
В машинном обучении различают оценки качества для задачи классификации и регрессии. Причем оценка задачи классификации часто значительно сложнее, чем оценка регрессии.
Матрица ошибок (англ. Сonfusion matrix)
Перед переходом к самим метрикам необходимо ввести важную концепцию для описания этих метрик в терминах ошибок классификации — confusion matrix (матрица ошибок).
Допустим, что у нас есть два класса и алгоритм, предсказывающий принадлежность каждого объекта одному из классов.
Рассмотрим пример. Пусть банк использует систему классификации заёмщиков на кредитоспособных и некредитоспособных. При этом первым кредит выдаётся, а вторые получат отказ. Таким образом, обнаружение некредитоспособного заёмщика () можно рассматривать как «сигнал тревоги», сообщающий о возможных рисках.
Любой реальный классификатор совершает ошибки. В нашем случае таких ошибок может быть две:
- Кредитоспособный заёмщик распознается моделью как некредитоспособный и ему отказывается в кредите. Данный случай можно трактовать как «ложную тревогу».
- Некредитоспособный заёмщик распознаётся как кредитоспособный и ему ошибочно выдаётся кредит. Данный случай можно рассматривать как «пропуск цели».
Несложно увидеть, что эти ошибки неравноценны по связанным с ними проблемам. В случае «ложной тревоги» потери банка составят только проценты по невыданному кредиту (только упущенная выгода). В случае «пропуска цели» можно потерять всю сумму выданного кредита. Поэтому системе важнее не допустить «пропуск цели», чем «ложную тревогу».
Поскольку с точки зрения логики задачи нам важнее правильно распознать некредитоспособного заёмщика с меткой , чем ошибиться в распознавании кредитоспособного, будем называть соответствующий исход классификации положительным (заёмщик некредитоспособен), а противоположный — отрицательным (заемщик кредитоспособен ). Тогда возможны следующие исходы классификации:
- Некредитоспособный заёмщик классифицирован как некредитоспособный, т.е. положительный класс распознан как положительный. Наблюдения, для которых это имеет место называются истинно-положительными (True Positive — TP).
- Кредитоспособный заёмщик классифицирован как кредитоспособный, т.е. отрицательный класс распознан как отрицательный. Наблюдения, которых это имеет место, называются истинно отрицательными (True Negative — TN).
- Кредитоспособный заёмщик классифицирован как некредитоспособный, т.е. имела место ошибка, в результате которой отрицательный класс был распознан как положительный. Наблюдения, для которых был получен такой исход классификации, называются ложно-положительными (False Positive — FP), а ошибка классификации называется ошибкой I рода.
- Некредитоспособный заёмщик распознан как кредитоспособный, т.е. имела место ошибка, в результате которой положительный класс был распознан как отрицательный. Наблюдения, для которых был получен такой исход классификации, называются ложно-отрицательными (False Negative — FN), а ошибка классификации называется ошибкой II рода.
Таким образом, ошибка I рода, или ложно-положительный исход классификации, имеет место, когда отрицательное наблюдение распознано моделью как положительное. Ошибкой II рода, или ложно-отрицательным исходом классификации, называют случай, когда положительное наблюдение распознано как отрицательное. Поясним это с помощью матрицы ошибок классификации:
-
Истинно-положительный (True Positive — TP) Ложно-положительный (False Positive — FP) Ложно-отрицательный (False Negative — FN) Истинно-отрицательный (True Negative — TN)
Здесь — это ответ алгоритма на объекте, а — истинная метка класса на этом объекте.
Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP).
P означает что классификатор определяет класс объекта как положительный (N — отрицательный). T значит что класс предсказан правильно (соответственно F — неправильно). Каждая строка в матрице ошибок представляет спрогнозированный класс, а каждый столбец — фактический класс.
# код для матрицы ошибок # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import confusion_matrix from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (англ. Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе # Для расчета матрицы ошибок сначала понадобится иметь набор прогнозов, чтобы их можно было сравнивать с фактическими целями y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687], # [ 1891, 3530]])
Безупречный классификатор имел бы только истинно-положительные и истинно отрицательные классификации, так что его матрица ошибок содержала бы ненулевые значения только на своей главной диагонали (от левого верхнего до правого нижнего угла):
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.metrics import confusion_matrix
mnist = fetch_openml('mnist_784', version=1)
X, y = mnist["data"], mnist["target"]
y = y.astype(np.uint8)
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки
y_test_5 = (y_test == 5)
y_train_perfect_predictions = y_train_5 # притворись, что мы достигли совершенства
print(confusion_matrix(y_train_5, y_train_perfect_predictions))
# array([[54579, 0],
# [ 0, 5421]])
Аккуратность (англ. Accuracy)
Интуитивно понятной, очевидной и почти неиспользуемой метрикой является accuracy — доля правильных ответов алгоритма:
Эта метрика бесполезна в задачах с неравными классами, что как вариант можно исправить с помощью алгоритмов сэмплирования и это легко показать на примере.
Допустим, мы хотим оценить работу спам-фильтра почты. У нас есть 100 не-спам писем, 90 из которых наш классификатор определил верно (True Negative = 90, False Positive = 10), и 10 спам-писем, 5 из которых классификатор также определил верно (True Positive = 5, False Negative = 5).
Тогда accuracy:
Однако если мы просто будем предсказывать все письма как не-спам, то получим более высокую аккуратность:
При этом, наша модель совершенно не обладает никакой предсказательной силой, так как изначально мы хотели определять письма со спамом. Преодолеть это нам поможет переход с общей для всех классов метрики к отдельным показателям качества классов.
# код для для подсчета аккуратности: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import accuracy_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(accuracy_score(y_train_5, y_train_pred)) # == (53892 + 3530) / (53892 + 3530 + 1891 +687) # 0.9570333333333333
Точность (англ. Precision)
Точностью (precision) называется доля правильных ответов модели в пределах класса — это доля объектов действительно принадлежащих данному классу относительно всех объектов которые система отнесла к этому классу.
Именно введение precision не позволяет нам записывать все объекты в один класс, так как в этом случае мы получаем рост уровня False Positive.
Полнота (англ. Recall)
Полнота — это доля истинно положительных классификаций. Полнота показывает, какую долю объектов, реально относящихся к положительному классу, мы предсказали верно.
Полнота (recall) демонстрирует способность алгоритма обнаруживать данный класс вообще.
Имея матрицу ошибок, очень просто можно вычислить точность и полноту для каждого класса. Точность (precision) равняется отношению соответствующего диагонального элемента матрицы и суммы всей строки класса. Полнота (recall) — отношению диагонального элемента матрицы и суммы всего столбца класса. Формально:
Результирующая точность классификатора рассчитывается как арифметическое среднее его точности по всем классам. То же самое с полнотой. Технически этот подход называется macro-averaging.
# код для для подсчета точности и полноты: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.metrics import precision_score, recall_score from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) # print(confusion_matrix(y_train_5, y_train_pred)) # array([[53892, 687] # [ 1891, 3530]]) print(precision_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 687) print(recall_score(y_train_5, y_train_pred)) # == 3530 / (3530 + 1891) # 0.8370879772350012 # 0.6511713705958311
F-мера (англ. F-score)
Precision и recall не зависят, в отличие от accuracy, от соотношения классов и потому применимы в условиях несбалансированных выборок.
Часто в реальной практике стоит задача найти оптимальный (для заказчика) баланс между этими двумя метриками. Понятно что чем выше точность и полнота, тем лучше. Но в реальной жизни максимальная точность и полнота не достижимы одновременно и приходится искать некий баланс. Поэтому, хотелось бы иметь некую метрику которая объединяла бы в себе информацию о точности и полноте нашего алгоритма. В этом случае нам будет проще принимать решение о том какую реализацию запускать в производство (у кого больше тот и круче). Именно такой метрикой является F-мера.
F-мера представляет собой гармоническое среднее между точностью и полнотой. Она стремится к нулю, если точность или полнота стремится к нулю.
Данная формула придает одинаковый вес точности и полноте, поэтому F-мера будет падать одинаково при уменьшении и точности и полноты. Возможно рассчитать F-меру придав различный вес точности и полноте, если вы осознанно отдаете приоритет одной из этих метрик при разработке алгоритма:
где принимает значения в диапазоне если вы хотите отдать приоритет точности, а при приоритет отдается полноте. При формула сводится к предыдущей и вы получаете сбалансированную F-меру (также ее называют ).
-

Рис.1 Сбалансированная F-мера,
-

Рис.2 F-мера c приоритетом точности,
-

Рис.3 F-мера c приоритетом полноты,
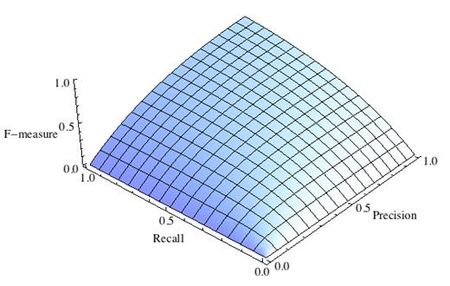
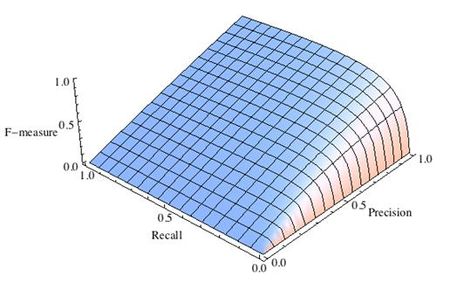
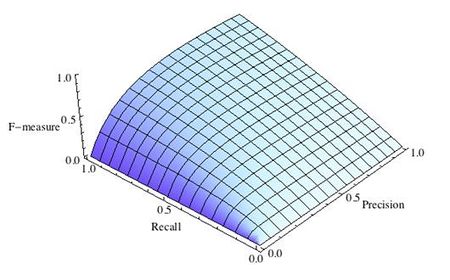
F-мера достигает максимума при максимальной полноте и точности, и близка к нулю, если один из аргументов близок к нулю.
F-мера является хорошим кандидатом на формальную метрику оценки качества классификатора. Она сводит к одному числу две других основополагающих метрики: точность и полноту. Имея «F-меру» гораздо проще ответить на вопрос: «поменялся алгоритм в лучшую сторону или нет?»
# код для подсчета метрики F-mera: # Пример классификатора, способного проводить различие между всего лишь двумя # классами, "пятерка" и "не пятерка" из набора рукописных цифр MNIST import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier from sklearn.metrics import f1_score mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распознавать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) print(f1_score(y_train_5, y_train_pred)) # 0.7325171197343846
ROC-кривая
Кривая рабочих характеристик (англ. Receiver Operating Characteristics curve).
Используется для анализа поведения классификаторов при различных пороговых значениях.
Позволяет рассмотреть все пороговые значения для данного классификатора.
Показывает долю ложно положительных примеров (англ. false positive rate, FPR) в сравнении с долей истинно положительных примеров (англ. true positive rate, TPR).
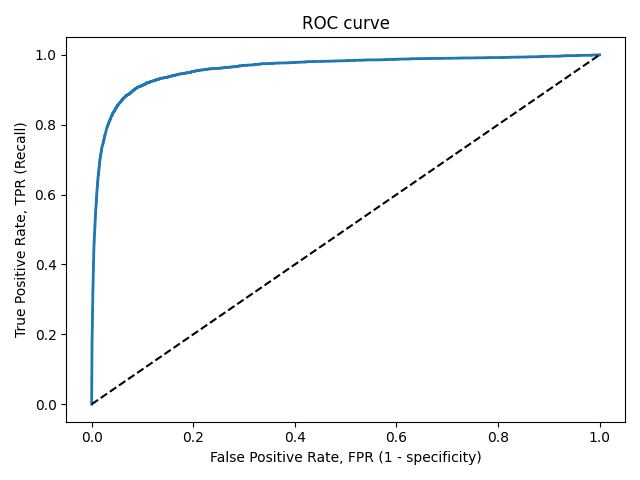
Доля FPR — это пропорция отрицательных образцов, которые были некорректно классифицированы как положительные.
- ,
где TNR — доля истинно отрицательных классификаций (англ. Тrие Negative Rate), представляющая собой пропорцию отрицательных образцов, которые были корректно классифицированы как отрицательные.
Доля TNR также называется специфичностью (англ. specificity). Следовательно, ROC-кривая изображает чувствительность (англ. seпsitivity), т.е. полноту, в сравнении с разностью 1 — specificity.
Прямая линия по диагонали представляет ROC-кривую чисто случайного классификатора. Хороший классификатор держится от указанной линии настолько далеко, насколько это
возможно (стремясь к левому верхнему углу).
Один из способов сравнения классификаторов предусматривает измерение площади под кривой (англ. Area Under the Curve — AUC). Безупречный классификатор будет иметь площадь под ROC-кривой (ROC-AUC), равную 1, тогда как чисто случайный классификатор — площадь 0.5.
# Код отрисовки ROC-кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import roc_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") fpr, tpr, thresholds = roc_curve(y_train_5, y_scores) def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0, 1], [0, 1], 'k--') # dashed diagonal plt.xlabel('False Positive Rate, FPR (1 - specificity)') plt.ylabel('True Positive Rate, TPR (Recall)') plt.title('ROC curve') plt.savefig("ROC.png") plot_roc_curve(fpr, tpr) plt.show()
Precison-recall кривая
Чувствительность к соотношению классов.
Рассмотрим задачу выделения математических статей из множества научных статей. Допустим, что всего имеется 1.000.100 статей, из которых лишь 100 относятся к математике. Если нам удастся построить алгоритм , идеально решающий задачу, то его TPR будет равен единице, а FPR — нулю. Рассмотрим теперь плохой алгоритм, дающий положительный ответ на 95 математических и 50.000 нематематических статьях. Такой алгоритм совершенно бесполезен, но при этом имеет TPR = 0.95 и FPR = 0.05, что крайне близко к показателям идеального алгоритма.
Таким образом, если положительный класс существенно меньше по размеру, то AUC-ROC может давать неадекватную оценку качества работы алгоритма, поскольку измеряет долю неверно принятых объектов относительно общего числа отрицательных. Так, алгоритм , помещающий 100 релевантных документов на позиции с 50.001-й по 50.101-ю, будет иметь AUC-ROC 0.95.
Precison-recall (PR) кривая. Избавиться от указанной проблемы с несбалансированными классами можно, перейдя от ROC-кривой к PR-кривой. Она определяется аналогично ROC-кривой, только по осям откладываются не FPR и TPR, а полнота (по оси абсцисс) и точность (по оси ординат). Критерием качества семейства алгоритмов выступает площадь под PR-кривой (англ. Area Under the Curve — AUC-PR)
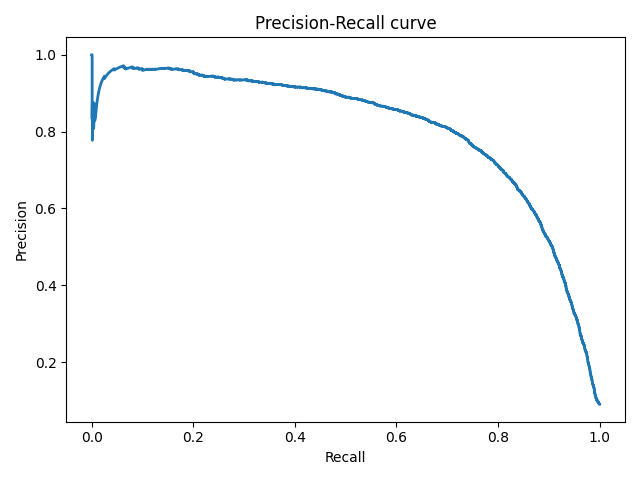
# Код отрисовки Precison-recall кривой # На примере классификатора, способного проводить различие между всего лишь двумя классами # "пятерка" и "не пятерка" из набора рукописных цифр MNIST from sklearn.metrics import precision_recall_curve import matplotlib.pyplot as plt import numpy as np from sklearn.datasets import fetch_openml from sklearn.model_selection import cross_val_predict from sklearn.linear_model import SGDClassifier mnist = fetch_openml('mnist_784', version=1) X, y = mnist["data"], mnist["target"] y = y.astype(np.uint8) X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:] y_train_5 = (y_train == 5) # True для всех пятерок, False для в сех остальных цифр. Задача опознать пятерки y_test_5 = (y_test == 5) sgd_clf = SGDClassifier(random_state=42) # классификатор на основе метода стохастического градиентного спуска (Stochastic Gradient Descent SGD) sgd_clf.fit(X_train, y_train_5) # обучаем классификатор распозновать пятерки на целом обучающем наборе y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function") precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores) def plot_precision_recall_vs_threshold(precisions, recalls, thresholds): plt.plot(recalls, precisions, linewidth=2) plt.xlabel('Recall') plt.ylabel('Precision') plt.title('Precision-Recall curve') plt.savefig("Precision_Recall_curve.png") plot_precision_recall_vs_threshold(precisions, recalls, thresholds) plt.show()
Наиболее типичными мерами качества в задачах регрессии являются
Средняя квадратичная ошибка (англ. Mean Squared Error, MSE)
MSE применяется в ситуациях, когда нам надо подчеркнуть большие ошибки и выбрать модель, которая дает меньше больших ошибок прогноза. Грубые ошибки становятся заметнее за счет того, что ошибку прогноза мы возводим в квадрат. И модель, которая дает нам меньшее значение среднеквадратической ошибки, можно сказать, что что у этой модели меньше грубых ошибок.
- и
Cредняя абсолютная ошибка (англ. Mean Absolute Error, MAE)
Среднеквадратичный функционал сильнее штрафует за большие отклонения по сравнению со среднеабсолютным, и поэтому более чувствителен к выбросам. При использовании любого из этих двух функционалов может быть полезно проанализировать, какие объекты вносят наибольший вклад в общую ошибку — не исключено, что на этих объектах была допущена ошибка при вычислении признаков или целевой величины.
Среднеквадратичная ошибка подходит для сравнения двух моделей или для контроля качества во время обучения, но не позволяет сделать выводов о том, на сколько хорошо данная модель решает задачу. Например, MSE = 10 является очень плохим показателем, если целевая переменная принимает значения от 0 до 1, и очень хорошим, если целевая переменная лежит в интервале (10000, 100000). В таких ситуациях вместо среднеквадратичной ошибки полезно использовать коэффициент детерминации —
Коэффициент детерминации
Коэффициент детерминации измеряет долю дисперсии, объясненную моделью, в общей дисперсии целевой переменной. Фактически, данная мера качества — это нормированная среднеквадратичная ошибка. Если она близка к единице, то модель хорошо объясняет данные, если же она близка к нулю, то прогнозы сопоставимы по качеству с константным предсказанием.
Средняя абсолютная процентная ошибка (англ. Mean Absolute Percentage Error, MAPE)
Это коэффициент, не имеющий размерности, с очень простой интерпретацией. Его можно измерять в долях или процентах. Если у вас получилось, например, что MAPE=11.4%, то это говорит о том, что ошибка составила 11,4% от фактических значений.
Основная проблема данной ошибки — нестабильность.
Корень из средней квадратичной ошибки (англ. Root Mean Squared Error, RMSE)
Примерно такая же проблема, как и в MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня.
Cимметричная MAPE (англ. Symmetric MAPE, SMAPE)
Средняя абсолютная масштабированная ошибка (англ. Mean absolute scaled error, MASE)
MASE является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Обратите внимание, что в MASE мы имеем дело с двумя суммами: та, что в числителе, соответствует тестовой выборке, та, что в знаменателе — обучающей. Вторая фактически представляет собой среднюю абсолютную ошибку прогноза. Она же соответствует среднему абсолютному отклонению ряда в первых разностях. Эта величина, по сути, показывает, насколько обучающая выборка предсказуема. Она может быть равна нулю только в том случае, когда все значения в обучающей выборке равны друг другу, что соответствует отсутствию каких-либо изменений в ряде данных, ситуации на практике почти невозможной. Кроме того, если ряд имеет тенденцию к росту либо снижению, его первые разности будут колебаться около некоторого фиксированного уровня. В результате этого по разным рядам с разной структурой, знаменатели будут более-менее сопоставимыми. Всё это, конечно же, является очевидными плюсами MASE, так как позволяет складывать разные значения по разным рядам и получать несмещённые оценки.
Недостаток MASE в том, что её тяжело интерпретировать. Например, MASE=1.21 ни о чём, по сути, не говорит. Это просто означает, что ошибка прогноза оказалась в 1.21 раза выше среднего абсолютного отклонения ряда в первых разностях, и ничего более.
Время на прочтение
11 мин
Количество просмотров 11K
предыдущие главы
15. Одновременная оценка нескольких идей во время анализа ошибок
У вашей команды есть несколько идей, как улучшить определитель кошек в вашем приложении:
- Решить проблему с тем, что ваш алгоритм относит собак к кошкам
- Решить проблему с тем, что ваш алгоритм распознает больших диких кошек (львов, пантер, т. п.) как домашних
- Улучшить работу системы на нечетких изображениях
- …
Можно оценить все эти идеи одновременно. Обычно я создаю специальную таблицу и заполняю ее для примерно 100 случаев ошибочной классификации валидационной (dev) выборки. Так же я делаю краткие комментарии, которые могут помочь мне вспомнить конкретные примеры в последствие. Для иллюстрации этого процесса, давайте рассмотрим сводную таблицу, которую вы могли бы создать из небольшого набора примеров вашей валидационной (dev) выборки
| Изображение | Собаки | Большие кошки | Нечеткие | Комментарии |
|---|---|---|---|---|
| 1 | х | Питбуль необычного цвета | ||
| 2 | ||||
| 3 | х | х | Лев; фотография сделана в зоопарке в дождливый день | |
| 4 | х | Пантера за деревом | ||
| Доля (%) | 25% | 50% | 50% |
Изображение 3 в приведенной таблице относится и к большим кошкам и к нечетким. Таким образом, из-за того, что мы можем отнести одно изображение к нескольким категориям ошибок, суммарные проценты в нижней строчке не ограничиваются 100%.
Несмотря на то, что в начале работы вы можете сформировать определенный набор категорий для ошибок (Собаки, Большие кошки, Нечеткие изображения) в процессе ручного отнесения ошибок классификации к этим категориям, возможно вы решите добавить новые типы ошибок. Например, предположим, вы рассмотрели дюжину изображений и решили, что много ошибок сделаны классификатором на изображениях из Инстаграмма, на которые наложены цветовые фильтры. Вы можете переделать таблицу, добавить в нее столбец «Инстаграмм» и заново классифицировать ошибки с учетом этой категории. Рассматривая вручную примеры, на которых ошибается алгоритм и задавая себе вопрос как вы, как человек, смогли правильно разметить изображение, вы сможете увидеть новые категории ошибок и, возможно, вдохновиться на поиск новых решений.
Наиболее полезными категориями ошибок будут те, по которым у вас есть идея для улучшения системы. Например, добавление категории «Инстаграмм» будет наиболее полезным, если у вас есть идея, как убрать фильтры и восстановить изначальное изображение. Но вы не должны ограничивать себя только теми категориями ошибок, для которых у вас есть рецепт их устранения; целью процесса анализа ошибок является развитие вашей интуиции при выборе наиболее перспективных направлений сосредоточения усилий.
Анализ ошибок это итеративный процесс. Не переживайте, если вы его начнете, не придумав ни одной категории. После просмотра пары изображений, у вас появятся несколько идей для категоризации ошибок. После ручной категоризации нескольких изображений, возможно, вам захочется добавить новые категории и пересмотреть ошибки классификации в свете вновь добавленных категорий и так далее.
Предположим, что вы закончили анализ ошибок из 100 ошибочно классифицированных примеров валидационной выборки и получили следующее:
| Изображение | Собаки | Большие кошки | Нечеткие | Комментарии |
|---|---|---|---|---|
| 1 | Х | Питбуль необычного цвета | ||
| 2 | Х | |||
| 3 | Х | Х | Лев; фотография сделана в зоопарке в дождливый день | |
| 4 | Х | Пантера за деревом | ||
| … | … | … | … | … |
| Доля (%) | 8% | 43% | 61% |
Теперь вы знаете, что работа над проектом по устранению ошибочной классификации собак, как кошек, в лучшем случае устранит 8% ошибок. Работа над Большими кошками или над Нечеткими изображениями поможет избавиться от существенно большего количества ошибок. Поэтому вы можете выбрать одну из этих двух категорий и сфокусироваться на них. Если в вашей команде достаточно людей для одновременной работы по нескольким направлениям, вы можете попросить нескольких инженеров заняться большими кошками, сконцентрировав усилия остальных на нечетких изображениях.
Анализ ошибок не дает жесткой математической формулы, указывающей вам какой задаче необходимо назначить самый высокий приоритет. Вы также должны соотносить прогресс, получаемый в результате работы над различными категориями ошибок и усилия, которые необходимо затратить на эту работу.
16. Очистка валидационной и тестовой выборок от неправильно маркированных примеров
Производя анализа ошибок, вы можете заметить, что некоторые примеры в вашей валидационной выборке неправильно маркированы (отнесены не к тому классу). Когда я говорю «ошибочно маркированные», я имею ввиду, что изображения уже были неправильно классифицированы при их разметке человеком, прежде чем алгоритм это обнаружил. То есть при разметке примера (х, у) для у было указано неправильное значение. Например, предположим некоторые изображения, на которых нет кошек ошибочно размечены, как содержащие кошек и наоборот. Если вы подозреваете, что доля ошибочно размеченных примеров значительная, добавьте соответствующую категорию для отслеживания неверно размеченных примеров:
| Изображение | Собаки | Большие кошки | Нечеткие | Ошибка в разметке | Комментарии |
|---|---|---|---|---|---|
| … | … | … | … | … | … |
| 98 | Х | Ошибочно размечена, как имеющая кошку на заднем плане | |||
| 99 | Х | ||||
| 100 | Х | Нарисованная кошка (не настоящая) | |||
| Доля (%) | 8% | 43% | 61% | 6% |
Нужно ли исправлять неверную размеченные данные в вашей валидационной выборке? Напомню, что задачей использования валидационной выборки является помощь вам в быстрой оценке алгоритмов, чтобы вы могли решить, является ли алгоритм А лучше, чем В. Если доля валидационной выборки, которая размечена неправильно, мешает вам сделать такое суждение, тогда имеет смысл потратить время для исправления ошибок в разметке валидационной выборке.
Например, представьте, что точность, которую показывает ваш классификатор следующая:
- Общая точность на валидационной выборке…………..90% (10% общая ошибка)
- Ошибка, связанная с ошибками разметки……………..0.6% (6% от общей ошибки на валидационной выборке)
- Ошибка, связанная с другими причинами…………9.4% (94% от общей ошибки на валидационной выборке)
Здесь, погрешность в 0.6% в следствии неправильной маркировки может быть недостаточно значительной по отношению к 9.4% ошибки, которые вы могли бы улучшить. Ручное исправление ошибок разметки валидационной выборки не будет лишним, но ее исправление не является критически важным так как не принципиально, составляет ли реальная общая ошибка вашей системы 9.4% или 10%
Предположим, вы улучшаете кошачий классификатор и достигли следующих показателей точности:
- Общая точность на валидационной выборке…………..98% (2% общая ошибка)
- Ошибка, связанная с ошибками разметки……………..0.6% (30% от общей ошибки на валидационной выборке)
- Ошибка, связанная с другими причинами…………1.4% (70% от общей ошибки на валидационной выборке)
30% вашей ошибки приходится на неправильную маркировку изображений валидационной выборки, эта доля вносит весомый вклад в общую ошибку при оценке точности вашей системы. В данном случае стоит заняться улучшением разметки валидационной выборки. Устранение неверно размеченных примеров поможет вам выяснить к чему ближе ошибки вашего классификатора к 1.4% или к 2%. Между 1.4 и 2 значительная относительная разница.
Не редко бывает так, что неверно размеченные изображения валидационной или тестовой выборки начинают обращать на себя ваше внимание только после того, как ваша система улучшится настолько, что доля ошибки, связанная с неправильными примерами, вырастит относительно общей ошибки на этих выборках.
Последующая глава объясняет, как вы можете улучшить категории ошибок, таких как Собаки, Большие кошки и Нечеткие в процессе работы над улучшением алгоритмов. В этой главе вы узнали, что вы можете уменьшать ошибку, связанную с категорией «Ошибки в разметке» и повышать качество путем улучшения разметки данных.
Независимо от того, какой подход вы примените для разметки валидационной выборки, не забудьте применить его же к разметке тестовой выборки, таким образом ваша валидационная и тестовая выборки будут иметь одно и тоже распределение. Применяя один и тот же подход к валидационной и тестовой выборкам вы предупредите проблему, которую мы обсуждали в Главе 6, когда ваша команда оптимизирует качество работы алгоритма на валидационной выборке, и позднее понимает, что это качество оценивалось на базе отличающейся от валидационной тестовой выборки.
Если вы решили улучшить качество разметки, рассмотрите возможность двойной проверки. Проверьте как разметку примеров, которые ваши система классифицировала неправильно, так и разметку примеров, которые классифицируются правильно. Возможно, что оба и первоначальная разметка и ваш обучающийся алгоритм ошиблись на одном и том же примере. Если вы исправите только разметку тех примеров, на которых ваша система ошиблась в классификации, вы можете привнести систематическую ошибку в вашу оценку. Если вы возьмете 1000 примеров валидационной выборки, и если ваш классификатор показывает точность 98.0%, проще проверить 20 примеров, которые были классифицированы неправильно, чем 980 правильно классифицированных примеров. Из-за того, что на практике проще проверить только неправильно классифицированные примеры, в некоторых случаях в валидационные выборки может закрасться систематическая ошибка. Такая ошибка допустима, если вы заинтересованы только в разработке приложений, но это будет проблемой, если вы планируете использовать ваш результат в академической исследовательской статье или нуждаетесь в измерениях точности работы алгоритма на тестовой выборке полностью освобожденных от систематической ошибки.
17. Если у вас большая валидационная выборка, разделите ее на две подвыборки, и рассматривайте только одну из них
Предположим у вас большая валидационная выборка, состоящая из 5000 примеров на которых доля ошибок составляет 20%. Таким образом, ваш алгоритм неправильно классифицирует порядка 1000 валидационных изображений. Ручная оценка 1000 изображений потребует долгого времени, поэтому мы можем решить не использовать их всех для целей анализа ошибок.
В этом случае, я бы однозначно разделил валидационную выборку на две подвыборки, за одной из которых вы будете наблюдать, а за другой нет. Вы скорее переобучатись на той части, которую вы будете вручную анализировать. Вы можете использовать ту часть, которую вы не не используете для ручного анализа, для настройки параметров моделей.

Давайте продолжим наш пример, описанный выше, в котором алгоритм неправильно классифицировал 1000 примеров из 5000 составляющих валидационную выборку. Представьте, что вы хотите взять 100 ошибок для анализа (10% от всех ошибок валидационной выборки). Нужно случайным образом выбрать 10% примеров из валидационной выборки и составить из них «Валидационную выборку глазного яблока » ( Eyeball dev set), мы их так назвали для того, чтобы все время помнить, что мы изучаем эти примеры при помощи собственных глаз.
Замечание переводчика: с моей точки зрения определение «выборка глазного яблока» звучит совсем не благозвучно (особенно с точки зрения русского языка). Но при всем уважении к Эндрю (и принимая во внимание, что ничего лучше я не придумал), оставлю это опредление
(Для проекта по распознаванию речи, в котором вы будете прослушивать аудио клипы, возможно вы бы вместо этого названия использовали что-то вроде «валидационная выборка для ушей»). Таким образом Валидационная выборка глазного яблока состоит из 500 примеров, в которых должно быть порядка 100 неправильно классифицированных. Вторая подвыборка валидационной выборки, которую мы назовем Валидационной выборкой черного ящика (Blackbox dev set), будет состоять из 4500 примеров. Вы можете использовать «Подвыборку черного ящика» для автоматической оценки качества работы классификаторов, измеряя по ней их доли ошибок. Вы так же можете использовать эту подвыборку для выбора между алгоритмами или для настройки гиперпараметров. Однако, вы должны избегать рассмотрения примеров этой подвыборки вашими глазами. Мы используем термин «Черный ящик» потому что мы будем использовать подвыборку, его составляющую, как «черный ящик»
прим. переводчика: т. е. Объект структура которого нам не известна
для оценки качества классификаторов.

Зачем мы явно разделяем валидационную выборку на «Подвыборку глазного яблока» и «Подвыборку черного ящика»?
Поскольку с какого-то момента вы будете все лучше чувствовать (понимать) примеры в «Подвыборке глазного яблока», повысится вероятность, что вы переобучитесь на этой подвыборке. Для контроля переобучения будем использовать «Подвыборку черного ящика». Если вы видите, что качество алгоритмов на «Выборке глазного яблока» растет существенно быстрее, чем качество на «Выборке Черного ящика», по-видимому вы переобучились на «Глазном яблоке». В таком случае вам возможно потребуется отбросить имеющуюся подвыборку «Глазного яблока» и создать новую, перенеся больше примеров из «Черного ящика» в «Глазное яблоко» или взяв новую порцию размеченных данных.
Таким образом разбиение валидационной выборки на «Подвыборку глазного яблока» и «Подвыборку черного ящика» позволяет вам увидеть момент, когда процесс ручного анализа ошибок приведет вас к переобучению на подвыборке глазного яблока.
18 Насколько большими должны быть Выборка глазного яблока и Выборка черного ящика?
Ваша выборка глазного яблока должна быть достаточно большой для того, чтобы вы обнаружили основные категории ошибок классификации вашего алгоритма. Если вы работаете над задачей, с которой может справиться человек (такой, как распознавание кошек на изображениях), можно дать следующие достаточно грубые рекомендации:
- Валидационная выборка глазного яблока, которая содержит 10 ошибок вашего классификатора, будет считаться очень маленькой. Имея только 10 ошибок очень тяжело аккуратно оценить влияние различных категорий ошибок на качество классификатора. Но если у вас очень мало данных и нет возможности добавить больше примеров в выборку глазного яблока, это все равно лучше, чем ничего и в любом случае поможет с приоритизацией работы над проектом.
- Если ваш классификатор ошибается порядка 20 раз на выборке глазного яблока, вы сможете сделать грубые прикидки основных источников ошибок.
- С примерно 50 ошибками, вы получите хорошее представление об основных источниках ошибок вашего классификатора.
- Если у вас порядка 100 ошибок, вы получите очень хорошее понимание откуда приходят основные ошибки. Я встречал людей, которые вручную анализировали даже больше ошибок иногда до 500. Почему бы и нет, если вы имеете достаточно данных.
Допустим, доля ошибок вашего классификатора составляет 5%. Для того, чтобы с уверенностью получить порядка 100 неправильно размеченных примеров в выборке глазного яблока, эта выборка должна содержать порядка 2000 примеров (так как 0.05*2000 = 100). Чем меньше доля ошибок вашего классификатора, тем большая необходима выборка глазного яблока, чтобы получить из нее достаточно большую выборку ошибок для анализа.
Если вы работаете над такой задачей, в которой даже людям тяжело правильно классифицировать примеры, то упражнения по проверке валидационной выборки глазного яблока не будут особенно полезными, из-за того, что тяжело понять почему алгоритм не смог корректно классифицировать пример. В этом случае вы можете пропустить настройку Выборки глазного яблока. Мы обсудим рекомендации для таких проектов в следующих главах.
А что можно сказать про «Выборку черного ящика»? Мы уже упоминали, что в общем случае валидационная выборка содержит 1000 — 10000 примеров. Дополним это утверждение, Валидационная выборка черного ящика, состоящая из 1000 — 10000 примеров обычно (часто) дает вам достаточно данных для настройки гиперпараметров и выбора между моделями, но если вы возьмете больше данных для выборки черного ящика, хуже не будет. Выборка черного ящика из 100 примеров конечно маловата, но все еще будет полезной (лучше чем ничего).
Если у вас маленькая валидационная выборка, в ней может не оказаться достаточно данных для ее разделения на выборки глазного яблока и черного ящика, чтобы они обе были достаточно большими и могли служить целям, описанным выше. В этом случае возможно придется использовать всю вашу валидационную выборку в качестве выборки глазного яблока.
Т. е. Вы будете вручную изучать все данные валидационной выборки.
Я считаю, что Выборка глазного яблока важнее, чем Выборка черного ящика (предполагая, что вы работаете над проблемой, в которой люди хорошо справляются с определением классов и ручная проверка примеров поможет вам получать представление о ваших данных). Если у вас в наличие есть только выборка глазного яблока, вы можете работать над анализом ошибок, выбором моделей и настройкой гиперпараметров используя только ее. Недостатком работы только с выборкой глазного яблока является то, что в этом случае возрастает риск переобучения модели на валидационной выборке.
Если в вашем распоряжении обилие данных, то размер выборки глазного яблока будет определяться главным образом тем, сколько времени вы можете посвятить ручному анализу данных. Например я редко встречал кого-то, кто бы вручную анализировал больше, чем 1000 ошибок.
19 Выводы: Базовый анализ ошибок
- Когда вы начинаете новый проект, особенно в области, в которой вы не являетесь экспертом, довольно сложно предположить наиболее эффективное направление приложения усилий
- Поэтому не пытайтесь сразу разработать и построить идеальную систему. Вместо этого постройте и натренируйте простую систему настолько быстро, насколько это возможно — может быть за несколько дней. Затем используйте анализ ошибок, который поможет вам определить наиболее эффективные направления работы и затем итеративно улучшайте ваш алгоритм исходя из этого.
- Проводите анализ ошибок, вручную изучая порядка 100 примеров из валидационной выборки, которые ваш алгоритм неправильно классифицировал и оценивайте, какие категории ошибок вносят основной вклад в общую ошибку классификации. Используйте эту информацию для приоритизации работы над типами ошибок, которые нужно исправить.
- Рассмотрите возможность разделения вашей валидационной выборки на Выборку глазного яблока, которую вы будете исследовать вручную и Выборку черного ящика, которую не будете трогать руками. Если качество работы алгоритма на выборке глазного яблока много лучше, чем качество на выборке черного ящика, у вас произошло переобучение алгоритма на выборке глазного яблока и нужно рассмотреть возможность добавления в нее большего количества данных.
- Валидационная выборка глазного яблока должна быть достаточно большой для того, чтобы количества ошибок вашего алгоритма на ней хватило для ручного анализа. Валидационной выборки черного ящика, состоящей из 1000-10000 примеров обычно хватает для разработки приложений.
- Если ваша валидационная выборка не достаточно большая, для того, чтобы разбить ее на выборку глазного яблока и выборку черного ящика, просто используйте Валидационную выборку глазного яблока для ручного анализа ошибок, выбора моделей и настройки гиперпараметров.
продолжение
Программная
ошибка
– это расхождение между программой и
её спецификацией, причём тогда и только
тогда, когда спецификация существует
и она правильная.
Программная
ошибка
– это ситуация, когда программа не
делает того, чего пользователь от неё
вполне обоснованно ожидает.
Ошибки
пользовательского интерфейса.
С программой может быть трудно (или даже
невозможно) работать по множеству
причин. Их все можно объединить под
названием “ошибки пользовательского
интерфейса”. Вот несколько разновидностей
таких ошибок.
Функциональность.
Функциональные недостатки имеют место,
если программа не делает того, что
должна, выполняет одну из своих функций
плохо или не полностью. Хотя функции
программы достаточно подробно описываются
в ее спецификации, окончательное
представление о том, что программа
должна делать, существует только в умах
ее пользователей.
Функциональные
недостатки есть абсолютно у всех
программ, поскольку ожидания пользователей
— вещь субъективная: у разных пользователей
они различны. Оправдать их все просто
невозможно, а попытка этого добиться
может привести лишь к усложнению и
потере концептуальной целостности
программного продукта.
Однако
во многих случаях функциональный
недостаток вполне очевиден. Если
предусмотренную программой задачу
трудно выполнить, если она решается
неуклюже или при определенных
обстоятельствах вообще не может быть
решена — проблема налицо. И когда ожидания
пользователей вполне разумны и
обоснованны, эту проблему без колебаний
можно назвать ошибкой.
Взаимодействие
программы с пользователем. Насколько
сложно пользователю разобраться в том,
как работать с программой? Откуда вообще
он об этом узнает? Как обстоит дело с
экранными инструкциями и подсказками?
Достаточно ли их? Понятны ли они? Имеется
ли в программе интерактивная справка
и может ли пользователь в случае
затруднений найти в ней реальную помощь?
Насколько корректно программа сообщает
пользователю о его ошибках и объясняет,
как их исправить? Нет ли в программе
элементов, которые могут раздражать
пользователя, сбивать его с толку или
просто выглядеть неуклюже?
Организация
программы.
Насколько легко потеряться в вашей
программе? Нет ли в ней непонятных команд
или таких, которые легко спутать между
собой? Какие ошибки чаще всего делает
пользователь, на что он тратит больше
всего времени и почему?
Пропущенные
команды.
Чего в программе не хватает? Не заставляет
ли программа выполнять некоторые
действия странным, неестественным или
крайне неэффективным способом? Нельзя
ли привести ее в соответствие с привычным
стилем пользователя? Допускает ли она
хотя бы некоторую степень настройки?
Производительность.
В интерактивном программном обеспечении
очень важна скорость. Плохо, если у
пользователя создается впечатление,
что программа работает медленно, если
он чувствует задержки в ее реакции
(особенно если конкурирующие программы
работают ощутимо быстрее).
Выходные
данные.
Большинство программ так или иначе
формируют выходные данные: отображают
информацию на экране, печатают ее или
сохраняют в файлах. Получаете ли вы то,
что хотите? Правильно ли формируются
отчеты, наглядны ли диаграммы и достаточно
ли отчетливо они выглядят на бумаге?
Сохраняются ли данные в формате, доступном
и для других аналогичных программ?
Обладает ли программа достаточной
гибкостью, чтобы можно было подстраивать
ее под нужды конкретного пользователя?
Обработка
ошибок. Процедуры
обработки ошибок — это очень важная
часть программы. Но, к сожалению, в них
тоже очень часто встречаются ошибки.
Кроме того, правильно определив ошибку,
программа не всегда выдает о ней
достаточно информативное сообщение.
Ошибки,
связанные с обработкой граничных
условий.
Простейшими граничными условиями
являются числовые. Но существует и много
других граничных ситуаций. Любой аспект
работы программы к которому применимы
понятия больше или меньше, раньше или
позже, первый или последний, короче или
длиннее, обязательно должен быть проверен
на границах диапазона. Внутри диапазонов
программа обычно работает прекрасно,
а вот на их границах случаются самые
неожиданные отклонения.
Ошибки
вычислений.
Программирование даже самых простых
арифметических операций чревато
ошибками. Нечего и говорить о сложных
формулах и расчетах. Одними из самых
распространенных среди математических
ошибок являются ошибки округления.
После нескольких промежуточных вычислений
может оказаться, что 2 + 2 = -1, даже если
на промежуточных этапах не было логических
ошибок.
Ошибки
начального и последующих состояний.
Бывает, что при выполнении какой-либо
функции программы сбой происходит
только однажды — при самом первом
обращении к этой функции. Причиной
такого поведения программы может быть
отсутствие файла с инициализационной
информацией. После первого же запуска
программа создаст такой файл, и дальше
все будет в порядке. Получается, что
такую ошибку невозможно повторить
(точнее, для ее повторения нужно установить
новую копию программы). Но не стоит
думать, что ошибка, проявляющаяся только
при первом запуске программы, безвредна:
ведь это будет первое, с чем столкнется
каждый новый пользователь. Иногда,
программируя процесс, связанный с
последовательными преобразованиями
информации, разработчики забывают о
том, что пользователю может понадобиться
вернуться к исходным данным и изменить
их. Насколько корректно поведет себя
программа в такой ситуации? Позволит
ли она внести нужные изменения и не
будет ли из-за этого потеряна вся
выполненная пользователем работа? Что
увидит пользователь при возвращении к
исходному состоянию программы: свои
данные или стандартные значения, которыми
программа инициализирует переменные
при запуске?
Ошибки
передачи или интерпретации данных.
Один модуль может передавать данные
другому или даже другой программе.
Некоторые данные могут передаваться
между модулями множество раз, и на
каком-то этапе они могут быть разрушены
или неверно интерпретированы. Изменения,
внесенные одной из частей программы,
могут потеряться или достичь не всех
частей системы, где они важны.
Ситуация
гонок. Классическая
ситуация гонок описывается так.
Предположим, в системе ожидаются два
события, А и Б. Первым может произойти
любое из них. Но если первым произойдет
событие А, выполнение программы
продолжится, а если первым наступит
событие Б, то в работе программы произойдет
сбой. Программист полагал, что первым
всегда должно быть событие А, и не ожидал,
что Б может выиграть гонки. Тестировать
ситуации гонок довольно сложно. Наиболее
типичны они для систем, где параллельно
выполняются взаимодействующие процессы
и потоки, а также для многопользовательских
систем реального времени. Ошибки в таких
системах трудно воспроизвести, и на их
выявление обычно требуется очень много
времени.
Перегрузки.
Программа может не справляться с
повышенными нагрузками. Например, она
может не выдерживать интенсивной и
длительной эксплуатации или не справляться
со слишком большими объемами данных.
Кроме того, сбои могут происходить из-за
нехватки памяти или отсутствия других
необходимых ресурсов. У каждой программы
свои пределы. Вопрос в том, соответствуют
ли реальные возможности и требования
программы к ресурсам спецификации, и
как программа себя поведет при перегрузках.
Некорректная
работа с аппаратным обеспечением.
Программы могут посылать устройствам
неверные данные, игнорировать сообщения
об ошибках, пытаться использовать
устройства, которые заняты или вообще
отсутствуют. Даже если нужное устройство
просто сломано, программа должна понять
это, а не сбоить при попытке к нему
обратится.
Ошибки
документации.
Сама по себе документация не является
программным обеспечением, но все же это
часть программного продукта. И если она
плохо написана, пользователь может
подумать, что и сама программа не намного
лучше.
Ошибки
тестирования.
Обнаружение ошибок, допущенных
тестировщиками, — дело обычное. Конечно,
если таких ошибок будет слишком много,
вы быстро потеряете доверие остальных
членов команды. Но нужно иметь в виду,
что иногда ошибки тестировщика отражают
проблемы пользовательского интерфейса:
если программа заставляет пользователя
делать ошибки, значит, с ней что-то не
так. Конечно, многие ошибки тестирования
вызваны просто неверными тестовыми
данными.
Характерные
ошибки программирования:
-
Вид
ошибкиПример
Неправильная
постановка задачиПравильное
решение неверно сформулированной
задачиНеверный
метод (алгоритм)Выбор
метода (алгоритма) приводящего к
неточному
или не эффективному решению
задачЛогические
ошибкиНеполный
учет ситуаций, которые могут
возникнутьНапример,
-
неверное
указание ветви алгоритма после
проверки некоторого условия, -
неверное
условие выполнения или окончания
цикла, -
неполный
учет возможных условий, -
пропуск
в программе одного или более блоков
алгоритма.
Семантические
ошибкиНепонимание
работы оператораСинтаксические
ошибкиНарушение
правил установленных в
данном языке программированияНапример,
-
неправильная
запись формата оператора, -
повторное
использование имени переменной для
обозначения другой, -
ошибочное
использование одной переменной
вместо другой, -
несогласованность
скобок, -
пропуск
разделителей.
Ошибки
времени выполненияНапример,
в Delphi, они называются исключениями
(exception), как правило, легко устранимы.
Они обычно проявляются уже при первых
запусках программы и во время
тестирования. При возникновении
ошибки в программе, запущенной из
Delphi, среда разработки прерывает работу
программы, и на экране появляется
диалоговое окно, которое содержит
сообщение об ошибке и информацию о
типе (классе) ошибки. -
Вопросы
для самопроверки:
-
Дайте
определение понятия «программная
ошибка». -
Перечислите
источники ошибок
программного обеспечения. -
Классифицируйте
ошибки программного обеспечения.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Дефекты программного обеспечения можно обнаружить на каждом этапе разработки и тестирования продукта. Чтобы гарантировать исправление наиболее серьезных дефектов программного обеспечения, тестировщикам важно иметь хорошее представление о различных типах дефектов, которые могут возникнуть.

В этой статье мы обсудим самые распространенные типы ПО дефекты и способы их выявления.
Что такое дефект?
Дефект программного обеспечения — это ошибка, изъян, сбой или неисправность в компьютерной программе, из-за которой она выдает неправильный или неожиданный результат или ведет себя непреднамеренным образом. Программная ошибка возникает, когда фактические результаты не совпадают с ожидаемыми. Разработчики и программисты иногда допускают ошибки, которые создают ошибки, называемые дефектами. Большинство ошибок возникает из-за ошибок, которые допускают разработчики или программисты.
Обязательно прочтите: Разница между дефектом, ошибкой, ошибкой и сбоем
Типы программных ошибок при тестировании программного обеспечения
Существует множество различных типов дефектов программного обеспечения, и тестировщикам важно знать наиболее распространенные из них, чтобы они могут эффективно тестировать их.
Ошибки программного обеспечения подразделяются на три типа:
- Дефекты программного обеспечения по своей природе
- Дефекты программного обеспечения по их приоритету
- Дефекты программного обеспечения по их серьезности
Обычно мы можем видеть приоритет и серьезность классификаторов в большинстве инструментов отслеживания ошибок. Если мы настроим классификатор в соответствии с характером ошибки, а также приоритетом и серьезностью, это поможет легко управлять распределением обязанностей по исправлению ошибок соответствующим командам.
#1. Дефекты программного обеспечения по своей природе
Ошибки в программном обеспечении имеют широкий спектр природы, каждая из которых имеет свой собственный набор симптомов. Несмотря на то, что таких багов много, сталкиваться с ними можно не часто. Вот наиболее распространенные ошибки программного обеспечения, классифицированные по характеру, с которыми вы, скорее всего, столкнетесь при тестировании программного обеспечения.
#1. Функциональные ошибки
Как следует из названия, функциональные ошибки — это те, которые вызывают сбои в работе программного обеспечения. Хорошим примером этого может служить кнопка, при нажатии на которую должно открываться новое окно, но вместо этого ничего не происходит.
Функциональные ошибки можно исправить, выполнив функциональное тестирование.
#2. Ошибки на уровне модуля
Ошибки на уровне модуля — это дефекты, связанные с функциональностью отдельного программного модуля. Программный модуль — это наименьшая тестируемая часть приложения. Примеры программных модулей включают классы, методы и процедуры. Ошибки на уровне подразделения могут существенно повлиять на общее качество программного обеспечения.
Ошибки на уровне модуля можно исправить, выполнив модульное тестирование.
#3. Ошибки уровня интеграции
Ошибки уровня интеграции — это дефекты, возникающие при объединении двух или более программных модулей. Эти дефекты может быть трудно найти и исправить, потому что они часто требуют координации между несколькими командами. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки интеграции можно исправить, выполнив интеграционное тестирование.
#4. Дефекты юзабилити
Ошибки юзабилити — это дефекты, влияющие на работу пользователя с программным обеспечением и затрудняющие его использование. Дефект юзабилити — это дефект пользовательского опыта программного обеспечения, который затрудняет его использование. Ошибки юзабилити — это такие ошибки, как если веб-сайт сложен для доступа или обойти, или процесс регистрации сложен для прохождения.
Во время тестирования удобства использования тестировщики программного обеспечения проверяют приложения на соответствие требованиям пользователей и Руководству по доступности веб-контента (WCAG) для выявления таких проблем. Однако они могут оказать существенное влияние на общее качество программного обеспечения.
Ошибки, связанные с удобством использования, можно исправить, выполнив тестирование удобства использования.
#5. Дефекты производительности
Ошибки производительности — это дефекты, влияющие на производительность программного обеспечения. Это может включать в себя такие вещи, как скорость программного обеспечения, объем используемой памяти или количество потребляемых ресурсов. Ошибки уровня производительности сложно отследить и исправить, поскольку они могут быть вызваны рядом различных факторов.
Ошибки юзабилити можно исправить, выполнив тестирование производительности.
#6. Дефекты безопасности
Ошибки безопасности — это тип дефекта программного обеспечения, который может иметь серьезные последствия, если его не устранить. Эти дефекты могут позволить злоумышленникам получить доступ к конфиденциальным данным или системам или даже позволить им получить контроль над уязвимым программным обеспечением. Таким образом, очень важно, чтобы ошибкам уровня безопасности уделялось первоочередное внимание и устранялись как можно скорее.
Ошибки безопасности можно исправить, выполнив тестирование безопасности.
#7. Дефекты совместимости
Дефекты совместимости — это те ошибки, которые возникают, когда приложение несовместимо с оборудованием, на котором оно работает, или с другим программным обеспечением, с которым оно должно взаимодействовать. Несовместимость программного и аппаратного обеспечения может привести к сбоям, потере данных и другому непредсказуемому поведению. Тестировщики должны знать о проблемах совместимости и проводить соответствующие тесты. Программное приложение, имеющее проблемы с совместимостью, не работает последовательно на различных видах оборудования, операционных системах, веб-браузерах и устройствах при подключении к определенным программам или работе в определенных сетевых условиях.
Ошибки совместимости можно исправить, выполнение тестирования совместимости.
#8. Синтаксические ошибки
Синтаксические ошибки являются самым основным типом дефекта. Они возникают, когда код нарушает правила языка программирования. Например, использование неправильной пунктуации или забывание закрыть скобку может привести к синтаксической ошибке. Синтаксические ошибки обычно мешают запуску кода, поэтому их относительно легко обнаружить и исправить.
#9. Логические ошибки
Логические ошибки — это дефекты, из-за которых программа выдает неправильные результаты. Эти ошибки может быть трудно найти и исправить, потому что они часто не приводят к каким-либо видимым ошибкам. Логические ошибки могут возникать в любом типе программного обеспечения, но они особенно распространены в приложениях, требующих сложных вычислений или принятия решений.
Общие симптомы логических ошибок включают:
- Неверные результаты или выходные данные
- Неожиданное поведение
- Сбой или зависание программного обеспечения
Чтобы найти и исправить логические ошибки, тестировщикам необходимо иметь четкое представление о коде программы и о том, как она должна работать. Часто лучший способ найти такие ошибки — использовать инструменты отладки или пошаговое выполнение, чтобы отслеживать выполнение программы и видеть, где что-то идет не так.
#2. Дефекты программного обеспечения по степени серьезности
Уровень серьезности присваивается дефекту по его влиянию. В результате серьезность проблемы отражает степень ее влияния на функциональность или работу программного продукта. Дефекты серьезности классифицируются как критические, серьезные, средние и незначительные в зависимости от степени серьезности.
#1. Критические дефекты
Критический дефект — это программная ошибка, имеющая серьезные или катастрофические последствия для работы приложения. Критические дефекты могут привести к сбою, зависанию или некорректной работе приложения. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение критическим дефектам, поскольку их необходимо исправить как можно скорее.
#2. Серьезные дефекты
Серьезный дефект — это программная ошибка, существенно влияющая на работу приложения. Серьезные дефекты могут привести к замедлению работы приложения или другому неожиданному поведению. Они также могут привести к потере данных или уязвимостям в системе безопасности. Разработчики и тестировщики часто придают первостепенное значение серьезным дефектам, поскольку их необходимо исправить как можно скорее.
#3. Незначительные дефекты
Незначительный дефект — это программная ошибка, которая оказывает небольшое или незначительное влияние на работу приложения. Незначительные дефекты могут привести к тому, что приложение будет работать немного медленнее или демонстрировать другое неожиданное поведение. Разработчики и тестировщики часто не придают незначительным дефектам приоритет, потому что их можно исправить позже.
#4. Тривиальные дефекты
Тривиальный дефект – это программная ошибка, не влияющая на работу приложения. Тривиальные дефекты могут привести к тому, что приложение отобразит сообщение об ошибке или проявит другое неожиданное поведение. Разработчики и тестировщики часто присваивают тривиальным дефектам самый низкий приоритет, потому что они могут быть исправлены позже.
#3. Дефекты программного обеспечения по приоритету
#1. Дефекты с низким приоритетом
Дефекты с низким приоритетом, как правило, не оказывают серьезного влияния на работу программного обеспечения и могут быть отложены для исправления в следующей версии или выпуске. В эту категорию попадают косметические ошибки, такие как орфографические ошибки, неправильное выравнивание и т. д.
#2. Дефекты со средним приоритетом
Дефекты со средним приоритетом — это ошибки, которые могут быть исправлены после предстоящего выпуска или в следующем выпуске. Приложение, возвращающее ожидаемый результат, которое, однако, неправильно форматируется в конкретном браузере, является примером дефекта со средним приоритетом.
#3. Дефекты с высоким приоритетом
Как следует из названия, дефекты с высоким приоритетом — это те, которые сильно влияют на функционирование программного обеспечения. В большинстве случаев эти дефекты необходимо исправлять немедленно, так как они могут привести к серьезным нарушениям нормального рабочего процесса. Дефекты с высоким приоритетом обычно классифицируются как непреодолимые, так как они могут помешать пользователю продолжить выполнение поставленной задачи.
Некоторые распространенные примеры дефектов с высоким приоритетом включают:
- Дефекты, из-за которых приложение не работает. сбой
- Дефекты, препятствующие выполнению задачи пользователем
- Дефекты, приводящие к потере или повреждению данных
- Дефекты, раскрывающие конфиденциальную информацию неавторизованным пользователям
- Дефекты, делающие возможным несанкционированный доступ к системе
- Дефекты, приводящие к потере функциональности
- Дефекты, приводящие к неправильным результатам или неточным данным
- Дефекты, вызывающие проблемы с производительностью, такие как чрезмерное использование памяти или медленное время отклика
#4. Срочные дефекты
Срочные дефекты — это дефекты, которые необходимо устранить в течение 24 часов после сообщения о них. В эту категорию попадают дефекты со статусом критической серьезности. Однако дефекты с низким уровнем серьезности также могут быть классифицированы как высокоприоритетные. Например, опечатка в названии компании на домашней странице приложения не оказывает технического влияния на программное обеспечение, но оказывает существенное влияние на бизнес, поэтому считается срочной.
#4. Дополнительные дефекты
#1. Отсутствующие дефекты
Отсутствующие дефекты возникают из-за требований, которые не были включены в продукт. Они также считаются несоответствиями спецификации проекта и обычно негативно сказываются на пользовательском опыте или качестве программного обеспечения.
#2. Неправильные дефекты
Неправильные дефекты — это те дефекты, которые удовлетворяют требованиям, но не должным образом. Это означает, что хотя функциональность достигается в соответствии с требованиями, но не соответствует ожиданиям пользователя.
#3. Дефекты регрессии
Дефект регрессии возникает, когда изменение кода вызывает непреднамеренное воздействие на независимую часть программного обеспечения.
Часто задаваемые вопросы — Типы программных ошибок< /h2>
Почему так важна правильная классификация дефектов?
Правильная классификация дефектов важна, поскольку она помогает эффективно использовать ресурсы и управлять ими, правильно приоритизировать дефекты и поддерживать качество программного продукта.
Команды тестирования программного обеспечения в различных организациях используют различные инструменты отслеживания дефектов, такие как Jira, для отслеживания дефектов и управления ими. Несмотря на то, что в этих инструментах есть несколько вариантов классификации дефектов по умолчанию, они не всегда могут наилучшим образом соответствовать конкретным потребностям организации.
Следовательно, важно сначала определить и понять типы дефектов программного обеспечения, которые наиболее важны для организации, а затем соответствующим образом настроить инструмент управления дефектами.
Правильная классификация дефектов также гарантирует, что команда разработчиков сможет сосредоточиться на критических дефектах и исправить их до того, как они повлияют на конечных пользователей.
Кроме того, это также помогает определить потенциальные области улучшения в процессе разработки программного обеспечения, что может помочь предотвратить появление подобных дефектов в будущих выпусках.
Таким образом, отслеживание и устранение дефектов программного обеспечения может показаться утомительной и трудоемкой задачей. , правильное выполнение может существенно повлиять на качество конечного продукта.
Как найти лежащие в основе ошибки программного обеспечения?
Определение основной причины программной ошибки может быть сложной задачей даже для опытных разработчиков. Чтобы найти лежащие в основе программные ошибки, тестировщики должны применять систематический подход. В этот процесс входят различные этапы:
1) Репликация. Первым этапом является воспроизведение ошибки. Это включает в себя попытку воспроизвести тот же набор шагов, в котором возникла ошибка. Это поможет проверить, является ли ошибка реальной или нет.
2) Изоляция. После того, как ошибка воспроизведена, следующим шагом будет попытка ее изоляции. Это включает в себя выяснение того, что именно вызывает ошибку. Для этого тестировщики должны задать себе несколько вопросов, например:
– Какие входные данные вызывают ошибку?
– При каких различных условиях возникает ошибка?
– Каковы различные способы проявления ошибки?
3) Анализ: после Изолируя ошибку, следующим шагом будет ее анализ. Это включает в себя понимание того, почему возникает ошибка. Тестировщики должны задать себе несколько вопросов, таких как:
– Какова основная причина ошибки?
– Какими способами можно исправить ошибку?
– Какое исправление было бы наиболее эффективным? эффективно?
4) Отчет. После анализа ошибки следующим шагом является сообщение о ней. Это включает в себя создание отчета об ошибке, который включает всю соответствующую информацию об ошибке. Отчет должен быть четким и кратким, чтобы разработчики могли его легко понять.
5) Проверка. После сообщения об ошибке следующим шагом является проверка того, была ли она исправлена. Это включает в себя повторное тестирование программного обеспечения, чтобы убедиться, что ошибка все еще существует. Если ошибка исправлена, то тестер может подтвердить это и закрыть отчет об ошибке. Если ошибка все еще существует, тестировщик может повторно открыть отчет об ошибке.
Заключение
В индустрии программного обеспечения дефекты — неизбежная реальность. Однако благодаря тщательному анализу и пониманию их характера, серьезности и приоритета дефектами можно управлять, чтобы свести к минимуму их влияние на конечный продукт.
Задавая правильные вопросы и применяя правильные методы, тестировщики могут помочь обеспечить чтобы дефекты обнаруживались и исправлялись как можно раньше в процессе разработки.
TAG: qa
Ошибки в программировании – дело обычное, хоть и неприятное. В данной статье будет рассказано о том, какими бывают ошибки (баги), а также что собой представляют исключения.
Определение
Ошибка в программировании (или так называемый баг) – это ситуация у разработчиков, при которой определенный код вследствие обработки выдает неверный результат. Причин данному явлению множество: неисправность компилятора, сбои интерфейса, неточности и нарушения в программном коде.
Баги обнаруживаются чаще всего в момент отладки или бета-тестирования. Реже – после итогового релиза готовой программы. Вот несколько вариантов багов:
- Появляется сообщение об ошибке, но приложение продолжает функционировать.
- ПО вылетает или зависает. Никаких предупреждений или предпосылок этому не было. Процедура осуществляется неожиданно для пользователя. Возможен вариант, при котором контент перезапускается самостоятельно и непредсказуемо.
- Одно из событий, описанных ранее, сопровождается отправкой отчетов разработчикам.
Ошибки в программах могут привести соответствующее приложение в негодность, а также к непредсказуемым алгоритмам функционирования. Желательно обнаруживать баги на этапе ранней разработки или тестирования. Лишь в этом случае программист сможет оперативно и относительно недорого внести необходимые изменения в код для отладки ПО.
История происхождения термина
Баг – слово, которое используется разработчиками в качестве сленга. Оно произошло от слова «bug» – «жук». Точно неизвестно, откуда в программировании и IT возник соответствующий термин. Существуют две теории:
- 9 сентября 1945 года ученые из Гарварда тестировали очередную вычислительную машину. Она называлась Mark II Aiken Relay Calculator. Устройство начало работать с ошибками. Когда его разобрали, то ученые заметили мотылька, застрявшего между реле. Тогда некая Грейс Хоппер назвала произошедший сбой упомянутым термином.
- Слово «баг» появилось задолго до появления Mark II. Термин использовался Томасом Эдисоном и указывал на мелкие недочеты и трудности. Во время Второй Мировой войны «bugs» называли проблемы с радарной электроникой.
Второй вариант кажется более реалистичным. Это факт, который подтвержден документально. Со временем научились различать различные типы багов в IT. Далее они будут рассмотрены более подробно.
Как классифицируют
Ошибки работы программ разделяются по разным факторам. Классификация у рядовых пользователей и разработчиков различается. То, что для первых – «просто программа вылетела» или «глючит», для вторых – огромная головная боль. Но существует и общепринятая классификация ошибок. Пример – по критичности:
- Серьезные неполадки. Это нарушения работоспособности приложения, которые могут приводить к непредвиденным крупным изменениям.
- Незначительные ошибки в программах. Чаще всего не оказывают серьезного воздействия на функциональность ПО.
- Showstopper. Критические проблемы в приложении или аппаратном обеспечении. Приводят к выходу программы из строя почти всегда. Для примера можно взять любое клиент-серверное приложение, в котором не получается авторизоваться через логин и пароль.
Последний вариант требует особого внимания со стороны программистов. Их стараются обнаружить и устранить в первую очередь. Критические ошибки могут отложить релиз исходной программы на неопределенный срок.
Также существуют различные виды сбоев в плане частоты проявления: постоянные и «разовые». Вторые встречаются редко, чаще – при определенных настройках и действиях со стороны пользователя. Первые появляются независимо от используемой платформы и выполненных клиентом манипуляций.
Иногда может получиться так, что ошибка возникает только на устройстве конкретного пользователя. В данном случае устранение неполадки требует индивидуального подхода. Иногда – полной замены компьютера. Связано это с тем, что никто не будет редактировать исходный код, когда он «глючит» только у одного пользователя.
Виды
Существуют различные типы ошибок в программах в зависимости от типовых условий использования приложений. Пример – сбои, которые возникают при возрастании нагрузки на оперативную память или центральный процессор устройства. Есть баги граничных условий, сбоя идентификаторов, несовместимости с архитектурой процессора (наиболее распространенная проблема на мобильных устройствах).
Разработчики выделяют следующие типы ошибок по уровню сложности:
- «Борбаг» – «стабильная» неполадка. Она легко обнаруживается на этапе разработки и компилирования. Иногда – во время тестирования наработкой исходной программы.
- «Гейзенбаг» – баги с поддержкой изменения свойств, включая зависимость от среды, в которой было запущено приложение. Сюда относят периодические неполадки в программах. Они могут исчезать на некоторое время, но через какой-то промежуток вновь дают о себе знать.
- «Мандельбаг» – непредвиденные ошибки. Обладают энтропийным поведением. Предсказать, к чему они приведут, практически невозможно.
- «Шрединбаг» – критические неполадки. Приводят к тому, что злоумышленники могут взломать программу. Данный тип ошибок обнаружить достаточно трудно, потому что они никак себя не проявляют.
Также есть классификация «по критичности». Тут всего два варианта – warning («варнинги») и критические весомые сбои. Первые сопровождаются характерными сообщениями и отчетами для разработчиков. Они не представляют серьезной опасности для работоспособности приложения. При компилировании такие сбои легко исправляются. В отдельных случаях компилятор справляется с этой задачей самостоятельно. А вот критические весомые сбои говорят сами за себя. Они приводят к серьезным нарушениям ПО. Исправляются обычно путем проработки логики и значительных изменений программного кода.
Типы багов
Ошибки в программах бывают:
- логическими;
- синтаксическими;
- взаимодействия;
- компиляционные;
- ресурсные;
- арифметические;
- среды выполнения.
Это – основная классификация сбоев в приложениях и операционных системах. Логические, синтаксические и «среды выполнения» встречаются в разработке чаще остальных. На них будет сделан основной акцент.
Ошибки синтаксиса
Синтаксические баги распространены среди новичков. Они относятся к категории «самых безобидных». С данной категорией ошибок способны справиться компиляторы тех или иных языков. Соответствующие инструменты показывают, где допущена неточность. Остается лишь понять, как исправить ее.
Синтаксические ошибки – ошибки синтаксиса, правил языка. Вот пример в Паскале:

Код написан неверно. Согласно действующим синтаксическим нормам, в Pascal в первой строчке нужно в конце поставить точку с запятой.
Логические
Тут стоит выделить обычные и арифметические типы. Вторые возникают, когда программе при работе необходимо вычислить много переменных, но на каком-то этапе расчетов возникают неполадки или нечто непредвиденное. Пример – получение в результатах «бесконечности».
Логические сбои обычного типа – самые сложные и неприятные. Их тяжелее всего обнаружить и исправить. С точки зрения языка программа может быть написана идеально, но работать неправильно. Подобное явление – следствие логической ошибки. Компиляторы их не обнаруживают.

Выше – пример логической ошибки в программе. Тут:
- Происходит сравнение значения i с 15.
- На экран выводится сообщение, если I = 15.
- В заданном цикле i не будет равно 15. Связано это с диапазоном значений – от 1 до 10.
Может показаться, что ошибка безобидная. В приведенном примере так и есть, но в более крупных программах такое явление приводит к серьезным последствиям.
Время выполнения
Run-time сбои – это ошибка времени выполнения программы. Встречается даже когда исходный код лишен логических и синтаксических ошибок. Связаны такие неполадки с ходом выполнения программного продукта. Пример – в процессе функционирования ПО был удален файл, считываемый программой. Если игнорировать подобные неполадки, можно столкнуться с аварийным завершением работы контента.
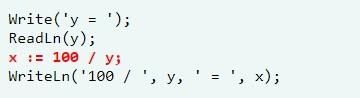
Самый распространенный пример в данной категории – это неожиданное деление на ноль. Предложенный фрагмент кода с точки зрения синтаксиса и логики написан грамотно. Но, если клиент наберет 0, произойдет сбой системы.
Компиляционный тип
Встречается при разработке на языках высокого уровня. Во время преобразований в машинный тип «что-то идет не так». Причиной служат синтаксические ошибки или сбои непосредственно в компиляторе.
Наличие подобных неполадок делает бета-тестирование невозможным. Компиляционные ошибки устраняются при разработке-отладке.
Ресурсные
Ресурсный тип ошибок – это сбои вроде «переполнение буфера» или «нехватка памяти». Тесно связаны с «железом» устройства. Могут быть вызваны действиями пользователя. Пример – запуск «свежих» игр на стареньких компьютерах.
Исправить ситуацию помогают основательные работы над исходным кодом. А именно – полное переписывание программы или «проблемного» фрагмента.
Взаимодействие
Подразумевается взаимодействие с аппаратным или программным окружением. Пример – ошибка при использовании веб-протоколов. Это приведет к тому, что облачный сервис не будет нормально функционировать. При постоянном возникновении соответствующей неполадки остается один путь – полностью переписывать «проблемный» участок кода, ответственный за соответствующий баг.
Исключения и как избежать багов
Исключение – событие, при возникновении которых начинается «неправильное» поведение программы. Механизм, необходимый для стабилизации обработки неполадок независимо от типа ПО, платформ и иных условий. Помогают разрабатывать единые концепции ответа на баги со стороны операционной системы или контента.
Исключения бывают:
- Программными. Они генерируются приложением или ОС.
- Аппаратными. Создаются процессором. Пример – обращение к невыделенной памяти.
Исключения нужны для охвата критических багов. Избежать неполадок помогут отладчики на этапе разработки. А еще – своевременное поэтапное тестирование программы.
P. S. Большой выбор курсов по тестированию есть и в Otus. Присутствуют варианты как для продвинутых, так и для начинающих пользователей.
Содержание:

Введение
Программное обеспечение, согласно ГОСТ 19781-90, – совокупность программ системы обработки информации и программных документов, необходимых для их эксплуатации.
Существует и другое, более простое определение, согласно которому программное обеспечение представляет собой совокупность компьютерных инструкций. Оно охватывает программы, подпрограммы (разделы программы) и данные. Таким образом, программное обеспечение указывает компьютеру, что делать, как, когда, в какой последовательности и как часто. Нередко программное обеспечение называют просто программой.
Проблема надежности программного обеспечения относится, похоже, к категории «вечных». В посвященной ей монографии Г.Майерса, выпущенной в 1980 году (американское издание — в 1976), отмечается, что, хотя этот вопрос рассматривался еще на заре применения вычислительных машин, в 1952 году, он не потерял актуальности до настоящего времени. Отношение к проблеме довольно выразительно сформулировано в книге Р.Гласса: «Надежность программного обеспечения — беспризорное дитя вычислительной техники». Следует далее отметить, что сама проблема надежности программного обеспечения имеет, по крайней мере, два аспекта: обеспечение и оценка (измерение) надежности. Практически вся имеющаяся литература на эту тему, включая упомянутые выше монографии, посвящена первому аспекту, а вопрос оценки надежности компьютерных программ оказывается еще более «беспризорным». Вместе с тем очевидно, что надежность программы гораздо важнее таких традиционных ее характеристик, как время исполнения или требуемый объем оперативной памяти, однако никакой общепринятой количественной меры надежности программ до сих пор не существует.
Для обеспечения надежности программ предложено множество подходов, включая организационные методы разработки, различные технологии и технологические программные средства, что требует, очевидно, привлечения значительных ресурсов. Однако отсутствие общепризнанных критериев надежности не позволяет ответить на вопрос, насколько надежнее становится программное обеспечение при соблюдении данных процедур и технологий и в какой степени оправданы расходы. Получается, что таким образом, приоритет задачи оценки надежности должен быть выше приоритета задачи ее обеспечения, чего на самом деле не наблюдается.
Цель данной работы – рассмотреть классификацию ошибок программного обеспечения для обеспечения его надежности.
Надежность программного обеспечения
Показатели качества программного обеспечения
Оценка качества программного обеспечения могут проводиться с двух позиций: с позиции положительной эффективности и непосредственной адекватности их характеристик назначению, целям создания и применения, а также с негативной позиции, возможного при этом ущерба – риска от пользования ПС или системы. Показатели качества преимущественно отражают положительный эффект от применения программного обеспечения и основная задача разработчиков проекта состоит в обеспечении высоких значений качества. Риски характеризуют возможные негативные последствия проявившихся в ходе эксплуатации ошибок или ущерб для пользователя при применении и функционировании программного обеспечения.
Согласно ГОСТ 9126[2], качество программного обеспечения – это весь объем признаков и характеристик программного обеспечения, который относится к ее способности удовлетворять установленным или предполагаемым потребностям.
Качество программного обеспечения оценивается следующими характеристиками:
- Функциональные возможности (Functionality). Набор атрибутов, относящихся к сути набора функций и их конкретным свойствам. Функциями являются те, которые реализуют установленные или предполагаемые потребности.
- Надежность (Reliability). Набор атрибутов относящихся к способности программного обеспечения сохранять свой уровень качества функционирования при установленных условиях за установленный период времени.
- Практичность (Usability). Набор атрибутов, относящихся к объему работ, требуемых для использования и индивидуальной оценки такого использования определенным и предполагаемым кругом пользователей.
- Эффективность (Efficiencies). Набор атрибутов, относящихся к соотношению между уровнем качества функционирования программного обеспечения и объемом используемых ресурсов при установленных условиях.
- Сопровождаемость (Maintainability). Набор атрибутов, относящихся к объему работ, требуемых для проведения конкретных изменений (модификаций).
- Мобильность (Portability). Набор атрибутов, относящихся к способности программного обеспечения быть перенесенным из одного окружения в другое.
В общем случае под ошибкой подразумевается неправильность, погрешность или неумышленное искажение объекта или процесса, что может быть причиной ущерба – риска при функционировании или применении программы. При этом предполагается, что известно правильное, эталонное состояние объекта или процесса по отношению к которому может быть определено наличие отклонения. Исходным эталоном для любого программного обеспечения являются спецификации требований заказчика или потенциального пользователя, предъявляемых к программам и ожидаемый пользователем или заказчиком эффект от использования программного обеспечения. Важной особенностью при этом является отсутствие полностью определенной программы – эталона, которой должны соответствовать текст и результаты функционирования разрабатываемой программы. Поэтому определить качество программного обеспечения и наличие ошибок в нем путем сравнения разрабатываемой программы с эталонной программой невозможно.
Риски проявляются как негативные последствия проявления ошибок в программном обеспечении в ходе его пользования и функционирования, которые могут нанести ущерб системе, в которой используется это программное обеспечение, внешней среде или пользователям этой системы в результате отклонения характеристик программного обеспечения заданных или ожидаемых пользователем или заказчиком.
Исходя из определения ошибки в программном обеспечении, приведенном выше, можно сделать вывод, что ошибки, возникающие в ходе использования программного обеспечения, могут изменять некоторые или все показатели качества. В работе рассматриваются ошибки, изменения которых влияют на надежность использования программного обеспечения.
По правилу, установленному в [2], надежность – свойство объекта осуществлять заданные функции, храня во времени значения установленных эксплуатационных показателей в заданных пределах, соответствующим заданным режимам и условиям использования, ремонта, технического обслуживания, хранения, транспортирования.

Рис. 1. Надежность по ГОСТ 27.002 – 89
При этом надежность является комплексным свойством, которое в зависимости от функции объекта и условий его использования может включать безотказность, ремонтопригодность, долговечность, сохраняемость или некоторые сочетания данных свойств (рис. 1). Так как программное обеспечение в процессе эксплуатации не изнашивается, его поломка и ремонт в общепринятом смысле не делается, то надежность программного обеспечения имеет смысл характеризовать только с точки зрения безотказности его функционирования и возможности исправления функционирования после отказов по вызванных проявлениями ошибок.
В [3] надежность программного обеспечения предлагается характеризовать с помощью следующих характеристик (рис. 2): стабильность, устойчивость и восстанавливаемость.

Рис. 2. Надежность программного обеспечения
В этом случае стабильность и устойчивость характеризуют безотказность программного обеспечения, а восстанавливаемость – возможность восстановления функционирования программного обеспечения после его отказа. Для количественной оценки надежности программного обеспечения необходимо определить показатели надежности для каждого свойства и методику их определения (оценки).
Для оценки стабильности программного обеспечения возможно использование показателей характеризующих безотказность технических устройств [2] (рис. 3).

Рис. 3. Показатели безотказности
В большинстве случаев поток программных ошибок может быть описан негомогенным процессом Пуассона [4]. Это означает, что программные ошибки происходят в статистически независимые моменты времени, наработки подчиняются экспоненциальному распределению, а интенсивность проявления ошибок изменяется во времени. Обычно используют убывающую интенсивность проявления ошибок. Это означает, что ошибки, как только они выявлены, эффективно устраняются без введения новых ошибок. Главная цель анализа надежности программного обеспечения заключается в том, чтобы определить форму функции интенсивности проявления ошибок и оценить ее параметры по наблюдаемым данным. Как только функция интенсивности проявления ошибок определена, могут быть найдены такие показатели надежности как:
- общее количество ошибок;
- количество остающихся ошибок;
- время до проявления следующей ошибки;
- вероятность безошибочной работы;
- интенсивность проявления ошибок;
- остаточное время испытаний (до принятия решения);
- максимальное количество ошибок (относительно срока службы).
При этом следует различать понятия ошибка и отказ. Применительно к надежности программного обеспечения ошибка это погрешность или искажение кода программы, неумышленно внесенные в нее в процессе разработки, которые в ходе функционирования этой программы могут вызвать отказ или снижение эффективности функционирования. Под отказом в общем случае понимают событие, заключающееся в нарушении работоспособности объекта [2]. Состояние объекта, при котором значения всех параметров характеризующих способность выполнять заданные функции, соответствуют требованиям нормативно – технической и (или) конструкторской (проектной) документации – называется работоспособным. При этом критерии отказов, как признаки или совокупность признаков нарушения работоспособного состояния программного обеспечения, должны определяться исходя из его предназначения в нормативно – технической и (или) конструкторской (проектной) документации.
В общем случае отказ программного обеспечения можно определить как:
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) на время превышающее заданный порог;
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) на время не превышающее заданный порог, но с потерей всех или части обрабатываемых данных;
- прекращение функционирования программы (искажения нормального хода ее выполнения, зацикливание) потребовавшее перезагрузки ЭВМ, на которой функционирует программное обеспечение.
При этом исходя из [2], все отказы в программном обеспечении следует трактовать как сбои (самоустраняющиеся отказы или однократные отказы, устраняемые незначительным вмешательством оператора), поскольку восстановление работоспособного состояния программного обеспечения может произойти без вмешательства оператора (перезагрузка ЭВМ не требуется), либо при участии оператора или эксплуатирующего персонала (перезагрузка ЭВМ необходима).
Приведенные выше критерии отказов приводят к необходимости анализа временных характеристик функционирования программы и динамических характеристик потребителей данных, полученных в ходе функционирования программного обеспечения. Временная зона перерыва нормальной выдачи информации и потери работоспособности, которую следует рассматривать как зону сбоя (отказа), тем шире, чем более инертный объект находится под воздействием данных, полученным в ходе работы программы. Пороговое время восстановления работоспособного состояния системы, при превышении которого следует соответствующему потребителю (абоненту).
Для любого потребителя данных существует допустимое время отсутствия данных от программы, при котором его характеристики находятся в допустимых пределах. Исходя из этого времени, можно установить границы временной зоны, которая разделяет работоспособное и неработоспособное состояние программного обеспечения и позволяет использовать данные критерии отказов.
Из приведенного выше определения программной ошибки с точки зрения надежности, можно сделать вывод о том, что ошибки, при их проявлении, не всегда вызывают отказ программного обеспечения и каждую ошибку можно характеризовать условной вероятностью возникновения отказа при проявлении этой ошибки. Следует также отметить, что само по себе наличие ошибки в исходном коде не определяет надежность программы до тех пор, пока не произойдет проявления этой ошибки, поэтому пользоваться для оценки надежности программного обеспечения только показателями характеризующие общее количество ошибок в программе, количество оставшихся ошибок и максимального количества ошибок нельзя.
В [5] стабильность предлагается оценивать вероятностью безотказной работы, которая оценивается исходя из модели относительной частоты, при этом применение ее ограничено периодом эксплуатации программного обеспечения, что не всегда приемлемо, поскольку надежность объекта, как правило, необходимо оценивать не только в процессе его эксплуатации, но и до начала эксплуатации этого объекта. Ограничение модели относительной частоты вызвано тем, что в этой модели не учитываются процессы тестирования и отладки, а конкретно то, что при возникновении отказа программного обеспечения, ошибка, вызвавшая этот отказ, исправляется.
Наиболее приемлемыми показателями характеризующими стабильность (безотказность) программного обеспечения представляются показатели сходные с показателями безотказности технических систем: вероятность безотказной работы, интенсивность отказов, и среднее время наработки на отказ. Эти показатели взаимосвязаны и, зная один из них, можно определить другие [2]. При определении этих показателей в большинстве случаев можно исходить из модели надежности, предполагающей, что интенсивность проявления ошибок убывает по мере исправления этих ошибок, время между проявлениями ошибок распределено экспоненциально, а интенсивность проявления ошибок постоянна между двумя соседними проявлениями ошибок. Применение такой модели надежности программного обеспечения позволит оценить надежность программного обеспечения во время тестирования и отладки.
Устойчивость, как свойство или совокупность свойств программного обеспечения, характеризующие его возможность поддерживать приемлемый уровень функционирования при проявлениях ошибок в нем, можно оценивать условной вероятностью безотказной работы при проявлении ошибки. Согласно [5] устойчивость оценивается с помощью трех метрик, включающих двадцать оценочных элементов (рис. 4). Результаты оценки каждой метрики определяются результатами оценки определяющих ее оценочных элементов, а результат оценки устойчивости определяются результатами соответствующих ему метрик. Программное обеспечение по каждому из оценочных элементов оценивается группой экспертов – специалистов, компетентных в решении данной задачи, на базе их опыта и интуиции. Для оценочных элементов принимается единая шкала оценки от 0 до 1.
Недостатком такого подхода является одинаковая оценка устойчивости для всех возможных ошибок. Поскольку вероятность возникновения отказа при проявлении разных ошибок может быть разной, возникает необходимость разделения ошибок на несколько категорий. Признаком, по которому в этом случае можно относить ошибки к той или иной категории, можно считать тяжесть ошибки. Под тяжестью ошибки в этом случае следует понимать количественную или качественную оценку вероятного ущерба при проявлении этой ошибки [6], а если говорить о надежности, то оценку вероятности возникновения отказа при проявлении ошибки. При этом категорией тяжести последствий ошибки будет являться классификационная группа ошибок по тяжести их последствий, характеризуемая определенным сочетанием качественных и/или количественных учитываемых составляющих ожидаемого (вероятного) отказа или нанесенного отказом ущерба.
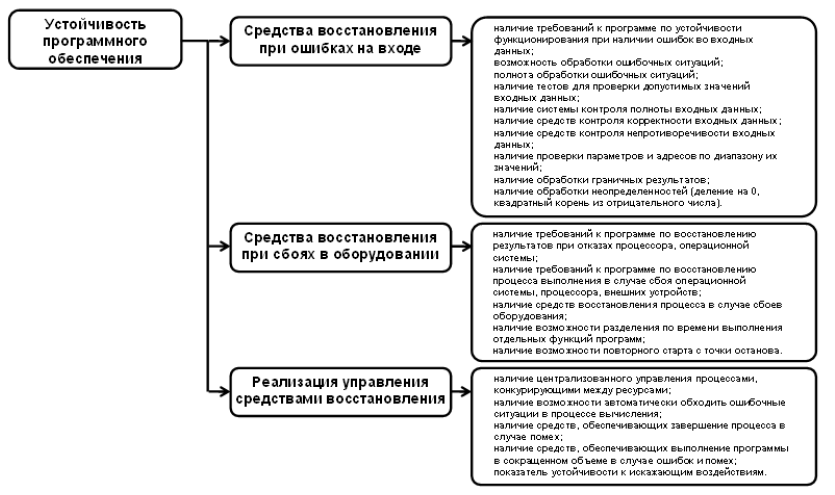
Рис. 4. Метрики и оценочные элементы устойчивости программного обеспечения по ГОСТ 28195 – 89
В качестве показателя степени тяжести ошибки, позволяющего дать количественную оценку тяжести проявления последствий ошибки целесообразно использовать условную вероятность отказа и его возможных последствий при проявлении ошибок разных категорий. Для программного обеспечения, создаваемого для систем управления, потеря работоспособности которых может повлечь за собой катастрофические последствия, возможные категории тяжести ошибок приведены в таблице 1.
Таблица 1. Категории тяжести ошибки в программном обеспечении, нарушение работоспособности которого могут привести к катастрофическим последствиям
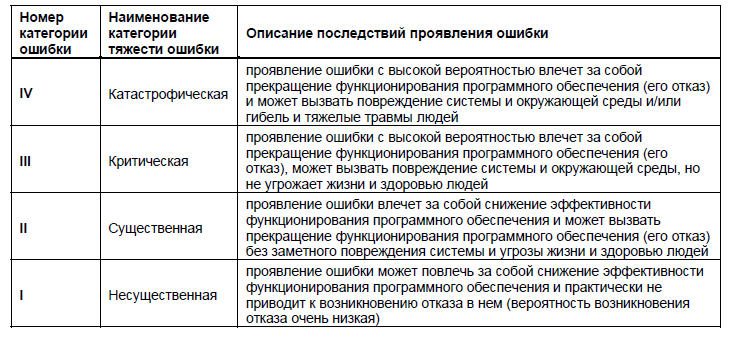
Для программного обеспечения общего применения или программного обеспечения систем, нарушение работоспособности которых не представляет угрозы жизни людей и не приводит к разрушению самой системы, возможные категории тяжести приведены в таблице 2.
Таблица 2. Категории тяжести ошибки в программном обеспечении, нарушение работоспособности которого не приводят к катастрофическим последствиям

Оценку степени тяжести ошибки как условной вероятности возникновения отказа (последствий этого отказа), можно производить согласно [5], используя метрики и оценочные элементы, характеризующие устойчивость программного обеспечения. При этом оценка производится для каждой ошибки в отдельности, а не для всего программного обеспечения. Далее исходя из проведенных оценок возможно определение устойчивости программного обеспечения к проявлениям ошибок каждой из категорий.
Восстанавливаемость программного обеспечения, как свойство или совокупность свойств характеризующих способность программного обеспечения восстановления своего уровня пригодности и восстановления данных, непосредственно поврежденных вследствии проявлении ошибки (отказа), характеризуется полнотой и длительностью восстановления функционирования программ в процессе перезапуска или перезагрузки ЭВМ. В [5] восстанавливаемость предлагается оценивать по среднему времени восстановления. При этом следует учитывать, что время восстановления функционирования программного обеспечения складывается не только из времени потребного для перезагрузки ЭВМ и загрузки самого программного обеспечения, но и из времени необходимого для восстановления данных и это время в ряде случаев может значительно превышать время перезагрузки.
Показатели надежности программного обеспечения в значительной степени адекватны аналогичным характеристикам, принятых для других технических систем. Наиболее широко используется показатель наработки на отказ. Наработка на отказ – это отношение суммарной наработки объекта к математическому ожиданию числа его отказов в течении этой наработки. Для программного обеспечения использование данного показателя затруднено, в силу особенностей тестирования и отладки программного обеспечения (ошибка вызвавшая отказ, как правило, исправляется и больше не повторяется). Поэтому целесообразно использовать показатель средней наработки до отказа – математического ожидания времени функционирования программного обеспечения до отказа. При использовании модели надежности программного обеспечения предполагающей экспоненциальное распределение времени между отказами, среднее время наработки до отказа равно величине обратной интенсивности отказов. Интенсивность отказов можно оценить исходя из оценок стабильности и устойчивости программного обеспечения. Обобщение характеристик отказов и восстановлений производится в показателе коэффициент готовности [2]. Коэффициент готовности программного обеспечения это вероятность того, что программное обеспечение окажется в работоспособном состоянии в произвольный момент времени. Значение коэффициента готовности соответствует доле времени полезной работы программного обеспечения на достаточно большом интервале времени, содержащем отказы и восстановления.
Источники ошибок программного обеспечения
Источниками ошибок в программном обеспечении являются специалисты – конкретные люди с их индивидуальными особенностями, квалификацией, талантом и опытом. Вследствие этого плотность потоков ошибок и размеры необходимых корректировок в модулях и компонентах при разработке и сопровождении программного обеспечения могут различаться в десятки раз. Однако в крупных комплексах программ статистика и распределение ошибок и типов выполняемых изменений, необходимых для их исправления, для коллективов разных специалистов нивелируются и проявляются общие закономерности, которые могут использоваться как ориентиры при выявлении ошибок и их систематизации. Этому могут помогать оценки типовых ошибок, модификаций и корректировок путем их накопления и обобщения по опыту создания определенных классов программного обеспечения.
Основными причинами ошибок программного обеспечения являются:
- Большая сложность программного обеспечения, например, по сравнению с аппаратурой ЭВМ.
- Неправильный перевод информации из одного представления в другое на макро и микро уровнях. На макро уровне, уровне проекта, осуществляется передача и преобразование различных видов информации между организациями, подразделениями и конкретными исполнителями на всех этапах жизненного цикла ПО. На микро уровне, уровне исполнителя, производится преобразование информации по схеме: получить информацию, запомнить, выбрать из памяти, воспроизвести информацию.
Источниками ошибок программного обеспечения являются:
Внутренние: ошибки проектирования, ошибки алгоритмизации, ошибки программирования, недостаточное качество средств защиты, ошибки в документации.
Внешние: ошибки пользователей, сбои и отказы аппаратуры ЭВМ, искажение информации в каналах связи, изменения конфигурации системы.
- Признаками выявления ошибок являются:
- Преждевременное окончание программы.
- Увеличение времени выполнения программы.
- Нарушение последовательности вызова отдельных подпрограмм.
Ошибки выхода информации, поступающей от внешних источников, между входной информацией возникает не соответствие из-за: искажение данных на первичных носителях, сбои и отказы в аппаратуре, шумы и сбои в каналах связи, ошибки в документации.
Ошибки, скрытые в самой программе: ошибка вычислений, ошибка ввода-вывода, логические ошибки, ошибка манипулирования данными, ошибка совместимости, ошибка сопряжения.
Искажения входной информации, подлежащей обработке: искажения данных на первичных носителях информации; сбои и отказы в аппаратуре ввода данных с первичных носителей информации; шумы и сбои в каналах связи при передачи сообщений по линиям связи; сбои и отказы в аппаратуре передачи или приема информации; потери или искажения сообщений в буферных накопителях вычислительных систем; ошибки в документировании; используемой для подготовки ввода данных; ошибки пользователей при подготовки исходной информации.
Неверные действия пользователя:
- Неправильная интерпретация сообщений.
- Неправильные действия пользователя в процессе диалога с программным обеспечением.
- Неверные действия пользователя или по-другому, их можно назвать ошибками пользователя, которые возникают вследствие некачественной программной документации: неверные описания возможности программ; неверные описания режимов работы; неверные описания форматов входной и выходной информации; неверные описания диагностических сообщений.
Неисправности аппаратуры установки: приводят к нарушениям нормального хода вычислительного процесса; приводят к искажениям данных и текстов программ в основной и внешней памяти.
Итак, при рассмотрении основных причин возникновения отказа и сбоев программного обеспечения можно сказать, что эти знания позволяют своевременно принимать необходимые меры по недопущению отказов и сбоев программного обеспечения.
Виды ошибок программного обеспечения
Характеристика основных видов ошибок программного обеспечения
Рассмотрим классификацию ошибок по месту их возникновения, которая рассмотрена в книге С. Канера «Тестирование программного обеспечения». Фундаментальные концепции менеджмента бизнес-приложений. Главным критерием программы должно быть ее качество, которое трактуется как отсутствие в ней недостатков, а также сбоев и явных ошибок. Недостатки программы зависят от субъективной оценкой ее качества потенциальным пользователем. При этом авторы скептически относятся к спецификации и утверждают, что даже при ее наличии, выявленные на конечном этапе недостатки говорят о ее низком качестве. При таком подходе преодоление недостатков программы, особенно на заключительном этапе проектирования, может приводить к снижению надежности. Очевидно, что для разработки ответственного и безопасного программного обеспечения (ПО) такой подход не годится, однако проблемы наличия ошибок в спецификациях, субъективного оценивания пользователем качества программы существуют и не могут быть проигнорированы. Должна быть разработана система некоторых ограничений, которая бы учитывала эти факторы при разработке и сертификации такого рода ПО. Для обычных программ все проблемы, связанные с субъективным оцениванием их качества и наличием ошибок, скорее всего неизбежны.
В краткой классификации выделяются следующие ошибки.
- ошибки пользовательского интерфейса.
- ошибки вычислений.
- ошибки управления потоком.
- ошибки передачи или интерпретации данных.
- перегрузки.
- контроль версий.
- ошибка выявлена и забыта.
- ошибки тестирования.
1. Ошибки пользовательского интерфейса.
Многие из них субъективны, т.к. часто они являются скорее неудобствами, чем «чистыми» логическими ошибками. Однако они могут провоцировать ошибки пользователя программы или же замедлять время его работы до неприемлемой величины. В результате чего мы будем иметь ошибки информационной системы (ИС) в целом. Основным источником таких ошибок является сложный компромисс между функциональностью программы и простотой обучения и работы пользователя с этой программой. Проблему надо начинать решать при проектировании системы на уровне ее декомпозиции на отдельные модули, исходя из того, что вряд ли удастся спроектировать простой и удобный пользовательский интерфейс для модуля, перегруженного различными функциями. Кроме того, необходимо учитывать рекомендации по проектированию пользовательских интерфейсов. На этапе тестирования ПО полезно предусмотреть встроенные средства тестирования, которые бы запоминали последовательности действий пользователя, время совершения отдельных операций, расстояния перемещения курсора мыши. Кроме этого возможно применение гораздо более сложных средств психо-физического тестирования на этапе тестирования интерфейса пользователя, которые позволят оценить скорость реакции пользователя, частоту этих реакций, утомляемость и т.п. Необходимо отметить, что такие ошибки очень критичны с точки зрения коммерческого успеха разрабатываемого ПО, т.к. они будут в первую очередь оцениваться потенциальным заказчиком.
2.Ошибки вычислений.
Выделяют следующие причины возникновения таких ошибок:
- неверная логика (может быть следствием, как ошибок проектирования, так и кодирования);
- неправильно выполняются арифметические операции (как правило — это ошибки кодирования);
- неточные вычисления (могут быть следствием, как ошибок проектирования, так и кодирования). Очень сложная тема, надо выработать свое отношение к ней с точки зрения разработки безопасного ПО.
Выделяются подпункты: устаревшие константы; ошибки вычислений; неверно расставленные скобки; неправильный порядок операторов; неверно работает базовая функция; переполнение и потеря значащих разрядов; ошибки отсечения и округления; путаница с представлением данных; неправильное преобразование данных из одного формата в другой; неверная формула; неправильное приближение.
3.Ошибки управления потоком.
В этот раздел относится все то, что связано с последовательностью и обстоятельствами выполнения операторов программы.
Выделяются подпункты:
- очевидно неверное поведение программы;
- переход по GOTO;
- логика, основанная на определении вызывающей подпрограммы;
- использование таблиц переходов;
- выполнение данных (вместо команд). Ситуация возможна из-за ошибок работы с указателями, отсутствия проверок границ массивов, ошибок перехода, вызванных, например, ошибкой в таблице адресов перехода, ошибок сегментирования памяти.
4.Ошибки обработки или интерпретации данных.
Выделяются подпункты:
- проблемы при передаче данных между подпрограммами (сюда включены несколько видов ошибок: параметры указаны не в том порядке или пропущены, несоответствие типов данных, псевдонимы и различная интерпретация содержимого одной и той же области памяти, неправильная интерпретация данных, неадекватная информация об ошибке, перед аварийным выходом из подпрограммы не восстановлено правильное состояние данных, устаревшие копии данных, связанные переменные не синхронизированы, локальная установка глобальных данных (имеется в виду путаница локальных и глобальных переменных), глобальное использование локальных переменных, неверная маска битового поля, неверное значение из таблицы);
- границы расположения данных (сюда включены несколько видов ошибок: не обозначен конец нуль-терминированной строки, неожиданный конец строки, запись/чтение за границами структуры данных или ее элемента, чтение за пределами буфера сообщения, чтение за пределами буфера сообщения, дополнение переменных до полного слова, переполнение и выход за нижнюю границу стека данных, затирание кода или данных другого процесса);
- проблемы с обменом сообщений (сюда включены несколько видов ошибок: отправка сообщения не тому процессу или не в тот порт, ошибка распознавания полученного сообщения, недостающие или несинхронизированные сообщения, сообщение передано только N процессам из N+1, порча данных, хранящихся на внешнем устройстве, потеря изменений, не сохранены введенные данные, объем данных слишком велик для процесса-получателя, неудачная попытка отмены записи данных).
5.Повышенные нагрузки.
При повышенных нагрузках или нехватке ресурсов могут возникнуть дополнительные ошибки. Выделяются подпункты: требуемый ресурс недоступен; не освобожден ресурс; нет сигнала об освобождении устройства; старый файл не удален с накопителя; системе не возвращена неиспользуемая память; лишние затраты компьютерного времени; нет свободного блока памяти достаточного размера; недостаточный размер буфера ввода или очереди; не очищен элемент очереди, буфера или стека; потерянные сообщения; снижение производительности; повышение вероятности ситуационных гонок; при повышенной нагрузке объем необязательных данных не сокращается; не распознается сокращенный вывод другого процесса при повышенной загрузке; не приостанавливаются задания с низким приоритетом.
7.Ошибки тестирования.
Являются ошибками сотрудников группы тестирования, а не программы. Выделяются подпункты:
- пропущенные ошибки в программе;
- не замечена проблема (отмечаются следующие причины этого: тестировщик не знает, каким должен быть правильный результат, ошибка затерялась в большом объеме выходных данных, тестировщик не ожидал такого результата теста, тестировщик устал и невнимателен, ему скучно, механизм выполнения теста настолько сложен, что тестировщик уделяет ему больше внимания, чем результатам);
- пропуск ошибок на экране;
- не документирована проблема (отмечаются следующие причины этого: тестировщик неаккуратно ведет записи, тестировщик не уверен в том, что данные действия программы являются ошибочными, ошибка показалась слишком незначительной, тестировщик считает, что ошибку не будет исправлена, тестировщика просили не документировать больше подобные ошибки).
8.Ошибка выявлена и забыта.
Описываются ошибки использования результатов тестирования. По-моему, раздел следует объединить с предыдущим. Выделяются подпункты: не составлен итоговый отчет; серьезная проблема не документирована повторно; не проверено исправление; перед выпуском продукта не проанализирован список нерешенных проблем.
Необходимо заметить, что изложенные в 2-х последних разделах ошибки тестирования требуют для устранения средств автоматизации тестирования и составления отчетов. В идеальном случае, эти средства должны быть проинтегрированы со средствами и технологиями проектирования ПО. Они должны стать важными инструментальными средствами создания высококачественного ПО. При разработке средств автоматизированного тестирования следует избегать ошибок, которые присущи любому ПО, поэтому нужно потребовать, чтобы такие средства обладали более высокими характеристиками надежности, чем проверяемое с их помощью ПО.
Меры по повышению надежности программного обеспечения
Лучшим и самым оптимальным способом (если не брать во внимание научно-технический прогресс и постоянное развитие IT-технологий, которые способствуют повышению качества характеристик программ) повышения надёжности программного обеспечения является строжайший контроль продукции на выходе с предприятия.
В последние годы сформировалась комплексная система управления качеством продукции TQM (Totaly Quality Management), которая концептуально близка к предшествующей более общей системе на основе стандартов ИСО серии 9000. Система ориентирована на удовлетворение требований потребителя, на постоянное улучшение процессов производства или проектирования, на управление процессами со стороны руководства предприятия на основе фактического состояния проекта. Основные достижения TQM состоят в углублении и дифференциации требований потребителей по реализации процессов, их взаимодействию и обеспечению качества продукции. Системный подход поддержан рядом специализированных инструментальных средств, ориентированных на управление производством продукции. Поэтому эта система пока не находит применения в области обеспечения качества жизненного цикла программных средств.
Применение этого комплекса может служить основой для систем обеспечения качества программных средств, однако требуется корректировка, адаптация или исключение некоторых положений стандартов применительно к принципиальным особенностям технологий и характеристик этого вида продукции. Кроме того, при реализации систем качества необходимо привлечение ряда стандартов, формально не относящихся к этой серии и регламентирующих показатели качества, жизненный цикл, верификацию и тестирование, испытания, документирование и другие особенности комплексов программ.
Активные методы повышения надежности ПС совершенствуются за счет развития средств автоматизации тестирования программ. Сложность ПС и высокие требования по их надежности требуют выработки принципов структурного построения сложных программных средств, обеспечивающих гибкость модификации ПС и эффективность их отладки. К таким принципам в работе относят:
- модульность и строгую иерархию в структурном построении программ;
- унификацию правил проектирования, структурного построения и взаимодействия компонент ПС;
- унификацию правил организации межмодульного интерфейса;
- поэтапный контроль полноты и качества решения функциональных задач.
Заключение
Несмотря на очевидную актуальность, вопрос надежности программного обеспечения не привлекает должного внимания. Вместе с тем, даже поверхностный анализ проблемы с теоретико-вероятностной точки зрения позволяет выявить некоторые закономерности.
В заключение можно подвести итог:
- В программном обеспечении имеется ошибка, если оно не выполняет того, что пользователю разумно от него ожидать;
- Отказ программного обеспечения — это появление в нем ошибки;
- Надежность программного обеспечения — есть вероятность его работы без отказов в течении определенного периода времени, рассчитанного с учетом стоимости для пользователя каждого отказа.
Из данных определений можно сделать важные выводы:
- Надежность программного обеспечения является не только внутренним свойством программы;
- Надежность программного обеспечения — это функция как самого ПО, так и ожиданий (действий) его пользователей.
Основными причинами ошибок программного обеспечения являются:
- большая сложность ПО, например, по сравнению с аппаратурой ЭВМ;
- неправильный перевод информации из одного представления в другое.
Список использованной литературы
- ГОСТ 27.002 – 89. Надежность в технике. Основные понятия. Термины и определения. // М.: Издательство стандартов, 1990.
- ГОСТ Р ИСО/МЭК 9126 – 93. Информационная технология. Оценка программной продукции. Характеристики качества и руководства по их применению. // М.: Издательство стандартов, 1994.
- ГОСТ 51901.5 – 2005. Менеджмент риска. Руководство по применению методов анализа надежности. // М.: Издательство стандартов, 2007.
- ГОСТ 28195 – 89. Оценка качества программных средств. Общие положения. // М.: Издательство стандартов, 1989.
- ГОСТ 27.310 – 95. Надежность в технике. Анализ видов, последствий и критичности отказов. // М.: Издательство стандартов, 1995.
- ГОСТ 51901.12 – 2007. Менеджмент риска. Метод анализа видов и последствий отказов. // М.: Издательство стандартов, 2007.
- Братчиков И.Л. «Синтаксис языков программирования» Наука, М.:Инси, 2005. — 344 с.
- Дейкстра Э. Заметки по структурному программированию.- М.:Дрофа, 2006, — 455 с.
- Ершов А.П. Введение в теоретическое программирование.- М.:РОСТО, 2008, — 288 с.
- Кнут Д. Искусство программирования для ЭВМ, т.1. М.: 2006, 735 с.
- Коган Д.И., Бабкина Т.С. «Основы теории конечных автоматов и регулярных языков. Учебное пособие» Издательство ННГУ, 2002. — 97 с.
- Липаев В. В. / Программная инженерия. Методологические основы. // М.: ТЕИС, 2006.
- Майерс Г. Надежность программного обеспечения.- М.:Дрофа, 2008, — 360 с.
- Рудаков А. В. Технология разработки программных продуктов. М.:Издательский центр «Академия», 2006. — 306 с.
- Тыугу, Э.Х. Концептуальное программирование. — М.: Наука, 2001, — 256 с.
- Хьюз Дж., Мичтом Дж. Структурный подход к программированию.-М.:Мир, 2000, — 278 с.

- Разработка клиент-серверного приложения по работе с базой данных «Локомотивное депо «
- Анализ особенности управления мотивацией сотрудников на предприятиях гостиничного и ресторанного бизнеса на примере АО ТГК «Вега»
- СУЩНОСТЬ И СОДЕРЖАНИЕ БАНКОВСКОГО МАРКЕТИНГА
- Оформление и ведение учета операций с сомнительными, неплатежеспособными и имеющими признаки подделки денежными знаками
- Виды, понятия, задачи оплаты труда на предприятии
- ценообразование на услуги фитнес-клубов (Российский рынок фитнес-услуг)
- Место и роль спортивной индустрии в экономике России (Теоретические аспекты индустрии спорта)
- Влияние кадровой стратегии на работу службы персонала. (СОДЕРЖАНИЕ И СУЩНОСТЬ КАДРОВОЙ СТРАТЕГИИ)
- Эффективный лидер и его команда (Виды лидерства)
- Межфирменная научно-техническая кооперация
- Прогнозирование эффективности реальных инвестиций коммерческого банка. Анализ инвестиционной деятельности ПАО «Сбербанк»
- Страхование и его государственное регулирование в РФ
Классификация — одна из наиболее популярных технологий интеллектуального анализа данных. С необходимостью построения классификаторов рано или поздно сталкивается любой аналитик. Но даже построив модель, необходимо прежде всего убедиться в ее работоспособности. Для этого разработано большое количество мер качества. Наиболее популярные из них рассматриваются в данной статье.
Для классификационных моделей, как и для моделей регрессии, актуальна задача оценки их качества для определения работоспособности моделей и их сравнения. Однако решение этой задачи для моделей классификации вообще, и бинарной классификации в частности, сложнее, чем для регрессии. Связано это с тем, что целевая переменная (метка класса) является категориальным (дискретным) значением, и, следовательно, ошибка классификации не может быть выражена числовым значением.
Поэтому в основе оценки качества классификационных моделей лежит статистика результатов классификации обучающих примеров. С ее помощью вычисляются метрики качества — показатели, которые зависят от результатов классификации и не зависят от внутреннего состояния модели.
Среди наиболее популярных методов оценки качества классификаторов можно выделить следующие:
- Матрица ошибок (Сonfusion matrix).
- Меткость (Accuracy).
- Точность (Precision).
- Полнота (Recall).
- Специфичность (Specificity).
- F1-мера (F1-score).
- Метрика P4 .
- Площадь под ROC-кривой (Area under ROC-curve, AUC-ROC).
- Площадь под кривой полнота-точность (Area under precision-recall curve, AUC-PR).
- Коэффициент корреляции Мэтьюса (Matthews correlation coefficient, MCC).
- Функция потерь логистической регрессии (Logistic loss function, Log Loss).
Матрица ошибок
Прежде чем переходить к описанию собственно метрик качества бинарных классификаторов, рассмотрим методику описания этих метрик в терминах ошибок классификации. Пусть заданы два класса y=left { 0,1 right } и алгоритм, предсказывающий принадлежность каждого объекта одному из классов. Эта задача анализа известна как бинарная классификация.
Приведем пример. Пусть в страховой компании используется аналитическая платформа для поддержки принятия решений о целесообразности страхования того или иного объекта. Если риск наступления страхового события выше определенного порога, то такие объекты страховать нецелесообразно. Именно выявление таких объектов и является целью анализа. Тогда для объектов, страхование которых целесообразно, система должна установить класс 0, а объектам, в страховании которых отказано, — класс 1.
Любой реальный классификатор совершает ошибки. В нашем случае таких ошибок может быть две:
- класс 0 распознается классификатором как класс 1, что можно интерпретировать как «ложную тревогу»;
- класс 1 распознается как класс 0, что можно трактовать как «пропуск цели».
Очевидно, что приведенные ошибки неравноценны по связанным с ними издержкам классификации. В случае «ложной тревоги» компания потеряет только потенциальную страховую премию, т.е. будет иметь место всего лишь упущенная выгода. В случае «пропуска цели» возможна потеря значительной суммы из-за наступления страхового случая. Поэтому важнее не допустить «пропуск цели», чем «ложную тревогу».
Иными словами, важнее правильно определить объект, нежелательный для страхования из-за высокого риска, чем ошибиться в распознавании желательного. Будем называть соответствующий исход классификации положительным (объект не подлежит страхованию y=1), а противоположный — отрицательным (объект подлежит страхованию y=0). Тогда возможны следующие исходы классификации:
- Объект, нежелательный для страхования, классифицирован как нежелательный, т.е. «положительный» класс распознан как положительный. Такой исход классификации (а также пример, для которого он получен) называют истинноположительным.
- Объект, желательный для страхования, распознан как желательный, т.е. «отрицательный» класс распознан как отрицательный. Такой исход классификации называют истинноотрицательными.
- Объект, желаемый для страхования, классифицирован как не желаемый, т.е. имела место ошибка, в результате которой отрицательный класс был распознан как положительный. Данный исход классификации называют ложноположительным, а ошибка классификации называется ошибкой I рода.
- Нежелательный объект распознан как желательный, т.е. имела место ошибка, в результате которой положительный класс был распознан как отрицательный. Такой исход классификации называется ложноотрицательным, а ошибка классификации — ошибкой II рода.
Таким образом, ошибка I рода, или ложноположительный исход классификации, имеет место, когда пример, с которым связано отрицательное событие распознан моделью как положительный. Ошибкой II рода, или ложноотрицательным исходом классификации, называют случай, когда пример, с которым связано положительное событие, распознан как отрицательный. Поясним это с помощью матрицы ошибок классификации, называемой также таблицей сопряженности:
| y=0 | y=1 | |
|---|---|---|
| widehat{y}=0 | Истинноположительный (True Positive — TP) | Ложноположительный (False Positive — FP) |
| widehat{y}=1 | Ложноотрицательный (False Negative — FN) | Истинноотрицательный (True Negative — TN) |
Здесь widehat{y} — отклик модели, а y — фактическое значение. Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP). В данном случае P означает, что классификатор определяет класс объекта как положительный, а N как — отрицательный. T значит, что класс предсказан правильно, соответственно, F — неправильно. Каждая строка в матрице ошибок представляет предсказанный класс, а каждый столбец — фактически наблюдаемый класс.
Идеальный классификатор, если бы он существовал, выдавал бы только истинноположительные и истинноотрицательные классификации, и его матрица ошибок содержала бы значения, отличные от нуля, только на главной диагонали.
Меткость
Представляет собой долю правильных классификаций модели:
ACC=frac{TP+TN}{TP+TN+FP+FN}.
Несложно увидеть, что сумма в знаменателе формулы представляет собой общее число классифицируемых примеров. Графически это можно интерпретировать следующим образом:
Рисунок 1. Меткость
В английском языке этот термин обозначается как «accuracy», поэтому в интернете он часто упоминается как «аккуратность», хотя это слово и не передает смыслового значения данной величины.
Несмотря на то, что эта мера хорошо интерпретируется, на практике она используется достаточно редко, поскольку плохо работает в случае дисбаланса классов в обучающей выборке.
Поясним это на примере кредитного скоринга. Пусть требуется классифицировать заемщиков на добросовестных (не допустивших просрочку) и недобросовестных (допустивших просрочку). Целью является выявление недобросовестных заемщиков, поскольку связанные с ними издержки выше. Следовательно, классификация заемщика как недобросовестного является положительным событием, а как добросовестного — отрицательным.
Выборка содержит 1000 добросовестных заемщиков, 900 из которых классификатор предсказал правильно (TN=900, FP=100), и 100 недобросовестных, 50 из которых классификатор также определил верно (TP=50, FN=50).
Несложно вычислить, что:
ACC=frac{50+900}{50+900+100+50}=0.866.
Однако, если построить «наивную» модель, которая просто будет классифицировать всех клиентов, как добросовестных (на основании того, что таковых большинство), то меткость такой модели окажется:
ACC=frac{0+1000}{0+1000+0+100}=0.909.
Таким образом, оказалось, что меткость «бесполезной» модели, не имеющей предсказательной силы, выше, чем «рабочей» модели. Это противоречит здравому смыслу. Поэтому на практике стараются использовать альтернативные меры качества.
Точность
Точность равна доле истинноположительных классификаций к общему числу положительных классификаций. Данная величина часто упоминается как positive predictive value (PPV) или положительное прогностическое значение:
Pr=PPV=frac{TP}{TP+FP}.
Поясним данное выражение с помощью рисунка:
Рисунок 2. Точность
Несложно увидеть, что попытка отнести все объекты к одному классу неизбежно приведет к росту FP и уменьшению значения точности.
Полнота
Полнота, известная еще как чувствительность или доля истинноположительных примеров (TPR — true positive rate), определяется как число истинноположительных классификаций относительно общего числа положительных наблюдений:
Re=TPR=frac{TP}{TP+FN}.
Таким образом, полноту можно рассматривать как способность классификатора обнаруживать определенный класс. Графически полноту можно проиллюстрировать с помощью рисунка:
Рисунок 3. Полнота
Точность и полноту для каждого класса легко определять с помощью матрицы ошибок. Точность равна отношению соответствующего диагонального элемента матрицы и суммы элементов всей строки класса, а полнота — отношению диагонального элемента матрицы и суммы элементов всего столбца класса.
PPV_{c}=frac{A_{cc}}{sumlimits_{i=1}^{n}A_{ci}},
TPR_{c}=frac{A_{cc}}{sumlimits_{i=1}^{n}A_{ic}},
где c — класс, n — число элементов столбца (равно числу классов), i — номер элемента в столбце, A — элемент матрицы ошибок.
Специфичность
Специфичность классификатора — это доля истинноотрицательных (True Negative Rate — TNR) классификаций в общем числе отрицательных классификаций:
Sp=TNR=frac{TN}{TN+FP}.
TNR показывает, насколько хорошо модель классифицирует отрицательные примеры. Поясним это с помощью рисунка.
Рисунок 4. Специфичность
Очевидно, что если все отрицательные примеры классифицированы правильно (т.е. число ложноположительных случаев равно 0), то TPR=1.
F1-мера
Точность и полнота, в отличие от меткости, не зависят от соотношения классов и, следовательно, могут применяться в условиях несбалансированных выборок. На практике часто встречается задача поиска оптимального баланса между точностью и полнотой. Действительно, улучшая настройку модели на один класс, например, путем изменения дискриминационного порога, мы тем самым ухудшаем настройку на другой.
Чем выше точность и полнота, тем лучше модель. Но на практике их максимальные значения одновременно недостижимы, поэтому приходится искать баланс между ними. Для этого используется метрика, объединяющая в себе информацию о точности и полноте. Она называется F1-мера и вычисляется следующим образом:
F1=frac{2cdot PPVcdot TPR}{PPV+TPR}=frac{2cdot TP}{2cdot TP+FP+FN}.
В данном выражении точность PPV и полнота TPR имеют одинаковый вес, поэтому при их уменьшении F1-мера сокращается пропорционально.
Однако на практике чаще используется сбалансированная F1-мера, в которой точности и полноте присваиваются разные веса с целью найти оптимальный баланс между данными метриками. Для этого в формулу для F1-меры вводится дополнительный балансировочный параметр, обозначаемый β. Сбалансированная F1-мера вычисляется следующим образом:
F1=frac{(1-beta ^{2})cdot PPVcdot TPR}{beta ^{2}cdot PPV+TPR}.
Если параметр принимает значения из диапазона 0< beta < 1, то приоритет имеет точность, а если beta> 1, то полнота.
Еще одним источником критики F1-меры является отсутствие симметрии. Это означает, что она может изменить свое значение при инверсии положительного и отрицательного классов.
Метрика P4
Метрика P_{4} была разработана как расширение F1-меры, обладающее симметрией относительно инверсии классов. Вычисляется по формуле:
P_{4}=frac{4cdot TPcdot TN}{4cdot TPcdot TN+(TP+TN)cdot (FP+FN)}.
Метрика P_{4} изменяется в диапазоне от 0 до 1. Чем ближе значение метрики к 1, тем лучше работает модель. Очевидно, что значение меры стремится к 0, если хотя бы один из множителей в числителе становится равным нулю, т.е. когда модель теряет способность правильно распознавать положительные или отрицательные примеры.
AUC-ROC
ROC-кривая, или кривая рабочих характеристик приемника (Receiver Operating Characteristics curve), позволяет не только оценить качество работы классификатора, но и исследовать его поведение при различных значениях дискриминационного порога. Технология оценки качества моделей бинарной классификации с помощью ROC-кривых известна как ROC-анализ.
Рассмотрим совместно TPR и TNR классификатора. TPR показывает, насколько хорошо модель классифицирует положительные примеры. Очевидно, что если все положительные примеры классифицированы правильно (т.е. число ложноотрицательных случаев равно 0), то TPR=1. TNR показывает, насколько хорошо модель классифицирует отрицательные примеры. Очевидно, что если все отрицательные примеры классифицированы правильно (т.е. число ложноположительных случаев равно 0), то TPR=1.
Таким образом, по отдельности TPR и TNR характеризуют способность модели распознавать только один из классов. Но их совместное использование помогает создать метрику, которая позволяет выбирать значение дискриминационного порога, который оптимально балансирует модель между способностью распознавать положительные и отрицательные примеры. Именно эта задача и решается с помощью ROC-кривой.
Действительно, если изменять дискриминационный порог от 0 до 1 и наносить по оси абсцисс точки 1−TNR, а по оси ординат TPR, то полученный график и будет ROC-кривой. Величину 1−TNR называют долей ложноположительных классификаций (false positive rate) или показателем ложной тревоги. Она вычисляется следующим образом:
1-TNR=FPR=frac{FP}{FP+TN}.
При пороге, равном 1, все примеры будут классифицированы как отрицательные (FPR=1, TPR=1), а при пороге, равном 0, — как положительные (FPR=0, TPR=0). Поэтому ROC-кривая всегда идет от точки (0,0) до точки (1,1).
Рисунок 5. ROC-кривая
Несложно увидеть, что для идеальной модели ROC-кривая превращается в ломаную, проходящую через точки (0,0), (0,1) и (1,1). При этом площадь под ROC-кривой (AUC — Area Under Curve) окажется равной 1. Площадь под кривой выделена на рисунке светло-серым цветом.
Точка (0,1) соответствует идеальному состоянию модели, в котором и TPR, и TNR одновременно равны 1. Т.е. модель одинаково хорошо «научилась» работать как с положительными, так и с отрицательными примерами при существующем в обучающей выборке балансе классов.
Идеальная модель является скорее гипотетической и на практике, как правило, недостижима. Поэтому обычно приходится иметь дело с ROC-кривыми, которые не проходят через точку (0,1), а приближаются к ней на определенное расстояние. Соответственно и AUC−ROC оказывается меньше 1.
Таким образом показатель AUC−ROC является удобной мерой качества классификатора относительно идеального. Принята следующая шкала оценки качества.
| AUC | Оценка |
|---|---|
| 0.9 — 1 | Отличное |
| 0.8 — 0.9 | Очень хорошее |
| 0.7 — 0.8 | Хорошее |
| 0.6 — 0.7 | Удовлетворительное |
| 0.5 — 0.7 | Плохое |
Если AUC-ROC=0.5, то ROC-кривая превращается в линию, проходящую через точки (0,0) и (1,1), которая соответствует бесполезному классификатору, работающему как случайный предсказатель. Если AUC-ROC< 0.5, то получается модель, которая работает хуже случайного предсказателя и от ее использования следует отказаться.
AUC-PR
PR-кривые определяются аналогично ROC-кривым, но только по оси абсцисс у них откладываются значения полноты, а по оси ординат — точности.
Точность и полнота — две наиболее важные метрики, на которые следует обращать внимание при оценке качества модели бинарной классификации в условиях несбалансированности классов. Они помогают увидеть, какая часть фактически положительных наблюдений была классифицирована правильно, и какие среди классифицированных как положительные, были истинноположительными.
Если точность равна 1, то ложноположительные классификации отсутствуют. Но это ничего не говорит о том, были ли распознаны все положительные примеры. Если полнота равна 1, то все положительные объекты были распознаны правильно, а ложноотрицательные классификации отсутствуют. При этом ничего не говорится о том, сколько было допущено ложноположительных классификаций.
Таким образом, точность и полнота не особенно полезны для оценки качества классификатора, если их использовать по отдельности. В задаче классификации оценка точности, равная 1 для класса C, означает, что каждый элемент, помеченный как принадлежащий классу C, действительно принадлежит к классу C, но ничего не говорит о количестве элементов из класса
C, которые не были правильно классифицированы. Тогда как полнота, равная 1, означает, что каждый элемент из класса C был помечен как принадлежащий к классу C, но ничего не говорит о том, сколько элементов из других классов были также неправильно классифицированы как принадлежащие к классу C.
Обычно показатели точности и полноты не используются по отдельности. Вместо этого либо значения одной меры сравниваются с фиксированным уровнем другой (например, точность на уровне полноты 0.75), либо обе меры объединяются в один показатель. Примерами такой комбинации и является F1-мера — взвешенное гармоническое среднее точности и полноты.
Еще одним способом комбинирования точности и полноты в задаче оценки качества классификации являются так называемые кривые полнота-точность, которые строятся в системе координат, где по оси абсцисс откладывается полнота, а по оси ординат — точность. Кривая точность-полнота показывает, как выбор порога влияет на точность классификатора, а также помогает выбрать лучшее значение дискриминационного порога для определенного баланса классов.
Рисунок 6. Кривая точность-полнота
Каждая точка PR-кривой представляет определенное значение дискриминационного порога, а ее расположение соответствует результирующей точности и полноте, когда этот порог выбран. Точка 1 на рисунке соответствует значению дискриминационного порога, равному 1, а точка 3 — значению порога 0. Точка 2 соответствует идеальному классификатору и совпадает с координатами (1,1), а точка 4 — оптимальному значению порога (точка кривой, наиболее близкая к идеальной точке (1,1)).
Преимущества PR-кривой по сравнению с ROC:
- ROC-кривая, как правило, дает чрезмерно оптимистичную картину в условиях несбалансированности классов.
- При изменении распределения классов ROC-кривая не меняется, а PR-кривая отражает изменение.
Аналогично ROC-кривой, площадь под PR-кривой (для отличия от ROC ее часто называют PR−AUC) отражает качество классификатора и позволяет сравнивать кривые, соответствующие различным балансам классов и значениям порога. Чем выше площадь, тем лучше работает модель.
Пунктирная линия внизу графика соответствует бесполезному классификатору (no-skill model — модель без навыков, или базовая модель), уровень которой изменяется при изменении баланса классов. Такая модель будет присваивать рейтинг 0.5 для любого примера.
На рисунке ниже представлена линия, соответствующая балансу классов, когда положительные примеры составляют 10% от обучающей выборки.
Рисунок 7. Кривая точность-полнота при фиксированном балансе классов
На рисунке точка 1 соответствует порогу 0.5, точка 2 соответствует порогу [0, 0.5). Для порогов (0.5, 1] точность не определена из-за деления на ноль. Можно увидеть, что точность здесь является константой, то есть PPV=0.1 (соответствует доле положительного класса), PR−AUC=0.1.
Таким образом, полнота базовой модели лежит в диапазоне (0.5, 1] независимо от дисбаланса классов, а точность равна доле положительного класса в обучающей выборке.
На следующем рисунке представлена PR-кривая для идеальной модели. На ней точка 1 соответствует порогу (0, 1], точка 2 соответствует порогу 0. Очевидно, что PR−AUC=1.
Рисунок 8. Кривая точность-полнота для идеальной модели
И, наконец, на рисунке ниже отображена PR-кривая (красная линия) для модели, которая работает хуже, чем базовая модель «без навыков» (синяя пунктирная линия). Она расположена ниже линии базовой модели.
Рисунок 9. Кривая точность-полнота для модели хуже бесполезной
Очевидный способ повысить качество «плохой» модели без каких-либо настроек — просто инвертировать классы (класс 0 изменить на класс 1). Это автоматически приведет к повышению точности по сравнению с базовой моделью.
Обычно «плохая» PR-кривая классификатора указывает на то, что в обучающих данных присутствуют проблемы: они содержат шум или классы в них плохо выражены (модель не может выявить закономерность, в соответствии с которой один класс отличается от другого). В этом случае PR−AUC не превышает доли положительных примеров обучающей выборке.
Возможен гибридный случай, когда «плохая» модель работает лучше, чем модель «без навыков», но для определенных пороговых значений.
Коэффициент корреляции Мэтьюса
Коэффициент используется в качестве показателя качества бинарных классификаторов. Он учитывает истинные и ложные классификации и обычно рассматривается как сбалансированная мера, которую можно использовать даже в условиях сильного дисбаланса классов.
MCC, по сути, коэффициент корреляции между фактическими и предсказанными моделью бинарными классификациями. Он изменяется в диапазоне от -1 до 1. MCC=1 указывает на идеальную классификацию, когда фактические и предсказанные классы совпадают для всех обучающих примеров (т.е. ложноположительные и ложноотрицательные классификации отсутствуют). Модель, для которой MCC=0, соответствует случайному предсказателю. MCC=−1 указывает на полное расхождение между фактом и предсказанием (т.е. вместо положительного класса модель всегда предсказывает отрицательный, и наоборот), следовательно, истинноположительные и истинноотрицательные классификации отсутствуют.
Формула для расчета MCC имеет вид:
MCC=frac{TPcdot TN-FPcdot FN}{sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}}.
Несложно увидеть, что если в этой формуле обнулить все ложные классификации, то MCC=1, что соответствует ранее сделанным заключениям. Если число истинных и ложных классификаций равны, то числитель формулы становится равным 0 и MCC=0. И, наконец, если число истинных классификаций равно нулю, то числитель становится отрицательным, и делает таковым результат формулы.
Если какая-либо из четырех сумм в знаменателе равна нулю, знаменатель можно произвольно установить равным единице, это приводит к нулевому коэффициенту корреляции Мэтьюса.
Функция потерь логистической регрессии (Logistic loss function, Log Loss).
Функция потерь в задачах классификации показывает, какую «цену» придется заплатить за неточность предсказаний классификационной модели. Для логистической регрессии, решающей задачу бинарной классификации, она может быть вычислена следующим образом:
Log Loss=-frac{1}{l}sumlimits_{i=1}^{l}(y_{i}cdot log(widehat{y_{i}})+(1-y_{i})cdot log(1-widehat{y_{i}})),
где l — размер выборки, y_{i}=left { 0,1 right } — бинарная метка класса, заданная в примере, widehat{y_{i}} — предсказание модели.
Несложно увидеть, что функция потерь получается путем суммирования логарифма потерь на каждом примере. Потери на каждом примере определяются следующим образом: если предсказанный класс совпадает с фактическим, то потери равны 0, в противном случае потери равны 1. Очевидно, чем больше будет неправильных классификаций, тем больше будет значение LogLoss и тем хуже будет модель. Таким образом, чтобы получить лучшую модель, нужно минимизировать функцию потерь.
Преимуществом метрики LogLoss является устойчивость к выбросам и аномальным значениям в данных и простота вычисления. Недостатком — сложность интерпретации из-за нелинейного характера.
Сравнение метрик
Подведем итоги, кратко резюмируя преимущества и недостатки рассмотренных мер качества классификационных моделей.
| Мера | Преимущества | Недостатки |
|---|---|---|
| Меткость | Хорошо интерпретируется. | Чувствительна к дисбалансу классов. Неадекватно отражает точность классификации. |
| Точность | Не чувствительна к дисбалансу классов. | Отражает качество классификации только для положительного класса. |
| Полнота | Не чувствительна к дисбалансу классов. | Не учитывает отрицательные классификации. |
| Специфичность | Просто вычисляется и интерпретируется. | Характеризует способность модели распознавать только один класс. |
| F1-мера | Позволяет найти баланс между точностью и полнотой. | Чувствительность к дисбалансу, отсутствие симметрии. |
| P4 | Симметрична относительно инверсии классов. | Чувствительность к дисбалансу классов. |
| AUC-ROC | Наглядна, хорошо интерпретируется. | В условиях дисбаланса классов завышает качество модели. Не отражает изменения баланса классов. |
| AUC-PR | Наглядна, хорошо интерпретируется. | Не учитывает отрицательные классификации. |
| Коэффициент Мэтьюса | Более информативен, поскольку использует все типы результатов классификации. | Не может применяться, если один из множителей в знаменателе обращается в 0. |
| LogLoss | Устойчивость к выбросам в данных, простота вычисления. | Сложность интерпретации из-за нелинейного характера. |
В статье рассмотрены наиболее общие меры оценки качества моделей бинарной классификации, отмечены их преимущества и недостатки. Однако в литературе авторы предлагают и другие подходы, которые показали хорошие результаты при решении конкретных задач и не претендующие на универсальность.
Другие материалы по теме:
Метрики качества линейных регрессионных моделей
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
Классификация ошибок
Грамматические ошибки (Г) – это ошибки в структуре языковой единицы: слова, словосочетания или предложения, т.е. нарушение какой-либо грамматической нормы – словообразовательной, морфологической, синтаксической.
|
№ п/п |
Вид ошибки |
Примеры |
|
Г1 |
Ошибочное словообразование. Ошибочное образование форм существительного, прилагательного, числительного, местоимения, глагола (личных форм глаголов, действительных и страдательных причастий, деепричастий). |
Благородность, чуда техники, подчерк, надсмехаться; более интереснее, красивше; с пятистами рублями; жонглировал обоими руками, ихнего пафоса, вокруг его ничего нет; сколько нравственных принципов мы лишились из-за утраты духовности; им двигает чувство сострадания; ручейки воды, стекаемые вниз, поразили автора текста; вышев на сцену, певцы поклонились. |
|
Г2 |
Нарушение норм согласования |
Я знаком с группой ребят, серьезно увлекающимися джазом. |
|
Г3 |
Нарушение норм управления |
Нужно сделать природу более красивую. Все удивлялись его силой. |
|
Г4 |
Нарушение связи между подлежащим и сказуемым или способа выражения сказуемого |
Главное, чему теперь я хочу уделить внимание, это художественной стороне произведения. Он написал книгу, которая эпопея. Все были рады, счастливы и веселые. |
|
Г5 |
Ошибки в построении предложения с однородными членами |
Страна любила и гордилась поэтом. В сочинении я хотел сказать о значении спорта и почему я его люблю. |
|
Г6 |
Ошибки в построении предложения с деепричастным оборотом |
Читая текст, возникает такое чувство сопереживания. |
|
Г7 |
Ошибки в построении предложения с причастным оборотом |
Узкая дорожка была покрыта проваливающимся снегом под ногами. |
|
Г8 |
Ошибки в построении сложного предложения |
Эта книга научила меня ценить и уважать друзей, которую я прочитал еще в детстве. Человеку показалось то, что это сон. |
|
Г9 |
Смешение прямой и косвенной речи |
Автор сказал, что я не согласен с мнением рецензента. |
|
Г10 |
Нарушение границ предложения |
Его не приняли в баскетбольную команду. Потому что он был невысокого роста. |
|
Г11 |
Нарушение видовременной соотнесенности глагольных форм |
Замирает на мгновение сердце и вдруг застучит вновь. |
|
Г12 |
Пропуск члена предложения (эллипсис) |
На собрании было принято (?) провести субботник. |
|
Г13 |
Ошибки, связанные с употреблением частиц: отрыв частицы от того компонента предложения, к которому она относится |
Хорошо было бы, если бы на картине стояла бы подпись художника. В тексте всего раскрываются две проблемы. |
Речевые ошибки (Р) – это ошибки не в построении предложения, не в структуре языковой единицы, а в ее использовании, чаще всего в употреблении слова, т. е. нарушение лексических норм. Это плеоназм, тавтология, речевые штампы, неуместное использование просторечной лексики, диалектизмов, жаргонизмов; экспрессивных средств, неразличение паронимов. Ошибки в употреблении омонимов, антонимов, синонимов, не устраненная контекстом многозначность.
|
№ п/п |
Вид ошибки |
Примеры |
|
Р1 |
Употребление слова в несвойственном ему значении |
Мы были шокированы прекрасной игрой актеров. Благодаря пожару, лес сгорел. |
|
Р2 |
Неоправданное употребление диалектных и просторечных слов |
Таким людям всегда удается объегорить других. Обломов ничем не занимался и целыми днями валял дурака. |
|
Р3 |
Неудачное употребление местоимений |
Текст написал В. Белов. Он относится к художественному стилю; У меня сразу же возникла картина в своем воображении. |
|
Р4 |
Употребление слов иной стилевой окраски; смешение лексики разных эпох; неуместное употребление канцелярита, экспрессивных, эмоционально окрашенных слов, устаревшей лексики, жаргонизмов, неуместное употребление фразеологизмов |
По задумке автора, герой побеждает; Молчалин работает секретарем Фамусова; В романе А.С. Пушкина имеют место лирические отступления; Автор то и дело прибегает к употреблению метафор и олицетворений. Если бы я был там, то за такое отношение к матери я бы этому кексу в грызло бы дал; Зощенко палец в рот не клади, а дай только посмешить читателя. |
|
Р5 |
Неразличение оттенков значения, вносимых в слово приставкой и суффиксом |
В таких случаях я взглядываю в словарь. |
|
Р6 |
Неразличение паронимов, синонимичных слов; ошибки в употреблении антонимов при построении антитезы; разрушение образного значения фразеологизма в неудачно организованном контексте |
Были приняты эффектные меры; Имя этого поэта знакомо во многих странах; В третьей части текста не веселый, но и не мажорный мотив заставляет нас задуматься; грампластинка не сказала еще своего последнего слова. |
|
Р7 |
Нарушение лексической сочетаемости |
Автор использует художественные особенности. |
|
Р8 |
Употребление лишних слов, в том числе плеоназм |
Молодой юноша; очень прекрасный. |
|
Р9 |
Употребление рядом или близко однокоренных слов (тавтология) |
В этом рассказе рассказывается о реальных событиях. |
|
Р10 |
Неоправданное повторение слова |
Герой рассказа не задумывается над своим поступком. Герой даже не понимает всей глубины содеянного им. |
|
Р11 |
Бедность и однообразие синтаксических конструкций |
Когда писатель пришел в редакцию, его принял главный редактор. Когда они поговорили, писатель отправился в гостиницу. |
|
Р12 |
Употребление лишних слов, лексическая избыточность |
Тогда о том, чтобы вы могли улыбнуться, об этом позаботится книжный наш магазин. |
Логические ошибки (Л). Логические ошибки связаны с нарушением логической правильности речи. Они возникают в результате нарушения законов логики, допущенного как в пределах одного предложения, суждения, так и на уровне целого текста.
|
№ п/п |
Вид ошибки |
Примеры |
|
Л1 |
Сопоставление (противопоставление) двух логически неоднородных (различных по объему и по содержанию) понятий в предложении, тексте |
На уроке присутствовали директор, библиотекарь, а также Анна Петровна Иванова и Зоя Ивановна Петрова; Он облокотился спиной на батарею; За хорошую учебу и воспитание детей родители обучающихся получили благодарственные письма от администрации школы. |
|
Л2 |
Нарушение причинно-следственных отношений |
В последние годы очень много сделано для модернизации образования, однако педагоги работают по-старому, так как вопросы модернизации образования решаются слабо. |
|
Л3 |
Пропуск звена в объяснении, «логический скачок». |
Людской поток через наш двор перекрыть вряд ли возможно. [?] А как хочется, чтобы двор был украшением и школы, и поселка. |
|
Л4 |
Перестановка частей текста (если она не обусловлена заданием к сочинению или изложению) |
Пора вернуть этому слову его истинный смысл! Честь… Но как это сделать? |
|
Л5 |
Неоправданная подмена лица, от которого ведется повествование (например, сначала от первого, затем от третьего лица) |
Автор пишет о природе, описывает природу севера, вижу снега и просторы снежных равнин. |
|
Л6 |
Сопоставление логически несопоставимых понятий |
Синтаксис энциклопедических статей отличен от других научных статей. |
|
Композиционно-текстовые ошибки |
||
|
Л7 |
Неудачный зачин |
Текст начинается предложением, содержащим указание на предыдущий контекст, который в самом тексте отсутствует, наличием указательных словоформ в первом предложении, например: В этом тексте автор… |
|
Л8 |
Ошибки в основной части |
а) Сближение относительно далеких мыслей в одном предложении. б) Отсутствие последовательности в изложении; бессвязность и нарушение порядка предложений. в) Использование разнотипных по структуре предложений, ведущее к затруднению понимания смысла. |
|
Л9 |
Неудачная концовка |
Дублирование вывода, неоправданное повторение высказанной ранее мысли. |
Фактические ошибки (Ф) — разновидность неязыковых ошибок, заключающаяся в том, что пишущий приводит факты, противоречащие действительности, дает неправильную информацию о фактических обстоятельствах, как связанных, так и не связанных с анализируемым текстом (фоновые знания)
|
№ п/п |
Вид ошибки |
Примеры |
|
Ф1 |
Искажение содержания литературного произведения, неправильное толкование, неудачный выбор примеров |
Базаров был нигилист и поэтому убил старуху топором; Ленский вернулся в свое имение из Англии; Счастьем для Обломова было одиночество и равнодушие. |
|
Ф2 |
Неточность в цитате. Отсутствие указания на автора цитаты. Неверно названный автор цитаты. |
Книга очень много для меня значит, ведь еще Ленин сказал: «Век живи – век учись!» |
|
Ф3 |
Незнание исторических и др. фактов, в том числе временное смещение. |
Великая Отечественная война 1812 года; Столица США — Нью-Йорк. |
|
Ф4 |
Неточности в именах, фамилиях, прозвищах литературных героев. Искажения в названиях литературных произведений, их жанров, ошибка в указании автора. |
Тургеньев; «Тарас и Бульба»; в повести Тургенева «Преступление и наказание». |
ОШИБКИ ОРФОГРАФИЧЕСКИЕ, ПУНКТУАЦИОННЫЕ, ГРАФИЧЕСКИЕ, ОПИСКИ
При проверке грамотности (К7-К8) учитываются ошибки
- на изученные правила;
- негрубые (две негрубые считаются за одну):
- в исключениях из правил;
- в написании большой буквы в составных собственных наименованиях;
- в случаях раздельного и слитного написания не с прилагательными и причастиями, выступающими в роли сказуемого;
- в написании и и ы после приставок;
- в трудных случаях различения не и ни (Куда он только не обращался! Куда он ни обращался, никто не мог дать ему ответ. Никто иной не …; не кто иной, как…; ничто иное не …; не что иное, как … и др.);
- в случаях, когда вместо одного знака препинания поставлен другой;
- в пропуске одного из сочетающихся знаков препинания или в нарушении их последовательности;
- повторяющиеся (считается за одну ошибку повтор в одном и том же слове или в корне однокоренных слов);
- однотипные (первые три однотипные ошибки считаются за одну ошибку,
каждая следующая подобная ошибка учитывается как самостоятельная):
ошибки на одно правило, если условия выбора правильного написания заключены в грамматических (в армии, в роще; колют, борются) и фонетических (пирожок, сверчок) особенностях данного слова.
! Не считаются однотипными ошибки на такое правило, в котором для выяснения правильного написания одного слова требуется подобрать другое (опорное) слово или его форму (вода – воды, рот – ротик, грустный – грустить, резкий – резок).
! Понятие об однотипных ошибках не распространяется на пунктуационные ошибки.
! Ошибки (две и более) в одном непроверяемом слове считаются за одну ошибку.
При проверке грамотности (К7-К8) не учитываются ошибки
- орфографические:
- в переносе слов;
- буквы э/е после согласных в иноязычных словах (рэкет, пленэр) и после гласных в собственных именах (Мариетта);
- прописная / строчная буквы
- в названиях, связанных с религией: М(м)асленица, Р(р)ождество, Б(б)ог.
- при переносном употреблении собственных имен (Обломовы и обломовы).
- в собственных именах нерусского происхождения; написание фамилий с первыми частями дон, ван, сент… (дон Педро и Дон Кихот).
- слитное / дефисное / раздельное написание
- в сложных существительных без соединительной гласной (в основном заимствования), не регулируемых правилами и не входящих в словарь-минимум (ленд-лиз, люля-кебаб, ноу-хау, папье-маше, перекати-поле, гуляй-город пресс-папье, но бефстроганов, метрдотель, портшез, прейскурант);
- на правила, которые не включены в школьную программу (например, правило слитного / раздельного написания наречных единиц / наречий с приставкой /предлогом, например: в разлив, за глаза ругать, под стать, в бегах, в рассрочку, на попятную, в диковинку, на ощупь, на подхвате, на попа ставить (ср. действующее написание напропалую, врассыпную);
- пунктуационные ошибки:
- тире в неполном предложении;
- обособление несогласованных определений, относящихся к нарицательным именам существительным;
- запятые при ограничительно-выделительных оборотах;
- различение омонимичных частиц и междометий и, соответственно, невыделение или выделение их запятыми;
- в передаче авторской пунктуации;
- графические ошибки (средства письменности языка, фиксирующие отношения между буквами на письме и звуками устной речи); различные приемы сокращения слов, использование пробелов между словами, различных подчеркиваний и шрифтовых выделений;
- описки и опечатки:
— искажение звукового облика слова (рапотает вместо работает, мемля вместо земля);.
— пропуски букв (весь роман стоится на этом конфликте;
— перестановки букв (новые наименования пордуктов);
— замены одних буквенных знаков другими (лешендарное Ледовое побоище);
— добавление лишних букв (в любых, дашже самых сложных условиях).