
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).

Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).

Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
Полученные
в результате статистического исследования
средние и относительные величины должны
отражать закономерности, характерные
для всей совокупности. Результаты
исследования обычно тем достовернее,
чем больше сделано наблюдений, и наиболее
точными они являются при сплошном
исследовании (т.е. при изучении генеральной
совокупности). Однако должны быть
достаточно надежные и данные, полученные
путем выборочных исследований, т.е. на
относительно небольшом числе наблюдений.
Различие
результатов выборочного исследования
и результатов, которые могут быть
получены на генеральной совокупности,
представляет собой ошибку выборочного
исследования, которую можно точно
определить математическим путем. Метод
ее оценки основан на закономерностях
случайных вариаций, установленных
теорией вероятности.
1.
Оценка достоверности средней
арифметической.
Средняя
арифметическая, полученная при обработке
результатов научно-практических
исследований, под влиянием случайных
явлений может отличаться от средних,
полученных при проведении повторных
исследований. Поэтому, чтобы иметь
представление о возможных пределах
колебаний средней, о том, с какой
вероятностью возможно перенести
результаты исследования с выборочной
совокупности на всю генеральную
совокупность, определяют степень
достоверности средней величины.
Мерой
достоверности средней является средняя
ошибка средней арифметической (ошибка
репрезентативности – m).
Ошибки репрезентативности возникают
в связи с тем, что при выборочным
наблюдении изучается только часть
генеральной совокупности, которая
недостаточно точно ее представляет.
Фактически ошибка репрезентативности
является разностью между средними,
полученными при выборочном статистическом
наблюдении, и средними, которые были бы
получены при сплошном наблюдении (т.е.
при изучении всей генеральной
совокупности).
Средняя
ошибка средней арифметической вычисляется
по формуле:
—
при числе наблюдений больше 30 (n
> 30):
![]()
—
при небольшом числе наблюдений (n
< 30):
![]()
Ошибка
репрезентативности прямо пропорциональна
колеблемости ряда (сигме) и обратно
пропорциональна числу наблюдений.
Следовательно,
чем больше
число наблюдений
(т.е. чем ближе по числу наблюдений
выборочная совокупность к генеральной),
тем меньше
ошибка репрезентативности.
Интервал,
в котором с заданным уровнем вероятности
колеблется истинное значение средней
величины или показателя, называется
доверительным
интервалом,
а его границы – доверительными
границами.
Они используются для определения
размеров средней или показателя в
генеральной совокупности.
Доверительные
границы
средней арифметической и показателя в
генеральной совокупности равны:
M
+
tm
P
+
tm,
где
t
– доверительный коэффициент.
Доверительный
коэффициент (t)
– это число, показывающее, во сколько
раз надо увеличить ошибку средней
величины или показателя, чтобы при
данном числе наблюдений с желаемой
степенью вероятности утверждать, что
они не выйдут за полученные таким образом
пределы.
С
увеличением t
степень вероятности возрастает.
Т.к.
известно, что полученная средняя или
показатель при повторных наблюдениях,
даже при одинаковых условиях, в силу
случайных колебаний будут отличаться
от предыдущего результат, теорией
статистики установлена степень
вероятности, с которой можно ожидать,
что колебания эти не выйдут за определенные
пределы. Так, колебания средней
в интервале M
+
1m
гарантируют ее точность с вероятностью
68.3% (такая
степень вероятности не удовлетворяет
исследователей), в
интервале M
+
2m
– 95.5%
(достаточная степень вероятности) и в
интервале M
+
3m
– 99,7% (большая
степень вероятности).
Для
медико-биологических исследований
принята степень вероятности 95% (t
= 2), что соответствует доверительному
интервалу M
+
2m.
Это
означает, что практически
с полной достоверностью (в 95%) можно
утверждать, что полученный средний
результат (М) отклоняется от истинного
значения не больше, чем на удвоенную (M
+
2m) ошибку.
Конечный
результат любого медико-статистического
исследования выражается средней
арифметической и ее параметрами:
![]()
2.
Оценка достоверности относительных
величин (показателей).
Средняя
ошибка показателя также служит для
определения пределов его случайных
колебаний, т.е. дает представление, в
каких пределах может находиться
показатель в различных выборках в
зависимости от случайных причин. С
увеличением численности выборки ошибка
уменьшается.
Мерой
достоверности показателя является его
средняя ошибка (m),
которая показывает, на сколько результат,
полученный при выборочным исследовании,
отличается от результата, который был
бы получен при изучении всей генеральной
совокупности.
Средняя
ошибка показателя определяется по
формуле:
![]() ,
,
где mp
– ошибка относительного показателя,
р
– показатель,
q
– величина, обратная показателю (100-p,
1000-р и т.д. в зависимости от того, на какое
основание рассчитан показатель);
n
– число наблюдений.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
![]()
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
![]()
Используя более привычные обозначения, формулу записывают как:
![]()
где σ2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
![]()
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
![]()
Формула стандартной ошибки средней при использовании выборочной дисперсии
![]()
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
![]()
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).
Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).
Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Поделиться в социальных сетях:
Когда вы применяете функцию СРЕДНЕЕ для вычисления среднего значения диапазона ячеек, включающего некоторые значения ошибок, вы получите результат ошибки. В следующей статье будет рассказано о том, как усреднить ячейки, игнорируя ошибки в Excel.
Средние ячейки, игнорирующие значения ошибок с помощью формул массива
 Средние ячейки, игнорирующие значения ошибок с помощью формул массива
Средние ячейки, игнорирующие значения ошибок с помощью формул массива
Следующие удобные формулы массива могут помочь вам вычислить среднее значение ячеек без учета ошибок. Пожалуйста, сделайте так:
1. Введите эту формулу массива: = СРЕДНИЙ (ЕСЛИ (ЕСТЬ ОШИБКА (A1: C6); «»; A1: C6)), см. снимок экрана:

2, Затем нажмите Shift + Ctrl + Enter одновременно, и вы получите средний результат, как показано на скриншоте ниже:

Ноты:
1. Кроме приведенной выше формулы, вам может помочь еще одна формула: = СРЕДНИЙ (ЕСЛИ (ЕЧИСЛО (A1: C6); A1: C6)), пожалуйста, не забудьте нажать Shift + Ctrl + Enter ключи.
2. В приведенных выше формулах A1: C6 — это диапазон данных, который вы хотите вычислить, вы можете изменить его по своему усмотрению.
Статьи по теме:
Как усреднить абсолютные значения в Excel?
Как усреднить только положительные или отрицательные числа в Excel?
Как усреднить диапазон данных, игнорируя ноль в Excel?
Как рассчитать среднее значение без максимальных и минимальных значений в Excel?
Лучшие инструменты для работы в офисе
Kutools for Excel Решит большинство ваших проблем и повысит вашу производительность на 80%
- Снова использовать: Быстро вставить сложные формулы, диаграммы и все, что вы использовали раньше; Зашифровать ячейки с паролем; Создать список рассылки и отправлять электронные письма …
- Бар Супер Формулы (легко редактировать несколько строк текста и формул); Макет для чтения (легко читать и редактировать большое количество ячеек); Вставить в отфильтрованный диапазон…
- Объединить ячейки / строки / столбцы без потери данных; Разделить содержимое ячеек; Объединить повторяющиеся строки / столбцы… Предотвращение дублирования ячеек; Сравнить диапазоны…
- Выберите Дубликат или Уникальный Ряды; Выбрать пустые строки (все ячейки пустые); Супер находка и нечеткая находка во многих рабочих тетрадях; Случайный выбор …
- Точная копия Несколько ячеек без изменения ссылки на формулу; Автоматическое создание ссылок на несколько листов; Вставить пули, Флажки и многое другое …
- Извлечь текст, Добавить текст, Удалить по позиции, Удалить пробел; Создание и печать промежуточных итогов по страницам; Преобразование содержимого ячеек в комментарии…
- Суперфильтр (сохранять и применять схемы фильтров к другим листам); Расширенная сортировка по месяцам / неделям / дням, периодичности и др .; Специальный фильтр жирным, курсивом …
- Комбинируйте книги и рабочие листы; Объединить таблицы на основе ключевых столбцов; Разделить данные на несколько листов; Пакетное преобразование xls, xlsx и PDF…
- Более 300 мощных функций. Поддерживает Office/Excel 2007-2021 и 365. Поддерживает все языки. Простое развертывание на вашем предприятии или в организации. Полнофункциональная 30-дневная бесплатная пробная версия. 60-дневная гарантия возврата денег.
")
Вкладка Office: интерфейс с вкладками в Office и упрощение работы
- Включение редактирования и чтения с вкладками в Word, Excel, PowerPoint, Издатель, доступ, Visio и проект.
- Открывайте и создавайте несколько документов на новых вкладках одного окна, а не в новых окнах.
- Повышает вашу продуктивность на 50% и сокращает количество щелчков мышью на сотни каждый день!
")
Комментарии (13)
Оценок пока нет. Оцените первым!
Функция СРЗНАЧЕСЛИ
В этой статье описаны синтаксис формулы и использование СРЗНАЧЕСЛИ функция в Microsoft Excel.
Описание
Возвращает среднее значение (среднее арифметическое) всех ячеек в диапазоне, которые соответствуют данному условию.
Синтаксис
СРЗНАЧЕСЛИ(диапазон, условия, [диапазон_усреднения])
Аргументы функции СРЗНАЧЕСЛИ указаны ниже.
Диапазон. Обязательный. Одна или несколько ячеек для вычисления среднего, включающих числа или имена, массивы или ссылки, содержащие числа.
Условие. Обязательный. Условие в форме числа, выражения, ссылки на ячейку или текста, которое определяет ячейки, используемые при вычислении среднего. Например, условие может быть выражено следующим образом: 32, «32», «>32», «яблоки» или B4.
Диапазон_усреднения. Необязательный. Фактическое множество ячеек для вычисления среднего. Если этот параметр не указан, используется диапазон.
Замечания
Ячейки в диапазоне, которые содержат значения ИСТИНА или ЛОЖЬ, игнорируются.
Если ячейка в «диапазоне_усреднения» пустая, функция СРЗНАЧЕСЛИ игнорирует ее.
Если диапазон является пустым или текстовым значением, СРЗНАЧЕСЛИ Возвращает #DIV0! значение ошибки #ЗНАЧ!.
Если ячейка в условии пустая, «СРЗНАЧЕСЛИ» обрабатывает ее как ячейки со значением 0.
Если ни одна из ячеек в диапазоне не удовлетворяет критерию, СРЗНАЧЕСЛИ Возвращает #DIV/0! значение ошибки #ДЕЛ/0!.
В этом аргументе можно использовать подстановочные знаки: вопросительный знак (?) и звездочку (*). Вопросительный знак соответствует любому одиночному символу; звездочка — любой последовательности символов. Если нужно найти сам вопросительный знак или звездочку, то перед ними следует поставить знак тильды (
Значение «диапазон_усреднения» не обязательно должно совпадать по размеру и форме с диапазоном. При определении фактических ячеек, для которых вычисляется среднее, в качестве начальной используется верхняя левая ячейка в «диапазоне_усреднения», а затем добавляются ячейки с совпадающим размером и формой. Например:
Если диапазон равен
Примечание: Функция СРЗНАЧЕСЛИ измеряет среднее значение, то есть центр набора чисел в статистическом распределении. Существует три наиболее распространенных способа определения среднего значения: :
Среднее значение — это среднее арифметическое, которое вычисляется путем сложения набора чисел с последующим делением полученной суммы на их количество. Например, средним значением для чисел 2, 3, 3, 5, 7 и 10 будет 5, которое является результатом деления их суммы, равной 30, на их количество, равное 6.
Медиана — это число, которое является серединой множества чисел, то есть половина чисел имеют значения большие, чем медиана, а половина чисел имеют значения меньшие, чем медиана. Например, медианой для чисел 2, 3, 3, 5, 7 и 10 будет 4.
Мода — это число, наиболее часто встречающееся в данном наборе чисел. Например, модой для чисел 2, 3, 3, 5, 7 и 10 будет 3.
При симметричном распределении множества чисел все три значения центральной тенденции будут совпадать. При смещенном распределении множества чисел значения могут быть разными.
Примеры
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
How to dou
Анализ НОРМАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ | АНАЛИЗ ДАННЫХ #4
Table of Contents:

Когда вы создаете граф в Excel и ваши данные являются средствами, рекомендуется включить стандартную ошибку каждого значения на вашем графике. Это дает зрителю представление о распространении баллов вокруг каждого среднего.
Вот пример ситуации, когда это возникает. Данные являются (вымышленными) результатами тестов для четырех групп людей. Каждый заголовок столбца указывает количество времени подготовки для восьми человек в группе. Вы можете использовать графические возможности Excel для рисования графика. Поскольку независимая переменная является количественной, граф линии является подходящим.
Четыре группы, их средства, стандартные отклонения и стандартные ошибки. На графике показаны групповые средства.
Для каждой группы вы можете использовать AVERAGE для вычисления среднего и STDEV. S для вычисления стандартного отклонения. Вы можете рассчитать стандартную ошибку каждого среднего. Выберите ячейку B12, поэтому в поле формулы показано, что вы вычислили стандартную ошибку для столбца B по этой формуле:
= B11 / SQRT (COUNT (B2: B9))
Фокус в том, чтобы получить каждую стандартную ошибку в графике. В Excel 2016 это легко сделать, и оно отличается от предыдущих версий Excel. Начните с выбора графика. Это приведет к появлению вкладок Design and Format. Выберите
Дизайн | Добавить элемент диаграммы | Ошибка баров | Дополнительные параметры ошибок.

Путь к вставке баров ошибок.
В меню «Бары ошибок» вы должны быть осторожны. Один из вариантов — стандартная ошибка. Избегай это. Если вы считаете, что этот выбор указывает Excel на стандартную ошибку каждого значения на графике, будьте уверены, что Excel не имеет абсолютно никакого представления о том, о чем вы говорите. Для этого выбора Excel вычисляет стандартную ошибку набора из четырех средств — не стандартную ошибку в каждой группе.
Дополнительные параметры панели ошибок являются подходящим выбором. Откроется панель «Формат ошибок».

Панель «Ошибки формата».
В области «Направление» панели выберите переключатель рядом с «Оба», а в области «Стиль конца» выберите переключатель рядом с «Кап».
Один выбор в области «Сумма ошибки» — это стандартная ошибка. Избегайте этого. Это не означает, что Excel помещает стандартную ошибку каждого среднего на график.
Прокрутите вниз до области «Сумма ошибки» и выберите переключатель рядом с «Пользовательский». Это активирует кнопку «Укажите значение». Нажмите эту кнопку, чтобы открыть диалоговое окно «Пользовательские ошибки». С помощью курсора в поле «Положительное значение ошибки» выберите диапазон ячеек, который содержит стандартные ошибки ($ B $ 12: $ E $ 12). Вставьте вкладку «Отрицательная ошибка» и сделайте то же самое.

Диалоговое окно «Нестандартные ошибки».
Это поле Negative Error Value может дать вам небольшую проблему. Перед тем, как вводить диапазон ячеек, убедитесь, что он очищен от значений по умолчанию.
Нажмите «ОК» в диалоговом окне «Нестандартные ошибки» и закройте диалоговое окно «Формат ошибок», и график будет выглядеть следующим образом.

График группы означает, включая стандартную ошибку каждого среднего.
Стандартная ошибка средней арифметической
Среднее арифметическое, как известно, используется для получения обобщающей характеристики некоторого набора данных. Если данные более-менее однородны и в них нет аномальных наблюдений (выбросов), то среднее хорошо обобщает данные, сведя к минимуму влияние случайных факторов (они взаимопогашаются при сложении).
Когда анализируемые данные представляют собой выборку (которая состоит из случайных значений), то среднее арифметическое часто (но не всегда) выступает в роли приближенной оценки математического ожидания. Почему приближенной? Потому что среднее арифметическое – это величина, которая зависит от набора случайных чисел, и, следовательно, сама является случайной величиной. При повторных экспериментах (даже в одних и тех же условиях) средние будут отличаться друг от друга.
Для того, чтобы на основе статистического анализа данных делать корректные выводы, необходимо оценить возможный разброс полученного результата. Для этого рассчитываются различные показатели вариации. Но то исходные данные. И как мы только что установили, среднее арифметическое также обладает разбросом, который необходимо оценить и учитывать в дальнейшем (в выводах, в выборе метода анализа и т.д.).
Интуитивно понятно, что разброс средней должен быть как-то связан с разбросом исходных данных. Основной характеристикой разброса средней выступает та же дисперсия.
Дисперсия выборочных данных – это средний квадрат отклонения от средней, и рассчитать ее по исходным данным не составляет труда, например, в Excel предусмотрены специальные функции. Однако, как же рассчитать дисперсию средней, если в распоряжении есть только одна выборка и одно среднее арифметическое?
Расчет дисперсии и стандартной ошибки средней арифметической
Чтобы получить дисперсию средней арифметической нет необходимости проводить множество экспериментов, достаточно иметь только одну выборку. Это легко доказать. Для начала вспомним, что средняя арифметическая (простая) рассчитывается по формуле:
где xi – значения переменной,
n – количество значений.
Теперь учтем два свойства дисперсии, согласно которым, 1) — постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат и 2) — дисперсия суммы независимых случайных величин равняется сумме соответствующих дисперсий. Предполагается, что каждое случайное значение xi обладает одинаковым разбросом, поэтому несложно вывести формулу дисперсии средней арифметической:
Используя более привычные обозначения, формулу записывают как:
где σ 2 – это дисперсия, случайной величины, причем генеральная.
На практике же, генеральная дисперсия известна далеко не всегда, точнее совсем редко, поэтому в качестве оной используют выборочную дисперсию:
Стандартное отклонение средней арифметической называется стандартной ошибкой средней и рассчитывается, как квадратный корень из дисперсии.
Формула стандартной ошибки средней при использовании генеральной дисперсии
Формула стандартной ошибки средней при использовании выборочной дисперсии
Последняя формула на практике используется чаще всего, т.к. генеральная дисперсия обычно не известна. Чтобы не вводить новые обозначения, стандартную ошибку средней обычно записывают в виде соотношения стандартного отклонения выборки и корня объема выборки.
Назначение и свойство стандартной ошибки средней арифметической
Стандартная ошибка средней много, где используется. И очень полезно понимать ее свойства. Посмотрим еще раз на формулу стандартной ошибки средней:
Числитель – это стандартное отклонение выборки и здесь все понятно. Чем больше разброс данных, тем больше стандартная ошибка средней – прямо пропорциональная зависимость.
Посмотрим на знаменатель. Здесь находится квадратный корень из объема выборки. Соответственно, чем больше объем выборки, тем меньше стандартная ошибка средней. Для наглядности изобразим на одной диаграмме график нормально распределенной переменной со средней равной 10, сигмой – 3, и второй график – распределение средней арифметической этой же переменной, полученной по 16-ти наблюдениям (которое также будет нормальным).
Судя по формуле, разброс стандартной ошибки средней должен быть в 4 раза (корень из 16) меньше, чем разброс исходных данных, что и видно на рисунке выше. Чем больше наблюдений, тем меньше разброс средней.
Казалось бы, что для получения наиболее точной средней достаточно использовать максимально большую выборку и тогда стандартная ошибка средней будет стремиться к нулю, а сама средняя, соответственно, к математическому ожиданию. Однако квадратный корень объема выборки в знаменателе говорит о том, что связь между точностью выборочной средней и размером выборки не является линейной. Например, увеличение выборки с 20-ти до 50-ти наблюдений, то есть на 30 значений или в 2,5 раза, уменьшает стандартную ошибку средней только на 36%, а со 100-а до 130-ти наблюдений (на те же 30 значений), снижает разброс данных лишь на 12%.
Лучше всего изобразить эту мысль в виде графика зависимости стандартной ошибки средней от размера выборки. Пусть стандартное отклонение равно 10 (на форму графика это не влияет).
Видно, что примерно после 50-ти значений, уменьшение стандартной ошибки средней резко замедляется, после 100-а – наклон постепенно становится почти нулевым.
Таким образом, при достижении некоторого размера выборки ее дальнейшее увеличение уже почти не сказывается на точности средней. Этот факт имеет далеко идущие последствия. Например, при проведении выборочного обследования населения (опроса) чрезмерное увеличение выборки ведет к неоправданным затратам, т.к. точность почти не меняется. Именно поэтому количество опрошенных редко превышает 1,5 тысячи человек. Точность при таком размере выборки часто является достаточной, а дальнейшее увеличение выборки – нецелесообразным.
Подведем итог. Расчет дисперсии и стандартной ошибки средней имеет довольно простую формулу и обладает полезным свойством, связанным с тем, что относительно хорошая точность средней достигается уже при 100 наблюдениях (в этом случае стандартная ошибка средней становится в 10 раз меньше, чем стандартное отклонение выборки). Больше, конечно, лучше, но бесконечно увеличивать объем выборки не имеет практического смысла. Хотя, все зависит от поставленных задач и цены ошибки. В некоторых опросах участие принимают десятки тысяч людей.
Дисперсия и стандартная ошибка средней имеют большое практическое значение. Они используются в проверке гипотез и расчете доверительных интервалов.
Стандартная ошибка в Excel
Расчет с помощью комбинаций функций
На примере рассмотрим составленный алгоритм действий по расчету ошибки средней арифметической с использованием комбинаций функций. Для того чтобы выполнить задачу, нужно использовать операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ. Выборка будет использоваться из 12 чисел, которые представлены в таблице.
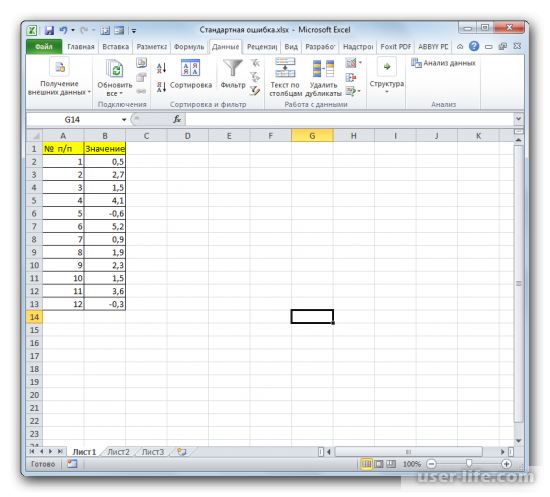
Выделите ячейку, в которой отобразится итоговое значение стандартной ошибки. Кликаете на иконку «Вставить функцию».
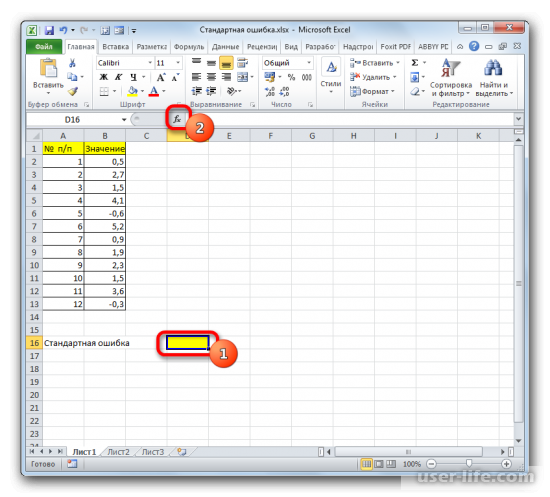
Появится Мастер функций, в котором нужно произвести перемещение в блок «Статистические». Появится список наименований, выбираете «СТАНДОТКЛОН.В».
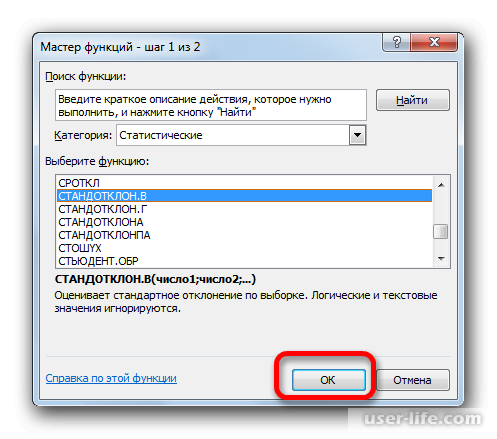
Запустится окно аргументов выбранного оператора, предназначенного для оценивания стандартного отклонения при выборке. У него такой синтаксис — =СТАНДОТКЛОН.В(число1;число2;…). Устанавливаете курсор в полу «Число1». Далее, зажав левую кнопку мыши, выделяете курсором весь диапазон выборки, чтобы координаты этого массива отобразились там же в поле окна. Кликаете на ОК.
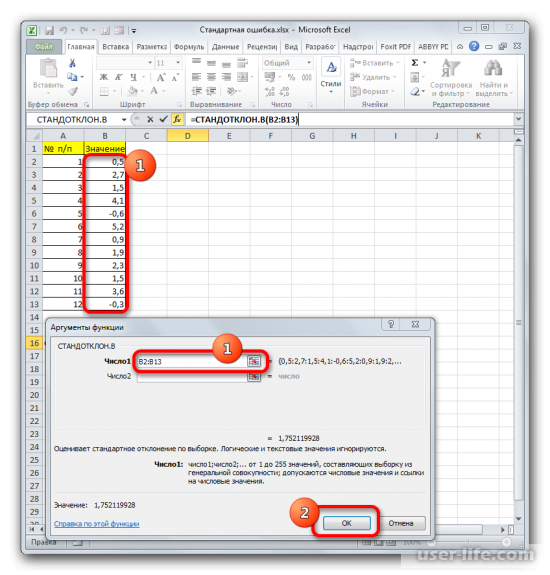
В ячейке появится проделанный результат, но это еще не то, что мы хотим получить в итоге. Теперь нужно стандартное отклонение разделить на квадратный корень от числа элементов выборки. Выделяете ячейку с нужной функцией и устанавливаете курсор мышки в строку формул. Дописываете выражение, которое там уже существует, знаком деления (/). Далее нажимаете на пиктограмму перевернутого вниз углом треугольника (находится слева от строки формул). Должен открыться список недавно использованных функций. Находите оператора «КОРЕНЬ» и нажимаете на него. Если его нет в списке, то кликайте на «Другие функции…».
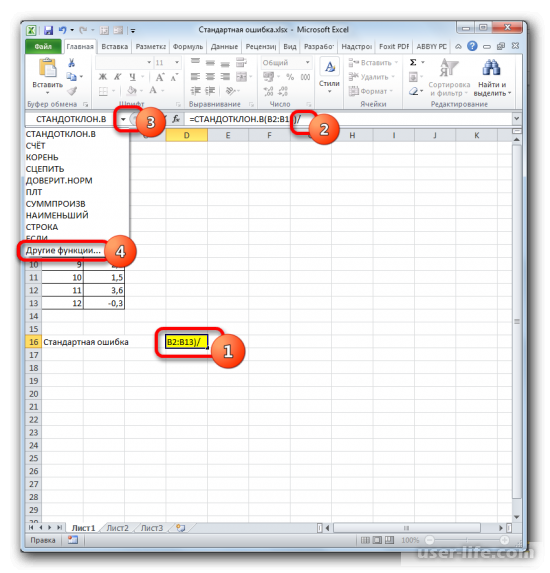
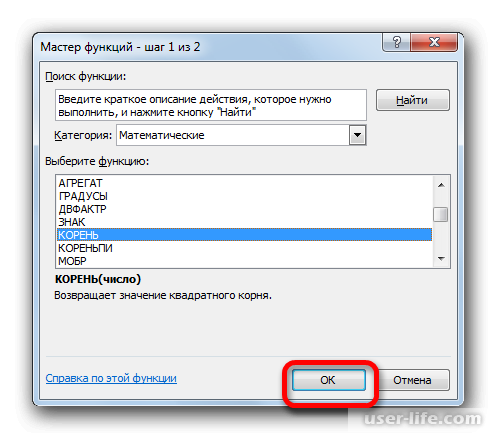
Должен снова запуститься Мастер функций, в котором нужно перейти в категорию «Математические». Выделяете там «КОРЕНЬ» и кликаете ОК.
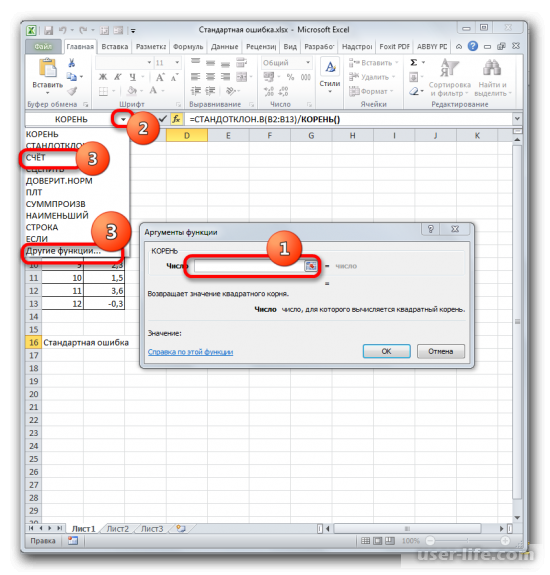
Далее должно открыться окно аргументов функции КОРЕНЬ. Его синтаксис простой — =КОРЕНЬ(число). Устанавливаете курсор в поле «Число» и нажимаете на уже знакомый треугольник, чтобы показался список последних использованных функций. Находите «СЧЕТ» и нажимаете на него. Если в списке его нет, тогда нажимаете на «Другие функции…».
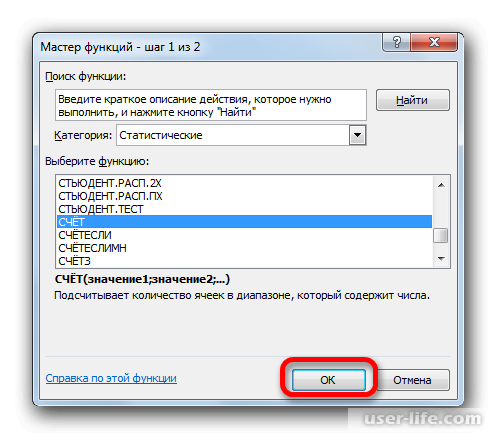
Появится раскрывшееся окно Мастера функций, в котором нужно переместиться в группу «Статистические». В ней выделяете «СЧЕТ» и кликаете ОК.
Должно запуститься окно аргументов функции СЧЕТ. Синтаксис функции будет таким — =СЧЁТ(значение1;значение2;…). Ставите курсор в строку «Значение1» и зажимаете левую кнопку мыши, чтобы выделить весь диапазон выборки. Когда координаты отобразятся, жмите ОК.
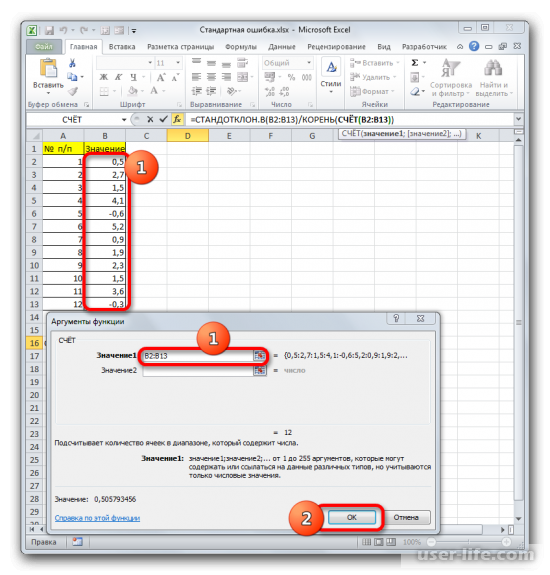
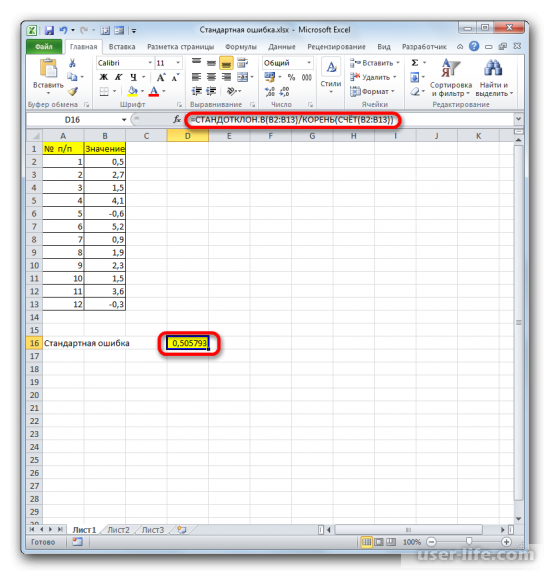
Когда будет выполнено последнее действие, то не только произведется расчет количества ячеек, которые заполнены числами, но и вычисляется ошибка средней арифметической. Величина будет выведена в ячейку с размещенной сложной формулой, вид которой таков — =СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)).
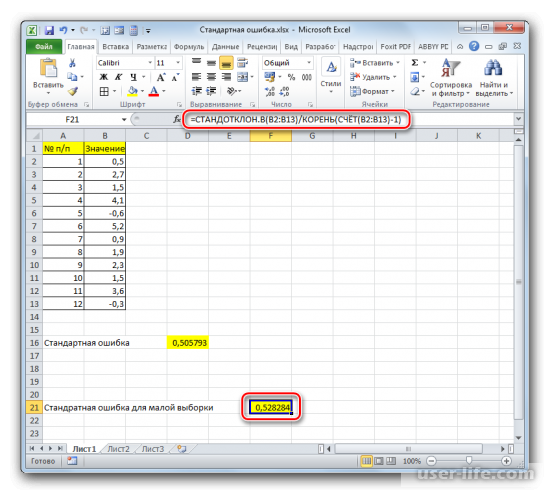
Если выборка до 30 единиц, тогда лучше применять немного другую формулу — =СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1).
Применение инструмента «Описательная статистика»
Когда будет открыт документ с выборкой, нужно перейти во вкладку «Файл».
В левом вертикальном меню заходите в раздел «Параметры».
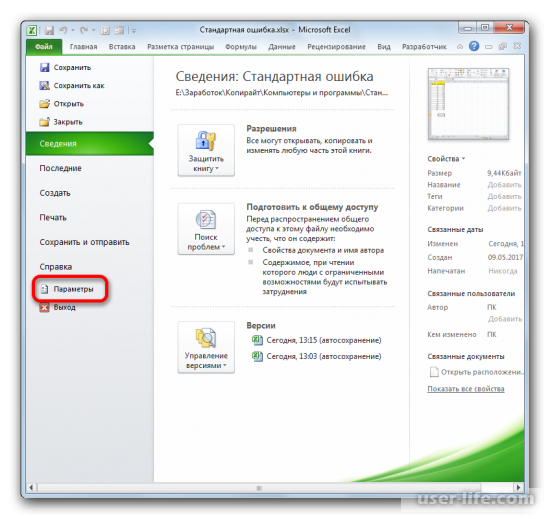
Должно запуститься окно параметров Excel, в левой части которого нужно перейти в «Надстройки».
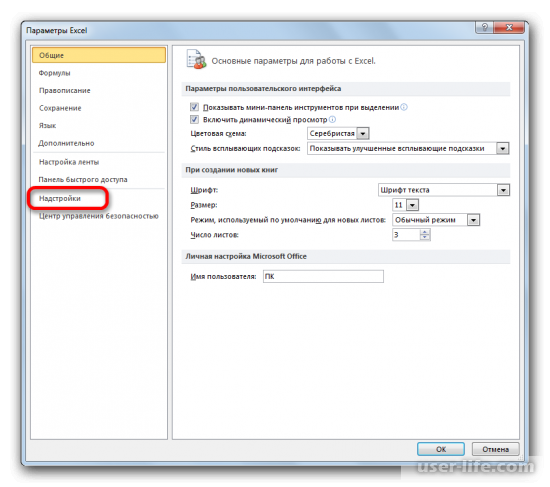
В самом низу окна находите «Управление» в выставляете в нем параметр «Надстройки Excel». Кликаете на «Перейти…» справа от него.
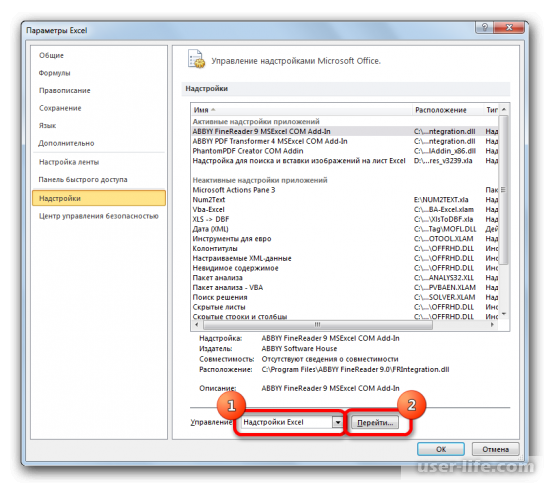
В окне надстроек появится список скриптов, которые доступны и нужно отметить галочкой «Пакет анализа», а затем нажать ОК.
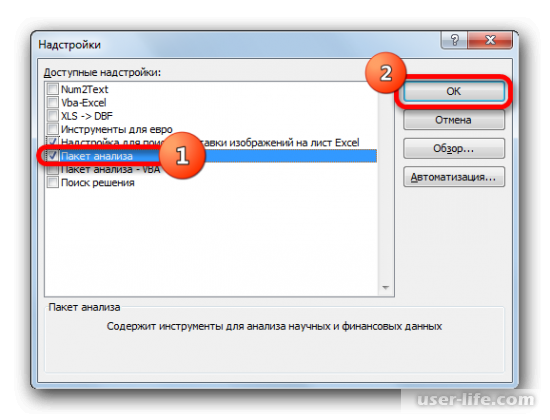
Теперь на странице должна появиться новая группа инструментов «Анализ». Для перехода к ней кликаете на вкладку «Данные».
Кликаете на «Анализ данных» в блоке инструментов «Анализ» в самом конце.
Запустится окно выбора инструмента анализа, в котором необходимо выделить «Описательная статистика» и нажать справа на ОК.
Далее запустится окно настроек инструмента комплексного статистического анализа «Описательная статистика». Здесь нужно установить все так, в зависимости от того, что именно вы хотите получить в итоге.
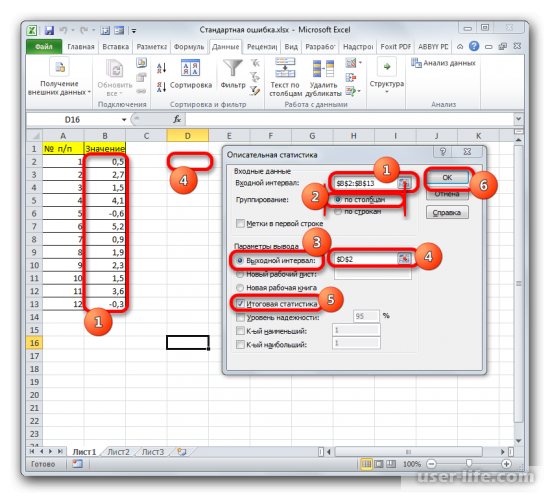
После всех совершенных манипуляций, инструмент «Описательная статистика» должен отобразить результаты обработки выборки на текущем листе. Разноплановых статистических показателей будет немало, но среди них находится и тот, который нам нужен – «Стандартная ошибка».
Функция СРЗНАЧЕСЛИ
В этой статье описаны синтаксис формулы и использование СРЗНАЧЕСЛИ функция в Microsoft Excel.
Описание
Возвращает среднее значение (среднее арифметическое) всех ячеек в диапазоне, которые соответствуют данному условию.
Синтаксис
СРЗНАЧЕСЛИ(диапазон, условия, [диапазон_усреднения])
Аргументы функции СРЗНАЧЕСЛИ указаны ниже.
Диапазон. Обязательный. Одна или несколько ячеек для вычисления среднего, включающих числа или имена, массивы или ссылки, содержащие числа.
Условие. Обязательный. Условие в форме числа, выражения, ссылки на ячейку или текста, которое определяет ячейки, используемые при вычислении среднего. Например, условие может быть выражено следующим образом: 32, «32», «>32», «яблоки» или B4.
Диапазон_усреднения. Необязательный. Фактическое множество ячеек для вычисления среднего. Если этот параметр не указан, используется диапазон.
Замечания
Ячейки в диапазоне, которые содержат значения ИСТИНА или ЛОЖЬ, игнорируются.
Если ячейка в «диапазоне_усреднения» пустая, функция СРЗНАЧЕСЛИ игнорирует ее.
Если диапазон является пустым или текстовым значением, СРЗНАЧЕСЛИ Возвращает #DIV0! значение ошибки #ЗНАЧ!.
Если ячейка в условии пустая, «СРЗНАЧЕСЛИ» обрабатывает ее как ячейки со значением 0.
Если ни одна из ячеек в диапазоне не удовлетворяет критерию, СРЗНАЧЕСЛИ Возвращает #DIV/0! значение ошибки #ДЕЛ/0!.
В этом аргументе можно использовать подстановочные знаки: вопросительный знак (?) и звездочку (*). Вопросительный знак соответствует любому одиночному символу; звездочка — любой последовательности символов. Если нужно найти сам вопросительный знак или звездочку, то перед ними следует поставить знак тильды (
Значение «диапазон_усреднения» не обязательно должно совпадать по размеру и форме с диапазоном. При определении фактических ячеек, для которых вычисляется среднее, в качестве начальной используется верхняя левая ячейка в «диапазоне_усреднения», а затем добавляются ячейки с совпадающим размером и формой. Например:
Если диапазон равен
Примечание: Функция СРЗНАЧЕСЛИ измеряет среднее значение, то есть центр набора чисел в статистическом распределении. Существует три наиболее распространенных способа определения среднего значения: :
Среднее значение — это среднее арифметическое, которое вычисляется путем сложения набора чисел с последующим делением полученной суммы на их количество. Например, средним значением для чисел 2, 3, 3, 5, 7 и 10 будет 5, которое является результатом деления их суммы, равной 30, на их количество, равное 6.
Медиана — это число, которое является серединой множества чисел, то есть половина чисел имеют значения большие, чем медиана, а половина чисел имеют значения меньшие, чем медиана. Например, медианой для чисел 2, 3, 3, 5, 7 и 10 будет 4.
Мода — это число, наиболее часто встречающееся в данном наборе чисел. Например, модой для чисел 2, 3, 3, 5, 7 и 10 будет 3.
При симметричном распределении множества чисел все три значения центральной тенденции будут совпадать. При смещенном распределении множества чисел значения могут быть разными.
Примеры
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Представление результатов исследования
В научных публикациях важно представление результатов исследования. Очень часто окончательный результат приводится в следующем виде: M±m, где M – среднее арифметическое, m –ошибка среднего арифметического. Например, 163,7±0,9 см.
Прежде чем разбираться в правилах представления результатов исследования, давайте точно усвоим, что же такое ошибка среднего арифметического.
Ошибка среднего арифметического
Среднее арифметическое, вычисленное на основе выборочных данных (выборочное среднее), как правило, не совпадает с генеральным средним (средним арифметическим генеральной совокупности). Экспериментально проверить это утверждение невозможно, потому что нам неизвестно генеральное среднее. Но если из одной и той же генеральной совокупности брать повторные выборки и вычислять среднее арифметическое, то окажется, что для разных выборок среднее арифметическое будет разным.
Чтобы оценить, насколько выборочное среднее арифметическое отличается от генерального среднего, вычисляется ошибка среднего арифметического или ошибка репрезентативности.
Ошибка среднего арифметического обозначается как m или ![]()
Ошибка среднего арифметического рассчитывается по формуле:

где: S — стандартное отклонение, n – объем выборки; Например, если стандартное отклонение равно S=5 см, объем выборки n=36 человек, то ошибка среднего арифметического равна: m=5/6 = 0,833.
Ошибка среднего арифметического показывает, какая ошибка в среднем допускается, если использовать вместо генерального среднего выборочное среднее.
Так как при небольшом объеме выборки истинное значение генерального среднего не может быть определено сколь угодно точно, поэтому при вычислении выборочного среднего арифметического нет смысла оставлять большое число значащих цифр.
Правила записи результатов исследования
- В записи ошибки среднего арифметического оставляем две значащие цифры, если первые цифры в ошибке «1» или «2».
- В остальных случаях в записи ошибки среднего арифметического оставляем одну значащую цифру.
- В записи среднего арифметического положение последней значащей цифры должно соответствовать положению первой значащей цифры в записи ошибки среднего арифметического.
Представление результатов научных исследований
В своей статье «Осторожно, статистика!», опубликованной в 1989 году В.М. Зациорский указал, какие числовые характеристики должны быть представлены в публикации, чтобы она имела научную ценность. Он писал, что исследователь «…должен назвать: 1) среднюю величину (или другой так называемый показатель положения); 2) среднее квадратическое отклонение (или другой показатель рассеяния) и 3) число испытуемых. Без них его публикация научной ценности иметь не будет “с. 52
В научных публикациях в области физической культуры и спорта очень часто окончательный результат приводится в виде: (М±m) (табл.1).
Таблица 1 — Изменение механических свойств латеральной широкой мышцы бедра под воздействием физической нагрузки (n=34)
| Эффективный модуль
упругости (Е), кПа |
Эффективный модуль
вязкости (V), Па с |
|||
| Этап
эксперимента |
Рассл. | Напряж. | Рассл. | Напряж. |
| До ФН | 7,0±0,3 | 17,1±1,4 | 29,7±1,7 | 46±4 |
| После ФН | 7,7±0,3 | 18,7±1,4 | 30,9±2,0 | 53±6 |
Литература
- Высшая математика и математическая статистика: учебное пособие для вузов / Под общ. ред. Г. И. Попова. – М. Физическая культура, 2007.– 368 с.
- Гласс Дж., Стэнли Дж. Статистические методы в педагогике и психологии. М.: Прогресс. 1976.- 495 с.
- Зациорский В.М. Осторожно — статистика! // Теория и практика физической культуры, 1989.- №2.
- Катранов А.Г. Компьютерная обработка данных экспериментальных исследований: Учебное пособие/ А. Г. Катранов, А. В. Самсонова; СПб ГУФК им. П.Ф. Лесгафта. – СПб.: изд-во СПб ГУФК им. П.Ф. Лесгафта, 2005. – 131 с.
- Основы математической статистики: Учебное пособие для ин-тов физ. культ / Под ред. В.С. Иванова.– М.: Физкультура и спорт, 1990. 176 с.