
From Wikipedia, the free encyclopedia
In computer programming, a logic error is a bug in a program that causes it to operate incorrectly, but not to terminate abnormally (or crash). A logic error produces unintended or undesired output or other behaviour, although it may not immediately be recognized as such.
Logic errors occur in both compiled and interpreted languages. Unlike a program with a syntax error, a program with a logic error is a valid program in the language, though it does not behave as intended. Often the only clue to the existence of logic errors is the production of wrong solutions, though static analysis may sometimes spot them.
Debugging logic errors[edit]
One of the ways to find this type of error is to put out the program’s variables to a file or on the screen in order to determine the error’s location in code. Although this will not work in all cases, for example when calling the wrong subroutine, it is the easiest way to find the problem if the program uses the incorrect results of a bad mathematical calculation.
Examples[edit]
This example function in C to calculate the average of two numbers contains a logic error. It is missing parentheses in the calculation, so it compiles and runs but does not give the expected answer due to operator precedence (division is evaluated before addition).
float average(float a, float b) { return a + b / 2; // should be (a + b) / 2 }
See also[edit]
- Syntax error
- Off-by-one error

Опытные программисты знают, что ошибки в программе делятся на два основных типа. Первая разновидность — это баги, которые вылавливаются при компиляции. К ним относятся преимущественно проблемы с синтаксисом, явная несовместимости типов и т.д. Эту разновидность багов исправляют на этапе разработки, так как компилятор «вылетает по ошибке». Их просто невозможно не заметить.
Второй тип – системные или логические ошибки – намного сложнее выявить. Компилятор их не замечает. Программа полностью работоспособна. Но в некоторых случаях она начинает выдавать результаты, отличные от ожидаемых.
Выявить этот вид багов удается только на этапе тестирования. И хорошо, если ошибку удается исправить локальной «заплаткой». Нередко приходится менять практически весь алгоритм. А это – дополнительные затраты времени, сил, а в коммерческих проектах – финансовые, а иногда и репутационные потери.
Застраховаться полностью от логических ошибок невозможно. Но вполне реально изучить самые распространенные типы таких багов и проверять на них программу на самых ранних этапах.
Алгоритм – основа всех основ
Написание алгоритма – это самый первый этап разработки, когда идеи только обретают форму еще без привязки к языку программирования. Нередко начинающие программисты относятся к созданию алгоритма «спустя рукава» — делают только «общие наброски» или вообще приступают к кодингу сразу без предварительной проработки логики «на бумаге».
Такой подход возможен при решении учебных задач на 10-15 строк кода. Но при работе над серьезным программным продуктом пренебрежение алгоритмом – почти гарантированный путь к логическим ошибкам и катастрофическим результатам.
Как работать с алгоритмом:
- Начинайте с малого. Запишите алгоритм упрощенно, в виде «черных ящиков» (логических блоков без подробностей их работы). Это поможет оценить работоспособность идеи в целом.
- Двигайтесь сверху вниз. Сначала – общая идея «в целом», далее – детализация основных функций и так далее. Не бойтесь ставить «заглушки» и прорабатывать мелкие детали в последнюю очередь. Двигаться сверху вниз проще и с точки зрения логики, и психологически.
- Пишите команды «от имени компьютера». Помните, что вы имеете дело не с человеком, а с компьютером, который буквально выполняет команды и после каждого шага ждет ответа на вопрос «что делать». Например, логический блок «сохранение документа» будет понятен вам, но не компьютеру. Он вполне подойдет на этапе крупных блоков в качестве заглушки. Но далее придется проработать все действия пошагово с учетом выбранного языка программирования.
- Делите код на отдельные модули (блоки), которые можно будет запускать отдельно друг от друга. Это сильно облегчит как алгоритмизацию, так и процесс отладки.
- Читайте алгоритм «как будто компьютер». Проверяйте себя на каждом этапе. Главное правило – одинаковые данные всегда должны вести к одинаковым результатам.
Итак, алгоритм написан и проверен со всех сторон. Выбран язык программирования. Начинается процесс кодинга. Давайте разбираться, на что обращать особое внимание.

«Не туда положил»: о типах данных
Здесь проблемы возникают в двух случаях:
- При статической типизации в таких языках, как С++, Java или С# неверно определен тип переменной. Большинство подобных ошибок выявляет компилятор. Но здесь есть свои «лазейки» для багов. Например, в С# вполне возможно «положить» вещественное значение в целочисленную переменную. И оно просто округлится до целого. Т.е. вместо 1,3 у вас будет храниться значение 1. Само собой, все дальнейшие вычисления будут содержать ошибку.
- При динамической типизации (JavaScript, Python, PHP) неявное приведение типов – самое обычное дело. А потому здесь даже компилятор промолчит в случае ошибки. Например, вы планируете получить целочисленное значение, для чего отправляете результаты вычислений в переменную типа int. Но программа видит «знаки после запятой», и переменная без вашего участия меняет тип на float.
Самый известный пример подобной ошибки – деление двух целых чисел с остатком.
int a = 25;
int b = 8;
float c = a/b;
Console.Write(c);
Как вы думаете, какое число будет выведено на экран после выполнения последней строки? По идее, это должно быть 3,125. Но, например, в C# вы увидите целую цифру «3». Причем, тип переменной С будет float, как вы и заказывали.
Здесь проблема в другом: компилятор сначала проводит целочисленное деление, так как определяет переменные A и B как относящиеся к типу int. И полученный результат отправляет в переменную C (тип float). Целое значение (32 разряда) прекрасно помещается в 64-разрядный float, отведенный под хранение результата. Компилятор не видит ошибки. А у вас в программе появляются неточные вычисления, которые могут повлечь за собой большие проблемы.
Аналогичным образом компилятор округлит значение до целого и в Python 2. А уже в Python 3 алгоритм преобразования типов сработает иначе: сначала определится тип переменной, куда отправляется значение, а потом будет проводиться деление. После компиляции кода в Python 3 вы получите c=3,125.
Необходимо четко понимать, как работает преобразование типов в выбранном языке программирования. И в случае любых сомнений проверять результаты в отладчике.
Высвобождение ресурсов: до 100% загрузки процессора
Если вы работаете с языком, где реализована автоматическая сборка мусора, внимательно следите за тем, как происходит высвобождение ресурсов. В отдельных случаях эта полезная функция может начать работать во вред: отбирать для себя максимум памяти, загружать дополнительными задачами процессор, замедлять и даже «подвешивать» программу.
Например, в Java этот процесс работает так:
- Виртуальная машина проводит поиск ненужных объектов;
- Составляет из них очередь на удаление;
- По мере продвижения очереди очищает ячейки памяти.
В результате очередь может стать настолько большой, что компьютер перестанет с ней справляться. А до удаления всех ненужных объектов дело может даже не дойти.
Как итог, программа «загрязняет» память служебной информацией. Кроме того, формируется уязвимость: в этой «свалке данных» могут оказаться логины с паролями и другие личные данные.
Намного надежнее своевременно применять функции типа try-with-resources и try-finally. И все ресурсы очищать в том коде, где вы их получили.
И еще: не забывайте закрывать сессии и файлы сразу после того, как они перестают быть нужны. Это должно быть также естественно, как закрыть скобку в коде.

Конфликт потоков: кто первый успеет?
Если программа работает с несколькими потоками одновременно, необходимо исключить ситуацию конфликта потоков. Так бывает, когда процессы наперегонки пытаются работать с общими ресурсами, в итоге нарушают целостность данных и последовательность действий.
Например: первый поток в результате вычислений получает значение 1, отправляет его в переменную. В это время второй поток перехватывает доступ и обнуляет эту переменную. А первый – сохраняет значение. В результате вы планировали запомнить значение 1. А у вас сразу после вычислений сохраняется 0. И далее копятся ошибка за ошибкой.
Чтобы избежать этой проблемы не забывайте при работе с разными потоками ставить блокировки, чтобы они не обращались одновременно к одним и тем же ресурсам. Можно применять и другие методы синхронизации – события, семафоры, критические секции.
Переменные: склонность к глобализации
Эта ошибка популярна у новичков – стремление объявить сразу все переменные и сделать их глобальными. В результате таких действий вы:
- перегружаете ресурсы оборудования;
- получаете множество уязвимостей, которые сложно закрыть;
- усложняете в разы отладку и поиск багов.
На глобальном уровне определяют только необходимый минимум – те самые глобальные переменные, с которыми работают практически все модули. Все остальные объявляйте в тех модулях, где они работают. И не забывайте об идентификаторах ограничения доступа: public, private и protected.
Переполнение буфера в С/С++: «танцы на граблях»
В большинстве современных языках программирования высокого уровня вопрос буферизации решен на автоматическом уровне. Например, Java самостоятельно контролирует размер буфера и определяет границы массивов.
Но нередко для экономии ресурсов программисты используют C-библиотеки. В этом случае очень важно следить за буферизацией. Дело в том, что языки C/С++ очень уязвимы к переполнению буфера. Если он окажется меньше, чем нужно для работы, программа попытается использовать память за пределами выделенного участка. Результат – многочисленные, можно сказать, легендарные ошибки, когда в обрабатываемые данные попадает «неведомый мусор».
Хуже того, это очень известная уязвимость. С 1988 года хакеры пользуются этой «дырой», чтобы подменить адрес возврата в стеке на собственный. Так в программу попадает подставная функция, которая передает управление коду мошенников.
Изучите особенности работы с буфером и методы борьбы с его переполнением, чтобы не пополнить число «танцующих на граблях с 30-летней историей».
Отладка и поиск логических багов
И, напоследок, несколько советов, как выявить проблему, если вы подозреваете, что с программой что-то не так.
- Пользуйтесь возможностями отладчика вашей IDE. Ставьте контрольные точки, отражайте на консоли ход выполнения и значения переменных, переходите в «пошаговый режим» выполнения в наиболее «подозрительных» участках кода. Так вы быстрее сможете локализовать проблему.
- Помните: компилятор может неправильно указывать строку с ошибкой. Если вам повезло, и компилятор помог вам выявить баг, не спешите радоваться. При «завершении с ошибкой» вы видите номер строки, в которой выполнение программы стало невозможным. Если проблема в простейшей опечатке (синтаксис), то строка с багом вам известна. В случае логических ошибок вероятнее всего, проблема появилась на более ранних этапах работы программы. А в указанной строке была попытка использовать ошибочные данные, что и привело к аварийному завершению.
- Старый добрый листинг программы тоже может помочь. Если вы запутались и не знаете, что делать, распечатайте код и попробуйте его «выполнить» как будто вы – и есть компьютер. Шаг за шагом двигайте по командам. Переходите от блока к блоку так, как это делает программа. На каждом этапе вычисляйте и фиксируйте значения переменных (калькулятором пользоваться можно). И сверяйте результаты с ожидаемыми. Все в порядке? Двигайтесь дальше. Что-то не так? Ура! Вы локализовали баг. Можно возвращаться за компьютер и разбираться подробнее в этом фрагменте кода в отладчике.
И самое главное: не бойтесь что-то менять, в том числе, на глобальном уровне. Лучше переписать «сырой» код на раннем этапе разработки практически полностью, чем из-за серьезной логической ошибки терять в скорости и качестве работы программы, пытаясь использовать кучу «заплаток». От ошибок не застрахован никто. Потраченного времени жаль, но это – ваш личный практический опыт. А программа должна работать быстро, надежно и, самое главное, правильно.

Ошибки в программировании – дело обычное, хоть и неприятное. В данной статье будет рассказано о том, какими бывают ошибки (баги), а также что собой представляют исключения.
Определение
Ошибка в программировании (или так называемый баг) – это ситуация у разработчиков, при которой определенный код вследствие обработки выдает неверный результат. Причин данному явлению множество: неисправность компилятора, сбои интерфейса, неточности и нарушения в программном коде.
Баги обнаруживаются чаще всего в момент отладки или бета-тестирования. Реже – после итогового релиза готовой программы. Вот несколько вариантов багов:
- Появляется сообщение об ошибке, но приложение продолжает функционировать.
- ПО вылетает или зависает. Никаких предупреждений или предпосылок этому не было. Процедура осуществляется неожиданно для пользователя. Возможен вариант, при котором контент перезапускается самостоятельно и непредсказуемо.
- Одно из событий, описанных ранее, сопровождается отправкой отчетов разработчикам.
Ошибки в программах могут привести соответствующее приложение в негодность, а также к непредсказуемым алгоритмам функционирования. Желательно обнаруживать баги на этапе ранней разработки или тестирования. Лишь в этом случае программист сможет оперативно и относительно недорого внести необходимые изменения в код для отладки ПО.
История происхождения термина
Баг – слово, которое используется разработчиками в качестве сленга. Оно произошло от слова «bug» – «жук». Точно неизвестно, откуда в программировании и IT возник соответствующий термин. Существуют две теории:
- 9 сентября 1945 года ученые из Гарварда тестировали очередную вычислительную машину. Она называлась Mark II Aiken Relay Calculator. Устройство начало работать с ошибками. Когда его разобрали, то ученые заметили мотылька, застрявшего между реле. Тогда некая Грейс Хоппер назвала произошедший сбой упомянутым термином.
- Слово «баг» появилось задолго до появления Mark II. Термин использовался Томасом Эдисоном и указывал на мелкие недочеты и трудности. Во время Второй Мировой войны «bugs» называли проблемы с радарной электроникой.
Второй вариант кажется более реалистичным. Это факт, который подтвержден документально. Со временем научились различать различные типы багов в IT. Далее они будут рассмотрены более подробно.
Как классифицируют
Ошибки работы программ разделяются по разным факторам. Классификация у рядовых пользователей и разработчиков различается. То, что для первых – «просто программа вылетела» или «глючит», для вторых – огромная головная боль. Но существует и общепринятая классификация ошибок. Пример – по критичности:
- Серьезные неполадки. Это нарушения работоспособности приложения, которые могут приводить к непредвиденным крупным изменениям.
- Незначительные ошибки в программах. Чаще всего не оказывают серьезного воздействия на функциональность ПО.
- Showstopper. Критические проблемы в приложении или аппаратном обеспечении. Приводят к выходу программы из строя почти всегда. Для примера можно взять любое клиент-серверное приложение, в котором не получается авторизоваться через логин и пароль.
Последний вариант требует особого внимания со стороны программистов. Их стараются обнаружить и устранить в первую очередь. Критические ошибки могут отложить релиз исходной программы на неопределенный срок.
Также существуют различные виды сбоев в плане частоты проявления: постоянные и «разовые». Вторые встречаются редко, чаще – при определенных настройках и действиях со стороны пользователя. Первые появляются независимо от используемой платформы и выполненных клиентом манипуляций.
Иногда может получиться так, что ошибка возникает только на устройстве конкретного пользователя. В данном случае устранение неполадки требует индивидуального подхода. Иногда – полной замены компьютера. Связано это с тем, что никто не будет редактировать исходный код, когда он «глючит» только у одного пользователя.
Виды
Существуют различные типы ошибок в программах в зависимости от типовых условий использования приложений. Пример – сбои, которые возникают при возрастании нагрузки на оперативную память или центральный процессор устройства. Есть баги граничных условий, сбоя идентификаторов, несовместимости с архитектурой процессора (наиболее распространенная проблема на мобильных устройствах).
Разработчики выделяют следующие типы ошибок по уровню сложности:
- «Борбаг» – «стабильная» неполадка. Она легко обнаруживается на этапе разработки и компилирования. Иногда – во время тестирования наработкой исходной программы.
- «Гейзенбаг» – баги с поддержкой изменения свойств, включая зависимость от среды, в которой было запущено приложение. Сюда относят периодические неполадки в программах. Они могут исчезать на некоторое время, но через какой-то промежуток вновь дают о себе знать.
- «Мандельбаг» – непредвиденные ошибки. Обладают энтропийным поведением. Предсказать, к чему они приведут, практически невозможно.
- «Шрединбаг» – критические неполадки. Приводят к тому, что злоумышленники могут взломать программу. Данный тип ошибок обнаружить достаточно трудно, потому что они никак себя не проявляют.
Также есть классификация «по критичности». Тут всего два варианта – warning («варнинги») и критические весомые сбои. Первые сопровождаются характерными сообщениями и отчетами для разработчиков. Они не представляют серьезной опасности для работоспособности приложения. При компилировании такие сбои легко исправляются. В отдельных случаях компилятор справляется с этой задачей самостоятельно. А вот критические весомые сбои говорят сами за себя. Они приводят к серьезным нарушениям ПО. Исправляются обычно путем проработки логики и значительных изменений программного кода.
Типы багов
Ошибки в программах бывают:
- логическими;
- синтаксическими;
- взаимодействия;
- компиляционные;
- ресурсные;
- арифметические;
- среды выполнения.
Это – основная классификация сбоев в приложениях и операционных системах. Логические, синтаксические и «среды выполнения» встречаются в разработке чаще остальных. На них будет сделан основной акцент.
Ошибки синтаксиса
Синтаксические баги распространены среди новичков. Они относятся к категории «самых безобидных». С данной категорией ошибок способны справиться компиляторы тех или иных языков. Соответствующие инструменты показывают, где допущена неточность. Остается лишь понять, как исправить ее.
Синтаксические ошибки – ошибки синтаксиса, правил языка. Вот пример в Паскале:

Код написан неверно. Согласно действующим синтаксическим нормам, в Pascal в первой строчке нужно в конце поставить точку с запятой.
Логические
Тут стоит выделить обычные и арифметические типы. Вторые возникают, когда программе при работе необходимо вычислить много переменных, но на каком-то этапе расчетов возникают неполадки или нечто непредвиденное. Пример – получение в результатах «бесконечности».
Логические сбои обычного типа – самые сложные и неприятные. Их тяжелее всего обнаружить и исправить. С точки зрения языка программа может быть написана идеально, но работать неправильно. Подобное явление – следствие логической ошибки. Компиляторы их не обнаруживают.

Выше – пример логической ошибки в программе. Тут:
- Происходит сравнение значения i с 15.
- На экран выводится сообщение, если I = 15.
- В заданном цикле i не будет равно 15. Связано это с диапазоном значений – от 1 до 10.
Может показаться, что ошибка безобидная. В приведенном примере так и есть, но в более крупных программах такое явление приводит к серьезным последствиям.
Время выполнения
Run-time сбои – это ошибка времени выполнения программы. Встречается даже когда исходный код лишен логических и синтаксических ошибок. Связаны такие неполадки с ходом выполнения программного продукта. Пример – в процессе функционирования ПО был удален файл, считываемый программой. Если игнорировать подобные неполадки, можно столкнуться с аварийным завершением работы контента.
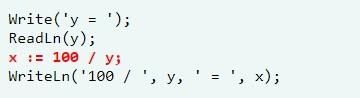
Самый распространенный пример в данной категории – это неожиданное деление на ноль. Предложенный фрагмент кода с точки зрения синтаксиса и логики написан грамотно. Но, если клиент наберет 0, произойдет сбой системы.
Компиляционный тип
Встречается при разработке на языках высокого уровня. Во время преобразований в машинный тип «что-то идет не так». Причиной служат синтаксические ошибки или сбои непосредственно в компиляторе.
Наличие подобных неполадок делает бета-тестирование невозможным. Компиляционные ошибки устраняются при разработке-отладке.
Ресурсные
Ресурсный тип ошибок – это сбои вроде «переполнение буфера» или «нехватка памяти». Тесно связаны с «железом» устройства. Могут быть вызваны действиями пользователя. Пример – запуск «свежих» игр на стареньких компьютерах.
Исправить ситуацию помогают основательные работы над исходным кодом. А именно – полное переписывание программы или «проблемного» фрагмента.
Взаимодействие
Подразумевается взаимодействие с аппаратным или программным окружением. Пример – ошибка при использовании веб-протоколов. Это приведет к тому, что облачный сервис не будет нормально функционировать. При постоянном возникновении соответствующей неполадки остается один путь – полностью переписывать «проблемный» участок кода, ответственный за соответствующий баг.
Исключения и как избежать багов
Исключение – событие, при возникновении которых начинается «неправильное» поведение программы. Механизм, необходимый для стабилизации обработки неполадок независимо от типа ПО, платформ и иных условий. Помогают разрабатывать единые концепции ответа на баги со стороны операционной системы или контента.
Исключения бывают:
- Программными. Они генерируются приложением или ОС.
- Аппаратными. Создаются процессором. Пример – обращение к невыделенной памяти.
Исключения нужны для охвата критических багов. Избежать неполадок помогут отладчики на этапе разработки. А еще – своевременное поэтапное тестирование программы.
P. S. Большой выбор курсов по тестированию есть и в Otus. Присутствуют варианты как для продвинутых, так и для начинающих пользователей.
Привет всем зрителям и слушателям нашего портала Loftblog! Продолжим наш увлекательный разговор о программировании. Наверно, не существует на свете программиста, который мог бы сразу написать код без ошибок. Ошибки программирования будут изначально присутствовать во всех программах, написанных вами. И на сегодняшнем видеоуроке мы поговорим об этих ошибках, рассмотрим их разновидности и узнаем, как их уменьшить.
История появления слова «Баг»
Ошибки в программах называются багами, а их исправление – отладкой или дебаггингом. С английского языка слово «баг» переводится как жук. Впервые оно было использовано в 1946 году Грейс Хоппер, которая работала в Гарвардском университете с вычислительной машиной Harvard Mark II.
Грейс долго искала ошибку в программе, и когда она дошла до электромеханического реле машины, то нашла между замкнувшимися контактами сгоревшего мотылька. Животное было вклеено в дневник с иронической надписью – первый реальный случай бага (жучка).
Виды ошибок программирования
В программах есть 3 вида багов:
- 1. Синтаксические ошибки программирования;
- 2. Ошибки выполнения;
- 3. Логические ошибки программирования.
Некоторые из них легко обнаружить, а чтобы найти другие, придется приложить немалые усилия, но в любом случае есть способы найти ошибки программирования и исправить их.
Синтаксические ошибки программирования
Синтаксическими ошибками являются опечатки в ключевых словах или неверные отступы (актуально для Python). Такие ошибки программирования обнаруживаются перед выполнением программы и их легко отладить. Посмотрите внимательно на код и найдите в нем синтаксические ошибки:
[php]
i = 5
wile i < 15:
print (i)
i = i + 2
[/php]
Ошибки выполнения
Эти ошибки программирования проявляются в ходе работы программы, например, когда мы складываем число и строку или когда делим число на ноль. Следует отметить, что такие ошибки программирования свойственны для Python, в других же языках будут другие ошибки выполнения, характерные для этих языков. Пример ошибок выполнения приведен ниже:
[php]
print (‘dima’ + 1)
print (10/0)
[/php]
Логические ошибки программирования
Эти ошибки программирования заключаются в том, как мы придумали код. Программы с логическими ошибками являются, по сути, правильными программами, но ведут себя не так, как мы задумали. Это связано с неправильными действиями на этапе принятия решений. Вот как, скажем, в этом примере:
[php]
age = 7
if (age < 5 and age >
print (‘free ticket!’)
[/php]
Как же писать код без ошибок?
1. Проверьте свой код на синтаксические ошибки программирования, все ли ключевые слова написаны правильно? Заключен ли текст в кавычки? Сделаны ли необходимые отступы?
2. Дайте просмотреть свой код другу или коллеге, чтобы он проверил ваш код своим свежим взглядом.
Ошибки программирования будут существовать всегда. Только от вашего профессионализма будет зависеть, насколько быстро будете вы их находить и насколько верно исправлять. А профессионализм достигается только с практикой, с опытом. Поэтому, дорогие друзья, практикуйтесь как можно больше.
Если с вами когда-нибудь случались забавные истории по поиску багов в коде, напишите их в комментариях. Всем спасибо!
Приятного всем просмотра! Учитесь с удовольствием! Всегда ваш LoftBlog!
Виды ошибок в программах
Я учусь на своих ошибках. Ругаю себя за это, но продолжаю ошибаться. С другой стороны — это всё-таки лучше, чем не учиться совсем, и наступать на одни и те же грабли бесконечно.
При создании программ, даже простых, ошибки неизбежны. Поэтому для поиска ошибок во всех средствах разработки имеются особые инструменты для отладки. Но сегодня не об отладке и не о поиске ошибок. Сегодня о видах ошибок, которые встречаются в программах.
Итак, основных вида всего три:
- Синтаксические ошибки
- Логические ошибки
- Ошибки выполнения программы
Синтаксические ошибки в программах
Эти ошибки довольно распространены, особенно среди начинающих. Но эти ошибки — самые безобидные. Потому что компиляторы легко находят ошибки синтаксиса и указывают место в исходном коде, где обнаружена такая ошибка. Программисту остаётся только исправить её.
Синтаксические ошибки — это ошибки синтаксиса (а то бы вы не догадались))). То есть ошибки правил языка. Например, для Паскаля это будет синтаксической ошибкой:
WriteLn('Hello, World !!!')
ReadLn;
Потому что после первой строки нет точки с запятой.
Подобные ошибки очень часто совершают новички. И это вгоняет их в ступор — они пугаются и не могут понять, что же не так с их кодом. Хотя если бы они внимательно его посмотрели и прочитали сообщение об ошибке, то легко могли бы исправить её:

Потому что в сообщении чётко сказано:
Syntax error, ";" expected but "identifier READLN" found
что можно перевести как
синтаксическая ошибка, ";" ожидалось, но "READLN" найден
То есть компилятор говорит нам: я ожидал увидеть точку с запятой, а нашёл идентификатор READLN.
Логические ошибки в программах
Это самые противные и самые труднонаходимые ошибки. Программа может быть написана совершенно правильно с точки зрения синтаксиса языка, и при этом она будет неправильно работать. Потому что программист допустил где-то логическую ошибку.
И компилятор вам ничего об этой ошибке не расскажет, потому что правила языка не нарушены.
Поиски таких ошибок могут занять много времени и отнять у вас немало здоровья. Поэтому при разработке программ лучше не торопиться и стараться не допускать логических ошибок.
Пример логической ошибки:
for i := 1 to 10 do
if i = 15 then WriteLn('i = 15');
Здесь мы сравниваем значение i с числом 15, и выводим сообщение, если i = 15.
Но фишка в том, что в данном цикле i не будет равно 15 НИКОГДА, потому что в цикле переменной i присваиваются значения от 1 до 10.
Эта ошибка довольно безобидная. Здесь мы имеем просто бессмысленный код, который не причинит никакого вреда.
Однако представьте, что программа должна выдавать какой-то сигнал тревоги, если i = 15. Тогда получится, что никакого сигнала пользователь никогда не услышит, даже если случилось что-то страшное. А всё потому, что программист немного ошибся. Вот так вот и падают ракеты и самолёты…
Распространённые логические ошибки в С++ вы можете посмотреть здесь.
Ошибки времени выполнения программы
Даже если исходный код не содержит ни логических, не синтаксических ошибок, это ещё не означает, что ваша программа безупречна. Потому что ошибки могут возникнуть в ходе выполнения программы. Например, случайно будет удалён файл, который должна читать программа, и она не сможет его найти. Если не принять мер, то программа может завершиться аварийно. А пользователям такое поведение программ очень не нравится.
Одна из самых рапространённых ошибок времени выполнения — это неожиданное деление на ноль. Пример:
Write('y = ');
ReadLn(y);
x := 100 / y;
WriteLn('100 / ', y, ' = ', x);
Что здесь такого? Всё правильно и с точки зрения логики, и с точки зрения синтаксиса. И в большинстве случаев программа отработает без каких-либо неожиданностей.
Но представьте, что пользователь введёт ноль. Что тогда будет? Правильно — попытка деления на ноль. А на ноль делить нельзя. Поэтому во время выполнения этой программы произойдёт ошибка, которая очень расстроит пользователя. Потому что в случае, например, с консольным приложением программа просто закроется, и пользователь не поймёт, что это было. Но зато поймёт, что программа — говно, и программы от этого разработчика лучше больше никогда не использовать.
В данном случае, если вы не уверены на 100%, что y будет отличаться от нуля, надо всегда делать проверку на ноль. И хороший код должен быть хотя бы таким:
Write('y = ');
ReadLn(y);
if y = 0 then WriteLn('ERROR: y = 0')
else
begin
x := 100 / y;
WriteLn('100 / ', y, ' = ', x);
end;
Ну что же. На этом с видами ошибок пока всё. Изучайте программирование и поменьше ошибайтесь.
|
|
Основы программирования Каждый профессионал когда-то был чайником. Наверняка вам знакомо состояние, когда “не знаешь как начать думать, чтобы до такого додуматься”. Наверняка вы сталкивались с ситуацией, когда вы просто не знаете, с чего начать. Эта книга ориентирована как раз на таких людей, кто хотел бы стать программистом, но совершенно не знает, как начать этот путь. Подробнее… |

Опытные программисты знают, что ошибки в программе делятся на два основных типа. Первая разновидность — это баги, которые вылавливаются при компиляции. К ним относятся преимущественно проблемы с синтаксисом, явная несовместимости типов и т.д. Эту разновидность багов исправляют на этапе разработки, так как компилятор «вылетает по ошибке». Их просто невозможно не заметить.
Второй тип – системные или логические ошибки – намного сложнее выявить. Компилятор их не замечает. Программа полностью работоспособна. Но в некоторых случаях она начинает выдавать результаты, отличные от ожидаемых.
Выявить этот вид багов удается только на этапе тестирования. И хорошо, если ошибку удается исправить локальной «заплаткой». Нередко приходится менять практически весь алгоритм. А это – дополнительные затраты времени, сил, а в коммерческих проектах – финансовые, а иногда и репутационные потери.
Застраховаться полностью от логических ошибок невозможно. Но вполне реально изучить самые распространенные типы таких багов и проверять на них программу на самых ранних этапах.
Алгоритм – основа всех основ
Написание алгоритма – это самый первый этап разработки, когда идеи только обретают форму еще без привязки к языку программирования. Нередко начинающие программисты относятся к созданию алгоритма «спустя рукава» — делают только «общие наброски» или вообще приступают к кодингу сразу без предварительной проработки логики «на бумаге».
Такой подход возможен при решении учебных задач на 10-15 строк кода. Но при работе над серьезным программным продуктом пренебрежение алгоритмом – почти гарантированный путь к логическим ошибкам и катастрофическим результатам.
Как работать с алгоритмом:
- Начинайте с малого. Запишите алгоритм упрощенно, в виде «черных ящиков» (логических блоков без подробностей их работы). Это поможет оценить работоспособность идеи в целом.
- Двигайтесь сверху вниз. Сначала – общая идея «в целом», далее – детализация основных функций и так далее. Не бойтесь ставить «заглушки» и прорабатывать мелкие детали в последнюю очередь. Двигаться сверху вниз проще и с точки зрения логики, и психологически.
- Пишите команды «от имени компьютера». Помните, что вы имеете дело не с человеком, а с компьютером, который буквально выполняет команды и после каждого шага ждет ответа на вопрос «что делать». Например, логический блок «сохранение документа» будет понятен вам, но не компьютеру. Он вполне подойдет на этапе крупных блоков в качестве заглушки. Но далее придется проработать все действия пошагово с учетом выбранного языка программирования.
- Делите код на отдельные модули (блоки), которые можно будет запускать отдельно друг от друга. Это сильно облегчит как алгоритмизацию, так и процесс отладки.
- Читайте алгоритм «как будто компьютер». Проверяйте себя на каждом этапе. Главное правило – одинаковые данные всегда должны вести к одинаковым результатам.
Итак, алгоритм написан и проверен со всех сторон. Выбран язык программирования. Начинается процесс кодинга. Давайте разбираться, на что обращать особое внимание.
«Не туда положил»: о типах данных
Здесь проблемы возникают в двух случаях:
- При статической типизации в таких языках, как С++, Java или С# неверно определен тип переменной. Большинство подобных ошибок выявляет компилятор. Но здесь есть свои «лазейки» для багов. Например, в С# вполне возможно «положить» вещественное значение в целочисленную переменную. И оно просто округлится до целого. Т.е. вместо 1,3 у вас будет храниться значение 1. Само собой, все дальнейшие вычисления будут содержать ошибку.
- При динамической типизации (JavaScript, Python, PHP) неявное приведение типов – самое обычное дело. А потому здесь даже компилятор промолчит в случае ошибки. Например, вы планируете получить целочисленное значение, для чего отправляете результаты вычислений в переменную типа int. Но программа видит «знаки после запятой», и переменная без вашего участия меняет тип на float.
Самый известный пример подобной ошибки – деление двух целых чисел с остатком.
int a = 25;
int b = 8;
float c = a/b;
Console.Write(c);
Как вы думаете, какое число будет выведено на экран после выполнения последней строки? По идее, это должно быть 3,125. Но, например, в C# вы увидите целую цифру «3». Причем, тип переменной С будет float, как вы и заказывали.
Здесь проблема в другом: компилятор сначала проводит целочисленное деление, так как определяет переменные A и B как относящиеся к типу int. И полученный результат отправляет в переменную C (тип float). Целое значение (32 разряда) прекрасно помещается в 64-разрядный float, отведенный под хранение результата. Компилятор не видит ошибки. А у вас в программе появляются неточные вычисления, которые могут повлечь за собой большие проблемы.
Аналогичным образом компилятор округлит значение до целого и в Python 2. А уже в Python 3 алгоритм преобразования типов сработает иначе: сначала определится тип переменной, куда отправляется значение, а потом будет проводиться деление. После компиляции кода в Python 3 вы получите c=3,125.
Необходимо четко понимать, как работает преобразование типов в выбранном языке программирования. И в случае любых сомнений проверять результаты в отладчике.
Высвобождение ресурсов: до 100% загрузки процессора
Если вы работаете с языком, где реализована автоматическая сборка мусора, внимательно следите за тем, как происходит высвобождение ресурсов. В отдельных случаях эта полезная функция может начать работать во вред: отбирать для себя максимум памяти, загружать дополнительными задачами процессор, замедлять и даже «подвешивать» программу.
Например, в Java этот процесс работает так:
- Виртуальная машина проводит поиск ненужных объектов;
- Составляет из них очередь на удаление;
- По мере продвижения очереди очищает ячейки памяти.
В результате очередь может стать настолько большой, что компьютер перестанет с ней справляться. А до удаления всех ненужных объектов дело может даже не дойти.
Как итог, программа «загрязняет» память служебной информацией. Кроме того, формируется уязвимость: в этой «свалке данных» могут оказаться логины с паролями и другие личные данные.
Намного надежнее своевременно применять функции типа try-with-resources и try-finally. И все ресурсы очищать в том коде, где вы их получили.
И еще: не забывайте закрывать сессии и файлы сразу после того, как они перестают быть нужны. Это должно быть также естественно, как закрыть скобку в коде.
Конфликт потоков: кто первый успеет?
Если программа работает с несколькими потоками одновременно, необходимо исключить ситуацию конфликта потоков. Так бывает, когда процессы наперегонки пытаются работать с общими ресурсами, в итоге нарушают целостность данных и последовательность действий.
Например: первый поток в результате вычислений получает значение 1, отправляет его в переменную. В это время второй поток перехватывает доступ и обнуляет эту переменную. А первый – сохраняет значение. В результате вы планировали запомнить значение 1. А у вас сразу после вычислений сохраняется 0. И далее копятся ошибка за ошибкой.
Чтобы избежать этой проблемы не забывайте при работе с разными потоками ставить блокировки, чтобы они не обращались одновременно к одним и тем же ресурсам. Можно применять и другие методы синхронизации – события, семафоры, критические секции.
Переменные: склонность к глобализации
Эта ошибка популярна у новичков – стремление объявить сразу все переменные и сделать их глобальными. В результате таких действий вы:
- перегружаете ресурсы оборудования;
- получаете множество уязвимостей, которые сложно закрыть;
- усложняете в разы отладку и поиск багов.
На глобальном уровне определяют только необходимый минимум – те самые глобальные переменные, с которыми работают практически все модули. Все остальные объявляйте в тех модулях, где они работают. И не забывайте об идентификаторах ограничения доступа: public, private и protected.
Переполнение буфера в С/С++: «танцы на граблях»
В большинстве современных языках программирования высокого уровня вопрос буферизации решен на автоматическом уровне. Например, Java самостоятельно контролирует размер буфера и определяет границы массивов.
Но нередко для экономии ресурсов программисты используют C-библиотеки. В этом случае очень важно следить за буферизацией. Дело в том, что языки C/С++ очень уязвимы к переполнению буфера. Если он окажется меньше, чем нужно для работы, программа попытается использовать память за пределами выделенного участка. Результат – многочисленные, можно сказать, легендарные ошибки, когда в обрабатываемые данные попадает «неведомый мусор».
Хуже того, это очень известная уязвимость. С 1988 года хакеры пользуются этой «дырой», чтобы подменить адрес возврата в стеке на собственный. Так в программу попадает подставная функция, которая передает управление коду мошенников.
Изучите особенности работы с буфером и методы борьбы с его переполнением, чтобы не пополнить число «танцующих на граблях с 30-летней историей».
Отладка и поиск логических багов
И, напоследок, несколько советов, как выявить проблему, если вы подозреваете, что с программой что-то не так.
- Пользуйтесь возможностями отладчика вашей IDE. Ставьте контрольные точки, отражайте на консоли ход выполнения и значения переменных, переходите в «пошаговый режим» выполнения в наиболее «подозрительных» участках кода. Так вы быстрее сможете локализовать проблему.
- Помните: компилятор может неправильно указывать строку с ошибкой. Если вам повезло, и компилятор помог вам выявить баг, не спешите радоваться. При «завершении с ошибкой» вы видите номер строки, в которой выполнение программы стало невозможным. Если проблема в простейшей опечатке (синтаксис), то строка с багом вам известна. В случае логических ошибок вероятнее всего, проблема появилась на более ранних этапах работы программы. А в указанной строке была попытка использовать ошибочные данные, что и привело к аварийному завершению.
- Старый добрый листинг программы тоже может помочь. Если вы запутались и не знаете, что делать, распечатайте код и попробуйте его «выполнить» как будто вы – и есть компьютер. Шаг за шагом двигайте по командам. Переходите от блока к блоку так, как это делает программа. На каждом этапе вычисляйте и фиксируйте значения переменных (калькулятором пользоваться можно). И сверяйте результаты с ожидаемыми. Все в порядке? Двигайтесь дальше. Что-то не так? Ура! Вы локализовали баг. Можно возвращаться за компьютер и разбираться подробнее в этом фрагменте кода в отладчике.
И самое главное: не бойтесь что-то менять, в том числе, на глобальном уровне. Лучше переписать «сырой» код на раннем этапе разработки практически полностью, чем из-за серьезной логической ошибки терять в скорости и качестве работы программы, пытаясь использовать кучу «заплаток». От ошибок не застрахован никто. Потраченного времени жаль, но это – ваш личный практический опыт. А программа должна работать быстро, надежно и, самое главное, правильно.
Ошибки в программировании – дело обычное, хоть и неприятное. В данной статье будет рассказано о том, какими бывают ошибки (баги), а также что собой представляют исключения.
Определение
Ошибка в программировании (или так называемый баг) – это ситуация у разработчиков, при которой определенный код вследствие обработки выдает неверный результат. Причин данному явлению множество: неисправность компилятора, сбои интерфейса, неточности и нарушения в программном коде.
Баги обнаруживаются чаще всего в момент отладки или бета-тестирования. Реже – после итогового релиза готовой программы. Вот несколько вариантов багов:
- Появляется сообщение об ошибке, но приложение продолжает функционировать.
- ПО вылетает или зависает. Никаких предупреждений или предпосылок этому не было. Процедура осуществляется неожиданно для пользователя. Возможен вариант, при котором контент перезапускается самостоятельно и непредсказуемо.
- Одно из событий, описанных ранее, сопровождается отправкой отчетов разработчикам.
Ошибки в программах могут привести соответствующее приложение в негодность, а также к непредсказуемым алгоритмам функционирования. Желательно обнаруживать баги на этапе ранней разработки или тестирования. Лишь в этом случае программист сможет оперативно и относительно недорого внести необходимые изменения в код для отладки ПО.
История происхождения термина
Баг – слово, которое используется разработчиками в качестве сленга. Оно произошло от слова «bug» – «жук». Точно неизвестно, откуда в программировании и IT возник соответствующий термин. Существуют две теории:
- 9 сентября 1945 года ученые из Гарварда тестировали очередную вычислительную машину. Она называлась Mark II Aiken Relay Calculator. Устройство начало работать с ошибками. Когда его разобрали, то ученые заметили мотылька, застрявшего между реле. Тогда некая Грейс Хоппер назвала произошедший сбой упомянутым термином.
- Слово «баг» появилось задолго до появления Mark II. Термин использовался Томасом Эдисоном и указывал на мелкие недочеты и трудности. Во время Второй Мировой войны «bugs» называли проблемы с радарной электроникой.
Второй вариант кажется более реалистичным. Это факт, который подтвержден документально. Со временем научились различать различные типы багов в IT. Далее они будут рассмотрены более подробно.
Как классифицируют
Ошибки работы программ разделяются по разным факторам. Классификация у рядовых пользователей и разработчиков различается. То, что для первых – «просто программа вылетела» или «глючит», для вторых – огромная головная боль. Но существует и общепринятая классификация ошибок. Пример – по критичности:
- Серьезные неполадки. Это нарушения работоспособности приложения, которые могут приводить к непредвиденным крупным изменениям.
- Незначительные ошибки в программах. Чаще всего не оказывают серьезного воздействия на функциональность ПО.
- Showstopper. Критические проблемы в приложении или аппаратном обеспечении. Приводят к выходу программы из строя почти всегда. Для примера можно взять любое клиент-серверное приложение, в котором не получается авторизоваться через логин и пароль.
Последний вариант требует особого внимания со стороны программистов. Их стараются обнаружить и устранить в первую очередь. Критические ошибки могут отложить релиз исходной программы на неопределенный срок.
Также существуют различные виды сбоев в плане частоты проявления: постоянные и «разовые». Вторые встречаются редко, чаще – при определенных настройках и действиях со стороны пользователя. Первые появляются независимо от используемой платформы и выполненных клиентом манипуляций.
Иногда может получиться так, что ошибка возникает только на устройстве конкретного пользователя. В данном случае устранение неполадки требует индивидуального подхода. Иногда – полной замены компьютера. Связано это с тем, что никто не будет редактировать исходный код, когда он «глючит» только у одного пользователя.
Виды
Существуют различные типы ошибок в программах в зависимости от типовых условий использования приложений. Пример – сбои, которые возникают при возрастании нагрузки на оперативную память или центральный процессор устройства. Есть баги граничных условий, сбоя идентификаторов, несовместимости с архитектурой процессора (наиболее распространенная проблема на мобильных устройствах).
Разработчики выделяют следующие типы ошибок по уровню сложности:
- «Борбаг» – «стабильная» неполадка. Она легко обнаруживается на этапе разработки и компилирования. Иногда – во время тестирования наработкой исходной программы.
- «Гейзенбаг» – баги с поддержкой изменения свойств, включая зависимость от среды, в которой было запущено приложение. Сюда относят периодические неполадки в программах. Они могут исчезать на некоторое время, но через какой-то промежуток вновь дают о себе знать.
- «Мандельбаг» – непредвиденные ошибки. Обладают энтропийным поведением. Предсказать, к чему они приведут, практически невозможно.
- «Шрединбаг» – критические неполадки. Приводят к тому, что злоумышленники могут взломать программу. Данный тип ошибок обнаружить достаточно трудно, потому что они никак себя не проявляют.
Также есть классификация «по критичности». Тут всего два варианта – warning («варнинги») и критические весомые сбои. Первые сопровождаются характерными сообщениями и отчетами для разработчиков. Они не представляют серьезной опасности для работоспособности приложения. При компилировании такие сбои легко исправляются. В отдельных случаях компилятор справляется с этой задачей самостоятельно. А вот критические весомые сбои говорят сами за себя. Они приводят к серьезным нарушениям ПО. Исправляются обычно путем проработки логики и значительных изменений программного кода.
Типы багов
Ошибки в программах бывают:
- логическими;
- синтаксическими;
- взаимодействия;
- компиляционные;
- ресурсные;
- арифметические;
- среды выполнения.
Это – основная классификация сбоев в приложениях и операционных системах. Логические, синтаксические и «среды выполнения» встречаются в разработке чаще остальных. На них будет сделан основной акцент.
Ошибки синтаксиса
Синтаксические баги распространены среди новичков. Они относятся к категории «самых безобидных». С данной категорией ошибок способны справиться компиляторы тех или иных языков. Соответствующие инструменты показывают, где допущена неточность. Остается лишь понять, как исправить ее.
Синтаксические ошибки – ошибки синтаксиса, правил языка. Вот пример в Паскале:
Код написан неверно. Согласно действующим синтаксическим нормам, в Pascal в первой строчке нужно в конце поставить точку с запятой.
Логические
Тут стоит выделить обычные и арифметические типы. Вторые возникают, когда программе при работе необходимо вычислить много переменных, но на каком-то этапе расчетов возникают неполадки или нечто непредвиденное. Пример – получение в результатах «бесконечности».
Логические сбои обычного типа – самые сложные и неприятные. Их тяжелее всего обнаружить и исправить. С точки зрения языка программа может быть написана идеально, но работать неправильно. Подобное явление – следствие логической ошибки. Компиляторы их не обнаруживают.
Выше – пример логической ошибки в программе. Тут:
- Происходит сравнение значения i с 15.
- На экран выводится сообщение, если I = 15.
- В заданном цикле i не будет равно 15. Связано это с диапазоном значений – от 1 до 10.
Может показаться, что ошибка безобидная. В приведенном примере так и есть, но в более крупных программах такое явление приводит к серьезным последствиям.
Время выполнения
Run-time сбои – это ошибка времени выполнения программы. Встречается даже когда исходный код лишен логических и синтаксических ошибок. Связаны такие неполадки с ходом выполнения программного продукта. Пример – в процессе функционирования ПО был удален файл, считываемый программой. Если игнорировать подобные неполадки, можно столкнуться с аварийным завершением работы контента.
Самый распространенный пример в данной категории – это неожиданное деление на ноль. Предложенный фрагмент кода с точки зрения синтаксиса и логики написан грамотно. Но, если клиент наберет 0, произойдет сбой системы.
Компиляционный тип
Встречается при разработке на языках высокого уровня. Во время преобразований в машинный тип «что-то идет не так». Причиной служат синтаксические ошибки или сбои непосредственно в компиляторе.
Наличие подобных неполадок делает бета-тестирование невозможным. Компиляционные ошибки устраняются при разработке-отладке.
Ресурсные
Ресурсный тип ошибок – это сбои вроде «переполнение буфера» или «нехватка памяти». Тесно связаны с «железом» устройства. Могут быть вызваны действиями пользователя. Пример – запуск «свежих» игр на стареньких компьютерах.
Исправить ситуацию помогают основательные работы над исходным кодом. А именно – полное переписывание программы или «проблемного» фрагмента.
Взаимодействие
Подразумевается взаимодействие с аппаратным или программным окружением. Пример – ошибка при использовании веб-протоколов. Это приведет к тому, что облачный сервис не будет нормально функционировать. При постоянном возникновении соответствующей неполадки остается один путь – полностью переписывать «проблемный» участок кода, ответственный за соответствующий баг.
Исключения и как избежать багов
Исключение – событие, при возникновении которых начинается «неправильное» поведение программы. Механизм, необходимый для стабилизации обработки неполадок независимо от типа ПО, платформ и иных условий. Помогают разрабатывать единые концепции ответа на баги со стороны операционной системы или контента.
Исключения бывают:
- Программными. Они генерируются приложением или ОС.
- Аппаратными. Создаются процессором. Пример – обращение к невыделенной памяти.
Исключения нужны для охвата критических багов. Избежать неполадок помогут отладчики на этапе разработки. А еще – своевременное поэтапное тестирование программы.
P. S. Большой выбор курсов по тестированию есть и в Otus. Присутствуют варианты как для продвинутых, так и для начинающих пользователей.
1. найди что-нибудь интересное >>> 2. нажми/кликни на какую-нибудь картинку >>> 3. сыграй в пазл ………………..1. найди что-нибудь интересное >>> 2. нажми/кликни на какую-нибудь картинку >>> 3. сыграй в пазл
………………..
… В программировании логической ошибкой называется баг, который приводит к некорректной работе программы, но …
- Эта статья о логической ошибке в программировании. Об ошибках, связанных с нарушением логической правильности рассуждений, см. Логическая ошибка (b) .
В программировании (b) логической ошибкой называется баг (b) , который приводит к некорректной работе программы, но не к краху программы (b) .
Логические ошибки могут происходить как в компиляторах (b) , так и в интерпретаторах (b) . В отличие от синтаксических ошибок, программы с логическим изъяном являются правильными программами, хотя в большинстве случаев ведут себя не так, как задумано первоначально[1].
Существование данного вида ошибок связано с неправильными действиями на этапе принятия решений.
В C++ (b) логической ошибкой также называется особое исключение (b) (logic_exception).
Общие причины
Ошибки могут быть связаны как с простейшими опечатками в написании операторов, так и в запутанном выборе веток алгоритма. Существует также масса других причин: некорректное приведение типа (b) , использование переменной вне её области видимости (b) , отсутствие фрагмента кода и ошибочное понимание разработчиком требований.
Отладка логических ошибок
Одним из способов поиска этого типа ошибки является распечатка списка переменных (b) в программе (во внешний файл или на экран). Хотя этот способ не работает, если ошибка заключается в вызове не той функции (b) , он всё же является самым простым в случае неправильной реализации математического алгоритма (b) .
Примеры
В этом примере задачей функции является возвращение среднего (b) для двух переданных чисел. Ошибка кроется в неучёте приоритета операторов (деление в выражении вычисляется до операции сложения) и отсутствии по этой причине скобок.
int average(int a, int b){ return a + b / 2; /* правильная запись (a + b) / 2 */}
См. также
- Синтаксическая ошибка (программирование) (b)
- Ошибка на единицу (b)
- Runtime error detection (b) [en]
- Compilation error (b) [en]
Примечания
- ↑ Знайте свои ошибки. Три типа ошибок в программировании. Microsoft. Дата обращения: 5 января 2017. Архивировано 6 января 2017 года.
|
|---|

Эта статья опубликована с веб-сайта Wikipedia. Исходная статья может быть немного сокращена или изменена. Некоторые ссылки могли быть изменены. Текст находится под лицензией «Creative Commons — Attribution — Sharealike» [1], а часть текста также может быть лицензирована в соответствии с условиями «Лицензии свободной документации GNU» [2]. К медиафайлам могут применяться дополнительные условия. Используя этот сайт, вы соглашаетесь с нашими юридическими страницами[3] [4] [5] [6] [7]. Веб-ссылки: [1] [2]
W w W
Логическая ошибка (программирование)
-
Эта статья о логической ошибке в программировании. Об ошибках, связанных с нарушением логической правильности рассуждений, см. Логическая ошибка.В программировании логической ошибкой называется баг, который приводит к некорректной работе программы, но не к краху программы.
Логические ошибки могут происходить как в компиляторах, так и в интерпретаторах. В отличие от синтаксических ошибок, программы с логическим изъяном являются правильными программами, хотя в большинстве случаев ведут себя не так, как задумано первоначально.
Существование данного вида ошибок связано с неправильными действиями на этапе принятия решений.
В С++ логической ошибкой также называется особое исключение (logic_exception).
Источник: Википедия
Связанные понятия
Код ошибки (англ. Error code) в программировании, — это номер (или сочетания буквы и номера), который соответствует конкретной проблеме в работе программы. Коды ошибок используются для идентификации неправильной работы аппаратного и программного обеспечения, неверного ввода данных пользователем без обработки возникающей при этом исключительной ситуации в коде программы, хотя иногда коды ошибок используются в сочетании с обработкой исключений. Коды ошибок не следует путать с кодами возврата, хотя…
Перегрузка операторов в программировании — один из способов реализации полиморфизма, заключающийся в возможности одновременного существования в одной области видимости нескольких различных вариантов применения оператора, имеющих одно и то же имя, но различающихся типами параметров, к которым они применяются.
Программи́рование ме́тодом копи́рования-вста́вки, C&P-программирование или копипаста в программировании — процесс создания программного кода с часто повторяющимися частями, произведёнными операциями копировать-вставить (англ. copy-paste). Обычно этот термин используется в уничижительном понимании для обозначения недостаточных навыков компьютерного программирования или отсутствия выразительной среды разработки, в которой, как правило, можно использовать подключаемые библиотеки.
Стратегия вычисления (англ. evaluation strategy) — правила семантики языка программирования, определяющие, когда следует вычислять аргументы функции (метода, операции, отношения), и какие значения следует передавать. Например, стратегия «вызов-при-упоминании/передача-по-ссылке» (call-by-worth/pass-by-reference) диктует, что аргументы должны быть вычислены перед выполнением тела вызываемой функции, и что ей должны быть предоставлены две возможности в отношении каждого аргумента: чтение текущего значения…
Опера́тор ветвле́ния (усло́вная инстру́кция, усло́вный опера́тор) — оператор, конструкция языка программирования, обеспечивающая выполнение определённой команды (набора команд) только при условии истинности некоторого логического выражения, либо выполнение одной из нескольких команд (наборов команд) в зависимости от значения некоторого выражения.
Подробнее: Ветвление (программирование)
Упоминания в литературе
Слишком абстрактные, слишком широкие формулировки гипотез допускают потом «игру в наперсток», многочисленные манипуляции, которые затрудняют осознание истинного положения дел – что гипотеза не получает подтверждения. В результате в работах встречаются логические ошибки, примеры фактического опровержения которых во множестве представлены в данной книге. Самые частые ошибки, встречающиеся в статьях, содержащих адаптационистские объяснения, следующие.
• целостность поведения (behavioral integrity): система ведет себя, как предполагается, и не допускает логических ошибок;
Пожалуй, главным в процессе мышления каждого человека, если тот, конечно, не желает допускать логических ошибок, является знание и правильное применение логических законов.
Ясно, что сведение всего смысла объективности к его «слабой» компоненте было просто следствием «дуалистической эпистемологии», которую мы рассматривали в предшествующих разделах. Именно благодаря этому предрассудку упомянутое отождествление стало казаться не логической ошибкой (а именно принятие необходимого условия за достаточное), а просто следствием фактического обстоятельства (т. е. невозможности когда-либо выполнить требование «сильного» смысла объективности). Если теперь рассмотреть конкретно науку, мы можем сказать, что в истории современной науки можно увидеть нечто вроде резюме общей разноголосицы, которую мы попытались изобразить при анализе понятия «объективное знание». Начиная с Галилея, наука рассматривалась как поставщик объективного знания в сильном смысле, поскольку, как мы видели, предполагалось, что она имеет дело непосредственно с некоторыми внутренними (пусть уже и не существенными) свойствами вещей. С очень немногочисленными исключениями это убеждение оставалось глубоко укорененным в умах практикующих ученых, так же как и в общераспространенном здравом смысле, по крайней мере до конца XIX столетия. А тем временем философия, с другой стороны, совершила переход от античной концепции сильной объективности к новой концепции слабой объективности. К концу XIX в., а еще более с началом XX в. нечто подобное утрате веры в возможность «постичь объект» произошло и в науке, повторяя в некотором смысле ситуацию, имевшую место в философии в период от Галилея до Канта[70].
Можно привести и другие, столь же мудреные и ненадежные определения. В чем их недостаток? Они для определения интеллекта используют сложные понятия. Это грубая логическая ошибка. Хорошее определение может свести понятие к более общему с добавлением достаточного уточняющего признака. Например, белая береза – это дерево с белой корой. При условии что понятие «дерево» уже определено и больше деревьев с белой корой не существует, это определение вполне удачно. Причем черную березу (а такая тоже есть) мы в определении отмели, так как ограничились именно белой.
Связанные понятия (продолжение)
Продолжение (англ. continuation) представляет состояние программы в определённый момент, которое может быть сохранено и использовано для перехода в это состояние. Продолжения содержат всю информацию, чтобы продолжить выполнения программы с определённой точки. Состояние глобальных переменных обычно не сохраняется, однако для функциональных языков это несущественно (выборочное сохранение/восстановление значений глобальных объектов в Scheme достигается отдельным механизмом dynamic-wind). Продолжения…
Си (англ. C) — компилируемый статически типизированный язык программирования общего назначения, разработанный в 1969—1973 годах сотрудником Bell Labs Деннисом Ритчи как развитие языка Би. Первоначально был разработан для реализации операционной системы UNIX, но впоследствии был перенесён на множество других платформ. Согласно дизайну языка, его конструкции близко сопоставляются типичным машинным инструкциям, благодаря чему он нашёл применение в проектах, для которых был свойственен язык ассемблера…
Структу́рное программи́рование — парадигма программирования, в основе которой лежит представление программы в виде иерархической структуры блоков.
Байесовское программирование — это формальная система и методология определения вероятностных моделей и решения задач, когда не вся необходимая информация является доступной.
Правило одного определения (One Definition Rule, ODR) — один из основных принципов языка программирования C++. Назначение ODR состоит в том, чтобы в программе не могло появиться два или более конфликтующих между собой определения одной и той же сущности (типа данных, переменной, функции, объекта, шаблона). Если это правило соблюдено, программа ведёт себя так, как будто в ней существует только одно, общее определение любой сущности. Нарушение ODR, если оно не будет обнаружено при компиляции и сборке…
Логика Хоара (англ. Hoare logic, также Floyd—Hoare logic, или Hoare rules) — формальная система с набором логических правил, предназначенных для доказательства корректности компьютерных программ. Была предложена в 1969 году английским учёным в области информатики и математической логики Хоаром, позже развита самим Хоаром и другими исследователями. Первоначальная идея была предложена в работе Флойда, который опубликовал похожую систему в применении к блок-схемам (англ. flowchart).
Обнаруже́ние оши́бок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи.
Пролог (англ. Prolog) — язык и система логического программирования, основанные на языке предикатов математической логики дизъюнктов Хорна, представляющей собой подмножество логики предикатов первого порядка.
Алгори́тм (лат. algorithmi — от арабского имени математика Аль-Хорезми) — конечная совокупность точно заданных правил решения произвольного класса задач или набор инструкций, описывающих порядок действий исполнителя для решения некоторой задачи. В старой трактовке вместо слова «порядок» использовалось слово «последовательность», но по мере развития параллельности в работе компьютеров слово «последовательность» стали заменять более общим словом «порядок». Независимые инструкции могут выполняться…
Терна́рная усло́вная опера́ция (от лат. ternarius — «тройной») (обычно записывается как ?:) — во многих языках программирования операция, возвращающая свой второй или третий операнд в зависимости от значения логического выражения, заданного первым операндом. Как можно судить из названия, тернарная операция принимает всего три указанных операнда. Аналогом тернарной условной операции в математической логике и булевой алгебре является условная дизъюнкция, которая записывается в виде и реализует алгоритм…
Синтаксический сахар (англ. syntactic sugar) в языке программирования — это синтаксические возможности, применение которых не влияет на поведение программы, но делает использование языка более удобным для человека.
Гейзенбаг (англ. heisenbug) — жаргонный термин, используемый в программировании для описания программной ошибки, которая исчезает или меняет свои свойства при попытке её обнаружения. Это слово, в отличие от слова «баг» (англ. bug), в русском языке используется редко. Не полностью идентичный, но достаточно близкий по значению русскоязычный термин — «плавающая ошибка», жаргонный термин — «глюк».
Программирование методом подбора, который иногда называют «случайным программированием», это подход к разработке программного обеспечения, при котором программист решает проблему итеративно, делая небольшие изменения (перестановки) и тестирование каждого изменения, чтобы увидеть, ведёт ли оно себя, как хотелось бы.
Поиск клонов в исходном коде — анализ исходного кода с помощью различных алгоритмов, с целью обнаружения клонированного кода, который может иметь вредоносный характер.
Функциона́льное программи́рование — раздел дискретной математики и парадигма программирования, в которой процесс вычисления трактуется как вычисление значений функций в математическом понимании последних (в отличие от функций как подпрограмм в процедурном программировании).
Пара́метр в программировании — принятый функцией аргумент. Термин «аргумент» подразумевает, что конкретно и какой конкретной функции было передано, а параметр — в каком качестве функция применила это принятое. То есть вызывающий код передает аргумент в параметр, который определен в члене спецификации функции.
Вариативный шаблон или шаблон с переменным числом аргументов в программировании — шаблон с заранее неизвестным числом аргументов, которые формируют один или несколько так называемых пакетов параметров.
Обучение с ошибками (англ. Learning with errors) — это концепция машинного обучения, суть которой заключается в том, что в простые вычислительные задачи (например, системы линейных уравнений) намеренно вносится ошибка, делая их решение известными методами неосуществимым за приемлемое время.
В области математики и теории информации линейный код — это важный тип блокового кода, использующийся в схемах определения и коррекции ошибок. Линейные коды, по сравнению с другими кодами, позволяют реализовывать более эффективные алгоритмы кодирования и декодирования информации.
Подробнее: Линейный код
Полный перебор (или метод «грубой силы», англ. brute force) — метод решения математических задач. Относится к классу методов поиска решения исчерпыванием всевозможных вариантов. Сложность полного перебора зависит от количества всех возможных решений задачи. Если пространство решений очень велико, то полный перебор может не дать результатов в течение нескольких лет или даже столетий.
В приведённой ниже таблице отмечено наличие или отсутствие тех или иных возможностей в некоторых популярных сегодня языках программирования. Столбцы упорядочены по алфавиту. Если возможность в языке недоступна напрямую, но может быть эмулирована с помощью других средств, то в таблице отмечено, что её нет.
Подробнее: Сравнение языков программирования
Мультиме́тод (англ. multimethod) или мно́жественная диспетчериза́ция (англ. multiple dispatch) — механизм, позволяющий выбрать одну из нескольких функций в зависимости от динамических типов или значений аргументов. Представляет собой расширение одиночной диспетчеризации (виртуальных функций), где выбор метода осуществляется динамически на основе фактического типа объекта, для которого этот метод был вызван. Множественная диспетчеризация обобщает динамическую диспетчеризацию для случаев с двумя или…
Самопримени́мость в теории алгоритмов — свойство алгоритма успешно завершаться на данных, представляющих собой формальную запись этого же алгоритма.
В информатике типобезопасность (англ. type safety) языка программирования означает безопасность (или надёжность) его системы типов.
Перебор по словарю (англ. dictionary attack) — атака на систему защиты, использующая метод полного перебора (англ. brute-force) предполагаемых паролей, используемых для аутентификации, осуществляемого путём последовательного пересмотра всех слов (паролей в чистом виде или их зашифрованных образов) определённого вида и длины из словаря с целью последующего взлома системы и получения доступа к секретной информации.
Конкатенативный язык программирования — это язык программирования, основанный на том, что конкатенация двух фрагментов кода выражает их композицию. В таком языке широко используется неявное указание аргументов функций (см. бесточечное программирование), новые функции определяются как композиция функций, а вместо аппликации применяется конкатенация. Этому подходу противопоставляется аппликативное программирование.
Обобщённое программирование (англ. generic programming) — парадигма программирования, заключающаяся в таком описании данных и алгоритмов, которое можно применять к различным типам данных, не меняя само это описание. В том или ином виде поддерживается разными языками программирования. Возможности обобщённого программирования впервые появились в виде дженериков (обобщённых функций) в 1970-х годах в языках Клу и Ада, затем в виде параметрического полиморфизма в ML и его потомках, а затем во многих объектно-ориентированных…
Неопределённое поведение (англ. undefined behaviour, в ряде источников непредсказуемое поведение) — свойство некоторых языков программирования (наиболее заметно в Си), программных библиотек и аппаратного обеспечения в определённых маргинальных ситуациях выдавать результат, зависящий от реализации компилятора (библиотеки, микросхемы) и случайных факторов наподобие состояния памяти или сработавшего прерывания. Другими словами, спецификация не определяет поведение языка (библиотеки, микросхемы) в любых…
Перегрузка процедур и функций — возможность использования одноимённых подпрограмм: процедур или функций в языках программирования.
Присва́ивание — механизм связывания в программировании, позволяющий динамически изменять связи имён объектов данных (как правило, переменных) с их значениями. Строго говоря, изменение значений является побочным эффектом операции присваивания, и во многих современных языках программирования сама операция также возвращает некоторый результат (как правило, копию присвоенного значения). На физическом уровне результат операции присвоения состоит в проведении записи и перезаписи ячеек памяти или регистров…
Сравнение с обменом (англ. compare and set, compare and swap, CAS) — атомарная инструкция, сравнивающая значение в памяти с одним из аргументов, и в случае успеха записывающая второй аргумент в память. Поддерживается в семействах процессоров x86, Itanium, Sparc и других.
Хеширование (англ. hashing – «превращать в фарш», «мешанина») — преобразование массива входных данных произвольной длины в (выходную) битовую строку установленной длины, выполняемое определённым алгоритмом. Функция, воплощающая алгоритм и выполняющая преобразование, называется «хеш-функцией» или «функцией свёртки». Исходные данные называются входным массивом, «ключом» или «сообщением». Результат преобразования (выходные данные) называется «хешем», «хеш-кодом», «хеш-суммой», «сводкой сообщения».
Каламбур типизации является прямым нарушением типобезопасности. Традиционно возможность построить каламбур типизации связывается со слабой типизацией, но и некоторые сильно типизированные языки или их реализации предоставляют такие возможности (как правило, используя в связанных с ними идентификаторах слова unsafe или unchecked). Сторонники типобезопасности утверждают, что «необходимость» каламбуров типизации является мифом.
Синтаксическая ошибка может возникать при некорректном вводе уравнения в калькулятор. Это может быть вызвано, например, путём открытия скобок без их закрытия, или, реже, вводом нескольких десятичных разделителей подряд.
Блокировка с двойной проверкой (англ. Double checked locking) — параллельный шаблон проектирования, предназначающийся для уменьшения накладных расходов, связанных с получением блокировки. Сначала проверяется условие блокировки без какой-либо синхронизации; поток делает попытку получить блокировку, только если результат проверки говорит о том, что получение блокировки необходимо.
Автома́тное программи́рование — это парадигма программирования, при использовании которой программа или её фрагмент осмысливается как модель какого-либо формального автомата. Известна также и другая «парадигма автоматного программирования, состоящая в представлении сущностей со сложным поведением в виде автоматизированных объектов управления, каждый из которых представляет собой объект управления и автомат». При этом о программе, как в автоматическом управлении, предлагается думать как о системе…
Фортра́н (англ. Fortran) — первый язык программирования высокого уровня, получивший практическое применение, имеющий транслятор и испытавший дальнейшее развитие. Создан в период с 1954 по 1957 год группой программистов под руководством Джона Бэкуса в корпорации IBM. Название Fortran является сокращением от FORmula TRANslator (переводчик формул). Фортран широко используется в первую очередь для научных и инженерных вычислений. Одно из преимуществ современного Фортрана — большое количество написанных…
Виртуальный метод (виртуальная функция) — в объектно-ориентированном программировании метод (функция) класса, который может быть переопределён в классах-наследниках так, что конкретная реализация метода для вызова будет определяться во время исполнения. Таким образом, программисту необязательно знать точный тип объекта для работы с ним через виртуальные методы: достаточно лишь знать, что объект принадлежит классу или наследнику класса, в котором объявлен метод. Одним из переводов слова virtual с…
Криптографические хеш-функции — это выделенный класс хеш-функций, который имеет определенные свойства, делающие его пригодным для использования в криптографии.
Подробнее: Криптографическая хеш-функция
Код с запашко́м (код с душко́м, дурно пахнущий код англ. code smell) — термин, обозначающий код с признаками (запахами) проблем в системе. Был введён Кентом Беком и использован Мартином Фаулером в его книге Рефакторинг. Улучшение существующего кода.
Программная ошибка (жарг. баг) — означает ошибку в программе или в системе, из-за которой программа выдает неожиданное поведение и, как следствие, результат. Большинство программных ошибок возникают из-за ошибок, допущенных разработчиками программы в её исходном коде, либо в её дизайне. Также некоторые ошибки возникают из-за некорректной работы инструментов разработчика, например из-за компилятора, вырабатывающего некорректный код. Программу, которая содержит большое число ошибок, серьёзно ограничивающие…
Обучение с ошибками в кольце (англ. Ring learning with errors, RLWE)— это вычислительная задача, которая была сформулирована как вариант более общей задачи обучения с ошибками (с англ. LWE), с целью использовать преимущество дополнительной алгебраической структуры (т.е. кольца многочленов) из теории решеток, что дало возможность повысить и расширить возможности шифрования тех криптографических приложений, которые ранее основывались на LWE. Задача RLWE стала основой новых криптографических алгоритмов…
Ошибка на единицу или ошибка неучтённой единицы (англ. off-by-one error) — логическая ошибка в алгоритме, включающая в частности дискретный вариант нарушения граничных условий.
Принцип минимальной длины описания (англ. minimum description length, MDL) — это формализация бритвы Оккама, в которой лучшая гипотеза (модель и её параметры) для данного набора данных это та, которая ведёт к лучшему сжиманию даных. Принцип MDL предложил Йорма Риссанен в 1978. Принцип является важной концепцией в теории информации и теории вычислительного обучения.
Ссылочная прозрачность и ссылочная непрозрачность — это свойства частей компьютерных программ. Выражение называется ссылочно прозрачным, если его можно заменить соответствующим значением без изменения поведения программы. В результате вычисления ссылочно прозрачной функции дает одно и то же значение для одних и тех же аргументов. Такие функции называются чистыми функциями.