
Применение математической статистики при обработке результатов анализа
Страницы работы
Содержание работы
ПРИМЕНЕНИЕ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
ПРИ ОБРАБОТКЕ РЕЗУЛЬТАТОВ АНАЛИЗА
Ошибки измерений.
Во всякой экспериментальной работе большое значение имеет точность измерений,
воспроизводимость и правильность результатов анализа. Опыт показывает, что
любая измеряемая величина имеет свою ошибку; это обусловлено несовершенством
приборов, их ограниченной точностью, влиянием внешних условий, потерей
вещества, загрязнениями, неправильно проведенными записями и пр.
Кроме того, при измерениях могут появляться
ошибки от ряда причин, природа которых остается неизвестной. Поэтому в
результате эксперимента аналитик всегда устанавливает только приближенное
значение определяемой величины, но никогда не может получить истинного ее
значения . Вследствие этого измеряемая величина имеет некоторую ошибку,
величину которой принято определять как абсолютную и относительную ошибку.
Абсолютной ошибкой М измеряемой величины называют
разницу между полученным результатом измерения X и истинным (или более достоверным) значением А определяемой
величины:
М = А — X,(97)
Абсолютную ошибку определяют в абсолютных
единицах, ее размерность отвечает размерности измеряемой величины.
Относительной ошибкой V измеряемой величины называют отношение абсолютной ошибки М
к точному значению А определяемой величины:
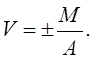
(1)
Но так как истинное значение измеряемой
величины неизвестно и абсолютная ошибка М очень мала по сравнению с
величинами Л и X, то в формуле (1) величину А можно заменить очень
близкой к ней величиной X. Тогда относительная
ошибка будет определяться по формуле
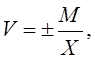
(2)
откуда
![]()
(3)
Относительная ошибка, как видно из формулы
(2), является отношением двух величин одной и той же размерности, поэтому
относительные ошибки — всегда безразмерные величины. Относительную ошибку, как
правило, выражают в процентах
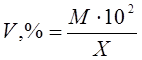
(4)
В связи с этим возникает необходимость оценить
степень приближения определяемой величины к истинному ее значению, иными
словами, дать оценку точности полученных данных эксперимента, а в некоторых
случаях выяснить и устранить причины, обусловливающие появление ошибок.
Цель будет достигнута, если для обработки
экспериментальных данных применить методы математической статистики,
сформулированные в теории ошибок.
Все ошибки разделяют на систематические,
случайные и грубые (промахи).
Систематические сшибки зависят от неправильных показаний измерительных приборов,
неправильно градуированных приборов, мерных колб, пипеток, бюреток,
невыверенных разновесов и др. Систематические ошибки должны быть устранены. Для
этого перед работой все приборы необходимо прокалибровать, неисправные заменить
на исправные и т. д. В показания выверенных приборов следует внести
соответствующие поправки.
Случайные ошибки возникают от различных помех, несовершенства органов чувств
экспериментатора и других случайных причин. Ограниченная точность приборов,
изменение условий, при которых проводится опыт (особенно это имеет значение при
параллельных определениях), также приводят к возникновению случайных ошибок. Устранить
их при измерениях невозможно, однако, пользуясь методом теории ошибок, можно
уменьшить их влияние на результаты анализа и более точно установить вероятную
ошибку в этих результатах.
Грубые ошибки в основном связаны с субъективными свойствами экспериментатора:
невнимательностью и неряшливостью, занятием посторонними делами во время работы
и др. Это приводит к неверным отсчетам, неправильным записям. При обработке
результатов анализа грубые ошибки во внимание не принимают — их отбрасывают.
Метод математической статистики, применяемый
для обработки результатов измерений, вполне оправдал себя в ряде областей
науки. Однако в области химического анализа его применение еще недостаточно,
хотя в этом имеется необходимость.
Известно, что анализ вещества сопровождается
рядом массовых однотипных операций; это: взятие навески, растворение,
градуировка мерной посуды, титрование, измерение силы тока и др. Все эти
операции выполняются различными приборами, среди которых можно выделить
совокупность таких однотипных приборов, как гальванометры, аналитические весы,
микропипетки и многие другие. Поэтому работа аналитика относится к таким
процессам, к которым можно применять методы математической статистики для
обработки результатов эксперимента.
Широкое использование методов математической
статистики для обработки экспериментальных данных, а также для оценки
аналитических данных в любой лаборатории приносит очень большую пользу.
Нормальное распределение. Результаты каждого
анализа представляют собой сумму большого числа взаимно независимых слагаемых
(процессов взвешивания, растворения, осаждения и др.), которые подвергаются
воздействию многообразных факторов. Поэтому можно считать, что случайные ошибки
при всех химических анализах подчиняются закону нормального (гауссовского)
распределения вероятностей и описываются уравнением:
Похожие материалы
- Задание на практическое занятие № 3 по теме «Обыкновенные дифференциальные уравнения»
- Ионизирующее излучение, основы дозиметрии. Первичные продукты радиолиза воды и их взаимодействие с биомолекулами
- Математическая статистика. Генеральная и выборочная совокупности. Статистическое распределение выборки. Полигон и гистограмма
Информация о работе
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание — внизу страницы.
Рассмотрим
некоторые понятия
и основные подходы к классификации
погрешностей.
По способу вычисления погрешности можно
подразделить на
абсолютные и относительные.
Абсолютная
погрешность
равна
разности среднего измерения величины
х
и
истинного значения этой величины:
![]()
В
отдельных случаях, если это необходимо,
рассчитывают погрешности единичных
определений:
![]()
Заметим,
что измеренной величиной в химическом
анализе может быть как содержание
компонента, так и аналитический сигнал.
В зависимости от того, завышает или
занижает погрешность результат анализа,
погрешности могут быть положительные
и
отрицательные.
Относительная
погрешность
может
быть выражена в долях или процентах
и обычно знака не имеет:
![]() или
или
![]()
Можно
классифицировать погрешности по
источникам их происхождения.
Так как источников погрешностей
чрезвычайно много, то их классификация
не может быть однозначной.
Чаще
всего погрешности классифицируют по
характеру причин,
их вызывающих. При этом погрешности
делят на систематические
и случайные,
выделяют также промахи (или грубые
погрешности).
К
систематическим
относят
погрешности, которые вызваны постоянно
действующей причиной, постоянны во всех
измерениях или меняются по постоянно
действующему закону, могут быть выявлены
и устранены.
Случайные
погрешности,
причины появления которых неизвестны,
могут быть оценены
методами математической статистики.
Промах
—
это погрешность, резко искажающая
результат анализа и обычно легко
обнаруживаемая, вызванная, как правило,
небрежностью или некомпетентностью
аналитика. На рис. 1.1 представлена схема,
поясняющая понятия систематических и
погрешностей и промахов. Прямая 1
отвечает
тому идеальному случаю,
когда во всех N определениях отсутствуют
систематические и случайные
погрешности. Линии 2 и 3 тоже идеализированные
примеры химического
анализа. В одном случае (прямая 2) полностью
отсутствуют случайные погрешности,
но все N
определений
имеют постоянную отрицательную
систематическую погрешность Δх ; в
другом случае (линия 3)
полностью
отсутствует систематическая погрешность.
Реальную ситуацию отражает линия
4:имеются
как случайные, так и систематические
погрешности.

Рис.
4.2.1 Систематические
и случайные погрешности химического
анализа.
Деление
погрешностей на систематические и
случайные в известной степени условно.
Систематические
погрешности одной выборки результатов
при рассмотрении большего
числа данных могут переходить в
случайные. Например, систематическая
погрешность, обусловленная неправильными
показаниями прибора, при измерении
аналитического сигнала на разных
приборах
в разных лабораториях переходит
в случайную.
Воспроизводимость
характеризует
степень близости друг к другу единичных
определений, рассеяние единичных
результатов относительно среднего
(рис. 1.2).

Рис.
4.2..2. Воспроизводимость и правильность
химического анализа
В
отдельных случаях
наряду с термином «воспроизводимость»
используют
термин «сходимость».
При
этом под сходимостью понимают рассеяние
результатов
параллельных определений, а под
воспроизводимостью — рассеяние
результатов, полученных разными методами,
в разных лабораториях, в разное время
и т. п.
Правильность
—
это качество химического анализа,
отражающее близость к нулю систематической
погрешности. Правильность характеризует
отклонение
полученного результата анализа от
истинного значения измеряемой
величины (см. рис.1.2).
Генеральная
совокупность
—
гипотетическая совокупность всех
мыслимых
результатов от -∞ до +∞;
Анализ
экспериментальных данных показывает,
что большие по значению погрешности
наблюдаются реже,
чем малые. Отмечается также, что при
увеличении числа наблюдений одинаковые
погрешности разного знака встречаются
одинаково
часто. Эти и другие свойства случайных
погрешностей описываются нормальным
распределением или уравнением
Гаусса, которое
описывает плотность вероятности ![]() .
.

![]()
где
х-значение
случайной величины;
μ
– генеральное
среднее
(математическое
ожидание-постоянный
параметр);
Математическое
ожидание —
для
непрерывной случайной величины
представляет собой предел, к которому
стремится среднее
![]() при неограниченном увеличении выборки.
при неограниченном увеличении выборки.
Таким образом, математическое ожидание
является средним значением для всей
генеральной совокупности в целом, иногда
его называют
генеральным
средним.
σ2
—дисперсия
(постоянный параметр) —
характеризует рассеяние случайной
величины относительно своего
математического ожидания;
σ
– стандартное отклонение.
Дисперсия
– характеризует рассеяние случайной
величины относительно своего
математического ожидания.
Выборочная
совокупность (выборка)
— реальное
число (n) результатов, которое имеет
исследователь ,
n
= 3 ÷ 10.
Нормальный
закон распределения неприемлем
для обработки малого числа изменений
выборочной совокупности (обычно 3 – 10)
– даже если генеральная совокупность
в целом распределена нормально. Для
малых выборок вместо нормального
распределения используют распределение
Стьюдента (t
– распределение),
которое связывает между собой три
основные характеристики выборочной
совокупности –
-ширину
доверительного интервала;
-соответствующую
ему вероятность;
—
объем выборочной совокупности.
Перед
обработкой данных с применением методов
математической статистики необходимо
выявить промахи
(грубые ошибки) и исключить их из числа
рассматриваемых результатов. Одним из
наиболее простых является метод
выявления промахов с применением Q –
критерия с числом измерений n
< 10:
![]()
где
R
= хмакс
—
хмин
– размах варьирования; х1
–
подозрительно выделяющееся значение;
х2
– результат единичного определения,
ближайший по значению к х1.
Полученное
значение сравнивают с критическим
значением Qкрит
при доверительной вероятности Р = 0,95.
Если Q
> Qкрит,
выпадающий результат является промахом
и его отбрасывают.
Основные
характеристики выборочной совокупности.
Для выборки из n
результатов
рассчитывают среднее,
![]() :
:

и
дисперсию,
характеризующую рассеяние результатов
относительно среднего:

Дисперсия
в явном виде не может быть использована
для количественной характеристики
рассеяния результатов, поскольку ее
размерность не совпадает с размерностью
результата анализа. Для характеристики
рассеяния используют стандартное
отклонение, S.
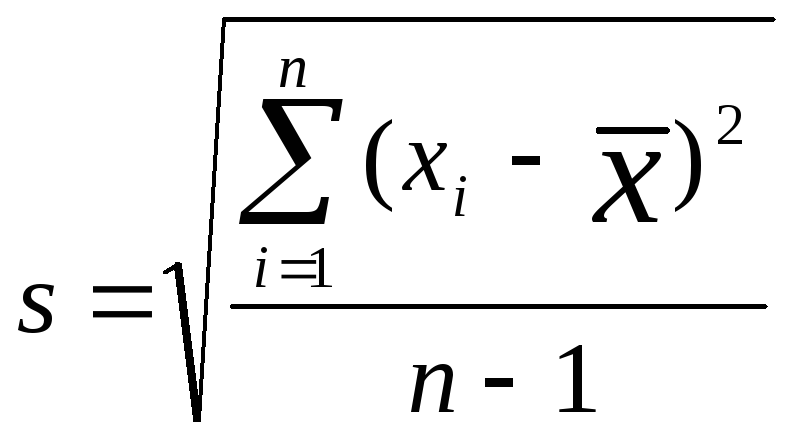
Эту
величину называют также средним
квадратичным (или квадратическим)
отклонением или средней квадратичной
погрешностью отдельного результата.
Относительное
стандартное отклонение
или
коэффициент вариации (V)
вычисляют по соотношению
![]()
Дисперсию
среднего арифметического
вычисляют:

и
стандартное отклонение среднего

Следует
отметить, что все величины – дисперсия,
стандартное отклонение и относительное
стандартное отклонение, а так же дисперсия
среднего арифметического и стандартное
отклонение среднего арифметического
– характеризуют воспроизводимость
результатов химического анализа.
Используемое
при обработке небольших (n<20)
выборок из нормально распределенной
генеральной совокупности t
– распределение (т.е. распределение
нормированной случайной величины)
характеризуется соотношением
![]()
где
tp,f
– распределение
Стьюдента при числе степеней свободы
f=n-1
и
доверительной вероятности
Р=0,95 (или
уровня значимости
р=0,05).
Значения
t
— распределения приведены в таблицах,
по ним рассчитывают для выборки в n
результатов
величину доверительного интервала
измеряемой величины для заданной
доверительной вероятности по формуле
![]()
Доверительный
интервал
характеризует как воспроизводимость
результатов химического анализа, так
и – если известно истинное значение
хист
– их правильность.
Пример
выполнения контрольной работы № 2
Задание
При
анализе
воздуха на содержание азота
хроматографическим методом для двух
серий опытов получены следующие
результаты:
|
№ |
Результат |
|||||||
|
1 |
77,95 |
78,08 |
77,90 |
77,92 |
78,10 |
78,05 |
78,07 |
77,99 |
|
2 |
78,08 |
78,13 |
78,02 |
78,16 |
78,20 |
78,26 |
78,14 |
78,23 |
Рассчитать
среднее значение концентрации компонента
и его доверительный интервал. Принадлежат
ли результаты обеих выборок одной и той
же генеральной совокупности.
Решение:
Проверяем
ряды на наличие грубых ошибок по
Q-критерию.
Для чего их располагаем результаты в
ряд по убыванию (от минимума к максимуму
или наоборот) :
Первая
серия:
77,90<77,92<77,95<77,99<78,05<78,07<78,08<78,10
Проверяем
крайние результаты ряда (не содержат
ли они грубую ошибку).
![]()
Полученное
значение сравниваем с табличным (табл.2
приложения). Для n=8,
p=0,95
Qтаб=0,55.
Т.к.
Qтаб
>Q1
расчет ,
левая крайняя цифра не является
«промахом».
Проверяем
крайнюю правую цифру
![]()
Qрасч<Qтаб,
т.к. 0,1<0,55 (n=8,
p=0,95).
Крайняя
правая цифра так же не является ошибочной.
Располагаем
результаты
второго ряда
в порядке их возрастания:
78,02<78,08<78,13<78,14<78,16<78,20<78,23<78,26.
Проверяем
крайние результаты опытов — не являются
ли они ошибочными.
![]()
Q
(n=8,
p=0,95)=0,55.
Табличное значение.
![]() <Q(n=8,
<Q(n=8,
p=0,95),
т.е. 0,25<0,55
Крайнее
левое значение – не ошибочное.
Крайняя
правая цифра (не является ли она
ошибочной).
![]()
![]() ,
,
т.е. 0,125<0,55
Крайнее
правое число не является «промахом».
Подвергаем
результаты опытов статистической
обработке.
-
Вычисляем
средневзвешенные результатов:
 —
—
для первого ряда результатов.
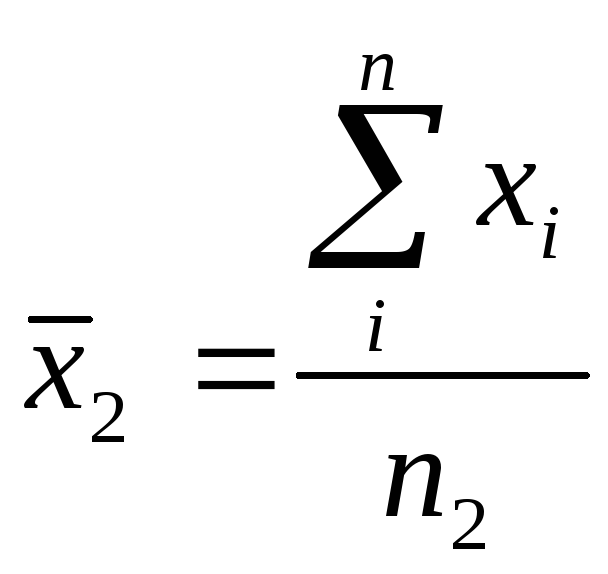 —
—
для второго ряда результатов.
-
Дисперсия
относительно среднего:
 —
—
для первого ряда.
 —
—
для второго ряда.
-
Стандартное
отклонение:
 —
—
для первого ряда.
 —
—
для второго ряда.
-
Стандартное
отклонение среднего арифметического:


При
небольших (n<20)
выборках из нормально распределенной
генеральной совокупности следует
использовать t
– распределение, т.е. распределение
Стьюдента при числе степени свободы
f=n-1
и доверительной вероятности p=0,95.
Пользуясь
таблицами t
– распределения, определяют для выборки
в n
– результатов величину доверительного
интервала измеряемой величины для
заданной доверительной вероятности.
Этот интервал можно рассчитать:

Сравниваем
дисперсии и
средние результаты двух
выборочных совокупностей.
Сравнение
двух дисперсий проводится при помощи
F-
распределения (распределения Фишера).
Если мы имеем две выборочные совокупности
с дисперсиями S21
и
S22
и
числами степеней свободы f1=n1-1
и f2=n2-1,
соответственно, то рассчитываем значение
F:
F=S21
/
S22
Причем в
числителе всегда находится большая из
двух
сравниваемых выборочных дисперсий.
Полученный результат сравнивают с
табличным значением. Если F0
>
Fкрит
(при р=0,95; n1,
n2),
то расхождение между дисперсиями значимо
и рассматриваемые выборочные совокупности
различаются по воспроизводимости.
Если
расхождение между дисперсиями незначимо,
возможно сравнить средние x1
и
х2
двух выборочных совокупностей, т.е.
выяснить, есть ли статистически значимая
разница между результатами анализов.
Для решения поставленной задачи
используют t
– распределение. Предварительно
рассчитывают средневзвешенное двух
дисперсий:
![]()
И
средневзвешенное стандартное отклонение
![]()
а
затем – величину t:
![]()
Значение
tэксп
сравнивают с tкрит
при числе степеней свободы f=f1+f2=(n1+n2-2)
и выборочной доверительной вероятности
р=0,95. Если при этом tэксп
> tкрит
,то
расхождение между средними
![]()
и
![]()
значимо и выборка не принадлежит одной
и той же генеральной совокупности. Если
tэксп<
tкрит,
расхождение между средними незначимо,
т.е. выборки принадлежат одной и той же
генеральной совокупности, и, следовательно,
данные обеих серий можно объединить и
рассматривать их как одну выборочную
совокупность из n1+n2
результатов.

Контрольное
задание № 2
Анализ
воздуха на содержание компонента Х
хроматографическим методом для двух
серий дал следующие результаты
(таблица-1).
1.
Для каждой из двух серий опытов рассчитать
среднее значение концентрации компонента
и его доверительный интервал (провести
статистическую обработку результатов
для двух серии опытов).
3.
Принадлежат ли результаты обеих выборок
и одной и той же генеральной совокупности.
Проверить по критерию Стьюдента t (р =
0,95; n
= 8).
Таблица-4.2.1-
Исходные данные по контрольному заданию
№ 2
|
№ варианта |
Ком-понент |
№ серии |
Содержание |
|||||||
|
1 |
N2 |
I |
79,42 |
81,18 |
79,24 |
79,16 |
80,90 |
78,78 |
79,12 |
79,20 |
|
II |
79,75 |
80,81 |
79,94 |
79,90 |
80,74 |
80,74 |
79,68 |
79,91 |
||
|
2 |
O2 |
I |
18,80 |
18,90 |
18,95 |
18,82 |
18,76 |
18,93 |
18,91 |
18,97 |
|
II |
19,10 |
18,98 |
18,94 |
18,92 |
18,89 |
18,86 |
18,84 |
18,90 |
||
|
3 |
Ar2 |
I |
0,933 |
0,928 |
0,916 |
0,922 |
0,935 |
0,933 |
0,930 |
0,929 |
|
II |
0,945 |
0,942 |
0,939 |
0,937 |
0,940 |
0,944 |
0,938 |
0,936 |
||
|
4 |
N2 |
I |
78,08 |
78,20 |
78,34 |
78,28 |
78,50 |
78,32 |
78,47 |
78,11 |
|
II |
78,60 |
78,45 |
78,56 |
78,56 |
78,70 |
78,58 |
78,49 |
78,42 |
||
|
5 |
O2 |
I |
19,70 |
19,75 |
19,72 |
19,20 |
19,68 |
19,80 |
19,78 |
19,81 |
|
II |
20,68 |
20,56 |
20,54 |
20,60 |
20,52 |
20,55 |
20,42 |
20,40 |
||
|
6 |
Ar2 |
I |
0,956 |
0,954 |
0,952 |
0,956 |
0,953 |
0,958 |
0,957 |
0,956 |
|
II |
0,962 |
0,968 |
0,964 |
0,965 |
0,960 |
0,961 |
0,965 |
0,963 |
||
|
7 |
N2 |
I |
80,05 |
80,20 |
80,16 |
80,26 |
80,34 |
80,10 |
80,12 |
80,28 |
|
II |
79,98 |
80,06 |
79,90 |
80,26 |
80,15 |
80,30 |
80,29 |
80,31 |
||
|
8 |
O2 |
I |
20,95 |
20,88 |
20,93 |
21,00 |
20,89 |
20,98 |
20,92 |
20,90 |
|
II |
20,87 |
20,85 |
20,81 |
20,86 |
21,12 |
20,92 |
20,84 |
20,87 |
||
|
9 |
Ar2 |
I |
0,923 |
0,926 |
0,926 |
0,920 |
0,918 |
0,924 |
0,925 |
0,919 |
|
II |
0,932 |
0,936 |
0,928 |
0,929 |
0,930 |
0,935 |
0,940 |
0,938 |
||
|
10 |
N2 |
I |
77,95 |
78,08 |
77,90 |
77,92 |
78,10 |
78,05 |
78,07 |
77,99 |
|
II |
78,08 |
78,13 |
78,02 |
78,16 |
78,20 |
78,26 |
78,14 |
78,23 |
||
|
11 |
O2 |
I |
21,90 |
21,87 |
21,80 |
21,86 |
21,89 |
21,82 |
21,92 |
21,85 |
|
II |
21,78 |
21,85 |
21,92 |
21,89 |
21,84 |
21,89 |
21,95 |
21,98 |
||
|
12 |
Ar2 |
I |
0,954 |
0,956 |
0,953 |
0,549 |
0,548 |
0,950 |
0,952 |
0,949 |
|
II |
0,936 |
0,946 |
0,938 |
0,944 |
0,948 |
0,939 |
0,940 |
0,941 |
||
|
13 |
N2 |
I |
81,06 |
81,13 |
81,25 |
81,34 |
81,23 |
81,30 |
81,17 |
81,35 |
|
II |
81,25 |
81,03 |
81,32 |
81,29 |
81,19 |
81,10 |
81,28 |
81,15 |
||
|
14 |
O2 |
I |
20,34 |
20,66 |
20,38 |
20,45 |
20,48 |
20,41 |
20,40 |
20,36 |
|
II |
20,62 |
20,68 |
20,56 |
20,61 |
20,64 |
20,58 |
20,66 |
20,59 |
||
|
15 |
Ar2 |
I |
0,910 |
0,913 |
0,915 |
0,900 |
0,908 |
0,916 |
0,918 |
0,912 |
|
II |
0,920 |
0,926 |
0,921 |
0,928 |
0,923 |
0,926 |
0,927 |
0,922 |
||
|
16 |
N2 |
I |
78,65 |
78,56 |
78,63 |
78,50 |
78,70 |
78,60 |
78,69 |
78,63 |
|
II |
78,81 |
78,83 |
78,77 |
78,80 |
78,76 |
78,50 |
78,69 |
78,65 |
||
|
17 |
O2 |
I |
19,20 |
19,26 |
19,17 |
19,30 |
19,10 |
19,11 |
19,24 |
19,29 |
|
II |
18,98 |
18,88 |
19,00 |
19,10 |
19,05 |
19,03 |
19,01 |
19,09 |
||
|
18 |
Ar2 |
I |
0,956 |
0,959 |
0,962 |
0,964 |
0,965 |
0,963 |
0,952 |
0,960 |
|
II |
0,950 |
0,964 |
0,953 |
0,952 |
0,968 |
0,963 |
0,965 |
0,961 |
||
|
19 |
N2 |
I |
79,65 |
79,35 |
79,59 |
79,25 |
79,58 |
79,68 |
79,60 |
79,45 |
|
II |
79,42 |
79,00 |
79,39 |
79,48 |
79,60 |
79,36 |
79,40 |
79,37 |
||
|
20 |
O2 |
I |
21,30 |
21,35 |
21,46 |
21,33 |
21,42 |
21,36 |
21,40 |
21,43 |
|
II |
21,00 |
21,20 |
21,09 |
21,25 |
21,13 |
21,10 |
21,24 |
21,08 |
||
|
21 |
Ar2 |
I |
0,926 |
0928 |
0,930 |
0,929 |
0,932 |
0,935 |
0,927 |
0,934 |
|
II |
0,933 |
0,935 |
0,934 |
0,932 |
0,936 |
0,933 |
0,937 |
0,938 |
||
|
22 |
N2 |
I |
78,00 |
78,16 |
78,20 |
77,96 |
77,98 |
78,14 |
78,18 |
78,09 |
|
II |
78,31 |
78,26 |
78,15 |
77,80 |
78,36 |
78,29 |
78,29 |
78,21 |
||
|
23 |
O2 |
I |
20,60 |
20,69 |
20,59 |
20,61 |
20,63 |
20,69 |
20,61 |
20,68 |
|
II |
20,53 |
20,54 |
20,69 |
20,64 |
20,58 |
20,53 |
20,55 |
20,62 |
||
|
24 |
Ar2 |
I |
0,900 |
0,910 |
0,912 |
0,908 |
0,909 |
0,910 |
0,907 |
0,905 |
|
II |
0,910 |
0,916 |
0,920 |
0,926 |
0,924 |
0,927 |
0,930 |
0,925 |
||
|
25 |
N2 |
I |
81,19 |
81,34 |
81,00 |
81,29 |
81,26 |
81,17 |
81,21 |
81,21 |
|
II |
80,96 |
81,05 |
81,24 |
81,19 |
81,13 |
81,23 |
81,11 |
81,00 |
Классификация и оценка погрешностей количественного анализа
По способу вычисления различают абсолютную  и относительную
и относительную  (ранее
(ранее 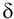 ) погрешности.
) погрешности.
Если среднее арифметическое значение 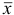 для
для 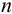 полученных результатов анализа составляет:
полученных результатов анализа составляет:
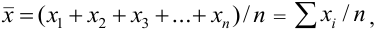
то абсолютную погрешность выражают как
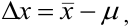
где 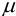 — истинное содержание определяемого компонента (например, известное для стандартного образца или контрольной пробы). Очевидно, что абсолютная погрешность может быть положительной или отрицательной, в зависимости от того, каким получился результат: завышенным или заниженным по сравнению с истинным (рис. 9.1).
— истинное содержание определяемого компонента (например, известное для стандартного образца или контрольной пробы). Очевидно, что абсолютная погрешность может быть положительной или отрицательной, в зависимости от того, каким получился результат: завышенным или заниженным по сравнению с истинным (рис. 9.1).
Относительная погрешность может быть выражена в долях или процентах и обычно не имеет знака:
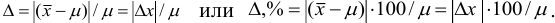
По происхождению погрешности делят на систематические, случайные и промахи (грубые ошибки).
Погрешность определения, обусловленная постоянно действующей причиной, неизменная во всех измерениях, сохраняющая знак от опыта к опыту или закономерно изменяющаяся, называется систематической погрешностью. Погрешность, случайным образом изменяющаяся от опыта к опыту, называется случайной погрешностью. Грубые погрешности или промахи резко искажают результат анализа, вызываются небрежностью и обычно легко обнаруживаются.
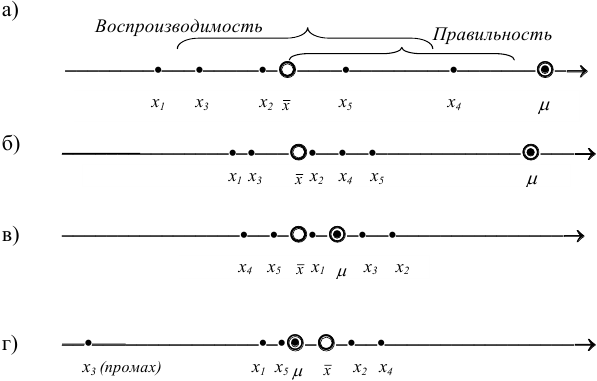
Рис. 9.1. Воспроизводимость и правильность химического анализа. Результаты: а) невоспроизводимы и неправильны; б) воспроизводимы, но неправильны; в) воспроизводимы и правильны; г) воспроизводимы и правильны, но есть промах.
С систематическими погрешностями связана правильность анализа, со случайными погрешностями — воспроизводимость. Правильность и воспроизводимость являются метрологическими характеристиками анализа и входят в понятие «точность анализа».
Воспроизводимость результатов анализа характеризует рассеяние единичных результатов относительно среднего.
Правильность характеризует отклонение полученного результата от истинного и показывает, насколько близка к нулю систематическая погрешность. Систематические погрешности выявляют и устраняют. Если же устранение невозможно, то при постоянном значении систематической погрешности ее учитывают, вводя поправку. Для выявления используют различные приемы и методы, например “введено — найдено”, анализ стандартного образца, “двойной или тройной добавки”.
Оценка случайных погрешностей проводится методами математической статистики. В обычной практике выполняют ограниченное число параллельных измерений п (обычно 3-5), называемое выборочной совокупностью данных или просто выборкой (в отличие от генеральной совокупности — при 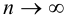 ). При
). При 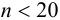 математическую обработку результатов проводят с использованием распределения Стьюдепта, связывающего вероятность попадания величины в данный доверительный интервал и объем выборки . Среднее для ряда параллельных определений,
математическую обработку результатов проводят с использованием распределения Стьюдепта, связывающего вероятность попадания величины в данный доверительный интервал и объем выборки . Среднее для ряда параллельных определений, 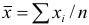 , является наиболее вероятным значением измеряемой величины.
, является наиболее вероятным значением измеряемой величины.
Характеристики случайной погрешности (воспроизводимости) для выборки: выборочная дисперсия 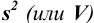 , стандартное отклонение
, стандартное отклонение 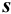 и относительное стандартное отклонение
и относительное стандартное отклонение 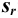 :
:
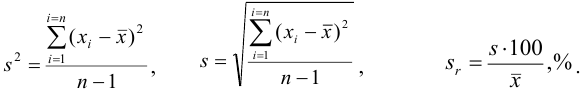
С ними связаны дисперсия среднего 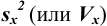 и стандартное отклонение среднего
и стандартное отклонение среднего 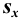 :
: 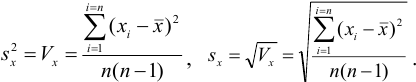
При обработке данных химического анализа определяют границы доверительного интервала 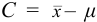 , вводя число степеней свободы
, вводя число степеней свободы 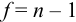 .
.
Доверительный интервал (С) — это интервал значений, в котором для данного вида распределения случайных величин (при отсутствии систематических погрешностей), при заданной доверительной вероятности Р и числе степеней свободы 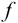 лежит истинное значение определяемой величины:
лежит истинное значение определяемой величины:
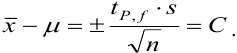
Доверительная вероятность попадания величины внутрь доверительного интервала в химическом анализе принята равной 0,95 или 95 %. Это означает, что в рассчитанный интервал попадут 95 из 100 значений. Коэффициенты 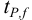 — коэффициенты нормированных отклонений Стьюдента приведены в табл. 8 приложения. Зависимость
— коэффициенты нормированных отклонений Стьюдента приведены в табл. 8 приложения. Зависимость 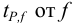 показывает, что с возрастанием числа степеней свободы, т. е. числа параллельных результатов, увеличивается и точность анализа, поскольку доверительный интервал характеризует воспроизводимость и, в какой-то мере, правильность результатов химического анализа. С учетом доверительного интервала истинное значение представляют выражением:
показывает, что с возрастанием числа степеней свободы, т. е. числа параллельных результатов, увеличивается и точность анализа, поскольку доверительный интервал характеризует воспроизводимость и, в какой-то мере, правильность результатов химического анализа. С учетом доверительного интервала истинное значение представляют выражением:
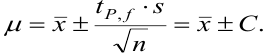
Оценка промахов (выбраковка результатов). Перед обработкой данных методами математической статистики необходимо выявить промахи и исключить их из числа обрабатываемых результатов. Для выявления промахов используют различные критерии, в частности, 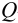 -критерий. Проверку соответствия -критерию про водят следующим образом. Все параллельные результаты располагают в последовательности их убывания или возрастания. При этом
-критерий. Проверку соответствия -критерию про водят следующим образом. Все параллельные результаты располагают в последовательности их убывания или возрастания. При этом 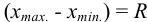 — размах варьирования. Затем рассчитывают
— размах варьирования. Затем рассчитывают 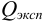 :
:
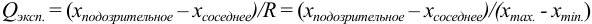
и сравнивают с критическим значением 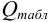 при доверительной вероятности 0,90 (табл. 9 приложения).
при доверительной вероятности 0,90 (табл. 9 приложения).
Если 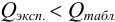 , то промах отсутствует и подозрительный результат оставляют в составе выборки. Если же
, то промах отсутствует и подозрительный результат оставляют в составе выборки. Если же 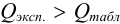 , то подозрительное значение является промахом, грубой погрешностью; его отбрасывают.
, то подозрительное значение является промахом, грубой погрешностью; его отбрасывают.
— критерий рекомендуется применять к выборкам с 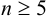 . При малой выборке
. При малой выборке 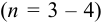 заметно отличающийся от других результат просто отбрасывают, а определение повторяют и после этого оценивают случайную погрешность. Если
заметно отличающийся от других результат просто отбрасывают, а определение повторяют и после этого оценивают случайную погрешность. Если 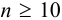 , промахи можно установить с помощью
, промахи можно установить с помощью 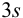 — критерия, проверяя для каждого отклонения
— критерия, проверяя для каждого отклонения 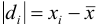 выполнение условия
выполнение условия 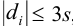 , позволяющего оставить результат в составе выборки.
, позволяющего оставить результат в составе выборки.
Пример 9.1.
Контрольный раствор соли кальция имеет концентрацию 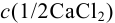 , равную 0,1056 моль/л. Студентом было получено методом перманганатометрии среднее значение
, равную 0,1056 моль/л. Студентом было получено методом перманганатометрии среднее значение 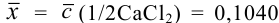 . Вычислите абсолютную и относительную погрешности.
. Вычислите абсолютную и относительную погрешности.
Решение:
Абсолютная погрешность результата:
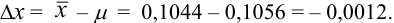
Относительная погрешность:
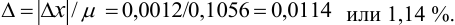
Пример 9.2.
При определении содержания аскорбиновой кислоты в пробе картофеля по новой методике пробоподготовки получены следующие результаты (мг/100 г): 14,50; 14,43; 14,54; 14,45; 14,44; 14,52; 14,58; 14,40; 14,25; 14,49. Оцените:
а) наличие грубых погрешностей (промахов);
б) воспроизводимость результатов анализа.
Решение:
а) наличие промахов оценим по -критерию. Представим экспериментальные данные в порядке возрастания: 14,25; 14,40; 14,43; 14,44; 14,45; 14,49; 14,50; 14,52; 14,54; 14,58. Проверим подозрительные значения 14,25 и 14,58. Вычислим — критерий для этих величин:
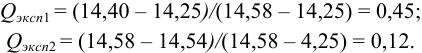
Из табл. 9 приложения при 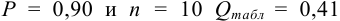 ;
; 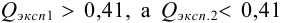 , следовательно, значение 14,25 недостоверно и его исключаем, сокращая объем выборки до
, следовательно, значение 14,25 недостоверно и его исключаем, сокращая объем выборки до 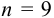 .
.
б) после исключения промаха найдем среднее и характеристики воспроизводимости: дисперсию 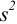 , стандартное отклонение
, стандартное отклонение 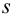 и относительное стандартное отклонение
и относительное стандартное отклонение 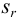 :
:

Пример 9.3.
Используя условия примера 9.2 и считая, что содержание аскорбиновой кислоты для той же пробы картофеля, определенное по стандартной методике составляет 14,58 мг/100 г, рассчитайте доверительный интервал и установите, свидетельствуют ли полученные результаты о наличии систематической погрешности при работе по новой методике?
Решение:
Для расчета доверительного интервала при числе степеней свободы 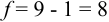 и доверительной вероятности Р = 0,95 из табл. 8 приложения находим коэффициент Стьюдента
и доверительной вероятности Р = 0,95 из табл. 8 приложения находим коэффициент Стьюдента 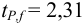 .
.
Находим полуширину доверительного интервала, оставляя значащие цифры:
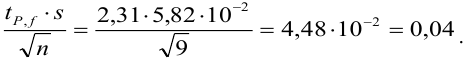
Таким образом, среднее содержание аскорбиновой кислоты лежит в границах
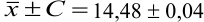 или
или 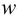 (кислоты), мг/100 г = 14,48 ± 0,04. Истинное значение содержания аскорбиновой кислоты14,58 не попадает в доверительный интервал, следовательно, такой метод пробоподготовки картофеля к анализу имеет систематическую погрешность, причину которой надо выяснять.
(кислоты), мг/100 г = 14,48 ± 0,04. Истинное значение содержания аскорбиновой кислоты14,58 не попадает в доверительный интервал, следовательно, такой метод пробоподготовки картофеля к анализу имеет систематическую погрешность, причину которой надо выяснять.
Пример 9.4.
При анализе стандартного образца, содержащего 1,44 % 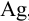 , были получены результаты (%): 1,31; 1,45; 1,42; 1,32; 1,30. Определить стандартное отклонение, доверительный интервал и сделать выводы о наличии систематической погрешности в использованном методе определения серебра.
, были получены результаты (%): 1,31; 1,45; 1,42; 1,32; 1,30. Определить стандартное отклонение, доверительный интервал и сделать выводы о наличии систематической погрешности в использованном методе определения серебра.
Решение:
Проверим наличие грубых погрешностей по -критерию. Располагаем экспериментальные данные в порядке возрастания численных значений: 1,30; 1,31; 1,32; 1,42; 1,45. Предполагаем, что значение 1,45 является результатом грубой погрешности. Рассчитываем для него -критерий:
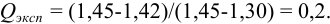
Для 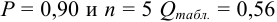 (табл. 9 приложения). Вычисленное значение -критерия
(табл. 9 приложения). Вычисленное значение -критерия 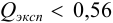 , следовательно, грубая погрешность отсутствует.
, следовательно, грубая погрешность отсутствует.
Находим среднее значение из пяти определений:
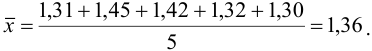
Вычисляем стандартное отклонение:
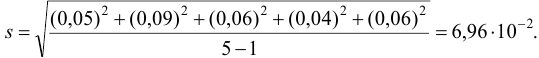
По табл. 8 приложения для 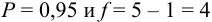 находим
находим 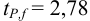 и рассчитываем полуширину доверительного интервала для
и рассчитываем полуширину доверительного интервала для 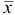 :
:
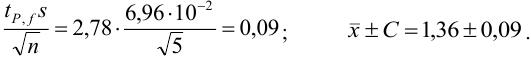
Результат представляем в виде: 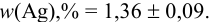
Наличие систематической погрешности можно выявить, как в предыдущем примере, проверяя попадает ли истинное значение содержания серебра в доверительный интервал. В данном случае для 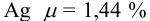 попадает в границы доверительного интервала, следовательно, систематическая погрешность в этом методе определения серебра отсутствует.
попадает в границы доверительного интервала, следовательно, систематическая погрешность в этом методе определения серебра отсутствует.
Ответить на вопрос задачи о присутствии систематической погрешности можно, используя критерий Стьюдента и сравнивая вычисленное значение 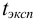 с табличным значением
с табличным значением 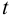 — критерия при
— критерия при 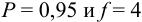 , равным 2,78:
, равным 2,78:
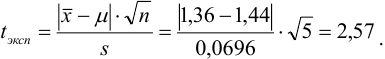
Поскольку 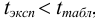 делаем вывод о вероятном отсутствии систематической погрешности.
делаем вывод о вероятном отсутствии систематической погрешности.
Пример 9.5.
При определении ванадия были получены результаты: 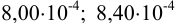 г. Чему равен доверительный интервал? Сколько параллельных определений необходимо провести для достижения доверительного интервала с полушириной
г. Чему равен доверительный интервал? Сколько параллельных определений необходимо провести для достижения доверительного интервала с полушириной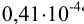 ?
?
Решение:
Находим среднее значение:
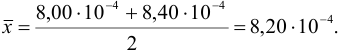
Вычислим стандартное отклонение:

По табл. 8 приложения находим 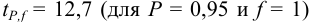 и вычисляем полуширину доверительного интервала:
и вычисляем полуширину доверительного интервала:
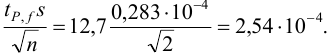
Требуется же получить доверительный интервал с полушириной 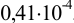 Найдем необходимое для этого соотношение
Найдем необходимое для этого соотношение  :
:
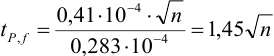 или
или 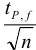 должно быть
должно быть 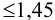 .
.
При 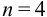 значение критерия
значение критерия 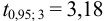 , а отношение
, а отношение 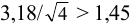 ; при
; при 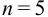 значение критерия
значение критерия 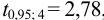 , а отношение
, а отношение 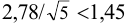 .
.
Таким образом, для сужения границ доверительного интервала до 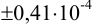 необходимо провести 5 параллельных определений.
необходимо провести 5 параллельных определений.
Эти примеры взяты со страницы примеров решения задач по аналитической химии:
Решение задач по аналитической химии
Возможны вам будут полезны эти страницы:
