
- sklearn.metrics.mean_absolute_percentage_error(y_true, y_pred, *, sample_weight=None, multioutput=‘uniform_average’)[source]¶
-
Mean absolute percentage error (MAPE) regression loss.
Note here that the output is not a percentage in the range [0, 100]
and a value of 100 does not mean 100% but 1e2. Furthermore, the output
can be arbitrarily high wheny_trueis small (which is specific to the
metric) or whenabs(y_true - y_pred)is large (which is common for most
regression metrics). Read more in the
User Guide.New in version 0.24.
- Parameters:
-
- y_truearray-like of shape (n_samples,) or (n_samples, n_outputs)
-
Ground truth (correct) target values.
- y_predarray-like of shape (n_samples,) or (n_samples, n_outputs)
-
Estimated target values.
- sample_weightarray-like of shape (n_samples,), default=None
-
Sample weights.
- multioutput{‘raw_values’, ‘uniform_average’} or array-like
-
Defines aggregating of multiple output values.
Array-like value defines weights used to average errors.
If input is list then the shape must be (n_outputs,).- ‘raw_values’ :
-
Returns a full set of errors in case of multioutput input.
- ‘uniform_average’ :
-
Errors of all outputs are averaged with uniform weight.
- Returns:
-
- lossfloat or ndarray of floats
-
If multioutput is ‘raw_values’, then mean absolute percentage error
is returned for each output separately.
If multioutput is ‘uniform_average’ or an ndarray of weights, then the
weighted average of all output errors is returned.MAPE output is non-negative floating point. The best value is 0.0.
But note that bad predictions can lead to arbitrarily large
MAPE values, especially if somey_truevalues are very close to zero.
Note that we return a large value instead ofinfwheny_trueis zero.
Examples
>>> from sklearn.metrics import mean_absolute_percentage_error >>> y_true = [3, -0.5, 2, 7] >>> y_pred = [2.5, 0.0, 2, 8] >>> mean_absolute_percentage_error(y_true, y_pred) 0.3273... >>> y_true = [[0.5, 1], [-1, 1], [7, -6]] >>> y_pred = [[0, 2], [-1, 2], [8, -5]] >>> mean_absolute_percentage_error(y_true, y_pred) 0.5515... >>> mean_absolute_percentage_error(y_true, y_pred, multioutput=[0.3, 0.7]) 0.6198... >>> # the value when some element of the y_true is zero is arbitrarily high because >>> # of the division by epsilon >>> y_true = [1., 0., 2.4, 7.] >>> y_pred = [1.2, 0.1, 2.4, 8.] >>> mean_absolute_percentage_error(y_true, y_pred) 112589990684262.48
In this tutorial, you’ll learn how to use Python to calculate the MAPE, or the mean absolute percentage error. This error is often used to measure the accuracy of machine learning models.
By the end of this tutorial, you’ll have learned:
- What the Mean Absolute Percentage Error is
- What a good value for the MAPE is
- How to calculate the MAPE in Python
- What some common cautions are with the MAPE
Let’s get started!
What is the Mean Absolute Percentage Error?
The Mean Absolute Percentage Error (MAPE) can be used in machine learning to measure the accuracy of a model. More specifically, the MAPE is a loss function that defines the error of a given model.
The MAPE is calculated by finding the absolute difference between the actual and predicted values, divided by the actual value. These ratios are added for all values and the mean is taken.
More concisely, the formula for the MAPE is:
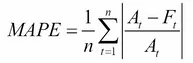
In the formula above:
Σindicates to add all the resulting valuesnis the sample sizeAis the actual valueFis the predicted value
Should the MAPE be High or Low?
The MAPE is a commonly used measure in machine learning because of how easy it is to interpret. The lower the value for MAPE, the better the machine learning model is at predicting values. Inversely, the higher the value for MAPE, the worse the model is at predicting values.
For example, if we calculate a MAPE value of 20% for a given machine learning model, then the average difference between the predicted value and the actual value is 20%.
As a percentage, the error measurement is more intuitive to understand than other measures such as the mean square error. This is because many other error measurements are relative to the range of values. This requires you to jump through some additional mental hurdles to determine the scope of the error.
What is a Good MAPE Score?
The MAPE returns a percentage, which can make it intuitive to understand. Because the percentage reflects the average percentage error, the lower the score the better.
Below, you’ll find some general guidelines on what a good MAPE score is:
| MAPE Score | Interpretation of Score |
|---|---|
| > 50 % | Poor |
| 20% – 50% | Relatively good |
| 10% – 20% | Good |
| < 10% | Great |
A MAPE score, like anything else in machine learning, should not be taken at face value. Keep in mind the range of your data (as lower ranges will amplify the MAPE) and the type of data you’re working with.
As you’ll learn in a later section, the MAPE does have some problems with some data, especially lower volume data. Because of this, make sure you have a good sense of how your data is structured before making decisions using MAPE alone.
Use Python to Calculate the MAPE Score from Scratch
It’s very simple to create a function for the MAPE using the built-in numpy library.
Let’s see how we can do this:
# Creating a Function for MAPE
import numpy as np
def mape(y_test, pred):
y_test, pred = np.array(y_test), np.array(pred)
mape = np.mean(np.abs((y_test - pred) / y_test))
return mapeLet’s break down what we did here:
- We imported numpy to simplify array operations
- We defined a function,
mape, that takes two arrays: the testing array and the predicted array - Both these arrays are converted into numpy arrays
- The MAPE is calculated using the formula above
Let’s run through a very simple machine learning example using a linear regression model in Scikit-Learn:
# A practical example of MAPE in machine learning
import numpy as np
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
def mape(y_test, pred):
y_test, pred = np.array(y_test), np.array(pred)
mape = np.mean(np.abs((y_test - pred) / y_test))
return mape
data = load_diabetes()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
lnr = LinearRegression()
lnr.fit(X_train, y_train)
predictions = lnr.predict(X_test)
print(mape(y_test, predictions))
# Returns: 0.339In the example above, we created a simple machine learning model. The model predicted some values – these were stored in the predictions variable.
We tested the accuracy of our model by passing in our predictions and the actual values, y_test into our function, mape(). This returned a value of 0.339, which is equal to 33.9%.
Calculating the MAPE Using Sklearn
Scikit-Learn also comes with a function for the MAPE built-in, the mean_absolute_percentage_error() function from the metrics module.
Like our function above, the function takes the true values and the predicted values as input:
# Using the mean_absolute_percentage_error function
from sklearn.metrics import mean_absolute_percentage_error
error = mean_absolute_percentage_error(y_true, predictions)Let’s recreate our earlier example using this function:
# A practical example of MAPE in sklearn
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_percentage_error
data = load_diabetes()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
lnr = LinearRegression()
lnr.fit(X_train, y_train)
predictions = lnr.predict(X_test)
print(mean_absolute_percentage_error(y_test, predictions))
# Returns: 0.339In the next section, you’ll learn about some common problems with the MAPE score.
Common Problems with the MAPE score
While the MAPE is easy to understand, this simplicity can also lead to some problems. One of the major problems with the MAPE score is how easily it is influenced by values of a low range.
For example, a predicted value of 3 and a true value of 2 indicate an error of 50%. Meanwhile, the data are only 1 off. If the real value was 100 and the predicted value was 101, then the error would only be 1%.
This is where the matter of interpretation comes in. In the example above, a difference between the values of 2 and 3 may be insignificant (in which case the MAPE is a poor metric). However, the difference may actually be incredibly meaningful, in which case the MAPE is a good metric.
Keep in mind the context of your data when interpreting the score.
Conclusion
In this tutorial, you learned how to use Python to calculate the MAPE score. You learned what the MAPE score is and how to interpret it. You also learned how to calculate the score from scratch, as well as how to use a sklearn function to calculate the mean absolute percentage error.
Additional Resources
To learn more about related topics, check out the tutorials below:
- Introduction to Scikit-Learn (sklearn) in Python
- Linear Regression in Scikit-Learn (sklearn): An Introduction
- Calculate Manhattan Distance in Python (City Block Distance)
- Official Documentation: MAPE in Sklearn
Hello, readers! In our series of Error Metrics, we have understood and implemented Root Mean Square Error.
Today, we will be focusing on another important error metric in model building — Mean Absolute Percentage Error (MAPE) in Python.
What is MAPE?
Mean Absolute Percentage Error (MAPE) is a statistical measure to define the accuracy of a machine learning algorithm on a particular dataset.
MAPE can be considered as a loss function to define the error termed by the model evaluation. Using MAPE, we can estimate the accuracy in terms of the differences in the actual v/s estimated values.
Let us have a look at the below interpretation of Mean Absolute Percentage Error–
As seen above, in MAPE, we initially calculate the absolute difference between the Actual Value (A) and the Estimated/Forecast value (F). Further, we apply the mean function on the result to get the MAPE value.
MAPE can also be expressed in terms of percentage. Lower the MAPE, better fit is the model.
Mean Absolute Percentage Error with NumPy module
Let us now implement MAPE using Python NumPy module.
At first, we have imported the dataset into the environment. You can find the dataset here.
Further, we have split the dataset into training and testing datasets using the Python train_test_split() function.
Then, we have defined a function to implement MAPE as follows–
- Calculate the difference between the actual and the predicted values.
- Then, use
numpy.abs() functionto find the absolute value of the above differences. - Finally, apply
numpy.mean() functionto get the MAPE.
Example:
import numpy as np
from sklearn.model_selection import train_test_split
import pandas as pd
bike = pd.read_csv("Bike.csv")
#Separating the dependent and independent data variables into two data frames.
X = bike.drop(['cnt'],axis=1)
Y = bike['cnt']
# Splitting the dataset into 80% training data and 20% testing data.
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=.20, random_state=0)
#Defining MAPE function
def MAPE(Y_actual,Y_Predicted):
mape = np.mean(np.abs((Y_actual - Y_Predicted)/Y_actual))*100
return mape
Now, we have implemented a Linear Regression to check the error rate of the model using MAPE.
Here, we have made use of LinearRegression() function to apply linear regression on the dataset. Further, we have used the predict() function to predict the values for the testing dataset.
At last, we have called the MAPE() function created above to estimate the error value in the predictions as shown below:
#Building the Linear Regression Model
from sklearn.linear_model import LinearRegression
linear_model = LinearRegression().fit(X_train , Y_train)
#Predictions on Testing data
LR_Test_predict = linear_model.predict(X_test)
# Using MAPE error metrics to check for the error rate and accuracy level
LR_MAPE= MAPE(Y_test,LR_Test_predict)
print("MAPE: ",LR_MAPE)
Output:
Mean Absolute Percentage Error with Python scikit learn library
In this example, we have implemented the concept of MAPE using Python sklearn library.
Python sklearn library offers us with mean_absolute_error() function to calculate the MAPE value as shown below–
Example:
from sklearn.metrics import mean_absolute_error Y_actual = [1,2,3,4,5] Y_Predicted = [1,2.5,3,4.1,4.9] mape = mean_absolute_error(Y_actual, Y_Predicted)*100 print(mape)
Output:
Conclusion
By this, we have come to the end of this topic. Feel free to comment below, in case you come across any question.
For more such posts related to Python, Stay tuned here and till then, Happy Learning!! 🙂
References
- Mean Absolute Percentage Error — Wikipedia
- MAPE with Python sklearn library — Documentation
17 авг. 2022 г.
читать 1 мин
Средняя абсолютная процентная ошибка (MAPE) обычно используется для измерения прогностической точности моделей. Он рассчитывается как:
MAPE = (1/n) * Σ(|фактическое значение – прогноз| / |фактическое значение|) * 100
куда:
- Σ – символ, означающий «сумма»
- n – размер выборки
- фактический – фактическое значение данных
- предсказание – предсказанное значение данных
MAPE обычно используется, потому что его легко интерпретировать и легко объяснить. Например, значение MAPE, равное 11,5%, означает, что средняя разница между прогнозируемым значением и фактическим значением составляет 11,5%.
Чем ниже значение MAPE, тем лучше модель способна предсказывать значения. Например, модель с MAPE 5% более точна, чем модель с MAPE 10%.
Как рассчитать MAPE в Python
В Python нет встроенной функции для вычисления MAPE, но мы можем создать для этого простую функцию:
import numpy as np
def mape( actual , pred ):
actual, pred = np.array(actual), np.array(pred)
return np.mean(np.abs((actual - pred) / actual)) * 100
Затем мы можем использовать эту функцию для вычисления MAPE для двух массивов: одного, содержащего фактические значения данных, и другого, содержащего прогнозируемые значения данных.
actual = [12, 13, 14, 15, 15,22, 27]
pred = [11, 13, 14, 14, 15, 16, 18]
mape(actual, pred)
10.8009
Из результатов видно, что средняя абсолютная процентная ошибка для этой модели составляет 10,8009%.Другими словами, средняя разница между прогнозируемым значением и фактическим значением составляет 10,8009%.
Предостережения по использованию MAPE
Хотя MAPE легко рассчитать и интерпретировать, его использование имеет два потенциальных недостатка:
1. Поскольку формула для расчета абсолютной процентной ошибки |фактическое предсказание| / |фактическое| это означает, что MAPE будет неопределенным, если какое-либо из фактических значений равно нулю.
2. MAPE не следует использовать с данными небольшого объема. Например, если фактический спрос на какой-либо товар равен 2, а прогноз равен 1, значение абсолютной процентной ошибки будет |2-1| / |2| = 50%, что создает впечатление, что ошибка прогноза довольно высока, несмотря на то, что прогноз отличается всего на одну единицу.
As noted (for example, in Wikipedia), MAPE can be problematic. Most pointedly, it can cause division-by-zero errors. My guess is that this is why it is not included in the sklearn metrics.
However, it is simple to implement.
from sklearn.utils import check_arrays
def mean_absolute_percentage_error(y_true, y_pred):
y_true, y_pred = check_arrays(y_true, y_pred)
## Note: does not handle mix 1d representation
#if _is_1d(y_true):
# y_true, y_pred = _check_1d_array(y_true, y_pred)
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
Use like any other metric…:
> y_true = [3, -0.5, 2, 7]; y_pred = [2.5, -0.3, 2, 8]
> mean_absolute_percentage_error(y_true, y_pred)
Out[19]: 17.738095238095237
(Note that I’m multiplying by 100 and returning a percentage.)
… but with caution:
> y_true = [3, 0.0, 2, 7]; y_pred = [2.5, -0.3, 2, 8]
> #Note the zero in y_pred
> mean_absolute_percentage_error(y_true, y_pred)
-c:8: RuntimeWarning: divide by zero encountered in divide
Out[21]: inf