
Вы ищете память, которая имеет доступ к более высоким скоростям и совместима с большим количеством платформ? Или вы ищете долговечную память, которая может работать 24 часа в сутки, 7 дней в неделю, выявлять больше ошибок, но для этого приходится жертвовать скоростью?
Модули ОЗУ (оперативной памяти) являются важной частью каждой системы, но не все модули одинаковы. Помимо емкости, частоты и задержки, модули могут характеризоваться наличием или отсутствием системы исправления ошибок (ECC).
Разница между ними заключается в том, что память ECC защитит вашу систему от потенциального сбоя, исправив любые ошибки в данных, в то время как память без ECC игнорирует такие ошибки.
Думайте о памяти без ECC как о памяти, ориентированной на скорость, а ECC – памяти, ориентированной на выносливость и надёжности.

Поскольку не все платформы поддерживают ECC-память, и не каждой системе она нужна, давайте обсудим, что такое ECC-память, как она работает и нужна ли она вам.
Что такое ECC-память
Чтобы понять, как работает память с коррекцией ошибок (ECC), сначала нужно понять, что такое однобитовая ошибка. Потому что это основная проблема, для решения которой была создан ECC.
Однобитовая ошибка – это когда один бит (двоичный 0 или 1) в данных в ОЗУ случайно изменяется на противоположное значение.
Такого рода ошибки незначительны, и компьютер может не распознать их автоматически, что может привести ко многим проблемам.
Вы можете думать об однобитовых ошибках как о метафорических сорняках на лужайке. Ваш газон – это оперативная память, а ECC-часть вашей памяти – это использование гербицида.
Память без ECC не избавит вас от «сорняков». ECC уничтожит все сорняки, но газон будет расти немного медленнее.
Однобитовые ошибки могут возникать из-за магнитных или электрических помех внутри компьютера, присутствующих в каждой системе в виде фонового излучения.

Перенапряжение, колебания температуры, удар по корпусу или даже чтение или запись данных не так, как предполагалось изначально, могут привести к однобитовой ошибке.
Память ECC позаботится об этих ошибках и исправит их до того, как они превратятся в большую проблему.
Память с ECC очень похожа на память без ECC. Самая большая разница между ними заключается в том, что память ECC обычно имеет немного дополнительной памяти, предназначенной исключительно для обеспечения того, чтобы фактическая память работала без ошибок.
ECC – это, по сути, небольшой чип на обычной планке ОЗУ, который гарантирует, что каждый бит данных, который входит и выходит, является именно тем, чем он должен быть.
Что он делает, так это то, что создаёт зашифрованный фрагмент кода из данных, записываемых в основную память, и сохраняет этот код в дополнительном бите памяти. Когда необходимо получить доступ к данным, хранящимся в основной памяти, он создаёт новый код и сравнивает этот фрагмент кода с кодом, который был сгенерирован ранее.
Если он обнаружит, что они оба одинаковы и что данные не были каким-либо образом изменены, он разрешает чтение данных. Но, если он обнаруживает, что новый код отличается от сохраненного кода, он попытается решить проблему, расшифровывая код, чтобы точно определить, в чём заключается ошибка.
Если он не сможет найти ошибку, то, по крайней мере, гарантирует, что вы будете знать, что что-то пошло не так, вместо того, чтобы молча продолжать работать.
Это похоже на сравнение хэшей MD5 при загрузке программы, чтобы убедиться, что вы загружаете именно то, что вам действительно нужно, а не другой мошеннический секретный файл.
Вот почему ECC работает немного медленнее – потому что ему приходится создавать эти дополнительные коды.
Согласно исследованиям, вероятность возникновения такой ошибки составляет одна однобитовая ошибка каждые 14-40 часов на гигабит ОЗУ.
Необходимость исправления ошибок на серверах и рабочих станциях
В системе, используемой для повседневного просмотра и игр, исправление ошибок не является необходимостью. Однако, в мире серверов и профессиональных рабочих станций ставки выше.
Если вы ведёте бизнес, специализирующийся на финансах, однобитовая ошибка может привести к сбою сервера, который потенциально может стереть транзакции с вашего сервера.
Такая ошибка памяти также может привести к ошибке транскрипции данных, что может привести к неправильному размещению десятичного разделителя или изменению числа.
Очевидно, что это наносит ущерб честности и надёжности бизнеса. Если бы вы пошли покупать кошке новую игрушку и в итоге заплатили 1000 рублей вместо 100, это было бы довольно трагично.
Если вы посетили своего врача, и счет составил 56 987 рублей вместо 5945 рублей, вы только что стали жертвой компьютерной ошибки, связанной с ECC. И вы, скорее всего, больше никогда не воспользуетесь их услугами.
Потеря времени – ещё одна проблема, которую может предотвратить память ECC. Если вы визуализируете сложные изображения в высоком разрешении или работаете с моделью глубокого обучения, необходимость начинать заново после нескольких недель обработки из-за некоторых ошибок памяти – это огромная трата времени и денег для вашего бизнеса.
Память ECC необходима и в медицинской промышленности. При уходе за пациентом точность записей имеет решающее значение, и ошибка в одном бите может привести к неправильному диагнозу, что может привести к летальному исходу.
Выбор памяти может создать или уничтожить репутацию бизнеса.
Без памяти ECC не только существует вероятность подобных ошибок, но вы также не узнаете, что они произошли, пока кто-нибудь не просмотрит данные и не найдёт ошибку. А иногда это может быть слишком поздно.
Какие платформы поддерживают память ECC
Что касается серверов, то линейки процессоров Intel Xeon и линейки серверов AMD Epyc поддерживают память ECC. Обратите внимание, что для использования памяти ECC и процессор, и используемая материнская плата должны поддерживать память ECC.
Помните аналогию с газоном и гербицидом? Думайте о процессоре и материнской плате как об инструментах, которые вы используете для эффективной работы с ECC. Вам нужны подходящие инструменты для распространения гербицидов на газоне.

На основных платформах, используемых сегодня, большинство процессоров Intel (даже некоторые бюджетные модели Celeron) будут поддерживать память ECC, если вы используете материнскую плату, совместимую с такой памятью.
С AMD все процессоры Ryzen поддерживают память ECC с совместимой материнской платой с набором микросхем X570, тогда как набор микросхем B550 не поддерживает память ECC с процессорами Ryzen 2000. Процессоры Ryzen со встроенной видеокартой или ускоренным процессором (APU), серии 3000 G и серии 4000 G потребуют от вас использования процессора PRO для поддержки ECC.
Недостатки использования памяти ECC
Наиболее распространенная проблема с памятью ECC – совместимость. Несмотря на то, что большинство современных платформ поддерживают её, вы должны убедиться, что конкретная комбинация процессора и материнской платы работает с памятью ECC.
Это менее проблематично в мире серверов, где обычно используется память ECC. Серверное оборудование обычно поддерживает ECC по умолчанию.
Ценник тоже отличается. Модули памяти с ECC дороже, чем модули без ECC из-за дополнительных функций. В зависимости от емкости, которую вы покупаете, разница в цене составляет около 10-20%.
Также наблюдается небольшой спад производительности из-за дополнительного времени, которое требуется памяти ECC для проверки наличия ошибок. По словам Corsair, можно ожидать падения около 2%.
Подведение итогов – нужна ли вам память ECC
Когда вы создаете профессиональную рабочую станцию или сервер, который должен работать круглосуточно и без выходных, память ECC просто необходима.
Обойтись без ECC в этом сценарии было бы все равно, что использовать борзую, чтобы тянуть повозку, когда вам нужна крепкая рабочая лошадка.
И разница в цене, и снижение производительности того стоят, если учесть, что вам не придётся беспокоиться о возможности однобитовой ошибки, которая вызовет у вас головную боль.
Вы ведь не хотели бы перепроверять каждую квитанцию, чтобы убедиться, что она верна, верно? Проявите такую же любезность к своим клиентам и заказчикам.
Но если всё, что вы делаете, это играете в игры и используете свой компьютер для другой некритической работы, вам, скорее всего, не понадобится ECC, и вам важнее сохранить эти 2% производительности.
Время на прочтение
4 мин
Количество просмотров 27K
Код исправления ошибок (Error Correction Code или ECC) добавляется к передаваемому сигналу и позволяет не только выявить ошибки при передаче, но и при необходимости исправить их (что в общем-то очевидно из названия), без повторного запроса данных у передатчика. Такой алгоритм работы позволяет передавать данные с постоянной скоростью, что может быть важно во многих случаях. Например, когда вы смотрите цифровое телевидение — смотреть на застывшую картинку, ожидая, пока осуществляются многократные повторные запросы данных, было бы весьма неинтересно.

В 1948 году Клод Шеннон опубликовал свою знаменитую работу о передаче информации, в которой, помимо прочего, была сформулирована теорема о передаче информации по каналу с помехами. После публикации, было разработано немало алгоритмов исправления ошибок с помощью некоторого увеличения объема передаваемых данных, но одним из часто встречающихся семейств алгоритмов, являются алгоритмы, основанные на коде с малой плотностью проверок на четность (Low-density parity-check code, LDPC-code, низкоплотностный код), получившие сейчас распространение за счет простоты реализации.

Клод Шеннон
LDPC был впервые представлен миру в стенах MIT Робертом Греем Галлагером (Robert Gray Gallager), выдающимся специалистом в области коммуникационных сетей. Произошло это в 1960 году, и LDPC опередил свое время. Компьютеры на вакуумных лампах, распространенные в то время, редко обладали мощностью достаточной, для эффективной работы с LDPC. Компьютер, способный обрабатывать такие данные в реальном времени, в те годы занимал площадь почти в 200 квадратных метров, и это автоматически делало все алгоритмы, основанные на LDPC экономически невыгодными. Поэтому, на протяжении почти 40 лет использовались более простые коды, а LDPC оставался скорее изящным теоретическим построением.

Роберт Галлагер
В середине 90-х, инженеры, работающие над алгоритмами спутниковой передачи цифрового телевидения, «стряхнули пыль» с LDPC и стали его использовать, поскольку компьютеры к тому времени стали и мощней, и меньше. К началу 2000-х годов, LDPC получает повсеместное распространение, поскольку он позволяет с большой эффективностью исправлять ошибки при высокоскоростной передаче данных в условиях высоких помех (например при сильных электромагнитных наводках). Так же распространению способствовало появление специализированных систем на чипах, использующихся в WiFi технике, жестких дисках, контроллерах SCSI и т.д., такие SoC оптимизируются под задачи, и для них вычисления, связанные с LDPC вообще не представляют проблемы. В 2003 году LDPC-код, вытеснил технологию турбо-кода, и стал частью стандарта спутниковой передачи данных для цифрового телевидения DVB-S2. Аналогичная замена произошла и в стандарте DVB-T2 для цифрового «эфирного» телевидения.
Стоит сказать, что на базе LDPC строятся очень разные решения, нет «единственно правильной» эталонной реализации. Часто решения, основанные на LDPC несовместимы между собой и код, разработанный, например, для спутникового телевидения, не может быть портирован и использован в жестких дисках. Хотя чаще всего, объединение усилий инженеров разных областей дает массу преимуществ, и LDPC «в целом» является технологией не запатентованной, разные ноу-хау и проприетарные технологии вместе с корпоративными интересами встают на пути. Чаще всего, подобное сотрудничество возможно только в пределах одной компании. В качестве примера можно привести решение для канала чтения HDD от LSI под названием TrueStore®, которое компания предлагает на протяжении уже 3 лет. После приобретения компании SandForce, инженеры LSI стали работать над алгоритмами исправления ошибок SHIELD™ для SSD контроллеров (основанными на LDPC), не существовало портов алгоритмов для работы с SSD, но знания инженерной команды, работавшей над решениями для HDD очень помогли в разработке новых алгоритмов.
Тут, разумеется, у большинства читателей возникнет вопрос: чем алгоритмы, каждый алгоритм LDPC отличается от остальных? Большинство решений LDPC начинаются как декодеры с жестким решением, то есть такой декодер работает с жестко ограниченным набором данных (чаще всего 0 и 1) и использует код коррекции ошибок при малейших отклонениях от нормы. Такое решение, конечно, позволяет эффективно обнаруживать ошибки в передаваемых данных и исправлять их, но в случае высокого уровня ошибок, что иногда случается при работе с SSD, такие алгоритмы перестают справляться с ними. Как вы помните из наших предыдущих статей, любая флеш-память подвержена росту количества ошибок в процессе эксплуатации. Этот неизбежный процесс стоит учитыавть при разработке алгоритмов корреции ошибок для SSD накопителей. Что же делать в случае роста числа ошибок?
Тут на помощь приходят LDPC с мягким решением, являющиеся по сути «более аналоговыми». Подобные алгоритмы «смотрят» глубже, чем «жесткие», и, обладают большим набором возможностей. Примером самого простого такого решения может быть попытка прочитать данные снова, используя другое напряжение, так же как мы часто просим собеседника повторить фразу погромче. Продолжая метафоры с общением людей, можно привести пример более сложных алгоритмов коррекции. Представьте, что вы общаетесь на английском с человеком, говорящим с сильнейшим акцентом. В данном случае сильный акцент выступает в роли помехи. Ваш собеседник произнес некую длинную фразу, которую вы не поняли. В роли LDPC с мягким решением в данном случае будут выступать несколько коротких наводящих вопросов, которые вы можете задать и прояснить весь смысл фразы, которую вы изначально не поняли. Подобные мягкие решения часто используют так же сложные статистические алгоритмы, позволяющие исключить ложнопозитивные срабатывания. В общем, как вы уже поняли, такие решения заметно сложней в реализации, но они чаще всего показывают куда лучшие результаты по сравнению с «жексткими».
В 2013 году, на саммите, посвященном флэш-памяти, проходившем в Санта-Кларе, Калифорния, LSI представили свою технологию расширенной коррекции ошибок SHIELD. Комбинируя подходы с мягким и жестким решением, DSP SHIELD предлагает ряд уникальных оптимизаций для будущих технологий Flash-памяти. Например, технология Adaptive Code Rate, позволяет менять объем, отведенный под ECC так, чтоб он занимал как можно меньше места изначально, и динамически увеличивался по мере неизбежного роста количества ошибок, характерных для SSD.
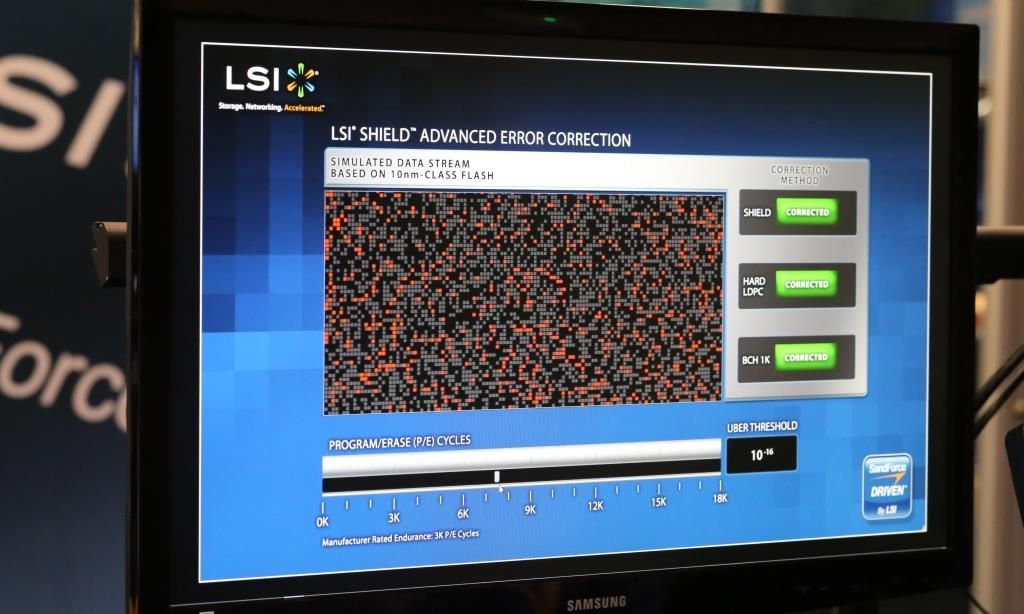
Как видите, различные решения LDPC работают очень по-разному, и предлагают разные фунции и возможности, от которых во многом будет зависеть и качество работы финального продукта.
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code, (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complicated function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
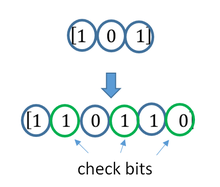
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]

A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.

A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- Algebraic geometry code
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most
 bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters


See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
- Linear code
- Quantum error correction
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
Код коррекции ошибок
Коды коррекции
ошибок (Error
Correcting
Code
ECC)
позволяют не только обнаружить ошибку,
но и исправить ее в одном разряде. Поэтому
компьютер, в котором используются
подобные коды, в случае ошибки в одном
разряде может работать без прерывания,
причем данные не будут искажены. Коды
коррекции ошибок в большинстве
персональных компьютеров позволяют
только обнаруживать, но не исправлять
ошибки в двух разрядах. Но приблизительно
98% сбоев памяти вызвано именно ошибкой
в одном разряде, т.е. она успешно
исправляется с помощью данного типа
кодов. В кодах коррекции ошибок этого
типа для каждых 32 бит требуется
дополнительно семь контрольных разрядов
при 4-байтовой и восемь
при 8-байтовой организации. Реализация
кода коррекции ошибок при 4-байтовой
организации, очевидно, дороже реализации
проверки нечетности или четности, но
при 8-байтовой организации стоимость
реализации кода коррекции ошибок не
превышает стоимости реализации проверки
четности.
Для использования
кодов коррекции ошибок необходим
контроллер памяти, вычисляющий контрольные
разряды при операции записи в память.
При чтении из памяти такой контроллер
сравнивает прочитанные и вычисленные
значения контрольных разрядов и при
необходимости исправляет испорченный
бит (или биты). Стоимость дополнительных
логических схем для реализации кода
коррекции ошибок в контроллере памяти
не очень высока, но это может значительно
снизить быстродействие памяти при
операциях записи. Это происходит потому,
что при операциях записи и чтения
необходимо ждать, когда завершится
вычисление контрольных разрядов. При
записи части слова вначале следует
прочитать полное слово, затем перезаписать
изменяемые байты и только после этого
новые вычисленные контрольные разряды.
Большинство сбоев
памяти происходит в одном разряде, и
потому такие ошибки успешно исправляются
кодом коррекции ошибок. Использование
отказоустойчивой памяти обеспечивает
высокую надежность компьютера.
Контрольные вопросы
-
Основные
типы запоминающих устройств. -
Причины ошибок
памяти. -
Контроль четности.
-
Код
коррекции ошибок.
13
Соседние файлы в папке Сватов лабы
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
На чтение 9 мин Просмотров 14.1к. Опубликовано 08.09.2021 Обновлено 13.09.2021
Оглавление
- Память с коррекцией ошибок
- Принцип работы
- Однобитовые ошибки
- Регистровая память
- Чем отличается серверная оперативная память от обычной
- Чем еще отличается ОЗУ для сервера
- Нужна ли серверная память в обычном компьютере
- Почему серверная память не работает на обычных компьютерах
- Где необходима ОЗУ c ECC?
В этой статье мы разберемся, что такое серверная оперативная память. Узнаем, чем память для сервера отличается от обычной и что такое поддержка ECC. Поймем, можно ли вставить планку серверной памяти в обычный компьютер и запустить его.
В серверах и рабочих станциях используется не совсем обычная оперативная память.
Основные ее отличия — это поддержка специфических технологий, таких как контроль четности и ECC (коррекция ошибок).
Серверная оперативная память не обладает выдающимися скоростными характеристиками. Для нее намного важнее стабильность и безотказность в работе. Применяется в тех областях, где критически важна бесперебойная работа. Например, финансы и облачные вычисления.
Рассмотрим подробнее технологии, которые применяют в серверной памяти ⇓
- Error-Correcting Code (ECC) или память с коррекцией ошибок;
- Регистр между микросхемами модуля и контроллером памяти. Так называемая регистровая оперативка.
Память с коррекцией ошибок
ECC (Error-Correcting Code) позволяет исправлять некоторые ошибки в процессе работы оперативной памяти. В том числе, случайные неточности, то есть те, которые могут возникать под воздействием электромагнитных помех или высокоэнергетических элементарных частиц.
Подобная погрешность появляется из-за изменения значения одного бита в машинном слове. Результат такой ошибки может быть самым непредсказуемым. От изменения одного символа в набранном тексте до зависания всей системы.
Применение технологии ECC необходимо для обнаружения и если это возможно, то исправления подобных проблем. Память, не имеющая поддержки коррекции ошибок, обозначается non-ECC.
Принцип работы
ECC модуль имеет дополнительные микросхемы, по одной на каждые 8 чипов. То есть, при одностороннем дизайне модуля, будет задействовано 9 чипов вместо привычных 8. А при двухстороннем — 18 вместо 16. В дополнительных чипах лежат контрольные суммы машинных слов, хранящихся в памяти.

Если при проверке контрольная сумма машинного слова не совпадает с контрольной сумой, находящейся в чипе-буфере, значит, найдена неточность. При возможности устранить проблему, система продолжает работу, но если коррекция невозможна, то операционной системе отправляется сообщение.
Если ОЗУ использует только технологию ECC, то это не совсем серверная оперативная память. Она рассчитана, в первую очередь, на профессиональные рабочие станции.
Для использования ECC RAM ОЗУ требуется поддержка как со стороны процессора, в котором размещен контроллер памяти, так и со стороны материнской платы. Впрочем, у не самых дешевых CPU и системных плат подобная поддержка нередко есть. Следовательно, память с коррекцией ошибок на них успешно заработает.
Какие преимущества получит обычный домашний или офисный компьютер в этом случае? Теоретически, он будет стабильнее работать. Но стоит учитывать, что применение Error-Correcting Code требует определенных вычислительных мощностей, как следствие, быстродействие снижается, пусть и не намного.
Однобитовые ошибки
Бит представляет собой единую двоичную цифру (1 или 0), причем восемь битов формируют байт — исторически наименьшую единицу адресной памяти, которую компьютеры считают либо как одно число, либо букву. Однобитовая ошибка заключается в том, что электрический заряд бит изменяется, переворачивая его от 0 до 1 или наоборот.
Причины однобитовых ошибок возникают в двух основных вариантах — жестких и мягких ⇓
- жесткие вызваны такими физическими факторами, как изменение температуры или мощности, а также напряжение на оборудовании;
- мягкие возникают из-за более сложных факторов, таких как магнитные помехи и даже космические лучи.
В любом случае результат однобитовой ошибки тот же. Неточность, влияющая на одну двоичную цифру, не приведет к концу света, но перевернутый бит может серьезно повлиять на важные данные.
Хотя ошибка может быть безвредной или иметь сравнительно мягкий эффект (например, неправильно окрашенный пиксель в изображении), это может привести к полностью искаженному файлу или сбою всей системы.
В приложениях, обрабатывающих большие объемы чувствительных или высокоценных данных, даже одна однобитовая ошибка может быть катастрофической.
ОЗУ с ECC предотвращает однобитовые ошибки, обнаруживая и исправляя их, гарантируя, что данные будут должным образом сохранены.
Регистровая память
По-настоящему серверной можно считать только регистровую (registered) или буферизованную (buffered) память. Основная ее особенность — это наличие на модуле еще одной микросхемы — регистра.

Регистр выполняет роль буфера между микросхемами памяти на модуле и контроллером ОЗУ. Это необходимо для снятия электрической нагрузки с контроллера, что позволяет установить большое количество модулей.
Наличие регистров уменьшает электрическую нагрузку на контроллер памяти, что позволяет устанавливать большее количество модулей памяти на один канал. Таким образом, обеспечение максимального объема памяти, поддерживаемого современными процессорами, возможно только при использовании регистровой памяти
Вся регистровая оперативка в обязательном порядке поддерживает технологию ECC. Такие модули обычно имеют маркировку ECC reg. Отличие памяти с ECC от регистровой, заключается только в отсутствии микросхемы регистра и компоновке чипов памяти на планке.

Чем отличается серверная оперативная память от обычной
В первую очередь такая оперативка предназначена для бизнеса и профессиональных задач, где критически важна работа с данными и точностью их обработки и передачи.
По сравнению с обычной, ОЗУ ECC имеет очевидные преимущества. Из-за встроенных возможностей для исправления ошибок, системы с ОЗУ ECC имеют намного меньше отказов, чем с памятью без коррекции ошибок. На практике это означает меньшую потерю данных, меньшее количество сбоев и больше времени безотказной работы.
Однако из-за дополнительной обработки, требуемой для чипов, ECC может оказать небольшое влияние на производительность. Это вряд ли является серьезной проблемой, когда пользователи уделяют первостепенное внимание минимизации ошибок и максимальному времени бесперебойной работы, которые обеспечивает ECC RAM, даже если она действительно имеет незначительный проигрыш в производительности.
Еще одна очевидная разница между памятью с ECC и без нее — это цена. Благодаря своим расширенным функциям память с коррекцией ошибок стоит дороже, чем обычная и поддерживается только на специализированных (дорогостоящих) материнских платах и высокопроизводительных серверных процессорах, таких как Intel Xeon и т.п. В обычную метеринку вставить ее можно, но она там не заработает.
Определить серверная память или нет, можно легко визуально по наличию дополнительных чипов памяти и расположению микросхем на модуле.
ECC RAM нельзя комбинировать с памятью без коррекции ошибок. Поэтому, если вы хотите возможности Error-Correcting Code, вам придется заменить всю оперативку на новые модули.
Чем еще отличается ОЗУ для сервера
- вполне закономерно, что оперативная память для круглосуточно работающего сервера должна иметь максимальную надежность. Поэтому серверные модули проходят тщательное тестирование, в том числе, и в условиях высокого нагрева;
- использование серверной регистровой оперативной памяти возможно только если процессор и материнская плата поддерживают ее;
- серверная оперативная память, также как и обычная, выпускается в разных стандартах: ddr, ddr2, ddr3, ddr4. Физически, серверные модули сохраняют совместимость с десктопными, но работоспособность в обычных материнских платах невозможна;
- скорость работы буферизованной RAM ниже, чем у стандартного модуля ОЗУ, а вот цена может оказаться заметно выше.
Нужна ли серверная память в обычном компьютере
Конечно неприятно, когда ваш домашний компьютер или ноутбук падает из-за ошибки, но это вряд ли будет иметь серьезные долгосрочные последствия.
Собирать домашний компьютер на серверном железе — достаточно спорное решение. Кроме самих модулей серверной памяти, придется установить серверную системную плату. А для нормальной работы системной платы может потребоваться соответствующий корпус и блок питания, что в итоге приведет к неоправданным расходам и даст только избыточную для большинства домашних систем надежность.
Почему серверная память не работает на обычных компьютерах
Для бизнес-критических серверных приложений короткий ответ — да. На сервере, обрабатывающем конфиденциальную информацию о клиенте или финансовых транзакциях, даже одна ошибка имеет потенциал для катастрофы.
ECC reg RAM настоятельно рекомендуется организациям, которые обрабатывают большие объемы данных клиентов в Интернете, для защиты от финансовых потерь, вызванных поврежденными данными, или репутационного ущерба, вызванного простоями после сбоя системы.
Можно ли играть на серверной оперативной памяти?
Что лучше серверная оперативная память или обычная?

Александр
В 1998 году — первое знакомство с компьютером. С 2002 года постоянно развиваюсь и изучаю компьютерные технологии и интернет. Сейчас военный пенсионер. Занимаюсь детьми, спортом и этим проектом.
Задать вопрос