
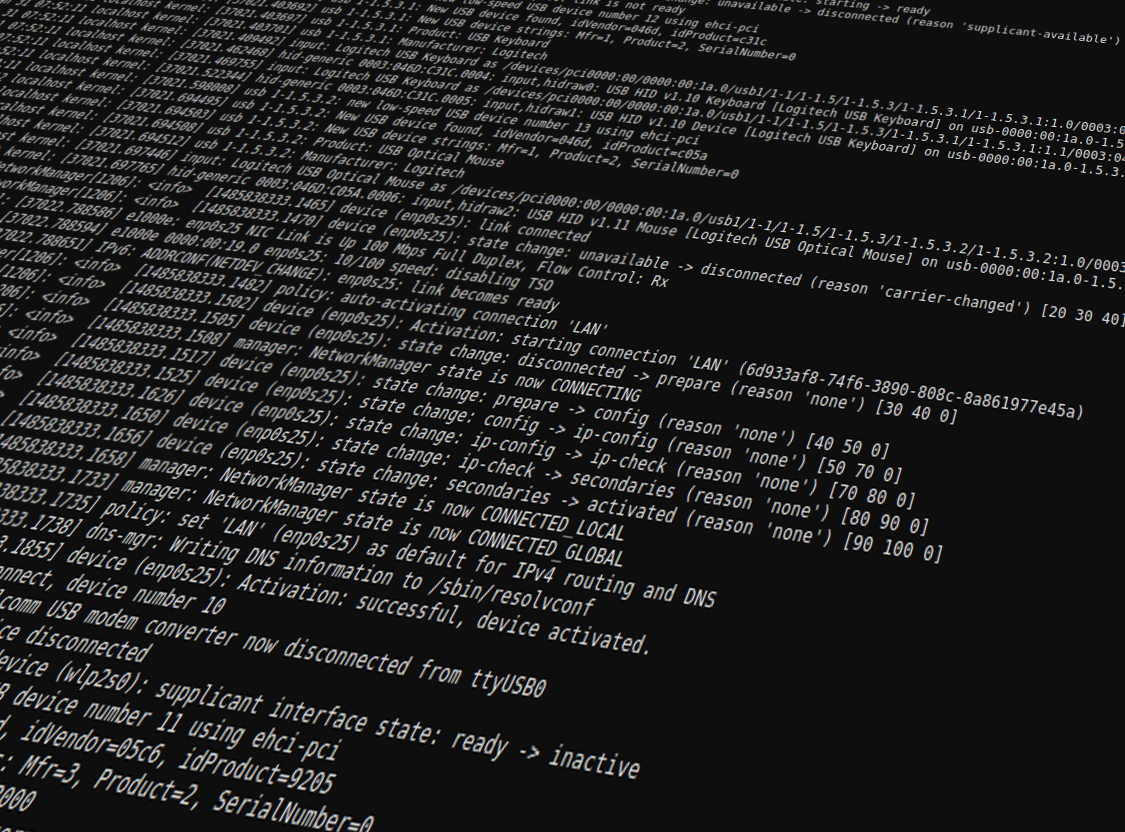
Лог (log) — это текстовый файл, куда автоматически записывается важная информация о работе системы или программы. Чаще всего говорят о логах сервера. Их записывает программное обеспечение, которое управляет внутренней частью сайта или онлайн-системы. Лог-файл — своеобразный журнал событий.
В логи записываются сведения об ошибках, действиях пользователей и других событиях, которые происходят на сервере или в системе. Разработчики и инженеры пользуются ими при отладке или при проверке, как работает программное обеспечение.
Лог-файл (log file) содержит в себе информацию в сокращенном формате. Для обычного пользователя это непонятный набор символов. Но у записей есть смысл, и специалисты должны уметь читать их — в файлах много важной информации о работе.
Для чего нужны логи
Устранение неполадок. По логам можно понять, когда и из-за чего в работе системы возник сбой. А когда станет понятна причина, устранить его будет легче.
Контроль работы. Логи позволяют лучше отслеживать процессы, делать прогнозы на будущее и в целом контролировать работу сервера. По ним понятно, нормально ли работает система, что нужно доработать, какая у сайта посещаемость и так далее.
Проверка стабильности. Даже если с системой все хорошо, рекомендуется периодически проверять ее логи. Так можно на ранних этапах найти уязвимость или недочет — еще до того, как он станет проблемой.
Выявление злоумышленников. Вирус или взлом можно обнаружить по логам. Они фиксируют любые действия пользователей или программ в системе, поэтому по ним специалист может отследить подозрительную активность.
Маркетинг. Логи — источник ценной информации для развития сайта. Они позволяют собрать статистику по посещаемости с «сырыми» техническими данными. Например, понять, откуда приходят пользователи, где они находятся и какими устройствами пользуются для визита.
Какими бывают логи
Информации в логах много, поэтому для каждого типа сведений существует свой лог-файл. Возьмем для примера логи веб-сервера. Вот какими они могут быть:
- основной рассказывает о главных событиях, которые произошли непосредственно с серверным ПО;
- журнал доступа содержит сведения о посетителях сайта;
- лог ошибок сообщает обо всех сбоях, которые произошли во время работы ПО;
- лог веб-сервера рассказывает об обращениях к серверу и о возможных ошибках;
- лог баз данных записывает сведения о действиях с БД, запросах и ошибках;
- лог почтового сервера содержит информацию об отправленных и полученных письмах и так далее.
Наиболее важными считаются логи сервера, доступа и ошибок, но проверять советуют не только их. Мы перечислили только несколько примеров: отдельные журналы могут быть у планировщика задач, клиента передачи файлов, хостинга и многих других подсистем. Информация по каждой из них пишется в свой лог.
Что может содержаться в логах
В лог-файлах находится полный журнал событий, связанных с конкретным узлом. Там описываются время события, тип запроса, реакция сервера, код ответа, IP-адрес пользователя, количество переданной информации и многое другое. Если произошла ошибка, это будет помечено в логах отдельно.
Но вся перечисленная информация представлена в очень сжатом виде. Поэтому незнакомый с правилами записи человек может в ней запутаться. Более того, в логах много сведений, поэтому они очень подробные и обширные. Бывает сложно отделить нужную информацию от той, которая не пригодится сейчас.
Как правильно читать лог
Вручную. Логи хранятся в файлах с расширением .log. Их можно открыть как обычные текстовые файлы и просмотреть содержимое. Перед этим стоит посмотреть, как настроен формат записи логов, если у вас есть доступ к этим параметрам.
Например, так выглядит формат по умолчанию для лога доступа с веб-сервера:
[доменное имя сайта][IP-адрес пользователя][дата и время визита][тип запроса][URL, к которому обратился пользователь][протокол, по которому пользователь соединился с сайтом][код ответа сервера][количество байт информации, которую передали пользователю][дополнительная информация]
Данные чаще всего разделяются пробелами, иногда также дефисами или слэшами. Каждая запись показывается с новой строчки. Читать полные логи в таком формате довольно трудоемко, поэтому главное — найти нужные строки и сконцентрироваться на них.
Это не единственный возможный способ записи лога. Например, в логе ошибок каждая строчка — это запись об ошибке с полной информацией о ней: датой и временем, адресом страницы, на которой возник сбой, и так далее.
С помощью анализатора. Второй вариант — не просматривать лог вручную, а воспользоваться специальной программой-анализатором. Она парсит лог-файл — «разбирает» его на составляющие и представляет в удобном для пользователя виде. Так информация показывается в виде понятного отчета, иногда с графиками и диаграммами.
Анализаторы бывают разными, например Weblog Expert, Analog и пр. Некоторые из них также умеют интегрироваться с сервисами для сбора статистики, чтобы показывать более полную картинку.
Проверять и читать логи вам понадобится, если вы будете работать с профессиональным ПО для разработчиков, вебмастеров или инженеров. Это сложно только с первого взгляда — если понять принцип, расшифровать их не составит труда. А анализаторы помогут лучше и быстрее сориентироваться в записях.
Узнать больше о сетевых технологиях и получить новую профессию вы можете на курсах. Записывайтесь и станьте востребованным IT-специалистом.
Блоги, форумы, посадочные страницы и другие интернет-ресурсы представляют собой совокупность графического, текстового, аудио- и видео-контента, размещенного на веб-страницах в виде кода. Чтобы обеспечить к ним доступ пользователей через интернет, файлы размещают на серверах. Это аппаратное обеспечение (персональный компьютер или рабочая станция), на жестком диске которого и хранится код. Ключевые функции выполняются без участия человека, что актуально для всех типов оборудования, включая виртуальный выделенный сервер. Но это не означает, что контроль не осуществляется. Большинство событий, которые происходят при участии оборудования, пользователей и софта, включая ошибки, логи сервера фиксируют и сохраняют. Из этой статьи вы узнаете, что они собой представляют, зачем нужны, и как их читать.

Что такое логи
Это текстовые файлы, которые хранятся на жестком диске сервера. Создаются и заполняются в автоматическом режиме, в хронологическом порядке. В них записываются:
- системная информация о переданных пользователю данных;
- сообщения о сбоях и ошибках;
- протоколирующие данные о посетителях платформы.
Посмотреть логи сервера может каждый, у кого есть к ним доступ, но непосвященному обывателю этот набор символов может показаться бессмысленным. Интерпретировать записи и получить пользу после прочтения проще профессионалу.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Классификация логов
Для каждой разновидности софта предусмотрены соответствующие файлы. Все логи сервера могут храниться на одном диске или даже на отдельном сервере. Существует довольно много разновидностей логов, вот наиболее распространенные:
- доступа (access_log) — записывают IP-адрес, время запроса, другую информацию о пользователях;
- ошибок (error_log) — показывают файлы, в которых выявлены ошибки и классифицируют сбои;
- FTP-авторизаций — отображают данные о попытках входа по FTP-соединению;
- загрузки системы — с его помощью выполняется отладка при появлении проблем, в файл записываются основные системные события, включая сбои;
- основной — содержит информацию о действиях с файерволом, DNS-сервером, ядром системы, FTP-сервисом;
- планировщика задач — в нем выполняется протоколирование задач, отображаются ошибки при запуске cron;
- баз данных — хранит подробности о запросах, сбоях, ошибки в логах сервера отображаются наравне с другой важной информацией;
- хостинговой панели — включает статистику использования ресурсов сервера, время и количество входов в панель, обновление лицензии;
- веб-сервера — содержит информацию о возникавших ошибках, обращениях;
- почтового сервера — в нем ведутся записи о входящих и исходящих сообщениях, отклонениях писем.
Записи в системные журналы выполняет установленный софт.
Зачем нужны логи
Анализ логов сервера — неотъемлемая часть работы системного администратора или веб-разработчика. Обрабатывая их, специалисты получают массу полезных сведений. Используются в следующих целях:
- поиск ошибок и сбоев в работе системы;
- выявление вредоносной активности;
- сбор статистики посещения веб-ресурса.
После изучения информации можно получить точную статистику в виде сводных цифр, информацию о юзерах, выявить поведенческие закономерности пользовательских групп.
Читайте также

Где посмотреть логи
Расположение определяется хостинг-провайдером или настройками установленного софта. На виртуальном хостинге доступ к лог-файлам предоставляется из панели управления хостингом. Если администратор не открыл его для владельца сайта, получить информацию не получится. Но большинство провайдеров разрешают свободно пользоваться журналами и проводить анализ логов сервера. Независимо от разновидности сервера лог-файлы хранятся в текстовом документе. По умолчанию он называется access.log, но настройки позволяют переименовать файл. Это актуально для Nginx, Apache, прокси-разновидностей squid, других типов. Для просмотра их надо скачать и открыть в текстовом редакторе. В качестве альтернативы можно использовать Grep и схожие утилиты. Они позволяют открыть и отфильтровать логи прямо на сервере.

Как читать логи. Пример
Существует довольно много форматов записи, combined — один из наиболее распространенных. В нем строчка кода может выглядеть так:
%h %l %u %t «%r» %>s %b «%{Referer}i» «%{User-Agent}i»
Директивы имеют следующее значение:
- %h — IP-адрес, с которого был сделан запрос;
- %l — длинное имя удаленного хоста;
- %u — удаленный пользователь, если запрос был сделан аутентифицированным юзером;
- %t — время запроса к серверу и его часовой пояс;
- %r — тип и содержимое запроса;
- %s — код состояния HTTP;
- %b — количество байт информации, отданных сервером;
- %{Referer} — URL-источник запроса;
- %{User-Agent} — HTTP-заголовок.
Еще один пример чтения логов можно посмотреть в статье «Как читать логи сервера».
Опытные веб-мастера для сбора и чтения лог-файлов используют программы-анализаторы. Они позволяют читать логи сервера без значительных временных затрат. Вот некоторые из наиболее востребованных:
- Analog. Один из самых популярных анализаторов, что во многом объясняется высокой скоростью обработки данных и экономным расходованием системных ресурсов. Хорошо справляется с объемными записями, совместим с любыми ОС.
- Weblog Expert. Программа доступна в трех вариациях: Lite (бесплатная версия), Professional и Standard (платные релизы). Версии отличаются функциональными возможностями, но каждая позволяет анализировать лог-файлы и создает отчеты в PDF и HTML.
- SpyLOG Flexolyzer. Простой аналитический инструмент, позволяющий получать отчеты с высокой степенью детализации. Интегрируется c системой статистики SpyLOG, позволяет решать задачи любой сложности.
Логи сервера с ошибками error.log
Это журнал с информацией об ошибках на сайте. В нем можно посмотреть, какие страницы отсутствуют, откуда пришел пользователь с конкретным запросом, имеются ли «битые» ссылки, другие недочеты, включая те, которые не удалось классифицировать. Используется для выявления багов и погрешностей в коде.
Каждая ошибка в логе сервера error.log отображается с новой строки. Идентифицировав и устранив ее, программист сможет наладить работу сайта. Используя журнал, можно выявить и слабые места веб-платформы. Это простой и удобный инструмент анализа, которым должен уметь пользоваться каждый веб-мастер, системный администратор и программист.
13.04.2021
Дата обновления: 02.03.2022
Если в работе сервера, компьютера или программного обеспечения возникла неизвестная ошибка, в первую очередь смотрят логи. Лог — текстовый файл с информацией о действиях программного обеспечения или пользователей, который хранится на компьютере или сервере. Это хронология событий и их источников, ошибок и причин, по которым они произошли. Читать и анализировать логи можно с помощью специального ПО.
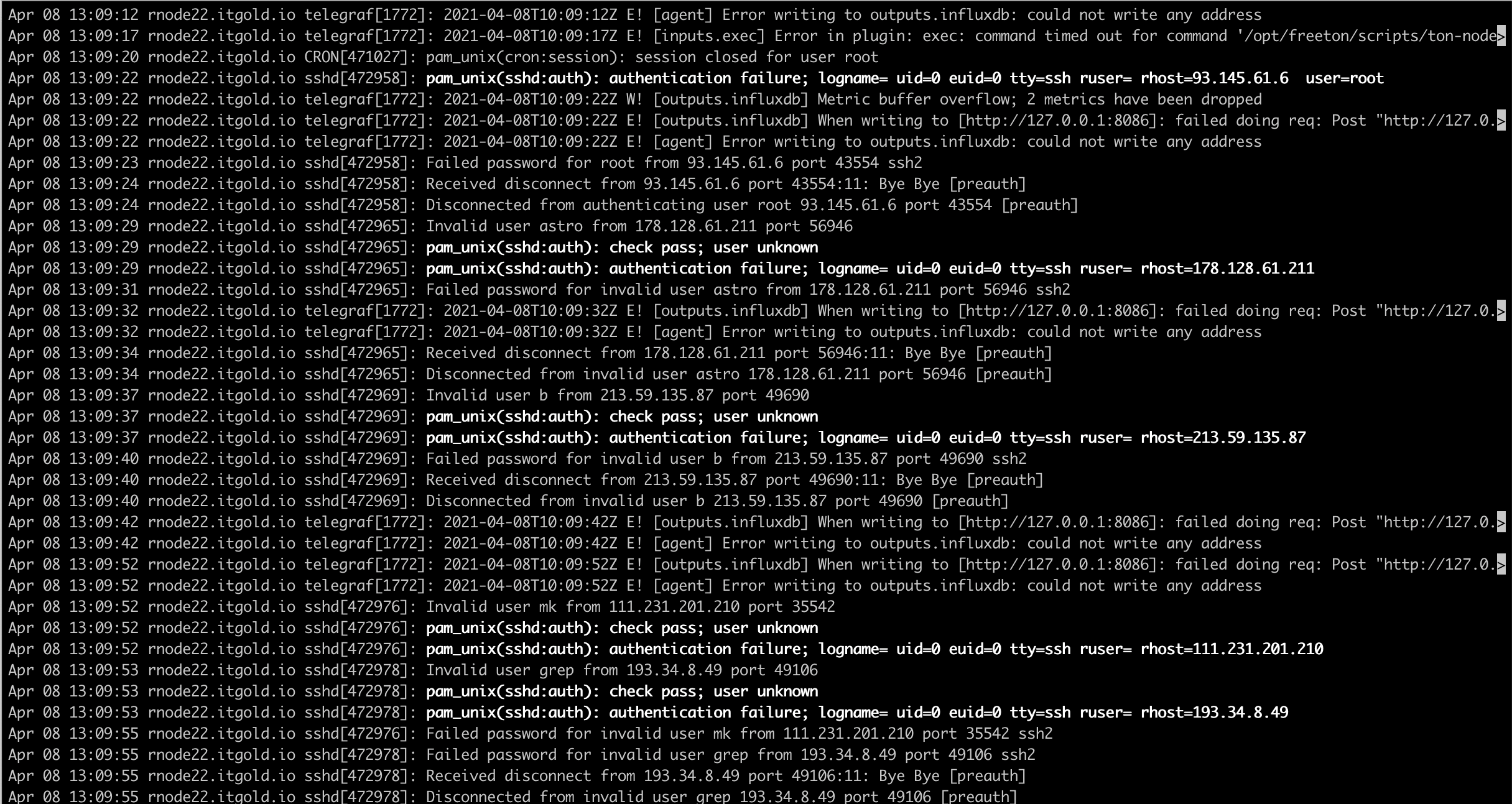
Логирование: что это и где применяется
Логированием называют запись логов. Оно позволяет ответить на вопросы, что происходило, когда и при каких обстоятельствах. Без логов сложно понять, из-за чего появляется ошибка, если она возникает периодически и только при определенных условиях. Чтобы облегчить задачу администраторам и программистам, в лог записывается информация не только об ошибках, но и о причинах их возникновения.
После перехода в продакшен, работу приложения нужно постоянно мониторить, чтобы предотвращать и быстро реагировать на потенциальные ЧП. Анализ логов — один из базовых инструментов в работе ИТ-специалистов. Он помогает обнаружить источники многих проблем, выявить конфликты в конфигурационных файлах, отследить события, связанные с ИБ. А главное, благодаря логам найденные ошибки можно быстро исправить. Поэтому логирование так важно при отладке программ, поиске источников проблем с прикладным программным обеспечением и базами данных.
Логи должны записываться во время работы каждого ИТ-компонента.
Вот несколько типичных случаев, в которых применяются логи:
- Администратор ищет причины возникновения технических проблем, сбоев в устройства или операционной системы и недоступности сайта.
- Разработчик проводит дебаг, то есть ищет, локализует и устраняет ошибки.
- Seo-специалисты собирают статистику посещаемости, оценивают качество целевого трафика.
- Администратор интернет-магазина отслеживает историю взаимодействия с платежными системами и данные об изменениях в заказах.
Типы логов
Существуют разные уровни и разные подробности логирования. Когда ошибку сложно воспроизвести, используют максимально подробные логи; если это не требуется, собирают только ключевую информацию. Для работы с логами и поиском информации в огромных текстовых данных используют специализированные инструменты.
Для удобной работы с логами их делят на типы. Это помогает быстрее находить нужные и выбирать правильные инструменты для работы с ними. Например, выделяют:
- системные логи, то есть те, которые связаны с системными событиями;
- серверные логи, регистрирующие обращения к серверу и возникшие при этом ошибки;
- логи баз данных, фиксирующие запросы к базам данных;
- почтовые логи, относящиеся к входящим/исходящим письмам и отслеживающие ошибки, из-за которых письма не были доставлены;
- логи авторизации;
- логи аутентификации;
- логи приложений, установленных на этих операционных системах.
Также логи можно типизировать по степени их важности:
- Fatal/critical error — то, что нужно срочно исправить.
- Not critical error — ошибки, которые не влияют на пользователя.
- Warning — предупреждения, то, на что нужно обратить внимание.
- Initial information — информация о вызовах API сервиса, запросах в БД, вызовах других сервисов.
Где ITGLOBAL.COM использует логирование
Специалисты ITGLOBAL.COM настраивают автоматический сбор, хранение и обработку логов в облачном хранилище. Облако позволяет воспроизвести события на целевой системе даже при ее полном отказе.
Поясним на примере. Допустим, файловая система одной из виртуальных машин повредилась и все данные на сервере были уничтожены. Инженеры получают уведомление об этом инциденте от системы мониторинга и восстанавливают работоспособность сервера через бэкапы. После этого они анализируют логи, которые сохранились благодаря удаленной системе хранения. Они похожи на черный ящик самолета, так как с их помощью специалисты восстанавливают последовательность событий при инциденте, делают выводы и вырабатывают решения, которые предотвратят появление таких инцидентов в будущем.
Также инженеры ITGLOBAL.COM используют логи для анализа действий пользователей. Они в любой момент могут восстановить, кто и когда совершал определенные действия внутри системы. Для этого специалисты используют инструменты, которые автоматически контролируют базовые события, касающиеся безопасности. Например, если в субботу ночью появится учетная запись с правами суперпользователя, система сразу зарегистрирует это событие и пришлет уведомление. Инженеры уточнят легитимность новой записи, чтобы предотвратить попытку несанкционированного доступа.
Инструменты
Сбор, хранение и анализ логов выполняется с помощью специальных инструментов. Расскажем, какие из них используют специалисты ITGLOBAL.COM.
Elasticsearch, Logstash и Kibana
Логи всех информационных систем, подключенных к услуге Managed IT, хранятся в распределенном хранилище на базе решения ELK (Elasticsearch, Logstash и Kibana). Механизм сбора логов выглядит так: Logstash собирает логи и переносит их в хранилище, Elasticsearch помогает найти нужные строки в этих логах, а Kibana визуализирует их. Все три компонента разработаны на основе открытого кода, благодаря чему их можно модифицировать под потребности компании.
- Logstash — приложение для работы с большими объемами данных, собирает информацию из разных источников и переводит ее в удобный формат.
- Elasticsearch — система для поиска информации. Помогает быстро найти нужные строки в файлах хранения.
- Kibana — плагин визуализации данных и аналитики в Elasticsearch. Помогает обрабатывать информацию, находить в ней закономерности и слабые места.
Wazuh
Решение с открытым кодом для поиска логов, коррелирующих с моделями угроз информационной безопасности. С его помощью специалисты ITGLOBAL.COM мониторят целостность ИТ-систем и оперативно реагируют на инциденты.
Wazuh помогает:
- обнаружить скрытые процессы программ, которые используют уязвимости в ПО для обхода антивирусных систем;
- автоматически блокировать сетевую атаку, останавливать вредоносные процессы и файлы, зараженные вирусами.
Почему логирование нужно каждой компании
Логирование — еще один способ эффективно контролировать состояние инфраструктуры. В ITGLOBAL.COM оно входит в пакет услуг Managed IT. Вместе с сервисами мониторинга логирование существенно экономит время инженеров при расследовании тех или иных инцидентов. А главное, с помощью анализа логов можно предотвратить инциденты в будущем.
Компании, которые используют логирование в рамках услуги Managed IT, уменьшают общее количество инцидентов и получают принципиально другой уровень контроля над инфраструктурой.
Также сервис удобен для разработчиков, которые с помощью простых интерфейсов могут в режиме реального времени отслеживать работу своих приложений.
Как читать логи сервера и что это такое?
Логи – это инструмент, при помощи которого можно отслеживать рабочий процесс сервера или сайта. Поэтому знать, как читать логи это полезное умение для выявления сбоев в работе ПО, быстрого и результативного реагирования на другие проблемы (выявление злонамеренных действий), эффективного анализа рабочий процесс, противодействия DDoS-атакам.
Содержание:
- Что такое логи и зачем они нужны?
- Типы логов и где их найти
- Какая информация хранится в логах и как ее интерпретировать
Что такое логи и зачем они нужны
Логи (log) – это специальные текстовые файлы, в которых в хронологическом порядке фиксируется информация обо всех действиях программы или пользователей. Проще говоря, это журнал регистрации всех событий происходивших в системе:
- ошибки сервера (сбои), возникающие при обращении к некоторым функциям сайта или задачам;
- данные о доступе – запись о подключении (или попытке входа) каждого пользователя, откуда и как он попал на сайт;
- прочие, записывающие информацию о работе компонентов сервера.

Логи доступа указывают на уязвимые места сайта (в случае взлома), помогают собирать статистику посещаемости, узнавать откуда проводились запросы и какие ресурсы ссылаются на этот сайт, оценивать популярность страниц. По файлам ошибок проще найти источник проблемы и оперативно устранить баги и сбои. Журналы сервера (server logs) облегчают контроль рабочего процесса серверной машины.
В файлах логов записывается и отслеживается история работы всего программного комплекса. Поэтому специалисты рекомендуют периодически просматривать их, даже если никаких подозрительных моментов не произошло. И тем более немедленно обратиться к ним, если резко возросло количество ошибок, посыпался спам или заметно увеличилась нагрузка на сервер.
Типы логов и где их найти
Месторасположение логов зависит от используемого ПО, настроек, прописанного админом пути. Чаще всего server logs сохраняются в var/log/. Однако, не все сервисы помещают файлы регистрации в эту директорию. В любом случае, можно уточнить такую информацию у веб-хостера.
У дистрибутивов Linux CentOS или Fedora логи серверной машины лежат в /var/log/. Там можно найти:
- файл регистрации ошибок error.log;
- данные о доступах log;
- основной системный журнал syslog;
- файл загрузки ОС dmesg;
- журнал nginx.
Лог ошибок MySQL ($hostname.err) хранится в /var/lib/mysql/. Для Debian или Ubuntu местоположение логов аналогично, за исключением log file ошибок MySQL: /mysql/error.log. А также – логи веб сервера Apache сохраняются по пути /var/log/apache2.
У ОС Windows дружной метод структурирования log-файлов. События делятся на несколько уровней:
- предупреждение – Warning;
- подробности (System и EventData);
- ошибка – Error;
- сведения – Information;
- критический – Critical.
Их можно отсортировать или отфильтровать и выбрать необходимое.

Запуск и отключение логов осуществляется с административной панели. Как правило, доступ через раздел «журнал» или «логи». При этом стоит учитывать, что файлы не сохраняются годами. Поэтому, при необходимости посмотреть log, это нужно сделать своевременно.
Какая информация хранится в логах и как ее интерпретировать?
Для большинства пользователей содержимое log-файлов это бессмысленный набор символов. Как читать логи, чтобы понять, что в них зашифровано?
Строка access.log сервера содержит:
- адрес ресурса;
- IP-адрес пользователя;
- дата и время посещения, часовой пояс;
- GET/POST – запрос на получение или отправку данных;
- к какой странице обращались;
- протокол пользователя (как зашел на ресурс);
- код отклика сервера;
- число переданных байтов;
- информация о посетителе (боте) – устройство, ОС, другие данные.
Как правило, такой информации достаточно, чтобы проанализировать ситуацию и сделать нужные выводы. Например, заблокировать бота, который создал чрезмерную нагрузку на сайт.
Файл ошибок (error.log) регистрирует моменты, когда что-то пошло не так. Из них можно узнать:
- когда произошла ошибка (дата, время), ее тип и IP-адрес пользователя;
- тип события;
- где находится сам файл и строка с сообщением
Конечно, даже после расшифровки, данных логов еще нужно проанализировать. Для этого существует различное ПО, которое помогает отрабатывать данные из логов – Weblog Expert, WebAlyzer, Analog, Webtrends, Awstats, SpyLOG Flexolyzer и другие платные и бесплатные программы.
Известно, что программисты проводят много времени, отлаживая свои программы, пытаясь разобраться, почему они не работают — или работают неправильно. Когда говорят про отладку, обычно подразумевают либо отладочную печать, либо использование специальных программ – дебагеров. С их помощью отслеживается выполнение кода по шагам, во время которого видно, как меняется содержимое переменных. Эти способы хорошо работают в небольших программах, но в реальных приложениях быстро становятся неэффективными.
- Сложность реальных приложений
- Логирование
- Уровни логирования
- Ротация логов
Сложность реальных приложений
Возьмем для примера типичный сайт. Что он в себя включает?
- DNS. Система трансляции имени сайта в ip-адрес сервера.
- Веб-сервер. Программа, обслуживающая входящие запросы, перенаправляет их в код приложения и забирает от приложения данные для пользователей.
- Физический сервер (или виртуальный) с его окружением. Включает в себя операционную систему, установленные и запущенные обслуживающие программы, например, мониторинг.
- База данных. Внешнее хранилище, с которым связывается код приложения и обменивается информацией.
- Само приложение. Помимо кода, который пишут программисты, приложение включает в себя сотни тысяч и миллионы строк кода сторонних библиотек. Кроме этого, код работает внутри фреймворка, у которого свои собственные правила обработки входящих запросов.
- Фронтенд часть. Код, который выполняется в браузере пользователя. И системы сборки для разработки, например, Webpack.
И это только самый простой случай. Реальность же значительно сложнее: множество разноплановых серверов, системы кеширования (ускорения доступа), асинхронный код, очереди, внешние сервисы, облачные сервисы. Все это выглядит как многослойный пирог, внутри которого где-то работает написанный нами код. И этот код составляет лишь небольшую часть всего происходящего. Как в такой ситуации понять, на каком этапе был сбой, или все пошло не по плану? Для этого, как минимум, нужно определить, в каком слое произошла ошибка. Но даже это не самое сложное. Об ошибках в работающем приложении узнают не сразу, а уже потом, — когда ошибка случилась и, иногда, больше не воспроизводится.
Логирование
И для всего этого многообразия систем существует единое решение — логирование. В простейшем случае логирование сводится к файлу на диске, куда разные программы записывают (логируют) свои действия во время работы. Такой файл называют логом или журналом. Как правило, внутри лога одна строчка соответствует одному действию.
# Формат: ip-address / date / HTTP-method / uri / response code / body size
173.245.52.110 - [19/Jan/2021:01:54:20 +0000] "GET /my HTTP/1.1" 200 46018
108.162.219.13 - [19/Jan/2021:01:54:20 +0000] "GET /sockjs-node/244/gdt1vvwa/websocket HTTP/1.1" 0 0
162.158.62.12 - [19/Jan/2021:01:54:20 +0000] "GET /packs/css/application.css HTTP/1.1" 304 0
162.158.62.84 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/runtime-eb0a99abbe8cf813f110.js HTTP/1.1" 304 0
108.162.219.111 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/application-2cba5619945c4e5946f1.js HTTP/1.1" 304 0
108.162.219.21 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/0564a7b5d773bab52e53.js HTTP/1.1" 304 0
108.162.219.243 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/6fb7e908211839fac06e.js HTTP/1.1" 304 0
Выше небольшой кусок лога веб-сервера Хекслета. Из него видно ip-адрес, с которого выполнялся запрос на страницу и какие ресурсы загружались, метод HTTP, ответ бекенда (кода) и размер тела ответа в HTTP. Очень важно наличие даты. Благодаря ей всегда можно найти лог за конкретный период, например на то время, когда возникла ошибка. Для этого логи грепают:
# Выведет 4 минуты логов за 31 марта 2020 года с 19:31 по 19:35
grep "31/Mar/2020:19:3[1-5]" access.log
Когда программисты только начинают свой путь, они, часто не зная причину ошибки, опускают руки и говорят «я не знаю, что случилось, и что делать». Опытный же разработчик всегда первым делом говорит «а что в логах?». Анализировать логи — один из базовых навыков в разработке. В любой непонятной ситуации нужно смотреть логи. Логи пишут все программы без исключения, но делают это по-разному и в разные места. Чтобы точно узнать, куда и как, нужно идти в документацию конкретной программы и читать соответствующий раздел документации. Вот несколько примеров:
- Ruby On Rails (Ruby)
- Django (Python)
- Laravel (PHP)
- Spring Boot (Java)
- Fastify (Node.js)
Многие программы логируют прямо в консоль, например Webpack показывает процесс и результаты сборки:
# Сюда же выводятся ошибки, если они были
「wds」: Project is running at http://hexletdev4.com/
「wds」: webpack output is served from /packs/
「wds」: Content not from webpack is served from /root/hexlet/public/packs
「wds」: 404s will fallback to /index.html
「wdm」: assets by chunk 10.8 MiB (auxiliary name: application) 115 assets
sets by path js/ 13.8 MiB
assets by path js/*.js 13.8 MiB 52 assets
assets by path js/pages/*.js 5.1 KiB
asset js/pages/da223d3affe56711f31f.js 2.6 KiB [emitted] [immutable] (name: pages/my_learning) 1 related asset
asset js/pages/04adacfdd660803b19f1.js 2.5 KiB [emitted] [immutable] (name: pages/referral) 1 related asset
sets by chunk 9.14 KiB (auxiliary id hint: vendors)
Во фронтенде файлов нет, поэтому логируют либо прямо в консоль, либо к себе в бекенды (что сложно), либо в специализированные сервисы, такие как LogRocket.
Уровни логирования
Чем больше информации выводится в логах, тем лучше и проще отладка, но когда данных слишком много, то в них тяжело искать нужное. В особо сложных случаях логи могут генерироваться с огромной скоростью и в гигантских размерах. Работать в такой ситуации нелегко. Чтобы как-то сгладить ситуацию, системы логирования вводят разные уровни. Обычно это:
- debug
- info
- warning
- error
Поддержка уровней осуществляется двумя способами. Во-первых, внутри самой программы расставляют вызовы библиотеки логирования в соответствии с уровнями. Если произошла ошибка, то логируем как error, если это отладочная информация, которая не нужна в обычной ситуации, то уровень debug.
// Пример логирования внутри программы
// Логер: https://github.com/pinojs/pino
import buildLogger from 'pino';
const logger = buildLogger(/* возможная конфигурация */);
logger.info('тут что то полезное');
Во-вторых, во время запуска программы указывается уровень логирования, необходимый в конкретной ситуации. По умолчанию используется уровень info, который используется для описания каких-то ключевых и важных вещей. При таком уровне будут выводиться и warning, и error. Если поставить уровень error, то будут выводиться только ошибки. А если debug, то мы получим лог, максимально наполненный данными. Обычно debug приводит к многократному росту выводимой информации.
Уровни логирования, обычно, выставляются через переменную окружения во время запуска программы. Например, так:
# https://github.com/fastify/fastify-cli#options
FASTIFY_LOG_LEVEL=debug fastify-server.js
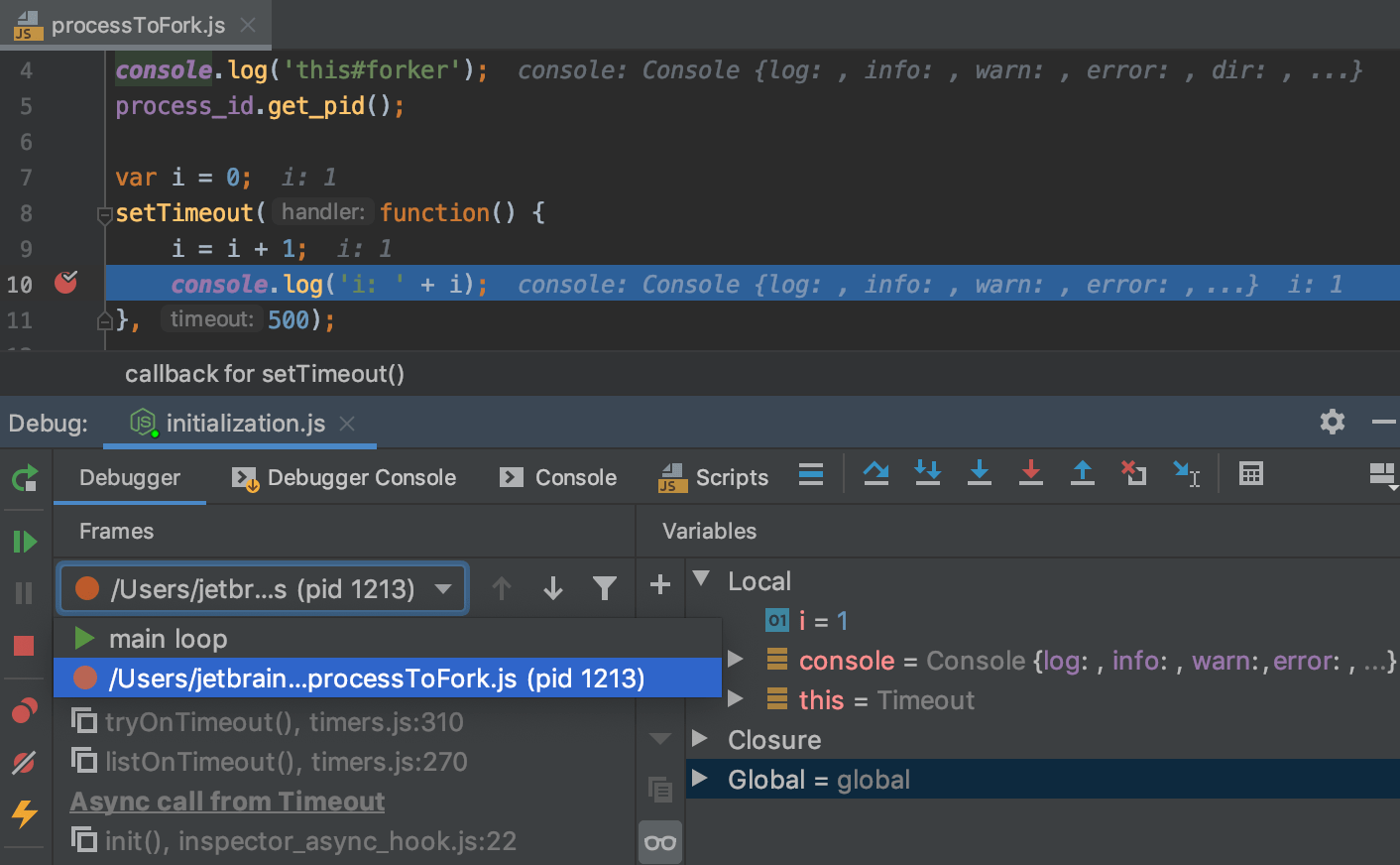
Существует и другой подход, основанный не на уровнях, а на пространствах имен. Этот подход получил широкое распространение в JS-среде, и является там основным. Фактически, он построен вокруг одной единственной библиотеки debug для логирования, которой пронизаны практически все JavaScript-библиотеки как на фронтенде, так и на бекенде.
Принцип работы здесь такой. Под нужную ситуацию создается специализированная функция логирования с указанием пространства имен, которая затем используется для всех событий одного процесса. В итоге библиотека позволяет легко отфильтровать только нужные записи, соответствующие нужному пространству.
import debug from 'debug';
// Пространство имен http
const logHttp = debug('http');
const logSomethingElse = debug('another-namespace');
// Где-то в коде
logHttp(/* информация о http запросе */);
Запуск с нужным пространством:
DEBUG=http server.js
Ротация логов
Со временем количество логов становится большим, и с ними нужно что-то делать. Для этого используется ротация логов. Иногда за это отвечает сама программа, но чаще — внешнее приложение, задачей которого является чистка. Эта программа по необходимости разбивает логи на более мелкие файлы, сжимает, перемещает и, если нужно, удаляет. Подобная система встроена в любую операционную систему для работы с логами самой системы и внешних программ, которые могут встраиваться в нее.
С веб-сайтами все еще сложнее. Даже на небольших проектах используется несколько серверов, на каждом из которых свои логи. А в крупных проектах тысячи серверов. Для управления такими системами созданы специализированные программы, которые следят за логами на всех машинах, скачивают их, складывают в заточенные под логи базы данных и предоставляют удобный способ поиска по ним.
Здесь тоже есть несколько путей. Можно воспользоваться готовыми решениями, такими как DataDog Logging, либо устанавливать и настраивать все самостоятельно через, например, ELK Stack
13.04.2021
Дата обновления: 02.03.2022
Если в работе сервера, компьютера или программного обеспечения возникла неизвестная ошибка, в первую очередь смотрят логи. Лог — текстовый файл с информацией о действиях программного обеспечения или пользователей, который хранится на компьютере или сервере. Это хронология событий и их источников, ошибок и причин, по которым они произошли. Читать и анализировать логи можно с помощью специального ПО.
Логирование: что это и где применяется
Логированием называют запись логов. Оно позволяет ответить на вопросы, что происходило, когда и при каких обстоятельствах. Без логов сложно понять, из-за чего появляется ошибка, если она возникает периодически и только при определенных условиях. Чтобы облегчить задачу администраторам и программистам, в лог записывается информация не только об ошибках, но и о причинах их возникновения.
После перехода в продакшен, работу приложения нужно постоянно мониторить, чтобы предотвращать и быстро реагировать на потенциальные ЧП. Анализ логов — один из базовых инструментов в работе ИТ-специалистов. Он помогает обнаружить источники многих проблем, выявить конфликты в конфигурационных файлах, отследить события, связанные с ИБ. А главное, благодаря логам найденные ошибки можно быстро исправить. Поэтому логирование так важно при отладке программ, поиске источников проблем с прикладным программным обеспечением и базами данных.
Логи должны записываться во время работы каждого ИТ-компонента.
Вот несколько типичных случаев, в которых применяются логи:
- Администратор ищет причины возникновения технических проблем, сбоев в устройства или операционной системы и недоступности сайта.
- Разработчик проводит дебаг, то есть ищет, локализует и устраняет ошибки.
- Seo-специалисты собирают статистику посещаемости, оценивают качество целевого трафика.
- Администратор интернет-магазина отслеживает историю взаимодействия с платежными системами и данные об изменениях в заказах.
Типы логов
Существуют разные уровни и разные подробности логирования. Когда ошибку сложно воспроизвести, используют максимально подробные логи; если это не требуется, собирают только ключевую информацию. Для работы с логами и поиском информации в огромных текстовых данных используют специализированные инструменты.
Для удобной работы с логами их делят на типы. Это помогает быстрее находить нужные и выбирать правильные инструменты для работы с ними. Например, выделяют:
- системные логи, то есть те, которые связаны с системными событиями;
- серверные логи, регистрирующие обращения к серверу и возникшие при этом ошибки;
- логи баз данных, фиксирующие запросы к базам данных;
- почтовые логи, относящиеся к входящим/исходящим письмам и отслеживающие ошибки, из-за которых письма не были доставлены;
- логи авторизации;
- логи аутентификации;
- логи приложений, установленных на этих операционных системах.
Также логи можно типизировать по степени их важности:
- Fatal/critical error — то, что нужно срочно исправить.
- Not critical error — ошибки, которые не влияют на пользователя.
- Warning — предупреждения, то, на что нужно обратить внимание.
- Initial information — информация о вызовах API сервиса, запросах в БД, вызовах других сервисов.
Где ITGLOBAL.COM использует логирование
Специалисты ITGLOBAL.COM настраивают автоматический сбор, хранение и обработку логов в облачном хранилище. Облако позволяет воспроизвести события на целевой системе даже при ее полном отказе.
Поясним на примере. Допустим, файловая система одной из виртуальных машин повредилась и все данные на сервере были уничтожены. Инженеры получают уведомление об этом инциденте от системы мониторинга и восстанавливают работоспособность сервера через бэкапы. После этого они анализируют логи, которые сохранились благодаря удаленной системе хранения. Они похожи на черный ящик самолета, так как с их помощью специалисты восстанавливают последовательность событий при инциденте, делают выводы и вырабатывают решения, которые предотвратят появление таких инцидентов в будущем.
Также инженеры ITGLOBAL.COM используют логи для анализа действий пользователей. Они в любой момент могут восстановить, кто и когда совершал определенные действия внутри системы. Для этого специалисты используют инструменты, которые автоматически контролируют базовые события, касающиеся безопасности. Например, если в субботу ночью появится учетная запись с правами суперпользователя, система сразу зарегистрирует это событие и пришлет уведомление. Инженеры уточнят легитимность новой записи, чтобы предотвратить попытку несанкционированного доступа.
Инструменты
Сбор, хранение и анализ логов выполняется с помощью специальных инструментов. Расскажем, какие из них используют специалисты ITGLOBAL.COM.
Elasticsearch, Logstash и Kibana
Логи всех информационных систем, подключенных к услуге Managed IT, хранятся в распределенном хранилище на базе решения ELK (Elasticsearch, Logstash и Kibana). Механизм сбора логов выглядит так: Logstash собирает логи и переносит их в хранилище, Elasticsearch помогает найти нужные строки в этих логах, а Kibana визуализирует их. Все три компонента разработаны на основе открытого кода, благодаря чему их можно модифицировать под потребности компании.
- Logstash — приложение для работы с большими объемами данных, собирает информацию из разных источников и переводит ее в удобный формат.
- Elasticsearch — система для поиска информации. Помогает быстро найти нужные строки в файлах хранения.
- Kibana — плагин визуализации данных и аналитики в Elasticsearch. Помогает обрабатывать информацию, находить в ней закономерности и слабые места.
Wazuh
Решение с открытым кодом для поиска логов, коррелирующих с моделями угроз информационной безопасности. С его помощью специалисты ITGLOBAL.COM мониторят целостность ИТ-систем и оперативно реагируют на инциденты.
Wazuh помогает:
- обнаружить скрытые процессы программ, которые используют уязвимости в ПО для обхода антивирусных систем;
- автоматически блокировать сетевую атаку, останавливать вредоносные процессы и файлы, зараженные вирусами.
Почему логирование нужно каждой компании
Логирование — еще один способ эффективно контролировать состояние инфраструктуры. В ITGLOBAL.COM оно входит в пакет услуг Managed IT. Вместе с сервисами мониторинга логирование существенно экономит время инженеров при расследовании тех или иных инцидентов. А главное, с помощью анализа логов можно предотвратить инциденты в будущем.
Компании, которые используют логирование в рамках услуги Managed IT, уменьшают общее количество инцидентов и получают принципиально другой уровень контроля над инфраструктурой.
Также сервис удобен для разработчиков, которые с помощью простых интерфейсов могут в режиме реального времени отслеживать работу своих приложений.
Написали программу с применением нейросети, но она выдает кучу ошибок? Где потом искать эти ошибки? Как структурировать полученную информацию?
Помочь с поиском ошибок может логирование — группа методов для сбора и сохранения информации о работе программы. Всю интересующую нас информацию мы можем записывать в текстовые файлы и потом их обрабатывать. К примеру, вот таким образом в случае деления на 0:
Тогда консоль нам покажет следующее:
А в логе с файлом увидим:
Конечно, реализовать самостоятельно такой способ — просто, и многие этим пользуются. Но у него тоже есть минус: если проект большой, надо не забывать придерживаться определенного формата их заполнения.
Но Python же один из самых дружелюбных языков.) Разработчики уже подумали о нас и создали хорошую библиотеку «logging».
Для работы с ней нам необходимо импортировать библиотеку logging и указать основные параметры. Всего параметров для настройки 6.
Так же существует 5 уровней логирования информации: от DEBUG (отладка) до critical (критичные ошибки).
На этом можно закончить с теорией, и перейдем к практике.
Теперь мы будем логировать нашу функцию деления уже с учетом модуля logging и попытаемся собрать максимум информации о ее работе. Давайте рассмотрим код нашего простенького скрипта, но уже с учетом использования логов.
Как мы видим он немного увеличился в размерах, но при этом, для записи также использует лишь одна строчка.
В начале мы создаем переменную, в которой указываем идентификатор лога. Это нужно для того, к примеру, чтобы мы не путались из какого скрипта записываем лог. Это делается строкой —
logger = logging.getLogger(‘Stat’) —
После – мы указываем уровень лога и имя файла, в который мы будем его записывать:
logger.setLevel(logging.INFO)
file_name = logging.FileHandler(‘data.log’)
В конце нам надо создать формат записи, в котором мы укажем: время записи, имя скрипта, названия уровня и само сообщение. Остается только применить данный формат для нашего «логгера».
format_log = logging.Formatter(‘%(asctime)s — %(name)s — %(levelname)s — %(message)s’)
file_name.setFormatter(format_log)
logger.addHandler(file_name)
Вот, на этом и все) В дальнейшем мы можем использовать наш логгер простым вызовом logger.info(‘Division’) или в случае описания ошибки logger.error(error_text). По окончанию работы скрипта данные будут сохранены в файл ‘data.log’.
А теперь посмотрим, что мы получили в логе:
Запись со временем, уровнем и сообщением! Такой лог, во-первых – удобно читать, а, во-вторых – удобно обрабатывать!
Использование модуля «logger» на маленьких программах, может, и не заметно, а вот на больших польза становится очевидна. Особенно, если эти логи в дальнейшем нуждаются в обработке, например, для Process Mining-а.
Вот таким простым способом мы с вами научились делать понятную и удобную запись логов в нашем скрипте!
Логирование в Java
Введение
Логирование(logging) — это процесс записи информации о событиях, происходящих в рамках какого-либо процесса с некоторым объектом. Запись может проводиться в файл регистрации или в базу данных.
Слово
log, на самом деле, имеет множество значений, например протокол или журнал.
Однако обычно все говорят именно лог и производные от него: логирование и логировать.Хотя правильнее было бы говорить наверное журналирование/протоколирование и вести журнал/протокол соответственно.
Но так никто никогда не говорит, конечно ¯(ツ)/¯
По сути логирование — это то, что позволяет следить за ходом выполнения вашего приложения, вашего кода.
При работе приложения надо понимать, что вообще происходит внутри, особенно при разборе ошибок и инцидентов. В этом как раз и помогают логи — это как запись черного ящика на самолетах.
Нет информации о происходящих событий в приложении — мы ничего не знаем о том, что происходит. И если такое поведение может устраивать в случае, когда все идеально работает (да и то сомнительно), то во всех остальных случаях такое поведение категорически не устраивает никого.
Поэтому «логи всякие нужны, логи всякие важны».
Пришла пора сформулировать требования — чего вообще хотелось бы от логера.
Требования
Еще одним важным вопросом на который надо ответить — это что логировать.
Работа приложения — это происходящие в нем события, которые в свою очередь могут быть классифицированы на:
- события, связанные с бизнес-логикой
- события, связанные с безопасностью приложения
- и системные события, связанные с уже конкретикой реализации — вызовов ОС, использования библиотек, фреймворков и т.д.
Все ли нужно логировать?
Если вы вдруг залогируете в общий файл-лога пароль и логин пользователя, то никто такому рад не будет, что подводит нас к мысли, что логировать надо тоже с умом.
Опять же, если логировать все подряд, то размеры таких логов будут не просто большими, они будут огромными. И у вас возникнет уже другая проблема — где все это хранить.
Добавим сюда еще и то, что логирование — это тоже работа, а значит процессорное время. И чем больше логов мы пишем — тем больше процессорного времени тратится на это, а в ситуации, когда все работает хорошо такое чрезмерное логирование только тормозит.
С другой стороны, при возникновении проблем, особенно спорадических ошибок, чем больше у вас информации — тем лучше.
Т.е возникает требование управления информацией, которая нам нужна в данный момент, а также форматом ее вывода.
При этом, логично, что изменения этого формата и того, что мы хотим видеть в логе не должны требовать перекомпиляции всего проекта или изменения кода.
Уровни логирования
Уровень логирования — это разделение событий по приоритетам, по степени важности. Например, error — пишем ошибки, debug — пишем более подробно в лог и т.д.
| Уровень логирования | Описание |
|---|---|
| ALL | Все сообщения |
| TRACE | Сообщение для более точной отладки |
| DEBUG | Дебаг-сообщение, для отладки |
| INFO | Обычное сообщение |
| WARN | Предупреждение, не фатально, но что-то не идеально |
| ERROR | Ошибка |
| FATAL | Фатальная ошибка, дело совсем плохо |
| OFF | Без сообщения |
Если проиллюстрировать это:

Принципы и понятия
В основе большинства библиотек логирования лежат три понятия: logger, appender и layout.
Это наиболее распространенные и устоявшиеся понятия, можно сказать, что это — стандарт.
Logger
Логер — это объект, область ответственности которого — вывод данных в лог и управление уровнем (детализацией) этого вывода.
Логер создается с помощью фабрики и на этапе создания ему присваивается имя. Имя может быть любым, но по стандарту имя должно быть сопряжено с именем класса, в котором вы собираетесь что-то логировать:
Logger logger = LoggerFactory.getLogger(SomeClass.class.getName());
Это дает нам имя логера в виде: ru.aarexer.example.SomeClass.
Почему так рекомендуется делать?
Потому что важным свойством логгеров является то, что они организованы иерархично. Каждый логгер имеет имя, описывающее иерархию, к которой он принадлежит. Разделитель – точка. Принцип полностью аналогичен формированию имени пакета в Java.
Получается выстраивается следующая иерархия логеров:
root <- ru <- aarexer <- example <- SomeClass
И каждому логеру можно выставить свой уровень. Установленный логгеру уровень вывода распространяется на все его дочерние логгеры, для которых явно не выставлен уровень.
При этом во главе иерархии логеров всегда стоит некотрый дефолтный рутовый(корневой) логер.
Поэтому у всех логеров будет уровень логирования, даже если явно мы не прописали для ru.aarexer.example.SomeClass его, то он унаследуется от рутового.
Вопрос:
Мы установили рутовый уровень в INFO, а ru.aarexer в DEBUG, остальным в иерархии уровень не назначен, т.е:
| Логер | Назначенный уровень |
|---|---|
| root | INFO |
| ru | Не назначен |
| ru.aarexer | DEBUG |
| ru.aarexer.example | Не назначен |
Какой у какого логера будет уровень логирования?
Ответ:
Вспоминаем, что, если уровень логирования не назначен для логера, то он унаследует его от родительского, смотрим на иерархию:
root <- ru <- aarexer <- example
И получаем ответ:
| Logger | Назначенный уровень | Уровень, который будет |
|---|---|---|
| root | Все сообщения | INFO |
| ru | Не назначен | INFO |
| ru.aarexer | DEBUG | DEBUG |
| ru.aarexer.example | Не назначен | DEBUG |
Подход с иерархией логеров очень гибкий – можно для всех выставить требуемый уровень, например, ERROR, а для необходимых логеров его менять, причем как в сторону понижения, так и в сторону повышения уровня.
Задача логера одна — это вызывать событие, которое приведет к логированию.
logger.info("Application started"); logger.debug("Or not");
Это событие по сути состоит из двух полей:
message = "Application started" level = Level.Info
Appender
Аппендер – это та точка, куда события приходят в конечном итоге.
Это может быть файл, БД, консоль, сокет и т.д.
Здесь нас никто не ограничивает — можно написать свой аппендер, который пишет сообщения куда-угодно.
Получается у нас есть две точки, первая — это логгер, это начало пути, вторая — аппендер, это уже конечная точка.
Логеры и аппендеры связаны в отношении many-to-many.
У одного логгера может быть несколько аппендеров, а к одному аппендеру может быть привязано несколько логгеров.
Логеры при этому наследуют от родительских не только уровни логирования, но и аппендеры.
Например, если к root-логгеру привязан аппендер A1, а к логгеру ru.aarexer – A2, то вывод в логгер ru.aarexer попадет в A2 и A1, а вывод в ru – только в A1.
Вопрос:
Пусть у нас есть несколько аппендеров и логеров
| Logger | Appender |
|---|---|
| root | А1 |
| ru.aarexer | А2 |
| ru.aarexer.example.SomeClass | А3 |
В какой аппендер попадет лог-сообщение:
LoggerFactory.getLogger(SomeClass.class.getName()).info("hello");
Ответ:
У логеров есть такое свойство как additivity. По умолчанию она установлена в true.
Это говорит о том, что логер-наследник будет свои события передавать логеру-родителю.
Смотрим на иерархию:
root <- ru <- aarexer <- example
Из всего вышесказанного делаем вывод, что событие «hello» с уровнем Level.INFO попадет во все три аппендера.
Но такое наследование аппендеров можно отключить через конфигурацию, для этого стоит посмотреть в сторону выставления флага additivity="false" на логгерах.
Layout
Layout — это формат вывода данных.
Т.е как лог-сообщения будут отформативарованы, соответственно тут у каждой библиотеки свой набор доступных форматов.
Теперь пришла пора посмотреть — что вообще есть в Java.
Библиотеки логирования в Java
Ну и самым первым логером, который можно представить себе, был и есть System.out.println и System.err.println. При этом надо помнить, что err и out — это два разных потока вывода, где err вывод не буферизуется и работает быстрее, чем out.
По сути, такой логер может писать либо info-сообщения, либо error.
Однако он не отвечает всем тем требованиям, которые мы сформулировали выше, поэтому рассмотрим альтернативы.
Наиболее популярные библиотеки логирования в Java:
java.util.loggingилиJUL, является частьюJDK.Apache log4jlogback, разработанная создателямиlog4jApache log4j2, продолжениеlog4j
Это все по сути реализации логеров в Java, ну а мы бы не писали на Java, если бы не попытались сделать нечто объединяющее, чтобы иметь возможность подменять реализации, не изменяя свой код. Некоторый адаптер.
И поэтому появились еще две библиотеки:
Apache Commons Logging—JCLSimple Logging Facade for Java—SLF4J
Apache log4j
Это самая первая библиотека логирования, появилась еще в 1999 году.
Конфигурируется через xml, либо через properties.
Поддерживает большое количество способов вывода логов: от консоли и файла до записи в БД.
Также имеет поддержку обширного формата логирования: от обычного текстового вывода до html.
Именно он ввел понятие appender — кто пишет в лог, layout — форматирование.
В конфигурации задаются эти самые appender-ы и какого уровня сообщения попадают к какому appender-у.
Ввел соответствие иерархичности категорий и пакетов: например, можно логгировать все сообщения из org.hibernate и заглушить всё из org.hibernate.type.
Благодаря подобной иерархии лишнее отсекается и поэтому логер работает быстро.

Проект сейчас не развивается и по сути заброшен, с версией Java 9 уже не совместим.
Поэтому на данный момент рекомендуется использовать log4j2, о котором речь пойдет ниже.
Вклад
log4jв мир логирования настолько велик, что многие идеи были взяты в библиотеки логирования для других языков.
JUL
Зачем нужно было изобретать что-то новое, если уже был log4j мне лично не понятно, однако в рамках формирования JSR 47 взяли не log4j, так появился JUL.
Логер включен в стандарт(в рамках JSR 47) и поставляется вместе с JDK. JUL имеет следующие уровни логгирования по возрастанию: FINEST, FINER, FINE, CONFIG, INFO, WARNING, SEVERE, а так же ALL и OFF, включающий и отключающий все уровни соответственно.
Вот эти все FINEST, FINER, FINE — это три уровня логирования для отладочных сообщений, три, Карл!

Чувствуете насколько все переосложнено?
JUL очень похож на log4j, но предоставляет гораздо меньше возможностей.
Так как стандартных средств форматирования логов недостаточно, то все сводилось к тому, что писались свои. Это при том, что log4j предоставлял больший функционал, работал как минимум не медленнее и в целом себя чувствовал хорошо.
Настраивается только с помощью properties.
И вот мы уже имеем два логгера, одни библиотеки использовали log4j, другие jul и это было начало хаоса.
Именно это послужило толчком к созданию Apache Commons Logging или JCL.
JCL
Как уже было сказано, JCL — это обертка над log4j и JUL.
Уровни логгирования у JCL совпадают с log4j, а в случае взаимодействия с JUL происходит следующее сопоставление:
| JCL | JUL |
|---|---|
| ALL | Все сообщения |
| TRACE | Level.FINEST |
| DEBUG | Level.FINE |
| INFO | Level.INFO |
| WARN | Level.WARNING |
| ERROR | Level.SEVERE |
| FATAL | Level.SEVERE |
| OFF | Без сообщения |
Конфигурация JCL содержит отдельные блоки для log4j, JUL и собственной реализации.
Внутри себя она часто использует reflection, поэтому проседает по производительности и утяжеляет приложение.
JCL на данный момент почти никогда не встречается в новых проектах, это довольно старая библиотека, которая встречается разве что в старых legacy-проектах.
С уверенностю можно сказать сейчас, что в эту сторону даже смотреть не стоит. Пациент мертв.
Разработчик
JCLдаже как-то высказался в духе: Commons Logging was my fault.
| Лицензия | Apache License Version 2.0 |
| Последняя версия | 1.2 |
| Дата выпуска последней версии | июль 2014 |
Apache log4j2
Какое-то время все так и существовало, но по мере попытки усидеть на двух стульях происходит раскол и создание log4j2 — на новых идеях, использующая все модные фишки.
При этом она оказывается полностью несовместима с log4j.
Но добавили много нового, парочка из них:
- Система плагинов, которая позволяет добавить новые
appender-ы,layout-ы и т.д - Улучшения производительности.
- Появилась поддержка конфигруаций через
jsonиyaml. - Поддержка
jmx.
Полный список тут.
Правда перестали поддерживать properties конфигурации и конфигурации от log4j на xml надо было переписывать заново.
На данный момент рекомендуется использовать именно log4j2. Однако надо помнить, что Log4j 2 работает только с Java 6+.
| Лицензия | Apache License Version 2.0 |
| Последняя версия | 2.11.2 |
| Дата выпуска последней версии | февраль 2019 |
SLF4J
Появление нового логера и проблемы JCL послужили появлению slf4j — еще одной обертке.
Помимо того, что она не имеет проблем с производительностью, как у JCL, является оберткой над всеми известными логерами типа logback, log4j, jul и т.д, она предоставляет еще параметризованные сообщения:
log.debug("User {} connected from {}", user, request.getRemoteAddr());
При этом преобразование параметров в строку и окончательное форматирование лог-записи происходит только при установленном уровне DEBUG.
| Лицензия | MIT License |
| Последняя версия | 2.0.0-alpha0 |
| Дата выпуска последней версии | июнь 2019 |
Logback
logback был сделан разработчиком log4j, поэтому многие фишки перекочевали сразу, а учитывая, что разрабатывался он позже, то старческие болячки log4j обошли.
При этом, logback не является частью Apache или еще какой-то компании и независим.
Может быть сконфигурирован через xml и groovy.
Для logback:
| Лицензия | EPL/LGPL 2.1 |
| Последняя версия | 1.3.0-alpha4 |
| Дата выпуска последней версии | февраль 2018 |
На данный момент это самый мощный логер по количеству предоставляемых возможностей ‘из коробки’. Однако, из-за некоторой его обособленности и сложной лицензии многие опасаются его использования и предпочитают log4j или log4j2.
В данный момент все чаще встречаются проекты, которые выбрали связку SLF4J + Logback.
При этом в версии
1.2.3стоит явное ограничение на количество файлов, с которым умеет работать логер при ротировании — это трехзначное число, в поздней версии это ограничение убрали.
Что выбрать
Сейчас я бы выбрал связку SLF4J и logback, так как при необходимости вы сможете переключиться с logback на другую реализацию логера. При этом logback обладает всеми преимуществами slf4j, но без старых болячек и с дополнительными плюшками.
Из минусов logback — это лицензия(LGPL/EPL) и то, что он независимый. Т.е он не принадлежит ни Apache, ни каким-то еще компаниям, а это для некоторых может стать серьезным минусом.
Если минусы для вас существенны, то я бы выбирал log4j2 или log4j.
В случае, если ваш проект мал и прост, при этом вы не разрабатываете библиотеку, а пишите именно законченный, маленький продукт и логирование вам не слишком важно — можно взять и jul.
Разбираем SLF4J
Так как из адаптеров это по сути единственный выбор, да и встречается slf4j все чаще, то стоит рассмотреть его устройство.
Вся обертка делится на две части — API, который используется приложениями, и реализация логера, которая представлена отдельными jar-файлами для каждого вида логирования. Такие реализиации для slf4j называются binding. Например, slf4j-log4j12 или logback-classic.
Достаточно только положить в CLASSPATH нужный binding, после чего — опа! весь код проекта и все используемые библиотеки (при условии, что они обращаются к SLF4J) будут логировать в нужном направлении.
Вопрос:
А что будет, если в CLASSPATH окажется несколько binding-ов?
Ответ:
SLF4J найдет все доступные binding-и и напишет об этом, после чего выберет какой-то и тоже об этом напишет.
Вот пример поведения slf4j, когда в CLASSPATH оказалось два binding: logback и slf4j-log4j12:
SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:.gradle/caches/modules-2/files-2.1/ch.qos.logback/logback-classic/1.2.3/7c4f3c474fb2c041d8028740440937705ebb473a/logback-classic-1.2.3.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:.gradle/caches/modules-2/files-2.1/org.slf4j/slf4j-log4j12/1.7.26/12f5c685b71c3027fd28bcf90528ec4ec74bf818/slf4j-log4j12-1.7.26.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [ch.qos.logback.classic.util.ContextSelectorStaticBinder]
Что делать при такой ситуации. Если коротко, то надо просто вычистить из CLASSPATH-а все ненужные binding-и и оставить только один.
Т.е вы строите дерево зависимостей проекта, после чего методично вырезаем все, что нам не нужно в CLASSPATH-е.
Вроде все проблемы решены, пусть и такими радикальными способоами.
Но это еще не все.

Проблема
В идеальном мире все должны выводить сообщения через интерфейс обертки, и тогда у нас все будет хорошо, но реальный мир диктует свои правила и приходится взаимодействовать со сторонними библиотеками, которые используют другие логгеры и которые ничего знать не знают о slf4j.
Например, Spring использует адаптер jcl.
И вот в такой ситуации, чтобы все работало с slf4j используют так называемые bridge-ы.
Что такое bridge? Это jar-ник, который кладется в CLASSPATH вместо настоящей библиотеки логирования, в этом jar-нике все классы, которые существуют в настойщей библиотеке логирования, но они просто делегируют все события логирования в slf4j.
Например, jcl-over-slf4j.jar, log4j-over-slf4j.jar или jul-to-slf4j.jar, которые переопределяют поведение соответствующих логгеров и перенаправляют сообщения в slf4j.
Таким образом, чтобы работать со Spring получается надо сделать CLASSPATH подобным образом:
compile "org.slf4j:jcl-over-slf4j:$slf4_version" exclude group: "commons-logging", module: "commons-logging"
Т.е исключить из CLASSPATH уже не нужный нам jcl, после чего добавить bridge, чтобы он перенаправлял все события логирования Spring в slf4j.
Подробнее об этом.
Проблемы bridge-а:
-
Если конфигурация сделана программно, то
bridgeне будет работать. -
В
CLASSPATHможет оказаться иbinding, иbridgeна один и тот же логгер. В этом случае они начнут бесконечно перекидывать друг другу сообщения логирования, пока не свалятся наStackOverflowError.Например,
log4j-over-slf4j.jarиslf4j-log4j12в одномCLASSPATHприведут кStackOverflowError. -
Проблема с
JUL.Если вы внимательно читали то, что мы говорили про
bridge, то уже поняли в чем дело:bridgeпо сути подменяет классы, а подменить классыjdk— нельзя.Поэтому
bridgeдляjdkлогера работает иначе — устанавливается специальный обработчик наrootлогер, который заворачивает события вslf4j.И все бы ничего, но такой обработчик заворачивает все события от
jul, даже те, для которых не указаныappender-ы. Отсюда мы получаем большойoverheadи проседает производительность.

Заключение
Проблема логирования в Java стоит остро до сих пор. В том, что появилась такая проблема как многообразие логеров и отсутствие какого-то внятного стандарта виноваты все, в том числе и, на мой взгляд, какие-то политические моменты, как например с JSR 47.
Бесконтрольно подтягиваемые транзитивные зависимости библиотек, которые вы используете в своем проекте, рано или поздно принесут какие-то свои библиотеки логирования, отчего могут открыться врата прямиком в ад.
Поэтому следите за CLASSPATH, смотрите что вы используете и не разводите log-зоопарк.
Если говорить о выборе, то я бы выбрал связку SLF4J и logback, так как при необходимости вы сможете переключиться с logback на другую реализацию логера. При этом logback довольно мощная библиотека, предоставляющая большое количество возможностей и layout-ов.
При этом, если вы разрабатываете библиотеку, то:
- Не используейте
jul. - Задумайтесь о том, что нужна ли библиотека логирования, которую вы используете, другим людям как транзитивная зависимость вашей библиотеки?
Очень важно также не забывать о том, что такое логирование и для чего оно нужно.
Поэтому нельзя скатываться в бесмысленные записи в лог, вывод личных данных и так далее.
Думайте о том что вы пишите в лог!
Полезные ссылки
- Java Logging: история кошмара
- Владимир Красильщик — Что надо знать о логировании прагматичному Java-программисту
- Ведение лога приложения
- Java logging. Hello World

Евгений Холодов
техлид в Dunice
Каждый проект так или иначе имеет жизненные циклы: планирование, разработка MVP, тестирование, доработка функциональности и поддержка. Скорость роста проектов может отличаться, но при этом желание не сбавлять обороты и двигаться только вперёд у всех одинаковые. Перед нами встаёт вопрос: как при работе над крупным проектом минимизировать время на выявление, отладку и устранение ошибок и при этом не потерять в качество?
Существует много различных инструментов для повышения стабильности проекта:
- статические анализаторы (ESLint, TSLint, Pylint и др.);
- контейнеризация (Docker, Vagrant и др.);
- различные виды тестирования (функциональное тестирование, тестирование производительности, системное тестирование, модульное тестирование, тестирование безопасности);
- менеджеры зависимостей (npm, yarn, pip и др.);
- логирование + мониторинг;
- менеджеры процессов;
- системные менеджеры.
В данной статье я хочу поговорить об одном из таких инструментов — логировании.
Логи — это файлы, содержащие системную информацию о работе сервера или любой другой программы, в которые вносятся определённые действия пользователя или программы.
Логи полезны для отладки различных частей приложения, а также для сбора и анализа информации о работе системы с целью выявления ошибок. Всё это необходимо для контроля работы приложения, так как даже после релиза могут встретиться ошибки, а пользователи не всегда сообщают о багах в техподдержку. Чем больше процессов у вас автоматизировано, тем быстрее будет идти разработка.
Допустим, есть клиентское приложение, балансировщик в лице Nginx, серверное приложение и база данных.
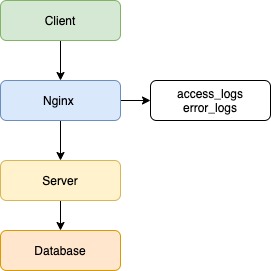
В данном примере не важны язык/фреймворк бэкенда, фронтенда или тип базы данных, а вот про веб-сервер Nginx давайте поговорим. В данный момент Nginx популярнее остальных решений для высоконагруженных сайтов. Среди известных проектов, использующих Nginx: Рамблер, Яндекс, ВКонтакте, Facebook, Netflix, Instagram, Mail.ru и многие другие. Nginx записывает логи по умолчанию, без каких-либо дополнительных настроек.
Логи доступны 2 типов:
- логи ошибок (logs/error.log) — хранят запросы, которые завершились с ошибкой;
- логи доступа (logs/access.log) — хранят информацию обо всех запросах, которые были отправлены на сервер.
Клиент отправляет запрос на сервер, и в данной ситуации Nginx будет записывать все входящие запросы. Если возникнут ошибки при обработке запросов, сервером будет записана ошибка.
2020/04/10 13:20:49 [error] 4891#4891: *25197 connect() failed (111: Connection refused) while connecting to upstream, client: 5.139.64.242, server: app.dunice-testing.com, request: "GET /api/v1/users/levels HTTP/2.0", upstream: "http://127.0.0.1:5000/api/v1/users/levels", host: "app.dunice-testing.com"
Всё, что мы смогли бы узнать в случае возникновения ошибки, — это лишь факт наличия таковой, не более. Это полезная информация, но мы пойдём дальше. В данной ситуации помог Nginx и его настройки по умолчанию. Но что же нужно сделать, чтобы решить проблему раз и навсегда? Необходимо настроить логирование на сервере, так как он является общей точкой для всех клиентов и имеет доступ к базе данных.
Первым делом каждый запрос должен получать свой уникальный идентификатор, что поможет отличить его от других запросов. Для этого используем UUID/v4. На случай возникновения ошибки, каждый обработчик запроса на сервере должен иметь обёртку, которая отловит эти самые ошибки. В этой ситуации может помочь конструкция try/catch, реализация которой есть в большинстве языков.
В конце каждого запроса должен сохраняться лог об успешной обработке запроса или, если произошла ошибка, сервер должен обработать её и записать следующие данные: ID запроса, все заголовки, тело запроса, параметры запроса, отметку времени и информацию об ошибке (имя, сообщение, трассировка стека).
Собранная информация даст не только понимание, где произошла ошибка, но и возможную причину её возникновения. Обычно для решения ошибки информации из лога достаточно, но в некоторых случаях может быть полезен контекст запроса. Для этого необходимо при старте запроса не только генерировать ID запроса, но и сгенерировать контекст, в который мы будем записывать всю информацию по работе сервера, начиная от результата вызова функции и заканчивая результатом запроса к базе данных. Такая реализация даст не только входные данные, но и промежуточные результаты работы сервера, что позволит понять причину появления ошибки.

При микросервисном подходе система не ограничивается одним сервером, и при запросе от клиента происходит взаимодействие нескольких серверов внутри системы. Наша реализация логирования на сервере позволит выявить дефект в работе конкретного ресурса, но не позволит понять, почему запрос вернулся с ошибкой. В данной ситуации поможет трассировка запросов.
Трассировка — процесс пошагового выполнения программы. В режиме трассировки программист видит последовательность выполнения команд и значения переменных на каждом шаге выполнения программы.
В нашем случае требуется передавать метаинформацию о запросе при взаимодействии серверов и записывать логи в единое хранилище (такими могут быть ClickHouse, Apache Cassandra или MongoDB). Такой подход позволит привязать различные контексты серверов к уникальному идентификатору запроса, а отметки времени — понять последовательность и последнюю выполненную операцию. После этого команда разработки сможет приступить к устранению.

В некоторых случаях, которые встречаются крайне редко, к ошибке приводят неочевидные факторы: компилятор, ядро операционной системы, конфигурации сервера, юзабилити, сеть. В таких случаях при возникновении ошибки потребуется дополнительно сохранять переменные окружения, слепок оперативной памяти и дамп базы. Такие случаи настолько редки, что не стоит беспочвенно акцентировать на них внимание.
С сервером разобрались, что же делать, если у нас сбои даёт клиент и запросы просто не приходят? В такой ситуации нам помогут логи на стороне клиента. Все обработчики должны отправлять информацию на сервер с пометкой, что ошибка с клиента, а также общие сведения: версия и тип браузера, тип устройства и версия операционной системы. Данная информация позволит понять, какой участок кода дал сбой и в каком окружении пользователь взаимодействовал с информацией.

Также есть возможность отправлять уведомления на почту разработчикам, если произошли ошибки, что позволит оперативно узнавать о сбоях в системе. Такие подходы активно используются в системах мониторинга и аналитики логов.
Способы, которые мы рассмотрели в статье, помогут следить за качеством продукта и минимизируют затраты на исправление недочётов в системе.