
| Error function | |
|---|---|

Plot of the error function |
|
| General information | |
| General definition |  |
| Fields of application | Probability, thermodynamics |
| Domain, Codomain and Image | |
| Domain |  |
| Image |  |
| Basic features | |
| Parity | Odd |
| Specific features | |
| Root | 0 |
| Derivative |  |
| Antiderivative |  |
| Series definition | |
| Taylor series |  |
In mathematics, the error function (also called the Gauss error function), often denoted by erf, is a complex function of a complex variable defined as:[1]

This integral is a special (non-elementary) sigmoid function that occurs often in probability, statistics, and partial differential equations. In many of these applications, the function argument is a real number. If the function argument is real, then the function value is also real.
In statistics, for non-negative values of x, the error function has the following interpretation: for a random variable Y that is normally distributed with mean 0 and standard deviation 1/√2, erf x is the probability that Y falls in the range [−x, x].
Two closely related functions are the complementary error function (erfc) defined as

and the imaginary error function (erfi) defined as

where i is the imaginary unit
Name[edit]
The name «error function» and its abbreviation erf were proposed by J. W. L. Glaisher in 1871 on account of its connection with «the theory of Probability, and notably the theory of Errors.»[2] The error function complement was also discussed by Glaisher in a separate publication in the same year.[3]
For the «law of facility» of errors whose density is given by

(the normal distribution), Glaisher calculates the probability of an error lying between p and q as:


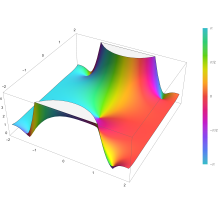
Plot of the error function Erf(z) in the complex plane from -2-2i to 2+2i with colors created with Mathematica 13.1 function ComplexPlot3D

Applications[edit]
When the results of a series of measurements are described by a normal distribution with standard deviation σ and expected value 0, then erf (a/σ √2) is the probability that the error of a single measurement lies between −a and +a, for positive a. This is useful, for example, in determining the bit error rate of a digital communication system.
The error and complementary error functions occur, for example, in solutions of the heat equation when boundary conditions are given by the Heaviside step function.
The error function and its approximations can be used to estimate results that hold with high probability or with low probability. Given a random variable X ~ Norm[μ,σ] (a normal distribution with mean μ and standard deviation σ) and a constant L < μ:
![{displaystyle {begin{aligned}Pr[Xleq L]&={frac {1}{2}}+{frac {1}{2}}operatorname {erf} {frac {L-mu }{{sqrt {2}}sigma }}&approx Aexp left(-Bleft({frac {L-mu }{sigma }}right)^{2}right)end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f3cb760eaf336393db9fd0bb12c4465655a27de8)
where A and B are certain numeric constants. If L is sufficiently far from the mean, specifically μ − L ≥ σ√ln k, then:
![{displaystyle Pr[Xleq L]leq Aexp(-Bln {k})={frac {A}{k^{B}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2baadea015e20a45d1034fd88eed861e7fcce178)
so the probability goes to 0 as k → ∞.
The probability for X being in the interval [La, Lb] can be derived as
![{displaystyle {begin{aligned}Pr[L_{a}leq Xleq L_{b}]&=int _{L_{a}}^{L_{b}}{frac {1}{{sqrt {2pi }}sigma }}exp left(-{frac {(x-mu )^{2}}{2sigma ^{2}}}right),mathrm {d} x&={frac {1}{2}}left(operatorname {erf} {frac {L_{b}-mu }{{sqrt {2}}sigma }}-operatorname {erf} {frac {L_{a}-mu }{{sqrt {2}}sigma }}right).end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cd2214f0db2c1d36075815825b616501175c6283)
Properties[edit]
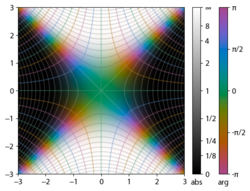
Integrand exp(−z2)

erf z
The property erf (−z) = −erf z means that the error function is an odd function. This directly results from the fact that the integrand e−t2 is an even function (the antiderivative of an even function which is zero at the origin is an odd function and vice versa).
Since the error function is an entire function which takes real numbers to real numbers, for any complex number z:

where z is the complex conjugate of z.
The integrand f = exp(−z2) and f = erf z are shown in the complex z-plane in the figures at right with domain coloring.
The error function at +∞ is exactly 1 (see Gaussian integral). At the real axis, erf z approaches unity at z → +∞ and −1 at z → −∞. At the imaginary axis, it tends to ±i∞.
Taylor series[edit]
The error function is an entire function; it has no singularities (except that at infinity) and its Taylor expansion always converges, but is famously known «[…] for its bad convergence if x > 1.»[4]
The defining integral cannot be evaluated in closed form in terms of elementary functions, but by expanding the integrand e−z2 into its Maclaurin series and integrating term by term, one obtains the error function’s Maclaurin series as:
![{displaystyle {begin{aligned}operatorname {erf} z&={frac {2}{sqrt {pi }}}sum _{n=0}^{infty }{frac {(-1)^{n}z^{2n+1}}{n!(2n+1)}}[6pt]&={frac {2}{sqrt {pi }}}left(z-{frac {z^{3}}{3}}+{frac {z^{5}}{10}}-{frac {z^{7}}{42}}+{frac {z^{9}}{216}}-cdots right)end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c80541f305af070bb0510625c584fe1559a0cd2c)
which holds for every complex number z. The denominator terms are sequence A007680 in the OEIS.
For iterative calculation of the above series, the following alternative formulation may be useful:
![{displaystyle {begin{aligned}operatorname {erf} z&={frac {2}{sqrt {pi }}}sum _{n=0}^{infty }left(zprod _{k=1}^{n}{frac {-(2k-1)z^{2}}{k(2k+1)}}right)[6pt]&={frac {2}{sqrt {pi }}}sum _{n=0}^{infty }{frac {z}{2n+1}}prod _{k=1}^{n}{frac {-z^{2}}{k}}end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dca22e8e7dee0297e87a455249c282c6b92fedcb)
because −(2k − 1)z2/k(2k + 1) expresses the multiplier to turn the kth term into the (k + 1)th term (considering z as the first term).
The imaginary error function has a very similar Maclaurin series, which is:
![{displaystyle {begin{aligned}operatorname {erfi} z&={frac {2}{sqrt {pi }}}sum _{n=0}^{infty }{frac {z^{2n+1}}{n!(2n+1)}}[6pt]&={frac {2}{sqrt {pi }}}left(z+{frac {z^{3}}{3}}+{frac {z^{5}}{10}}+{frac {z^{7}}{42}}+{frac {z^{9}}{216}}+cdots right)end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ff91095cd6825137cc951ec0a786db0b7f68fac)
which holds for every complex number z.
Derivative and integral[edit]
The derivative of the error function follows immediately from its definition:

From this, the derivative of the imaginary error function is also immediate:

An antiderivative of the error function, obtainable by integration by parts, is

An antiderivative of the imaginary error function, also obtainable by integration by parts, is

Higher order derivatives are given by

where H are the physicists’ Hermite polynomials.[5]
Bürmann series[edit]
An expansion,[6] which converges more rapidly for all real values of x than a Taylor expansion, is obtained by using Hans Heinrich Bürmann’s theorem:[7]
![{displaystyle {begin{aligned}operatorname {erf} x&={frac {2}{sqrt {pi }}}operatorname {sgn} xcdot {sqrt {1-e^{-x^{2}}}}left(1-{frac {1}{12}}left(1-e^{-x^{2}}right)-{frac {7}{480}}left(1-e^{-x^{2}}right)^{2}-{frac {5}{896}}left(1-e^{-x^{2}}right)^{3}-{frac {787}{276480}}left(1-e^{-x^{2}}right)^{4}-cdots right)[10pt]&={frac {2}{sqrt {pi }}}operatorname {sgn} xcdot {sqrt {1-e^{-x^{2}}}}left({frac {sqrt {pi }}{2}}+sum _{k=1}^{infty }c_{k}e^{-kx^{2}}right).end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/164e7f029977edb47c83845b04abfe5b2d28b837)
where sgn is the sign function. By keeping only the first two coefficients and choosing c1 = 31/200 and c2 = −341/8000, the resulting approximation shows its largest relative error at x = ±1.3796, where it is less than 0.0036127:

Inverse functions[edit]
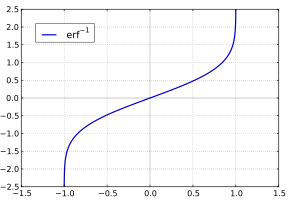
Given a complex number z, there is not a unique complex number w satisfying erf w = z, so a true inverse function would be multivalued. However, for −1 < x < 1, there is a unique real number denoted erf−1 x satisfying

The inverse error function is usually defined with domain (−1,1), and it is restricted to this domain in many computer algebra systems. However, it can be extended to the disk |z| < 1 of the complex plane, using the Maclaurin series

where c0 = 1 and

So we have the series expansion (common factors have been canceled from numerators and denominators):

(After cancellation the numerator/denominator fractions are entries OEIS: A092676/OEIS: A092677 in the OEIS; without cancellation the numerator terms are given in entry OEIS: A002067.) The error function’s value at ±∞ is equal to ±1.
For |z| < 1, we have erf(erf−1 z) = z.
The inverse complementary error function is defined as

For real x, there is a unique real number erfi−1 x satisfying erfi(erfi−1 x) = x. The inverse imaginary error function is defined as erfi−1 x.[8]
For any real x, Newton’s method can be used to compute erfi−1 x, and for −1 ≤ x ≤ 1, the following Maclaurin series converges:

where ck is defined as above.
Asymptotic expansion[edit]
A useful asymptotic expansion of the complementary error function (and therefore also of the error function) for large real x is
![{displaystyle {begin{aligned}operatorname {erfc} x&={frac {e^{-x^{2}}}{x{sqrt {pi }}}}left(1+sum _{n=1}^{infty }(-1)^{n}{frac {1cdot 3cdot 5cdots (2n-1)}{left(2x^{2}right)^{n}}}right)[6pt]&={frac {e^{-x^{2}}}{x{sqrt {pi }}}}sum _{n=0}^{infty }(-1)^{n}{frac {(2n-1)!!}{left(2x^{2}right)^{n}}},end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/35a11e2e5b22ca898c74f2e913d276c9ac11124a)
where (2n − 1)!! is the double factorial of (2n − 1), which is the product of all odd numbers up to (2n − 1). This series diverges for every finite x, and its meaning as asymptotic expansion is that for any integer N ≥ 1 one has

where the remainder, in Landau notation, is

as x → ∞.
Indeed, the exact value of the remainder is

which follows easily by induction, writing

and integrating by parts.
For large enough values of x, only the first few terms of this asymptotic expansion are needed to obtain a good approximation of erfc x (while for not too large values of x, the above Taylor expansion at 0 provides a very fast convergence).
Continued fraction expansion[edit]
A continued fraction expansion of the complementary error function is:[9]

Integral of error function with Gaussian density function[edit]

which appears related to Ng and Geller, formula 13 in section 4.3[10] with a change of variables.
Factorial series[edit]
The inverse factorial series:

converges for Re(z2) > 0. Here

zn denotes the rising factorial, and s(n,k) denotes a signed Stirling number of the first kind.[11][12]
There also exists a representation by an infinite sum containing the double factorial:

Numerical approximations[edit]
Approximation with elementary functions[edit]
- Abramowitz and Stegun give several approximations of varying accuracy (equations 7.1.25–28). This allows one to choose the fastest approximation suitable for a given application. In order of increasing accuracy, they are:
(maximum error: 5×10−4)
where a1 = 0.278393, a2 = 0.230389, a3 = 0.000972, a4 = 0.078108
(maximum error: 2.5×10−5)
where p = 0.47047, a1 = 0.3480242, a2 = −0.0958798, a3 = 0.7478556
(maximum error: 3×10−7)
where a1 = 0.0705230784, a2 = 0.0422820123, a3 = 0.0092705272, a4 = 0.0001520143, a5 = 0.0002765672, a6 = 0.0000430638
(maximum error: 1.5×10−7)
where p = 0.3275911, a1 = 0.254829592, a2 = −0.284496736, a3 = 1.421413741, a4 = −1.453152027, a5 = 1.061405429
All of these approximations are valid for x ≥ 0. To use these approximations for negative x, use the fact that erf x is an odd function, so erf x = −erf(−x).
- Exponential bounds and a pure exponential approximation for the complementary error function are given by[13]
- The above have been generalized to sums of N exponentials[14] with increasing accuracy in terms of N so that erfc x can be accurately approximated or bounded by 2Q̃(√2x), where
In particular, there is a systematic methodology to solve the numerical coefficients {(an,bn)}N
n = 1 that yield a minimax approximation or bound for the closely related Q-function: Q(x) ≈ Q̃(x), Q(x) ≤ Q̃(x), or Q(x) ≥ Q̃(x) for x ≥ 0. The coefficients {(an,bn)}N
n = 1 for many variations of the exponential approximations and bounds up to N = 25 have been released to open access as a comprehensive dataset.[15] - A tight approximation of the complementary error function for x ∈ [0,∞) is given by Karagiannidis & Lioumpas (2007)[16] who showed for the appropriate choice of parameters {A,B} that
They determined {A,B} = {1.98,1.135}, which gave a good approximation for all x ≥ 0. Alternative coefficients are also available for tailoring accuracy for a specific application or transforming the expression into a tight bound.[17]
- A single-term lower bound is[18]
where the parameter β can be picked to minimize error on the desired interval of approximation.
-
- Another approximation is given by Sergei Winitzki using his «global Padé approximations»:[19][20]: 2–3
where
This is designed to be very accurate in a neighborhood of 0 and a neighborhood of infinity, and the relative error is less than 0.00035 for all real x. Using the alternate value a ≈ 0.147 reduces the maximum relative error to about 0.00013.[21]
This approximation can be inverted to obtain an approximation for the inverse error function:
- An approximation with a maximal error of 1.2×10−7 for any real argument is:[22]
with
and














Table of values[edit]
| x | erf x | 1 − erf x |
|---|---|---|
| 0 | 0 | 1 |
| 0.02 | 0.022564575 | 0.977435425 |
| 0.04 | 0.045111106 | 0.954888894 |
| 0.06 | 0.067621594 | 0.932378406 |
| 0.08 | 0.090078126 | 0.909921874 |
| 0.1 | 0.112462916 | 0.887537084 |
| 0.2 | 0.222702589 | 0.777297411 |
| 0.3 | 0.328626759 | 0.671373241 |
| 0.4 | 0.428392355 | 0.571607645 |
| 0.5 | 0.520499878 | 0.479500122 |
| 0.6 | 0.603856091 | 0.396143909 |
| 0.7 | 0.677801194 | 0.322198806 |
| 0.8 | 0.742100965 | 0.257899035 |
| 0.9 | 0.796908212 | 0.203091788 |
| 1 | 0.842700793 | 0.157299207 |
| 1.1 | 0.880205070 | 0.119794930 |
| 1.2 | 0.910313978 | 0.089686022 |
| 1.3 | 0.934007945 | 0.065992055 |
| 1.4 | 0.952285120 | 0.047714880 |
| 1.5 | 0.966105146 | 0.033894854 |
| 1.6 | 0.976348383 | 0.023651617 |
| 1.7 | 0.983790459 | 0.016209541 |
| 1.8 | 0.989090502 | 0.010909498 |
| 1.9 | 0.992790429 | 0.007209571 |
| 2 | 0.995322265 | 0.004677735 |
| 2.1 | 0.997020533 | 0.002979467 |
| 2.2 | 0.998137154 | 0.001862846 |
| 2.3 | 0.998856823 | 0.001143177 |
| 2.4 | 0.999311486 | 0.000688514 |
| 2.5 | 0.999593048 | 0.000406952 |
| 3 | 0.999977910 | 0.000022090 |
| 3.5 | 0.999999257 | 0.000000743 |
[edit]
Complementary error function[edit]
The complementary error function, denoted erfc, is defined as
-
Plot of the complementary error function Erfc(z) in the complex plane from -2-2i to 2+2i with colors created with Mathematica 13.1 function ComplexPlot3D
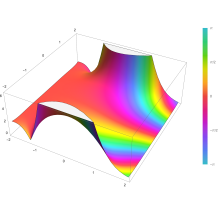
![{displaystyle {begin{aligned}operatorname {erfc} x&=1-operatorname {erf} x[5pt]&={frac {2}{sqrt {pi }}}int _{x}^{infty }e^{-t^{2}},mathrm {d} t[5pt]&=e^{-x^{2}}operatorname {erfcx} x,end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4acd0062271e2a19c209a02c8cc33d44a28af7cc)
which also defines erfcx, the scaled complementary error function[23] (which can be used instead of erfc to avoid arithmetic underflow[23][24]). Another form of erfc x for x ≥ 0 is known as Craig’s formula, after its discoverer:[25]

This expression is valid only for positive values of x, but it can be used in conjunction with erfc x = 2 − erfc(−x) to obtain erfc(x) for negative values. This form is advantageous in that the range of integration is fixed and finite. An extension of this expression for the erfc of the sum of two non-negative variables is as follows:[26]

Imaginary error function[edit]
The imaginary error function, denoted erfi, is defined as

Plot of the imaginary error function Erfi(z) in the complex plane from -2-2i to 2+2i with colors created with Mathematica 13.1 function ComplexPlot3D
![{displaystyle {begin{aligned}operatorname {erfi} x&=-ioperatorname {erf} ix[5pt]&={frac {2}{sqrt {pi }}}int _{0}^{x}e^{t^{2}},mathrm {d} t[5pt]&={frac {2}{sqrt {pi }}}e^{x^{2}}D(x),end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bfd2dd94cd6d0325224d412f6b5e5ed63ca81d4a)
where D(x) is the Dawson function (which can be used instead of erfi to avoid arithmetic overflow[23]).
Despite the name «imaginary error function», erfi x is real when x is real.
When the error function is evaluated for arbitrary complex arguments z, the resulting complex error function is usually discussed in scaled form as the Faddeeva function:

Cumulative distribution function[edit]
The error function is essentially identical to the standard normal cumulative distribution function, denoted Φ, also named norm(x) by some software languages[citation needed], as they differ only by scaling and translation. Indeed,
-

the normal cumulative distribution function plotted in the complex plane
![{displaystyle {begin{aligned}Phi (x)&={frac {1}{sqrt {2pi }}}int _{-infty }^{x}e^{tfrac {-t^{2}}{2}},mathrm {d} t[6pt]&={frac {1}{2}}left(1+operatorname {erf} {frac {x}{sqrt {2}}}right)[6pt]&={frac {1}{2}}operatorname {erfc} left(-{frac {x}{sqrt {2}}}right)end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/89a9e9eaaddcd7a91ade15a41b8d1e272d437559)
or rearranged for erf and erfc:
![{displaystyle {begin{aligned}operatorname {erf} (x)&=2Phi left(x{sqrt {2}}right)-1[6pt]operatorname {erfc} (x)&=2Phi left(-x{sqrt {2}}right)&=2left(1-Phi left(x{sqrt {2}}right)right).end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/86c84a4d2d79631fe9996e30f1d6c0da3089bfe2)
Consequently, the error function is also closely related to the Q-function, which is the tail probability of the standard normal distribution. The Q-function can be expressed in terms of the error function as

The inverse of Φ is known as the normal quantile function, or probit function and may be expressed in terms of the inverse error function as

The standard normal cdf is used more often in probability and statistics, and the error function is used more often in other branches of mathematics.
The error function is a special case of the Mittag-Leffler function, and can also be expressed as a confluent hypergeometric function (Kummer’s function):

It has a simple expression in terms of the Fresnel integral.[further explanation needed]
In terms of the regularized gamma function P and the incomplete gamma function,

sgn x is the sign function.
Generalized error functions[edit]

Graph of generalised error functions En(x):
grey curve: E1(x) = 1 − e−x/√π
red curve: E2(x) = erf(x)
green curve: E3(x)
blue curve: E4(x)
gold curve: E5(x).
Some authors discuss the more general functions:[citation needed]

Notable cases are:
- E0(x) is a straight line through the origin: E0(x) = x/e√π
- E2(x) is the error function, erf x.
After division by n!, all the En for odd n look similar (but not identical) to each other. Similarly, the En for even n look similar (but not identical) to each other after a simple division by n!. All generalised error functions for n > 0 look similar on the positive x side of the graph.
These generalised functions can equivalently be expressed for x > 0 using the gamma function and incomplete gamma function:

Therefore, we can define the error function in terms of the incomplete gamma function:

Iterated integrals of the complementary error function[edit]
The iterated integrals of the complementary error function are defined by[27]
![{displaystyle {begin{aligned}operatorname {i} ^{n}!operatorname {erfc} z&=int _{z}^{infty }operatorname {i} ^{n-1}!operatorname {erfc} zeta ,mathrm {d} zeta [6pt]operatorname {i} ^{0}!operatorname {erfc} z&=operatorname {erfc} zoperatorname {i} ^{1}!operatorname {erfc} z&=operatorname {ierfc} z={frac {1}{sqrt {pi }}}e^{-z^{2}}-zoperatorname {erfc} zoperatorname {i} ^{2}!operatorname {erfc} z&={tfrac {1}{4}}left(operatorname {erfc} z-2zoperatorname {ierfc} zright)end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c3e7b953efaa4d730a5479bd61a2c378c8f761dc)
The general recurrence formula is

They have the power series

from which follow the symmetry properties

and

Implementations[edit]
As real function of a real argument[edit]
- In Posix-compliant operating systems, the header
math.hshall declare and the mathematical librarylibmshall provide the functionserfanderfc(double precision) as well as their single precision and extended precision counterpartserff,erflanderfcf,erfcl.[28] - The GNU Scientific Library provides
erf,erfc,log(erf), and scaled error functions.[29]
As complex function of a complex argument[edit]
libcerf, numeric C library for complex error functions, provides the complex functionscerf,cerfc,cerfcxand the real functionserfi,erfcxwith approximately 13–14 digits precision, based on the Faddeeva function as implemented in the MIT Faddeeva Package
See also[edit]
[edit]
- Gaussian integral, over the whole real line
- Gaussian function, derivative
- Dawson function, renormalized imaginary error function
- Goodwin–Staton integral
In probability[edit]
- Normal distribution
- Normal cumulative distribution function, a scaled and shifted form of error function
- Probit, the inverse or quantile function of the normal CDF
- Q-function, the tail probability of the normal distribution
References[edit]
- ^ Andrews, Larry C. (1998). Special functions of mathematics for engineers. SPIE Press. p. 110. ISBN 9780819426161.
- ^ Glaisher, James Whitbread Lee (July 1871). «On a class of definite integrals». London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science. 4. 42 (277): 294–302. doi:10.1080/14786447108640568. Retrieved 6 December 2017.
- ^ Glaisher, James Whitbread Lee (September 1871). «On a class of definite integrals. Part II». London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science. 4. 42 (279): 421–436. doi:10.1080/14786447108640600. Retrieved 6 December 2017.
- ^ «A007680 – OEIS». oeis.org. Retrieved 2 April 2020.
- ^ Weisstein, Eric W. «Erf». MathWorld.
- ^ Schöpf, H. M.; Supancic, P. H. (2014). «On Bürmann’s Theorem and Its Application to Problems of Linear and Nonlinear Heat Transfer and Diffusion». The Mathematica Journal. 16. doi:10.3888/tmj.16-11.
- ^ Weisstein, Eric W. «Bürmann’s Theorem». MathWorld.
- ^ Bergsma, Wicher (2006). «On a new correlation coefficient, its orthogonal decomposition and associated tests of independence». arXiv:math/0604627.
- ^ Cuyt, Annie A. M.; Petersen, Vigdis B.; Verdonk, Brigitte; Waadeland, Haakon; Jones, William B. (2008). Handbook of Continued Fractions for Special Functions. Springer-Verlag. ISBN 978-1-4020-6948-2.
- ^ Ng, Edward W.; Geller, Murray (January 1969). «A table of integrals of the Error functions». Journal of Research of the National Bureau of Standards Section B. 73B (1): 1. doi:10.6028/jres.073B.001.
- ^ Schlömilch, Oskar Xavier (1859). «Ueber facultätenreihen». Zeitschrift für Mathematik und Physik (in German). 4: 390–415. Retrieved 4 December 2017.
- ^ Nielson, Niels (1906). Handbuch der Theorie der Gammafunktion (in German). Leipzig: B. G. Teubner. p. 283 Eq. 3. Retrieved 4 December 2017.
- ^ Chiani, M.; Dardari, D.; Simon, M.K. (2003). «New Exponential Bounds and Approximations for the Computation of Error Probability in Fading Channels» (PDF). IEEE Transactions on Wireless Communications. 2 (4): 840–845. CiteSeerX 10.1.1.190.6761. doi:10.1109/TWC.2003.814350.
- ^ Tanash, I.M.; Riihonen, T. (2020). «Global minimax approximations and bounds for the Gaussian Q-function by sums of exponentials». IEEE Transactions on Communications. 68 (10): 6514–6524. arXiv:2007.06939. doi:10.1109/TCOMM.2020.3006902. S2CID 220514754.
- ^ Tanash, I.M.; Riihonen, T. (2020). «Coefficients for Global Minimax Approximations and Bounds for the Gaussian Q-Function by Sums of Exponentials [Data set]». Zenodo. doi:10.5281/zenodo.4112978.
- ^ Karagiannidis, G. K.; Lioumpas, A. S. (2007). «An improved approximation for the Gaussian Q-function» (PDF). IEEE Communications Letters. 11 (8): 644–646. doi:10.1109/LCOMM.2007.070470. S2CID 4043576.
- ^ Tanash, I.M.; Riihonen, T. (2021). «Improved coefficients for the Karagiannidis–Lioumpas approximations and bounds to the Gaussian Q-function». IEEE Communications Letters. 25 (5): 1468–1471. arXiv:2101.07631. doi:10.1109/LCOMM.2021.3052257. S2CID 231639206.
- ^ Chang, Seok-Ho; Cosman, Pamela C.; Milstein, Laurence B. (November 2011). «Chernoff-Type Bounds for the Gaussian Error Function». IEEE Transactions on Communications. 59 (11): 2939–2944. doi:10.1109/TCOMM.2011.072011.100049. S2CID 13636638.
- ^ Winitzki, Sergei (2003). «Uniform approximations for transcendental functions». Computational Science and Its Applications – ICCSA 2003. Lecture Notes in Computer Science. Vol. 2667. Springer, Berlin. pp. 780–789. doi:10.1007/3-540-44839-X_82. ISBN 978-3-540-40155-1.
- ^ Zeng, Caibin; Chen, Yang Cuan (2015). «Global Padé approximations of the generalized Mittag-Leffler function and its inverse». Fractional Calculus and Applied Analysis. 18 (6): 1492–1506. arXiv:1310.5592. doi:10.1515/fca-2015-0086. S2CID 118148950.
Indeed, Winitzki [32] provided the so-called global Padé approximation
- ^ Winitzki, Sergei (6 February 2008). «A handy approximation for the error function and its inverse».
- ^ Numerical Recipes in Fortran 77: The Art of Scientific Computing (ISBN 0-521-43064-X), 1992, page 214, Cambridge University Press.
- ^ a b c Cody, W. J. (March 1993), «Algorithm 715: SPECFUN—A portable FORTRAN package of special function routines and test drivers» (PDF), ACM Trans. Math. Softw., 19 (1): 22–32, CiteSeerX 10.1.1.643.4394, doi:10.1145/151271.151273, S2CID 5621105
- ^ Zaghloul, M. R. (1 March 2007), «On the calculation of the Voigt line profile: a single proper integral with a damped sine integrand», Monthly Notices of the Royal Astronomical Society, 375 (3): 1043–1048, Bibcode:2007MNRAS.375.1043Z, doi:10.1111/j.1365-2966.2006.11377.x
- ^ John W. Craig, A new, simple and exact result for calculating the probability of error for two-dimensional signal constellations Archived 3 April 2012 at the Wayback Machine, Proceedings of the 1991 IEEE Military Communication Conference, vol. 2, pp. 571–575.
- ^ Behnad, Aydin (2020). «A Novel Extension to Craig’s Q-Function Formula and Its Application in Dual-Branch EGC Performance Analysis». IEEE Transactions on Communications. 68 (7): 4117–4125. doi:10.1109/TCOMM.2020.2986209. S2CID 216500014.
- ^ Carslaw, H. S.; Jaeger, J. C. (1959), Conduction of Heat in Solids (2nd ed.), Oxford University Press, ISBN 978-0-19-853368-9, p 484
- ^ https://pubs.opengroup.org/onlinepubs/9699919799/basedefs/math.h.html
- ^ «Special Functions – GSL 2.7 documentation».
Further reading[edit]
- Abramowitz, Milton; Stegun, Irene Ann, eds. (1983) [June 1964]. «Chapter 7». Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. Applied Mathematics Series. Vol. 55 (Ninth reprint with additional corrections of tenth original printing with corrections (December 1972); first ed.). Washington D.C.; New York: United States Department of Commerce, National Bureau of Standards; Dover Publications. p. 297. ISBN 978-0-486-61272-0. LCCN 64-60036. MR 0167642. LCCN 65-12253.
- Press, William H.; Teukolsky, Saul A.; Vetterling, William T.; Flannery, Brian P. (2007), «Section 6.2. Incomplete Gamma Function and Error Function», Numerical Recipes: The Art of Scientific Computing (3rd ed.), New York: Cambridge University Press, ISBN 978-0-521-88068-8
- Temme, Nico M. (2010), «Error Functions, Dawson’s and Fresnel Integrals», in Olver, Frank W. J.; Lozier, Daniel M.; Boisvert, Ronald F.; Clark, Charles W. (eds.), NIST Handbook of Mathematical Functions, Cambridge University Press, ISBN 978-0-521-19225-5, MR 2723248
External links[edit]
- A Table of Integrals of the Error Functions
| Error function | |
|---|---|
|
Plot of the error function |
|
| General information | |
| General definition | |
| Fields of application | Probability, thermodynamics |
| Domain, Codomain and Image | |
| Domain | |
| Image | |
| Basic features | |
| Parity | Odd |
| Specific features | |
| Root | 0 |
| Derivative | |
| Antiderivative | |
| Series definition | |
| Taylor series | |
In mathematics, the error function (also called the Gauss error function), often denoted by erf, is a complex function of a complex variable defined as:[1]
This integral is a special (non-elementary) sigmoid function that occurs often in probability, statistics, and partial differential equations. In many of these applications, the function argument is a real number. If the function argument is real, then the function value is also real.
In statistics, for non-negative values of x, the error function has the following interpretation: for a random variable Y that is normally distributed with mean 0 and standard deviation 1/√2, erf x is the probability that Y falls in the range [−x, x].
Two closely related functions are the complementary error function (erfc) defined as
and the imaginary error function (erfi) defined as
where i is the imaginary unit
Name[edit]
The name «error function» and its abbreviation erf were proposed by J. W. L. Glaisher in 1871 on account of its connection with «the theory of Probability, and notably the theory of Errors.»[2] The error function complement was also discussed by Glaisher in a separate publication in the same year.[3]
For the «law of facility» of errors whose density is given by
(the normal distribution), Glaisher calculates the probability of an error lying between p and q as:
-
Plot of the error function Erf(z) in the complex plane from -2-2i to 2+2i with colors created with Mathematica 13.1 function ComplexPlot3D
Applications[edit]
When the results of a series of measurements are described by a normal distribution with standard deviation σ and expected value 0, then erf (a/σ √2) is the probability that the error of a single measurement lies between −a and +a, for positive a. This is useful, for example, in determining the bit error rate of a digital communication system.
The error and complementary error functions occur, for example, in solutions of the heat equation when boundary conditions are given by the Heaviside step function.
The error function and its approximations can be used to estimate results that hold with high probability or with low probability. Given a random variable X ~ Norm[μ,σ] (a normal distribution with mean μ and standard deviation σ) and a constant L < μ:
where A and B are certain numeric constants. If L is sufficiently far from the mean, specifically μ − L ≥ σ√ln k, then:
so the probability goes to 0 as k → ∞.
The probability for X being in the interval [La, Lb] can be derived as
Properties[edit]
Integrand exp(−z2)
erf z
The property erf (−z) = −erf z means that the error function is an odd function. This directly results from the fact that the integrand e−t2 is an even function (the antiderivative of an even function which is zero at the origin is an odd function and vice versa).
Since the error function is an entire function which takes real numbers to real numbers, for any complex number z:
where z is the complex conjugate of z.
The integrand f = exp(−z2) and f = erf z are shown in the complex z-plane in the figures at right with domain coloring.
The error function at +∞ is exactly 1 (see Gaussian integral). At the real axis, erf z approaches unity at z → +∞ and −1 at z → −∞. At the imaginary axis, it tends to ±i∞.
Taylor series[edit]
The error function is an entire function; it has no singularities (except that at infinity) and its Taylor expansion always converges, but is famously known «[…] for its bad convergence if x > 1.»[4]
The defining integral cannot be evaluated in closed form in terms of elementary functions, but by expanding the integrand e−z2 into its Maclaurin series and integrating term by term, one obtains the error function’s Maclaurin series as:
which holds for every complex number z. The denominator terms are sequence A007680 in the OEIS.
For iterative calculation of the above series, the following alternative formulation may be useful:
because −(2k − 1)z2/k(2k + 1) expresses the multiplier to turn the kth term into the (k + 1)th term (considering z as the first term).
The imaginary error function has a very similar Maclaurin series, which is:
which holds for every complex number z.
Derivative and integral[edit]
The derivative of the error function follows immediately from its definition:
From this, the derivative of the imaginary error function is also immediate:
An antiderivative of the error function, obtainable by integration by parts, is
An antiderivative of the imaginary error function, also obtainable by integration by parts, is
Higher order derivatives are given by
where H are the physicists’ Hermite polynomials.[5]
Bürmann series[edit]
An expansion,[6] which converges more rapidly for all real values of x than a Taylor expansion, is obtained by using Hans Heinrich Bürmann’s theorem:[7]
where sgn is the sign function. By keeping only the first two coefficients and choosing c1 = 31/200 and c2 = −341/8000, the resulting approximation shows its largest relative error at x = ±1.3796, where it is less than 0.0036127:
Inverse functions[edit]
Given a complex number z, there is not a unique complex number w satisfying erf w = z, so a true inverse function would be multivalued. However, for −1 < x < 1, there is a unique real number denoted erf−1 x satisfying
The inverse error function is usually defined with domain (−1,1), and it is restricted to this domain in many computer algebra systems. However, it can be extended to the disk |z| < 1 of the complex plane, using the Maclaurin series
where c0 = 1 and
So we have the series expansion (common factors have been canceled from numerators and denominators):
(After cancellation the numerator/denominator fractions are entries OEIS: A092676/OEIS: A092677 in the OEIS; without cancellation the numerator terms are given in entry OEIS: A002067.) The error function’s value at ±∞ is equal to ±1.
For |z| < 1, we have erf(erf−1 z) = z.
The inverse complementary error function is defined as
For real x, there is a unique real number erfi−1 x satisfying erfi(erfi−1 x) = x. The inverse imaginary error function is defined as erfi−1 x.[8]
For any real x, Newton’s method can be used to compute erfi−1 x, and for −1 ≤ x ≤ 1, the following Maclaurin series converges:
where ck is defined as above.
Asymptotic expansion[edit]
A useful asymptotic expansion of the complementary error function (and therefore also of the error function) for large real x is
where (2n − 1)!! is the double factorial of (2n − 1), which is the product of all odd numbers up to (2n − 1). This series diverges for every finite x, and its meaning as asymptotic expansion is that for any integer N ≥ 1 one has
where the remainder, in Landau notation, is
as x → ∞.
Indeed, the exact value of the remainder is
which follows easily by induction, writing
and integrating by parts.
For large enough values of x, only the first few terms of this asymptotic expansion are needed to obtain a good approximation of erfc x (while for not too large values of x, the above Taylor expansion at 0 provides a very fast convergence).
Continued fraction expansion[edit]
A continued fraction expansion of the complementary error function is:[9]
Integral of error function with Gaussian density function[edit]
which appears related to Ng and Geller, formula 13 in section 4.3[10] with a change of variables.
Factorial series[edit]
The inverse factorial series:
converges for Re(z2) > 0. Here
zn denotes the rising factorial, and s(n,k) denotes a signed Stirling number of the first kind.[11][12]
There also exists a representation by an infinite sum containing the double factorial:
Numerical approximations[edit]
Approximation with elementary functions[edit]
- Abramowitz and Stegun give several approximations of varying accuracy (equations 7.1.25–28). This allows one to choose the fastest approximation suitable for a given application. In order of increasing accuracy, they are:
(maximum error: 5×10−4)
where a1 = 0.278393, a2 = 0.230389, a3 = 0.000972, a4 = 0.078108
(maximum error: 2.5×10−5)
where p = 0.47047, a1 = 0.3480242, a2 = −0.0958798, a3 = 0.7478556
(maximum error: 3×10−7)
where a1 = 0.0705230784, a2 = 0.0422820123, a3 = 0.0092705272, a4 = 0.0001520143, a5 = 0.0002765672, a6 = 0.0000430638
(maximum error: 1.5×10−7)
where p = 0.3275911, a1 = 0.254829592, a2 = −0.284496736, a3 = 1.421413741, a4 = −1.453152027, a5 = 1.061405429
All of these approximations are valid for x ≥ 0. To use these approximations for negative x, use the fact that erf x is an odd function, so erf x = −erf(−x).
- Exponential bounds and a pure exponential approximation for the complementary error function are given by[13]
- The above have been generalized to sums of N exponentials[14] with increasing accuracy in terms of N so that erfc x can be accurately approximated or bounded by 2Q̃(√2x), where
In particular, there is a systematic methodology to solve the numerical coefficients {(an,bn)}N
n = 1 that yield a minimax approximation or bound for the closely related Q-function: Q(x) ≈ Q̃(x), Q(x) ≤ Q̃(x), or Q(x) ≥ Q̃(x) for x ≥ 0. The coefficients {(an,bn)}N
n = 1 for many variations of the exponential approximations and bounds up to N = 25 have been released to open access as a comprehensive dataset.[15] - A tight approximation of the complementary error function for x ∈ [0,∞) is given by Karagiannidis & Lioumpas (2007)[16] who showed for the appropriate choice of parameters {A,B} that
They determined {A,B} = {1.98,1.135}, which gave a good approximation for all x ≥ 0. Alternative coefficients are also available for tailoring accuracy for a specific application or transforming the expression into a tight bound.[17]
- A single-term lower bound is[18]
where the parameter β can be picked to minimize error on the desired interval of approximation.
-
- Another approximation is given by Sergei Winitzki using his «global Padé approximations»:[19][20]: 2–3
where
This is designed to be very accurate in a neighborhood of 0 and a neighborhood of infinity, and the relative error is less than 0.00035 for all real x. Using the alternate value a ≈ 0.147 reduces the maximum relative error to about 0.00013.[21]
This approximation can be inverted to obtain an approximation for the inverse error function:
- An approximation with a maximal error of 1.2×10−7 for any real argument is:[22]
with
and
Table of values[edit]
| x | erf x | 1 − erf x |
|---|---|---|
| 0 | 0 | 1 |
| 0.02 | 0.022564575 | 0.977435425 |
| 0.04 | 0.045111106 | 0.954888894 |
| 0.06 | 0.067621594 | 0.932378406 |
| 0.08 | 0.090078126 | 0.909921874 |
| 0.1 | 0.112462916 | 0.887537084 |
| 0.2 | 0.222702589 | 0.777297411 |
| 0.3 | 0.328626759 | 0.671373241 |
| 0.4 | 0.428392355 | 0.571607645 |
| 0.5 | 0.520499878 | 0.479500122 |
| 0.6 | 0.603856091 | 0.396143909 |
| 0.7 | 0.677801194 | 0.322198806 |
| 0.8 | 0.742100965 | 0.257899035 |
| 0.9 | 0.796908212 | 0.203091788 |
| 1 | 0.842700793 | 0.157299207 |
| 1.1 | 0.880205070 | 0.119794930 |
| 1.2 | 0.910313978 | 0.089686022 |
| 1.3 | 0.934007945 | 0.065992055 |
| 1.4 | 0.952285120 | 0.047714880 |
| 1.5 | 0.966105146 | 0.033894854 |
| 1.6 | 0.976348383 | 0.023651617 |
| 1.7 | 0.983790459 | 0.016209541 |
| 1.8 | 0.989090502 | 0.010909498 |
| 1.9 | 0.992790429 | 0.007209571 |
| 2 | 0.995322265 | 0.004677735 |
| 2.1 | 0.997020533 | 0.002979467 |
| 2.2 | 0.998137154 | 0.001862846 |
| 2.3 | 0.998856823 | 0.001143177 |
| 2.4 | 0.999311486 | 0.000688514 |
| 2.5 | 0.999593048 | 0.000406952 |
| 3 | 0.999977910 | 0.000022090 |
| 3.5 | 0.999999257 | 0.000000743 |
[edit]
Complementary error function[edit]
The complementary error function, denoted erfc, is defined as
-
Plot of the complementary error function Erfc(z) in the complex plane from -2-2i to 2+2i with colors created with Mathematica 13.1 function ComplexPlot3D
which also defines erfcx, the scaled complementary error function[23] (which can be used instead of erfc to avoid arithmetic underflow[23][24]). Another form of erfc x for x ≥ 0 is known as Craig’s formula, after its discoverer:[25]
This expression is valid only for positive values of x, but it can be used in conjunction with erfc x = 2 − erfc(−x) to obtain erfc(x) for negative values. This form is advantageous in that the range of integration is fixed and finite. An extension of this expression for the erfc of the sum of two non-negative variables is as follows:[26]
Imaginary error function[edit]
The imaginary error function, denoted erfi, is defined as
Plot of the imaginary error function Erfi(z) in the complex plane from -2-2i to 2+2i with colors created with Mathematica 13.1 function ComplexPlot3D
where D(x) is the Dawson function (which can be used instead of erfi to avoid arithmetic overflow[23]).
Despite the name «imaginary error function», erfi x is real when x is real.
When the error function is evaluated for arbitrary complex arguments z, the resulting complex error function is usually discussed in scaled form as the Faddeeva function:
Cumulative distribution function[edit]
The error function is essentially identical to the standard normal cumulative distribution function, denoted Φ, also named norm(x) by some software languages[citation needed], as they differ only by scaling and translation. Indeed,
-
the normal cumulative distribution function plotted in the complex plane
or rearranged for erf and erfc:
Consequently, the error function is also closely related to the Q-function, which is the tail probability of the standard normal distribution. The Q-function can be expressed in terms of the error function as
The inverse of Φ is known as the normal quantile function, or probit function and may be expressed in terms of the inverse error function as
The standard normal cdf is used more often in probability and statistics, and the error function is used more often in other branches of mathematics.
The error function is a special case of the Mittag-Leffler function, and can also be expressed as a confluent hypergeometric function (Kummer’s function):
It has a simple expression in terms of the Fresnel integral.[further explanation needed]
In terms of the regularized gamma function P and the incomplete gamma function,
sgn x is the sign function.
Generalized error functions[edit]
Graph of generalised error functions En(x):
grey curve: E1(x) = 1 − e−x/√π
red curve: E2(x) = erf(x)
green curve: E3(x)
blue curve: E4(x)
gold curve: E5(x).
Some authors discuss the more general functions:[citation needed]
Notable cases are:
- E0(x) is a straight line through the origin: E0(x) = x/e√π
- E2(x) is the error function, erf x.
After division by n!, all the En for odd n look similar (but not identical) to each other. Similarly, the En for even n look similar (but not identical) to each other after a simple division by n!. All generalised error functions for n > 0 look similar on the positive x side of the graph.
These generalised functions can equivalently be expressed for x > 0 using the gamma function and incomplete gamma function:
Therefore, we can define the error function in terms of the incomplete gamma function:
Iterated integrals of the complementary error function[edit]
The iterated integrals of the complementary error function are defined by[27]
The general recurrence formula is
They have the power series
from which follow the symmetry properties
and
Implementations[edit]
As real function of a real argument[edit]
- In Posix-compliant operating systems, the header
math.hshall declare and the mathematical librarylibmshall provide the functionserfanderfc(double precision) as well as their single precision and extended precision counterpartserff,erflanderfcf,erfcl.[28] - The GNU Scientific Library provides
erf,erfc,log(erf), and scaled error functions.[29]
As complex function of a complex argument[edit]
libcerf, numeric C library for complex error functions, provides the complex functionscerf,cerfc,cerfcxand the real functionserfi,erfcxwith approximately 13–14 digits precision, based on the Faddeeva function as implemented in the MIT Faddeeva Package
See also[edit]
[edit]
- Gaussian integral, over the whole real line
- Gaussian function, derivative
- Dawson function, renormalized imaginary error function
- Goodwin–Staton integral
In probability[edit]
- Normal distribution
- Normal cumulative distribution function, a scaled and shifted form of error function
- Probit, the inverse or quantile function of the normal CDF
- Q-function, the tail probability of the normal distribution
References[edit]
- ^ Andrews, Larry C. (1998). Special functions of mathematics for engineers. SPIE Press. p. 110. ISBN 9780819426161.
- ^ Glaisher, James Whitbread Lee (July 1871). «On a class of definite integrals». London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science. 4. 42 (277): 294–302. doi:10.1080/14786447108640568. Retrieved 6 December 2017.
- ^ Glaisher, James Whitbread Lee (September 1871). «On a class of definite integrals. Part II». London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science. 4. 42 (279): 421–436. doi:10.1080/14786447108640600. Retrieved 6 December 2017.
- ^ «A007680 – OEIS». oeis.org. Retrieved 2 April 2020.
- ^ Weisstein, Eric W. «Erf». MathWorld.
- ^ Schöpf, H. M.; Supancic, P. H. (2014). «On Bürmann’s Theorem and Its Application to Problems of Linear and Nonlinear Heat Transfer and Diffusion». The Mathematica Journal. 16. doi:10.3888/tmj.16-11.
- ^ Weisstein, Eric W. «Bürmann’s Theorem». MathWorld.
- ^ Bergsma, Wicher (2006). «On a new correlation coefficient, its orthogonal decomposition and associated tests of independence». arXiv:math/0604627.
- ^ Cuyt, Annie A. M.; Petersen, Vigdis B.; Verdonk, Brigitte; Waadeland, Haakon; Jones, William B. (2008). Handbook of Continued Fractions for Special Functions. Springer-Verlag. ISBN 978-1-4020-6948-2.
- ^ Ng, Edward W.; Geller, Murray (January 1969). «A table of integrals of the Error functions». Journal of Research of the National Bureau of Standards Section B. 73B (1): 1. doi:10.6028/jres.073B.001.
- ^ Schlömilch, Oskar Xavier (1859). «Ueber facultätenreihen». Zeitschrift für Mathematik und Physik (in German). 4: 390–415. Retrieved 4 December 2017.
- ^ Nielson, Niels (1906). Handbuch der Theorie der Gammafunktion (in German). Leipzig: B. G. Teubner. p. 283 Eq. 3. Retrieved 4 December 2017.
- ^ Chiani, M.; Dardari, D.; Simon, M.K. (2003). «New Exponential Bounds and Approximations for the Computation of Error Probability in Fading Channels» (PDF). IEEE Transactions on Wireless Communications. 2 (4): 840–845. CiteSeerX 10.1.1.190.6761. doi:10.1109/TWC.2003.814350.
- ^ Tanash, I.M.; Riihonen, T. (2020). «Global minimax approximations and bounds for the Gaussian Q-function by sums of exponentials». IEEE Transactions on Communications. 68 (10): 6514–6524. arXiv:2007.06939. doi:10.1109/TCOMM.2020.3006902. S2CID 220514754.
- ^ Tanash, I.M.; Riihonen, T. (2020). «Coefficients for Global Minimax Approximations and Bounds for the Gaussian Q-Function by Sums of Exponentials [Data set]». Zenodo. doi:10.5281/zenodo.4112978.
- ^ Karagiannidis, G. K.; Lioumpas, A. S. (2007). «An improved approximation for the Gaussian Q-function» (PDF). IEEE Communications Letters. 11 (8): 644–646. doi:10.1109/LCOMM.2007.070470. S2CID 4043576.
- ^ Tanash, I.M.; Riihonen, T. (2021). «Improved coefficients for the Karagiannidis–Lioumpas approximations and bounds to the Gaussian Q-function». IEEE Communications Letters. 25 (5): 1468–1471. arXiv:2101.07631. doi:10.1109/LCOMM.2021.3052257. S2CID 231639206.
- ^ Chang, Seok-Ho; Cosman, Pamela C.; Milstein, Laurence B. (November 2011). «Chernoff-Type Bounds for the Gaussian Error Function». IEEE Transactions on Communications. 59 (11): 2939–2944. doi:10.1109/TCOMM.2011.072011.100049. S2CID 13636638.
- ^ Winitzki, Sergei (2003). «Uniform approximations for transcendental functions». Computational Science and Its Applications – ICCSA 2003. Lecture Notes in Computer Science. Vol. 2667. Springer, Berlin. pp. 780–789. doi:10.1007/3-540-44839-X_82. ISBN 978-3-540-40155-1.
- ^ Zeng, Caibin; Chen, Yang Cuan (2015). «Global Padé approximations of the generalized Mittag-Leffler function and its inverse». Fractional Calculus and Applied Analysis. 18 (6): 1492–1506. arXiv:1310.5592. doi:10.1515/fca-2015-0086. S2CID 118148950.
Indeed, Winitzki [32] provided the so-called global Padé approximation
- ^ Winitzki, Sergei (6 February 2008). «A handy approximation for the error function and its inverse».
- ^ Numerical Recipes in Fortran 77: The Art of Scientific Computing (ISBN 0-521-43064-X), 1992, page 214, Cambridge University Press.
- ^ a b c Cody, W. J. (March 1993), «Algorithm 715: SPECFUN—A portable FORTRAN package of special function routines and test drivers» (PDF), ACM Trans. Math. Softw., 19 (1): 22–32, CiteSeerX 10.1.1.643.4394, doi:10.1145/151271.151273, S2CID 5621105
- ^ Zaghloul, M. R. (1 March 2007), «On the calculation of the Voigt line profile: a single proper integral with a damped sine integrand», Monthly Notices of the Royal Astronomical Society, 375 (3): 1043–1048, Bibcode:2007MNRAS.375.1043Z, doi:10.1111/j.1365-2966.2006.11377.x
- ^ John W. Craig, A new, simple and exact result for calculating the probability of error for two-dimensional signal constellations Archived 3 April 2012 at the Wayback Machine, Proceedings of the 1991 IEEE Military Communication Conference, vol. 2, pp. 571–575.
- ^ Behnad, Aydin (2020). «A Novel Extension to Craig’s Q-Function Formula and Its Application in Dual-Branch EGC Performance Analysis». IEEE Transactions on Communications. 68 (7): 4117–4125. doi:10.1109/TCOMM.2020.2986209. S2CID 216500014.
- ^ Carslaw, H. S.; Jaeger, J. C. (1959), Conduction of Heat in Solids (2nd ed.), Oxford University Press, ISBN 978-0-19-853368-9, p 484
- ^ https://pubs.opengroup.org/onlinepubs/9699919799/basedefs/math.h.html
- ^ «Special Functions – GSL 2.7 documentation».
Further reading[edit]
- Abramowitz, Milton; Stegun, Irene Ann, eds. (1983) [June 1964]. «Chapter 7». Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. Applied Mathematics Series. Vol. 55 (Ninth reprint with additional corrections of tenth original printing with corrections (December 1972); first ed.). Washington D.C.; New York: United States Department of Commerce, National Bureau of Standards; Dover Publications. p. 297. ISBN 978-0-486-61272-0. LCCN 64-60036. MR 0167642. LCCN 65-12253.
- Press, William H.; Teukolsky, Saul A.; Vetterling, William T.; Flannery, Brian P. (2007), «Section 6.2. Incomplete Gamma Function and Error Function», Numerical Recipes: The Art of Scientific Computing (3rd ed.), New York: Cambridge University Press, ISBN 978-0-521-88068-8
- Temme, Nico M. (2010), «Error Functions, Dawson’s and Fresnel Integrals», in Olver, Frank W. J.; Lozier, Daniel M.; Boisvert, Ronald F.; Clark, Charles W. (eds.), NIST Handbook of Mathematical Functions, Cambridge University Press, ISBN 978-0-521-19225-5, MR 2723248
External links[edit]
- A Table of Integrals of the Error Functions
График функции
В математике функция ошибок (также называемая Функция ошибок Гаусса ), часто обозначаемая erf, является сложной функцией комплексной определяемой как:
- erf z = 2 π ∫ 0 ze — t 2 dt. { displaystyle operatorname {erf} z = { frac {2} { sqrt { pi}}} int _ {0} ^ {z} e ^ {- t ^ {2}} , dt.}

Этот интеграл является особой (не элементарной ) и сигмоидной функцией, которая часто встречается в статистике вероятность, и уравнения в частных производных. Во многих из этих приложений аргумент функции является действительным числом. Если аргумент функции является действительным, значение также является действительным.
В статистике для неотрицательных значений x функция имеет интерпретацию: для случайной величины Y, которая нормально распределена с среднее 0 и дисперсия 1/2, erf x — это вероятность того, что Y попадает в диапазон [-x, x].
Две связанные функции: дополнительные функции ошибок (erfc ), определенная как
- erfc z = 1 — erf z, { displaystyle operatorname {erfc} z = 1- operatorname {erf} z,}
и функция мнимой ошибки (erfi ), определяемая как
- erfi z = — i erf (iz), { displaystyle operatorname {erfi} z = -i operatorname {erf} (iz),}

, где i — мнимая единица.
Содержание
- 1 Имя
- 2 Приложения
- 3 Свойства
- 3.1 Ряд Тейлора
- 3.2 Производная и интеграл
- 3.3 Ряд Бюрмана
- 3.4 Обратные функции
- 3.5 Асимптотическое разложение
- 3.6 Разложение на непрерывную дробь
- 3,7 Интеграл функции ошибок с функцией плотности Гаусса
- 3.8 Факториальный ряд
- 4 Численные приближения
- 4.1 Аппроксимация с элементарными функциями
- 4.2 Полином
- 4.3 Таблица значений
- 5 Связанные функции
- 5.1 функция дополнительных ошибок
- 5.2 Функция мнимой ошибки
- 5.3 Кумулятивная функци я распределения на
- 5.4 Обобщенные функции ошибок
- 5.5 Итерированные интегралы дополнительных функций ошибок
- 6 Реализации
- 6.1 Как действующая функция действительного аргумента
- 6.2 Как комплексная функция комплексного аргумента
- 7 См. Также
- 7.1 Связанные функции
- 7.2 Вероятность
- 8 Ссылки
- 9 Дополнительная литература
- 10 Внешние ссылки
Имя
Название «функция ошибки» и его аббревиатура erf были предложены Дж. В. Л. Глейшер в 1871 г. по причине его связи с «теорией вероятности, и особенно теорией ошибок ». Дополнение функции ошибок также обсуждалось Глейшером в отдельной публикации в том же году. Для «закона удобства» ошибок плотность задана как
- f (x) = (c π) 1 2 e — cx 2 { displaystyle f (x) = left ({ frac {c } { pi}} right) ^ { tfrac {1} {2}} e ^ {- cx ^ {2}}}

(нормальное распределение ), Глейшер вычисляет вероятность ошибки, лежащей между p { displaystyle p} и q { displaystyle q}
и q { displaystyle q} как:
как:
- (c π) 1 2 ∫ pqe — cx 2 dx = 1 2 (erf (qc) — erf (pc)). { displaystyle left ({ frac {c} { pi}} right) ^ { tfrac {1} {2}} int _ {p} ^ {q} e ^ {- cx ^ {2} } dx = { tfrac {1} {2}} left ( operatorname {erf} (q { sqrt {c}}) — operatorname {erf} (p { sqrt {c}}) right).}

Приложения
Когда результаты серии измерений описываются нормальным распределением со стандартным отклонением σ { displaystyle sigma} и ожидаемое значение 0, затем erf (a σ 2) { displaystyle textstyle operatorname {erf} left ({ frac {a} { sigma { sqrt {2}) }}} right)}
и ожидаемое значение 0, затем erf (a σ 2) { displaystyle textstyle operatorname {erf} left ({ frac {a} { sigma { sqrt {2}) }}} right)} — это вероятность того, что ошибка единичного измерения находится между −a и + a, для положительного a. Это полезно, например, при определении коэффициента битовых ошибок цифровой системы связи.
— это вероятность того, что ошибка единичного измерения находится между −a и + a, для положительного a. Это полезно, например, при определении коэффициента битовых ошибок цифровой системы связи.
Функции и дополнительные функции ошибок возникают, например, в решениях уравнения теплопроводности, когда граничные ошибки задаются ступенчатой функцией Хевисайда.
Функция ошибок и ее приближения Программу присвоили себе преподавателей, которые получили с высокой вероятностью или с низкой вероятностью. Дана случайная величина X ∼ Norm [μ, σ] { displaystyle X sim operatorname {Norm} [ mu, sigma]}![X sim operatorname {Norm} [ му, sigma]](https://wikimedia.org/api/rest_v1/media/math/render/svg/84024bc6827355ec6d23a062283a26d54b29698d) и константа L < μ {displaystyle L<mu }
и константа L < μ {displaystyle L<mu } :
:
- Pr [X ≤ L ] = 1 2 + 1 2 erf (L — μ 2 σ) ≈ A ехр (- B (L — μ σ) 2) { Displaystyle Pr [X Leq L] = { frac {1} {2 }} + { frac {1} {2}} operatorname {erf} left ({ frac {L- mu} {{ sqrt {2}} sigma}} right) приблизительно A exp left (-B left ({ frac {L- mu} { sigma}} right) ^ {2} right)}
![{ displaystyle Pr [X leq L ] = { frac {1} {2}} + { frac {1} {2}} operatorname {erf} left ({ frac {L- mu} {{ sqrt {2}} sigma }} right) приблизительно A exp left (-B left ({ frac {L- mu} { sigma}} right) ^ {2} right)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a72302c46832449e128a4d4e1adb28b514131270)
где A и B — верх числовые константы. Если L достаточно далеко от среднего, то есть μ — L ≥ σ ln k { displaystyle mu -L geq sigma { sqrt { ln {k}}}} , то:
, то:
- Pr [X ≤ L] ≤ A exp (- B ln k) = A К B { displaystyle Pr [X leq L] leq A exp (-B ln {k}) = { frac {A} {k ^ {B}}}}
, поэтому становится вероятность 0 при k → ∞ { displaystyle k to infty} .
.
Свойства
Графики на комплексной плоскости  Интегрируем exp (-z)
Интегрируем exp (-z)  erf (z)
erf (z)
Свойство erf (- z) = — erf (z) { displaystyle operatorname {erf} (-z) = — operatorname {erf} (z)} означает, что функция является ошибкой нечетной функции. Это связано с тем, что подынтегральное выражение e — t 2 { displaystyle e ^ {- t ^ {2}}}
означает, что функция является ошибкой нечетной функции. Это связано с тем, что подынтегральное выражение e — t 2 { displaystyle e ^ {- t ^ {2}}} является четной функцией.
является четной функцией.
Для любого комплексное число z:
- erf (z ¯) = erf (z) ¯ { displaystyle operatorname {erf} ({ overline {z}}) = { overline { operatorname {erf} (z)}}}

где z ¯ { displaystyle { overline {z}}} — комплексное сопряжение число z.
— комплексное сопряжение число z.
Подынтегральное выражение f = exp (−z) и f = erf (z) показано в комплексной плоскости z на рисунках 2 и 3. Уровень Im (f) = 0 показан жирным зеленым цветом. линия. Отрицательные целые значения Im (f) показаны жирными красными линиями. Положительные целые значения Im (f) показаны толстыми синими линиями. Промежуточные уровни Im (f) = проявляются тонкими зелеными линиями. Промежуточные уровни Re (f) = показаны тонкими красными линиями для отрицательных значений и тонкими синими линиями для положительных значений.
Функция ошибок при + ∞ равна 1 (см. интеграл Гаусса ). На действительной оси erf (z) стремится к единице при z → + ∞ и к −1 при z → −∞. На мнимой оси он стремится к ± i∞.
Серия Тейлора
Функция ошибок — это целая функция ; у него нет сингулярностей (кроме бесконечности), и его разложение Тейлора всегда сходится, но, как известно, «[…] его плохая сходимость, если x>1».
определяющий интеграл нельзя вычислить в закрытой форме в терминах элементарных функций, но путем расширения подынтегрального выражения e в его ряд Маклорена и интегрирована почленно, можно получить ряд Маклорена функции ошибок как:
- erf (z) = 2 π ∑ n = 0 ∞ (- 1) nz 2 n + 1 n! (2 n + 1) знак равно 2 π (z — z 3 3 + z 5 10 — z 7 42 + z 9 216 — ⋯) { displaystyle operatorname {erf} (z) = { frac {2} { sqrt { pi}}} sum _ {n = 0} ^ { infty} { frac {(-1) ^ {n} z ^ {2n + 1}} {n! (2n + 1)}} = { frac {2} { sqrt { pi}}} left (z — { frac {z ^ {3}} {3}} + { frac {z ^ { 5}} {10}} — { frac {z ^ {7}} {42}} + { frac {z ^ {9}} {216}} — cdots right)}

, которое выполняется для каждого комплексного числа г. Члены знаменателя представляют собой последовательность A007680 в OEIS.
Для итеративного вычисления нового ряда может быть полезна следующая альтернативная формулировка:
- erf (z) = 2 π ∑ n = 0 ∞ (z ∏ К знак равно 1 N — (2 К — 1) Z 2 К (2 К + 1)) знак равно 2 π ∑ N = 0 ∞ Z 2 N + 1 ∏ К = 1 N — Z 2 К { Displaystyle OperatorName { erf} (z) = { frac {2} { sqrt { pi}}} sum _ {n = 0} ^ { infty} left (z prod _ {k = 1} ^ {n} { frac {- (2k-1) z ^ {2}} {k (2k + 1)}} right) = { frac {2} { sqrt { pi}}} sum _ {n = 0} ^ { infty} { frac {z} {2n + 1}} prod _ {k = 1} ^ {n} { frac {-z ^ {2}} {k}}}

потому что что — (2 k — 1) z 2 k (2 k + 1) { displaystyle { frac {- (2k-1) z ^ {2}} {k (2k + 1))}} } выражает множитель для превращения члена k в член (k + 1) (рассматривая z как первый член).
выражает множитель для превращения члена k в член (k + 1) (рассматривая z как первый член).
Функция мнимой ошибки имеет очень похожий ряд Маклорена:
- erfi (z) = 2 π ∑ n = 0 ∞ z 2 n + 1 n! (2 n + 1) знак равно 2 π (z + z 3 3 + z 5 10 + z 7 42 + z 9 216 + ⋯) { displaystyle operatorname {erfi} (z) = { frac {2} { sqrt { pi}}} sum _ {n = 0} ^ { infty} { frac {z ^ {2n + 1}} {n! (2n + 1)}} = { frac {2} { sqrt { pi}}} left (z + { frac {z ^ {3}} {3}} + { frac {z ^ { 5}} {10}} + { frac {z ^ {7}} {42}} + { frac {z ^ {9}} {216}} + cdots right)}

, которое выполняется для любого комплексного числа z.
Производная и интеграл
Производная функция ошибок сразу следует из ее определения:
- ddz erf (z) = 2 π e — z 2. { displaystyle { frac {d} {dz}} operatorname {erf} (z) = { frac {2} { sqrt { pi}}} e ^ {- z ^ {2}}.}

Отсюда немедленно вычисляется производная функция мнимой ошибки :
- ddz erfi (z) = 2 π ez 2. { displaystyle { frac {d} {dz}} operatorname {erfi} (z) = { frac {2} { sqrt { pi }}} e ^ {z ^ {2}}.}

первообразная функции ошибок, которые можно получить посредством интегрирования по частям, составляет
- z erf (z) + е — z 2 π. { displaystyle z operatorname {erf} (z) + { frac {e ^ {- z ^ {2}}} { sqrt { pi}}}.}

Первообразная мнимой функции ошибок, также можно получить интегрированием по частям:
- z erfi (z) — ez 2 π. { displaystyle z operatorname {erfi} (z) — { frac {e ^ {z ^ {2}}} { sqrt { pi}}}.}

Производные высшего порядка задаются как
- erf (k) (z) = 2 (- 1) k — 1 π H k — 1 (z) e — z 2 = 2 π dk — 1 dzk — 1 (e — z 2), k = 1, 2, … { Displaystyle operatorname {erf} ^ {(k)} (z) = { frac {2 (-1) ^ {k-1}} { sqrt { pi}}} { mathit {H} } _ {k-1} (z) e ^ {- z ^ {2}} = { frac {2} { sqrt { pi}}} { frac {d ^ {k-1}} {dz ^ {k-1}}} left (e ^ {- z ^ {2}} right), qquad k = 1,2, dots}

где H { displaystyle { mathit {H}}} — физики многочлены Эрмита.
— физики многочлены Эрмита.
ряд Бюрмана
Расширение, которое сходится быстрее для всех реальных значений x { displaystyle x} , чем разложение Тейлора, получается с помощью теоремы Ганса Генриха Бюрмана :
, чем разложение Тейлора, получается с помощью теоремы Ганса Генриха Бюрмана :
- erf (x) = 2 π sgn (x) 1 — e — x 2 (1 — 1 12 ( 1 — e — x 2) — 7 480 (1 — e — x 2) 2 — 5 896 (1 — e — x 2) 3 — 787 276480 (1 — e — x 2)) 4 — ⋯) знак равно 2 π знак (x) 1 — e — x 2 (π 2 + ∑ k = 1 ∞ cke — kx 2). { displaystyle { begin {align} operatorname {erf} (x) = { frac {2} { sqrt { pi}}} operatorname {sgn} (x) { sqrt {1-e ^ {-x ^ {2}}}} left (1 — { frac {1} {12}} left (1-e ^ {- x ^ {2}} right) — { frac {7} {480}} left (1-e ^ {- x ^ {2}} right) ^ {2} — { frac {5} {896}} left (1-e ^ {- x ^ {2 }} right) ^ {3} — { frac {787} {276480}} left (1-e ^ {- x ^ {2}} right) ^ {4} — cdots right) [10pt] = { frac {2} { sqrt { pi}}} operatorname {sgn} (x) { sqrt {1-e ^ {- x ^ {2}}}} left ({ frac { sqrt { pi}} {2}} + sum _ {k = 1} ^ { infty} c_ {k} e ^ {- kx ^ {2}} right). end {выровнено}}
![{ displaystyle { begin {align} operatorname {erf} (x) = { frac {2} { sqrt { pi}}} operatorname {sgn} (x) { sqrt {1-e ^ {- x ^ {2}}}} left (1 - { frac {1} {12}} left (1 -e ^ {- x ^ {2}} right) - { frac {7} {480}} left (1-e ^ {- x ^ {2}} right) ^ {2} - { frac {5} {896}} left (1-e ^ {- x ^ {2}} right) ^ {3} - { frac {787} {276480}} left (1-e ^ {- x ^ {2 }} right) ^ {4} - cdots right) [10pt] = { frac {2} { sqrt { pi}}} operatorname {sgn} (x) { sqrt {1 -e ^ {- x ^ {2}}}} left ({ frac { sqrt { pi}} {2}} + sum _ {k = 1} ^ { infty} c_ {k} e ^ {- kx ^ {2}} right). end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/24ddba05e595a553fee25644a3542188281bd844)
Сохраняя только первые два коэффициента и выбирая c 1 = 31 200 { displaystyle c_ {1} = { frac {31} {200}}} и c 2 = — 341 8000, { displaystyle c_ {2} = — { frac {341} {8000}},}
и c 2 = — 341 8000, { displaystyle c_ {2} = — { frac {341} {8000}},} результирующая аппроксимация дает наибольшую относительную ошибку при x = ± 1,3796, { displaystyle x = pm 1,3796,}
результирующая аппроксимация дает наибольшую относительную ошибку при x = ± 1,3796, { displaystyle x = pm 1,3796,} , где оно меньше 3,6127 ⋅ 10 — 3 { displaystyle 3.6127 cdot 10 ^ {- 3}}
, где оно меньше 3,6127 ⋅ 10 — 3 { displaystyle 3.6127 cdot 10 ^ {- 3}} :
:
- erf (x) ≈ 2 π sign (x) 1 — e — x 2 (π 2 + 31 200 e — x 2 — 341 8000 e — 2 х 2). { displaystyle operatorname {erf} (x) приблизительно { frac {2} { sqrt { pi}}} operatorname {sgn} (x) { sqrt {1-e ^ {- x ^ {2 }}}} left ({ frac { sqrt { pi}} {2}} + { frac {31} {200}} e ^ {- x ^ {2}} — { frac {341} {8000}} e ^ {- 2x ^ {2}} right).}

Обратные функции
Обратная функция
Учитывая комплексное число z, не существует уникального комплексного числа w, удовлетворяющего erf (w) = z { displaystyle operatorname {erf} (w) = z} , поэтому истинная обратная функция будет многозначной. Однако для −1 < x < 1, there is a unique real number denoted erf — 1 (x) { displaystyle operatorname {erf} ^ {- 1} (x)}
, поэтому истинная обратная функция будет многозначной. Однако для −1 < x < 1, there is a unique real number denoted erf — 1 (x) { displaystyle operatorname {erf} ^ {- 1} (x)} , удовлетворяющего
, удовлетворяющего
- erf (erf — 1 ( х)) = х. { displaystyle operatorname {erf} left ( operatorname {erf} ^ {- 1} (x) right) = x.}

Обратная функция ошибок обычно определяется с помощью домена (- 1,1), и он ограничен этой областью многих систем компьютерной алгебры. Однако его можно продолжить и на диск | z | < 1 of the complex plane, using the Maclaurin series
- erf — 1 (z) знак равно ∑ К знак равно 0 ∞ ck 2 k + 1 (π 2 z) 2 k + 1, { displaystyle operatorname {erf} ^ {- 1} (z) = sum _ {k = 0} ^ { infty} { frac {c_ {k}} {2k + 1}} left ({ frac { sqrt { pi}} {2}} z right) ^ {2k + 1},}

где c 0 = 1 и
- ck = ∑ m = 0 k — 1 cmck — 1 — m (m + 1) (2 m + 1) = {1, 1, 7 6, 127 90, 4369 2520, 34807 16200,…}. { displaystyle c_ {k} = sum _ {m = 0} ^ {k-1} { frac {c_ {m} c_ {k-1-m}} {(m + 1) (2m + 1) }} = left {1,1, { frac {7} {6}}, { frac {127} {90}}, { frac {4369} {2520}}, { frac {34807} {16200}}, ldots right }.}

Итак, у нас есть разложение в ряд (общие множители были удалены из числителей и знаменателей):
- erf — 1 (z) = 1 2 π ( z + π 12 z 3 + 7 π 2 480 z 5 + 127 π 3 40320 z 7 + 4369 π 4 5806080 z 9 + 34807 π 5 182476800 z 11 + ⋯). { displaystyle operatorname {erf} ^ {- 1} (z) = { tfrac {1} {2}} { sqrt { pi}} left (z + { frac { pi} {12} } z ^ {3} + { frac {7 pi ^ {2}} {480}} z ^ {5} + { frac {127 pi ^ {3}} {40320}} z ^ {7} + { frac {4369 pi ^ {4}} {5806080}} z ^ {9} + { frac {34807 pi ^ {5}} {182476800}} z ^ {11} + cdots right). }

(После отмены дроби числителя / знаменателя характерми OEIS : A092676 / OEIS : A092677 в OEIS ; без отмены членов числителя в записи OEIS : A002067.) Значение функции ошибок при ± ∞ равно ± 1.
Для | z | < 1, we have erf (erf — 1 (z)) = z { displaystyle operatorname {erf} left ( operatorname {erf} ^ {- 1} (z) right) = z} .
.
обратная дополнительная функция ошибок определяется как
- erfc — 1 (1 — z) = erf — 1 (z). { displaystyle operatorname {erfc} ^ {- 1} (1-z) = operatorname {erf} ^ {- 1} (z).}

Для действительного x существует уникальное действительное число erfi — 1 (x) { displaystyle operatorname {erfi} ^ {- 1} (x)} удовлетворяет erfi (erfi — 1 (x)) = x { displaystyle operatorname { erfi} left ( operatorname {erfi} ^ {- 1} (x) right) = x}
удовлетворяет erfi (erfi — 1 (x)) = x { displaystyle operatorname { erfi} left ( operatorname {erfi} ^ {- 1} (x) right) = x} . функция обратной мнимой ошибки определяется как erfi — 1 (x) { displaystyle operatorname {erfi} ^ {- 1} (x)}.
. функция обратной мнимой ошибки определяется как erfi — 1 (x) { displaystyle operatorname {erfi} ^ {- 1} (x)}.
Для любого действительного x, Метод Ньютона можно использовать для вычислений erfi — 1 (x) { displaystyle operatorname {erfi} ^ {- 1} (x)}, а для — 1 ≤ x ≤ 1 { displaystyle -1 leq x leq 1} , сходится следующий ряд Маклорена:
, сходится следующий ряд Маклорена:
- erfi — 1 (z) = ∑ k = 0 ∞ (- 1) ККК 2 К + 1 (π 2 Z) 2 К + 1, { Displaystyle OperatorName {erfi} ^ {- 1} (г) = сумма _ {к = 0} ^ { infty} { гидроразрыва {(-1) ^ {k} c_ {k}} {2k + 1}} left ({ frac { sqrt { pi}} {2}} z right) ^ {2k + 1},}

, где c k определено, как указано выше.
Асимптотическое разложение
Полезным асимптотическим разложением дополнительные функции (и, следовательно, также и функции ошибок) для больших вещественных x
- erfc (x) = e — x 2 x π [1 + ∑ n = 1 ∞ (- 1) n 1 ⋅ 3 ⋅ 5 ⋯ (2 n — 1) (2 x 2) n] = e — x 2 x π ∑ n = 0 ∞ (- 1) п (2 п — 1)! ! (2 х 2) n, { displaystyle operatorname {erfc} (x) = { frac {e ^ {- x ^ {2}}} {x { sqrt { pi}}}} left [1 + sum _ {n = 1} ^ { infty} (- 1) ^ {n} { frac {1 cdot 3 cdot 5 cdots (2n-1)} {(2x ^ {2}) ^ {n}}} right] = { frac {e ^ {- x ^ {2}}} {x { sqrt { pi}}}} sum _ {n = 0} ^ { infty} ( -1) ^ {n} { frac {(2n-1) !!} {(2x ^ {2}) ^ {n}}},}
![{ displaystyle operatorname {erfc} (x) = { frac {e ^ {- x ^ {2}}} {x { sqrt { pi}}}} left [1+ sum _ {n = 1} ^ { infty} (-1) ^ {n} { frac {1 cdot 3 cdot 5 cdots (2n-1)} {(2x ^ {2}) ^ { n}}} right] = { frac {e ^ {-x ^ {2}}} {x { sqrt { pi}}}} sum _ {n = 0} ^ { infty} (- 1) ^ {n} { frac {(2n-1) !!} {(2x ^ {2}) ^ {n}}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7fc8c3aefff3ba787b080c5186dd3aec8ec76ef9)
где (2n — 1) !! — это двойной факториал числа (2n — 1), которое является произведением всех нечетных чисел до (2n — 1). Этот ряд расходуется для любого конечного x, и его значение как асимптотического разложения состоит в том, что для любого N ∈ N { displaystyle N in mathbb {N}} имеется
имеется
- erfc (Икс) знак равно е — Икс 2 Икс π ∑ N знак равно 0 N — 1 (- 1) N (2 N — 1)! ! (2 х 2) n + RN (x) { displaystyle operatorname {erfc} (x) = { frac {e ^ {- x ^ {2}}} {x { sqrt { pi}}}} sum _ {n = 0} ^ {N-1} (- 1) ^ {n} { frac {(2n-1) !!} {(2x ^ {2}) ^ {n}}} + R_ {N} (x)}

где остаток в нотации Ландау равен
- RN (x) = O (x 1 — 2 N e — x 2) { displaystyle R_ {N} ( x) = O left (x ^ {1-2N} e ^ {- x ^ {2}} right)}

при x → ∞. { displaystyle x to infty.}
Действительно, точное значение остатка равно
- R N (x): = (- 1) N π 2 1 — 2 N (2 N)! N! ∫ Икс ∞ T — 2 N e — T 2 dt, { Displaystyle R_ {N} (x): = { frac {(-1) ^ {N}} { sqrt { pi}}} 2 ^ { 1-2N} { frac {(2N)!} {N!}} Int _ {x} ^ { infty} t ^ {- 2N} e ^ {- t ^ {2}} , dt,}

который легко следует по индукции, записывая
- e — t 2 = — (2 t) — 1 (e — t 2) ′ { displaystyle e ^ {- t ^ {2}} = — (2t) ^ {- 1} left (e ^ {- t ^ {2}} right) ‘}
и интегрирование по частям.
Для достаточно больших значений x, только первые несколько этих асимптотических разностей необходимы, чтобы получить хорошее приближение erfc (x) (в то время как для не слишком больших значений x приведенное выше разложение Тейлора при 0 обеспечивает очень быструю сходимость).
Расширение непрерывной дроби
A Разложение непрерывной дроби дополнительные функции ошибок:
- erfc (z) = z π e — z 2 1 z 2 + a 1 1 + a 2 z 2 + a 3 1 + ⋯ am = м 2. { displaystyle operatorname {erfc} (z) = { frac {z} { sqrt { pi}}} e ^ {- z ^ {2}} { cfrac {1} {z ^ {2} + { cfrac {a_ {1}} {1 + { cfrac {a_ {2}} {z ^ {2} + { cfrac {a_ {3}} {1+) dotsb}}}}}}}} qquad a_ {m} = { frac {m} {2}}.}

Интеграл функции ошибок с функцией плотности Гаусса
- ∫ — ∞ ∞ erf (ax + б) 1 2 π σ 2 е — (Икс — μ) 2 2 σ 2 dx знак равно erf [a μ + b 1 + 2 a 2 σ 2], a, b, μ, σ ∈ R { displaystyle int _ {- infty} ^ { infty} operatorname {erf} left (ax + b right) { frac {1} { sqrt {2 pi sigma ^ {2}}}} e ^ {- { frac {(x- mu) ^ {2}} {2 sigma ^ {2}}}} , dx = operatorname {erf} left [{ frac {a mu + b } { sqrt {1 + 2a ^ {2} sigma ^ {2}}} right], qquad a, b, mu, sigma in mathbb {R}}
![{ displaystyle int _ {- infty} ^ { infty} operatorname {erf} left (ax + b right) { frac {1} { sqrt {2 pi sigma ^ {2}}}} e ^ {- { frac {(x- mu) ^ {2}} {2 sigma ^ {2}}}} , dx = operatorname {erf} left [{ frac {a mu + b} { sqrt {1 + 2a ^ {2} sigma ^ {2}}} right], qquad a, b, му, sigma in mathbb {R}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9b6adc2c661b24b44dc1e3d7e16be70023daacd8)
Факториальный ряд
- Обратное:
-
- erfc z = e — z 2 π z ∑ n = 0 ∞ (- 1) n Q n (z 2 + 1) n ¯ = e — z 2 π z (1 — 1 2 1 (z 2 + 1) + 1 4 1 (z 2 + 1) (z 2 + 2) — ⋯) { displaystyle { begin {align} operatorname {erfc} z = { frac {e ^ {- z ^ {2}}} {{ sqrt { pi}} , z}} sum _ {n = 0} ^ { infty} { frac {(-1) ^ {n} Q_ {n}} {{(z ^ {2} + 1)} ^ { ba r {n}}}} = { frac {e ^ {- z ^ {2}}} {{ sqrt { pi}} , z}} left ( 1 — { frac {1} {2}} { frac {1} {(z ^ {2} +1)}} + { frac {1} {4}} { frac {1} {(z ^ {2} +1) (z ^ {2} +2)}} — cdots right) end {align}}}
- erfc z = e — z 2 π z ∑ n = 0 ∞ (- 1) n Q n (z 2 + 1) n ¯ = e — z 2 π z (1 — 1 2 1 (z 2 + 1) + 1 4 1 (z 2 + 1) (z 2 + 2) — ⋯) { displaystyle { begin {align} operatorname {erfc} z = { frac {e ^ {- z ^ {2}}} {{ sqrt { pi}} , z}} sum _ {n = 0} ^ { infty} { frac {(-1) ^ {n} Q_ {n}} {{(z ^ {2} + 1)} ^ { ba r {n}}}} = { frac {e ^ {- z ^ {2}}} {{ sqrt { pi}} , z}} left ( 1 — { frac {1} {2}} { frac {1} {(z ^ {2} +1)}} + { frac {1} {4}} { frac {1} {(z ^ {2} +1) (z ^ {2} +2)}} — cdots right) end {align}}}
- сходится для Re (z 2)>0. { displaystyle operatorname {Re} (z ^ {2})>0.}Здесь
- Q n = def 1 Γ (1/2) ∫ 0 ∞ τ (τ — 1) ⋯ ( τ — n + 1) τ — 1/2 е — τ d τ знак равно ∑ К знак равно 0 N (1 2) к ¯ s (n, k), { displaystyle Q_ {n} { stackrel { text {def}} {=}} { frac {1} { Gamma (1/2)}} int _ {0} ^ { infty} tau ( tau -1) cdots ( tau -n + 1) tau ^ {-1/2} e ^ {- tau} d tau = sum _ {k = 0} ^ {n} left ({ frac {1} {2}} right) ^ { bar {k}} s (n, k),}
- Q n = def 1 Γ (1/2) ∫ 0 ∞ τ (τ — 1) ⋯ ( τ — n + 1) τ — 1/2 е — τ d τ знак равно ∑ К знак равно 0 N (1 2) к ¯ s (n, k), { displaystyle Q_ {n} { stackrel { text {def}} {=}} { frac {1} { Gamma (1/2)}} int _ {0} ^ { infty} tau ( tau -1) cdots ( tau -n + 1) tau ^ {-1/2} e ^ {- tau} d tau = sum _ {k = 0} ^ {n} left ({ frac {1} {2}} right) ^ { bar {k}} s (n, k),}
- zn ¯ { displaystyle z ^ { bar {n}}}обозначает возрастающий факториал, а s (n, k) { displaystyle s (n, k)}обозначает знаковое число Стирлинга первого рода.

 обозначает возрастающий факториал, а s (n, k) { displaystyle s (n, k)}
обозначает возрастающий факториал, а s (n, k) { displaystyle s (n, k)} обозначает знаковое число Стирлинга первого рода.
обозначает знаковое число Стирлинга первого рода.- Представление бесконечной суммой, составляющей двойной факториал :
-
- ERF (Z) знак равно 2 π ∑ N знак равно 0 ∞ (- 2) N (2 N — 1)! (2 N + 1)! Z 2 N + 1 { Displaystyle OperatorName {ERF} (г) = { frac {2} { sqrt { pi}}} sum _ {n = 0} ^ { infty} { frac {( -2) ^ {n} (2n-1) !!} {(2n + 1)!}} Z ^ {2n + 1}}
- ERF (Z) знак равно 2 π ∑ N знак равно 0 ∞ (- 2) N (2 N — 1)! (2 N + 1)! Z 2 N + 1 { Displaystyle OperatorName {ERF} (г) = { frac {2} { sqrt { pi}}} sum _ {n = 0} ^ { infty} { frac {( -2) ^ {n} (2n-1) !!} {(2n + 1)!}} Z ^ {2n + 1}}

Численные приближения
Приближение элементов сарными функциями
- Абрамовиц и Стегун дают несколько приближений с точностью (уравнения 7.1.25–28). Это позволяет выбрать наиболее быстрое приближение, подходящее для данного приложения. В порядке увеличения точности они следующие:
-
- erf (x) ≈ 1 — 1 (1 + a 1 x + a 2 x 2 + a 3 x 3 + a 4 x 4) 4, x ≥ 0 { displaystyle имя оператора {erf} (x) приблизительно 1 — { frac {1} {(1 + a_ {1} x + a_ {2} x ^ {2} + a_ {3} x ^ {3} + a_ { 4} x ^ {4}) ^ {4}}}, qquad x geq 0}
- erf (x) ≈ 1 — 1 (1 + a 1 x + a 2 x 2 + a 3 x 3 + a 4 x 4) 4, x ≥ 0 { displaystyle имя оператора {erf} (x) приблизительно 1 — { frac {1} {(1 + a_ {1} x + a_ {2} x ^ {2} + a_ {3} x ^ {3} + a_ { 4} x ^ {4}) ^ {4}}}, qquad x geq 0}
- (максимальная ошибка: 5 × 10)

- , где a 1 = 0,278393, a 2 = 0,230389, a 3 = 0,000972, a 4 = 0,078108
-
- erf (x) ≈ 1 — (a 1 t + a 2 t 2 + a 3 t 3) e — x 2, t = 1 1 + px, x ≥ 0 { displaystyle operatorname {erf} (x) приблизительно 1- (a_ {1} t + a_ {2} t ^ {2} + a_ {3} t ^ {3}) e ^ {- x ^ {2}}, quad t = { frac {1} {1 + px}}, qquad x geq 0}(максимальная ошибка: 2,5 × 10)
- erf (x) ≈ 1 — (a 1 t + a 2 t 2 + a 3 t 3) e — x 2, t = 1 1 + px, x ≥ 0 { displaystyle operatorname {erf} (x) приблизительно 1- (a_ {1} t + a_ {2} t ^ {2} + a_ {3} t ^ {3}) e ^ {- x ^ {2}}, quad t = { frac {1} {1 + px}}, qquad x geq 0}
 (максимальная ошибка: 2,5 × 10)
(максимальная ошибка: 2,5 × 10)- где p = 0,47047, a 1 = 0,3480242, a 2 = -0,0958798, a 3 = 0,7478556
-
- erf (x) ≈ 1 — 1 (1 + a 1 x + a 2 x 2 + ⋯ + a 6 x 6) 16, x ≥ 0 { displaystyle operatorname {erf} (x) приблизительно 1 — { frac {1} {(1 + a_ {1} x + a _ {2} x ^ {2} + cdots + a_ {6} x ^ {6}) ^ {16}}}, qquad x geq 0}(максимальная ошибка: 3 × 10)
- erf (x) ≈ 1 — 1 (1 + a 1 x + a 2 x 2 + ⋯ + a 6 x 6) 16, x ≥ 0 { displaystyle operatorname {erf} (x) приблизительно 1 — { frac {1} {(1 + a_ {1} x + a _ {2} x ^ {2} + cdots + a_ {6} x ^ {6}) ^ {16}}}, qquad x geq 0}
 (максимальная ошибка: 3 × 10)
(максимальная ошибка: 3 × 10)- , где a 1 = 0,0705230784, a 2 = 0,0422820123, a 3 = 0,0092705272, a 4 = 0,0001520143, a 5 = 0,0002765672, a 6 = 0,0000430638
-
- erf (x) ≈ 1 — (a 1 t + a 2 t 2 + ⋯ + a 5 t 5) e — x 2, t = 1 1 + px { displaystyle operatorname {erf} (x) приблизительно 1- (a_ {1} t + a_ {2} t ^ {2} + cdots + a_ {5} t ^ {5}) e ^ {- x ^ {2}}, quad t = { frac {1} {1 + px}}}(максимальная ошибка: 1,5 × 10)
- erf (x) ≈ 1 — (a 1 t + a 2 t 2 + ⋯ + a 5 t 5) e — x 2, t = 1 1 + px { displaystyle operatorname {erf} (x) приблизительно 1- (a_ {1} t + a_ {2} t ^ {2} + cdots + a_ {5} t ^ {5}) e ^ {- x ^ {2}}, quad t = { frac {1} {1 + px}}}
 (максимальная ошибка: 1,5 × 10)
(максимальная ошибка: 1,5 × 10)- , где p = 0,3275911, a 1 = 0,254829592, a 2 = −0,284496736, a 3 = 1,421413741, a 4 = −1,453152027, a 5 = 1,061405429
- Все эти приближения действительны для x ≥ 0 Чтобы использовать эти приближения для отрицательного x, викорируйте тот факт, что erf (x) — нечетная функция, поэтому erf (x) = −erf (−x).
- Экспоненциальные границы и чисто экспоненциальное приближение для дополнительных функций задаются как
-
- erfc (x) ≤ 1 2 e — 2 x 2 + 1 2 e — x 2 ≤ e — x 2, x>0 erfc ( х) ≈ 1 6 е — х 2 + 1 2 е — 4 3 х 2, х>0. { displaystyle { begin {align} operatorname {erfc} (x) leq { frac {1} {2}} e ^ {- 2x ^ {2}} + { frac {1} {2} } e ^ {- x ^ {2}} leq e ^ {- x ^ {2}}, qquad x>0 имя оператора {erfc} (x) приблизительно { frac {1} { 6}} e ^ {- x ^ {2}} + { frac {1} {2}} e ^ {- { frac {4} {3}} x ^ {2}}, qquad x>0. end {align}}}
- erfc (x) ≤ 1 2 e — 2 x 2 + 1 2 e — x 2 ≤ e — x 2, x>0 erfc ( х) ≈ 1 6 е — х 2 + 1 2 е — 4 3 х 2, х>0. { displaystyle { begin {align} operatorname {erfc} (x) leq { frac {1} {2}} e ^ {- 2x ^ {2}} + { frac {1} {2} } e ^ {- x ^ {2}} leq e ^ {- x ^ {2}}, qquad x>0 имя оператора {erfc} (x) приблизительно { frac {1} { 6}} e ^ {- x ^ {2}} + { frac {1} {2}} e ^ {- { frac {4} {3}} x ^ {2}}, qquad x>0. end {align}}}

-
- erfc (x) ≈ (1 — e — A x) e — x 2 B π х. { displaystyle operatorname {erfc} left (x right) приблизительно { frac { left (1-e ^ {- Ax} right) e ^ {- x ^ {2}}} {B { sqrt { pi}} x}}.}
- erfc (x) ≈ (1 — e — A x) e — x 2 B π х. { displaystyle operatorname {erfc} left (x right) приблизительно { frac { left (1-e ^ {- Ax} right) e ^ {- x ^ {2}}} {B { sqrt { pi}} x}}.}

- Они определили {A, B} = {1.98, 1.135}, { displaystyle {A, B } = {1.98,1.135 },}, что дает хорошее приближение для всех x ≥ 0. { displaystyle x geq 0.}
 , что дает хорошее приближение для всех x ≥ 0. { displaystyle x geq 0.}
, что дает хорошее приближение для всех x ≥ 0. { displaystyle x geq 0.}
- Одноканальная нижняя граница:
-
- erfc (x) ≥ 2 e π β — 1 β е — β Икс 2, Икс ≥ 0, β>1, { Displaystyle OperatorName {erfc} (x) geq { sqrt { frac {2e} { pi}}} { frac { sqrt { beta -1}} { beta}} e ^ {- beta x ^ {2}}, qquad x geq 0, beta>1,}
- erfc (x) ≥ 2 e π β — 1 β е — β Икс 2, Икс ≥ 0, β>1, { Displaystyle OperatorName {erfc} (x) geq { sqrt { frac {2e} { pi}}} { frac { sqrt { beta -1}} { beta}} e ^ {- beta x ^ {2}}, qquad x geq 0, beta>1,}

- где параметр β может быть выбран, чтобы минимизировать ошибку на желаемом интервале приближения.
- Другое приближение дано Сергеем Виницким с использованием его «глобальных приближений Паде»:
-
- erf (x) ≈ sgn (x) 1 — exp (- x 2 4 π + ax 2 1 + ax 2) { displaystyle operatorname {erf} (x) приблизительно Operatorname {sgn} (x) { sqrt {1- exp left (-x ^ {2} { frac {{ frac {4} { pi) })} + ax ^ {2}} {1 + ax ^ {2}}} right)}}}
- erf (x) ≈ sgn (x) 1 — exp (- x 2 4 π + ax 2 1 + ax 2) { displaystyle operatorname {erf} (x) приблизительно Operatorname {sgn} (x) { sqrt {1- exp left (-x ^ {2} { frac {{ frac {4} { pi) })} + ax ^ {2}} {1 + ax ^ {2}}} right)}}}

- где
-
- a = 8 (π — 3) 3 π (4 — π) ≈ 0, 140012. { displaystyle a = { frac {8 ( pi -3)} {3 pi (4- pi)}} приблизительно 0,140012.}
- a = 8 (π — 3) 3 π (4 — π) ≈ 0, 140012. { displaystyle a = { frac {8 ( pi -3)} {3 pi (4- pi)}} приблизительно 0,140012.}
- Это сделано так, чтобы быть очень точным в окрестностях 0 и добавление бесконечности, а относительная погрешность меньше 0,00035 для всех действительных x. Использование альтернативного значения ≈ 0,147 снижает максимальную относительную ошибку примерно до 0,00013.
- Это приближение можно инвертировать, чтобы получить приближение для других функций ошибок:
-
- erf — 1 (x) ≈ sgn (x) (2 π a + ln (1 — x 2) 2) 2 — ln (1 — x 2) a — (2 π a + ln (1 — x 2) 2). { displaystyle operatorname {erf} ^ {- 1} (x) приблизительно operatorname {sgn} (x) { sqrt {{ sqrt { left ({ frac {2} { pi a}} + { frac { ln (1-x ^ {2})} {2}} right) ^ {2} — { frac { ln (1-x ^ {2})} {a}}}} — left ({ frac {2} { pi a}} + { frac { ln (1-x ^ {2})} {2}} right)}}.}
- erf — 1 (x) ≈ sgn (x) (2 π a + ln (1 — x 2) 2) 2 — ln (1 — x 2) a — (2 π a + ln (1 — x 2) 2). { displaystyle operatorname {erf} ^ {- 1} (x) приблизительно operatorname {sgn} (x) { sqrt {{ sqrt { left ({ frac {2} { pi a}} + { frac { ln (1-x ^ {2})} {2}} right) ^ {2} — { frac { ln (1-x ^ {2})} {a}}}} — left ({ frac {2} { pi a}} + { frac { ln (1-x ^ {2})} {2}} right)}}.}

Многочлен
Приближение с максимальной ошибкой 1,2 × 10-7 { displaystyle 1,2 times 10 ^ {- 7}} для любого действительного аргумента:
для любого действительного аргумента:
- erf ( x) = {1 — τ x ≥ 0 τ — 1 x < 0 {displaystyle operatorname {erf} (x)={begin{cases}1-tau xgeq 0tau -1x<0end{cases}}}

с
- τ = t ⋅ exp (- x 2 — 1,26551223 + 1,00002368 t + 0,37409196 t 2 + 0,09678418 t 3 — 0,18628806 t 4 + 0,27886807 t 5 — 1,13520398 t 6 + 1,48851587 t 7 — 0,82215223 t 8 + 0,17087277 t 9) { displaystyle { begin {align} tau = t cdot exp left (-x ^ {2} -1,26551223 + 1,00002368 t + 0,37409196t ^ {2} + 0,09678418t ^ {3} -0,18628806t ^ {4} вправо. left. qquad qquad qquad + 0,27886807t ^ {5} -1,13520398t ^ {6} + 1,48851587t ^ {7} -0,82215223t ^ {8} + 0,17087 277t ^ {9} right) end {align}}}
и
- t = 1 1 + 0,5 | х |. { displaystyle t = { frac {1} {1 + 0,5 | x |}}.}

Таблица значений
| x | erf(x) | 1-erf (x) |
|---|---|---|
| 0 | 0 | 1 |
| 0,02 | 0,022564575 | 0,977435425 |
| 0,04 | 0,045111106 | 0,954888894 |
| 0,06 | 0,067621594 | 0, 932378406 |
| 0,08 | 0.090078126 | 0,909921874 |
| 0,1 | 0,112462916 | 0,887537084 |
| 0,2 | 0,222702589 | 0,777297411 |
| 0,3 | 0,328626759 | 0,671373241 |
| 0, 4 | 0,428392355 | 0,571607645 |
| 0,5 | 0,520499878 | 0,479500122 |
| 0,6 | 0.603856091 | 0,396143909 |
| 0,7 | 0,677801194 | 0,322198806 |
| 0,8 257> | 0,742100965 | 0,257899035 |
| 0,9 | 0,796908212 | 0,203091788 |
| 1 | 0,842700793 | 0, 157299207 |
| 1,1 | 0,88020507 | 0,11979493 |
| 1,2 | 0,910313978 | 0,089686022 |
| 1,3 | 0,934007945 | 0,065992055 |
| 1,4 | 0.95228512 | 0,04771488 |
| 1,5 | 0, 966105146 | 0,033894854 |
| 1,6 | 0,976348383 | 0,023651617 |
| 1,7 | 0,983790459 | 0,016209541 |
| 1,8 | 0,989090502 | 0,010909498 |
| 1,9 | 0,992790429 | 0,007209571 |
| 2 | 0,995322265<25767> | 0,00477 |
| 2.1 | 0.997020533 | 0.002979467 |
| 2.2 | 0.998137154 | 0,001862846 |
| 2,3 | 0,998856823 | 0,001143177 |
| 2,4 | 0,999311486 | 0,000688514 |
| 2,5 | 0.999593048 | 0.000406952 |
| 3 | 0.99997791 | 0,00002209 |
| 3,5 | 0,999999257 | 0,000000743 |
Связанные функции
Дополнительная функция
дополнительная функция ошибок, обозначается erfc { displaystyle mathrm {erfc}} , определяется как
, определяется как
- erfc (x) = 1 — erf (x) = 2 π ∫ x ∞ e — t 2 dt знак равно е — Икс 2 erfcx (х), { displaystyle { begin {выровнено} OperatorName {erfc} (x) = 1- operatorname {erf} (x) [5p t] = { frac {2} { sqrt { pi}}} int _ {x} ^ { infty} e ^ {- t ^ {2}} , dt [5pt] = e ^ {- x ^ {2}} operatorname {erfcx} (x), end {align}}}
![{ displaystyle { begin {align} operatorname {erfc} (x) = 1- operatorname {erf} (x) [5pt ] = { frac {2} { sqrt { pi}}} int _ {x} ^ { infty} e ^ {- t ^ {2}} , dt [5pt] = e ^ {- x ^ {2}} operatorname {erfcx} (x), end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8808e6f3ad9aab23f14d55db707a39388d256788)
, который также определяет erfcx { displaystyle mathrm {erfcx} } , масштабированная дополнительная функция ошибок (которую можно использовать вместо erfc, чтобы избежать арифметического переполнения ). Известна другая форма erfc (x) { displaystyle operatorname {erfc} (x)}
, масштабированная дополнительная функция ошибок (которую можно использовать вместо erfc, чтобы избежать арифметического переполнения ). Известна другая форма erfc (x) { displaystyle operatorname {erfc} (x)} для неотрицательного x { displaystyle x}как формула Крейга после ее первооткрывателя:
для неотрицательного x { displaystyle x}как формула Крейга после ее первооткрывателя:
- erfc (x ∣ x ≥ 0) = 2 π ∫ 0 π / 2 exp (- x 2 sin 2 θ) d θ. { displaystyle operatorname {erfc} (x mid x geq 0) = { frac {2} { pi}} int _ {0} ^ { pi / 2} exp left (- { frac {x ^ {2}} { sin ^ {2} theta}} right) , d theta.}

Это выражение действительно только для положительных значений x, но его можно использовать вместе с erfc (x) = 2 — erfc (−x), чтобы получить erfc (x) для отрицательных значений. Эта форма выгодна тем, что диапазон интегрирования является фиксированным и конечным. Расширение этого выражения для erfc { displaystyle mathrm {erfc}}суммы двух неотрицательных чисел следующим образом:
- erfc (x + y ∣ x, y ≥ 0) = 2 π ∫ 0 π / 2 ехр (- x 2 sin 2 θ — y 2 cos 2 θ) d θ. { displaystyle operatorname {erfc} (x + y mid x, y geq 0) = { frac {2} { pi}} int _ {0} ^ { pi / 2} exp left (- { frac {x ^ {2}} { sin ^ {2} theta}} — { frac {y ^ {2}} { cos ^ {2} theta}} right) , d theta.}

Функция мнимой ошибки
мнимой ошибки, обозначаемая erfi, обозначает ошибки как
- erfi (x) = — i erf (ix) Знак равно 2 π ∫ 0 xet 2 dt знак равно 2 π ex 2 D (x), { displaystyle { begin {align} operatorname {erfi} (x) = — i operatorname {erf} (ix) [ 5pt] = { frac {2} { sqrt { pi}}} int _ {0} ^ {x} e ^ {t ^ {2}} , dt [5pt] = { frac {2} { sqrt { pi}}} e ^ {x ^ {2}} D (x), end {align}}}
![{ displaystyle { begin {align} operatorname {erfi} (x) = - i operatorname {erf} (ix) [5pt] = { frac {2} { sqrt { pi}}} int _ {0} ^ {x} e ^ {t ^ {2 }} , dt [5pt] = { frac {2} { sqrt { pi}}} e ^ {x ^ {2}} D (x), end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4480a8ec17e274a7ad6b8ef25cc76234d48c0433)
где D (x) — функция Доусона (который можно использовать вместо erfi, чтобы избежать арифметического переполнения ).
Несмотря на название «функция мнимой ошибки», erfi (x) { displaystyle operatorname {erfi} (x)} реально, когда x действительно.
реально, когда x действительно.
Функция Когда ошибки оценивается для произвольных сложных аргументов z, результирующая комплексная функция ошибок обычно обсуждается в масштабированной форме как функция Фаддеева :
- w (z) = e — z 2 erfc (- iz) = erfcx (- iz). { displaystyle w (z) = e ^ {- z ^ {2}} operatorname {erfc} (-iz) = operatorname {erfcx} (-iz).}
Кумулятивная функция распределения
Функция ошибок по существующей стандартной стандартной функции нормального кумулятивного распределения, обозначаемой нормой (x) в некоторых языках программного обеспечения, поскольку они отличаются только масштабированием и переводом. Действительно,
- Φ (x) = 1 2 π ∫ — ∞ xe — t 2 2 dt = 1 2 [1 + erf (x 2)] = 1 2 erfc (- x 2) { displaystyle Phi (x) = { frac {1} { sqrt {2 pi}}} int _ {- infty} ^ {x} e ^ { tfrac {-t ^ {2}} {2}} , dt = { frac {1} {2}} left [1+ operatorname {erf} left ({ frac {x} { sqrt {2}}} right) right] = { frac {1} {2}} operatorname {erfc} left (- { frac {x} { sqrt {2}}} right)}
![{ displaystyle Phi (x) = { frac {1} { sqrt {2 pi}}} int _ {- infty} ^ {x } e ^ { tfrac {-t ^ {2}} {2}} , dt = { frac {1} {2}} left [1+ operatorname {erf} left ({ frac {x } { sqrt {2}}} right) right] = { frac {1} {2}} operatorname {erfc} left (- { frac {x} { sqrt {2}}} справа)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e19dc7206f8b3b571e81153816c478abd91a679e)
или переставлен для erf и erfc:
- erf ( x) = 2 Φ (x 2) — 1 erfc (x) = 2 Φ (- x 2) = 2 (1 — Φ (x 2)). { displaystyle { begin {align} operatorname {erf} (x) = 2 Phi left (x { sqrt {2}} right) -1 operatorname {erfc} (x) = 2 Phi left (-x { sqrt {2}} right) = 2 left (1- Phi left (x { sqrt {2}} right) right). End {выравнивается} }}

Следовательно, функция ошибок также тесно связана с Q-функцией, которая является вероятностью хвоста стандартного нормального распределения. Q-функция может быть выражена через функцию ошибок как
- Q (x) = 1 2 — 1 2 erf (x 2) = 1 2 erfc (x 2). { displaystyle Q (x) = { frac {1} {2}} — { frac {1} {2}} operatorname {erf} left ({ frac {x} { sqrt {2}}) } right) = { frac {1} {2}} operatorname {erfc} left ({ frac {x} { sqrt {2}}} right).}

Обратное значение из Φ { displaystyle Phi} известен как функция нормальной квантиля или функция пробит и может быть выражена в терминах обратная функция ошибок как
известен как функция нормальной квантиля или функция пробит и может быть выражена в терминах обратная функция ошибок как
- пробит (p) = Φ — 1 (p) = 2 erf — 1 (2 p — 1) = — 2 erfc — 1 (2 p). { displaystyle operatorname {probit} (p) = Phi ^ {- 1} (p) = { sqrt {2}} operatorname {erf} ^ {- 1} (2p-1) = — { sqrt {2}} operatorname {erfc} ^ {- 1} (2p).}
Стандартный нормальный cdf чаще используется в вероятности и статистике, а функция ошибок чаще используется в других разделах математики.
Функция ошибки является частным случаем функции Миттаг-Леффлера и может также быть выражена как сливающаяся гипергеометрическая функция (функция Куммера):
- erf (х) знак равно 2 х π M (1 2, 3 2, — х 2). { displaystyle operatorname {erf} (x) = { frac {2x} { sqrt { pi}}} M left ({ frac {1} {2}}, { frac {3} {2 }}, — x ^ {2} right).}

Он имеет простое выражение в терминах интеграла Френеля.
В терминах регуляризованной гамма-функции P и неполная гамма-функция,
- erf (x) = sgn (x) P (1 2, x 2) = sgn (x) π γ (1 2, x 2). { displaystyle operatorname {erf} (x) = operatorname {sgn} (x) P left ({ frac {1} {2}}, x ^ {2} right) = { frac { operatorname {sgn} (x)} { sqrt { pi}}} gamma left ({ frac {1} {2}}, x ^ {2} right).}

sgn (x) { displaystyle operatorname {sgn} (x)} — знаковая функция .
— знаковая функция .
Обобщенные функции ошибок
График обобщенных функций ошибок E n (x):. серая кривая: E 1 (x) = (1 — e) /
π { displaystyle scriptstyle { sqrt { pi}}}
 . красная кривая: E 2 (x) = erf (x). зеленая кривая: E 3 (x). синяя кривая: E 4 (x). золотая кривая: E 5 (x).
. красная кривая: E 2 (x) = erf (x). зеленая кривая: E 3 (x). синяя кривая: E 4 (x). золотая кривая: E 5 (x).
Некоторые авторы обсуждают более общие функции:
- E n (x) = n! π ∫ 0 Икс е — Т N д т знак равно N! π ∑ п знак равно 0 ∞ (- 1) п Икс N п + 1 (N п + 1) п!. { displaystyle E_ {n} (x) = { frac {n!} { sqrt { pi}}} int _ {0} ^ {x} e ^ {- t ^ {n}} , dt = { frac {n!} { sqrt { pi}}} sum _ {p = 0} ^ { infty} (- 1) ^ {p} { frac {x ^ {np + 1}} {(np + 1) p!}}.}

Примечательные случаи:
- E0(x) — прямая линия, проходящая через начало координат: E 0 (x) = xe π { displaystyle textstyle E_ {0} (x) = { dfrac {x} {e { sqrt { pi}}}}}
- E2(x) — функция, erf (x) ошибки.

После деления на n!, все E n для нечетных n выглядят похожими (но не идентичными) друг на друга. Аналогично, E n для четного n выглядят похожими (но не идентичными) друг другу после простого деления на n!. Все обобщенные функции ошибок для n>0 выглядят одинаково на положительной стороне x графика.
Эти обобщенные функции могут быть эквивалентно выражены для x>0 с помощью гамма-функции и неполной гамма-функции :
- E n (x) = 1 π Γ (n) (Γ (1 n) — Γ (1 n, xn)), x>0. { displaystyle E_ {n} (x) = { frac {1} { sqrt { pi}}} Gamma (n) left ( Gamma left ({ frac {1} {n}} right) — Gamma left ({ frac {1} {n}}, x ^ {n} right) right), quad quad x>0.}

Следовательно, мы можем определить ошибку функция в терминах неполной гамма-функции:
- erf (x) = 1 — 1 π Γ (1 2, x 2). { displaystyle operatorname {erf} (x) = 1 — { frac {1} { sqrt { pi}}} Gamma left ({ frac {1} {2}}, x ^ {2} right).}

Итерированные интегралы дополнительных функций
Повторные интегралы дополнительные функции ошибок определения как
- inerfc (z) = ∫ z ∞ in — 1 erfc (ζ) d ζ i 0 erfc (z) = erfc (z) i 1 erfc (z) = ierfc (z) знак равно 1 π е — z 2 — z erfc (z) я 2 erfc (z) = 1 4 [erfc (z) — 2 z ierfc (z)] { displaystyle { begin {align } operatorname {i ^ {n} erfc} (z) = int _ {z} ^ { infty} operatorname {i ^ {n-1} erfc} ( zeta) , d zeta имя оператора {i ^ {0} erfc} (z) = operatorname {erfc} (z) operatorname {i ^ {1} erfc} (z) = operat orname {ierfc} (z) = { frac { 1} { sqrt { pi}}} e ^ {- z ^ {2}} — z operatorname {erfc} (z) operatorname {i ^ {2} erfc} (z) = { frac {1} {4}} left [ operatorname {erfc} (z) -2z operatorname {ierfc} (z) right] end {выровнено}}
![{ displaystyle { begin {align} operatorname { i ^ {n} erfc} (z) = int _ {z} ^ { infty} operatorname {i ^ {n-1} erfc} ( zeta) , d zeta имя оператора {i ^ {0} erfc} (z) = operatorname {erfc} (z) operatorname {i ^ {1} erfc} (z) = operatorname {ierfc} (z) = { frac {1} { sqrt { pi}}} e ^ {- z ^ {2}} - z operatorname {erfc} (z) operatorname {i ^ {2} erfc} (z) = { frac { 1} {4}} left [ operatorname {erfc} (z) -2z operatorname {ierfc} (z) right] конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/66b57abb0a01139b31a14f5a8d651e4aa2e5f4f2)
Общая рекуррентная формула:
- 2 ninerfc (z) = in — 2 erfc (z) — 2 цинк — 1 erfc (z) { displaystyle 2n operatorname {i ^ {n} erfc} (z) = operatorname {i ^ { n-2} erfc} (z) -2z operatorname {i ^ {n-1} erfc} (z)}

У них есть степенной ряд
- в erfc (z) = ∑ j = 0 ∞ (- Z) J 2 N — JJ! Γ (1 + N — J 2), { displaystyle i ^ {n} operatorname {erfc} (z) = sum _ {j = 0} ^ { infty} { frac {(-z) ^ { j}} {2 ^ {nj} j! Gamma left (1 + { frac {nj} {2}} right)}},}

из следуют свойства симметрии
- i 2 m ERFC (- Z) знак равно — я 2 m ERFC (Z) + ∑ Q знак равно 0 мZ 2 д 2 2 (м — д) — 1 (2 д)! (м — д)! { displaystyle i ^ {2m} operatorname {erfc} (-z) = — i ^ {2m} operatorname {erfc} (z) + sum _ {q = 0} ^ {m} { frac {z ^ {2q}} {2 ^ {2 (mq) -1} (2q)! (Mq)!}}}

и
- i 2 m + 1 erfc (- z) = i 2 m + 1 erfc (г) + ∑ ä знак равно 0 ìZ 2 ä + 1 2 2 ( м — д) — 1 (2 д + 1)! (м — д)!. { displaystyle i ^ {2m + 1} operatorname {erfc} (-z) = i ^ {2m + 1} operatorname {erfc} (z) + sum _ {q = 0} ^ {m} { гидроразрыва {z ^ {2q + 1}} {2 ^ {2 (mq) -1} (2q + 1)! (mq)!}}.}

Реализации
Как действительная функция вещественного аргумента
- В операционных системах, совместимых с Posix, заголовок math.h должен являть, а математическая библиотека libm должна быть функция erf и erfc (двойная точность ), а также их одинарная точность и расширенная точность аналоги erff, erfl и erfc, erfcl.
- Библиотека GNU Scientific предоставляет функции erf, erfc, log (erf) и масштабируемые функции ошибок.
Как сложная функция комплексного аргумента
- libcerf, числовая библиотека C для сложных функций, предоставляет комплексные функции cerf, cerfc, cerfcx и реальные функции erfi, erfcx с точностью 13–14 цифр на основе функции Фаддеева, реализованной в пакете MIT Faddeeva Package
См. также
Связанные ции
- интеграл Гаусса, по всей действительной прямой
- функция Гаусса, производная
- функция Доусона, перенормированная функция мнимой ошибки
- интеграл Гудвина — Стона
по вероятности
- Нормальное распределение
- Нормальная кумулятивная функция распределения, масштабированная и сдвинутая форма функций ошибок
- Пробит, обратная или квантильная функция нормального CDF
- Q-функция, вероятность хвоста нормального распределения
Ссылки
Дополнительная литература
- Abramowitz, Milton ; Стегун, Ирен Энн, ред. (1983) [июнь 1964]. «Глава 7». Справочник по математическим функциям с формулами, графики и математическими таблицами. Прикладная математика. 55 (Девятое переиздание с дополнительными исправлениями; десятое оригинальное издание с исправлениями (декабрь 1972 г.); первое изд.). Вашингтон.; Нью-Йорк: Министерство торговли США, Национальное бюро стандартов; Dover Publications. п. 297. ISBN 978-0-486-61272-0. LCCN 64-60036. MR 0167642. LCCN 65-12253.
- Press, William H.; Теукольский, Саул А.; Веттерлинг, Уильям Т.; Фланнери, Брайан П. (2007), «Раздел 6.2. Неполная гамма-функция и функция ошибок », Числовые рецепты: Искусство научных вычислений (3-е изд.), Нью-Йорк: Cambridge University Press, ISBN 978-0-521- 88068-8
- Темме, Нико М. (2010), «Функции ошибок, интегралы Доусона и Френеля», в Олвер, Фрэнк У. Дж. ; Лозье, Даниэль М.; Бойсверт, Рональд Ф.; Кларк, Чарльз В. (ред.), Справочник NIST по математическим функциям, Cambridge University Press, ISBN 978-0-521-19225-5, MR 2723248
Внешние ссылки
- MathWorld — Erf
- Таблица интегралов функций ошибок
Регрессия как задача машинного обучения
38 мин на чтение
(55.116 символов)
Постановка задачи регрессии

Источник: Analytics Vidhya.
Задача регрессии — это одна из основных задач машинного обучения. И хотя, большинство задач на практике относятся к другому типу — классификации, мы начнем знакомство с машинным обучением именно с регрессии. Регрессионные модели были известны задолго до появления машинного обучения как отрасли и активно применяются в статистике, эконометрике, математическом моделировании. Машинное обучение предлагает новый взгляд на уже известные модели. И этот новый взгляд позволит строить более сложные и мощные модели, чем классические математические дисциплины.
Задача регрессии относится к категории задач обучения с учителем. Это значит, что набор данных, который используется для обучения, должен иметь определенную структуру. Обычно, наборы данных для машинного обучения представляют собой таблицу, в которой по строкам перечислены разные объекты наблюдений или измерений. В столбцах — различные характеристики, или атрибуты, объектов. А на пересечении строк и столбцов — значение данной характеристики у данного объекта. Обычно один атрибут (или переменная) имеет особый характер — именно ее значение мы и хотим научиться предсказывать с помощью модели машинного обучения. Эта характеристика объекта называется целевая переменная. И если эта целевая переменная выражена числом (а точнее, некоторой непрерывной величиной) — то мы говорим о задаче регрессии.
Задачи регрессии на практике встречаются довольно часто. Например, предсказание цены объекта недвижимости — классическая регрессионная задача. В таких проблемах атрибутами выступают разные характеристики квартир или домов — площадь, этажность, расположение, расстояние до центра города, количество комнат, год постройки. В разных наборах данных собрана разная информация И, соответственно, модели тоже должны быть разные. Другой пример — предсказание цены акций или других финансовых активов. Или предсказание температуры завтрашним днем.
Во всех таких задачах нам нужно иметь данные, которые позволят осуществить такое предсказание. Да, “предсказание” — это условный термин, не всегда мы говорим о будущих событиях. Регрессионные модели используют информацию об объектах в обучающем наборе данных, чтобы сделать вывод о возможном значении целевой переменной. И для этого нужно, чтобы ее значение имело какую-то зависимость от имеющихся у нас атрибутов. Если построить модель предсказания цены акции, но на вход подать информацию о футбольных матчах — ничего не получится. Мы предполагаем, что в наборе данных собраны именно те атрибуты объектов, которые имеют влияние на на значение целевой переменной. И чем больше это предположение выполняется, тем точнее будет потенциально наша модель.
Немного поговорим о терминах. Набор данных который мы используем для обучения модели называют датасетом (dataset) или обучающей выборкой (training set). Объекты, которые описываются в датасете еще называют точками данных (data points). Целевую переменную еще называют на статистический манер зависимой переменной (dependent variable) или результативной, выходной (output), а остальные атрибуты — независимыми переменными (dependent variables), или признаками (features), или факторами, или входными переменными (input). Значения одного конкретного атрибута для всех объектов обучающей выборки часто представляют как вектор этого признака (feature vector). А всю таблицу всех атрибутов называют матрицей атрибутов (feature matrix). Соответственно, еще есть вектор целевой переменной, он не входит в матрицу атрибутов.
С точки зрения информатики, регрессионная модель — это функция, которая принимает на вход значения атрибутов какого-то конкретного объекта и выдает на выходе предполагаемое значение целевой переменной. В большинстве случаев мы предполагаем, что целевая переменная у нас одна. Если стоит задача предсказания нескольких характеристик, то их чаще воспринимают как несколько независимых задач регрессии на одних и тех же атрибутах.
Мы пока ничего не говорили о том, как изнутри устроена регрессионная модель. Это потому, что она может быть какой угодно. Это может быть математическое выражение, условный алгоритм, сложная программа со множеством ветвлений и циклов, нейронная сеть — все это можно представить регрессионной моделью. Единственное требование к модели машинного обучения — она должна быть параметрической. То есть иметь какие-то внутренние параметры, от которых тоже зависит результат вычисления. В простых случаях, чаще всего в качестве регрессионной модели используют аналитические функции. Таких функций бесконечное количество, но чаще всего используется самая простая функция, с которой мы и начнем изучение регрессии — линейная функция.
Так же надо сказать, что иногда регрессионные модели подразделяют на парную и множественную регрессии. Парная регрессия — это когда у нас всего один атрибут. Множественная — когда больше одного. Конечно, на практике парная регрессия почти не встречается, но на примере такой простой модели мы поймем основные концепции машинного обучения. Плюс, парную регрессию очень удобно и наглядно можно изобразить на графике. Когда у нас больше двух переменных, графики уже не особо построишь, и модели приходится визуализировать иначе, более косвенно.
Выводы:
- Регрессия — это задача машинного обучения с учителем, которая заключается в предсказании некоторой непрерывной величины.
- Для использования регрессионных моделей нужно, чтобы в датасете были характеристики объектов и “правильные” значения целевой переменной.
- Примеры регрессионных задач — предсказание цены акции, оценка цены объекта недвижимости.
- Задача регрессии основывается на предположении, что значение целевой переменной зависит от значения признаков.
- Регрессионная модель принимает набор значений и выдает предсказание значения целевой переменной.
- В качестве регрессионных моделей часто берут аналитические функции, например, линейную.
Линейная регрессия с одной переменной
Функция гипотезы

Напомним, что в задачах регрессии мы принимаем входные переменные и пытаемся получить более-менее достоверное значение целевой переменной. Любая функция, даже самая простая линейная может выдавать совершенно разные значения для одних и тех же входных данных, если в функции будут разные параметры. Поэтому, любая регрессионная модель — это не какая-то конкретная математическая функция, а целое семейство функций. И задача алгоритма обучения — подобрать значения параметров таким образом, чтобы для объектов обучающей выборки, для которых мы уже знаем правильные ответы, предсказанные (или теоретические, вычисленные из модели) значения были как можно ближе к тем, которые есть в датасете (эмпирические, истинные значения).
Парная, или одномерная (univariate) регрессия используется, когда вы хотите предсказать одно выходное значение (чаще всего обозначаемое $y$), зависящее от одного входного значения (обычно обозначается $x$). Сама функция называется функцией гипотезы или моделью. В качестве функции гипотезы для парной регрессии можно выбрать любую функцию, но мы пока потренируемся с самой простой функцией одной переменной — линейной функцией. Тогда нашу модель можно назвать парной линейной регрессией.
В случае парной линейной регрессии функция гипотезы имеет следующий общий вид:
[hat{y} = h_b (x) = b_0 + b_1 x]
Обратите внимание, что это похоже на уравнение прямой. Эта модель соответствует множеству всех возможных прямых на плоскости. Когда мы конкретизируем модель значениями параметров (в данном случае — $b_0$ и $b_1$), мы получаем конкретную прямую. И наша задача состоит в том, чтобы выбрать такую прямую, которая бы лучше всего “легла” в точки из нашей обучающей выборки.
В данном случае, мы пытаемся подобрать функцию h(x) таким образом, чтобы отобразить данные нам значения x в данные значения y.
Допустим, мы имеем следующий обучающий набор данных:
| входная переменная x | выходная переменная y |
| 0 | 4 |
| 1 | 7 |
| 2 | 7 |
| 3 | 8 |
Мы можем составить случайную гипотезу с параметрами $ b_0 = 2, b_1 = 2 $. Тогда для входного значения $ x=1 $ модель выдаст предсказание, что $ y=4 $, что на 3 меньше данного. Значение $y$б которое посчитала модель будем называть теоретическим или предсказанным (predicted), а значение, которое дано в наборе данных — эмпирическим или истинным (true). Задача регрессии состоит в нахождении таких параметров функции гипотезы, чтобы она отображала входные значения в выходные как можно более точно, или, другими словами, описывала линию, наиболее точно ложащуюся в данные точки на плоскости $(x, y)$.
Выводы:
- Модель машинного обучения — это параметрическая функция.
- Задача обучения состоит в том, чтобы подобрать параметры модели таким образом, чтобы она лучше всего описывала обучающие данные.
- Парная линейная регрессия работает, если есть всего одна входящая переменная.
- Парная линейная регрессия — одна из самых простых моделей машинного обучения.
- Парная линейная регрессия соответствует множеству всех прямых на плоскости. Из них мы выбираем одну, наиболее подходящую.
Функция ошибки
Как мы уже говорили, разные значения параметров дают разные модели. Для того, чтобы подобрать наилучшую модель, нам нужно средство измерения “точности” модели, некоторая функция, которая показывает, насколько модель хорошо или плохо соответствует имеющимся данным.

В простых случаях мы можем отличить хорошие модели от плохих, только взглянув на график. Но это затруднительно, если количество признаков очень велико, если модели лишь немного отличаются друг от друга. Да и для автоматизации процесса нужен способ формализовать наше общее представление о том, что модель “ложится” в точки данных.
Такая функция называется функцией ошибки (cost function). Она измеряет отклонения теоретических значений (то есть тех, которые предсказывает модель) от эмпирических (то есть тех, которые есть в данных). Чем выше значение функции ошибки, тем хуже модель соответствует имеющимся данным, хуже описывает их. Если модель полностью соответствует данным, то значение функции ошибки будет нулевым.

В задачах регрессии в качестве функции ошибки чаще всего берут среднеквадратичное отклонение теоретических значений от эмпирических. То есть сумму квадратов отклонений, деленную на удвоенное количество измерений.
[J(b_0, b_1)
= frac{1}{2m} sum_{i=1}^{m} (hat{y_i} — y_i)^2
= frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
Эту функцию называют «функцией квадрата ошибки» или «среднеквадратичной ошибкой» (mean squared error, MSE). Среднее значение уменьшено вдвое для удобства вычисления градиентного спуска, так как производная квадратичной функции будет отменять множитель 1/2. Вообще, функцию ошибки можно свободно домножить или разделить на любое число (положительное), ведь нам не важна конкретная величина этой функции. Нам важно, что какие-то модели (то есть наборы значений параметров модели) имеют низкую ошибку, они нам подходят больше, а какие-то — высокую ошибку, они подходят нам меньше.
Возведение в квадрат в этой формуле нужно для того, чтобы положительные отклонения не компенсировали отрицательные. Можно было бы для этого брать, например, абсолютное значение, но эта функция не везде дифференцируема, а это станет нам важно позднее.
Обратите внимание, что в качестве аргументов у функции ошибки выступают параметры нашей функции гипотезы. Ведь функция ошибки оценивает отклонение конкретной функции гипотезы (то есть набора значений параметров этой функции) от эмпирических значений, то есть ставит в соответствие каждому набору параметров модели число, характеризующее ошибку этого набора.
Давайте проследим формирование функции ошибки на еще более простом примере. Возьмем упрощенную форму линейной модели — прямую пропорциональность. Она выражается формулой:
[hat{y} = h_b (x) = b_1 x]
Эта модель поможет нам, так как у нее всего один параметр. И функцию ошибки можно будет изобразить на плоскости. Возьмем фиксированный набор точек и попробуем несколько значений параметра для вычисления функции ошибки. Слева на графике изображены точки данных и текущая функция гипотезы, а на правом графике бы будем отмечать значение использованного параметра (по горизонтали) и получившуюся величину функции ошибки (по вертикали):

При значении $b_1 = -1$ линия существенно отклоняется от точек. Отметим уровень ошибки (примерно 10) на правом графике.

Если взять значение $b_1 = 0$ линия гораздо ближе к точкам, но ошибка все еще есть. Отметим новое значение на правом графике в точке 0.

При значении $b_1 = 1$ график точно ложится в точки, таким образом ошибка становится равной нулю. Отмечаем ее так же.

При дальнейшем увеличении $b_1$ линия становится выше точек. Но функция ошибки все равно будет положительной. Теперь она опять станет расти.

На этом примере мы видим еще одно преимущество возведения в квадрат — это то, что такая функция в простых случаях имеет один глобальный минимум. На правом графике формируется точка за точкой некоторая функция, которая похожа очертаниями на параболу. Но мы не знаем аналитического вида этой параболы, мы можем лишь строить ее точка за точкой.
В нашем примере, в определенной точке функция ошибки обращается в ноль. Это соответствует “идеальной” функции гипотезы. То есть такой, когда она проходит четко через все точки. В нашем примере это стало возможно благодаря тому, что точки данных и так располагаются на одной прямой. В общем случае это не выполняется и функция ошибки, вообще говоря, не обязана иметь нули. Но она должна иметь глобальный минимум. Рассмотрим такой неидеальный случай:





Какое бы значение параметра мы не использовали, линейная функция неспособна идеально пройти через такие три точки, которые не лежат на одной прямой. Эта ситуация называется “недообучение”, об этом мы еще будем говорить дальше. Это значит, что наша модель слишком простая, чтобы идеально описать данные. Но зачастую, идеальная модель и не требуется. Важно лишь найти наилучшую модель из данного класса (например, линейных функций).
Выше мы рассмотрели упрощенный пример с функцией гипотезы с одним параметром. Но у парной линейной регрессии же два параметра. В таком случае, функция ошибки будет описывать не параболу, а параболоид:

Теперь мы можем конкретно измерить точность нашей предсказывающей функции по сравнению с правильными результатами, которые мы имеем, чтобы мы могли предсказать новые результаты, которых у нас нет.
Если мы попытаемся представить это наглядно, наш набор данных обучения будет разбросан по плоскости x-y. Мы пытаемся подобрать прямую линию, которая проходит через этот разбросанный набор данных. Наша цель — получить наилучшую возможную линию. Лучшая линия будет такой, чтобы средние квадраты вертикальных расстояний точек от линии были наименьшими. В лучшем случае линия должна проходить через все точки нашего набора данных обучения. В таком случае значение J будет равно 0.


В более сложных моделях параметров может быть еще больше, но это не важно, ведь нам не нужно строить функцию ошибки, нам нужно лишь оптимизировать ее.
Выводы:
- Функция ошибки нужна для того, чтобы отличать хорошие модели от плохих.
- Функция ошибки показывает численно, насколько модель хорошо описывает данные.
- Аргументами функции ошибки являются параметры модели, ошибка зависит от них.
- Само значение функции ошибки не несет никакого смысла, оно используется только в сравнении.
- Цель алгоритма машинного обучения — минимизировать функцию ошибки, то есть найти такой набор параметров модели, при которых ошибка минимальна.
- Чаще всего используется так называемая L2-ошибка — средний квадрат отклонений теоретических значений от эмпирических (метрика MSE).
Метод градиентного спуска
Таким образом, у нас есть функция гипотезы, и способ оценить, насколько хорошо конкретная гипотеза вписывается в данные. Теперь нам нужно подобрать параметры функции гипотезы. Вот где приходит на помощь метод градиентного спуска.
Это происходит при помощи производной функции ошибки. Необходимое условие минимума функции — обращение в ноль ее производной. А так как мы знаем, что квадратичная функция имеет один глобальный экстремум — минимум, то наша задача очень проста — вычислить производную функции ошибки и найти, где она равна нулю.
Давайте найдем производную среднеквадратической функции ошибки:
[J(b_0, b_1) = frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
[J(b_0, b_1) = frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
[frac{partial}{partial b_i} J =
frac{1}{m} sum_{i=1}^{m} (h_b(x_i) — y^{(i)}) cdot frac{partial}{partial b_i} h_b(x_i)]
[J(b_0, b_1) = frac{1}{2m} sum_{i=1}^{m} (b_0 + b_1 x_i — y_i)^2]
[frac{partial J}{partial b_0} =
frac{1}{m} sum (b_0 + b_1 x_i — y_i) =
frac{1}{m} sum (h_b(x_i) — y_i)]
[frac{partial J}{partial b_1} =
frac{1}{m} sum (b_0 + b_1 x_i — y_i) cdot x_i =
frac{1}{m} sum (h_b(x_i) — y_i) cdot x_i]
Проблема в том, что мы не можем просто решить эти уравнения аналитически. Ведь мы не знаем общий вид функции ошибки, не то, что ее производной. Ведь он зависит, от всех точек данных. Но мы можем вычислить эту функцию (и ее производную) в любой точке. А точка на этой функции — это конкретный набор значений параметров модели. Поэтому пришлось изобрести численный алгоритм. Он работает следующим образом.
Сначала, мы выбираем произвольное значение параметров модели. То есть, произвольную точку в области определения функции. Мы не знаем, является ли эта точка оптимальной (скорее нет), не знаем, насколько она далека от оптимума. Но мы можем вычислить направление к оптимуму. Ведь мы знаем наклон касательной к графику функции ошибки.

Наклон касательной является производной в этой точке, и это даст нам направление движения в сторону самого крутого уменьшения значения функции. Если представить себе функцию одной переменной (параболу), то там все очень просто. Если производная в точке отрицательна, значит функция убывает, значит, что оптимум находится справа от данной точки. То есть, чтобы приблизиться к оптимуму надо увеличить аргумент функции. Если же производная положительна, то все наоборот — функция возрастает, оптимум находится слева и нам нужно уменьшить значение аргумента. Причем, чем дальше от оптимума, тем быстрее возрастает или убывает функция. То есть значение производной дает нам не только направление, но и величину нужного шага. Сделав шаг, пропорциональный величине производной и в направлении, противоположном ей, можно повторить процесс и еще больше приблизиться к оптимуму. С каждой итерацией мы будем приближаться к минимуму ошибки и математически доказано, что мы можем приблизиться к ней произвольно близко. То есть, данный метод сходится в пределе.
В случае с функцией нескольких переменных все немного сложнее, но принцип остается прежним. Только мы оперируем не полной производной функции, а вектором частных производных по каждому параметру. Он задает нам направление максимального увеличения функции. Чтобы получить направление максимального спада функции нужно просто домножить этот вектор на -1. После этого нужно обновить значения каждого компонента вектора параметров модели на величину, пропорциональную соответствующему компоненту вектора градиента. Таким образом мы делаем шаги вниз по функции ошибки в направлении с самым крутым спуском, а размер каждого шага пропорционален определяется параметром $alpha$, который называется скоростью обучения.
Алгоритм градиентного спуска:
повторяйте до сходимости:
[b_j := b_j — alpha frac{partial}{partial b_j} J(b_0, b_1)]
где j=0,1 — представляет собой индекс номера признака.
Это общий алгоритм градиентного спуска. Она работает для любых моделей и для любых функций ошибки. Это итеративный алгоритм, который сходится в пределе. То есть, мы никогда не придем в сам оптимум, но можем приблизиться к нему сколь угодно близко. На практике нам не так уж важно получить точное решение, достаточно решения с определенной точностью.
Алгоритм градиентного спуска имеет один параметр — скорость обучения. Он влияет на то, как быстро мы будем приближаться к оптимуму. Кажется, что чем быстрее, тем лучше, но оказывается, что если значение данного параметра слишком велико, то мы буем постоянно промахиваться и алгоритм будет расходиться.

Алгоритм градиентного спуска для парной линейной регрессии:
повторяйте до сходимости:
[b_0 := b_0 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)} )- y^{(i)})]
[b_1 := b_1 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x^{(i)}]
На практике “повторяйте до сходимости” означает, что мы повторяем алгоритм градиентного спуска до тех пор, пока значение функции ошибки не перестанет значимо изменяться. Это будет означать, что мы уже достаточно близко к минимуму и дальнейшие шаги градиентного спуска слишком малы, чтобы быть целесообразными. Конечно, это оценочное суждение, но на практике обычно, нескольких значащих цифр достаточно для практического применения моделей машинного обучения.
Алгоритм градиентного спуска имеет одну особенность, про которую нужно помнить. Он в состоянии находить только локальный минимум функции. Он в принципе, по своей природе, локален. Поэтому, если функция ошибки будет очень сложна и иметь несколько локальных оптимумов, то результат работы градиентного спуска будет зависеть от выбора начальной точки:


На практике эту проблему решают методом семплирования — запускают градиентный спуск из множества случайных точек и выбирают то минимум, который оказался меньше по значению функции ошибки. Но этот подход понадобится нам при рассмотрении более сложных и глубоких моделей машинного обучения. Для простых линейных, полиномиальных и других моделей метод градиентного спуска работает прекрасно. В настоящее время этот алгоритм — это основная рабочая лошадка классических моделей машинного обучения.
Выводы:
- Метод градиентного спуска нужен, чтобы найти минимум функции, если мы не можем ее вычислить аналитически.
- Это численный итеративный алгоритм локальной оптимизации.
- Для запуска градиентного спуска нужно знать частную производную функции ошибки.
- Для начала мы берем произвольные значения параметров, затем обновляем их по данной формуле.
- Доказано, что этот метод сходится к локальному минимуму.
- Если функция ошибки достаточно сложная, то разные начальные точки дадут разный результат.
- Метод градиентного спуска имеет свой параметр — скорость обучения. Обычно его подстаивают автоматически.
- Метод градиентного спуска повторяют много раз до тех пор, пока функция ошибки не перестанет значимо изменяться.
Регрессия с несколькими переменными
Множественная линейная регрессия

Парная регрессия, как мы увидели выше, имеет дело с объектами, которые характеризуются одним числовым признаком ($x$). На практике, конечно, объекты характеризуются несколькими признаками, а значит в модели должна быть не одна входящая переменная, а несколько (или, что то же самое, вектор). Линейная регрессия с несколькими переменными также известна как «множественная линейная регрессия». Введем обозначения для уравнений, где мы можем иметь любое количество входных переменных:
$ x^{(i)} $- вектор-столбец всех значений признаков i-го обучающего примера;
$ x_j^{(i)} $ — значение j-го признака i-го обучающего примера;
$ x_j $ — вектор j-го признака всех обучающих примеров;
m — количество примеров в обучающей выборке;
n — количество признаков;
X — матрица признаков;
b — вектор параметров регрессии.
Задачи множественной регрессии уже очень сложно представить на графике, ведь количество параметров каждого объекта обучающей выборки соответствует измерению, в котором находятся точки данных. Плюс нужно еще одно измерение для целевой переменной. И вместо того, чтобы подбирать оптимальную прямую, мы будем подбирать оптимальную гиперплоскость. Но в целом идея линейной регрессии остается неизменной.
Для удобства примем, что $ x_0^{(i)} = 1 $ для всех $i$. Другими словами, мы ведем некий суррогатный признак, для всех объектов равный единице. Это никак не сказывается на самой функции гипотезы, это лишь условность обозначения, но это сильно упростит математические выкладки, особенно в матричной форме.
Теперь определим множественную форму функции гипотезы следующим образом, используя несколько признаков. Она очень похожа на парную, но имеет больше входных переменных и, как следствие, больше параметров.
Общий вид модели множественной линейной регрессии:
[h_b(x) = b_0 + b_1 x_1 + b_2 x_2 + … + b_n x_n]
Или в матричной форме:
[h_b(x) = X cdot vec{b}]
Используя определение матричного умножения, наша многопараметрическая функция гипотезы может быть кратко представлена в виде: $h(x) = B X$.
Обратите внимание, что в любой модели линейной регрессии количество параметров на единицу больше количества входных переменных. Это верно для любой линейной модели машинного обучения. Вообще, всегда чем больше признаков, тем больше параметров. Это будет важно для нас позже, когда мы будем говорить о сложности моделей.
Теперь, когда мы знаем виды функции гипотезы, то есть нашей модели, мы можем переходить к следующему шагу: функции ошибки. Мы построим ее по аналогии с функцией ошибки для парной модели. Для множественной регрессии функция ошибки от вектора параметров b выглядит следующим образом:
Функция ошибки для множественной линейной регрессии:
[J(b) = frac{1}{2m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)})^2]
Или в матричной форме:
[J(b) = frac{1}{2m} (X b — vec{y})^T (X b — vec{y})]
Обратите внимание, что мы специально не раскрываем выражение (h_b(x^{(i)})). Это нужно, чтобы подчеркнуть, что форма функции ошибки не зависит от функции гипотезы, она выражается через нее.
Теперь нам нужно взять производную этой функции ошибки. Здесь уже нужно знать производную самой функции гипотезы, так как:
[frac{partial}{partial b_i} J =
frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot frac{partial}{partial b_i} h_b(x^{(i)})]
В такой формулировке мы представляем частные производные функции ошибки (градиент) через частную производную функции гипотезы. Это так называемое моделенезависимое представление градиента. Ведь для этой формулы совершенно неважно, какой функцией будет наша гипотеза. Пока она является дифференцируемой, мы можем использовать градиент ее функции ошибки. Именно поэтому метод градиентного спуска работает с любыми аналитическими моделями, и нам не нужно каждый раз заново “переизобретать” математику градиентного спуска, адаптировать ее к каждой конкретной модели машинного обучения. Достаточно изучить этот метод один раз, в общей форме.
Метод градиентного спуска для множественной регрессии определяется следующими уравнениями:
повторять до сходимости:
[b_0 := b_0 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_0^{(i)}]
[b_1 := b_1 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_1^{(i)}]
[b_2 := b_2 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_2^{(i)}]
[…]
Или в матричной форме:
[b := b — frac{alpha}{m} X^T (X b — vec{y})]
Выводы:
- Множественная регрессия очень похожа на парную, но с большим количеством признаков.
- Для удобства и однообразия, почти всегда обозначают $x_0 = 1$.
- Признаки образуют матрицу, поэтому уравнения множественной регрессии часто приводят в матричной форме, так короче.
- Алгоритм градиентного спуска для множественной регрессии точно такой же, как и для парной.
Нормализация признаков
Мы можем ускорить сходимость метода градиентного спуска, преобразовав входные данные таким образом, чтобы все атрибуты имели значения примерно в том же диапазоне. Это называется нормализация данных — приведение всех признаков к одной шкале. Это ускоряет сходимость градиентного спуска за счет эффекта масштаба. Дело в том, что зачастую значения разных признаков измеряются по шкалам с очень разным порядком величины. Например, $x_1$ измеряется в миллионах, а $x_2$ — в долях единицы.
В таком случае форма функции ошибки будет очень вытянутой. Это не проблема для математической формализации градиентного спуска — при достаточно малых $alpha$ метод все равно рано или поздно сходится. Проблема в практической реализации. Получается, что если выбрать скорость обучения выше определенного предела по самому компактному признаку, спуск разойдется. Значит, скорость обучения надо делать меньше. Но тогда в направлении второго признака спуск будет проходить слишком медленно. И получается, что градиентный спуск потребует гораздо больше итераций для завершения.
Эту проблему можно решить если изменить диапазоны входных данных, чтобы они выражались величинами примерно одного порядка. Это не позволит одному измерению численно доминировать над другим. На практике применяют несколько алгоритмов нормализации, самые распространенные из которых — минимаксная нормализация и стандартизация или z-оценки.
Минимаксная нормализация — это изменение входных данных по следующей формуле:
[x’ = frac{x — x_{min}}{x_{max} — x_{min}}]
После преобразования все значения будут лежать в диапазоне $x in [0; 1]$.
Z-оценки или стандартизация производится по формуле:
[x’ = frac{x — M[x]}{sigma_x}]
В таком случае данный признак приводится к стандартному распределению, то есть такому, у которого среднее 0, а дисперсия — 1.
У каждого из этих двух методов нормализации есть по два параметра. У минимаксной — минимальное и максимальное значение признака. У стандартизации — выборочные среднее и дисперсия. Параметры нормализации, конечно, вычисляются по каждому признаку (столбцу данных) отдельно. Причем, эти параметры надо запомнить, чтобы при использовании модели для предсказании использовать именно их (вычисленные по обучающей выборке). Даже если вы используете тестовую выборку, ее надо нормировать с использованием параметров, вычисленных по обучающей. Да, при этом может получиться, что при применении модели на данных, которых не было в обучающей выборке, могут получиться значения, например, меньше нуля или больше единицы (при использовании минимаксной нормализации). Это не страшно, главное, что будет соблюдена последовательность вычисления нормированных значений.
Целевая переменная не нормируется.
При использовании библиотечных моделей машинного обучения беспокоиться о нормализации входных данных вручную, как правило, не нужно. Большинство готовых реализаций моделей уже включают нормализацию как неотъемлемый этап подготовки данных. Более того, некоторые типы моделей обучения с учителем вовсе не нуждаются в нормализации. Но об этом пойдет речь в следующих главах.
Выводы:
- Нормализация нужна для ускорения метода градиентного спуска.
- Есть два основных метода нормализации — минимаксная и стандартизация.
- Параметры нормализации высчитываются по обучающей выборке.
- Нормализация встроена в большинство библиотечных методов.
- Некоторые методы более чувствительны к нормализации, чем другие.
- Нормализацию лучше сделать, чем не делать.
Полиномиальная регрессия

Функция гипотезы не обязательно должна быть линейной, если это не соответствует данным. На практике вы не всегда будете иметь данные, которые можно хорошо аппроксимировать линейной функцией. Наглядный пример вы видите на иллюстрации. Вполне очевидно, что в среднем увеличение целевой переменной замедляется с ростом входной переменной. Это значит, что данные демонстрируют нелинейную динамику. И это так же значит, что мы никак не сможем их хорошо приблизить линейной моделью.
Надо подчеркнуть, что это не свидетельствует о несовершенстве наших методов оптимизации. Мы действительно можем найти самую лучшую линейную функцию для данных точек, но проблема в том, что мы всегда выбираем лучшую функцию из некоторого класса функций, в данном случае — линейных. То есть проблема не в алгоритмах оптимизации, а в ограничении самого вида модели.
вполне логично предположить, что для описания таких нелинейных наборов данных следует использовать нелинейные же функции моделей. Но очень бы не хотелось, для каждого нового класса функций изобретать собственный метод оптимизации, поэтому мы постараемся максимально “переиспользовать” те подходы, которые описали выше. И механизм множественной регрессии в этом сильно поможет.
Мы можем изменить поведение или кривую нашей функции гипотезы, сделав ее квадратичной, кубической или любой другой формой.
Например, если наша функция гипотезы
$ hat{y} = h_b (x) = b_0 + b_1 x $,
то мы можем добавить еще один признак, основанный на $ x_1 $, получив квадратичную функцию
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 x^2]
или кубическую функцию
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 x^2 + b_3 x^3]
В кубической функции мы по сути ввели два новых признака:
$ x_2 = x^2, x_3 = x^3 $.
Точно таким же образом, мы можем создать, например, такую функцию:
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 sqrt{x}]
В любом случае, мы из парной линейной функции сделали какую-то другую функцию. И к этой нелинейной функции можно относиться по разному. С одной стороны, это другой класс функций, который обладает нелинейным поведением, а следовательно, может описывать более сложные зависимости в данных. С другой стороны, это линейна функция от нескольких переменных. Только сами эти переменные оказываются в функциональной зависимости друг от друга. Но никто не говорил, что признаки должны быть независимы.
И вот такое представление нелинейной функции как множественной линейной позволяет нам без изменений воспользоваться алгоритмом градиентного спуска для множественной линейной регрессии. Только вместо $ x_2, x_3, … , x_n $ нам нужно будет подставить соответствующие функции от $ x_1 $.

Источник: Wikimedia.
Очевидно, что нелинейных функций можно придумать бесконечное количество. Поэтому встает вопрос, как выбрать нужный класс функций для решения конкретной задачи. В случае парной регрессии мы можем взглянув на график точек обучающей выборки сделать предположение о том, какой вид нелинейной зависимости связывает входную и целевую переменные. Но если у нас множество признаков, просто так проанализировать график нам не удастся. Поэтому по умолчанию используют полиномиальную регрессию, когда в модель добавляют входные переменные второго, третьего, четвертого и так далее порядков.
Порядок полиномиальной регрессии подбирается в качестве компромисса между качеством получаемой регрессии, и вычислительной сложностью. Ведь чем выше порядок полинома, тем более сложные зависимости он может аппроксимировать. И вообще, чем выше степень полинома, тем меньше будет ошибка при прочих равных. Если степень полинома на единицу меньше количества точек — ошибка будет нулевая. Но одновременно с этим, чем выше степень полинома, тем больше в модели параметров, тем она сложнее и занимает больше времени на обучение. Есть еще вопросы переобучения, но про это мы поговорим позднее.
А что делать, если изначально в модели было несколько признаков? Тогда обычно для определенной степени полинома берутся все возможные комбинации признаком соответствующей степени и ниже. Например:
Для регрессии с двумя признаками.
Линейная модель (полином степени 1):
[h_b (x) = b_0 + b_1 x_1 + b_2 x_2]
Квадратичная модель (полином степени 2):
[h_b (x) = b_0 + b_1 x + b_2 x_2 + b_3 x_1^2 + b_4 x_2^2 + b_5 x_1 x_2]
Кубическая модель (полином степени 3):
[hat{y} = h_b (x) = b_0 + b_1 x_1 + b_2 x_2 + b_3 x_1^2 + b_4 x_2^2 + b_5 x_1 x_2 + b_6 x_1^3 + b_7 x_2^3 + b_7 x_1^2 x_2 + b_8 x_1 x_2^2]
При этом количество признаков и, соответственно, количество параметров растет экспоненциально с ростом степени полинома. Поэтому полиномиальные модели обычно очень затратные в обучении при больших степенях. Но полиномы высоких степеней более универсальны и могут аппроксимировать более сложные данные лучше и точнее.
Выводы:
- Данные в датасете не всегда располагаются так, что их хорошо может описывать линейная функция.
- Для описания нелинейных зависимостей нужна более сложная, нелинейная модель.
- Чтобы не изобретать алгоритм обучения заново, можно просто ввести в модель суррогатные признаки.
- Суррогатный признак — это новый признак, который считается из существующих атрибутов.
- Чаще всего используют полиномиальную регрессию — это когда в модель вводят полиномиальные признаки — степени существующих атрибутов.
- Обычно берут все комбинации факторов до какой-то определенной степени полинома.
- Полиномиальная регрессия может аппроксимировать любую функцию, нужно только подобрать степень полинома.
- Чем больше степень полиномиальной регрессии, тем она сложнее и универсальнее, но вычислительно сложнее (экспоненциально).
Практическое построение регрессии
В данном разделе мы посмотрим, как можно реализовать методы линейной регрессии на практике. Сначала мы попробуем создать алгоритм регрессии с нуля, а затем воспользуемся библиотечной функцией. Это поможет нам более полно понять, как работают модели машинного обучения в целом и в библиотеке sckikit-learn (самом популярном инструменте для создания и обучения моделей на языке программирования Python) в частности.
Для понимания данного раздела предполагаем, что читатель знаком с основами языка программирования Python. Нам понадобится знание его базового синтаксиса, немного — объектно-ориентированного программирования, немного — использования стандартных библиотек и модулей. Никаких продвинутых возможностей языка (типа метапрограммирования или декораторов) мы использовать не будем.
Как должны быть представлены данные для машинного обучения?
Применение любых моделей машинного обучения начинается с подготовки данных в необходимом формате. Для этого очень удобными для нас будут библиотеки numpy и pandas. Они практически всегда используются совместно с библиотекой sckikit-learn и другими инструментами машинного обучения. В первую очередь мы будем использовать numpy для создания массивов и операций с векторами и матрицами. Pandas нам понадобится для работы с табличными структурами — датасетами.
Если вы хотите самостоятельно задать в явном виде данные обучающей выборки, то нет ничего лучше использования обычных массивов ndarray. Обычно в одном массиве хранятся значения атрибутов — x, а в другом — значения целевой переменной — y.
1
2
3
4
5
6
7
8
9
10
11
import numpy as np
x = np.array([1.46, 1.13, -2.30, 1.74, 0.04,
-0.61, 0.32, -0.76, 0.58, -1.10,
0.87, 1.62, -0.53, -0.25, -1.07,
-0.38, -0.17, -0.32, -2.06, -0.88, ])
y = np.array([101.16, 78.44, -159.24, 120.72, 2.92,
-42.33, 22.07, -52.67, 40.32, -76.10,
59.88, 112.38, -36.54, -17.25, -74.24,
-26.57, -11.93, -22.31, -142.54, -60.74,])
Если мы имеем дело с задачей множественной регрессии, то в массиве атрибутов будет уже двумерный массив, состоящий из нескольких векторов атрибутов, вот так:
1
2
3
4
5
x = np.array([
[0, 1, 2, 3, 4],
[5, 4, 9, 6, 3],
[7.8, -0.1, 0.0, -2.14, 10.7],
])
Важно следить за тем, чтобы в массиве атрибутов в каждом вложенном массиве количество элементов было одинаковым и в свою очередь совпадало с количеством элементов в массиве целевой переменной. Это называется соблюдение размерности задачи. Если размерность не соблюдается, то модели машинного обучения будут работать неправильно. А библиотечные функции чаще всего будут выдавать ошибку, связанную с формой массива (shape).
Но чаще всего вы не будете задавать исходные данные явно. Практически всегда их приходится читать из каких-либо входных файлов. Удобнее всего это сделать при помощи библиотеки pandas вот так:
1
2
3
4
import pandas as pd
x = pd.read_csv('x.csv', index_col=0)
y = pd.read_csv('y.csv', index_col=0)
Или, если данные лежат в одном файле в общей таблице (что происходит чаще всего), тогда его читают в один датафрейм, а затем выделяют целевую переменную, и факторные переменные:
1
2
3
4
5
6
7
8
import pandas as pd
data = pd.read_csv('data.csv', index_col=0)
y = data.Y
y = data["Y"]
x = data.drop(["Y"])
Обратите внимание, что матрицу атрибутов проще всего сформировать, удалив из полной таблицы целевую переменную. Но, если вы хотите выбрать только конкретные столбцы, тогда можно использовать более явный вид, через перечисление выбранных колонок.
Если вы используете pandas или numpy для формирования массивов данных, то получившиеся переменные будут разных типов — DataFrame или ndarray, соответственно. Но на дальнейшую работу это не повлияет, так как интерфейс работы с этими структурами данных очень похож. Например, неважно, какие именно массивы мы используем, их можно изобразить на графике вот так:
1
2
3
4
5
import maiplotlib.pyplot as plt
plt.figure()
plt.scatter(x, y)
plt.show()
Конечно, такая визуализация будет работать только в случае задачи парной регрессии. Если x многомерно, то простой график использовать не получится.
Давайте соберем весь наш код вместе:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import numpy as np
import pandas as pd
import maiplotlib.pyplot as plt
# x = pd.read_csv('x.csv', index_col=0)
x = np.array([1.46, 1.13, -2.30, 1.74, 0.04,
-0.61, 0.32, -0.76, 0.58, -1.10,
0.87, 1.62, -0.53, -0.25, -1.07,
-0.38, -0.17, -0.32, -2.06, -0.88, ])
# y = pd.read_csv('y.csv', index_col=0)
y = np.array([101.16, 78.44, -159.24, 120.72, 2.92,
-42.33, 22.07, -52.67, 40.32, -76.10,
59.88, 112.38, -36.54, -17.25, -74.24,
-26.57, -11.93, -22.31, -142.54, -60.74,])
plt.figure()
plt.scatter(x, y)
plt.show()
Это код генерирует вот такой вот график:

Как работает метод машинного обучения “на пальцах”?
Для того, чтобы более полно понимать, как работает метод градиентного спуска для линейной регрессии, давайте реализуем его самостоятельно, не обращаясь к библиотечным методам. На этом примере мы проследим все шаги обучения модели.
Мы будем использовать объектно-ориентированный подход, так как именно он используется в современных библиотеках. Начнем строить класс, который будет реализовывать метод парной линейной регрессии:
1
2
3
4
5
class hypothesis(object):
"""Модель парной линейной регрессии"""
def __init__(self):
self.b0 = 0
self.b1 = 0
Здесь мы определили конструктор класса, который запоминает в полях экземпляра параметры регрессии. Начальные значения этих параметров не очень важны, так как градиентный спуск сойдется из любой точки. В данном случае мы выбрали нулевые, но можно задать любые другие начальные значения.
Реализуем метод, который принимает значение входной переменной и возвращает теоретическое значение выходной — это прямое действие нашей регрессии — метод предсказания результата по факторам (в случае парной регрессии — по одному фактору):
1
2
def predict(self, x):
return self.b0 + self.b1 * x
Название выбрано не случайно, именно так этот метод называется и работает в большинстве библиотечных классов.
Теперь зададим функцию ошибки:
1
2
def error(self, X, Y):
return sum((self.predict(X) - Y)**2) / (2 * len(X))
В данном случае мы используем простую функцию ошибки — среднеквадратическое отклонение (mean squared error, MSE). Можно использовать и другие функции ошибки. Именно вид функции ошибки будет определять то, какой вид регрессии мы реализуем. Существует много разных вариаций простого алгоритма регрессии. О большинстве распространенных методах регрессии можно почитать в официальной документации sklearn.
Теперь реализуем метод градиентного спуска. Он должен принимать массив X и массив Y и обновлять параметры регрессии в соответствии в формулами градиентного спуска:
1
2
3
4
5
6
def BGD(self, X, Y):
alpha = 0.5
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
О выборе конкретного значения alpha мы говорить пока не будем,на практике его довольно просто подбирают, мы же возьмем нейтральное значение.
Давайте создадим объект регрессии и проверим начальное значение ошибки. В примерах приведены значения на модельном наборе данных, но этот метод можно использовать на любых данных, которые подходят по формату — x и y должны быть одномерными массивами чисел.
1
2
3
4
5
6
7
8
hyp = hypothesis()
print(hyp.predict(0))
print(hyp.predict(100))
J = hyp.error(x, y)
print("initial error:", J)
0
0
initial error: 36271.58344889084
Как мы видим, для начала оба параметра регрессии равны нулю. Конечно, такая модель не дает надежных предсказаний, но в этом и состоит суть метода градиентного спуска: начиная с любого решения мы постепенно его улучшаем и приходим к оптимальному решению.
Теперь все готово к запуску градиентного спуска.
1
2
3
4
5
6
7
8
9
10
hyp.BGD(x, y)
J = hyp.error(x, y)
print("error after gradient descent:", J)
error after gradient descent: 6734.135540194945
X0 = np.linspace(60, 180, 100)
Y0 = hyp.predict(X0)
plt.figure()
plt.scatter(x, y)
plt.plot(X0, Y0, 'r')
plt.show()
Как мы видим, численное значение ошибки значительно уменьшилось. Да и линия на графике существенно приблизилась к точкам. Конечно, наша модель еще далека от совершенства. Мы прошли всего лишь одну итерацию градиентного спуска. Модифицируем метод так, чтобы он запускался в цикле пока ошибка не перестанет меняться существенно:
1
2
3
4
5
6
7
8
9
10
11
12
13
def BGD(self, X, Y, alpha=0.5, accuracy=0.01, max_steps=5000):
step = 0
old_err = hyp.error(X, Y)
new_err = hyp.error(X, Y)
dJ = 1
while (dJ > accuracy) and (step < max_steps):
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
old_err = new_err
new_err = hyp.error(X, Y)
dJ = abs(old_err - new_err)
Заодно мы проверяем, насколько изменилось значение функции ошибки. Если оно изменилось на величину, меньшую, чем заранее заданная точность, мы завершаем спуск. Таким образом, мы реализовали два стоп-механизма — по количеству итераций и по стабилизации ошибки. Вы можете выбрать любой или использовать оба в связке.
Запустим наш градиентный спуск:
1
2
3
4
5
hyp = hypothesis()
hyp.BGD(x, y)
J = hyp.error(x, y)
print("error after gradient descent:", J)
error after gradient descent: 298.76881676471504
Как мы видим, теперь ошибка снизилась гораздо больше. Однако, она все еще не достигла нуля. Заметим, что нулевая ошибка не всегда возможна в принципе из-за того, что точки данных не всегда будут располагаться на одной линии. Нужно стремиться не к нулевой, а к минимально возможной ошибке.
Посмотрим, как теперь наша регрессия выглядит на графике:
1
2
3
4
5
6
X0 = np.linspace(60, 180, 100)
Y0 = hyp.predict(X0)
plt.figure()
plt.scatter(x, y)
plt.plot(X0, Y0, 'r')
plt.show()

Уже значительно лучше. Линия регрессии довольно похожа на оптимальную. Так ли это на самом деле, глядя на график, сказать сложно, для этого нужно проанализировать, как ошибка регрессии менялась со временем:
Как оценить качество регрессионной модели?
В простых случаях качество модели можно оценить визуально на графике. Но если у вас многомерная задача, это уже не представляется возможным. Кроме того, если ошибка и сама модель меняется незначительно, то очень сложно определить, стало хуже или лучше. Поэтому для диагностики моделей машинного обучения используют кривые.
Самая простая кривая обучения — зависимость ошибки от времени (итерации градиентного спуска). Для того, чтобы построить эту кривую, нам нужно немного модифицировать наш метод обучения так, чтобы он возвращал нужную нам информацию:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def BGD(self, X, Y, alpha=0.1, accuracy=0.01, max_steps=1000):
steps, errors = [], []
step = 0
old_err = hyp.error(X, Y)
new_err = hyp.error(X, Y) - 1
dJ = 1
while (dJ > accuracy) and (step < max_steps):
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
old_err = new_err
new_err = hyp.error(X, Y)
dJ = abs(old_err - new_err)
step += 1
steps.append(step)
errors.append(new_err)
return steps, errors
Мы просто запоминаем в массивах на номер шаа и ошибку на каждом шаге. Получив эти данные можно легко построить их на графике:
1
2
3
4
5
6
hyp = hypothesis()
steps, errors = hyp.BGD(x, y)
plt.figure()
plt.plot(steps, errors, 'g')
plt.show()

На этом графике наглядно видно, что в начале обучения ошибка падала быстро, но в ходе градиентного спуска она вышла на плато. Учитывая, что мы используем гладкую функцию ошибки второго порядка, это свидетельствует о том, что мы достигли локального оптимума и дальнейшее повторение алгоритма не принесет улучшения модели.
Если бы мы наблюдали на графике обучения ситуацию, когда по достижении конца обучения ошибка все еще заметно снижалась, это значит, что мы рано прекратили обучение, и нужно продолжить его еще на какое-то количество итераций.
При анализе графиков с библиотечными моделями не получится таких гладких графиков, они больше напоминают случайные колебания. Это из-за того, что в готовых реализациях используется очень оптимизированный вариант метода градиентного спуска. А он может работать с произвольными флуктуациями. В любом случае, нас интересует общий вид этой кривой.
Как подбирать скорость обучения?
В нашей реализации метода градиентного спуска есть один параметр — скорость обучения — который нам приходится так же подбирать руками. Какой смысл автоматизировать подбор параметров линейной регрессии, если все равно приходится вручную подбирать какой-то другой параметр?
На самом деле подобрать скорость обучения гораздо легче. Нужно использовать тот факт, что при превышении определенного порогового значения ошибка начинает возрастать. Кроме того, мы знаем, что скорость обучения должна быть положительна, но меньше единицы. Вся проблема в этом пороговом значении, которое сильно зависит от размерности задачи. При одних данных хорошо работает $ alpha = 0.5 $, а при каких-то приходится уменьшать ее на несколько порядков, например, $ alpha = 0.00000001 $.
Мы еще не говорили о нормализации данных, которая тоже практически всегда применяется при обучении. Она “благотворно” влияет на возможный диапазон значений скорости обучения. При использовании нормализации меньше вероятность, что скорость обучения нужно будет уменьшать очень сильно.
Подбирать скорость обучения можно по следующему алгоритму. Сначала мы выбираем $ alpha $ близкое к 1, скажем, $ alpha = 0.7 $. Производим одну итерацию градиентного спуска и оцениваем, как изменилась ошибка. Если она уменьшилась, то ничего не надо менять, продолжаем спуск как обычно. Если же ошибка увеличилась, то скорость обучения нужно уменьшить. Например, раа в два. После чего мы повторяем первый шаг градиентного спуска. Таким образом мы не начинаем спуск, пока скорость обучения не снизится настолько, чтобы он начал сходиться.
Как применять регрессию с использованием scikit-learn?
Для серьезной работы, все-таки рекомендуется использовать готовые библиотечные решения. Они работаю гораздо быстрее, надежнее и гораздо проще, чем написанные самостоятельно. Мы будем использовать библиотеку scikit-learn для языка программирования Python как наш основной инструмент реализации простых моделей. Сегодня это одна их самых популярных библиотек для машинного обучения. Мы не будем повторять официальную документацию этой библиотеки, которая на редкость подробная и понятная. Наша задача — на примере этих инструментов понять, как работают и как применяются модели машинного обучения.
В библиотеке scikit-learn существует огромное количество моделей машинного обучения и других функций, которые могут понадобиться для их работы. Поэтому внутри самой библиотеки есть много разных пакетов. Все простые модели, например, модель линейной регрессии, собраны в пакете linear_models. Подключить его можно так:
1
from sklearn import linear_model
Надо помнить, что все модели машинного обучения из это библиотеки имеют одинаковый интерфейс. Это очень удобно и универсально. Но это значит, в частности, что все модели предполагают, что массив входных переменных — двумерный, а массивы целевых переменных — одномерный. Отдельного класса для парной регрессии не существует. Поэтому надо убедиться, что наш массив имеет нужную форму. Проще всего для преобразования формы массива использовать метод reshape, например, вот так:
Если вы используете DataFrame, то они обычно всегда настроены правильно, поэтому этого шага может не потребоваться. Важно запомнить, что все методы библиотечных моделей машинного обучения предполагают, что в x будет двумерный массив или DataFrame, а в y, соответственно, одномерный массив или Series.
Эта строка преобразует любой массив в вектор-столбец. Это если у вас один признак, то есть парная регрессия. Если признаков несколько, то вместо 1 следует указать число признаков. -1 на первой позиции означает, что по нулевому измерению будет столько элементов, сколько останется в массиве.
Само использование модели машинного обучения в этой библиотеке очень просто и сводится к трем действиям: создание экземпляра модели, обучение модели методом fit(), получение предсказаний методом predict(). Это общее поведение для любых моделей библиотеки. Для модели парной линейной регрессии нам понадобится класс LinearRegression.
1
2
3
4
5
6
reg = linear_model.LinearRegression()
reg.fit(x, y)
y_pred = reg.predict(x)
print(reg.score(x, y))
print("Коэффициенты: n", reg.coef_)
В этом классе кроме уже упомянутых методов fit() и predict(), которые есть в любой модели, есть большое количество методов и полей для получения дополнительной информации о моделях. Так, практически в каждой модели есть встроенный метод score(), который оценивает качество полученной модели. А поле coef_ содержит коэффициенты модели.
Обратите внимание, что в большинстве моделей коэффициентами считаются именно параметры при входящих переменных, то есть $ b_1, b_2, …, b_n $. Коэффициент $b_0$ считается особым и хранится отдельно в поле intercept_
Так как мы работаем с парной линейной регрессией, результат можно нарисовать на графике:
1
2
3
4
plt.figure(figsize=(12, 9))
plt.scatter(x, y, color="black")
plt.plot(x, y_pred, color="blue", linewidth=3)
plt.show()
Как мы видим, результат ничем не отличается от модели, которую мы обучили сами, вручную:

Соберем код вместе и получим пример довольно реалистичного фрагмента работы с моделью машинного обучение. Примерно такой код можно встретить и в промышленных проектах по интеллектуальному анализу данных:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from sklearn.linear_model import LinearRegression
x = x.reshape((-1, 1))
reg = LinearRegression()
reg.fit(x, y)
print(reg.score(x, y))
from sklearn.metrics import mean_squared_error, r2_score
y_pred = reg.predict(x)
print("Коэффициенты: n", reg.coef_)
print("Среднеквадратичная ошибка: %.2f" % mean_squared_error(y, y_pred))
print("Коэффициент детерминации: %.2f" % r2_score(y, y_pred))
plt.figure(figsize=(12, 9))
plt.scatter(x, y, color="black")
plt.plot(x, y_pred, color="blue", linewidth=3)
plt.show()
1
Лексические нормы. Практика
2
Классификация лексических ошибок (упражнения) 1. Непонимание значения слова 2. Лексическая сочетаемость 3. Употребление синонимов, омонимов, многозначных слов 1. Многословие 2. Лексическая неполнота высказывания 3. Употребление слов с ограниченной сферой распространения 4. Фразеологизмы, устойчивые сочетания, клише и штампы
3
4
Перепишите предложения, исправив ошибки и указав их причины 1. Подвижный состав нового выпуска был представлен на презентации железнодорожного транспорта. 2. Можно привести армады цифр, характеризующих экономику страны. 3. Трест, сооружающий новые мощности, систематически перевыполняет программу строительства. У нас самая дешевая стоимость транспортных услуг. 4. Утвержден план регулировки парков пассажирских вагонов для поездов международного сообщения. 5. Студенты на научной конференции ставили вопросы выступающим. 6. Докладчики часто оперируют примерами из реальной жизни.
5
Перепишите предложения, исправив ошибки и указав их причины 1. Партнер — это соучастник какого — либо действия, игры, события. 2. После долгих дебатов на совещании достигли альянса. 3. Бунин затрагивает темы бытия чиновников, учителей, обедневших дворян. 4. Пейзаж города обогатился новыми зданиями. 5. В деле повышения производства используются новые альтернативы. 6. Допущены дефекты при введении локомотива в эксплуатацию. 7. Среди пассажиров превалировали представители льготных категорий.
6
Расположите предложения в логической последовательности 1. Расчёты будут производиться в «цифровых деньгах». 2. В большинстве своём эксперты едины в том, что информационная и коммуникационная техника будет по-прежнему стремительно развиваться и к 2013 году проникнет в новые сферы нашей повседневной жизни. 3. С помощью домашних компьютеров можно будет не только рассылать электронную почту и совершать банковские операции в режиме online, но и делать покупки в «электронных супермаркетах», которые будут открыты круглые сутки. 4. Так, в «умных домах» компьютер будет самостоятельно управлять системами отопления, кондиционирования воздуха и освещения и следить за их исправным функционированием. 5. Почти все эксперты считают, что эта картина будущего станет реальностью ещё до 2010 года. 6. Мультимедиа и виртуальная реальность по-прежнему будут завоевывать квартиры и позволят «вживую» ездить в путешествия и смотреть спортивные состязания.
7
Объясните значение слов — паронимов и составьте с ними словосочетания Выборный — выборочный, жилищный — жилой, изготовить — приготовить, дипломат — дипломант — дипломник, стилевой — стилистический, одеть — надеть, экономна — экономика, усвоить — освоить, основание — обоснование, деловой деловитый, специальный — специализированный, новшество — новинка, регулируемый — регулирующий, подвижной — подвижный. Проверьте значения паронимов по толковым словарям.
8
Подберите паронимическую пару, объясните разницу Путевой — ?, поступок — ?, опечатка — ?, представить — ?, ванна — ?, расчетный — ?, хозяйский — ?, опровергать — ?, невежа — ?, абонент — ?, доходный — ?, подозревать — ?, акционерный — ?.
9
Исправьте речевые ошибки, связанные с употреблением паронимов Ι. 1. Отчет представляется в двух экземплярах. 2. Перед нами стал вопрос. 3.Планировка средств выполнения работ оказалась преждевременной. 4. В конце учебника предоставлен список рекомендательной литературы. 5. Земля надела землю снегом. 6. Скорые поезда укротили время прибытия пассажиров. 7. Студенты быстро освоили новый материал. 8. В новых кварталах города находятся самые высотные дома.
10
Исправьте речевые ошибки, связанные с употреблением паронимов II. 1. Она пришла в (цветном, цветастом, цветистом) платье. 2. (Командированному, командировочному) пришлось долго ждать оформления (командированных, командировочных) удостоверений. 3. Главное для писателя — (духовный, душевный) мир человека. 4. (Исполнительная, исполнительская) власть на местах должна активизировать свою работу. 5. (Конструктивные, конструкторские) предложения улучшили качество трансформатора.
11
12
Выпишите в 3 колонки слова с различной степенью их сочетаемости: 1) сочетаются; 2) нарушены границы сочетаемости; 3) намеренное сочетание несочетающихся слов. Исправьте речевые ошибки 1. Необходимо повысить эффективность каждого рабочего за счет организации труда. 2. Недостаточно автомобилей для широкого охвата перевозок груза. 3. Живой труп на работе — человек бездейственный. 4. Выращена была особая порода казенной мебели. 5. Внеклассная работа играет положительное значение в развитии детей. 6. Этот актер давно заслужил признание зрителей. 7. В лицее применяется индивидуальный подход с учетом способностей и интересов обучающихся. 8. В конце 90-х годов в стране сложилась ужасно сложная ситуация. 9. Многие были не в состоянии разрешить транспортные проблемы. 10. Большая половина лекции уже прошла. 11. Задача правительства — снизить инфляцию. 12. Деканаты делают сильный акцент на культмассовую работу. 13. Значительное число заданий было выполнено. 14. Отдых на море в летний период — обыкновенное чудо.
13
Определите лексически сочетаемые слова 1. Снизить (количество изделий, учебу, успеваемость, запросы, требования). 2. Проявить (заботу, желание, дисциплину, медлительность, уважение, грубость, порядок, равнодушие). 3. Момент (единый, один, единственный). 4. Истинный, настоящий, подлинный, натуральный, заправский (друг, человек, аметист, охотник, документ). 5. Теорема (обосновать, основать, утверждать, доказать). 6. Оказать (доверие, помощь, содействие, дружбу, невнимание, возражение). 7. Провести (совещание, организацию, курсовую работу, оценку, контроль, лекцию).
14
Как правильно? Иметь существенную роль ИЛИ иметь существенное значение? Оказать значение ИЛИ оказать влияние? Иметь значение ИЛИ играть значение? Играть значение ИЛИ играть роль? Произвел большое влияние ИЛИ оказал большое влияние?
15
Исправьте ошибки, связанные с неоправданным употреблением эмоционально окрашенной лексики в текстах делового стиля В Красноярском районе был проведен форум доярок. Строители обещали воздвигнуть здание в сентябре. Бригада вышла на новые рубежи. Труд — вот истинный оплот мастерства. Все рабочие фабрики являются поборниками технического прогресса. Бригадир так быстро мотался по стройке, что поймать его было невозможно. Хищения производились путем непосредственного изъятия продуктов из кладовки. У бригады есть возможность начать работу без раскачки. Кара за небрежность в работе постигнет любого нарушителя.
16
17
Подберите русские синонимы к следующим словам 1.Деликатный (человек), актуальный (вопрос), вибрационный (конвейер), комбинированный (вагон), тарифный (маршрут), коммерческий (груз), транзитный (пассажир), транспортные (средства), феноменальная (память), дезинфекционный (поезд); 2.Локомотив, реле, эксперт, ревизор, автоблокировка, территория, менталитет, диспетчер, инвестор, дилер, дистрибьютор, маркетинг, менеджер, импорт, патент, прайс-лист, сертификат, багаж, компост, броня.
18
Прочитайте предложения, выбрав из скобок одно из синонимичных слов В новом оборудовании, прибывшем на фабрику, разбирались (вместе — совместно — сообща). 2. Поражение команды — (итог- результат- плод) тактических (ошибок — промахов- недочетов — просчетов). 3. В институте (кончилась — завершилась- закончилась- окончилась) научная конференция. 4. Надеемся, что к концу года уровень производства начнет (расти- увеличиваться- подниматься- повышаться- усиливаться- возрастать). 5. Свободные экономические зоны могут содействовать (реализации-осуществлению- выполнению) стратегических планов России.
19
Определите различия в следующих синонимах 1. Человек по улице (идет, бредет, плетется, шагает, вышагивает, мчится, летит). 2. Удачный, успешный, счастливый, благополучный. 3. Пассажир с вагонной подножки (спрыгнул, соскочил, слез, сполз). 4. Есть- кушать- уплетать. 5. Глаза- очи- гляделки- моргалки- глазища. 6. Сотрудник -коллега- деляга- труженик- соучастник- единомышленник.
20
Подберите к устаревшим словам современные синонимы Перст, уста, долонь, брать, глаголет, льзя, брадобрей, зрачный, чело, ланиты, лепота, сей, надобно. Слова: щеки, говорит, губы, лоб, можно, видный, парикмахер, палец, битва, ладонь, красота, необходимо, этот.
21
Найдите речевые ошибки, связанные с неверным употреблением синонимов 1. Помимо подписи документы часто удостоверяют приложением печати. 2. Вышеперечисленный металл требуется для изготовления нестандартного оборудования. 3. Прошу разъяснить, за счет каких средств выплачивается денежное содержание лицам, зачисленным в аспирантуру. 4. Отмеченные признаки гетерогенны. 5. Завод просит в кратчайшие сроки прислать правомочную комиссию, чтобы решить конфликт на месте. 6. Ему очень печально, но в то же время интересно читать эту книгу 7. Я уже давно не кушаю в этой столовой. 8. Я мыслю, что сдам экзамены. 9. Станция может с большим эффектом снабжать энергией железную дорогу.
22
Распределите синонимы, соединив их со словами в скобках 1. Фальшивый, искусственный (документ, кожа). 2. Повысить, усилить (внимание, интерес). 3. Истинный, настоящий, подлинный, заправский (друг, человек, документ, охотник). 4. Побороть, победить, сломать, преодолеть, превозмочь (болезнь, чувство страха, противника, волю, препятствие). 5. Обнаружить, открыть (закон, закономерность). 6. Долгий, продолжительный, длинный (путь, сборы, кредит, воздействие, период). 7. Осведомлен, извещен, информирован (диспетчер, истец, студент).
23
Установите, какое значение имеет прилагательное простой в следующих предложениях. Замените его антонимами, синонимами. I.1.Это простая задача. 2. В нашей семье принято есть простую пишу. 3. Ребенок рисует простым карандашом. 4. Купи одну простую тетрадь. 5. Профессор очень простой человек. II. 1. Дайте три простых конверта. 2. Детям лучше носить простые колготки. 3. Осталась одна простая сезонка. 4. На улице грязно, надень простые туфли. 5. Стремление сохранить мир понятно всем простым людям.
24
Подберите антонимы к словам и словосочетанием Получить, разрешить, адресат, получатель, присутствовать, удовлетворить просьбу, положительно, удовлетворительный ответ, письмо-запрос, ответственность, низкие цены, прямая речь, здоровый, продать. Для справок: отправить, отказать, большой, адресант, отсутствовать, неудовлетворительный ответ, отказать в просьбе, отрицательно, письмо-ответ, безответственность, высокие цены, косвенная речь, купить.
25
Определите, с чем связаны речевые ошибки 1. Уровень жизни в последнее время не только не повышается, но постоянно уменьшается. 2. Иванов исключен из училища из-за отсутствия наличия признаков старания. 3. На девочке было рваное платье и большие маленькие ботинки. 4. Можем перейти на зимнее время и в летних сандалиях. 5. Почему наши богатые такие бедные? 6. Жаль, что близкие бывают недалекими.
26
Определите роль антонимов в поэтических текстах. 1. И ненавидим мы, и любим мы случайно, Ничем не жертвуя, ни злобе, ни любви, И царствует в душе какой-то холод тайный, Когда огонь кипит в крови. 2. Мне все равно, друзья ль вы мне, враги ли И вам я мил иль ненавистен вам, Но знаю: вы томились и любили. Вы душу предавали тайным снам. 3. Люблю я пышное природы увяданье Убогая роскошь наряда. 5. И в памяти взрослое детство Военной дорогой идет.
27
Устраните двусмысленность, связанную с употреблением омонимов и многозначных слов. 1. Врач обошел седьмую палату. 2. Студенты прослушали важное сообщение. 3. Редактор просмотрел эти строки. 4. Проблемам словообразования посвящена настоящая статья. 5. Билет годен только для помывки одного лица (объявление в бане). 6. Играя, он забывал об очках. 7. Мальчики шагали за гранатами. 8. «Чудо-йогурт» всем полезен, всем хорош. 9. Она такая лиса.
28
Составьте словосочетания или предложения со следующими омонимами Среда, горка, свет, кондуктор, башмак, мотив, проспект, сорок, вина, акция, бумагодержатель.
29
Найдите в тексте омонимы и объясните их значение I. Минные поля безвластия. Тем временем высшие чины МВД и Минобороны изо всех сил продолжают делать хорошие мины при плохой игре. Жаль только, что эта их плохая игра оборачивается минами, на которых подрываются вверенные им солдатики — не игрушечные, а реальные молодые мальчишки. II. — Откуда идешь так поздно? — спросил его царь. — Из «депа», Ваше императорское величество! — громогласно ответил юнкер. — Дурак! Разве «депо» склоняется? — крикнул царь. — Все склоняется перед вашим императорским величеством! – еще громче гаркнул юнкер. Этот ответ понравился царю. Он вообще любил, когда перед ним склонялись. (С.Н. Сергиев- Ценский. Севастопольская страда).
30
31
Назовите вид многословия и определите допустимые в языке словосочетания В конечном итоге, ошибочное заблуждение, вечерняя серенада, информационное сообщение, коллега по профессии, внутренний интерьер, завещать в наследство, в зимний период времени, огромная махина, ошибочное заблуждение, прейскурант цен, для проформы, травматические повреждения, отступать назад, в июне месяце, впервые познакомиться, будущие перспективы, смелый риск, первое боевое крещение, памятный сувенир, демобилизация из армии, хронометраж времени, народный фольклор, свободная вакансия, прогрессировать вперед, странный парадокс, научные монографии, моя автобиография, железнодорожники с железной дороги
32
Исправьте речевые ошибки. Назовите вид многословия 1. Необходимо реалистично и без иллюзий взвесить наши экономические шансы. 2. Писатель показал, как боролась с врагами молодая, почти юная молодежь. 3. Татьяна, это самое, была, это самое, как бы любимой героиней Пушкина. 4. В библиотеке вуза наблюдается нехватка учебной литературы. 5. В Государственной Думе при решении жилищно-коммунальных проблем был полный кворум. 6. Успехи в экономике привели к заметному прогрессу и в других областях. 7. Эта традиция возродилась вновь в нашей стране. 8. Ударение в русском языке, ну, разноместное, значит, ну, оно подвижное. 9. Необходимо осуществить внедрение новых рацпредложений в работу инженерно-технического персонала. 11. Теплые весенние дни пришлись на начало апреля.
33
34
Восстановите неполноту высказывания в следующих предложениях 1. Отдельные члены группы не явились на экзамен по математике. 2. Лучшие будут приглашены к сотрудничеству в газете. 3. Наши дворники обязаны были посыпать песком тротуары, мосты и другие, что в их ведении. 4. Необходимо повысить эффективность. 5. Кто за билетами? 6. В основе романа лежит типичная дворянская семья. 7. На лекциях студенты хорошо ведут.
35
36
Замените просторечные слова и словосочетания литературными Вагоновожатый, туфель, манатки, расценок, теперича, чё, алё, ехай, лягте, богатей, аккурат по расписанию, сработанный проект, бронь, строгий препод, дембеля, умаяться, смотаться, зачётка, рельса, очи.
37
Найдите слова с ограниченной сферой распространения, замените их на литературно нормированные синонимы A).Устаревшая лексика (архаизмы, историзмы) — 1. Современное развитие общества позволило заменить паровозы электровозами. 2. Наши сверхзвуковые аэропланы были представлены на международной выставке. 3. Истинно российским сувениром являются деревянные ложки с хохломской росписью и плетёные лапти. 4. Посему есть предложение поддержать ручное искусство, где так много духовной лепоты.
38
Найдите слова с ограниченной сферой распространения, замените их на литературно нормированные синонимы Б).Сниженная лексика (просторечия, разговорные слова, речевые неологизмы, социальные жаргонизмы) — 1. Студенты, имеющие задолженности в зачётную неделю, не допускаются к сессии. 2. Я постоянно думаю об успешном заканчивании вуза. 3. У этного парня квартира — отпад. В ней мы и тусуемся. 4. К выборам «яблочники» собираются подойти с «отработанной экономической и политической идеологией».
39
Найдите слова с ограниченной сферой распространения, замените их на литературно нормированные синонимы B).Диалектизмы, профессионализмы, иноязычные слова: 1. На Пасху всю ночь пекём сочни — калиточки зовутся, кислы — кислые шаночки. 2. Диктор прокомментировал выступление президента. 3. Изменён регламент работы компьютеров. 4. Путевое реле постоянного тока имеет дефекты.
40
Найдите слова с ограниченной сферой распространения, замените их на литературно нормированные синонимы Г).Канцеляризмы: 1. Убедившись в правильности исполнения документа, следует завизировать его. 2. Обстановку, в которой протекало детство поэта, нельзя не признать весьма неблагоприятной (из работ абитуриентов). 3. После вышеописанного происшествия петух Горлач находился в припадке и пришёл в себя только после того, как его облили водой (из работ абитуриентов). 4. Из книги К.Чуковского «Живой, как жизнь»; «…не менее важна и реакция старухи на сообщение ей старика о неиспользовании им откупа рыбки, употребление старухой ряда вульгаризмов, направленных в адрес старика и понудивших его к повторной встрече с рыбкой, посвященной вопросу о старом корыте« (пародия на канцеляризмы).
41
Определить вид речевой ошибки, связанной с употреблением лексики ограниченной сферы. Сделайте правку предложений 1. Необходимо принять меры для обеспечения экономии электроэнергии. 2. Работу на практике студенты начинали с первыми кочетами. 3. Косы были у девок, горбуши называлися. 4. Амортизационные отчисления надобно производить ежемесячно. 5. Столярку нужно хранить в специально подготовленном помещении. 6. После долгих дебатов на совещании достигли консенсуса. 7. Сколь это ни странно, у нас нет контактов с этим институтом. 8. Мозговали долго и, наконец, нашли решение. 9. Следует приложить все усилия для устранения негативных последствий этого явления. 10. Срок выполнения заказа может быть пролонгирован.
42
43
Отметьте случаи неправильного употребления фразеологизмов. Устраните ошибки 1. Кадровый вопрос должен быть поставлен во главу развития предприятия. 2. Умение смотреть прямо в глаза фактов с опытом, с уверенностью в своих силах. 3. Хорошо, когда на их пути постигает удача. 4. Каждый элемент несёт определённую функцию. 5. Нельзя всех мерить под одну гребёнку. 6. Каждый нарушитель должен твердо усвоить, что ему не сойдет даже малейшее отступление от устава. 7. Книга оказала большую пользу студентам. 8. Лица, не выполняющие решений производственных совещаний, нередко выводятся на чистую воду и подвержены резкой критике в газете. 9. Приехавшим корреспондентам пришлось восстанавливать событие с третьих рук. 10. Он полслова на лету схватывает.
44
Выпишите сочетания, которые являются устойчивыми Поставить на ноги, белая бумага, из рук вон, светлая голова, золотые серьги, золотые руки, железная дорога, железная рука, повестка дня, встреча без галстуков, держать в курсе, втирать очки, лесной орех, прямой угол, командировочное удостоверение, локомотивное депо.
45
Сопоставьте свободные и устойчивые словосочетания, определите разницу в значениях 1. Первое время после перенесенной болезни девочка не могла ходить, и приходилось носить её на руках. — Певец пользовался огромным успехом, публика носила его на руках. 2. От большого физического напряжения у спортсмена заболела правая рука.- Руководитель лаборатории предложил провести эксперимент своему сотруднику, который был его правой рукой в научных делах. 3. Неожиданно начался отлив, и корабль сел на мель.- Непредвиденных расходов оказалось так много, что я чуть не сел на мель.
46
Замените выделенные слова фразеологизмами в соответствии со смыслом 1. Чтобы стать настоящим учителем, нужно действительно любить школу, быть преданным ей безгранично. 2. Без Художественного театра Чехов не создал бы «Вишневого сада» — своего последнего значительного произведения. З. Не пойму, почему я не ответил на этот вопрос, ведь я же знал его очень хорошо. 4. С мальчиком надо поговорить серьезно, в последнее время он совсем никого не слушается. 5. Они сразу же понравились друг другу. 6. Это совершенно одинаковые люди, они очень похожи друг друга. 7. Способный ученик решил задачу моментально.
47
Назовите первоначальные фразеологизмы, по аналогии с которыми даны заголовки газетных статей 1. Валюта строить и жить помогает. 2. Велика Россия, а жить негде. 3. В Минфин со своим уставом. 4. О бедном солдате замолвите слово. 5. Смело, товарищи, в лапу. 6. Большому рублю большое плавание.
48
Выделите речевые штампы и клише 1. Этот праздник оставил неизгладимый след в душах людей. 2. Обмен опытом полезем при работе с наставниками. 3. В праздники телезрители у голубого экрана. 4. Город на Неве отметил своё 300-летие. 5. За выдающиеся заслуги в медицине в День Медика люди в белых халатах чествовать своих героев. 6. Япония — страна восходящего солнца. 7. Квартальный отчёт составляется работниками бухгалтерии. 8. Старые методы руководства неэффективны. 9. Открытие нашло горячий отклик в сердцах горожан. 10. Передовые технологии способствуют повышению эффективности труда.
49
Назовите речевые клише, выражающие: — приветствие (утром, днём, вечером); -прощание; -извинение; -поздравление; -благодарность.
50
Литература
![]()
1. Лектории выполняют большую роль. 2. Неожиданно для
всех наступила война. 3. Благоприятно сказался для промышленников Указ
императора Павла 1. 4. Как опыт западных стран, так и отечественная практика
богаты фактами разорения и краха не только мелких предприятий, но и крупных
заводов. 5. Есть возможность тяжелых осложнений. 6. Многочисленные стихийные
базары значительно обезобразили город.
7. Всё это несет определённую функцию.
![]()
Светило науки — 2 ответа — 0 раз оказано помощи
2.Неожидано для всех началась война. 3.Благополучно сказался для промышленников Указ императора Павла I. 5. Есть возможность осложнений.
Здравствуйте, есть вот такое задание:
Написать функцию, принимающую список целых чисел и указатель на функцию типа int (int), и заменяющую каждый элемент списка на результат применения к нему функции-параметра.
Я попытался написать эту функцию, вот как выглядит мой код:
#include <iostream>
#include <ctype.h>
#include "fixedstack.h"
using namespace std;
template<typename int>
void function3(int [], int, int(*)(int));
int foo(int);
int main()
int size = 0;
int number = 0;
int i = 0;
int* array = NULL;
cout << "Enter amount of numbers: ";
cin >> size;
array = new int[size];
for (int i = 0; i < size; i++)
{
cin >> number;
array[i] = number;
}
function3(array, size, foo);
return 0;
}
template<typename int>
void function3(int array[], int size, int(*func)())
{
for (int i = 0; i < size; i++)
{
array[i] = foo(array[i]);
}
cout << "nResult:" << endl;
for (int i = 0; i < size; i++)
{
cout << array[i] << " ";
}
cout << endl;
}
int foo(int number)
{
return number * 10;
}В результате VS выдает такие ошибки:
Ошибка C2672 «function3»: не найдена соответствующая перегруженная функция
Ошибка C2783 void function3(int [],int,int (__cdecl *)(int)): не удается составить аргумент шаблон для «__formal»
Ошибка (активно) E0304 отсутствуют экземпляры перегруженная функция «function3», соответствующие списку аргументов
Ошибки в коде — это несоответствия правилам и синтаксису языка HTML, использование некорректных или недопустимых тегов, атрибутов или значений. Ошибки приводят к неправильному отображению элементов, снижению производительности и доступности сайта.
Что нужно, чтобы писать код правильно и не допускать ошибок? Знать самые распространённые ошибки и не совершать их.
Вложенный тег закрывается позже родительского
<section>
<p>Пример текста на сайте.</section>
</p>
В этом примере элемент <p> закрывается после <section>, хотя является вложенным. Это может привести к проблемам в отображении элементов. Такая ошибка повторяется из-за невнимательности и некорректной структуры HTML-документа. Если вы будете следить за вложенностью, то не ошибётесь, где должен закрываться вложенный тег, а где — его родитель.
Правильный способ вложения этих элементов:
<section>
<p>Пример текста на сайте.</p>
</section>
Пример корректного написания кода, где видна вложенность и шансов совершить ошибку меньше:
<ul class="user-menu">
<li>
<a href="#">Закладки</a>
</li>
<li>
<a href="#">Корзина</a>
</li>
<li>
<a href="#">Оформить заказ</a>
</li>
</ul>
Нет закрывающего тега
<section class="advantages">
<h2>Что выделяет нас среди конкурентов?</h2>
<ul class="advantages-list">
<li>Используем только природные материалы</li>
<li>Ежедневные отчёты о ходе работ</li>
<li>Сами соберём мебель для вас</li>
<li>Бесплатное гарантийное обслуживание в течение 10 лет</li>
</section>
В примере у списка отсутствует закрывающий тег — </ul>. В этом случае список и все его элементы отразятся некорректно. Будьте внимательны, такие мелкие ошибки могут принести много неприятностей.
Правильный вариант:
<section class="advantages">
<h2>Что выделяет нас среди конкурентов?</h2>
<ul class="advantages-list">
<li>Используем только природные материалы</li>
<li>Ежедневные отчёты о ходе работ</li>
<li>Сами соберём мебель для вас</li>
<li>Бесплатное гарантийное обслуживание в течение 10 лет</li>
</ul>
</section>
Повторяются идентификаторы
<form action="https://echo.htmlacademy.ru" method="post">
<table>
<tr>
<td>
<label for="login-field">Ваш логин</label>
</td>
<td>
<input type="text" id="login-field" name="login">
</td>
</tr>
...
<form action="https://echo.htmlacademy.ru" method="post">
<table>
<tr>
<td>
<label for="login-field">Ваш пароль</label>
</td>
<td>
<input type="text" id="login-field" name="password">
</td>
</tr>
Тег id — это идентификатор, который связывает определённое поле ввода input с текстом подписи. В каждой форме должен быть свой уникальный id, чтобы формой можно было пользоваться и отправлять данные на сервер.
У пароля из примера выше должен быть свой уникальный id:
<form action="https://echo.htmlacademy.ru" method="post">
<table>
<tr>
<td>
<label for="password-field">Ваш пароль</label>
</td>
<td>
<input type="text" id="password-field" name="password">
</td>
</tr>
Неправильное использование семантических тегов
<section class="products">
<h2>Курс для фронтендеров</h2>
…
<div>Купить курс</div>
</section>
Здесь <div> ошибочно используется вместо кнопки <button>.
Тег <div> — это универсальный контейнер без собственного значения. Он используется, когда нужно разметить некрупный элемент вёрстки или отдельный фрагмент с текстом. Его использование не создаст кнопку, которая может открыть другую страницу или форму для записи.
Кнопка <button> отвечает за выполнение определённой функции: добавить в корзину, купить, отправить, проголосовать и другие.
<section class="products">
<h2>Курс для фронтендеров</h2>
…
<button class="button">
Купить курс
</button>
</section>
👉🏼 Правило для определения <div>:
Если перед вами раздел, которому сложно найти определение, получается что-то наподобие «новости и фотогалерея» или «правая колонка» — можно разметить как <div>.
Семантические теги <header>, <main>, <footer> предназначены для выделения основных структурных блоков на странице сайта, а теги <nav>, <section>, <article>, <aside> — для разметки крупных смысловых разделов. Все теги должны быть использованы в соответствии со своим назначением.
- Что такое семантическая вёрстка и зачем она нужна
- Как сделать кнопку в HTML
Отсутствие атрибута alt для изображений img
<img src="image/logo.png" width="200" height="100">
Атрибут alt задаёт альтернативный текст, описывающий картинку для пользователей, у которых изображение очень долго загружается или вообще недоступно. Также alt помогает сайтам оставаться доступными, например, для категории пользователей, которая не имеет возможности видеть картинки.
<img src="image/logo.png" alt="Логотип" width="200" height="100">
6 простых правил хорошего alt-текста
Определение уровня заголовка по размеру текста на макете
<main>
<h1>Мы — молодая креативная компания</h1>
<section class="products">
<h2>Обувь и аксессуары</h2>
…
</section>
<section class="about">
<h2>Мы надёжные партнёры и поставщики</h2>
…
</section>
<section class="companies">
<h2>Уже много лет мы сотрудничаем с самыми крупными производителями</h2>
…
</section>
</main>
Не весь крупный текст — заголовки. Основная роль заголовка — резюмирующая, он сжато передаёт содержание последующего текста. Прочитав заголовок, пользователь должен легко понять, чему посвящён раздел. Также не все заголовки видимые на странице сайта, они могут быть прописаны в разметке и скрыты, так как их задача — помогать структурировать страницу.
<main>
<h1>Интернет магазин «Фактура»</h1>
<section class="products">
<h2>Товары</h2>
…
</section>
<section class="about">
<h2>О нас</h2>
…
</section>
<section class="companies">
<h2>Производители</h2>
…
</section>
</main>
Также неверно обозначать заголовок не специальными тегами h1-h6, а использовать выделение текста тегами <b> или <strong>.
Включать в main то, что повторяется на других страницах
Это может быть навигация, копирайты и так далее.
<body>
<h1>Интернет магазин «Фактура»</h1>
<main>
<nav class="user-nav">
<ul class="user-menu">
<li>
<a href="https://htmlacademy.ru/blog">Меню</a>
</li>
<li>
<a href="https://htmlacademy.ru/blog">Корзина</a>
</li>
<li>
<a href="https://htmlacademy.ru/blog">Оформить заказ</a>
</li>
</ul>
</nav>
<section class="about">
<h2>О нас</h2>
…
</section>
</main>
<footer class="main-footer">
<!-- Подвал сайта -->
</footer>
</body>
Тег <main> выделяет основное содержание страницы, которое не повторяется на других страницах. И на странице используется один тег <main>. Если навигация одинаковая на всех страницах сайта, то лучше размещать её в <header>.
Неверное обозначение комментариев
Если комментарий неправильно разметить, то он будет виден на странице.
<-- Это комментарий -->
Комментарии начинаются последовательностью <!--, например:
<!-- Это комментарий -->
Не использовать <li> для элементов списка
<ul class="user-menu">
<div>
<a href="https://htmlacademy.ru">Закладки</a>
</div>
<div>
<a href="https://htmlacademy.ru">Корзина</a>
</div>
<div>
<a href="https://htmlacademy.ru">Оформить заказ</a>
</div>
</ul>
Непосредственно в теге <ul> могут находиться только теги <li>, которые обозначают элементы или пункты списка. Пунктов может быть неограниченное количество, но не менее одного.
<ul class="user-menu">
<li>
<a href="https://htmlacademy.ru">Закладки</a>
</li>
<li>
<a href="https://htmlacademy.ru">Корзина</a>
</li>
<li>
<a href="https://htmlacademy.ru">Оформить заказ</a>
</li>
</ul>
Материалы по теме
- Как проверить валидность HTML-разметки
- Как сделать картинку ссылкой
- Флексы для начинающих
- Шаблон HTML-формы
«Доктайп» — журнал о фронтенде. Читайте, слушайте и учитесь с нами.
ТелеграмПодкастБесплатные учебники