
Стандартная ошибка измерения: определение и пример
17 авг. 2022 г.
читать 2 мин
Стандартная ошибка измерения , часто обозначаемая как SE m , оценивает отклонение от «истинного» показателя для индивидуума при повторных измерениях.
Он рассчитывается как:
SE m = s√ 1-R
куда:
- s: стандартное отклонение измерений
- R: коэффициент надежности теста.
Обратите внимание, что коэффициент надежности находится в диапазоне от 0 до 1 и рассчитывается путем двукратного проведения теста для многих людей и расчета корреляции между их результатами теста.
Чем выше коэффициент надежности, тем чаще тест дает стабильные результаты.
Пример: расчет стандартной ошибки измерения
Предположим, человек проходит определенный тест 10 раз в течение недели, целью которого является измерение общего интеллекта по шкале от 0 до 100. Он получает следующие баллы:
Очки: 88, 90, 91, 94, 86, 88, 84, 90, 90, 94.
Среднее значение выборки равно 89,5, а стандартное отклонение выборки равно 3,17.
Если известно, что тест имеет коэффициент надежности 0,88, то мы рассчитываем стандартную ошибку измерения как:
SE м = с√1 -R = 3,17√1-0,88 = 1,098
Как использовать SE m для создания доверительных интервалов
Используя стандартную ошибку измерения, мы можем создать доверительный интервал, который, вероятно, будет содержать «истинную» оценку человека по определенному тесту с определенной степенью достоверности.
Если человек получает по тесту оценку x , мы можем использовать следующие формулы для расчета различных доверительных интервалов для этой оценки:
- 68% доверительный интервал = [ x – SE m , x + SE m ]
- 95% доверительный интервал = [ x – 2*SE m , x + 2*SE m ]
- 99% доверительный интервал = [ x – 3*SE m , x + 3*SE m ]
Например, предположим, что человек набрал 92 балла по определенному тесту, который, как известно, имеет SE m 2,5. Мы могли бы рассчитать 95% доверительный интервал как:
- 95% доверительный интервал = [92 – 2*2,5, 92 + 2*2,5] = [87, 97]
Это означает, что мы на 95% уверены в том, что «истинный» результат этого теста человека находится между 87 и 97.
Надежность и стандартная ошибка измерения
Существует простая зависимость между коэффициентом надежности теста и стандартной ошибкой измерения:
- Чем выше коэффициент надежности, тем меньше стандартная ошибка измерения.
- Чем ниже коэффициент надежности, тем выше стандартная ошибка измерения.
Чтобы проиллюстрировать это, рассмотрим человека, который проходит тест 10 раз и имеет стандартное отклонение баллов, равное 2 .
Если тест имеет коэффициент надежности 0,9 , то стандартная ошибка измерения будет рассчитываться как:
- SE m = s√1 -R = 2√1-0,9 = 0,632
Однако, если тест имеет коэффициент надежности 0,5 , то стандартная ошибка измерения будет рассчитываться как:
- SE м = с√ 1-R = 2√ 1-,5 = 1,414
Это должно иметь смысл интуитивно: если результаты теста менее надежны, то ошибка измерения «истинного» результата будет выше.
Когда нам нужно получить одно число в качестве оценки параметра совокупности, мы используем точечную оценку. Тем не менее, из-за ошибки выборки, точечная оценка не будет в точности равняться параметру совокупности при любом размере данной выборки.
Часто, вместо точечной оценки, более полезным подходом будет найти диапазон значений, в рамках которого, как мы ожидаем, может находится значение искомого параметра с заданным уровнем вероятности.
Этот подход называется интервальной оценкой параметра (англ. ‘interval estimate of parameter’), а доверительный интервал выполняет роль этого диапазона значений.
Определение доверительного интервала.
Доверительный интервал (англ. ‘confidence interval’) представляет собой диапазон, для которого можно утверждать, с заданной вероятностью (1 — alpha ), называемой степенью доверия (или степенью уверенности, англ. ‘degree of confidence’), что он будет содержать оцениваемый параметр.
Этот интервал часто упоминается как (100 (1 — alpha)% ) доверительный интервал для параметра.
Конечные значения доверительного интервала называются нижним и верхним доверительными пределами (или доверительными границами или предельной погрешностью, англ. ‘lower/upper confidence limits’).
В этом чтении, мы имеем дело только с двусторонними доверительными интервалами — доверительные интервалами, для которых мы вычисляем и нижние и верхние пределы.
Кроме того, можно определить два типа односторонних доверительных интервалов для параметра совокупности.
Нижний односторонний доверительный интервал устанавливает только нижний предел. Это означает допущение, что с определенной степенью доверия параметр совокупности равен или превышает нижний предел.
Верхний односторонний доверительный интервал устанавливает только верхний предел. Это означает допущение, что с определенной степенью доверия параметр совокупности меньше или равен верхнему пределу.
Инвестиционные аналитики редко используют односторонние доверительные интервалы.
Доверительные интервалы часто дают либо вероятностную интерпретацию, либо практическую интерпретацию.
При вероятностной интерпретации, мы интерпретируем 95%-ный доверительный интервал для среднего значения совокупности следующим образом.
При повторяющейся выборке, 95% таких доверительных интервалов будут, в конечном счете, включать в себя среднее значение совокупности.
Например, предположим, что мы делаем выборку из совокупности 1000 раз, и на основании каждой выборки мы построим 95%-ный доверительный интервал, используя вычисленное выборочное среднее.
Из-за случайного характера выборок, эти доверительные интервалы отличаются друг от друга, но мы ожидаем, что 95% (или 950) этих интервалов включают неизвестное значение среднего по совокупности.
На практике мы обычно не делаем такие повторяющиеся выборки. Поэтому в практической интерпретации, мы утверждаем, что мы 95% уверены в том, что один 95%-ный доверительный интервал содержит среднее по совокупности.
Мы вправе сделать это заявление, потому что мы знаем, что 95% всех возможных доверительных интервалов, построенных аналогичным образом, будут содержать среднее по совокупности.
Доверительные интервалы, которые мы обсудим в этом чтении, имеют структуры, подобные описанной ниже базовой структуре.
Построение доверительных интервалов.
Доверительный интервал (100 (1 — alpha)% ) для параметра имеет следующую структуру.
Точечная оценка (pm) Фактор надежности (times) Стандартная ошибка
где
- Точечная оценка = точечная оценка параметра (значение выборочной статистики).
- Фактор надежности (англ. ‘reliability factor’) = коэффициент, основанный на предполагаемом распределении точечной оценки и степени доверия ((1 — alpha)) для доверительного интервала.
- Стандартная ошибка = стандартная ошибка выборочной статистики, значение которой получено с помощью точечной оценки.
Величину (Фактор надежности) (times) (Cтандартная ошибка) иногда называют точностью оценки (англ. ‘precision of estimator’). Большие значения этой величины подразумевают более низкую точность оценки параметра совокупности.
Самый базовый доверительный интервал для среднего значения по совокупности появляется тогда, когда мы делаем выборку из нормального распределения с известной дисперсией. Фактор надежности в данном случае на основан стандартном нормальном распределении, которое имеет среднее значение, равное 0 и дисперсию 1.
Стандартная нормальная случайная величина обычно обозначается как (Z). Обозначение (z_alpha ) обозначает такую точку стандартного нормального распределения, в которой (alpha) вероятности остается в правом хвосте.
Например, 0.05 или 5% возможных значений стандартной нормальной случайной величины больше, чем ( z_{0.05} = 1.65 ).
Предположим, что мы хотим построить 95%-ный доверительный интервал для среднего по совокупности, и для этой цели, мы сделали выборку размером 100 из нормально распределенной совокупности с известной дисперсией (sigma^2) = 400 (значит, (sigma) = 20).
Мы рассчитываем выборочное среднее как ( overline X = 25 ). Наша точечная оценка среднего по совокупности, таким образом, 25.
Если мы перемещаем 1.96 стандартных отклонений выше среднего значения нормального распределения, то 0.025 или 2.5% вероятности остается в правом хвосте. В силу симметрии нормального распределения, если мы перемещаем 1.96 стандартных отклонений ниже среднего, то 0.025 или 2.5% вероятности остается в левом хвосте.
В общей сложности, 0.05 или 5% вероятности лежит в двух хвостах и 0.95 или 95% вероятности лежит между ними.
Таким образом, ( z_{0.025} = 1.96) является фактором надежности для этого 95%-ного доверительного интервала. Обратите внимание на связь (100 (1 — alpha)% ) для доверительного интервала и (z_{alpha/2}) для фактора надежности.
Стандартная ошибка среднего значения выборки, заданная Формулой 1, равна:
( sigma_{overline X} = 20 Big / sqrt{100} = 2 )
Доверительный интервал, таким образом, имеет нижний предел:
( overline X — 1.96 sigma_{overline X} ) = 25 — 1.96(2) = 25 — 3.92 = 21.08.
Верхний предел доверительного интервала равен:
( overline X + 1.96sigma_{overline X} ) = 25 + 1.96(2) = 25 + 3.92 = 28.92
95%-ный доверительный интервал для среднего по совокупности охватывает значения от 21.08 до 28.92.
Доверительные интервалы для среднего по совокупности (нормально распределенная совокупность с известной дисперсией).
Доверительный интервал (100 (1 — alpha)% ) для среднего по совокупности ( mu ), когда мы делаем выборку из нормального распределения с известной дисперсией ( sigma^2 ) задается формулой:
( Large dst overline X pm z_{alpha /2}{sigma over sqrt n} ) (Формула 4)
Факторы надежности для наиболее часто используемых доверительных интервалов приведены ниже.
Факторы надежности для доверительных интервалов на основе стандартного нормального распределения.
Мы используем следующие факторы надежности при построении доверительных интервалов на основе стандартного нормального распределения:
- 90%-ные доверительные интервалы: используется (z_{0.05}) = 1.65
- 95%-ные доверительные интервалы: используется (z_{0.025}) = 1.96
- 99%-ные доверительные интервалы: используется (z_{0.005}) = 2.58
На практике, большинство финансовых аналитиков используют значения для (z_{0.05}) и (z_{0.005}), округленные до двух знаков после запятой.
Для справки, более точными значениями для (z_{0.05}) и (z_{0.005}) являются 1.645 и 2.575, соответственно.
Для быстрого расчета 95%-ного доверительного интервала (z_{0.025}) иногда округляют 1.96 до 2.
Эти факторы надежности подчеркивают важный факт о всех доверительных интервалах. По мере того, как мы повышаем степень доверия, доверительный интервал становится все шире и дает нам менее точную информацию о величине, которую мы хотим оценить.
«Чем уверенней мы хотим быть, тем меньше мы должны быть уверены»
см. Freund и Williams (1977), стр. 266.
На практике, допущение о том, что выборочное распределение выборочного среднего, по меньшей мере, приблизительно нормальное, часто является обоснованным, либо потому, что исходное распределение приблизительно нормальное, либо потому что мы имеем большую выборку и поэтому к ней применима центральная предельная теорема.
Однако, на практике, мы редко знаем дисперсию совокупности. Когда дисперсия генеральной совокупности неизвестна, но выборочное среднее, по меньшей мере, приблизительно нормально распределено, у нас есть два приемлемых пути чтобы вычислить доверительные интервалы для среднего значения совокупности.
Вскоре мы обсудим более консервативный подход, который основан на t-распределении Стьюдента (t-распределение, для краткости).
Распределение статистики (t) называется t-распределением Стьюдента (англ. «Student’s t-distribution») из-за псевдонима «Студент» (Student), использованного британским математиком Уильямом Сили Госсеттом, который опубликовал свою работу в 1908 году.
В финансовой литературе, это наиболее часто используемый подход для статистической оценки и проверки статистических гипотез, касающихся среднего значения, когда дисперсия генеральной совокупности не известна, как для малого, так и для большого размер выборки.
Второй подход к доверительным интервалам для среднего по совокупности, основанного на стандартном нормальном распределении, — это z-альтернатива (англ. ‘z-alternative’). Он может быть использован только тогда, когда размер выборки является большим (в общем случае, размер выборки 30 или больше, можно считать большим).
В отличии от доверительного интервала, приведенного в Формуле 4, этот доверительный интервал использует стандартное отклонение выборки (s) при вычислении стандартной ошибки выборочного среднего (по Формуле 2).
Доверительные интервалы для среднего по совокупности — z-альтернатива (большая выборка, дисперсия совокупности неизвестна).
Доверительный интервал (100 (1 — alpha)% ) для среднего по совокупности ( mu ) при выборке из любого распределения с неизвестной дисперсией, когда размер выборки большой, задается формулой:
( Large dst overline X pm z_{alpha /2}{s over sqrt n} ) (Формула 5)
Поскольку этот тип доверительного интервала применяется довольно часто, мы проиллюстрируем его вычисление в Примере 4.
Пример (4) расчета доверительного интервала для среднего по совокупности коэффициентов Шарпа с использованием z-статистики.
Предположим, что инвестиционный аналитик делает случайную выборку акций взаимных фондов США и рассчитывает средний коэффициент Шарпа.
[см. также: CFA — Коэффициент Шарпа]
Размер выборки равен 100, а средний коэффициент Шарпа составляет 0.45. Выборка имеет стандартное отклонение 0.30.
Рассчитайте и интерпретируйте 90-процентный доверительный интервал для среднего по совокупности всех акций взаимных фондов США с использованием фактора надежности на основе стандартного нормального распределения.
Фактор надежности для 90-процентного доверительного интервала, как указано ранее, составляет ( z_{0.05} = 1.65 ).
Доверительный интервал будет равен:
( begin{aligned} & overline X pm z_{0.05}{s over sqrt n } \ &= 0.45 pm 1.65{0.30 over sqrt {100}} \ &= 0.45 pm 1.65(0.03) = 0.45 pm 0.0495 end{aligned} )
Доверительный интервал охватывает значения 0.4005 до 0.4995, или от 0.40 до 0.50, с округлением до двух знаков после запятой. Аналитик может сказать с 90-процентной уверенностью, что интервал включает среднее по совокупности.
В этом примере аналитик не делает никаких конкретных предположений о распределении вероятностей, характеризующем совокупность. Скорее всего, аналитик опирается на центральную предельную теорему для получения приближенного нормального распределения для выборочного среднего.
Как показывает Пример 4, даже если мы не уверены в характере распределения совокупности, мы все еще можем построить доверительные интервалы для среднего по совокупности, если размер выборки достаточно большой, поскольку можем применить центральную предельную теорему.
Концепция степеней свободы.
Обратимся теперь к консервативной альтернативе и используем t-распределение Стьюдента, чтобы построить доверительные интервалы для среднего по совокупности, когда дисперсия генеральной совокупности не известна.
Для доверительных интервалов на основе выборок из нормально распределенных совокупностей с неизвестной дисперсией, теоретически правильный фактор надежности основан на t-распределении. Использование фактора надежности, основанного на t-распределении, имеет важное значение для выборок небольшого размера.
Применение фактора надежности (t) уместно, когда дисперсия генеральной совокупности неизвестна, даже если у нас есть большая выборка и мы можем использовать центральную предельную теорему для обоснования использования фактора надежности (z). В этом случае большой выборки, t-распределение обеспечивает более консервативные (широкие) доверительные интервалы.
t-распределение является симметричным распределением вероятностей и определяется одним параметром, известным как степени свободы (DF, от англ. ‘degrees of freedom’). Каждое значение для числа степеней свободы определяет одно распределение в этом семействе распределений.
Далее мы сравним t-распределения со стандартным нормальным распределением, но сначала мы должны понять концепцию степеней свободы. Мы можем сделать это путем изучения расчета выборочной дисперсии.
Формула 3 дает несмещенную оценку выборочной дисперсии, которую мы используем. Выражение в знаменателе, ( n — 1 ), означающее размер выборки минус 1, это число степеней свободы при расчете дисперсии совокупности с использованием Формулы 3.
Мы также используем ( n — 1 ) как число степеней свободы для определения факторов надежности на основе распределения Стьюдента. Термин «степени свободы» используются, так как мы предполагаем, что в случайной выборке наблюдения отобраны независимо друг от друга. Числитель выборочной дисперсии, однако, использует выборочное среднее.
Каким образом использование выборочного среднего влияет на количество наблюдений, отобранных независимо, для формулы выборочной дисперсии?
При выборке размера 10 и среднем значении в 10%, к примеру, мы можем свободно отобрать только 9 наблюдений. Независимо от отобранных 9 наблюдений, мы всегда можем найти значение для 10-го наблюдения, которое дает среднее значение, равное 10%. С точки зрения формулы выборочной дисперсии, здесь есть 9 степеней свободы.
Учитывая, что мы должны сначала вычислить выборочное среднее от общего числа (n) независимых наблюдений, только (n — 1) наблюдений могут быть отобраны независимо друг от друга для расчета выборочной дисперсии.
Концепция степеней свободы часто применяется в финансовой статистике, и вы встретите ее в последующих чтениях.
t-распределение Стьюдента.
Предположим, что мы делаем выборку из нормального распределения.
Коэффициент (z = (overline X — mu) Big / (sigma big / sqrt n) ) нормально распределен со средним значением 0 и стандартным отклонением 1, однако, коэффициент (t = (overline X — mu) Big / (s big / sqrt n) ) следует t-распределению со средним 0 и (n — 1) степеней свободы.
Коэффициент (t) не является нормальным, поскольку представляет собой отношение двух случайных величин, выборочного среднего и стандартного отклонения выборки.
Определение стандартной нормальной случайной величины включает в себя только одну случайную величину, выборочное среднее. По мере увеличения степеней свободы, однако, t-распределение приближается к стандартному нормальному распределению.
На Рисунке 1 показано стандартное нормальное распределение и два t-распределения, одно с DF = 2 и одно с DF = 8.
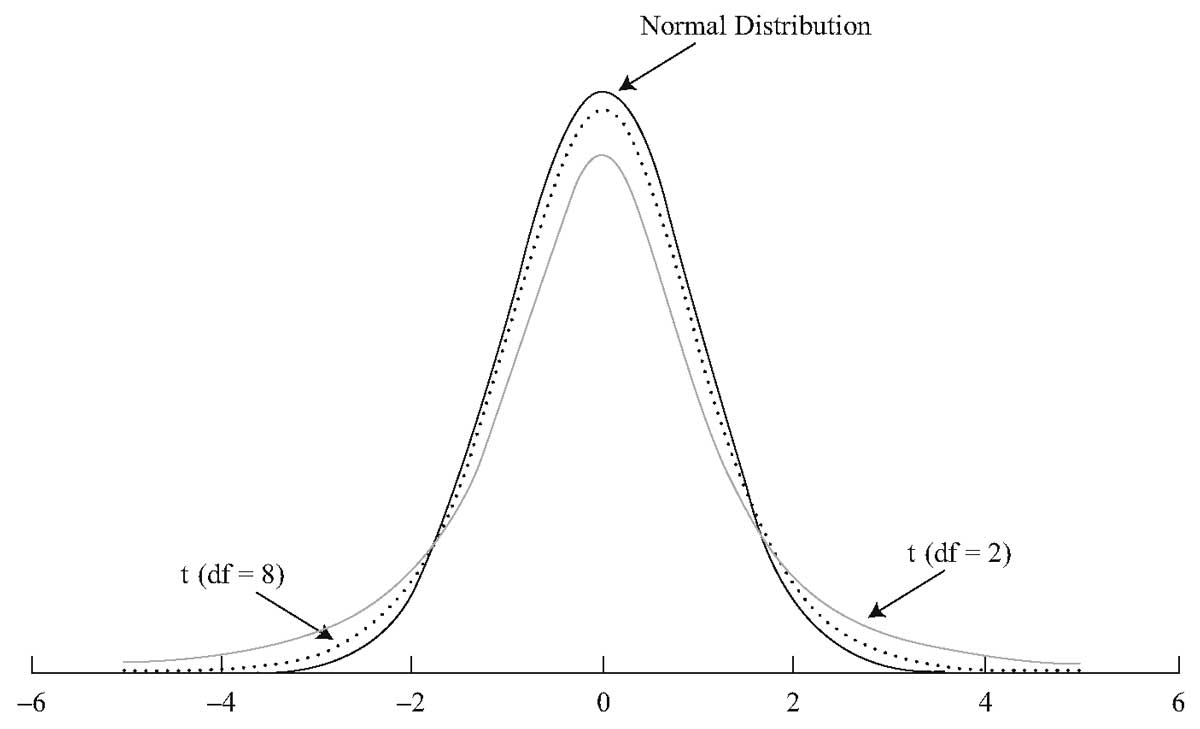 Рисунок (1) t-распределение Стьюдента по сравнению со стандартным нормальным распределением.
Рисунок (1) t-распределение Стьюдента по сравнению со стандартным нормальным распределением.
Из трех распределений, показанных на Рисунке 1, стандартное нормальное распределение имеет хвосты, которые стремятся к нулю быстрее, чем хвосты двух t-распределений. t-распределение симметрично распределено вокруг среднего нулевого значения, так же как и нормальное распределение.
По мере увеличения степеней свободы, t-распределение приближается к стандартному нормальному распределению. t-распределение с DF = 8 ближе к стандартному нормальному, чем t-распределение с DF = 2.
Помимо области плюс и минус четырех стандартных отклонений от среднего значения, остальная область под стандартным нормальным распределением, как представляется, близка к 0. Однако, оба t-распределения содержать некоторую площадь под каждой кривой за пределом четырех стандартных отклонений.
t-распределения имеют более толстые хвосты, но хвосты t-распределения Стьюдента с DF = 8 сильнее напоминают хвосты нормального распределения. По мере увеличения степеней свободы, хвосты распределения Стьюдента становятся менее толстыми.
Для часто используемых значений распределения Стьюдента составлены таблицы. Например, для каждой степени свободы (t_{0.10}), (t_{0.05}), (t_{0.025}), (t_{0.01}) и (t_{0.005}) значения будут такими, что соответственно, 0.10, 0.05, 0.025, 0.01 и 0.005 вероятности останется в правом хвосте для заданного числа степеней свободы.
Значения (t_{0.10}), (t_{0.05}), (t_{0.025}), (t_{0.01}) и (t_{0.005}) также называют односторонними критическими значениями t на значимых уровнях 0.10, 0.05, 0.025, 0.01 и 0.005, для указанного числа степеней свободы.
Например,
для DF = 30,
(t_{0.10}) = 1.310,
(t_{0.05}) = 1.697,
(t_{0.025}) = 2.042,
(t_{0.01}) = 2.457,
(t_{0.005}) = 2.750.
Приведем форму доверительных интервалов для среднего по совокупности, используя распределение Стьюдента.
Доверительные интервалы для среднего по совокупности (дисперсия совокупности неизвестна) — t-распределение.
Если мы делаем выборку из генеральной совокупности с неизвестной дисперсией и соблюдается одно из перечисленных ниже условий:
- выборка является большой, или
- выборка небольшая, но совокупность имеет нормальное распределение, или приблизительно нормально распределена,
то доверительный интервал (100 (1 — alpha)% ) для среднего совокупности ( mu ) задается формулой:
( Large dst overline X pm t_{alpha /2}{s over sqrt n} ) (Формула 6)
где число степеней свободы для ( t_{alpha /2}) равно ( n-1 ), а ( n ) — это размер выборки.
Пример 5 использует данные Примера 4, но применяет t-статистику, а не z-статистику, чтобы рассчитать доверительный интервал для среднего значения совокупности коэффициентов Шарпа.
Пример (5) расчета доверительного интервала для среднего по совокупности коэффициентов Шарпа с использованием t-статистики.
Как и в Примере 4, инвестиционный аналитик стремится вычислить 90-процентный доверительный интервал для среднего по совокупности коэффициентов Шарпа, основанных на случайной выборке из 100 взаимных фондов США.
Выборочное среднее коэффициентов Шарпа составляет 0.45, а выборочное стандартное отклонение — 0.30.
Теперь, признав, что дисперсия генеральной совокупности распределения коэффициентов Шарпа неизвестна, аналитик решает вычислить доверительный интервал, используя теоретически правильную t-статистику.
Поскольку размер выборки равен 100, DF = 99. Используя таблицу степеней свободы, мы находим, что (t_{0.05}) = 1.66.
Этот фактор надежности немного больше, чем фактор надежности (z_{0.05}) = 1.65, который был использован в Примере 4.
Доверительный интервал будет:
( begin{aligned} & overline X pm t_{0.05}{s over sqrt n } \ &= 0.45 pm 1.66{0.30 over sqrt {100}} \ &= 0.45 pm 1.66(0.03) = 0.45 pm 0.0498 end{aligned} )
Доверительный интервал охватывает значения 0.4002 до 0.4998, или 0.40 до 0.50, с двумя знаками после запятой. При округлении до двух знаков после запятой, доверительный интервал не изменился по сравнению с Примером 4.
В Таблице 3 приведены различные факторы надежности, которые мы использовали.
|
Выборка из: |
Статистика для выборки малого размера |
Статистика для выборки большого размера |
|---|---|---|
|
Нормальное распределение с известной дисперсией |
(z) |
(z) |
|
Нормальное распределение с неизвестной дисперсией |
(t) |
(t)* |
|
Ненормальное распределение с известной дисперсией |
недоступно |
(z) |
|
Ненормальное распределение с неизвестной дисперсией |
недоступно |
(t)* |
* Использование (z) также приемлемо.
Стандартное
отклонение для оценки обозначается Se
и рассчитывается по формуле
среднеквадратичного отклонения:
![]() .
.
Величина стандартного
отклонения характеризует точность
прогноза.
Вариант
5. Возвращаясь к данным нашего примера,
рассчитаем значение Se:
![]()
Предположим,
необходимо оценить значение Y для
конкретного значения независимой
переменной, например, спрогнозировать
объем продаж при затратах на рекламу в
объеме 10 тыс. долл. Обычно при этом также
требуется оценить степень достоверности
результата, одним из показателей которого
является доверительный интервал для
Y.
Граница доверительного
интервала для Y при заданной величине
X рассчитывается следующим образом:

где
Хp
– выбранное значение независимой
переменной, на основе которого выполняется
прогноз. Обратите внимание: t – это
критическое значение текущего уровня
значимости. Например, для уровня
значимости, равного 0,025 (что соответствует
уровню доверительности двухстороннего
критерия, равному 95%) и числа степеней
свободы, равного 10, критическое значение
t равно 2, 228 (см. Приложение II). Как можно
увидеть, доверительный интервал – это
интервал, ограниченный с двух сторон
граничными значениями предсказания
(зависимой переменной).
Вариант
6. Для нашего примера расходов на рекламу
в размере 10 тыс. долл. интервал предсказания
зависимой переменной (объема продаж) с
уровнем доверительности в 95% находится
в пределах [10,5951; 21,8361]. Его границы
определяются следующим образом (обратите
внимание, что в Варианте 2 Y’=16,2156):

Из приведенного
расчета имеем: для заданных расходов
на рекламу в объеме 10 тыс. долл., объем
продаж изменяется в диапазоне от 10,5951
до 21,8361 тыс. долл. При этом:
10,5951=16,2156-5,6205 и 21,8361=16,2156+5,6205.
3. Стандартное отклонение для коэффициента регрессии Sb и t-статистика
Значения
стандартного отклонения для коэффициентов
регрессии Sb
и значение статистики тесно взаимосвязаны.
Sb
рассчитываются как
![]()
Или в сокращенной
форме:
![]()
Sb
задает интервал, в который попадают.
Все возможные значения коэффициента
регрессии. t-статистика
(или t-значение)
– мера статистической значимости
влияния независимой переменной Х на
зависимую переменную Y
определяется путем деления оценки
коэффициента b
на его стандартное отклонение Sb.
Полученное значение затем сравнивается
с табличным (см. табл. В Приложении II).
Таким
образом, t-статистика
показывает, насколько велики величина
стандартного отклонения для коэффициента
регрессии (насколько оно больше нуля).
Практика показывает, что любое t-значение,
не принадлежащее интервалу [-2;2], является
приемлемым. Чем выше t-значение,
тем выше достоверность коэффициента
(т.е. точнее прогноз на его основе). Низкое
t-значение
свидетельствует о низкой прогнозирующей
силе коэффициента регрессии.
Вариант
7. Sb
для нашего примера равно:
![]()
t-статистика
определяется:
![]()
Так
как t=3,94>2,
можно заключить,
что
коэффициент
b
является
статистически
значимым.
Как
отмечалось раньше,
табличное
критическое
значение (уровень отсечения)
для 10 степеней свободы равно
2,228
(см.
табл.
в
Приложении
11).
Обратите
внимание:
—
t-значения
играют большую
роль для коэффициентов
множественной регрессии
(множественная
модель описывается
с помощью
нескольких
коэффициентов
b);
—
R2
характеризует
общее согласие (всего
«леса»
невязок
на
диаграмме
разброса),
в
то время как
t-значение
характеризует
отдельную
независимую переменную
(отдельное
«дерево»
невязок).
В
общем случае
табличное
t-значение
для
заданных
числа
степеней свободы и уровня
значимости используется,
чтобы:
—
установить
диапазон
предсказания:
верхнюю
и нижнюю границы
для прогнозируемого
значения при заданном значении
независимой
переменной;
-установить
доверительные
интервалы
для
коэффициентов
регрессии;
—
определить
уровень
отсечения
для t-теста.
РЕГРЕССИОННЫЙ
АНАЛИЗ С ПРИМЕНЕНИЕМ ЭЛЕКТРОННЫХ ТАБЛИЦ
MS EXCEL
Электронные
таблицы,
такие
как Excel,
имеют
встроенную
процедуру
регрессионного
анализа,
легкую
в
применении.
Регрессионный
анализ
с помощью
MS Ехсеl
требует
выполнения
следующих
действий:
—
выберите
пункт
меню
«Сервис
— Надстройки»;
—
в
появившемся
окне отметьте
галочкой
надстройку
Analysis
ToolPak
–
VBA нажмите
кнопку
ОК.
Если
в списке Analysis
ToolPak
—
VВА
отсутствует,
выйдите
из MS Ехсеl
и добавьте эту надстройку,
воспользовавшись
программой
установки Мiсrosоft
Office.
Затем
запустите Ехсеl
снова
и повторите
эти действия.
Убедившись,
что
надстройка
Analysis
ToolPak
—
VВА
доступна,
запустите
инструмент
регрессионного
анализа,
выполнив
следующие
действия:
—
выберите
пункт меню «Сервис
—
Анализ»
данных;
—
в появившемся окне выберите
пункт
«Регрессия»
и
нажмите
кнопку
ОК.
На
рисунке 16.3
показано окно ввода данных для
регрессионного
анализа.

Рисунок 16.3 – Окно
ввода данных для регрессионного анализа
Таблица
16.2
показывает
выходной
результат
регрессии,
содержащий
описанные
выше статистические
данные.
Примечание:
для
того чтобы получить
поточечный
график
(ХY график),
используйте
«Мастер
Диаграмм»
MS
Excel.
Получаем:
Y’
= 10,5386
+ 0,563197
Х (d
виде
Y’
=
а
+
bХ)
с R2=0,608373=60,84%.
Все
полученные
данные
ответствуют
данным,
рассчитанным
вручную.
Таблица 16.2 –
Результаты регрессионного анализа
в
электронных таблицах MS
Excel
|
Вывод |
||||||
|
Регрессионная |
||||||
|
Множественный |
0,7800 |
|||||
|
R-квадрат |
0,6084 |
|||||
|
Нормированный |
0,5692 |
|||||
|
Стандартная |
2,3436 |
|||||
|
Наблюдения |
12 |
|||||
|
Дисперсионный |
||||||
|
df |
SS |
MS |
F |
Значимость |
||
|
Регрессия |
1 |
85,3243 |
85,3243 |
15,5345 |
0,0028 |
|
|
Остаток |
10 |
54,9257 |
5,4926 |
|||
|
Итого |
11 |
140,2500 |
||||
|
Коэффи-циенты |
Стандарт-ная |
t-статистика |
Р- |
Нижние |
Верхние |
|
|
Свободный |
10,5836 |
2,1796 |
4,8558 |
0,0007 |
5,7272 |
15,4401 |
|
Линейный |
0,563197 |
0,1429 |
3,9414 |
0,0028 |
0,2448 |
0,8816 |
|
*Р |
Таблица
16.3 показывает выходной результат
регрессии, полученный с применением
популярного программного обеспечения
Minitab
для статистического анализа.
Таблица
16.3 – Результаты регрессионного анализа
Minitab
|
Анализ регрессии
Уравнение FO=10,6+0,563DLH |
|||||
|
Прогнозируемые |
Коэффициент |
Стандартное |
t-значение |
P |
|
|
Константа |
10,584 |
2,180 |
4,86 |
0,000 |
|
|
DLH |
0,5632 |
0,1429 |
3,94 |
0,003 |
|
|
s=2,344 |
R-квадрат=60,8% |
R-квадрат |
|||
|
Анализ |
|||||
|
Показатель |
DF |
SS |
MS |
F |
P |
|
Регрессия |
1 |
85,324 |
85,324 |
15,53 |
0,003 |
|
Отклонение |
10 |
54,926 |
5,493 |
||
|
Итого |
11 |
140,250 |
ВЫВОДЫ
C
помощью регрессионного анализа
устанавливается
зависимость
между
изменениями
независимых
переменных
и
значениями зависимой
переменной.
Регрессионный
анализ
— популярный
метод для прогнозирования
продаж.
В
этой
главе обсуждался
широко
распространенный
способ
оценки значений,
так
называемый
метод
наименьших
квадратов.
Метод
наименьших
квадратов
рассматривался
применительно
к
модели
простой
регрессии
Y
=
а
+ bх.
Обсуждались
различные
статистические
коэффициенты,
характеризующие
добротность
и надежность
уравнения
(согласие
модели)
и помогающие установить
доверительный
интервал.
Показано
применение
электронных
таблиц MS Ехсеl для
проведения
регрессионного
анализа
шаг за шагом.
С
помощью электронных
таблиц
можно не только составить
уравнение
регрессии,
но
и рассчитать статистические
коэффициенты.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Понимание центральной предельной теоремы, стандартной ошибки и доверительных интервалов
Перевод
Ссылка на автора
В этом посте мы создадим интуитивное понимание описательной статистики, включая среднее и стандартное отклонение, а также выводной статистики, включая стандартную ошибку среднего и доверительные интервалы. Мы также разработаем понимание центральной предельной теоремы в этом процессе. Код R, используемый для генерации примеров в этом посте, доступен Вот,
Давайте начнем наше путешествие, предположив, что у нас есть N = 10 000 учеников в стране, которые изучали физику в своем первом классе. Мы отметили оценки, которые они получили, из 100, после их финального экзамена, и гистограмма (с интервалами 10) этих отметок показана на рисунке 1. Эта гистограмма отражает распределение населения.

Теперь мы можем рассчитать среднее значение по населению (μ) и стандартное отклонение (σ), используя следующие формулы:

где xᵢ представляет оценки, набранные iᵗʰ учеником, а N — общее количество студентов по всей стране. Для распределения населения, показанного на рисунке 1, μ = 71,52 и σ = 16,15. Они оба являются описательной статистикой, потому что они описывают некоторые особенности данных в руке. Среднее значение представляет центральность данных (центр — это медиана), а стандартное отклонение показывает, насколько каждая точка отличается от среднего значения в среднем смысле. Маленькое σ означает, что значения в наборе данных в среднем близки к среднему значению данных, а большое σ означает, что значения в наборе данных находятся в среднем дальше от среднего значения. Мы можем видеть, что у нашего распределения населения более длинный хвост слева по сравнению с правым, и такие распределения известны как левый перекос.
Следует отметить, что наше распределение населения требует данных от всех студентов по всей стране. Это требование практически очень трудно выполнить, и мы обычно не имеем доступа к распределению населения (и соответствующей описательной статистике: μ и σ). В таких ситуациях мы прибегаем к случайной выборкеделать выводописательная статистика основного распределения населения из описательной статистики выборочного распределения — давайте поймем это!
Случайная выборка означает, что вместо сбора данных от всех учащихся, то есть всего населения, мы случайным образом выбираем несколько репрезентативных студентов по всей стране для проведения нашего анализа. Давайте предположим, что в нашей первой попытке случайной выборки s1 мы отобрали не более 50 репрезентативных студентов по всей стране и записали их оценки. Давайте обозначим описательную статистику для s₁ как µ₁ и σ₁, а также обозначим наше первое событие случайной выборки как s₁: n₁, µ₁, σ₁. Следуя этой записи и процедуре случайной выборки, мы можем случайным образом выбрать несколько групп репрезентативных студентов из нашего распределения населения. Помните, что распределение населения включает всех учащихся по всей стране, а выборочное распределение содержит только 50 случайно выбранных студентов — каждое выборочное распределение является подмножеством распределения населения.
Как описательная статистика наших выборочных распределений соотносится с описательной статистикой нашего распределения населения? Ответ даетсяЦентральная предельная теоремакоторый простыми словами утверждает, что —
Для независимые случайные величины распределение средних выборочных распределений стремится к нормальному распределению (неофициальнокривая колокола»), Независимо от формы распределения населения.
Теперь давайте применим эту теорему к нашему примеру и посмотрим, что мы можем понять с помощью этого упражнения. Случайные переменные в нашем случае — это оценки, полученные каждым учеником, и они действительно являются независимыми случайными переменными, потому что оценки, набранные одним студентом, не зависят от оценок, выставленных другим. Далее, скажем, мы получаем r = 20 случайных выборок, каждая с n = 50 студентами, из нашего распределения населения, и эти распределения выборок можно записать как:

здесь n₁ = n₂ =… nᵣ = 50 и r = 20. Среднее из 20 выборочных средних можно вычислить следующим образом:

Давайте теперь наметим средства из наших 20 примеров дистрибутивов и посмотрим, как выглядит их распределение. Из рисунка 2 видно, что распределение действительно выглядит как кривая колокола, независимо от формы нашего распределения населения (которое фактически является бета-распределением, см. Код для деталей).

Нормальность распределения средних значений для образца намного выше, если мы получим (r =) 80 случайных выборок (каждая размером n = 50) вместо (r =) 20, как показано на рисунке 3. Среднее значение 80 выборочных средних можно рассчитать следующим образом:


Из рисунка 2 и рисунка 3 также видно, что среднее значение выборки означает приближение к среднему значению населенности, когда мы рисуем больше случайных выборок. Обратите внимание, что только при r * n = 80 * 50 = 4000 баллов по студентам мы можем получить достаточно точную оценку (μ₈₀means = 71,66) среднего значения по совокупности (μ = 71,52) N = 10000 баллов по студентам. Это означает, что если у нас есть достаточное количество случайных выборок, тогда нам фактически не нужно полное распределение населения для нашего анализа.
В. Должны ли мы использовать несколько случайных выборок, каждая с меньшим числом наблюдений, или одну случайную выборку с большим количеством наблюдений для реальной задачи анализа данных?
Мы только что увидели, что, используя 80 случайных выборок, каждая из которых имеет 50 наблюдений (баллов по студентам), мы можем приблизить среднее значение основного распределения населения. Однако на практике мы обычно работаем с одной случайной выборкой, содержащей достаточно большое количество (n) точек данных (баллов студентов), так что n ≪ N, здесь n представляет количество студентов в нашей случайной выборке, а N представляет всю совокупность студентов по всей стране.
Теперь мы будем работать с одной случайной выборкой, содержащей n студентов, и обозначим стандартное отклонение и среднее значение этой случайной выборки как s и μₑ (e как в оценке), соответственно. На рисунке 4 показано, что принципы центральной предельной теоремы все еще остаются в силе — для n = 4000 распределение нашей случайной выборки имеет форму колокола, и его среднее значение µₑ = 71,58 является хорошей оценкой среднего числа населения (µ = 71,52).


Важно отметить, что оба, µₑ и s, сами являются случайными переменными, потому что их значения зависят от стратегии, используемой для случайной выборки.
Выведенный статистика
Вышеупомянутые наблюдения имеют большое значение для анализа данных, потому что мы обычно не имеем доступа ко всему населению, и поэтому описательная статистика распределения населения обычно неизвестна. В таких ситуациях центральная предельная теорема дает нам возможность проводить анализ данных со случайно выбранными точками данных иточность такого анализаможет быть определен количественно с помощьювыведенный статистикавключая стандартную ошибку среднего и доверительных интервалов, которые обсуждаются далее. Эти статистические данные являются выводными, потому что мы используем распределения случайной выборки, чтобы вывести характеристики основного распределения населения.
Стандартная ошибка среднего (SEM): Из центральной предельной теоремы мы знаем, что наше выборочное распределение нормально со средним значением = μₑ. Но μₑ сама по себе является случайной величиной, поскольку она зависит от выбора наших случайных выборок. Другими словами, любое изменение в нашем распределении выборок изменяет наш μₑ. Стандартная ошибка среднего просто количественно определяет это изменение, вычисляя стандартное отклонение нашей оценки, µₑ, среднего значения популяции (µ). Формально это можно вычислить следующим образом:

Взяв квадратный корень с обеих сторон вышеприведенного уравнения, мы получим требуемую стандартную ошибку среднего:

Обратите внимание, что мы можем использовать одну случайную выборку с достаточным размером выборки (n), чтобы вычислить стандартную оценку ошибки среднего значения по совокупности. Если у нас достаточно большое n, мы можем получить почти нулевую стандартную ошибку. Это означает, что если мы имеем большую случайную выборку точек данных, то среднее распределение нашей выборки точно приближает среднее значение лежащего в основе неизвестного распределения населения. Таким образом, более высокое n часто желательно в различных задачах машинного обучения и статистических данных для лучшей обобщения.
Доверительные интервалы:Доверительный интервал — это интервал вокруг расчетного среднего значения (μₑ), который может включать неизвестное среднее значение по совокупности (μ). Давайте разберемся в этом — мы хотим оценить среднее значение µ основного распределения населения, и у нас есть доступ к случайной выборке, содержащей n наблюдений со стандартным отклонением s и средним значением µ understand. Доверительные интервалы построены науровень доверия, например, 95%, выбранный пользователем. Уровень достоверности описывает неопределенность, связанную сметод отбора проб, Предположим, что мы использовали один и тот же метод выборки, чтобы выбрать несколько случайных выборок и рассчитать доверительные интервалы, используя μₑ каждой случайной выборки. Естественно, у нас будет несколько доверительных интервалов (один вокруг каждого μₑ). Некоторые из этих интервальных оценок будут включать среднее значение, μ, а некоторые не будут Уровень достоверности 95% означает, что мы ожидаем, что 95% интервальных оценок будут включать среднее значение по населению. Обычно мы работаем только с одной случайной выборкой, содержащей большое количество точек данных, и в этом случае у нас есть только одна оценка доверительного интервала, которая может быть рассчитана следующим образом для уровня достоверности 95%:

Обратите внимание, что член после знака плюс-минус в правой части вышеприведенного уравнения количественно определяет неопределенность в оценке среднего значения для населения (μ) в терминах среднего значения для выборки (μₑ). 1.96 умножается на стандартную ошибку среднего, потому что для стандартного нормального распределения N (0,1) 95% данных находятся в пределах 1,96 стандартных отклонений от среднего значения, как показано на рисунке 5.

Иногда 1,96 округляется до 2 для целей расчета. Наконец, более высокая стандартная ошибка приводит к более широкому доверительному интервалу, который указывает на то, что среднее значение μₑ нашей случайной выборки не является хорошим приближением к среднему значению μ основного распределения населения.
2.1. Стандартное отклонение среднего выборочного значения (ошибка среднего) и доверительный интервал
Результаты измерений обычно показывают с так называемой «средней статистической ошибкой средней величины» и для нашего случая (см. табл. 1.1) это будет запись: «высота сеянцев в опыте составила 5,0 ± 0,28 см». Словосочетание «средняя статистическая ошибка» обычно сокращают до названия «ошибка среднего» или просто «ошибка», обозначают буквой m и определяют по очень простой формуле. Для итогов упомянутой таблицы, где расчеты по 25 высотам дали значение δ = 1,42 см, эта ошибка составит:
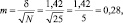 (2.1)
(2.1)
|
где δ – |
стандартное отклонение; |
|
N – |
число наблюдений или объем выборки, шт. |
Если объем выборки взять 100 шт., то ошибка снизится в 2 раза: 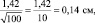 а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
а если увеличить до 10000 шт., то в 10 раз, до 0,014 см.
Рассмотрим эту «среднюю статистическую ошибку» (далее просто ошибка) подробно, так как именно в ней скрыто понимание того, что называют статистическим мышлением. Интуитивно мы понимаем, что малая выборка дает большую ошибку, т.е. неточное определение среднего значения. Последний термин настолько привычен, что мы даже не задумываемся о том, что его правильное и полное название «среднее выборочное значение», т.е. среднее, определяемое в некоторой выборке. И выборки могут быть очень разные по численности. Начнем с самых малых. Например, что произойдет с ошибкой, если объем выборки сократить до 2 измерений? Такие выборки бывают, например, в почвенных исследованиях, когда каждое измерение достается дорогой ценой. Для этого вернемся к рис. 1.1. На нем стандартное отклонение ±δ, которое отражает разброс значений вокруг среднего в левую и правую сторону в виде холма, наблюдается при объеме выборки 1 шт. В этом случае ошибка среднего выборочного значения будет равна стандартному отклонению: m = δ = 1,42. С увеличением N ошибка уменьшается:
при объеме выборки N = 2 ошибка будет
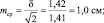
при объеме выборки N = 4 ошибка будет
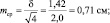
при объеме выборки N = 16 ошибка будет
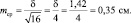
Важно понять, что ряд распределения частот этих выборочных средних будет постепенно как бы съеживаться и приближаться к центру, где находится так называемое «генеральное» среднее. Поясним, что в математике генеральное среднее значение называется математическим ожиданием и его обозначают буквой «М». Например, это может быть средняя высота, рассчитанная по всем измеренным в теплице сеянцам, или среднее число семян в 1 шишке у дерева после подсчета семян во всех собранных с дерева шишках (50, 100, 500 и т.д., т.е. весьма небольшая генеральная совокупность). Распределение частот значений выборочных средних, которых может быть множество, будет иметь форму такого же холма, как и распределение единичных значений на рис. 1.1. При этом, если выборка будет из 1 шт., то холм будет в точности таким же, но при выборках из 2 шт. его форма съежится в 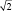 = в 1,41 раза; при выборках из 4 шт. –
= в 1,41 раза; при выборках из 4 шт. –
в 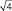 = в 2 раза; при выборках из 9 шт. – в
= в 2 раза; при выборках из 9 шт. – в 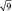 = в 3 раза и т.д.
= в 3 раза и т.д.
Для этих сокращающихся рядов распределения выборочных средних можно рассчитать свое, особое стандартное отклонение. Вероятно, чтобы не путать его со СТАНДОТКЛ, его стали называть по-другому, т.е. «средней статистической ошибкой средней величины». Чем больше по объему выборки, тем короче ряд распределения средних значений этих выборок с его «хвостами» в левую и правую сторону, и тем меньше величина этого особого стандартного отклонения. Закон распределения частот выборочных средних точно такой же, и имеет те же свойства: в пределах ±2m находится 95 % всех значений выборочных средних, в пределах ±3m – 99,5 %, а в пределах ±4m находится 100 % всех значений xср. Форма этого распределения меняется от пологой при малых выборках до очень крутой, вплоть до «схлопывания» в центре при выборках большого объема, когда ошибка среднего стремится к нулю.
Здесь следует пояснить, что, на наш взгляд, словосочетание «средняя статистическая ошибка средней величины», сокращаемое до «ошибки среднего значения» или просто до «ошибки», вводит нас в некоторое заблуждение, так как мы привыкли со школы, что ошибки надобно исправлять. Более правильным, вместо слов «ошибка среднего значения», будет использование слов «стандартное отклонение выборочных средних значений от генерального среднего». Не случайно математики выбрали для обозначения величины этого отклонения букву «m», а для обозначения генерального среднего (математического ожидания) – букву «М». Слова для объяснения этих сложных явлений могут быть разными, но и у математиков, и у биологов есть единодушие в понимании статистического смысла, лежащего за этими буквенными символами. Вообще, лучше было бы ввести некий иной термин вместо слов «ошибка» или «отклонение», так как они изначально имеют в нашем сознании иной смысл; на наш взгляд, более всего подходит слово «скачок» (чем сильнее отскакивает выборочное среднее от генерального среднего, тем реже оно встречается). Но так уж получилось, что не нашлось нейтрального (иностранного) слова, и слово «ошибка» традиционно используют, и мы также будем его использовать; важно понимать его иной, чем в обыденном употреблении, математический и статистический смысл.
Для самого точного определения средней высоты сеянцев нужно измерять все растения в питомнике, и тогда мы получим «генеральное среднее значение». Но так не делают, а измеряют несколько сотен растений в разных местах и этого бывает достаточно для определения среднего выборочного значения с приемлемой точностью. В нашем примере при 100 растениях ошибка его определения составит 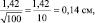 а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
а ее отнесение к средней высоте сеянцев 5,0 см, выражаемое в %, дает нам так называемую точность опыта: 0,14/5,0×100 = 2,8 %. В биологии точность опыта ±2–3 % считается высокой, ±5 % – достаточной, а ±6–7 % – пониженной, но это весьма упрощенное представление о планировании эксперимента.
Вообще, точность опыта не самоцель; гораздо важнее сократить численность (объем) выборки до минимума. Представим себе, что средняя высота сеянцев xср = 5,0 см, а ее ±δ = 1,42 см, рассмотренные выше, получены при измерении 1000 растений потомства сосны, например, из Кунгура. Поделив ±δ на корень из 1000 получаем ошибку опыта m = ±0,045 см. Далее получаем точность опыта
Р = m/xср×100 = 0,045/5,0×100 = 0,9 %.
Точность получилась очень высокой. Но в питомнике есть потомства и из других мест и такой уровень точности совершенно не нужен, так как нужно узнать еще высоты сеянцев, например, из Очера, Осы, Добрянки и других районов. Если выборку из 1 тыс. растений снижать, то будет увеличиваться ошибка в определении средней высоты. И нужно найти приемлемую величину такой ошибки, которая позволит нам, тем не менее, уверенно утверждать, что это потомство растет быстрее, либо медленнее других. Причем происхождений может быть несколько сотен и минимизация выборок крайне важна, так как масштабы работ ограничены физическими возможностями бригады селекционеров. Следовательно, надо сокращать объем выборки. Как это сделать правильно?
Рассмотрим два потомства. Первое – это упомянутые сеянцы происхождением из Кунгура (хср1), второе – сеянцы из Кизела с хср2 = 6,0 см и δ2 = ± 1,0 см (превышение высоты на 20 %). Надо это превышение доказать. При выборках из 100 растений ранее определенная ошибка m1 была равна 0,14 см, вторая ошибка m2 после расчетов по формуле (2.1) составит 0,1 см. По закону нормального распределения 99,5 % всех возможных значений этих средних хср1 и хср2 будут в пределах «плюс-минус три ошибки», что можно показать графически (рис. 2.1) или в виде формул:
хср1 ± 3m1 = 5,0 ± 3×0,14 = 5,0 ± 0,4 см
и
хср2 ± 3m2 = 6,0 ± 3×0,1 = 6,0 ± 0,3 см.
Возможные теоретические значения средних в генеральной совокупности не перекрывают друг друга, значит, различие достоверно. А если сократить выборки до 50 сеянцев? Тогда 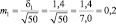 и
и 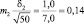 и пределы колебаний возможных значений средних будут:
и пределы колебаний возможных значений средних будут:
хср1 ± 3m1 = 5,0 ± 3×0,20 = 5,0 ± 0,6 см;
хср2 ± 3m2 = 6,0 ± 3×0,14 = 6,0 ± 0,3 см.

Рис. 2.1. Средние значения по выборкам из 100 растений и их тройные ошибки (пределы возможных значений выборочных средних в 99,5 % случаев)
Снова вынесем эти пределы на график (рис. 2.2).

Рис. 2.2. Средние значения при N = 50 растений и их тройные ошибки
Как видим, пределы сблизились и если еще сократить выборки, то они перекроются. Можно ли далее снижать объем выборки?
Можно, но здесь вступает в силу так называемое условие безошибочного прогноза. Мы это условие задали на уровне 99,5 % и для этого взяли ±3m для распределения ошибок. Но можно взять уровень пониже, с пределами ±2δ (уровень 95 %) и даже с пределами ±1,7δ (уровень 90 %).
При выборках из 25 штук сеянцев, получаем две ошибки: 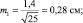
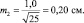 Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
Тогда пределы значений для этих двух выборочных средних для уровня прогноза в 95 % будут:
хср1 ± 2m1 = 5,0 ± 2×0,28 = 5,0 ± 0,56 см;
хср2 ± 2m2 = 6,0 ± 2×0,20 = 6,0 ± 0,40 см.
Выносим эти пределы опять на график (рис. 2.3).
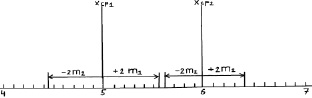
Рис. 2.3. Средние значения при N = 25 растений и их двойные ошибки (пределы возможных значений средних в 95 % случаев)
Как видим, просвет все еще есть, и поэтому между возможными значениями средних высот сеянцев в других выборках из происхождений Кунгур и Кизел различия будут опять доказаны. Но уровень доказательства понизился до 95 %, и для 5 % оставшихся случаев нет гарантии, что различия будут иметь место при выборке из 25 растений. Их может и не быть, но эту вероятность в 5 % мы допускаем.
The confidence interval signifies how much uncertainty is present in statistical data. In other words, it is defined as an interval that depicts a population parameter with a probability of 1 – α. The expression for the confidence interval is given below,
x̄ ± tα / 2,N – 1 Sx̄
Here,
x̄ ± tα / 2 : It signifies the value required to form an area of α / 2 (each tail of a t-distribution where
degree of freedom = n – 1)
Sx̄ = s / √n : It represents the standard error of the mean
Determining confidence interval in R:
Firstly we need to create sample data. R provides inbuilt datasets. In this article, we are going to use the iris dataset for illustration. iris dataset depicts the sepal length, sepal width, petal length, and petal width in centimeters. It provides the data of fifty flowers from each of the three species of iris. The species are:
- Iris setosa
- versicolor
- virginica
R
Output:

Method 1: Calculating Intervals using base R
In this method, we will find the confidence interval step-by-step using mathematical formulas and R functions. You can follow the below steps to determine the confidence interval in R.
Step 1: Calculate the mean. The very first step is to determine the mean of the given sample data.
R
mean_value <- mean(iris$Sepal.Length)
Step 2: Now let’s compute the standard error of the mean.
In order to compute the standard error of the mean (Sx̄), we need to find the standard deviation (s) and the length of the sample data (n).
R
n <- length(iris$Sepal.Length)
standard_deviation <- sd(iris$Sepal.Length)
standard_error <- standard_deviation / sqrt(n)
Step 3: Determine the t-score that is linked to the confidence level.
In this step, we will compute the t-score related to the confidence level. We are required to have exactly α / 2 probability in the lower and upper tail. R provides qt() function using which we can calculate the t-score easily. The syntax is given below,
Syntax:
qt(random_variable, degree_of_freedom)
Parameters:
random_variable: It must be a random variable
degree_of_freedom: It must be degree of Freedom
R
alpha = 0.05
degrees_of_freedom = sample.n - 1
t_score = qt(p=alpha/2, df=degrees_of_freedom,lower.tail=F)
print(t_score)
Step 4: Compute the margin of error and form the confidence interval.
The margin of error is given by,
tα / 2,N – 1 Sx̄
It can be easily calculated as,
R
margin_error <- t_score * standard_error
The confidence interval is equal to the mean +/- margin of error. It can be calculated as,
R
lower_bound <- mean_value - margin_error
upper_bound <- mean_value + margin_error
Combining all the steps
Example:
R
mean_value <- mean(iris$Sepal.Length)
n <- length(iris$Sepal.Length)
standard_deviation <- sd(iris$Sepal.Length)
standard_error <- standard_deviation / sqrt(n)
alpha = 0.05
degrees_of_freedom = n - 1
t_score = qt(p=alpha/2, df=degrees_of_freedom,lower.tail=F)
margin_error <- t_score * standard_error
lower_bound <- mean_value - margin_error
upper_bound <- mean_value + margin_error
print(c(lower_bound,upper_bound))
Output:

Method 2: Calculating Confidence Intervals using confint() function
We can compute confidence interval using the inbuilt functions in R. The steps are given below,
Step 1: Calculating mean and standard error.
R provides us lm() function which is used to fit linear models into data frames. We can calculate the mean and standard error (that are required to find confidence interval) using this function. The syntax is given below,
Syntax:
lm(fitting_formula, dataframe)
Parameters:
fitting_formula: It must be the formula for the linear model.
dataframe: It must be the name of the data frame that contains the data.
R
l_model <- lm(Sepal.Length ~ 1, iris)
Step 2: Finding confidence interval.
Now, to find the confidence interval we have confint() function in R. This function is specifically used to compute confidence intervals for one or more parameters in a fitted model. The syntax is given below,
Syntax:
confint(object, parm, level = 0.95, …)
Parameters:
object: It represents fitted model object.
parm : It represents parameters to be given confidence intervals (either a vector)
level : It represents the confidence level.
… : It represents additional argument for different methods.
R
confint(model, level=0.95)
Combining all the steps
Example:
R
model <- lm(Sepal.Length ~ 1, iris)
confint(model, level=0.95)
Output:

Last Updated :
23 Feb, 2022
Like Article
Save Article
Бутстреп и А/Б тестирование
Время на прочтение
10 мин
Количество просмотров 26K
Привет, Хабр! В этой статье разберёмся, как с помощью бутстрепа оценивать стандартное отклонение, строить доверительные интервалы и проверять гипотезы. Узнаем, когда бутстреп незаменим, и в чём его недостатки.

Продолжаем писать серию статей по А/Б тестированию, это наша вторая статья. Первую можно посмотреть тут: Стратификация. Как разбиение выборки повышает чувствительность A/B теста.
Метрики и точность их оценки
Давайте представим, что мы работаем аналитиками в сервисе по доставке заказов онлайн-магазина. Нам поставили задачу оценить, как быстро мы выполняем заказы. У нас есть данные со временем выполнения каждого заказа, осталось выбрать метрику и оценить её значение. В этой статье положим, что мы работаем с независимыми одинаково распределенными случайными величинами. Случай зависимых случайных величин будет разобран в последующих статьях.
Самый простой вариант метрики — среднее время выполнения заказа. Для оценки среднего времени выполнения заказа можно взять все заказы за какой-то промежуток времени, например, за последний месяц, и вычислить среднее время их выполнения.
Допустим, мы получили оценку среднего времени доставки, равную 90 минутам. Насколько ей можно верить? Понятно, что это, скорее всего, не истинное значение среднего времени доставки. Если мы подождём ещё месяц и повторим вычисление, то получим чуть большее или чуть меньшее значение. Важно оценить стандартное отклонение полученной оценки, чтобы понять, насколько она точна, так как 90±1 минута и 90±30 минут — совсем разные ситуации.
Для среднего оценка стандартного отклонения вычисляется по формуле:

где ![]() — размер выборки,
— размер выборки, ![]() — случайные величины времени доставки,
— случайные величины времени доставки, ![]() — выборочное среднее времени доставки.
— выборочное среднее времени доставки.
Рассмотрим пример вычисления оценки среднего и стандартного отклонения. Допустим, что у нас есть информация о 1000 доставках. Распределение времени доставки в реальной жизни может быть произвольным. В примере будем генерировать время доставки из нормального распределения со средним 90 и стандартным отклонением 20. Сгенерируем выборку, оценим среднее и стандартное отклонение среднего.
import numpy as np
n = 1000
values = np.random.normal(90, 20, n)
mean = values.mean()
std = values.std() / np.sqrt(n)
print(f'Оценка среднего времени доставки: {mean:0.2f}')
print(f'Оценка std для среднего времени доставки: {std:0.2f}')Оценка среднего времени доставки: 90.23
Оценка std для среднего времени доставки: 0.64Получилось, что в нашем примере 1000 наблюдений оказалось достаточно, чтобы стандартное отклонение оценки среднего было меньше минуты.
Квантили
Мы оценили среднее время выполнения заказа. Это хорошо, но это всего лишь “среднее по больнице”. Кто-то получает заказы быстрее, кто-то медленнее. Мы хотим, чтобы подавляющее большинство клиентов получали заказы достаточно быстро. Оценить, за сколько доставляется бОльшая часть заказов можно, например, с помощью 90% квантиля. Какой физический смысл квантиля? Если 90% квантиль равен 2 часам, то 90% заказов доставляются не более, чем за 2 часа.

Мы легко можем оценить 90% квантиль по данным, но как оценить стандартное отклонение полученной оценки? Простой универсальной теоретической формулы для оценки стандартного отклонения квантиля нет.
Было бы хорошо, если у нас было 100 параллельных вселенных. Мы бы в каждой вселенной собрали данные, посчитали 100 квантилей и оценили стандартное отклонения по полученным значениям. Но у нас нет 100 параллельных вселенных.

Кто-то может предложить разбить наши данные из 1000 наблюдений на 10 частей по 100 значений в каждом. В каждой части посчитать значение квантиля и оценить стандартное отклонение по этим 10 значениям. Такой подход даст неверный результат, так как стандартное отклонение оценки зависит от количества наблюдений, используемых при оценке значения квантиля. Чем больше данных, тем точнее оценка и меньше стандартное отклонение.
Что же делать? Оказывается, есть способ, который позволяет оценить стандартное отклонение произвольной статистики, в том числе квантиля. Он называется бутстреп.
Бутстреп
Бутстреп (bootstrap) — это метод для оценки стандартных отклонений и нахождения доверительных интервалов статистических функционалов.
Разберёмся, как работает бутстреп. Напомним, что мы хотим оценить стандартное отклонение произвольной статистики. В статье мы будет оценивать стандартное отклонение оценки 90% квантиля.
Если бы мы могли получать данные из исходного распределения, то могли бы сгенерировать из этого распределения 100 выборок, посчитать по ним 100 квантилей и оценить стандартное отклонение. Истинного распределения мы не знаем, но можем его оценить по имеющимся данным.
В качестве оценки функции распределения будем использовать эмпирическую функцию распределения (ЭФР). ЭФР является несмещённой оценкой и сходится к истинной ФР при увеличении размера выборки.
Определение ФР и ЭФР


Заметим, что ЭФР — это ФР дискретной СВ, которая получается в предположении, что элементы выборки независимы и одинаково распределены. Действительно, давайте каждому наблюдению придадим вес 1/n
|
Значение |
X_1 |
X_2 |
… |
X_n |
|
Вероятность |
1/n |
1/n |
… |
1/n |
Данное табличное распределение и есть распределение ЭФР.
Теоремы сходимости ЭФР к ФР

Посмотрим как визуально выглядит ЭФР для данных разного размера из стандартного нормального распределения.
Код
import matplotlib.pyplot as plt
from scipy import stats
def plot_ecdf(values, label, xlim):
"""Построить график ЭФР."""
X_ = sorted(set(values))
Y_ = [np.mean(values <= x) for x in X_]
X = [xlim[0]] + sum([[v, v] for v in X_], []) + [xlim[1]]
Y = [0, 0] + sum([[v, v] for v in Y_], [])
plt.plot(X, Y, label=label)
# Генерируем данные и строим ЭФР
for size in [20, 200]:
values = np.random.normal(size=size)
plot_ecdf(values, f'ЭФР, size={size}', [-3, 3])
# Строим ФР
X = np.linspace(-3, 3, 1000)
Y = stats.norm.cdf(X)
plt.plot(X, Y, '--', color='k', label='ФР')
plt.title('ФР и ЭФР стандартного нормального распределения')
plt.legend()
plt.show()
На графике видно, что при увеличении размера выборки ЭФР лучше приближает истинную функцию распределения. Если увеличить размер выборки до нескольких тысяч, то ЭФР визуально будет сложно отличить от истинной функции распределения.
Так как нам известно, что ЭФР «хорошо» приближает истинную ФР, давайте генерировать данные из неё! Как это сделать?
Сгенерировать подвыборку размера ![]() из ЭФР — это тоже самое, что выбрать случайно с возвращением
из ЭФР — это тоже самое, что выбрать случайно с возвращением ![]() элементов из исходной выборки. Это можно сделать одной строчкой кода
элементов из исходной выборки. Это можно сделать одной строчкой кода
np.random.choice(values, size=n, replace=True)Теперь мы можем оценить стандартное отклонение оценки квантиля. Для этого 1000 раз сгенерируем подвыборки из ЭФР, вычислим значение статистики в каждой подвыборке и оценим стандартное отклонение получившихся значений.
n = 1000 # размер исходной выборки
B = 1000 # количество генерируемых подвыборок
values = np.random.normal(90, 20, n)
quantile = np.quantile(values, 0.9)
bootstrap_quantiles = []
for _ in range(B):
bootstrap_values = np.random.choice(values, n, True)
bootstrap_quantiles.append(np.quantile(bootstrap_values, 0.9))
std = np.std(bootstrap_quantiles)
print(f'Оценка 90% квантиля: {quantile:0.2f}')
print(f'Оценка std для 90% квантиля: {std:0.2f}')Оценка 90% квантиля: 115.24
Оценка std для 90% квантиля: 1.56Мы только что применили бутстреп для оценки стандартного отклонения 90% квантиля.
Обратим внимание на два момента:
-
Чтобы оценка стандартного отклонения была несмещённой, необходимо генерировать выборки такого же размера, как и размер исходной выборки;
-
Количество итераций бутстрепа рекомендуется брать в диапазоне от 1000 до 10000. Этого, как правило, хватает для получения достаточно точных результатов.
Доверительные интервалы
Мы научились оценивать стандартное отклонение оценки статистики. Зная стандартное отклонение, можно интуитивно понять насколько достоверны полученные результаты. Для получения более точных результатов можно построить доверительный интервал.
Доверительный интервал (ДИ) — это интервал, который покрывает оцениваемый параметр с заданной вероятностью.
Строгое определение ДИ

Вероятность следует понимать в том смысле, что если бы мы провели эксперимент множество раз, то в среднем для 95% доверительного интервала в 95 экспериментах из 100 истинный параметр принадлежал бы доверительному интервалу.
В строгом смысле доверительный интервал – это случайный вектор. В реальности же мы имеем дело с реализацией доверительного интервала (не со случайными величинами) и говорить о вероятности отличной от 0 или 1 не приходится (истиный параметр или принадлежит интервалу, или не принадлежит). Но для простоты мы пишем «доверительный интервал» вместо «реализация доверительного интервала» так же, как часто говорим «выборка» вместо «реализация выборки».
Вернёмся к примеру с доставкой из онлайн-магазина и построим ДИ среднего времени доставки. В нашей статье будем использовать 95% доверительный интервал. Если данных много, то, независимо от распределения исходных данных (предполагается, что дисперсия существует и не равна нулю), по центральной предельной теореме среднее будет распределено нормально. Для нормально распределённых статистик ДИ можно вычислить по формуле
![]()
где ![]() — квантиль стандартного нормального распределения,
— квантиль стандартного нормального распределения, ![]() — уровень значимости. Для 95% доверительного интервала уровень значимости равен 0.05.
— уровень значимости. Для 95% доверительного интервала уровень значимости равен 0.05.

Для построения ДИ квантиля мы, как вы наверное уже догадались, будем использовать бутстреп. ДИ с помощью бутстрепа можно построить тремя способами.
Первый способ аналогичен тому, как мы строили ДИ для среднего. Для его вычисления нужно выполнить следующие три шага:
-
оценить значение квантиля по исходным данным;
-
с помощью бутстрепа оценить стандартное отклонение оценки квантиля;
-
по формуле вычислить ДИ
![[widehat{pe} - z_{1 - alpha/2} * widehat{std}, widehat{pe} + z_{1 - alpha/2} * widehat{std}]](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%20357%2033'%3E%3C/svg%3E) ,
,где
 — это точечная оценка (point estimation).
— это точечная оценка (point estimation).
Такой ДИ называется нормальным доверительным интервалом.
Нормальный доверительный интервал отлично подходит, когда распределение статистики близко к нормальному распределению. Если распределение статистики несимметричное, то нормальный доверительный интервал может давать странный результат. На графике ниже изображена ситуация, когда граница доверительного интервала выходит за минимальное значение распределения.

В случае несимметричных распределений мы можем использовать перцентильный доверительный интервал. Чтобы построить перцентильный ДИ, нужно отрезать с каждой стороны по ![]() площади распределения. Для 95% ДИ нужно отрезать по 2.5%. На практике для вычисления границ ДИ нужно оценить квантиль
площади распределения. Для 95% ДИ нужно отрезать по 2.5%. На практике для вычисления границ ДИ нужно оценить квантиль ![]() и
и ![]() по значениям статистик полученных с помощью бутстрепа. Доверительный интервал будет иметь следующий вид
по значениям статистик полученных с помощью бутстрепа. Доверительный интервал будет иметь следующий вид
![]()
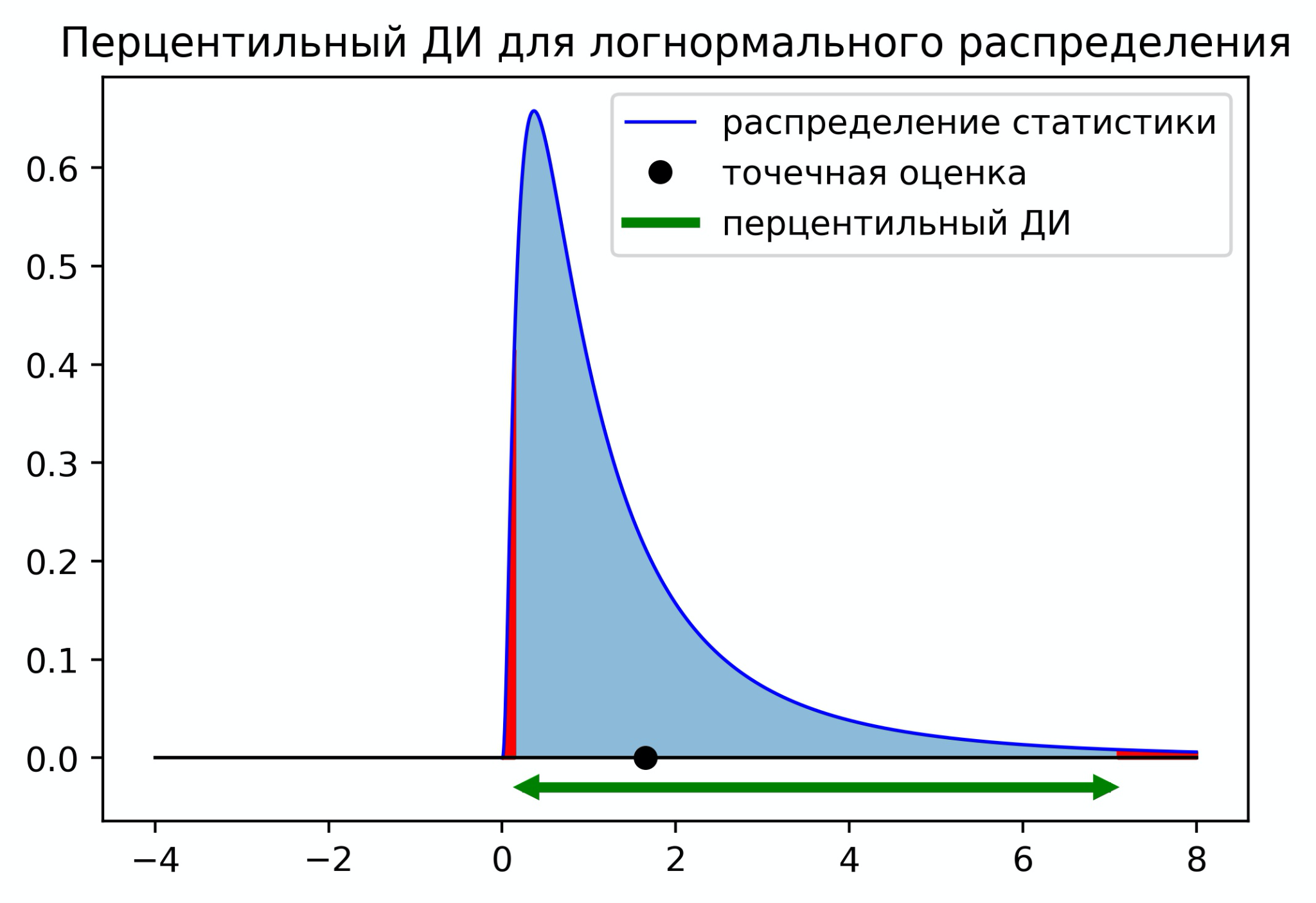
Существует ещё один вариант — центральный доверительный интервал. Его границы равны
![]()
На первый взгляд этот доверительный интервал кажется нелогичным, но он имеет под собой строгое математическое обоснование.

Центральный ДИ для логнормального распределения смещён в сторону с нулевой плотностью. Это можно интерпретировать как стремление перестраховаться на случай, если у нас неполная информация о распределении, и левее нуля на самом деле могут быть значения.
Мы познакомились с тремя способами построения доверительных интервалов с помощью бутстрепа. Ниже приведён пример кода построения этих ДИ.
Код
import seaborn as sns
def get_normal_ci(bootstrap_stats, pe, alpha):
"""Строит нормальный доверительный интервал."""
z = stats.norm.ppf(1 - alpha / 2)
se = np.std(bootstrap_stats)
left, right = pe - z * se, pe + z * se
return left, right
def get_percentile_ci(bootstrap_stats, pe, alpha):
"""Строит перцентильный доверительный интервал."""
left, right = np.quantile(bootstrap_stats, [alpha / 2, 1 - alpha / 2])
return left, right
def get_pivotal_ci(bootstrap_stats, pe, alpha):
"""Строит центральный доверительный интервал."""
left, right= 2 * pe - np.quantile(bootstrap_stats, [1 - alpha / 2, alpha / 2])
return left, right
n = 1000
B = 10000
alpha = 0.05
values = np.random.normal(90, 20, n)
quantile = np.quantile(values, 0.9)
bootstrap_quantiles = np.quantile(np.random.choice(values, (B, n), True), 0.9, axis=1)
normal_ci = get_normal_ci(bootstrap_quantiles, quantile, alpha)
percentile_ci = get_percentile_ci(bootstrap_quantiles, quantile, alpha)
pivotal_ci = get_pivotal_ci(bootstrap_quantiles, quantile, alpha)
sns.kdeplot(bootstrap_quantiles, label='kde статистики')
plt.plot([quantile], [0], 'o', c='k', markersize=6, label='точечная оценка')
plt.plot([109, 120], [0, 0], 'k', linewidth=1)
d = 0.02
plt.plot(normal_ci, [-d, -d], label='нормальный ДИ')
plt.plot(percentile_ci, [-d*2, -d*2], label='перцентильный ДИ')
plt.plot(pivotal_ci, [-d*3, -d*3], label='центральный ДИ')
plt.title('Доверительные интервалы для 90% квантиля')
plt.legend()
plt.show()
Бутстреп и А/Б тестирование
Мы научились строить доверительные интервалы. С помощью доверительного интервала можно не только получать дополнительную информацию о значении метрики, но и проверять статистические гипотезы. Чтобы проверить гипотезу о равенстве квантилей на уровне значимости 5% достаточно построить 95% доверительный интервал для разности квантилей между группами. Если ноль находится вне доверительного интервала, то отличия статистически значимы, иначе нет.

Опишем ещё раз алгоритм проверки гипотез о равенстве двух произвольных метрик с помощью бутстрепа:
-
Генерируем пару подвыборок того же размера из исходных данных контрольной и экспериментальной групп;
-
Считаем метрики (реализация оценки метрики) для каждой из групп;
-
Вычисляем разность метрик, сохраняем полученное значение;
-
Повторяем шаги 1-3 от 1000 до 10000 раз;
-
Строим доверительный интервал с уровнем значимости
 ;
; -
Если 0 не принадлежит ДИ, то отличия статистически значимы на уровне значимости
, иначе нет.
Посмотрим, как этот алгоритм можно реализовать в коде. Для примера, при генерации данных в экспериментальной группе уменьшим дисперсию, это приведёт к уменьшению значения 90% квантиля.
n = 1000
B = 10000
alpha = 0.05
values_a = np.random.normal(90, 20, n)
values_b = np.random.normal(90, 15, n)
pe = np.quantile(values_b, 0.9) - np.quantile(values_a, 0.9)
bootstrap_values_a = np.random.choice(values_a, (B, n), True)
bootstrap_metrics_a = np.quantile(bootstrap_values_a, 0.9, axis=1)
bootstrap_values_b = np.random.choice(values_b, (B, n), True)
bootstrap_metrics_b = np.quantile(bootstrap_values_b, 0.9, axis=1)
bootstrap_stats = bootstrap_metrics_b - bootstrap_metrics_a
ci = get_percentile_ci(bootstrap_stats, pe, alpha)
has_effect = not (ci[0] < 0 < ci[1])
print(f'Значение 90% квантиля изменилось на: {pe:0.2f}')
print(f'{((1 - alpha) * 100)}% доверительный интервал: ({ci[0]:0.2f}, {ci[1]:0.2f})')
print(f'Отличия статистически значимые: {has_effect}')Значение 90% квантиля изменилось на: -6.69
95.0% доверительный интервал: (-9.66, -3.41)
Отличия статистически значимые: TrueПолучилось, что 90% квантиль статистически значимо уменьшился.
В данном примере для построения ДИ использовался перцентильный ДИ. На практике все три способа построения ДИ зачастую дают схожие по точности результаты. Однако могут быть и исключения, результат будет зависеть от природы данных и сравниваемых метрик. Чтобы понять какой способ лучше работает в вашей ситуации, нужно оценить ошибки первого и второго рода по историческим данным. Как это сделать можно прочитать в нашей прошлой статье Стратификация. Как разбиение выборки повышает чувствительность A/B теста.
Ограничения бутстрепа
Бутстреп является весьма универсальным методом. Он позволяет численно исследовать свойства распределений произвольных статистик, а не только квантиля. Это делает его незаменимым для построения доверительных интервалов и проверки гипотез с нетривиальными метриками.
Если бутстреп так хорош, то почему его не используют во всех задачах? Основной недостаток бутстрепа – его скорость работы. Применение бутстрепа является вычислительно трудоёмкой процедурой. Это становится ощутимо, когда приходится работать с большими объёмами данных и многократно применять бутстреп. Вычисления могут занимать часы, дни и даже недели.
Обратим внимание, что во всех примерах выше предполагалось, что мы имеем дело с независимыми одинаково распределёнными случайными величинами. В таких ситуациях для генерации подвыборок можно случайно выбирать значения из исходной выборки. Если же исходные данные зависимы и имеют сложную природу, то при генерации подвыборок нужно это учесть, иначе оценка распределения статистики с помощью бутстрепа может плохо приближать истинное распределение.
Важно не забывать про качество исходных данных, с которыми работает бутстреп. Если эти данные нерепрезентативны и плохо отражают реальное состояние, то достоверных результатов ожидать не стоит.
Заключение
Мы разобрали статистический метод, позволяющий получать оценки стандартного отклонения и строить доверительные интервалы самых нетривиальных статистик. Обсудили, как применять бутстреп для проверки гипотез, когда он незаменим и в чём его недостатки.
Полезные материалы: Larry Wasserman. All of Statistics: A Concise Course in Statistical Inference.
Авторы: Николай Назаров, Александр Сахнов