
Содержание:
Ошибки измерения: Опыт убеждает, что измерения объектов не могут быть произведены абсолютно точно и каждое конкретное измерение дает лишь, как правило, приближенное значение величины явления, истинное значение которой (A) нам неизвестно. Ошибки измерения (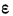
Рассмотрим такие измерения, которые производятся одним наблюдателем, одним и тем же инструментом, в одинаковых условиях, т. е. равноточные измерения.
Различают два вида ошибок измерения:
- систематические ошибки, т. е. такие, которые при данных условиях проведения измерения имеют вполне определенное значение (например, ошибка измерительного прибора);
- случайные — такие, которые являются результатом взаимодействия большого числа незначительных в отдельности факторов и имеют в каждом отдельном случае различные значения.
Задача математической статистики — предусмотреть возможность возникновения систематических ошибок и добиться их ликвидации или сведения к минимуму.
Случайные ошибки измерения обладают рядом свойств: при большом числе измерений крупные ошибки встречаются реже мелких и число положительных ошибок примерно равно числу отрицательных, вследствие чего сумма всех ошибок близка к нулю.
Если ошибки получаются весьма малыми по сравнению с величиной явления, то ими просто пренебрегают или считаются с наибольшей возможной ошибкой, чтобы обезопасить себя от влияния случайной неточности.
В теории ошибок изучаются те ошибки, которые, являясь, с одной стороны, ошибками случайного характера, по своему абсолютному значению настолько велики, что ими пренебречь нельзя, а с другой стороны, для них существует закон, позволяющий установить зависимость между величиной ошибки и вероятностью ее появления. Закон случайных ошибок, полученный Гауссом, состоит в том, что случайные ошибки подчиняются закону нормального распределения.
Средняя ошибка сводного результата измерения
Принимая за действительное значение измеряемой величины при равноточном измерении среднюю арифметическую из всех результатов n измерений, можно охарактеризовать точность одного измерения с помощью средней арифметической из абсолютных величин значений ошибок:
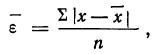
где n — число измерений, х — численное значение отдельных измерений, 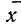 — средняя арифметическая из результатов измерений.
— средняя арифметическая из результатов измерений.
За меру точности соответствия принятой средней арифметической 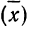 истинному значению измеряемой величины (A) принимают среднюю ошибку сводного результата измерения, вычисляемую по формуле:
истинному значению измеряемой величины (A) принимают среднюю ошибку сводного результата измерения, вычисляемую по формуле:
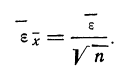
Пример 1. Произведено 10-кратное измерение размера детали (в мм), давшее следующие, расположенные в возрастающем порядке результаты: 138; 139; 140; 141; 141; 142; 142; 143; 144; 145.
Охарактеризуем сначала точность одного измерения, т. е. вычислим среднюю арифметическую из абсолютных значений ошибок. Для этой цели вычислим среднюю арифметическую из результатов измерений:
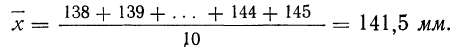
Найдем ошибки измерения:
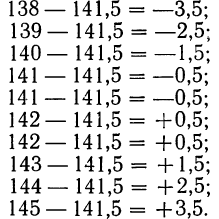
Следовательно:
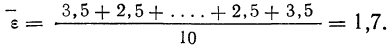
Теперь можно вычислить среднюю ошибку сводного результата измерения:
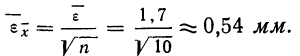
Значит, мерой точности соответствия 141,5 мм истинной величине размера детали является средняя ошибка, равная 0,54 мм.
Средняя квадратическая ошибка
Если в качестве меры точности одного измерения принять не среднюю арифметическую из абсолютных значений ошибок (средняя ошибка), а среднюю квадратическую из ошибок измерений, т. е.
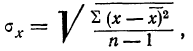
то средняя квадратическая ошибка найденной средней арифметической из ошибок измерения вычисляется по формуле:
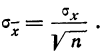
Между средней -квадратической ошибкой и средней ошибкой сводного результата измерения существует связь: 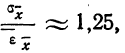 если случайные ошибки подчиняются Гауссову закону нормального распределения.
если случайные ошибки подчиняются Гауссову закону нормального распределения.
Пример 2. Используя данные предыдущего примера, находим меру точности одного измерения, т. е. среднюю квадратическую ошибку:
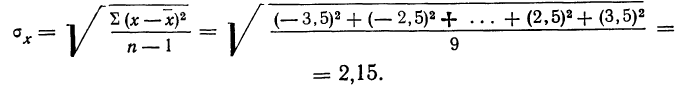
Затем исчисляем среднюю квадратическую ошибку найденной средней арифметической, равной 141,5 мм:
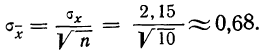
Сопоставляя среднюю квадратическую ошибку сводного результата измерения со средней ошибкой, получаем:
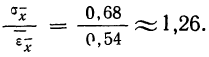
Вероятная ошибка
За меру точности одного измерения иногда принимают вероятную ошибку:
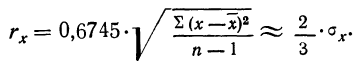
Тогда в качестве вероятной ошибки сводного результата измерения используют соотношение:
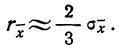
Пример 3. Используя данные предыдущих примеров, находим вероятную ошибку сводного результата измерения:
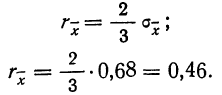
Наиболее вероятные границы сводных результатов измерения
Математическое ожидание случайной ошибки равно нулю. В качестве значения измеряемой величины применяется средняя арифметическая всех измерений (если они равноточны). Использование отклонений результатов измерений (х) от средней из них 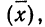 называемых в теории ошибок «кажущимися ошибками»
называемых в теории ошибок «кажущимися ошибками» 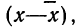 позволяет произвести оценку точности соответствия средней арифметической неизвестному истинному значению измеряемой величины (A).
позволяет произвести оценку точности соответствия средней арифметической неизвестному истинному значению измеряемой величины (A).
Для этой цели используют удвоенную или утроенную среднюю квадратическую ошибку сводного результата измерения или его вероятную ошибку и получают:
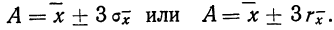
Найденные границы неизвестной истинной величины в случае, если ошибки подчинены нормальному закону распределения Гаусса (чаще всего так и бывает), соблюдаются с большой вероятностью (0,997 и 0,954).
Пример 4. По данным предыдущих примеров находим границы истинного значения размера детали 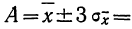
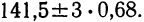 Значит, истинное значение размера детали находится в границах от 141,5—2,04 до 141,5+2,04.
Значит, истинное значение размера детали находится в границах от 141,5—2,04 до 141,5+2,04.
- Методы математической статистики
- Комбинаторика — правила, формулы и примеры
- Классическое определение вероятности
- Геометрические вероятности
- Законы распределения случайных величин
- Дисперсионный анализ
- Математическая обработка динамических рядов
- Корреляция — определение и вычисление
Математическое ожидание — ошибка
Cтраница 1
Математическое ожидание ошибки называется систематической ошибкой, ее среднее квадратическое отклонение — среднеквадра-тической ошибкой. Анализ качества систем управления сводится к определению указанных ошибок по вероятностным характеристикам случайных внешних воздействий.
[2]
Математическое ожидание ошибки слежения равно ее среднеарифметическому значению.
[3]
Система имеет математическое ожидание ошибки тст 0 и центрированную составляющую С, подчиненную нормальному закону распределения.
[4]
Известно, что математическое ожидание ошибки уменьшается с увеличением частоты замеров и с уменьшением скорости линейного изменения коэффициентом.
[5]
В этом случае математическое ожидание ошибки равно нулю.
[6]
Учитывая, что при усечении математическое ожидание ошибки квантования отлично от нуля, более целесообразно использовать округление.
[7]
При совпадении ПФ с видом г математическое ожидание ошибки прогноза будет равно нулю.
[9]
Получаемые вероятностные оценки поступают на сумматор 2, который определяет величину математического ожидания ошибок Мп для каждой из сравниваемых кодовых комбинаций.
[10]
Формулы (5.5.12) и (5.5.14) характеризуют собой общие выражения соответственно корреляционной функции и математического ожидания ошибки положения для партии механизмов.
[11]
При приеме в целом принятая кодовая комбинация будет ошибочной, если при математическом ожидании ошибок на ее длине Мл Мп mln и зафиксированное значение кодовой комбинации содержит любые варианты ошибок.
[12]
Согласно соотношению ( 11) каждому из возможных состояний канала связи соответствует случайная величина математического ожидания ошибок Мс, которая через финальные вероятности состояний принятой модели может указать на наличие того или иного состояния с некоторой вероятностью правдоподобия рс.
[13]
Чтобы упростить сравнение указанных методов, будем полагать, что первичные параметры взаимонезависимы, а математическое ожидание ошибок ( допусков) равно нулю.
[14]
Функция потерь) в общем случае является функционалом от выходных сигналов объекта и модели или от математического ожидания ошибок оценок параметров.
[15]
Страницы:
1
2
11
ЛЕКЦИЯ 4.
Случайные
погрешности измерений и способы их
описания.
При выполнении
повторных измерений одной и той же
величины легко убедиться, что результаты
отдельных измерений отличаются друг
от друга. Это объясняется действием
случайных погрешностей. Случайные
погрешности вызываются большим числом
причин, действующих независимо друг от
друга. Их нельзя исключить опытным
путем, но их влияние на результат
измерения можно оценить, проведя ряд
наблюдений одной и той же величины.
Результат измерения всегда содержит
как систематическую С,
так и случайную погрешности, т.е.
![]() ,
,
поэтому погрешность результата измерения
в общем случае нужно рассматривать как
случайную величину. Тогда систематическая
погрешность есть математическое ожидание
этой величины, а случайная погрешность
– центрированная случайная величина.
Со статистических позиций можно дать
следующие определения составляющих
погрешности.
Систематическая
погрешность
![]()
– отклонение математического ожидания
mx
результатов
наблюдений от истинного значения А
измеряемой величины:
![]() .
.
Случайная
погрешность
![]()
— разность между результатом единичного
наблюдения и математическим ожиданием
результатов:
![]() .
.
Математическое
ожидание погрешности
равно математическому ожиданию
систематической составляющей погрешности,
так как математическое ожидание случайной
погрешности всегда равно нулю:
![]() .
.
Законы распределения случайных величин
Полным описанием
случайной величины, а, следовательно,
и погрешности является ее закон
распределения. Этим законом распределения
и определяется характер появления
различных результатов отдельных
измерений в ряду наблюдений.
В практике
электрических измерений встречаются
различные законы распределения. Это
равномерное (прямоугольное) распределение,
нормальное распределение Гаусса,
распределение 2
(хи-квадрат), распределение t-Стьюдента
и др. Одним из наиболее распространенных
законов распределения погрешностей
является нормальный закон (Гаусса),
который базируется на центральной
предельной теореме теории вероятностей,
согласно которой нормальное распределение
плотности вероятности имеет сумма
бесконечно большого числа бесконечно
малых случайных возмущений с любыми
распределениями. Применительно к
измерениям это означает, что нормальное
распределение случайных погрешностей
возникает тогда, когда на результат
измерения действует множество случайных
возмущений и ни одно из которых не
является преобладающим. Практически,
суммарное воздействие даже сравнительно
небольшого числа возмущений приводит
к закону распределения результатов и
погрешностей измерений, близкому к
нормальному. Закон нормального
распределения имеет фундаментальное
значение для теории обработки результатов
измерений. Он позволяет вести расчеты
даже тогда, когда действительный закон
неизвестен.
Математически
нормальное распределение случайных
погрешностей может быть представлено
формулой
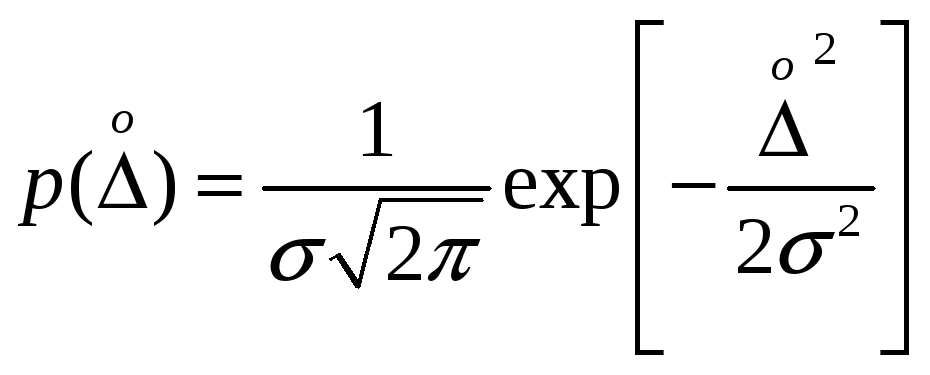 ,
,
где p(![]() )
)
– плотность вероятности случайной
погрешности
![]() ;
;
s — среднее
квадратическое отклонение.
 Характер
Характер
кривых, описываемых этим уравнением
для двух значений s
(![]() ),
),
показан на рис.4.1.
Из этих кривых
видно, что чем меньше s,
тем чаще встречаются малые случайные
погрешности, т.е. тем точнее выполнены
измерения. Кривые симметричны относительно
оси ординат, так как положительные и
отрицательные погрешности встречаются
одинаково часто.
Основные
характеристики законов распределения.
Основными
характеристиками являются математическое
ожидание и дисперсия.
Математическое
ожидание ряда наблюдений есть
величина, относительно которой
рассеиваются результаты отдельных
измерений. Если систематическая
погрешность отсутствует, и разброс
результатов отдельных измерений
обусловлен только случайной погрешностью,
то математическим ожиданием такого
ряда наблюдений будет истинное значение
измеряемой величины. Если же результаты
отдельных измерений кроме случайной
погрешности содержат постоянную
систематическую погрешность, то
математическое ожидание ряда наблюдений
будет смещено от истинного значения
измеряемой величины на значение
систематической погрешности.
Дисперсия D
ряда наблюдений характеризует степень
рассеивания (разброса) результатов
отдельных наблюдений вокруг математического
ожидания. Чем меньше дисперсия, тем
меньше разброс отдельных результатов,
тем точнее выполнены измерения.
Следовательно, дисперсия может служить
характеристикой точности проведенных
измерений. Однако, дисперсия выражается
в единицах в квадрате измеряемой
величины. Поэтому в качестве характеристики
точности ряда наблюдений наиболее часто
применяют среднее квадратическое
отклонение результата наблюдения (СКО)
s,
равное корню квадратному из дисперсии
с положительным знаком и выражаемое в
единицах измеряемой величины. Среднее
квадратическое отклонение, отнесенное
к значению измеряемой величины, может
быть выражено в относительных единицах
или процентах.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Сформулируем новый набор предпосылок, который будем называть предпосылками линейной модели со стохастическими регрессорами. Начнем с модели парной регрессии.
Предпосылки линейной модели со стохастическим регрессором (случай парной регрессии):
-
Модель линейна по параметрам и правильно специфицирована:
(y_{i} = beta_{1} + beta_{2}x_{i} + varepsilon_{i}, i = 1,2,ldots, n.)
-
Наблюдения ({left( x_{i},y_{i} right),text{~i} = 1,ldots,n}) независимы и одинаково распределены.
-
(x_{i}) и (y_{i}) имеют ненулевые конечные четвертые моменты распределения (Eleft( x_{i}^{4} right) < infty,) (Eleft( y_{i}^{4} right) < infty).
-
Случайные ошибки имеют нулевое условное математическое ожидание при заданном (x_{i}): (Eleft( varepsilon_{i} middle| x_{i} right) = 0).
Сравним предпосылки этой модели с предпосылками классической линейной модели парной регрессии (КЛМПР) из главы 2.
Первая предпосылка стандартна и остается без изменений.
Вторая предпосылка в КЛМПР требовала, чтобы регрессоры были неслучайными величинами. Теперь мы отказываемся от неё, допуская, что объясняющие переменные могут быть случайными. При этом мы требуем, чтобы наблюдения ({left( x_{i},y_{i} right),text{~i} = 1,ldots,n}) были независимыми и одинаково распределенными (independent and identically distributed, i.i.d.).
Это требование вовсе не означает, что (y_{i}) не зависит от (x_{i}) (ясно, что в этом случае анализировать модель их взаимосвязи было бы бессмысленно). Зато оно говорит о том, что векторы (left( x_{1},y_{1} right),left( x_{2},y_{2} right)), (left( x_{3},y_{3} right)ldots) независимы друг от друга в вероятностном смысле. Иными словами, отдельные наблюдения в нашей модели не влияют друг на друга.
Для пространственных данных эта предпосылка практически всегда выполняется1. В то же время следует помнить, что при работе с временными рядами эта предпосылка часто нарушается, так как для временных рядов естественно предполагать, что будущие значения переменных зависят от прошлых2. Поскольку пока мы в основном концентрируемся на пространственных данных, для нас она остается весьма реалистичной.
Лирическое отступление о неслучайных и случайных регрессорах
Отвлечемся ненадолго от технических деталей и обратимся к вопросу: как следует думать об объясняющих переменных с содержательной точки зрения? Следует ли считать их скорее детерминированными величинами или скорее случайными?
Ответ, разумеется, зависит от того, с какими данными вы работаете, и какова процедура их сбора.
Представим, например, что вы анализируете зависимость логарифма реального ВВП от номера года. То есть оцениваете параметры линии тренда для временного ряда:
({ln y}_{t} = beta_{1} + beta_{2}*t + varepsilon_{t})
Здесь (y_{t}) — ВВП в год t. В данном примере регрессор (номер года t) вполне естественно считать неслучайным (детерминированным). Действительно, мы точно знаем, что в принятой нами системе летоисчисления за 2020-ым годом последует 2021-ый, а затем наступит 2022-ой. Никакой случайности тут нет.
Теперь представим, что вас интересуют параметры следующей модели для инфляции:
(pi_{t} = beta_{1} + beta_{2}pi_{t — 1} + beta_{2}x_{t} + varepsilon_{t})
(pi_{t}) — это уровень инфляции в год t, а (x_{t}) — это, например, отклонение фактического ВВП от потенциального ВВП в год t 3. Обратите внимание: здесь предполагается, что инфляция в текущем периоде зависит от инфляции в прошлом периоде. Однако инфляция прошлого периода (pi_{t — 1}), в свою очередь, зависит от (varepsilon_{t — 1}), а значит уж точно является случайной величиной. Следовательно, в данном примере по крайней мере один из регрессоров (переменная (pi_{t — 1})) заведомо является случайным (стохастическим).
В двух приведенных примерах детерминированная или стохастическая природа объясняющих переменных может быть определена однозначно из соображений здравого смысла. В то же время, во многих ситуациях решение о том, как воспринимать регрессоры — как неслучайные величины или как случайные — это исключительно вопрос технического удобства. В частности, при использовании асимптотического подхода второй вариант более удобен, поэтому в современных эконометрических приложениях по умолчанию используют его.
Третья предпосылка выглядит достаточно устрашающе. Однако в действительности никак не ограничивает исследователя. По существу, она означает, что очень большие выбросы в данных маловероятны. Это техническая предпосылка, которая, как мы увидим в дальнейшем, позволяет гарантировать асимптотическую нормальность оценок коэффициентов. Это даст нам возможность тестировать гипотезы и строить доверительные интервалы.
Проверить эту предпосылку сложно, однако она достаточно слабая, и потому на практике обычно считают, что она выполнена. Во всяком случае, легко согласиться с тем, что она выполняется гораздо чаще, чем предпосылка КЛМПР №6 о нормальности случайных ошибок. А ведь именно её она, в сущности, заменяет.
Четвертая предпосылка играет ключевую роль в получении корректных результатов эконометрического моделирования. В последующих параграфах и главах мы увидим, что именно вопрос о выполнении или нарушении этой предпосылки оказывается в центре дискуссии об уместности применения тех или иных методов и спецификаций моделей в различных ситуациях.
Содержательно эта предпосылка говорит о том, что «прочие факторы», которые «спрятаны» в случайной ошибке (varepsilon_{i}), никак не связаны с регрессором. Поэтому знание (x_{i}) никак не влияет на ожидания по поводу случайной величины (varepsilon_{i}).
Чтобы на конкретных числах «пощупать» эту предпосылку, а заодно вспомнить, что такое условное математическое ожидание и как его считать, рассмотрим следующий простой пример.
Пример 6.3. Об условном математическом ожидании
Пусть известен совместный закон распределения случайных величин (x_{i}) и (varepsilon_{i}).
| (varepsilon_{i} = — 1) | (varepsilon_{i} = 0) | (varepsilon_{i} = 1) | |
|---|---|---|---|
| (x_{i} = 0) | 0,2 | 0,1 | 0,2 |
| (x_{i} = 1) | 0,1 | 0,3 | 0,1 |
(а) Проверьте, выполняется ли в данном случае предпосылка №4 об условном математическом ожидании случайной ошибки?
(б) Вычислите безусловное математическое ожидание случайной ошибки.
(в) Вычислите (text{cov}left( varepsilon_{i},x_{i} right)).
Решение:
(а) Напомним, что по определению условным математическим ожиданием случайной величины (varepsilon_{i}) при условии (x_{i}) называется математическое ожидание условного распределения случайной величины (varepsilon_{i}) при условии (x_{i}).
Запишем закон условного распределения (varepsilon_{i}) при условии, что (x_{i} = 0). Для этого отметим, что вероятность события (x_{i} = 0) в нашем примере составляет 0,2+0,1+0,2=0,5.
| (varepsilon_{i} = — 1) | (varepsilon_{i} = 0) | (varepsilon_{i} = 1) | |
|---|---|---|---|
| (Pleft( varepsilon_{i}|x_{i} = 0 right)) | (frac{0,2}{0,5}) | (frac{0,1}{0,5}) | (frac{0,2}{0,5}) |
Зная этот закон распределения, легко посчитать математическое ожидание:
(Eleft( varepsilon_{i}|x_{i} = 0 right) = — 1*frac{0,2}{0,5} + 0*frac{0,1}{0,5} + 1*frac{0,2}{0,5} = 0)
Аналогично получаем условное математическое ожидание (varepsilon_{i}) при условии, что (x_{i} = 1).
| (varepsilon_{i} = — 1) | (varepsilon_{i} = 0) | (varepsilon_{i} = 1) | |
|---|---|---|---|
| (Pleft( varepsilon_{i}|x_{i} = 1 right)) | (frac{0,1}{0,5}) | (frac{0,3}{0,5}) | (frac{0,1}{0,5}) |
(Eleft( varepsilon_{i}|x_{i} = 1 right) = — 1*frac{0,1}{0,5} + 0*frac{0,3}{0,5} + 1*frac{0,1}{0,5} = 0)
Таким образом, для любого возможного значения (x_{i}) условие (Eleft( varepsilon_{i}|x_{i} right) = 0) соблюдается. То есть предпосылка выполнена.
(б) (Eleft( varepsilon_{i} right) = Pleft( varepsilon_{i} = — 1 right)*( — 1) + Pleft( varepsilon_{i} = 0 right)*0 + Pleft( varepsilon_{i} = 1 right)*(1) =)
(= 0,3*( — 1) + 0,4*0 + 0,3*1 = 0)
Следовательно, безусловное математическое ожидание случайной ошибки тоже равно нулю.
(в) (text{cov}left( varepsilon_{i},x_{i} right) = Eleft( varepsilon_{i}x_{i} right) — Eleft( varepsilon_{i} right)*Eleft( x_{i} right) = Eleft( varepsilon_{i}x_{i} right) — 0*Eleft( x_{i} right) = Eleft( varepsilon_{i}x_{i} right))
(Eleft( varepsilon_{i}x_{i} right) = 0,2*( — 1)*0 + 0,1*0*0 + 0,2*1*0 +)
(+ 0,1*( — 1)*1 + 0,3*0*1 + 0,1*1*1 = 0)
В нашем примере оказалось, что предпосылке №4 соответствует выполнение условий (Eleft( varepsilon_{i} right) = 0) и (text{cov}left( varepsilon_{i},x_{i} right) = 0). На самом деле это не случайный результат. Его можно обобщить, доказав два важных следствия из предпосылки №4.
Следствие 1. Если случайные ошибки имеют нулевое условное математическое ожидание при заданном (x_{i}): (Eleft( varepsilon_{i} middle| x_{i} right) = 0), то они имеют нулевое безусловное математическое ожидание: (Eleft( varepsilon_{i} right) = 0)
Доказательство этого следствия является хорошим примером применения закона повторного математического ожидания.
Напомним формулировку закона повторного математического ожидания:
(E(xi) = Eleft( Eleft( xi middle| eta right) right))
В нашем случае в соответствии с этим законом:
(Eleft( varepsilon_{i} right) = Eleft( Eleft( varepsilon_{i} middle| x_{i} right) right) = E(0) = 0.)
Поэтому, сформулировав предпосылку №4, мы не нуждаемся в том, чтобы отдельно формулировать предположение по поводу безусловного математического ожидания случайной ошибки, которое мы делаем в КЛМПР.
Подчеркнем, что обратное утверждение, вообще говоря, неверно. Вполне возможна ситуация, когда безусловное математическое ожидание случайной ошибки равно нулю, а её условное математическое ожидание при условии (x_{i}) — нет. См. пример 6.4 далее.
Следствие 2. Если случайные ошибки имеют нулевое условное математическое ожидание при любом заданном (x_{i}): (Eleft( varepsilon_{i} middle| x_{i} right) = 0), то регрессор и случайная ошибка не коррелированы друг с другом: (text{cov}left( varepsilon_{i},x_{i} right) = 0).
Для доказательства сначала отметим, что по свойству теоретической ковариации:
(text{cov}left( varepsilon_{i},x_{i} right) = Eleft( varepsilon_{i}x_{i} right) — Eleft( varepsilon_{i} right)Eleft( x_{i} right) = Eleft( varepsilon_{i}x_{i} right) — 0*Eleft( x_{i} right) = Eleft( varepsilon_{i}x_{i} right).)
А затем снова воспользуемся законом повторного математического ожидания:
(Eleft( varepsilon_{i}x_{i} right) = Eleft( Eleft( varepsilon_{i}x_{i} middle| x_{i} right) right) = Eleft( x_{i}Eleft( varepsilon_{i} middle| x_{i} right) right) = Eleft( x_{i}*0 right) = E(0) = 0)
Регрессор, который не коррелирован со случайной ошибкой модели, обычно называют экзогенным регрессором. Таким образом, предпосылку №4 иногда называют предпосылкой об экзогенности регрессора.
Если же объясняющая переменная в модели, наоборот, коррелирована со случайной ошибкой (text{cov}left( varepsilon_{i},x_{i} right) neq 0), то её называют эндогенным регрессором.
Пример 6.4. Об условном математическом ожидании (продолжение)
Пусть теперь совместный закон распределения (x_{i}) и (varepsilon_{i}) имеет такой вид:
| (varepsilon_{i} = — 1) | (varepsilon_{i} = 0) | (varepsilon_{i} = 1) | |
|---|---|---|---|
| (x_{i} = 0) | 0,3 | 0,1 | 0,1 |
| (x_{i} = 1) | 0,1 | 0,1 | 0,3 |
Покажите, что в этом случае условие (Eleft( varepsilon_{i} right) = 0) выполнено, а условие (Eleft( varepsilon_{i} middle| x_{i} right) = 0) нарушается.
Решение:
(Eleft( varepsilon_{i} right) = Pleft( varepsilon_{i} = — 1 right)*( — 1) + Pleft( varepsilon_{i} = 0 right)*0 + Pleft( varepsilon_{i} = 1 right)*(1) =)
(= 0,4*( — 1) + 0,2*0 + 0,4*1 = 0)
Чтобы показать, что предпосылка (Eleft( varepsilon_{i}|x_{i} right) = 0) не выполняется, достаточно привести любое значение (x_{i}), для которого указанное равенство нарушено. Рассмотрим, например, случай (x_{i} = 0).
(Eleft( varepsilon_{i}|x_{i} = 0 right) = — 1*frac{0,3}{0,5} + 0*frac{0,1}{0,5} + 1*frac{0,1}{0,5} = — 0,4)
Следовательно, предпосылка (Eleft( varepsilon_{i}|x_{i} right) = 0) не выполняется: регрессор в модели является эндогенным.
***
Выполнение четырех предпосылок линейной модели со стохастическими регрессорами (случай парной регрессии) гарантирует, что применение МНК будет приводить к хорошим результатам. Говоря более строго, эти гарантии можно сформулировать в виде следующей теоремы:
Теорема о состоятельности и асимптотической нормальности МНК-оценок в парной регрессии. Если предпосылки №1–4 выполнены, то МНК-оценки коэффициентов (beta_{1}) и (beta_{2}) состоятельны и асимптотически нормальны.
Доказательство этой теоремы приводится в параграфах 6.3 и 6.4. В первом из них доказывается состоятельность, а во втором — асимптотическая нормальность. Однако прежде, чем переходить к доказательству, обсудим значение теоремы для прикладных исследований. Забегая вперед, отметим, что оно велико.
Первый из результатов — состоятельность — даёт нам уверенность, что при достаточно слабых предположениях МНК будет обеспечивать верные ответы на интересующие нас вопросы о мире. Для получения этих ответов нужно лишь собрать достаточно много данных, чтобы асимптотические свойства были применимы. В практических исследованиях вполне хватает нескольких сотен точек (хотя, конечно, когда речь идет об асимптотических методах, то чем больше, тем лучше).
Второй результат — асимптотическая нормальность — позволяет нам легко тестировать гипотезы и строить доверительные интервалы, не делая жестких предположений о распределении отдельных случайных ошибок и отдельных переменных. Детали см. в параграфе 6.5. Это ценно потому, что на практике обычно нет никакой уверенности в том, что случайные ошибки модели распределены нормально. А ведь в рамках КЛМПР, как вы помните, мы были вынуждены делать такую предпосылку.
Отметим также, что в рамках нашей новой модели, в отличие от КЛМПР, мы не требуем гомоскедастичности. Действительно, мы сделали предположение по поводу того, что константой должно быть условное математическое ожидание случайной ошибки (Eleft( varepsilon_{i} middle| x_{i} right)), однако по поводу условной дисперсии случайной ошибки (text{var}(varepsilon_{i}|x_{i})) мы никаких предпосылок не делали. Следовательно, эта величина может меняться при изменении (x_{i}), то есть в модели может наблюдаться гетероскедастичность (в таком случае её также называют условной гетероскедастичностью).
Аналогичный набор предпосылок и аналогичная теорема могут быть, разумеется, сформулированы и для множественной регрессии:
Предпосылки линейной модели со стохастическими регрессорами (случай множественной регрессии):
-
Модель линейна по параметрам:
(y_{i} = beta_{1} + beta_{2}*x_{i}^{(2)} + beta_{3}*x_{i}^{(3)} + ldots + beta_{k}*x_{i}^{(k)} + varepsilon_{i}, i = 1,2,ldots, n.)
-
Наблюдения (left{ left( x_{i}^{(2)},ldots,x_{i}^{(k)},y_{i} right),text{~i} = 1,ldots,n right}) независимы и одинаково распределены.
-
(x_{i}^{(2)},ldots,x_{i}^{(k)},y_{i}) имеют ненулевые конечные четвертые моменты.
-
Случайные ошибки имеют нулевое условное математическое ожидание при заданных значениях регрессоров:
(Eleft( varepsilon_{i} middle| x_{i}^{(2)},ldots,x_{i}^{(k)} right) = 0, i = 1,ldots,n)
-
В модели с вероятностью единица отсутствует чистая мультиколлинеарность.
Теорема о состоятельности и асимптотической нормальности МНК-оценок (случай множественной регрессии). Если предпосылки №1–5 выполнены, то МНК-оценки коэффициентов модели множественной регрессии состоятельны и асимптотически нормальны.
Легко видеть, что набор предпосылок полностью идентичен случаю парной регрессии за одним исключением: нам пришлось добавить требование отсутствия мультиколлинеарности. Как мы знаем, при его нарушении МНК-оценки в модели множественной регрессии в принципе невозможно определить однозначно. Упоминание вероятности в формулировке предпосылки связано с тем, что теперь регрессоры являются стохастическими, то есть при каждой реализации их набор может отличаться.
Таблица 6.1. Сопоставление различных регрессионных моделей
| Название модели | Классическая линейная модель множественной регрессии | Обобщенная линейная модель множественной регрессии | Линейная модель со стохастическими регрессорами |
|---|---|---|---|
| Где эта модель описана |
В параграфе 3.2 (а также для случая парной регрессии в параграфе 2.3) |
В параграфе 5.5 | В параграфе 6.2 |
| Предположение о детерминированности (неслучайности) регрессоров | Требуется | Требуется | Не требуется |
| Предположение о нормальности случайных ошибок | Требуется для тестирования гипотез | Требуется для тестирования гипотез | Не требуется |
| Предположение об отсутствии гетероскедастичности | Требуется | Не требуется | Не требуется |
В таблице 6.1 содержится сопоставление предпосылок трёх основных моделей, в условиях которых мы исследуем свойства МНК-оценок. Из неё легко видеть, что предпосылки нашей новой модели, действительно, являются сравнительно более мягкими, что делает её максимально реалистичной моделью для практической работы с пространственными данными.
-
Исключение составляет специфический класс моделей пространственной автокорреляции, которые обычно рассматриваются отдельно.↩︎
-
Пример такой ситуации приведен далее в лирическом отступлении о неслучайных и случайных регрессорах.↩︎
-
Макроэкономист узнает в такой спецификации одну из возможных версий современной кривой Филлипса с адаптивными инфляционными ожиданиями. Однако даже человек, незнакомый с макроэкономическими моделями, наверняка согласится с тем, что если инфляция была высока в прошлом месяце, то и в этом она тоже наверняка будет высокой. Иными словами, текущая инфляция зависит от своих прошлых значений, что и отражено в данной модели.↩︎
Содержание ▲
- ТЕМА ЛЕКЦИИ:
«ОБЩИЕ ПОНЯТИЯ ТЕОРИИ ОШИБОК… - СПИСОК РЕКОМЕНДУЕМОЙ ЛИТЕРАТУРЫ
Маслов А.В.…
- Задачи теории ошибок измерений.
Задачи теории… - 1. Задачи теории ошибок измерений.…
- Теория ошибок измерений решает
Теория ошибок… - 2. Сущность и виды измерений.
Измерения…
- Непосредственными или прямыми называ-ются…
- Под равноточными понимают измерения, полученные…
- Необходимыми считаются измерения, которые…
- Зависимыми называют измерения, имеющие некоторые…
- 3. Ошибки измерений, их классификация и…
- Причинами возникновения ошибок являются…
- В теории ошибок более важное значение имеет…
- Систематические ошибки подразделяются на…
- Случайными называются ошибки, которые не связаны…
- Случайные ошибки основного типа обладают…
- 4. Понятие о законах распределения ошибок.
4.… - Распределение случайных ошибок измерений наиболее…
- График функции (3) называется кривой нормального…
- Есть ошибки, которые подчиняются закону…
- Основными характеристиками распределения…
- Для непрерывной случайной величины с плотностью…
- Дисперсией случайной величины Х называ-ется…
- Положительное значение квадратного корня из…
- Для случайных ошибок измерений, как уже…
- 5.Числовые характеристики точности измерений.…
- При большом значении n
При большом значении… - Оценку точности измерений характеризуют также…
- Обычно для τ принимают значения 3, 2.5, или 2.…
- При нормальном распределении средняя ошибка v…
-
СПАСИБО ЗА ВНИМАНИЕ.
… - Скачать
- Похожие презентации
Вы можете ознакомиться и скачать презентацию на
тему ОБЩИЕ ПОНЯТИЯ ТЕОРИИ ОШИБОК ИЗМЕРЕНИЙ.
Доклад-сообщение содержит 31 слайдов.
Презентации для любого класса можно скачать бесплатно.
Если материал и наш сайт презентаций Mypresentation Вам понравились – поделитесь
им с друзьями с помощью социальных кнопок и добавьте в закладки в своем
браузере.
Слайды и текст этой презентации
Слайд 1

Описание слайда:
ТЕМА ЛЕКЦИИ:
«ОБЩИЕ ПОНЯТИЯ ТЕОРИИ ОШИБОК ИЗМЕРЕНИЙ»
Слайд 2

Описание слайда:
СПИСОК РЕКОМЕНДУЕМОЙ ЛИТЕРАТУРЫ
Маслов А.В. Геодезия: учеб. и уч. пособие для вузов/ А.В. Маслов, А.В. Гордеев, Ю.Г. Батраков: – М.: Колос, 2006. – 598 с.
Маслов А.В. Геодезические работы при землеустройстве: учеб. пособие для вузов / А.В. Маслов, А.Г. Юнусов, Г.И. Горохов 2-е изд., перераб. и доп. — М.: Недра, 1990. – 215 с. .
Неумывакин Ю.К. Геодезическое обеспечение землеустроительных и кадастровых работ: справ. пособие/ Ю.К.Неумывакин, М.И. Перский: – М.: «Картгеоцентр» — «Геодезиздат», 1996. – 344 с.
Геодезия: учеб.-метод. комплекс / БГСХА; сост. С.И. Помелов, Д.А. Чиж. – Горки, 2006. – 256 с.
Практикум по геодезии / Под ред.Бакановой В.В. – М.: Недра, 1989 .
Слайд 3

Описание слайда:
Задачи теории ошибок измерений.
Задачи теории ошибок измерений.
Сущность и виды измерений.
Ошибки измерений, их классификация и свойства.
Понятие о законах распределения ошибок.
Числовые характеристики точности измерений.
Слайд 4

Описание слайда:
1. Задачи теории ошибок измерений.
Геодезические работы связаны с различными методами измерений длин линий, углов, превышений, площадей и пр. Любые измерения, как бы тщательно они не выполнялись, сопровождаются неизбежными ошибками (погрешностями) поэтому измеренные значения величин будут отклоняться от истинных.
На практике измерения выполняют так, чтобы получить результаты с некоторой заданной точностью. Для обоснования необходимой и достаточной точности измерений надо знать причины возникновения ошибок измерений и их свойства. Эти вопросы рассматриваются в теории ошибок измерений, которая в свою очередь основывается на теории вероятностей и математической статистики.
Слайд 5

Описание слайда:
Теория ошибок измерений решает
Теория ошибок измерений решает
четыре основные задачи:
1. Изучение законов возникновения и распределения ошибок измерений и вычислений.
2. Оценка точности результатов измерений и их функций.
З. Отыскание наиболее надёжного значения определяемой величины и характеристики точности.
4. Установление допусков, ограничивающих использование результатов измерений в заданных пределах точности, т. е. критериев указывающих на наличие грубых ошибок.
Слайд 6

Описание слайда:
2. Сущность и виды измерений.
Измерения различают на непосредственные (прямые), посредственные (косвенные), равноточные, неравноточные, необходимые, дополнительные (избыточные), зависимые и независимые.
Под измерением данной физической величины понимается процесс сравнения ее с другой физической величиной того же рода, принятой за единицу измерения.
Полученное именованное число называется результатом измерения.
Слайд 7

Описание слайда:
Непосредственными или прямыми называ-ются измерения, при которых измеряемая величина непосредственно сравнивается с единицей меры.
Непосредственными или прямыми называ-ются измерения, при которых измеряемая величина непосредственно сравнивается с единицей меры.
Например, измерения линий лентой, углов транспортиром и т.д.
Посредственными или косвенными называются измерения, когда искомая величина находится путем измерения других величин.
Например, определение неприступных расстояний.
Слайд 8

Описание слайда:
Под равноточными понимают измерения, полученные одним и тем же прибором (или различными приборами одного класса точности), одним и тем же или равноценны-ми методами, одинаковым числом приемов и в одинаковых условиях.
Под равноточными понимают измерения, полученные одним и тем же прибором (или различными приборами одного класса точности), одним и тем же или равноценны-ми методами, одинаковым числом приемов и в одинаковых условиях.
Пример: измерения углов теодолитами одинаковой точности.
Если указанные условия не соблюдаются, то результаты измерений будут неравноточ-ными. Например, измерение углов теодо-литами разной точности или одним теодо-литом, но разным числом приемов.
Слайд 9

Описание слайда:
Необходимыми считаются измерения, которые позволяют получить искомую величину только один раз.
Необходимыми считаются измерения, которые позволяют получить искомую величину только один раз.
Если одна величина измерена n-раз, то одно измерение будет необходимым, а остальные n–1 — избыточными.
Например, для определения всех сторон и углов в треугольнике необходимо знать не менее трех его элементов, в т.ч. хотя бы одну сторону. Если измерены все углы и стороны, то три величины будут избыточными.
Избыточные измерения нужны для контроля и повышения точности определения искомых величин, а также оценки точности искомых величин.
Слайд 10
Описание слайда:
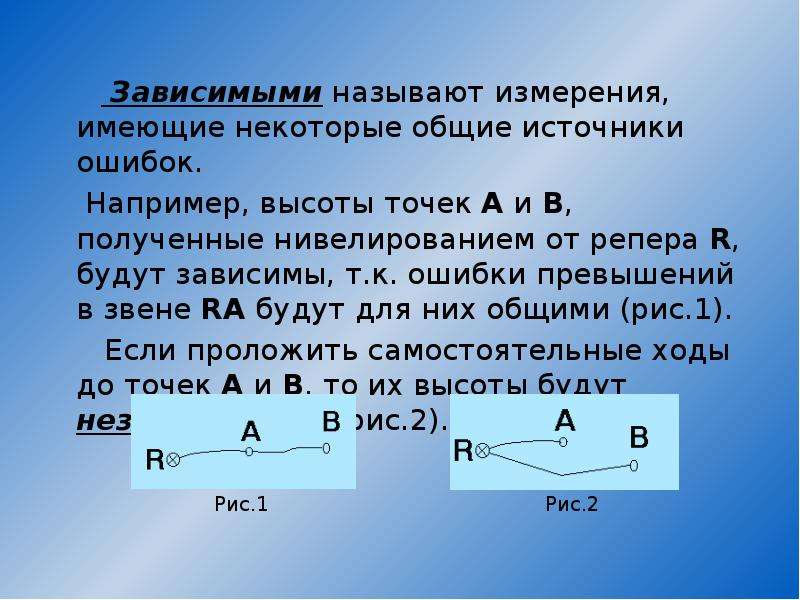
Зависимыми называют измерения, имеющие некоторые общие источники ошибок.
Зависимыми называют измерения, имеющие некоторые общие источники ошибок.
Например, высоты точек А и В, полученные нивелированием от репера R, будут зависимы, т.к. ошибки превышений в звене RA будут для них общими (рис.1).
Если проложить самостоятельные ходы до точек А и В, то их высоты будут независимыми (рис.2).
Слайд 11

Описание слайда:
3. Ошибки измерений, их классификация и свойства.
Ошибкой результата измерения называется разность между результатом измерения и точным (истинным) значением измеряемой величины, т.е.
∆= l–x, (1)
где ∆ – ошибка измерения (иcтинная ошибка);
l – результат измерения;
x – точное значение величины.
Слайд 12

Описание слайда:
Причинами возникновения ошибок являются неточности в изготовлении и юстировке приборов, влияние внешних условий, неточности выполнения операций наблюдателем, изменения самого объекта измерения и несовершенство метода измерений.
Причинами возникновения ошибок являются неточности в изготовлении и юстировке приборов, влияние внешних условий, неточности выполнения операций наблюдателем, изменения самого объекта измерения и несовершенство метода измерений.
В соответствии с источниками возникновения различают ошибки:
1) приборов;
2) внешние;
3) личные;
4) объекта;
5) метода измерений.
Приведенная классификация ошибок по источникам возникновения имеет большое значение при изучении приборов и методов измерений.
Слайд 13

Описание слайда:
В теории ошибок более важное значение имеет классификация ошибок по закономерностям их появления. По характеру действия на конечный результат ошибки делятся на грубые, систематические и случайные.
В теории ошибок более важное значение имеет классификация ошибок по закономерностям их появления. По характеру действия на конечный результат ошибки делятся на грубые, систематические и случайные.
Грубые ошибки (промахи) вызываются невнима-тельностью наблюдателя или неисправностью прибора. Они превосходят по абсолютной величине некоторый предел, установленный для данных условий измерений.
Измерения, содержащие грубые ошибки, бракуются и заменяются новыми. Для выявления грубых ошибок производятся избыточные измерения (линии измеряют дважды, в треугольнике измеряют все три угла и т. п.).
Слайд 14

Описание слайда:
Систематические ошибки подразделяются на постоянные, переменные и односторонне действующие.
Систематические ошибки подразделяются на постоянные, переменные и односторонне действующие.
Постоянные систематические ошибки при измерении одной и той же величины несколько раз, всякий раз появляются с одним знаком и одинаковые по величине. Например, ошибки за счет неточного центрирования теодолита при измерении углов несколькими приемами будут одинаковыми в каждом приеме.
Переменные систематические ошибки меняются от приема к приему, следуя определённому закону. Например, ошибки в направлениях, обусловленные эксцентриситетом алидады, или ошибками нанесения штрихов лимба теодолита.
Односторонне действующие систематические ошибки изменяются случайным образом, но сохраняют знак. Например, ошибка в длине линии из-за отклонения мерной ленты от створа.
Слайд 15

Описание слайда:
Случайными называются ошибки, которые не связаны функциональной зависимостью с какими-либо факторами. Ни величину, ни знак случайной ошибки заранее предсказать нельзя. В последовательности появления ошибок тоже нет никакой закономерности. Однако, если рассматривать их в большом количестве, то выявляются определенные статистические закономерности.
Случайными называются ошибки, которые не связаны функциональной зависимостью с какими-либо факторами. Ни величину, ни знак случайной ошибки заранее предсказать нельзя. В последовательности появления ошибок тоже нет никакой закономерности. Однако, если рассматривать их в большом количестве, то выявляются определенные статистические закономерности.
Слайд 16

Описание слайда:
Случайные ошибки основного типа обладают следующими вероятными свойствами:
Случайные ошибки основного типа обладают следующими вероятными свойствами:
1. По абсолютной величине ошибки не превосходят некоторого предела.
2. Положительные и отрицательные ошибки, равные по абсолютной величине, имеют равные вероятности, т.е. встречаются одинаково часто.
З. Чем больше ошибка по абсолютной величине, тем меньше ее вероятность появления.
4. Среднее арифметическое из значений случайных ошибок при неограниченном возрастании числа измерений одной и той же величины имеет пределом нуль, т. е. математическое ожидание ошибки равно нулю
.
Слайд 17

Описание слайда:
4. Понятие о законах распределения ошибок.
4. Понятие о законах распределения ошибок.
Свойства случайных ошибок являются проявлением закона их распределения.
В общем случае закон распределения ошибок отражает связь между размером ошибки и вероятностью ее появления.
PΔ= f(Δ)dΔ, (2)
где Р∆ – вероятность появления ошибки в интервале (∆, ∆+d∆);
∆ – случайная ошибка;
f(∆) – плотность распределения ошибок.
Слайд 18

Описание слайда:
Распределение случайных ошибок измерений наиболее точно описывается законом нормального распределения.
Распределение случайных ошибок измерений наиболее точно описывается законом нормального распределения.
Плотность нормального распределения выражается формулой
(3)
где σ – среднее квадратическое отклонение случайной ошибки.
Слайд 19
Описание слайда:
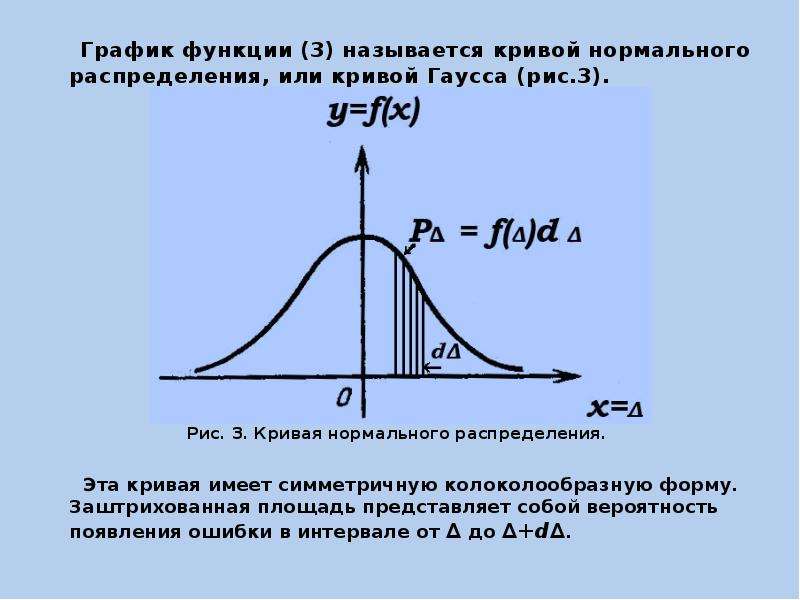
График функции (3) называется кривой нормального распределения, или кривой Гаусса (рис.3).
График функции (3) называется кривой нормального распределения, или кривой Гаусса (рис.3).
Рис. 3. Кривая нормального распределения.
Эта кривая имеет симметричную колоколообразную форму. Заштрихованная площадь представляет собой вероятность появления ошибки в интервале от ∆ до ∆+d∆.
Слайд 20

Описание слайда:
Есть ошибки, которые подчиняются закону равномерного или равновероятного распределения, к примеру, ошибки округления. Плотность распределения их выражается формулой:
Есть ошибки, которые подчиняются закону равномерного или равновероятного распределения, к примеру, ошибки округления. Плотность распределения их выражается формулой:
(4)
где α – наибольшее значение ошибки.
Слайд 21

Описание слайда:
Основными характеристиками распределения случайной величины являются математическое ожидание и дисперсия.
Основными характеристиками распределения случайной величины являются математическое ожидание и дисперсия.
Математическим ожиданием дискретной случайной величины х называют сумму произведений всех возможных значений случайной величины на соответствующие им вероятности р
. (5)
Слайд 22

Описание слайда:
Для непрерывной случайной величины с плотностью распределения f(x) матема-тическое ожидание определяется по формуле:
Для непрерывной случайной величины с плотностью распределения f(x) матема-тическое ожидание определяется по формуле:
. (6)
Слайд 23

Описание слайда:
Дисперсией случайной величины Х называ-ется число, определяемое по формуле:
Дисперсией случайной величины Х называ-ется число, определяемое по формуле:
. (7)
Слайд 24

Описание слайда:
Положительное значение квадратного корня из дисперсии называют стандартом или средним квадратическим отклонением
Положительное значение квадратного корня из дисперсии называют стандартом или средним квадратическим отклонением
. (8)
Слайд 25

Описание слайда:
Для случайных ошибок измерений, как уже отмечалось, математическое ожидание равно нулю =0. Поэтому
Для случайных ошибок измерений, как уже отмечалось, математическое ожидание равно нулю =0. Поэтому
, (9)
или
(10)
при n стремящемуся к бесконечности.
Слайд 26

Описание слайда:
5.Числовые характеристики точности измерений.
В качестве теоретической характеристики точности измерений обычно пользуются средним квадратическим отклонением σ.
Поскольку величина σ не известна, практически пользуются ее приближенным значением – средней квадратической ошибкой (СКО), определяемой по формуле:
, (11)
где ∆1, ∆2, …, ∆n – истинные ошибки измерений.
Слайд 27

Описание слайда:
При большом значении n
При большом значении n
m ≈ σ. (12)
При ограниченном числе измерений величина m будет характеризовать величину σ с некоторой ошибкой. Для оценки точности определения самой средней квадратической ошибки существует формула:
(13)
Слайд 28

Описание слайда:
Оценку точности измерений характеризуют также предельной ошибкой, вычисляемой по формуле:
Оценку точности измерений характеризуют также предельной ошибкой, вычисляемой по формуле:
∆пр= τm, (14)
где τ – коэффициент, значение которого прини-мают таким, чтобы была мала вероятность появления ошибки больше вероятной.
Слайд 29

Описание слайда:
Обычно для τ принимают значения 3, 2.5, или 2.
Обычно для τ принимают значения 3, 2.5, или 2.
В дальнейшем при решении задач по оценке точности измерений будем пользоваться формулой
∆пр= 3m.
Для оценки точности иногда пользуются средней ошибкой v и вероятной ошибкой r. Средняя ошибка вычисляется по формуле
(15)
Слайд 30

Описание слайда:
При нормальном распределении средняя ошибка v связана со средней квадратичеcкой ошибкой m примерным соотношением
При нормальном распределении средняя ошибка v связана со средней квадратичеcкой ошибкой m примерным соотношением
(16)
Если все ошибки расположить в ряд по возрастанию абсолютных значений, то ошибка оказавшаяся в середине ряда будет вероятной. Со средней квадратической ошибкой она связана соотношением
(17)
Ошибка, выраженная в единицах измерения, называется абсолютной. Отношение ее к измеренной величине называется относительной ошибкой.
Слайд 31

Описание слайда:
СПАСИБО ЗА ВНИМАНИЕ.