
В процессе обучения двигательным действиям ставится задача научить управлять своими действиями. Это значит — регулировать прилагаемые усилия, быстроту выполнения, форму, амплитуду, направление движения.
Весь процесс обучения двигательным действиям включает в себя три этапа, которые отличаются друг от друга как частными задачами, так и особенностями методики.
1. Этап начального разучивания. Цель — сформировать у обучаемого основы техники изучаемого движения и добиться его выполнения в общих чертах.
Основные задачи.
1. Сформировать смысловое и зрительное представления о двигательном действии и способе его выполнения.
2. Создать двигательные представления по основным опорным
точкам (элементам действия) путем освоения подводящих упражнений или структурных элементов изучаемого действия.
3. Добиться целостного выполнения двигательного действия в
общих чертах.
4. Предупредить или устранить значительные искажения в технике двигательного действия.
Решение этих задач осуществляется поочередно. Представления о технике у учеников формируются в результате объяснения упражнения преподавателем, восприятия показываемых движений, просмотра наглядных пособий, анализа собственных мышечных и других ощущений, возникающих при первых попытках выполнения движений, наблюдений за действиями других занимающихся. Все это создает ориентировочную основу, без которой невозможно освоение техники действия.
В зависимости от особенностей и сложности изучаемой техники действия, физической подготовленности занимающихся двигательное действие разучивается по частям или в целом. На этом этапе разучивания действия широко применяют подводящие упражнения в условиях, облегчающих выполнение движений.
Как правило, обучение начинается с ведущего звена техники. Если же ведущее звено существенно зависит от подготовительных фаз, то вначале разучиваются эти фазы. В отдельных случаях изучение техники действия начинается с завершающих фаз, если необходимо предупредить травмирование.
Первые попытки выполнения обычно сопровождаются повышенным напряжением всего двигательного аппарата, лишними движениями, замедленным и скованным выполнением. Это вполне нормальная ситуация, так как ученику необходимо держать под усиленным контролем все основные опорные точки, т.е. те элементы, фазы двигательного действия, которые определяют успешность самого действия и требуют концентрации внимания при исполнении. При первоначальных попытках очень важно своевременно использовать методы и приемы обучения, помогающие ориентироваться в управлении движениями. Выполнять действия следует в стандартных условиях, так как любые изменения могут ухудшать качество исполнения.
При завершении попытки выполнить действие следуют анализ и оценка его выполнения и постановка задач по совершенствованию действия при следующей попытке.
Для практического освоения техники двигательного действия нужны неоднократные повторения движений с установкой на лучшее разрешение двигательной задачи, устранение допущенных ошибок, с тем чтобы качественнее и быстрее осваивать движения.
На этапе начального разучивания наиболее типичны (т.е. имеющие массовый характер) следующие двигательные ошибки:
– лишние, ненужные движения;
– искажение движения по амплитуде и направлению;
– нарушение ритма двигательного действия;
– закрепощенность движения.
Причинами ошибок могут быть:
– недостаточно ясное представление о двигательной задаче;
– неправильное выполнение предыдущих действий;
– слабое развитие координационных способностей и других двигательных способностей;
– состояние утомления;
– влияние конкурирующих навыков;
– недостаточность двигательного опыта занимающегося;
– неблагоприятные условия выполнение действий (плохой инвентарь или оборудование, метеоусловия);
– психологические причины: боязнь, невнимательность, неуверенность, повышенная возбудимость занимающихся и др.
Понимание причин позволит найти наиболее верный способ исправления. Ошибки рекомендуется исправлять как можно быстрее и тщательнее, чтобы они не автоматизировались.
Наиболее распространенные правила исправления ошибок:
1. Ошибка должна быть понята. Для этого применяется словесный или письменный отчет обучаемого о своих движениях и действиях с последующим анализом его вместе с преподавателем.
2. Ошибки следует исправлять не все сразу, а последовательно, по степени их значимости. Вначале исправляются грубые, искажающие основу техники действия. Затем исправляются ошибки в деталях техники.
3. Указания преподавателя об исправлении ошибки должно соответствовать возможностям обучаемого в данный момент.
4. Не рекомендуется показывать ошибки в утрированном виде.
Для повышения эффективности освоения двигательных действий и профилактики ошибок большое значение имеет правильный регламент их выполнения. Основными параметрами такого регламента являются число повторений и интервалы отдыха между ними. Поэтому следует соблюдать следующие общие правила:
– число повторений нового действия определяется возможностями обучаемого улучшать движение при каждой новой попытке;
– повторное выполнение с одними и теми же ошибками является сигналом к перерыву для отдыха и обдумыванию своих действий;
– интервалы отдыха должны обеспечивать оптимальную готовность к выполнению очередной попытки (готовность как физическую, так и психическую);
– продолжать освоение движений в условиях прогрессирующего утомления нецелесообразно и даже вредно;
– обучение двигательным действиям целесообразно проводить в начале основной части занятия.
– интервалы между занятиями рекомендуется делать по возможности короткими, чтобы избежать угасания ещё не стойких умений.
Продолжительность этапа начального разучивания двигательного действия зависит от:
1) степени сложности техники изучаемого действия;
2) уровня подготовленности занимающихся;
3) их индивидуальных особенностей;
4) возможности использовать положительный эффект переноса навыков.
2. Этап углубленного разучивания. Цель — сформировать полноценное двигательное умение.
Основные задачи.
1. Уточнить действия во всех основных опорных точках как в основе, так и в деталях техники (с учетом индивидуальных особенностей занимающихся).
2. Добиться целостного выполнения двигательного действия на основе сознательного контроля пространственных, временных и динамических характеристик техники.
3. Устранить мелкие ошибки в технике, особенно в ее основном звене.
Данные задачи могут решаться одновременно.
Ведущее значение приобретает метод целостного упражнения. В числе методов передачи устной информации ведущими становятся анализ и разбор техники действия, беседа. Широко применяются методы обеспечения наглядности показ (непосредственный и опосредованный), направленного прочувствование двигательного действия, срочной информации, для создания ощущений правильного исполнения деталей техники. Часто используется метод идеомоторного упражнения.
Дополнительные ориентиры используемые на первом этапе, постепенно убирают с тем, чтобы приблизить условия выполнения действия к естественным. Постепенно устраняются и облегчающая физическая помощь.
Возрастает роль мышечных ощущений в непосредственном управлении движениями. Следует постепенно усложнять задания по концентрации внимания на «опорных точках» в каждый момент двигательного акта и последовательному опережающему движения переключению внимания на очередные «опорные точки». Используются методический приём: выполнение действия в усложненных условиях сенсорного самоконтроля (ограничивается или полностью отключается зрительный самоконтроль). Включаются вариативные упражнения.
Регламентация нагрузки:
В отдельном занятии интенсивность и число повторений изучаемого действия возрастает. Главный критерий дозирования нагрузки – отсутствие ошибок.
В рамках одного занятия обучение на этом этапе необходимо планировать в первой половине основной части урока, когда еще не наступило значительное утомление.
3. Этап закрепления и дальнейшего совершенствования. Цель — двигательное умение перевести в навык, обладающий возможностью его целевого использования.
Основные задачи.
1. Добиться стабильности и автоматизма выполнения двигательного действия.
2. Довести до необходимой степени совершенства индивидуальные черты техники.
3. Добиться выполнения двигательного действия в соответствии с требованиями его практического использования (максимальные усилия и скорости, экономичность, точность, рациональный ритм и т.д.).
4. Обеспечить вариативное использование действия в зависимости от конкретных практических обстоятельств.
Эти задачи могут решаться как одновременно, так и последовательно, так как все они тесно взаимосвязаны.
На этом этапе увеличивается количество повторений в обычных и новых, непривычных условиях, что позволяет вырабатывать гибкий навык.
В целях совершенствования движений применяют различные методические приемы: повышение высоты снарядов, увеличение амплитуды и скорости движений, поточное выполнение упражнений, повторение в форме соревнования на качество исполнения и результат, в игровой форме и др.
Вариативность действия достигается его многократным воспроизведением в самых различных условиях, когда оно выполняется с изменениями деталей кинематической, динамической и ритмической характеристик движения. Это может происходить:
а) при усложнении внешних условий (условия опоры, ограничение пространства, неблагоприятные метеоусловия);
а) при изменениях в физическом и психическом состоянии занимающихся (при утомлении, отвлечении внимания, волнения и.т.п.);
в) различных сочетаниях с другими действиями, и в том числе в сочетаниях, требующих преодолевать отрицательный перенос навыков;
г) при возрастающих физических усилиях.
Условия выполнения действия усложняется вначале постепенно. Данный этап характеризуется органическим слиянием процессов совершенствования техники и развития двигательных способностей, обеспечивающих максимальную эффективность действия. Это особенно актуально в спортивной тренировке.
 С этим файлом связано 7 файл(ов). Среди них: Моя будущая профессия нспк.docx, В педагогическом процессе И.docx, Практическое занятие 7.docx, Практическое занятие 8.docx, Респираторные заболевания.pptx, нк.pptx, ХЕЛИКАБАКТОР ПИЛОРИ.pptx.
С этим файлом связано 7 файл(ов). Среди них: Моя будущая профессия нспк.docx, В педагогическом процессе И.docx, Практическое занятие 7.docx, Практическое занятие 8.docx, Респираторные заболевания.pptx, нк.pptx, ХЕЛИКАБАКТОР ПИЛОРИ.pptx.
Показать все связанные файлы
Подборка по базе: ОТВЕТЫ 100 баллов.pdf, Контроль знаний 4_1 (все верно).pdf, 1 Верно Баллов_ 1,00 из 1,00 Текст вопроса в записи числа 0, 030, 77 баллов из 100.docx, 1 Верно Баллов_ 1,00 из 1,00 Отметить вопрос Текст вопроса Анато, Таблица баллов по СОР и СОЧ.docx, КСП 29 повторение 40 баллов.docx, Право социального обеспечения-тест-100 баллов.docx, 1ВыполненБаллов_ 20,00 из20,00Вопрос 2ВерноБаллов_ 1,00 из1,00Во, Задание (Максимальное количество баллов – 3) Культура общения –
Вопрос 1
Верно
Баллов: 1,00 из 1,00
 Отметить вопрос
Отметить вопрос
Текст вопроса
Выбор методов обучения зависит от… (отметьте несколько вариантов правильных ответов):
Выберите один или несколько ответов:
 a. возрастных и индивидуальных особенностей детей
a. возрастных и индивидуальных особенностей детей
 b. интересов детей
b. интересов детей
c. этапа обучения
d. количества занимающихся
Вопрос 2
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Группы методов, создающих зрительное, слуховое, мышечное представление о движении – это…
Выберите один ответ:
 a. словесные методы
a. словесные методы
b. игровой
c. практические методы
 d. наглядные методы
d. наглядные методы
Вопрос 3
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Деятельность, характеризующая активность двигательного аппарата ребенка.
Выберите один ответ:
a. физическое развитие
b. физическая культура
c. двигательная деятельность
d. двигательная активность
Вопрос 4
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Исходные дидактические положения, отражающие протекание объективных законов и закономерностей процесса обучения — это
Выберите один ответ:
a. принципы развития
b. принципы воспитания
c. принципы разучивания
d. принципы обучения
Вопрос 5
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Комплекс биологических и психических свойств организма определяющий силовые, скоростно-силовые и временные характеристики движения человека:
Выберите один ответ:
a. психофизические качества
b. физическое развитие
c. здоровье
d. физические упражнения
Вопрос 6
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Метод, при котором ребенку сообщается готовая информация и осуществляется показ образца выполнения движения – это…
Выберите один ответ:
a. информационно-рецептивный метод
b. репродуктивный метод
c. проблемный метод
d. игровой
Вопрос 7
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Методы, относящиеся к специфическим методам физического воспитания(отметьте несколько вариантов правильных ответов):
Выберите один или несколько ответов:
a. метод круговой тренировки
b. информационно-рецептивный
c. репродуктивный.
d. строго регламентированного упражнения
Вопрос 8
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Наука, изучающая общие закономерности, содержание, специфику и формы построения системы физического воспитания ребенка:
Выберите один ответ:
a. дошкольная педагогика
b. анатомия
c. физиология
d. теория и методика физического воспитания и развития ребенка
Вопрос 9
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Педагогический процесс, направленный на формирование и совершенствование двигательных умений, навыков, психофизических качеств:
Выберите один ответ:
a. образование
b. физическое воспитание
c. физическое образование
d. физическое совершенство
Вопрос 10
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Переход от первоначального умения к навыку возможен в результате
Выберите один ответ:
a. контроля
b. разучивания
c. повторения
d. закрепления
Вопрос 11
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Показ, частичный показ упражнения, подражание зрительные ориентиры (разметка поля) относятся к группе…
Выберите один ответ:
a. практических методов
b. словесных методов
c. наглядных методов
d. проблемных методов
Вопрос 12
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
При расчлененном показе движения педагог
Выберите один ответ:
a. использует счет
b. иногда использует счет
c. использует музыку
d. не использует счет
Вопрос 13
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Приемы коррекции ошибок применяются только на:
Выберите один ответ:
a. первом этапе обучения
b. не используется
c. втором этапе обучения
d. третьем этапе обучения
Вопрос 14
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Принцип, обеспечивающий последовательность, преемственность, частоту занятий физическими упражнениями:
Выберите один ответ:
a. возрастной адекватности
b. непрерывности
c. интеграции
d. цикличности
Вопрос 15
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Принципы, отражающие закономерности обучения называются…
Выберите один ответ:
a. общедидактическими
b. комплексными
c. специфическими
d. развивающими
Вопрос 16
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Процесс изменения форм и функций организма под воздействием условий жизни и воспитания:
Выберите один ответ:
a. физическое совершенство
b. физическая культура
c. адаптация
d. физическое развитие
Вопрос 17
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Разметка, зрительные ориентиры, схемы движения – это метод…
Выберите один ответ:
a. практический
b. словесный
c. игровой
d. наглядный
Вопрос 18
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Соответствие уровня развития двигательных умений и навыков человека требованиям нормативных документов, результат физической подготовки – это…
Выберите один ответ:
a. физическое развитие
b. спорт
c. физическая подготовленность
d. здоровье
Вопрос 19
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Специальная деятельность, направленная на достижения наивысших результатов в разных видах физических упражнений, выявленных в результате соревнования
Выберите один ответ:
a. физическое образование
b. спорт
c. физкультура
d. гимнастика
Вопрос 20
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Специальные движения, а также сложные виды деятельности ребенка, применяемые в качестве средств физического воспитания – это …
Выберите один ответ:
a. танец
b. система физического воспитания
c. физические упражнения
d. естественные силы природы
Вопрос 21
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Способность в процессе двигательных действий преодолевать внешнее сопротивление или противодействовать ему посредством мышечных напряжений называется…
Выберите один ответ:
a. координацией
b. силой
c. гибкостью
d. равновесием
Вопрос 22
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Способность противостоять утомлению в какой-либо деятельности называется…
Выберите один ответ:
a. ловкостью
b. равновесием
c. выносливостью
d. гибкостью
Вопрос 23
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Стадия формирования двигательного навыка, характеризующаяся неуверенностью в движениях, напряженностью мускулатуры, наличием лишних движений:
Выберите один ответ:
a. специализация
b. иррадиация
c. стабилизация
d. адаптация
Вопрос 24
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Стадия, характеризуемая упрочнением динамического стереотипа:
Выберите один ответ:
a. иррадиация
b. специализация
c. адаптация
d. стабилизация
Вопрос 25
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Уточнение правильности выполнения деталей техники, исправление ошибок является целью этапа:
Выберите один ответ:
a. закрепление навыка
b. углубленное разучивание
c. первоначальное разучивание
d. совершенствование техники движений
Вопрос 26
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Физическое качество, при котором человек способен быстро овладевать новыми движениями, действовать в изменяющихся условиях — это…
Выберите один ответ:
a. гибкость
b. равновесие
c. ловкость
d. быстрота
Вопрос 27
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Форма двигательного действия, характеризующаяся явлением автоматизации.
Выберите один ответ:
a. исходное положение
b. умение
c. упражнение
d. двигательный навык
Вопрос 28
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Часть общей культуры человека, характеризующая достижения общества в области физического психического и социального здоровья человека:
Выберите один ответ:
a. двигательная активность
b. спорт
c. физическая культура
d. хореография
Вопрос 29
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Этап обучения, на котором используются игровой и соревновательный методы:
Выберите один ответ:
a. углубленное разучивание
b. первоначальное разучивание
c. закрепление навыка и совершенствование техники движений
d. не используется
Вопрос 30
Верно
Баллов: 1,00 из 1,00
Отметить вопрос
Текст вопроса
Этапу углубленного разучивание соответствует стадия:
Выберите один ответ:
a. специализация
b. иррадиация
c. синхронизация
d. стабилизация
На этапе начального разучивания действия наиболее типичны следующие двигательные ошибки:
• лишние, ненужные движения (не предусмотренные программой действия и не требующиеся для его выполнения);
• искажение пространственных параметров движений (неточность их по направлению, амплитуде и т.п.);
• отклонения от заданных временных и пространственно- временных параметров движений (несвоевременное начало следующих друг за другом движений, замедленность их, нарушение ритма движений);
• излишние затраты мышечных усилий, закрепощённость, скованность движений.
Причины ошибок:
• недостаточная подготовленность обучаемых к разучиванию данного двигательного действия (недостаточная степень развития силовых, скоростных качеств, гибкости и других физических способностей, небольшой фонд двигательных умений и навыков);
• изъяны в информации, сообщаемой преподавателем при формировании ООД (её неполнота, искажённость в тех или иных моментах, недостаточная доходчивость для обучаемых) несовершенство методов её передачи;
• искажённость воспринятой информации в результате неадекватного освоения её обучаемым, недостаточный самоконтроль;
• отрицательное взаимодействие в процессе выполнения движений (отрицательный перенос навыков), негативное влияние факторов утомления, боязнь, неуверенность, повышенная возбудимость занимающихся;
• неблагоприятные внешние условия выполнения действия (некачественное учебное оборудование и инвентарь, отсутствие технических средств обучения, неблагоприятные гигиенические и метеорологические условия).
Во всех случаях ошибочного выполнения действия необходимо в первую очередь вскрыть конкретные причины и устранить, прежде всего именно их (а не поверхностно подмеченные частные следствия). Необходимо указать обучаемому на ошибку, показать правильное исполнение и предоставить ученику дополнительные попытки овладеть правильным способом исполнения. Если это не дало результат, следует вернуться к подводящим упражнениям, использовать корригирующие и контрастные задания.
Контроль. Педагогический контроль за становлением исполнения занимающимся двигательного действия ведётся на основе оценки отклонения выполняемых движений от заданных параметров. Эти отклонения выявляются преподавателем визуально (с опорой на вспомогательные ориентиры, разметку, предметы и т. д.). Объективизации таких визуальных оценок способствует использование в учебном процессе кино- и видеомагнитофонной записи и других современных технических средств.
Это позволяет существенно повысить эффективность не только контроля со стороны преподавателя, но и самоконтроль за построением действия. Средствами, облегчающими самоконтроль, являются также различного рода ориентиры и предметные ограничители, как бы вынуждающие соблюдать заданные параметры движений (разметка площадки или зала, направляющие плоскости оборудования, набивные мячи, щиты и другие предметные препятствия, мешающие отклонениям от необходимых параметров движений и др.).
В целом можно считать, что задачи решены на первом этапе разучивания, если обучаемые более или менее ясно представляют его ориентировочную основу во всех ООТ и не допускают грубых ошибок в основных операциях, входящих в действие при его выполнении.
Обнаружение ошибок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи.
Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды).
Содержание
- 1 Способы борьбы с ошибками
- 2 Коды обнаружения и исправления ошибок
- 2.1 Блоковые коды
- 2.1.1 Линейные коды общего вида
- 2.1.1.1 Минимальное расстояние и корректирующая способность
- 2.1.1.2 Коды Хемминга
- 2.1.1.3 Общий метод декодирования линейных кодов
- 2.1.2 Линейные циклические коды
- 2.1.2.1 Порождающий (генераторный) полином
- 2.1.2.2 Коды CRC
- 2.1.2.3 Коды БЧХ
- 2.1.2.4 Коды коррекции ошибок Рида — Соломона
- 2.1.3 Преимущества и недостатки блоковых кодов
- 2.1.1 Линейные коды общего вида
- 2.2 Свёрточные коды
- 2.2.1 Преимущества и недостатки свёрточных кодов
- 2.3 Каскадное кодирование. Итеративное декодирование
- 2.4 Оценка эффективности кодов
- 2.4.1 Граница Хемминга и совершенные коды
- 2.4.2 Энергетический выигрыш
- 2.5 Применение кодов, исправляющих ошибки
- 2.1 Блоковые коды
- 3 Автоматический запрос повторной передачи
- 3.1 Запрос ARQ с остановками (stop-and-wait ARQ)
- 3.2 Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)
- 3.3 Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)
- 4 См. также
- 5 Литература
- 6 Ссылки
Способы борьбы с ошибками
В процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях модели OSI).
В системах связи возможны несколько стратегий борьбы с ошибками:
- обнаружение ошибок в блоках данных и автоматический запрос повторной передачи повреждённых блоков — этот подход применяется в основном на канальном и транспортном уровнях;
- обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков — такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу;
- исправление ошибок (forward error correction) применяется на физическом уровне.
Коды обнаружения и исправления ошибок
Корректирующие коды — коды, служащие для обнаружения или исправления ошибок, возникающих при передаче информации под влиянием помех, а также при её хранении.
Для этого при записи (передаче) в полезные данные добавляют специальным образом структурированную избыточную информацию (контрольное число), а при чтении (приёме) её используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода.
С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от первых, последние могут только установить факт наличия ошибки в переданных данных, но не исправить её.
В действительности, используемые коды обнаружения ошибок принадлежат к тем же классам кодов, что и коды, исправляющие ошибки. Фактически, любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить большее число ошибок, чем был способен исправить).
По способу работы с данными коды, исправляющие ошибки делятся на блоковые, делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и свёрточные, работающие с данными как с непрерывным потоком.
Блоковые коды
Пусть кодируемая информация делится на фрагменты длиной k бит, которые преобразуются в кодовые слова длиной n бит. Тогда соответствующий блоковый код обычно обозначают  . При этом число
. При этом число 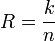 называется скоростью кода.
называется скоростью кода.
Если исходные k бит код оставляет неизменными, и добавляет n − k проверочных, такой код называется систематическим, иначе несистематическим.
Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из k информационных бит сопоставляется n бит кодового слова. Однако, хороший код должен удовлетворять, как минимум, следующим критериям:
- способность исправлять как можно большее число ошибок,
- как можно меньшая избыточность,
- простота кодирования и декодирования.
Нетрудно видеть, что приведённые требования противоречат друг другу. Именно поэтому существует большое количество кодов, каждый из которых пригоден для своего круга задач.
Практически все используемые коды являются линейными. Это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования.
Линейные коды общего вида
Линейный блоковый код — такой код, что множество его кодовых слов образует k-мерное линейное подпространство (назовём его C) в n-мерном линейном пространстве, изоморфное пространству k-битных векторов.
Это значит, что операция кодирования соответствует умножению исходного k-битного вектора на невырожденную матрицу G, называемую порождающей матрицей.
Пусть  — ортогональное подпространство по отношению к C, а H — матрица, задающая базис этого подпространства. Тогда для любого вектора
— ортогональное подпространство по отношению к C, а H — матрица, задающая базис этого подпространства. Тогда для любого вектора 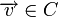 справедливо:
справедливо:

Минимальное расстояние и корректирующая способность
Расстоянием Хемминга (метрикой Хемминга) между двумя кодовыми словами 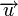 и
и 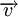 называется количество отличных бит на соответствующих позициях,
называется количество отличных бит на соответствующих позициях, 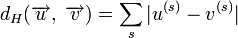 , что равно числу «единиц» в векторе
, что равно числу «единиц» в векторе 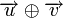 .
.
Минимальное расстояние Хемминга 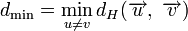 является важной характеристикой линейного блокового кода. Она показывает насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
является важной характеристикой линейного блокового кода. Она показывает насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
 , округляем «вниз», так чтобы 2t < dmin.
, округляем «вниз», так чтобы 2t < dmin.
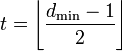 , округляем «вниз», так чтобы
, округляем «вниз», так чтобы Корректирующая способность определяет, сколько ошибок передачи кода (типа 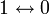 ) можно гарантированно исправить. То есть вокруг каждого кода A имеем t-окрестность At, которая состоит из всех возможных вариантов передачи кода A с числом ошибок () не более t. Никакие две окрестности двух любых кодов не пересекаются друг с другом, так как расстояние между кодами (то есть центрами этих окрестностей) всегда больше двух их радиусов
) можно гарантированно исправить. То есть вокруг каждого кода A имеем t-окрестность At, которая состоит из всех возможных вариантов передачи кода A с числом ошибок () не более t. Никакие две окрестности двух любых кодов не пересекаются друг с другом, так как расстояние между кодами (то есть центрами этих окрестностей) всегда больше двух их радиусов  .
.
Таким образом получив искажённый код из At декодер принимает решение, что был исходный код A, исправляя тем самым не более t ошибок.
Поясним на примере. Предположим, что есть два кодовых слова A и B, расстояние Хемминга между ними равно 3. Если было передано слово A, и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову A, чем к любому другому, и в частности к B. Но если каналом были внесены ошибки в двух битах (в которых A отличалось от B) то результат ошибочной передачи A окажется ближе к B, чем A, и декодер примет решение что передавалось слово B.
Коды Хемминга
Коды Хемминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные исправить одну ошибку. Код Хемминга может быть представлен в таком виде, что синдром
- , где — принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.
 , где
, где 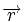 — принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.
— принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.Общий метод декодирования линейных кодов
Любой код (в том числе нелинейный) можно декодировать с помощью обычной таблицы, где каждому значению принятого слова 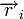 соответствует наиболее вероятное переданное слово
соответствует наиболее вероятное переданное слово  . Однако, данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
. Однако, данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
Для линейных кодов этот метод можно существенно упростить. При этом для каждого принятого вектора вычисляется синдром 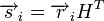 . Поскольку
. Поскольку 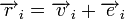 , где
, где 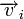 — кодовое слово, а
— кодовое слово, а 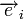 — вектор ошибки, то
— вектор ошибки, то  . Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
. Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
Линейные циклические коды
Несмотря на то, что декодирование линейных кодов уже значительно проще декодирования большинства нелинейных, для большинства кодов этот процесс всё ещё достаточно сложен. Циклические коды, кроме более простого декодирования, обладают и другими важными свойствами.
Циклическим кодом является линейный код, обладающий следующим свойством: если является кодовым словом, то его циклическая перестановка также является кодовым словом.
Слова циклического кода удобно представлять в виде многочленов. Например, кодовое слово 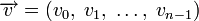 представляется в виде полинома
представляется в виде полинома 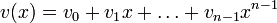 . При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на x по модулю xn − 1.
. При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на x по модулю xn − 1.
В дальнейшем, если не указано иное, мы будем считать, что циклический код является двоичным, то есть 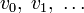 могут принимать значения 0 или 1.
могут принимать значения 0 или 1.
Порождающий (генераторный) полином
Можно показать, что все кодовые слова конкретного циклического кода кратны определённому порождающему полиному g(x). Порождающий полином является делителем xn − 1.
С помощью порождающего полинома осуществляется кодирование циклическим кодом. В частности:
- несистематическое кодирование осуществляется путём умножения кодируемого вектора на g(x): v(x) = u(x)g(x);
- систематическое кодирование осуществляется путём «дописывания» к кодируемому слову остатка от деления xn − ku(x) на g(x), то есть .
![v(x)=x^{n-k}u(x)+[x^{n-k}u(x),bmod,g(x)]](https://dic.academic.ru/pictures/wiki/files/97/ab852c2832864dffc1acf3cbd9eff59e.png) .
.Коды CRC
Коды CRC (cyclic redundancy check — циклическая избыточная проверка) являются систематическими кодами, предназначенными не для исправления ошибок, а для их обнаружения. Они используют способ систематического кодирования, изложенный выше: «контрольная сумма» вычисляется путем деления xn − ku(x) на g(x). Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
Таким образом, вид полинома g(x) задаёт конкретный код CRC. Примеры наиболее популярных полиномов:
| название кода | степень | полином |
|---|---|---|
| CRC-12 | 12 | x12 + x11 + x3 + x2 + x + 1 |
| CRC-16 | 16 | x16 + x15 + x2 + 1 |
| CRC-x16 + x12 + x5 + 1 | ||
| CRC-32 | 32 | x32 + x26 + x23 + x22 + x16 + x12 + x11 + x10 + x8 + x7 + x5 + x4 + x2 + x + 1 |
Коды БЧХ
Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их отличительное свойство — возможность построения кода БЧХ с минимальным расстоянием не меньше заданного. Это важно, потому что, вообще говоря, определение минимального расстояния кода есть очень сложная задача.
Математически полинома g(x) на множители в поле Галуа.
Коды коррекции ошибок Рида — Соломона
Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида-Соломона, работающие с байтами (октетами).
Математически коды Рида — Соломона являются кодами БЧХ.
Преимущества и недостатки блоковых кодов
Хотя блоковые коды, как правило, хорошо справляются с редкими, но большими пачками ошибок, их эффективность при частых, но небольших ошибках (например, в канале с АБГШ), менее высока.
Свёрточные коды
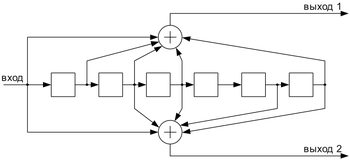
Свёрточный кодер (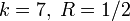 )
)
Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных.
Свёрточные коды, как правило, порождаются дискретной линейной инвариантной во времени системой. Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании.
Кодирование свёрточным кодом производится с помощью регистра сдвига, отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше.
Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби, который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия.
Преимущества и недостатки свёрточных кодов
Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок.
Каскадное кодирование. Итеративное декодирование
Преимущества разных способов кодирования можно объединить, применив каскадное кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в результате получается код-произведение.
Например, популярной является следующая конструкция: данные кодируются кодом Рида-Соломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется декодирование кода Рида — Соломона.
Некоторые коды-произведения специально сконструированы для итеративного декодирования, при котором декодирование осуществляется в несколько проходов, каждый из которых использует информацию от предыдущего. Это позволяет добиться большой эффективности, однако, декодирование требует больших ресурсов. К таким кодам относят турбо-коды и LDPC-коды (коды Галлагера).
Оценка эффективности кодов
Эффективность кодов определяется количеством ошибок, которые тот может исправить, количеством избыточной информации, добавление которой требуется, а также сложностью реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ).
Граница Хемминга и совершенные коды
Пусть имеется двоичный блоковый (n,k) код с корректирующей способностью t. Тогда справедливо неравенство (называемое границей Хемминга):
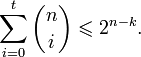
Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хемминга. Часто применяемые на практике коды с большой корректирующей способностью (такие, как коды Рида — Соломона) не являются совершенными.
Энергетический выигрыш
При передаче информации по каналу связи вероятность ошибки зависит от отношения сигнал/шум на входе демодулятора, таким образом при постоянном уровне шума решающее значение имеет мощность передатчика. В системах спутниковой и мобильной, а также других типов связи остро стоит вопрос экономии энергии. Кроме того, в определённых системах связи (например, телефонной) неограниченно повышать мощность сигнала не дают технические ограничения.
Поскольку помехоустойчивое кодирование позволяет исправлять ошибки, при его применении мощность передатчика можно снизить, оставляя скорость передачи информации неизменной. Энергетический выигрыш определяется как разница отношений с/ш при наличии и отсутствии кодирования.
Применение кодов, исправляющих ошибки
Коды, исправляющие ошибки, применяются:
- в системах цифровой связи, в том числе: спутниковой, радиорелейной, сотовой, передаче данных по телефонным каналам.
- в системах хранения информации, в том числе магнитных и оптических.
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней.
Автоматический запрос повторной передачи
Системы с автоматическим запросом повторной передачи (ARQ — Automatic Repeat reQuest) основаны на технологии обнаружения ошибок. Распространены следующие методы автоматического запроса:
Запрос ARQ с остановками (stop-and-wait ARQ)
Идея этого метода заключается в том, что передатчик ожидает от приемника подтверждения успешного приема предыдущего блока данных перед тем как начать передачу следующего. В случае, если блок данных был принят с ошибкой, приемник передает отрицательное подтверждение (negative acknowledgement, NAK), и передатчик повторяет передачу блока. Данный метод подходит для полудуплексного канала связи. Его недостатком является низкая скорость из-за высоких накладных расходов на ожидание.
Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)
Для этого метода необходим полнодуплексный канал. Передача данных от передатчика к приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с ошибочного блока (то есть, передается ошибочный блок и все последующие).
Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)
При этом подходе осуществляется передача только ошибочно принятых блоков данных.
См. также
- Цифровая связь
- Линейный код
- Циклический код
- Код Боуза — Чоудхури — Хоквингема
- Код Рида — Соломона
- LDPC
- Свёрточный код
- Турбо-код
Литература
- Мак-Вильямс Ф. Дж., Слоэн Н. Дж. А. Теория кодов, исправляющих ошибки. М.: Радио и связь, 1979.
- Блейхут Р. Теория и практика кодов, контролирующих ошибки. М.: Мир, 1986.
- Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение. М.: Техносфера, 2005. — ISBN 5-94836-035-0
Ссылки
- Помехоустойчивое кодирование (11 ноября 2001). — реферат по проблеме кодирования сообщений с исправлением ошибок. Проверено 25 декабря 2006.
Wikimedia Foundation.
2010.
1.1 Аппаратная часть дисков
1.1.1 Магнитные диски
Более подробная информация — http://ru.wikipedia.org/wiki/Жёсткий_диск
Демонстрация работы жесткого диска

Устройство жесткого диска с IDE разъемом
Основные понятия:
Головка (Head) — электромагнит, скользящий над поверхностью диска, для каждой поверхности используется своя головка. Нумерация начинается с 0.

Головка HDD

Продольная (верхний рисунок) и перпендикулярная (нижний рисунок) запись информации на диске
Примерно с 2005 года идет переход с продольной на перпендикулярную запись информации на диске, что обеспечивает большую плотность записи данных.
С 2011-2013 планируется переход на «тепловую магнитную запись», место записи будет предварительно нагреваться лазером, что уменьшит размер домена и повысит надежность хранения. Предположительная максимальная емкость от 30 до 50 ТБ.
Дорожка (Track) — концентрическая окружность, которое может прочитать головка в одной позиции. Нумерация дорожек начинается с внешней (первая имеет номер — 0).
Цилиндр (Cylinder) — совокупность всех дорожек с одинаковым номером на всех дисках, т.к. дисков может быть много и на каждом диске запись может быть с двух сторон.
Маркер — от него начинается нумерация дорожек, есть на каждом диске.
Сектор — на сектора разбивается каждая дорожка, сектор содержит минимальный блок информации. Нумерация секторов начинается от маркера.

Дорожки, цилиндры, сектора, головки
Геометрия жесткого диска — набор параметров диска, количество головок, количество цилиндров и количество секторов.
У современных жестких дисков контроллер встроен в само устройство, и берет на себя большую часть работы, которую не видит ОС.
Например, скрывают физическую геометрию диска, предоставляя виртуальную геометрии.

Физическая и виртуальная геометрия диска
На внешних дорожках число секторов делают больше, а на внутренних меньше. На реальных дисках таких зон может быть несколько десятков.
1.1.2 RAID (Redundant Array of Independent Disk — массив независимых дисков с избыточностью)
Более подробная информация — http://ru.wikipedia.org/wiki/RAID
Для увеличения производительности или надежности операций ввода-вывода с диском был разработан стандарт для распараллеливания или дублирования этих операций
Основные шесть уровней RAID:
-
RAID 0 — чередующий набор, соединение нескольких дисков в один большой логический диск, но логический диск разбит так, что запись и чтение происходит сразу с несколько дисков. Например, записываем блок 1, 2, 3, 4, 5, каждый блок будет записываться на свой диск.
Преимущества
— удобство одного диска
— увеличивает скорость записи и чтения
Недостатки
— уменьшает надежность (в случае выхода одного диска, массив будет разрушен), избыточность не предусмотрена. -
RAID 1 — зеркальный набор, параллельная запись и чтение на несколько дисков с дублированием (избыточность).
Преимущества
— дублирование записей
— увеличивает скорость чтения (но не записи)
Недостатки
— требует в два раза больше дисковых накопителей -
RAID 2 — работает на уровне слов и даже байт. Например, берется полбайта (4 бита) и прибавляется 3 бита четности (1, 2, 4 — рассчитанные по Хэммингу), образуется 7-битовое слово. В случае семи дисков слово записывается побитно на каждый диск. Так как слово пишется сразу на все диски, они должны быть синхронизированы.
Преимущества
— надежность
— увеличивает скорость записи и чтения (при потоке, но при отдельных запросах не увеличивает)
Недостатки
— нужна синхронизация дисков. -
RAID 3 — упрощенная версия RAID 2, для каждого слова считается только один бит четности.
Преимущества
— надежность
— увеличивает скорость записи и чтения (при потоке, но при отдельных запросах не увеличивает)
Недостатки
— нужна синхронизация дисков. -
RAID 4 — аналогичен уровню RAID 0, но с добавлением диска четности. Если любой из дисков выйдет из строя, его можно восстановить с помощью диска четности.
Преимущества
— надежность
— не нужна синхронизация дисков
Недостатки
— не дает увеличения производительности, узким местом становится диск четности при постоянных пересчетах контрольных сумм. -
RAID 5 — аналогичен уровню RAID 4, но биты четности равномерно распределены по дискам.
На практике, как правило, используют RAID 0, 1 и 5.

Системы RAID уровней от 0 до 5.
1.1.3 Компакт-диски
Более подробная информация — http://ru.wikipedia.org/wiki/Компакт-диск

Фото диска

Фото устройства для работы с дисками

Устройство в работе
Демонстрация работы CD-drive
Запись на CD-ROM диски производятся с помощью штамповки.

CD-ROM под электронным микроскопом.
Длина пита варьируется от 850 нм до 3,5 мкм
Сначала CD-диски использовались только для записи звука, стандарт которого был описан ISO 10149 («Красная книга«).
Пит — единица записи информации (впадина при штамповке, темное пятно, прожженное в слое краски в CD-R, область фазового перехода)

Запись на CD-ROM производится спирально
В 1984 году была опубликована «Желтая книга«, в которой описан следующий стандарт.
Для записи данных было необходимо повысить надежность, для этого каждый байт (8 бит) стали кодировать в 14 разрядное число (по размеру почти дублирование записи, но за счет кодирования эффективность может быть, как при тройной записи), чтобы можно было восстановить потерянные биты.

Логическое расположение данных на CD-ROM для режима 1
Заголовок содержит:
-
Первые 12-ть байт заголовка содержат 00FFFFFFFFFFFFFFFFFFFF00, чтобы считывающее устройство могло распознать начало сектора.
-
Следующие три байта содержат номер сектора.
-
Последний байт содержит код режима
ECC (Error Correction Code) — код исправления ошибок.
В режиме 2 поле данных объединено с полем ECC в 2336-байтное поле данных. Этот режим можно использовать, если не требуется коррекция ошибок, например, видео и аудио запись.
Коррекция ошибок осуществляется на трех уровнях:
-
внутри слова
-
в кадре
-
в CD-ROM-секторе
Поэтому 7203 байта содержат только 2048 байта полезной нагрузки, около 28%.
В 1986 году была выпущена «Зеленая книга«, к стандарту была добавлена графика, и возможность совмещения в одном секторе аудио, видео и данных.
Файловая система для CD-ROM называется High Sierra , которая оформлена в стандарт ISO 9660.
Файловая система имеет три уровня:
-
1 уровень — файлы имеют имена формата, схожего с MS-DOS — 8 символов имя файла плюс до трех символов расширения, файлы должны быть непрерывными. Глубина вложенности каталогов ограничена восемью. Этот уровень понимают почти все операционные системы.
-
2 уровень — имена файлов могут быть до 31 символов, файлы должны быть непрерывными.
-
3 уровень — позволяет использовать сегментированные файлы.
Для этого стандарта существуют расширения:
-
Rock Ridge — позволяет использовать длинные файлы, а также UID, GID и символические ссылки.
1.1.3.1 Компакт-диски с возможностью записи CD-R
Запись на CD-R диски производятся с помощью локального прожигания нанесенного слоя красителя.
Используются лазеры с двумя уровнями разной мощности, для записи 8-16 мВт, для чтения 0.5 мВт.
В 1989 году была выпущена «Оранжевая книга«, это документ определяет формат CD-R, а также новый формат CD-ROM XA , который позволяет посекторно дописывать информацию на CD-R.
CD-R-дорожка — последовательно записанные за один раз секторы. Для каждой такой дорожки создается свой VTOC (Volume Table of Contents — таблица содержания тома), в котором перечисляются записанные файлы.
Каждая запись производится за одну непрерывную операцию, поэтому если у вас будет слишком загружен компьютер (мало памяти или медленный диск), то вы можете испортить диск, т.к. данные не будут поспевать поступать на CD-ROM.
1.1.3.2 Многократно перезаписываемые компакт-диски CD-RW
Запись на CD-RW диски производятся локального перевода слоя из кристаллического в аморфное состояние.
Используются лазеры с тремя уровнями разной мощности.
Эти диски можно отформатировать (UDF), использовать их в место дискет и дисков.
1.1.3.3 Универсальный цифровой диск DVD (Digital Versatile Disk)
Более подробная информация — http://ru.wikipedia.org/wiki/DVD
Были сделаны следующие изменения:
-
Размер пита уменьшили в два раза (с 0.8 мкм до 0.4мкм)
-
Более тугая спираль (0.74 мкм между дорожками, вместо 1.6 у компакт-дисков)
-
Уменьшение длины волны лазера (650 нм вместо 780 нм)
Это позволило увеличить объем с 650 Мбайт до 4.7 Гбайт.
Определены четыре следующих формата:
-
Односторонний, одноуровневый (4.7 Гбайт)
-
Односторонний, двухуровневый (8.5 Гбайт), размеры пита второго уровня приходится делать больше, иначе не будут считаны, т.к. первый полуотражающий слой половину потока отразит и частично рассеет.
-
Двухсторонний, одноуровневый (9.4 Гбайт)
-
Двухсторонний, двухуровневый (17 Гбайт)
1.1.3.4 Универсальный цифровой диск Blu-ray (blue ray — синий)
Более подробная информация — http://ru.wikipedia.org/wiki/Blu-ray_Disc
Были сделаны следующие изменения:
-
Размер пита уменьшили
-
Более тугая спираль ( 0,32 мкм между дорожками, вместо 0.72 у DVD)
-
Уменьшение длины волны лазера (405 нм вместо 650 нм в DVD), «синего» (технически сине-фиолетового) лазера, отсюда и название
Определены следующие формата:
-
однослойный диск 23,3/25/27 или 33 Гб
-
двухслойный диск 46,6/50/54 или 66 Гб
-
четырёх слойный 100 Гб
-
восьми слойный 200 Гб
1.1.4 Твердотельные накопители (Flash, SSD, …)
Устройство ячейки памяти:
Используются полевые транзисторы с плавающим затвором.

Устройство ячейки памяти
Считывание информации:
Если ток через npn-переход идет, то «считывается 0».
Ток идет за счет туннельного эффекта, который возникает под действием управляющего затвора, на который подается «+».

Считывание «0»
Если ток через npn-переход не идет, то «считывается 1».
Ток не идет за счет «экранирования» управляющего затвора плавающим затвором, на котором накоплен «-«.

Считывание «1»
Запись информации:
«Запись» делается накоплением электронов в плавающем затворе, за счет повышенного напряжения на управляющем затворе и стоке.

Запись информации
Затирание информации:
«Затирание» делается «изъятием» электронов из плавающего затворе, за счет положительного напряжения на истоке и отрицательного на управляющем затворе, но стоке 0В.

Затирание информации
1.2 Форматирование дисков (программная часть)
1.2.1 Низкоуровневое форматирование
Низкоуровневое форматирование — разбивка диска на сектора, производится производителями дисков.
Каждый сектор состоит из:
-
Заголовка (Prefix portion) — по которому определяется начало (последовательность определенных битов) сектора и его номер, и номер цилиндра.
-
Область данных (как правило, 512 байт, планируют перейти на 4 Кб (к 2010г.))
-
Конец сектора (Suffix portion) — содержит контрольную сумму ECC (Error Correction Code — код корректировки ошибок). Позволяет обнаружить или даже исправить ошибки чтения. Размер зависит от производителя, и показывает, как производитель относится к надежности работы диска.
![]()
Сектор диска
На диске могут быть запасные сектора, которые могут быть использованы для замены секторов с дефектами (а они почти всегда есть). За счет этого обеспечивается одинаковая емкость на выходе.
При низкоуровневом форматировании часть полезного объема уменьшается, примерно до 80%.
Перекос цилиндров
Перекос цилиндров — сдвиг 0-го сектора каждой последующей дорожки, относительно предыдущей. служит для увеличения скорости. Головка тратит, какое то время на смену дорожки, и если 0-й сектор будет начинаться в том же месте, что и предыдущий, то головка уже проскочит его, и будет ждать целый круг.

Перекос цилиндров
Перекос цилиндров делают разным в зависимости скоростей вращения и перемещения головок.
Перекос головок — приходится применять, т.к. на переключение с головки на головку тратится время..
Чередование секторов
Если, например, один сектор прочитан, а для второго нет в буфере места, пока данные копируются из буфера в память, второй сектор уже проскочит головку.
Чтобы этого не случилось, применяют чередование секторов.

Чередование секторов
Если копирование очень медленное, может применяться двукратное чередование, или больше.
1.2.2 Разделы диска
Более подробная информация — http://ru.wikipedia.org/wiki/Раздел_диска
После низкоуровневого форматирования диск разбивается на разделы, эти разделы воспринимаются ОС как отдельные диски.
Для чего можно использовать разделы:
-
Отделить системные файлы от пользовательских (например, своп-файлы)
-
Более эффективно использовать пространство (например, для администрирования).
-
На разные разделы можно установить разные ОС.
Основные разделы диска:
-
Первичный (Primary partition) — некоторые ОС могут загружаться только с первичного раздела. (В MBR под таблицу разделов выделено 64 байта. Каждая запись занимает 16 байт. Таким образом, всего на жестком диске может быть создано не более 4 разделов. Раньше это считалось достаточным.)
-
Расширенный (Extended partition) — непосредственно данные не содержит, служит для создания логических дисков (создается, что бы обойти ограничение в 4-ре раздела).
-
Логический (Logical partition) — может быть любое количество.
Информация о разделах записывается в 0-м секторе 0-го цилиндра, головка 0. И называется таблицей разделов.
Таблица разделов (Partition Table) — содержит информацию о разделах, номер начальных секторов и размеры разделов. На Pentium-компьютерах в таблице есть место только для четырех записей, т.е. может быть только 4 раздела (к логическим это не относится, их может быть не ограниченное количество).
Этот сектор называется главной загрузочной записью.
Главная загрузочная запись MBR (Master Boot Record) — содержит загрузочную программу и таблицу разделов.
Более подробная информация — http://ru.wikipedia.org/wiki/Главная_загрузочная_запись
Т.к. MBR может работать только с разделами до 2.2 ТБ (2.2 ? 1012 байт), насмену приходит GPT.
Таблица разделов GUID (GUID Partition Table — GPT) — позволяет создавать разделы диска размером до 9.4 ЗБ (9.4 ? 1021 байт).
Более подробная информация — http://ru.wikipedia.org/wiki/Таблица_разделов_GUID.
Активный раздел — раздел, с которого загружается ОС, может быть и логическим. В одном сеансе загрузки может быть только один активный раздел.

Пример структуры разделов
В Windows разделы будут называться (для пользователей) устройствами C:, D:, E: и т.д.
1.2.3 Высокоуровневое форматирование
Высокоуровневое форматирование (создание файловой системы) — проводится для каждого раздела в отдельности, и выполняет следующее:
-
Создает загрузочный сектор (Boot Sector)
-
Создает список свободных блоков (для UNIX) или таблицу (ы) размещения файлов (для FAT или NTFS)
-
Создает корневой каталог
-
Создает, пустую файловую систему
-
Указывает, какая файловая система
-
Помечает дефектные кластеры
Кластеры и блоки — единица хранения информации в файловых системах, файлы записываются на диск, разбитыми на блоки ли кластеры.
При загрузке системы, происходит следующее:
-
Запускается BIOS
-
BIOS считывает главную загрузочную запись, и передает ей управление
-
Загрузочная программа определяет, какой раздел активный
-
Из этого раздела считывается и запускается загрузочный сектор
-
Программа загрузочного сектора находит в корневом каталоге определенный файл (загрузочный файл)
-
Этот файл загружается в память и запускается (ОС начинает загрузку)
1.3 Алгоритмы планирования перемещения головок
Факторы, влияющие на время считывания или записи на диск:
-
Время поиска (время перемещения головки на нужный цилиндр)
-
Время переключения головок
-
Задержка вращения (время, требуемое для поворота нужного сектора под головку)
-
Время передачи данных
Для большинства дисков самое большое, это время поиска. Поэтому, оптимизируя время поиска можно существенно повысить быстродействие.
Алгоритмы могут быть реализованы в контроллере, в драйверах, в самой ОС.
1.3.1 Алгоритм «первый пришел — первым обслужен» FCFS (First Come, First Served)
Рассмотрим пример. Пусть у нас на диске из 28 цилиндров (от 0 до 27) есть следующая очередь запросов:
27, 2, 26, 3, 19, 0
и головки в начальный момент находятся на 1 цилиндре. Тогда положение головок будет меняться следующим образом:

Алгоритм FCFS
Как видно алгоритм не очень эффективный, но простой в реализации.
1.3.2 Алгоритм короткое время поиска первым (или ближайший цилиндр первым) SSF (Shortest Seek First)
Для предыдущего примера алгоритм даст следующую последовательность положений головок:

Алгоритм SSF
Как видим, этот алгоритм более эффективен. Но у него есть не достаток, если будут поступать постоянно новые запросы, то головка будет всегда находиться в локальном месте, вероятнее всего в средней части диска, а крайние цилиндры могут быть не обслужены никогда.
1.3.3 Алгоритмы сканирования (SCAN, C-SCAN, LOOK, C-LOOK)
SCAN – головки постоянно перемещаются от одного края диска до его другого края, по ходу дела обслуживая все встречающиеся запросы. Просто, но не всегда эффективно.
LOOK — если мы знаем, что обслужили последний попутный запрос в направлении движения головок, то мы можем не доходить до края диска, а сразу изменить направление движения на обратное
C-SCAN — циклическое сканирование. Когда головка достигает одного из краев диска, она без чтения попутных запросов перемещается на 0-й цилиндр, откуда вновь начинает свое движение.
C-LOOK — по аналогии с предыдущим.
1.4 Обработка ошибок
Т.к. создать диск без дефектов сложно, а вовремя использования появляются новые дефекты.
Поэтому системе приходится контролировать и исправлять ошибки.
Ошибки могут быть обнаружены на трех уровнях:
-
На уровне дефектного сектора ECC (используются запасные, делает сам производитель)
-
Дефектные блоки или кластеры могут обрабатываться контроллером или самой ОС.
Блоки и кластеры не должны содержать дефектные сектора, поэтому система должна уметь помечать дефектные сектора.

Способы замены дефектных кластеров
Обнаруже́ние оши́бок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи.
Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды).
Содержание
- 1 Способы борьбы с ошибками
- 2 Коды обнаружения и исправления ошибок
- 2.1 Блоковые коды
- 2.1.1 Линейные коды общего вида
- 2.1.1.1 Минимальное расстояние и корректирующая способность
- 2.1.1.2 Коды Хемминга
- 2.1.1.3 Общий метод декодирования линейных кодов
- 2.1.2 Линейные циклические коды
- 2.1.2.1 Порождающий (генераторный) полином
- 2.1.2.2 Коды CRC
- 2.1.2.3 Коды БЧХ
- 2.1.2.4 Коды коррекции ошибок Рида — Соломона
- 2.1.3 Преимущества и недостатки блоковых кодов
- 2.1.1 Линейные коды общего вида
- 2.2 Свёрточные коды
- 2.2.1 Преимущества и недостатки свёрточных кодов
- 2.3 Каскадное кодирование. Итеративное декодирование
- 2.4 Сетевое кодирование
- 2.5 Оценка эффективности кодов
- 2.5.1 Граница Хемминга и совершенные коды
- 2.5.2 Энергетический выигрыш
- 2.6 Применение кодов, исправляющих ошибки
- 2.1 Блоковые коды
- 3 Автоматический запрос повторной передачи
- 3.1 Запрос ARQ с остановками (stop-and-wait ARQ)
- 3.2 Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)
- 3.3 Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)
- 4 См. также
- 5 Литература
- 6 Ссылки
Способы борьбы с ошибками
В процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях сетевой модели OSI).
В системах связи возможны несколько стратегий борьбы с ошибками:
- обнаружение ошибок в блоках данных и автоматический запрос повторной передачи повреждённых блоков — этот подход применяется, в основном, на канальном и транспортном уровнях;
- обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков — такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу;
- исправление ошибок (англ. forward error correction) применяется на физическом уровне.
Коды обнаружения и исправления ошибок
Корректирующие коды — коды, служащие для обнаружения или исправления ошибок, возникающих при передаче информации под влиянием помех, а также при её хранении.
Для этого при записи (передаче) в полезные данные добавляют специальным образом структурированную избыточную информацию (контрольное число), а при чтении (приёме) её используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода.
С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от первых, последние могут только установить факт наличия ошибки в переданных данных, но не исправить её.
В действительности используемые коды обнаружения ошибок принадлежат к тем же классам кодов, что и коды, исправляющие ошибки. Фактически любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить большее число ошибок, чем был способен исправить).
По способу работы с данными коды, исправляющие ошибки, делятся на блоковые, делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и свёрточные, работающие с данными как с непрерывным потоком.
Блоковые коды
Пусть кодируемая информация делится на фрагменты длиной  бит, которые преобразуются в кодовые слова длиной
бит, которые преобразуются в кодовые слова длиной  бит. Тогда соответствующий блоковый код обычно обозначают
бит. Тогда соответствующий блоковый код обычно обозначают  . При этом число
. При этом число  называется скоростью кода.
называется скоростью кода.
Если исходные бит код оставляет неизменными, и добавляет  проверочных, такой код называется систематическим, иначе — несистематическим.
проверочных, такой код называется систематическим, иначе — несистематическим.
Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из информационных бит сопоставляется бит кодового слова. Однако хороший код должен удовлетворять как минимум следующим критериям:
- способность исправлять как можно большее число ошибок,
- как можно меньшая избыточность,
- простота кодирования и декодирования.
Нетрудно видеть, что приведённые требования противоречат друг другу. Именно поэтому существует большое количество кодов, каждый из которых пригоден для своего круга задач.
Практически все используемые коды являются линейными. Это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования.
Линейные коды общего вида
Линейный блоковый код — такой код, что множество его кодовых слов образует -мерное линейное подпространство (назовём его  ) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
) в -мерном линейном пространстве, изоморфное пространству -битных векторов.
Это значит, что операция кодирования соответствует умножению исходного -битного вектора на невырожденную матрицу  , называемую порождающей матрицей.
, называемую порождающей матрицей.
Пусть  — ортогональное подпространство по отношению к , а
— ортогональное подпространство по отношению к , а  — матрица, задающая базис этого подпространства. Тогда для любого вектора
— матрица, задающая базис этого подпространства. Тогда для любого вектора  справедливо:
справедливо:

Минимальное расстояние и корректирующая способность
Расстоянием Хемминга (метрикой Хемминга) между двумя кодовыми словами  и
и  называется количество отличных бит на соответствующих позициях:
называется количество отличных бит на соответствующих позициях:
- .

Минимальное расстояние Хемминга  является важной характеристикой линейного блокового кода. Она показывает, насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
является важной характеристикой линейного блокового кода. Она показывает, насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность:
- .

Корректирующая способность определяет, сколько ошибок передачи кода (типа  ) можно гарантированно исправить. То есть вокруг каждого кодового слова
) можно гарантированно исправить. То есть вокруг каждого кодового слова  имеем
имеем  -окрестность
-окрестность  , которая состоит из всех возможных вариантов передачи кодового слова с числом ошибок () не более . Никакие две окрестности двух любых кодовых слов не пересекаются друг с другом, так как расстояние между кодовыми словами (то есть центрами этих окрестностей) всегда больше двух их радиусов
, которая состоит из всех возможных вариантов передачи кодового слова с числом ошибок () не более . Никакие две окрестности двух любых кодовых слов не пересекаются друг с другом, так как расстояние между кодовыми словами (то есть центрами этих окрестностей) всегда больше двух их радиусов  .
.
Таким образом, получив искажённую кодовую комбинацию из , декодер принимает решение, что исходной была кодовая комбинация , исправляя тем самым не более ошибок.
Поясним на примере. Предположим, что есть два кодовых слова и  , расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и, в частности, к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ), то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение, что передавалось слово .
, расстояние Хемминга между ними равно 3. Если было передано слово , и канал внёс ошибку в одном бите, она может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к любому другому, и, в частности, к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ), то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение, что передавалось слово .
Коды Хемминга
Коды Хемминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные исправить одну ошибку. Код Хемминга может быть представлен в таком виде, что синдром
- , где — принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.


Общий метод декодирования линейных кодов
Любой код (в том числе нелинейный) можно декодировать с помощью обычной таблицы, где каждому значению принятого слова  соответствует наиболее вероятное переданное слово
соответствует наиболее вероятное переданное слово  . Однако данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
. Однако данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
Для линейных кодов этот метод можно существенно упростить. При этом для каждого принятого вектора вычисляется синдром  . Поскольку
. Поскольку  , где
, где  — кодовое слово, а
— кодовое слово, а  — вектор ошибки, то
— вектор ошибки, то  . Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
. Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
Линейные циклические коды
Несмотря на то, что декодирование линейных кодов значительно проще декодирования большинства нелинейных, для большинства кодов этот процесс всё ещё достаточно сложен. Циклические коды, кроме более простого декодирования, обладают и другими важными свойствами.
Циклическим кодом является линейный код, обладающий следующим свойством: если является кодовым словом, то его циклическая перестановка также является кодовым словом.
Слова циклического кода удобно представлять в виде многочленов. Например, кодовое слово  представляется в виде полинома
представляется в виде полинома  . При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на
. При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на  по модулю
по модулю  .
.
В дальнейшем, если не указано иное, мы будем считать, что циклический код является двоичным, то есть  могут принимать значения 0 или 1.
могут принимать значения 0 или 1.
Порождающий (генераторный) полином
Можно показать, что все кодовые слова конкретного циклического кода кратны определённому порождающему полиному  . Порождающий полином является делителем .
. Порождающий полином является делителем .
С помощью порождающего полинома осуществляется кодирование циклическим кодом. В частности:
Коды CRC
Коды CRC (англ. cyclic redundancy check — циклическая избыточная проверка) являются систематическими кодами, предназначенными не для исправления ошибок, а для их обнаружения. Они используют способ систематического кодирования, изложенный выше: «контрольная сумма» вычисляется путём деления  на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
Таким образом, вид полинома задаёт конкретный код CRC. Примеры наиболее популярных полиномов:
| Название кода | Степень | Полином |
|---|---|---|
| CRC-12 | 12 | 
|
| CRC-16 | 16 | 
|
| CRC-CCITT | 16 | 
|
| CRC-32 | 32 | 
|
Коды БЧХ
Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их отличительное свойство — возможность построения кода БЧХ с минимальным расстоянием не меньше заданного. Это важно, потому что, вообще говоря, определение минимального расстояния кода есть очень сложная задача.
Коды коррекции ошибок Рида — Соломона
Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида-Соломона, работающие с байтами (октетами).
Математически коды Рида — Соломона являются кодами БЧХ.
Преимущества и недостатки блоковых кодов
Хотя блоковые коды, как правило, хорошо справляются с редкими, но большими пачками ошибок, их эффективность при частых, но небольших ошибках (например, в канале с АБГШ), менее высока.
Свёрточные коды

Свёрточный кодер ( )
)
Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных.
Свёрточные коды, как правило, порождаются дискретной линейной инвариантной во времени системой. Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании.
Кодирование свёрточным кодом производится с помощью регистра сдвига, отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше.
Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби, который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия.
Преимущества и недостатки свёрточных кодов
Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок.
Каскадное кодирование. Итеративное декодирование
Преимущества разных способов кодирования можно объединить, применив каскадное кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в результате получается код-произведение.
Например, популярной является следующая конструкция: данные кодируются кодом Рида-Соломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется декодирование кода Рида — Соломона.
Некоторые коды-произведения специально сконструированы для итеративного декодирования, при котором декодирование осуществляется в несколько проходов, каждый из которых использует информацию от предыдущего. Это позволяет добиться большой эффективности, однако декодирование требует больших ресурсов. К таким кодам относят турбо-коды и LDPC-коды (коды Галлагера).
Сетевое кодирование
Оценка эффективности кодов
Эффективность кодов определяется количеством ошибок, которые тот может исправить, количеством избыточной информации, добавление которой требуется, а также сложностью реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ).
Граница Хемминга и совершенные коды
Пусть имеется двоичный блоковый  код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):
код с корректирующей способностью . Тогда справедливо неравенство (называемое границей Хемминга):

Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хемминга. Часто применяемые на практике коды с большой корректирующей способностью (такие, как коды Рида — Соломона) не являются совершенными.
Энергетический выигрыш
При передаче информации по каналу связи вероятность ошибки зависит от отношения сигнал/шум на входе демодулятора, таким образом, при постоянном уровне шума решающее значение имеет мощность передатчика. В системах спутниковой и мобильной, а также других типов связи остро стоит вопрос экономии энергии. Кроме того, в определённых системах связи (например, телефонной) неограниченно повышать мощность сигнала не дают технические ограничения.
Поскольку помехоустойчивое кодирование позволяет исправлять ошибки, при его применении мощность передатчика можно снизить, оставляя скорость передачи информации неизменной. Энергетический выигрыш определяется как разница отношений с/ш при наличии и отсутствии кодирования.
Применение кодов, исправляющих ошибки
Коды, исправляющие ошибки, применяются:
- в системах цифровой связи, в том числе: спутниковой, радиорелейной, сотовой, передаче данных по телефонным каналам.
- в системах хранения информации, в том числе магнитных и оптических.
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней.
Автоматический запрос повторной передачи
Системы с автоматическим запросом повторной передачи (ARQ — Automatic Repeat reQuest) основаны на технологии обнаружения ошибок. Распространены следующие методы автоматического запроса:
Запрос ARQ с остановками (stop-and-wait ARQ)
Идея этого метода заключается в том, что передатчик ожидает от приемника подтверждения успешного приема предыдущего блока данных перед тем, как начать передачу следующего. В случае, если блок данных был принят с ошибкой, приемник передает отрицательное подтверждение (negative acknowledgement, NAK), и передатчик повторяет передачу блока. Данный метод подходит для полудуплексного канала связи. Его недостатком является низкая скорость из-за высоких накладных расходов на ожидание.
Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)
Для этого метода необходим полнодуплексный канал. Передача данных от передатчика к приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с ошибочного блока (то есть передается ошибочный блок и все последующие).
Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)
При этом подходе осуществляется передача только ошибочно принятых блоков данных.
См. также
- Цифровая связь
- Код ответа (Код причины завершения)
- Линейный код
- Циклический код
- Код Боуза — Чоудхури — Хоквингема
- Код Рида — Соломона
- LDPC
- Свёрточный код
- Турбо-код
Литература
- Блейхут Р. Теория и практика кодов, контролирующих ошибки = Theory and Practice of Error Control Codes. — М.: Мир, 1986. — 576 с.
- Мак-Вильямс Ф. Дж., Слоэн Н. Дж. А. Теория кодов, исправляющих ошибки. М.: Радио и связь, 1979.
- Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение / пер. с англ. В. Б. Афанасьева. — М.: Техносфера, 2006. — 320 с. — (Мир связи). — 2000 экз. — ISBN 5-94836-035-0.
Ссылки
- Помехоустойчивое кодирование (11 ноября 2001). — реферат по проблеме кодирования сообщений с исправлением ошибок. Проверено 25 декабря 2006. Архивировано 25 августа 2011 года.
- Коды Рида-Соломона. Простой пример. Просто, доступно, на конкретных числах. Для начинающих.

To clean up transmission errors introduced by Earth’s atmosphere (left), Goddard scientists applied Reed–Solomon error correction (right), which is commonly used in CDs and DVDs. Typical errors include missing pixels (white) and false signals (black). The white stripe indicates a brief period when transmission was interrupted.
In information theory and coding theory with applications in computer science and telecommunication, error detection and correction (EDAC) or error control are techniques that enable reliable delivery of digital data over unreliable communication channels. Many communication channels are subject to channel noise, and thus errors may be introduced during transmission from the source to a receiver. Error detection techniques allow detecting such errors, while error correction enables reconstruction of the original data in many cases.
Definitions[edit]
Error detection is the detection of errors caused by noise or other impairments during transmission from the transmitter to the receiver.
Error correction is the detection of errors and reconstruction of the original, error-free data.
History[edit]
In classical antiquity, copyists of the Hebrew Bible were paid for their work according to the number of stichs (lines of verse). As the prose books of the Bible were hardly ever written in stichs, the copyists, in order to estimate the amount of work, had to count the letters.[1] This also helped ensure accuracy in the transmission of the text with the production of subsequent copies.[2][3] Between the 7th and 10th centuries CE a group of Jewish scribes formalized and expanded this to create the Numerical Masorah to ensure accurate reproduction of the sacred text. It included counts of the number of words in a line, section, book and groups of books, noting the middle stich of a book, word use statistics, and commentary.[1] Standards became such that a deviation in even a single letter in a Torah scroll was considered unacceptable.[4] The effectiveness of their error correction method was verified by the accuracy of copying through the centuries demonstrated by discovery of the Dead Sea Scrolls in 1947–1956, dating from c. 150 BCE-75 CE.[5]
The modern development of error correction codes is credited to Richard Hamming in 1947.[6] A description of Hamming’s code appeared in Claude Shannon’s A Mathematical Theory of Communication[7] and was quickly generalized by Marcel J. E. Golay.[8]
Principles[edit]
All error-detection and correction schemes add some redundancy (i.e., some extra data) to a message, which receivers can use to check consistency of the delivered message and to recover data that has been determined to be corrupted. Error detection and correction schemes can be either systematic or non-systematic. In a systematic scheme, the transmitter sends the original (error-free) data and attaches a fixed number of check bits (or parity data), which are derived from the data bits by some encoding algorithm. If error detection is required, a receiver can simply apply the same algorithm to the received data bits and compare its output with the received check bits; if the values do not match, an error has occurred at some point during the transmission. If error correction is required, a receiver can apply the decoding algorithm to the received data bits and the received check bits to recover the original error-free data. In a system that uses a non-systematic code, the original message is transformed into an encoded message carrying the same information and that has at least as many bits as the original message.
Good error control performance requires the scheme to be selected based on the characteristics of the communication channel. Common channel models include memoryless models where errors occur randomly and with a certain probability, and dynamic models where errors occur primarily in bursts. Consequently, error-detecting and correcting codes can be generally distinguished between random-error-detecting/correcting and burst-error-detecting/correcting. Some codes can also be suitable for a mixture of random errors and burst errors.
If the channel characteristics cannot be determined, or are highly variable, an error-detection scheme may be combined with a system for retransmissions of erroneous data. This is known as automatic repeat request (ARQ), and is most notably used in the Internet. An alternate approach for error control is hybrid automatic repeat request (HARQ), which is a combination of ARQ and error-correction coding.
Types of error correction[edit]
There are three major types of error correction.[9]
Automatic repeat request[edit]
Automatic repeat request (ARQ) is an error control method for data transmission that makes use of error-detection codes, acknowledgment and/or negative acknowledgment messages, and timeouts to achieve reliable data transmission. An acknowledgment is a message sent by the receiver to indicate that it has correctly received a data frame.
Usually, when the transmitter does not receive the acknowledgment before the timeout occurs (i.e., within a reasonable amount of time after sending the data frame), it retransmits the frame until it is either correctly received or the error persists beyond a predetermined number of retransmissions.
Three types of ARQ protocols are Stop-and-wait ARQ, Go-Back-N ARQ, and Selective Repeat ARQ.
ARQ is appropriate if the communication channel has varying or unknown capacity, such as is the case on the Internet. However, ARQ requires the availability of a back channel, results in possibly increased latency due to retransmissions, and requires the maintenance of buffers and timers for retransmissions, which in the case of network congestion can put a strain on the server and overall network capacity.[10]
For example, ARQ is used on shortwave radio data links in the form of ARQ-E, or combined with multiplexing as ARQ-M.
Forward error correction[edit]
Forward error correction (FEC) is a process of adding redundant data such as an error-correcting code (ECC) to a message so that it can be recovered by a receiver even when a number of errors (up to the capability of the code being used) are introduced, either during the process of transmission or on storage. Since the receiver does not have to ask the sender for retransmission of the data, a backchannel is not required in forward error correction. Error-correcting codes are used in lower-layer communication such as cellular network, high-speed fiber-optic communication and Wi-Fi,[11][12] as well as for reliable storage in media such as flash memory, hard disk and RAM.[13]
Error-correcting codes are usually distinguished between convolutional codes and block codes:
- Convolutional codes are processed on a bit-by-bit basis. They are particularly suitable for implementation in hardware, and the Viterbi decoder allows optimal decoding.
- Block codes are processed on a block-by-block basis. Early examples of block codes are repetition codes, Hamming codes and multidimensional parity-check codes. They were followed by a number of efficient codes, Reed–Solomon codes being the most notable due to their current widespread use. Turbo codes and low-density parity-check codes (LDPC) are relatively new constructions that can provide almost optimal efficiency.
Shannon’s theorem is an important theorem in forward error correction, and describes the maximum information rate at which reliable communication is possible over a channel that has a certain error probability or signal-to-noise ratio (SNR). This strict upper limit is expressed in terms of the channel capacity. More specifically, the theorem says that there exist codes such that with increasing encoding length the probability of error on a discrete memoryless channel can be made arbitrarily small, provided that the code rate is smaller than the channel capacity. The code rate is defined as the fraction k/n of k source symbols and n encoded symbols.
The actual maximum code rate allowed depends on the error-correcting code used, and may be lower. This is because Shannon’s proof was only of existential nature, and did not show how to construct codes that are both optimal and have efficient encoding and decoding algorithms.
Hybrid schemes[edit]
Hybrid ARQ is a combination of ARQ and forward error correction. There are two basic approaches:[10]
- Messages are always transmitted with FEC parity data (and error-detection redundancy). A receiver decodes a message using the parity information and requests retransmission using ARQ only if the parity data was not sufficient for successful decoding (identified through a failed integrity check).
- Messages are transmitted without parity data (only with error-detection information). If a receiver detects an error, it requests FEC information from the transmitter using ARQ and uses it to reconstruct the original message.
The latter approach is particularly attractive on an erasure channel when using a rateless erasure code.
Error detection schemes[edit]
Error detection is most commonly realized using a suitable hash function (or specifically, a checksum, cyclic redundancy check or other algorithm). A hash function adds a fixed-length tag to a message, which enables receivers to verify the delivered message by recomputing the tag and comparing it with the one provided.
There exists a vast variety of different hash function designs. However, some are of particularly widespread use because of either their simplicity or their suitability for detecting certain kinds of errors (e.g., the cyclic redundancy check’s performance in detecting burst errors).
Minimum distance coding[edit]
A random-error-correcting code based on minimum distance coding can provide a strict guarantee on the number of detectable errors, but it may not protect against a preimage attack.
Repetition codes[edit]
A repetition code is a coding scheme that repeats the bits across a channel to achieve error-free communication. Given a stream of data to be transmitted, the data are divided into blocks of bits. Each block is transmitted some predetermined number of times. For example, to send the bit pattern 1011, the four-bit block can be repeated three times, thus producing 1011 1011 1011. If this twelve-bit pattern was received as 1010 1011 1011 – where the first block is unlike the other two – an error has occurred.
A repetition code is very inefficient and can be susceptible to problems if the error occurs in exactly the same place for each group (e.g., 1010 1010 1010 in the previous example would be detected as correct). The advantage of repetition codes is that they are extremely simple, and are in fact used in some transmissions of numbers stations.[14][15]
Parity bit[edit]
A parity bit is a bit that is added to a group of source bits to ensure that the number of set bits (i.e., bits with value 1) in the outcome is even or odd. It is a very simple scheme that can be used to detect single or any other odd number (i.e., three, five, etc.) of errors in the output. An even number of flipped bits will make the parity bit appear correct even though the data is erroneous.
Parity bits added to each word sent are called transverse redundancy checks, while those added at the end of a stream of words are called longitudinal redundancy checks. For example, if each of a series of m-bit words has a parity bit added, showing whether there were an odd or even number of ones in that word, any word with a single error in it will be detected. It will not be known where in the word the error is, however. If, in addition, after each stream of n words a parity sum is sent, each bit of which shows whether there were an odd or even number of ones at that bit-position sent in the most recent group, the exact position of the error can be determined and the error corrected. This method is only guaranteed to be effective, however, if there are no more than 1 error in every group of n words. With more error correction bits, more errors can be detected and in some cases corrected.
There are also other bit-grouping techniques.
Checksum[edit]
A checksum of a message is a modular arithmetic sum of message code words of a fixed word length (e.g., byte values). The sum may be negated by means of a ones’-complement operation prior to transmission to detect unintentional all-zero messages.
Checksum schemes include parity bits, check digits, and longitudinal redundancy checks. Some checksum schemes, such as the Damm algorithm, the Luhn algorithm, and the Verhoeff algorithm, are specifically designed to detect errors commonly introduced by humans in writing down or remembering identification numbers.
Cyclic redundancy check[edit]
A cyclic redundancy check (CRC) is a non-secure hash function designed to detect accidental changes to digital data in computer networks. It is not suitable for detecting maliciously introduced errors. It is characterized by specification of a generator polynomial, which is used as the divisor in a polynomial long division over a finite field, taking the input data as the dividend. The remainder becomes the result.
A CRC has properties that make it well suited for detecting burst errors. CRCs are particularly easy to implement in hardware and are therefore commonly used in computer networks and storage devices such as hard disk drives.
The parity bit can be seen as a special-case 1-bit CRC.
Cryptographic hash function[edit]
The output of a cryptographic hash function, also known as a message digest, can provide strong assurances about data integrity, whether changes of the data are accidental (e.g., due to transmission errors) or maliciously introduced. Any modification to the data will likely be detected through a mismatching hash value. Furthermore, given some hash value, it is typically infeasible to find some input data (other than the one given) that will yield the same hash value. If an attacker can change not only the message but also the hash value, then a keyed hash or message authentication code (MAC) can be used for additional security. Without knowing the key, it is not possible for the attacker to easily or conveniently calculate the correct keyed hash value for a modified message.
Error correction code[edit]
Any error-correcting code can be used for error detection. A code with minimum Hamming distance, d, can detect up to d − 1 errors in a code word. Using minimum-distance-based error-correcting codes for error detection can be suitable if a strict limit on the minimum number of errors to be detected is desired.
Codes with minimum Hamming distance d = 2 are degenerate cases of error-correcting codes and can be used to detect single errors. The parity bit is an example of a single-error-detecting code.
Applications[edit]
Applications that require low latency (such as telephone conversations) cannot use automatic repeat request (ARQ); they must use forward error correction (FEC). By the time an ARQ system discovers an error and re-transmits it, the re-sent data will arrive too late to be usable.
Applications where the transmitter immediately forgets the information as soon as it is sent (such as most television cameras) cannot use ARQ; they must use FEC because when an error occurs, the original data is no longer available.
Applications that use ARQ must have a return channel; applications having no return channel cannot use ARQ.
Applications that require extremely low error rates (such as digital money transfers) must use ARQ due to the possibility of uncorrectable errors with FEC.
Reliability and inspection engineering also make use of the theory of error-correcting codes.[16]
Internet[edit]
In a typical TCP/IP stack, error control is performed at multiple levels:
- Each Ethernet frame uses CRC-32 error detection. Frames with detected errors are discarded by the receiver hardware.
- The IPv4 header contains a checksum protecting the contents of the header. Packets with incorrect checksums are dropped within the network or at the receiver.
- The checksum was omitted from the IPv6 header in order to minimize processing costs in network routing and because current link layer technology is assumed to provide sufficient error detection (see also RFC 3819).
- UDP has an optional checksum covering the payload and addressing information in the UDP and IP headers. Packets with incorrect checksums are discarded by the network stack. The checksum is optional under IPv4, and required under IPv6. When omitted, it is assumed the data-link layer provides the desired level of error protection.
- TCP provides a checksum for protecting the payload and addressing information in the TCP and IP headers. Packets with incorrect checksums are discarded by the network stack and eventually get retransmitted using ARQ, either explicitly (such as through three-way handshake) or implicitly due to a timeout.
Deep-space telecommunications[edit]
The development of error-correction codes was tightly coupled with the history of deep-space missions due to the extreme dilution of signal power over interplanetary distances, and the limited power availability aboard space probes. Whereas early missions sent their data uncoded, starting in 1968, digital error correction was implemented in the form of (sub-optimally decoded) convolutional codes and Reed–Muller codes.[17] The Reed–Muller code was well suited to the noise the spacecraft was subject to (approximately matching a bell curve), and was implemented for the Mariner spacecraft and used on missions between 1969 and 1977.
The Voyager 1 and Voyager 2 missions, which started in 1977, were designed to deliver color imaging and scientific information from Jupiter and Saturn.[18] This resulted in increased coding requirements, and thus, the spacecraft were supported by (optimally Viterbi-decoded) convolutional codes that could be concatenated with an outer Golay (24,12,8) code. The Voyager 2 craft additionally supported an implementation of a Reed–Solomon code. The concatenated Reed–Solomon–Viterbi (RSV) code allowed for very powerful error correction, and enabled the spacecraft’s extended journey to Uranus and Neptune. After ECC system upgrades in 1989, both crafts used V2 RSV coding.
The Consultative Committee for Space Data Systems currently recommends usage of error correction codes with performance similar to the Voyager 2 RSV code as a minimum. Concatenated codes are increasingly falling out of favor with space missions, and are replaced by more powerful codes such as Turbo codes or LDPC codes.
The different kinds of deep space and orbital missions that are conducted suggest that trying to find a one-size-fits-all error correction system will be an ongoing problem. For missions close to Earth, the nature of the noise in the communication channel is different from that which a spacecraft on an interplanetary mission experiences. Additionally, as a spacecraft increases its distance from Earth, the problem of correcting for noise becomes more difficult.
Satellite broadcasting[edit]
The demand for satellite transponder bandwidth continues to grow, fueled by the desire to deliver television (including new channels and high-definition television) and IP data. Transponder availability and bandwidth constraints have limited this growth. Transponder capacity is determined by the selected modulation scheme and the proportion of capacity consumed by FEC.
Data storage[edit]
Error detection and correction codes are often used to improve the reliability of data storage media.[19] A parity track capable of detecting single-bit errors was present on the first magnetic tape data storage in 1951. The optimal rectangular code used in group coded recording tapes not only detects but also corrects single-bit errors. Some file formats, particularly archive formats, include a checksum (most often CRC32) to detect corruption and truncation and can employ redundancy or parity files to recover portions of corrupted data. Reed-Solomon codes are used in compact discs to correct errors caused by scratches.
Modern hard drives use Reed–Solomon codes to detect and correct minor errors in sector reads, and to recover corrupted data from failing sectors and store that data in the spare sectors.[20] RAID systems use a variety of error correction techniques to recover data when a hard drive completely fails. Filesystems such as ZFS or Btrfs, as well as some RAID implementations, support data scrubbing and resilvering, which allows bad blocks to be detected and (hopefully) recovered before they are used.[21] The recovered data may be re-written to exactly the same physical location, to spare blocks elsewhere on the same piece of hardware, or the data may be rewritten onto replacement hardware.
Error-correcting memory[edit]
Dynamic random-access memory (DRAM) may provide stronger protection against soft errors by relying on error-correcting codes. Such error-correcting memory, known as ECC or EDAC-protected memory, is particularly desirable for mission-critical applications, such as scientific computing, financial, medical, etc. as well as extraterrestrial applications due to the increased radiation in space.
Error-correcting memory controllers traditionally use Hamming codes, although some use triple modular redundancy. Interleaving allows distributing the effect of a single cosmic ray potentially upsetting multiple physically neighboring bits across multiple words by associating neighboring bits to different words. As long as a single-event upset (SEU) does not exceed the error threshold (e.g., a single error) in any particular word between accesses, it can be corrected (e.g., by a single-bit error-correcting code), and the illusion of an error-free memory system may be maintained.[22]
In addition to hardware providing features required for ECC memory to operate, operating systems usually contain related reporting facilities that are used to provide notifications when soft errors are transparently recovered. One example is the Linux kernel’s EDAC subsystem (previously known as Bluesmoke), which collects the data from error-checking-enabled components inside a computer system; besides collecting and reporting back the events related to ECC memory, it also supports other checksumming errors, including those detected on the PCI bus.[23][24][25] A few systems[specify] also support memory scrubbing to catch and correct errors early before they become unrecoverable.
See also[edit]
- Berger code
- Burst error-correcting code
- ECC memory, a type of computer data storage
- Link adaptation
- List of algorithms § Error detection and correction
- List of hash functions
References[edit]
- ^ a b «Masorah». Jewish Encyclopedia.
- ^ Pratico, Gary D.; Pelt, Miles V. Van (2009). Basics of Biblical Hebrew Grammar: Second Edition. Zondervan. ISBN 978-0-310-55882-8.
- ^ Mounce, William D. (2007). Greek for the Rest of Us: Using Greek Tools Without Mastering Biblical Languages. Zondervan. p. 289. ISBN 978-0-310-28289-1.
- ^ Mishneh Torah, Tefillin, Mezuzah, and Sefer Torah, 1:2. Example English translation: Eliyahu Touger. The Rambam’s Mishneh Torah. Moznaim Publishing Corporation.
- ^ Brian M. Fagan (5 December 1996). «Dead Sea Scrolls». The Oxford Companion to Archaeology. Oxford University Press. ISBN 0195076184.
- ^ Thompson, Thomas M. (1983), From Error-Correcting Codes through Sphere Packings to Simple Groups, The Carus Mathematical Monographs (#21), The Mathematical Association of America, p. vii, ISBN 0-88385-023-0
- ^ Shannon, C.E. (1948), «A Mathematical Theory of Communication», Bell System Technical Journal, 27 (3): 379–423, doi:10.1002/j.1538-7305.1948.tb01338.x, hdl:10338.dmlcz/101429, PMID 9230594
- ^ Golay, Marcel J. E. (1949), «Notes on Digital Coding», Proc.I.R.E. (I.E.E.E.), 37: 657
- ^ Gupta, Vikas; Verma, Chanderkant (November 2012). «Error Detection and Correction: An Introduction». International Journal of Advanced Research in Computer Science and Software Engineering. 2 (11). S2CID 17499858.
- ^ a b A. J. McAuley, Reliable Broadband Communication Using a Burst Erasure Correcting Code, ACM SIGCOMM, 1990.
- ^ Shah, Pradeep M.; Vyavahare, Prakash D.; Jain, Anjana (September 2015). «Modern error correcting codes for 4G and beyond: Turbo codes and LDPC codes». 2015 Radio and Antenna Days of the Indian Ocean (RADIO): 1–2. doi:10.1109/RADIO.2015.7323369. ISBN 978-9-9903-7339-4. S2CID 28885076. Retrieved 22 May 2022.
- ^ «IEEE SA — IEEE 802.11ac-2013». IEEE Standards Association.
- ^ «Transition to Advanced Format 4K Sector Hard Drives | Seagate US». Seagate.com. Retrieved 22 May 2022.
- ^ Frank van Gerwen. «Numbers (and other mysterious) stations». Archived from the original on 12 July 2017. Retrieved 12 March 2012.
- ^ Gary Cutlack (25 August 2010). «Mysterious Russian ‘Numbers Station’ Changes Broadcast After 20 Years». Gizmodo. Retrieved 12 March 2012.
- ^ Ben-Gal I.; Herer Y.; Raz T. (2003). «Self-correcting inspection procedure under inspection errors» (PDF). IIE Transactions. IIE Transactions on Quality and Reliability, 34(6), pp. 529-540. Archived from the original (PDF) on 2013-10-13. Retrieved 2014-01-10.
- ^ K. Andrews et al., The Development of Turbo and LDPC Codes for Deep-Space Applications, Proceedings of the IEEE, Vol. 95, No. 11, Nov. 2007.
- ^ Huffman, William Cary; Pless, Vera S. (2003). Fundamentals of Error-Correcting Codes. Cambridge University Press. ISBN 978-0-521-78280-7.
- ^ Kurtas, Erozan M.; Vasic, Bane (2018-10-03). Advanced Error Control Techniques for Data Storage Systems. CRC Press. ISBN 978-1-4200-3649-7.[permanent dead link]
- ^ Scott A. Moulton. «My Hard Drive Died». Archived from the original on 2008-02-02.
- ^ Qiao, Zhi; Fu, Song; Chen, Hsing-Bung; Settlemyer, Bradley (2019). «Building Reliable High-Performance Storage Systems: An Empirical and Analytical Study». 2019 IEEE International Conference on Cluster Computing (CLUSTER): 1–10. doi:10.1109/CLUSTER.2019.8891006. ISBN 978-1-7281-4734-5. S2CID 207951690.
- ^ «Using StrongArm SA-1110 in the On-Board Computer of Nanosatellite». Tsinghua Space Center, Tsinghua University, Beijing. Archived from the original on 2011-10-02. Retrieved 2009-02-16.
- ^ Jeff Layton. «Error Detection and Correction». Linux Magazine. Retrieved 2014-08-12.
- ^ «EDAC Project». bluesmoke.sourceforge.net. Retrieved 2014-08-12.
- ^ «Documentation/edac.txt». Linux kernel documentation. kernel.org. 2014-06-16. Archived from the original on 2009-09-05. Retrieved 2014-08-12.
Further reading[edit]
- Shu Lin; Daniel J. Costello, Jr. (1983). Error Control Coding: Fundamentals and Applications. Prentice Hall. ISBN 0-13-283796-X.
- SoftECC: A System for Software Memory Integrity Checking
- A Tunable, Software-based DRAM Error Detection and Correction Library for HPC
- Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing
External links[edit]
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay, contains chapters on elementary error-correcting codes; on the theoretical limits of error-correction; and on the latest state-of-the-art error-correcting codes, including low-density parity-check codes, turbo codes, and fountain codes.
- ECC Page — implementations of popular ECC encoding and decoding routines