
В
статистике выделяют два основных метода
исследования — сплошной и выборочный.
При проведении выборочного исследования
обязательным является соблюдение
следующих требований: репрезентативность
выборочной совокупности и достаточное
число единиц наблюдений. При выборе
единиц наблюдения возможны ошибки
смещения,
т.е. такие события, появление которых
не может быть точно предсказуемым. Эти
ошибки являются объективными и
закономерными. При определении степени
точности выборочного исследования
оценивается величина ошибки, которая
может произойти в процессе выборки
— случайная
ошибка репрезентативности (m)
— является
фактической разностью между средними
или относительными величинами, полученными
при проведении выборочного исследования
и аналогичными величинами, которые были
бы получены при проведении исследования
на генеральной совокупности.
Оценка
достоверности результатов исследования
предусматривает определение:
1.
ошибки репрезентативности
2.
доверительных границ средних (или
относительных) величин в генеральной
совокупности
3.
достоверности разности средних (или
относительных) величин (по критерию t)
Расчет
ошибки репрезентативности
(mм)
средней арифметической величины
(М):
![]()
![]() ,
,
где σ
— среднее квадратическое отклонение; n
— численность выборки (>30).
Расчет
ошибки репрезентативности (mР)
относительной величины (Р):
![]() ,
,
где Р — соответствующая относительная
величина (рассчитанная, например, в %);
q
=100 — Ρ%
— величина, обратная Р; n
— численность выборки (n>30)
В
клинических и экспериментальных работах
довольно часто приходится использовать
малую
выборку, когда
число наблюдений меньше или равно 30.
При малой выборке для расчета ошибок
репрезентативности, как средних, так
и относительных величин,
число
наблюдений уменьшается на единицу,
т.е.
![]() ;
;
![]() .
.
Величина
ошибки репрезентативности зависит от
объема выборки: чем больше число
наблюдений, тем меньше ошибка. Для оценки
достоверности выборочного показателя
принят следующий подход: показатель
(или средняя величина) должен в 3 раза
превышать свою ошибку, в этом случае он
считается достоверным.
83. Определение доверительных границ средних и относительных величин.
Знание
величины ошибки недостаточно для того,
чтобы быть уверенным в результатах
выборочного исследования, так как
конкретная ошибка выборочного
исследования может быть значительно
больше (или меньше) величины средней
ошибки репрезентативности. Для
определения точности, с которой
исследователь желает получить результат,
в статистике используется такое понятие,
как вероятность безошибочного
прогноза, которая является характеристикой
надежности результатов выборочных
медико-биологических статистических
исследований. Обычно, при проведении
медико-биологических статистических
исследований используют вероятность
безошибочного прогноза 95% или 99%. В
наиболее ответственных случаях, когда
необходимо сделать особенно важные
выводы в теоретическом или практическом
отношении, используют вероятность
безошибочного прогноза 99,7%
Определенной
степени вероятности безошибочного
прогноза соответствует определенная
величина предельной
ошибки случайной выборки (Δ
— дельта),
которая определяется по формуле:
Δ=t
* m
, где t
— доверительный коэффициент, который
при большой выборке при вероятности
безошибочного прогноза 95% равен 2,6;
при вероятности безошибочного
прогноза 99% — 3,0; при вероятности
безошибочного прогноза 99,7% — 3,3, а при
малой выборке определяется по специальной
таблице значений t
Стьюдента.
Используя
предельную ошибку выборки (Δ),
можно определить доверительные
границы,
в которых с определенной вероятностью
безошибочного прогноза заключено
действительное значение статистической
величины,
характеризующей
всю генеральную совокупность (средней
или относительной).
Для
определения доверительных границ
используются следующие формулы:
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Ошибка выборки — определение, типы, контроль и уменьшение ошибок
Опубликовано 2023-02-11 19:54 пользователем

Что такое ошибка выборки?
Ошибка выборки возникает, когда выборка, используемая в исследовании, не является репрезентативной для всей популяции. Ошибки выборки случаются часто, поэтому исследователи всегда рассчитывают предел ошибки при получении окончательных результатов в качестве статистической практики. Предел погрешности — это величина погрешности, допустимая при неправильном расчете, представляющая собой разницу между выборкой и реальной популяцией.
Выберите своих респондентов
Каковы наиболее распространенные ошибки выборки в маркетинговых исследованиях?
Вот четыре основные ошибки маркетинговых исследований при составлении выборки:
- Ошибка спецификации популяции: Ошибка спецификации популяции возникает, когда исследователи не знают, кого именно нужно опросить. Например, представьте себе исследование, посвященное детской одежде. Кого нужно опросить? Это могут быть оба родителя, только мать или ребенок. Родители принимают решение о покупке, но дети могут повлиять на их выбор.
- Ошибка выборочной совокупности: Ошибки выборочной совокупности возникают, когда исследователи неправильно ориентируются на субпопуляцию при отборе выборки. Например, выборка из телефонного справочника может иметь ошибочные включения, поскольку люди меняют свои города. Ошибочные исключения происходят, когда люди предпочитают не указывать свои номера. Богатые домохозяйства могут иметь более одного подключения, что приводит к многократным включениям.
- Ошибка отбора: Ошибка отбора происходит, когда респонденты сами выбирают себя для участия в исследовании. Отвечают только те, кто заинтересован. Ошибки отбора можно контролировать, если сделать дополнительный шаг и запросить ответы у всей выборки. Планирование перед опросом, последующие действия и аккуратный и чистый дизайн опроса повысят процент участия респондентов. Кроме того, попробуйте такие методы, как CATI-опросы и личные интервью, чтобы максимизировать количество ответов.
- Ошибки выборки: Ошибки выборки возникают из-за неравномерной репрезентативности респондентов. В основном это происходит, когда исследователь не планирует тщательно свою выборку. Эти ошибки выборки можно контролировать и устранять, создавая тщательный план выборки, имея достаточно большую выборку, отражающую все население, или используя для сбора ответов онлайн-выборку или аудиторию опроса.
Контроль ошибки выборки
Статистические теории помогают исследователям измерить вероятность ошибки выборки в зависимости от размера выборки и населения. Размер выборки, рассматриваемой из совокупности, в первую очередь определяет размер ошибки выборки. При больших размерах выборки вероятность ошибки ниже. Для понимания и оценки погрешности исследователи используют метрику, известную как предел погрешности. Обычно желаемым уровнем достоверности считается уровень достоверности в 95%.
Про совет: Если вам нужна помощь в расчете собственного предела погрешности, вы можете воспользоваться нашим калькулятором предела погрешности.
Каковы шаги по сокращению ошибок выборки?
Ошибки выборки легко выявить. Вот несколько простых шагов по уменьшению ошибки выборки:
- Увеличение размера выборки: Больший размер выборки дает более точный результат, поскольку исследование приближается к реальному размеру популяции.
- Разделение популяции на группы: Тестируйте группы в соответствии с их размером в популяции вместо случайной выборки. Например, если люди определенной демографической группы составляют 20% населения, убедитесь, что ваше исследование состоит из этой переменной, чтобы уменьшить смещение выборки.
- Знать свое население: Изучите свое население и поймите его демографический состав. Знайте, какие демографические группы используют ваш продукт и услугу, и убедитесь, что вы нацелены только на ту выборку, которая имеет значение.
Мы также создали инструмент, который поможет вам легко определить вашу выборку: Калькулятор размера выборки.
Ошибка выборки поддается измерению, и исследователи могут использовать ее в своих интересах, чтобы оценить точность своих выводов и оценить дисперсию.
Рубрика:
- Бизнес
Ключевые слова:
- аудитория
Автор:
- Dan Fleetwood
Источник:
- questionpro
Перевод:
- Дмитрий Л
Понятие репрезентативности часто встречается в статистических отчетностях и при подготовке выступлений и докладов. Пожалуй, без нее трудно представить себе какой-либо из видов подачи информации на обозрение.
Репрезентативность — что это?
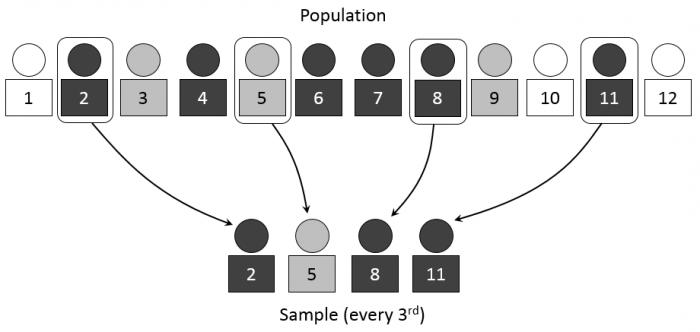
Репрезентативность отражает, насколько выбранные объекты или части соответствуют содержанию и смыслу совокупности данных, из которой они были выбраны.
Другие определения
Понятие репрезентативности можно раскрывать в разных контекстах. Но по своему смыслу репрезентативность – это соответствие черт и свойств выбранных единиц из общей совокупности, которые точно отражают характеристики всей генеральной базы данных в целом.

Также репрезентативность информации определяют как способность выборочных данных представить параметры и свойства совокупности, важные с точки зрения проводимого исследования.
Репрезентативная выборка
Принцип формирования выборки заключается в избрании наиболее важных и точно отображающих свойства общей совокупности данных. Для этого используются различные методы, которые позволяют получать точные результаты и общее представление о генеральной совокупности, используя только выборочные материалы, описывающие качества всех данных.
Таким образом, нет необходимости изучать весь материал, а достаточно рассмотреть выборочную репрезентативность. Что это? Это выборка отдельных данных для того, чтобы иметь понятие об общей массе информации.

Их в зависимости от способа различают как вероятностные и невероятностные. Вероятностная – это выборка, которая производится путем вычисления наиболее важных и интересных данных, являющихся в дальнейшем представителями генеральной совокупности. Это обдуманный выбор или случайная выборка, тем не менее, обоснованная своим содержанием.
Невероятностная – это одна из разновидностей случайной выборки, составляющаяся по принципу обычной лотереи. В таком случае не учитывается мнение того, кто составляет такую выборку. Используется лишь слепой жребий.
Вероятностная выборка
Вероятностные выборки также могут подразделяться на несколько видов:
- Одна из самых простых и понятных принципов – это нерепрезентативная выборка. К примеру, такой способ часто используется при проведении социальных опросов. При этом участники опроса не выбираются из толпы по каким-либо определенным признакам, и получение информации производится у первых 50 людей, принявших участие в нём.
- Преднамеренные выборки отличаются тем, что имеют ряд требований и условий при отборе, однако все же полагаются на случайное совпадение, не преследуя своей целью достижение хорошей статистики.
- Выборка на основании квот – это еще одна из вариаций невероятностной выборки, которая часто используется для исследования больших совокупностей данных. Для нее используется множество условий и норм. Подбираются объекты, которые должны им соответствовать. То есть на примере социального опроса можно предположить, что опрошены будут 100 человек, но только мнение некоторого числа людей, которые будут соответствовать установленным требованиям, будут учтены при составлении статистического отчета.

Вероятностные выборки
Для вероятностных выборок исчисляется ряд параметров, которым объекты в выборке будут соответствовать, и среди них разными способами могут избираться именно те факты и данные, которые будут представлены как репрезентативность данных выборки. Такими способами вычисления нужных данных могут быть:
- Простая случайная выборка. Заключается в том, что среди выбранного сегмента совершенно случайным методом лотереи выбирается необходимое количество данных, которые будут являться репрезентативной выборкой.
- Систематическая и случайная выборка дает возможность составить систему вычисления необходимых данных на основе случайно выбранного сегмента. Таким образом, если первое случайное число, которое указывает на порядковый номер данных, выбранных из общей совокупности, будет 5, то последующими данными, которые будут выбраны, могут стать, например, 15, 25, 35 и так далее. Этот пример наглядно объясняет, что даже случайный выбор может основываться на систематических вычислениях необходимых исходных данных.
Выборка потребителей
Осмысленная выборка – это способ, который заключается в рассмотрении каждого отдельного сегмента, и на основании его оценки составляется совокупность, отражающая характеристики и свойства общей базы данных. Таким образом набирается большее количество данных, соответствующих требованиям репрезентативной выборки. Можно легко отобрать некоторое количество вариантов, которые не войдут в общее число, не потеряв при этом качество отобранных данных, представляющих общую совокупность. Таким способом определяется репрезентативность результатов исследования.
Размер выборки
Не последний вопрос, который необходимо решить, – это размер выборки для репрезентативного представления генеральной совокупности. Размер выборки не всегда зависит от количества исходников в генеральной совокупности. Однако репрезентативность выборочной совокупности напрямую зависит от того, на сколько сегментов должен быть в итоге разделён результат. Чем больше таких сегментов, тем больше данных попадает в результативную выборку. Если результаты требуют общего обозначения и не требуют конкретики, тогда, соответственно, выборка становится меньше, поскольку, не вдаваясь в детали, информация излагается более поверхностно, а значит, ее прочтение будет общим.

Понятие ошибки репрезентативности
Ошибка репрезентативности – это конкретные расхождения между характеристиками генеральной совокупности и выборочных данных. При проведении любого выборочного исследования невозможно получить абсолютно точные данные, как при полном исследовании генеральных совокупностей и выборки, представленной лишь частью сведений и параметров, тогда как более детальное изучение возможно только при исследовании всей совокупности. Таким образом, неизбежны некоторые погрешности и ошибки.
Виды ошибок
Различают некоторые ошибки, которые возникают при составлении репрезентативной выборки:
- Систематические.
- Случайные.
- Преднамеренные.
- Непреднамеренные.
- Стандартные.
- Предельные.
Основанием для появления случайных ошибок может быть несплошной характер исследования общей совокупности. Обычно случайная ошибка репрезентативности имеет незначительный размер и характер.
Систематические ошибки между тем возникают при нарушении правил отбора данных из общей совокупности.

Средняя ошибка – это разница между усредненными значениями выборки и основной совокупностью. Она не зависит от количества единиц в выборке. Она обратно пропорциональна объему выборки. Тогда чем больше объем, тем меньше значение средней ошибки.
Предельная ошибка – это наибольшая возможная разница между усредненными значениями сделанной выборки и общей совокупностью. Такая ошибка охарактеризовывается как максимум вероятных ошибок при заданных условиях их появления.
Преднамеренные и непреднамеренные ошибки репрезентативности
Ошибки смещения данных бывают преднамеренными и непреднамеренными.
Тогда причинами появления преднамеренных ошибок является подход к подбору данных по методу определения тенденций. Непреднамеренные ошибки возникают еще на стадии подготовки выборочного наблюдения, формирования репрезентативной выборки. Для недопущения подобных ошибок необходимо создать хорошую основу для выборки, составляющей списки единиц отбора. Она должна полностью соответствовать целям проведения выборки, быть достоверной, охватывающей все аспекты исследования.
Валидность, надежность, репрезентативность. Расчет ошибок
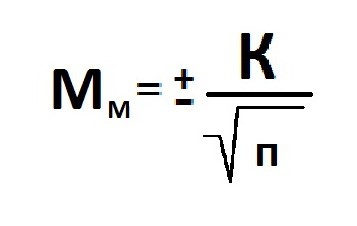
Расчет ошибки репрезентативности (Мм) средней арифметической величины (М).
Среднее квадратическое отклонение: численность выборки (>30).
Ошибка репрезентативности (Мр) и относительная величина (Р): численность выборки (n>30).
В том случае, когда приходится изучать совокупность, где количество выборки мало и составляет меньше 30 единиц, тогда число наблюдений станет меньше на одну единицу.
Величина ошибки прямо порциональна объему выборки. Репрезентативность информации и вычисление степени возможности составления точного прогноза отражает определенная величина предельной ошибки.
Репрезентативные системы
Не только в процессе оценки подачи информации используется репрезентативная выборка, но и сам человек, получающий информацию, использует репрезентативные системы. Таким образом, мозг обрабатывает некоторое количество информации, создавая репрезентативную выборку из всего потока информации, чтобы качественно и быстро оценить подаваемые данные и понять суть вопроса. Ответить на вопрос: «Репрезентативность — что это?» — в масштабах человеческого сознания довольно просто. Для этого мозг использует все подвластные органы чувств, в зависимости от того, какую именно информацию необходимо вычленить из общего потока. Таким образом, различают:
- Визуальную репрезентативную систему, где задействуются органы зрительного восприятия глаза. Люди, часто использующие подобную систему, называются визуалами. С помощью этой системы человек обрабатывает информацию, поступающую в виде изображений.
- Аудиальная репрезентативная система. Главный орган, который используется – это слух. Информация, подаваемая в виде звуковых файлов или речи, обрабатываются именно этой системой. Люди, лучше воспринимающие информацию на слух, называются аудиалами.
- Кинестетическая репрезентативная система представляет собой обработку потока информации, путем восприятия его с помощью обонятельных и осязательных каналов.
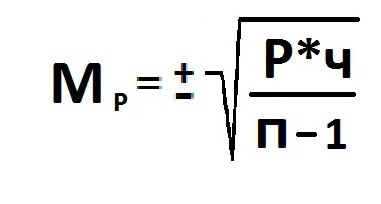
- Дигитальная репрезентативная система используется вместе с другими как средство получения информации извне. Это субъективно-логическое восприятие и осмысление полученных данных.

Итак, репрезентативность — что это? Простая выборка из множества или неотъемлемая процедура при обработке информации? Однозначно можно сказать, что репрезентативность во многом определяет наше восприятие потоков данных, помогая вычленить из него наиболее веские и значимые.
Для измерения ошибки репрезентативности некоторой статистики может служить дисперсия выборочного распределения [c.101]
Из теории математической статистики известно, что в том случае, когда распределение исходного признака X не слишком сильно отличается от нормального вида, а объем выборки не слишком мал (на практике л ЗО), квадратическая ошибка репрезентативности средней арифметической может быть найдена по формуле [c.101]
Показатель точности оценок. Судить о точности, с какой определена та или иная выборочная средняя, позволяет отношение ошибки репрезентативности к своей средней. Этот показатель, обозначаемый символом s (обычно выражен в процентах), определяют по одной из следующих формул [c.105]
Ошибками репрезентативности сопровождаются и другие выборочные показатели, из которых необходимо отметить следующие. [c.106]
Гипотезу о законе распределения можно проверить разными способами, в частности с помощью коэффициентов асимметрии Ле и эксцесса Ех. При нормальном распределении эти показатели равны нулю. В действительности такое равенство почти не наблюдается. Выборочные показатели и Ех, определяемые по формулам (48) и (49), являются случайными величинами, которые сопровождаются ошибками. В качестве критерия нормальности распределения служат /л и 1ех. являющиеся отношениями выборочных коэффициентов А я Ех к. их ошибкам репрезентативности, которые определяют обычно по следующим приближенным формулам [c.137]
Чтобы уменьшить ошибку репрезентативности вдвое, нужно объем выборки увеличить в четыре раза (9-4=36). Обобщая эти данные, можно сделать вывод для уменьшения ошибки выборочной средней в К раз нужно увеличить объем выборки в раз. [c.309]
Планирование эксперимента можно проводить лишь в случае устранения источников нестабильности. Объем выборки, в частности, должен быть достаточным для описания свойств общей совокупности, т. е. выборка должна быть репрезентативной (представительной). Одним из основных путей получения подобной выборки является проведение достаточного количества параллельных определений. Число образцов т, обеспечивающее определение средней величины показателя прочности с заданной относительной ошибкой у и попадание ее в доверительный интервал с заданной вероятностью, вычисляют по формуле [96] [c.100]
Репрезентативность — важнейшее свойство данных, используемых для построения аналитических моделей. Независимо от того, в какой предметной области и какими методами производятся выборочные исследования, отсутствие репрезентативности выборки приводит к некорректным результатам. В статье рассказываем подробнее об этом важном свойстве.
Репрезентативность — важнейшее свойство данных, используемых для построения аналитических моделей. Оно отражает способность данных представлять зависимости и закономерности исследуемой предметной области, которые должна обнаружить и научиться воспроизводить построенная модель. Иными словами, репрезентативность показывает, содержат ли анализируемые данные достаточно информации для построения качественной модели, а так же, может ли эта информация быть использована алгоритмом построения модели.
Репрезентативность генеральной совокупности отражает способность совокупности описывать существенные свойства, зависимости и закономерности объектов, процессов и явлений предметной области. Она достигается за счёт правильной организации сбора и консолидации первичных данных.
Репрезентативность выборки описывает способность выборочных данных отражать структурные свойства совокупности, из которой они были извлечены. Т.е. даёт ответ на вопрос: можно ли в исследовании заменить совокупность на выборку без значимого ухудшения результатов анализа. Репрезентативность выборки достигается с помощью правильного выбора метода сэмплинга.
Таким образом, репрезентативность выборки касается только воспроизведения характеристик совокупности. Если сама исходная совокупность плохо представляет предметную область, то, даже если полученная из неё выборка будет репрезентативной, построить на её основе корректную с точки зрения предметной области модель невозможно.
Например, пусть компания собирается вывести на рынок новый продукт. При этом она хочет провести маркетинговые исследования в виде опроса клиентов о желаемых характеристиках и параметрах продукта. Число клиентов компании насчитывает сотни тысяч человек (генеральная совокупность), поэтому опросить их всех не представляется возможным физически, не является целесообразным экономически.
Поэтому компания формирует выборку клиентов для проведения опроса. Если мнение клиентов из выборки отражает мнение большинства клиентов и может быть использовано для принятия решений о параметрах и характеристиках нового продукта, то такая выборка будет репрезентативной.
Независимо от того, в какой предметной области и какими методами производятся выборочные исследования, отсутствие репрезентативности выборки приводит к некорректным результатам. Поэтому в процессе анализа необходимо убедиться, что сформированная выборка репрезентативна.
Таким образом, репрезентативная выборка — это такая выборка, в которой представлены все подгруппы, важные для исследования. Помимо этого, характер распределения рассматриваемых параметров в выборке должен быть таким же, как в генеральной совокупности.
Особенно важным является обеспечение репрезентативности в машинном обучении, для построения моделей классификации и регрессии используется несколько выборок: обучающая, тестовая и валидационная, которые тем или иным способом отбираются из исходного набора данных. И все эти выборки должны быть репрезентативными.
Обеспечение репрезентативности
В основе построения репрезентативной выборки лежит правильный выбор используемого алгоритма сэмплинга. При этом размер выборки, хотя и является важным, сам по себе не гарантирует ее репрезентативности. Например, интернет-опрос может показать, что 100% людей пользуется интернетом, хотя это не соответствует действительности (т.е. репрезентативность нарушена).
Выделяют качественную (структурную) и количественную репрезентативность.
Рисунок 1. Количественная и качественная репрезентативность
Качественная репрезентативность
Качественная репрезентативность показывает, что все группы, присутствующие в совокупности, будут представлены и в выборке. Для этого каждый элемент совокупности должен иметь равную вероятность, быть выбранным, а сама выборка должна производиться из однородных групп.
Наиболее оптимальным способом формирования репрезентативной выборки является простой случайный сэмплинг, поскольку в этом случае у любого представителя генеральной совокупности будет одинаковая вероятность попасть в выборку.
Например, при формировании выборки клиентов для опроса, в нее попадут люди из различных социальных групп пропорционально их долям в генеральной совокупности. В результате, выборка будет представлять собой уменьшенную копию генеральной совокупности.
Случайность отбора респондентов в выборку может обеспечивается различными методами. Например, для опроса клиентов берутся номера клиентских карт, которые случайным образом отбираются компьютерной программой с использованием генератора случайных чисел.
Однако, на практике применить простой случайный сэмплинг не всегда представляется возможным. Это связано с тем, что генеральная совокупность может быть неоднородной и будет содержать группы объектов.
Например, если опрос будет проводиться по телефону, то большинство откликов будет получено от пенсионеров, как людей менее занятых и более склонных идти на контакт. Очевидно, что если опрос проводится о продукте, ориентированном на молодёжь, то ценность мнения пенсионеров вряд ли будет высокой.
Чтобы решить эту проблему, можно использовать случайный стратифицированный сэмплинг, когда исходная совокупность сначала разделяется на слои (страты) по некоторому признаку. Например, клиенты могут быть стратифицированы по возрасту. Тогда страты могут быть сформированы пропорционально доле объектов в группах, что позволит уменьшить или увеличить долю той или иной группы, сохранив репрезентативность.
Другой вариант — использовать кластерный (групповой) сэмплинг, когда клиенты предварительно разбиваются на качественно однородные группы — кластеры, и отбор производится из каждого кластера независимо. При этом вероятность отбора может быть одинаковой для всех кластеров, или различной. Можно некоторые кластеры вообще исключить из отбора. В нашем примере клиенты могут быть разбиты на кластеры по социальному статусу — студенты, работающие, пенсионеры, военнослужащие и т.д. Таким образом, долю, пенсионеров в выборке, можно уменьшить или совсем исключить.
Количественная репрезентативность
Количественная репрезентативность показывает, является ли достаточным число элементов выборки для представления характеристик генеральной совокупности с заданной погрешностью. Например, при неизвестной величине генеральной совокупности, когда результат отражается в виде показателя относительной доли, число элементов выборки, обеспечивающее количественную репрезентативность, может быть вычислено по формуле:
n=frac{t^{2}cdot pcdot q}{Delta ^{2}}
где t — доверительный коэффициент, показывающий, какова вероятность того, что размеры показателя не будут выходить за границы предельной ошибки, p — доля единиц наблюдения, обладающих изучаемым признаком, q=1−p — доля единиц наблюдения, не обладающих изучаемым признаков, Δ — допустимая ошибка выборки.
Например, одним из показателей качества кредитного портфеля банка является доля заёмщиков, допустивших просрочку. Предельная ошибка, которую можно допустить, чтобы разброс значений показателя не превышал разумные границы, Δ=5% . При этом показатель может принимать значения 25% ±5%, т.е. от 20% до 30%. Допуская t=2, что обеспечивает 95% вероятность, получаем
n=frac{2^{2}cdot 0,25cdot 0,75}{0,05^{2}}=300 заёмщиков.
Если же показатель — не относительная средняя величина просроченной задолженности по всем клиентам, то число наблюдений будет:
n=frac{t^{2}cdot sigma ^{2}}{Delta ^{2}}
где sigma ^{2} — среднеквадратическое отклонение значений исследуемого признака.
Если используется выборка без возврата и размер генеральной совокупности известен, то для определения необходимого размера случайной выборки при использования относительных величин (долей) применяется формула:
n=frac{t^{2}cdot pcdot qcdot N}{Delta ^{2}cdot N+t^{2}cdot pcdot q}
где N — число наблюдений генеральной совокупности. Для средних значений исследуемой величины формула примет вид:
n=frac{t^{2}cdot sigma ^{2}cdot N^{2}}{Delta ^{2}cdot N^{2}+t^{2}cdot sigma ^{2}}
Тогда, в предыдущем примере, положив число клиентов N=500, получим:
n=frac{2^{2}cdot 0,25cdot 0,75cdot 500}{0,05^{2}cdot 500+2^{2}cdot 0,25cdot 0,75}approx 188 клиентов.
Таким образом, необходимый объем выборки при безвозвратном отборе меньше, чем при возвратном (соответственнo, 188 и 300).
В целом, число наблюдений, требуемое для получения репрезентативной выборки, изменяется обратно пропорционально квадрату допустимой ошибки.
Методы оценки репрезентативности
Формально, выборку называют репрезентативной, когда результат оценки определенного параметра по данной выборке совпадает с результатом, оцененным по генеральной совокупности с учетом допустимой погрешности (ошибки репрезентативности). Если выборочная оценка отличается от оценки по генеральной совокупности более, чем на заданный уровень погрешности, то такая выборка считается нерепрезентативной.
Репрезентативность оценивается по отдельным параметрам выборки и совокупности. При этом выборка может оказаться репрезентативной по одним параметрам и нерепрезентативной по другим. Поэтому говорить о репрезентативности как о дихотомическом свойстве выборки (репрезентативна или нерепрезентативна) было бы не верно: выборка может одни параметры генеральной совокупности воспроизводить более точно, а другие — менее. Поэтому правильнее говорить о мере репрезентативности определённой выборки по конкретным параметрам.
Основным моментом в определении репрезентативности выборки является обоснование погрешности, в пределах которой выборка признается репрезентативной. Одна и та же выборка может быть достаточно репрезентативной для одной задачи и недостаточно для другой. Кроме этого, нужно проверять репрезентативность выборки по параметрам, имеющим существенное значение для предметной области исследования. Например, в маркетинговых исследованиях для анализа клиентов важны пол, возрасту, образование и пр.
Следует отметить, что далеко не все задачи бизнес-аналитики требуют строгого статистического подтверждения репрезентативности выборок. Как правило, это задачи точного прогнозирования. Что касается обычных задач, связанных, например, с определением предпочтений действующих и потенциальных клиентов, то они решаются охватом типичной клиентуры, которую можно найти непосредственно в торговых центрах.
Статистические методы
Данные, полученные в результате выборочных обследований, являются реализациями случайных величин (возраст, стаж работы, доход и т.д.). Обычно, на практике считают, что выборка является репрезентативной, если её статистические параметры (среднее значение, дисперсия, среднеквадратичное отклонение и т.д.) отличаются от параметров совокупности не более, чем на 5%.
Однако, данный подход применим только при условии, что вся генеральная совокупность известна и для неё можно вычислить статистические характеристики. Но на практике такое встречается редко, поскольку часть потенциально интересных для исследования объектов оказывается недоступной для наблюдения.
В этом случае прибегают к формированию двух независимых выборок, вычисляют и сравнивают их характеристики, и если они совпадают (не различаются значимо), то выборки считаются репрезентативными. В теоретическом плане такой подход является достаточно привлекательным, однако, на практике сложно реализуем. Во-первых, формирование нескольких выборок ведёт к дополнительным затратам, а во-вторых, если параметры выборок значимо различаются, то невозможно сказать, какая из них репрезентативна.
Для сравнения двух выборок используются два вида критериев: непараметрические и параметрические. Первые не используют в расчётах значений параметров статистических распределений, а оперируют частотами и рангами. К числу наиболее популярных непараметрических критериев можно отнести критерий Уилкоксона и U-критерий Манна-Уитни. Второй рекомендуется использовать, если число наблюдений превышает 30. К числу популярных параметрических критериев относится t-критерий Стьюдента, критерий однородности Смирнова, Q-критерий Розенбаума и др.
Нестатистические методы
Статистические методы оценки репрезентативности выборочных данных, хотя и являются строго обоснованными, но довольно сложны в использовании (особенно для пользователей, не имеющих достаточной математической подготовки). Кроме этого они могут иметь ограничения (например, независимость выборок), удовлетворить которым достаточно сложно.
Статистические подходы к оценке репрезентативности выборок имеет смысл использовать, если для анализа данных используются статистические методы. Методы машинного обучения, которые является эвристическими и в большинстве случаев не обеспечивают точного и единственного решения, вообще говоря, не нуждаются в точной оценке репрезентативности обучающих выборок. Поэтому в них используются свои техники для определения того, насколько обучающая или тестовая выборка хорошо представляют исходную совокупность.
Ещё одной особенностью выборок, используемых в машинном обучении, является то, что объём исходной совокупности, из которой формируются обучающее, тестовое, а при необходимости, и валидационное множество, известен, поскольку данные содержатся в консолидированных таблицах источника данных.
Обычно нестатистические меры репрезентативности используют расстояния между векторами наблюдений в пространстве признаков. Рассмотрим, например, такой показатель как индекс ближайшего соседа (Nearest Neighbours Index — NNI). Предположим, что выборка включает n ближайших соседей внутри некоторой области пространства признаков. Вычислим величину, представляющую собой среднее расстояние между i-м объектом и всеми остальными объектами в выборке (области соседства):
overline{D}_{sample}=frac{1}{n}sumlimits_{i=1}^{n}D_{i}
где D_i — расстояние от i-го объекта до остальных объектов выборки, n — число объектов выборки.
Затем вычислим величину:
overline{D}_{total}=sqrt{frac{D_{_{total}}}{N}}
где D_{_{total}} — общее расстояние по всей совокупности, N — число наблюдений совокупности.
Тогда индекс ближайшего соседа будет:
NNI=frac{overline{D}_{sample}}{overline{D}_{total}}
Если значение данного показателя близко к 1, то точки выборки имеют равномерное пространственное распределение. Если меньше 1, то пространственное распределение точек неоднородно. Если NNI больше 1, то имеет место значительная дисперсия значений внутри выборки.
Очевидно, что наилучшим вариантом с точки зрения репрезентативности будет первый случай, когда пространственное распределение точек данных в совокупности и выборке примерно одинаковое. Второй случай показывает, что внутри выборки могут присутствовать некоторое локальные особенности, нехарактерные для всей совокупности.
В литературе можно найти больше количество разнообразных алгоритмов и методов оценки репрезентативности выборок для машинного обучения, разработанных для различных предметных областей исследования и типов задач анализа. Большинство их них являются эвристическими и не гарантируют получения наилучшего результата. Поэтому самым надёжным критерием репрезентативности выборки, на основе которой строилась определённая обучаемая модель, является точность и обобщающая способность самой модели.
Ремонт выборки
Возникает вопрос: а что делать в ситуации, когда аналитику доступна только выборка «как есть», а её репрезентативность неудовлетворительная? При этом доступ к генеральной совокупности для формирования более репрезентативной выборки у него отсутствует (например, из-за проблем с сетью, невозможности повторных исследований из-за высоких затрат и т.д.). В этом случае улучшить ситуацию может специальная процедура, которая называется «ремонт выборки».
Все действия аналитика, связанные с репрезентативностью, можно разделить на два этапа: контроль и ремонт.
- Контроль выборки — процедура сравнения генеральной совокупности и выборки, выявление степени их расхождения, обнаружение причин отклонений и разработка возможных способов их устранения.
- Ремонт выборки — процесс устранения расхождения генеральной совокупности и выборки.
Контроль и ремонт выборки рассматриваются как обязательные этапы любого выборочного исследования. Хотя, некоторые авторы не разделяют эти два этапа, а включают ремонт в общую процедуру контроля выборки. Ряд вопросов, связанных с контролем выборки был рассмотрен выше.
Основной целью ремонта является повышение качества выборки в смысле отражения ею зависимостей и закономерностей исследуемых процессов и явлений, которые требуется обнаружить в процессе анализа. При этом не следует путать ремонт выборки с повышением качества данных вообще.
Ремонт выборки, обычно, включает следующие задачи:
- Коррекция выборки. Заключается в замене ранее выбранных объектов совокупности. Коррекция может потребоваться, например, если в выборке произошло искажение распределения объектов относительно исходной совокупности, например, получился избыток пенсионеров, мужчин, женщин или людей с определённым уровнем образования. Замена может быть произвольной (например, следующий клиент по списку) или эквивалентной (подыскивается клиент с теми же параметрами — пенсионера меняем на пенсионера и т.д.).
- Расширение основы выборки. Позволяет включить в выборку большее разнообразие наблюдений. Основа выборки — это подмножество элементов генеральной совокупности, из которого будет формироваться выборка. Использование основы выборки позволяет сделать отбор более целевым, исключив обработку данных, не относящихся к задаче анализа, лучше сфокусироваться на целевой группе. В анализе клиентской базы основой выборки могут быть только мужчины, только женщины, люди в возрасте от 30 до 60 и т.д. Если выборка получилась недостаточно репрезентативной, то решить проблему можно расширяя границы основы выборки. Например, если изначально основой выборки являлась только люди пенсионного возраста, то при необходимости она может быть расширена и на людей предпенсионного возраста.
- Взвешивание. При взвешивании объектам выборки могут присваиваться весовые коэффициенты, которые могут учитываться в алгоритме анализа. Например, повышенные весовые коэффициенты могут присваиваться клиентам, которые наиболее активно пользовались услугами компании (купили товаров и услуг на сумму выше некоторого порога). Логично предположить, что мнение таких клиентов будет более значимым.
Следует отметить, что единого, строго обоснованного подхода к ремонту выборок, вообще говоря, не существует, хотя в литературе можно встретить некоторые общие рекомендации. В большинстве практических случаев аналитику приходится самостоятельно выбирать, какие преобразования следует применить к выборке для повышения её репрезентативности.
Другие материалы по теме:
Обработка пропусков в данных
Loginom Data Quality. Очистка клиентских данных. Деморолик