
From Wikipedia, the free encyclopedia
An error correction model (ECM) belongs to a category of multiple time series models most commonly used for data where the underlying variables have a long-run common stochastic trend, also known as cointegration. ECMs are a theoretically-driven approach useful for estimating both short-term and long-term effects of one time series on another. The term error-correction relates to the fact that last-period’s deviation from a long-run equilibrium, the error, influences its short-run dynamics. Thus ECMs directly estimate the speed at which a dependent variable returns to equilibrium after a change in other variables.
History[edit]
Yule (1926) and Granger and Newbold (1974) were the first to draw attention to the problem of spurious correlation and find solutions on how to address it in time series analysis.[1][2] Given two completely unrelated but integrated (non-stationary) time series, the regression analysis of one on the other will tend to produce an apparently statistically significant relationship and thus a researcher might falsely believe to have found evidence of a true relationship between these variables. Ordinary least squares will no longer be consistent and commonly used test-statistics will be non-valid. In particular, Monte Carlo simulations show that one will get a very high R squared, very high individual t-statistic and a low Durbin–Watson statistic. Technically speaking, Phillips (1986) proved that parameter estimates will not converge in probability, the intercept will diverge and the slope will have a non-degenerate distribution as the sample size increases.[3] However, there might be a common stochastic trend to both series that a researcher is genuinely interested in because it reflects a long-run relationship between these variables.
Because of the stochastic nature of the trend it is not possible to break up integrated series into a deterministic (predictable) trend and a stationary series containing deviations from trend. Even in deterministically detrended random walks spurious correlations will eventually emerge. Thus detrending does not solve the estimation problem.
In order to still use the Box–Jenkins approach, one could difference the series and then estimate models such as ARIMA, given that many commonly used time series (e.g. in economics) appear to be stationary in first differences. Forecasts from such a model will still reflect cycles and seasonality that are present in the data. However, any information about long-run adjustments that the data in levels may contain is omitted and longer term forecasts will be unreliable.
This led Sargan (1964) to develop the ECM methodology, which retains the level information.[4][5]
Estimation[edit]
Several methods are known in the literature for estimating a refined dynamic model as described above. Among these are the Engle and Granger 2-step approach, estimating their ECM in one step and the vector-based VECM using Johansen’s method.[6]
Engle and Granger 2-step approach[edit]
The first step of this method is to pretest the individual time series one uses in order to confirm that they are non-stationary in the first place. This can be done by standard unit root DF testing and ADF test (to resolve the problem of serially correlated errors).
Take the case of two different series  and
and  . If both are I(0), standard regression analysis will be valid. If they are integrated of a different order, e.g. one being I(1) and the other being I(0), one has to transform the model.
. If both are I(0), standard regression analysis will be valid. If they are integrated of a different order, e.g. one being I(1) and the other being I(0), one has to transform the model.
If they are both integrated to the same order (commonly I(1)), we can estimate an ECM model of the form

If both variables are integrated and this ECM exists, they are cointegrated by the Engle–Granger representation theorem.
The second step is then to estimate the model using ordinary least squares: 
If the regression is not spurious as determined by test criteria described above, Ordinary least squares will not only be valid, but in fact super consistent (Stock, 1987).
Then the predicted residuals  from this regression are saved and used in a regression of differenced variables plus a lagged error term
from this regression are saved and used in a regression of differenced variables plus a lagged error term

One can then test for cointegration using a standard t-statistic on  .
.
While this approach is easy to apply, there are, however numerous problems:
VECM[edit]
The Engle–Granger approach as described above suffers from a number of weaknesses. Namely it is restricted to only a single equation with one variable designated as the dependent variable, explained by another variable that is assumed to be weakly exogeneous for the parameters of interest. It also relies on pretesting the time series to find out whether variables are I(0) or I(1). These weaknesses can be addressed through the use of Johansen’s procedure. Its advantages include that pretesting is not necessary, there can be numerous cointegrating relationships, all variables are treated as endogenous and tests relating to the long-run parameters are possible. The resulting model is known as a vector error correction model (VECM), as it adds error correction features to a multi-factor model known as vector autoregression (VAR). The procedure is done as follows:
- Step 1: estimate an unrestricted VAR involving potentially non-stationary variables
- Step 2: Test for cointegration using Johansen test
- Step 3: Form and analyse the VECM.
An example of ECM[edit]
The idea of cointegration may be demonstrated in a simple macroeconomic setting. Suppose, consumption  and disposable income
and disposable income  are macroeconomic time series that are related in the long run (see Permanent income hypothesis). Specifically, let average propensity to consume be 90%, that is, in the long run
are macroeconomic time series that are related in the long run (see Permanent income hypothesis). Specifically, let average propensity to consume be 90%, that is, in the long run  . From the econometrician’s point of view, this long run relationship (aka cointegration) exists if errors from the regression
. From the econometrician’s point of view, this long run relationship (aka cointegration) exists if errors from the regression  are a stationary series, although and are non-stationary. Suppose also that if suddenly changes by
are a stationary series, although and are non-stationary. Suppose also that if suddenly changes by  , then changes by
, then changes by  , that is, marginal propensity to consume equals 50%. Our final assumption is that the gap between current and equilibrium consumption decreases each period by 20%.
, that is, marginal propensity to consume equals 50%. Our final assumption is that the gap between current and equilibrium consumption decreases each period by 20%.
In this setting a change  in consumption level can be modelled as
in consumption level can be modelled as  . The first term in the RHS describes short-run impact of change in on , the second term explains long-run gravitation towards the equilibrium relationship between the variables, and the third term reflects random shocks that the system receives (e.g. shocks of consumer confidence that affect consumption). To see how the model works, consider two kinds of shocks: permanent and transitory (temporary). For simplicity, let
. The first term in the RHS describes short-run impact of change in on , the second term explains long-run gravitation towards the equilibrium relationship between the variables, and the third term reflects random shocks that the system receives (e.g. shocks of consumer confidence that affect consumption). To see how the model works, consider two kinds of shocks: permanent and transitory (temporary). For simplicity, let  be zero for all t. Suppose in period t − 1 the system is in equilibrium, i.e.
be zero for all t. Suppose in period t − 1 the system is in equilibrium, i.e.  . Suppose that in the period t, disposable income increases by 10 and then returns to its previous level. Then first (in period t) increases by 5 (half of 10), but after the second period begins to decrease and converges to its initial level. In contrast, if the shock to is permanent, then slowly converges to a value that exceeds the initial
. Suppose that in the period t, disposable income increases by 10 and then returns to its previous level. Then first (in period t) increases by 5 (half of 10), but after the second period begins to decrease and converges to its initial level. In contrast, if the shock to is permanent, then slowly converges to a value that exceeds the initial  by 9.
by 9.
This structure is common to all ECM models. In practice, econometricians often first estimate the cointegration relationship (equation in levels), and then insert it into the main model (equation in differences).
References[edit]
- ^ Yule, Georges Udny (1926). «Why do we sometimes get nonsense correlations between time series? – A study in sampling and the nature of time-series». Journal of the Royal Statistical Society. 89 (1): 1–63. JSTOR 2341482.
- ^ Granger, C.W.J.; Newbold, P. (1978). «Spurious regressions in Econometrics». Journal of Econometrics. 2 (2): 111–120. JSTOR 2231972.
- ^ Phillips, Peter C.B. (1985). «Understanding Spurious Regressions in Econometrics» (PDF). Cowles Foundation Discussion Papers 757. Cowles Foundation for Research in Economics, Yale University.
- ^ Sargan, J. D. (1964). «Wages and Prices in the United Kingdom: A Study in Econometric Methodology», 16, 25–54. in Econometric Analysis for National Economic Planning, ed. by P. E. Hart, G. Mills, and J. N. Whittaker. London: Butterworths
- ^ Davidson, J. E. H.; Hendry, D. F.; Srba, F.; Yeo, J. S. (1978). «Econometric modelling of the aggregate time-series relationship between consumers’ expenditure and income in the United Kingdom». Economic Journal. 88 (352): 661–692. JSTOR 2231972.
- ^ Engle, Robert F.; Granger, Clive W. J. (1987). «Co-integration and error correction: Representation, estimation and testing». Econometrica. 55 (2): 251–276. JSTOR 1913236.
Further reading[edit]
- Dolado, Juan J.; Gonzalo, Jesús; Marmol, Francesc (2001). «Cointegration». In Baltagi, Badi H. (ed.). A Companion to Theoretical Econometrics. Oxford: Blackwell. pp. 634–654. doi:10.1002/9780470996249.ch31. ISBN 0-631-21254-X.
- Enders, Walter (2010). Applied Econometric Time Series (Third ed.). New York: John Wiley & Sons. pp. 272–355. ISBN 978-0-470-50539-7.
- Lütkepohl, Helmut (2006). New Introduction to Multiple Time Series Analysis. Berlin: Springer. pp. 237–352. ISBN 978-3-540-26239-8.
- Martin, Vance; Hurn, Stan; Harris, David (2013). Econometric Modelling with Time Series. New York: Cambridge University Press. pp. 662–711. ISBN 978-0-521-13981-6.
An модель коррекции ошибок (ECM) принадлежит к категории множественных Временные ряды модели, наиболее часто используемые для данных, в которых базовые переменные имеют долгосрочный стохастический тренд, также известный как коинтеграция. ECM — это теоретически обоснованный подход, полезный для оценки как краткосрочного, так и долгосрочного воздействия одного временного ряда на другой. Термин исправление ошибок относится к тому факту, что отклонение последнего периода от долгосрочного равновесия, ошибка, влияет на его краткосрочную динамику. Таким образом, ECM напрямую оценивают скорость, с которой зависимая переменная возвращается в состояние равновесия после изменения других переменных.
История ECM
Йоль (1926) и Грейнджер и Ньюболд (1974) первыми привлекли внимание к проблеме ложная корреляция и найти решения, как решить эту проблему при анализе временных рядов.[1][2] Учитывая два совершенно не связанных, но интегрированных (нестационарных) временных ряда, регрессивный анализ одного на другом, будет иметь тенденцию давать явно статистически значимую взаимосвязь, и поэтому исследователь может ошибочно полагать, что нашел доказательства истинной взаимосвязи между этими переменными. Обычный метод наименьших квадратов больше не будет согласованным, и часто используемая тестовая статистика будет недействительной. Особенно, Моделирование Монте-Карло покажи, что получишь очень высокий R в квадрате, очень высокий человек t-статистика и низкий Статистика Дарбина – Ватсона. С технической точки зрения Филлипс (1986) доказал, что оценки параметров не сходятся по вероятности, то перехватить будут расходиться, и наклон будет иметь невырожденное распределение по мере увеличения размера выборки.[3] Однако может быть общий стохастический тренд к обеим сериям, которые действительно интересуют исследователя, потому что они отражают долгосрочную взаимосвязь между этими переменными.
Из-за стохастического характера тренда невозможно разбить интегрированный ряд на детерминированный (предсказуемый) тенденция и стационарный ряд, содержащий отклонения от тренда. Даже при детерминированном исключении тренда случайные прогулки в конечном итоге возникнут ложные корреляции. Таким образом, снятие тренда не решает проблему оценки.
Чтобы по-прежнему использовать Подход Бокса – Дженкинса, можно было различать ряды, а затем оценивать такие модели, как ARIMA, учитывая, что многие часто используемые временные ряды (например, в экономике) кажутся стационарными в первых разностях. Прогнозы на основе такой модели по-прежнему будут отражать циклы и сезонность, которые присутствуют в данных. Однако любая информация о долгосрочных корректировках, которую могут содержать данные в уровнях, опускается, и долгосрочные прогнозы будут ненадежными.
Это привело Сарган (1964) для разработки методологии ECM, которая сохраняет информацию об уровне.[4][5]
Оценка
В литературе известно несколько методов оценки уточненной динамической модели, как описано выше. Среди них двухэтапный подход Энгла и Грейнджера, оценивающий их ECM за один шаг, и VECM на основе векторов с использованием Метод Йохансена.[6]
Двухэтапный подход Энгла и Грейнджер
Первым шагом этого метода является предварительная проверка используемых индивидуальных временных рядов, чтобы подтвердить, что они нестационарный на первом месте. Это можно сделать стандартным единичный корень Пеленгационные испытания и Тест АПД (для решения проблемы серийно коррелированных ошибок). Возьмем случай двух разных серий. и . Если оба равны I (0), будет действителен стандартный регрессионный анализ. Если они интегрированы другого порядка, например один — I (1), а другой — I (0), необходимо преобразовать модель.
Если они оба интегрированы в одном порядке (обычно I (1)), мы можем оценить модель ECM в виде
Если обе переменные интегрированы, и этот ECM существует, они коинтегрируются теоремой Энгла – Грейнджера о представлении.
Затем на втором этапе оценивается модель с использованием обыкновенный метод наименьших квадратов: Если регрессия не является ложной, как определено критериями тестирования, описанными выше, Обычный метод наименьших квадратов будет не только актуально, но и по сути супер последовательный (Сток, 1987). Тогда прогнозируемые остатки из этой регрессии сохраняются и используются в регрессии разностных переменных плюс запаздывающий член ошибки
Затем можно протестировать коинтеграцию, используя стандартный t-статистика на Хотя этот подход прост в применении, существует множество проблем:
VECM
Подход Энгла – Грейнджера, описанный выше, имеет ряд недостатков. А именно, он ограничен только одним уравнением с одной переменной, обозначенной как зависимая переменная, объясненной другой переменной, которая, как предполагается, является слабо экзогенной для интересующих параметров. Он также основан на предварительном тестировании временных рядов, чтобы выяснить, являются ли переменные I (0) или I (1). Эти недостатки могут быть устранены с помощью процедуры Йохансена. Его преимущества заключаются в том, что предварительное тестирование не требуется, может существовать множество коинтегрирующих взаимосвязей, все переменные рассматриваются как эндогенные и возможны тесты, относящиеся к долгосрочным параметрам. Полученная модель известна как модель векторной коррекции ошибок (VECM), поскольку она добавляет функции коррекции ошибок в многофакторную модель, известную как векторная авторегрессия (VAR). Порядок действий следующий:
- Шаг 1: оцените неограниченную VAR с потенциально нестационарными переменными
- Шаг 2. Проверьте коинтеграцию с помощью Тест Йохансена
- Шаг 3: Сформируйте и проанализируйте VECM.
Пример ECM
Идея коинтеграции может быть продемонстрирована в простой макроэкономической обстановке. Предположим, потребление и располагаемый доход представляют собой макроэкономические временные ряды, которые связаны в долгосрочной перспективе (см. Гипотеза постоянного дохода ). В частности, пусть средняя склонность к потреблению быть 90%, то есть в долгосрочной перспективе . С точки зрения эконометриста, эта долгосрочная связь (также известная как коинтеграция) существует, если ошибки из регрессии площадь стационарный серия, хотя и нестационарны. Предположим также, что если внезапно меняется на , тогда изменения на , то есть, предельная склонность к потреблению равняется 50%. Наше последнее предположение состоит в том, что разрыв между текущим и равновесным потреблением уменьшается каждый период на 20%.
В этой настройке изменение по уровню потребления можно смоделировать как . Первый член в RHS описывает краткосрочное влияние изменения в на , второй член объясняет долгосрочное стремление к равновесному соотношению между переменными, а третий член отражает случайные шоки, которые получает система (например, шоки доверия потребителей, влияющие на потребление). Чтобы увидеть, как работает модель, рассмотрим два вида шоков: постоянные и временные (временные). Пусть для простоты равняться нулю для всех t. Предположим в период т — 1 система находится в равновесии, т.е. . Предположим, что в период t увеличивается на 10, а затем возвращается на предыдущий уровень. потом первый (в период t) увеличивается на 5 (половина от 10), но после второго периода начинает уменьшаться и сходится к исходному уровню. Напротив, если шок постоянно, то медленно сходится к значению, превышающему начальное на 9.
Эта структура общая для всех моделей ECM. На практике эконометристы часто сначала оценивают взаимосвязь коинтеграции (уравнение в уровнях), а затем вставляют его в основную модель (уравнение в разностях).
Рекомендации
- ^ Юль, Жорж Удный (1926). «Почему мы иногда получаем бессмысленные корреляции между временными рядами? — Исследование выборки и природы временных рядов». Журнал Королевского статистического общества. 89 (1): 1–63. JSTOR 2341482.
- ^ Granger, C.W.J .; Ньюболд П. (1978). «Ложные регрессии в эконометрике». Журнал эконометрики. 2 (2): 111–120. JSTOR 2231972.
- ^ Филлипс, Питер Си Би (1985). «Понимание ложных регрессий в эконометрике» (PDF). Документы для обсуждения в Фонде Коулза 757. Фонд Коулза по исследованиям в области экономики, Йельский университет.
- ^ Сарган, Дж. Д. (1964). «Заработная плата и цены в Соединенном Королевстве: исследование по эконометрической методологии», 16, 25–54. в Эконометрический анализ для национального экономического планирования, изд. П. Э. Харта, Дж. Миллса и Дж. Н. Уиттакера. Лондон: Баттервортс
- ^ Davidson, J.E.H .; Хендри, Д.Ф.; Srba, F .; Йео, Дж. С. (1978). «Эконометрическое моделирование совокупной взаимосвязи временных рядов между расходами и доходами потребителей в Соединенном Королевстве». Экономический журнал. 88 (352): 661–692. JSTOR 2231972.
- ^ Энгл, Роберт Ф .; Грейнджер, Клайв В. Дж. (1987). «Совместная интеграция и исправление ошибок: представление, оценка и тестирование». Econometrica. 55 (2): 251–276. JSTOR 1913236.
дальнейшее чтение
- Доладо, Хуан Дж .; Гонсало, Хесус; Мармол, Франсеск (2001). «Коинтеграция». В Балтаги, Бади Х. (ред.). Компаньон теоретической эконометрики. Оксфорд: Блэквелл. стр.634 –654. Дои:10.1002 / 9780470996249.ch31. ISBN 0-631-21254-X.
- Эндерс, Уолтер (2010). Прикладные эконометрические временные ряды (Третье изд.). Нью-Йорк: Джон Вили и сыновья. С. 272–355. ISBN 978-0-470-50539-7.
- Люткеполь, Гельмут (2006). Новое введение в анализ множественных временных рядов. Берлин: Springer. стр.237 –352. ISBN 978-3-540-26239-8.
- Мартин, Вэнс; Херн, Стэн; Харрис, Дэвид (2013). Эконометрическое моделирование с использованием временных рядов. Нью-Йорк: Издательство Кембриджского университета. С. 662–711. ISBN 978-0-521-13981-6.
6. ECM – error
correction model.
В динамических
регрессионных моделям важно различать
долгосрочную и краткосрочную динамику.
![]()
—
модель ADL(1,1) (8)
• В долгосрочном
аспекте:
Пусть
установились стационарные уровни Х и
У (![]()
):
![]()
![]()
перестала
фигурировать, т.к. устанавливается
стационарный уровень.
![]()
(14)
![]()
(15)
Эта модель
описывает долгосрочное стационарное
состояние экономического процесса. ![]()
—
это коэффициент долгосрочного влияния
X на Y.
• Модель
ADL(1,1) можно привести к виду, который
отражает краткосрочную динамику
экономической системы, и таким образом
получаем так называемую модель исправления
ошибок.
Для этого из
выражения (8) нужно вычесть ![]()
в
левой и в правой части. Затем вычесть и
прибывать ![]()
,
тогда получим:
![]()
= с учетом
(15) = ![]()
это модель
исправления ошибок.
Трактовка
модели:
Если в предыдущий период переменная Y
отклонилась от своего долгосрочного
значения ![]()
,
то член (![]()
)
корректирует динамику в нужном
направлении. Но для этого необходимо,
чтобы ![]()
.
Бывает, что из теории известно, что ![]()
.
И часто именно такую модель называют
ECM.
Несложно
увидеть, что модель частично приспособления
и модель адаптивных ожиданий является
частным случаем исправления ошибок,
причем не только формально математически,
но и по экономическому смыслу.
Например,
модель частичного приспособления в
форме ECM выглядит следующим образом:
![]()
:
29.МоделиСАМР
Модель оценки
финансовых активов предполагает, что:
трансакционные издержки отсутствуют;
все активы обращаются на открытом рынке;
а инвестиции бесконечно делимы (т.
е. можно купить любую долю от единицы
данного актива). Кроме того, предполагается
возможность свободного доступа к
одной и той же информации для всех
инвесторов, и из этого следует, что
инвесторы не могут выявить на рынке
переоцененные и недооцененные активы.
Все эти предположения позволяют инвестору
быть «диверсифицированным» без
дополнительных издержек. В предельном
случае их портфели не только включат
каждый из обращающихся на рынке активов,
но и, помимо всего прочего, рискованные
активы будут обладать одинаковыми
весами (на основе их рыночной стоимости).
Тот факт, что
в данный портфель включаются все
обращающиеся на рынке активы, служит
основанием для того, чтобы его называли
рыночным портфелем. В этом нет ничего
удивительного, учитывая выигрыши от
диверсификации и отсутствие
трансакционных издержек в модели оценки
финансовых активов. Если диверсификация
сокращает степень подверженности риску
на уровне фирмы, и отсутствуют издержки,
связанные с добавлением дополнительных
активов в портфель, то логическим
ограничением диверсификации станет
владение небольшой долей каждого из
обращающихся активов в экономике.
Если это определение кажется слишком
абстрактным, представим себе, что
рыночный портфель представляет собой
очень хорошо диверсифицированный
взаимный фонд, который держит акции и
реальные активы. В модели САРМ все
инвесторы будут держать комбинации,
состоящие из более рискованного
актива и этого взаимного фонда.
Портфели
инвесторов в САРМ. Если все инвесторы
на рынке имеют одинаковые рыночные
портфели, то каким образом выражается
реакция инвесторов, обусловленная
неприятием риска в совершаемых ими
инвестициях? В модели оценки финансовых
активов когда инвесторы при распределении
средств решают: сколько им следует
вложить в безрисковый актив, а сколько
— в рыночный портфель, они опираются
на свои предпочтения в области риска.
Инвесторы, избегающие риска, могут
принять решение вложить все свои
сбережения в безрисковый актив. Инвесторы,
желающие принять на себя больше риска,
вложат значительную часть своих
сбережений, или даже все, в рыночный
портфель. Инвесторы, уже вложившие все
свои средства в рыночный портфель
и, тем не менее, желающие принять на себя
еще больше риска, могли бы добиться
этого, заняв средства по безрисковой
ставке и инвестировав их в тот же самый
рыночный портфель, следуя примеру всех
остальных.
Данные
предположения основываются на двух
дополнительных допущениях. Во-первых,
существует безрисковый актив, ожидаемый
доход которого известен с абсолютной
определенностью. Во-вторых, инвесторы
могут ссужать и занимать средства по
безрисковой ставке для достижения
оптимальности размещения средств.
В то время как ссуда по безрисковой
ставке не доставляет особых проблем
(индивиду для этого достаточно приобрести
казначейские векселя или казначейские
облигации), получение ссуд по безрисковой
ставке может оказаться куда более
затруднительным для отдельного лица.
Существуют версии модели САРМ, позволяющие
несколько смягчить эти допущения и,
тем не менее, получить выводы, совместимые
с моделью.
Измерение
рыночного риска отдельного актива. Риск
любого актива для инвестора — это риск,
добавляемый данным активом к портфелю
инвестора в целом. В мире САРМ, где
все инвесторы владеют рыночным портфелем,
риск отдельного актива для инвестора
— это риск, который данный актив
добавляет к рыночному портфелю. На
интуитивном уровне понятно, что если
движение актива происходит независимо
от рыночного портфеля, то этот актив не
добавит слишком уж много риска к
рыночному портфелю. Другими словами,
большая часть риска данного актива
является специфическим риском фирмы,
а потому может быть диверсифицирована.
С другой стороны, если стоимость актива
имеет тенденцию к росту одновременно
с повышением стоимости портфеля, равно
как и тенденцию к падению при снижении
стоимости рыночного портфеля, то актив
увеличивает риск портфеля. Такой актив
обладает в большей степени рыночным
риском и в меньшей — специфическим
риском фирмы. Статистически, добавленный
риск измеряется ковариацией актива с
рыночным портфелем.


Поскольку
ковариация рыночного портфеля с самим
собой является его дисперсией, бета
рыночного портфеля (также как и его
среднего актива) равна 1. Активы, чья
рискованность выше среднего уровня
(если использовать эту меру риска),
будут иметь коэффициент бета выше
единицы, а активы, которые безопаснее
среднего уровня, будут обладать бетой
менее единицы. У безрисковых активов
коэффициент бета равен нулю.
Получение
ожидаемых доходов. Факт удержания каждым
инвестором некоторой комбинации
безрискового актива и рыночного портфеля
приводит к заключению, что ожидаемый
доход на актив линейно зависит от беты
актива. В частности, ожидаемый доход на
актив можно записать как функцию
безрисковой ставки и беты этого актива:
Для использования
модели оценки финансовых активов нам
необходимо иметь три входные величины.
Следующая глава будет посвящена
детальному разбору процесса оценки,
поэтому пока только заметим, что каждая
из этих входных величин оценивается
следующим образом.
■ Безрисковый
актив определяется как актив, относительно
которого инвестору с абсолютной
определенностью известна ожидаемая
доходность для временного горизонта
анализа.
■ Премия
за риск является премией, запрашиваемой
инвесторами за инвестирование в
рыночный портфель,
включающий все рисковые активы на
рынке, вместо инвестирования в безрисковый
актив.
■ Коэффициент
бета, который определяется как ковариация
актива, поделенная на дисперсию
рыночного портфеля, измеряет риск,
добавляемый инвестицией к рыночному
портфелю.
Таким образом,
в модели оценки финансовых активов весь
рыночный риск охватывается одним
коэффициентом бета, измеренным по
отношению к рыночному портфелю, который,
хотя бы теоретически, должен содержать
все обращающиеся на рынке активы
пропорционально их рыночной стоимости.
30.ПрименениеРегрессионногоанализавпроцессаххеджирования.
Регрессио́нный (линейный) анализ — статистический
метод исследования
влияния одной или нескольких независимых
переменных ![]()
на зависимую
переменную ![]()
.
Независимые переменные иначе называют
регрессорами или предикторами, а
зависимые переменные — критериальными.
Терминология зависимых и независимых переменных
отражает лишь математическую зависимость
переменных (см. Ложная
корреляция),
а не причинно-следственные отношения.
Хеджирование (от англ. hedge —
страховка, гарантия) — открытие сделок
на одном рынке для компенсации воздействия
ценовых рисков равной, но противоположной
позиции на другом рынке. Обычно
хеджирование осуществляется с
целью страхования рисков
изменения цен путем заключения сделок
на срочных
рынках.
Для того чтобы успешно
осуществлять хеджирование, необходимо
четко знать как зависят друг от друга
имеющаяся открытая позиция банка и
потенциальный инструмент, которым
данная позиция будет хеджироваться.
Одним из самых простых показателей
степени зависимости двух показателей
между собой является ковариация. Формула
для вычисления ковариации выглядит
следующим образом [11, стр. 222]:
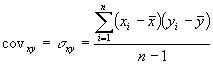
, (2.1)
где xi и yi —
, показатели, а ![]()
и ![]()
—
средние значения показателей.
Ковариационный
анализ посвящен определению степени
взаимосвязи двух рядов величин,
которыми, в зависимости от рассматриваемых
инструментов, могут быть процентные
ставки, обменные курсы и т. п. Если два
ряда данных возрастают и убывают
одновременно, то их ковариация является
положительной. Если, однако, ряды
являются независимыми, то имеет место
нулевая ковариация. При противоположном
изменении обоих рядов ковариация
является отрицательной.
Ковариации нескольких
переменных удобно отражать в виде
дисперсионно-ковариационной матрицы.
Коэффициент
корреляции удобнее использовать, чем
ковариацию, так как в нем преодолевается
зависимость от числа наблюдений, кроме
того, он независим от единиц измерения
исследуемых величин.
Для исследований в основном
используется линейный коэффициент
корреляции, обычно называемый Пирсоновским
коэффициентом корреляции, хорошо
применимый для линейных связей.
Линейный коэффициент
корреляции между двумя рядами Х и Y определяется
по следующей формуле [11,
стр. 224]:

где σx и σy –
среднеквадратичное (стандартное)
отклонение значений рядов X и Y соответственно.
Коэффициенты корреляции
также могут быть представлены в
виде матриц. В таблице 2 показаны
коэффициенты корреляции всех возможных
пар из группы трех активов.
Рассмотрим регрессионный
анализ для простой линейной зависимости
между зависимой переменной Y и
одной независимой X [15,
стр. 262]:
Y
= a
+
βХ+e, (2.6)
где α – постоянная, отражающая
значение Y при X=0, β –
коэффициент регрессии («бета»-коэффициент), e –
ошибка или значение помехи (оценивает
влияние других факторов, не включенных
в модель).
Для статистической проверки
взаимосвязи чаще других используется
метод наименьших квадратов. Он дает
наилучшие линейные несмещенные оценки.
Допущения при расчете:
— линейная
зависимость между переменными;
— значение
ошибки ei нормально
распределено со средней, равной нулю,
и постоянной дисперсией σ2;
— значения e независимы
друг от друга, т.е. факторы, которые
послужили причиной ошибки для одной из
величин Y,
не приводят автоматически к ошибкам
для всех наблюдений Y (т.е.
данные неавтокоррелированы).
Коэффициенты можно найти
по следующим формулам [15, стр.
270]:
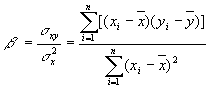
, (2.7)
![]()
. (2.8)
Значение
фактической ошибки e вычисляется
как фактическая разница между фактическими
значениями переменной yi и
рассчитанными значениями ![]()
исходя
из формулы линейной регрессии [11, стр.
233]:
![]()
Можно использовать как
метод простой линейной, так и множественной
регрессии. Множественную регрессию
следует использовать для анализа
зависимости между более чем двумя
переменными. Например, зависимость
между ценой облигации спот и ценой
фьючерсного контракта на облигацию
и возможное внешнее влияние на эти
инструменты, допустим, обменного курса.
В этом случае линейная регрессионная
зависимость между ценой облигации и
ценой фьючерсного контракта имела
бы следующую форму [7, стр. 13]:
Цена облигации Х
=а+b*
(Цена фьючерсного контракта)+
+с*(Курс конвертации Y)
При использовании регрессионных
методов для определения коэффициентов
хеджирования возникают следующие
проблемы:
— «исторические»
зависимости между двумя взаимосвязанными
рядами процентных ставок могут быть
нестабильными, и имеющиеся критерии
изменчивости цен могут быть не пригодными
для прогнозирования относительной
изменчивости цен в будущем;
— использование
слишком короткого периода для исследования
зависимости между инструментами
может быть недостаточным для получения
результата, отражающего истинное
положение дел (для инструментов с
длительными сроками погашения могут
отсутствовать длинные ряды данных, если
операции с этими инструментами
производились в течение лишь короткого
периода времени)
31.МодельМонте-Карло
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
28.03.20165.12 Mб40Немов Р.С. Психологический словарь.pdf
- #
- #
- #
- #
- #
- #
- #
- #
Модель исправления ошибок (ECM) относится к категории моделей нескольких временных рядов, наиболее часто используемых для данных, в которых базовые переменные имеют долгосрочный общий стохастический тренд, также известный как коинтеграция . ECM — это теоретически обоснованный подход, полезный для оценки как краткосрочных, так и долгосрочных эффектов одного временного ряда на другой. Термин «исправление ошибок» относится к тому факту, что отклонение последнего периода от долгосрочного равновесия, ошибка , влияет на его краткосрочную динамику. Таким образом, ECM напрямую оценивают скорость, с которой зависимая переменная возвращается в состояние равновесия после изменения других переменных.
История ECM
Юл (1926) и Грейнджер и Ньюболд (1974) были первыми, кто привлек внимание к проблеме ложной корреляции и нашел решения о том, как ее решать при анализе временных рядов. Учитывая два совершенно не связанных, но интегрированных (нестационарных) временных ряда, регрессионный анализ одного по другому будет иметь тенденцию давать явно статистически значимую взаимосвязь, и, таким образом, исследователь может ошибочно полагать, что нашел доказательства истинной взаимосвязи между этими переменными. Обычные методы наименьших квадратов больше не будут согласованными, а часто используемые тестовые статистические данные будут недействительными. В частности, моделирование методом Монте-Карло показывает, что можно получить очень высокий R-квадрат , очень высокую индивидуальную t-статистику и низкую статистику Дарбина – Ватсона . С технической точки зрения Филлипс (1986) доказал, что оценки параметров не будут сходиться по вероятности , точка пересечения будет расходиться, а наклон будет иметь невырожденное распределение по мере увеличения размера выборки. Однако может существовать общий стохастический тренд для обоих рядов, который искренне интересует исследователя, поскольку он отражает долгосрочную взаимосвязь между этими переменными.
Из-за стохастической природы тренда невозможно разбить интегрированный ряд на детерминированный (предсказуемый) тренд и стационарный ряд, содержащий отклонения от тренда. Даже при детерминированном исключении тренда случайного блуждания в конечном итоге возникнут ложные корреляции. Таким образом, снятие тренда не решает проблему оценки.
Чтобы по-прежнему использовать подход Бокса – Дженкинса , можно было бы различать ряды, а затем оценивать модели, такие как ARIMA , учитывая, что многие обычно используемые временные ряды (например, в экономике) кажутся стационарными в первых различиях. Прогнозы на основе такой модели по-прежнему будут отражать циклы и сезонность, которые присутствуют в данных. Однако любая информация о долгосрочных корректировках, которую могут содержать данные в уровнях, опускается, и долгосрочные прогнозы будут ненадежными.
Это привело Саргана (1964) к разработке методологии ECM, которая сохраняет информацию об уровне.
Предварительный расчет
В литературе известно несколько методов оценки уточненной динамической модели, как описано выше. К ним относятся двухэтапный подход Энгла и Грейнджера, оценивающий их ECM за один этап, и VECM на основе векторов с использованием метода Йохансена .
Двухэтапный подход Энгла и Грейнджер
Первым шагом этого метода является предварительная проверка отдельных используемых временных рядов, чтобы подтвердить, что они изначально нестационарны . Это можно сделать с помощью стандартного модульного корневого DF-тестирования и ADF-теста (для решения проблемы серийно коррелированных ошибок). Возьмем случай двух разных серий и . Если оба равны I (0), будет действителен стандартный регрессионный анализ. Если они интегрированы в другом порядке, например, один является I (1), а другой — I (0), необходимо преобразовать модель.
Если они оба интегрированы в одном порядке (обычно I (1)), мы можем оценить модель ECM в виде
Если обе переменные интегрированы и этот ЕСМ существует, они объединяются теоремой Энгла – Грейнджера о представлении.
Второй этап затем оценить модель с помощью обычных наименьших квадратов :
Если регрессия не поддельный , как определено в соответствии с критериями испытаний было описано выше, метод наименьших квадратов будет не только силу, но на самом деле очень последовательным (Шток, 1987). Затем прогнозируемые остатки из этой регрессии сохраняются и используются в регрессии разностных переменных плюс запаздывающий член ошибки.
Затем можно проверить коинтеграцию с помощью стандартного т-статистики на . Хотя этот подход прост в применении, существует множество проблем:
VECM
Подход Энгла – Грейнджера, описанный выше, страдает рядом недостатков. А именно, он ограничен только одним уравнением с одной переменной, обозначенной как зависимая переменная, объясненной другой переменной, которая, как предполагается, является слабо экзогенной для интересующих параметров. Он также основан на предварительном тестировании временных рядов, чтобы выяснить, являются ли переменные I (0) или I (1). Эти недостатки можно устранить с помощью процедуры Йохансена. Его преимущества заключаются в том, что предварительное тестирование не требуется, может существовать множество коинтегрирующих взаимосвязей, все переменные рассматриваются как эндогенные, и возможны тесты, относящиеся к долгосрочным параметрам. Полученная модель известна как модель векторной коррекции ошибок (VECM), поскольку она добавляет функции коррекции ошибок в многофакторную модель, известную как векторная авторегрессия (VAR). Процедура выполняется следующим образом:
- Шаг 1: оцените неограниченную VAR, включающую потенциально нестационарные переменные
- Шаг 2: Проверьте коинтеграцию с помощью теста Йохансена
- Шаг 3: Сформируйте и проанализируйте VECM.
Пример ECM
Идея коинтеграции может быть продемонстрирована в простой макроэкономической обстановке. Предположим, потребление и располагаемый доход — это макроэкономические временные ряды, которые связаны в долгосрочном плане (см. Гипотезу о постоянном доходе ). В частности, пусть средняя склонность к потреблению будет 90%, то есть в долгосрочной перспективе . С точки зрения эконометриста, эта долгосрочная взаимосвязь (также известная как коинтеграция) существует, если ошибки регрессии являются стационарными рядами, хотя и нестационарны. Предположим также, что если внезапно изменяется на , то изменяется на , то есть предельная склонность к потреблению равна 50%. Наше окончательное предположение состоит в том, что разрыв между текущим и равновесным потреблением уменьшается каждый период на 20%.
В этой настройке изменение уровня потребления можно смоделировать как . Первый член в правой части таблицы описывает краткосрочное влияние изменения на , второй член объясняет долгосрочное стремление к равновесному соотношению между переменными, а третий член отражает случайные шоки, которые получает система (например, шоки уверенности потребителей в том, что влияют на расход). Чтобы увидеть, как работает модель, рассмотрим два вида шоков: постоянные и временные (временные). Для простоты положим равным нулю для всех t. Предположим , что в период т — 1 система находится в равновесии, то есть . Предположим, что за период t увеличивается на 10, а затем возвращается на прежний уровень. Затем первый (в период t) увеличивается на 5 (половина от 10), но после второго периода начинает уменьшаться и сходится к своему исходному уровню. Напротив, если шок является постоянным, то медленно приближается к значению, превышающему начальное на 9.
Эта структура общая для всех моделей ECM. На практике эконометристы часто сначала оценивают взаимосвязь коинтеграции (уравнение в уровнях), а затем вставляют его в основную модель (уравнение в разностях).
использованная литература
дальнейшее чтение
- Доладо, Хуан Дж .; Гонсало, Хесус; Мармол, Франсеск (2001). «Коинтеграция». В Балтаги, Бади Х. (ред.). Компаньон теоретической эконометрики . Оксфорд: Блэквелл. стр. 634 -654. DOI : 10.1002 / 9780470996249.ch31 . ISBN 0-631-21254-X .
- Эндерс, Уолтер (2010). Прикладные эконометрические временные ряды (Третье изд.). Нью-Йорк: Джон Вили и сыновья. С. 272–355. ISBN 978-0-470-50539-7 .
- Lütkepohl, Гельмут (2006). Новое введение в анализ множественных временных рядов . Берлин: Springer. стр. 237 -352. ISBN 978-3-540-26239-8 .
- Мартин, Вэнс; Херн, Стэн; Харрис, Дэвид (2013). Эконометрическое моделирование с использованием временных рядов . Нью-Йорк: Издательство Кембриджского университета. С. 662–711. ISBN 978-0-521-13981-6 .
Векторная модель коррекции ошибок
Рассмотрим модель р-го порядка:
![]()
Где:
-
yt.
k-мерный вектор нестационарных
переменных; -
xt.
d-мерный вектор экзогенных
переменных; -
et.
k-мерный вектор случайных
составляющих.
Модель можно представить в виде:
![]()
Где:
![]()
Ключевая теорема Гранжера гласит, что если матрица П имеет неполный
ранг r<k,
то существуют kxr
матрицы α и β, каждая ранга r,
такие, что П = α · βT,
ряд βT является
стационарным, и каждый столбец матрицы β является коинтеграционным
вектором, r — число коинтеграционных
связей. Элементы матрицы α называют сглаживающими параметрами модели коррекции
ошибок.
Если у вас имеется k эндогенных
переменных (каждая из которых содержит единичный корень), то может существовать
от нуля до k-1 линейно независимой
коинтеграционной связи. Если коинтеграционных
связей нет, к ряду в первых разностях может быть применен стандартный
анализ временных рядов. И наоборот, если в системе имеется одно коинтеграционное
уравнение, в каждое уравнение системы должна быть добавлена одна линейная
комбинация эндогенных переменных βTyt-1.
После умножения на коэффициент уравнения (т.е. на сглаживающий параметр
α) получается результирующая составляющая α · βT · yt-1,
которая и является составляющей коррекции ошибок. Каждое следующее коинтеграционное
уравнение будет вносить дополнительную составляющую коррекции ошибок,
уникальную по линейной комбинации параметров.
Если существует k коинтеграционных
связей, то ни один из рядов не имеет единичного корня и модель может быть
описана без взятия разностей.
Изучаемые ряды могут содержать ненулевое среднее, или тренд. Аналогично
коинтеграционные уравнения могут содержать константу и тренд. На практике
чаще используются следующие виды моделей:
| Ряд y | Коинтеграционные уравнения | Модель |
| Тренда нет | Константы нет | |
| Тренда нет | Константа есть | |
| Линейный тренд | Константа есть | |
| Линейный тренд | Линейный тренд | |
| Квадратичный тренд |
Линейный тренд |
α’ — матрица, рассчитывающаяся из соотношения αT · α, = 0
В рамках такой схемы, при построении модели, можно варьировать два параметра.
Можно фиксировать вид модели и варьировать ранг. Или наоборот, фиксировать
ранг и выбирать наиболее подходящую форму модели. При построении помимо
статистических критериев следует руководствоваться экономической адекватностью
модели. Следует обратить внимание на нормализованные коинтеграционные
уравнения, чтобы убедится в том, что они отвечают вашим ожиданиям о природе
рассматриваемого процесса.
Модель также может быть приведена к более общему виду:
![]()
См. также:
Библиотека методов и моделей
| Коинтегрированные процессы |
Модель коррекции ошибок |
Модель «Векторная
модель коррекции ошибок» | ISmErrorCorrectionModel
An модель коррекции ошибок (ECM) принадлежит к категории множественных Временные ряды модели, наиболее часто используемые для данных, в которых базовые переменные имеют долгосрочный стохастический тренд, также известный как коинтеграция. ECM — это теоретически обоснованный подход, полезный для оценки как краткосрочного, так и долгосрочного воздействия одного временного ряда на другой. Термин исправление ошибок относится к тому факту, что отклонение последнего периода от долгосрочного равновесия, ошибка, влияет на его краткосрочную динамику. Таким образом, ECM напрямую оценивают скорость, с которой зависимая переменная возвращается в состояние равновесия после изменения других переменных.
История ECM
Йоль (1926) и Грейнджер и Ньюболд (1974) первыми привлекли внимание к проблеме ложная корреляция и найти решения, как решить эту проблему при анализе временных рядов.[1][2] Учитывая два совершенно не связанных, но интегрированных (нестационарных) временных ряда, регрессивный анализ одного на другом, будет иметь тенденцию давать явно статистически значимую взаимосвязь, и поэтому исследователь может ошибочно полагать, что нашел доказательства истинной взаимосвязи между этими переменными. Обычный метод наименьших квадратов больше не будет согласованным, и часто используемая тестовая статистика будет недействительной. Особенно, Моделирование Монте-Карло покажи, что получишь очень высокий R в квадрате, очень высокий человек t-статистика и низкий Статистика Дарбина – Ватсона. С технической точки зрения Филлипс (1986) доказал, что оценки параметров не сходятся по вероятности, то перехватить будут расходиться, и наклон будет иметь невырожденное распределение по мере увеличения размера выборки.[3] Однако может быть общий стохастический тренд к обеим сериям, которые действительно интересуют исследователя, потому что они отражают долгосрочную взаимосвязь между этими переменными.
Из-за стохастического характера тренда невозможно разбить интегрированный ряд на детерминированный (предсказуемый) тенденция и стационарный ряд, содержащий отклонения от тренда. Даже при детерминированном исключении тренда случайные прогулки в конечном итоге возникнут ложные корреляции. Таким образом, снятие тренда не решает проблему оценки.
Чтобы по-прежнему использовать Подход Бокса – Дженкинса, можно было различать ряды, а затем оценивать такие модели, как ARIMA, учитывая, что многие часто используемые временные ряды (например, в экономике) кажутся стационарными в первых разностях. Прогнозы на основе такой модели по-прежнему будут отражать циклы и сезонность, которые присутствуют в данных. Однако любая информация о долгосрочных корректировках, которую могут содержать данные в уровнях, опускается, и долгосрочные прогнозы будут ненадежными.
Это привело Сарган (1964) для разработки методологии ECM, которая сохраняет информацию об уровне.[4][5]
Оценка
В литературе известно несколько методов оценки уточненной динамической модели, как описано выше. Среди них двухэтапный подход Энгла и Грейнджера, оценивающий их ECM за один шаг, и VECM на основе векторов с использованием Метод Йохансена.[6]
Двухэтапный подход Энгла и Грейнджер
Первым шагом этого метода является предварительная проверка используемых индивидуальных временных рядов, чтобы подтвердить, что они нестационарный на первом месте. Это можно сделать стандартным единичный корень Пеленгационные испытания и Тест АПД (для решения проблемы серийно коррелированных ошибок). Возьмем случай двух разных серий. и . Если оба равны I (0), будет действителен стандартный регрессионный анализ. Если они интегрированы другого порядка, например один — I (1), а другой — I (0), необходимо преобразовать модель.
Если они оба интегрированы в одном порядке (обычно I (1)), мы можем оценить модель ECM в виде
Если обе переменные интегрированы, и этот ECM существует, они коинтегрируются теоремой Энгла – Грейнджера о представлении.
Затем на втором этапе оценивается модель с использованием обыкновенный метод наименьших квадратов: Если регрессия не является ложной, как определено критериями тестирования, описанными выше, Обычный метод наименьших квадратов будет не только актуально, но и по сути супер последовательный (Сток, 1987). Тогда прогнозируемые остатки из этой регрессии сохраняются и используются в регрессии разностных переменных плюс запаздывающий член ошибки
Затем можно протестировать коинтеграцию, используя стандартный t-статистика на Хотя этот подход прост в применении, существует множество проблем:
VECM
Подход Энгла – Грейнджера, описанный выше, имеет ряд недостатков. А именно, он ограничен только одним уравнением с одной переменной, обозначенной как зависимая переменная, объясненной другой переменной, которая, как предполагается, является слабо экзогенной для интересующих параметров. Он также основан на предварительном тестировании временных рядов, чтобы выяснить, являются ли переменные I (0) или I (1). Эти недостатки могут быть устранены с помощью процедуры Йохансена. Его преимущества заключаются в том, что предварительное тестирование не требуется, может существовать множество коинтегрирующих взаимосвязей, все переменные рассматриваются как эндогенные и возможны тесты, относящиеся к долгосрочным параметрам. Полученная модель известна как модель векторной коррекции ошибок (VECM), поскольку она добавляет функции коррекции ошибок в многофакторную модель, известную как векторная авторегрессия (VAR). Порядок действий следующий:
- Шаг 1: оцените неограниченную VAR с потенциально нестационарными переменными
- Шаг 2. Проверьте коинтеграцию с помощью Тест Йохансена
- Шаг 3: Сформируйте и проанализируйте VECM.
Пример ECM
Идея коинтеграции может быть продемонстрирована в простой макроэкономической обстановке. Предположим, потребление и располагаемый доход представляют собой макроэкономические временные ряды, которые связаны в долгосрочной перспективе (см. Гипотеза постоянного дохода ). В частности, пусть средняя склонность к потреблению быть 90%, то есть в долгосрочной перспективе . С точки зрения эконометриста, эта долгосрочная связь (также известная как коинтеграция) существует, если ошибки из регрессии площадь стационарный серия, хотя и нестационарны. Предположим также, что если внезапно меняется на , тогда изменения на , то есть, предельная склонность к потреблению равняется 50%. Наше последнее предположение состоит в том, что разрыв между текущим и равновесным потреблением уменьшается каждый период на 20%.
В этой настройке изменение по уровню потребления можно смоделировать как . Первый член в RHS описывает краткосрочное влияние изменения в на , второй член объясняет долгосрочное стремление к равновесному соотношению между переменными, а третий член отражает случайные шоки, которые получает система (например, шоки доверия потребителей, влияющие на потребление). Чтобы увидеть, как работает модель, рассмотрим два вида шоков: постоянные и временные (временные). Пусть для простоты равняться нулю для всех t. Предположим в период т — 1 система находится в равновесии, т.е. . Предположим, что в период t увеличивается на 10, а затем возвращается на предыдущий уровень. потом первый (в период t) увеличивается на 5 (половина от 10), но после второго периода начинает уменьшаться и сходится к исходному уровню. Напротив, если шок постоянно, то медленно сходится к значению, превышающему начальное на 9.
Эта структура общая для всех моделей ECM. На практике эконометристы часто сначала оценивают взаимосвязь коинтеграции (уравнение в уровнях), а затем вставляют его в основную модель (уравнение в разностях).
Рекомендации
- ^ Юль, Жорж Удный (1926). «Почему мы иногда получаем бессмысленные корреляции между временными рядами? — Исследование выборки и природы временных рядов». Журнал Королевского статистического общества. 89 (1): 1–63. JSTOR 2341482.
- ^ Granger, C.W.J .; Ньюболд П. (1978). «Ложные регрессии в эконометрике». Журнал эконометрики. 2 (2): 111–120. JSTOR 2231972.
- ^ Филлипс, Питер Си Би (1985). «Понимание ложных регрессий в эконометрике» (PDF). Документы для обсуждения в Фонде Коулза 757. Фонд Коулза по исследованиям в области экономики, Йельский университет.
- ^ Сарган, Дж. Д. (1964). «Заработная плата и цены в Соединенном Королевстве: исследование по эконометрической методологии», 16, 25–54. в Эконометрический анализ для национального экономического планирования, изд. П. Э. Харта, Дж. Миллса и Дж. Н. Уиттакера. Лондон: Баттервортс
- ^ Davidson, J.E.H .; Хендри, Д.Ф.; Srba, F .; Йео, Дж. С. (1978). «Эконометрическое моделирование совокупной взаимосвязи временных рядов между расходами и доходами потребителей в Соединенном Королевстве». Экономический журнал. 88 (352): 661–692. JSTOR 2231972.
- ^ Энгл, Роберт Ф .; Грейнджер, Клайв В. Дж. (1987). «Совместная интеграция и исправление ошибок: представление, оценка и тестирование». Econometrica. 55 (2): 251–276. JSTOR 1913236.
дальнейшее чтение
- Доладо, Хуан Дж .; Гонсало, Хесус; Мармол, Франсеск (2001). «Коинтеграция». В Балтаги, Бади Х. (ред.). Компаньон теоретической эконометрики. Оксфорд: Блэквелл. стр.634 –654. Дои:10.1002 / 9780470996249.ch31. ISBN 0-631-21254-X.
- Эндерс, Уолтер (2010). Прикладные эконометрические временные ряды (Третье изд.). Нью-Йорк: Джон Вили и сыновья. С. 272–355. ISBN 978-0-470-50539-7.
- Люткеполь, Гельмут (2006). Новое введение в анализ множественных временных рядов. Берлин: Springer. стр.237 –352. ISBN 978-3-540-26239-8.
- Мартин, Вэнс; Херн, Стэн; Харрис, Дэвид (2013). Эконометрическое моделирование с использованием временных рядов. Нью-Йорк: Издательство Кембриджского университета. С. 662–711. ISBN 978-0-521-13981-6.
Векторные модели коррекции ошибок
Многомерные линейные модели, включая коинтегрирующие отношения и переменные экзогенного предиктора
Модели коррекции векторных ошибок (VEC), или cointegrated VAR models, адресуют нестационарность в многомерных временных рядах, возникающих в результате совместных движений нескольких рядов откликов. Для примера анализа с использованием инструментов моделирования VEC, смотрите Моделирование экономики США.
Функции
расширить все
Создайте модель
vecm |
Создайте вектор коррекции векторной ошибки (VEC) |
Подгонка модели к данным
estimate |
Подбор модели коррекции ошибок вектора (VEC) к данным |
infer |
Инновации модели коррекции ошибок вектора вывода (VEC) |
summarize |
Отобразите результаты оценки вектора коррекции ошибок (VEC) |
Преобразуйте между моделями
arma2ar |
Преобразуйте модель ARMA в модель AR |
arma2ma |
Преобразуйте модель ARMA в модель MA |
vec2var |
Преобразуйте модель VEC в модель VAR |
var2vec |
Преобразуйте модель VAR в модель VEC |
varm |
Преобразуйте модель вектора исправлением ошибок (VEC) в модель векторной авторегрессии (VAR) |
Сгенерируйте симуляции или импульсные характеристики
simulate |
Симуляция Монте-Карло модели вектора исправления ошибок (VEC) |
filter |
Фильтруйте нарушения порядка через векторную модель коррекции ошибок (VEC) |
irf |
Сгенерируйте вектор модель исправления ошибок (VEC) импульсных характеристик |
fevd |
Сгенерируйте векторную модель коррекции ошибок (VEC), прогнозирующую разложение отклонения ошибок (FEVD) |
Сгенерируйте минимальные прогнозы квадратной ошибки
forecast |
Прогнозные ответы модели коррекции ошибок вектора (VEC) |
Темы
тип модели временного ряда
Модель коррекции ошибок (ECM) принадлежит к Категория нескольких моделей временных рядов , наиболее часто используемых для данных, в которых базовые переменные имеют долгосрочный стохастический тренд, также известный как коинтеграция. ECM — это теоретически обоснованный подход, полезный для оценки как краткосрочного, так и долгосрочного воздействия одного временного ряда на другой. Термин «исправление ошибок» относится к тому факту, что отклонение последнего периода от долгосрочного равновесия, ошибка, влияет на его краткосрочную динамику. Таким образом, ECM напрямую оценивают скорость, с которой зависимая переменная возвращается в состояние равновесия после изменения других переменных.
Содержание
- 1 История ECM
- 2 Оценка
- 2.1 Двухэтапный подход Энгла и Грейнджера
- 2.2 VECM
- 2.3 Пример ECM
- 3 Ссылки
- 4 Далее чтение
История ECM
Юл (1926) и Грейнджер и Ньюболд (1974) первыми привлекли внимание к проблеме ложной корреляции и нашли решения, как ее решить. в анализе временных рядов. Учитывая два совершенно несвязанных, но интегрированных (нестационарных) временных ряда, регрессионный анализ одного из другого будет иметь тенденцию давать явно статистически значимую взаимосвязь, и, таким образом, исследователь может ошибочно полагать, что нашел доказательства существования истинная взаимосвязь между этими переменными. Обычный метод наименьших квадратов больше не будет согласованным, а часто используемая тестовая статистика будет недействительной. В частности, моделирования Монте-Карло показывают, что можно получить очень высокий R в квадрате, очень высокий индивидуальный t-статистический и низкий Дарбина – Ватсона. статистика. С технической точки зрения Филлипс (1986) доказал, что оценки параметров не будут сходиться по вероятности, точка пересечения будет расходиться, а наклон будет иметь невырожденное распределение по мере увеличения размера выборки. Однако может существовать общий стохастический тренд для обоих рядов, который искренне интересует исследователя, поскольку он отражает долгосрочную взаимосвязь между этими переменными.
Из-за стохастического характера тренда невозможно разбить интегрированный ряд на детерминированный (предсказуемый) тренд и стационарный ряд, содержащий отклонения от тренда. Даже при детерминированном удалении тренда случайных блужданий в конечном итоге возникнут ложные корреляции. Таким образом, детрендирование не решает проблему оценки.
Чтобы по-прежнему использовать подход Бокса – Дженкинса, можно было бы различать ряды, а затем оценивать такие модели, как ARIMA, учитывая, что многие часто используемые временные ряды ( например, в экономике) кажутся стационарными в первых разностях. Прогнозы на основе такой модели по-прежнему будут отражать циклы и сезонность, которые присутствуют в данных. Однако любая информация о долгосрочных корректировках, которую могут содержать данные в уровнях, опускается, и долгосрочные прогнозы будут ненадежными.
Это привело Саргана (1964) к разработке методологии ECM, которая сохраняет информацию об уровне.
Оценка
В литературе известно несколько методов. для оценки уточненной динамической модели, как описано выше. Среди них двухэтапный подход Энгла и Грейнджера, оценивающий их ECM за один этап, и векторный VECM с использованием метода Йохансена.
двухэтапного подхода Энгла и Грейнджера
Первый этап этот метод заключается в предварительном тестировании отдельных временных рядов, которые используются, чтобы подтвердить, что они нестационарны в первую очередь. Это можно сделать с помощью стандартного модульного корневого тестирования DF и теста ADF (для решения проблемы серийно коррелированных ошибок). Возьмем случай двух разных серий x t { displaystyle x_ {t}}и y t { displaystyle y_ {t}}. Если оба равны I (0), будет действителен стандартный регрессионный анализ. Если они интегрированы другого порядка, например один — I (1), а другой — I (0), необходимо преобразовать модель.
Если они оба интегрированы в одном порядке (обычно I (1)), мы можем оценить модель ECM в виде
- A (L) Δ yt = γ + B (L) Δ xt + α (yt — 1 — β 0 — β 1 xt — 1) + ν t. { Displaystyle A (L) , Delta y_ {t} = gamma + B (L) , Delta x_ {t} + alpha (y_ {t-1} — beta _ {0} — beta _ {1} x_ {t-1}) + nu _ {t}.}

Если обе переменные интегрированы и этот ECM существует, они коинтегрируются теоремой Энгла – Грейнджера о представлении.
Затем на втором этапе оценивается модель с помощью обычных наименьших квадратов : yt = β 0 + β 1 xt + ε t { displaystyle y_ {t} = beta _ {0} + beta _ {1} x_ {t} + varepsilon _ {t}}Если регрессия не является ложной в соответствии с критериями тестирования, описанными выше, Обычный метод наименьших квадратов будет не только действительным, но и действительно супер согласованным (Stock, 1987). Тогда прогнозируемые остатки ε t ^ = yt — β 0 — β 1 xt { displaystyle { hat { varepsilon _ {t}}} = y_ {t} — beta _ {0} — beta _ {1} x_ {t}}из этой регрессии сохраняются и используются в регрессии разностных переменных плюс запаздывающий член ошибки
- A (L) Δ yt = γ + B (L) Δ xt + α ε ^ t — 1 + ν t. { Displaystyle A (L) , Delta y_ {t} = gamma + B (L) , Delta x_ {t} + alpha { hat { varepsilon}} _ {t-1} + nu _ {t}.}
Затем можно протестировать коинтеграцию, используя стандартную t-статистику на α { displaystyle alpha}. Хотя этот подход прост в применении, однако существует множество проблем:
VECM
Энгл-Грейнджер описанный выше подход имеет ряд недостатков. А именно, он ограничен только одним уравнением с одной переменной, обозначенной как зависимая переменная, объясненной другой переменной, которая, как предполагается, является слабо экзогенной для интересующих параметров. Он также основан на предварительном тестировании временных рядов, чтобы выяснить, являются ли переменные I (0) или I (1). Эти недостатки могут быть устранены с помощью процедуры Йохансена. Его преимущества заключаются в том, что в предварительном тестировании нет необходимости, может быть множество коинтегрирующих взаимосвязей, все переменные рассматриваются как эндогенные, и возможны тесты, относящиеся к долгосрочным параметрам. Полученная модель известна как модель векторной коррекции ошибок (VECM), поскольку она добавляет функции коррекции ошибок в многофакторную модель, известную как векторная авторегрессия (VAR). Процедура выполняется следующим образом:
- Шаг 1: оценка неограниченной VAR, включающей потенциально нестационарные переменные
- Шаг 2: Тест на коинтеграцию с использованием теста Йохансена
- Шаг 3: Сформировать и проанализировать VECM.
Пример ECM
Идея коинтеграции может быть продемонстрирована в простых макроэкономических условиях. Предположим, потребление C t { displaystyle C_ {t}}и располагаемый доход Y t { displaystyle Y_ {t}}представляют собой макроэкономические временные ряды, которые связаны в долгосрочной перспективе (см. гипотезу о постоянном доходе ). В частности, пусть средняя склонность к потреблению составляет 90%, то есть в долгосрочной перспективе C t = 0,9 Y t { displaystyle C_ {t} = 0,9Y_ {t}}. С точки зрения эконометриста, эта долгосрочная связь (также известная как коинтеграция) существует, если ошибки из регрессии C t = β Y t + ε t { displaystyle C_ {t} = beta Y_ {t} + varepsilon _ {t}}— это стационарный ряд, хотя Y t { displaystyle Y_ {t}}и C t { displaystyle C_ {t}}нестационарны. Предположим также, что если Y t { displaystyle Y_ {t}}внезапно изменяется на Δ Y t { displaystyle Delta Y_ {t}}, то C t { displaystyle C_ {t}}изменяется на Δ C t = 0,5 Δ Y t { displaystyle Delta C_ {t} = 0,5 , Delta Y_ {t }}, то есть предельная склонность к потреблению равна 50%. Наше последнее предположение состоит в том, что разрыв между текущим и равновесным потреблением уменьшается каждый период на 20%.
В этой настройке изменение Δ C t = C t — C t — 1 { displaystyle Delta C_ {t} = C_ {t} -C_ {t-1}}в уровне потребления можно смоделировать как Δ C t = 0,5 Δ Y t — 0,2 (C t — 1 — 0,9 Y t — 1) + ε t { displaystyle Delta C_ {t} = 0,5 , Delta Y_ {t} -0.2 (C_ {t-1} -0.9Y_ {t-1}) + varepsilon _ {t}}. Первый член в правой части страницы описывает краткосрочное влияние изменения Y t { displaystyle Y_ {t}}на C t { displaystyle C_ {t}}, второй член объясняет долгосрочное стремление к равновесному соотношению между переменными, а третий член отражает случайные шоки, которые получает система (например, шоки доверия потребителей, влияющие на потребление). Чтобы увидеть, как работает модель, рассмотрим два вида шоков: постоянные и временные (временные). Для простоты пусть ε t { displaystyle varepsilon _ {t}}равно нулю для всех t. Предположим, что в период t — 1 система находится в равновесии, т.е. C t — 1 = 0.9 Y t — 1 { displaystyle C_ {t-1} = 0.9Y_ {t-1}}. Предположим, что в период t Y t { displaystyle Y_ {t}}увеличивается на 10, а затем возвращается на свой предыдущий уровень. Тогда C t { displaystyle C_ {t}}сначала (в период t) увеличивается на 5 (половина от 10), но после второго периода C t { displaystyle C_ { t}}начинает убывать и сходится к исходному уровню. Напротив, если удар Y t { displaystyle Y_ {t}}является постоянным, то C t { displaystyle C_ {t}}медленно сходится к значению, которое превышает исходное значение C t — 1 { displaystyle C_ {t-1}}на 9.
Эта структура является общей для всех моделей ECM. На практике эконометристы часто сначала оценивают взаимосвязь коинтеграции (уравнение в уровнях), а затем вставляют его в основную модель (уравнение в разностях).
Ссылки
Дополнительная литература
- Dolado, Juan J.; Гонсало, Хесус; Мармол, Франсеск (2001). «Коинтеграция». В Балтаги, Бади Х. (ред.). Компаньон теоретической эконометрики. Оксфорд: Блэквелл. Стр. 634 –654. doi : 10.1002 / 9780470996249.ch31. ISBN 0-631-21254-X.
- Эндерс, Уолтер (2010). Прикладные эконометрические временные ряды (Третье изд.). Нью-Йорк: Джон Вили и сыновья. С. 272–355. ISBN 978-0-470-50539-7.
- Lütkepohl, Helmut (2006). Новое введение в анализ множественных временных рядов. Берлин: Springer. Стр. 237 –352. ISBN 978-3-540-26239-8.
- Мартин, Вэнс; Херн, Стэн; Харрис, Дэвид (2013). Эконометрическое моделирование с использованием временных рядов. Нью-Йорк: Издательство Кембриджского университета. С. 662–711. ISBN 978-0-521-13981-6.
МАТЕМАТИЧЕСКИЕ И ИНСТРУМЕНТАЛЬНЫЕ МЕТОДЫ
ЭКОНОМИКИ
MATHEMATICAL AND INSTRUMENTAL METHODS
OF ECONOMICS
DOI: 10.18287/2542-0461-2021-12-3-147-154 ЮУ
НАУЧНАЯ СТАТЬЯ УДК 330.4
Дата поступления: 20.05.2021 рецензирования: 26.06.2021 принятия: 27.08.2021
Векторная модель коррекции ошибок при моделировании взаимосвязи показателей банковского кредитования и темпов роста российской
экономики
Д.Ю. Иванов
Самарский национальный исследовательский университет имени академика С.П. Королева,
г. Самара, Российская ФедерацияЕ-mail: ivanov.dyu@ssau.ru. ORCID: http://orcid.org/0000-0003-0619-9340
М.М.Т. Тали
Самарский национальный исследовательский университет имени академика С.П. Королева,
г. Самара, Российская Федерация E-mail: m.economic@mail.ru
Аннотация: В статье рассматривается проблема моделирования функциональной зависимости объема выданных кредитов и темпов роста российской экономики. Актуальность данного исследования обусловлена необходимостью выявления факторов, влияющих на рост показателя реального валового внутреннего продукта. Проанализированные отечественные и зарубежные источники не дают единого набора факторов, влияющих на темп роста национальной экономики, выделяя финансовые механизмы, производственные процессы, объемы кредитования физических и юридических лиц, инвестиционную активность и т. д. В статье отмечается проблема формирования многофакторной модели влияния различных параметров на показатель темпа роста национальной экономики. Процесс моделирования функциональной зависимости ВВП от элементов вектора влияния затрудняется из-за специфики статистических данных. С целью избежать подобных проблем, связанных с коинтеграцией рядов, была предложена векторная модель корректировки ошибок. Модель апробирована на статистических данных организаций банковского сектора и предприятий реального сектора российской экономики. Выявлено, что при существующих условиях организации процесса кредитования банковская система работает не столько на увеличение объемов производства, сколько на поддержание уровня финансового состояния хозяйствующих субъектов (поддержание уровня ликвидности и увеличение финансовых вложений), не способствуя при этом изменению общей структуры российской экономики. Разработанная векторная модель корректировки ошибок позволяет измерить отклонения от равновесия и скорость его восстановления, что указывает на большую эффективность данной методики. При этом приведенные результаты позволяют сделать вывод о том, что при наличии положительной взаимосвязи между объемами кредитования и основными показателями, степень влияния кредитования на экономический рост в целом незначительна.
Ключевые слова: векторная модель; корректировка ошибок; темп роста экономики; кредитование; эконометрическое моделирование; коинтеграция рядов.
Цитирование. Иванов Д.Ю., Тали М.М.Т. Векторная модель коррекции ошибок при моделировании взаимосвязи показателей банковского кредитования и темпов роста российской экономики // Вестник Самарского университета. Экономика и управление. 2021. Т. 12, № 3. С. 147-154. DOI: http://doi.org/10.18287/2542-0461-2021-12-3-147-54.
Информация о конфликте интересов: авторы заявляют об отсутствии конфликта интересов. © Иванов Д.Ю., Тали М.М.Т., 2021
Дмитрий Юрьевич Иванов — доктор экономических наук, профессор, заведующий кафедрой менеджмента и организации производства, Самарский национальный исследовательский университет имени академика С.П. Королева, 443086, Российская Федерация, г. Самара, Московское шоссе, 34.
Тали Махди Мохаммед Тали — аспирант, Самарский национальный исследовательский университет имени академика С.П. Королева, 443086, Российская Федерация, г. Самара, Московское шоссе, 34.
SCTENTTFTC ARTICLE
Submitted: 20.05.2021 Revised: 26.06.2021 Accepted: 27.08.2021
Vector model of error correction in modeling the relationship between bank lending indicators and the growth rates of the Russian economy
D.Yu. Ivanov
Samara National Research University, Samara, Russian Federation E-mail: ivanov.dyu@ssau.ru. ORCID: http://orcid.org/0000-0003-0619-9340
M.M.T. Tali
Samara National Research University, Samara, Russian Federation
E-mail: m.economic@mail.ru
Abstract: The article discusses the problem of modeling the functional dependence of the volume of loans issued and the growth rate of the Russian economy. The relevance of this study is due to the need to identify the factors affecting the growth of the indicator of real gross domestic product. The analyzed domestic and foreign sources do not provide a single set of factors affecting the growth rate of the national economy, highlighting financial mechanisms, production processes, lending volumes to individuals and legal entities, investment activity, etc. The article notes the problem of the formation of a multifactor model of the influence of various parameters on the indicator of the growth rate of the national economy. The process of modeling the functional dependence of GDP on the elements of the influence vector is complicated by the specifics of statistical data. In order to avoid such problems associated with series cointegration, a vector error correction model was proposed. The model was tested on statistical data of organizations in the banking sector and enterprises of the real sector of the Russian economy. It was revealed that under the existing conditions of organizing the lending process, the banking system works not so much to increase production volumes as to maintain the level of the financial condition of economic entities (maintaining the level of liquidity and increasing financial investments), while not contributing to a change in the overall structure of the Russian economy. The developed vector model of error correction makes it possible to measure deviations from equilibrium and the rate of its recovery, which indicates the greater efficiency of this technique. At the same time, the above results allow us to conclude that in the presence of a positive relationship between the volume of lending and the main indicators, the degree of influence of lending on economic growth is generally insignificant
Key words: vector model; error correction; economic growth topics; lending; econometric modeling; cointegration of series.
Citation. Ivanov D.Yu., Tali M.M.T. Vector model of error correction in modeling the relationship between bank lending indicators and the growth rates of the Russian economy. Vestnik Samarskogo universiteta. Ekonomika i upravlenie = Vestnik of Samara University. Economics and Management, 2021, vol. 12, no. 3, pp. 147-154. DOI: http://doi.org/10.18287/2542-0461-2021-12-3-147-154. (In Russ.) Information on the conflict of interest: authors declare no conflict of interest.
© Ivanov D.Yu., M.M.T. Tali, 2021
Dmitriy Yu. Ivanov — Doctor of Economics, professor, head of the Department of Management and Production Organization, Samara National Research University, 34, Moskovskoye shosse, Samara, 443086, Russian Federation.
Tali Mahdi Mohammed Tali — postgraduate student, Samara National Research University, 34, Moskovskoye shosse, Samara, 443086, Russian Federation.
Введение
Тем роста национальной экономики любого государства является важным показателем эффективности деятельности экономических, политических, финансовых и прочих механизмов в стране. Взаимное влияние различных факторов отражается в инвестиционной активности, объемах кредитования, в обороте организаций реального и финансового секторов экономики. Финансовые показатели инвестиционного процесса и кредитования физических и юридических лиц характеризуют развитие бизнеса и уровень доходов домохозяйств. Можно сказать, что коммерческие банки, которые действуют в соответствии с денежно-кредитной политикой государства, осуществляют регулировку движения денежных потоков, воздействуя на скорость их оборота, эмиссию, общую массу. Современный банковский сектор осуществляет управление финансовыми потоками в государственной системе платежей и расчетов, реализуя свою деятельность при помощи механизмов депозитов, инвестиций и кредитных операций.
Проблема влияния процессов банковского кредитования на темп роста национальной экономики рассматривался авторами применительно к различным факторам. Так, по мнению R.I. McKinnon, влияние кредитной системы на темпы роста экономики заключаются в росте следующих показателей: реальный ВВП на душу населения, скорость прироста материального капитала и т.д. [1]. D.S. Allen и L. Ndikumana определяют влияние как положительное изменение уровня создания товаров и национального дохода, которые предоставляются страной в течение определенного периода времени. Это обычно измеряется с точки зрения уровня производства в экономике [2].
Согласно теории V.R. Bencivenga и B.D. Smith, влияние кредитных ресурсов на рост экономики заключается в формировании труда и капитала. Предприниматель, который использует банковский кредит, с целью формирования капитала, инвестированного в бизнес, стимулирует производство товаров и услуг для экономического роста [3]. Как отмечали экономисты R.W. Goldsmith [4] и E.S. Shaw [5], банковское кредитование и экономический рост положительно коррелируют: в качестве основного фактора роста экономики они выделяют потребительское кредитование (кредиты населению). J.A. Schumpeter, напротив, полагал, что финансовые посредники способствуют росту путем выявления и перенаправления средств на инновационные проекты. Ученый отмечал, что существенная функция кредита состоит в том, чтобы позволить предпринимателю изъять необходимые ему товары, осуществляя спрос на них, и тем самым заставить экономическую систему перейти на новые каналы [6].
J.G. Gurley и E.S. Shaw утверждали, что если доход растет с гарантированной скоростью, то спрос на финансовые активы также растет с определенной скоростью. Кроме того, существует спрос на операции с деньгами, чтобы идти в ногу с растущим доходом [7]. Соответственно, накопление активов и рост доходов стимулируют спрос за счет расходных единиц на финансовые услуги во все большем разнообразии. Ученые утверждали, что влияние банковского кредитования на долгосрочные темпы экономического роста проявляется в виде мобилизации сбережений. Банковский сектор мобилизует сбережения, предлагая широкий спектр инструментов для деноминированных сбережений различных сумм.
Эконометрическое моделирование темпов роста российской экономики, валового внутреннего продукта и макроэкономических показателей представлено в ряде работ отечественных ученых [8 — 12].
Как видим, авторы отмечают влияние на экономику государства различных факторов: финансовых и производственных, кредитования физических и юридических лиц, рыночных
механизмов и т.д. При этом отсутствует единое мнение относительно набора этих факторов и степени их влияния. Процесс моделирования функциональной зависимости ВВП от элементов вектора влияния затрудняется из-за специфики статистических данных. С целью избежать подобных проблем, связанных с коинтеграцией рядов, была предложена векторная модель корректировки ошибок.
Разработка векторной модели корректировки ошибок
Новизна предлагаемой методики заключается в формировании подходов, подтверждающих наличие коинтеграции в многомерной модели, если рассматриваемых рядов больше двух. При этом было установлено, что для большого количества рядов будет существовать ряд коинтеграционных соотношений. Предлагается критерий выбора и оценки лучшего ко-интеграционного соотношения для модели. В рамках теста Йохансена была осуществлена проверка нулевой гипотезы о существовании максимума г коинтеграционных векторов, и альтернативной гипотезы в том, что их г+1. Если величина тестов оказывается значимой, то нулевая гипотеза отвергается. Найденное максимальное значение г является рангом коинтеграции. Для одиночных уравнений проверка на интегрированность заключается в выявлении равенства, указывающего на наличие единичных корней в соответствующей авторегрессии. В общем виде процедура тестирования коинтеграции выглядит следующим образом: рассматривается векторная модель авторегрессии (VAR):
Р
Ух = 1 AiУt-1 + Вхх + £ , (1)
I=1
где Ai — матрица, состоящая из коинтеграционных векторов, £ — стационарные процессы
гт! к
£ = а Ух = IЩУи . i=1
Модель (1) можно представить в виде векторной модели
Р
Лу = Пу-1 + I Г7 Лу — 7 + Вх1 + £, 7=1
РР
п= IА -1,г7 = — IА i=1 i=7+1
Из данного представления возможно предположить, что если первые разности рядов у стационарны, то Пум — тоже стационарна. Если ранг коинтеграции меньше числа переменных, матрицу П можно представить в виде произведения двух матриц а$ , где вторая матрица — матрица из коинтегрирующих векторов. Ранг матрицы П определяет ранг коинтеграции. Задача нахождения параметров $ эквивалентна задаче нахождения собственных векторов определенной матрицы. Для тестирования ранга коинтеграции использовался тест отношения правдоподобия (ЬЯ), показатели которого в данном случае сводятся к функции от собственных значений данной матрицы. Нулевая гипотеза заключается в предположении, что ранг коинтеграции равен данному значению г.
Векторная модель коррекции ошибок обусловлена тем, что проверка гипотезы начинается с ранга 0 до ранга к — 1. Если гипотеза не отвергается для ранга 0, то ранг считается нулевым, все переменные имеют интегрированность /(1) или кратность /(1) и отсутствие коинтеграции. Аналогично до г=к. В таком случае П обратима и принимается альтернативная гипотеза о стационарности исходных рядов, все переменные имеют порядок интегрированности /(0). Явление коинтеграции допустимо лишь при 0<г<1.
Рассмотрим подробнее случай, когда 0<г<1, коинтеграция присутствует и П представим в виде произведения двух матриц а$ . Имеются два ряда хх, у порядка интеграции 1(1), их ли-
нейная комбинация представима в виде: у — х6_ум = ^(х — хм) + или Ау = + Рассматриваемые ряды описывают некоторые экономические данные, которые могут не меняться с течением времени. Тогда у = _ум = … = у0 и х( = хм = … = х, то есть все члены рассматриваемой линейной комбинации равны нулю, а остатки е( будут стационарны. На практике найти такое соотношение между у и х не представляется возможным. С целью избежать подобных проблем, связанных с коинтеграцией рядов была предложена векторная модель корректировки ошибок («УЕСМ). Для вышеописанного случая она будет выглядеть следующим образом:
Ду = ДДх? + + 0з(У-1 — ^-1 — Ъ-1) + Ъ .
По своей сути «УЕСМ ограничивает в установленном временном периоде динамику эндогенных переменных и возвращает их к коинтеграционному отношению, при этом коррекци-онная динамика допускается. Коинтеграционный параметр является параметром коррекции ошибок, поскольку данные ошибки (нарушения) равновесия корректируются за счет изменений в зависимости от степени отклонения основных показателей.
Результаты моделирования
С целью выявления эффективности использования данной модели был представлен ряд стандартных диагностических тестов с константой и к=2, подтверждающих равенство нулю эндогенных переменных на данном лаге, которое (равенство) доказывается при помощи теста Вальда. Данный тест позволяет обнулить коэффициенты при каждых переменных на данном лаге и обеспечивает выделение статистики значимости обнуления. Переменные избыточны, если коэффициенты незначимы. Кроме того, тестирование показало, что «УЕСМ имеет гомоскедастичные и некоррелируемые остатки, однако это непринципиально для теста на коинтеграцию.
В рамках выявления ранга коинтеграции г, были проверены три нулевые гипотезы (НО): г = 0, г < 1 и г < 2, а также выделены две статистики, которые отвечают на вопрос: «коинте-грированы переменные или нет?». Обе статистики опровергают НО: г = 0 и не опровергают НО г <1 (таблица 1). Следовательно, наблюдается коинтеграция с г = 1. Тождественность указанных статистических данных при г < 2 подтверждает наличие единичного корня. При этом в ходе тестирования были выделены коинтегрирующий вектор (Ь) матрицы Р и корректирующий коэффициент (а) при параметре коррекции. Обеспечение единичного порядка позволило идентифицировать Ь и сформулировать его экономический смысл, при котором Ь может быть записано в рамках коинтегрирующего уравнения, подтверждающего долговременную равновесную взаимосвязь переменных и подлинность их корреляции.
Таблица 1 — Значения показателей векторной модели коррекции ошибок
Table 1 — Values of indicators of the vector error correction model
r След матрицы Максимальное число Коинтегрирующий вектор Корректирующий коэффициент
0 47,989 (0,000) 34,745 (0,000) 1, -0,00532, -0,00035 -1,142
1 13,244 (0,106) 13,221 (0,073)
2 0,023 (0,880) 0,023 (0,880)
В рамках апробации данной модели был проведен анализ деятельности банковского сектора и его влияния на экономический рост, который (анализ) позволил определить положительную корреляцию между коэффициентами финансовой глубины (и, в частности, объемами выданных кредитов) и показателями экономического роста. В качестве примера был рассмотрен реальный сектор — предприятия, работающие на внутреннем рынке (таблица 2).
Таблица 2 — Расчет коэффициентов корреляции между объемами выданных кредитов и показателями экономического роста
Table 2 — Calculation of correlation coefficients between the volume of loans issued and indicators of economic growth______
2015 2016 2017 2018 2019 Корреляция
Промышленность 35,88 9,03 20,36 10,25 10,68 0,81765
Сельское хозяйство 73,84 45,61 44,70 46,99 47,56 0,94296
Строительство -0,37 24,81 32,65 35,01 34,14 0,01243
Торговля и обществен- 50,57 31,29 26,50 19,96 19,70 0,23862
ное питание
Транспорт и связь 24,17 21,78 47,06 23,12 23,45 0,51606
Таблица 3 — Показатель задолженности предприятий основных отраслей экономики Table 3 — Indicator of indebtedness of enterprises in the main sectors of the ^ economy
2014 2015 2016 2017 2018 2019
Показатель задолженности предприятий основных отраслей экономики 5,43 8,05 7,9 7,8 6,2 6,5
Таблица 4 — Значения общих показателей кредитования в соотношении с совокупными активами и собственным капиталом банковских организаций
Table 4 — Values of general lending indicators in relation to total assets and equity of banking organizations_______
Показатель 2014 2015 2016 2017 2018 2019
Объемы выданных 20 778 21 423 22 146 24 033 26 992 27 199
кредитов банковски- 931 025 708 477 457 743
ми организациями,
млн. руб.
Объемы выданных 61,1 61,4 60,0 57,0 56,1 56,9
кредитов банковски-
ми организациями, % от общего объема
кредитов
Совокупные активы 77 653 82 999,7 800 63,3 814 29,9 801 34,7 815 60,4
банковских органи-
заций, млрд. руб.
Совокупные активы 98,0 99,7 93,0 93,6 92,1 92,7
банковских органи-
заций, % к ВВП
iНе можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Собственный капи- 7 928,4 9 008,6 9 387,1 9 144,3 9441,7 9 231,0
тал банковских орга-
низаций, млрд. руб.
Собственный капи- 10,0 10,8 10,9 10,5 10,4 10,5
тал банковских орга-
низаций, % к ВВП
Банки наиболее активно предоставляют кредитные ресурсы предприятиям экспортоори-ентированных отраслей (до 45% задолженности предприятий основных отраслей экономики (таблица 3), основная часть кредитов реальному сектору экономики носит преимущественно краткосрочный характер и направлена в большей степени на пополнение оборотных средств. Увеличение объемов долгосрочных кредитов, с одной стороны, сдерживает рост финансовой несбалансированности в реальном секторе: уменьшение сальдированного финансового ре-
зультата и, как возможное следствие, увеличение разрыва между динамикой доходов и предполагаемых выплат заемщиков. С другой стороны, очевидно несоответствие срочности ресурсной базы банковского сектора потребностям заемщиков и возможное увеличение конъюнктурного риска вследствие доминирования в масштабах среди клиентов банков предприятий сырьевых и экспортоориентированных секторов.
В рамках разработки векторной модели коррекции ошибок, а также развития функций импульсной реакции на вариацию переменных (подтверждающих наличие коинтеграции в многомерной модели, включающей более двух рядов), было отмечено, что при существующих условиях организации процесса кредитования банковская система работает не столько на увеличение объемов производства, сколько на поддержание уровня финансового состояния хозяйствующих субъектов (поддержание уровня ликвидности и увеличение финансовых вложений), не способствуя при этом изменению общей структуры российской экономики (таблица 4).
Заключение
Таким образом, объединяя в себе статическую долгосрочную и динамическую краткосрочную связи между переменными, VECM дает возможность измерить отклонения от равновесия и скорость его восстановления, что указывает на большую эффективность данной методики. При этом отметим, что приведенные результаты позволяют сделать вывод о том, что при наличии положительной взаимосвязи между объемами кредитования и основными показателями, степень влияния кредитования на экономический рост в целом незначительна.
Библиографический список
1. McKinnon R.I. Money and Capital in Economic Development. Washington, DC: Brooking Institution, 1973. 184 p. URL: https://www.brookings.edu/book/money-and-capital-in-economic-development/.
2. Allen D.S. Financial Intermediation and Economic Growth in Southern Africa / D.S. Allen, L. Ndikumana // Journal of African Economies. 2000. № 9. P. 132-160. DOI: http://dx.doi.org/10.1093/jae/9.2.132.
3. Bencivenga V.R. Financial Intermediation and Endogenous Growth / V.R. Bencivenga, B.D. Smith // The Review of Economic Studies. 1991. № 58. P. 195-209. URL: http://linksjstor.org/sici?sici=0034-6527%28199104%2958%3A2%3C195%3AFIAEG%3E2 0.C0%3B2-3.
4. Goldsmith R.W. Financial Structure and Development / R.W. Goldsmith. New Haven, CT: Yale University Press, 1969. 561 p.
5. Shaw E.S. Financial Deepening in Economic Development / E.S. Shaw. New York: Oxford University Press, 1973. 270 p.
6. Schumpeter J.A. The Theory of Economic Development // Harvard Economic Studies. 1911-1912. № 46. P. 72-74.
7. Gurley J.G. Financial Aspects of Economic Development / J.G. Gurley, E.S. Shaw // The American Economic Review. 1955. № 3. P. 515-538.
8. Андреева Е.Г., Сухова А.Н. Экономический рост. Модели экономического роста // Омский научный вестник. 2011. № 6 (102). С. 46-50. URL: https://elibrary.ru/item.asp?id=17942321.
9. Гогин, А.А. Многофакторная модель экономического роста и прогноз развития региона в среднесрочной перспективе: автореф. дис. … канд. экон. наук: 08.00.13 / Гогин Андрей Александрович. Иваново, 2013. 15 с. URL: https://dspace.kpfu.ru/xmlui/bitstream/handle/net/147187/0- 803711.pdf?sequence=-1&isAllowed=y.
10. Гиблова, Н.М. Влияние денежно-кредитной политики на экономический рост в условиях нестабильности // Банковское дело. 2015. № 2. С. 14-20. URL: http://www.library.fa.ru/files/Giblova.pdf; https://elibrary.ru/item. asp? id=23 098674.
11. Дембилов, О.Э. Роль денежно-кредитной политики Банка России в экономическом развитии государства // Российское предпринимательство. 2015. Т. 16. № 20. С. 3387-3398. DOI: http://doi.org/10.18334/rp.16.20.2009.
12. Иванов, Д.Ю., Орлова К.Ю. Моделирование взаимодействия участников банковской системы с учетом рисков // Известия Самарского научного центра Российской академии наук. 2013. Т. 15. № 6-4. С. 10741077. URL: http://www.ssc.smr.ru/media/joumals/izvestia/2013/2013_6_1074_1077.pdf; https://elibrary.ru/item.asp?id= 21834487.
References
1. McKinnon R.I. Money and Capital in Economic Development. Washington, DC: Brooking Institution, 1973, 184 p. Available at: https://www.brookings.edu/book/money-and-capital-in-economic-development/.
2. Allen D.S., Ndikumana L. Financial Intermediation and Economic Growth in Southern Africa. Journal of African Economies, 2000, no. 9, pp. 132-160. DOI: http://dx.doi.org/10.1093/jae/9.2.132.
3. Bencivenga V.R., Smith B.D. Financial Intermediation and Endogenous Growth. The Review of Economic Studies, 1991, no. 58, pp. 195-209. Available at: http://linksjstor.org/sici?sici=0034-6527%28199104%2958%3A2%3C195%3AFIAEG%3E2.0.C0%3B2-3.
4. Goldsmith R.W. Financial Structure and Development. New Haven, CT: Yale University Press, 1969, 561 p.
5. Shaw E.S. Financial Deepening in Economic Development. New York: Oxford University Press, 1973, 270 p.
6. Schumpeter J.A. The Theory of Economic Development. Harvard Economic Studies, 1911-1912, no. 46, pp. 72-74.
7. Gurley J.G., Shaw E.S. Financial Aspects of Economic Development. The American Economic Review, 1955, no. 3, pp. 515-538.
8. Andreeva E.G., Sukhova A.N. Economic growth. Models of economic growth. Omsk Scientific Bulletin, 2011, no. 6 (102), pp. 46-50. Available at: https://elibrary.ru/item.asp?id=17942321. (In Russ.)
9. Gogin A.A. A multifactor model of economic growth and a forecast for the development of the region in the medium term. Ivanovo, 2013, 15 p. Available at: https://dspace.kpfu.ru/xmlui/bitstream/handle/net/147187/0-803711.pdf?sequence=-1&isAllowed=y. (In Russ.)
10. Giblova N.M. The influence of monetary policy on economic growth in conditions of instability. Banking, 2015, no. 2, pp. 14-20. Available at: http://www.library.fa.ru/files/Giblova.pdf; https://elibrary.ru/ item.asp?id=23098674. (In Russ.)
11. Dembilov O.E. The role of monetary policy of the Bank of Russia in the state’s economic development. Russian Journal of Entrepreneurship, 2015, vol. 16, no. 20, pp. 3387-3398. DOI: https://doi.org/10.18334/rp.16.20.2009. (In Russ.)
12. Orlova C.Yu., Ivanov D.Y. Banking system participants interaction modeling with an allowance for risk. Izvestia of Samara Scientific Center of the Russian Academy of Sciences, 2013, vol. 15, no. 6-4, pp. 1074-1077. Available at: http://www.ssc.smr.ru/media/journals/izvestia/2013/2013_6_1074_1077.pdf; https://elibrary.ru/ item.asp?id=21834487. (In Russ.)
Модель исправления ошибок (ECM) относится к категории моделей нескольких временных рядов, наиболее часто используемых для данных, в которых базовые переменные имеют долгосрочный общий стохастический тренд, также известный как коинтеграция . ECM — это теоретически обоснованный подход, полезный для оценки как краткосрочных, так и долгосрочных эффектов одного временного ряда на другой. Термин «исправление ошибок» относится к тому факту, что отклонение последнего периода от долгосрочного равновесия, ошибка , влияет на его краткосрочную динамику. Таким образом, ECM напрямую оценивают скорость, с которой зависимая переменная возвращается в состояние равновесия после изменения других переменных.
История ECM
Юл (1926) и Грейнджер и Ньюболд (1974) были первыми, кто привлек внимание к проблеме ложной корреляции и нашел решения о том, как ее решать при анализе временных рядов. Учитывая два совершенно не связанных, но интегрированных (нестационарных) временных ряда, регрессионный анализ одного по другому будет иметь тенденцию давать явно статистически значимую взаимосвязь, и, таким образом, исследователь может ошибочно полагать, что нашел доказательства истинной взаимосвязи между этими переменными. Обычные методы наименьших квадратов больше не будут согласованными, а часто используемые тестовые статистические данные будут недействительными. В частности, моделирование методом Монте-Карло показывает, что можно получить очень высокий R-квадрат , очень высокую индивидуальную t-статистику и низкую статистику Дарбина – Ватсона . С технической точки зрения Филлипс (1986) доказал, что оценки параметров не будут сходиться по вероятности , точка пересечения будет расходиться, а наклон будет иметь невырожденное распределение по мере увеличения размера выборки. Однако может существовать общий стохастический тренд для обоих рядов, который искренне интересует исследователя, поскольку он отражает долгосрочную взаимосвязь между этими переменными.
Из-за стохастической природы тренда невозможно разбить интегрированный ряд на детерминированный (предсказуемый) тренд и стационарный ряд, содержащий отклонения от тренда. Даже при детерминированном исключении тренда случайного блуждания в конечном итоге возникнут ложные корреляции. Таким образом, снятие тренда не решает проблему оценки.
Чтобы по-прежнему использовать подход Бокса – Дженкинса , можно было бы различать ряды, а затем оценивать модели, такие как ARIMA , учитывая, что многие обычно используемые временные ряды (например, в экономике) кажутся стационарными в первых различиях. Прогнозы на основе такой модели по-прежнему будут отражать циклы и сезонность, которые присутствуют в данных. Однако любая информация о долгосрочных корректировках, которую могут содержать данные в уровнях, опускается, и долгосрочные прогнозы будут ненадежными.
Это привело Саргана (1964) к разработке методологии ECM, которая сохраняет информацию об уровне.
Предварительный расчет
В литературе известно несколько методов оценки уточненной динамической модели, как описано выше. К ним относятся двухэтапный подход Энгла и Грейнджера, оценивающий их ECM за один этап, и VECM на основе векторов с использованием метода Йохансена .
Двухэтапный подход Энгла и Грейнджер
Первым шагом этого метода является предварительная проверка отдельных используемых временных рядов, чтобы подтвердить, что они изначально нестационарны . Это можно сделать с помощью стандартного модульного корневого DF-тестирования и ADF-теста (для решения проблемы серийно коррелированных ошибок). Возьмем случай двух разных серий и . Если оба равны I (0), будет действителен стандартный регрессионный анализ. Если они интегрированы в другом порядке, например, один является I (1), а другой — I (0), необходимо преобразовать модель.
Если они оба интегрированы в одном порядке (обычно I (1)), мы можем оценить модель ECM в виде
Если обе переменные интегрированы и этот ЕСМ существует, они объединяются теоремой Энгла – Грейнджера о представлении.
Второй этап затем оценить модель с помощью обычных наименьших квадратов :
Если регрессия не поддельный, как определено в соответствии с критериями испытаний было описано выше, метод наименьших квадратов будет не только силу, но на самом деле очень последовательным (Шток, 1987). Затем прогнозируемые остатки из этой регрессии сохраняются и используются в регрессии разностных переменных плюс запаздывающий член ошибки.
Затем можно проверить коинтеграцию с помощью стандартного т-статистики на . Хотя этот подход прост в применении, существует множество проблем:
VECM
Подход Энгла – Грейнджера, описанный выше, страдает рядом недостатков. А именно, он ограничен только одним уравнением с одной переменной, обозначенной как зависимая переменная, объясненной другой переменной, которая, как предполагается, является слабо экзогенной для интересующих параметров. Он также основан на предварительном тестировании временных рядов, чтобы выяснить, являются ли переменные I (0) или I (1). Эти недостатки можно устранить с помощью процедуры Йохансена. Его преимущества заключаются в том, что предварительное тестирование не требуется, может существовать множество коинтегрирующих взаимосвязей, все переменные рассматриваются как эндогенные, и возможны тесты, относящиеся к долгосрочным параметрам. Полученная модель известна как модель векторной коррекции ошибок (VECM), поскольку она добавляет функции коррекции ошибок в многофакторную модель, известную как векторная авторегрессия (VAR). Процедура выполняется следующим образом:
- Шаг 1: оцените неограниченную VAR, включающую потенциально нестационарные переменные
- Шаг 2: Проверьте коинтеграцию с помощью теста Йохансена
- Шаг 3: Сформируйте и проанализируйте VECM.
Пример ECM
Идея коинтеграции может быть продемонстрирована в простой макроэкономической обстановке. Предположим, потребление и располагаемый доход — это макроэкономические временные ряды, которые связаны в долгосрочном плане (см. Гипотезу о постоянном доходе ). В частности, пусть средняя склонность к потреблению будет 90%, то есть в долгосрочной перспективе . С точки зрения эконометриста, эта долгосрочная взаимосвязь (также известная как коинтеграция) существует, если ошибки регрессии являются стационарными рядами, хотя и нестационарны. Предположим также, что если внезапно изменяется на , то изменяется на , то есть предельная склонность к потреблению равна 50%. Наше окончательное предположение состоит в том, что разрыв между текущим и равновесным потреблением уменьшается каждый период на 20%.
В этой настройке изменение уровня потребления можно смоделировать как . Первый член в правой части таблицы описывает краткосрочное влияние изменения на , второй член объясняет долгосрочное стремление к равновесному соотношению между переменными, а третий член отражает случайные шоки, которые получает система (например, шоки уверенности потребителей в том, что влияют на расход). Чтобы увидеть, как работает модель, рассмотрим два вида шоков: постоянные и временные (временные). Для простоты положим равным нулю для всех t. Предположим, что в период т — 1 система находится в равновесии, то есть . Предположим, что за период t увеличивается на 10, а затем возвращается на прежний уровень. Затем первый (в период t) увеличивается на 5 (половина от 10), но после второго периода начинает уменьшаться и сходится к своему исходному уровню. Напротив, если шок является постоянным, то медленно приближается к значению, превышающему начальное на 9.
Эта структура общая для всех моделей ECM. На практике эконометристы часто сначала оценивают взаимосвязь коинтеграции (уравнение в уровнях), а затем вставляют его в основную модель (уравнение в разностях).
использованная литература
дальнейшее чтение
- Доладо, Хуан Дж .; Гонсало, Хесус; Мармол, Франсеск (2001). «Коинтеграция». В Балтаги, Бади Х. (ред.). Компаньон теоретической эконометрики . Оксфорд: Блэквелл. стр. 634 -654. DOI : 10.1002 / 9780470996249.ch31 . ISBN 0-631-21254-X .
- Эндерс, Уолтер (2010). Прикладные эконометрические временные ряды (Третье изд.). Нью-Йорк: Джон Вили и сыновья. С. 272–355. ISBN 978-0-470-50539-7 .
- Lütkepohl, Гельмут (2006). Новое введение в анализ множественных временных рядов . Берлин: Springer. стр. 237 -352. ISBN 978-3-540-26239-8 .
- Мартин, Вэнс; Херн, Стэн; Харрис, Дэвид (2013). Эконометрическое моделирование с использованием временных рядов . Нью-Йорк: Издательство Кембриджского университета. С. 662–711. ISBN 978-0-521-13981-6 .
Цель данной статьи — поделиться результатами сравнительного анализ двух тестов на коинтеграцию, теста Энгла-Гренджера и теста Йохансена. Для этого нам понадобится рассмотреть соотношение между двумя и более переменными, понять, что такое VAR процесс, как перейти к VECM модели, в чем заключается процедура Йохансена, и как интерпретировать результат статистического теста, полученного от стандартного пакета типа Matlab.
VAR процесс
Регрессия полезна, когда анализируются только два ряда, потому что в этом случае может быть не более одного коэффициента коинтеграции. В случае со многими переменными может быть более одного вектора коинтеграции. Следовательно, нужна методология, которая бы определила структуру всех векторов коинтеграции.
Векторный авторегрессионный (VAR) процесс, основанный на гауссовых (нормально распределенных) ошибках, часто использовался в качестве описания макроэкономических временных рядов. Причин для этого много: VAR-модель гибкая, легко оцениваемая и, как правило, хорошо вписывается в макроэкономические данные. Однако возможность объединения долгосрочной и краткосрочной информации с использованием свойств коинтеграции, вероятно, является наиболее важной причиной, по которой VAR-модель продолжает вызывать интерес как у эконометристов, так и у прикладных экономистов.
Теоретические экономические модели традиционно разрабатывались как неслучайные математические сущности и часто применялись к эмпирическим данным путем добавления процесса случайных ошибок в математическую модель.
С эконометрической точки зрения эти два подхода принципиально отличаются друг от друга: первый начинается с явной случайной формулировки всех данных, а затем сужает общую статистическую (динамическую) модель путем наложения поддающихся проверке ограничений на параметры, второй начинается с математической (статической) формулировки теоретической модели, а затем расширяет модель путем добавления случайных компонентов.
К сожалению, было доказано, что эти два подхода, даже если применяются к идентичным данным, дают очень разные результаты, поэтому приводят к различным выводам. С научной точки зрения это неудовлетворительно. Поэтому здесь мы попытаемся преодолеть разрыв между двумя точками зрения, начав с некоторых типичных вопросов, которые представляют теоретический интерес, а затем покажем, как можно ответить на эти вопросы на основе статистического анализа VAR-модели. Поскольку статистический анализ по своей конструкции «больше», чем теоретическая модель, он не только отвечает на конкретные теоретические вопросы, но и дает дополнительное представление о макроэкономической проблеме.
Теоретическую модель можно упростить, сделав допущение «при прочих равных условиях», то есть что «все остальное неизменно», в то время как статистически четкая эмпирическая модель должна решать теоретическую проблему в контексте «все остальное меняется». Встраивая теоретическую модель в более широкие эмпирические рамки, анализ статистически обоснованной модели может подтвердить наличие подводных камней в макроэкономическом рассуждении. В этом смысле VAR-анализ может быть полезен для создания новых гипотез или для изменения слишком узко заданных теоретических моделей.
На практике полезно классифицировать переменные, которые характеризуются высокой степенью персистентности во времени (незначительный возврат к среднему), как нестационарные, а переменные, характеризующиеся значительной тенденцией возврата к среднему, как стационарные. Однако важно подчеркнуть, что стационарность / нестационарность или, наоборот, порядок интегрирования являются не свойством экономической переменной, а удобным статистическим приближением для разграничения краткосрочных, среднесрочных и долгосрочных изменений в данных.
Перейдем к случаю, когда мы наблюдаем вектор ![]() переменных. В этом случае необходимо дополнительно обсудить ковариации между переменными в момент времени
переменных. В этом случае необходимо дополнительно обсудить ковариации между переменными в момент времени ![]() , а также их ковариации между моментами времени
, а также их ковариации между моментами времени ![]() и
и ![]() . Ковариации содержат информацию о статических и динамических связях между переменными, которую мы хотели бы раскрыть с помощью эконометрики. Для простоты
. Ковариации содержат информацию о статических и динамических связях между переменными, которую мы хотели бы раскрыть с помощью эконометрики. Для простоты ![]() будет использоваться для обозначения как случайной величины, так и ее реализации.
будет использоваться для обозначения как случайной величины, так и ее реализации.
Рассмотрим ![]() -мерный вектор
-мерный вектор ![]() :
:
![x_t = left[begin{array}{c} x_{1,t} x_{2,t} vdots x_{p,t} end{array}right], t = 1,dots,T.](https://habrastorage.org/getpro/habr/upload_files/d8b/a7e/61e/d8ba7e61e9820c631601ea21aeb9cfce.svg)
Введем следующее обозначение на случай, когда не были сделаны упрощающие предположения:
![E[x_t] = left[begin{array}{c} mu_{1,t} mu_{2,t} vdots mu_{p,t} end{array}right], Cov[x_t,x_{t-h}] = left[begin{array}{cccc} sigma_{11.h} & sigma_{12.h} & dots & sigma_{1p.h} sigma_{21.h} & sigma_{22.h} & dots & sigma_{2p.h} vdots & vdots & ddots & vdots sigma_{p1.h} & sigma_{p2.h} & dots & sigma_{pp.h} end{array}right] = Sigma_{t.h}, t = 1,dots,T.](https://habrastorage.org/getpro/habr/upload_files/7d1/db4/723/7d1db472364665e54e606f66553b3238.svg)
Теперь предположим, что одно и то же распределение применимо ко всем ![]() и что распределение приблизительно нормально, поэтому первые два момента вокруг среднего значения (центральные моменты) являются достаточными для описания вариации в данных. Введем обозначение:
и что распределение приблизительно нормально, поэтому первые два момента вокруг среднего значения (центральные моменты) являются достаточными для описания вариации в данных. Введем обозначение:
![Z = left[begin{array}{c} x_1 x_2 vdots x_T end{array}right], E[Z] = left[begin{array}{c} mu_1 mu_2 vdots mu_T end{array}right] = tilde mu,](https://habrastorage.org/getpro/habr/upload_files/00d/e07/0cf/00de070cfef179e12d7d01ee2fc8e7a5.svg)
где ![]() — вектор размерности
— вектор размерности ![]() . Ковариационная матрица представлена следующим образом
. Ковариационная матрица представлена следующим образом
![E[(Z - tilde mu)(Z - tilde mu)'] = left[begin{array}{ccccc} Sigma_{1.0} & Sigma_{2.1}^{'} & dots & Sigma_{T-1.T-2}^{'} & Sigma_{T.T-1}^{'} Sigma_{2.1} & Sigma_{2.0} & & dots & Sigma_{T.T-2}^{'} vdots & vdots & ddots & vdots & vdots Sigma_{T-1.T-2} & vdots & & Sigma_{T-1.0} & Sigma_{T.1}^{'} Sigma_{T.T-1} & Sigma_{T.T-2} & dots & Sigma_{T.1} & Sigma_{T.0} end{array}right] = sum_{(Tp times Tp)}^{sim},](https://habrastorage.org/getpro/habr/upload_files/ba5/7f5/e1b/ba57f5e1b467f2ee3d2f270411fff33b.svg)
где ![]() . Вышеприведенное обозначение дает полное общее описание многомерного нормального векторного случайного процесса. Поскольку параметров для оценки гораздо больше, чем наблюдений, то с практической точки зрения такое описание бесполезно, и необходимо упростить предположения для сокращения числа параметров. Эмпирические модели обычно основаны на следующих предположениях:
. Вышеприведенное обозначение дает полное общее описание многомерного нормального векторного случайного процесса. Поскольку параметров для оценки гораздо больше, чем наблюдений, то с практической точки зрения такое описание бесполезно, и необходимо упростить предположения для сокращения числа параметров. Эмпирические модели обычно основаны на следующих предположениях:
Теперь мы можем записать среднее значение и ковариации в более простой форме:
![tilde mu = left[begin{array}{c} mu mu vdots mu end{array}right], tilde Sigma = left[begin{array}{ccccc} Sigma_{0} & Sigma_{1}^{'} & Sigma_{2}^{'} & dots & Sigma_{T-1}^{'} Sigma_{1} & Sigma_{0} & Sigma_{1}^{'} & ddots & vdots Sigma_{2} & Sigma_{1} & Sigma_{0} & ddots & Sigma_{2}^{'} vdots & ddots & ddots & ddots & Sigma_{1}^{'} Sigma_{T-1} & dots & Sigma_{2} & Sigma_{1} & Sigma_{0} end{array}right].](https://habrastorage.org/getpro/habr/upload_files/c13/eda/a3b/c13edaa3b7ed93aa43f83d4b842172ce.svg)
Два приведенных выше допущения для бесконечного ![]() определяют слабо стационарный процесс. Когда эти два предположения будут выполнены, VAR-модель будет иметь постоянные параметры.
определяют слабо стационарный процесс. Когда эти два предположения будут выполнены, VAR-модель будет иметь постоянные параметры.
Пусть ![]() — случайный процесс (упорядоченный ряд случайных переменных) для
— случайный процесс (упорядоченный ряд случайных переменных) для ![]() . Тогда
. Тогда ![]() считается стационарным в широком смысле. Стационарность в узком смысле требует, чтобы распределение
считается стационарным в широком смысле. Стационарность в узком смысле требует, чтобы распределение ![]() было таким же, как
было таким же, как ![]() для
для ![]()
Эмпирический анализ начинается с матрицы ![]() , где
, где ![]() — это
— это ![]() вектор переменных. Исходя из предположения, что наблюдаемые данные
вектор переменных. Исходя из предположения, что наблюдаемые данные ![]() являются реализацией случайного процесса, можно выразить совместную вероятность
являются реализацией случайного процесса, можно выразить совместную вероятность ![]() при заданном начальном значении
при заданном начальном значении ![]() и значении параметра
и значении параметра ![]() , описывающего случайный процесс:
, описывающего случайный процесс:
![]()
Для данной функции вероятности оценки максимального правдоподобия могут быть найдены путем максимизации функции правдоподобия. Здесь мы ограничимся обсуждением многомерного нормального распределения. Для выражения совместной вероятности ![]() удобно использовать процесс
удобно использовать процесс ![]() вместо
вместо ![]() матрицы
матрицы ![]() . Поскольку у
. Поскольку у ![]() размерность
размерность ![]() , а у
, а у ![]() —
— ![]() , то параметров гораздо больше, чем наблюдений без упрощения допущений. Но даже если мы вводим упрощающие ограничения на среднее значение и ковариации процесса, они не дают прямой информации об экономическом поведении. Поэтому, разложив совместный процесс на условный и частный, а затем последовательно повторяя разложение для частного процесса, мы можем получить более полезную формулировку:
, то параметров гораздо больше, чем наблюдений без упрощения допущений. Но даже если мы вводим упрощающие ограничения на среднее значение и ковариации процесса, они не дают прямой информации об экономическом поведении. Поэтому, разложив совместный процесс на условный и частный, а затем последовательно повторяя разложение для частного процесса, мы можем получить более полезную формулировку:

где
![]()
Теперь покажем, что VAR-модель является условным процессом
![]()
Можно увидеть, как ![]() и
и ![]() связаны с
связаны с ![]() и
и ![]() . Сначала разложим данные на два набора, вектор
. Сначала разложим данные на два набора, вектор ![]() и условный набор
и условный набор ![]() , то есть
, то есть
![X = left[begin{array}{c} x_t X_{t-1}^0 end{array}right].](https://habrastorage.org/getpro/habr/upload_files/f6b/69f/479/f6b69f47914f0948b2282bba306c5fd4.svg)
Запишем частный и условный процесс:
![]()
![]()
![y_{2,t} = left[begin{array}{c} x_{t-1} x_{t-2} vdots x_1 end{array}right],](https://habrastorage.org/getpro/habr/upload_files/f70/769/0ff/f707690ff1095995fb459cbcf82dabd1.svg)
![m_2 = left[begin{array}{c} E[x_{t-1}] E[x_{t-2}] vdots E[x_1] end{array}right],](https://habrastorage.org/getpro/habr/upload_files/4a0/9fb/25d/4a09fb25dd0d8ab40c1920cf1a6b0d9c.svg)
![tilde Sigma = left[begin{array}{c|ccc} Sigma_0 & Sigma_1^{'} & dots & Sigma_{T-1}^{'} hline Sigma_1 & Sigma_{0} & Sigma_1^{'} & vdots vdots & ddots & ddots & Sigma_1^{'} Sigma_{T-1} & dots & Sigma_1 & Sigma_0 end{array}right] = left[begin{array}{cc} Sigma_{11} & Sigma_{12} Sigma_{21} & Sigma_{22} end{array}right].](https://habrastorage.org/getpro/habr/upload_files/79d/23c/978/79d23c9784d2ae8021131119b86c1be3.svg)
Теперь можно вывести параметры условной модели:
![]()
где
![]()
и
![]()
Разница между наблюдаемым значением процесса и его условным средним значением обозначена как ![]() :
:
![]()
Подставляя выражение для условного среднего значения, получаем:
![]()
![]()
Используя обозначение ![]() ,
, ![]() и принимая, что
и принимая, что ![]() , получаем векторную авторегрессионную модель
, получаем векторную авторегрессионную модель ![]() -го порядка:
-го порядка:
![]()
![]()
где ![]() —
— ![]() , а
, а ![]() считаются заданными.
считаются заданными.
Если верно предположение, что ![]() является многомерным нормальным
является многомерным нормальным ![]() процессом, то из этого следует, что VAR-модель:
процессом, то из этого следует, что VAR-модель:
-
линейна по параметрам;
-
имеет постоянные параметры;
-
имеет нормально распределенные ошибки
 .
.
Обратите внимание, что постоянство параметров зависит от постоянства ковариационных матриц ![]() и
и ![]() . Если какая-либо из них изменится в результате преобразования или вмешательства во время анализа выборки, вероятно, изменятся как свободный член
. Если какая-либо из них изменится в результате преобразования или вмешательства во время анализа выборки, вероятно, изменятся как свободный член ![]() , так и «коэффициенты наклона»
, так и «коэффициенты наклона» ![]() . Таким образом, допущения о постоянстве параметров сильно зависят от контекста и обычно требуют, чтобы для соответствующего периода времени моделировались все основные известные структурные изменения.
. Таким образом, допущения о постоянстве параметров сильно зависят от контекста и обычно требуют, чтобы для соответствующего периода времени моделировались все основные известные структурные изменения.
Было показано, что VAR-модель по сути представляет собой переформулировку ковариаций данных. Вопрос заключается в том, можно ли интерпретировать модель с точки зрения рационального экономического поведения, и если да, то можно ли использовать модель в качестве «плана эксперимента», когда данные собираются путем пассивных наблюдений. Идея заключается в интерпретации условного среднего значения ![]() VAR-модели как описания планов агентов во время
VAR-модели как описания планов агентов во время ![]() с учетом имеющейся информации
с учетом имеющейся информации ![]() . В соответствии с допущениями VAR-модели, разница между средним значением и фактической реализацией представляет собой процесс белого шума
. В соответствии с допущениями VAR-модели, разница между средним значением и фактической реализацией представляет собой процесс белого шума
![]()
![]()
![]()
Таким образом, допущение ![]() согласуется с экономическими агентами, которые рациональны в том смысле, что они не допускают систематических ошибок при составлении планов на время
согласуется с экономическими агентами, которые рациональны в том смысле, что они не допускают систематических ошибок при составлении планов на время ![]() на основе имеющейся информации в момент времени
на основе имеющейся информации в момент времени ![]() . Например, VAR-модель с автокоррелированными и/или гетероскедастическими остатками описывает агентов, которые не используют всю информацию, содержащуюся в данных, как можно более эффективно. Это связано с тем, что, включив систематические изменения в остатки, агенты могут повысить точность, с которой они реализуют свои планы. Поэтому проверка предположений модели, то есть проверка остатков на соответствие белому шуму, имеет решающее значение не только для правильного статистического вывода, но и для экономической интерпретации модели как примерного описания поведения рациональных агентов.
. Например, VAR-модель с автокоррелированными и/или гетероскедастическими остатками описывает агентов, которые не используют всю информацию, содержащуюся в данных, как можно более эффективно. Это связано с тем, что, включив систематические изменения в остатки, агенты могут повысить точность, с которой они реализуют свои планы. Поэтому проверка предположений модели, то есть проверка остатков на соответствие белому шуму, имеет решающее значение не только для правильного статистического вывода, но и для экономической интерпретации модели как примерного описания поведения рациональных агентов.
К сожалению, во многих экономических приложениях допущение о многомерной нормальности для VAR-модели в ее простейшей форме не выполняется. Поскольку в целом статистические выводы справедливы только в той степени, в какой удовлетворяются предположения, заложенные в основу модели, это потенциально является серьезной проблемой. Поэтому нужно спросить, возможно ли модифицировать базовую VAR-модель таким образом, чтобы она сохраняла свою привлекательность в качестве удобного описания основных свойств данных и в то же время позволяла делать обоснованные выводы.
Исследования в области моделирования показали, что достоверные статистические выводы чувствительны к нарушению некоторых допущений, таких как параметрическая нестабильность, автокорреляция остатков (чем выше, тем хуже) и асимметричные остатки, при этом достаточно устойчивы к другим, таким как избыточный коэффициент эксцесса и гетероскедастичность остатков.
В любом случае, прямое или косвенное тестирование предположений имеет решающее значение для успеха эмпирического применения. Как только мы поймем причины, по которым модель не удовлетворяет допущениям, часто появляется возможность модифицировать модель, чтобы в итоге получить статистически «хорошо себя зарекомендовавшую» модель. Важными инструментами в этом контексте являются:
-
использование интервенционных фиктивных переменных для объяснения значимых политических или институциональных событий в выборке;
-
обусловленность слабо или сильно экзогенными переменными;
-
проверка измерений выбранных переменных;
-
коррекция периода выборки, чтобы избежать структурных изменений или разделить выборку на более однородные периоды.
ECM процесс
Так называемая векторная модель исправления ошибок (далее VECM) дает удобную переформулировку VAR-модели в терминах разностей, запаздывающих разностей и уровней процесса. У этой формулировки есть несколько преимуществ:
-
Эффект мультиколлинеарности, который обычно сильно проявляется в данных временных рядов, значительно снижается в форме исправления ошибок. Разности гораздо более «ортогональны», чем уровни переменных.
-
Вся информация о долгосрочных эффектах обобщается в матрице уровней (в дальнейшем обозначена как
 ). Следовательно, ей можно уделить особое внимание при решении проблемы коинтеграции.
). Следовательно, ей можно уделить особое внимание при решении проблемы коинтеграции. -
Интерпретация оценок интуитивно более понятна, поскольку коэффициенты можно естественным образом разделить на краткосрочные и долгосрочные эффекты.
-
Формулировка VECM дает прямой ответ на вопрос, «почему цена актива изменилась с предыдущего по настоящий период в результате изменений в выбранном наборе информации».
Теперь рассмотрим модель VAR![]() , сформулированную в общей форме VECM без константы и тренда:
, сформулированную в общей форме VECM без константы и тренда:
![]()
где ![]() — целое число между 1 и
— целое число между 1 и ![]() , определяющее положение лага ECM-члена. Обратите внимание, что значение функции правдоподобия не меняется даже при изменении значения
, определяющее положение лага ECM-члена. Обратите внимание, что значение функции правдоподобия не меняется даже при изменении значения ![]() .
.
VAR(2)-модель в VECM формулировке при ![]() определена как:
определена как:
![]()
где ![]() , а
, а ![]() . В уравнении лагированная матрица уровней
. В уравнении лагированная матрица уровней ![]() находится во времени
находится во времени ![]() .
.
CVAR процесс
Рассмотрим нестационарную VAR-модель и покажем, что наличие единичных корней (стохастических трендов) приводит к условию неполного ранга ![]() на матрице долгосрочных уровней
на матрице долгосрочных уровней ![]() .
.
Коинтеграция подразумевает, что определенные линейные комбинации переменных векторного процесса интегрированы более низким порядком, чем сам процесс. Таким образом, если нестационарность одной переменной соответствует нестационарности другой, то существует их линейная комбинация, которая становится стационарной. Другой способ выразить это взаимоотношение заключается в том, что когда две или несколько переменных имеют общие стохастические (и детерминистические) тренды, они будут иметь тенденцию двигаться вместе в долгосрочной перспективе. Такие векторы коинтеграции ![]() часто могут быть интерпретированы как долгосрочные равновесные соотношения переменных и, следовательно, представляют значительный экономический интерес.
часто могут быть интерпретированы как долгосрочные равновесные соотношения переменных и, следовательно, представляют значительный экономический интерес.
В рамках VAR-модели гипотеза о коинтеграции может быть сформулирована в виде ограничения на неполный ранг матрицы ![]() . Воспроизведем ниже VAR(2)-модель в виде ECM с
. Воспроизведем ниже VAR(2)-модель в виде ECM с ![]() :
:
![]()
и дадим оценку неограниченной матрице ![]() .
.
Если ![]() , то
, то ![]() . Из этого следует, что
. Из этого следует, что ![]() не может иметь полного ранга, так как обратное приведет к логическому несоответствию в уравнении. Рассмотрим
не может иметь полного ранга, так как обратное приведет к логическому несоответствию в уравнении. Рассмотрим ![]() как простую матрицу с полным рангом. В этом случае в каждом уравнении стационарная переменная
как простую матрицу с полным рангом. В этом случае в каждом уравнении стационарная переменная ![]() будет равна нестационарной переменной
будет равна нестационарной переменной ![]() плюс некоторые запаздывающие стационарные переменные
плюс некоторые запаздывающие стационарные переменные ![]() и член со стационарной ошибкой. Поскольку стационарная переменная не может быть равна нестационарной переменной, то либо
и член со стационарной ошибкой. Поскольку стационарная переменная не может быть равна нестационарной переменной, то либо ![]() , либо матрица должна иметь неполный ранг:
, либо матрица должна иметь неполный ранг:
![]()
где ![]() и
и ![]() —
— ![]() -матрицы,
-матрицы, ![]() . Таким образом, при гипотезе
. Таким образом, при гипотезе ![]() имеем коинтегрированную VAR(2)-модель:
имеем коинтегрированную VAR(2)-модель:
![]()
где ![]() —
— ![]() — вектор коинтеграции.
— вектор коинтеграции. ![]() интерпретируется как скорость приведения процесса к равновесию. В соответствии с гипотезой о том, что
интерпретируется как скорость приведения процесса к равновесию. В соответствии с гипотезой о том, что ![]() , все стохастические компоненты в модели являются стационарными, и система теперь логически непротиворечива.
, все стохастические компоненты в модели являются стационарными, и система теперь логически непротиворечива.
Если ![]() , то
, то ![]() стационарно, и применяется стандартный вывод. Если
стационарно, и применяется стандартный вывод. Если ![]() , то в
, то в ![]() существует
существует ![]() автономных трендов, так что каждый
автономных трендов, так что каждый ![]() является нестационарным со своим собственным индивидуальным трендом. По сути мы имеем VAR-процесс в ряде разностей. В этом случае векторный процесс управляется
является нестационарным со своим собственным индивидуальным трендом. По сути мы имеем VAR-процесс в ряде разностей. В этом случае векторный процесс управляется ![]() различными стохастическими трендами, и невозможно получить векторы коинтеграции между уровнями переменных. Мы говорим, что переменные не имеют общих стохастических трендов и, следовательно, не движутся вместе во времени.
различными стохастическими трендами, и невозможно получить векторы коинтеграции между уровнями переменных. Мы говорим, что переменные не имеют общих стохастических трендов и, следовательно, не движутся вместе во времени.
В этом случае VAR-модель с уровнями может быть переформулирована в VAR-модель с разностями без потери долгосрочной информации. Поскольку ![]() , в модели с разностями применяется стандартный вывод. Если
, в модели с разностями применяется стандартный вывод. Если ![]() , то
, то ![]() и существует
и существует ![]() направлений, по которым процесс можно сделать стационарным с помощью линейных комбинаций. Это и есть векторы коинтеграции. Причина нашего интереса к ним заключается в том, что они часто могут быть интерпретированы как отклонения от стабильных экономических отношений.
направлений, по которым процесс можно сделать стационарным с помощью линейных комбинаций. Это и есть векторы коинтеграции. Причина нашего интереса к ним заключается в том, что они часто могут быть интерпретированы как отклонения от стабильных экономических отношений.
R процесс (консолидация общей VAR модели)
Рассмотрим VAR![]() модель в форме ECM с
модель в форме ECM с ![]() :
:
![]()
где ![]() ,
, ![]() — это
— это ![]() вектор,
вектор, ![]() ,
, ![]() — количество детерминированных компонент, таких как константа или тренд, а начальные значения
— количество детерминированных компонент, таких как константа или тренд, а начальные значения ![]() считаются заданными.
считаются заданными.
Мы используем следующие сокращенные обозначения:
![Z_{0t} = Delta x_t,Z_{1t} = tilde x_{t - 1},Z_{2t} = [Delta x'_{t -1}, Delta x'_{t-2}, dots, Delta x'_{t - k + 1}],](https://habrastorage.org/getpro/habr/upload_files/860/758/c6c/860758c6c96eaacf910f6e26ed73c11b.svg)
тогда мы можем переписать VAR![]() модель в более компактной форме:
модель в более компактной форме:
![]()
где ![]() . Теперь мы консолидируем краткосрочные «транзитные» эффекты,
. Теперь мы консолидируем краткосрочные «транзитные» эффекты, ![]() , чтобы получить «чистую» модель долгосрочной коррекции. Чтобы объяснить идею «консолидации», которая используется во многих различных ситуациях в эконометрике, мы сначала проиллюстрируем ее использование в модели множественной регрессии.
, чтобы получить «чистую» модель долгосрочной коррекции. Чтобы объяснить идею «консолидации», которая используется во многих различных ситуациях в эконометрике, мы сначала проиллюстрируем ее использование в модели множественной регрессии.
Теорема Фриша-Во-Ловела (Frisch-Waugh-Lovell, FWL) гласит, что OLS-оценка ![]() в модели линейной регрессии,
в модели линейной регрессии, ![]() может быть получена в два этапа.
может быть получена в два этапа.
-
Построить регрессию
от  , получая остатки из
, получая остатки из  .
.
Построить регрессиюот , получая остатки из  .
. -
Построить регрессию
от , чтобы получить оценку  , то есть
, то есть  .
.
Таким образом сначала мы консолидируем влияние ![]() на
на ![]() и
и ![]() , а затем строим регрессию для «очищенного»
, а затем строим регрессию для «очищенного» ![]() , то есть
, то есть ![]() , от «очищенного»
, от «очищенного» ![]() , то есть
, то есть ![]() .
.
Воспользуемся той же идеей для VAR-модели. Сначала определим вспомогательные регрессии:

где ![]() ,
, ![]() — МНК оценки,
— МНК оценки, ![]() . Таким образом, это эмпирические аналоги ковариационных матриц
. Таким образом, это эмпирические аналоги ковариационных матриц ![]() .
.
Консолидированная модель
![]()
важна для понимания как статистических, так и экономических свойств VAR-модели. Путем консолидации исходная «грязная» VAR, содержащая краткосрочные эффекты коррекции и интервенции, была преобразована в «чистую» равновесную форму коррекции, в которой коррекция происходит исключительно в направлении долгосрочных равновесных отношений. Это означает, что мы не только преобразовали «грязную» эмпирическую модель в красивую статистическую модель, но и в более интерпретируемую экономическую форму.
Тест Йохансена
Тест Йохансена, также называемый LR-тестом на коинтеграционный ранг или тестом следа (трейс тестом), основан на VAR-модели в R-форме, где сконцентрирована вся краткосрочная динамика, фиктивные и другие детерминированные компоненты:
![]()
Тест Йохансена называется тестом следа, потому что асимптотическое распределение статистики является следом матрицы, основанной на функциях броуновского движения или стандартных винеровских процессах. Тест Йохансена для определения ранга коинтеграции ![]() включает следующие гипотезы:
включает следующие гипотезы:
Соответствующая LR-статистика имеет вид (статистика следа):

где ![]() можно интерпретировать как квадрат канонических корреляций между линейной комбинацией уровней
можно интерпретировать как квадрат канонических корреляций между линейной комбинацией уровней ![]() и линейной комбинацией разностей
и линейной комбинацией разностей ![]() . В этом смысле величина
. В этом смысле величина ![]() является показателем того, насколько сильно линейное отношение
является показателем того, насколько сильно линейное отношение ![]() коррелирует со стационарной частью процесса
коррелирует со стационарной частью процесса ![]() . Когда
. Когда ![]() , линейная комбинация нестационарна и не существует поправки на равновесие.
, линейная комбинация нестационарна и не существует поправки на равновесие.
Процедура тестирования заключается в следующем. Сначала проверяется нулевая гипотеза о том, что существует один вектор коинтеграции, затем гипотеза о двух векторах и т.д. Мы отвергаем нулевую гипотезу, что ![]() — число векторов коинтеграции — меньше чем
— число векторов коинтеграции — меньше чем ![]() , если значение статистического критерия больше указанного критического значения.
, если значение статистического критерия больше указанного критического значения.
Также возможна проверка нулевой гипотезы против альтернативной о том, что ранг на единицу больше, чем предполагается в нулевой гипотезе:
-
 ;
; -
 .
.
В таком случае применяется статистика максимального собственного числа:
![]()
Пример: преобразование VAR(3) в ECM
Возьмем в качестве примера VAR(3) процесс:
![]()
Это достаточно сложное уравнение может быть выражено в матричной форме (опустим вектор с ошибками для краткости):
![left[begin{array}{c} x_{1,t} x_{2,t} end{array}right] = left[begin{array}{cc} a_1 & b_1 c_1 & d_1 end{array}right] cdot left[begin{array}{c} x_{1,t-1} x_{2,t-1} end{array}right] + left[begin{array}{cc} a_2 & b_2 c_2 & d_2 end{array}right] cdot left[begin{array}{c} x_{1,t-2} x_{2,t-2} end{array}right] + left[begin{array}{cc} a_3 & b_3 c_3 & d_3 end{array}right] cdot left[begin{array}{c} x_{1,t-3} x_{2,t-3} end{array}right],](https://habrastorage.org/getpro/habr/upload_files/f41/084/a9a/f41084a9adc574a8655fe4f05445a617.svg)
![left[begin{array}{c} x_{1,t} x_{2,t} end{array}right] = Pi_1 cdot left[begin{array}{c} x_{1,t-1} x_{2,t-1} end{array}right] + Pi_2 cdot left[begin{array}{c} x_{1,t-2} x_{2,t-2} end{array}right] + Pi_3 cdot left[begin{array}{c} x_{1,t-3} x_{2,t-3} end{array}right] + left[ begin{array}{c} varepsilon_{1,t} varepsilon_{2,t} end{array} right].](https://habrastorage.org/getpro/habr/upload_files/b03/9d4/b54/b039d4b54f162e69a805866b9275e455.svg)
Далее мы должны преобразовать модель через разности. Это можно сделать следующим образом. Во-первых, мы вычитаем
![left[ begin{array}{c} x_{1,t-1} x_{2,t-1} end{array} right]](https://habrastorage.org/getpro/habr/upload_files/a08/cd2/8f1/a08cd28f15f39080f49504e9ea18a04f.svg)
из обеих частей уравнения, преобразуя левую сторону уравнения в разности:
![left[begin{array}{c} x_{1,t} x_{2,t} end{array}right] - left[begin{array}{c} x_{1,t-1} x_{2,t-1} end{array}right] = Pi_1 cdot left[begin{array}{c} x_{1,t-1} x_{2,t-1} end{array}right] - left[begin{array}{c} x_{1,t-1} x_{2,t-1} end{array}right] + Pi_2 cdot left[begin{array}{c} x_{1,t-2} x_{2,t-2} end{array}right] + Pi_3 cdot left[begin{array}{c} x_{1,t-3} x_{2,t-3} end{array}right],](https://habrastorage.org/getpro/habr/upload_files/51c/0fd/e54/51c0fde549c2a2912c592b883141c554.svg)
![left[begin{array}{c} Delta x_{1,t} Delta x_{2,t} end{array}right] = (Pi_1 - I) cdot left[begin{array}{c} x_{1,t-1} x_{2,t-1} end{array}right] + Pi_2 cdot left[begin{array}{c} x_{1,t-2} x_{2,t-2} end{array}right] + Pi_3 cdot left[begin{array}{c} x_{1,t-3} x_{2,t-3} end{array}right] + left[ begin{array}{c} varepsilon_{1,t} varepsilon_{2,t} end{array} right].](https://habrastorage.org/getpro/habr/upload_files/6ef/72f/b72/6ef72fb720d9468578eabd28405de1d7.svg)
Мы можем преобразовать это выражение следующим образом:
![left[begin{array}{c} Delta x_{1,t} Delta x_{2,t} end{array}right] = (Pi_1 - I) cdot left[begin{array}{c} x_{1,t-1} x_{2,t-1} end{array}right] + (Pi_2 + Pi_1 - I - (Pi_1 - I)) cdot left[begin{array}{c} x_{1,t-2} x_{2,t-2} end{array}right] + + Pi_3 cdot left[ begin{array}{c} x_{1,t-3} x_{2,t-3} end{array} right].](https://habrastorage.org/getpro/habr/upload_files/47a/f72/351/47af723517c4f28b59f56bc2b8bb1643.svg)
Открывая скобки, получаем:
![left[begin{array}{c} Delta x_{1,t} Delta x_{2,t} end{array}right] = (Pi_1 - I) cdot left[begin{array}{c} x_{1,t-1} x_{2,t-1} end{array}right] + (Pi_1 + Pi_2 - I) cdot left[begin{array}{c} x_{1,t-2} x_{2,t-2} end{array}right] - (Pi_1 - I) cdot left[begin{array}{c} x_{1,t-2} x_{2,t-2} end{array}right] + + Pi_3 cdot left[begin{array}{c} x_{1,t-3} x_{2,t-3} end{array}right].](https://habrastorage.org/getpro/habr/upload_files/b37/13d/f59/b3713df59bffb94a3efac3291b4e17eb.svg)
Группируем члены с общими множителями:
![left[begin{array}{c} Delta x_{1,t} Delta x_{2,t} end{array}right] = (Pi_1 - I) cdot left(left[begin{array}{c} x_{1,t-1} x_{2,t-1} end{array}right] - left[begin{array}{c} x_{1,t-2} x_{2,t-2} end{array}right]right) + (Pi_1 + Pi_2 - I) cdot left[begin{array}{c} x_{1,t-2} x_{2,t-2} end{array}right] + + Pi_3 cdot left[begin{array}{c} x_{1,t-3} x_{2,t-3} end{array}right].](https://habrastorage.org/getpro/habr/upload_files/d7d/cbe/f38/d7dcbef38a4cdc5fffffd7616c623d53.svg)
В результате получим выражение:
![left[begin{array}{c} Delta x_{1,t} Delta x_{2,t} end{array}right] = (Pi_1 - I) cdot left[begin{array}{c} Delta x_{1,t-1} Delta x_{2,t-1} end{array}right] + (Pi_1 + Pi_2 - I) cdot left[begin{array}{c} x_{1,t-2} x_{2,t-2} end{array}right] + Pi_3 cdot left[begin{array}{c} x_{1,t-3} x_{2,t-3} end{array}right].](https://habrastorage.org/getpro/habr/upload_files/095/52b/280/09552b280aae10d8d6046fdac3103327.svg)
Схожая процедура применяется по отношению к матрице ![]() :
:
![left[begin{array}{c} Delta x_{1,t} Delta x_{2,t} end{array}right] = (Pi_1 - I) cdot left[begin{array}{c} Delta x_{1,t-1} Delta x_{2,t-1} end{array}right] + (Pi_1 + Pi_2 - I) cdot left[begin{array}{c} x_{1,t-2} x_{2,t-2} end{array}right] + + (Pi_3 + Pi_1 + Pi_2 - I - (Pi_1 + Pi_2 - I)) cdot left[begin{array}{c} x_{1,t-3} x_{2,t-3} end{array}right].](https://habrastorage.org/getpro/habr/upload_files/899/6ac/d83/8996acd8339b41a52c17c416c2aa3e4b.svg)
Открывая скобки, получаем:
![left[begin{array}{c} Delta x_{1,t} Delta x_{2,t} end{array}right] = (Pi_1 - I) cdot left[begin{array}{c} Delta x_{1,t-1} Delta x_{2,t-1} end{array}right] + (Pi_1 + Pi_2 - I) cdot left[begin{array}{c} x_{1,t-2} x_{2,t-2} end{array}right] + + (Pi_1 + Pi_2 + Pi_3 - I) cdot left[begin{array}{c} x_{1,t-3} x_{2,t-3} end{array}right] - (Pi_1 + Pi_2 - I) cdot left[begin{array}{c} x_{1,t-3} x_{2,t-3} end{array}right].](https://habrastorage.org/getpro/habr/upload_files/56b/2fd/8c4/56b2fd8c41fb84a4c113e4c0639fd85e.svg)
Группируем члены с общими множителями:
![left[begin{array}{c} Delta x_{1,t} Delta x_{2,t} end{array}right] = (Pi_1 - I) cdot left[begin{array}{c} Delta x_{1,t-1} Delta x_{2,t-1} end{array}right] + (Pi_1 + Pi_2 - I) cdot left( left[begin{array}{c} x_{1,t-2} x_{2,t-2} end{array}right] - left[begin{array}{c} x_{1,t-3} x_{2,t-3} end{array}right] right) + + (Pi_1 + Pi_2 + Pi_3 - I) cdot left[begin{array}{c} x_{1,t-3} x_{2,t-3} end{array}right].](https://habrastorage.org/getpro/habr/upload_files/dc9/bce/327/dc9bce327cd0ebefa5010c66c5efb6d9.svg)
В результате получаем:
![left[begin{array}{c} Delta x_{1,t} Delta x_{2,t} end{array}right] = (Pi_1 - I) cdot left[begin{array}{c} Delta x_{1,t-1} Delta x_{2,t-1} end{array}right] + (Pi_1 + Pi_2 - I) cdot left[begin{array}{c} Delta x_{1,t-2} Delta x_{2,t-2} end{array}right] + + (Pi_1 + Pi_2 + Pi_3 - I) cdot left[begin{array}{c} x_{1,t-3} x_{2,t-3} end{array}right].](https://habrastorage.org/getpro/habr/upload_files/4b9/48c/cdb/4b948ccdb9a9b8dade98b6a795cdbd1e.svg)
Обозначим ![]() ,
, ![]() ,
, ![]() , получим VAR(3) модель в ECM форме:
, получим VAR(3) модель в ECM форме:
![]()
Мы видим, что VAR-процесс уровней рядов может быть записан как VAR-процесс разностей за исключением одного члена ![]() .
.
Ранг матрицы ![]() дает число векторов коинтеграции в рядах динамики (ранг матрицы — это число линейно независимых рядов). Таким образом, ранг матрицы говорит о том, что следует делать. Если
дает число векторов коинтеграции в рядах динамики (ранг матрицы — это число линейно независимых рядов). Таким образом, ранг матрицы говорит о том, что следует делать. Если ![]() имеет нулевой ранг, то матрица
имеет нулевой ранг, то матрица ![]() — нулевая. Это показывает, что коинтеграции в рядах данных нет, и для достижения стационарности требуется нахождение разностей.
— нулевая. Это показывает, что коинтеграции в рядах данных нет, и для достижения стационарности требуется нахождение разностей.
Если матрица ![]() — полная, то ряды уже стационарны (матрица
— полная, то ряды уже стационарны (матрица ![]() имеет обратную, и, таким образом, выражение может быть решено для уровней, выраженных в разностях. Это будет верным только если ряды уровней
имеет обратную, и, таким образом, выражение может быть решено для уровней, выраженных в разностях. Это будет верным только если ряды уровней ![]() ).
).
Если ранг ![]() лежит между 0 и
лежит между 0 и ![]() (
( ![]() , в нашем случае
, в нашем случае ![]() ,
, ![]() ), то существует
), то существует ![]() векторов коинтеграции. Модель исправления ошибки включает в себя краткосрочные изменения, которые поддерживают долгосрочное равновесие.
векторов коинтеграции. Модель исправления ошибки включает в себя краткосрочные изменения, которые поддерживают долгосрочное равновесие.
Тест Йохансена в MATLAB
У нас есть два ряда цен акций, ![]() и
и ![]() . Мы хотим, чтобы
. Мы хотим, чтобы ![]() и
и ![]() были коинтегрированными, то есть чтобы ранг коинтеграции был равен 1. Рассмотрим два тикера Московской биржи, TATN
были коинтегрированными, то есть чтобы ранг коинтеграции был равен 1. Рассмотрим два тикера Московской биржи, TATN ![]() и TATNP
и TATNP ![]() за 2020 год:
за 2020 год:
![]()

Тест Йохансена выполняется с помощью функции jcitest, которая на вход принимает массив из временных рядов, в данном случае размера ![]() , где
, где ![]() — количество торговых дней. На выходе функция возвращает логическое значение, равное 1, если нулевая гипотеза отвергается в пользу альтернативной, и 0 – иначе.
— количество торговых дней. На выходе функция возвращает логическое значение, равное 1, если нулевая гипотеза отвергается в пользу альтернативной, и 0 – иначе.
testPrices(:,1) = prices(:,indexY);
testPrices(:,2) = prices(:,indexX);
[hjt,pValuejt,statjt,cValuejt,mles] = jcitest(testPrices, 'model', 'H2');
[hjtm,pValuejtm,statjtm,cValuejtm,mlesm] = jcitest(testPrices, 'model', 'H2', 'test', 'maxeig');Статистика следа
Дальше начинается самое интересное: программа выдает ответ, который обычному человеку сложно понять, потому что он приходит в виде массива логических значений.

Википедия нас к такому не готовила, поэтому давайте разберемся, что здесь происходит. Гипотетически тест следа может привести к трем различным вариантам ранга коинтеграции и, следовательно, количествам единичных корней.
-
 ,
,  , когда
, когда 
-
, , когда ,
-
, , когда ,
где ![]() — статистика следа,
— статистика следа, ![]() — соответствующие критические значения,
— соответствующие критические значения, ![]() в нашем случае равно 2, так как у нас две переменные,
в нашем случае равно 2, так как у нас две переменные, ![]() (TATN) и
(TATN) и ![]() (TATNP). Поэтому, чтобы оценить значение
(TATNP). Поэтому, чтобы оценить значение ![]() , мы должны выполнить последовательность тестов.
, мы должны выполнить последовательность тестов.
Отметим, что асимптотические таблицы определяются так, что когда ![]() истинна, тогда
истинна, тогда ![]() , где
, где ![]() задается как:
задается как:

Рассмотрим результат теста для нулевого ранга. В чем здесь заключается нулевая гипотеза?
Из ответа матлаба мы видим, что нулевая гипотеза отвергается для нулевого ранга ( ![]() для
для ![]() ). Это означает, что
). Это означает, что ![]() асимптотически.
асимптотически.
Рассмотрим результат теста для первого ранга. В чем здесь заключалась нулевая гипотеза?
Следующее значение ![]() соответствует
соответствует ![]() , истинному коинтеграционному числу, а
, истинному коинтеграционному числу, а ![]() в соответствии с ответом матлаба о том, что нулевая гипотеза не отвергается для первого ранга (
в соответствии с ответом матлаба о том, что нулевая гипотеза не отвергается для первого ранга ( ![]() для
для ![]() ). Таким образом последний вариант
). Таким образом последний вариант ![]() .
.
Резюмируем:
Таким образом правильное значение ![]() асимптотически принимается в 95% всех случаев, что как раз и должна делать процедура 5%-ного теста.
асимптотически принимается в 95% всех случаев, что как раз и должна делать процедура 5%-ного теста.
Статистика максимального собственного числа
Практически тот же самый результат мы видим для статистики максимального собственного числа.

Здесь у нас есть следующие варианты:
где ![]() — статистика максимального собственного числа,
— статистика максимального собственного числа, ![]() — соответствующие критические значения.
— соответствующие критические значения.
Напомним, что ![]() задается как:
задается как:
![]()
Рассмотрим результат теста для нулевого ранга. В чем здесь заключается нулевая гипотеза?
Из ответа матлаба мы видим, что нулевая гипотеза отвергается для нулевого ранга ( ![]() для
для ![]() ). Это означает, что
). Это означает, что ![]() асимптотически.
асимптотически.
Рассмотрим результат теста для первого ранга. В чем здесь заключалась нулевая гипотеза?
Следующее значение ![]() соответствует истинному коинтеграционному числу, а
соответствует истинному коинтеграционному числу, а ![]() в соответствии с ответом матлаба о том, что нулевая гипотеза не отвергается для первого ранга (
в соответствии с ответом матлаба о том, что нулевая гипотеза не отвергается для первого ранга ( ![]() для
для ![]() ).
).
По результатам обеих статистик мы видим, что пара (TATN, TATNP) является коинтегрированной.
Тест Энгла-Грэнджера vs Тест Йохансена
Мной была проанализирована 1 621 пара акций Московской биржи за 2020 год на дневных данных. В 87% случаев результаты теста Энгла-Гренджера и теста Йохансена совпали.
Также было проанализировано 3 193 890 пар на американских биржах (NYSE, NASDAQ и AMEX) за 2020 год на дневных данных. Также в 87% случаев результаты теста Энгла-Гренджера и теста Йохансена совпали.
Еще было проанализировано 21 725 пар на криптобиржах (Poloniex, Binance, Kraken) за 2020 год на дневных данных. В 86% случаев результаты теста Энгла-Гренджера и теста Йохансена совпали.
С практической точки зрения для принятия решения о том, стоит ли добавлять пару активов в портфель, а также для оценки весовых коэффициентов лучше использовать оба теста на коинтеграцию.
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
15 |
||||||||||||||||
|
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||||||||
|
C(2) |
1.014411 |
0.020750 |
48.88608 |
0.0000 |
|||||||||||||
|
C(3) |
0.702102 |
0.078268 |
8.970448 |
0.0000 |
|||||||||||||
|
т.е. yt |
= 1.014 yt – 1 + 0.702 (xt – 1.014 xt – 1) + e t , или |
||||||||||||||||
|
yt |
= 1.014 yt – 1 + 0.702 xt |
– 0.712 xt – 1 + e t |
Отметим близость результатов, полученных тремя методами:
|
yt = |
1.005 yt – 1 + 0.695 xt |
– 0.707 xt – 1 + et |
(метод 1), |
|
yt = |
yt – 1 + 0.710 xt |
– 0.710 xt – 1 + et |
(метод 2), |
|
yt = |
1.014 yt – 1 + 0.702 xt |
– 0.712 xt – 1 + e t |
(метод 3). |
Фактически, во всех трех случаях воспроизводится одна и та же линейная модель связи между рядами разностей:
∆yt = 0.7 ∆xt + et .
Эта регрессионная связь между продифференцированными рядами не является ложной (в отличие от регрессионной связи между рядами уровней): статистика Дарбина – Уотсона принимает значение 1.985; P-значение критерия Jarque – Bera равно 0.344.
Замечание
В связи с результатами, полученными при рассмотрении последних примеров, естественно возникает следующий вопрос, который поднимался в свое время различными исследователями. Не будет ли разумным, имея дело с рядами, траектории которых обнаруживают выраженный тренд, сразу приступать к оцениванию связей между рядами разностей (между продифференцированными рядами) ?
Против некритичного использования такого подхода говорят два обстоятельства:
(a)Если ряды в действительности стационарны относительно детерминированного тренда, то тогда дифференцирование приводит к
передифференцированным рядам, имеющим необратимую MA
составляющую.
(b)Если ряды являются интегрированными порядка 1 и при этом коинтегрированы, то при переходе к продифференцированным рядам теряется информация о долговременной связи между уровнями этих рядов.
Дифференцирование рядов оправданно и полезно, если ряды являются интегрированными, но при этом между ними отсутствует коинтеграционная связь.
Пусть yt ~ I(1), xt ~ I(0). Строить регрессию yt на xt в этом случае бессмысленно, т.к. для любых a и b в такой ситуации
yt – a – b xt ~ I(1).
Пусть, наоборот, yt ~ I(0), xt ~ I(1). Для любых a и b ≠ 0 здесь опять yt – a – b xt ~ I(1),
и только при b = 0 получаем yt – a – b xt ~ I(0),
так что и в таком сочетании строить регрессию одного ряда на другой не имеет смысла.
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
16 |
|
|
Пусть теперь yt ~ I(1), |
xt ~ I(1) – два интегрированных ряда. |
|
|
Если для любого b |
||
|
yt – b xt ~ I(1), |
||
|
то регрессия yt на |
xt является фиктивной, и мы уже выяснили, как следует |
действовать в такой ситуации.
Обратимся теперь к случаю, когда при некотором b ≠ 0 yt – b xt ~ I(0) – стационарный ряд.
Если это так, то ряды yt и xt называют коинтегрированными рядами, а вектор (1, – b)T – коинтегрирующим вектором.
Вообще, ряды yt ~ I(1), xt ~ I(1) называют коинтегрированными (в узком смысле – детерминистская коинтеграция), если существует ненулевой (коинтегрирующий)
вектор β = (β1, β2)T ≠ 0 , для которого
β1 xt + β2 yt ~ I(0) – стационарный ряд.
Заметим, что если вектор β = (β1, β2)T является коинтегрирующим вектором для рядов xt и yt , то тогда коинтегрирующим для этих рядов будет и любой вектор вида сβ = (сβ1, сβ2)T , где с ≠ 0 – постоянная величина. Чтобы выделить какой-то определенный вектор, приходится вводить условие нормировки, например, рассматривать только векторы вида (1, – b)T (или только векторы (– a, 1)T ).
Поскольку мы предполагаем сейчас, что xt , yt ~ I(1), то ряды разностей ∆xt , ∆yt стационарны. Будем предполагать в дополнение, что стационарен векторный ряд (∆xt , ∆yt)T , так что для него существует разложение Вольда в виде скользящего среднего
(∆xt , ∆yt)T = µ + B(L) εt ,
где
µ = (µ 1, µ 2 )T , µ 1 = E(∆xt ) , µ 2 = E(∆yt) ;
εt = (ε1t , ε2t )T – векторный белый шум,
т.е.
|
ε 1, ε 2 , … |
– последовательность не коррелированных между собой, одинаково |
||||||||
|
распределенных случайных векторов, для которых |
|||||||||
|
E(εt) = (0, 0)T , |
D(ε1t) = σ12 , D(ε2t) = σ22 , Cov(ε1t , ε2t ) = σ12 – постоянные величины; |
||||||||
|
1 |
0 |
∞ b |
(k ) |
b |
(k ) |
k |
|||
|
11 |
12 |
L |
. |
||||||
|
B(L) = |
0 |
1 |
+∑ |
b |
(k ) |
b |
(k ) |
||
|
k =1 |
|||||||||
|
21 |
22 |
Знаменитый результат Гренджера ([Granger (1983)], см. также [Engle, Granger (1987)])
состоит в том, что в случае коинтегрированности I(1) рядов xt и yt (в узком смысле)
|
(I) |
В разложении Вольда (∆xt , ∆yt)T = µ + B(L) εt матрица B(1) имеет ранг 1. |
|
(II)Система рядов xt и yt допускает векторное ARMA представление |
A(L) (xt, yt )T = c + d(L)εt ,
в котором
εt – тот же векторный белый шум, что и в (I), c = (c1, c2)T , c1 и c2 – постоянные,
A(L) – матричный полином от оператора запаздывания, d(L) – скалярный полином от оператора запаздывания, причем
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
17 |
A(0) = I2 (единичная матрица размера 2×2), rank A(1) = 1 (ранг 2×2-матрицы A(1) равен 1),
значение d(1) конечно.
Всвязи с тем, что в последнем представлении ранг (2×2)-матрицы A(1) меньше двух, об этом представлении часто говорят как о векторной авторегрессии пониженного ранга (reduced rank VAR).
Вразвернутой форме представление (II) имеет вид
|
p |
q |
|||||||||||||||
|
xt =c1 + |
∑(a1j xt − j +b1j yt − j )+ |
∑θkε1,t − k , |
||||||||||||||
|
j =1 |
k = 0 |
|||||||||||||||
|
p |
(a |
)+ |
q θ |
|||||||||||||
|
y |
t |
=c |
2 |
+ |
2 j |
x |
t − j |
+b |
y |
t − j |
ε |
2,t − k |
||||
|
∑ |
2 j |
∑ k |
||||||||||||||
|
j =1 |
k = 0 |
При этом верхние пределы p и q у сумм в правых частях могут быть бесконечными.
Если возможно векторное AR представление, то в нем d(L) ≡ 1 , p < ∞ .
|
(III) |
Система рядов xt и yt допускает представление в форме модели |
||
|
коррекции ошибок (error correction model – ECM) |
|||
|
∆xt =µ1 +α1zt −1 +∑∞ (γ 1j ∆xt − j +δ1j ∆yt − j )+ ∑∞ θkε1,t − k , |
|||
|
j =1 |
k = 0 |
||
|
∆yt = µ2 +α2 zt −1 +∑∞ (γ 2 j ∆xt − j +δ 2 j ∆yt − j )+ ∑∞ θkε2,t − k , |
|||
|
j =1 |
k = 0 |
||
|
где |
|||
|
zt = yt – β xt – E(yt – β xt) |
– стационарный ряд с нулевым |
математическим |
|
|
ожиданием, |
zt ~ I(0),
и
α12 + α22 > 0.
Если в (II) возможно векторное AR(p) представление (p < ∞), то тогда ECM принимает вид
∆xt =µ1 +α1zt −1 +∑p −1(γ 1j ∆xt − j +δ1j ∆yt − j ) +ε1,t , j =1
∆yt = µ2 +α2 zt −1 +∑p −1(γ 2 j ∆xt − j +δ 2 j ∆yt − j )+ε2,t , j =1
Здесь важно отметить следующее:
•Если ряды xt , yt ~ I(1) коинтегрированы, то все составляющие в ECM стационарны.
•Если векторный ряд (xt , yt)T ~ I(1) (так что векторный ряд (∆xt , ∆yt)T стационарен) и порождается ECM моделью, то ряды xt и yt коинтегрированы. (Действительно, в этом случае все составляющие ECM, отличные от zt–1, стационарны; но тогда стационарна и zt – 1.)
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
18 |
• Если ряды xt , yt ~ I(1) коинтегрированы, то тогда VAR в разностях не может иметь конечный порядок. (В отличие от случая, когда ряды xt и yt не коинтегрированы.)
|
Абсолютную величину zt = yt – α – β xt , где α = E(yt – β xt), |
можно рассматривать как |
|
|
расстояние, отделяющее систему в |
момент t от |
равновесия, задаваемого |
|
соотношением yt – α – β xt = 0. |
Величины и направления изменений xt и yt |
принимают во внимание величину и знак предыдущего отклонения от равновесия zt – 1 . Ряд zt , конечно, вовсе не обязательно убывает по абсолютной величине при переходе от одного периода времени к другому, но он является стационарным рядом, и поэтому расположен к движению по направлению к своему среднему.
Замечание 1
Переменная xt не является причиной по Гренджеру для переменной yt , если неучет прошлых значений переменной xt не приводит к ухудшению качества прогноза значения yt по совокупности прошлых значений этих двух переменных. Переменная yt не является причиной по Гренджеру для переменной xt , если неучет прошлых значений переменной yt не приводит к ухудшению качества прогноза значения xt по совокупности прошлых значений этих двух переменных. (Качество прогноза измеряется среднеквадратичной ошибкой прогноза.)
Если xt , yt ~ I(1) и коинтегрированы, то должна иметь место причинность по Гренджеру , по крайней мере, в одном направлении. Этот факт вытекает из представления такой системы рядов в форме ECM, в которой α12 + α22 > 0. Значение xt
– 1 через посредство zt– 1 помогает в прогнозировании значения yt (т.е. переменная xt является причиной по Гренджеру для переменной yt), если α2 ≠ 0. Значение yt – 1 через посредство zt– 1 помогает в прогнозировании значения xt (т.е. переменная yt является причиной по Гренджеру для переменной xt), если α1 ≠ 0.
Замечание 2
Пусть xt , yt ~ I(1) коинтегрированы и wt ~ I(0). Тогда для любого k коинтегрированы ряды xt и γ yt – k + wt , γ ≠ 0. Формально, если xt ~ I(1), то коинтегрированы ряды xt
и xt – k . (Действительно, тогда xt – xt – k = ∆xt + ∆xt – 1 + … + ∆xt – k – сумма I(0)- переменных, которая также является I(0)-переменной.)
Итак, при коинтегрированности рядов xt , yt ~ I(1) мы имеем
|
• |
модель долговременной (равновесной) связи yt = α + β xt ; |
•модель краткосрочной динамики в форме ECM,
иэти модели согласуются друг с другом.
Проблема, однако, состоит в том, что для построения ECM по реальным статистическим данным нам надо знать коинтегрирующий вектор (в данном случае, знать значение β). Хорошо, если этот вектор определяется экономической теорией. К сожалению, чаще его приходится оценивать по имеющимся данным.
Энгл и Гренджер [Engle, Granger (1987)] рассмотрели двухшаговую процедуру, в которой на первом шаге значения α и β оцениваются в рамках модели регрессии yt на xt
yt = α + β xt + ut .
Получив методом наименьших квадратов оценки αˆ и βˆ (НK-оценки), мы тем самым находим оцененные значения отклонений от положения равновесия
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
19 |
zˆt = yt – αˆ – βˆ xt
– это просто остатки от оцененной регрессии.
После этого, на втором шаге, методом наименьших квадратов раздельно (не как система!) оцениваются уравнения
∆xt =µ1 +α1zˆt −1 +∑p −1(γ 1j ∆xt − j +δ1j ∆yt − j ) +ν t , j =1
∆yt = µ2 +α2 zˆt −1 + ∑p −1(γ 2 j ∆xt − j +δ 2 j ∆yt − j ) +wt , j =1
(т.е. предполагается модель VAR(p) для xt , yt).
Определяющим в этой процедуре является то обстоятельство, что получаемая на первом шаге оценка βˆ быстрее обычного приближается (по вероятности) к истинному
значению β – второй компоненте коинтегрирующего вектора (1, β)T . ( βˆ является суперсостоятельной оценкой для β .) Это, в конечном счете, приводит к тому, что оценки в отдельном уравнении ECM, использующие оцененные значения zt−1 , имеют то же самое асимптотическое распределение, что и оценка максимального правдоподобия, использующая истинные значения zt−1 . (Обычно это асимптотически
нормальное распределение.) При этом НК-оценки стандартных ошибок всех коэффициентов являются состоятельными оценками истинных стандартных ошибок.
Заметим, что последние результаты справедливы несмотря на то, что ряд оцененных значений zˆt формально не является стационарным, поскольку βˆ ≠ β.
Отметим также, что если мы хотим использовать другую нормировку коинтегрирующего вектора в виде (β, 1)T , то нам придется оценивать регрессию xt на константу и yt , и это приведет к вектору, не пропорциональному вектору, оцененному в первом случае.
Замечание
|
ˆ |
|
|
Тот факт, что β |
быстрее обычного сходится (по вероятности) к β , вовсе не |
означает,что мы можем пользоваться на первом шаге процедуры Энгла – Гренджера обычными регрессионными критериями. Дело в том, что получаемые на первом шаге оценки и статистики, вообще говоря, имеют нестандартные асимптотические распределения.
Однако первый шаг является в данном контексте вспомогательным, и на этом шаге нет необходимости обращать внимание на сообщаемые в протоколах соответствующих пакетов программ значения статистик.
Напротив, на втором шаге мы можем использовать обычные статистические процедуры (разумеется, если количество наблюдений не мало и если коинтеграция имеется).
Пример Расмотрим реализацию процесса порождения данных
DGP: xt = xt – 1 + εt , yt = 2 xt + νt ,
где x1 = 0, а εt и νt – порождаемые независимо друг от друга последовательности независимых, одинаково распределенных случайных величин, имеющих стандартное
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
20 |
|||||||||||
|
нормальное распределение |
N(0, |
1). Графики полученных реализаций рядов |
xt |
и |
yt |
|||||||
|
имеют следующий вид |
||||||||||||
|
10 |
||||||||||||
|
0 |
||||||||||||
|
-10 |
||||||||||||
|
-20 |
||||||||||||
|
-30 |
||||||||||||
|
-40 |
||||||||||||
|
10 |
20 |
30 |
40 |
50 |
60 |
70 |
80 |
90 |
100 |
|||
|
Y |
X |
Пара (xt , yt) образует векторный процесс авторегрессии
xt = xt – 1 + εt , yt = 2 xt – 1 + ηt ,
где ηt = νt + 2εt ~ i.i.d. N(0, 5).
В форме ECM пара уравнений принимает вид
∆xt = εt ,
∆yt = – (yt – 1 – 2 xt – 1) + ηt = – zt + где zt = yt – 2 xt ,
или
∆xt = α1 zt – 1 + εt ,
∆yt = α2 zt – 1 + ηt ,
где α1 = 0, α2 = – 1, так что α12
На практике, приступая к анализу статистических данных, исследователь не знает точно, какой порядок имеет VAR в DGP. Имея это в виду, выберем для оценивания в качестве статистической модели ECM в виде
∆xt = α1 zt – 1 + γ11∆xt – 1 + δ11∆yt – 1 + vt ,
∆yt = α2 zt – 1 + γ21∆xt – 1 + δ21∆yt – 1 + wt ,
допуская, что данные порождаются моделью векторной авторегрессии второго порядка (p = 2). Для анализа используем 100 наблюдений.
(I шаг) Исходим из модели yt = α + β xt + ut . Оцененная модель:
|
Dependent Variable: Y |
||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
C |
-0.006764 |
0.165007 |
-0.040992 |
0.9674 |
|
X |
1.983373 |
0.020852 |
95.11654 |
0.0000 |
|
R-squared |
0.989284 |
Durbin-Watson stat |
2.217786 |
т.е.
yt = – 0.006764 + 1.983373 xt + uˆt ,
так что
zˆt = uˆt = yt + 0.006764 – 1.983373 xt .
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
21 |
Допустив, что VAR имеет порядок 2, при использовании критерия Дики – Фуллера для проверки рядов yt и xt на коинтегрированность в правую часть уравнения включаем одну запаздывающую разность:
∆zˆt = φ zˆt−1 + θ1∆zˆt−1 + ζt . ,
Оценивая последнее уравнение получаем:
Augmented Dickey-Fuller Test Equation Dependent Variable: D(Z) Sample(adjusted): 3 100
Included observations: 98 after adjusting endpoints
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
Z(-1) |
-1.153515 |
0.151497 |
-7.614088 |
0.0000 |
||||||||
|
D(Z(-1)) |
0.038156 |
0.100190 |
0.380837 |
0.7042 |
||||||||
Полученное значение тестовой статистики tφ = – 7.614 намного ниже 5% критического уровня –3.396 (см. [Patterson (2000), таблица 8.7]). Гипотеза некоинтегрированности рассматриваемых рядов уверенно отвергается. (Ввиду статистической незначимости коэффициента при запаздывающей разности, можно было бы переоценить модель, не включая запаздывающую разность в правую часть уравнения. Это дало бы значение tφ = – 11.423, при котором гипотеза некоинтегрированности отвергается еще более уверенно.)
Таким образом, мы принимаем решение о коинтегрированности рядов yt и xt , и переходим к построению модели коррекции ошибок.
(Шаг II) Сначала отдельно оцениваем уравнение для ∆xt :
|
Dependent Variable: D(X) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
C |
-0.028016 |
0.100847 |
-0.277810 |
0.7818 |
||||||||
|
Z(-1) |
0.250942 |
0.176613 |
1.420858 |
0.1587 |
||||||||
|
D(X(-1)) |
0.639967 |
0.257823 |
2.482201 |
0.0148 |
||||||||
|
D(Y(-1)) |
-0.258740 |
0.116654 |
-2.218019 |
0.0290 |
||||||||
Поочередное исключение из правой части уравнения переменных со статистически незначимыми коэффициентами и наибольшим P-значением приводит к оцененной модели
|
Dependent Variable: D(X) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
D(X(-1)) |
0.115141 |
0.100249 |
1.148554 |
0.2536 |
||||||||
и, в конечном счете, к модели
∆xt = νt ,
которая и была использована при порождении ряда xt . Оценивая теперь уравнение для ∆yt , получаем
|
Dependent Variable: D(Y) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
C |
-0.060101 |
0.211899 |
-0.283630 |
0.7773 |
||||||||
|
Z(-1) |
-0.641060 |
0.371097 |
-1.727472 |
0.0874 |
||||||||
|
D(X(-1)) |
1.313872 |
0.541733 |
2.425311 |
0.0172 |
||||||||
|
D(Y(-1)) |
-0.482981 |
0.245111 |
-1.970459 |
0.0517 |
||||||||
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
22 |
Исключая из правой части оцениваемого уравнения константу, получаем:
|
Dependent Variable: D(Y) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
Z(-1) |
-0.638888 |
0.369218 |
-1.730381 |
0.0868 |
||||||||
|
D(X(-1)) |
1.317763 |
0.538932 |
2.445138 |
0.0163 |
||||||||
|
D(Y(-1)) |
-0.483722 |
0.243908 |
-1.983217 |
0.0502 |
||||||||
Хотя формально здесь следовало бы начать исключение статистически незначимых переменных с zˆt −1 , мы должны принять во внимание уже принятое решение о
коинтегрированности рядов yt и xt . Но если эти ряды действительно коинтегрированы, то в ECM должно выполняться соотношение α12 + α22 > 0. Поскольку же переменная zt – 1 не вошла в правую часть уравнения для ∆xt , она должна оставаться в правой части уравнения для ∆yt . Если начать исключение с переменной ∆yt – 1 , то в оцененном редуцированном уравнении
|
Dependent Variable: D(Y) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
Z(-1) |
-1.186411 |
0.248876 |
-4.767072 |
0.0000 |
||||||||
|
D(X(-1)) |
0.331411 |
0.210732 |
1.572671 |
0.1191 |
||||||||
статистически незначим коэффициент при ∆xt – 1 , что приводит нас к уравнению ∆yt = α2 zˆt−1 + wt , оценивая которое, получаем
|
Dependent Variable: D(Y) |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
Z(-1) |
-1.273584 |
0.247887 |
-5.137760 |
0.0000 |
||||||||
Проверка гипотезы H0: α2 = – 1 дает:
|
Null Hypothesis: |
C(1)= -1 |
|||||||||
|
F-statistic |
1.218077 |
Probability |
0.272441 |
|||||||
|
Chi-square |
1.218077 |
Probability |
0.269738 |
|||||||
Поскольку эта гипотеза не отвергается, мы можем остановиться на модели ECM
∆xt = εt , ∆yt = – zˆt−1 + wt ,
где
zˆt−1 = yt – 1 + 0.006764 – 1.983373 xt – 1 .
Подстановка последнего выражения для zˆt−1 в уравнение для ∆yt приводит к соотношению
yt = – 0.0068 + 1.983 xt – 1 + wt ,
которое близко к соотношению yt = 2 xt – 1 + ηt ,
соответствующему использованному DGP.
Заметим, наконец, что последовательность wt = ∆yt + zˆt−1 идентифицируется по
наблюдаемой ее реализации как гауссовский белый шум с оцененной дисперсией 4.62 (использованному DGP соответствует значение 5.00), а последовательность εt = ∆xt идентифицируется как гауссовский белый шум с оцененной дисперсией 1.04 (использованному DGP соответствует значение 1.00).
Оценив ECM и остановившись на модели
∆xt = εt , ∆yt = – zˆt−1 + wt ,
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
23 |
мы тем самым обнаруживаем, что коррекция производится только в отношении ряда yt : при положительных zˆt−1 , т.е. при
yt– 1 – (– 0.0068 + 1.983 xt – 1) > 0,
в правой части уравнения для ∆yt корректирующая составляющая – zˆt−1 отрицательна и действует в сторону уменьшения приращения переменной yt . Напротив, при отрицательных zˆt−1 корректирующая составляющая действует в сторону увеличения приращения переменной yt .
Прошлые значения переменной xt через посредство zˆt−1 помогают в прогнозировании
значения yt , т.е. переменная xt является причиной по Гренджеру для переменной yt . В то же время, прошлые значения переменной yt никак не помогают прогнозированию значения xt , так что yt не является причиной по Гренджеру для xt .
Заметим далее, что даже если в ECM Cov(vt, wt) ≠ 0, оценивание пары уравнений ЕСМ как системы не повышает эффективности оценок, поскольку в правые части обоих уравнений входят одни и те же переменные.
Расмотренный в нашем примере процесс порождения данных
DGP: xt = xt – 1 + εt , yt = 2 xt + νt ,
является частным случаем модели, известной как треугольная система Филлипса. В общем случае (для двух рядов) эта система имеет вид
yt = β xt + νt , xt = xt – 1 + εt ,
где (εt , νt)T ~ i.i.d. N2(0, Σ) – последовательность независимых, одинаково распределенных случайных векторов, имеющих двумерное нормальное распределение с нулевым математическим ожиданием и ковариационной матрицей Σ . (Такая последовательность называется двумерным гауссовским белым шумом.)
Если матрица Σ диагональная, так что Cov(εt , νt) = 0, то тогда xt является экзогенной переменной в первом уравнении, и никаких проблем с оцениванием коэффициента β в этом случае не возникает.
Если же Cov(εt , νt) ≠ 0, то тогда xt уже не является экзогенной переменной в первом уравнении, т.к. при этом Cov(xt , νt) = Cov(xt – 1 + εt , νt) ≠ 0. Поэтому получаемая в первом уравнении оценка наименьших квадратов для β не имеет даже асимптотически нормального распределения.
В дальнейшем мы еще вернемся к проблеме оценивания коинтегрирующего вектора, а сейчас обратимся к вопросу о коинтеграции нескольких временных рядов.
Пусть мы имеем N временных рядов y1t , … , yN t , каждый из которых является интегрированным порядка 1. Если существует такой вектор β = (β1, … , βN)T , отличный от нулевого, для которого
β1 y1t + … + βN yN t ~ I(0) – стационарный ряд,
то говорят, что эти ряды коинтегрированы (в узком смысле); такой вектор β называется коинтегрирующим вектором. Если при этом
c = E(β1 y1t + … + βN yN t),
то тогда можно говорить о долговременном положении равновесия системы в виде
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
24 |
β1 y1t + … + βN yN t = c .
В каждый конкретный момент времени t существует некоторое отклонение системы от этого положения равновесия, характеризующееся величиной
zt = β1 y1t + … + βN yN t – c .
Ряд zt , в силу сделанных предположений, является стационарным рядом, имеющим нулевое математическое ожидание, так что он достаточно часто пересекает нулевой уровень, т.е. система колеблется вокруг указанного выше положения равновесия.
Естественной процедурой для проверки коинтегрированности рядов y1t , … , yN t является построение регрессии одного из этих рядов на остальные N – 1 рядов и проверка гипотезы наличия единичного корня у ряда zt на основании исследования ряда остатков от оцененной регрессии. Иначе говоря, мы оцениваем, например, модель
y1t = θ1 + θ2 y2 t + … + θN yN t + ut ,
и проверяем гипотезу единичного корня на основании исследования ряда остатков uˆt = y1t – (θˆ1+ θˆ2 y2 t + … + θˆN yN t),
опираясь на статистику Дики – Фуллера. Критические значения можно найти, следуя
[MacKinnon (1991)] (см. также [Patterson (2000), таблица A8.1]).
Если гипотеза единичного корня отвергается, то вектор
βˆ = (1, – θˆ2 , … , – θˆN )
берется в качестве оцененного коинтегрирующего вектора. При этом отклонение системы от положения равновесия оценивается величиной
zˆt = uˆt .
Поясним теперь, что мы имели в виду, оговаривая, что приведенные выше определения коинтеграции соответствуют коинтеграции в узком смысле.
В приведенных определениях ненулевой вектор β = (β1, … , βN)T определялся как коинтегрирующий вектор, если β1 y1t + … + βN yN t – стационарный ряд. Это означает, что если ряды y1t , … , yN t (по крайней мере, некоторые из них) содержат, наряду со стохастическим, еще и детерминированные тренды, то тогда коинтегрирующий вектор должен аннулировать оба вида трендов одновременно. И в связи с этим, коинтеграцию в узком смысле называют еще детерминистской коинтеграцией.
7.3. Проверка нескольких рядов на коинтегрированность. Критерии Дики – Фуллера
Здесь надо различать несколько случаев.
(1) Коинтегрирующий вектор определяется экономической теорией.
Тогда надо просто проверить на наличие единичного корня соответствующую линейную комбинацию
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
25 |
β1 y1t + … + βN yN t .
При этом используются те же критические значения, которые рассчитаны на применение к отдельно взятому ряду; эти значения не зависят от количества задействованных рядов N .
Пусть возможный коинтегрирующий вектор не определен заранее.
Тогда отдельно рассматриваются следующие ситуации.
(2) Ряды y1t , … , yN t не имеют детерминированного тренда (точнее, E(∆yk t) = 0).
(2a) В коинтеграционное соотношение (SM) константа не включается.
В этом случае мы оцениваем
SM: y1t = γ2 y2t + … + γN yN t + ut ,
получаем ряд остатков
uˆt = y1t − (γˆ2 y2 t +K+ γˆN yN t ),
оцениваем модель регрессии
∆uˆt = ϕ uˆt −1 +ζ1∆uˆt −1 +K+ζ K ∆uˆt − K + εt
с достаточным количеством запаздывающих разностей и проверяем гипотезу H0: φ
= 0 против альтернативы H0: φ < 0 .
На этот раз критические значения для t-статистики tφ зависят от количества задействованных рядов N . При большом количестве наблюдений можно использовать
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
26 |
критические значения, приведенные в [Hamilton (1994), Table B.9, Case 1]. Однако на практике в правую часть оцениваемого уравнения константа обычно включается.
(2b) В коинтеграционное соотношение (SM) константа включается.
В этом случае мы оцениваем
SM: y1t = α + γ2 y2t + … + γN yN t + ut ,
опять получаем ряд остатков – теперь это будет ряд
uˆt = y1t − (αˆ + γˆ2 y2 t +K+ γˆN yN t ),
оцениваем модель регрессии
∆uˆt = ϕ uˆt −1 +ζ1∆uˆt −1 +K+ζ K ∆uˆt − K + εt
с достаточным количеством запаздывающих разностей и проверяем гипотезу H0: φ
= 0 против альтернативы H0: φ < 0 .
Критические значения в этом случае отличаются от случая (2a). При большом
количестве наблюдений можно использовать критические значения, приведенные в
[Hamilton (1994), Table B.9, Case 2]. При небольших T критические значения
вычисляются по формуле, приведенной в [MacKinnon (1991), таблица 1 (вариант “no
trend”)] и воспроизведенной в [Patterson (2000)].
|
(3) |
Хотя бы один из рядов y2t , … , yN t имеет линейный тренд , так что E(∆yk t) |
|
≠ 0 |
хотя бы для одного из регрессоров. |
(3a) В коинтеграционное соотношение включается константа.
В этом случае оценивается
SM: y1t = α + γ2 y2t + … + γN yN t + ut .
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
27 |
Далее действуем опять как в (2b), только критические значения другие. При
большом количестве наблюдений можно использовать критические значения,
приведенные в [Hamilton (1994), Table B.9, Case 3]. При небольших T критические
значения вычисляются по формуле, приведенной в работе [MacKinnon (1991), Table
1 (вариант “with trend”)] и воспроизведенной в [Patterson (2000)].
(3b) В коинтеграционное соотношение включается линейный тренд.
В этом случае оценивается
SM: y1t = α + δt + γ2 y2t + … + γN yN t + ut .
Действуя так же, как и ранее, используем те же таблицы, что и в (3a), но только не для N , а для N + 1 переменных.
Включение тренда в коинтеграционное соотношение приводит к уменьшению
мощности критерия из-за необходимости оценивания “мешающего” параметра δ .
Однако такой подход вполне уместен в тех случаях, когда нет полной уверенности в
том, имеется ли ненулевой тренд хотя бы у одного из рядов y1t, y2t , … , yN t .
Пример
Смоделируем реализации четырех рядов y1t , y2t , y3t , y4t , следуя процессу порождения данных
DGP: y1t = y2, t + y3, t + y4, t + ε1t ,
y2t = y2, t – 1 + ε2t , y3t = y3, t – 1 + ε3t , y4t = y4, t – 1 + ε4t ,
где ε1t , ε2t , ε3t , ε4t – независимые друг от друга процессы гауссовского белого шума с дисперсиями, равными 1 для ε2t , ε3t , ε4t и 2 для ε1t .
Графики полученных реализаций для T = 200 приведены ниже.
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
28 |
|||||||||
|
60 |
||||||||||
|
40 |
||||||||||
|
20 |
||||||||||
|
0 |
||||||||||
|
-20 |
||||||||||
|
-40 |
||||||||||
|
-60 |
||||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
|
Y1 |
Y3 |
|||||||||
|
Y2 |
Y4 |
Не зная точно процесс порождения данных, мы должны были бы начать с исследования отдельных рядов. У всех четырех рядов не обнаруживается детерминированного тренда. Проверка по критерию Дики – Фуллера дает значения t-статистик, равные – 2.18, – 1.78, – 0.57, –1.70, соответственно. Все 4 ряда признаются интегрированными. Продифференцированные ряды идентифицируются как гауссовские белые шумы, так что ряды y1t , y2t , y3t , y4t идентифицируются как AR(1) ряды с единичным корнем, т.е. как интегрированные ряды порядка 1.
Теперь можно приступить к проверке этих четырех рядов на коинтегрированность. (1) Если “экономическая теория” предполагает теоретическое
долговременное соотношение между рассматриваемыми рядами в форме
|
y1t = y2, t + y3, t + y4, t , |
|||||||||
|
то мы просто проверяем на интегрированность ряд |
|||||||||
|
y1t – y2, t – y3, t – y4, t . |
|||||||||
|
График этого ряда |
|||||||||
|
8 |
|||||||||
|
6 |
|||||||||
|
4 |
|||||||||
|
2 |
|||||||||
|
0 |
|||||||||
|
-2 |
|||||||||
|
-4 |
|||||||||
|
-6 |
|||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
COINT |
вполне похож на график стационарного ряда, что подтверждается проверкой по критерию Дики – Фуллера: вычисленное значение t-статистики критерия равно – 15.07. Гипотеза некоинтегрированности рядов отвергается.
Представим теперь, что теория не предлагает нам готового коинтегрирующего вектора.
(2a) Оценивание статистической модели без включения в нее константы дает:
Dependent Variable: Y1
Method: Least Squares
|
Variable |
Coefficient Std. Error |
t-Statistic |
Prob. |
|||||||||
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
29 |
||||||||||||||
|
Y2 |
0.996084 |
0.009973 |
99.88161 |
0.0000 |
|||||||||||
|
Y3 |
0.992550 |
0.009578 |
103.6296 |
0.0000 |
|||||||||||
|
Y4 |
1.002305 |
0.012393 |
80.87922 |
0.0000 |
|||||||||||
При оценивании тестового уравнения Дики – Фуллера для ряда остатков получаем
|
Augmented Dickey-Fuller Test Equation |
|||||||||||||
|
Dependent Variable: D(RESID_2A) |
|||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|||||||||
|
RESID_2A(-1) |
-1.075552 |
0.070892 |
-15.17178 |
0.0000 |
|||||||||
Вычисленное значение t-статистики критерия равно – 15.17, что намного ниже 5%
критического значения – 3.74 ([Hamilton (1994), Table B.9, Case 1]). Гипотеза некоинтегрированности отвергается.
(2b) Оценивание статистической модели с включением константы:
|
Dependent Variable: Y1 |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
C |
0.332183 |
0.373542 |
0.889279 |
0.3749 |
||||||||
|
Y2 |
1.002583 |
0.012369 |
81.05843 |
0.0000 |
||||||||
|
Y3 |
0.987369 |
0.011215 |
88.04048 |
0.0000 |
||||||||
|
Y4 |
0.999022 |
0.012937 |
77.22129 |
0.0000 |
||||||||
При оценивании тестового уравнения Дики – Фуллера для ряда остатков получаем
|
Augmented Dickey-Fuller Test Equation |
|||||||||||||
|
Dependent Variable: D(RESID_2B) |
|||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|||||||||
|
RESID_2B(-1) |
-1.079049 |
0.070861 |
-15.22764 |
0.0000 |
|||||||||
Вычисленное значение t-статистики – 15.23 опять намного ниже 5% критического значения, которое здесь равно – 4.11 ([Hamilton (1994), Table B.9, Case 2]). Гипотеза некоинтегрированности отвергается.
|
(3) Модифицируем теперь ряд y1t , переходя к ряду y*1t = y1t + 0.75t , график которого |
|||||||||
|
в сравнении с графиком ряда y1t |
имеет следующий вид: |
||||||||
|
200 |
|||||||||
|
150 |
|||||||||
|
100 |
|||||||||
|
50 |
|||||||||
|
0 |
|||||||||
|
-50 |
|||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
Y1 |
Y1_STAR |
||||||||
|
Картина изменения всех 4 рядов принимает вид |
www.iet.ru/mipt/2/text/curs_econometrics.htm

|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
30 |
|||||||||
|
200 |
||||||||||
|
150 |
||||||||||
|
100 |
||||||||||
|
50 |
||||||||||
|
0 |
||||||||||
|
-50 |
||||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
|
Y1_STAR |
Y3 |
|||||||||
|
Y2 |
Y4 |
(3a) Оцениваем статистическую модель с константой в правой части:
|
Dependent Variable: Y1_STAR |
|||
|
Variable |
Coefficient Std. Error |
t-Statistic |
Prob. |
|
C |
11.49053 |
2.704802 |
4.248195 |
0.0000 |
||||||
|
Y2 |
-1.333762 |
0.089561 |
-14.89224 |
0.0000 |
||||||
|
Y3 |
2.856952 |
0.081207 |
35.18115 |
0.0000 |
||||||
|
Y4 |
0.072630 |
0.093677 |
0.775323 |
0.4391 |
||||||
|
В этом случае график остатков имеет несколько отличный вид: |
||||||||||
|
15 |
||||||||||
|
10 |
||||||||||
|
5 |
||||||||||
|
0 |
||||||||||
|
-5 |
||||||||||
|
-10 |
||||||||||
|
-15 |
||||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
|
|
RESID_3A |
||||||||||
|
Проверка по Дики – Фуллеру дает следующие результаты: |
При оценивании тестового уравнения Дики – Фуллера для ряда остатков получаем
|
Augmented Dickey-Fuller Test Equation |
||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
||||||||
|
RESID_3A(-1) |
-0.119805 |
0.033630 |
-3.562431 |
0.0005 |
||||||||
Вычисленное значение t-статистики – 3.56 выше 5% критического значения, которое здесь равно – 4.16 ([Hamilton (1994), Table B.9, Case 3]). Гипотеза некоинтегрированности не отвергается.
(3b) Включаем в правую часть тренд:
|
Dependent Variable: Y1_STAR |
||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|
C |
0.304068 |
0.390739 |
0.778187 |
0.4374 |
www.iet.ru/mipt/2/text/curs_econometrics.htm
|
Эконометрика. Введение в регрессионный анализ временных рядов. В.П.Носко www.iet.ru |
31 |
||||||||||
|
@TREND |
0.751890 |
0.007507 |
100.1621 |
0.0000 |
|||||||
|
Y2 |
1.008470 |
0.026468 |
38.10166 |
0.0000 |
|||||||
|
Y3 |
0.982658 |
0.021830 |
45.01453 |
0.0000 |
|||||||
|
Y4 |
1.001356 |
0.015942 |
62.81247 |
0.0000 |
|||||||
|
График остатков: |
|||||||||||
|
8 |
|||||||||||
|
6 |
|||||||||||
|
4 |
|||||||||||
|
2 |
|||||||||||
|
0 |
|||||||||||
|
-2 |
|||||||||||
|
-4 |
|||||||||||
|
-6 |
|||||||||||
|
-8 |
|||||||||||
|
20 |
40 |
60 |
80 |
100 |
120 |
140 |
160 |
180 |
200 |
||
|
RESID_3B |
|||||||||||
|
Последний график похож на график стационарного ряда, что подтверждается |
|||||||||||
|
проверкой по Дики – Фуллеру: |
|
Augmented Dickey-Fuller Test Equation |
|||||||||||||
|
Dependent Variable: D(RESID_3B) |
|||||||||||||
|
Variable |
Coefficient |
Std. Error |
t-Statistic |
Prob. |
|||||||||
|
RESID_3B(-1) |
-1.079492 |
0.070859 |
-15.23448 |
0.0000 |
|||||||||
Вычисленное значение t-статистики – 15.234 намного ниже 5% критического значения, которое здесь равно –4.49 ([Hamilton (1994), Table B.9, Case 3]). Гипотеза некоинтегрированности отвергается.
Последние два результата весьма важны для уточнения того, что понимается под коинтеграцией в настоящее время.
Фактически, мы обнаружили следующее. Ряды y1t , y2t , y3t , y4t коинтегрированы в том смысле, который был определен выше (коинтегрированы в узком смысле). Именно в таком виде ввели в обиход понятие коинтеграции Энгл и Гренджер. Ряды y*1t , y2t , y3t , y4t не являются коинтегрированными в узком смысле. В то же время, включение в правую часть статистической модели трендовой составляющей приводит к стационарным остаткам.
Вспомним в связи с этим, что при включении тренда в правую часть линейного регрессионного уравнения коэффициенты при объясняющих переменных интерпретируются как коэффициенты линейной связи между переменными, очищенными от детерминированного тренда. Последние же действительно были коинтегрированы по построению.
Наблюдаемая ситуация известна теперь под названием “стохастическая коинтеграция”. Оно указывает на наличие коинтеграционной связи между стохастическими трендами, входящими в состав рассматриваемых рядов, и не требует согласованности детерминированных трендовых составляющих ( если таковые имеются). В этом случае коинтегрирующий вектор аннулирует стохастический тренд, но не обязан одновременно аннулировать и детерминированный тренд. Другими словами, существует линейная комбинация рассматриваемых рядов, которая образует ряд, стационарный относительно детерминированного тренда, но не обязательно стационарный.
В противоположность стохастической коинтеграции, при наличии коинтеграции в узком смысле коинтегрирующий вектор аннулирует и стохастический и
www.iet.ru/mipt/2/text/curs_econometrics.htm