
В российском бизнесе распространены случаи, когда сотрудника, который ошибся, увольняют на следующий день. Однако от ошибок не застрахован ни один руководитель, вне зависимости от сферы работы. Важнее понять, как реагировать на промахи и какие выводы делать после. За годы работы на руководящих постах управляющий директор Diebold Nixdorf Михаил Рыбчинский вывел собственные правила «эффективных ошибок» — в материале он делится своим опытом.
Откуда возникает страх ошибки
Страх не свойственен только маленьким детям — они просто не знают, что это такое. Но взрослея, ребенок обучается, и именно реакция страха позволяет ему выживать. Благодаря ей мы не переходим улицу на красный свет, не берем провода мокрыми руками и не делаем другие очевидно опасные вещи.
Но этот же механизм для выживания может сильно ограничивать взрослого и опытного человека при решении бизнес-задач. Именно страх быть непонятым, осмеянным или маргинальным является серьезным психологическим блоком, ограничивающим фактором на карьерном пути менеджера.
Страх не позволяет пробовать новые методы, делать что-то впервые. В связи с этим иногда английское слово Fear расшифровывают как False Evidence Appearing Real — «Ложное доказательство, которое кажется реальным». Событие не произошло и вообще непонятно, произойдет ли — но человек уже меняет поведение.
Такая смена может сыграть злую шутку. Исследование австралийских психологов Эндрю Мартина и Герберта Марша показало: студенты, которые боялись ошибиться, могли добиваться высоких результатов. Однако когда они претерпевали неудачи, ошибки становились для них доказательством собственной несостоятельности. Более того, в ответ на страх студенты часто даже саботировали шансы на успех: оттягивали выполнение задач до последнего или прикладывали к ним меньше усилий.
При этом промахи неизбежны. Мы можем работать с одинаковой эффективностью все время только в случае выполнения одинаковых рутинных процедур. Чем более креативная работа, тем выше вероятность наделать ошибок. Когда инвесторы или Private equity фонды оценивают стартапы, они более лояльны к тем компаниям, которые уже наделали большое количество ошибок, научились на них, нежели к компаниям, с самого начала демонстрирующим впечатляющие результаты, руководство которых не совершило ни одной ошибки.
Я выделяю два подхода, которые сложились у руководителей в работе с ошибками.
Первый — это жесткий супервайзинг, когда управленец не дает сотруднику ошибаться самому. Такой путь минимизирует количество ошибок, но и не дает работникам развиваться. Если руководитель-ментор сменится, то специалист, приученный к готовым решениям, вряд ли возьмет на себя инициативу. Для нового менеджера он останется таким же «белым листом». А если такого сотрудника повысят, у него за спиной не будет опыта своих ошибок и, соответственно, методов их исправления.
Второй — управление с возможностью ошибаться, но по правилам. Да, польза от ошибок не столь очевидна, как краткосрочные негативные последствия, которые прямо влияют на результаты и реноме управленца. Однако я нахожу этот способ наиболее эффективным, поскольку он учитывает природу человека и в перспективе помогает развивать кадры. Сделав ошибку на проекте, где цена вопроса — $100, вы можете избежать такой же ошибки на проекте в $1 млн, при этом вы учитесь и развиваетесь, становитесь более квалифицированным специалистом. Недостаток системы в том, что правила должны соблюдать и сам руководитель, и сотрудники, иначе она не будет работать.
Опытным путем я вывел для себя четыре таких правила.
Правила эффективных ошибок
- Ошибки не так критичны на ранних этапах. Всевозможные поиски решений, тестирование допустимы именно в начале проекта. Чем ближе к финалу, тем тщательнее должна быть проверка и тем более устойчивыми должны быть решения.
- Ошибки допустимы, если они не повторяются. Не так страшно, если в новой для себя роли руководитель рискнул и выбрал менее эффективное решение по стратегии продаж. Если оно не принесло катастрофического результата для бизнеса, все можно исправить. Хуже, если он следует этому подходу, совершая все те же ошибки. Тогда это сознательное игнорирование или неумение делать выводы по обратной связи.
- Чем опытнее сотрудник, тем меньше промахов он должен совершать в принципе. Поэтому, кстати, существует возрастной ценз для руководителей. Понятно, что есть вундеркинды, которые заканчивают школу в 14, а в 20 уже руководят проектами. Однако во время найма таких самородков я бы рекомендовал смотреть на их трек рекорд, чтобы выяснить опыт работы с негативными ситуациями. Одаренностью нельзя компенсировать недостаток опыта — его можно получить только в процессе самостоятельной работы. Поэтому, когда руководители корпораций ставят на ответственные позиции неопытного менеджера, они стараются нанимать профессиональных тьюторов, менторов или коучей, чтобы снизить цену ошибок на первых порах.
- Об ошибках нужно сразу сообщать руководству и вместе с этим предлагать решения проблемы. Герман Греф, выступая перед командой Сбербанка, как-то заявил, что если человек сделал ошибку, то ему это можно простить. Но если специалист попытался избежать ответственности и скрыть факт ошибки, то такое поведение может привести только к увольнению. Я согласен, что умалчивание проблемы должно приравниваться к попытке обмана и нести серьезные последствия. Люди склонны умалчивать свои промахи, опять же из-за страхов. Но можно добиться лучшего эффекта и для себя, и для компании, если показать заинтересованность в устранении последствий, а не в их сокрытии.
Как минимизировать количество ошибок
Самое большое количество ошибок «первого уровня» совершается из-за несовершенства бизнес-процессов. Полноценный ритм бизнеса и «бесшовное» взаимодействие позволит компании свести количество такого рода ошибок к нулю. Гораздо сложнее решить проблему ошибок руководителей.
Мне импонирует идея «песочницы» для руководителей или молодых специалистов — тренировочного пространства, в котором ошибки имеют минимальный негативный эффект. Идея не нова: девелоперы уже несколько десятилетий обкатывают свои разработки на искусственных сценариях, прежде чем запустить решение в производство. Эту же идею, но в применении к персоналу, используют все Big Tech компании. Например, в Microsoft есть программа раннего развития молодых специалистов MACH (Microsoft Academy of College Hires), такая же есть в Amazon. Их прелесть в том, что они позволяют вчерашним студентам ошибаться под присмотром опытных наставников и получать профессиональное развитие.
Кроме того, можно периодически устраивать классы как для новых сотрудников, так и для «старичков» с разыгрыванием лучших бизнес-кейсов и практик. Благодаря им можно не только «проиграть» ситуации успеха, но и выяснить, какие стратегии могут стать неудачными. В одной такой бизнес-игре наша команда заняла второе место. Мы вложились в долгосрочную стратегию и, в конце концов, могли бы выиграть, но игра имела ограничение по времени и выиграла команда, которая использовала больше тактических инструментов. Это поражение помогло мне понять, что иногда фокус на среднесрочную перспективу может быть более оправданным, чем длинные инвестиции и стратегическое развитие.
Понятно, что сферы бывают разные. Если отдел продаж рискует только деньгами и репутацией компании, то на производстве, в лечебном деле, атомной и космической отрасли от решений зависит сохранность дорогостоящего имущества и жизни людей. Поэтому чем более серьезная ответственность возлагается на специалиста, тем дольше должен быть период такой «песочницы», когда инструкции заучиваются наизусть. А к реальной практике допускаются только те, кто выучил их применение до автоматизма.
Сейчас много внимания уделяется цифровой трансформации, когда бизнес-процессы улучшают с помощью искусственного интеллекта. К сожалению, пока нейросети и близко не подошли к решению задач среднего уровня. Искусственный интеллект может проанализировать планы по продажам и даже построить прогноз, учитывающий кучу факторов, включая геополитическую ситуацию, но он пока не может заменить интуицию и жизненный опыт руководителей со стажем.
Главные мысли
- Ошибки в работе, в том числе управленца, неизбежны;
- Страх перед провалами может усугубить их последствия;
- Главное не то, сколько ошибок совершил управленец, а то, исключает ли он их повторы и как справляется с последствиями;
- Эффективный метод сокращения числа ошибок — система «песочницы» с наставничеством и разыгрыванием кейсов в режиме бизнес-игры или тренировки.
Все совершают ошибки, это практически норма вещей. Но у всех ошибок разные последствия. Какие-то из них могут быть даже позитивными, но чаще всего ошибка несёт за собой негатив.
И если ошибки персонала и программ уже давно смогли категоризировать, то почему-то ошибки управленцев (в том числе проектного менеджмента) классифицировать никто не спешит. А ведь ошибки руководителей, менеджеров проектов и менеджеров продуктов чаще всего имеют самые серьёзные последствия.
Ниже попытаемся исправить данную несправедливость.
Зачем нужна градация ошибок?

Ну, во-первых, человек привык всё вокруг себя классифицировать, ведь именно научный подход и всесторонний анализ помогает добиваться нам таких результатов. Стандартизация – это лучший друг технического прогресса и науки. Так проще всё задокументировать, а значит – передать следующим поколениям.
Но документирование – не первопричина. Важнее – накопление опыта.
Ошибки могут быть одиночными или повторяющимися, иметь абсолютное и относительное измерение последствий, они могут оказывать прямое или косвенное воздействие на проект и т.п.
Систематизация ошибок помогает предусмотреть вероятность их возникновения, а значит, предотвратить или принять все возможные меры для того, чтобы в ситуациях наступления ошибок можно было минимизировать их последствия.
В рамках крупного предприятия/компании процесс управления рисками и ошибками называется риск-менеджментом – смотрите статью «Система управления рисками в компании».
По аналогии может помочь система градации ошибок менеджмента (системы управления предприятием или проектом).
Если ошибки предотвратимые или имеют некритичные последствия для предприятия, то ответственные лица могут быть наказаны за них в соответствие с заранее разработанной градацией – в рамках премирования/депремирования.
Концепция «вина-ответственность» всегда остается актуальной.
Классификация рисков в IT-проектах
IT-шники и программисты больше всех любят всё детализировать и классифицировать. Но когда ты работаешь с новым проектом, нужно быть готовым ко всему. Несмотря на то, что во многих гибких методологиях управления проектами (топ-10 методологий управления) контроль и выявление ошибок – это сквозной и непрерывный процесс, да и многие команды обязательно организуют тестирование своих продуктов, ошибки всё равно возникают. И возникают они как на стадии реализации проекта, так и после его сдачи.
Как ускорить обработку ошибок и их устранения? Логично категоризировать их на входе (при получении обратной связи от заказчиков или от конечных пользователей), чтобы в будущем распределять функции исправления по ответственным за них сотрудникам, желательно, обладающим необходимой квалификацией и полномочиями.
Внутри каждой команды могут быть свои группы ошибок, которые будут привязываться к частоте возникновения и к особенностям архитектуры проекта.
Сэм Канер в книге «Тестирование программного обеспечения» приводит следующую общую классификацию ошибок внутри программных продуктов:
- Ошибки интерфейса (UX/UI).
- Логика обработки ошибок (для облегчения их обнаружения).
- Ошибки вычислений.
- Ошибки обработки/интерпретации данных (очень близки по смыслу к вычислениям).
- Проблемы начального и конечного состояния.
- Превышение нагрузки.
- Ситуация спешки.
- Ошибки аппаратного обеспечения и несовместимость.
- Контроль идентификаторов (процессов).
- Ошибки, связанные с граничными условиями.
Но и это далеко не эталон. С появлением DevOps-подхода логика работы программ стала заметно сложнее. Ведь у вас в распоряжении могут быть контролируемые и неконтролируемые среды: сетевые стеки, сторонние сервисы и службы, и т.п.
Как можно классифицировать ошибки проектного менеджмента?
Наиболее эффективную систему градации ошибок проектного менеджмента можно составить только с привязкой к конкретной команде и к руководителям, а также с учётом зависимости от текущих условий ведения проекта и различных внешних факторов.
Наиболее универсальный подход в классификации любых ошибок – опирание на функции и задачи.
За что отвечает менеджер проекта? Ранее мы рассматривали обязанности администратора проекта, которые во многом дублируют обязанности менеджера (ведь администратор – правая рука руководителя команды).
Если обозначить общие задачи, то они сводятся к планированию, обеспечению коммуникаций, снабжению необходимыми материалами и ресурсами, к контролю и анализу.
Но менеджер проекта не действует в одиночку. Он исполняет директивы заказчика (спонсора, владельца, клиента и т.п., подробнее о стейкхолдерах, о тех, кто так или иначе влияет на проект).
Группы ошибок проектного менеджмента в зависимости от их источника
Руководитель проекта:
- Проблемы управления рисками или полное отсутствие такого управления.
- Отсутствие управления ожиданиями заказчиков (стейкхолдеров).
- Неправильная оценка ресурсов (имеющихся или необходимых для реализации задач).
- Отсутствие управления изменениями.
- Неправильно выстроенная система коммуникаций и мотивации.
- Неправильный режим управления (например, бессистемность, аврал, слишком жесткий стиль/слишком мягкий контроль и т.п.).
Заказчик:
- Неправильные критерии оценки проекта.
- Завышенные ожидания.
- Непонимание отдельных внутренних процессов работы проектной команды.
Команда в целом (включая в том числе руководителя):
- Неправильная оценка сроков реализации (слишком оптимистично, слишком пессимистично, нетипичная задача, которая повышает уровень неопределённости).
- Неправильная мотивация (отсутствие заинтересованности).
- Нежелание адаптироваться к новым задачам и целям (особенно, при отсутствии конкретной программы управления изменениями).
Внешняя среда:
- Нестабильная экономическая ситуация на рынке или в конкретной (важной для проекта) сфере.
- Изменение условий поставщиков (а поставщики есть даже в IT-проектах).
Как снизить количество ошибок проектного менеджмента?
Во-первых, на качество планирования и организацию работ существенно влияет опыт и квалификация руководителя проекта. Именно он задаёт тон во всех направлениях деятельности. Самоорганизующиеся команды – это практически несбыточная мечта. Поэтому весь груз ответственности за любые решения внутри команды так или иначе взваливается на плечи лидера (гласного или негласного).
Во-вторых, все потенциальные ошибки управления должны быть идентифицированы (как в матрице рисков) и для каждой конкретной ошибки должна быть определена вероятность наступления + определён эффект последствий (цена ошибки). Так вы сможете заранее оценить потенциальные проблемы и спланировать пути их обхода.
В-третьих, не менее важны участники команды. Можно сильно формализовать все отношения внутри, детализировать операции до мельчайших подробностей (микроменеджмент), но вы всё равно не сможете добиться нужной вам эффективности. В любой коллективной работе важен вклад каждого отдельного участника.
В-четвёртых, по возможности нужно стандартизировать подход к управлению. Каждый должен знать свои обязанности и задачи, чётко понимать сроки и ответственность, иметь достаточную свободу действий, чтобы не тормозить процесс.
И тут мы приходим к одному из важнейших пунктов – автоматизация рутины. Чтобы команда могла работать, руководитель — планировать, и все могли коммуницировать в едином формате, в любой момент прогресс можно было отследить как для заказчиков проекта, так и для его участников, нужна специальная система распределения задач.
Если вы хотите ознакомиться с примерами типовых ошибок в проектах, у нас есть отдельный материал – «Почему стартапы терпят неудачи».

Директор по стандартам Американского общества управления проектами Вильям Дункан считает, что проектным менеджерам в любой стране и в любой сфере бизнеса необходимы одни и те же навыки. Формированию этих навыков посвящены тренинги, которые он проводит в России по приглашению компании PSM Consulting
«Все ошибки одинаковы, независимо от страны»
Вильям Дункан – один из авторов первых версий стандарта по управлению проектами PMBoK, разработанного Институтом проектного менеджмента США (PMI USA). Долгое время он был директором этого института. Сегодня Дункан – совладелец и директор компании Project Management Partners, работающей в области консультирования и подготовки по управлению проектами. Свои тренинги он основывает на 30-летнем опыте управления и консультирования.
Дункан разработал «процессную модель» управления проектами, которая была использована при разработке международного стандарта ISO 10006. Он также сформулировал модель корпоративной культуры управления проектами. Согласно этой модели, каждая организация, которая стремится быть успешной в проектной деятельности, должна отвечать трем условиям: работать с перспективными проектами, создавать среду, в которой у большинства проектов будет шанс на успех, и содействовать проектным командам в выполнении работы.
– В чем специфика вашего подхода к управлению проектами?
– Я рассматриваю проектный менеджмент не сам по себе, а в рамках системы – корпоративной культуры, стратегии компании, отношений в команде и т. д. Для успеха проекта важно установить связь между разными аспектами, которые влияют на развитие проекта. Мы определили девять сфер, в которых проектный менеджер должен быть компетентен. Это управление отношениями между акционерами или другими заинтересованными лицами, влияние на коллектив, планирование, совершенствование проекта, юридические вопросы, а также запуск, презентация проекта, бюджетирование и разработка корпоративной культуры.
Международный стандарт, который мы с рабочей группой сейчас формируем, поможет определять компетенцию проектных менеджеров по всему миру.
В России, как и во всех остальных странах, руководители компаний хотят получить определенную гарантию, что специалисты, которых они нанимают для управления проектами, будут компетентны и успешно реализуют задуманное.
Кроме того, существование международного стандарта позволит не проходить сертификацию проектным менеджерам при перемещении из одной страны в другую.
– Каковы основные ошибки управления проектами в России?
– Я бы не стал делать акцент на каких-то специфических российских ошибках – они во всех компаниях, независимо от страны, одинаковы.
В первую очередь, ошибки связаны с определением основной цели бизнес-проекта. Часто компании, запуская тот или иной проект, не задумываются, зачем они это делают, какую проблему они пытаются таким образом решить. Люди думают, что знают назначение своего бизнеса, но на самом деле это не так.
Многие проектные менеджеры, отвечая на вопрос о цели проекта, говорят, например: «Наша задача – построить завод». Но, по сути, они не называют реальной цели – зачем им этот завод. А если ты не понимаешь назначения проекта, ты автоматически принимаешь неверные решения.
В других случаях инициаторы проекта сформулировали для себя цель проекта, но не разъяснили ее четко и внятно всем, кто над ним работает. Поэтому в процессе команда может незаметно для самой себя отклониться от намеченной цели.
Другая распространенная ошибка – недостаточное понимание процесса оценки проекта. Многие путают оценку и формирование бюджета. В отличие от бюджетирования, оценка учитывает множество косвенных факторов, которые влияют на проект.
Я обычно в этом случае привожу пример с поездкой в аэропорт. Вы понимаете, что она может занять у вас два часа. Но на самом деле время, которое вы отводите на поездку, зависит от того, кого вы там встречаете – любимую девушку или тещу.
Так и с проектом – многие субъективные факторы влияют на него и, следовательно, на его бюджет.
Поэтому если формировать бюджет без проведения предварительной оценки, то, скорее всего, он будет занижен и в его рамках выполнить проект будет невозможно. А это, в свою очередь, станет причиной других проблем: вы не сможете выделить достаточно ресурсов на проект, людям придется работать сверхурочно, это снизит мотивацию сотрудников компании и приведет к увеличению текучести кадров.
В итоге компания начнет искать пути сокращения расходов на выполнение проекта. Скорее всего, это будет происходить за счет изменения характеристик продукта.
А это уже третья ошибка управления проектом. Многие менеджеры стремятся в первую очередь не выйти за рамки бюджета и соблюсти сроки, но не следят за качеством продукта. Один из моих клиентов так и говорил: «Я не понимаю, зачем улучшать управление проектом, если нам и так удается его выполнить вовремя».
В итоге продукт не оправдал ожиданий заказчика. Чтобы исправить ошибки и улучшить продукт, пришлось потратить $3 млн. – в полтора раза больше изначального бюджета на проект. И такое отношение встречается очень часто.
Например, напротив нашего офиса стоит здание, которое возвели совсем недавно, но уже видно, что при строительстве старались сэкономить. В результате у них уже отвалилась кровля, хотя прошел всего год.
Иногда некоторым менеджерам везет, и, несмотря на заниженный бюджет и несогласованность в работе проектной команды, им удается закончить проект вовремя и получить нужный продукт. Но никто не понимает, что это всего лишь везение.
«Это все равно что учить грамоте»
– Как за короткий срок научить человека управлять проектами?
– Лучший способ – не обучать каким-либо знаниям, а готовить проектного менеджера применять полученные знания на практике. То есть показывать, как это может работать. Поэтому три четверти учебной программы – это практические занятия.
В процессе тренинга мы пошагово выполняем весь проект, проходим все фазы его развития. Участники тренируются на проектах из своей практики, мы разбираем реальные ситуации. И если у них возникают какие-то вопросы, всегда есть возможность спросить консультанта, уточнить какие-то моменты.
– Но ведь все проекты разные. Как можно все свести к единому алгоритму?
– В изучении проектного менеджмента есть два направления: одно ориентировано на продукт, другое – на сам проект. В своих тренингах я не ориентируюсь на продукт. Этим занимаются специалисты конкретных сфер бизнеса – например, строительства или информационных технологий. Я же фокусируюсь на процессах управления проектами – а они одинаковы, независимо от продукта.
Например, во всех проектах нужно проводить оценку, и мы обучаем, как наиболее эффективно оценивать. Эти знания можно применять как в строительной, так и в IT-компании. Это все равно что учить грамоте. Я просто формирую навык, как использовать ручку и бумагу, как правильно писать слова, составлять предложения. И не важно, что именно вы пишете, книгу или брошюру, о светской жизни или о географии.
– Какие стадии развития проекта вы разбираете?
– Начинается все с предварительного соглашения между участниками проектной команды о том, как будет выглядеть продукт. Это не детальное его описание, а общее определение, что это – например, жилой дом или гостиница. Затем мы переходим к планированию: определяем состав работ по проекту, планируем их последовательность, подсчитываем стоимость. Мы уделяем довольно много времени командообразованию, обсуждению критериев успешности проекта и их измерению. Естественно, мы говорим об управлении рисками, затрагиваем вопросы управления изменениями проекта, учим, как измерять стоимость проекта.
Прослушав один базовый курс, нельзя стать специалистом в управлении проектами. Для этого надо развивать в себе другие навыки – лидерские качества, умение вести переговоры и т. д.
«Мы моделируем не проблемы, а реальные ситуации»
– Как имитировать реальную обстановку для участников тренинга?
– Я не создаю искусственных проблем участникам тренинга, они и так преодолевают массу сложностей в процессе работы над проектом. Но мы обязательно говорим о тех трудностях, с которыми они могут столкнуться при реализации своих проектов.
Мы не просто проводим какую-то игру или упражнение, но и расставляем акценты – вот так происходит в реальной жизни, вот такие могут быть сложности. Например, если это упражнение по командообразованию, то мы берем человека из одной группы и переводим в другую – именно так и происходит при работе над проектами, когда в команде появляется новый человек.
Так что мы моделируем не проблемы, а реальные ситуации. Но, скажем, во время упражнения по риск-менеджменту участники составляют список рисков, и один из членов команды представляет план управления рисками другой команде. В данном случае он играет роль проектного менеджера, и понятно, что здесь есть определенные ролевые установки, хотя никто не объявляет, что это ролевая игра.
Мы также используем и элемент случайности. Например, в том же упражнении по риск-менеджменту где-то на середине проекта мы останавливаем игру, бросаем кубик и, в зависимости от того, какая цифра выпадет, выбираем тот или иной риск из заранее составленного списка. Все как в реальной ситуации.
Игра, конечно, должна быть максимально реалистичной. В короткие сроки нам удается смоделировать максимально приближенные к реальной жизни ситуации, при этом мы проводим нечто вроде анализа – указываем на проблему с коммуникациями или планированием. А главное – участники тренинга разбирают не абстрактные проекты, а свои собственные, над которыми они в данный момент работают.
Источник: mybiz.ru
Ткаченко Елена
Логика управления проектами
-
Управление
проектами подчиняется четкой логике,
которая связывает между собой различные
области знаний и процессы управления
проектами. -
У
проекта обязательно имеются одна
или несколько целей. -
Достижение
целей проекта может быть реализовано
различными способами. Для сравнения
этих способов необходимы критерии
успешности
достижения поставленных целей. -
В
число основных критериев оценки
различных вариантов исполнения проекта
входят сроки
и стоимость
достижения результатов. -
Запланированные
цели
и качество
служат основными ограничениями при
рассмотрении и оценке различных
вариантов. -
Для
управления проектами необходимы рычаги. -
К
основным рычагам управления можно
отнести ресурсы
проекта и используемые технологии.
Кроме этих основных существуют и
вспомогательные средства, предназначенные
для управления основными. К таким
средствам можно отнести контракты и
организацию работ.
Жизненный цикл проекта и фазы проекта
 Начало
Начало
жизненного цикла проекта совпадает по
времени с началом проекта, а его окончание
– с завершением проекта.
Наиболее
традиционным является разбиение проекта
на
четыре крупных этапа:
разработка
концепции проекта(постановка), планирование
(разработка), реализация(исполнение) и
завершение(закрытие проекта) (рис. 1).

Рисунок
1 – Жизненный цикл проекта
1. Концепция проекта.
Разработка
концепции проекта, по существу
подразумевает функцию выбора проекта.
Решения
принимаются исходя из наличия ресурсов,
и в первую очередь финансовых возможностей.
2. Разработка (Планирование).
Планирование
в том или ином виде производится в
течении всего срока реализации проекта.
В самом начале жизненного цикла проекта
обычно разрабатывается неофициальный
предварительный план — грубое представление
о том, что потребуется выполнить в случае
реализации проекта. Решение о выборе
проекта в значительной степени
основывается на оценках предварительного
плана.
Что
надо сделать?
Кто
сделает это?
Как
это будет сделано?
Когда
это должно быть сделано?
Сколько
это будет стоить?
Что
нам нужно чтобы сделать это?
Именно
на этапе планирования используются
компьютерные системы для управления
проектами, предоставляющие руководителю
проекта набор средств для разработки
формального плана.
Как
правило, план проекта не остается
неизменным, и по мере осуществления
проекта подвергается постоянной
корректировке с учетом текущей ситуации.
3. Реализация (Осуществление).
После
утверждения формального плана на
менеджера ложиться задача по его
реализации. Задачей менеджера является
анализ возможного влияния отклонений
в выполненных объемах работ на ход
реализации проекта в целом и в выработке
соответствующих управленческих решений.
На
правильном ли мы пути?
Если
нет, что нужно сделать?
Следует
ли изменить план?
4.
Завершение.
Рано
или поздно, но проекты заканчиваются.
Проект заканчивается, когда достигнуты
поставленные перед ним цели.
Что
сделано хорошо?
Что
следовало бы улучшить?
Что
мы узнали нового?
Процессы
управления проектами
Для
реализации различных функций управления
проектом необходимы действия, которые
именуются процессами
управления проектами.
Процессы
управления проектами могут быть разбиты
на шесть основных групп (рис. 2):
1.
процессы инициации;
2.
процессы планирования;
3.
процессы исполнения
4.
процессы анализа;
5.
процессы управления;
6.
процессы завершения.

Рисунок
2 – Процессы управления проектами
Процессы
инициации
Данный
процесс представляет собой принятие
решения о начале выполнения проекта.
Процессы
планирования
Процесс
определения целей и критериев успеха
проекта и разработка рабочих схем их
достижения
Планирование
необходимо для того, чтобы можно было
осуществлять контроль. Контроль проекта
‑ систематическое сравнение плановых
и фактических показателей для принятия
управленческих решений.
Ошибка
многих руководителей: они полагают, что
никакой
план не спасет от экстремальных
ситуаций.
Опыт
показывает, что при хорошем планировании
можно избежать многих экстремальных
ситуаций. И если они все-таки имеют
место,
то случаются гораздо реже, а их масштаб
и последствия меньше. И значит, вам легче
сохранить контроль над ходом выполнения
проекта.
Процессы
планирования представлены
на рисунке 3.

Рисунок
3 – Процессы планирования
Этапы
планирования
-
Разработка
формулировки миссии, целей и задач
проекта.
Формулировка
миссии
разрабатывается для того, чтобы
предотвратить путаницу с определением
направления проекта. Она же служит
основой для разработки целей и задач.
Заказчик
проекта
– главная сторона, заинтересованная в
осуществлении проекта и достижении его
результатов.
При
разработке формулировки миссии проекта
необходимо предварительно выяснить у
заказчиков,
каковы их нужды, как они видят качество,
и затем определить, что надо сделать
для выполнения этих требований. Участие
основных членов команды проекта тоже
важно.
Формулировка
миссии должна отвечать на три вопроса:
Что
мы делаем?
Для
кого мы это делаем?
Как
мы делаем это?
Когда
формулировка миссии разработана, можно
определить цели проекта. Цели намного
более конкретны, чем миссия.
Цель
–
это формулировка, которая говорит о
том, какой должен быть получен результат.
Цель должна быть конкретной, измеримой,
достижимой, реальной, ограниченной во
времени.
Два
важных вопроса при установлении целей:
Каков
желаемый результат?
Как
вы узнаете, когда достигли желаемого
результата?
В этой статье расскажем как команда Alto справляется со срывами сроков. Материал будет полезен руководителям, менеджерам проектов и всем, кто испытывает трудности с соблюдением дедлайнов.
Согласно исследованию компании Hewlett-Packard 96% IT-проектов в России завершаются не вовремя. Это одни из самых низких показателей в Европе. В то время как в Швеции этот показатель равен 64%. Когда такое количество проектов срываются по срокам, вы начинаете искать решение этой проблемы.
Первое, что необходимо понять — любая задача относится или к проектам или к процессам. Процессы — это повторяющиеся процедуры. Тогда как проекты — это запуск новых продуктов. Например, проект — это разработка сайта или запуск веб-приложения. А процесс — обработка входящих заявок с сайта.
Процессы выполняют по инструкции с минимальными изменениями. Например, алгоритм работы может выглядеть так:
- Получаем вводные данные A.
- Если данные соответствуют условию B, переходим на последовательность действий C;
- Если данные соответствуют условию D, выполняем действия E.
- Полученный результат передается на выход.
Здесь сотрудник следует четко определенному алгоритму. За него уже предусмотрены основные варианты и способы их решения..
В проектной работе ситуация противоположная. Сотрудник сталкивается с трудно прогнозируемыми факторами, которые ведут к нескольким вариантам развития. Из-за чего не всегда получается предсказать сроки.
Мы в Alto еще не нашли волшебную таблетку для решения этой проблемы. Скорее всего её и не существует. Как и нет в мире такой компании, где все проекты заканчивают вовремя. Проектная работа — это хаос. Поэтому все что нужно — это понять, как работать среди этого.
Для этого мы проанализировали ситуации из-за которых задерживались проекты. Здесь собран опыт нашей компании, коллег и даже опыт нескольких индустрий. Выявили причины, объединили по группам и предложили способы их решения.
Причины по которым команды срывает сроки:
- Ошибки при оценке задач
- Ошибки при управлении изменениями
- Проблемы в коммуникации и ожиданиях
- Ошибки при подготовке к проекту
- Недостаточная компетенция исполнителя
- Демотивация команды
1. Ошибки при оценке задач
Человеку свойственно быть оптимистичным при оценке задач. Даже если эта оценка основана на прошлом опыте. Например, если последняя задача заняла 24 часа. Сотрудник подумает, что в этот раз сможет сделать аналогичную задачу за 22 часа. Опираясь на идею, что теперь у него больше знаний и опыта. На практике этот оптимизм часто приводит к срыву срока.
Причины оптимистичны оптимистичной оценки включают:
- Ожидание, что на проекте не будет проблем. Все пойдет по плану.
- Пренебрежение оценкой на выполнение аналогичных задач.
- Не учитывает ограничения проекта.
- Ожидание, что этот проект будет проще.
Как давать реалистичную оценку
Решение — полагаться на анализ и данные. Если у вас есть данные по аналогичной задаче, то вы можете использовать их для оценки. Чем больше у вас данных, тем увереннее вы будете в своих оценках.
Если у вас недостаточно данных для оценки, тогда вы используйте следующие методы.
Метод 1. Оценка по трем точкам
При этом методе нужно взять несколько оценок и скомбинировать их так, чтобы получить более реалистичную. То есть вы оцениваете три возможных исхода: оптимистичный, пессимистичный и реалистичный.
Для оценки по трем точкам есть формула:
Итоговая оценка = ((O + (3 × R) + P)) / 6
где,
О — оптимистичная оценка, если все идет по плану.
P — пессимистичная оценка, если все идет не по плану.
R — реалистичная оценка, среднее значение.
Метод 2. Декомпозиция.
Этот подход требует, чтобы вы оценивали каждую отдельную задачу, а затем объединяли в общую оценку. Главное преимущество декомпозиции в том, что она укрепляет уверенность сотрудника в сроках.
Метод 3. Создание резервов.
Есть два вида резервов: деньги и время. Постарайтесь создать резервы для всех известных рисков. . Так вы учтете возможные проблемы на проекте и повысите вероятность выполнения проекта в срок.
Есть несложная формула, как рассчитать резервы.
Резервы = P х I, где
P – вероятность в процентах,
I – влияние в часах или в деньгах
Рассмотрим на примере. Представьте, что у вас на проекте есть риск того, что заказчик затянет согласование дизайна. Вы анализируете, какое влияние имеет этот риск. Допустим, на согласование уходит 3 дня. Вероятность, что заказчик затянет согласование – 30%. Это ваша экспертная оценка, которая опирается на ваш опыт. Если это случится, тогда повышается вероятность сорвать сроки. Используя формулу, получаем:
Резерв = 30% х 72 часа = 21,6 часа
Получается, что на этот риск можно заложить 22 часа.
Допустим, что риск сработал, заказчик задержал согласование на неделю, а мы отложили только 22 часа. Для этой ситуации у нас есть другие резервы. Все риски сразу никогда не сработают. Сработает только часть, а другая останется. Заложенные на них резервы останутся. Поэтому берем резервы с тех рисков, которые не сработали.
Именно поэтому рисков должно быть много — хотя бы 20. Если у вас будет 2-3 риска, то резервов не хватит, чтобы все компенсировать.
2. Ошибки при управлении изменениями
Управление изменениями — это методология, которая помогает управлять запросами на изменение проекта.
Каждый кто работал с digital-проектами сталкивался с ситуацией, когда клиент просит внести незапланированные правки. При этом аргументируя это тем, что здесь работы на 10 минут. В итоге таких правок за время проекта может быть сотни. Как результат этого — просроченный дедлайн.
Решение проблемы:
Проговорите какой объем изменений на проекте возможен. Например, определите количество итераций дизайна или допустимое отклонение по часам без изменения срока.
Убедитесь, что клиент понимает, как это будет выглядеть на практике. Для этого объясняйте на примерах, а также фиксируйте все в договоре. А именно пропишите количество дополнительных правок, которые доступны клиенту. Обычно хватает 2-3 итерации правок.
Это значит, что клиент должен собрать как можно больше правок при каждой итерации. Например, в первом письме попросил изменить цвет кнопок, а через 4 дня прислал еще письмо с правками для карточки товара. В этом случае это будут две разные итерации правок.
Все что клиенту нужно сделать, так это собрать все эти правки в одном письме. Только тогда это считается одним циклом правок. Поэтому объясните клиенту, что их письма с правками должны быть как можно более объемными..
3. Проблемы в коммуникации и ожиданиях
Представьте себе следующий разговор с программистом:
Как руководитель, у вас может сложиться впечатление, что член вашей команды должен закончить работу до пятницы. При условии если нет критических ошибок. Тем не менее, программист может, истолковать это так, что вам нужно это сделать к пятнице, но если есть ошибки, то крайний срок — понедельник.
Как правильно сообщить об ожиданиях
Крайний срок для задачи может быть понятным в вашем уме, но это не значит, что все в вашей команде думают также.
Вот три способа как можно проверить, что ваша команда понимает свои сроки.
Способ 1. Используйте сервисы для управления проектами
Если вы ставите задачи в мессенджере или через почту, то ее легко могут забыть, посчитать неважной или неверно истолковать ваши слова. Например, если вы напишите: «Мне нужно сделать это к концу недели». Сотрудник может воспринять это как просьбу, а не как жесткий крайний срок.
Именно поэтому рекомендуем вести все задачи в сервисе для управления проектами.
Мы в Alto используем Trello. Она интуитивно понятная и при определенных настройках позволяет фиксировать время на задачу, показывать отчеты.
Способ 2. Получите обратную связь
Это самый простой способ убедиться, что вас правильно поняли. Для этого попросите сотрудника повторить обозначенный срок.
Давайте пересмотрим приведенном выше диалог с учетом этого способа.
В итоге вы бы сразу узнали об этом до того, как сроки будут сорваны.
Способ 3. Внедрите периодические проверки
Добавьте периодические проверки в свой график. Так вы достигнете двух целей:
- Напомните сотрудникам о дедлайне.
- Дополнительная обратной связь
Это поможет вам выявить потенциально слабые места и не прибегать к микро-управлению вашей командой.
4. Ошибки при подготовке к проекту
Любой проект требует ресурсов. В каскадных проекта их необходимо планировать и распределять до начала проекта. В Agile-проектах управление ресурсами происходит на каждом цикле разработки: Независимо от проекта задача руководителя будет одна — определить, какие ресурсы потребуются и какого качества они должны быть.
Давайте рассмотрим, какие могут быть ресурсы проекта.
-
Человеческие ресурсы. Убедитесь, что у членов вашей команды достаточно знаний, навыков и опыта для выполнения своих задач. Также сотрудники могут заболеть, уйти в отпуск или даже покинуть команду.
- Финансовые ресурсы. Оцените и распределите их на самом раннем этапе разработки. Для контроля пользуйтесь инструментом, который будет отслеживать затраты с использованием почасовых ставок.
-
Материальные ресурсы. Включают в себя сервера, программное обеспечение. документацию. Задача менеджера — получить их в нужном количестве и в нужное время.
- Время. Постройте график проекта. Отслеживайте время для анализа производительности команды, контрольных точек и планирования работ.
5. Недостаточная компетенция исполнителей
По данным отчета The Boston Consulting Group (BCG) почти 45% сотрудников в России не соответствуют занимаемой ими должности. В США этот показатель равен 33,5%, а в Германии — 37,2%.
Задача руководителя в этой ситуации — подбирать специалистов соразмерно задаче или наоборот. То есть менеджер должен сопоставить сложность проекта и возможности исполнителя.
Если у вас есть время до начала проекта — проверьте исполнителя. Например, отправьте тестовые задания или поработайте с ним на другом проекте.
Что делать если сотруднику не хватает компетенций:
- Заложите больше часов на задачу. Во многих случаях, задача решаема, если выделить на нее больше времени.
- Возьмите консультацию у senior-специалиста. Как показывает практика при поддержке опытного наставник junior-специалист выполняет задачу на уровне «middle».
- Проведите обучение. Если сотрудник не обладает технологией, а заменить исполнителя уже нельзя. В этом случае разработайте программу обучения и внедрите ее в регулярный план работ. В короткой перспективе это замедлит проект, но к середине проекта вы заметите рост производительности
6. Демотивация команды
Многие факторы могут демотивировать вашу команду. Массовые увольнения, потеря ключевого клиента, обесценивание, возникновение разногласий — все это может снизить моральный дух команды. А чем меньше мотивация, тем меньше вероятность успеть проект в срок.
Персональная демотивация
В первую очередь поговорите со своей командой. Узнайте, что им важно, чего они хотят. Естественно люди не всегда знают чего они хотят, но их ответы дадут вам информацию для принятия решений.
Давай разберем несколько ситуаций
— Мне хотелось бы попробовать новые технологии на этом проекте. Я считаю, что мы слишком долго используем 1С-Битрикс, пора переходить на node.js.
Здесь можно найти решение если рассмотреть несколько смысловых слоев. На первом человек говорит про Битрикс и Node.js. На втором смысловом слое — хочет попробовать новое. Поэтому если хотите замотивировать этого сотрудника — дайте возможность сделать что-нибудь новое. Если такой возможности нет — создайте. Придумайте небольшой проект, где такая возможность появится
— Скучно, я уже такое делал. Знаю точно, что справлюсь. Хочется чего-то другого.
Этот сотрудник говорит нам, что проект ему по зубам, не хватает вызова. Значит его мотивируют сложные проекты, но при этом возможные. Для этой задачи найдите исполнителя с меньшим опытом, либо создать в дополнительные сложности в этом проекте.
— Все хорошо, мне все нравится. Важно, чтобы не было срывов сроков. И не приходилось задерживаться.
Эти исполнители нацелены на то, чтобы не напрягаться. В этом ничего плохого нет. В жизни людей есть не только работа. Все, что можно сделать — это поддерживать оптимальный уровень нагрузки и ориентировать на спокойствие.
Командная демотивация
Одна из популярных проблем низкой мотивации — отсутствие дофаминового подкрепления. Человеческий мозг так устроен, что каждому важно видеть промежуточные успехи. Эти успехи заряжает нас, позволяют двигаться все дальше и дальше.
Когда вам дают проект длиною в год — это демотивирует. Здесь легко потерять заряд энергии, который у вас был в начале проекта.
Дайте команде возможность видеть свои успехи, как можно чаще. Отчасти для этого были придуманы гибкие методологии. Возможное решение:
- Поделите вашу работу на спринты.
- Планируйте объем работ на каждый спринт
- Подводите итоги спринта,
- Следите за тем успеваете ли вы в срок
Итог кратко
Мы не можем заглянуть в будущее, но можем предсказать основные ошибки из-за которых срываются сроки. Давай еще раз перечислим их:
- Ошибки при оценке задач
- Ошибки при управлении изменениями
- Проблемы в коммуникации и ожиданиях
- Ошибки при подготовке к проекту
- Недостаточная компетенция исполнителя
- Демотивация команды
Если вы научитесь их предсказывать — это 95% успеха. Остальные 5% — это внешние обстоятельства, на которые мы не всегда можем повлиять.
Напоследок оставим несколько полезных ссылок:
- Наш канал в telegram.
- Кейсы команды Alto
Последние публикации:
- Инструменты для подготовки ТЗ + шаблон
- Альтернатива курсам: программа обучения для project-менеджера
- Как управлять проектом, когда не знаешь, что будет завтра
- От формата киосков до сервиса по доставке блюд в кризисный год
 Число ошибок растет как снежный ком. Большая часть из них объясняется недостатками планирования или сбоями в процессе организации взаимодействия (между отдельными участниками проекта или проектной командой и ее спонсорами). Ошибки могут привести и к фатальному исходу. С другой стороны, имеется возможность их избежать. И кому, как не поставщикам решений и консультантам по вопросам управления проектами, лучше других должны быть известны наиболее распространенные ошибки. (Им же следует и предложить пути выхода.)
Число ошибок растет как снежный ком. Большая часть из них объясняется недостатками планирования или сбоями в процессе организации взаимодействия (между отдельными участниками проекта или проектной командой и ее спонсорами). Ошибки могут привести и к фатальному исходу. С другой стороны, имеется возможность их избежать. И кому, как не поставщикам решений и консультантам по вопросам управления проектами, лучше других должны быть известны наиболее распространенные ошибки. (Им же следует и предложить пути выхода.)
Предлагаемый ниже список из 14 наиболее распространенных ошибок, допускаемых при управлении проектами, призван помочь вам очертить круг неверных действий и предложить меры, которые необходимо принять для нормализации ситуации. Устранение самых общих ошибок при управлении проектами сулит огромную потенциальную выгоду. Повышается не только уровень успешности проекта, но и степень удовлетворенности внутренних клиентов, растет ценность ИТ-активов организации, а бизнес своевременно и в рамках отведенного на эти цели бюджета получает системы, укрепляющие его конкурентоспособность.
Просчеты, связанные с персоналом
Ошибка № 1: Проекту не хватает ресурсов и квалифицированных исполнителей.
Проявление: Наличие квалифицированных исполнителей имеет критически важное значение. Наряду с этим в числе наиболее существенных ошибок, связанных с управлением проектами, следует отметить неверное распределение ресурсов. Отсутствие грамотных специалистов может погубить проект. «Ключевое условие успешной реализации проекта — тщательный подбор людей, обладающих требуемой квалификацией, — отметил Джоэл Коппельман, генеральный директор компании Primavera, специализирующейся на разработке программного обеспечения управления проектами. — Решение даже самых нужных и важных задач по организации планирования не может застраховать нас от дефицита талантов».
Решение: ИТ-руководителям и менеджерам проектов необходимо внимательно следить за уровнем квалификации и загруженностью персонала, включая консультантов, поставщиков услуг аутсорсинга и сотрудников, работающих по контракту. Именно люди, относящиеся к этим категориям, обычно избегают предварительной проверки на профпригодность, хотя и выполняют львиную долю работы. Программное обеспечение управления проектами позволяет оценить квалификацию и степень загрузки каждого из сотрудников. А когда сотрудники ИТ-службы и менеджеры проектов знают, кто и что делает, им гораздо проще понять, каким образом следует распределять ресурсы, выделенные на реализацию множества проектов и решениее повседневных задач.
«Существует масса организационных моделей, — отметил Ричард Скэннелл, один из основателей компании GlassHouse Technologies, предоставляющей консультационные услуги, связанные с построением ИТ-инфраструктуры. — Но я никогда еще не видел, чтобы хорошо работало абсолютно все. На вопросы, касающиеся распределения ресурсов, к сожалению, не существует простого ответа».
«Необходимо добиваться синхронизации проектов и человеческих усилий, — считает Коппельман. — Одним из возможных выходов здесь может стать учреждение должности менеджера по распределению ресурсов между проектами, который будет отвечать за справедливую привязку специалистов требуемого уровня квалификации к тому или иному проекту».
Скэннелл предлагает формировать «команды тигров», члены которых освобождаются от своих традиционных обязанностей на год или больше ради участия в конкретном проекте. Кен Чени, директор центра HP Software’s PPM Center, рекомендует распределять ресурсы на уровне проекта, не опускаясь до конкретных задач, поскольку сделать это гораздо труднее.
Если у вас возникают трудности с поиском квалифицированных исполнителей для реализации проектов, можно попытаться освободить ресурсы, отказавшись от тех из задач, которые не связаны тесно со стратегией ведения бизнеса. Имеет смысл оценить целиком портфель проектов, над которым трудятся сотрудники ИТ-службы, выделив компоненты, имеющие критически важное значение. «Приостановив выполнение этих проектов и перераспределив ресурсы в пользу тех задач, которым отводится более существенная роль, вы добьетесь более весомого успеха для организации в целом», — подчеркнул Чени.
Ошибка № 2: Нехватка опытных руководителей проектов.
Проявление: При отсутствии грамотного руководителя проекты могут быстро выйти из-под контроля.
Решение: Нанимайте руководителей проектов, прошедших необходимую аттестацию и обладающих навыками тонкого общения с заинтересованными лицами. Мэтью Стразза, вице-президент компании CA по обслуживанию клиентов в Северной Америке, считает, что руководители проектов должны иметь не только прочные профессиональные знания, но и хорошие коммуникативные и управленческие навыки. От них требуется умело организовать совещание, управлять рисками, находить общий язык с многочисленными заинтересованными лицами — представителями бизнеса, контролирующими реализацию тех или иных функций, с ИТ-специалистами, занимающимися вопросами безопасности, а также с финансистами, которых волнует бюджет.
«Если не решать своевременно финансовые вопросы, не следить еженедельно за бюджетом и не уведомлять клиентов о любых изменениях, то очень скоро вы окажетесь в весьма непростой ситуации, — предупредил Стразза. — Кроме того, квалифицированным руководителям проектов необходимо хорошо знать те технологии, которые применяются при их реализации».
Процедурные ошибки
Ошибка № 3: Управление проектами осуществляется при отсутствии стандартных, повторяющихся процедур.
Проявление: Это вторая по своей распространенности ошибка, связанная с управлением проектами. Отсутствие методологии повышает риск срыва отдельных задач проекта, повторного выполнения одних и тех же работ, а в конечном итоге и выхода за рамки установленных сроков или бюджета.
Решение: Методология управления проектами помогает вам осуществлять их эффективную реализацию и находиться в курсе всех мероприятий, сопряженных с выполнением проекта. «Наличие базиса, включающего стандарты и методологии, позволит избежать многих рисков, связанных с претворением ИТ-проектов в жизнь», — отметил Чени.
Дуглас Кларк, генеральный директор компании Metier, поставляющей решения в области управления портфелями проектов, для определения содержания и границ проекта, сроков выполнения его отдельных этапов, порядка распределения ресурсов и взаимодействия с заинтересованными лицами рекомендует использовать повторяющиеся процедуры. «Этими вещами следует заняться в первую очередь, потому что именно
от них вы сможете получить наибольшую отдачу», — пояснил он.
Ошибка № 4: Слишком большое число процедур, ограничивающих ваши возможности.
Проявление: Слишком большое количество процедур лишает проектную команду гибкости, а это вызывает разочарование у заинтересованных лиц.
Фуми Кондо, управляющий директор консультационной компании Intellilink Solutions, однажды была свидетелем интересного разговора между разработчиком программ и руководителем проекта. Разработчик заявлял, что функционал приложения можно расширить, не прилагая никаких дополнительных усилий. Руководитель проекта убеждал разработчика не добавлять никаких новых функций, потому что пользователи об этом не просили. «Тогда я посоветовала им следующее: ступайте к пользователям и посмотрите, действительно ли им нужны эти функции, — вспоминала Кондо. — Не вижу ничего плохого в том, чтобы предоставить клиентам больше того, что они ожидают, если при этом вы не выходите за рамки бюджета и установленных сроков».
Решение: Проявляйте гибкость и поддерживайте постоянную связь со спонсорами проекта и другими заинтересованными лицами.
Ошибка № 5: Изменения не соответствуют содержанию и границам проекта.
Проявление: Бюджет проекта устойчиво растет. То же самое происходит и со сроками.
Решение: Стразза рекомендует следовать официальным запросам на изменение проекта. Индивидуальные потребности в изменении содержания (связанном, например, с реализацией дополнительных функций) должны находить отражение в соответствующих документах, а руководителю проекта следует оценить, какое влияние эти изменения окажут на бюджет и сроки. Внесение изменений необходимо утвердить у спонсора проекта.
Ошибка № 6: Отсутствие актуальной информации о состоянии проектов.
Проявление: Как говорил Питер Друкер, нельзя управлять тем, что вы не можете оценить. А Чени добавил, что в такой ситуации вам не удастся также координировать ресурсы и реагировать на изменения в содержании и границах проекта.
Решение: Программное обеспечение.
Ошибка № 7: Игнорирование возникающих проблем.
Проявление: Осложнения не рассасываются сами по себе. Чем дольше вы их игнорируете, тем сильнее они обостряются, отражаясь в конечном итоге на стоимости проекта.
Решение: «Если вы допустили ошибку, все дальнейшее будет зависеть от того, насколько хорошо вам удастся ее исправить, — заметил Скэннелл. — Многие начинают замечать, что что-то не так, и пытаются внести коррективы лишь через месяц. Необходимо как можно раньше понять, где была допущена ошибка, и постараться привлечь к ее устранению как можно больше заинтересованных лиц».
Планируемые недочеты
Ошибка № 8: Игнорирование необходимости определения содержания и границ проекта.
Проявление: Если четко не определены границы и содержание как с точки зрения бизнеса, так и со стороны ИТ-специалистов, то проект в конечном итоге может раздуться. Кроме того, у сотрудников ИТ-службы не будет ясного понимания, что все-таки им необходимо для завершения проекта в заданные сроки, не выходя при этом за рамки бюджета и не обманывая ожиданий представителей бизнеса.
Решение: Неясные проекты — повод для обсуждения ситуации с представителями бизнеса и уточнения содержания планируемых задач и их ограничений.
Ошибка № 9: Отсутствие понимания зависимостей, существующих между проектами.
Проявление: Проекты не существуют в изоляции. Как правило, они связаны с другими проектами, которые реализуются параллельно. И когда руководители проектов допускают просчеты при оценке зависимостей между различными задачами (например, если специалисты, принимающие участие в реализации одного проекта, вдруг срочно нужны для выполнения других работ), возникают задержки. Подобные простои могут негативно повлиять на все проекты.
Решение: При планировании реализации проектов необходимо учитывать зависимости между ними. А раскрыть эти зависимости вам поможет общение с заинтересованными лицами и диаграммы, описывающие ход реализации проектов.
Ошибка № 10: Игнорирование законов Мерфи.
Проявление: При реализации проекта возникают непредвиденные обстоятельства, что вызывает удивление ИТ-персонала. И пока эти сотрудники пытаются справиться с неожиданно возникшими задачами, сроки реализации проекта отодвигаются.
Одна из фирм, вошедших в состав компании GlassHouse Technologies, решила перенести свой мэйнфрейм в новый центр данных. Всю субботу ИТ-группа занималась разборкой мэйнфрейма, чтобы на следующий день переместить его в новый ЦОД. А когда в воскресенье сотрудники ИТ-службы занялись перевозкой, на пути у них выросли участники гей-парада, перекрывшие все возможные выезды. Обойти их не было никакой возможности. Пришлось возвращаться в старый ЦОД и начинать все сначала. Недостатки планирования привели к тому, что персоналу ИТ-службы пришлось выполнить гораздо больший объем работ, чем предполагалось изначально.
Решение: В рамках планирования проекта проведите оценку рисков. С помощью мозгового штурма, в котором должны участвовать члены вашей команды, постарайтесь выявить факторы, мешающие реализации проекта или замедляющие ее ход, заставляющие расширять рамки ранее определенного бюджета, а также препятствующие выполнению сформулированных требований. Затем продумайте способы снижения указанных рисков. «Остановившись на некоторое время и оценив существующие риски, можно составить весьма полезный список, — заметил Коппельман. — Это не займет много времени, но зато поможет получить представление о возможных подводных камнях, прежде чем они возникнут на вашем пути».
Ошибка № 11: Дефицит времени, выделяемого на управление изменениями.
Проявление: Время, деньги и тяжелый труд, связанный с реализацией ИТ-проектов, могут быть потрачены впустую, если пользователи не примут новую технологию.
Решение: «На этапе планирования проекта подумайте, где он может встретить сопротивление и как этого сопротивления избежать», — советует Кларк. Определите, на работу каких заинтересованных лиц новые возможности оказывают непосредственное влияние. Тщательно спланируйте потоки работ и изменения, вносимые в бизнес-процессы. Ваша задача заключается в том, чтобы изменения не воспринимались негативно.
Ошибка № 12: Незавершенность графика проектов.
Проявление: Участники проекта не знают, что и когда им нужно сделать, в результате чего сроки реализации проекта оказываются под угрозой.
Решение: По мнению Кларка, самый быстрый способ составить график проекта — это определить все необходимые мероприятия (содержание и границы проекта, предъявляемые к нему требования, процедуры тестирования и внедрения) и конкретные сроки их выполнения в соответствии с окончательными сроками реализации проекта. Составить такие графики вам поможет программное обеспечение управления проектами.
Проблемы взаимодействия
Ошибка № 13: Нереальные сроки проекта, которые ИТ-специалисты не в состоянии изменить.
Проявление: ИТ-специалисты не справляются с поставленными задачами, за ними закрепляется репутация людей, не умеющих завершать проекты в установленные сроки.
По словам Кларка, представители ИТ-служб прилагают немалые усилия, для того чтобы привести сроки, установленные генеральным директором, в соответствие с реальностью. Однако все их усилия порождают лишь новые осложнения и еще больше затрудняют реализацию проекта в заданные сроки.
Решение: ИТ-руководителям следует разъяснять генеральному директору, какие последствия реализация проекта в установленные руководством сроки повлечет за собой с точки зрения финансовых затрат и необходимых ресурсов. С учетом этих обстоятельств генеральный директор должен сам выбрать компромиссный вариант с приемлемыми затратами, содержанием и границами проекта и сроками его реализации.
Ошибка № 14: Недостатки взаимодействия со спонсорами проекта и заинтересованными в его реализации лицами.
Проявление: Предложенная техническая реализация не отвечает ожидаемым требованиям.
Решение: «Взаимодействие в процессе реализации проекта должно отвечать интересам сторон», — отметила Кондо. В содержании и границах проекта, а также в системных требованиях вряд ли можно разобраться, если сотрудники ИТ-службы посылают представителям основного бизнеса электронную таблицу из нескольких тысяч строк, в которой описаны функции и спецификации системы. Поскольку у владельцев бизнеса нет времени изучать такие подробные технические документы, они их просто игнорируют.
«Возможна также ситуация, при которой одна из сторон в процессе взаимодействия изъясняется на языке, совершенно непонятном другой стороне, — заметила Кондо. — В конце концов раздосадованные ИТ-специалисты восклицают: “Но ведь мы обо всем этом говорили. Почему же полученный результат не удовлетворяет конечного пользователя?”»
Всем заинтересованным лицам со стороны бизнеса предлагается заранее раздать общий план реализации проекта в целом, начиная от изложения замысла и заканчивая процедурой развертывания. В этом обзоре должны быть особо выделены мероприятия, требующие взаимодействия с бизнес-подразделениями. Кроме того, следует пояснить, для чего именно сотрудники бизнес-подразделений здесь нужны.
ИТ-служба должна прилагать больше усилий, разъясняя представителям бизнеса этапы реализации проекта.
«Ведя открытый диалог о своих потребностях, реальных достижениях и ходе внедрения проекта, вы неизбежно будете затрагивать вопросы стоимости, а также касаться содержания и границ проекта, — пояснила Кондо. — В результате выход за рамки отведенного бюджета не обязательно будет восприниматься как просчет».
С одним из своих клиентов Кондо работала над реализацией проекта по развертыванию финансовой системы. Сотрудники этого клиента никогда ранее не принимали участия во внедрении крупных систем. Когда проектирование системы было закончено и специалисты Intellilink приступили к разработке плана тестирования, представителям клиента решено было объяснить, почему тестирование имеет такое важное значение.
«Мы говорили о различных подходах к тестированию, о вариантах с привлечением представителей клиента и без, — вспоминала Кондо. — Мы разъясняли, почему так важна обратная связь с пользователями, какой должна быть входная информация и сколько времени потребуется на ее ввод. В результате люди поняли, почему процесс тестирования отнимает так много времени».
Meridith Levinson. The 14 Most Common Project Management Mistakes. CIO.com. 07/23/2008
Часто компании тратят кучу денег и времени на идеи, которые в итоге никак не могут реализовать. Так почему интересные проекты часто оказываются провальными? В
материале мы
собрали 12 типичных ошибок по управлению проектами и объяснили, как с ними можно справиться.
Ошибка №1: Вы выбрали не того project-менеджера

Бывает, что на этапе распределения обязанностей большинство усилий уходит на поиск исполнителей проекта, а не его руководителя. Менеджера зачастую отбирают по
критерию
«свободен от поручений», а не «подходит по компетенциям». Таким образом, неверно выбранный или не имеющий необходимого опыта руководитель может
запросто
загубить полученный проект.
Решение: поручайте руководить проектом только того, кто действительно разбирается в предстоящих задачах.
Ошибка №2: В вашей команде отсутствует мотивация

Проект обречен на неудачу, если не все его исполнители вовлечены в рабочий процесс. Руководитель мог не объяснить роль каждого, либо не замотивировал работой
на результат.
Может быть, менеджер не донес значимости проекта. Это приводит к тому, что сотрудники без энтузиазма относятся к своей работе.
Решение: Project-менеджер, в первую очередь, должен собрать всю команду вместе. В том числе и сотрудников, работающих на удаленной основе (с помощью
skype или
других интернет-сервисов). Руководитель обязан подробно рассказать о проекте и выступить перед сотрудниками так, чтобы взбодрить и замотивировать их на усердную
работу.
Ошибка №3: Ваш проект никто не контролирует

«Нет начальника – значит нет постоянного отчитывания. Полная свобода действий» –, можете подумать вы. Как раз это и плохо. Без работы под наблюдением
высшего
руководства нет стимула держать себя в тонусе.
Решение: Реализация проектов всегда должна идти под контролем директора компании, в которой вы работаете. Или же «надсмотрщиком» будет ваш заказчик.
В любом
случае, когда проект выполняется сам по себе, он, скорее всего, окажется провальным.
Ошибка №4: Вы берете на себя сразу несколько проектов

Многие думают, что у них получится сделать больше, если они будут по чуть-чуть выполнять несколько задач одновременно. Такая стратегия неэффективна. Работа над
несколькими
проектами сразу только замедляет менеджеров. Что самое ужасное, они не успевают своевременно проверять работу исполнителей. Те же просто ждут проверки и какой-
то период
времени ничем не заняты.
Решение: Стоит отказаться от ведения нескольких проектов одновременно. Так вы не будете оставлять какие-то задачи незавершенными и сможете помогать
своей команде –
отвечать на их вопросы или давать консультации. Чем меньше на данный момент у вас проектов, тем быстрее и качественнее пойдет работа.
Ошибка №5: В вашей команде не налажена коммуникация

Умение найти общий язык с каждым сотрудником – один из ключевых навыков менеджера проектов. Если регулярно не поддерживать со всеми связь, вся команда
просто
разбежится, и проект будет завален.
Решение: Выделите день и точное время на неделе, когда вы будете собираться все вместе (в интернете или вживую) и придерживайтесь его. Заранее
спланированный день
позволит каждому быть в курсе дел по проекту и поможет продвижению проекта.
Ошибка №6: У вас нет четкой конечной цели проекта или вы меняете ее в ходе работы

Любой проект, у которого нет четко сформулированной цели, скорее всего, так и не будет готов. А менять цель на полпути крайне опасно. Вы можете перерасходовать
свои время и
деньги. Любые незапланированные мелочи (изменение цвета в логотипе или добавочная страница на сайте) могут привести к непредвиденным трудностям.
Решение: Четко обозначьте цель проекта на его начальном этапе. Затем регулярно следите, все ли придерживаются цели. Отдельно записывайте возможные
изменения и
сразу же оценивайте, как это скажется на графике вашей работы. Не забудьте согласовать изменения с заказчиком или руководством компании.
Ошибка №7: Вы неверно рассчитали время для реализации проекта

Сделать все как можно скорее, чтобы угодить клиенту – неплохое желание. Но если вы выделите слишком мало времени и не успеете завершить проект к сроку, это
вызовет только
недоверие и раздражение со стороны заказчика.
Решение: Правильно подобранное программное обеспечение для реализации проектов позволит организовать ваш рабочий процесс. Однако всегда важно
иметь запасные
деньги и время для экстренного случая. Особенно это касается проектов, связанных с IT-сферой.
Ошибка №8: Вы не идете на уступки

Не относитесь к плану проекта как к Библии, которая строго диктует, что и кем должно быть сделано, когда все должно быть готово. Не отвергайте новые предложения,
которые
приходят в голову сотрудникам в процессе работы.
Решение: Посмотрите на проект со стороны. Подумайте, не нужно ли в нем что-то изменить. Это не значит, что нужно постоянно что-то менять – просто будьте
открытыми к
предложениям со стороны, если они пойдут на пользу проекту.
Ошибка №9: Вы не систематично отслеживаете изменения в проекте

Проект не дойдет до финального этапа, если вы периодически не подводите промежуточные итоги. Также обязательно нужны специально отведенные место и время для
обсуждения
изменений в проекте.
Решение: Вы должны разработать четкую схему промежуточного контроля (чеклисты). Отслеживайте в них все до деталей – стоимость, значимость, влияние на
проект в
целом. А чтобы найти ошибки в уже готовом проекте, проведите полный прогон или тестовый запуск системы.
Ошибка №10: Вы руководите каждым шагом своих сотрудников

Не нянчитесь с исполнителями. Некоторые менеджеры считают, что им нужно ходить вокруг своих сотрудников и заставлять всех работать. Иначе ничего не получится.
Решение: Вместо того, чтобы отслеживать каждый шаг исполнителей проекта, установите для них индивидуальные еженедельные чеклисты. Таким образом,
команда будет
настроена на еженедельный прогресс и уже сама будет работать на результат.
Ошибка №11: Вы нечетко распределили обязанности в команде

Важно, чтобы в команде никто не дублировал обязанности другого и выполнял сугубо свою работу. Бывает, что сотрудники, желая помочь, берутся еще и за «не свои»
задачи. В
результате они не только плохо выполняют чужую работу, но и не успевают делать свою.
Решение: Не допускайте, чтобы кто-то занимался не своим делом. Максимально детально пропишите обязанности каждого и периодически проводите
индивидуальные
чеклисты по проделанной работе. Такой подход позволит придерживаться плана проекта и даст возможность равномерно распределить нагрузку на всех сотрудников.

Работая над проектом, представьте, что конкретно сделает его идеальным, и стремитесь именно к этому. Когда вы поймете, что ваш проект все-таки стал самым
масштабным, самым
стильным или самым полезным, вы будете уверены, что все сделали правильно.
Решение: Project-менеджер должен точно знать, что для заказчика будет являться успешно реализованным проектом. Этот фактор придаст уверенности, что
когда проект
закончен, все его исполнители могут спокойно расходиться.
Если мы не указали еще какую-то ошибку по управлению проектами, которая известна вам, напишите об этом в комментариях и расскажите, как ее можно избежать.
- Авторы
- Резюме
- Файлы
- Ключевые слова
- Литература
Усова Ю.П.
1
Чинарева О.И.
1
1 ФГБОУ ВПО «Воронежская государственная лесотехническая академия»
Как показывает практика, определенные проблемы возникают в ходе реализации любого проекта. Некоторые из них имеют четкую структуру, выраженный характер и различные возможности их решения; другие, напротив, не имеют структуры, их характер определить невозможно, и, соответственно, у них нет решений. В действительности, в ходе управления проектом редко бывает достаточно информации или времени для того, чтобы объективно, с полной уверенностью выявить сущность возникающих проблем, а, следовательно, выбранный метод их решения может оказаться малоэффективным. В связи с этим первым этапом решения проблем, возникающих в ходе управления проектом, является их определение. В статье предлагается решение некоторых, наиболее острых проблем. В зависимости от своей сущности эти проблемы могут приводить к срыву проекта посредством перерасхода средств, задержек в выполнении, а также получению иного результата и полного краха проекта.
квалификация управленческого персонала.
система вознаграждения
программное обеспечение
проблемы
управление проектами
1. Ветлужских Е. Система вознаграждения: Как разработать цели и KPI. – М. : Альпина Паблишер, 2013. — 217 с
2. Гаврилов Н.Н., Козлов А.С., Матвеев А.А., Богатов А.А. «Естественный отбор» руководителя проектом. — URL: http://www.pmsoft.ru/knowledgebase/articles/detail.php?ID=1500
3. Деминг Э. Выход из кризиса. Новая парадигма управления людьми, системами и процессами. – М. : Альпина Бизнес Букс, 2007. – 418 с.
4. Пятенко С.В. Методы анализа наиболее типичных проблем управления проектом / Элитариум: Центр дистанционного образования. — URL: www.elitarium.ru
5. A guide to the project management body of knowledge. PMBOK guide. 5th edition. – Project Management Institute, 2013. – 616 с.
Введение
В настоящее время проектный подход становится все масштабнее и наблюдается все большее его проникновение в управленческую практику. Достаточно много организаций начинает рассматривать себя через призму проектно-ориентированной деятельности. При этом наблюдается рост потребности в профессиональных руководителях проектов, так как все заинтересованные стороны ожидают от проекта достаточно высоких положительных результатов.
В практике управления проектами есть множество примеров, когда в ходе реализации проектов были допущены перерасходы в разы, а ввод их в эксплуатацию был задержан на несколько лет, через короткий промежуток времени эти проекты становились национальными символами и считались наиболее успешными. Но достаточно часто встречаются проекты, которые завершаются с превышением бюджета, с нарушением сроков, неудовлетворенностью заказчика полученным результатом. Часть из проектов останавливаются на полпути и заканчиваются крахом.
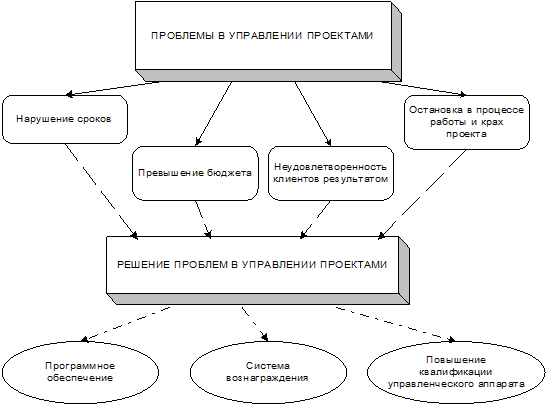
Рис. 1. Проблемы и их решения в управлении проектами.
Разрешением таких проблем является внедрение программного обеспечения и повышение квалификации управленческого аппарата.
Программное обеспечение (ПО) управления проектами позволяет снизить рутинность работы и максимально облегчить и ускорить обработку данных и отчетов в ходе работы над проектом. Компьютер поможет в составлении планов, сетевых диаграмм, подготовке отчетов и во многом другом. Но, несмотря на много положительных моментов, следует отметить главный недостаток — ПО не сможет за вас управлять проектом.
Профессиональный руководитель проекта не должен следовать за ПО, «идти у него на поводу», его задача — заставить ПО работать в соответствии с его потребностями.
Большинство существующих программных средств предлагают планирование проектов по собственным методикам, зачастую не соответствующим общепринятым (стандартным) для проектного менеджмента — это и порождает множество серьезных проблем, таких как срыв сроков, перерасход бюджета и т.д.
Даже применение ПО от лидеров сегмента — MS Project, Primavera, не страхует от возможных проблем, ведь это всего лишь инструменты, эффективно работающие в руках профессионала, а не искусственный интеллект, решающий все ваши проблемы [2].
Понимание алгоритмов, лежащих в основе ПО, или хотя бы поверхностное знание методик, применяемых в управлении проектами, поможет вам избежать множества проблем.
Следующим способом решения выше обозначенных проблем является активное использование системы вознаграждения. Чаще всего в российских компаниях используется стандартная система вознаграждения: в небольших по длительности проектах (например, до шести месяцев) сотрудники поощряются за выполнение проекта в срок, а при более долгосрочных проектах – за завершение каждого этапа и всего проекта в срок. Причем за выполнение первого этапа проекта размер вознаграждения обычно меньше, чем за завершение всего проекта. Например, если проект состоит из трех этапов, а общее вознаграждение составляет 100%, то за завершение первого этапа выплачивается 20% от общей суммы вознаграждения, 30% – за второй и этап и за завершение всего проекта – остальные 50%.
При этом используются два варианта взаимосвязи с вознаграждением:
- вариант жесткий (одноуровневый): если этап (проект) выполнен в срок, менеджер получает вознаграждение, если нет – наказывается и остается без премии. Такой вариант используется в проектах, имеющих жесткие сроки выполнения (например: Олимпиаду нельзя перенести, все строительные объекты должны быть сданы вовремя).
- вариант более мягкий: разрабатывается таблица с пороговым значением, при котором уже возможна выплата вознаграждения.
Участники проектов вознаграждаются при достижении поставленных целей всей командой проекта, а также за выполнение в срок своих операций.
Преимущество такой системы вознаграждения: сбалансированность, комплексность, прозрачность и понятность. Однако, несмотря на все плюсы данной системы вознаграждения, следует выделить проблемы, которые возникают при использовании данной системы вознаграждения.
Чтобы получить вознаграждение, каждый менеджер проектов при оценке длительности работ закладывает достаточный (не всегда необходимый) временной резерв на непредвиденные обстоятельства, а также запас по бюджету. Причем, если даже проект можно завершить раньше срока, менеджеры этого не делают, т.к. не получают за это дополнительного поощрения и опасаются того, что в следующий раз руководство, скорее всего, сократит планируемую длительность проекта. И если даже сотрудник (участник проекта) выполнил свою операцию раньше срока, это никак не поощряется руководителем, разве что он может нагрузить его дополнительной работой. Поэтому сотруднику нет никакого смысла завершать свою операцию раньше срока. То же самое с бюджетом, нет никакого резона его экономить.
Если проект можно выполнить раньше срока, то экономится ресурс – оплачиваемые человеко-часы (кроме того, свободных специалистов можно будет уже занять другим проектом). Но это никому не выгодно: есть риски, что руководство на следующем подобном проекте урежет бюджет. Поэтому сотрудники делают вид работы или спокойно работают над улучшением полученных результатов. В результате менеджеры учат подчиненных соблюдать установленные сроки и не поощряют сотрудников, закончивших работу досрочно. Кроме того, некоторые «умные» сотрудники иногда специально задерживают сроки сдачи работы, чтобы получить оплату за сверхурочные.
Свое негативное влияние оказывает и так называемый студенческий синдром: большинство людей склонны откладывать выполнение задания до последнего. Исследования показали, что менее трети задания обычно выполняется в первые две трети срока, отведенного на него, и две трети – за последнюю треть срока. Кроме того, сотрудников постоянно отвлекают на выполнение новых заданий, а многозадачность, как известно, ведет к увеличению длительности выполнения проекта. Чтобы быть хорошим в глазах руководителя, сотрудник просто обязан брать и выполнять новые задания, в результате – он перегружен, что часто приводит к стрессу и в конечном итоге еще к большему увеличению длительности проекта. Поэтому проекты редко выполняются досрочно. Если бы некоторые этапы проекта завершались сотрудниками досрочно, то возникающий запас времени мог бы использоваться на непредвиденные обстоятельства, которые всегда могут возникнуть на завершающих этапах проекта [1].
А так получается, что существует постоянный конфликт между целями компании: удовлетворением требований клиента и руководства, достижением большего результата за минимальные сроки и деньги и личными целями каждого члена команды — личной успешностью (а для этого нужно закладывать запас времени, не сдавать работу досрочно, укладываться в бюджет, но ни в коем случае не экономить, брать новые задания, чтобы быть хорошим в глазах руководителя и т.д.). Формируется определенный стереотип поведения, выгодный сотруднику. Получается, что вроде все работают хорошо с точки зрения индивидуального результата, но нужных результатов для бизнеса нет [3].
В настоящее время квалификация управленческого персонала на промышленных предприятиях не отвечает международным требованиям к компетентности специалистов по управлению проектами. В связи с этим возникает необходимость обучения сотрудников предприятий проектному менеджменту. С учетом вступления России во Всемирную торговую организацию, перехода предприятий России на международную систему финансовой отчетности повышается необходимость создания на каждом предприятии отдела управления проектами, отвечающего за вопросы анализа и мониторинга инвестиционных проектов развития.
Уникальность проекта диктует необходимость владения междисциплинарными знаниями и навыками, в отличие от руководителя функциональной организации, который может являться профессионалом только в одной области.
Для иллюстрации такой ситуации введем качественные показатели «требования проекта» и «квалификация руководителя проекта». Под понятием «требования проекта» будем понимать совокупный уровень знаний и навыков, необходимых для успешной реализации проекта. Под понятием «квалификация руководителя проекта» будем понимать совокупный уровень знаний и навыков, которыми обладает руководитель проекта на определенный момент времени. Требования проекта и квалификация руководителя проекта – это динамичные характеристики [2].
Графическая иллюстрация понятий «требования проекта» и «квалификация руководителя проекта» приведена на рисунке 2.
Рис. 2. Качественные соотношения динамики требований проекта и квалификации руководителя проекта.
Введем предположение, что по мере выполнения проекта его требования сначала возрастают за счет постоянного уточнения и детализации требований к продукту, услуге, цели проекта. Затем, достигнув максимального уровня, состав и уровень требований стабилизируются и некоторое время могут оставаться неизменными, определяясь требованиями к качеству проекта. Далее, при завершении проекта, его требования естественным образом снижаются (в принципе, до нулевого уровня к завершению проекта). Вместе с тем с развитием технологий требования каждого следующего проекта больше, чем у предыдущих подобных ему проектов в той же прикладной области. Введенное предположение верно не для всех проектов — требования к проекту могут уменьшаться или оставаться постоянной величиной [2; 3].
Квалификация же руководителя проекта в большей степени определяется личностными характеристиками. В каждый конкретный момент своей жизни руководитель проектов должен принимать решение: либо повышать свою квалификацию, либо остаться на прежнем уровне. В принципе, может существовать и третий вариант — деградация, но такие ситуации мы рассматривать не будем. Однако важно принимать во внимание, что при современных темпах развития технологий, оставаясь на прежнем уровне развития, человек в каком-то смысле деградирует в своем профессиональном развитии.
При «входе» в проект квалификация руководителя проекта должна быть не ниже требований проекта на момент вхождения. В ходе реализации проекта квалификация руководителя проекта должна все время соответствовать требованиям проекта. Если по каким-либо причинам на некотором интервале времени требования проекта превышают квалификацию руководителя проекта, то можно утверждать, что данный проект с данным руководителем будет либо выполняться не эффективно и потребуется заменить руководителя проектом, либо вообще проект потерпит фиаско. Для дальнейшего продолжения карьеры в качестве руководителя проектов, по завершении очередного проекта, квалификация его руководителя должна соответствовать требованиям следующего проекта [5].
Исходя из всего сказанного, можно сказать, что понятия «требования проекта» и «квалификация руководителя проекта» естественным образом взаимосвязаны. Для того чтобы быть руководителем проекта, необходимо иметь соответствующую квалификацию и постоянно ее повышать. С другой стороны, для управления конкретным проектом необходим профессионал соответствующей квалификации.
Возникновение тех или иных проблем в процессе выполнения проекта — нормальное явление. Существует немало разнообразных методов их структуризации и разрешения. Выбор наиболее эффективного метода зависит от множества разных обстоятельств. Главное — работать над разрешением проблем систематически и организованно. Накопленный опыт позволяет выявить обычные ошибки при решении проблем:
- неосведомленность о проблеме;
- неверный «диагноз»;
- решение не «продано» топ-менеджменту;
- принятие решений без запланированных действий;
- действия при отсутствии рамок решения;
- неспособность действовать тогда, когда нужно;
- действия, не соответствующие принятым решениям [4].
Таким образом, в данной статье мы рассмотрели решение некоторых проблем, возникающих в ходе управления проектом. Появление их нельзя считать чем-то необычным или неестественным – без них не обходится ни один проект, однако умение вовремя определить проблему, выявить причины ее возникновения и устранить их и является основным достоинством проектного менеджера.
Рецензенты:
Демченко А.Ф., д.э.н., профессор кафедры экономики, финансов и менеджмента Воронежского филиала Российской академии народного хозяйства и государственной службы при Президенте Российской Федерации, г. Воронеж.
Трещевский Ю.И., д.э.н., профессор, заведующий кафедрой экономики и управления организациями Воронежского государственного университета, г. Воронеж.
Библиографическая ссылка
Усова Ю.П., Чинарева О.И. ПРОБЛЕМЫ В УПРАВЛЕНИИ ПРОЕКТАМИ И СПОСОБЫ ИХ РЕШЕНИЯ // Современные проблемы науки и образования. – 2013. – № 6.
;
URL: https://science-education.ru/ru/article/view?id=11844 (дата обращения: 29.01.2023).
Предлагаем вашему вниманию журналы, издающиеся в издательстве «Академия Естествознания»
(Высокий импакт-фактор РИНЦ, тематика журналов охватывает все научные направления)
Technique to Manage Software Safety
Jean-Louis Boulanger, in Certifiable Software Applications 1, 2016
6.2.2.2 Summary
Error processing is one of the difficult aspects of design; the conventional methods of error management can be easily ignored by programmers (lapse in return codes, not processing error codes, systematic propagation of errors codes, nonrecovery of exceptions, etc.).
In view of the addition of specific treatments (adding a parameter, condition, connection, etc.) for error management, the complete error processing by conventional methods greatly complicates the logic of a program.
The cyclomatic complexity (V(g)) is incremented by at least one for each error processing and it becomes very difficult to understand, maintain and test a software application integrating this type of technique.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781785481178500064
Systems thinking simplified – four primary concepts
James McKinlay, Vicki Williamson, in The Art of People Management in Libraries, 2010
[D] Throughputs: ‘How do we get there?’
This is the final phase of the planning and change process. This is where change occurs – or not – depending on the degree of success that is achieved. Just because this is the final phase doesn’t meant that it is the end. In fact it is both – the beginning of the end and the end of the beginning. As we work through this phase, we end up recycling right into the next planning phase, because in best practice organisations this process is a continual one that continues year after year. They develop a continuous planning and change management process. We call this approach Strategic Management. This phrase intentionally includes the ‘strategic’ portion of strategic planning and the ‘management’ portion of change management. For lasting success, both components are needed – good strategic planning practices and good change management practices.
We have seen far too many examples of organisations that are guilty of either of these two glaring management errors:
- ■
-
Developing plans and then failing to execute and bring about the changes as outlined. This is the dreaded ‘SPOTS Syndrome’ – Strategic Plan On Top Shelf, gathering dust. When this occurs, staff become frustrated, cynical and disenchanted, because the potential benefits are never realised.
- ■
-
Attempting to introduce major changes without having a clearly articulated plan in place that provides a sound rationale for the change. When this occurs, staff are confused and feel like victims, because there is little or no explanation as to why the change is required and what things will look like after the changes are in place.
In this phase you begin the process of creating intentional change. What’s the point of putting a detailed plan together, if all you are planning to do is maintain the status quo? If that’s the case, don’t waste time developing a plan – just keep doing what you’ve been doing and hope for the best. Here we take all of the various inputs that you have to work with and we ‘put them through a process of change’ (throughputs) in order to achieve the desired outputs. Inputs → Throughputs → Outputs. This is the normal process used to create anything – a car, a cake, a book, a new program, a successful organisation. In systems thinking, the primary difference is that we start with the outputs first, and then apply the skills of backwards thinking to return to the inputs, before we start the throughput phase as outlined earlier.
Because this is planned change, you can increase your odds of success when you become very skilled at anticipating the types of emotional response that you are most likely to encounter as the plan unfolds and the changes begin to occur. Human behaviour during periods of change is actually very normal, very natural and very predictable. Armed with this awareness, you will be better prepared to face, appropriately address and resolve the issues that people experience as they adapt to the personal adjustments each is required to make in order to embrace the changes that will help to achieve the ideal future state. The next section on Concept 4 will delve into the dynamics of change in detail.
In summary, we have discovered in working with clients that following the simple A-B-C-D-E planning process and asking the related questions at each phase provides the template for sound planning and change. As we noted in the section on the Brief History of the Science of Systems Thinking, Stephen Haines and I began our venture into this field by looking for a better way to conduct strategic planning. We backed into the field of systems thinking. I wish that we could have been smart enough to grasp the concepts of systems thinking up front and then used them to develop a better strategic planning model. If we had, some of the situations we encountered would have made more sense to us when they occurred and we would have been better prepared to deal with them. We had to go through the process of exploration and trial and error before we landed on the solution that made the most sense. That is not uncommon. Remember, as noted in the Chapter 1, ‘An education at the school of hard knocks can be very valuable, but the tuition can be very expensive’.
Later, as we examine an approach for developing a Strategic Human Resource Management Plan – or a People Plan – as we call it, you’ll see that the more detailed planning model we have developed is merely an expanded version of this simple Systems Thinking Framework. It covers the same five phases, in the same order, and digs deeper at each phase because of the level of complexity of the planning task at hand.
By keeping the simple A-B-C-D-E model framed in my mind, I am able to have different conversations with people that produce better results. This is true, whether:
- ■
-
I’m having a discussion with a clerk in a shop where I am not receiving the service I need, or when
- ■
-
I’m getting the runaround and numerous transfers on a complicated phone enquiry, or when
- ■
-
I’m having a confrontational conversation with a client, colleague or co-worker, or when
- ■
-
I’m having a discussion with a family member about something where we have different points of view, or when
- ■
-
I’m in a situation where I need to go through a process that is critical and possibly uncomfortable, such as being wise enough to handle the frustration of clearing security at an airport, without becoming impatient or upset.
I always try to remind myself of my ‘desired outcomes’, which in the last example are to get through the security check with as little difficulty as possible, and to board my plane on time. When I forget this, I usually end up being detained for a more thorough check, becoming very frustrated and possibly angry and risk missing my flight entirely.
By keeping the ‘end in mind’, it is easier to deal with immediate difficulties. To reinforce the importance of this point, we jokingly recommend that clients have this simple model tattooed on the inside of their eyelids, so that they will be able to use it at any moment, to obtain the results they want to achieve. When you apply this technique regularly, you do see the world differently.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781843344230500055
Evolution of the Tore Supra data acquisition system: towards the steady state
B. Guillerminet, … J. Signoret, in Fusion Technology 1996, 1997
In operation since 1988, the Tore Supra data acquisition system provides continuous data taking, storage and displays. But several limitations are observed, as the weak errors management, the performances of data transfer and of feedback control. The tied proprietary operating systems and as outcome, the lack of processors evolution prevent from upgrading the original system. So, the data acquisition system has been completely re-engineered aiming long pulse operations. It is based on a commercial package which provides all the basic modules to build a distributed on-line software from the data acquisition level up to the run control and data display. The continuous operation requests a few enhancements we explore in the last part.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780444827623501968
Data Link Management
Edward Insam PhD, BSc, in TCP/IP Embedded Internet Applications, 2003
What is the Job of the Data Link Layer?
The previous chapter covered a few of the basic networking technologies available and the methods used for transferring data between nodes and for maintaining a connection, namely the physical PHY layer. Some of the functions described there, such as addressing and collision handling, were more the remit of the data link layer in the model, but because of their close interlinking with the hardware components, had to be included as part of that section.
Figure 6-1 shows where the data link layer fits in relation to the various conceptual models. The functions the layer manages are as follows:

Figure 6-1. Data link layer model correspondence
-
Basic level error management: The layer provides the simplest form of error handling consistent with the quality of the channel. Little provision for error management may be required for example, in reliable channels such as wired Ethernet. More sophisticated error management methods will be needed for less predictable channels such as wireless networks. From the diagram above, we can see how the IEEE has developed parallel data link layer MAC strategies depending on the physical method used. This allows the provision of the right kind of error management for each physical media characteristics.
-
Channel contention: The layer is responsible for ensuring the shared medium is used effectively. Various carrier sense techniques are used to guarantee only one station makes use of the medium at a time. Again, the techniques will depend according to the physical characteristics of the medium.
-
Addressing: Each station connected to the network must have a unique physical address. The layer must include facilities for stations to know of the existence of others in the network, and to access facilities for accessing or recognizing the address of other station in the network, even using centrally provided facilities for allocating and managing these addresses.
-
Data flow: The layer is responsible for ensuring that data transferred from the upper layers is queued and transmitted onto the medium, and that data received is separated from its preambles, and clock information, and after simple quality checking, that is, checksum calculation, passed on to the next layer up.
-
Data packaging: The layer is also responsible for packaging the data into acceptable blocks or frames of sizes ideally suited for the physical medium. This may include breaking the data into smaller grouped segments, and reassembling them on reception. Some applications may send data continuously (streamed), others blocked into large or small chunks. One job for the data link layer is to break these down into manageable sized packets or frames. Frames consist of blocks of data containing a payload (the data to be sent) plus a header that containing data and control fields such as addresses, commands and checksums. The receiver uses these to determine what to do with the frame and whether it has arrived without any errors.
Within the data link layer, the MAC layer provides for
- •
-
Individual methods for channel contention: by the use of various carrier sense techniques, such as hidden node detection, and ACK methods for local error management and re-transmission requests.
- •
-
Management of overlapped multiple networks: these are networks that may be present in the same medium space. This is mainly relevant in the case of wireless technologies.
- •
-
Privacy and access control: by the use of passwords and encryption.
- •
-
Dynamic addressing: including facilities for seamless moving between and across overlapping nearby networks.
The LLC layer provides for a variety of data flow channel services including unacknowledged connectionless, connection oriented and acknowledged connectionless services. As their names imply, different qualities of services can be provided by this layer. There is some overlap in the way these services may be used by the layers above. For example, a local network user database manager may use a connection oriented channel, whereas IP services may use an unacknowledged connectionless channel (do not confuse these services with similarly named ones offered by higher-layer protocols). LLC also provides for encapsulation, which is another word for data packaging. The LLC is responsible for presenting clean payloads to the layer above, and to perform all conversions required to transform a data payload into one suitable for transmission down the medium.
In the Internet model, the network access layer encompasses both the OSI data link layer and the physical layer. The network access layer is a combination of access methods defined by various standards. These include old and new access technologies from Local Area Networks (LANs) and Wide Area Networks (WANs). In the IEEE 802.x model, the data link layer covers the logical link control (LLC defined in IEEE 802.2) and the media access control (MAC). Because the operation of the MAC is intertwined with the physical method of transmission, the MACs are defined individually for each of the physical formats used. For example, 802.3 describes CSMA/CD (Ethernet), 802.5 token ring, and 802.11 wireless technologies.
To explore link control further, we must relate it to the general technologies it applies to, in WANs and LANs. These are discussed in the next sections.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780750657358500333
Architectures and approaches to manage the evolving health information infrastructure
Brian E. Dixon, … Shaun J. Grannis, in Health Information Exchange (Second Edition), 2023
8.5 Benefits of the OpenHIE interoperability layer
Collectively, the OpenHIE IL provides a solution to overcome many of the prominent barriers that can inhibit health information sharing. The ability to restrict access to a single entry point simplifies security, monitoring, and error management for the entire HIE infrastructure. The ability of the IL to process requests without the use of a specific message format is critical because no individual standards can exhaustively meet the demands of all prevailing and forthcoming information systems [28]. The flexibility of the IL structure enables OpenHIE to adapt as clinical guidelines, technology, and the needs of the stakeholders evolve over time [29]. Services can be added or changed as needed, and the loose component-based architecture can be leveraged to accommodate fluctuations in transaction volumes.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780323908023000010
LAN Access Technologies
Edward Insam PhD, BSc, in TCP/IP Embedded Internet Applications, 2003
Error handling
A first-level check on the quality of the received frame is performed at the receiver by calculating the Ethernet FCS checksum. Any frames in error are generally dropped, and a general message is passed to the rest of the system noting that a frame has been received in error. Error handling by these lower layers is nothing more than simple checks on quality. Most of the real error management will be performed at the higher layers. This is the most efficient way to do this for this technology. During the development of a protocol, deciding how much error protection should be performed at a particular layer is a real art. Doing too little, forces the higher layers to do all the work, and many ‘bad’ packets will be passed up, resulting in wasted bandwidth. Doing too much, means that there may be lots of delay and congestion at the low levels, especially if error management is handled repeatedly by more than one layer. The method of error management will also depend on the physical medium, and how predictable and reliable it is. A highly reliable wired LAN network will require less error protection than a radio-based system.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780750657358500321
User Needs Analysis
Tom Brinck, … Scott D. Wood, in User Experience Re-Mastered, 2010
Human-Error-Tolerant Design
Designing systems that are tolerant of human error becomes crucial when any task has potentially dangerous and costly consequences, or when the outcome is not easily reversible. Financial and medical Web applications are prime examples of sites where reducing the human error is especially important. A central theme in designing for human error is to build a multilayered defense. Designing for human error effectively requires addressing several aspects of error management, including the following:
-
Prevention: Eliminate the potential for error to occur by changing key features of the task or interface. This is always the preferred and the most effective method for error management.
-
Reduction: Reduce the likelihood that the user will get into an error state when prevention is not possible by ensuring the user is aware of action consequences and by training users on both normal and error-recovery procedures.
-
Detection and identification: Ensure that if the user does err, the system makes it easy for the user to detect and identify the error.
-
Recovery: Following error detection and identification, ensure that the system facilitates rapid correction, task resumption, and movement to a stable system state.
-
Mitigation: Minimize the damage or consequences of errors if they cannot be recovered from. Even when all the other error management steps have been taken, errors will still be made, so systems should be designed such that catastrophic outcomes from human error are not possible.
Example: Error Recovery
The issues for error recovery are detection, identification, correction, and resumption. For the user the questions are simple: What happened? What do I do now? Electronic commerce is a prime domain for error-recovery design flaws that can adversely affect usability. Consider, for example, the order form in Fig. 2.9a (slightly modified from http://www.netopia.com). Here, the form indicates that certain asterisked fields are required. The credit card selection menu is not indicated as a required field and is easy to miss (the card type is not really necessary and can be derived from the card number). Also note the instructions at the bottom of the form telling the user not to use the Stop or Back buttons. These instructions help prevent users from accidentally performing multiple transactions or from mistakenly believing that a transaction was canceled when it was not. The problem is that this error-management measure hinders recovery from other error types. If the user forgets to select the credit card type from the pull-down menu, the commerce server indicates an error by displaying the screen shown in Fig. 2.9b.

FIGURE 2.9. An error prevention and recovery problem.
(a) The form indicates that asterisked fields are required. It does not indicate that selecting the credit card type from the pull-down menu is also required. (b) The error page indicates that an error has happened, but doesn’t clearly identify the error. It also doesn’t provide the user with adequate navigation instructions to correct the error.
The user detects that an error has occurred from the message heading. The system even identifies the error as an invalid entry in “WXK_PAYMETH” field. Unfortunately, that field name is only clear to the system and its programmers. Most users would not know from this that the problem is an incorrect entry for the payment method. In fact, the credit card menu is not strictly a field and does not really reflect an entry as the message suggests. This would likely cause more confusion. Even if the error is deduced by the user, correction is hindered by the message on the original order form that said, “Do not use the STOP or BACK button.” There is no other navigation on the error page, so using the Back button is, in fact, the only option.
A better way to handle incorrect data entries is to return the user to a facsimile of the order form, with the missing or erroneous data fields highlighted in red (or indicated in some other salient way). Examples of correct entries can also be helpful. Minimally, error pages should identify errors in a way that users can understand and provide clear recovery paths when possible.
Simple, practical techniques, when applied consistently, can dramatically improve the Web site development process. More significantly, these fundamental task analysis methodologies please the ultimate critic: the user.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123751140000050
Agile Systems Requirements Definition and Analysis
Bruce Powel Douglass Ph.D., in Agile Systems Engineering, 2016
5.2.1 Identify System Use Cases
This task creates system use cases. For the most part, these correspond directly with the stakeholder use cases. However, it often happens that capabilities not yet identified rear their head (usually because not all stakeholders have been considered). This is especially true for capabilities specifically required by regulatory standards or secondary capabilities such as error and fault management and self tests. In addition, deeper system thinking may demonstrate the some system use cases are too large or complex to be defined within a single iteration, and require decomposition in some fashion to get them to a manageable size. This decomposition may be either via the «include» or «extend» relations (creating aggregation taxonomies) or via the generalization relation (creating type taxonomies). As we identify new system use cases, they will be added to the system engineering iteration plan for analysis during either the current iteration or a future one.
In any event, the stakeholder use cases are a great place to start.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128021200000059
Analysis of Computer Networks Components
Paul J. Fortier, Howard E. Michel, in Computer Systems Performance Evaluation and Prediction, 2003
Interface units
Insofar as its role in the network is concerned, the interface unit is the most complex unit with respect to both hardware and software. The basic function of the IU is to enable its processor to communicate with others in the network as well as to contribute to overall network functioning. This involves system (re)initialization, flow control, error detection, and management.
When the IU detects that its processor has a message to send, it formats the message for transmission and becomes a contender for exclusive use of the communications channels. Upon allocation of control, the controller transmits the message and, depending on the implementation, may await a response from the destination processor.
Upon completion of resource (bus) utilization, the IU must be able to pass control to the next candidate according to the allocation scheme. If there is an IU failure, the other IUs must be able to substitute for it insofar as its network control responsibilities are concerned.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781555582609500151
Software Application Architecture Verification
Jean-Louis Boulanger, in Certifiable Software Applications 3, 2018
10.2.2.7.2 Principles
We generally call it integration testing but it would be preferable to refer to as interface testing. In fact, the purpose of integration testing is to test the set of interfaces of the software application. In order to test the interfaces, it is therefore necessary to have a description of the set of interfaces included in the architecture documents (SwAD and SwCD).
An interface is not only defined by its name and its type but, as has already been stated, we will have to describe at least:
- −
-
the list of data exchanged and for each data element:
- —
-
the name;
- —
-
the family and/or the type;
- —
-
the units (if necessary);
- —
-
the range of acceptable values;
- —
-
the values representing an error;
- −
-
real-time characteristics (time constraint, protocol, etc.);
- −
-
error management:
- —
-
Is the interface capable of detecting errors during exchanges?
- —
-
If yes, what are the associated behaviors?
- —
-
Is there exception handling management?
- −
-
memory management:
- —
-
Is there memory allocation?
- —
-
Is there a buffer? If yes, what happens when it is full?
- —
-
If there is no memorization mechanism, what happens if several data elements are received at the same time?
The name integration testing means that once all the basic components have been verified, it is possible to perform their integration in order to obtain the final application. The integration of a software application can be achieved through two approaches:
- −
-
the so-called “big bang” approach: the whole of the software application is integrated once. Basically, if the software application compiles, it is integrated. This approach is not without risks especially when using the C language. It may happen that parameters are reversed but that they are of similar types, therefore the compilation succeeds;
- −
-
the so-called “progressive integration” approach: based on the architecture documents (SwAD and SwCD), an integrated strategy is implemented which allows building the components of the upper levels gradually until the application software is obtained. This approach allows for detecting interface defects at the earliest. Figure 10.6 reveals two possibilities for connecting the two components and according to the architecture one of the configurations is erroneous.

Figure 10.6. Example of interface defects

The objective of progressive integration is to look for defects in interfaces; we are in the piping system of the software application and analogously to a plumber, leaks and bad connections should be discovered. This is maybe what makes this activity less enjoyable among developers.
The interfaces of a component are of two types, logical interfaces (software/software interface) and physical interfaces (software/hardware interface). Consequently, there are two families of integration tests to implement: S/S integration tests and S/H integration tests.
S/S integration tests can be carried out on the development machine but S/H integration tests will be carried out on actual hardware (final target). For S/H integrations tests, they can be executed at different levels but at lower architecture levels; it will be easier to test all the behaviors induced by the physical interface.
The implementation of a component integration strategy as part of a process for verifying logical and physical interfaces can lead to identifying errors at the definition level (incompatibility, value never used, etc.) of the interfaces and/or of their uses (too many messages, lack of exception handling, etc.).
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781785481192500108
Расширение класса Error

При написании кода важно учитывать различные сценарии, в которых могут возникнуть ошибки. Они играют неотъемлемую часть в вашем веб-приложении, потому что вы можете избежать смертельных сценариев (например, полного сбоя приложения), которых в противном случае не удалось бы избежать, если бы их не обработали.
В этой статье будут рассмотрены некоторые передовые методы управления ошибками и их обработки в JavaScript.
Расширение ошибки
Часто бывает полезно предоставить более подробное описание ошибки в обработчиках ошибок. И под этим я не просто имею в виду более четкое сообщение об ошибке. Я имею в виду расширение класса Error.
Сделав это, вы можете настроить свойства name и message, которые будут полезны для отладки, а также прикрепите пользовательские методы получения, установки и методы, которые в этом нуждаются:
Это может обеспечить более плавную отладку, особенно если у вас есть несколько блоков кода, которые генерируются одинаково. Когда несколько сценариев в вашем коде могут генерироваться по одним и тем же причинам и требовать некоторого дополнительного контекста, может стать немного сложно вернуться и точно выяснить, почему он был сгенерирован без утилиты (в зависимости от типа ошибки, конечно ).
Давайте рассмотрим сценарий, в котором это станет полезным.
Допустим, у вас есть функция, которая принимает список функций преобразователя. Функция принимает аргумент, и при запуске она перебирает преобразователи и передает аргумент каждой функции. Если функция возвращает результат, она останавливает цикл и возвращает результат:
Теперь представим, что мы создаем страницу, предлагающую пользователю ввести год своего рождения, прежде чем отнести его к какой-либо группе в зависимости от возраста:
Этот код запрашивает пользователя, и когда он нажимает ОК, его возраст присваивается userInput и отправляется в качестве аргумента функции, созданной composeResolvers:

И когда он завершается, он запускает window.alert, чтобы показать пользователю вычисленную группу:

Это работает нормально, но что, если пользователь не использовал браузер Chrome? Это означает, что эта строка не будет работать:
resolvers.push(someResolverFn)
Это приводит к неприятному неожиданному результату:

Мы можем предотвратить подобные необработанные ошибки, выдав нормальный Error, или мы можем использовать более конкретный BadParametersError:
Таким образом, у ошибки гораздо меньше шансов добраться до пользователя, и это заставляет разработчика исправить ошибку:

Если несколько функций используют эту стратегию и прикрепляют свойство, например, recommended, отладка становится намного проще.
Теперь это можно записать примерно так, что является лучшим защитным механизмом:
Используйте TypeError
Мы часто обрабатываем ошибки, бросая Error. Но когда доступны встроенные ошибки JavaScript для сужения сценария, когда появляется возможность, полезно просто использовать их:
Тестирование
Используя производные Errors, тестирование становится более надежным, так как вы можете напрямую использовать их для своих утверждений:
Переусердствовать
Зная, насколько это полезно, также возникает соблазн просто создать кучу настраиваемых ошибок для каждого возможного сценария, о котором вы только можете подумать, особенно когда вы только начинаете изучать JavaScript. Итак, если у вас есть приложение малого или среднего размера, и вы попали в такую ситуацию:
Затем вы можете переосмыслить этот подход и определить, действительно нужно это делать или нет. В большинстве случаев этого достаточно, чтобы отобразить более четкую ошибку message. Утверждение о пользовательских ошибках дает максимальную пользу только тогда, когда вам нужно добавить к нему некоторый дополнительный контекст (например, токен для повторной попытки по запросу с тайм-аутом):
Заключение
Управление ошибками обеспечивает контроль над вашим приложением. Это также экономит ваше время и деньги.
Это знаменует конец статьи. Я надеюсь, что вы сочли полезным. Ищите больше в будущем!

Существует две фундаментальные стратегии: обработка исправимых ошибок (исключения, коды возврата по ошибке, функции-обработчики) и неисправимых (assert(), abort()). В каких случаях какую стратегию лучше использовать?
Виды ошибок
Ошибки возникают по разным причинам: пользователь ввёл странные данные, ОС не может дать вам обработчика файла или код разыменовывает (dereferences) nullptr. Каждая из описанных ошибок требует к себе отдельного подхода. По причинам ошибки делятся на три основные категории:
- Пользовательские ошибки: здесь под пользователем подразумевается человек, сидящий перед компьютером и действительно «использующий» программу, а не какой-то программист, дёргающий ваш API. Такие ошибки возникают тогда, когда пользователь делает что-то неправильно.
- Системные ошибки появляются, когда ОС не может выполнить ваш запрос. Иными словами, причина системных ошибок — сбой вызова системного API. Некоторые возникают потому, что программист передал системному вызову плохие параметры, так что это скорее программистская ошибка, а не системная.
- Программистские ошибки случаются, когда программист не учитывает предварительные условия API или языка программирования. Если API требует, чтобы вы не вызывали
foo()с0в качестве первого параметра, а вы это сделали, — виноват программист. Если пользователь ввёл0, который был переданfoo(), а программист не написал проверку вводимых данных, то это опять же его вина.
Каждая из описанных категорий ошибок требует особого подхода к их обработке.
Пользовательские ошибки
Сделаю очень громкое заявление: такие ошибки — на самом деле не ошибки.
Все пользователи не соблюдают инструкции. Программист, имеющий дело с данными, которые вводят люди, должен ожидать, что вводить будут именно плохие данные. Поэтому первым делом нужно проверять их на валидность, сообщать пользователю об обнаруженных ошибках и просить ввести заново.
Поэтому не имеет смысла применять к пользовательским ошибкам какие-либо стратегии обработки. Вводимые данные нужно как можно скорее проверять, чтобы ошибок не возникало.
Конечно, такое не всегда возможно. Иногда проверять вводимые данные слишком дорого, иногда это не позволяет сделать архитектура кода или разделение ответственности. Но в таких случаях ошибки должны обрабатываться однозначно как исправимые. Иначе, допустим, ваша офисная программа будет падать из-за того, что вы нажали backspace в пустом документе, или ваша игра станет вылетать при попытке выстрелить из разряженного оружия.
Если в качестве стратегии обработки исправимых ошибок вы предпочитаете исключения, то будьте осторожны: исключения предназначены только для исключительных ситуаций, к которым не относится большинство случаев ввода пользователями неверных данных. По сути, это даже норма, по мнению многих приложений. Используйте исключения только тогда, когда пользовательские ошибки обнаруживаются в глубине стека вызовов, вероятно, внешнего кода, когда они возникают редко или проявляются очень жёстко. В противном случае лучше сообщать об ошибках с помощью кодов возврата.
Системные ошибки
Обычно системные ошибки нельзя предсказать. Более того, они недетерминистские и могут возникать в программах, которые до этого работали без нареканий. В отличие от пользовательских ошибок, зависящих исключительно от вводимых данных, системные ошибки — настоящие ошибки.
Но как их обрабатывать, как исправимые или неисправимые?
Это зависит от обстоятельств.
Многие считают, что ошибка нехватки памяти — неисправимая. Зачастую не хватает памяти даже для обработки этой ошибки! И тогда приходится просто сразу же прерывать выполнение.
Но падение программы из-за того, что ОС не может выделить сокет, — это не слишком дружелюбное поведение. Так что лучше бросить исключение и позволить catch аккуратно закрыть программу.
Но бросание исключения — не всегда правильный выбор.
Кто-то даже скажет, что он всегда неправильный.
Если вы хотите повторить операцию после её сбоя, то обёртывание функции в try-catch в цикле — медленное решение. Правильный выбор — возврат кода ошибки и цикличное исполнение, пока не будет возвращено правильное значение.
Если вы создаёте вызов API только для себя, то просто выберите подходящий для своей ситуации путь и следуйте ему. Но если вы пишете библиотеку, то не знаете, чего хотят пользователи. Дальше мы разберём подходящую стратегию для этого случая. Для потенциально неисправимых ошибок подойдёт «обработчик ошибок», а при других ошибках необходимо предоставить два варианта развития событий.
Обратите внимание, что не следует использовать подтверждения (assertions), включающиеся только в режиме отладки. Ведь системные ошибки могут возникать и в релизной сборке!
Программистские ошибки
Это худший вид ошибок. Для их обработки я стараюсь сделать так, чтобы мои ошибки были связаны только с вызовами функций, то есть с плохими параметрами. Прочие типы программистских ошибок могут быть пойманы только в runtime, с помощью отладочных макросов (assertion macros), раскиданных по коду.
При работе с плохими параметрами есть две стратегии: дать им определённое или неопределённое поведение.
Если исходное требование для функции — запрет на передачу ей плохих параметров, то, если их передать, это считается неопределённым поведением и должно проверяться не самой функцией, а оператором вызова (caller). Функция должна делать только отладочное подтверждение (debug assertion).
С другой стороны, если отсутствие плохих параметров не является частью исходных требований, а документация определяет, что функция будет бросать bad_parameter_exception при передаче ей плохого параметра, то передача — это хорошо определённое поведение (бросание исключения или любая другая стратегия обработки исправимых ошибок), и функция всегда должна это проверять.
В качестве примера рассмотрим получающие функции (accessor functions) std::vector<T>operator[] говорится, что индекс должен быть в пределах валидного диапазона, при этом at() сообщает нам, что функция кинет исключение, если индекс не попадает в диапазон. Более того, большинство реализаций стандартных библиотек обеспечивают режим отладки, в котором проверяется индекс operator[], но технически это неопределённое поведение, оно не обязано проверяться.
Примечание: необязательно бросать исключение, чтобы получилось определённое поведение. Пока это не упомянуто в исходных условиях для функции, это считается определённым. Всё, что прописано в исходных условиях, не должно проверяться функцией, это неопределённое поведение.
Когда нужно проверять только с помощью отладочных подтверждений, а когда — постоянно?
К сожалению, однозначного рецепта нет, решение зависит от конкретной ситуации. У меня есть лишь одно проверенное правило, которому я следую при разработке API. Оно основано на наблюдении, что проверять исходные условия должен вызывающий, а не вызываемый. А значит, условие должно быть «проверяемым» для вызывающего. Также условие «проверяемое», если можно легко выполнить операцию, при которой значение параметра всегда будет правильным. Если для параметра это возможно, то это получается исходное условие, а значит, проверяется только посредством отладочного подтверждения (а если слишком дорого, то вообще не проверяется).
Но конечное решение зависит от многих других факторов, так что очень трудно дать какой-то общий совет. По умолчанию я стараюсь свести к неопределённому поведению и использованию только подтверждений. Иногда бывает целесообразно обеспечить оба варианта, как это делает стандартная библиотека с operator[] и at().
Хотя в ряде случаев это может быть ошибкой.
Об иерархии std::exception
Если в качестве стратегии обработки исправимых ошибок вы выбрали исключения, то рекомендуется создать новый класс и наследовать его от одного из классов исключений стандартной библиотеки.
Я предлагаю наследовать только от одного из этих четырёх классов:
std::bad_alloc: для сбоев выделения памяти.std::runtime_error: для общих runtime-ошибок.std::system_error(производное отstd::runtime_error): для системных ошибок с кодами ошибок.std::logic_error: для программистских ошибок с определённым поведением.
Обратите внимание, что в стандартной библиотеке разделяются логические (то есть программистские) и runtime-ошибки. Runtime-ошибки — более широкое определение, чем «системные». Оно описывает «ошибки, обнаруживаемые только при выполнении программы». Такая формулировка не слишком информативна. Лично я использую её для плохих параметров, которые не являются исключительно программистскими ошибками, а могут возникнуть и по вине пользователей. Но это можно определить лишь глубоко в стеке вызовов. Например, плохое форматирование комментариев в standardese приводит к исключению при парсинге, проистекающему из std::runtime_error. Позднее оно ловится на соответствующем уровне и фиксируется в логе. Но я не стал бы использовать этот класс иначе, как и std::logic_error.
Подведём итоги
Есть два пути обработки ошибок:
- как исправимые: используются исключения или возвращаемые значения (в зависимости от ситуации/религии);
- как неисправимые: ошибки журналируются, а программа прерывается.
Подтверждения — это особый вид стратегии обработки неисправимых ошибок, только в режиме отладки.
Есть три основных источника ошибок, каждый требует особого подхода:
- Пользовательские ошибки не должны обрабатываться как ошибки на верхних уровнях программы. Всё, что вводит пользователь, должно проверяться соответствующим образом. Это может обрабатываться как ошибки только на нижних уровнях, которые не взаимодействуют с пользователями напрямую. Применяется стратегия обработки исправимых ошибок.
- Системные ошибки могут обрабатываться в рамках любой из двух стратегий, в зависимости от типа и тяжести. Библиотеки должны работать как можно гибче.
- Программистские ошибки, то есть плохие параметры, могут быть запрещены исходными условиями. В этом случае функция должна использовать только проверку с помощью отладочных подтверждений. Если же речь идёт о полностью определённом поведении, то функции следует предписанным образом сообщать об ошибке. Я стараюсь по умолчанию следовать сценарию с неопределённым поведением и определяю для функции проверку параметров лишь тогда, когда это слишком трудно сделать на стороне вызывающего.
Гибкие методики обработки ошибок в C++
Иногда что-то не работает. Пользователи вводят данные в недопустимом формате, файл не обнаруживается, сетевое соединение сбоит, в системе кончается память. Всё это ошибки, и их надо обрабатывать.
Это относительно легко сделать в высокоуровневых функциях. Вы точно знаете, почему что-то пошло не так, и можете обработать это соответствующим образом. Но в случае с низкоуровневыми функциями всё не так просто. Они не знают, что пошло не так, они знают лишь о самом факте сбоя и должны сообщить об этом тому, кто их вызвал.
В C++ есть два основных подхода: коды возврата ошибок и исключения. Сегодня широко распространено использование исключений. Но некоторые не могут / думают, что не могут / не хотят их использовать — по разным причинам.
Я не буду принимать чью-либо сторону. Вместо этого я опишу методики, которые удовлетворят сторонников обоих подходов. Особенно методики пригодятся разработчикам библиотек.
Проблема
Я работаю над проектом foonathan/memory. Это решение предоставляет различные классы выделения памяти (allocator classes), так что в качестве примера рассмотрим структуру функции выделения.
Для простоты возьмём malloc(). Она возвращает указатель на выделяемую память. Если выделить память не получается, то возвращается nullptr, то есть NULL, то есть ошибочное значение.
У этого решения есть недостатки: вам нужно проверять каждый вызов malloc(). Если вы забудете это сделать, то выделите несуществующую память. Кроме того, по своей натуре коды ошибок транзитивны: если вызвать функцию, которая может вернуть код ошибки, и вы не можете его проигнорировать или обработать, то вы тоже должны вернуть код ошибки.
Это приводит нас к ситуации, когда чередуются нормальные и ошибочные ветви кода. Исключения в таком случае выглядят более подходящим решением. Благодаря им вы сможете обрабатывать ошибки только тогда, когда вам это нужно, а в противном случае — достаточно тихо передать их обратно вызывающему.
Это можно расценить как недостаток.
Но в подобных ситуациях исключения имеют также очень большое преимущество: функция выделения памяти либо возвращает валидную память, либо вообще ничего не возвращает. Это функция «всё или ничего», возвращаемое значение всегда будет валидным. Это полезное следствие согласно принципу Скотта Майера «Make interfaces hard to use incorrectly and easy to use correctly».
Учитывая вышесказанное, можно утверждать, что вам следует использовать исключения в качестве механизма обработки ошибок. Этого мнения придерживается большинство разработчиков на С++, включая и меня. Но проект, которым я занимаюсь, — это библиотека, предоставляющая средства выделения памяти, и предназначена она для приложений, работающих в реальном времени. Для большинства разработчиков подобных приложений (особенно для игроделов) само использование исключений — исключение.
Каламбур детектед.
Чтобы уважить эту группу разработчиков, моей библиотеке лучше обойтись без исключений. Но мне и многим другим они нравятся за элегантность и простоту обработки ошибок, так что ради других разработчиков моей библиотеке лучше использовать исключения.
Так что же делать?
Идеальное решение: возможность включать и отключать исключения по желанию. Но, учитывая природу исключений, нельзя просто менять их местами с кодами ошибок, поскольку у нас не будет внутреннего кода проверки на ошибки — весь внутренний код опирается на предположение о прозрачности исключений. И даже если бы внутри можно было использовать коды ошибок и преобразовывать их в исключения, это лишило бы нас большинства преимуществ последних.
К счастью, я могу определить, что вы делаете, когда обнаруживаете ошибку нехватки памяти: чаще всего вы журналируете это событие и прерываете программу, поскольку она не может корректно работать без памяти. В таких ситуациях исключения — просто способ передачи контроля другой части кода, которая журналирует и прерывает программу. Но есть старый и эффективный способ передачи контроля: указатель функции (function pointer), то есть функция-обработчик (handler function).
Если у вас включены исключения, то вы просто их бросаете. В противном случае вызываете функцию-обработчика и затем прерываете программу. Это предотвратит бесполезную работу функции-обработчика, та позволит программе продолжить выполняться в обычном режиме. Если не прервать, то произойдёт нарушение обязательного постусловия функции: всегда возвращать валидный указатель. Ведь на выполнении этого условия может быть построена работа другого кода, да и вообще это нормальное поведение.
Я называю такой подход обработкой исключений и придерживаюсь его при работе с памятью.
Решение 1: обработчик исключений
Если вам нужно обработать ошибку в условиях, когда наиболее распространённым поведением будет «журналировать и прервать», то можно использовать обработчика исключений. Это такая функция-обработчик, которая вызывается вместо бросания объекта-исключения. Её довольно легко реализовать даже в уже существующем коде. Для этого нужно поместить управление обработкой в класс исключений и обернуть в макрос выражение throw.
Сначала дополним класс и добавим функции для настройки и, возможно, запрашивания функции-обработчика. Я предлагаю делать это так же, как стандартная библиотека обрабатывает std::new_handler:
class my_fatal_error
{
public:
// тип обработчика, он должен брать те же параметры, что и конструктор,
// чтобы у них была одинаковая информация
using handler = void(*)( ... );
// меняет функцию-обработчика
handler set_handler(handler h);
// возвращает текущего обработчика
handler get_handler();
... // нормальное исключение
};Поскольку это входит в область видимости класса исключений, вам не нужно именовать каким-то особым образом. Отлично, нам же легче.
Если исключения включены, то для удаления обработчика можно использовать условное компилирование (conditional compilation). Если хотите, то также напишите обычный подмешанный класс (mixin class), дающий требуемую функциональность.
Конструктор исключений элегантен: он вызывает текущую функцию-обработчика, передавая ей требуемые аргументы из своих параметров. А затем комбинирует с последующим макросом throw:
If```cpp #if EXCEPTIONS #define THROW(Ex) throw (Ex) #else #define THROW(Ex) (Ex), std::abort() #endif> Такой макрос throw также предоставляется [foonathan/compatiblity](https://github.com/foonathan/compatibility).
Можно использовать его и так:
```cpp
THROW(my_fatal_error(...))
Если у вас включена поддержка исключений, то будет создан и брошен объект-исключение, всё как обычно. Но если поддержка выключена, то объект-исключение всё равно будет создан, и — это важно — только после этого произойдёт вызов std::abort(). А поскольку конструктор вызывает функцию-обработчика, то он и работает, как требуется: вы получаете точку настройки для журналирования ошибки. Благодаря же вызову std::abort() после конструктора пользователь не может нарушить постусловие.
Когда я работаю с памятью, то при включённых исключениях у меня также включён и обработчик, который вызывается при бросании исключения.
Так что при этой методике вам ещё будет доступна определённая степень кастомизации, даже если вы отключите исключения. Конечно, замена неполноценная, мы только журналируем и прерываем работу программы, без дальнейшего продолжения. Но в ряде случаев, в том числе при исчерпании памяти, это вполне пригодное решение.
А если я хочу продолжить работу после бросания исключения?
Методика с обработчиком исключений не позволяет этого сделать в связи с постусловием кода. Как же тогда продолжить работу?
Ответ прост — никак. По крайней мере, это нельзя сделать так же просто, как в других случаях. Нельзя просто так вернуть код ошибки вместо исключения, если функция на это не рассчитана.
Есть только одно решение: сделать две функции. Одна возвращает код ошибки, а вторая бросает исключения. Клиенты, которым нужны исключения, будут использовать второй вариант, остальные — первый.
Извините, что говорю такие очевидные вещи, но ради полноты изложения я должен был об этом сказать.
Для примера снова возьмём функцию выделения памяти. В этом случае я использую такие функции:
void* try_malloc(..., int &error_code) noexcept;
void* malloc(...);
При сбое выделения памяти первая версия возвращает nullptr и устанавливает error_code в коде ошибки. Вторая версия не возвращает nullptr, зато бросает исключение. Обратите внимание, что в рамках первой версии очень легко реализовать вторую:
void* malloc(...)
{
auto error_code = 0;
auto res = try_malloc(..., error_code);
if (!res)
throw malloc_error(error_code);
return res;
}Не делайте этого в обратной последовательности, иначе вам придётся ловить исключение, а это дорого. Также это не даст нам скомпилировать код без включённой поддержки исключений. Если сделаете, как показано, то можете просто стереть другую перегрузку (overload) с помощью условного компилирования.
Но даже если у вас включена поддержка исключений, клиенту всё равно может понадобиться вторая версия. Например, когда нужно выделить наибольший возможный объём памяти, как в нашем примере. Будет проще и быстрее вызывать в цикле и проверять по условию, чем ловить исключение.
Решение 2: предоставить две перегрузки
Если недостаточно обработчика исключений, то нужно предоставить две перегрузки. Одна использует код возврата, а вторая бросает исключение.
Если рассматриваемая функция не имеет возвращаемого значения, то можете её использовать для кода ошибки. В противном случае вам придётся возвращать недопустимое значение для сигнализирования об ошибке — как nullptr в вышеприведённом примере, — а также установить выходной параметр для кода ошибки, если хотите предоставить вызывающему дополнительную информацию.
Пожалуйста, не используйте глобальную переменную errno или что-то типа GetLastError()!
Если возвращаемое значение не содержит недопустимое значение для обозначения сбоя, то по мере возможности используйте std::optional или что-то похожее.
Перегрузка исключения (exception overload) может — и должна — быть реализована в рамках версии с кодом ошибки, как это показано выше. Если компилируете без исключений, сотрите перегрузку с помощью условного компилирования.
std::system_error
Подобная система идеально подходит для работы с кодами ошибок в С++ 11.
Она возвращает непортируемый (non-portable) код ошибки std::error_code, то есть возвращаемый функцией операционной системы. С помощью сложной системы библиотечных средств и категорий ошибок вы можете добавить собственные коды ошибок, или портируемые std::error_condition. Для начала почитайте об этом здесь. Если нужно, то можете использовать в функции кода ошибки std::error_code. А для функции исключения есть подходящий класс исключения: std::system_error. Он берёт std::error_code и применяется для передачи этих ошибок в виде исключений.
Эту или подобную систему должны использовать все низкоуровневые функции, являющиеся закрытыми обёртками ОС-функций. Это хорошая — хотя и сложная — альтернатива службе кодов ошибок, предоставляемой операционной системой.
Да, и мне ещё нужно добавить подобное в функции виртуальной памяти. На сегодняшний день они не предоставляют коды ошибок.
std::expected
Выше упоминалось о проблеме, когда у вас нет возвращаемого значения, содержащего недопустимое значение, которое можно использовать для сигнализирования об ошибке. Более того, выходной параметр — не лучший способ получения кода ошибки.
А глобальные переменные вообще не вариант!
В № 4109 предложено решение: std::expected. Это шаблон класса, который также хранит возвращаемое значение или код ошибки. В вышеприведённом примере он мог бы использоваться так:
std::expected<void*, std::error_code> try_malloc(...);
В случае успеха std::expected будет хранить не-null указатель памяти, а при сбое — std::error_code. Сейчас эта методика работает при любых возвращаемых значениях. Комбинация std::expected и функции исключения определённо допускает любые варианты использования.
Заключение
Если вы создаёте библиотеки, то иногда приходится обеспечивать максимальную гибкость использования. Под этим подразумевается и разнообразие средств обработки ошибок: иногда требуются коды возврата, иногда — исключения.
Одна из возможных стратегий — улаживание этих противоречий с помощью обработчика исключений. Просто удостоверьтесь, что когда нужно, то вызывается callback, а не бросается исключение. Это замена для критических ошибок, которая в любом случае будет журналироваться перед прерыванием работы программы. Как таковой этот способ не универсален, вы не можете переключаться в одной программе между двумя версиями. Это лишь обходное решение при отключённой поддержке исключений.
Более гибкий подход — просто предоставить две перегрузки, одну с исключениями, а вторую без. Это даст пользователям максимальную свободу, они смогут выбирать ту версию, что лучше подходит в их ситуации. Недостаток этого подхода: вам придётся больше потрудиться при создании библиотеки.