
|
|

|
|
|
|||
| n0ther
08.02.10 — 10:30 |
Что такое «наведенная ошибка» ?
* навеяно последним релизом УПП |
||
| АЛьФ
1 — 08.02.10 — 10:31 |
2(0) Ошибка, которая возникла из-за изменений в другом коде. |
||
|
n0ther 2 — 08.02.10 — 10:32 |
(1) thnx |
|
Список тем форума
|
Я в одной книжке по программированию как то прочитал: «Есть два вида языков, одни постоянно ругают, а вторыми никто не пользуется.»
Ветка сдана в архив.
![]()
наведённая ошибка
-
1
propagated errorУниверсальный англо-русский словарь > propagated error
-
2
induzierte FehlerУниверсальный немецко-русский словарь > induzierte Fehler
См. также в других словарях:
-
Волшебство мира Гарри Поттера — Эта статья является частью цикла статей о волшебном мире Гарри Поттера. Эта статья об объекте вымышленного мира описывает его только на основе самого художественного произведения. Статья, состоящая только из инфор … Википедия
-
Октябрьская революция — У этого термина существуют и другие значения, см. Октябрьская революция (значения). Октябрьское восстание … Википедия
-
Гражданская война в Испании — Смерть республиканца анархиста Федерико Боррелла Гарсии (фотография Роберта Капы) … Википедия
-
Гибель тургруппы Дятлова — В таком виде спасатели нашли палатку группы. Фото спасателя Вадима Брусницына 26 или 28 февраля 1959 г. Слева поисковик Юрий Коптёлов Гибель тургруппы Дятлова событие, случившееся предположительно в ночь с 1 на 2 … Википедия
-
Видоискатель — Запрос «Визир» перенаправляется сюда; см. также другие значения. Видоискатель, Визир, Визирное устройство элемент фотоаппарата, показывающий границы будущего снимка, иногда резкость и параметры съёмки. Также видоискатели используются в… … Википедия
-
Assassin’s Creed — Assassin’s Creed Разработчик Ubisoft Montreal Издатели … Википедия
-
Assassin’s Creed — Assassin’s Creed Разработчик Ubisoft Montreal Издатели … Википедия
-
Assassin’s Creed — Это статья о компьютерной игре. О серии компьютерных игр см. статью Assassin s Creed (серия игр) Assassin’s Creed Разработчик Ubisoft Montreal … Википедия
Вряд ли в мире был хоть один случай тестирования системы без замечаний. Среди них, как и среди требований, попадаются замечания-дичь, но мы разберём объективные и наиболее часто возникающие: их виды, причины и даже примеры из замечаний к тестированию ECM-системы. Спасибо за предоставленный материал ИТ-компании Акелон, чьи аналитики слона съели на этой теме и поделились выдержками из своей Базы знаний.
Для начала определимся в какой форме может быть высказано замечание:
- Дефект – невыполнение требования, связанного с предназначенным использованием и зафиксированного в следующих источниках: документация на систему, проектные решения, тех. проекты, проект тестирования, а также общепринятые документы (например, правила русского языка). К описанию дефектов по программным продуктам могут относиться: нелогичности и несоответствия стандартам, ошибки выполнения команд; по документам – неточности в технологических документах, их несоответствие реальным процессам, ошибки и опечатки и так далее.
- Пожелание – предложение об осуществлении чего-либо относительно продукта. Пожелания, как правило, бывают связаны с расширением функциональности элемента, оптимизацией его работы и использования, дополнительным контролем некорректных действий пользователя и т.д. Например, наличие нового типа документа, многоадресные служебные записки.
- Новая фича – крупная разработка/кардинальное преобразование в существующих продуктах, которая не является улучшением или пожеланием по развитию существующей функциональности. Например, чат-боты, новый модуль «Закупки», интеллектуальная обработка документов и так далее.
Мы выделили пять основных причин для подобного рода замечаний
-
Несоответствие требованиям. Такое замечание можно классифицировать как дефект продукта. Несоответствие требованиям может быть вызвано некорректной разработкой или некорректной настройкой.
ПРИМЕР некорректного требования
Требование: «Специалист должен иметь возможность фильтровать список входящих документов по полю Подписал со стороны корреспондента». В результате разработали фильтрацию по полю Адресат.
В техпроекте написано: «Добавить поле в справочник <наименование справочника>, с возможностью выбора записи из справочника Сотрудники, а в результате разработали обычное текстовое поле / не добавили новое поле / поле недоступно для редактирования и так далее.
2. Некорректно зафиксированное требование. Это тот случай, когда некорректно сформулировано или некачественно проработано требование, либо в процессе появились дополнительные пожелания к продукту и требования неполные (не выявили при проектировании, осознали необходимость на этапе разработки или тестирования); есть ещё противоречащие требования.
ПРИМЕР
Первоначальное требование: сотрудники должны загружаться в систему при интеграции с HR-системой.
В карточке записи справочника Сотрудники должно быть предусмотрено обязательное поле Непосредственный руководитель. Дефект требования в том, что, при попытке заполнить непосредственного руководителя сотрудник может быть еще не загружен из HR-системы, в связи с этим будут возникать ошибки интеграции. Правильнее было сделать поле Непосредственный руководитель необязательным, либо заполнять его после первичной загрузки (поэтапный запуск сеанса интеграции).
3. Некорректное проектирование. Это дефекты, которые могли появиться по причине некачественного проектирования при разработке проектных решений, системных анализов, а также при разработке техпроекта модификаций/интеграции.
ПРИМЕР
В проектных решениях консультант описал бизнес — процесс «Работа с договорными документами» следующим образом: «… После смены состояния документа на Утвержден происходит сеанс интеграции с учетной системой. Передаются следующие данные о договоре: Рег.№, Контрагент, Подписант…». Ошибка в том, что в учетную систему должна попадать информация о договоре в случае, если состояние документа изменяется на Действующий, то есть документ зарегистрирован и подписан с обеих сторон.
4. Наведенные дефекты. Проявляется, когда исправлен один дефект, после чего возникли дефекты в связанных элементах разработки.
ПРИМЕР
Удалили поле Уполномоченное лицо в карточке документа, в результате регламент согласования отрабатывает некорректно, так как в этапе Согласование с уполномоченным лицом исполнитель вычисляется из данного поля.
5. Несоответствие общепринятым нормам. Когда разработка или настройка не соответствует требованиям законодательства, правилам русского языка, нормативным документам, положениям об ЭДО и так далее.
ПРИМЕР
Разработано новое решение, которое включает в себя заключение трудовых договоров. Согласно требованиям проекта ФЗ об участии в эксперименте минтруда система должна поддерживать выгрузку трудовых договоров в необходимом формате. При разработке данное требование не было учтено, выгрузка не была реализована, что противоречит требованиям ФЗ.
Это лишь часть большой статьи руководителя группы консультирования Сергея Птицына о “Работе с замечаниями при тестировании системы”. В следующих постах мы расскажем, как оформлять замечания и тестировать исправления так, чтобы остановить цепочку замечаний по замечаниям замечаний ))).
- Суть методики
- Особенности
- Что требуется, чтобы эффективно (пред)угадывать ошибки
- Примеры
- Преимущества и недостатки методики
Что это
Техники тест-дизайна — это то, чем должен хорошо владеть каждый тестировщик, даже стажер. Наиболее часто применяемые техники: эквивалентные классы, анализ граничных значений, и предугадывание ошибок.
В данной методике (типологически относится к тестированию черного ящика) нет какого-то специфического метода идентификации ошибок. Тестировщик действует, исходя из своего опыта и интуиции, пытаясь предугадать проблемные места в приложении. Поэтому успешность этой методики сильно зависит от опыта и скиллов, и глубины понимания тестируемого продукта.
Особенности
Как уже сказано, эффективность зависит от опыта, особенно с похожими приложениями ранее. Поэтому лучше и быстрее с такой задачей справляются QA-инженеры с опытом 1 год и более.
Методика направлена на поиск багов, не поддающихся другим методикам черного ящика. Поэтому стандартно выполняется уже после них.
Частыми ошибками в приложениях (следовательно, наиболее вероятными ошибками в тестируемом приложении) являются, например:
- Ввод некорректных (невалидных) параметров и символов
- Например, ввод пробела в “цифровые” поля, где это недопустимо
- Ошибка-исключение null pointer exception
- Деление на ноль
- Превышение максимального количества передаваемых файлов
- И подобные «типичные пользовательские» ошибки
Итак, цель предугадывания — найти ошибки, которые трудно “выловить” другими методиками черного ящика. Готовятся тест-кейсы, направленные на области наиболее вероятных ошибок; по возможности покрываются все проблемные места; но без избыточности.
Методика, разумеется, не является идеальной, способной обеспечить высокое качество — ведь она основана на интуиции, поэтому ограничена по умолчанию, зависит от умений и, главное, опытности QA-инженера. Она вовсе не гарантирует высокого покрытия, и должна сочетаться с другими методиками, дополнять их.
Что нужно, чтобы хорошо угадывать ошибки
- Интуиция тестировщика
- И его знание продукта
- Опыт прошлых проектов
- Чек-лист
- Риск-репорты
- Знание типичных проблем с интерфейсом
- Идеальное знание общих принципов тестирования
- Результаты предыдущих тестов
- Характерные ошибки, случавшиеся ранее
Примеры предугадывания ошибок
Пример 1
В приложении есть функция ввода номера телефона клиента, и он должен быть стандартной длины, то есть 10 цифр. Методика предугадывания ошибок в данном случае может проверить, например:
- Что случится, если ввести не цифру, а букву или пробел
- Если ввести только 8 цифр
- Если оставить поле пустым
- Если ввести не 10, а 12 цифр
Если такие невалидные значения введены, и функция ведёт себя как ожидается — то есть показывает ошибку, она расценивается как не имеющая багов; в противном случае заводится баг, и функция передается разработчикам, чтобы те устранили баг.
Пример 2
Счет на банковской карте настроен так, что принимает только суммы от 5000 до 7000 рублей (так нужно клиенту). Действуя по методике предугадывания ошибок, подбираем значения ввода, пытаясь добиться наибольшего покрытия:
| Значение | Результат |
| 6000 | ОК |
| 5500 | ОК |
| 4000 | Ошибка |
| 7200 | Ошибка |
| 7400 | Ошибка |
| 8000 | Ошибка |
| Пустое | Ошибка |
| 100$ | Ошибка |
| … | … |
| … и так далее |
Преимущества и недостатки методики
Преимущества
- Неплохой контроль возможных проблемных мест в проекте (они обычно стандартные)
- Отлично работает в сочетании с другими техниками тест-дизайна и дополняет их
- Позволяет довольно просто находить баги, которые доступны только при исчерпывающем тестировании (всех комбинаций ввода, что невозможно из-за недостатка времени)
Недостатки
- Является как бы ориентированной на личность тестировщика методикой, а не на процессы, что более правильно; то есть не является универсальной, а сильно зависит от скиллов тестировщика
- Не обеспечивает хорошее покрытие сама по себе
- Не очень подходит новичкам, неопытным, плохо знакомым с продуктом или областью его применения
***
Обработка ошибок
Каждая фаза компиляции может обнаружить ошибки в транслируемой программе. После обнаружения ошибки фаза должна каким-то образом справиться с возникшей ситуацией. Иными словами, процесс компиляции должен быть продолжен, причем так, чтобы была возможность поиска следующих ошибок в исходной программе. Компилятор, который останавливается после обнаружения первой ошибки, не может быть признан достаточно хорошим. Впрочем, в некоторых ситуациях это вполне приемлемо. Такие ситуации возникают, например, если разрабатывается диалоговый транслятор, который будет использоваться в учебных целях, поскольку начинающему программисту, с одной стороны, вполне достаточно получать информацию об одной ошибке, с другой стороны, получение информации сразу о большом количестве ошибках может его дезориентировать. Одно из основных требований, предъявляемых промышленным трансляторам, заключается в том, чтобы пользователь получил как можно больше корректных ошибок за одну трансляцию. Мы не зря использовали прилагательное «корректные», говоря об ошибках, которые обнаруживает компилятор. Дело в том, что иногда трансляторы выдают информацию о так называемых «наведенных» ошибках. Наведенные ошибки, т.е. такие, которых в программе на самом деле нет, могут возникнуть в результате не совсем корректной работы транслятора после обнаружения какой-нибудь ошибки.
Наибольшая доля ошибок приходится, как правило, на две фазы: синтаксический анализ и фазу контроля типов. Лексический анализатор может обнаружить только те ошибки, которые связаны, например, с использованием неверных литер, или если выделенная лексема не принадлежит ни одному из лексических классов языка. Количество типов ошибок, которые может обнаружить фаза лексического анализа, весьма незначительно, поскольку лексический анализатор «видит» только небольшой, локальный, участок программы. Например, лексический анализатор не сможет обнаружить ошибку в следующем контексте:
Ошибки, связанные с нарушением синтаксической структуры исходной программы, определяются на фазе синтаксического анализа. Ошибки, возникающие на фазе контроля типов, связаны с неверным использованием идентификаторов, с некорректной передачей фактических параметров процедурам и т.п.
Обычно, фазы оптимизации и генерации не обнаруживают ошибки, хотя и здесь бывают исключения. Например, представим себе, что в реализуемом языке определено присваивание одной структуры другой по именам полей. Это означает, что если у нас есть две структуры, то присваивание одной структуры другой будет иметь эффект в том случае, если обе из этих структур имеют по крайней мере одну пару одинаковых выделителей полей. При таком определении присваивания структур, компилятор, должен проверить, возможно ли такое присваивание, и если все выделители полей структур различны, должен выдать сообщение об ошибке. Понятно, что ситуация такого рода станет ясна только после контроля типов. Кроме того, поскольку компилятор должен выполнить так называемую «расклейку» присваивания (т.е. преобразовать исходное присваивание в одно или несколько присваиваний соответствующих полей), то такого рода действия можно считать оптимизирующими и, соответственно, сообщение об ошибке в случае, если все имена полей структуры-получателя и структуры-источника различны, будет выдавать фаза оптимизации.
Информация, необходимая для выдачи сообщения об ошибке
В однопросмотровом компиляторе все фазы выполняются параллельно. Если возникает ошибка в исходной программе, то текущая позиция лексического анализатора является приемлемой аппроксимацией позиции исходной программы, содержащей ошибку. В таком компиляторе лексический анализатор сохраняет текущую позицию в глобальной переменной. Процедура, предназначенная для выдачи сообщений об ошибках, печатает сообщение об ошибке и значение переменной, содержащей текущую позицию.
Компиляторы, состоящие более чем из одного просмотра, часто выполняют синтаксический анализ и типовой анализ на разных просмотрах. Естественно, это облегчает жизнь в различных аспектах, но существенно усложняет выдачу сообщений о типовых ошибках. Лексический анализатор достигает конца исходной программы раньше, чем начнет выполняться фаза контроля типов. Контроль типов осуществляется во время обхода синтаксического дерева, поэтому невозможно использовать текущую позицию в исходной программе, которую поддерживает лексический анализатор, для выдачи информации об ошибке. Поэтому каждый узел синтаксического дерева должен содержать позицию соответствующей ему конструкции в исходном файле, т.е. структура, определяющая узел дерева, должна содержать поле pos, предназначенное для этой цели. Это поле pos само является структурой из двух полей: номера строки исходной программы и номера позиции в строке. Понятно, что текущая позиция первоначально определяется лексическим анализатором (оно является одним из полей структуры Lexeme ), а затем передается синтаксическому анализатору, который и помещает это значение в поле pos узла синтаксического дерева. Для более точного определения позиции в исходном файле каждый узел синтаксического дерева обычно содержит два поля, определяющих положение конструкции, а именно, позицию начала конструкции и позицию ее конца ( beg_pos и end_pos соответственно).
Привет, Вы узнаете про виды ошибок программного обеспечения, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
виды ошибок программного обеспечения, принципы отладки , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
1. Отладка программы
Отладка, как мы уже говорили, бывает двух видов:
Синтаксическая отладка. Синтаксические ошибки выявляет компилятор, поэтому исправлять их достаточно легко.
Семантическая (смысловая) отладка. Ее время наступает тогда, когда синтаксических ошибок не осталось, но результаты программа выдает неверные. Здесь компилятор сам ничего выявить не сможет, хотя в среде программирования обычно существуют вспомогательные средства отладки, о которых мы еще поговорим.
Отладка — это процесс локализации и исправления ошибок в программе.
Как бы тщательно мы ни писали, отладка почти всегда занимает больше времени, чем программирование.
2. Локализация ошибок
Локализация — это нахождение места ошибки в программе.
В процессе поиска ошибки мы обычно выполняем одни и те же действия:
- прогоняем программу и получаем результаты;
- сверяем результаты с эталонными и анализируем несоответствие;
- выявляем наличие ошибки, выдвигаем гипотезу о ее характере и месте в программе;
- проверяем текст программы, исправляем ошибку, если мы нашли ее правильно.
Способы обнаружения ошибки:
- Аналитический — имея достаточное представление о структуре программы, просматриваем ее текст вручную, без прогона.
- Экспериментальный — прогоняем программу, используя отладочную печать и средства трассировки, и анализируем результаты ее работы.
Оба способа по-своему удобны и обычно используются совместно.
3.
принципы отладки
Принципы локализации ошибок:
- Большинство ошибок обнаруживается вообще без запуска программы — просто внимательным просматриванием текста.
- Если отладка зашла в тупик и обнаружить ошибку не удается, лучше отложить программу. Когда глаз «замылен», эффективность работы упорно стремится к нулю.
- Чрезвычайно удобные вспомогательные средства — это отладочные механизмы среды разработки: трассировка, промежуточный контроль значений. Можно использовать даже дамп памяти, но такие радикальные действия нужны крайне редко.
- Экспериментирования типа «а что будет, если изменить плюс на минус» — нужно избегать всеми силами. Обычно это не дает результатов, а только больше запутывает процесс отладки, да еще и добавляет новые ошибки.
Принципы исправления ошибок еще больше похожи на законы Мерфи:
- Там, где найдена одна ошибка, возможно, есть и другие.
- Вероятность, что ошибка найдена правильно, никогда не равна ста процентам.
- Наша задача — найти саму ошибку, а не ее симптом.
Это утверждение хочется пояснить. Если программа упорно выдает результат 0,1 вместо эталонного нуля, простым округлением вопрос не решить. Если результат получается отрицательным вместо эталонного положительного, бесполезно брать его по модулю — мы получим вместо решения задачи ерунду с подгонкой.
Исправляя одну ошибку, очень легко внести в программу еще парочку. «Наведенные» ошибки — настоящий бич отладки.
Исправление ошибок зачастую вынуждает нас возвращаться на этап составления программы. Это неприятно, но порой неизбежно.
4. Методы отладки
Силовые методы
- — Использование дампа (распечатки) памяти.Это интересно с познавательной точки зрения: можно досконально разобраться в машинных процессах. Иногда такой подход даже необходим — например, когда речь идет о выделении и высвобождении памяти под динамические переменные с использованием недокументированных возможностей языка. Однако, в большинстве случаев мы получаем огромное количество низкоуровневой информации, разбираться с которой — не пожелаешь и врагу, а результативность поиска — исчезающе низка.
- — Использование отладочной печати в тексте программы — произвольно и в большом количестве.Получать информацию о выполнении каждого оператора тоже небезынтересно. Но здесь мы снова сталкиваемся со слишком большими объемами информации. Кроме того, мы здорово захламляем программу добавочными операторами, получая малочитабельный текст, да еще рискуем внести десяток новых ошибок.
- — Использование автоматических средств отладки — трассировки с отслеживанием промежуточных значений переменых.Пожалуй, это самый распространенный способ отладки. Не нужно только забывать, что это только один из способов, и применять всегда и везде только его — часто невыгодно.
Сложности возникают, когда приходится отслеживать слишком большие структуры данных или огромное их число. Еще проблематичнее трассировать проект, где выполнение каждой подпрограммы приводит к вызову пары десятков других. Но для небольших программ трассировки вполне достаточно.
С точки зрения «правильного» программирования силовые методы плохи тем, что не поощряют анализ задачи.
Суммируя свойства силовых методов, получаем практические советы:
— использовать трассировку и отслеживание значений переменных для небольших проектов, отдельных подпрограмм;
— использовать отладочную печать в небольших количества и «по делу»;
— оставить дамп памяти на самый крайний случай.
Метод индукции — анализ программы от частного к общему.
Просматриваем симптомы ошибки и определяем данные, которые имеют к ней хоть какое-то отношение. Затем, используя тесты, исключаем маловероятные гипотезы, пока не остается одна, которую мы пытаемся уточнить и доказать.
Метод дедукции — от общего к частному.
Выдвигаем гипотезу, которая может объяснить ошибку, пусть и не полностью. Затем при помощи тестов эта гипотеза проверяется и доказывается.
Обратное движение по алгоритму.
Отладка начинается там, где впервые встретился неправильный результат. Затем работа программы прослеживается (мысленно или при помощи тестов) в обратном порядке, пока не будет обнаружено место возможной ошибки.
Метод тестирования.
Давайте рассмотрим процесс локализации ошибки на конкретном примере. Пусть дана небольшая программа, которая выдает значение максимального из трех введенных пользователем чисел.
var
a, b, c: real;
begin
writeln('Программа находит значение максимального из трех введенных чисел');
write('Введите первое число '); readln(a);
write('Введите второе число '); readln(b);
write('Введите третье число '); readln(c);
if (a>b)and(a>c) then
writeln('Наибольшим оказалось первое число ',a:8:2)
else if (b>a)and(a>c) then
writeln('Наибольшим оказалось второе число ',b:8:2)
else
writeln('Наибольшим оказалось третье число ',b:8:2);
end.
Обе выделенные ошибки можно обнаружить невооруженным глазом: первая явно допущена по невнимательности, вторая — из-за того, что скопированную строку не исправили.
Тестовые наборы данных должны учитывать все варианты решения, поэтому выберем следующие наборы чисел:
Данные Ожидаемый результат
a=10; b=-4; c=1 max=a=10
a=-2; b=8; c=4 max=b=8
a=90; b=0; c=90.4 max=c=90.4
В результате выполнения программы мы, однако, получим следующие результаты:
Для a=10; b=-4; c=1:
Наибольшим оказалось первое число 10.00
Для a=-2; b=8; c=4: < pre class=»list»>Наибольшим оказалось третье число 8.00Для a=90; b=0; c=90.4:
Наибольшим оказалось третье число 0.00
Вывод во втором и третьем случаях явно неверен. Будем разбираться.
1. Трассировка и промежуточная наблюдение за переменными
Добавляем промежуточную печать или наблюдение за переменными:
- — вывод a, b, c после ввода (проверяем, правильно ли получили данные)
- — вывод значения каждого из условий (проверяем, правильно ли записали условия)
Листинг программы существенно увеличился и стал вот таким:
var
a, b, c: real;
begin
writeln(‘Программа находит значение максимального из трех введенных чисел’);
write(‘Введите первое число ‘); readln(a);
writeln(‘Вы ввели число ‘,a:8:2); {отл.печать}
write(‘Введите второе число ‘); readln(b);
writeln(‘Вы ввели число ‘,b:8:2); {отл.печать}
write(‘Введите третье число ‘); readln(c);
writeln(‘Вы ввели число ‘,c:8:2); {отл.печать}
writeln(‘a>b=’,a>b,’, a>c=’,a>c,’, (a>b)and(a>c)=’,(a>b)and(a>c)); {отл.печать}
if (a>b)and(a>c) then
writeln(‘Наибольшим оказалось первое число ‘,a:8:2)
else begin
writeln(‘b>a=’,b>a,’, b>c=’,b>c,’, (b>a)and(b>c)=’,(b>a)and(b>c)); {отл.печать}
if (b>a)and(a>c) then
writeln(‘Наибольшим оказалось второе число ‘,b:8:2)
else
writeln(‘Наибольшим оказалось третье число ‘,b:8:2);
end;
end.
В принципе, еще при наборе у нас неплохой шанс отловить ошибку в условии: подобные кусочки кода обычно не перебиваются, а копируются, и если дать себе труд слегка при этом задуматься, ошибку найти легко.
Но давайте считать, что глаз «замылен» совершенно, и найти ошибку не удалось.
Вывод для второго случая получается следующим:
Программа находит значение максимального из трех введенных чисел
Введите первое число -2
Вы ввели число -2.00
Введите второе число 8
Вы ввели число 8.00
Введите третье число 4
Вы ввели число 4.00
a>b=FALSE, a>c=FALSE, (a>b)and(a>c)=FALSE
b>a=TRUE, b>c=TRUE, (b>a)and(b>c)=TRUE
Наибольшим оказалось третье число 8.00
Со вводом все в порядке . Об этом говорит сайт https://intellect.icu . Впрочем, в этом сомнений и так было немного. А вот что касается второй группы операторов печати, то картина вышла интересная: в результате выводится верное число (8.00), но неправильное слово («третье», а не «второе»).
Вероятно, проблемы в выводе результатов. Тщательно проверяем текст и обнаруживаем, что действительно в последнем случае выводится не c, а b. Однако к решению текущей проблемы это не относится: исправив ошибку, мы получаем для чисел -2.0, 8.0, 4.0 следующий результат.
Наибольшим оказалось третье число 4.00
Теперь ошибка локализована до расчетного блока и, после некоторых усилий, мы ее находим и исправляем.
2. Метод индукции
Судя по результатам, ошибка возникает, когда максимальное число — второе или третье (если максимальное — первое, то определяется оно правильно, для доказательства можно програть еще два-три теста).
Просматриваем все, относящееся к переменным b и с. Со вводом никаких проблем не замечено, а что касается вывода — то мы быстро натыкаемся на замену b на с. Исправляем.
Как видно, невыявленные ошибки в программе остаются. Просматриваем расчетный блок: все, что относится к максимальному b (максимум с получается «в противном случае»), и обнаруживаем пресловутую проблему «a>c» вместо «b>c». Программа отлажена.
3. Метод дедукции
Неверные результаты в нашем случае могут получиться из-за ошибки в:
- — вводе данных;
- — расчетном блоке;
- — собственно выводе.
Для доказательства мы можем пользоваться отладочной печатью, трассировкой или просто набором тестов. В любом случае мы выявляем одну ошибку в расчете и одну в выводе.
4. Обратное движение по алгоритму
Зная, что ошибка возникает при выводе результатов, рассматриваем код, начиная с операторов вывода. Сразу же находим лишнюю b в операторе writeln.
Далее, смотрим по конкретной ветке условного оператора, откуда взялся результат. Для значений -2.0, 8.0, 4.0 расчет идет по ветке с условием if (b>a)and(a>c) then… где мы тут же обнаруживаем искомую ошибку.
5. Тестирование
В нашей задаче для самого полного набора данных нужно выбрать такие переменные, что
a > b > c
a > c > b
b > a > c
b > c > a
c > a > b
c > b > a
Анализируя получившиеся в каждом из этих случаев результаты, мы приходим к тому, что проблемы возникают при b>c>a и с — максимальном. Зная эти подробности, мы можем заострить внимание на конкретных участках программы.
Конечно, в реальной работе мы не расписываем так занудно каждый шаг, не прибегаем исключительно к одной методике, да и вообще частенько не задумываемся, каким образом искать ляпы. Теперь, когда мы разобрались со всеми подходами, каждый волен выбрать те из них, которые кажутся самыми удобными.
5. Средства отладки
Помимо методик, хорошо бы иметь представление о средствах, которые помогают нам выявлять ошибки. Это:
1) Аварийная печать — вывод сообщений о ненормальном завершении отдельных блоков и всей программы в целом.
2) Печать в узлах программы — вывод промежуточных значений параметров в местах, выбранных программистом. Обычно, это критичные участки алгоритма (например, значение, от которого зависит дальнейший ход выполнения) или составные части сложных формул (отдельно просчитать и вывести числитель и знаменатель большой дроби).
3) Непосредственное слежение:
- — арифметическое (за тем, чему равны, когда и как изменяются выбранные переменные),
- — логическое (когда и как выполняется выбранная последовательность операторов),
- — контроль выхода индексов за допустимые пределы,
- — отслеживание обращений к переменным,
- — отслеживание обращений к подпрограммам,
- — проверка значений индексов элементов массивов и т.д.
Нынешние среды разработки часто предлагают нам реагировать на возникающую проблему в диалоговом режиме. При этом можно:
- — просмотреть текущие значения переменных, состояние памяти, участок алгоритма, где произошел сбой;
- — прервать выполнение программы;
- — внести в программу изменения и повторно запустить ее (в компиляторных средах для этого потребуется перекомпилировать код, в интерпретаторных выполнение можно продолжить прямо с измененного оператора).
 Рис Пример отладки приложения
Рис Пример отладки приложения
6. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
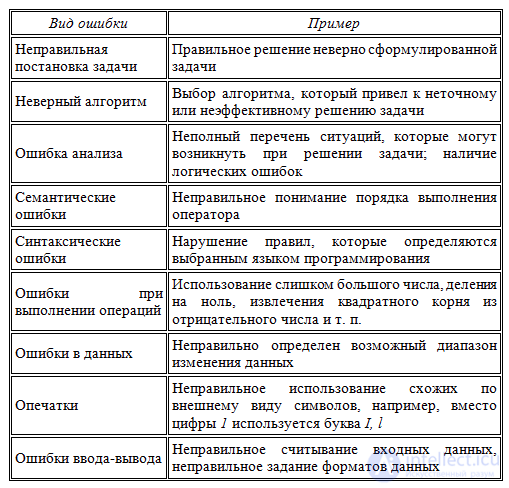
Если вы удручены тем, что насажали в текст программы глупых ошибок — не расстраивайтесь. Ошибки вообще не бывают умными, хотя и могут относиться к самым разным частям кода:
- — ошибки обращения к данным,
- — ошибки описания данных,
- — ошибки вычислений,
- — ошибки при сравнении,
- — ошибки в передаче управления,
- — ошибки ввода-вывода,
- — ошибки интерфейса,
- и т д
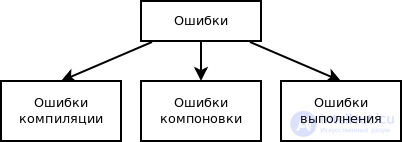
Классификация ошибок по этапу обработки программы
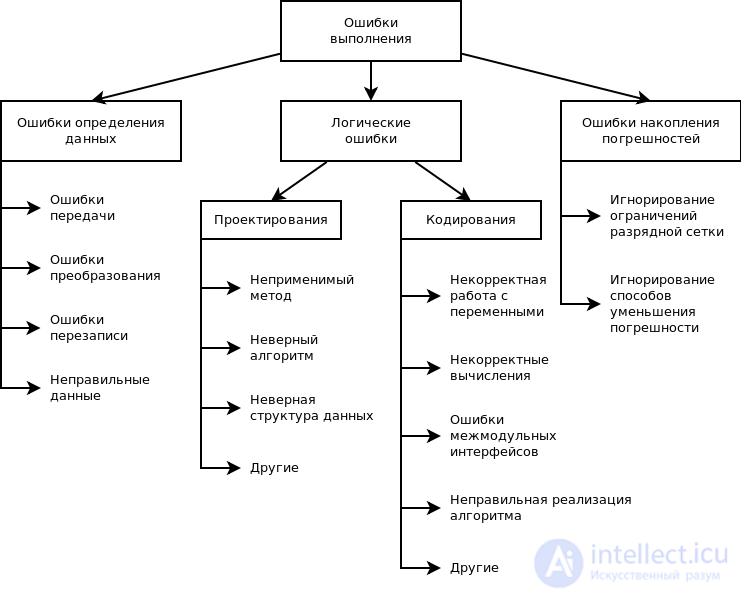
рис Классификация ошибок этапа выполнения по возможным причинам
Синтаксические ошибки
Синтаксические ошибки зачастую выявляют уже на этапе трансляции. К сожалению, многие ошибки других видов транслятор выявить не в силах, т.к. ему не известен задуманный или требуемый результат работы программы. Отсутствие сообщений транслятора о наличии синтаксических ошибок является необходимым условием правильности программы, но не может свидетельствовать о том, что она даст правильный результат.
Примеры синтаксических ошибок :
- отсутствие знака пунктуации;
- несоответствие количества открывающих и закрывающих скобок;
- неправильно сформированный оператор;
- неправильная запись имени переменной;
- ошибка в написании служебных слов;
- отсутствие условия окончания цикла;
- отсутствие описания массивов и т.п.
Ошибки, которые не обнаруживает транслятор
В случае правильного написания операторов в программе может присутствовать большое количество ошибок, которые транслятор не может обнаружить. Рассмотрим примеры таких ошибок:
Логические ошибки: после проверки заданного условия неправильно указана ветвь алгоритма; неполный перечень возможных условий при решении задачи; один или более блоков алгоритма в программе пропущен.
Ошибки в циклах: неправильно указано начало цикла; неправильно указаны условия окончания цикла; неправильно указано количество повторений цикла; использование бесконечного цикла.
Ошибки ввода-вывода; ошибки при работе с данными: неправильно задан тип данных; организовано считывание меньшего или большего объема данных, чем нужно; неправильно отредактированы данные.
Ошибки в использовании переменных: используются переменных, для которых не указаны начальные значения; ошибочно указана одна переменная вместо другой. Ошибки при работе с массивами: пропущено предварительное обнуление массивов; неправильное описание массивов; индексы массивов следуют в ошибочном порядке.
ошибки безопасности, умышленные и не умышленные уязвимости в системе, открытость к отказам в обслуживании. несанкционированном доступе. екхолы
Ошибки в арифметических операциях: неправильное использование типа переменной (например, для сохранения результата деления используется целочисленная переменная); неправильно определен порядок действий; выполняется деление на нуль; при расчете выполняется попытка извлечения квадратного корня из отрицательного числа; не учитываются значащие разряды числа.
ошибки в архитектуре приложения пприводящие к увеличени технического долга
Методы (пути) снижение ошибок в программировании
- использование тестиования
- использование более простых решений
- использование систем с наименьшим числом составлящих
- использование ранее использованных и проверенных компонентов
- использование более квалифицрованных специалистов
7. Советы отладчику
1) Проверяйте тщательнее: ошибка скорее всего находится не в том месте, в котором кажется.
2) Часто оказывается легче выделить те места программы, ошибок в которых нет, а затем уже искать в остальных.
3) Тщательнее следить за объявлениями констант, типов и переменных, входными данными.
4) При последовательной разработке приходится особенно аккуратно писать драйверы и заглушки — они сами могут быть источником ошибок.
5) Анализировать код, начиная с самых простых вариантов. Чаще всего встречаются ошибки:
— значения входных аргументов принимаются не в том порядке,
— переменная не проинициализирована,
— при повторном прохождении модуля, перемен ная повторно не инициализируется,
— вместо предполагаемого полного копирования структуры данных, копируется только верхний уровень (например, вместо создания новой динамической переменной и присваивания ей нужного значения, адрес тупо копируется из уже существующей переменной),
— скобки в сложном выражении расставлены неправильно.
6) При упорной длительной отладке глаз «замыливается». Хороший прием — обратиться за помощью к другому лицу, чтобы не повторять ошибочных рассуждений. Правда, частенько остается проблемой убедить это другое лицо помочь вам.
7) Ошибка, скорее всего окажется вашей и будет находиться в тексте программы. Гораздо реже она оказывается:
- в компиляторе,
- операционной системе,
- аппаратной части,
- электропроводке в здании и т.д.
Но если вы совершенно уверены, что в программе ошибок нет, просмотрите стандартные модули, к которым она обращается, выясните, не менялась ли версия среды разработки, в конце концов, просто перегрузите компьютер — некоторые проблемы (особенно в DOS-средах, запускаемых из-под Windows) возникают из-за некорректной работы с памятью.
 Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
Убедитесь, что исходный текст программы соответствует скомпилированному объектному коду (текст может быть изменен, а запускаемый модуль, который вы тестируете — скомпилирован еще из старого варианта).
9) Навязчивый поиск одной ошибки почти всегда непродуктивен. Не получается — отложите задачу, возьмитесь за написание следующего модуля, на худой конец займитесь документированием.
10) Старайтесь не жалеть времени, чтобы уясненить причину ошибки. Это поможет вам:
исправить программу,
обнаружить другие ошибки того же типа,
не делать их в дальнейшем.
11) Если вы уже знаете симптомы ошибки, иногда полезно не исправлять ее сразу, а на фоне известного поведения программы поискать другие ляпы.
12) Самые труднообнаруживаемые ошибки — наведенные, то есть те, что были внесены в код при исправлении других.
8. Тестирование
Тестирование — это выполнение программы для набора проверочных входных значений и сравнение полученных результатов с ожидаемыми.
Цель тестирования — проверка и доказательство правильности работы программы. В противном случае — выявление того, что в ней есть ошибки. Тестирование само не показывает местонахождение ошибки и не указывает на ее причины.
Принципы тестирования.
1) Тест — просчитанный вручную пример выполнения программы от исходных данных до ожидаемых результатов расчета. Эти результаты считаются эталонными.
Полномаршрутным будет такое тестирование, при котором каждый линейный участок программы будет пройден хотя бы при выполнении одного теста.
2) При прогоне программы по тестовым начальным данным, полученные результаты нужно сверить с эталонными и проанализировать разницу, если она есть.
3) При разработке тестов нужно учитывать не только правильные, но и неверные исходные данные.
4) Мы должны проверить программу на нежелательные побочные эффекты при задании некоторых исходных данных (деление на ноль, попытка считывания из несуществующего файла и т.д.).
5) Тестирование нужно планировать: заранее выбрать, что мы контролируем и как это сделать лучше. Обычно тесты планируются на этапе алгоритмизации или выбора численного метода решения. Причем, составляя тесты, мы предполагаем, что ошибки в программе есть.
6) Чем больше ошибок в коде мы уже нашли, тем больше вероятность, что мы обнаружим еще не найденные.
Хорошим называют тест, который с большой вероятностью должен обнаруживать ошибки, а удачным — тот, который их обнаружил.
9. Проектирование тестов
Тесты просчитываются вручную, значит, они должны быть достаточно просты для этого.
Тесты должны проверять каждую ветку алгоритма. По возможности, конечно. Так что количество и сложность тестов зависит от сложности программы.
Тесты составляются до кодирования и отладки: во время разработки алгоритма или даже составления математической модели.
Обычно для экономии времени сначала пропускают более простые тесты, а затем более сложные.
Давайте рассмотрим задачу: нужно проверить, попадает ли введенное число в заданный пользователем диапазон.
program Example;
(******************************************************
* Задача: проверить, попадает ли введенное число в *
* заданный пользователем диапазон *
******************************************************)
var
min, max, A, tmp: real;
begin
writeln(‘Программа проверяет, попадают ли введенные пользователем’);
writeln(‘значения в заданный диапазон’);
writeln;
writeln(‘Введите нижнюю границу диапазона ‘); readln(min);
writeln(‘Введите верхнюю границу диапазона ‘); readln(max);
if min>max then begin
writeln(‘Вы перепутали диапазоны, и я их поменяю’);
tmp:=min;
min:=max;
max:=tmp;
end;
repeat
writeln(‘Введите число для проверки (0 — конец работы) ‘); readln(A);
if (A>=min)and(A<=max) then
writeln(‘Число ‘,A,’ попадает в диапазон [‘,min,’..’,max,’]’)
else
writeln(‘Число ‘,A,’ не попадает в диапазон [‘,min,’..’,max,’]’);
until A=0;
writeln;
end.
Если исходить из алгоритма программы, мы должны составить следующие тесты:
ввод границ диапазона
— min< max
— min>max
ввод числа
— A < min (A<>0)
— A > max (A<>0)
— min <= A <= max (A<>0)
— A=0
Как видите, программа очень мала, а тестов для проверки всех ветвей ее алгоритма, требуется довольно много.
10. Стратегии тестирования
1) Тестирование программы как «черного ящика».
Мы знаем только о том, что делает программа, но даже не задумываемся о ее внутренней структуре. Задаем набор входных данных, получаем результаты, сверяем с эталонными.
При этом обнаружить все ошибки мы можем только если составили тесты для всех возможных наборов данных. Естественно, это противоречит экономическим принципам, да и просто достаточно глупо.
«Черным ящиком» удобно тестировать небольшие подпрограммы.
2) Тестирование программы как «белого ящика».
Здесь перед составлением теста мы изучаем логику программы, ее внутреннюю структуру. Тестирование будет считаться удачным, если проверяет программу по всем направлениям. Однако, как мы уже говорили, это требует огромного количества тестов.
На практике мы, как всегда, совместно используем оба принципа.
3) Тестирование программ модульной структуры.
Мы снова возвращаемся к вопросу о структурном программировании. Если вы помните, программы строятся из модулей не в последнюю очередь для того, чтобы их легко было отлаживать и тестировать. Действительно, структурированную программу мы будем тестировать частями. При этом нам нужно:
строить набор тестов;
комбинировать модули для тестирования.
Такое комбинирование может строиться двумя способами:
Пошаговое тестирование — тестируем каждый модуль, присоединяя его к уже оттестированным. При этом можем соединять части программы сверху вниз (нисходящий способ) или снизу вверх (восходящий).
Монолитное тестирование — каждый модуль тестируется отдельно, а затем из них формируется готовая рабочая программа и тестируется уже целиком.
Чтобы протестировать отдельный модуль, нужен модуль-драйвер (всегда один) и модул и-заглушки (этих может быть несколько).
Модуль-драйвер содержит фиксированные исходные данные. Он вызывает тестируемый модуль и отображает (а возможно, и анализирует) результаты.
Модуль-заглушка нужен, если в тестируемом модуле есть вызовы других. Вместо этого вызова управление передается модулю-заглушке, и уже он имитирует необходимые действия.
К сожалению, мы опять сталкиваемся с тем, что драйверы и заглушки сами могут оказаться источником ошибок. Поэтому создаваться они должны с большой осторожностью.
Вау!! 😲 Ты еще не читал? Это зря!
- ошибки в приложениях , bugs , баг репорт , bug report ,
- Фича
- GIGO
- Патч
- тестирование
- цикломатическая сложность
- баг репорт
- качество программного обеспечения
К сожалению, в одной статье не просто дать все знания про виды ошибок программного обеспечения. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое виды ошибок программного обеспечения, принципы отладки
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
наведённая ошибка
-
1
propagated errorУниверсальный англо-русский словарь > propagated error
-
2
induzierte FehlerУниверсальный немецко-русский словарь > induzierte Fehler
См. также в других словарях:
-
Волшебство мира Гарри Поттера — Эта статья является частью цикла статей о волшебном мире Гарри Поттера. Эта статья об объекте вымышленного мира описывает его только на основе самого художественного произведения. Статья, состоящая только из инфор … Википедия
-
Октябрьская революция — У этого термина существуют и другие значения, см. Октябрьская революция (значения). Октябрьское восстание … Википедия
-
Гражданская война в Испании — Смерть республиканца анархиста Федерико Боррелла Гарсии (фотография Роберта Капы) … Википедия
-
Гибель тургруппы Дятлова — В таком виде спасатели нашли палатку группы. Фото спасателя Вадима Брусницына 26 или 28 февраля 1959 г. Слева поисковик Юрий Коптёлов Гибель тургруппы Дятлова событие, случившееся предположительно в ночь с 1 на 2 … Википедия
-
Видоискатель — Запрос «Визир» перенаправляется сюда; см. также другие значения. Видоискатель, Визир, Визирное устройство элемент фотоаппарата, показывающий границы будущего снимка, иногда резкость и параметры съёмки. Также видоискатели используются в… … Википедия
-
Assassin’s Creed — Assassin’s Creed Разработчик Ubisoft Montreal Издатели … Википедия
-
Assassin’s Creed — Assassin’s Creed Разработчик Ubisoft Montreal Издатели … Википедия
-
Assassin’s Creed — Это статья о компьютерной игре. О серии компьютерных игр см. статью Assassin s Creed (серия игр) Assassin’s Creed Разработчик Ubisoft Montreal … Википедия
Здравствуйте, Klatu, Вы писали:
K>И ты за всем пустословием упустил самое главное. В управляемом коде надо еще постараться, чтобы получить наведенную ошибку.
Легко! Наведенная ошибка — это практически любая неправильно обработанная ошибка или пропущенная где-то ранее ошибка. Самый очевидный пример — когда-то ранее null сохранили без проверки, а в момент использования получи ошибку. Вот тебе классическая наведенная ошибка, найти которую не поможет никакой стек-трейс, т.к. в момент возникновения ошибки ее предыстория неизвестна. Она встречается на несколько порядков чаще в дотнете, да и в нейтиве тоже, чем проходы по памяти. По-сути ты называешь главной причиной наведенных ошибок ту, которая составляет доли одного процента от всех причин для наведенных ошибок. Сие нелепо.
K>А в С++ надо очень постараться, чтобы их не получить.
Разве? ![]()
И ты за всем пустословием упустил самое главное.
Ну так напомню, что ты и тебе подобные постоянно игнорируют тот факт, что всякие переполнения буфера происходят в основном в legacy-коде, который был писан черти когда на голом С или на самых первых версиях C++, на котором все-равно писали как на С. Уже более 10-15 лет никто не создает в С++ массивы памяти вручную. Стал бы ты, даже имея такую возможность в дотнете (а она есть, через класс Marshal) выделять и вручную следить за блоками памяти? Это же жутко неудобно! ![]() Аналогично и в С++ — использование безопасных библиотек удобнее гораздо, банально меньше кода, и голова не болит следить за байтами.
Аналогично и в С++ — использование безопасных библиотек удобнее гораздо, банально меньше кода, и голова не болит следить за байтами.
Откуда же такое внимание к ошибкам именно в нейтиве? Наверно от того, что из нейтива можно сделать гораздо больше, чем из дотнета, в плане злонамеренно навредить, т.к. все АПИ ОС всё еще нейтивные. А ты тут на весь интернет путаешь частоту проявления ошибки с ее важностью. К тому же, сам факт спора о технологии, которой недостаточно владеешь, профанирует весь спор. Я постоянно последние почти лет 10 (еще с первых бет) использую как С#, так и C++. И какой аспект не возьми, но организовать на С++ статическую проверку всегда проще, чем на C#, на котором каждую мелочь, отсутствующую в стандартных либах, надо писать вручную. Дотнет хорош своей огромной функциональностью, данной на халяву, а так же визуальными редакторами GUI. Но в плане кол-ва словленных ошибок… если не касается использование имеющихся библиотек, а нужно некую функциональность делать практически с 0-ля, то программисты C# допускают намного больше ошибок, чем программисты на C++. Как раз из-за более бедных языковых ср-в. Причем, это медицинский факт, который я подметил еще в первые 3-4 года дотнета. Хотя, всякие FxCorp и Resharper помогают (частично), но тогда этих инструментов не было, и прелести технологии были видны во всей красе. Из-за этого что-то делать с 0-ля на дотнете в те времена можно было только в явовском стилее TDD, ввиду невозможности обложить код достаточными статическими проверками, нивелирующими надобность в ~90% этих тестов. А если брать ситуацию на сейчас, то под С++ уже полно ср-в как статического анализа кода, так и динамического. Серьезных, прямо скажем ср-в, аналогов которых под дотнет еще ждать и ждать.
В общем, повторю, возможность писать безопасно на С++ есть, и эта возможность на этапе компиляции всяко пошире, чем на C#. Возможность писать небезопасно тоже есть, но это считается хакерством, как беспричинный unsafe в дотнете, полностью аналогично. Ну и тыкать плюсовиков ошибками в старом С-коде — это надо совсем не разбираться в технологиях.