
Мы уже рассказывали, как машинное обучение применяется для прогнозирования будущих событий в финансовом секторе, нефтегазовой промышленности, логистике, HR-менеджменте, девелопменте, страховании, муниципальном управлении, маркетинге, ритейле и других отраслях экономики. Сегодня рассмотрим еще несколько практических примеров такого приложения Machine Learning и в этом контексте разберем одно из ключевых понятий Data Science по оценке моделей. Читайте в нашей статье, что такое матрица ошибок (confusion matrix) и как она помогает измерить эффективность используемых ML-алгоритмов и других инструментов бизнес-аналитики, оценив потенциальные убытки и выгоды от возможных сценариев будущего в задаче прогнозирования спроса.
От ритейла до банка: 5 примеров применения Big Data и Machine Learning в задачах прогнозирования спроса и предложения
Вообще сегодня задача прогнозирования спроса стала довольно обыденным приложением методов Machine Learning (ML) в реальном бизнесе. В частности, в декабре 2019 года сервис объявлений «Юла» ускорил публикацию объявлений по продаже товаров с помощью функции их распознавания по фотографии. Помимо собственно распознавания того, что сфотографировано, нейросетевые модели предлагают пользователю уточнить характеристики продукта и оценивают его стоимость в среднем по рынку. При этом пользователю выдается прогноз, насколько быстро он продаст товар при различных ценах [1].
Другой пример, московский сервис приготовления и доставки еды навынос «Кухня на районе» с помощью нейросетей и ежедневной статистики продаж рассчитывает, сколько продуктов нужно привезти на каждую точку, чтобы минимизировать количество остатков. Анализируя данные по проданным позициям в разных локациях, нейросеть из 3 500 вариантов отбирает сотню блюд, которые будут максимально востребованы, чтобы готовить именно их на районных кухнях в течение следующей недели [2].
Подобным образом, на основе постоянного анализа продаж, машинное обучение позволяет эффективно решить задачу ценообразования, установив наиболее оптимальную стоимость на отдельные продукты и целые товарные категории. Например, именно это было сделано в отечественном интернет-магазине детских игрушек Babadu.ru, когда методы Machine Learning помогли разработать несколько маркетинговых стратегий, наиболее выгодных для ритейлера [3]. Аналогично строятся ML-модели эластичного спроса в другом российском гиганте интернет-торговли, Ozon.ru. Разработанный алгоритм анализирует значения более 150 признаков в истории продаж, чтобы на выходе предоставить точный прогноз по будущим заказам. При этом в модели заложена функция минимизации денежных потерь на покупку и хранение лишних товаров на складе или отток клиента (Churn Rate) из-за отсутствия нужного продукта [4].
Похожая задача прогнозирования спроса актуальна и для банков, которые стремятся оптимизировать процессы работы с наличными деньгами в своих банкоматах. Финансовые корпорации хотят, с одной стороны, чтобы средства не лежали в банкоматах «без дела»: гораздо выгоднее, например, разместить их на краткосрочном депозите. Но, клиенты будут недовольны, когда столкнутся с отказом из-за недостаточного количества денег в банкомате. Это грозит репутационными потерями, поэтому банк стремится решить данную проблему с помощью точного предсказания спроса на наличность в каждой точке расположения банкоматов. При этом нужно учитывать, что спрос на наличные зависит от множества параметров: макроэкономические факторы, политические новости, социальные события, расположение банкомата, прогноз погоды, время года, день недели и т.д. Чтобы предсказать завтрашнюю потребность в наличных для конкретного банкомата, Сбербанк, например, с 2016 года использует адаптивные алгоритмы машинного обучения вместе с классическими методами анализа временных рядов. Такие модели обеспечивают динамическое перестроение всех анализируемых параметров, предоставляя на выходе эффективный план оптимального распределения и перемещения наличных между банкоматами [5].
Машинное обучение на Python
Код курса
PYML
Ближайшая дата курса
19 июня, 2023
Длительность обучения
24 ак.часов
Стоимость обучения
49 500 руб.
Что такое матрица ошибок и зачем она нужна: пример расчета стоимости ошибки прогнозирования
Поскольку в бизнесе поиск баланса между спросом и предложением напрямую конвертируется в деньги, возникает вопрос, насколько выгодно применение методов Machine Learning для решения этой задачи. С целью сопоставления предсказаний и реальности в Data Science используется матрица ошибок (confusion matrix) – таблица с 4 различными комбинациями прогнозируемых и фактических значений. Прогнозируемые значения описываются как положительные и отрицательные, а фактические – как истинные и ложные [6]. Вообще матрица ошибок используется для оценки точности моделей в задачах классификации. Но прогнозирование и распознавание образов можно рассматривать как частный случай этой проблемы, поэтому confusion matrix актуальна и для измерения точности предсказаний. Важно, что матрица ошибок позволяет оценить эффективность прогноза не только в качественном, но и в количественном выражении, т.е. измерить стоимость ошибки в деньгах. Например, каковы будут расходы на удержание пользователя, если машинное обучение предсказало, что он перестанет приносить компании пользу [7]? Аналогичный вопрос по предсказанию оттока (Churn Rate) актуален и в HR-сфере для удержания ключевых сотрудников, мотивация которых снижается. Впрочем, матрица ошибок может использоваться не только в рамках применения Machine Learning. По сути, этот метод оценки стоимости прогноза является универсальным аналитическим инструментом.
|
Прогноз |
Реальность |
|
|
+ |
— |
|
|
+ |
True Positive (истинно-положительное решение): прогноз совпал с реальностью, результат положительный произошел, как и было предсказано ML-моделью |
False Positive (ложноположительное решение): ошибка 1-го рода, ML-модель предсказала положительный результат, а на самом деле он отрицательный |
|
— |
False Negative (ложноотрицательное решение): ошибка 2-го рода – ML-модель предсказала отрицательный результат, но на самом деле он положительный |
True Negative (истинно-отрицательное решение): результат отрицательный, ML-прогноз совпал с реальностью |

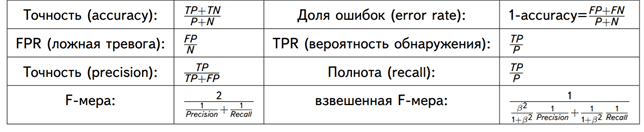
С математической точки зрения оценить точность ML-модели можно с помощью следующих метрик [8]:
- Точность – сколько всего результатов было предсказано верно;
- Доля ошибок;
- Полнота – сколько истинных результатов было предсказано верно;
- F-мера, которая позволяет сравнить 2 модели, одновременно оценив полноту и точность. Здесь используется среднее гармоническое вместо среднего арифметического, сглаживая расчеты за счет исключения экстремальных значений.
В количественном выражении это будет выглядеть так:
- P – число истинных результатов, P = TP + FN;
- N – число ложных результатов, N = TN + FP.
Рассмотрим матрицу ошибок на практическом примере для задачи прогнозирования спроса на скоропортящуюся продукцию, которая должна быть продана конечному пользователю в течение суток. Например, букеты цветов, продающиеся по цене k рублей при закупочной стоимости в p рублей. Предположим, с помощью Machine Learning было предложена 2 варианта:
- Положительный прогноз (+), что по цене k будут полностью раскуплены все цветы в количестве n букетов.
- Отрицательный прогноз (+), что по цене k будут полностью раскуплены не все цветы, останется m не проданных букетов.
Соответственно, матрица ошибок для этого случая будет выглядеть следующим образом:
|
Прогноз |
Реальность |
|
|
Проданы все букеты цветов |
Остались не проданные m букетов |
|
|
+: Проданы все n букетов по k рублей c ценой закупки p |
True Positive: прогноз совпал с реальностью, все закупленные n букетов проданы Выручка = n*k Затраты = n*p Прибыль = n*(k-p) Стоимость ошибки = 0 |
False Positive: ошибка 1-го рода, ML-модель предсказала, что будет n продаж, а на самом деле их было (n-m), осталось m не проданных букетов, которые пропали и не вернули затраты на их покупку Выручка = (n-m)*k Затраты = n*p Прибыль = n*(k-p) – m*k Стоимость ошибки = m*p |
|
—: Остались не проданные m букетов c ценой закупки p |
False Negative: ошибка 2-го рода – ML-модель предсказала, что n букетов не будет продано, поэтому закупили (n-m) букетов, но спрос был на n букетов. Эффект недополученной прибыли Выручка = (n-m)*k Затраты = (n-m)*p Прибыль = (n-m)*(k-p) Стоимость ошибки = m*k |
True Negative: ML-прогноз совпал с реальностью, было раскуплено (n-m) букетов по цене k, сколько и было изначально закуплено по цене p Выручка = (n-m)*k Затраты = (n-m)*p Прибыль = (n-m)*(k-p) Стоимость ошибки = 0 |
Аналитика больших данных для руководителей
Код курса
BDAM
Ближайшая дата курса
28 июня, 2023
Длительность обучения
24 ак.часов
Стоимость обучения
66 000 руб.
Таким образом, с помощью confusion matrix можно измерить эффективность прогноза в денежном выражении, что весьма актуально для практического бизнес-приложения Machine Learning. Впрочем, отметим еще раз, что данный метод предварительной оценки будущих сценариев можно использовать и вне сферы Data Science, оценивая риски и перспективы в рамках классического бизнес-анализа.

Другие практические вопросы системного и бизнес-анализа рассматриваются в рамках нашей Школы прикладного бизнес-анализа. А особенности практического применения больших данных и машинного обучения разбираются на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- Аналитика больших данных для руководителей
- Машинное обучение на Python
Источники
- https://www.the-village.ru/village/city/news-city/371179-tseny
- https://www.the-village.ru/village/business/businessmen/371631-kuhnya-na-rayone
- https://chernobrovov.ru/articles/kak-mashinnoe-obuchenie-pomogaet-pravilno-ustanavlivat-pravilnye-ceny.html
- https://habr.com/ru/company/ozontech/blog/431950/
- http://futurebanking.ru/post/3213
- https://hranalytic.ru/kak-ponyat-matrica-nesootvetstvij-confusion-matrix/
- https://chernobrovov.ru/articles/kak-izmerit-effektivnost-machine-learning-schitaem-metriki-i-dengi-na-primere-prognozirovaniya-ottoka-polzovatelej.html
- http://www.machinelearning.ru/wiki/images/archive/5/54/20151001162720!Kitov-ML-05-Model_evaluation.pdf
Матрица ошибок – это метрика производительности классифицирующей модели Машинного обучения (ML).
Когда мы получаем данные, то после очистки и предварительной обработки, первым делом передаем их в модель и, конечно же, получаем результат в виде вероятностей. Но как мы можем измерить эффективность нашей модели? Именно здесь матрица ошибок и оказывается в центре внимания.
Матрица ошибок – это показатель успешности классификации, где классов два или более. Это таблица с 4 различными комбинациями сочетаний прогнозируемых и фактических значений.

Давайте рассмотрим значения ячеек (истинно позитивные, ошибочно позитивные, ошибочно негативные, истинно негативные) с помощью «беременной» аналогии.

Истинно позитивное предсказание (True Positive, сокр. TP)
Вы предсказали положительный результат, и женщина действительно беременна.
Истинно отрицательное предсказание (True Negative, TN)
Вы предсказали отрицательный результат, и мужчина действительно не беременен.
Ошибочно положительное предсказание (ошибка типа I, False Positive, FN)
Вы предсказали положительный результат (мужчина беременен), но на самом деле это не так.
Ошибочно отрицательное предсказание (ошибка типа II, False Negative, FN)
Вы предсказали, что женщина не беременна, но на самом деле она беременна.
Давайте разберемся в матрице ошибок с помощью арифметики.
Пример. Мы располагаем датасетом пациентов, у которых диагностируют рак. Зная верный диагноз (столбец целевой переменной «Y на самом деле»), хотим усовершенствовать диагностику с помощью модели Машинного обучения. Модель получила тренировочные данные, и на тестовой части, состоящей из 7 записей (в реальных задачах, конечно, больше) и изображенной ниже, мы оцениваем, насколько хорошо прошло обучение.

Модель сделала свои предсказания для каждого пациента и записала вероятности от 0 до 1 в столбец «Предсказанный Y». Мы округляем эти числа, приводя их к нулю или единице, с помощью порога, равного 0,6 (ниже этого значения – ноль, пациент здоров). Результаты округления попадают в столбец «Предсказанная вероятность»: например, для первой записи модель указала 0,5, что соответствует нулю. В последнем столбце мы анализируем, угадала ли модель.
Теперь, используя простейшие формулы, мы рассчитаем Отзыв (Recall), точность результата измерений (Precision), точность измерений (Accuracy), и наконец поймем разницу между этими метриками.
Отзыв
Из всех положительных значений, которые мы предсказали правильно, сколько на самом деле положительных? Подсчитаем, сколько единиц в столбце «Y на самом деле» (4), это и есть сумма TP + FN. Теперь определим с помощью «Предсказанной вероятности», сколько из них диагностировано верно (2), это и будет TP.
$$Отзыв = frac{TP}{TP + FN} = frac{2}{2 + 2} = frac{1}{2}$$
Точность результата измерений (Precision)
В этом уравнении из неизвестных только FP. Ошибочно диагностированных как больных здесь только одна запись.
$$Точностьspaceрезультатаspaceизмерений = frac{TP}{TP + FP} = frac{2}{2 + 1} = frac{2}{3}$$
Точность измерений (Accuracy)
Последнее значение, которое предстоит экстраполировать из таблицы – TN. Правильно диагностированных моделью здоровых людей здесь 2.
$$Точностьspaceизмерений = frac{TP + TN}{Всегоspaceзначений} = frac{2 + 2}{7} = frac{4}{7}$$
F-мера точности теста
Эти метрики полезны, когда помогают вычислить F-меру – конечный показатель эффективности модели.
$$F-мера = frac{2 * Отзыв * Точностьspaceизмерений}{Отзыв + Точностьspaceизмерений} = frac{2 * frac{1}{2} * frac{2}{3}}{frac{1}{2} + frac{2}{3}} = 0,56$$
Наша скромная модель угадывает лишь 56% процентов диагнозов, и такой результат, как правило, считают промежуточным и работают над улучшением точности модели.
SkLearn
С помощью замечательной библиотеки Scikit-learn мы можем мгновенно определить множество метрик, и матрица ошибок – не исключение.
from sklearn.metrics import confusion_matrix
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
confusion_matrix(y_true, y_pred)Выводом будет ряд, состоящий из трех списков:
array([[2, 0, 0],
[0, 0, 1],
[1, 0, 2]])Значения диагонали сверху вниз слева направо [2, 0, 2] – это число верно предсказанных значений.
Фото: @opeleye
Время на прочтение
7 мин
Количество просмотров 36K

Проверка знаний на собеседованиях — обычная практика. И мы сейчас не о глупых «Где вы видите себя через 5 лет?», а о нормальных вопросах по специальности. Специально к старту нового потока курса Data Scientist, в этой статье мы собрали топ-20 вопросов, которые задают дата-сайентистам, чтобы проверить их уровень знаний. Все это реальные вопросы на реальных собеседованиях в российских компаниях. Но нас попросили не упоминать названия, чтобы не давать соискателям лишнего преимущества. Некоторые вопросы простые, другие — посложнее. Не будем затягивать, поехали.
1. В чём разница между контролируемым и неконтролируемым машинным обучением?
Контролируемое машинное обучение:
-
Использует известные и маркированные данные в качестве входных.
-
Имеет механизм обратной связи.
-
Наиболее часто используемые алгоритмы контролируемого обучения — деревья решений, логистическая регрессия и метод опорных векторов.
Неконтролируемое обучение:
-
Использует немаркированные данные в качестве входных.
-
Не имеет механизма обратной связи.
-
Наиболее часто используемые алгоритмы неконтролируемого обучения — кластеризация методом k-средних, иерархическая кластеризация и априорный алгоритм.
2. Перечислите этапы построения дерева решений
-
Взять весь набор входных данных.
-
Вычислить энтропию целевой переменной, а также прогнозные атрибуты.
-
Рассчитать прирост информации по всем атрибутам (информацию о том, как отсортировать разные объекты друг от друга).
-
Выбрать атрибут с наибольшим объёмом информации в качестве корневого узла.
-
Повторить ту же процедуру для каждой ветви, пока узел решения каждой ветви не будет завершён.
3. Что такое проблемы взрывающегося и затухающего градиента?
Градиент — это вектор частных производных функции потерь по весам нейросети. Он показывает вектор наибольшего роста функции для всех весов.
В процессе обучения при обратном распространении ошибки при прохождении через слои нейронной сети в элементах градиента могут накапливаться большие значения, что будет приводить к сильным изменениям весов. Это дестабилизирует алгоритм нейросети. Эта проблема называется взрывающимся градиентом.
Аналогичная обратная проблема, в которой при прохождении ошибки через слои градиент становится меньше, называется затухающим градиентом.
Чем больше количество слоев нейросети, тем выше риски данных ошибок. Для решения сложных задач с помощью нейронных сетей необходимо уметь определять и устранять её.

4. Как рассчитать точность прогноза, используя матрицу ошибок?
В матрице ошибок есть значения для общего количества данных, истинных значений и прогнозируемых значений.

Формула точности:
Точность = (истинно положительные + истинно отрицательные) / общее количество наблюдений.
Предположим, что истинно положительных значений у нас 2981, истинно отрицательных — 110, а всего — 3311. Используя формулу, находим, что точность прогноза составляет 93,36 %.
5. Как работает ROC-кривая?
ROC-кривая — это графическое изображение контраста между показателями истинно положительных и ложноположительных результатов при различных пороговых значениях.
Если считать TPR и FPR для фиксированного порога μ є [0,1], то их можно представить в виде функций от аргумента μ:
TPR = TPR(μ), FPR = FPR(μ). При этом обе функции монотонно возрастают от 0 до 1, а значит, определена функция:
ROC(x) = TPR(FPR-1(x)), x є [0,1]
ROC-кривая — это график функции.

Как правило, у хорошего классификатора кривая лежит по большей части либо целиком выше прямой y=x. Это связано с тем что при хорошей классификации надо получать максимальный TPR при минимальном FPR.
6. Объясните алгоритм машинного обучения SVM
SVM, или метод опорных векторов, — это набор алгоритмов обучения с учителем, который используется для классификации и регрессионного анализа.
Его основная идея — построение гиперплоскости, которая разделяет объекты выборки максимально эффективным способом. Сделать это можно с помощью алгоритма линейной классификации.

7. Что такое ансамбль методов?
Ансамбль методов — это использование нескольких алгоритмов с целью получения более высокой эффективности прогнозирования, чем можно было бы получить, используя эти алгоритмы отдельно.
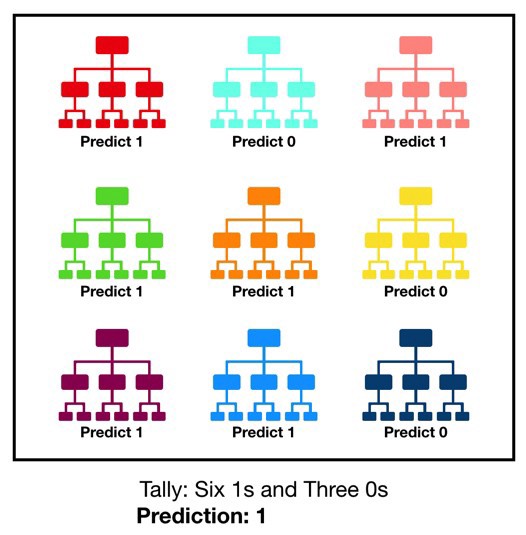
8. Что такое Random Forest?
Random Forest, или случайный лес, — это один из немногих универсальных алгоритмов обучения, который способен выполнять задачи классификации, регрессии и кластеризации.
Случайный лес состоит из большого количества отдельных деревьев решений, которые по сути являются ансамблем методов. Каждое дерево в случайном лесу возвращает прогноз класса, и класс с наибольшим количеством голосов становится прогнозом леса.
9. Какой метод перекрёстной проверки вы бы использовали для набора данных временных рядов?
Нормальная k-кратная процедура перекрёстной проверки может быть проблематичной для временных рядов.
Наиболее результативный подход для временных рядов — это прямая цепочка, где процедура выглядит примерно так:
-
сгиб 1: тренировка [1], тест [2];
-
сгиб 2: тренировка [1 2], тест [3];
-
сгиб 3: тренировка [1 2 3], тест [4];
-
сгиб 4: тренировка [1 2 3 4], тест [5];
-
сгиб 5: тренировка [1 2 3 4 5], тест [6].
Это более точно показывает ситуацию, где можно моделировать прошлые данные и прогнозировать прогнозные данные.
10. Что такое логистическая регрессия? Или приведите пример логистической регрессии.
Логистическая регрессия — это статистическая модель, которую используют для прогнозирования вероятности какого-либо события.
Например, нужно предсказать, победит конкретный политический лидер на выборах или нет.
В этом случае результат прогноза будет двоичным, то есть 0 или 1 (выигрыш/проигрыш). В качестве переменных-предикторов здесь будут: сумма денег, потраченных на предвыборную агитацию конкретного кандидата, количество времени, затраченного на агитацию, и так далее.
11. Что вы понимаете под термином «нормальное распределение»?
Нормальное распределение — одно из основных распределений вероятности.
Плотность нормального распределения выражается функцией Гаусса:
![]()
Где μ — математическое ожидание, σ — среднеквадратическое отклонение, σ ² — дисперсия, медиана и мода нормального распределения равны математическому ожиданию μ.
Примеры нормального распределения: погрешности измерений, отклонения при стрельбе, показатели живых популяций в природе.
12. Что такое глубокое обучение?
Глубокое обучение — совокупность большого количества методов машинного обучения, основанных на имитации работы человеческого мозга в процессе обработки данных и принятия решений.
По сути они основаны на обучении представлениям, а не специализированным алгоритмам под конкретные задачи. Из-за чего обучение нейронных сетей ведётся дольше, чем традиционное машинное обучение, но точность результатов получается выше.
13. В чём разница между машинным обучением и глубоким обучением?
Машинное обучение позволяет обучать компьютерную систему без её фактического программирования. А глубокое обучение — это подвид машинного обучения, который основан на аналогии нейронных сетей человеческого мозга. Это похоже на то, как наш мозг работает для решения проблем: чтобы найти ответ, он пропускает запросы через различные иерархии концепций и связанных вопросов.
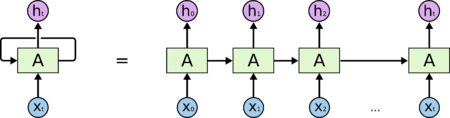
14. Что такое рекуррентные нейронные сети (RNN)?
Рекуррентные нейронные сети — это вид нейросетей, в которых связи между элементами образуют направленную последовательность. Это позволяет обрабатывать серии событий во времени или последовательные пространственные цепочки.
Они используются преимущественно для задач, где нечто цельное состоит из ряда объектов, например при распознавании рукописного текста или речи.
15. Что такое обучение с подкреплением?
Обучение с подкреплением очень схоже по смыслу с обучением с учителем, но в роли учителя выступает среда, в которой система может выполнять какие-либо действия.
Обучение с подкреплением активно используется в задачах, где нужно выбрать лучший вариант среди многих или достичь сложной цели за множество ходов. К примеру, это могут быть шахматы или го, где нейросети дают только правила, а она совершенствует свои навыки с помощью игр с самой собой.
Машина пытается решить задачу, ошибается, учится на своих ошибках, совершенствуется, и так множество раз.

16. Объясните, что такое регуляризация и почему она полезна
Регуляризация в машинном обучении — метод добавления дополнительных ограничений к условию для того, чтобы предотвратить переобучение системы или решить некорректно поставленную задачу. Часто это ограничение представляет собой штраф за излишнюю сложность модели.
Прогнозы модели должны затем минимизировать функцию потерь, вычисленную на регуляризованном обучающем наборе.

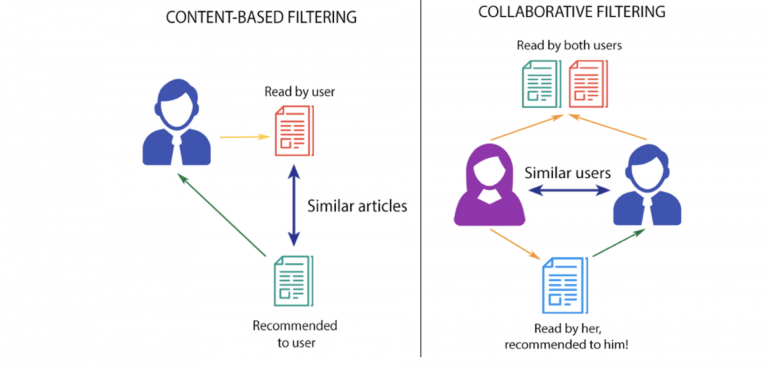
17. Что такое рекомендательные системы?
Подкласс систем фильтрации информации, что применяются для прогнозирования предпочтений или оценок, которые пользователь поставит продукту. Рекомендательные системы широко используются в фильмах, новостях, статьях, товарах, музыке и так далее.
18. Какова цель A/B-тестирования?
A/B-тестирование — это статистическая проверка гипотез для рандомизированных экспериментов с двумя переменными, A и B.
Его цель — обнаружение любых изменений на веб-странице, чтобы максимизировать или повысить результат стратегии.
19. Что такое закон больших чисел?
Это принцип теории вероятностей, который описывает результат выполнения одного и того же эксперимента множество раз.
При достаточно длительной серии экспериментов закон больших чисел гарантирует устойчивость средних значений от случайных событий. И среднее значение конечной выборки фиксированного распределения будет очень близко к математическому ожиданию выборки.
К примеру, при бросках шестигранного кубика. Чем больше бросков, тем больше среднее значение близится к математическому ожиданию 3,5.

20. Назовите несколько фреймворков для глубокого обучения
-
Pytorch.
-
TensorFlow.
-
Microsoft Cognitive Toolkit.
-
Keras.
-
Caffe.
-
Chainer.
Естественно, в этой выборке только теоретические вопросы, ведь практических задач (под реальные бизнес-кейсы компаний) просто бесконечное количество. Но всему этому мы учим на наших курсах по профессиям Data Scientist и Data Analyst, а карьерные консультанты помогают подготовиться к собеседованию. Про общую подготовку к собеседованию читайте здесь.

-
Курс по Data Science (12 месяцев)
-
Курс по Аналитике данных (6 месяцев)
-
Курс по Data Engineering
У нас еще много направлений для состоявшихся профи и новичков
Руководство для новичков о том, как рассчитать точность, отзыв и F1-оценку для задачи классификации нескольких классов.

Матрица неточностей — это табличный способ визуализации производительности вашей модели прогнозирования. Каждая запись в матрице неточностей обозначает количество прогнозов, сделанных моделью, в которой классы были правильно или неправильно классифицированы.
Любой, кто уже знаком с матрицей неточностей, знает, что в большинстве случаев это объясняется проблемой двоичной классификации. Что ж, это объяснение не из их числа. Сегодня мы увидим, как матрица путаницы работает в мультиклассовых моделях машинного обучения. Тем не менее, мы начнем с небольшой предыстории, используя двоичную классификацию, чтобы увидеть вещи в перспективе.
Матрица неточностей для двоичной классификации

Как видите, в задаче двоичной классификации нужно классифицировать только два класса, предпочтительно положительный и отрицательный. Теперь давайте посмотрим на показатели Матрицы неточностей.
Истинно положительный (TP): Это относится к количеству прогнозов, при которых классификатор правильно предсказывает положительный класс как положительный.
Истинно отрицательный (TN): Это относится к количеству прогнозов, в которых классификатор правильно предсказывает отрицательный класс как отрицательный.
Ложноположительный (FP): Это относится к количеству прогнозов, в которых классификатор неверно предсказывает отрицательный класс как положительный.
Ложноотрицательный (FN): Это относится к количеству прогнозов, в которых классификатор неверно предсказывает положительный класс как отрицательный.
Всегда лучше использовать матрицу путаницы в качестве критерия оценки модели машинного обучения. Он дает вам очень простые, но эффективные меры производительности для вашей модели. Вот некоторые из наиболее распространенных показателей производительности, которые вы можете использовать из матрицы неточностей.
Точность: показывает общую точность модели, то есть долю от общего числа выборок, которые были правильно классифицированы классификатором. Для расчета точности используйте следующую формулу: (TP + TN) / (TP + TN + FP + FN).
Уровень ошибочной классификации. Он показывает, какая часть прогнозов была неверной. Это также известно как ошибка классификации. Вы можете рассчитать его, используя (FP + FN) / (TP + TN + FP + FN) или (1-точность). .
Точность. Он сообщает вам, какая доля прогнозов в качестве положительного класса была на самом деле положительной. Для расчета точности используйте следующую формулу: TP / (TP + FP).
Напомнить: он сообщает вам, какая доля всех положительных образцов была правильно определена классификатором как положительные. Он также известен как истинно положительный коэффициент (TPR), чувствительность, вероятность обнаружения. Чтобы рассчитать отзыв, используйте следующую формулу: TP / (TP + FN).
Специфичность. Он сообщает вам, какая доля всех отрицательных образцов правильно предсказана классификатором как отрицательная. Он также известен как True Negative Rate (TNR). Для расчета специфичности используйте следующую формулу: TN / (TN + FP).
F1-оценка: он сочетает в себе точность и запоминаемость в одном измерении. Математически это гармоническое среднее значение точности и запоминания. Его можно рассчитать следующим образом:

Теперь, в идеальном мире, нам нужна модель с точностью 1 и отзывом 1. Это означает, что F1-оценка равна 1, то есть 100% точность, которая часто не соответствует модели машинного обучения. . Итак, что мы должны попробовать, так это получить более высокую точность с более высоким значением отзыва. Хорошо, теперь, когда мы знаем о показателях эффективности матрицы путаницы, давайте посмотрим, как мы можем использовать это в модели машинного обучения с несколькими классами.
Матрица неточностей для многоклассовой классификации
Для простоты давайте рассмотрим нашу задачу классификации нескольких классов как задачу классификации трех классов. Скажем, у нас есть набор данных с тремя метками класса, а именно Apple, Orange и Манго. Ниже приводится возможная матрица путаницы для этих классов.

В отличие от бинарной классификации здесь нет положительных или отрицательных классов. Сначала может быть немного сложно найти TP, TN, FP и FN, поскольку нет положительных или отрицательных классов, но на самом деле это довольно просто. Здесь нам нужно найти TP, TN, FP и FN для каждого отдельного класса. Например, если мы возьмем класс Apple, то давайте посмотрим, каковы значения показателей из матрицы неточностей.
- TP = 7
- TN = (2+3+2+1) = 8
- FP = (8+9) = 17
- FN = (1+3) = 4
Поскольку у нас есть все необходимые метрики для класса Apple из матрицы путаницы, теперь мы можем рассчитать показатели производительности для класса Apple. Например, у класса Apple есть
- Точность = 7 / (7 + 17) = 0,29
- Напоминание = 7 / (7 + 4) = 0,64
- F1-оценка = 0,40
Аналогичным образом мы можем рассчитать меры для других классов. Вот таблица, в которой показаны значения каждой меры для каждого класса.

Теперь мы можем сделать больше с помощью этих мер. Мы можем объединить оценку F1 каждого класса, чтобы получить единый показатель для всей модели. Есть несколько способов сделать это, давайте рассмотрим их сейчас.
Микро F1
Это называется микро-усредненным баллом F1. Он рассчитывается с учетом общего TP, общего FP и общего FN модели. Он не рассматривает каждый класс в отдельности, он рассчитывает показатели глобально. Итак, для нашего примера
- Общий TP = (7 + 2 + 1) = 10
- Всего FP = (8 + 9) + (1 + 3) + (3 + 2) = 26
- Итого FN = (1 + 3) + (8 + 2) + (9 + 3) = 26
Следовательно,
- Точность = 10 / (10 + 26) = 0,28
- Напоминание = 10 / (10 + 26) = 0,28
Теперь мы можем использовать обычную формулу для оценки F1 и получить оценку Micro F1, используя указанную выше точность и отзыв.
Micro F1 = 0,28
Как видите, когда мы рассчитываем показатели в глобальном масштабе, все показатели становятся равными. Также, если вы рассчитаете точность, вы увидите, что
Точность = Напоминание = Микро F1 = Точность
Макрос F1
Это макро-средний показатель F1. Он рассчитывает показатели для каждого класса индивидуально, а затем берет невзвешенное среднее значение показателей. Как видно из рисунка «Точность, отзывчивость и F1-оценка для каждого класса»,
- Оценка Apple в классе F1 = 0,40
- Оценка F1 класса Orange = 0,22
- Оценка F1 Class Mango = 0,11
Следовательно,
Макрос F1 = (0,40 + 0,22 + 0,11) / 3 = 0,24
Взвешенный F1
Последний — это средневзвешенный показатель F1. В отличие от макроса F1, он принимает средневзвешенное значение показателей. Веса для каждого класса — это общее количество выборок этого класса. Поскольку у нас было 11 яблок, 12 апельсинов и 13 манго,
Взвешенный F1 = ((0,40 * 11) + (0,22 * 12) + (0,11 * 13)) / (11 + 12 + 13) = 0,24
Наконец, давайте рассмотрим сценарий для вычисления этих показателей с помощью Python Scikit-learn.
Вот результат работы скрипта.

Примечание: Scikit-Learn использует строки как истинный класс, а столбцы — как прогнозируемый класс. Это противоположно нашему рассмотрению для примера Apple, Orange и Mango, но логически схоже. В любом случае вы можете рассматривать истинный и предсказанный класс. Но если вы используете Scikit-Learn, то вам придется играть по их правилам.
Надеюсь, вы нашли то, что искали. Спасибо за прочтение.
Гораздо легче что-то измерить, чем понять, что именно вы измеряете
Джон Уильям Салливан
Задачи машинного обучения с учителем как правило состоят в восстановлении зависимости между парами (признаковое описание, целевая переменная) по данным, доступным нам для анализа. Алгоритмы машинного обучения (learning algorithm), со многими из которых вы уже успели познакомиться, позволяют построить модель, аппроксимирующую эту зависимость. Но как понять, насколько качественной получилась аппроксимация?
Почти наверняка наша модель будет ошибаться на некоторых объектах: будь она даже идеальной, шум или выбросы в тестовых данных всё испортят. При этом разные модели будут ошибаться на разных объектах и в разной степени. Задача специалиста по машинному обучению – подобрать подходящий критерий, который позволит сравнивать различные модели.
Перед чтением этой главы мы хотели бы ещё раз напомнить, что качество модели нельзя оценивать на обучающей выборке. Как минимум, это стоит делать на отложенной (тестовой) выборке, но, если вам это позволяют время и вычислительные ресурсы, стоит прибегнуть и к более надёжным способам проверки – например, кросс-валидации (о ней вы узнаете в отдельной главе).
Выбор метрик в реальных задачах
Возможно, вы уже участвовали в соревнованиях по анализу данных. На таких соревнованиях метрику (критерий качества модели) организатор выбирает за вас, и она, как правило, довольно понятным образом связана с результатами предсказаний. Но на практике всё бывает намного сложнее.
Например, мы хотим:
- решить, сколько коробок с бананами нужно завтра привезти в конкретный магазин, чтобы минимизировать количество товара, который не будет выкуплен и минимизировать ситуацию, когда покупатель к концу дня не находит желаемый продукт на полке;
- увеличить счастье пользователя от работы с нашим сервисом, чтобы он стал лояльным и обеспечивал тем самым стабильный прогнозируемый доход;
- решить, нужно ли направить человека на дополнительное обследование.
В каждом конкретном случае может возникать целая иерархия метрик. Представим, например, что речь идёт о стриминговом музыкальном сервисе, пользователей которого мы решили порадовать сгенерированными самодельной нейросетью треками – не защищёнными авторским правом, а потому совершенно бесплатными. Иерархия метрик могла бы иметь такой вид:
- Самый верхний уровень: будущий доход сервиса – невозможно измерить в моменте, сложным образом зависит от совокупности всех наших усилий;
- Медианная длина сессии, возможно, служащая оценкой радости пользователей, которая, как мы надеемся, повлияет на их желание продолжать платить за подписку – её нам придётся измерять в продакшене, ведь нас интересует реакция настоящих пользователей на новшество;
- Доля удовлетворённых качеством сгенерированной музыки асессоров, на которых мы потестируем её до того, как выставить на суд пользователей;
- Функция потерь, на которую мы будем обучать генеративную сеть.
На этом примере мы можем заметить сразу несколько общих закономерностей. Во-первых, метрики бывают offline и online (оффлайновыми и онлайновыми). Online метрики вычисляются по данным, собираемым с работающей системы (например, медианная длина сессии). Offline метрики могут быть измерены до введения модели в эксплуатацию, например, по историческим данным или с привлечением специальных людей, асессоров. Последнее часто применяется, когда метрикой является реакция живого человека: скажем, так поступают поисковые компании, которые предлагают людям оценить качество ранжирования экспериментальной системы еще до того, как рядовые пользователи увидят эти результаты в обычном порядке. На самом же нижнем этаже иерархии лежат оптимизируемые в ходе обучения функции потерь.
В данном разделе нас будут интересовать offline метрики, которые могут быть измерены без привлечения людей.
Функция потерь $neq$ метрика качества
Как мы узнали ранее, методы обучения реализуют разные подходы к обучению:
- обучение на основе прироста информации (как в деревьях решений)
- обучение на основе сходства (как в методах ближайших соседей)
- обучение на основе вероятностной модели данных (например, максимизацией правдоподобия)
- обучение на основе ошибок (минимизация эмпирического риска)
И в рамках обучения на основе минимизации ошибок мы уже отвечали на вопрос: как можно штрафовать модель за предсказание на обучающем объекте.
Во время сведения задачи о построении решающего правила к задаче численной оптимизации, мы вводили понятие функции потерь и, обычно, объявляли целевой функцией сумму потерь от предсказаний на всех объектах обучающей выборке.
Важно понимать разницу между функцией потерь и метрикой качества. Её можно сформулировать следующим образом:
-
Функция потерь возникает в тот момент, когда мы сводим задачу построения модели к задаче оптимизации. Обычно требуется, чтобы она обладала хорошими свойствами (например, дифференцируемостью).
-
Метрика – внешний, объективный критерий качества, обычно зависящий не от параметров модели, а только от предсказанных меток.
В некоторых случаях метрика может совпадать с функцией потерь. Например, в задаче регрессии MSE играет роль как функции потерь, так и метрики. Но, скажем, в задаче бинарной классификации они почти всегда различаются: в качестве функции потерь может выступать кросс-энтропия, а в качестве метрики – число верно угаданных меток (accuracy). Отметим, что в последнем примере у них различные аргументы: на вход кросс-энтропии нужно подавать логиты, а на вход accuracy – предсказанные метки (то есть по сути argmax логитов).
Бинарная классификация: метки классов
Перейдём к обзору метрик и начнём с самой простой разновидности классификации – бинарной, а затем постепенно будем наращивать сложность.
Напомним постановку задачи бинарной классификации: нам нужно по обучающей выборке ${(x_i, y_i)}_{i=1}^N$, где $y_iin{0, 1}$ построить модель, которая по объекту $x$ предсказывает метку класса $f(x)in{0, 1}$.
Первым критерием качества, который приходит в голову, является accuracy – доля объектов, для которых мы правильно предсказали класс:
$$ color{#348FEA}{text{Accuracy}(y, y^{pred}) = frac{1}{N} sum_{i=1}^N mathbb{I}[y_i = f(x_i)]} $$
Или же сопряженная ей метрика – доля ошибочных классификаций (error rate):
$$text{Error rate} = 1 — text{Accuracy}$$
Познакомившись чуть внимательнее с этой метрикой, можно заметить, что у неё есть несколько недостатков:
- она не учитывает дисбаланс классов. Например, в задаче диагностики редких заболеваний классификатор, предсказывающий всем пациентам отсутствие болезни будет иметь достаточно высокую accuracy просто потому, что больных людей в выборке намного меньше;
- она также не учитывает цену ошибки на объектах разных классов. Для примера снова можно привести задачу медицинской диагностики: если ошибочный положительный диагноз для здорового больного обернётся лишь ещё одним обследованием, то ошибочно отрицательный вердикт может повлечь роковые последствия.
Confusion matrix (матрица ошибок)
Исторически задача бинарной классификации – это задача об обнаружении чего-то редкого в большом потоке объектов, например, поиск человека, больного туберкулёзом, по флюорографии. Или задача признания пятна на экране приёмника радиолокационной станции бомбардировщиком, представляющем угрозу охраняемому объекту (в противовес стае гусей).
Поэтому класс, который представляет для нас интерес, называется «положительным», а оставшийся – «отрицательным».
Заметим, что для каждого объекта в выборке возможно 4 ситуации:
- мы предсказали положительную метку и угадали. Будет относить такие объекты к true positive (TP) группе (true – потому что предсказали мы правильно, а positive – потому что предсказали положительную метку);
- мы предсказали положительную метку, но ошиблись в своём предсказании – false positive (FP) (false, потому что предсказание было неправильным);
- мы предсказали отрицательную метку и угадали – true negative (TN);
- и наконец, мы предсказали отрицательную метку, но ошиблись – false negative (FN). Для удобства все эти 4 числа изображают в виде таблицы, которую называют confusion matrix (матрицей ошибок):
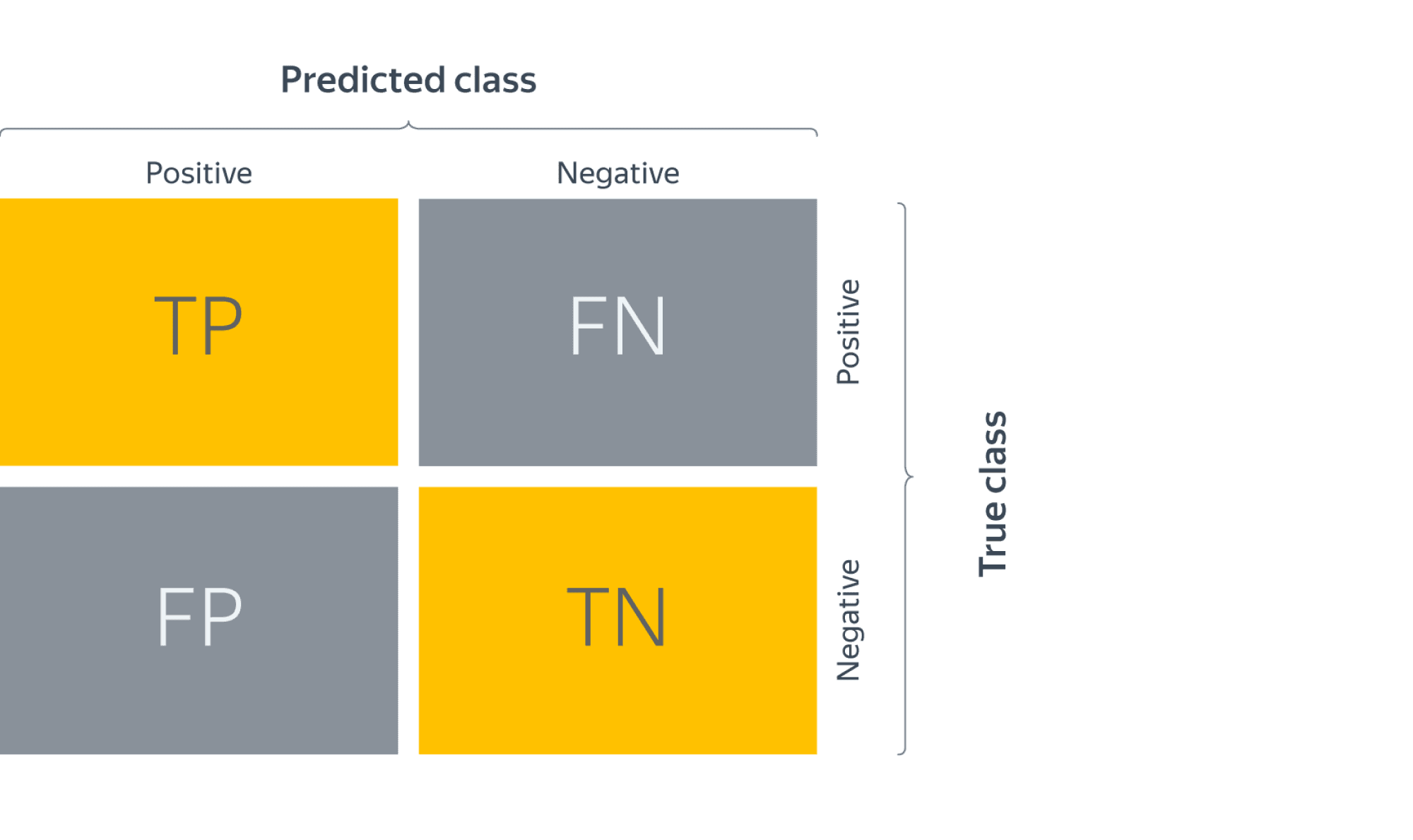
Не волнуйтесь, если первое время эти обозначения будут сводить вас с ума (будем откровенны, даже профи со стажем в них порой путаются), однако логика за ними достаточно простая: первая часть названия группы показывает угадали ли мы с классом, а вторая – какой класс мы предсказали.

Пример
Попробуем воспользоваться введёнными метриками в боевом примере: сравним работу нескольких моделей классификации на Breast cancer wisconsin (diagnostic) dataset.
Объектами выборки являются фотографии биопсии грудных опухолей. С их помощью было сформировано признаковое описание, которое заключается в характеристиках ядер клеток (таких как радиус ядра, его текстура, симметричность). Положительным классом в такой постановке будут злокачественные опухоли, а отрицательным – доброкачественные.
Модель 1. Константное предсказание.
Решение задачи начнём с самого простого классификатора, который выдаёт на каждом объекте константное предсказание – самый часто встречающийся класс.
Зачем вообще замерять качество на такой модели?При разработке модели машинного обучения для проекта всегда желательно иметь некоторую baseline модель. Так нам будет легче проконтролировать, что наша более сложная модель действительно дает нам прирост качества.
from sklearn.datasets
import load_breast_cancer
the_data = load_breast_cancer()
# 0 – "доброкачественный"
# 1 – "злокачественный"
relabeled_target = 1 - the_data["target"]
from sklearn.model_selection import train_test_split
X = the_data["data"]
y = relabeled_target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
from sklearn.dummy import DummyClassifier
dc_mf = DummyClassifier(strategy="most_frequent")
dc_mf.fit(X_train, y_train)
from sklearn.metrics import confusion_matrix
y_true = y_test y_pred = dc_mf.predict(X_test)
dc_mf_tn, dc_mf_fp, dc_mf_fn, dc_mf_tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 0 | FN = 53 |
| Истинный класс — | FP = 0 | TN = 90 |
Обучающие данные таковы, что наш dummy-классификатор все объекты записывает в отрицательный класс, то есть признаёт все опухоли доброкачественными. Такой наивный подход позволяет нам получить минимальный штраф за FP (действительно, нельзя ошибиться в предсказании, если положительный класс вообще не предсказывается), но и максимальный штраф за FN (в эту группу попадут все злокачественные опухоли).
Модель 2. Случайный лес.
Настало время воспользоваться всем арсеналом моделей машинного обучения, и начнём мы со случайного леса.
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
y_true = y_test
y_pred = rfc.predict(X_test)
rfc_tn, rfc_fp, rfc_fn, rfc_tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 52 | FN = 1 |
| Истинный класс — | FP = 4 | TN = 86 |
Можно сказать, что этот классификатор чему-то научился, т.к. главная диагональ матрицы стала содержать все объекты из отложенной выборки, за исключением 4 + 1 = 5 объектов (сравните с 0 + 53 объектами dummy-классификатора, все опухоли объявляющего доброкачественными).
Отметим, что вычисляя долю недиагональных элементов, мы приходим к метрике error rate, о которой мы говорили в самом начале:
$$text{Error rate} = frac{FP + FN}{ TP + TN + FP + FN}$$
тогда как доля объектов, попавших на главную диагональ – это как раз таки accuracy:
$$text{Accuracy} = frac{TP + TN}{ TP + TN + FP + FN}$$
Модель 3. Метод опорных векторов.
Давайте построим еще один классификатор на основе линейного метода опорных векторов.
Не забудьте привести признаки к единому масштабу, иначе численный алгоритм не сойдется к решению и мы получим гораздо более плохо работающее решающее правило. Попробуйте проделать это упражнение.
from sklearn.svm import LinearSVC
from sklearn.preprocessing import StandardScaler
ss = StandardScaler() ss.fit(X_train)
scaled_linsvc = LinearSVC(C=0.01,random_state=42)
scaled_linsvc.fit(ss.transform(X_train), y_train)
y_true = y_test
y_pred = scaled_linsvc.predict(ss.transform(X_test))
tn, fp, fn, tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 50 | FN = 3 |
| Истинный класс — | FP = 1 | TN = 89 |
Сравним результаты
Легко заметить, что каждая из двух моделей лучше классификатора-пустышки, однако давайте попробуем сравнить их между собой. С точки зрения error rate модели практически одинаковы: 5/143 для леса против 4/143 для SVM.
Посмотрим на структуру ошибок чуть более внимательно: лес – (FP = 4, FN = 1), SVM – (FP = 1, FN = 3). Какая из моделей предпочтительнее?
Замечание: Мы сравниваем несколько классификаторов на основании их предсказаний на отложенной выборке. Насколько ошибки данных классификаторов зависят от разбиения исходного набора данных? Иногда в процессе оценки качества мы будем получать модели, чьи показатели эффективности будут статистически неразличимыми.
Пусть мы учли предыдущее замечание и эти модели действительно статистически значимо ошибаются в разную сторону. Мы встретились с очевидной вещью: на матрицах нет отношения порядка. Когда мы сравнивали dummy-классификатор и случайный лес с помощью Accuracy, мы всю сложную структуру ошибок свели к одному числу, т.к. на вещественных числах отношение порядка есть. Сводить оценку модели к одному числу очень удобно, однако не стоит забывать, что у вашей модели есть много аспектов качества.
Что же всё-таки важнее уменьшить: FP или FN? Вернёмся к задаче: FP – доля доброкачественных опухолей, которым ошибочно присваивается метка злокачественной, а FN – доля злокачественных опухолей, которые классификатор пропускает. В такой постановке становится понятно, что при сравнении выиграет модель с меньшим FN (то есть лес в нашем примере), ведь каждая не обнаруженная опухоль может стоить человеческой жизни.
Рассмотрим теперь другую задачу: по данным о погоде предсказать, будет ли успешным запуск спутника. FN в такой постановке – это ошибочное предсказание неуспеха, то есть не более, чем упущенный шанс (если вас, конечно не уволят за срыв сроков). С FP всё серьёзней: если вы предскажете удачный запуск спутника, а на деле он потерпит крушение из-за погодных условий, то ваши потери будут в разы существеннее.
Итак, из примеров мы видим, что в текущем виде введенная нами доля ошибочных классификаций не даст нам возможности учесть неравную важность FP и FN. Поэтому введем две новые метрики: точность и полноту.
Точность и полнота
Accuracy — это метрика, которая характеризует качество модели, агрегированное по всем классам. Это полезно, когда классы для нас имеют одинаковое значение. В случае, если это не так, accuracy может быть обманчивой.
Рассмотрим ситуацию, когда положительный класс это событие редкое. Возьмем в качестве примера поисковую систему — в нашем хранилище хранятся миллиарды документов, а релевантных к конкретному поисковому запросу на несколько порядков меньше.
Пусть мы хотим решить задачу бинарной классификации «документ d релевантен по запросу q». Благодаря большому дисбалансу, Accuracy dummy-классификатора, объявляющего все документы нерелевантными, будет близка к единице. Напомним, что $text{Accuracy} = frac{TP + TN}{TP + TN + FP + FN}$, и в нашем случае высокое значение метрики будет обеспечено членом TN, в то время для пользователей более важен высокий TP.
Поэтому в случае ассиметрии классов, можно использовать метрики, которые не учитывают TN и ориентируются на TP.
Если мы рассмотрим долю правильно предсказанных положительных объектов среди всех объектов, предсказанных положительным классом, то мы получим метрику, которая называется точностью (precision)
$$color{#348FEA}{text{Precision} = frac{TP}{TP + FP}}$$
Интуитивно метрика показывает долю релевантных документов среди всех найденных классификатором. Чем меньше ложноположительных срабатываний будет допускать модель, тем больше будет её Precision.
Если же мы рассмотрим долю правильно найденных положительных объектов среди всех объектов положительного класса, то мы получим метрику, которая называется полнотой (recall)
$$color{#348FEA}{text{Recall} = frac{TP}{TP + FN}}$$
Интуитивно метрика показывает долю найденных документов из всех релевантных. Чем меньше ложно отрицательных срабатываний, тем выше recall модели.
Например, в задаче предсказания злокачественности опухоли точность показывает, сколько из определённых нами как злокачественные опухолей действительно являются злокачественными, а полнота – какую долю злокачественных опухолей нам удалось выявить.
Хорошее понимание происходящего даёт следующая картинка: 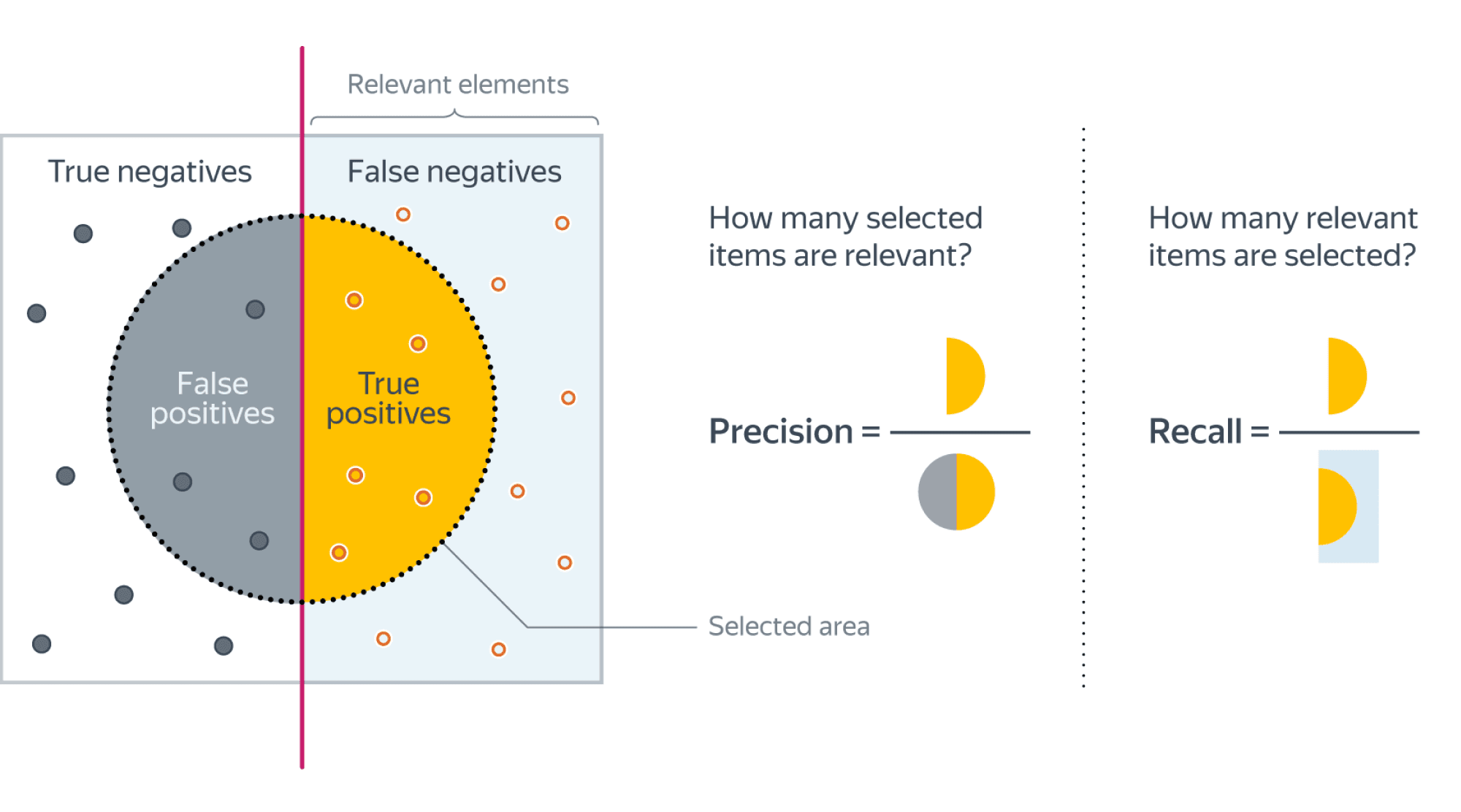 (источник картинки)
(источник картинки)
Recall@k, Precision@k
Метрики Recall и Precision хорошо подходят для задачи поиска «документ d релевантен запросу q», когда из списка рекомендованных алгоритмом документов нас интересует только первый. Но не всегда алгоритм машинного обучения вынужден работать в таких жестких условиях. Может быть такое, что вполне достаточно, что релевантный документ попал в первые k рекомендованных. Например, в интерфейсе выдачи первые три подсказки видны всегда одновременно и вообще не очень понятно, какой у них порядок. Тогда более честной оценкой качества алгоритма будет «в выдаче D размера k по запросу q нашлись релевантные документы». Для расчёта метрики по всей выборке объединим все выдачи и рассчитаем precision, recall как обычно подокументно.
F1-мера
Как мы уже отмечали ранее, модели очень удобно сравнивать, когда их качество выражено одним числом. В случае пары Precision-Recall существует популярный способ скомпоновать их в одну метрику — взять их среднее гармоническое. Данный показатель эффективности исторически носит название F1-меры (F1-measure).
$$
color{#348FEA}{F_1 = frac{2}{frac{1}{Recall} + frac{1}{Precision}}} = $$
$$ = 2 frac{Recall cdot Precision }{Recall + Precision} = frac
{TP} {TP + frac{FP + FN}{2}}
$$
Стоит иметь в виду, что F1-мера предполагает одинаковую важность Precision и Recall, если одна из этих метрик для вас приоритетнее, то можно воспользоваться $F_{beta}$ мерой:
$$
F_{beta} = (beta^2 + 1) frac{Recall cdot Precision }{Recall + beta^2Precision}
$$
Бинарная классификация: вероятности классов
Многие модели бинарной классификации устроены так, что класс объекта получается бинаризацией выхода классификатора по некоторому фиксированному порогу:
$$fleft(x ; w, w_{0}right)=mathbb{I}left[g(x, w) > w_{0}right].$$
Например, модель логистической регрессии возвращает оценку вероятности принадлежности примера к положительному классу. Другие модели бинарной классификации обычно возвращают произвольные вещественные значения, но существуют техники, называемые калибровкой классификатора, которые позволяют преобразовать предсказания в более или менее корректную оценку вероятности принадлежности к положительному классу.
Как оценить качество предсказываемых вероятностей, если именно они являются нашей конечной целью? Общепринятой мерой является логистическая функция потерь, которую мы изучали раньше, когда говорили об устройстве некоторых методов классификации (например уже упоминавшейся логистической регрессии).
Если же нашей целью является построение прогноза в терминах метки класса, то нам нужно учесть, что в зависимости от порога мы будем получать разные предсказания и разное качество на отложенной выборке. Так, чем ниже порог отсечения, тем больше объектов модель будет относить к положительному классу. Как в этом случае оценить качество модели?
AUC
Пусть мы хотим учитывать ошибки на объектах обоих классов. При уменьшении порога отсечения мы будем находить (правильно предсказывать) всё большее число положительных объектов, но также и неправильно предсказывать положительную метку на всё большем числе отрицательных объектов. Естественным кажется ввести две метрики TPR и FPR:
TPR (true positive rate) – это полнота, доля положительных объектов, правильно предсказанных положительными:
$$ TPR = frac{TP}{P} = frac{TP}{TP + FN} $$
FPR (false positive rate) – это доля отрицательных объектов, неправильно предсказанных положительными:
$$FPR = frac{FP}{N} = frac{FP}{FP + TN}$$
Обе эти величины растут при уменьшении порога. Кривая в осях TPR/FPR, которая получается при варьировании порога, исторически называется ROC-кривой (receiver operating characteristics curve, сокращённо ROC curve). Следующий график поможет вам понять поведение ROC-кривой.
Желтая и синяя кривые показывают распределение предсказаний классификатора на объектах положительного и отрицательного классов соответственно. То есть значения на оси X (на графике с двумя гауссианами) мы получаем из классификатора. Если классификатор идеальный (две кривые разделимы по оси X), то на правом графике мы получаем ROC-кривую (0,0)->(0,1)->(1,1) (убедитесь сами!), площадь под которой равна 1. Если классификатор случайный (предсказывает одинаковые метки положительным и отрицательным объектам), то мы получаем ROC-кривую (0,0)->(1,1), площадь под которой равна 0.5. Поэкспериментируйте с разными вариантами распределения предсказаний по классам и посмотрите, как меняется ROC-кривая.
Чем лучше классификатор разделяет два класса, тем больше площадь (area under curve) под ROC-кривой – и мы можем использовать её в качестве метрики. Эта метрика называется AUC и она работает благодаря следующему свойству ROC-кривой:
AUC равен доле пар объектов вида (объект класса 1, объект класса 0), которые алгоритм верно упорядочил, т.е. предсказание классификатора на первом объекте больше:
$$
color{#348FEA}{operatorname{AUC} = frac{sumlimits_{i = 1}^{N} sumlimits_{j = 1}^{N}mathbb{I}[y_i < y_j] I^{prime}[f(x_{i}) < f(x_{j})]}{sumlimits_{i = 1}^{N} sumlimits_{j = 1}^{N}mathbb{I}[y_i < y_j]}}
$$
$$
I^{prime}left[f(x_{i}) < f(x_{j})right]=
left{
begin{array}{ll}
0, & f(x_{i}) > f(x_{j}) \
0.5 & f(x_{i}) = f(x_{j}) \
1, & f(x_{i}) < f(x_{j})
end{array}
right.
$$
$$
Ileft[y_{i}< y_{j}right]=
left{
begin{array}{ll}
0, & y_{i} geq y_{j} \
1, & y_{i} < y_{j}
end{array}
right.
$$
Чтобы детальнее разобраться, почему это так, советуем вам обратиться к материалам А.Г.Дьяконова.
В каких случаях лучше отдать предпочтение этой метрике? Рассмотрим следующую задачу: некоторый сотовый оператор хочет научиться предсказывать, будет ли клиент пользоваться его услугами через месяц. На первый взгляд кажется, что задача сводится к бинарной классификации с метками 1, если клиент останется с компанией и $0$ – иначе.
Однако если копнуть глубже в процессы компании, то окажется, что такие метки практически бесполезны. Компании скорее интересно упорядочить клиентов по вероятности прекращения обслуживания и в зависимости от этого применять разные варианты удержания: кому-то прислать скидочный купон от партнёра, кому-то предложить скидку на следующий месяц, а кому-то и новый тариф на особых условиях.
Таким образом, в любой задаче, где нам важна не метка сама по себе, а правильный порядок на объектах, имеет смысл применять AUC.
Утверждение выше может вызывать у вас желание использовать AUC в качестве метрики в задачах ранжирования, но мы призываем вас быть аккуратными.
ПодробнееУтверждение выше может вызывать у вас желание использовать AUC в качестве метрики в задачах ранжирования, но мы призываем вас быть аккуратными.» details=»Продемонстрируем это на следующем примере: пусть наша выборка состоит из $9100$ объектов класса $0$ и $10$ объектов класса $1$, и модель расположила их следующим образом:
$$underbrace{0 dots 0}_{9000} ~ underbrace{1 dots 1}_{10} ~ underbrace{0 dots 0}_{100}$$
Тогда AUC будет близка к единице: количество пар правильно расположенных объектов будет порядка $90000$, в то время как общее количество пар порядка $91000$.
Однако самыми высокими по вероятности положительного класса будут совсем не те объекты, которые мы ожидаем.
Average Precision
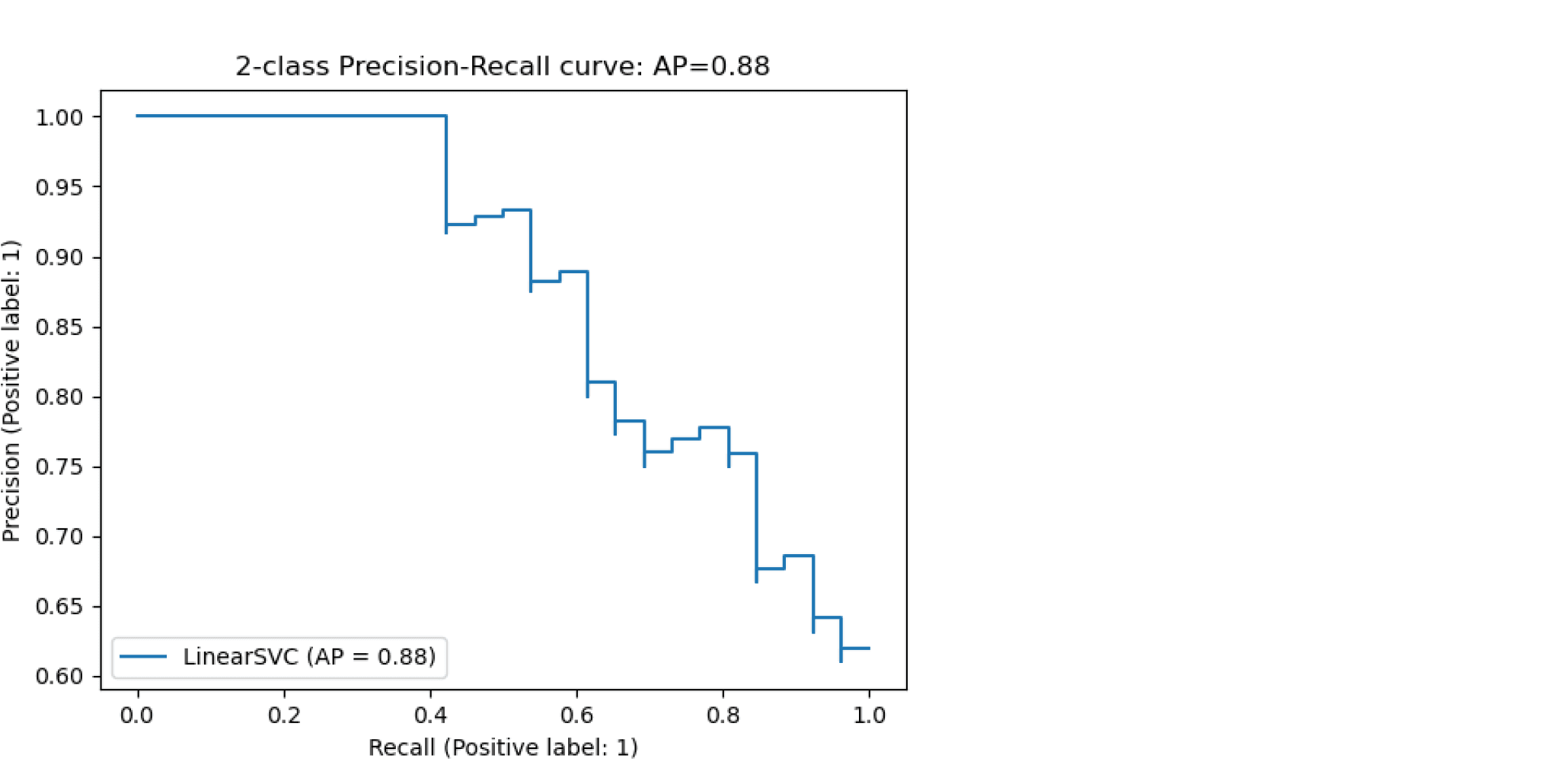
Будем постепенно уменьшать порог бинаризации. При этом полнота будет расти от $0$ до $1$, так как будет увеличиваться количество объектов, которым мы приписываем положительный класс (а количество объектов, на самом деле относящихся к положительному классу, очевидно, меняться не будет). Про точность же нельзя сказать ничего определённого, но мы понимаем, что скорее всего она будет выше при более высоком пороге отсечения (мы оставим только объекты, в которых модель «уверена» больше всего). Варьируя порог и пересчитывая значения Precision и Recall на каждом пороге, мы получим некоторую кривую примерно следующего вида:
 (источник картинки)
(источник картинки)
Рассмотрим среднее значение точности (оно равно площади под кривой точность-полнота):
$$ text { AP }=int_{0}^{1} p(r) d r$$
Получим показатель эффективности, который называется average precision. Как в случае матрицы ошибок мы переходили к скалярным показателям эффективности, так и в случае с кривой точность-полнота мы охарактеризовали ее в виде числа.
Многоклассовая классификация
Если классов становится больше двух, расчёт метрик усложняется. Если задача классификации на $K$ классов ставится как $K$ задач об отделении класса $i$ от остальных ($i=1,ldots,K$), то для каждой из них можно посчитать свою матрицу ошибок. Затем есть два варианта получения итогового значения метрики из $K$ матриц ошибок:
- Усредняем элементы матрицы ошибок (TP, FP, TN, FN) между бинарными классификаторами, например $TP = frac{1}{K}sum_{i=1}^{K}TP_i$. Затем по одной усреднённой матрице ошибок считаем Precision, Recall, F-меру. Это называют микроусреднением.
- Считаем Precision, Recall для каждого классификатора отдельно, а потом усредняем. Это называют макроусреднением.
Порядок усреднения влияет на результат в случае дисбаланса классов. Показатели TP, FP, FN — это счётчики объектов. Пусть некоторый класс обладает маленькой мощностью (обозначим её $M$). Тогда значения TP и FN при классификации этого класса против остальных будут не больше $M$, то есть тоже маленькие. Про FP мы ничего уверенно сказать не можем, но скорее всего при дисбалансе классов классификатор не будет предсказывать редкий класс слишком часто, потому что есть большая вероятность ошибиться. Так что FP тоже мало. Поэтому усреднение первым способом сделает вклад маленького класса в общую метрику незаметным. А при усреднении вторым способом среднее считается уже для нормированных величин, так что вклад каждого класса будет одинаковым.
Рассмотрим пример. Пусть есть датасет из объектов трёх цветов: желтого, зелёного и синего. Желтого и зелёного цветов почти поровну — 21 и 20 объектов соответственно, а синих объектов всего 4.
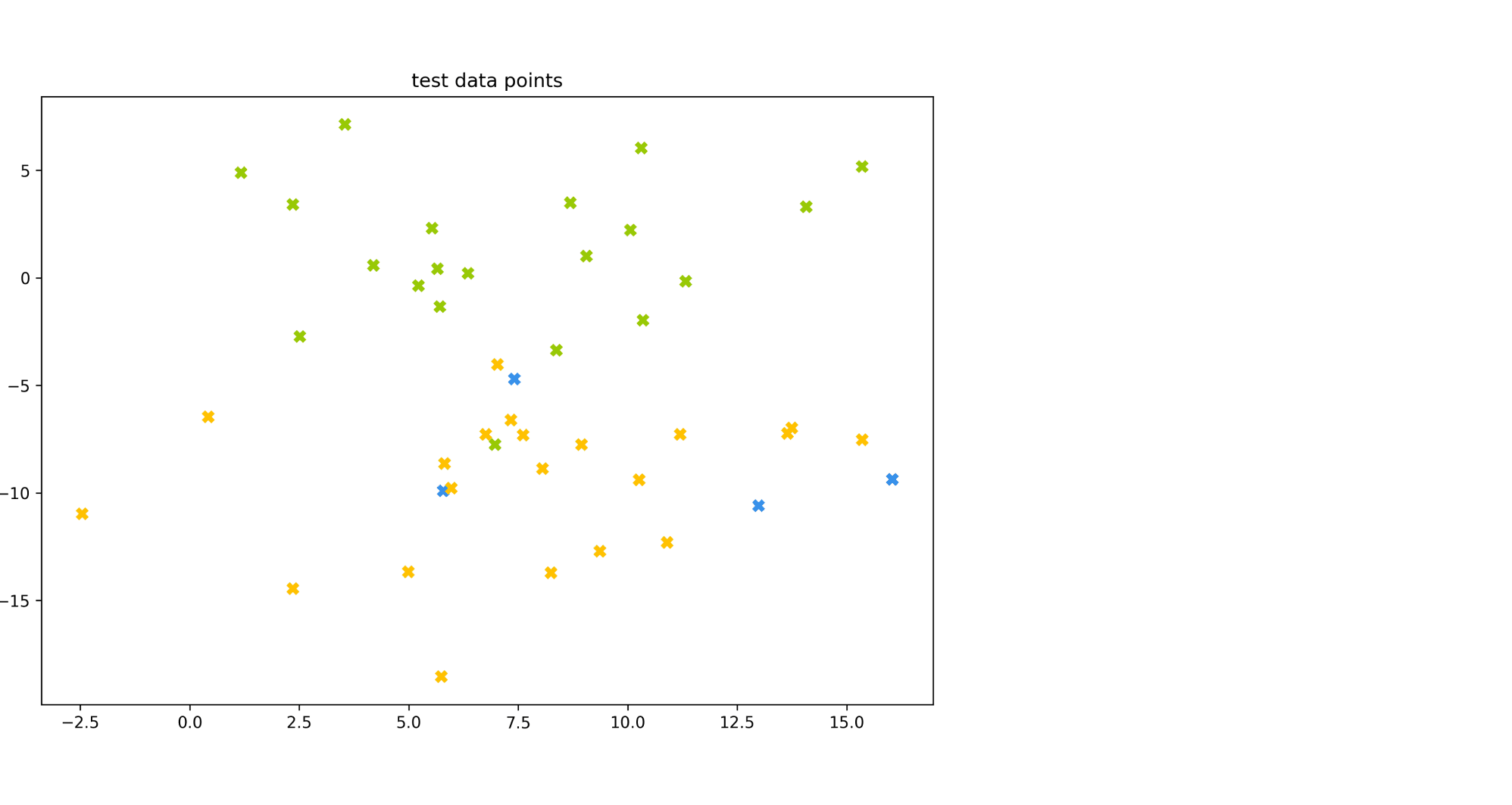
Модель по очереди для каждого цвета пытается отделить объекты этого цвета от объектов оставшихся двух цветов. Результаты классификации проиллюстрированы матрицей ошибок. Модель «покрасила» в жёлтый 25 объектов, 20 из которых были действительно жёлтыми (левый столбец матрицы). В синий был «покрашен» только один объект, который на самом деле жёлтый (средний столбец матрицы). В зелёный — 19 объектов, все на самом деле зелёные (правый столбец матрицы).
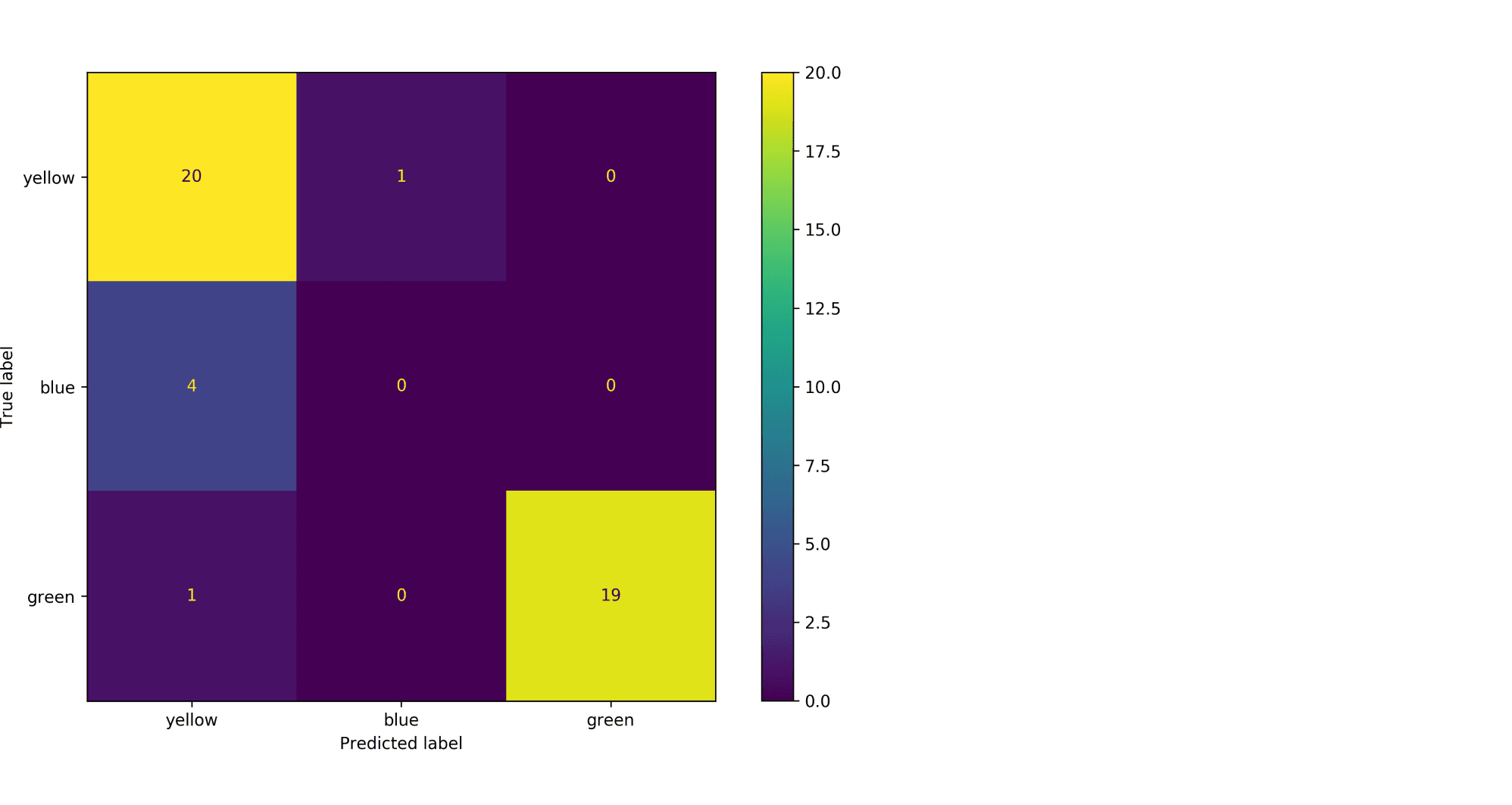
Посчитаем Precision классификации двумя способами:
- С помощью микроусреднения получаем $$
text{Precision} = frac{dfrac{1}{3}left(20 + 0 + 19right)}{dfrac{1}{3}left(20 + 0 + 19right) + dfrac{1}{3}left(5 + 1 + 0right)} = 0.87
$$ - С помощью макроусреднения получаем $$
text{Precision} = dfrac{1}{3}left( frac{20}{20 + 5} + frac{0}{0 + 1} + frac{19}{19 + 0}right) = 0.6
$$
Видим, что макроусреднение лучше отражает тот факт, что синий цвет, которого в датасете было совсем мало, модель практически игнорирует.
Как оптимизировать метрики классификации?
Пусть мы выбрали, что метрика качества алгоритма будет $F(a(X), Y)$. Тогда мы хотим обучить модель так, чтобы $F$ на валидационной выборке была минимальная/максимальная. Лучший способ добиться минимизации метрики $F$ — оптимизировать её напрямую, то есть выбрать в качестве функции потерь ту же $F(a(X), Y)$. К сожалению, это не всегда возможно. Рассмотрим, как оптимизировать метрики иначе.
Метрики precision и recall невозможно оптимизировать напрямую, потому что эти метрики нельзя рассчитать на одном объекте, а затем усреднить. Они зависят от того, какими были правильная метка класса и ответ алгоритма на всех объектах. Чтобы понять, как оптимизировать precision, recall, рассмотрим, как расчитать эти метрики на отложенной выборке. Пусть модель обучена на стандартную для классификации функцию потерь (LogLoss). Для получения меток класса специалист по машинному обучению сначала применяет на объектах модель и получает вещественные предсказания модели ($p_i in left(0, 1right)$). Затем предсказания бинаризуются по порогу, выбранному специалистом: если предсказание на объекте больше порога, то метка класса 1 (или «положительная»), если меньше — 0 (или «отрицательная»). Рассмотрим, что будет с метриками precision, recall в крайних положениях порога.
- Пусть порог равен нулю. Тогда всем объектам будет присвоена положительная метка. Следовательно, все объекты будут либо TP, либо FP, потому что отрицательных предсказаний нет, $TP + FP = N$, где $N$ — размер выборки. Также все объекты, у которых метка на самом деле 1, попадут в TP. По формуле точность $text{Precision} = frac{TP}{TP + FP} = frac1N sum_{i = 1}^N mathbb{I} left[ y_i = 1 right]$ равна среднему таргету в выборке. А полнота $text{Recall} = frac{TP}{TP + FN} = frac{TP}{TP + 0} = 1$ равна единице.
- Пусть теперь порог равен единице. Тогда ни один объект не будет назван положительным, $TP = FP = 0$. Все объекты с меткой класса 1 попадут в FN. Если есть хотя бы один такой объект, то есть $FN ne 0$, будет верна формула $text{Recall} = frac{TP}{TP + FN} = frac{0}{0+ FN} = 0$. То есть при пороге единица, полнота равна нулю. Теперь посмотрим на точность. Формула для Precision состоит только из счётчиков положительных ответов модели (TP, FP). При единичном пороге они оба равны нулю, $text{Precision} = frac{TP}{TP + FP} = frac{0}{0 + 0}$то есть при единичном пороге точность неопределена. Пусть мы отступили чуть-чуть назад по порогу, чтобы хотя бы несколько объектов были названы моделью положительными. Скорее всего это будут самые «простые» объекты, которые модель распознает хорошо, потому что её предсказание близко к единице. В этом предположении $FP approx 0$. Тогда точность $text{Precision} = frac{TP}{TP + FP} approx frac{TP}{TP + 0} approx 1$ будет близка к единице.
Изменяя порог, между крайними положениями, получим графики Precision и Recall, которые выглядят как-то так:
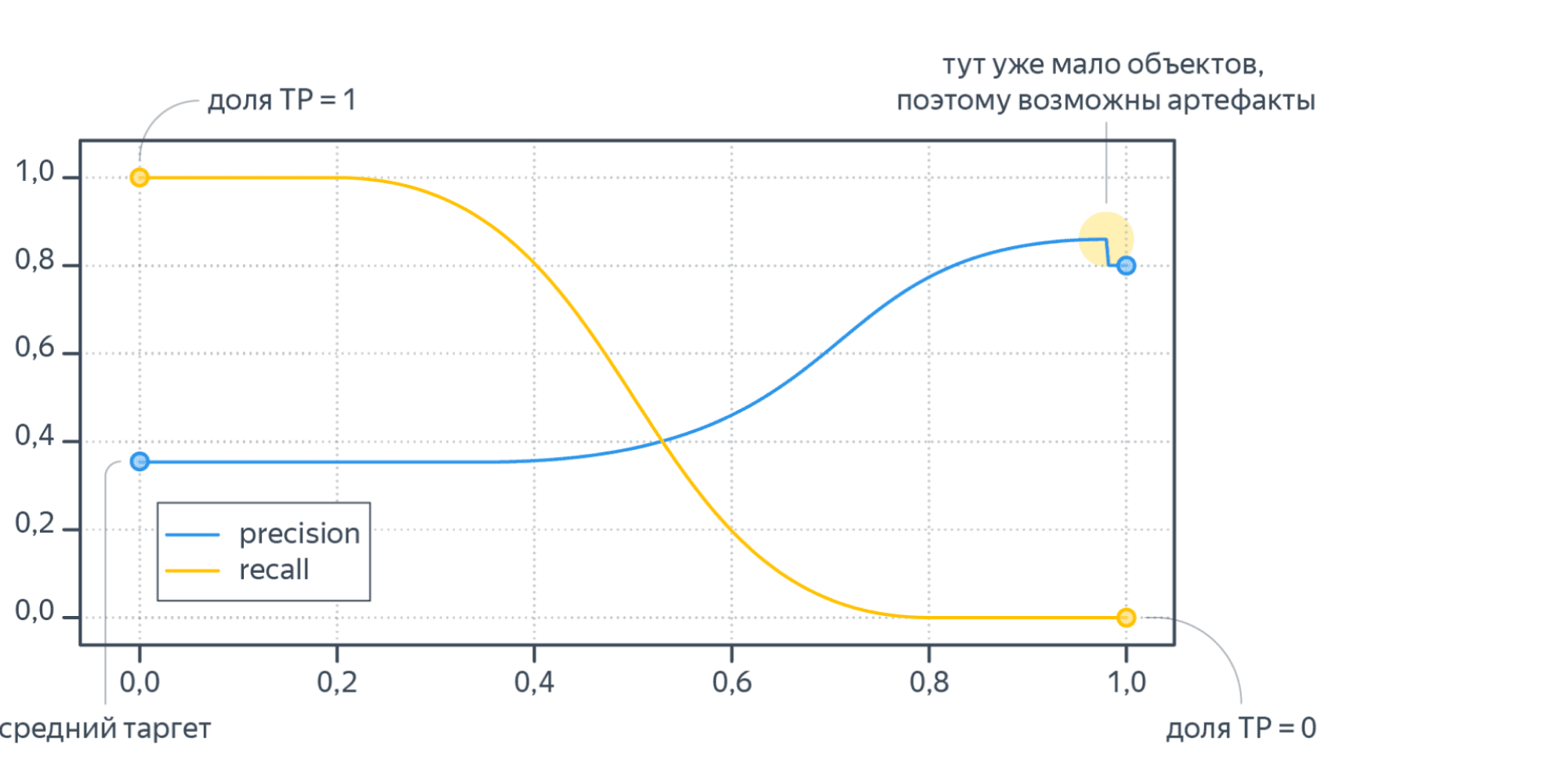
Recall меняется от единицы до нуля, а Precision от среднего тагрета до какого-то другого значения (нет гарантий, что график монотонный).
Итого оптимизация precision и recall происходит так:
- Модель обучается на стандартную функцию потерь (например, LogLoss).
- Используя вещественные предсказания на валидационной выборке, перебирая разные пороги от 0 до 1, получаем графики метрик в зависимости от порога.
- Выбираем нужное сочетание точности и полноты.
Пусть теперь мы хотим максимизировать метрику AUC. Стандартный метод оптимизации, градиентный спуск, предполагает, что функция потерь дифференцируема. AUC этим качеством не обладает, то есть мы не можем оптимизировать её напрямую. Поэтому для метрики AUC приходится изменять оптимизационную задачу. Метрика AUC считает долю верно упорядоченных пар. Значит от исходной выборки можно перейти к выборке упорядоченных пар объектов. На этой выборке ставится задача классификации: метка класса 1 соответствует правильно упорядоченной паре, 0 — неправильно. Новой метрикой становится accuracy — доля правильно классифицированных объектов, то есть доля правильно упорядоченных пар. Оптимизировать accuracy можно по той же схеме, что и precision, recall: обучаем модель на LogLoss и предсказываем вероятности положительной метки у объекта выборки, считаем accuracy для разных порогов по вероятности и выбираем понравившийся.
Регрессия
В задачах регрессии целевая метка у нас имеет потенциально бесконечное число значений. И природа этих значений, обычно, связана с каким-то процессом измерений:
- величина температуры в определенный момент времени на метеостанции
- количество прочтений статьи на сайте
- количество проданных бананов в конкретном магазине, сети магазинов или стране
- дебит добывающей скважины на нефтегазовом месторождении за месяц и т.п.
Мы видим, что иногда метка это целое число, а иногда произвольное вещественное число. Обычно случаи целочисленных меток моделируют так, словно это просто обычное вещественное число. При таком подходе может оказаться так, что модель A лучше модели B по некоторой метрике, но при этом предсказания у модели A могут быть не целыми. Если в бизнес-задаче ожидается именно целочисленный ответ, то и оценивать нужно огрубление.
Общая рекомендация такова: оценивайте весь каскад решающих правил: и те «внутренние», которые вы получаете в результате обучения, и те «итоговые», которые вы отдаёте бизнес-заказчику.
Например, вы можете быть удовлетворены, что стали ошибаться не во втором, а только в третьем знаке после запятой при предсказании погоды. Но сами погодные данные измеряются с точностью до десятых долей градуса, а пользователь и вовсе может интересоваться лишь целым числом градусов.
Итак, напомним постановку задачи регрессии: нам нужно по обучающей выборке ${(x_i, y_i)}_{i=1}^N$, где $y_i in mathbb{R}$ построить модель f(x).
Величину $ e_i = f(x_i) — y_i $ называют ошибкой на объекте i или регрессионным остатком.
Весь набор ошибок на отложенной выборке может служить аналогом матрицы ошибок из задачи классификации. А именно, когда мы рассматриваем две разные модели, то, глядя на то, как и на каких объектах они ошиблись, мы можем прийти к выводу, что для решения бизнес-задачи нам выгоднее взять ту или иную модель. И, аналогично со случаем бинарной классификации, мы можем начать строить агрегаты от вектора ошибок, получая тем самым разные метрики.
MSE, RMSE, $R^2$
MSE – одна из самых популярных метрик в задаче регрессии. Она уже знакома вам, т.к. применяется в качестве функции потерь (или входит в ее состав) во многих ранее рассмотренных методах.
$$ MSE(y^{true}, y^{pred}) = frac1Nsum_{i=1}^{N} (y_i — f(x_i))^2 $$
Иногда для того, чтобы показатель эффективности MSE имел размерность исходных данных, из него извлекают квадратный корень и получают показатель эффективности RMSE.
MSE неограничен сверху, и может быть нелегко понять, насколько «хорошим» или «плохим» является то или иное его значение. Чтобы появились какие-то ориентиры, делают следующее:
-
Берут наилучшее константное предсказание с точки зрения MSE — среднее арифметическое меток $bar{y}$. При этом чтобы не было подглядывания в test, среднее нужно вычислять по обучающей выборке
-
Рассматривают в качестве показателя ошибки:
$$ R^2 = 1 — frac{sum_{i=1}^{N} (y_i — f(x_i))^2}{sum_{i=1}^{N} (y_i — bar{y})^2}.$$
У идеального решающего правила $R^2$ равен $1$, у наилучшего константного предсказания он равен $0$ на обучающей выборке. Можно заметить, что $R^2$ показывает, какая доля дисперсии таргетов (знаменатель) объяснена моделью.
MSE квадратично штрафует за большие ошибки на объектах. Мы уже видели проявление этого при обучении моделей методом минимизации квадратичных ошибок – там это проявлялось в том, что модель старалась хорошо подстроиться под выбросы.
Пусть теперь мы хотим использовать MSE для оценки наших регрессионных моделей. Если большие ошибки для нас действительно неприемлемы, то квадратичный штраф за них — очень полезное свойство (и его даже можно усиливать, повышая степень, в которую мы возводим ошибку на объекте). Однако если в наших тестовых данных присутствуют выбросы, то нам будет сложно объективно сравнить модели между собой: ошибки на выбросах будет маскировать различия в ошибках на основном множестве объектов.
Таким образом, если мы будем сравнивать две модели при помощи MSE, у нас будет выигрывать та модель, у которой меньше ошибка на объектах-выбросах, а это, скорее всего, не то, чего требует от нас наша бизнес-задача.
История из жизни про бананы и квадратичный штраф за ошибкуИз-за неверно введенных данных метка одного из объектов оказалась в 100 раз больше реального значения. Моделировалась величина при помощи градиентного бустинга над деревьями решений. Функция потерь была MSE.
Однажды уже во время эксплуатации случилось ч.п.: у нас появились предсказания, в 100 раз превышающие допустимые из соображений физического смысла значения. Представьте себе, например, что вместо обычных 4 ящиков бананов система предлагала поставить в магазин 400. Были распечатаны все деревья из ансамбля, и мы увидели, что постепенно число ящиков действительно увеличивалось до прогнозных 400.
Было решено проверить гипотезу, что был выброс в данных для обучения. Так оно и оказалось: всего одна точка давала такую потерю на объекте, что алгоритм обучения решил, что лучше переобучиться под этот выброс, чем смириться с большим штрафом на этом объекте. А в эксплуатации у нас возникли точки, которые плюс-минус попадали в такие же листья ансамбля, что и объект-выброс.
Избежать такого рода проблем можно двумя способами: внимательнее контролируя качество данных или адаптировав функцию потерь.
Аналогично, можно поступать и в случае, когда мы разрабатываем метрику качества: менее жёстко штрафовать за большие отклонения от истинного таргета.
MAE
Использовать RMSE для сравнения моделей на выборках с большим количеством выбросов может быть неудобно. В таких случаях прибегают к также знакомой вам в качестве функции потери метрике MAE (mean absolute error):
$$ MAE(y^{true}, y^{pred}) = frac{1}{N}sum_{i=1}^{N} left|y_i — f(x_i)right| $$
Метрики, учитывающие относительные ошибки
И MSE и MAE считаются как сумма абсолютных ошибок на объектах.
Рассмотрим следующую задачу: мы хотим спрогнозировать спрос товаров на следующий месяц. Пусть у нас есть два продукта: продукт A продаётся в количестве 100 штук, а продукт В в количестве 10 штук. И пусть базовая модель предсказывает количество продаж продукта A как 98 штук, а продукта B как 8 штук. Ошибки на этих объектах добавляют 4 штрафных единицы в MAE.
И есть 2 модели-кандидата на улучшение. Первая предсказывает товар А 99 штук, а товар B 8 штук. Вторая предсказывает товар А 98 штук, а товар B 9 штук.
Обе модели улучшают MAE базовой модели на 1 единицу. Однако, с точки зрения бизнес-заказчика вторая модель может оказаться предпочтительнее, т.к. предсказание продажи редких товаров может быть приоритетнее. Один из способов учесть такое требование – рассматривать не абсолютную, а относительную ошибку на объектах.
MAPE, SMAPE
Когда речь заходит об относительных ошибках, сразу возникает вопрос: что мы будем ставить в знаменатель?
В метрике MAPE (mean absolute percentage error) в знаменатель помещают целевое значение:
$$ MAPE(y^{true}, y^{pred}) = frac{1}{N} sum_{i=1}^{N} frac{ left|y_i — f(x_i)right|}{left|y_iright|} $$
С особым случаем, когда в знаменателе оказывается $0$, обычно поступают «инженерным» способом: или выдают за непредсказание $0$ на таком объекте большой, но фиксированный штраф, или пытаются застраховаться от подобного на уровне формулы и переходят к метрике SMAPE (symmetric mean absolute percentage error):
$$ SMAPE(y^{true}, y^{pred}) = frac{1}{N} sum_{i=1}^{N} frac{ 2 left|y_i — f(x_i)right|}{y_i + f(x_i)} $$
Если же предсказывается ноль, штраф считаем нулевым.
Таким переходом от абсолютных ошибок на объекте к относительным мы сделали объекты в тестовой выборке равнозначными: даже если мы делаем абсурдно большое предсказание, на фоне которого истинная метка теряется, мы получаем штраф за этот объект порядка 1 в случае MAPE и 2 в случае SMAPE.
WAPE
Как и любая другая метрика, MAPE имеет свои границы применимости: например, она плохо справляется с прогнозом спроса на товары с прерывистыми продажами. Рассмотрим такой пример:
| Понедельник | Вторник | Среда | |
|---|---|---|---|
| Прогноз | 55 | 2 | 50 |
| Продажи | 50 | 1 | 50 |
| MAPE | 10% | 100% | 0% |
Среднее MAPE – 36.7%, что не очень отражает реальную ситуацию, ведь два дня мы предсказывали с хорошей точностью. В таких ситуациях помогает WAPE (weighted average percentage error):
$$ WAPE(y^{true}, y^{pred}) = frac{sum_{i=1}^{N} left|y_i — f(x_i)right|}{sum_{i=1}^{N} left|y_iright|} $$
Если мы предсказываем идеально, то WAPE = 0, если все предсказания отдаём нулевыми, то WAPE = 1.
В нашем примере получим WAPE = 5.9%
RMSLE
Альтернативный способ уйти от абсолютных ошибок к относительным предлагает метрика RMSLE (root mean squared logarithmic error):
$$ RMSLE(y^{true}, y^{pred}| c) = sqrt{ frac{1}{N} sum_{i=1}^N left(vphantom{frac12}log{left(y_i + c right)} — log{left(f(x_i) + c right)}right)^2 } $$
где нормировочная константа $c$ вводится искусственно, чтобы не брать логарифм от нуля. Также по построению видно, что метрика пригодна лишь для неотрицательных меток.
Веса в метриках
Все вышеописанные метрики легко допускают введение весов для объектов. Если мы из каких-то соображений можем определить стоимость ошибки на объекте, можно брать эту величину в качестве веса. Например, в задаче предсказания спроса в качестве веса можно использовать стоимость объекта.
Доля предсказаний с абсолютными ошибками больше, чем d
Еще одним способом охарактеризовать качество модели в задаче регрессии является доля предсказаний с абсолютными ошибками больше заданного порога $d$:
$$frac{1}{N} sum_{i=1}^{N} mathbb{I}left[ left| y_i — f(x_i) right| > d right] $$
Например, можно считать, что прогноз погоды сбылся, если ошибка предсказания составила меньше 1/2/3 градусов. Тогда рассматриваемая метрика покажет, в какой доле случаев прогноз не сбылся.
Как оптимизировать метрики регрессии?
Пусть мы выбрали, что метрика качества алгоритма будет $F(a(X), Y)$. Тогда мы хотим обучить модель так, чтобы F на валидационной выборке была минимальная/максимальная. Аналогично задачам классификации лучший способ добиться минимизации метрики $F$ — выбрать в качестве функции потерь ту же $F(a(X), Y)$. К счастью, основные метрики для регрессии: MSE, RMSE, MAE можно оптимизировать напрямую. С формальной точки зрения MAE не дифференцируема, так как там присутствует модуль, чья производная не определена в нуле. На практике для этого выколотого случая в коде можно возвращать ноль.
Для оптимизации MAPE придётся изменять оптимизационную задачу. Оптимизацию MAPE можно представить как оптимизацию MAE, где объектам выборки присвоен вес $frac{1}{vert y_ivert}$.