
Время на прочтение
9 мин
Количество просмотров 8.6K

Перевод статьи Coding A.I. Techniques in Elixir: The Generate and Test Algorithm
В последнее время, я работал над проектом в области И.И. (искусственный интеллект). По моим ожиданиям, работа над этим проектом займет ещё значительное время. Цель состояла в том, чтобы написать проект 100% на языке Elixir, но прежде чем я смог принять это решение, мне нужно было удостовериться, что я смогу реализовать некоторые из самых популярных решений в области И.И. на Elixir. На протяжении нескольких дней я изучал некоторые из наиболее эффективных техник, которые применяют исследователи в области И.И. для решения проблем программными средствами.
В этой статье я сделаю краткое объяснение метода, называемого алгоритмом генерации и испытаний — Generate and test algorithm (он же проб и ошибок), а затем я буду использовать вариацию этого метода для решения простой задачи с использованием языка программирования Elixir.
В И.И. есть много областей, из которых наиболее известными на сегодняшний день являются машинное обучение, обработка естественного языка (natural language processing) и робототехника. Тем не менее, для меня моя любимая дисциплина в И.И. известна как автоматизированные рассуждения — Automated reasoning. Программа, которую я продемонстрирую попадет в эту область И.И.
Проблема
Предположим, что вы получили задание написать программу, которая должна сформировать вопросительное предложение о том является ли сумма группы очень больших натуральных чисел четным числом, и затем сформировать ответ на этот вопрос. Давайте попробуем применить метод автоматизированных рассуждений для решения этой простой задачи.
Решение
Алгоритм автоматизированных рассуждений лучше всего подходит для решения простых задач, как та, что приведена выше. Способ работы алгоритма довольно прост. Можно выделить 3 основных шага.
1. Сформировать возможное решение
2. Проверка того, что получено ожидаемое решение
3. Если решение верно, возвращаем его и завершаем работу, в противном случае повторяем шаги с 1 по 3Имея в виду эту концепцию, давайте создадим умную программу, которая может ответить на вопрос: «Является ли результат х + у четным?». В этом упражнении мы будем заботиться только о четных суммах, так что, когда система обнаруживает, что результат подсчета суммы является четным числом, мы будем реагировать соответствующим образом подтвердив, что найден ожидаемый результат. Обычно, когда мы получаем истинный ответ, используя эту технику, мы должны были бы остановить всю обработку. Тем не менее, в нашем случае мы хотим только остановиться, когда все вопросы, подготовленные системой будут услышаны. И, наконец, на вопросы сумма чисел в которых является не четным числом, мы будем отвечать Нет.
Код
При написании решения для этой задачи, я заметил, что код, который вы собираетесь увидеть, охватывает большинство основных возможностей языка Elixir. Так что, если вы никогда не использовали Elixir до этого момента, эти примеры кода дадут вам практическое представление о том, как работает язык.
Первый шаг заключается в создании модуля с названием SumAndTest, который будет содержать весь код реализации.
defmodule SumAndTest do
@moduledoc """
This script is designed to show the functionality of the AI Algorithm
that is known as Generate and Test. It will produce the results to a
addition question and answer whether or not the answer is even.
"""-
Elixit организует код с помощью модулей. СЛАВА БОГУ, НИКАКИХ КЛАССОВ!!!
- @moduledoc является макросом для добавления комментария, который позволяет дать краткое описание того, для чего предназначен данный модуль.
Мы должны ответить на вопрос: «Является ли результат х + у четным числом?». Так что давайте двигаться далее и создадим функцию, которая содержит этот вопрос.
defp addition_question(first_numbaer, second_number) do
"Is the result of #{first_numbaer} + #{second_number} even?"
end-
Мы определяем функцию
addition_questionс двумя аргументами - Интерполяция в строке в Elixir имеет тот же синтаксис, что и в Ruby
Теперь у нас есть наш вопрос. Следующим шагом является определение двух возможных ответов, которыми наша система будет отвечать на вопрос. Мы будем использовать возможность Elixir давать альтернативные определения одной и той же функции в зависимости от переданных аргументов.
defp say_answer(true) do
"YES! Even result found."
end
defp say_answer(false) do
"No."
end-
Когда передан аргумент
true, мы говорим «да», когдаfalse, мы просто говорим «нет» - Проверка соответствия аргументов является ключевой особенностью, которая отличает Elixir от большинства других языков программирования. Весьма подходящей для программирования искусственного интеллекта.
Мы создали возможность отвечать да и нет. Но что будет инициировать этот ответ? Нам необходимо определить, является ли результат на суммы 2 чисел четным числом. Создадим соответствующую функцию.
defp even?(number) when is_number(number) do
if rem(number, 2) == 0, do: true, else: false
endТак же возможно переписать тело функции просто как rem(number, 2) == 0, что само по себе возвращает true или false (прим. пер.).
-
Elixir имеет возможность определить валидацию аргументов функции с помощью ключевого слова
when. Если аргументы не удовлетворяют условию валидации, то данное определение функции считается не подходящим и возможно будет применено одно из ее следующих определений (прим. пер.) -
В Elixir имеется аналог тернарного оператора в одну строку
rem()является функцией Elixir, принадлежащий к модулю Kernel (ядро). Она определяет остаток от деления нацело.
Основные строительные блоки теперь готовы, но мы стремимся к созданию автоматизированных рассуждений. Мы хотим, чтобы система сама автоматически придумывала вопрос, так чтобы мы могли убедиться, что наша система действительно отвечает на этот вопрос правильно. Давайте создадим функцию generate, ответственную за это.
defp generate(amount_of_questions) when is_number(amount_of_questions) do
generate(0, amount_of_questions)
end
defp generate(accumulator, amount_of_questions) when amount_of_questions >= 1 do
question = addition_question(Enum.random(1..100_000), Enum.random(1..100_000))
build_list(question)
generate(accumulator + 1, amount_of_questions - 1)
end
defp generate(total, 0) do
IO.puts "#{total} addition questions generated."
:ok
end-
Вы растеряны? Не нужно. В Elixir обычно не используются циклы. Функции являются вашим основным инструментом. В случае необходимости повторно выполнять действия используют рекурсию.
-
С помощью сопоставления аргументов (pattern matching) мы можем в методе
generateпринять необходимое количество вопросов и передать его в версию того же метода, но с двумя аргументами. Первый аргумент имеет значение 0, потому что это, где начальное значение количества уже сгенерированных вопросов. -
Второй вариант функция
generateвызывается только тогда, когда она получает два аргумента второй из которых не меньше 1. -
Функция
Enum.randomпринимает заданный диапазон и возвращает случайное число в пределах верхней и нижней границы этого диапазона. Это идеально подходит для нашей системы, мы не знаем, какие числа будут использованы. Это позволит отлично проверить правильность работы нашей системы! -
После того, как вопрос сгенерирован нам нужен способ, чтобы сохранить его, чтобы мы могли иметь возможность использования списка всех вопросов для проверки системы. Для этого используется функция
build_list, которую мы реализуем в ближайшее время. -
Наконец в конце функции, мы вызываем снова функцию
generate, на этот раз увеличивая аккумулятор (счетчик) на единицу, и отнимая единицу от общего количества вопросов, которые еще нужно сгенерировать. - После завершения рекурсии наш счетчик вопросов должен быть равен 0, и мы выводим информацию о том сколько всего вопросов было сгенерировано.
Мы довольно близки к завершению. Но есть еще кое что важное. В функции generate/2 мы вызывали функцию build_list. Почему нам это нужно?
Elixir имеет неизменные структуры данных. Это означает, что состояние не поддерживается за пределами текущей функции. Это отлично для программирования И.И., потому что все может усложняться очень быстро, если вы создаете систему с большой степенью изменчивости. В области, где вы могли бы иметь дело с астрономическим количеством не известных возможностей, вам нужно иметь некоторую согласованность. Эта согласованность — данные.
Мы создали эти вопросы, но нам нужен способ, чтобы сохранить их, так что система не потеряет их после того, как мы выйдем из функции. Вот где вступают агенты Elixir. Агенты в Elixir позволяют программе удерживать состояние. Это делает отслеживание изменений структуры данных с течением времени независимым. Использование агентов довольно просто, и они могут быть главной причиной, почему Джо Армстронг (создатель Erlang) говорит, что с Erlang и Elixir «Вам не нужна база данных!». Давайте создадим агента, который в начале будет содержать пустой список. Этот список будет хранить наши вопросы.
defp start_list do
Agent.start(fn() -> [] end, [name: __MODULE__])
end-
Мы видим создание агента с двумя аргументами. Первый — функция, которая возвращает пустой список. Второй аргумент представляет собой список ключ-значений (keyword list). Функция получает имя от текущего модуля.
- (ПРИМЕЧАНИЕ) Всегда давайте имена своим агентам!
Здорово! Теперь, когда наш агент имеет возможность инициализации и может содержать состояние, модно двигаться далее и реализовать функцию build_list которая встречалась ранее.
defp build_list(question) do
Agent.update(__MODULE__, fn(list) -> [question | list] end)
end- Функция принимает один аргумент — вопрос, и на самом деле
build_listявляется оберткой функцииAgent.update, которая принимает два аргумента. Первый аргумент является именем агента. Второй аргумент это функция, которая берет текущий список и добавляет текущий вопрос к новой версии списка.
Чтобы увидеть все вопросы, на которые системе необходимо ответить, нужно получить текущее состояние агента. Мы можем просто использовать функцию Agent.get/2. Назовем эту функцию questions.
defp questions do
Agent.get(__MODULE__, &(&1))
endAgent.getпринимает два аргумента. Название текущего модуля, и короткую версию функцииfn(x) -> x end.
Теперь нам нужно связать всю эту логику вместе, так что вся обработка может происходить в одном последовательном вызове функций (pipeline). Наш pipeline должен сделать следующее…
1. Получить все подстроки содержащте по одному числу из строки вопроса.
2. Преобразовать подстроки в целые числа.
3. Подсчитать сумму.
4. Проверить четная ли сумма.
5. Ответить "Да" или "Нет".Здесь мы будем использовать pipeline оператор (или оператор конвейера). Этот оператор представляет собой мышечную ткань языка программирования Elixir, и это делает алгоритмы обработки И.И. гораздо нагляднее, чем они в были бы в LISP.
defp answer_to(question) do
Regex.scan(~r/(d+) + (d+)/, question, [capture: :all_but_first])
|> List.flatten
|> Enum.map(&String.to_integer(&1))
|> Enum.reduce(0, fn(n, acc) -> n + acc end)
|> even?
|> say_answer
end- Оператор конвейера (pipeline) принимает результат вызова функции расположенный перед ним и использует его в качестве первого аргумента следующей функции.
Для работы с большими числами мы можем немного оптимизировать функцию answer_to/1 изменив регулярное выражение, чтобы выбирать из строки вопроса только последнюю цифру каждого числа, так как четность суммы не измениться (следующих двух вариантов функции answer_to/1 нет в оригинальной статье)
defp answer_to(question) do
Regex.scan(~r/d*(d) + d*(d)/, question, [capture: :all_but_first])
|> List.flatten
|> Enum.map(&String.to_integer(&1))
|> Enum.reduce(0, fn(n, acc) -> n + acc end)
|> even?
|> say_answer
endИли используя модуль Bitwise можем учитывать только последнюю цифру числа в двоичной системе (1 или 0). Оператор ^^^ вычисляет побитовую операцию XOR своих аргументов.
use Bitwise
defp answer_to(question) do
Regex.run(~r/(d+) + (d+)/, question, [capture: :all_but_first])
|> List.flatten
|> Enum.map(&String.to_integer(&1))
|> Enum.reduce(0, fn(n, acc) -> acc ^^^ (n &&& 1) end)
|> even?
|> say_answer
endТеперь для того, чтобы пользователи системы, могли увидеть, что она делает давайте создадим функцию отображения, которая показывает вопрос, а также ответ на него.
defp display_answer_for(question) do
IO.puts(question)
IO.puts(answer_to(question))
endIOявляется главным модулем для работы стандартного ввода/вывода для устройств.
Наконец-то! Мы в последней части системы. Нам нужен способ, для того чтобы вызвать весь этот процесс. Нам нужна функция запуска, которая выполняет следующие действия…
1. Вызвать `start_list`, чтобы запустить агент.
2. Затем сгенерировать определенное количество вопросов. Давайте начнем с 20-ти.
3. Для каждого вопроса мы должны показать ответ на этот вопрос.Вот как эта функция может выглядеть.
def start do
start_list
generate(20)
Enum.each(questions, &display_answer_for(&1))
end- После того как агент запущен мы можем сообщить системе, чтобы сгенерировать 20 вопросов. Для каждого из этих вопросов, мы отображает вопрос и ответ на него.
Мы готовы! Что происходит, когда мы вызываем SumAndTest.start? Система производит 20 случайных вопросов с соответствующими ответами. Смотрите вывод ниже!!
$ iex
Erlang/OTP 18 [erts-7.3] [source] [64-bit] [smp:8:8] [async-threads:10] [hipe] [kernel-poll:false] [dtrace]
Interactive Elixir (1.3.1) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)> c("sum_and_test.ex")
[SumAndTest]
iex(2)> SumAndTest.start
20 addition questions generated.
Is the result of 31956 + 95609 even?
No.
Is the result of 56902 + 37929 even?
No.
Is the result of 63154 + 23758 even?
YES! Even result found.
Is the result of 22268 + 66438 even?
YES! Even result found.
Is the result of 76068 + 36127 even?
No.
Is the result of 14158 + 84195 even?
No.
Is the result of 55174 + 13171 even?
No.
Is the result of 53028 + 68694 even?
YES! Even result found.
Is the result of 82027 + 39083 even?
YES! Even result found.
Is the result of 32349 + 70547 even?
YES! Even result found.
Is the result of 41416 + 37714 even?
YES! Even result found.
Is the result of 91326 + 32635 even?
No.
Is the result of 42663 + 21205 even?
YES! Even result found.
Is the result of 90054 + 71218 even?
YES! Even result found.
Is the result of 38305 + 69972 even?
No.
Is the result of 59014 + 3954 even?
YES! Even result found.
Is the result of 55096 + 34449 even?
No.
Is the result of 89363 + 16018 even?
No.
Is the result of 60760 + 12438 even?
YES! Even result found.
Is the result of 10044 + 47646 even?
YES! Even result found.
:okВывод
Это, вероятно, самый простой из всех алгоритмов искусственного интеллекта. Его простота это то почему я решил написать об этом алгоритме в моей первой статье на «Automating the Future». Я бы рассматривал возможность использования метода проб и ошибок, если бы я имел дело с проблемой, в которой фигурируют только небольшое количество возможных исходов.
Автор: Quentin Thomas
исходный код
Коротко
Обучение с подкреплением (Reinforcement Learning) – это метод машинного обучения, в котором наша система (агент) обучается методом проб и ошибок. Идея заключается в том, что агент взаимодействует со средой, параллельно обучаясь, и получает вознаграждение за выполнение действий.
Как оно работает?
В обучении с подкреплением используется способ положительной награды за правильное действие и отрицательной за неправильное. Таким образом, метод присваивает положительные значения желаемым действиям, чтобы побудить агента, и отрицательные значения – к нежелательным. Это программирует нашего агента на поиск долгосрочного и максимального общего вознаграждения для достижения оптимального решения. Эти долгосрочные цели не дают агенту возможности останавливаться на достигнутом. Со временем система учится избегать негативных действий и совершает только позитивные.
Обучение на основе взаимодействия с окружающей средой происходит методом проб и ошибок.
Представьте, что у нас есть стол для игры в пинг-понг и две ракетки. Пусть наша цель – такая система, где мяч не должен пропускаться ни одной из ракеток. Когда каждая из ракеток отбивает мяч, наша позитивная награда увеличивается на единицу (+1), соответственно, в случае пропуска мяча агент получает отрицательное вознаграждение (-1).
Необходимые термины в Reinforcement Learning
- Агент (agent): Наша система, которая выполняет действия в среде, чтобы получить некоторую награду.
- Среда (environment, e): сценарий/окружение, с которым должен столкнуться агент.
- Награда (reward, R): немедленный возврат, который предоставляется агенту, после выполнения определенного действия или задачи. Является положительной и отрицательной, как было упомянуто выше.
- Состояние (state, s): Состояние относится к текущему положению, возвращаемой средой.
- Политика (policy, π): стратегия, которая применяется агентом для принятия решения о следующем действии на основе текущего состояния.
- Стоимость (value, V): награда, которая ожидается в долгосрочной перспективе. По сравнению с краткосрочным вознаграждением, принимаем во внимание скидку (discount).
- Значение Функции (value function): определяет размер переменной, которой является общая сумма награды.
- Модель среды (Model of the environment): имитатор поведения окружающей среды (просто говоря, демо-версия вашей модели). Это помогает определить, как будет вести себя среда.
- Значение Q или значение действия (Q): значение Q очень похоже на value (V). Но главное различие между ними в том, что он принимает дополнительный параметр в качестве текущего действия.
Где использовать Reinforcement Learning?
Обучение с подкреплением используется в следующих сферах:
- Робототехника для промышленной автоматизации (например, конвейерная сборка).
- Планирование бизнес-стратегии.
- Автоматизация внутри самого машинного обучения.
- Продвинутые система рекомендации, например, на университетских ресурсах для дополнительного обучения студентов.
- Управление движением робота, автопилот.
Следует помнить, что обучение с подкреплением требует больших вычислительных ресурсов и времени, особенно когда пространство для действий у модели велико.
Какие алгоритмы использовать?
Область обучения с подкреплением состоит из нескольких алгоритмов, использующих разные подходы. Различия в основном связаны с их стратегиями взаимодействия с окружающей средой.
- State-Action-Reward-State-Action (SARSA). Этот алгоритм обучения с подкреплением начинается с предоставления агенту такого коэффициента, как политика (on-policy). В данном случае политика – это вероятность, с помощью которой алгоритм оценивает шансы определенных действий, приводящих к вознаграждениям или положительным состояниям.
- Q-Learning. В этом подходе к Reinforcement Learning используется противоположный подход. Агент не получает политики (on-policy), соответственно, его исследование окружающей среды является более самостоятельным. В Q-learning у нас нет ограничений на выбор действия (action) для алгоритма. Он полагает, что все последующие выборы actions будут оптимальными по умолчанию, поэтому алгоритм производит операцию выбора исходя из максимизации оценки Q.
- Deep Q-Networks (Глубокие Q-сети). Этот алгоритм использует нейронные сети в дополнение к методам обучения с подкреплением (reinforcement learning). Нейросети осуществляют самостоятельное исследование (research) среды обучения с подкреплением для выбора наиболее оптимального значения. То, как алгоритм будет себя вести и подбирать значения, основано на выборке прошлых положительных действий, полученных нейронной сетью.
Чем отличается от классического глубокого обучения (Deep Learning)?
- Обучение с подкреплением похоже на глубокое обучение, за исключением одного момента: в случае Reinforcement Learning машина обучаются методом проб и ошибок, используя данные из собственного опыта.
- Алгоритм обучения с подкреплением – это независимая система с самообучением. Чтобы добиться наилучших результатов, машина учится в режиме постоянной практики, из чего следует концепция обучения методом проб и ошибок.
Человек в какой-то степени представляет из себя пример обучения с подкреплением. Например, попытки научиться ездить на велосипеде, или плавать: процесс состоит из правильных и неправильных ходов.
- Глубокое обучение предполагает исследование уже существующей “даты”, на основе чего мы позже применяем наши наработки к новому набору данных.
- Обучение с подкреплением, в свою очередь, является динамическим (самостоятельным) обучением, которое использует метод проб и ошибок для того, чтоб обоснованно принять решение.
Проблемы, стоящие перед Reinforcement Learning
Обучение с подкреплением, хотя и имеет высокий потенциал, может быть трудным для развертывания и, к сожалению, остается ограниченным в применении. Одно из препятствий для развертывания этой сферы машинного обучения – это зависимость от исследования окружающей среды.
К примеру, если вы развернули робота, который применяет обучение с подкреплением для навигации в окружающей среде, то он будет искать новые состояния и предпринимать различные действия во время движения. Однако сложно последовательно предпринимать наилучшие действия из-за частых изменений в окружающей среде. Так, если вы задали роботу environment (окружающую среду) в виде вашего дома, то после перестановки предметов или мебели ваше устройство придется полностью адаптировать к новым условиям.
Время, необходимое для правильного обучения с помощью reinforcement learning может ограничить его полезность и потребовать значительных вычислительных ресурсов. По мере того как среда обучения становится более сложной, растут и требования ко времени и вычислительным ресурсам. Именно эти проблемы специалистам в области обучения с подкреплением предстоит решить в ближайшем будущем.
В заключение
Обучение с подкреплением – это вычислительный подход к обучению на основе взаимодействий внутри среды.
Более того, Reinforcement Learning является передовой технологией, которая рано или поздно изменит наш мир. Это то, что делает машинное обучение творческим процессом, так как самостоятельный поиск машиной новых, инновационных способов решения задач уже является творчеством.
Внедрение Reinforcement Learning уже происходит: например, знаменитая AlphaGo DeepMind (алгоритм для игры в популярную азиатскую игру Go) использует игровую тактику, которую сначала считали ошибочной, но впоследствии машина обыграла одного из сильнейших игроков в Go, Lee Sedol. А продвинутая версия AlphaGo Zero всего за 40 дней самообучения превзошла AlphaGo DeepMind.
Таким образом, обучение с подкреплением уже является революционной технологией и, несомненно, будет следующим шагом в развитии индустрии искусственного интеллекта.
***
В этой статье мы узнали:
- как работает обучение с подкреплением;
- где применяется обучение с подкреплением;
- алгоритмы и проблематику Reinforcement Learning;
Материалы по теме
- Numpy, Pandas, matplotlib – необходимый минимум для старта в Machine Learning
- Машинное обучение для начинающих: алгоритм случайного леса (Random Forest)
- Генеративная состязательная сеть (GAN) для чайников – пошаговое руководство
2.3. МЕТОДЫ СИНТЕЗА ВАРИАНТОВ РЕАЛИЗАЦИЙ ПРОГРАММ
Чтобы отобрать оптимальное решение, необходимо синтезировать множество возможных решений (вариантов), включающих оптимальное решение.
Ни одна задача не решается сама по себе. Чтобы получить решение, производятся различные умственные действия. Действия эти не хаотичны, а имеют методическую направленность, хотя обычно человек об этом не подозревает.
Существует множество методов синтеза вариантов проекта. Вот лишь некоторые, из наиболее приемлемых для программирования: метод проб и ошибок; эвристических приемов; мозгового штурма; метод аналогий и морфологических таблиц.
Ранее и до настоящего времени большая часть нестандартных задач решалась человеком на интуитивном уровне, т. е. методом проб и ошибок.
Метод проб и ошибок — это последовательное выдвижение и рассмотрение идей. Человек, сталкиваясь с проблемой, многократно мысленно ищет ответ, перебирает варианты и, наконец, находит решение. Десятки, сотни, тысячи попыток на протяжении дней, недель, лет. В конце концов в большинстве случаев решение находится. В программировании этот метод традиционно применяется для оптимизации архитектуры систем и структуры программ.
Главный недостаток метода проб и ошибок — это, во-первых, медленное генерирование новых идей, а во-вторых, отсутствие защиты от психологической инерции, т. е. выдвижение идей тривиальных, обыденных, неоригинальных.
Следующим шагом в совершенствовании технологии явился переход к направленным методам поиска решений, которые базируются на раскрытии и описании процесса решения, представлении его в виде некоторого эвристического алгоритма. Направленность эвристических методов — «раскачать» мышление, помочь по-новому увидеть задачу, преодолеть стереотипы.
Если, решая конкретную задачу, проектировщик не ограничится достижением только сиюминутной цели, а сможет «заглянуть в будущее» и выделить инвариантные части системы, то эти части, являясь как бы строительным материалом для данной системы, могут послужить основой и для систем, которые еще будут проектироваться. Будущие системы могут решать совсем иные задачи. В этой связи полезно было бы создавать и накапливать библиотеки инвариантных частей системы или даже параллельно проектировать несколько систем (объектов), преследующих как сходные, так и различные цели. «Заглянуть в будущее» можно лишь хорошо зная прошлое и настоящее, а также новые достижения программирования.
Целенаправленные методы творчества вполне применимы не только к техническим системам, но и программным. Рассмотрим наиболее известные из них, а также их возможное применение как при коллективном, так и индивидуальном использовании.
Метод эвристических приемов позволяет не только соединять по-новому известные части, но и изобретать новые. Он базируется на выделении базовых приемов, найденных при анализе лучших программных изделий.
При успешном решении какой-либо творческой задачи человек получает два результата — само решение поставленной задачи и методический опыт, т. е. уяснение процесса решения данной конкретной задачи. Но проблема заключается в том, что решение одной задачи нельзя просто перенести на решение другой. Поэтому только после решения определенного числа задач у человека появлялся набор правил, указаний или приемов решения той или иной задачи. Такие методические правила называют эвристическими приемами.
Эвристический прием — способ разрешения определенного противоречия. В эвристическом приеме содержится краткое предписание или указание, как преобразовать исходный прототип или в каком направлении нужно искать, чтобы получить искомое решение. Эвристический прием содержит подсказку, но не гарантирует нахождение решения.
Сложность использования эвристических приемов заключается в том, что не любой человек может видеть задачу в целом, т. е. не обладает системным подходом в решении задач. Причем необходимость в таком подходе возрастает с увеличением сложности задачи. Это приводит к тому, что человек не может применить эвристический прием к конкретной задаче и не понимает, о чем идет речь. Различным людям требуется приложить различные усилия, чтобы догадаться о том, как применить эвристический прием и получить решение задачи. Но перед решением задачи должны быть описаны и уяснены критерии, по которым будет оцениваться полученное решение. Это поможет отбросить ненужные решения при использовании эвристических приемов и понять, в каком направлении следует двигаться, чтобы прийти к решению.
Итак, у каждого человека, занимающегося созданием программ, со временем накапливается опыт и появляются способы решения разнообразных задач. Причем с увеличением опыта в этих способах увеличивается доля системного подхода, т. е. со временем человек получает такой способ, который становится применимым для решения большего числа задач, чем было раньше.
Постепенно у специалиста накапливается фонд таких практических приемов, но этот фонд индивидуален и не всегда доступен другим пользователям. Поэтому необходимо систематизировать такие фонды и сделать их более систематическими. Актуальной задачей является создание фонда эвристических приемов, применимого для решения задач оптимизации программных разработок.
Наибольшее число эвристических приемов ориентировано на преодоление противоречий. Противоречие в задаче — ситуация, требующая одновременного улучшения двух противоречивых показателей качества и совмещения, казалось бы, несовместимых требований. Ряд приемов просто способствует активизации мышления.
Первое, что приходит в голову в ситуации с противоречиями, — найти наилучшее соотношение между показателями. Если потенциальные возможности структуры объекта велики, то на этом пути иногда удается получить приемлемые значения всех показателей. Однако удается это не всегда.
Следующий естественный для человека шаг в ситуации, когда потенциальные возможности структуры недостаточны и компромисс оказывается неприемлемым, — перейти к новой структуре с большими потенциями, обеспечивающими достижение приемлемых значений конкурирующих показателей качества.
Однако предпочтительным является иной вариант действий. Как показывает опыт, во многих ситуациях содержатся скрытые ресурсы, использование которых позволяет кардинальным образом разрешить противоречие. Такими скрытыми ресурсами во многих случаях являются три вида ресурсов: временные, пространственные и «бросовые». К «бросовым» мы относим ресурсы, имеющиеся в системе (но, как правило, не считающиеся ресурсом, по крайней мере, в рамках решаемой задачи), использование которых не связано с какими-то дополнительными затратами.
Наиболее продуктивные способы разрешения противоречий — разнесение их во времени, пространстве или использование «бросовых» ресурсов. Эти общие рекомендации могут иметь различную трактовку в конкретных ситуациях.
Целесообразность использования метода эвристических приемов для постановки задач разработки программ проверена педагогической практикой авторов. Зачастую достаточно короткой подсказки обучаемым в виде эвристического приема, чтобы они самостоятельно правильно сформулировали задачу.
Используя фонд эвристических приемов, Б.С. Воинов и В.В. Костерин успешно синтезировали ряд новых механизмов алгоритма поиска глобального экстремума функций многих переменных на сетке кода Грея.
Пример использования метода эвристических приемов для создания алгоритмов описан в книге Д. Пойа. Укороченный фонд эвристических приемов для программирования описан в приложении 3.
Метод мозгового штурма — один из популярных методов коллективного творчества. Его психологическая основа — взаимная стимуляция мышления в группе. Конкуренция между людьми за количество выдвинутых идей делает этот метод более эффективным по сравнению с работой каждого отдельного человека вне группы. Метод мозгового штурма является по сути тем же методом проб и ошибок, однако он создает условия для психологической активизации творческого процесса, снижает инерцию мышления, чему особенно способствует наличие в группе людей со стороны. Метод прост, доступен и эффективен. Реализация метода выглядит следующим образом.
Решение проводится в два этапа — генерации и анализа. На этапе генерации создается творческая группа из 5—15 человек (специалисты-смежники и люди «со стороны», не имеющие никакого опыта в области, к которой относится решаемая задача). Группе объясняется суть задачи, требующей решения, и проводится этап генерации идей. На этом этапе не допускается критика предлагаемых идей. Поощряется выдвижение даже сумасбродных идей. Затем группа экспертов анализирует высказанные идеи и отбирает те, которые заслуживают более тщательной проработки.
Методом мозгового штурма работают команды знатоков в популярной телепередаче: «Что? Где? Когда?» Пятьдесят секунд идет генерация идей и только десять секунд тратится на обсуждение выдвинутых идей.
Применительно к программам методом мозгового штурма можно сгенерировать идеи по распределению функций обработки информации между людьми и машиной; набору основных прототипов и заимствованных из них идей; реализации некоторых эвристических алгоритмов обработки информации; рекламе и сбыту программной продукции; созданию новых программ на базе частей создаваемых и ранее созданных программ.
Методы аналогий являются наиболее популярными методами для программистов. Преодолеть психологическую инерцию, найти новое решение помогают неожиданные сравнения, позволяющие взглянуть на ситуацию под необычным углом.
Суть одного из методов состоит в следующем. Совершенствуемую систему держат как бы в фокусе внимания и переносят на нее свойства других программ из коллекции, не имеющих к ней никакого отношения. При этом возникают необычные сочетания, которые стараются развить дальше.
Согласно проведенному опросу, большинство профессиональных программистов именно этим методом генерировали внешний облик своих программных систем и определили способы реализации многих функций программ.
Метод морфологических таблиц является простым и эффективным особенно там, где необходимо найти большое число вариантов достижения цели. В последнее время он используется достаточно широко как средство развития творческого воображения. Метод по сути аналогичен сборке разных вариантов дома из кубиков деревянного конструктора и заключается в том, что для интересующего нас объекта формируется набор отличительных признаков: наиболее характерных подсистем, свойств или функций. Затем для каждого из них определяются альтернативные варианты реализации (детали конструктора). Комбинируя альтернативные варианты, можно получить множество различных решений. Анализируя их, выделяют предпочтительные варианты.
Примером морфологической таблицы является прайс-лист компьютерной фирмы. В прайс-листе содержится информация о нескольких типах корпусов ЭВМ; материнских плат; процессоров и т. д. Каждая часть снабжена техническими характеристиками и ценой. Не все варианты частей могут быть состыкованы между собой. Главное, что характеризует прайс-лист, — это отсутствие критерия качества целого компьютера для конкретного пользователя. Глядя на прайс-лист, надо синтезировать данный критерий и выбрать оптимальный состав частей. Как результат синтеза могут быть выявлены варианты построения компьютеров, ориентированных на различные категории пользователей.
Трудность здесь такая же, как и в ситуации подбора одежды для девушки. Если ознакомиться с товаром в ряде магазинов, то нетрудно по рекомендации «лучшее — дорогое» купить отдельные элементы гардероба. Скорее всего эти «лучшие» элементы не будут в целом смотреться на девушке из-за несовместимости цветов, фасона, да и самого облика и характера девушки, т. е. отсутствует оптимизация по критерию целого.
Покупка в одиночку может превратиться в мучительное хождение по магазинам с тысячами примерок. При этом скорее всего будет ошибочно приобретен не тот товар.
Для анализа критерия целого лучше привлечь опытных экспертов (например, пойти по магазинам с подругами), которые могут указать на ошибки выбора.
Опытный кутюрье поможет сделать выбор дорогой модной одежды. Возможно, чтобы еще лучше подходить под предложенную одежду, вам придется позаниматься с психологом, косметологом и инструктором физкультуры для изменения имиджа. К счастью, многие девушки способны сами одеваться «дешево и сердито» и умеют самостоятельно адаптировать свой имидж.
Морфологическая таблица, составленная в компактной форме, поможет избежать многократного хождения по одним и тем же магазинам, что сэкономит ваше время и время экспертов. Морфологическая таблица позволит вам и экспертам просмотреть значительно большее число вариантов и сделать более оптимальный выбор.
В 1983 г. В.В. Костериным была успешно применена морфологическая таблица для синтеза идей построения алгоритма нелинейного программирования поиска глобального экстремума функций многих переменных на сетке кода Грея. Алгоритмы нелинейного программирования предназначены для поиска экстремумов функций многих переменных. В методах прямого поиска экстремум выявляется путем расчета множества точек функции при аргументах, определяемых самим алгоритмом поиска. В табл. 2.2 приведена данная морфологическая таблица, которая содержит классификационные признаки отдельных механизмов алгоритмов нелинейного программирования на уровне основных принципов. Приведенные классификационные признаки выделялись по основным функциональным признакам отдельных механизмов. Каждому классификационному признаку соответствует множество реализаций механизмов в виде значений классификационных признаков.
Интересно отметить, что число возможных реализаций алгоритмов нелинейного программирования по этой таблице составляет N = 5*6*8*5*7*7*6 = 352800, что значительно превышает число опубликованных методов (около 2000)!
Таблица 2.2
Морфологическая таблица принципов функционирования алгоритмов нелинейного программирования
Классификационные признаки
Значения классификационных признаков
Начальная точка поиска
1.1
1.2
1.3
1.4
1.5
Зондирование гиперповерхности
2.1
2.2
2.3
2.4
2.5
2.6
Стратегия шагов поиска
3.1
3.2
3.3
3.4
3.5
3.6
3.7
3.8
Направление поиска на шаге
4.1
4.2
4.3
4.4
4.5
Стратегия шага поиска
5.1
5.2
5.3
5.4
5.5
5.6
Механизм самообучения
6.1
6.2
6.3
6.4
6.5
6.6
6.7
Механизм завершения поиска
7.1
7.2
7.3
7.4
7.5
7.6
Значения классификационных признаков классификационного признака «Механизм начальной точки поиска»:
признак 1.1 — из точки, указанной пользователем;
признак 1.2 — из средней точки области определения;
признак 1.3 — из точки на границе области определения;
признак 1.4 — из случайной начальной точки поиска;
признак 1.5 — начальная точка поиска не задается.
Значения классификационных признаков классификационного признака «Первичное зондирование гиперповерхности»:
признак 2.1 — в виде большого числа случайных точек, зондирующих всю гиперповерхность;
признак 2.2 — поочередные спуски из ряда случайных начальных точек;
признак 2.3 — конкурирующие спуски из добавляемых случайных точек;
признак 2.4 — зондирование гиперповерхности случайными точками с выявлением и более тщательным исследованием «подозрительных областей»;
признак 2.5 — сканирование всей гиперповерхности с использованием различных разверток, например Пеано;
признак 2.6 — отдельный механизм начала поиска отсутствует.
Значения классификационных признаков классификационного признака «Стратегия шагов поиска»:
признак 3.1 — один шаг;
признак 3.2 — последовательные шаги до выявления экстремума;
признак 3.3 — осуществлять все шаги по одному и тому же механизму;
признак 3.4 — переключать механизмы шагов от глобального метода до локального;
признак 3.5 — переключать механизмы шагов от глобальных далее до усредненных и до локальных;
признак 3.6 — переключать механизмы шагов по эвристическим правилам;
признак 3.7 — малое количество последовательных шагов из ограниченного ряда лидирующих конкурирующих начальных точек;
признак 3.8 — шаги поиска отсутствуют.
Значения классификационных признаков классификационного признака «Направление поиска на шаге»:
признак 4.1 — новая точка в направлении аппроксимации градиента, построенного на основе данных текущей и предшествующей пробной точек;
признак 4.2 — по результатам обработки небольшого числа перспективных точек, полученных на предшествующих шагах;
признак 4.3 — по результатам анализа функции, аппроксимирующей случайные точки в перспективном направлении;
признак 4.4 — зондирование гиперповерхности большим количеством случайных точек и последующим построением аппроксимирующей функции;
признак 4.5 — вдоль границы области определения целевой функции;
признак 4.6 — механизм отсутствует.
Значения классификационных признаков классификационного признака «Механизм стратегии шага поиска»:
признак 5.1 — пробные точки только на расстоянии предполагаемого экстремума;
признак 5.2 — пробные точки на большем расстоянии, чем предполагаемый экстремум;
признак 5.3 — пробные точки на расстоянии, несколько меньшем, чем у предполагаемого экстремума;
признак 5.4 — объединение признаков 5.1 и 5.2;
признак 5.5 — объединение признаков 5.1, 5.2 и 5.3;
признак 5.6 — совмещение поиска направления и расстояния до экстремума;
признак 5.7 — разделение поиска направления и расстояния до экстремума.
Значения классификационных признаков классификационного признака «Механизм самообучения»:
признак 6.1 — сужение границ поиска по мере продвижения к экстремуму;
признак 6.2 — постепенное повышение точности поиска;
признак 6.3 — выявление формы гиперповерхности по результатам предшествующих шагов и переход на специальный механизм уточнения экстремума;
признак 6.4 — выявление формы гиперповерхности по результатам предшествующих шагов и переход на специальный механизм продвижения вдоль оврагов;
признак 6.5 — выявление формы гиперповерхности по результатам предшествующих шагов и отказ от текущего найденного экстремума;
признак 6.6 — изменение плотности вероятности случайных точек для разных зон поиска;
признак 6.7 — механизм отсутствует.
Значения классификационных признаков классификационного признака «Механизм завершения поиска»:
признак 7.1 — не выявляется направление улучшения функции на следующем шаге;
признак 7.2 — израсходован ресурс времени;
признак 7.3 — достигнуто заранее заданное значение целевой функции;
признак 7.4 — исчерпаны возможности алгоритма поиска экстремума;
признак 7.5 — выполнено заранее заданное количество шагов поиска;
признак 7.6 — нет улучшений в «дальней» и «близкой» окрестностях.
Очередной принцип построения метода нелинейного программирования получается путем отбора по одному из значений классификационных признаков в каждой отдельной строке табл. 2.2.
Оболочки визуального программирования, например Delphi, реализуют метод морфологического синтеза при построении форм диалога программ на основе визуальных компонент.
Читайте также
Сравнение старой и новой реализаций
Сравнение старой и новой реализаций
Между заголовками буферов и новой структурой bio существуют важные отличия. Структура bio представляет операцию ввода-вывода, которая может включать одну или больше страниц в физической памяти. С другой стороны, заголовок буфера связан
4.5. Отношения на диаграмме вариантов использования
4.5. Отношения на диаграмме вариантов использования
Между компонентами диаграммы вариантов использования могут существовать различные отношения, которые описывают взаимодействие экземпляров одних актеров и вариантов использования с экземплярами других актеров и
4.6. Пример построения диаграммы вариантов использования
4.6. Пример построения диаграммы вариантов использования
В качестве примера рассмотрим процесс моделирования системы продажи товаров по каталогу, которая может быть использована при создании соответствующих информационных систем.В качестве актеров данной системы
4.7. Рекомендации по разработке диаграмм вариантов использования
4.7. Рекомендации по разработке диаграмм вариантов использования
Главное назначение диаграммы вариантов использования заключается в формализации функциональных требований к системе с помощью понятий соответствующего пакета и возможности согласования полученной
6.16.8 Конец списка вариантов и отсутствие операций
6.16.8 Конец списка вариантов и отсутствие операций
Вариант «без операций» (No Operation) применяется для заполнения промежутков между вариантами датаграмм. Например, он используется для выравнивания следующего варианта по 16- или 32-разрядной границе.Конец списка вариантов (End of
6.16.9 Кодирование вариантов
6.16.9 Кодирование вариантов
Существуют два однобайтовых варианта, кодируемых следующим образом:No Operation 00000001End of Option List 00000000Оставшиеся варианты задаются несколькими битами. Каждый начинается октетом типа и октетом длины.Для рассматриваемых вариантов возникает следующий
Предложите пару вариантов на выбор
Предложите пару вариантов на выбор
Вы, может быть, удивитесь, но лучший способ усилить интерес посетителя к покупке – это ограничить его выбор двумя-тремя вариантами. При этом пользователю будет легче принять решение, и оно в любом случае приведет к покупке: «Вы
7. Выбор вариантов
7. Выбор вариантов
Хотите научиться создавать мощные, «интеллектуальные», универсальные и полезные программы? Тогда вам потребуется язык, обеспечивающий три основные формы управления процессом выполнения программ. Согласно теории вычислительных систем (которая
Использование операторов if для выбора вариантов
Использование операторов if для выбора вариантов
Ключевые слова: if, else Общие замечания: В каждой из следующих форм оператор может быть либо простым, либо составным оператором. Вообще говоря, «истинное» выражение означает выражение с ненулевым значением. Форма
Изменчивость Реализаций (Implementation Variation)
Изменчивость Реализаций (Implementation Variation)
Шаблон has является весьма общим; и, как мы уже убедились, на практике имеется широкий выбор соответствующих структур данных и алгоритмов. Нельзя ожидать, что один модуль сможет обеспечить работу в столь разнообразных условиях, — он
Интерфейс и повторное использование реализаций
Интерфейс и повторное использование реализаций
Знакомясь с объектным подходом по другим источникам, вы могли видеть в них предостережения использования «наследования реализаций». Однако в нем нет ничего плохого.Повторное использование имеет две формы: использование
Слово в защиту реализаций
Слово в защиту реализаций
В чем же причина недоверия к наследованию реализаций? Я пришел к выводу, что ответ лежит в области психологии. Тридцатилетний программистский опыт оставил нам лишь сомнения насчет самой идеи реализаций. И даже слово «реализация» приобрело в
Вставка, поиск, удаление
Приведем рекурсивную функцию поиска в бинарном дереве поиска (эта и следующая функция добавлены в класс, реализующий бинарные деревья поиска):
has (x: G): BOOLEAN
— Есть ли x в каком-либо узле?
require
argument_exists: x /= Void
do
if x ~ item then
Result := True
elseif x < item then
Result := (left /=Void) and then left.has (x)
else — x > item
Result := (right /= Void) and then right.has (x)
end
end
Алгоритм имеет сложность O(h), где h – высота дерева, что означает O(log n) для полного или почти полного дерева.
В этом варианте приводится простая нерекурсивная версия алгоритма:
has1 (x: G): BOOLEAN
— Есть ли x в каком-либо узле?
require
argument_exists: x /= Void
local
node: BINARY_TREE [G]
do
from
node := Current
until
Result or node = Void
invariant
— x не находится в вышерасположенных узлах на нисходящем пути от корня
loop
if x < item then
node := left
elseif x > item then
node := right
else
Result := True
end
variant
— (Высота дерева) – (Длина пути от корня к узлу)
end
end
Для вставки элемента можно использовать следующую рекурсивную процедуру:
put (x: G)
— Вставка x, если он не присутствует в дереве.
require
argument_exists: x /= Void
do
if x < item then
if left = Void then
add_left (x)
else
left.put (x)
end
elseif x > item then
if right = Void then
add_right (x)
else
right.put (x)
end
end
end
Отсутствие ветви else во внешнем if отражает наше решение не размещать дублирующую информацию. Как следствие, вызов put с уже присутствующим значением не имеет эффекта. Это корректное поведение («не жучок, а свойство»), о чем и уведомляет заголовочный комментарий. Некоторые пользователи могут, однако, предпочитать другой API с предусловием, устанавливающим not has(x).
Нерекурсивная версия остается в качестве упражнения.
Возникает естественный вопрос: как написать процедуру удаления – remove(x:G)? Это не так просто, поскольку нельзя просто удалить узел, содержащий x, если только это не лист дерева. Удаление листа сводится к обнулению одной из ссылок – left или right. Удаление произвольного узла приводило бы к нарушению инварианта бинарного дерева поиска.
Мы могли бы дополнять узел специальным булевским атрибутом, указывающим, удален ли узел фактически или нет. Но это решение слишком сложное, требует дополнительной памяти и мешает реализации других алгоритмов.
Что следует сделать, так это реорганизовать дерево, перемещая узлы, лежащие в основании узла с найденным значением x, так, чтобы сохранить истинность инварианта.
В удаляемый узел нужно поместить элемент дерева, лежащий ниже удаляемого элемента. Есть два кандидата на эту роль, позволяющие сохранить истинность инварианта:
- в левом поддереве – это элемент с максимальным значением (такой элемент является листом дерева или имеет только одну связь);
- в правом поддереве – это элемент с минимальным значением.
Если перемещаемый элемент является листом дерева, то после перемещения соответствующий узел удаляется. Если элемент имеет одну ссылку, то ссылка родителя перемещаемого элемента связывается с потомком перемещаемого элемента, тем самым перемещаемый узел исключается из дерева. Инвариант при этих операциях сохраняется.
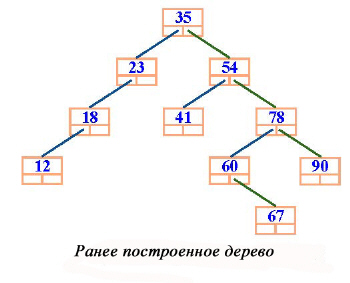
Рис.
8.18.
Ранее построенное дерево
Предположим, что удаляется корень дерева – remove (35). Тогда в корень можно поместить либо элемент 23 (из левого поддерева), либо элемент 41 из правого поддерева.
Подобно поиску и вставке процесс удаления должен выполняться за время O(h), где h – это высота дерева. Процедура удаления остается в качестве упражнения.
Время программирования!
Удаление в бинарном дереве поиска
Напишите процедуру remove(x:G), которая удаляет элемент x, если он присутствует в дереве, сохраняя инвариант.
8.5. Перебор с возвратами и альфа-бета
Прежде чем исследовать теоретические основы рекурсивного программирования, полезно познакомиться еще с одним приложением, а точнее – с целым классом приложений, для которого рекурсия является естественным инструментом: алгоритмами перебора с возвратом. В имени отражена основная идея алгоритма: отыскивается решение некоторой проблемы, последовательно перебираются возможные пути; всякий раз, когда решение на данном пути заходит в тупик, происходит возврат назад к предыдущей развилке, из которой не все возможные пути были исследованы. Процесс заканчивается успешно, если на одном из путей достигается решение задачи. Неуспех в решении возникает тогда, когда ни на одном пути решение не получено или достигнут лимит времени, отведенный на поиск решения.
Перебор с возвратами применим к задаче, если каждое ее потенциальное решение может рассматриваться как последовательность выборов.
Бедственное положение застенчивого туриста
При необходимости достижения некоторой цели путешествия в незнакомом городе как к последней надежде можно прибегнуть к перебору с возвратом. Скажем, Вы находитесь в точке А (главная станция Цюриха) и хотите добраться до точки В (между главными зданиями ЕТН и Университета Цюриха):
Не имея карты и по застенчивости не отваживаясь спросить дорогу к цели, вы решили исследовать прилежащие улицы и проверять после каждой попытки, не достигнута ли цель (предполагается, что у вас есть фотография конечной точки). Вы знаете, что цель расположена на востоке, так что во избежание зацикливания все западно-ориентированные сегменты игнорируются.
На каждом этапе вы проверяете отрезки улиц, начиная с севера и двигаясь по часовой стрелке. Первая попытка приводит в точку 1. Здесь вы понимаете, что это не отвечает вашей цели, так как далее все возможные пути ведут на запад, то есть это тупик и нужно возвращаться назад в исходную точку А. Далее вы испытываете следующий выбор, приводящий в 2. Здесь есть несколько возможностей, и вначале вы проверяете путь, ведущий в 3, который оказывается тупиком, так что приходится вернуться в точку 2.
Если все «правильные» (не ведущие на запад) пути в 2 были исследованы и приводили к тупикам, то из 2 пришлось бы вернуться в точку А. Но в данной ситуации из 2 есть еще не исследованный выбор, ведущий в точку 4.
Процесс продолжается аналогичным образом, вы можете дополнить его самостоятельно, используя приведенную карту. Возможно, это не лучшая стратегия для путешествия в незнакомом городе, но иногда она может быть единственно возможной. Более важно, что она представляет общую схему метода «проб и ошибок», характерную для программирования перебора с возвратами. Схема может быть описана с помощью рекурсивной процедуры:
find ( p: PAT H): PATH
— Решение, если оно существует, начинающееся в P.
require
meaningful: p /= Void
local
c: LIST [CHOICE]
do
if p.is_solution then
Result := p
else
c := p.choices
from c.start until
(Result /= Void) or c.after
loop
Result := find ( p + c)
c.forth
end
end
end
Здесь применяются следующие соглашения. Выборы на каждом шаге описываются типом CHOICE (во многих ситуациях для этой цели можно использовать тип INTEGER). Есть также тип PATH, но каждый путь path – это просто последовательность выборов, и p + c – это путь, полученный присоединением c к p. Мы идентифицируем решение с путем, приводящим к цели, так что find возвращает PATH. По соглашению, если find не находит решения, то возвращается void. Запрос is_solution позволяет выяснить, найдено ли решение. Список выборов – p.choices, доступных из p, является пустым списком, если p – это тупик.
Для получения решения достаточно использовать find(p0), где p0 – начальный пустой путь.
Как обычно, Result инициализируется значением Void. Если в вызове find(p) ни один из рекурсивных вызовов на возможных расширениях p + c не вырабатывает решения (в частности, если таких расширений вообще нет, поскольку p.choices пусто), то цикл завершится со значением c.after, и тогда find(p) вернет значение Void. Если это был начальный вызов find(p0), то процесс завершается, не достигнув положительного результата, в противном случае рекурсивно включается следующий вызов, пока не будет получен результат или не будут перебраны все возможности.
Если один из вызовов находит, что p является решением, то p возвращается в качестве результата, и, подымаясь вверх по цепочке вызовов, результат возвращается, поскольку Result /= Void является условием выхода.
Рекурсия дает четкую основу для управления такой схемой. Это естественный способ выразить природу метода проб и ошибок в алгоритмах перебора с возвратом – техническая реализация рекурсии заботится обо всех деталях. Для осознания этого вклада представьте на секунду, как пришлось бы программировать эту схему без рекурсии, – понадобилось бы сохранять всю предысторию пройденных путей (я не предполагаю, что вам необходимо написать полную не рекурсивную версию, по крайней мере, на данном этапе, когда еще не изучены способы реализации рекурсии, излагаемые позже в данной лекции).
Дальнейшее обсуждение также показывает, как улучшить эффективность данного алгоритма, удаляя излишние записи. Например, фактически нет необходимости передавать путь как явно заданный аргумент, освобождая пространство в стеке вызовов. Вместо этого p может быть атрибутом, если мы добавим p:= p+x перед рекурсивным вызовом и p:= p.head после него (где head вырабатывает копию последовательности с удаленным последним элементом). Мы разработаем общий каркас, позволяющий безопасно выполнять такую оптимизацию.
Правильная организация перебора с возвратом
Общая схема перебора с возвратом требует некоторой настройки для практического использования. Прежде всего, в том виде, как она приведена, не гарантируется завершаемость. Чтобы убедиться в завершаемости любого выполнения, необходимо одно из двух:
- иметь гарантию (приходящую от проблемной области), что нет бесконечных путей, другими словами, что при расширении любого пути настанет момент, когда появится пустой список выборов;
- определить длину максимального пути и адаптировать алгоритм так, чтобы достижение границы рассматривалось как тупик. Вместо длины пути можно аналогично вводить ограничение по времени. Любой вариант реализуется простыми изменениями предыдущего алгоритма.
Дополнительно практическая реализация обычно может обнаруживать эквивалентность некоторых путей, например, для ситуации, представленной на рисунке:

Рис.
8.20.
Путь с циклом
Пути [1, 2, 3, 4], [1, 2, 3, 4, 2, 3, 4], [1, 2, 3, 4, 2, 3, 4, 2, 3, 4] и так далее являются эквивалентными. Пример, демонстрирующий нахождение маршрута без циклов, состоял в важной рекомендации – «никогда не уезжайте на запад, молодой человек». Конечно, этот совет не может служить общей рекомендацией и связан лишь с конкретной проблемной ситуацией. Чтобы справиться с циклом, необходимо сохранять информацию о ранее посещенных точках и игнорировать любой путь, ведущий к такой точке.
Перебор с возвратами и деревья
Для любой задачи, в решении которой может помочь перебор с возвратами, может помочь и построение модели в виде дерева. При установке соответствия будем использовать деревья, где каждый узел будет иметь произвольное число потомков, обобщая концепции, рассмотренные при определении бинарных деревьев. Путь в дереве (последовательность узлов) соответствует пути в алгоритме перебора (последовательность выборов). Дерево в примере с маршрутами представлено на
рис.
8.21.
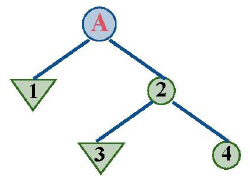
Рис.
8.21.
Дерево путей при переборе с возвратами
Мы можем представлять всю карту города подобным образом: узлы отражают местоположение указанных на карте точек, дуги представляют отрезки улиц, соединяющих точки. В результате получается граф. Граф может быть деревом только в том случае, если в нем нет циклов. Если граф не является деревом, то на его основе можно построить дерево, называемое остовным деревом графа, которое содержит все узлы графа и некоторые из его дуг. Для этого используются методы, упомянутые ранее, а также существует соглашение, позволяющее избежать цикла (никогда не ходите на запад) или построения путей из корня и исключающее любую дугу, которая ведет к ранее встречающемуся узлу. Вышеприведенное дерево является остовным деревом для части нашего примера, включающего узлы А, 1, 2, 3 и 4.
Для такого представления нашей задачи в виде дерева:
- решением является узел, удовлетворяющий заданному критерию (свойство, ранее названное is_solution, адаптированное для применения к узлам);
- выполнение алгоритма сводится к префиксному обходу дерева (самый левый в глубину).
В нашем примере этот порядок приведет к посещению узлов А, 1, 2, 3, 4.
Это соответствие указывает, что «Префиксный обход» и «Перебор с возвратами» основаны на одной и той же идее: всякий раз, когда мы рассматриваем возможный путь, мы разматываем все его возможные продолжения – все поддеревья узла, – прежде чем обращаемся к любому альтернативному выбору на уровне, представляющем непосредственных потомков узла. Например, если А на предыдущем рисунке будет иметь третьего потомка, то обход не будет его рассматривать, прежде чем не обойдет все поддеревья 2.
Единственное свойство, отличающее алгоритм перебора с возвратами от префиксного обхода, состоит в том, что он останавливается сразу же, как только найден узел, удовлетворяющий выбранному критерию.
Префиксный порядок был определен для бинарных деревьев следующим образом: посетить корень, затем обойти левое поддерево, затем правое. Порядок слева направо обобщается на произвольные деревья в предположении, что дети каждого узла упорядочены, – это не играет здесь существенной роли. Точно так же можно считать, что выборы для алгоритма перебора на каждом шаге упорядочены и просматриваются в соответствии с заданным порядком.
Мину. Математическое программирование.Теория и алгоритмы.- М.: Наука, 1990.]. Например, если функции f,gi – линейные и S Zn , тозадача (1.1) относится к классу задач целочисленного линейного программирования.В отдельный класс выделим задачи комбинаторной оптимизации. Они возникают,например, при проектировании информационно-управляющих систем реального времени.В постановке любой задачи комбинаторной оптимизации присутствуют некоторыеобъекты, которые требуется определенным образом разместить, упорядочить или разбитьна группы.
В этом случае множество S состоит из решений X, описывающихвсевозможные размещения/упорядочивания/разбиения на группы исходно заданныхобъектов. Математически множество S описывается набором ограничений, которыетребуют согласованного изменения значений элементов X: изменение значения одного изэлементов для сохранения корректности решения может требовать принятия конкретныхзначений ряда других элементов.
Допустимые значения этих переменных в отличии отзадач целочисленной оптимизации единственны.Поясним сказанное выше для задачи построения многопроцессорных расписаний сминимизацией числа используемых процессоров. Задано множество взаимодействующихработ подлежащих планированию. На множестве работ определено отношение частичногопорядка, которое задает ограничения на последовательность выполнения работ.Отношение частичного порядка является ацикличным и транзитивным.
Для каждойработы задано время ее выполнения. Расписание определено, если для каждой работы3задан процессор, на котором она выполняется и порядковый номер выполнения работы напроцессоре (работа не может начать выполняться, пока не выполнены все работы сменьшими номерами). Требуется построить расписание выполнения работ на минимальнонеобходимом числе процессоров время выполнения которого не превосходит исходнозаданный директивный срок. Для этой задачи значением функции f является числопроцессоров, функция g задает ограничение: время выполнения расписания не должнопревышать директивный срок. Множество S определяется следующими ограничениями:1.
Каждая работа должна быть назначена на процессор для выполнения.2. Каждая работа должна быть назначена лишь на один процессор.3. Частичный порядок, заданный на множестве работ должен быть сохранен врасписании.4. Расписание должно быть беступиковым. Условием беступиковости расписанияявляется ацикличность отношения частичного порядка в расписании.Если эти условия не выполняются, то мы не можем вычислить время выполнениярасписания.Если мы изменяем расписание путем перемещения работы с процессора А напроцессор В, то номера работ на процессоре А больше перемещаемой должныуменьшиться на 1, а номера работ на процессоре В, которые должны выполняться послеперемещаемой работы должны увеличиться на 1.1.2. Понятие «сложных» задач условной оптимизации. Проблемыприменения оптимальных и эвристических алгоритмов, использующихаприорно известные свойства о целевой функции и функцияхограниченийПод сложными задачами условной оптимизации будем понимать задачи (1.1) длякоторых отсутствует априорная информация о функциях f,gi и множестве S, котораяможет быть использована для организации поиска оптимального решения, или сложностьполучения этой информации неприемлема.
Можно выделить следующие основныеособенности сложных задач условной оптимизации:1. Функций f,gi могут быть операторами, заданными правилами/алгоритмами ихвычисления, т.е. их аналитическая структура не может быть использована дляорганизации поиска оптимального решения задачи (1.1).2.
Негладкий характер функций f,gi.43. Отсутствие информации о производных функций f,gi или их производные неявляются непрерывными.4. Множество S может быть компонентно разнородным: S = SR SZ SF SKS, т.е.различные компоненты вектора X могут принадлежать подмножествам множествадействительных чисел (R), целых чисел (Z), функций (F) и комбинаторных структур (KS).Указанные выше особенности делают проблематичным применение оптимальныхи эвристических методов, использующих некоторые априорно известные свойства задачидля организации поиска оптимального решения.
При больших размерности и/илиразмерах задачи (1.1) методы полного перебора допустимых решений также оказываютсянеприемлемыми по сложности.Идея о целесообразности случайного поведения, при наличии неопределенности,т.е. отсутствии достаточной информации, которая может быть использована дляорганизации поиска оптимального решения/поведения, впервые в четкой форме быласформулирована У.Р. Эшби в работе [У. Росс Эшби. Конструкция мозга.- М.:, ИЛ, 1962.] иреализована в известном гомеостате (гомеостат Эшби). Применительно к сложнымзадачам условной оптимизации, алгоритм поиска оптимального решения долженопираться на метод проб и ошибок.
Только такой процесс позволяет извлечь информацию,необходимую для организации поиска решения. Метод проб и ошибок основан напонятии случайного эксперимента: случайного выбора значений компонентов вектора X,что дает возможность получить информацию о функциях f,gi и множестве S, котораяможет быть использована для организации поиска решения сложной задачи условнойоптимизации.Наиболееширокоприменяемымиподходамикпостроениюалгоритмовоптимизации опирающихся на метод проб и ошибок являются следующие:алгоритмы случайного поиска (ненаправленного, направленного,направленного с самообучением) [ Л.А.
Растригин. Статистические методы поиска.- М.:Наука, 1968.],алгоритмы имитации отжига [Уоссермен Ф. Нейрокомпьютерная техника. Теория ипрактика.- М.: Мир, 1992. – 240с.],генетические и эволюционные алгоритмы [Holland J.N. Adaptation in Natural andArtificial Systems. Ann Arbor, Michigan: Univ. of Michigan Press, 1975.],муравьиные алгоритмы [Dorigo M.
Optimization, Learning and Natural Algorithms. // PhDThesis. Dipartimento di Elettronica, Politechnico Di Milano, Milano. 1992.], [Штовба С.Д.Муравьиные алгоритмы: теория и применение// Программирование. 2005. №4.].51.3. Классические задачи комбинаторной оптимизации1.3.1. Задача коммивояжераЗадачу коммивояжёра можно представить в виде нахождения пути на графе.Вершины графа соответствуют городам, а ребра между вершинами являются путямисообщения между этими городами.
Граф является полносвязным, т.е. между любымидвумя вершинами есть ребро. Каждому ребру можно сопоставить вес, который можнопонимать, например, как расстояние между городами, время или стоимость поездки.Маршрутом (гамильтоновым циклом) называется маршрут на таком графе, в которыйвходит по одному разу каждая вершина графа. Задача заключается в отысканиикратчайшего маршрута. Длина маршрута определяется как сумма весов входящих внего ребер. Маршрут может быть описан циклической перестановкой номеров городовJ ( j1 , j2 , jn , jn1 ) , где ji — номер города находящийся в i –ой позиции перестановки.Пространством поиска решений является множество перестановок n городов, таких,что все j1 , j2 , jn разные и j1 jn1 .Существует несколько частных случаев общей постановки задачи, в частности:симметричная задача коммивояжера,асимметричная задача коммивояжера,метрическая задача коммивояжера.В симметричной задаче коммивояжера задается неориентированный граф и всепары ребер между одними и теми же вершинами имеют одинаковый вес, т.е.
длялюбого ребра (i,j) wij w ji .В асимметричной задаче коммивояжера задается ориентированный граф и дугимежду одними вершинами могут иметь разный вес, т.е. wij w ji .Симметричная задача коммивояжера является метрической, если для весов ребервыполняется правило треугольника: wij wik wkj . То есть прямой путь междулюбыми двумя вершинами не длиннее любого обходного пути.В практических задачах, если между некоторыми вершинами не существует ребер,то они искусственно добавляются в граф и им присваиваются большие веса. Из-забольшого веса такое ребро никогда не попадает в оптимальный маршрут и маршруты,близкие по длине к оптимальному маршруту.6Данная задача принадлежит к классу NP-трудных задач и часто используется кактестовая задача для сравнения качества работы различных алгоритмов опирающихсяна метод проб и ошибок.Математическиематематическойформулировкиформулировкизадачиопределяетсямогутбытьклассомразными.алгоритма,Выборкоторыйпредполагается использовать для решения задачи.1.3.2.
Задача о рюкзакеИмеется рюкзак объемом b и набор n различных товаров. Для каждого товара iзаданы: объем ai и стоимость ci. Требуется упаковать рюкзак так, чтобы суммарнаястоимость упакованных товаров была максимальной и их суммарный объем непревышал объем рюкзака b.Математически эту задачу можно записать следующим образом:nmax( ci xi )Xi 1na xi 1iibi 1,, n : xi 0 или 1Если товар упакован в рюкзак, то xi=1, если нет xi=0.Если все коэффициенты ai целые числа и b целое число, то задача является NPтрудной. Если все коэффициенты ai вещественные, то задача может быть решенажадным алгоритмом сложности O(n·log n). Обе задачи о рюкзаке обладают свойствомоптимальности для подзадач. Вынув товар i из оптимально загруженного рюкзака,получим решение задачи о рюкзаке с максимальным объемом b-ai и набором из n-1товара.
То есть, жадный алгоритм может быть построен как для непрерывной, так идискретной задачи. Вычислим относительную стоимость всех товаров в расчете наединицу объема ci ai . Оптимальный жадный алгоритм для непрерывной задачизаключается в следующем: сначала в рюкзак укладывается по максимуму товар ссамой дорогой относительной стоимостью. Если товар закончился, а рюкзак незаполнен, то укладывается следующий по относительной стоимости товар, затемследующий, и так далее, пока не набран вес b .
В [Кормен Т., Лейзерсон Ч., Ривест Р.Алгоритмы: построение и анализ. М.: МЦНМО, 2000.] показано, что аналогичный жадныйалгоритм может не получать оптимум в дискретной задаче о рюкзаке.71.3.3. Задачи построения расписаний и их классификацияОпишем общую задачу построения расписания согласно [Теория расписаний ивычислительные машины.
Под ред. Э.Г. Коффмана. М.: Наука, 1984. 334 с.]. Модель в рамках котороймогутбытьсформулированымногиезадачипостроениярасписанийзадаетсясовокупностью моделей ресурсов, системы заданий (работ) и меры оценки расписаний.Ресурсы. В большинстве моделей ресурсы состоят просто из набора процессоров P.В наиболее общей модели еще имеется набор дополнительных типов ресурсов R,некоторое подмножество которых используется на протяжении всего времени выполнениязадания на некотором процессоре. Общее количество ресурса типа Ri задается целымположительным числом.Система работ может быть определена через T, , [τji], {Rj}, где:T={T1,T2,…,Tn} — набор работ подлежащих планированию; — заданное на T отношение частичного порядка, которое определяетограничение на последовательность выполнения работ.