
В статистике регрессия — это метод, который можно использовать для анализа взаимосвязи между переменными-предикторами и переменной-откликом.
Когда вы используете программное обеспечение (например, R, SAS, SPSS и т. д.) для выполнения регрессионного анализа, вы получите в качестве выходных данных таблицу регрессии, в которой суммируются результаты регрессии. Важно уметь читать эту таблицу, чтобы понимать результаты регрессионного анализа.
В этом руководстве рассматривается пример регрессионного анализа и дается подробное объяснение того, как читать и интерпретировать выходные данные таблицы регрессии.
Пример регрессии
Предположим, у нас есть следующий набор данных, который показывает общее количество часов обучения, общее количество сданных подготовительных экзаменов и итоговый балл за экзамен, полученный для 12 разных студентов:

Чтобы проанализировать взаимосвязь между учебными часами и сданными подготовительными экзаменами и окончательным экзаменационным баллом, который получает студент, мы запускаем множественную линейную регрессию, используя отработанные часы и подготовительные экзамены, взятые в качестве переменных-предикторов, и итоговый экзаменационный балл в качестве переменной ответа.
Мы получаем следующий вывод:

Проверка соответствия модели
В первом разделе показано несколько различных чисел, которые измеряют соответствие регрессионной модели, т. е. насколько хорошо регрессионная модель способна «соответствовать» набору данных.

Вот как интерпретировать каждое из чисел в этом разделе:
Несколько R
Это коэффициент корреляции.Он измеряет силу линейной зависимости между переменными-предикторами и переменной отклика. R, кратный 1, указывает на идеальную линейную зависимость, тогда как R, кратный 0, указывает на отсутствие какой-либо линейной зависимости. Кратный R — это квадратный корень из R-квадрата (см. ниже).
В этом примере множитель R равен 0,72855 , что указывает на довольно сильную линейную зависимость между предикторами часов обучения и подготовительных экзаменов и итоговой оценкой экзаменационной переменной ответа.
R-квадрат
Его часто записывают как r 2 , а также называют коэффициентом детерминации.Это доля дисперсии переменной отклика, которая может быть объяснена предикторной переменной.
Значение для R-квадрата может варьироваться от 0 до 1. Значение 0 указывает, что переменная отклика вообще не может быть объяснена предикторной переменной. Значение 1 указывает, что переменная отклика может быть полностью объяснена без ошибок с помощью переменной-предиктора.
В этом примере R-квадрат равен 0,5307 , что указывает на то, что 53,07% дисперсии итоговых экзаменационных баллов можно объяснить количеством часов обучения и количеством сданных подготовительных экзаменов.
Связанный: Что такое хорошее значение R-квадрата?
Скорректированный R-квадрат
Это модифицированная версия R-квадрата, которая была скорректирована с учетом количества предикторов в модели. Он всегда ниже R-квадрата. Скорректированный R-квадрат может быть полезен для сравнения соответствия различных моделей регрессии друг другу.
В этом примере скорректированный R-квадрат равен 0,4265.
Стандартная ошибка регрессии
Стандартная ошибка регрессии — это среднее расстояние, на которое наблюдаемые значения отклоняются от линии регрессии. В этом примере наблюдаемые значения отклоняются от линии регрессии в среднем на 7,3267 единиц.
Связанный: Понимание стандартной ошибки регрессии
Наблюдения
Это просто количество наблюдений в нашем наборе данных. В этом примере общее количество наблюдений равно 12 .
Тестирование общей значимости регрессионной модели
В следующем разделе показаны степени свободы, сумма квадратов, средние квадраты, F-статистика и общая значимость регрессионной модели.

Вот как интерпретировать каждое из чисел в этом разделе:
Степени свободы регрессии
Это число равно: количеству коэффициентов регрессии — 1. В этом примере у нас есть член пересечения и две переменные-предикторы, поэтому у нас всего три коэффициента регрессии, что означает, что степени свободы регрессии равны 3 — 1 = 2 .
Всего степеней свободы
Это число равно: количество наблюдений – 1. В данном примере у нас 12 наблюдений, поэтому общее количество степеней свободы 12 – 1 = 11 .
Остаточные степени свободы
Это число равно: общая df – регрессионная df.В этом примере остаточные степени свободы 11 – 2 = 9 .
Средние квадраты
Средние квадраты регрессии рассчитываются как регрессия SS / регрессия df.В этом примере регрессия MS = 546,53308/2 = 273,2665 .
Остаточные средние квадраты вычисляются как остаточный SS / остаточный df.В этом примере остаточная MS = 483,1335/9 = 53,68151 .
F Статистика
Статистика f рассчитывается как регрессия MS/остаточная MS. Эта статистика показывает, обеспечивает ли регрессионная модель лучшее соответствие данным, чем модель, которая не содержит независимых переменных.
По сути, он проверяет, полезна ли регрессионная модель в целом. Как правило, если ни одна из переменных-предикторов в модели не является статистически значимой, общая F-статистика также не является статистически значимой.
В этом примере статистика F равна 273,2665/53,68151 = 5,09 .
Значение F (P-значение)
Последнее значение в таблице — это p-значение, связанное со статистикой F. Чтобы увидеть, значима ли общая модель регрессии, вы можете сравнить p-значение с уровнем значимости; распространенные варианты: 0,01, 0,05 и 0,10.
Если p-значение меньше уровня значимости, имеется достаточно доказательств, чтобы сделать вывод о том, что регрессионная модель лучше соответствует данным, чем модель без переменных-предикторов. Этот вывод хорош, потому что он означает, что переменные-предикторы в модели действительно улучшают соответствие модели.
В этом примере p-значение равно 0,033 , что меньше обычного уровня значимости 0,05. Это указывает на то, что регрессионная модель в целом статистически значима, т. е. модель лучше соответствует данным, чем модель без переменных-предикторов.
Тестирование общей значимости регрессионной модели
В последнем разделе показаны оценки коэффициентов, стандартная ошибка оценок, t-stat, p-значения и доверительные интервалы для каждого термина в регрессионной модели.

Вот как интерпретировать каждое из чисел в этом разделе:
Коэффициенты
Коэффициенты дают нам числа, необходимые для записи оценочного уравнения регрессии:
у шляпа знак равно б 0 + б 1 Икс 1 + б 2 Икс 2 .
В этом примере расчетное уравнение регрессии имеет вид:
итоговый балл за экзамен = 66,99 + 1,299 (часы обучения) + 1,117 (подготовительные экзамены)
Каждый отдельный коэффициент интерпретируется как среднее увеличение переменной отклика на каждую единицу увеличения данной переменной-предиктора при условии, что все остальные переменные-предикторы остаются постоянными. Например, для каждого дополнительного часа обучения среднее ожидаемое увеличение итогового экзаменационного балла составляет 1,299 балла при условии, что количество сданных подготовительных экзаменов остается постоянным.
Перехват интерпретируется как ожидаемый средний итоговый балл за экзамен для студента, который учится ноль часов и не сдает подготовительных экзаменов. В этом примере ожидается, что учащийся наберет 66,99 балла, если он будет заниматься ноль часов и не сдавать подготовительных экзаменов. Однако будьте осторожны при интерпретации перехвата выходных данных регрессии, потому что это не всегда имеет смысл.
Например, в некоторых случаях точка пересечения может оказаться отрицательным числом, что часто не имеет очевидной интерпретации. Это не означает, что модель неверна, это просто означает, что перехват сам по себе не должен интерпретироваться как означающий что-либо.
Стандартная ошибка, t-статистика и p-значения
Стандартная ошибка — это мера неопределенности оценки коэффициента для каждой переменной.
t-stat — это просто коэффициент, деленный на стандартную ошибку. Например, t-stat для часов обучения составляет 1,299 / 0,417 = 3,117.
В следующем столбце показано значение p, связанное с t-stat. Это число говорит нам, является ли данная переменная отклика значимой в модели. В этом примере мы видим, что значение p для часов обучения равно 0,012, а значение p для подготовительных экзаменов равно 0,304. Это указывает на то, что количество учебных часов является важным предиктором итогового экзаменационного балла, а количество подготовительных экзаменов — нет.
Доверительный интервал для оценок коэффициентов
В последних двух столбцах таблицы представлены нижняя и верхняя границы 95% доверительного интервала для оценок коэффициентов.
Например, оценка коэффициента для часов обучения составляет 1,299, но вокруг этой оценки есть некоторая неопределенность. Мы никогда не можем знать наверняка, является ли это точным коэффициентом. Таким образом, 95-процентный доверительный интервал дает нам диапазон вероятных значений истинного коэффициента.
В этом случае 95% доверительный интервал для часов обучения составляет (0,356, 2,24). Обратите внимание, что этот доверительный интервал не содержит числа «0», что означает, что мы вполне уверены, что истинное значение коэффициента часов обучения не равно нулю, т. е. является положительным числом.
Напротив, 95% доверительный интервал для Prep Exams составляет (-1,201, 3,436). Обратите внимание, что этот доверительный интервал действительно содержит число «0», что означает, что истинное значение коэффициента подготовительных экзаменов может быть равно нулю, т. е. несущественно для прогнозирования результатов итоговых экзаменов.
Дополнительные ресурсы
Понимание нулевой гипотезы для линейной регрессии
Понимание F-теста общей значимости в регрессии
Как сообщить о результатах регрессии
Для того чтобы модель линейной регрессии можно было применять на практике необходимо сначала оценить её качество. Для этих целей предложен ряд показателей, каждый из которых предназначен для использования в различных ситуациях и имеет свои особенности применения (линейные и нелинейные, устойчивые к аномалиям, абсолютные и относительные, и т.д.). Корректный выбор меры для оценки качества модели является одним из важных факторов успеха в решении задач анализа данных.
«Хорошая» аналитическая модель должна удовлетворять двум, зачастую противоречивым, требованиям — как можно лучше соответствовать данным и при этом быть удобной для интерпретации пользователем. Действительно, повышение соответствия модели данным как правило связано с её усложнением (в случае регрессии — увеличением числа входных переменных модели). А чем сложнее модель, тем ниже её интерпретируемость.
Поэтому при выборе между простой и сложной моделью последняя должна значимо увеличивать соответствие модели данным чтобы оправдать рост сложности и соответствующее снижение интерпретируемости. Если это условие не выполняется, то следует выбрать более простую модель.
Таким образом, чтобы оценить, насколько повышение сложности модели значимо увеличивает её точность, необходимо использовать аппарат оценки качества регрессионных моделей. Он включает в себя следующие меры:
- Среднеквадратичная ошибка (MSE).
- Корень из среднеквадратичной ошибки (RMSE).
- Среднеквадратичная ошибка в процентах (MSPE).
- Средняя абсолютная ошибка (MAE).
- Средняя абсолютная ошибка в процентах (MAPE).
- Cимметричная средняя абсолютная процентная ошибка (SMAPE).
- Средняя абсолютная масштабированная ошибка (MASE)
- Средняя относительная ошибка (MRE).
- Среднеквадратичная логарифмическая ошибка (RMSLE).
- Коэффициент детерминации R-квадрат.
- Скорректированный коэффициент детеминации.
Прежде чем перейти к изучению метрик качества, введём некоторые базовые понятия, которые нам в этом помогут. Для этого рассмотрим рисунок.
Рисунок 1. Линейная регрессия
Наклонная прямая представляет собой линию регрессии с переменной, на которой расположены точки, соответствующие предсказанным значениям выходной переменной widehat{y} (кружки синего цвета). Оранжевые кружки представляют фактические (наблюдаемые) значения y . Расстояния между ними и линией регрессии — это ошибка предсказания модели y-widehat{y} (невязка, остатки). Именно с её использованием вычисляются все приведённые в статье меры качества.
Горизонтальная линия представляет собой модель простого среднего, где коэффициент при независимой переменной x равен нулю, и остаётся только свободный член b, который становится равным среднему арифметическому фактических значений выходной переменной, т.е. b=overline{y}. Очевидно, что такая модель для любого значения входной переменной будет выдавать одно и то же значение выходной — overline{y}.
В линейной регрессии такая модель рассматривается как «бесполезная», хуже которой работает только «случайный угадыватель». Однако, она используется для оценки, насколько дисперсия фактических значений y относительно линии среднего, больше, чем относительно линии регрессии с переменной, т.е. насколько модель с переменной лучше «бесполезной».
MSE
Среднеквадратичная ошибка (Mean Squared Error) применяется в случаях, когда требуется подчеркнуть большие ошибки и выбрать модель, которая дает меньше именно больших ошибок. Большие значения ошибок становятся заметнее за счет квадратичной зависимости.
Действительно, допустим модель допустила на двух примерах ошибки 5 и 10. В абсолютном выражении они отличаются в два раза, но если их возвести в квадрат, получив 25 и 100 соответственно, то отличие будет уже в четыре раза. Таким образом модель, которая обеспечивает меньшее значение MSE допускает меньше именно больших ошибок.
MSE рассчитывается по формуле:
MSE=frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y}_{i})^{2},
где n — количество наблюдений по которым строится модель и количество прогнозов, y_{i} — фактические значение зависимой переменной для i-го наблюдения, widehat{y}_{i} — значение зависимой переменной, предсказанное моделью.
Таким образом, можно сделать вывод, что MSE настроена на отражение влияния именно больших ошибок на качество модели.
Недостатком использования MSE является то, что если на одном или нескольких неудачных примерах, возможно, содержащих аномальные значения будет допущена значительная ошибка, то возведение в квадрат приведёт к ложному выводу, что вся модель работает плохо. С другой стороны, если модель даст небольшие ошибки на большом числе примеров, то может возникнуть обратный эффект — недооценка слабости модели.
RMSE
Корень из среднеквадратичной ошибки (Root Mean Squared Error) вычисляется просто как квадратный корень из MSE:
RMSE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y_{i}})^{2}}
MSE и RMSE могут минимизироваться с помощью одного и того же функционала, поскольку квадратный корень является неубывающей функцией. Например, если у нас есть два набора результатов работы модели, A и B, и MSE для A больше, чем MSE для B, то мы можем быть уверены, что RMSE для A больше RMSE для B. Справедливо и обратное: если MSE(A)<MSE(B), то и RMSE(A)<RMSE(B).
Следовательно, сравнение моделей с помощью RMSE даст такой же результат, что и для MSE. Однако с MSE работать несколько проще, поэтому она более популярна у аналитиков. Кроме этого, имеется небольшая разница между этими двумя ошибками при оптимизации с использованием градиента:
frac{partial RMSE}{partial widehat{y}_{i}}=frac{1}{2sqrt{MSE}}frac{partial MSE}{partial widehat{y}_{i}}
Это означает, что перемещение по градиенту MSE эквивалентно перемещению по градиенту RMSE, но с другой скоростью, и скорость зависит от самой оценки MSE. Таким образом, хотя RMSE и MSE близки с точки зрения оценки моделей, они не являются взаимозаменяемыми при использовании градиента для оптимизации.
Влияние каждой ошибки на RMSE пропорционально величине квадрата ошибки. Поэтому большие ошибки оказывают непропорционально большое влияние на RMSE. Следовательно, RMSE можно считать чувствительной к аномальным значениям.
MSPE
Среднеквадратичная ошибка в процентах (Mean Squared Percentage Error) представляет собой относительную ошибку, где разность между наблюдаемым и фактическим значениями делится на наблюдаемое значение и выражается в процентах:
MSPE=frac{100}{n}sumlimits_{i=1}^{n}left ( frac{y_{i}-widehat{y}_{i}}{y_{i}} right )^{2}
Проблемой при использовании MSPE является то, что, если наблюдаемое значение выходной переменной равно 0, значение ошибки становится неопределённым.
MSPE можно рассматривать как взвешенную версию MSE, где вес обратно пропорционален квадрату наблюдаемого значения. Таким образом, при возрастании наблюдаемых значений ошибка имеет тенденцию уменьшаться.
MAE
Cредняя абсолютная ошибка (Mean Absolute Error) вычисляется следующим образом:
MAE=frac{1}{n}sumlimits_{i=1}^{n}left | y_{i}-widehat{y}_{i} right |
Т.е. MAE рассчитывается как среднее абсолютных разностей между наблюдаемым и предсказанным значениями. В отличие от MSE и RMSE она является линейной оценкой, а это значит, что все ошибки в среднем взвешены одинаково. Например, разница между 0 и 10 будет вдвое больше разницы между 0 и 5. Для MSE и RMSE, как отмечено выше, это не так.
Поэтому MAE широко используется, например, в финансовой сфере, где ошибка в 10 долларов должна интерпретироваться как в два раза худшая, чем ошибка в 5 долларов.
MAPE
Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error) вычисляется следующим образом:
MAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{left | y_{i} right |}
Эта ошибка не имеет размерности и очень проста в интерпретации. Её можно выражать как в долях, так и в процентах. Если получилось, например, что MAPE=11.4, то это говорит о том, что ошибка составила 11.4% от фактического значения.
SMAPE
Cимметричная средняя абсолютная процентная ошибка (Symmetric Mean Absolute Percentage Error) — это мера точности, основанная на процентных (или относительных) ошибках. Обычно определяется следующим образом:
SMAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{(left | y_{i} right |+left | widehat{y}_{i} right |)/2}
Т.е. абсолютная разность между наблюдаемым и предсказанным значениями делится на полусумму их модулей. В отличие от обычной MAPE, симметричная имеет ограничение на диапазон значений. В приведённой формуле он составляет от 0 до 200%. Однако, поскольку диапазон от 0 до 100% гораздо удобнее интерпретировать, часто используют формулу, где отсутствует деление знаменателя на 2.
Одной из возможных проблем SMAPE является неполная симметрия, поскольку в разных диапазонах ошибка вычисляется неодинаково. Это иллюстрируется следующим примером: если y_{i}=100 и widehat{y}_{i}=110, то SMAPE=4.76, а если y_{i}=100 и widehat{y}_{i}=90, то SMAPE=5.26.
Ограничение SMAPE заключается в том, что, если наблюдаемое или предсказанное значение равно 0, ошибка резко возрастет до верхнего предела (200% или 100%).
MASE
Средняя абсолютная масштабированная ошибка (Mean absolute scaled error) — это показатель, который позволяет сравнивать две модели. Если поместить MAE для новой модели в числитель, а MAE для исходной модели в знаменатель, то полученное отношение и будет равно MASE. Если значение MASE меньше 1, то новая модель работает лучше, если MASE равно 1, то модели работают одинаково, а если значение MASE больше 1, то исходная модель работает лучше, чем новая модель. Формула для расчета MASE имеет вид:
MASE=frac{MAE_{i}}{MAE_{j}}
MASE симметрична и устойчива к выбросам.
MRE
Средняя относительная ошибка (Mean Relative Error) вычисляется по формуле:
MRE=frac{1}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y}_{i}right |}{left | y_{i} right |}
Несложно увидеть, что данная мера показывает величину абсолютной ошибки относительно фактического значения выходной переменной (поэтому иногда эту ошибку называют также средней относительной абсолютной ошибкой, MRAE). Действительно, если значение абсолютной ошибки, скажем, равно 10, то сложно сказать много это или мало. Например, относительно значения выходной переменной, равного 20, это составляет 50%, что достаточно много. Однако относительно значения выходной переменной, равного 100, это будет уже 10%, что является вполне нормальным результатом.
Очевидно, что при вычислении MRE нельзя применять наблюдения, в которых y_{i}=0.
Таким образом, MRE позволяет более адекватно оценить величину ошибки, чем абсолютные ошибки. Кроме этого она является безразмерной величиной, что упрощает интерпретацию.
RMSLE
Среднеквадратичная логарифмическая ошибка (Root Mean Squared Logarithmic Error) представляет собой RMSE, вычисленную в логарифмическом масштабе:
RMSLE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(log(widehat{y}_{i}+1)-log{(y_{i}+1}))^{2}}
Константы, равные 1, добавляемые в скобках, необходимы чтобы не допустить обращения в 0 выражения под логарифмом, поскольку логарифм нуля не существует.
Известно, что логарифмирование приводит к сжатию исходного диапазона изменения значений переменной. Поэтому применение RMSLE целесообразно, если предсказанное и фактическое значения выходной переменной различаются на порядок и больше.
R-квадрат
Перечисленные выше ошибки не так просто интерпретировать. Действительно, просто зная значение средней абсолютной ошибки, скажем, равное 10, мы сразу не можем сказать хорошая это ошибка или плохая, и что нужно сделать чтобы улучшить модель.
В этой связи представляет интерес использование для оценки качества регрессионной модели не значения ошибок, а величину показывающую, насколько данная модель работает лучше, чем модель, в которой присутствует только константа, а входные переменные отсутствуют или коэффициенты регрессии при них равны нулю.
Именно такой мерой и является коэффициент детерминации (Coefficient of determination), который показывает долю дисперсии зависимой переменной, объяснённой с помощью регрессионной модели. Наиболее общей формулой для вычисления коэффициента детерминации является следующая:
R^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}}
Практически, в числителе данного выражения стоит среднеквадратическая ошибка оцениваемой модели, а в знаменателе — модели, в которой присутствует только константа.
Главным преимуществом коэффициента детерминации перед мерами, основанными на ошибках, является его инвариантность к масштабу данных. Кроме того, он всегда изменяется в диапазоне от −∞ до 1. При этом значения близкие к 1 указывают на высокую степень соответствия модели данным. Очевидно, что это имеет место, когда отношение в формуле стремится к 0, т.е. ошибка модели с переменными намного меньше ошибки модели с константой. R^{2}=0 показывает, что между независимой и зависимой переменными модели имеет место функциональная зависимость.
Когда значение коэффициента близко к 0 (т.е. ошибка модели с переменными примерно равна ошибке модели только с константой), это указывает на низкое соответствие модели данным, когда модель с переменными работает не лучше модели с константой.
Кроме этого, бывают ситуации, когда коэффициент R^{2} принимает отрицательные значения (обычно небольшие). Это произойдёт, если ошибка модели среднего становится меньше ошибки модели с переменной. В этом случае оказывается, что добавление в модель с константой некоторой переменной только ухудшает её (т.е. регрессионная модель с переменной работает хуже, чем предсказание с помощью простой средней).
На практике используют следующую шкалу оценок. Модель, для которой R^{2}>0.5, является удовлетворительной. Если R^{2}>0.8, то модель рассматривается как очень хорошая. Значения, меньшие 0.5 говорят о том, что модель плохая.
Скорректированный R-квадрат
Основной проблемой при использовании коэффициента детерминации является то, что он увеличивается (или, по крайней мере, не уменьшается) при добавлении в модель новых переменных, даже если эти переменные никак не связаны с зависимой переменной.
В связи с этим возникают две проблемы. Первая заключается в том, что не все переменные, добавляемые в модель, могут значимо увеличивать её точность, но при этом всегда увеличивают её сложность. Вторая проблема — с помощью коэффициента детерминации нельзя сравнивать модели с разным числом переменных. Чтобы преодолеть эти проблемы используют альтернативные показатели, одним из которых является скорректированный коэффициент детерминации (Adjasted coefficient of determinftion).
Скорректированный коэффициент детерминации даёт возможность сравнивать модели с разным числом переменных так, чтобы их число не влияло на статистику R^{2}, и накладывает штраф за дополнительно включённые в модель переменные. Вычисляется по формуле:
R_{adj}^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}/(n-k)}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}/(n-1)}
где n — число наблюдений, на основе которых строится модель, k — количество переменных в модели.
Скорректированный коэффициент детерминации всегда меньше единицы, но теоретически может принимать значения и меньше нуля только при очень малом значении обычного коэффициента детерминации и большом количестве переменных модели.
Сравнение метрик
Резюмируем преимущества и недостатки каждой приведённой метрики в следующей таблице:
| Мера | Сильные стороны | Слабые стороны |
|---|---|---|
| MSE | Позволяет подчеркнуть большие отклонения, простота вычисления. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. Сложность интерпретации из-за квадратичной зависимости. |
| RMSE | Простота интерпретации, поскольку измеряется в тех же единицах, что и целевая переменная. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. |
| MSPE | Нечувствительна к выбросам. Хорошо интерпретируема, поскольку имеет линейный характер. | Поскольку вклад всех ошибок отдельных наблюдений взвешивается одинаково, не позволяет подчёркивать большие и малые ошибки. |
| MAPE | Является безразмерной величиной, поэтому её интерпретация не зависит от предметной области. | Нельзя использовать для наблюдений, в которых значения выходной переменной равны нулю. |
| SMAPE | Позволяет корректно работать с предсказанными значениями независимо от того больше они фактического, или меньше. | Приближение к нулю фактического или предсказанного значения приводит к резкому росту ошибки, поскольку в знаменателе присутствует как фактическое, так и предсказанное значения. |
| MASE | Не зависит от масштаба данных, является симметричной: положительные и отрицательные отклонения от фактического значения учитываются одинаково. Устойчива к выбросам. Позволяет сравнивать модели. | Сложность интерпретации. |
| MRE | Позволяет оценить величину ошибки относительно значения целевой переменной. | Неприменима для наблюдений с нулевым значением выходной переменной. |
| RMSLE | Логарифмирование позволяет сделать величину ошибки более устойчивой, когда разность между фактическим и предсказанным значениями различается на порядок и выше | Может быть затруднена интерпретация из-за нелинейности. |
| R-квадрат | Универсальность, простота интерпретации. | Возрастает даже при включении в модель бесполезных переменных. Плохо работает когда входные переменные зависимы. |
| R-квадрат скорр. | Корректно отражает вклад каждой переменной в модель. | Плохо работает, когда входные переменные зависимы. |
В данной статье рассмотрены наиболее популярные меры качества регрессионных моделей, которые часто используются в различных аналитических приложениях. Эти меры имеют свои особенности применения, знание которых позволит обоснованно выбирать и корректно применять их на практике.
Однако в литературе можно встретить и другие меры качества моделей регрессии, которые предлагаются различными авторами для решения конкретных задач анализа данных.
Другие материалы по теме:
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
Логистическая регрессия и ROC-анализ — математический аппарат
Регрессия позволяет прогнозировать зависимую переменную на основании значений фактора. В
MS
EXCEL
имеется множество функций, которые возвращают не только наклон и сдвиг линии регрессии, характеризующей линейную взаимосвязь между факторами, но и регрессионную статистику. Здесь рассмотрим простую линейную регрессию, т.е. прогнозирование на основе одного фактора.
Disclaimer
: Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей
Регрессионного анализа.
Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения
Регрессии
– плохая идея.
Статья про
Регрессионный анализ
получилась большая, поэтому ниже для удобства приведены ее разделы:
- Немного теории и основные понятия
- Предположения линейной регрессионной модели
- Задачи регрессионного анализа
- Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
- Оценка неизвестных параметров линейной модели (через статистики выборок)
- Оценка неизвестных параметров линейной модели (матричная форма)
- Построение линии регрессии
- Коэффициент детерминации
- Стандартная ошибка регрессии
- Стандартные ошибки и доверительные интервалы для наклона и сдвига
- Проверка значимости взаимосвязи переменных
- Доверительные интервалы для нового наблюдения Y и среднего значения
- Проверка адекватности линейной регрессионной модели
Примечание
: Если прогнозирование переменной осуществляется на основе нескольких факторов, то имеет место
множественная регрессия
.
Чтобы разобраться, чем может помочь MS EXCEL при проведении регрессионного анализа, напомним вкратце теорию, введем термины и обозначения, которые могут отличаться в зависимости от различных источников.
Примечание
: Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части —
оценке неизвестных параметров линейной модели
.
Немного теории и основные понятия
Пусть у нас есть массив данных, представляющий собой значения двух переменных Х и Y. Причем значения переменной Х мы можем произвольно задавать (контролировать) и использовать эту переменную для предсказания значений зависимой переменной Y. Таким образом, случайной величиной является только переменная Y.
Примером такой задачи может быть производственный процесс изготовления некого волокна, причем
прочность этого волокна
(Y) зависит только от
рабочей температуры процесса
в реакторе (Х), которая задается оператором.
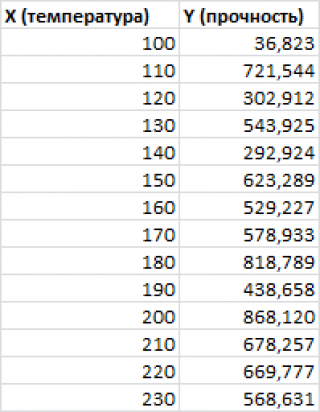
Построим
диаграмму рассеяния
(см.
файл примера лист Линейный
), созданию которой
посвящена отдельная статья
. Вообще, построение
диаграммы рассеяния
для целей
регрессионного анализа
де-факто является стандартом.
СОВЕТ
: Подробнее о построении различных типов диаграмм см. статьи
Основы построения диаграмм
и
Основные типы диаграмм
.
Приведенная выше
диаграмма рассеяния
свидетельствует о возможной
линейной взаимосвязи
между Y от Х: очевидно, что точки данных в основном располагаются вдоль прямой линии.
Примечание
: Наличие даже такой очевидной
линейной взаимосвязи
не может являться доказательством о наличии причинной взаимосвязи переменных. Наличие
причинной
взаимосвязи не может быть доказано на основании только анализа имеющихся измерений, а должно быть обосновано с помощью других исследований, например теоретических выкладок.
Примечание
: Как известно, уравнение прямой линии имеет вид
Y
=
m
*
X
+
k
, где коэффициент
m
отвечает за наклон линии (
slope
),
k
– за сдвиг линии по вертикали (
intercept
),
k
равно значению Y при Х=0.
Предположим, что мы можем зафиксировать переменную Х (
рабочую температуру процесса
) при некотором значении Х
i
и произвести несколько наблюдений переменной Y (
прочность нити
). Очевидно, что при одном и том же значении Хi мы получим различные значения Y. Это обусловлено влиянием других факторов на Y. Например, локальные колебания давления в реакторе, концентрации раствора, наличие ошибок измерения и др. Предполагается, что воздействие этих факторов имеет случайную природу и для каждого измерения имеются одинаковые условия проведения эксперимента (т.е. другие факторы не изменяются).
Полученные значения Y, при заданном Хi, будут колебаться вокруг некого
значения
. При увеличении количества измерений, среднее этих измерений, будет стремиться к
математическому ожиданию
случайной величины Y (при Х
i
) равному μy(i)=Е(Y
i
).
Подобные рассуждения можно привести для любого значения Хi.
Чтобы двинуться дальше, воспользуемся материалом из раздела
Проверка статистических гипотез
. В статье о
проверке гипотезы о среднем значении генеральной совокупности
в качестве
нулевой
гипотезы
предполагалось равенство неизвестного значения μ заданному μ0.
В нашем случае
простой линейной регрессии
в качестве
нулевой
гипотезы
предположим, что между переменными μy(i) и Хi существует линейная взаимосвязь μ
y(i)
=α* Х
i
+β. Уравнение μ
y(i)
=α* Х
i
+β можно переписать в обобщенном виде (для всех Х и μ
y
) как μ
y
=α* Х +β.
Для наглядности проведем прямую линию соединяющую все μy(i).
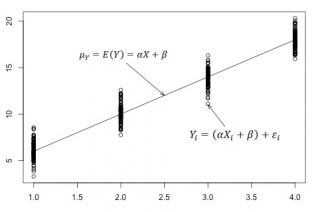
Данная линия называется
регрессионной линией генеральной совокупности
(population regression line), параметры которой (
наклон
a и
сдвиг β
) нам не известны (по аналогии с
гипотезой о среднем значении генеральной совокупности
, где нам было неизвестно истинное значение μ).
Теперь сделаем переход от нашего предположения, что μy=a* Х +
β
, к предсказанию значения случайной переменной Y в зависимости от значения контролируемой переменной Х. Для этого уравнение связи двух переменных запишем в виде Y=a*X+β+ε, где ε — случайная ошибка, которая отражает суммарный эффект влияния других факторов на Y (эти «другие» факторы не участвуют в нашей модели). Напомним, что т.к. переменная Х фиксирована, то ошибка ε определяется только свойствами переменной Y.
Уравнение Y=a*X+b+ε называют
линейной регрессионной моделью
. Часто Х еще называют
независимой переменной
(еще
предиктором
и
регрессором
, английский термин
predictor
,
regressor
), а Y –
зависимой
(или
объясняемой
,
response
variable
). Так как
регрессор
у нас один, то такая модель называется
простой линейной регрессионной моделью
(
simple
linear
regression
model
). α часто называют
коэффициентом регрессии.
Предположения линейной регрессионной модели перечислены в следующем разделе.
Предположения линейной регрессионной модели
Чтобы модель линейной регрессии Yi=a*Xi+β+ε
i
была адекватной — требуется:
-
Ошибки ε
i
должны быть независимыми переменными; -
При каждом значении Xi ошибки ε
i
должны быть иметь нормальное распределение (также предполагается равенство нулю математического ожидания, т.е. Е[ε
i
]=0); -
При каждом значении Xi ошибки ε
i
должны иметь равные дисперсии (обозначим ее σ
2
).
Примечание
: Последнее условие называется
гомоскедастичность
— стабильность, гомогенность дисперсии случайной ошибки e. Т.е.
дисперсия
ошибки σ
2
не должна зависеть от значения Xi.
Используя предположение о равенстве математического ожидания Е[ε
i
]=0 покажем, что μy(i)=Е[Yi]:
Е[Yi]= Е[a*Xi+β+ε
i
]= Е[a*Xi+β]+ Е[ε
i
]= a*Xi+β= μy(i), т.к. a, Xi и β постоянные значения.
Дисперсия
случайной переменной Y равна
дисперсии
ошибки ε, т.е. VAR(Y)= VAR(ε)=σ
2
. Это является следствием, что все значения переменной Х являются const, а VAR(ε)=VAR(ε
i
).
Задачи регрессионного анализа
Для проверки гипотезы о линейной взаимосвязи переменной Y от X делают выборку из генеральной совокупности (этой совокупности соответствует
регрессионная линия генеральной совокупности
, т.е. μy=a* Х +β). Выборка будет состоять из n точек, т.е. из n пар значений {X;Y}.
На основании этой выборки мы можем вычислить оценки наклона a и сдвига β, которые обозначим соответственно
a
и
b
. Также часто используются обозначения â и b̂.
Далее, используя эти оценки, мы также можем проверить гипотезу: имеется ли линейная связь между X и Y статистически значимой?
Таким образом:
Первая задача
регрессионного анализа
– оценка неизвестных параметров (
estimation
of
the
unknown
parameters
). Подробнее см. раздел
Оценки неизвестных параметров модели
.
Вторая задача
регрессионного анализа
–
Проверка адекватности модели
(
model
adequacy
checking
).
Примечание
: Оценки параметров модели обычно вычисляются
методом наименьших квадратов
(МНК),
которому посвящена отдельная статья
.
Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
Неизвестные параметры
простой линейной регрессионной модели
Y=a*X+β+ε оценим с помощью
метода наименьших квадратов
(в
статье про МНК подробно описано этот метод
).
Для вычисления параметров линейной модели методом МНК получены следующие выражения:
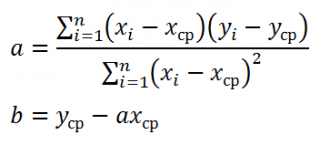
Таким образом, мы получим уравнение прямой линии Y=
a
*X+
b
, которая наилучшим образом аппроксимирует имеющиеся данные.
Примечание
: В статье про
метод наименьших квадратов
рассмотрены случаи аппроксимации
линейной
и
квадратичной функцией
, а также
степенной
,
логарифмической
и
экспоненциальной функцией
.
Оценку параметров в MS EXCEL можно выполнить различными способами:
-
с помощью функций
НАКЛОН()
и
ОТРЕЗОК()
; -
с помощью функции
ЛИНЕЙН()
; см. статьюФункция MS EXCEL ЛИНЕЙН()
-
формулами через статистики выборок
;
-
в матричной форме
;
-
с помощью
инструмента Регрессия надстройки Пакет Анализа
.
Сначала рассмотрим функции
НАКЛОН()
,
ОТРЕЗОК()
и
ЛИНЕЙН()
.
Пусть значения Х и Y находятся соответственно в диапазонах
C
23:
C
83
и
B
23:
B
83
(см.
файл примера
внизу статьи).
Примечание
: Значения двух переменных Х и Y можно сгенерировать, задав тренд и величину случайного разброса (см. статью
Генерация данных для линейной регрессии в MS EXCEL
).
В MS EXCEL наклон прямой линии
а
(
оценку
коэффициента регрессии
), можно найти по
методу МНК
с помощью функции
НАКЛОН()
, а сдвиг
b
(
оценку
постоянного члена
или
константы регрессии
), с помощью функции
ОТРЕЗОК()
. В английской версии это функции SLOPE и INTERCEPT соответственно.
Аналогичный результат можно получить с помощью функции
ЛИНЕЙН()
, английская версия LINEST (см.
статью об этой функции
).
Формула
=ЛИНЕЙН(C23:C83;B23:B83)
вернет наклон
а
. А формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
— сдвиг
b
. Здесь требуются пояснения.
Функция
ЛИНЕЙН()
имеет 4 аргумента и возвращает целый массив значений:
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Если 4-й аргумент
статистика
имеет значение ЛОЖЬ или опущен, то функция
ЛИНЕЙН()
возвращает только оценки параметров модели:
a
и
b
.
Примечание
: Остальные значения, возвращаемые функцией
ЛИНЕЙН()
, нам потребуются при вычислении
стандартных ошибок
и для
проверки значимости регрессии
. В этом случае аргумент
статистика
должен иметь значение ИСТИНА.
Чтобы вывести сразу обе оценки:
- в одной строке необходимо выделить 2 ячейки,
-
ввести формулу в
Строке формул
-
нажать
CTRL
+
SHIFT
+
ENTER
(см. статью проформулы массива
).
Если в
Строке формул
выделить формулу =
ЛИНЕЙН(C23:C83;B23:B83)
и нажать
клавишу F9
, то мы увидим что-то типа {3,01279389265416;154,240057900613}. Это как раз значения
a
и
b
. Как видно, оба значения разделены точкой с запятой «;», что свидетельствует, что функция вернула значения «в нескольких ячейках одной строки».
Если требуется вывести параметры линии не в одной строке, а одном столбце (ячейки друг под другом), то используйте формулу =
ТРАНСП(ЛИНЕЙН(C23:C83;B23:B83))
. При этом выделять нужно 2 ячейки в одном столбце. Если теперь выделить новую формулу и нажать клавишу F9, то мы увидим что 2 значения разделены двоеточием «:», что означает, что значения выведены в столбец (функция
ТРАНСП()
транспонировала строку в столбец
).
Чтобы разобраться в этом подробнее необходимо ознакомиться с
формулами массива
.
Чтобы не связываться с вводом
формул массива
, можно
использовать функцию ИНДЕКС()
. Формула =
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1)
или просто
ЛИНЕЙН(C23:C83;B23:B83)
вернет параметр, отвечающий за наклон линии, т.е.
а
. Формула
=ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2)
вернет параметр
b
.
Оценка неизвестных параметров линейной модели (через статистики выборок)
Наклон линии, т.е. коэффициент
а
, можно также вычислить через
коэффициент корреляции
и
стандартные отклонения выборок
:
=
КОРРЕЛ(B23:B83;C23:C83) *(СТАНДОТКЛОН.В(C23:C83)/ СТАНДОТКЛОН.В(B23:B83))
Вышеуказанная формула математически эквивалентна отношению
ковариации
выборок Х и Y и
дисперсии
выборки Х:
=
КОВАРИАЦИЯ.В(B23:B83;C23:C83)/ДИСП.В(B23:B83)
И, наконец, запишем еще одну формулу для нахождения сдвига
b
. Воспользуемся тем фактом, что
линия регрессии
проходит через точку
средних значений
переменных Х и Y.
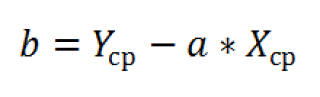
Вычислив
средние значения
и подставив в формулу ранее найденный наклон
а
, получим сдвиг
b
.
Оценка неизвестных параметров линейной модели (матричная форма)
Также параметры
линии регрессии
можно найти в матричной форме (см.
файл примера лист Матричная форма
).
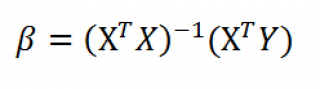
В формуле символом β обозначен столбец с искомыми параметрами модели: β0 (сдвиг
b
), β1 (наклон
a
).
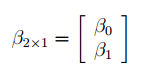
Матрица Х равна:
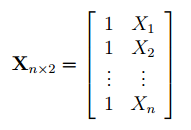
Матрица
Х
называется
регрессионной матрицей
или
матрицей плана
. Она состоит из 2-х столбцов и n строк, где n – количество точек данных. Первый столбец — столбец единиц, второй – значения переменной Х.
Матрица
Х
T
– это
транспонированная матрица
Х
. Она состоит соответственно из n столбцов и 2-х строк.
В формуле символом
Y
обозначен столбец значений переменной Y.
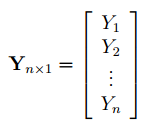
Чтобы
перемножить матрицы
используйте функцию
МУМНОЖ()
. Чтобы
найти обратную матрицу
используйте функцию
МОБР()
.
Пусть дан массив значений переменных Х и Y (n=10, т.е.10 точек).
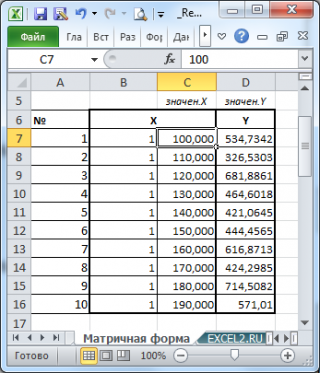
Слева от него достроим столбец с 1 для матрицы Х.
Записав формулу
=
МУМНОЖ(МОБР(МУМНОЖ(ТРАНСП(B7:C16);(B7:C16))); МУМНОЖ(ТРАНСП(B7:C16);(D7:D16)))
и введя ее как
формулу массива
в 2 ячейки, получим оценку параметров модели.
Красота применения матричной формы полностью раскрывается в случае
множественной регрессии
.
Построение линии регрессии
Для отображения
линии регрессии
построим сначала
диаграмму рассеяния
, на которой отобразим все точки (см.
начало статьи
).
Для построения прямой линии используйте вычисленные выше оценки параметров модели
a
и
b
(т.е. вычислите
у
по формуле
y
=
a
*
x
+
b
) или функцию
ТЕНДЕНЦИЯ()
.
Формула =
ТЕНДЕНЦИЯ($C$23:$C$83;$B$23:$B$83;B23)
возвращает расчетные (прогнозные) значения ŷi для заданного значения Хi из столбца
В2
.
Примечание
:
Линию регрессии
можно также построить с помощью функции
ПРЕДСКАЗ()
. Эта функция возвращает прогнозные значения ŷi, но, в отличие от функции
ТЕНДЕНЦИЯ()
работает только в случае одного регрессора. Функция
ТЕНДЕНЦИЯ()
может быть использована и в случае
множественной регрессии
(в этом случае 3-й аргумент функции должен быть ссылкой на диапазон, содержащий все значения Хi для выбранного наблюдения i).
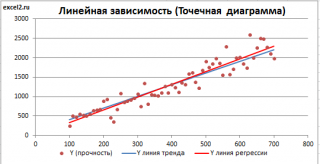
Как видно из диаграммы выше
линия тренда
и
линия регрессии
не обязательно совпадают: отклонения точек от
линии тренда
случайны, а МНК лишь подбирает линию наиболее точно аппроксимирующую случайные точки данных.
Линию регрессии
можно построить и с помощью встроенных средств диаграммы, т.е. с помощью инструмента
Линия тренда.
Для этого выделите диаграмму, в меню выберите
вкладку Макет
, в
группе Анализ
нажмите
Линия тренда
, затем
Линейное приближение.
В диалоговом окне установите галочку
Показывать уравнение на диаграмме
(подробнее см. в
статье про МНК
).
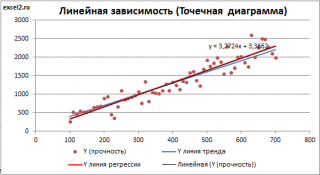
Построенная таким образом линия, разумеется, должна совпасть с ранее построенной нами
линией регрессии,
а параметры уравнения
a
и
b
должны совпасть с параметрами уравнения отображенными на диаграмме.
Примечание:
Для того, чтобы вычисленные параметры уравнения
a
и
b
совпадали с параметрами уравнения на диаграмме, необходимо, чтобы тип у диаграммы был
Точечная, а не График
, т.к. тип диаграммы
График
не использует значения Х, а вместо значений Х используется последовательность 1; 2; 3; … Именно эти значения и берутся при расчете параметров
линии тренда
. Убедиться в этом можно если построить диаграмму
График
(см.
файл примера
), а значения
Хнач
и
Хшаг
установить равным 1. Только в этом случае параметры уравнения на диаграмме совпадут с
a
и
b
.
Коэффициент детерминации R
2
Коэффициент детерминации
R
2
показывает насколько полезна построенная нами
линейная регрессионная модель
.
Предположим, что у нас есть n значений переменной Y и мы хотим предсказать значение yi, но без использования значений переменной Х (т.е. без построения
регрессионной модели
). Очевидно, что лучшей оценкой для yi будет
среднее значение
ȳ. Соответственно, ошибка предсказания будет равна (yi — ȳ).
Примечание
: Далее будет использована терминология и обозначения
дисперсионного анализа
.
После построения
регрессионной модели
для предсказания значения yi мы будем использовать значение ŷi=a*xi+b. Ошибка предсказания теперь будет равна (yi — ŷi).
Теперь с помощью диаграммы сравним ошибки предсказания полученные без построения модели и с помощью модели.
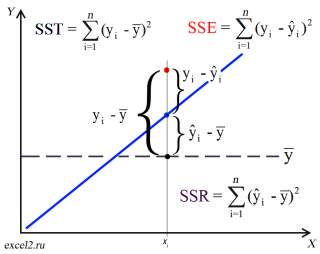
Очевидно, что используя
регрессионную модель
мы уменьшили первоначальную (полную) ошибку (yi — ȳ) на значение (ŷi — ȳ) до величины (yi — ŷi).
(yi — ŷi) – это оставшаяся, необъясненная ошибка.
Очевидно, что все три ошибки связаны выражением:
(yi — ȳ)= (ŷi — ȳ) + (yi — ŷi)
Можно показать, что в общем виде справедливо следующее выражение:
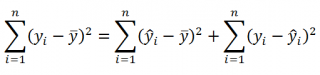
Доказательство:
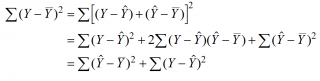
или в других, общепринятых в зарубежной литературе, обозначениях:
SST
=
SSR
+
SSE
Что означает:
Total Sum of Squares
=
Regression Sum of Squares
+
Error Sum of Squares
Примечание
: SS — Sum of Squares — Сумма Квадратов.
Как видно из формулы величины SST, SSR, SSE имеют размерность
дисперсии
(вариации) и соответственно описывают разброс (изменчивость):
Общую изменчивость
(Total variation),
Изменчивость объясненную моделью
(Explained variation) и
Необъясненную изменчивость
(Unexplained variation).
По определению
коэффициент детерминации
R
2
равен:
R
2
=
Изменчивость объясненная моделью / Общая изменчивость.
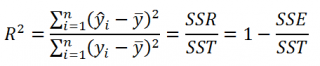
Этот показатель равен квадрату
коэффициента корреляции
и в MS EXCEL его можно вычислить с помощью функции
КВПИРСОН()
или
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3)
R
2
принимает значения от 0 до 1 (1 соответствует идеальной линейной зависимости Y от Х). Однако, на практике малые значения R2 вовсе не обязательно указывают, что переменную Х нельзя использовать для прогнозирования переменной Y. Малые значения R2 могут указывать на нелинейность связи или на то, что поведение переменной Y объясняется не только Х, но и другими факторами.
Стандартная ошибка регрессии
Стандартная ошибка регрессии
(
Standard Error of a regression
) показывает насколько велика ошибка предсказания значений переменной Y на основании значений Х. Отдельные значения Yi мы можем предсказывать лишь с точностью +/- несколько значений (обычно 2-3, в зависимости от формы распределения ошибки ε).
Теперь вспомним уравнение
линейной регрессионной модели
Y=a*X+β+ε. Ошибка ε имеет случайную природу, т.е. является случайной величиной и поэтому имеет свою функцию распределения со
средним значением
μ и
дисперсией
σ
2
.
Оценив значение
дисперсии
σ
2
и вычислив из нее квадратный корень – получим
Стандартную ошибку регрессии.
Чем точки наблюдений на диаграмме
рассеяния
ближе находятся к прямой линии, тем меньше
Стандартная ошибка.
Примечание
:
Вспомним
, что при построении модели предполагается, что
среднее значение
ошибки ε равно 0, т.е. E[ε]=0.
Оценим
дисперсию σ
2
. Помимо вычисления
Стандартной ошибки регрессии
эта оценка нам потребуется в дальнейшем еще и при построении
доверительных интервалов
для оценки параметров регрессии
a
и
b
.
Для оценки
дисперсии
ошибки ε используем
остатки регрессии
— разности между имеющимися значениями
yi
и значениями, предсказанными регрессионной моделью ŷ. Чем лучше регрессионная модель согласуется с данными (точки располагается близко к прямой линии), тем меньше величина остатков.
Для оценки
дисперсии σ
2
используют следующую формулу:
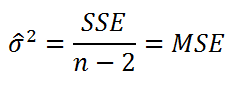
где SSE – сумма квадратов значений ошибок модели ε
i
=yi — ŷi (
Sum of Squared Errors
).
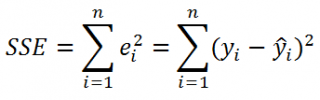
SSE часто обозначают и как SSres – сумма квадратов остатков (
Sum
of
Squared
residuals
).
Оценка
дисперсии
s
2
также имеет общепринятое обозначение MSE (Mean Square of Errors), т.е. среднее квадратов
ошибок
или MSRES (Mean Square of Residuals), т.е. среднее квадратов
остатков
. Хотя правильнее говорить сумме квадратов остатков, т.к. ошибка чаще ассоциируется с ошибкой модели ε, которая является непрерывной случайной величиной. Но, здесь мы будем использовать термины SSE и MSE, предполагая, что речь идет об остатках.
Примечание
: Напомним, что когда
мы использовали МНК
для нахождения параметров модели, то критерием оптимизации была минимизация именно SSE (SSres). Это выражение представляет собой сумму квадратов расстояний между наблюденными значениями yi и предсказанными моделью значениями ŷi, которые лежат на
линии регрессии.
Математическое ожидание
случайной величины MSE равно
дисперсии ошибки
ε, т.е.
σ
2
.
Чтобы понять почему SSE выбрана в качестве основы для оценки
дисперсии
ошибки ε, вспомним, что
σ
2
является также
дисперсией
случайной величины Y (относительно
среднего значения
μy, при заданном значении Хi). А т.к. оценкой μy является значение ŷi =
a
* Хi +
b
(значение
уравнения регрессии
при Х= Хi), то логично использовать именно SSE в качестве основы для оценки
дисперсии
σ
2
. Затем SSE усредняется на количество точек данных n за вычетом числа 2. Величина n-2 – это количество
степеней свободы
(
df
–
degrees
of
freedom
), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y). В случае
простой линейной регрессии
число степеней свободы
равно n-2, т.к. при построении
линии регрессии
было оценено 2 параметра модели (на это было «потрачено» 2
степени свободы
).
Итак, как сказано было выше, квадратный корень из s
2
имеет специальное название
Стандартная ошибка регрессии
(
Standard Error of a regression
) и обозначается SEy. SEy показывает насколько велика ошибка предсказания. Отдельные значения Y мы можем предсказывать с точностью +/- несколько значений SEy (см.
этот раздел
). Если ошибки предсказания ε имеют
нормальное распределение
, то примерно 2/3 всех предсказанных значений будут на расстоянии не больше SEy от
линии регрессии
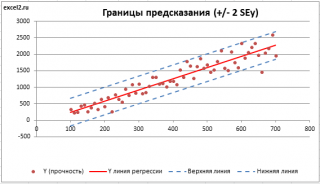
. SEy имеет размерность переменной Y и откладывается по вертикали. Часто на
диаграмме рассеяния
строят
границы предсказания
соответствующие +/- 2 SEy (т.е. 95% точек данных будут располагаться в пределах этих границ).
В MS EXCEL
стандартную ошибку
SEy можно вычислить непосредственно по формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
Стандартные ошибки и доверительные интервалы для наклона и сдвига
В разделе
Оценка неизвестных параметров линейной модели
мы получили точечные оценки наклона
а
и сдвига
b
. Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со
средним значением
и
дисперсией
. Но, чтобы перейти от
точечных оценок
к
интервальным
, необходимо вычислить соответствующие
стандартные ошибки
(т.е.
стандартные отклонения
).
Стандартная ошибка коэффициента регрессии
a
вычисляется на основании
стандартной ошибки регрессии
по следующей формуле:
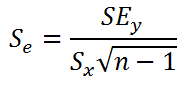
где Sx – стандартное отклонение величины х, вычисляемое по формуле:
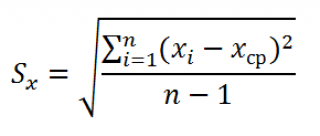
где Sey –
стандартная ошибка регрессии,
т.е. ошибка предсказания значения переменой Y
(
см. выше
).
В MS EXCEL
стандартную ошибку коэффициента регрессии
Se можно вычислить впрямую по вышеуказанной формуле:
=
КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))/ СТАНДОТКЛОН.В(B23:B83) /КОРЕНЬ(СЧЁТ(B23:B83) -1)
или с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;1)
Формулы приведены в
файле примера на листе Линейный
в разделе
Регрессионная статистика
.
Примечание
: Подробнее о функции
ЛИНЕЙН()
см.
эту статью
.
При построении
двухстороннего доверительного интервала
для
коэффициента регрессии
его границы определяются следующим образом:
![]()
где —
квантиль распределения Стьюдента
с n-2 степенями свободы. Величина
а
с «крышкой» является другим обозначением
наклона
а
.
Например для
уровня значимости
альфа=0,05, можно вычислить с помощью формулы
=СТЬЮДЕНТ.ОБР.2Х(0,05;n-2)
Вышеуказанная формула следует из того факта, что если ошибки регрессии распределены нормально и независимо, то выборочное распределение случайной величины
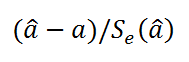
является
t-распределением Стьюдента
с n-2 степенью свободы (то же справедливо и для наклона
b
).
Примечание
: Подробнее о построении
доверительных интервалов
в MS EXCEL можно прочитать в этой статье
Доверительные интервалы в MS EXCEL
.
В результате получим, что найденный
доверительный интервал
с вероятностью 95% (1-0,05) накроет истинное значение
коэффициента регрессии.
Здесь мы считаем, что
коэффициент регрессии
a
имеет
распределение Стьюдента
с n-2
степенями свободы
(n – количество наблюдений, т.е. пар Х и Y).
Примечание
: Подробнее о построении
доверительных интервалов
с использованием t-распределения см. статью про построение
доверительных интервалов
для среднего
.
Стандартная ошибка сдвига
b
вычисляется по следующей формуле:
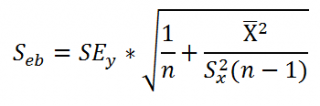
В MS EXCEL
стандартную ошибку сдвига
Seb можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);2;2)
При построении
двухстороннего доверительного интервала
для
сдвига
его границы определяются аналогичным образом как для
наклона
:
b
+/- t*Seb.
Проверка значимости взаимосвязи переменных
Когда мы строим модель Y=αX+β+ε мы предполагаем, что между Y и X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X (в рамках модели Y=αX+β+ε), возможен, когда
коэффициент регрессии
a
равен 0.
Чтобы убедиться, что вычисленная нами оценка
наклона
прямой линии не обусловлена лишь случайностью (не случайно отлична от 0), используют
проверку гипотез
. В качестве
нулевой гипотезы
Н
0
принимают, что связи нет, т.е. a=0. В качестве альтернативной гипотезы
Н
1
принимают, что a <>0.
Ниже на рисунках показаны 2 ситуации, когда
нулевую гипотезу
Н
0
не удается отвергнуть.
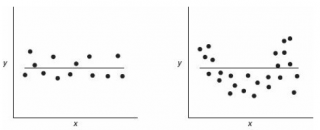
На левой картинке отсутствует любая зависимость между переменными, на правой – связь между ними нелинейная, но при этом
коэффициент линейной корреляции
равен 0.
Ниже — 2 ситуации, когда
нулевая гипотеза
Н
0
отвергается.
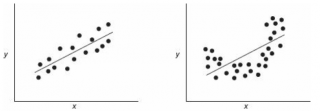
На левой картинке очевидна линейная зависимость, на правой — зависимость нелинейная, но коэффициент корреляции не равен 0 (метод МНК вычисляет показатели наклона и сдвига просто на основании значений выборки).
Для проверки гипотезы нам потребуется:
-
Установить
уровень значимости
, пусть альфа=0,05;
-
Рассчитать с помощью функции
ЛИНЕЙН()
стандартное отклонение
Se для
коэффициента регрессии
(см.предыдущий раздел
);
-
Рассчитать число степеней свободы: DF=n-2 или по формуле =
ИНДЕКС(ЛИНЕЙН(C24:C84;B24:B84;;ИСТИНА);4;2)
-
Вычислить значение тестовой статистики t
0
=a/S
e
, которая имеетраспределение Стьюдента
с
числом степеней свободы
DF=n-2; -
Сравнить значение
тестовой статистики
|t0| с пороговым значением t
альфа
,n-2. Если значение
тестовой статистики
больше порогового значения, то
нулевая гипотеза
отвергается (
наклон
не может быть объяснен лишь случайностью при заданном уровне альфа) либо -
вычислить
p-значение
и сравнить его с
уровнем значимости
.
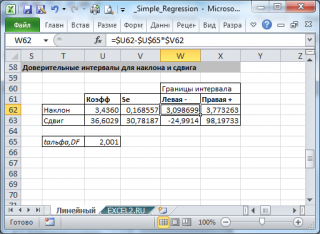
В
файле примера
приведен пример проверки гипотезы:
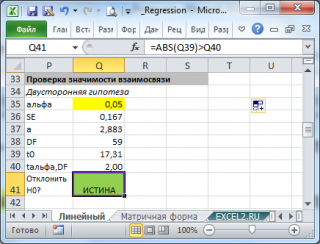
Изменяя
наклон
тренда k (ячейка
В8
) можно убедиться, что при малых углах тренда (например, 0,05) тест часто показывает, что связь между переменными случайна. При больших углах (k>1), тест практически всегда подтверждает значимость линейной связи между переменными.
Примечание
: Проверка значимости взаимосвязи эквивалентна
проверке статистической значимости коэффициента корреляции
. В
файле примера
показана эквивалентность обоих подходов. Также проверку значимости можно провести с помощью
процедуры F-тест
.
Доверительные интервалы для нового наблюдения Y и среднего значения
Вычислив параметры
простой линейной регрессионной модели
Y=aX+β+ε мы получили точечную оценку значения нового наблюдения Y при заданном значении Хi, а именно: Ŷ=
a
* Хi +
b
Ŷ также является точечной оценкой для
среднего значения
Yi при заданном Хi. Но, при построении
доверительных интервалов
используются различные
стандартные ошибки
.
Стандартная ошибка
нового наблюдения Y при заданном Хi учитывает 2 источника неопределенности:
-
неопределенность связанную со случайностью оценок параметров модели
a
и
b
; - случайность ошибки модели ε.
Учет этих неопределенностей приводит к
стандартной ошибке
S(Y|Xi), которая рассчитывается с учетом известного значения Xi.
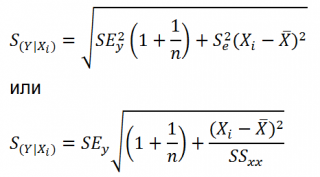
где SS
xx
– сумма квадратов отклонений от
среднего
значений переменной Х:
![]()
Примечание
: Se –
стандартная ошибка коэффициента регрессии
(
наклона
а
).
В
MS EXCEL 2010
нет функции, которая бы рассчитывала эту
стандартную ошибку
, поэтому ее необходимо рассчитывать по вышеуказанным формулам.
Доверительный интервал
или
Интервал предсказания для нового наблюдения
(Prediction Interval for a New Observation) построим по схеме показанной в разделе
Проверка значимости взаимосвязи переменных
(см.
файл примера лист Интервалы
). Т.к. границы интервала зависят от значения Хi (точнее от расстояния Хi до среднего значения Х
ср
), то интервал будет постепенно расширяться при удалении от Х
ср
.
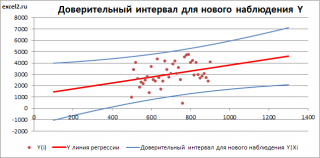
Границы
доверительного интервала
для
нового наблюдения
рассчитываются по формуле:
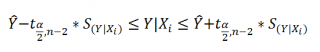
Аналогичным образом построим
доверительный интервал
для
среднего значения
Y при заданном Хi (Confidence Interval for the Mean of Y). В этом случае
доверительный интервал
будет уже, т.к.
средние значения
имеют меньшую изменчивость по сравнению с отдельными наблюдениями (
средние значения,
в рамках нашей линейной модели Y=aX+β+ε, не включают ошибку ε).
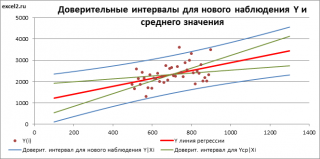
Стандартная ошибка
S(Yср|Xi) вычисляется по практически аналогичным формулам как и
стандартная ошибка
для нового наблюдения:
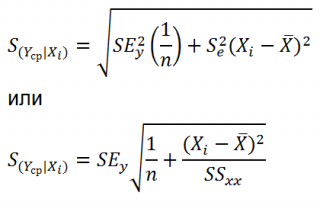
Как видно из формул,
стандартная ошибка
S(Yср|Xi) меньше
стандартной ошибки
S(Y|Xi) для индивидуального значения
.
Границы
доверительного интервала
для
среднего значения
рассчитываются по формуле:
![]()
Проверка адекватности линейной регрессионной модели
Модель адекватна, когда все предположения, лежащие в ее основе, выполнены (см. раздел
Предположения линейной регрессионной модели
).
Проверка адекватности модели в основном основана на исследовании остатков модели (model residuals), т.е. значений ei=yi – ŷi для каждого Хi. В рамках
простой линейной модели
n остатков имеют только n-2 связанных с ними
степеней свободы
. Следовательно, хотя, остатки не являются независимыми величинами, но при достаточно большом n это не оказывает какого-либо влияния на проверку адекватности модели.
Чтобы проверить предположение о
нормальности распределения
ошибок строят
график проверки на нормальность
(Normal probability Plot).
В
файле примера на листе Адекватность
построен
график проверки на нормальность
. В случае
нормального распределения
значения остатков должны быть близки к прямой линии.
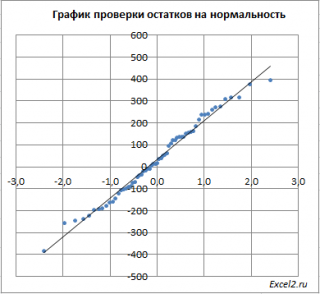
Так как значения переменной Y мы
генерировали с помощью тренда
, вокруг которого значения имели нормальный разброс, то ожидать сюрпризов не приходится – значения остатков располагаются вблизи прямой.
Также при проверке модели на адекватность часто строят график зависимости остатков от предсказанных значений Y. Если точки не демонстрируют характерных, так называемых «паттернов» (шаблонов) типа вор
о
нок или другого неравномерного распределения, в зависимости от значений Y, то у нас нет очевидных доказательств неадекватности модели.
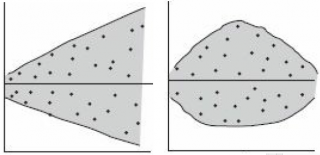
В нашем случае точки располагаются примерно равномерно.
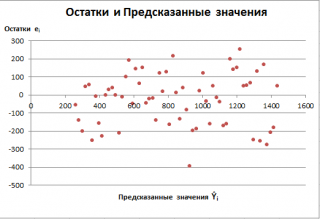
Часто при проверке адекватности модели вместо остатков используют нормированные остатки. Как показано в разделе
Стандартная ошибка регрессии
оценкой
стандартного отклонения ошибок
является величина SEy равная квадратному корню из величины MSE. Поэтому логично нормирование остатков проводить именно на эту величину.
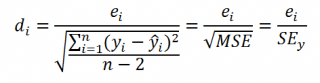
SEy можно вычислить с помощью функции
ЛИНЕЙН()
:
=
ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83;;ИСТИНА);3;2)
Иногда нормирование остатков производится на величину
стандартного отклонения
остатков (это мы увидим в статье об инструменте
Регрессия
, доступного в
надстройке MS EXCEL Пакет анализа
), т.е. по формуле:
Вышеуказанное равенство приблизительное, т.к. среднее значение остатков близко, но не обязательно точно равно 0.
Стандартная
ошибка оценки по регрессии.
Как было отмечено, несмещённая оценка
дисперсии остатков уравнения регрессии
называется остаточной дисперсией
 =
=
 =
= .
.
Корень
квадратный из остаточной дисперсии
называется стандартной ошибкой оценки
по регрессии. Обозначается она обычно
Sy,x
и вычисляется по формуле
Sy,x
=
 .
.
Стандартная
ошибка оценки по регрессии показывает,
насколько в среднем мы ошибаемся,
оценивая значение зависимой переменной
по найденному уравнению регрессии при
фиксированном значении независимой
переменной.
Оценка
значимости уравнения регрессии
(дисперсионный анализ регрессии).
Для
оценки значимости уравнения регрессии
устанавливают, соответствует ли выбранная
модель анализируемым данным. Для этого
используется дисперсионный анализ
регрессии. Основная его посылка – это
разложение общей суммы квадратов
отклонений
 на
на
составляющие. Известно, что такое
разложение имеет вид
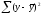 =
= +
+ ,
,
если
в уравнении регрессии присутствует
свободный член. В противном случае в
правую часть надо добавить слагаемое
2
 .
.
Но как было показано, второй член этого
слагаемого ( равен нулю, если в уравнении регрессии
равен нулю, если в уравнении регрессии
присутствует свободный член.
Второе
слагаемое в правой части этого разложения
уже встречалось и обсуждалось – это
часть общей суммы квадратов отклонений,
объясняемая действием случайных и
неучтенных факторов. Первое слагаемое
этого разложения –
это часть общей суммы квадратов
отклонений, объясняемая регрессионной
зависимостью. Следовательно, если
регрессионная зависимость между у
и х
отсутствует, то общая сумма квадратов
отклонений объясняется действием только
случайных факторов или ошибок, т.е.
 =
=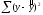 .
.
В случае функциональной зависимости
между
у
и х
действие случайных факторов и ошибок
отсутствует и тогда
 =
= .
.
Будучи
отнесёнными к соответствующему числу
степеней свободы эти суммы называются
средними квадратами отклонений и служат
оценками дисперсии
 в разных предположениях. Одна из них
в разных предположениях. Одна из них
рассчитывается в предположении отсутствия
регрессионной зависимости, а другая –
без такого предположения. Следовательно,
если регрессионная зависимость
отсутствует, то эти оценки должны быть
близкими. Сравниваются они на основеF-отношения:
F
= MSR/
MSE.
Таким образом, F-статистика
проверяет гипотезу о незначимости
уравнения регрессии (H0:
 =
=
0), т. е. о том, что зависимости между
анализируемыми переменными нет. Если
верна нулевая гипотеза, тоF-статистика
следует распределению Фишера и, зная
уровень значимости и число степеней
свободы числителя и знаменателя, можно
определить критические значения этого
распределения.
Расчётное
значение F-статистики
сравнивается с критическим значением
(в нашем случае число степеней свободы
числителя равно 1 (число регрессоров),
а число степеней свободы знаменателя
равно (n
– 2)) с уровнем значимости
 .
.
ЕслиF <
<
F,
то гипотеза о незначимости уравнения
регрессии не отклоняется, т. е. не
отклоняется гипотеза о том, что
 =
=
0, и уравнение регрессии признаётся
незначимым. В этом случае надо либо
изменить вид зависимости, либо пересмотреть
набор исходных данных.
При
компьютерных расчётах в некоторых
статистических пакетах программ оценка
значимости уравнения регрессии
осуществляется на основе дисперсионного
анализа в таблицах вида:
Таблица
1.1 – Дисперсионный анализ регрессии
|
Источник вариации |
Суммы квадратов |
Степени свободы |
Средние квадраты |
F- |
p-value |
|
Модель |
SSR |
1 |
MSR |
MSR/ |
Уровень |
|
Ошибки |
SSE |
n |
MSE |
знач-ти |
|
|
Общая |
SST |
n |
Здесь
p-value
– это вероятность выполнения неравенства
F <
<
F
или расчётный уровень значимости. Если
эта вероятность мала (меньше
 ),
),
то нулевая гипотеза отклоняется.
В
некоторых статистических пакетах
программ значение F-статистики
и вероятность для неё приводятся без
показа процедуры их вычисления.
Если
в уравнении регрессии нет константы,
то в некоторых статистических пакетах
F-статистика
просто не вычисляется.
Интервальные
оценки параметров уравнения регрессии.
При использовании параметров уравнения
регрессии в анализе и прогнозировании
для них необходимо уметь строить
интервальные оценки.
Доверительный
интервал для коэффициента регрессии
определяется из соотношения (b t
t Sb),
Sb),
где Sb
– стандартная ошибка оценки коэффициента
регрессии. Известно, что
Sb= .
.
Доверительный
интервал для свободного члена уравнения
регрессии определяется из соотношения
(а t
t Sа),
Sа),
где Sа
– стандартная ошибка оценки свободного
члена уравнения регрессии. Известно,
что
Sа= .
.
Интервальная
оценка расчетных значений
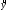 определяется доверительным интервалом
определяется доверительным интервалом
(
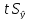 ),
),
где
 стандартная
стандартная
ошибка оценки ,
,
определяемая из соотношения
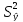 =
=
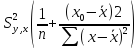 .
.
Интервальная
оценка прогнозных значений определяется
из подобного же соотношения, только в
стандартную ошибку добавляется ещё
стандартное отклонение ,
,
характеризующее рассеяние прогнозных
значений зависимой переменной вокруг
линии регрессии.
Проверка
значимости параметров уравнения
регрессии.
Кроме проверки значимости уравнения
регрессии в целом необходимо уметь
проверять значимость каждого параметра
уравнения регрессии в отдельности.
Осуществляется это на основе t-статистик.
Значения этих статистик рассчитываются
из соотношений: ta
=
a/Sa,
tb
=
b/Sb.
Для этих статистик определяются
критические значения или расчётные
уровни значимости, на основе которых и
принимаются решения о значимости или
незначимости соответствующих параметров.
В
случае парной линейной регрессии
проверка значимости уравнения регрессии
в целом и проверка значимости коэффициента
уравнения регрессии по сути дела одно
и то же, т. к. в том и другом случае
проверяется одна и та же гипотеза о том,
что коэффициент уравнения регрессии
равен нулю. Кроме того, можно показать,
что для парной линейной регрессии F
=
 .
.
Уравнение
простой регрессии в компьютерных
расчётах обычно выдаётся в виде следующей
таблицы.
Таблица
1.2 – Уравнение простой регрессии
|
Параметр |
Оценка |
Ст. |
t-статистика |
р-value |
|
Пересечение |
а |
Sa |
ta=a/Sa |
|
|
Наклон |
b |
Sb |
tb |
Пересечение
и наклон
– это другое название свободного члена
уравнения регрессии и его коэффициента,
основанное на геометрическом смысле
этих величин, если рассматривать
уравнение регрессии как уравнение
прямой линии или линии регрессии. Смысл
остальных столбцов понятен из их
названия.
Кроме
уже рассмотренных показателей точности
уравнения регрессии обычно ещё используют
коэффициент
детерминации.
Коэффициент
детерминации
(R—квадрат)
является удобной оценкой качества
подгонки данных моделью. Выясним его
смысл. В общем случае коэффициент
детерминации определяется из соотношения
R2
=
 ,
,
т.
е. это доля выборочной дисперсии
переменной y,
которая объясняется моделью. Следует
иметь в виду, что
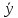 также соответствует выборочному среднему
также соответствует выборочному среднему (см. соотношение (1.2)). Следовательно,
(см. соотношение (1.2)). Следовательно,
коэффициент детерминации характеризует
долю вариации зависимой переменной,
обусловленную вариацией независимой
переменной. Обычно он выражается в
процентах, поэтому, например, еслиR2
=
75%, то это значит, что 75% вариации зависимой
переменной у
объясняется вариацией независимой
переменной х,
а остальные 25% изменения у
объясняются либо ошибками наблюдений,
либо действием неучтенных факторов,
либо тем и другим.
Известно,
что если модель содержит свободный
член, то справедливо соотношение (следует
из
 )
)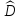 (
( )
)
= (
( )
)
+ (
( ),
),
откуда следует, что
 =
=
1 –
 = 1 –
= 1 – .
.
Отсюда
следует, что
 действительно
действительно
определяет, какую долю выборочной
вариации можно объяснить моделью.
можно объяснить моделью.
Если
уравнение регрессии содержит свободный
член, то оба выражения для
 эквивалентны. Кроме того, в этом случае
эквивалентны. Кроме того, в этом случае
можно показать, что 0 все
все равны 0 и равен 1, если в уравнении
равны 0 и равен 1, если в уравнении
регрессии содержится только константа).
Можно
показать, что в случае парной линейной
регрессии коэффициент детерминации
равен квадрату коэффициента корреляции,
т.е. R2
= .
.
Следует
иметь в виду, что
 измеряет только качество линейной
измеряет только качество линейной
аппроксимации, но не меру качества
статистической модели. Кроме того, чувствителен к определению зависимой
чувствителен к определению зависимой
переменной и в случае её изменения
разные модели по сравнивать нельзя.
сравнивать нельзя.
-
Спецификация
уравнения регрессии
Под
спецификацией уравнения регрессии
понимают выбор объясняющих переменных
и установление вида связи между изучаемыми
явлениями. В случае парной регрессии
эта задача сводится к выбору независимой
переменной и вида связи. Решение этих
вопросов должна давать теория, описывающая
взаимосвязи изучаемых процессов.
К
ошибкам спецификации в случае парной
регрессии можно отнести неправильный
выбор доминирующего фактора, влияющего
на изменение изучаемого показателя,
или неправильный выбор вида зависимости
между изучаемыми показателями. И в том
и в другом случае будут нарушены
предпосылки МНК, особенно 3-я и 4-я, т.е.
остатки регрессии будут гетероскедастичными
и автокоррелироваными.
Гетероскедастичность
и автокорреляция остатков уравнения
регрессии могут сказаться на эффективности
оценок, полученных на основе МНК и на
смещённости оценки их дисперсии. Поэтому
интервальные оценки и статистические
выводы о значимости оценок в этом случае
могут быть ненадёжными.
Разработаны
специальные статистические методы
проверки остатков на гомоскедастичность
и автокорреляцию. Рассмотрим сначала
наиболее простые из них.
1.3.1.
Проверка остатков регрессии на
гетероскедастичность
(тест Голдфелда –
Квандта)
Этот
тест применяется в предположении
нормально распределённых остатков и в
предположении их пропорциональности
величинам объясняющей переменной х.
Для применения рассматриваемого теста
пары наблюдений упорядочиваются в
порядке роста значений независимой
переменной х.
Затем выбираются первые и последние
наблюдения в количестве не менее n/3.
По выбранным наблюдениям строятся
уравнения регрессии (отдельно по каждому
набору) и сравниваются их остаточные
суммы квадратов. Гипотеза о гомоскедастичности
в этом случае будет равносильна гипотезе
о том, что остатки в этих уравнениях
представляют собой выборочные наблюдения
нормально распределённых случайных
величин с одинаковыми дисперсиями.
Сравнивая эти дисперсии по критерию
Фишера (число степеней свободы числителя
и знаменателя здесь совпадают, т. к.
слева и справа берётся одинаковое число
наблюдений) принимаем или отклоняем
гипотезу о гомоскедастичности остатков.
Несмотря
на ограниченность применения этого
критерия (пропорциональность величин
остатков значениям независимой
переменной), данный тест работает с
элементами выборки и не требует больших
объёмов выборки как асимптотические
тесты.
.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #