
From Wikipedia, the free encyclopedia
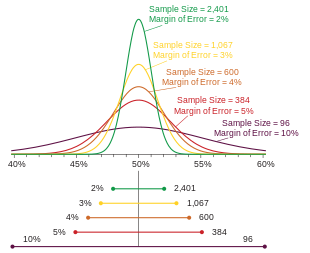
Probability densities of polls of different sizes, each color-coded to its 95% confidence interval (below), margin of error (left), and sample size (right). Each interval reflects the range within which one may have 95% confidence that the true percentage may be found, given a reported percentage of 50%. The margin of error is half the confidence interval (also, the radius of the interval). The larger the sample, the smaller the margin of error. Also, the further from 50% the reported percentage, the smaller the margin of error.
The margin of error is a statistic expressing the amount of random sampling error in the results of a survey. The larger the margin of error, the less confidence one should have that a poll result would reflect the result of a census of the entire population. The margin of error will be positive whenever a population is incompletely sampled and the outcome measure has positive variance, which is to say, whenever the measure varies.
The term margin of error is often used in non-survey contexts to indicate observational error in reporting measured quantities.
Concept[edit]
Consider a simple yes/no poll  as a sample of
as a sample of  respondents drawn from a population
respondents drawn from a population  reporting the percentage
reporting the percentage  of yes responses. We would like to know how close is to the true result of a survey of the entire population
of yes responses. We would like to know how close is to the true result of a survey of the entire population  , without having to conduct one. If, hypothetically, we were to conduct poll over subsequent samples of respondents (newly drawn from ), we would expect those subsequent results
, without having to conduct one. If, hypothetically, we were to conduct poll over subsequent samples of respondents (newly drawn from ), we would expect those subsequent results  to be normally distributed about
to be normally distributed about  . The margin of error describes the distance within which a specified percentage of these results is expected to vary from .
. The margin of error describes the distance within which a specified percentage of these results is expected to vary from .
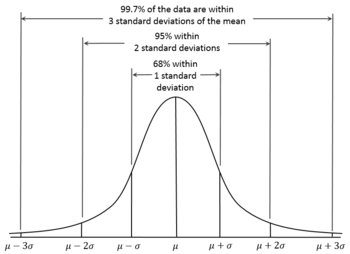
According to the 68-95-99.7 rule, we would expect that 95% of the results will fall within about two standard deviations ( ) either side of the true mean . This interval is called the confidence interval, and the radius (half the interval) is called the margin of error, corresponding to a 95% confidence level.
) either side of the true mean . This interval is called the confidence interval, and the radius (half the interval) is called the margin of error, corresponding to a 95% confidence level.
Generally, at a confidence level  , a sample sized of a population having expected standard deviation
, a sample sized of a population having expected standard deviation  has a margin of error
has a margin of error

where  denotes the quantile (also, commonly, a z-score), and
denotes the quantile (also, commonly, a z-score), and  is the standard error.
is the standard error.
Standard deviation and standard error[edit]
We would expect the average of normally distributed values to have a standard deviation which somehow varies with . The smaller , the wider the margin. This is called the standard error  .
.
For the single result from our survey, we assume that  , and that all subsequent results together would have a variance
, and that all subsequent results together would have a variance  .
.

Note that  corresponds to the variance of a Bernoulli distribution.
corresponds to the variance of a Bernoulli distribution.
Maximum margin of error at different confidence levels[edit]
For a confidence level , there is a corresponding confidence interval about the mean  , that is, the interval
, that is, the interval ![{displaystyle [mu -z_{gamma }sigma ,mu +z_{gamma }sigma ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a4568060e0cffbc8dfb793aa2ef4617c89cb9e94) within which values of should fall with probability . Precise values of are given by the quantile function of the normal distribution (which the 68-95-99.7 rule approximates).
within which values of should fall with probability . Precise values of are given by the quantile function of the normal distribution (which the 68-95-99.7 rule approximates).
Note that is undefined for  , that is,
, that is,  is undefined, as is
is undefined, as is  .
.
|
|
|
|
|
|
|---|---|---|---|---|
| 0.68 | 0.994457883210 | 0.999 | 3.290526731492 | |
| 0.90 | 1.644853626951 | 0.9999 | 3.890591886413 | |
| 0.95 | 1.959963984540 | 0.99999 | 4.417173413469 | |
| 0.98 | 2.326347874041 | 0.999999 | 4.891638475699 | |
| 0.99 | 2.575829303549 | 0.9999999 | 5.326723886384 | |
| 0.995 | 2.807033768344 | 0.99999999 | 5.730728868236 | |
| 0.997 | 2.967737925342 | 0.999999999 | 6.109410204869 |
Since  at
at  , we can arbitrarily set
, we can arbitrarily set  , calculate
, calculate  , , and
, , and  to obtain the maximum margin of error for at a given confidence level and sample size , even before having actual results. With
to obtain the maximum margin of error for at a given confidence level and sample size , even before having actual results. With 


Also, usefully, for any reported 

Specific margins of error[edit]
If a poll has multiple percentage results (for example, a poll measuring a single multiple-choice preference), the result closest to 50% will have the highest margin of error. Typically, it is this number that is reported as the margin of error for the entire poll. Imagine poll reports  as
as 
 (as in the figure above)
(as in the figure above)



As a given percentage approaches the extremes of 0% or 100%, its margin of error approaches ±0%.
Comparing percentages[edit]
Imagine multiple-choice poll reports as  . As described above, the margin of error reported for the poll would typically be
. As described above, the margin of error reported for the poll would typically be  , as
, as  is closest to 50%. The popular notion of statistical tie or statistical dead heat, however, concerns itself not with the accuracy of the individual results, but with that of the ranking of the results. Which is in first?
is closest to 50%. The popular notion of statistical tie or statistical dead heat, however, concerns itself not with the accuracy of the individual results, but with that of the ranking of the results. Which is in first?
If, hypothetically, we were to conduct poll over subsequent samples of respondents (newly drawn from ), and report result  , we could use the standard error of difference to understand how
, we could use the standard error of difference to understand how  is expected to fall about
is expected to fall about  . For this, we need to apply the sum of variances to obtain a new variance,
. For this, we need to apply the sum of variances to obtain a new variance,  ,
,

where  is the covariance of
is the covariance of  and
and  .
.
Thus (after simplifying),



Note that this assumes that  is close to constant, that is, respondents choosing either A or B would almost never chose C (making and close to perfectly negatively correlated). With three or more choices in closer contention, choosing a correct formula for becomes more complicated.
is close to constant, that is, respondents choosing either A or B would almost never chose C (making and close to perfectly negatively correlated). With three or more choices in closer contention, choosing a correct formula for becomes more complicated.
Effect of finite population size[edit]
The formulae above for the margin of error assume that there is an infinitely large population and thus do not depend on the size of population , but only on the sample size . According to sampling theory, this assumption is reasonable when the sampling fraction is small. The margin of error for a particular sampling method is essentially the same regardless of whether the population of interest is the size of a school, city, state, or country, as long as the sampling fraction is small.
In cases where the sampling fraction is larger (in practice, greater than 5%), analysts might adjust the margin of error using a finite population correction to account for the added precision gained by sampling a much larger percentage of the population. FPC can be calculated using the formula[1]

…and so, if poll were conducted over 24% of, say, an electorate of 300,000 voters,


Intuitively, for appropriately large ,


In the former case, is so small as to require no correction. In the latter case, the poll effectively becomes a census and sampling error becomes moot.
See also[edit]
- Engineering tolerance
- Key relevance
- Measurement uncertainty
- Random error
References[edit]
- ^ Isserlis, L. (1918). «On the value of a mean as calculated from a sample». Journal of the Royal Statistical Society. Blackwell Publishing. 81 (1): 75–81. doi:10.2307/2340569. JSTOR 2340569. (Equation 1)
Sources[edit]
- Sudman, Seymour and Bradburn, Norman (1982). Asking Questions: A Practical Guide to Questionnaire Design. San Francisco: Jossey Bass. ISBN 0-87589-546-8
- Wonnacott, T.H.; R.J. Wonnacott (1990). Introductory Statistics (5th ed.). Wiley. ISBN 0-471-61518-8.
External links[edit]
- «Errors, theory of», Encyclopedia of Mathematics, EMS Press, 2001 [1994]
- Weisstein, Eric W. «Margin of Error». MathWorld.
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
Средняя и предельная ошибки выборки
Средняя ошибка выборкивсегда
присутствует в выборочных исследованиях
и появляется вследствие того, что
обследуются не все единицы статистической
совокупности, а лишь ее часть.
Средняя ошибка выборки превращается в
предельную ошибкуΔ
при умножении ее на коэффициент
доверияt, который задается
предварительно, исходя из требуемой
точности наблюдения. Предельная ошибка
позволяет судить об «истинном» размере
параметра в генеральной совокупности
с определенной степенью вероятности
|
|
При типическом и серийном
отборе, при расчете ошибки выборки
вместо общей дисперсии (σ2)
следует использовать
среднюю из внутригрупповых дисперсий
и межгрупповую дисперсию![]() ,
,
где![]() —
—
частная дисперсия i группы,![]() объем i группы
объем i группы
Формулы предельной ошибки случайной
выборки при определении средней
Для повторного отбора
|
|
где |
Для бесповторного отбора
|
|
Формулы предельной ошибки случайной
выборки при определении доли
Для повторного отбора
|
|
где |
Для бесповторного отбора
|
|
где |
Формулы численности случайной
выборки при определении средней величины
|
Для повторного |
Для |
|
|
|
Формулы численности случайной выборки при определении доли изучаемого признака
|
Для повторного |
Для |
|
|
|
Предельная разница между генеральной
и выборочной средней соответствует
величине предельной ошибки
|
для средней |
для доли: |
|
|
|
Значения вероятности и соответственно
tнаходятся по таблицам
распределения:
-
Лапласа
-
Стьюдента (в случае малой выборки)
Формулы случайной выборки подходят и
для механической выборки.
При необходимости округления, при
случайной выборке – округление в большую
сторону, при механической – в меньшую.
Малая выборка
Если численность выборочной совокупности
не более 30 единиц, то средняя ошибка
малой выборки при определении средней
величины рассчитывается по формуле:
|
при определении доли |
|
|
|
|
Для расчета ошибки малой выборки
применяется уточненная формула дисперсии
|
|
где n-1 — |
Типы задач выборочного наблюдения
-
определение ошибки выборки,
-
определение численности выборочной
совокупности n
, -
определение вероятности того, что
выборочная средняя (или доля) отклонится
от генеральной не более, чем на заданную
величину t=Δ/μ, -
оценка случайности расхождений
показателей выборочных наблюдений, -
перенос выборочных характеристик на
генеральную совокупность.
Проверка гипотез о средней и доле
Оценка случайности расхождений
показателей выборочных наблюдений
|
|
|
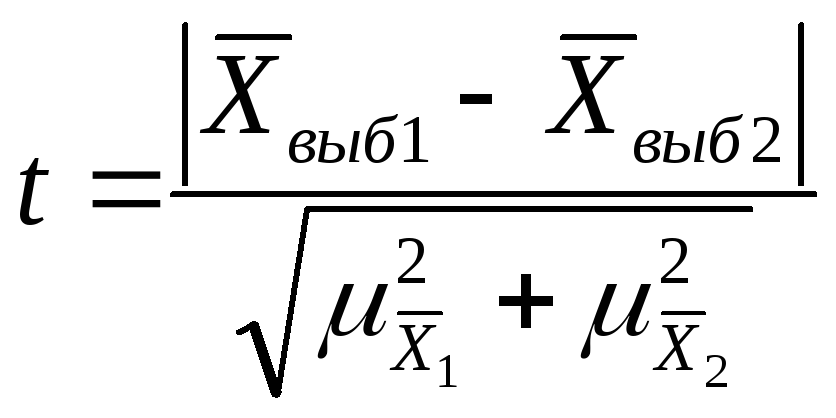
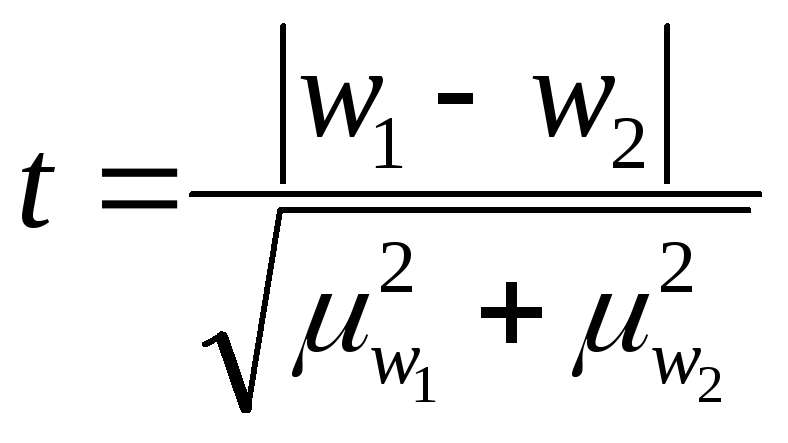
-
Если при n>30 коэффициент t<3, то делается
вывод о случайности расхождений. -
Если n≤ 30 , то полученное
значение t сравнивают с табличным,
определяемым по таблице распределения
Стьюдента -
Если
 ,
,
расхождение считается существенным. -
Если
,
расхождение считается случайным.
Методы переноса выборочных данных на
генеральную совокупность
-
метод взвешивания;
-
метод перевзвешивания;
-
метод заполнения случайным подбором
в классах замещения.
Предельная ошибка выборки
Предельная ошибка — максимально возможное расхождение средних или максимум ошибок при заданной вероятности ее появления.
1. Предельную ошибку выборки для средней при повторном отборе в контрольных по статистике в ВУЗах рассчитывают по формуле:

где t — нормированное отклонение — «коэффициент доверия», который зависит от вероятности, гарантирующей предельную ошибку выборки;
мю х — средняя ошибка выборки.
2. Предельная ошибка выборки для доли при повторном отборе определяется по формуле:

3. Предельная ошибка выборки для средней при бесповторном отборе:

4. Предельная ошибка выборки для доли при бесповторном отборе:

Предельная относительная ошибка выборки
Предельную относительную ошибку выборки определяют как процентное соотношение предельной ошибки выборки к соответствующей характеристике выборочной совокупности. Она определяется таким образом:

Малая выборка
Теория малых выборок была разработана английским статистиком Стьюдентом в начале 20 века. В 1908 г. он выявил специальное распределение, которое позволяет и при малых выборках соотносить t и доверительную вероятность F(t). При n больше 100 дают такие же результаты, что и таблицы интеграла вероятностей Лапласа, при 30 < n < 100 различия получаются незначительные. Поэтому на практике к малым выборкам относятся выборки объемом менее 30 единиц.

Средняя и предельная ошибки для малой выборки
В малой выборке средняя ошибка рассчитывается по формуле:

Предельная ошибка малой выборки рассчитывается по формуле:

где t — отношение Стьюдента
Источник: Балинова B.C. Статистика в вопросах и ответах: Учеб. пособие. — М.: ТК. Велби, Изд-во Проспект, 2004. — 344 с.
Материалы сайта
Обращаем Ваше внимание на то, что все материалы опубликованы для образовательных целей.

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет