
What is RLC?
The Russian Learner Corpus (RLC) is a collection of texts produced by two categories of non-standard speakers of Russian: learners of Russian as a Foreign language and speakers of Heritage Russian with different dominant languages. The corpus contains both oral and written production and enables search by morphological properties and a variety of deviations from Standard Russian ranging from mistakes in orthography and grammar to non-standard use of lexical and syntactic constructions.
The preliminary linguistic analysis and tagging is done by the members of the Learner Russian Research Group under Ekaterina Rakhilina (Higher School of Economics).
The majority of texts are coming from teachers of Russian as a second language and/or Heritage language in different countries. RLC comprises both academic and non-academic texts, such as movie and picture descriptions, book summaries, expository essays and others (see HELP).
Part of RLC is RULEC – a longitudinal subcorpus of Academic Writing produced by Heritage and L2 speakers of Russian collected by Olessya Kisselev and Anna Alsufieva of Portland State University over a period of 4 years.
Data on Heritage Russian oral production include the results of experimental studies: frog stories (based on the methodology described in Berman & Slobin 1994; Slobin 2004) and narratives based on a short cartoon (“Nu pogodi!”) (see Isurin & Ivanova-Sullivan 2008 and Polinsky 2008 for more details).
Also, see our «Partners»
Metadata
Each text in the Corpus is assigned background information.
Mandatory fields
- Oral / Written
- Author’s language background (Heritage / L2)
- Author’s dominant language
- Author’s proficiency in Russian
Optional Fields
- Author’s gender
- Date
- Genre
A more elaborated system of text marking is used in RULEC.
Partners
Maria Polinsky (Harvard University)
Olessya Kisselev (Penn State University)
Anna Alsufieva
Evgeny Dengub (Middlebury Langugage Schools)
Irina Dubinina (Brandeis University)
Anna Mikhaylova (University of Oregon)
Alla Smyslova (Columbia University)
Ekaterina Protassova (University of Helsinki)
Anna Pavlova (University of Mainz)
Anna Möhl (Johannes Gutenberg University of Zurich)
Anka Bergmann (Humboldt University of Berlin)
Irina Kor Chahine (University of Nice Sophia Antipolis)
Suhyoun Lee (Seoul National University)
Svetlana Slavkova (Bologna University)
Francesca Biagini (Bologna University)
Monica Perotto (Bologna University)
Svetlana Sokolova (Tromse University)
Natalia Ringblom (University of Stockholm)
Hayashida Rie (Osaka University)
Tsuneto Shogo (Osaka University)
Margarita Kazakevich (Osaka Universty)
Nazija Zhanpeisova (Aktubinsk University)
Alexander Krasovitsky (University of Oxford)
Rashida Kasymova (Al-Farabi Kazakh National University)
Aimgyl Kazkenova (Satbayev University)
Oksana Palikova (University of Tartu)
Languages
Currently, RLC contains production by L2 and Heritage speakers who have as their dominant language:
Abkhaz
Albanian
Amharic
Arabic
Azerbaijani
Bengali
Bulgarian
Chinese
Croatian
Czech
Dagestanian
Dari
Dutch
English
Estonian
Farsi
Finnish
French
Georgian
German (including Swiss German
Hebrew
Hindi
Hungarian
Indonesian
Italian
Japanese
Kazakh
Korean
Lao
Macedonian
Mongolian
Nepali
Norwegian
Pashto
Portuguese
Romanian
Serbian
Shona
Slovak
Slovene
Spanish
Swedish
Tajik
Thai
Turkish
Turkmen
Uzbek
Vietnamese
Search
RLC enables both lexico-grammatical search and exact search. A user can specify morphological and grammatical features of a word, as well as search by types of deviations from Standard Russian (errors).
See HELP for detailed information.
Search results
Apart from the original sentence, the user is presented with its two-levelled correction: the first level shows formal corrections (orthography, case forms, gender / number agreement, tense and aspect), the second level displays corrected lexical and constructional violations.
Using RLC
Comprising texts from two different groups of non-sandard speakers of Russian, RLC is a valuable source for various studies in the fields of Second Language Acquisition, Second Language teaching, language interference and theoretical linguistics.
Corpus data and its flexible search system provide a sound basis for comparative research in Heritage and L2 production and enables a deeper insight into complicated phenomena, such as non-standard use of Russian aspect, cases, prepositional phrases, as well as lexical and semantic misuse in multi-word constructions.
Apart from telling a lot about non-standard Russian, RLC is a powerful tool for opening new facets of Standard Russian grammar: deviations in language use help uncover subtle rules that previously have been paid no attention to.
Our team
The corpus was created by the Linguistic Laboratory of Corpus Technologies of National Research University Higher School of Economics:
Chief: Ekaterina Rakhilina
Tagging and Research: Anastasia Vyrenkova
Anastasia Ivanenko
Alina Ladygina
Olga Eremina
Daniil Fedorov
Ekaterina Shnittke
Ekaterina Vlasova
Olga Kultepina
Olga Vedenina
Ivan Smirnov
Kirill Semenov
Kirill Aksenov
Maria Grabovskaya
Sofia Goldina
Students of School of Linguistics (HSE)
:
Elena Sokur
Ekaterina Uetova
Elmira Mustakimova
Timofey Arkhangelskiy
If you have any questions concerning the error classification, the state of the project or partnership, or if you encounter any problems with the corpus’ functionality, please, contact the chiefs of the corpus and the developer : small.corpora@gmail.com.
Publications
2017
Vyrenkova A. S., Rakhilina E. V. Learner corpora supporting lexical typology, in: XVII April International Academic Conference on Economic and Social Development: в 4 кн. / Ed.: E.G. Yasin, Vol. 4. М. : HSE Publishing House, 2017. P. 450-460.
2016
Polinsky M., Ekaterina Rakhilina, Anastasia Vyrenkova. Linguistic creativity in heritage speakers // Glossa. 2016. Vol. 43. P. 1-29.
Ekaterina Rakhilina, Anastasia Vyrenkova, Elmira Mustakimova, Alina Ladygina, Ivan Smirnov. Building a learner corpus for Russian // Proceedings of the joint workshop on NLP for Computer Assisted Language Learning and NLP for Language Acquisition at SLTC, Umeå, 16th November 2016. http://aclweb.org/anthology/W16-65
Zarifyan M., Melnik A. A., Vyrenkova A. S. A case of using a Multilingual Database of synonyms for designing lexical drills / NRU HSE. Series WP BRP «Linguistics». 2016.
Рахилина Е. В. О новых инструментах описания русской грамматики: корпус ошибок // Русский язык за рубежом. 2016. № 3. С. 20-25
Рахилина Е.В., Ладыгина А.А. Русские конструкции со значением чередования ситуаций. Язык: поиски, факты, гипотезы. Лексрус Москва, 2016. С. 320-335
2015
Рахилина Е. В., Выренкова А. С. Корпусные исследования особенностей речи нестандартных говорящих («херитажный русский») // Acta Linguistica Petropolitana. Труды института лингвистических исследований. 2015. Т. XI. № 1. С. 621-639.
Ладыгина А.А. Изменения в предложных конструкциях в эритажном русском (Russian Heritage language)//IV конференция «Русский язык:конструкционные и лексико-семантические подходы», Санкт-Петербург, 16-18 апреля 2015 г.
K. Rakhilina, O. Kisselev, E. Smolovskaya, E. Mescheryakova. Доклад: Russian in the English mirror: (non)grammatical constructions in learner Russian. Corpus Linguistics 2015 (Lancaster).
Е. Смоловская. Доклад: Ошибки нестандартных говорящих: некоторые особенности русской речи иностранцев с доминирующим английским. XIII КОНГРЕСС МАПРЯЛ «Русский язык и литература в пространстве мировой культуры» (Гранада)
2014
Полинская М., Рахилина Е. В., Выренкова А. С. Грамматика ошибок и грамматика конструкций: «эритажный» («унаследованный») русский язык // Вопросы языкознания. 2014. № 3. С. 3-19.
Rakhilina E. V., Vyrenkova A. S. Language Interference in Heritage Russian: Constructional Violations / Working papers by NRU HSE. Series WP BRP «Linguistics». 2014. No. 11.
Ладыгина А.А. Русские эритажные конструкции: корпусное исследование. Дипломная работа. Москва, МГУ
Ладыгина А.А. Семантика конструкций «Х обладает Y», «X владеет Y» (корпусное исследование)//Постерный доклад на I Международной научно-практической конференции «Корпусные технологии и компьютерные методы в современной гуманитарной науке», НИУ-ВШЭ, Нижний Новгород, 11-12 апреля 2014
2013
Ладыгина А.А. Корпус Russisch in Deutschland: состав и особенности разметки// Материалы международной научно-практической конференции «Корпусные технологии. Digital Humanities и современное знание», Нижний Новгород 18-19 октября 2013 г.
Рахилина Е. В., Выренкова А. С. Ошибки в речи херитажных говорящих (на материале текстов русских эмигрантов в США) // В кн.: Проблемы онтолингвистики — 2013 / Рук.: Т. Круглякова; сост.: Т. Круглякова; отв. ред.: Т. Круглякова; под общ. ред.: Т. Круглякова; науч. ред.: Т. Круглякова. СПб. : Российский государственный педагогический университет им. А.И. Герцена, 2013. С. 435-439.
Рахилина Е.В., Ладыгина А.А. То взлёт, то посадка// Тезисы докладов, третья конференция «Русский язык: конструкционные и лексико-семантические подходы», ИЛИ РАН, СПб, 12-14 сентября 2013
Links
- Conferences
- «Russian language in a multilingual world» — section of April International Academic Conference
- What is the Corpus? — see the introduction page on the website of Russian National Corpus
- Learner corpora
- Corpus of Russian Student Texts
- Russian Learner Translator Corpus
- Russian Error-Annotated Learner English Corpus
Другие корпуса
Общие корпуса современного русского языка
- Упсальский и Тюбингенский корпуса (доступны для скачивания)
- Хельсинкский аннотированный корпус русских текстов ХАНКО (доступен для онлайн-поиска)
- Корпус русского литературного языка (доступен для онлайн-поиска)
- Открытый корпус русского языка (доступен для скачивания)
- База данных русской прессы «Integrum» (доступна по платной подписке)
- Корпус текстов Елены Викторовны Падучевой
- 01Общие корпуса современного русского языка
- 02Интернет-корпуса русского языка
- 03Синтаксические корпуса русского языка
- 04Учебные и устные корпуса русского языка
- 05Диалектные корпуса русского языка
- 06Диахронические корпуса русского языка
- 07Корпуса славянских языков
- 08Корпуса неславянских языков
- 09Параллельные корпуса
- 10Коллекции и репозитории корпусов
Интернет-корпуса русского языка
- Генеральный интернет-корпус русского языка (доступен для поиска после регистрации, корпус со снятой омонимией — для скачивания)
- Русские корпуса на сайте Сергея Шарова (Лидс): интернет-корпус ruWAC, НКРЯ, корпус блогов и другие (доступны для онлайн-поиска)
- ruTenTen: интернет-корпус русского языка в составе системы SketchEngine (доступен для онлайн-поиска после регистрации)
- Araneum Russicum: интернет-корпус русского языка (доступен по запросу)
Синтаксические корпуса русского языка
- Тестовый корпус с параллельной синтаксической разметкой (доступен для онлайн-поиска)
- Русскоязычный дискурсивный корпус (доступен для онлайн-поиска)
- UD-Russian: корпуса с разметкой в формате Universal Dependencies (доступны для онлайн-поиска и скачивания)
Учебные и устные корпуса русского языка
- «Рассказы о сновидениях» и другие корпуса звучащей речи (доступны для просмотра и прослушивания, а также скачивания в формате ELAN)
- Русский учебный корпус: образцы устной и письменной речи изучающих русский язык как иностранный и так называемых эритажных говорящих (доступен для онлайн-поиска)
- Корпус русских учебных (академических) текстов (КРУТ): коллекция текстов на русском языке, написанных студентами разных вузов (доступен для онлайн-поиска)
- Корпуса русской речи билингвов-носителей других языков: башкирского, бесермянского, дагестанских, карельского, цыганского, чувашского, якутского
Диахронические корпуса русского языка
- Регенсбургский диахронический корпус русского языка (древнерусские тексты) (требуется заполнить лицензионное соглашение)
- Рукописные памятники Древней Руси: берестяные грамоты (полнотекстовая база данных), летописи (три летописи с размеченной грамматической информацией доступны для онлайн-поиска).
- СКАТ – Санкт-Петербургский корпус агиографических текстов (доступен для скачивания и онлайн-поиска по словоуказателю с переходом к фрагментам текста)
- Корпус «Манускрипт» Удмуртского государственного университета (доступен для онлайн-поиска; для поиска по всем текстам требуется регистрация)
- Корпус русских публицистических текстов второй половины XIX века Петрозаводского государственного университета (доступен для онлайн-поиска)
Корпуса славянских языков
- Корпус текстов украинского языка Лаборатории компьютерной лингвистики Киевского университета (доступен для онлайн-поиска)
- ГРАК: Генеральный регионально аннотированный корпус украинского языка (доступен для онлайн-поиска)
- «Лаборатория украинского»: веб-корпус, корпус со снятой омонимией, параллельные корпуса
- Открытые корпуса украинского языка группы lang-uk (доступны для скачивания)
- Украинский веб-корпус на SketchEngine (платный доступ)
- Устный русинский корпус
- Белорусский корпус (доступен для онлайн-поиска)
- Белорусский веб-корпус Araneum Albaruthenicum
- Экспериментальный корпус белорусского языка
- Белорусский параллельный библейский корпус
- Corpus Albaruthenicum — корпус научных белорусских текстов (доступен для онлайн-поиска)
- Национальный корпус польского языка (доступен для онлайн-поиска)
- Корпус польского языка издательства PWN
- Корпусная поисковая система для польского языка MONCO
- Устный польский корпус Spokes
- Корпус польского языка XVII-XVIII вв. (до 1772 г.)
- Корпус польского языка XVI в.
- Польско-русский параллельный корпус (доступен для онлайн-поиска)
- Польско-украинский параллельный корпус (доступен для онлайн-поиска)
- Чешский национальный корпус (доступен для онлайн-поиска частично, для полного доступа требуется регистрация)
- Старочешский текстовый банк
- Словацкий национальный корпус (доступен для онлайн-поиска частично, для полного доступа требуется регистрация с отправкой запроса в печатном виде по почте)
- Верхнелужицкий корпус (доступен для онлайн-поиска)
- Нижнелужицкий корпус (доступен для онлайн-поиска)
- Страница ссылок на корпуса языков бывшей Югославии
- FIDA — словенский корпус (доступен для онлайн-поиска, требуется регистрация)
- Nova beseda — словенский корпус (доступен для онлайн-поиска)
- GOS — устный словенский корпус (доступен для онлайн-поиска)
- GRALIS — параллельный корпус с участием сербских, хорватских и боснийских текстов Грацского университета (доступен для онлайн-поиска, требуется регистрация по e-mail)
- Хорватский национальный корпус (доступен для онлайн-поиска через программу-клиент)
- Корпус хорватского языка Riznica (доступен для онлайн-поиска)
- Боснийский корпус университета Осло (доступен для онлайн-поиска, требуется регистрация)
- Черногорско-английский параллельный корпус (доступен для онлайн-поиска)
- Болгарский национальный корпус (доступен для онлайн-поиска, для полного доступа требуется регистрация)
- Болгарско-русский параллельный корпус (доступен для онлайн-поиска)
- Македонский корпус университета Осло (доступен для онлайн-поиска, требуется регистрация)
Корпуса неславянских языков
Германские
- Коллекция корпусов английского языка Марка Дэвиса
- Британский национальный корпус в версии Марка Дэвиса (BYU-BNC) (доступен для онлайн-поиска, возможна регистрация)
- Корпус современного американского английского (COCA) (доступен для онлайн-поиска, возможна регистрация)
- Исторический корпус американского английского (COHA) (доступен для онлайн-поиска, возможна регистрация)
- WaCKy — большие открытые веб-корпуса английского языка (доступны для скачивания)
- Корпус шотландского (германского) языка (доступен для онлайн-поиска)
- Немецкий справочный корпус (DeReKo) (доступен для онлайн-поиска через программу-клиент COSMAS II, требуется регистрация)
- Банк данных разговорного немецкого (DGD) (требуется регистрация)
- Корпуса немецкого языка на сайте CorpusEye (доступны для онлайн-поиска, некоторые корпуса требуют пароля)
- Корпус языка идиш (доступен для онлайн-поиска)
- Мультимедийный корпус языка идиш (доступен для онлайн-поиска)
- Ссылки на корпуса нидерландского языка (коммерческие и некоммерческие)
- KorpusDK: датский корпус (доступен для онлайн-поиска)
- Корпуса датского языка на сайте CorpusEye (доступны для онлайн-поиска, большинство не требует пароля)
- Банк шведского языка (корпуса и словари доступны для онлайн-поиска)
- Корпуса шведского языка на сайте CorpusEye (доступны для онлайн-поиска)
- Корпус размеченных норвежских текстов: букмол, нюнорск (оба доступны для онлайн-поиска, требуется регистрация), другие норвежские корпуса
- Корпуса норвежского языка на сайте CorpusEye (доступны для онлайн-поиска)
- Корпус исландского языка (Википедия) на сайте CorpusEye (доступен для онлайн-поиска)
- Исторический корпус исландского языка (доступен для скачивания)
- Корпуса фарерского языка на сайте CorpusEye (доступны для онлайн-поиска)
Романские
- База французских текстов FranText (доступна для онлайн-поиска, требуется подписка от имени академического/образовательного учреждения)
- Корпуса французского языка на сайте CorpusEye (доступы для онлайн-поиска)
- База данных по средневековому французскому языку (доступна для онлайн-поиска, для основной части требуется регистрация)
- Лингвистическая база данных функционально эквивалентных фрагментов на материале поливариантного русско-французского корпуса (доступна для онлайн-поиска)
- Корпус испанского языка Марка Дэвиса (доступен для онлайн-поиска)
- Корпуса испанского языка на сайте CorpusEye (доступны для онлайн-поиска, большинство не требует пароля)
- Корпуса письменного итальянского языка CORIS и CODIS (доступны для онлайн-поиска)
- Корпуса итальянского языка на сайте CorpusEye (доступны для онлайн-поиска)
- Корпус португальского языка Марка Дэвиса (доступен для онлайн-поиска)
- Корпуса португальского языка на сайте CorpusEye (доступны для онлайн-поиска, большинство не требует пароля)
- Корпус румынской прессы на сайте CorpusEye (доступен для онлайн-поиска)
Другие индоевропейские
- Исторический корпус валлийского языка (доступны конкордансы по словоуказателю)
- Корпус современного литовского языка (доступен для онлайн-поиска)
- Сбалансированный корпус современных латышских текстов (доступен для онлайн-поиска через программу-клиент)
- Греческий национальный корпус (доступен для онлайн-поиска)
- Корпус новогреческого языка (доступен для онлайн-поиска)
- Восточноармянский национальный корпус (доступен для онлайн-поиска)
- Осетинский национальный корпус (иронский диалект) (доступен для онлайн-поиска)
- Албанский национальный корпус (доступен для онлайн-поиска)
- Корпус языка хинди (доступен для онлайн-поиска)
- Параллельный хинди-английский корпус
- Корпус цыганского языка (доступен для онлайн-поиска)
- Синтаксический корпус хеттского языка (доступен для онлайн-поиска, требуется регистрация)
- Аннотированный корпус лувийских текстов (доступен для онлайн-поиска)
Неиндоевропейские и искусственные
- Коллекции текстов на малых языках России (доступны для скачивания)
- Языковой банк Финляндии (требуется регистрация или подписка)
- Веб-интерфейс Языкового банка Финляндии: корпуса финно-угорских (финский, мордовские и др.), германских (финляндский шведский, английский, немецкий и др.), русского (финско-русский параллельный корпус) и других языков (требуется регистрация или подписка)
- Описание корпусов уральских языков на сайте Хельсинкского университета (различные режимы доступа)
- Справочный корпус эстонского языка (доступен для онлайн-поиска)
- Фонетический корпус спонтанной эстонской речи (доступен для онлайн-поиска)
- Другие корпуса эстонского языка (различные режимы доступа)
- Корпус вепсского языка (доступен для онлайн-поиска)
- Венгерский национальный корпус (доступен для онлайн-поиска)
- Корпуса коми-зырянского языка (доступны для онлайн-поиска)
- Корпуса лугового марийского языка (доступны для онлайн-поиска)
- Устный корпус лугового марийского языка (доступен для онлайн-поиска)
- Корпуса мокшанского языка (доступны для онлайн-поиска)
- Корпуса эрзянского языка (доступны для онлайн-поиска)
- Корпуса удмуртского языка (доступны для онлайн-поиска)
- Грузинский национальный корпус
- Грузинский диалектный корпус (доступен для онлайн-поиска)
- Корпус грузинского языка университета им. Ильи Чавчавадзе (доступен для онлайн-поиска)
- Англо-грузинский параллельный корпус научных текстов (доступен для онлайн-поиска)
- Проект Armazi: картвельские тексты во Франкфуртском университете (доступны для онлайн-поиска и скачивания)
- Корпус адыгейского языка (доступен для онлайн-поиска)
- Устный корпус адыгейского языка (доступен для онлайн-поиска)
- Устный корпус абазинского языка (доступен для онлайн-поиска)
- Устный корпус бесленеевского диалекта кабардино-черкесского языка (доступен для онлайн-поиска)
- Корпус баскского языка Ereduzko Prosa Gaur (доступен для онлайн-поиска)
- Корпус баскского языка XX века (доступен для онлайн-поиска)
- Древнетюркский корпус (доступен для онлайн-поиска)
- Турецкий национальный корпус (доступен для онлайн-поиска, требуется регистрация)
- Турецкие корпуса на SketchEngine (платный доступ)
- Корпус устного турецкого (фрагмент доступен для онлайн-поиска; для полного доступа требуется подписать соглашение об использовании)
- Азербайджанский веб-корпус на SketchEngine (платный доступ)
- Крымскотатарский корпус (доступен для онлайн-поиска)
- Туркменский веб-корпус на SketchEngine (платный доступ)
- Алматинский корпус казахского языка (доступен для онлайн-поиска)
- Казахский веб-корпус на SketchEngine (платный доступ)
- Киргизский веб-корпус на SketchEngine (платный доступ)
- Узбекский веб-корпус на SketchEngine (платный доступ)
- Татарский национальный корпус «Туган тел», версия на другом сайте (доступен для онлайн-поиска)
- Письменный корпус татарского языка (доступен для онлайн-поиска)
- Национальный корпус башкирского языка (доступен для онлайн-поиска)
- Устный диалектный корпус башкирского языка (доступен для онлайн-поиска)
- Башкирский поэтический корпус (доступен для онлайн-поиска)
- Машинный фонд башкирского языка (включает несколько корпусов)
- Двуязычный корпус чувашского языка (доступен для онлайн-поиска)
- Корпус якутского языка (доступен для онлайн-поиска)
- Электронный корпус хакасского языка (доступен для онлайн-поиска)
- Устный корпус диалектов хакасского языка (доступен для онлайн-поиска)
- Электронный корпус тувинского языка (доступен для онлайн-поиска)
- Ненецкий, телеутский, шорский и эвенкийский корпусы ИЭА РАН (доступны для онлайн-поиска)
- Калмыцкий корпус (доступен для онлайн-поиска)
- Бурятский корпус (доступен для онлайн-поиска)
- Монгольский корпус (доступен для онлайн-поиска)
- Корпус арабского языка ArabiCorpus (доступен для онлайн-поиска, требуется регистрация, затем доступ по e-mail, тексты доступны для скачивания)
- Корпус иврита (доступен для онлайн-поиска)
- Корпус амхарского языка (доступен для онлайн-поиска)
- Сбалансированный корпус письменного японского языка (10-миллионный фрагмент доступен для онлайн-поиска)
- Обучающий корпус японского языка (доступен для онлайн-поиска)
- Японско-английский параллельный корпус (доступен для онлайн-поиска)
- Оксфордский древнеяпонский корпус (доступен для скачивания)
- Тайский корпус HSE (доступен для онлайн-поиска)
- Хельсинкский корпус суахили (для доступа требуется подписать соглашение об использовании)
- Справочный корпус бамана (доступен для онлайн-поиска)
- Справочный корпус манинка (доступен для онлайн-поиска)
- Корпуса эсперанто на сайте CorpusEye (доступны для онлайн-поиска, большинство не требует пароля)
- Корпус эсперанто фонда «Esperantic Studies Foundation» (доступен для онлайн-поиска)
Параллельные корпуса
- Корпус слушаний Европарламента (доступен для скачивания)
- Корпус документов Евросоюза (более 20 языков) (доступен для скачивания)
- ParaSol: параллельный корпус славянских и других языков Бернского университета (бывший Регенсбургский) (доступен для онлайн-поиска, требуется регистрация по e-mail)
- InterCorp: параллельные корпуса Пражского университета (доступен для онлайн-поиска, требуется регистрация, дающая доступ также к Чешскому национальному корпусу)
- PROIEL — корпус древних переводов Нового завета университета Осло (доступен для онлайн-поиска, требуется регистрация, общая для всех проектов университета)
- Параллельный корпус переводов «Слова о полку Игореве» (доступен для онлайн-поиска)
- Параллельный корпус русских и французских поэтических текстов первой трети XIX в. (доступен для онлайн-поиска)
Коллекции и репозитории корпусов
- MetaShare: Поисковик по лингвистическим ресурсам
- CLARIN: европейская коллекция языковых ресурсов
- WebCorp: Инструмент для построения конкордансов на материале Интернета для разных языков (Web-as-Corpus)
- SketchEngine: Собрание корпусов и лингвистических ресурсов на одноименном поисковом движке (платный доступ)
- Universal Dependencies: размеченные в едином формате синтаксические корпуса разных языков
- Коллекция корпусов Лейпцигского университета
- Linghub: коллекция ресурсов Высшей школы экономики
- Коллекция устных корпусов Лаборатории языковой конвергенции ВШЭ: русский как L2, диалекты, языки России
- Многоязычные корпуса университета Осло (доступны для поиска, требуется регистрация, общая для всех проектов университета)
- TITUS — тезаурус материалов по индоевропейским языкам, Франкфурт (тексты доступны для поиска, просмотра и скачивания)
Каталоги и коллекции материалов по малоресурсным языкам и языкам, которым угрожает исчезновение:
- Pangloss
- Elarchive
- Paradisec
- Коллекции текстов на малых языках России
О корпусе речевых образцов с ошибками в употреблении русского языка как иностранного: способы представления данных и параметры глубинной разметки
https://doi.org/10.37493/2409-1030.2022.4.17
Полный текст:
- Аннотация
- Об авторах
- Список литературы
Аннотация
Цель исследования, результаты которого представлены в статье, состоит в разработке оптимального состава и способа представления данных в разрабатываемом корпусе русских речевых образцов с ошибками, допущенными иностранными обучающимися. Разработка такого корпуса обусловлена, во-первых, необходимостью научного описания ошибочных языковых выражений, как подвергаются описанию в настоящее время все значимые факты применения языка, во-вторых, необходимостью создания в лингводидактических целях единой базы систематизированных данных об ошибках в речи изучающих русский язык. Создание такого корпуса требует глубинного описания ошибок в речи, поэтому в настоящей статье предлагается описывать ошибочное языковое выражение как нарушение определенной языковой нормы, определенной семантической, морфологической, синтаксической или лексической языковой модели, лежащей в основе нормативно правильного выражения, с указанием вида речевой деятельности, речевой ситуации, родного языка, специальности обучающегося. В рамках поставленной задачи по созданию корпуса ошибка понимается как сбой на определенном уровне порождения речи, поэтому в основу модели описания ошибок положена модель описания языковых выражений, разработанная отечественными исследователями при создании толково-комбинаторного словаря. Предлагаемая в статье модель глубинного аннотирования ошибочных выражений включает схематизированные модели семантического представления, синтаксической и лексической сочетаемости (в зависимости от характера ошибки) языкового выражения, что призвано, с одной стороны, точно локализовать ошибку в употреблении языка, с другой – послужить учебным материалом в лингводидактике. Сделан вывод, что при достижении статистически значимого количества аннотированных образцов с ошибками в русской речи, допущенными иностранными обучающимися, данные корпуса вполне могут использоваться как источник эмпирических данных для комплексного научного описания фактов языковой действительности. Также сделан вывод, что для жизнеспособности предлагаемого корпуса он должен представлять собой открытую систему, предполагающую включение в глубинное аннотирование новых параметров описания.
Ключевые слова
Об авторах
С. В. Гусаренко
Северо-Кавказский федеральный университет
Россия
Гусаренко Сергей Викторович – доктор филологических наук, профессор кафедры русского как иностранного
Адрес: д.1, ул. Пушкина, 355017, Ставрополь
М. К. Гусаренко
Северо-Кавказский федеральный университет
Россия
Гусаренко Марина Константиновна – кандидат филологических наук, доцент кафедры лингвистики, лингводидактики и межкультурной коммуникации
Адрес: д.1, ул. Пушкина, 355017, Ставрополь
Список литературы
1. Апресян Ю. Д. Типы информации для поверхностно-семантического компонента модели «Смысл↔Текст». Wien: Wiener Slavistischer Almanach, 1980. 119 с.
2. Апресян Ю. Д., Богуславский И. М., Иомдин Б. Л., Иомдин Л. Л., Санников А. В., Санников В. З., Сизов В. Г., Цинман Л. Л. Синтаксически и семантически аннотированный корпус русского языка: современное состояние и перспективы. // Национальный корпус русского языка: 2003-2005 (результаты и перспективы). М.: Индрик, 2005. С. 193–214.
3. Баранчикова А. Д., Сперанская А. Н. Динамика глагольной сочетаемости субстантива клятва по данным Национального корпуса русского языка // Мир русского слова. 2019. №2. С.19–23.
4. Грудева Е. В., Бучилова И. А. Волкова Н. А. Корпусы ошибок: целевая аудитория, возможная архитектура корпуса // Вестник Череповецкого государственного университета. 2018. №5 (86). С. 63–72.
5. Золотов П.Ю. Лингводидактические свойства корпусных технологий. // Вестник Тамбовского университета. Серия: Гуманитарные науки. 2020. Т. 25. №185. С. 75–82.
6. Корпус русских учебных текстов. URL: https://ling.hse.ru/krut (Дата обращения 25.10.2021)
7. Ляшевская О. Н., Кашкин Е. В. Типы информации о лексических конструкциях в системе ФреймБанк // Труды института русского языка им. В. В. Виноградова. М.: Инст. РЯ им. В. В. Виноградова РАН. № 6. 2015. С. 464–555.
8. Ляшевская О. Н. Корпусные инструменты в грамматических исследованиях русского языка. М.: Издательский Дом ЯСК, 2016. 520 c.
9. Мельчук И. А. Опыт теории лингвистических моделей «смысл↔текст». Семантика. Синтаксис. М.: Наука, 1974. 314 с.
10. Мельчук И. А., Жолковский А. К. Толково-комбинаторный словарь русского языка. Опыты семантико-синтаксического описания русской лексики. Wien: Wiener Slavistischer Almanach, 1984. 992 с.
11. Мельчук И. А. Русский язык в модели “смысл↔текст”. Москва – Вена: Школа «Языки русской культуры», Венский славистический альманах, 1995. 682 с.
12. Резанова З. И., Веснина Г. Ю. Подкорпус русской речи билингвов лингвистического корпуса «Томский региональный текст»: принципы разметки и метаразметки корпуса // Вопросы лексикографии. 2016. № 1. С. 29–39.
13. Русский учебный корпус RLC. URL: https://web-corpora.net/RLS/ (Дата обращения 25.10.2021)
14. FrameNet Project. URL: https://framenet.icsi.berkeley.edu/fndrupal/ (Дата обращения: 25.10.2021)
Рецензия
Для цитирования:
Гусаренко С.В., Гусаренко М.К. О корпусе речевых образцов с ошибками в употреблении русского языка как иностранного: способы представления данных и параметры глубинной разметки. Гуманитарные и юридические исследования. 2022;9(4):650-658. https://doi.org/10.37493/2409-1030.2022.4.17
For citation:
Gusarenko S.V., Gusarenko M.K. On the corpus of speech samples with errors in the use of Russian as a foreign language: methods of data representation and deep markup parameters. Humanities and law research. 2022;9(4):650-658.
(In Russ.)
https://doi.org/10.37493/2409-1030.2022.4.17
Просмотров: 19
Русский язык | Филологический аспект №6 (38) Июнь, 2018
УДК 81
Дата публикации 18.06.2018
кандидат филол.наук, старший преподаватель кафедры русского языка как иностранного и методики его преподавания, Санкт-Петербургский государственный университет, РФ, г. Санкт-Петербург, bestpava@hotmail.com
Аннотация: В статье рассматриваются типичные ошибки иностранцев на этапе подготовки к сдаче теста ТРКИ-2, которые появились на более ранних стадиях обучения. Анализу подверглись лексика и грамматика. Автор рассмотрел природу каждой из ошибок и представил варианты искоренения недочётов. Особое внимание в статье уделяется ошибкам, являющимся частотными в речи разных национальностей. Работа представляет собой первую часть масштабного исследования, которое ставит своей целью оптимизацию и усовершенствование преподавания русского языка иностранцам.
Ключевые слова: модальность, предикатив, происхождение ошибки, устранение ошибок, двойное отрицание, прямой перевод
Typical language mistakes of foreigners (B1-B2)
Pavlov Alexei Igorevich
Candidate of Science, Senior instructor of Russian as a foreign language and methods of its teaching department, St.Petersburg State University, Russia, St.Petersburg
Abstract: This article examines the typical mistakes of the previous levels of foreigners, while they prepare to pass TORFL2. Lexical and grammar mistakes were the matter of analysis. The author could define the nature of every mistake and gave the methods for their correction. Special attention was paid to mistakes which are common for the speech of separate nations. This work is a first part of a global research, which has the goal to optimize and make the teaching of Russian to foreigners more perfect.
Keywords: modality, predicative, the origin of the mistake, double negative, direct translation
Каждый год в свет выходит множество работ, которые описывают те или иные ошибки студентов-иностранцев в русском языке. Некоторые исследователи уделяют внимание характерным для отдельных наций ошибкам[6], другие рассматривают грамматическую, лексическую, фонетическую или их коммуникативную природу[3], третьи обращаются собственно к методике преподавания иностранного языка[8]. Каждый из подходов обладает своими сильными и слабыми сторонами. Скажем, обращаясь к конкретной нации, мы отдаём себе отчёт в том, что статья рассчитана на достаточно узкий круг реципиентов, но одновременно с этим её достоинством является более детальная, глубокая проработка проблемы. Если мы делаем предметом своего изучения ошибки в совершенно определённом аспекте языка, то мы наряду с проработкой и искоренением их намеренно игнорируем недостатки на других языковых уровнях. Создавая методику, мы указываем на принципы, по которым должны строиться занятия, логику следования одного занятия за другим, а также пути формирования навыков и умений у учащихся. Как видим, в этом случае отсутствует работа над ошибками, как самостоятельный аспект.
Данная статья своей целью ставит анализ типичных ошибок у иностранных студентов, которые готовятся сдавать тест В2 (ТРКИ-2 –Тест по русскому языку как иностранному, второй сертификационный уровень), то есть обладают уже достаточной языковой компетенцией. При этом контингент самый разнообразный с точки зрения национальной принадлежности. Этот подход позволит нам не только установить общую природу ошибок, выявить закономерности их появления в речи и временные этапы, когда это происходит, но и установить правильный алгоритм действий по их искоренению. Всего в исследовании приняли участие 155 человек, обучавшихся в группах на подготовительном факультете Санкт-Петербургского государственного университета. Такого количества реципиентов достаточно для установления языковых закономерностей.
Классификацию ошибок на рассматриваемом уровне владения языком необходимо создать, исходя из времени их появления. Сегодня мы поговорим об ошибках уровня А1 (ТРКИ-1 – Тест по русскому языку как иностранному, первый сертификационный уровень).
Данная группа включает в себя элементарные, казалось бы, оплошности. Сюда относим ошибки на всех уровнях, но по частотности фонетические и грамматические превалируют. Это вполне объяснимо, так как лексический запас и коммуникативные навыки на этом этапе ещё не развиты. В этом вопросе целесообразно было бы привести точку зрения С.А. Хаврониной, считавшей, что основную природу ошибок в устной и письменной речи иностранных учащихся на русском языке следует искать в сложном взаимодействии механизмов межъязыковой и внутриязыковой интерференции [9], и Игнатьевой О.П., которая полагает, что ошибки являются результатом просчётов обучающего[5].
1. Грамматические ошибки
А) Я надо
Действительно, это ошибка, которая должна была исчезнуть в самом начале изучения языка. Её природа очевидна, и в этом, вероятно, кроется причина её живучести. Практически в любом языке безличные предложения отсутствуют, являясь, по сути, особенностью только русской грамматической системы. В качестве типичного примера западных языков возьмём английский, где порядок слов является краеугольным камнем. Субъект при этом занимает препозицию, а для безличного предложения в нашем понимании существует формальный субъект – it [2].
Например: I need to go to school. = Мне надо пойти в школу.
It is cold today. = Сегодня холодно.
Интересно, что в восточных языках иногда модальность и вовсе устраняется из предложения или присутствует в нём имплицитно. Возьмём в качестве примера корейский язык.
Например: Мне надо пойти в университет. = nanin gaya daehakgyo
В препозиции стоит субъект «я» (на + нын – обозначение уже известного, упоминавшегося ранее субъекта), дальше глагол движения и собственно пункт назначения. Иными словами, типичная личная конструкция с глаголом движения в настоящем времени.
Синонимия может быть и в сторону описательности.
Например: Gua feng le = Ветрено.
Дословно с китайского такое предложение переводится так: Подул ветер. В нашем понимании обыкновенное двусоставное предложение, а для китайца – безличное.
Таким образом, очевидно, безличное предложение представляет собой трудность, прежде всего, из-за своего отсутствия в грамматической системе самых разных языков.
Устранение ошибки: Если до уровня В2 недочёт присутствует в речи иностранцев, то в большей степени это недоработка преподавателя на предыдущем уровне. Пожалуй, лучшим решением видится разграничение конструкций со значением действия и тех, что описывают состояние. В первом случае необходим субъект, который это действие и производит. Во втором – за его отсутствием нет надобности и в активном деятеле. Остаётся эту идею довести до обучающихся и закрепить упражнениями на синонимию, в частности, с учётом специфики каждой страны. Если группа смешанная, то стоит при составлении упражнений учесть все особенности её членов.
Например: Переведите на свой родной язык предложения
Сегодня ветрено. Сегодня дует ветер.
Это должно быть показательно для китайской аудитории. Что касается корейского языка, то тут должна быть другая оппозиция.
Например: Переведите на родной язык предложения
Жарко. Солнце печёт.
В первом случае перевод будет через предикатив, который максимально приближен к значению безличного предложения. Второе предложение и в корейском языке личное. Надо сказать, что если группа корейская, то это правильное время, чтобы разграничить полные и краткие прилагательные по их значению. Дело в том, что русский и корейский языки в этом аспекте похожи. Кроме того, стоит обратить внимание на ещё одну простую ошибку, которая связана с этим материалом.
Б) Я меня есть
Студенты могут задать вопрос относительно идеи состояния, так как в конструкции «У + Р.п. есть + И.п.» оно также присутствует. Тут стоит разделить понятие обладания чем-либо и ощущение чего-либо, что характеризует употребление Дательного падежа с наречием или категорией состояния на -о. Что касается самой природы ошибки, то она восходит всё к той же разнице между грамматическими системами языков. В случае употребления местоимения «я» в данном случае мы получаем простое предложение с двумя субъектами, что противоречит основой идее грамматики. В английском языке, например, употребление субъекта в этом типе конструкций указывает на его активную роль.
Например: I have a pencil. = У меня есть карандаш.
Корейский вариант также предполагает употребление активного субъекта (нанын ёнрильыль итсымнида).Иными словами, независимо от состава группа мы в данном случае можем прибегнуть к универсальному средству устранения этой ошибки – структура предложения с одним субъектом + значение пассивного обладания чем-либо.
В) Мы хорошо дружимся.
Принцип аналогии не всегда является полезным. Это мы в полной мере можем сказать о данной конструкции, которая употребляется с ошибкой у студентов из разных стран, которые уже достаточно продолжительное время изучают русский язык. Конечно, мы можем обнаружить данный глагол в словарях [10], но он является просторечной формой, синонимом глагола дружить. Совершенно ясно, что иностранные студенты таким набором знаний не обладают на этом этапе обучения, а потому употребление ими дружиться – это ошибка. Мы можем также с лёгкостью определить и время её появления. Творительный падеж употребляется после ряда глаголов, в том числе и почти после всех возвратных глаголов.
Например: Он дружит с Виктором со школы. Они общаются с одноклассниками и всегда готовы им помочь.
Дружить и общаться могут быть названы очень близкими, если не родственными по значению глаголами, а потому первый из глаголов принимает постфикс -ся по аналогии. В пользу именно этой версии происхождения ошибки говорит также сочетаемость глагола с наречиями.
Ср.: Они активно общаются. — Они активно дружатся.
Совершенно понятно, что диалектная форма подобными языковыми связями не обладает.
Устранение ошибки: Опыт занятий показывает чрезвычайную живучесть ошибки. К сожалению, мы должны констатировать в данном случае просчёт преподавателя, работавшего на ранних этапах обучения, так как, зная о возможных ассоциативных сложностях [1], необходимо было чётко дистанцироваться и разграничить глаголы дружить и общаться. Кроме того, стоило провести ряд упражнений, которые бы позволили запомнить форму НСВ дружить в значении долгого периода времени и СВ подружиться в значении начала дружбы между людьми. Вполне допустим после проведённых объяснений ассоциативный эксперимент в адаптированном для конкретной цели виде. В условиях уже сложившейся речевой компетенции исправить её поможет комплекс упражнений направленного действия, то есть акцентирующий внимание на свойствах каждого из глаголов. Таким образом, не останется ниши для применения дружиться, так как все необходимые значения будут передавать правильные формы.
Например:
Выберите правильный вариант
- Мы (дружили, дружим, подружились) в далёком 1979 году и до сих пор вместе.
- Они (дружили, подружились, дружат) вот уже 10 лет.
- В школьные годы они (дружили, подружились, дружат), но жизнь развела их по разным городам.
Г) Двойное отрицание
Надо сказать, что эта ошибка является типичной прежде всего для английского языка, так как в нём может быть только одно отрицание [4]. Мы берём один из самых полных современных учебников. Впрочем, можно привести ссылку на любое издание, так как это краеугольный камень английской грамматики. В век глобализации усваиваются, к сожалению, и чужие ошибки, а потому географический принцип не может быть применён в данном случае. Японцы, китайцы или арабы словно по трафарету наступают на одни и те же грабли.
Например: Я всегда не делаю домашнее задание.
Ср: I never do my homework.
Тут было бы уместно задаться вопросом, почему неправильное употребление не является прямым переводом. Ответ на него достаточно прост: по программе студенты сначала знакомятся с отрицательной конструкцией с частицей не, которая вводится в качестве антонимичной к положительной конструкции. Совершенно правильная установка на обучение отрицанию влечёт целый букет проблем в будущем. Дело в том, что примерно в то время происходит знакомство учащихся с отрицательной конструкцией с Родительным падежом.
Например: У меня нет машины.
Сложности, которые появляются именно на этом этапе обучения, таким образом сводятся к следующему:
— смешение не и нет
— только одно отрицание, где должно быть два
— нет/нету
Первый случай чрезвычайно опасен, так как ошибка быстро укореняется в сознании, а исправить её по этой причине становится достаточно трудно. Вместе с тем достаточно элементарно донести информацию до учащегося о предикации в предложении. Наличие глагола предполагает употребление отрицательной частицы не, а отрицательная конструкция отсутствия чего-либо включает в свой состав нет и Родительный падеж существительного. Несколько упражнений на усвоение этого формального механизма создадут необходимую основу для дальнейшего искоренения ошибки.
Упражнение
Выберите не или нет
- Девочка сегодня … читает книги.
- Она … красивая, а умная.
- Сегодня у меня … времени.
О природе второй группы ошибок мы уже поговорили. Для того, чтобы избавиться от этой типичной ошибки, необходимо обратить внимание на то, что в случае с негативной формой глагола местоимение, которое употребляемся в предложении, также отрицательное.
Например: Я ещё нигде не был, так что хочу начать осмотр города.
Ошибки: Я ещё везде не был. — Я ещё нигде был.
I haven’t been anywhere yet — I have been nowhere yet.
Наверное, более логичным выглядит второй вариант, так как это, по сути, калька: в английском предложении отрицание вводится при помощи лексики. Тем не менее, частотной оказывается именно модель с отрицательным глаголом. Главным образом это происходит из необходимости употребить формальное отрицание, чтобы точно передать семантику предложения.
Избавиться от данной ошибки, когда она стала частью лексикона студента, трудно, но возможно. Помогут в этом упражнения на употребление наречий в отрицательных конструкциях.
Например: Он всегда говорил правду. — Он никогда не лгал.
Конечно, семантические нюансы значений двух предложений сделают повторение на этом этапе не только полезным, но и интересным.
Наконец, просторечное «нету», которое, к сожалению, очень распространено в разговорной речи. Иностранцы копируют её автоматически, а потому добавляются ещё и грамматические ошибки.
Ср: — У тебя есть время? — — Ты придёшь сегодня на вечеринку?
— Нету. — Нету.
Первый пример представляет собой диалог, в котором просторечный вариант заменяет нормативный по позиции, а вот во втором случае перед нами частотная ошибка, так как замене уже подвергается отрицание действия, функций которого у просторечного варианта нет. Честно говоря, исправление этой ошибки предполагает согласие преподавателя на то, что студент будет употреблять просторечия. Следовательно, во-первых, стоит пояснить, что соответствует нормам литературного языка, а что считается периферией. Исходя из этого, можно дать ряд упражнений, которые бы не только искоренили грамматическую ошибку, но и продемонстрировали ситуативное и стилевое использование частиц, не углубляясь, естественно, в её предикативные характеристики.
Таким образом, грамматические ошибки, которые остаются на уровне В2 изучения языка, появившись гораздо раньше, имеют разную природу и причины возникновения, а также включаются в речь представителей совершенно разных национальностей и языковых систем. Исправление ошибок в большинстве случаев возможно средствами упражнений в любом составе групп учащихся.
2. Лексические ошибки
В эту группу мы относим прежде всего неправильное употребление тех или иных глаголов или других частей речи.
А) Он не успел сдать экзамен
Чрезвычайно частотная ошибка, которая имеет совершенно определённый круг учащихся, который подвержен ей. Это студенты из Японии, Кореи и Китая. Объяснение тут достаточно тривиальное. В словарных статьях для этих языков есть ошибка. Успеть имеет значение не смочь, хотя в русском языке есть чёткая темпоральная обусловленность: не хватило времени, чтобы куда либо попасть. Отсюда множество ошибок.
Ср.: Он не успел на экзамене. — Он провалился на экзамене.
На неправильное значение глагола, в частности, указывает его управление. В случае употребления глагола успевать/успеть в его прямом значении после него должна появиться предложно-падежная группа, отвечающая на вопрос куда? (Он не успел на поезд). Можно было бы предположить, что студент оперировал значением в рамках сдать – не сдать экзамен. В этом и заключается главный просчёт преподавателя. Для исправления ошибки тут же предлагаются упражнения, в которых один человек успешно преодолел испытание (сдал экзамен), а другой по каким- либо причинам не смог этого сделать (не сдал экзамен). Сочетаемость глагола остаётся за скобками, а потому и ошибка во многих случаях продолжает своё существование. Вместе с тем всё указывает на подмену глагола проваливаться/провалиться формой успевать/успеть. В этом контексте вполне становится понятно, почему англоговорящие студенты также делают ошибки в этом случае.
Например: Он провалился на собеседовании. — He failed at the interview.
Прямой перевод становится невозможен, если преподаватель не ввёл вовремя нужный глагол. Происходит замена на глагол сдавать/сдать, но грамматическое окружение по инерции остаётся прежним.
Устранение ошибки должно включать в себя тренировку нового глагола в его противопоставлении с ранее изученным не сдавать/не сдать. Кроме того, внимание стоит уделить и глаголу успевать, выполнив ряд упражнений на сочетаемость с ним.
Б) Яблоко сломалось.
Недостаточный синонимический ряд порой ведёт к унификации в языке, которую студенты выполняют самостоятельно, чтобы упростить себе жизнь. Другое дело, что возникает вопрос о времени подачи того или иного материала. Сейчас речь идёт об ошибках на уровне подготовки к сдаче A1, которые благополучно дожили до уровня В2, то есть укоренились в сознании. С одной стороны, существуют совершенно конкретные методические рекомендации [7], в которых к концу начального этапа студент должен знать 3000 лексических единиц, из которых 1000 оказывается пассивным багажом. С другой стороны, формализм в подходе к решению этой задачи как раз и становится причиной появления подобных рассматриваемых сейчас ошибок. Преподаватель в рамках коммуникативной темы, например, мой день вводит новый глагол.
Например: Мой будильник сломался, поэтому я опоздал на занятие.
Иногда добавляется значение глагола разбиться, но обычно на более позднем этапе. Иными словами, студент поставлен перед фактом: всё, что выходит из строя, ломается. Достаточно опасная установка, так как позднее на этапе В2 уже будет гораздо труднее убедить человека в том, что яблоко не имеет связи с механикой, а потому сломаться не может. Значит, стоит тут же на студента обрушить весь поток знаний в данной области? Вовсе нет. Мы должны исходить из принципа разумной необходимости, который предполагает не только сиюминутный результат, но дальнюю перспективу. Ещё одним типичным примером отсутствия такого рода планов и размышлений является следующий пример.
В) Наш пловец хорошо играл на Олимпиаде.
Ошибка очевидная для любого носителя языка, но её природа не так очевидна. Можно было бы подумать, что студент элементарно забыл глагол «выступать». Проблема в том, что его и не знал. В самом начале обучения на уровне A1 традиционно вводится глагол «играть» с управлением в+ В.п. в значении спорта и на + П.п. в связи с музыкальными инструментами. Следовательно, гораздо позже, при подготовке к ТРКИ-2, студент неожиданно для себя обнаруживает, что спортсмены, которые не участвуют в игровых видах спорта, выступают на соревнованиях. Мы, конечно, не будем обвинять во всём преподавателя, который не ввёл необходимый материал вовремя, не только из солидарности, но и по объективным причинам. Дело в том, что в японско-русском и корейско-русском словарях существует неточность в отношении этого понятия. Впрочем, китайские студенты также часто пеняют на свои источники, где видим ошибку.
Устранение ошибки
В данном случае чрезвычайное значение имеет количественный фактор, так как именно благодаря частотному правильному употреблению с обязательным противопоставлением с глаголом «играть» возможно выработать необходимый навык.
Г) – Это правда, или у меня есть ошибка?
Разница между прилагательными правильный – истинный – честный – правдивый должна быть предметом изучения в рамках отдельной статьи, посвящённой лексическим трудностям на уровне В2-С1 (Второй и Третий сертификационные уровни). Нас в данный момент интересует чрезвычайно важный фактор разграничения существительного правда и наречия правильно в их коммуникативной функции выражения согласия с чьим-либо утверждением или вопроса-подтверждения своей правоты. На первых порах это один из наиболее важных элементов поступательного освоения материала, когда студент надеется на одобрение со стороны преподавателя, выполнив упражнение или ответив на вопрос. Если существует путаница, то необходимо чётко пояснить, что правильно предполагает оценку слушателя слов говорящего. Например, преподаватель таким образом высказывает своё мнение по поводу услышанного от студента. Это может быть реакция человека на рассказ, который он услышал от своего собеседника. Тогда уместно говорить о поддержке, предоставляемой этим способом. В свою очередь правда – это констатация некоего факта, который не требует оценки со стороны слушающего. По этой причине упражнения на устранение ошибки также должны включать в себя не только тренировку лексических навыков, но и учитывать коммуникативные особенности каждой языковой единицы.
Обобщая сказанное о лексических ошибках уровня А1, нашедших своё отражение в языке иностранных студентов на этапе подготовки к сдаче экзамена В2, следует, с одной стороны, отметить их большую спецификацию по странам, из которых приехали учащиеся, с другой стороны, нужно обратить внимание на унификацию, к которой пытаются прибегать студенты в своей спонтанной речи. Чёткая расстановка акцентов и блоки упражнений на закрепление способны исключить ошибки из речи без существенной потере, скажем, в темпе речи.
Таким образом, рассмотренные в статье ошибки уровня А1 не являются единственными, но наиболее характерными из тех, что встречаются в речи студентов, готовящихся к тому, чтобы сдать ТРКИ (Второй сертификационных уровень). Правильные методологические приёмы и практические действия помогут исправить недочёты, большинство из которых представляет собой синтез из особенностей родного языка, которые при сопоставлении с грамматической системой русского языка обнаруживают несоответствия, и ошибок преподавателя, не сумевшего вовремя провести разграничение и закрепить разницу при помощи упражнений.
Список литературы
1. Ахутина Т.В. Порождение речи. Нейролингвистический анализ синтаксиса. М.,1989.
2. Бархударов Л.С. Структура простого предложения современного английского языка М.,1966.
3. Богомазов Г.М. Некоторые типичные ошибки на сочетания русских согласных в речи иностранцев. Сборник методических статей. М., 1981. С.141-166.
4. Васильев Александр Английский: правила произношениях и чтения. М.,2005.
5. Игнатьева О.П. Лингводидактическая природа ошибки и пути преодоления ошибок в речи иностранных учащихся. М.,2006.
6. Корчик Л.С. Некоторые типичные устойчивые ошибки в речи китайских студентов на занятиях по русскому языку// Вестник Российского университета дружбы народов. Серия: Вопросы образования: языки и специальность, М.,2010.
7. Митрофанова О.Д., Костомаров В.Г. и др. Методика преподавания русского языка как иностранного. М.,1990..
8. Федотова Н.Л. Методика преподавания русского языка как иностранного (практический курс). СПб., 2013.
9. Хавронина С.А., Крылова О.А. Обучение иностранцев порядку слов в русском языке М.,1989. С.160.
Список источников
10. Толковый словарь русского языка: В 4 т./ Под ред. Проф. Д. Ушакова. М.,2007.
← Предыдущая статьяЯзыковые особенности создания образа горца художественных текстах А.А. Бестужева-Марлинского
Следующая статья →Лексические средства выражения временных отношений (на материале текстов дневников и воспоминаний)
Текущая страница: 10 (всего у книги 11 страниц) [доступный отрывок для чтения: 2 страниц]
Существует огромное количество хранящихся в памяти выражений. По самым грубым подсчетам, их число сопоставимо с количеством лексем в словаре. Едва ли они являются маргинальным компонентом нашего языкового опыта (Jackendoff 1995: 136).
В целом, этот новый подход, в котором когнитивная и корпусная лингвистка дополняют и обогащают друг друга, ориентирован на исследование и моделирование сознания человека. Но в отличие от генеративной грамматики Н. Хомского, это направление обращает внимание не на виртуальное конструирование языковых единиц, а на реальное существование языка (англ. usage-based model). Наиболее радикальные сторонники этого подхода отрицают существование языка в том смысле, в котором этот термин использует Ф. де Соссюр.
Итак, современная корпусная лингвистика, несмотря на относительно короткую историю существования, является хорошо разработанным направлением языкознания, тесно связанным с компьютерной и когнитивной лингвистикой. С первой она связана технологией и инструментами обработки языкового материала, со второй совпадает в базовой предпосылке: как когнитивная, так и корпусная лингвистика интересуется речевой деятельностью, представленной в бесконечном числе текстов (Gonzalez-Marquez et al. 2007). В определенном смысле корпусная лингвистика меняет приоритеты исследования: объектом изучения становится речь, несводимая к языковой абстракции, нормам литературного языка, суждениям о правильности/неправильности в языке, основанным исключительно на интуиции образованного исследователя. Вторым важным теоретическим следствием корпусных исследований можно считать то, что соссюровская дихотомия langue-parole заменяется представлением о первичности речевой деятельности с плавной шкалой от речевого штампа до грамматического правила.
Наконец, следует помнить, что корпусная лингвистика – при всей революционности тех возможностей, которые она открывает, – всего лишь часть из обширного методологического инструментария современной науки. Последнее я хочу проиллюстрировать отличным замечанием Чарлза Филлмора:
Я не думаю, что существует корпуса – какими бы большими они ни были – которые содержат всю информацию об английской грамматике и лексиконе. <..> Но работа с любым корпусом – каким бы маленьким он ни был – предоставляла мне данные, которые я не смог бы найти никаким другим способом (Fillmore 1992: 35).
Любой корпус удивляет нас неожиданными открытиями, трудно улавливаемыми без обращения к реальному языковому материалу. Но даже самые крупные корпуса не в состоянии отразить все возможное в языке. Компьютер сам по себе не может стать автором лингвистических открытий, он лишь эффективный инструмент в руках современного лингвиста.
Дополнительная литература
1. Aarts J. Does corpus linguistics exist? Some old and new issues // From the COLT’s mouth… and others: language corpora studies in honour of Anna-Brita Stenström. Amsterdam, 2002. Р. 1–17.
2. Andor J. The master and his performance: An interview with Noam Chomsky // Intercultural Pragmatics. 2004. № 1:1. Р. 93–111.
3. Brazil D. A Grammar of Speech (Describing English Language). Oxford, 1995.
4. Fillmore Ch. Corpus linguistics or computer-aided armchair linguistics // Directions in Corpus Linguistics: Proceedings of Nobel Symposium 82. Stockholm, 4–8 August, 1991. Berlin, 1992. Р. 35–60.
5. Gonzalez-Marquez М., Mittelberg I. et al. (eds) Methods in Cognitive Linguistics. Amsterdam/Philadelphia, 2007.
6. Hunston S., Gill F. Pattern Grammar: a Corpus-driven Approach to the Lexical Grammar of English. Amsterdam, 2000.
7. Janda L. (ed). Cognitive Linguistics: The Quantitative Turn. The Essential Reader. De Gruyter Mouton, 2013.
8. Janda L. et al. Why Russian aspectual prefixes aren’t empty: prefixes as verb classifiers. Bloomington: Slavica Publishers, 2013.
9. McEnery T., Xiao R., Tono Yu. Corpus-based Language Studies: An Advanced Resource Book. London, 2006.
10. Mukherjee J. The state of the art in corpus linguistics: three book-length perspectives // English Language and Linguistics. 2004. № 8:1. Р. 103–119.
11. Sinclair J. Corpus, Concordance, Collocation. Oxford, 1991.
12. Sinclair J., Mauranen A. Linear Unit Grammar; Integrating speech and writing. Amsterdam, 2006.
13. Tognini-Bonelli E. Theoretical overview of the evolution of corpus linguistics // Routledge Handbook of Corpus Linguistics. Abingdon: Routledge. 2010. P. 14–27.
14. Зализняк А. А., Микаэлян И. Л. О некоторых дискуссионных моментах аспектологической концепции Лоры Янды // Вопросы языкознания. 2012. № 6. C. 48–65.
Словарь терминов
Словарь содержит основные термины корпусной лингвистики и смежных областей. Термины, имеющие более широкое значение (например, в статистике или теории информации), толкуются здесь только применительно к корпусной лингвистике. Лишь часть из приведенных в словаре терминов объясняется в учебнике. Таким образом, словарь стоит рассматривать как самостоятельную главу, чтение которой может составить небесполезное, хотя и скучное занятие. Для большинства терминов в скобках даются английские переводы. При этом следует иметь в виду, что употребление многих терминов (особенно русских) еще не устоялось: существует и синонимия, и орфографическая вариативность. В таких случаях для основной статьи выбран наиболее частотный термин, альтернативные термины даны на своем месте, с отсылками к основному. При отборе терминов использовались следующие источники:
● Baker P., Hardie A., McEnery T. A glossary of corpus linguistics. Edinburgh: Edinburgh University Press, 2006.
● Википедия (wikipedia.org)
ASCII (англ. American Standard Code for Information Interchange) – стандарт кодирования символов (→ см.), в основе которого лежат символы латинского алфавита, с его помощью может быть закодировано 128 символов (цифры, латинский алфавит, знаки пунктуации и некоторые другие символы). Расширенная версия ASCII включает 256 символов и позволяет закодировать и кириллицу.
Framenet – проект семантической разметки (→ см.), создаваемый в университете Беркли, США. Теоретическая основа проекта связана с идеями глубинных падежей и фреймовой семантики (Ч. Филлмор и др.). Например, предложения Иван продал машину Марии и Мария купила машину у Ивана описывают одну и ту же ситуацию (фрейм) с различных точек зрения, которая и будет описана в формате этой теории.
ipm (англ. instances per million) / чмс (частота на миллион) – стандартное представление частоты токена или леммы (→ см.), вычисляемое относительно условного корпуса в миллион единиц независимо от объема реального корпуса. Вычисляется как соотношение ipm(x)=freq(x) × 1 000 000/corp, где freq(x) – частота единицы в корпусе, а corp – объем реального корпуса.
KWIC (читается «квик», англ. key word in context) – формат вывода конкорданса (→ см.) на экран таким образом, что искомые слова располагаются по центру в один столбик, что облегчает их быстрый просмотр и анализ.
MI-тест (англ. MI-test, где MI это mutual information, ‘взаимная информация’) – стандартная мера выявления устойчивых сочетаний (→ см. коллокация, коллигация) в текcте (→ см. мера правдоподобия). Вычисляется по формуле:
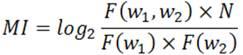
где F(w1) – частота первого коллоката в корпусе, F(w2) – частота второго коллоката, F(w1, w2) – частота коллокации W1W2, N – общее число токенов в корпусе (ср. t-score, логарифмическая функция правдоподобия).
n-грамма / n-грамм (англ. n-gram) – цепочка, состоящая из идущих подряд двух, трех, четырех и т. д. текстоформ (которые называются соответственно биграммы, триграммы и т. д.). Например, предложение «корпусная лингвистка изучает язык с помощью корпуса» может быть представлено в виде шести биграмм (корпусная лингвистика, лингвистика изучает и т. д.) или пяти триграмм (корпусная лингвистика изучает, лингвистика изучает язык и т. д.).
Text Encoding Initiative (TEI) – общественная организация, разрабатывающая стандарт представления и аннотирования данных (→ см.) в формате XML ((→ см.).
T-score – стандартная мера выявления устойчивых сочетаний (→ см. коллокация, коллигация) в текcте. Вычисляется по формуле:
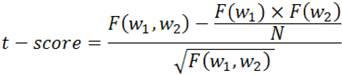
где F(w1, w2) – частота коллокации W1W2, F(w1) – частота первого коллоката (→ см. коллокат) в корпусе, F(w2) – частота второго коллоката, N – общее число токенов в корпусе. (ср MI-тест, логарифмическая функция правдоподобия)
Unicode – см. Юникод.
Wordnet – лексическая база данных (→ см. база данных), представляющая в унифицированном и формальном виде связи между лексемами. Базовой словарной единицей в WordNet является не отдельное слово, а так называемый синонимический ряд – синсет (→ см.). Синсеты связаны между собой различными семантическими отношениями (гипонимия, антонимия, «часть-целое» и т. д.). Используется для создания словарей и тезаурусов (→ см.), а также для семантического аннотирования корпусов (→ см. семантическая разметка).
XML (расширяемый язык разметки, англ. eXtensible Markup Language) – легко настраиваемый язык разметки документа, удобный как для машинной обработки, так и для чтения человеком. Представляет собой собственно данные (например, тексты) и разметку (→ см. аннотация), вводимую <в угловых скобках>.
Абсолютная частота (англ. absolute frequency) – величина, показывающая, сколько раз единица встретилась в корпусе.
Аккуратность (англ. accuracy) – мера оценки качества автоматического аннотирования. Вычисляется как отношение числа токенов, размеченных верно, к общему числу токенов.
Альтернативный тег (англ. portmanteau tag) – тег (→ см. тег), используемый для решения проблемы неоднозначности (→ см. языковая неоднозначность). При невозможности однозначного анализа указываются все варианты, при этом более вероятный обычно указывается на первом месте. Например, в Британском национальном корпусе существует тег VVD-VVN для единиц типа written, annotated, означающий «либо прошедшее время, либо причастие прошедшего времени».
Анализ, направляемый корпусом (англ. corpus-driven analysis/approach) – языковой анализ, рассматривающий корпус как данные, на основе которых можно выявить закономерности и исключения в языке. Такой анализ предполагает исключение (или минимальное использование) заранее заданных теоретических положений относительно языка. Примером такого подхода может служить автоматическое определение словоизменительных классов, не заданных заранее классификацией частей речи, а извлеченных из корпуса.
Анализ, использующий корпус (англ. corpus-informed analysis/approach) – языковой анализ, при котором корпусные данные используются лишь как источник примеров на естественном языке. Количественного анализа не предполагается, хотя роль интроспекции (языковой интуиции самого исследователя) существенно снижается.
Анализ, основанный на корпусе (англ. corpus-based approach/analysis) – языковой анализ, при котором корпусные данные анализируются как качественно, так и количественно, при этом исходные теоретические положения заранее заданы и не меняются в ходе эксперимента. Например, поиск частотности существительных третьего склонения в корпусе не ставит под сомнения существование самого концепта склонения, в том числе и его третьего типа.
Аннотация – см. разметка.
Аннотированный / размеченный корпус (англ. annotated corpus) – корпус, содержащий помимо собственно текстов лингвистическую информацию об этих текстах, словах, предложениях и т. д. Самым распространенным видом разметки является морфологическое аннотирование (→ см. морфологическая разметка).
Анонимизация (англ. anonymisation) – удаление или замена имен и других личных данных для невозможности идентификации автора или информанта в том случае, если материал является конфиденциальным (личная переписка, неизданные работы и т. п.).
Атрибут (англ. attribute) – 1. (в онтологии → см.) признак, характеризующий определенный объект в рамках онтологии. Например, объект «мужчина» имеет атрибут «мужской пол». 2. (в языке XML → см.) признак, содержащий дополнительную информацию об элементе текста. Например, в следующей записи Звонили<ana lemma=»ЗВОНИТЬ» /> тег ana имеет дополнительный атрибут lemma.
База данных (англ. database) – формально представленная совокупность связанных данных.
Бессловарный метод – метод морфологического аннотирования (→ см. морфологическая разметка), при котором текстоформы (→ см. токен) не заданы заранее, а анализируются на основе правил (например, наличия определенных окончаний).
Биграм (англ. bigram) – n-грамма, состоящая из цепочки в два токена (→ см. n-грам).
Битекст (англ. bitext / parallel text) – см. параллельный текст
Вероятностное снятие неоднозначности (англ. probabilistic disambiguation) – набор методов для выбора верного тега при автоматической разметке текста (→ см. аннотация), который основывается на известной вероятности того, какой тег является верным в данном контексте. Для анализа неразмеченных текстов используются частоты, полученные для ранее размеченных корпусов.
Вероятностно-статистические методы (англ. stochastic / probabilistic models) – методы лингвистического анализа, основанные на статистическом выделении и аннотировании единиц текста.
Выравнивание (англ. alignment) – процедура представления текстов, в результате которой одинаковые фрагменты текста и его перевода оказываются связанными друг с другом.
Выравнивание по абзацам (англ. paragraph аlignment) – выравнивание параллельных текстов (→ см.), в результате которого абзац исходного текста оказывается связан с соответствующим абзацем перевода.
Выравнивание по предложениям (англ. sentence alignment) – выравнивание параллельных текстов (→ см.), в результате которого предложение исходного текста оказывается связанным с соответствующим предложением перевода.
Данные (англ. data) – информация любого рода. В корпусной лингвистике это обычно текст, содержащийся в корпусе, а также аудио-, видеозаписи и др. C помощью различных статистических инструментов из исходных данных извлекаются производные данные, например, список коллокаций (→ см.) или самых частотных существительных.
Двунаправленный корпус (англ. bidirectional corpus) – параллельный корпус (→ см.), содержащий оригинальные тексты и переводы на двух языках. Например, оригинальные английские и русские тексты и их переводы на русский и английский языки соответственно.
Двуязычный корпус (англ. bilingual corpus) – параллельный корпус (→ см.), содержащий тексты на двух языках (оригиналы и их переводы).
Диалектный корпус (англ. dialect corpus) – особый вид звукового или текстового корпуса (→ см. корпус), создаваемый для исследования региональных вариантов языка. Такой корпус обычно включает диалектную и географическую разметку (→ см. аннотация), иногда с возможностью отражения данных на карте.
Дивергенция / расхождение (англ. divergence) – математическая величина, описывающая расхождение признаков от заданной точки.
Дизамбигуация / снятие омонимии / снятие неоднозначности (англ. disambiguation) – процедура выбора правильного языкового разбора из предложенных программой аннотирования (→ см. теггер) омонимичных вариантов (→ см. омонимы).
Дистантная многокомпонентная единица (англ. skipgram / concgram / non-contiguous MWE) – набор токенов, образующих многокомпонентную единицу, но располагающихся дистантно. Например, «то…, то…», «или…, или…».
«Длинный хвост» (англ. long tail) – группа низкочастотных единиц одного ранга (→ см.), которые на графике частотного распределения образуют длинную, не изменяющую своих характеристик линию.
Доцифровой корпус (англ. pre-electronic corpus) – корпус, созданный в эпоху, предшествовавшую активному вхождению компьютера и электронных технологий в лингвистическую практику.
Древовидный (англ. tree hierarchy) – принцип семантической разметки, при котором единица может попадать только в одну классификационную ячейку (ср. фасеточный).
Звуковой корпус (англ. speech corpus, spoken corpus) – см. корпус звучащей речи.
Значение (в XML) (англ. value) – приписанное атрибутам XML разметки значение, позволяющие включить дополнительную информацию о единицах текста. Обычно именно атрибуты и их значения представляют собой аннотацию корпуса. Например, lemma=»ЗВОНИТЬ», атрибут lemma имеет значение «ЗВОНИТЬ».
Золотой стандарт (англ. gold standard) – тщательно проверенный вручную размеченный корпус. Используется для оценки систем автоматического аннотирования, например программ частеречной разметки. Результат автоматического аннотирования сравнивается с «золотым стандартом», что позволяет сделать вывод о точности аннотирования.
Иллюстративный корпус (англ. sample corpus) – небольшой по объему корпус, задача которого не представлять весь язык (или его разновидность) во всем его многообразии, а лишь иллюстрировать те или иные явления, например в учебных или юридических целях.
Индекс лексического разнообразия (англ. type/token ratio, TTR) – мера, определяющая лексическое богатство текста. Вычисляется как число уникальных лемм в тексте, деленное на общее число токенов и выраженное в процентах. Высокое значение этого параметра предполагает, что текст представляет богатое лексическое разнообразие.
Индекс удобочитаемости (англ. readability test) – мера, определяющая сложность текста для восприятия. Он вычисляется на основе нескольких параметров: длины токенов и предложений, числа наиболее частотных слов и т. д.
Индивид (англ. individual) / экземпляр (англ. instance) (в онтологии → см.) – конкретные представители класса, например, Петя, Алексей – представители класса мужчин.
Интер(ъ)язык (англ. interlanguage) – динамическая лингвистическая система, которая складывается в процессе обучения иностранному языку у ученика, не полностью овладевшего этим языком, но находящегося в процессе активного усвоения. Этот язык характеризуется сохранением влияния родного языка, гиперобобщением или упрощением правил иностранного языка.
Исторический корпус (англ. historical corpus) – корпус, представляющий язык или вариант языка в прошлом. С помощью такого корпуса возможно исследовать определенный период развития в языке или сравнить с другим периодом (например, с корпусом современного языка). Разновидностью исторического корпуса является диахронический корпус, который включает в себя тексты, представляющие большой период времени.
Классы (англ. classes) / понятия (англ. concepts) (в онтологии → см.) группа объектов, объединенных общим признаком. Например, «мужчина» и «женщина» входят в класс «человек»; класс «человек» входит в класс «млекопитающие» и т. д.
Ключевое слово (англ. keyword) – 1. токен или лемма, которое появляется в тексте или подкорпусе значительно чаще, чем в целом по корпусу. Стандартными инструментами выявления ключевых слов являются тест χ² (→ см.) или log-likelihood (→ см.). Типичными ключевыми словами являются, например, знаменательные слова (показатели содержания текста), имена собственные, служебные слова (показатели стилистического профиля текста). 2. Токен, лемма или группа токенов/лемм, являющиеся непосредственным объектом поиска в корпусе. Именно ключевое слово пользователь набирает в поисковой строке и получает выделенным тем или иным способом в результатах поиска.
Кодировка символов (англ. character set/encoding) – набор символов, используемых для цифрового представления текста. Традиционно для представления европейских языков используется кодировка ASCII (→ см.), однако в последнее время получил распространение формат Юникод (→ см.), который включает большой набор символов, достаточный для представления всех письменных систем мира.
Коллигация (англ. colligation) – устойчивое сочетание грамматических показателей двух или более токенов или лемм. Например, коллигация «до + сущ. род. пад.», где лемма «до» устойчиво сочетается с существительными в род. падеже.
Коллокат (англ. collocate) – токен, входящий в коллокацию. Например, день – первый коллокат в коллокации «день и ночь».
Коллокация (англ. collocation) – устойчивое сочетание токенов или лемм. Например, «день и ночь».
Компьютерная/машинная морфология (КМ) (англ. computational/machine morphology) – прикладная адаптация морфологической теории, предназначенная для обработки и представления морфологической структуры языка в компьютерных системах.
Конкорданс (англ. concordance) – список найденных примеров (вхождений) нужного слова в минимальном контексте. Обычно такой контекст представляет собой фрагмент из нескольких слов слева и справа.
Конкордансер (англ. concordancer) – программа для автоматического создания конкордансов.
Контактная неомонимичная многокомпонентная единица (англ. unambiguous contiguous MWE) – набор токенов (→ см.), непосредственно располагающихся друг за другом и образующих многокомпонентную единицу. Например, составные числительные («тридцать три», «33») и единицы типа «потому что», «несмотря на».
Контактная омонимичная многокомпонентная единица (англ. ambiguous contiguous MWE) – набор токенов (→ см.), непосредственно располагающихся друг за другом, образующих единицу, омонимичную (→ см. омонимы) сочетанию двух (или более) слов, связанных синтаксически или же не имеющих непосредственной синтаксической связи. Например, «в общем» (ср. «в общем вагоне»), «в прошлом» (ср. «в прошлом году») и т. д.
Контекстуальная неоднозначность (англ. contextual ambuguity) – неоднозначность (→ см. языковая неоднозначность), при которой близкий контекст не дает достаточных оснований для выбора правильного варианта разбора. Например, в предложении Двери не открывать невозможно точно определить падеж существительного «двери».
Копирайт (англ. copyright) – право публиковать и продавать литературные, музыкальные и художественные произведения. При создании корпуса необходимо получить разрешение на использование текстов у правообладателя или обеспечить недоступность данных без специального разрешения.
Корпус «Сделай сам» (англ. DIY-corpus, do-it-yourself corpus) → см. собственный корпус.
Корпус lingua franca (англ. lingua franca corpus) – корпус текстов, созданных людьми, которые регулярно используют неродной язык для общения.
Корпус n-грамм (англ. n-gram corpus) – фрагментированный корпус (→ см., содержащий n-граммы (→ см.).
Корпус второго поколения (англ. second generation corpus) – обобщающее название для корпусов, которые создаются с 90-х годов по настоящее время. Они характеризуются большим объемом данных (более 100 млн слов) и богатой разметкой (→ см. аннотация). Примерами корпусов второго поколения являются the British National Corpus, the Longman Corpus Network или Национальный корпус русского языка.
Корпус звучащей речи / звуковой корпус (англ. speech corpus, spoken corpus) – корпус, материалы которого представляют собой записанные в аудио/видео формате записи разговорной речи. Обычно такой корпус содержит расшифровку и аннотирование (→ см. аннотация) таких записей для более удобного поиска.
Корпус наследуемого языка, или херитажный корпус (англ. heritage language corpus) – корпус текстов, созданных людьми, владеющими двумя или более языками. В такой корпус обычно включается более слабый язык, усвоенный вне школы – в семейном окружении.
Корпус не носителей языка (англ. L2 corpus) – это собранная систематическим образом электронная коллекция текстов, созданных не носителями данного языка.
Корпус ошибок (англ. error corpus) – корпус, в котором собраны тексты, созданные людьми, изучающими иностранный язык, и содержащий разметку ошибок, сделанных этими учениками (ср. ученический корпус).
Корпус первого поколения (англ. first generation corpus) – обобщающее название для первых электронных корпусов сравнительно небольшого размера, которые были созданы по схожему образцу и не содержали аннотирования (→ см. аннотация). К ним относятся, например, Brown Corpus of American English и Lancaster-Oslo/Bergen Corpus of British English.
Корпус переводов / параллельный корпус (англ. parallel или translation corpus) – параллельный корпус, состоящий из оригинальных текстов и их переводов на другие языки.
Корпус ученических текстов (англ. learner corpus) – см. ученический корпус.
Корпус / текстовый корпус (англ. (text) corpus) – собрание языковых материалов (текстов, аудио/видеозаписей и т. д.), собранных в соответствии с определенными принципами, размеченных по определенному стандарту (→ см. аннотация) и обеспеченных специализированной поисковой системой (→ см. корпус-менеджер). Корпусом (неразмеченным корпусом) могут называть любое собрание текстов, объединенных каким-то общим признаком (языком, жанром, автором, периодом создания текстов).
Корпус-менеджер (англ. corpus manager) – программы, позволяющие осуществлять поиск в корпусе и производить определенные числовые подсчеты.
Корпусная лингвистика (англ. corpus linguistics) – 1. раздел компьютерной лингвистики, связанный с созданием корпусов. 2. раздел языкознания, использующий корпуса текстов для анализа данных с помощью корпусных методов.
Коэффициент вариации D (англ. coefficient of dispersion D / Juilland’s D) – числовое значение, показывающее, насколько равномерно единица распределена по всем текстам корпуса. Вычисляется по формуле:
где δ – среднеквадратичное отклонение (→ см.) частоты токенов (→ см.), а n – сумма частот всех токенов.
Критерий согласия Пирсона (англ. test for independence, Pearson’s chi-squared test) – см. тест χ² (хи-квадрат)
Лемма (англ. lemma) – совокупность текстоформ (→ см. токен), отличающихся друг от друга только морфологическим значением. Таким образом, лексическое значение или разница в ударении при лемматизации (→ см. лемматизация) не учитывается. Например, в предложении «Зáмок закрывается на замóк» две леммы: «замок» и «закрываться».
Лемматизатор (англ. lemmatizer) – программа, автоматически сводящая текстоформы (→ см. токен) к леммам (→ см.) без приписывания им морфологической информации.
Лемматизация (англ. lemmatization) – автоматическое приписывание текстоформы (→ см. токен) к ее лемме (→ см.).
Лингвистически аннотированный корпус (англ. linguistically annotated corpus) – языковой корпус, содержащий, помимо собственно текстов, лингвистическую информацию (разметку, см. аннотация), что позволяет искать не только отдельные слова, но и целые лингвистические классы, например глаголы в прошедшем времени и т. п. Чаще всего аннотированный корпус содержит морфологическую информацию обо всех единицах корпуса (→ см. морфологическая разметка).
Линейка / уровень аннотации (англ. tier) – набор параллельных разметок в мультимодальном корпусе (→ см. мультимедийный корпус), маркирующих разные каналы коммуникации. Эти разметки обычно выровнены по общей временной шкале.
Логарифмическая функция правдоподобия / мера правдоподобия (англ. log-likelihood) – мера статистической значимости, которая используется в корпусном анализе, например, для анализа коллокаций (→ см.) или ключевых слов (→ см.). Как и тест χ² (→ см.), log-likelihood сравнивает наблюдаемые и ожидаемые значения для двух наборов данных, однако использует другую формулу: G2=2∑xij (logexij—logemij), где xij – это наблюдаемая частота, а mij – ожидаемая частота. Например, для определения степени связанности частей той или иной коллокации в качестве ожидаемой частоты мы указываем абсолютные частоты (→ см.) каждого из коллокатов в корпусе, а в качестве наблюдаемой – частоту данной коллокации.
Машинная морфология (англ. computational/machine morphology) – см. компьютерная морфология.
Медиана (англ. median) – статистическая мера, позволяющая разделить высоко– и низкочастотные данные (→ см. частота встречаемости). За медиану принимается значение, стоящее ровно посередине выстроенного по частоте ряда полученных данных. Например, в ряду 120-150-200 медианой является 150.
Мера правдоподобия (англ. log-likelihood) – см. логарифмическая функция правдоподобия.
Мера устойчивости (анл. lexical association measure) – величина, показывающая, насколько случайны или устойчивы сочетания единиц в составе коллокации (→ см.) или коллигации (→ см.). Для ее вычисления используется множество разных методов, например MI-score (→ см. мера MI), t-score (→ см. t-score) и др.
Метаданные / метатекстовая разметка (англ. metadata) – разметка (→ см. аннотация), содержащая информацию в целом о тексте или совокупности текстов: обстоятельства создания, социальные и возрастные характеристики автора, жанр и т. д.
Многоуровневая / мультимодальная разметка (англ. multimodal grid) – языковая аннотация (→ см.), состоящая из разметки лингвистических единиц на нескольких уровнях: звуковом, морфологическом и т. д. и отражающая несколько взаимосвязанных каналов коммуникации: речь, жесты, позы и т. п.
Многоязычный корпус (англ. multilingual corpus) – корпус, в состав которого входят тексты на нескольких языках
Мода (англ. mode) – величина, которая указывает не среднее, а самое часто встречающееся значение (→ см. частота встречаемости). Например, в ряду данных 120-120-150-200 мода равна 120.
Мониторный корпус (англ. dynamic/monitor corpus) – постоянно пополняемый корпус, создаваемый с целью мониторинга изменений в определенном подъязыке или языке в целом.
Морфологическая разметка (англ. morphological annotation/ tagging) – морфологический разбор текстоформы (→ см. токен), приписывание ему релевантных морфологических признаков. Результат разметки хранится в корпусе и доступен для поиска.
Морфологический анализатор / морфологический теггер (англ. morphological analyser/tagger) – программа, анализирующая форму токена (→ см. токен) с целью определения его морфологических параметров.
Мультимедийный / мультимодальный корпус (англ. multimedia / multimodal corpus) – аннотированная коллекция сообщений (→ см. аннотация), передаваемых по нескольким взаимосвязанным каналам коммуникации: речь, жесты, позы и т. п. На практике мультимедийный корпус наиболее полно отражает реальные акты коммуникации.
Мультимодальный корпус (англ. multimodal corpus) – см. мультимедийный корпус.
Национальный корпус (англ. national corpus) – сбалансированный репрезентативный корпус (→ см. сбалансированность, репрезентативность), представляющий национальный язык в целом во всех его жанрах и разновидностях.
Неоднословная лексическая единица / оборот (англ. multiword expressions, MWE) – последовательность двух или более токенов/лемм (→ см. токен, лемма), свойства которой не выводятся из суммы свойств входящих в нее текстоформ/лемм. Например, сыграть в ящик, потому что, в общем и т. д.
Нормальное распределение (англ. normal distribution) – статистическая мера, определяющая случайность или не случайность отклонения полученных данных от средней величины.