
224
11.1. Типы ошибок
Если программа, представленная компилятору, написана с ошибками, не на «исходном» языке, «недружелюбный» компилятор может просто проинформировать пользователя об этом, не указав, где произошла ошибка. Большинство пользователей не удовлетворит такой подход, поскольку они ожидают от компилятора:
1)точного указания, где находится (первая) ошибка программирования;
2)продолжения компиляции (или, по крайней мере, анализа) про-
граммы после обнаружения первой ошибки с целью обнаружения остальных.
Основные причины возникновения ошибок программирования можно классифицировать следующим образом.
Программист не совсем понимает язык, на котором он пишет, и использует неправильную конструкцию программы.
Программист недостаточно осторожен в применении конструкции языка и забывает описать идентификатор или согласовать открывающую скобку с закрывающей и т.д.
Программист неправильно пишет слово языка или какого-либо другой символ в программе.
Ошибки, обусловленные этими тремя факторами, по-разному обнаруживаются компилятором. Ошибки первого типа вылавливаются синтаксическим анализатором, и генерируется сообщение с указанием того символа, на котором поток программы стал недействительным. Ошибки второго типа распадаются на две категории. Те, которые относятся к контекстным свойствам языка (отсутствие идентификатора и д.р.), обнаруживаются процедурой выборки из таблицы символов во время синтаксического анализа. Такие ошибки, как недостающие скобки, обнаруживаются самим анализатором во время выполнения фазы одного из проходов. Ошибки третьего типа обычно выявляются во время лексического анализа.
Существуют ошибки еще одного типа, когда программа пытается выполнить деление на ноль или считывание за пределами файла. Они называются ошибками времени прогона, и обычно их нельзя обнаружить в процессе компиляции. Наша задача проанализировать методы диагностики всех видов ошибок фазы компиляции и рассмотреть -ме тоды их коррекции.
225
11.2. Лексические ошибки
Задача лексического анализатора – сгруппировать последовательность литер в символы исходного языка. При этом он работает исключительно с локальной информацией. В его распоряжении имеется небольшой объем памяти, и он не осуществляет предварительного просмотра. В тех случаях, когда лексический анализатор окажется не в состоянии сгруппировать какие-либо последовательности литер в символы (лексемы), будут возникать ошибки. Лексические ошибки можно разделить на следующие группы.
Одна из литер оказывается недействительной, т.е. она не может быть включена ни в один из символов. В таком случае лексический анализатор либо игнорирует эту литеру, либо заменяет ее какой-либо другой.
При попытке собрать выделенное слово языка выясняется, что последовательность букв не соответствует ни одному из этих .словВ этом случае можно воспользоваться алгоритмом подбора слова, чтобы идентифицировать слово, имеющее несколько другое написание. Например, realab представить как real ab.
Собирая числа, лексический анализатор может испытывать затруднения с последовательностью вида 42.34.41. Возможное решение здесь
– допустить, какая бы ошибка не была, что предполагалось одно число, и предупредить программиста, что вместо этого числа принято конкретное число по умолчанию.
Отсутствие в программе какой-либо литеры приводит к тому, что лексический анализатор не может отделить один символ от другого. Например, если в А+В пропущен знак «+», то лексический анализатор просто пропустит идентификатор АВ, не оповещая об ошибке на этой стадии. Однако отсутствие знака «+» в 1+А вызовет ошибку, хотя лексический анализатор не будет знать, к какой группе ошибок отнести 1А – к недопустимым идентификаторам или еще чему-либо.
Обычно проблему для лексического анализатора создают недостающие кавычки строки символов
string food=”BREFD
Следовательно, в остальной части программы открывающие и закрывающие кавычки могут быть перепутаны. В результате обрушится лавина сообщений об ошибках. «Смышленый» анализатор смог бы обнаружить неправдоподобную последовательность литер внутри кавычек (например, end) и исправить ошибку, поставив в нужном месте кавычки.
226
Многие компиляторы завершают свою работу тем проходом, где обнаружена ошибка. Однако современная тенденция построения компиляторов базируется на принципе обнаружения максимального числа ошибок. Таким образом желательно, чтобы компилятор продвинулся в своей работе как можно дальше. Поэтому лексический анализатор должен передать следующему проходу (фазе) последовательность действительных символов (а необязательно действительную последовательность символов). Для правильных в лексическом смысле программ это не представляет трудностей. При лексически неправильных программах приходится или игнорировать последовательность символов, или включать дополнительные. Может потребоваться изменить написание символов, разбить строки на действительные символы. Игнорировать последовательность литерсамое простое средство, но оно практически всегда приводит к возникновению синтаксических ошибок. Методы исправления лексическим анализатором недопустимых входов зависят от обстоятельств, и на практике их выбор определяется компилируемым языком.
11.3. Ошибки в употреблении скобок
Ошибки, связанные с употреблением скобок, обнаруживаются относительно легко. Обычно компиляторы содержат фазу, предшествующую полному синтаксическому анализу, на которой производится согласование скобок. Если применять скобки только одного типа, например «(» и «)», проверку можно осуществлять с помощью целочисленного счетчика. Этот счетчик первоначально устанавливается на нуль, затем увеличивается на единицу для каждой открывающей скобки и уменьшается на единицу для каждой закрывающей скобки. Последовательность скобок считается допустимой в том случае, когда:
1)счетчик ни при каких обстоятельствах не становится отрицательным;
2)при завершении работы счетчик будет на нуле.
Вбольшинстве языков программирования встречаются различные типы скобок, например
{}
|
[ |
] |
|
begin |
end |
|
if |
fi |
|
case |
esac |
В этом случае необходимо согласовывать каждую закрывающую с соответствующей открывающей скобкой. Алгоритм согласования ско-
227
бок читает скобочную структуру слева направо, помещая каждую открывающую скобку в вершину стека. Когда встречается закрывающая скобка, соответствующая открывающая скобка удаляется из стека. Последовательность скобок считается допустимой, если:
1)при чтении закрывающей скобки не окажется, что она не соответствует открывающей, помещенной в вершине стека;
2)при завершении работы стек станет пустым.
Ошибка в употреблении скобок должна отразиться в четком сообщении, типа
BRACKET MISMATCH.
Если ошибка возникла из-за того, что не достает закрывающей скобки, то тип последней можно вывести на основании той скобки, которая находится в вершине стека. Один из возможных путей исправления ошибки заключается в том, что берется предполагаемая недостающая закрывающая скобка, открывающая скобка удаляется из стека, и выдается сообщение с указанием предполагаемого источника ошибки.
Диагностическое сообщение появится, однако, не в том месте, где был допущен пропуск скобки, так как ошибка останется незамеченной до тех пор, пока не встретится другая закрывающая скобка иного типа. При продолжении синтаксического анализа желательно, чтобы скобочная структура была исправлена. Пример
if b then x else (p+q´r**2 fi.
Здесь пропущена закрывающая скобка «)». Это не обнаружится до тех пор, пока не встретиться fi. Однако неясно, где должна стоять эта скобка: после r, после q, после p или 2. Выяснить, что предполагал программист, невозможно. Поэтому самый легкий способ«исправления» — поставить закрывающую скобку непосредственно передfi. Синтаксический анализатор продолжает работать, а на выход выдается сообщение о введенных изменениях.
11.4. Синтаксические ошибки
Термин «синтаксическая ошибка» употребляется для обозначения ошибки, обнаруживаемой контекстно-свободным синтаксическим анализатором. Современные анализаторы обладают этим важным свойством – обнаруживать синтаксически неправильную программу на первом недопустимом символе, т.е. они могут генерировать сообщения при чтении символа, который не должен следовать за прочитанной к тому времени последовательностью символов.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
When the token pattern does not match the prefix of the remaining input, the lexical analyzer gets stuck and has to recover from this state to analyze the remaining input. In simple words, a lexical error occurs when a sequence of characters does not match the pattern of any token. It typically happens during the execution of a program.
Types of Lexical Error:
Types of lexical error that can occur in a lexical analyzer are as follows:
1. Exceeding length of identifier or numeric constants.
Example:
C++
#include <iostream>
using namespace std;
int main() {
int a=2147483647 +1;
return 0;
}
This is a lexical error since signed integer lies between −2,147,483,648 and 2,147,483,647
2. Appearance of illegal characters
Example:
C++
#include <iostream>
using namespace std;
int main() {
printf("Geeksforgeeks");$
return 0;
}
This is a lexical error since an illegal character $ appears at the end of the statement.
3. Unmatched string
Example:
C++
#include <iostream>
using namespace std;
int main() {
/* comment
cout<<"GFG!";
return 0;
}
This is a lexical error since the ending of comment “*/” is not present but the beginning is present.
4. Spelling Error
C++
#include <iostream>
using namespace std;
int main() {
int 3num= 1234;
return 0;
}
5. Replacing a character with an incorrect character.
C++
#include <iostream>
using namespace std;
int main() {
int x = 12$34;
return 0;
}
Other lexical errors include
6. Removal of the character that should be present.
C++
#include <iostream> /*missing 'o' character
hence lexical error*/
using namespace std;
int main() {
cout<<"GFG!";
return 0;
}
7. Transposition of two characters.
C++
#include <iostream>
using namespace std;
int mian()
{
cout << "GFG!";
return 0;
}
Error Recovery Technique
When a situation arises in which the lexical analyzer is unable to proceed because none of the patterns for tokens matches any prefix of the remaining input. The simplest recovery strategy is “panic mode” recovery. We delete successive characters from the remaining input until the lexical analyzer can identify a well-formed token at the beginning of what input is left.
Error-recovery actions are:
- Transpose of two adjacent characters.
- Insert a missing character into the remaining input.
- Replace a character with another character.
- Delete one character from the remaining input.
Last Updated :
14 Mar, 2023
Like Article
Save Article
Существует множество
ошибок, которые транслятор выявить не
в состоянии, если используемые в программе
операторы сформированы верно. Приведем
примеры таких ошибок.
Логические
ошибки:
-
неверное указание
ветви алгоритма после проверки некоторого
условия; -
неполный учет
возможных условий; -
пропуск в программе
одного или более блоков алгоритма.
Ошибки в циклах:
-
неправильное
указание начала цикла; -
неправильное
указание условий окончания цикла; -
неправильное
указание числа повторений цикла; -
бесконечный цикл.
Ошибки ввода-вывода;
ошибки при работе с данными:
-
неправильное
задание тип данных; -
организация
считывания меньшего или большего объёма
даных, чем требуется; -
неправильное
редактирование данных.
Ошибки в
использовании переменных:
-
использование
переменных без указания их начальных
значений; -
ошибочное указание
одной переменной вместо другой.
Ошибки при работе
с массивами:
-
массивы предварительно
не обнулены; -
массивы неправильно
описаны; -
индексы следуют
в неправильном порядке.
Ошибки в
арифметических операциях:
-
неверное указание
типа переменной (например, целочисленного
вместо вещественного); -
неверное определение
порядка действий; -
деление на нуль;
-
извлечение
квадратного корня из отрицательного
числа; -
потеря значащих
разрядов числа.
Все эти ошибки
обнаруживаются с помощью тестирования.
8.13. Сопровождение программы
Сопровождение
программ
— это работы, связанные с обслуживанием
программ в процессе их эксплуатации.
Многократное
использование разработанной программы
для решения различных задач заданного
класса требует проведения следующих
дополнительных работ:
-
исправление
обнаруженных ошибок; -
модификация
программы для удовлетворения изменяющихся
эксплуатационных требований; -
доработка программы
для решения конкретных задач; -
проведениe
дополнительных тестовых просчетов; -
внесение исправлений
в рабочую документацию; -
усовершенствование
программы и т.д.
Применительно ко
многим программам работы по сопровождению
поглощают более половины затрат,
приходящихся на весь период времени
существования программы (начиная от
выработки первоначальной концепции и
кончая моральным ее устареванием) в
стоимостном выражении.
Программа,
предназначеная для длительной
эксплуатации, должна иметь соответствующую
документацию и инструкцию по её
использованию.
9.Применение компьютерной техники
9.1. Использувание компьютеров в быту
В последнее время
компьютеры <проникли> в жилища людей
и постепенно становятся предметами
первой необходимости. Есть два основных
направления использования компьютеров
дома.
-
Обеспечение
нормальной жизнедеятельности жилища:
-
охранная автоматика,
противопожарная автоматика,
газоанализаторная автоматика; -
управление
освещенностью, расходом электроэнергии,
отопительной системой, управление
микроклиматом; -
электроплиты,
холодильники, стиральные машины со
встроенными микропроцессорами.
Обеспечение
информационных потребностей людей,
находящихся в жилище:
-
заказы на товары
и услуги; -
процессы
обучения; -
общение с базами
данных
и знаний; -
сбор данных о
состоянии
здоровья; -
обеспечение
досуга и развлечений; -
обеспечение
справочной информацией; -
электронная
почта,
телеконференции; -
Интернет.
Соседние файлы в предмете Информатика
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Екатерина Андреевна Гапонько
Эксперт по предмету «Информатика»
Задать вопрос автору статьи
Виды ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
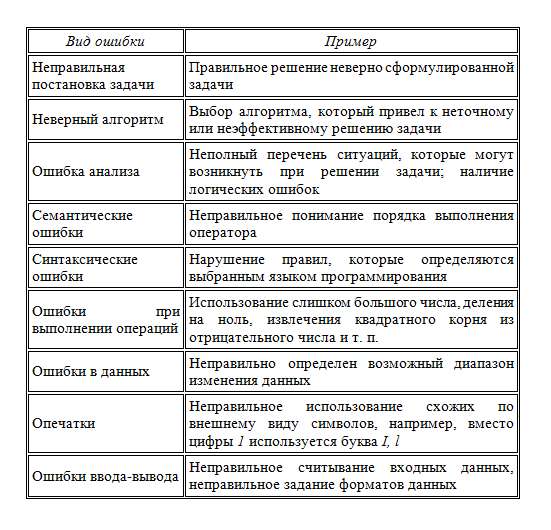
Рассмотрим более подробно некоторые из вышеприведенных видов ошибок.
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы.
Начни разбираться в искусстве
Обучающие курсы по психологии, маркетингу, нутрициологии и работе в сфере кино
Выбрать программу
Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примерами синтаксических ошибок является:
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Синтаксическая ошибка «Не задан идентификатор»:
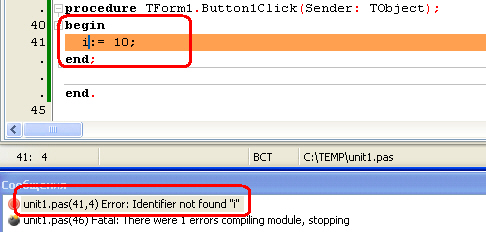
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
«Ошибки в программах » 👇
Логические ошибки:
- после проверки заданного условия неправильно указана ветвь алгоритма;
- неполный перечень возможных условий при решении задачи;
- один или более блоков алгоритма в программе пропущен.
Ошибки в циклах:
- неправильно указано начало цикла;
- неправильно указаны условия окончания цикла;
- неправильно указано количество повторений цикла;
- использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными:
- неправильно задан тип данных;
- организовано считывание меньшего или большего объёма данных, чем нужно;
- неправильно отредактированы данные.
Ошибки в использовании переменных:
- используются переменных, для которых не указаны начальные значения;
- ошибочно указана одна переменная вместо другой.
Ошибки при работе с массивами:
- пропущено предварительное обнуление массивов;
- неправильное описание массивов;
- индексы массивов следуют в ошибочном порядке.
Ошибки в арифметических операциях:
- неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная);
- неправильно определен порядок действий;
- выполняется деление на нуль;
- при расчете выполняется попытка извлечения квадратного корня из отрицательного числа;
- не учитываются значащие разряды числа.
Ошибка в арифметических операциях «Деление на нуль»:

Все вышеописанные ошибки можно обнаружить методом тестирования.
Сопровождение программы
Сопровождением программ называются работы по обслуживанию программ в процессе их эксплуатации.
В случае многократного использования разработанной программы для решения различных задач определенного класса требуется проведение таких дополнительных работ, как:
- при обнаружении ошибок работы программы они должны исправляться;
- при изменении требований эксплуатации необходимая модификация программы;
- выполнение доработки программы с целью решения конкретных задач;
- выполнение дополнительных тестовых расчетов;
- внесение исправлений в рабочую документацию;
- улучшение программы и т.д.
Замечание 1
При проведении работ по сопровождению многих программ стоимость этого сопровождения превышает половину затрат, которые приходятся на весь период времени существования программы (от разработки начального алгоритма до морального ее устаревания).
Программа, которая предназначена для длительной эксплуатации, должна сопровождаться соответствующей документацией и инструкцией по ее использованию.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
| [ начало главы ] [ предыдущий ] |
[ содержание ] |
8.12. Какие ошибки не
обнаруживаются транслятором?
Существует множество ошибок, которые
транслятор выявить не в состоянии, если
используемые в программе операторы
сформированы верно. Приведем примеры таких
ошибок.
Логические ошибки:
Ошибки в циклах:
Ошибки ввода-вывода; ошибки
при работе с данными:
Ошибки в использовании
переменных:
Ошибки при работе с
массивами:
Ошибки в арифметических
операциях:
Все эти ошибки обнаруживаются с помощью
тестирования.