эффекту. Вместо этого лучше обеспечить простоту алгоритма и сбалансированность данных, что повысит точность модели и позволит избежать негативных эффектов.
- Неразумно ожидать, что модель покажет хорошие результаты в случаях, примеров которых она видела очень мало. Наилучший способ обеспечения хороших результатов заключается в повышении разнообразия данных.
- Попытки устранения систематической ошибки при помощи инженерных техник — это дорогой и длительный процесс. Гораздо дешевле и проще изначально обучать модели на данных без перекосов, освободив ресурсы инженеров для работы над реализацией.
Данные — это лишь одна часть проблемы систематических ошибок. Однако эта часть фундаментальна и влияет на всё, что идёт после неё. Именно поэтому мы считаем, что данные содержат ключ к частичному решению, обеспечивая потенциальные систематические улучшения в исходных материалах. Если вы не размечаете критические классы (например, гендер или этническую принадлежность) явным образом, то невозможно сделать так, чтобы эти классы не были источником систематической ошибки.
Такая ситуация контринтуитивна. Кажется, что если нам нужно построить модель, не зависящую от чувствительных характеристик наподобие гендера, возраста или этнической принадлежности, то лучше исключить эти свойства из данных обучения, чтобы модель не могла их учитывать.
Однако принцип «справедливости, реализуемой через неведение» на самом деле усугубляет проблему. Модели ML превосходно справляются с выводом заключений из признаков, они не прекращают делать этого, если мы не разметили эти признаки явным образом. Систематические ошибки просто остаются невыявленными, из-за чего их сложнее устранить.
Единственный надёжный способ решения проблемы заключается в разметке большего количества данных, чтобы сбалансировать распределение имён. Мы использовали отдельную модель ML для идентификации предложений в корпусах Reuters и Brown, с большой вероятностью содержащих женские имена, а затем разметили эти предложения в нашем конвейере NER, чтобы дополнить CoNLL.
Получившийся массив данных, который мы назвали CoNLL-Balanced, содержит на 400 с лишним больше женских имён. После повторного обучения на нём модели NER мы обнаружили, что алгоритм больше не имеет систематической ошибки, приводящей к снижению показателей при распознавании женских имён:
Кроме того, модель улучшила показатели и при распознавании мужских имён.
Это стало впечатляющей демонстрацией важности данных. Благодаря устранению перекоса в исходном материале нам не пришлось вносить никаких изменений в нашу модель ML, что позволило сэкономить на времени разработки. И мы достигли этого без негативного влияния на точность модели; на самом деле, она даже слегка увеличилась.
Чтобы позволить сообществу разработчиков развивать нашу работу и устранять гендерный перекос в моделях, построенных на основе CoNLL-2003, мы выложили на наш веб-сайте дополненный массив данных в open source, в том числе и добавив гендерную информацию.
Сообщество разработчиков ИИ/ML имеет проблемы с культурными различиями, но мы испытываем умеренный оптимизм от этих результатов. Они намекают на то, что мы, возможно, сможем предложить техническое решение насущной социальной проблемы, если займёмся проблемой сразу же, выявим сокрытые систематические ошибки и улучшим точность модели для всех.
Сейчас мы изучаем, как этот подход можно применить к ещё одному критичному атрибуту — этнической принадлежности — чтобы придумать, как создать надёжную систему для устранения перекоса в массивах данных, распространяющегося и на другие охраняемые от дискриминации категории населения.
Кроме того, это показывает, почему наша компания уделяет так много внимания качеству данных. Если нельзя доказать, что данные точны, сбалансированы и лишены систематических ошибок, то нет гарантии того, что создаваемые на их основе модели будут безопасными и точными. А без этого мы не сможем создавать качественно новых ИИ-технологий, идущих на пользу всем людям.
Благодарности
Упоминаемый в этом посте массив данных CoNLL 2003 — это тестовый набор Reuters-21578, Distribution 1.0, доступный для скачивания на странице проекта исходного эксперимента 2003 года: https://www.clips.uantwerpen.be/conll2003/ner/.
















Исключение систематических погрешностей
- Выше было подчеркнуто, что систематические ошибки могут вызвать смещение результатов измерений. Наибольшую опасность в этом отношении представляют систематические ошибки, которые остаются незамеченными, Подозреваемый. Это была не случайная ошибка, а систематическая ошибка, которая стала причиной ложных научных выводов, установления ложных физических законов и неудовлетворительного проектирования измерительных приборов и дефектных изделий. Методы устранения и учета систематических ошибок можно разделить на четыре основные группы: 1.
Устранение причины ошибок перед началом измерения (предотвращение ошибок). 2. Замена, компенсация ошибок знаком, контраст, устранение ошибок процесса измерения симметричным наблюдением (исключение ошибок экспериментом). 3. Внесение известных исправлений в результаты измерений (устранение ошибок расчета). 4. Оцените границы систематических ошибок, если они не могут быть исключены.
Пневматический прибор надежен, он оборудован с измеряя соплом малого размера, его можно установить в труднодоступные места, он может легко получить сумму и разницу сигналов.
Людмила Фирмаль
Устранение причин ошибок перед измерением Этот метод устранения систематических ошибок является наиболее разумным, поскольку он устраняет необходимость устранения ошибок в процессе измерения и расчета результатов с учетом поправок. Другими словами, устранение источника ошибок значительно упрощает и ускоряет процесс измерения. Устраняя причину ошибки, необходимо понимать как ее прямое устранение (например, удаление источника тепла), так и защиту измерительного прибора и объекта измерения от воздействия этих причин.
Причины ошибок прибора, характерные для данного экземпляра прибора, могут быть устранены во время калибровки или ремонта перед началом измерения, и необходимость устанавливается во время проверки. Таким образом, вы можете сделать вывод, что прибор должен быть проверен до начала измерения (один, серия или в течение определенного периода времени). Выполнимость вопроса ремонта или наладки определяется по результатам проверки. Причину ошибок из-за неправильной установки часто можно устранить до начала измерения. Устранить температурные эффекты.
Так называемые термостаты широко используются для предотвращения температурных ошибок. Это гарантирует определенную температуру окружающей среды с определенным допуском. Термостат большой комнаты (мастерская, лаборатория), маленькой комнаты (комната, комната), измеритель Цельные или отдельные детали (резистивные катушки, нормальные элементы, свободный конец термопары, стабилизатор частоты кристалла и т. Д.) В зависимости от жестких требований температурных условий используются разные методы контроля температуры. Прежде всего, нужно вызвать естественный термостат.
Другими словами, изоляция поддерживает определенную температуру в комнате. Примером такого термостата является часть помещения Всесоюзного ордена профсоюза Красного флага в Институте метрологии. Д. И. Ленинградский Менделеев (ВНИИМ). Эти объекты находятся в центре здания и имеют огромные капитальные стены. Вокруг них большой коридор, образованный вторым рядом капитальных стен, за которым следуют лаборатория и кабинет с самыми большими наружными стенами. Это окно имеет тройной кадр. Аккумулятор радиатора размещается вдоль наружной стены.
Благодаря устройству этого здания центральная комната поддерживается постоянной температуры. Небольшие колебания температуры происходят очень медленно. Во многих случаях подвалы используются для создания комнаты с термостатическим управлением, но это накладывает много требований (таких как недостаток влаги). Чем глубже подвал, тем ниже степень, необходимая для поддержания постоянной естественной температуры и ее искусственного поддержания. Затопление Земли также используется для небольшого контроля температуры.
По этой причине свободные концы термопар и отправная точка медных проводов от них часто размещаются в небольших коробках, расположенных на земле под полом здания. Поддержание необходимого уровня температуры, естественно, не всегда возможно. Чаще полагайтесь на искусственное поддержание температуры — нагревание или охлаждение. При наличии электрической сети нагревательное устройство не вызывает серьезных проблем. Выполнение контролируемого охлаждения намного сложнее.
Поэтому, если позволяет измерительное оборудование, выбирается стабильный уровень температуры, чтобы исключить необходимость охлаждения и использовать только нагреватели. Температура стабильна на уровне 30-40 ° С или выше. В небольших количествах используются не только воздушные термостаты, но и жидкости, которые окружают измерительное устройство или объект измерения водой, маслом или другими жидкостями. Это значительно снижает температурные колебания и облегчает поддержание постоянного уровня.
Это, вообще говоря, способы устранения несоответствия температуры между измерительным прибором и средой, окружающей объект, что является одним из наиболее опасных источников ошибок. Сегодня термостаты часто заменяются кондиционерами. Во время кондиционирования поддерживается не только температура на требуемом уровне, но и другие параметры окружающего воздуха, особенно влажность. Термостаты и кондиционеры обеспечивают отличную защиту от прямого воздействия тепла.
Однако неправильное расположение нагревателя в термостате или в помещении, контролируемом термостатом, и отсутствие устройства (такого как смеситель), которое равномерно распределяет тепло по объему, само по себе может привести к ошибкам. Во многих современных измерительных приборах источник тепла находится в корпусе. Например, потребляемая мощность многих электронных измерительных устройств может достигать 1 кВт или более. Такие устройства обычно прогреваются на некоторое время, прежде чем проводить измерения. Устранение эффектов магнитного поля.
Эффекты магнитных полей не всегда легко обнаружить. Степень влияния поля на значения измерений различных приборов также различна. Рассмотрим меры, принятые для устранения воздействия магнитных полей. Поскольку магнитное поле Земли низкое, значительный риск удара возникает только в устройствах, которые характеризуются повышенной чувствительностью. Единственным средством защиты устройства от воздействия магнитного поля Земли является устройство с закрытым непрерывным экраном из магнитомягкого материала.
Линии магнитного поля перемещаются вокруг экранированного пространства, а небольшие зазоры в магнитной цепи экрана (неточная подгонка соединений компонентов) могут значительно снизить эффективность экрана. В настоящее время экран от воздействия магнитного поля Земли и экран от магнитного поля, образованного постоянным током и переменным током, распространяются. Этому способствовало изобретение магнитомягких сплавов (таких как пермаллой) с большой начальной проницаемостью и низкой коэрцитивной силой.
Устройства с магнитным экранированием имеют нежелательные явления даже при использовании пермаллоя. Если вы измените конфигурацию линий внешнего магнитного поля, экран также повлияет на конфигурацию линии внутреннего ( действия ) магнитного поля и, в некоторых случаях, на показания прибора. Помните, что экран не идеален и внешнее магнитное поле может воздействовать на экранированное измерительное устройство. Стандарты (такие как ГОСТ 1845-59) установили различные категории защиты от воздействия внешних магнитных полей. Экранирование от высокочастотных электромагнитных полей немного проще.
В этом случае возможно и наиболее целесообразно использовать материалы с высокой проводимостью. Этот эффект достигается вихревыми токами и создаваемым ими обратным электромагнитным полем. Кроме того, такие экраны защищают механизм от электрических полей. Удалить вредные вибрации и тремор. Эти эффекты устраняются амортизацией инструмента и его компонентов. В зависимости от частоты этих вибраций и чувствительности прибора к этим воздействиям для амортизации используются различные типы поглотителей вибрации.
Например, Оттепель резиновая в сочетании с различными видами упругих подвесок (струны, пружины) Устранение других видов вредных воздействий. Влияние таких факторов, как изменение атмосферного давления простыми средствами, не может быть исключено. Если соблюдение определенных требований является обязательным, следует использовать камеру давления с регулируемым давлением. Как правило, эти камеры могут контролировать влажность и температуру одновременно. Регулировка давления в помещении во время кондиционирования требует принудительной герметизации помещения, что делает установку очень сложной.
Устранить систематические ошибки в процессе измерения Устранение систематических ошибок в процессе измерения является эффективным способом устранения многих вредных воздействий. Нет необходимости в специальных установках или устройствах. Как правило, эти или их методы измерения могут не только устранить ошибки, возникающие в результате воздействия, но и оценить их степень. Исключением из этого метода являются в основном ошибки оборудования, ошибки установки и ошибки от внешних воздействий.
Некоторые постоянные ошибки субъективного характера могут быть устранены только в процессе измерения путем повторных измерений несколькими людьми. Особенности метода устранения ошибок процесса измерения, рассмотренные ниже, в основном применяются к измерению стабильных параметров и являются ленивыми, потому что он требует повторных измерений. Метод замены. Это один из самых распространенных способов устранения ошибок. Дело в том, что измеряемый объект заменяется известной мерой. Это в то же время это было в то же время Я сам.
Давайте рассмотрим некоторые из наиболее типичных примеров использования альтернативных методов. Точное взвешивание часто выполняется с использованием следующего жирного метода: Поместите взвешенную массу на одну чашу весов. Весы уравновешиваются путем применения другой нагрузки (негигроскопичной, неиспаряющейся и т. Д.), Например, некоторой нагрузки, которая не изменяется во время измерения. Когда равновесие достигнуто, взвешенная масса удаляется, и вес помещается на место до достижения равновесия.
Общий вес весов, необходимый для восстановления равновесия, соответствует значению взвешенного веса. Поэтому можно сделать исключение из результатов взвешивания ошибок, вызванных неоднородностями баланса. Этот метод был усовершенствован Д. И. Менделеевым. Все взвешивания прикреплены к чаше весов для взвешивания, а весы уравновешены любой нагрузкой. Затем поместите груз на чашку, в которую он был помещен, и удалите часть веса, чтобы восстановить равновесие. Общая масса полученных весов соответствует значению взвешенной массы.
Этот вариант метода замены не только устраняет ошибки из несбалансированного баланса, но также сохраняет неизменной чувствительность при взвешивании различных масс. Степень чувствительности рычажной шкалы зависит от нагрузки. В результате только одна нагрузка может обеспечить постоянную чувствительность. В настоящее время лабораторные весы, построенные по этому принципу, производятся в Советском Союзе и за рубежом и используются для снятия гирь с помощью рычага с внешним управлением и для подсчета значения массы взятых гирь.
Он оснащен. Методы замены широко используются при измерении электрических параметров — сопротивления, емкости и индуктивности. Процедура измерения в основном такая же, как и во время взвешивания. Объект, электрическое сопротивление, индуктивность или емкость которого подлежат измерению, содержится в той или иной измерительной цепи. В большинстве случаев метод нулевого баланса (мост, компенсация и т. Д.) Используется для выполнения электрического баланса цепи. После балансировки переменные значения измерения включаются вместо объекта измерения без изменения схемы.
Сопротивление накопителя, емкость, индуктивность. Переменный конденсатор или индуктивность. Изменяя свою стоимость, они достигают восстановления цепного равновесия. В этом случае метод замены устраняет остаточные дисбалансы в мостовой схеме, влияние магнитных и электрических полей на цепь, взаимное влияние отдельных элементов цепи, а также утечки и другие паразитные явления. Другим примером является определение характеристик источника света путем сравнения его со стандартной лампой накаливания с использованием фотометра.
Фотометр наблюдает за двумя смежными белыми полями (визуально или с использованием фотоэлементов), одно из которых освещается исследуемым источником света, а другое освещается так называемой лампой сравнения. Отрегулируйте оба поля, чтобы иметь одинаковое освещение. Затем вместо исследуемого источника света будет установлена примерная лампа, и будет достигнуто равномерное восстановление освещенности обоих полей фотометра без изменения настройки лампы сравнения. В этом случае альтернативный способ исключает влияние изменения степени поглощения света в обоих оптических каналах фотометра.
Приведенный выше пример не исчерпывает возможности использования метода замещения для устранения многих ошибок, возникающих во время измерения. Метод исправления знаковых ошибок. Способ устранения этой ошибки состоит в том, что измерение выполняется дважды. Поэтому ошибка, которая изначально неизвестна по размеру, включена в результат с обратным знаком. Ошибки исключаются при расчете среднего значения.
В алгебраической форме это может быть выражено как: Пусть X1 и x2 — результаты двух измерений. A — Систематическая ошибка, природа которой известна. Важность неизвестна. Ся — это безошибочное значение измерения. тогда X1 = xl + b Xa = xd-A. Среднее значение — = * + * = (Xd + D) + (x, -D) X 2 2 Чтобы повысить точность результата и оценить его уровень, выполняется серия повторных измерений, и все ошибки с положительным знаком равны одинаковому количеству отрицательных ошибок, чтобы устранить указанную ошибку. Так что должно быть выполнено четное количество измерений. Этот метод ограничен.
Используется для исключения только тех ошибок, в которых источник имеет указанное действие. Типичным примером компенсации является устранение ошибок, вызванных воздействием магнитного поля Земли. Этот метод применяется. Известно (или предполагается), что показания могут быть подвержены ошибкам под воздействием магнитного поля Земли при использовании приборов для измерений. (VI. ) Первое измерение может быть выполнено, когда прибор находится в любом положении.
Перед выполнением второго измерения поверните прибор на 180 ° в горизонтальной плоскости. В первом случае магнитное поле Земли, добавленное к магнитному полю прибора, вызывает положительную ошибку, и если оно поворачивается на 180 °, магнитное поле Земли оказывает противоположный эффект, вызывая отрицательную ошибку, равную начальной величине. Дальнейшее внимание может быть уделено применению метода для исправления ошибки знака, чтобы устранить ошибки, вызванные воздействием магнитных полей различного происхождения. Имейте в виду, что поле от источника неоднородно, даже если не очень близко.
- Часть измерительного прибора, которая воздействует на магнитное поле, может быть размещена в другом месте. Ошибка, вызванная влиянием магнитного поля, в этом случае меняет не только знак, но и размер. Кроме того, внешнее магнитное поле может меняться со временем. Описанный метод, безусловно, полезен для обнаружения воздействия магнитных полей на измерительный прибор. Повторяя его, вы также можете проверить, являются ли эти эффекты постоянными и стабильными.
Использование метода, который исправляет ошибки знака, устраняет ошибки, вызванные явлениями гистерезиса (такими как магнитный гистерезис в ферромагнитных материалах и механический гистерезис в упругих материалах). Контрастный метод. Этот метод очень похож на исправление ошибок знака. Это связано с тем, что, поскольку измерение выполняется дважды, причина первой ошибки измерения будет отрицательно влиять на результат второго измерения. Примером является взвешивание равновесного равновесия (метод, предложенный Гауссом для устранения ошибок из-за остаточной неравномерности).
Единицей светового потока является люмен, равный световому потоку, излучаемому точечным источником под твердым углом 1 СР со светимостью 1 кд.
Людмила Фирмаль
При первом взвешивании масса x, помещенная в одну чашку весов, уравновешивается весом общей массы pi, помещенной в другую чашку. тогда Где 1g 11 — фактическое соотношение плеч. Взвешенная масса затем переносится в чашку, в которую помещается вес, и масса переносится в чашку, где размещается вес. Поскольку отношение плеч 4 A не совсем равно 1, баланс нарушается, и для баланса массы x необходимо использовать общую массу вес Ig. (U1.3) Разделив уравнение (V1.2) на уравнение (V1.3), получаем x = Или ГП и если немного отличается друг от друга Это уравнение и уравнение (U1.1) совпадают.
Однако уравнение (U1.1), полученное путем исправления ошибки со знаком, точно отражает суть исключения ошибки. В этом случае формула является приблизительной. Сравнивая оба метода с формулой, вы можете увидеть, что метод исправления ошибок включает в себя ошибку, которая удаляется как термин (алгебраически), а не как коэффициент. Особенностью противоположного метода является то, что фактическая пропорция плеча может быть определена.
Следовательно, умножение уравнений (VI.2) и (Y1.3) в примере взвешивания по Гауссу дает: Основной областью применения метода оппозиции является устранение ошибок при сравнении измерений с измерениями примерно равных значений. Методы контрастирования используются, например, в равновеликих мостах для измерения параметров электрических цепей, главным образом при измерении электрического сопротивления постоянному току. Пример. Сопротивление x измеряется с использованием равного плеча моста, где каждый рычаг r2 и r3 (см. Гл. X на рисунке 34) равен 1000 Ом.
Мостовое равновесие было достигнуто при r = 1000,4 Ом. После изменения положения x и r равновесие достигалось при Г1 = 1000.2 Ом. x-D-4 + 2 a1 , 3 Ом. Определите фактическую пропорцию плеча 1000.4-1000.2 = г, 2 1000, 2 Симметричный метод наблюдения. Симметричные методы наблюдения используются для устранения прогрессивных ошибок, которые являются линейными функциями времени (или другой величины). Такую функцию можно нарисовать в виде графика (рисунок 14).
Время нанесено на абсциссу, В зависимости от прогрессивной ошибки и характеристик измерительного прибора, прогрессивная ошибка может увеличиваться с момента первого измерения. После этого это происходит по всем вторым, третьим и последующим измерениям. Уже включает прогрессив Греховность. Симметричные методы наблюдения состоят в том, что измерения производятся непрерывно через равные промежутки времени. При обработке используйте свойства результата любых двух наблюдений. Симметричная относительная средняя точка интервала наблюдения.
Это свойство Ошибка, полученная в результате пары симметричных наблюдений, равна ошибке, соответствующей средней точке интервала. Например, было проведено 5 измерений. Началось в то время, когда ошибка была T1 1 (см. Рисунок 14). Легко показать, что = ^ y- * = m. Количество измерений Может быть. тогда ch-n x + 14 2 2 2 Три измерения (минимальное количество измерений) и нулевая начальная ошибка упрощают расчет. Если начальная неоднородность постепенно увеличивается, рассмотрим пример применения симметричного метода наблюдения при взвешивании по методу Боде (метод замещения).
Четыре взвешивания выполняются. 1. Взвешенная масса x уравновешена массой g. Предположим, что это соответствует точке А согласно расписанию (см. Рисунок 13). Где 12 11 — коэффициент плеча этих весов, когда на них не влияет причина прогрессивной ошибки. 2. Удалите массу x и уравновесите массу g и массу (их общая масса обозначена I1). Происходит во время 2 = + ч) г- 3. Балансировка повторяется таким образом, чтобы значение веса балансировочного веса считалось равным 1z, когда ошибка достигает значения tz. В результате общая масса t2, которая уравновешивает массу g, изменяется.
Удалите ожоги и поместите взвешенную массу * в чашку. Поскольку неравномерность изменилась и ошибка достигла m4 к времени 4, одна из чашек должна добавить некоторую массу в виде веса для достижения равновесия. Знак плюс перед m указывает, что эта масса добавлена в чашку с массой x, и что знак минус добавлен в чашку с массой r.
Среднее из первого и четвертого измерений (U1.4) Для второго и третьего взвешивания t1 + t, H-NZH, 2 и 2 на (U1.5) Поскольку средняя ошибка результата пары симметричных измерений равна друг другу, h + t4 g, + -s3 2 2 Правые части равенства (U1.4) и (U1.5) также равны. В результате левая часть этих уравнений также равна (U1.6) Оказывается, исключаются не только прогрессивные ошибки из-за изменений неравенства, но также некоторые ошибки из неравенства ( hM).
Как уже указывалось, одной из причин прогрессирующей ошибки в электрических измерениях является постепенное падение напряжения батареи или батареи, питающей схему измерения. Рисунок 15. Схема потенциометра постоянного тока Рассмотрим пример устранения прогрессивной погрешности потенциометра постоянного тока из падения напряжения батареи B (Рисунок 15). Сделайте три измерения. Сначала включите гальванометр G в цепь ЭДС.
Регулировка сопротивления r нормального элемента (переключатель 7 в положении 7) уравновешивает падение напряжения и падение напряжения на сопротивлении образца напряжением от рабочего тока I. Медленное снижение рабочего тока по, Затем поверните переключатель P в положение 2, чтобы отрегулировать сопротивление Ex и измерить требуемое напряжение Ex. Повторите первое измерение здесь. Из-за постепенной ошибки достигается равновесие с новыми значениями рабочего тока и модельного сопротивления E.
Принимая это во внимание, после соответствующего преобразования получите значение Ex без какой-либо прогрессивной ошибки. + Если не ясно, есть ли прогрессивная ошибка, рекомендуется использовать симметричный метод наблюдения. Многие измерения, выполненные в порядке, показанном в сочетании с каким-либо методом для исключения определенных ошибок, могут выявить и устранить любые прогрессивные ошибки. Известная коррекция результатов измерений Результат измерения корректируется расчетом.
Наиболее распространенным случаем коррекции является алгебраическое сложение результатов измерений и коррекций (с учетом их знака). Числовая поправка равна систематической ошибке, а знак противоположен. В других случаях ошибка устраняется путем умножения результата измерения на поправочный коэффициент. Поправочный коэффициент может быть немного больше или меньше 1. Только когда коррекция мала по сравнению с измеренным значением или когда поправочный коэффициент близок к 1, может быть рассчитана высокая точность результата коррекции.
Предположим, что поправочный коэффициент включает одно и два десятичных знака, причем первая цифра равна нулю. Первый десятичный знак (1,1) соответствует 10% -ной ошибке, и такая большая ошибка встречается редко. Поэтому поправочный коэффициент часто составляет 1,01. 1,02; 1,03 литра и т. Д. Чтобы умножить такое число на результат измерения, умножьте на 1 100, переместите запятую на два символа влево и добавьте ее к значению результата. Например, показание прибора составляет 85, а поправочный коэффициент равен 1,02. Одна половина 85 — 1,70.
Скорректированный результат измерения составляет 85 + 1,7 = 86,7. Этот прием также следует использовать, когда поправочный коэффициент меньше 1. Например, 0,96 = 1-0,04 поправочный коэффициент. Чтобы умножить показания устройства на него, вам нужно получить 4 100 устройства. 85 0,96 = 85 (1-0,04) = 85-3,4 = 81,6. Во многих случаях показания прибора должны быть умножены на коэффициент, называемый преобразованием (2; 2,5; 3; 5; 10; 20 и т. Д.). Не объединяйте поправочный коэффициент с коэффициентом пересчета, потому что это усложняет вычисление результатов измерения. Числовой пример.
В результате комбинации был получен коэффициент 2,88. Трудно умножить это число на число в вашем уме. Если вы используете каждый фактор отдельно, умножение не вызовет проблем. Множитель 2,88 является результатом умножения коэффициента преобразования 3 на поправочный коэффициент 0,96. Значение считывания измерительного устройства составляет 115. тогда 115-0,96 = 115 (1-0,04) = 115-4,6 = 110,4; 110.4-3 = 331.2 (как вы знаете, порядок умножения на коэффициенты не играет роли).
В отличие от поправок, поправочные коэффициенты используются, когда погрешность пропорциональна показаниям прибора в определенном диапазоне измерений. В некоторых случаях удобнее указывать фактический размер каждого номинального размера (или дисплея прибора), то есть размер, для которого коррекция уже была введена. Этот модифицированный метод учета в основном используется в качестве контрмеры. Преимущество особенно заметно при применении ряда мер. Фактический размер комплекта, составленного В процессе измерения получается суммирование фактических размеров мер, входящих в комплект.
Сумма этих размеров немного сложнее, чем номинальный размер, но обычно компенсируется номинальным размером. Поскольку операция добавления исключена, результат коррекции быстрее. Кроме того, уменьшается вероятность ошибок расчета. Может указывать фактический размер и ошибку. В этом нет необходимости, поскольку вы можете более уверенно определять признаки коррекции.
Чтобы исправить результаты измерений любым из описанных методов, вы должны сначала определить эти поправки. Чтобы исключить ошибки метода, необходимо знать параметры прибора, который может рассчитать коррекцию результата измерения (если он может быть рассчитан) справочная формула (U1.5) Пример. В случае измерения сопротивления x согласно схеме, показанной на рисунке 10b, были получены следующие измеренные значения амперметра и вольтметра.
Исправьте сопротивление амперметра. Это 0,2 Ом. Фактическое значение сопротивления xd = 2,5-0,2 = = 2,3 Ом. Как правило, ошибки измерительного прибора и другие данные и зависимости, необходимые для определения и создания поправок, идентифицируются до измерения. Однако это можно определить после измерения, но это не следует считать неправильным. В качестве примера мы можем сослаться на точное определение времени на основе астрономических наблюдений и измерений. Коррекция в этом случае определяется после измерения.
Оценка границ систематической ошибки В некоторых случаях систематическое устранение ошибок практически невозможно. Прежде всего, речь идет о методе измерения, и его систематическая ошибка не совсем понятна. Кроме того, существует большая группа приборов, для которых систематические ошибки были изучены и могут быть измерены и определены, но не могут быть использованы для корректировки результатов измерений. Это интегрированная группа инструментов, чаще всего называемая счетчиками.
Скорее, показания счетчиков могут корректироваться только в очень ограниченных случаях, которые не характерны для их применения и предполагаемых условий. Давайте проанализируем вышеупомянутые детали на примере счетчика электрической энергии (обычно называемого электрическим счетчиком). Как правило, угловая скорость каждого встречного диска Текущий момент пропорционален потребляемой мощности. На практике, однако, он не строго пропорционален мощности, и, как следствие, существуют разные нагрузки , то есть разные систематические ошибки для разных мощностей.
На рисунке 13 показана зависимость погрешности счетчика от потребляемой мощности, выраженная в процентах от номинальной мощности (соответствует номинальным значениям тока и напряжения). Каждое значение мощности соответствует определенной ошибке. Однако эти ошибки можно использовать для исправления индикации только в том случае, если значение мощности не изменилось в течение всего процесса измерения. Если измерения с использованием счетчика выполняются с переменными значениями мощности, это очень сложно и в большинстве случаев невозможно рассчитать поправку.
Если систематические ошибки не могут быть исключены (даже если они известны, как в примере выше), оценить возможные границы систематических ошибок. Ошибки счетчика иногда считаются случайными, потому что причина их появления неизвестна, но это не так, потому что каждой величине энергопотребления соответствует конкретная ошибка. Потребляемая мощность не является случайной величиной, а зависит от режима работы электрического устройства, потребляющего энергию. В большинстве случаев ошибка измерения энергии счетчика меньше максимальной ошибки.
Эта ошибка является наибольшей только тогда, когда режим энергопотребления всегда одинаков и ошибка соответствует наиболее важному моменту (см. Рисунок 12). Этот случай маловероятен. При изменении нагрузки признаки ошибок могут меняться, что приводит к частичной компенсации в целом. Поэтому нет способа определить результирующую ошибку, и необходимо внести исправление. Обратите внимание, что если погрешность измерительной системы не превышает ± 2%, ошибка измерения энергии в конечном итоге составит менее 2%.
То, что было сказано об электрических счетчиках, также можно отнести к другим встроенным измерительным приборам и измерениям, проводимым с их помощью. Повторим еще раз: при разработке новых методов измерения и новых инструментов необходимо выявить и исследовать все возможные систематические ошибки.
Смотрите также:
Решение задач по метрологии
