
Misspecification in Linear Spatial Regression Models
Raymond J.G.M. Florax, Peter Nijkamp, in Encyclopedia of Social Measurement, 2005
Spatial Dependence and Spatial Heterogeneity
Spatial effects include spatial heterogeneity and spatial dependence. Spatial heterogeneity refers to structural relations that vary over space, either in a discrete or categorical fashion (for instance, urban vs. rural, or according to an urban hierarchy), or in a continuous manner (such as on a trend surface). Spatial dependence points to systematic spatial variation that results in observable clusters or a systematic spatial pattern. These descriptions already show that in an observational sense, spatial dependence and spatial heterogeneity are not always easily discernible. The clustering of high values in, for instance, urban areas and urban fringes can be interpreted as spatial clustering of high values pertaining to urban areas and to low values to rural areas, but it may as well be viewed as spatial heterogeneity, distinguishing metropolitan areas from their hinterland.
The typical feature of spatial dependence or spatial autocorrelation is that it is two-dimensional and multidirectional. An observation of an attribute at one location can be correlated with the value of the same attribute at a different location, and vice versa, and the causation pattern can occur in different directions. Figure 1 shows two identical (7 × 10) regular grid systems with distinct spatial distributions of the same values. The absolute location of the nonzero values is the same in both grids, but graph A shows a clustering of relatively low values on the left-hand side and high values to the right. Graph B shows a much more random spatial allocation of values. In terms of spatial effects, note that the distribution in graph A exhibits spatial dependence and spatial heterogeneity, whereas graph B does not.

Figure 1. Hypothetical example of a spatial distribution of values on a 7 × 10 regular grid. Adapted from Upton and Fingleton (1985).
The occurrence of spatial heterogeneity does not necessarily have severe implications for the information that can be obtained from a spatial data series. Spatial autocorrelation does, however, because an observation is partly predictable from neighboring observations. A series of spatially dependent observations therefore contains less information. This is similar to the situation in time series analysis, wherein a forecast with respect to the future can be partly inferred from what happened in the past. The two-dimensional and multidirectional nature of spatial autocorrelation ensures that the spatial case is more complex.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0123693985003510
Modeling Microbehavioral Decisions: Statistical Considerations
S. Niggol Seo, in Microbehavioral Econometric Methods, 2016
3.6 Spatial econometric models
In the discrete choice models introduced up to now, spatial effects are by land large left unexplained. Spatial effects refer to spatial dependence in empirical data including spatial autocorrelation and spatial heterogeneity (Anselin, 1988, 1998; Case 1992; Beron and Vijberberg, 2004). Spatial dependence can arise because of an omitted variable that is correlated with spatial locations of sample data, for example, uncaptured county characteristics (Deschenes and Greenstone, 2007, 2012). Spatial dependence can take the form of spatial heterogeneity of observations as some farms are located in primarily rural areas while other farms are located in suburban areas (Mendelsohn et al., 1994).
Following Anselin (1998), let S be a set composed of N geographical units (eg, districts, counties, census tracts). The set S can be partitioned into R nonoverlapping spatially-defined subsets Sr (with r = 1, 2, …, R) such that for any r, q(r ≠ q), Sr∩Sq=0 and ∪r=1,…,RSr=S. In other words, the subsets are mutually exclusive and exhaustive. Spatial heteroscedasticity across the spatially-defined subsets is defined as follows:
(3.95)Var(ɛi)=σr2, ∀ i∈Sr.
Spatial autocorrelation refers to the coincidence of value similarity with location similarity. It takes the form of nonzero covariance between the observations from two distinct spatially-defined groups r, q:
(3.96)Cov(πi,πj)=σij>0, ∀i,j s.t. i∈Sr,j∈Sq.
Furthermore, let s denote a specific spatial location and h a directional distance from a specific location. Then, we can define the following variance Vs(h) using profit (π) differences in two locations:
(3.97)Vs(h)=12Var[π(s+h)−π(s)].
If there is spatial continuity in the observed profits, the profits observed in two closer locations should exhibit smaller differences than the profits observed in two farther apart locations. The larger the h, the larger the Vs(h). That is, the farther apart are two locations, the larger the variance in the profit differences.
A spatial weights matrix is used to code spatial dependence, both spatial heterogeneity and spatial autocorrelation (Anselin, 1998; Schlenker et al., 2006; Schlenker and Roberts 2009). Spatial dependence can take a variety of forms, so does a spatial weights matrix. To give an example, a spatial weights matrix can be defined based on the defined neighborhoods. Let W be an N ∗ N matrix with cij as its component. For each location i (as the row) which belongs to the predefined neighborhood Si, the columns in the neighborhood of Si are assigned nonzero values and the columns not in the neighborhood are assigned zero values. That is, for each row i, the matrix elements cij are given the following values, with Si defined to be the neighborhood of location i:
(3.98)cij≠0, ∀ j∈Si=0, ∀ j∉Si.
Without loss of generality, the elements of the spatial weights matrix are typically row-standardized. That is, for a given i, ∑j=1Ncij=1.
Another way to define a spatial weights matrix is by spatial distances among sample locations. In the spatial weights matrix based on defined neighborhoods, explained earlier, the matrix elements are given either zero or nonzero values depending upon whether each element belongs to a defined neighborhood or not. Alternatively, the elements can be defined as the distance (d) between the two locations:
(3.99)cij=d(i,j),∀i,j.
The most commonly used specification test for the existence of spatial autocorrelation is Moran’s I, which is a two-dimensional analog of the time-series autocorrelation (Moran, 1948, 1950a, b; Johnston and DiNardo, 1997). Moran’s I is defined as follows:
(3.100)I=(N/Z0)(eˆ′Weˆ/eˆ′eˆ)with Z0=∑i∑jcij.
where eˆ is a vector of Ordinary Least Squares (OLS) residuals and Z0 is a standardization factor that corresponds to the sum of weights for the nonzero cross-products.
Inference for Moran’s I statistic is based on a normal approximation, using a standardized z-value which is obtained from the mean and variance of the statistic shown in Eq. 3.100 (Cliff and Ord, 1972, 1981). Moran’s I statistic can be used for tests of the residuals in the 2SLS (2 Stage Least Squares) models as well as for tests of the generalized residuals in the Probit models (Anselin and Kelejian, 1997; Pinkse, 1998). Asymptotic normality of the Moran’s I statistic in a large variety of regression models and conditions is provided by Pinkse (1998) and Kelejian and Prucha (1998).
In a standard outcome equation such as the first equation in Eq. 3.61, spatial dependence can be incorporated parametrically into the model using one of the following two ways. First, it can be incorporated as an additional regressor in the form of a spatially lagged dependent variable. Second, it can be incorporated into the error structure of the model. The former is called a spatial lag model while the latter is called a spatial error model (Anselin, 1998).
A spatial lag model, also called a spatial autoregressive model, is expressed as follows in the vector form:
(3.101)y=ρWy+Xβ+ɛ,
where y is the vector of outcome variables, for example, profit, ρ is a spatial autoregressive coefficient, W is a spatial weights matrix, and ɛ is a vector of residuals which is assumed to be iid normal with mean zero and variance σ2. W is called a spatial lag operator.
A spatial error model is specified with a nonspherical error term in which off-diagonal elements of the covariance matrix capture the nature of spatial dependence. One way to express the spatial error model is through the spatial autoregressive error terms:
(3.102)y=Xβ+εand ε=λWε+u,
where u is a spherical error term.
Alternatively, spatial dependence can be incorporated in a nonparametric manner through simulation methods (Seo, 2011b, 2012a, 2015b; Efron 1979, 1981). Let’s go back to the neighborhood definition before: R nonoverlapping neighborhoods with Sr denoting an individual neighborhood. Let’s assume that the spatial neighborhood effect is zero outside the neighborhood Sr and nonzero within the neighborhood. The size of spatial neighborhood effect may vary from one neighborhood to another. The spatial weights matrix defined above in Eq. 3.98 is a special case of this neighborhood definition. That is, if the size of spatial neighborhood effect is assumed to be constant across the neighborhood, the spatial weights matrix in Eq. 3.98 captures this type of spatial dependence.
A researcher can model this form of neighborhood effect in a nonparametric way by spatially resampling from the neighborhoods. First, a researcher randomly samples one observation from each neighborhood Sr across the whole dataset S, which is denoted Sr1. Then, the first sub-sample is composed of the following elements with size R:
(3.103){S11,S21,…,Sr1,…,SR1}.
Second, one estimates a multinomial Logit probability for each alternative j for this first sub-sample and denotes it by Pj1. Third, one repeats this procedure for a large number of times and denotes the kth subsample and the Bth subsample as well as estimated subsample probabilities as follows:
(3.104)S1k,S2k,…,Srk,…,SRk and PjkS1B,S2B,…,SrB,…,SRB and PjB.
Finally, the researcher calculates the mean of the subsample probabilities for this alternative and denote it by P⌣j:
(3.105)P⌣j=1B∑b=1BPjb, ∀j.
This probability takes care of spatial dependence in a nonparametric way. A wide range of parametric spatial dependence models can be approximated nonparametrically using the spatial resampling method, described above, by specifying the neighborhoods accordingly and sampling from the defined neighborhoods by employing proper sampling strategies.
In a variety of parametric spatial dependence model which has a continuous form of spatial dependence, for example, through a spatial weights matrix which has element-wise distances as its elements, a researcher can approximate it nonparametrically with a spatial resampling method by employing a sampling strategy, which is pertinent to the nature of spatial dependence in question (McFadden, 1999b; Bryman and Bell, 2015).
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128041369000035
Handbook of Economic Growth
Enrico Spolaore, Romain Wacziarg, in Handbook of Economic Growth, 2014
3.4.1.2 Regional Controls and Analysis
In Table 3.3, we run a variety of regressions accounting for regional effects. In column 1, we include a full set of continental dummy variables capturing both whether the countries in a pair are both located on the same specific continent (an effect presumed to go in the direction of reducing the difference in economic performance between these countries); and whether they are located on different ones (as further defined in the footnote to Table 3.3). The idea behind this test is to further control for geographic factors not already captured by the included geographic distance variables. However, this is a demanding test, since continent effects could capture geographic barriers but also part of the effect of human barriers that could be mismeasured when using genetic distance. Nonetheless the effect of genetic distance remains robust to controlling for a full set of 12 same- and different-continent dummies. While the effect of genetic distance falls in magnitude, it remains large and highly significant statistically.
Table 3.3. Income difference regressions, regional controls, and sample splits (dependent variable: difference in log per capital income in 2005, 1870 for column 3)
| (1) | (2) | (3) | (4) | (5) | (6) | |
|---|---|---|---|---|---|---|
| Continent dummies | Europe 2005 income | Europe with 1870 income | Excluding Europe | Control for Europeans | Excluding SS Africa | |
| Fst gen. dist. relative to the USA, weighted | 3.403 (1.284)** | 5.183 (1.232)*** | 5.624 (1.143)*** | 4.851 (1.443)*** | ||
| Genetic distance, relative to the English | 25.920 (11.724)** | 27.054 (6.557)*** | ||||
| Abs. difference in the shares of people of European descent | 0.626 (0.125)*** | |||||
| Constant | 1.541 (0.315)** | 0.345 (0.201)* | 0.495 (0.154)*** | 1.006 (0.123)*** | 0.864 (0.097)*** | 0.853 (0.071)*** |
| Observations | 10,440 | 253 | 136 | 6,328 | 10,153 | 5,253 |
| Standardized Beta (%) | 16.27 | 31.28 | 43.62 | 24.99 | 27.15 | 17.12 |
| R-Squared | 0.20 | 0.24 | 0.24 | 0.08 | 0.17 | 0.06 |
Two-way clustered standard errors in parentheses.
In all regressions, controls are included for: Absolute difference in latitudes, absolute difference in longitudes, geodesic distance, dummy for contiguity, dummy if either country is an island, dummy if either country is landlocked, dummy if pair shares at least one sea or ocean.
Column 1 includes continental dummies defined as follows: both in Asia dummy, both in Africa dummy, both in Europe dummy, both in North America dummy, both in Latin America/Caribbean dummy, both in Oceania dummy, dummy if one and only one country is in Asia, dummy if one and only one country is in Africa, dummy if one and only one country is in Europe, dummy if one and only one country is in North America, dummy if one and only one country is in South America.
- *
- Significant at 10%.
- **
- Significant at 5%.
- ***
- Significant at 1%.
Columns 2 and 3 make use of the separate genetic distance dataset we have for 26 countries in Europe. Here, the relevant measure of genetic distance is FST distance to the English (England being the birthplace of the Industrial Revolution), though the results do not change if we use distance to the Germans instead. We find that within Europe, genetic distance is again a strong predictor of absolute differences in log per capita income. The standardized beta on genetic distance relative to the English is of the same order of magnitude as that found in the world sample, and it is highly significant. There are two major genetic clines in Europe: one separating the north and the south, another one separating the east and the west. These correspond to north-south and east-west income differences. Since the east-west cline overlaps to a large degree with regions that were on either side of the Iron Curtain during the Cold War, to assess whether this historical feature explains all of the effect of genetic distance on economic performance, we repeat our regression using income in 1870 (from Maddison), well prior to the rise of the Eastern bloc. We find that the effect of genetic distance is in fact larger in magnitude in the immediate aftermath of the Industrial Revolution, with the standardized beta rising to almost 44%. This result assuages concerns that the contemporary results were a result of the fact that the Iron Curtain as a first approximation, separated Slavic from non-Slavic Europeans. It is also highly consistent with the barriers story since, as we further explore below, the effect of genetic distance should be larger around the time of a large innovation, in the midst of the process whereby countries other than the frontier are busy adopting the frontier technology in proportion to how genetically far they are from the frontier. In sum, our effects hold within Europe, where genetic distance is better measured.
Since the basic result of this chapter holds so strongly for Europe, might Europe drive the World results? To test this, in column 4 we exclude any pairs of countries containing at least one European country. Compared to the baseline results, the standardized effect of genetic distance relative to the USA declines from 30% to 25%, but remains large and statistically significant—highlighting that the results are not due to Europe alone. To drive home the point, in column 5 we control for the absolute difference in the share of the population of European descent, using data from the Putterman and Weil (2010) migration matrix. The regression now controls more broadly for the effect of European-ness, and while the effect of the absolute difference in the share of Europeans is a positive and statistically significant determinant of differences in per capita income, its inclusion in the regression only moderately reduces the standardized effect of relative genetic distance (to 27%). We conclude that our results are not driven by the inclusion of European countries in the sample, nor are they driven by the genetic difference between Europeans and the rest.
The final geographic concern that we explore is whether Sub-Saharan Africa drives our results. As Figure 3.2 illustrates, Sub-Saharan African populations are genetically distant from the rest of the world: the out-of-Africa migrations occurring about 70,000 years ago were the first foray of modern humans out of Africa, and consequently Africans and other world populations have had the longest time to drift apart genetically from each other. Sub-Saharan populations also have some of the lowest per capita GDPs recorded in the world. While it is part of our story to ascribe some of the poverty of Africa to the barriers to technological transmission brought about by its high degree of genealogical distance from the rest of the world, it would be concerning if our results were entirely driven by Sub-Saharan Africa. To address this concern, in column (6) of Table 3.3 we exclude any pair that involves at least one Sub-Saharan country from our sample. We find that the effect of genetic distance falls a little, but remains positive, statistically significant, and large in magnitude with a standardized beta equal to 17%. Together with the strong results within Europe, this should lay to rest any notion that our results are driven solely by Sub-Saharan Africa.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780444535382000034
Spatial Econometrics: Theory and Applications in Health Economics
F. Moscone, E. Tosetti, in Encyclopedia of Health Economics, 2014
Concluding Remarks
This article has surveyed the most recent econometric methods for panel data dealing with spatial effects. Recent developments in spatial econometrics offer new methods for representing the spatiotemporal dynamics of many health economics phenomena. However, the range of spatial techniques adopted until now in health economics is rather limited, when compared to the methods developed in the literature. For instance, only few works have incorporated in their specification time-invariant unobserved heterogeneity and/or temporal dynamics. The use of recently developed techniques in spatial econometrics may offer insights and raise new questions in several areas of health economics.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123756787007197
Forest Ecology
Timothy J. Fahey, in Encyclopedia of Biodiversity (Second Edition), 2013
Pollution
Local declines of forests has been associated conclusively with point-source releases of air pollutants, especially sulfur dioxide, fluoride, and toxic metals from smelters. Broad scale, regional effects of air pollution on forests have been more difficult to demonstrate. Regional pollution – by ozone smog in the southwestern United States and by acidic deposition in the eastern United States and Europe – probably has contributed to documented forest declines. Although improvements in emission controls and regulations in these regions are likely to reduce the chances of further damage, rapid industrialization without adequate emission controls in other regions of the world threatens forest health and biodiversity.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123847195000587
Regional Input–Output Analysis
Eveline S. van Leeuwen, … Piet Rietveld, in Encyclopedia of Social Measurement, 2005
Regional Multipliers
When working with a regional input–output table, regional multipliers can also be derived. Depending on the kind of table, relevant economic effects on the region, on other regions, or on the national economy can be computed. These effects are interesting, for example, when the government has to decide upon a new location for a military base or for a new main post office. If the government wants to use this relocation to stimulate a certain region, the regional effects on employment or income are relevant.
The effect of a change in final demand within a region (region 1) on the region, the regional (output) multiplier, can be derived as follows:
Ma=(X11−X10)impulse,
where Ma is the regional multiplier, X11 is the total output of region 1 after the impulse, and X10 is the total output of region 1 before the impulse. The essence of an interregional input–output model is that it includes impacts in one region (region 2) that are caused by changes in another region; this effect is measured by the spillover multiplier. Later, we explain in more detail how the multipliers can be computed.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0123693985003492
Interregional disparity and the development of inland regions
Yanqing Jiang, in China, 2014
Introduction
Since the start of economic reform in the 1980s, China has achieved remarkable growth in the past three decades. However, China’s rapid growth has been accompanied by growing inequality that ‘threatens the social compact and thus the political basis for economic growth and social development’ (Fan et al., 2009). The Gini coefficient, which measures economic inequality in society, was 0.33 in 1980 and later rose by about 40 percent to around 0.46 in the early 2000s (Sisci, 2005; WB, 2005; Fan and Sun, 2008). Such a rate of increase, according to the World Bank, was the fastest in the world. Spatial income disparities, especially those between coastal and inland regions, have been on the rise and became a prominent issue in China during the country’s growth and transition (Yin, 2011). In the present study we focus on the relatively backward inland regions of China. Specifically, we examine the potential effects of three factors – international openness, domestic coastal–inland market integration, and human capital accumulation – on TFP (total factor productivity) growth in China’s inland provinces.
Growth and development theories suggest that openness to foreign trade and FDI (foreign direct investment) promote the income growth of a country (or region) by raising the level of domestic (or local) productivity. For example, foreign trade opens up access to new technology embodied in imported goods, enlarges the market faced by domestic producers so that they can increase their returns from innovations, and motivates the country’s specialization in research-intensive production (Harrison, 1996). It has been widely argued that China’s impressive economic takeoff can be attributed, to a large extent, to the country’s radical initiatives encouraging openness to foreign trade and inward flows of FDI. However, the degree of participation in foreign trade varies greatly from one Chinese region to another, and FDI inflows are also highly unevenly distributed across different regions. How does this uneven openness affect the income gap between inland and coastal regions of China? To answer this question, the role of openness in promoting regional TFP growth in China, especially TFP growth in inland regions, needs to be thoroughly analyzed.
Another important factor affecting TFP growth in China’s inland regions is coastal–inland market integration. China is a very large country characterized by striking economic disparities across regions and between rural and urban areas. Recent regional productivity studies of China (e.g., Zheng and Hu, 2006; Yang and Lahr, 2010; Jiang, 2011) often fail to explore the pattern of spatial interdependence of China’s regions. Such studies tend to treat each region as an isolated and independent entity and overlook spatial effects and interregional dynamics.2 Ignoring spatial interdependence in regional studies could generate serious misspecification problems and lead to questionable parameter estimates and statistical inferences (Abreu et al., 2005; Fingleton and López-Bazo, 2006; Özyurt and Mitze, 2012). Spatial interdependence implies interactions between China’s different regions. In this chapter we are interested in examining how interregional market integration (interregional trade) between coastal and inland regions in China affects TFP growth in inland regions. Intuitively, coastal–inland market integration in China implies that inland regions can realize growth in TFP by taking advantage of technology spillovers from higher TFP coastal regions or of gains from regional production specialization facilitated by interregional trade.
Human capital in inland regions is yet another factor that can be crucial in promoting local TFP growth. Human capital may exert a dual effect on income growth. First, human capital has a direct static impact on income growth as an accumulable factor of production. Second, human capital may have an indirect dynamic impact on income growth via its contribution to TFP growth. The key point is, as Benhabib and Spiegel (1994) have pointed out, the most important contribution of human capital to income growth may lie not in its static effect as a direct production input, but in its dynamic role in promoting TFP growth.
The remainder of this chapter is organized as follows. In the second section ‘The model’ we present the theoretical framework and empirical model on which our later regression analysis will be based. In the third section ‘The variables and data’, following the empirical model presented in the preceding section, we discuss various issues concerning the sample, data, and variables. In the fourth section ‘Regressions and results’ we discuss our regression methods, run the regressions, and present the results.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781843347620500062
Users and uses of Google’s information
Elad Segev, in Google and the Digital Divide, 2010
Main classification system
To compare information uses in different countries, this study employed a classification system of content integrated in Google Search, called the Open Directory Project (ODP), which is a very comprehensive humanedited directory developed and constantly updated by the online community. Each chosen editor qualified to add and maintain the open directory has to prove a good knowledge of the language, the culture and the field of the category to be edited. New information appearing on the web is constantly classified by the network community itself, and categories and subcategories are added and edited through a system of checks and balances and quality assurance. The Open Directory powers the core directory services in Google, AOL/Netscape Search and many other large and popular search engines and portals (DMOZ, 2005).
One of the main principles that ODP editors are required to follow is to organise websites by topics (e.g. news, business and games), rather than simply by region. This principle works well with the concept of functionality and usability of information, and refers directly to the research problem of this study. Furthermore, there are two main advantages in exploiting the ODP classification system in this study. First, content has already been classified, which means consistency and accuracy in the classification process – different coders using the ODP classification system will always attain similar results. The second advantage is that the ODP enterprise is international and its editors are local. It therefore already contains wide knowledge and experience, and provides an expert-specific classification of content by culture and language. As ODP editors are required to have the cultural, language and even topical background of the category they manage, it is reasonable to assume that they classify and sort information more accurately than people who do not know the field, the language or the cultural context of the classified content. The ODP’s central management, hierarchical structure of editors and its developed system of checks and balances ensure consistency and accuracy of classification, even when done by different editors.
Google Web Directory is based on the ODP and provides 14 different topical categories. For each category there are 1–17 subcategories, which are divided again into 1–20 third-level subcategories, and so on. The main categories of Google Web Directory are: Arts (with 12 subcategories, such as Movies, Music and Television), Business (with eight subcategories, such as Employment, Financial Services and Investing), Computers (with seven subcategories, such as Hardware, Internet and Programming), Games (with six subcategories, such as Gambling, Role-playing and Video Games), Health (with four subcategories, such as Alternative, Beauty and Nutrition), Home (with four subcategories, such as Do-It-Yourself, Cooking and Family), News (with four subcategories such as Breaking News, Online Archives and Weather), Recreation (with 13 subcategories such as Humor, Outdoors, and Travel), Reference (with five subcategories, such as Education, Dictionaries and Maps), Science (with three subcategories: Astronomy, Technology and Earth Sciences), Shopping (with eight subcategories, such as Auctions, Clothing and Flowers), Society (with nine subcategories, such as Chats and Forums, Government and Religion and Spirituality) and Sports (with 17 subcategories, such as Basketball, Football and Soccer). Appendix B displays the full list of categories and subcategories.
A search query submitted to the ODP or to Google Web Directory provides in return not only a list of results with their specific classifications, but also the main and most frequent classification of most results.14Because of this, it was possible for the study to automatically ascribe the most frequent and common ODP classification for each popular search query. Even though the process of classifying search queries into categories and subcategories was mostly automatic, there was careful human control involved for each query, checking the integrity, and filtering the regional effect of the classification process. Hence, for example, the query ‘herr der ringe’ (in English: ‘The lord of the rings’) appeared in Google Germany in January 2004, and was automatically classified as World > Deutsch > Arts > Films > Titles > H, as the query was written in German. In this case, the first regional categories were manually filtered and the classification started with Arts > Films > Titles, as the three categories to be checked and compared. When a query was automatically classified as regional, the subcategories were used as the main classification in order to maintain integrity with results from other national interfaces. Another example is the query ‘eastenders’ in Google UK. This query was classified automatically as: Regional > Europe > United Kingdom > Arts > Television > Programs, and was counted only as: Arts > Television > Programs, for research purposes. The only case in this research when a query was classified as regional was when the query itself was a region, such as the query ‘france’ in Google France in July 2004. Apart from exceptional and very rare regional queries, all search queries were classified first by their topic and usability, using the automatic subcategories suggested.
To reiterate, although the main method of classifying search queries was Google Web Directory, the automatic classification process for each query was also manually monitored in order to maintain the integrity of the results and to filter the regional effect, resulting in a better comparative exercise.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9781843345657500046
Knowledge, Education, and Skills, Geography of
P. Meusburger, in International Encyclopedia of the Social & Behavioral Sciences, 2001
3.2 Research Topics and Possible Future Directions
The newly emerging ‘geography of knowledge, skills and education’ in its early period of the 1960s and 1970s first focused on spatial diversities of school systems (size, equipment, location criteria, and catchment areas of schools and universities), on spatial patterns of expenditure on education, on the evolution of patterns of school provision, on cultural and economic effects of schools and universities, on spatial effects of educational policies and school planning concepts, on the effects of school closures, and on spatial disparities of educational achievement.
On the spatial macro-scale, indicators of educational achievement are used to describe the spatial dimension of social stratification and the spatial distribution of human resources. The educational achievement of the adult population is measured by indicators such as the proportion of illiterates, the proportion of the adult population who completed a certain level of education (e.g. proportion of university graduates) or by median school years completed. Literacy is often regarded as a precondition for the modernization process. Spatial disparities in the educational attainment and behavior of pupils (students) can be measured by indicators such as the proportion of an age group attending (a certain type of?) school, by transition rates of an age group to various types of secondary schools and universities, by school completion rates, by the scale of dropout and truancy, the suspension rates and many other indicators.
From the 1980s onward geography studied the personnel employed at schools, universities and research institutions. This included spatial disparities of the age-structure, skills, income, gender, social, ethnic, and regional origin, careers, and regional mobility of teachers, scientists, and other knowledge workers.
Influenced by research in economy and sociology, geography started to study the spatial variations in the transition from the school system to the occupational system in the 1980s and 1990s. The main research interests dealt with the correlation between educational achievement, first positioning in the labor market and professional career, and the spatial discrepancies and balancing mechanisms between supply and demand of skilled and unskilled labor. Migration motive patterns and distances of highly and lowly educated, of skilled and unskilled persons, and the interrelationship between career and regional mobility are central issues in this research field. The ‘brain drain’ and the transfer of talent from peripheries to centers strongly contribute to the long-term persistence of spatial disparities at all scales.
The more recent research topics and possible future directions include issues such as: (a) spatial disparities of research input (financial, technical and human resources, infrastructures), and research output (e.g. patent density, innovation density); (b) spatial differences in the quality of schools (measured by achievement tests); (c) the necessity of adjusting curricula to local economic needs or cultural traditions; (d) the role of schools (teachers) for local cultures and local empowerment; (e) the definition and spatial delimitation of creative (innovative) milieus, regional, and international differences of high-tech competitiveness; (f) the effects of telecommunications on the spatial distribution of work places for knowledge workers; (g) the role of indigenous and religious knowledge; (h) the evolvement and long term spatial effects of scientific networks; (i) the relation between human resources, endogenous economic development and economic conduct; (?j) the role of knowledge producers in the construction of historical narratives, national memories, and regional identities; and (k) the use of knowledge or enforced ignorance as a means to discipline and control. This list of research topics is never closed and strongly depends on the region, culture and time period studied. As knowledge is ‘a capacity for social action’ (Stehr 1994), and as it influences the perception, evaluation, decision making and actions of individuals, and the conduct of constituencies, a knowledge-based approach can be applied to a broad range of topics in human geography.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B0080430767025614
Landscape Genetics
Andrew Storfer, in Encyclopedia of Biodiversity (Second Edition), 2013
Ordination and Regression
Ordination (e.g., principal components analysis, or PCA, canonical correspondence analysis or CCA) has also been shown to be a powerful technique for investigating the spatial arrangement of genotypes on a landscape (Balkenhol et al., 2009a). Because space can explicitly be included in CCA (Borcard et al., 1992), the analytical method can be used to identify correlations between allele frequency distributions and gradients in environmental variables (ter Braak and Verdonschot, 1995). Recently, it was shown that partial CCA was effective in accounting for spatial effects through the incorporation of coordinates as covariates (Balkenhol et al., 2009a). A simulation study that compared CCA with several other statistical methods, including Mantel tests and partial Mantel tests, showed the method had higher power to detect landscape effects on spatial genetic structuring (Balkenhol et al., 2009a). Despite its potential, however, ordination has most often been used in empirical studies to cluster the genetic data without including landscape variables (Storfer et al., 2010).
Linear regression or general linear models have also commonly been used in landscape genetics studies. However, these methods should be cautiously used because they are generally inappropriate in situations of substantial autocorrelation (i.e., spatial non-independence of genetic and landscape data), unless significance testing relies on data permutation approaches (Fortin and Dale, 2005). Potential alternatives that attempt to account for non-independence and spatial autocorrelation are classification and regression tree (CART) models (Murphy et al., 2010), geographically weighted regression (Spear and Storfer, 2008), and network models (Garroway et al., 2011; Murphy et al., 2010).
Multiple matrix regression techniques also hold promise, and one approach that has been applied in landscape genetics studies is multiple regression of distance matrices (MRDM; Legendre et al. (1994)). This procedure involves a stepwise regression of a dependent (genetic) distance matrix and multiple independent pairwise (landscape) matrices. Landscape data are pairwise estimates of spatial separation between sampling points or localities. An MRDM analysis was used to understand landscape influence on genetic structure of the bush cricket, Metrioptera roeseli, whereby historic landscape patterns (50 years old) explained genetic structure better than current landscape pattern (Holzhauer et al., 2006). Relative to other methods, including Mantel tests and Bayesian analyses, MRDM had high power and low type I error rates in a simulation study (Balkenhol et al., 2009a).
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123847195003865
Моде́ль с простра́нственной зави́симостью в оши́бках (англ. spatial error model, SEM), пространственно-эконометрическая модель, применяемая при моделировании процессов с использованием региональных данных.
Применение данной модели целесообразно в случаях, когда в линейных регрессионных моделях в качестве объектов наблюдений используются страны, регионы и т. д., имеющие общие границы, потоки товаров, услуг и др., т. к. предположение о независимости данных наблюдений, которое входит в условие теоремы Гаусса – Маркова, нарушается. Если пространственная зависимость между факторами в моделях, оцениваемых по таким наблюдениям, не учтена, то она проявится в ошибках регрессии.
Пространственная зависимость шоков для соседних (в широком смысле) географических единиц может быть учтена с помощью модели с пространственной зависимостью в ошибках:
Y=αin+Xβ+ε, ε=λWε+u,Y=αi_{n}+ Xβ+ε, ε=λWε+u,
где nn – число наблюдений, YY – зависимая переменная, ini _{n} – единичный nn-мерный вектор, XX – матрица объясняющих переменных, α,βα,β – оцениваемые коэффициенты, ε varepsilon – ошибки регрессии, WW – пространственная матрица, λ lambda – коэффициент пространственной корреляции ошибок регрессии, uu – независимые одинаково распределённые случайные величины с дисперсией σu2 sigma _u^2 (в предположении о нормальном распределении).
Для ответа на вопрос, действительно ли имеет место пространственная зависимость в остатках, обычно проверяется гипотеза (Fischer, Wang, 2011) H0:λ=0H _{0} : λ=0 с помощью тестовой статистики Лагранжа:
LM=(e′Wee′en−1)21tr[W′W+W2]LM= ( frac{e’We}{{e’en}^{-1} }) ^2 frac{1}{tr[W’W+W^2]} .
Поскольку ковариационная матрица ошибок регрессии, в случае их пространственной зависимости, не пропорциональна единичной, а именно var[e]=σu2(I−λW)−1(I−λW′)−1var[e]= sigma _u^2 (I-λW)^{-1}(I-λW’)^{-1}, то оценки параметров α,βα,β методом наименьших квадратов будут несмещёнными, но их стандартные ошибки (а следовательно и t-статистики для проверки значимости) будут вычислены неверно. Поэтому для оценки параметров обычно используют метод максимального правдоподобия.
Оценки коэффициентов ββ в модели с пространственной зависимостью в ошибках интерпретируются традиционным для линейных моделей образом: если коэффициент jj при переменной XjX _{j} значим, то при увеличении XjX _{j} на одну единицу, зависимая переменная изменится на jj единиц.
Для интерпретации коэффициента пространственной корреляции λ lambda ошибок регрессии удобно использовать следующее представление ошибок регрессии:
ε=(I−λW)−1u=(I+λW+λ2W2+…)u=u+λWu+λ2W2u+…, varepsilon = (I- lambda W)^{-1}u=(I+ lambda W+ lambda ^2 W^2+…)u=u+ lambda Wu
+ lambda ^2W^2u+…,
где ε=(ε1,…,εn)′, u=(u1,…,un)′, Wu=((Wu)1,…,(Wu)n)′, (Wu)i=∑j=1nwijuj varepsilon = ( varepsilon_1,…, varepsilon _{n})’, u = ( u_1,…, u _{n})’, Wu = ( (Wu)_1,…, (Wu) _{n})’, (Wu)_i = sum_{j=1}^n w_{ij} u_{j} и т. д.
В этом разложении uiu_i характеризует шок переменной, произошедший в рассматриваемом ii-м регионе, а (Wu)i(Wu)_i – средние шоки этой же переменной в соседних с ii-м регионах, (W2u)i(W^2u)_i – шоки в соседних с соседними регионами и т. д. Чем меньше ∣λ∣| lambda |, тем быстрее затухает влияние шока, произошедшего в рассматриваемом ii-м регионе, в соседних регионах.
Дата публикации: 1 марта 2023 г. в 21:46 (GMT+3)
«Пространственная статистика» перенаправляется сюда. Об академическом журнале см. Пространственная статистика.

Пространственный анализ или же пространственная статистика включает любые формальные техники который изучает организации, используя топологический, геометрический, или же географический характеристики. Пространственный анализ включает в себя множество методов, многие из которых все еще находятся на ранней стадии разработки, с использованием различных аналитических подходов и применяемых в столь разных областях, как астрономия, с его исследованиями размещения галактик в космос, в технологии изготовления микросхем, с использованием «места и маршрута» алгоритмы строить сложные электромонтажные конструкции. В более узком смысле, пространственный анализ — это метод, применяемый к структурам в человеческом масштабе, в первую очередь при анализе географические данные.
При пространственном анализе возникают сложные проблемы, многие из которых не определены и не решены полностью, но составляют основу текущих исследований. Наиболее фундаментальной из них является проблема определения пространственного положения изучаемых объектов.
Классификация методов пространственного анализа затруднена из-за большого количества задействованных различных областей исследования, различных фундаментальных подходов, которые можно выбрать, и множества форм, которые могут принимать данные.
История
Возможно, можно рассмотреть пространственный анализ[согласно кому? ] возникнуть с ранними попытками картография и геодезия но многие области способствовали его появлению в современной форме. Биология внесенный через ботанический исследования глобального распространения растений и локальных местоположений растений, этологический исследования передвижения животных, ландшафт экологический исследования блоков растительности, экологический исследования пространственной динамики населения, а также изучение биогеография. Эпидемиология способствовал ранней работе по картированию болезней, в частности Джон Сноу работа по картированию вспышки холеры, с исследованиями по картированию распространения болезни и с изучением местоположения для оказания медицинской помощи. Статистика внес большой вклад в работу в области пространственной статистики. Экономика внесла значительный вклад в пространственная эконометрика. Географическая информационная система в настоящее время вносит большой вклад из-за важности географического программного обеспечения в современном аналитическом наборе инструментов. Дистанционное зондирование внес большой вклад в морфометрический и кластерный анализ. Информатика внес большой вклад в изучение алгоритмов, особенно в вычислительная геометрия. Математика продолжает предоставлять фундаментальные инструменты для анализа и раскрытия сложности пространственной области, например, в недавних работах по фракталы и масштабная инвариантность. Научное моделирование обеспечивает полезную основу для новых подходов.
Фундаментальные вопросы
Пространственный анализ сталкивается со многими фундаментальными проблемами в определении объектов исследования, в построении аналитических операций, которые будут использоваться, в использовании компьютеров для анализа, в ограничениях и особенностях известных анализов, а также в представлении аналитических результатов. Многие из этих вопросов являются активными предметами современных исследований.
Общие ошибки часто возникают в пространственном анализе, некоторые из-за математики пространства, некоторые из-за особых способов представления данных в пространстве, некоторые из-за доступных инструментов. Данные переписи, поскольку они защищают личную жизнь путем агрегирования данных по местным единицам, порождают ряд статистических проблем. Фрактальный характер береговой линии делает точное измерение ее длины трудным, а то и невозможным. Компьютерное программное обеспечение, подгоняющее прямые линии к изгибу береговой линии, может легко вычислить длины линий, которые оно определяет. Однако эти прямые линии могут не иметь внутреннего значения в реальном мире, как было показано на примере береговая линия Британии.
Эти проблемы представляют собой проблему для пространственного анализа из-за силы карт как средства представления. Когда результаты представлены в виде карт, представление объединяет пространственные данные, которые, как правило, точны, с аналитическими результатами, которые могут быть неточными, что создает впечатление, что аналитические результаты более точны, чем показывают данные.[1]
Пространственная характеристика
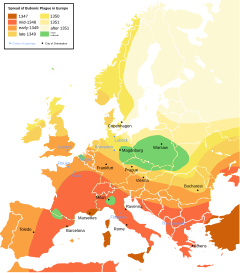
Распространение бубонной чумы в средневековой Европе.[нужна цитата ] Цвета показывают пространственное распределение вспышек чумы во времени.
Определение пространственного присутствия объекта ограничивает возможный анализ, который может быть применен к этому объекту, и влияет на окончательные выводы, которые могут быть сделаны. Хотя это свойство в принципе верно для всех анализ, это особенно важно в пространственном анализе, потому что инструменты для определения и изучения сущностей предпочитают конкретные характеристики изучаемых сущностей. Статистические методы отдают предпочтение пространственному определению объектов как точек, потому что существует очень мало статистических методов, которые работают непосредственно с элементами линий, площадей или объемов. Компьютерные инструменты способствуют пространственному определению объектов как однородных и отдельных элементов из-за ограниченного количества база данных доступные элементы и вычислительные структуры, а также легкость, с которой эти примитивные структуры могут быть созданы.
Пространственная зависимость или автокорреляция
Пространственная зависимость — это совместное изменение свойств в пределах географического пространства: характеристики в ближайших местоположениях коррелируют, положительно или отрицательно. Пространственная зависимость приводит к пространственному автокорреляция проблема в статистике, поскольку, как и временная автокорреляция, это нарушает стандартные статистические методы, предполагающие независимость наблюдений. Например, регресс анализы, которые не компенсируют пространственную зависимость, могут иметь нестабильные оценки параметров и давать ненадежные тесты значимости. Модели пространственной регрессии (см. Ниже) фиксируют эти отношения и не страдают этими недостатками. Также уместно рассматривать пространственную зависимость как источник информации, а не как то, что нужно исправить.[2]
Локальные эффекты также проявляются как пространственные неоднородность, или очевидное изменение процесса относительно местоположения в географическом пространстве. Если пространство не является однородным и безграничным, каждое место будет иметь некоторую степень уникальности относительно других мест. Это влияет на отношения пространственной зависимости и, следовательно, на пространственный процесс. Пространственная неоднородность означает, что общие параметры, оцененные для всей системы, могут неадекватно описывать процесс в любом данном месте.
Масштабирование
Пространственный измерение масштаб — постоянная проблема в пространственном анализе; более подробная информация доступна на модифицируемая проблема единичной площади (MAUP) запись в теме. Ландшафтные экологи разработали серию масштабный инвариант метрики для аспектов экологии, которые фрактал в природе.[3] В более общем плане, нет независимого от масштаба метода анализ широко используется для пространственной статистики.
Отбор проб
Пространственный отбор проб включает определение ограниченного количества местоположений в географическом пространстве для точного измерения явлений, которые подвержены зависимости и неоднородности.[нужна цитата ] Зависимость предполагает, что, поскольку одно местоположение может предсказать ценность другого местоположения, нам не нужны наблюдения в обоих местах. Но неоднородность предполагает, что это отношение может меняться в пространстве, и поэтому мы не можем доверять наблюдаемой степени зависимости за пределами региона, который может быть небольшим. Базовые схемы пространственной выборки включают случайную, кластерную и систематическую. Эти базовые схемы могут применяться на нескольких уровнях в определенной пространственной иерархии (например, городской район, город, район). Также можно использовать вспомогательные данные, например, используя значения свойств в качестве ориентира в схеме пространственной выборки для измерения уровня образования и дохода. Пространственные модели, такие как статистика автокорреляции, регрессия и интерполяция (см. Ниже), также могут определять дизайн выборки.[нужна цитата ]
Распространенные ошибки пространственного анализа
Фундаментальные проблемы пространственного анализа приводят к многочисленным проблемам в анализе, включая систематические ошибки, искажения и явные ошибки в сделанных выводах. Эти проблемы часто взаимосвязаны, но были предприняты различные попытки отделить отдельные проблемы друг от друга.[4]
Длина
Обсуждая береговая линия Британии, Бенуа Мандельброт показали, что определенные пространственные концепции бессмысленны по своей сути, несмотря на презумпцию их достоверности. Длина в экологии напрямую зависит от масштаба, в котором они измеряются и испытываются. Таким образом, хотя геодезисты обычно измеряют длину реки, эта длина имеет значение только в контексте соответствия метода измерения изучаемому вопросу.
-

Британия измеряется длинной меркой
-
Великобритания измеряется средним критерием
-
Британия измеряется короткой меркой


Ошибка местоположения
Ошибка расположения относится к ошибке из-за конкретной пространственной характеристики, выбранной для элементов исследования, в частности, выбора размещения для пространственного присутствия элемента.
Пространственные характеристики могут быть упрощенными или даже неправильными. Исследования людей часто сводят пространственное существование людей к одной точке, например к их домашнему адресу. Это может легко привести к плохому анализу, например, при рассмотрении передачи болезни, которая может произойти на работе или в школе и, следовательно, вдали от дома.
Пространственная характеристика может неявно ограничивать предмет исследования. Например, в последнее время стал популярен пространственный анализ данных о преступности, но эти исследования могут описывать только те конкретные виды преступлений, которые могут быть описаны пространственно. Это приводит к множеству карт нападений, но не к любым картам хищений с политическими последствиями при концептуализации преступности и разработке политики для решения этой проблемы.[5]
Атомная ошибка
Это описывает ошибки из-за обработки элементов как отдельных «атомов» вне их пространственного контекста. Ошибка заключается в переносе индивидуальных выводов на пространственные единицы.[6]
Экологическая ошибка
В экологическая ошибка описывает ошибки из-за выполнения анализа совокупных данных при попытке сделать выводы по отдельным единицам.[нужна цитата ] Частично ошибки возникают из-за пространственной агрегации. Например, пиксель представляет собой среднюю температуру поверхности в пределах области. Экологическим заблуждением было бы предположение, что все точки в пределах области имеют одинаковую температуру. Эта тема тесно связана с модифицируемая проблема единичной площади.
Решения фундаментальных вопросов
Географическое пространство
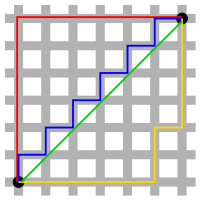
Расстояние между Манхэттеном и Евклидовым расстоянием: красная, синяя и желтая линии имеют одинаковую длину (12) как в евклидовой геометрии, так и в геометрии такси. В евклидовой геометрии зеленая линия имеет длину 6 ×√2 ≈ 8,48, и является единственным кратчайшим путем. В геометрии такси длина зеленой линии по-прежнему равна 12, что делает ее не короче, чем любой другой показанный путь.
Математическое пространство существует всякий раз, когда у нас есть набор наблюдений и количественных измерений их атрибутов. Например, мы можем представить доходы людей или годы образования в системе координат, где местоположение каждого человека может быть указано по обоим измерениям. Расстояние между людьми в этом пространстве является количественной мерой их различий в доходах и образовании. Однако в пространственном анализе нас интересуют определенные типы математических пространств, а именно географическое пространство. В географическом пространстве наблюдения соответствуют местоположениям в системе пространственных измерений, которые фиксируют их близость в реальном мире. Точки в системе пространственных измерений часто представляют собой местоположения на поверхности Земли, но это не обязательно. Система пространственных измерений также может фиксировать близость, например, по отношению к межзвездному пространству или внутри биологического объекта, такого как печень. Основной принцип Первый закон географии Тоблера: если взаимосвязь между объектами увеличивается по мере приближения в реальном мире, то целесообразно представление в географическом пространстве и оценка с использованием методов пространственного анализа.
В Евклидово расстояние между местоположениями часто представляет их близость, хотя это только одна возможность. Помимо евклидова, существует бесконечное количество расстояний, которые могут поддерживать количественный анализ. Например, «Манхэттен» (или «Такси «) расстояния, на которых движение ограничено путями, параллельными осям, могут быть более значимыми, чем евклидовы расстояния в городских условиях. Помимо расстояний, существуют другие географические взаимосвязи, такие как возможность соединения (например, наличие или степень общих границ) и направление также может влиять на отношения между объектами. Также возможно вычислить пути с минимальной стоимостью через поверхность стоимости; например, это может означать близость между местоположениями, когда путешествие должно происходить по пересеченной местности.
Типы
Пространственные данные бывают самых разнообразных, и нелегко прийти к системе классификации, которая одновременно является исключительной, исчерпывающей, творческой и удовлетворительной. — Г. Аптон и Б. Фингелтон[7]
Анализ пространственных данных
Городские и региональные исследования имеют дело с большими таблицами пространственных данных, полученных в результате переписей и обследований. Необходимо упростить огромное количество подробной информации, чтобы выделить основные тенденции. Многопараметрический анализ (или Факторный анализ, FA) позволяет заменять переменные, преобразовывая многие переменные переписи, обычно коррелированные между собой, в меньшее количество независимых «Факторов» или «Основных компонентов», которые фактически являются собственные векторы матрицы корреляции данных, взвешенной по инверсии их собственных значений. Такая замена переменных имеет два основных преимущества:
- Поскольку информация сконцентрирована на первых новых факторах, можно сохранить лишь некоторые из них, потеряв при этом лишь небольшой объем информации; их отображение дает меньше и более значимых карт
- Факторы, фактически собственные векторы, ортогональны по построению, то есть не коррелированы. В большинстве случаев доминирующим фактором (с наибольшим собственным значением) является социальный компонент, разделяющий богатых и бедных в городе. Поскольку факторы не коррелированы, во втором, третьем, … факторах появляются другие более мелкие процессы, чем социальный статус, который в противном случае оставался бы скрытым.
Факторный анализ зависит от измерения расстояний между наблюдениями: выбор важной метрики имеет решающее значение. Евклидова метрика (анализ главных компонентов), расстояние хи-квадрат (анализ соответствия) или обобщенное расстояние Махаланобиса (дискриминантный анализ) являются одними из наиболее широко используемых.[8] Были предложены более сложные модели, использующие общности или ротации.[9]
Использование многомерных методов в пространственном анализе началось на самом деле в 1950-х годах (хотя некоторые примеры относятся к началу века) и достигли высшей точки в 1970-х годах, когда мощность и доступность компьютеров возросли. Уже в 1948 году в фундаментальной публикации два социолога Венделл Белл и Эшреф Шевки,[10] показали, что большинство городского населения в США и в мире может быть представлено тремя независимыми факторами: 1- «социально-экономический статус», противопоставляющий богатые и бедные районы и распределенный по секторам, идущим вдоль автомагистралей от центра города, 2- «Жизненный цикл», т.е. возрастная структура домохозяйств, распределенных концентрическими кругами, и 3- «расовая и этническая принадлежность», определяющая участки мигрантов, расположенные в пределах города. В 1961 году в новаторском исследовании британские географы использовали FA для классификации британских городов.[11] Брайан Дж. Берри из Чикагского университета и его студенты широко использовали этот метод,[12] применяя его к наиболее важным городам мира и демонстрируя общие социальные структуры.[13] Использование факторного анализа в географии, которое стало настолько простым благодаря современным компьютерам, было очень широким, но не всегда очень разумным.[14]
Поскольку извлеченные векторы определяются матрицей данных, невозможно сравнивать коэффициенты, полученные из разных переписей. Решение состоит в объединении нескольких матриц переписи в единую таблицу, которая затем может быть проанализирована. Это, однако, предполагает, что определение переменных не изменилось с течением времени и приводит к очень большим таблицам, с которыми трудно работать. Лучшее решение, предложенное психометристами,[15] группирует данные в «кубическую матрицу» с тремя записями (например, местоположения, переменные, периоды времени). Трехфакторный факторный анализ затем дает три группы факторов, связанных небольшой кубической «основной матрицей».[16] Этот метод, который показывает эволюцию данных с течением времени, не получил широкого распространения в географии.[17] В Лос-Анжелес,[18] тем не менее, в течение нескольких десятилетий он демонстрировал традиционно игнорируемую роль Даунтауна как организационного центра для всего города.
Пространственная автокорреляция
Пространственный автокорреляция статистика измеряет и анализирует степень зависимости между наблюдениями в географическом пространстве. Классическая пространственная автокорреляционная статистика включает: Морана  , Гири
, Гири  , Getis’s
, Getis’s  и эллипс стандартного отклонения. Эти статистические данные требуют измерения матрицы пространственных весов, которая отражает интенсивность географической взаимосвязи между наблюдениями в районе, например, расстояния между соседями, протяженность общей границы или то, попадают ли они в определенный класс направленности, такой как «запад». Классическая статистика пространственной автокорреляции сравнивает пространственные веса с ковариационными отношениями в парах местоположений. Пространственная автокорреляция, более положительная, чем ожидалось от случайного, указывает на кластеризацию аналогичных значений в географическом пространстве, в то время как значительная отрицательная пространственная автокорреляция указывает на то, что соседние значения более непохожи, чем ожидалось случайно, что предполагает пространственный образец, похожий на шахматную доску.
и эллипс стандартного отклонения. Эти статистические данные требуют измерения матрицы пространственных весов, которая отражает интенсивность географической взаимосвязи между наблюдениями в районе, например, расстояния между соседями, протяженность общей границы или то, попадают ли они в определенный класс направленности, такой как «запад». Классическая статистика пространственной автокорреляции сравнивает пространственные веса с ковариационными отношениями в парах местоположений. Пространственная автокорреляция, более положительная, чем ожидалось от случайного, указывает на кластеризацию аналогичных значений в географическом пространстве, в то время как значительная отрицательная пространственная автокорреляция указывает на то, что соседние значения более непохожи, чем ожидалось случайно, что предполагает пространственный образец, похожий на шахматную доску.
Статистика пространственной автокорреляции, например, Морана. и Гири являются глобальными в том смысле, что они оценивают общую степень пространственной автокорреляции для набора данных. Возможность пространственной неоднородности предполагает, что предполагаемая степень автокорреляции может значительно варьироваться в зависимости от географического пространства. Статистика локальной пространственной автокорреляции предоставлять оценки, дезагрегированные на уровне единиц пространственного анализа, что позволяет оценить отношения зависимости в пространстве. статистика сравнивает районы со средним глобальным значением и выявляет локальные регионы с сильной автокорреляцией. Локальные версии и также доступна статистика.
Пространственная стратифицированная неоднородность
Пространственная стратифицированная неоднородность, относящаяся к дисперсии внутри слоев меньше, чем дисперсия между слоями, повсеместно встречается в экологических явлениях, таких как экологические зоны и многие экологические переменные. Пространственная стратифицированная неоднородность атрибута может быть измерена географическим детектором. q-статистический:[19]


где население разделено на час = 1, …, L страты; N обозначает численность населения, σ2 обозначает вариацию атрибута. Значение q находится в пределах [0, 1], 0 указывает на отсутствие пространственной стратифицированной неоднородности, 1 указывает на идеальную пространственную стратифицированную неоднородность. q указывает процент отклонения атрибута, объясняемого стратификацией. q следует нецентральному F функция плотности вероятности.

Ручная карта с разными пространственными узорами. Примечание: п это вероятность q-статистический; * обозначает статистическую значимость на уровне 0,05, ** для 0,001, *** для менее 10−3; (D) индексы 1, 2, 3 из q и п обозначает страты Z1 + Z2 с Z3, Z1 с Z2 + Z3 и Z1 и Z2 и Z3 по отдельности, соответственно; (E) индексы 1 и 2 из q и п обозначает страты Z1 + Z2 с Z3 + Z4 и Z1 + Z3 с Z2 + Z4 соответственно.
Пространственная интерполяция
Пространственная интерполяция Методы оценивают переменные в ненаблюдаемых местах в географическом пространстве на основе значений в наблюдаемых местах. Основные методы включают обратное взвешивание расстояний: это ослабляет переменную по мере уменьшения расстояния от наблюдаемого местоположения. Кригинг — это более сложный метод, который интерполирует в пространстве в соответствии с отношением пространственного запаздывания, которое имеет как систематические, так и случайные компоненты. Это может приспособить широкий диапазон пространственных отношений для скрытых значений между наблюдаемыми местоположениями. Кригинг обеспечивает оптимальные оценки с учетом предполагаемой зависимости запаздывания, а оценки ошибок могут быть отображены, чтобы определить, существуют ли пространственные закономерности.
Пространственная регрессия
Методы пространственной регрессии фиксируют пространственную зависимость в регрессивный анализ, избегая статистических проблем, таких как нестабильные параметры и ненадежные тесты значимости, а также предоставляя информацию о пространственных отношениях между задействованными переменными. В зависимости от конкретного метода пространственная зависимость может входить в регрессионную модель как отношения между независимыми переменными и зависимыми, между зависимыми переменными и их пространственным запаздыванием или в условиях ошибок. Географически взвешенная регрессия (GWR) — это локальная версия пространственной регрессии, которая генерирует параметры, дезагрегированные по пространственным единицам анализа.[20] Это позволяет оценить пространственную неоднородность в предполагаемых отношениях между независимыми и зависимыми переменными. Использование Байесовское иерархическое моделирование[21] в сочетании с Цепь Маркова Монте-Карло (MCMC) методы недавно показали свою эффективность при моделировании сложных отношений с использованием моделей Пуассона-Гамма-CAR, Пуассона-логнормального-SAR или сверхдисперсных логит-моделей. Статистические пакеты для реализации таких байесовских моделей с использованием MCMC включают WinBugs и CrimeStat.
Пространственные случайные процессы, такие как Гауссовские процессы также все чаще используются в анализе пространственной регрессии. Основанные на моделях версии GWR, известные как модели с пространственно изменяющимися коэффициентами, были применены для проведения байесовского вывода.[21] Пространственный случайный процесс может стать вычислительно эффективными и масштабируемыми моделями гауссовских процессов, такими как гауссовские процессы прогнозирования.[22] и гауссовские процессы ближайшего соседства (NNGP).[23]
Пространственное взаимодействие
Пространственное взаимодействие или «гравитационные модели «оценить поток людей, материалов или информации между точками в географическом пространстве. Факторы могут включать в себя движущие переменные происхождения, такие как количество пассажиров в жилых районах, переменные привлекательности места назначения, такие как количество офисных площадей в зонах занятости, и отношения близости между местоположения, измеряемые с точки зрения расстояния или времени в пути. Кроме того, топологические или соединительный отношения между областями должны быть идентифицированы, особенно с учетом часто конфликтующих отношений между расстоянием и топологией; например, два пространственно близких квартала могут не демонстрировать какого-либо значительного взаимодействия, если они разделены шоссе. После определения функциональных форм этих отношений аналитик может оценить параметры модели, используя данные наблюдаемого потока и стандартные методы оценки, такие как обычный метод наименьших квадратов или максимальное правдоподобие. Версии моделей пространственного взаимодействия с конкурирующими пунктами назначения включают в себя близость пунктов назначения (или пунктов отправления) в дополнение к близости исходной точки к месту назначения; это фиксирует влияние кластеризации получателя (источника) на потоки. Вычислительные методы, такие как искусственные нейронные сети может также оценивать отношения пространственного взаимодействия между местоположениями и может обрабатывать зашумленные и качественные данные.[нужна цитата ]
Моделирование и моделирование
Модели пространственного взаимодействия бывают агрегатными и нисходящими: они определяют общие управляющие отношения для потока между местоположениями. Эта характеристика также характерна для городских моделей, таких как модели, основанные на математическом программировании, потоках между секторами экономики или теории ставки ренты. Альтернативный подход к моделированию состоит в том, чтобы представить систему на максимально возможном уровне дезагрегирования и изучить восходящее возникновение сложных паттернов и взаимосвязей из поведения и взаимодействий на индивидуальном уровне.[нужна цитата ]
Сложные адаптивные системы Теория применительно к пространственному анализу предполагает, что простые взаимодействия между ближайшими объектами могут привести к сложным, устойчивым и функциональным пространственным объектам на агрегированных уровнях. Два фундаментально пространственных метода моделирования — это клеточные автоматы и агентное моделирование. Клеточные автоматы моделирование накладывает фиксированные пространственные рамки, такие как ячейки сетки, и определяет правила, которые определяют состояние ячейки на основе состояний соседних с ней ячеек. С течением времени возникают пространственные паттерны, поскольку клетки меняют состояния в зависимости от своих соседей; это изменяет условия для будущих периодов времени. Например, ячейки могут представлять местоположения в городской зоне, а их состояния могут быть разными типами землепользования. Модели, которые могут возникнуть в результате простого взаимодействия местных землепользователей, включают офисные районы и разрастание городов. Агентное моделирование использует программные объекты (агенты), которые имеют целенаправленное поведение (цели) и могут реагировать, взаимодействовать и изменять свою среду, стремясь к достижению своих целей. В отличие от клеток клеточных автоматов, симуляторы могут позволить агентам быть мобильными по отношению к космосу. Например, можно смоделировать транспортный поток и динамику, используя агентов, представляющих отдельные автомобили, которые пытаются минимизировать время в пути между указанными пунктами отправления и назначения. При минимальном времени в пути агенты должны избегать столкновений с другими транспортными средствами, также стремясь минимизировать время в пути. Клеточные автоматы и агентное моделирование дополняют друг друга. Их можно интегрировать в общую географическую систему автоматов, где одни агенты являются фиксированными, а другие — мобильными.
Калибровка играет ключевую роль в подходах к моделированию как CA, так и ABM. Первоначальные подходы к CA предлагали надежные подходы к калибровке, основанные на стохастических методах Монте-Карло.[24][25] Подходы ABM основаны на правилах принятия решений агентами (во многих случаях извлеченных из методов качественной исследовательской базы, таких как анкеты).[26] Современные алгоритмы машинного обучения калибруются с использованием обучающих наборов, например, чтобы понять качества созданной среды.[27]
Многоточечная геостатистика (MPS)
Пространственный анализ концептуальной геологической модели — основная цель любого алгоритма MPS. Этот метод анализирует пространственную статистику геологической модели, называемую обучающим образом, и генерирует реализации явлений, которые учитывают эти входные многоточечные статистики.
Последний алгоритм MPS, использованный для выполнения этой задачи, — это основанный на шаблонах метод Хонархаха.[28] В этом методе для анализа закономерностей в тренировочном образе используется подход, основанный на расстоянии. Это позволяет воспроизводить многоточечную статистику и сложные геометрические особенности тренировочного образа. Каждый выход алгоритма MPS — это реализация, представляющая случайное поле. Вместе несколько реализаций могут использоваться для количественной оценки пространственной неопределенности.
Один из последних методов представлен Tahmasebi et al.[29] использует функцию взаимной корреляции для улучшения воспроизведения пространственного шаблона. Они называют свой метод моделирования MPS алгоритмом CCSIM.Этот метод позволяет количественно оценить пространственную связанность, изменчивость и неопределенность. Кроме того, этот метод не чувствителен к каким-либо типам данных и может моделировать как категориальные, так и непрерывные сценарии. Алгоритм CCSIM может использоваться для любых стационарных, нестационарных и многомерных систем и может обеспечить высококачественную модель визуальной привлекательности.,[30][31]
Геопространственный анализ

Геопространственный анализ, или просто пространственный анализ,[32] это подход к применению статистический анализ и другие методы анализа данных, имеющих географический или пространственный аспект. В таком анализе обычно используется программное обеспечение, способное отображать карты, обрабатывать пространственные данные и применять аналитический методы наземного или географический наборы данных, включая использование географические информационные системы и геоматика.[33][34][35]
Использование географической информационной системы
Географические информационные системы (ГИС) — большой домен, который предоставляет множество возможностей, предназначенных для сбора, хранения, обработки, анализа, управления и представления всех типов географических данных — использует геопространственный анализ в различных контекстах, операциях и приложениях.
Основные приложения
Геопространственный анализ с использованием ГИС, был разработан для задач в области экологии и наук о жизни, в частности экология, геология и эпидемиология. Он распространился почти на все отрасли, включая оборону, разведку, коммунальные услуги, природные ресурсы (например, нефть и газ, лесное хозяйство … и т. Д.), Социальные науки, медицину и т. Д. Общественная безопасность (например, управление чрезвычайными ситуациями и криминология), снижение и управление рисками стихийных бедствий (DRRM) и адаптация к изменению климата (CCA). Пространственная статистика обычно является результатом наблюдения, а не экспериментов.
Основные операции
На основе векторов ГИС обычно связано с такими операциями, как наложение карты (объединение двух или более карт или слоев карты в соответствии с предопределенными правилами), простая буферизация (определение областей карты в пределах указанного расстояния от одной или нескольких функций, таких как города, дороги или реки) и аналогичные базовые операции. Это отражает (и находит отражение в) использование термина пространственный анализ в рамках Open Geospatial Consortium (OGC ) «Простые характеристики функций». Для растровых ГИС, широко используемых в науках об окружающей среде и дистанционном зондировании, это обычно означает ряд действий, применяемых к ячейкам сетки одной или нескольких карт (или изображений), часто включающих фильтрацию и / или алгебраические операции (алгебра карт). Эти методы включают обработку одного или нескольких растровых слоев в соответствии с простыми правилами, в результате чего создается новый слой карты, например, замена каждого значения ячейки некоторой комбинацией значений его соседей или вычисление суммы или разности конкретных значений атрибутов для каждой ячейки сетки в два совпадающих набора растровых данных. Описательная статистика, такая как количество ячеек, средние, дисперсии, максимумы, минимумы, совокупные значения, частоты и ряд других показателей и вычисления расстояний, также часто включаются в этот общий термин пространственный анализ. Пространственный анализ включает в себя большое количество статистических методов (описательных, исследовательский, и пояснительный статистика ), которые применяются к данным, которые различаются в пространстве и могут изменяться со временем. Некоторые более продвинутые статистические методы включают Getis-ord Gi * или Anselin Local Moran’s I, которые используются для определения моделей кластеризации пространственно привязанных данных.
Расширенные операции
Геопространственный анализ выходит за рамки 2D- и 3D-картографии и пространственной статистики. Это включает в себя:
- Анализ поверхности — в частности, анализ свойств физических поверхностей, таких как градиент, аспект и видимость, и анализ поверхностных «полей» данных;
- Сетевой анализ — изучение свойств природных и искусственных сетей с целью понимания поведения потоков внутри и вокруг таких сетей; и анализ местоположения. Сетевой анализ на основе ГИС может использоваться для решения широкого круга практических задач, таких как выбор маршрута и расположение объекта (основные темы в области исследование операций ), и проблемы, связанные с потоками, например, в гидрология и транспортные исследования. Во многих случаях проблемы определения местоположения связаны с сетями и, как таковые, решаются с помощью инструментов, разработанных для этой цели, но в других существующие сети могут иметь незначительное значение или не иметь никакого отношения или могут быть непрактичными для включения в процесс моделирования. Проблемы, которые конкретно не ограничены сетью, такие как прокладка новой дороги или трубопровода, расположение регионального склада, расположение мачты мобильного телефона или выбор мест для оказания медицинской помощи в сельских общинах, могут быть эффективно проанализированы (по крайней мере, на начальном этапе) без ссылки на существующие физические сети. Анализ местоположения «в плоскости» также применим в тех случаях, когда подходящие наборы сетевых данных недоступны, слишком велики или дороги для использования, или когда алгоритм определения местоположения очень сложен или включает изучение или моделирование очень большого количества альтернативных конфигураций. .
- Геовизуализация — создание и изменение изображений, карт, диаграмм, диаграмм, трехмерных видов и связанных с ними наборов табличных данных. Пакеты ГИС все чаще предоставляют набор таких инструментов, предоставляя статические или вращающиеся виды, обтягивая изображения поверх 2,5-мерных представлений поверхности, обеспечивая анимацию и пролёт, динамическое связывание и кисть, а также пространственно-временную визуализацию. Этот последний класс инструментов является наименее развитым, что частично отражает ограниченный диапазон подходящих совместимых наборов данных и ограниченный набор доступных аналитических методов, хотя эта картина быстро меняется. Все эти средства дополняют основные инструменты, используемые в пространственном анализе на протяжении всего аналитического процесса (исследование данных, выявление закономерностей и взаимосвязей, построение моделей и передача результатов).
Мобильные геопространственные вычисления
Традиционно геопространственные вычисления выполнялись в основном на персональных компьютерах (ПК) или серверах. Однако из-за растущих возможностей мобильных устройств геопространственные вычисления в мобильных устройствах становятся быстрорастущей тенденцией.[36] Портативный характер этих устройств, а также наличие полезных датчиков, таких как приемники глобальной навигационной спутниковой системы (GNSS) и датчики атмосферного давления, делают их полезными для сбора и обработки геопространственной информации в полевых условиях. Помимо локальной обработки геопространственной информации на мобильных устройствах, еще одной растущей тенденцией являются облачные геопространственные вычисления. В этой архитектуре данные можно собирать в полевых условиях с помощью мобильных устройств, а затем передавать на облачные серверы для дальнейшей обработки и окончательного хранения. Аналогичным образом геопространственная информация может быть доступна подключенным мобильным устройствам через облако, что позволяет получить доступ к обширным базам данных геопространственной информации в любом месте, где доступно беспроводное соединение для передачи данных.
Географическая информатика и пространственный анализ

Эта карта маршрута злополучного марша Наполеона на Москву — ранний и знаменитый пример геовизуализации. Он показывает направление армии во время ее движения, места, через которые проходили войска, размер армии, когда солдаты умирали от голода и ран, а также низкие температуры, которые они испытывали.
Географические информационные системы (ГИС) и лежащие в основе географическая информатика Развитие этих технологий оказывает сильное влияние на пространственный анализ. Растущая способность захвата и обработки географических данных означает, что пространственный анализ происходит в средах с постоянно увеличивающимся объемом данных. Системы сбора географических данных включают изображения с дистанционным зондированием, системы мониторинга окружающей среды, такие как интеллектуальные транспортные системы, и технологии определения местоположения, такие как мобильные устройства, которые могут сообщать о местоположении почти в реальном времени. ГИС предоставляют платформы для управления этими данными, вычисления пространственных отношений, таких как расстояние, связность и направленные отношения между пространственными единицами, а также визуализации как исходных данных, так и результатов пространственного анализа в картографическом контексте. Подтипы включают:
- Геовизуализация (GVis) объединяет научную визуализацию с цифровая картография для поддержки исследования и анализа географических данных и информации, включая результаты пространственного анализа или моделирования. GVis использует ориентацию человека на обработку визуальной информации при исследовании, анализе и передаче географических данных и информации. В отличие от традиционной картографии, GVis обычно является трехмерным или четырехмерным (последнее включает время) и интерактивным для пользователя.
- Открытие географических знаний (GKD) — это ориентированный на человека процесс применения эффективных вычислительных инструментов для исследования массивных пространственные базы данных. ГКД включает географические сбор данных, но также включает связанные действия, такие как выбор данных, очистка и предварительная обработка данных, а также интерпретация результатов. GVis также может играть центральную роль в процессе GKD. GKD основан на предпосылке, что массивные базы данных содержат интересные (действительные, новые, полезные и понятные) шаблоны, которые невозможно найти с помощью стандартных аналитических методов. GKD может служить процессом создания гипотез для пространственного анализа, создавая предварительные модели и взаимосвязи, которые следует подтверждать с помощью методов пространственного анализа.
- Системы поддержки пространственных решений (SDSS) использует существующие пространственные данные и различные математические модели для прогнозирования будущего. Это позволяет городским и региональным планировщикам проверять решения о вмешательстве до их реализации.[37]
Смотрите также
- Общие темы
- Картография
- Полная пространственная случайность
- GeoComputation
- Геопространственный интеллект
- Геопространственное прогнозное моделирование
- Размерно расширенная модель девяти пересечений (ДЭ-9ИМ)
- Географическая информатика
- Математическая статистика
- Задача изменяемой площади
- Пространственная автокорреляция
- Пространственная описательная статистика
- Пространственное отношение
- Список программ пространственного анализа
- Конкретные приложения
- Географические информационные системы
- Геодемографическая сегментация
- Анализ видимости
- Нечеткий архитектурно-пространственный анализ
- Анализ пригодности
- Анализ области экстраполяции
- Геоинформатика
- Геостатистика
- Краевая задача (в пространственном анализе)
- Пространственная эпидемиология
- Пространственная эконометрика
Рекомендации
- ^ Марк Монмонье Как лгать с картами Издательство Чикагского университета, 1996.
- ^ Knegt, De; Coughenour, M.B .; Скидмор, А.К .; Heitkönig, I.M.A .; Knox, N.M .; Slotow, R .; Prins, H.H.T. (2010). «Пространственная автокорреляция и масштабирование отношений между видами и средой». Экология. 91 (8): 2455–2465. Дои:10.1890/09-1359.1. PMID 20836467.
- ^ Halley, J.M .; Hartley, S .; Каллиманис, А. С .; Кунин, В. Э .; Леннон, Дж. Дж .; Сгарделис, С. П. (2004-03-01). «Использование и злоупотребления фрактальной методологией в экологии». Письма об экологии. 7 (3): 254–271. Дои:10.1111 / j.1461-0248.2004.00568.x. ISSN 1461-0248.
- ^ Оканья-Риола, Р. (2010). «Распространенные ошибки в картировании болезней». Геопространственное здоровье. 4 (2): 139–154. Дои:10.4081 / gh.2010.196. PMID 20503184.
- ^ «Понимание пространственных заблуждений». Руководство по геопространственному анализу для учащихся. Департамент географии штата Пенсильвания. Получено 27 апреля 2018.
- ^ Кватрочи, Дейл А. (01.02.2016). Интеграция масштаба в дистанционное зондирование и ГИС. ISBN 9781482218268. OCLC 973767077.
- ^ Грэм Дж. Аптон и Бернард Фингелтон: Анализ пространственных данных на примере тома 1: точечный образец и количественные данные John Wiley & Sons, Нью-Йорк. 1985 г.
- ^ Харман Х Х (1960) Современный факторный анализ, University of Chicago Press
- ^ Раммель Р. Дж. (1970) Прикладной факторный анализ. Эванстон, ILL: издательство Северо-Западного университета.
- ^ Bell W & E Шевки (1955) Анализ социальной сферы, Stanford University Press
- ^ Мозер C A&W Скотт (1961) Британские города; Статистическое исследование их социальных и экономических различий, Оливер и Бойд, Лондон.
- ^ Берри Би Джей и Ф Хортон (1971) Географические перспективы городских систем, Джон Уайли, штат Нью-Йорк.
- ^ Берри Б. Дж. И К. Б. Смит редакторы (1972) Справочник по классификации городов: методы и применение, Джон Уайли, штат Нью-Йорк.
- ^ Цицери М-Ф (1974) Méthodes d’analyse multivariée dans la géographie anglo-saxonne, Université de Paris-1; бесплатно скачать на http://www-ohp.univ-paris1.fr
- ^ Такер Л. Р. (1964) «Расширение факторного анализа на трехмерные матрицы», в ред. Фредериксена Н. и Х. Гулликсена, Вклад в математическую психологию, Холт, Райнхарт и Уинстон, штат Нью-Йорк.
- ^ Р. Коппи и С. Боласко, ред. (1989), Многосторонний анализ данных, Эльзевир, Амстердам.
- ^ Кант, Р. (1971). «Изменения в местонахождении производства в Новой Зеландии 1957-1968: применение трехрежимного факторного анализа». Географ Новой Зеландии. 27: 38–55. Дои:10.1111 / j.1745-7939.1971.tb00636.x.
- ^ Маршан Б. (1986) Возникновение Лос-Анджелеса, 1940-1970 гг., Pion Ltd, Лондон
- ^ Wang, JF; Чжан, TL; Фу, Би Джей (2016). «Мера пространственной стратифицированной неоднородности». Экологические показатели. 67: 250–256. Дои:10.1016 / j.ecolind.2016.02.052.
- ^ Brunsdon, C .; Fotheringham, A.S .; Чарльтон, M.E. (1996). «Географически взвешенная регрессия: метод исследования пространственной нестационарности». Географический анализ. 28 (4): 281–298. Дои:10.1111 / j.1538-4632.1996.tb00936.x.
- ^ а б Банерджи, Судипто; Карлин, Брэдли П.; Гельфанд, Алан Э. (2014), Иерархическое моделирование и анализ пространственных данных, второе издание, Монографии по статистике и прикладной теории вероятностей (2-е изд.), Chapman and Hall / CRC, ISBN 9781439819173
- ^ Банерджи, Судипто; Гельфанд, Алан Э .; Финли, Эндрю О .; Пел, Хуэйянь (2008). «Гауссовские модели прогнозирования для больших наборов пространственных данных». Журнал Королевского статистического общества, серия B. 70 (4): 825–848. Дои:10.1111 / j.1467-9868.2008.00663.x. ЧВК 2741335. PMID 19750209.
- ^ Датта, Абхируп; Банерджи, Судипто; Финли, Эндрю О .; Гельфанд, Алан Э. (2016). «Иерархические модели гауссовского процесса ближайшего соседа для больших наборов геостатистических данных». Журнал Американской статистической ассоциации. 111 (514): 800–812. arXiv:1406.7343. Дои:10.1080/01621459.2015.1044091. ЧВК 5927603. PMID 29720777.
- ^ Silva, E. A .; Кларк, К. (2002). «Калибровка модели городского роста SLEUTH для Лиссабона и Порту, Португалия». Компьютеры, окружающая среда и городские системы. 26 (6): 525–552. Дои:10.1016 / S0198-9715 (01) 00014-X.
- ^ Сильва, Е.А. (2003). «Сложность, возникновение и сотовые модели городов: уроки, извлеченные из применения SLEUTH в двух португальских мегаполисах». Европейские исследования в области планирования. 13 (1): 93–115. Дои:10.1080/0965431042000312424. S2CID 197257.
- ^ Лю и Сильва (2017). «Изучение динамики взаимодействия между развитием креативных индустрий и городской пространственной структурой с помощью агент-ориентированного моделирования: на примере Нанкина, Китай». Урбанистика. 65 (5): 113–125. Дои:10.1177/0042098016686493. S2CID 157318972.
- ^ Лю, Лун; Silva, Elisabete A .; Ву, Чуньян; Ван, Хуэй (2017). «Метод на основе машинного обучения для крупномасштабной оценки качества городской среды» (PDF). Компьютеры Окружающая среда и городские системы. 65: 113–125. Дои:10.1016 / j.compenvurbsys.2017.06.003.
- ^ Хонархах, М; Каерс, Дж (2010). «Стохастическое моделирование паттернов с использованием дистанционного моделирования паттернов». Математические науки о Земле. 42 (5): 487–517. Дои:10.1007 / s11004-010-9276-7. S2CID 73657847.
- ^ Tahmasebi, P .; Хезархани, А .; Сахими, М. (2012). «Многоточечное геостатистическое моделирование на основе взаимно корреляционных функций». Вычислительные науки о Земле. 16 (3): 779–79742. Дои:10.1007 / s10596-012-9287-1. S2CID 62710397.
- ^ Tahmasebi, P .; Сахими, М. (2015). «Реконструкция нестационарных неупорядоченных материалов и сред: преобразование водораздела и функция взаимной корреляции». Физический обзор E. 91 (3): 032401. Bibcode:2015PhRvE..91c2401T. Дои:10.1103 / PhysRevE.91.032401. PMID 25871117.
- ^ Tahmasebi, P .; Сахими, М. (2015). «Геостатистическое моделирование и реконструкция пористых сред с помощью функции кросс-корреляции и интеграции жестких и мягких данных». Транспорт в пористой среде. 107 (3): 871–905. Дои:10.1007 / s11242-015-0471-3. S2CID 123432975.
- ^ «Аспирантура по пространственному анализу». Университет Райерсона. Университет Райерсона. Получено 17 декабря 2015.
- ^ геопространственный. Словарь английского языка Коллинза — полное и несокращенное 11-е издание. Получено 5 августа 2012 г. с веб-сайта CollinsDictionary.com:http://www.collinsdictionary.com/dictionary/english/geospatial
- ^ Лексикон 21-го века Dictionary.com Copyright © 2003-2010 Dictionary.com, LLC http://dictionary.reference.com/browse/geospatial
- ^ Геопространственная паутина — смесь физического и виртуального пространства. В архиве 2011-10-02 на Wayback Machine, Арно Шарл в журнале «Ресивер», осень 2008 г.
- ^ Чен, Руичжи; Гиннесс, Роберт Э. (2014). Геопространственные вычисления в мобильных устройствах (1-е изд.). Норвуд, Массачусетс: Artech House. п. 228. ISBN 978-1-60807-565-2. Получено 1 июля 2014.
- ^ Гонсалес, Айнхоа; Доннелли, Элисон; Джонс, Майк; Хрисулакис, Нектарий; Лопес, Мириам (2012). «Система поддержки принятия решений для устойчивого городского метаболизма в Европе». Обзор оценки воздействия на окружающую среду. 38: 109–119. Дои:10.1016 / j.eiar.2012.06.007.
дальнейшее чтение
- Р. Аблер, Дж. Адамс и П. Гулд (1971) Пространственная организация — взгляд на мир географа, Энглвуд Клиффс, Нью-Джерси: Прентис-Холл.
- Анселин, Л. (1995) «Локальные индикаторы пространственной ассоциации — LISA». Географический анализ, 27, 93–115.
- Аванге, Джозеф; Паланц, Бела (2016). Геопространственные алгебраические вычисления, теория и приложения, третье издание. Нью-Йорк: Спрингер. ISBN 978-3319254630.
- Банерджи, Судипто; Карлин, Брэдли П.; Гельфанд, Алан Э. (2014), Иерархическое моделирование и анализ пространственных данных, второе издание, Монографии по статистике и прикладной теории вероятностей (2-е изд.), Chapman and Hall / CRC, ISBN 9781439819173
- Бененсон И. и П. М. Торренс. (2004). Геосимуляция: автоматическое моделирование городских явлений. Вайли.
- Фотерингем А.С., К. Брансдон и М. Чарльтон (2000) Количественная география: перспективы анализа пространственных данных, Мудрец.
- Фотерингем А.С. и М.Э. О’Келли (1989) Модели пространственного взаимодействия: формулировки и приложения, Kluwer Academic
- Fotheringham, A.S .; Роджерсон, П. А. (1993). «ГИС и проблемы пространственного анализа». Международный журнал географических информационных систем. 7: 3–19. Дои:10.1080/02693799308901936.
- Гудчайлд, М. Ф. (1987). «Пространственный аналитический взгляд на географические информационные системы». Международный журнал географических информационных систем. 1 (4): 327–44. Дои:10.1080/02693798708927820.
- МакИчрен, А.М. и Д. Р. Ф. Тейлор (ред.) (1994) Визуализация в современной картографии, Пергам.
- Левин, Н. (2010). CrimeStat: программа пространственной статистики для анализа мест совершения преступлений. Версия 3.3. Ned Levine & Associates, Хьюстон, Техас, и Национальный институт правосудия, Вашингтон, округ Колумбия. Гл. 1-17 + 2 обновить главы [1]
- Миллер, Х. Дж. (2004). «Первый закон Тоблера и пространственный анализ». Летопись Ассоциации американских географов. 94 (2): 284–289. Дои:10.1111 / j.1467-8306.2004.09402005.x. S2CID 19172678.
- Миллер, Х. Дж. И Дж. Хан (ред.) (2001) Географический анализ данных и открытие знаний, Тейлор и Фрэнсис.
- О’Салливан, Д. и Д. Анвин (2002) Анализ географической информации, Wiley.
- Паркер, Д. С .; Manson, S.M .; Янссен, М.А.; Hoffmann, M. J .; Мертвец, П. (2003). «Многоагентные системы для моделирования землепользования и изменения земного покрова: обзор». Летопись Ассоциации американских географов. 93 (2): 314–337. CiteSeerX 10.1.1.109.1825. Дои:10.1111/1467-8306.9302004. S2CID 130096094.
- Белый, R .; Энгелен, Г. (1997). «Клеточные автоматы как основа интегрированного динамического регионального моделирования». Окружающая среда и планирование B: планирование и дизайн. 24 (2): 235–246. Дои:10.1068 / b240235. S2CID 62516646.
- Шельдеман, X. и ван Зонневельд, М. (2010). Учебное пособие по пространственному анализу разнообразия и распространения растений. Bioversity International.
- Фишер М.М., Леунг Й. (2001) Геокомпьютерное моделирование: методы и приложения. Springer Verlag, Берлин
- Фотерингем, S; Кларк, G; Абрахарт, Б. (1997). «Геокомпьютинг и ГИС». Транзакции в ГИС. 2 (3): 199–200. Дои:10.1111 / j.1467-9671.1997.tb00010.x.
- Openshaw S и Abrahart RJ (2000) GeoComputation. CRC Press
- Диаппи Лидия (2004) Развивающиеся города: геокомпьютация в территориальном планировании. Ашгейт, Англия
- Longley PA, Brooks SM, McDonnell R, Macmillan B (1998), Geocomputation, учебник для начинающих. Джон Уайли и сыновья, Чичестер
- Элен, Дж; Колдуэлл, Д.Р .; Хардинг, S (2002). «GeoComputation: что это?». Comput Environ и Urban Syst. 26 (4): 257–265. Дои:10.1016 / s0198-9715 (01) 00047-3.
- Гахеган, М. (1999). «Что такое геокомпьютация?». Транзакция в ГИС. 3 (3): 203–206. Дои:10.1111/1467-9671.00017.
- Мурганте Б., Боррузо Г., Лапуччи А. (2009) «Геокомпьютация и городское планирование» Исследования в области вычислительного интеллекта, Vol. 176. Springer-Verlag, Берлин.
- Reis, José P .; Silva, Elisabete A .; Пинхо, Пауло (2016). «Пространственные метрики для изучения городских структур в растущих и сокращающихся городах». Городская география. 37 (2): 246–271. Дои:10.1080/02723638.2015.1096118. S2CID 62886095.
- Пападимитриу, Ф. (2002). «Моделирование показателей и индексов сложности ландшафта: подход с использованием G.I.S». Экологические показатели. 2 (1–2): 17–25. Дои:10.1016 / S1470-160X (02) 00052-3.
- Фишер М., Люнг Ю. (2010) «Геокомпьютерное моделирование: методы и приложения» Успехи в области пространственной науки. Шпрингер-Верлаг, Берлин.
- Мурганте Б., Боррузо Г., Лапуччи А. (2011) «Геокомпьютинг, устойчивость и экологическое планирование» Исследования в области вычислительного интеллекта, Vol. 348. Springer-Verlag, Берлин.
- Tahmasebi, P .; Хезархани, А .; Сахими, М. (2012). «Многоточечное геостатистическое моделирование на основе взаимно корреляционных функций». Вычислительные науки о Земле. 16 (3): 779–79742. Дои:10.1007 / s10596-012-9287-1. S2CID 62710397.
- Геза, Тот; Арон, Кинцес; Золтан, Надь (2014). «Европейская пространственная структура». LAP LAMBERT Academic Publishing. Дои:10.13140/2.1.1560.2247.
внешняя ссылка
- Комиссия МКА по геопространственному анализу и моделированию
- Образовательный ресурс по пространственной статистике и геостатистике
- Подробное руководство по принципам, методам и программным инструментам
- Социальное и пространственное неравенство
- Национальный центр географической информации и анализа (NCGIA)
- Международная картографическая ассоциация (ICA), всемирная организация профессионалов в области картографии и ГИС
Введение. Исследуется пространственная неоднородность эффекта переноса валютного курса в потребительские цены в российских регионах. Тестируются две гипотезы. Первая заключается в существовании различий в величине эффекта переноса между регионами РФ, вторая – в значимом влиянии на величину эффекта переноса пространственных взаимосвязей между регионами. Теоретический анализ. Проанализированы факторы, которые могут влиять на межрегиональные различия эффекта переноса: доля импорта в структуре потребления, доля добавленной стоимости, произведенной на внутреннем рынке, в конечной цене товара, наличие трансакционных издержек, уровень конкуренции и структура рынка. Эмпирический анализ. На первом шаге в рамках векторной модели авторегрессии получены оценки эффекта переноса для каждого региона. На втором шаге исследована пространственная зависимость эффекта переноса на основе глобальных и локальных индексов Морана и Гири, моделей SAR и SEM. Результаты. Полученные результаты свидетельствуют о неоднородности эффекта переноса в регионах РФ, что подтверждает первую из выдвинутых гипотез. Подтверждение второй гипотезы обнаружено только для продовольственных товаров в краткосрочном периоде, что обусловлено характером товарных потоков между российскими регионами. Сделан вывод о необходимости исследования пространственных взаимосвязей эффекта переноса на основе дезагрегированных цен.
1. вещание в широком пространстве (SAC)
1. Модельная форма
В целом модель космической регрессии (spatial autocorrelation,SAC) В то же время он описывает сущность пространства и пространственного нарушения, а его форма — модель космического лага (SAR) И модель ошибок пространства (SEM) Комбинация, например, стильПоказывать:

в, W1а также W2Опишите корреляцию между переменными интерпретации у людей разных раздела и корреляцией между ошибками, и они могут быть одинаковыми.
Условия применения:
(1)SARВ структуре ошибок есть пространственные зависимости модели
(2)какW2 Указывает, что место второго порядка рядом с матрицей,Поскольку на объясненная переменная влияет второй раунд пространственного явления,Сделайте структуру нарушения с высокими пространственными зависимостями.
(3)какW1Указывает, что первое пространство заказатся рядом с матрицей,W2Чтобы указать на угловую матрицу расстояния между городом и центром центра, эта структура пространственной матрицы веса показывает, что только соседняя зависимость не может полностью объяснить пространственный эффект.
2. Модельная работа
Модель SAC может быть решена через программное обеспечение Stata. Код выглядит следующим образом:
Используйте li3.1.dta, clear // Откройте данные //
Рег lninno lnrdk lnrdl /* обычная минимум двух -времена, что удобно для сравнения* /
SSC Установка Spregsac // Установочный пакет //
SPREGSAC LNINNO LNRDK LNRDL, WMFILE (LI3.1W.DTA) // Широкая космическая самостоятельная модель, LI3.W -это пространственная матрица веса //Результаты работы показаны на рисунке:


Во -вторых, модель пространственной ошибки
1. Модельная форма
Модель ошибок пространства (spatial error model,SEM) Опишите общую корреляцию космических помех и общего пространства, его форма заключается в следующемПоказывать:

Среди них взаимосвязь между пространственной ошибкой является направление и степень влияния воздействия ошибки на переменную интерпретации на значение наблюдения индивидуума;WЭто пространственная матрица веса, из которых элементы𝒘𝒊𝒋 Опишите первоеjОдин и первыйiКоррекция между отдельными элементами ошибки раздела. SEMМодель иллюстрирует результат случайного воздействия между регионами. Экономическое значение состоит в том, что воздействие произошло в определенной области, будет передано в соседнюю область с формой координирующей дифференциальной структуры, и эта форма передачи является длительной непрерывностью и постепенно затухание.
общийSEMМодель разделена на следующие типы в соответствии с настройкой ошибки:
а𝜺=𝜆𝑾𝜺+𝜇,ноSEMМодель принадлежит пространствуAR(1)В форме, когда взаимодействие между областями отличается из -за относительных положений, используется эта модель, и его форма настройки чаще используется, чем другие типы.
беременный𝜺=𝝁−𝜽𝑾𝝁,ноSEMМодель принадлежит пространствуMA(1)форма.
в𝜺=𝜆𝑾𝜺−𝜽𝑾𝝁+𝜇,ноSEMМодель принадлежит пространствуARMA(1)форма.
2. Модельная работа
Модель SEM может быть решена через программное обеспечение Stata. Код выглядит следующим образом:
SSC Установка SPREGSEM // Установочный пакет //
SPREGSEM LNINNO LNRDK LNRDL, WMFILE (LI3.1W.DTA) // Модель ошибок пространства //Результаты работы:

3. Сравнение заключения
Результаты моделей OLS, SAC и SEM могут быть объединены в таблицу для сравнения (небольшая таблица здесь), и результаты показывают, что в результатах влиятельных факторов количества проектов НИОКР и ее модели пространственной корреляции IT лучше, чем классическая регрессионная модель OLS, но значение коэффициента коэффициента эффекта космического лага в модели SAC невелика и не значима. СЭМ с отставанием, модель SEM лучше, чем отстающий эффект пространства. Кроме того, экономический смысл параметров может быть дополнительно объяснен.