
Написание надежного, без ошибок сценария bash всегда является сложной задачей. Даже если вы написать идеальный сценарий bash, он все равно может не сработать из-за внешних факторов, таких как некорректный ввод или проблемы с сетью.
В оболочке bash нет никакого механизма поглощения исключений, такого как конструкции try/catch. Некоторые ошибки bash могут быть молча проигнорированы, но могут иметь последствия в дальнейшем. ![]()
Проверка статуса завершения команды
Всегда рекомендуется проверять статус завершения команды, так как ненулевой статус выхода обычно указывает на ошибку
if ! command; then
echo "command returned an error"
fiДругой (более компактный) способ инициировать обработку ошибок на основе статуса выхода — использовать OR:
<command_1> || <command_2>С помощью оператора OR, <command_2> выполняется тогда и только тогда, когда <command_1> возвращает ненулевой статус выхода.
В качестве второй команды, можно использовать свою Bash функцию обработки ошибок
error_exit()
{
echo "Error: $1"
exit 1
}
bad-command || error_exit "Some error"В Bash имеется встроенная переменная $?, которая сообщает вам статус выхода последней выполненной команды.
Когда вызывается функция bash, $? считывает статус выхода последней команды, вызванной внутри функции. Поскольку некоторые ненулевые коды выхода имеют специальные значения, вы можете обрабатывать их выборочно.
status=$?
case "$status" in
"1") echo "General error";;
"2") echo "Misuse of shell builtins";;
"126") echo "Command invoked cannot execute";;
"128") echo "Invalid argument";;
esacВыход из сценария при ошибке в Bash
Когда возникает ошибка в сценарии bash, по умолчанию он выводит сообщение об ошибке в stderr, но продолжает выполнение в остальной части сценария. Даже если ввести неправильную команду, это не приведет к завершению работы сценария. Вы просто увидите ошибку «command not found».
Такое поведение оболочки по умолчанию может быть нежелательным для некоторых bash сценариев. Например, если скрипт содержит критический блок кода, в котором не допускаются ошибки, вы хотите, чтобы ваш скрипт немедленно завершал работу при возникновении любой ошибки внутри этого блока . Чтобы активировать это поведение «выход при ошибке» в bash, вы можете использовать команду set следующим образом.
set -e
# некоторый критический блок кода, где ошибка недопустима
set +eВызванная с опцией -e, команда set заставляет оболочку bash немедленно завершить работу, если любая последующая команда завершается с ненулевым статусом (вызванным состоянием ошибки). Опция +e возвращает оболочку в режим по умолчанию. set -e эквивалентна set -o errexit. Аналогично, set +e является сокращением команды set +o errexit.
set -e
true | false | true
echo "Это будет напечатано" # "false" внутри конвейера не обнаруженоЕсли необходимо, чтобы при любом сбое в работе конвейеров также завершался сценарий bash, необходимо добавить опцию -o pipefail.
set -o pipefail -e
true | false | true # "false" внутри конвейера определен правильно
echo "Это не будет напечатано"Для «защиты» критический блока в сценарии от любого типов ошибок команд или ошибок конвейера, необходимо использовать следующую комбинацию команд set.
set -o pipefail -e
# некоторый критический блок кода, в котором не допускается ошибка или ошибка конвейера
set +o pipefail +eОбработка ошибок — очень важная часть любого языка программирования. У Bash нет лучшего варианта, чем другие языки программирования, для обработки ошибки скрипта. Но важно, чтобы скрипт Bash был безошибочным во время выполнения скрипта из терминала. Функция обработки ошибок может быть реализована для сценария Bash несколькими способами. В этой статье показаны различные методы обработки ошибок в сценарии Bash.
Пример 1. Обработка ошибок с использованием условного оператора
Создайте файл Bash со следующим сценарием, который показывает использование условного оператора для обработки ошибок. Первый оператор «if» используется для проверки общего количества аргументов командной строки и вывода сообщения об ошибке, если значение меньше 2. Затем значения делимого и делителя берутся из аргументов командной строки. Если значение делителя равно 0, генерируется ошибка, и сообщение об ошибке печатается в файле error.txt. Вторая команда «if» используется для проверки того, является ли файл error.txt пустым или нет. Сообщение об ошибке печатается, если файл error.txt не пуст.
#!/bin/bash #Проверить значения аргументов if [ $# -lt 2 ]; then echo "Отсутствует один или несколько аргументов." exit fi #Чтение значения делимого из первого аргумента командной строки dividend=$1 #Читание значения делителя из второго аргумента командной строки divisor=$2 #Деление делимого на делитель result=`echo "scale=2; $dividend/$divisor"|bc 2>error.txt` #Читать содержимое файла ошибки content=`cat error.txt` if [ -n "$content" ]; then #Распечатать сообщение об ошибке, если файл error.txt непустой echo "Произошла ошибка, кратная нулю." else #Распечатать результат echo "$dividend/$divisor = $result"
Вывод:
Следующий вывод появляется после выполнения предыдущего скрипта без каких-либо аргументов:
andreyex@andreyex:-/Desktop/bash$ bash error1.bash One or more argument is missing. andreyex@andreyex:~/Desktop/bash$
Следующий вывод появляется после выполнения предыдущего скрипта с одним значением аргумента:
andreyex@andreyex:-/Desktop/bash$ bash error1.bash 75 One or more argument is missing. andreyex@andreyex:~/Desktop/bash$
Следующий вывод появляется после выполнения предыдущего скрипта с двумя допустимыми значениями аргумента:
andreyex@andreyex:-/Desktop/bash$ bash error1.bash 75 8 75/8 = 9.37 andreyex@andreyex:-/Desktop/bash$
Следующий вывод появляется после выполнения предыдущего скрипта с двумя значениями аргументов, где второй аргумент равен 0. Выводится сообщение об ошибке:
andreyex@andreyex:~/Desktop/bash$ bash error1.bash 75 0 Divisible by zero error occurred. andreyex@andreyex:~/Desktop/bash$
Пример 2: Обработка ошибок с использованием кода состояния выхода
Создайте файл Bash со следующим сценарием, который показывает использование обработки ошибок Bash по коду состояния выхода. Любая команда Bash принимается в качестве входного значения, и эта команда выполняется позже. Если код состояния выхода не равен нулю, печатается сообщение об ошибке. В противном случае печатается сообщение об успешном выполнении.
#!/bin/bash #Взять имя команды Linux echo -n "Введите команду: " read cmd_name #Выполнить команду $cmd_name #Проверить, действительна ли команда, if [ $? -ne 0 ]; then echo "$cmd_name - недопустимая команда." else echo "$cmd_name является корректной командой." fi fi
Вывод:
Следующий вывод появляется после выполнения предыдущего скрипта с допустимой командой. Здесь «data» принимается как команда во входном значении, которая является допустимой:
andreyex@andreyex:-/Desktop/bash$ bash error2.bash Enter a command: date Tue Dec 27 19:18:39 +06 2022 date is a valid command. andreyex@andreyex:-/Desktop/bash$
Следующий вывод появляется после выполнения предыдущего скрипта для недопустимой команды. Здесь «cmd» воспринимается как недопустимая команда во входном значении:
andreyex@andreyex:-/Desktop/bash$ bash error2.bash Enter a command: cmd error2.bash: line 7: cmd: command not found cmd is a invalid command. andreyex@andreyex: -/Desktop/bash$
Пример 3: остановить выполнение при первой ошибке
Создайте файл Bash со следующим сценарием, который показывает метод остановки выполнения при появлении первой ошибки сценария. В следующем скрипте используются две недопустимые команды. Таким образом, выдаются две ошибки. Сценарий останавливает выполнение после выполнения первой недопустимой команды с помощью команды «set -e».
#!/bin/bash #Установите параметр для завершения скрипта при первой ошибке set -e echo 'Текущие дата и время: ' #Действительная команда date echo 'Текущий рабочий каталог: ' #Неверная команда cwd echo 'имя пользователя: ' #Действительная команда whoami echo 'Список файлов и папок: ' #Неверный список list
Вывод:
Следующий вывод появляется после выполнения предыдущего скрипта. Сценарий останавливает выполнение после выполнения недопустимой команды «cwd»:
andreyex@andreyex:-/Desktop/bash$ bash error3.bash Current date and time: Tue Dec 27 19:19:38 +06 2022 Current orking Directory: error3.bash: line 9: cwd: command not found andreyex@andreyex:-/Desktop/bash$
Пример 4: остановить выполнение для неинициализированной переменной
Создайте файл Bash со следующим сценарием, который показывает метод остановки выполнения сценария для неинициализированной переменной. Значения имени пользователя и пароля берутся из значений аргументов командной строки. Если какое-либо из значений этих переменных не инициализировано, выводится сообщение об ошибке. Если обе переменные инициализированы, сценарий проверяет, являются ли имя пользователя и пароль действительными или недействительными.
#!/bin/bash #Установите параметр завершения сценария для неинициализированной переменной set -u #Установите значение первого аргумента командной строки на имя пользователя username=$1 #Проверьте правильность или недопустимость имени пользователя и пароля password=$2 #Проверьте правильность или недопустимость имени пользователя и пароля if [[ $username == 'admin' && $password == 'hidenseek' ]]; then echo "Действительный пользователь." else echo "Неверный пользователь." fi
Вывод:
Следующий вывод появляется, если сценарий выполняется без использования какого-либо значения аргумента командной строки. Скрипт останавливает выполнение после получения первой неинициализированной переменной:
andreyex@andreyex:~/Desktop/bash$ bash error4.bash error4.bash: line 7: $1: unbound variable andreyex@andreyex:~/Desktop/bash$
Следующий вывод появляется, если сценарий выполняется с одним значением аргумента командной строки. Скрипт останавливает выполнение после получения второй неинициализированной переменной:
andreyex@andreyex:-/Desktop/bash$ bash error4.bash admin error4.bash: line 9: $2: unbound variable andreyex@andreyex:-/Desktop/bash$
Следующий вывод появляется, если сценарий выполняется с двумя значениями аргумента командной строки — «admin» и «hide». Здесь имя пользователя действительно, но пароль недействителен. Итак, выводится сообщение «Invalid user»:
andreyex@andreyex:-/Desktop/bash$ bash error4.bash admin hide Invalid user. andreyex@andreyex:-/Desktop/bash$
Следующий вывод появляется, если сценарий выполняется с двумя значениями аргументов командной строки — «admin» и «hidenseek». Здесь имя пользователя и пароль действительны. Итак, выводится сообщение «Valid user»:
andreyex@andreyex:-/Desktop/bash$ bash error4.bash admin hidenseek Valid user. andreyex@andreyex:~/Desktop/bash$
Заключение
Различные способы обработки ошибок в скрипте Bash показаны в этой статье на нескольких примерах. Мы надеемся, что это поможет пользователям Bash реализовать функцию обработки ошибок в своих сценариях Bash.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Using trap is not always an option. For example, if you’re writing some kind of re-usable function that needs error handling and that can be called from any script (after sourcing the file with helper functions), that function cannot assume anything about exit time of the outer script, which makes using traps very difficult. Another disadvantage of using traps is bad composability, as you risk overwriting previous trap that might be set earlier up in the caller chain.
There is a little trick that can be used to do proper error handling without traps. As you may already know from other answers, set -e doesn’t work inside commands if you use || operator after them, even if you run them in a subshell; e.g., this wouldn’t work:
#!/bin/sh
# prints:
#
# --> outer
# --> inner
# ./so_1.sh: line 16: some_failed_command: command not found
# <-- inner
# <-- outer
set -e
outer() {
echo '--> outer'
(inner) || {
exit_code=$?
echo '--> cleanup'
return $exit_code
}
echo '<-- outer'
}
inner() {
set -e
echo '--> inner'
some_failed_command
echo '<-- inner'
}
outer
But || operator is needed to prevent returning from the outer function before cleanup. The trick is to run the inner command in background, and then immediately wait for it. The wait builtin will return the exit code of the inner command, and now you’re using || after wait, not the inner function, so set -e works properly inside the latter:
#!/bin/sh
# prints:
#
# --> outer
# --> inner
# ./so_2.sh: line 27: some_failed_command: command not found
# --> cleanup
set -e
outer() {
echo '--> outer'
inner &
wait $! || {
exit_code=$?
echo '--> cleanup'
return $exit_code
}
echo '<-- outer'
}
inner() {
set -e
echo '--> inner'
some_failed_command
echo '<-- inner'
}
outer
Here is the generic function that builds upon this idea. It should work in all POSIX-compatible shells if you remove local keywords, i.e. replace all local x=y with just x=y:
# [CLEANUP=cleanup_cmd] run cmd [args...]
#
# `cmd` and `args...` A command to run and its arguments.
#
# `cleanup_cmd` A command that is called after cmd has exited,
# and gets passed the same arguments as cmd. Additionally, the
# following environment variables are available to that command:
#
# - `RUN_CMD` contains the `cmd` that was passed to `run`;
# - `RUN_EXIT_CODE` contains the exit code of the command.
#
# If `cleanup_cmd` is set, `run` will return the exit code of that
# command. Otherwise, it will return the exit code of `cmd`.
#
run() {
local cmd="$1"; shift
local exit_code=0
local e_was_set=1; if ! is_shell_attribute_set e; then
set -e
e_was_set=0
fi
"$cmd" "$@" &
wait $! || {
exit_code=$?
}
if [ "$e_was_set" = 0 ] && is_shell_attribute_set e; then
set +e
fi
if [ -n "$CLEANUP" ]; then
RUN_CMD="$cmd" RUN_EXIT_CODE="$exit_code" "$CLEANUP" "$@"
return $?
fi
return $exit_code
}
is_shell_attribute_set() { # attribute, like "x"
case "$-" in
*"$1"*) return 0 ;;
*) return 1 ;;
esac
}
Example of usage:
#!/bin/sh
set -e
# Source the file with the definition of `run` (previous code snippet).
# Alternatively, you may paste that code directly here and comment the next line.
. ./utils.sh
main() {
echo "--> main: $@"
CLEANUP=cleanup run inner "$@"
echo "<-- main"
}
inner() {
echo "--> inner: $@"
sleep 0.5; if [ "$1" = 'fail' ]; then
oh_my_god_look_at_this
fi
echo "<-- inner"
}
cleanup() {
echo "--> cleanup: $@"
echo " RUN_CMD = '$RUN_CMD'"
echo " RUN_EXIT_CODE = $RUN_EXIT_CODE"
sleep 0.3
echo '<-- cleanup'
return $RUN_EXIT_CODE
}
main "$@"
Running the example:
$ ./so_3 fail; echo "exit code: $?"
--> main: fail
--> inner: fail
./so_3: line 15: oh_my_god_look_at_this: command not found
--> cleanup: fail
RUN_CMD = 'inner'
RUN_EXIT_CODE = 127
<-- cleanup
exit code: 127
$ ./so_3 pass; echo "exit code: $?"
--> main: pass
--> inner: pass
<-- inner
--> cleanup: pass
RUN_CMD = 'inner'
RUN_EXIT_CODE = 0
<-- cleanup
<-- main
exit code: 0
The only thing that you need to be aware of when using this method is that all modifications of Shell variables done from the command you pass to run will not propagate to the calling function, because the command runs in a subshell.
Bash, or the Bourne-Again Shell, is a powerful command-line interface (CLI) that is commonly used in Linux and Unix systems. When working with Bash, it is important to understand how to handle errors that may occur during the execution of commands. In this article, we will discuss various ways to understand and ignore errors in Bash. Bash scripting is a powerful tool for automating and simplifying various tasks in Linux and Unix systems. However, errors can occur during the execution of commands and can cause scripts to fail. In this article, we will explore the various ways to understand and handle errors in Bash. We will look at ways to check the exit status code and error messages of commands, as well as techniques for ignoring errors when necessary. By understanding and properly handling errors, you can ensure that your Bash scripts run smoothly and achieve the desired outcome.
Step-by-step approach for understanding and ignoring errors in Bash:
Step 1: Understand how errors are generated in Bash.
- When a command is executed, it returns an exit status code.
- A successful command will have an exit status of 0, while a failed command will have a non-zero exit status.
- Error messages are generated when a command returns a non-zero exit status code.
Step 2: Check the exit status code of a command.
- To check the exit status code of a command, you can use the $? variable, which holds the exit status of the last executed command.
- For example, after executing the command ls non_existent_directory, you can check the exit status code by running echo $? The output
- will be non-zero (e.g., 2) indicating that the command failed.
Step 3: Check the error message of a command.
- To check the error message of a command, you can redirect the standard error output (stderr) to a file or to the standard output (stdout) using the 2> operator.
- For example, you can redirect the stderr of the command ls non_existent_directory to a file by running ls non_existent_directory 2> error.log. Then you can view the error message by running cat error.log.
Step 4: Use the set -e command.
- The set -e command causes the script to exit immediately if any command exits with a non-zero status. This can be useful for detecting and handling errors early on in a script.
- For example, if you run set -e followed by ls non_existent_directory, the script will exit immediately with an error message.
Step 5: Ignore errors when necessary.
- To ignore errors, you can use the command || true construct. This construct allows you to execute a command, and if it returns a non-zero exit status, the command following the || operator (in this case, true) will be executed instead.
- For example, you can run rm non_existent_file || true to remove a file that does not exist without exiting with an error.
- Another way to ignore errors is to use the command 2> /dev/null construct, which redirects the standard error output (stderr) of a command to the null device, effectively ignoring any error messages.
- Additionally, you can use the command 2>&1 >/dev/null construct to ignore both standard error and standard output.
- You can also use the command || : construct which allows you to execute a command and if it returns a non-zero exit status, the command following the || operator (in this case, 🙂 will be executed instead. The: command is a no-op command that does nothing, effectively ignoring the error.
Practical Explanation for Understanding Errors
First, let’s examine how errors are generated in Bash. When a command is executed, it returns an exit status code. This code indicates whether the command was successful (exit status 0) or not (non-zero exit status). For example, the following command attempts to list the files in a directory that does not exist:
$ ls non_existent_directory ls: cannot access 'non_existent_directory': No such file or directory

As you can see, the command generated an error message and returned a non-zero exit status code. To check the exit status code of a command, you can use the $? variable, which holds the exit status of the last executed command.
$ echo $? 2
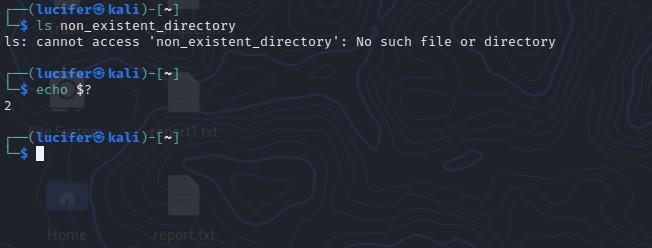
In addition to the exit status code, you can also check the standard error output (stderr) of a command to understand errors. This can be done by redirecting the stderr to a file or to the standard output (stdout) using the 2> operator.
For example, the following script will redirect the stderr of a command to a file:
$ ls non_existent_directory 2> error.log $ cat error.log ls: cannot access 'non_existent_directory': No such file or directory

You can also redirect the stderr to the stdout using the 2>&1 operator, which allows you to see the error message along with the standard output of the command.
$ ls non_existent_directory 2>&1 ls: cannot access 'non_existent_directory': No such file or directory

Another useful tool for understanding errors is the set -e command, which causes the script to exit immediately if any command exits with a non-zero status. This can be useful for detecting and handling errors early on in a script.
$ set -e $ ls non_existent_directory # as soon as you hit enter this will exit shell and will close the terminal.
After this command script will exit from the shell if the exit code is nonzero.
Practical Explanation for Ignoring Errors
While it is important to handle errors in Bash scripts, there may be certain situations where you want to ignore errors and continue running the script. In this section, we will discuss different methods for ignoring errors in Bash and provide examples of how to implement them.
Heredoc
Heredoc is a feature in Bash that allows you to specify a string or command without having to escape special characters. This can be useful when you want to ignore errors that may occur while executing a command. The following example demonstrates how to use Heredoc to ignore errors.
#!/bin/bash # Example of ignoring errors using Heredoc # The `command` will fail but it will not stop execution cat <<EOF | while read line; do echo $line done command that will fail EOF # Rest of the script
In this example, the command that is inside the Heredoc will fail, but the script will not stop execution. This is because the output of the command is piped to the while loop, which reads the output and ignores the error.
Pipefail
The pipe fails option in Bash can be used to change the behavior of pipelines so that the exit status of the pipeline is the value of the last (rightmost) command to exit with a non-zero status or zero if all commands exit successfully. This can be useful when you want to ignore errors that may occur while executing multiple commands in a pipeline. The following example demonstrates how to use the pipe fail option to ignore errors.
#!/bin/bash # Example of ignoring errors using pipefail # The `command1` will fail but it will not stop execution set -o pipefail command1 | command2 # Rest of the script
In this example, command1 will fail, but command2 will continue to execute, and the script will not stop execution.
Undefined Variables
By default, Bash will stop the execution of a script if an undefined variable is used. However, you can use the -u option to ignore this behavior and continue running the script even if an undefined variable is used. The following example demonstrates how to ignore undefined variables.
#!/bin/bash # Example of ignoring undefined variables set +u echo $undefined_variable # Rest of the script
In this example, the script will not stop execution when an undefined variable is used.
Compiling and Interpreting
When compiling or interpreting a script, errors may occur. However, these errors can be ignored by using the -f option when running the script. The following example demonstrates how to ignore errors when compiling or interpreting a script.
#!/bin/bash # Example of ignoring errors when compiling or interpreting bash -f script.sh # Rest of the script
In this example, the script will continue to run even if there are errors during the compilation or interpretation process.
Traps
A trap is a way to execute a command or a set of commands when a specific signal is received by the script. This can be useful when you want to ignore errors and run a cleanup command instead. The following example demonstrates how to use a trap to ignore errors.
#!/bin/bash
# Example of ignoring errors using a trap
# Set a trap to run the cleanup function when an error occurs
trap cleanup ERR
# Function to run when an error occurs
cleanup() {
echo "Cleaning up before exiting..."
}
# Command that will cause an error
command_that_will_fail
# Rest of the script
In this example, when the command_that_will_fail causes an error, the script will execute the cleanup function instead of stopping execution. This allows you to perform any necessary cleanup before exiting the script.
Examples of Bash for Error Handling:
Example 1: Error Handling Using a Conditional Condition
One way to handle errors in Bash is to use a conditional statement. The following example demonstrates how to check for a specific error and handle it accordingly.
#!/bin/bash # Example of error handling using a conditional condition file=example.txt if [ ! -f $file ]; then echo "Error: $file does not exist" exit 1 fi # Rest of the script
In this example, we check if the file “example.txt” exists using the -f option of the [ command. If the file does not exist, the script will print an error message and exit with a status code of 1. This allows the script to continue running if the file exists and exit if it does not.
Example 2: Error Handling Using the Exit Status Code
Another way to handle errors in Bash is to check the exit status code of a command. Every command in Bash returns an exit status code when it completes, with a code of 0 indicating success and any other code indicating an error. The following example demonstrates how to check the exit status code of a command and handle it accordingly.
#!/bin/bash # Example of error handling using the exit status code command1 if [ $? -ne 0 ]; then echo "Error: command1 failed" exit 1 fi # Rest of the script
In this example, the script runs the command “command1” and then checks the exit status code using the special variable $?. If the exit status code is not 0, the script will print an error message and exit with a status code of 1.
Example 3: Stop the Execution on the First Error
When running a script, it can be useful to stop the execution on the first error that occurs. This can be achieved by using the set -e command, which tells Bash to exit the script if any command exits with a non-zero status code.
#!/bin/bash # Stop execution on the first error set -e command1 command2 command3 # Rest of the script
In this example, if any of the commands “command1”, “command2” or “command3” fail, the script will exit immediately.
Example 4: Stop the Execution for Uninitialized Variable
Another way to stop execution on error is if an uninitialized variable is used during script execution. This can be achieved by using the set -u command, which tells Bash to exit the script if any uninitialized variable is used.
#!/bin/bash # Stop execution for uninitialized variable set -u echo $uninitialized_variable # Rest of the script
In this example, if the uninitialized_variable is not defined, the script will exit immediately.
Conclusion
In conclusion, understanding and ignoring errors in Bash is an important aspect of working with the command-line interface. By checking the exit status code of a command, its associated error message, and redirecting the stderr to a file or the stdout, you can understand what went wrong. And by using the command || true, command 2> /dev/null, command 2>&1 >/dev/null, and command || : constructs, you can ignore errors when necessary. It’s always a good practice to test these constructs in a testing environment before using them in production.
In this article, I present a few tricks to handle error conditions—Some strictly don’t fall under the category of error handling (a reactive way to handle the unexpected) but also some techniques to avoid errors before they happen.
Case study: Simple script that downloads a hardware report from multiple hosts and inserts it into a database.
Say that you have a cron job on each one of your Linux systems, and you have a script to collect the hardware information from each:
#!/bin/bash
# Script to collect the status of lshw output from home servers
# Dependencies:
# * LSHW: http://ezix.org/project/wiki/HardwareLiSter
# * JQ: http://stedolan.github.io/jq/
#
# On each machine you can run something like this from cron (Don't know CRON, no worries: https://crontab-generator.org/)
# 0 0 * * * /usr/sbin/lshw -json -quiet > /var/log/lshw-dump.json
# Author: Jose Vicente Nunez
#
declare -a servers=(
dmaf5
)
DATADIR="$HOME/Documents/lshw-dump"
/usr/bin/mkdir -p -v "$DATADIR"
for server in ${servers[*]}; do
echo "Visiting: $server"
/usr/bin/scp -o logLevel=Error ${server}:/var/log/lshw-dump.json ${DATADIR}/lshw-$server-dump.json &
done
wait
for lshw in $(/usr/bin/find $DATADIR -type f -name 'lshw-*-dump.json'); do
/usr/bin/jq '.["product","vendor", "configuration"]' $lshw
doneIf everything goes well, then you collect your files in parallel because you don’t have more than ten systems. You can afford to ssh to all of them at the same time and then show the hardware details of each one.
Visiting: dmaf5
lshw-dump.json 100% 54KB 136.9MB/s 00:00
"DMAF5 (Default string)"
"BESSTAR TECH LIMITED"
{
"boot": "normal",
"chassis": "desktop",
"family": "Default string",
"sku": "Default string",
"uuid": "00020003-0004-0005-0006-000700080009"
}Here are some possibilities of why things went wrong:
- Your report didn’t run because the server was down
- You couldn’t create the directory where the files need to be saved
- The tools you need to run the script are missing
- You can’t collect the report because your remote machine crashed
- One or more of the reports is corrupt
The current version of the script has a problem—It will run from the beginning to the end, errors or not:
./collect_data_from_servers.sh
Visiting: macmini2
Visiting: mac-pro-1-1
Visiting: dmaf5
lshw-dump.json 100% 54KB 48.8MB/s 00:00
scp: /var/log/lshw-dump.json: No such file or directory
scp: /var/log/lshw-dump.json: No such file or directory
parse error: Expected separator between values at line 3, column 9Next, I demonstrate a few things to make your script more robust and in some times recover from failure.
The nuclear option: Failing hard, failing fast
The proper way to handle errors is to check if the program finished successfully or not, using return codes. It sounds obvious but return codes, an integer number stored in bash $? or $! variable, have sometimes a broader meaning. The bash man page tells you:
For the shell’s purposes, a command which exits with a zero exit
status has succeeded. An exit status of zero indicates success.
A non-zero exit status indicates failure. When a command
terminates on a fatal signal N, bash uses the value of 128+N as
the exit status.
As usual, you should always read the man page of the scripts you’re calling, to see what the conventions are for each of them. If you’ve programmed with a language like Java or Python, then you’re most likely familiar with their exceptions, different meanings, and how not all of them are handled the same way.
If you add set -o errexit to your script, from that point forward it will abort the execution if any command exists with a code != 0. But errexit isn’t used when executing functions inside an if condition, so instead of remembering that exception, I rather do explicit error handling.
Take a look at version two of the script. It’s slightly better:
1 #!/bin/bash
2 # Script to collect the status of lshw output from home servers
3 # Dependencies:
4 # * LSHW: http://ezix.org/project/wiki/HardwareLiSter
5 # * JQ: http://stedolan.github.io/jq/
6 #
7 # On each machine you can run something like this from cron (Don't know CRON, no worries: https://crontab-generator.org/ )
8 # 0 0 * * * /usr/sbin/lshw -json -quiet > /var/log/lshw-dump.json
9 Author: Jose Vicente Nunez
10 #
11 set -o errtrace # Enable the err trap, code will get called when an error is detected
12 trap "echo ERROR: There was an error in ${FUNCNAME-main context}, details to follow" ERR
13 declare -a servers=(
14 macmini2
15 mac-pro-1-1
16 dmaf5
17 )
18
19 DATADIR="$HOME/Documents/lshw-dump"
20 if [ ! -d "$DATADIR" ]; then
21 /usr/bin/mkdir -p -v "$DATADIR"|| "FATAL: Failed to create $DATADIR" && exit 100
22 fi
23 declare -A server_pid
24 for server in ${servers[*]}; do
25 echo "Visiting: $server"
26 /usr/bin/scp -o logLevel=Error ${server}:/var/log/lshw-dump.json ${DATADIR}/lshw-$server-dump.json &
27 server_pid[$server]=$! # Save the PID of the scp of a given server for later
28 done
29 # Iterate through all the servers and:
30 # Wait for the return code of each
31 # Check the exit code from each scp
32 for server in ${!server_pid[*]}; do
33 wait ${server_pid[$server]}
34 test $? -ne 0 && echo "ERROR: Copy from $server had problems, will not continue" && exit 100
35 done
36 for lshw in $(/usr/bin/find $DATADIR -type f -name 'lshw-*-dump.json'); do
37 /usr/bin/jq '.["product","vendor", "configuration"]' $lshw
38 done
Here’s what changed:
- Lines 11 and 12, I enable error trace and added a ‘trap’ to tell the user there was an error and there is turbulence ahead. You may want to kill your script here instead, I’ll show you why that may not be the best.
- Line 20, if the directory doesn’t exist, then try to create it on line 21. If directory creation fails, then exit with an error.
- On line 27, after running each background job, I capture the PID and associate that with the machine (1:1 relationship).
- On lines 33-35, I wait for the
scptask to finish, get the return code, and if it’s an error, abort. - On line 37, I check that the file could be parsed, otherwise, I exit with an error.
So how does the error handling look now?
Visiting: macmini2
Visiting: mac-pro-1-1
Visiting: dmaf5
lshw-dump.json 100% 54KB 146.1MB/s 00:00
scp: /var/log/lshw-dump.json: No such file or directory
ERROR: There was an error in main context, details to follow
ERROR: Copy from mac-pro-1-1 had problems, will not continue
scp: /var/log/lshw-dump.json: No such file or directoryAs you can see, this version is better at detecting errors but it’s very unforgiving. Also, it doesn’t detect all the errors, does it?
When you get stuck and you wish you had an alarm
The code looks better, except that sometimes the scp could get stuck on a server (while trying to copy a file) because the server is too busy to respond or just in a bad state.
Another example is to try to access a directory through NFS where $HOME is mounted from an NFS server:
/usr/bin/find $HOME -type f -name '*.csv' -print -fprint /tmp/report.txtAnd you discover hours later that the NFS mount point is stale and your script is stuck.
A timeout is the solution. And, GNU timeout comes to the rescue:
/usr/bin/timeout --kill-after 20.0s 10.0s /usr/bin/find $HOME -type f -name '*.csv' -print -fprint /tmp/report.txtHere you try to regularly kill (TERM signal) the process nicely after 10.0 seconds after it has started. If it’s still running after 20.0 seconds, then send a KILL signal (kill -9). If in doubt, check which signals are supported in your system (kill -l, for example).
If this isn’t clear from my dialog, then look at the script for more clarity.
/usr/bin/time /usr/bin/timeout --kill-after=10.0s 20.0s /usr/bin/sleep 60s
real 0m20.003s
user 0m0.000s
sys 0m0.003sBack to the original script to add a few more options and you have version three:
1 #!/bin/bash
2 # Script to collect the status of lshw output from home servers
3 # Dependencies:
4 # * Open SSH: http://www.openssh.com/portable.html
5 # * LSHW: http://ezix.org/project/wiki/HardwareLiSter
6 # * JQ: http://stedolan.github.io/jq/
7 # * timeout: https://www.gnu.org/software/coreutils/
8 #
9 # On each machine you can run something like this from cron (Don't know CRON, no worries: https://crontab-generator.org/)
10 # 0 0 * * * /usr/sbin/lshw -json -quiet > /var/log/lshw-dump.json
11 # Author: Jose Vicente Nunez
12 #
13 set -o errtrace # Enable the err trap, code will get called when an error is detected
14 trap "echo ERROR: There was an error in ${FUNCNAME-main context}, details to follow" ERR
15
16 declare -a dependencies=(/usr/bin/timeout /usr/bin/ssh /usr/bin/jq)
17 for dependency in ${dependencies[@]}; do
18 if [ ! -x $dependency ]; then
19 echo "ERROR: Missing $dependency"
20 exit 100
21 fi
22 done
23
24 declare -a servers=(
25 macmini2
26 mac-pro-1-1
27 dmaf5
28 )
29
30 function remote_copy {
31 local server=$1
32 echo "Visiting: $server"
33 /usr/bin/timeout --kill-after 25.0s 20.0s
34 /usr/bin/scp
35 -o BatchMode=yes
36 -o logLevel=Error
37 -o ConnectTimeout=5
38 -o ConnectionAttempts=3
39 ${server}:/var/log/lshw-dump.json ${DATADIR}/lshw-$server-dump.json
40 return $?
41 }
42
43 DATADIR="$HOME/Documents/lshw-dump"
44 if [ ! -d "$DATADIR" ]; then
45 /usr/bin/mkdir -p -v "$DATADIR"|| "FATAL: Failed to create $DATADIR" && exit 100
46 fi
47 declare -A server_pid
48 for server in ${servers[*]}; do
49 remote_copy $server &
50 server_pid[$server]=$! # Save the PID of the scp of a given server for later
51 done
52 # Iterate through all the servers and:
53 # Wait for the return code of each
54 # Check the exit code from each scp
55 for server in ${!server_pid[*]}; do
56 wait ${server_pid[$server]}
57 test $? -ne 0 && echo "ERROR: Copy from $server had problems, will not continue" && exit 100
58 done
59 for lshw in $(/usr/bin/find $DATADIR -type f -name 'lshw-*-dump.json'); do
60 /usr/bin/jq '.["product","vendor", "configuration"]' $lshw
61 done
What are the changes?:
- Between lines 16-22, check if all the required dependency tools are present. If it cannot execute, then ‘Houston we have a problem.’
- Created a
remote_copyfunction, which uses a timeout to make sure thescpfinishes no later than 45.0s—line 33. - Added a connection timeout of 5 seconds instead of the TCP default—line 37.
- Added a retry to
scpon line 38—3 attempts that wait 1 second between each.
There other ways to retry when there’s an error.
Waiting for the end of the world-how and when to retry
You noticed there’s an added retry to the scp command. But that retries only for failed connections, what if the command fails during the middle of the copy?
Sometimes you want to just fail because there’s very little chance to recover from an issue. A system that requires hardware fixes, for example, or you can just fail back to a degraded mode—meaning that you’re able to continue your system work without the updated data. In those cases, it makes no sense to wait forever but only for a specific amount of time.
Here are the changes to the remote_copy, to keep this brief (version four):
#!/bin/bash
# Omitted code for clarity...
declare REMOTE_FILE="/var/log/lshw-dump.json"
declare MAX_RETRIES=3
# Blah blah blah...
function remote_copy {
local server=$1
local retries=$2
local now=1
status=0
while [ $now -le $retries ]; do
echo "INFO: Trying to copy file from: $server, attempt=$now"
/usr/bin/timeout --kill-after 25.0s 20.0s
/usr/bin/scp
-o BatchMode=yes
-o logLevel=Error
-o ConnectTimeout=5
-o ConnectionAttempts=3
${server}:$REMOTE_FILE ${DATADIR}/lshw-$server-dump.json
status=$?
if [ $status -ne 0 ]; then
sleep_time=$(((RANDOM % 60)+ 1))
echo "WARNING: Copy failed for $server:$REMOTE_FILE. Waiting '${sleep_time} seconds' before re-trying..."
/usr/bin/sleep ${sleep_time}s
else
break # All good, no point on waiting...
fi
((now=now+1))
done
return $status
}
DATADIR="$HOME/Documents/lshw-dump"
if [ ! -d "$DATADIR" ]; then
/usr/bin/mkdir -p -v "$DATADIR"|| "FATAL: Failed to create $DATADIR" && exit 100
fi
declare -A server_pid
for server in ${servers[*]}; do
remote_copy $server $MAX_RETRIES &
server_pid[$server]=$! # Save the PID of the scp of a given server for later
done
# Iterate through all the servers and:
# Wait for the return code of each
# Check the exit code from each scp
for server in ${!server_pid[*]}; do
wait ${server_pid[$server]}
test $? -ne 0 && echo "ERROR: Copy from $server had problems, will not continue" && exit 100
done
# Blah blah blah, process the files you just copied...
How does it look now? In this run, I have one system down (mac-pro-1-1) and one system without the file (macmini2). You can see that the copy from server dmaf5 works right away, but for the other two, there’s a retry for a random time between 1 and 60 seconds before exiting:
INFO: Trying to copy file from: macmini2, attempt=1
INFO: Trying to copy file from: mac-pro-1-1, attempt=1
INFO: Trying to copy file from: dmaf5, attempt=1
scp: /var/log/lshw-dump.json: No such file or directory
ERROR: There was an error in main context, details to follow
WARNING: Copy failed for macmini2:/var/log/lshw-dump.json. Waiting '60 seconds' before re-trying...
ssh: connect to host mac-pro-1-1 port 22: No route to host
ERROR: There was an error in main context, details to follow
WARNING: Copy failed for mac-pro-1-1:/var/log/lshw-dump.json. Waiting '32 seconds' before re-trying...
INFO: Trying to copy file from: mac-pro-1-1, attempt=2
ssh: connect to host mac-pro-1-1 port 22: No route to host
ERROR: There was an error in main context, details to follow
WARNING: Copy failed for mac-pro-1-1:/var/log/lshw-dump.json. Waiting '18 seconds' before re-trying...
INFO: Trying to copy file from: macmini2, attempt=2
scp: /var/log/lshw-dump.json: No such file or directory
ERROR: There was an error in main context, details to follow
WARNING: Copy failed for macmini2:/var/log/lshw-dump.json. Waiting '3 seconds' before re-trying...
INFO: Trying to copy file from: macmini2, attempt=3
scp: /var/log/lshw-dump.json: No such file or directory
ERROR: There was an error in main context, details to follow
WARNING: Copy failed for macmini2:/var/log/lshw-dump.json. Waiting '6 seconds' before re-trying...
INFO: Trying to copy file from: mac-pro-1-1, attempt=3
ssh: connect to host mac-pro-1-1 port 22: No route to host
ERROR: There was an error in main context, details to follow
WARNING: Copy failed for mac-pro-1-1:/var/log/lshw-dump.json. Waiting '47 seconds' before re-trying...
ERROR: There was an error in main context, details to follow
ERROR: Copy from mac-pro-1-1 had problems, will not continue
If I fail, do I have to do this all over again? Using a checkpoint
Suppose that the remote copy is the most expensive operation of this whole script and that you’re willing or able to re-run this script, maybe using cron or doing so by hand two times during the day to ensure you pick up the files if one or more systems are down.
You could, for the day, create a small ‘status cache’, where you record only the successful processing operations per machine. If a system is in there, then don’t bother to check again for that day.
Some programs, like Ansible, do something similar and allow you to retry a playbook on a limited number of machines after a failure (--limit @/home/user/site.retry).
A new version (version five) of the script has code to record the status of the copy (lines 15-33):
15 declare SCRIPT_NAME=$(/usr/bin/basename $BASH_SOURCE)|| exit 100
16 declare YYYYMMDD=$(/usr/bin/date +%Y%m%d)|| exit 100
17 declare CACHE_DIR="/tmp/$SCRIPT_NAME/$YYYYMMDD"
18 # Logic to clean up the cache dir on daily basis is not shown here
19 if [ ! -d "$CACHE_DIR" ]; then
20 /usr/bin/mkdir -p -v "$CACHE_DIR"|| exit 100
21 fi
22 trap "/bin/rm -rf $CACHE_DIR" INT KILL
23
24 function check_previous_run {
25 local machine=$1
26 test -f $CACHE_DIR/$machine && return 0|| return 1
27 }
28
29 function mark_previous_run {
30 machine=$1
31 /usr/bin/touch $CACHE_DIR/$machine
32 return $?
33 }
Did you notice the trap on line 22? If the script is interrupted (killed), I want to make sure the whole cache is invalidated.
And then, add this new helper logic into the remote_copy function (lines 52-81):
52 function remote_copy {
53 local server=$1
54 check_previous_run $server
55 test $? -eq 0 && echo "INFO: $1 ran successfully before. Not doing again" && return 0
56 local retries=$2
57 local now=1
58 status=0
59 while [ $now -le $retries ]; do
60 echo "INFO: Trying to copy file from: $server, attempt=$now"
61 /usr/bin/timeout --kill-after 25.0s 20.0s
62 /usr/bin/scp
63 -o BatchMode=yes
64 -o logLevel=Error
65 -o ConnectTimeout=5
66 -o ConnectionAttempts=3
67 ${server}:$REMOTE_FILE ${DATADIR}/lshw-$server-dump.json
68 status=$?
69 if [ $status -ne 0 ]; then
70 sleep_time=$(((RANDOM % 60)+ 1))
71 echo "WARNING: Copy failed for $server:$REMOTE_FILE. Waiting '${sleep_time} seconds' before re-trying..."
72 /usr/bin/sleep ${sleep_time}s
73 else
74 break # All good, no point on waiting...
75 fi
76 ((now=now+1))
77 done
78 test $status -eq 0 && mark_previous_run $server
79 test $? -ne 0 && status=1
80 return $status
81 }
The first time it runs, a new new message for the cache directory is printed out:
./collect_data_from_servers.v5.sh
/usr/bin/mkdir: created directory '/tmp/collect_data_from_servers.v5.sh'
/usr/bin/mkdir: created directory '/tmp/collect_data_from_servers.v5.sh/20210612'
ERROR: There was an error in main context, details to follow
INFO: Trying to copy file from: macmini2, attempt=1
ERROR: There was an error in main context, details to follow
If you run it again, then the script knows that dma5f is good to go, no need to retry the copy:
./collect_data_from_servers.v5.sh
INFO: dmaf5 ran successfully before. Not doing again
ERROR: There was an error in main context, details to follow
INFO: Trying to copy file from: macmini2, attempt=1
ERROR: There was an error in main context, details to follow
INFO: Trying to copy file from: mac-pro-1-1, attempt=1Imagine how this speeds up when you have more machines that should not be revisited.
Leaving crumbs behind: What to log, how to log, and verbose output
If you’re like me, I like a bit of context to correlate with when something goes wrong. The echo statements on the script are nice but what if you could add a timestamp to them.
If you use logger, you can save the output on journalctl for later review (even aggregation with other tools out there). The best part is that you show the power of journalctl right away.
So instead of just doing echo, you can also add a call to logger like this using a new bash function called ‘message’:
SCRIPT_NAME=$(/usr/bin/basename $BASH_SOURCE)|| exit 100
FULL_PATH=$(/usr/bin/realpath ${BASH_SOURCE[0]})|| exit 100
set -o errtrace # Enable the err trap, code will get called when an error is detected
trap "echo ERROR: There was an error in ${FUNCNAME[0]-main context}, details to follow" ERR
declare CACHE_DIR="/tmp/$SCRIPT_NAME/$YYYYMMDD"
function message {
message="$1"
func_name="${2-unknown}"
priority=6
if [ -z "$2" ]; then
echo "INFO:" $message
else
echo "ERROR:" $message
priority=0
fi
/usr/bin/logger --journald<<EOF
MESSAGE_ID=$SCRIPT_NAME
MESSAGE=$message
PRIORITY=$priority
CODE_FILE=$FULL_PATH
CODE_FUNC=$func_name
EOF
}
You can see that you can store separate fields as part of the message, like the priority, the script that produced the message, etc.
So how is this useful? Well, you could get the messages between 1:26 PM and 1:27 PM, only errors (priority=0) and only for our script (collect_data_from_servers.v6.sh) like this, output in JSON format:
journalctl --since 13:26 --until 13:27 --output json-pretty PRIORITY=0 MESSAGE_ID=collect_data_from_servers.v6.sh{
"_BOOT_ID" : "dfcda9a1a1cd406ebd88a339bec96fb6",
"_AUDIT_LOGINUID" : "1000",
"SYSLOG_IDENTIFIER" : "logger",
"PRIORITY" : "0",
"_TRANSPORT" : "journal",
"_SELINUX_CONTEXT" : "unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023",
"__REALTIME_TIMESTAMP" : "1623518797641880",
"_AUDIT_SESSION" : "3",
"_GID" : "1000",
"MESSAGE_ID" : "collect_data_from_servers.v6.sh",
"MESSAGE" : "Copy failed for macmini2:/var/log/lshw-dump.json. Waiting '45 seconds' before re-trying...",
"_CAP_EFFECTIVE" : "0",
"CODE_FUNC" : "remote_copy",
"_MACHINE_ID" : "60d7a3f69b674aaebb600c0e82e01d05",
"_COMM" : "logger",
"CODE_FILE" : "/home/josevnz/BashError/collect_data_from_servers.v6.sh",
"_PID" : "41832",
"__MONOTONIC_TIMESTAMP" : "25928272252",
"_HOSTNAME" : "dmaf5",
"_SOURCE_REALTIME_TIMESTAMP" : "1623518797641843",
"__CURSOR" : "s=97bb6295795a4560ad6fdedd8143df97;i=1f826;b=dfcda9a1a1cd406ebd88a339bec96fb6;m=60972097c;t=5c494ed383898;x=921c71966b8943e3",
"_UID" : "1000"
}
Because this is structured data, other logs collectors can go through all your machines, aggregate your script logs, and then you not only have data but also the information.
You can take a look at the whole version six of the script.
Don’t be so eager to replace your data until you’ve checked it.
If you noticed from the very beginning, I’ve been copying a corrupted JSON file over and over:
Parse error: Expected separator between values at line 4, column 11
ERROR parsing '/home/josevnz/Documents/lshw-dump/lshw-dmaf5-dump.json'
That’s easy to prevent. Copy the file into a temporary location and if the file is corrupted, then don’t attempt to replace the previous version (and leave the bad one for inspection. lines 99-107 of version seven of the script):
function remote_copy {
local server=$1
check_previous_run $server
test $? -eq 0 && message "$1 ran successfully before. Not doing again" && return 0
local retries=$2
local now=1
status=0
while [ $now -le $retries ]; do
message "Trying to copy file from: $server, attempt=$now"
/usr/bin/timeout --kill-after 25.0s 20.0s
/usr/bin/scp
-o BatchMode=yes
-o logLevel=Error
-o ConnectTimeout=5
-o ConnectionAttempts=3
${server}:$REMOTE_FILE ${DATADIR}/lshw-$server-dump.json.$$
status=$?
if [ $status -ne 0 ]; then
sleep_time=$(((RANDOM % 60)+ 1))
message "Copy failed for $server:$REMOTE_FILE. Waiting '${sleep_time} seconds' before re-trying..." ${FUNCNAME[0]}
/usr/bin/sleep ${sleep_time}s
else
break # All good, no point on waiting...
fi
((now=now+1))
done
if [ $status -eq 0 ]; then
/usr/bin/jq '.' ${DATADIR}/lshw-$server-dump.json.$$ > /dev/null 2>&1
status=$?
if [ $status -eq 0 ]; then
/usr/bin/mv -v -f ${DATADIR}/lshw-$server-dump.json.$$ ${DATADIR}/lshw-$server-dump.json && mark_previous_run $server
test $? -ne 0 && status=1
else
message "${DATADIR}/lshw-$server-dump.json.$$ Is corrupted. Leaving for inspection..." ${FUNCNAME[0]}
fi
fi
return $status
}Choose the right tools for the task and prep your code from the first line
One very important aspect of error handling is proper coding. If you have bad logic in your code, no amount of error handling will make it better. To keep this short and bash-related, I’ll give you below a few hints.
You should ALWAYS check for error syntax before running your script:
bash -n $my_bash_script.shSeriously. It should be as automatic as performing any other test.
Read the bash man page and get familiar with must-know options, like:
set -xv
my_complicated_instruction1
my_complicated_instruction2
my_complicated_instruction3
set +xvUse ShellCheck to check your bash scripts
It’s very easy to miss simple issues when your scripts start to grow large. ShellCheck is one of those tools that saves you from making mistakes.
shellcheck collect_data_from_servers.v7.sh
In collect_data_from_servers.v7.sh line 15:
for dependency in ${dependencies[@]}; do
^----------------^ SC2068: Double quote array expansions to avoid re-splitting elements.
In collect_data_from_servers.v7.sh line 16:
if [ ! -x $dependency ]; then
^---------^ SC2086: Double quote to prevent globbing and word splitting.
Did you mean:
if [ ! -x "$dependency" ]; then
...
If you’re wondering, the final version of the script, after passing ShellCheck is here. Squeaky clean.
You noticed something with the background scp processes
You probably noticed that if you kill the script, it leaves some forked processes behind. That isn’t good and this is one of the reasons I prefer to use tools like Ansible or Parallel to handle this type of task on multiple hosts, letting the frameworks do the proper cleanup for me. You can, of course, add more code to handle this situation.
This bash script could potentially create a fork bomb. It has no control of how many processes to spawn at the same time, which is a big problem in a real production environment. Also, there is a limit on how many concurrent ssh sessions you can have (let alone consume bandwidth). Again, I wrote this fictional example in bash to show you how you can always improve a program to better handle errors.
Let’s recap
[ Download now: A sysadmin’s guide to Bash scripting. ]
1. You must check the return code of your commands. That could mean deciding to retry until a transitory condition improves or to short-circuit the whole script.
2. Speaking of transitory conditions, you don’t need to start from scratch. You can save the status of successful tasks and then retry from that point forward.
3. Bash ‘trap’ is your friend. Use it for cleanup and error handling.
4. When downloading data from any source, assume it’s corrupted. Never overwrite your good data set with fresh data until you have done some integrity checks.
5. Take advantage of journalctl and custom fields. You can perform sophisticated searches looking for issues, and even send that data to log aggregators.
6. You can check the status of background tasks (including sub-shells). Just remember to save the PID and wait on it.
7. And finally: Use a Bash lint helper like ShellCheck. You can install it on your favorite editor (like VIM or PyCharm). You will be surprised how many errors go undetected on Bash scripts…
If you enjoyed this content or would like to expand on it, contact the team at enable-sysadmin@redhat.com.