
Оглавление
- Вступление
- Коррекция ошибок
- Финансовая сторона
- Тестовый стенд
- Методика тестирования
- Результаты тестирования
- Тест памяти
- 3DMark
- 7Zip
- Cinebench
- CrystalMark
- Fritz
- LinX
- wPrime
- AIDA64 Extreme
- Заключение
Вступление
На сегодняшний день на просторах Рунета можно встретить открытые темы на форумах с вопросами – стоит ли брать рабочую станцию с ECC-памятью или можно обойтись обычной? В данных ветках можно прочесть множество противоречивых утверждений, и часть из них говорит о том, что коррекция ошибок сильно замедляет память, а следовательно и ЦП. Но мало кто это проверял на деле на современных процессорах.
Сегодня мы разберемся в этом вопросе и сравним производительность серверного процессора с обоими типами памяти. Но для начала небольшой экскурс.
Коррекция ошибок
Для чего необходима коррекция? И почему в работе памяти возникают ошибки? Перед ответом на эти вопросы следует разделить ошибки на два типа:
- Аппаратные ошибки;
- Случайные ошибки.
Причиной появления аппаратных ошибок является дефектная микросхема DRAM, а случайные ошибки возникают под воздействием излучения, альфа-частиц, элементарных частиц и прочего. Соответственно, первые в принципе неисправимы – если чип дефектный, то поможет только его замена; а вот вторые могут быть исправлены.
Почему же так необходима коррекция ошибок в рабочих станциях и серверах? Однобитовая ошибка в 64-битном слове меняет содержимое ячейки памяти, а в конечном итоге на жесткий диск может быть записано другое число, другие данные, при этом компьютер не зафиксирует эту подмену. А изменение бита в оперативной памяти может вызвать сбой программы, что для рабочей станции и сервера недопустимо.
рекомендации
-40% на Xiaomi 12X 256Gb в Ситилинке — надо брать
-100000р на 65″ Samsung Neo QLED 8K Ultra HD
На порядок упала цена компа MSI на i7 12700
-8000р на 4060 Ti Gigabyte Gaming в Ситилинке
Вдвое снижена цена REALME C31 4/64Gb
-30% на SSD Kingston 4Tb — смотри цену
RTX 3070 за 45 тр в Регарде
-35% на INFINIX Zero X pro 8/128Gb в Ситилинке
10 видов RTX 4060 Ti уже в продаже
Компьютеры от 10 тр в Ситилинке
4080 Gigabyte Gaming дешево в Регарде
-35% на Lenovo Legion с 3070 и Ryzen 5 5600G
Много <b>4070</b> в Ситилинке
-30% на MSI Infinite Core i5 16Gb DDR4 512Gb SSD
Для обнаружения изменения битов памяти можно использовать метод подсчета контрольной суммы, но он позволяет лишь обнаруживать ошибки без их исправления.
В свое время было предложено много различных способов решения данной проблемы, но на сегодняшний день наибольшее распространение получил метод коррекции ошибок или ECC (Error-Correcting Code). Данный метод позволяет автоматически исправлять однобитовые ошибки в 64-битном слове – SEC (Single Error Correction) и детектировать двухбитовые – DED (Double Error Detection).
Физическая реализация ECC заключается в размещении дополнительной микросхемы памяти на модуле ОЗУ – соответственно, при одностороннем дизайне модуля памяти вместо восьми чипов располагается девять, а при двустороннем вместо шестнадцати – восемнадцать. Таким образом, ширина модуля становится не 64 бита, а 72 бита.
Метод коррекции ошибок работает следующим образом: при записи 64 бит данных в ячейку памяти происходит подсчет контрольной суммы, составляющей 8 бит. Когда процессор обращается к этим данным и производит считывание, проводится повторный подсчет контрольной суммы и сравнение с исходной. Если суммы не совпадают – произошла ошибка. Если она однобитовая, то неправильный бит исправляется автоматически, если двухбитовая – детектируется и сообщается ОС.
Финансовая сторона
Прежде чем приступить к тестированию, необходимо затронуть финансовый вопрос.
Стоимость обычного модуля памяти DDR3-1600 с напряжением 1.35 В и объемом 8 Гбайт составляет около 3600 рублей, а с коррекцией ошибок – 4800 рублей. На первый взгляд ECC-память выходит на 30-35% дороже, что, в целом, не позволяет их сравнивать в силу существенно большей стоимости последней. Но почему же тогда такой вопрос возникает при сборке рабочей станции? Все просто – необходимо смотреть на данный вопрос шире, а именно – смотреть на общую стоимость рабочей станции.
Ценник однопроцессорной станции на базе четырехъядерного восьмипоточного Xeon (настольные процессоры серий i5 и i7 не поддерживают ECC-память) с 32 Гбайтами памяти, материнской платы с чипсетом C222/С224/С226 (десктопные наборы логики Z87/Z97 и другие также не поддерживают память с коррекцией ошибок) будет превышать 70 000 рублей (при условии, что устанавливаются серверные SSD с повышенным ресурсом). А если включить в эту стоимость и дискретную видеокарту, и прочие сопутствующие компоненты, например, ИБП, то ценник из пятизначного превратится в шестиизначный, перевалив планку в 100 000 рублей.
Покупка 32 Гбайт памяти с коррекцией ошибок потребует дополнительных 4-6 тысяч рублей, что по отношению к общей стоимости рабочей станции не превышает 5%, то есть не является критичным. Также переход от десктопного к серверному железу предоставит и другие преимущества, например: интегрированные графические карты P4600 в процессорах Intel Xeon E3-1200 третьего поколения получили оптимизированные драйверы, которые должны повышать производительность в профессиональных приложениях, например, в CAD; поддержка технологии Intel VT-d, которая позволяет пробрасывать устройства в виртуальную среду, например, видеокарты; прочие серверные технологии – Intel AMT или IPMI, WatchDog и другие, которые также могут оказаться полезными.
Таким образом, хоть и сама ECC-память стоит заметно дороже обычной, в общей стоимости рабочей станции данная статья затрат является несущественной, и переплата не превышает 5%.
Тестовый стенд
Для данного обзора использовалась следующая конфигурация:
- Материнская плата: Supermicro X10SAE (Intel C226, LGA 1150);
- Процессор: Xeon E3-1245V3 (Turbo Boost – off, EIST – off, HT – on);
- Оперативная память:
- 2x Kingston DDR3-1600 ECC 8 Гбайт (KVR16LE11/8 CL11, 1.35 В);
- 2x Kingston DDR3-1600 8 Гбайт (KVR16LN11/8 CL11, 1.35 В);
- ОС: Windows 8.1 Pro 64-bit.
Методика тестирования
В рамках тестирования были произведены замеры производительности как при одноканальном режиме работы ИКП, так и при двухканальном. Суммарный объем ОЗУ составил 8 (один модуль) и 16 Гбайт (два модуля) соответственно.
Программное обеспечение:
- 3DMark 2006 1.2;
- 7Zip 9.20;
- AIDA64 Extreme 5.20.3400;
- Cinebench R15;
- CrystalMark 2004R3;
- Fritz 4.20;
- LinX 0.6.5;
- wPrime 2.10.
Результаты тестирования
Тест памяти
Перед тем, как приступить к тестированию, проведем замер пропускной способности памяти и латентности.

При изучении результатов можно заключить, что производительность ECC- и non-ECC- памяти находится на одном и том же уровне в рамках погрешности.

Если в предыдущем тесте от замера к замеру выигрывал то один, то другой тип памяти, то при замере латентности ECC-память постоянно показывает большие задержки. Но разница несущественна – всего лишь 1 нс.
Таким образом, замер ПС и латентности памяти не показал особых различий между ECC- и non-ECC-памятью. Посмотрим, повторится ли это в последующих тестах.
3DMark
Тестовый пакет 3DMark содержит подтесты как для процессора, так и для графической карты. Здесь и кроется самое интересное – давно известно, что встроенному видеоядру не хватает существующей ПСП в 25.6 Гбайт/с, поэтому именно в графических подтестах можно выявить негативное влияние коррекции ошибок, если оно вообще есть,…

… но разницы нет – что ECC, что non-ECC. Ни процессор, ни интегрированное ядро никак не реагируют на замену обычной памяти на DDR с коррекцией ошибок – результаты одинаковы в рамках погрешности. Среднеарифметическая разница составила 0.02% в пользу ECC-памяти для одноканального режима и 1.6% для двухканального режима.
При этом нельзя сказать, что встроенная видеокарта P4600 не зависит от скорости ОЗУ – при одноканальном доступе общий результат почти на 30% ниже, чем при двухканальном. Другими словами, скорость ОЗУ критична для графического ядра, но сами по себе «ECC-версии» не влияют ни на скорость ОЗУ, ни на видеокарту.
7Zip
Архиваторы, как известно, чувствительны к памяти, поэтому, возможно, здесь получится зафиксировать влияние типа памяти на производительность.

Ситуация с архивацией неоднозначная: с одной стороны – в одноканальном режиме (как при распаковке, так и при сжатии) ECC-память уверенно оказывается медленнее на 2%; с другой – в двухканальном режиме при сжатии ECC-память уверенно быстрее, а при распаковке – медленнее, а среднее арифметическое – быстрее на 0.65%.
Скорее всего, причина в следующем – пропускной способности памяти при одноканальном доступе процессору явно недостаточно, и поэтому чуть большая латентность ECC-памяти сказывается на производительности; а при двухканальном доступе ПСП полностью покрывает нужды CPU и поэтому чуть большая латентность памяти с коррекцией ошибок не сказывается на производительности. В любом случае зафиксировать существенного влияния на скорость архивации не получилось.
Cinebench
Тестовый пакет Cinebench содержит подтест как процессора, так и видеокарты.

Но ни первый, ни вторая никак не отреагировали на ECC-память.
Зато налицо явная зависимость видеокарты от ПСП – при одноканальном доступе результат в OpenGL оказался на 25% ниже, чем при двухканальном. Вспоминая результаты 3DMark и смотря на нынешние, можно заключить, что производительность интегрированной видеокарты хоть и зависит от ПСП, но ECC-память не оказывает на нее негативного влияния.
Модули оперативной памяти. Технология исправления ошибок Chipkill.
На работу модулей оперативной памяти оказывают влияние множество негативных факторов, которые могут вызвать появление ошибок в считанной информации. Ошибки памяти можно подразделить на аппаратные и случайные. Аппаратные ошибки обычно обусловлены неустранимыми дефектами кремниевого кристалла или монтажных соединений микросхем DRAM. Случайные ошибки (сбои) обычно вызываются заряженными частицами или излучением. Такие ошибки непостоянны и действуют кратковременно. Ранее основной причиной случайных ошибок были альфа-частицы, но более строгий контроль качества материала, из которого делаются корпуса микросхем DRAM, позволил производителям практически ликвидировать эту причину сбоев. В настоящее время основной источник случайных ошибок в микросхемах DRAM — электрические возмущения, вызванные космическими лучами — потоками высокоэнергетических элементарных частиц, приходящими из космоса. Для повышения надежности функционирования компьютерной техники, применяется метод контроля четности памяти, но этот метод позволяет лишь обнаруживать ошибки, а не исправлять их.
Но для наиболее ответственных приложений, где цена ошибки очень высока, используют модули памяти с коррекцией ошибок ECC (Error Checking and Correcting — обнаружение и исправление ошибок).
Идея, лежащая в основе метода ECC, довольно проста — каждый разряд памяти входит более чем в одну контрольную сумму. Это увеличивает число контрольных разрядов, но дает возможность восстанавливать значение сбойного бита по несовпадающим контрольным суммам. Основной недостаток при использования ECC — снижение общей производительности системы, на которую возлагаются дополнительные вычисления.
Другой способ реализации ECC — размещение логики контроля не в контроллере памяти на системной плате, а на самом модуле. Это позволяет избежать снижения производительности, но стоимость таких модулей выше, чем обычных. Поскольку ошибки в большем числе разрядов случались чрезвычайно редко, метод ECC позволил существенно повысить надежность систем. Сегодня технология ECC стала стандартом и применяется практически во всех серверах.
Еще одним механизмом исправления ошибок, который был предложен как одна из составных частей инициативы X-Architecture корпорации IBM, стала технология исправления ошибок Chipkill. Эта технология обеспечивает защиту серверов от отказов отдельных микросхем и многоразрядных ошибок в модулях памяти. Технология Chipkill, перенесенная IBM с больших систем, существенно сокращает среднее время простоя серверов и обеспечивает более надежную платформу для клиент-серверных вычислений на базе микропроцессоров Intel. Она призвана повысить надежность систем, доступность и удобство в эксплуатации, что является ключевыми характеристиками серверов масштаба предприятия, обслуживающих критически важные приложения.
Архитектура Chipkill позволяет системе безболезненно воспринимать ошибки, которые в обычных условиях приводят к неустранимым сбоям, тем самым обеспечивая сохранность данных и высокую доступность системы. В системах высокой доступности, таких как серверы масштаба предприятия IBM S/390, проблема многоразрядных ошибок памяти DRAM отсутствует благодаря особой архитектуре оперативной памяти. Подсистема памяти сконструирована так, что отказ отдельной микросхемы, независимо от ее разрядности, не затронет более одного разряда в каком-либо из нескольких слов ECC. Например, в 4-разрядной микросхеме DRAM отдельные биты из всей четверки попадают в разные слова ECC, т. е. в разные адресные пространства памяти. Поэтому даже в случае полного отказа микросхемы количество ошибочных разрядов в словах ECC не превысит единицу, а такую ошибку механизм ECC устраняет автоматически. Данная архитектура обеспечивает отказоустойчивость всей подсистемы памяти.
Тщательно продуманная конструкция мэйнфреймов защищает их и от сбоев микросхем памяти. В каждом модуле памяти разрядность микросхем равна числу разрядов, защищенных механизмом ECC. Нынешние серверы на базе микропроцессоров Intel такого механизма не поддерживают так как рынок требует дешевой памяти, вынуждая проектировщиков создавать очень плотные микросхемы памяти, поддерживающие отраслевой стандарт (исключительно ECC).
Предлагаемая технология Chipkill является механизмом, позволяющим памяти противостоять многоразрядным ошибкам на отдельных микросхемах DRAM, в том числе и сбою всех разрядов данных. В механизме Chipkill есть два основных метода исправления ошибок, причем они могут применяться совместно. Эти методы базируются на определенном наборе микросхем и особой аппаратной архитектуре системы, поэтому их поддержку невозможно обеспечить простым обновлением ПО.
В первом методе каждый бит данных модуля памяти размещается в отдельном «слове ECC», которое представляет собой набор разрядов данных и контрольных разрядов, в котором обнаружение и исправление ошибок обеспечивается алгоритмом ECC.) Предположим, что разрядность системы памяти составляет 32 байт (или 256 разрядов). Биты ECC добавляются так, чтобы общая ширина блока (и контрольные, и биты данных) составляла 288 разрядов. Четыре слова ECC, каждое из которых состоит из 64 разрядов данных и 8 контрольных разрядов ECC, поддерживают механизм SEC/DED. Эти четыре слова ECC распределяются по DRAM-модулям. Например, если DIMM содержит модули х4 DRAM, четыре бита каждого устройства распределяются по разным словам ECC (рис. 1). Сбой всех четырех битов — это всего лишь четыре единичные ошибки в четырех словах ECC, и они устраняются автоматически. В этом примере механизм Chipkill поддерживается только на DIMM-модулях, состоящих из микросхем х4 DRAM.
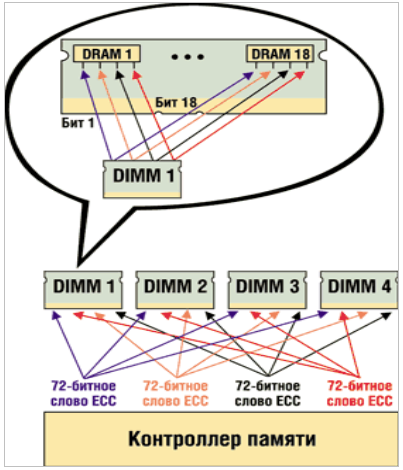
Рис. 1. Пример технологии Chipkill.
Второй метод заключается в предоставлении механизму ECC большего числа разрядов для хранения контрольных кодов, чтобы обеспечить исправление не одного, а нескольких разрядов. При этом используются соответствующие математические алгоритмы устранения многоразрядных ошибок при определенном количестве контрольных битов ECC и битов данных. Например, 144-разрядное слово ECC, состоящее из 128 разрядов данных и 16 битов ECC, позволяет исправлять ошибки, охватывающие до 4 разрядов данных. Для исправления сбоя четырех бит необходимо, чтобы они были смежными, а не располагались случайно. Соотношение разрядов ECC и разрядов данных такое же, как и в предыдущем примере (16/128 и 8/64), однако более длинное слово ECC позволяет применить более эффективный алгоритм обнаружения и исправления ошибок.
Совместное использование этих двух методов обеспечивает коррекцию по механизму Chipkill на DIMM-модулях с микросхемами х8 DRAM. Два 144-разрядных слова ECC распределяются так, чтобы на каждом DRAM в первом и втором словах ECC исправлялись по 4 разряда. Этот метод обеспечивает поддержку механизма Chipkill при использовании DIMM-модулей, состоящих как из микросхем х4 DRAM, так и из х8 DRAM. Инженеры IBM решили эту проблему, разместив избыточный массив недорогих микросхем DRAM (Redundant Array of Inexpensive DRAM, RAID) непосредственно на DIMM-модулях. При каждом доступе к памяти RAID-микросхема вычисляет контрольный код ECC для всего набора микросхем и сохраняет результат в резервной памяти на защищаемом DIMM-модуле. В случае отказа одной микросхемы DIMM-модуля сохраненная на RAID-массиве информация применяется для восстановления потерянных данных, обеспечивая бесперебойную работу всего сервера Netfinity. Такая RAID-технология напоминает RAID-механизмы, применяемые для защиты данных в дисковых массивах, и называется Chipkill DRAM.
Специалисты компании IBM разработали заказную специализированную микросхему для Chipkill, которая называется ECC ASIC (Application-Specific Integrated Circuit) и выполняет исправление ошибок без замедления доступа к высокопроизводительной EDO-памяти со временем доступа 50 нс. Таким образом, при установке DIMM-модулей IBM Chipkill на серверы Netfinity, оборудованные процессором Intel Xeon, модификация плат памяти не нужна, а новые модули не вызывают снижения производительности.
Технология IBM Chipkill Memory позволила снизить число отказов серверов Netfinity по причине сбоев подсистемы памяти до невероятно низкого уровня. Основной задачей механизма Chipkill является исправление ошибок памяти, в нем применяются такие же способы обнаружения и оповещения, что и в ECC. Обнаружение и оповещение Chipkill никак не сказывается на производительности оборудования или ПО (потери те же, что и для стандартных механизмов ECC). Обнаружение постоянных и случайных ошибок, исправление ошибок памяти и оповещение о них в серверных архитектурах с применением обоих механизмов — ECC и Chipkill выполняется в системном наборе микросхем. Для обнаружения, код исправления ошибок (ECC) генерируется при записи и проверяется при чтении во всех системных операциях с памятью «прозрачно» для прикладных программ. Обнаруженная ошибка автоматически исправляется до передачи данных получателю. При этом событие ошибки регистрируется оборудованием, а системная BIOS уведомляется об исправлении ошибки и о месте, где она произошла. Набор микросхем также ведет учет исправленных ошибок, что позволяет BIOS выявлять DIMM-модули, в которых ошибки возникают и исправляются постоянно. Получив уведомление, система BIOS опрашивает регистры набора микросхем, чтобы определить, где произошла ошибка памяти (порядок такого опроса сильно зависит от конструкции конкретной системы, поэтому он и выполняется на уровне BIOS). Обнаружив модуль DIMM, вызвавший ошибку, BIOS регистрирует эту информацию в системном журнале, который является, например, частью встроенной системы управления сервером (Embedded Server Management).
Дефектные DIMM-модули легко заменить в процессе эксплуатации, для них требуется лишь предсказательное оповещение об ошибках и замене, поэтому нет необходимости локализовать ошибки с точностью до отдельной микросхемы на плате DIMM-модуля. Получая за сравнительно короткое время повторяющиеся сообщения об исправленных ошибках от одного и того же DIMM-модуля, BIOS отключает соответствующий механизм оповещения и регистрирует этот факт в журнале системы управления сервером. Это избавляет систему от дополнительной нагрузки, обусловленной обработкой всех ошибок памяти.
Программное обеспечение управления системой, поставляемое в составе многих серверов, анализирует системный журнал при каждом внесении записи системой BIOS. Ошибки единичных разрядов инициируют уведомления одного из трех возможных уровней: warning («предупреждение»), critical («критическая»), nonrecoverable («неустранимая»). По-настоящему случайная ошибка вряд ли инициирует уведомление в стеке программы управления системой. Однако в случае постоянных неполадок в работе DIMM-модуля инициируется уведомление программе управления системой, после чего та назначает службе технической поддержки задание на замену неисправного DIMM-модуля. А постоянная ошибка, вызвавшая отключение механизма регистрации исправлений, в любом случае инициирует уведомление. Конечно постоянные ошибки в одном разряде или ошибки, устраняемые средствами Chipkill, не вызывают отказа системы, но тем не менее они увеличивают вероятность того, что очередная случайная ошибка приведет к критическому, неустранимому сбою, поэтому администраторы системы внимательно следят за уведомлениями о дефектных DIMM-модулях и своевременно выдают ремонтной службе задания на их замену.
Технология Chipkill поддерживается и в новом универсальном наборе микросхем IBM Summit, который хорошо подходит как для 64-разрядных микропроцессоров семейства Itanium, так и для 32-64 разрядных процессоров Xeon. Чипсет сможет поддерживать до четырех процессоров, позволяя им разделять такие ресурсы, как шины ввода-вывода и шины памяти. Четыре набора могут связываться воедино, что даст серверам на базе Summit возможность поддерживать до 16 полностью автономных микропроцессоров (например, в четырехпроцессорном сервере можно будет выделить три кристалла под Windows, а один — под Linux, а если все процессоры работают в одной среде, можно будет проводить их «горячую» замену).
По мнению ряда экспертов, присущая мэйнфреймам надежность и отказоустойчивость скоро потребуется и в небольших серверах, оборудованных микропроцессорами Intel.
From Wikipedia, the free encyclopedia

ECC DIMMs typically have nine memory chips on each side, one more than usually found on non-ECC DIMMs (some modules may have 5 or 18).[1]
Error correction code memory (ECC memory) is a type of computer data storage that uses an error correction code[a] (ECC) to detect and correct n-bit data corruption which occurs in memory. ECC memory is used in most computers where data corruption cannot be tolerated, like industrial control applications, critical databases, and infrastructural memory caches.
Typically, ECC memory maintains a memory system immune to single-bit errors: the data that is read from each word is always the same as the data that had been written to it, even if one of the bits actually stored has been flipped to the wrong state. Most non-ECC memory cannot detect errors, although some non-ECC memory with parity support allows detection but not correction.
Description[edit]
Error correction codes protect against undetected data corruption and are used in computers where such corruption is unacceptable, examples being scientific and financial computing applications, or in database and file servers. ECC can also reduce the number of crashes in multi-user server applications and maximum-availability systems.
Electrical or magnetic interference inside a computer system can cause a single bit of dynamic random-access memory (DRAM) to spontaneously flip to the opposite state. It was initially thought that this was mainly due to alpha particles emitted by contaminants in chip packaging material, but research has shown that the majority of one-off soft errors in DRAM chips occur as a result of background radiation, chiefly neutrons from cosmic ray secondaries, which may change the contents of one or more memory cells or interfere with the circuitry used to read or write to them.[2] Hence, the error rates increase rapidly with rising altitude; for example, compared to sea level, the rate of neutron flux is 3.5 times higher at 1.5 km and 300 times higher at 10-12 km (the cruising altitude of commercial airplanes).[3] As a result, systems operating at high altitudes require special provisions for reliability.
As an example, the spacecraft Cassini–Huygens, launched in 1997, contained two identical flight recorders, each with 2.5 gigabits of memory in the form of arrays of commercial DRAM chips. Due to built-in EDAC functionality, the spacecraft’s engineering telemetry reported the number of (correctable) single-bit-per-word errors and (uncorrectable) double-bit-per-word errors. During the first 2.5 years of flight, the spacecraft reported a nearly constant single-bit error rate of about 280 errors per day. However, on November 6, 1997, during the first month in space, the number of errors increased by more than a factor of four on that single day. This was attributed to a solar particle event that had been detected by the satellite GOES 9.[4]
There was some concern that as DRAM density increases further, and thus the components on chips get smaller, while operating voltages continue to fall, DRAM chips will be affected by such radiation more frequently, since lower-energy particles will be able to change a memory cell’s state.[3] On the other hand, smaller cells make smaller targets, and moves to technologies such as SOI may make individual cells less susceptible and so counteract, or even reverse, this trend. Recent studies[5] show that single-event upsets due to cosmic radiation have been dropping dramatically with process geometry and previous concerns over increasing bit cell error rates are unfounded.
Research[edit]
Work published between 2007 and 2009 showed widely varying error rates with over 7 orders of magnitude difference, ranging from 10−10 error/bit·h (roughly one bit error per hour per gigabyte of memory) to 10−17 error/bit·h (roughly one bit error per millennium per gigabyte of memory).[5][6][7] A large-scale study based on Google’s very large number of servers was presented at the SIGMETRICS/Performance ’09 conference.[6] The actual error rate found was several orders of magnitude higher than the previous small-scale or laboratory studies, with between 25,000 (2.5 × 10−11 error/bit·h) and 70,000 (7.0 × 10−11 error/bit·h, or 1 bit error per gigabyte of RAM per 1.8 hours) errors per billion device hours per megabit. More than 8% of DIMM memory modules were affected by errors per year.
The consequence of a memory error is system-dependent. In systems without ECC, an error can lead either to a crash or to corruption of data; in large-scale production sites, memory errors are one of the most-common hardware causes of machine crashes.[6] Memory errors can cause security vulnerabilities.[6] A memory error can have no consequences if it changes a bit which neither causes observable malfunctioning nor affects data used in calculations or saved. A 2010 simulation study showed that, for a web browser, only a small fraction of memory errors caused data corruption, although, as many memory errors are intermittent and correlated, the effects of memory errors were greater than would be expected for independent soft errors.[8]
Some tests conclude that the isolation of DRAM memory cells can be circumvented by unintended side effects of specially crafted accesses to adjacent cells. Thus, accessing data stored in DRAM causes memory cells to leak their charges and interact electrically, as a result of high cell density in modern memory, altering the content of nearby memory rows that actually were not addressed in the original memory access. This effect is known as row hammer, and it has also been used in some privilege escalation computer security exploits.[9][10]
An example of a single-bit error that would be ignored by a system with no error-checking, would halt a machine with parity checking, or would be invisibly corrected by ECC: a single bit is stuck at 1 due to a faulty chip, or becomes changed to 1 due to background or cosmic radiation; a spreadsheet storing numbers in ASCII format is loaded, and the character «8» (decimal value 56 in the ASCII encoding) is stored in the byte that contains the stuck bit at its lowest bit position; then, a change is made to the spreadsheet and it is saved. As a result, the «8» (0011 1000 binary) has silently become a «9» (0011 1001).
Solutions[edit]
Several approaches have been developed to deal with unwanted bit-flips, including immunity-aware programming, RAM parity memory, and ECC memory.
This problem can be mitigated by using DRAM modules that include extra memory bits and memory controllers that exploit these bits. These extra bits are used to record parity or to use an error-correcting code (ECC). Parity allows the detection of all single-bit errors (actually, any odd number of wrong bits). The most-common error correcting code, a single-error correction and double-error detection (SECDED) Hamming code, allows a single-bit error to be corrected and (in the usual configuration, with an extra parity bit) double-bit errors to be detected. Chipkill ECC is a more effective version that also corrects for multiple bit errors, including the loss of an entire memory chip.
Implementations[edit]

In 1982 this 512KB memory board from Cromemco used 22 bits of storage per 16 bit word to allow for single-bit error correction
Seymour Cray famously said «parity is for farmers» when asked why he left this out of the CDC 6600.[11] Later, he included parity in the CDC 7600, which caused pundits to remark that «apparently a lot of farmers buy computers». The original IBM PC and all PCs until the early 1990s used parity checking.[12] Later ones mostly did not.
An ECC-capable memory controller can generally[a] detect and correct errors of a single bit per word[b] (the unit of bus transfer), and detect (but not correct) errors of two bits per word. The BIOS in some computers, when matched with operating systems such as some versions of Linux, BSD, and Windows (Windows 2000 and later[13]), allows counting of detected and corrected memory errors, in part to help identify failing memory modules before the problem becomes catastrophic.
Some DRAM chips include «internal» on-chip error correction circuits, which allow systems with non-ECC memory controllers to still gain most of the benefits of ECC memory.[14][15] In some systems, a similar effect may be achieved by using EOS memory modules.
Error detection and correction depends on an expectation of the kinds of errors that occur. Implicitly, it is assumed that the failure of each bit in a word of memory is independent, resulting in improbability of two simultaneous errors. This used to be the case when memory chips were one-bit wide, what was typical in the first half of the 1980s; later developments moved many bits into the same chip. This weakness is addressed by various technologies, including IBM’s Chipkill, Sun Microsystems’ Extended ECC, Hewlett-Packard’s Chipspare, and Intel’s Single Device Data Correction (SDDC).
DRAM memory may provide increased protection against soft errors by relying on error correcting codes. Such error-correcting memory, known as ECC or EDAC-protected memory, is particularly desirable for high fault-tolerant applications, such as servers, as well as deep-space applications due to increased radiation. Some systems also «scrub» the memory, by periodically reading all addresses and writing back corrected versions if necessary to remove soft errors.
Interleaving allows for distribution of the effect of a single cosmic ray, potentially upsetting multiple physically neighboring bits across multiple words by associating neighboring bits to different words. As long as a single event upset (SEU) does not exceed the error threshold (e.g., a single error) in any particular word between accesses, it can be corrected (e.g., by a single-bit error correcting code), and an effectively error-free memory system may be maintained.[16]
Error-correcting memory controllers traditionally use Hamming codes, although some use triple modular redundancy (TMR). The latter is preferred because its hardware is faster than that of Hamming error correction scheme.[16] Space satellite systems often use TMR,[17][18][19] although satellite RAM usually uses Hamming error correction.[20]
Many early implementations of ECC memory mask correctable errors, acting «as if» the error never occurred, and only report uncorrectable errors. Modern implementations log both correctable errors (CE) and uncorrectable errors (UE). Some people proactively replace memory modules that exhibit high error rates, in order to reduce the likelihood of uncorrectable error events.[21]
Many ECC memory systems use an «external» EDAC circuit between the CPU and the memory. A few systems with ECC memory use both internal and external EDAC systems; the external EDAC system should be designed to correct certain errors that the internal EDAC system is unable to correct.[14] Modern desktop and server CPUs integrate the EDAC circuit into the CPU,[22] even before the shift toward CPU-integrated memory controllers, which are related to the NUMA architecture. CPU integration enables a zero-penalty EDAC system during error-free operation.
As of 2009, the most-common error-correction codes use Hamming or Hsiao codes that provide single-bit error correction and double-bit error detection (SEC-DED). Other error-correction codes have been proposed for protecting memory – double-bit error correcting and triple-bit error detecting (DEC-TED) codes, single-nibble error correcting and double-nibble error detecting (SNC-DND) codes, Reed–Solomon error correction codes, etc. However, in practice, multi-bit correction is usually implemented by interleaving multiple SEC-DED codes.[23][24]
Early research attempted to minimize the area and delay overheads of ECC circuits. Hamming first demonstrated that SEC-DED codes were possible with one particular check matrix. Hsiao showed that an alternative matrix with odd weight columns provides SEC-DED capability with less hardware area and shorter delay than traditional Hamming SEC-DED codes. More recent research also attempts to minimize power in addition to minimizing area and delay.[25][26][27]
Cache[edit]
Many CPUs use error-correction codes in the on-chip cache, including the Intel Itanium, Xeon, Core and Pentium (since P6 microarchitecture)[28][29] processors, the AMD Athlon, Opteron, all Zen-[30] and Zen+-based[31] processors (EPYC, EPYC Embedded, Ryzen and Ryzen Threadripper), and the DEC Alpha 21264.[23][32]
As of 2006, EDC/ECC and ECC/ECC are the two most-common cache error-protection techniques used in commercial microprocessors. The EDC/ECC technique uses an error-detecting code (EDC) in the level 1 cache. If an error is detected, data is recovered from ECC-protected level 2 cache. The ECC/ECC technique uses an ECC-protected level 1 cache and an ECC-protected level 2 cache.[33] CPUs that use the EDC/ECC technique always write-through all STOREs to the level 2 cache, so that when an error is detected during a read from the level 1 data cache, a copy of that data can be recovered from the level 2 cache.
Registered memory[edit]

Registered, or buffered, memory is not the same as ECC; the technologies perform different functions. It is usual for memory used in servers to be both registered, to allow many memory modules to be used without electrical problems, and ECC, for data integrity. Memory used in desktop computers is usually neither, for economy. However, unbuffered (not-registered) ECC memory is available,[34] and some non-server motherboards support ECC functionality of such modules when used with a CPU that supports ECC.[35] Registered memory does not work reliably in motherboards without buffering circuitry, and vice versa.
Advantages and disadvantages[edit]
Ultimately, there is a trade-off between protection against unusual loss of data and a higher cost.
ECC memory usually involves a higher price when compared to non-ECC memory, due to additional hardware required for producing ECC memory modules, and due to lower production volumes of ECC memory and associated system hardware. Motherboards, chipsets and processors that support ECC may also be more expensive.
ECC support varies among motherboard manufacturers so ECC memory may simply not be recognized by a ECC-incompatible motherboard. Most motherboards and processors for less critical applications are not designed to support ECC. Some ECC-enabled boards and processors are able to support unbuffered (unregistered) ECC, but will also work with non-ECC memory; system firmware enables ECC functionality if ECC memory is installed.
ECC may lower memory performance by around 2–3 percent on some systems, depending on the application and implementation, due to the additional time needed for ECC memory controllers to perform error checking.[36] However, modern systems integrate ECC testing into the CPU, generating no additional delay to memory accesses as long as no errors are detected.[22][37][38]
ECC supporting memory may contribute to additional power consumption due to error correcting circuitry.
Notes[edit]
- ^ a b Most ECC memory uses a SECDED code.
- ^ While 72-bit word with 64 data bits and 8 checking bits are common, ECC is also used with smaller and larger sizes.
References[edit]
- ^ Werner Fischer. «RAM Revealed». admin-magazine.com. Retrieved October 20, 2014.
- ^ Single Event Upset at Ground Level, Eugene Normand, Member, IEEE, Boeing Defense & Space Group, Seattle, WA 98124-2499
- ^ a b «A Survey of Techniques for Modeling and Improving Reliability of Computing Systems», IEEE TPDS, 2015
- ^ Gary M. Swift and Steven M. Guertin. «In-Flight Observations of Multiple-Bit Upset in DRAMs». Jet Propulsion Laboratory
- ^ a b Borucki, «Comparison of Accelerated DRAM Soft Error Rates Measured at Component and System Level», 46th Annual International Reliability Physics Symposium, Phoenix, 2008, pp. 482–487
- ^ a b c d Schroeder, Bianca; Pinheiro, Eduardo; Weber, Wolf-Dietrich (2009). DRAM Errors in the Wild: A Large-Scale Field Study (PDF). SIGMETRICS/Performance. ACM. ISBN 978-1-60558-511-6.
- Robin Harris (October 4, 2009). «DRAM error rates: Nightmare on DIMM street». ZDNet.
- ^ «A Memory Soft Error Measurement on Production Systems». Archived from the original on 2017-02-14. Retrieved 2011-06-27.
- ^ Li, Huang; Shen, Chu (2010). ««A Realistic Evaluation of Memory Hardware Errors and Software System Susceptibility». Usenix Annual Tech Conference 2010″ (PDF).
- ^ Yoongu Kim; Ross Daly; Jeremie Kim; Chris Fallin; Ji Hye Lee; Donghyuk Lee; Chris Wilkerson; Konrad Lai; Onur Mutlu (2014-06-24). «Flipping Bits in Memory Without Accessing Them: An Experimental Study of DRAM Disturbance Errors» (PDF). ece.cmu.edu. IEEE. Retrieved 2015-03-10.
- ^ Dan Goodin (2015-03-10). «Cutting-edge hack gives super user status by exploiting DRAM weakness». Ars Technica. Retrieved 2015-03-10.
- ^ «CDC 6600». Microsoft Research. Retrieved 2011-11-23.
- ^ «Parity Checking». Pcguide.com. 2001-04-17. Retrieved 2011-11-23.
- ^ DOMARS. «mca — Windows drivers». docs.microsoft.com. Retrieved 2021-03-27.
- ^ a b
A. H. Johnston. «Space Radiation Effects in Advanced Flash Memories» Archived 2016-03-04 at the Wayback Machine. NASA Electronic Parts and Packaging Program (NEPP). 2001. - ^ «ECC DRAM – Intelligent Memory». intelligentmemory.com. Archived from the original on 2019-02-12. Retrieved 2021-06-12.
- ^ a b «Using StrongArm SA-1110 in the On-Board Computer of Nanosatellite». Tsinghua Space Center, Tsinghua University, Beijing. Archived from the original on 2011-10-02. Retrieved 2009-02-16.
- ^ «Actel engineers use triple-module redundancy in new rad-hard FPGA». Military & Aerospace Electronics. Archived from the original on 2012-07-14. Retrieved 2009-02-16.
- ^ «SEU Hardening of Field Programmable Gate Arrays (FPGAs) For Space Applications and Device Characterization». Klabs.org. 2010-02-03. Archived from the original on 2011-11-25. Retrieved 2011-11-23.
- ^ «FPGAs in Space». Techfocusmedia.net. Retrieved 2011-11-23.[permanent dead link]
- ^ «Commercial Microelectronics Technologies for Applications in the Satellite Radiation Environment». Radhome.gsfc.nasa.gov. Archived from the original on 2001-03-04. Retrieved 2011-11-23.
- ^
Doug Thompson, Mauro Carvalho Chehab.
«EDAC — Error Detection And Correction» Archived 2009-09-05 at the Wayback Machine.
2005 — 2009.
«The ‘edac’ kernel module goal is to detect and report errors that occur
within the computer system running under linux.» - ^ a b «AMD-762™ System Controller Software/BIOS Design Guide, p. 179» (PDF).
- ^ a b Doe Hyun Yoon; Mattan Erez. «Memory Mapped ECC: Low-Cost Error Protection for Last Level Caches». 2009. p. 3
- ^ Daniele Rossi; Nicola Timoncini; Michael Spica; Cecilia Metra.
«Error Correcting Code Analysis for Cache Memory High Reliability and Performance» Archived 2015-02-03 at the Wayback Machine. - ^ Shalini Ghosh; Sugato Basu; and Nur A. Touba. «Selecting Error Correcting Codes to Minimize Power in Memory Checker Circuits» Archived 2015-02-03 at the Wayback Machine. p. 2 and p. 4.
- ^ Chris Wilkerson; Alaa R. Alameldeen; Zeshan Chishti; Wei Wu; Dinesh Somasekhar; Shih-lien Lu. «Reducing cache power with low-cost, multi-bit error-correcting codes». doi:10.1145/1816038.1815973.
- ^ M. Y. Hsiao. «A Class of Optimal Minimum Odd-weight-column SEC-DED Codes». 1970.
- ^
Intel Corporation.
«Intel Xeon Processor E7 Family: Reliability, Availability, and Serviceability».
2011.
p. 12. - ^ «Bios and Cache — Custom Build Computers». www.custom-build-computers.com. Retrieved 2021-03-27.
- ^ «AMD Zen microarchitecture — Memory Hierarchy». WikiChip. Retrieved 15 October 2018.
- ^ «AMD Zen+ microarchitecture — Memory Hierarchy». WikiChip. Retrieved 15 October 2018.
- ^
Jangwoo Kim; Nikos Hardavellas; Ken Mai; Babak Falsafi; James C. Hoe.
«Multi-bit Error Tolerant Caches Using Two-Dimensional Error Coding».
2007.
p. 2. - ^
Nathan N. Sadler and Daniel J. Sorin.
«Choosing an Error Protection Scheme for a Microprocessor’s L1 Data Cache».
2006.
p. 1. - ^ «Typical unbuffered ECC RAM module: Crucial CT25672BA1067».
- ^ Specification of desktop motherboard that supports both ECC and non-ECC unbuffered RAM with compatible CPUs
- ^ «Discussion of ECC on pcguide». Pcguide.com. 2001-04-17. Retrieved 2011-11-23.
- ^ Benchmark of AMD-762/Athlon platform with and without ECC Archived 2013-06-15 at the Wayback Machine
- ^ «ECCploit: ECC Memory Vulnerable to Rowhammer Attacks After All». Systems and Network Security Group at VU Amsterdam. Retrieved 2018-11-22.
External links[edit]
- SoftECC: A System for Software Memory Integrity Checking
- A Tunable, Software-based DRAM Error Detection and Correction Library for HPC
- Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing
- Single-Bit Errors: A Memory Module Supplier’s perspective on cause, impact and detection
- Intel Xeon Processor E3 — 1200 Product Family Memory Configuration Guide
- Linus Torvalds On The Importance Of ECC RAM, Calls Out Intel’s «Bad Policies» Over ECC
Джефф Этвуд, возможно, самый читаемый программист-блоггер, опубликовал пост против использования памяти ECC. Как я понимаю, его доводы такие:
- В Google не использовали ECC, когда собирали свои серверы в 1999 году.
- Большинство ошибок ОЗУ — это ошибки систематические, а не случайные.
- Ошибки ОЗУ возникают редко, потому что аппаратное обеспечение улучшилось.
- Если бы память ECC имела на самом деле важное значение, то она использовались бы везде, а не только в серверах. Плата за такого рода опциональный материал явно слишком сомнительна.
Давайте рассмотрим эти аргументы один за другим:
1. В Google не использовали ECC в 1999 году
Если вы делаете нечто только из-за того, что когда-то это сделал Google, то попробуйте:
A. Поместите свои серверы в транспортные контейнеры.
Сегодня все ещё пишут статьи о том, что это — отличная идея, хотя Google всего лишь провёл эксперимент, который был расценен как неудачный. Оказывается, даже эксперименты Google не всегда удаются. Фактически, их известное пристрастие к «прорывным проектам» («луншоты») означает, что у них имеется больше неудачных экспериментов, чем у большинства компаний. По-моему, для них это существенное конкурентное преимущество. Не стоит делать это преимущество больше, чем оно есть, слепо копируя провалившиеся эксперименты.
B. Вызывайте пожары в своих собственных центрах обработки данных.
Часть поста Этвуда обсуждает, насколько удивительными были эти серверы:
Некоторые могут взглянуть на эти ранние серверы Google и увидеть непрофессионализм в отношении опасности пожара. Не я. Я вижу здесь дальновидное понимание того, как недорогое стандартное оборудование будет формировать современный интернет.
Последняя часть высказанного — это правда. Но и в первой части есть доля правды. Когда Google начал разрабатывать свои собственные платы, одно их поколение имело проблему «роста» (1), вызвавшую ненулевое число возгораний.
Кстати, если вы перейдёте к посту Джеффа и посмотрите на фотографию, на которую ссылается цитата, то вы увидите, что на платах много кабелей-перемычек. Это вызывало проблемы и было исправлено в следующем поколении оборудования. Также можно видеть довольно неряшливо выполненную кабельную разводку, что дополнительно вызывало проблемы и что также было быстро устранено. Были и другие проблемы, но я оставлю их в качестве упражнения для читателя.
C. Создавайте серверы, которые травмируют ваших сотрудников
Острые грани одного из поколений серверов Google заработали им репутацию сделанных из «бритвенных лезвий и ненависти».
D. Создавайте свою погоду в ваших центрах обработки данных
После разговоров с сотрудниками многих крупных технологических компаний создаётся впечатление, что в большинстве компаний был такой климат-контроль, что в их центрах обработки данных образовывались облака или туман. Можно было бы назвать это расчётливым и коварным планом Google по воспроизведению сиэтловской погоды, чтобы переманивать сотрудников Microsoft. Как вариант, это мог быть план создания в буквальном смысле «облачных вычислений». А может и нет.
Обратите внимание, что всё указанное Google попробовал, а затем изменил. Делать ошибки, а затем устранять их — распространённое явление в любой организации, успешно занимающейся разработками. Если вы боготворите инженерную практику, то следует держаться, по крайней мере, за современную практику, а не за сделанное в 1999 году.
Когда Google использовал серверы без ECC в 1999 году, на них проявился ряд симптомов, которые, как в конце концов выяснилось, были вызваны повреждением памяти. В том числе индекс поиска, который возвращал фактически случайные результаты в запросы. Реальный режим сбоя здесь поучителен. Я часто слышу, что на этих машинах можно игнорировать ECC, потому что ошибки в отдельных результатах являются допустимыми. Но даже если вы считаете для себя случайные ошибки допустимыми, их игнорирование означает, что существует опасность полного повреждения данных, если только не проводить тщательный анализ с целью убедиться, что одна ошибка может лишь незначительно исказить один результат.
В исследованиях, проведённых на файловых системах, неоднократно было показано, что, несмотря на героические попытки создания систем, устойчивых к одной ошибке, сделать это крайне сложно. По существу, каждая сильно тестируемая файловая система может иметь серьёзный сбой из-за единственной ошибки (см. результаты работы исследовательской группы Андреа и Ремзи, Висконсин, если вам интересно это). Я не собираюсь нападать на разработчиков файловых систем. Они лучше разбираются в таком анализе, чем 99,9% программистов. Просто неоднократно уже было показано, что эта проблема настолько трудная, что люди не могут достаточно обоснованно обсуждать её, и автоматизированное инструментальное средство для такого анализа ещё далеко от процесса простого нажатия кнопки. В своём справочнике по компьютерной обработке складских данных Google обсуждает обнаружение и исправление ошибок, и память ECC рассматривается как самый правильный вариант, когда очевидно, что необходимо использовать исправление ошибок аппаратного обеспечения (2).
Google имеет отличную инфраструктуру. Из того, что я слышал об инфраструктуре в других крупных инфотехнологических компаниях, Google представляется лучшим в мире. Но это не значит, что следует копировать всё, что они делают. Даже если рассматривать только их хорошие идеи, для большинства компаний нет смысла копировать их. Они создали замену планировщику перехвата работ Linux, который использует как аппаратную информацию времени выполнения, так и статические трассировки, чтобы позволить им использовать преимущества нового оборудования в серверных процессорах Intel, что позволяет динамически разбивать кэш между ядрами. Если использовать это на всём их оборудовании, то Google сэкономит за неделю больше денег, чем компания Stack Exchange потратила на все свои машины за всю свою историю. Означает ли это, что вы должны скопировать Google? Нет, если на вас уже не свалилась манна небесная, например, в виде того, что ваша основная инфраструктура написана на высокооптимизированном C++, а не на Java или (не дай бог) Ruby. И дело в том, что для подавляющего большинства компаний написание программ на языке, который влечёт 20-кратное снижение производительности, — совершенно разумное решение.
2. Большинство ошибок ОЗУ — это систематические ошибки
Аргументация против ECC воспроизводит следующий раздел исследования ошибок DRAM (выделение дано Джеффом):
Наше исследование имеет несколько основных результатов. Во-первых, мы обнаружили, что приблизительно 70% сбоев DRAM является повторяющимися (например, постоянными) сбоями, тогда как только 30% является неустойчивыми (перемежающимися) сбоями. Во-вторых, мы обнаружили, что большие многобитовые сбои, такие как сбои, которые затрагивают всю строку, столбец или блок, составляют более 40% всех сбоев DRAM. В-третьих, мы обнаружили, что почти 5% отказов DRAM влияют на схемы на уровне платы, такие как линии данных (DQ) или стробирования (DQS). Наконец, мы обнаружили, что функция Chipkill уменьшила частоту отказов системы, вызываемих сбоями DRAM, в 36 раз.
Цитата кажется несколько ироничной, поскольку она выглядит не аргументом против ECC, а аргументом за Chipkill — определённый класс ECC. Отложив это в сторону, пост Джеффа указывает, что систематические ошибки встречаются в два раза чаще, чем ошибки случайные. Затем пост сообщает, что они запускают memtest на своих машинах, когда происходят систематические ошибки.
Во-первых, соотношение 2:1 не столь велико, чтобы просто игнорировать случайные ошибки. Во-вторых, пост подразумевает веру Джеффа, что систематические ошибки, по существу, неизменны и не могут проявиться через некоторое время. Это неверно. Электроника изнашивается точно так же, как изнашиваются механические устройства. Механизмы разные, но эффекты схожи. Действительно, если сравнить анализ надёжности чипов с другими видами анализа надёжности, то можно видеть, что они часто используют одни и те же семейства распределений для моделирования отказов. В-третьих, ход рассуждений Джеффа подразумевает, что ECC не может помочь в обнаружении или исправлении ошибок, что не только неверно, но и прямо противоречит цитате.
Итак, как часто вы собираетесь запускать memtest на своих машинах в попытках поймать эти системные ошибки и сколько потерь данных вы готовы пережить? Одно из ключевых применений ECC состоит не в том, чтобы исправить ошибки, а в том, чтобы сигнализировать об ошибках, благодаря чему оборудование может быть заменено до того, как произойдёт «silent corruption» («скрытое повреждение данных»). Кто согласится закрывать всё на машине каждый день, чтобы запустить memtest? Это было бы намного дороже, чем просто купить ECC-память. И даже если бы вы смогли убедить гонять тестирование памяти, memtest не обнаружил бы столько ошибок, сколько сможет найти ECC.
Когда я работал в компании с парком в примерно тысячу машин, мы заметили, что у нас происходят странные отказы при проверке целостности данных, и примерно через полгода мы поняли, что отказы на одних машинах более вероятны, чем на других. Эти отказы были довольно редкими (может быть, пару раз в неделю в среднем), поэтому потребовалось много времени для накопления информации и понимания, что же происходит. Без знания причины анализ логов с целью понять, что ошибки были вызваны единичными случаями инвертирования битов (с большой вероятностью), также был нетривиальным. Нам повезло, что в качестве побочного эффекта процесса, который мы использовали, контрольные суммы вычислялись в отдельном процессе на другой машине в разное время, так что ошибка не могла исказить результат и распространить это повреждение на контрольную сумму.
Если вы просто пытаетесь защитить себя с помощью контрольных сумм в памяти, есть немалая вероятность того, что вы выполните операцию вычисления контрольной суммы на уже повреждённых данных и получите правильную контрольную сумму неправильных данных, если только вы не делаете некоторые действительно необычные операции с вычислениями, которые дают их собственные контрольные суммы. А если вы серьёзно относитесь к исправлению ошибок, то вы, вероятно, всё же используете ECC.
Во всяком случае, после завершения анализа мы обнаружили, что memtest не мог обнаружить какие-либо проблемы, но замена ОЗУ на плохих машинах привела к уменьшению частоты ошибок на один-два порядка. У большинства сервисов нет такого рода контрольных сумм, которые были у нас; эти сервисы будут просто молча записывать повреждённые данные в постоянное хранилище и не увидят проблему, пока клиент не начнёт жаловаться.
3. Благодаря развитию аппаратного обеспечения ошибки стали очень редкими
Данных в посте недостаточно для такого утверждения. Обратите внимание, что поскольку использование ОЗУ возрастает и продолжает увеличиваться экспоненциально, отказы ОЗУ должны уменьшаться с большей экспоненциальной скоростью, чтобы фактически уменьшить частоту повреждения данных. Кроме того, поскольку чипы продолжают уменьшаться, элементы становятся меньше, что делает более актуальными проблемы износа, обсуждаемые во втором пункте. Например, при технологии 20 нм конденсатор DRAM может накпливать где-то электронов 50, и это число будет меньше для следующего поколения DRAM при сохранении тенденции уменьшения.
Исследование 2012 года, которое цитирует Этвуд, имеет этот график по исправленным ошибкам (подмножество всех ошибок) на десяти случайно выбранных отказавших узлах (6% узлов имели по крайней мере один отказ):

Рис. 1. Исправленные за месяц ошибки для выбранных случайным образом узлов. Количество ошибок показывает тип сбоя, возникший в каждом узле.
Речь идёт о количестве ошибок от 10 до 10 тыс. для типичного узла, у которого происходит отказ, и это — тщательно отобранное исследование с поста, утверждающего, что вам не нужна память ECC. Обратите внимание, что здесь рассматриваются узлы с ОЗУ только 16 ГБ, что на порядок меньше, чем у современных серверов, и что исследование было проведено на более старом техпроцессе, который был менее уязвим для шума, чем нынешний.
Для тех, кто привык иметь дело с проблемами надёжности и просто хочет знать значение FIT (единица измерения интенсивности отказов): исследование показывает, что значение FIT составляет 0,057-0,071 сбоев на один мегабит (что — в противоположность утверждению Этвуда — не является поразительно низким числом).
Если взять самое оптимистичное значение FIT, равное 0,057, и провести расчёт для сервера не с самой большой оперативной памятью (здесь я использую 128 ГБ, поскольку серверы, которые я вижу в настоящее время, обычно имеют ОЗУ от 128 до 1,5 ТБ), то получим ожидаемое значение 0,057 * 1 000 * 1 000 * 8 760 /1 000 000 000 = 0,5 сбоя в год на каждый сервер. Обратите внимание, что это относится к сбоям, а не к ошибкам. Из графика выше видно, что сбой может легко вызвать сотни или тысячи ошибок в месяц. Ещё нужно отметить, что есть несколько узлов, у которых нет ошибок в начале исследования, но ошибки появляются позже.
Компания Sun/Oracle серьёзно столкнулась с этим несколько десятилетий назад. Транзисторы и конденсаторы DRAM становились всё меньше, как это происходит и сейчас, а использование памяти и кэши росли, так же как и в настоящее время. Столкнувшись, с одной стороны, со всё уменьшающимся транзистором, который был менее стойким к временному нарушению и более сложным в изготовлении, а, с другой стороны, с растущим встроенным кэшем, подавляющее большинство поставщиков серверов ввело ECC в свои кэши. Компания Sun решила сэкономить несколько долларов и не использовать ECC. Прямым результатом было то, что ряд клиентов Sun сообщил о периодических повреждении данных. В результате затем Sun несколько лет занималась разработкой новой архитектуры с кэшем на ECC и заставляла клиентов подписывать NDA для замены чипов.
Конечно, невозможно постоянно скрывать подобные вещи, и когда они всплыли, репутация Sun по созданию надёжных серверов получила сильный удар, во многом похожий на случай, когда Sun пыталась скрыть плохие показатели производительности, введя в свои условия использования запрет на бенчмарки.
Ещё одно замечание: когда вы платите за ECC, вы платите не просто за память ECC — вы платите за детали (процессоры, платы), которые являются более качественными. Такое легко можно видеть с частотой отказа дисков, и я слышал, что многие замечают такое в своих личных наблюдениях.
Если приводить общедоступные исследования: насколько помню, группа Андреа и Ремзи несколько лет назад выпустила документ SIGMETRICS, который показал, что вероятность сбоя при чтении у диска SATA в 4 раза выше, чем у диска SCSI, а вероятность скрытого повреждения данных — в 10 раз выше. Это соотношение сохранялось даже при использовании дисков одного изготовителя. Нет особой причины думать, что интерфейс SCSI должен быть более надёжным, чем интерфейс SATA, но речь идёт не об интерфейсе. Речь идёт о покупке высоконадёжных серверных компонентов по сравнению с клиентскими. Возможно, конкретно надёжность диска вас не интересует, потому что у вас всё на контрольных суммах, и повреждения легко находятся, но есть некоторые виды нарушений, которые обнаружить труднее.
4. Если бы память ECC имела, действительно, важное значение, то её использовали бы везде, а не только в серверах.
Немного перефразируя этот аргумент, можно сказать, что «если бы эта характеристика была, действительно, важна для серверов, то она использовалась бы и в не-серверах». Можно применить этот аргумент к довольно большому количеству аппаратных средств сервера. На самом деле это одна из наиболее неприятных проблем, стоящих перед крупными поставщиками облачных решений.
У них достаточно рычагов воздействия, чтобы получать большинство компонентов по подходящей цене. Но поторговаться получится только там, где есть более одного жизнеспособного поставщика.
Одной из немногих областей, где нет каких-либо жизнеспособных конкурентов, является производство центральных процессоров и видеоускорителей. К счастью для крупных поставщиков, видеоускорители им обычно не нужны, нужны процессоры, много — уже давно так сложилось. Было несколько попыток поставщиков процессоров войти на серверный рынок, но всегда каждая такая попытка с самого начала имела фатальные недостатки, делавшие очевидной её обречённость (а это часто проекты, требующие не менее 5 лет, т.е. необходимо было потратить очень много времени без уверенности в успехе).
Усилия Qualcomm получили много шума, но, когда я общаюсь с моими контактами в Qualcomm, они все говорят мне, что сделанный в данный момент чип предназначен, по существу, для пробы. Так получилось, потому что компании Qualcomm нужно было узнать, как сделать серверный чип, у всех тех специалистов, которых она переманила из IBM, и что следующий чип будет первым, который, можно надеяться, станет конкурентоспособным. Я возлагаю большие надежды на Qualcomm, а также на усилия ARM по созданию хороших серверных компонентов, но эти усилия пока не дают желаемого результата.
Почти полная непригодность текущих вариантов ARM (и POWER) (не считая гипотетических вариантов впечатляющего чипа ARM от Apple) для большинства рабочих нагрузок серверов с точки зрения производительности на доллар совокупной стоимости владения (TCO) — эта тема немного в стороне, поэтому я оставлю её для другой публикации. Но дело в том, что Intel имеет такую позицию на рынке, что может заставить людей платить сверху за серверные функции. И Intel это делает. Кроме того, некоторые функции действительно важнее для серверов, чем для мобильных устройств с несколькими гигабайтами оперативной памяти и энергетическим бюджетом в несколько ватт, мобильных устройств, от которых всё равно ожидают периодические вылеты и перезагрузки.
Заключение
Следует ли покупать ECC-ОЗУ? Это зависит от многого. Для серверов это, вероятно, хороший вариант, учитывая затраты. Хотя на самом деле трудно провести анализ затрат/выгод, потому что довольно сложно определить ущерб от скрытого повреждения данных или затраты на риск потерять полгода времени разработчика на отслеживание перемежающихся сбоев, только чтобы обнаружить, что они вызваны использованием памяти без ECC.
Для настольных компьютеров я тоже сторонник ECC. Но если вы не делаете регулярные бэкапы, то вам полезнее вложиться в регулярные бэкапы, чем в ECC-память. И если у вас есть резервные копии без ECC, то вы можете легко записать повреждённые данные в основное хранилище и реплицировать эти повреждённые данные в резервную копию.
Спасибо Прабхакару Рагде, Тому Мерфи, Джею Вайскопфу, Лии Хансон, Джо Уайлдеру и Ральфу Кордерою за обсуждение / комментарии / исправления. Кроме того, спасибо (или, может быть, не-спасибо) Лии за то, что убедила меня написать этот устный экспромт как пост в блоге. Приносим извинения за любые ошибки, отсутствие ссылок и возвышенную прозу; это, по существу, запись половины обсуждения, и я не объяснил условия, не предоставил ссылки или не проверил факты на том уровне детализации, как я обычно делаю.
1. Одним из забавных примеров является (по крайней мере, для меня) магическая самовосстанавливающаяся плавкая перемычка. Хотя реализаций много, представим себе плавкую перемычку на чипе как некоторый резистор. Если вы пропускаете через неё какой-то ток, то вы должны получить соединение. Если ток слишком большой, то резистор разогреется и, в конце концов, разрушится. Это обычно используется для отключения элементов на микросхемах или для таких действий, как задание тактовой частоты. Основной принцип состоит в том, что после сгорания перемычки нет возможности вернуть её в исходное состояние.
Давным давно жил да был производитель полупроводниковых устройств, который немного поторописля со своим производственным процессом и несколько чрезмерно уменьшил допуски в некотором технологическом поколении. Через несколько месяцев (или лет) соединение между двумя концами подобной перемычки смогло снова появиться и восстановить его. Если вам повезёт, то такая перемычка будет чем-то вроде старшего бита множителя тактовой частоты, который в случае его изменения будет выводить чип из строя. Если не повезёт, то это приведёт к скрытому повреждению данных.
Я слышал от многих людей в разных компаниях о проблемах в этом технологическом поколении этого производителя, так что это не были отдельные случаи. Когда я говорю, что это забавно, я имею в виду, что забавно услышать эту историю в баре. Менее забавно обнаружить через год тестирования, что некоторые из ваших чипов не работают, потому что их установки для перемычек бессмысленны, и необходимо переделать ваш чип и отложить выпуск на 3 месяца. Кстати, эта ситуация с восстановлением плавкой перемычки — ещё один пример класса ошибок, остроту которых можно сгладить с помощью ECC.
Это не проблема Google; я упоминаю об этом только потому, что многие люди, с которыми я общаюсь, удивлены тем, каким образом аппаратное обеспечение может выйти из строя.
2. Если вы не хотите копаться во всей книге, то вот нужный фрагмент:
В системе, которая может выдержать ряд отказов на программном уровне, минимальное требование, предъявляемое к аппаратной части, заключается в том, что сбои этой части всегда обнаруживаются и сообщаются программному обеспечению достаточно своевременно, чтобы позволить программной инфраструктуре ограничить их и принять соответствующие действия по восстановлению. Необязательно, чтобы аппаратное обеспечение явно справлялось со всеми сбоями. Это не означает, что оборудование для таких систем должно быть спроектировано без возможности исправления ошибок. Всякий раз, когда функциональные возможности исправления ошибок могут быть предложены с разумной ценой или сложностью, поддержка их часто окупается. Это означает, что, если аппаратная коррекция ошибок была бы чрезвычайно дорогостоящей, то система могла бы иметь возможность использования более дешёвой версии, которая предоставляла бы возможности только обнаружения. Современные системы DRAM являются хорошим примером ситуации, в которой мощная коррекция ошибок может быть предоставлена при очень низких дополнительных затратах. Однако смягчение требования об обнаружении аппаратных ошибок было бы намного сложнее, поскольку это означало бы, что каждый программный компонент был бы обременён необходимостью проверки его собственного правильного выполнения. На начальном этапе своей истории Google пришлось иметь дело с серверами, на которых у DRAM отсутствовал даже контроль чётности. Создание индекса веб-поиска состоит, по существу, из очень большой операции сортировки/слияния, использующей длительно несколько машин. В 2000 году одно из ежемесячных обновлений веб-индекса Google не прошло предварительную проверку, когда обнаружилось, что некоторое подмножество проверенных запросов возвращает документы, по-видимому, случайным образом. После некоторого исследования в новых индексных файлах была выявлена ситуация, которая соответствовала фиксации бита на нуле в определённом месте в структурах данных, что было негативным побочным эффектом потоковой передачи большого количества данных через неисправный чип DRAM. В структуры данных индекса были добавлены проверки непротиворечивости, чтобы свести к минимуму вероятность повторения этой проблемы, и в дальнейшем проблем такого характера не было. Однако следует отметить, что этот способ не гарантирует 100% обнаружения ошибок в проходе индексации, так как не все позиции памяти проверяются — инструкции, например, остаются без проверки. Это сработало потому, что структуры данных индекса были настолько больше, чем все другие данные, участвующие в вычислении, что наличие этих самоконтролируемых структур данных делало очень вероятным, что машины с дефектным DRAM будут идентифицированы и исключены из кластера. Следующее поколение машин в Google уже содержало обнаружение чётности в памяти, и как только цена памяти с ECC опустилась до конкурентного уровня, все последующие поколения использовали ECC-DRAM.
Проверка чётности (Parity) и ЕСС для определения ошибок оперативной памяти компьютера.
Parity Checking (Проверка четности)
Один из установленных для отрасли стандартов IBM заключается в том, что в банке чипа памяти находятся девять бит данных: 8 бит на символ плюс 1 дополнительный бит, называемый бит чётности.
Бит чётности позволяет схеме управления памятью следить за другими 8 битами — встроенной перекрёстной проверкой целостности каждого байта в системе.
Первоначально все ПК-системы, для обеспечения точности, использовали память с проверкой чётности. Но, начиная с 1994 года, большинство поставщиков стали продавать системы без проверки на чётность и любые другие способы обнаружения или исправления ошибок «на лету». В этих системах использовались более дешёвые nonparity модули, которые экономили на стоимости памяти для системы около 10% -15%.
Parity память приводит к увеличению первоначальной стоимости системы, в первую очередь из-за дополнительных бит памяти. Parity не может исправить системные ошибки, но поскольку чётность может обнаруживать ошибки, она может информировать пользователя об этих ошибках памяти, когда они происходят.
С тех пор Intel, AMD и другие производители поставляют поддержку памяти ECC, в основном на серверных чипсетах и процессорах. Чипсеты и процессоры для систем стандартного рабочего стола или ноутбука обычно не поддерживают parity или ECC.
Как работает Parity Checking Works
IBM, для проверки ошибок, первоначально установила стандарт чётности. Попробуем объяснить, что подразумевается под нечётным паритетом.
Поскольку в памяти, в байте хранятся 8 отдельных бит, генератор проверки чётности, который является либо частью ЦП, либо расположен в специальном чипе на материнской плате, оценивает биты данных способом суммирования числа в 1 байте.
Если найдено чётное число, генератор проверки чётности создаёт 1 и сохраняет его как девятый бит (бит чётности) в чипе памяти чётности. Сумма для всех 9 бит (включая бит чётности), даёт нечётное число.
Если исходная сумма из 8 бит данных — нечётное число, созданный бит чётности будет 0, сохраняя сумму для всех 9 бит нечётным числом. Основное правило заключается в том, что значение бит чётности всегда выбирается так, чтобы сумма всех 9 бит (8 бит данных плюс 1 бит чётности) хранилась как нечётное число.
Если бы система использовала чётность, пример был бы таким же, за исключением того, что бит чётности был бы создан для обеспечения чётной суммы. Не имеет значения, используется ли чётное или нечётное соотношение. Система использует то или другое и полностью прозрачна для чипов памяти.
Помните, что 8 бит данных в байте нумеруются 0 1 2 3 4 5 6 7.
Для понимания приведём следующие примеры:
Бит данных: 0 1 2 3 4 5 6 7 Бит чётности
Значение бита данных: 1 0 1 1 0 0 1 1 0
В этом примере, поскольку общее количество бит данных со значением 1 — нечётное число (5), чтобы обеспечить нечётную сумму для всех 9 бит, бит чётности должен иметь значение 0.
Вот другой пример:
Бит данных: 0 1 2 3 4 5 6 7 Бит чётности
Значение бита данных: 1 1 1 1 0 0 1 1 1
В этом примере потому что общее количество битов данных со значением 1 — чётное число (6), бит чётности для создания нечётной суммы всех 9 битов, должен иметь значение 1.
Когда система считывает память обратно из хранилища, он проверяет информацию о чётности. Если байт (9-бит) имеет чётное количество бит, байт должен иметь сообщение об ошибке.
Система не может определить какой бит изменился и изменился ли только один бит. Например, если было изменено 3 бита, байт по-прежнему отметит ошибку проверки чётности. Однако, если изменились 2 бита, плохой байт может пройти незамеченным. Поскольку множественные битовые ошибки (в одном байте) редки, эта схема даёт разумное и недорогое указание на состояние памяти.
ECC
ECC — большой шаг за пределы обнаружения простых ошибок чётности. Вместо простого обнаружения ошибок, ECC позволяет исправлять одну битовую ошибку, что означает, система может продолжать работать без перерыва и без искажения данных.
Реализованное в большинстве ПК — ECC, может только обнаружить, не правильные, двухбитовые ошибки. Так как исследования показали, что примерно 98% ошибок памяти однобитовые, наиболее часто используемый тип ECC — это тот, в котором контроллер памяти обнаруживает и исправляет в доступных данных однобитовые ошибки. (Двухбитовые ошибки могут быть обнаружены, но не скорректированы.)

Этот тип ECC известен как исправление однобитовых ошибок с обнаружением двухбитовых ошибкой (SEC-DED) и требует дополнительных 7 проверочных бит над 32 битами в 4- байтовую систему и ещё 8 контрольных битов на 64 бита в 8-байтовой системе
Если в системе используется SIMM, для каждого банка добавляются два 36-битных (чётность) SIMM, которые составляют 72 бита, и ECC — на уровне банка. Если система использует DIMM, в качестве банка используется один 72-разрядный DIMM с контролем чётности/ECC и предоставляет дополнительные биты.
RIMM, в зависимости от чипсета и материнской платы, устанавливаются в одиночку или в парах. Если требуется чётность/ECC, они должны быть 18-битными версиями.
ECC предполагает, что контроллер памяти вычисляет контрольные биты в операции записи в память. Выполняет сравнение между считываемыми и вычисленными контрольными битами в операции чтения и, при необходимости, исправляя неправильные биты.
Дополнительная логика ECC в контроллере памяти не очень значительна в этой недорогой высокопроизводительной логике VLSI, но ECC фактически влияет на производительность памяти при записи.
Это связано с тем, что операция должна быть рассчитана на ожидание вычисления контрольных битов и, когда система дожидается исправленных данных, чтения. При написании части слова все слово должно быть сначала прочитано, пострадавший байт(ы) переписан, а затем вычислены новые контрольные биты. Это превращает операции замещения части слова в более медленную чтение-изменение записи. К счастью, удар по производительности небольшой, порядка нескольких процентов, поэтому компромисс для повышения надёжности хороший.
Большинство ошибок памяти имеют однобитовый характер, который ECC может исправить. Включение этого отказоустойчивого метода обеспечивает высокую надёжность системы и доступность обслуживания.
Система на базе ECC хороший выбор для серверов, рабочих станций или критически важных приложений, в которых стоимость потенциальной ошибки памяти перевешивает дополнительную память и стоимость исправления системы, а также гарантирует, что она не будет снижать надёжность системы.
К сожалению, большинство стандартных настольных и переносных ПК, материнских плат (чипсетов) и модулей памяти не поддерживают ECC.
Если вы хотите поддерживающую ECC систему, убедитесь, что все задействованные компоненты поддерживают ECC. Обычно это означает покупку более дорогих процессоров, материнских плат и оперативной памяти, предназначенных для серверных или высокопроизводительных приложений для рабочих станций.